
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh
|
#!/usr/bin/env bash
export PYTHONPATH="../":"${PYTHONPATH}"
export WANDB_PROJECT=dmar
export MAX_LEN=128
export m=sshleifer/student_marian_en_ro_6_1
python finetune.py \
--learning_rate=3e-4 \
--do_train \
--fp16 \
--data_dir wmt_en_ro \
--max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
--freeze_encoder --freeze_embeds \
--train_batch_size=48 --eval_batch_size=64 \
--tokenizer_name $m --model_name_or_path $m --num_train_epochs=1 \
--warmup_steps 500 --logger_name wandb --gpus 1 \
--fp16_opt_level=O1 --task translation \
"$@"
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh
|
#!/usr/bin/env bash
export PYTHONPATH="../":"${PYTHONPATH}"
export WANDB_PROJECT=dmar
# export MAX_LEN=128
python distillation.py \
--learning_rate=3e-4 \
--do_train \
--fp16 \
--val_check_interval 0.25 \
--teacher Helsinki-NLP/opus-mt-en-ro \
--max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
--student_decoder_layers 3 --student_encoder_layers 6 \
--freeze_encoder --freeze_embeds \
--model_name_or_path IGNORED \
--alpha_hid=3. \
--train_batch_size=$BS --eval_batch_size=$BS \
--tokenizer_name Helsinki-NLP/opus-mt-en-ro \
--warmup_steps 500 --logger_name wandb \
--fp16_opt_level O1 --task translation --normalize_hidden --num_sanity_val_steps=0 \
"$@"
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh
|
#!/usr/bin/env bash
export PYTHONPATH="../":"${PYTHONPATH}"
# From appendix C of paper https://arxiv.org/abs/1912.08777
# Set --gradient_accumulation_steps so that effective batch size is 256 (2*128, 4*64, 8*32, 16*16)
python finetune.py \
--learning_rate=1e-4 \
--do_train \
--do_predict \
--n_val 1000 \
--val_check_interval 0.25 \
--max_source_length 512 --max_target_length 56 \
--freeze_embeds --label_smoothing 0.1 --adafactor --task summarization_xsum \
"$@"
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py
|
#!/usr/bin/env python
import os
from pathlib import Path
from typing import Dict, List
import fire
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from transformers.utils.logging import get_logger
logger = get_logger(__name__)
def remove_prefix(text: str, prefix: str):
if text.startswith(prefix):
return text[len(prefix) :]
return text # or whatever
def sanitize(sd):
return {remove_prefix(k, "model."): v for k, v in sd.items()}
def average_state_dicts(state_dicts: List[Dict[str, torch.Tensor]]):
new_sd = {}
for k in state_dicts[0].keys():
tensors = [sd[k] for sd in state_dicts]
new_t = sum(tensors) / len(tensors)
assert isinstance(new_t, torch.Tensor)
new_sd[k] = new_t
return new_sd
def convert_pl_to_hf(pl_ckpt_path: str, hf_src_model_dir: str, save_path: str) -> None:
"""Cleanup a pytorch-lightning .ckpt file or experiment dir and save a huggingface model with that state dict.
Silently allows extra pl keys (like teacher.) Puts all ckpt models into CPU RAM at once!
Args:
pl_ckpt_path (:obj:`str`): Path to a .ckpt file saved by pytorch_lightning or dir containing ckpt files.
If a directory is passed, all .ckpt files inside it will be averaged!
hf_src_model_dir (:obj:`str`): Path to a directory containing a correctly shaped checkpoint
save_path (:obj:`str`): Directory to save the new model
"""
hf_model = AutoModelForSeq2SeqLM.from_pretrained(hf_src_model_dir)
if os.path.isfile(pl_ckpt_path):
ckpt_files = [pl_ckpt_path]
else:
assert os.path.isdir(pl_ckpt_path)
ckpt_files = list(Path(pl_ckpt_path).glob("*.ckpt"))
assert ckpt_files, f"could not find any ckpt files inside the {pl_ckpt_path} directory"
if len(ckpt_files) > 1:
logger.info(f"averaging the weights of {ckpt_files}")
state_dicts = [sanitize(torch.load(x, map_location="cpu")["state_dict"]) for x in ckpt_files]
state_dict = average_state_dicts(state_dicts)
missing, unexpected = hf_model.load_state_dict(state_dict, strict=False)
assert not missing, f"missing keys: {missing}"
hf_model.save_pretrained(save_path)
try:
tok = AutoTokenizer.from_pretrained(hf_src_model_dir)
tok.save_pretrained(save_path)
except Exception:
pass
# dont copy tokenizer if cant
if __name__ == "__main__":
fire.Fire(convert_pl_to_hf)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh
|
#!/usr/bin/env bash
export PYTHONPATH="../":"${PYTHONPATH}"
export BS=32
export GAS=1
python finetune.py \
--learning_rate=3e-5 \
--fp16 \
--gpus 1 \
--do_train \
--do_predict \
--val_check_interval 0.25 \
--n_val 500 \
--num_train_epochs 2 \
--freeze_encoder --freeze_embeds --data_dir cnn_dm \
--max_target_length 142 --val_max_target_length=142 \
--train_batch_size=$BS --eval_batch_size=$BS --gradient_accumulation_steps=$GAS \
--model_name_or_path sshleifer/student_cnn_12_6 \
--tokenizer_name facebook/bart-large \
--warmup_steps 500 \
--output_dir distilbart-cnn-12-6 \
"$@"
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/finetune.py
|
#!/usr/bin/env python
import argparse
import glob
import logging
import os
import sys
import time
from collections import defaultdict
from pathlib import Path
from typing import Dict, List, Tuple
import numpy as np
import pytorch_lightning as pl
import torch
from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
from torch import nn
from torch.utils.data import DataLoader
from transformers import MBartTokenizer, T5ForConditionalGeneration
from transformers.models.bart.modeling_bart import shift_tokens_right
from utils import (
ROUGE_KEYS,
LegacySeq2SeqDataset,
Seq2SeqDataset,
assert_all_frozen,
calculate_bleu,
calculate_rouge,
check_output_dir,
flatten_list,
freeze_embeds,
freeze_params,
get_git_info,
label_smoothed_nll_loss,
lmap,
pickle_save,
save_git_info,
save_json,
use_task_specific_params,
)
# need the parent dir module
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
logger = logging.getLogger(__name__)
class SummarizationModule(BaseTransformer):
mode = "summarization"
loss_names = ["loss"]
metric_names = ROUGE_KEYS
default_val_metric = "rouge2"
def __init__(self, hparams, **kwargs):
if hparams.sortish_sampler and hparams.gpus > 1:
hparams.replace_sampler_ddp = False
elif hparams.max_tokens_per_batch is not None:
if hparams.gpus > 1:
raise NotImplementedError("Dynamic Batch size does not work for multi-gpu training")
if hparams.sortish_sampler:
raise ValueError("--sortish_sampler and --max_tokens_per_batch may not be used simultaneously")
super().__init__(hparams, num_labels=None, mode=self.mode, **kwargs)
use_task_specific_params(self.model, "summarization")
save_git_info(self.hparams.output_dir)
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
pickle_save(self.hparams, self.hparams_save_path)
self.step_count = 0
self.metrics = defaultdict(list)
self.model_type = self.config.model_type
self.vocab_size = self.config.tgt_vocab_size if self.model_type == "fsmt" else self.config.vocab_size
self.dataset_kwargs: dict = {
"data_dir": self.hparams.data_dir,
"max_source_length": self.hparams.max_source_length,
"prefix": self.model.config.prefix or "",
}
n_observations_per_split = {
"train": self.hparams.n_train,
"val": self.hparams.n_val,
"test": self.hparams.n_test,
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.target_lens = {
"train": self.hparams.max_target_length,
"val": self.hparams.val_max_target_length,
"test": self.hparams.test_max_target_length,
}
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
if self.hparams.freeze_embeds:
freeze_embeds(self.model)
if self.hparams.freeze_encoder:
freeze_params(self.model.get_encoder())
assert_all_frozen(self.model.get_encoder())
self.hparams.git_sha = get_git_info()["repo_sha"]
self.num_workers = hparams.num_workers
self.decoder_start_token_id = None # default to config
if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
self.model.config.decoder_start_token_id = self.decoder_start_token_id
self.dataset_class = (
Seq2SeqDataset if hasattr(self.tokenizer, "prepare_seq2seq_batch") else LegacySeq2SeqDataset
)
self.already_saved_batch = False
self.eval_beams = self.model.config.num_beams if self.hparams.eval_beams is None else self.hparams.eval_beams
if self.hparams.eval_max_gen_length is not None:
self.eval_max_length = self.hparams.eval_max_gen_length
else:
self.eval_max_length = self.model.config.max_length
self.val_metric = self.default_val_metric if self.hparams.val_metric is None else self.hparams.val_metric
def save_readable_batch(self, batch: Dict[str, torch.Tensor]) -> Dict[str, List[str]]:
"""A debugging utility"""
readable_batch = {
k: self.tokenizer.batch_decode(v.tolist()) if "mask" not in k else v.shape for k, v in batch.items()
}
save_json(readable_batch, Path(self.output_dir) / "text_batch.json")
save_json({k: v.tolist() for k, v in batch.items()}, Path(self.output_dir) / "tok_batch.json")
self.already_saved_batch = True
return readable_batch
def forward(self, input_ids, **kwargs):
return self.model(input_ids, **kwargs)
def ids_to_clean_text(self, generated_ids: List[int]):
gen_text = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
return lmap(str.strip, gen_text)
def _step(self, batch: dict) -> Tuple:
pad_token_id = self.tokenizer.pad_token_id
src_ids, src_mask = batch["input_ids"], batch["attention_mask"]
tgt_ids = batch["labels"]
if isinstance(self.model, T5ForConditionalGeneration):
decoder_input_ids = self.model._shift_right(tgt_ids)
else:
decoder_input_ids = shift_tokens_right(tgt_ids, pad_token_id)
if not self.already_saved_batch: # This would be slightly better if it only happened on rank zero
batch["decoder_input_ids"] = decoder_input_ids
self.save_readable_batch(batch)
outputs = self(src_ids, attention_mask=src_mask, decoder_input_ids=decoder_input_ids, use_cache=False)
lm_logits = outputs["logits"]
if self.hparams.label_smoothing == 0:
# Same behavior as modeling_bart.py, besides ignoring pad_token_id
ce_loss_fct = nn.CrossEntropyLoss(ignore_index=pad_token_id)
assert lm_logits.shape[-1] == self.vocab_size
loss = ce_loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), tgt_ids.view(-1))
else:
lprobs = nn.functional.log_softmax(lm_logits, dim=-1)
loss, nll_loss = label_smoothed_nll_loss(
lprobs, tgt_ids, self.hparams.label_smoothing, ignore_index=pad_token_id
)
return (loss,)
@property
def pad(self) -> int:
return self.tokenizer.pad_token_id
def training_step(self, batch, batch_idx) -> Dict:
loss_tensors = self._step(batch)
logs = dict(zip(self.loss_names, loss_tensors))
# tokens per batch
logs["tpb"] = batch["input_ids"].ne(self.pad).sum() + batch["labels"].ne(self.pad).sum()
logs["bs"] = batch["input_ids"].shape[0]
logs["src_pad_tok"] = batch["input_ids"].eq(self.pad).sum()
logs["src_pad_frac"] = batch["input_ids"].eq(self.pad).float().mean()
# TODO(SS): make a wandb summary metric for this
return {"loss": loss_tensors[0], "log": logs}
def validation_step(self, batch, batch_idx) -> Dict:
return self._generative_step(batch)
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
self.step_count += 1
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
loss = losses["loss"]
generative_metrics = {
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
}
metric_val = (
generative_metrics[self.val_metric] if self.val_metric in generative_metrics else losses[self.val_metric]
)
metric_tensor: torch.FloatTensor = torch.tensor(metric_val).type_as(loss)
generative_metrics.update({k: v.item() for k, v in losses.items()})
losses.update(generative_metrics)
all_metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
all_metrics["step_count"] = self.step_count
self.metrics[prefix].append(all_metrics) # callback writes this to self.metrics_save_path
preds = flatten_list([x["preds"] for x in outputs])
return {
"log": all_metrics,
"preds": preds,
f"{prefix}_loss": loss,
f"{prefix}_{self.val_metric}": metric_tensor,
}
def calc_generative_metrics(self, preds, target) -> Dict:
return calculate_rouge(preds, target)
def _generative_step(self, batch: dict) -> dict:
t0 = time.time()
# parser.add_argument('--eval_max_gen_length', type=int, default=None, help='never generate more than n tokens')
generated_ids = self.model.generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
use_cache=True,
decoder_start_token_id=self.decoder_start_token_id,
num_beams=self.eval_beams,
max_length=self.eval_max_length,
)
gen_time = (time.time() - t0) / batch["input_ids"].shape[0]
preds: List[str] = self.ids_to_clean_text(generated_ids)
target: List[str] = self.ids_to_clean_text(batch["labels"])
loss_tensors = self._step(batch)
base_metrics = dict(zip(self.loss_names, loss_tensors))
rouge: Dict = self.calc_generative_metrics(preds, target)
summ_len = np.mean(lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **rouge)
return base_metrics
def test_step(self, batch, batch_idx):
return self._generative_step(batch)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, prefix="test")
def get_dataset(self, type_path) -> Seq2SeqDataset:
n_obs = self.n_obs[type_path]
max_target_length = self.target_lens[type_path]
dataset = self.dataset_class(
self.tokenizer,
type_path=type_path,
n_obs=n_obs,
max_target_length=max_target_length,
**self.dataset_kwargs,
)
return dataset
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
dataset = self.get_dataset(type_path)
if self.hparams.sortish_sampler and type_path != "test" and type_path != "val":
sampler = dataset.make_sortish_sampler(batch_size, distributed=self.hparams.gpus > 1)
return DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=False,
num_workers=self.num_workers,
sampler=sampler,
)
elif self.hparams.max_tokens_per_batch is not None and type_path != "test" and type_path != "val":
batch_sampler = dataset.make_dynamic_sampler(
self.hparams.max_tokens_per_batch, distributed=self.hparams.gpus > 1
)
return DataLoader(
dataset,
batch_sampler=batch_sampler,
collate_fn=dataset.collate_fn,
# shuffle=False,
num_workers=self.num_workers,
# batch_size=None,
)
else:
return DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle,
num_workers=self.num_workers,
sampler=None,
)
def train_dataloader(self) -> DataLoader:
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
return dataloader
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
add_generic_args(parser, root_dir)
parser.add_argument(
"--max_source_length",
default=1024,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--max_target_length",
default=56,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--val_max_target_length",
default=142, # these defaults are optimized for CNNDM. For xsum, see README.md.
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--test_max_target_length",
default=142,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--freeze_encoder", action="store_true")
parser.add_argument("--freeze_embeds", action="store_true")
parser.add_argument("--sortish_sampler", action="store_true", default=False)
parser.add_argument("--overwrite_output_dir", action="store_true", default=False)
parser.add_argument("--max_tokens_per_batch", type=int, default=None)
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_val", type=int, default=500, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument(
"--task", type=str, default="summarization", required=False, help="# examples. -1 means use all."
)
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
parser.add_argument("--src_lang", type=str, default="", required=False)
parser.add_argument("--tgt_lang", type=str, default="", required=False)
parser.add_argument("--eval_beams", type=int, default=None, required=False)
parser.add_argument(
"--val_metric", type=str, default=None, required=False, choices=["bleu", "rouge2", "loss", None]
)
parser.add_argument("--eval_max_gen_length", type=int, default=None, help="never generate more than n tokens")
parser.add_argument("--save_top_k", type=int, default=1, required=False, help="How many checkpoints to save")
parser.add_argument(
"--early_stopping_patience",
type=int,
default=-1,
required=False,
help=(
"-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
" val_check_interval will effect it."
),
)
return parser
class TranslationModule(SummarizationModule):
mode = "translation"
loss_names = ["loss"]
metric_names = ["bleu"]
default_val_metric = "bleu"
def __init__(self, hparams, **kwargs):
super().__init__(hparams, **kwargs)
self.dataset_kwargs["src_lang"] = hparams.src_lang
self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
def calc_generative_metrics(self, preds, target) -> dict:
return calculate_bleu(preds, target)
def main(args, model=None) -> SummarizationModule:
Path(args.output_dir).mkdir(exist_ok=True)
check_output_dir(args, expected_items=3)
if model is None:
if "summarization" in args.task:
model: SummarizationModule = SummarizationModule(args)
else:
model: SummarizationModule = TranslationModule(args)
dataset = Path(args.data_dir).name
if (
args.logger_name == "default"
or args.fast_dev_run
or str(args.output_dir).startswith("/tmp")
or str(args.output_dir).startswith("/var")
):
logger = True # don't pollute wandb logs unnecessarily
elif args.logger_name == "wandb":
from pytorch_lightning.loggers import WandbLogger
project = os.environ.get("WANDB_PROJECT", dataset)
logger = WandbLogger(name=model.output_dir.name, project=project)
elif args.logger_name == "wandb_shared":
from pytorch_lightning.loggers import WandbLogger
logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
if args.early_stopping_patience >= 0:
es_callback = get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
else:
es_callback = False
lower_is_better = args.val_metric == "loss"
trainer: pl.Trainer = generic_train(
model,
args,
logging_callback=Seq2SeqLoggingCallback(),
checkpoint_callback=get_checkpoint_callback(
args.output_dir, model.val_metric, args.save_top_k, lower_is_better
),
early_stopping_callback=es_callback,
logger=logger,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
if not args.do_predict:
return model
model.hparams.test_checkpoint = ""
checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "*.ckpt"), recursive=True))
if checkpoints:
model.hparams.test_checkpoint = checkpoints[-1]
trainer.resume_from_checkpoint = checkpoints[-1]
trainer.logger.log_hyperparams(model.hparams)
# test() without a model tests using the best checkpoint automatically
trainer.test()
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
main(args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/requirements.txt
|
tensorboard
scikit-learn
psutil
sacrebleu
rouge-score
tensorflow_datasets
pytorch-lightning
matplotlib
git-python==1.0.3
faiss-cpu
streamlit
elasticsearch
nltk
pandas
datasets >= 1.1.3
fire
pytest
conllu
sentencepiece != 0.1.92
protobuf
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py
|
import argparse
import logging
import os
import sys
import tempfile
from pathlib import Path
import lightning_base
import pytest
import pytorch_lightning as pl
import torch
from convert_pl_checkpoint_to_hf import convert_pl_to_hf
from distillation import distill_main
from finetune import SummarizationModule, main
from huggingface_hub import list_models
from parameterized import parameterized
from run_eval import generate_summaries_or_translations
from torch import nn
from transformers import AutoConfig, AutoModelForSeq2SeqLM
from transformers.testing_utils import CaptureStderr, CaptureStdout, TestCasePlus, require_torch_gpu, slow
from utils import label_smoothed_nll_loss, lmap, load_json
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
CUDA_AVAILABLE = torch.cuda.is_available()
CHEAP_ARGS = {
"max_tokens_per_batch": None,
"supervise_forward": True,
"normalize_hidden": True,
"label_smoothing": 0.2,
"eval_max_gen_length": None,
"eval_beams": 1,
"val_metric": "loss",
"save_top_k": 1,
"adafactor": True,
"early_stopping_patience": 2,
"logger_name": "default",
"length_penalty": 0.5,
"cache_dir": "",
"task": "summarization",
"num_workers": 2,
"alpha_hid": 0,
"freeze_embeds": True,
"enc_only": False,
"tgt_suffix": "",
"resume_from_checkpoint": None,
"sortish_sampler": True,
"student_decoder_layers": 1,
"val_check_interval": 1.0,
"output_dir": "",
"fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
"no_teacher": False,
"fp16_opt_level": "O1",
"gpus": 1 if CUDA_AVAILABLE else 0,
"n_tpu_cores": 0,
"max_grad_norm": 1.0,
"do_train": True,
"do_predict": True,
"accumulate_grad_batches": 1,
"server_ip": "",
"server_port": "",
"seed": 42,
"model_name_or_path": "sshleifer/bart-tiny-random",
"config_name": "",
"tokenizer_name": "facebook/bart-large",
"do_lower_case": False,
"learning_rate": 0.3,
"lr_scheduler": "linear",
"weight_decay": 0.0,
"adam_epsilon": 1e-08,
"warmup_steps": 0,
"max_epochs": 1,
"train_batch_size": 2,
"eval_batch_size": 2,
"max_source_length": 12,
"max_target_length": 12,
"val_max_target_length": 12,
"test_max_target_length": 12,
"fast_dev_run": False,
"no_cache": False,
"n_train": -1,
"n_val": -1,
"n_test": -1,
"student_encoder_layers": 1,
"freeze_encoder": False,
"auto_scale_batch_size": False,
"overwrite_output_dir": False,
"student": None,
}
def _dump_articles(path: Path, articles: list):
content = "\n".join(articles)
Path(path).open("w").writelines(content)
ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
T5_TINY = "patrickvonplaten/t5-tiny-random"
T5_TINIER = "sshleifer/t5-tinier-random"
BART_TINY = "sshleifer/bart-tiny-random"
MBART_TINY = "sshleifer/tiny-mbart"
MARIAN_TINY = "sshleifer/tiny-marian-en-de"
FSMT_TINY = "stas/tiny-wmt19-en-de"
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
def make_test_data_dir(tmp_dir):
for split in ["train", "val", "test"]:
_dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
_dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
return tmp_dir
class TestSummarizationDistiller(TestCasePlus):
@classmethod
def setUpClass(cls):
logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
return cls
@slow
@require_torch_gpu
def test_hub_configs(self):
"""I put require_torch_gpu cause I only want this to run with self-scheduled."""
model_list = list_models()
org = "sshleifer"
model_ids = [x.modelId for x in model_list if x.modelId.startswith(org)]
allowed_to_be_broken = ["sshleifer/blenderbot-3B", "sshleifer/blenderbot-90M"]
failures = []
for m in model_ids:
if m in allowed_to_be_broken:
continue
try:
AutoConfig.from_pretrained(m)
except Exception:
failures.append(m)
assert not failures, f"The following models could not be loaded through AutoConfig: {failures}"
def test_distill_no_teacher(self):
updates = {"student_encoder_layers": 2, "student_decoder_layers": 1, "no_teacher": True}
self._test_distiller_cli(updates)
def test_distill_checkpointing_with_teacher(self):
updates = {
"student_encoder_layers": 2,
"student_decoder_layers": 1,
"max_epochs": 4,
"val_check_interval": 0.25,
"alpha_hid": 2.0,
"model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
}
model = self._test_distiller_cli(updates, check_contents=False)
ckpts = list(Path(model.output_dir).glob("*.ckpt"))
self.assertEqual(1, len(ckpts))
transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
self.assertEqual(len(transformer_ckpts), 2)
examples = lmap(str.strip, Path(model.hparams.data_dir).joinpath("test.source").open().readlines())
out_path = tempfile.mktemp() # XXX: not being cleaned up
generate_summaries_or_translations(examples, out_path, str(model.output_dir / "best_tfmr"))
self.assertTrue(Path(out_path).exists())
out_path_new = self.get_auto_remove_tmp_dir()
convert_pl_to_hf(ckpts[0], transformer_ckpts[0].parent, out_path_new)
assert os.path.exists(os.path.join(out_path_new, "pytorch_model.bin"))
def test_loss_fn(self):
model = AutoModelForSeq2SeqLM.from_pretrained(BART_TINY)
input_ids, mask = model.dummy_inputs["input_ids"], model.dummy_inputs["attention_mask"]
target_ids = torch.tensor([[0, 4, 8, 2], [0, 8, 2, 1]], dtype=torch.long, device=model.device)
decoder_input_ids = target_ids[:, :-1].contiguous() # Why this line?
lm_labels = target_ids[:, 1:].clone() # why clone?
model_computed_loss = model(
input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, labels=lm_labels, use_cache=False
).loss
logits = model(input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, use_cache=False).logits
lprobs = nn.functional.log_softmax(logits, dim=-1)
smoothed_loss, nll_loss = label_smoothed_nll_loss(
lprobs, lm_labels, 0.1, ignore_index=model.config.pad_token_id
)
with self.assertRaises(AssertionError):
# TODO: understand why this breaks
self.assertEqual(nll_loss, model_computed_loss)
def test_distill_mbart(self):
updates = {
"student_encoder_layers": 2,
"student_decoder_layers": 1,
"num_train_epochs": 4,
"val_check_interval": 0.25,
"alpha_hid": 2.0,
"task": "translation",
"model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
"tokenizer_name": MBART_TINY,
"teacher": MBART_TINY,
"src_lang": "en_XX",
"tgt_lang": "ro_RO",
}
model = self._test_distiller_cli(updates, check_contents=False)
assert model.model.config.model_type == "mbart"
ckpts = list(Path(model.output_dir).glob("*.ckpt"))
self.assertEqual(1, len(ckpts))
transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
all_files = list(Path(model.output_dir).glob("best_tfmr/*"))
assert len(all_files) > 2
self.assertEqual(len(transformer_ckpts), 2)
def test_distill_t5(self):
updates = {
"student_encoder_layers": 1,
"student_decoder_layers": 1,
"alpha_hid": 2.0,
"teacher": T5_TINY,
"model_name_or_path": T5_TINY,
"tokenizer_name": T5_TINY,
}
self._test_distiller_cli(updates)
def test_distill_different_base_models(self):
updates = {
"teacher": T5_TINY,
"student": T5_TINIER,
"model_name_or_path": T5_TINIER,
"tokenizer_name": T5_TINIER,
}
self._test_distiller_cli(updates)
def _test_distiller_cli(self, updates, check_contents=True):
default_updates = {
"label_smoothing": 0.0,
"early_stopping_patience": -1,
"train_batch_size": 1,
"eval_batch_size": 2,
"max_epochs": 2,
"alpha_mlm": 0.2,
"alpha_ce": 0.8,
"do_predict": True,
"model_name_or_path": "sshleifer/tinier_bart",
"teacher": CHEAP_ARGS["model_name_or_path"],
"val_check_interval": 0.5,
}
default_updates.update(updates)
args_d: dict = CHEAP_ARGS.copy()
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
model = distill_main(argparse.Namespace(**args_d))
if not check_contents:
return model
contents = os.listdir(output_dir)
contents = {os.path.basename(p) for p in contents}
ckpt_files = [p for p in contents if p.endswith("ckpt")]
assert len(ckpt_files) > 0
self.assertIn("test_generations.txt", contents)
self.assertIn("test_results.txt", contents)
metrics = load_json(model.metrics_save_path)
last_step_stats = metrics["val"][-1]
self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
self.assertGreaterEqual(1.0, last_step_stats["val_avg_gen_time"])
self.assertIsInstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) + 1)
self.assertEqual(len(metrics["val"]), desired_n_evals)
self.assertEqual(len(metrics["test"]), 1)
return model
class TestTheRest(TestCasePlus):
@parameterized.expand(
[T5_TINY, BART_TINY, MBART_TINY, MARIAN_TINY, FSMT_TINY],
)
def test_finetune(self, model):
args_d: dict = CHEAP_ARGS.copy()
task = "translation" if model in [MBART_TINY, MARIAN_TINY, FSMT_TINY] else "summarization"
args_d["label_smoothing"] = 0.1 if task == "translation" else 0
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(
data_dir=tmp_dir,
model_name_or_path=model,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
output_dir=output_dir,
do_predict=True,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
assert "n_train" in args_d
args = argparse.Namespace(**args_d)
module = main(args)
input_embeds = module.model.get_input_embeddings()
assert not input_embeds.weight.requires_grad
if model == T5_TINY:
lm_head = module.model.lm_head
assert not lm_head.weight.requires_grad
assert (lm_head.weight == input_embeds.weight).all().item()
elif model == FSMT_TINY:
fsmt = module.model.model
embed_pos = fsmt.decoder.embed_positions
assert not embed_pos.weight.requires_grad
assert not fsmt.decoder.embed_tokens.weight.requires_grad
# check that embeds are not the same
assert fsmt.decoder.embed_tokens != fsmt.encoder.embed_tokens
else:
bart = module.model.model
embed_pos = bart.decoder.embed_positions
assert not embed_pos.weight.requires_grad
assert not bart.shared.weight.requires_grad
# check that embeds are the same
assert bart.decoder.embed_tokens == bart.encoder.embed_tokens
assert bart.decoder.embed_tokens == bart.shared
example_batch = load_json(module.output_dir / "text_batch.json")
assert isinstance(example_batch, dict)
assert len(example_batch) >= 4
def test_finetune_extra_model_args(self):
args_d: dict = CHEAP_ARGS.copy()
task = "summarization"
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
args_d.update(
data_dir=tmp_dir,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
do_predict=False,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
# test models whose config includes the extra_model_args
model = BART_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d1 = args_d.copy()
args_d1.update(
model_name_or_path=model,
output_dir=output_dir,
)
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
args_d1[p] = 0.5
args = argparse.Namespace(**args_d1)
model = main(args)
for p in extra_model_params:
assert getattr(model.config, p) == 0.5, f"failed to override the model config for param {p}"
# test models whose config doesn't include the extra_model_args
model = T5_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d2 = args_d.copy()
args_d2.update(
model_name_or_path=model,
output_dir=output_dir,
)
unsupported_param = "encoder_layerdrop"
args_d2[unsupported_param] = 0.5
args = argparse.Namespace(**args_d2)
with pytest.raises(Exception) as excinfo:
model = main(args)
assert str(excinfo.value) == f"model config doesn't have a `{unsupported_param}` attribute"
def test_finetune_lr_schedulers(self):
args_d: dict = CHEAP_ARGS.copy()
task = "summarization"
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
model = BART_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(
data_dir=tmp_dir,
model_name_or_path=model,
output_dir=output_dir,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
do_predict=False,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
# emulate finetune.py
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
args = {"--help": True}
# --help test
with pytest.raises(SystemExit) as excinfo:
with CaptureStdout() as cs:
args = parser.parse_args(args)
assert False, "--help is expected to sys.exit"
assert excinfo.type == SystemExit
expected = lightning_base.arg_to_scheduler_metavar
assert expected in cs.out, "--help is expected to list the supported schedulers"
# --lr_scheduler=non_existing_scheduler test
unsupported_param = "non_existing_scheduler"
args = {f"--lr_scheduler={unsupported_param}"}
with pytest.raises(SystemExit) as excinfo:
with CaptureStderr() as cs:
args = parser.parse_args(args)
assert False, "invalid argument is expected to sys.exit"
assert excinfo.type == SystemExit
expected = f"invalid choice: '{unsupported_param}'"
assert expected in cs.err, f"should have bailed on invalid choice of scheduler {unsupported_param}"
# --lr_scheduler=existing_scheduler test
supported_param = "cosine"
args_d1 = args_d.copy()
args_d1["lr_scheduler"] = supported_param
args = argparse.Namespace(**args_d1)
model = main(args)
assert (
getattr(model.hparams, "lr_scheduler") == supported_param
), f"lr_scheduler={supported_param} shouldn't fail"
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/_test_make_student.py
|
import tempfile
import unittest
from make_student import create_student_by_copying_alternating_layers
from transformers import AutoConfig
from transformers.file_utils import cached_property
from transformers.testing_utils import require_torch
TINY_BART = "sshleifer/bart-tiny-random"
TINY_T5 = "patrickvonplaten/t5-tiny-random"
@require_torch
class MakeStudentTester(unittest.TestCase):
@cached_property
def teacher_config(self):
return AutoConfig.from_pretrained(TINY_BART)
def test_valid_t5(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=1)
self.assertEqual(student.config.num_hidden_layers, 1)
def test_asymmetric_t5(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=None)
def test_same_decoder_small_encoder(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=None)
self.assertEqual(student.config.encoder_layers, 1)
self.assertEqual(student.config.decoder_layers, self.teacher_config.encoder_layers)
def test_small_enc_small_dec(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=1)
self.assertEqual(student.config.encoder_layers, 1)
self.assertEqual(student.config.decoder_layers, 1)
def test_raises_assert(self):
with self.assertRaises(AssertionError):
create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=None, d=None)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/_test_bash_script.py
|
#!/usr/bin/env python
import argparse
import os
import sys
from unittest.mock import patch
import pytorch_lightning as pl
import timeout_decorator
import torch
from distillation import SummarizationDistiller, distill_main
from finetune import SummarizationModule, main
from transformers import MarianMTModel
from transformers.file_utils import cached_path
from transformers.testing_utils import TestCasePlus, require_torch_gpu, slow
from utils import load_json
MARIAN_MODEL = "sshleifer/mar_enro_6_3_student"
class TestMbartCc25Enro(TestCasePlus):
def setUp(self):
super().setUp()
data_cached = cached_path(
"https://cdn-datasets.huggingface.co/translation/wmt_en_ro-tr40k-va0.5k-te0.5k.tar.gz",
extract_compressed_file=True,
)
self.data_dir = f"{data_cached}/wmt_en_ro-tr40k-va0.5k-te0.5k"
@slow
@require_torch_gpu
def test_model_download(self):
"""This warms up the cache so that we can time the next test without including download time, which varies between machines."""
MarianMTModel.from_pretrained(MARIAN_MODEL)
# @timeout_decorator.timeout(1200)
@slow
@require_torch_gpu
def test_train_mbart_cc25_enro_script(self):
env_vars_to_replace = {
"$MAX_LEN": 64,
"$BS": 64,
"$GAS": 1,
"$ENRO_DIR": self.data_dir,
"facebook/mbart-large-cc25": MARIAN_MODEL,
# "val_check_interval=0.25": "val_check_interval=1.0",
"--learning_rate=3e-5": "--learning_rate 3e-4",
"--num_train_epochs 6": "--num_train_epochs 1",
}
# Clean up bash script
bash_script = (self.test_file_dir / "train_mbart_cc25_enro.sh").open().read().split("finetune.py")[1].strip()
bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
for k, v in env_vars_to_replace.items():
bash_script = bash_script.replace(k, str(v))
output_dir = self.get_auto_remove_tmp_dir()
# bash_script = bash_script.replace("--fp16 ", "")
args = f"""
--output_dir {output_dir}
--tokenizer_name Helsinki-NLP/opus-mt-en-ro
--sortish_sampler
--do_predict
--gpus 1
--freeze_encoder
--n_train 40000
--n_val 500
--n_test 500
--fp16_opt_level O1
--num_sanity_val_steps 0
--eval_beams 2
""".split()
# XXX: args.gpus > 1 : handle multi_gpu in the future
testargs = ["finetune.py"] + bash_script.split() + args
with patch.object(sys, "argv", testargs):
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
model = main(args)
# Check metrics
metrics = load_json(model.metrics_save_path)
first_step_stats = metrics["val"][0]
last_step_stats = metrics["val"][-1]
self.assertEqual(len(metrics["val"]), (args.max_epochs / args.val_check_interval))
assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
self.assertGreater(last_step_stats["val_avg_gen_time"], 0.01)
# model hanging on generate. Maybe bad config was saved. (XXX: old comment/assert?)
self.assertLessEqual(last_step_stats["val_avg_gen_time"], 1.0)
# test learning requirements:
# 1. BLEU improves over the course of training by more than 2 pts
self.assertGreater(last_step_stats["val_avg_bleu"] - first_step_stats["val_avg_bleu"], 2)
# 2. BLEU finishes above 17
self.assertGreater(last_step_stats["val_avg_bleu"], 17)
# 3. test BLEU and val BLEU within ~1.1 pt.
self.assertLess(abs(metrics["val"][-1]["val_avg_bleu"] - metrics["test"][-1]["test_avg_bleu"]), 1.1)
# check lightning ckpt can be loaded and has a reasonable statedict
contents = os.listdir(output_dir)
ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
full_path = os.path.join(args.output_dir, ckpt_path)
ckpt = torch.load(full_path, map_location="cpu")
expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
assert expected_key in ckpt["state_dict"]
assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
# TODO: turn on args.do_predict when PL bug fixed.
if args.do_predict:
contents = {os.path.basename(p) for p in contents}
assert "test_generations.txt" in contents
assert "test_results.txt" in contents
# assert len(metrics["val"]) == desired_n_evals
assert len(metrics["test"]) == 1
class TestDistilMarianNoTeacher(TestCasePlus):
@timeout_decorator.timeout(600)
@slow
@require_torch_gpu
def test_opus_mt_distill_script(self):
data_dir = f"{self.test_file_dir_str}/test_data/wmt_en_ro"
env_vars_to_replace = {
"--fp16_opt_level=O1": "",
"$MAX_LEN": 128,
"$BS": 16,
"$GAS": 1,
"$ENRO_DIR": data_dir,
"$m": "sshleifer/student_marian_en_ro_6_1",
"val_check_interval=0.25": "val_check_interval=1.0",
}
# Clean up bash script
bash_script = (
(self.test_file_dir / "distil_marian_no_teacher.sh").open().read().split("distillation.py")[1].strip()
)
bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
bash_script = bash_script.replace("--fp16 ", " ")
for k, v in env_vars_to_replace.items():
bash_script = bash_script.replace(k, str(v))
output_dir = self.get_auto_remove_tmp_dir()
bash_script = bash_script.replace("--fp16", "")
epochs = 6
testargs = (
["distillation.py"]
+ bash_script.split()
+ [
f"--output_dir={output_dir}",
"--gpus=1",
"--learning_rate=1e-3",
f"--num_train_epochs={epochs}",
"--warmup_steps=10",
"--val_check_interval=1.0",
"--do_predict",
]
)
with patch.object(sys, "argv", testargs):
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
# assert args.gpus == gpus THIS BREAKS for multi_gpu
model = distill_main(args)
# Check metrics
metrics = load_json(model.metrics_save_path)
first_step_stats = metrics["val"][0]
last_step_stats = metrics["val"][-1]
assert len(metrics["val"]) >= (args.max_epochs / args.val_check_interval) # +1 accounts for val_sanity_check
assert last_step_stats["val_avg_gen_time"] >= 0.01
assert first_step_stats["val_avg_bleu"] < last_step_stats["val_avg_bleu"] # model learned nothing
assert 1.0 >= last_step_stats["val_avg_gen_time"] # model hanging on generate. Maybe bad config was saved.
assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
# check lightning ckpt can be loaded and has a reasonable statedict
contents = os.listdir(output_dir)
ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
full_path = os.path.join(args.output_dir, ckpt_path)
ckpt = torch.load(full_path, map_location="cpu")
expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
assert expected_key in ckpt["state_dict"]
assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
# TODO: turn on args.do_predict when PL bug fixed.
if args.do_predict:
contents = {os.path.basename(p) for p in contents}
assert "test_generations.txt" in contents
assert "test_results.txt" in contents
# assert len(metrics["val"]) == desired_n_evals
assert len(metrics["test"]) == 1
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/lightning_base.py
|
import argparse
import logging
import os
from pathlib import Path
from typing import Any, Dict
import pytorch_lightning as pl
from pytorch_lightning.utilities import rank_zero_info
from transformers import (
AdamW,
AutoConfig,
AutoModel,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
AutoModelWithLMHead,
AutoTokenizer,
PretrainedConfig,
PreTrainedTokenizer,
)
from transformers.optimization import (
Adafactor,
get_cosine_schedule_with_warmup,
get_cosine_with_hard_restarts_schedule_with_warmup,
get_linear_schedule_with_warmup,
get_polynomial_decay_schedule_with_warmup,
)
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
require_version("pytorch_lightning>=1.0.4")
MODEL_MODES = {
"base": AutoModel,
"sequence-classification": AutoModelForSequenceClassification,
"question-answering": AutoModelForQuestionAnswering,
"pretraining": AutoModelForPreTraining,
"token-classification": AutoModelForTokenClassification,
"language-modeling": AutoModelWithLMHead,
"summarization": AutoModelForSeq2SeqLM,
"translation": AutoModelForSeq2SeqLM,
}
# update this and the import above to support new schedulers from transformers.optimization
arg_to_scheduler = {
"linear": get_linear_schedule_with_warmup,
"cosine": get_cosine_schedule_with_warmup,
"cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
"polynomial": get_polynomial_decay_schedule_with_warmup,
# '': get_constant_schedule, # not supported for now
# '': get_constant_schedule_with_warmup, # not supported for now
}
arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
class BaseTransformer(pl.LightningModule):
def __init__(
self,
hparams: argparse.Namespace,
num_labels=None,
mode="base",
config=None,
tokenizer=None,
model=None,
**config_kwargs,
):
"""Initialize a model, tokenizer and config."""
super().__init__()
# TODO: move to self.save_hyperparameters()
# self.save_hyperparameters()
# can also expand arguments into trainer signature for easier reading
self.save_hyperparameters(hparams)
self.step_count = 0
self.output_dir = Path(self.hparams.output_dir)
cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
if config is None:
self.config = AutoConfig.from_pretrained(
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
**({"num_labels": num_labels} if num_labels is not None else {}),
cache_dir=cache_dir,
**config_kwargs,
)
else:
self.config: PretrainedConfig = config
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(self.hparams, p, None):
assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
setattr(self.config, p, getattr(self.hparams, p))
if tokenizer is None:
self.tokenizer = AutoTokenizer.from_pretrained(
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
cache_dir=cache_dir,
)
else:
self.tokenizer: PreTrainedTokenizer = tokenizer
self.model_type = MODEL_MODES[mode]
if model is None:
self.model = self.model_type.from_pretrained(
self.hparams.model_name_or_path,
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
config=self.config,
cache_dir=cache_dir,
)
else:
self.model = model
def load_hf_checkpoint(self, *args, **kwargs):
self.model = self.model_type.from_pretrained(*args, **kwargs)
def get_lr_scheduler(self):
get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
scheduler = get_schedule_func(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return scheduler
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay)"""
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
if self.hparams.adafactor:
optimizer = Adafactor(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
)
else:
optimizer = AdamW(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
)
self.opt = optimizer
scheduler = self.get_lr_scheduler()
return [optimizer], [scheduler]
def test_step(self, batch, batch_nb):
return self.validation_step(batch, batch_nb)
def test_epoch_end(self, outputs):
return self.validation_end(outputs)
def total_steps(self) -> int:
"""The number of total training steps that will be run. Used for lr scheduler purposes."""
num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
def setup(self, mode):
if mode == "test":
self.dataset_size = len(self.test_dataloader().dataset)
else:
self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
self.dataset_size = len(self.train_dataloader().dataset)
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
raise NotImplementedError("You must implement this for your task")
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
def test_dataloader(self):
return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
def _feature_file(self, mode):
return os.path.join(
self.hparams.data_dir,
"cached_{}_{}_{}".format(
mode,
list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
str(self.hparams.max_seq_length),
),
)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default=None,
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--encoder_layerdrop",
type=float,
help="Encoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--decoder_layerdrop",
type=float,
help="Decoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--dropout",
type=float,
help="Dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--attention_dropout",
type=float,
help="Attention dropout probability (Optional). Goes into model.config",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--lr_scheduler",
default="linear",
choices=arg_to_scheduler_choices,
metavar=arg_to_scheduler_metavar,
type=str,
help="Learning rate scheduler",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
parser.add_argument("--train_batch_size", default=32, type=int)
parser.add_argument("--eval_batch_size", default=32, type=int)
parser.add_argument("--adafactor", action="store_true")
class LoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
pl_module.logger.log_metrics(lrs)
def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Validation results *****")
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Test results *****")
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))
def add_generic_args(parser, root_dir) -> None:
# To allow all pl args uncomment the following line
# parser = pl.Trainer.add_argparse_args(parser)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O2",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
parser.add_argument(
"--gradient_accumulation_steps",
dest="accumulate_grad_batches",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
)
def generic_train(
model: BaseTransformer,
args: argparse.Namespace,
early_stopping_callback=None,
logger=True, # can pass WandbLogger() here
extra_callbacks=[],
checkpoint_callback=None,
logging_callback=None,
**extra_train_kwargs,
):
pl.seed_everything(args.seed)
# init model
odir = Path(model.hparams.output_dir)
odir.mkdir(exist_ok=True)
# add custom checkpoints
if checkpoint_callback is None:
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
)
if early_stopping_callback:
extra_callbacks.append(early_stopping_callback)
if logging_callback is None:
logging_callback = LoggingCallback()
train_params = {}
# TODO: remove with PyTorch 1.6 since pl uses native amp
if args.fp16:
train_params["precision"] = 16
train_params["amp_level"] = args.fp16_opt_level
if args.gpus > 1:
train_params["distributed_backend"] = "ddp"
train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
train_params["profiler"] = extra_train_kwargs.get("profiler", None)
trainer = pl.Trainer.from_argparse_args(
args,
weights_summary=None,
callbacks=[logging_callback] + extra_callbacks,
logger=logger,
checkpoint_callback=checkpoint_callback,
**train_params,
)
if args.do_train:
trainer.fit(model)
return trainer
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/callbacks.py
|
import logging
from pathlib import Path
import numpy as np
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.utilities import rank_zero_only
from utils import save_json
def count_trainable_parameters(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
return params
logger = logging.getLogger(__name__)
class Seq2SeqLoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
pl_module.logger.log_metrics(lrs)
@rank_zero_only
def _write_logs(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
) -> None:
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
metrics = trainer.callback_metrics
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
# Log results
od = Path(pl_module.hparams.output_dir)
if type_path == "test":
results_file = od / "test_results.txt"
generations_file = od / "test_generations.txt"
else:
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
# If people want this it will be easy enough to add back.
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
results_file.parent.mkdir(exist_ok=True)
generations_file.parent.mkdir(exist_ok=True)
with open(results_file, "a+") as writer:
for key in sorted(metrics):
if key in ["log", "progress_bar", "preds"]:
continue
val = metrics[key]
if isinstance(val, torch.Tensor):
val = val.item()
msg = f"{key}: {val:.6f}\n"
writer.write(msg)
if not save_generations:
return
if "preds" in metrics:
content = "\n".join(metrics["preds"])
generations_file.open("w+").write(content)
@rank_zero_only
def on_train_start(self, trainer, pl_module):
try:
npars = pl_module.model.model.num_parameters()
except AttributeError:
npars = pl_module.model.num_parameters()
n_trainable_pars = count_trainable_parameters(pl_module)
# mp stands for million parameters
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
@rank_zero_only
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
save_json(pl_module.metrics, pl_module.metrics_save_path)
return self._write_logs(trainer, pl_module, "test")
@rank_zero_only
def on_validation_end(self, trainer: pl.Trainer, pl_module):
save_json(pl_module.metrics, pl_module.metrics_save_path)
# Uncommenting this will save val generations
# return self._write_logs(trainer, pl_module, "valid")
def get_checkpoint_callback(output_dir, metric, save_top_k=1, lower_is_better=False):
"""Saves the best model by validation ROUGE2 score."""
if metric == "rouge2":
exp = "{val_avg_rouge2:.4f}-{step_count}"
elif metric == "bleu":
exp = "{val_avg_bleu:.4f}-{step_count}"
elif metric == "loss":
exp = "{val_avg_loss:.4f}-{step_count}"
else:
raise NotImplementedError(
f"seq2seq callbacks only support rouge2, bleu and loss, got {metric}, You can make your own by adding to"
" this function."
)
checkpoint_callback = ModelCheckpoint(
dirpath=output_dir,
filename=exp,
monitor=f"val_{metric}",
mode="min" if "loss" in metric else "max",
save_top_k=save_top_k,
)
return checkpoint_callback
def get_early_stopping_callback(metric, patience):
return EarlyStopping(
monitor=f"val_{metric}", # does this need avg?
mode="min" if "loss" in metric else "max",
patience=patience,
verbose=True,
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py
|
# as due to their complexity multi-gpu tests could impact other tests, and to aid debug we have those in a separate module.
import os
import sys
from pathlib import Path
import torch
from transformers.testing_utils import TestCasePlus, execute_subprocess_async, require_torch_multi_gpu
from utils import load_json
CUDA_AVAILABLE = torch.cuda.is_available()
ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
CHEAP_ARGS = {
"max_tokens_per_batch": None,
"supervise_forward": True,
"normalize_hidden": True,
"label_smoothing": 0.2,
"eval_max_gen_length": None,
"eval_beams": 1,
"val_metric": "loss",
"save_top_k": 1,
"adafactor": True,
"early_stopping_patience": 2,
"logger_name": "default",
"length_penalty": 0.5,
"cache_dir": "",
"task": "summarization",
"num_workers": 2,
"alpha_hid": 0,
"freeze_embeds": True,
"enc_only": False,
"tgt_suffix": "",
"resume_from_checkpoint": None,
"sortish_sampler": True,
"student_decoder_layers": 1,
"val_check_interval": 1.0,
"output_dir": "",
"fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
"no_teacher": False,
"fp16_opt_level": "O1",
"gpus": 1 if CUDA_AVAILABLE else 0,
"n_tpu_cores": 0,
"max_grad_norm": 1.0,
"do_train": True,
"do_predict": True,
"accumulate_grad_batches": 1,
"server_ip": "",
"server_port": "",
"seed": 42,
"model_name_or_path": "sshleifer/bart-tiny-random",
"config_name": "",
"tokenizer_name": "facebook/bart-large",
"do_lower_case": False,
"learning_rate": 0.3,
"lr_scheduler": "linear",
"weight_decay": 0.0,
"adam_epsilon": 1e-08,
"warmup_steps": 0,
"max_epochs": 1,
"train_batch_size": 2,
"eval_batch_size": 2,
"max_source_length": 12,
"max_target_length": 12,
"val_max_target_length": 12,
"test_max_target_length": 12,
"fast_dev_run": False,
"no_cache": False,
"n_train": -1,
"n_val": -1,
"n_test": -1,
"student_encoder_layers": 1,
"freeze_encoder": False,
"auto_scale_batch_size": False,
"overwrite_output_dir": False,
"student": None,
}
def _dump_articles(path: Path, articles: list):
content = "\n".join(articles)
Path(path).open("w").writelines(content)
def make_test_data_dir(tmp_dir):
for split in ["train", "val", "test"]:
_dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
_dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
return tmp_dir
class TestSummarizationDistillerMultiGPU(TestCasePlus):
@classmethod
def setUpClass(cls):
return cls
@require_torch_multi_gpu
def test_multi_gpu(self):
updates = {
"no_teacher": True,
"freeze_encoder": True,
"gpus": 2,
"overwrite_output_dir": True,
"sortish_sampler": True,
}
self._test_distiller_cli_fork(updates, check_contents=False)
def _test_distiller_cli_fork(self, updates, check_contents=True):
default_updates = {
"label_smoothing": 0.0,
"early_stopping_patience": -1,
"train_batch_size": 1,
"eval_batch_size": 2,
"max_epochs": 2,
"alpha_mlm": 0.2,
"alpha_ce": 0.8,
"do_predict": True,
"model_name_or_path": "sshleifer/tinier_bart",
"teacher": CHEAP_ARGS["model_name_or_path"],
"val_check_interval": 0.5,
}
default_updates.update(updates)
args_d: dict = CHEAP_ARGS.copy()
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
def convert(k, v):
if k in ["tgt_suffix", "server_ip", "server_port", "out", "n_tpu_cores"]:
return ""
if v is False or v is None:
return ""
if v is True: # or len(str(v))==0:
return f"--{k}"
return f"--{k}={v}"
cli_args = [x for x in (convert(k, v) for k, v in args_d.items()) if len(x)]
cmd = [sys.executable, f"{self.test_file_dir}/distillation.py"] + cli_args
execute_subprocess_async(cmd, env=self.get_env())
contents = os.listdir(output_dir)
contents = {os.path.basename(p) for p in contents}
ckpt_files = [p for p in contents if p.endswith("ckpt")]
assert len(ckpt_files) > 0
self.assertIn("test_generations.txt", contents)
self.assertIn("test_results.txt", contents)
# get the following from the module, (we don't have access to `model` here)
metrics_save_path = os.path.join(output_dir, "metrics.json")
val_metric = "rouge2"
metrics = load_json(metrics_save_path)
# {'test': [{'test_avg_loss': 10.63731575012207, 'test_avg_rouge1': 0.0, 'test_avg_rouge2': 0.0, 'test_avg_rougeL': 0.0, 'test_avg_gen_time': 0.1822289228439331, 'test_avg_gen_len': 142.0, 'step_count': 1}]}
print(metrics)
last_step_stats = metrics["val"][-1]
self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
self.assertIsInstance(last_step_stats[f"val_avg_{val_metric}"], float)
self.assertEqual(len(metrics["test"]), 1)
desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) / 2 + 1)
self.assertEqual(len(metrics["val"]), desired_n_evals)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/layoutlmv3/README.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification with LayoutLMv3 (PyTorch version)
This directory contains a script, `run_funsd_cord.py`, that can be used to fine-tune (or evaluate) LayoutLMv3 on form understanding datasets, such as [FUNSD](https://guillaumejaume.github.io/FUNSD/) and [CORD](https://github.com/clovaai/cord).
The script `run_funsd_cord.py` leverages the 🤗 Datasets library and the Trainer API. You can easily customize it to your needs.
## Fine-tuning on FUNSD
Fine-tuning LayoutLMv3 for token classification on [FUNSD](https://guillaumejaume.github.io/FUNSD/) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name funsd \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--evaluation_strategy steps \
--eval_steps 100 \
--learning_rate 1e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-funsd
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd. By specifying the `push_to_hub` flag, the model gets uploaded automatically to the hub (regularly), together with a model card, which includes metrics such as precision, recall and F1. Note that you can easily update the model card, as it's just a README file of the respective repo on the hub.
There's also the "Training metrics" [tab](https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd/tensorboard), which shows Tensorboard logs over the course of training. Pretty neat, huh?
## Fine-tuning on CORD
Fine-tuning LayoutLMv3 for token classification on [CORD](https://github.com/clovaai/cord) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name cord \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--evaluation_strategy steps \
--eval_steps 100 \
--learning_rate 5e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-cord
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-cord. Note that a model card gets generated automatically in case you specify the `push_to_hub` flag.
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/layoutlmv3/run_funsd_cord.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning LayoutLMv3 for token classification on FUNSD or CORD.
"""
# You can also adapt this script on your own token classification task and datasets. Pointers for this are left as
# comments.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import datasets
import numpy as np
from datasets import ClassLabel, load_dataset, load_metric
import transformers
from transformers import (
AutoConfig,
AutoModelForTokenClassification,
AutoProcessor,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.data.data_collator import default_data_collator
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.19.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
default="microsoft/layoutlmv3-base",
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
processor_name: Optional[str] = field(
default=None, metadata={"help": "Name or path to the processor files if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
dataset_name: Optional[str] = field(
default="nielsr/funsd-layoutlmv3",
metadata={"help": "The name of the dataset to use (via the datasets library)."},
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
)
text_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
)
label_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: int = field(
default=512,
metadata={
"help": (
"The maximum total input sequence length after tokenization. If set, sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
label_all_tokens: bool = field(
default=False,
metadata={
"help": (
"Whether to put the label for one word on all tokens of generated by that word or just on the "
"one (in which case the other tokens will have a padding index)."
)
},
)
return_entity_level_metrics: bool = field(
default=False,
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
self.task_name = self.task_name.lower()
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name == "funsd":
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
"nielsr/funsd-layoutlmv3",
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=True if model_args.use_auth_token else None,
)
elif data_args.dataset_name == "cord":
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
"nielsr/cord-layoutlmv3",
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=True if model_args.use_auth_token else None,
)
else:
raise ValueError("This script only supports either FUNSD or CORD out-of-the-box.")
if training_args.do_train:
column_names = dataset["train"].column_names
features = dataset["train"].features
else:
column_names = dataset["test"].column_names
features = dataset["test"].features
image_column_name = "image"
text_column_name = "words" if "words" in column_names else "tokens"
boxes_column_name = "bboxes"
label_column_name = (
f"{data_args.task_name}_tags" if f"{data_args.task_name}_tags" in column_names else column_names[1]
)
remove_columns = column_names
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
# If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
# Otherwise, we have to get the list of labels manually.
if isinstance(features[label_column_name].feature, ClassLabel):
label_list = features[label_column_name].feature.names
# No need to convert the labels since they are already ints.
id2label = dict(enumerate(label_list))
label2id = {v: k for k, v in enumerate(label_list)}
else:
label_list = get_label_list(datasets["train"][label_column_name])
id2label = dict(enumerate(label_list))
label2id = {v: k for k, v in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and processor
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
processor = AutoProcessor.from_pretrained(
model_args.processor_name if model_args.processor_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=True,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
add_prefix_space=True,
apply_ocr=False,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
# Set the correspondences label/ID inside the model config
model.config.label2id = label2id
model.config.id2label = id2label
# Preprocessing the dataset
# The processor does everything for us (prepare the image using LayoutLMv3ImageProcessor
# and prepare the words, boxes and word-level labels using LayoutLMv3TokenizerFast)
def prepare_examples(examples):
images = examples[image_column_name]
words = examples[text_column_name]
boxes = examples[boxes_column_name]
word_labels = examples[label_column_name]
encoding = processor(
images,
words,
boxes=boxes,
word_labels=word_labels,
truncation=True,
padding="max_length",
max_length=data_args.max_seq_length,
)
return encoding
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
train_dataset = dataset["train"]
if data_args.max_train_samples is not None:
train_dataset = train_dataset.select(range(data_args.max_train_samples))
with training_args.main_process_first(desc="train dataset map pre-processing"):
train_dataset = train_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
validation_name = "test"
if validation_name not in dataset:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = dataset[validation_name]
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
with training_args.main_process_first(desc="validation dataset map pre-processing"):
eval_dataset = eval_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
if "test" not in datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = datasets["test"]
if data_args.max_predict_samples is not None:
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
predict_dataset = predict_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
# Metrics
metric = load_metric("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
if data_args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=processor,
data_collator=default_data_collator,
compute_metrics=compute_metrics,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
trainer.save_model() # Saves the tokenizer too for easy upload
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Predict
if training_args.do_predict:
logger.info("*** Predict ***")
predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# Save predictions
output_predictions_file = os.path.join(training_args.output_dir, "predictions.txt")
if trainer.is_world_process_zero():
with open(output_predictions_file, "w") as writer:
for prediction in true_predictions:
writer.write(" ".join(prediction) + "\n")
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/layoutlmv3/requirements.txt
|
datasets
seqeval
pillow
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/README.md
|
<!---
Copyright 2021 NVIDIA Corporation. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Huggingface QDQBERT Quantization Example
The QDQBERT model adds fake quantization (pair of QuantizeLinear/DequantizeLinear ops) to:
* linear layer inputs and weights
* matmul inputs
* residual add inputs
In this example, we use QDQBERT model to do quantization on SQuAD task, including Quantization Aware Training (QAT), Post Training Quantization (PTQ) and inferencing using TensorRT.
Required:
- [pytorch-quantization toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization)
- [TensorRT >= 8.2](https://developer.nvidia.com/tensorrt)
- PyTorch >= 1.10.0
## Setup the environment with Dockerfile
Under the directory of `transformers/`, build the docker image:
```
docker build . -f examples/research_projects/quantization-qdqbert/Dockerfile -t bert_quantization:latest
```
Run the docker:
```
docker run --gpus all --privileged --rm -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 bert_quantization:latest
```
In the container:
```
cd transformers/examples/research_projects/quantization-qdqbert/
```
## Quantization Aware Training (QAT)
Calibrate the pretrained model and finetune with quantization awared:
```
python3 run_quant_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir calib/bert-base-uncased \
--do_calib \
--calibrator percentile \
--percentile 99.99
```
```
python3 run_quant_qa.py \
--model_name_or_path calib/bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 4e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir finetuned_int8/bert-base-uncased \
--tokenizer_name bert-base-uncased \
--save_steps 0
```
### Export QAT model to ONNX
To export the QAT model finetuned above:
```
python3 run_quant_qa.py \
--model_name_or_path finetuned_int8/bert-base-uncased \
--output_dir ./ \
--save_onnx \
--per_device_eval_batch_size 1 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased
```
Use `--recalibrate-weights` to calibrate the weight ranges according to the quantizer axis. Use `--quant-per-tensor` for per tensor quantization (default is per channel).
Recalibrating will affect the accuracy of the model, but the change should be minimal (< 0.5 F1).
