
title stringlengths 2 169 | diff stringlengths 235 19.5k | body stringlengths 0 30.5k | url stringlengths 48 84 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 | updated_at stringlengths 20 20 | diff_len float64 101 3.99k | repo_name stringclasses 83
values | __index_level_0__ int64 15 52.7k |
|---|---|---|---|---|---|---|---|---|---|---|
poloniex error mapping | diff --git a/js/poloniex.js b/js/poloniex.js
index 40b212539ac1..e46db845be54 100644
--- a/js/poloniex.js
+++ b/js/poloniex.js
@@ -223,7 +223,7 @@ module.exports = class poloniex extends Exchange {
},
'broad': {
'Total must be at least': InvalidOrder, // {"error":"... | https://api.github.com/repos/ccxt/ccxt/pulls/11935 | 2022-02-11T19:42:44Z | 2022-02-11T20:24:14Z | 2022-02-11T20:24:14Z | 2022-02-11T20:24:14Z | 194 | ccxt/ccxt | 13,751 | |
livecoin safeSymbol | diff --git a/js/livecoin.js b/js/livecoin.js
index a9c7a7d70771..e729b7fcaa2e 100644
--- a/js/livecoin.js
+++ b/js/livecoin.js
@@ -448,21 +448,8 @@ module.exports = class livecoin extends Exchange {
cost = amount * price;
}
}
- let symbol = undefined;
const marketI... | https://api.github.com/repos/ccxt/ccxt/pulls/7679 | 2020-10-02T17:56:41Z | 2020-10-03T00:27:34Z | 2020-10-03T00:27:34Z | 2020-10-03T00:27:34Z | 582 | ccxt/ccxt | 13,385 | |
Update changing.py | diff --git a/manimlib/mobject/changing.py b/manimlib/mobject/changing.py
index 0f10f5e3a0..69e9302ba3 100644
--- a/manimlib/mobject/changing.py
+++ b/manimlib/mobject/changing.py
@@ -92,7 +92,7 @@ def update_path(self):
self.get_points()[-1] = new_point
# Second to last point
- np... | To fix the error of "AttributeError: 'TracedPath' object has no attribute 'n_points_per_cubic_curve'" (because in the CONFIG dictionary of VMobject class, the n_points_per_cubic_curve dose not exist, and now 'n_points_per_curve' is used instead) | https://api.github.com/repos/3b1b/manim/pulls/1386 | 2021-02-13T13:08:38Z | 2021-02-13T13:15:24Z | 2021-02-13T13:15:24Z | 2021-02-13T13:16:07Z | 163 | 3b1b/manim | 18,462 |
Fix typos (user-facing and non-user-facing | diff --git a/.github/workflows/release-snap.yml b/.github/workflows/release-snap.yml
index afb22e841f..c415edd76e 100644
--- a/.github/workflows/release-snap.yml
+++ b/.github/workflows/release-snap.yml
@@ -15,7 +15,7 @@ jobs:
strategy:
# If any of the stages fail, then we'll stop the action
- # to g... | Found via `codespell -q 3 -L datas,medias,warmup` | https://api.github.com/repos/httpie/cli/pulls/1357 | 2022-04-15T21:57:39Z | 2022-04-15T23:06:34Z | 2022-04-15T23:06:34Z | 2022-04-20T02:16:30Z | 1,765 | httpie/cli | 33,938 |
[generic] prefer enclosures over following links in rss feeds | diff --git a/youtube_dl/extractor/generic.py b/youtube_dl/extractor/generic.py
index e3cb5c5ce51..c548a164907 100644
--- a/youtube_dl/extractor/generic.py
+++ b/youtube_dl/extractor/generic.py
@@ -190,6 +190,16 @@ class GenericIE(InfoExtractor):
'title': 'pdv_maddow_netcast_m4v-02-27-2015-201624',
... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/16189 | 2018-04-14T15:39:25Z | 2018-04-29T15:14:38Z | 2018-04-29T15:14:38Z | 2018-04-29T17:21:14Z | 451 | ytdl-org/youtube-dl | 49,817 |
Updated registration.py | diff --git a/gym/envs/registration.py b/gym/envs/registration.py
index 7014939a4c4..fd23b9fce0a 100644
--- a/gym/envs/registration.py
+++ b/gym/envs/registration.py
@@ -1,7 +1,6 @@
import re
import copy
import importlib
-import warnings
from gym import error, logger
@@ -104,16 +103,6 @@ def make(self, path, **k... | Changes:
Re-registering the same environment ID in using gym.register() now raises a warning instead of an exception
Deprecate Python 2.7 by changing ImportError to ModuleNotFoundError
Remove the deprecated _step, _reset, and render(close) methods (These have been deprecated since at least 2018, but not removed)... | https://api.github.com/repos/openai/gym/pulls/2375 | 2021-08-29T17:20:28Z | 2021-09-01T18:27:01Z | 2021-09-01T18:27:01Z | 2021-09-01T18:27:01Z | 732 | openai/gym | 5,429 |
Disable Initial Prompt Task for en and es Locales | diff --git a/.github/workflows/deploy-to-node.yaml b/.github/workflows/deploy-to-node.yaml
index bbb04f7b3a..4a16cffd4c 100644
--- a/.github/workflows/deploy-to-node.yaml
+++ b/.github/workflows/deploy-to-node.yaml
@@ -38,6 +38,7 @@ jobs:
S3_REGION: ${{ secrets.S3_REGION }}
AWS_ACCESS_KEY: ${{ secrets.AWS... | To help clear the prompt backlog, as per https://github.com/LAION-AI/Open-Assistant/issues/1659, and Andreas's suggestions in https://github.com/LAION-AI/Open-Assistant/pull/1824, this adds the option to disable initial prompts for configured languages. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/1849 | 2023-02-24T19:40:18Z | 2023-04-04T20:48:16Z | 2023-04-04T20:48:16Z | 2023-04-04T20:52:00Z | 878 | LAION-AI/Open-Assistant | 37,424 |
ref(text-overflow): Update TextOverflow Component | diff --git a/docs-ui/components/textOverflow.stories.js b/docs-ui/components/textOverflow.stories.js
index 1bee66a89e19da..aa94836eb2277c 100644
--- a/docs-ui/components/textOverflow.stories.js
+++ b/docs-ui/components/textOverflow.stories.js
@@ -1,5 +1,6 @@
import React from 'react';
import {withInfo} from '@storybo... | Unites the `ParagraphOverflow` and `TextOverflow` components
Introduce the prop `ellipsisDirection` which can be `left` or `right`

:
for name in list(six.iterkeys(params)):
if '... | #### Reference Issues/PRs
fixes a typo introduced in #1769
#### What does this implement/fix? Explain your changes.
just fixes a small spelling mistake in a comment | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/10348 | 2017-12-20T19:17:21Z | 2017-12-20T22:16:56Z | 2017-12-20T22:16:56Z | 2017-12-20T22:16:56Z | 167 | scikit-learn/scikit-learn | 45,887 |
Add note to feature_request.yml about not opening issues for new algorithms | diff --git a/.github/ISSUE_TEMPLATE/feature_request.yml b/.github/ISSUE_TEMPLATE/feature_request.yml
index 09a159b2193e..20823bd58ab1 100644
--- a/.github/ISSUE_TEMPLATE/feature_request.yml
+++ b/.github/ISSUE_TEMPLATE/feature_request.yml
@@ -6,6 +6,7 @@ body:
attributes:
value: >
Before requesting... | ### Describe your change:
Modify feature_request.yml to indicate any issues about implementations of new algorithms will be closed.
See #9343
* [ ] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [x] Documentation change?
### Checklist:
* [x] I have read [CONTRIBUTING.md](https... | https://api.github.com/repos/TheAlgorithms/Python/pulls/10142 | 2023-10-08T20:13:53Z | 2023-10-15T23:44:07Z | 2023-10-15T23:44:07Z | 2023-10-15T23:44:07Z | 238 | TheAlgorithms/Python | 29,544 |
Update README.md | diff --git a/README.md b/README.md
index baddd8b864..86c2a080ba 100644
--- a/README.md
+++ b/README.md
@@ -100,14 +100,14 @@ For a new language request, please refer to [Guideline for new language_requests
- [Quick Start](./doc/doc_en/quickstart_en.md)
- [PaddleOCR Overview and Installation](./doc/doc_en/paddleOCR_ov... | Update README.md | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/3960 | 2021-09-07T13:30:37Z | 2021-09-07T13:30:47Z | 2021-09-07T13:30:47Z | 2021-09-07T13:30:47Z | 879 | PaddlePaddle/PaddleOCR | 42,738 |
Add unit tests to test openai tools agent | diff --git a/libs/langchain/langchain/agents/openai_tools/base.py b/libs/langchain/langchain/agents/openai_tools/base.py
index 56868d903adeb1..c1206ea4efc12b 100644
--- a/libs/langchain/langchain/agents/openai_tools/base.py
+++ b/libs/langchain/langchain/agents/openai_tools/base.py
@@ -19,7 +19,6 @@ def create_openai_t... | This PR adds unit testing to test openai tools agent.
| https://api.github.com/repos/langchain-ai/langchain/pulls/15843 | 2024-01-10T20:27:47Z | 2024-01-10T22:06:31Z | 2024-01-10T22:06:30Z | 2024-01-10T22:06:31Z | 3,466 | langchain-ai/langchain | 43,735 |
Add alipay | diff --git a/README.md b/README.md
index be530c0ed..3f7260772 100644
--- a/README.md
+++ b/README.md
@@ -469,6 +469,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
* [merchant](https://github.com/agiliq/merchant) - A Django app to accept payments from various payment processors.
