
repo stringlengths 6 65 | file_url stringlengths 81 311 | file_path stringlengths 6 227 | content stringlengths 0 32.8k | language stringclasses 1
value | license stringclasses 7
values | commit_sha stringlengths 40 40 | retrieved_at stringdate 2026-01-04 15:31:58 2026-01-04 20:25:31 | truncated bool 2
classes |
|---|---|---|---|---|---|---|---|---|
gitui-org/gitui | https://github.com/gitui-org/gitui/blob/d68f366b1b7106223a0b5ad2481a782a7bd68883/filetreelist/src/treeitems_iter.rs | filetreelist/src/treeitems_iter.rs | use crate::{filetreeitems::FileTreeItems, item::FileTreeItem};
pub struct TreeItemsIterator<'a> {
tree: &'a FileTreeItems,
index: usize,
increments: Option<usize>,
max_amount: usize,
}
impl<'a> TreeItemsIterator<'a> {
pub const fn new(
tree: &'a FileTreeItems,
start: usize,
max_amount: usize,
) -> Self {
... | rust | MIT | d68f366b1b7106223a0b5ad2481a782a7bd68883 | 2026-01-04T15:40:16.730844Z | false |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/src/lib.rs | src/lib.rs | pub(crate) mod colors;
pub(crate) mod input;
pub use colors::*;
pub use input::*;
use std::io::{self, BufReader, Read, Write};
use clap::ValueEnum;
pub enum Base {
Binary,
Octal,
Decimal,
Hexadecimal,
}
#[derive(Copy, Clone)]
pub enum ByteCategory {
Null,
AsciiPrintable,
AsciiWhitespace... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | true |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/src/tests.rs | src/tests.rs | use super::*;
#[test]
fn unit_multipliers() {
use Unit::*;
assert_eq!(Kilobyte.get_multiplier(), 1000 * Byte.get_multiplier());
assert_eq!(Megabyte.get_multiplier(), 1000 * Kilobyte.get_multiplier());
assert_eq!(Gigabyte.get_multiplier(), 1000 * Megabyte.get_multiplier());
assert_eq!(Terabyte.get_m... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | false |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/src/main.rs | src/main.rs | use std::fs::File;
use std::io::{self, prelude::*, BufWriter, SeekFrom};
use std::num::{NonZeroI64, NonZeroU64};
use std::path::PathBuf;
use clap::builder::ArgPredicate;
use clap::{ArgAction, CommandFactory, Parser, ValueEnum};
use clap_complete::aot::{generate, Shell};
use anyhow::{anyhow, bail, Context, Result};
u... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | false |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/src/colors.rs | src/colors.rs | use owo_colors::{colors, AnsiColors, Color, DynColors, OwoColorize};
use std::str::FromStr;
use std::sync::LazyLock;
pub static COLOR_NULL: LazyLock<String> =
LazyLock::new(|| init_color("NULL", AnsiColors::BrightBlack));
pub static COLOR_OFFSET: LazyLock<String> =
LazyLock::new(|| init_color("OFFSET", AnsiCol... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | false |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/src/input.rs | src/input.rs | use std::fs;
use std::io::{self, copy, sink, Read, Seek, SeekFrom};
pub enum Input<'a> {
File(fs::File),
Stdin(io::StdinLock<'a>),
}
impl Read for Input<'_> {
fn read(&mut self, buf: &mut [u8]) -> io::Result<usize> {
match *self {
Input::File(ref mut file) => file.read(buf),
... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | false |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/tests/integration_tests.rs | tests/integration_tests.rs | use assert_cmd::Command;
fn hexyl() -> Command {
let mut cmd = Command::cargo_bin("hexyl").unwrap();
cmd.current_dir("tests/examples");
cmd
}
trait PrettyAssert<S>
where
S: AsRef<str>,
{
fn pretty_stdout(self, other: S);
}
// https://github.com/assert-rs/assert_cmd/issues/121#issuecomment-84993737... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | true |
sharkdp/hexyl | https://github.com/sharkdp/hexyl/blob/2e2643782d6ced9b5ac75596169a79127d8e535a/examples/simple.rs | examples/simple.rs | use std::io;
use hexyl::{BorderStyle, PrinterBuilder};
fn main() {
let input = [
0x89, 0x50, 0x4e, 0x47, 0x0d, 0x0a, 0x1a, 0x0a, 0x00, 0x00, 0x00, 0x0d, 0x49, 0x48, 0x44,
0x52, 0x00, 0x00, 0x00, 0x80, 0x00, 0x00, 0x00, 0x44, 0x08, 0x02, 0x00, 0x00, 0x00,
];
let stdout = io::stdout();
... | rust | Apache-2.0 | 2e2643782d6ced9b5ac75596169a79127d8e535a | 2026-01-04T15:43:36.733781Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/diagnostics.rs | src/diagnostics.rs | use TSPL::ParseError;
use crate::fun::{display::DisplayFn, Name, Source};
use std::{
collections::BTreeMap,
fmt::{Display, Formatter},
ops::Range,
};
pub const ERR_INDENT_SIZE: usize = 2;
#[derive(Debug, Clone, Default)]
pub struct Diagnostics {
pub diagnostics: BTreeMap<DiagnosticOrigin, Vec<Diagnostic>>,
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/lib.rs | src/lib.rs | use crate::{
fun::{book_to_hvm, net_to_term::net_to_term, term_to_net::Labels, Book, Ctx, Term},
hvm::{
add_recursive_priority::add_recursive_priority,
check_net_size::{check_net_sizes, MAX_NET_SIZE_CUDA},
eta_reduce::eta_reduce_hvm_net,
hvm_book_show_pretty,
inline::inline_hvm_book,
mutual_... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/utils.rs | src/utils.rs | /// A macro for creating iterators that can have statically known
/// different types. Useful for iterating over tree children, where
/// each tree node variant yields a different iterator type.