### Benchmark the INT8 QAT ONNX model inference with TensorRT using dummy input
```
trtexec --onnx=model.onnx --explicitBatch --workspace=16384 --int8 --shapes=input_ids:64x128,attention_mask:64x128,token_type_ids:64x128 --verbose
```
### Benchmark the INT8 QAT ONNX model inference with [ONNX Runtime-TRT](https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html) using dummy input
```
python3 ort-infer-benchmark.py
```
### Evaluate the INT8 QAT ONNX model inference with TensorRT
```
python3 evaluate-hf-trt-qa.py \
--onnx_model_path=./model.onnx \
--output_dir ./ \
--per_device_eval_batch_size 64 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased \
--int8 \
--seed 42
```
## Fine-tuning of FP32 model for comparison
Finetune a fp32 precision model with [transformers/examples/pytorch/question-answering/](../../pytorch/question-answering/):
```
python3 ../../pytorch/question-answering/run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir ./finetuned_fp32/bert-base-uncased \
--save_steps 0 \
--do_train \
--do_eval
```
## Post Training Quantization (PTQ)
### PTQ by calibrating and evaluating the finetuned FP32 model above:
```
python3 run_quant_qa.py \
--model_name_or_path ./finetuned_fp32/bert-base-uncased \
--dataset_name squad \
--calibrator percentile \
--percentile 99.99 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir ./calib/bert-base-uncased \
--save_steps 0 \
--do_calib \
--do_eval
```
### Export the INT8 PTQ model to ONNX
```
python3 run_quant_qa.py \
--model_name_or_path ./calib/bert-base-uncased \
--output_dir ./ \
--save_onnx \
--per_device_eval_batch_size 1 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased
```
### Evaluate the INT8 PTQ ONNX model inference with TensorRT
```
python3 evaluate-hf-trt-qa.py \
--onnx_model_path=./model.onnx \
--output_dir ./ \
--per_device_eval_batch_size 64 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased \
--int8 \
--seed 42
```
### Quantization options
Some useful options to support different implementations and optimizations. These should be specified for both calibration and finetuning.
|argument|description|
|--------|-----------|
|`--quant-per-tensor`| quantize weights with one quantization range per tensor |
|`--fuse-qkv` | use a single range (the max) for quantizing QKV weights and output activations |
|`--clip-gelu N` | clip the output of GELU to a maximum of N when quantizing (e.g. 10) |
|`--disable-dropout` | disable dropout for consistent activation ranges |
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/Dockerfile
|
# coding=utf-8
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
FROM nvcr.io/nvidia/pytorch:22.02-py3
LABEL maintainer="Hugging Face"
LABEL repository="transformers"
RUN apt-get update
RUN apt-get install sudo
RUN python3 -m pip install --no-cache-dir --upgrade pip
RUN python3 -m pip install --no-cache-dir --ignore-installed pycuda
RUN python3 -m pip install --no-cache-dir \
pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
RUN python3 -m pip install --no-cache-dir onnxruntime-gpu==1.11
WORKDIR /workspace
COPY . transformers/
RUN cd transformers/ && \
python3 -m pip install --no-cache-dir .
RUN python3 -m pip install --no-cache-dir datasets \
accelerate
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/utils_qa.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Post-processing utilities for question answering.
"""
import collections
import json
import logging
import os
from typing import Optional, Tuple
import numpy as np
from tqdm.auto import tqdm
logger = logging.getLogger(__name__)
def postprocess_qa_predictions(
examples,
features,
predictions: Tuple[np.ndarray, np.ndarray],
version_2_with_negative: bool = False,
n_best_size: int = 20,
max_answer_length: int = 30,
null_score_diff_threshold: float = 0.0,
output_dir: Optional[str] = None,
prefix: Optional[str] = None,
log_level: Optional[int] = logging.WARNING,
):
"""
Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
original contexts. This is the base postprocessing functions for models that only return start and end logits.
Args:
examples: The non-preprocessed dataset (see the main script for more information).
features: The processed dataset (see the main script for more information).
predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
first dimension must match the number of elements of :obj:`features`.
version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the underlying dataset contains examples with no answers.
n_best_size (:obj:`int`, `optional`, defaults to 20):
The total number of n-best predictions to generate when looking for an answer.
max_answer_length (:obj:`int`, `optional`, defaults to 30):
The maximum length of an answer that can be generated. This is needed because the start and end predictions
are not conditioned on one another.
null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
The threshold used to select the null answer: if the best answer has a score that is less than the score of
the null answer minus this threshold, the null answer is selected for this example (note that the score of
the null answer for an example giving several features is the minimum of the scores for the null answer on
each feature: all features must be aligned on the fact they `want` to predict a null answer).
Only useful when :obj:`version_2_with_negative` is :obj:`True`.
output_dir (:obj:`str`, `optional`):
If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
:obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
answers, are saved in `output_dir`.
prefix (:obj:`str`, `optional`):
If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
``logging`` log level (e.g., ``logging.WARNING``)
"""
if len(predictions) != 2:
raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
all_start_logits, all_end_logits = predictions
if len(predictions[0]) != len(features):
raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
# Build a map example to its corresponding features.
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# The dictionaries we have to fill.
all_predictions = collections.OrderedDict()
all_nbest_json = collections.OrderedDict()
if version_2_with_negative:
scores_diff_json = collections.OrderedDict()
# Logging.
logger.setLevel(log_level)
logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
# Let's loop over all the examples!
for example_index, example in enumerate(tqdm(examples)):
# Those are the indices of the features associated to the current example.
feature_indices = features_per_example[example_index]
min_null_prediction = None
prelim_predictions = []
# Looping through all the features associated to the current example.
for feature_index in feature_indices:
# We grab the predictions of the model for this feature.
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
# This is what will allow us to map some the positions in our logits to span of texts in the original
# context.
offset_mapping = features[feature_index]["offset_mapping"]
# Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
# available in the current feature.
token_is_max_context = features[feature_index].get("token_is_max_context", None)
# Update minimum null prediction.
feature_null_score = start_logits[0] + end_logits[0]
if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
min_null_prediction = {
"offsets": (0, 0),
"score": feature_null_score,
"start_logit": start_logits[0],
"end_logit": end_logits[0],
}
# Go through all possibilities for the `n_best_size` greater start and end logits.
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
# to part of the input_ids that are not in the context.
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or len(offset_mapping[start_index]) < 2
or offset_mapping[end_index] is None
or len(offset_mapping[end_index]) < 2
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
# Don't consider answer that don't have the maximum context available (if such information is
# provided).
if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
continue
prelim_predictions.append(
{
"offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
"score": start_logits[start_index] + end_logits[end_index],
"start_logit": start_logits[start_index],
"end_logit": end_logits[end_index],
}
)
if version_2_with_negative:
# Add the minimum null prediction
prelim_predictions.append(min_null_prediction)
null_score = min_null_prediction["score"]
# Only keep the best `n_best_size` predictions.
predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
# Add back the minimum null prediction if it was removed because of its low score.
if version_2_with_negative and not any(p["offsets"] == (0, 0) for p in predictions):
predictions.append(min_null_prediction)
# Use the offsets to gather the answer text in the original context.
context = example["context"]
for pred in predictions:
offsets = pred.pop("offsets")
pred["text"] = context[offsets[0] : offsets[1]]
# In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
# failure.
if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
# Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
# the LogSumExp trick).
scores = np.array([pred.pop("score") for pred in predictions])
exp_scores = np.exp(scores - np.max(scores))
probs = exp_scores / exp_scores.sum()
# Include the probabilities in our predictions.
for prob, pred in zip(probs, predictions):
pred["probability"] = prob
# Pick the best prediction. If the null answer is not possible, this is easy.
if not version_2_with_negative:
all_predictions[example["id"]] = predictions[0]["text"]
else:
# Otherwise we first need to find the best non-empty prediction.
i = 0
while predictions[i]["text"] == "":
i += 1
best_non_null_pred = predictions[i]
# Then we compare to the null prediction using the threshold.
score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
if score_diff > null_score_diff_threshold:
all_predictions[example["id"]] = ""
else:
all_predictions[example["id"]] = best_non_null_pred["text"]
# Make `predictions` JSON-serializable by casting np.float back to float.
all_nbest_json[example["id"]] = [
{k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
for pred in predictions
]
# If we have an output_dir, let's save all those dicts.
if output_dir is not None:
if not os.path.isdir(output_dir):
raise EnvironmentError(f"{output_dir} is not a directory.")
prediction_file = os.path.join(
output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
)
nbest_file = os.path.join(
output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
)
if version_2_with_negative:
null_odds_file = os.path.join(
output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
)
logger.info(f"Saving predictions to {prediction_file}.")
with open(prediction_file, "w") as writer:
writer.write(json.dumps(all_predictions, indent=4) + "\n")
logger.info(f"Saving nbest_preds to {nbest_file}.")
with open(nbest_file, "w") as writer:
writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
if version_2_with_negative:
logger.info(f"Saving null_odds to {null_odds_file}.")
with open(null_odds_file, "w") as writer:
writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
return all_predictions
def postprocess_qa_predictions_with_beam_search(
examples,
features,
predictions: Tuple[np.ndarray, np.ndarray],
version_2_with_negative: bool = False,
n_best_size: int = 20,
max_answer_length: int = 30,
start_n_top: int = 5,
end_n_top: int = 5,
output_dir: Optional[str] = None,
prefix: Optional[str] = None,
log_level: Optional[int] = logging.WARNING,
):
"""
Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
cls token predictions.
Args:
examples: The non-preprocessed dataset (see the main script for more information).
features: The processed dataset (see the main script for more information).
predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
first dimension must match the number of elements of :obj:`features`.
version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the underlying dataset contains examples with no answers.
n_best_size (:obj:`int`, `optional`, defaults to 20):
The total number of n-best predictions to generate when looking for an answer.
max_answer_length (:obj:`int`, `optional`, defaults to 30):
The maximum length of an answer that can be generated. This is needed because the start and end predictions
are not conditioned on one another.
start_n_top (:obj:`int`, `optional`, defaults to 5):
The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
end_n_top (:obj:`int`, `optional`, defaults to 5):
The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
output_dir (:obj:`str`, `optional`):
If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
:obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
answers, are saved in `output_dir`.
prefix (:obj:`str`, `optional`):
If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
``logging`` log level (e.g., ``logging.WARNING``)
"""
if len(predictions) != 5:
raise ValueError("`predictions` should be a tuple with five elements.")
start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
if len(predictions[0]) != len(features):
raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
# Build a map example to its corresponding features.
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# The dictionaries we have to fill.
all_predictions = collections.OrderedDict()
all_nbest_json = collections.OrderedDict()
scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
# Logging.
logger.setLevel(log_level)
logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
# Let's loop over all the examples!
for example_index, example in enumerate(tqdm(examples)):
# Those are the indices of the features associated to the current example.
feature_indices = features_per_example[example_index]
min_null_score = None
prelim_predictions = []
# Looping through all the features associated to the current example.
for feature_index in feature_indices:
# We grab the predictions of the model for this feature.
start_log_prob = start_top_log_probs[feature_index]
start_indexes = start_top_index[feature_index]
end_log_prob = end_top_log_probs[feature_index]
end_indexes = end_top_index[feature_index]
feature_null_score = cls_logits[feature_index]
# This is what will allow us to map some the positions in our logits to span of texts in the original
# context.
offset_mapping = features[feature_index]["offset_mapping"]
# Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
# available in the current feature.
token_is_max_context = features[feature_index].get("token_is_max_context", None)
# Update minimum null prediction
if min_null_score is None or feature_null_score < min_null_score:
min_null_score = feature_null_score
# Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
for i in range(start_n_top):
for j in range(end_n_top):
start_index = int(start_indexes[i])
j_index = i * end_n_top + j
end_index = int(end_indexes[j_index])
# Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
# p_mask but let's not take any risk)
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# Don't consider answers with a length negative or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
# Don't consider answer that don't have the maximum context available (if such information is
# provided).
if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
continue
prelim_predictions.append(
{
"offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
"score": start_log_prob[i] + end_log_prob[j_index],
"start_log_prob": start_log_prob[i],
"end_log_prob": end_log_prob[j_index],
}
)
# Only keep the best `n_best_size` predictions.
predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
# Use the offsets to gather the answer text in the original context.
context = example["context"]
for pred in predictions:
offsets = pred.pop("offsets")
pred["text"] = context[offsets[0] : offsets[1]]
# In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
# failure.
if len(predictions) == 0:
predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": -2e-6})
# Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
# the LogSumExp trick).
scores = np.array([pred.pop("score") for pred in predictions])
exp_scores = np.exp(scores - np.max(scores))
probs = exp_scores / exp_scores.sum()
# Include the probabilities in our predictions.
for prob, pred in zip(probs, predictions):
pred["probability"] = prob
# Pick the best prediction and set the probability for the null answer.
all_predictions[example["id"]] = predictions[0]["text"]
if version_2_with_negative:
scores_diff_json[example["id"]] = float(min_null_score)
# Make `predictions` JSON-serializable by casting np.float back to float.
all_nbest_json[example["id"]] = [
{k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
for pred in predictions
]
# If we have an output_dir, let's save all those dicts.
if output_dir is not None:
if not os.path.isdir(output_dir):
raise EnvironmentError(f"{output_dir} is not a directory.")
prediction_file = os.path.join(
output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
)
nbest_file = os.path.join(
output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
)
if version_2_with_negative:
null_odds_file = os.path.join(
output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
)
logger.info(f"Saving predictions to {prediction_file}.")
with open(prediction_file, "w") as writer:
writer.write(json.dumps(all_predictions, indent=4) + "\n")
logger.info(f"Saving nbest_preds to {nbest_file}.")
with open(nbest_file, "w") as writer:
writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
if version_2_with_negative:
logger.info(f"Saving null_odds to {null_odds_file}.")
with open(null_odds_file, "w") as writer:
writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
return all_predictions, scores_diff_json
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py
|
# coding=utf-8
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning the library models for question-answering on SQuAD (DistilBERT, Bert, XLM, XLNet)."""
import argparse
import logging
import os
import time
import timeit
import datasets
import numpy as np
import pycuda.autoinit # noqa: F401
import pycuda.driver as cuda
import tensorrt as trt
import torch
from absl import logging as absl_logging
from accelerate import Accelerator
from datasets import load_dataset, load_metric
from torch.utils.data import DataLoader
from utils_qa import postprocess_qa_predictions
import transformers
from transformers import AutoTokenizer, EvalPrediction, default_data_collator, set_seed
from transformers.trainer_pt_utils import nested_concat, nested_truncate
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
absl_logger = absl_logging.get_absl_logger()
absl_logger.setLevel(logging.WARNING)
logger = logging.getLogger(__name__)
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--onnx_model_path",
default=None,
type=str,
required=True,
help="Path to ONNX model: ",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Other parameters
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
required=True,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, the SQuAD examples contain some that do not have an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help="If null_score - best_non_null is greater than the threshold predict null.",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help=(
"The maximum total input sequence length after WordPiece tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded."
),
)
parser.add_argument(
"--doc_stride",
default=128,
type=int,
help="When splitting up a long document into chunks, how much stride to take between chunks.",
)
parser.add_argument("--per_device_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation.")
parser.add_argument(
"--n_best_size",
default=20,
type=int,
help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
)
parser.add_argument(
"--max_answer_length",
default=30,
type=int,
help=(
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
),
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
required=True,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--preprocessing_num_workers", type=int, default=4, help="A csv or a json file containing the training data."
)
parser.add_argument("--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision instead of 32-bit",
)
parser.add_argument(
"--int8",
action="store_true",
help="Whether to use INT8",
)
args = parser.parse_args()
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=True)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
logger.info("Training/evaluation parameters %s", args)
args.eval_batch_size = args.per_device_eval_batch_size
INPUT_SHAPE = (args.eval_batch_size, args.max_seq_length)
# TRT Engine properties
STRICT_TYPES = True
engine_name = "temp_engine/bert-fp32.engine"
if args.fp16:
engine_name = "temp_engine/bert-fp16.engine"
if args.int8:
engine_name = "temp_engine/bert-int8.engine"
# import ONNX file
if not os.path.exists("temp_engine"):
os.makedirs("temp_engine")
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(
network, TRT_LOGGER
) as parser:
with open(args.onnx_model_path, "rb") as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
# Query input names and shapes from parsed TensorRT network
network_inputs = [network.get_input(i) for i in range(network.num_inputs)]
input_names = [_input.name for _input in network_inputs] # ex: ["actual_input1"]
with builder.create_builder_config() as config:
config.max_workspace_size = 1 << 50
if STRICT_TYPES:
config.set_flag(trt.BuilderFlag.STRICT_TYPES)
if args.fp16:
config.set_flag(trt.BuilderFlag.FP16)
if args.int8:
config.set_flag(trt.BuilderFlag.INT8)
profile = builder.create_optimization_profile()
config.add_optimization_profile(profile)
for i in range(len(input_names)):
profile.set_shape(input_names[i], INPUT_SHAPE, INPUT_SHAPE, INPUT_SHAPE)
engine = builder.build_engine(network, config)
# serialize_engine and store in file (can be directly loaded and deserialized):
with open(engine_name, "wb") as f:
f.write(engine.serialize())
# run inference with TRT
def model_infer(inputs, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream):
input_ids = np.asarray(inputs["input_ids"], dtype=np.int32)
attention_mask = np.asarray(inputs["attention_mask"], dtype=np.int32)
token_type_ids = np.asarray(inputs["token_type_ids"], dtype=np.int32)
# Copy inputs
cuda.memcpy_htod_async(d_inputs[0], input_ids.ravel(), stream)
cuda.memcpy_htod_async(d_inputs[1], attention_mask.ravel(), stream)
cuda.memcpy_htod_async(d_inputs[2], token_type_ids.ravel(), stream)
# start time
start_time = time.time()
# Run inference
context.execute_async(
bindings=[int(d_inp) for d_inp in d_inputs] + [int(d_output0), int(d_output1)], stream_handle=stream.handle
)
# Transfer predictions back from GPU
cuda.memcpy_dtoh_async(h_output0, d_output0, stream)
cuda.memcpy_dtoh_async(h_output1, d_output1, stream)
# Synchronize the stream and take time
stream.synchronize()
# end time
end_time = time.time()
infer_time = end_time - start_time
outputs = (h_output0, h_output1)
# print(outputs)
return outputs, infer_time
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
accelerator = Accelerator()
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
# accelerator.is_local_main_process is only True for one process per machine.
logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
raise ValueError("Evaluation requires a dataset name")
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Preprocessing the datasets.
# Preprocessing is slighlty different for training and evaluation.
column_names = raw_datasets["validation"].column_names
question_column_name = "question" if "question" in column_names else column_names[0]
context_column_name = "context" if "context" in column_names else column_names[1]
answer_column_name = "answers" if "answers" in column_names else column_names[2]
# Padding side determines if we do (question|context) or (context|question).
pad_on_right = tokenizer.padding_side == "right"
if args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
# Validation preprocessing
def prepare_validation_features(examples):
# Some of the questions have lots of whitespace on the left, which is not useful and will make the
# truncation of the context fail (the tokenized question will take a lots of space). So we remove that
# left whitespace
examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
# corresponding example_id and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
eval_examples = raw_datasets["validation"]
# Validation Feature Creation
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
data_collator = default_data_collator
eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
eval_dataloader = DataLoader(
eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
)
# Post-processing:
def post_processing_function(examples, features, predictions, stage="eval"):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions = postprocess_qa_predictions(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=args.version_2_with_negative,
n_best_size=args.n_best_size,
max_answer_length=args.max_answer_length,
null_score_diff_threshold=args.null_score_diff_threshold,
output_dir=args.output_dir,
prefix=stage,
)
# Format the result to the format the metric expects.
if args.version_2_with_negative:
formatted_predictions = [
{"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)
metric = load_metric("squad_v2" if args.version_2_with_negative else "squad")
# Evaluation!
logger.info("Loading ONNX model %s for evaluation", args.onnx_model_path)
with open(engine_name, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime, runtime.deserialize_cuda_engine(
f.read()
) as engine, engine.create_execution_context() as context:
# setup for TRT inferrence
for i in range(len(input_names)):
context.set_binding_shape(i, INPUT_SHAPE)
assert context.all_binding_shapes_specified
def binding_nbytes(binding):
return trt.volume(engine.get_binding_shape(binding)) * engine.get_binding_dtype(binding).itemsize
# Allocate device memory for inputs and outputs.
d_inputs = [cuda.mem_alloc(binding_nbytes(binding)) for binding in engine if engine.binding_is_input(binding)]
# Allocate output buffer
h_output0 = cuda.pagelocked_empty(tuple(context.get_binding_shape(3)), dtype=np.float32)
h_output1 = cuda.pagelocked_empty(tuple(context.get_binding_shape(4)), dtype=np.float32)
d_output0 = cuda.mem_alloc(h_output0.nbytes)
d_output1 = cuda.mem_alloc(h_output1.nbytes)
# Create a stream in which to copy inputs/outputs and run inference.
stream = cuda.Stream()
# Evaluation
logger.info("***** Running Evaluation *****")
logger.info(f" Num examples = {len(eval_dataset)}")
logger.info(f" Batch size = {args.per_device_eval_batch_size}")
total_time = 0.0
niter = 0
start_time = timeit.default_timer()
all_preds = None
for step, batch in enumerate(eval_dataloader):
outputs, infer_time = model_infer(batch, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream)
total_time += infer_time
niter += 1
start_logits, end_logits = outputs
start_logits = torch.tensor(start_logits)
end_logits = torch.tensor(end_logits)
# necessary to pad predictions and labels for being gathered
start_logits = accelerator.pad_across_processes(start_logits, dim=1, pad_index=-100)
end_logits = accelerator.pad_across_processes(end_logits, dim=1, pad_index=-100)
logits = (accelerator.gather(start_logits).cpu().numpy(), accelerator.gather(end_logits).cpu().numpy())
all_preds = logits if all_preds is None else nested_concat(all_preds, logits, padding_index=-100)
if all_preds is not None:
all_preds = nested_truncate(all_preds, len(eval_dataset))
evalTime = timeit.default_timer() - start_time
logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(eval_dataset))
# Inference time from TRT
logger.info("Average Inference Time = {:.3f} ms".format(total_time * 1000 / niter))
logger.info("Total Inference Time = {:.3f} ms".format(total_time * 1000))
logger.info("Total Number of Inference = %d", niter)
prediction = post_processing_function(eval_examples, eval_dataset, all_preds)
eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
logger.info(f"Evaluation metrics: {eval_metric}")
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/run_quant_qa.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for question answering.
"""
# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import datasets
import quant_trainer
from datasets import load_dataset, load_metric
from trainer_quant_qa import QuestionAnsweringTrainer
from utils_qa import postprocess_qa_predictions
import transformers
from transformers import (
AutoTokenizer,
DataCollatorWithPadding,
EvalPrediction,
HfArgumentParser,
PreTrainedTokenizerFast,
QDQBertConfig,
QDQBertForQuestionAnswering,
TrainingArguments,
default_data_collator,
set_seed,
)
from transformers.trainer_utils import SchedulerType, get_last_checkpoint
from transformers.utils import check_min_version
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.9.0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
do_calib: bool = field(default=False, metadata={"help": "Whether to run calibration of quantization ranges."})
num_calib_batch: int = field(
default=4,
metadata={"help": "Number of batches for calibration. 0 will disable calibration "},
)
save_onnx: bool = field(default=False, metadata={"help": "Whether to save model to onnx."})
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: int = field(
default=384,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
pad_to_max_length: bool = field(
default=True,
metadata={
"help": (
"Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
" batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
version_2_with_negative: bool = field(
default=False, metadata={"help": "If true, some of the examples do not have an answer."}
)
null_score_diff_threshold: float = field(
default=0.0,
metadata={
"help": (
"The threshold used to select the null answer: if the best answer has a score that is less than "
"the score of the null answer minus this threshold, the null answer is selected for this example. "
"Only useful when `version_2_with_negative=True`."
)
},
)
doc_stride: int = field(
default=128,
metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
)
n_best_size: int = field(
default=20,
metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
)
max_answer_length: int = field(
default=30,
metadata={
"help": (
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
)
},
)
def __post_init__(self):
if (
self.dataset_name is None
and self.train_file is None
and self.validation_file is None
and self.test_file is None
):
raise ValueError("Need either a dataset name or a training/validation file/test_file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if self.test_file is not None:
extension = self.test_file.split(".")[-1]
assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
# quant_trainer arguments
quant_trainer.add_arguments(parser)
# if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# # If we pass only one argument to the script and it's the path to a json file,
# # let's parse it to get our arguments.
# model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
# else:
model_args, data_args, training_args, quant_trainer_args = parser.parse_args_into_dataclasses()
# setup QAT training args for scheduler (default to use cosine annealing learning rate schedule)
training_args.lr_scheduler_type = SchedulerType.COSINE
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files, field="data", cache_dir=model_args.cache_dir)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# set default quantization parameters before building model
quant_trainer.set_default_quantizers(quant_trainer_args)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = QDQBertConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=True,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
model = QDQBertForQuestionAnswering.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
# Tokenizer check: this script requires a fast tokenizer.
if not isinstance(tokenizer, PreTrainedTokenizerFast):
raise ValueError(
"This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
" https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
" this requirement"
)
# Preprocessing the datasets.
# Preprocessing is slighlty different for training and evaluation.
if training_args.do_train or model_args.do_calib:
column_names = raw_datasets["train"].column_names
elif training_args.do_eval or model_args.save_onnx:
column_names = raw_datasets["validation"].column_names
else:
column_names = raw_datasets["test"].column_names
question_column_name = "question" if "question" in column_names else column_names[0]
context_column_name = "context" if "context" in column_names else column_names[1]
answer_column_name = "answers" if "answers" in column_names else column_names[2]
# Padding side determines if we do (question|context) or (context|question).
pad_on_right = tokenizer.padding_side == "right"
if data_args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
# Training preprocessing
def prepare_train_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=data_args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length" if data_args.pad_to_max_length else False,
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The offset mappings will give us a map from token to character position in the original context. This will
# help us compute the start_positions and end_positions.
offset_mapping = tokenized_examples.pop("offset_mapping")
# Let's label those examples!
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
# We will label impossible answers with the index of the CLS token.
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
answers = examples[answer_column_name][sample_index]
# If no answers are given, set the cls_index as answer.
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Start/end character index of the answer in the text.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
if training_args.do_train or model_args.do_calib:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
# We will select sample from whole data if agument is specified
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
# Create train feature from dataset
with training_args.main_process_first(desc="train dataset map pre-processing"):
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
if data_args.max_train_samples is not None:
# Number of samples might increase during Feature Creation, We select only specified max samples
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
# Validation preprocessing
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=data_args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length" if data_args.pad_to_max_length else False,
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
# corresponding example_id and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
if training_args.do_eval or model_args.save_onnx:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_examples = raw_datasets["validation"]
if data_args.max_eval_samples is not None:
# We will select sample from whole data
max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
eval_examples = eval_examples.select(range(max_eval_samples))
# Validation Feature Creation
with training_args.main_process_first(desc="validation dataset map pre-processing"):
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
if data_args.max_eval_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
if training_args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_examples = raw_datasets["test"]
if data_args.max_predict_samples is not None:
# We will select sample from whole data
predict_examples = predict_examples.select(range(data_args.max_predict_samples))
# Predict Feature Creation
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
predict_dataset = predict_examples.map(
prepare_validation_features,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on prediction dataset",
)
if data_args.max_predict_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
# Data collator
# We have already padded to max length if the corresponding flag is True, otherwise we need to pad in the data
# collator.
data_collator = (
default_data_collator
if data_args.pad_to_max_length
else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
)
# Post-processing:
def post_processing_function(examples, features, predictions, stage="eval"):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions = postprocess_qa_predictions(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=data_args.version_2_with_negative,
n_best_size=data_args.n_best_size,
max_answer_length=data_args.max_answer_length,
null_score_diff_threshold=data_args.null_score_diff_threshold,
output_dir=training_args.output_dir,
log_level=log_level,
prefix=stage,
)
# Format the result to the format the metric expects.
if data_args.version_2_with_negative:
formatted_predictions = [
{"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)
metric = load_metric("squad_v2" if data_args.version_2_with_negative else "squad")
def compute_metrics(p: EvalPrediction):
return metric.compute(predictions=p.predictions, references=p.label_ids)
# Initialize our Trainer
trainer = QuestionAnsweringTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train or model_args.do_calib else None,
eval_dataset=eval_dataset if training_args.do_eval or model_args.save_onnx else None,
eval_examples=eval_examples if training_args.do_eval or model_args.save_onnx else None,
tokenizer=tokenizer,
data_collator=data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
quant_trainer_args=quant_trainer_args,
)
# Calibration
if model_args.do_calib:
logger.info("*** Calibrate ***")
results = trainer.calibrate()
trainer.save_model()
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
quant_trainer.configure_model(trainer.model, quant_trainer_args)
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
quant_trainer.configure_model(trainer.model, quant_trainer_args, eval=True)
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Prediction
if training_args.do_predict:
logger.info("*** Predict ***")
results = trainer.predict(predict_dataset, predict_examples)
metrics = results.metrics
max_predict_samples = (
data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
if training_args.push_to_hub:
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
trainer.push_to_hub(**kwargs)
if model_args.save_onnx:
logger.info("Exporting model to onnx")
results = trainer.save_onnx(output_dir=training_args.output_dir)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py
|
import os
import time
import numpy as np
import onnxruntime as ort
os.environ["ORT_TENSORRT_INT8_ENABLE"] = "1"
os.environ["ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE"] = "0"
os.environ["ORT_TENSORRT_ENGINE_CACHE_ENABLE"] = "1"
sess_opt = ort.SessionOptions()
sess_opt.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
print("Create inference session...")
execution_provider = ["TensorrtExecutionProvider", "CUDAExecutionProvider"]
sess = ort.InferenceSession("model.onnx", sess_options=sess_opt, providers=execution_provider)
run_opt = ort.RunOptions()
sequence = 128
batch = 1
input_ids = np.ones((batch, sequence), dtype=np.int64)
attention_mask = np.ones((batch, sequence), dtype=np.int64)
token_type_ids = np.ones((batch, sequence), dtype=np.int64)
print("Warm up phase...")
sess.run(
None,
{
sess.get_inputs()[0].name: input_ids,
sess.get_inputs()[1].name: attention_mask,
sess.get_inputs()[2].name: token_type_ids,
},
run_options=run_opt,
)
print("Start inference...")
start_time = time.time()
max_iters = 2000
predict = {}
for iter in range(max_iters):
predict = sess.run(
None,
{
sess.get_inputs()[0].name: input_ids,
sess.get_inputs()[1].name: attention_mask,
sess.get_inputs()[2].name: token_type_ids,
},
run_options=run_opt,
)
print("Average Inference Time = {:.3f} ms".format((time.time() - start_time) * 1000 / max_iters))
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/quant_trainer.py
|
# coding=utf-8
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Helper functions for training models with pytorch-quantization"""
import logging
import re
import pytorch_quantization
import pytorch_quantization.nn as quant_nn
import torch
from pytorch_quantization import calib
from pytorch_quantization.tensor_quant import QuantDescriptor
logger = logging.getLogger(__name__)
name_width = 50 # max width of layer names
qname_width = 70 # max width of quantizer names
# ========================================== Quant Trainer API ==========================================
def add_arguments(parser):
"""Add arguments to parser for functions defined in quant_trainer."""
group = parser.add_argument_group("quant_trainer arguments")
group.add_argument("--wprec", type=int, default=8, help="weight precision")
group.add_argument("--aprec", type=int, default=8, help="activation precision")
group.add_argument("--quant-per-tensor", action="store_true", help="per tensor weight scaling")
group.add_argument("--quant-disable", action="store_true", help="disable all quantizers")
group.add_argument("--quant-disable-embeddings", action="store_true", help="disable all embeddings quantizers")
group.add_argument("--quant-disable-keyword", type=str, nargs="+", help="disable quantizers by keyword")
group.add_argument("--quant-disable-layer-module", type=str, help="disable quantizers by keyword under layer.")
group.add_argument("--quant-enable-layer-module", type=str, help="enable quantizers by keyword under layer")
group.add_argument("--calibrator", default="max", help="which quantization range calibrator to use")
group.add_argument("--percentile", default=None, type=float, help="percentile for PercentileCalibrator")
group.add_argument("--fuse-qkv", action="store_true", help="use the same scale factor for qkv")
group.add_argument("--clip-gelu", metavar="N", type=float, help="clip gelu output maximum value to N")
group.add_argument(
"--recalibrate-weights",
action="store_true",
help=(
"recalibrate weight amaxes by taking the max of the weights."
" amaxes will be computed with the current quantization granularity (axis)."
),
)
def set_default_quantizers(args):
"""Set default quantizers before creating the model."""
if args.calibrator == "max":
calib_method = "max"
elif args.calibrator == "percentile":
if args.percentile is None:
raise ValueError("Specify --percentile when using percentile calibrator")
calib_method = "histogram"
elif args.calibrator == "mse":
calib_method = "histogram"
else:
raise ValueError(f"Invalid calibrator {args.calibrator}")
input_desc = QuantDescriptor(num_bits=args.aprec, calib_method=calib_method)
weight_desc = QuantDescriptor(num_bits=args.wprec, axis=(None if args.quant_per_tensor else (0,)))
quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
def configure_model(model, args, calib=False, eval=False):
"""Function called before the training loop."""
logger.info("Configuring Model for Quantization")
logger.info(f"using quantization package {pytorch_quantization.__file__}")
if not calib:
if args.quant_disable_embeddings:
set_quantizer_by_name(model, ["embeddings"], which="weight", _disabled=True)
if args.quant_disable:
set_quantizer_by_name(model, [""], _disabled=True)
if args.quant_disable_keyword:
set_quantizer_by_name(model, args.quant_disable_keyword, _disabled=True)
if args.quant_disable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_disable_layer_module], _disabled=True)
if args.quant_enable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_enable_layer_module], _disabled=False)
if args.recalibrate_weights:
recalibrate_weights(model)
if args.fuse_qkv:
fuse_qkv(model, args)
if args.clip_gelu:
clip_gelu(model, args.clip_gelu)
# if args.local_rank in [-1, 0] and not calib:
print_quant_summary(model)
def enable_calibration(model):
"""Enable calibration of all *_input_quantizer modules in model."""
logger.info("Enabling Calibration")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
logger.info(f"{name:80}: {module}")
def finish_calibration(model, args):
"""Disable calibration and load amax for all "*_input_quantizer modules in model."""
logger.info("Loading calibrated amax")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax("percentile", percentile=args.percentile)
module.enable_quant()
module.disable_calib()
else:
module.enable()
model.cuda()
print_quant_summary(model)
# ========================================== Helper Function ==========================================
def fuse_qkv(model, args):
"""Adjust quantization ranges to match an implementation where the QKV projections are implemented with a single GEMM.
Force the weight and output scale factors to match by taking the max of (Q,K,V).
"""
def fuse3(qq, qk, qv):
for mod in [qq, qk, qv]:
if not hasattr(mod, "_amax"):
print(" WARNING: NO AMAX BUFFER")
return
q = qq._amax.detach().item()
k = qk._amax.detach().item()
v = qv._amax.detach().item()
amax = max(q, k, v)
qq._amax.fill_(amax)
qk._amax.fill_(amax)
qv._amax.fill_(amax)
logger.info(f" q={q:5.2f} k={k:5.2f} v={v:5.2f} -> {amax:5.2f}")
for name, mod in model.named_modules():
if name.endswith(".attention.self"):
logger.info(f"FUSE_QKV: {name:{name_width}}")
fuse3(mod.matmul_q_input_quantizer, mod.matmul_k_input_quantizer, mod.matmul_v_input_quantizer)
if args.quant_per_tensor:
fuse3(mod.query._weight_quantizer, mod.key._weight_quantizer, mod.value._weight_quantizer)
def clip_gelu(model, maxval):
"""Clip activations generated by GELU to maxval when quantized.
Implemented by adjusting the amax of the following input_quantizer.
"""
for name, mod in model.named_modules():
if name.endswith(".output.dense") and not name.endswith("attention.output.dense"):
amax_init = mod._input_quantizer._amax.data.detach().item()
mod._input_quantizer._amax.data.detach().clamp_(max=maxval)
amax = mod._input_quantizer._amax.data.detach().item()
logger.info(f"CLIP_GELU: {name:{name_width}} amax: {amax_init:5.2f} -> {amax:5.2f}")
def expand_amax(model):
"""Expand per-tensor amax to be per channel, where each channel is assigned the per-tensor amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer") and mod._weight_quantizer.axis is not None:
k = mod.weight.shape[0]
amax = mod._weight_quantizer._amax.detach()
mod._weight_quantizer._amax = torch.ones(k, dtype=amax.dtype, device=amax.device) * amax
print(f"expanding {name} {amax} -> {mod._weight_quantizer._amax}")
def recalibrate_weights(model):
"""Performs max calibration on the weights and updates amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer"):
if not hasattr(mod.weight_quantizer, "_amax"):
print("RECALIB: {name:{name_width}} WARNING: NO AMAX BUFFER")
continue
# determine which axes to reduce across
# e.g. a 4D tensor quantized per axis 0 should reduce over (1,2,3)
axis_set = set() if mod._weight_quantizer.axis is None else set(mod._weight_quantizer.axis)
reduce_axis = set(range(len(mod.weight.size()))) - axis_set
amax = pytorch_quantization.utils.reduce_amax(mod.weight, axis=reduce_axis, keepdims=True).detach()
logger.info(f"RECALIB: {name:{name_width}} {mod._weight_quantizer._amax.flatten()} -> {amax.flatten()}")
mod._weight_quantizer._amax = amax
def print_model_summary(model, name_width=25, line_width=180, ignore=None):
"""Print model quantization configuration."""
if ignore is None:
ignore = []
elif not isinstance(ignore, list):
ignore = [ignore]
name_width = 0
for name, mod in model.named_modules():
if not hasattr(mod, "weight"):
continue
name_width = max(name_width, len(name))
for name, mod in model.named_modules():
input_q = getattr(mod, "_input_quantizer", None)
weight_q = getattr(mod, "_weight_quantizer", None)
if not hasattr(mod, "weight"):
continue
if type(mod) in ignore:
continue
if [True for s in ignore if isinstance(s, str) and s in name]:
continue
act_str = f"Act:{input_q.extra_repr()}"
wgt_str = f"Wgt:{weight_q.extra_repr()}"
s = f"{name:{name_width}} {act_str} {wgt_str}"
if len(s) <= line_width:
logger.info(s)
else:
logger.info(f"{name:{name_width}} {act_str}")
logger.info(f'{" ":{name_width}} {wgt_str}')
def print_quant_summary(model):
"""Print summary of all quantizer modules in the model."""
count = 0
for name, mod in model.named_modules():
if isinstance(mod, pytorch_quantization.nn.TensorQuantizer):
print(f"{name:80} {mod}")
count += 1
print(f"{count} TensorQuantizers found in model")
def set_quantizer(name, mod, quantizer, k, v):
"""Set attributes for mod.quantizer."""
quantizer_mod = getattr(mod, quantizer, None)
if quantizer_mod is not None:
assert hasattr(quantizer_mod, k)
setattr(quantizer_mod, k, v)
else:
logger.warning(f"{name} has no {quantizer}")
def set_quantizers(name, mod, which="both", **kwargs):
"""Set quantizer attributes for mod."""
s = f"Warning: changing {which} quantizers of {name:{qname_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
if which in ["input", "both"]:
set_quantizer(name, mod, "_input_quantizer", k, v)
if which in ["weight", "both"]:
set_quantizer(name, mod, "_weight_quantizer", k, v)
logger.info(s)
def set_quantizer_by_name(model, names, **kwargs):
"""Set quantizer attributes for layers where name contains a substring in names."""
for name, mod in model.named_modules():
if hasattr(mod, "_input_quantizer") or hasattr(mod, "_weight_quantizer"):
for n in names:
if re.search(n, name):
set_quantizers(name, mod, **kwargs)
elif name.endswith("_quantizer"):
for n in names:
if re.search(n, name):
s = f"Warning: changing {name:{name_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
setattr(mod, k, v)
logger.info(s)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A subclass of `Trainer` specific to Question-Answering tasks
"""
import logging
import os
import quant_trainer
import torch
from torch.utils.data import DataLoader
from transformers import Trainer, is_torch_tpu_available
from transformers.trainer_utils import PredictionOutput
logger = logging.getLogger(__name__)
if is_torch_tpu_available(check_device=False):
import torch_xla.core.xla_model as xm
import torch_xla.debug.metrics as met
class QuestionAnsweringTrainer(Trainer):
def __init__(self, *args, eval_examples=None, post_process_function=None, quant_trainer_args=None, **kwargs):
super().__init__(*args, **kwargs)
self.eval_examples = eval_examples
self.post_process_function = post_process_function
self.quant_trainer_args = quant_trainer_args
self.calib_num = 128 # default number of calibration samples
def get_calib_dataloader(self, calib_dataset=None):
"""
Returns the calibration dataloader :class:`~torch.utils.data.DataLoader`.
Args:
calib_dataset (:obj:`torch.utils.data.Dataset`, `optional`)
"""
if calib_dataset is None and self.calib_dataset is None:
raise ValueError("Trainer: calibration requires an calib_dataset.")
calib_dataset = calib_dataset if calib_dataset is not None else self.calib_dataset
calib_dataset = self._remove_unused_columns(calib_dataset, description="Calibration")
return DataLoader(
calib_dataset,
batch_size=self.args.eval_batch_size,
collate_fn=self.data_collator,
drop_last=self.args.dataloader_drop_last,
num_workers=self.args.dataloader_num_workers,
pin_memory=self.args.dataloader_pin_memory,
shuffle=True,
)
def calibrate(self, calib_dataset=None):
calib_dataset = self.train_dataset if calib_dataset is None else calib_dataset
calib_dataloader = self.get_calib_dataloader(calib_dataset)
model = self.model
quant_trainer.configure_model(model, self.quant_trainer_args, calib=True)
model.eval()
quant_trainer.enable_calibration(model)
logger.info("***** Running calibration *****")
logger.info(f" Num examples = {self.calib_num}")
logger.info(f" Batch size = {calib_dataloader.batch_size}")
for step, inputs in enumerate(calib_dataloader):
# Prediction step
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only=True)
if (step + 1) * calib_dataloader.batch_size >= self.calib_num:
break
quant_trainer.finish_calibration(model, self.quant_trainer_args)
self.model = model
def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
eval_dataloader = self.get_eval_dataloader(eval_dataset)
eval_examples = self.eval_examples if eval_examples is None else eval_examples
# Temporarily disable metric computation, we will do it in the loop here.
compute_metrics = self.compute_metrics
self.compute_metrics = None
eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
try:
output = eval_loop(
eval_dataloader,
description="Evaluation",
# No point gathering the predictions if there are no metrics, otherwise we defer to
# self.args.prediction_loss_only
prediction_loss_only=True if compute_metrics is None else None,
ignore_keys=ignore_keys,
)
finally:
self.compute_metrics = compute_metrics
if self.post_process_function is not None and self.compute_metrics is not None:
eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)
metrics = self.compute_metrics(eval_preds)
# Prefix all keys with metric_key_prefix + '_'
for key in list(metrics.keys()):
if not key.startswith(f"{metric_key_prefix}_"):
metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
self.log(metrics)
else:
metrics = {}
if self.args.tpu_metrics_debug or self.args.debug:
# tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
xm.master_print(met.metrics_report())
self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
return metrics
def predict(self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test"):
predict_dataloader = self.get_test_dataloader(predict_dataset)
# Temporarily disable metric computation, we will do it in the loop here.
compute_metrics = self.compute_metrics
self.compute_metrics = None
eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
try:
output = eval_loop(
predict_dataloader,
description="Prediction",
# No point gathering the predictions if there are no metrics, otherwise we defer to
# self.args.prediction_loss_only
prediction_loss_only=True if compute_metrics is None else None,
ignore_keys=ignore_keys,
)
finally:
self.compute_metrics = compute_metrics
if self.post_process_function is None or self.compute_metrics is None:
return output
predictions = self.post_process_function(predict_examples, predict_dataset, output.predictions, "predict")
metrics = self.compute_metrics(predictions)
# Prefix all keys with metric_key_prefix + '_'
for key in list(metrics.keys()):
if not key.startswith(f"{metric_key_prefix}_"):
metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
def save_onnx(self, output_dir="./"):
eval_dataset = self.eval_dataset
eval_dataloader = self.get_eval_dataloader(eval_dataset)
batch = next(iter(eval_dataloader))
# saving device - to make it consistent
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# convert to tuple
input_tuple = tuple(v.to(device) for k, v in batch.items())
logger.info("Converting model to be onnx compatible")
from pytorch_quantization.nn import TensorQuantizer
TensorQuantizer.use_fb_fake_quant = True
model = self.model.to(device)
model.eval()
model.float()
model_to_save = model.module if hasattr(model, "module") else model
quant_trainer.configure_model(model_to_save, self.quant_trainer_args)
output_model_file = os.path.join(output_dir, "model.onnx")
logger.info(f"exporting model to {output_model_file}")
axes = {0: "batch_size", 1: "seq_len"}
torch.onnx.export(
model_to_save,
input_tuple,
output_model_file,
export_params=True,
opset_version=13,
do_constant_folding=True,
input_names=["input_ids", "attention_mask", "token_type_ids"],
output_names=["output_start_logits", "output_end_logits"],
dynamic_axes={
"input_ids": axes,
"attention_mask": axes,
"token_type_ids": axes,
"output_start_logits": axes,
"output_end_logits": axes,
},
verbose=True,
)
logger.info("onnx export finished")
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/README.md
|
# Text Summarization with Pretrained Encoders
This folder contains part of the code necessary to reproduce the results on abstractive summarization from the article [Text Summarization with Pretrained Encoders](https://arxiv.org/pdf/1908.08345.pdf) by [Yang Liu](https://nlp-yang.github.io/) and [Mirella Lapata](https://homepages.inf.ed.ac.uk/mlap/). It can also be used to summarize any document.
The original code can be found on the Yang Liu's [github repository](https://github.com/nlpyang/PreSumm).
The model is loaded with the pre-trained weights for the abstractive summarization model trained on the CNN/Daily Mail dataset with an extractive and then abstractive tasks.
## Setup
```
git clone https://github.com/huggingface/transformers && cd transformers
pip install .
pip install nltk py-rouge
cd examples/seq2seq/bertabs
```
## Reproduce the authors' ROUGE score
To be able to reproduce the authors' results on the CNN/Daily Mail dataset you first need to download both CNN and Daily Mail datasets [from Kyunghyun Cho's website](https://cs.nyu.edu/~kcho/DMQA/) (the links next to "Stories") in the same folder. Then uncompress the archives by running:
```bash
tar -xvf cnn_stories.tgz && tar -xvf dailymail_stories.tgz
```
And move all the stories to the same folder. We will refer as `$DATA_PATH` the path to where you uncompressed both archive. Then run the following in the same folder as `run_summarization.py`:
```bash
python run_summarization.py \
--documents_dir $DATA_PATH \
--summaries_output_dir $SUMMARIES_PATH \ # optional
--no_cuda false \
--batch_size 4 \
--min_length 50 \
--max_length 200 \
--beam_size 5 \
--alpha 0.95 \
--block_trigram true \
--compute_rouge true
```
The scripts executes on GPU if one is available and if `no_cuda` is not set to `true`. Inference on multiple GPUs is not supported yet. The ROUGE scores will be displayed in the console at the end of evaluation and written in a `rouge_scores.txt` file. The script takes 30 hours to compute with a single Tesla V100 GPU and a batch size of 10 (300,000 texts to summarize).
## Summarize any text
Put the documents that you would like to summarize in a folder (the path to which is referred to as `$DATA_PATH` below) and run the following in the same folder as `run_summarization.py`:
```bash
python run_summarization.py \
--documents_dir $DATA_PATH \
--summaries_output_dir $SUMMARIES_PATH \ # optional
--no_cuda false \
--batch_size 4 \
--min_length 50 \
--max_length 200 \
--beam_size 5 \
--alpha 0.95 \
--block_trigram true \
```
You may want to play around with `min_length`, `max_length` and `alpha` to suit your use case. If you want to compute ROUGE on another dataset you will need to tweak the stories/summaries import in `utils_summarization.py` and tell it where to fetch the reference summaries.
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/utils_summarization.py
|
import os
from collections import deque
import torch
from torch.utils.data import Dataset
# ------------
# Data loading
# ------------
class CNNDMDataset(Dataset):
"""Abstracts the dataset used to train seq2seq models.
The class will process the documents that are located in the specified
folder. The preprocessing will work on any document that is reasonably
formatted. On the CNN/DailyMail dataset it will extract both the story
and the summary.
CNN/Daily News:
The CNN/Daily News raw datasets are downloaded from [1]. The stories are
stored in different files; the summary appears at the end of the story as
sentences that are prefixed by the special `@highlight` line. To process
the data, untar both datasets in the same folder, and pass the path to this
folder as the "data_dir argument. The formatting code was inspired by [2].
[1] https://cs.nyu.edu/~kcho/
[2] https://github.com/abisee/cnn-dailymail/
"""
def __init__(self, path="", prefix="train"):
"""We initialize the class by listing all the documents to summarize.
Files are not read in memory due to the size of some datasets (like CNN/DailyMail).
"""
assert os.path.isdir(path)
self.documents = []
story_filenames_list = os.listdir(path)
for story_filename in story_filenames_list:
if "summary" in story_filename:
continue
path_to_story = os.path.join(path, story_filename)
if not os.path.isfile(path_to_story):
continue
self.documents.append(path_to_story)
def __len__(self):
"""Returns the number of documents."""
return len(self.documents)
def __getitem__(self, idx):
document_path = self.documents[idx]
document_name = document_path.split("/")[-1]
with open(document_path, encoding="utf-8") as source:
raw_story = source.read()
story_lines, summary_lines = process_story(raw_story)
return document_name, story_lines, summary_lines
def process_story(raw_story):
"""Extract the story and summary from a story file.
Arguments:
raw_story (str): content of the story file as an utf-8 encoded string.
Raises:
IndexError: If the story is empty or contains no highlights.
"""
nonempty_lines = list(filter(lambda x: len(x) != 0, [line.strip() for line in raw_story.split("\n")]))
# for some unknown reason some lines miss a period, add it
nonempty_lines = [_add_missing_period(line) for line in nonempty_lines]
# gather article lines
story_lines = []
lines = deque(nonempty_lines)
while True:
try:
element = lines.popleft()
if element.startswith("@highlight"):
break
story_lines.append(element)
except IndexError:
# if "@highlight" is absent from the file we pop
# all elements until there is None, raising an exception.
return story_lines, []
# gather summary lines
summary_lines = list(filter(lambda t: not t.startswith("@highlight"), lines))
return story_lines, summary_lines
def _add_missing_period(line):
END_TOKENS = [".", "!", "?", "...", "'", "`", '"', "\u2019", "\u2019", ")"]
if line.startswith("@highlight"):
return line
if line[-1] in END_TOKENS:
return line
return line + "."
# --------------------------
# Encoding and preprocessing
# --------------------------
def truncate_or_pad(sequence, block_size, pad_token_id):
"""Adapt the source and target sequences' lengths to the block size.
If the sequence is shorter we append padding token to the right of the sequence.
"""
if len(sequence) > block_size:
return sequence[:block_size]
else:
sequence.extend([pad_token_id] * (block_size - len(sequence)))
return sequence
def build_mask(sequence, pad_token_id):
"""Builds the mask. The attention mechanism will only attend to positions
with value 1."""
mask = torch.ones_like(sequence)
idx_pad_tokens = sequence == pad_token_id
mask[idx_pad_tokens] = 0
return mask
def encode_for_summarization(story_lines, summary_lines, tokenizer):
"""Encode the story and summary lines, and join them
as specified in [1] by using `[SEP] [CLS]` tokens to separate
sentences.
"""
story_lines_token_ids = [tokenizer.encode(line) for line in story_lines]
story_token_ids = [token for sentence in story_lines_token_ids for token in sentence]
summary_lines_token_ids = [tokenizer.encode(line) for line in summary_lines]
summary_token_ids = [token for sentence in summary_lines_token_ids for token in sentence]
return story_token_ids, summary_token_ids
def compute_token_type_ids(batch, separator_token_id):
"""Segment embeddings as described in [1]
The values {0,1} were found in the repository [2].
Attributes:
batch: torch.Tensor, size [batch_size, block_size]
Batch of input.
separator_token_id: int
The value of the token that separates the segments.
[1] Liu, Yang, and Mirella Lapata. "Text summarization with pretrained encoders."
arXiv preprint arXiv:1908.08345 (2019).
[2] https://github.com/nlpyang/PreSumm (/src/prepro/data_builder.py, commit fac1217)
"""
batch_embeddings = []
for sequence in batch:
sentence_num = -1
embeddings = []
for s in sequence:
if s == separator_token_id:
sentence_num += 1
embeddings.append(sentence_num % 2)
batch_embeddings.append(embeddings)
return torch.tensor(batch_embeddings)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/run_summarization.py
|
#! /usr/bin/python3
import argparse
import logging
import os
import sys
from collections import namedtuple
import torch
from modeling_bertabs import BertAbs, build_predictor
from torch.utils.data import DataLoader, SequentialSampler
from tqdm import tqdm
from transformers import BertTokenizer
from .utils_summarization import (
CNNDMDataset,
build_mask,
compute_token_type_ids,
encode_for_summarization,
truncate_or_pad,
)
logger = logging.getLogger(__name__)
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
Batch = namedtuple("Batch", ["document_names", "batch_size", "src", "segs", "mask_src", "tgt_str"])
def evaluate(args):
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased", do_lower_case=True)
model = BertAbs.from_pretrained("remi/bertabs-finetuned-extractive-abstractive-summarization")
model.to(args.device)
model.eval()
symbols = {
"BOS": tokenizer.vocab["[unused0]"],
"EOS": tokenizer.vocab["[unused1]"],
"PAD": tokenizer.vocab["[PAD]"],
}
if args.compute_rouge:
reference_summaries = []
generated_summaries = []
import nltk
import rouge
nltk.download("punkt")
rouge_evaluator = rouge.Rouge(
metrics=["rouge-n", "rouge-l"],
max_n=2,
limit_length=True,
length_limit=args.beam_size,
length_limit_type="words",
apply_avg=True,
apply_best=False,
alpha=0.5, # Default F1_score
weight_factor=1.2,
stemming=True,
)
# these (unused) arguments are defined to keep the compatibility
# with the legacy code and will be deleted in a next iteration.
args.result_path = ""
args.temp_dir = ""
data_iterator = build_data_iterator(args, tokenizer)
predictor = build_predictor(args, tokenizer, symbols, model)
logger.info("***** Running evaluation *****")
logger.info(" Number examples = %d", len(data_iterator.dataset))
logger.info(" Batch size = %d", args.batch_size)
logger.info("")
logger.info("***** Beam Search parameters *****")
logger.info(" Beam size = %d", args.beam_size)
logger.info(" Minimum length = %d", args.min_length)
logger.info(" Maximum length = %d", args.max_length)
logger.info(" Alpha (length penalty) = %.2f", args.alpha)
logger.info(" Trigrams %s be blocked", ("will" if args.block_trigram else "will NOT"))
for batch in tqdm(data_iterator):
batch_data = predictor.translate_batch(batch)
translations = predictor.from_batch(batch_data)
summaries = [format_summary(t) for t in translations]
save_summaries(summaries, args.summaries_output_dir, batch.document_names)
if args.compute_rouge:
reference_summaries += batch.tgt_str
generated_summaries += summaries
if args.compute_rouge:
scores = rouge_evaluator.get_scores(generated_summaries, reference_summaries)
str_scores = format_rouge_scores(scores)
save_rouge_scores(str_scores)
print(str_scores)
def save_summaries(summaries, path, original_document_name):
"""Write the summaries in fies that are prefixed by the original
files' name with the `_summary` appended.
Attributes:
original_document_names: List[string]
Name of the document that was summarized.
path: string
Path were the summaries will be written
summaries: List[string]
The summaries that we produced.
"""
for summary, document_name in zip(summaries, original_document_name):
# Prepare the summary file's name
if "." in document_name:
bare_document_name = ".".join(document_name.split(".")[:-1])
extension = document_name.split(".")[-1]
name = bare_document_name + "_summary." + extension
else:
name = document_name + "_summary"
file_path = os.path.join(path, name)
with open(file_path, "w") as output:
output.write(summary)
def format_summary(translation):
"""Transforms the output of the `from_batch` function
into nicely formatted summaries.
"""
raw_summary, _, _ = translation
summary = (
raw_summary.replace("[unused0]", "")
.replace("[unused3]", "")
.replace("[PAD]", "")
.replace("[unused1]", "")
.replace(r" +", " ")
.replace(" [unused2] ", ". ")
.replace("[unused2]", "")
.strip()
)
return summary
def format_rouge_scores(scores):
return """\n
****** ROUGE SCORES ******
** ROUGE 1
F1 >> {:.3f}
Precision >> {:.3f}
Recall >> {:.3f}
** ROUGE 2
F1 >> {:.3f}
Precision >> {:.3f}
Recall >> {:.3f}
** ROUGE L
F1 >> {:.3f}
Precision >> {:.3f}
Recall >> {:.3f}""".format(
scores["rouge-1"]["f"],
scores["rouge-1"]["p"],
scores["rouge-1"]["r"],
scores["rouge-2"]["f"],
scores["rouge-2"]["p"],
scores["rouge-2"]["r"],
scores["rouge-l"]["f"],
scores["rouge-l"]["p"],
scores["rouge-l"]["r"],
)
def save_rouge_scores(str_scores):
with open("rouge_scores.txt", "w") as output:
output.write(str_scores)
#
# LOAD the dataset
#
def build_data_iterator(args, tokenizer):
dataset = load_and_cache_examples(args, tokenizer)
sampler = SequentialSampler(dataset)
def collate_fn(data):
return collate(data, tokenizer, block_size=512, device=args.device)
iterator = DataLoader(
dataset,
sampler=sampler,
batch_size=args.batch_size,
collate_fn=collate_fn,
)
return iterator
def load_and_cache_examples(args, tokenizer):
dataset = CNNDMDataset(args.documents_dir)
return dataset
def collate(data, tokenizer, block_size, device):
"""Collate formats the data passed to the data loader.
In particular we tokenize the data batch after batch to avoid keeping them
all in memory. We output the data as a namedtuple to fit the original BertAbs's
API.
"""
data = [x for x in data if not len(x[1]) == 0] # remove empty_files
names = [name for name, _, _ in data]
summaries = [" ".join(summary_list) for _, _, summary_list in data]
encoded_text = [encode_for_summarization(story, summary, tokenizer) for _, story, summary in data]
encoded_stories = torch.tensor(
[truncate_or_pad(story, block_size, tokenizer.pad_token_id) for story, _ in encoded_text]
)
encoder_token_type_ids = compute_token_type_ids(encoded_stories, tokenizer.cls_token_id)
encoder_mask = build_mask(encoded_stories, tokenizer.pad_token_id)
batch = Batch(
document_names=names,
batch_size=len(encoded_stories),
src=encoded_stories.to(device),
segs=encoder_token_type_ids.to(device),
mask_src=encoder_mask.to(device),
tgt_str=summaries,
)
return batch
def decode_summary(summary_tokens, tokenizer):
"""Decode the summary and return it in a format
suitable for evaluation.
"""
summary_tokens = summary_tokens.to("cpu").numpy()
summary = tokenizer.decode(summary_tokens)
sentences = summary.split(".")
sentences = [s + "." for s in sentences]
return sentences
def main():
"""The main function defines the interface with the users."""
parser = argparse.ArgumentParser()
parser.add_argument(
"--documents_dir",
default=None,
type=str,
required=True,
help="The folder where the documents to summarize are located.",
)
parser.add_argument(
"--summaries_output_dir",
default=None,
type=str,
required=False,
help="The folder in wich the summaries should be written. Defaults to the folder where the documents are",
)
parser.add_argument(
"--compute_rouge",
default=False,
type=bool,
required=False,
help="Compute the ROUGE metrics during evaluation. Only available for the CNN/DailyMail dataset.",
)
# EVALUATION options
parser.add_argument(
"--no_cuda",
default=False,
type=bool,
help="Whether to force the execution on CPU.",
)
parser.add_argument(
"--batch_size",
default=4,
type=int,
help="Batch size per GPU/CPU for training.",
)
# BEAM SEARCH arguments
parser.add_argument(
"--min_length",
default=50,
type=int,
help="Minimum number of tokens for the summaries.",
)
parser.add_argument(
"--max_length",
default=200,
type=int,
help="Maixmum number of tokens for the summaries.",
)
parser.add_argument(
"--beam_size",
default=5,
type=int,
help="The number of beams to start with for each example.",
)
parser.add_argument(
"--alpha",
default=0.95,
type=float,
help="The value of alpha for the length penalty in the beam search.",
)
parser.add_argument(
"--block_trigram",
default=True,
type=bool,
help="Whether to block the existence of repeating trigrams in the text generated by beam search.",
)
args = parser.parse_args()
# Select device (distibuted not available)
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
# Check the existence of directories
if not args.summaries_output_dir:
args.summaries_output_dir = args.documents_dir
if not documents_dir_is_valid(args.documents_dir):
raise FileNotFoundError(
"We could not find the directory you specified for the documents to summarize, or it was empty. Please"
" specify a valid path."
