
language stringclasses 15
values | src_encoding stringclasses 34
values | length_bytes int64 6 7.85M | score float64 1.5 5.69 | int_score int64 2 5 | detected_licenses listlengths 0 160 | license_type stringclasses 2
values | text stringlengths 9 7.85M |
|---|---|---|---|---|---|---|---|
Markdown | UTF-8 | 1,428 | 3.171875 | 3 | [] | no_license | # Immutable state vs Mutable state
우선 concurrency(동시성) 과 paralelism(병렬) 차이점에 대해 알아 볼 필요가 있다.. 이 둘은 비슷한 것 같지만 서로 다르다.
옛날에 concurrent 에 대해 두 가지 모델이 있었다.
- 1. Shared state concurrency
- 2. Message passing concurrency
그 당시 "Message passing concurrency"를 따랐던 언어는 거의 없었고
거의 대부분 엔지니어들은 shared state 쪽이었다.
message passing concurrency 에는 shared state 가 없다. 모든 계산은 프로세스에서 수행되며 데이터를 교환하는 유일한 방법은 asynchronous message passing(비동기 메시지 전달)을 사용하는 것이다.
shared state concurrency 는 "mutable state(변경 가능한 상태)"라는 개념을 포함하고 있다. 즉 memory가 변경 될 수 있다.
만약 프로세스가 하나 밖에 없으면 괜찮다. 하지만 여러 개의 프로세스가 동일한 메모리를 공유하고 수정하는 경우 이는 심각한 문제가 될 수 있다. shared memory를 동시에 수정하지 못하게 locking 메커니즘이 필요한데 mutex 또는 synchronised method 가 있다.
Immutable Data Structures = No Locks
Immutable Data Structures = Easy to parallelize
## Reference
[Immutable vs mutable state… Concurrency models](https://medium.com/@ostvp/immutable-vs-mutable-state-concurrency-models-5895debc14a) |
Python | UTF-8 | 3,985 | 3.046875 | 3 | [
"MIT"
] | permissive | import sqlite3
from utils.store import create_sugg_table, insert, countSuggestionsInDB, getMaxID, getNameOfLastRow, deleteExtraFakeRecord # noqa: E501
from utils.setup import selectshopbyname, selectshops, selectshopbyid, updateshopbyname, updateshopbyservice # noqa: E501
conn = sqlite3.connect('./data/suggestedShops.db', check_same_thread=False)
c = conn.cursor()
def test_suggTableMade():
""" Tests the create_sugg_table method by checking if the table exists
"""
create_sugg_table()
c.execute('SELECT name FROM sqlite_master WHERE type = ? AND name = ?',
('table', 'suggestedShops',))
result = c.fetchone()[0]
assert(result == "suggestedShops")
if result == "suggestedShops":
print("passed test 1")
else:
print("failed test 1")
def test_insertSuggestion():
""" Inserts a new row to suggestions table then checks if last inserted
record matches it. If it passes, it deletes the extra record
"""
# get ID of last record
x = getMaxID()
id = x+1
# increments by 1
# inserts new record using ID and fake inputs
insert(id, "FakeNameRestaurantTester", "Image", "website.com",
"fakeservice", "fakeplace", "restaurant")
# Gets name from last inserted record
name = getNameOfLastRow()
assert(name == "FakeNameRestaurantTester")
if name == "FakeNameRestaurantTester":
print("passed test 2")
# removes the added row after test passes
deleteExtraFakeRecord()
else:
print("failed test 2")
def test_countSugg_insert():
""" Tests insert and countSuggestionsInDB methods concurrently
"""
original = countSuggestionsInDB()
max_id = getMaxID()
id = max_id + 1
insert(id, "FakeNameRestaurantTester", "Image", "website.com",
"fakeservice", "fakeplace", "restaurant")
after = countSuggestionsInDB()
difference = after - original
assert(difference == 1)
if difference == 1:
print("passed test 3")
deleteExtraFakeRecord()
else:
print("failed test 3")
deleteExtraFakeRecord()
def test_selectShopName():
""" Tests if selectShopName can accurately select a shop given a name.
"""
term = "Jamaica Breeze"
lower_term = term.lower()
results = selectshopbyname(lower_term)
# checks if index and name of record pulled match the searched term
if results[0][0] == 234 and results[0][1] == "Jamaica Breeze":
print("passed test 4")
else:
print("failed test 4")
def test_selectShop():
""" Tests selectShop() to see if it will pull the same amount of records given
a substring and the full string of a unqiue search term
"""
term = "Queens"
lower_term = term.lower()
results = selectshops(lower_term)
original = len(results)
substring_term = "Qu"
lower_substring = substring_term.lower()
substring_results = selectshops(lower_substring)
substr = len(substring_results)
difference = substr - original
if difference == 0:
print("passed test 5")
else:
print("Failed test 5")
def test_updateShopName():
""" Tests updateshopbyname() to see if it will change the name given id"""
id = 10
shop = selectshopbyid(id)
oldname = shop[1]
newname = "Smthing"
updateshopbyname(id, newname)
shop = selectshopbyid(id)
assert(shop[1] == newname)
updateshopbyname(id, oldname)
def test_updateShopService():
""" Tests updateshopbyservice() to see if it will change
the service given id
"""
id = 10
shop = selectshopbyid(id)
oldservice = shop[4]
newservice = "sit in only"
updateshopbyservice(id, newservice)
shop = selectshopbyid(id)
assert(shop[4] == newservice)
updateshopbyservice(id, oldservice)
test_suggTableMade()
test_insertSuggestion()
test_countSugg_insert()
test_selectShopName()
test_selectShop()
test_updateShopName()
test_updateShopService()
|
Python | UTF-8 | 351 | 3.875 | 4 | [] | no_license | sayi1 = float(input("birinci sayı: "))
sayi2 = float(input("ikinci sayı: "))
print("\n")
print("========================================")
print("toplama sonucu :",sayi1+sayi2)
print("çıkarma sonucu :",sayi1-sayi2)
print("çarpma sonucu :",sayi1*sayi2)
print("bölüm sonucu :",sayi1/sayi2)
print("========================================") |
Java | UTF-8 | 358 | 1.585938 | 2 | [] | no_license | package org.archer.archermq.protocol.persistence.domain;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class MsgContent {
@Id
private String msgId;
@Column
private String msgKey;
@Column
private byte[] msgContent;
@Column
private String msgProperties;
}
|
Swift | UTF-8 | 1,007 | 3.484375 | 3 | [
"MIT"
] | permissive | //
// SelectSort.swift
// Interview
//
// Created by jackfrow on 2019/6/1.
// Copyright © 2019 jackfrow. All rights reserved.
//
import Foundation
//选择排序
//选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
func selectionSort(sortArray: [Int]) -> [Int] {
var tempArray = sortArray
let count = sortArray.count
for i in 0..<count {
var minIndex = i
for j in minIndex+1 ..< count{
if tempArray[minIndex] < tempArray[j]{
minIndex = j
}
}
let temp = tempArray[i]
tempArray[i] = tempArray[minIndex]
tempArray[minIndex] = temp
}
return tempArray
}
|
PHP | WINDOWS-1250 | 585 | 2.703125 | 3 | [] | no_license | <?php
session_start();
date_default_timezone_set("America/Santiago");
class Conectar
{
public static function con()
{
$server = "localhost";
$username = "root";
$password = "sergio81";
$database = "DB_Daincar_V3";
$con = mysqli_connect($server,$username,$password,$database);
mysqli_query($con,"SET NAMES 'utf8'");
if (!$con) {
echo "Error: No se pudo conectar a MySQL." . PHP_EOL;
echo "Errno de depuracin: " . mysqli_connect_errno() . PHP_EOL;
echo "Error de depuracin: " . mysqli_connect_error() . PHP_EOL;
exit;
}else {
return $con;
}
}
}
?> |
Python | UTF-8 | 224 | 2.96875 | 3 | [] | no_license | def sum_of_cubes_odd_number(n):
if n <= 0:
return-1
n = (2*int(n)-1)
ans = 0
while n > 0:
ans += pow(n, 3)
n -= 2
print(ans % 1000000007)
return
sum_of_cubes_odd_number(567)
|
Java | UTF-8 | 579 | 2.9375 | 3 | [] | no_license | package com.twx.eot;
public class ScoreBoard {
private int playerOneScore;
private int playerTwoScore;
public ScoreBoard(int playerOneScore, int playerTwoScore) {
this.playerOneScore = playerOneScore;
this.playerTwoScore = playerTwoScore;
}
public int getPlayerOneScore() {
return playerOneScore;
}
public int getPlayerTwoScore() {
return playerTwoScore;
}
public void add(Result result) {
playerOneScore += result.getPlayerOneScore();
playerTwoScore += result.getPlayerTwoScore();
}
}
|
Java | UTF-8 | 591 | 2.046875 | 2 | [] | no_license | package com.golubev.testtask.service;
import com.golubev.testtask.entity.Role;
import com.golubev.testtask.entity.User;
import com.golubev.testtask.exception.valid.UserStorageServiceException;
import java.util.List;
public interface UserStorageService {
void add(User user) throws UserStorageServiceException;
void remove(User user) throws UserStorageServiceException;
void update(User oldUser, User newUser) throws UserStorageServiceException;
User findById(long id) throws UserStorageServiceException;
List<User> findAll() throws UserStorageServiceException;
}
|
Markdown | UTF-8 | 516 | 3.734375 | 4 | [
"Apache-2.0"
] | permissive | # Remap Array
Takes an input array and iterates through each object in the the array, creates a new object with only the matching keys from the Values property, and outputs an array of the new objects.
For example, given this input array of objects:
`[{"URL": "https://magick.com/", "Title": "Magick"}, {"URL": "https://www.foo.bar/", "Title": "Foo Bar"}]`
and a Values property "URL" it will return an array of objects with only the URL key:
`[{"URL": "https://magick.com/"}, {"URL": "https://www.foo.bar/"}]`
|
PHP | UTF-8 | 9,726 | 2.515625 | 3 | [] | no_license | <?php
namespace app\modules\front\models;
use Yii;
use Thunder\Shortcode\ShortcodeFacade;
use Thunder\Shortcode\Shortcode\ShortcodeInterface;
/**
* This is the model class for table "EnglishHadithTable".
*
* The followings are the available columns in table 'EnglishHadithTable':
* @property string $collection
* @property integer $volumeNumber
* @property integer $bookNumber
* @property string $bookName
* @property integer $babNumber
* @property string $babName
* @property integer $hadithNumber
* @property string $hadithText
* @property string $bookID
* @property string $grade
* @property string $comments
* @property integer $ourHadithNumber
*/
class ArabicHadith extends Hadith
{
private $util = null;
public $arabicReference = null; // For non-verified ahadith
private $facade;
public $shortcode_parsed = false;
public function sanadizer(ShortcodeInterface $s) {
return sprintf('<span class="arabic_sanad">%s</span>', $s->getContent());
}
public function matnizer(ShortcodeInterface $s) {
return sprintf('<span class="arabic_text_details">%s</span>', $s->getContent());
}
public function commentaryizer(ShortcodeInterface $s) {
$type = $s->getParameter("type");
if (is_null($type)) { $type = ""; }
// return sprintf('<div class="'.$type.'commentary">%s</div>', $s->getContent());
return sprintf('<div class="arabic_sanad">%s</div>', $s->getContent());
}
public function narratorHandler(ShortcodeInterface $s) {
return sprintf('<a href="/narrator/%s" title="%s" rel="nofollow">%s</a>',
$s->getParameter("id"),
addslashes($s->getParameter("tooltip")),
$s->getContent());
}
private function makeShortcodeParser() {
$this->facade = new ShortcodeFacade();
$this->facade->addHandler('prematn', array($this, 'sanadizer'));
$this->facade->addHandler('postmatn', array($this, 'sanadizer'));
$this->facade->addHandler('matn', array($this, 'matnizer'));
$this->facade->addHandler('commentary', array($this, 'commentaryizer'));
$this->facade->addHandler('narrator', array($this, 'narratorHandler'));
}
public function process_text()
{
$processed_text = trim($this->hadithText);
$processed_text = preg_replace("/^- /", "", $processed_text);
if (strpos($processed_text, "]")) {
$this->makeShortcodeParser();
$processed_text = $this->facade->process($processed_text);
$this->shortcode_parsed = true;
}
// Collection-specific processing of text
if (strcmp($this->collection, "muslim")) {
//$processed_text = preg_replace("/\n+/", "<br>\n", $processed_text);
}
if (strcmp($this->collection, "riyadussalihin") == 0) {
}
if (strcmp($this->collection, "qudsi") == 0) {
}
$processed_text = preg_replace("/\n\n/", "<br><p>\n", $processed_text);
$this->hadithText = $processed_text;
}
public function populateReferences($util, $collection = null, $book = null)
{
if (is_null($collection)) { $collection = $util->getCollection($this->collection); }
if (is_null($book)) { $book = $util->getBook($this->collection, $this->bookID, "arabic"); }
if ($book->status === 4) {
$hadithNumber = $this->hadithNumber;
if ($collection->name == "muslim" && $book->ourBookID !== -1) {
$hadithNumber = preg_replace("/(\d)\s*([a-zA-Z])/", "$1$2", $hadithNumber);
}
if (!is_null($book->reference_template)) {
$reference_string = $book->reference_template;
$reference_string = str_replace("{hadithNumber}", $hadithNumber, $reference_string);
$this->canonicalReference = $reference_string;
} else {
$this->canonicalReference = $collection->englishTitle . " " . $hadithNumber;
}
$bookNumberReference = "Book " . $book->ourBookID;
if (!is_null($book->ourBookNum) && strlen($book->ourBookNum) > 0) {
$bookNumberReference = "Book " . $book->ourBookNum;
} elseif ($book->ourBookID === -1) {
$bookNumberReference = "Introduction";
}
$this->inbookReference = $bookNumberReference . ", ";
if (($this->collection === "muslim") && ($book->ourBookID === -1)) {
$this->inbookReference .= "Narration ";
} else {
$this->inbookReference .= "Hadith ";
}
$this->inbookReference .= $this->ourHadithNumber;
}
else {
if ($this->ourHadithNumber > 0) {
$this->sunnahReference = "";
if ($collection->hasbooks === "yes") { $this->sunnahReference .= "Book ".$this->bookNumber.", "; }
$this->sunnahReference .= "Hadith ".$this->ourHadithNumber;
}
$this->arabicReference = "";
if ($collection->hasbooks === "yes") { $this->arabicReference .= "Book ".$this->bookNumber.", "; }
$this->arabicReference .= "Hadith ".$this->hadithNumber;
}
}
public function populatePermalink($util, $collection = null, $book = null) {
if (is_null($collection)) { $collection = $util->getCollection($this->collection); }
if (is_null($book)) { $book = $util->getBook($this->collection, $this->bookID, "arabic"); }
$use_colon_permalinks = true;
if ($book->status === 4) {
if ($use_colon_permalinks) {
// In case an entry lists multiple hadith numbers, use the first one
$hadithNumber = explode(",", $this->hadithNumber)[0];
$hadithNumber = preg_replace("/(\d)\s*([a-zA-Z])/", "$1$2", $hadithNumber);
$this->permalink = "/$collection->name:".$hadithNumber;
// Special cases
if ($collection->name == "forty") { $this->permalink = "/$book->linkpath:$this->hadithNumber"; }
if ($collection->name == "muslim" && $book->ourBookID == -1 && substr($this->hadithNumber, 0, 12) == "Introduction") {
$this->permalink = "/muslim/introduction/$this->ourHadithNumber";
}
}
else {
if (!is_null($book->linkpath)) {
$this->permalink = "/$book->linkpath/$this->ourHadithNumber";
} else {
if ($collection->hasbooks === "yes") {
if (!is_null($book->ourBookNum)) {
$booklinkpath = $book->ourBookNum;
} else {
$booklinkpath = (string)$book->ourBookID;
}
$this->permalink = "/" . $collection->name . "/$booklinkpath/$this->ourHadithNumber";
} else {
$this->permalink = "/" . $collection->name . "/$this->ourHadithNumber";
} // This collection has no books.