#[macro_export]
macro_rules! multi_iterator {
($Iter:ident { $($Variant:ident),* $(,)? }) => {
#[derive(Debug, Clone)]
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/main.rs | src/main.rs | use bend::{
check_book, compile_book, desugar_book,
diagnostics::{Diagnostics, DiagnosticsConfig, Severity},
fun::{Book, Name},
hvm::hvm_book_show_pretty,
imports::DefaultLoader,
load_file_to_book, run_book, AdtEncoding, CompileOpts, CompilerTarget, OptLevel, RunOpts,
};
use clap::{Args, CommandFactory, Par... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imp/order_kwargs.rs | src/imp/order_kwargs.rs | use crate::{
fun::{parser::ParseBook, Name},
imp::{Definition, Expr, Stmt},
};
use indexmap::IndexMap;
impl Definition {
/// Traverses the program's definitions and adjusts the order of keyword arguments
/// in call/constructor expressions to match the order specified in the function or constructor definition.... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imp/parser.rs | src/imp/parser.rs | use crate::{
fun::{
parser::{is_num_char, make_ctr_type, make_fn_type, Indent, ParseResult, ParserCommons},
Adt, AdtCtr, CtrField, HvmDefinition, Name, Num, Op, Source, SourceKind, Type, STRINGS,
},
imp::{AssignPattern, Definition, Expr, InPlaceOp, MatchArm, Stmt},
maybe_grow,
};
use TSPL::Parser;
pub ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | true |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imp/gen_map_get.rs | src/imp/gen_map_get.rs | use crate::fun::Name;
use super::{AssignPattern, Definition, Expr, Stmt};
impl Definition {
/// Generates a map from `Stmt` to `Substitutions` for each definition in the program.
/// Iterates over all definitions in the program and applies `gen_map_get` to their bodies.
/// It replaces `Expr::MapGet` expression... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imp/to_fun.rs | src/imp/to_fun.rs | use super::{AssignPattern, Definition, Expr, InPlaceOp, Stmt};
use crate::{
diagnostics::Diagnostics,
fun::{
self,
builtins::{LCONS, LNIL},
parser::ParseBook,
Book, Name,
},
};
impl ParseBook {
// TODO: Change all functions to return diagnostics
pub fn to_fun(mut self) -> Result<Book, Diagnos... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imp/mod.rs | src/imp/mod.rs | pub mod gen_map_get;
mod order_kwargs;
pub mod parser;
pub mod to_fun;
use crate::fun::{Name, Num, Op, Source, Type};
use interner::global::GlobalString;
#[derive(Clone, Debug)]
pub enum Expr {
// "*"
Era,
// [a-zA-Z_]+
Var { nam: Name },
// "$" [a-zA-Z_]+
Chn { nam: Name },
// [0-9_]+
Num { val: Num ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/prune.rs | src/hvm/prune.rs | use super::{net_trees, tree_children};
use crate::maybe_grow;
use hvm::ast::{Book, Tree};
use std::collections::HashSet;
pub fn prune_hvm_book(book: &mut Book, entrypoints: &[String]) {
let mut state = PruneState { book, unvisited: book.defs.keys().map(|x| x.to_owned()).collect() };
for name in entrypoints {
s... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
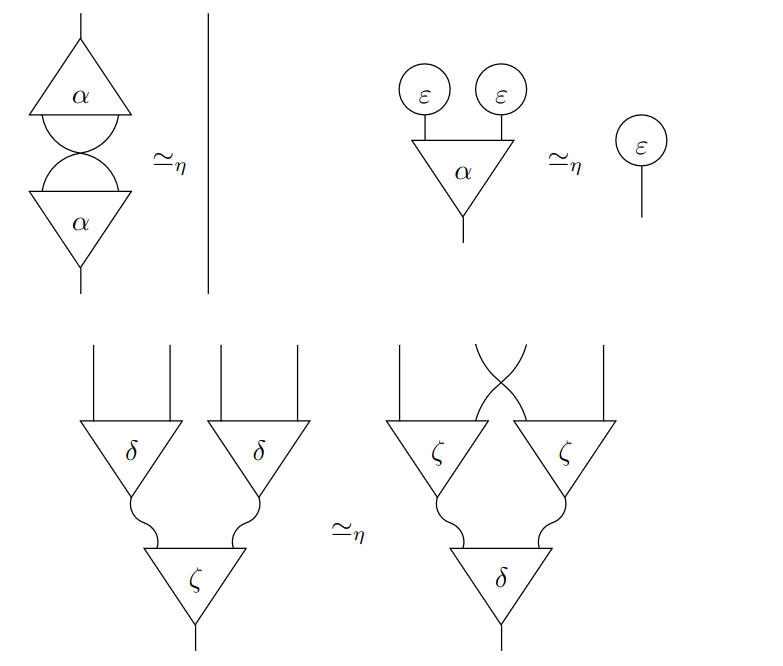
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/eta_reduce.rs | src/hvm/eta_reduce.rs | //! Carries out simple eta-reduction, to reduce the amount of rewrites at
//! runtime.
//!
//! ### Eta-equivalence
//!
//! In interaction combinators, there are some nets that are equivalent and
//! have no observable difference
//!
//! 
//!
