
title stringlengths 1 185 | diff stringlengths 0 32.2M | body stringlengths 0 123k ⌀ | url stringlengths 57 58 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 ⌀ | updated_at stringlengths 20 20 |
|---|---|---|---|---|---|---|---|
Adds Hamilton to match ecosystem.md | diff --git a/doc/source/ecosystem.rst b/doc/source/ecosystem.rst
index 53b7aae3f7ab1..1d0232c80ffcc 100644
--- a/doc/source/ecosystem.rst
+++ b/doc/source/ecosystem.rst
@@ -600,3 +600,20 @@ Install pandas-stubs to enable basic type coverage of pandas API.
Learn more by reading through :issue:`14468`, :issue:`26766`, :... | Just noticed that ecosystem.rst wasn't in sync with ecosystem.md. So adding part about Hamilton to it.
- [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or addi... | https://api.github.com/repos/pandas-dev/pandas/pulls/51694 | 2023-02-28T16:12:48Z | 2023-03-08T00:04:43Z | 2023-03-08T00:04:43Z | 2023-03-14T03:29:58Z |
STYLE Reduce merge conflicts with `force_grid_wrap=1` | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 576c929c26b9b..a785607eca3fc 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -409,9 +409,9 @@ repos:
- flake8-pyi==22.8.1
- id: future-annotations
name: import annotations from __future__
- entry: ... | - [ ] closes #50274 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51693 | 2023-02-28T13:54:37Z | 2023-04-01T07:56:25Z | null | 2023-04-01T07:56:25Z |
BUG: DataFrame.stack losing EA dtypes with multi-columns and mixed dtypes | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 47a61d41b2440..29e681b1b85d1 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -202,6 +202,7 @@ Groupby/resample/rolling
Reshaping
^^^^^^^^^
+- Bug in :meth:`DataFrame.stack` losing extension dtypes ... | - [x] closes #45740
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51691 | 2023-02-28T12:17:23Z | 2023-03-09T17:13:54Z | 2023-03-09T17:13:54Z | 2023-03-17T22:04:19Z |
CLN: rename confusing variable name | diff --git a/pandas/_libs/algos.pyx b/pandas/_libs/algos.pyx
index 81fd5792ee9e5..5cc5c6514a2e0 100644
--- a/pandas/_libs/algos.pyx
+++ b/pandas/_libs/algos.pyx
@@ -752,7 +752,7 @@ def is_monotonic(ndarray[numeric_object_t, ndim=1] arr, bint timelike):
tuple
is_monotonic_inc : bool
is_monotonic_d... | null | https://api.github.com/repos/pandas-dev/pandas/pulls/51690 | 2023-02-28T10:59:02Z | 2023-03-02T23:38:14Z | 2023-03-02T23:38:13Z | 2023-03-03T12:25:17Z |
BUG: mask/where raising for mixed dtype frame and no other | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index 821e41db6b065..25af8400281c7 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -6123,8 +6123,8 @@ def _is_mixed_type(self) -> bool_t:
def _check_inplace_setting(self, value) -> bool_t:
"""check whether we allow in-place s... | - [x] closes #51685 (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51689 | 2023-02-28T10:57:00Z | 2023-03-08T21:44:54Z | 2023-03-08T21:44:54Z | 2023-03-08T23:46:13Z |
BUG: ArrowExtensionArray logical ops raising KeyError | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index e09f3e2753ee6..15e3d66ecc551 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1371,6 +1371,7 @@ ExtensionArray
- Bug in :class:`Series` constructor unnecessarily overflowing for nullable unsigned inte... | - [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotati... | https://api.github.com/repos/pandas-dev/pandas/pulls/51688 | 2023-02-28T10:25:57Z | 2023-03-06T23:43:21Z | 2023-03-06T23:43:21Z | 2023-03-17T22:04:30Z |
STYLE start enabling TCH | diff --git a/pandas/_config/config.py b/pandas/_config/config.py
index 4d87e8dca6d16..0149ea545a4c5 100644
--- a/pandas/_config/config.py
+++ b/pandas/_config/config.py
@@ -66,10 +66,8 @@
)
import warnings
-from pandas._typing import (
- F,
- T,
-)
+from pandas._typing import F # noqa: TCH001
+from pandas._t... | This one should actually make a difference to performance, https://github.com/snok/flake8-type-checking#examples
- [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a b... | https://api.github.com/repos/pandas-dev/pandas/pulls/51687 | 2023-02-28T10:19:54Z | 2023-03-02T09:04:42Z | 2023-03-02T09:04:42Z | 2023-03-02T14:21:36Z |
DOC: fix EX02 errors for three docstrings in plotting | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index 2d5e9cc031158..865f6d46cfee0 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -564,9 +564,6 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
pandas.api.types.is_datetime64_any_dtype \
pandas.api.types.is_datetime64_ns_dtype \
... | Some work towards issue https://github.com/pandas-dev/pandas/issues/51236
Makes docstrings pass for:
`pandas.plotting.andrews_curves`
`pandas.plotting.autocorrelation_plot`
`pandas.plotting.lag_plot`
Some prior conversation happened here ... https://github.com/pandas-dev/pandas/pull/51596 ... because I acciden... | https://api.github.com/repos/pandas-dev/pandas/pulls/51686 | 2023-02-28T06:10:10Z | 2023-02-28T07:35:46Z | 2023-02-28T07:35:46Z | 2023-02-28T07:35:46Z |
BUG: concat sorting when sort=False for all dti | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 410a324be829e..dfa5adaaeadee 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -208,6 +208,7 @@ Groupby/resample/rolling
Reshaping
^^^^^^^^^
- Bug in :meth:`DataFrame.stack` losing extension dtypes wh... | - [ ] closes #51210 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51683 | 2023-02-28T00:49:12Z | 2023-07-07T17:43:34Z | null | 2023-08-28T21:09:47Z |
Updates Hamilton references | diff --git a/web/pandas/community/ecosystem.md b/web/pandas/community/ecosystem.md
index 861f3bd8e1ea7..935ef12694a52 100644
--- a/web/pandas/community/ecosystem.md
+++ b/web/pandas/community/ecosystem.md
@@ -401,7 +401,7 @@ Learn more by reading through these issues [14468](https://github.com/pandas-dev
See install... | This updates a reference on the ecosystem page. We recently moved the repository and updated what is used for documentation.
