
title stringlengths 2 169 | diff stringlengths 235 19.5k | body stringlengths 0 30.5k | url stringlengths 48 84 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 | updated_at stringlengths 20 20 | diff_len float64 101 3.99k | repo_name stringclasses 83
values | __index_level_0__ int64 15 52.7k |
|---|---|---|---|---|---|---|---|---|---|---|
[gaskrank] Add new extractor | diff --git a/youtube_dl/extractor/extractors.py b/youtube_dl/extractor/extractors.py
index 5ba8efb0eaa..937356d9abb 100644
--- a/youtube_dl/extractor/extractors.py
+++ b/youtube_dl/extractor/extractors.py
@@ -330,6 +330,7 @@
from .gamersyde import GamersydeIE
from .gamespot import GameSpotIE
from .gamestar import Ga... | - [x] At least skimmed through [adding new extractor tutorial](https://github.com/rg3/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/rg3/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?q=is%3Apr&type=Issues) ... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/11685 | 2017-01-11T19:25:07Z | 2017-02-05T16:19:38Z | 2017-02-05T16:19:38Z | 2017-02-05T19:40:46Z | 1,634 | ytdl-org/youtube-dl | 49,704 |
Add missing `__eq__` and `__repr__ ` methods | diff --git a/gym/spaces/box.py b/gym/spaces/box.py
index f3ff2c73fa6..d0d41f27aeb 100644
--- a/gym/spaces/box.py
+++ b/gym/spaces/box.py
@@ -35,15 +35,18 @@ def __init__(self, low=None, high=None, shape=None, dtype=None):
def sample(self):
return gym.spaces.np_random.uniform(low=self.low, high=self.high... | Fixes #1171
- Add missing `__eq__` and `__repr__ ` methods
- Update tests | https://api.github.com/repos/openai/gym/pulls/1178 | 2018-09-23T19:34:25Z | 2018-09-24T18:11:04Z | 2018-09-24T18:11:03Z | 2018-09-24T18:53:21Z | 2,097 | openai/gym | 5,208 |
Add cover to Travis CI build matrix | diff --git a/.travis.yml b/.travis.yml
index 1a63f343f7d..c444081d9f8 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -20,3 +20,4 @@ script: travis_retry tox
env:
- TOXENV=py${TRAVIS_PYTHON_VERSION//[.]/}
- TOXENV=lint
+ - TOXENV=cover
| https://api.github.com/repos/certbot/certbot/pulls/106 | 2014-11-30T02:33:19Z | 2014-11-30T05:33:20Z | 2014-11-30T05:33:20Z | 2016-05-06T19:21:26Z | 104 | certbot/certbot | 710 | |
Update __init__.py | diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/__init__.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/__init__.py
index 19734d29b84..3df0b8172ff 100644
--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/__init__.py
+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/__init__.py
@@ -161,8 +161,8 @@
zone option. The zone wil... | - A trivial doc change to avoid a writing nit commonly seen in newer American writers.
- do not list in credits. | https://api.github.com/repos/certbot/certbot/pulls/9653 | 2023-04-01T22:27:14Z | 2023-04-02T01:15:09Z | 2023-04-02T01:15:09Z | 2023-04-02T01:15:09Z | 251 | certbot/certbot | 823 |
Added example to persist graph | diff --git a/docs/understanding/storing/storing.md b/docs/understanding/storing/storing.md
index 85dae3f104163..77f530895fafe 100644
--- a/docs/understanding/storing/storing.md
+++ b/docs/understanding/storing/storing.md
@@ -10,6 +10,12 @@ The simplest way to store your indexed data is to use the built-in `.persist()`
... | # Description
Added example to store `Composable Graph`.
Fixes # (issue)
NA
## Type of Change
Please delete options that are not relevant.
- [x] This change requires a documentation update
# How Has This Been Tested?
Please describe the tests that you ran to verify your changes. Provide instructi... | https://api.github.com/repos/run-llama/llama_index/pulls/8558 | 2023-10-29T13:52:05Z | 2023-10-30T03:31:23Z | 2023-10-30T03:31:22Z | 2023-10-30T03:31:26Z | 166 | run-llama/llama_index | 6,402 |
update prune infer model size | diff --git a/doc/doc_ch/models_list.md b/doc/doc_ch/models_list.md
index 1f8c65c107..d8c2b77c3e 100644
--- a/doc/doc_ch/models_list.md
+++ b/doc/doc_ch/models_list.md
@@ -31,7 +31,7 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
-|ch_ppocr_mobile_slim_v2.0_det|s... | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/2893 | 2021-05-24T08:30:53Z | 2021-05-24T08:30:59Z | 2021-05-24T08:30:59Z | 2021-05-24T08:30:59Z | 1,218 | PaddlePaddle/PaddleOCR | 42,095 | |
Add SEC EDGAR data API to finance | diff --git a/README.md b/README.md
index 3547ed61b0..8f36290c3c 100644
--- a/README.md
+++ b/README.md
@@ -692,6 +692,7 @@ API | Description | Auth | HTTPS | CORS |
| [Polygon](https://polygon.io/) | Historical stock market data | `apiKey` | Yes | Unknown |
| [Razorpay IFSC](https://razorpay.com/docs/) | Indian Finan... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x]... | https://api.github.com/repos/public-apis/public-apis/pulls/2827 | 2021-10-30T18:45:16Z | 2021-10-30T19:37:43Z | 2021-10-30T19:37:43Z | 2021-10-30T19:37:43Z | 312 | public-apis/public-apis | 35,526 |
[extractor/discogs] Add extractor | diff --git a/yt_dlp/extractor/_extractors.py b/yt_dlp/extractor/_extractors.py
index 69464b6f002..fcfce7f2895 100644
--- a/yt_dlp/extractor/_extractors.py
+++ b/yt_dlp/extractor/_extractors.py
@@ -499,6 +499,7 @@
DeuxMNewsIE
)
from .digitalconcerthall import DigitalConcertHallIE
+from .discogs import DiscogsRele... | **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
Add an extractor for the playlists embedded in Release and Master Release pages on discogs.com (an online music database). The generic extractor used to be able to read these, but that stopped worki... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/6624 | 2023-03-24T22:00:09Z | 2023-06-14T18:40:07Z | 2023-06-14T18:40:07Z | 2023-06-14T18:40:07Z | 579 | yt-dlp/yt-dlp | 7,896 |
Nest | diff --git a/Recursion Visulaizer/.recursionVisualizer.py.swp b/Recursion Visulaizer/.recursionVisualizer.py.swp
new file mode 100644
index 0000000000..872ad8254b
Binary files /dev/null and b/Recursion Visulaizer/.recursionVisualizer.py.swp differ
diff --git a/Recursion Visulaizer/Magneticfieldlines.PNG b/Recursion Vis... | https://api.github.com/repos/geekcomputers/Python/pulls/1381 | 2021-09-18T16:52:58Z | 2021-09-26T19:17:29Z | 2021-09-26T19:17:29Z | 2021-09-26T19:17:29Z | 862 | geekcomputers/Python | 31,801 | |
declare Python 3.7 support in setup.py | diff --git a/setup.py b/setup.py
index 8c47f67ce35..bd666e93c47 100644
--- a/setup.py
+++ b/setup.py
@@ -56,6 +56,7 @@ def has_environment_marker_platform_impl_support():
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',... | Scrapy supports 3.7 since #3326. | https://api.github.com/repos/scrapy/scrapy/pulls/3547 | 2018-12-26T08:19:46Z | 2018-12-26T14:09:08Z | 2018-12-26T14:09:08Z | 2019-01-30T10:33:13Z | 142 | scrapy/scrapy | 34,306 |
Fix regression in Cloudflare library | diff --git a/certbot-dns-cloudflare/certbot_dns_cloudflare/__init__.py b/certbot-dns-cloudflare/certbot_dns_cloudflare/__init__.py
index 81c053c04fa..b72f19f0816 100644
--- a/certbot-dns-cloudflare/certbot_dns_cloudflare/__init__.py
+++ b/certbot-dns-cloudflare/certbot_dns_cloudflare/__init__.py
@@ -39,7 +39,7 @@
zone... | Fixes #9407
## Pull Request Checklist
- [x] The Certbot team has recently expressed interest in reviewing a PR for this. If not, this PR may be closed due our limited resources and need to prioritize how we spend them. (https://github.com/certbot/certbot/issues/9407#issuecomment-1257842294)
- [X] If the change b... | https://api.github.com/repos/certbot/certbot/pulls/9417 | 2022-09-26T18:59:20Z | 2022-09-26T21:48:30Z | 2022-09-26T21:48:30Z | 2022-09-26T22:04:05Z | 1,177 | certbot/certbot | 1,114 |
Optimize preprocess for ragged batching | diff --git a/deepspeed/inference/v2/ragged/ragged_wrapper.py b/deepspeed/inference/v2/ragged/ragged_wrapper.py
index 15abd1987aa1..056ecfa2ac40 100644
--- a/deepspeed/inference/v2/ragged/ragged_wrapper.py
+++ b/deepspeed/inference/v2/ragged/ragged_wrapper.py
@@ -113,12 +113,23 @@ def __init__(self, config: DSStateManag... | This PR improves efficiency of preprocessing for ragged batching.
It is not efficient to iterate substituting values to tensor slices or copy/fill calls for small numbers of values. This PR records the values in python lists or primitives and copy them at once. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/4942 | 2024-01-12T00:46:10Z | 2024-01-13T01:59:16Z | 2024-01-13T01:59:16Z | 2024-01-13T01:59:21Z | 1,267 | microsoft/DeepSpeed | 10,085 |
parallelize writing of layer checkpoint files across data parallel instances | diff --git a/deepspeed/runtime/config.py b/deepspeed/runtime/config.py
index 6d377e5dc6a2..b602d9d10958 100755
--- a/deepspeed/runtime/config.py
+++ b/deepspeed/runtime/config.py
@@ -669,6 +669,19 @@ def get_checkpoint_tag_validation_mode(checkpoint_params):
)
+def get_checkpoint_parallel_write_pipeline(ch... | This is work in progress, but I wanted to open it early for discussion. Also, I wrote this before MOE was added, and it will need to be updated to account for that. I can help with that if this approach is approved.