//! This m... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/add_recursive_priority.rs | src/hvm/add_recursive_priority.rs | use super::tree_children;
use crate::maybe_grow;
use hvm::ast::{Book, Net, Tree};
use std::collections::{HashMap, HashSet};
pub fn add_recursive_priority(book: &mut Book) {
// Direct dependencies
let deps = book.defs.iter().map(|(nam, net)| (nam.clone(), dependencies(net))).collect::<HashMap<_, _>>();
// Recursi... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/inline.rs | src/hvm/inline.rs | use super::{net_trees_mut, tree_children, tree_children_mut};
use crate::maybe_grow;
use core::ops::BitOr;
use hvm::ast::{Book, Net, Tree};
use std::collections::{HashMap, HashSet};
pub fn inline_hvm_book(book: &mut Book) -> Result<HashSet<String>, String> {
let mut state = InlineState::default();
state.populate_i... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/mutual_recursion.rs | src/hvm/mutual_recursion.rs | use super::tree_children;
use crate::{
diagnostics::{Diagnostics, WarningType, ERR_INDENT_SIZE},
fun::transform::definition_merge::MERGE_SEPARATOR,
maybe_grow,
};
use hvm::ast::{Book, Tree};
use indexmap::{IndexMap, IndexSet};
use std::fmt::Debug;
type Ref = String;
type Stack<T> = Vec<T>;
type RefSet = IndexSet... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/mod.rs | src/hvm/mod.rs | use crate::multi_iterator;
use hvm::ast::{Net, Tree};
pub mod add_recursive_priority;
pub mod check_net_size;
pub mod eta_reduce;
pub mod inline;
pub mod mutual_recursion;
pub mod prune;
pub fn tree_children(tree: &Tree) -> impl DoubleEndedIterator<Item = &Tree> + Clone {
multi_iterator!(ChildrenIter { Zero, Two })... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/hvm/check_net_size.rs | src/hvm/check_net_size.rs | use super::tree_children;
use crate::{diagnostics::Diagnostics, fun::Name, CompilerTarget};
use hvm::ast::{Book, Net, Tree};
pub const MAX_NET_SIZE_C: usize = 4095;
pub const MAX_NET_SIZE_CUDA: usize = 64;
pub fn check_net_sizes(
book: &Book,
diagnostics: &mut Diagnostics,
target: &CompilerTarget,
) -> Result<(... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/net/hvm_to_net.rs | src/net/hvm_to_net.rs | use super::{INet, INode, INodes, NodeId, NodeKind::*, Port, SlotId, ROOT};
use crate::{
fun::Name,
net::{CtrKind, NodeKind},
};
use hvm::ast::{Net, Tree};
pub fn hvm_to_net(net: &Net) -> INet {
let inodes = hvm_to_inodes(net);
inodes_to_inet(&inodes)
}
fn hvm_to_inodes(net: &Net) -> INodes {
let mut inodes ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/net/mod.rs | src/net/mod.rs | pub mod hvm_to_net;
use crate::fun::Name;
pub type BendLab = u16;
use NodeKind::*;
#[derive(Debug, Clone)]
/// Net representation used only as an intermediate for converting to hvm-core format
pub struct INet {
nodes: Vec<Node>,
}
#[derive(Debug, Clone)]
pub struct Node {
pub main: Port,
pub aux1: Port,
pub ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/parser.rs | src/fun/parser.rs | use crate::{
fun::{
display::DisplayFn, Adt, AdtCtr, Adts, Constructors, CtrField, FanKind, HvmDefinition, HvmDefinitions,
MatchRule, Name, Num, Op, Pattern, Rule, Source, SourceKind, Tag, Term, Type, STRINGS,
},
imp::parser::ImpParser,
imports::{Import, ImportCtx, ImportType},
maybe_grow,
};
use high... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | true |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/term_to_net.rs | src/fun/term_to_net.rs | use crate::{
diagnostics::Diagnostics,
fun::{num_to_name, Book, FanKind, Name, Op, Pattern, Term},
hvm::{net_trees, tree_children},
maybe_grow,
net::CtrKind::{self, *},
};
use hvm::ast::{Net, Tree};
use loaned::LoanedMut;
use std::{
collections::{hash_map::Entry, HashMap},
ops::{Index, IndexMut},
};
#[de... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/net_to_term.rs | src/fun/net_to_term.rs | use crate::{
diagnostics::{DiagnosticOrigin, Diagnostics, Severity},
fun::{term_to_net::Labels, Book, FanKind, Name, Num, Op, Pattern, Tag, Term},
maybe_grow,
net::{BendLab, CtrKind, INet, NodeId, NodeKind, Port, SlotId, ROOT},
};
use hvm::hvm::Numb;
use std::collections::{BTreeSet, HashMap, HashSet};
/// Conv... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/display.rs | src/fun/display.rs | use super::{Book, Definition, FanKind, Name, Num, Op, Pattern, Rule, Tag, Term, Type};
use crate::maybe_grow;
use std::{fmt, ops::Deref, sync::atomic::AtomicU64};
/* Some aux structures for things that are not so simple to display */
pub struct DisplayFn<F: Fn(&mut fmt::Formatter) -> fmt::Result>(pub F);
impl<F: Fn(... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/builtins.rs | src/fun/builtins.rs | use super::{
parser::{FunParser, ParseBook},
Book, Name, Num, Pattern, Term,
};
use crate::maybe_grow;
const BUILTINS: &str = include_str!(concat!(env!("CARGO_MANIFEST_DIR"), "/src/fun/builtins.bend"));
pub const LIST: &str = "List";
pub const LCONS: &str = "List/Cons";
pub const LNIL: &str = "List/Nil";
pub cons... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/mod.rs | src/fun/mod.rs | use crate::{
diagnostics::{Diagnostics, DiagnosticsConfig, TextSpan},
imports::Import,
maybe_grow, multi_iterator, ENTRY_POINT,
};
use indexmap::{IndexMap, IndexSet};
use interner::global::{GlobalPool, GlobalString};
use itertools::Itertools;
use std::{
borrow::Cow,
hash::Hash,
ops::{Deref, Range},
};
pub ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | true |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/load_book.rs | src/fun/load_book.rs | use super::{
parser::{FunParser, ParseBook},
Book, Name, Source, SourceKind,
};
use crate::{
diagnostics::{Diagnostics, DiagnosticsConfig, TextSpan},
imports::PackageLoader,
};
use std::path::Path;
// TODO: Refactor so that we don't mix the two syntaxes here.