)
os.makedirs(args.summaries_output_dir, exist_ok=True)
evaluate(args)
def documents_dir_is_valid(path):
if not os.path.exists(path):
return False
file_list = os.listdir(path)
if len(file_list) == 0:
return False
return True
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/configuration_bertabs.py
|
# coding=utf-8
# Copyright 2019 The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" BertAbs configuration """
import logging
from transformers import PretrainedConfig
logger = logging.getLogger(__name__)
BERTABS_FINETUNED_CONFIG_MAP = {
"bertabs-finetuned-cnndm": "https://huggingface.co/remi/bertabs-finetuned-cnndm-extractive-abstractive-summarization/resolve/main/config.json",
}
class BertAbsConfig(PretrainedConfig):
r"""Class to store the configuration of the BertAbs model.
Arguments:
vocab_size: int
Number of tokens in the vocabulary.
max_pos: int
The maximum sequence length that this model will be used with.
enc_layer: int
The numner of hidden layers in the Transformer encoder.
enc_hidden_size: int
The size of the encoder's layers.
enc_heads: int
The number of attention heads for each attention layer in the encoder.
enc_ff_size: int
The size of the encoder's feed-forward layers.
enc_dropout: int
The dropout probability for all fully connected layers in the
embeddings, layers, pooler and also the attention probabilities in
the encoder.
dec_layer: int
The numner of hidden layers in the decoder.
dec_hidden_size: int
The size of the decoder's layers.
dec_heads: int
The number of attention heads for each attention layer in the decoder.
dec_ff_size: int
The size of the decoder's feed-forward layers.
dec_dropout: int
The dropout probability for all fully connected layers in the
embeddings, layers, pooler and also the attention probabilities in
the decoder.
"""
model_type = "bertabs"
def __init__(
self,
vocab_size=30522,
max_pos=512,
enc_layers=6,
enc_hidden_size=512,
enc_heads=8,
enc_ff_size=512,
enc_dropout=0.2,
dec_layers=6,
dec_hidden_size=768,
dec_heads=8,
dec_ff_size=2048,
dec_dropout=0.2,
**kwargs,
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.max_pos = max_pos
self.enc_layers = enc_layers
self.enc_hidden_size = enc_hidden_size
self.enc_heads = enc_heads
self.enc_ff_size = enc_ff_size
self.enc_dropout = enc_dropout
self.dec_layers = dec_layers
self.dec_hidden_size = dec_hidden_size
self.dec_heads = dec_heads
self.dec_ff_size = dec_ff_size
self.dec_dropout = dec_dropout
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/requirements.txt
|
transformers == 3.5.1
# For ROUGE
nltk
py-rouge
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/modeling_bertabs.py
|
# MIT License
# Copyright (c) 2019 Yang Liu and the HuggingFace team
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
import copy
import math
import numpy as np
import torch
from configuration_bertabs import BertAbsConfig
from torch import nn
from torch.nn.init import xavier_uniform_
from transformers import BertConfig, BertModel, PreTrainedModel
MAX_SIZE = 5000
BERTABS_FINETUNED_MODEL_ARCHIVE_LIST = [
"remi/bertabs-finetuned-cnndm-extractive-abstractive-summarization",
]
class BertAbsPreTrainedModel(PreTrainedModel):
config_class = BertAbsConfig
load_tf_weights = False
base_model_prefix = "bert"
class BertAbs(BertAbsPreTrainedModel):
def __init__(self, args, checkpoint=None, bert_extractive_checkpoint=None):
super().__init__(args)
self.args = args
self.bert = Bert()
# If pre-trained weights are passed for Bert, load these.
load_bert_pretrained_extractive = True if bert_extractive_checkpoint else False
if load_bert_pretrained_extractive:
self.bert.model.load_state_dict(
{n[11:]: p for n, p in bert_extractive_checkpoint.items() if n.startswith("bert.model")},
strict=True,
)
self.vocab_size = self.bert.model.config.vocab_size
if args.max_pos > 512:
my_pos_embeddings = nn.Embedding(args.max_pos, self.bert.model.config.hidden_size)
my_pos_embeddings.weight.data[:512] = self.bert.model.embeddings.position_embeddings.weight.data
my_pos_embeddings.weight.data[512:] = self.bert.model.embeddings.position_embeddings.weight.data[-1][
None, :
].repeat(args.max_pos - 512, 1)
self.bert.model.embeddings.position_embeddings = my_pos_embeddings
tgt_embeddings = nn.Embedding(self.vocab_size, self.bert.model.config.hidden_size, padding_idx=0)
tgt_embeddings.weight = copy.deepcopy(self.bert.model.embeddings.word_embeddings.weight)
self.decoder = TransformerDecoder(
self.args.dec_layers,
self.args.dec_hidden_size,
heads=self.args.dec_heads,
d_ff=self.args.dec_ff_size,
dropout=self.args.dec_dropout,
embeddings=tgt_embeddings,
vocab_size=self.vocab_size,
)
gen_func = nn.LogSoftmax(dim=-1)
self.generator = nn.Sequential(nn.Linear(args.dec_hidden_size, args.vocab_size), gen_func)
self.generator[0].weight = self.decoder.embeddings.weight
load_from_checkpoints = False if checkpoint is None else True
if load_from_checkpoints:
self.load_state_dict(checkpoint)
def init_weights(self):
for module in self.decoder.modules():
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
for p in self.generator.parameters():
if p.dim() > 1:
xavier_uniform_(p)
else:
p.data.zero_()
def forward(
self,
encoder_input_ids,
decoder_input_ids,
token_type_ids,
encoder_attention_mask,
decoder_attention_mask,
):
encoder_output = self.bert(
input_ids=encoder_input_ids,
token_type_ids=token_type_ids,
attention_mask=encoder_attention_mask,
)
encoder_hidden_states = encoder_output[0]
dec_state = self.decoder.init_decoder_state(encoder_input_ids, encoder_hidden_states)
decoder_outputs, _ = self.decoder(decoder_input_ids[:, :-1], encoder_hidden_states, dec_state)
return decoder_outputs
class Bert(nn.Module):
"""This class is not really necessary and should probably disappear."""
def __init__(self):
super().__init__()
config = BertConfig.from_pretrained("bert-base-uncased")
self.model = BertModel(config)
def forward(self, input_ids, attention_mask=None, token_type_ids=None, **kwargs):
self.eval()
with torch.no_grad():
encoder_outputs, _ = self.model(
input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, **kwargs
)
return encoder_outputs
class TransformerDecoder(nn.Module):
"""
The Transformer decoder from "Attention is All You Need".
Args:
num_layers (int): number of encoder layers.
d_model (int): size of the model
heads (int): number of heads
d_ff (int): size of the inner FF layer
dropout (float): dropout parameters
embeddings (:obj:`onmt.modules.Embeddings`):
embeddings to use, should have positional encodings
attn_type (str): if using a separate copy attention
"""
def __init__(self, num_layers, d_model, heads, d_ff, dropout, embeddings, vocab_size):
super().__init__()
# Basic attributes.
self.decoder_type = "transformer"
self.num_layers = num_layers
self.embeddings = embeddings
self.pos_emb = PositionalEncoding(dropout, self.embeddings.embedding_dim)
# Build TransformerDecoder.
self.transformer_layers = nn.ModuleList(
[TransformerDecoderLayer(d_model, heads, d_ff, dropout) for _ in range(num_layers)]
)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
# forward(input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask)
# def forward(self, input_ids, state, attention_mask=None, memory_lengths=None,
# step=None, cache=None, encoder_attention_mask=None, encoder_hidden_states=None, memory_masks=None):
def forward(
self,
input_ids,
encoder_hidden_states=None,
state=None,
attention_mask=None,
memory_lengths=None,
step=None,
cache=None,
encoder_attention_mask=None,
):
"""
See :obj:`onmt.modules.RNNDecoderBase.forward()`
memory_bank = encoder_hidden_states
"""
# Name conversion
tgt = input_ids
memory_bank = encoder_hidden_states
memory_mask = encoder_attention_mask
# src_words = state.src
src_words = state.src
src_batch, src_len = src_words.size()
padding_idx = self.embeddings.padding_idx
# Decoder padding mask
tgt_words = tgt
tgt_batch, tgt_len = tgt_words.size()
tgt_pad_mask = tgt_words.data.eq(padding_idx).unsqueeze(1).expand(tgt_batch, tgt_len, tgt_len)
# Encoder padding mask
if memory_mask is not None:
src_len = memory_mask.size(-1)
src_pad_mask = memory_mask.expand(src_batch, tgt_len, src_len)
else:
src_pad_mask = src_words.data.eq(padding_idx).unsqueeze(1).expand(src_batch, tgt_len, src_len)
# Pass through the embeddings
emb = self.embeddings(input_ids)
output = self.pos_emb(emb, step)
assert emb.dim() == 3 # len x batch x embedding_dim
if state.cache is None:
saved_inputs = []
for i in range(self.num_layers):
prev_layer_input = None
if state.cache is None:
if state.previous_input is not None:
prev_layer_input = state.previous_layer_inputs[i]
output, all_input = self.transformer_layers[i](
output,
memory_bank,
src_pad_mask,
tgt_pad_mask,
previous_input=prev_layer_input,
layer_cache=state.cache["layer_{}".format(i)] if state.cache is not None else None,
step=step,
)
if state.cache is None:
saved_inputs.append(all_input)
if state.cache is None:
saved_inputs = torch.stack(saved_inputs)
output = self.layer_norm(output)
if state.cache is None:
state = state.update_state(tgt, saved_inputs)
# Decoders in transformers return a tuple. Beam search will fail
# if we don't follow this convention.
return output, state # , state
def init_decoder_state(self, src, memory_bank, with_cache=False):
"""Init decoder state"""
state = TransformerDecoderState(src)
if with_cache:
state._init_cache(memory_bank, self.num_layers)
return state
class PositionalEncoding(nn.Module):
def __init__(self, dropout, dim, max_len=5000):
pe = torch.zeros(max_len, dim)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) * -(math.log(10000.0) / dim)))
pe[:, 0::2] = torch.sin(position.float() * div_term)
pe[:, 1::2] = torch.cos(position.float() * div_term)
pe = pe.unsqueeze(0)
super().__init__()
self.register_buffer("pe", pe)
self.dropout = nn.Dropout(p=dropout)
self.dim = dim
def forward(self, emb, step=None):
emb = emb * math.sqrt(self.dim)
if step:
emb = emb + self.pe[:, step][:, None, :]
else:
emb = emb + self.pe[:, : emb.size(1)]
emb = self.dropout(emb)
return emb
def get_emb(self, emb):
return self.pe[:, : emb.size(1)]
class TransformerDecoderLayer(nn.Module):
"""
Args:
d_model (int): the dimension of keys/values/queries in
MultiHeadedAttention, also the input size of
the first-layer of the PositionwiseFeedForward.
heads (int): the number of heads for MultiHeadedAttention.
d_ff (int): the second-layer of the PositionwiseFeedForward.
dropout (float): dropout probability(0-1.0).
self_attn_type (string): type of self-attention scaled-dot, average
"""
def __init__(self, d_model, heads, d_ff, dropout):
super().__init__()
self.self_attn = MultiHeadedAttention(heads, d_model, dropout=dropout)
self.context_attn = MultiHeadedAttention(heads, d_model, dropout=dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm_1 = nn.LayerNorm(d_model, eps=1e-6)
self.layer_norm_2 = nn.LayerNorm(d_model, eps=1e-6)
self.drop = nn.Dropout(dropout)
mask = self._get_attn_subsequent_mask(MAX_SIZE)
# Register self.mask as a saved_state in TransformerDecoderLayer, so
# it gets TransformerDecoderLayer's cuda behavior automatically.
self.register_buffer("mask", mask)
def forward(
self,
inputs,
memory_bank,
src_pad_mask,
tgt_pad_mask,
previous_input=None,
layer_cache=None,
step=None,
):
"""
Args:
inputs (`FloatTensor`): `[batch_size x 1 x model_dim]`
memory_bank (`FloatTensor`): `[batch_size x src_len x model_dim]`
src_pad_mask (`LongTensor`): `[batch_size x 1 x src_len]`
tgt_pad_mask (`LongTensor`): `[batch_size x 1 x 1]`
Returns:
(`FloatTensor`, `FloatTensor`, `FloatTensor`):
* output `[batch_size x 1 x model_dim]`
* attn `[batch_size x 1 x src_len]`
* all_input `[batch_size x current_step x model_dim]`
"""
dec_mask = torch.gt(tgt_pad_mask + self.mask[:, : tgt_pad_mask.size(1), : tgt_pad_mask.size(1)], 0)
input_norm = self.layer_norm_1(inputs)
all_input = input_norm
if previous_input is not None:
all_input = torch.cat((previous_input, input_norm), dim=1)
dec_mask = None
query = self.self_attn(
all_input,
all_input,
input_norm,
mask=dec_mask,
layer_cache=layer_cache,
type="self",
)
query = self.drop(query) + inputs
query_norm = self.layer_norm_2(query)
mid = self.context_attn(
memory_bank,
memory_bank,
query_norm,
mask=src_pad_mask,
layer_cache=layer_cache,
type="context",
)
output = self.feed_forward(self.drop(mid) + query)
return output, all_input
# return output
def _get_attn_subsequent_mask(self, size):
"""
Get an attention mask to avoid using the subsequent info.
Args:
size: int
Returns:
(`LongTensor`):
* subsequent_mask `[1 x size x size]`
"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype("uint8")
subsequent_mask = torch.from_numpy(subsequent_mask)
return subsequent_mask
class MultiHeadedAttention(nn.Module):
"""
Multi-Head Attention module from
"Attention is All You Need"
:cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.
Similar to standard `dot` attention but uses
multiple attention distributions simulataneously
to select relevant items.
.. mermaid::
graph BT
A[key]
B[value]
C[query]
O[output]
subgraph Attn
D[Attn 1]
E[Attn 2]
F[Attn N]
end
A --> D
C --> D
A --> E
C --> E
A --> F
C --> F
D --> O
E --> O
F --> O
B --> O
Also includes several additional tricks.
Args:
head_count (int): number of parallel heads
model_dim (int): the dimension of keys/values/queries,
must be divisible by head_count
dropout (float): dropout parameter
"""
def __init__(self, head_count, model_dim, dropout=0.1, use_final_linear=True):
assert model_dim % head_count == 0
self.dim_per_head = model_dim // head_count
self.model_dim = model_dim
super().__init__()
self.head_count = head_count
self.linear_keys = nn.Linear(model_dim, head_count * self.dim_per_head)
self.linear_values = nn.Linear(model_dim, head_count * self.dim_per_head)
self.linear_query = nn.Linear(model_dim, head_count * self.dim_per_head)
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
self.use_final_linear = use_final_linear
if self.use_final_linear:
self.final_linear = nn.Linear(model_dim, model_dim)
def forward(
self,
key,
value,
query,
mask=None,
layer_cache=None,
type=None,
predefined_graph_1=None,
):
"""
Compute the context vector and the attention vectors.
Args:
key (`FloatTensor`): set of `key_len`
key vectors `[batch, key_len, dim]`
value (`FloatTensor`): set of `key_len`
value vectors `[batch, key_len, dim]`
query (`FloatTensor`): set of `query_len`
query vectors `[batch, query_len, dim]`
mask: binary mask indicating which keys have
non-zero attention `[batch, query_len, key_len]`
Returns:
(`FloatTensor`, `FloatTensor`) :
* output context vectors `[batch, query_len, dim]`
* one of the attention vectors `[batch, query_len, key_len]`
"""
batch_size = key.size(0)
dim_per_head = self.dim_per_head
head_count = self.head_count
def shape(x):
"""projection"""
return x.view(batch_size, -1, head_count, dim_per_head).transpose(1, 2)
def unshape(x):
"""compute context"""
return x.transpose(1, 2).contiguous().view(batch_size, -1, head_count * dim_per_head)
# 1) Project key, value, and query.
if layer_cache is not None:
if type == "self":
query, key, value = (
self.linear_query(query),
self.linear_keys(query),
self.linear_values(query),
)
key = shape(key)
value = shape(value)
if layer_cache is not None:
device = key.device
if layer_cache["self_keys"] is not None:
key = torch.cat((layer_cache["self_keys"].to(device), key), dim=2)
if layer_cache["self_values"] is not None:
value = torch.cat((layer_cache["self_values"].to(device), value), dim=2)
layer_cache["self_keys"] = key
layer_cache["self_values"] = value
elif type == "context":
query = self.linear_query(query)
if layer_cache is not None:
if layer_cache["memory_keys"] is None:
key, value = self.linear_keys(key), self.linear_values(value)
key = shape(key)
value = shape(value)
else:
key, value = (
layer_cache["memory_keys"],
layer_cache["memory_values"],
)
layer_cache["memory_keys"] = key
layer_cache["memory_values"] = value
else:
key, value = self.linear_keys(key), self.linear_values(value)
key = shape(key)
value = shape(value)
else:
key = self.linear_keys(key)
value = self.linear_values(value)
query = self.linear_query(query)
key = shape(key)
value = shape(value)
query = shape(query)
# 2) Calculate and scale scores.
query = query / math.sqrt(dim_per_head)
scores = torch.matmul(query, key.transpose(2, 3))
if mask is not None:
mask = mask.unsqueeze(1).expand_as(scores)
scores = scores.masked_fill(mask, -1e18)
# 3) Apply attention dropout and compute context vectors.
attn = self.softmax(scores)
if predefined_graph_1 is not None:
attn_masked = attn[:, -1] * predefined_graph_1
attn_masked = attn_masked / (torch.sum(attn_masked, 2).unsqueeze(2) + 1e-9)
attn = torch.cat([attn[:, :-1], attn_masked.unsqueeze(1)], 1)
drop_attn = self.dropout(attn)
if self.use_final_linear:
context = unshape(torch.matmul(drop_attn, value))
output = self.final_linear(context)
return output
else:
context = torch.matmul(drop_attn, value)
return context
class DecoderState(object):
"""Interface for grouping together the current state of a recurrent
decoder. In the simplest case just represents the hidden state of
the model. But can also be used for implementing various forms of
input_feeding and non-recurrent models.
Modules need to implement this to utilize beam search decoding.
"""
def detach(self):
"""Need to document this"""
self.hidden = tuple([_.detach() for _ in self.hidden])
self.input_feed = self.input_feed.detach()
def beam_update(self, idx, positions, beam_size):
"""Need to document this"""
for e in self._all:
sizes = e.size()
br = sizes[1]
if len(sizes) == 3:
sent_states = e.view(sizes[0], beam_size, br // beam_size, sizes[2])[:, :, idx]
else:
sent_states = e.view(sizes[0], beam_size, br // beam_size, sizes[2], sizes[3])[:, :, idx]
sent_states.data.copy_(sent_states.data.index_select(1, positions))
def map_batch_fn(self, fn):
raise NotImplementedError()
class TransformerDecoderState(DecoderState):
"""Transformer Decoder state base class"""
def __init__(self, src):
"""
Args:
src (FloatTensor): a sequence of source words tensors
with optional feature tensors, of size (len x batch).
"""
self.src = src
self.previous_input = None
self.previous_layer_inputs = None
self.cache = None
@property
def _all(self):
"""
Contains attributes that need to be updated in self.beam_update().
"""
if self.previous_input is not None and self.previous_layer_inputs is not None:
return (self.previous_input, self.previous_layer_inputs, self.src)
else:
return (self.src,)
def detach(self):
if self.previous_input is not None:
self.previous_input = self.previous_input.detach()
if self.previous_layer_inputs is not None:
self.previous_layer_inputs = self.previous_layer_inputs.detach()
self.src = self.src.detach()
def update_state(self, new_input, previous_layer_inputs):
state = TransformerDecoderState(self.src)
state.previous_input = new_input
state.previous_layer_inputs = previous_layer_inputs
return state
def _init_cache(self, memory_bank, num_layers):
self.cache = {}
for l in range(num_layers):
layer_cache = {"memory_keys": None, "memory_values": None}
layer_cache["self_keys"] = None
layer_cache["self_values"] = None
self.cache["layer_{}".format(l)] = layer_cache
def repeat_beam_size_times(self, beam_size):
"""Repeat beam_size times along batch dimension."""
self.src = self.src.data.repeat(1, beam_size, 1)
def map_batch_fn(self, fn):
def _recursive_map(struct, batch_dim=0):
for k, v in struct.items():
if v is not None:
if isinstance(v, dict):
_recursive_map(v)
else:
struct[k] = fn(v, batch_dim)
self.src = fn(self.src, 0)
if self.cache is not None:
_recursive_map(self.cache)
def gelu(x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
class PositionwiseFeedForward(nn.Module):
"""A two-layer Feed-Forward-Network with residual layer norm.
Args:
d_model (int): the size of input for the first-layer of the FFN.
d_ff (int): the hidden layer size of the second-layer
of the FNN.
dropout (float): dropout probability in :math:`[0, 1)`.
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.actv = gelu
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x):
inter = self.dropout_1(self.actv(self.w_1(self.layer_norm(x))))
output = self.dropout_2(self.w_2(inter))
return output + x
#
# TRANSLATOR
# The following code is used to generate summaries using the
# pre-trained weights and beam search.
#
def build_predictor(args, tokenizer, symbols, model, logger=None):
# we should be able to refactor the global scorer a lot
scorer = GNMTGlobalScorer(args.alpha, length_penalty="wu")
translator = Translator(args, model, tokenizer, symbols, global_scorer=scorer, logger=logger)
return translator
class GNMTGlobalScorer(object):
"""
NMT re-ranking score from
"Google's Neural Machine Translation System" :cite:`wu2016google`
Args:
alpha (float): length parameter
beta (float): coverage parameter
"""
def __init__(self, alpha, length_penalty):
self.alpha = alpha
penalty_builder = PenaltyBuilder(length_penalty)
self.length_penalty = penalty_builder.length_penalty()
def score(self, beam, logprobs):
"""
Rescores a prediction based on penalty functions
"""
normalized_probs = self.length_penalty(beam, logprobs, self.alpha)
return normalized_probs
class PenaltyBuilder(object):
"""
Returns the Length and Coverage Penalty function for Beam Search.
Args:
length_pen (str): option name of length pen
cov_pen (str): option name of cov pen
"""
def __init__(self, length_pen):
self.length_pen = length_pen
def length_penalty(self):
if self.length_pen == "wu":
return self.length_wu
elif self.length_pen == "avg":
return self.length_average
else:
return self.length_none
"""
Below are all the different penalty terms implemented so far
"""
def length_wu(self, beam, logprobs, alpha=0.0):
"""
NMT length re-ranking score from
"Google's Neural Machine Translation System" :cite:`wu2016google`.
"""
modifier = ((5 + len(beam.next_ys)) ** alpha) / ((5 + 1) ** alpha)
return logprobs / modifier
def length_average(self, beam, logprobs, alpha=0.0):
"""
Returns the average probability of tokens in a sequence.
"""
return logprobs / len(beam.next_ys)
def length_none(self, beam, logprobs, alpha=0.0, beta=0.0):
"""
Returns unmodified scores.
"""
return logprobs
class Translator(object):
"""
Uses a model to translate a batch of sentences.
Args:
model (:obj:`onmt.modules.NMTModel`):
NMT model to use for translation
fields (dict of Fields): data fields
beam_size (int): size of beam to use
n_best (int): number of translations produced
max_length (int): maximum length output to produce
global_scores (:obj:`GlobalScorer`):
object to rescore final translations
copy_attn (bool): use copy attention during translation
beam_trace (bool): trace beam search for debugging
logger(logging.Logger): logger.
"""
def __init__(self, args, model, vocab, symbols, global_scorer=None, logger=None):
self.logger = logger
self.args = args
self.model = model
self.generator = self.model.generator
self.vocab = vocab
self.symbols = symbols
self.start_token = symbols["BOS"]
self.end_token = symbols["EOS"]
self.global_scorer = global_scorer
self.beam_size = args.beam_size
self.min_length = args.min_length
self.max_length = args.max_length
def translate(self, batch, step, attn_debug=False):
"""Generates summaries from one batch of data."""
self.model.eval()
with torch.no_grad():
batch_data = self.translate_batch(batch)
translations = self.from_batch(batch_data)
return translations
def translate_batch(self, batch, fast=False):
"""
Translate a batch of sentences.
Mostly a wrapper around :obj:`Beam`.
Args:
batch (:obj:`Batch`): a batch from a dataset object
fast (bool): enables fast beam search (may not support all features)
"""
with torch.no_grad():
return self._fast_translate_batch(batch, self.max_length, min_length=self.min_length)
# Where the beam search lives
# I have no idea why it is being called from the method above
def _fast_translate_batch(self, batch, max_length, min_length=0):
"""Beam Search using the encoder inputs contained in `batch`."""
# The batch object is funny
# Instead of just looking at the size of the arguments we encapsulate
# a size argument.
# Where is it defined?
beam_size = self.beam_size
batch_size = batch.batch_size
src = batch.src
segs = batch.segs
mask_src = batch.mask_src
src_features = self.model.bert(src, segs, mask_src)
dec_states = self.model.decoder.init_decoder_state(src, src_features, with_cache=True)
device = src_features.device
# Tile states and memory beam_size times.
dec_states.map_batch_fn(lambda state, dim: tile(state, beam_size, dim=dim))
src_features = tile(src_features, beam_size, dim=0)
batch_offset = torch.arange(batch_size, dtype=torch.long, device=device)
beam_offset = torch.arange(0, batch_size * beam_size, step=beam_size, dtype=torch.long, device=device)
alive_seq = torch.full([batch_size * beam_size, 1], self.start_token, dtype=torch.long, device=device)
# Give full probability to the first beam on the first step.
topk_log_probs = torch.tensor([0.0] + [float("-inf")] * (beam_size - 1), device=device).repeat(batch_size)
# Structure that holds finished hypotheses.
hypotheses = [[] for _ in range(batch_size)] # noqa: F812
results = {}
results["predictions"] = [[] for _ in range(batch_size)] # noqa: F812
results["scores"] = [[] for _ in range(batch_size)] # noqa: F812
results["gold_score"] = [0] * batch_size
results["batch"] = batch
for step in range(max_length):
decoder_input = alive_seq[:, -1].view(1, -1)
# Decoder forward.
decoder_input = decoder_input.transpose(0, 1)
dec_out, dec_states = self.model.decoder(decoder_input, src_features, dec_states, step=step)
# Generator forward.
log_probs = self.generator(dec_out.transpose(0, 1).squeeze(0))
vocab_size = log_probs.size(-1)
if step < min_length:
log_probs[:, self.end_token] = -1e20
# Multiply probs by the beam probability.
log_probs += topk_log_probs.view(-1).unsqueeze(1)
alpha = self.global_scorer.alpha
length_penalty = ((5.0 + (step + 1)) / 6.0) ** alpha
# Flatten probs into a list of possibilities.
curr_scores = log_probs / length_penalty
if self.args.block_trigram:
cur_len = alive_seq.size(1)
if cur_len > 3:
for i in range(alive_seq.size(0)):
fail = False
words = [int(w) for w in alive_seq[i]]
words = [self.vocab.ids_to_tokens[w] for w in words]
words = " ".join(words).replace(" ##", "").split()
if len(words) <= 3:
continue
trigrams = [(words[i - 1], words[i], words[i + 1]) for i in range(1, len(words) - 1)]
trigram = tuple(trigrams[-1])
if trigram in trigrams[:-1]:
fail = True
if fail:
curr_scores[i] = -10e20
curr_scores = curr_scores.reshape(-1, beam_size * vocab_size)
topk_scores, topk_ids = curr_scores.topk(beam_size, dim=-1)
# Recover log probs.
topk_log_probs = topk_scores * length_penalty
# Resolve beam origin and true word ids.
topk_beam_index = topk_ids.div(vocab_size)
topk_ids = topk_ids.fmod(vocab_size)
# Map beam_index to batch_index in the flat representation.
batch_index = topk_beam_index + beam_offset[: topk_beam_index.size(0)].unsqueeze(1)
select_indices = batch_index.view(-1)
# Append last prediction.
alive_seq = torch.cat([alive_seq.index_select(0, select_indices), topk_ids.view(-1, 1)], -1)
is_finished = topk_ids.eq(self.end_token)
if step + 1 == max_length:
is_finished.fill_(1)
# End condition is top beam is finished.
end_condition = is_finished[:, 0].eq(1)
# Save finished hypotheses.
if is_finished.any():
predictions = alive_seq.view(-1, beam_size, alive_seq.size(-1))
for i in range(is_finished.size(0)):
b = batch_offset[i]
if end_condition[i]:
is_finished[i].fill_(1)
finished_hyp = is_finished[i].nonzero().view(-1)
# Store finished hypotheses for this batch.
for j in finished_hyp:
hypotheses[b].append((topk_scores[i, j], predictions[i, j, 1:]))
# If the batch reached the end, save the n_best hypotheses.
if end_condition[i]:
best_hyp = sorted(hypotheses[b], key=lambda x: x[0], reverse=True)
score, pred = best_hyp[0]
results["scores"][b].append(score)
results["predictions"][b].append(pred)
non_finished = end_condition.eq(0).nonzero().view(-1)
# If all sentences are translated, no need to go further.
if len(non_finished) == 0:
break
# Remove finished batches for the next step.
topk_log_probs = topk_log_probs.index_select(0, non_finished)
batch_index = batch_index.index_select(0, non_finished)
batch_offset = batch_offset.index_select(0, non_finished)
alive_seq = predictions.index_select(0, non_finished).view(-1, alive_seq.size(-1))
# Reorder states.
select_indices = batch_index.view(-1)
src_features = src_features.index_select(0, select_indices)
dec_states.map_batch_fn(lambda state, dim: state.index_select(dim, select_indices))
return results
def from_batch(self, translation_batch):
batch = translation_batch["batch"]
assert len(translation_batch["gold_score"]) == len(translation_batch["predictions"])
batch_size = batch.batch_size
preds, _, _, tgt_str, src = (
translation_batch["predictions"],
translation_batch["scores"],
translation_batch["gold_score"],
batch.tgt_str,
batch.src,
)
translations = []
for b in range(batch_size):
pred_sents = self.vocab.convert_ids_to_tokens([int(n) for n in preds[b][0]])
pred_sents = " ".join(pred_sents).replace(" ##", "")
gold_sent = " ".join(tgt_str[b].split())
raw_src = [self.vocab.ids_to_tokens[int(t)] for t in src[b]][:500]
raw_src = " ".join(raw_src)
translation = (pred_sents, gold_sent, raw_src)
translations.append(translation)
return translations
def tile(x, count, dim=0):
"""
Tiles x on dimension dim count times.
"""
perm = list(range(len(x.size())))
if dim != 0:
perm[0], perm[dim] = perm[dim], perm[0]
x = x.permute(perm).contiguous()
out_size = list(x.size())
out_size[0] *= count
batch = x.size(0)
x = x.view(batch, -1).transpose(0, 1).repeat(count, 1).transpose(0, 1).contiguous().view(*out_size)
if dim != 0:
x = x.permute(perm).contiguous()
return x
#
# Optimizer for training. We keep this here in case we want to add
# a finetuning script.
#
class BertSumOptimizer(object):
"""Specific optimizer for BertSum.
As described in [1], the authors fine-tune BertSum for abstractive
summarization using two Adam Optimizers with different warm-up steps and
learning rate. They also use a custom learning rate scheduler.
[1] Liu, Yang, and Mirella Lapata. "Text summarization with pretrained encoders."
arXiv preprint arXiv:1908.08345 (2019).
"""
def __init__(self, model, lr, warmup_steps, beta_1=0.99, beta_2=0.999, eps=1e-8):
self.encoder = model.encoder
self.decoder = model.decoder
self.lr = lr
self.warmup_steps = warmup_steps
self.optimizers = {
"encoder": torch.optim.Adam(
model.encoder.parameters(),
lr=lr["encoder"],
betas=(beta_1, beta_2),
eps=eps,
),
"decoder": torch.optim.Adam(
model.decoder.parameters(),
lr=lr["decoder"],
betas=(beta_1, beta_2),
eps=eps,
),
}
self._step = 0
self.current_learning_rates = {}
def _update_rate(self, stack):
return self.lr[stack] * min(self._step ** (-0.5), self._step * self.warmup_steps[stack] ** (-1.5))
def zero_grad(self):
self.optimizer_decoder.zero_grad()
self.optimizer_encoder.zero_grad()
def step(self):
self._step += 1
for stack, optimizer in self.optimizers.items():
new_rate = self._update_rate(stack)
for param_group in optimizer.param_groups:
param_group["lr"] = new_rate
optimizer.step()
self.current_learning_rates[stack] = new_rate
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/convert_bertabs_original_pytorch_checkpoint.py
|
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Convert BertExtAbs's checkpoints.
The script looks like it is doing something trivial but it is not. The "weights"
proposed by the authors are actually the entire model pickled. We need to load
the model within the original codebase to be able to only save its `state_dict`.
"""
import argparse
import logging
from collections import namedtuple
import torch
from model_bertabs import BertAbsSummarizer
from models.model_builder import AbsSummarizer # The authors' implementation
from transformers import BertTokenizer
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
SAMPLE_TEXT = "Hello world! cécé herlolip"
BertAbsConfig = namedtuple(
"BertAbsConfig",
[
"temp_dir",
"large",
"use_bert_emb",
"finetune_bert",
"encoder",
"share_emb",
"max_pos",
"enc_layers",
"enc_hidden_size",
"enc_heads",
"enc_ff_size",
"enc_dropout",
"dec_layers",
"dec_hidden_size",
"dec_heads",
"dec_ff_size",
"dec_dropout",
],
)
def convert_bertabs_checkpoints(path_to_checkpoints, dump_path):
"""Copy/paste and tweak the pre-trained weights provided by the creators
of BertAbs for the internal architecture.
"""
# Instantiate the authors' model with the pre-trained weights
config = BertAbsConfig(
temp_dir=".",
finetune_bert=False,
large=False,
share_emb=True,
use_bert_emb=False,
encoder="bert",
max_pos=512,
enc_layers=6,
enc_hidden_size=512,
enc_heads=8,
enc_ff_size=512,
enc_dropout=0.2,
dec_layers=6,
dec_hidden_size=768,
dec_heads=8,
dec_ff_size=2048,
dec_dropout=0.2,
)
checkpoints = torch.load(path_to_checkpoints, lambda storage, loc: storage)
original = AbsSummarizer(config, torch.device("cpu"), checkpoints)
original.eval()
new_model = BertAbsSummarizer(config, torch.device("cpu"))
new_model.eval()
# -------------------
# Convert the weights
# -------------------
logging.info("convert the model")
new_model.bert.load_state_dict(original.bert.state_dict())
new_model.decoder.load_state_dict(original.decoder.state_dict())
new_model.generator.load_state_dict(original.generator.state_dict())
# ----------------------------------
# Make sure the outpus are identical
# ----------------------------------
logging.info("Make sure that the models' outputs are identical")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# prepare the model inputs
encoder_input_ids = tokenizer.encode("This is sample éàalj'-.")
encoder_input_ids.extend([tokenizer.pad_token_id] * (512 - len(encoder_input_ids)))
encoder_input_ids = torch.tensor(encoder_input_ids).unsqueeze(0)
decoder_input_ids = tokenizer.encode("This is sample 3 éàalj'-.")
decoder_input_ids.extend([tokenizer.pad_token_id] * (512 - len(decoder_input_ids)))
decoder_input_ids = torch.tensor(decoder_input_ids).unsqueeze(0)
# failsafe to make sure the weights reset does not affect the
# loaded weights.
assert torch.max(torch.abs(original.generator[0].weight - new_model.generator[0].weight)) == 0
# forward pass
src = encoder_input_ids
tgt = decoder_input_ids
segs = token_type_ids = None
clss = None
mask_src = encoder_attention_mask = None
mask_tgt = decoder_attention_mask = None
mask_cls = None
# The original model does not apply the geneator layer immediatly but rather in
# the beam search (where it combines softmax + linear layer). Since we already
# apply the softmax in our generation process we only apply the linear layer here.
# We make sure that the outputs of the full stack are identical
output_original_model = original(src, tgt, segs, clss, mask_src, mask_tgt, mask_cls)[0]
output_original_generator = original.generator(output_original_model)
output_converted_model = new_model(
encoder_input_ids, decoder_input_ids, token_type_ids, encoder_attention_mask, decoder_attention_mask
)[0]
output_converted_generator = new_model.generator(output_converted_model)
maximum_absolute_difference = torch.max(torch.abs(output_converted_model - output_original_model)).item()
print("Maximum absolute difference beween weights: {:.2f}".format(maximum_absolute_difference))
maximum_absolute_difference = torch.max(torch.abs(output_converted_generator - output_original_generator)).item()
print("Maximum absolute difference beween weights: {:.2f}".format(maximum_absolute_difference))
are_identical = torch.allclose(output_converted_model, output_original_model, atol=1e-3)
if are_identical:
logging.info("all weights are equal up to 1e-3")
else:
raise ValueError("the weights are different. The new model is likely different from the original one.")
# The model has been saved with torch.save(model) and this is bound to the exact
# directory structure. We save the state_dict instead.
logging.info("saving the model's state dictionary")
torch.save(
new_model.state_dict(), "./bertabs-finetuned-cnndm-extractive-abstractive-summarization/pytorch_model.bin"
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--bertabs_checkpoint_path",
default=None,
type=str,
required=True,
help="Path the official PyTorch dump.",
)
parser.add_argument(
"--pytorch_dump_folder_path",
default=None,
type=str,
required=True,
help="Path to the output PyTorch model.",
)
args = parser.parse_args()
convert_bertabs_checkpoints(
args.bertabs_checkpoint_path,
args.pytorch_dump_folder_path,
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bertabs/test_utils_summarization.py
|
# coding=utf-8
# Copyright 2019 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import torch
from .utils_summarization import build_mask, compute_token_type_ids, process_story, truncate_or_pad
class SummarizationDataProcessingTest(unittest.TestCase):
def setUp(self):
self.block_size = 10
def test_fit_to_block_sequence_too_small(self):
"""Pad the sequence with 0 if the sequence is smaller than the block size."""
sequence = [1, 2, 3, 4]
expected_output = [1, 2, 3, 4, 0, 0, 0, 0, 0, 0]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_fit_exactly(self):
"""Do nothing if the sequence is the right size."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_too_big(self):
"""Truncate the sequence if it is too long."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_process_story_no_highlights(self):
"""Processing a story with no highlights returns an empty list for the summary."""
raw_story = """It was the year of Our Lord one thousand seven hundred and
seventy-five.\n\nSpiritual revelations were conceded to England at that
favoured period, as at this."""
_, summary_lines = process_story(raw_story)
self.assertEqual(summary_lines, [])
def test_process_empty_story(self):
"""An empty story returns an empty collection of lines."""
raw_story = ""
story_lines, summary_lines = process_story(raw_story)
self.assertEqual(story_lines, [])
self.assertEqual(summary_lines, [])
def test_process_story_with_missing_period(self):
raw_story = (
"It was the year of Our Lord one thousand seven hundred and "
"seventy-five\n\nSpiritual revelations were conceded to England "
"at that favoured period, as at this.\n@highlight\n\nIt was the best of times"
)
story_lines, summary_lines = process_story(raw_story)
expected_story_lines = [
"It was the year of Our Lord one thousand seven hundred and seventy-five.",
"Spiritual revelations were conceded to England at that favoured period, as at this.",
]
self.assertEqual(expected_story_lines, story_lines)
expected_summary_lines = ["It was the best of times."]
self.assertEqual(expected_summary_lines, summary_lines)
def test_build_mask_no_padding(self):
sequence = torch.tensor([1, 2, 3, 4])
expected = torch.tensor([1, 1, 1, 1])
np.testing.assert_array_equal(build_mask(sequence, 0).numpy(), expected.numpy())
def test_build_mask(self):
sequence = torch.tensor([1, 2, 3, 4, 23, 23, 23])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 23).numpy(), expected.numpy())
def test_build_mask_with_padding_equal_to_one(self):
sequence = torch.tensor([8, 2, 3, 4, 1, 1, 1])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 1).numpy(), expected.numpy())
def test_compute_token_type_ids(self):
separator = 101
batch = torch.tensor([[1, 2, 3, 4, 5, 6], [1, 2, 3, 101, 5, 6], [1, 101, 3, 4, 101, 6]])
expected = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 1, 1, 0, 0, 0], [1, 0, 0, 0, 1, 1]])
result = compute_token_type_ids(batch, separator)
np.testing.assert_array_equal(result, expected)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/README.md
|
# Patience-based Early Exit
Patience-based Early Exit (PABEE) is a plug-and-play inference method for pretrained language models.
We have already implemented it on BERT and ALBERT. Basically, you can make your LM faster and more robust with PABEE. It can even improve the performance of ALBERT on GLUE. The only sacrifice is that the batch size can only be 1.
Learn more in the paper ["BERT Loses Patience: Fast and Robust Inference with Early Exit"](https://arxiv.org/abs/2006.04152) and the official [GitHub repo](https://github.com/JetRunner/PABEE).

## Training
You can fine-tune a pretrained language model (you can choose from BERT and ALBERT) and train the internal classifiers by:
```bash
export GLUE_DIR=/path/to/glue_data
export TASK_NAME=MRPC
python ./run_glue_with_pabee.py \
--model_type albert \
--model_name_or_path bert-base-uncased/albert-base-v2 \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--data_dir "$GLUE_DIR/$TASK_NAME" \
--max_seq_length 128 \
--per_gpu_train_batch_size 32 \
--per_gpu_eval_batch_size 32 \
--learning_rate 2e-5 \
--save_steps 50 \
--logging_steps 50 \
--num_train_epochs 5 \
--output_dir /path/to/save/ \
--evaluate_during_training
```
## Inference
You can inference with different patience settings by:
```bash
export GLUE_DIR=/path/to/glue_data
export TASK_NAME=MRPC
python ./run_glue_with_pabee.py \
--model_type albert \
--model_name_or_path /path/to/save/ \
--task_name $TASK_NAME \
--do_eval \
--do_lower_case \
--data_dir "$GLUE_DIR/$TASK_NAME" \
--max_seq_length 128 \
--per_gpu_eval_batch_size 1 \
--learning_rate 2e-5 \
--logging_steps 50 \
--num_train_epochs 15 \
--output_dir /path/to/save/ \
--eval_all_checkpoints \
--patience 3,4,5,6,7,8
```
where `patience` can be a list of patience settings, separated by a comma. It will help determine which patience works best.
When evaluating on a regression task (STS-B), you may add `--regression_threshold 0.1` to define the regression threshold.
## Results
On the GLUE dev set:
| Model | \#Param | Speed | CoLA | MNLI | MRPC | QNLI | QQP | RTE | SST\-2 | STS\-B |
|--------------|---------|--------|-------|-------|-------|-------|-------|-------|--------|--------|
| ALBERT\-base | 12M | | 58\.9 | 84\.6 | 89\.5 | 91\.7 | 89\.6 | 78\.6 | 92\.8 | 89\.5 |
| \+PABEE | 12M | 1\.57x | 61\.2 | 85\.1 | 90\.0 | 91\.8 | 89\.6 | 80\.1 | 93\.0 | 90\.1 |
| Model | \#Param | Speed\-up | MNLI | SST\-2 | STS\-B |
|---------------|---------|-----------|-------|--------|--------|
| BERT\-base | 108M | | 84\.5 | 92\.1 | 88\.9 |
| \+PABEE | 108M | 1\.62x | 83\.6 | 92\.0 | 88\.7 |
| ALBERT\-large | 18M | | 86\.4 | 94\.9 | 90\.4 |
| \+PABEE | 18M | 2\.42x | 86\.8 | 95\.2 | 90\.6 |
## Citation
If you find this resource useful, please consider citing the following paper:
```bibtex
@misc{zhou2020bert,
title={BERT Loses Patience: Fast and Robust Inference with Early Exit},
author={Wangchunshu Zhou and Canwen Xu and Tao Ge and Julian McAuley and Ke Xu and Furu Wei},
year={2020},
eprint={2006.04152},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/run_glue_with_pabee.py
|
# coding=utf-8
# Copyright 2020 The Google AI Language Team Authors, The HuggingFace Inc. team and Microsoft Corporation.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Training and inference using the library models for sequence classification on GLUE (Bert, Albert) with PABEE."""
import argparse
import glob
import json
import logging
import os
import random
import numpy as np
import torch
from pabee.modeling_pabee_albert import AlbertForSequenceClassificationWithPabee
from pabee.modeling_pabee_bert import BertForSequenceClassificationWithPabee
from torch import nn
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
AlbertConfig,
AlbertTokenizer,
BertConfig,
BertTokenizer,
get_linear_schedule_with_warmup,
)
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_convert_examples_to_features as convert_examples_to_features
from transformers import glue_output_modes as output_modes
from transformers import glue_processors as processors
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
MODEL_CLASSES = {
"bert": (BertConfig, BertForSequenceClassificationWithPabee, BertTokenizer),
"albert": (AlbertConfig, AlbertForSequenceClassificationWithPabee, AlbertTokenizer),
}
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def train(args, train_dataset, model, tokenizer):
"""Train the model"""
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = nn.parallel.DistributedDataParallel(
model,
device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=True,
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
# set global_step to gobal_step of last saved checkpoint from model path
global_step = int(args.model_name_or_path.split("-")[-1].split("/")[0])
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(
" Will skip the first %d steps in the first epoch",
steps_trained_in_current_epoch,
)
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained,
int(args.num_train_epochs),
desc="Epoch",
disable=args.local_rank not in [-1, 0],
)
set_seed(args) # Added here for reproductibility
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"labels": batch[3],
}
inputs["token_type_ids"] = batch[2]
outputs = model(**inputs)
loss = outputs[0] # model outputs are always tuple in transformers (see doc)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
logs = {}
if (
args.local_rank == -1 and args.evaluate_during_training
): # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, model, tokenizer)
for key, value in results.items():
eval_key = "eval_{}".format(key)
logs[eval_key] = value
loss_scalar = (tr_loss - logging_loss) / args.logging_steps
learning_rate_scalar = scheduler.get_lr()[0]
logs["learning_rate"] = learning_rate_scalar
logs["loss"] = loss_scalar
logging_loss = tr_loss
for key, value in logs.items():
tb_writer.add_scalar(key, value, global_step)
print(json.dumps({**logs, **{"step": global_step}}))
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix="", patience=0):
if args.model_type == "albert":
model.albert.set_regression_threshold(args.regression_threshold)
model.albert.set_patience(patience)
model.albert.reset_stats()
elif args.model_type == "bert":
model.bert.set_regression_threshold(args.regression_threshold)
model.bert.set_patience(patience)
model.bert.reset_stats()
else:
raise NotImplementedError()
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
eval_outputs_dirs = (args.output_dir, args.output_dir + "-MM") if args.task_name == "mnli" else (args.output_dir,)
results = {}
for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
os.makedirs(eval_output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu eval
if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
model = nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"labels": batch[3],
}
inputs["token_type_ids"] = batch[2]
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs["labels"].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
if args.output_mode == "classification":
preds = np.argmax(preds, axis=1)
elif args.output_mode == "regression":
preds = np.squeeze(preds)
result = compute_metrics(eval_task, preds, out_label_ids)
results.update(result)
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
print(" %s = %s" % (key, str(result[key])))
writer.write("%s = %s\n" % (key, str(result[key])))
if args.eval_all_checkpoints and patience != 0:
if args.model_type == "albert":
model.albert.log_stats()
elif args.model_type == "bert":
model.bert.log_stats()
else:
raise NotImplementedError()
return results
def load_and_cache_examples(args, task, tokenizer, evaluate=False):
if args.local_rank not in [-1, 0] and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
processor = processors[task]()
output_mode = output_modes[task]
# Load data features from cache or dataset file
cached_features_file = os.path.join(
args.data_dir,
"cached_{}_{}_{}_{}".format(
"dev" if evaluate else "train",
list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
str(task),
),
)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
label_list = processor.get_labels()
if task in ["mnli", "mnli-mm"] and args.model_type in ["roberta", "xlmroberta"]:
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
examples = (
processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
)
features = convert_examples_to_features(
examples,
tokenizer,
label_list=label_list,
max_length=args.max_seq_length,
output_mode=output_mode,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
if args.local_rank == 0 and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
if output_mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif output_mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
)
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pre-trained model or shortcut name.",
)
parser.add_argument(
"--task_name",
default=None,
type=str,
required=True,
help="The name of the task to train selected in the list: " + ", ".join(processors.keys()),
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--patience",
default="0",
type=str,
required=False,
)
parser.add_argument(
"--regression_threshold",
default=0,
type=float,
required=False,
)
# Other parameters
parser.add_argument(
"--config_name",
default="",
type=str,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training",
action="store_true",
help="Run evaluation during training at each logging step.",
)
parser.add_argument(
"--do_lower_case",
action="store_true",
help="Set this flag if you are using an uncased model.",
)
parser.add_argument(
"--per_gpu_train_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for training.",
)
parser.add_argument(
"--per_gpu_eval_batch_size",
default=1,
type=int,
help="Batch size per GPU/CPU for evaluation.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
default=5e-5,
type=float,
help="The initial learning rate for Adam.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs",
default=3.0,
type=float,
help="Total number of training epochs to perform.",
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
parser.add_argument(
"--save_steps",
type=int,
default=500,
help="Save checkpoint every X updates steps.",
)
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
parser.add_argument(
"--overwrite_output_dir",
action="store_true",
help="Overwrite the content of the output directory",
)
parser.add_argument(
"--overwrite_cache",
action="store_true",
help="Overwrite the cached training and evaluation sets",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument(
"--local_rank",
type=int,
default=-1,
help="For distributed training: local_rank",
)
parser.add_argument("--server_ip", type=str, default="", help="For distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="For distant debugging.")
args = parser.parse_args()
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Prepare GLUE task
args.task_name = args.task_name.lower()
if args.task_name not in processors:
raise ValueError("Task not found: %s" % (args.task_name))
processor = processors[args.task_name]()
args.output_mode = output_modes[args.task_name]
label_list = processor.get_labels()
num_labels = len(label_list)
if args.patience != "0" and args.per_gpu_eval_batch_size != 1:
raise ValueError("The eval batch size must be 1 with PABEE inference on.")
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
args.model_type = args.model_type.lower()
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
config = config_class.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
num_labels=num_labels,
finetuning_task=args.task_name,
cache_dir=args.cache_dir if args.cache_dir else None,
)
tokenizer = tokenizer_class.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
)
model = model_class.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
model.to(args.device)
print("Total Model Parameters:", sum(param.numel() for param in model.parameters()))
output_layers_param_num = sum(param.numel() for param in model.classifiers.parameters())
print("Output Layers Parameters:", output_layers_param_num)
single_output_layer_param_num = sum(param.numel() for param in model.classifiers[0].parameters())
print(
"Added Output Layers Parameters:",
output_layers_param_num - single_output_layer_param_num,
)
logger.info("Training/evaluation parameters %s", args)
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = model_class.from_pretrained(args.output_dir)
tokenizer = tokenizer_class.from_pretrained(args.output_dir)
model.to(args.device)
# Evaluation
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
patience_list = [int(x) for x in args.patience.split(",")]
tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = [
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
model = model_class.from_pretrained(checkpoint)
model.to(args.device)
print(f"Evaluation for checkpoint {prefix}")
for patience in patience_list:
result = evaluate(args, model, tokenizer, prefix=prefix, patience=patience)
result = {k + "_{}".format(global_step): v for k, v in result.items()}
results.update(result)
return results
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/test_run_glue_with_pabee.py
|
import argparse
import logging
import sys
from unittest.mock import patch
import run_glue_with_pabee
from transformers.testing_utils import TestCasePlus
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
def get_setup_file():
parser = argparse.ArgumentParser()
parser.add_argument("-f")
args = parser.parse_args()
return args.f
class PabeeTests(TestCasePlus):
def test_run_glue(self):
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_glue_with_pabee.py
--model_type albert
--model_name_or_path albert-base-v2
--data_dir ./tests/fixtures/tests_samples/MRPC/
--output_dir {tmp_dir}
--overwrite_output_dir
--task_name mrpc
--do_train
--do_eval
--per_gpu_train_batch_size=2
--per_gpu_eval_batch_size=1
--learning_rate=2e-5
--max_steps=50
--warmup_steps=2
--seed=42
--max_seq_length=128
""".split()
with patch.object(sys, "argv", testargs):
result = run_glue_with_pabee.main()
for value in result.values():
self.assertGreaterEqual(value, 0.75)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/requirements.txt
|
transformers == 3.5.1
| 0
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_bert.py
|
# coding=utf-8
# Copyright 2020 The Google AI Language Team Authors, The HuggingFace Inc. team and Microsoft Corporation.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch BERT model with Patience-based Early Exit. """
import logging
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.models.bert.modeling_bert import (
BERT_INPUTS_DOCSTRING,
BERT_START_DOCSTRING,
BertEncoder,
BertModel,
BertPreTrainedModel,
)
logger = logging.getLogger(__name__)
class BertEncoderWithPabee(BertEncoder):
def adaptive_forward(self, hidden_states, current_layer, attention_mask=None, head_mask=None):
layer_outputs = self.layer[current_layer](hidden_states, attention_mask, head_mask[current_layer])
hidden_states = layer_outputs[0]
return hidden_states
@add_start_docstrings(
"The bare Bert Model transformer with PABEE outputting raw hidden-states without any specific head on top.",
BERT_START_DOCSTRING,
)
class BertModelWithPabee(BertModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in `Attention is all you need`_ by Ashish Vaswani,
Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as a decoder the model needs to be initialized with the
:obj:`is_decoder` argument of the configuration set to :obj:`True`; an
:obj:`encoder_hidden_states` is expected as an input to the forward pass.
.. _`Attention is all you need`:
https://arxiv.org/abs/1706.03762
"""
def __init__(self, config):
super().__init__(config)
self.encoder = BertEncoderWithPabee(config)
self.init_weights()
self.patience = 0
self.inference_instances_num = 0
self.inference_layers_num = 0
self.regression_threshold = 0
def set_regression_threshold(self, threshold):
self.regression_threshold = threshold
def set_patience(self, patience):
self.patience = patience
def reset_stats(self):
self.inference_instances_num = 0
self.inference_layers_num = 0
def log_stats(self):
avg_inf_layers = self.inference_layers_num / self.inference_instances_num
message = (
f"*** Patience = {self.patience} Avg. Inference Layers = {avg_inf_layers:.2f} Speed Up ="
f" {1 - avg_inf_layers / self.config.num_hidden_layers:.2f} ***"
)
print(message)
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_dropout=None,
output_layers=None,
regression=False,
):
r"""
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = embedding_output
if self.training:
res = []
for i in range(self.config.num_hidden_layers):
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs, current_layer=i, attention_mask=extended_attention_mask, head_mask=head_mask
)
pooled_output = self.pooler(encoder_outputs)
logits = output_layers[i](output_dropout(pooled_output))
res.append(logits)
elif self.patience == 0: # Use all layers for inference
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
)
pooled_output = self.pooler(encoder_outputs[0])
res = [output_layers[self.config.num_hidden_layers - 1](pooled_output)]
else:
patient_counter = 0
patient_result = None
calculated_layer_num = 0
for i in range(self.config.num_hidden_layers):
calculated_layer_num += 1
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs, current_layer=i, attention_mask=extended_attention_mask, head_mask=head_mask
)
pooled_output = self.pooler(encoder_outputs)
logits = output_layers[i](pooled_output)
if regression:
labels = logits.detach()
if patient_result is not None:
patient_labels = patient_result.detach()
if (patient_result is not None) and torch.abs(patient_result - labels) < self.regression_threshold:
patient_counter += 1
else:
patient_counter = 0
else:
labels = logits.detach().argmax(dim=1)
if patient_result is not None:
patient_labels = patient_result.detach().argmax(dim=1)
if (patient_result is not None) and torch.all(labels.eq(patient_labels)):
patient_counter += 1
else:
patient_counter = 0
patient_result = logits
if patient_counter == self.patience:
break
res = [patient_result]
self.inference_layers_num += calculated_layer_num
self.inference_instances_num += 1
return res
@add_start_docstrings(
"""Bert Model transformer with PABEE and a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
BERT_START_DOCSTRING,
)
class BertForSequenceClassificationWithPabee(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModelWithPabee(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifiers = nn.ModuleList(
[nn.Linear(config.hidden_size, self.config.num_labels) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples::
from transformers import BertTokenizer, BertForSequenceClassification
from pabee import BertForSequenceClassificationWithPabee
from torch import nn
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassificationWithPabee.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2]
"""
logits = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_dropout=self.dropout,
output_layers=self.classifiers,
regression=self.num_labels == 1,
)
outputs = (logits[-1],)
if labels is not None:
total_loss = None
total_weights = 0
for ix, logits_item in enumerate(logits):
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits_item.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits_item.view(-1, self.num_labels), labels.view(-1))
if total_loss is None:
total_loss = loss
else:
total_loss += loss * (ix + 1)
total_weights += ix + 1
outputs = (total_loss / total_weights,) + outputs
return outputs
| 0
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience
|
hf_public_repos/transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_albert.py
|
# coding=utf-8
# Copyright 2020 Google AI, Google Brain, the HuggingFace Inc. team and Microsoft Corporation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ALBERT model with Patience-based Early Exit. """
import logging
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.models.albert.modeling_albert import (
ALBERT_INPUTS_DOCSTRING,
ALBERT_START_DOCSTRING,
AlbertModel,
AlbertPreTrainedModel,
AlbertTransformer,
)
logger = logging.getLogger(__name__)
class AlbertTransformerWithPabee(AlbertTransformer):
def adaptive_forward(self, hidden_states, current_layer, attention_mask=None, head_mask=None):
if current_layer == 0:
hidden_states = self.embedding_hidden_mapping_in(hidden_states)
else:
hidden_states = hidden_states[0]
layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
# Index of the hidden group
group_idx = int(current_layer / (self.config.num_hidden_layers / self.config.num_hidden_groups))
layer_group_output = self.albert_layer_groups[group_idx](
hidden_states,
attention_mask,
head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
)
hidden_states = layer_group_output[0]
return (hidden_states,)
@add_start_docstrings(
"The bare ALBERT Model transformer with PABEE outputting raw hidden-states without any specific head on top.",
ALBERT_START_DOCSTRING,
)
class AlbertModelWithPabee(AlbertModel):
def __init__(self, config):
super().__init__(config)
self.encoder = AlbertTransformerWithPabee(config)
self.init_weights()
self.patience = 0
self.inference_instances_num = 0
self.inference_layers_num = 0
self.regression_threshold = 0
def set_regression_threshold(self, threshold):
self.regression_threshold = threshold
def set_patience(self, patience):
self.patience = patience
def reset_stats(self):
self.inference_instances_num = 0
self.inference_layers_num = 0
def log_stats(self):
avg_inf_layers = self.inference_layers_num / self.inference_instances_num
message = (
f"*** Patience = {self.patience} Avg. Inference Layers = {avg_inf_layers:.2f} Speed Up ="
f" {1 - avg_inf_layers / self.config.num_hidden_layers:.2f} ***"
)
print(message)
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_dropout=None,
output_layers=None,
regression=False,
):
r"""
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = embedding_output
if self.training:
res = []
for i in range(self.config.num_hidden_layers):
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](output_dropout(pooled_output))
res.append(logits)
elif self.patience == 0: # Use all layers for inference
encoder_outputs = self.encoder(encoder_outputs, extended_attention_mask, head_mask=head_mask)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
res = [output_layers[self.config.num_hidden_layers - 1](pooled_output)]
else:
patient_counter = 0
patient_result = None
calculated_layer_num = 0
for i in range(self.config.num_hidden_layers):
calculated_layer_num += 1
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](pooled_output)
if regression:
labels = logits.detach()
if patient_result is not None:
patient_labels = patient_result.detach()
if (patient_result is not None) and torch.abs(patient_result - labels) < self.regression_threshold:
patient_counter += 1
else:
patient_counter = 0
else:
labels = logits.detach().argmax(dim=1)
if patient_result is not None:
patient_labels = patient_result.detach().argmax(dim=1)
if (patient_result is not None) and torch.all(labels.eq(patient_labels)):
patient_counter += 1
else:
patient_counter = 0
patient_result = logits
if patient_counter == self.patience:
break
res = [patient_result]
self.inference_layers_num += calculated_layer_num
self.inference_instances_num += 1
return res
@add_start_docstrings(
"""Albert Model transformer with PABEE and a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
ALBERT_START_DOCSTRING,
)
class AlbertForSequenceClassificationWithPabee(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModelWithPabee(config)
self.dropout = nn.Dropout(config.classifier_dropout_prob)
self.classifiers = nn.ModuleList(
[nn.Linear(config.hidden_size, self.config.num_labels) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in ``[0, ..., config.num_labels - 1]``.