- [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if f... | https://api.github.com/repos/pandas-dev/pandas/pulls/51682 | 2023-02-27T23:32:03Z | 2023-02-28T10:54:36Z | 2023-02-28T10:54:36Z | 2023-02-28T15:52:26Z |
Backport PR #51658 on branch 2.0.x (ENH: Improve replace lazy copy handling) | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 35a7855b8240f..7a24649fc60af 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -714,6 +714,8 @@ def replace_list(
(x, y) for x, y in zip(src_list, dest_list) if self._can_hold_element(x)... | Backport PR #51658: ENH: Improve replace lazy copy handling | https://api.github.com/repos/pandas-dev/pandas/pulls/51679 | 2023-02-27T21:53:34Z | 2023-02-27T23:36:29Z | 2023-02-27T23:36:29Z | 2023-02-27T23:36:30Z |
BUG: Prevent erroring out when comparing unordered categories with different permutations | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index 55185afc0a098..38c3176a25d0e 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1137,6 +1137,7 @@ Categorical
- Bug in :meth:`DataFrame.groupby` and :meth:`Series.groupby` would reorder categories when ... | - [x] closes #51543
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51678 | 2023-02-27T20:19:07Z | 2023-04-17T17:13:38Z | null | 2023-04-17T17:13:39Z |
Use union to combine indexes, matching behaivor when two indexes have different index types | diff --git a/pandas/core/indexes/api.py b/pandas/core/indexes/api.py
index fcf529f5be9ac..a0ce5f6951001 100644
--- a/pandas/core/indexes/api.py
+++ b/pandas/core/indexes/api.py
@@ -297,7 +297,8 @@ def _find_common_index_dtype(inds):
dtype = _find_common_index_dtype(indexes)
index = indexes[0]
... | - [ ] closes #51666
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [ ]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51677 | 2023-02-27T17:45:06Z | 2023-04-24T18:53:45Z | null | 2023-04-24T18:53:46Z |
BUG: ArrowDtype().type raising for fixed size pa binary | diff --git a/pandas/core/arrays/arrow/dtype.py b/pandas/core/arrays/arrow/dtype.py
index e8adab019b097..b6515c2875718 100644
--- a/pandas/core/arrays/arrow/dtype.py
+++ b/pandas/core/arrays/arrow/dtype.py
@@ -108,7 +108,11 @@ def type(self):
return float
elif pa.types.is_string(pa_type):
... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51674 | 2023-02-27T13:59:26Z | 2023-03-04T01:28:36Z | 2023-03-04T01:28:36Z | 2023-03-08T21:23:09Z |
ENH: Support na_position for sort_index and sortlevel | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 12d35288d1ee6..e6a114b491670 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -28,6 +28,7 @@ enhancement2
Other enhancements
^^^^^^^^^^^^^^^^^^
+- :meth:`MultiIndex.sortlevel` and :meth:`Index.sortl... | - [x] closes #51612 (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51672 | 2023-02-27T13:29:15Z | 2023-03-08T00:10:53Z | 2023-03-08T00:10:53Z | 2023-08-15T22:13:28Z |
CLN: Ensure that setitem ops don't coerce values | diff --git a/pandas/core/frame.py b/pandas/core/frame.py
index d80c80fa5d0ab..dbbe2c0751f3a 100644
--- a/pandas/core/frame.py
+++ b/pandas/core/frame.py
@@ -4757,6 +4757,14 @@ def insert(
if not isinstance(loc, int):
raise TypeError("loc must be int")
+ if isinstance(value, DataFrame) and... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51671 | 2023-02-27T11:45:48Z | 2023-02-28T10:24:36Z | 2023-02-28T10:24:36Z | 2023-02-28T10:24:40Z |
ENH: Add CoW mechanism to replace_regex | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index f9a14a4a9e877..20e986b75a099 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -651,6 +651,7 @@ def _replace_regex(
value,
inplace: bool = False,
mask=None,
+ using_... | - [ ] xref #49473 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51669 | 2023-02-27T10:48:51Z | 2023-03-01T12:19:57Z | 2023-03-01T12:19:57Z | 2023-03-01T12:32:00Z |
WEB: Added stying for pre element within the codeblock divs | diff --git a/web/pandas/static/css/codehilite.css b/web/pandas/static/css/codehilite.css
index 4642fc0378008..4a0078e141d87 100644
--- a/web/pandas/static/css/codehilite.css
+++ b/web/pandas/static/css/codehilite.css
@@ -72,3 +72,4 @@ span.linenos.special { color: #000000; background-color: #ffffc0; padding-left:
.cod... | - [x] closes ##51657 (Replace xxxx with the GitHub issue number)
- ENH: Enhancement, adding styling (padding and border) for code blocks
| https://api.github.com/repos/pandas-dev/pandas/pulls/51665 | 2023-02-27T05:03:27Z | 2023-03-07T11:47:37Z | 2023-03-07T11:47:37Z | 2023-03-07T11:48:07Z |
Backport PR #51660 on branch 2.0.x (DEPS: Bump Cython to 0.29.33) | diff --git a/asv_bench/asv.conf.json b/asv_bench/asv.conf.json
index 16f8f28b66d31..c503ae5e17471 100644
--- a/asv_bench/asv.conf.json
+++ b/asv_bench/asv.conf.json
@@ -42,7 +42,7 @@
// followed by the pip installed packages).
"matrix": {
"numpy": [],
- "Cython": ["0.29.32"],
+ "Cython"... | Backport PR #51660: DEPS: Bump Cython to 0.29.33 | https://api.github.com/repos/pandas-dev/pandas/pulls/51663 | 2023-02-27T02:12:09Z | 2023-02-27T10:52:50Z | 2023-02-27T10:52:50Z | 2023-02-27T10:52:50Z |
Backport PR #51517 on branch 2.0.x (PERF: maybe_convert_objects convert_numeric=False) | diff --git a/pandas/_libs/lib.pyi b/pandas/_libs/lib.pyi
index 1f6ae49b76adc..fbc577712d294 100644
--- a/pandas/_libs/lib.pyi
+++ b/pandas/_libs/lib.pyi
@@ -71,6 +71,7 @@ def maybe_convert_objects(
*,
try_float: bool = ...,
safe: bool = ...,
+ convert_numeric: bool = ...,
convert_datetime: Litera... | Backport PR #51517: PERF: maybe_convert_objects convert_numeric=False | https://api.github.com/repos/pandas-dev/pandas/pulls/51661 | 2023-02-27T01:05:34Z | 2023-02-27T12:53:51Z | 2023-02-27T12:53:51Z | 2023-02-27T12:53:51Z |
DEPS: Bump Cython to 0.29.33 | diff --git a/asv_bench/asv.conf.json b/asv_bench/asv.conf.json
index 16f8f28b66d31..c503ae5e17471 100644
--- a/asv_bench/asv.conf.json
+++ b/asv_bench/asv.conf.json
@@ -42,7 +42,7 @@
// followed by the pip installed packages).
"matrix": {
"numpy": [],
- "Cython": ["0.29.32"],
+ "Cython"... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51660 | 2023-02-27T00:27:40Z | 2023-02-27T02:12:01Z | 2023-02-27T02:12:01Z | 2023-02-27T02:12:03Z |
ENH: Improve replace lazy copy for categoricals | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 7a24649fc60af..2cfab63f8a63f 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -701,8 +701,7 @@ def replace_list(
# TODO: avoid special-casing
# GH49404
if usin... | - [ ] xref #49473 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51659 | 2023-02-27T00:03:13Z | 2023-02-28T22:44:20Z | 2023-02-28T22:44:20Z | 2023-02-28T22:44:31Z |
ENH: Improve replace lazy copy handling | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 35a7855b8240f..7a24649fc60af 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -714,6 +714,8 @@ def replace_list(
(x, y) for x, y in zip(src_list, dest_list) if self._can_hold_element(x)... | - [ ] xref #49473 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51658 | 2023-02-26T23:50:36Z | 2023-02-27T21:53:01Z | 2023-02-27T21:53:01Z | 2023-06-27T02:10:44Z |