/// Reads a file and parses to a definition book.
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/shared_names.rs | src/fun/check/shared_names.rs | use crate::fun::{Ctx, Name};
use indexmap::IndexMap;
use std::fmt::Display;
#[derive(Debug, Clone)]
pub struct RepeatedTopLevelNameErr {
kind_fst: NameKind,
kind_snd: NameKind,
name: Name,
}
impl Ctx<'_> {
/// Checks if there are any repeated top level names. Constructors
/// and functions can't share names... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/unbound_refs.rs | src/fun/check/unbound_refs.rs | use crate::{
diagnostics::Diagnostics,
fun::{Book, Ctx, Name, Term},
maybe_grow,
};
use std::collections::HashSet;
impl Ctx<'_> {
pub fn check_unbound_refs(&mut self) -> Result<(), Diagnostics> {
for def in self.book.defs.values() {
let mut unbounds = HashSet::new();
for rule in def.rules.iter(... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/type_check.rs | src/fun/check/type_check.rs | //! Optional Hindley-Milner-like type system.
//!
//! Based on https://github.com/developedby/algorithm-w-rs
//! and https://github.com/mgrabmueller/AlgorithmW.
use crate::{
diagnostics::Diagnostics,
fun::{num_to_name, Adt, Book, Ctx, FanKind, MatchRule, Name, Num, Op, Pattern, Tag, Term, Type},
maybe_grow,
};
us... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/check_untyped.rs | src/fun/check/check_untyped.rs | use crate::{
diagnostics::Diagnostics,
fun::{Ctx, FanKind, Pattern, Tag, Term},
maybe_grow,
};
impl Ctx<'_> {
/// Checks that terms that cannot be typed are only used inside untyped functions.
pub fn check_untyped_terms(&mut self) -> Result<(), Diagnostics> {
for def in self.book.defs.values() {
if... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/set_entrypoint.rs | src/fun/check/set_entrypoint.rs | use crate::{
diagnostics::WarningType,
fun::{Book, Ctx, Definition, Name},
ENTRY_POINT, HVM1_ENTRY_POINT,
};
#[derive(Debug, Clone)]
pub enum EntryErr {
NotFound(Name),
Multiple(Vec<Name>),
MultipleRules,
}
impl Ctx<'_> {
pub fn set_entrypoint(&mut self) {
let mut entrypoint = None;
let (custom... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/mod.rs | src/fun/check/mod.rs | pub mod check_untyped;
pub mod set_entrypoint;
pub mod shared_names;
pub mod type_check;
pub mod unbound_refs;
pub mod unbound_vars;
| rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/check/unbound_vars.rs | src/fun/check/unbound_vars.rs | use crate::{
diagnostics::Diagnostics,
fun::{transform::desugar_bend, Ctx, Name, Pattern, Term},
maybe_grow,
};
use std::collections::HashMap;
#[derive(Debug, Clone)]
pub enum UnboundVarErr {
Local(Name),
Global { var: Name, declared: usize, used: usize },
}
impl Ctx<'_> {
/// Checks that there are no unb... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_open.rs | src/fun/transform/desugar_open.rs | use crate::{
diagnostics::Diagnostics,
fun::{Adts, Ctx, Term},
maybe_grow,
};
impl Ctx<'_> {
pub fn desugar_open(&mut self) -> Result<(), Diagnostics> {
for def in self.book.defs.values_mut() {
for rule in def.rules.iter_mut() {
if let Err(err) = rule.body.desugar_open(&self.book.adts) {
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/float_combinators.rs | src/fun/transform/float_combinators.rs | use crate::{
fun::{Book, Definition, Name, Pattern, Rule, Source, Term},
maybe_grow, multi_iterator,
};
use std::collections::{BTreeMap, HashSet};
pub const NAME_SEP: &str = "__C";
impl Book {
/// Extracts combinator terms into new definitions.
///
/// Precondition: Variables must have been sanitized.
///... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_use.rs | src/fun/transform/desugar_use.rs | use crate::{
fun::{Book, Term},
maybe_grow,
};
impl Book {
/// Inline copies of the declared bind in the `use` expression.
///
/// Example:
/// ```bend
/// use id = λx x
/// (id id id)
///
/// // Transforms to:
/// (λx x λx x λx x)
/// ```
pub fn desugar_use(&mut self) {
for def in self.d... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_with_blocks.rs | src/fun/transform/desugar_with_blocks.rs | use crate::{
diagnostics::Diagnostics,
fun::{Ctx, Name, Pattern, Term},
maybe_grow,
};
use std::collections::HashSet;
impl Ctx<'_> {
/// Converts `ask` terms inside `with` blocks into calls to a monadic bind operation.
pub fn desugar_with_blocks(&mut self) -> Result<(), Diagnostics> {
let def_names = sel... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/linearize_matches.rs | src/fun/transform/linearize_matches.rs | use crate::{
fun::{Book, Name, Pattern, Term},
maybe_grow,
};
use std::collections::{BTreeSet, HashMap, HashSet, VecDeque};
/* Linearize preceding binds */
impl Book {
/// Linearization of binds preceding match/switch terms, up to the
/// first bind used in either the scrutinee or the bind.
