
title stringlengths 2 169 | diff stringlengths 235 19.5k | body stringlengths 0 30.5k | url stringlengths 48 84 | created_at stringlengths 20 20 | closed_at stringlengths 20 20 | merged_at stringlengths 20 20 | updated_at stringlengths 20 20 | diff_len float64 101 3.99k | repo_name stringclasses 83
values | __index_level_0__ int64 15 52.7k |
|---|---|---|---|---|---|---|---|---|---|---|
Add max capabilities when creating nested stacks | diff --git a/localstack/services/cloudformation/models/cloudformation.py b/localstack/services/cloudformation/models/cloudformation.py
index a3bd60abc3b02..e8dd56d8525d1 100644
--- a/localstack/services/cloudformation/models/cloudformation.py
+++ b/localstack/services/cloudformation/models/cloudformation.py
@@ -48,6 +4... | ## Motivation
Nested stacks can also contain transformations and are thus subject to capability checks.
This caused users to report issues regarding failed stack deployments to pop up in support which this PR aims to prevent.
## Changes
- When creating a nested stack (`AWS::CloudFormation::Stack`) it will now... | https://api.github.com/repos/localstack/localstack/pulls/8920 | 2023-08-16T11:00:34Z | 2023-08-16T12:24:06Z | 2023-08-16T12:24:06Z | 2023-08-16T12:24:09Z | 171 | localstack/localstack | 29,293 |
Fix enable_mod for "run" command | diff --git a/letsencrypt-apache/letsencrypt_apache/configurator.py b/letsencrypt-apache/letsencrypt_apache/configurator.py
index 31b5f0bc57a..01c9d4f3045 100644
--- a/letsencrypt-apache/letsencrypt_apache/configurator.py
+++ b/letsencrypt-apache/letsencrypt_apache/configurator.py
@@ -493,7 +493,7 @@ def prepare_server_... | Fixes #690 and #691
| https://api.github.com/repos/certbot/certbot/pulls/693 | 2015-08-17T18:37:25Z | 2015-08-17T20:41:07Z | 2015-08-17T20:41:06Z | 2016-05-06T19:22:13Z | 2,243 | certbot/certbot | 944 |
[pre-commit.ci] pre-commit autoupdate | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 31e141049441..97603510b426 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -16,7 +16,7 @@ repos:
- id: auto-walrus
- repo: https://github.com/astral-sh/ruff-pre-commit
- rev: v0.1.11
+ rev: v0.1.13
hooks:
... | <!--pre-commit.ci start-->
updates:
- [github.com/astral-sh/ruff-pre-commit: v0.1.11 → v0.1.13](https://github.com/astral-sh/ruff-pre-commit/compare/v0.1.11...v0.1.13)
- [github.com/tox-dev/pyproject-fmt: 1.5.3 → 1.6.0](https://github.com/tox-dev/pyproject-fmt/compare/1.5.3...1.6.0)
- [github.com/pre-commit/mirrors-pre... | https://api.github.com/repos/TheAlgorithms/Python/pulls/11246 | 2024-01-15T17:59:26Z | 2024-01-15T18:19:37Z | 2024-01-15T18:19:37Z | 2024-01-15T18:19:44Z | 272 | TheAlgorithms/Python | 29,437 |
Quick fix for sms method | diff --git a/interpreter/core/computer/calendar/calendar.py b/interpreter/core/computer/calendar/calendar.py
index 86ad36912..4c39797b4 100644
--- a/interpreter/core/computer/calendar/calendar.py
+++ b/interpreter/core/computer/calendar/calendar.py
@@ -30,7 +30,16 @@ def get_events(self, start_date=datetime.date.today(... | ### Describe the changes you have made:
Prevents newline characters from breaking computer.sms.send
### Reference any relevant issues (e.g. "Fixes #000"):
### Pre-Submission Checklist (optional but appreciated):
- [ ] I have included relevant documentation updates (stored in /docs)
- [x] I have read `docs/... | https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/1067 | 2024-03-12T00:00:17Z | 2024-03-12T05:55:31Z | 2024-03-12T05:55:31Z | 2024-03-12T05:55:55Z | 2,436 | OpenInterpreter/open-interpreter | 40,767 |
Korean: add missing translations | diff --git a/selfdrive/ui/translations/main_ko.ts b/selfdrive/ui/translations/main_ko.ts
index 1d7ddbe6e842e5..73a5da5ad78b2e 100644
--- a/selfdrive/ui/translations/main_ko.ts
+++ b/selfdrive/ui/translations/main_ko.ts
@@ -1195,12 +1195,12 @@ location set</source>
<message>
<location filename="../qt/offro... | translation unfinished fix | https://api.github.com/repos/commaai/openpilot/pulls/25647 | 2022-09-02T13:57:45Z | 2022-09-05T23:11:23Z | 2022-09-05T23:11:23Z | 2022-09-07T10:14:11Z | 304 | commaai/openpilot | 8,958 |
Duplicate word in comments | diff --git a/mvc.py b/mvc.py
index 7df613fc..42137ef7 100644
--- a/mvc.py
+++ b/mvc.py
@@ -6,7 +6,7 @@ def __iter__(self):
raise NotImplementedError
def get(self, item):
- """Returns an an object with a .items() call method
+ """Returns an object with a .items() call method
that i... | https://api.github.com/repos/faif/python-patterns/pulls/130 | 2016-03-07T15:38:08Z | 2016-03-08T19:51:59Z | 2016-03-08T19:51:59Z | 2016-03-08T19:51:59Z | 112 | faif/python-patterns | 33,455 | |
Add period when finished sentence. | diff --git a/README.md b/README.md
index 8f0432ffc..9ed3b87ca 100644
--- a/README.md
+++ b/README.md
@@ -93,7 +93,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
* [pyenv](https://github.com/yyuu/pyenv) - Simple Python version management.
* [virtualenv](https://pypi.python.org/... | https://api.github.com/repos/vinta/awesome-python/pulls/256 | 2014-11-14T06:46:21Z | 2014-11-14T07:54:32Z | 2014-11-14T07:54:32Z | 2014-11-14T07:54:32Z | 253 | vinta/awesome-python | 26,905 | |
Add Carbon Interface API | diff --git a/README.md b/README.md
index a29b46e8f4..8309e6481b 100644
--- a/README.md
+++ b/README.md
@@ -322,6 +322,7 @@ API | Description | Auth | HTTPS | CORS |
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
| [AirVisual](https://airvisual.com/api) | Air quality and weather data | `apiKey` | Yes... | <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x] ... | https://api.github.com/repos/public-apis/public-apis/pulls/1503 | 2020-12-27T21:45:52Z | 2021-04-14T20:56:25Z | 2021-04-14T20:56:25Z | 2021-04-14T20:56:26Z | 253 | public-apis/public-apis | 35,427 |
COMPAT: mpl 3.0 | diff --git a/doc/source/whatsnew/v0.24.0.txt b/doc/source/whatsnew/v0.24.0.txt
index 481c31d2410a9..3e1711edb0f27 100644
--- a/doc/source/whatsnew/v0.24.0.txt
+++ b/doc/source/whatsnew/v0.24.0.txt
@@ -193,6 +193,8 @@ Other Enhancements
- :meth:`Series.resample` and :meth:`DataFrame.resample` have gained the :meth:`Res... | Closes #22790 | https://api.github.com/repos/pandas-dev/pandas/pulls/22870 | 2018-09-28T13:06:29Z | 2018-09-28T15:06:16Z | 2018-09-28T15:06:16Z | 2018-09-28T17:59:41Z | 1,290 | pandas-dev/pandas | 45,236 |
attempt to fix the repetition/hallucination issue identified in #1046 | diff --git a/whisper/audio.py b/whisper/audio.py
index a19b7ab0..513ab7c9 100644
--- a/whisper/audio.py
+++ b/whisper/audio.py
@@ -1,6 +1,6 @@
import os
from functools import lru_cache
-from typing import Union
+from typing import Optional, Union
import ffmpeg
import numpy as np
@@ -15,10 +15,8 @@
N_MELS = 80
H... | https://api.github.com/repos/openai/whisper/pulls/1052 | 2023-03-07T21:48:40Z | 2023-03-08T04:08:46Z | 2023-03-08T04:08:46Z | 2023-03-14T19:35:58Z | 1,585 | openai/whisper | 45,785 | |
add oa_leet10k instruction dataset | diff --git a/data/datasets/__init__.py b/data/datasets/__init__.py
index a9ac0b21c1..fb573c7d6c 100644
--- a/data/datasets/__init__.py
+++ b/data/datasets/__init__.py
@@ -19,6 +19,7 @@
"zhihu-kol": "wangrui6/zhihu-kol",
"tell_a_joke": "mikegarts/oa_tell_a_joke_20000",
"oa_wiki_qa_bart_10000row": "michael... | add oa_leet10k instruction dataset | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2407 | 2023-04-08T17:44:36Z | 2023-04-09T13:09:06Z | 2023-04-09T13:09:06Z | 2023-04-09T13:09:06Z | 175 | LAION-AI/Open-Assistant | 37,029 |
DeepSpeed webinar announcement | diff --git a/README.md b/README.md
index edfcb2a98e6c..5b441da16b11 100755
--- a/README.md
+++ b/README.md
@@ -26,6 +26,8 @@ information [here](https://innovation.microsoft.com/en-us/exploring-ai-at-scale)
# News
+* [2020/07/24] [DeepSpeed webinar](https://note.microsoft.com/MSR-Webinar-DeepSpeed-Registration-Live... | 
| https://api.github.com/repos/microsoft/DeepSpeed/pulls/301 | 2020-07-24T19:06:52Z | 2020-07-25T05:13:12Z | 2020-07-25T05:13:12Z | 2020-07-25T05:13:16Z | 1,136 | microsoft/DeepSpeed | 10,124 |
AutoAnchor improved initialization robustness | diff --git a/utils/autoanchor.py b/utils/autoanchor.py
index 51d4de306ef..a631c21a3b2 100644
--- a/utils/autoanchor.py
+++ b/utils/autoanchor.py
@@ -125,15 +125,17 @@ def print_results(k, verbose=True):
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # mu... | Resolves https://github.com/ultralytics/yolov5/issues/6809#issuecomment-1054338046
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Refinement of anchor box initialization in YOLOv5's autoanchor utility to handle edge cases.
### 📊 Key Changes
... | https://api.github.com/repos/ultralytics/yolov5/pulls/6854 | 2022-03-04T09:25:02Z | 2022-03-04T09:32:18Z | 2022-03-04T09:32:18Z | 2024-01-19T12:27:53Z | 514 | ultralytics/yolov5 | 25,022 |
allow moderators to ban user | diff --git a/website/package-lock.json b/website/package-lock.json
index 9b369be40f..18b1fc19ab 100644
--- a/website/package-lock.json
+++ b/website/package-lock.json
@@ -85,6 +85,7 @@
"msw-storybook-addon": "^1.7.0",
"prettier": "2.8.1",
"prisma": "^4.7.1",
+ "ts-essentials": "^9.3.0"... | - Allow mod to ban users (mods can only ban and unban user, they can't promote user to mod or admin, they can't ban other mods and admins too).