WEB: Sort and fix link to under discussions PDEPs | diff --git a/web/pandas_web.py b/web/pandas_web.py
index e4ffa2cde7cc9..954018a81683f 100755
--- a/web/pandas_web.py
+++ b/web/pandas_web.py
@@ -301,9 +301,9 @@ def roadmap_pdeps(context):
with open(pathlib.Path(context["target_path"]) / "pdeps.json", "w") as f:
json.dump(pdeps, f)
- for ... | The links to the under discussion PDEPs in https://pandas.pydata.org/about/roadmap.html point to the API page, not the html page, fixing. Also, sorting the list by title. | https://api.github.com/repos/pandas-dev/pandas/pulls/51656 | 2023-02-26T22:14:31Z | 2023-02-27T00:47:04Z | 2023-02-27T00:47:04Z | 2023-02-27T00:47:08Z |
Backport PR #51654 on branch 2.0.x (DOC: Remove 1.5.4 release notes) | diff --git a/doc/source/whatsnew/index.rst b/doc/source/whatsnew/index.rst
index 69f845096ea24..821f77dbba3e2 100644
--- a/doc/source/whatsnew/index.rst
+++ b/doc/source/whatsnew/index.rst
@@ -24,7 +24,6 @@ Version 1.5
.. toctree::
:maxdepth: 2
- v1.5.4
v1.5.3
v1.5.2
v1.5.1
diff --git a/doc/source/... | Backport PR #51654: DOC: Remove 1.5.4 release notes | https://api.github.com/repos/pandas-dev/pandas/pulls/51655 | 2023-02-26T22:01:32Z | 2023-02-27T00:28:10Z | 2023-02-27T00:28:10Z | 2023-02-27T00:28:11Z |
DOC: Remove 1.5.4 release notes | diff --git a/doc/source/whatsnew/index.rst b/doc/source/whatsnew/index.rst
index 0044734b5ff99..568c19c57aee0 100644
--- a/doc/source/whatsnew/index.rst
+++ b/doc/source/whatsnew/index.rst
@@ -32,7 +32,6 @@ Version 1.5
.. toctree::
:maxdepth: 2
- v1.5.4
v1.5.3
v1.5.2
v1.5.1
diff --git a/doc/source/... | xref https://github.com/pandas-dev/pandas/issues/46776#issuecomment-1440748034 | https://api.github.com/repos/pandas-dev/pandas/pulls/51654 | 2023-02-26T19:04:29Z | 2023-02-26T22:01:24Z | 2023-02-26T22:01:24Z | 2023-02-26T22:01:34Z |
POC: implement __array_function__ | diff --git a/pandas/compat/numpy/__init__.py b/pandas/compat/numpy/__init__.py
index 6f31358dabe86..c6861b6f192c0 100644
--- a/pandas/compat/numpy/__init__.py
+++ b/pandas/compat/numpy/__init__.py
@@ -27,8 +27,24 @@
)
+def _is_nep18_active():
+ # copied from dask.array.utils
+
+ class A:
+ def __a... | Some day I hope to merge something like this, but for now it is mostly a demonstration for the numpy devs (cc @seberg not sure who else to ping) for how difficult it is to implement `__array_function__` correctly. The "ask" is for something like `_array_func_fallback` to be implemented upstream (xref similar request h... | https://api.github.com/repos/pandas-dev/pandas/pulls/51653 | 2023-02-26T18:44:06Z | 2023-03-09T18:31:53Z | null | 2023-03-09T18:32:00Z |
Backport PR #50918 on branch 2.0.x (ENH: Optimize replace to avoid copying when not necessary) | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 9b435aa31bd16..35a7855b8240f 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -552,6 +552,7 @@ def replace(
inplace: bool = False,
# mask may be pre-computed if we're called from r... | Backport PR #50918: ENH: Optimize replace to avoid copying when not necessary | https://api.github.com/repos/pandas-dev/pandas/pulls/51652 | 2023-02-26T18:42:34Z | 2023-02-26T22:01:48Z | 2023-02-26T22:01:48Z | 2023-02-26T22:01:49Z |
ENH: Add na_position support to midx.sort_values | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index fc09f3d5853a2..23e06b8f0af6e 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -28,6 +28,7 @@ enhancement2
Other enhancements
^^^^^^^^^^^^^^^^^^
+- :meth:`MultiIndex.sort_values` now supports ``na_po... | - [ ] xref #51612 (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51651 | 2023-02-26T18:07:14Z | 2023-03-08T21:51:23Z | 2023-03-08T21:51:23Z | 2023-03-08T23:45:50Z |
Backport PR #51239 on branch 2.0.x (API / CoW: constructing DataFrame from DataFrame/BlockManager creates lazy copy) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index caacf8a5b9f43..2e7a9ca452607 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -246,6 +246,10 @@ Copy-on-Write improvements
a modification to the data happens) when constructing a Series from an exist... | Backport PR #51239: API / CoW: constructing DataFrame from DataFrame/BlockManager creates lazy copy | https://api.github.com/repos/pandas-dev/pandas/pulls/51650 | 2023-02-26T17:43:41Z | 2023-02-26T20:20:03Z | 2023-02-26T20:20:03Z | 2023-02-26T20:20:03Z |
WEB: Fix blog links | diff --git a/web/pandas/community/blog/index.html b/web/pandas/community/blog/index.html
index 154d9cccdb7dc..6f0bee2e11407 100644
--- a/web/pandas/community/blog/index.html
+++ b/web/pandas/community/blog/index.html
@@ -4,10 +4,10 @@
{% for post in blog.posts %}
<div class="card">
<div class... | Supersedes #51637
Fix the links in the blog.
| https://api.github.com/repos/pandas-dev/pandas/pulls/51649 | 2023-02-26T17:41:02Z | 2023-02-26T20:20:49Z | 2023-02-26T20:20:49Z | 2023-02-26T20:20:54Z |
EHN: allow for to_sql `multi` method with oracle backend | diff --git a/doc/source/whatsnew/v2.2.0.rst b/doc/source/whatsnew/v2.2.0.rst
index ea7850b6f2a5f..cbf409cd24246 100644
--- a/doc/source/whatsnew/v2.2.0.rst
+++ b/doc/source/whatsnew/v2.2.0.rst
@@ -74,6 +74,7 @@ enhancement2
Other enhancements
^^^^^^^^^^^^^^^^^^
+- :meth:`to_sql` with method parameter set to ``multi... | - [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added an entry in the latest `doc/source/whatsnew/v2.2.0.rst` file if fixing a bug or adding a new feature.
| https://api.github.com/repos/pandas-dev/pandas/pulls/51648 | 2023-02-26T14:00:59Z | 2023-10-18T00:36:06Z | 2023-10-18T00:36:06Z | 2023-10-18T00:36:06Z |
ENH: add na_action to Categorical.map & CategoricalIndex.map | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 38faf90f1de74..5646aa5947bee 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -28,6 +28,9 @@ enhancement2
Other enhancements
^^^^^^^^^^^^^^^^^^
+- :meth:`Categorical.map` and :meth:`CategoricalIndex... | - [x] closes #44279
- [x] closes #22527
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.htm... | https://api.github.com/repos/pandas-dev/pandas/pulls/51645 | 2023-02-26T06:56:51Z | 2023-03-30T16:10:51Z | 2023-03-30T16:10:51Z | 2023-03-30T16:29:46Z |
API: ArrowExtensionArray._cmp_method to return pyarrow.bool_ type | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 47a61d41b2440..10f735abf0e18 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -86,7 +86,7 @@ See :ref:`install.dependencies` and :ref:`install.optional_dependencies` for mor
Other API changes
^^^^^^... | - [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotati... | https://api.github.com/repos/pandas-dev/pandas/pulls/51643 | 2023-02-26T01:13:51Z | 2023-03-09T17:11:48Z | 2023-03-09T17:11:48Z | 2023-03-17T22:04:20Z |
Backport PR #51626 on branch 2.0.x (DOC: Improvements to groupby.rst) | diff --git a/doc/source/user_guide/groupby.rst b/doc/source/user_guide/groupby.rst
index 2fdd36d861e15..15baedbac31ba 100644
--- a/doc/source/user_guide/groupby.rst
+++ b/doc/source/user_guide/groupby.rst
@@ -36,9 +36,22 @@ following:
* Discard data that belongs to groups with only a few members.