///
/// Exampl... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_bend.rs | src/fun/transform/desugar_bend.rs | use crate::{
diagnostics::Diagnostics,
fun::{Ctx, Definition, Name, Rule, Source, Term},
maybe_grow,
};
use indexmap::IndexMap;
pub const RECURSIVE_KW: &str = "fork";
const NEW_FN_SEP: &str = "__bend";
impl Ctx<'_> {
pub fn desugar_bend(&mut self) -> Result<(), Diagnostics> {
let mut new_defs = IndexMap::... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/fix_match_terms.rs | src/fun/transform/fix_match_terms.rs | use crate::{
diagnostics::{Diagnostics, WarningType, ERR_INDENT_SIZE},
fun::{Adts, Constructors, CtrField, Ctx, MatchRule, Name, Num, Term},
maybe_grow,
};
use std::collections::HashMap;
enum FixMatchErr {
AdtMismatch { expected: Name, found: Name, ctr: Name },
NonExhaustiveMatch { typ: Name, missing: Name }... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_match_defs.rs | src/fun/transform/desugar_match_defs.rs | use crate::{
diagnostics::{Diagnostics, WarningType},
fun::{builtins, Adts, Constructors, Ctx, Definition, FanKind, Name, Num, Pattern, Rule, Tag, Term},
maybe_grow,
};
use itertools::Itertools;
use std::collections::{BTreeSet, HashSet};
pub enum DesugarMatchDefErr {
AdtNotExhaustive { adt: Name, ctr: Name },
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/encode_match_terms.rs | src/fun/transform/encode_match_terms.rs | use crate::{
fun::{Book, MatchRule, Name, Pattern, Term},
maybe_grow, AdtEncoding,
};
impl Book {
/// Encodes pattern matching expressions in the book into their
/// core form. Must be run after [`Ctr::fix_match_terms`].
///
/// ADT matches are encoded based on `adt_encoding`.
///
/// Num matches are e... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/resolve_refs.rs | src/fun/transform/resolve_refs.rs | use crate::{
diagnostics::Diagnostics,
fun::{Ctx, Name, Pattern, Term},
maybe_grow,
};
use std::collections::{HashMap, HashSet};
#[derive(Debug, Clone)]
pub struct ReferencedMainErr;
impl Ctx<'_> {
/// Decides if names inside a term belong to a Var or to a Ref.
/// Converts `Term::Var(nam)` into `Term::Ref(... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/resugar_list.rs | src/fun/transform/resugar_list.rs | use crate::{
fun::{builtins, Pattern, Tag, Term},
maybe_grow, AdtEncoding,
};
impl Term {
/// Converts lambda-encoded lists ending with List/Nil to list literals.
pub fn resugar_lists(&mut self, adt_encoding: AdtEncoding) {
match adt_encoding {
AdtEncoding::Scott => self.resugar_lists_scott(),
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/linearize_vars.rs | src/fun/transform/linearize_vars.rs | use crate::{
fun::{Book, FanKind, Name, Pattern, Tag, Term},
maybe_grow, multi_iterator,
};
use std::collections::HashMap;
/// Erases variables that weren't used, dups the ones that were used more than once.
/// Substitutes lets into their variable use.
/// In details:
/// For all var declarations:
/// If they'r... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/expand_generated.rs | src/fun/transform/expand_generated.rs | use std::collections::{BTreeSet, HashMap, HashSet};
use crate::{
fun::{Book, Name, Term},
maybe_grow,
};
/// Dereferences any non recursive generated definitions in the term.
/// Used after readback.
impl Term {
pub fn expand_generated(&mut self, book: &Book, recursive_defs: &RecursiveDefs) {
maybe_grow(|| ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/resugar_string.rs | src/fun/transform/resugar_string.rs | use crate::{
fun::{builtins, Name, Num, Pattern, Tag, Term},
maybe_grow, AdtEncoding,
};
impl Term {
/// Converts lambda-encoded strings ending with String/nil to string literals.
pub fn resugar_strings(&mut self, adt_encoding: AdtEncoding) {
match adt_encoding {
AdtEncoding::Scott => self.try_resuga... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/definition_pruning.rs | src/fun/transform/definition_pruning.rs | use crate::{
diagnostics::WarningType,
fun::{Book, Ctx, Name, SourceKind, Term},
maybe_grow,
};
use hvm::ast::{Net, Tree};
use std::collections::{hash_map::Entry, HashMap};
#[derive(Clone, Copy, Debug, PartialEq)]
enum Used {
/// Definition is accessible from the main entry point, should never be pruned.
Mai... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/expand_main.rs | src/fun/transform/expand_main.rs | use crate::{
fun::{Book, Name, Pattern, Term},
maybe_grow,
};
use std::collections::HashMap;
impl Book {
/// Expands the main function so that it is not just a reference.
/// While technically correct, directly returning a reference is never what users want.
pub fn expand_main(&mut self) {
if self.entryp... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/encode_adts.rs | src/fun/transform/encode_adts.rs | use crate::{
fun::{Book, Definition, Name, Num, Pattern, Rule, Source, Term},
AdtEncoding,
};
impl Book {
/// Defines a function for each constructor in each ADT in the book.
pub fn encode_adts(&mut self, adt_encoding: AdtEncoding) {
let mut defs = vec![];
for (_, adt) in self.adts.iter() {
for ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/mod.rs | src/fun/transform/mod.rs | pub mod apply_args;
pub mod definition_merge;
pub mod definition_pruning;
pub mod desugar_bend;
pub mod desugar_fold;
pub mod desugar_match_defs;
pub mod desugar_open;
pub mod desugar_use;
pub mod desugar_with_blocks;
pub mod encode_adts;
pub mod encode_match_terms;
pub mod expand_generated;
pub mod expand_main;
pub mo... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/fix_match_defs.rs | src/fun/transform/fix_match_defs.rs | use crate::{
diagnostics::Diagnostics,
fun::{Adts, Constructors, Ctx, Pattern, Rule, Term},
};
impl Ctx<'_> {
/// Makes every pattern matching definition have correct a left-hand side.