}
}
}
else {
if ($this->ourHadithNumber > 0) {
if ($collection->hasbooks === "yes") {
$this->permalink = "/" . $collection->name . "/$book->ourBookID/$this->ourHadithNumber";
if ($book->ourBookID === -1) { $this->permalink = "/" . $collection->name . "/introduction/$this->ourHadithNumber"; }
} else $this->permalink = "/" . $collection->name . "/$this->ourHadithNumber"; // This collection has no books.
}
else {
$this->permalink = "/urn/$this->arabicURN";
}
}
}
public static function tableName()
{
return '{{ArabicHadithTable}}';
}
/**
* @return array validation rules for model attributes.
*/
public function rules()
{
// NOTE: you should only define rules for those attributes that
// will receive user inputs.
return array(
);
}
/**
* @return array relational rules.
*/
public function relations()
{
// NOTE: you may need to adjust the relation name and the related
// class name for the relations automatically generated below.
return array(
);
}
/**
* @return array customized attribute labels (name=>label)
*/
public function attributeLabels()
{
return array(
'arabicURN' => 'Arabic Urn',
'collection' => 'Collection',
'volumeNumber' => 'Volume Number',
'bookNumber' => 'Book Number',
'bookName' => 'Book Name',
'babNumber' => 'Bab Number',
'babName' => 'Bab Name',
'hadithNumber' => 'Hadith Number',
'hadithText' => 'Hadith Text',
'bookID' => 'Book',
'comments' => 'Comments',
'ourHadithNumber' => 'Our Hadith Number',
'matchingEnglishURN' => 'Matching English Urn',
);
}
/**
* Retrieves a list of models based on the current search/filter conditions.
* @return CActiveDataProvider the data provider that can return the models based on the search/filter conditions.
*/
public function search()
{
// Warning: Please modify the following code to remove attributes that
// should not be searched.
$criteria=new CDbCriteria;
$criteria->compare('arabicURN',$this->arabicURN);
return new CActiveDataProvider($this, array(
'criteria'=>$criteria,
));
}
}
|
C++ | UTF-8 | 5,266 | 3.046875 | 3 | [] | no_license | #include <iostream>
#include <iomanip>
#include <string>
#include "base.h"
namespace Base {
/// �������� ������������
base::base() : base(0) {
}
base::base(size_t rnc) : base(rnc, rnc) {
}
base::base(size_t Row, size_t Col) : row(Row), col(Col) {
if (Row == 0 || Col == 0) {
mass = nullptr; row = 0; col = 0;
}
else
mass = new double[row * col]();
}
base::base(const base& obj) : row(obj.row), col(obj.col) {
std::copy(obj.mass, obj.mass + row * col, mass);
}
base::base(base&& obj) noexcept : row(obj.row), col(obj.col), mass(nullptr) {
std::swap(mass, obj.mass);
}
///
//�������
matrix::matrix() : base(0) {
}
matrix::matrix(size_t rnc) : base(rnc, rnc) {
}
matrix::matrix(size_t Row, size_t Col) : base(Row, Col){
}
matrix::matrix(const matrix& obj) : base(obj) {
}
matrix::matrix(matrix&& obj) noexcept : base(obj) {
}
matrix::matrix(const base& obj) : base(obj) {
}
matrix::~matrix() {
delete[] mass;
}
// �������
vector::vector(): base(0) {
}
vector::vector(size_t col) : base(1,col) {
}
vector::vector(const vector& obj): base(obj) {
}
vector::vector(vector&& obj) noexcept : base(obj) {
}
vector::vector(const base& obj) : base(obj) {
}
vector::~vector() {
delete[] mass;
}
double vector::operator[](size_t ind) const {
if(ind >= 0 || ind < this->col)
return mass[ind];
}
double& vector::operator[](size_t ind) {
if (ind >= 0 || ind < this->col)
return mass[ind];
}
base::massRow::massRow(const base* obj, size_t R) :
row(R* obj->row),
Array(obj) {
}
base::massRow::massRow(base* obj, size_t R):
row( R*obj->row),
Array(obj){
}
double base::massRow::operator[](size_t ind) const { return Array->mass[row + ind]; }
double& base::massRow::operator[](size_t ind) { return Array->mass[row + ind]; }
base::massRow base::operator[](size_t ind) { return massRow(this, ind); }
const base::massRow base::operator[](size_t ind) const { return massRow(this, ind); }
std::string matrix::GetType() const {
return "matrix";
}
std::string vector::GetType()const {
return "vector";
}
base& base::operator+=(const base& obj) {
if (this->GetType() == "matrix" && obj.GetType() == "vector") {
if (this->col == obj.col) {
for (int i = 0; i < this->col; i++)
this->mass[i] += obj.mass[i];
return *this;
}
}
else if(this->GetType() == "vector" && obj.GetType() == "matrix"){
return *this;
}
else {
if (this->check_sub(obj)) {
for (int i = 0; i < this->col; i++)
for (int j = 0; j < this->row; j++)
this->mass[i * this->row + j]+=obj.mass[i*obj.row+j];
return *this;
}
}
}
base& base::operator-=(const base& obj) {
if (this->GetType() == "matrix" && obj.GetType() == "vector") {
return *this;
}
else {
return *this;
}
}
base& base::operator*=(const base& obj) {
if (this->GetType() == "matrix" && obj.GetType() == "vector") {
return *this;
}
else {
return *this;
}
}
base& base::operator*=(const double item) {
for (int i = 0; i < this->row * this->col; i++)
this->mass[i]*=item;
return *this;
}
matrix operator+(const base& fobj, const base& sobj) {
if (fobj.GetType() != "vector")
return matrix(fobj) += sobj;
else
return matrix(sobj) += fobj;
}
matrix operator-(const base& fobj, const base& sobj) {
if (fobj.GetType() != "vector")
return matrix(fobj) -= sobj;
else
return matrix(sobj) -= fobj;
}
matrix operator*(const base& fobj, const base& sobj) {
if (fobj.GetType() != "vector")
return matrix(fobj) *= sobj;
else
return matrix(sobj) *= fobj;
}
matrix operator*(const matrix& obj, const double item) {
return matrix(obj) *= item;
}
matrix operator*(const double item, const base& obj) {
return matrix(obj) *= item;
}
std::ostream& operator<<(std::ostream& out, const matrix& obj) {
int Width = out.width();
for (int i = 0; i < obj.col; i++) {
for (int j = 0; j < obj.row; j++) {
out << std::setw(5) << obj.mass[i*obj.col + j];
}
out << std::endl;
}
return out;
}
vector operator+(const vector& fobj, const vector& sobj) {
return vector(fobj) += sobj;
}
vector operator-(const vector& fobj, const vector& sobj) {
return vector(fobj) -= sobj;
}
vector operator*(const vector& obj, const double item) {
return vector(obj) *= item;
}
vector operator*(const double item, const vector& obj) {
return vector(obj) *= item;
}
std::ostream& operator<<(std::ostream& out, const vector& obj) {
int Width = out.width();
for (int i = 0; i < obj.col; i++) {
out << std::setw(5) << obj.mass[i];
}
return out;
}
bool base::check_sub(const base& obj) {
if (this->GetType() == "vector" && obj.GetType() == "vector") {
}
else if(this->GetType() == "matrix" && obj.GetType() == "matrix") {
}
else if(this->GetType() == "matrix" && obj.GetType() == "vector") {
}
else {
}
return false;
}
bool base::check_mul(const base& obj) {
if (this->GetType() == "vector" && obj.GetType() == "vector") {
}
else if (this->GetType() == "matrix" && obj.GetType() == "matrix") {
}
else if(this->GetType() == "matrix" && obj.GetType() == "vector") {
}
return false;
}
}
|
Markdown | UTF-8 | 1,611 | 2.921875 | 3 | [] | no_license | ---
title: 魔女 BLOG 初中級日麻講座 笔记
date: 2019/2/28 14:35
tags:
---
针对自己打牌的一些不良习惯的记录
<!-- more -->
1. 配牌不佳的情况下,役牌多留一下
2. 4445 形的搭子在早巡价值不大
3. 有效牌重复的搭子要注意
4. 常见复合搭子
>兩\三間搭兩\三間搭指的是類似 468, 或 2468 等連續卡窿的牌形.不少初學者都會覺得卡窿是惡形, 不太喜歡此等牌形. 不過我們要留意: 一個246 的兩間搭, 跟一個兩面搭的入章牌數是一樣的, 分別是前者要 3 隻牌, 後者只需兩隻, 前者的效率稍低.雖然它稱不上是好牌形, 不過在序盤搭子仍不夠時, 兩間搭仍然是很有用.
>3556 形35+56 的兩搭, 表面跟上次談過的 35+67 形差不多, 實際上相去甚遠. 原因是35,56 就犯了有效牌重覆的毛病. 在這情況之下, 35 搭的價格很低, 如果已經夠搭, 35 差不多會是最早被打的一組. 剩下 56, 或 556 就已經夠了.
>5566 形大家可能以為 5566 是兩面, 又有機會成一盃口. 但在我心目中, 它是一個很差的形態. 5566 是一個完完全全的有放牌重覆, 求兩次 47 表面上很容易, 但當在有其他更好的搭子時, 這個必然會先被處理.
5. 不宜過早確定雀頭
6. 一副牌最多只需要兩個對子, 第三個或以後對子效能是十分低.
7. 立直自摸七對裡 2 的跳滿, 是一副如何差的牌都有機會完成的役種. 當你已經無路可走時, 七對子很多時都會變成你的希望.