- Fix a bug where the admin can not ban user login in discord.
- Forward ref on discord icon component to support tooltip | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/1458 | 2023-02-11T06:35:42Z | 2023-02-11T08:10:10Z | 2023-02-11T08:10:10Z | 2023-02-11T08:10:11Z | 2,783 | LAION-AI/Open-Assistant | 37,603 |
Add files via upload | diff --git a/Armstrong_number.py b/Armstrong_number.py
new file mode 100644
index 0000000000..be6ca4bd68
--- /dev/null
+++ b/Armstrong_number.py
@@ -0,0 +1,12 @@
+#checking for armstrong number
+a=input('Enter a number')
+n=int(a)
+S=0
+while n>0:
+ d=n%10
+ S=S+d*d*d
+ n=n/10
+if int(a)==S:
+ prin... | Program to find armstrong number | https://api.github.com/repos/geekcomputers/Python/pulls/1451 | 2022-01-03T08:45:11Z | 2022-01-03T11:01:22Z | 2022-01-03T11:01:22Z | 2022-01-03T11:01:22Z | 138 | geekcomputers/Python | 31,374 |
HKG: Car Port for Kia Sorento 2022 | diff --git a/RELEASES.md b/RELEASES.md
index eea69d295f5b1e..1b5ef8f7a7b97c 100644
--- a/RELEASES.md
+++ b/RELEASES.md
@@ -6,6 +6,7 @@ Version 0.9.1 (2022-12-XX)
* Chevrolet Bolt EV 2022-23 support thanks to JasonJShuler!
* Genesis GV60 2023 support thanks to sunnyhaibin!
* Hyundai Tucson 2022-23 support
+* Kia Sore... | **Checklist**
- [x] added entry to CarInfo in selfdrive/car/*/values.py and ran `selfdrive/car/docs.py` to generate new docs
- [x] test route added to [routes.py](https://github.com/commaai/openpilot/blob/master/selfdrive/car/tests/routes.py)
- [x] route with openpilot: `1d0d000db3370fd0|2023-01-04--22-28-42`
- [x]... | https://api.github.com/repos/commaai/openpilot/pulls/26874 | 2023-01-04T16:29:44Z | 2023-01-12T05:17:58Z | 2023-01-12T05:17:58Z | 2023-08-20T15:09:56Z | 3,356 | commaai/openpilot | 9,731 |
Adding negative prompts to Loras in extra networks | diff --git a/extensions-builtin/Lora/ui_edit_user_metadata.py b/extensions-builtin/Lora/ui_edit_user_metadata.py
index c7011909055..3160aecfa38 100644
--- a/extensions-builtin/Lora/ui_edit_user_metadata.py
+++ b/extensions-builtin/Lora/ui_edit_user_metadata.py
@@ -54,12 +54,13 @@ def __init__(self, ui, tabname, page):
... | ## Description
This pull request adds the ability to specify a negative prompt with weight that will be added alongside the prompt to their respective texbox, when clicking a lora card in the extra networks tab. If nothing is specified no additional text will be added to the negative prompts.
To achieve this I modi... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/14475 | 2023-12-30T21:37:55Z | 2023-12-31T19:32:29Z | 2023-12-31T19:32:28Z | 2023-12-31T19:32:29Z | 2,081 | AUTOMATIC1111/stable-diffusion-webui | 39,964 |
Improve contributing.md | diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 884bae3ddf6..f3d6d687b9c 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,3 +1,12 @@
+Keras 3 is a high-velocity open-source project. We welcome contributions!
+
+Contributions can be made in a variety of ways, including coding, enriching documentation, refin... | I've made small updates to `CONTRIBUTING.md` to improve clarity and ease for new contributors. | https://api.github.com/repos/keras-team/keras/pulls/19115 | 2024-01-29T19:18:57Z | 2024-01-29T21:03:20Z | 2024-01-29T21:03:20Z | 2024-04-02T18:40:03Z | 698 | keras-team/keras | 47,744 |
ngrok logging does not use the shared logger module | diff --git a/extensions/ngrok/script.py b/extensions/ngrok/script.py
index 46f39bd327..7bfb9f6e1f 100644
--- a/extensions/ngrok/script.py
+++ b/extensions/ngrok/script.py
@@ -8,7 +8,6 @@
# See this example for full list of options: https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py
# or the RE... | - when running `start_linux.sh`, ngrok will not display the created URL unless the logs are run through the shared logger module
## Checklist:
- [x] I have read the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines).
| https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5570 | 2024-02-23T20:38:21Z | 2024-02-25T05:35:59Z | 2024-02-25T05:35:59Z | 2024-02-25T05:35:59Z | 245 | oobabooga/text-generation-webui | 25,956 |
zh-Hans: Fix typo | diff --git a/README-zh-Hans.md b/README-zh-Hans.md
index bce8bfb131..f1a2f9e3cd 100644
--- a/README-zh-Hans.md
+++ b/README-zh-Hans.md
@@ -1621,7 +1621,7 @@ Notes
| 设计类似于 Google 的搜索引擎 | [queue.acm.org](http://queue.acm.org/detail.cfm?id=988407)<br/>[stackexchange.com](http://programmers.stackexchange.com/question... | https://api.github.com/repos/donnemartin/system-design-primer/pulls/246 | 2019-01-15T02:37:22Z | 2019-01-20T19:59:43Z | 2019-01-20T19:59:43Z | 2019-01-20T20:00:20Z | 488 | donnemartin/system-design-primer | 36,806 | |
Parallelize SNS message delivery for improved performance | diff --git a/localstack/services/sns/sns_listener.py b/localstack/services/sns/sns_listener.py
index a99ee2ced3a77..366dfd44b425d 100644
--- a/localstack/services/sns/sns_listener.py
+++ b/localstack/services/sns/sns_listener.py
@@ -7,6 +7,7 @@
import six
import requests
import xmltodict
+import asyncio
from flask ... | (Re-creating PR #4101 to trigger PR build.)
> With this PR the SNS service delivers the messages to the subscribers of a topic in an async way.
> Addresses #3670 | https://api.github.com/repos/localstack/localstack/pulls/4103 | 2021-06-06T07:42:02Z | 2021-06-06T18:07:55Z | 2021-06-06T18:07:55Z | 2021-06-06T18:07:55Z | 3,002 | localstack/localstack | 28,992 |
Modified the shaders slightly | diff --git a/manimlib/shaders/inserts/finalize_color.glsl b/manimlib/shaders/inserts/finalize_color.glsl
index 0664deb0b5..e7b64eee3a 100644
--- a/manimlib/shaders/inserts/finalize_color.glsl
+++ b/manimlib/shaders/inserts/finalize_color.glsl
@@ -17,16 +17,16 @@ vec4 add_light(vec4 color,
float shadow){... | ## Motivation
- `camera_distance` is set to be 6 and doesn't change with the `focal_distance`.
- The z coordinate is used to check whether the surface is facing the camera. It generates the wrong result which is particularly obvious when `focal_distance` is small.
## Proposed changes
- Replace `float camera_dista... | https://api.github.com/repos/3b1b/manim/pulls/1530 | 2021-06-05T14:07:41Z | 2021-06-14T16:44:02Z | 2021-06-14T16:44:02Z | 2021-06-14T16:44:02Z | 744 | 3b1b/manim | 18,057 |
bpo-32228: Reset raw_pos after unwinding the raw stream | diff --git a/Lib/test/test_io.py b/Lib/test/test_io.py
index 9bfe4b0bc6e4be..dc1c7c8e72a776 100644
--- a/Lib/test/test_io.py
+++ b/Lib/test/test_io.py
@@ -1723,6 +1723,23 @@ def test_truncate(self):
with self.open(support.TESTFN, "rb", buffering=0) as f:
self.assertEqual(f.read(), b"abc")
+ d... | This issue was happening because - after write in the given case, `write_pos` and `write_end` are ending up to be 0. Nothing wrong here. But when doing truncate, we flush writer changes. During that, even when `write_pos == write_end`, we've to reset `write_end to -1`. That was not happening.
<!-- issue-number: bpo-... | https://api.github.com/repos/python/cpython/pulls/4858 | 2017-12-14T05:46:17Z | 2018-01-28T16:00:09Z | 2018-01-28T16:00:09Z | 2018-01-28T16:42:59Z | 892 | python/cpython | 4,694 |
Fix super tiny type error | diff --git a/timm/scheduler/cosine_lr.py b/timm/scheduler/cosine_lr.py
index e2c975fb79..4eaaa86a81 100644
--- a/timm/scheduler/cosine_lr.py
+++ b/timm/scheduler/cosine_lr.py
@@ -8,6 +8,7 @@
import math
import numpy as np
import torch
+from typing import List
from .scheduler import Scheduler
@@ -77,7 +78,7 @@ d... | IMHO, for example, CosineLRScheduler returns list of floats, instead of a single float. Therefore, the type signature may need to be updated. Please correct me if I am wrong! | https://api.github.com/repos/huggingface/pytorch-image-models/pulls/2124 | 2024-03-23T03:27:44Z | 2024-04-02T21:31:38Z | 2024-04-02T21:31:38Z | 2024-04-03T00:39:19Z | 1,394 | huggingface/pytorch-image-models | 16,166 |
Format Document | diff --git a/ARKA.py b/ARKA.py
index 0611cba1c1..0132c4ce54 100644
--- a/ARKA.py
+++ b/ARKA.py
@@ -1,9 +1,8 @@
-def sumOfSeries(n):
- x = (n * (n + 1) / 2)
- return (int)(x * x)
+def sumOfSeries(n):
+ x = n * (n + 1) / 2
+ return (int)(x * x)
-
-# Driver Function
+# Driver Function
n = 5
-print(sumOfSeri... | https://api.github.com/repos/geekcomputers/Python/pulls/1774 | 2022-10-14T17:15:16Z | 2022-10-14T20:12:07Z | 2022-10-14T20:12:07Z | 2022-10-14T20:18:08Z | 155 | geekcomputers/Python | 31,738 | |
Fix Trainer for Datasets that don't have dict items | diff --git a/src/transformers/trainer_utils.py b/src/transformers/trainer_utils.py
index afc2e0d1561cd..46fd0cdd05b6f 100644
--- a/src/transformers/trainer_utils.py
+++ b/src/transformers/trainer_utils.py
@@ -676,6 +676,8 @@ def __init__(
self.message_logged = False
def _remove_columns(self, feature: di... | # What does this PR do?
This PR fixes a break in `Trainer` when the dataset items are not dictionaries. | https://api.github.com/repos/huggingface/transformers/pulls/17239 | 2022-05-13T15:35:28Z | 2022-05-13T15:49:23Z | 2022-05-13T15:49:23Z | 2022-05-15T11:51:29Z | 158 | huggingface/transformers | 12,002 |
Add: PowerBI | diff --git a/config.py b/config.py
index 57c98307a..1d8aafc07 100644
--- a/config.py
+++ b/config.py
@@ -90,6 +90,9 @@
# TODO: check if the classname exists
ALIASES = {
"onprem": {
+ "analytics": {
+ "Powerbi": "PowerBI"
+ },
"ci": {
"Circleci": "CircleCI",
... | Adding PowerBI as an on-premise analytics resource.