///
/// Does not check exhaustiveness of rules and type mismatches. (Inter-ctr/type proprieties)
pub fn fix_match_defs(&mu... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/resolve_type_ctrs.rs | src/fun/transform/resolve_type_ctrs.rs | use crate::{
diagnostics::Diagnostics,
fun::{Adts, Ctx, Type},
maybe_grow,
};
impl Ctx<'_> {
/// Resolves type constructors in the book.
pub fn resolve_type_ctrs(&mut self) -> Result<(), Diagnostics> {
for def in self.book.defs.values_mut() {
let res = def.typ.resolve_type_ctrs(&self.book.adts);
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/definition_merge.rs | src/fun/transform/definition_merge.rs | use crate::{
fun::{Book, Definition, Name, Rule, Term},
maybe_grow,
};
use indexmap::{IndexMap, IndexSet};
use itertools::Itertools;
use std::collections::BTreeMap;
pub const MERGE_SEPARATOR: &str = "__M_";
impl Book {
/// Merges definitions that have the same structure into one definition.
/// Expects variab... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/lift_local_defs.rs | src/fun/transform/lift_local_defs.rs | use std::collections::BTreeSet;
use indexmap::IndexMap;
use crate::{
fun::{Book, Definition, Name, Pattern, Rule, Term},
maybe_grow,
};
impl Book {
pub fn lift_local_defs(&mut self) {
let mut defs = IndexMap::new();
for (name, def) in self.defs.iter_mut() {
let mut gen = 0;
for rule in def.... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/desugar_fold.rs | src/fun/transform/desugar_fold.rs | use std::collections::HashSet;
use crate::{
diagnostics::Diagnostics,
fun::{Adts, Constructors, Ctx, Definition, Name, Pattern, Rule, Source, Term},
maybe_grow,
};
impl Ctx<'_> {
/// Desugars `fold` expressions into recursive `match`es.
/// ```bend
/// foo xs =
/// ...
/// fold bind = init with x1... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/unique_names.rs | src/fun/transform/unique_names.rs | // Pass to give all variables in a definition unique names.
use crate::{
fun::{Book, Name, Term},
maybe_grow,
};
use std::collections::HashMap;
impl Book {
/// Makes all variables in each definition have a new unique name.
/// Skips unbound variables.
/// Precondition: Definition references have been resolv... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/fun/transform/apply_args.rs | src/fun/transform/apply_args.rs | use crate::{
diagnostics::Diagnostics,
fun::{Ctx, Pattern, Rule, Term},
};
impl Ctx<'_> {
/// Applies the arguments to the program being run by applying them to the main function.
///
/// Example:
/// ```hvm
/// main x1 x2 x3 = (MainBody x1 x2 x3)
/// ```
/// Calling with `bend run <file> arg1 arg2 a... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imports/packages.rs | src/imports/packages.rs | use super::{loader::PackageLoader, normalize_path, BoundSource, ImportCtx, ImportType, ImportsMap};
use crate::{
diagnostics::Diagnostics,
fun::{load_book::do_parse_book, parser::ParseBook, Name},
};
use indexmap::{IndexMap, IndexSet};
use std::{cell::RefCell, collections::VecDeque, path::PathBuf};
#[derive(Defaul... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imports/mod.rs | src/imports/mod.rs | use crate::{
diagnostics::{Diagnostics, WarningType},
fun::Name,
};
use indexmap::{IndexMap, IndexSet};
use itertools::Itertools;
use std::fmt::Display;
pub mod book;
pub mod loader;
pub mod packages;
pub use loader::*;
pub type BindMap = IndexMap<Name, Name>;
#[derive(Debug, Clone, Default)]
pub struct ImportC... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imports/loader.rs | src/imports/loader.rs | use super::{BoundSource, Import, ImportType};
use crate::fun::Name;
use indexmap::IndexMap;
use std::{
collections::HashSet,
path::{Component, Path, PathBuf},
};
pub type Sources = IndexMap<Name, String>;
/// Trait to load packages from various sources.
pub trait PackageLoader {
/// Load a package specified by ... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/src/imports/book.rs | src/imports/book.rs | use super::{BindMap, ImportsMap, PackageLoader};
use crate::{
diagnostics::{Diagnostics, DiagnosticsConfig},
fun::{
parser::ParseBook, Adt, AdtCtr, Book, Definition, HvmDefinition, Name, Pattern, Source, SourceKind, Term,
},
imp::{self, Expr, MatchArm, Stmt},
imports::packages::Packages,
maybe_grow,
};
... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
HigherOrderCO/Bend | https://github.com/HigherOrderCO/Bend/blob/d184863f03e796d1d657958a51dd6dd331ade92d/tests/golden_tests.rs | tests/golden_tests.rs | //! This module runs snapshot tests for compiling and running Bend programs.
//!
//! The result of each test is saved as a snapshot and used as golden output
//! for future tests. This allows us to test regressions in compilation and
//! have a history of how certain programs compiled and ran.
//!
//! These tests use `... | rust | Apache-2.0 | d184863f03e796d1d657958a51dd6dd331ade92d | 2026-01-04T15:41:39.511038Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/config.rs | compute_tools/src/config.rs | use anyhow::Result;
use std::fmt::Write as FmtWrite;
use std::fs::{File, OpenOptions};
use std::io;
use std::io::Write;
use std::io::prelude::*;
use std::path::Path;
use compute_api::responses::TlsConfig;
use compute_api::spec::{
ComputeAudit, ComputeMode, ComputeSpec, DatabricksSettings, GenericOption,
};
use cr... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/swap.rs | compute_tools/src/swap.rs | use std::path::Path;
use anyhow::{Context, anyhow};
use tracing::{instrument, warn};
pub const RESIZE_SWAP_BIN: &str = "/neonvm/bin/resize-swap";
#[instrument]
pub fn resize_swap(size_bytes: u64) -> anyhow::Result<()> {
// run `/neonvm/bin/resize-swap --once {size_bytes}`
//
// Passing '--once' causes re... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/tls.rs | compute_tools/src/tls.rs | use std::{io::Write, os::unix::fs::OpenOptionsExt, path::Path, time::Duration};
use anyhow::{Context, Result, bail};
use compute_api::responses::TlsConfig;
use ring::digest;
use x509_cert::Certificate;
#[derive(Clone, Copy)]
pub struct CertDigest(digest::Digest);
pub async fn watch_cert_for_changes(cert_path: String... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/catalog.rs | compute_tools/src/catalog.rs | use std::path::Path;
use std::process::Stdio;
use std::result::Result;
use std::sync::Arc;
use compute_api::responses::CatalogObjects;
use futures::Stream;
use postgres::NoTls;
use tokio::io::{AsyncBufReadExt, BufReader};
use tokio::process::Command;
use tokio::spawn;
use tokio_stream::{self as stream, StreamExt};
use... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/extension_server.rs | compute_tools/src/extension_server.rs | // Download extension files from the extension store
// and put them in the right place in the postgres directory (share / lib)
/*
The layout of the S3 bucket is as follows:
5615610098 // this is an extension build number
├── v14
│ ├── extensions
│ │ ├── anon.tar.zst
│ │ └── embedding.tar.zst
│ └── ext_inde... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/lib.rs | compute_tools/src/lib.rs | //! Various tools and helpers to handle cluster / compute node (Postgres)
//! configuration.