... | An Unofficial Alipay API for Python
| https://api.github.com/repos/vinta/awesome-python/pulls/357 | 2015-04-16T07:16:12Z | 2015-04-16T14:43:12Z | 2015-04-16T14:43:12Z | 2015-04-16T14:43:12Z | 187 | vinta/awesome-python | 27,237 |
[zero] refactor model data tracing | diff --git a/colossalai/utils/memory_tracer/model_data_memtracer.py b/colossalai/utils/memory_tracer/model_data_memtracer.py
index e8cb9f7c6748..fafe3169049c 100644
--- a/colossalai/utils/memory_tracer/model_data_memtracer.py
+++ b/colossalai/utils/memory_tracer/model_data_memtracer.py
@@ -22,6 +22,7 @@ class ModelData... | Tracing cpu model data changes. | https://api.github.com/repos/hpcaitech/ColossalAI/pulls/522 | 2022-03-25T06:43:26Z | 2022-03-25T10:03:33Z | 2022-03-25T10:03:32Z | 2022-03-25T10:03:36Z | 3,817 | hpcaitech/ColossalAI | 11,292 |
Added --timeout command line option | diff --git a/AUTHORS.md b/AUTHORS.md
index cb60bfd8701..d82ddcb7688 100644
--- a/AUTHORS.md
+++ b/AUTHORS.md
@@ -138,6 +138,7 @@ Authors
* [Joubin Jabbari](https://github.com/joubin)
* [Juho Juopperi](https://github.com/jkjuopperi)
* [Kane York](https://github.com/riking)
+* [Katsuyoshi Ozaki](https://github.com/mor... | Fixes #6513
Added --timeout command line option.
This option specifies the timeout value in seconds for obtaining a certificate from Certificate Authority.
Default timeout value currently hard-coded as 90sec moved to constants.
## Pull Request Checklist
- [x] If the change being made is to a [distributed co... | https://api.github.com/repos/certbot/certbot/pulls/9056 | 2021-10-05T11:30:23Z | 2021-11-29T21:17:07Z | 2021-11-29T21:17:06Z | 2021-11-29T21:17:07Z | 1,574 | certbot/certbot | 3,007 |
manual update improve | diff --git a/code/default/launcher/lang/zh_CN/LC_MESSAGES/messages.po b/code/default/launcher/lang/zh_CN/LC_MESSAGES/messages.po
index 135bd53cd0..885b5a33aa 100644
--- a/code/default/launcher/lang/zh_CN/LC_MESSAGES/messages.po
+++ b/code/default/launcher/lang/zh_CN/LC_MESSAGES/messages.po
@@ -177,10 +177,19 @@ msgid "... | https://api.github.com/repos/XX-net/XX-Net/pulls/9109 | 2017-12-19T03:14:43Z | 2017-12-19T09:28:58Z | 2017-12-19T09:28:58Z | 2017-12-21T02:52:26Z | 2,198 | XX-net/XX-Net | 17,157 | |
Update `is_writeable()` for 2 methods | diff --git a/utils/general.py b/utils/general.py
index 6201320d3c6..e8b158a773d 100755
--- a/utils/general.py
+++ b/utils/general.py
@@ -112,17 +112,19 @@ def user_config_dir(dir='Ultralytics'):
return path
-def is_writeable(dir):
- # Return True if directory has write permissions
- # return os.access(pa... |
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhanced directory write permission checking in Ultralytics YOLOv5's utility functions.
### 📊 Key Changes
- 🛠️ Modified the `is_writeable` function in `utils/general.py` to include two methods... | https://api.github.com/repos/ultralytics/yolov5/pulls/4744 | 2021-09-10T15:10:23Z | 2021-09-10T15:52:33Z | 2021-09-10T15:52:33Z | 2024-01-19T15:48:06Z | 300 | ultralytics/yolov5 | 24,811 |
[extractor/rbgtum] fix m3u8 regex, add new hostname | diff --git a/yt_dlp/extractor/_extractors.py b/yt_dlp/extractor/_extractors.py
index ae73a9f9608..5245c92a3cf 100644
--- a/yt_dlp/extractor/_extractors.py
+++ b/yt_dlp/extractor/_extractors.py
@@ -1585,6 +1585,7 @@
from .rbgtum import (
RbgTumIE,
RbgTumCourseIE,
+ RbgTumNewCourseIE,
)
from .rcs import (... | **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be un... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/7690 | 2023-07-25T12:19:12Z | 2023-09-21T17:37:58Z | 2023-09-21T17:37:58Z | 2023-09-21T17:37:58Z | 1,948 | yt-dlp/yt-dlp | 7,975 |
use request parameter resolvers | diff --git a/localstack/services/apigateway/helpers.py b/localstack/services/apigateway/helpers.py
index d29b4fc1264ee..5233a9c586b6c 100644
--- a/localstack/services/apigateway/helpers.py
+++ b/localstack/services/apigateway/helpers.py
@@ -401,8 +401,7 @@ def resolve(self, context: ApiInvocationContext) -> Integration... |
## Motivation
Improves community PR by using the `RequestParametersResolver` that can handle, headers, path and query strings and also static values.
Fixes the previous test - static values are configured using single quotes, "'Fixed-Header-Value'", but transformed into normal header values when passed to the i... | https://api.github.com/repos/localstack/localstack/pulls/10049 | 2024-01-10T23:11:03Z | 2024-01-23T07:46:44Z | 2024-01-23T07:46:44Z | 2024-01-23T07:46:45Z | 1,269 | localstack/localstack | 29,248 |
multipart-fix | diff --git a/mitmproxy/net/http/multipart.py b/mitmproxy/net/http/multipart.py
index a854d47fd4..4edf76acd3 100644
--- a/mitmproxy/net/http/multipart.py
+++ b/mitmproxy/net/http/multipart.py
@@ -1,8 +1,43 @@
import re
-
+import mimetypes
+from urllib.parse import quote
from mitmproxy.net.http import headers
+def ... | Fixes #3175 | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/3420 | 2018-12-14T16:03:11Z | 2019-11-15T18:04:48Z | 2019-11-15T18:04:48Z | 2019-11-16T13:13:19Z | 2,275 | mitmproxy/mitmproxy | 28,052 |
update code-owners | diff --git a/CODEOWNERS b/CODEOWNERS
index d4b74d4ce8..b0658a770f 100644
--- a/CODEOWNERS
+++ b/CODEOWNERS
@@ -1,7 +1,7 @@
* @yk @andreaskoepf
/website/ @AbdBarho @notmd @yk @andreaskoepf
/website/src/data/team.json @yk @andreaskoepf @fozziethebeat @AbdBarho @notmd @theblackcat102 @sanagno @olliestanley @andrewm4894... | ## What
Added @shahules786 to Code owners | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3584 | 2023-07-19T07:19:18Z | 2023-07-19T07:41:59Z | 2023-07-19T07:41:59Z | 2023-07-19T07:41:59Z | 258 | LAION-AI/Open-Assistant | 37,744 |
added Transfer Learning for Natural Language Processing | diff --git a/courses.md b/courses.md
index 73f13f90..69cdcf0e 100644
--- a/courses.md
+++ b/courses.md
@@ -38,4 +38,6 @@ The following is a list of free or paid online courses on machine learning, stat
* [Transfer Learning for Natural Language Processing](https://www.manning.com/books/transfer-learning-for-natural-lan... | Hi,
Branko from Manning here, I thought this book of ours could be a good resource here.
Thanks for checking it out! | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/726 | 2020-09-29T14:13:54Z | 2020-09-30T13:23:38Z | 2020-09-30T13:23:38Z | 2020-09-30T13:23:38Z | 229 | josephmisiti/awesome-machine-learning | 52,288 |
Invoke pipstrap in tox and during the CI | diff --git a/.azure-pipelines/templates/jobs/extended-tests-jobs.yml b/.azure-pipelines/templates/jobs/extended-tests-jobs.yml
index 0e1a988614a..67fa3488029 100644
--- a/.azure-pipelines/templates/jobs/extended-tests-jobs.yml
+++ b/.azure-pipelines/templates/jobs/extended-tests-jobs.yml
@@ -3,6 +3,8 @@ jobs:
vari... | Partial fix for #8256
This PR makes tox calls pipstrap before any `commands` is executed, and Azure Pipelines calls pipstrap when appropriate (when an actual call to `pip` is done). Docker is already covered since `pipstrap` is called in the `certbot/certbot` docker on the Python system interpreter, and that interpr... | https://api.github.com/repos/certbot/certbot/pulls/8316 | 2020-09-23T18:47:10Z | 2020-09-25T00:12:13Z | 2020-09-25T00:12:13Z | 2020-09-25T00:12:13Z | 1,847 | certbot/certbot | 2,257 |
Bump llama-index-core from 0.10.12 to 0.10.24 in /llama-index-integrations/llms/llama-index-llms-friendli | diff --git a/llama-index-integrations/llms/llama-index-llms-friendli/poetry.lock b/llama-index-integrations/llms/llama-index-llms-friendli/poetry.lock
index bc69700e34256..bdb6af63c50b1 100644
--- a/llama-index-integrations/llms/llama-index-llms-friendli/poetry.lock
+++ b/llama-index-integrations/llms/llama-index-llms-... | Bumps [llama-index-core](https://github.com/run-llama/llama_index) from 0.10.12 to 0.10.24.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/run-llama/llama_index/releases">llama-index-core's releases</a>.</em></p>
<blockquote>
<h2>v0.10.24</h2>
<p>No release notes provided.</p... | https://api.github.com/repos/run-llama/llama_index/pulls/12730 | 2024-04-10T22:25:48Z | 2024-04-11T00:51:07Z | 2024-04-11T00:51:06Z | 2024-04-11T00:51:07Z | 831 | run-llama/llama_index | 6,282 |
Add LeetCode | diff --git a/data.json b/data.json
index 199e56c5d..1dc39f80c 100644
--- a/data.json
+++ b/data.json
@@ -643,6 +643,14 @@
"username_claimed": "blue",
"username_unclaimed": "noonewouldeverusethis7"
},
+ "LeetCode": {
+ "errorType": "status_code",
+ "rank": 0,
+ "url": "https://leetcode.com/{... | Add support for [LeetCode](https://leetcode.com/)
Best regards | https://api.github.com/repos/sherlock-project/sherlock/pulls/240 | 2019-07-14T07:44:31Z | 2019-07-14T07:54:09Z | 2019-07-14T07:54:09Z | 2019-07-14T07:54:10Z | 198 | sherlock-project/sherlock | 36,422 |
Add LCEL to output parser doc | diff --git a/docs/docs/modules/model_io/output_parsers/index.ipynb b/docs/docs/modules/model_io/output_parsers/index.ipynb
new file mode 100644
index 00000000000000..8e445eb08c48e6
--- /dev/null
+++ b/docs/docs/modules/model_io/output_parsers/index.ipynb
@@ -0,0 +1,259 @@
+{
+ "cells": [
+ {
+ "cell_type": "raw",
+ ... | https://api.github.com/repos/langchain-ai/langchain/pulls/11880 | 2023-10-16T19:06:33Z | 2023-10-16T19:35:18Z | 2023-10-16T19:35:18Z | 2023-10-16T19:35:19Z | 3,518 | langchain-ai/langchain | 43,676 | |
Add PatentsView API | diff --git a/README.md b/README.md
index aa684c5568..2ea0e66051 100644
--- a/README.md
+++ b/README.md
@@ -992,6 +992,7 @@ API | Description | Auth | HTTPS | CORS |
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
| [EPO](https://developers.epo.org/) | European patent search system api | `OAuth` | Yes... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [✔] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [✔] My addition is ordered alphabetically
- [✔]... | https://api.github.com/repos/public-apis/public-apis/pulls/2489 | 2021-10-11T13:47:26Z | 2021-10-24T21:10:16Z | 2021-10-24T21:10:16Z | 2021-10-25T08:41:50Z | 234 | public-apis/public-apis | 35,628 |
Fixed #30259 -- Fixed crash of admin views when properties don't have admin_order_field attribute. | diff --git a/django/contrib/admin/templatetags/admin_list.py b/django/contrib/admin/templatetags/admin_list.py
index fe4249ae5b16b..4fd9c45a57353 100644
--- a/django/contrib/admin/templatetags/admin_list.py
+++ b/django/contrib/admin/templatetags/admin_list.py
@@ -130,7 +130,7 @@ def result_headers(cl):
ad... | Ticket [30259](https://code.djangoproject.com/ticket/30259).