If ``config.num_labels == 1`` a regression loss is computed (Mean-Square loss),
If ``config.num_labels > 1`` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
loss (`optional`, returned when ``labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
Classification (or regression if config.num_labels==1) loss.
logits ``torch.FloatTensor`` of shape ``(batch_size, config.num_labels)``
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples::
from transformers import AlbertTokenizer
from pabee import AlbertForSequenceClassificationWithPabee
from torch import nn
import torch
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertForSequenceClassificationWithPabee.from_pretrained('albert-base-v2')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2]
"""
logits = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_dropout=self.dropout,
output_layers=self.classifiers,
regression=self.num_labels == 1,
)
outputs = (logits[-1],)
if labels is not None:
total_loss = None
total_weights = 0
for ix, logits_item in enumerate(logits):
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits_item.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits_item.view(-1, self.num_labels), labels.view(-1))
if total_loss is None:
total_loss = loss
else:
total_loss += loss * (ix + 1)
total_weights += ix + 1
outputs = (total_loss / total_weights,) + outputs
return outputs
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/mm-imdb/README.md
|
## MM-IMDb
Based on the script [`run_mmimdb.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/mm-imdb/run_mmimdb.py).
[MM-IMDb](http://lisi1.unal.edu.co/mmimdb/) is a Multimodal dataset with around 26,000 movies including images, plots and other metadata.
### Training on MM-IMDb
```
python run_mmimdb.py \
--data_dir /path/to/mmimdb/dataset/ \
--model_type bert \
--model_name_or_path bert-base-uncased \
--output_dir /path/to/save/dir/ \
--do_train \
--do_eval \
--max_seq_len 512 \
--gradient_accumulation_steps 20 \
--num_image_embeds 3 \
--num_train_epochs 100 \
--patience 5
```
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/mm-imdb/run_mmimdb.py
|
# coding=utf-8
# Copyright (c) Facebook, Inc. and its affiliates.
# Copyright (c) HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning the library models for multimodal multiclass prediction on MM-IMDB dataset."""
import argparse
import glob
import json
import logging
import os
import random
import numpy as np
import torch
from sklearn.metrics import f1_score
from torch import nn
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
from utils_mmimdb import ImageEncoder, JsonlDataset, collate_fn, get_image_transforms, get_mmimdb_labels
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
AutoConfig,
AutoModel,
AutoTokenizer,
MMBTConfig,
MMBTForClassification,
get_linear_schedule_with_warmup,
)
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def train(args, train_dataset, model, tokenizer, criterion):
"""Train the model"""
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(
train_dataset,
sampler=train_sampler,
batch_size=args.train_batch_size,
collate_fn=collate_fn,
num_workers=args.num_workers,
)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
best_f1, n_no_improve = 0, 0
model.zero_grad()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])
set_seed(args) # Added here for reproductibility
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
model.train()
batch = tuple(t.to(args.device) for t in batch)
labels = batch[5]
inputs = {
"input_ids": batch[0],
"input_modal": batch[2],
"attention_mask": batch[1],
"modal_start_tokens": batch[3],
"modal_end_tokens": batch[4],
}
outputs = model(**inputs)
logits = outputs[0] # model outputs are always tuple in transformers (see doc)
loss = criterion(logits, labels)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
logs = {}
if (
args.local_rank == -1 and args.evaluate_during_training
): # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, model, tokenizer, criterion)
for key, value in results.items():
eval_key = "eval_{}".format(key)
logs[eval_key] = value
loss_scalar = (tr_loss - logging_loss) / args.logging_steps
learning_rate_scalar = scheduler.get_lr()[0]
logs["learning_rate"] = learning_rate_scalar
logs["loss"] = loss_scalar
logging_loss = tr_loss
for key, value in logs.items():
tb_writer.add_scalar(key, value, global_step)
print(json.dumps({**logs, **{"step": global_step}}))
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
torch.save(model_to_save.state_dict(), os.path.join(output_dir, WEIGHTS_NAME))
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank == -1:
results = evaluate(args, model, tokenizer, criterion)
if results["micro_f1"] > best_f1:
best_f1 = results["micro_f1"]
n_no_improve = 0
else:
n_no_improve += 1
if n_no_improve > args.patience:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, criterion, prefix=""):
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_output_dir = args.output_dir
eval_dataset = load_examples(args, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
os.makedirs(eval_output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset)
eval_dataloader = DataLoader(
eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size, collate_fn=collate_fn
)
# multi-gpu eval
if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
model = nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
batch = tuple(t.to(args.device) for t in batch)
labels = batch[5]
inputs = {
"input_ids": batch[0],
"input_modal": batch[2],
"attention_mask": batch[1],
"modal_start_tokens": batch[3],
"modal_end_tokens": batch[4],
}
outputs = model(**inputs)
logits = outputs[0] # model outputs are always tuple in transformers (see doc)
tmp_eval_loss = criterion(logits, labels)
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = torch.sigmoid(logits).detach().cpu().numpy() > 0.5
out_label_ids = labels.detach().cpu().numpy()
else:
preds = np.append(preds, torch.sigmoid(logits).detach().cpu().numpy() > 0.5, axis=0)
out_label_ids = np.append(out_label_ids, labels.detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
result = {
"loss": eval_loss,
"macro_f1": f1_score(out_label_ids, preds, average="macro"),
"micro_f1": f1_score(out_label_ids, preds, average="micro"),
}
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return result
def load_examples(args, tokenizer, evaluate=False):
path = os.path.join(args.data_dir, "dev.jsonl" if evaluate else "train.jsonl")
transforms = get_image_transforms()
labels = get_mmimdb_labels()
dataset = JsonlDataset(path, tokenizer, transforms, labels, args.max_seq_length - args.num_image_embeds - 2)
return dataset
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .jsonl files for MMIMDB.",
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
# Other parameters
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default=None,
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--num_image_embeds", default=1, type=int, help="Number of Image Embeddings from the Image Encoder"
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
)
parser.add_argument(
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight deay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
)
parser.add_argument("--patience", default=5, type=int, help="Patience for Early Stopping.")
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
parser.add_argument("--num_workers", type=int, default=8, help="number of worker threads for dataloading")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument("--server_ip", type=str, default="", help="For distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="For distant debugging.")
args = parser.parse_args()
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
# Setup model
labels = get_mmimdb_labels()
num_labels = len(labels)
transformer_config = AutoConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir,
)
transformer = AutoModel.from_pretrained(
args.model_name_or_path, config=transformer_config, cache_dir=args.cache_dir
)
img_encoder = ImageEncoder(args)
config = MMBTConfig(transformer_config, num_labels=num_labels)
model = MMBTForClassification(config, transformer, img_encoder)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Training
if args.do_train:
train_dataset = load_examples(args, tokenizer, evaluate=False)
label_frequences = train_dataset.get_label_frequencies()
label_frequences = [label_frequences[l] for l in labels]
label_weights = (
torch.tensor(label_frequences, device=args.device, dtype=torch.float) / len(train_dataset)
) ** -1
criterion = nn.BCEWithLogitsLoss(pos_weight=label_weights)
global_step, tr_loss = train(args, train_dataset, model, tokenizer, criterion)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
torch.save(model_to_save.state_dict(), os.path.join(args.output_dir, WEIGHTS_NAME))
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = MMBTForClassification(config, transformer, img_encoder)
model.load_state_dict(torch.load(os.path.join(args.output_dir, WEIGHTS_NAME)))
tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
model.to(args.device)
# Evaluation
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = [
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
model = MMBTForClassification(config, transformer, img_encoder)
model.load_state_dict(torch.load(checkpoint))
model.to(args.device)
result = evaluate(args, model, tokenizer, criterion, prefix=prefix)
result = {k + "_{}".format(global_step): v for k, v in result.items()}
results.update(result)
return results
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/mm-imdb/utils_mmimdb.py
|
# coding=utf-8
# Copyright (c) Facebook, Inc. and its affiliates.
# Copyright (c) HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
from collections import Counter
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
from torch import nn
from torch.utils.data import Dataset
POOLING_BREAKDOWN = {1: (1, 1), 2: (2, 1), 3: (3, 1), 4: (2, 2), 5: (5, 1), 6: (3, 2), 7: (7, 1), 8: (4, 2), 9: (3, 3)}
class ImageEncoder(nn.Module):
def __init__(self, args):
super().__init__()
model = torchvision.models.resnet152(pretrained=True)
modules = list(model.children())[:-2]
self.model = nn.Sequential(*modules)
self.pool = nn.AdaptiveAvgPool2d(POOLING_BREAKDOWN[args.num_image_embeds])
def forward(self, x):
# Bx3x224x224 -> Bx2048x7x7 -> Bx2048xN -> BxNx2048
out = self.pool(self.model(x))
out = torch.flatten(out, start_dim=2)
out = out.transpose(1, 2).contiguous()
return out # BxNx2048
class JsonlDataset(Dataset):
def __init__(self, data_path, tokenizer, transforms, labels, max_seq_length):
self.data = [json.loads(l) for l in open(data_path)]
self.data_dir = os.path.dirname(data_path)
self.tokenizer = tokenizer
self.labels = labels
self.n_classes = len(labels)
self.max_seq_length = max_seq_length
self.transforms = transforms
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sentence = torch.LongTensor(self.tokenizer.encode(self.data[index]["text"], add_special_tokens=True))
start_token, sentence, end_token = sentence[0], sentence[1:-1], sentence[-1]
sentence = sentence[: self.max_seq_length]
label = torch.zeros(self.n_classes)
label[[self.labels.index(tgt) for tgt in self.data[index]["label"]]] = 1
image = Image.open(os.path.join(self.data_dir, self.data[index]["img"])).convert("RGB")
image = self.transforms(image)
return {
"image_start_token": start_token,
"image_end_token": end_token,
"sentence": sentence,
"image": image,
"label": label,
}
def get_label_frequencies(self):
label_freqs = Counter()
for row in self.data:
label_freqs.update(row["label"])
return label_freqs
def collate_fn(batch):
lens = [len(row["sentence"]) for row in batch]
bsz, max_seq_len = len(batch), max(lens)
mask_tensor = torch.zeros(bsz, max_seq_len, dtype=torch.long)
text_tensor = torch.zeros(bsz, max_seq_len, dtype=torch.long)
for i_batch, (input_row, length) in enumerate(zip(batch, lens)):
text_tensor[i_batch, :length] = input_row["sentence"]
mask_tensor[i_batch, :length] = 1
img_tensor = torch.stack([row["image"] for row in batch])
tgt_tensor = torch.stack([row["label"] for row in batch])
img_start_token = torch.stack([row["image_start_token"] for row in batch])
img_end_token = torch.stack([row["image_end_token"] for row in batch])
return text_tensor, mask_tensor, img_tensor, img_start_token, img_end_token, tgt_tensor
def get_mmimdb_labels():
return [
"Crime",
"Drama",
"Thriller",
"Action",
"Comedy",
"Romance",
"Documentary",
"Short",
"Mystery",
"History",
"Family",
"Adventure",
"Fantasy",
"Sci-Fi",
"Western",
"Horror",
"Sport",
"War",
"Music",
"Musical",
"Animation",
"Biography",
"Film-Noir",
]
def get_image_transforms():
return transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.46777044, 0.44531429, 0.40661017],
std=[0.12221994, 0.12145835, 0.14380469],
),
]
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/README.md
|
# End-to-End finetuning of RAG (including DPR retriever) for Question Answering.
This finetuning script is actively maintained by [Shamane Siri](https://github.com/shamanez). Feel free to ask questions on the [Forum](https://discuss.huggingface.co/) or post an issue on [GitHub](https://github.com/huggingface/transformers/issues/new/choose) and tag @shamanez.
Others that helped out: Patrick von Platen (@patrickvonplaten), Quentin Lhoest (@lhoestq), and Rivindu Weerasekera (@rivinduw)
The original RAG implementation is able to train the question encoder and generator end-to-end.
This extension enables complete end-to-end training of RAG including the context encoder in the retriever component.
Please read the [accompanying blog post](https://shamanesiri.medium.com/how-to-finetune-the-entire-rag-architecture-including-dpr-retriever-4b4385322552) for details on this implementation.
The original RAG code has also been modified to work with the latest versions of pytorch lightning (version 1.2.10) and RAY (version 1.3.0). All other implementation details remain the same as the [original RAG code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/rag).
Read more about RAG at https://arxiv.org/abs/2005.11401.
This code can be modified to experiment with other research on retrival augmented models which include training of the retriever (e.g. [REALM](https://arxiv.org/abs/2002.08909) and [MARGE](https://arxiv.org/abs/2006.15020)).
To start training, use the bash script (finetune_rag_ray_end2end.sh) in this folder. This script also includes descriptions on each command-line argument used.
# Latest Update
⚠️ Updated the rag-end2end-retriever to be compatible with PL==1.6.4 and RAY==1.13.0 (latest versions to the date 2022-June-11)
# Note
⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
# Testing
The following two bash scripts can be used to quickly test the implementation.
1. sh ./test_run/test_finetune.sh script
- Tests the full end-to-end fine-tuning ability with a dummy knowlendge-base and dummy training dataset (check test_dir directory).
- Users can replace the dummy dataset and knowledge-base with their own to do their own finetuning.
- Please read the comments in the test_finetune.sh file.
2. sh ./test_run/test_rag_new_features.sh
- Tests the newly added functions (set_context_encoder and set_context_encoder_tokenizer) related to modeling rag.
- This is sufficient to check the model's ability to use the set functions correctly.
# Comparison of end2end RAG (including DPR finetuning) VS original-RAG
We conducted a simple experiment to investigate the effectiveness of this end2end training extension using the SQuAD dataset. Please execute the following steps to reproduce the results.
- Create a knowledge-base using all the context passages in the SQuAD dataset with their respective titles.
- Use the question-answer pairs as training data.
- Train the system for 10 epochs.
- Test the Exact Match (EM) score with the SQuAD dataset's validation set.
- Training dataset, the knowledge-base, and hyperparameters used in experiments can be accessed from [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing).
# Results
- We train both models for 10 epochs.
| Model Type | EM-Score|
| --------------------| --------|
| RAG-original | 28.12 |
| RAG-end2end with DPR| 40.02 |
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py
|
import logging
import random
import ray
from transformers import RagConfig, RagRetriever, RagTokenizer
from transformers.models.rag.retrieval_rag import CustomHFIndex
logger = logging.getLogger(__name__)
class RayRetriever:
def __init__(self):
self.initialized = False
def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
if not self.initialized:
self.retriever = RagRetriever(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
index=index,
init_retrieval=False,
)
self.initialized = True
def init_retrieval(self):
self.retriever.index.init_index()
def clear_object(self):
# delete the old self.retriever object before assigning the new index
del self.retriever
self.initialized = False
def retrieve(self, question_hidden_states, n_docs):
doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
doc_dicts = self.retriever.index.get_doc_dicts(doc_ids)
return doc_ids, retrieved_doc_embeds, doc_dicts
class RagRayDistributedRetriever(RagRetriever):
"""
A distributed retriever built on top of the ``Ray`` API, a library
for building distributed applications (https://docs.ray.io/en/master/).
package. During training, all training workers initialize their own
instance of a `RagRayDistributedRetriever`, and each instance of
this distributed retriever shares a common set of Retrieval Ray
Actors (https://docs.ray.io/en/master/walkthrough.html#remote
-classes-actors) that load the index on separate processes. Ray
handles the communication between the `RagRayDistributedRetriever`
instances and the remote Ray actors. If training is done in a
non-distributed setup, the index will simply be loaded in the same
process as the training worker and Ray will not be used.
Args:
config (:class:`~transformers.RagConfig`):
The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer that was used to tokenize the question.
It is used to decode the question and then use the generator_tokenizer.
generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer used for the generator part of the RagModel.
retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
These actor classes run on remote processes and are responsible for performing the index lookup.
index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
If specified, use this index instead of the one built using the configuration
"""
def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
raise ValueError(
"When using Ray for distributed fine-tuning, "
"you'll need to provide the paths instead, "
"as the dataset and the index are loaded "
"separately. More info in examples/rag/use_own_knowledge_dataset.py "
)
super().__init__(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
index=index,
init_retrieval=False,
)
self.retrieval_workers = retrieval_workers
self.question_encoder_tokenizer = question_encoder_tokenizer
self.generator_tokenizer = generator_tokenizer
if len(self.retrieval_workers) > 0:
ray.get(
[
worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
for worker in self.retrieval_workers
]
)
def init_retrieval(self):
"""
Retriever initialization function, needs to be called from the
training process. This function triggers retrieval initialization
for all retrieval actors if using distributed setting, or loads
index into current process if training is not distributed.
"""
logger.info("initializing retrieval")
if len(self.retrieval_workers) > 0:
ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
else:
# Non-distributed training. Load index into this same process.
self.index.init_index()
def retrieve(self, question_hidden_states, n_docs):
"""
Retrieves documents for specified ``question_hidden_states``. If
running training with multiple workers, a random retrieval actor is
selected to perform the index lookup and return the result.
Args:
question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
A batch of query vectors to retrieve with.
n_docs (:obj:`int`):
The number of docs retrieved per query.
Output:
retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
The retrieval embeddings of the retrieved docs per query.
doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
The ids of the documents in the index
doc_dicts (:obj:`List[dict]`):
The retrieved_doc_embeds examples per query.
"""
if len(self.retrieval_workers) > 0:
# Select a random retrieval actor.
random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
doc_ids, retrieved_doc_embeds, doc_dicts = ray.get(
random_worker.retrieve.remote(question_hidden_states, n_docs)
)
else:
doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
doc_dicts = self.index.get_doc_dicts(doc_ids)
return retrieved_doc_embeds, doc_ids, doc_dicts
@classmethod
def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
@classmethod
def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
question_encoder_tokenizer = rag_tokenizer.question_encoder
generator_tokenizer = rag_tokenizer.generator
if indexed_dataset is not None:
config.index_name = "custom"
index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
else:
index = cls._build_index(config)
return cls(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
retrieval_workers=actor_handles,
index=index,
)
def re_load(self):
logger.info("re-loading the new dataset with embeddings")
# access from the training loop
ray.get([worker.clear_object.remote() for worker in self.retrieval_workers])
# build the index object again
index = self._build_index(self.config)
ray.get(
[
worker.create_rag_retriever.remote(
self.config, self.question_encoder_tokenizer, self.generator_tokenizer, index
)
for worker in self.retrieval_workers
]
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
|
import logging
from pathlib import Path
import numpy as np
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.utilities import rank_zero_only
from utils_rag import save_json
def count_trainable_parameters(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
return params
logger = logging.getLogger(__name__)
def get_checkpoint_callback(output_dir, metric):
"""Saves the best model by validation EM score."""
if metric == "rouge2":
exp = "{val_avg_rouge2:.4f}-{step_count}"
elif metric == "bleu":
exp = "{val_avg_bleu:.4f}-{step_count}"
elif metric == "em":
exp = "{val_avg_em:.4f}-{step_count}"
elif metric == "loss":
exp = "{val_avg_loss:.4f}-{step_count}"
else:
raise NotImplementedError(
f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
" function."
)
checkpoint_callback = ModelCheckpoint(
dirpath=output_dir,
filename=exp,
monitor=f"val_{metric}",
mode="max",
save_top_k=1,
every_n_epochs=1, # works only with PL > 1.3
)
return checkpoint_callback
def get_early_stopping_callback(metric, patience):
return EarlyStopping(
monitor=f"val_{metric}", # does this need avg?
mode="min" if "loss" in metric else "max",
patience=patience,
verbose=True,
)
class Seq2SeqLoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
pl_module.logger.log_metrics(lrs)
@rank_zero_only
def _write_logs(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
) -> None:
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
metrics = trainer.callback_metrics
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
# Log results
od = Path(pl_module.hparams.output_dir)
if type_path == "test":
results_file = od / "test_results.txt"
generations_file = od / "test_generations.txt"
else:
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
# If people want this it will be easy enough to add back.
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
results_file.parent.mkdir(exist_ok=True)
generations_file.parent.mkdir(exist_ok=True)
with open(results_file, "a+") as writer:
for key in sorted(metrics):
if key in ["log", "progress_bar", "preds"]:
continue
val = metrics[key]
if isinstance(val, torch.Tensor):
val = val.item()
msg = f"{key}: {val:.6f}\n"
writer.write(msg)
if not save_generations:
return
if "preds" in metrics:
content = "\n".join(metrics["preds"])
generations_file.open("w+").write(content)
@rank_zero_only
def on_train_start(self, trainer, pl_module):
try:
npars = pl_module.model.model.num_parameters()
except AttributeError:
npars = pl_module.model.num_parameters()
n_trainable_pars = count_trainable_parameters(pl_module)
# mp stands for million parameters
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
@rank_zero_only
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
save_json(pl_module.metrics, pl_module.metrics_save_path)
return self._write_logs(trainer, pl_module, "test")
@rank_zero_only
def on_validation_end(self, trainer: pl.Trainer, pl_module):
save_json(pl_module.metrics, pl_module.metrics_save_path)
# Uncommenting this will save val generations
# return self._write_logs(trainer, pl_module, "valid")
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py
|
import logging
import os
from dataclasses import dataclass, field
from functools import partial
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import List, Optional
import faiss
import torch
from datasets import Features, Sequence, Value, load_dataset
from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast, HfArgumentParser
logger = logging.getLogger(__name__)
torch.set_grad_enabled(False)
device = "cuda" if torch.cuda.is_available() else "cpu"
def split_text(text: str, n=100, character=" ") -> List[str]:
"""Split the text every ``n``-th occurrence of ``character``"""
text = text.split(character)
return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
def split_documents(documents: dict) -> dict:
"""Split documents into passages"""
titles, texts = [], []
for title, text in zip(documents["title"], documents["text"]):
if text is not None:
for passage in split_text(text):
titles.append(title if title is not None else "")
texts.append(passage)
return {"title": titles, "text": texts}
def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
"""Compute the DPR embeddings of document passages"""
input_ids = ctx_tokenizer(
documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
)["input_ids"]
embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
return {"embeddings": embeddings.detach().cpu().numpy()}
def main(
rag_example_args: "RagExampleArguments",
processing_args: "ProcessingArguments",
index_hnsw_args: "IndexHnswArguments",
):
######################################
logger.info("Step 1 - Create the dataset")
######################################
# The dataset needed for RAG must have three columns:
# - title (string): title of the document
# - text (string): text of a passage of the document
# - embeddings (array of dimension d): DPR representation of the passage
# Let's say you have documents in tab-separated csv files with columns "title" and "text"
assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
# You can load a Dataset object this way
dataset = load_dataset(
"csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
)
# More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
# Then split the documents into passages of 100 words
dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
# And compute the embeddings
ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
new_features = Features(
{"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
) # optional, save as float32 instead of float64 to save space
dataset = dataset.map(
partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
batched=True,
batch_size=processing_args.batch_size,
features=new_features,
)
# And finally save your dataset
passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
dataset.save_to_disk(passages_path)
# from datasets import load_from_disk
# dataset = load_from_disk(passages_path) # to reload the dataset
######################################
logger.info("Step 2 - Index the dataset")
######################################
# Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
dataset.add_faiss_index("embeddings", custom_index=index)
# And save the index
index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
dataset.get_index("embeddings").save(index_path)
# dataset.load_faiss_index("embeddings", index_path) # to reload the index
@dataclass
class RagExampleArguments:
csv_path: str = field(
default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
)
question: Optional[str] = field(
default=None,
metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
)
rag_model_name: str = field(
default="facebook/rag-sequence-nq",
metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
)
dpr_ctx_encoder_model_name: str = field(
default="facebook/dpr-ctx_encoder-multiset-base",
metadata={
"help": (
"The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
" 'facebook/dpr-ctx_encoder-multiset-base'"
)
},
)
output_dir: Optional[str] = field(
default=str(Path(__file__).parent / "test_run" / "dummy-kb"),
metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
)
@dataclass
class ProcessingArguments:
num_proc: Optional[int] = field(
default=None,
metadata={
"help": "The number of processes to use to split the documents into passages. Default is single process."
},
)
batch_size: int = field(
default=16,
metadata={
"help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
},
)
@dataclass
class IndexHnswArguments:
d: int = field(
default=768,
metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
)
m: int = field(
default=128,
metadata={
"help": (
"The number of bi-directional links created for every new element during the HNSW index construction."
)
},
)
if __name__ == "__main__":
logging.basicConfig(level=logging.WARNING)
logger.setLevel(logging.INFO)
parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
with TemporaryDirectory() as tmp_dir:
rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
main(rag_example_args, processing_args, index_hnsw_args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh
|
# Sample script to finetune RAG using Ray for distributed retrieval.
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
#creates the custom knowlegebase
python use_own_knowledge_dataset.py \
--csv_path /DIR/SQUAD-KB/squad-kb.csv \
--output_dir /DIR/SQUAD-KB
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python finetune_rag.py \
--data_dir /DIR/squad-training-data \
--output_dir /DIR/model_checkpoints \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--fp16 \
--gpus 2 \
--profile \
--do_train \
--end2end \
--do_predict \
--n_val -1 \
--train_batch_size 4 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 10 \
--warmup_steps 500 \
--gradient_accumulation_steps 8 \
--distributed_retriever ray \
--num_retrieval_workers 4 \
--passages_path /DIR/SQUAD-KB/my_knowledge_dataset \
--index_path /DIR/SQUAD-KB/my_knowledge_dataset_hnsw_index.faiss \
--index_name custom \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--csv_path /DIR/SQUAD-KB/squad-kb.csv \
--index_gpus 1 \
--gpu_order [5,6,7,8,9,0,1,2,3,4] \
--shard_dir ./test_dir/kb-shards \
--indexing_freq 500
# Stop the Ray cluster.
ray stop
#this script was used to test the SQuAD data.
#change the dir paramater acording to your prefernece.
#please use the same device ordere when running CUDA_VISIBLE_DEVICES=5,6,7,8,9,0,1,2,3,4 sh finetune_rag_ray_end2end.sh
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/utils_rag.py
|
import itertools
import json
import linecache
import os
import pickle
import re
import socket
import string
from collections import Counter
from logging import getLogger
from pathlib import Path
from typing import Callable, Dict, Iterable, List
import git
import torch
from torch.utils.data import Dataset
from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
tokenizer.padding_side = padding_side
return tokenizer(
[line],
max_length=max_length,
padding="max_length" if pad_to_max_length else None,
truncation=True,
return_tensors=return_tensors,
add_special_tokens=True,
**extra_kw,
)
def trim_batch(
input_ids,
pad_token_id,
attention_mask=None,
):
"""Remove columns that are populated exclusively by pad_token_id"""
keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
if attention_mask is None:
return input_ids[:, keep_column_mask]
else:
return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
class Seq2SeqDataset(Dataset):
def __init__(
self,
tokenizer,
data_dir,
max_source_length,
max_target_length,
type_path="train",
n_obs=None,
src_lang=None,
tgt_lang=None,
prefix="",
):
super().__init__()
self.src_file = Path(data_dir).joinpath(type_path + ".source")
self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
self.src_lens = self.get_char_lens(self.src_file)
self.max_source_length = max_source_length
self.max_target_length = max_target_length
assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
self.tokenizer = tokenizer
self.prefix = prefix
if n_obs is not None:
self.src_lens = self.src_lens[:n_obs]
self.src_lang = src_lang
self.tgt_lang = tgt_lang
def __len__(self):
return len(self.src_lens)
def __getitem__(self, index) -> Dict[str, torch.Tensor]:
index = index + 1 # linecache starts at 1
source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
assert source_line, f"empty source line for index {index}"
assert tgt_line, f"empty tgt line for index {index}"
# Need to add eos token manually for T5
if isinstance(self.tokenizer, T5Tokenizer):
source_line += self.tokenizer.eos_token
tgt_line += self.tokenizer.eos_token
# Pad source and target to the right
source_tokenizer = (
self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
)
target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
source_ids = source_inputs["input_ids"].squeeze()
target_ids = target_inputs["input_ids"].squeeze()
src_mask = source_inputs["attention_mask"].squeeze()
return {
"input_ids": source_ids,
"attention_mask": src_mask,
"decoder_input_ids": target_ids,
}
@staticmethod
def get_char_lens(data_file):
return [len(x) for x in Path(data_file).open().readlines()]
def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
input_ids = torch.stack([x["input_ids"] for x in batch])
masks = torch.stack([x["attention_mask"] for x in batch])
target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
y = trim_batch(target_ids, tgt_pad_token_id)
source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
batch = {
"input_ids": source_ids,
"attention_mask": source_mask,
"decoder_input_ids": y,
}
return batch
logger = getLogger(__name__)
def flatten_list(summary_ids: List[List]):
return list(itertools.chain.from_iterable(summary_ids))
def save_git_info(folder_path: str) -> None:
"""Save git information to output_dir/git_log.json"""
repo_infos = get_git_info()
save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
def save_json(content, path, indent=4, **json_dump_kwargs):
with open(path, "w") as f:
json.dump(content, f, indent=indent, **json_dump_kwargs)
def load_json(path):
with open(path) as f:
return json.load(f)
def get_git_info():
repo = git.Repo(search_parent_directories=True)
repo_infos = {
"repo_id": str(repo),
"repo_sha": str(repo.head.object.hexsha),
"repo_branch": str(repo.active_branch),
"hostname": str(socket.gethostname()),
}
return repo_infos
def lmap(f: Callable, x: Iterable) -> List:
"""list(map(f, x))"""
return list(map(f, x))
def pickle_save(obj, path):
"""pickle.dump(obj, path)"""
with open(path, "wb") as f:
return pickle.dump(obj, f)
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
def remove_articles(text):
return re.sub(r"\b(a|an|the)\b", " ", text)
def white_space_fix(text):
return " ".join(text.split())
def remove_punc(text):
exclude = set(string.punctuation)
return "".join(ch for ch in text if ch not in exclude)
def lower(text):
return text.lower()
return white_space_fix(remove_articles(remove_punc(lower(s))))
def f1_score(prediction, ground_truth):
prediction_tokens = normalize_answer(prediction).split()
ground_truth_tokens = normalize_answer(ground_truth).split()
common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
num_same = sum(common.values())
if num_same == 0:
return 0
precision = 1.0 * num_same / len(prediction_tokens)
recall = 1.0 * num_same / len(ground_truth_tokens)
f1 = (2 * precision * recall) / (precision + recall)
return f1
def exact_match_score(prediction, ground_truth):
return normalize_answer(prediction) == normalize_answer(ground_truth)
def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
assert len(output_lns) == len(reference_lns)
em = 0
for hypo, pred in zip(output_lns, reference_lns):
em += exact_match_score(hypo, pred)
if len(output_lns) > 0:
em /= len(output_lns)
return {"em": em}
def is_rag_model(model_prefix):
return model_prefix.startswith("rag")
def set_extra_model_params(extra_params, hparams, config):
equivalent_param = {p: p for p in extra_params}
# T5 models don't have `dropout` param, they have `dropout_rate` instead
equivalent_param["dropout"] = "dropout_rate"
for p in extra_params:
if getattr(hparams, p, None):
if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
logger.info("config doesn't have a `{}` attribute".format(p))
delattr(hparams, p)
continue
set_p = p if hasattr(config, p) else equivalent_param[p]
setattr(config, set_p, getattr(hparams, p))
delattr(hparams, p)
return hparams, config
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/finetune_rag.py
|
"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
import argparse
import copy
import json
import logging
import multiprocessing
import os
import random
import shutil
import sys
import time
from collections import defaultdict
from pathlib import Path
from typing import Any, Dict, List, Tuple
import numpy as np
import pytorch_lightning as pl
import torch
import torch.distributed as dist
from datasets import concatenate_datasets, load_from_disk
from torch.utils.data import DataLoader
from transformers import (
AutoConfig,
AutoTokenizer,
BartForConditionalGeneration,
BatchEncoding,
DPRConfig,
DPRContextEncoder,
DPRContextEncoderTokenizerFast,
RagConfig,
RagSequenceForGeneration,
RagTokenForGeneration,
RagTokenizer,
T5ForConditionalGeneration,
)
from transformers import logging as transformers_logging
from transformers.integrations import is_ray_available
if is_ray_available():
import ray
from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
from glob import glob
from callbacks_rag import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
from kb_encode_utils import add_index, embed_update
from lightning_base import BaseTransformer, add_generic_args, generic_train
from pynvml import nvmlDeviceGetCount, nvmlDeviceGetHandleByIndex, nvmlDeviceGetMemoryInfo, nvmlInit
from utils_rag import (
Seq2SeqDataset,
calculate_exact_match,
get_git_info,
is_rag_model,
lmap,
pickle_save,
save_git_info,
save_json,
set_extra_model_params,
)
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
transformers_logging.set_verbosity_info()
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
isEmUpdateBusy = False
isAddIndexBusy = False
processes = []
threadHandle_index = None
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
class GenerativeQAModule(BaseTransformer):
mode = "generative_qa"
loss_names = ["loss"]
metric_names = ["em"]
val_metric = "em"
def __init__(self, hparams, **kwargs):
# when loading from a pytorch lightning checkpoint, hparams are passed as dict
if isinstance(hparams, dict):
hparams = AttrDict(hparams)
if hparams.model_type == "rag_sequence":
self.model_class = RagSequenceForGeneration
elif hparams.model_type == "rag_token":
self.model_class = RagTokenForGeneration
elif hparams.model_type == "bart":
self.model_class = BartForConditionalGeneration
else:
self.model_class = T5ForConditionalGeneration
self.is_rag_model = is_rag_model(hparams.model_type)
config_class = RagConfig if self.is_rag_model else AutoConfig
config = config_class.from_pretrained(hparams.model_name_or_path)
# set retriever parameters
config.index_name = hparams.index_name or config.index_name
config.passages_path = hparams.passages_path or config.passages_path
config.index_path = hparams.index_path or config.index_path
config.use_dummy_dataset = hparams.use_dummy_dataset
# set extra_model_params for generator configs and load_model
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
if self.is_rag_model:
if hparams.prefix is not None:
config.generator.prefix = hparams.prefix
config.label_smoothing = hparams.label_smoothing
hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
if hparams.distributed_retriever == "ray":
# The Ray retriever needs the handles to the retriever actors.
retriever = RagRayDistributedRetriever.from_pretrained(
hparams.model_name_or_path, hparams.actor_handles, config=config
)
if hparams.end2end:
ctx_encoder_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
"facebook/dpr-ctx_encoder-multiset-base"
)
retriever.set_ctx_encoder_tokenizer(ctx_encoder_tokenizer)
else:
logger.info("please use RAY as the distributed retrieval method")
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
if hparams.end2end:
ctx_encoder = DPRContextEncoder.from_pretrained(hparams.context_encoder_name)
model.set_context_encoder_for_training(ctx_encoder)
prefix = config.question_encoder.prefix
else:
if hparams.prefix is not None:
config.prefix = hparams.prefix
hparams, config = set_extra_model_params(extra_model_params, hparams, config)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
prefix = config.prefix
tokenizer = (
RagTokenizer.from_pretrained(hparams.model_name_or_path)
if self.is_rag_model
else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
)
self.config_dpr = DPRConfig.from_pretrained(hparams.context_encoder_name)
self.custom_config = hparams
self.context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(hparams.context_encoder_name)
super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
save_git_info(self.hparams.output_dir)
self.output_dir = Path(self.hparams.output_dir)
self.dpr_ctx_check_dir = str(Path(self.hparams.output_dir)) + "/dpr_ctx_checkpoint"
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
pickle_save(self.hparams, self.hparams_save_path)
self.step_count = 0
self.metrics = defaultdict(list)
self.dataset_kwargs: dict = {
"data_dir": self.hparams.data_dir,
"max_source_length": self.hparams.max_source_length,
"prefix": prefix or "",
}
n_observations_per_split = {
"train": self.hparams.n_train,
"val": self.hparams.n_val,
"test": self.hparams.n_test,
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.target_lens = {
"train": self.hparams.max_target_length,
"val": self.hparams.val_max_target_length,
"test": self.hparams.test_max_target_length,
}
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
self.hparams.git_sha = get_git_info()["repo_sha"]
self.num_workers = hparams.num_workers
self.distributed_port = self.hparams.distributed_port
# For single GPU training, init_ddp_connection is not called.
# So we need to initialize the retrievers here.
if hparams.gpus <= 1:
if hparams.distributed_retriever == "ray":
self.model.retriever.init_retrieval()
else:
logger.info("please use RAY as the distributed retrieval method")
self.distributed_retriever = hparams.distributed_retriever
def forward(self, input_ids, **kwargs):
return self.model(input_ids, **kwargs)
def ids_to_clean_text(self, generated_ids: List[int]):
gen_text = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
return lmap(str.strip, gen_text)
def _step(self, batch: dict) -> Tuple:
source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
rag_kwargs = {}
if isinstance(self.model, T5ForConditionalGeneration):
decoder_input_ids = self.model._shift_right(target_ids)
lm_labels = target_ids
elif isinstance(self.model, BartForConditionalGeneration):
decoder_input_ids = target_ids[:, :-1].contiguous()
lm_labels = target_ids[:, 1:].clone()
else:
assert self.is_rag_model
generator = self.model.rag.generator
if isinstance(generator, T5ForConditionalGeneration):
decoder_start_token_id = generator.config.decoder_start_token_id
decoder_input_ids = (
torch.cat(
[torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
dim=1,
)
if target_ids.shape[0] < self.target_lens["train"]
else generator._shift_right(target_ids)
)
elif isinstance(generator, BartForConditionalGeneration):
decoder_input_ids = target_ids
lm_labels = decoder_input_ids
rag_kwargs["reduce_loss"] = True
assert decoder_input_ids is not None
outputs = self(
source_ids,
attention_mask=source_mask,
decoder_input_ids=decoder_input_ids,
use_cache=False,
labels=lm_labels,
**rag_kwargs,
)
loss = outputs["loss"]
return (loss,)
@property
def pad(self) -> int:
raise NotImplementedError("pad not implemented")
def training_step(self, batch, batch_idx) -> Dict:
global isEmUpdateBusy # use to check whether the entire embedding update process is finished or not
global isAddIndexBusy # use to check whether the entire indexing process is finished or not
global processes # use to keep threads embedding update processes
global threadHandle_index # use to keep thread in embedding indexing processes
if (self.trainer.global_rank == 0) and (self.custom_config.end2end):
if (not batch_idx == 0) and (batch_idx % self.custom_config.indexing_freq == 0):
free_gpu_list = []
nvmlInit()
deviceCount = nvmlDeviceGetCount()
my_list = json.loads(self.custom_config.gpu_order)
for i in range(deviceCount):
handle = nvmlDeviceGetHandleByIndex(i)
info = nvmlDeviceGetMemoryInfo(handle)
if info.used / 1e6 < 15:
position = my_list.index(i)
free_gpu_list.append("cuda:" + str(position))
if len(free_gpu_list) >= self.custom_config.index_gpus:
has_free_gpus = True
else:
has_free_gpus = False
if (not isEmUpdateBusy) and has_free_gpus:
model_copy = type(self.model.rag.ctx_encoder)(
self.config_dpr
) # get a new instance #this will be load in the CPU
model_copy.load_state_dict(self.model.rag.ctx_encoder.state_dict()) # copy weights
processes = []
if len(free_gpu_list) > self.custom_config.index_gpus:
cuda_devices = random.sample(free_gpu_list, self.custom_config.index_gpus)
else:
cuda_devices = free_gpu_list
num_processes = len(cuda_devices)
for rank in range(num_processes):
logger.info("Iniitializing embedding calculation process rank{}".format(rank))
device = cuda_devices[rank]
p = multiprocessing.Process(
target=embed_update,
args=(
copy.deepcopy(model_copy),
num_processes,
device,
rank,
self.custom_config.shard_dir,
self.custom_config.csv_path,
),
)
processes.append(p)
for p in processes:
p.start()
isEmUpdateBusy = True
if isEmUpdateBusy and (not isAddIndexBusy):
index_process_list = [processes[k].is_alive() for k in range(self.custom_config.index_gpus)]
if (
sum(index_process_list) == 0
): # If entire list is false, we can say all embedding calculation process has finished
logger.info("Start adding the index")
threadHandle_index = multiprocessing.Process(
target=add_index,
args=(
self.custom_config.shard_dir,
self.config.index_path,
),
)
threadHandle_index.start()
isAddIndexBusy = True
# check when index building has started
if isAddIndexBusy:
# check still the index_building process is happening
if not threadHandle_index.is_alive():
logger.info("Merging the dataset shards")
saved_dataset_shards = []
for address in glob(str(self.custom_config.shard_dir) + "/*/"):
saved_dataset_shards.append(load_from_disk(address))
concat = concatenate_datasets(saved_dataset_shards)
concat.save_to_disk(self.config.passages_path) # here we update the main passage file on the disk
logger.info("done updating the dataset")
# To Do (@Aaron) : Useful in the future dynamic memory implementation.
# if you load the index from the disk make sure to update the index file here, otherwise it is ok to update the index file from the worker.
# logger.info("then updating the index")
# shutil.copy(self.custom_config.temp_index, self.config.idex_path)
logger.info("Loading new passages and iniitalzing new index")
self.trainer.model.module.module.model.rag.retriever.re_load()
self.trainer.model.module.module.model.rag.retriever.init_retrieval()
isEmUpdateBusy = False
isAddIndexBusy = False
self.trainer.strategy.barrier("barrier")
loss_tensors = self._step(batch)
logs = dict(zip(self.loss_names, loss_tensors))
# tokens per batch
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
logs["tpb"] = (
batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
)
self.log("loss", loss_tensors[0])
return loss_tensors[0]
def validation_step(self, batch, batch_idx) -> Dict:
return self._generative_step(batch)
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
self.step_count += 1
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
loss = losses["loss"]
gen_metrics = {
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
}
metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
gen_metrics.update({k: v.item() for k, v in losses.items()})
# fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
if dist.is_initialized():
dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
metrics_tensor = metrics_tensor / dist.get_world_size()
gen_metrics.update({self.val_metric: metrics_tensor.item()})
losses.update(gen_metrics)
metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
metrics["step_count"] = self.step_count
self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
log_dict = {
f"{prefix}_avg_em": metrics[f"{prefix}_avg_em"],
"step_count": metrics["step_count"],
f"{prefix}_avg_loss": metrics[f"{prefix}_avg_loss"],
f"{prefix}_loss": loss,
f"{prefix}_em": metrics_tensor,
}
self.log_dict(log_dict)
def save_metrics(self, latest_metrics, type_path) -> None:
self.metrics[type_path].append(latest_metrics)
save_json(self.metrics, self.metrics_save_path)
def calc_generative_metrics(self, preds, target) -> Dict:
return calculate_exact_match(preds, target)
def _generative_step(self, batch: dict) -> dict:
start_time = time.time()
batch = BatchEncoding(batch).to(device=self.model.device)
generated_ids = self.model.generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
do_deduplication=False, # rag specific parameter
use_cache=True,
min_length=1,
max_length=self.target_lens["val"],
)
gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
preds: List[str] = self.ids_to_clean_text(generated_ids)
target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
# print(preds,target)
loss_tensors = self._step(batch)
base_metrics = dict(zip(self.loss_names, loss_tensors))
gen_metrics: Dict = self.calc_generative_metrics(preds, target)
summ_len = np.mean(lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
return base_metrics
def test_step(self, batch, batch_idx):
return self._generative_step(batch)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, prefix="test")
def get_dataset(self, type_path) -> Seq2SeqDataset:
n_obs = self.n_obs[type_path]
max_target_length = self.target_lens[type_path]
dataset = Seq2SeqDataset(
self.tokenizer,
type_path=type_path,
n_obs=n_obs,
max_target_length=max_target_length,
**self.dataset_kwargs,
)
return dataset
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
dataset = self.get_dataset(type_path)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle,
num_workers=self.num_workers,
)
return dataloader
def train_dataloader(self) -> DataLoader:
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
return dataloader
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
self.model.config.save_step = self.step_count
# self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
if self.custom_config.end2end:
modified_state_dict = self.model.state_dict()
for key in self.model.state_dict().keys():
if key.split(".")[1] == "ctx_encoder":
del modified_state_dict[key]
self.model.save_pretrained(save_directory=save_path, state_dict=modified_state_dict)
save_path_dpr = os.path.join(self.dpr_ctx_check_dir, "checkpoint{}".format(self.step_count))
self.model.rag.ctx_encoder.save_pretrained(save_path_dpr)
self.context_tokenizer.save_pretrained(save_path_dpr)
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
add_generic_args(parser, root_dir)
parser.add_argument(
"--max_source_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--val_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--test_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
parser.add_argument(
"--prefix",
type=str,
default=None,
help="Prefix added at the beginning of each text, typically used with T5-based models.",
)
parser.add_argument(
"--early_stopping_patience",
type=int,
default=-1,
required=False,
help=(
"-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
" val_check_interval will effect it."
),
)
parser.add_argument(
"--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
)
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart", "t5"],
type=str,
help=(
"RAG model type: sequence or token, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
parser.add_argument(
"--context_encoder_name",
default="facebook/dpr-ctx_encoder-multiset-base",
type=str,
help="Name of the pre-trained context encoder checkpoint from the DPR",
)
parser.add_argument(
"--csv_path",
default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
type=str,
help="path of the raw KB csv",
)
parser.add_argument("--end2end", action="store_true", help="whether to train the system end2end or not")
parser.add_argument("--index_gpus", type=int, help="how many GPUs used in re-encoding process")
parser.add_argument(
"--shard_dir",
type=str,
default=str(Path(__file__).parent / "test_run" / "kb-shards"),
help="directory used to keep temporary shards during the re-encode process",
)
parser.add_argument(
"--gpu_order",
type=str,
help=(
"order of the GPU used during the fine-tuning. Used to finding free GPUs during the re-encode"
" process. I do not have many GPUs :)"
),
)
parser.add_argument("--indexing_freq", type=int, help="frequency of re-encode process")
return parser
@staticmethod
def add_retriever_specific_args(parser):
parser.add_argument(
"--index_name",
type=str,
default=None,
help=(
"Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
" for a local index, or 'legacy' for the orignal one)"
),
)
parser.add_argument(
"--passages_path",
type=str,
default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset"),
help=(
"Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--index_path",
type=str,
default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset_hnsw_index.faiss"),
help=(
"Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--distributed_retriever",
choices=["ray", "pytorch"],
type=str,
default="ray",
help=(
"What implementation to use for distributed retriever? If "
"pytorch is selected, the index is loaded on training "
"worker 0, and torch.distributed is used to handle "
"communication between training worker 0, and the other "
"training workers. If ray is selected, the Ray library is "
"used to create load the index on separate processes, "
"and Ray handles the communication between the training "
"workers and the retrieval actors."
),
)
parser.add_argument(
"--use_dummy_dataset",
type=bool,
default=False,
help=(
"Whether to use the dummy version of the dataset index. More info about custom indexes in the"
" RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
return parser
@staticmethod
def add_ray_specific_args(parser):
# Ray cluster address.
parser.add_argument(
"--ray-address",
default="auto",
type=str,
help=(
"The address of the Ray cluster to connect to. If not "
"specified, Ray will attempt to automatically detect the "
"cluster. Has no effect if pytorch is used as the distributed "
"retriever."
),
)
parser.add_argument(
"--num_retrieval_workers",
type=int,
default=1,
help=(
"The number of retrieval actors to use when Ray is selected "
"for the distributed retriever. Has no effect when "
"distributed_retriever is set to pytorch."
),
)
return parser
def main(args=None, model=None) -> GenerativeQAModule:
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
args = args or parser.parse_args()
Path(args.output_dir).mkdir(exist_ok=True)
Path(args.output_dir + "/dpr_ctx_checkpoint").mkdir(
exist_ok=True
) # save dpr_context encoder seprately for the future use
print(args.shard_dir)
if os.path.exists(args.shard_dir): # we do not need previous kb shards used in dataset re-conding and re-indexing
shutil.rmtree(args.shard_dir)
Path(args.shard_dir).mkdir(exist_ok=True)
if os.path.exists(
args.cache_dir
): # we do not need previous cache files used in dataset re-conding and re-indexing
shutil.rmtree(args.cache_dir)
Path(args.cache_dir).mkdir(exist_ok=True)
named_actors = []
if args.distributed_retriever == "ray" and args.gpus > 1:
if not is_ray_available():
raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
# Connect to an existing Ray cluster.
try:
ray.init(address=args.ray_address, namespace="rag")
except (ConnectionError, ValueError):
logger.warning(
"Connection to Ray cluster failed. Make sure a Ray "
"cluster is running by either using Ray's cluster "
"launcher (`ray up`) or by manually starting Ray on "
"each node via `ray start --head` for the head node "
"and `ray start --address='<ip address>:6379'` for "
"additional nodes. See "
"https://docs.ray.io/en/master/cluster/index.html "
"for more info."
)
raise
# Create Ray actors only for rank 0.
if ("LOCAL_RANK" not in os.environ or os.environ["LOCAL_RANK"] == 0) and (
"NODE_RANK" not in os.environ or os.environ["NODE_RANK"] == 0
):
remote_cls = ray.remote(RayRetriever)
named_actors = [
remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
for i in range(args.num_retrieval_workers)
]
else:
logger.info(
"Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
)
)
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
args.actor_handles = named_actors
assert args.actor_handles == named_actors
if model is None:
model: GenerativeQAModule = GenerativeQAModule(args)
dataset = Path(args.data_dir).name
if (
args.logger_name == "default"
or args.fast_dev_run
or str(args.output_dir).startswith("/tmp")
or str(args.output_dir).startswith("/var")
):
training_logger = True # don't pollute wandb logs unnecessarily
elif args.logger_name == "wandb":
from pytorch_lightning.loggers import WandbLogger
project = os.environ.get("WANDB_PROJECT", dataset)
training_logger = WandbLogger(name=model.output_dir.name, project=project)
elif args.logger_name == "wandb_shared":
from pytorch_lightning.loggers import WandbLogger
training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
es_callback = (
get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
if args.early_stopping_patience >= 0
else False
)
trainer: pl.Trainer = generic_train(
model,
args,
logging_callback=Seq2SeqLoggingCallback(),
checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
early_stopping_callback=es_callback,
logger=training_logger,
profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
if not args.do_predict:
return model
# test() without a model tests using the best checkpoint automatically
trainer.test()
return model
if __name__ == "__main__":
multiprocessing.set_start_method("spawn")
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
parser = GenerativeQAModule.add_ray_specific_args(parser)
# Pytorch Lightning Profiler
parser.add_argument(
"--profile",
action="store_true",
help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
)
args = parser.parse_args()
main(args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/requirements.txt
|
faiss-cpu >= 1.7.2
datasets
psutil >= 5.9.1
torch >= 1.11.0
pytorch-lightning == 1.6.4
nvidia-ml-py3 == 7.352.0
ray >= 1.13.0
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/eval_rag.py
|
""" Evaluation script for RAG models."""
import argparse
import ast
import logging
import os
import sys
import pandas as pd
import torch
from tqdm import tqdm
from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
from transformers import logging as transformers_logging
sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
transformers_logging.set_verbosity_info()
def infer_model_type(model_name_or_path):
if "token" in model_name_or_path:
return "rag_token"
if "sequence" in model_name_or_path:
return "rag_sequence"
if "bart" in model_name_or_path:
return "bart"
return None
def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
return max(metric_fn(prediction, gt) for gt in ground_truths)
def get_scores(args, preds_path, gold_data_path):
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
answers = []
if args.gold_data_mode == "qa":
data = pd.read_csv(gold_data_path, sep="\t", header=None)
for answer_list in data[1]:
ground_truths = ast.literal_eval(answer_list)
answers.append(ground_truths)
else:
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
answers = [[reference] for reference in references]
f1 = em = total = 0
for prediction, ground_truths in zip(hypos, answers):
total += 1
em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
em = 100.0 * em / total
f1 = 100.0 * f1 / total
logger.info(f"F1: {f1:.2f}")
logger.info(f"EM: {em:.2f}")
def get_precision_at_k(args, preds_path, gold_data_path):
k = args.k
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
em = total = 0
for hypo, reference in zip(hypos, references):
hypo_provenance = set(hypo.split("\t")[:k])
ref_provenance = set(reference.split("\t"))
total += 1
em += len(hypo_provenance & ref_provenance) / k
em = 100.0 * em / total
logger.info(f"Precision@{k}: {em: .2f}")
def evaluate_batch_retrieval(args, rag_model, questions):
def strip_title(title):
if title.startswith('"'):
title = title[1:]
if title.endswith('"'):
title = title[:-1]
return title
retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions,
return_tensors="pt",
padding=True,
truncation=True,
)["input_ids"].to(args.device)
question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
question_enc_pool_output = question_enc_outputs[0]
result = rag_model.retriever(
retriever_input_ids,
question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
prefix=rag_model.rag.generator.config.prefix,
n_docs=rag_model.config.n_docs,
return_tensors="pt",
)
all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
provenance_strings = []
for docs in all_docs:
provenance = [strip_title(title) for title in docs["title"]]
provenance_strings.append("\t".join(provenance))
return provenance_strings
def evaluate_batch_e2e(args, rag_model, questions):
with torch.no_grad():
inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions, return_tensors="pt", padding=True, truncation=True
)
input_ids = inputs_dict.input_ids.to(args.device)
attention_mask = inputs_dict.attention_mask.to(args.device)
outputs = rag_model.generate( # rag_model overwrites generate
input_ids,
attention_mask=attention_mask,
num_beams=args.num_beams,
min_length=args.min_length,
max_length=args.max_length,
early_stopping=False,
num_return_sequences=1,
bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
)
answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
if args.print_predictions:
for q, a in zip(questions, answers):
logger.info("Q: {} - A: {}".format(q, a))
return answers
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart"],
type=str,
help=(
"RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
parser.add_argument(
"--index_name",
default=None,
choices=["exact", "compressed", "legacy"],
type=str,
help="RAG model retriever type",
)
parser.add_argument(
"--index_path",
default=None,
type=str,
help="Path to the retrieval index",
)
parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
)
parser.add_argument(
"--eval_mode",
choices=["e2e", "retrieval"],
default="e2e",
type=str,
help=(
"Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
" precision@k."