N.B. Apparently someone forgot to generate the documentation for "OPNSense" alias. I double checked and it is the right alias in this PR. | https://api.github.com/repos/mingrammer/diagrams/pulls/337 | 2020-10-05T12:50:28Z | 2021-01-27T12:28:56Z | 2021-01-27T12:28:56Z | 2021-01-27T12:28:56Z | 494 | mingrammer/diagrams | 52,720 |
tik_tak game | diff --git a/tik_tak.py b/tik_tak.py
new file mode 100644
index 0000000000..e4b4d28942
--- /dev/null
+++ b/tik_tak.py
@@ -0,0 +1,108 @@
+
+l=["anything",1,2,3,4,5,6,7,8,9]
+i=0
+j=9
+print("\n\t\t\tTIK-TAC-TOE")
+def board():
+ #import os
+ #os.system('cls')
+ print("\n\n")
+ print(" | |" )
+ prin... | https://api.github.com/repos/geekcomputers/Python/pulls/364 | 2018-09-14T05:53:43Z | 2018-09-24T11:02:57Z | 2018-09-24T11:02:57Z | 2018-09-24T11:02:57Z | 882 | geekcomputers/Python | 31,597 | |
introduce debug utils | diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index 4692bb709079..3c695d921a5a 100755
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -38,6 +38,7 @@
import deepspeed.runtime.lr_schedules as lr_schedules
from deepspeed.utils import logger, log_dist, init_distributed
fro... | While working on integration of wav2vec2 https://github.com/huggingface/transformers/pull/11638 which is dramatically different from transformers models, I run into multiple problems in the model and deepspeed and the current debug tools were very difficult to use. So I developed a whole set of tools which I placed int... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1136 | 2021-06-05T06:11:33Z | 2021-06-23T20:08:30Z | 2021-06-23T20:08:29Z | 2021-06-23T20:31:37Z | 3,714 | microsoft/DeepSpeed | 10,143 |
Minor fixes to bigip_cli_alias | diff --git a/lib/ansible/modules/network/f5/bigip_cli_alias.py b/lib/ansible/modules/network/f5/bigip_cli_alias.py
index ae39da6df34bfb..e66819dab3d6e1 100644
--- a/lib/ansible/modules/network/f5/bigip_cli_alias.py
+++ b/lib/ansible/modules/network/f5/bigip_cli_alias.py
@@ -405,8 +405,9 @@ def main():
supports... | ##### SUMMARY
<!--- Describe the change below, including rationale and design decisions -->
<!--- HINT: Include "Fixes #nnn" if you are fixing an existing issue -->
Minor fixes to bigip_cli_alias
##### ISSUE TYPE
<!--- Pick one below and delete the rest -->
- Bugfix Pull Request
##### COMPONENT NAME
<!---... | https://api.github.com/repos/ansible/ansible/pulls/48452 | 2018-11-10T04:13:50Z | 2018-11-10T04:39:51Z | 2018-11-10T04:39:51Z | 2019-07-22T17:14:59Z | 734 | ansible/ansible | 48,864 |
blib2to3: support unparenthesized wulruses in more places | diff --git a/CHANGES.md b/CHANGES.md
index 47e64cfa274..d28d766f4c0 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -11,6 +11,8 @@
hardened to handle more edge cases during quote normalization (#2437)
- Avoid changing a function return type annotation's type to a tuple by adding a
trailing comma (#2384)
+- Parsing s... | ### Description
Implementation stolen from PR davidhalter/parso#162. Thanks parso!
I could add support for these newer syntactical constructs in the target version detection logic, but until I get diff-shades up and running I don't feel very comfortable adding the code.
### Checklist - did you ...
- [x] Add... | https://api.github.com/repos/psf/black/pulls/2447 | 2021-08-26T20:29:58Z | 2021-08-26T20:59:01Z | 2021-08-26T20:59:01Z | 2021-08-26T20:59:04Z | 1,280 | psf/black | 24,388 |
Issue35925 Remove trailing commas | diff --git a/pandas/tests/test_multilevel.py b/pandas/tests/test_multilevel.py
index 724558bd49ea2..274860b3fdb5c 100644
--- a/pandas/tests/test_multilevel.py
+++ b/pandas/tests/test_multilevel.py
@@ -1846,7 +1846,7 @@ def test_multilevel_index_loc_order(self, dim, keys, expected):
# GH 22797
# Try to... | #35925
Files edited:
- pandas/tests/test_multilevel.py
- pandas/tests/test_nanops.py
- pandas/tests/window/moments/test_moments_consistency_rolling.py
- pandas/tests/window/moments/test_moments_ewm.py
- pandas/tests/window/moments/test_moments_rolling.py
- pandas/tests/window/test_base_indexer.py
- pandas/tes... | https://api.github.com/repos/pandas-dev/pandas/pulls/35996 | 2020-08-30T17:56:06Z | 2020-08-31T09:59:18Z | 2020-08-31T09:59:18Z | 2020-08-31T09:59:26Z | 3,387 | pandas-dev/pandas | 45,140 |
Fix code sample for "65539 local variables" example | diff --git a/README.md b/README.md
index 68b6c09..44ba6e4 100644
--- a/README.md
+++ b/README.md
@@ -2264,7 +2264,8 @@ nan
```py
import dis
exec("""
- def f():* """ + """
+ def f():
+ """ + """
""".join(["X"+str(x)+"=" + str(x) for x in range(65539)]))
f()
| https://api.github.com/repos/satwikkansal/wtfpython/pulls/60 | 2018-01-27T16:35:10Z | 2018-01-29T10:10:03Z | 2018-01-29T10:10:03Z | 2018-01-29T10:39:49Z | 114 | satwikkansal/wtfpython | 25,779 | |
[MRG] Makes roc_auc_score and average_precision_score docstrings more explicit | diff --git a/sklearn/metrics/ranking.py b/sklearn/metrics/ranking.py
index 2003ed8b314c8..fde1f1c441125 100644
--- a/sklearn/metrics/ranking.py
+++ b/sklearn/metrics/ranking.py
@@ -116,7 +116,7 @@ def average_precision_score(y_true, y_score, average="macro",
Parameters
----------
y_true : array, shape = ... | <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/master/CONTRIBUTING.md#Contributing-Pull-Requests
-->
#### Reference Issue
<!-- Example: Fixes #1234 -->
Fixes issue #9554
#### What does this imp... | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/9557 | 2017-08-15T19:20:30Z | 2017-08-22T00:02:03Z | 2017-08-22T00:02:03Z | 2017-08-22T00:02:03Z | 440 | scikit-learn/scikit-learn | 46,411 |
proper initialization | diff --git a/homeassistant/components/sensor/tellduslive.py b/homeassistant/components/sensor/tellduslive.py
index ae05ce47e195ab..364b790ce6f03e 100644
--- a/homeassistant/components/sensor/tellduslive.py
+++ b/homeassistant/components/sensor/tellduslive.py
@@ -18,7 +18,6 @@
ATTR_LAST_UPDATED = "time_last_updated"
... | fix issue where sensors and switches were duplicated because of component getting initialized twice. closes #913
| https://api.github.com/repos/home-assistant/core/pulls/931 | 2016-01-18T18:47:41Z | 2016-01-19T02:01:12Z | 2016-01-19T02:01:12Z | 2017-03-17T20:23:25Z | 385 | home-assistant/core | 39,230 |
Run LocalStack tests against LocalStack Pro in Github Action | diff --git a/.github/workflows/pro-integration.yml b/.github/workflows/pro-integration.yml
new file mode 100644
index 0000000000000..f6cd54fd34646
--- /dev/null
+++ b/.github/workflows/pro-integration.yml
@@ -0,0 +1,130 @@
+name: integration-tests-against-pro
+on:
+ workflow_dispatch:
+ inputs:
+ targetRef:
+ ... | This Action runs the LocalStack integration tests against a Pro Instance, to check if any problems arise and reports them.
This should provide more confidence that LocalStack changes do not brick any features in Pro or vice versa.
To be merged after #4485 | https://api.github.com/repos/localstack/localstack/pulls/4486 | 2021-08-25T11:33:51Z | 2021-09-08T11:19:36Z | 2021-09-08T11:19:36Z | 2021-09-08T14:16:31Z | 1,394 | localstack/localstack | 28,909 |
Update README.md | diff --git a/README.md b/README.md
index 9cc4603d544..c2f7885b220 100644
--- a/README.md
+++ b/README.md
@@ -60,6 +60,7 @@ Translations
* [Georgian](https://github.com/sqlmapproject/sqlmap/blob/master/doc/translations/README-ka-GE.md)
* [German](https://github.com/sqlmapproject/sqlmap/blob/master/doc/translations/REA... | https://api.github.com/repos/sqlmapproject/sqlmap/pulls/5552 | 2023-10-22T06:19:26Z | 2023-10-22T09:11:51Z | 2023-10-22T09:11:50Z | 2023-10-22T09:11:51Z | 407 | sqlmapproject/sqlmap | 14,933 | |
Bugfix for renaming of faces | diff --git a/tools/alignments.py b/tools/alignments.py
index 6a1cbe498b..4ae27ab8be 100644
--- a/tools/alignments.py
+++ b/tools/alignments.py
@@ -38,8 +38,9 @@ def process(self):
job = Draw(self.alignments, self.args)
elif self.args.job == "extract":
job = Extract(self.alignments, se... | An issue occurred when more than 10 faces were found within a frame. On removing frames and renaming, indexes were not processed in the correct order, meaning that files could potentially be renamed to existing file names. This fixes that bug | https://api.github.com/repos/deepfakes/faceswap/pulls/485 | 2018-08-28T21:21:21Z | 2018-08-28T21:21:37Z | 2018-08-28T21:21:37Z | 2018-08-28T21:21:37Z | 1,251 | deepfakes/faceswap | 18,596 |
Update lstm_seq2seq.py(from 22% to 87% acc) | diff --git a/examples/lstm_seq2seq.py b/examples/lstm_seq2seq.py
index 88fa5768858..e320fd1bf85 100644
--- a/examples/lstm_seq2seq.py
+++ b/examples/lstm_seq2seq.py
@@ -114,6 +114,7 @@
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
enc... | I added the codes for applying one-hot encoding on the end of sentences about encoder_input_data, decoder_input_data, and decoder_target_data. I added an accuracy metric for model training. The original code has 22% accuracy, but the proposed code had 87% validation accuracy.