In case a pipeline stage has multiple layers, this parallelizes the task of writing the layer check... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1419 | 2021-09-30T19:11:57Z | 2022-10-21T18:31:21Z | 2022-10-21T18:31:21Z | 2022-10-27T20:11:14Z | 1,805 | microsoft/DeepSpeed | 10,093 |
[Apache v2] Adding nodes 2/3 : add_child_directive() | diff --git a/certbot-apache/certbot_apache/augeasparser.py b/certbot-apache/certbot_apache/augeasparser.py
index e340519ce61..5fd5247c15d 100644
--- a/certbot-apache/certbot_apache/augeasparser.py
+++ b/certbot-apache/certbot_apache/augeasparser.py
@@ -221,12 +221,26 @@ def add_child_block(self, name, parameters=None, ... | This PR implements add_child_directive() and is built on top of #7497
Note: this PR uses temporarily #7497 as base to help to hide the unnecessary diffs. This also means that the tests won't run before it's changed back to `apache-parser-v2` | https://api.github.com/repos/certbot/certbot/pulls/7517 | 2019-11-06T09:22:58Z | 2019-11-12T22:19:02Z | 2019-11-12T22:19:02Z | 2019-11-12T22:19:06Z | 887 | certbot/certbot | 1,641 |
add a template of infinity_outpainting | diff --git a/visual_chatgpt.py b/visual_chatgpt.py
index fd3b978d..e9614894 100644
--- a/visual_chatgpt.py
+++ b/visual_chatgpt.py
@@ -5,9 +5,11 @@
import cv2
import re
import uuid
-from PIL import Image
+from PIL import Image, ImageDraw, ImageOps
+import math
import numpy as np
import argparse
+import inspect
... | welcome to add more template for visual-chatgpt | https://api.github.com/repos/chenfei-wu/TaskMatrix/pulls/269 | 2023-03-22T15:44:59Z | 2023-03-22T16:09:48Z | 2023-03-22T16:09:48Z | 2023-03-22T16:09:54Z | 3,043 | chenfei-wu/TaskMatrix | 40,929 |
0.10 | diff --git a/.travis.yml b/.travis.yml
index d2c7552312..062bb77b50 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -3,8 +3,7 @@ python:
- "2.7"
# command to install dependencies, e.g. pip install -r requirements.txt --use-mirrors
install:
- - "pip install --upgrade git+https://github.com/mitmproxy/netlib.git"
- ... | Hi, I've added 3 replay features to version 0.10:
--replay_ignore_content: tells mitmdump to ignore request content in flow matching
--replay-ignore-param: (can be passed multiple times) creates a list of query parameters that will be ignored in flow matching (useful for dealing with sites that add random numbers or re... | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/368 | 2014-09-30T10:45:12Z | 2014-10-22T20:02:31Z | 2014-10-22T20:02:31Z | 2014-10-22T20:02:31Z | 3,521 | mitmproxy/mitmproxy | 27,695 |
merge profile output path fix | diff --git a/deepspeed/profiling/flops_profiler/profiler.py b/deepspeed/profiling/flops_profiler/profiler.py
index d599736b8f1e..1a20ae470a2b 100644
--- a/deepspeed/profiling/flops_profiler/profiler.py
+++ b/deepspeed/profiling/flops_profiler/profiler.py
@@ -254,7 +254,7 @@ def print_model_profile(self,
origin... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/2397 | 2022-10-06T19:35:45Z | 2022-10-06T19:35:57Z | 2022-10-06T19:35:57Z | 2022-10-06T19:35:57Z | 170 | microsoft/DeepSpeed | 10,694 | |
Fixed #16734 -- Set script prefix in django.setup() to allow its usage outside of requests. | diff --git a/django/__init__.py b/django/__init__.py
index 3025f721bd4ec..c9c3ecf17ac00 100644
--- a/django/__init__.py
+++ b/django/__init__.py
@@ -1,3 +1,5 @@
+from __future__ import unicode_literals
+
from django.utils.version import get_version
VERSION = (1, 10, 0, 'alpha', 0)
@@ -5,14 +7,21 @@
__version__ = g... | https://api.github.com/repos/django/django/pulls/5470 | 2015-10-23T19:21:03Z | 2015-10-29T19:13:23Z | 2015-10-29T19:13:23Z | 2015-10-29T19:13:51Z | 1,532 | django/django | 51,273 | |
Update MODEL_CARD.md | diff --git a/MODEL_CARD.md b/MODEL_CARD.md
index 0a2718c18..18d9dfea8 100644
--- a/MODEL_CARD.md
+++ b/MODEL_CARD.md
@@ -10,7 +10,7 @@ Meta developed and released the Llama 2 family of large language models (LLMs),
**Output** Models generate text only.
-**Model Architecture** Llama 2 is an auto-regressive language... | https://api.github.com/repos/meta-llama/llama/pulls/511 | 2023-07-23T09:28:10Z | 2023-08-26T02:17:53Z | 2023-08-26T02:17:53Z | 2023-08-26T02:17:58Z | 724 | meta-llama/llama | 31,997 | |
loggerd: speedup unit tests | diff --git a/system/loggerd/tests/test_loggerd.py b/system/loggerd/tests/test_loggerd.py
index 49d97505e830fc..dde12b646db4d5 100755
--- a/system/loggerd/tests/test_loggerd.py
+++ b/system/loggerd/tests/test_loggerd.py
@@ -5,7 +5,6 @@
import string
import subprocess
import time
-import unittest
from collections imp... | https://api.github.com/repos/commaai/openpilot/pulls/31115 | 2024-01-23T00:51:22Z | 2024-01-23T01:24:43Z | 2024-01-23T01:24:43Z | 2024-01-23T01:24:44Z | 1,973 | commaai/openpilot | 9,398 | |
Add IG.com | diff --git a/README.md b/README.md
index b6a7cfb6bc..af4238596c 100644
--- a/README.md
+++ b/README.md
@@ -250,6 +250,7 @@ API | Description | Auth | HTTPS | Link |
| Barchart OnDemand | Stock, Futures, and Forex Market Data | `apiKey` | Yes | [Go!](https://www.barchartondemand.com/free) |
| Consumer Financial Protec... | Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md).
- [x] Your changes are made in the [README](../README.md) fi... | https://api.github.com/repos/public-apis/public-apis/pulls/520 | 2017-10-21T10:00:54Z | 2017-10-22T02:38:37Z | 2017-10-22T02:38:37Z | 2017-10-22T02:38:39Z | 299 | public-apis/public-apis | 35,239 |
Update avl_tree.py | diff --git a/data_structures/binary_tree/avl_tree.py b/data_structures/binary_tree/avl_tree.py
index cb043cf188b7..71dede2ccacc 100644
--- a/data_structures/binary_tree/avl_tree.py
+++ b/data_structures/binary_tree/avl_tree.py
@@ -1,6 +1,11 @@
"""
-An auto-balanced binary tree!
+Implementation of an auto-balanced bina... | it's true definition of AVL tree,change left and right rotation,and add avl_tree doctest
### **Describe your change:**
* [ ] Add an algorithm?
* [x] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### **Checklist:**
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgor... | https://api.github.com/repos/TheAlgorithms/Python/pulls/2145 | 2020-06-22T03:22:25Z | 2020-06-25T07:55:14Z | 2020-06-25T07:55:14Z | 2020-06-25T07:55:14Z | 3,252 | TheAlgorithms/Python | 30,213 |
fix for Files property missing on Computer module | diff --git a/interpreter/core/computer/computer.py b/interpreter/core/computer/computer.py
index 175f71586..7ccdd2d73 100644
--- a/interpreter/core/computer/computer.py
+++ b/interpreter/core/computer/computer.py
@@ -14,7 +14,7 @@
from .skills.skills import Skills
from .sms.sms import SMS
from .terminal.terminal imp... | ### Describe the changes you have made:
Import the missing Files module into the Computer module
### Reference any relevant issues (e.g. "Fixes #000"):
https://github.com/OpenInterpreter/open-interpreter/issues/1106
### Pre-Submission Checklist (optional but appreciated):
- [ n/a ] I have included relevant d... | https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/1107 | 2024-03-21T23:21:57Z | 2024-03-24T05:58:34Z | 2024-03-24T05:58:34Z | 2024-03-24T05:58:34Z | 185 | OpenInterpreter/open-interpreter | 40,875 |
lambda: Fix adding environment variables to functions previously not having any | diff --git a/lib/ansible/modules/cloud/amazon/lambda.py b/lib/ansible/modules/cloud/amazon/lambda.py
index 2c5ad38226eec3..0a0a9897b33766 100644
--- a/lib/ansible/modules/cloud/amazon/lambda.py
+++ b/lib/ansible/modules/cloud/amazon/lambda.py
@@ -330,7 +330,7 @@ def main():
func_kwargs.update({'Timeout': t... | ##### ISSUE TYPE
<!--- Pick one below and delete the rest: -->
- Bugfix Pull Request
##### COMPONENT NAME
<!--- Name of the module/plugin/module/task -->
lambda
##### ANSIBLE VERSION
<!--- Paste verbatim output from “ansible --version” between quotes below -->
```
ansible 2.2.1.0
config file = /home/mm... | https://api.github.com/repos/ansible/ansible/pulls/22313 | 2017-03-06T13:56:03Z | 2017-03-06T16:10:40Z | 2017-03-06T16:10:40Z | 2019-04-26T20:52:34Z | 701 | ansible/ansible | 49,053 |
[Update core.py]: comment the support for with-statement | diff --git a/gym/core.py b/gym/core.py
index 11ba5842d1e..8657afdec2d 100644
--- a/gym/core.py
+++ b/gym/core.py
@@ -145,9 +145,11 @@ def __str__(self):
return '<{}<{}>>'.format(type(self).__name__, self.spec.id)
def __enter__(self):
+ """Support with-statement for the environment. """
... | https://api.github.com/repos/openai/gym/pulls/1627 | 2019-08-01T20:26:54Z | 2019-10-25T22:48:21Z | 2019-10-25T22:48:21Z | 2019-10-25T22:48:21Z | 142 | openai/gym | 5,859 | |
Replace 404 url | diff --git a/youtube_dl/extractor/howstuffworks.py b/youtube_dl/extractor/howstuffworks.py
index 68684b99744..fccc2388408 100644
--- a/youtube_dl/extractor/howstuffworks.py
+++ b/youtube_dl/extractor/howstuffworks.py
@@ -28,13 +28,13 @@ class HowStuffWorksIE(InfoExtractor):
}
},
{
- ... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/3923 | 2014-10-11T10:34:20Z | 2014-10-11T18:48:11Z | 2014-10-11T18:48:11Z | 2014-10-11T23:44:29Z | 345 | ytdl-org/youtube-dl | 50,204 | |
Fix ci status badge error | diff --git a/README.md b/README.md
index d2b5df45d9..6a31b02fdc 100644
--- a/README.md
+++ b/README.md
@@ -21,7 +21,7 @@
[](https://httpie.org/docs/cli)
[:
_VALID_URL = r'https?://(?:www\.)?clipfish\.de/(?:[^/]+/)+video/(?P... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/12865 | 2017-04-27T16:12:00Z | 2017-04-27T19:51:31Z | 2017-04-27T19:51:31Z | 2017-04-27T19:55:27Z | 249 | ytdl-org/youtube-dl | 50,454 |
`BaseTracer` helper method for `Run` lookup | diff --git a/libs/core/langchain_core/tracers/base.py b/libs/core/langchain_core/tracers/base.py
index c37aec08d211d5..db0301b2a1a5fd 100644
--- a/libs/core/langchain_core/tracers/base.py
+++ b/libs/core/langchain_core/tracers/base.py
@@ -92,6 +92,17 @@ def _get_execution_order(self, parent_run_id: Optional[str] = None... | I observed the same run ID extraction logic is repeated many times in `BaseTracer`.