),
)
parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
parser.add_argument(
"--evaluation_set",
default=None,
type=str,
required=True,
help="Path to a file containing evaluation samples",
)
parser.add_argument(
"--gold_data_path",
default=None,
type=str,
required=True,
help="Path to a tab-separated file with gold samples",
)
parser.add_argument(
"--gold_data_mode",
default="qa",
type=str,
choices=["qa", "ans"],
help=(
"Format of the gold data file"
"qa - a single line in the following format: question [tab] answer_list"
"ans - a single line of the gold file contains the expected answer string"
),
)
parser.add_argument(
"--predictions_path",
type=str,
default="predictions.txt",
help="Name of the predictions file, to be stored in the checkpoints directory",
)
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument(
"--eval_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for evaluation.",
)
parser.add_argument(
"--recalculate",
help="Recalculate predictions even if the prediction file exists",
action="store_true",
)
parser.add_argument(
"--num_beams",
default=4,
type=int,
help="Number of beams to be used when generating answers",
)
parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
parser.add_argument(
"--print_predictions",
action="store_true",
help="If True, prints predictions while evaluating.",
)
parser.add_argument(
"--print_docs",
action="store_true",
help="If True, prints docs retried while generating.",
)
args = parser.parse_args()
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
return args
def main(args):
model_kwargs = {}
if args.model_type is None:
args.model_type = infer_model_type(args.model_name_or_path)
assert args.model_type is not None
if args.model_type.startswith("rag"):
model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
model_kwargs["n_docs"] = args.n_docs
if args.index_name is not None:
model_kwargs["index_name"] = args.index_name
if args.index_path is not None:
model_kwargs["index_path"] = args.index_path
else:
model_class = BartForConditionalGeneration
checkpoints = (
[f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
if args.eval_all_checkpoints
else [args.model_name_or_path]
)
logger.info("Evaluate the following checkpoints: %s", checkpoints)
score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
for checkpoint in checkpoints:
if os.path.exists(args.predictions_path) and (not args.recalculate):
logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
score_fn(args, args.predictions_path, args.gold_data_path)
continue
logger.info("***** Running evaluation for {} *****".format(checkpoint))
logger.info(" Batch size = %d", args.eval_batch_size)
logger.info(" Predictions will be stored under {}".format(args.predictions_path))
if args.model_type.startswith("rag"):
retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
model.retriever.init_retrieval()
else:
model = model_class.from_pretrained(checkpoint, **model_kwargs)
model.to(args.device)
with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
questions = []
for line in tqdm(eval_file):
questions.append(line.strip())
if len(questions) == args.eval_batch_size:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers) + "\n")
preds_file.flush()
questions = []
if len(questions) > 0:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers))
preds_file.flush()
score_fn(args, args.predictions_path, args.gold_data_path)
if __name__ == "__main__":
args = get_args()
main(args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py
|
import os
from functools import partial
from glob import glob
import faiss
from datasets import Features, Sequence, Value, concatenate_datasets, load_dataset, load_from_disk
from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast
def split_text(text, n=100, character=" "):
"""Split the text every ``n``-th occurrence of ``character``"""
text = text.split(character)
return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
def split_documents(documents):
"""Split documents into passages"""
titles, texts = [], []
for title, text in zip(documents["title"], documents["text"]):
if text is not None:
for passage in split_text(text):
titles.append(title if title is not None else "")
texts.append(passage)
return {"title": titles, "text": texts}
def embed_update(ctx_encoder, total_processes, device, process_num, shard_dir, csv_path):
kb_dataset = load_dataset(
"csv", data_files=[csv_path], split="train", delimiter="\t", column_names=["title", "text"]
)
kb_dataset = kb_dataset.map(
split_documents, batched=True, num_proc=1
) # if you want you can load already splitted csv.
kb_list = [kb_dataset.shard(total_processes, i, contiguous=True) for i in range(total_processes)]
data_shrad = kb_list[process_num]
arrow_folder = "data_" + str(process_num)
passages_path = os.path.join(shard_dir, arrow_folder)
context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
ctx_encoder = ctx_encoder.to(device=device)
def embed(
documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast, device
) -> dict:
"""Compute the DPR embeddings of document passages"""
input_ids = ctx_tokenizer(
documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
)["input_ids"]
embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
return {"embeddings": embeddings.detach().cpu().numpy()}
new_features = Features(
{"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
) # optional, save as float32 instead of float64 to save space
dataset = data_shrad.map(
partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=context_tokenizer, device=device),
batched=True,
batch_size=16,
features=new_features,
)
dataset.save_to_disk(passages_path)
def add_index(shard_dir, index_path):
data_shard_list = []
for shard_address in glob(str(shard_dir) + "/*/"):
data_shard_list.append(load_from_disk(shard_address))
concat = concatenate_datasets(data_shard_list)
faiss.omp_set_num_threads(96)
index = faiss.IndexHNSWFlat(768, 128, faiss.METRIC_INNER_PRODUCT)
concat.add_faiss_index("embeddings", custom_index=index)
concat.get_index("embeddings").save(
index_path
) # since we load the index in to memory,we can directly update the index in the disk
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/lightning_base.py
|
import argparse
import logging
import os
from pathlib import Path
from typing import Any, Dict
import pytorch_lightning as pl
from pytorch_lightning.utilities import rank_zero_info
from transformers import (
AdamW,
AutoConfig,
AutoModel,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
AutoModelWithLMHead,
AutoTokenizer,
PretrainedConfig,
PreTrainedTokenizer,
)
from transformers.optimization import (
Adafactor,
get_cosine_schedule_with_warmup,
get_cosine_with_hard_restarts_schedule_with_warmup,
get_linear_schedule_with_warmup,
get_polynomial_decay_schedule_with_warmup,
)
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
require_version("pytorch_lightning>=1.0.4")
MODEL_MODES = {
"base": AutoModel,
"sequence-classification": AutoModelForSequenceClassification,
"question-answering": AutoModelForQuestionAnswering,
"pretraining": AutoModelForPreTraining,
"token-classification": AutoModelForTokenClassification,
"language-modeling": AutoModelWithLMHead,
"summarization": AutoModelForSeq2SeqLM,
"translation": AutoModelForSeq2SeqLM,
}
# update this and the import above to support new schedulers from transformers.optimization
arg_to_scheduler = {
"linear": get_linear_schedule_with_warmup,
"cosine": get_cosine_schedule_with_warmup,
"cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
"polynomial": get_polynomial_decay_schedule_with_warmup,
# '': get_constant_schedule, # not supported for now
# '': get_constant_schedule_with_warmup, # not supported for now
}
arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
class BaseTransformer(pl.LightningModule):
def __init__(
self,
hparams: argparse.Namespace,
num_labels=None,
mode="base",
config=None,
tokenizer=None,
model=None,
**config_kwargs,
):
"""Initialize a model, tokenizer and config."""
super().__init__()
# TODO: move to self.save_hyperparameters()
# self.save_hyperparameters()
# can also expand arguments into trainer signature for easier reading
self.save_hyperparameters(hparams)
self.step_count = 0
self.output_dir = Path(self.hparams.output_dir)
cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
if config is None:
self.config = AutoConfig.from_pretrained(
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
**({"num_labels": num_labels} if num_labels is not None else {}),
cache_dir=cache_dir,
**config_kwargs,
)
else:
self.config: PretrainedConfig = config
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(self.hparams, p, None):
assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
setattr(self.config, p, getattr(self.hparams, p))
if tokenizer is None:
self.tokenizer = AutoTokenizer.from_pretrained(
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
cache_dir=cache_dir,
)
else:
self.tokenizer: PreTrainedTokenizer = tokenizer
self.model_type = MODEL_MODES[mode]
if model is None:
self.model = self.model_type.from_pretrained(
self.hparams.model_name_or_path,
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
config=self.config,
cache_dir=cache_dir,
)
else:
self.model = model
def load_hf_checkpoint(self, *args, **kwargs):
self.model = self.model_type.from_pretrained(*args, **kwargs)
def get_lr_scheduler(self):
get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
scheduler = get_schedule_func(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return scheduler
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay)"""
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)
], # check this named paramters
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
if self.hparams.adafactor:
optimizer = Adafactor(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
)
else:
optimizer = AdamW(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
)
self.opt = optimizer
scheduler = self.get_lr_scheduler()
return [optimizer], [scheduler]
def test_step(self, batch, batch_nb):
return self.validation_step(batch, batch_nb)
def test_epoch_end(self, outputs):
return self.validation_end(outputs)
def total_steps(self) -> int:
"""The number of total training steps that will be run. Used for lr scheduler purposes."""
num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
def setup(self, stage):
if stage == "test":
self.dataset_size = len(self.test_dataloader().dataset)
else:
self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
self.dataset_size = len(self.train_dataloader().dataset)
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
raise NotImplementedError("You must implement this for your task")
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
def test_dataloader(self):
return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
def _feature_file(self, mode):
return os.path.join(
self.hparams.data_dir,
"cached_{}_{}_{}".format(
mode,
list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
str(self.hparams.max_seq_length),
),
)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default=None,
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default=str(Path(__file__).parent / "test_run" / "cache"),
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--encoder_layerdrop",
type=float,
help="Encoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--decoder_layerdrop",
type=float,
help="Decoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--dropout",
type=float,
help="Dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--attention_dropout",
type=float,
help="Attention dropout probability (Optional). Goes into model.config",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--lr_scheduler",
default="linear",
choices=arg_to_scheduler_choices,
metavar=arg_to_scheduler_metavar,
type=str,
help="Learning rate scheduler",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
parser.add_argument("--train_batch_size", default=32, type=int)
parser.add_argument("--eval_batch_size", default=32, type=int)
parser.add_argument("--adafactor", action="store_true")
class InitCallback(pl.Callback):
# this process can also be done with PL ddp plugging.
# But still it is experimental (check original RAG, I updated that with pluggin (shamanez))
def on_sanity_check_start(self, trainer, pl_module):
if (
trainer.is_global_zero and trainer.global_rank == 0
): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
class CheckParamCallback(pl.Callback):
# check whether new added model paramters are differentiable
def on_after_backward(self, trainer, pl_module):
# print(pl_module.model.rag)
for name, param in pl_module.model.rag.named_parameters():
if param.grad is None:
print(name)
class LoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
pl_module.logger.log_metrics(lrs)
def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Validation results *****")
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Test results *****")
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))
def add_generic_args(parser, root_dir) -> None:
# To allow all pl args uncomment the following line
# parser = pl.Trainer.add_argparse_args(parser)
parser.add_argument(
"--output_dir",
default=str(Path(__file__).parent / "test_run" / "model_checkpoints"),
type=str,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O2",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
parser.add_argument(
"--gradient_accumulation_steps",
dest="accumulate_grad_batches",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--data_dir",
default=str(Path(__file__).parent / "test_run" / "dummy-train-data"),
type=str,
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
)
def generic_train(
model: BaseTransformer,
args: argparse.Namespace,
early_stopping_callback=None,
logger=True, # can pass WandbLogger() here
extra_callbacks=[],
checkpoint_callback=None,
logging_callback=None,
**extra_train_kwargs,
):
pl.seed_everything(args.seed)
# init model
odir = Path(model.hparams.output_dir)
odir.mkdir(exist_ok=True)
# add custom checkpoints
if checkpoint_callback is None:
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
)
if early_stopping_callback:
extra_callbacks.append(early_stopping_callback)
if logging_callback is None:
logging_callback = LoggingCallback()
train_params = {}
if args.fp16:
train_params["precision"] = 16
if args.gpus > 1:
train_params["accelerator"] = "auto"
train_params["strategy"] = "ddp"
train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
train_params["profiler"] = None
train_params["devices"] = "auto"
trainer = pl.Trainer.from_argparse_args(
args,
weights_summary=None,
callbacks=[logging_callback] + extra_callbacks + [InitCallback()] + [checkpoint_callback],
logger=logger,
val_check_interval=1,
num_sanity_val_steps=2,
**train_params,
)
if args.do_train:
trainer.fit(model)
else:
print("RAG modeling tests with new set functions successfuly executed!")
return trainer
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh
|
export PYTHONPATH="../":"${PYTHONPATH}"
python use_own_knowledge_dataset.py
ray start --head
python finetune_rag.py \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--fp16 \
--gpus 1 \
--profile \
--end2end \
--index_name custom
ray stop
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh
|
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
#creates the custom knowlegebase
python use_own_knowledge_dataset.py
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python finetune_rag.py \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--fp16 \
--gpus 2 \
--profile \
--do_train \
--end2end \
--do_predict \
--n_val -1 \
--train_batch_size 1 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 10 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
--distributed_retriever ray \
--num_retrieval_workers 4 \
--index_name custom \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--index_gpus 2 \
--gpu_order [2,3,4,5,6,7,8,9,0,1] \
--indexing_freq 5
# Stop the Ray cluster.
ray stop
#CUDA_VISIBLE_DEVICES=2,3,4,5,6,7,8,9,0,1 sh ./test_run/test_finetune.sh
#Make sure --gpu_order is same.
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv
|
Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target
|
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source
|
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source
|
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target
|
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source
|
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
| 0
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run
|
hf_public_repos/transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target
|
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/README.md
|
# LXMERT DEMO
1. make a virtualenv: ``virtualenv venv`` and activate ``source venv/bin/activate``
2. install reqs: ``pip install -r ./requirements.txt``
3. usage is as shown in demo.ipynb
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/utils.py
|
"""
coding=utf-8
Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal, Huggingface team :)
Adapted From Facebook Inc, Detectron2
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.import copy
"""
import copy
import fnmatch
import json
import os
import pickle as pkl
import shutil
import sys
import tarfile
import tempfile
from collections import OrderedDict
from contextlib import contextmanager
from functools import partial
from io import BytesIO
from pathlib import Path
from urllib.parse import urlparse
from zipfile import ZipFile, is_zipfile
import cv2
import numpy as np
import requests
import wget
from filelock import FileLock
from huggingface_hub.utils import insecure_hashlib
from PIL import Image
from tqdm.auto import tqdm
from yaml import Loader, dump, load
try:
import torch
_torch_available = True
except ImportError:
_torch_available = False
try:
from torch.hub import _get_torch_home
torch_cache_home = _get_torch_home()
except ImportError:
torch_cache_home = os.path.expanduser(
os.getenv("TORCH_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "torch"))
)
default_cache_path = os.path.join(torch_cache_home, "transformers")
CLOUDFRONT_DISTRIB_PREFIX = "https://cdn.huggingface.co"
S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
PATH = "/".join(str(Path(__file__).resolve()).split("/")[:-1])
CONFIG = os.path.join(PATH, "config.yaml")
ATTRIBUTES = os.path.join(PATH, "attributes.txt")
OBJECTS = os.path.join(PATH, "objects.txt")
PYTORCH_PRETRAINED_BERT_CACHE = os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path)
PYTORCH_TRANSFORMERS_CACHE = os.getenv("PYTORCH_TRANSFORMERS_CACHE", PYTORCH_PRETRAINED_BERT_CACHE)
TRANSFORMERS_CACHE = os.getenv("TRANSFORMERS_CACHE", PYTORCH_TRANSFORMERS_CACHE)
WEIGHTS_NAME = "pytorch_model.bin"
CONFIG_NAME = "config.yaml"
def load_labels(objs=OBJECTS, attrs=ATTRIBUTES):
vg_classes = []
with open(objs) as f:
for object in f.readlines():
vg_classes.append(object.split(",")[0].lower().strip())
vg_attrs = []
with open(attrs) as f:
for object in f.readlines():
vg_attrs.append(object.split(",")[0].lower().strip())
return vg_classes, vg_attrs
def load_checkpoint(ckp):
r = OrderedDict()
with open(ckp, "rb") as f:
ckp = pkl.load(f)["model"]
for k in copy.deepcopy(list(ckp.keys())):
v = ckp.pop(k)
if isinstance(v, np.ndarray):
v = torch.tensor(v)
else:
assert isinstance(v, torch.tensor), type(v)
r[k] = v
return r
class Config:
_pointer = {}
def __init__(self, dictionary: dict, name: str = "root", level=0):
self._name = name
self._level = level
d = {}
for k, v in dictionary.items():
if v is None:
raise ValueError()
k = copy.deepcopy(k)
v = copy.deepcopy(v)
if isinstance(v, dict):
v = Config(v, name=k, level=level + 1)
d[k] = v
setattr(self, k, v)
self._pointer = d
def __repr__(self):
return str(list((self._pointer.keys())))
def __setattr__(self, key, val):
self.__dict__[key] = val
self.__dict__[key.upper()] = val
levels = key.split(".")
last_level = len(levels) - 1
pointer = self._pointer
if len(levels) > 1:
for i, l in enumerate(levels):
if hasattr(self, l) and isinstance(getattr(self, l), Config):
setattr(getattr(self, l), ".".join(levels[i:]), val)
if l == last_level:
pointer[l] = val
else:
pointer = pointer[l]
def to_dict(self):
return self._pointer
def dump_yaml(self, data, file_name):
with open(f"{file_name}", "w") as stream:
dump(data, stream)
def dump_json(self, data, file_name):
with open(f"{file_name}", "w") as stream:
json.dump(data, stream)
@staticmethod
def load_yaml(config):
with open(config) as stream:
data = load(stream, Loader=Loader)
return data
def __str__(self):
t = " "
if self._name != "root":
r = f"{t * (self._level-1)}{self._name}:\n"
else:
r = ""
level = self._level
for i, (k, v) in enumerate(self._pointer.items()):
if isinstance(v, Config):
r += f"{t * (self._level)}{v}\n"
self._level += 1
else:
r += f"{t * (self._level)}{k}: {v} ({type(v).__name__})\n"
self._level = level
return r[:-1]
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path: str, **kwargs):
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
return cls(config_dict)
@classmethod
def get_config_dict(cls, pretrained_model_name_or_path: str, **kwargs):
cache_dir = kwargs.pop("cache_dir", None)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
if os.path.isdir(pretrained_model_name_or_path):
config_file = os.path.join(pretrained_model_name_or_path, CONFIG_NAME)
elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
config_file = pretrained_model_name_or_path
else:
config_file = hf_bucket_url(pretrained_model_name_or_path, filename=CONFIG_NAME, use_cdn=False)
try:
# Load from URL or cache if already cached
resolved_config_file = cached_path(
config_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
)
# Load config dict
if resolved_config_file is None:
raise EnvironmentError
config_file = Config.load_yaml(resolved_config_file)
except EnvironmentError:
msg = "Can't load config for"
raise EnvironmentError(msg)
if resolved_config_file == config_file:
print("loading configuration file from path")
else:
print("loading configuration file cache")
return Config.load_yaml(resolved_config_file), kwargs
# quick compare tensors
def compare(in_tensor):
out_tensor = torch.load("dump.pt", map_location=in_tensor.device)
n1 = in_tensor.numpy()
n2 = out_tensor.numpy()[0]
print(n1.shape, n1[0, 0, :5])
print(n2.shape, n2[0, 0, :5])
assert np.allclose(n1, n2, rtol=0.01, atol=0.1), (
f"{sum([1 for x in np.isclose(n1, n2, rtol=0.01, atol=0.1).flatten() if x is False])/len(n1.flatten())*100:.4f} %"
" element-wise mismatch"
)
raise Exception("tensors are all good")
# Hugging face functions below
def is_remote_url(url_or_filename):
parsed = urlparse(url_or_filename)
return parsed.scheme in ("http", "https")
def hf_bucket_url(model_id: str, filename: str, use_cdn=True) -> str:
endpoint = CLOUDFRONT_DISTRIB_PREFIX if use_cdn else S3_BUCKET_PREFIX
legacy_format = "/" not in model_id
if legacy_format:
return f"{endpoint}/{model_id}-{filename}"
else:
return f"{endpoint}/{model_id}/{filename}"
def http_get(
url,
temp_file,
proxies=None,
resume_size=0,
user_agent=None,
):
ua = "python/{}".format(sys.version.split()[0])
if _torch_available:
ua += "; torch/{}".format(torch.__version__)
if isinstance(user_agent, dict):
ua += "; " + "; ".join("{}/{}".format(k, v) for k, v in user_agent.items())
elif isinstance(user_agent, str):
ua += "; " + user_agent
headers = {"user-agent": ua}
if resume_size > 0:
headers["Range"] = "bytes=%d-" % (resume_size,)
response = requests.get(url, stream=True, proxies=proxies, headers=headers)
if response.status_code == 416: # Range not satisfiable
return
content_length = response.headers.get("Content-Length")
total = resume_size + int(content_length) if content_length is not None else None
progress = tqdm(
unit="B",
unit_scale=True,
total=total,
initial=resume_size,
desc="Downloading",
)
for chunk in response.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def get_from_cache(
url,
cache_dir=None,
force_download=False,
proxies=None,
etag_timeout=10,
resume_download=False,
user_agent=None,
local_files_only=False,
):
if cache_dir is None:
cache_dir = TRANSFORMERS_CACHE
if isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
os.makedirs(cache_dir, exist_ok=True)
etag = None
if not local_files_only:
try:
response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
if response.status_code == 200:
etag = response.headers.get("ETag")
except (EnvironmentError, requests.exceptions.Timeout):
# etag is already None
pass
filename = url_to_filename(url, etag)
# get cache path to put the file
cache_path = os.path.join(cache_dir, filename)
# etag is None = we don't have a connection, or url doesn't exist, or is otherwise inaccessible.
# try to get the last downloaded one
if etag is None:
if os.path.exists(cache_path):
return cache_path
else:
matching_files = [
file
for file in fnmatch.filter(os.listdir(cache_dir), filename + ".*")
if not file.endswith(".json") and not file.endswith(".lock")
]
if len(matching_files) > 0:
return os.path.join(cache_dir, matching_files[-1])
else:
# If files cannot be found and local_files_only=True,
# the models might've been found if local_files_only=False
# Notify the user about that
if local_files_only:
raise ValueError(
"Cannot find the requested files in the cached path and outgoing traffic has been"
" disabled. To enable model look-ups and downloads online, set 'local_files_only'"
" to False."
)
return None
# From now on, etag is not None.
if os.path.exists(cache_path) and not force_download:
return cache_path
# Prevent parallel downloads of the same file with a lock.
lock_path = cache_path + ".lock"
with FileLock(lock_path):
# If the download just completed while the lock was activated.
if os.path.exists(cache_path) and not force_download:
# Even if returning early like here, the lock will be released.
return cache_path
if resume_download:
incomplete_path = cache_path + ".incomplete"
@contextmanager
def _resumable_file_manager():
with open(incomplete_path, "a+b") as f:
yield f
temp_file_manager = _resumable_file_manager
if os.path.exists(incomplete_path):
resume_size = os.stat(incomplete_path).st_size
else:
resume_size = 0
else:
temp_file_manager = partial(tempfile.NamedTemporaryFile, dir=cache_dir, delete=False)
resume_size = 0
# Download to temporary file, then copy to cache dir once finished.
# Otherwise you get corrupt cache entries if the download gets interrupted.
with temp_file_manager() as temp_file:
print(
"%s not found in cache or force_download set to True, downloading to %s",
url,
temp_file.name,
)
http_get(
url,
temp_file,
proxies=proxies,
resume_size=resume_size,
user_agent=user_agent,
)
os.replace(temp_file.name, cache_path)
meta = {"url": url, "etag": etag}
meta_path = cache_path + ".json"
with open(meta_path, "w") as meta_file:
json.dump(meta, meta_file)
return cache_path
def url_to_filename(url, etag=None):
url_bytes = url.encode("utf-8")
url_hash = insecure_hashlib.sha256(url_bytes)
filename = url_hash.hexdigest()
if etag:
etag_bytes = etag.encode("utf-8")
etag_hash = insecure_hashlib.sha256(etag_bytes)
filename += "." + etag_hash.hexdigest()
if url.endswith(".h5"):
filename += ".h5"
return filename
def cached_path(
url_or_filename,
cache_dir=None,
force_download=False,
proxies=None,
resume_download=False,
user_agent=None,
extract_compressed_file=False,
force_extract=False,
local_files_only=False,
):
if cache_dir is None:
cache_dir = TRANSFORMERS_CACHE
if isinstance(url_or_filename, Path):
url_or_filename = str(url_or_filename)
if isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
if is_remote_url(url_or_filename):
# URL, so get it from the cache (downloading if necessary)
output_path = get_from_cache(
url_or_filename,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
user_agent=user_agent,
local_files_only=local_files_only,
)
elif os.path.exists(url_or_filename):
# File, and it exists.
output_path = url_or_filename
elif urlparse(url_or_filename).scheme == "":
# File, but it doesn't exist.
raise EnvironmentError("file {} not found".format(url_or_filename))
else:
# Something unknown
raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
if extract_compressed_file:
if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
return output_path
# Path where we extract compressed archives
# We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
output_dir, output_file = os.path.split(output_path)
output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
return output_path_extracted
# Prevent parallel extractions
lock_path = output_path + ".lock"
with FileLock(lock_path):
shutil.rmtree(output_path_extracted, ignore_errors=True)
os.makedirs(output_path_extracted)
if is_zipfile(output_path):
with ZipFile(output_path, "r") as zip_file:
zip_file.extractall(output_path_extracted)
zip_file.close()
elif tarfile.is_tarfile(output_path):
tar_file = tarfile.open(output_path)
tar_file.extractall(output_path_extracted)
tar_file.close()
else:
raise EnvironmentError("Archive format of {} could not be identified".format(output_path))
return output_path_extracted
return output_path
def get_data(query, delim=","):
assert isinstance(query, str)
if os.path.isfile(query):
with open(query) as f:
data = eval(f.read())
else:
req = requests.get(query)
try:
data = requests.json()
except Exception:
data = req.content.decode()
assert data is not None, "could not connect"
try:
data = eval(data)
except Exception:
data = data.split("\n")
req.close()
return data
def get_image_from_url(url):
response = requests.get(url)
img = np.array(Image.open(BytesIO(response.content)))
return img
# to load legacy frcnn checkpoint from detectron
def load_frcnn_pkl_from_url(url):
fn = url.split("/")[-1]
if fn not in os.listdir(os.getcwd()):
wget.download(url)
with open(fn, "rb") as stream:
weights = pkl.load(stream)
model = weights.pop("model")
new = {}
for k, v in model.items():
new[k] = torch.from_numpy(v)
if "running_var" in k:
zero = torch.tensor([0])
k2 = k.replace("running_var", "num_batches_tracked")
new[k2] = zero
return new
def get_demo_path():
print(f"{os.path.abspath(os.path.join(PATH, os.pardir))}/demo.ipynb")
def img_tensorize(im, input_format="RGB"):
assert isinstance(im, str)
if os.path.isfile(im):
img = cv2.imread(im)
else:
img = get_image_from_url(im)
assert img is not None, f"could not connect to: {im}"
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if input_format == "RGB":
img = img[:, :, ::-1]
return img
def chunk(images, batch=1):
return (images[i : i + batch] for i in range(0, len(images), batch))
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/extracting_data.py
|
import getopt
import json
import os
# import numpy as np
import sys
from collections import OrderedDict
import datasets
import numpy as np
import torch
from modeling_frcnn import GeneralizedRCNN
from processing_image import Preprocess
from utils import Config
"""
USAGE:
``python extracting_data.py -i <img_dir> -o <dataset_file>.datasets <batch_size>``
"""
TEST = False
CONFIG = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
DEFAULT_SCHEMA = datasets.Features(
OrderedDict(
{
"attr_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"attr_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"boxes": datasets.Array2D((CONFIG.MAX_DETECTIONS, 4), dtype="float32"),
"img_id": datasets.Value("int32"),
"obj_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"obj_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"roi_features": datasets.Array2D((CONFIG.MAX_DETECTIONS, 2048), dtype="float32"),
"sizes": datasets.Sequence(length=2, feature=datasets.Value("float32")),
"preds_per_image": datasets.Value(dtype="int32"),
}
)
)
class Extract:
def __init__(self, argv=sys.argv[1:]):
inputdir = None
outputfile = None
subset_list = None
batch_size = 1
opts, args = getopt.getopt(argv, "i:o:b:s", ["inputdir=", "outfile=", "batch_size=", "subset_list="])
for opt, arg in opts:
if opt in ("-i", "--inputdir"):
inputdir = arg
elif opt in ("-o", "--outfile"):
outputfile = arg
elif opt in ("-b", "--batch_size"):
batch_size = int(arg)
elif opt in ("-s", "--subset_list"):
subset_list = arg
assert inputdir is not None # and os.path.isdir(inputdir), f"{inputdir}"
assert outputfile is not None and not os.path.isfile(outputfile), f"{outputfile}"
if subset_list is not None:
with open(os.path.realpath(subset_list)) as f:
self.subset_list = {self._vqa_file_split()[0] for x in tryload(f)}
else:
self.subset_list = None
self.config = CONFIG
if torch.cuda.is_available():
self.config.model.device = "cuda"
self.inputdir = os.path.realpath(inputdir)
self.outputfile = os.path.realpath(outputfile)
self.preprocess = Preprocess(self.config)
self.model = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=self.config)
self.batch = batch_size if batch_size != 0 else 1
self.schema = DEFAULT_SCHEMA
def _vqa_file_split(self, file):
img_id = int(file.split(".")[0].split("_")[-1])
filepath = os.path.join(self.inputdir, file)
return (img_id, filepath)
@property
def file_generator(self):
batch = []
for i, file in enumerate(os.listdir(self.inputdir)):
if self.subset_list is not None and i not in self.subset_list:
continue
batch.append(self._vqa_file_split(file))
if len(batch) == self.batch:
temp = batch
batch = []
yield list(map(list, zip(*temp)))
for i in range(1):
yield list(map(list, zip(*batch)))
def __call__(self):
# make writer
if not TEST:
writer = datasets.ArrowWriter(features=self.schema, path=self.outputfile)
# do file generator
for i, (img_ids, filepaths) in enumerate(self.file_generator):
images, sizes, scales_yx = self.preprocess(filepaths)
output_dict = self.model(
images,
sizes,
scales_yx=scales_yx,
padding="max_detections",
max_detections=self.config.MAX_DETECTIONS,
pad_value=0,
return_tensors="np",
location="cpu",
)
output_dict["boxes"] = output_dict.pop("normalized_boxes")
if not TEST:
output_dict["img_id"] = np.array(img_ids)
batch = self.schema.encode_batch(output_dict)
writer.write_batch(batch)
if TEST:
break
# finalizer the writer
if not TEST:
num_examples, num_bytes = writer.finalize()
print(f"Success! You wrote {num_examples} entry(s) and {num_bytes >> 20} mb")
def tryload(stream):
try:
data = json.load(stream)
try:
data = list(data.keys())
except Exception:
data = [d["img_id"] for d in data]
except Exception:
try:
data = eval(stream.read())
except Exception:
data = stream.read().split("\n")
return data
if __name__ == "__main__":
extract = Extract(sys.argv[1:])
extract()
if not TEST:
dataset = datasets.Dataset.from_file(extract.outputfile)
# wala!
# print(np.array(dataset[0:2]["roi_features"]).shape)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/demo.ipynb
|
# %pip install-r requirements.txtfrom IPython.display import clear_output, Image, display
import PIL.Image
import io
import json
import torch
import numpy as np
from processing_image import Preprocess
from visualizing_image import SingleImageViz
from modeling_frcnn import GeneralizedRCNN
from utils import Config
import utils
from transformers import LxmertForQuestionAnswering, LxmertTokenizer
import wget
import pickle
import os
# URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/images/input.jpg",
URL = "https://vqa.cloudcv.org/media/test2014/COCO_test2014_000000262567.jpg"
OBJ_URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/objects_vocab.txt"
ATTR_URL = "https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/attributes_vocab.txt"
GQA_URL = "https://raw.githubusercontent.com/airsplay/lxmert/master/data/gqa/trainval_label2ans.json"
VQA_URL = "https://raw.githubusercontent.com/airsplay/lxmert/master/data/vqa/trainval_label2ans.json"
# for visualizing output
def showarray(a, fmt="jpeg"):
a = np.uint8(np.clip(a, 0, 255))
f = io.BytesIO()
PIL.Image.fromarray(a).save(f, fmt)
display(Image(data=f.getvalue()))# load object, attribute, and answer labels
objids = utils.get_data(OBJ_URL)
attrids = utils.get_data(ATTR_URL)
gqa_answers = utils.get_data(GQA_URL)
vqa_answers = utils.get_data(VQA_URL)# load models and model components
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
image_preprocess = Preprocess(frcnn_cfg)
lxmert_tokenizer = LxmertTokenizer.from_pretrained("unc-nlp/lxmert-base-uncased")
lxmert_gqa = LxmertForQuestionAnswering.from_pretrained("unc-nlp/lxmert-gqa-uncased")
lxmert_vqa = LxmertForQuestionAnswering.from_pretrained("unc-nlp/lxmert-vqa-uncased")# image viz
frcnn_visualizer = SingleImageViz(URL, id2obj=objids, id2attr=attrids)
# run frcnn
images, sizes, scales_yx = image_preprocess(URL)
output_dict = frcnn(
images,
sizes,
scales_yx=scales_yx,
padding="max_detections",
max_detections=frcnn_cfg.max_detections,
return_tensors="pt",
)
# add boxes and labels to the image
frcnn_visualizer.draw_boxes(
output_dict.get("boxes"),
output_dict.pop("obj_ids"),
output_dict.pop("obj_probs"),
output_dict.pop("attr_ids"),
output_dict.pop("attr_probs"),
)
showarray(frcnn_visualizer._get_buffer())test_questions_for_url1 = [
"Where is this scene?",
"what is the man riding?",
"What is the man wearing?",
"What is the color of the horse?",
]
test_questions_for_url2 = [
"Where is the cat?",
"What is near the disk?",
"What is the color of the table?",
"What is the color of the cat?",
"What is the shape of the monitor?",
]
# Very important that the boxes are normalized
normalized_boxes = output_dict.get("normalized_boxes")
features = output_dict.get("roi_features")
for test_question in test_questions_for_url2:
# run lxmert
test_question = [test_question]
inputs = lxmert_tokenizer(
test_question,
padding="max_length",
max_length=20,
truncation=True,
return_token_type_ids=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors="pt",
)
# run lxmert(s)
output_gqa = lxmert_gqa(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
visual_feats=features,
visual_pos=normalized_boxes,
token_type_ids=inputs.token_type_ids,
output_attentions=False,
)
output_vqa = lxmert_vqa(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
visual_feats=features,
visual_pos=normalized_boxes,
token_type_ids=inputs.token_type_ids,
output_attentions=False,
)
# get prediction
pred_vqa = output_vqa["question_answering_score"].argmax(-1)
pred_gqa = output_gqa["question_answering_score"].argmax(-1)
print("Question:", test_question)
print("prediction from LXMERT GQA:", gqa_answers[pred_gqa])
print("prediction from LXMERT VQA:", vqa_answers[pred_vqa])
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/modeling_frcnn.py
|
"""
coding=utf-8
Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
Adapted From Facebook Inc, Detectron2 && Huggingface Co.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.import copy
"""
import itertools
import math
import os
from abc import ABCMeta, abstractmethod
from collections import OrderedDict, namedtuple
from typing import Dict, List, Tuple
import numpy as np
import torch
from torch import nn
from torch.nn.modules.batchnorm import BatchNorm2d
from torchvision.ops import RoIPool
from torchvision.ops.boxes import batched_nms, nms
from utils import WEIGHTS_NAME, Config, cached_path, hf_bucket_url, is_remote_url, load_checkpoint
# other:
def norm_box(boxes, raw_sizes):
if not isinstance(boxes, torch.Tensor):
normalized_boxes = boxes.copy()
else:
normalized_boxes = boxes.clone()
normalized_boxes[:, :, (0, 2)] /= raw_sizes[:, 1]
normalized_boxes[:, :, (1, 3)] /= raw_sizes[:, 0]
return normalized_boxes
def pad_list_tensors(
list_tensors,
preds_per_image,
max_detections=None,
return_tensors=None,
padding=None,
pad_value=0,
location=None,
):
"""
location will always be cpu for np tensors
"""
if location is None:
location = "cpu"
assert return_tensors in {"pt", "np", None}
assert padding in {"max_detections", "max_batch", None}
new = []
if padding is None:
if return_tensors is None:
return list_tensors
elif return_tensors == "pt":
if not isinstance(list_tensors, torch.Tensor):
return torch.stack(list_tensors).to(location)
else:
return list_tensors.to(location)
else:
if not isinstance(list_tensors, list):
return np.array(list_tensors.to(location))
else:
return list_tensors.to(location)
if padding == "max_detections":
assert max_detections is not None, "specify max number of detections per batch"
elif padding == "max_batch":
max_detections = max(preds_per_image)
for i in range(len(list_tensors)):
too_small = False
tensor_i = list_tensors.pop(0)
if tensor_i.ndim < 2:
too_small = True
tensor_i = tensor_i.unsqueeze(-1)
assert isinstance(tensor_i, torch.Tensor)
tensor_i = nn.functional.pad(
input=tensor_i,
pad=(0, 0, 0, max_detections - preds_per_image[i]),
mode="constant",
value=pad_value,
)
if too_small:
tensor_i = tensor_i.squeeze(-1)
if return_tensors is None:
if location == "cpu":
tensor_i = tensor_i.cpu()
tensor_i = tensor_i.tolist()
if return_tensors == "np":
if location == "cpu":
tensor_i = tensor_i.cpu()
tensor_i = tensor_i.numpy()
else:
if location == "cpu":
tensor_i = tensor_i.cpu()
new.append(tensor_i)
if return_tensors == "np":
return np.stack(new, axis=0)
elif return_tensors == "pt" and not isinstance(new, torch.Tensor):
return torch.stack(new, dim=0)
else:
return list_tensors
def do_nms(boxes, scores, image_shape, score_thresh, nms_thresh, mind, maxd):
scores = scores[:, :-1]
num_bbox_reg_classes = boxes.shape[1] // 4
# Convert to Boxes to use the `clip` function ...
boxes = boxes.reshape(-1, 4)
_clip_box(boxes, image_shape)
boxes = boxes.view(-1, num_bbox_reg_classes, 4) # R x C x 4
# Select max scores
max_scores, max_classes = scores.max(1) # R x C --> R
num_objs = boxes.size(0)
boxes = boxes.view(-1, 4)
idxs = torch.arange(num_objs).to(boxes.device) * num_bbox_reg_classes + max_classes
max_boxes = boxes[idxs] # Select max boxes according to the max scores.
# Apply NMS
keep = nms(max_boxes, max_scores, nms_thresh)
keep = keep[:maxd]
if keep.shape[-1] >= mind and keep.shape[-1] <= maxd:
max_boxes, max_scores = max_boxes[keep], max_scores[keep]
classes = max_classes[keep]
return max_boxes, max_scores, classes, keep
else:
return None
# Helper Functions
def _clip_box(tensor, box_size: Tuple[int, int]):
assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
h, w = box_size
tensor[:, 0].clamp_(min=0, max=w)
tensor[:, 1].clamp_(min=0, max=h)
tensor[:, 2].clamp_(min=0, max=w)
tensor[:, 3].clamp_(min=0, max=h)
def _nonempty_boxes(box, threshold: float = 0.0) -> torch.Tensor:
widths = box[:, 2] - box[:, 0]
heights = box[:, 3] - box[:, 1]
keep = (widths > threshold) & (heights > threshold)
return keep
def get_norm(norm, out_channels):
if isinstance(norm, str):
if len(norm) == 0:
return None
norm = {
"BN": BatchNorm2d,
"GN": lambda channels: nn.GroupNorm(32, channels),
"nnSyncBN": nn.SyncBatchNorm, # keep for debugging
"": lambda x: x,
}[norm]
return norm(out_channels)
def _create_grid_offsets(size: List[int], stride: int, offset: float, device):
grid_height, grid_width = size
shifts_x = torch.arange(
offset * stride,
grid_width * stride,
step=stride,
dtype=torch.float32,
device=device,
)
shifts_y = torch.arange(
offset * stride,
grid_height * stride,
step=stride,
dtype=torch.float32,
device=device,
)
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
return shift_x, shift_y
def build_backbone(cfg):
input_shape = ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN))
norm = cfg.RESNETS.NORM
stem = BasicStem(
in_channels=input_shape.channels,
out_channels=cfg.RESNETS.STEM_OUT_CHANNELS,
norm=norm,
caffe_maxpool=cfg.MODEL.MAX_POOL,
)
freeze_at = cfg.BACKBONE.FREEZE_AT
if freeze_at >= 1:
for p in stem.parameters():
p.requires_grad = False
out_features = cfg.RESNETS.OUT_FEATURES
depth = cfg.RESNETS.DEPTH
num_groups = cfg.RESNETS.NUM_GROUPS
width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
bottleneck_channels = num_groups * width_per_group
in_channels = cfg.RESNETS.STEM_OUT_CHANNELS
out_channels = cfg.RESNETS.RES2_OUT_CHANNELS
stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
res5_dilation = cfg.RESNETS.RES5_DILATION
assert res5_dilation in {1, 2}, "res5_dilation cannot be {}.".format(res5_dilation)
num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
stages = []
out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
max_stage_idx = max(out_stage_idx)
for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
dilation = res5_dilation if stage_idx == 5 else 1
first_stride = 1 if idx == 0 or (stage_idx == 5 and dilation == 2) else 2
stage_kargs = {
"num_blocks": num_blocks_per_stage[idx],
"first_stride": first_stride,
"in_channels": in_channels,
"bottleneck_channels": bottleneck_channels,
"out_channels": out_channels,
"num_groups": num_groups,
"norm": norm,
"stride_in_1x1": stride_in_1x1,
"dilation": dilation,
}
stage_kargs["block_class"] = BottleneckBlock
blocks = ResNet.make_stage(**stage_kargs)
in_channels = out_channels
out_channels *= 2
bottleneck_channels *= 2
if freeze_at >= stage_idx:
for block in blocks:
block.freeze()
stages.append(blocks)
return ResNet(stem, stages, out_features=out_features)
def find_top_rpn_proposals(
proposals,
pred_objectness_logits,
images,
image_sizes,
nms_thresh,
pre_nms_topk,
post_nms_topk,
min_box_side_len,
training,
):
"""Args:
proposals (list[Tensor]): (L, N, Hi*Wi*A, 4).
pred_objectness_logits: tensors of length L.
nms_thresh (float): IoU threshold to use for NMS
pre_nms_topk (int): before nms
post_nms_topk (int): after nms
min_box_side_len (float): minimum proposal box side
training (bool): True if proposals are to be used in training,
Returns:
results (List[Dict]): stores post_nms_topk object proposals for image i.
"""
num_images = len(images)
device = proposals[0].device
# 1. Select top-k anchor for every level and every image
topk_scores = [] # #lvl Tensor, each of shape N x topk
topk_proposals = []
level_ids = [] # #lvl Tensor, each of shape (topk,)
batch_idx = torch.arange(num_images, device=device)
for level_id, proposals_i, logits_i in zip(itertools.count(), proposals, pred_objectness_logits):
Hi_Wi_A = logits_i.shape[1]
num_proposals_i = min(pre_nms_topk, Hi_Wi_A)
# sort is faster than topk (https://github.com/pytorch/pytorch/issues/22812)
# topk_scores_i, topk_idx = logits_i.topk(num_proposals_i, dim=1)
logits_i, idx = logits_i.sort(descending=True, dim=1)
topk_scores_i = logits_i[batch_idx, :num_proposals_i]
topk_idx = idx[batch_idx, :num_proposals_i]
# each is N x topk
topk_proposals_i = proposals_i[batch_idx[:, None], topk_idx] # N x topk x 4
topk_proposals.append(topk_proposals_i)
topk_scores.append(topk_scores_i)
level_ids.append(torch.full((num_proposals_i,), level_id, dtype=torch.int64, device=device))
# 2. Concat all levels together
topk_scores = torch.cat(topk_scores, dim=1)
topk_proposals = torch.cat(topk_proposals, dim=1)
level_ids = torch.cat(level_ids, dim=0)
# if I change to batched_nms, I wonder if this will make a difference
# 3. For each image, run a per-level NMS, and choose topk results.
results = []
for n, image_size in enumerate(image_sizes):
boxes = topk_proposals[n]
scores_per_img = topk_scores[n]
# I will have to take a look at the boxes clip method
_clip_box(boxes, image_size)
# filter empty boxes
keep = _nonempty_boxes(boxes, threshold=min_box_side_len)
lvl = level_ids
if keep.sum().item() != len(boxes):
boxes, scores_per_img, lvl = (
boxes[keep],
scores_per_img[keep],
level_ids[keep],
)
keep = batched_nms(boxes, scores_per_img, lvl, nms_thresh)
keep = keep[:post_nms_topk]
res = (boxes[keep], scores_per_img[keep])
results.append(res)
# I wonder if it would be possible for me to pad all these things.
return results
def subsample_labels(labels, num_samples, positive_fraction, bg_label):
"""
Returns:
pos_idx, neg_idx (Tensor):
1D vector of indices. The total length of both is `num_samples` or fewer.
"""
positive = torch.nonzero((labels != -1) & (labels != bg_label)).squeeze(1)
negative = torch.nonzero(labels == bg_label).squeeze(1)
num_pos = int(num_samples * positive_fraction)
# protect against not enough positive examples
num_pos = min(positive.numel(), num_pos)
num_neg = num_samples - num_pos
# protect against not enough negative examples
num_neg = min(negative.numel(), num_neg)
# randomly select positive and negative examples
perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
pos_idx = positive[perm1]
neg_idx = negative[perm2]
return pos_idx, neg_idx
def add_ground_truth_to_proposals(gt_boxes, proposals):
raise NotImplementedError()
def add_ground_truth_to_proposals_single_image(gt_boxes, proposals):
raise NotImplementedError()
def _fmt_box_list(box_tensor, batch_index: int):
repeated_index = torch.full(
(len(box_tensor), 1),
batch_index,
dtype=box_tensor.dtype,
device=box_tensor.device,
)
return torch.cat((repeated_index, box_tensor), dim=1)
def convert_boxes_to_pooler_format(box_lists: List[torch.Tensor]):
pooler_fmt_boxes = torch.cat(
[_fmt_box_list(box_list, i) for i, box_list in enumerate(box_lists)],
dim=0,
)
return pooler_fmt_boxes
def assign_boxes_to_levels(
box_lists: List[torch.Tensor],
min_level: int,
max_level: int,
canonical_box_size: int,
canonical_level: int,
):
box_sizes = torch.sqrt(torch.cat([boxes.area() for boxes in box_lists]))
# Eqn.(1) in FPN paper
level_assignments = torch.floor(canonical_level + torch.log2(box_sizes / canonical_box_size + 1e-8))
# clamp level to (min, max), in case the box size is too large or too small
# for the available feature maps
level_assignments = torch.clamp(level_assignments, min=min_level, max=max_level)
return level_assignments.to(torch.int64) - min_level
# Helper Classes
class _NewEmptyTensorOp(torch.autograd.Function):
@staticmethod
def forward(ctx, x, new_shape):
ctx.shape = x.shape
return x.new_empty(new_shape)
@staticmethod
def backward(ctx, grad):
shape = ctx.shape
return _NewEmptyTensorOp.apply(grad, shape), None
class ShapeSpec(namedtuple("_ShapeSpec", ["channels", "height", "width", "stride"])):
def __new__(cls, *, channels=None, height=None, width=None, stride=None):
return super().__new__(cls, channels, height, width, stride)
class Box2BoxTransform(object):
"""
This R-CNN transformation scales the box's width and height
by exp(dw), exp(dh) and shifts a box's center by the offset
(dx * width, dy * height).
"""
def __init__(self, weights: Tuple[float, float, float, float], scale_clamp: float = None):
"""
Args:
weights (4-element tuple): Scaling factors that are applied to the
(dx, dy, dw, dh) deltas. In Fast R-CNN, these were originally set
such that the deltas have unit variance; now they are treated as
hyperparameters of the system.
scale_clamp (float): When predicting deltas, the predicted box scaling
factors (dw and dh) are clamped such that they are <= scale_clamp.
"""
self.weights = weights
if scale_clamp is not None:
self.scale_clamp = scale_clamp
else:
"""
Value for clamping large dw and dh predictions.
The heuristic is that we clamp such that dw and dh are no larger
than what would transform a 16px box into a 1000px box
(based on a small anchor, 16px, and a typical image size, 1000px).
"""
self.scale_clamp = math.log(1000.0 / 16)
def get_deltas(self, src_boxes, target_boxes):
"""
Get box regression transformation deltas (dx, dy, dw, dh) that can be used
to transform the `src_boxes` into the `target_boxes`. That is, the relation
``target_boxes == self.apply_deltas(deltas, src_boxes)`` is true (unless
any delta is too large and is clamped).
Args:
src_boxes (Tensor): source boxes, e.g., object proposals
target_boxes (Tensor): target of the transformation, e.g., ground-truth
boxes.
"""
assert isinstance(src_boxes, torch.Tensor), type(src_boxes)
assert isinstance(target_boxes, torch.Tensor), type(target_boxes)
src_widths = src_boxes[:, 2] - src_boxes[:, 0]
src_heights = src_boxes[:, 3] - src_boxes[:, 1]
src_ctr_x = src_boxes[:, 0] + 0.5 * src_widths
src_ctr_y = src_boxes[:, 1] + 0.5 * src_heights
target_widths = target_boxes[:, 2] - target_boxes[:, 0]
target_heights = target_boxes[:, 3] - target_boxes[:, 1]
target_ctr_x = target_boxes[:, 0] + 0.5 * target_widths
target_ctr_y = target_boxes[:, 1] + 0.5 * target_heights
wx, wy, ww, wh = self.weights
dx = wx * (target_ctr_x - src_ctr_x) / src_widths
dy = wy * (target_ctr_y - src_ctr_y) / src_heights
dw = ww * torch.log(target_widths / src_widths)
dh = wh * torch.log(target_heights / src_heights)
deltas = torch.stack((dx, dy, dw, dh), dim=1)
assert (src_widths > 0).all().item(), "Input boxes to Box2BoxTransform are not valid!"
return deltas
def apply_deltas(self, deltas, boxes):
"""
Apply transformation `deltas` (dx, dy, dw, dh) to `boxes`.
Args:
deltas (Tensor): transformation deltas of shape (N, k*4), where k >= 1.
deltas[i] represents k potentially different class-specific
box transformations for the single box boxes[i].
boxes (Tensor): boxes to transform, of shape (N, 4)
"""
boxes = boxes.to(deltas.dtype)
widths = boxes[:, 2] - boxes[:, 0]
heights = boxes[:, 3] - boxes[:, 1]
ctr_x = boxes[:, 0] + 0.5 * widths
ctr_y = boxes[:, 1] + 0.5 * heights
wx, wy, ww, wh = self.weights
dx = deltas[:, 0::4] / wx
dy = deltas[:, 1::4] / wy
dw = deltas[:, 2::4] / ww
dh = deltas[:, 3::4] / wh
# Prevent sending too large values into torch.exp()
dw = torch.clamp(dw, max=self.scale_clamp)
dh = torch.clamp(dh, max=self.scale_clamp)
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
pred_boxes = torch.zeros_like(deltas)
pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w # x1
pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h # y1
pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w # x2
pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h # y2
return pred_boxes
class Matcher(object):
"""
This class assigns to each predicted "element" (e.g., a box) a ground-truth
element. Each predicted element will have exactly zero or one matches; each
ground-truth element may be matched to zero or more predicted elements.
The matching is determined by the MxN match_quality_matrix, that characterizes
how well each (ground-truth, prediction)-pair match each other. For example,
if the elements are boxes, this matrix may contain box intersection-over-union
overlap values.
The matcher returns (a) a vector of length N containing the index of the
ground-truth element m in [0, M) that matches to prediction n in [0, N).
(b) a vector of length N containing the labels for each prediction.
"""
def __init__(
self,
thresholds: List[float],
labels: List[int],
allow_low_quality_matches: bool = False,
):
"""
Args:
thresholds (list): a list of thresholds used to stratify predictions
into levels.
labels (list): a list of values to label predictions belonging at
each level. A label can be one of {-1, 0, 1} signifying
{ignore, negative class, positive class}, respectively.
allow_low_quality_matches (bool): if True, produce additional matches or predictions with maximum match quality lower than high_threshold.
For example, thresholds = [0.3, 0.5] labels = [0, -1, 1] All predictions with iou < 0.3 will be marked with 0 and
thus will be considered as false positives while training. All predictions with 0.3 <= iou < 0.5 will be marked with -1 and
thus will be ignored. All predictions with 0.5 <= iou will be marked with 1 and thus will be considered as true positives.
"""
thresholds = thresholds[:]
assert thresholds[0] > 0
thresholds.insert(0, -float("inf"))
thresholds.append(float("inf"))
assert all(low <= high for (low, high) in zip(thresholds[:-1], thresholds[1:]))
assert all(label_i in [-1, 0, 1] for label_i in labels)
assert len(labels) == len(thresholds) - 1
self.thresholds = thresholds
self.labels = labels
self.allow_low_quality_matches = allow_low_quality_matches
def __call__(self, match_quality_matrix):
"""
Args:
match_quality_matrix (Tensor[float]): an MxN tensor, containing the pairwise quality between M ground-truth elements and N predicted
elements. All elements must be >= 0 (due to the us of `torch.nonzero` for selecting indices in :meth:`set_low_quality_matches_`).
Returns:
matches (Tensor[int64]): a vector of length N, where matches[i] is a matched ground-truth index in [0, M)
match_labels (Tensor[int8]): a vector of length N, where pred_labels[i] indicates true or false positive or ignored
"""
assert match_quality_matrix.dim() == 2
if match_quality_matrix.numel() == 0:
default_matches = match_quality_matrix.new_full((match_quality_matrix.size(1),), 0, dtype=torch.int64)
# When no gt boxes exist, we define IOU = 0 and therefore set labels
# to `self.labels[0]`, which usually defaults to background class 0
# To choose to ignore instead,
# can make labels=[-1,0,-1,1] + set appropriate thresholds
default_match_labels = match_quality_matrix.new_full(
(match_quality_matrix.size(1),), self.labels[0], dtype=torch.int8
)
return default_matches, default_match_labels
assert torch.all(match_quality_matrix >= 0)
# match_quality_matrix is M (gt) x N (predicted)
# Max over gt elements (dim 0) to find best gt candidate for each prediction
matched_vals, matches = match_quality_matrix.max(dim=0)
match_labels = matches.new_full(matches.size(), 1, dtype=torch.int8)
for l, low, high in zip(self.labels, self.thresholds[:-1], self.thresholds[1:]):
low_high = (matched_vals >= low) & (matched_vals < high)
match_labels[low_high] = l
if self.allow_low_quality_matches:
self.set_low_quality_matches_(match_labels, match_quality_matrix)
return matches, match_labels
def set_low_quality_matches_(self, match_labels, match_quality_matrix):
"""
Produce additional matches for predictions that have only low-quality matches.
Specifically, for each ground-truth G find the set of predictions that have
maximum overlap with it (including ties); for each prediction in that set, if
it is unmatched, then match it to the ground-truth G.
This function implements the RPN assignment case (i)
in Sec. 3.1.2 of Faster R-CNN.
"""
# For each gt, find the prediction with which it has highest quality
highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1)
# Find the highest quality match available, even if it is low, including ties.
# Note that the matches qualities must be positive due to the use of
# `torch.nonzero`.
of_quality_inds = match_quality_matrix == highest_quality_foreach_gt[:, None]
if of_quality_inds.dim() == 0:
(_, pred_inds_with_highest_quality) = of_quality_inds.unsqueeze(0).nonzero().unbind(1)
else:
(_, pred_inds_with_highest_quality) = of_quality_inds.nonzero().unbind(1)
match_labels[pred_inds_with_highest_quality] = 1
class RPNOutputs(object):
def __init__(
self,
box2box_transform,
anchor_matcher,
batch_size_per_image,
positive_fraction,
images,
pred_objectness_logits,
pred_anchor_deltas,
anchors,
boundary_threshold=0,
gt_boxes=None,
smooth_l1_beta=0.0,
):
"""
Args:
box2box_transform (Box2BoxTransform): :class:`Box2BoxTransform` instance for anchor-proposal transformations.
anchor_matcher (Matcher): :class:`Matcher` instance for matching anchors to ground-truth boxes; used to determine training labels.
batch_size_per_image (int): number of proposals to sample when training
positive_fraction (float): target fraction of sampled proposals that should be positive
images (ImageList): :class:`ImageList` instance representing N input images
pred_objectness_logits (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A, Hi, W)
pred_anchor_deltas (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A*4, Hi, Wi)
anchors (list[torch.Tensor]): nested list of boxes. anchors[i][j] at (n, l) stores anchor array for feature map l
boundary_threshold (int): if >= 0, then anchors that extend beyond the image boundary by more than boundary_thresh are not used in training.
gt_boxes (list[Boxes], optional): A list of N elements.
smooth_l1_beta (float): The transition point between L1 and L2 lossn. When set to 0, the loss becomes L1. When +inf, it is ignored
"""
self.box2box_transform = box2box_transform
self.anchor_matcher = anchor_matcher
self.batch_size_per_image = batch_size_per_image
self.positive_fraction = positive_fraction
self.pred_objectness_logits = pred_objectness_logits
self.pred_anchor_deltas = pred_anchor_deltas
self.anchors = anchors
self.gt_boxes = gt_boxes
self.num_feature_maps = len(pred_objectness_logits)
self.num_images = len(images)
self.boundary_threshold = boundary_threshold
self.smooth_l1_beta = smooth_l1_beta
def _get_ground_truth(self):
raise NotImplementedError()
def predict_proposals(self):
# pred_anchor_deltas: (L, N, ? Hi, Wi)
# anchors:(N, L, -1, B)
# here we loop over specific feature map, NOT images
proposals = []
anchors = self.anchors.transpose(0, 1)
for anchors_i, pred_anchor_deltas_i in zip(anchors, self.pred_anchor_deltas):
B = anchors_i.size(-1)
N, _, Hi, Wi = pred_anchor_deltas_i.shape
anchors_i = anchors_i.flatten(start_dim=0, end_dim=1)
pred_anchor_deltas_i = pred_anchor_deltas_i.view(N, -1, B, Hi, Wi).permute(0, 3, 4, 1, 2).reshape(-1, B)
proposals_i = self.box2box_transform.apply_deltas(pred_anchor_deltas_i, anchors_i)
# Append feature map proposals with shape (N, Hi*Wi*A, B)
proposals.append(proposals_i.view(N, -1, B))
proposals = torch.stack(proposals)
return proposals
def predict_objectness_logits(self):
"""
Returns:
pred_objectness_logits (list[Tensor]) -> (N, Hi*Wi*A).
"""
pred_objectness_logits = [
# Reshape: (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
score.permute(0, 2, 3, 1).reshape(self.num_images, -1)
for score in self.pred_objectness_logits
]
return pred_objectness_logits
# Main Classes
class Conv2d(nn.Conv2d):
def __init__(self, *args, **kwargs):
norm = kwargs.pop("norm", None)
activation = kwargs.pop("activation", None)
super().__init__(*args, **kwargs)
self.norm = norm
self.activation = activation
def forward(self, x):
if x.numel() == 0 and self.training:
assert not isinstance(self.norm, nn.SyncBatchNorm)
if x.numel() == 0:
assert not isinstance(self.norm, nn.GroupNorm)
output_shape = [
(i + 2 * p - (di * (k - 1) + 1)) // s + 1
for i, p, di, k, s in zip(
x.shape[-2:],
self.padding,
self.dilation,
self.kernel_size,
self.stride,
)
]
output_shape = [x.shape[0], self.weight.shape[0]] + output_shape
empty = _NewEmptyTensorOp.apply(x, output_shape)
if self.training:
_dummy = sum(x.view(-1)[0] for x in self.parameters()) * 0.0
return empty + _dummy
else:
return empty
x = super().forward(x)
if self.norm is not None:
x = self.norm(x)
if self.activation is not None:
x = self.activation(x)
return x
class LastLevelMaxPool(nn.Module):
"""
This module is used in the original FPN to generate a downsampled P6 feature from P5.
"""
def __init__(self):
super().__init__()
self.num_levels = 1
self.in_feature = "p5"
def forward(self, x):
return [nn.functional.max_pool2d(x, kernel_size=1, stride=2, padding=0)]
class LastLevelP6P7(nn.Module):
"""
This module is used in RetinaNet to generate extra layers, P6 and P7 from C5 feature.
"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.num_levels = 2
self.in_feature = "res5"
self.p6 = nn.Conv2d(in_channels, out_channels, 3, 2, 1)
self.p7 = nn.Conv2d(out_channels, out_channels, 3, 2, 1)
def forward(self, c5):
p6 = self.p6(c5)
p7 = self.p7(nn.functional.relu(p6))
return [p6, p7]
class BasicStem(nn.Module):
def __init__(self, in_channels=3, out_channels=64, norm="BN", caffe_maxpool=False):
super().__init__()
self.conv1 = Conv2d(
in_channels,
out_channels,
kernel_size=7,
stride=2,
padding=3,
bias=False,
norm=get_norm(norm, out_channels),
)
self.caffe_maxpool = caffe_maxpool
# use pad 1 instead of pad zero
def forward(self, x):
x = self.conv1(x)
x = nn.functional.relu_(x)
if self.caffe_maxpool:
x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=0, ceil_mode=True)
else:
x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=1)
return x
@property
def out_channels(self):
return self.conv1.out_channels
@property
def stride(self):
return 4 # = stride 2 conv -> stride 2 max pool
class ResNetBlockBase(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.stride = stride
def freeze(self):
for p in self.parameters():
p.requires_grad = False
return self
class BottleneckBlock(ResNetBlockBase):
def __init__(
self,
in_channels,
out_channels,
bottleneck_channels,
stride=1,
num_groups=1,
norm="BN",
stride_in_1x1=False,
dilation=1,
):
super().__init__(in_channels, out_channels, stride)
if in_channels != out_channels:
self.shortcut = Conv2d(
in_channels,
out_channels,
kernel_size=1,
stride=stride,
bias=False,
norm=get_norm(norm, out_channels),
)
else:
self.shortcut = None
# The original MSRA ResNet models have stride in the first 1x1 conv
# The subsequent fb.torch.resnet and Caffe2 ResNe[X]t implementations have
# stride in the 3x3 conv
stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
self.conv1 = Conv2d(
in_channels,
bottleneck_channels,
kernel_size=1,
stride=stride_1x1,
bias=False,
norm=get_norm(norm, bottleneck_channels),
)
self.conv2 = Conv2d(
bottleneck_channels,
bottleneck_channels,
kernel_size=3,
stride=stride_3x3,
padding=1 * dilation,
bias=False,
groups=num_groups,
dilation=dilation,
norm=get_norm(norm, bottleneck_channels),
)
self.conv3 = Conv2d(
bottleneck_channels,
out_channels,
kernel_size=1,
bias=False,
norm=get_norm(norm, out_channels),
)
def forward(self, x):
out = self.conv1(x)
out = nn.functional.relu_(out)
out = self.conv2(out)
out = nn.functional.relu_(out)
out = self.conv3(out)
if self.shortcut is not None:
shortcut = self.shortcut(x)
else:
shortcut = x
out += shortcut
out = nn.functional.relu_(out)
return out
class Backbone(nn.Module, metaclass=ABCMeta):
def __init__(self):
super().__init__()
@abstractmethod
def forward(self):
pass
@property
def size_divisibility(self):
"""
Some backbones require the input height and width to be divisible by a specific integer. This is
typically true for encoder / decoder type networks with lateral connection (e.g., FPN) for which feature maps need to match
dimension in the "bottom up" and "top down" paths. Set to 0 if no specific input size divisibility is required.
"""
return 0
def output_shape(self):
return {
name: ShapeSpec(
channels=self._out_feature_channels[name],
stride=self._out_feature_strides[name],
)
for name in self._out_features
}
@property
def out_features(self):
"""deprecated"""
return self._out_features
@property
def out_feature_strides(self):
"""deprecated"""
return {f: self._out_feature_strides[f] for f in self._out_features}
@property
def out_feature_channels(self):
"""deprecated"""
return {f: self._out_feature_channels[f] for f in self._out_features}
class ResNet(Backbone):
def __init__(self, stem, stages, num_classes=None, out_features=None):
"""
Args:
stem (nn.Module): a stem module
stages (list[list[ResNetBlock]]): several (typically 4) stages, each contains multiple :class:`ResNetBlockBase`.
num_classes (None or int): if None, will not perform classification.
out_features (list[str]): name of the layers whose outputs should be returned in forward. Can be anything in:
"stem", "linear", or "res2" ... If None, will return the output of the last layer.
"""
super(ResNet, self).__init__()
self.stem = stem
self.num_classes = num_classes
current_stride = self.stem.stride
self._out_feature_strides = {"stem": current_stride}
self._out_feature_channels = {"stem": self.stem.out_channels}
self.stages_and_names = []
for i, blocks in enumerate(stages):
for block in blocks:
assert isinstance(block, ResNetBlockBase), block
curr_channels = block.out_channels
stage = nn.Sequential(*blocks)
name = "res" + str(i + 2)
self.add_module(name, stage)
self.stages_and_names.append((stage, name))
self._out_feature_strides[name] = current_stride = int(
current_stride * np.prod([k.stride for k in blocks])
)
self._out_feature_channels[name] = blocks[-1].out_channels
if num_classes is not None:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(curr_channels, num_classes)
# Sec 5.1 in "Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour":
# "The 1000-way fully-connected layer is initialized by
# drawing weights from a zero-mean Gaussian with std of 0.01."
nn.init.normal_(self.linear.weight, stddev=0.01)
name = "linear"
if out_features is None:
out_features = [name]
self._out_features = out_features
assert len(self._out_features)
children = [x[0] for x in self.named_children()]
for out_feature in self._out_features:
assert out_feature in children, "Available children: {}".format(", ".join(children))
def forward(self, x):
outputs = {}
x = self.stem(x)
if "stem" in self._out_features:
outputs["stem"] = x
for stage, name in self.stages_and_names:
x = stage(x)
if name in self._out_features:
outputs[name] = x
if self.num_classes is not None:
x = self.avgpool(x)
x = self.linear(x)
if "linear" in self._out_features:
outputs["linear"] = x
return outputs
def output_shape(self):
return {
name: ShapeSpec(
channels=self._out_feature_channels[name],
stride=self._out_feature_strides[name],
)
for name in self._out_features
}
@staticmethod
def make_stage(
block_class,
num_blocks,
first_stride=None,
*,
in_channels,
out_channels,
**kwargs,
):
"""
Usually, layers that produce the same feature map spatial size
are defined as one "stage".