8. 筋牌防守时, 注意不要考虑确定对对的那一家的筋 |
Rust | UTF-8 | 7,902 | 3.046875 | 3 | [
"MIT"
] | permissive | //--------------------------------------------------------------------
// polygon.rs
//--------------------------------------------------------------------
// Provides various utilitiy functions for polygons
//--------------------------------------------------------------------
use crate::geometry::*;
fn inside_segment_collinear(x0: Vec2, x1: Vec2, y: Vec2, strict: bool) -> bool {
let d = (x1 - x0).dot(y - x0);
if strict { d > 0.0 && d < (x1 - x0).length_sq() }
else { d >= 0.0 && d <= (x1 - x0).length_sq() }
}
fn segments_intersect(p0: Vec2, p1: Vec2, q0: Vec2, q1: Vec2, strict: bool) -> bool {
// The cross products
let crossq0 = (p1 - p0).cross(q0 - p0);
let crossq1 = (p1 - p0).cross(q1 - p0);
let crossp0 = (q1 - q0).cross(p0 - q0);
let crossp1 = (q1 - q0).cross(p1 - q0);
// If two points are equal, we have only containment (not considered in strict case)
if p0.roughly_equals(p1) {
return !strict && crossp0.roughly_zero_squared() && inside_segment_collinear(q0, q1, p0, strict);
}
if q0.roughly_equals(q1) {
return !strict && crossq0.roughly_zero_squared() && inside_segment_collinear(p0, p1, q0, strict);
}
// Point coincidence is considered a false result on strict mode
if strict {
if p0.roughly_equals(q0) || p0.roughly_equals(q1)
|| p1.roughly_equals(q0) || p1.roughly_equals(q1) {
return false;
}
}
// Containment (not considered on strict mode)
if crossq0.roughly_zero_squared() { return !strict && inside_segment_collinear(p0, p1, q0, strict); }
if crossq1.roughly_zero_squared() { return !strict && inside_segment_collinear(p0, p1, q1, strict); }
if crossp0.roughly_zero_squared() { return !strict && inside_segment_collinear(q0, q1, p0, strict); }
if crossp1.roughly_zero_squared() { return !strict && inside_segment_collinear(q0, q1, p1, strict); }
// Check everything is on one side
if crossq0 < 0.0 && crossq1 < 0.0 { return false; }
if crossq0 > 0.0 && crossq1 > 0.0 { return false; }
if crossp0 < 0.0 && crossp1 < 0.0 { return false; }
if crossp0 > 0.0 && crossp1 > 0.0 { return false; }
// Otherwise...
true
}
pub fn polygon_winding(poly: &[Vec2]) -> Coord {
let mut winding = 0.0;
for i in 0..poly.len() {
let ik = (i+1) % poly.len();
winding += poly[i].cross(poly[ik]);
}
winding
}
pub fn segment_equivalent(poly: &[Vec2]) -> Option<(Vec2, Vec2)> {
// If the polygon is already a segment or its winding is non-negligible, return it or no equivalent
if poly.len() == 2 { Some((poly[0], poly[1])) }
else if !polygon_winding(poly.as_ref()).roughly_zero_squared() { None }
else {
// Else, build the segment
let mut imin = 0;
let mut imax = 0;
for i in 1..poly.len() {
if poly[imin].x > poly[i].x { imin = i; }
if poly[imax].x < poly[i].x { imax = i; }
}
Some((poly[imin], poly[imax]))
}
}
fn polygon_contains_point(poly: &[Vec2], p: Vec2, strict: bool) -> bool {
let mut contains = false;
for i in 0..poly.len() {
let mut p0 = poly[i];
let mut p1 = poly[if i == 0 { poly.len()-1 } else { i-1 }];
// If the two points are equal, skip
if p0.roughly_equals(p1) { continue; }
// For strictness, if the line is "inside" the polygon, we have a problem
if strict && (p1-p0).cross(p-p0).roughly_zero_squared()
&& inside_segment_collinear(p0, p1, p, false) { return false; }
if p0.x < p.x && p1.x < p.x { continue; }
if p0.x < p.x { p0 = p1 + (p.x - p1.x) / (p0.x - p1.x) * (p0 - p1); }
if p1.x < p.x { p1 = p0 + (p.x - p0.x) / (p1.x - p0.x) * (p1 - p0); }
if (p0.y >= p.y) != (p1.y >= p.y) { contains = !contains; }
}
contains
}
fn polygon_segment_intersect(poly: &[Vec2], a: Vec2, b: Vec2, strict: bool) -> bool {
// Check for segments intersection
for i in 0..poly.len() {
let p0 = poly[i];
let p1 = poly[if i == 0 { poly.len()-1 } else { i-1 }];
if segments_intersect(p0, p1, a, b, strict) { return true; }
}
// Check for overlapping of the segment point
if polygon_contains_point(poly, a, strict) || polygon_contains_point(poly, b, strict) {
return true;
}
// Otherwise...
false
}
pub fn polygons_overlap(poly0: &[Vec2], poly1: &[Vec2], strict: bool) -> bool {
// Check first for segment polygons
let s0 = segment_equivalent(poly0);
let s1 = segment_equivalent(poly1);
if let (Some((p0,p1)), Some((q0,q1))) = (s0, s1) {
return segments_intersect(p0, p1, q0, q1, strict);
} else if let Some((p0,p1)) = s0 {
return polygon_segment_intersect(poly1, p0, p1, strict);
} else if let Some((q0,q1)) = s1 {
return polygon_segment_intersect(poly0, q0, q1, strict);
}
// Check for segments intersection
for j in 0..poly0.len() {
for i in 0..poly1.len() {
let p0 = poly0[j];
let p1 = poly0[if j == 0 { poly0.len()-1 } else { j-1 }];
let q0 = poly1[i];
let q1 = poly1[if i == 0 { poly1.len()-1 } else { i-1 }];
if segments_intersect(p0, p1, q0, q1, strict) { return true; }
}
}
// Check for overlapping of any of the points
if poly0.iter().any(|&p| polygon_contains_point(poly1, p, strict)) { return true; }
if poly1.iter().any(|&p| polygon_contains_point(poly0, p, strict)) { return true; }
// Otherwise...
false
}
pub fn convex_hull(mut points: Vec<Vec2>) -> Vec<Vec2> {
// Sort the points using the canonical comparer
points.sort_by(canonical);
points.dedup();
let mut hull = Vec::with_capacity(points.len() + 1);
// Work with the points array forwards and backwards
for _ in 0..2 {
let old_len = hull.len();
// Add the first two points
hull.push(points[0]);
hull.push(points[1]);
// Run through the array
for i in 2..points.len() {
// Rollback the possible vertex
while hull.len() > old_len+1 &&
(hull[hull.len()-1] - hull[hull.len()-2]).cross(points[i] - hull[hull.len()-1]) >= 0.0 {
hull.pop();
}
// Add the vertex
hull.push(points[i]);
}
// Remove the last vertex
hull.pop();
points.reverse();
}
hull.reverse();
hull
}
pub fn simplify_polygon(poly: &[Vec2]) -> Vec<Vec2> {
// Quickly discard degenerate polygons
if poly.len() < 3 { return poly.iter().copied().collect(); }
// Auxiliary function to follow the same direction
fn same_direction(u: Vec2, v: Vec2) -> bool {
u.cross(v).roughly_zero_squared() && u.dot(v) <= 0.0
}
// Find a non-collinear starting vertex
let len = poly.len();
let mut istart = 0;
while istart < len {
let ik = (istart + 1) % len;
let ip = (istart + len - 1) % len;
if !same_direction(poly[ik] - poly[istart], poly[ip] - poly[istart]) { break; }
istart += 1;
}
// If there are no non-collinear vertices, just return a line
if istart == len {
let mut imin = 0;
let mut imax = 0;
for i in 1..poly.len() {
if poly[imin].x > poly[i].x { imin = i; }
if poly[imax].x < poly[i].x { imax = i; }
}
vec![poly[imin], poly[imax]]
} else {
// Start with a single point
let mut pts = vec![poly[istart]];
// Only add the point if it doesn't form a parallel line with the next point on the line
for i in (istart+1..len).chain(0..istart) {
if !same_direction(poly[(i+1)%len] - poly[i], pts[pts.len()-1] - poly[i]) {
pts.push(poly[i]);
}
}
pts
}
}
|
Java | UTF-8 | 1,249 | 3.75 | 4 | [] | no_license | /*
Ex 7-5: Random Permutation
Objective: Write Java and C programs that
1. Generates a random permutation of 1...n where n is given
2. Your program should use a boolean (or int in C) array
to check if the number is generated or not
3. All the arrays should by dynamically-sized
(use "new" in Java, and "malloc" in C)
Submission: RandPerm.java, RandPerm.c
$ java RandPerm
n? 9
9 1 6 3 2 5 7 8 4
*/
import java.util.Scanner;
public class RandPerm {
public static void main(String args[]) {
Scanner sc;
int rv;
int n, count;
boolean is_generated[];
System.out.print("n? ");
sc = new Scanner(System.in);
n = sc.nextInt();
is_generated = new boolean[n];
for (count=0; count < n; count++) {
// although we already know that the initial values of the arrays
// in java are all zero (false for boolean),
// it is desirable to make sure by filling in false initially
is_generated[count] = false;
}
for (count=0; count < n; ) {
rv = (int)(Math.random() * n); // 0...n-1
if ( !is_generated[rv] ) {
is_generated[rv] = true;
System.out.print((rv+1) + " ");
count++; // increase the number of generated values
}
}
System.out.println("");
}
}
|
JavaScript | UTF-8 | 1,236 | 3.25 | 3 | [] | no_license | function getDate() {
var months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"];
var days = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"];
var today = new Date();
var year = today.getFullYear();
var month = months[today.getMonth()];
var day = days[today.getDay()];
var date = today.getDate();
var dateString = day + ", " + month + " " + date + ", " + year;
document.getElementById("date").innerHTML = dateString;
}
function getTime() {
//var setInterval;
var hour;
var period;
setInterval(function() {
var today = new Date();
var hours = today.getHours();
var minutes = today.getMinutes();
var minute = minutes.toString();
if (minute.length < 2) {
minute = "0" + minutes;
}
var timeString = hours + ":" + minute;
document.getElementById("time").innerHTML = timeString;
}, 500);
}
function refreshFromHTML() {
var sec = 1000;
var min = sec * 60;
var hr = min * 60;
setInterval(function() {
location.reload(false);
}, 300000);
} |
PHP | UTF-8 | 1,178 | 2.640625 | 3 | [
"MIT"
] | permissive | <?php
/**
* Project: Veemo
* User: ddedic
* Email: dedic.d@gmail.com
* Date: 16/03/15
* Time: 23:46
*/
namespace Veemo\Themes\Adapters;
/**
* Interface ThemeManagerAdapterInterface
* @package Veemo\Themes\Adapters
*/
interface ThemeManagerAdapterInterface
{
/**
* @param $slug
* @return bool
*/
public function exist($slug);
/**
* @return mixed
*/
public function getAll();
/**
* @param bool $enabled
* @return mixed
*/
public function getFrontend($enabled = true);
/**
* @param bool $enabled
* @return mixed
*/
public function getBackend($enabled = true);
/**
* @param $slug
* @return mixed
*/
public function find($slug);
/**
* @return bool
*/
public function isEnabled($slug);
/**
* @return bool
*/
public function isDisabled($slug);
/**
* @param $slug
* @return mixed
*/
public function enable($slug);
/**
* @param $slug
* @return mixed
*/
public function disable($slug);
/**
* @param $slug
* @return mixed
*/
public function setActive($slug);
} |
Markdown | UTF-8 | 2,395 | 3.34375 | 3 | [] | no_license | ---
layout: post
comments: false
title: "Math of Intelligence : Temporal Difference Learning"
date: 2019-03-09
tags: math-of-intelligence, reinforcement-learning, artificial-intelligence
---
# Math Of Intelligence : Temporal Difference Learning
#### Monte Carlo:
$$
\begin{equation}
V(S_{t}) \leftarrow V(S_{t}) + \alpha (G_t - V(S_{t+1}))
\end{equation}
$$
Monte Carlo methods wait until the end of episode to update the state value function $$V(S_t)$$ for a state $$S_t$$ where $$G_t$$ is the actual return at time t.
#### TD Learning:
Also,
$$
\begin{equation}
v_\pi(s) = E_\pi[G_t | S_t = s] \\
= E_\pi[R_{t+1} + \gamma G_{t+1} | S_t = s]
\end{equation}
$$
So, eq. (1) becomes
$$
\begin{equation}
V(S_t) \leftarrow V(S_t) + \alpha[R_{t+1} + \gamma V(S_{t+1})-V(S_t)]
\end{equation}
$$
With this equation, $$V(S_t)$$ can be updated as soon as $$R_{t+1}$$ is received. This is called TD(0) or one-step TD Learning.
$$
\begin{equation}
V(S_t) \leftarrow V(S_t) + \alpha[G_t - V(S_t)]
\end{equation}
$$
$$
\begin{equation}
V(S_t) \leftarrow V(S_t) + \alpha[R_{t+1} + \gamma V(S_{t+1})-V(S_t)]
\end{equation}
$$
After taking an action at time t, we know the value of $$ R_{t+1} $$ as the reward received, so we can update the state value of the state $$ S_t $$ based on the above equation.