This PR creates a helper method for DRY code. | https://api.github.com/repos/langchain-ai/langchain/pulls/14139 | 2023-12-01T20:10:08Z | 2023-12-02T22:05:50Z | 2023-12-02T22:05:50Z | 2023-12-02T22:49:34Z | 1,943 | langchain-ai/langchain | 42,794 |
bitz XBT mapping | diff --git a/js/bitz.js b/js/bitz.js
index 079a17433d29..01d8b56be084 100644
--- a/js/bitz.js
+++ b/js/bitz.js
@@ -142,6 +142,7 @@ module.exports = class bitz extends Exchange {
// https://github.com/ccxt/ccxt/issues/3881
// https://support.bit-z.pro/hc/en-us/articles/360007500654-BOX-... | https://www.bitz.ai/en/exchange/xbt_usdt
conflict with BTC | https://api.github.com/repos/ccxt/ccxt/pulls/9900 | 2021-08-30T16:13:52Z | 2021-08-30T16:37:12Z | 2021-08-30T16:37:12Z | 2021-08-30T16:37:12Z | 153 | ccxt/ccxt | 13,731 |
Use submit and blur for quick settings textbox | diff --git a/modules/ui_settings.py b/modules/ui_settings.py
index 0c560b30f9f..a6076bf3060 100644
--- a/modules/ui_settings.py
+++ b/modules/ui_settings.py
@@ -260,13 +260,20 @@ def add_functionality(self, demo):
component = self.component_dict[k]
info = opts.data_labels[k]
- ... | ## Description
[[Bug]: Can't normal edit Directory name pattern after add it to Quicksettings list ! ](https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/11740)
when textbox is in quick settings fit one typing too fast can cause the textbox to glitch
the issue is caused by the settings update speed is un... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/11750 | 2023-07-12T14:35:58Z | 2023-07-13T11:49:48Z | 2023-07-13T11:49:48Z | 2023-07-13T17:30:05Z | 294 | AUTOMATIC1111/stable-diffusion-webui | 40,507 |
Improve prompts-from-file script to support negative prompts and sampler-by-name | diff --git a/scripts/prompts_from_file.py b/scripts/prompts_from_file.py
index 32fe6bdbaf4..6e118ddb552 100644
--- a/scripts/prompts_from_file.py
+++ b/scripts/prompts_from_file.py
@@ -9,6 +9,7 @@
import modules.scripts as scripts
import gradio as gr
+from modules import sd_samplers
from modules.processing imp... | I updated the prompt-from-file script so that you can add custom prompts and custom negative prompts when also using other flags. I also added support for specifying a sampler by name rather than by index.
This significantly increases the flexibility of the script for power users. To the best of my knowledge, this d... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/5699 | 2022-12-13T17:08:13Z | 2022-12-24T08:16:09Z | 2022-12-24T08:16:09Z | 2023-10-01T18:55:35Z | 454 | AUTOMATIC1111/stable-diffusion-webui | 39,876 |
get_handler_file_from_name when path contains periods | diff --git a/localstack/services/awslambda/lambda_utils.py b/localstack/services/awslambda/lambda_utils.py
index aafd9878746da..0d47456700305 100644
--- a/localstack/services/awslambda/lambda_utils.py
+++ b/localstack/services/awslambda/lambda_utils.py
@@ -128,24 +128,35 @@ def is_provided_runtime(runtime_details: Unio... | Fixes for get_handler_file_from_name, fixing incorrectly returning '.js' from '.build/handler.execute' (Typescript).
Revisiting #1774 / #1775
Also appears related to both #5485 and #3969 with '.webpack/service/first.hello'
This appears to have either regressed or not been fixed, due to `handler_name.split(delimite... | https://api.github.com/repos/localstack/localstack/pulls/5849 | 2022-04-12T16:26:52Z | 2022-04-19T19:28:42Z | 2022-04-19T19:28:41Z | 2022-04-19T20:29:32Z | 1,151 | localstack/localstack | 28,753 |
add API from asterank.com for minor planets | diff --git a/README.md b/README.md
index b7cdd386aa..59c8bc5a91 100644
--- a/README.md
+++ b/README.md
@@ -128,6 +128,11 @@ A collective list of JSON APIs for use in web development.
| Drupal.org | Drupal.org API | No | [Go!](https://www.drupal.org/drupalorg/api) |
| Libraries.io | Open source software libraries | No... | asterank.com offers a couple of neat api's. One of the most interesting is the Minor Planets which I added to your list.
| https://api.github.com/repos/public-apis/public-apis/pulls/175 | 2016-04-24T10:20:02Z | 2016-04-24T12:29:49Z | 2016-04-24T12:29:49Z | 2016-04-24T12:29:49Z | 181 | public-apis/public-apis | 36,172 |
Support MPS backend for MacOS devices | diff --git a/README.md b/README.md
index d0f438ea5e..9c805fa8e1 100644
--- a/README.md
+++ b/README.md
@@ -90,6 +90,11 @@ This runs on the CPU only and does not require GPU. It requires around 60GB of C
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --device cpu
```
+### Metal Backend (Mac compu... | https://api.github.com/repos/lm-sys/FastChat/pulls/250 | 2023-04-06T14:29:10Z | 2023-04-06T14:42:42Z | 2023-04-06T14:42:42Z | 2023-06-29T11:48:26Z | 2,384 | lm-sys/FastChat | 41,381 | |
Force nginx tests to run during CI | diff --git a/tests/boulder-integration.sh b/tests/boulder-integration.sh
index 08c4826768a..d86a6fb8c78 100755
--- a/tests/boulder-integration.sh
+++ b/tests/boulder-integration.sh
@@ -203,7 +203,9 @@ common revoke --cert-path "$root/conf/live/le2.wtf/cert.pem" \
common unregister
-if type nginx;
+# Most CI system... | If for some reason our Nginx set up gets broken in Travis, our tests will currently silently pass without making us aware of the issue. Let's fix this!
[Travis source](https://docs.travis-ci.com/user/environment-variables/#Default-Environment-Variables)
[Circle source](https://circleci.com/docs/1.0/environment-vari... | https://api.github.com/repos/certbot/certbot/pulls/4558 | 2017-04-27T21:18:25Z | 2017-05-16T19:19:08Z | 2017-05-16T19:19:08Z | 2017-05-16T19:19:12Z | 152 | certbot/certbot | 3,633 |
Fix syntax error | diff --git a/requests/auth.py b/requests/auth.py
index 4529ec7aac..edf4c8dcd7 100644
--- a/requests/auth.py
+++ b/requests/auth.py
@@ -51,7 +51,7 @@ def __eq__(self, other):
return all([
self.username == getattr(other, 'username', None),
self.password == getattr(other, 'password', Non... | https://api.github.com/repos/psf/requests/pulls/2986 | 2016-01-30T18:56:10Z | 2016-01-30T19:14:20Z | 2016-01-30T19:14:20Z | 2021-09-08T05:00:59Z | 187 | psf/requests | 32,437 | |
FIX: localstack is running inside the docker config flag | diff --git a/localstack/config.py b/localstack/config.py
index ba5f00842cfb1..b8ae3a032b786 100644
--- a/localstack/config.py
+++ b/localstack/config.py
@@ -245,11 +245,28 @@ def ping(host):
def in_docker():
- """ Returns True if running in a docker container, else False """
+ """
+ Returns True if runnin... | Added mechanism to check whether localstack instance is running inside the docker or on the host. It also will support cgroup v2.
Fix for #3675 | https://api.github.com/repos/localstack/localstack/pulls/3717 | 2021-03-13T09:37:03Z | 2021-03-14T11:45:22Z | 2021-03-14T11:45:22Z | 2021-03-14T11:45:22Z | 332 | localstack/localstack | 29,364 |
Use region-agnostic bucket create for Transcribe tests | diff --git a/tests/aws/services/transcribe/test_transcribe.py b/tests/aws/services/transcribe/test_transcribe.py
index 2d9d49ace0176..6f25632c9e81d 100644
--- a/tests/aws/services/transcribe/test_transcribe.py
+++ b/tests/aws/services/transcribe/test_transcribe.py
@@ -241,6 +241,7 @@ def test_transcribe_start_job(
... | ## Motivation
This PR fixes test execution error when a non-default `TEST_AWS_REGION_NAME` is used.
This happens because S3 CreateBucket requires `LocationConstraint` information when any region other than `us-east-1` is used. Our `s3_create_bucket` fixture takes care of such situations.