#![deny(unsafe_code)]
#![deny(clippy::undocumented_unsafe_blocks)]
pub mod checker;
pub mod communicator_socket_client;
pub mod config;
pub mod configurator;
pub mod http;
#[macro_use]
pub mod logger;
pub mod catalog;
pub mod ... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/logger.rs | compute_tools/src/logger.rs | use std::collections::HashMap;
use std::sync::{LazyLock, RwLock};
use tracing::Subscriber;
use tracing::info;
use tracing_appender;
use tracing_subscriber::prelude::*;
use tracing_subscriber::{fmt, layer::SubscriberExt, registry::LookupSpan};
/// Initialize logging to stderr, and OpenTelemetry tracing and exporter.
//... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/params.rs | compute_tools/src/params.rs | pub const DEFAULT_LOG_LEVEL: &str = "info";
// From Postgres docs:
// To ease transition from the md5 method to the newer SCRAM method, if md5 is specified
// as a method in pg_hba.conf but the user's password on the server is encrypted for SCRAM
// (see below), then SCRAM-based authentication will automatically ... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/spec_apply.rs | compute_tools/src/spec_apply.rs | use std::collections::{HashMap, HashSet};
use std::fmt::{Debug, Formatter};
use std::future::Future;
use std::iter::{empty, once};
use std::sync::Arc;
use anyhow::{Context, Result};
use compute_api::responses::ComputeStatus;
use compute_api::spec::{ComputeAudit, ComputeSpec, Database, PgIdent, Role};
use futures::futu... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | true |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/pg_isready.rs | compute_tools/src/pg_isready.rs | use anyhow::{Context, anyhow};
// Run `/usr/local/bin/pg_isready -p {port}`
// Check the connectivity of PG
// Success means PG is listening on the port and accepting connections
// Note that PG does not need to authenticate the connection, nor reserve a connection quota for it.
// See https://www.postgresql.org/docs/... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/pgbouncer.rs | compute_tools/src/pgbouncer.rs | pub const PGBOUNCER_PIDFILE: &str = "/tmp/pgbouncer.pid";
| rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/local_proxy.rs | compute_tools/src/local_proxy.rs | //! Local Proxy is a feature of our BaaS Neon Authorize project.
//!
//! Local Proxy validates JWTs and manages the pg_session_jwt extension.
//! It also maintains a connection pool to postgres.
use anyhow::{Context, Result};
use camino::Utf8Path;
use compute_api::spec::LocalProxySpec;
use nix::sys::signal::Signal;
us... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/compute_promote.rs | compute_tools/src/compute_promote.rs | use crate::compute::ComputeNode;
use anyhow::{Context, bail};
use compute_api::responses::{LfcPrewarmState, PromoteConfig, PromoteState};
use std::time::Instant;
use tracing::info;
impl ComputeNode {
/// Returns only when promote fails or succeeds. If http client calling this function
/// disconnects, this doe... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/sync_sk.rs | compute_tools/src/sync_sk.rs | // Utils for running sync_safekeepers
use anyhow::Result;
use tracing::info;
use utils::lsn::Lsn;
#[derive(Copy, Clone, Debug)]
pub enum TimelineStatusResponse {
NotFound,
Ok(TimelineStatusOkResponse),
}
#[derive(Copy, Clone, Debug)]
pub struct TimelineStatusOkResponse {
flush_lsn: Lsn,
commit_lsn: Ls... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/checker.rs | compute_tools/src/checker.rs | use anyhow::{Ok, Result, anyhow};
use tokio_postgres::NoTls;
use tracing::{error, instrument, warn};
use crate::compute::ComputeNode;
/// Update timestamp in a row in a special service table to check
/// that we can actually write some data in this particular timeline.
#[instrument(skip_all)]
pub async fn check_writa... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/monitor.rs | compute_tools/src/monitor.rs | use std::sync::Arc;
use std::thread;
use std::time::Duration;
use chrono::{DateTime, Utc};
use compute_api::responses::ComputeStatus;
use compute_api::spec::ComputeFeature;
use postgres::{Client, NoTls};
use tracing::{Level, error, info, instrument, span};
use crate::compute::ComputeNode;
use crate::metrics::{PG_CURR... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/rsyslog.rs | compute_tools/src/rsyslog.rs | use std::fs;
use std::io::ErrorKind;
use std::path::Path;
use std::process::Command;
use std::time::Duration;
use std::{fs::OpenOptions, io::Write};
use url::{Host, Url};
use anyhow::{Context, Result, anyhow};
use hostname_validator;
use tracing::{error, info, instrument, warn};
const POSTGRES_LOGS_CONF_PATH: &str = ... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/communicator_socket_client.rs | compute_tools/src/communicator_socket_client.rs | //! Client for making request to a running Postgres server's communicator control socket.