<!--
Please make sure you've read and u... | https://api.github.com/repos/keras-team/keras/pulls/13269 | 2019-08-30T06:27:05Z | 2019-09-11T20:19:52Z | 2019-09-11T20:19:52Z | 2019-09-11T20:19:52Z | 392 | keras-team/keras | 47,769 |
bitfinex2: unify market | diff --git a/js/bitfinex2.js b/js/bitfinex2.js
index fc75093e7138..9ca7e06d17f0 100644
--- a/js/bitfinex2.js
+++ b/js/bitfinex2.js
@@ -990,8 +990,9 @@ module.exports = class bitfinex2 extends Exchange {
*/
await this.loadMarkets ();
const precision = this.safeValue (this.options, 'precision'... | https://api.github.com/repos/ccxt/ccxt/pulls/14140 | 2022-07-01T03:20:23Z | 2022-07-01T05:04:54Z | 2022-07-01T05:04:54Z | 2022-07-01T05:04:54Z | 242 | ccxt/ccxt | 13,095 | |
Added new sandbox configs to sweep.yaml | diff --git a/sweep.yaml b/sweep.yaml
index dd2e801d3e..a4aac75937 100644
--- a/sweep.yaml
+++ b/sweep.yaml
@@ -9,7 +9,10 @@ description: 'Python project for AI code generation with next token prediction L
# Default Values: https://github.com/sweepai/sweep/blob/main/sweep.yaml
sandbox:
- enabled: true
- image: "Py... | This PR adds the new sandbox configs to `sweep.yaml` which runs pre-commit before every Sweep commit.
I also added rules, which makes Sweep ensure that all newly edited functions and classes will have up-to-date docstrings.
| https://api.github.com/repos/gpt-engineer-org/gpt-engineer/pulls/748 | 2023-09-29T22:18:09Z | 2023-10-02T17:55:00Z | 2023-10-02T17:55:00Z | 2023-10-02T17:55:01Z | 207 | gpt-engineer-org/gpt-engineer | 33,362 |
Fix index variable in for loop in paddlestructure.cpp | diff --git a/deploy/cpp_infer/src/paddlestructure.cpp b/deploy/cpp_infer/src/paddlestructure.cpp
index b2e35f8c77..994df0ca0b 100644
--- a/deploy/cpp_infer/src/paddlestructure.cpp
+++ b/deploy/cpp_infer/src/paddlestructure.cpp
@@ -144,7 +144,7 @@ PaddleStructure::rebuild_table(std::vector<std::string> structure_html_ta... | PaddleStructure::rebuild_table函数中`structure_boxes`的索引用错了,可能导致dis和iou无法正确计算。
原代码段:
```
for (int j = 0; j < structure_boxes.size(); j++) {
if (structure_boxes[i].size() == 8) {
structure_box = Utility::xyxyxyxy2xyxy(structure_boxes[j]);
} else {
structure_box = structure_boxes[j];
... | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/10810 | 2023-09-02T03:33:26Z | 2023-09-21T02:32:43Z | 2023-09-21T02:32:43Z | 2023-09-21T09:40:45Z | 209 | PaddlePaddle/PaddleOCR | 42,659 |
Update expected values in CodeGen tests | diff --git a/tests/models/codegen/test_modeling_codegen.py b/tests/models/codegen/test_modeling_codegen.py
index 37919b04398a7..b59adc78181d1 100644
--- a/tests/models/codegen/test_modeling_codegen.py
+++ b/tests/models/codegen/test_modeling_codegen.py
@@ -503,7 +503,7 @@ def test_codegen_sample(self):
output_... | # What does this PR do?
Update expected values in CodeGen test `test_codegen_sample`. The currently value works for other GPU, but for Nvidia T4, we need the values in this PR.
Note that `do_sample` will call `self.sample` (in `generatioin_utils.py`) which uses `torch.multinomial`, which is not 100% reproducible... | https://api.github.com/repos/huggingface/transformers/pulls/17888 | 2022-06-27T06:17:39Z | 2022-07-01T13:33:37Z | 2022-07-01T13:33:37Z | 2022-07-01T13:45:01Z | 201 | huggingface/transformers | 12,132 |
Added a command for appending flows to server replay list | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 64292246ea..fc72f5d1ba 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -7,6 +7,8 @@
* ASGI/WSGI apps can now listen on all ports for a specific hostname.
This makes it simpler to accept both HTTP and HTTPS.
([#5725](https://github.com/mitmproxy/mitmproxy/pull/5725)... | #### Description
Added a command `replay.server.add` for appending flows to server replay responses.
I find it easier to use when you need to add new flows for server playback instead of replacing them.
#### Checklist
- [x] I have updated tests where applicable.
- [x] I have added an entry to the CHANGEL... | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/5851 | 2023-01-06T12:28:46Z | 2023-01-06T15:49:55Z | 2023-01-06T15:49:55Z | 2023-01-06T15:49:55Z | 633 | mitmproxy/mitmproxy | 28,310 |
Update export format docstrings | diff --git a/README.md b/README.md
index fa0645d4fd2..59abd084572 100644
--- a/README.md
+++ b/README.md
@@ -62,15 +62,14 @@ See the [YOLOv5 Docs](https://docs.ultralytics.com) for full documentation on tr
<details open>
<summary>Install</summary>
-[**Python>=3.6.0**](https://www.python.org/) is required with all
-... | General docstring improvements.
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Simplification and expansion of installation, inference, and training instructions; add model format options for detect.py and val.py.
### 📊 Key Changes
- Streaml... | https://api.github.com/repos/ultralytics/yolov5/pulls/6151 | 2022-01-02T00:04:32Z | 2022-01-03T00:09:46Z | 2022-01-03T00:09:46Z | 2024-01-19T13:45:04Z | 3,287 | ultralytics/yolov5 | 25,166 |
🌐 Add German translation for `docs/de/docs/advanced/response-cookies.md` | diff --git a/docs/de/docs/advanced/response-cookies.md b/docs/de/docs/advanced/response-cookies.md
new file mode 100644
index 0000000000000..0f09bd4441197
--- /dev/null
+++ b/docs/de/docs/advanced/response-cookies.md
@@ -0,0 +1,49 @@
+# Response-Cookies
+
+## Einen `Response`-Parameter verwenden
+
+Sie können einen Par... | ← `advanced/additional-responses.md` (#10626)
→ `advanced/response-headers.md` (#10628)
[German translation progress](https://github.com/tiangolo/fastapi/discussions/10582) | https://api.github.com/repos/tiangolo/fastapi/pulls/10627 | 2023-11-12T08:37:56Z | 2024-03-30T20:19:18Z | 2024-03-30T20:19:18Z | 2024-04-01T01:22:00Z | 753 | tiangolo/fastapi | 23,549 |
A few more README fixes | diff --git a/README.md b/README.md
index 7535d6d5845..f44cc0fa89f 100644
--- a/README.md
+++ b/README.md
@@ -24,6 +24,9 @@ To use keras-core, you should also install the backend of choice: `tensorflow`,
Note that `tensorflow` is required for using certain Keras 3 features: certain preprocessing layers
as well as `tf.... | https://api.github.com/repos/keras-team/keras/pulls/18517 | 2023-09-27T21:22:46Z | 2023-09-27T22:00:07Z | 2023-09-27T22:00:07Z | 2023-09-27T22:00:11Z | 409 | keras-team/keras | 47,874 | |
DOC: Follows ISO 639-1 code | diff --git a/doc/cheatsheet/Pandas_Cheat_Sheet_JA.pdf b/doc/cheatsheet/Pandas_Cheat_Sheet_JA.pdf
new file mode 100644
index 0000000000000..daa65a944e68a
Binary files /dev/null and b/doc/cheatsheet/Pandas_Cheat_Sheet_JA.pdf differ
diff --git a/doc/cheatsheet/Pandas_Cheat_Sheet_JA.pptx b/doc/cheatsheet/Pandas_Cheat_Sheet... | ## Changes
- change suffix `_JP` to `_JA` according to `ISO 639`
- fixed typo in `Pandas_Cheat_Sheet_JA.pdf`
- translated `Pandas_Cheat_Sheet_JA.pptx` in Japanese | https://api.github.com/repos/pandas-dev/pandas/pulls/22657 | 2018-09-10T08:51:47Z | 2018-09-30T21:27:18Z | 2018-09-30T21:27:18Z | 2018-09-30T21:27:18Z | 340 | pandas-dev/pandas | 45,719 |
minor changes to cartpole+acrobot, upgrade to v1 | diff --git a/gym/envs/__init__.py b/gym/envs/__init__.py
index a0edcec270e..31f8ff2554f 100644
--- a/gym/envs/__init__.py
+++ b/gym/envs/__init__.py
@@ -57,6 +57,13 @@
reward_threshold=195.0,
)
+register(
+ id='CartPole-v1',
+ entry_point='gym.envs.classic_control:CartPoleEnv',
+ timestep_limit=500,
+ ... | cartpole: bump timestep limit to 500, so you need to have a decent balancing policy to solve it
acrobot: change observation to use cos/sin of angles, and increase timestep limit so acrobot gets solved by random exploration
| https://api.github.com/repos/openai/gym/pulls/260 | 2016-07-23T21:40:57Z | 2016-08-06T07:15:50Z | 2016-08-06T07:15:50Z | 2017-01-04T17:57:43Z | 874 | openai/gym | 5,823 |
Fix placeholder value in FastGen Blog | diff --git a/blogs/deepspeed-fastgen/2024-01-19/README.md b/blogs/deepspeed-fastgen/2024-01-19/README.md
index b734b3f50dea..a98c9856164c 100644
--- a/blogs/deepspeed-fastgen/2024-01-19/README.md
+++ b/blogs/deepspeed-fastgen/2024-01-19/README.md
@@ -25,7 +25,7 @@
Today, we are happy to share that we are improving Dee... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/5000 | 2024-01-23T17:55:36Z | 2024-01-23T17:59:37Z | 2024-01-23T17:59:37Z | 2024-01-23T17:59:40Z | 285 | microsoft/DeepSpeed | 10,411 | |
Fix typo in flask_container_ci/README.md | diff --git a/exercises/flask_container_ci/README.md b/exercises/flask_container_ci/README.md
index 35c85eea3..e4ac21db1 100644
--- a/exercises/flask_container_ci/README.md
+++ b/exercises/flask_container_ci/README.md
@@ -13,8 +13,8 @@ If any of the following steps is not working, it is expected from you to fix the
1... | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/123 | 2020-12-18T00:20:33Z | 2020-12-18T11:29:47Z | 2020-12-18T11:29:47Z | 2020-12-18T11:29:47Z | 355 | bregman-arie/devops-exercises | 17,668 | |
handling transcribe exceptions. | diff --git a/whisper/transcribe.py b/whisper/transcribe.py
index 509e322e..d5b3d433 100644
--- a/whisper/transcribe.py
+++ b/whisper/transcribe.py
@@ -1,5 +1,6 @@
import argparse
import os
+import traceback
import warnings
from typing import TYPE_CHECKING, Optional, Tuple, Union
@@ -468,8 +469,12 @@ def valid_mod... | When processing multiple files through CLI, whisper dies on the first transcribe failure.