This is called $$ TD(0) $$ or one step TD. It is called so because it is a special case of $$ TD(\lambda) $$ where $$ \lambda=0 $$
In TD method, the value in brackets is called TD-error $$(\delta_{t})$$
$$
\delta_t = G_t - V(S_t) \\
= R_{t+1} + \gamma V(S_{t+1}) - V(S_t)
$$
TD method convergence proof? - TODO \\
Which one converges faster? TD or MC? How do we formalize this question? - TODO \\
Similarly for action value function:
$$
Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha(R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t))
$$
#### SARSA :
On policy TD Control
The next action is picked based on current policy + $$\epsilon$$ - greedy.
$$Q(s,a)$$ is learned from actions taken from the current policy $$\pi$$
#### Q-Learning:
Off policy TD control
We pick next action based on max Q-values + $$\epsilon$$ - greedy.
$$Q(s,a)$$ value does not depend on policy $$\pi$$
So,
$$
Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha(R_{t+1} + \gamma max_a Q(S_{t+1},a) - Q(S_t, A_t))
$$
### References:
Richard S. Sutton, Andrew G. Barto - Reinforcement Learning: An Introduction
|
Python | UTF-8 | 2,844 | 2.9375 | 3 | [
"BSD-3-Clause"
] | permissive | #!/usr/bin/env python
# encoding: utf-8
r"""Calculate refinement resolutions given ratios provided"""
from __future__ import absolute_import
from __future__ import print_function
import argparse
import numpy as np
from . import topotools
from six.moves import range
def calculate_resolution(ratios, base_resolutions=[0.25,0.25],
lat_long=True,
latitude=24.0):
r"""Given *ratios* and starting resolutions, calculate level resolutions"""
num_levels = len(ratios) + 1
# Calculate resolution on each level
natural_resolutions = np.empty((num_levels, 2))
natural_resolutions[0,:] = base_resolutions
for level in range(1,num_levels):
natural_resolutions[level, :] = natural_resolutions[level-1, :] / ratios[level-1]
# Print out and convert to meters if applicable
if lat_long:
meter_resolutions = np.empty((num_levels,2))
for level in range(num_levels):
meter_resolutions[level,:] = topotools.dist_latlong2meters(
natural_resolutions[level,0],
natural_resolutions[level,1],
latitude)
print("Resolutions:")
for level in range(num_levels):
level_string = " Level %s" % str(level + 1)
if lat_long:
level_string = " - ".join((level_string, "(%sº,%sº)" % (natural_resolutions[level,0], natural_resolutions[level,1])))
level_string = " - ".join((level_string, "(%s m,%s m)" % (meter_resolutions[level,0], meter_resolutions[level,1])))
else:
level_string = " - ".join((level_string, "(%s m,%s m)" % (natural_resolutions[level,0], natural_resolutions[level,1])))
print(level_string)
if __name__ == "__main__":
parser = argparse.ArgumentParser(prog="resolutions",
description="Compute the effective resolution of refinement")
parser.add_argument('ratios', metavar="ratios", type=int, nargs="+",
help="Ratios used in refinement")
parser.add_argument('--latlong','-l', dest='lat_long', action='store_true',
help="Computer assuming lat-long base grid")
parser.add_argument('--base', metavar="resolution", dest='base_resolutions',
action='store', nargs=2, default=[0.25,0.25],
help="Base resolutions")
parser.add_argument('--lat', dest='latitude', action='store', default=24.0,
help="Latitude to use in degrees to meters conversion")
args = parser.parse_args()
calculate_resolution(args.ratios, base_resolutions=args.base_resolutions,
lat_long=args.lat_long, latitude=args.latitude) |
Python | UTF-8 | 254 | 2.9375 | 3 | [] | no_license | pessoa = {
'nome': 'Fulano',
'idade': 43,
'cursos': ['React', 'Python']
}
print(pessoa)
pessoa.pop('idade')
print(pessoa)
pessoa.update({
'cargo': 'Analista Desemvolvedor',
'sexo': 'M'
})
print(pessoa)
pessoa.clear()
print(pessoa) |
Java | UTF-8 | 247 | 1.742188 | 2 | [] | no_license | /**
*
*/
package org.forumj.checkip.connector;
/**
* @author andrew
*
*/
public interface SourceConnector {
public String getSourceName();
public Boolean isListedAsSpammer(String ip) throws ConnectorException;
}
|
TypeScript | UTF-8 | 314 | 2.65625 | 3 | [] | no_license | import { Messages } from '../enums/messages.enum';
export class ResolvedResult<T> {
Result: T;
ResultMessage: Messages;
Message: string;
constructor(result: T, resultMessage: Messages, message: string) {
this.Result = result;
this.ResultMessage = resultMessage;
this.Message = message;
}
}
|
Java | UTF-8 | 2,782 | 2.5625 | 3 | [] | no_license | /*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package Iso14496.Boxes;
import Iso14496.Box;
import Iso14496.IsoReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
*
* @author mac
*/
public class DINF extends Box{
public DINF() {
super(Box.DINF);
}
@Override
public byte[] toBinary() {
ByteArrayOutputStream tempStream = new ByteArrayOutputStream();
if (children.size() > 0) {
for (Box box : children) {
try {
tempStream.write(box.toBinary());
} catch (IOException ex) {
Logger.getLogger(MOOV.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
try {
byteStream.write(intToByteArray(8 + tempStream.size()));
byteStream.write(intToByteArray(type));
byteStream.write(tempStream.toByteArray());
} catch (IOException ex) {
Logger.getLogger(MOOV.class.getName()).log(Level.SEVERE, null, ex);
}
return byteStream.toByteArray();
}
@Override
public void loadData() {
int boxType;
int offset = 0;
int boxSize;
Box box = null;
Class boxClass = null;
internalSize = IsoReader.readIntAt(fileData, internalOffset + offset); //get box size
offset += 8; //Account for head length
//Now Find boxes inside MOOV
do {
boxSize = IsoReader.readIntAt(fileData, internalOffset + offset); //get box size
boxType = IsoReader.readIntAt(fileData, internalOffset + offset + 4); // get box code
//System.out.println(IsoFile.toASCII(boxType));
//System.out.println(boxSize);
//now lookup box code
try {
boxClass = Box.boxTable.get(boxType);
if (boxClass != null) {
box = (Box) boxClass.newInstance();
box.setOffset(internalOffset + offset);
box.setFileData(fileData);
box.setContainer(this);
box.loadData();
children.add(box);
}
} catch (InstantiationException | IllegalAccessException ex) {
System.out.println("box code not found");
}
//System.out.println("box length: " + boxSize + " box code:" + toASCII(boxCode));
offset = offset + boxSize;
} while (offset < internalSize);
}
}
|
Java | UTF-8 | 967 | 2.90625 | 3 | [] | no_license | package com.buaa.texaspoker.network;
/**
* 在客户端和服务端直接字节数据的包装接口
* 所有实现<code>IPacket</code>的子类可通过{@link PacketBuffer}实现数据的序列化和反序列化
* @param <T> 特定的数据处理类
* @author CPunisher
* @see PacketBuffer
* @see INetHandler
*/
public interface IPacket<T extends INetHandler> {
/**
* 将数据从{@link PacketBuffer}字节缓冲中读取,也就是反序列化
* @param buf 字节缓冲
* @throws Exception
*/
void readData(PacketBuffer buf) throws Exception;
/**
* 将数据写入{@link PacketBuffer}字节缓冲中,也就是序列化
* @param buf 字节缓冲
* @throws Exception
*/
void writeData(PacketBuffer buf) throws Exception;
/**
* 调用特定的处理类对响应<code>IPacket</code>的数据并进行处理
* @param netHandler 数据处理类
*/
void process(T netHandler);
}
|
JavaScript | UTF-8 | 688 | 2.5625 | 3 | [] | no_license | import React, { useContext } from 'react';
import { TyperContext } from '../contexts/TyperContext';
const TyperForm = () => {
const { type: { text, setText, checkKeyword, nextKeyword } } = useContext(TyperContext);
React.useEffect(() => checkKeyword(), [checkKeyword, text])
const changeHandler = e => {
if ( e !== ' ' ) {
setText(e)
}
}
const keyHandler = ({keyCode}) => {
return keyCode === 32 && text.trim().length > 0 ? nextKeyword() : null
}
return (
<input type="text" value={text} className="input" onKeyDown={keyHandler} onChange={e => changeHandler(e.target.value)} />
)
}
export default TyperForm |
Python | UTF-8 | 7,986 | 2.578125 | 3 | [] | no_license | from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from openpyxl import load_workbook
from PySide6 import QtCore
from PySide6.QtWidgets import QApplication
import pyperclip
import pandas as pd
import time
import os
import sys
class Web_HitHorizon(QtCore.QThread):
#This is the signal that will be emitted during the processing.
#By including int as an argument, it lets the signal know to expect
#an integer argument when emitting.
updateProgress = QtCore.Signal(int)
def append_df_to_excel(filename, df, sheet_name='Sheet1', startrow=None,
truncate_sheet=False,
**to_excel_kwargs):
# Excel file doesn't exist - saving and exiting
if not os.path.isfile(filename):
df.to_excel(
filename,
sheet_name=sheet_name,
startrow=startrow if startrow is not None else 0,
**to_excel_kwargs)
return
# ignore [engine] parameter if it was passed
if 'engine' in to_excel_kwargs:
to_excel_kwargs.pop('engine')
writer = pd.ExcelWriter(filename, engine='openpyxl', mode='a')
# try to open an existing workbook
writer.book = load_workbook(filename)
# get the last row in the existing Excel sheet
# if it was not specified explicitly
if startrow is None and sheet_name in writer.book.sheetnames:
startrow = writer.book[sheet_name].max_row
# truncate sheet
if truncate_sheet and sheet_name in writer.book.sheetnames:
# index of [sheet_name] sheet
idx = writer.book.sheetnames.index(sheet_name)
# remove [sheet_name]
writer.book.remove(writer.book.worksheets[idx])
# create an empty sheet [sheet_name] using old index
writer.book.create_sheet(sheet_name, idx)
# copy existing sheets
writer.sheets = {ws.title:ws for ws in writer.book.worksheets}
if startrow is None:
startrow = 0
# write out the new sheet
df.to_excel(writer, sheet_name, startrow=startrow, **to_excel_kwargs)
# save the workbook
writer.save()
# get folder path which has been converted into binary file. (sys._MEIPASS)
@staticmethod
def resource_path(relative_path):
try:
base_path = sys._MEIPASS
except Exception:
base_path = os.path.dirname(__file__)
return os.path.join(base_path, relative_path)
def create_driver(self):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("prefs", {"intl.accept_languages": "en-US"})
chrome_options.add_experimental_option("excludeSwitches", ['enable-logging'])
return webdriver.Chrome(executable_path=self.resource_path('ChromeDriver\chromedriver.exe'), options=chrome_options)
# return webdriver.Chrome(executable_path = os.path.relpath('ChromeDriver\chromedriver.exe'), options=chrome_options)
# df_company = pd.read_excel(r"C:\Users\ADMIN\Documents\Aufinia\Data_Test.xlsx",sheet_name='Euro', converters={'LFA1_LIFNR':str,'LFA1_STCD1':str},usecols={'LFA1_LIFNR','LFA1_NAME1','COUNTRY','LFA1_STCD1','LFA1_LAND1'})
def crawling_execution(self,df_company):
df_company_output = df_company[['Supplier_number','Supplier_name','Country','Tax_code','Country_code']]
driver = self.create_driver()
driver.get('https://www.hithorizons.com/search?Name=')
try:
for idx in range(len(df_company_output)):
time.sleep(3)
# get company_name, country_name from dataframe
company_name = df_company_output.loc[idx,'Supplier_name']
country_name = df_company_output.loc[idx,'Country']
# send company_name keys
driver.implicitly_wait(15)
company_name_input = driver.find_element(By.ID, "Name")
company_name_input.clear()
company_name_input.send_keys(company_name)
# send country_name keys
driver.implicitly_wait(15)
country_name_input = driver.find_element(By.ID, "Address")
country_name_input.clear()
country_name_input.send_keys(country_name)
#click search button
search_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='main-content']/div[1]/div/form/div[1]/div[3]/button")))
driver.execute_script("arguments[0].click();", search_button)
time.sleep(3)
try:
driver.find_element(By.XPATH, "//*[@id='main-content']/div[2]/div[1]/div/div[1]/div[1]/div[1]/h3/a")
except NoSuchElementException:
df_company_output.loc[idx,'Exception'] = "No information found"
# emit signal to main_GUI
QApplication.processEvents()
self.updateProgress.emit(((idx+1) * 100)/len(df_company_output))
time.sleep(0.1)
print(str(idx) +": "+str(company_name)+ " not found")
else:
print(str(idx) +": "+str(company_name))
driver.refresh()
#click first href link
first_result = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='main-content']/div[2]/div[1]/div/div[1]/div[1]/div[1]/h3/a")))
first_result.click()
driver.implicitly_wait(10)
# click copy clipboard
clipboard_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, "//*[@id='chart-content']/div/div/div[1]/div[1]/div[2]/div/div[1]/div")))
clipboard_button.click()
clipboard_text= pyperclip.paste()
text_line = clipboard_text.splitlines()
df_company_output.loc[idx,'Name found in HitHorizons'] = text_line[0].strip()
df_company_output.loc[idx,'Address found in HitHorizons'] = text_line[1].strip()
if(len(text_line) == 3):
df_company_output.loc[idx,'Tax code found in HitHorizons'] = text_line[2].strip()
else:
df_company_output.loc[idx,'Tax code found in HitHorizons'] = 'None'
df_company_output.loc[idx,'Industry found in HitHorizons'] = driver.find_element(By.XPATH, "//*[@id='chart-content']/div/div/div[1]/div[1]/div[2]/div/div[2]/ul/li[1]/span").text.strip()
df_company_output.loc[idx,'URL of HitHorizons'] = driver.current_url
# emit signal to main_GUI
QApplication.processEvents()
self.updateProgress.emit(((idx+1) * 100)/len(df_company_output))
time.sleep(0.1)
# Get back to previous page
driver.back()
driver.close()
df_company_output = df_company_output.fillna('None')
return df_company_output
except WebDriverException:
df_company_output = df_company_output.fillna('None')
return df_company_output
|
C++ | UTF-8 | 3,079 | 2.765625 | 3 | [] | no_license | #ifndef EVENT_H
#define EVENT_H
class Core;
class My_viewer;
class Screen;
class Event
{
public:
Event(Core & core, My_viewer & viewer, Screen & calling_screen) :
_core(core),
_viewer(viewer),
_calling_screen(calling_screen)
{ }
virtual bool trigger() = 0;
protected:
Core & _core;
My_viewer & _viewer;
Screen & _calling_screen;
};
// First explain goal:
// Event 1
// - disable controls
// - show molecule releaser
// Hide Event 1, create time delayed Event 2
// - wait for some molecules to be released
// Event 2, create immediate Event 3
// - show portal
// Event 3, create Event 4 catching the placement of the heat element
// - show button for heat element, enable controls
// - let user place heat element
// Event 4
// - stop, explain the control elements on that
// Event 5
// -
class Intro_event : public Event
{
public:
Intro_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Camera_controls_event : public Event
{
public:
Camera_controls_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Intro_done_event : public Event
{
public:
Intro_done_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Molecule_releaser_event : public Event
{
public:
Molecule_releaser_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Portal_event : public Event
{
public:
Portal_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Heat_button_event : public Event
{
public:
Heat_button_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Static_existing_heat_element_event : public Event
{
public:
Static_existing_heat_element_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Movable_existing_heat_element_event : public Event
{
public:
Movable_existing_heat_element_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Heat_element_placed_event : public Event
{
public:
Heat_element_placed_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
};
class Heat_turned_up_event : public Event
{
public:
Heat_turned_up_event(Core & core, My_viewer & viewer, Screen & calling_screen) : Event(core, viewer, calling_screen)
{ }
bool trigger() override;
private:
float _last_time_too_low;
};
#endif // EVENT_H
|
C++ | UTF-8 | 1,763 | 2.828125 | 3 | [] | no_license | #ifndef MOTIONPLANNER_HPP_
#define MOTIONPLANNER_HPP_
#include "GoalQueueHandler.hpp"
#include <ros/ros.h>
#include <ros/time.h>
#include <actionlib/client/simple_action_client.h>
#include <actionlib/client/terminal_state.h>
#include <string>
#include <map>
/** The motionplanner interface contains test code that uses functionality of the RobotInterface. */
namespace MotionPlanner
{
/**
* @brief Class that contains the demonstration and acts as MotionPlanner.