* Filter out... | Backport PR #51626: DOC: Improvements to groupby.rst | https://api.github.com/repos/pandas-dev/pandas/pulls/51642 | 2023-02-26T00:24:03Z | 2023-02-26T03:05:27Z | 2023-02-26T03:05:27Z | 2023-02-26T03:05:28Z |
ENH: Add downcast as method to DataFrame and Series | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 12d35288d1ee6..06746192532fd 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -28,6 +28,7 @@ enhancement2
Other enhancements
^^^^^^^^^^^^^^^^^^
+- Added :meth:`DataFrame.downcast` and :meth:`Series.... | - [ ] xref #40988 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51641 | 2023-02-26T00:14:09Z | 2023-05-05T10:33:14Z | null | 2023-08-28T21:09:22Z |
COMPAT: Update code for latest Cython 3 beta | diff --git a/.github/workflows/ubuntu.yml b/.github/workflows/ubuntu.yml
index 0b42a71c8c13b..951cf24c2168d 100644
--- a/.github/workflows/ubuntu.yml
+++ b/.github/workflows/ubuntu.yml
@@ -15,9 +15,6 @@ on:
- "doc/**"
- "web/**"
-env:
- PANDAS_CI: 1
-
permissions:
contents: read
@@ -33,6 +30,7 @@... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51640 | 2023-02-25T23:40:50Z | 2023-03-01T22:54:28Z | 2023-03-01T22:54:28Z | 2023-03-10T18:21:20Z |
Backport PR #51411 on branch 2.0.x (ENH: Optimize CoW for fillna with ea dtypes) | diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 1aba48371b430..9b435aa31bd16 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -1758,9 +1758,14 @@ def fillna(
downcast=downcast,
using_cow=using_cow,
)... | Backport PR #51411: ENH: Optimize CoW for fillna with ea dtypes | https://api.github.com/repos/pandas-dev/pandas/pulls/51639 | 2023-02-25T22:47:02Z | 2023-02-26T00:23:07Z | 2023-02-26T00:23:07Z | 2023-02-26T00:23:07Z |
CI: Don't run tests when web folder is updated | diff --git a/.github/workflows/macos-windows.yml b/.github/workflows/macos-windows.yml
index bc6ecd7c5e5d0..647dcf715c956 100644
--- a/.github/workflows/macos-windows.yml
+++ b/.github/workflows/macos-windows.yml
@@ -13,6 +13,7 @@ on:
- 1.5.x
paths-ignore:
- "doc/**"
+ - "web/**"
env:
PAND... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51638 | 2023-02-25T22:42:20Z | 2023-02-26T08:16:48Z | 2023-02-26T08:16:48Z | 2023-02-28T23:40:34Z |
WEB: Fix redirect of blog posts | diff --git a/web/pandas/community/blog/index.html b/web/pandas/community/blog/index.html
index 154d9cccdb7dc..627aaa450893b 100644
--- a/web/pandas/community/blog/index.html
+++ b/web/pandas/community/blog/index.html
@@ -4,10 +4,10 @@
{% for post in blog.posts %}
<div class="card">
<div class... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51637 | 2023-02-25T20:07:07Z | 2023-02-26T17:45:34Z | null | 2023-02-26T17:45:40Z |
Backport PR #51571 on branch 2.0.x (ENH: DataFrame.fillna making deep copy for dict arg) | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index 81d15de4f833a..65f76f7e295a6 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -6876,8 +6876,10 @@ def fillna(
"with dict/Series column "
"by column"
)
-
- ... | Backport PR #51571: ENH: DataFrame.fillna making deep copy for dict arg | https://api.github.com/repos/pandas-dev/pandas/pulls/51636 | 2023-02-25T17:45:38Z | 2023-02-25T20:52:52Z | 2023-02-25T20:52:52Z | 2023-02-25T20:52:53Z |
PERF: ArrowExtensionArray.fillna when array does not contains any nulls | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index c6783e46faaee..3f898ca23bd6f 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -120,6 +120,7 @@ Performance improvements
- Performance improvement in :func:`read_parquet` and :meth:`DataFrame.to_parquet... | - [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotati... | https://api.github.com/repos/pandas-dev/pandas/pulls/51635 | 2023-02-25T17:06:20Z | 2023-03-17T23:46:30Z | 2023-03-17T23:46:30Z | 2023-03-18T11:01:29Z |
DOC trying to improve readability of example | diff --git a/pandas/errors/__init__.py b/pandas/errors/__init__.py
index 3ecee50ffbaa7..c4b804de6a110 100644
--- a/pandas/errors/__init__.py
+++ b/pandas/errors/__init__.py
@@ -455,12 +455,14 @@ class CSSWarning(UserWarning):
Examples
--------
>>> df = pd.DataFrame({'A': [1, 1, 1]})
- >>> (df.style.ap... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51634 | 2023-02-25T16:28:42Z | 2023-02-25T17:40:38Z | 2023-02-25T17:40:38Z | 2023-02-26T09:29:34Z |
Backport PR #51627 on branch 2.0.x (BUG: Change default of group_keys to True) | diff --git a/pandas/core/frame.py b/pandas/core/frame.py
index 906535377e80f..70f39956c6676 100644
--- a/pandas/core/frame.py
+++ b/pandas/core/frame.py
@@ -8208,7 +8208,7 @@ def groupby(
level: IndexLabel | None = None,
as_index: bool = True,
sort: bool = True,
- group_keys: bool | li... | Backport PR #51627: BUG: Change default of group_keys to True | https://api.github.com/repos/pandas-dev/pandas/pulls/51632 | 2023-02-25T15:26:07Z | 2023-02-25T17:33:31Z | 2023-02-25T17:33:31Z | 2023-02-25T17:33:31Z |
BUG: Series.any and Series.all for empty or all-null pyarrow-backed dtypes | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index cb72b68fd319b..fd7593737387f 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -199,7 +199,7 @@ Sparse
ExtensionArray
^^^^^^^^^^^^^^
--
+- Bug in :meth:`Series.any` and :meth:`Series.all` returning `... | - [x] closes #51624
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51631 | 2023-02-25T15:19:14Z | 2023-02-25T21:23:14Z | 2023-02-25T21:23:14Z | 2023-03-17T22:04:33Z |
PERF: ArrowExtensionArray.isna when zero nulls or all nulls | diff --git a/asv_bench/benchmarks/frame_methods.py b/asv_bench/benchmarks/frame_methods.py
index ac6ac6f576891..f3eaa3f114b72 100644
--- a/asv_bench/benchmarks/frame_methods.py
+++ b/asv_bench/benchmarks/frame_methods.py
@@ -444,6 +444,22 @@ def time_dropna_axis_mixed_dtypes(self, how, axis):
self.df_mixed.dro... | - [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotati... | https://api.github.com/repos/pandas-dev/pandas/pulls/51630 | 2023-02-25T14:32:05Z | 2023-02-25T17:37:06Z | 2023-02-25T17:37:06Z | 2023-03-17T22:04:35Z |
BUG: Change default of group_keys to True | diff --git a/pandas/core/frame.py b/pandas/core/frame.py
index dd37b94b6428b..05c2348043701 100644
--- a/pandas/core/frame.py
+++ b/pandas/core/frame.py
@@ -8211,7 +8211,7 @@ def groupby(
level: IndexLabel | None = None,
as_index: bool = True,
sort: bool = True,
- group_keys: bool | li... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51627 | 2023-02-25T03:24:16Z | 2023-02-25T15:25:40Z | 2023-02-25T15:25:40Z | 2023-02-25T15:44:47Z |
DOC: Improvements to groupby.rst | diff --git a/doc/source/user_guide/groupby.rst b/doc/source/user_guide/groupby.rst
index 2fdd36d861e15..15baedbac31ba 100644
--- a/doc/source/user_guide/groupby.rst
+++ b/doc/source/user_guide/groupby.rst
@@ -36,9 +36,22 @@ following:
* Discard data that belongs to groups with only a few members.
* Filter out... | - [x] closes #46415 (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51626 | 2023-02-25T02:48:22Z | 2023-02-26T00:23:54Z | 2023-02-26T00:23:54Z | 2023-03-02T01:02:44Z |
ENH: use native filesystem (if available) for read_orc | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 3b24310014ff8..839ab8d50df43 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -103,7 +103,7 @@ Performance improvements
- Performance improvement in :meth:`DataFrame.first_valid_index` and :meth:`DataF... | Similar to https://github.com/pandas-dev/pandas/pull/51609 | https://api.github.com/repos/pandas-dev/pandas/pulls/51623 | 2023-02-24T23:35:16Z | 2023-02-25T21:49:51Z | 2023-02-25T21:49:51Z | 2023-02-25T21:51:43Z |
REF: remove iterate_slices | diff --git a/pandas/core/groupby/generic.py b/pandas/core/groupby/generic.py
index 499bef2b61046..3dfad7f172cda 100644
--- a/pandas/core/groupby/generic.py
+++ b/pandas/core/groupby/generic.py
@@ -15,7 +15,6 @@
Any,
Callable,
Hashable,
- Iterable,
Literal,
Mapping,
NamedTuple,
@@ -1337,... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51622 | 2023-02-24T23:15:10Z | 2023-02-25T20:56:51Z | 2023-02-25T20:56:51Z | 2023-02-25T21:14:05Z |
Backport PR #51542 on branch 2.0.x (API: ArrowExtensionArray.value_counts returns pyarrow.int64 type) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index 58c6b51752b26..caacf8a5b9f43 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -818,6 +818,7 @@ Other API changes
- :class:`DataFrame` and :class:`DataFrameGroupBy` aggregations (e.g. "sum") with object... | Backport PR #51542: API: ArrowExtensionArray.value_counts returns pyarrow.int64 type | https://api.github.com/repos/pandas-dev/pandas/pulls/51620 | 2023-02-24T22:21:59Z | 2023-02-25T01:52:36Z | 2023-02-25T01:52:36Z | 2023-02-25T01:52:37Z |