This change allows the processing to keep going and displays which files failed processing. | https://api.github.com/repos/openai/whisper/pulls/1682 | 2023-09-28T17:01:45Z | 2023-11-06T10:06:20Z | 2023-11-06T10:06:20Z | 2023-11-06T10:06:20Z | 260 | openai/whisper | 45,788 |
fix(webhooks): Include event ID (autoincrementing) in request body | diff --git a/src/sentry/features/__init__.py b/src/sentry/features/__init__.py
index 9166d44d5fe9a..989a9a75cf38b 100644
--- a/src/sentry/features/__init__.py
+++ b/src/sentry/features/__init__.py
@@ -76,6 +76,7 @@
default_manager.add('organizations:gitlab-integration', OrganizationFeature) # NOQA
default_manager.ad... | See ISSUE-237 for a lot more context. From that ticket:
> This was "broken" as a result of post-processing changes that switched to using a Kafka consumer of the event stream as the mechanism for events being dispatched. | https://api.github.com/repos/getsentry/sentry/pulls/11086 | 2018-12-18T22:00:33Z | 2018-12-18T23:35:18Z | 2018-12-18T23:35:18Z | 2020-12-21T00:02:32Z | 636 | getsentry/sentry | 43,919 |
Missing Support for TLSv1.3 - Disabled hostname and certificate validation | diff --git a/lib/request/httpshandler.py b/lib/request/httpshandler.py
index 05e1ccf8be8..03c4079dc48 100644
--- a/lib/request/httpshandler.py
+++ b/lib/request/httpshandler.py
@@ -69,6 +69,11 @@ def create_sock():
sock = create_sock()
if protocol not in _contexts:
... | Introduction of the `PROTOCOL_TLS_CLIENT` constant in Issue #5392 enables `ssl.CERT_REQUIRED` and `SSLContext.check_hostname`, which will restrict sqlmap from scanning endpoints that present unknown, self-signed, expired, or otherwise invalid certificates - including invalid Subject Names and Subject Alternative Names.... | https://api.github.com/repos/sqlmapproject/sqlmap/pulls/5395 | 2023-04-17T22:19:38Z | 2023-04-24T13:06:57Z | 2023-04-24T13:06:57Z | 2023-04-24T13:06:58Z | 190 | sqlmapproject/sqlmap | 14,998 |
Add training scripts for Baichuan & Clean BOS/EOS tokens during data cleaning | diff --git a/fastchat/data/optional_replace.py b/fastchat/data/optional_replace.py
new file mode 100644
index 0000000000..1114151a9b
--- /dev/null
+++ b/fastchat/data/optional_replace.py
@@ -0,0 +1,82 @@
+"""
+Do optional replace of bos/eos/pad/unk.
+
+Usage:
+python3 -m fastchat.data.optional_replace --in input.json -... | <!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
1. Compared to llama, there are certain differences in the word s... | https://api.github.com/repos/lm-sys/FastChat/pulls/1940 | 2023-07-13T08:52:50Z | 2023-07-16T21:02:17Z | 2023-07-16T21:02:17Z | 2023-07-16T21:09:18Z | 3,907 | lm-sys/FastChat | 41,365 |
Revert using own cast app for media | diff --git a/homeassistant/components/cast/media_player.py b/homeassistant/components/cast/media_player.py
index f62a73860f39dd..788da18e8bd059 100644
--- a/homeassistant/components/cast/media_player.py
+++ b/homeassistant/components/cast/media_player.py
@@ -39,7 +39,6 @@
SUPPORT_VOLUME_SET,
)
from homeassistant... | ## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
or resolves a feature request, be sure to link to that issue in the
additional information section.
-->
We are reverting this for now so we can... | https://api.github.com/repos/home-assistant/core/pulls/40937 | 2020-10-01T09:04:24Z | 2020-10-01T09:05:01Z | 2020-10-01T09:05:01Z | 2020-10-01T19:58:20Z | 189 | home-assistant/core | 39,446 |
Fix UPDATING.md | diff --git a/UPDATING.md b/UPDATING.md
index e47917e002bb2..2ffc8348bfa9c 100644
--- a/UPDATING.md
+++ b/UPDATING.md
@@ -1710,9 +1710,9 @@ https://cloud.google.com/compute/docs/disks/performance
Hence, the default value for `master_disk_size` in `DataprocCreateClusterOperator` has been changed from 500GB to 1TB.
-... | **Before**:
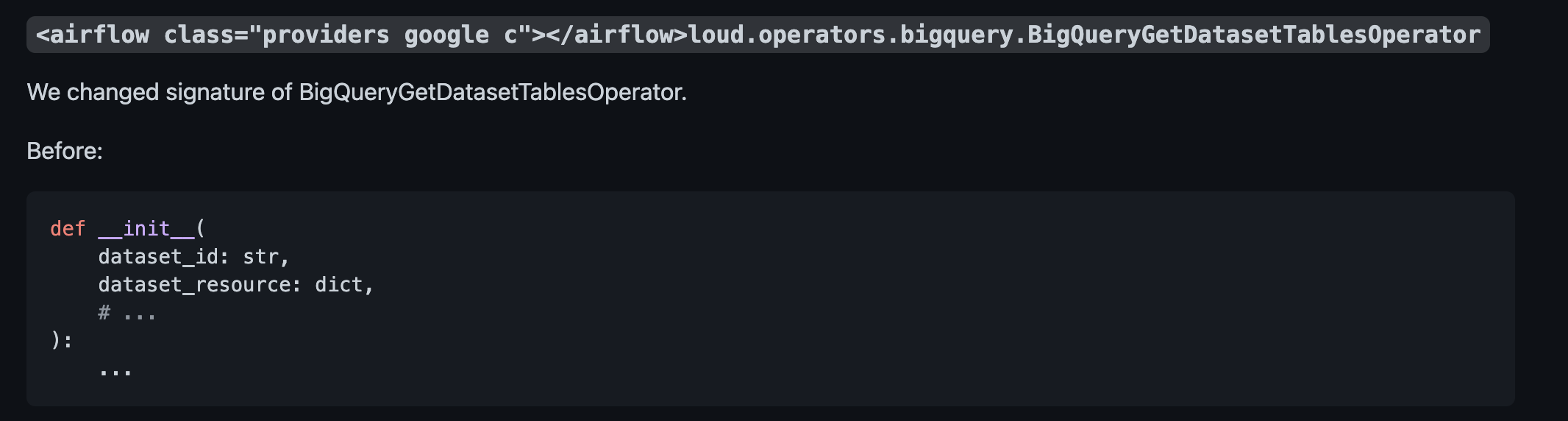
**After**:
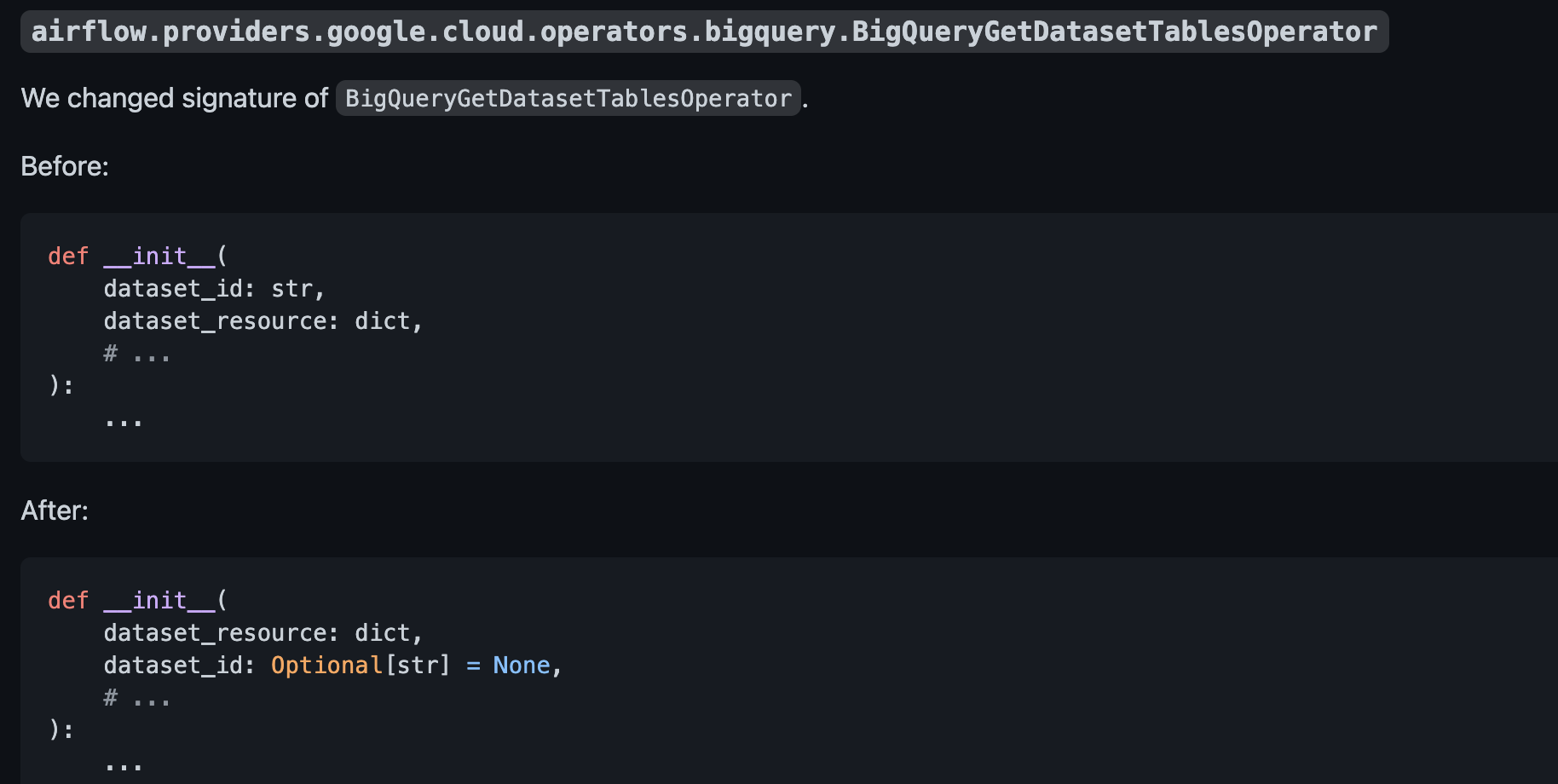
<!--
Thank you for contributing! Please make sure that your ... | https://api.github.com/repos/apache/airflow/pulls/16933 | 2021-07-11T23:56:49Z | 2021-07-12T00:21:01Z | 2021-07-12T00:21:01Z | 2021-07-12T21:22:57Z | 187 | apache/airflow | 14,633 |
Expose font_aspect_ratio as parameter on SVG export | diff --git a/CHANGELOG.md b/CHANGELOG.md
index d6eebd4fd..9a0d43253 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -14,6 +14,7 @@ and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0
- Add support for `FORCE_COLOR` env var https://github.com/Textualize/rich/pull/2449
- Allow a `max_depth`... | ## Type of changes
- [ ] Bug fix
- [ ] New feature
- [ ] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added t... | https://api.github.com/repos/Textualize/rich/pulls/2539 | 2022-09-23T10:55:03Z | 2022-09-23T11:13:28Z | 2022-09-23T11:13:28Z | 2022-09-23T11:13:29Z | 1,081 | Textualize/rich | 48,275 |
added --pdb command option to enable pdb debugger on failure. | diff --git a/scrapy/command.py b/scrapy/command.py
index 872e59a5aff..9a80dae9f96 100644
--- a/scrapy/command.py
+++ b/scrapy/command.py
@@ -4,6 +4,7 @@
import os
from optparse import OptionGroup
+from twisted.python import failure
from scrapy import log
from scrapy.utils.conf import arglist_to_dict
@@ -80,6 +8... | This just enable twisted's debug feature on failure objects.