I didn't add a separate test because the original test `test_change_list_sorting_property()` is falling after adding a property to the list of fields. | https://api.github.com/repos/django/django/pulls/11154 | 2019-04-01T08:38:56Z | 2019-04-01T13:11:55Z | 2019-04-01T13:11:55Z | 2019-04-01T14:35:55Z | 475 | django/django | 51,397 |
fix: Do not call lastEventId | diff --git a/src/sentry/static/sentry/app/utils/sdk.js b/src/sentry/static/sentry/app/utils/sdk.js
index 4681c35e23e9e3..c0baa857807124 100644
--- a/src/sentry/static/sentry/app/utils/sdk.js
+++ b/src/sentry/static/sentry/app/utils/sdk.js
@@ -58,7 +58,7 @@ document.addEventListener('sentryLoaded', function() {
};
... | https://api.github.com/repos/getsentry/sentry/pulls/9046 | 2018-07-16T08:30:45Z | 2018-07-17T11:32:19Z | 2018-07-17T11:32:19Z | 2020-12-21T18:13:15Z | 153 | getsentry/sentry | 44,392 | |
Refs #31169 -- Added DatabaseCreation.setup_worker_connection() hook. | diff --git a/django/db/backends/base/creation.py b/django/db/backends/base/creation.py
index 78480fc0f8c88..15c2167be4bf3 100644
--- a/django/db/backends/base/creation.py
+++ b/django/db/backends/base/creation.py
@@ -369,3 +369,13 @@ def test_db_signature(self):
settings_dict["ENGINE"],
self._... | https://api.github.com/repos/django/django/pulls/15457 | 2022-02-23T10:36:58Z | 2022-02-23T11:16:42Z | 2022-02-23T11:16:42Z | 2022-02-23T11:16:55Z | 414 | django/django | 51,544 | |
Fixed #2250 | diff --git a/requests/utils.py b/requests/utils.py
index 1868f861ba..182348daad 100644
--- a/requests/utils.py
+++ b/requests/utils.py
@@ -567,7 +567,7 @@ def parse_header_links(value):
replace_chars = " '\""
- for val in value.split(","):
+ for val in re.split(", *<", value):
try:
... | Fixed #2250 with #2271
| https://api.github.com/repos/psf/requests/pulls/2271 | 2014-10-09T02:28:13Z | 2014-10-10T18:30:18Z | 2014-10-10T18:30:18Z | 2021-09-08T10:01:06Z | 111 | psf/requests | 32,552 |
Update README.md | diff --git a/Server Side Template Injection/README.md b/Server Side Template Injection/README.md
index 656dc05b54..6018c46301 100644
--- a/Server Side Template Injection/README.md
+++ b/Server Side Template Injection/README.md
@@ -199,7 +199,11 @@ You can try your payloads at [https://try.freemarker.apache.org](https... | Add some efficient but new payloads in freemaker | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/608 | 2022-12-27T10:35:59Z | 2022-12-27T17:26:52Z | 2022-12-27T17:26:52Z | 2022-12-27T17:26:52Z | 299 | swisskyrepo/PayloadsAllTheThings | 8,639 |
Highlight -o/--options | diff --git a/httpie/output/ui/rich_help.py b/httpie/output/ui/rich_help.py
index c897a51e75..57cda0e961 100644
--- a/httpie/output/ui/rich_help.py
+++ b/httpie/output/ui/rich_help.py
@@ -29,17 +29,19 @@
LEFT_PADDING_4 = (0, 0, 0, 4)
-class RequestItemHighlighter(RegexHighlighter):
+class OptionsHighlighter(RegexHi... | 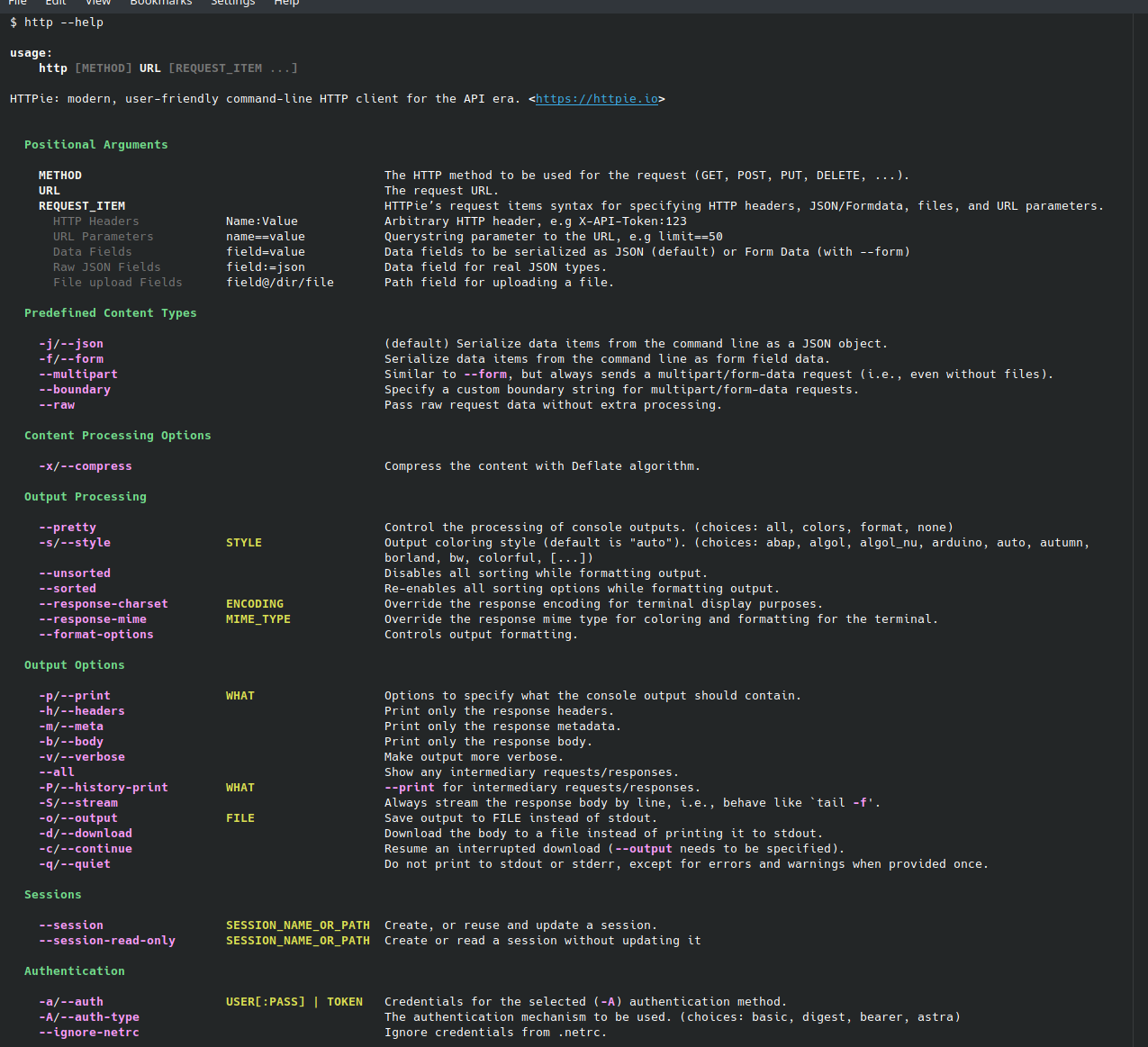
| https://api.github.com/repos/httpie/cli/pulls/1340 | 2022-03-31T13:50:33Z | 2022-03-31T13:50:40Z | 2022-03-31T13:50:40Z | 2022-03-31T13:50:40Z | 903 | httpie/cli | 33,824 |
fix(ui): Fix releases + issues pagination | diff --git a/static/app/components/asyncComponent.tsx b/static/app/components/asyncComponent.tsx
index 4ed9632eade038..5bc0a8151714b2 100644
--- a/static/app/components/asyncComponent.tsx
+++ b/static/app/components/asyncComponent.tsx
@@ -247,7 +247,7 @@ export default class AsyncComponent<
let query = (params &... | - fixes pagination of issues on release detail page
- fixes pagination on releases page when the statsPeriod is different than 14d (https://app.asana.com/0/1168903747282474/1192198721871433/f) | https://api.github.com/repos/getsentry/sentry/pulls/26707 | 2021-06-18T08:45:53Z | 2021-06-21T08:38:22Z | 2021-06-21T08:38:22Z | 2022-05-09T11:42:51Z | 643 | getsentry/sentry | 44,743 |
community: add len() implementation to Chroma | diff --git a/libs/community/langchain_community/vectorstores/chroma.py b/libs/community/langchain_community/vectorstores/chroma.py
index 3bcb389cff5e10..7723285fafa6c7 100644
--- a/libs/community/langchain_community/vectorstores/chroma.py
+++ b/libs/community/langchain_community/vectorstores/chroma.py
@@ -795,3 +795,7 ... | Thank you for contributing to LangChain!