Under such definition, stride_per_block[1:] should all be 1.
"""
if first_stride is not None:
assert "stride" not in kwargs and "stride_per_block" not in kwargs
kwargs["stride_per_block"] = [first_stride] + [1] * (num_blocks - 1)
blocks = []
for i in range(num_blocks):
curr_kwargs = {}
for k, v in kwargs.items():
if k.endswith("_per_block"):
assert (
len(v) == num_blocks
), f"Argument '{k}' of make_stage should have the same length as num_blocks={num_blocks}."
newk = k[: -len("_per_block")]
assert newk not in kwargs, f"Cannot call make_stage with both {k} and {newk}!"
curr_kwargs[newk] = v[i]
else:
curr_kwargs[k] = v
blocks.append(block_class(in_channels=in_channels, out_channels=out_channels, **curr_kwargs))
in_channels = out_channels
return blocks
class ROIPooler(nn.Module):
"""
Region of interest feature map pooler that supports pooling from one or more
feature maps.
"""
def __init__(
self,
output_size,
scales,
sampling_ratio,
canonical_box_size=224,
canonical_level=4,
):
super().__init__()
# assumption that stride is a power of 2.
min_level = -math.log2(scales[0])
max_level = -math.log2(scales[-1])
# a bunch of testing
assert math.isclose(min_level, int(min_level)) and math.isclose(max_level, int(max_level))
assert len(scales) == max_level - min_level + 1, "not pyramid"
assert 0 < min_level and min_level <= max_level
if isinstance(output_size, int):
output_size = (output_size, output_size)
assert len(output_size) == 2 and isinstance(output_size[0], int) and isinstance(output_size[1], int)
if len(scales) > 1:
assert min_level <= canonical_level and canonical_level <= max_level
assert canonical_box_size > 0
self.output_size = output_size
self.min_level = int(min_level)
self.max_level = int(max_level)
self.level_poolers = nn.ModuleList(RoIPool(output_size, spatial_scale=scale) for scale in scales)
self.canonical_level = canonical_level
self.canonical_box_size = canonical_box_size
def forward(self, feature_maps, boxes):
"""
Args:
feature_maps: List[torch.Tensor(N,C,W,H)]
box_lists: list[torch.Tensor])
Returns:
A tensor of shape(N*B, Channels, output_size, output_size)
"""
x = list(feature_maps.values())
num_level_assignments = len(self.level_poolers)
assert len(x) == num_level_assignments and len(boxes) == x[0].size(0)
pooler_fmt_boxes = convert_boxes_to_pooler_format(boxes)
if num_level_assignments == 1:
return self.level_poolers[0](x[0], pooler_fmt_boxes)
level_assignments = assign_boxes_to_levels(
boxes,
self.min_level,
self.max_level,
self.canonical_box_size,
self.canonical_level,
)
num_boxes = len(pooler_fmt_boxes)
num_channels = x[0].shape[1]
output_size = self.output_size[0]
dtype, device = x[0].dtype, x[0].device
output = torch.zeros(
(num_boxes, num_channels, output_size, output_size),
dtype=dtype,
device=device,
)
for level, (x_level, pooler) in enumerate(zip(x, self.level_poolers)):
inds = torch.nonzero(level_assignments == level).squeeze(1)
pooler_fmt_boxes_level = pooler_fmt_boxes[inds]
output[inds] = pooler(x_level, pooler_fmt_boxes_level)
return output
class ROIOutputs(object):
def __init__(self, cfg, training=False):
self.smooth_l1_beta = cfg.ROI_BOX_HEAD.SMOOTH_L1_BETA
self.box2box_transform = Box2BoxTransform(weights=cfg.ROI_BOX_HEAD.BBOX_REG_WEIGHTS)
self.training = training
self.score_thresh = cfg.ROI_HEADS.SCORE_THRESH_TEST
self.min_detections = cfg.MIN_DETECTIONS
self.max_detections = cfg.MAX_DETECTIONS
nms_thresh = cfg.ROI_HEADS.NMS_THRESH_TEST
if not isinstance(nms_thresh, list):
nms_thresh = [nms_thresh]
self.nms_thresh = nms_thresh
def _predict_boxes(self, proposals, box_deltas, preds_per_image):
num_pred = box_deltas.size(0)
B = proposals[0].size(-1)
K = box_deltas.size(-1) // B
box_deltas = box_deltas.view(num_pred * K, B)
proposals = torch.cat(proposals, dim=0).unsqueeze(-2).expand(num_pred, K, B)
proposals = proposals.reshape(-1, B)
boxes = self.box2box_transform.apply_deltas(box_deltas, proposals)
return boxes.view(num_pred, K * B).split(preds_per_image, dim=0)
def _predict_objs(self, obj_logits, preds_per_image):
probs = nn.functional.softmax(obj_logits, dim=-1)
probs = probs.split(preds_per_image, dim=0)
return probs
def _predict_attrs(self, attr_logits, preds_per_image):
attr_logits = attr_logits[..., :-1].softmax(-1)
attr_probs, attrs = attr_logits.max(-1)
return attr_probs.split(preds_per_image, dim=0), attrs.split(preds_per_image, dim=0)
@torch.no_grad()
def inference(
self,
obj_logits,
attr_logits,
box_deltas,
pred_boxes,
features,
sizes,
scales=None,
):
# only the pred boxes is the
preds_per_image = [p.size(0) for p in pred_boxes]
boxes_all = self._predict_boxes(pred_boxes, box_deltas, preds_per_image)
obj_scores_all = self._predict_objs(obj_logits, preds_per_image) # list of length N
attr_probs_all, attrs_all = self._predict_attrs(attr_logits, preds_per_image)
features = features.split(preds_per_image, dim=0)
# fun for each image too, also I can experiment and do multiple images
final_results = []
zipped = zip(boxes_all, obj_scores_all, attr_probs_all, attrs_all, sizes)
for i, (boxes, obj_scores, attr_probs, attrs, size) in enumerate(zipped):
for nms_t in self.nms_thresh:
outputs = do_nms(
boxes,
obj_scores,
size,
self.score_thresh,
nms_t,
self.min_detections,
self.max_detections,
)
if outputs is not None:
max_boxes, max_scores, classes, ids = outputs
break
if scales is not None:
scale_yx = scales[i]
max_boxes[:, 0::2] *= scale_yx[1]
max_boxes[:, 1::2] *= scale_yx[0]
final_results.append(
(
max_boxes,
classes,
max_scores,
attrs[ids],
attr_probs[ids],
features[i][ids],
)
)
boxes, classes, class_probs, attrs, attr_probs, roi_features = map(list, zip(*final_results))
return boxes, classes, class_probs, attrs, attr_probs, roi_features
def training(self, obj_logits, attr_logits, box_deltas, pred_boxes, features, sizes):
pass
def __call__(
self,
obj_logits,
attr_logits,
box_deltas,
pred_boxes,
features,
sizes,
scales=None,
):
if self.training:
raise NotImplementedError()
return self.inference(
obj_logits,
attr_logits,
box_deltas,
pred_boxes,
features,
sizes,
scales=scales,
)
class Res5ROIHeads(nn.Module):
"""
ROIHeads perform all per-region computation in an R-CNN.
It contains logic of cropping the regions, extract per-region features
(by the res-5 block in this case), and make per-region predictions.
"""
def __init__(self, cfg, input_shape):
super().__init__()
self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
self.positive_sample_fraction = cfg.ROI_HEADS.POSITIVE_FRACTION
self.in_features = cfg.ROI_HEADS.IN_FEATURES
self.num_classes = cfg.ROI_HEADS.NUM_CLASSES
self.proposal_append_gt = cfg.ROI_HEADS.PROPOSAL_APPEND_GT
self.feature_strides = {k: v.stride for k, v in input_shape.items()}
self.feature_channels = {k: v.channels for k, v in input_shape.items()}
self.cls_agnostic_bbox_reg = cfg.ROI_BOX_HEAD.CLS_AGNOSTIC_BBOX_REG
self.stage_channel_factor = 2**3 # res5 is 8x res2
self.out_channels = cfg.RESNETS.RES2_OUT_CHANNELS * self.stage_channel_factor
# self.proposal_matcher = Matcher(
# cfg.ROI_HEADS.IOU_THRESHOLDS,
# cfg.ROI_HEADS.IOU_LABELS,
# allow_low_quality_matches=False,
# )
pooler_resolution = cfg.ROI_BOX_HEAD.POOLER_RESOLUTION
pooler_scales = (1.0 / self.feature_strides[self.in_features[0]],)
sampling_ratio = cfg.ROI_BOX_HEAD.POOLER_SAMPLING_RATIO
res5_halve = cfg.ROI_BOX_HEAD.RES5HALVE
use_attr = cfg.ROI_BOX_HEAD.ATTR
num_attrs = cfg.ROI_BOX_HEAD.NUM_ATTRS
self.pooler = ROIPooler(
output_size=pooler_resolution,
scales=pooler_scales,
sampling_ratio=sampling_ratio,
)
self.res5 = self._build_res5_block(cfg)
if not res5_halve:
"""
Modifications for VG in RoI heads:
1. Change the stride of conv1 and shortcut in Res5.Block1 from 2 to 1
2. Modifying all conv2 with (padding: 1 --> 2) and (dilation: 1 --> 2)
"""
self.res5[0].conv1.stride = (1, 1)
self.res5[0].shortcut.stride = (1, 1)
for i in range(3):
self.res5[i].conv2.padding = (2, 2)
self.res5[i].conv2.dilation = (2, 2)
self.box_predictor = FastRCNNOutputLayers(
self.out_channels,
self.num_classes,
self.cls_agnostic_bbox_reg,
use_attr=use_attr,
num_attrs=num_attrs,
)
def _build_res5_block(self, cfg):
stage_channel_factor = self.stage_channel_factor # res5 is 8x res2
num_groups = cfg.RESNETS.NUM_GROUPS
width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
bottleneck_channels = num_groups * width_per_group * stage_channel_factor
out_channels = self.out_channels
stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
norm = cfg.RESNETS.NORM
blocks = ResNet.make_stage(
BottleneckBlock,
3,
first_stride=2,
in_channels=out_channels // 2,
bottleneck_channels=bottleneck_channels,
out_channels=out_channels,
num_groups=num_groups,
norm=norm,
stride_in_1x1=stride_in_1x1,
)
return nn.Sequential(*blocks)
def _shared_roi_transform(self, features, boxes):
x = self.pooler(features, boxes)
return self.res5(x)
def forward(self, features, proposal_boxes, gt_boxes=None):
if self.training:
"""
see https://github.com/airsplay/py-bottom-up-attention/\
blob/master/detectron2/modeling/roi_heads/roi_heads.py
"""
raise NotImplementedError()
assert not proposal_boxes[0].requires_grad
box_features = self._shared_roi_transform(features, proposal_boxes)
feature_pooled = box_features.mean(dim=[2, 3]) # pooled to 1x1
obj_logits, attr_logits, pred_proposal_deltas = self.box_predictor(feature_pooled)
return obj_logits, attr_logits, pred_proposal_deltas, feature_pooled
class AnchorGenerator(nn.Module):
"""
For a set of image sizes and feature maps, computes a set of anchors.
"""
def __init__(self, cfg, input_shape: List[ShapeSpec]):
super().__init__()
sizes = cfg.ANCHOR_GENERATOR.SIZES
aspect_ratios = cfg.ANCHOR_GENERATOR.ASPECT_RATIOS
self.strides = [x.stride for x in input_shape]
self.offset = cfg.ANCHOR_GENERATOR.OFFSET
assert 0.0 <= self.offset < 1.0, self.offset
"""
sizes (list[list[int]]): sizes[i] is the list of anchor sizes for feat map i
1. given in absolute lengths in units of the input image;
2. they do not dynamically scale if the input image size changes.
aspect_ratios (list[list[float]])
strides (list[int]): stride of each input feature.
"""
self.num_features = len(self.strides)
self.cell_anchors = nn.ParameterList(self._calculate_anchors(sizes, aspect_ratios))
self._spacial_feat_dim = 4
def _calculate_anchors(self, sizes, aspect_ratios):
# If one size (or aspect ratio) is specified and there are multiple feature
# maps, then we "broadcast" anchors of that single size (or aspect ratio)
if len(sizes) == 1:
sizes *= self.num_features
if len(aspect_ratios) == 1:
aspect_ratios *= self.num_features
assert self.num_features == len(sizes)
assert self.num_features == len(aspect_ratios)
cell_anchors = [self.generate_cell_anchors(s, a).float() for s, a in zip(sizes, aspect_ratios)]
return cell_anchors
@property
def box_dim(self):
return self._spacial_feat_dim
@property
def num_cell_anchors(self):
"""
Returns:
list[int]: Each int is the number of anchors at every pixel location, on that feature map.
"""
return [len(cell_anchors) for cell_anchors in self.cell_anchors]
def grid_anchors(self, grid_sizes):
anchors = []
for size, stride, base_anchors in zip(grid_sizes, self.strides, self.cell_anchors):
shift_x, shift_y = _create_grid_offsets(size, stride, self.offset, base_anchors.device)
shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
anchors.append((shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4))
return anchors
def generate_cell_anchors(self, sizes=(32, 64, 128, 256, 512), aspect_ratios=(0.5, 1, 2)):
"""
anchors are continuous geometric rectangles
centered on one feature map point sample.
We can later build the set of anchors
for the entire feature map by tiling these tensors
"""
anchors = []
for size in sizes:
area = size**2.0
for aspect_ratio in aspect_ratios:
w = math.sqrt(area / aspect_ratio)
h = aspect_ratio * w
x0, y0, x1, y1 = -w / 2.0, -h / 2.0, w / 2.0, h / 2.0
anchors.append([x0, y0, x1, y1])
return nn.Parameter(torch.tensor(anchors))
def forward(self, features):
"""
Args:
features List[torch.Tensor]: list of feature maps on which to generate anchors.
Returns:
torch.Tensor: a list of #image elements.
"""
num_images = features[0].size(0)
grid_sizes = [feature_map.shape[-2:] for feature_map in features]
anchors_over_all_feature_maps = self.grid_anchors(grid_sizes)
anchors_over_all_feature_maps = torch.stack(anchors_over_all_feature_maps)
return anchors_over_all_feature_maps.unsqueeze(0).repeat_interleave(num_images, dim=0)
class RPNHead(nn.Module):
"""
RPN classification and regression heads. Uses a 3x3 conv to produce a shared
hidden state from which one 1x1 conv predicts objectness logits for each anchor
and a second 1x1 conv predicts bounding-box deltas specifying how to deform
each anchor into an object proposal.
"""
def __init__(self, cfg, input_shape: List[ShapeSpec]):
super().__init__()
# Standard RPN is shared across levels:
in_channels = [s.channels for s in input_shape]
assert len(set(in_channels)) == 1, "Each level must have the same channel!"
in_channels = in_channels[0]
anchor_generator = AnchorGenerator(cfg, input_shape)
num_cell_anchors = anchor_generator.num_cell_anchors
box_dim = anchor_generator.box_dim
assert len(set(num_cell_anchors)) == 1, "Each level must have the same number of cell anchors"
num_cell_anchors = num_cell_anchors[0]
if cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS == -1:
hid_channels = in_channels
else:
hid_channels = cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS
# Modifications for VG in RPN (modeling/proposal_generator/rpn.py)
# Use hidden dim instead fo the same dim as Res4 (in_channels)
# 3x3 conv for the hidden representation
self.conv = nn.Conv2d(in_channels, hid_channels, kernel_size=3, stride=1, padding=1)
# 1x1 conv for predicting objectness logits
self.objectness_logits = nn.Conv2d(hid_channels, num_cell_anchors, kernel_size=1, stride=1)
# 1x1 conv for predicting box2box transform deltas
self.anchor_deltas = nn.Conv2d(hid_channels, num_cell_anchors * box_dim, kernel_size=1, stride=1)
for layer in [self.conv, self.objectness_logits, self.anchor_deltas]:
nn.init.normal_(layer.weight, std=0.01)
nn.init.constant_(layer.bias, 0)
def forward(self, features):
"""
Args:
features (list[Tensor]): list of feature maps
"""
pred_objectness_logits = []
pred_anchor_deltas = []
for x in features:
t = nn.functional.relu(self.conv(x))
pred_objectness_logits.append(self.objectness_logits(t))
pred_anchor_deltas.append(self.anchor_deltas(t))
return pred_objectness_logits, pred_anchor_deltas
class RPN(nn.Module):
"""
Region Proposal Network, introduced by the Faster R-CNN paper.
"""
def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
super().__init__()
self.min_box_side_len = cfg.PROPOSAL_GENERATOR.MIN_SIZE
self.in_features = cfg.RPN.IN_FEATURES
self.nms_thresh = cfg.RPN.NMS_THRESH
self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
self.positive_fraction = cfg.RPN.POSITIVE_FRACTION
self.smooth_l1_beta = cfg.RPN.SMOOTH_L1_BETA
self.loss_weight = cfg.RPN.LOSS_WEIGHT
self.pre_nms_topk = {
True: cfg.RPN.PRE_NMS_TOPK_TRAIN,
False: cfg.RPN.PRE_NMS_TOPK_TEST,
}
self.post_nms_topk = {
True: cfg.RPN.POST_NMS_TOPK_TRAIN,
False: cfg.RPN.POST_NMS_TOPK_TEST,
}
self.boundary_threshold = cfg.RPN.BOUNDARY_THRESH
self.anchor_generator = AnchorGenerator(cfg, [input_shape[f] for f in self.in_features])
self.box2box_transform = Box2BoxTransform(weights=cfg.RPN.BBOX_REG_WEIGHTS)
self.anchor_matcher = Matcher(
cfg.RPN.IOU_THRESHOLDS,
cfg.RPN.IOU_LABELS,
allow_low_quality_matches=True,
)
self.rpn_head = RPNHead(cfg, [input_shape[f] for f in self.in_features])
def training(self, images, image_shapes, features, gt_boxes):
pass
def inference(self, outputs, images, image_shapes, features, gt_boxes=None):
outputs = find_top_rpn_proposals(
outputs.predict_proposals(),
outputs.predict_objectness_logits(),
images,
image_shapes,
self.nms_thresh,
self.pre_nms_topk[self.training],
self.post_nms_topk[self.training],
self.min_box_side_len,
self.training,
)
results = []
for img in outputs:
im_boxes, img_box_logits = img
img_box_logits, inds = img_box_logits.sort(descending=True)
im_boxes = im_boxes[inds]
results.append((im_boxes, img_box_logits))
(proposal_boxes, logits) = tuple(map(list, zip(*results)))
return proposal_boxes, logits
def forward(self, images, image_shapes, features, gt_boxes=None):
"""
Args:
images (torch.Tensor): input images of length `N`
features (dict[str: Tensor])
gt_instances
"""
# features is dict, key = block level, v = feature_map
features = [features[f] for f in self.in_features]
pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
anchors = self.anchor_generator(features)
outputs = RPNOutputs(
self.box2box_transform,
self.anchor_matcher,
self.batch_size_per_image,
self.positive_fraction,
images,
pred_objectness_logits,
pred_anchor_deltas,
anchors,
self.boundary_threshold,
gt_boxes,
self.smooth_l1_beta,
)
# For RPN-only models, the proposals are the final output
if self.training:
raise NotImplementedError()
return self.training(outputs, images, image_shapes, features, gt_boxes)
else:
return self.inference(outputs, images, image_shapes, features, gt_boxes)
class FastRCNNOutputLayers(nn.Module):
"""
Two linear layers for predicting Fast R-CNN outputs:
(1) proposal-to-detection box regression deltas
(2) classification scores
"""
def __init__(
self,
input_size,
num_classes,
cls_agnostic_bbox_reg,
box_dim=4,
use_attr=False,
num_attrs=-1,
):
"""
Args:
input_size (int): channels, or (channels, height, width)
num_classes (int)
cls_agnostic_bbox_reg (bool)
box_dim (int)
"""
super().__init__()
if not isinstance(input_size, int):
input_size = np.prod(input_size)
# (do + 1 for background class)
self.cls_score = nn.Linear(input_size, num_classes + 1)
num_bbox_reg_classes = 1 if cls_agnostic_bbox_reg else num_classes
self.bbox_pred = nn.Linear(input_size, num_bbox_reg_classes * box_dim)
self.use_attr = use_attr
if use_attr:
"""
Modifications for VG in RoI heads
Embedding: {num_classes + 1} --> {input_size // 8}
Linear: {input_size + input_size // 8} --> {input_size // 4}
Linear: {input_size // 4} --> {num_attrs + 1}
"""
self.cls_embedding = nn.Embedding(num_classes + 1, input_size // 8)
self.fc_attr = nn.Linear(input_size + input_size // 8, input_size // 4)
self.attr_score = nn.Linear(input_size // 4, num_attrs + 1)
nn.init.normal_(self.cls_score.weight, std=0.01)
nn.init.normal_(self.bbox_pred.weight, std=0.001)
for item in [self.cls_score, self.bbox_pred]:
nn.init.constant_(item.bias, 0)
def forward(self, roi_features):
if roi_features.dim() > 2:
roi_features = torch.flatten(roi_features, start_dim=1)
scores = self.cls_score(roi_features)
proposal_deltas = self.bbox_pred(roi_features)
if self.use_attr:
_, max_class = scores.max(-1) # [b, c] --> [b]
cls_emb = self.cls_embedding(max_class) # [b] --> [b, 256]
roi_features = torch.cat([roi_features, cls_emb], -1) # [b, 2048] + [b, 256] --> [b, 2304]
roi_features = self.fc_attr(roi_features)
roi_features = nn.functional.relu(roi_features)
attr_scores = self.attr_score(roi_features)
return scores, attr_scores, proposal_deltas
else:
return scores, proposal_deltas
class GeneralizedRCNN(nn.Module):
def __init__(self, cfg):
super().__init__()
self.device = torch.device(cfg.MODEL.DEVICE)
self.backbone = build_backbone(cfg)
self.proposal_generator = RPN(cfg, self.backbone.output_shape())
self.roi_heads = Res5ROIHeads(cfg, self.backbone.output_shape())
self.roi_outputs = ROIOutputs(cfg)
self.to(self.device)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
config = kwargs.pop("config", None)
state_dict = kwargs.pop("state_dict", None)
cache_dir = kwargs.pop("cache_dir", None)
from_tf = kwargs.pop("from_tf", False)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_cdn = kwargs.pop("use_cdn", True)
# Load config if we don't provide a configuration
if not isinstance(config, Config):
config_path = config if config is not None else pretrained_model_name_or_path
# try:
config = Config.from_pretrained(
config_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
)
# Load model
if pretrained_model_name_or_path is not None:
if os.path.isdir(pretrained_model_name_or_path):
if os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
# Load from a PyTorch checkpoint
archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
else:
raise EnvironmentError(
"Error no file named {} found in directory {} ".format(
WEIGHTS_NAME,
pretrained_model_name_or_path,
)
)
elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
archive_file = pretrained_model_name_or_path
elif os.path.isfile(pretrained_model_name_or_path + ".index"):
assert from_tf, "We found a TensorFlow checkpoint at {}, please set from_tf to True to load from this checkpoint".format(
pretrained_model_name_or_path + ".index"
)
archive_file = pretrained_model_name_or_path + ".index"
else:
archive_file = hf_bucket_url(
pretrained_model_name_or_path,
filename=WEIGHTS_NAME,
use_cdn=use_cdn,
)
try:
# Load from URL or cache if already cached
resolved_archive_file = cached_path(
archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
)
if resolved_archive_file is None:
raise EnvironmentError
except EnvironmentError:
msg = f"Can't load weights for '{pretrained_model_name_or_path}'."
raise EnvironmentError(msg)
if resolved_archive_file == archive_file:
print("loading weights file {}".format(archive_file))
else:
print("loading weights file {} from cache at {}".format(archive_file, resolved_archive_file))
else:
resolved_archive_file = None
# Instantiate model.
model = cls(config)
if state_dict is None:
try:
try:
state_dict = torch.load(resolved_archive_file, map_location="cpu")
except Exception:
state_dict = load_checkpoint(resolved_archive_file)
except Exception:
raise OSError(
"Unable to load weights from pytorch checkpoint file. "
"If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
)
missing_keys = []
unexpected_keys = []
error_msgs = []
# Convert old format to new format if needed from a PyTorch state_dict
old_keys = []
new_keys = []
for key in state_dict.keys():
new_key = None
if "gamma" in key:
new_key = key.replace("gamma", "weight")
if "beta" in key:
new_key = key.replace("beta", "bias")
if new_key:
old_keys.append(key)
new_keys.append(new_key)
for old_key, new_key in zip(old_keys, new_keys):
state_dict[new_key] = state_dict.pop(old_key)
# copy state_dict so _load_from_state_dict can modify it
metadata = getattr(state_dict, "_metadata", None)
state_dict = state_dict.copy()
if metadata is not None:
state_dict._metadata = metadata
model_to_load = model
model_to_load.load_state_dict(state_dict)
if model.__class__.__name__ != model_to_load.__class__.__name__:
base_model_state_dict = model_to_load.state_dict().keys()
head_model_state_dict_without_base_prefix = [
key.split(cls.base_model_prefix + ".")[-1] for key in model.state_dict().keys()
]
missing_keys.extend(head_model_state_dict_without_base_prefix - base_model_state_dict)
if len(unexpected_keys) > 0:
print(
f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
" with another architecture (e.g. initializing a BertForSequenceClassification model from a"
" BertForPreTraining model).\n- This IS NOT expected if you are initializing"
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
" (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
)
else:
print(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
if len(missing_keys) > 0:
print(
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
" TRAIN this model on a down-stream task to be able to use it for predictions and inference."
)
else:
print(
f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
" training."
)
if len(error_msgs) > 0:
raise RuntimeError(
"Error(s) in loading state_dict for {}:\n\t{}".format(
model.__class__.__name__, "\n\t".join(error_msgs)
)
)
# Set model in evaluation mode to deactivate DropOut modules by default
model.eval()
return model
def forward(
self,
images,
image_shapes,
gt_boxes=None,
proposals=None,
scales_yx=None,
**kwargs,
):
"""
kwargs:
max_detections (int), return_tensors {"np", "pt", None}, padding {None,
"max_detections"}, pad_value (int), location = {"cuda", "cpu"}
"""
if self.training:
raise NotImplementedError()
return self.inference(
images=images,
image_shapes=image_shapes,
gt_boxes=gt_boxes,
proposals=proposals,
scales_yx=scales_yx,
**kwargs,
)
@torch.no_grad()
def inference(
self,
images,
image_shapes,
gt_boxes=None,
proposals=None,
scales_yx=None,
**kwargs,
):
# run images through backbone
original_sizes = image_shapes * scales_yx
features = self.backbone(images)
# generate proposals if none are available
if proposals is None:
proposal_boxes, _ = self.proposal_generator(images, image_shapes, features, gt_boxes)
else:
assert proposals is not None
# pool object features from either gt_boxes, or from proposals
obj_logits, attr_logits, box_deltas, feature_pooled = self.roi_heads(features, proposal_boxes, gt_boxes)
# prepare FRCNN Outputs and select top proposals
boxes, classes, class_probs, attrs, attr_probs, roi_features = self.roi_outputs(
obj_logits=obj_logits,
attr_logits=attr_logits,
box_deltas=box_deltas,
pred_boxes=proposal_boxes,
features=feature_pooled,
sizes=image_shapes,
scales=scales_yx,
)
# will we pad???
subset_kwargs = {
"max_detections": kwargs.get("max_detections", None),
"return_tensors": kwargs.get("return_tensors", None),
"pad_value": kwargs.get("pad_value", 0),
"padding": kwargs.get("padding", None),
}
preds_per_image = torch.tensor([p.size(0) for p in boxes])
boxes = pad_list_tensors(boxes, preds_per_image, **subset_kwargs)
classes = pad_list_tensors(classes, preds_per_image, **subset_kwargs)
class_probs = pad_list_tensors(class_probs, preds_per_image, **subset_kwargs)
attrs = pad_list_tensors(attrs, preds_per_image, **subset_kwargs)
attr_probs = pad_list_tensors(attr_probs, preds_per_image, **subset_kwargs)
roi_features = pad_list_tensors(roi_features, preds_per_image, **subset_kwargs)
subset_kwargs["padding"] = None
preds_per_image = pad_list_tensors(preds_per_image, None, **subset_kwargs)
sizes = pad_list_tensors(image_shapes, None, **subset_kwargs)
normalized_boxes = norm_box(boxes, original_sizes)
return OrderedDict(
{
"obj_ids": classes,
"obj_probs": class_probs,
"attr_ids": attrs,
"attr_probs": attr_probs,
"boxes": boxes,
"sizes": sizes,
"preds_per_image": preds_per_image,
"roi_features": roi_features,
"normalized_boxes": normalized_boxes,
}
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/requirements.txt
|
appdirs==1.4.3
argon2-cffi==20.1.0
async-generator==1.10
attrs==20.2.0
backcall==0.2.0
CacheControl==0.12.6
certifi==2023.7.22
cffi==1.14.2
chardet==3.0.4
click==7.1.2
colorama==0.4.3
contextlib2==0.6.0
cycler==0.10.0
datasets==1.0.0
decorator==4.4.2
defusedxml==0.6.0
dill==0.3.2
distlib==0.3.0
distro==1.4.0
entrypoints==0.3
filelock==3.0.12
future==0.18.3
html5lib==1.0.1
idna==2.8
ipaddr==2.2.0
ipykernel==5.3.4
ipython
ipython-genutils==0.2.0
ipywidgets==7.5.1
jedi==0.17.2
Jinja2>=2.11.3
joblib==1.2.0
jsonschema==3.2.0
jupyter==1.0.0
jupyter-client==6.1.7
jupyter-console==6.2.0
jupyter-core==4.6.3
jupyterlab-pygments==0.1.1
kiwisolver==1.2.0
lockfile==0.12.2
MarkupSafe==1.1.1
matplotlib==3.3.1
mistune==2.0.3
msgpack==0.6.2
nbclient==0.5.0
nbconvert==6.5.1
nbformat==5.0.7
nest-asyncio==1.4.0
notebook==6.4.12
numpy==1.22.0
opencv-python==4.4.0.42
packaging==20.3
pandas==1.1.2
pandocfilters==1.4.2
parso==0.7.1
pep517==0.8.2
pexpect==4.8.0
pickleshare==0.7.5
Pillow>=8.1.1
progress==1.5
prometheus-client==0.8.0
prompt-toolkit==3.0.7
ptyprocess==0.6.0
pyaml==20.4.0
pyarrow==1.0.1
pycparser==2.20
Pygments>=2.7.4
pyparsing==2.4.6
pyrsistent==0.16.0
python-dateutil==2.8.1
pytoml==0.1.21
pytz==2020.1
PyYAML>=5.4
pyzmq==19.0.2
qtconsole==4.7.7
QtPy==1.9.0
regex==2020.7.14
requests==2.31.0
retrying==1.3.3
sacremoses==0.0.43
Send2Trash==1.5.0
sentencepiece==0.1.91
six==1.14.0
terminado==0.8.3
testpath==0.4.4
tokenizers==0.8.1rc2
torch==1.6.0
torchvision==0.7.0
tornado==6.3.3
tqdm==4.48.2
traitlets
git+https://github.com/huggingface/transformers.git
urllib3==1.26.18
wcwidth==0.2.5
webencodings==0.5.1
wget==3.2
widgetsnbextension==3.5.1
xxhash==2.0.0
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/processing_image.py
|
"""
coding=utf-8
Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
Adapted From Facebook Inc, Detectron2
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.import copy
"""
import sys
from typing import Tuple
import numpy as np
import torch
from PIL import Image
from torch import nn
from transformers.image_utils import PILImageResampling
from utils import img_tensorize
class ResizeShortestEdge:
def __init__(self, short_edge_length, max_size=sys.maxsize):
"""
Args:
short_edge_length (list[min, max])
max_size (int): maximum allowed longest edge length.
"""
self.interp_method = "bilinear"
self.max_size = max_size
self.short_edge_length = short_edge_length
def __call__(self, imgs):
img_augs = []
for img in imgs:
h, w = img.shape[:2]
# later: provide list and randomly choose index for resize
size = np.random.randint(self.short_edge_length[0], self.short_edge_length[1] + 1)
if size == 0:
return img
scale = size * 1.0 / min(h, w)
if h < w:
newh, neww = size, scale * w
else:
newh, neww = scale * h, size
if max(newh, neww) > self.max_size:
scale = self.max_size * 1.0 / max(newh, neww)
newh = newh * scale
neww = neww * scale
neww = int(neww + 0.5)
newh = int(newh + 0.5)
if img.dtype == np.uint8:
pil_image = Image.fromarray(img)
pil_image = pil_image.resize((neww, newh), PILImageResampling.BILINEAR)
img = np.asarray(pil_image)
else:
img = img.permute(2, 0, 1).unsqueeze(0) # 3, 0, 1) # hw(c) -> nchw
img = nn.functional.interpolate(
img, (newh, neww), mode=self.interp_method, align_corners=False
).squeeze(0)
img_augs.append(img)
return img_augs
class Preprocess:
def __init__(self, cfg):
self.aug = ResizeShortestEdge([cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST)
self.input_format = cfg.INPUT.FORMAT
self.size_divisibility = cfg.SIZE_DIVISIBILITY
self.pad_value = cfg.PAD_VALUE
self.max_image_size = cfg.INPUT.MAX_SIZE_TEST
self.device = cfg.MODEL.DEVICE
self.pixel_std = torch.tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
self.pixel_mean = torch.tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
self.normalizer = lambda x: (x - self.pixel_mean) / self.pixel_std
def pad(self, images):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
image_sizes = [im.shape[-2:] for im in images]
images = [
nn.functional.pad(
im,
[0, max_size[-1] - size[1], 0, max_size[-2] - size[0]],
value=self.pad_value,
)
for size, im in zip(image_sizes, images)
]
return torch.stack(images), torch.tensor(image_sizes)
def __call__(self, images, single_image=False):
with torch.no_grad():
if not isinstance(images, list):
images = [images]
if single_image:
assert len(images) == 1
for i in range(len(images)):
if isinstance(images[i], torch.Tensor):
images.insert(i, images.pop(i).to(self.device).float())
elif not isinstance(images[i], torch.Tensor):
images.insert(
i,
torch.as_tensor(img_tensorize(images.pop(i), input_format=self.input_format))
.to(self.device)
.float(),
)
# resize smallest edge
raw_sizes = torch.tensor([im.shape[:2] for im in images])
images = self.aug(images)
# transpose images and convert to torch tensors
# images = [torch.as_tensor(i.astype("float32")).permute(2, 0, 1).to(self.device) for i in images]
# now normalize before pad to avoid useless arithmetic
images = [self.normalizer(x) for x in images]
# now pad them to do the following operations
images, sizes = self.pad(images)
# Normalize
if self.size_divisibility > 0:
raise NotImplementedError()
# pad
scales_yx = torch.true_divide(raw_sizes, sizes)
if single_image:
return images[0], sizes[0], scales_yx[0]
else:
return images, sizes, scales_yx
def _scale_box(boxes, scale_yx):
boxes[:, 0::2] *= scale_yx[:, 1]
boxes[:, 1::2] *= scale_yx[:, 0]
return boxes
def _clip_box(tensor, box_size: Tuple[int, int]):
assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
h, w = box_size
tensor[:, 0].clamp_(min=0, max=w)
tensor[:, 1].clamp_(min=0, max=h)
tensor[:, 2].clamp_(min=0, max=w)
tensor[:, 3].clamp_(min=0, max=h)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/lxmert/visualizing_image.py
|
"""
coding=utf-8
Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
Adapted From Facebook Inc, Detectron2
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.import copy
"""
import colorsys
import io
import cv2
import matplotlib as mpl
import matplotlib.colors as mplc
import matplotlib.figure as mplfigure
import numpy as np
import torch
from matplotlib.backends.backend_agg import FigureCanvasAgg
from utils import img_tensorize
_SMALL_OBJ = 1000
class SingleImageViz:
def __init__(
self,
img,
scale=1.2,
edgecolor="g",
alpha=0.5,
linestyle="-",
saveas="test_out.jpg",
rgb=True,
pynb=False,
id2obj=None,
id2attr=None,
pad=0.7,
):
"""
img: an RGB image of shape (H, W, 3).
"""
if isinstance(img, torch.Tensor):
img = img.numpy().astype("np.uint8")
if isinstance(img, str):
img = img_tensorize(img)
assert isinstance(img, np.ndarray)
width, height = img.shape[1], img.shape[0]
fig = mplfigure.Figure(frameon=False)
dpi = fig.get_dpi()
width_in = (width * scale + 1e-2) / dpi
height_in = (height * scale + 1e-2) / dpi
fig.set_size_inches(width_in, height_in)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.axis("off")
ax.set_xlim(0.0, width)
ax.set_ylim(height)
self.saveas = saveas
self.rgb = rgb
self.pynb = pynb
self.img = img
self.edgecolor = edgecolor
self.alpha = 0.5
self.linestyle = linestyle
self.font_size = int(np.sqrt(min(height, width)) * scale // 3)
self.width = width
self.height = height
self.scale = scale
self.fig = fig
self.ax = ax
self.pad = pad
self.id2obj = id2obj
self.id2attr = id2attr
self.canvas = FigureCanvasAgg(fig)
def add_box(self, box, color=None):
if color is None:
color = self.edgecolor
(x0, y0, x1, y1) = box
width = x1 - x0
height = y1 - y0
self.ax.add_patch(
mpl.patches.Rectangle(
(x0, y0),
width,
height,
fill=False,
edgecolor=color,
linewidth=self.font_size // 3,
alpha=self.alpha,
linestyle=self.linestyle,
)
)
def draw_boxes(self, boxes, obj_ids=None, obj_scores=None, attr_ids=None, attr_scores=None):
if len(boxes.shape) > 2:
boxes = boxes[0]
if len(obj_ids.shape) > 1:
obj_ids = obj_ids[0]
if len(obj_scores.shape) > 1:
obj_scores = obj_scores[0]
if len(attr_ids.shape) > 1:
attr_ids = attr_ids[0]
if len(attr_scores.shape) > 1:
attr_scores = attr_scores[0]
if isinstance(boxes, torch.Tensor):
boxes = boxes.numpy()
if isinstance(boxes, list):
boxes = np.array(boxes)
assert isinstance(boxes, np.ndarray)
areas = np.prod(boxes[:, 2:] - boxes[:, :2], axis=1)
sorted_idxs = np.argsort(-areas).tolist()
boxes = boxes[sorted_idxs] if boxes is not None else None
obj_ids = obj_ids[sorted_idxs] if obj_ids is not None else None
obj_scores = obj_scores[sorted_idxs] if obj_scores is not None else None
attr_ids = attr_ids[sorted_idxs] if attr_ids is not None else None
attr_scores = attr_scores[sorted_idxs] if attr_scores is not None else None
assigned_colors = [self._random_color(maximum=1) for _ in range(len(boxes))]
assigned_colors = [assigned_colors[idx] for idx in sorted_idxs]
if obj_ids is not None:
labels = self._create_text_labels_attr(obj_ids, obj_scores, attr_ids, attr_scores)
for i in range(len(boxes)):
color = assigned_colors[i]
self.add_box(boxes[i], color)
self.draw_labels(labels[i], boxes[i], color)
def draw_labels(self, label, box, color):
x0, y0, x1, y1 = box
text_pos = (x0, y0)
instance_area = (y1 - y0) * (x1 - x0)
small = _SMALL_OBJ * self.scale
if instance_area < small or y1 - y0 < 40 * self.scale:
if y1 >= self.height - 5:
text_pos = (x1, y0)
else:
text_pos = (x0, y1)
height_ratio = (y1 - y0) / np.sqrt(self.height * self.width)
lighter_color = self._change_color_brightness(color, brightness_factor=0.7)
font_size = np.clip((height_ratio - 0.02) / 0.08 + 1, 1.2, 2)
font_size *= 0.75 * self.font_size
self.draw_text(
text=label,
position=text_pos,
color=lighter_color,
)
def draw_text(
self,
text,
position,
color="g",
ha="left",
):
rotation = 0
font_size = self.font_size
color = np.maximum(list(mplc.to_rgb(color)), 0.2)
color[np.argmax(color)] = max(0.8, np.max(color))
bbox = {
"facecolor": "black",
"alpha": self.alpha,
"pad": self.pad,
"edgecolor": "none",
}
x, y = position
self.ax.text(
x,
y,
text,
size=font_size * self.scale,
family="sans-serif",
bbox=bbox,
verticalalignment="top",
horizontalalignment=ha,
color=color,
zorder=10,
rotation=rotation,
)
def save(self, saveas=None):
if saveas is None:
saveas = self.saveas
if saveas.lower().endswith(".jpg") or saveas.lower().endswith(".png"):
cv2.imwrite(
saveas,
self._get_buffer()[:, :, ::-1],
)
else:
self.fig.savefig(saveas)
def _create_text_labels_attr(self, classes, scores, attr_classes, attr_scores):
labels = [self.id2obj[i] for i in classes]
attr_labels = [self.id2attr[i] for i in attr_classes]
labels = [
f"{label} {score:.2f} {attr} {attr_score:.2f}"
for label, score, attr, attr_score in zip(labels, scores, attr_labels, attr_scores)
]
return labels
def _create_text_labels(self, classes, scores):
labels = [self.id2obj[i] for i in classes]
if scores is not None:
if labels is None:
labels = ["{:.0f}%".format(s * 100) for s in scores]
else:
labels = ["{} {:.0f}%".format(li, s * 100) for li, s in zip(labels, scores)]
return labels
def _random_color(self, maximum=255):
idx = np.random.randint(0, len(_COLORS))
ret = _COLORS[idx] * maximum
if not self.rgb:
ret = ret[::-1]
return ret
def _get_buffer(self):
if not self.pynb:
s, (width, height) = self.canvas.print_to_buffer()
if (width, height) != (self.width, self.height):
img = cv2.resize(self.img, (width, height))
else:
img = self.img
else:
buf = io.BytesIO() # works for cairo backend
self.canvas.print_rgba(buf)
width, height = self.width, self.height
s = buf.getvalue()
img = self.img
buffer = np.frombuffer(s, dtype="uint8")
img_rgba = buffer.reshape(height, width, 4)
rgb, alpha = np.split(img_rgba, [3], axis=2)
try:
import numexpr as ne # fuse them with numexpr
visualized_image = ne.evaluate("img * (1 - alpha / 255.0) + rgb * (alpha / 255.0)")
except ImportError:
alpha = alpha.astype("float32") / 255.0
visualized_image = img * (1 - alpha) + rgb * alpha
return visualized_image.astype("uint8")
def _change_color_brightness(self, color, brightness_factor):
assert brightness_factor >= -1.0 and brightness_factor <= 1.0
color = mplc.to_rgb(color)
polygon_color = colorsys.rgb_to_hls(*mplc.to_rgb(color))
modified_lightness = polygon_color[1] + (brightness_factor * polygon_color[1])
modified_lightness = 0.0 if modified_lightness < 0.0 else modified_lightness
modified_lightness = 1.0 if modified_lightness > 1.0 else modified_lightness
modified_color = colorsys.hls_to_rgb(polygon_color[0], modified_lightness, polygon_color[2])
return modified_color
# Color map
_COLORS = (
np.array(
[
0.000,
0.447,
0.741,
0.850,
0.325,
0.098,
0.929,
0.694,
0.125,
0.494,
0.184,
0.556,
0.466,
0.674,
0.188,
0.301,
0.745,
0.933,
0.635,
0.078,
0.184,
0.300,
0.300,
0.300,
0.600,
0.600,
0.600,
1.000,
0.000,
0.000,
1.000,
0.500,
0.000,
0.749,
0.749,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
1.000,
0.667,
0.000,
1.000,
0.333,
0.333,
0.000,
0.333,
0.667,
0.000,
0.333,
1.000,
0.000,
0.667,
0.333,
0.000,
0.667,
0.667,
0.000,
0.667,
1.000,
0.000,
1.000,
0.333,
0.000,
1.000,
0.667,
0.000,
1.000,
1.000,
0.000,
0.000,
0.333,
0.500,
0.000,
0.667,
0.500,
0.000,
1.000,
0.500,
0.333,
0.000,
0.500,
0.333,
0.333,
0.500,
0.333,
0.667,
0.500,
0.333,
1.000,
0.500,
0.667,
0.000,
0.500,
0.667,
0.333,
0.500,
0.667,
0.667,
0.500,
0.667,
1.000,
0.500,
1.000,
0.000,
0.500,
1.000,
0.333,
0.500,
1.000,
0.667,
0.500,
1.000,
1.000,
0.500,
0.000,
0.333,
1.000,
0.000,
0.667,
1.000,
0.000,
1.000,
1.000,
0.333,
0.000,
1.000,
0.333,
0.333,
1.000,
0.333,
0.667,
1.000,
0.333,
1.000,
1.000,
0.667,
0.000,
1.000,
0.667,
0.333,
1.000,
0.667,
0.667,
1.000,
0.667,
1.000,
1.000,
1.000,
0.000,
1.000,
1.000,
0.333,
1.000,
1.000,
0.667,
1.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.167,
0.000,
0.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.167,
0.000,
0.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.143,
0.143,
0.143,
0.857,
0.857,
0.857,
1.000,
1.000,
1.000,
]
)
.astype(np.float32)
.reshape(-1, 3)
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/README.md
|
# Intro
Authors: @patrickvonplaten and @lhoestq
Aimed at tackling the knowledge-intensive NLP tasks (think tasks a human wouldn't be expected to solve without access to external knowledge sources), RAG models are seq2seq models with access to a retrieval mechanism providing relevant context documents at training and evaluation time.
A RAG model encapsulates two core components: a question encoder and a generator.
During a forward pass, we encode the input with the question encoder and pass it
to the retriever to extract relevant context documents. The documents are then prepended to the input.
Such contextualized inputs are passed to the generator.
Read more about RAG at https://arxiv.org/abs/2005.11401.
# Note
⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
# Finetuning
Our finetuning logic is based on scripts from [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/tree/main/examples/legacy/seq2seq). We accept training data in the same format as specified there - we expect a directory consisting of 6 text files:
```bash
train.source
train.target
val.source
val.target
test.source
test.target
```
A sample finetuning command (run ` ./examples/research_projects/rag/finetune_rag.py --help` to list all available options):
```bash
python examples/research_projects/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8
```
We publish two `base` models which can serve as a starting point for finetuning on downstream tasks (use them as `model_name_or_path`):
- [`facebook/rag-sequence-base`](https://huggingface.co/facebook/rag-sequence-base) - a base for finetuning `RagSequenceForGeneration` models,
- [`facebook/rag-token-base`](https://huggingface.co/facebook/rag-token-base) - a base for finetuning `RagTokenForGeneration` models.
The `base` models initialize the question encoder with [`facebook/dpr-question_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base) and the generator with [`facebook/bart-large`](https://huggingface.co/facebook/bart-large).
If you would like to initialize finetuning with a base model using different question encoder and generator architectures, you can build it with a consolidation script, e.g.:
```
python examples/research_projects/rag/consolidate_rag_checkpoint.py \
--model_type rag_sequence \
--generator_name_or_path facebook/bart-large-cnn \
--question_encoder_name_or_path facebook/dpr-question_encoder-single-nq-base \
--dest path/to/checkpoint
```
You will then be able to pass `path/to/checkpoint` as `model_name_or_path` to the `finetune_rag.py` script.
## Document Retrieval
When running distributed fine-tuning, each training worker needs to retrieve contextual documents
for its input by querying a index loaded into memory. RAG provides two implementations for document retrieval,
one with [`torch.distributed`](https://pytorch.org/docs/stable/distributed.html) communication package and the other
with [`Ray`](https://docs.ray.io/en/master/).
This option can be configured with the `--distributed_retriever` flag which can either be set to `pytorch` or `ray`.
By default this flag is set to `pytorch`.
For the Pytorch implementation, only training worker 0 loads the index into CPU memory, and a gather/scatter pattern is used
to collect the inputs from the other training workers and send back the corresponding document embeddings.
For the Ray implementation, the index is loaded in *separate* process(es). The training workers randomly select which
retriever worker to query. To use Ray for distributed retrieval, you have to set the `--distributed_retriever` arg to `ray`.
To configure the number of retrieval workers (the number of processes that load the index), you can set the `num_retrieval_workers` flag.
Also make sure to start the Ray cluster before running fine-tuning.
```bash
# Start a single-node Ray cluster.
ray start --head
python examples/research_projects/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8
--distributed_retriever ray \
--num_retrieval_workers 4
# Stop the ray cluster once fine-tuning has finished.
ray stop
```
Using Ray can lead to retrieval speedups on multi-GPU settings since multiple processes load the index rather than
just the rank 0 training worker. Using Ray also allows you to load the index on GPU since the index is loaded on a separate
processes than the model, while with pytorch distributed retrieval, both are loaded in the same process potentially leading to GPU OOM.
# Evaluation
Our evaluation script enables two modes of evaluation (controlled by the `eval_mode` argument): `e2e` - end2end evaluation, returns EM (exact match) and F1 scores calculated for the downstream task and `retrieval` - which returns precision@k of the documents retrieved for provided inputs.
The evaluation script expects paths to two files:
- `evaluation_set` - a path to a file specifying the evaluation dataset, a single input per line.
- `gold_data_path` - a path to a file contaning ground truth answers for datapoints from the `evaluation_set`, a single output per line. Check below for expected formats of the gold data files.
## Retrieval evaluation
For `retrieval` evaluation, we expect a gold data file where each line will consist of a tab-separated list of document titles constituting positive contexts for respective datapoints from the `evaluation_set`. E.g. given a question `who sings does he love me with reba` in the `evaluation_set`, a respective ground truth line could look as follows:
```
Does He Love You Does He Love You Red Sandy Spika dress of Reba McEntire Greatest Hits Volume Two (Reba McEntire album) Shoot for the Moon (album)
```
We demonstrate how to evaluate retrieval against DPR evaluation data. You can download respective files from links listed [here](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py#L39-L45).
1. Download and unzip the gold data file. We use the `biencoder-nq-dev` from https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz.
```bash
wget https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz && gzip -d biencoder-nq-dev.json.gz
```
2. Parse the unziped file using the `parse_dpr_relevance_data.py`
```bash
mkdir output # or wherever you want to save this
python examples/research_projects/rag/parse_dpr_relevance_data.py \
--src_path biencoder-nq-dev.json \
--evaluation_set output/biencoder-nq-dev.questions \
--gold_data_path output/biencoder-nq-dev.pages
```
3. Run evaluation:
```bash
python examples/research_projects/rag/eval_rag.py \
--model_name_or_path facebook/rag-sequence-nq \
--model_type rag_sequence \
--evaluation_set output/biencoder-nq-dev.questions \
--gold_data_path output/biencoder-nq-dev.pages \
--predictions_path output/retrieval_preds.tsv \
--eval_mode retrieval \
--k 1
```
```bash
# EXPLANATION
python examples/research_projects/rag/eval_rag.py \
--model_name_or_path facebook/rag-sequence-nq \ # model name or path of the model we're evaluating
--model_type rag_sequence \ # RAG model type (rag_token or rag_sequence)
--evaluation_set output/biencoder-nq-dev.questions \ # an input dataset for evaluation
--gold_data_path poutput/biencoder-nq-dev.pages \ # a dataset containing ground truth answers for samples from the evaluation_set
--predictions_path output/retrieval_preds.tsv \ # name of file where predictions will be stored
--eval_mode retrieval \ # indicates whether we're performing retrieval evaluation or e2e evaluation
--k 1 # parameter k for the precision@k metric
```
## End-to-end evaluation
We support two formats of the gold data file (controlled by the `gold_data_mode` parameter):
- `qa` - where a single line has the following format: `input [tab] output_list`, e.g.:
```
who is the owner of reading football club ['Xiu Li Dai', 'Dai Yongge', 'Dai Xiuli', 'Yongge Dai']
```
- `ans` - where a single line contains a single expected answer, e.g.:
```
Xiu Li Dai
```
Predictions of the model for the samples from the `evaluation_set` will be saved under the path specified by the `predictions_path` parameter.
If this path already exists, the script will use saved predictions to calculate metrics.
Add `--recalculate` parameter to force the script to perform inference from scratch.
An example e2e evaluation run could look as follows:
```bash
python examples/research_projects/rag/eval_rag.py \
--model_name_or_path facebook/rag-sequence-nq \
--model_type rag_sequence \
--evaluation_set path/to/test.source \
--gold_data_path path/to/gold_data \
--predictions_path path/to/e2e_preds.txt \
--eval_mode e2e \
--gold_data_mode qa \
--n_docs 5 \ # You can experiment with retrieving different number of documents at evaluation time
--print_predictions \
--recalculate \ # adding this parameter will force recalculating predictions even if predictions_path already exists
```
# Use your own knowledge source
By default, RAG uses the English Wikipedia as a knowledge source, known as the 'wiki_dpr' dataset.
With `use_custom_knowledge_dataset.py` you can build your own knowledge source, *e.g.* for RAG.
For instance, if documents are serialized as tab-separated csv files with the columns "title" and "text", one can use `use_own_knowledge_dataset.py` as follows:
```bash
python examples/research_projects/rag/use_own_knowledge_dataset.py \
--csv_path path/to/my_csv \
--output_dir path/to/my_knowledge_dataset \
```
The created outputs in `path/to/my_knowledge_dataset` can then be used to finetune RAG as follows:
```bash
python examples/research_projects/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8
--index_name custom
--passages_path path/to/data/my_knowledge_dataset
--index_path path/to/my_knowledge_dataset_hnsw_index.faiss
```
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/distributed_ray_retriever.py
|
import logging
import random
import ray
from transformers import RagConfig, RagRetriever, RagTokenizer
from transformers.models.rag.retrieval_rag import CustomHFIndex
logger = logging.getLogger(__name__)
class RayRetriever:
def __init__(self):
self.initialized = False
def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
if not self.initialized:
self.retriever = RagRetriever(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
index=index,
init_retrieval=False,
)
self.initialized = True
def init_retrieval(self):
self.retriever.index.init_index()
def retrieve(self, question_hidden_states, n_docs):
doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
return doc_ids, retrieved_doc_embeds
class RagRayDistributedRetriever(RagRetriever):
"""
A distributed retriever built on top of the ``Ray`` API, a library
for building distributed applications (https://docs.ray.io/en/master/).
package. During training, all training workers initialize their own
instance of a `RagRayDistributedRetriever`, and each instance of
this distributed retriever shares a common set of Retrieval Ray
Actors (https://docs.ray.io/en/master/walkthrough.html#remote
-classes-actors) that load the index on separate processes. Ray
handles the communication between the `RagRayDistributedRetriever`
instances and the remote Ray actors. If training is done in a
non-distributed setup, the index will simply be loaded in the same
process as the training worker and Ray will not be used.
Args:
config (:class:`~transformers.RagConfig`):
The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer that was used to tokenize the question.
It is used to decode the question and then use the generator_tokenizer.
generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer used for the generator part of the RagModel.
retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
These actor classes run on remote processes and are responsible for performing the index lookup.
index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
If specified, use this index instead of the one built using the configuration
"""
def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
raise ValueError(
"When using Ray for distributed fine-tuning, "
"you'll need to provide the paths instead, "
"as the dataset and the index are loaded "
"separately. More info in examples/rag/use_own_knowledge_dataset.py "
)
super().__init__(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
index=index,
init_retrieval=False,
)
self.retrieval_workers = retrieval_workers
if len(self.retrieval_workers) > 0:
ray.get(
[
worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
for worker in self.retrieval_workers
]
)
def init_retrieval(self):
"""
Retriever initialization function, needs to be called from the
training process. This function triggers retrieval initialization
for all retrieval actors if using distributed setting, or loads
index into current process if training is not distributed.
"""
logger.info("initializing retrieval")
if len(self.retrieval_workers) > 0:
ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
else:
# Non-distributed training. Load index into this same process.
self.index.init_index()
def retrieve(self, question_hidden_states, n_docs):
"""
Retrieves documents for specified ``question_hidden_states``. If
running training with multiple workers, a random retrieval actor is
selected to perform the index lookup and return the result.
Args:
question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
A batch of query vectors to retrieve with.
n_docs (:obj:`int`):
The number of docs retrieved per query.
Output:
retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
The retrieval embeddings of the retrieved docs per query.
doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
The ids of the documents in the index
doc_dicts (:obj:`List[dict]`):
The retrieved_doc_embeds examples per query.
"""
if len(self.retrieval_workers) > 0:
# Select a random retrieval actor.
random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
doc_ids, retrieved_doc_embeds = ray.get(random_worker.retrieve.remote(question_hidden_states, n_docs))
else:
doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
@classmethod
def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
@classmethod
def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
question_encoder_tokenizer = rag_tokenizer.question_encoder
generator_tokenizer = rag_tokenizer.generator
if indexed_dataset is not None:
config.index_name = "custom"
index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
else:
index = cls._build_index(config)
return cls(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
retrieval_workers=actor_handles,
index=index,
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/callbacks_rag.py
|
import logging
from pathlib import Path
import numpy as np
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.utilities import rank_zero_only
from utils_rag import save_json
def count_trainable_parameters(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
return params
logger = logging.getLogger(__name__)
def get_checkpoint_callback(output_dir, metric):
"""Saves the best model by validation EM score."""
if metric == "rouge2":
exp = "{val_avg_rouge2:.4f}-{step_count}"
elif metric == "bleu":
exp = "{val_avg_bleu:.4f}-{step_count}"
elif metric == "em":
exp = "{val_avg_em:.4f}-{step_count}"
else:
raise NotImplementedError(
f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
" function."
)
checkpoint_callback = ModelCheckpoint(
dirpath=output_dir,
filename=exp,
monitor=f"val_{metric}",
mode="max",
save_top_k=3,
every_n_epochs=1, # maybe save a checkpoint every time val is run, not just end of epoch.
)
return checkpoint_callback
def get_early_stopping_callback(metric, patience):
return EarlyStopping(
monitor=f"val_{metric}", # does this need avg?
mode="min" if "loss" in metric else "max",
patience=patience,
verbose=True,
)
class Seq2SeqLoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
pl_module.logger.log_metrics(lrs)
@rank_zero_only
def _write_logs(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
) -> None:
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
metrics = trainer.callback_metrics
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
# Log results
od = Path(pl_module.hparams.output_dir)
if type_path == "test":
results_file = od / "test_results.txt"
generations_file = od / "test_generations.txt"
else:
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
# If people want this it will be easy enough to add back.
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
results_file.parent.mkdir(exist_ok=True)
generations_file.parent.mkdir(exist_ok=True)
with open(results_file, "a+") as writer:
for key in sorted(metrics):
if key in ["log", "progress_bar", "preds"]:
continue
val = metrics[key]
if isinstance(val, torch.Tensor):
val = val.item()
msg = f"{key}: {val:.6f}\n"
writer.write(msg)
if not save_generations:
return
if "preds" in metrics:
content = "\n".join(metrics["preds"])
generations_file.open("w+").write(content)
@rank_zero_only
def on_train_start(self, trainer, pl_module):
try:
npars = pl_module.model.model.num_parameters()
except AttributeError:
npars = pl_module.model.num_parameters()
n_trainable_pars = count_trainable_parameters(pl_module)
# mp stands for million parameters
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
@rank_zero_only
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
save_json(pl_module.metrics, pl_module.metrics_save_path)
return self._write_logs(trainer, pl_module, "test")
@rank_zero_only
def on_validation_end(self, trainer: pl.Trainer, pl_module):
save_json(pl_module.metrics, pl_module.metrics_save_path)
# Uncommenting this will save val generations
# return self._write_logs(trainer, pl_module, "valid")
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/consolidate_rag_checkpoint.py
|
"""
A script creating a RAG checkpoint from a generator and a question encoder checkpoints.