Backport PR #51514 on branch 2.0.x (DOC: object_dtype_tzaware_strings.atype(dt64) raises) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index e2705b353858b..94604fd843df1 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1214,6 +1214,7 @@ Datetimelike
- Bug in :func:`DataFrame.from_records` when given a :class:`DataFrame` input with timezone... | Backport PR #51514: DOC: object_dtype_tzaware_strings.atype(dt64) raises | https://api.github.com/repos/pandas-dev/pandas/pulls/51619 | 2023-02-24T19:49:41Z | 2023-02-24T21:57:09Z | 2023-02-24T21:57:09Z | 2023-02-24T21:57:10Z |
Backport PR #51585 on branch 2.0.x (BUG: not broadcasting when setting empty object) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index e2705b353858b..8896799ffa613 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1276,6 +1276,7 @@ Indexing
- Bug in :meth:`DataFrame.sort_values` where ``None`` was not returned when ``by`` is empty lis... | Backport PR #51585: BUG: not broadcasting when setting empty object | https://api.github.com/repos/pandas-dev/pandas/pulls/51618 | 2023-02-24T19:13:31Z | 2023-02-24T21:16:47Z | 2023-02-24T21:16:47Z | 2023-02-24T21:16:47Z |
Backport PR #51605 on branch 2.0.x (REGR: MultiIndex.isin with empty iterable raising) | diff --git a/pandas/core/indexes/multi.py b/pandas/core/indexes/multi.py
index 92cb7b5fd5f47..b381752818ba0 100644
--- a/pandas/core/indexes/multi.py
+++ b/pandas/core/indexes/multi.py
@@ -3748,6 +3748,8 @@ def delete(self, loc) -> MultiIndex:
@doc(Index.isin)
def isin(self, values, level=None) -> npt.NDArray... | Backport PR #51605: REGR: MultiIndex.isin with empty iterable raising | https://api.github.com/repos/pandas-dev/pandas/pulls/51617 | 2023-02-24T18:55:20Z | 2023-02-24T21:16:22Z | 2023-02-24T21:16:21Z | 2023-02-24T21:16:22Z |
STYLE: replace unwanted-patterns-strings-to-concatenate with ruff #51406 #51591 | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index f369fcabe3f01..33e475d4a9e20 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -342,11 +342,6 @@ repos:
(?x)
^(asv_bench|pandas/tests|doc)/
|scripts/validate_min_versions_in_sync\.py$
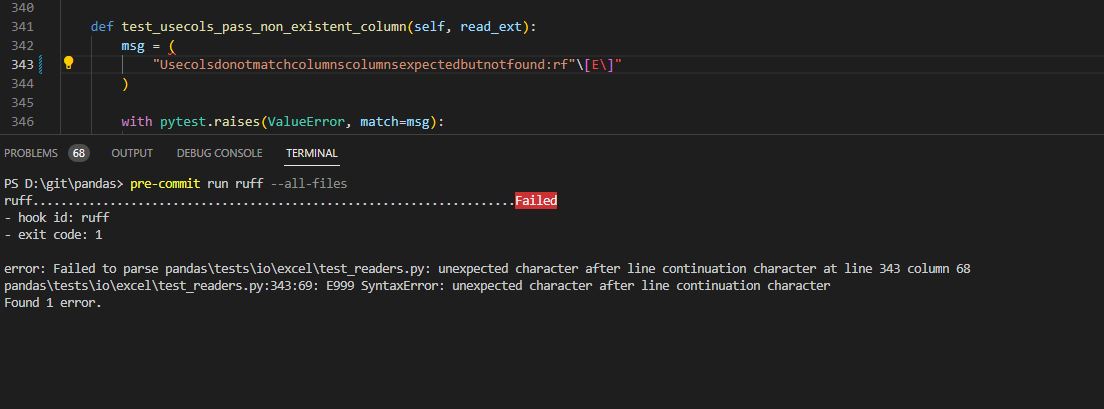
- - ... | 
| https://api.github.com/repos/pandas-dev/pandas/pulls/51615 | 2023-02-24T17:16:43Z | 2023-02-24T17:23:54Z | null | 2023-02-24T18:21:37Z |
DOC: fix EX02 errors in docstrings | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index 47e3ce0ae6ff7..2d5e9cc031158 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -567,9 +567,7 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
pandas.plotting.andrews_curves \
pandas.plotting.autocorrelation_plot \
panda... | Some work towards issue https://github.com/pandas-dev/pandas/issues/51236
Makes docstrings pass EX02 error for:
```
pandas.plotting.radviz
pandas.tseries.frequencies.to_offset
``` | https://api.github.com/repos/pandas-dev/pandas/pulls/51614 | 2023-02-24T16:23:31Z | 2023-02-27T21:14:53Z | 2023-02-27T21:14:53Z | 2023-02-27T21:14:53Z |
STYLE: replace unwanted-patterns-strings-to-concatenate with ruff | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index b1028ea9f52c3..576c929c26b9b 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -342,11 +342,6 @@ repos:
(?x)
^(asv_bench|pandas/tests|doc)/
|scripts/validate_min_versions_in_sync\.py$
- - ... | - [x] closes #51406
`Unwanted-patterns-strings-to-concatenate` replaced with ruff. | https://api.github.com/repos/pandas-dev/pandas/pulls/51613 | 2023-02-24T14:26:16Z | 2023-02-27T15:28:00Z | 2023-02-27T15:28:00Z | 2023-02-27T15:28:17Z |
BUG: Weighted rolling aggregations min_periods=0 | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 45b5c16415f9d..a60d4806252dd 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -187,6 +187,7 @@ Plotting
Groupby/resample/rolling
^^^^^^^^^^^^^^^^^^^^^^^^
- Bug in :meth:`DataFrameGroupBy.idxmin`, :me... | - [x] closes #51449
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [ ]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51611 | 2023-02-24T10:56:29Z | 2023-03-04T01:30:58Z | 2023-03-04T01:30:58Z | 2023-03-04T01:31:12Z |
Fix EX02 error:is_{integer,string}_dtype | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index c2ec22020bca2..47e3ce0ae6ff7 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -564,8 +564,6 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
pandas.api.types.is_datetime64_any_dtype \
pandas.api.types.is_datetime64_ns_dtype \
... | To fix issue #51236
| https://api.github.com/repos/pandas-dev/pandas/pulls/51610 | 2023-02-24T04:18:20Z | 2023-02-24T11:56:30Z | 2023-02-24T11:56:30Z | 2023-02-24T12:28:55Z |
ENH: use native filesystem (if available) for read_parquet with pyarrow engine | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 4fa5d7c6f392f..6e38983b39409 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -112,7 +112,8 @@ Performance improvements
- Performance improvement in :meth:`DataFrame.clip` and :meth:`Series.clip` (:iss... | Reboot of https://github.com/pandas-dev/pandas/pull/41194 cc @jorisvandenbossche | https://api.github.com/repos/pandas-dev/pandas/pulls/51609 | 2023-02-24T02:21:07Z | 2023-03-14T21:14:25Z | 2023-03-14T21:14:25Z | 2023-03-14T21:44:45Z |
CI: Debug segfaults on npdev | diff --git a/.github/actions/setup-conda/action.yml b/.github/actions/setup-conda/action.yml
index 002d0020c2df1..fce0cf4054ba2 100644
--- a/.github/actions/setup-conda/action.yml
+++ b/.github/actions/setup-conda/action.yml
@@ -32,5 +32,5 @@ runs:
channels: conda-forge
channel-priority: ${{ runner.os... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51608 | 2023-02-24T02:02:14Z | 2023-02-28T22:16:09Z | null | 2023-02-28T22:16:12Z |
Backport PR #51548 on branch 2.0.x (BUG: parsing pyarrow dtypes corner case) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index bdbde438217b9..0e9994a6b1988 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1417,7 +1417,7 @@ Metadata
Other
^^^^^
-
+- Bug in incorrectly accepting dtype strings containing "[pyarrow]" more than... | Backport PR #51548: BUG: parsing pyarrow dtypes corner case | https://api.github.com/repos/pandas-dev/pandas/pulls/51606 | 2023-02-23T23:38:14Z | 2023-02-24T03:00:37Z | 2023-02-24T03:00:37Z | 2023-02-24T03:00:38Z |
REGR: MultiIndex.isin with empty iterable raising | diff --git a/pandas/core/indexes/multi.py b/pandas/core/indexes/multi.py
index 92cb7b5fd5f47..b381752818ba0 100644
--- a/pandas/core/indexes/multi.py
+++ b/pandas/core/indexes/multi.py
@@ -3748,6 +3748,8 @@ def delete(self, loc) -> MultiIndex:
@doc(Index.isin)
def isin(self, values, level=None) -> npt.NDArray... | - [ ] closes #51599 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51605 | 2023-02-23T23:33:21Z | 2023-02-24T18:54:48Z | 2023-02-24T18:54:48Z | 2023-08-28T21:09:50Z |
CLN: Remove read_orc dtype checking | diff --git a/pandas/io/orc.py b/pandas/io/orc.py
index 5336e2a14f66d..4623539a19413 100644
--- a/pandas/io/orc.py
+++ b/pandas/io/orc.py
@@ -21,13 +21,6 @@
)
from pandas.compat._optional import import_optional_dependency
-from pandas.core.dtypes.common import (
- is_categorical_dtype,
- is_interval_dtype,
- ... | Benefit of `read_orc` immediately working if/when pyarrow ORC reader support any of the previously excluded types | https://api.github.com/repos/pandas-dev/pandas/pulls/51604 | 2023-02-23T23:01:10Z | 2023-02-24T01:13:44Z | 2023-02-24T01:13:44Z | 2023-02-24T02:02:11Z |
BUG: stack doesn't preserve lower precision floating dtypes | diff --git a/pandas/core/reshape/reshape.py b/pandas/core/reshape/reshape.py
index eaeb4a50d0bf3..7e27c924bfbed 100644
--- a/pandas/core/reshape/reshape.py
+++ b/pandas/core/reshape/reshape.py
@@ -747,7 +747,18 @@ def _convert_level_number(level_num: int, columns: Index):
if slice_len != levsize:
... | - [ ] closes #51059 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51602 | 2023-02-23T22:46:39Z | 2023-08-25T18:08:43Z | null | 2023-08-25T18:08:49Z |
DOC: Add orient=table explanation to read_json doc | diff --git a/pandas/io/json/_json.py b/pandas/io/json/_json.py
index 335d510666a1f..80d2f9eda7ce5 100644
--- a/pandas/io/json/_json.py
+++ b/pandas/io/json/_json.py
@@ -540,6 +540,7 @@ def read_json(
- ``'index'`` : dict like ``{{index -> {{column -> value}}}}``
- ``'columns'`` : dict like ``{{column ... | - [x] closes #51588
Add an explanation of `orient='table'` to the documentation of `pandas.read_json` | https://api.github.com/repos/pandas-dev/pandas/pulls/51601 | 2023-02-23T22:38:05Z | 2023-02-24T01:13:08Z | 2023-02-24T01:13:08Z | 2023-02-24T01:13:13Z |
Backport PR #49228 on branch 2.0.x (CLN/FIX/PERF: Don't buffer entire Stata file into memory) | diff --git a/doc/source/user_guide/io.rst b/doc/source/user_guide/io.rst
index 91cd3335d9db6..3c3a655626bb6 100644
--- a/doc/source/user_guide/io.rst
+++ b/doc/source/user_guide/io.rst
@@ -6033,6 +6033,14 @@ values will have ``object`` data type.