A test for this feature it would go like twisted's tests does:
https://github.com/twisted/twisted/blob/master/twisted/test/test_failure.py#L543
As I haven't seen a similar test in scrapy for options-only I didn't knew if it was worth to add a test.
| https://api.github.com/repos/scrapy/scrapy/pulls/242 | 2013-02-11T16:50:49Z | 2013-02-12T02:56:39Z | 2013-02-12T02:56:39Z | 2013-02-12T02:57:40Z | 270 | scrapy/scrapy | 35,029 |
[extractor/TwitCasting] expand extractor regex | diff --git a/yt_dlp/extractor/twitcasting.py b/yt_dlp/extractor/twitcasting.py
index dff353a4f9e..3890d5d8fb0 100644
--- a/yt_dlp/extractor/twitcasting.py
+++ b/yt_dlp/extractor/twitcasting.py
@@ -22,7 +22,7 @@
class TwitCastingIE(InfoExtractor):
- _VALID_URL = r'https?://(?:[^/]+\.)?twitcasting\.tv/(?P<uploade... | **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be un... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/8120 | 2023-09-16T02:45:54Z | 2023-09-16T20:43:12Z | 2023-09-16T20:43:12Z | 2023-09-16T21:14:15Z | 576 | yt-dlp/yt-dlp | 7,317 |
Fix "module not found" error in Docker | diff --git a/docker/docker-compose.yml b/docker/docker-compose.yml
index b3eda7f62b..66aad3be60 100644
--- a/docker/docker-compose.yml
+++ b/docker/docker-compose.yml
@@ -8,7 +8,7 @@ services:
image: fastchat:latest
ports:
- "21001:21001"
- entrypoint: ["python3", "-m", "fastchat.serve.controller", ... | <!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
When attempting to run via Docker Compose on a fresh Linux instal... | https://api.github.com/repos/lm-sys/FastChat/pulls/1681 | 2023-06-13T19:53:12Z | 2023-06-14T07:29:15Z | 2023-06-14T07:29:15Z | 2023-06-14T19:34:49Z | 577 | lm-sys/FastChat | 41,755 |
Add sorting transformer for snapshots | diff --git a/CODEOWNERS b/CODEOWNERS
index 50fd48aaee6d3..ca5d0d9e5fde2 100644
--- a/CODEOWNERS
+++ b/CODEOWNERS
@@ -40,6 +40,11 @@
# Analytics client
/localstack/utils/analytics/ @thrau
+# Snapshot testing
+/localstack/testing/snapshots/ @dominikschubert @steffyP
+/localstack/testing/pytest/ @dominikschubert
+/loc... | Makes it easier to reliably compare lists via snapshots by sorting them via a transformer instead of having to manually sorting the object before calling `match`.
Usage:
```python
snapshot.add_transformer(SortingTransformer("Aliases", lambda x: x["Name"]))
```
| https://api.github.com/repos/localstack/localstack/pulls/6822 | 2022-09-05T17:49:00Z | 2022-09-06T13:47:18Z | 2022-09-06T13:47:18Z | 2022-09-06T13:47:25Z | 1,026 | localstack/localstack | 28,833 |
Correct an English grammatic error in README.md | diff --git a/README.md b/README.md
index 934d16e6a7..4392886867 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
-XX-Net - A Reborn of Goagent
+XX-Net - A Reborn Goagent
========
翻墙工具套件 A firewall circumvention toolkit
* GAE proxy, 稳定、易用、快速
| A small improvement: "A Reborn of Goagent" should be "A Reborn Goagent".
| https://api.github.com/repos/XX-net/XX-Net/pulls/1856 | 2016-01-07T15:03:48Z | 2016-01-08T00:59:04Z | 2016-01-08T00:59:04Z | 2016-01-08T00:59:04Z | 105 | XX-net/XX-Net | 17,293 |
[ci] remove old prepare_docker | diff --git a/.buildkite/core.rayci.yml b/.buildkite/core.rayci.yml
index e2bee4c6d3983..0cc3c37327d41 100644
--- a/.buildkite/core.rayci.yml
+++ b/.buildkite/core.rayci.yml
@@ -270,7 +270,6 @@ steps:
instance_type: medium
commands:
- bazel run //ci/ray_ci:build_in_docker -- docker --python-version 3.8 ... | and directly tag images as `ha_integration`
| https://api.github.com/repos/ray-project/ray/pulls/41719 | 2023-12-08T03:50:38Z | 2023-12-08T06:20:07Z | 2023-12-08T06:20:07Z | 2023-12-08T06:20:08Z | 967 | ray-project/ray | 19,608 |
Bump rwkv from 0.7.2 to 0.7.3 | diff --git a/requirements.txt b/requirements.txt
index 882dc3000f..be51203212 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -8,7 +8,7 @@ markdown
numpy
peft==0.2.0
requests
-rwkv==0.7.2
+rwkv==0.7.3
safetensors==0.3.0
sentencepiece
pyyaml
| Bumps [rwkv](https://github.com/BlinkDL/ChatRWKV) from 0.7.2 to 0.7.3.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/BlinkDL/ChatRWKV/commits">compare view</a></li>
</ul>
</details>
<br />
[:
norm_group... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/4431 | 2023-10-01T11:40:06Z | 2023-10-03T17:17:26Z | 2023-10-03T17:17:26Z | 2023-10-03T20:32:53Z | 519 | microsoft/DeepSpeed | 10,679 | |
add ut to check code saving | diff --git a/tests/data/rsp_cache.json b/tests/data/rsp_cache.json
index 40d7d3953..75fc9ceb2 100644
--- a/tests/data/rsp_cache.json
+++ b/tests/data/rsp_cache.json
@@ -389,5 +389,11 @@
"reflection": "The implementation failed the test case where the input array is [1, 5, 2, 3, 4]. The issue arises because the... | https://api.github.com/repos/geekan/MetaGPT/pulls/857 | 2024-02-06T16:00:39Z | 2024-02-06T16:01:56Z | 2024-02-06T16:01:56Z | 2024-02-06T16:01:56Z | 2,794 | geekan/MetaGPT | 16,936 | |
Set WindowsProactorEventLoopPolicy after importing sk_function in python3.9+ | diff --git a/metagpt/_compat.py b/metagpt/_compat.py
index 91bc1e5a1..c442bd7de 100644
--- a/metagpt/_compat.py
+++ b/metagpt/_compat.py
@@ -2,19 +2,22 @@
import sys
import warnings
-if sys.implementation.name == "cpython" and platform.system() == "Windows" and sys.version_info[:2] == (3, 9):
+if sys.implementation... | - fix #360 | https://api.github.com/repos/geekan/MetaGPT/pulls/362 | 2023-09-24T17:00:41Z | 2023-09-25T05:37:53Z | 2023-09-25T05:37:53Z | 2023-09-26T01:59:49Z | 473 | geekan/MetaGPT | 16,815 |
[ie/tiktok] Restore `carrier_region` API param | diff --git a/yt_dlp/extractor/tiktok.py b/yt_dlp/extractor/tiktok.py
index 295e14932a8..3f5261ad968 100644
--- a/yt_dlp/extractor/tiktok.py
+++ b/yt_dlp/extractor/tiktok.py
@@ -155,6 +155,7 @@ def _build_api_query(self, query):
'locale': 'en',
'ac2': 'wifi5g',
'uoo': '1',
+ ... | Avoids some geo-blocks, see https://github.com/yt-dlp/yt-dlp/issues/9506#issuecomment-2041044419
Thanks @oifj34f34f
<details open><summary>Template</summary> <!-- OPEN is intentional -->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https:... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/9637 | 2024-04-06T23:34:13Z | 2024-04-07T15:32:11Z | 2024-04-07T15:32:11Z | 2024-04-07T15:32:11Z | 157 | yt-dlp/yt-dlp | 7,374 |
`torch.split()` 1.7.0 compatibility fix | diff --git a/utils/loss.py b/utils/loss.py
index a06330e034b..bf9b592d4ad 100644
--- a/utils/loss.py
+++ b/utils/loss.py
@@ -108,13 +108,15 @@ def __init__(self, model, autobalance=False):
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
- det = de_parallel(model).mod... | Fix for https://github.com/ultralytics/yolov5/issues/7085#issuecomment-1075224274
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancement of the loss calculation functionality in the YOLOv5 model.
### 📊 Key Changes
- Refactored variable n... | https://api.github.com/repos/ultralytics/yolov5/pulls/7102 | 2022-03-22T15:58:36Z | 2022-03-22T16:36:05Z | 2022-03-22T16:36:05Z | 2024-01-19T12:03:15Z | 678 | ultralytics/yolov5 | 25,598 |
keras_v2+python3, `load_weights_from_hdf5_group` character type bug | diff --git a/keras/engine/topology.py b/keras/engine/topology.py
index 85687439d9f..0c00abc4afb 100644
--- a/keras/engine/topology.py
+++ b/keras/engine/topology.py
@@ -2839,11 +2839,11 @@ def load_weights_from_hdf5_group(f, layers):
and weights file.
"""
if 'keras_version' in f.attrs:
- o... | Forgetting to decode bytes strings in `keras.engine.topology.load_weights_from_hdf5_group` and `load_weights_from_hdf5_group_by_name`.
`h5py` returns string as `bytes` object in Python3. `load_weights_from_hdf5_group()` call `preprocess_weights_for_loading()` with `original_backend` as bytes string.
https://githu... | https://api.github.com/repos/keras-team/keras/pulls/5762 | 2017-03-14T13:16:19Z | 2017-03-14T15:32:00Z | 2017-03-14T15:32:00Z | 2017-03-14T23:18:21Z | 322 | keras-team/keras | 47,220 |
BOTMETA: Update team_mysql | diff --git a/.github/BOTMETA.yml b/.github/BOTMETA.yml
index c88cfb0c98b447..930f73bc439313 100644
--- a/.github/BOTMETA.yml
+++ b/.github/BOTMETA.yml
@@ -1350,7 +1350,7 @@ macros:
team_macos: dagwieers kyleabenson
team_manageiq: gtanzillo abellotti zgalor yaacov cben
team_meraki: dagwieers kbreit
- team_mysq... | ##### SUMMARY
Add team members to the team. Welcome !