"""
import argparse
from pathlib import Path
from transformers import AutoConfig, AutoTokenizer, RagConfig, RagSequenceForGeneration, RagTokenForGeneration
def consolidate(
model_type,
generator_name_or_path: str,
question_encoder_name_or_path: str,
dest_dir: Path,
config_name_or_path: str = None,
generator_tokenizer_name_or_path: str = None,
question_encoder_tokenizer_name_or_path: str = None,
):
if config_name_or_path is None:
config_name_or_path = "facebook/rag-token-base" if model_type == "rag_token" else "facebook/rag-sequence-base"
if generator_tokenizer_name_or_path is None:
generator_tokenizer_name_or_path = generator_name_or_path
if question_encoder_tokenizer_name_or_path is None:
question_encoder_tokenizer_name_or_path = question_encoder_name_or_path
model_class = RagTokenForGeneration if model_type == "rag_token" else RagSequenceForGeneration
# Save model.
rag_config = RagConfig.from_pretrained(config_name_or_path)
gen_config = AutoConfig.from_pretrained(generator_name_or_path)
question_encoder_config = AutoConfig.from_pretrained(question_encoder_name_or_path)
rag_config.generator = gen_config
rag_config.question_encoder = question_encoder_config
rag_model = model_class.from_pretrained_question_encoder_generator(
question_encoder_name_or_path, generator_name_or_path, config=rag_config
)
rag_model.save_pretrained(dest_dir)
# Sanity check.
model_class.from_pretrained(dest_dir)
# Save tokenizers.
gen_tokenizer = AutoTokenizer.from_pretrained(generator_tokenizer_name_or_path)
gen_tokenizer.save_pretrained(dest_dir / "generator_tokenizer/")
question_encoder_tokenizer = AutoTokenizer.from_pretrained(question_encoder_tokenizer_name_or_path)
question_encoder_tokenizer.save_pretrained(dest_dir / "question_encoder_tokenizer/")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token"],
required=True,
type=str,
help="RAG model type: rag_sequence, rag_token",
)
parser.add_argument("--dest", type=str, required=True, help="Path to the output checkpoint directory.")
parser.add_argument("--generator_name_or_path", type=str, required=True, help="Generator model identifier")
parser.add_argument(
"--question_encoder_name_or_path", type=str, required=True, help="Question encoder model identifier"
)
parser.add_argument(
"--generator_tokenizer_name_or_path",
type=str,
help="Generator tokenizer identifier, if not specified, resolves to ``generator_name_or_path``",
)
parser.add_argument(
"--question_encoder_tokenizer_name_or_path",
type=str,
help="Question encoder tokenizer identifier, if not specified, resolves to ``question_encoder_name_or_path``",
)
parser.add_argument(
"--config_name_or_path",
type=str,
help=(
"Identifier of the model config to use, if not provided, resolves to a base config for a given"
" ``model_type``"
),
)
args = parser.parse_args()
dest_dir = Path(args.dest)
dest_dir.mkdir(exist_ok=True)
consolidate(
args.model_type,
args.generator_name_or_path,
args.question_encoder_name_or_path,
dest_dir,
args.config_name_or_path,
args.generator_tokenizer_name_or_path,
args.question_encoder_tokenizer_name_or_path,
)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/use_own_knowledge_dataset.py
|
import logging
import os
from dataclasses import dataclass, field
from functools import partial
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import List, Optional
import faiss
import torch
from datasets import Features, Sequence, Value, load_dataset
from transformers import (
DPRContextEncoder,
DPRContextEncoderTokenizerFast,
HfArgumentParser,
RagRetriever,
RagSequenceForGeneration,
RagTokenizer,
)
logger = logging.getLogger(__name__)
torch.set_grad_enabled(False)
device = "cuda" if torch.cuda.is_available() else "cpu"
def split_text(text: str, n=100, character=" ") -> List[str]:
"""Split the text every ``n``-th occurrence of ``character``"""
text = text.split(character)
return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
def split_documents(documents: dict) -> dict:
"""Split documents into passages"""
titles, texts = [], []
for title, text in zip(documents["title"], documents["text"]):
if text is not None:
for passage in split_text(text):
titles.append(title if title is not None else "")
texts.append(passage)
return {"title": titles, "text": texts}
def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
"""Compute the DPR embeddings of document passages"""
input_ids = ctx_tokenizer(
documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
)["input_ids"]
embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
return {"embeddings": embeddings.detach().cpu().numpy()}
def main(
rag_example_args: "RagExampleArguments",
processing_args: "ProcessingArguments",
index_hnsw_args: "IndexHnswArguments",
):
######################################
logger.info("Step 1 - Create the dataset")
######################################
# The dataset needed for RAG must have three columns:
# - title (string): title of the document
# - text (string): text of a passage of the document
# - embeddings (array of dimension d): DPR representation of the passage
# Let's say you have documents in tab-separated csv files with columns "title" and "text"
assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
# You can load a Dataset object this way
dataset = load_dataset(
"csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
)
# More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
# Then split the documents into passages of 100 words
dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
# And compute the embeddings
ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
new_features = Features(
{"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
) # optional, save as float32 instead of float64 to save space
dataset = dataset.map(
partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
batched=True,
batch_size=processing_args.batch_size,
features=new_features,
)
# And finally save your dataset
passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
dataset.save_to_disk(passages_path)
# from datasets import load_from_disk
# dataset = load_from_disk(passages_path) # to reload the dataset
######################################
logger.info("Step 2 - Index the dataset")
######################################
# Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
dataset.add_faiss_index("embeddings", custom_index=index)
# And save the index
index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
dataset.get_index("embeddings").save(index_path)
# dataset.load_faiss_index("embeddings", index_path) # to reload the index
######################################
logger.info("Step 3 - Load RAG")
######################################
# Easy way to load the model
retriever = RagRetriever.from_pretrained(
rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
)
model = RagSequenceForGeneration.from_pretrained(rag_example_args.rag_model_name, retriever=retriever)
tokenizer = RagTokenizer.from_pretrained(rag_example_args.rag_model_name)
# For distributed fine-tuning you'll need to provide the paths instead, as the dataset and the index are loaded separately.
# retriever = RagRetriever.from_pretrained(rag_model_name, index_name="custom", passages_path=passages_path, index_path=index_path)
######################################
logger.info("Step 4 - Have fun")
######################################
question = rag_example_args.question or "What does Moses' rod turn into ?"
input_ids = tokenizer.question_encoder(question, return_tensors="pt")["input_ids"]
generated = model.generate(input_ids)
generated_string = tokenizer.batch_decode(generated, skip_special_tokens=True)[0]
logger.info("Q: " + question)
logger.info("A: " + generated_string)
@dataclass
class RagExampleArguments:
csv_path: str = field(
default=str(Path(__file__).parent / "test_data" / "my_knowledge_dataset.csv"),
metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
)
question: Optional[str] = field(
default=None,
metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
)
rag_model_name: str = field(
default="facebook/rag-sequence-nq",
metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
)
dpr_ctx_encoder_model_name: str = field(
default="facebook/dpr-ctx_encoder-multiset-base",
metadata={
"help": (
"The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
" 'facebook/dpr-ctx_encoder-multiset-base'"
)
},
)
output_dir: Optional[str] = field(
default=None,
metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
)
@dataclass
class ProcessingArguments:
num_proc: Optional[int] = field(
default=None,
metadata={
"help": "The number of processes to use to split the documents into passages. Default is single process."
},
)
batch_size: int = field(
default=16,
metadata={
"help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
},
)
@dataclass
class IndexHnswArguments:
d: int = field(
default=768,
metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
)
m: int = field(
default=128,
metadata={
"help": (
"The number of bi-directional links created for every new element during the HNSW index construction."
)
},
)
if __name__ == "__main__":
logging.basicConfig(level=logging.WARNING)
logger.setLevel(logging.INFO)
parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
with TemporaryDirectory() as tmp_dir:
rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
main(rag_example_args, processing_args, index_hnsw_args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/test_distributed_retriever.py
|
import json
import os
import shutil
import sys
import tempfile
import unittest
from unittest import TestCase
from unittest.mock import patch
import faiss
import numpy as np
from datasets import Dataset
from transformers import BartConfig, BartTokenizer, DPRConfig, DPRQuestionEncoderTokenizer, RagConfig
from transformers.file_utils import is_datasets_available, is_faiss_available, is_psutil_available, is_torch_available
from transformers.integrations import is_ray_available
from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES as DPR_VOCAB_FILES_NAMES
from transformers.models.rag.retrieval_rag import CustomHFIndex, RagRetriever
from transformers.models.roberta.tokenization_roberta import VOCAB_FILES_NAMES as BART_VOCAB_FILES_NAMES
from transformers.testing_utils import require_ray
sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # noqa: E402 # isort:skip
if is_torch_available():
from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
else:
RagPyTorchDistributedRetriever = None
if is_ray_available():
import ray # noqa: E402 # isort:skip
from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever # noqa: E402 # isort:skip
else:
ray = None
RagRayDistributedRetriever = None
RayRetriever = None
def require_distributed_retrieval(test_case):
"""
Decorator marking a test that requires a set of dependencies necessary for pefrorm retrieval with
:class:`~transformers.RagRetriever`.
These tests are skipped when respective libraries are not installed.
"""
if not (is_datasets_available() and is_faiss_available() and is_psutil_available()):
test_case = unittest.skip("test requires Datasets, Faiss, psutil")(test_case)
return test_case
@require_distributed_retrieval
class RagRetrieverTest(TestCase):
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
self.retrieval_vector_size = 8
# DPR tok
vocab_tokens = [
"[UNK]",
"[CLS]",
"[SEP]",
"[PAD]",
"[MASK]",
"want",
"##want",
"##ed",
"wa",
"un",
"runn",
"##ing",
",",
"low",
"lowest",
]
dpr_tokenizer_path = os.path.join(self.tmpdirname, "dpr_tokenizer")
os.makedirs(dpr_tokenizer_path, exist_ok=True)
self.vocab_file = os.path.join(dpr_tokenizer_path, DPR_VOCAB_FILES_NAMES["vocab_file"])
with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
# BART tok
vocab = [
"l",
"o",
"w",
"e",
"r",
"s",
"t",
"i",
"d",
"n",
"\u0120",
"\u0120l",
"\u0120n",
"\u0120lo",
"\u0120low",
"er",
"\u0120lowest",
"\u0120newer",
"\u0120wider",
"<unk>",
]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
self.special_tokens_map = {"unk_token": "<unk>"}
bart_tokenizer_path = os.path.join(self.tmpdirname, "bart_tokenizer")
os.makedirs(bart_tokenizer_path, exist_ok=True)
self.vocab_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["vocab_file"])
self.merges_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["merges_file"])
with open(self.vocab_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(vocab_tokens) + "\n")
with open(self.merges_file, "w", encoding="utf-8") as fp:
fp.write("\n".join(merges))
def get_dpr_tokenizer(self) -> DPRQuestionEncoderTokenizer:
return DPRQuestionEncoderTokenizer.from_pretrained(os.path.join(self.tmpdirname, "dpr_tokenizer"))
def get_bart_tokenizer(self) -> BartTokenizer:
return BartTokenizer.from_pretrained(os.path.join(self.tmpdirname, "bart_tokenizer"))
def tearDown(self):
shutil.rmtree(self.tmpdirname)
def get_dummy_dataset(self):
dataset = Dataset.from_dict(
{
"id": ["0", "1"],
"text": ["foo", "bar"],
"title": ["Foo", "Bar"],
"embeddings": [np.ones(self.retrieval_vector_size), 2 * np.ones(self.retrieval_vector_size)],
}
)
dataset.add_faiss_index("embeddings", string_factory="Flat", metric_type=faiss.METRIC_INNER_PRODUCT)
return dataset
def get_dummy_pytorch_distributed_retriever(
self, init_retrieval: bool, port=12345
) -> RagPyTorchDistributedRetriever:
dataset = self.get_dummy_dataset()
config = RagConfig(
retrieval_vector_size=self.retrieval_vector_size,
question_encoder=DPRConfig().to_dict(),
generator=BartConfig().to_dict(),
)
with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
mock_load_dataset.return_value = dataset
retriever = RagPyTorchDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
)
if init_retrieval:
retriever.init_retrieval(port)
return retriever
def get_dummy_ray_distributed_retriever(self, init_retrieval: bool) -> RagRayDistributedRetriever:
# Have to run in local mode because sys.path modifications at top of
# file are not propogated to remote workers.
# https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
ray.init(local_mode=True)
config = RagConfig(
retrieval_vector_size=self.retrieval_vector_size,
question_encoder=DPRConfig().to_dict(),
generator=BartConfig().to_dict(),
)
remote_cls = ray.remote(RayRetriever)
workers = [remote_cls.remote() for _ in range(1)]
with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
mock_load_dataset.return_value = self.get_dummy_dataset()
retriever = RagRayDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
retrieval_workers=workers,
)
if init_retrieval:
retriever.init_retrieval()
return retriever
def get_dummy_custom_hf_index_pytorch_retriever(self, init_retrieval: bool, from_disk: bool, port=12345):
dataset = self.get_dummy_dataset()
config = RagConfig(
retrieval_vector_size=self.retrieval_vector_size,
question_encoder=DPRConfig().to_dict(),
generator=BartConfig().to_dict(),
index_name="custom",
)
if from_disk:
config.passages_path = os.path.join(self.tmpdirname, "dataset")
config.index_path = os.path.join(self.tmpdirname, "index.faiss")
dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
dataset.drop_index("embeddings")
dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
del dataset
retriever = RagPyTorchDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
)
else:
retriever = RagPyTorchDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
index=CustomHFIndex(config.retrieval_vector_size, dataset),
)
if init_retrieval:
retriever.init_retrieval(port)
return retriever
def get_dummy_custom_hf_index_ray_retriever(self, init_retrieval: bool, from_disk: bool):
# Have to run in local mode because sys.path modifications at top of
# file are not propogated to remote workers.
# https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
ray.init(local_mode=True)
dataset = self.get_dummy_dataset()
config = RagConfig(
retrieval_vector_size=self.retrieval_vector_size,
question_encoder=DPRConfig().to_dict(),
generator=BartConfig().to_dict(),
index_name="custom",
)
remote_cls = ray.remote(RayRetriever)
workers = [remote_cls.remote() for _ in range(1)]
if from_disk:
config.passages_path = os.path.join(self.tmpdirname, "dataset")
config.index_path = os.path.join(self.tmpdirname, "index.faiss")
dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
dataset.drop_index("embeddings")
dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
del dataset
retriever = RagRayDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
retrieval_workers=workers,
index=CustomHFIndex.load_from_disk(
vector_size=config.retrieval_vector_size,
dataset_path=config.passages_path,
index_path=config.index_path,
),
)
else:
retriever = RagRayDistributedRetriever(
config,
question_encoder_tokenizer=self.get_dpr_tokenizer(),
generator_tokenizer=self.get_bart_tokenizer(),
retrieval_workers=workers,
index=CustomHFIndex(config.retrieval_vector_size, dataset),
)
if init_retrieval:
retriever.init_retrieval()
return retriever
def distributed_retriever_check(self, retriever: RagRetriever, hidden_states: np.array, n_docs: int) -> None:
retrieved_doc_embeds, doc_ids, doc_dicts = retriever.retrieve(hidden_states, n_docs=n_docs)
self.assertEqual(retrieved_doc_embeds.shape, (2, n_docs, self.retrieval_vector_size))
self.assertEqual(len(doc_dicts), 2)
self.assertEqual(sorted(doc_dicts[0]), ["embeddings", "id", "text", "title"])
self.assertEqual(len(doc_dicts[0]["id"]), n_docs)
self.assertEqual(doc_dicts[0]["id"][0], "1") # max inner product is reached with second doc
self.assertEqual(doc_dicts[1]["id"][0], "0") # max inner product is reached with first doc
self.assertListEqual(doc_ids.tolist(), [[1], [0]])
def test_pytorch_distributed_retriever_retrieve(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
self.distributed_retriever_check(
self.get_dummy_pytorch_distributed_retriever(init_retrieval=True), hidden_states, n_docs
)
def test_custom_hf_index_pytorch_retriever_retrieve(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
self.distributed_retriever_check(
self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=False),
hidden_states,
n_docs,
)
def test_custom_pytorch_distributed_retriever_retrieve_from_disk(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
self.distributed_retriever_check(
self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=True),
hidden_states,
n_docs,
)
@require_ray
def test_ray_distributed_retriever_retrieve(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
self.distributed_retriever_check(
self.get_dummy_ray_distributed_retriever(init_retrieval=True), hidden_states, n_docs
)
ray.shutdown()
@require_ray
def test_custom_hf_index_ray_retriever_retrieve(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
with self.assertRaises(ValueError):
self.distributed_retriever_check(
self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=False),
hidden_states,
n_docs,
)
ray.shutdown()
@require_ray
def test_custom_ray_distributed_retriever_retrieve_from_disk(self):
n_docs = 1
hidden_states = np.array(
[np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
)
self.distributed_retriever_check(
self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=True), hidden_states, n_docs
)
ray.shutdown()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/_test_finetune_rag.py
|
import json
import logging
import os
import sys
from pathlib import Path
import finetune_rag
from transformers.file_utils import is_apex_available
from transformers.testing_utils import (
TestCasePlus,
execute_subprocess_async,
require_ray,
require_torch_gpu,
require_torch_multi_gpu,
)
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class RagFinetuneExampleTests(TestCasePlus):
def _create_dummy_data(self, data_dir):
os.makedirs(data_dir, exist_ok=True)
contents = {"source": "What is love ?", "target": "life"}
n_lines = {"train": 12, "val": 2, "test": 2}
for split in ["train", "test", "val"]:
for field in ["source", "target"]:
content = "\n".join([contents[field]] * n_lines[split])
with open(os.path.join(data_dir, f"{split}.{field}"), "w") as f:
f.write(content)
def _run_finetune(self, gpus: int, distributed_retriever: str = "pytorch"):
tmp_dir = self.get_auto_remove_tmp_dir()
output_dir = os.path.join(tmp_dir, "output")
data_dir = os.path.join(tmp_dir, "data")
self._create_dummy_data(data_dir=data_dir)
testargs = f"""
--data_dir {data_dir} \
--output_dir {output_dir} \
--model_name_or_path facebook/rag-sequence-base \
--model_type rag_sequence \
--do_train \
--do_predict \
--n_val -1 \
--val_check_interval 1.0 \
--train_batch_size 2 \
--eval_batch_size 1 \
--max_source_length 25 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-04 \
--num_train_epochs 1 \
--warmup_steps 4 \
--gradient_accumulation_steps 1 \
--distributed-port 8787 \
--use_dummy_dataset 1 \
--distributed_retriever {distributed_retriever} \
""".split()
if gpus > 0:
testargs.append(f"--gpus={gpus}")
if is_apex_available():
testargs.append("--fp16")
else:
testargs.append("--gpus=0")
testargs.append("--distributed_backend=ddp_cpu")
testargs.append("--num_processes=2")
cmd = [sys.executable, str(Path(finetune_rag.__file__).resolve())] + testargs
execute_subprocess_async(cmd, env=self.get_env())
metrics_save_path = os.path.join(output_dir, "metrics.json")
with open(metrics_save_path) as f:
result = json.load(f)
return result
@require_torch_gpu
def test_finetune_gpu(self):
result = self._run_finetune(gpus=1)
self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
@require_torch_multi_gpu
def test_finetune_multigpu(self):
result = self._run_finetune(gpus=2)
self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
@require_torch_gpu
@require_ray
def test_finetune_gpu_ray_retrieval(self):
result = self._run_finetune(gpus=1, distributed_retriever="ray")
self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
@require_torch_multi_gpu
@require_ray
def test_finetune_multigpu_ray_retrieval(self):
result = self._run_finetune(gpus=1, distributed_retriever="ray")
self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/utils_rag.py
|
import itertools
import json
import linecache
import os
import pickle
import re
import socket
import string
from collections import Counter
from logging import getLogger
from pathlib import Path
from typing import Callable, Dict, Iterable, List
import git
import torch
from torch.utils.data import Dataset
from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
tokenizer.padding_side = padding_side
return tokenizer(
[line],
max_length=max_length,
padding="max_length" if pad_to_max_length else None,
truncation=True,
return_tensors=return_tensors,
add_special_tokens=True,
**extra_kw,
)
def trim_batch(
input_ids,
pad_token_id,
attention_mask=None,
):
"""Remove columns that are populated exclusively by pad_token_id"""
keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
if attention_mask is None:
return input_ids[:, keep_column_mask]
else:
return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
class Seq2SeqDataset(Dataset):
def __init__(
self,
tokenizer,
data_dir,
max_source_length,
max_target_length,
type_path="train",
n_obs=None,
src_lang=None,
tgt_lang=None,
prefix="",
):
super().__init__()
self.src_file = Path(data_dir).joinpath(type_path + ".source")
self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
self.src_lens = self.get_char_lens(self.src_file)
self.max_source_length = max_source_length
self.max_target_length = max_target_length
assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
self.tokenizer = tokenizer
self.prefix = prefix
if n_obs is not None:
self.src_lens = self.src_lens[:n_obs]
self.src_lang = src_lang
self.tgt_lang = tgt_lang
def __len__(self):
return len(self.src_lens)
def __getitem__(self, index) -> Dict[str, torch.Tensor]:
index = index + 1 # linecache starts at 1
source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
assert source_line, f"empty source line for index {index}"
assert tgt_line, f"empty tgt line for index {index}"
# Need to add eos token manually for T5
if isinstance(self.tokenizer, T5Tokenizer):
source_line += self.tokenizer.eos_token
tgt_line += self.tokenizer.eos_token
# Pad source and target to the right
source_tokenizer = (
self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
)
target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
source_ids = source_inputs["input_ids"].squeeze()
target_ids = target_inputs["input_ids"].squeeze()
src_mask = source_inputs["attention_mask"].squeeze()
return {
"input_ids": source_ids,
"attention_mask": src_mask,
"decoder_input_ids": target_ids,
}
@staticmethod
def get_char_lens(data_file):
return [len(x) for x in Path(data_file).open().readlines()]
def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
input_ids = torch.stack([x["input_ids"] for x in batch])
masks = torch.stack([x["attention_mask"] for x in batch])
target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
y = trim_batch(target_ids, tgt_pad_token_id)
source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
batch = {
"input_ids": source_ids,
"attention_mask": source_mask,
"decoder_input_ids": y,
}
return batch
logger = getLogger(__name__)
def flatten_list(summary_ids: List[List]):
return list(itertools.chain.from_iterable(summary_ids))
def save_git_info(folder_path: str) -> None:
"""Save git information to output_dir/git_log.json"""
repo_infos = get_git_info()
save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
def save_json(content, path, indent=4, **json_dump_kwargs):
with open(path, "w") as f:
json.dump(content, f, indent=indent, **json_dump_kwargs)
def load_json(path):
with open(path) as f:
return json.load(f)
def get_git_info():
repo = git.Repo(search_parent_directories=True)
repo_infos = {
"repo_id": str(repo),
"repo_sha": str(repo.head.object.hexsha),
"repo_branch": str(repo.active_branch),
"hostname": str(socket.gethostname()),
}
return repo_infos
def lmap(f: Callable, x: Iterable) -> List:
"""list(map(f, x))"""
return list(map(f, x))
def pickle_save(obj, path):
"""pickle.dump(obj, path)"""
with open(path, "wb") as f:
return pickle.dump(obj, f)
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
def remove_articles(text):
return re.sub(r"\b(a|an|the)\b", " ", text)
def white_space_fix(text):
return " ".join(text.split())
def remove_punc(text):
exclude = set(string.punctuation)
return "".join(ch for ch in text if ch not in exclude)
def lower(text):
return text.lower()
return white_space_fix(remove_articles(remove_punc(lower(s))))
def f1_score(prediction, ground_truth):
prediction_tokens = normalize_answer(prediction).split()
ground_truth_tokens = normalize_answer(ground_truth).split()
common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
num_same = sum(common.values())
if num_same == 0:
return 0
precision = 1.0 * num_same / len(prediction_tokens)
recall = 1.0 * num_same / len(ground_truth_tokens)
f1 = (2 * precision * recall) / (precision + recall)
return f1
def exact_match_score(prediction, ground_truth):
return normalize_answer(prediction) == normalize_answer(ground_truth)
def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
assert len(output_lns) == len(reference_lns)
em = 0
for hypo, pred in zip(output_lns, reference_lns):
em += exact_match_score(hypo, pred)
if len(output_lns) > 0:
em /= len(output_lns)
return {"em": em}
def is_rag_model(model_prefix):
return model_prefix.startswith("rag")
def set_extra_model_params(extra_params, hparams, config):
equivalent_param = {p: p for p in extra_params}
# T5 models don't have `dropout` param, they have `dropout_rate` instead
equivalent_param["dropout"] = "dropout_rate"
for p in extra_params:
if getattr(hparams, p, None):
if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
logger.info("config doesn't have a `{}` attribute".format(p))
delattr(hparams, p)
continue
set_p = p if hasattr(config, p) else equivalent_param[p]
setattr(config, set_p, getattr(hparams, p))
delattr(hparams, p)
return hparams, config
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/finetune_rag.py
|
"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
import argparse
import logging
import os
import sys
import time
from collections import defaultdict
from pathlib import Path
from typing import Any, Dict, List, Tuple
import numpy as np
import pytorch_lightning as pl
import torch
import torch.distributed as dist
import torch.distributed as torch_distrib
from pytorch_lightning.plugins.training_type import DDPPlugin
from torch.utils.data import DataLoader
from transformers import (
AutoConfig,
AutoTokenizer,
BartForConditionalGeneration,
BatchEncoding,
RagConfig,
RagSequenceForGeneration,
RagTokenForGeneration,
RagTokenizer,
T5ForConditionalGeneration,
)
from transformers import logging as transformers_logging
from transformers.integrations import is_ray_available
if is_ray_available():
import ray
from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
from callbacks_rag import ( # noqa: E402 # isort:skipq
get_checkpoint_callback,
get_early_stopping_callback,
Seq2SeqLoggingCallback,
)
from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
from utils_rag import ( # noqa: E402 # isort:skip
calculate_exact_match,
flatten_list,
get_git_info,
is_rag_model,
lmap,
pickle_save,
save_git_info,
save_json,
set_extra_model_params,
Seq2SeqDataset,
)
# need the parent dir module
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
transformers_logging.set_verbosity_info()
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
class CustomDDP(DDPPlugin):
def init_ddp_connection(self, global_rank=None, world_size=None) -> None:
module = self.model
global_rank = global_rank if global_rank is not None else self.cluster_environment.global_rank()
world_size = world_size if world_size is not None else self.cluster_environment.world_size()
os.environ["MASTER_ADDR"] = self.cluster_environment.master_address()
os.environ["MASTER_PORT"] = str(self.cluster_environment.master_port())
if not torch.distributed.is_initialized():
logger.info(f"initializing ddp: GLOBAL_RANK: {global_rank}, MEMBER: {global_rank + 1}/{world_size}")
torch_distrib.init_process_group(self.torch_distributed_backend, rank=global_rank, world_size=world_size)
if module.is_rag_model:
self.distributed_port = module.hparams.distributed_port
if module.distributed_retriever == "pytorch":
module.model.rag.retriever.init_retrieval(self.distributed_port)
elif module.distributed_retriever == "ray" and global_rank == 0:
# For the Ray retriever, only initialize it once when global
# rank is 0.
module.model.rag.retriever.init_retrieval()
class GenerativeQAModule(BaseTransformer):
mode = "generative_qa"
loss_names = ["loss"]
metric_names = ["em"]
val_metric = "em"
def __init__(self, hparams, **kwargs):
# when loading from a pytorch lightning checkpoint, hparams are passed as dict
if isinstance(hparams, dict):
hparams = AttrDict(hparams)
if hparams.model_type == "rag_sequence":
self.model_class = RagSequenceForGeneration
elif hparams.model_type == "rag_token":
self.model_class = RagTokenForGeneration
elif hparams.model_type == "bart":
self.model_class = BartForConditionalGeneration
else:
self.model_class = T5ForConditionalGeneration
self.is_rag_model = is_rag_model(hparams.model_type)
config_class = RagConfig if self.is_rag_model else AutoConfig
config = config_class.from_pretrained(hparams.model_name_or_path)
# set retriever parameters
config.index_name = hparams.index_name or config.index_name
config.passages_path = hparams.passages_path or config.passages_path
config.index_path = hparams.index_path or config.index_path
config.use_dummy_dataset = hparams.use_dummy_dataset
# set extra_model_params for generator configs and load_model
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
if self.is_rag_model:
if hparams.prefix is not None:
config.generator.prefix = hparams.prefix
config.label_smoothing = hparams.label_smoothing
hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
if hparams.distributed_retriever == "pytorch":
retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
elif hparams.distributed_retriever == "ray":
# The Ray retriever needs the handles to the retriever actors.
retriever = RagRayDistributedRetriever.from_pretrained(
hparams.model_name_or_path, hparams.actor_handles, config=config
)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
prefix = config.question_encoder.prefix
else:
if hparams.prefix is not None:
config.prefix = hparams.prefix
hparams, config = set_extra_model_params(extra_model_params, hparams, config)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
prefix = config.prefix
tokenizer = (
RagTokenizer.from_pretrained(hparams.model_name_or_path)
if self.is_rag_model
else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
)
super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
save_git_info(self.hparams.output_dir)
self.output_dir = Path(self.hparams.output_dir)
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
pickle_save(self.hparams, self.hparams_save_path)
self.step_count = 0
self.metrics = defaultdict(list)
self.dataset_kwargs: dict = {
"data_dir": self.hparams.data_dir,
"max_source_length": self.hparams.max_source_length,
"prefix": prefix or "",
}
n_observations_per_split = {
"train": self.hparams.n_train,
"val": self.hparams.n_val,
"test": self.hparams.n_test,
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.target_lens = {
"train": self.hparams.max_target_length,
"val": self.hparams.val_max_target_length,
"test": self.hparams.test_max_target_length,
}
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
self.hparams.git_sha = get_git_info()["repo_sha"]
self.num_workers = hparams.num_workers
self.distributed_port = self.hparams.distributed_port
# For single GPU training, init_ddp_connection is not called.
# So we need to initialize the retrievers here.
if hparams.gpus <= 1:
if hparams.distributed_retriever == "ray":
self.model.retriever.init_retrieval()
elif hparams.distributed_retriever == "pytorch":
self.model.retriever.init_retrieval(self.distributed_port)
self.distributed_retriever = hparams.distributed_retriever
def forward(self, input_ids, **kwargs):
return self.model(input_ids, **kwargs)
def ids_to_clean_text(self, generated_ids: List[int]):
gen_text = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
return lmap(str.strip, gen_text)
def _step(self, batch: dict) -> Tuple:
source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
rag_kwargs = {}
if isinstance(self.model, T5ForConditionalGeneration):
decoder_input_ids = self.model._shift_right(target_ids)
lm_labels = target_ids
elif isinstance(self.model, BartForConditionalGeneration):
decoder_input_ids = target_ids[:, :-1].contiguous()
lm_labels = target_ids[:, 1:].clone()
else:
assert self.is_rag_model
generator = self.model.rag.generator
if isinstance(generator, T5ForConditionalGeneration):
decoder_start_token_id = generator.config.decoder_start_token_id
decoder_input_ids = (
torch.cat(
[torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
dim=1,
)
if target_ids.shape[0] < self.target_lens["train"]
else generator._shift_right(target_ids)
)
elif isinstance(generator, BartForConditionalGeneration):
decoder_input_ids = target_ids
lm_labels = decoder_input_ids
rag_kwargs["reduce_loss"] = True
assert decoder_input_ids is not None
outputs = self(
source_ids,
attention_mask=source_mask,
decoder_input_ids=decoder_input_ids,
use_cache=False,
labels=lm_labels,
**rag_kwargs,
)
loss = outputs["loss"]
return (loss,)
@property
def pad(self) -> int:
raise NotImplementedError("pad not implemented")
def training_step(self, batch, batch_idx) -> Dict:
loss_tensors = self._step(batch)
logs = {name: loss.detach() for name, loss in zip(self.loss_names, loss_tensors)}
# tokens per batch
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
logs["tpb"] = (
batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
)
return {"loss": loss_tensors[0], "log": logs}
def validation_step(self, batch, batch_idx) -> Dict:
return self._generative_step(batch)
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
self.step_count += 1
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
loss = losses["loss"]
gen_metrics = {
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
}
metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
gen_metrics.update({k: v.item() for k, v in losses.items()})
# fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
if dist.is_initialized():
dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
metrics_tensor = metrics_tensor / dist.get_world_size()
gen_metrics.update({self.val_metric: metrics_tensor.item()})
losses.update(gen_metrics)
metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
metrics["step_count"] = self.step_count
self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
preds = flatten_list([x["preds"] for x in outputs])
return {"log": metrics, "preds": preds, f"{prefix}_loss": loss, f"{prefix}_{self.val_metric}": metrics_tensor}
def save_metrics(self, latest_metrics, type_path) -> None:
self.metrics[type_path].append(latest_metrics)
save_json(self.metrics, self.metrics_save_path)
def calc_generative_metrics(self, preds, target) -> Dict:
return calculate_exact_match(preds, target)
def _generative_step(self, batch: dict) -> dict:
start_time = time.time()
batch = BatchEncoding(batch).to(device=self.model.device)
generated_ids = self.model.generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
do_deduplication=False, # rag specific parameter
use_cache=True,
min_length=1,
max_length=self.target_lens["val"],
)
gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
preds: List[str] = self.ids_to_clean_text(generated_ids)
target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
loss_tensors = self._step(batch)
base_metrics = dict(zip(self.loss_names, loss_tensors))
gen_metrics: Dict = self.calc_generative_metrics(preds, target)
summ_len = np.mean(lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
return base_metrics
def test_step(self, batch, batch_idx):
return self._generative_step(batch)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, prefix="test")
def get_dataset(self, type_path) -> Seq2SeqDataset:
n_obs = self.n_obs[type_path]
max_target_length = self.target_lens[type_path]
dataset = Seq2SeqDataset(
self.tokenizer,
type_path=type_path,
n_obs=n_obs,
max_target_length=max_target_length,
**self.dataset_kwargs,
)
return dataset
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
dataset = self.get_dataset(type_path)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle,
num_workers=self.num_workers,
)
return dataloader
def train_dataloader(self) -> DataLoader:
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
return dataloader
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
add_generic_args(parser, root_dir)
parser.add_argument(
"--max_source_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--val_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--test_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
parser.add_argument(
"--prefix",
type=str,
default=None,
help="Prefix added at the beginning of each text, typically used with T5-based models.",
)
parser.add_argument(
"--early_stopping_patience",
type=int,
default=-1,
required=False,
help=(
"-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
" val_check_interval will effect it."
),
)
parser.add_argument(
"--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
)
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart", "t5"],
type=str,
help=(
"RAG model type: sequence or token, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
return parser
@staticmethod
def add_retriever_specific_args(parser):
parser.add_argument(
"--index_name",
type=str,
default=None,
help=(
"Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
" for a local index, or 'legacy' for the orignal one)"
),
)
parser.add_argument(
"--passages_path",
type=str,
default=None,
help=(
"Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--index_path",
type=str,
default=None,
help=(
"Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--distributed_retriever",
choices=["ray", "pytorch"],
type=str,
default="pytorch",
help=(
"What implementation to use for distributed retriever? If "
"pytorch is selected, the index is loaded on training "
"worker 0, and torch.distributed is used to handle "
"communication between training worker 0, and the other "
"training workers. If ray is selected, the Ray library is "
"used to create load the index on separate processes, "
"and Ray handles the communication between the training "
"workers and the retrieval actors."
),
)
parser.add_argument(
"--use_dummy_dataset",
type=bool,
default=False,
help=(
"Whether to use the dummy version of the dataset index. More info about custom indexes in the"
" RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
return parser
@staticmethod
def add_ray_specific_args(parser):
# Ray cluster address.
parser.add_argument(
"--ray-address",
default="auto",
type=str,
help=(
"The address of the Ray cluster to connect to. If not "
"specified, Ray will attempt to automatically detect the "
"cluster. Has no effect if pytorch is used as the distributed "
"retriever."
),
)
parser.add_argument(
"--num_retrieval_workers",
type=int,
default=1,
help=(
"The number of retrieval actors to use when Ray is selected "
"for the distributed retriever. Has no effect when "
"distributed_retriever is set to pytorch."
),
)
return parser
def main(args=None, model=None) -> GenerativeQAModule:
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
args = args or parser.parse_args()
Path(args.output_dir).mkdir(exist_ok=True)
named_actors = []
if args.distributed_retriever == "ray" and args.gpus > 1:
if not is_ray_available():
raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
# Connect to an existing Ray cluster.
try:
ray.init(address=args.ray_address, namespace="rag")
except (ConnectionError, ValueError):
logger.warning(
"Connection to Ray cluster failed. Make sure a Ray "
"cluster is running by either using Ray's cluster "
"launcher (`ray up`) or by manually starting Ray on "
"each node via `ray start --head` for the head node "
"and `ray start --address='<ip address>:6379'` for "
"additional nodes. See "
"https://docs.ray.io/en/master/cluster/index.html "
"for more info."
)
raise
# Create Ray actors only for rank 0.
if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
"NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
):
remote_cls = ray.remote(RayRetriever)
named_actors = [
remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
for i in range(args.num_retrieval_workers)
]
else:
logger.info(
"Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
)
)
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
args.actor_handles = named_actors
assert args.actor_handles == named_actors
if model is None:
model: GenerativeQAModule = GenerativeQAModule(args)
dataset = Path(args.data_dir).name
if (
args.logger_name == "default"
or args.fast_dev_run
or str(args.output_dir).startswith("/tmp")
or str(args.output_dir).startswith("/var")
):
training_logger = True # don't pollute wandb logs unnecessarily
elif args.logger_name == "wandb":
from pytorch_lightning.loggers import WandbLogger
project = os.environ.get("WANDB_PROJECT", dataset)
training_logger = WandbLogger(name=model.output_dir.name, project=project)
elif args.logger_name == "wandb_shared":
from pytorch_lightning.loggers import WandbLogger
training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
es_callback = (
get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
if args.early_stopping_patience >= 0
else False
)
trainer: pl.Trainer = generic_train(
model,
args,
logging_callback=Seq2SeqLoggingCallback(),
checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
early_stopping_callback=es_callback,
logger=training_logger,
custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
if not args.do_predict:
return model
# test() without a model tests using the best checkpoint automatically
trainer.test()
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
parser = GenerativeQAModule.add_ray_specific_args(parser)
# Pytorch Lightning Profiler
parser.add_argument(
"--profile",
action="store_true",
help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
)
args = parser.parse_args()
main(args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/finetune_rag_ray.sh
|
# Sample script to finetune RAG using Ray for distributed retrieval.
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python examples/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 100 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
--distributed_retriever ray \
--num_retrieval_workers 4
# Stop the Ray cluster.
ray stop
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/distributed_pytorch_retriever.py
|
import logging
import os
from typing import List, Tuple
import numpy as np
import psutil
import torch
import torch.distributed as dist
from transformers import RagRetriever
logger = logging.getLogger(__name__)
class RagPyTorchDistributedRetriever(RagRetriever):
"""
A distributed retriever built on top of the ``torch.distributed`` communication package. During training all workers
initialize their own instance of the retriever, however, only the main worker loads the index into memory. The index is stored
in cpu memory. The index will also work well in a non-distributed setup.
Args:
config (:class:`~transformers.RagConfig`):
The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer that was used to tokenize the question.
It is used to decode the question and then use the generator_tokenizer.
generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
The tokenizer used for the generator part of the RagModel.
index (:class:`~transformers.models.rag.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
If specified, use this index instead of the one built using the configuration
"""
def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, index=None):
super().__init__(
config,
question_encoder_tokenizer=question_encoder_tokenizer,
generator_tokenizer=generator_tokenizer,
index=index,
init_retrieval=False,
)
self.process_group = None
def init_retrieval(self, distributed_port: int):
"""
Retriever initialization function, needs to be called from the training process. The function sets some common parameters
and environment variables. On top of that, (only) the main process in the process group loads the index into memory.
Args:
distributed_port (:obj:`int`):
The port on which the main communication of the training run is carried out. We set the port for retrieval-related
communication as ``distributed_port + 1``.
"""
logger.info("initializing retrieval")
# initializing a separate process group for retrieval as the default
# nccl backend doesn't support gather/scatter operations while gloo
# is too slow to replace nccl for the core gpu communication
if dist.is_initialized():
logger.info("dist initialized")
# needs to be set manually
os.environ["GLOO_SOCKET_IFNAME"] = self._infer_socket_ifname()
# avoid clash with the NCCL port
os.environ["MASTER_PORT"] = str(distributed_port + 1)
self.process_group = dist.new_group(ranks=None, backend="gloo")
# initialize retriever only on the main worker
if not dist.is_initialized() or self._is_main():
logger.info("dist not initialized / main")
self.index.init_index()
# all processes wait untill the retriever is initialized by the main process
if dist.is_initialized():
torch.distributed.barrier(group=self.process_group)
def _is_main(self):
return dist.get_rank(group=self.process_group) == 0
def _scattered(self, scatter_list, target_shape, target_type=torch.float32):
target_tensor = torch.empty(target_shape, dtype=target_type)
dist.scatter(target_tensor, src=0, scatter_list=scatter_list, group=self.process_group)
return target_tensor
def _infer_socket_ifname(self):
addrs = psutil.net_if_addrs()
# a hacky way to deal with varying network interface names
ifname = next((addr for addr in addrs if addr.startswith("e")), None)
return ifname
def retrieve(self, question_hidden_states: np.ndarray, n_docs: int) -> Tuple[np.ndarray, List[dict]]:
"""
Retrieves documents for specified ``question_hidden_states``. The main process, which has the access to the index stored in memory, gathers queries
from all the processes in the main training process group, performs the retrieval and scatters back the results.
Args:
question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
A batch of query vectors to retrieve with.
n_docs (:obj:`int`):
The number of docs retrieved per query.
Output:
retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
The retrieval embeddings of the retrieved docs per query.
doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
The ids of the documents in the index
doc_dicts (:obj:`List[dict]`):
The retrieved_doc_embeds examples per query.
"""
# single GPU training
if not dist.is_initialized():
doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
# distributed training
world_size = dist.get_world_size(group=self.process_group)
# gather logic
gather_list = None
if self._is_main():
gather_list = [torch.empty(question_hidden_states.shape, dtype=torch.float32) for _ in range(world_size)]
dist.gather(torch.tensor(question_hidden_states), dst=0, gather_list=gather_list, group=self.process_group)
# scatter logic
n_queries = question_hidden_states.shape[0]
scatter_ids = []
scatter_vectors = []
if self._is_main():
assert len(gather_list) == world_size
ids, vectors = self._main_retrieve(torch.cat(gather_list).numpy(), n_docs)
ids, vectors = torch.tensor(ids), torch.tensor(vectors)
scatter_ids = self._chunk_tensor(ids, n_queries)
scatter_vectors = self._chunk_tensor(vectors, n_queries)
doc_ids = self._scattered(scatter_ids, [n_queries, n_docs], target_type=torch.int64)
retrieved_doc_embeds = self._scattered(scatter_vectors, [n_queries, n_docs, question_hidden_states.shape[1]])
return retrieved_doc_embeds.numpy(), doc_ids.numpy(), self.index.get_doc_dicts(doc_ids)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/requirements.txt
|
faiss-cpu >= 1.6.3
datasets >= 1.0.1
psutil >= 5.7.0
torch >= 1.4.0
ray >= 1.10.0
pytorch-lightning >= 1.5.10, <=1.6.0
transformers
GitPython
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/eval_rag.py
|
""" Evaluation script for RAG models."""
import argparse
import ast
import logging
import os
import sys
import pandas as pd
import torch
from tqdm import tqdm
from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
from transformers import logging as transformers_logging
sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
transformers_logging.set_verbosity_info()
def infer_model_type(model_name_or_path):
if "token" in model_name_or_path:
return "rag_token"
if "sequence" in model_name_or_path:
return "rag_sequence"
if "bart" in model_name_or_path:
return "bart"
return None
def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
return max(metric_fn(prediction, gt) for gt in ground_truths)
def get_scores(args, preds_path, gold_data_path):
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
answers = []
if args.gold_data_mode == "qa":
data = pd.read_csv(gold_data_path, sep="\t", header=None)
for answer_list in data[1]:
ground_truths = ast.literal_eval(answer_list)
answers.append(ground_truths)
else:
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
answers = [[reference] for reference in references]
f1 = em = total = 0
for prediction, ground_truths in zip(hypos, answers):
total += 1
em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
em = 100.0 * em / total
f1 = 100.0 * f1 / total
logger.info(f"F1: {f1:.2f}")
logger.info(f"EM: {em:.2f}")
def get_precision_at_k(args, preds_path, gold_data_path):
k = args.k
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
em = total = 0
for hypo, reference in zip(hypos, references):
hypo_provenance = set(hypo.split("\t")[:k])
ref_provenance = set(reference.split("\t"))
total += 1
em += len(hypo_provenance & ref_provenance) / k
em = 100.0 * em / total
logger.info(f"Precision@{k}: {em: .2f}")
def evaluate_batch_retrieval(args, rag_model, questions):
def strip_title(title):
if title.startswith('"'):
title = title[1:]
if title.endswith('"'):
title = title[:-1]
return title
retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions,
return_tensors="pt",
padding=True,
truncation=True,
)["input_ids"].to(args.device)
question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
question_enc_pool_output = question_enc_outputs[0]
result = rag_model.retriever(
retriever_input_ids,
question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
prefix=rag_model.rag.generator.config.prefix,
n_docs=rag_model.config.n_docs,
return_tensors="pt",
)
all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
provenance_strings = []
for docs in all_docs:
provenance = [strip_title(title) for title in docs["title"]]
provenance_strings.append("\t".join(provenance))
return provenance_strings
def evaluate_batch_e2e(args, rag_model, questions):
with torch.no_grad():
inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions, return_tensors="pt", padding=True, truncation=True
)
input_ids = inputs_dict.input_ids.to(args.device)
attention_mask = inputs_dict.attention_mask.to(args.device)
outputs = rag_model.generate( # rag_model overwrites generate
input_ids,
attention_mask=attention_mask,
num_beams=args.num_beams,
min_length=args.min_length,
max_length=args.max_length,
early_stopping=False,
num_return_sequences=1,
bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
)
answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
if args.print_predictions:
for q, a in zip(questions, answers):
logger.info("Q: {} - A: {}".format(q, a))
return answers
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart"],
type=str,
help=(
"RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
parser.add_argument(
"--index_name",
default=None,
choices=["exact", "compressed", "legacy"],
type=str,
help="RAG model retriever type",
)
parser.add_argument(
"--index_path",
default=None,
type=str,
help="Path to the retrieval index",
)
parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
)
parser.add_argument(
"--eval_mode",
choices=["e2e", "retrieval"],
default="e2e",
type=str,
help=(
"Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
" precision@k."
),
)
parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
parser.add_argument(
"--evaluation_set",
default=None,
type=str,
required=True,
help="Path to a file containing evaluation samples",
)
parser.add_argument(
"--gold_data_path",
default=None,
type=str,
required=True,
help="Path to a tab-separated file with gold samples",
)
parser.add_argument(
"--gold_data_mode",
default="qa",
type=str,
choices=["qa", "ans"],
help=(
"Format of the gold data file"
"qa - a single line in the following format: question [tab] answer_list"
"ans - a single line of the gold file contains the expected answer string"
),
)
parser.add_argument(
"--predictions_path",
type=str,
default="predictions.txt",
help="Name of the predictions file, to be stored in the checkpoints directory",
)
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument(
"--eval_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for evaluation.",
)
parser.add_argument(
"--recalculate",
help="Recalculate predictions even if the prediction file exists",
action="store_true",
)
parser.add_argument(
"--num_beams",
default=4,
type=int,
help="Number of beams to be used when generating answers",
)
parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
parser.add_argument(
"--print_predictions",
action="store_true",
help="If True, prints predictions while evaluating.",
)
parser.add_argument(
"--print_docs",
action="store_true",
help="If True, prints docs retried while generating.",
)
args = parser.parse_args()
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
return args
def main(args):
model_kwargs = {}
if args.model_type is None:
args.model_type = infer_model_type(args.model_name_or_path)
assert args.model_type is not None
if args.model_type.startswith("rag"):
model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
model_kwargs["n_docs"] = args.n_docs
if args.index_name is not None:
model_kwargs["index_name"] = args.index_name
if args.index_path is not None:
model_kwargs["index_path"] = args.index_path
else:
model_class = BartForConditionalGeneration
checkpoints = (
[f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
if args.eval_all_checkpoints
else [args.model_name_or_path]
)
logger.info("Evaluate the following checkpoints: %s", checkpoints)
score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
for checkpoint in checkpoints:
if os.path.exists(args.predictions_path) and (not args.recalculate):
logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
score_fn(args, args.predictions_path, args.gold_data_path)
continue
logger.info("***** Running evaluation for {} *****".format(checkpoint))
logger.info(" Batch size = %d", args.eval_batch_size)
logger.info(" Predictions will be stored under {}".format(args.predictions_path))
if args.model_type.startswith("rag"):
retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
model.retriever.init_retrieval()
else:
model = model_class.from_pretrained(checkpoint, **model_kwargs)
model.to(args.device)
with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
questions = []
for line in tqdm(eval_file):
questions.append(line.strip())
if len(questions) == args.eval_batch_size:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers) + "\n")
preds_file.flush()
questions = []
if len(questions) > 0:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers))
preds_file.flush()
score_fn(args, args.predictions_path, args.gold_data_path)
if __name__ == "__main__":
args = get_args()
main(args)
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/__init__.py
|
import os
import sys
sys.path.insert(1, os.path.dirname(os.path.realpath(__file__)))
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/parse_dpr_relevance_data.py
|
"""
This script reads DPR retriever training data and parses each datapoint. We save a line per datapoint.
Each line consists of the query followed by a tab-separated list of Wikipedia page titles constituting
positive contexts for a given query.
"""
import argparse
import json
from tqdm import tqdm
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--src_path",
type=str,
default="biencoder-nq-dev.json",
help="Path to raw DPR training data",
)
parser.add_argument(
"--evaluation_set",
type=str,
help="where to store parsed evaluation_set file",
)
parser.add_argument(
"--gold_data_path",
type=str,
help="where to store parsed gold_data_path file",
)
args = parser.parse_args()
with open(args.src_path, "r") as src_file, open(args.evaluation_set, "w") as eval_file, open(
args.gold_data_path, "w"
) as gold_file:
dpr_records = json.load(src_file)
for dpr_record in tqdm(dpr_records):
question = dpr_record["question"]
contexts = [context["title"] for context in dpr_record["positive_ctxs"]]
eval_file.write(question + "\n")
gold_file.write("\t".join(contexts) + "\n")
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/lightning_base.py
|
import argparse
import logging
import os
from pathlib import Path
from typing import Any, Dict
import pytorch_lightning as pl
from pytorch_lightning.utilities import rank_zero_info
from transformers import (
AdamW,
AutoConfig,
AutoModel,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
AutoModelWithLMHead,
AutoTokenizer,
PretrainedConfig,
PreTrainedTokenizer,
)
from transformers.optimization import (
Adafactor,
get_cosine_schedule_with_warmup,
get_cosine_with_hard_restarts_schedule_with_warmup,
get_linear_schedule_with_warmup,
get_polynomial_decay_schedule_with_warmup,
)
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
require_version("pytorch_lightning>=1.0.4")
MODEL_MODES = {
"base": AutoModel,
"sequence-classification": AutoModelForSequenceClassification,
"question-answering": AutoModelForQuestionAnswering,
"pretraining": AutoModelForPreTraining,
"token-classification": AutoModelForTokenClassification,
"language-modeling": AutoModelWithLMHead,
"summarization": AutoModelForSeq2SeqLM,
"translation": AutoModelForSeq2SeqLM,
}
# update this and the import above to support new schedulers from transformers.optimization
arg_to_scheduler = {
"linear": get_linear_schedule_with_warmup,
"cosine": get_cosine_schedule_with_warmup,
"cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
"polynomial": get_polynomial_decay_schedule_with_warmup,
# '': get_constant_schedule, # not supported for now
# '': get_constant_schedule_with_warmup, # not supported for now
}
arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
class BaseTransformer(pl.LightningModule):
def __init__(
self,
hparams: argparse.Namespace,
num_labels=None,
mode="base",
config=None,
tokenizer=None,
model=None,
**config_kwargs,
):
"""Initialize a model, tokenizer and config."""
super().__init__()
# TODO: move to self.save_hyperparameters()
# self.save_hyperparameters()
# can also expand arguments into trainer signature for easier reading
self.save_hyperparameters(hparams)
self.step_count = 0
self.output_dir = Path(self.hparams.output_dir)
cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
if config is None:
self.config = AutoConfig.from_pretrained(
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
**({"num_labels": num_labels} if num_labels is not None else {}),
cache_dir=cache_dir,
**config_kwargs,
)
else:
self.config: PretrainedConfig = config
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(self.hparams, p, None):
assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
setattr(self.config, p, getattr(self.hparams, p))
if tokenizer is None:
self.tokenizer = AutoTokenizer.from_pretrained(
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
cache_dir=cache_dir,
)
else:
self.tokenizer: PreTrainedTokenizer = tokenizer
self.model_type = MODEL_MODES[mode]
if model is None:
self.model = self.model_type.from_pretrained(
self.hparams.model_name_or_path,
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
config=self.config,
cache_dir=cache_dir,
)
else:
self.model = model
def load_hf_checkpoint(self, *args, **kwargs):
self.model = self.model_type.from_pretrained(*args, **kwargs)
def get_lr_scheduler(self):
get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
scheduler = get_schedule_func(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return scheduler
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay)"""
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
if self.hparams.adafactor:
optimizer = Adafactor(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
)
else:
optimizer = AdamW(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
)
self.opt = optimizer
scheduler = self.get_lr_scheduler()
return [optimizer], [scheduler]
def test_step(self, batch, batch_nb):
return self.validation_step(batch, batch_nb)
def test_epoch_end(self, outputs):
return self.validation_end(outputs)
def total_steps(self) -> int:
"""The number of total training steps that will be run. Used for lr scheduler purposes."""
num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
def setup(self, stage):
if stage == "test":
self.dataset_size = len(self.test_dataloader().dataset)
else:
self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
self.dataset_size = len(self.train_dataloader().dataset)
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
raise NotImplementedError("You must implement this for your task")
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
def test_dataloader(self):
return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
def _feature_file(self, mode):
return os.path.join(
self.hparams.data_dir,
"cached_{}_{}_{}".format(
mode,
list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
str(self.hparams.max_seq_length),
),
)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default=None,
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--encoder_layerdrop",
type=float,
help="Encoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--decoder_layerdrop",
type=float,
help="Decoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--dropout",
type=float,
help="Dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--attention_dropout",
type=float,
help="Attention dropout probability (Optional). Goes into model.config",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--lr_scheduler",
default="linear",
choices=arg_to_scheduler_choices,
metavar=arg_to_scheduler_metavar,
type=str,
help="Learning rate scheduler",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
parser.add_argument("--train_batch_size", default=32, type=int)
parser.add_argument("--eval_batch_size", default=32, type=int)
parser.add_argument("--adafactor", action="store_true")
class InitCallback(pl.Callback):
# This method is better that using a custom DDP plugging with the latest pytorch-lightning (@shamanez)
def on_sanity_check_start(self, trainer, pl_module):
if (
trainer.is_global_zero and trainer.global_rank == 0
): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
class LoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
pl_module.logger.log_metrics(lrs)
def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Validation results *****")
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Test results *****")
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))
def add_generic_args(parser, root_dir) -> None:
# To allow all pl args uncomment the following line
# parser = pl.Trainer.add_argparse_args(parser)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O2",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
parser.add_argument(
"--gradient_accumulation_steps",
dest="accumulate_grad_batches",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
)
def generic_train(
model: BaseTransformer,
args: argparse.Namespace,
early_stopping_callback=None,
logger=True, # can pass WandbLogger() here
custom_ddp_plugin=None,
extra_callbacks=[],
checkpoint_callback=None,
logging_callback=None,
**extra_train_kwargs,
):
pl.seed_everything(args.seed)
# init model
odir = Path(model.hparams.output_dir)
odir.mkdir(exist_ok=True)
# add custom checkpoints
if checkpoint_callback is None:
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
)
if early_stopping_callback:
extra_callbacks.append(early_stopping_callback)
if logging_callback is None:
logging_callback = LoggingCallback()
train_params = {}
# TODO: remove with PyTorch 1.6 since pl uses native amp
if args.fp16:
train_params["precision"] = 16
# train_params["amp_level"] = args.fp16_opt_level
if args.gpus > 1:
train_params["accelerator"] = "auto" # "ddp"
train_params["strategy"] = "ddp"
train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
train_params["profiler"] = None # extra_train_kwargs.get("profiler", None) #get unwanted logs
train_params["devices"] = "auto"
trainer = pl.Trainer.from_argparse_args(
args,
weights_summary=None,
callbacks=[logging_callback] + extra_callbacks + [checkpoint_callback] + [InitCallback()],
# plugins=[custom_ddp_plugin],
logger=logger,
**train_params,
)
if args.do_train:
trainer.fit(model)
return trainer
| 0
|
hf_public_repos/transformers/examples/research_projects
|
hf_public_repos/transformers/examples/research_projects/rag/finetune_rag.sh
|
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag.sh --help to see all the possible options
python examples/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 100 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
| 0
|
hf_public_repos/transformers/examples/research_projects/rag
|
hf_public_repos/transformers/examples/research_projects/rag/test_data/my_knowledge_dataset.csv
|
Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Examples
This folder contains actively maintained examples of use of 🤗 Transformers using the PyTorch backend, organized by ML task.
## The Big Table of Tasks
Here is the list of all our examples:
- with information on whether they are **built on top of `Trainer`** (if not, they still work, they might
just lack some features),
- whether or not they have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library.
- whether or not they leverage the [🤗 Datasets](https://github.com/huggingface/datasets) library.
- links to **Colab notebooks** to walk through the scripts and run them easily,
<!--
Coming soon!
- links to **Cloud deployments** to be able to deploy large-scale trainings in the Cloud with little to no setup.
-->
| Task | Example datasets | Trainer support | 🤗 Accelerate | 🤗 Datasets | Colab
|---|---|:---:|:---:|:---:|:---:|
| [**`language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling) | [WikiText-2](https://huggingface.co/datasets/wikitext) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
| [**`multiple-choice`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) | [SWAG](https://huggingface.co/datasets/swag) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
| [**`question-answering`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) | [SQuAD](https://huggingface.co/datasets/squad) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
| [**`summarization`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) | [XSum](https://huggingface.co/datasets/xsum) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) | [GLUE](https://huggingface.co/datasets/glue) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
| [**`text-generation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation) | - | n/a | - | - | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)
| [**`token-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) | [CoNLL NER](https://huggingface.co/datasets/conll2003) | ✅ |✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
| [**`translation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) | [WMT](https://huggingface.co/datasets/wmt17) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
| [**`speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [TIMIT](https://huggingface.co/datasets/timit_asr) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)
| [**`multi-lingual speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [Common Voice](https://huggingface.co/datasets/common_voice) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)
| [**`audio-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) | [SUPERB KS](https://huggingface.co/datasets/superb) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)
| [**`image-pretraining`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) | [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) | ✅ | - |✅ | /
| [**`image-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) | [CIFAR-10](https://huggingface.co/datasets/cifar10) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)
| [**`semantic-segmentation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) | [SCENE_PARSE_150](https://huggingface.co/datasets/scene_parse_150) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)
## Running quick tests
Most examples are equipped with a mechanism to truncate the number of dataset samples to the desired length. This is useful for debugging purposes, for example to quickly check that all stages of the programs can complete, before running the same setup on the full dataset which may take hours to complete.
For example here is how to truncate all three splits to just 50 samples each:
```
examples/pytorch/token-classification/run_ner.py \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
[...]