## Implementation
J... | https://api.github.com/repos/localstack/localstack/pulls/9318 | 2023-10-09T13:14:20Z | 2023-10-10T09:13:51Z | 2023-10-10T09:13:51Z | 2023-10-10T09:13:55Z | 204 | localstack/localstack | 29,323 |
#921: Try printing alias before trying to fix a command | diff --git a/thefuck/entrypoints/main.py b/thefuck/entrypoints/main.py
index 013468702..865b9ca1a 100644
--- a/thefuck/entrypoints/main.py
+++ b/thefuck/entrypoints/main.py
@@ -22,10 +22,13 @@ def main():
elif known_args.version:
logs.version(get_installation_info().version,
sys.vers... | The shell functions could be changed in a way to unset `TF_HISTORY` before firing the subprocess. But it would be prone to regressions. So, changing the order of `if` statements and adding a comment should suffice. | https://api.github.com/repos/nvbn/thefuck/pulls/923 | 2019-06-04T18:35:46Z | 2019-06-26T18:01:39Z | 2019-06-26T18:01:39Z | 2019-06-26T18:38:50Z | 244 | nvbn/thefuck | 30,625 |
Add entity name translations to AVM Fritz!SmartHome | diff --git a/homeassistant/components/fritzbox/__init__.py b/homeassistant/components/fritzbox/__init__.py
index 38f0e375e874d5..bd246dd914fc53 100644
--- a/homeassistant/components/fritzbox/__init__.py
+++ b/homeassistant/components/fritzbox/__init__.py
@@ -113,8 +113,8 @@ def __init__(
self.ain = ain
... | <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
or... | https://api.github.com/repos/home-assistant/core/pulls/90707 | 2023-04-03T10:17:15Z | 2023-04-03T17:04:09Z | 2023-04-03T17:04:09Z | 2023-04-04T21:01:54Z | 3,731 | home-assistant/core | 39,077 |
docs: replace redirection with tee command with sudo for file creation | diff --git a/docs/installation/methods.yml b/docs/installation/methods.yml
index 1cc09762b8..290b0e2436 100644
--- a/docs/installation/methods.yml
+++ b/docs/installation/methods.yml
@@ -39,7 +39,7 @@ tools:
install:
- curl -SsL https://packages.httpie.io/deb/KEY.gpg | sudo gpg --dearmor -o /usr/share/k... |
This pull request addresses an issue where using `sudo`-prefixed `echo` does not grant elevated permissions for the subsequent redirection operation, resulting in a failure to write files under `/etc/apt`.
By replacing the redirection with a `sudo`-prefixed `tee` command, this change ensures that files are written w... | https://api.github.com/repos/httpie/cli/pulls/1557 | 2024-02-07T11:58:52Z | 2024-03-04T14:34:57Z | 2024-03-04T14:34:57Z | 2024-03-04T14:35:08Z | 255 | httpie/cli | 33,931 |
bybit: set endTime when since is not empty | diff --git a/ts/src/bybit.ts b/ts/src/bybit.ts
index 3759a09fe3e7..50ac008862df 100644
--- a/ts/src/bybit.ts
+++ b/ts/src/bybit.ts
@@ -2235,12 +2235,15 @@ export default class bybit extends Exchange {
*/
this.checkRequiredSymbol ('fetchFundingRateHistory', symbol);
await this.loadMarkets ();... | fix https://github.com/ccxt/ccxt/issues/15990
Bybit will return `Time is invalid` if `startTime` is set and `endTime` is empty. In this PR, I fix this issue.
```
$ node examples/js/cli bybit fetchFundingRateHistory ETH/USDT:USDT 'undefined' 10 '{"endTime":1673063081000}' --test
2023-04-05T09:37:02.032Z iteratio... | https://api.github.com/repos/ccxt/ccxt/pulls/17486 | 2023-04-05T09:38:03Z | 2023-04-06T09:56:16Z | 2023-04-06T09:56:16Z | 2023-04-06T09:56:17Z | 413 | ccxt/ccxt | 13,914 |
Add DINOv2 models with register tokens. Convert pos embed to not overlap with cls token. | diff --git a/timm/models/vision_transformer.py b/timm/models/vision_transformer.py
index 1ccb96db4e..0eb66176d0 100644
--- a/timm/models/vision_transformer.py
+++ b/timm/models/vision_transformer.py
@@ -567,7 +567,11 @@ def get_classifier(self):
def reset_classifier(self, num_classes: int, global_pool=None):
... | https://api.github.com/repos/huggingface/pytorch-image-models/pulls/2014 | 2023-10-30T00:07:08Z | 2023-10-30T06:03:48Z | 2023-10-30T06:03:48Z | 2023-10-30T06:08:09Z | 2,748 | huggingface/pytorch-image-models | 16,399 | |
fix(urllib3): :bug: could not find urllib3 DEFAULT_CIPHERS | diff --git a/httpie/ssl_.py b/httpie/ssl_.py
index b9438543eb..ac02ddb272 100644
--- a/httpie/ssl_.py
+++ b/httpie/ssl_.py
@@ -4,12 +4,50 @@
from httpie.adapters import HTTPAdapter
# noinspection PyPackageRequirements
from urllib3.util.ssl_ import (
- DEFAULT_CIPHERS, create_urllib3_context,
+ create_urllib3_c... | Default ciphers imported from urllib3 as a work around for https://github.com/httpie/httpie/issues/1499
Removed from urllib3 in this commit: https://github.com/urllib3/urllib3/commit/e5eac0c | https://api.github.com/repos/httpie/cli/pulls/1505 | 2023-05-18T17:14:28Z | 2023-05-19T19:18:56Z | 2023-05-19T19:18:56Z | 2023-05-31T09:24:15Z | 574 | httpie/cli | 33,993 |
Update README.md | diff --git a/README.md b/README.md
index 9011b728..f458f1c3 100644
--- a/README.md
+++ b/README.md
@@ -231,6 +231,7 @@ For a list of free-to-attend meetups and local events, go [here](https://github.
* [Clojush](https://github.com/lspector/Clojush) - The Push programming language and the PushGP genetic programming sy... | Added DL4CLJ, a Clojure wrapper for Deeplearning4j | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/351 | 2017-02-25T00:28:09Z | 2017-02-25T05:53:08Z | 2017-02-25T05:53:08Z | 2017-02-25T05:53:13Z | 301 | josephmisiti/awesome-machine-learning | 52,344 |
Use reference strings in Nexia | diff --git a/homeassistant/components/nexia/strings.json b/homeassistant/components/nexia/strings.json
index dcfb40b898ac65..876ea2d656f11b 100644
--- a/homeassistant/components/nexia/strings.json
+++ b/homeassistant/components/nexia/strings.json
@@ -10,12 +10,12 @@
}
},
"error": {
- "cannot_conne... | <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Breaking change
<!--
If your PR contains a breaking change for existing users, it is important
to tell them what breaks, how to make it work again and why we did th... | https://api.github.com/repos/home-assistant/core/pulls/41210 | 2020-10-04T13:15:47Z | 2020-10-04T13:38:52Z | 2020-10-04T13:38:52Z | 2020-10-04T13:38:53Z | 244 | home-assistant/core | 38,930 |
Adding a very rudimentary admin page that displays a table of users | diff --git a/website/src/components/UsersCell.tsx b/website/src/components/UsersCell.tsx
new file mode 100644
index 0000000000..b2b04c83dc
--- /dev/null
+++ b/website/src/components/UsersCell.tsx
@@ -0,0 +1,44 @@
+import { Table, TableCaption, TableContainer, Tbody, Td, Th, Thead, Tr } from "@chakra-ui/react";
+import ... | This starts #237 with a very basic and minimally styled version. This does not include any management functionality, that will be in a follow up PR. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/476 | 2023-01-07T10:14:17Z | 2023-01-07T11:17:02Z | 2023-01-07T11:17:02Z | 2023-01-07T11:17:03Z | 1,171 | LAION-AI/Open-Assistant | 37,168 |
Update README.md | diff --git a/README.md b/README.md
index e0f3994a22553..2973ac4704bbe 100644
--- a/README.md
+++ b/README.md
@@ -243,7 +243,7 @@ defined in [`config.py`](https://github.com/localstack/localstack/blob/master/lo
For example, to dynamically set `KINESIS_ERROR_PROBABILITY=1` at runtime, use the following command:
```
-... | Port refers to 4568, but commands run successfully on port 4566. Not sure if typo or version change, or if I have fundamentally misunderstood the purpose of the example commands...
**Please refer to the contribution guidelines in the README when submitting PRs.**
┆Issue is synchronized with this [Jira Bug](https://... | https://api.github.com/repos/localstack/localstack/pulls/3265 | 2020-11-22T14:11:17Z | 2020-11-22T23:32:18Z | 2020-11-22T23:32:18Z | 2020-11-22T23:32:19Z | 262 | localstack/localstack | 29,374 |
Simplify url_basename | diff --git a/youtube_dl/utils.py b/youtube_dl/utils.py
index d5069dcca98..4c7ad89c0b3 100644
--- a/youtube_dl/utils.py
+++ b/youtube_dl/utils.py
@@ -1092,7 +1092,5 @@ def remove_start(s, start):
def url_basename(url):
- m = re.match(r'(?:https?:|)//[^/]+/(?:[^?#]+/)?([^/?#]+)/?(?:[?#]|$)', url)
- if not m:
-... | Use urlparse from the standard library.