*/
class RobotInterface
{
public:
/**
* @brief default constructor of the interface (client)
*/
RobotInterface();
/**
* @brief the destructor of the interface (client)
*/
~RobotInterface();
/**
* @brief function that gets the current set goal
*
* @return robot_interface::PositionGoal action goal that was set
*/
const robot_interface::PositionGoal &getGoal();
/**
* @brief Set the Goal object
*
* @param aGoal the goal to be set
*/
void setGoal(const robot_interface::PositionGoal &aGoal);
/**
* @brief function that will cancel all set goals at the RobotInterface (server)
*
* @return true if the emergency stop was successfull
*/
bool sendEmergencyStop();
/**
* @brief function that sends a goal and waits untill the result is returned by the interface
*/
void sendGoalAndWaitResult();
/**
* @brief function that runs a demo instance of the motion-planner
*/
void runDemo();
/** The ActionClient */
actionlib::SimpleActionClient<robot_interface::PositionAction> ac;
private:
/** The goal of the client to be send to the server. */
robot_interface::PositionGoal currentGoal;
};
}
#endif //MOTIONPLANNER_HPP_ |
Ruby | UTF-8 | 546 | 4.59375 | 5 | [] | no_license | #In this project, we’ll write a program that takes a user’s input, then builds a hash from that input.
#Each key in the hash will be a word from the user; each value will be the number of times that word occurs.
puts "here is your statement:"
text = gets.chomp
words = text.split #creates an array of the text
frequencies = Hash.new(0)
words.each { |word| frequencies[word] += 1 }
frequencies = frequencies.sort_by do |word, count|
count
end
frequencies.reverse!
frequencies.each do |word, count|
puts word + " " + count.to_s
end |
Markdown | UTF-8 | 1,653 | 3.609375 | 4 | [
"MIT"
] | permissive |
# equals
compare values of any complexity for equivalence
## Getting Started
_With component_
$ component install jkroso/equals
_With npm_
$ npm install jkroso/equals --save
then in your app:
```js
var equals = require('equals')
```
## API
- [equals()](#equals)
### equals(...)
equals takes as many arguments as you like of any type you like and returns a boolean result. Primitive types are equal if they are equal. While composite types, i.e. Objects and Arrays, are considered equal if they have both the same structure and the same content. Specifically that means the same set of keys each pointing to the same values. Composite structures can be as big as you like and and circular references are perfectly safe.
Same structure:
```js
equals(
{ a : [ 2, 3 ], b : [ 4 ] },
{ a : [ 2, 3 ], b : [ 4 ] }
) // => true
```
Different Structure:
```js
equals(
{ x : 5, y : [6] },
{ x : 5}
) // => false
```
Same structure, different values:
```js
equal(
{ a: [ 1, 2 ], b : [ 4 ]},
{ a: [ 2, 3 ], b : [ 4 ]}
) // => false
```
Primitives:
```js
equal(new Date(0), new Date(0), new Date(1)) // => false
```
Some possible gotchas:
- `null` __is not__ equal to `undefined`.
- `NaN` __is__ equal to `NaN` (normally not the case).
- `-0` __is__ equal to `+0`.
- Strings will __not__ coerce to numbers.
- Non enumerable properties will not be checked. They can't be.
- `arguments.callee` is not considered when comparing arguments
## Running the tests
```bash
$ npm install
$ make
```
Then open your browser to the `./test` directory.
_Note: these commands don't work on windows._
## License
[MIT](License) |
Java | UTF-8 | 1,844 | 2.875 | 3 | [] | no_license | /*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package csheets.ext.networkgame;
import csheets.ext.connection.Server;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.List;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.swing.JLabel;
import javax.swing.JPanel;
/**
*
* @author Miguel
*/
public class GameExample extends Game{
JLabel lbl = new JLabel("In game!");
public GameExample(String name, List<Player> players, Server s,InetAddress address) {
super(name, players, s, address);
this.name = name;
this.players = players;
}
@Override
public void init(boolean isServer) {
//set up some variables
NetworkGameController.initJFrame("Example game");
NetworkGameController.mainWindow.add(lbl);
NetworkGameController.packJFrame();
}
@Override
public void start() {
//game logic here
String message = "Sending to: " + address + "GM"+"Player " + players.get(0).name + " wins";
try {
s.sendData(message.getBytes(), address.getHostName(), 7777);
System.out.println(message);
} catch (UnknownHostException ex) {
Logger.getLogger(GameExample.class.getName()).log(Level.SEVERE, null, ex);
}
}
@Override
public void handleData(byte[] dados) {
String s = "";
for (int i = 2; i < dados.length; i++) {
s += (char) dados[i];
}
lbl = new JLabel(s);
System.out.println("Recebido de "+ address.toString() +": "+s);
}
}
|
Java | UTF-8 | 6,622 | 2.671875 | 3 | [] | no_license | package com.cg.miniproject.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import org.apache.log4j.Logger;
import com.cg.miniproject.exception.LAPException;
import com.cg.miniproject.model.Loan;
import com.cg.miniproject.utility.JDBCUtility;
public class LapDaoImpl implements LapDao {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
static Logger logger = Logger.getLogger(LapDaoImpl.class);
@Override
public int addApplicationDetails(Loan loan) throws LAPException {
logger.info("in add Customer method");
/**
* method : addCustomerDetails
* argument : it's taking model object as an argument
* return type : this method return the generated id to the user
* Author : Capgemini
* Date : 17 - Jan - 2019
*
**/
connection = com.cg.miniproject.utility.JDBCUtility.getConnection();
logger.info("connection object created");
int generatedId = 0;
try {
statement = connection.prepareStatement(QueryMapper.insertLoanPrograms);
logger.debug("statement object created");
statement.setString(1, loan.getProgramName());
statement.setString(2, loan.getDescription());
statement.setString(3, loan.getType());
statement.setInt(4, loan.getDurationinyears());
statement.setInt(5, loan.getMinloanamount());
statement.setInt(6, loan.getMaxloanamount());
statement.setDouble(7, loan.getRateofinterest());
statement.setString(8, loan.getProofsrequired());
/*
* statement.setString(1, loan.getLoanProgram()); statement.setDouble(2,
* loan.getAmountOfLoan()); statement.setString(3, loan.getAddressOfProperty());
* statement.setDouble(4, loan.getAnnualFamilyIncome()); statement.setString(5,
* loan.getDocumentsProofAvailable()); statement.setString(6,
* loan.getGuaranteeCover()); statement.setDouble(7,
* loan.getMarketValueOfGuaranteeCover()); statement.setString(8,
* loan.getStatus());
*/
generatedId = statement.executeUpdate();
logger.info("execute update called");
/*
* statement = connection.prepareStatement(QueryMapper.getApplicationId);
* logger.info("statement created to getPurchaseId"); resultSet =
* statement.executeQuery(); logger.info("result object get created");
* resultSet.next(); generatedId = resultSet.getInt(1);
* logger.info("generated id is: " + generatedId);
*/
} catch (SQLException e) {
/*logger.error(e.getMessage());
throw new LAPException("problem occured while creating the statement object");*/
e.printStackTrace();
}
/*finally {
logger.info("in finally block");
try {
logger.info("resultset closed");
} catch (SQLException e) {
throw new LAPException("problem occured while closing resultset");
}
try {
statement.close();
logger.info("statement closed");
} catch (SQLException e) {
logger.error(e.getMessage());
throw new LAPException("problem occured while closing statement");
}
try {
connection.close();
logger.info("connection closed");
} catch (SQLException e) {
logger.error(e.getMessage());
throw new LAPException("problem occured while closing connection");
}
}
*/ return generatedId;
}
@Override
public List<Loan> getLoans() throws LAPException {
List<Loan> list = new ArrayList<>();
connection = JDBCUtility.getConnection();
try {
statement = connection.prepareStatement(QueryMapper.getLoans);
resultSet = statement.executeQuery();
while (resultSet.next()) {
String program = resultSet.getString(1);
String description = resultSet.getString(2);
String type = resultSet.getString(3);
int durationInYears = resultSet.getInt(4);
int minLoanAmount =resultSet.getInt(5);
int maxLoanAmount = resultSet.getInt(6);
int rateOfInterest=resultSet.getInt(7);
String proofsRequired = resultSet.getString(8);
Loan loan = new Loan();
loan.setProgramName(program);
loan.setDescription(description);
loan.setType(type);
loan.setDurationinyears(durationInYears);
loan.setMinloanamount(minLoanAmount);
loan.setMaxloanamount(maxLoanAmount);
loan.setRateofinterest(rateOfInterest);
loan.setProofsrequired(proofsRequired);
list.add(loan);
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
@Override
public List<Loan> getDetails(Loan loan) throws LAPException {
connection = JDBCUtility.getConnection();
List<Loan> list = new ArrayList<>();
try {
statement = connection.prepareStatement(QueryMapper.getDetails);
statement.setInt(1, loan.getApplicationId());
resultSet = statement.executeQuery();
while (resultSet.next()) {
String status = resultSet.getString(1);
loan.setStatus(status);
list.add(loan);
}
} catch (SQLException e) {
throw new LAPException("Statement was not created");
} finally {
try {
resultSet.close();
} catch (SQLException e) {
throw new LAPException("ResultSet was not closed");
}
try {
statement.close();
} catch (SQLException e) {
throw new LAPException("Statement was not closed");
}
try {
connection.close();
} catch (SQLException e) {
throw new LAPException("Connection was not closed");
}
}
return list;
}
@Override
public int addApplicationMapping(Loan loan1) throws LAPException {
connection = com.cg.miniproject.utility.JDBCUtility.getConnection();
logger.info("connection object created");
int generatedId = 0;
try {
statement = connection.prepareStatement(QueryMapper.insertApplicationPrograms);
logger.debug("statement object created");
statement.setInt(1, loan1.getApplicationId());
statement.setString(2, loan1.getLoanProgram());
statement.setString(3, loan1.getAddressOfProperty());
statement.setDouble(4, loan1.getAnnualFamilyIncome());
statement.setString(5, loan1.getDocumentsProofAvailable());
statement.setString(6, loan1.getGuaranteeCover());
statement.setDouble(7, loan1.getMarketValueOfGuaranteeCover());
statement.setString(8, loan1.getStatus());
generatedId = statement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return generatedId;
}
}
|
C++ | UTF-8 | 1,734 | 3.296875 | 3 | [
"MIT"
] | permissive | #include<iostream>
#include <pthread.h>
#include <string>
using namespace std;
#define NUM_THREADS 5
#define BLACK "\033[0m"
#define RED "\033[1;31m"
#define GREEN "\033[1;32m"
#define YELLOW "\033[1;33m"
#define BLUE "\033[1;34m"
#define CYAN "\033[1;36m"
static pthread_mutex_t mutex;
void * PrintAsciiText(void *id){
string colour;
//MUTEX serve per evitare che più thread accedano allo stesso codice contemporaneamente
pthread_mutex_lock(&mutex);
switch((long)id)
{
case 0:
colour = RED;
break;
case 1:
colour = GREEN;
break;
case 2:
colour = YELLOW;
break;
case 3:
colour = BLUE;
break;
case 4:
colour = CYAN;
break;
default:
colour = BLACK;
break;
}
cout << colour << "I'm a new thread, I'm number " << (long)id << BLACK << endl;
pthread_mutex_unlock(&mutex);
pthread_exit(NULL);
}
int main(){
cout<<"ciao3"<<endl;
pthread_t threads[NUM_THREADS];
for (long int i=0;i<NUM_THREADS;i++){
//referenza al thread
//NULL parametri di default
//PrintAsciiText-> Routine che vado ad eseguire
// Indice identificativo relativo al thread eseguito
int t= pthread_create(&threads[i],NULL,PrintAsciiText,(void*)i);
if (t !=0 ){
cout << "error Thread Creation"<<endl;
}
}
//Controlla se tutti i thread sono terminati
//In questo modo il programma non prosegue se tutti i thread non sono terminati
for (long int i=0; i< NUM_THREADS;i++){
void * status;
int t= pthread_join(threads[i],&status);
}
return 1;
} |
Python | UTF-8 | 10,292 | 3 | 3 | [
"MIT"
] | permissive | import numpy as np
import networkx as nx
from networkx.algorithms.flow import maximum_flow
from algorith.graphs.graph_utils import min_edge_cover
import re
import random
import collections
def min_cover_trigraph_edge_covers_heuristic(edges1,edges2):
c1=min_edge_cover(edges1)
c2=min_edge_cover(edges2)
vert_set = {}
for e in c1:
if e[1] not in vert_set:
tg = NeuralTriGraphCentralVert(e)
vert_set[e[1]] = tg
else:
vert_set[e[1]].add(e)
for e in c2:
if e[0] not in vert_set:
tg = NeuralTriGraphCentralVert(e)
vert_set[e[0]] = tg
else:
vert_set[e[0]].add(e)
for key in vert_set:
vert_set[key].edge_counts()
return vert_set
class NeuralTriGraphCentralVert():
def __init__(self,edge):
self.key = max(edge)
self.l_edges = []
self.r_edges = []
self.l_edges.append(min(edge))
def add(self,edge):
mi, mx = min(edge), max(edge)
if mi == self.key:
self.r_edges.append(mx)
elif mx == self.key:
self.l_edges.append(mi)
def edge_counts(self):
l_size = len(self.l_edges)
r_size = len(self.r_edges)
self.l_counts = np.ones(l_size)
self.r_counts = np.ones(r_size)
if l_size>r_size:
self.r_counts = distr_evenly(l_size,r_size)
elif l_size<r_size:
self.l_counts = distr_evenly(r_size,l_size)
class NeuralTriGraph():
"""
A neural tri-grpah is a special case of a tri-partite
graph. In it, the vertices can be segregated into three
layers. However unlike a tri-partite graph, connections
exist only between successive layers (1 and 2; 2 and 3).