- [x] **Add len() implementation to Chroma**: "package: community"
- [x] **PR message**:
- **Description:** add an implementation of the __len__() method for the Chroma vectostore, for convenience.
- **Issue:** no exposed method to know the size of a Chroma ve... | https://api.github.com/repos/langchain-ai/langchain/pulls/19419 | 2024-03-22T00:02:58Z | 2024-03-26T16:53:11Z | 2024-03-26T16:53:11Z | 2024-03-26T16:53:11Z | 312 | langchain-ai/langchain | 43,289 |
Create karatsuba.py | diff --git a/maths/karatsuba.py b/maths/karatsuba.py
new file mode 100644
index 000000000000..be4630184933
--- /dev/null
+++ b/maths/karatsuba.py
@@ -0,0 +1,31 @@
+""" Multiply two numbers using Karatsuba algorithm """
+
+def karatsuba(a, b):
+ """
+ >>> karatsuba(15463, 23489) == 15463 * 23489
+ True
+ >>>... | Added karatsuba algorithm for multiplication of two numbers | https://api.github.com/repos/TheAlgorithms/Python/pulls/1309 | 2019-10-08T10:20:40Z | 2019-10-08T12:25:51Z | 2019-10-08T12:25:51Z | 2019-10-08T12:25:51Z | 353 | TheAlgorithms/Python | 30,263 |
fix: check fill size none zero when resize (fixes #11425) | diff --git a/modules/images.py b/modules/images.py
index 7bbfc3e0b10..7935b122a2d 100644
--- a/modules/images.py
+++ b/modules/images.py
@@ -302,12 +302,14 @@ def resize(im, w, h):
if ratio < src_ratio:
fill_height = height // 2 - src_h // 2
- res.paste(resized.resize((width, fill_... | ## Description
* a simple description of what you're trying to accomplish
* a summary of changes in code
* which issues it fixes, if any
## Screenshots/videos:
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I hav... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/11748 | 2023-07-12T08:55:02Z | 2023-07-13T11:48:20Z | 2023-07-13T11:48:20Z | 2023-07-13T11:48:20Z | 416 | AUTOMATIC1111/stable-diffusion-webui | 39,997 |
Updating the readme.md to make it easier to follow | diff --git a/README.md b/README.md
index 5978a0e5dd7c55..523f459f3b7dc4 100644
--- a/README.md
+++ b/README.md
@@ -39,13 +39,17 @@ Running on a dedicated device in a car
------
To use openpilot in a car, you need four things
-* A supported device to run this software: a [comma 3X](https://comma.ai/shop/comma-3x) or... | <!-- Please copy and paste the relevant template -->
<!--- ***** Template: Car bug fix *****
**Description** [](A description of the bug and the fix. Also link any relevant issues.)
**Verification** [](Explain how you tested this bug fix.)
**Route**
Route: [a route with the bug fix]
-->
<!--- ***** T... | https://api.github.com/repos/commaai/openpilot/pulls/29820 | 2023-09-07T20:23:22Z | 2023-09-12T18:38:29Z | 2023-09-12T18:38:29Z | 2023-09-12T18:38:29Z | 607 | commaai/openpilot | 9,228 |
Explicitly use event timestamp when recording data in similarity index. | diff --git a/src/sentry/similarity.py b/src/sentry/similarity.py
index f59889b5174cb..65ad43ee14c11 100644
--- a/src/sentry/similarity.py
+++ b/src/sentry/similarity.py
@@ -12,6 +12,7 @@
from sentry.utils import redis
from sentry.utils.datastructures import BidirectionalMapping
+from sentry.utils.dates import to_ti... | https://api.github.com/repos/getsentry/sentry/pulls/5071 | 2017-03-13T19:59:45Z | 2017-03-13T20:10:58Z | 2017-03-13T20:10:58Z | 2020-12-23T04:40:49Z | 174 | getsentry/sentry | 44,769 | |
[AIRFLOW-6686] Fix syntax error constructing list of process ids | diff --git a/airflow/utils/helpers.py b/airflow/utils/helpers.py
index 35da593c79c17..1f57f0b746cbe 100644
--- a/airflow/utils/helpers.py
+++ b/airflow/utils/helpers.py
@@ -211,7 +211,7 @@ def signal_procs(sig):
# use sudo -n(--non-interactive) to kill the process
if err.errno == errno.EPERM:
... | Construction of list of pids passed in kill command raises a Syntax error because
ordering of the arguments to `map` function doesn't conform to function
parameter definition.
A list comprehension replaces the existing `map` function to make the code
forward compatible with Python 3 and at the same time expand to... | https://api.github.com/repos/apache/airflow/pulls/7298 | 2020-01-30T20:23:28Z | 2020-02-02T16:31:58Z | 2020-02-02T16:31:58Z | 2020-02-02T16:31:58Z | 169 | apache/airflow | 14,496 |
Only show gps event after 1 km | diff --git a/selfdrive/controls/controlsd.py b/selfdrive/controls/controlsd.py
index c078b3c4b6c6f5..37b7e802d64eda 100755
--- a/selfdrive/controls/controlsd.py
+++ b/selfdrive/controls/controlsd.py
@@ -128,6 +128,7 @@ def __init__(self, sm=None, pm=None, can_sock=None):
self.can_error_counter = 0
self.last_b... | Fixes #1745 | https://api.github.com/repos/commaai/openpilot/pulls/1747 | 2020-06-19T20:51:19Z | 2020-06-19T21:11:24Z | 2020-06-19T21:11:23Z | 2020-06-19T21:11:25Z | 431 | commaai/openpilot | 9,330 |
Add string_rotation to create multiple words from single word | diff --git a/string_rotation.py b/string_rotation.py
new file mode 100644
index 0000000000..a7928a1b07
--- /dev/null
+++ b/string_rotation.py
@@ -0,0 +1,20 @@
+def rotate(n):
+ a = list(n)
+ if len(a) == 0:
+ return print ([])
+ l = []
+ for i in range(1,len(a)+1):
+ a = [a[(i+1)%(len(a))] for... | https://api.github.com/repos/geekcomputers/Python/pulls/639 | 2019-10-20T16:47:58Z | 2019-10-20T18:36:14Z | 2019-10-20T18:36:14Z | 2019-10-20T18:36:14Z | 212 | geekcomputers/Python | 31,696 | |
docs: fix simple typo, assigining -> assigning | diff --git a/patterns/creational/borg.py b/patterns/creational/borg.py
index 3ddc8c1d..ab364f61 100644
--- a/patterns/creational/borg.py
+++ b/patterns/creational/borg.py
@@ -13,7 +13,7 @@
its own dictionary, but the Borg pattern modifies this so that all
instances have the same dictionary.
In this example, the __sh... | There is a small typo in patterns/creational/borg.py.
Should read `assigning` rather than `assigining`.
Semi-automated pull request generated by
https://github.com/timgates42/meticulous/blob/master/docs/NOTE.md | https://api.github.com/repos/faif/python-patterns/pulls/394 | 2022-07-02T09:50:09Z | 2022-07-04T19:27:22Z | 2022-07-04T19:27:22Z | 2022-07-04T19:27:22Z | 183 | faif/python-patterns | 33,619 |
Validations for Events.CreateConnection | diff --git a/localstack/services/events/provider.py b/localstack/services/events/provider.py
index 03484d8549ca1..c9fc1c6b18aed 100644
--- a/localstack/services/events/provider.py
+++ b/localstack/services/events/provider.py
@@ -11,8 +11,13 @@
from localstack import config
from localstack.aws.api import RequestCont... | This PR addresses issue #5943 where is shown that Localstack doesn't validate the name parameter when creating a new Connection for the Events service, which could lead to several problems.
Changes:
- Validation for the Name parameter and the AuthorizationType.
- Test addition.
| https://api.github.com/repos/localstack/localstack/pulls/5964 | 2022-04-30T04:08:28Z | 2022-05-20T18:00:40Z | 2022-05-20T18:00:40Z | 2022-07-13T22:24:19Z | 1,113 | localstack/localstack | 28,652 |
TFTrainer dataset doc & fix evaluation bug | diff --git a/src/transformers/trainer_tf.py b/src/transformers/trainer_tf.py
index 9b03fc614edb6..ecc15719a9aa9 100644
--- a/src/transformers/trainer_tf.py
+++ b/src/transformers/trainer_tf.py
@@ -38,9 +38,17 @@ class TFTrainer:
args (:class:`~transformers.TFTrainingArguments`):
The arguments to t... | discussed in #6551 | https://api.github.com/repos/huggingface/transformers/pulls/6618 | 2020-08-20T15:15:36Z | 2020-08-20T16:11:37Z | 2020-08-20T16:11:37Z | 2020-08-28T15:10:26Z | 1,302 | huggingface/transformers | 12,349 |
Update aspect ratio image overlay selectors after ui and core overhaul | diff --git a/javascript/aspectRatioOverlay.js b/javascript/aspectRatioOverlay.js
index 52e9f3817e9..96f1c00d0de 100644
--- a/javascript/aspectRatioOverlay.js
+++ b/javascript/aspectRatioOverlay.js
@@ -18,9 +18,9 @@ function dimensionChange(e,dimname){
return;
}
- var img2imgMode = gradioApp().querySelector("i... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/852 | 2022-09-22T14:23:22Z | 2022-09-22T16:29:20Z | 2022-09-22T16:29:20Z | 2022-09-22T16:44:12Z | 348 | AUTOMATIC1111/stable-diffusion-webui | 40,193 | |
[utils] Change Firefox 44 to 47 | diff --git a/youtube_dl/utils.py b/youtube_dl/utils.py
index f77ab865093..0acbd67de28 100644
--- a/youtube_dl/utils.py
+++ b/youtube_dl/utils.py
@@ -76,7 +76,7 @@ def register_socks_protocols():
compiled_regex_type = type(re.compile(''))
std_headers = {
- 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) G... | See commit title.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/9755 | 2016-06-11T09:36:45Z | 2016-06-11T09:38:45Z | 2016-06-11T09:38:45Z | 2016-06-11T09:39:37Z | 229 | ytdl-org/youtube-dl | 49,693 |
FROM nvcr.io/nvidia/pytorch:21.05-py3 | diff --git a/Dockerfile b/Dockerfile
index a5b9da06a3d..e22c1106f23 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -1,5 +1,5 @@
# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
-FROM nvcr.io/nvidia/pytorch:21.06-py3
+FROM nvcr.io/nvidia/pytorch:21.05-py3
# Install linux packag... |
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Updated the base Docker image in the `ultralytics/yolov5` project.