I think it does the same, the tests pass. I prefer that to a terrorific regex.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/1997 | 2013-12-17T13:58:14Z | 2013-12-17T15:08:48Z | 2013-12-17T15:08:48Z | 2013-12-17T15:08:53Z | 162 | ytdl-org/youtube-dl | 49,923 |
Update instances of acme-staging url to acme-staging-v02 (#5734) | diff --git a/certbot/constants.py b/certbot/constants.py
index a6878824b58..9dfc00c6b46 100644
--- a/certbot/constants.py
+++ b/certbot/constants.py
@@ -107,7 +107,7 @@
dns_route53=False
)
-STAGING_URI = "https://acme-staging.api.letsencrypt.org/directory"
+STAGING_URI = "https://acme-staging-v02.api.letsencryp... | * update instances of acme-staging url to acme-staging-v02
* keep example client as v1
* keep deactivate script as v1
(cherry picked from commit 5ecb68f2ed41474d65f70d309d2bd05c61fd6faf) | https://api.github.com/repos/certbot/certbot/pulls/5746 | 2018-03-16T23:42:00Z | 2018-03-17T00:11:13Z | 2018-03-17T00:11:13Z | 2018-03-17T00:11:16Z | 969 | certbot/certbot | 3,543 |
Added kanye.rest | diff --git a/README.md b/README.md
index 1a015120dc..1bdf6e31ea 100644
--- a/README.md
+++ b/README.md
@@ -601,6 +601,7 @@ API | Description | Auth | HTTPS | CORS |
| [FavQs.com](https://favqs.com/api) | FavQs allows you to collect, discover and share your favorite quotes | `apiKey` | Yes | Unknown |
| [Forismatic](h... | Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] Your additions are ordered alphabetically
- [x] Your s... | https://api.github.com/repos/public-apis/public-apis/pulls/901 | 2019-02-27T03:43:07Z | 2019-04-21T14:20:09Z | 2019-04-21T14:20:09Z | 2020-01-25T18:30:16Z | 286 | public-apis/public-apis | 35,561 |
Fixed linting errors | diff --git a/lib/tests/streamlit/metrics_util_test.py b/lib/tests/streamlit/metrics_util_test.py
index 17c2e2684a2e..2e6764da8324 100644
--- a/lib/tests/streamlit/metrics_util_test.py
+++ b/lib/tests/streamlit/metrics_util_test.py
@@ -43,7 +43,8 @@ def test_machine_id_from_etc(self):
"streamlit.metrics_uti... | Linting errors have been failing nightly builds and PRs. This is due to an upgrade in the black formatting library. This attempts to fix the linting errors. | https://api.github.com/repos/streamlit/streamlit/pulls/3178 | 2021-04-26T16:55:04Z | 2021-04-26T17:09:06Z | 2021-04-26T17:09:06Z | 2021-07-24T00:37:17Z | 782 | streamlit/streamlit | 22,405 |
Moved VERBS back to cli.py | diff --git a/letsencrypt/cli.py b/letsencrypt/cli.py
index 85a0d1d8a78..662e1a94b37 100644
--- a/letsencrypt/cli.py
+++ b/letsencrypt/cli.py
@@ -629,9 +629,13 @@ class HelpfulArgumentParser(object):
"""
def __init__(self, args, plugins, detect_defaults=False):
-
from letsencrypt import main
- ... | After looking at this more closely, I agree with @pde that `VERBS` is much nicer in `cli.py` than `main.py`. This PR moves it back to `cli.py` and incorporates the testing fixes to make that work. By moving `VERBS` creation into `__init__`, `MockedVerb` isn't necessary at all.
| https://api.github.com/repos/certbot/certbot/pulls/2666 | 2016-03-15T03:16:19Z | 2016-03-16T08:49:46Z | 2016-03-16T08:49:46Z | 2016-04-02T19:51:49Z | 1,290 | certbot/certbot | 587 |
gh-68395: Avoid naming conflicts by mangling variable names in Argument Clinic | diff --git a/Lib/test/clinic.test b/Lib/test/clinic.test
index 53e5df5ba872ed..564205274edd73 100644
--- a/Lib/test/clinic.test
+++ b/Lib/test/clinic.test
@@ -4102,3 +4102,172 @@ exit:
static PyObject *
test_paramname_module_impl(PyObject *module, PyObject *mod)
/*[clinic end generated code: output=4a2a849ecbcc8b53 ... | Add all internally used variable names to CLINIC_PREFIXED_ARGS.
<!-- gh-issue-number: gh-68395 -->
* Issue: gh-68395
<!-- /gh-issue-number -->
| https://api.github.com/repos/python/cpython/pulls/104065 | 2023-05-01T21:45:15Z | 2023-05-05T11:40:19Z | 2023-05-05T11:40:19Z | 2023-05-05T11:40:23Z | 1,952 | python/cpython | 4,637 |
[2.16] fix installing roles with symlinks containing '..' (#82165) | diff --git a/changelogs/fragments/ansible-galaxy-role-install-symlink.yml b/changelogs/fragments/ansible-galaxy-role-install-symlink.yml
new file mode 100644
index 00000000000000..856c501455c07a
--- /dev/null
+++ b/changelogs/fragments/ansible-galaxy-role-install-symlink.yml
@@ -0,0 +1,2 @@
+bugfixes:
+ - ansible-gala... | ##### SUMMARY
Backporting #82165
Set the tarfile attribute to a normalized value from unfrackpath instead of validating path parts and omiting potentially invald parts
Allow tarfile paths/links containing '..', '$', '~' as long as the normalized realpath is in the tarfile's role directory
(cherry picked from ... | https://api.github.com/repos/ansible/ansible/pulls/82323 | 2023-11-30T23:14:41Z | 2024-01-18T23:24:24Z | 2024-01-18T23:24:24Z | 2024-02-15T14:00:09Z | 3,744 | ansible/ansible | 49,655 |
Parameterized cache decorator metrics names | diff --git a/lib/streamlit/runtime/caching/__init__.py b/lib/streamlit/runtime/caching/__init__.py
index 1d37ec2aa582..f72f730ef9c8 100644
--- a/lib/streamlit/runtime/caching/__init__.py
+++ b/lib/streamlit/runtime/caching/__init__.py
@@ -106,18 +106,18 @@ def suppress_cached_st_function_warning() -> Iterator[None]:
)... | - The data team wants to track metrics on both the deprecated cache decorator names (`@st.experimental_memo`, `@st.experimental_singleton`) AND the new decorators names (`@st.cache_data`, `@st.cache_resource`)
- This PR parameterizes `CacheDataAPI` and `CacheResourceAPI` with the decorator metric name, to achieve the ... | https://api.github.com/repos/streamlit/streamlit/pulls/5818 | 2022-12-05T23:48:46Z | 2022-12-06T17:32:46Z | 2022-12-06T17:32:46Z | 2022-12-06T17:34:32Z | 2,215 | streamlit/streamlit | 21,852 |
Add support for Phind-CodeLlama models (#2415) | diff --git a/fastchat/conversation.py b/fastchat/conversation.py
index fcf882c5c4..496bba7db0 100644
--- a/fastchat/conversation.py
+++ b/fastchat/conversation.py
@@ -930,6 +930,19 @@ def get_conv_template(name: str) -> Conversation:
)
)
+# Phind template
+register_conv_template(
+ Conversation(
+ nam... | <!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
<!-- Please give a short summary of the change and the problem... | https://api.github.com/repos/lm-sys/FastChat/pulls/2416 | 2023-09-13T11:32:09Z | 2023-09-18T01:58:03Z | 2023-09-18T01:58:03Z | 2023-09-18T01:58:04Z | 476 | lm-sys/FastChat | 41,046 |
Adding IP2Location, FraudLabs Pro, etc... | diff --git a/README.md b/README.md
index b77e964245..8911817762 100644
--- a/README.md
+++ b/README.md
@@ -128,6 +128,7 @@ API | Description | Auth | HTTPS | CORS |
| [Freelancer](https://developers.freelancer.com) | Hire freelancers to get work done | `OAuth` | Yes | Unknown |
| [Gmail](https://developers.google.com... | Add Various API that provided free usage.
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] Your additions are ordered alphabetically
- [x] Your submission has a useful description
- [x] The description does not end with punctuation
- [x] Each tab... | https://api.github.com/repos/public-apis/public-apis/pulls/922 | 2019-03-27T05:28:19Z | 2019-10-06T10:53:46Z | 2019-10-06T10:53:46Z | 2019-10-06T10:53:50Z | 1,002 | public-apis/public-apis | 36,040 |
Bybit :: fix empty OHLCV | diff --git a/js/bybit.js b/js/bybit.js
index 814b63e883e2..091dbd64fba8 100644
--- a/js/bybit.js
+++ b/js/bybit.js
@@ -2049,7 +2049,7 @@ module.exports = class bybit extends Exchange {
// }
//
const result = this.safeValue (response, 'result');
- const ohlcvs = this.safeValue (resu... | - relates to https://github.com/ccxt/ccxt/issues/16097 | https://api.github.com/repos/ccxt/ccxt/pulls/16100 | 2022-12-15T15:31:13Z | 2022-12-15T15:33:23Z | 2022-12-15T15:33:23Z | 2022-12-15T15:33:23Z | 146 | ccxt/ccxt | 12,985 |
fix bedrock client initialisation | diff --git a/llama_index/embeddings/bedrock.py b/llama_index/embeddings/bedrock.py
index 0add636f79a6d..a90352aaacf33 100644
--- a/llama_index/embeddings/bedrock.py
+++ b/llama_index/embeddings/bedrock.py
@@ -201,7 +201,7 @@ def from_credentials(
def _get_embedding(self, payload: str, type: Literal["text", "quer... | # Description
The first parameter of the `set_credentials` method is the AWS region. The current call leads to an exception `botocore.exceptions.InvalidRegionError: Provided region_name 'amazon.titan-embed-text-v1' doesn't match a supported format.`
Fixes # (issue)
## Type of Change
Please delete options th... | https://api.github.com/repos/run-llama/llama_index/pulls/9671 | 2023-12-22T14:17:00Z | 2023-12-22T15:32:01Z | 2023-12-22T15:32:01Z | 2023-12-22T15:32:01Z | 153 | run-llama/llama_index | 6,541 |
Too many c's | diff --git a/lib/streamlit/__init__.py b/lib/streamlit/__init__.py
index b92f169585ae..d137db76d2b6 100644
--- a/lib/streamlit/__init__.py
+++ b/lib/streamlit/__init__.py
@@ -718,7 +718,7 @@ def stop():
>>> if not name:
>>> st.warning('Please input a name.')
>>> st.stop()
- >>> st.succcess('Thank ... | Quick typo fix!
---
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/1842 | 2020-08-11T23:26:54Z | 2020-08-12T04:35:04Z | 2020-08-12T04:35:04Z | 2020-10-01T17:14:46Z | 135 | streamlit/streamlit | 22,250 |
🔧 Update sponsors: add Coherence | diff --git a/README.md b/README.md
index 968ccf7a7472f..874abf8c65e29 100644
--- a/README.md
+++ b/README.md
@@ -53,6 +53,7 @@ The key features are:
<a href="https://reflex.dev" target="_blank" title="Reflex"><img src="https://fastapi.tiangolo.com/img/sponsors/reflex.png"></a>
<a href="https://github.com/scalar/scala... | 🔧 Update sponsors: add Coherence | https://api.github.com/repos/tiangolo/fastapi/pulls/11066 | 2024-01-31T22:08:34Z | 2024-01-31T22:13:52Z | 2024-01-31T22:13:52Z | 2024-01-31T22:13:53Z | 1,408 | tiangolo/fastapi | 23,608 |
Add docstrings for Clickhouse class methods | diff --git a/.gitignore b/.gitignore
index c24d6e3f564984..aed12c91c6a3b3 100644
--- a/.gitignore
+++ b/.gitignore
@@ -116,6 +116,7 @@ celerybeat.pid
.env
.envrc
.venv*
+venv*
env/
ENV/
env.bak/
diff --git a/libs/community/langchain_community/vectorstores/clickhouse.py b/libs/community/langchain_community/vectors... | Thank you for contributing to LangChain!