``int64`` for all integer types and ``float64`` for floating point da... | Backport PR #49228: CLN/FIX/PERF: Don't buffer entire Stata file into memory | https://api.github.com/repos/pandas-dev/pandas/pulls/51600 | 2023-02-23T22:09:37Z | 2023-02-24T00:15:34Z | 2023-02-24T00:15:34Z | 2023-02-24T00:15:34Z |
TST: Make tests less stateful | diff --git a/pandas/core/groupby/groupby.py b/pandas/core/groupby/groupby.py
index 39ba102ab3782..3973dc18abd59 100644
--- a/pandas/core/groupby/groupby.py
+++ b/pandas/core/groupby/groupby.py
@@ -3184,12 +3184,15 @@ def post_processor(
# Item "ExtensionDtype" of "Union[ExtensionDtype, str,
... | - closes #34373
Removing more statefulness in tests found by pytest-randomly.
Another issue should probably be opened up regarding `attrs` not being propagated correctly in binary operations. | https://api.github.com/repos/pandas-dev/pandas/pulls/51598 | 2023-02-23T21:29:14Z | 2023-02-23T23:35:44Z | 2023-02-23T23:35:44Z | 2023-02-23T23:58:20Z |
DOC: fix EX02 docstring errors for three plotting docstrings | Some work towards issue https://github.com/pandas-dev/pandas/issues/51236
The issue is being worked on by several people and has more docstrings remaining to do.
Makes docstrings pass for:
`pandas.plotting.andrews_curves`
`pandas.plotting.autocorrelation_plot`
`pandas.plotting.lag_plot` | https://api.github.com/repos/pandas-dev/pandas/pulls/51596 | 2023-02-23T20:19:06Z | 2023-02-28T05:02:43Z | null | 2023-02-28T06:14:44Z | |
Backport PR #51545 on branch 2.0.x (TST/CLN: Remove unnecessary pyarrow version checking) | diff --git a/pandas/core/arrays/arrow/array.py b/pandas/core/arrays/arrow/array.py
index 5c09a7a28856f..4facc194978d5 100644
--- a/pandas/core/arrays/arrow/array.py
+++ b/pandas/core/arrays/arrow/array.py
@@ -569,14 +569,8 @@ def argsort(
) -> np.ndarray:
order = "ascending" if ascending else "descending"... | Backport PR #51545: TST/CLN: Remove unnecessary pyarrow version checking | https://api.github.com/repos/pandas-dev/pandas/pulls/51595 | 2023-02-23T18:54:04Z | 2023-02-23T22:12:04Z | 2023-02-23T22:12:04Z | 2023-02-23T22:12:05Z |
REF: de-duplicate precision_from_unit attempt 2 | diff --git a/pandas/_libs/tslib.pyx b/pandas/_libs/tslib.pyx
index 19dd7aabe6b8e..d828ea424c5a0 100644
--- a/pandas/_libs/tslib.pyx
+++ b/pandas/_libs/tslib.pyx
@@ -56,7 +56,6 @@ from pandas._libs.tslibs.conversion cimport (
convert_timezone,
get_datetime64_nanos,
parse_pydatetime,
- precision_from_un... | precision_from_unit is getting called in situations where it shouldn't be. | https://api.github.com/repos/pandas-dev/pandas/pulls/51594 | 2023-02-23T18:22:48Z | 2023-02-24T19:02:36Z | 2023-02-24T19:02:36Z | 2023-02-24T19:05:58Z |
DOC Fix EX01 issues in docstrings | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index 759e07018a190..c2ec22020bca2 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -92,8 +92,6 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
pandas.Series.keys \
pandas.Series.item \
pandas.Series.pipe \
- pandas.... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51593 | 2023-02-23T17:54:53Z | 2023-02-23T21:39:39Z | 2023-02-23T21:39:39Z | 2023-02-24T08:43:10Z |
PERF: maybe_promote | diff --git a/pandas/core/dtypes/cast.py b/pandas/core/dtypes/cast.py
index 5877c60df41fd..8aadb67aea533 100644
--- a/pandas/core/dtypes/cast.py
+++ b/pandas/core/dtypes/cast.py
@@ -23,6 +23,7 @@
from pandas._libs.missing import (
NA,
NAType,
+ checknull,
)
from pandas._libs.tslibs import (
NaT,
@@ ... | Test runtime for pandas/tests/indexing/multiindex/test_indexing_slow.py decreases from 30s to 14.5s.