### 📊 Key Changes
- Changed the Nvidia PyTorch base image from version 21.06 to 21.05.
### 🎯 Purpose & Impact
- This adjustm... | https://api.github.com/repos/ultralytics/yolov5/pulls/3794 | 2021-06-26T15:12:37Z | 2021-06-26T15:12:43Z | 2021-06-26T15:12:43Z | 2024-01-19T17:16:57Z | 140 | ultralytics/yolov5 | 25,306 |
Added a function that checks if given string can be rearranged to form a palindrome. | diff --git a/strings/can_string_be_rearranged_as_palindrome.py b/strings/can_string_be_rearranged_as_palindrome.py
new file mode 100644
index 000000000000..92bc3b95b243
--- /dev/null
+++ b/strings/can_string_be_rearranged_as_palindrome.py
@@ -0,0 +1,113 @@
+# Created by susmith98
+
+from collections import Counter
+fro... | ### **Describe your change:**
* [x] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### **Checklist:**
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I h... | https://api.github.com/repos/TheAlgorithms/Python/pulls/2450 | 2020-09-19T10:20:48Z | 2020-09-19T19:49:38Z | 2020-09-19T19:49:38Z | 2020-09-19T19:49:38Z | 1,145 | TheAlgorithms/Python | 30,066 |
Update MySQL Injection.md | diff --git a/SQL Injection/MySQL Injection.md b/SQL Injection/MySQL Injection.md
index c4df66b94f..1764a1325a 100644
--- a/SQL Injection/MySQL Injection.md
+++ b/SQL Injection/MySQL Injection.md
@@ -389,6 +389,10 @@ Need the `filepriv`, otherwise you will get the error : `ERROR 1290 (HY000): The
' UNION ALL SELECT L... | TO_base64(LOAD_FILE('/var/www/html/index.php')); | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/422 | 2021-09-25T10:53:43Z | 2021-09-25T16:17:11Z | 2021-09-25T16:17:10Z | 2021-09-25T16:17:11Z | 161 | swisskyrepo/PayloadsAllTheThings | 8,708 |
Add PiXHost API to readme | diff --git a/README.md b/README.md
index 11e5c8034f..253af9cc92 100644
--- a/README.md
+++ b/README.md
@@ -509,6 +509,7 @@ API | Description | Auth | HTTPS | Link |
| Giphy | Get all your gifs | No | Yes | [Go!](https://github.com/Giphy/GiphyAPI) |
| Imgur | Images | `OAuth` | Yes | [Go!](https://apidocs.imgur.com/) ... | PiXhost like imgur is a image hosting service and is free to all users. Some people who have slightly more graphical content that gets rejected at imgur switch to PiXhost because it has more lenient rules. It also has an API that is not known.
From their website:
"Welcome to the PiXhost API!
You can use this API... | https://api.github.com/repos/public-apis/public-apis/pulls/502 | 2017-10-07T13:22:01Z | 2017-10-24T14:34:21Z | 2017-10-24T14:34:21Z | 2017-10-24T14:34:24Z | 252 | public-apis/public-apis | 35,205 |
[sharesix] Add new extractor | diff --git a/youtube_dl/extractor/__init__.py b/youtube_dl/extractor/__init__.py
index 7adca7df918..c76fb37273b 100644
--- a/youtube_dl/extractor/__init__.py
+++ b/youtube_dl/extractor/__init__.py
@@ -296,6 +296,7 @@
from .screencast import ScreencastIE
from .servingsys import ServingSysIE
from .shared import Shared... | Hi,
this adds support for [sharesix](http://sharesix.com/).
The download URL only works with the same user agent string that was used during extraction. Shouldn't there be some info message when he/she uses the `-g`, `--get-url` flag? As it might not be obvious to everyone.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/3690 | 2014-09-06T16:06:50Z | 2014-09-09T14:14:59Z | 2014-09-09T14:14:59Z | 2014-09-09T18:11:21Z | 1,014 | ytdl-org/youtube-dl | 49,803 |
Add blogs to dataset materials section | diff --git a/doc/source/data/dataset.rst b/doc/source/data/dataset.rst
index d14a4f3e0e604..2089a4051ba08 100644
--- a/doc/source/data/dataset.rst
+++ b/doc/source/data/dataset.rst
@@ -392,6 +392,8 @@ Talks and Materials
-------------------
- [slides] `Talk given at PyData 2021 <https://docs.google.com/presentation... | https://api.github.com/repos/ray-project/ray/pulls/21546 | 2022-01-12T03:11:49Z | 2022-01-12T06:09:57Z | 2022-01-12T06:09:57Z | 2022-01-12T06:09:57Z | 230 | ray-project/ray | 19,498 | |
Fixed lbfgs for ray-cluster | diff --git a/examples/lbfgs/driver.py b/examples/lbfgs/driver.py
index f74af6ddd0497..f81f1923363bf 100644
--- a/examples/lbfgs/driver.py
+++ b/examples/lbfgs/driver.py
@@ -10,103 +10,102 @@
from tensorflow.examples.tutorials.mnist import input_data
-if __name__ == "__main__":
- ray.init(num_workers=10)
-
- # De... | https://api.github.com/repos/ray-project/ray/pulls/180 | 2017-01-06T00:07:12Z | 2017-01-11T02:40:06Z | 2017-01-11T02:40:06Z | 2017-01-11T02:40:09Z | 3,325 | ray-project/ray | 19,701 | |
Reduce tests for applications | diff --git a/tests/integration_tests/applications_test.py b/tests/integration_tests/applications_test.py
index 6c707240cb2..04ec41f0c17 100644
--- a/tests/integration_tests/applications_test.py
+++ b/tests/integration_tests/applications_test.py
@@ -15,13 +15,22 @@
reason='Runs only when the relevant files have bee... | This PR reduces tests for applications and is a follow-up of #10341. | https://api.github.com/repos/keras-team/keras/pulls/10346 | 2018-06-03T07:10:30Z | 2018-06-04T17:07:24Z | 2018-06-04T17:07:24Z | 2018-06-05T00:26:14Z | 1,328 | keras-team/keras | 47,188 |
cleanup Amazon `CHANGELOG.rst` | diff --git a/airflow/providers/amazon/CHANGELOG.rst b/airflow/providers/amazon/CHANGELOG.rst
index a337648c50bd6..906de481a7851 100644
--- a/airflow/providers/amazon/CHANGELOG.rst
+++ b/airflow/providers/amazon/CHANGELOG.rst
@@ -40,7 +40,6 @@ Features
* ``Add deferrable mode for S3KeySensor (#31018)``
* ``Add Deferra... | <!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of an existing issue, reference it using one of the following:
closes: #ISSUE... | https://api.github.com/repos/apache/airflow/pulls/32031 | 2023-06-20T13:21:13Z | 2023-06-21T05:48:26Z | 2023-06-21T05:48:26Z | 2023-06-21T11:32:05Z | 298 | apache/airflow | 14,291 |
🌐 Add Korean translation for `docs/ko/docs/deployment/cloud.md` | diff --git a/docs/ko/docs/deployment/cloud.md b/docs/ko/docs/deployment/cloud.md
new file mode 100644
index 0000000000000..f2b965a9113b8
--- /dev/null
+++ b/docs/ko/docs/deployment/cloud.md
@@ -0,0 +1,17 @@
+# FastAPI를 클라우드 제공업체에서 배포하기
+
+사실상 거의 **모든 클라우드 제공업체**를 사용하여 여러분의 FastAPI 애플리케이션을 배포할 수 있습니다.
+
+대부분의 경우, 주요 클라우... | - Add Korean translation for ```docs/ko/docs/deployment/cloud.md```
- Related [FEATURE] Korean translations #2017 | https://api.github.com/repos/tiangolo/fastapi/pulls/10191 | 2023-09-02T05:47:04Z | 2023-09-25T23:03:00Z | 2023-09-25T23:03:00Z | 2023-09-25T23:03:00Z | 462 | tiangolo/fastapi | 23,121 |
Windows build | diff --git a/src/you_get/common.py b/src/you_get/common.py
index 5ee03631f0..faa7f7660a 100755
--- a/src/you_get/common.py
+++ b/src/you_get/common.py
@@ -555,7 +555,8 @@ def update(self):
def update_received(self, n):
self.received += n
- bytes_ps = n / (time.time() - self.last_updated)
+ ... | Starting from version **[0.4.136](https://github.com/soimort/you-get/releases/tag/v0.4.136)**, we will ship Windows binaries for every release of `you-get`, as I promised.