- [ ] **PR title**: "package: description"
- Where "package" is whichever of langchain, community, core, experimental, etc. is being modified. Use "docs: ..." for purely docs changes, "templates: ..." for template changes, "infra: ..." for CI changes.
- Example: "commun... | https://api.github.com/repos/langchain-ai/langchain/pulls/19195 | 2024-03-17T07:04:28Z | 2024-03-19T04:03:13Z | 2024-03-19T04:03:13Z | 2024-03-19T04:03:13Z | 996 | langchain-ai/langchain | 43,307 |
updated: only fetch on metered connection when necessary | diff --git a/common/params.cc b/common/params.cc
index b1fc15e4c5dfbc..b416b801a8db95 100644
--- a/common/params.cc
+++ b/common/params.cc
@@ -161,6 +161,7 @@ std::unordered_map<std::string, uint32_t> keys = {
{"NavPastDestinations", PERSISTENT},
{"NavSettingLeftSide", PERSISTENT},
{"NavSettingTime24h", ... | - [x] metered can wait a few days
- [x] same policy for non-metered connections
- [x] download button in UI always fetches | https://api.github.com/repos/commaai/openpilot/pulls/31041 | 2024-01-17T23:03:43Z | 2024-01-18T00:30:08Z | 2024-01-18T00:30:08Z | 2024-01-18T01:04:07Z | 1,469 | commaai/openpilot | 9,215 |
Fix the syntax highlighting in the example | diff --git a/docs/user/advanced.rst b/docs/user/advanced.rst
index 728ffbb684..f0b94b4f80 100644
--- a/docs/user/advanced.rst
+++ b/docs/user/advanced.rst
@@ -395,8 +395,8 @@ To do that, just set files to a list of tuples of ``(form_field_name, file_info)
>>> url = 'https://httpbin.org/post'
>>> multiple_fi... | Previously, dots were not included, which was breaking multiline syntax highlighting in for example in interactive mode. Example:
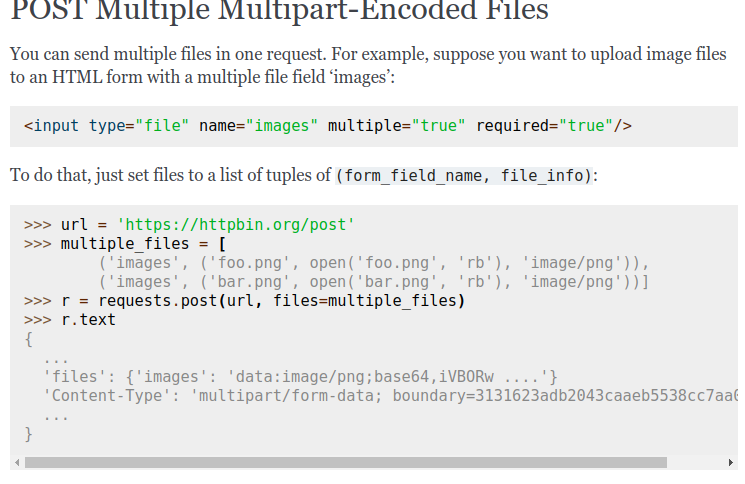
Here is how it looks after the fix:
![Screens... | https://api.github.com/repos/psf/requests/pulls/5276 | 2019-11-27T14:09:40Z | 2020-02-18T07:19:39Z | 2020-02-18T07:19:39Z | 2021-08-29T00:07:06Z | 216 | psf/requests | 32,480 |
[extractors/odnoklassniki] Add support for mobile URLs (closes #16081) | diff --git a/youtube_dl/extractor/odnoklassniki.py b/youtube_dl/extractor/odnoklassniki.py
index 5c8b37e18bf..d87d0960fbb 100644
--- a/youtube_dl/extractor/odnoklassniki.py
+++ b/youtube_dl/extractor/odnoklassniki.py
@@ -19,7 +19,7 @@
class OdnoklassnikiIE(InfoExtractor):
- _VALID_URL = r'https?://(?:(?:www|m|m... | ### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/rg3/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/rg3/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](http... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/16129 | 2018-04-08T10:49:08Z | 2018-04-08T15:13:00Z | 2018-04-08T15:13:00Z | 2018-04-08T15:13:01Z | 585 | ytdl-org/youtube-dl | 49,979 |
Litellm/fixes | diff --git a/llama_index/llms/litellm.py b/llama_index/llms/litellm.py
index e0325fd27980d..77c2f317b1435 100644
--- a/llama_index/llms/litellm.py
+++ b/llama_index/llms/litellm.py
@@ -29,7 +29,6 @@
acompletion_with_retry,
completion_with_retry,
from_openai_message_dict,
- is_chat_model,
is_funct... | # Description
Fixes LiteLLM Huggingface, Deep Infra integration
Fixes # (issue)
## Type of Change
Please delete options that are not relevant.
- [x] Bug fix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature t... | https://api.github.com/repos/run-llama/llama_index/pulls/7885 | 2023-09-28T21:08:24Z | 2023-10-22T04:30:52Z | 2023-10-22T04:30:52Z | 2023-10-22T04:30:52Z | 2,505 | run-llama/llama_index | 6,907 |
add answers to aws-cloud-practitioner.md | diff --git a/certificates/aws-cloud-practitioner.md b/certificates/aws-cloud-practitioner.md
index 6a77583cd..e7a0b1b21 100644
--- a/certificates/aws-cloud-practitioner.md
+++ b/certificates/aws-cloud-practitioner.md
@@ -400,8 +400,8 @@ Learn more [here](https://aws.amazon.com/snowmobile)
<details>
<summary>What is I... | Added some answers to the aws-cloud-practitioner.md.
I answered a few unanswered questions, and I also made a few modifications to existing answers.
Namely,
a) The answer to the question "What is IAM?" was modified to include what the acronym stands for (Identity and Access Management)
b) The answer to the quest... | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/396 | 2023-06-12T14:38:26Z | 2024-02-02T13:19:39Z | 2024-02-02T13:19:38Z | 2024-02-02T13:19:39Z | 838 | bregman-arie/devops-exercises | 17,669 |
[Windows|Unix] Avoid to re-execute challenges already validated | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 72482035667..07d00e3face 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -6,7 +6,8 @@ Certbot adheres to [Semantic Versioning](https://semver.org/).
### Added
-*
+* Avoid to process again challenges that are already validated
+ when a certificate is issued.
### Ch... | In response to #5342.
Currently, certbot will execute the operations necessary to validate a challenge even if the challenge has already been validated before against the acme ca server. This can occur for instance if a certificate is asked and issue correctly, then deleted locally, then asked again.
It is a corn... | https://api.github.com/repos/certbot/certbot/pulls/6551 | 2018-12-03T21:56:59Z | 2019-01-09T20:52:54Z | 2019-01-09T20:52:54Z | 2019-01-09T20:52:55Z | 1,921 | certbot/certbot | 439 |
fix upgrade script (bm25 nits) | diff --git a/docs/examples/retrievers/composable_retrievers.ipynb b/docs/examples/retrievers/composable_retrievers.ipynb
index 065170a5a86f2..78d8515001303 100644
--- a/docs/examples/retrievers/composable_retrievers.ipynb
+++ b/docs/examples/retrievers/composable_retrievers.ipynb
@@ -33,11 +33,12 @@
"outputs": [],
... | the upgrade script isn't idempotent, and this change doesn't really fix all the issues, but it does prevent replacing modules that already have "llama_index.core" with another core (llama_index.core.core) | https://api.github.com/repos/run-llama/llama_index/pulls/10624 | 2024-02-13T04:10:13Z | 2024-02-17T06:13:28Z | 2024-02-17T06:13:28Z | 2024-02-17T17:14:35Z | 1,126 | run-llama/llama_index | 6,131 |
[MRG] Support pd.NA in StringDtype columns for SimpleImputer | diff --git a/doc/whats_new/v1.1.rst b/doc/whats_new/v1.1.rst
index 95367bb35ce10..e5d9bd49dc63f 100644
--- a/doc/whats_new/v1.1.rst
+++ b/doc/whats_new/v1.1.rst
@@ -81,6 +81,9 @@ Changelog
:mod:`sklearn.impute`
.....................
+- |Enhancement| Added support for `pd.NA` in :class:`SimpleImputer`.
+ :pr:`21114... | <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md
-->
#### Reference Issues/PRs
<!--
Example: Fixes #1234. See also #3456.
Please use keywords (e.g., Fixes) to create link to th... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/21114 | 2021-09-23T05:20:58Z | 2021-11-05T11:13:22Z | 2021-11-05T11:13:22Z | 2021-11-05T11:13:22Z | 2,425 | scikit-learn/scikit-learn | 46,179 |
Fix OVO Energy Sensors | diff --git a/homeassistant/components/ovo_energy/__init__.py b/homeassistant/components/ovo_energy/__init__.py
index 3aff51fa044ee3..e98e81ba1c2f02 100644
--- a/homeassistant/components/ovo_energy/__init__.py
+++ b/homeassistant/components/ovo_energy/__init__.py
@@ -40,7 +40,14 @@ async def async_update_data() -> OVODa... | <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
... | https://api.github.com/repos/home-assistant/core/pulls/38849 | 2020-08-13T16:36:10Z | 2020-08-14T12:06:32Z | 2020-08-14T12:06:32Z | 2020-08-15T05:14:43Z | 599 | home-assistant/core | 38,989 |
Update test.py | diff --git a/test.py b/test.py
index 36d18132c78..1c6ea103489 100644
--- a/test.py
+++ b/test.py
@@ -68,7 +68,7 @@ def test(data,
model.eval()
is_coco = data.endswith('coco.yaml') # is COCO dataset
with open(data) as f:
- data = yaml.load(f, Loader=yaml.FullLoader) # model dict
+ data = y... | Fix for Arbitary Code Execution in Test file
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancing security by using safe YAML loader in testing script.