##### ISSUE TYPE
- Docs Pull Request
##### COMPONENT NAME
BOTMETA.yml | https://api.github.com/repos/ansible/ansible/pulls/52212 | 2019-02-14T02:00:40Z | 2019-02-14T02:47:14Z | 2019-02-14T02:47:14Z | 2019-07-25T16:48:49Z | 213 | ansible/ansible | 49,161 |
delay imports for replace policies and fix missing req | diff --git a/deepspeed/module_inject/replace_module.py b/deepspeed/module_inject/replace_module.py
index c58130f23185..31f16cce8109 100755
--- a/deepspeed/module_inject/replace_module.py
+++ b/deepspeed/module_inject/replace_module.py
@@ -387,6 +387,9 @@ def replace_module(model, orig_class, replace_fn, _replace_policy... | - [x] Add requirement for dev on importlib-metadata > 4, we were seeing pytest issues with importlib-metadata 2.0
- [x] Delay import of static class variables, this was causing our unit test framework to crash since importing megatron seems to initialize cuda which causes us python/pytorch multi-process issues :(
- [... | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1100 | 2021-05-24T22:06:01Z | 2021-05-24T23:43:37Z | 2021-05-24T23:43:37Z | 2021-05-24T23:43:39Z | 1,231 | microsoft/DeepSpeed | 10,734 |
fix appveyor | diff --git a/Pipfile b/Pipfile
index 51e8e8469f..3e0fd729eb 100644
--- a/Pipfile
+++ b/Pipfile
@@ -1,24 +1,24 @@
[[source]]
url = "https://pypi.org/simple/"
verify_ssl = true
+name = "pypi"
[dev-packages]
-
pytest = ">=2.8.0"
codecov = "*"
-"pytest-httpbin" = "==0.0.7"
-"pytest-mock" = "*"
-"pytest-cov" = "*"
-... | I don't know what's going on with Appveyor/Pipenv but it's no longer liking `-e .` installs out of the Pipfile. I went back to a version of Pipenv that we have successful builds for and it's still broken. I'd like to get builds fixed while we determine root cause. | https://api.github.com/repos/psf/requests/pulls/4647 | 2018-05-16T06:04:37Z | 2018-05-16T13:14:38Z | 2018-05-16T13:14:38Z | 2021-09-03T00:10:58Z | 444 | psf/requests | 32,629 |
Remove references to the `sel` object in shell.rst | diff --git a/docs/topics/shell.rst b/docs/topics/shell.rst
index 5c1cfbd475f..8fce0cea18a 100644
--- a/docs/topics/shell.rst
+++ b/docs/topics/shell.rst
@@ -85,9 +85,6 @@ Those objects are:
* ``response`` - a :class:`~scrapy.http.Response` object containing the last
fetched page
- * ``sel`` - a :class:`~scrapy.... | The current documentation has references to the deprecated `sel` when interacting with the shell. I've removed them and replaced uses of `sel.xpath` with `response.xpath` instead.
| https://api.github.com/repos/scrapy/scrapy/pulls/1154 | 2015-04-12T17:44:43Z | 2015-04-13T00:55:36Z | 2015-04-13T00:55:36Z | 2015-04-13T00:55:36Z | 730 | scrapy/scrapy | 34,761 |
Update common software development questions | diff --git a/topics/software_development/README.md b/topics/software_development/README.md
index 022f8cd83..be91232b1 100644
--- a/topics/software_development/README.md
+++ b/topics/software_development/README.md
@@ -41,6 +41,8 @@
<details>
<summary>What programming language do you prefer to use for DevOps related ... | https://api.github.com/repos/bregman-arie/devops-exercises/pulls/342 | 2023-01-31T12:20:43Z | 2023-02-02T11:00:42Z | 2023-02-02T11:00:42Z | 2023-02-02T14:12:37Z | 1,769 | bregman-arie/devops-exercises | 17,647 | |
Add EUI-48 and EUI-64 (MAC address) highlighting | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 3a05e6811..0913a7906 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,7 +5,11 @@ All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic ... | ## Type of changes
- [ ] Bug fix
- [x] New feature
- [ ] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [x] I've added t... | https://api.github.com/repos/Textualize/rich/pulls/369 | 2020-10-08T19:52:37Z | 2020-10-09T14:35:24Z | 2020-10-09T14:35:24Z | 2020-10-09T14:35:24Z | 1,520 | Textualize/rich | 48,140 |
dialog display on squeeze (fixes #280) | diff --git a/docs/using.rst b/docs/using.rst
index eb53fc54a9b..463b6524bc6 100644
--- a/docs/using.rst
+++ b/docs/using.rst
@@ -36,7 +36,6 @@ For squezze you will need to:
(``sudo`` is not installed by default) before running the bootstrap
script.
- Use ``virtualenv --no-site-packages -p python`` instead of ``-... | @jdkasten, @pavgup does this work for you?
| https://api.github.com/repos/certbot/certbot/pulls/337 | 2015-04-05T07:59:39Z | 2015-04-14T20:02:29Z | 2015-04-14T20:02:29Z | 2016-05-06T19:21:28Z | 288 | certbot/certbot | 2,004 |
Adjust `--preview` documentation | diff --git a/src/black/__init__.py b/src/black/__init__.py
index 6192f5c0f8..6a703e4504 100644
--- a/src/black/__init__.py
+++ b/src/black/__init__.py
@@ -258,7 +258,7 @@ def validate_regex(
"--preview",
is_flag=True,
help=(
- "Enable potentially disruptive style changes that will be added to Blac... | We may not adopt all preview changes immediately.
| https://api.github.com/repos/psf/black/pulls/2833 | 2022-01-30T19:27:46Z | 2022-01-30T19:53:46Z | 2022-01-30T19:53:46Z | 2022-01-30T19:54:20Z | 130 | psf/black | 23,938 |
Add webview docs and examples, Set webview as default | diff --git a/README.md b/README.md
index 451ec57de3..c07a1d4b22 100644
--- a/README.md
+++ b/README.md
@@ -41,7 +41,7 @@ As per the survey, here is a list of improvements to come
- [ ] 🚧 Improve Documentation (in /docs & Guides, Howtos, & Do video tutorials)
- [x] Improve the provider status list & updates
- [ ] Tu... | https://api.github.com/repos/xtekky/gpt4free/pulls/1742 | 2024-03-22T11:49:17Z | 2024-03-22T12:01:48Z | 2024-03-22T12:01:48Z | 2024-03-22T12:01:55Z | 2,335 | xtekky/gpt4free | 38,028 | |
🔥 Removed support for Python 3.6 | diff --git a/.github/workflows/test.yml b/.github/workflows/test.yml
index 88c791d5a..dd94314b9 100644
--- a/.github/workflows/test.yml
+++ b/.github/workflows/test.yml
@@ -21,8 +21,8 @@ jobs:
python: ["3.7", "3.8", "3.9", "3.10", "3.11"]
runs-on: ubuntu-latest
steps:
- - uses: actions/checkout@... | Related #855 | https://api.github.com/repos/mingrammer/diagrams/pulls/856 | 2023-02-22T10:09:03Z | 2023-10-30T14:07:32Z | 2023-10-30T14:07:32Z | 2023-10-30T14:22:16Z | 487 | mingrammer/diagrams | 52,678 |
Update sites.md | diff --git a/sites.md b/sites.md
index 612c18ab6..f546b6940 100644
--- a/sites.md
+++ b/sites.md
@@ -1,4 +1,4 @@
-## List Of Supported Sites (304 Sites In Total!)
+## List Of Supported Sites (305 Sites In Total!)
1. [2Dimensions](https://2Dimensions.com/)
2. [3dnews](http://forum.3dnews.ru/)
3. [4pda](https://4pda.r... | https://api.github.com/repos/sherlock-project/sherlock/pulls/742 | 2020-09-01T07:50:42Z | 2020-09-01T11:58:40Z | 2020-09-01T11:58:40Z | 2020-09-01T11:58:40Z | 117 | sherlock-project/sherlock | 36,313 | |
moved Neon from C++ to Python | diff --git a/README.md b/README.md
index 47fd2521..a7c83d59 100644
--- a/README.md
+++ b/README.md
@@ -127,7 +127,6 @@ For a list of free machine learning books available for download, go [here](http
* [Stan](http://mc-stan.org/) - A probabilistic programming language implementing full Bayesian statistical inference w... | https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/153 | 2015-06-04T00:33:15Z | 2015-06-04T01:06:23Z | 2015-06-04T01:06:23Z | 2015-06-04T01:06:26Z | 422 | josephmisiti/awesome-machine-learning | 52,079 | |
PostgreSQL integration test suite: really generate locales on Debian | diff --git a/test/integration/targets/setup_postgresql_db/tasks/main.yml b/test/integration/targets/setup_postgresql_db/tasks/main.yml
index 10f26c11aab29b..c811f1dd6c87b1 100644
--- a/test/integration/targets/setup_postgresql_db/tasks/main.yml
+++ b/test/integration/targets/setup_postgresql_db/tasks/main.yml
@@ -95,12... | ##### SUMMARY
With Debian, PostgreSQL integration test suite doesn't correctly setup test environment: required locales aren't generated. `/usr/sbin/locale-gen` behaves differently on Debian and Ubuntu. This pull-request propose to use the `locale-gen` ansible module instead of the `locale-gen` command.
##### ISSUE... | https://api.github.com/repos/ansible/ansible/pulls/23613 | 2017-04-14T15:48:01Z | 2017-04-28T01:10:21Z | 2017-04-28T01:10:21Z | 2019-04-26T21:09:03Z | 229 | ansible/ansible | 49,224 |
[extractor/mx3] Add extractor | diff --git a/yt_dlp/extractor/_extractors.py b/yt_dlp/extractor/_extractors.py
index 62103f13c14..c0f6b32b697 100644
--- a/yt_dlp/extractor/_extractors.py
+++ b/yt_dlp/extractor/_extractors.py
@@ -1124,6 +1124,11 @@
MusicdexArtistIE,
MusicdexPlaylistIE,
)
+from .mx3 import (
+ Mx3IE,
+ Mx3NeoIE,
+ M... | **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be un... | https://api.github.com/repos/yt-dlp/yt-dlp/pulls/8736 | 2023-12-09T17:30:22Z | 2024-01-21T02:45:38Z | 2024-01-21T02:45:38Z | 2024-01-21T02:45:38Z | 2,219 | yt-dlp/yt-dlp | 7,702 |
A third-party environment named RiverSwim | diff --git a/docs/environments.md b/docs/environments.md
index 7451b704ee1..30bf8c905b2 100644
--- a/docs/environments.md
+++ b/docs/environments.md
@@ -336,6 +336,12 @@ An environment for automated rule-based deductive program verification in the Ke
Learn more here: https://github.com/Flunzmas/gym-autokey
+### gy... | RiverSwim which is a simple hard exploration environment has been added to the list of third-party environments. | https://api.github.com/repos/openai/gym/pulls/2086 | 2020-11-04T12:38:45Z | 2021-07-26T19:51:08Z | 2021-07-26T19:51:08Z | 2021-07-26T19:51:08Z | 168 | openai/gym | 5,883 |
Properly fix dagrun update state endpoint | diff --git a/airflow/api/common/experimental/mark_tasks.py b/airflow/api/common/experimental/mark_tasks.py
index 945a9cc4a3596..28e733dd96a89 100644
--- a/airflow/api/common/experimental/mark_tasks.py
+++ b/airflow/api/common/experimental/mark_tasks.py
@@ -131,7 +131,6 @@ def set_state(
if sub_dag_run_ids:
... | The dagrun update state endpoint was recently added but is not working
as expected. This PR fixes it to work exactly like the UI mark dagrun state API
Closes: https://github.com/apache/airflow/issues/18363
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apac... | https://api.github.com/repos/apache/airflow/pulls/18370 | 2021-09-20T09:45:49Z | 2021-09-22T20:16:35Z | 2021-09-22T20:16:35Z | 2021-09-22T20:16:39Z | 1,406 | apache/airflow | 14,569 |
bitFlyer: Add getboardstate endpoint | diff --git a/js/bitflyer.js b/js/bitflyer.js
index af40744acc8b..4310528ce504 100644
--- a/js/bitflyer.js
+++ b/js/bitflyer.js
@@ -40,6 +40,7 @@ module.exports = class bitflyer extends Exchange {
'getticker',
'getexecutions',
'gethealth',
+ ... | `getboardstate` allows to determine the current status of the board.