Such graphs describe the layers of a neural network;
hence the name.
"""
def __init__(self, left_edges, right_edges):
self.left_edges = left_edges
self.right_edges = right_edges
self.vertices = set(left_edges.flatten())\
.union(set(right_edges.flatten()))
self.layer_1 = set(left_edges[:,0])
self.layer_2 = set(left_edges[:,1])
self.layer_3 = set(right_edges[:,1])
self.layer_1_size = len(self.layer_1)
self.layer_2_size = len(self.layer_2)
self.layer_3_size = len(self.layer_3)
self.layer_1_dict = {}
for e in left_edges:
if e[0] not in self.layer_1_dict:
self.layer_1_dict[e[0]] = set([e[1]])
else:
self.layer_1_dict[e[0]].add(e[1])
self.layer_3_dict = {}
for e in right_edges:
if e[1] not in self.layer_3_dict:
self.layer_3_dict[e[1]] = set([e[0]])
else:
self.layer_3_dict[e[1]].add(e[0])
self.central_vert_dict = create_central_vert_dict(left_edges,\
right_edges)
def create_bipartite_graph(self):
self.flow_graph = nx.DiGraph()
for ed in self.left_edges:
## The vertices from which flow travels only out.
v1 = "out_layer0_elem" + str(ed[0])
v2 = "in_layer1_elem" + str(ed[1])
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for ed in self.right_edges:
v1 = "out_layer1_elem" + str(ed[0])
v2 = "in_layer2_elem" + str(ed[1])
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for k in self.central_vert_dict.keys():
for l in self.central_vert_dict[k].l_edges:
for r in self.central_vert_dict[k].r_edges:
v1 = "out_layer0_elem" + str(l)
v2 = "in_layer2_elem" + str(r)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
v1="source"
for e in self.layer_1:
v2 = "out_layer0_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for e in self.layer_2:
v2 = "out_layer1_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for e in self.layer_3:
v2 = "out_layer2_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
v2="sink"
for e in self.layer_1:
v1 = "in_layer0_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for e in self.layer_2:
v1 = "in_layer1_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
for e in self.layer_3:
v1 = "in_layer2_elem" + str(e)
self.flow_graph.add_edge(v1,v2,capacity=1,weight=1)
def obtain_paths(self):
_, flow_dict = nx.maximum_flow(self.flow_graph, 'source', 'sink')
self.vert_disjoint_paths = max_matching_to_paths(flow_dict)
final_paths = []
for pth in self.vert_disjoint_paths:
if len(pth)==3:
final_paths.append(pth)
elif len(pth)==2:
left_layer = self.determine_layer(pth[0])
right_layer = self.determine_layer(pth[1])
if left_layer==0 and right_layer==2:
central_candidates = self.layer_1_dict[pth[0]]\
.intersection(self.layer_3_dict[pth[1]])
## Randomly pick a central vertex.
central = random.sample(central_candidates,1)[0]
pth1 = [pth[0],central,pth[1]]
final_paths.append(pth1)
elif left_layer==0:
right_sampled = random.sample(self.central_vert_dict[pth[1]]\
.r_edges,1)[0]
pth1 = [pth[0],pth[1],right_sampled]
final_paths.append(pth1)
elif right_layer==2:
left_sampled = random.sample(self.central_vert_dict[pth[0]]\
.l_edges,1)[0]
pth1 = [left_sampled,pth[0],pth[1]]
final_paths.append(pth1)
self.final_paths = final_paths
def determine_layer(self,ind):
if ind < self.layer_1_size:
return 0
elif ind < self.layer_2_size:
return 1
else:
return 2
def distr_evenly(n,l):
ceil=np.ceil(n/l)
flr=ceil-1
h=int(n-l*flr)
j=int(l*ceil-n)
h_arr = np.ones(h)*ceil
j_arr = np.ones(j)*flr
return np.concatenate((h_arr,j_arr))
def create_central_vert_dict(edges1,edges2):
vert_set = {}
for e in edges1:
if e[1] not in vert_set:
tg = NeuralTriGraphCentralVert(e)
vert_set[e[1]] = tg
else:
vert_set[e[1]].add(e)
for e in edges2:
if e[0] not in vert_set:
tg = NeuralTriGraphCentralVert(e)
vert_set[e[0]] = tg
else:
vert_set[e[0]].add(e)
return vert_set
def max_matching_to_paths(flow_dict):
paths = []; path=[]
seen_verts = set()
# Prioritize earlier layers to avoid starting larger paths from the middle,
# which will incorrectly split them into multiple paths.
for k in sorted(flow_dict.keys()):
# What if there is a path that doesn't start at layer0?
if k.startswith("out_"):
[_, vert_ind] = [int(st) for st in re.findall(r'\d+',k)]
if vert_ind not in seen_verts:
path.append(vert_ind)
curr_vert = k
## Embark on a walk along this path.
## Let's see how long it is.
#while len(flow_dict[curr_vert])>0:
while True:
flow_out = 0
for k1 in flow_dict[curr_vert].keys():
if flow_dict[curr_vert][k1]>0:
flow_out+=1
[nx_layer, nx_vert_ind] = [int(st) for st in re.findall(r'\d+',k1)]
curr_vert = "out_layer" + str(nx_layer) \
+ "_elem" + str(nx_vert_ind)
path.append(nx_vert_ind)
seen_verts.add(nx_vert_ind)
break
if flow_out==0:
break
if len(path)>0:
paths.append([i for i in path])
path = []
return paths
def max_matching_to_paths_v1(flow_dict):
paths = []; path=[]
seen_verts = set()
for k in sorted(flow_dict.keys()):
if k.startswith("out_") and "layer0" in k:
[_, vert_ind] = [int(st) for st in re.findall(r'\d+',k)]
if vert_ind not in seen_verts:
curr_key = k
while len(flow_dict[curr_key])>0:
[_, vert_ind] = [int(st) for st in re.findall(r'\d+',curr_key)]
if vert_ind not in seen_verts:
seen_verts.add(vert_ind)
if len(path)==0:
path = [vert_ind]
for k1 in flow_dict[curr_key].keys():
## Qn: Why do we need the first if??
if k1 in flow_dict[curr_key] and flow_dict[curr_key][k1]>0:
[nx_layer, nx_vert_ind] = [int(st) for st in re.findall(r'\d+',k1)]
curr_key = "out_layer" + str(nx_layer) \
+ "_elem" + str(nx_vert_ind)
seen_verts.add(nx_vert_ind)
path.append(nx_vert_ind)
if len(path)>0:
paths.append([i for i in path])
path=[]
return paths
def tst1():
## Test case-1
edges1 = np.array([[1,4],[2,4],[2,5],[3,5]])
edges2 = np.array([[4,6],[4,7],[5,8]])
nu = NeuralTriGraph(edges1,edges2)
nu.create_bipartite_graph()
##For debugging:
[e for e in nu.flow_graph.edges]
flow_val, flow_dict = nx.maximum_flow(nu.flow_graph, 'source', 'sink')
paths = max_matching_to_paths(flow_dict)
## Test case-2
edges1 = np.array([[1,5],[2,5],[3,7],[4,6]])
edges2 = np.array([[5,8],[5,9],[5,10],[7,11],[6,11]])
|
Java | UTF-8 | 8,432 | 1.898438 | 2 | [] | no_license | package kingroup_v2.ucm.import_sample;
import kingroup_v2.KinGroupV2MainUI;
import kingroup_v2.KinGroupV2Project;
import kingroup_v2.Kingroup;
import kingroup_v2.KingroupFrame;
import kingroup_v2.cervus.CervusFileFormat;
import kingroup_v2.cervus.CervusFileReader;
import kingroup_v2.cervus.view.CervusFileFormatView;
import kingroup_v2.io.FileIO;
import kingroup_v2.io.ImportPopOptions;
import kingroup_v2.kinship.KinshipFileFormat;
import kingroup_v2.kinship.KinshipFileReader;
import kingroup_v2.kinship.view.KinshipFileFormatView;
import kingroup_v2.pop.allele.freq.*;
import kingroup_v2.pop.sample.PopGroupView;
import kingroup_v2.pop.sample.PopView;
import kingroup_v2.pop.sample.sys.SysPop;
import kingroup_v2.pop.sample.sys.SysPopFactory;
import kingroup_v2.pop.sample.sys.SysPopView;
import kingroup_v2.pop.sample.usr.UsrPopFactory;
import kingroup_v2.pop.sample.usr.UsrPopSLOW;
import kingroup_v2.pop.sample.usr.UsrPopView;
import pattern.ucm.UCController;
import tsvlib.project.ProjectLogger;
import javax.iox.TextFile;
import javax.iox.TextFileView;
import javax.swing.*;
import javax.swingx.ApplyDialogUI;
import javax.swingx.UCShowImportFileUI;
import java.io.File;
/**
* Copyright KinGroup Team.
* User: jc138691, Date: 13/09/2005, Time: 16:57:33
*/
public class UCImportFile implements UCController {
private static ProjectLogger log = ProjectLogger.getLogger(UCImportFile.class);
public boolean run() {
Kingroup bean = KinGroupV2Project.getInstance();
String name = bean.getLastImportedFileName();
File file = bean.makeFile(name);
read(file);
return true;
}
public void read(File file) {
Kingroup project = KinGroupV2Project.getInstance();
if (project.getFileType() == project.KINSHIP_FILE) {
readKinshipFile(file, project);
}
else if (project.getFileType() == project.CERVUS_FILE) {
readCervusFile(file, project);
}
}
public void readKinshipFile(File file, Kingroup project) {
JFrame frame = KingroupFrame.getInstance();
if (frame != null && file != null) {
frame.setTitle(project.getAppName() + " "
+ project.getAppVersion()
+ " [KINSHIP input file: " + file.getName() + "]");
}
KinshipFileFormat format = project.getKinshipFileFormat();
TextFile fileModel = new TextFile();
fileModel.setFileName(file.getName());
fileModel.read(file, frame);
// KinshipFileReader.replaceTabDelims(fileModel, format); // MUST BE DONE!!!