### 📊 Key Changes
- Switched from `yaml.FullLoader` to `yaml.SafeLoader` in the test ... | https://api.github.com/repos/ultralytics/yolov5/pulls/1969 | 2021-01-18T07:27:35Z | 2021-01-18T18:46:46Z | 2021-01-18T18:46:46Z | 2024-01-19T19:46:18Z | 191 | ultralytics/yolov5 | 25,546 |
Update openai.py | diff --git a/CHANGELOG.md b/CHANGELOG.md
index c826317ed7c23..57f3151b9b54c 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,6 +5,7 @@
### Bug Fixes / Nits
- Fix elasticsearch hybrid scoring (#7852)
- Replace `get_color_mapping` and `print_text` Langchain dependency with internal implementation (#7845)
+- Fix asyn... | Fixed bug in astream_chat
# Description
Azure openai api when used in astream_chat mode with query engine tools returns error :
`query_engine_tools = [
QueryEngineTool(
query_engine=vector_engine,
metadata=ToolMetadata(
name="ask_vector_engine", description="Tool to query v... | https://api.github.com/repos/run-llama/llama_index/pulls/7856 | 2023-09-27T16:35:56Z | 2023-09-27T17:18:25Z | 2023-09-27T17:18:25Z | 2023-10-01T16:25:44Z | 408 | run-llama/llama_index | 6,885 |
[nightly-test] add 4-nodes shuffle-data-loader test | diff --git a/release/nightly_tests/nightly_tests.yaml b/release/nightly_tests/nightly_tests.yaml
index d2be830a56845..56cafc554f948 100644
--- a/release/nightly_tests/nightly_tests.yaml
+++ b/release/nightly_tests/nightly_tests.yaml
@@ -283,6 +283,29 @@
--data-dir s3://core-nightly-test/shuffle-data/
--no... | add shuffle_data_loader_4_nodes that run shuffle across 4 nodes with 400million rows.
Test plan:
-[x] schedule a run https://beta.anyscale.com/o/anyscale-internal/projects/prj_SVFGM5yBqK6DHCfLtRMryXHM/clusters/ses_Fie17wKrUbaLTRFKuDtQa6ee | https://api.github.com/repos/ray-project/ray/pulls/17155 | 2021-07-16T19:19:32Z | 2021-07-20T00:46:23Z | 2021-07-20T00:46:23Z | 2021-07-20T00:46:23Z | 933 | ray-project/ray | 19,002 |
MNT Replace pytest.warns(None) in test_ridge.py | diff --git a/sklearn/linear_model/tests/test_ridge.py b/sklearn/linear_model/tests/test_ridge.py
index fc20e0b576b46..02e42fc4b6254 100644
--- a/sklearn/linear_model/tests/test_ridge.py
+++ b/sklearn/linear_model/tests/test_ridge.py
@@ -4,6 +4,7 @@
from itertools import product
import pytest
+import warnings
fro... | <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md
-->
#### Reference Issues/PRs
<!--
Example: Fixes #1234. See also #3456.
Please use keywords (e.g., Fixes) to create link to th... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/22917 | 2022-03-22T04:11:23Z | 2022-03-22T12:47:38Z | 2022-03-22T12:47:38Z | 2022-03-22T12:47:38Z | 454 | scikit-learn/scikit-learn | 46,080 |
Add a job to test doc building (for realsies this time) | diff --git a/.github/workflows/build_doc_test.yml b/.github/workflows/build_doc_test.yml
new file mode 100644
index 0000000000000..348cc484a93d0
--- /dev/null
+++ b/.github/workflows/build_doc_test.yml
@@ -0,0 +1,49 @@
+name: Documentation test build
+
+on:
+ pull_request:
+ paths:
+ - "src/**"
+ - "docs/... | # What does this PR do?
This PR takes over from #14645 to do it properly this time, meaning:
- we don't rely on secrets anymore which doesn't work for pull-request
- we don't need the secrets as we are not pushing anywhere
- we actually checkout the content after the PR merge, and not just master 🤦
| https://api.github.com/repos/huggingface/transformers/pulls/14662 | 2021-12-07T18:12:45Z | 2021-12-09T12:01:03Z | 2021-12-09T12:01:03Z | 2021-12-09T16:58:31Z | 475 | huggingface/transformers | 12,070 |
rename PaddleOCR to PPOCR | diff --git a/deploy/cpp_infer/include/paddleocr.h b/deploy/cpp_infer/include/paddleocr.h
index 499fbee317..6db9d86cb1 100644
--- a/deploy/cpp_infer/include/paddleocr.h
+++ b/deploy/cpp_infer/include/paddleocr.h
@@ -39,10 +39,10 @@ using namespace paddle_infer;
namespace PaddleOCR {
-class PaddleOCR {
+class PPOCR ... | 1. fix mkdir error in win
2. Rename PaddleOCR to PPOCR to avoid name conflict with namespace | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/6044 | 2022-04-22T13:26:52Z | 2022-04-23T03:06:23Z | 2022-04-23T03:06:23Z | 2022-04-23T03:06:23Z | 1,923 | PaddlePaddle/PaddleOCR | 42,380 |
Update/run ci script | diff --git a/.github/workflows/ci_workflow.yml b/.github/workflows/ci_workflow.yml
index 56fb24fe0..06ffc6e9e 100644
--- a/.github/workflows/ci_workflow.yml
+++ b/.github/workflows/ci_workflow.yml
@@ -14,5 +14,5 @@ jobs:
- name: Give executable permissions to run_ci.sh inside the scripts directory
run: ... | I'd like to propose an improvement to the `run_ci` script.
- Change shebang for portability.
- Add shell options in the script. If there's an error it will automatically exit. e.g:
```bash
[2023-02-23 23:03:58] {afuscoar@afuscoar} (~/.Personal/Projects/devops-exercises) (update/run_ci-script)$ -> bash scripts/run... | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/352 | 2023-02-23T22:08:23Z | 2023-03-25T11:05:56Z | 2023-03-25T11:05:56Z | 2023-03-25T11:05:57Z | 477 | bregman-arie/devops-exercises | 17,589 |
[MRG+1] Make RedirectMiddleware respect Spider.handle_httpstatus_list | diff --git a/docs/topics/downloader-middleware.rst b/docs/topics/downloader-middleware.rst
index a6a2f7d6241..6d986bbf761 100644
--- a/docs/topics/downloader-middleware.rst
+++ b/docs/topics/downloader-middleware.rst
@@ -715,6 +715,15 @@ settings (see the settings documentation for more info):
If :attr:`Request.meta <... | Inspired by #1334
I have decided not to include the `HTTPERROR_ALLOWED_CODES` setting, as, unlike the `handle_httpstatus_list` Spider attribute, the name of that setting implies that it is directly tied to the HttpErrorMiddleware.
| https://api.github.com/repos/scrapy/scrapy/pulls/1364 | 2015-07-16T10:57:47Z | 2015-08-03T02:00:00Z | 2015-08-03T02:00:00Z | 2015-08-21T14:33:42Z | 773 | scrapy/scrapy | 34,778 |
The expected value changed for the proxies keyword | diff --git a/test_requests.py b/test_requests.py
index 13b9d64ced..dbb38064aa 100755
--- a/test_requests.py
+++ b/test_requests.py
@@ -1258,7 +1258,7 @@ class TestRedirects:
'cert': None,
'timeout': None,
'allow_redirects': False,
- 'proxies': None,
+ 'proxies': {},
}
... | It used to be None but a recent PR changed that before my last one was merged
Fixes #1975
| https://api.github.com/repos/psf/requests/pulls/1976 | 2014-03-26T13:13:26Z | 2014-03-26T15:34:36Z | 2014-03-26T15:34:36Z | 2021-09-08T23:06:27Z | 108 | psf/requests | 32,783 |
feat(open-pr-comments): queue task in webhook | diff --git a/src/sentry/integrations/github/webhook.py b/src/sentry/integrations/github/webhook.py
index 66ac0fd4050bd..7753c5d2d5abf 100644
--- a/src/sentry/integrations/github/webhook.py
+++ b/src/sentry/integrations/github/webhook.py
@@ -14,7 +14,7 @@
from django.views.decorators.csrf import csrf_exempt
from rest_... | Queue the open PR comment workflow task in the Github webhook if a PR has been opened and a `PullRequest` object was newly created.
This PR also includes a small fix to check for an existing comment in the open PR comment workflow.
For ER-1812 | https://api.github.com/repos/getsentry/sentry/pulls/60656 | 2023-11-27T22:43:22Z | 2023-11-28T21:39:19Z | 2023-11-28T21:39:19Z | 2023-12-14T00:02:19Z | 2,572 | getsentry/sentry | 43,789 |
Some changes in teams | diff --git a/website/public/locales/en/common.json b/website/public/locales/en/common.json
index fe8157842f..38068ceae1 100644
--- a/website/public/locales/en/common.json
+++ b/website/public/locales/en/common.json
@@ -47,6 +47,7 @@
"submit": "Submit",
"submit_your_answer": "Submit your answer",
"success": "Su... | Added Moderation Team,
Added myself,
Extracted locales + Translated to RU,
Rethought the name of one of the labels and thought I found a more befitting word to translate it | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2120 | 2023-03-19T11:48:16Z | 2023-03-19T13:05:20Z | 2023-03-19T13:05:20Z | 2023-03-19T14:14:41Z | 1,272 | LAION-AI/Open-Assistant | 37,606 |
[9gag] Adjusted for current website | diff --git a/youtube_dl/extractor/ninegag.py b/youtube_dl/extractor/ninegag.py
index dc6a27d3643..3753bc0a27b 100644
--- a/youtube_dl/extractor/ninegag.py
+++ b/youtube_dl/extractor/ninegag.py
@@ -3,102 +3,146 @@
import re
from .common import InfoExtractor
-from ..utils import str_to_int
+from ..utils import (
+ ... | ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *p... | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/23022 | 2019-11-09T02:30:56Z | 2021-01-19T09:21:37Z | 2021-01-19T09:21:37Z | 2021-01-27T02:38:04Z | 2,337 | ytdl-org/youtube-dl | 50,550 |
Updated ReadMe link to requirements | diff --git a/README.md b/README.md
index 5593ee4..dd054b6 100644
--- a/README.md
+++ b/README.md
@@ -35,7 +35,7 @@
## Requirements
-Please follow the requirements of [https://github.com/NVlabs/stylegan3](https://github.com/NVlabs/stylegan3).