See discussion around https://github.com/pandas-dev/pandas/pull/39692#issuecomment-1441051740 | https://api.github.com/repos/pandas-dev/pandas/pulls/51592 | 2023-02-23T17:43:34Z | 2023-03-02T02:04:14Z | 2023-03-02T02:04:14Z | 2023-03-02T02:09:53Z |
STYLE: replace unwanted-patterns-strings-to-concatenate with ruff #51406 | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index f369fcabe3f01..33e475d4a9e20 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -342,11 +342,6 @@ repos:
(?x)
^(asv_bench|pandas/tests|doc)/
|scripts/validate_min_versions_in_sync\.py$
- - ... | null | https://api.github.com/repos/pandas-dev/pandas/pulls/51591 | 2023-02-23T17:42:08Z | 2023-02-24T16:58:14Z | null | 2023-02-24T17:14:57Z |
CI: Try numpydev skip test | diff --git a/.github/workflows/32-bit-linux.yml b/.github/workflows/32-bit-linux.yml
index 4e363c7fd573d..e1b04f4a4391d 100644
--- a/.github/workflows/32-bit-linux.yml
+++ b/.github/workflows/32-bit-linux.yml
@@ -8,7 +8,6 @@ on:
- 1.5.x
pull_request:
branches:
- - main
- 2.0.x
- 1.5.x
... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51590 | 2023-02-23T16:05:14Z | 2023-03-01T23:20:22Z | null | 2023-03-01T23:20:23Z |
TST/bug: add test for NaT in Categorical.isin with empty string | diff --git a/pandas/tests/arrays/categorical/test_algos.py b/pandas/tests/arrays/categorical/test_algos.py
index ef165767ed5ed..d4c19a4970135 100644
--- a/pandas/tests/arrays/categorical/test_algos.py
+++ b/pandas/tests/arrays/categorical/test_algos.py
@@ -59,6 +59,15 @@ def test_isin_cats():
tm.assert_numpy_array... | - [x] closes #36550
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [ ]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51587 | 2023-02-23T12:09:01Z | 2023-02-24T19:10:21Z | 2023-02-24T19:10:21Z | 2023-02-24T19:10:28Z |
Backport PR #51573 on branch 2.0.x (CI: Fix failure due to warning) | diff --git a/pandas/tests/indexes/test_common.py b/pandas/tests/indexes/test_common.py
index d8e17e48a19b3..23677d77a5273 100644
--- a/pandas/tests/indexes/test_common.py
+++ b/pandas/tests/indexes/test_common.py
@@ -448,8 +448,15 @@ def test_hasnans_isnans(self, index_flat):
@pytest.mark.parametrize("na_position", ... | Backport PR #51573: CI: Fix failure due to warning | https://api.github.com/repos/pandas-dev/pandas/pulls/51586 | 2023-02-23T12:07:27Z | 2023-02-23T14:30:24Z | 2023-02-23T14:30:24Z | 2023-02-23T14:30:24Z |
BUG: not broadcasting when setting empty object | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index bdbde438217b9..a924b98237dbd 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -1273,6 +1273,7 @@ Indexing
- Bug in :meth:`DataFrame.sort_values` where ``None`` was not returned when ``by`` is empty lis... | - [ ] closes #51450 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51585 | 2023-02-23T12:02:34Z | 2023-02-24T19:13:22Z | 2023-02-24T19:13:22Z | 2023-08-28T21:09:51Z |
Revert "REF: de-duplicate precision_from_unit" | diff --git a/pandas/_libs/tslibs/conversion.pyx b/pandas/_libs/tslibs/conversion.pyx
index 18ea6bbb0a257..03a53b1b451e9 100644
--- a/pandas/_libs/tslibs/conversion.pyx
+++ b/pandas/_libs/tslibs/conversion.pyx
@@ -37,7 +37,6 @@ from pandas._libs.tslibs.np_datetime cimport (
NPY_FR_us,
check_dts_bounds,
co... | Reverts pandas-dev/pandas#51483 | https://api.github.com/repos/pandas-dev/pandas/pulls/51584 | 2023-02-23T11:10:03Z | 2023-02-23T14:15:54Z | 2023-02-23T14:15:54Z | 2023-02-23T14:16:09Z |
Add `ScatterPlot._scatter()`, similar to `HistPlot._plot()` | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 2ac20e97409e7..ef0afc459abfe 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -183,7 +183,7 @@ Period
Plotting
^^^^^^^^
--
+- Added :meth:`ScatterPlot._scatter()`, which is called by :meth:`ScatterP... | - [x] closes #51560
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [ ... | https://api.github.com/repos/pandas-dev/pandas/pulls/51582 | 2023-02-23T10:31:47Z | 2023-04-21T17:32:14Z | null | 2023-04-21T17:32:15Z |
Backport PR #51568 on branch 2.0.x (ENH: Series.fillna with empty argument making deep copy) | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index fdc54d70198bf..443daf2503632 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -6850,7 +6850,7 @@ def fillna(
# test_fillna_nonscalar
if inplace:
return Non... | Backport PR #51568: ENH: Series.fillna with empty argument making deep copy | https://api.github.com/repos/pandas-dev/pandas/pulls/51580 | 2023-02-23T10:18:10Z | 2023-02-23T14:29:28Z | 2023-02-23T14:29:28Z | 2023-02-23T14:29:28Z |
DOCS: fix category docs | diff --git a/doc/source/user_guide/categorical.rst b/doc/source/user_guide/categorical.rst
index e031a1443bc6f..1bd20b54242e6 100644
--- a/doc/source/user_guide/categorical.rst
+++ b/doc/source/user_guide/categorical.rst
@@ -263,14 +263,6 @@ All instances of ``CategoricalDtype`` compare equal to the string ``'category'... | - [x] closes #46770
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [ ]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51579 | 2023-02-23T10:14:34Z | 2023-02-24T19:14:48Z | 2023-02-24T19:14:48Z | 2023-02-24T19:18:01Z |
DOC: fix EX02 errors in docstrings | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index e8a9963438648..752ad23648ee2 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -569,14 +569,11 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
$BASE_DIR/scripts/validate_docstrings.py --format=actions --errors=EX02 --ignore_functions \
... | Related to issue #51236
This PR enables functions:
`pandas.api.types.infer_dtype`
`pandas.api.types.is_sparse`
`pandas.api.types.is_unsigned_integer_dtype`
EX03 errors appeared in the pr #51529 were fixed. | https://api.github.com/repos/pandas-dev/pandas/pulls/51578 | 2023-02-23T10:00:11Z | 2023-02-23T14:27:35Z | 2023-02-23T14:27:35Z | 2023-02-23T14:27:36Z |
Add `keep_whitespace` and `whitespace_chars` to `read_fwf` | diff --git a/doc/source/user_guide/io.rst b/doc/source/user_guide/io.rst
index 91cd7315f7213..115c0e7eaf8b0 100644
--- a/doc/source/user_guide/io.rst
+++ b/doc/source/user_guide/io.rst
@@ -1373,8 +1373,7 @@ Files with fixed width columns
While :func:`read_csv` reads delimited data, the :func:`read_fwf` function work... | - [x] closes #51569
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51577 | 2023-02-23T09:53:32Z | 2023-07-07T17:42:35Z | null | 2023-07-07T17:42:35Z |
BUG: TDI divison giving bogus .freq | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 1eab7b2fc411f..ed85b952e3bcd 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -124,6 +124,7 @@ Datetimelike
Timedelta
^^^^^^^^^
- Bug in :meth:`Timedelta.round` with values close to the implementatio... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51575 | 2023-02-23T00:58:55Z | 2023-02-25T20:38:18Z | 2023-02-25T20:38:18Z | 2023-02-25T21:15:33Z |
PERF: DataFrame.where for EA dtype mask | diff --git a/asv_bench/benchmarks/frame_methods.py b/asv_bench/benchmarks/frame_methods.py
index f3eaa3f114b72..f7da4882b0d3f 100644
--- a/asv_bench/benchmarks/frame_methods.py
+++ b/asv_bench/benchmarks/frame_methods.py
@@ -770,6 +770,21 @@ def time_memory_usage_object_dtype(self):
self.df2.memory_usage(deep=... | - [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x] Added [type annotati... | https://api.github.com/repos/pandas-dev/pandas/pulls/51574 | 2023-02-23T00:21:36Z | 2023-02-25T21:50:58Z | 2023-02-25T21:50:58Z | 2023-03-17T22:04:33Z |
CI: Fix failure due to warning | diff --git a/pandas/tests/indexes/test_common.py b/pandas/tests/indexes/test_common.py
index d8e17e48a19b3..23677d77a5273 100644
--- a/pandas/tests/indexes/test_common.py
+++ b/pandas/tests/indexes/test_common.py
@@ -448,8 +448,15 @@ def test_hasnans_isnans(self, index_flat):
@pytest.mark.parametrize("na_position", ... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51573 | 2023-02-23T00:05:55Z | 2023-02-23T12:07:18Z | 2023-02-23T12:07:18Z | 2023-02-23T16:19:31Z |