KinshipFileReader.separateDelimiters(fileModel, format); // MUST BE DONE!!!
// todo: can it be made expadable to max size?
// CONFIGURE KINSHIP FORMAT
TextFileView fileView = new TextFileView(fileModel);
KinshipFileFormatView formatView = new KinshipFileFormatView(format);
ApplyDialogUI dlg = new UCShowImportFileUI(FileIO.combine(formatView, fileView)
, frame, "Import " + file.getName());
dlg.setApplyBttnText("Import");
dlg.setVisible(true);
if (!dlg.apply())
return;
formatView.loadTo(format);
project.saveProjectToDefaultLocation(); // remember user input
// SHOW INPUT FILE
KinGroupV2MainUI ui = KinGroupV2MainUI.getInstance();
ui.resetAll();
ui.setImportFileView(fileView);
UsrPopSLOW usrPop = KinshipFileReader.importFile(fileModel, format);
if (usrPop == null) {
String error = "Unable to import.";
log.severe(error);
JOptionPane.showMessageDialog(frame, error);
return;
}
commonFinish(ui, usrPop, format);
setupGroups(ui, format);
}
private void setupGroups(KinGroupV2MainUI ui, KinshipFileFormat format) {
if (!format.getHasGroupId())
return;
JFrame frame = KingroupFrame.getInstance();
UsrPopSLOW usrPop = ui.getUsrPop();
UsrPopSLOW[] usrGroups = UsrPopFactory.toGroupArray(usrPop);
SysPop sysPop = ui.getSysPop();
SysPop[] sysGroups = SysPopFactory.makeGroupsFrom(sysPop);
if (usrGroups == null || usrGroups.length == 0) {
String mssg = "Internal error occurred while trying to set up groups:\nusrGroups == null || usrGroups.length == 0.";
log.severe(mssg);
JOptionPane.showMessageDialog(frame, mssg);
return;
}
if (usrGroups.length == 1) {
String mssg = "Note: Column of group ids contains only one group.";
log.severe(mssg);
JOptionPane.showMessageDialog(frame, mssg);
return;
}
if (usrGroups.length != sysGroups.length) {
String mssg = "Internal error. usrGroups.length != sysGroups.length";
log.severe(mssg);
JOptionPane.showMessageDialog(frame, mssg);
return;
}
if (format.getFreqSource() == format.FREQ_SOURCE_BIAS)
{
UsrAlleleFreq freq = UsrAlleleFreqFactory.calcFrom(usrPop);
for (int g = 0; g < usrGroups.length; g++) {
UsrPopSLOW usrGroup = usrGroups[g];
UsrAlleleFreq groupFreq = UsrAlleleFreqFactory.calcFrom(usrGroup);
UsrAlleleFreq newFreq = UsrAlleleFreqFactory.subtract(freq, groupFreq);
SysAlleleFreq sysFreq = SysAlleleFreqFactory.makeSysAlleleFreqFrom(newFreq);
if (format.getFreqUserNorm())
SysAlleleFreqFactory.copyToUserFreq(newFreq, sysFreq);
usrGroup.setFreq(newFreq);
sysGroups[g].setFreq(sysFreq);
}
}
PopGroupView popGroupView = new PopGroupView();
popGroupView.load(usrGroups, sysGroups, format);
PopView popView = ui.getPopView();
ui.setPopGroupView(popGroupView);
popView.setPopFocus();
}
public void readCervusFile(File file, Kingroup project) { //log.setDebug();
JFrame frame = KingroupFrame.getInstance();
if (frame != null && file != null) {
frame.setTitle(project.getAppName() + " "
+ project.getAppVersion()
+ " [CERVUS input file: " + file.getName() + "]");
}
CervusFileFormat format = project.getCervus().getFileFormat();
TextFile fileModel = new TextFile();
fileModel.setFileName(file.getName());
fileModel.read(file, frame); log.debug("input file\n", fileModel);
CervusFileReader.separateDelimiters(fileModel, format); log.debug("separateDelimiters\n", fileModel);
// CONFIGURE CERVUS FORMAT
TextFileView fileView = new TextFileView(fileModel);
CervusFileFormatView formatView = new CervusFileFormatView(format);
ApplyDialogUI dlg = new UCShowImportFileUI(FileIO.combine(formatView, fileView)
, frame, "Import " + file.getName());
dlg.setApplyBttnText("Import");
dlg.setVisible(true);
if (!dlg.apply())
return;
formatView.loadTo(format);
project.saveProjectToDefaultLocation(); // remember user input
// SHOW INPUT FILE
KinGroupV2MainUI ui = KinGroupV2MainUI.getInstance();
ui.resetAll();
ui.setImportFileView(fileView);
UsrPopSLOW usrPop = CervusFileReader.importFile(fileModel, format); log.debug("usrPop\n", usrPop);
if (usrPop == null) {
String error = "Unable to import.";
log.severe(error);
JOptionPane.showMessageDialog(frame, error);
return;
}
commonFinish(ui, usrPop, format);
}
private void commonFinish(KinGroupV2MainUI ui
, UsrPopSLOW usrPop
, ImportPopOptions format)
{
PopView popView = new PopView();
ui.setPopView(popView);
String delim = format.getColumnDelimStr() + " ";
UsrAlleleFreq usrFreq = usrPop.getFreq();
if (usrFreq != null) {
SysAlleleFreq sysFreq = SysAlleleFreqFactory.makeSysAlleleFreqFrom(usrFreq);
if (format.getFreqUserNorm())
SysAlleleFreqFactory.copyToUserFreq(usrFreq, sysFreq);
AlleleFreqView freqView = new AlleleFreqView();
freqView.setUserAlleleFreqView(new UsrAlleleFreqView(usrFreq, delim));
freqView.setSysAlleleFreqView(new SysAlleleFreqView(sysFreq));
popView.setAlleleFreqView(freqView);
freqView.setUsrFocus();
}
SysPop sysPop = SysPopFactory.makeSysPopFrom(usrPop);
if (sysPop == null) {
return;
}
SysPopView sysView = new SysPopView(sysPop);
popView.setSysPopView(sysView);
UsrPopView usrView = new UsrPopView(usrPop);
popView.setUserPopView(usrView);
popView.setPopFocus();
}
}
|
JavaScript | UTF-8 | 9,996 | 2.65625 | 3 | [
"ISC"
] | permissive | import React, { Component } from 'react';
import { connect } from 'react-redux';
import { bindActionCreators } from 'redux';
import { Field, reduxForm, reset } from 'redux-form';
import { getEmployeeById, updateEmployee, getEmployeeViewData } from '../../actions';
class UpdateEmployeeForm extends Component{
constructor(props){
super(props);
this.state = {
message: ''
}
}
componentDidUpdate(prevProps) {
// New ID, fetch employee info
if (this.props.id != prevProps.id) {
this.props.getEmployeeById(this.props.id).then( () => {
if (this.props.hasErrored) {
this.setState({message: 'Woops! Something went wrong. Try again.'});
} else {
this.initializeForm(this.props.employee);
}
});
}
}
initializeForm(employee) {
var startDate = new Date(employee.active_start_date);
var endDate = new Date(employee.active_end_date);
// Set form field values
const {first, last, discipline_id} = employee;
var data = { first, last, discipline_id,
startMonth: startDate.getUTCMonth() + 1,
startYear: startDate.getUTCFullYear(),
endMonth: endDate.getUTCMonth() + 1,
endYear: endDate.getUTCFullYear()
}
this.props.initialize(data);
}
renderField(field) {
const { meta: { touched, error} } = field;
const customClass = `form-group ${touched && error ? 'has-danger' : ''}`;
if (field.type === 'select') {
return (
<div className={customClass}>
<label>{field.label}</label>
<select className="form-control" {...field.input}>
{field.selectOptions}
</select>
<div className="text-help">
{touched ? error : ''}
</div>
</div>
);
} else {
return(
<div className={customClass}>
<label>{field.label}</label>
<input className="form-control"
type="text"
{...field.input}
/>
<div className="text-help">
{touched ? error : ''}
</div>
</div>
);
}
}
renderDisciplineOptions() {
var disciplines = this.props.disciplines;
var opts = [];
opts.push(<option key={0} value={0}>Select Discipline...</option>);
disciplines.map( d => {
opts.push(<option key={d.id} value={d.id}>{d.title}</option>);
})
return opts;
}
renderMonthOptions() {
var opts = [];
opts.push(<option key={0} value={0}>Select Month...</option>)
const months = ['January','February','March','April','May','June','July',
'August','September','October','November','December'];
months.map( (name, num) => {
opts.push(<option key={num+1} value={num+1}>{name}</option>)
});
return opts;
}
renderYearOptions() {
var yr = new Date().getFullYear();
var opts = [];
opts.push(<option key={0} value={0}>Select Year...</option>)
for (var i = yr - 40; i <= yr + 40; ++i) {
opts.push(<option key={i} value={i}>{i}</option>);
}
return opts;
}
onSubmit(employee){
var { first, last, discipline_id, startMonth, startYear, endMonth, endYear } = employee;
var data = { first, last, discipline_id };
if (startMonth < 10) {
startMonth = '0' + startMonth;
}
if (endMonth < 10) {
endMonth = '0' + endMonth;
}
data.active_start_date = startYear + '-' + startMonth + '-01';
data.active_end_date = endYear + '-' + endMonth + '-01';
data.id = this.props.id;
this.props.updateEmployee(data).then(() => {
if (this.props.updateHasErrored) {
this.setState({message: 'Woops! Something went wrong. Try again.'})
} else {
this.setState({message: ''})
this.props.reset();
// Update default form values with newly updated data, in case we
// re-select the same employee immediately, since the logic won't
// re-fetch based on ID.
this.initializeForm(data);
// Re-fetch the employee view data, since we've changed it
this.props.dispatch(getEmployeeViewData);
$('.bs-update-modal-lg').modal('hide');
}
})
}
render() {
const { handleSubmit, reset } = this.props;
return(
<form onSubmit={handleSubmit(this.onSubmit.bind(this))} >
<div className="row">
<div className="col-md-6">
<Field
label="First Name"
name="first"
component={this.renderField}
/>
</div>
<div className="col-md-6">
<Field
label="Last Name"
name="last"
component={this.renderField}
/>
</div>
</div>
<div className="row">
<div className="col-md-6">
<Field
label="Discipline"
name="discipline_id"
type="select"
selectOptions={this.renderDisciplineOptions()}
component={this.renderField}
/>
</div>
</div>
{/* Start Date Fields */}
<div className="row">
<div className="col-md-6">
<Field
label="Active Start Month"
name="startMonth"
type="select"
selectOptions={this.renderMonthOptions()}
component={this.renderField}
/>
</div>
<div className="col-md-6">
<Field
label="Active Start Year"
name="startYear"
type="select"
selectOptions={this.renderYearOptions()}
component={this.renderField}
/>
</div>
</div>
{/* End Date Fields */}
<div className="row">
<div className="col-md-6">
<Field
label="Active End Month"
name="endMonth"
type="select"
selectOptions={this.renderMonthOptions()}
component={this.renderField}
/>
</div>
<div className="col-md-6">
<Field
label="Active End Year"
name="endYear"
type="select"
selectOptions={this.renderYearOptions()}
component={this.renderField}
/>
</div>
</div>
<button type="submit" className="btn btn-primary">
Update Employee
</button>
<button className="btn btn-danger" data-dismiss="modal" onClick={reset}>Cancel</button>
<p>{this.state.message}</p>
</form>
)
}
}
function validate(values){
const errors = {};
const { first, last, discipline_id,
startMonth, startYear, endMonth, endYear } = values;
if(!first){
errors.first = "First name is required.";
}
if(!last){
errors.last = "Last name is required.";
}
if (discipline_id == 0) {
errors.discipline_id = "Discipline is required.";
}
if (!startMonth) {
errors.startMonth = "Start month is required.";
}
if (!startYear) {
errors.startYear = "Start year is required.";
}
if (!endMonth) {
errors.endMonth = "End month is required.";
}
if (!endYear) {
errors.endYear = "End year is required.";
}
if (startMonth && startYear && endMonth && endYear) {
if (startYear > endYear) {
errors.startYear = "Start year must be before end year.";
errors.endYear = "End year must be after start year.";
} else if (startYear == endYear) {
if (startMonth > endMonth) {
errors.startMonth = "Start month must be before end month.";
errors.endMonth = "End month must be after start month.";
}
}
}
return errors;
}
UpdateEmployeeForm = reduxForm({
validate,
form: 'UpdateEmployeeForm',
})(UpdateEmployeeForm);
function mapDispatchToProps(dispatch) {
return bindActionCreators({
getEmployeeById,
getEmployeeViewData,
updateEmployee
}, dispatch);
}
const mapStateToProps = (state) => {
return {
disciplines: state.disciplines,
employee: state.getEmployee,
hasErrored: state.getEmployeeHasErrored,
updateHasErrored: state.updateEmployeeHasErrored
}
}
export default connect(mapStateToProps, mapDispatchToProps)(UpdateEmployeeForm); |
TypeScript | UTF-8 | 3,129 | 2.625 | 3 | [
"MIT"
] | permissive | import type { StrategyOptions as OAuth2StrategyOptions } from 'passport-oauth2';
import type passport from 'passport';
import type express from 'express';
import type { SignOptions, Algorithm } from 'jsonwebtoken';
export interface Profile extends Pick<passport.Profile, 'provider'> {
expiresIn: number;
}
export interface AuthenticateOptions extends passport.AuthenticateOptions {
showDialog?: boolean;
}
export interface StrategyOptions
extends Omit<
OAuth2StrategyOptions,
'authorizationURL' | 'tokenURL' | 'clientID' | 'clientSecret'
> {
/**
* Your Team ID (aka Developer ID).