```
Most example scripts should have the first two command line arguments and some have the third one. You can quickly check if a given example supports any of these by passing a `-h` option, e.g.:
```
examples/pytorch/token-classification/run_ner.py -h
```
## Resuming training
You can resume training from a previous checkpoint like this:
1. Pass `--output_dir previous_output_dir` without `--overwrite_output_dir` to resume training from the latest checkpoint in `output_dir` (what you would use if the training was interrupted, for instance).
2. Pass `--resume_from_checkpoint path_to_a_specific_checkpoint` to resume training from that checkpoint folder.
Should you want to turn an example into a notebook where you'd no longer have access to the command
line, 🤗 Trainer supports resuming from a checkpoint via `trainer.train(resume_from_checkpoint)`.
1. If `resume_from_checkpoint` is `True` it will look for the last checkpoint in the value of `output_dir` passed via `TrainingArguments`.
2. If `resume_from_checkpoint` is a path to a specific checkpoint it will use that saved checkpoint folder to resume the training from.
### Upload the trained/fine-tuned model to the Hub
All the example scripts support automatic upload of your final model to the [Model Hub](https://huggingface.co/models) by adding a `--push_to_hub` argument. It will then create a repository with your username slash the name of the folder you are using as `output_dir`. For instance, `"sgugger/test-mrpc"` if your username is `sgugger` and you are working in the folder `~/tmp/test-mrpc`.
To specify a given repository name, use the `--hub_model_id` argument. You will need to specify the whole repository name (including your username), for instance `--hub_model_id sgugger/finetuned-bert-mrpc`. To upload to an organization you are a member of, just use the name of that organization instead of your username: `--hub_model_id huggingface/finetuned-bert-mrpc`.
A few notes on this integration:
- you will need to be logged in to the Hugging Face website locally for it to work, the easiest way to achieve this is to run `huggingface-cli login` and then type your username and password when prompted. You can also pass along your authentication token with the `--hub_token` argument.
- the `output_dir` you pick will either need to be a new folder or a local clone of the distant repository you are using.
## Distributed training and mixed precision
All the PyTorch scripts mentioned above work out of the box with distributed training and mixed precision, thanks to
the [Trainer API](https://huggingface.co/transformers/main_classes/trainer.html). To launch one of them on _n_ GPUs,
use the following command:
```bash
torchrun \
--nproc_per_node number_of_gpu_you_have path_to_script.py \
--all_arguments_of_the_script
```
As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
classification MNLI task using the `run_glue` script, with 8 GPUs:
```bash
torchrun \
--nproc_per_node 8 pytorch/text-classification/run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /tmp/mnli_output/
```
If you have a GPU with mixed precision capabilities (architecture Pascal or more recent), you can use mixed precision
training with PyTorch 1.6.0 or latest, or by installing the [Apex](https://github.com/NVIDIA/apex) library for previous
versions. Just add the flag `--fp16` to your command launching one of the scripts mentioned above!
Using mixed precision training usually results in 2x-speedup for training with the same final results (as shown in
[this table](https://github.com/huggingface/transformers/tree/main/examples/text-classification#mixed-precision-training)
for text classification).
## Running on TPUs
When using Tensorflow, TPUs are supported out of the box as a `tf.distribute.Strategy`.
When using PyTorch, we support TPUs thanks to `pytorch/xla`. For more context and information on how to setup your TPU environment refer to Google's documentation and to the
very detailed [pytorch/xla README](https://github.com/pytorch/xla/blob/master/README.md).
In this repo, we provide a very simple launcher script named
[xla_spawn.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/xla_spawn.py) that lets you run our
example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your
regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for
`torch.distributed`):
```bash
python xla_spawn.py --num_cores num_tpu_you_have \
path_to_script.py \
--all_arguments_of_the_script
```
As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
classification MNLI task using the `run_glue` script, with 8 TPUs (from this folder):
```bash
python xla_spawn.py --num_cores 8 \
text-classification/run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /tmp/mnli_output/
```
## Using Accelerate
Most PyTorch example scripts have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library
that exposes the training loop so it's easy for you to customize or tweak them to your needs. They all require you to
install `accelerate` with the latest development version
```bash
pip install git+https://github.com/huggingface/accelerate
```
Then you can easily launch any of the scripts by running
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch path_to_script.py --args_to_script
```
## Logging & Experiment tracking
You can easily log and monitor your runs code. The following are currently supported:
* [TensorBoard](https://www.tensorflow.org/tensorboard)
* [Weights & Biases](https://docs.wandb.ai/integrations/huggingface)
* [Comet ML](https://www.comet.ml/docs/python-sdk/huggingface/)
* [Neptune](https://docs.neptune.ai/integrations-and-supported-tools/model-training/hugging-face)
* [ClearML](https://clear.ml/docs/latest/docs/getting_started/ds/ds_first_steps)
* [DVCLive](https://dvc.org/doc/dvclive/ml-frameworks/huggingface)
### Weights & Biases
To use Weights & Biases, install the wandb package with:
```bash
pip install wandb
```
Then log in the command line:
```bash
wandb login
```
If you are in Jupyter or Colab, you should login with:
```python
import wandb
wandb.login()
```
To enable logging to W&B, include `"wandb"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to_all` if you have `wandb` installed.
Whenever you use `Trainer` or `TFTrainer` classes, your losses, evaluation metrics, model topology and gradients (for `Trainer` only) will automatically be logged.
Advanced configuration is possible by setting environment variables:
| Environment Variable | Value |
|---|---|
| WANDB_LOG_MODEL | Log the model as artifact (log the model as artifact at the end of training) (`false` by default) |
| WANDB_WATCH | one of `gradients` (default) to log histograms of gradients, `all` to log histograms of both gradients and parameters, or `false` for no histogram logging |
| WANDB_PROJECT | Organize runs by project |
Set run names with `run_name` argument present in scripts or as part of `TrainingArguments`.
Additional configuration options are available through generic [wandb environment variables](https://docs.wandb.com/library/environment-variables).
Refer to related [documentation & examples](https://docs.wandb.ai/integrations/huggingface).
### Comet.ml
To use `comet_ml`, install the Python package with:
```bash
pip install comet_ml
```
or if in a Conda environment:
```bash
conda install -c comet_ml -c anaconda -c conda-forge comet_ml
```
### Neptune
First, install the Neptune client library. You can do it with either `pip` or `conda`:
`pip`:
```bash
pip install neptune
```
`conda`:
```bash
conda install -c conda-forge neptune
```
Next, in your model training script, import `NeptuneCallback`:
```python
from transformers.integrations import NeptuneCallback
```
To enable Neptune logging, in your `TrainingArguments`, set the `report_to` argument to `"neptune"`:
```python
training_args = TrainingArguments(
"quick-training-distilbert-mrpc",
evaluation_strategy="steps",
eval_steps=20,
report_to="neptune",
)
trainer = Trainer(
model,
training_args,
...
)
```
**Note:** This method requires saving your Neptune credentials as environment variables (see the bottom of the section).
Alternatively, for more logging options, create a Neptune callback:
```python
neptune_callback = NeptuneCallback()
```
To add more detail to the tracked run, you can supply optional arguments to `NeptuneCallback`.
Some examples:
```python
neptune_callback = NeptuneCallback(
name = "DistilBERT",
description = "DistilBERT fine-tuned on GLUE/MRPC",
tags = ["args-callback", "fine-tune", "MRPC"], # tags help you manage runs in Neptune
base_namespace="callback", # the default is "finetuning"
log_checkpoints = "best", # other options are "last", "same", and None
capture_hardware_metrics = False, # additional keyword arguments for a Neptune run
)
```
Pass the callback to the Trainer:
```python
training_args = TrainingArguments(..., report_to=None)
trainer = Trainer(
model,
training_args,
...
callbacks=[neptune_callback],
)
```
Now, when you start the training with `trainer.train()`, your metadata will be logged in Neptune.
**Note:** Although you can pass your **Neptune API token** and **project name** as arguments when creating the callback, the recommended way is to save them as environment variables:
| Environment variable | Value |
| :------------------- | :--------------------------------------------------- |
| `NEPTUNE_API_TOKEN` | Your Neptune API token. To find and copy it, click your Neptune avatar and select **Get your API token**. |
| `NEPTUNE_PROJECT` | The full name of your Neptune project (`workspace-name/project-name`). To find and copy it, head to **project settings** → **Properties**. |
For detailed instructions and examples, see the [Neptune docs](https://docs.neptune.ai/integrations/transformers/).
### ClearML
To use ClearML, install the clearml package with:
```bash
pip install clearml
```
Then [create new credentials]() from the ClearML Server. You can get a free hosted server [here]() or [self-host your own]()!
After creating your new credentials, you can either copy the local snippet which you can paste after running:
```bash
clearml-init
```
Or you can copy the jupyter snippet if you are in Jupyter or Colab:
```python
%env CLEARML_WEB_HOST=https://app.clear.ml
%env CLEARML_API_HOST=https://api.clear.ml
%env CLEARML_FILES_HOST=https://files.clear.ml
%env CLEARML_API_ACCESS_KEY=***
%env CLEARML_API_SECRET_KEY=***
```
To enable logging to ClearML, include `"clearml"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to all` if you have `clearml` already installed.
Advanced configuration is possible by setting environment variables:
| Environment Variable | Value |
|---|---|
| CLEARML_PROJECT | Name of the project in ClearML. (default: `"HuggingFace Transformers"`) |
| CLEARML_TASK | Name of the task in ClearML. (default: `"Trainer"`) |
Additional configuration options are available through generic [clearml environment variables](https://clear.ml/docs/latest/docs/configs/env_vars).
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/conftest.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# tests directory-specific settings - this file is run automatically
# by pytest before any tests are run
import sys
import warnings
from os.path import abspath, dirname, join
# allow having multiple repository checkouts and not needing to remember to rerun
# 'pip install -e .[dev]' when switching between checkouts and running tests.
git_repo_path = abspath(join(dirname(dirname(dirname(__file__))), "src"))
sys.path.insert(1, git_repo_path)
# silence FutureWarning warnings in tests since often we can't act on them until
# they become normal warnings - i.e. the tests still need to test the current functionality
warnings.simplefilter(action="ignore", category=FutureWarning)
def pytest_addoption(parser):
from transformers.testing_utils import pytest_addoption_shared
pytest_addoption_shared(parser)
def pytest_terminal_summary(terminalreporter):
from transformers.testing_utils import pytest_terminal_summary_main
make_reports = terminalreporter.config.getoption("--make-reports")
if make_reports:
pytest_terminal_summary_main(terminalreporter, id=make_reports)
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/_tests_requirements.txt
|
tensorboard
scikit-learn
seqeval
psutil
sacrebleu >= 1.4.12
git+https://github.com/huggingface/accelerate@main#egg=accelerate
rouge-score
tensorflow_datasets
matplotlib
git-python==1.0.3
faiss-cpu
streamlit
elasticsearch
nltk
pandas
datasets >= 1.13.3
fire
pytest
conllu
sentencepiece != 0.1.92
protobuf
torchvision
jiwer
librosa
evaluate >= 0.2.0
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/test_accelerate_examples.py
|
# coding=utf-8
# Copyright 2018 HuggingFace Inc..
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import json
import logging
import os
import shutil
import sys
import tempfile
import unittest
from unittest import mock
from accelerate.utils import write_basic_config
from transformers.testing_utils import (
TestCasePlus,
backend_device_count,
run_command,
slow,
torch_device,
)
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
def get_setup_file():
parser = argparse.ArgumentParser()
parser.add_argument("-f")
args = parser.parse_args()
return args.f
def get_results(output_dir):
results = {}
path = os.path.join(output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
results = json.load(f)
else:
raise ValueError(f"can't find {path}")
return results
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class ExamplesTestsNoTrainer(TestCasePlus):
@classmethod
def setUpClass(cls):
# Write Accelerate config, will pick up on CPU, GPU, and multi-GPU
cls.tmpdir = tempfile.mkdtemp()
cls.configPath = os.path.join(cls.tmpdir, "default_config.yml")
write_basic_config(save_location=cls.configPath)
cls._launch_args = ["accelerate", "launch", "--config_file", cls.configPath]
@classmethod
def tearDownClass(cls):
shutil.rmtree(cls.tmpdir)
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_glue_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/text-classification/run_glue_no_trainer.py
--model_name_or_path distilbert-base-uncased
--output_dir {tmp_dir}
--train_file ./tests/fixtures/tests_samples/MRPC/train.csv
--validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--learning_rate=1e-4
--seed=42
--num_warmup_steps=2
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "glue_no_trainer")))
@unittest.skip("Zach is working on this.")
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_clm_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/language-modeling/run_clm_no_trainer.py
--model_name_or_path distilgpt2
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--block_size 128
--per_device_train_batch_size 5
--per_device_eval_batch_size 5
--num_train_epochs 2
--output_dir {tmp_dir}
--checkpointing_steps epoch
--with_tracking
""".split()
if backend_device_count(torch_device) > 1:
# Skipping because there are not enough batches to train the model + would need a drop_last to work.
return
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 100)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "clm_no_trainer")))
@unittest.skip("Zach is working on this.")
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_mlm_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/language-modeling/run_mlm_no_trainer.py
--model_name_or_path distilroberta-base
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--output_dir {tmp_dir}
--num_train_epochs=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 42)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "mlm_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_ner_no_trainer(self):
# with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
epochs = 7 if backend_device_count(torch_device) > 1 else 2
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/token-classification/run_ner_no_trainer.py
--model_name_or_path bert-base-uncased
--train_file tests/fixtures/tests_samples/conll/sample.json
--validation_file tests/fixtures/tests_samples/conll/sample.json
--output_dir {tmp_dir}
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=2
--num_train_epochs={epochs}
--seed 7
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
self.assertLess(result["train_loss"], 0.6)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "ner_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_squad_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/question-answering/run_qa_no_trainer.py
--model_name_or_path bert-base-uncased
--version_2_with_negative
--train_file tests/fixtures/tests_samples/SQUAD/sample.json
--validation_file tests/fixtures/tests_samples/SQUAD/sample.json
--output_dir {tmp_dir}
--seed=42
--max_train_steps=10
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
# Because we use --version_2_with_negative the testing script uses SQuAD v2 metrics.
self.assertGreaterEqual(result["eval_f1"], 28)
self.assertGreaterEqual(result["eval_exact"], 28)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "qa_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_swag_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/multiple-choice/run_swag_no_trainer.py
--model_name_or_path bert-base-uncased
--train_file tests/fixtures/tests_samples/swag/sample.json
--validation_file tests/fixtures/tests_samples/swag/sample.json
--output_dir {tmp_dir}
--max_train_steps=20
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.8)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "swag_no_trainer")))
@slow
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_summarization_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/summarization/run_summarization_no_trainer.py
--model_name_or_path t5-small
--train_file tests/fixtures/tests_samples/xsum/sample.json
--validation_file tests/fixtures/tests_samples/xsum/sample.json
--output_dir {tmp_dir}
--max_train_steps=50
--num_warmup_steps=8
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_rouge1"], 10)
self.assertGreaterEqual(result["eval_rouge2"], 2)
self.assertGreaterEqual(result["eval_rougeL"], 7)
self.assertGreaterEqual(result["eval_rougeLsum"], 7)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "summarization_no_trainer")))
@slow
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_translation_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/translation/run_translation_no_trainer.py
--model_name_or_path sshleifer/student_marian_en_ro_6_1
--source_lang en
--target_lang ro
--train_file tests/fixtures/tests_samples/wmt16/sample.json
--validation_file tests/fixtures/tests_samples/wmt16/sample.json
--output_dir {tmp_dir}
--max_train_steps=50
--num_warmup_steps=8
--num_beams=6
--learning_rate=3e-3
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--source_lang en_XX
--target_lang ro_RO
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_bleu"], 30)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "translation_no_trainer")))
@slow
def test_run_semantic_segmentation_no_trainer(self):
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
--dataset_name huggingface/semantic-segmentation-test-sample
--output_dir {tmp_dir}
--max_train_steps=10
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_overall_accuracy"], 0.10)
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline"})
def test_run_image_classification_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/image-classification/run_image_classification_no_trainer.py
--model_name_or_path google/vit-base-patch16-224-in21k
--dataset_name hf-internal-testing/cats_vs_dogs_sample
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--max_train_steps 2
--train_val_split 0.1
--seed 42
--output_dir {tmp_dir}
--with_tracking
--checkpointing_steps 1
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
# The base model scores a 25%
self.assertGreaterEqual(result["eval_accuracy"], 0.4)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "step_1")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "image_classification_no_trainer")))
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/old_test_xla_examples.py
|
# coding=utf-8
# Copyright 2018 HuggingFace Inc..
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import logging
import os
import sys
from time import time
from unittest.mock import patch
from transformers.testing_utils import TestCasePlus, require_torch_tpu
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
def get_results(output_dir):
results = {}
path = os.path.join(output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
results = json.load(f)
else:
raise ValueError(f"can't find {path}")
return results
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
@require_torch_tpu
class TorchXLAExamplesTests(TestCasePlus):
def test_run_glue(self):
import xla_spawn
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
./examples/pytorch/text-classification/run_glue.py
--num_cores=8
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path distilbert-base-uncased
--output_dir {tmp_dir}
--overwrite_output_dir
--train_file ./tests/fixtures/tests_samples/MRPC/train.csv
--validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
--do_train
--do_eval
--debug tpu_metrics_debug
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--learning_rate=1e-4
--max_steps=10
--warmup_steps=2
--seed=42
--max_seq_length=128
""".split()
with patch.object(sys, "argv", testargs):
start = time()
xla_spawn.main()
end = time()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
# Assert that the script takes less than 500 seconds to make sure it doesn't hang.
self.assertLess(end - start, 500)
def test_trainer_tpu(self):
import xla_spawn
testargs = """
./tests/test_trainer_tpu.py
--num_cores=8
./tests/test_trainer_tpu.py
""".split()
with patch.object(sys, "argv", testargs):
xla_spawn.main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/xla_spawn.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A simple launcher script for TPU training
Inspired by https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
::
>>> python xla_spawn.py --num_cores=NUM_CORES_YOU_HAVE
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
arguments of your training script)
"""
import importlib
import sys
from argparse import REMAINDER, ArgumentParser
from pathlib import Path
import torch_xla.distributed.xla_multiprocessing as xmp
def parse_args():
"""
Helper function parsing the command line options
@retval ArgumentParser
"""
parser = ArgumentParser(
description=(
"PyTorch TPU distributed training launch helper utility that will spawn up multiple distributed processes"
)
)
# Optional arguments for the launch helper
parser.add_argument("--num_cores", type=int, default=1, help="Number of TPU cores to use (1 or 8).")
# positional
parser.add_argument(
"training_script",
type=str,
help=(
"The full path to the single TPU training "
"program/script to be launched in parallel, "
"followed by all the arguments for the "
"training script"
),
)
# rest from the training program
parser.add_argument("training_script_args", nargs=REMAINDER)
return parser.parse_args()
def main():
args = parse_args()
# Import training_script as a module.
script_fpath = Path(args.training_script)
sys.path.append(str(script_fpath.parent.resolve()))
mod_name = script_fpath.stem
mod = importlib.import_module(mod_name)
# Patch sys.argv
sys.argv = [args.training_script] + args.training_script_args + ["--tpu_num_cores", str(args.num_cores)]
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/pytorch/test_pytorch_examples.py
|
# coding=utf-8
# Copyright 2018 HuggingFace Inc..
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import logging
import os
import sys
from unittest.mock import patch
from transformers import ViTMAEForPreTraining, Wav2Vec2ForPreTraining
from transformers.testing_utils import (
CaptureLogger,
TestCasePlus,
backend_device_count,
is_torch_fp16_available_on_device,
slow,
torch_device,
)
SRC_DIRS = [
os.path.join(os.path.dirname(__file__), dirname)
for dirname in [
"text-generation",
"text-classification",
"token-classification",
"language-modeling",
"multiple-choice",
"question-answering",
"summarization",
"translation",
"image-classification",
"speech-recognition",
"audio-classification",
"speech-pretraining",
"image-pretraining",
"semantic-segmentation",
]
]
sys.path.extend(SRC_DIRS)
if SRC_DIRS is not None:
import run_audio_classification
import run_clm
import run_generation
import run_glue
import run_image_classification
import run_mae
import run_mlm
import run_ner
import run_qa as run_squad
import run_semantic_segmentation
import run_seq2seq_qa as run_squad_seq2seq
import run_speech_recognition_ctc
import run_speech_recognition_ctc_adapter
import run_speech_recognition_seq2seq
import run_summarization
import run_swag
import run_translation
import run_wav2vec2_pretraining_no_trainer
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
def get_results(output_dir):
results = {}
path = os.path.join(output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
results = json.load(f)
else:
raise ValueError(f"can't find {path}")
return results
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class ExamplesTests(TestCasePlus):
def test_run_glue(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_glue.py
--model_name_or_path distilbert-base-uncased
--output_dir {tmp_dir}
--overwrite_output_dir
--train_file ./tests/fixtures/tests_samples/MRPC/train.csv
--validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
--do_train
--do_eval
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--learning_rate=1e-4
--max_steps=10
--warmup_steps=2
--seed=42
--max_seq_length=128
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_glue.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
def test_run_clm(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_clm.py
--model_name_or_path distilgpt2
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--do_train
--do_eval
--block_size 128
--per_device_train_batch_size 5
--per_device_eval_batch_size 5
--num_train_epochs 2
--output_dir {tmp_dir}
--overwrite_output_dir
""".split()
if backend_device_count(torch_device) > 1:
# Skipping because there are not enough batches to train the model + would need a drop_last to work.
return
if torch_device == "cpu":
testargs.append("--use_cpu")
with patch.object(sys, "argv", testargs):
run_clm.main()
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 100)
def test_run_clm_config_overrides(self):
# test that config_overrides works, despite the misleading dumps of default un-updated
# config via tokenizer
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_clm.py
--model_type gpt2
--tokenizer_name gpt2
--train_file ./tests/fixtures/sample_text.txt
--output_dir {tmp_dir}
--config_overrides n_embd=10,n_head=2
""".split()
if torch_device == "cpu":
testargs.append("--use_cpu")
logger = run_clm.logger
with patch.object(sys, "argv", testargs):
with CaptureLogger(logger) as cl:
run_clm.main()
self.assertIn('"n_embd": 10', cl.out)
self.assertIn('"n_head": 2', cl.out)
def test_run_mlm(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_mlm.py
--model_name_or_path distilroberta-base
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--output_dir {tmp_dir}
--overwrite_output_dir
--do_train
--do_eval
--prediction_loss_only
--num_train_epochs=1
""".split()
if torch_device == "cpu":
testargs.append("--use_cpu")
with patch.object(sys, "argv", testargs):
run_mlm.main()
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 42)
def test_run_ner(self):
# with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
epochs = 7 if backend_device_count(torch_device) > 1 else 2
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_ner.py
--model_name_or_path bert-base-uncased
--train_file tests/fixtures/tests_samples/conll/sample.json
--validation_file tests/fixtures/tests_samples/conll/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--do_train
--do_eval
--warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=2
--num_train_epochs={epochs}
--seed 7
""".split()
if torch_device == "cpu":
testargs.append("--use_cpu")
with patch.object(sys, "argv", testargs):
run_ner.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
self.assertLess(result["eval_loss"], 0.5)
def test_run_squad(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_qa.py
--model_name_or_path bert-base-uncased
--version_2_with_negative
--train_file tests/fixtures/tests_samples/SQUAD/sample.json
--validation_file tests/fixtures/tests_samples/SQUAD/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--max_steps=10
--warmup_steps=2
--do_train
--do_eval
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
""".split()
with patch.object(sys, "argv", testargs):
run_squad.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_f1"], 30)
self.assertGreaterEqual(result["eval_exact"], 30)
def test_run_squad_seq2seq(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_seq2seq_qa.py
--model_name_or_path t5-small
--context_column context
--question_column question
--answer_column answers
--version_2_with_negative
--train_file tests/fixtures/tests_samples/SQUAD/sample.json
--validation_file tests/fixtures/tests_samples/SQUAD/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--max_steps=10
--warmup_steps=2
--do_train
--do_eval
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--predict_with_generate
""".split()
with patch.object(sys, "argv", testargs):
run_squad_seq2seq.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_f1"], 30)
self.assertGreaterEqual(result["eval_exact"], 30)
def test_run_swag(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_swag.py
--model_name_or_path bert-base-uncased
--train_file tests/fixtures/tests_samples/swag/sample.json
--validation_file tests/fixtures/tests_samples/swag/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--max_steps=20
--warmup_steps=2
--do_train
--do_eval
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
""".split()
with patch.object(sys, "argv", testargs):
run_swag.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.8)
def test_generation(self):
testargs = ["run_generation.py", "--prompt=Hello", "--length=10", "--seed=42"]
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
model_type, model_name = (
"--model_type=gpt2",
"--model_name_or_path=sshleifer/tiny-gpt2",
)
with patch.object(sys, "argv", testargs + [model_type, model_name]):
result = run_generation.main()
self.assertGreaterEqual(len(result[0]), 10)
@slow
def test_run_summarization(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_summarization.py
--model_name_or_path t5-small
--train_file tests/fixtures/tests_samples/xsum/sample.json
--validation_file tests/fixtures/tests_samples/xsum/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--max_steps=50
--warmup_steps=8
--do_train
--do_eval
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--predict_with_generate
""".split()
with patch.object(sys, "argv", testargs):
run_summarization.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_rouge1"], 10)
self.assertGreaterEqual(result["eval_rouge2"], 2)
self.assertGreaterEqual(result["eval_rougeL"], 7)
self.assertGreaterEqual(result["eval_rougeLsum"], 7)
@slow
def test_run_translation(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_translation.py
--model_name_or_path sshleifer/student_marian_en_ro_6_1
--source_lang en
--target_lang ro
--train_file tests/fixtures/tests_samples/wmt16/sample.json
--validation_file tests/fixtures/tests_samples/wmt16/sample.json
--output_dir {tmp_dir}
--overwrite_output_dir
--max_steps=50
--warmup_steps=8
--do_train
--do_eval
--learning_rate=3e-3
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--predict_with_generate
--source_lang en_XX
--target_lang ro_RO
""".split()
with patch.object(sys, "argv", testargs):
run_translation.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_bleu"], 30)
def test_run_image_classification(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_image_classification.py
--output_dir {tmp_dir}
--model_name_or_path google/vit-base-patch16-224-in21k
--dataset_name hf-internal-testing/cats_vs_dogs_sample
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--remove_unused_columns False
--overwrite_output_dir True
--dataloader_num_workers 16
--metric_for_best_model accuracy
--max_steps 10
--train_val_split 0.1
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_image_classification.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.8)
def test_run_speech_recognition_ctc(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_speech_recognition_ctc.py
--output_dir {tmp_dir}
--model_name_or_path hf-internal-testing/tiny-random-wav2vec2
--dataset_name hf-internal-testing/librispeech_asr_dummy
--dataset_config_name clean
--train_split_name validation
--eval_split_name validation
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--remove_unused_columns False
--overwrite_output_dir True
--preprocessing_num_workers 16
--max_steps 10
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_speech_recognition_ctc.main()
result = get_results(tmp_dir)
self.assertLess(result["eval_loss"], result["train_loss"])
def test_run_speech_recognition_ctc_adapter(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_speech_recognition_ctc_adapter.py
--output_dir {tmp_dir}
--model_name_or_path hf-internal-testing/tiny-random-wav2vec2
--dataset_name hf-internal-testing/librispeech_asr_dummy
--dataset_config_name clean
--train_split_name validation
--eval_split_name validation
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--remove_unused_columns False
--overwrite_output_dir True
--preprocessing_num_workers 16
--max_steps 10
--target_language tur
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_speech_recognition_ctc_adapter.main()
result = get_results(tmp_dir)
self.assertTrue(os.path.isfile(os.path.join(tmp_dir, "./adapter.tur.safetensors")))
self.assertLess(result["eval_loss"], result["train_loss"])
def test_run_speech_recognition_seq2seq(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_speech_recognition_seq2seq.py
--output_dir {tmp_dir}
--model_name_or_path hf-internal-testing/tiny-random-speech-encoder-decoder
--dataset_name hf-internal-testing/librispeech_asr_dummy
--dataset_config_name clean
--train_split_name validation
--eval_split_name validation
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 4
--remove_unused_columns False
--overwrite_output_dir True
--preprocessing_num_workers 16
--max_steps 10
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_speech_recognition_seq2seq.main()
result = get_results(tmp_dir)
self.assertLess(result["eval_loss"], result["train_loss"])
def test_run_audio_classification(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_audio_classification.py
--output_dir {tmp_dir}
--model_name_or_path hf-internal-testing/tiny-random-wav2vec2
--dataset_name anton-l/superb_demo
--dataset_config_name ks
--train_split_name test
--eval_split_name test
--audio_column_name audio
--label_column_name label
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--remove_unused_columns False
--overwrite_output_dir True
--num_train_epochs 10
--max_steps 50
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_audio_classification.main()
result = get_results(tmp_dir)
self.assertLess(result["eval_loss"], result["train_loss"])
def test_run_wav2vec2_pretraining(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_wav2vec2_pretraining_no_trainer.py
--output_dir {tmp_dir}
--model_name_or_path hf-internal-testing/tiny-random-wav2vec2
--dataset_name hf-internal-testing/librispeech_asr_dummy
--dataset_config_names clean
--dataset_split_names validation
--learning_rate 1e-4
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--preprocessing_num_workers 16
--max_train_steps 2
--validation_split_percentage 5
--seed 42
""".split()
with patch.object(sys, "argv", testargs):
run_wav2vec2_pretraining_no_trainer.main()
model = Wav2Vec2ForPreTraining.from_pretrained(tmp_dir)
self.assertIsNotNone(model)
def test_run_vit_mae_pretraining(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_mae.py
--output_dir {tmp_dir}
--dataset_name hf-internal-testing/cats_vs_dogs_sample
--do_train
--do_eval
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--remove_unused_columns False
--overwrite_output_dir True
--dataloader_num_workers 16
--metric_for_best_model accuracy
--max_steps 10
--train_val_split 0.1
--seed 42
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_mae.main()
model = ViTMAEForPreTraining.from_pretrained(tmp_dir)
self.assertIsNotNone(model)
def test_run_semantic_segmentation(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
run_semantic_segmentation.py
--output_dir {tmp_dir}
--dataset_name huggingface/semantic-segmentation-test-sample
--do_train
--do_eval
--remove_unused_columns False
--overwrite_output_dir True
--max_steps 10
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--seed 32
""".split()
if is_torch_fp16_available_on_device(torch_device):
testargs.append("--fp16")
with patch.object(sys, "argv", testargs):
run_semantic_segmentation.main()
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_overall_accuracy"], 0.1)
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/semantic-segmentation/README.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Semantic segmentation examples
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT](https://huggingface.co/docs/transformers/main/en/model_doc/dpt)) using PyTorch.
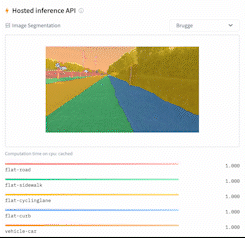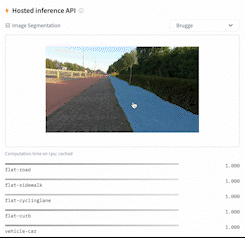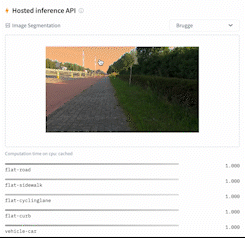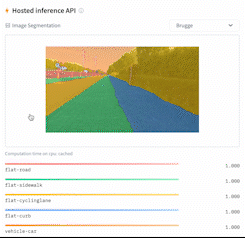
Content:
* [Note on custom data](#note-on-custom-data)
* [PyTorch version, Trainer](#pytorch-version-trainer)
* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
* [Reload and perform inference](#reload-and-perform-inference)
* [Important notes](#important-notes)
## Note on custom data
In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
### Creating a `DatasetDict`
The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
```python
from datasets import Dataset, DatasetDict, Image
# your images can of course have a different extension
# semantic segmentation maps are typically stored in the png format
image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
# same for validation
# image_paths_validation = [...]
# label_paths_validation = [...]
def create_dataset(image_paths, label_paths):
dataset = Dataset.from_dict({"image": sorted(image_paths),
"label": sorted(label_paths)})
dataset = dataset.cast_column("image", Image())
dataset = dataset.cast_column("label", Image())
return dataset
# step 1: create Dataset objects
train_dataset = create_dataset(image_paths_train, label_paths_train)
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
# step 2: create DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
}
)
# step 3: push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
dataset.push_to_hub("name of repo on the hub")
# optionally, you can push to a private repo on the hub
# dataset.push_to_hub("name of repo on the hub", private=True)
```
An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
### Creating an id2label mapping
Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names. An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). This can be created in Python as follows:
```python
import json
# simple example
id2label = {0: 'cat', 1: 'dog'}
with open('id2label.json', 'w') as fp:
json.dump(id2label, fp)
```
You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
## PyTorch version, Trainer
Based on the script [`run_semantic_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
Here we show how to fine-tune a [SegFormer](https://huggingface.co/nvidia/mit-b0) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset:
```bash
python run_semantic_segmentation.py \
--model_name_or_path nvidia/mit-b0 \
--dataset_name segments/sidewalk-semantic \
--output_dir ./segformer_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--evaluation_strategy steps \
--push_to_hub \
--push_to_hub_model_id segformer-finetuned-sidewalk-10k-steps \
--max_steps 10000 \
--learning_rate 0.00006 \
--lr_scheduler_type polynomial \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 100 \
--evaluation_strategy epoch \
--save_strategy epoch \
--seed 1337
```
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk-10k-steps. The corresponding Weights and Biases report [here](https://wandb.ai/nielsrogge/huggingface/reports/SegFormer-fine-tuning--VmlldzoxODY5NTQ2). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. E.g. from the SegFormer paper:
> We trained the models using AdamW optimizer for 160K iterations on ADE20K, Cityscapes, and 80K iterations on COCO-Stuff. (...) We used a batch size of 16 for ADE20K and COCO-Stuff, and a batch size of 8 for Cityscapes. The learning rate was set to an initial value of 0.00006 and then used a “poly” LR schedule with factor 1.0 by default.
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
## PyTorch version, no Trainer
Based on the script [`run_semantic_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
First, run:
```bash
accelerate config
```
and reply to the questions asked regarding the environment on which you'd like to train. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_semantic_segmentation_no_trainer.py --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
```
and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
With the default settings, the script fine-tunes a [SegFormer]((https://huggingface.co/docs/transformers/main/en/model_doc/segformer)) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset.
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk. Note that the script usually requires quite a few epochs to achieve great results, e.g. the SegFormer authors fine-tuned their model for 160k steps (batches) on [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150).
## Reload and perform inference
This means that after training, you can easily load your trained model as follows:
```python
from transformers import AutoImageProcessor, AutoModelForSemanticSegmentation
model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
image_processor = AutoImageProcessor.from_pretrained(model_name)
model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
```
and perform inference as follows:
```python
from PIL import Image
import requests
import torch
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# rescale logits to original image size
logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
size=image.size[::-1], # (height, width)
mode='bilinear',
align_corners=False)
predicted = logits.argmax(1)
```
For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
## Important notes
Some datasets, like [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
In case you're training on such a dataset, make sure to set the ``reduce_labels`` flag, which will take care of this.
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning any 🤗 Transformers model supported by AutoModelForSemanticSegmentation for semantic segmentation."""
import argparse
import json
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from huggingface_hub import Repository, create_repo, hf_hub_download
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.transforms import functional
from tqdm.auto import tqdm
import transformers
from transformers import (
AutoConfig,
AutoImageProcessor,
AutoModelForSemanticSegmentation,
SchedulerType,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.36.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
def pad_if_smaller(img, size, fill=0):
min_size = min(img.size)
if min_size < size:
original_width, original_height = img.size
pad_height = size - original_height if original_height < size else 0
pad_width = size - original_width if original_width < size else 0
img = functional.pad(img, (0, 0, pad_width, pad_height), fill=fill)
return img
class Compose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class Identity:
def __init__(self):
pass
def __call__(self, image, target):
return image, target
class Resize:
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = functional.resize(image, self.size)
target = functional.resize(target, self.size, interpolation=transforms.InterpolationMode.NEAREST)
return image, target
class RandomResize:
def __init__(self, min_size, max_size=None):
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
size = random.randint(self.min_size, self.max_size)
image = functional.resize(image, size)
target = functional.resize(target, size, interpolation=transforms.InterpolationMode.NEAREST)
return image, target
class RandomCrop:
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = pad_if_smaller(image, self.size)
target = pad_if_smaller(target, self.size, fill=255)
crop_params = transforms.RandomCrop.get_params(image, (self.size, self.size))
image = functional.crop(image, *crop_params)
target = functional.crop(target, *crop_params)
return image, target
class RandomHorizontalFlip:
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = functional.hflip(image)
target = functional.hflip(target)
return image, target
class PILToTensor:
def __call__(self, image, target):
image = functional.pil_to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
class ConvertImageDtype:
def __init__(self, dtype):
self.dtype = dtype
def __call__(self, image, target):
image = functional.convert_image_dtype(image, self.dtype)
return image, target
class Normalize:
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = functional.normalize(image, mean=self.mean, std=self.std)
return image, target
class ReduceLabels:
def __call__(self, image, target):
if not isinstance(target, np.ndarray):
target = np.array(target).astype(np.uint8)
# avoid using underflow conversion
target[target == 0] = 255
target = target - 1
target[target == 254] = 255
target = Image.fromarray(target)
return image, target
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to a pretrained model or model identifier from huggingface.co/models.",
default="nvidia/mit-b0",
)
parser.add_argument(
"--dataset_name",
type=str,
help="Name of the dataset on the hub.",
default="segments/sidewalk-semantic",
)
parser.add_argument(
"--reduce_labels",
action="store_true",
help="Whether or not to reduce all labels by 1 and replace background by 255.",
)
parser.add_argument(
"--train_val_split",
type=float,
default=0.15,
help="Fraction of the dataset to be used for validation.",
)
parser.add_argument(
"--cache_dir",
type=str,
help="Path to a folder in which the model and dataset will be cached.",
)
parser.add_argument(
"--use_auth_token",
action="store_true",
help="Whether to use an authentication token to access the model repository.",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--adam_beta1",
type=float,
default=0.9,
help="Beta1 for AdamW optimizer",
)
parser.add_argument(
"--adam_beta2",
type=float,
default=0.999,
help="Beta2 for AdamW optimizer",
)
parser.add_argument(
"--adam_epsilon",
type=float,
default=1e-8,
help="Epsilon for AdamW optimizer",
)
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="polynomial",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--trust_remote_code",
type=bool,
default=False,
help=(
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option"
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
required=False,
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
args = parser.parse_args()
# Sanity checks
if args.push_to_hub or args.with_tracking:
if args.output_dir is None:
raise ValueError(
"Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
)
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_semantic_segmentation_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
# We set device_specific to True as we want different data augmentation per device.
if args.seed is not None:
set_seed(args.seed, device_specific=True)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
# Clone repo locally
repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Load dataset
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
# TODO support datasets from local folders
dataset = load_dataset(args.dataset_name, cache_dir=args.cache_dir)
# Rename column names to standardized names (only "image" and "label" need to be present)
if "pixel_values" in dataset["train"].column_names:
dataset = dataset.rename_columns({"pixel_values": "image"})
if "annotation" in dataset["train"].column_names:
dataset = dataset.rename_columns({"annotation": "label"})
# If we don't have a validation split, split off a percentage of train as validation.
args.train_val_split = None if "validation" in dataset.keys() else args.train_val_split
if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
split = dataset["train"].train_test_split(args.train_val_split)
dataset["train"] = split["train"]
dataset["validation"] = split["test"]
# Prepare label mappings.
# We'll include these in the model's config to get human readable labels in the Inference API.
if args.dataset_name == "scene_parse_150":
repo_id = "huggingface/label-files"
filename = "ade20k-id2label.json"
else:
repo_id = args.dataset_name
filename = "id2label.json"
id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
label2id = {v: k for k, v in id2label.items()}
# Load pretrained model and image processor
config = AutoConfig.from_pretrained(
args.model_name_or_path, id2label=id2label, label2id=label2id, trust_remote_code=args.trust_remote_code
)
image_processor = AutoImageProcessor.from_pretrained(
args.model_name_or_path, trust_remote_code=args.trust_remote_code
)
model = AutoModelForSemanticSegmentation.from_pretrained(
args.model_name_or_path, config=config, trust_remote_code=args.trust_remote_code
)
# Preprocessing the datasets
# Define torchvision transforms to be applied to each image + target.
# Not that straightforward in torchvision: https://github.com/pytorch/vision/issues/9
# Currently based on official torchvision references: https://github.com/pytorch/vision/blob/main/references/segmentation/transforms.py
if "shortest_edge" in image_processor.size:
# We instead set the target size as (shortest_edge, shortest_edge) to here to ensure all images are batchable.
size = (image_processor.size["shortest_edge"], image_processor.size["shortest_edge"])
else:
size = (image_processor.size["height"], image_processor.size["width"])
train_transforms = Compose(
[
ReduceLabels() if args.reduce_labels else Identity(),
RandomCrop(size=size),
RandomHorizontalFlip(flip_prob=0.5),
PILToTensor(),
ConvertImageDtype(torch.float),
Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
# Define torchvision transform to be applied to each image.
# jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
val_transforms = Compose(
[
ReduceLabels() if args.reduce_labels else Identity(),
Resize(size=size),
PILToTensor(),
ConvertImageDtype(torch.float),
Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
def preprocess_train(example_batch):
pixel_values = []
labels = []
for image, target in zip(example_batch["image"], example_batch["label"]):
image, target = train_transforms(image.convert("RGB"), target)
pixel_values.append(image)
labels.append(target)
encoding = {}
encoding["pixel_values"] = torch.stack(pixel_values)
encoding["labels"] = torch.stack(labels)
return encoding
def preprocess_val(example_batch):
pixel_values = []
labels = []
for image, target in zip(example_batch["image"], example_batch["label"]):
image, target = val_transforms(image.convert("RGB"), target)
pixel_values.append(image)
labels.append(target)
encoding = {}
encoding["pixel_values"] = torch.stack(pixel_values)
encoding["labels"] = torch.stack(labels)
return encoding
with accelerator.main_process_first():
train_dataset = dataset["train"].with_transform(preprocess_train)
eval_dataset = dataset["validation"].with_transform(preprocess_val)
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(
eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
)
# Optimizer
optimizer = torch.optim.AdamW(
list(model.parameters()),
lr=args.learning_rate,
betas=[args.adam_beta1, args.adam_beta2],
eps=args.adam_epsilon,
)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Instantiate metric
metric = evaluate.load("mean_iou")
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("semantic_segmentation_no_trainer", experiment_config)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir,
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
)
if accelerator.is_main_process:
image_processor.save_pretrained(args.output_dir)
repo.push_to_hub(
commit_message=f"Training in progress {completed_steps} steps",
blocking=False,
auto_lfs_prune=True,
)
if completed_steps >= args.max_train_steps:
break
logger.info("***** Running evaluation *****")
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader, disable=not accelerator.is_local_main_process)):
with torch.no_grad():
outputs = model(**batch)
upsampled_logits = torch.nn.functional.interpolate(
outputs.logits, size=batch["labels"].shape[-2:], mode="bilinear", align_corners=False
)
predictions = upsampled_logits.argmax(dim=1)
predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metrics = metric.compute(
num_labels=len(id2label),
ignore_index=255,
reduce_labels=False, # we've already reduced the labels before
)
logger.info(f"epoch {epoch}: {eval_metrics}")
if args.with_tracking:
accelerator.log(
{
"mean_iou": eval_metrics["mean_iou"],
"mean_accuracy": eval_metrics["mean_accuracy"],
"overall_accuracy": eval_metrics["overall_accuracy"],
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
image_processor.save_pretrained(args.output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.with_tracking:
accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
image_processor.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
all_results = {
f"eval_{k}": v.tolist() if isinstance(v, np.ndarray) else v for k, v in eval_metrics.items()
}
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
json.dump(all_results, f)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import json
import logging
import os
import random
import sys
import warnings
from dataclasses import dataclass, field
from typing import Optional
import evaluate
import numpy as np
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from PIL import Image
from torch import nn
from torchvision import transforms
from torchvision.transforms import functional
import transformers
from transformers import (
AutoConfig,
AutoImageProcessor,
AutoModelForSemanticSegmentation,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
""" Finetuning any 🤗 Transformers model supported by AutoModelForSemanticSegmentation for semantic segmentation leveraging the Trainer API."""
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.36.0.dev0")
require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
def pad_if_smaller(img, size, fill=0):
size = (size, size) if isinstance(size, int) else size
original_width, original_height = img.size
pad_height = size[1] - original_height if original_height < size[1] else 0
pad_width = size[0] - original_width if original_width < size[0] else 0
img = functional.pad(img, (0, 0, pad_width, pad_height), fill=fill)
return img
class Compose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class Identity:
def __init__(self):
pass
def __call__(self, image, target):
return image, target
class Resize:
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = functional.resize(image, self.size)
target = functional.resize(target, self.size, interpolation=transforms.InterpolationMode.NEAREST)
return image, target
class RandomResize:
def __init__(self, min_size, max_size=None):
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
size = random.randint(self.min_size, self.max_size)
image = functional.resize(image, size)
target = functional.resize(target, size, interpolation=transforms.InterpolationMode.NEAREST)
return image, target
class RandomCrop:
def __init__(self, size):
self.size = size if isinstance(size, tuple) else (size, size)
def __call__(self, image, target):
image = pad_if_smaller(image, self.size)
target = pad_if_smaller(target, self.size, fill=255)
crop_params = transforms.RandomCrop.get_params(image, self.size)
image = functional.crop(image, *crop_params)
target = functional.crop(target, *crop_params)
return image, target
class RandomHorizontalFlip:
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = functional.hflip(image)
target = functional.hflip(target)
return image, target
class PILToTensor:
def __call__(self, image, target):
image = functional.pil_to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
class ConvertImageDtype:
def __init__(self, dtype):
self.dtype = dtype
def __call__(self, image, target):
image = functional.convert_image_dtype(image, self.dtype)
return image, target
class Normalize:
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = functional.normalize(image, mean=self.mean, std=self.std)
return image, target
class ReduceLabels:
def __call__(self, image, target):
if not isinstance(target, np.ndarray):
target = np.array(target).astype(np.uint8)
# avoid using underflow conversion
target[target == 0] = 255
target = target - 1
target[target == 254] = 255
target = Image.fromarray(target)
return image, target
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
them on the command line.
"""
dataset_name: Optional[str] = field(
default="segments/sidewalk-semantic",
metadata={
"help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
},
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_val_split: Optional[float] = field(
default=0.15, metadata={"help": "Percent to split off of train for validation."}
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
reduce_labels: Optional[bool] = field(
default=False,
metadata={"help": "Whether or not to reduce all labels by 1 and replace background by 255."},
)
def __post_init__(self):
if self.dataset_name is None and (self.train_dir is None and self.validation_dir is None):
raise ValueError(
"You must specify either a dataset name from the hub or a train and/or validation directory."
)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
default="nvidia/mit-b0",
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option"
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_semantic_segmentation", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Load dataset
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
# TODO support datasets from local folders
dataset = load_dataset(data_args.dataset_name, cache_dir=model_args.cache_dir)
# Rename column names to standardized names (only "image" and "label" need to be present)
if "pixel_values" in dataset["train"].column_names:
dataset = dataset.rename_columns({"pixel_values": "image"})
if "annotation" in dataset["train"].column_names:
dataset = dataset.rename_columns({"annotation": "label"})
# If we don't have a validation split, split off a percentage of train as validation.
data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
split = dataset["train"].train_test_split(data_args.train_val_split)
dataset["train"] = split["train"]
dataset["validation"] = split["test"]
# Prepare label mappings.
# We'll include these in the model's config to get human readable labels in the Inference API.
if data_args.dataset_name == "scene_parse_150":
repo_id = "huggingface/label-files"
filename = "ade20k-id2label.json"
else:
repo_id = data_args.dataset_name
filename = "id2label.json"
id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
label2id = {v: str(k) for k, v in id2label.items()}
# Load the mean IoU metric from the datasets package
metric = evaluate.load("mean_iou")
# Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
# predictions and label_ids field) and has to return a dictionary string to float.
@torch.no_grad()
def compute_metrics(eval_pred):
logits, labels = eval_pred
logits_tensor = torch.from_numpy(logits)
# scale the logits to the size of the label
logits_tensor = nn.functional.interpolate(
logits_tensor,
size=labels.shape[-2:],
mode="bilinear",
align_corners=False,
).argmax(dim=1)
pred_labels = logits_tensor.detach().cpu().numpy()
metrics = metric.compute(
predictions=pred_labels,
references=labels,
num_labels=len(id2label),
ignore_index=0,
reduce_labels=image_processor.do_reduce_labels,
)
# add per category metrics as individual key-value pairs
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
per_category_iou = metrics.pop("per_category_iou").tolist()
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
return metrics
config = AutoConfig.from_pretrained(
model_args.config_name or model_args.model_name_or_path,
label2id=label2id,
id2label=id2label,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForSemanticSegmentation.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
image_processor = AutoImageProcessor.from_pretrained(
model_args.image_processor_name or model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# Define torchvision transforms to be applied to each image + target.
# Not that straightforward in torchvision: https://github.com/pytorch/vision/issues/9
# Currently based on official torchvision references: https://github.com/pytorch/vision/blob/main/references/segmentation/transforms.py
if "shortest_edge" in image_processor.size:
# We instead set the target size as (shortest_edge, shortest_edge) to here to ensure all images are batchable.
size = (image_processor.size["shortest_edge"], image_processor.size["shortest_edge"])
else:
size = (image_processor.size["height"], image_processor.size["width"])
train_transforms = Compose(
[
ReduceLabels() if data_args.reduce_labels else Identity(),
RandomCrop(size=size),
RandomHorizontalFlip(flip_prob=0.5),
PILToTensor(),
ConvertImageDtype(torch.float),
Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
# Define torchvision transform to be applied to each image.
# jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
val_transforms = Compose(
[
ReduceLabels() if data_args.reduce_labels else Identity(),
Resize(size=size),
PILToTensor(),
ConvertImageDtype(torch.float),
Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
def preprocess_train(example_batch):
pixel_values = []
labels = []
for image, target in zip(example_batch["image"], example_batch["label"]):
image, target = train_transforms(image.convert("RGB"), target)
pixel_values.append(image)
labels.append(target)
encoding = {}
encoding["pixel_values"] = torch.stack(pixel_values)
encoding["labels"] = torch.stack(labels)
return encoding
def preprocess_val(example_batch):
pixel_values = []
labels = []
for image, target in zip(example_batch["image"], example_batch["label"]):
image, target = val_transforms(image.convert("RGB"), target)
pixel_values.append(image)
labels.append(target)
encoding = {}
encoding["pixel_values"] = torch.stack(pixel_values)
encoding["labels"] = torch.stack(labels)
return encoding
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
if data_args.max_train_samples is not None:
dataset["train"] = (
dataset["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
)
# Set the training transforms
dataset["train"].set_transform(preprocess_train)
if training_args.do_eval:
if "validation" not in dataset:
raise ValueError("--do_eval requires a validation dataset")
if data_args.max_eval_samples is not None:
dataset["validation"] = (
dataset["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
)
# Set the validation transforms
dataset["validation"].set_transform(preprocess_val)
# Initalize our trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=image_processor,
data_collator=default_data_collator,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate()
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Write model card and (optionally) push to hub
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"dataset": data_args.dataset_name,
"tags": ["image-segmentation", "vision"],
}
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/semantic-segmentation/requirements.txt
|
git://github.com/huggingface/accelerate.git
datasets >= 2.0.0
torch >= 1.3
evaluate
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/token-classification/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification
## PyTorch version
Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech
tagging (POS) or phrase extraction (CHUNKS). The main scrip `run_ner.py` leverages the 🤗 Datasets library and the Trainer API. You can easily
customize it to your needs if you need extra processing on your datasets.
It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
training and validation, you might just need to add some tweaks in the data preprocessing.
The following example fine-tunes BERT on CoNLL-2003:
```bash
python run_ner.py \
--model_name_or_path bert-base-uncased \
--dataset_name conll2003 \
--output_dir /tmp/test-ner \
--do_train \
--do_eval
```
or just can just run the bash script `run.sh`.
To run on your own training and validation files, use the following command:
```bash
python run_ner.py \
--model_name_or_path bert-base-uncased \
--train_file path_to_train_file \
--validation_file path_to_validation_file \
--output_dir /tmp/test-ner \
--do_train \
--do_eval
```
**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version
of the script.
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
## Old version of the script
You can find the old version of the PyTorch script [here](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
## Pytorch version, no Trainer
Based on the script [run_ner_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner_no_trainer.py).
Like `run_ner.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on a
token classification task, either NER, POS or CHUNKS tasks or your own data in a csv or a JSON file. The main difference is that this
script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
export TASK_NAME=ner
python run_ner_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
export TASK_NAME=ner
accelerate launch run_ner_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| 0
|
hf_public_repos/transformers/examples/pytorch
|
hf_public_repos/transformers/examples/pytorch/token-classification/run_ner_no_trainer.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on token classification tasks (NER, POS, CHUNKS) relying on the accelerate library
without using a Trainer.
"""
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import ClassLabel, load_dataset
from huggingface_hub import Repository, create_repo
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorForTokenClassification,
PretrainedConfig,
SchedulerType,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.36.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(
description="Finetune a transformers model on a text classification task (NER) with accelerate library"
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--text_column_name",
type=str,
default=None,
help="The column name of text to input in the file (a csv or JSON file).",
)
parser.add_argument(
"--label_column_name",
type=str,
default=None,
help="The column name of label to input in the file (a csv or JSON file).",
)
parser.add_argument(
"--max_length",
type=int,
default=128,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_length` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument(
"--label_all_tokens",
action="store_true",
help="Setting labels of all special tokens to -100 and thus PyTorch will ignore them.",
)
parser.add_argument(
"--return_entity_level_metrics",
action="store_true",
help="Indication whether entity level metrics are to be returner.",
)
parser.add_argument(
"--task_name",
type=str,
default="ner",
choices=["ner", "pos", "chunk"],
help="The name of the task.",
)
parser.add_argument(
"--debug",
action="store_true",
help="Activate debug mode and run training only with a subset of data.",
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--trust_remote_code",
type=bool,
default=False,
help=(
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option"
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
parser.add_argument(
"--ignore_mismatched_sizes",
action="store_true",
help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
)
args = parser.parse_args()
# Sanity checks
if args.task_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a task name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_ner_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator = (
Accelerator(log_with=args.report_to, project_dir=args.output_dir) if args.with_tracking else Accelerator()
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
# Clone repo locally
repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
# 'tokens' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.train_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files)
# Trim a number of training examples
if args.debug:
for split in raw_datasets.keys():
raw_datasets[split] = raw_datasets[split].select(range(100))
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
if raw_datasets["train"] is not None:
column_names = raw_datasets["train"].column_names
features = raw_datasets["train"].features
else:
column_names = raw_datasets["validation"].column_names
features = raw_datasets["validation"].features
if args.text_column_name is not None:
text_column_name = args.text_column_name
elif "tokens" in column_names:
text_column_name = "tokens"
else:
text_column_name = column_names[0]
if args.label_column_name is not None:
label_column_name = args.label_column_name
elif f"{args.task_name}_tags" in column_names:
label_column_name = f"{args.task_name}_tags"
else:
label_column_name = column_names[1]
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
# If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
# Otherwise, we have to get the list of labels manually.
labels_are_int = isinstance(features[label_column_name].feature, ClassLabel)
if labels_are_int:
label_list = features[label_column_name].feature.names
label_to_id = {i: i for i in range(len(label_list))}
else:
label_list = get_label_list(raw_datasets["train"][label_column_name])
label_to_id = {l: i for i, l in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(
args.config_name, num_labels=num_labels, trust_remote_code=args.trust_remote_code
)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(
args.model_name_or_path, num_labels=num_labels, trust_remote_code=args.trust_remote_code
)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
tokenizer_name_or_path = args.tokenizer_name if args.tokenizer_name else args.model_name_or_path
if not tokenizer_name_or_path:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if config.model_type in {"bloom", "gpt2", "roberta"}:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path, use_fast=True, add_prefix_space=True, trust_remote_code=args.trust_remote_code
)
else:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path, use_fast=True, trust_remote_code=args.trust_remote_code
)
if args.model_name_or_path:
model = AutoModelForTokenClassification.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
ignore_mismatched_sizes=args.ignore_mismatched_sizes,
trust_remote_code=args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForTokenClassification.from_config(config, trust_remote_code=args.trust_remote_code)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# Model has labels -> use them.
if model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
if sorted(model.config.label2id.keys()) == sorted(label_list):
# Reorganize `label_list` to match the ordering of the model.
if labels_are_int:
label_to_id = {i: int(model.config.label2id[l]) for i, l in enumerate(label_list)}
label_list = [model.config.id2label[i] for i in range(num_labels)]
else:
label_list = [model.config.id2label[i] for i in range(num_labels)]
label_to_id = {l: i for i, l in enumerate(label_list)}
else:
logger.warning(
"Your model seems to have been trained with labels, but they don't match the dataset: ",
f"model labels: {sorted(model.config.label2id.keys())}, dataset labels:"
f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
)
# Set the correspondences label/ID inside the model config
model.config.label2id = {l: i for i, l in enumerate(label_list)}
model.config.id2label = dict(enumerate(label_list))
# Map that sends B-Xxx label to its I-Xxx counterpart
b_to_i_label = []
for idx, label in enumerate(label_list):
if label.startswith("B-") and label.replace("B-", "I-") in label_list:
b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
else:
b_to_i_label.append(idx)
# Preprocessing the datasets.
# First we tokenize all the texts.
padding = "max_length" if args.pad_to_max_length else False
# Tokenize all texts and align the labels with them.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples[text_column_name],
max_length=args.max_length,
padding=padding,
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label_to_id[label[word_idx]])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
if args.label_all_tokens:
label_ids.append(b_to_i_label[label_to_id[label[word_idx]]])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
with accelerator.main_process_first():
processed_raw_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
desc="Running tokenizer on dataset",
)
train_dataset = processed_raw_datasets["train"]
eval_dataset = processed_raw_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorForTokenClassification` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
data_collator = DataCollatorForTokenClassification(
tokenizer, pad_to_multiple_of=(8 if accelerator.use_fp16 else None)
)
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Use the device given by the `accelerator` object.
device = accelerator.device
model.to(device)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("ner_no_trainer", experiment_config)
# Metrics
metric = evaluate.load("seqeval")
def get_labels(predictions, references):
# Transform predictions and references tensos to numpy arrays
if device.type == "cpu":
y_pred = predictions.detach().clone().numpy()
y_true = references.detach().clone().numpy()
else:
y_pred = predictions.detach().cpu().clone().numpy()
y_true = references.detach().cpu().clone().numpy()
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
true_labels = [
[label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
return true_predictions, true_labels
def compute_metrics():
results = metric.compute()
if args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
samples_seen = 0
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered, labels_gathered = accelerator.gather((predictions, labels))
# If we are in a multiprocess environment, the last batch has duplicates
if accelerator.num_processes > 1:
if step == len(eval_dataloader) - 1:
predictions_gathered = predictions_gathered[: len(eval_dataloader.dataset) - samples_seen]
labels_gathered = labels_gathered[: len(eval_dataloader.dataset) - samples_seen]
else:
samples_seen += labels_gathered.shape[0]
preds, refs = get_labels(predictions_gathered, labels_gathered)
metric.add_batch(
predictions=preds,
references=refs,
) # predictions and preferences are expected to be a nested list of labels, not label_ids
eval_metric = compute_metrics()
accelerator.print(f"epoch {epoch}:", eval_metric)
if args.with_tracking:
accelerator.log(
{
"seqeval": eval_metric,
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.with_tracking:
accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
if args.with_tracking:
all_results.update({"train_loss": total_loss.item() / len(train_dataloader)})
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
# Convert all float64 & int64 type numbers to float & int for json serialization
for key, value in all_results.items():
if isinstance(value, np.float64):
all_results[key] = float(value)
elif isinstance(value, np.int64):
all_results[key] = int(value)
json.dump(all_results, f)
if __name__ == "__main__":
main()
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.