Those binaries were built with [PyInstaller](https://github.com/pyinstaller/pyinstaller), so no more Python installation is required. The download ... | https://api.github.com/repos/soimort/you-get/pulls/755 | 2015-11-09T03:51:17Z | 2015-11-09T03:54:39Z | 2015-11-09T03:54:39Z | 2020-09-28T23:18:50Z | 277 | soimort/you-get | 21,333 |
[generic] ImportError fix - change get_testcases to gettestcases in check-porn.py | diff --git a/devscripts/check-porn.py b/devscripts/check-porn.py
index 7a219ebe97c..72b2ee42276 100644
--- a/devscripts/check-porn.py
+++ b/devscripts/check-porn.py
@@ -14,7 +14,7 @@
import sys
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from test.helper import get_testcases
+fr... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/14259 | 2017-09-19T02:26:28Z | 2017-09-19T15:51:21Z | 2017-09-19T15:51:21Z | 2017-09-19T15:51:21Z | 192 | ytdl-org/youtube-dl | 50,587 |
force refresh tqdm before close | diff --git a/modules/shared.py b/modules/shared.py
index 2fb9e3b5ada..f28a12ccc31 100644
--- a/modules/shared.py
+++ b/modules/shared.py
@@ -714,6 +714,7 @@ def updateTotal(self, new_total):
def clear(self):
if self._tqdm is not None:
+ self._tqdm.refresh()
self._tqdm.close()... | trivial pr to fix a bug where console tqdm total progress bar can be left ~90% upon completion of all operations. | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/8548 | 2023-03-12T13:21:42Z | 2023-03-12T13:51:30Z | 2023-03-12T13:51:30Z | 2023-03-12T14:29:42Z | 108 | AUTOMATIC1111/stable-diffusion-webui | 40,017 |
[mediaset] Fix extraction for more videos | diff --git a/yt_dlp/extractor/mediaset.py b/yt_dlp/extractor/mediaset.py
index f4db58e64af..26e7abc4930 100644
--- a/yt_dlp/extractor/mediaset.py
+++ b/yt_dlp/extractor/mediaset.py
@@ -44,7 +44,7 @@ class MediasetIE(ThePlatformBaseIE):
},
}, {
'url': 'https://www.mediasetplay.mediaset.it/video/ma... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/852 | 2021-09-01T16:59:22Z | 2021-09-01T18:53:20Z | 2021-09-01T18:53:19Z | 2021-09-01T18:53:20Z | 677 | yt-dlp/yt-dlp | 7,450 |
Update doc references for RTD | diff --git a/docs/changelog.md b/docs/changelog.md
index 1f7b10b0b3ea..fcae13ed251e 100644
--- a/docs/changelog.md
+++ b/docs/changelog.md
@@ -24,13 +24,13 @@ _Release date: May 18, 2020_
- ↕️ Ability to set the height of an `st.text_area` with the `height` argument
(expressed in pixels). See
- [docs](https://do... | Fixes #1482
| https://api.github.com/repos/streamlit/streamlit/pulls/1485 | 2020-05-21T19:02:28Z | 2020-05-22T13:27:33Z | 2020-05-22T13:27:33Z | 2020-05-22T13:27:38Z | 2,821 | streamlit/streamlit | 22,485 |
requirements.txt: manimpango v0.3.0 | diff --git a/requirements.txt b/requirements.txt
index c5f049a0f3..a265599b9b 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -16,4 +16,4 @@ pyreadline; sys_platform == 'win32'
validators
ipython
PyOpenGL
-manimpango>=0.2.0,<0.3.0'
+manimpango>=0.2.0,<0.4.0
| ## Motivation
manimpango v0.3.0 should work as there are no breaking changes for the API used here
I should bring in MarkupText here...
| https://api.github.com/repos/3b1b/manim/pulls/1521 | 2021-05-24T16:55:51Z | 2021-06-12T12:29:53Z | 2021-06-12T12:29:53Z | 2021-06-12T13:12:36Z | 107 | 3b1b/manim | 18,285 |
UX: make the fetch_opeml version warning more informative by listing alternative version numbers | diff --git a/sklearn/datasets/_openml.py b/sklearn/datasets/_openml.py
index 54ac34de64e24..99f78e3116187 100644
--- a/sklearn/datasets/_openml.py
+++ b/sklearn/datasets/_openml.py
@@ -307,12 +307,19 @@ def _get_data_info_by_name(
)
res = json_data["data"]["dataset"]
if len(res) > 1:
- ... | Quick fix for an annoying UX problem that I endured for so many years ;)
/cc @glemaitre. | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/27885 | 2023-12-01T18:55:59Z | 2023-12-08T14:51:41Z | 2023-12-08T14:51:41Z | 2023-12-10T18:12:57Z | 573 | scikit-learn/scikit-learn | 46,381 |
Simplified GIS test by removing unneeded Oracle branch. | diff --git a/tests/gis_tests/geoapp/tests.py b/tests/gis_tests/geoapp/tests.py
index 9d03d6ff78b88..3ec620dc8ec6c 100644
--- a/tests/gis_tests/geoapp/tests.py
+++ b/tests/gis_tests/geoapp/tests.py
@@ -103,35 +103,19 @@ def test_lookup_insert_transform(self):
# San Antonio in 'WGS84' (SRID 4326)
sa_432... | https://api.github.com/repos/django/django/pulls/7672 | 2016-12-09T19:40:09Z | 2016-12-15T14:32:12Z | 2016-12-15T14:32:12Z | 2016-12-15T18:29:02Z | 680 | django/django | 51,349 | |
Fix typo in README.md | diff --git a/API Key Leaks/README.md b/API Key Leaks/README.md
index 3a07a180d0..26a3a9a752 100644
--- a/API Key Leaks/README.md
+++ b/API Key Leaks/README.md
@@ -224,7 +224,7 @@ A Mapbox API Token is a JSON Web Token (JWT). If the header of the JWT is `sk`,
#Check token validity
curl "https://api.mapbox.com/tokens... | appropiate -> appropriate | https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/674 | 2023-09-21T15:11:42Z | 2023-09-22T12:50:50Z | 2023-09-22T12:50:50Z | 2023-09-22T12:50:50Z | 213 | swisskyrepo/PayloadsAllTheThings | 8,695 |
Release/1.26.0 | diff --git a/frontend/app/package.json b/frontend/app/package.json
index 28a52a53df00..8980a80a5dc8 100644
--- a/frontend/app/package.json
+++ b/frontend/app/package.json
@@ -1,6 +1,6 @@
{
"name": "@streamlit/app",
- "version": "1.24.1",
+ "version": "1.26.0",
"license": "Apache-2.0",
"private": true,
"h... |
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/7232 | 2023-08-24T20:05:03Z | 2023-08-24T23:23:18Z | 2023-08-24T23:23:18Z | 2023-08-24T23:23:18Z | 703 | streamlit/streamlit | 22,025 |
Fix for Arial.ttf redownloads with hub inference | diff --git a/utils/__init__.py b/utils/__init__.py
index 649b288b358..2af1466f1f1 100644
--- a/utils/__init__.py
+++ b/utils/__init__.py
@@ -1,3 +1,4 @@
+import sys
from pathlib import Path
import torch
@@ -5,6 +6,8 @@
FILE = Path(__file__).absolute()
ROOT = FILE.parents[1] # yolov5/ dir
+if str(ROOT) not in s... |
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Improved module import handling in YOLOv5 utility scripts.
### 📊 Key Changes
- Added an import statement for the `sys` module.
- Ensured the root directory of YOLOv5 is added to Python's system... | https://api.github.com/repos/ultralytics/yolov5/pulls/4627 | 2021-08-31T11:54:05Z | 2021-08-31T13:01:42Z | 2021-08-31T13:01:42Z | 2024-01-19T15:58:51Z | 152 | ultralytics/yolov5 | 25,625 |
docs: Update apify.ipynb for Document class import | diff --git a/docs/docs/integrations/tools/apify.ipynb b/docs/docs/integrations/tools/apify.ipynb
index 949bc93efad1b8..96e2fef7a99f6e 100644
--- a/docs/docs/integrations/tools/apify.ipynb
+++ b/docs/docs/integrations/tools/apify.ipynb
@@ -41,8 +41,8 @@
"outputs": [],
"source": [
"from langchain.indexes imp... | - **Description:**
Update to correctly import Document class -
from langchain_core.documents import Document
- **Issue:**
Fixes the notebook and the hosted documentation [here](https://python.langchain.com/docs/integrations/tools/apify)
| https://api.github.com/repos/langchain-ai/langchain/pulls/19598 | 2024-03-26T17:16:12Z | 2024-03-26T21:46:29Z | 2024-03-26T21:46:29Z | 2024-03-26T21:46:29Z | 175 | langchain-ai/langchain | 43,298 |
Update the error message for invalid use of poke-only sensors | diff --git a/airflow/sensors/base.py b/airflow/sensors/base.py
index 13b386d247c73..d3cf6451a047c 100644
--- a/airflow/sensors/base.py
+++ b/airflow/sensors/base.py
@@ -322,7 +322,7 @@ def mode_getter(_):
def mode_setter(_, value):
if value != "poke":
- raise ValueError("cannot se... | <!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of an existing issue, reference it using one of the following:
closes: #ISSUE... | https://api.github.com/repos/apache/airflow/pulls/30821 | 2023-04-23T07:09:05Z | 2023-04-23T10:37:43Z | 2023-04-23T10:37:43Z | 2023-04-23T13:00:06Z | 435 | apache/airflow | 14,367 |
[extractor/radiofrance] Add support for FIP, Le Mouv, France Musique | diff --git a/yt_dlp/extractor/radiofrance.py b/yt_dlp/extractor/radiofrance.py
index 0972f2c4f66..7b60b2617b2 100644
--- a/yt_dlp/extractor/radiofrance.py
+++ b/yt_dlp/extractor/radiofrance.py
@@ -58,7 +58,7 @@ def _real_extract(self, url):
class FranceCultureIE(InfoExtractor):
- _VALID_URL = r'https?://(?:www\... | <!--
# Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a ... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/4065 | 2022-06-13T09:44:51Z | 2022-06-19T01:36:14Z | 2022-06-19T01:36:14Z | 2022-06-19T07:31:45Z | 405 | yt-dlp/yt-dlp | 8,144 |
Added a shorter solution for the directory diff exercise | diff --git a/topics/shell/README.md b/topics/shell/README.md
index be96da865..2ec3c63ec 100644
--- a/topics/shell/README.md
+++ b/topics/shell/README.md
@@ -14,7 +14,7 @@
|Sum|Functions|[Exercise](sum.md)|[Solution](solutions/sum.md) | Basic
|Number of Arguments|Case Statement|[Exercise](num_of_args.md)|[Solution](so... | Signed-off-by: Fabio Kruger <10956489+krufab@users.noreply.github.com> | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/344 | 2023-02-01T00:25:50Z | 2023-02-02T11:00:24Z | 2023-02-02T11:00:23Z | 2023-02-03T14:15:24Z | 418 | bregman-arie/devops-exercises | 17,602 |
VW MQB: Audi RS3 | diff --git a/RELEASES.md b/RELEASES.md
index 8d8ee06d632fab..be6f2bb641dbe9 100644
--- a/RELEASES.md
+++ b/RELEASES.md
@@ -2,6 +2,7 @@ Version 0.8.14 (2022-0X-XX)
========================
* bigmodel!
* comma body support
+ * Audi RS3 support thanks to jyoung8607!
* Hyundai Ioniq Plug-in Hybrid 2019 support thank... | **Audi RS3**
Adding the fastest sibling of the A3 :: S3 :: RS3 family.