It is described only in Japanese documentation.
https://lightning.bitflyer.jp/docs?lang=ja#%E6%9D%BF%E3%81%AE%E7%8A%B6%E6%85%8B
It can be used in the playground.
https://lightning.bitflyer.jp/docs/playground?lang=en
| https://api.github.com/repos/ccxt/ccxt/pulls/2443 | 2018-04-03T08:33:08Z | 2018-04-03T08:41:47Z | 2018-04-03T08:41:47Z | 2018-04-03T08:41:47Z | 103 | ccxt/ccxt | 13,847 |
`ChatPromptTemplate` is not an `ABC`, it's instantiated directly. | diff --git a/libs/langchain/langchain/prompts/chat.py b/libs/langchain/langchain/prompts/chat.py
index b6cd9e0c036109..3c34b9fd974595 100644
--- a/libs/langchain/langchain/prompts/chat.py
+++ b/libs/langchain/langchain/prompts/chat.py
@@ -337,7 +337,7 @@ def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
]... | Its own `__add__` method constructs `ChatPromptTemplate` objects directly, it cannot be abstract.
Found while debugging something else with @nfcampos. | https://api.github.com/repos/langchain-ai/langchain/pulls/9468 | 2023-08-18T18:32:33Z | 2023-08-18T18:37:10Z | 2023-08-18T18:37:10Z | 2023-08-18T18:37:11Z | 143 | langchain-ai/langchain | 43,656 |
Allow preparing of Requests from Session settings without sending. | diff --git a/requests/models.py b/requests/models.py
index 2439153371..f2d8e5fd3a 100644
--- a/requests/models.py
+++ b/requests/models.py
@@ -217,19 +217,17 @@ def __repr__(self):
def prepare(self):
"""Constructs a :class:`PreparedRequest <PreparedRequest>` for transmission and returns it."""
p ... | Attempt to address #1445. All tests pass.
Note that I think it could likely make sense to change `Session.update_request` to be an internal method, since `Session.prepare_request` is really the only public use I can think of having use in practice.
| https://api.github.com/repos/psf/requests/pulls/1507 | 2013-07-31T04:51:20Z | 2013-08-01T01:21:28Z | 2013-08-01T01:21:28Z | 2021-09-09T00:01:13Z | 1,837 | psf/requests | 32,269 |
feat: generate_repo return project repo | diff --git a/metagpt/startup.py b/metagpt/startup.py
index 000b3c5d4..4a077cab7 100644
--- a/metagpt/startup.py
+++ b/metagpt/startup.py
@@ -1,5 +1,6 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
+
import asyncio
import shutil
from pathlib import Path
@@ -9,6 +10,7 @@
from metagpt.config2 import config
from m... | **Features**
- `generate_repo` returns `ProjectRepo` type. | https://api.github.com/repos/geekan/MetaGPT/pulls/803 | 2024-01-29T02:21:26Z | 2024-01-30T02:05:27Z | 2024-01-30T02:05:27Z | 2024-03-19T03:43:47Z | 283 | geekan/MetaGPT | 16,730 |
sillychange:) | diff --git a/PDF/images.py b/PDF/images.py
index 5566344df0..de31ab8c31 100644
--- a/PDF/images.py
+++ b/PDF/images.py
@@ -8,7 +8,7 @@
# Example to Append all the images inside a folder to pdf
pdf = FPDF()
-# Size of a A4 Page in mm Where P is for Potrail and L is for Landscape
+# Size of a A4 Page in mm Where P is... | https://api.github.com/repos/geekcomputers/Python/pulls/849 | 2020-09-30T21:00:52Z | 2020-10-02T17:59:47Z | 2020-10-02T17:59:47Z | 2020-10-02T17:59:47Z | 178 | geekcomputers/Python | 31,159 | |
don't iDisplay if logging | diff --git a/letsencrypt-apache/letsencrypt_apache/configurator.py b/letsencrypt-apache/letsencrypt_apache/configurator.py
index ff12055ac32..2a9fb025043 100644
--- a/letsencrypt-apache/letsencrypt_apache/configurator.py
+++ b/letsencrypt-apache/letsencrypt_apache/configurator.py
@@ -1302,6 +1302,7 @@ def restart(self)... | add a flag variable to view_config_changes which returns the changes as a string if we're logging it.
I'm unsure how to test since the comments left in https://github.com/letsencrypt/letsencrypt/pull/2009 don't specify where this issue was arising
| https://api.github.com/repos/certbot/certbot/pulls/2116 | 2016-01-08T10:46:53Z | 2016-01-08T19:02:15Z | 2016-01-08T19:02:15Z | 2016-05-06T19:22:01Z | 589 | certbot/certbot | 2,627 |
wazirx - fetchOHLCV | diff --git a/js/wazirx.js b/js/wazirx.js
index aa771f68d915..8e2f96db9f35 100644
--- a/js/wazirx.js
+++ b/js/wazirx.js
@@ -42,7 +42,7 @@ module.exports = class wazirx extends Exchange {
'fetchMarkets': true,
'fetchMarkOHLCV': false,
'fetchMyTrades': false,
- ... | https://api.github.com/repos/ccxt/ccxt/pulls/15778 | 2022-11-21T16:33:01Z | 2022-11-21T20:51:44Z | 2022-11-21T20:51:44Z | 2022-11-21T20:51:56Z | 1,093 | ccxt/ccxt | 13,462 | |
[NFC] polish colossalai/builder/builder.py code style | diff --git a/colossalai/builder/builder.py b/colossalai/builder/builder.py
index f4ccebfc7a2f..812ab78d7ab6 100644
--- a/colossalai/builder/builder.py
+++ b/colossalai/builder/builder.py
@@ -7,6 +7,7 @@
from colossalai.registry import *
+
def build_from_config(module, config: dict):
"""Returns an object of :... | https://api.github.com/repos/hpcaitech/ColossalAI/pulls/662 | 2022-04-03T03:59:03Z | 2022-04-03T03:59:57Z | 2022-04-03T03:59:57Z | 2022-04-03T03:59:57Z | 230 | hpcaitech/ColossalAI | 11,185 | |
Rename ignore_hash to allow_output_mutation | diff --git a/lib/streamlit/caching.py b/lib/streamlit/caching.py
index 2c75c996ff11..23bf7147408f 100644
--- a/lib/streamlit/caching.py
+++ b/lib/streamlit/caching.py
@@ -235,7 +235,7 @@ def _build_caching_func_error_message(persisted, func, caller_frame):
{copy_code}
```
- 2. Add `ignore_has... | **Issue:**
#412
- Rename `ignore_hash` to `allow_output_mutation`
- Help users migrate to the new name by throwing an error if `ignore_hash` is used
- Only added to `@st.cache` and not `class Cache` since only the decorator is exposed to the user right now | https://api.github.com/repos/streamlit/streamlit/pulls/422 | 2019-10-15T19:54:25Z | 2019-10-17T16:29:51Z | 2019-10-17T16:29:50Z | 2019-10-17T16:29:58Z | 2,850 | streamlit/streamlit | 21,956 |
Fix #13796 | diff --git a/modules/prompt_parser.py b/modules/prompt_parser.py
index 334efeef317..86b7acb50a8 100644
--- a/modules/prompt_parser.py
+++ b/modules/prompt_parser.py
@@ -5,7 +5,7 @@
from typing import List
import lark
-# a prompt like this: "fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tr... | Fix comment error that makes understanding scheduling more confusing.
## Description
Fixes a confusing comment.
## Screenshots/videos:
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-revie... | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/13797 | 2023-10-29T22:37:50Z | 2023-11-03T17:11:55Z | 2023-11-03T17:11:55Z | 2023-11-03T17:11:55Z | 251 | AUTOMATIC1111/stable-diffusion-webui | 40,488 |
Update PyPI links | diff --git a/certbot/docs/packaging.rst b/certbot/docs/packaging.rst
index 75349ad14e9..89e22bfc1d9 100644
--- a/certbot/docs/packaging.rst
+++ b/certbot/docs/packaging.rst
@@ -7,21 +7,21 @@ Releases
We release packages and upload them to PyPI (wheels and source tarballs).
-- https://pypi.python.org/pypi/acme
-- h... | Switch from the legacy pypi.python.org/pypi/ to the canonical pypi.org/project/; the former redirects to the latter. | https://api.github.com/repos/certbot/certbot/pulls/9733 | 2023-07-14T16:26:52Z | 2023-07-15T22:58:00Z | 2023-07-15T22:58:00Z | 2023-07-15T23:10:15Z | 587 | certbot/certbot | 3,610 |
Update C3 module | diff --git a/models/common.py b/models/common.py
index fcd87cbcb81..c3b51a46f14 100644
--- a/models/common.py
+++ b/models/common.py
@@ -29,7 +29,7 @@ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, k
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autop... | This PR updates the C3 module and moves it from experimental.py to common.py.
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Refactoring of the YOLOv5 architecture by modifying the activation function and restructuring the C3 module.
### 📊 K... | https://api.github.com/repos/ultralytics/yolov5/pulls/1705 | 2020-12-16T06:09:45Z | 2020-12-16T06:13:08Z | 2020-12-16T06:13:08Z | 2024-01-19T20:06:59Z | 1,223 | ultralytics/yolov5 | 24,873 |
a leftover for.15 compatibility | diff --git a/scrapy/core/engine.py b/scrapy/core/engine.py
index bd1a9f04b2e..4ef1d0fc639 100644
--- a/scrapy/core/engine.py
+++ b/scrapy/core/engine.py
@@ -263,10 +263,8 @@ def close_spider(self, spider, reason='cancelled'):
dfd.addBoth(lambda _: slot.scheduler.close(reason))
dfd.addErrback(log.err, ... | https://api.github.com/repos/scrapy/scrapy/pulls/925 | 2014-10-22T19:03:41Z | 2014-10-22T20:23:19Z | 2014-10-22T20:23:19Z | 2014-10-22T20:23:19Z | 260 | scrapy/scrapy | 34,577 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.