Backport PR #51566 on branch 2.0.x (DOC: Clean whatsnew links) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index 45a5d139349e9..243a6cb46be56 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -72,7 +72,7 @@ Below is a possibly non-exhaustive list of changes:
2. The various numeric datetime attributes of :class:`Da... | Backport PR #51566: DOC: Clean whatsnew links | https://api.github.com/repos/pandas-dev/pandas/pulls/51572 | 2023-02-23T00:02:01Z | 2023-02-23T10:16:05Z | 2023-02-23T10:16:05Z | 2023-02-23T10:16:05Z |
ENH: DataFrame.fillna making deep copy for dict arg | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index 9bdfb8da0c7cb..a169f098a727d 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -6885,8 +6885,10 @@ def fillna(
"with dict/Series column "
"by column"
)
-
- ... | - [ ] xref #49473 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51571 | 2023-02-22T23:31:16Z | 2023-02-25T17:45:30Z | 2023-02-25T17:45:30Z | 2023-03-01T23:20:30Z |
Backport PR #51312 on branch 2.0.x (CI/TST: Enable -W error:::pandas in pyproject.toml) | diff --git a/.github/workflows/macos-windows.yml b/.github/workflows/macos-windows.yml
index 7446ec00a87c9..bc6ecd7c5e5d0 100644
--- a/.github/workflows/macos-windows.yml
+++ b/.github/workflows/macos-windows.yml
@@ -18,8 +18,6 @@ env:
PANDAS_CI: 1
PYTEST_TARGET: pandas
PATTERN: "not slow and not db and not ne... | Backport PR #51312: CI/TST: Enable -W error:::pandas in pyproject.toml | https://api.github.com/repos/pandas-dev/pandas/pulls/51570 | 2023-02-22T23:31:02Z | 2023-02-23T11:25:22Z | 2023-02-23T11:25:22Z | 2023-02-23T11:25:22Z |
ENH: Series.fillna with empty argument making deep copy | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index 8e7d31f3f85e1..84f11ce9daa7a 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -6859,7 +6859,7 @@ def fillna(
# test_fillna_nonscalar
if inplace:
return Non... | - [ ] xref #49473 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/cont... | https://api.github.com/repos/pandas-dev/pandas/pulls/51568 | 2023-02-22T23:04:08Z | 2023-02-23T10:17:37Z | 2023-02-23T10:17:37Z | 2023-02-23T16:20:04Z |
DOC: Clean whatsnew links | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index eff79dda821a0..bdbde438217b9 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -72,7 +72,7 @@ Below is a possibly non-exhaustive list of changes:
2. The various numeric datetime attributes of :class:`Da... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51566 | 2023-02-22T22:07:48Z | 2023-02-23T00:01:54Z | 2023-02-23T00:01:54Z | 2023-02-23T00:06:29Z |
BUG: transpose inferring dtype for dt in object column | diff --git a/doc/source/whatsnew/v2.1.0.rst b/doc/source/whatsnew/v2.1.0.rst
index 12d35288d1ee6..9000b3fc446c5 100644
--- a/doc/source/whatsnew/v2.1.0.rst
+++ b/doc/source/whatsnew/v2.1.0.rst
@@ -195,7 +195,7 @@ Groupby/resample/rolling
Reshaping
^^^^^^^^^
--
+- Bug in :meth:`DataFrame.transpose` inferring dtype f... | - [x] closes #51546 (Replace xxxx with the GitHub issue number)
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51565 | 2023-02-22T21:57:32Z | 2023-03-07T19:40:00Z | 2023-03-07T19:39:59Z | 2023-03-07T22:29:21Z |
Backport PR #51430 on branch 2.0.x (BUG: transpose not respecting CoW) | diff --git a/doc/source/whatsnew/v2.0.0.rst b/doc/source/whatsnew/v2.0.0.rst
index 45a5d139349e9..eff79dda821a0 100644
--- a/doc/source/whatsnew/v2.0.0.rst
+++ b/doc/source/whatsnew/v2.0.0.rst
@@ -261,6 +261,8 @@ Copy-on-Write improvements
- :meth:`DataFrame.replace` will now respect the Copy-on-Write mechanism
whe... | Backport PR #51430: BUG: transpose not respecting CoW | https://api.github.com/repos/pandas-dev/pandas/pulls/51564 | 2023-02-22T21:33:39Z | 2023-02-23T10:16:27Z | 2023-02-23T10:16:27Z | 2023-02-23T10:16:28Z |
Auto Backport PR #50964 on branch 2.0.x (TST: Test ArrowExtensionArray with decimal types) | diff --git a/pandas/_testing/__init__.py b/pandas/_testing/__init__.py
index 00e949b1dd318..69ca809e4f498 100644
--- a/pandas/_testing/__init__.py
+++ b/pandas/_testing/__init__.py
@@ -215,6 +215,7 @@
FLOAT_PYARROW_DTYPES_STR_REPR = [
str(ArrowDtype(typ)) for typ in FLOAT_PYARROW_DTYPES
]
+ DECIMA... | * TST: Test ArrowExtensionArray with decimal types
* Version compat
* Add other xfails based on min version
* fix test
* fix typo
* another typo
* only for skipna
* Add comment
* Fix
* undo comments
* Bump version condition
* Skip masked indexing engine for decimal
* Some merge stuff... | https://api.github.com/repos/pandas-dev/pandas/pulls/51562 | 2023-02-22T20:35:42Z | 2023-02-22T23:32:38Z | 2023-02-22T23:32:38Z | 2023-02-22T23:42:08Z |
DOC Fix EX01 issues in docstrings | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index e8a9963438648..0317c251e66b0 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -92,13 +92,11 @@ if [[ -z "$CHECK" || "$CHECK" == "docstrings" ]]; then
pandas.Series.keys \
pandas.Series.item \
pandas.Series.pipe \
- panda... | - [ ] closes #xxxx (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/con... | https://api.github.com/repos/pandas-dev/pandas/pulls/51561 | 2023-02-22T19:27:24Z | 2023-02-23T00:03:28Z | 2023-02-23T00:03:27Z | 2023-02-23T13:59:25Z |
REGR: GH50127 fixes error for converting to / creating Index with dtype `S3` | diff --git a/.circleci/config.yml b/.circleci/config.yml
index e704c37df3e45..dfaade1d69c75 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -6,7 +6,7 @@ jobs:
image: ubuntu-2004:2022.04.1
resource_class: arm.large
environment:
- ENV_FILE: ci/deps/circle-38-arm64.yaml
+ ENV... | - [x] closes #50127
- [x] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [x] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#pre-commit).
- [x]... | https://api.github.com/repos/pandas-dev/pandas/pulls/51559 | 2023-02-22T17:11:30Z | 2023-11-27T18:47:41Z | null | 2023-11-27T18:47:41Z |
Backport PR #51469 on branch 2.0.x (DOC: Remove 1.0.0 versionadded/versionchanged) | diff --git a/doc/source/development/policies.rst b/doc/source/development/policies.rst
index d75262c08dfd6..d079cc59b0ca5 100644
--- a/doc/source/development/policies.rst
+++ b/doc/source/development/policies.rst
@@ -9,8 +9,6 @@ Policies
Version policy
~~~~~~~~~~~~~~
-.. versionchanged:: 1.0.0
-
pandas uses a loos... | Backport PR #51469: DOC: Remove 1.0.0 versionadded/versionchanged | https://api.github.com/repos/pandas-dev/pandas/pulls/51558 | 2023-02-22T17:10:08Z | 2023-02-22T21:02:09Z | 2023-02-22T21:02:09Z | 2023-02-22T21:02:09Z |
Backport PR #51552 on branch 2.0.x (DOC: Cleanup CoW dev docs) | diff --git a/doc/source/development/copy_on_write.rst b/doc/source/development/copy_on_write.rst
index 34625ed645615..757a871b495c5 100644
--- a/doc/source/development/copy_on_write.rst
+++ b/doc/source/development/copy_on_write.rst
@@ -14,15 +14,15 @@ behaves as a copy.
Reference tracking
------------------
-To be... | Backport PR #51552: DOC: Cleanup CoW dev docs | https://api.github.com/repos/pandas-dev/pandas/pulls/51556 | 2023-02-22T14:05:14Z | 2023-02-22T14:05:31Z | 2023-02-22T14:05:31Z | 2023-02-22T14:05:31Z |
TST: Add test for groupby rename categories with multiIndexes | diff --git a/pandas/tests/groupby/test_categorical.py b/pandas/tests/groupby/test_categorical.py
index dbbfab14d5c76..ac89a7d835270 100644
--- a/pandas/tests/groupby/test_categorical.py
+++ b/pandas/tests/groupby/test_categorical.py
@@ -2013,3 +2013,48 @@ def test_many_categories(as_index, sort, index_kind, ordered):
... | - [x] closes #51500 (Replace xxxx with the GitHub issue number)
- [ ] [Tests added and passed](https://pandas.pydata.org/pandas-docs/dev/development/contributing_codebase.html#writing-tests) if fixing a bug or adding a new feature
- [ ] All [code checks passed](https://pandas.pydata.org/pandas-docs/dev/development/co... | https://api.github.com/repos/pandas-dev/pandas/pulls/51555 | 2023-02-22T13:19:26Z | 2023-03-08T00:38:52Z | null | 2023-03-08T00:43:03Z |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.