- [x] owner dongle ID: not available
- [x] added to CARS
- [x] added to RELEASES
Thanks to RS3 owner mabnz! | https://api.github.com/repos/commaai/openpilot/pulls/24329 | 2022-04-26T03:36:59Z | 2022-04-26T04:06:23Z | 2022-04-26T04:06:23Z | 2022-06-03T21:14:40Z | 2,114 | commaai/openpilot | 9,203 |
Fix voice assistant error variable | diff --git a/homeassistant/components/voice_assistant/pipeline.py b/homeassistant/components/voice_assistant/pipeline.py
index ef13d54e6a1781..b41ab8ef9f74dc 100644
--- a/homeassistant/components/voice_assistant/pipeline.py
+++ b/homeassistant/components/voice_assistant/pipeline.py
@@ -197,7 +197,7 @@ async def prepare... | <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Breaking change
<!--
If your PR contains a breaking change for existing users, it is important
to tell them what breaks, how to make it work again and why we did th... | https://api.github.com/repos/home-assistant/core/pulls/90658 | 2023-04-02T03:22:48Z | 2023-04-02T03:34:53Z | 2023-04-02T03:34:53Z | 2023-04-04T01:28:22Z | 168 | home-assistant/core | 39,186 |
Remove broken external link | diff --git a/docs/en/docs/external-links.md b/docs/en/docs/external-links.md
index 34ba30e0a82df..d275f28611a09 100644
--- a/docs/en/docs/external-links.md
+++ b/docs/en/docs/external-links.md
@@ -25,8 +25,6 @@ Here's an incomplete list of some of them.
* <a href="https://medium.com/data-rebels/fastapi-authenticatio... | Fixes/ related to #1265 . | https://api.github.com/repos/tiangolo/fastapi/pulls/1565 | 2020-06-13T04:31:25Z | 2020-06-13T21:07:12Z | 2020-06-13T21:07:12Z | 2020-06-13T21:07:27Z | 447 | tiangolo/fastapi | 23,013 |
Fix the documented default of `tracebacks_word_wrap` | diff --git a/rich/logging.py b/rich/logging.py
index 8d166fd53..ca0605095 100644
--- a/rich/logging.py
+++ b/rich/logging.py
@@ -34,7 +34,7 @@ class RichHandler(Handler):
tracebacks_width (Optional[int], optional): Number of characters used to render tracebacks, or None for full width. Defaults to None.
... | ## Type of changes
- [ ] Bug fix
- [ ] New feature
- [x] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added t... | https://api.github.com/repos/Textualize/rich/pulls/974 | 2021-01-29T21:50:33Z | 2021-01-30T11:02:03Z | 2021-01-30T11:02:02Z | 2022-05-02T09:32:39Z | 235 | Textualize/rich | 47,940 |
Fix `pretty` cyclic reference handling | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 409c0280c..d678c0050 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -19,6 +19,7 @@ and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0
- Handle stdout/stderr being null https://github.com/Textualize/rich/pull/2513
- Fix NO_COLOR support on... | ## Type of changes
- [x] Bug fix
- [ ] New feature
- [ ] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [x] I've added t... | https://api.github.com/repos/Textualize/rich/pulls/2524 | 2022-09-14T20:52:03Z | 2022-09-20T10:16:20Z | 2022-09-20T10:16:20Z | 2022-09-20T10:16:21Z | 2,226 | Textualize/rich | 48,002 |
Fix inconsistent exception type in response.json() method | diff --git a/HISTORY.md b/HISTORY.md
index 59e4a9f707..ccf4e17400 100644
--- a/HISTORY.md
+++ b/HISTORY.md
@@ -4,7 +4,12 @@ Release History
dev
---
-- \[Short description of non-trivial change.\]
+- \[Short description of non-trivial change.\]
+
+- Added a `requests.exceptions.JSONDecodeError` to decrease inconsi... | ## Summary
Fixes the inconsistency of errors thrown in the `response.json()` method in `models.py`, while preserving backwards compatibility.
### What we used to have
Depending on whether or not `simplejson` was installed in the user's library, and whether the user was running Python 3+ versus Python 2, a differe... | https://api.github.com/repos/psf/requests/pulls/5856 | 2021-07-03T21:08:32Z | 2021-07-26T15:56:44Z | 2021-07-26T15:56:44Z | 2021-12-01T08:00:28Z | 1,980 | psf/requests | 32,581 |
DOC add example to make_ spd_matrix | diff --git a/sklearn/datasets/_samples_generator.py b/sklearn/datasets/_samples_generator.py
index dd170942eb224..0f2c1b517d1eb 100644
--- a/sklearn/datasets/_samples_generator.py
+++ b/sklearn/datasets/_samples_generator.py
@@ -1603,6 +1603,13 @@ def make_spd_matrix(n_dim, *, random_state=None):
See Also
---... | #### Reference Issues/PRs
Contributes to #27982
#### What does this implement/fix? Explain your changes.
It adds an example to the docstring of sklearn.datasets.make_spd_matrix
| https://api.github.com/repos/scikit-learn/scikit-learn/pulls/28170 | 2024-01-18T16:00:49Z | 2024-01-22T13:51:28Z | 2024-01-22T13:51:28Z | 2024-01-27T10:51:59Z | 192 | scikit-learn/scikit-learn | 46,060 |
Update blns.json | diff --git a/blns.json b/blns.json
index fc77c76..c935bcc 100644
--- a/blns.json
+++ b/blns.json
@@ -389,6 +389,8 @@
"<<SCRIPT>alert(\"XSS\");//<</SCRIPT>",
"<SCRIPT SRC=http://ha.ckers.org/xss.js?< B >",
"<SCRIPT SRC=//ha.ckers.org/.j>",
+ "'); alert('pwned'); console.log('",
+ "\"); alert('pwned'); cons... | those two strings is naughty if you want to prepare javascript in jsp
| https://api.github.com/repos/minimaxir/big-list-of-naughty-strings/pulls/69 | 2015-09-04T12:18:05Z | 2015-09-06T01:52:45Z | 2015-09-06T01:52:45Z | 2015-09-06T01:52:45Z | 164 | minimaxir/big-list-of-naughty-strings | 4,831 |
Renewer errors | diff --git a/letsencrypt/errors.py b/letsencrypt/errors.py
index 82331fcedd8..b15728c39f5 100644
--- a/letsencrypt/errors.py
+++ b/letsencrypt/errors.py
@@ -5,10 +5,6 @@ class Error(Exception):
"""Generic Let's Encrypt client error."""
-class SubprocessError(Error):
- """Subprocess handling error."""
-
-
c... | Replace Value Errors within storage.py with a more appropriate CertStorageError.
| https://api.github.com/repos/certbot/certbot/pulls/650 | 2015-08-04T22:00:17Z | 2015-08-04T22:50:09Z | 2015-08-04T22:50:09Z | 2016-05-06T19:22:13Z | 2,875 | certbot/certbot | 958 |
Fixed comment in example code of F.54 | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index b5a98b25e..1d8730505 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -3835,9 +3835,9 @@ It's confusing. Writing `[=]` in a member function appears to capture by value,
// [=,this] and [&,this] are not much better, and confusing
... | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1082 | 2017-11-17T14:28:46Z | 2017-11-17T15:20:10Z | 2017-11-17T15:20:10Z | 2017-11-17T15:20:10Z | 168 | isocpp/CppCoreGuidelines | 15,272 | |
Fix check for Alpine Linux | diff --git a/localstack/utils/common.py b/localstack/utils/common.py
index ee9cae06e9f3e..912ad777baad1 100644
--- a/localstack/utils/common.py
+++ b/localstack/utils/common.py
@@ -637,7 +637,7 @@ def is_linux():
def is_alpine():
try:
- if not os.path.exists('cat /etc/issue'):
+ if not os.path.exi... | Fix check for Alpine Linux | https://api.github.com/repos/localstack/localstack/pulls/1826 | 2019-12-04T21:58:41Z | 2019-12-04T21:58:49Z | 2019-12-04T21:58:49Z | 2019-12-04T21:58:53Z | 135 | localstack/localstack | 28,830 |
Tensorboard model visualization bug fix | diff --git a/train.py b/train.py
index 1f2b467e732..82043b7fff3 100644
--- a/train.py
+++ b/train.py
@@ -332,7 +332,7 @@ def train(hyp, opt, device, tb_writer=None):
Thread(target=plot_images, args=(imgs, targets, paths, f), daemon=True).start()
# if tb_writer:
... | This fix should allow for visualizing YOLOv5 model graphs correctly in Tensorboard by uncommenting line 335 in train.py:
```python
if tb_writer:
tb_writer.add_graph(torch.jit.trace(model, imgs, strict=False), []) # add model graph
```
The problem identified in #2284 was that the detect() layer checks the in... | https://api.github.com/repos/ultralytics/yolov5/pulls/2758 | 2021-04-10T23:31:04Z | 2021-04-10T23:33:55Z | 2021-04-10T23:33:55Z | 2024-01-19T18:50:02Z | 219 | ultralytics/yolov5 | 25,100 |
[Java] Re-enable remaining skipped Java test cases | diff --git a/java/test/src/main/java/io/ray/test/ExitActorTest.java b/java/test/src/main/java/io/ray/test/ExitActorTest.java
index a1c40e2ac8a1c..279af55c05e59 100644
--- a/java/test/src/main/java/io/ray/test/ExitActorTest.java
+++ b/java/test/src/main/java/io/ray/test/ExitActorTest.java
@@ -15,9 +15,7 @@
import org.t... | <!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your P... | https://api.github.com/repos/ray-project/ray/pulls/13979 | 2021-02-08T10:25:48Z | 2021-02-19T02:57:28Z | 2021-02-19T02:57:28Z | 2021-02-19T02:57:30Z | 1,183 | ray-project/ray | 19,045 |
Fixed #33508 -- Fixed DatabaseFeatures.supports_index_column_ordering on MariaDB 10.8+. | diff --git a/django/db/backends/mysql/features.py b/django/db/backends/mysql/features.py
index f5b9ef9b557be..1996208b46402 100644
--- a/django/db/backends/mysql/features.py
+++ b/django/db/backends/mysql/features.py
@@ -316,10 +316,9 @@ def can_introspect_json_field(self):
@cached_property
def supports_ind... | ticket-33508
| https://api.github.com/repos/django/django/pulls/15452 | 2022-02-21T15:34:32Z | 2022-02-26T15:25:22Z | 2022-02-26T15:25:22Z | 2022-02-28T04:52:15Z | 190 | django/django | 51,419 |
Fix: Exception in thread & KeyError: 'displayName' | diff --git a/gpt4free/quora/api.py b/gpt4free/quora/api.py
index 9e3c0b91fe..6402148940 100644
--- a/gpt4free/quora/api.py
+++ b/gpt4free/quora/api.py
@@ -168,9 +168,9 @@ def get_bots(self, download_next_data=True):
else:
next_data = self.next_data
- if not "availableBots" in self.viewer:... | This was due to a change with Poe. They changed the availableBots key to viewerBotList in the viewer data. | https://api.github.com/repos/xtekky/gpt4free/pulls/636 | 2023-06-01T19:19:02Z | 2023-06-03T22:28:23Z | 2023-06-03T22:28:23Z | 2023-06-03T22:28:23Z | 167 | xtekky/gpt4free | 38,157 |
Added MarkDown formatting support to examples/babi_memnn.py | diff --git a/docs/mkdocs.yml b/docs/mkdocs.yml
index 6a2c733bef0..e6b74030bc7 100644
--- a/docs/mkdocs.yml
+++ b/docs/mkdocs.yml
@@ -70,3 +70,4 @@ nav:
- Examples:
- Addition RNN: examples/addition_rnn.md
- Baby RNN: examples/babi_rnn.md
+ - Baby MemNN: examples/babi_memnn.md
diff --git a/examples/babi_memnn.py... | <!--
Please make sure you've read and understood our contributing guidelines;
https://github.com/keras-team/keras/blob/master/CONTRIBUTING.md
-->
### Summary
This pull request adds MarkDown formatting to ```examples/babi_memnn.py```.