//!
//! The storage communicator process that runs inside Postgres exposes an HTTP endpoint in
//! a Unix Domain Socket in the Postgres data directory. This provides access to it.
use std::path::Path;
use anyhow::Context;
use hy... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/installed_extensions.rs | compute_tools/src/installed_extensions.rs | use std::collections::HashMap;
use anyhow::Result;
use compute_api::responses::{InstalledExtension, InstalledExtensions};
use once_cell::sync::Lazy;
use tokio_postgres::error::Error as PostgresError;
use tokio_postgres::{Client, Config, NoTls};
use crate::metrics::INSTALLED_EXTENSIONS;
/// We don't reuse get_existin... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/disk_quota.rs | compute_tools/src/disk_quota.rs | use anyhow::Context;
use tracing::instrument;
pub const DISK_QUOTA_BIN: &str = "/neonvm/bin/set-disk-quota";
/// If size_bytes is 0, it disables the quota. Otherwise, it sets filesystem quota to size_bytes.
/// `fs_mountpoint` should point to the mountpoint of the filesystem where the quota should be set.
#[instrumen... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/hadron_metrics.rs | compute_tools/src/hadron_metrics.rs | use metrics::{
IntCounter, IntGaugeVec, core::Collector, proto::MetricFamily, register_int_counter,
register_int_gauge_vec,
};
use once_cell::sync::Lazy;
// Counter keeping track of the number of PageStream request errors reported by Postgres.
// An error is registered every time Postgres calls compute_ctl's /... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/metrics.rs | compute_tools/src/metrics.rs | use metrics::core::{AtomicF64, AtomicU64, Collector, GenericCounter, GenericGauge};
use metrics::proto::MetricFamily;
use metrics::{
IntCounter, IntCounterVec, IntGaugeVec, UIntGaugeVec, register_gauge, register_int_counter,
register_int_counter_vec, register_int_gauge_vec, register_uint_gauge_vec,
};
use once_... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/compute_prewarm.rs | compute_tools/src/compute_prewarm.rs | use crate::compute::ComputeNode;
use anyhow::{Context, Result, bail};
use async_compression::tokio::bufread::{ZstdDecoder, ZstdEncoder};
use compute_api::responses::LfcOffloadState;
use compute_api::responses::LfcPrewarmState;
use http::StatusCode;
use reqwest::Client;
use std::mem::replace;
use std::sync::Arc;
use std... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/pg_helpers.rs | compute_tools/src/pg_helpers.rs | use std::collections::HashMap;
use std::fmt::Write;
use std::fs;
use std::fs::File;
use std::io::{BufRead, BufReader};
use std::os::unix::fs::PermissionsExt;
use std::path::Path;
use std::process::Child;
use std::str::FromStr;
use std::time::{Duration, Instant};
use anyhow::{Result, bail};
use compute_api::responses::... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/lsn_lease.rs | compute_tools/src/lsn_lease.rs | use std::str::FromStr;
use std::sync::Arc;
use std::thread;
use std::time::{Duration, SystemTime};
use anyhow::{Result, bail};
use compute_api::spec::{ComputeMode, PageserverConnectionInfo, PageserverProtocol};
use pageserver_page_api as page_api;
use postgres::{NoTls, SimpleQueryMessage};
use tracing::{info, warn};
u... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/migration.rs | compute_tools/src/migration.rs | use anyhow::{Context, Result};
use fail::fail_point;
use tokio_postgres::{Client, Transaction};
use tracing::{error, info};
use crate::metrics::DB_MIGRATION_FAILED;
/// Runs a series of migrations on a target database
pub(crate) struct MigrationRunner<'m> {
client: &'m mut Client,
migrations: &'m [&'m str],
... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/compute.rs | compute_tools/src/compute.rs | use anyhow::{Context, Result};
use chrono::{DateTime, Utc};
use compute_api::privilege::Privilege;
use compute_api::responses::{
ComputeConfig, ComputeCtlConfig, ComputeMetrics, ComputeStatus, LfcOffloadState,
LfcPrewarmState, PromoteState, TlsConfig,
};
use compute_api::spec::{
ComputeAudit, ComputeFeature... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | true |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/configurator.rs | compute_tools/src/configurator.rs | use std::fs::File;
use std::thread;
use std::{path::Path, sync::Arc};
use anyhow::Result;
use compute_api::responses::{ComputeConfig, ComputeStatus};
use tracing::{error, info, instrument};
use crate::compute::{ComputeNode, ParsedSpec};
use crate::spec::get_config_from_control_plane;
#[instrument(skip_all)]
fn confi... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/spec.rs | compute_tools/src/spec.rs | use std::fs::File;
use std::fs::{self, Permissions};
use std::os::unix::fs::PermissionsExt;
use std::path::Path;
use anyhow::{Result, anyhow, bail};
use compute_api::responses::{
ComputeConfig, ControlPlaneComputeStatus, ControlPlaneConfigResponse,
};
use reqwest::StatusCode;
use tokio_postgres::Client;
use tracin... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
neondatabase/neon | https://github.com/neondatabase/neon/blob/015b1c7cb3259a6fcd5039bc2bd46a462e163ae8/compute_tools/src/bin/fast_import.rs | compute_tools/src/bin/fast_import.rs | //! This program dumps a remote Postgres database into a local Postgres database
//! and uploads the resulting PGDATA into object storage for import into a Timeline.
//!
//! # Context, Architecture, Design
//!
//! See cloud.git Fast Imports RFC (<https://github.com/neondatabase/cloud/pull/19799>)
//! for the full pictu... | rust | Apache-2.0 | 015b1c7cb3259a6fcd5039bc2bd46a462e163ae8 | 2026-01-04T15:40:24.223849Z | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.