+Please follow the requirements of [NVlabs/stylegan3](https://github.com/... | Made requirements link go directly to instructions section of README. | https://api.github.com/repos/XingangPan/DragGAN/pulls/73 | 2023-06-26T19:49:03Z | 2023-06-27T02:16:35Z | 2023-06-27T02:16:35Z | 2023-06-27T02:16:35Z | 119 | XingangPan/DragGAN | 26,830 |
#534: Improve open rule | diff --git a/README.md b/README.md
index 395253f4a..29d73ff13 100644
--- a/README.md
+++ b/README.md
@@ -202,7 +202,7 @@ using the matched rule and runs it. Rules enabled by default are as follows:
* `npm_wrong_command` – fixes wrong npm commands like `npm urgrade`;
* `no_command` – fixes wrong console co... | This change improves the `open` rule and its tests and implement one of the features suggested by @mlk on #534.
| https://api.github.com/repos/nvbn/thefuck/pulls/535 | 2016-08-12T04:12:01Z | 2016-08-13T12:20:12Z | 2016-08-13T12:20:12Z | 2016-08-13T22:24:22Z | 1,553 | nvbn/thefuck | 30,877 |
Depend on a stable version of curl_cffi | diff --git a/requirements.txt b/requirements.txt
index 7f5cb01167..6ec1953dae 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,6 +1,6 @@
requests
pycryptodome
-curl_cffi>=0.5.10b4
+curl_cffi>=0.5.10
aiohttp
certifi
browser_cookie3
@@ -26,4 +26,4 @@ async-property
undetected-chromedriver
asyncstdlib
as... | https://api.github.com/repos/xtekky/gpt4free/pulls/1359 | 2023-12-17T06:57:13Z | 2023-12-19T20:46:07Z | 2023-12-19T20:46:07Z | 2023-12-19T20:46:20Z | 136 | xtekky/gpt4free | 38,049 | |
added Graph-Powered Machine Learning | diff --git a/books.md b/books.md
index 5ef2bf31..4f6387b5 100644
--- a/books.md
+++ b/books.md
@@ -37,6 +37,7 @@ The following is a list of free, open source books on machine learning, statisti
* [Hands‑On Machine Learning with Scikit‑Learn and TensorFlow](http://index-of.es/Varios-2/Hands%20on%20Machine%20Learning%20... | Hi, I thought this title might be a great addition to your list of books. Thank you for your consideration | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/549 | 2018-10-21T11:03:38Z | 2018-10-21T15:54:44Z | 2018-10-21T15:54:44Z | 2018-10-21T15:54:44Z | 250 | josephmisiti/awesome-machine-learning | 52,030 |
Fix zero-1 bug related to stitching reduced grads across comm partitions | diff --git a/deepspeed/runtime/zero/stage1.py b/deepspeed/runtime/zero/stage1.py
index 80b51ffe4d12..c3941a907fbf 100755
--- a/deepspeed/runtime/zero/stage1.py
+++ b/deepspeed/runtime/zero/stage1.py
@@ -249,8 +249,7 @@ def __init__(self,
# RS: divide up the sub-partitions and keep track of offsets for ea... | Has been confirmed from 1p user to have fixed their issue. Also our original repro of the diverged loss shows the issue has fixed as well.
I believe the issue was related to the old copy gradients code was not stitching the sub-partitions together correctly. After simplifying this part of the code substantially this... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/318 | 2020-08-14T06:25:30Z | 2020-09-15T19:59:57Z | 2020-09-15T19:59:57Z | 2020-11-13T07:37:04Z | 679 | microsoft/DeepSpeed | 10,915 |
Add SwinIR and new features to readme | diff --git a/README.md b/README.md
index d355db34458..c1538100982 100644
--- a/README.md
+++ b/README.md
@@ -20,6 +20,8 @@ A browser interface based on Gradio library for Stable Diffusion.
- CodeFormer, face restoration tool as an alternative to GFPGAN
- RealESRGAN, neural network upscaler
- ESRGAN, ne... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/816 | 2022-09-21T21:10:42Z | 2022-09-22T04:18:00Z | 2022-09-22T04:18:00Z | 2022-09-22T04:18:00Z | 510 | AUTOMATIC1111/stable-diffusion-webui | 39,714 | |
skip bcast when enable pp but pp_group_size=1 | diff --git a/deepspeed/runtime/pipe/engine.py b/deepspeed/runtime/pipe/engine.py
index 6286aa6cf0c4..19b14f69b003 100644
--- a/deepspeed/runtime/pipe/engine.py
+++ b/deepspeed/runtime/pipe/engine.py
@@ -524,8 +524,8 @@ def _aggregate_total_loss(self):
assert self.global_rank in self.grid.pp_group
... | @guoyejun | https://api.github.com/repos/microsoft/DeepSpeed/pulls/3915 | 2023-07-10T05:50:33Z | 2023-07-14T20:48:22Z | 2023-07-14T20:48:22Z | 2023-07-14T20:48:23Z | 197 | microsoft/DeepSpeed | 10,298 |
BUG: GH2808 Apply with invalid returned indices raise correct Exception | diff --git a/RELEASE.rst b/RELEASE.rst
index 3e935879c197e..17a2fa0ba2d0d 100644
--- a/RELEASE.rst
+++ b/RELEASE.rst
@@ -258,6 +258,7 @@ pandas 0.11.0
- Upcast/split blocks when needed in a mixed DataFrame when setitem
with an indexer (GH3216_)
- Invoking df.applymap on a dataframe with dupe cols now raises... | closes #2808
| https://api.github.com/repos/pandas-dev/pandas/pulls/3228 | 2013-04-01T12:25:15Z | 2013-04-02T12:24:50Z | 2013-04-02T12:24:50Z | 2014-07-04T06:31:36Z | 1,553 | pandas-dev/pandas | 45,742 |
Add Webdam | diff --git a/README.md b/README.md
index 1eca18533a..30a707d22c 100644
--- a/README.md
+++ b/README.md
@@ -953,6 +953,7 @@ API | Description | Auth | HTTPS | CORS |
| [ReSmush.it](https://resmush.it/api) | Photo optimization | No | No | Unknown |
| [Unsplash](https://unsplash.com/developers) | Photography | `OAuth` |... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [X] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [X]... | https://api.github.com/repos/public-apis/public-apis/pulls/2101 | 2021-10-02T12:58:47Z | 2021-10-03T07:00:04Z | 2021-10-03T07:00:04Z | 2021-10-03T07:00:04Z | 193 | public-apis/public-apis | 35,373 |
Updated to Python 3 this files | diff --git a/pscheck.py b/pscheck.py
index 2153b19c88..399e955def 100644
--- a/pscheck.py
+++ b/pscheck.py
@@ -31,7 +31,6 @@ def ps():
except:
print("There was a problem with the program.")
-
def main():
if os.name == "posix": # Unix/Linux/MacOS/BSD/etc
ps() # Call the funct... | Updated print statements to Python 3
--------------------------------------------------------------------------------------
While testing, I had a Python version issue and changed some files to python3.
Is it okay if I try to change the rest of the files? | https://api.github.com/repos/geekcomputers/Python/pulls/440 | 2018-12-04T08:13:45Z | 2018-12-14T11:26:28Z | 2018-12-14T11:26:28Z | 2018-12-14T11:26:29Z | 3,319 | geekcomputers/Python | 31,140 |
Add funshion support, fix #215, replace #601, #604 | diff --git a/README.md b/README.md
index bcec3fc7f0..cb3550d183 100644
--- a/README.md
+++ b/README.md
@@ -43,6 +43,7 @@ Fork me on GitHub: <https://github.com/soimort/you-get>
* DouyuTV (斗鱼) <http://www.douyutv.com>
* eHow <http://www.ehow.com>
* Facebook <http://facebook.com>
+* Fun.tv (风行, Funshion) <http://www.f... | This should do.
<!-- Reviewable:start -->
[<img src="https://reviewable.io/review_button.png" height=40 alt="Review on Reviewable"/>](https://reviewable.io/reviews/soimort/you-get/619)
<!-- Reviewable:end -->
| https://api.github.com/repos/soimort/you-get/pulls/619 | 2015-09-02T18:54:41Z | 2015-09-02T18:58:09Z | 2015-09-02T18:58:09Z | 2015-09-02T18:58:12Z | 2,960 | soimort/you-get | 21,463 |
fixbug: WriteCode adds the content of the related code files. | diff --git a/metagpt/actions/write_code.py b/metagpt/actions/write_code.py
index 4c138a124..b20539e78 100644
--- a/metagpt/actions/write_code.py
+++ b/metagpt/actions/write_code.py
@@ -14,12 +14,13 @@
3. Encapsulate the input of RunCode into RunCodeContext and encapsulate the output of RunCode into
Ru... | fixbug: WriteCode adds the content of the related code files. | https://api.github.com/repos/geekan/MetaGPT/pulls/553 | 2023-12-12T08:43:50Z | 2023-12-12T08:48:04Z | 2023-12-12T08:48:04Z | 2024-01-02T11:16:56Z | 590 | geekan/MetaGPT | 16,581 |
fix(integrations): Fix GHE repo url | diff --git a/src/sentry/integrations/github_enterprise/repository.py b/src/sentry/integrations/github_enterprise/repository.py
index ecf0f5e99d1a4..8bf48aff238b1 100644
--- a/src/sentry/integrations/github_enterprise/repository.py
+++ b/src/sentry/integrations/github_enterprise/repository.py
@@ -18,7 +18,7 @@ def creat... | https://api.github.com/repos/getsentry/sentry/pulls/9260 | 2018-07-31T20:54:25Z | 2018-07-31T22:30:03Z | 2018-07-31T22:30:03Z | 2020-12-21T15:54:16Z | 168 | getsentry/sentry | 44,173 | |
Added Czech and Slovak Nameday API | diff --git a/README.md b/README.md
index 1a08213bf9..553b15ff07 100644
--- a/README.md
+++ b/README.md
@@ -115,6 +115,7 @@ API | Description | Auth | HTTPS | Link |
API | Description | Auth | HTTPS | Link |
|---|---|---|---|---|
| Church Calendar | Catholic liturgical calendar | No | No | [Go!](http://calapi.inadiut... | Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md).
- [x] Your changes are made in the [README](../README.md) fi... | https://api.github.com/repos/public-apis/public-apis/pulls/570 | 2017-12-23T11:15:06Z | 2017-12-23T18:23:31Z | 2017-12-23T18:23:31Z | 2017-12-23T18:23:33Z | 239 | public-apis/public-apis | 35,405 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.