### Related Issues
https://github.com/keras-team/keras/issues/12219
### PR O... | https://api.github.com/repos/keras-team/keras/pulls/12221 | 2019-02-07T11:09:22Z | 2019-02-07T17:35:11Z | 2019-02-07T17:35:11Z | 2019-02-07T17:35:11Z | 407 | keras-team/keras | 46,976 |
Remove hamming option from string distance tests | diff --git a/libs/langchain/tests/unit_tests/evaluation/string_distance/test_base.py b/libs/langchain/tests/unit_tests/evaluation/string_distance/test_base.py
index eff632f454f17e..70dc7aaa789851 100644
--- a/libs/langchain/tests/unit_tests/evaluation/string_distance/test_base.py
+++ b/libs/langchain/tests/unit_tests/e... | Description: We should not test Hamming string distance for strings that are not equal length, since this is not defined. Removing hamming distance tests for unequal string distances.
| https://api.github.com/repos/langchain-ai/langchain/pulls/9882 | 2023-08-28T21:16:32Z | 2023-09-11T20:50:20Z | 2023-09-11T20:50:20Z | 2023-09-11T21:02:08Z | 524 | langchain-ai/langchain | 43,565 |
Update CONTRIBUTING.md | diff --git a/.github/CONTRIBUTING.md b/.github/CONTRIBUTING.md
index 9a03948a724870..e639d827bf8be4 100644
--- a/.github/CONTRIBUTING.md
+++ b/.github/CONTRIBUTING.md
@@ -9,7 +9,7 @@ to contributions, whether they be in the form of new features, improved infra, b
### 👩💻 Contributing Code
To contribute to this pr... | fiixed few typos
| https://api.github.com/repos/langchain-ai/langchain/pulls/10700 | 2023-09-17T11:29:33Z | 2023-09-17T23:35:18Z | 2023-09-17T23:35:18Z | 2023-09-17T23:35:18Z | 1,011 | langchain-ai/langchain | 43,137 |
Fix timeout in create_async | diff --git a/g4f/Provider/AiAsk.py b/g4f/Provider/AiAsk.py
index 0a44af3ed2..870dd1ab43 100644
--- a/g4f/Provider/AiAsk.py
+++ b/g4f/Provider/AiAsk.py
@@ -1,11 +1,9 @@
from __future__ import annotations
-from aiohttp import ClientSession
-
+from aiohttp import ClientSession, ClientTimeout
from ..typing import Async... | https://api.github.com/repos/xtekky/gpt4free/pulls/997 | 2023-10-06T16:22:07Z | 2023-10-06T17:41:23Z | 2023-10-06T17:41:23Z | 2023-10-06T17:41:23Z | 2,277 | xtekky/gpt4free | 37,863 | |
Add fetchOpenOrders to SouthXchange | diff --git a/js/southxchange.js b/js/southxchange.js
index 2e891490f2ee..014a03083f0c 100644
--- a/js/southxchange.js
+++ b/js/southxchange.js
@@ -190,6 +190,45 @@ module.exports = class southxchange extends Exchange {
return this.parseTrades (response, market, since, limit);
}
+ parseOrder (order, m... | https://api.github.com/repos/ccxt/ccxt/pulls/2030 | 2018-02-23T14:45:46Z | 2018-02-25T03:53:18Z | 2018-02-25T03:53:18Z | 2018-02-25T03:53:18Z | 482 | ccxt/ccxt | 13,631 | |
langchain, community: Fixes in the Ontotext GraphDB Graph and QA Chain | diff --git a/docs/docs/use_cases/graph/graph_ontotext_graphdb_qa.ipynb b/docs/docs/use_cases/graph/graph_ontotext_graphdb_qa.ipynb
index b1afd3320af557..3f0a6c09c9b3b4 100644
--- a/docs/docs/use_cases/graph/graph_ontotext_graphdb_qa.ipynb
+++ b/docs/docs/use_cases/graph/graph_ontotext_graphdb_qa.ipynb
@@ -69,7 +69,7 @@... | - **Description:** Fixes in the Ontotext GraphDB Graph and QA Chain related to the error handling in case of invalid SPARQL queries, for which `prepareQuery` doesn't throw an exception, but the server returns 400 and the query is indeed invalid
- **Issue:** N/A
- **Dependencies:** N/A
- **Twitter handle:** @... | https://api.github.com/repos/langchain-ai/langchain/pulls/17239 | 2024-02-08T14:08:07Z | 2024-02-08T20:05:43Z | 2024-02-08T20:05:43Z | 2024-02-09T07:09:38Z | 2,462 | langchain-ai/langchain | 42,848 |
conditionally unused parameters can be declared using maybe_unused attribute. | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 9e9046796..df74ca978 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -2849,12 +2849,24 @@ Suppression of unused parameter warnings.
##### Example
- X* find(map<Blob>& m, const string& s, Hint); // once upon a time, a hint was used
... | conditionally unused parameters can be declared using maybe_unused attribute. | https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1863 | 2021-12-02T09:11:51Z | 2022-02-10T21:34:32Z | 2022-02-10T21:34:32Z | 2022-02-10T22:18:33Z | 264 | isocpp/CppCoreGuidelines | 15,958 |
Missing apostophe. | diff --git a/docs/patterns/sqlalchemy.rst b/docs/patterns/sqlalchemy.rst
index cdf663a681..40e048e003 100644
--- a/docs/patterns/sqlalchemy.rst
+++ b/docs/patterns/sqlalchemy.rst
@@ -33,7 +33,7 @@ SQLAlchemy. It allows you to define tables and models in one go, similar
to how Django works. In addition to the followi... | https://api.github.com/repos/pallets/flask/pulls/1565 | 2015-08-27T04:33:32Z | 2015-10-31T02:20:27Z | 2015-10-31T02:20:27Z | 2020-11-14T06:23:45Z | 166 | pallets/flask | 20,532 | |
Update pycairo requirement | diff --git a/requirements.txt b/requirements.txt
index 33c71720ab..df5fe4078a 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -6,5 +6,5 @@ progressbar==2.5
scipy==1.1.0
tqdm==4.24.0
opencv-python==3.4.2.17
-pycairo==1.17.1
+pycairo>=1.17.1
pydub==0.23.0
| Many issues, such as #535, stem from the odd installation procedure of cairo and pycairo on Windows. By changing the pycairo requirement in requirements.txt, pip will no longer attempt to uninstall the working version. This should have no effect on the functionality of manim, though new installations are likely to defa... | https://api.github.com/repos/3b1b/manim/pulls/555 | 2019-05-28T02:01:22Z | 2019-05-28T02:55:59Z | 2019-05-28T02:55:58Z | 2019-06-20T06:15:06Z | 117 | 3b1b/manim | 18,282 |
add the dropout_p parameter | diff --git a/models/common.py b/models/common.py
index 8b5ec1c786d..71340688d2e 100644
--- a/models/common.py
+++ b/models/common.py
@@ -846,12 +846,19 @@ def forward(self, x):
class Classify(nn.Module):
# YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)
- def __init__(self, c1, c2, k=1, s=1, p=None... | Addressing this issue #10804
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancement of the YOLOv5 classification head with customizable dropout.
### 📊 Key Changes
- Added a new parameter `dropout_p` to the `Classify` class initializer t... | https://api.github.com/repos/ultralytics/yolov5/pulls/10805 | 2023-01-20T23:00:01Z | 2023-02-08T07:32:30Z | 2023-02-08T07:32:30Z | 2024-01-19T03:18:56Z | 336 | ultralytics/yolov5 | 25,437 |
hitbtc3 parseTransaction unification | diff --git a/js/hitbtc3.js b/js/hitbtc3.js
index 9e9dfe363c6e..f29c6a9c0e76 100644
--- a/js/hitbtc3.js
+++ b/js/hitbtc3.js
@@ -1120,33 +1120,36 @@ module.exports = class hitbtc3 extends Exchange {
const sender = this.safeValue (native, 'senders');
const addressFrom = this.safeString (sender, 0);
... | ```
2022-12-29T22:33:25.327Z
Node.js: v18.4.0
CCXT v2.4.74
hitbtc3.fetchTransactions ()
2022-12-29T22:33:27.368Z iteration 0 passed in 477 ms
id | txid | type | code | currency | network | amount | status | timestamp | dat... | https://api.github.com/repos/ccxt/ccxt/pulls/16265 | 2022-12-29T22:34:06Z | 2022-12-30T23:28:15Z | 2022-12-30T23:28:15Z | 2022-12-31T20:17:26Z | 431 | ccxt/ccxt | 12,983 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.