*
* A 10-letter ID that can be found on your account page at https://developer.apple.com/account/#/membership.
*
* This ID requires Apple Developer Program membership ($100/yr).
*/
teamID: string;
/**
* Your Key ID for MusicKit.
*
* A 10-letter ID that can be found or created at https://developer.apple.com/account/resources/authkeys/list.
*
* The key **MUST** have "MusicKit" among "Enabled Services".
*
* To create Key ID with MusicKit access:
* 1) Create Music IDs Identifier at https://developer.apple.com/account/resources/identifiers
* 2) Register new Key at https://developer.apple.com/account/resources/authkeys/add
* 1. Enable (tick) MusicKit
* 2. Click "Configure" and select the Music ID from step 1)
* 3. Save / Continue
* 3) Confirm MusicKit is among enabled services when you go to https://developer.apple.com/account/resources/authkeys/review/<KeyID>
*/
keyID: string;
/**
* Path to the file with private key that belongs to the keyID.
*
* Private key can be downloaded from https://developer.apple.com/account/resources/authkeys/review/<KeyID>.
*
* Note: Private key can be downloaded only once.
*/
privateKeyLocation: string;
/** App Name shown on auth page */
appName?: string;
/** Url of app icon shown on auth page */
appIcon?: string;
jwtOptions?: SignOptions & {
/**
* Encryption algorithm as mentioned in Apple Music API token generation guide.
*
* DO NOT override this value unless you know what you are doing.
*
* Defaults to 'ES256'.
*
* See https://developer.apple.com/documentation/applemusicapi/getting_keys_and_creating_tokens.
*/
algorithm?: Algorithm;
/**
* JWT expiry.
*
* Maximum expiry for Apple Music API token is "180d".
*
* Expressed in seconds or a string describing a time span [zeit/ms](https://github.com/zeit/ms.js).
*
* Eg: 60, "2 days", "10h", "7d"
*/
expiresIn?: string | number;
};
}
export interface StrategyOptionsWithRequest
extends Omit<StrategyOptions, 'passReqToCallback'> {
passReqToCallback: true;
}
export type VerifyFunction = (
accessToken: string,
refreshToken: string,
profile: Profile,
done: (error: any, user?: any, info?: any) => void
) => void;
export type VerifyFunctionWithRequest = (
req: express.Request,
accessToken: string,
refreshToken: string,
profile: Profile,
done: (error: any, user?: any, info?: any) => void
) => void;
|
C++ | UTF-8 | 1,273 | 2.515625 | 3 | [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | // Copyright 2021 Garena Online Private Limited
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include "envpool/utils/resize.h"
#include <glog/logging.h>
#include <gtest/gtest.h>
#include <vector>
TEST(ResizeTest, Correctness) {
// shape
Array a(Spec<uint8_t>({4, 3, 1}));
Array b(Spec<uint8_t>({6, 7, 1}));
Resize(a, &b);
EXPECT_EQ(b.Shape(), std::vector<std::size_t>({6, 7, 1}));
EXPECT_NE(a.data(), b.data());
// same shape, no reference
Array a2(Spec<uint8_t>({4, 3, 2}));
a2(1, 0, 1) = 6;
a2(3, 1, 0) = 4;
Array b2(Spec<uint8_t>({4, 3, 2}));
Resize(a2, &b2);
EXPECT_EQ(a2.Shape(), b2.Shape());
EXPECT_NE(a2.data(), b2.data());
EXPECT_EQ(6, static_cast<int>(b2(1, 0, 1)));
EXPECT_EQ(4, static_cast<int>(b2(3, 1, 0)));
}
|
Python | UTF-8 | 2,175 | 3.265625 | 3 | [] | no_license | import pandas as pd
import os
import sqlite3
data = {'type': ['book', 'magazine', 'magazine', None, None, 'book', 'book', 'magazine'],
'author': ['peter', 'peter', 'peter', 'peter', 'mary', 'mary', 'mary', 'mary'],
'age': [1, 2, 3, 4, 5, 6, 7, 8]}
df = pd.DataFrame(data)
# Read and write pickle file
pd.to_pickle(df, os.path.join('.', 'data_frame.pickle'))
read_pickle = pd.read_pickle(os.path.join('.', 'data_frame.pickle'))
print(read_pickle)
# output
# type author age
# 0 book peter 1
# 1 magazine peter 2
# 2 magazine peter 3
# 3 None peter 4
# 4 None mary 5
# 5 book mary 6
# 6 book mary 7
# 7 magazine mary 8
# write to excel file
new_df = df.loc[2:5, :].copy()
print(new_df)
# output
# type author age
# 2 magazine peter 3
# 3 None peter 4
# 4 None mary 5
# 5 book mary 6
# write file with index
new_df.to_excel('data_frame.xlsx')
# write file without index
new_df.to_excel('data_frame_without_index.xlsx', index=False)
# write file with filtered columns
new_df.to_excel('data_frame_with_filtered_columns.xlsx', index=False, columns=['type', 'author'])
# multiple worksheets
excel_writer = pd.ExcelWriter('multiple_worksheets.xlsx')
df.to_excel(excel_writer, sheet_name='original_df', index=False)
new_df.to_excel(excel_writer, sheet_name='new_df', index=False)
excel_writer.save()
# Write to SQL table
with sqlite3.connect('myDb') as conn:
new_df.to_sql('MyTable', conn)
# Write to JSON
print(new_df.to_json())
# output
# {"type":{"2":"magazine","3":null,"4":null,"5":"book"},"author":{"2":"peter","3":"peter","4":"mary","5":"mary"},"age":{"2":3,"3":4,"4":5,"5":6}}
print(new_df.to_json(orient='table'))
# output
# {"schema":{"fields":[{"name":"index","type":"integer"},{"name":"type","type":"string"},{"name":"author","type":"string"},{"name":"age","type":"integer"}],"primaryKey":["index"],"pandas_version":"0.20.0"},"data":[{"index":2,"type":"magazine","author":"peter","age":3},{"index":3,"type":null,"author":"peter","age":4},{"index":4,"type":null,"author":"mary","age":5},{"index":5,"type":"book","author":"mary","age":6}]}
|
C++ | UTF-8 | 1,639 | 3.765625 | 4 | [] | no_license | /**
* The n-queens puzzle is the problem of placing n queens on an n×n chessboard such that no two
* queens attack each other.
* [one solution to the eight queens puzzle](https://assets.leetcode.com/uploads/2018/10/12/8-queens.png)
*
* Given an integer n, return the number of distinct solutions to the n-queens puzzle.
*
* Example:
* Input: 4
* Output: 2
* Explanation: There are two distinct solutions to the 4-queens puzzle as shown below.
* [
* [".Q..", // Solution 1
* "...Q",
* "Q...",
* "..Q."],
*
* ["..Q.", // Solution 2
* "Q...",
* "...Q",
* ".Q.."]
* ]
*/
#include <iostream>
#include <vector>
using std::vector;
class Solution {
public:
int total = 0;
int totalNQueens(int n) {
vector<int> pos(n, -1);
queue(0, n, pos);
return total;
}
void queue(int row, int n, vector<int> &pos) {
if (row == n) {
++total;
} else {
for (int c = 0; c < n; ++c) {
pos[row] = c;
if (isSafe(row, pos)) {
queue(row + 1, n, pos);
}
}
}
}
bool isSafe(int row, vector<int> &pos) {
for (int c = 0; c < row; ++c) {
if (pos[c] == pos[row] || c - pos[c] == row - pos[row]
|| c + pos[c] == row + pos[row])
return false;
}
return true;
}
};
int main() {
Solution s;
int testId = 1;
vector<int> ns{4, 8};
for (auto &n : ns) {
auto res = s.totalNQueens(n);
std::cout << "Case " << testId++ << ": " << res << std::endl;
}
} |
Markdown | UTF-8 | 2,372 | 3.1875 | 3 | [
"MIT"
] | permissive | ---
title: "[백준] 3109번 빵집"
author: steadev
date: 2019-08-19 16:01:00 +0900
categories: [Algorithm]
tags: [Baekjoon, algorithm]
---
<img src="https://steadev.github.io/assets/images/bj/bj-3109-1.png" />
<img src="https://steadev.github.io/assets/images/bj/bj-3109-2.png" />
# 풀이
이 문제는 DFS를 활용해서 Greedy 하게 풀 수 있는 문제입니다.
DFS를 활용한다는 건 점을 하나하나 이어가면서 x면 되돌아오는 식으로 하는 것으로 쉽게 이해할 수 있는데,
여기서 가장 중요한게 Greedy 부분입니다.
만약 DFS만 활용했을 경우에는
20 20
..................x.
..................x.
..................x.
(중략...)
....................
이런 입력에 대해서 시간초과가 나오게 됩니다.
x가 끝쪽에 있으니 거의 모든 경우의 경로를 다 돌아보게 되기 때문입니다.
그렇기 때문에 Greedy를 활용해 주어야 합니다.
이미 실패한 경로는 다시 가더라도 어짜피 결과는 FAIL 입니다.
그러므로 성공한 경로든 실패한 경로든 전부 방문한 걸로 치고 다시는 방문하지 않게 하는 것이 Key Point 입니다.
아래는 풀이한 코드입니다.
```c++
#include <iostream>
using namespace std;
char map[10000][500];
int xpos[] = { -1,0,1 };
int cnt = 0;
bool dfs(int x, int y, int r, int c) {
if (y == c - 1) {
cnt++;
return true;
}
for (int i = 0; i < sizeof(xpos) / sizeof(int); i++) {
int next_x = x + xpos[i];
int next_y = y + 1;
if (next_y < c && next_x >= 0 && next_x < r) {
if (map[next_x][next_y] != 'x') {
bool result = dfs(next_x, next_y, r, c);
// 결과에 상관없이 방문했다는 의미로 'x'표를 해줍니다.
// 실패했든 성공했든 다시는 그 경로로 갈 일이 없기 때문!!
map[next_x][next_y] = 'x';
if (result) return true;
}
}
}
return false;
}
int main(void) {
int r, c;
cin >> r >> c;
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
cin >> map[i][j];
}
}
for(int i=0;i<r;i++)
dfs(i, 0, r, c);
cout << cnt;
return 0;
}
```
질문이나 지적사항은 댓글 부탁드립니다 :) |
Python | UTF-8 | 4,527 | 3.84375 | 4 | [] | no_license | import matplotlib.pyplot as plt
import sys
##########################################################################################
# Name: parse
#
# Assumptions: None
#
# Purpose: parse takes a text file and separates all of the entries in the line.
# An entry is a string of text in between two delimiters, the beginning of a
# line and the delimiter, or the delimiter and the end of a line. Entries on
# the same line are put in a list, and the entries from each line is put in a
# larger list in the order that the lines appear.
#
# Arguments: filePath - a string that is the path of the file to be read
#
# delimiter - the string that serves as a delimiter for entries
#
# Returns: a list whose elements correspond to the entries in each line of the file.
# I.e. lines[i][j] gives the jth entry in the ith line of the text file.
#
##########################################################################################
def parse(filePath, delimiter):
# Read the the input file and the delimiter
inFile = open(filePath, "r")
# Split the columns
lines = []
for line in inFile:
lines.append(line.split(delimiter))
# Close the file and return
inFile.close()
return lines
##########################################################################################
# Name: trimMatrix
#
# Assumptions: trimMatrix assumes that the matrix has at least one row. If the matrix
# matrix does not have at least one row, this function will try to access
# a list entry that doesn't exist.
#
# Purpose: trimMatrix makes takes a matrix and makes it rectangular. The dimension of
# the resulting matrix has the width of the first row of the original matrix
# and a height of the number of consecutive rows that have the same width of
# the header row (including the header row).
#
# Arguments: matrix - the matrix (2D array) to be trimmed
#
# Returns: A matrix containing that is a subset of the original matrix. The returned
# matrix contains the first stretch of rows of the original sequence that have
# the same width. This matrix is returned in a dictionary along with its
# dimensions.
#
##########################################################################################
def trimMatrix(matrix):
# Make the width of the square matrix the width of the header
desiredWidth = len(matrix[0])
# Only keep rows that make the matrix a square
rectangle = []
for row in matrix:
if len(row) == desiredWidth:
rectangle.append(row)
else:
break
# Return the matrix along with its dimensions
return {"matrix": rectangle, "rows": len(rectangle), "columns": desiredWidth}
##########################################################################################
# Name: getColumn
#
# Assumptions: getColumn assumes that the matrix being subsetted is rectangular/
#
# Purpose: getColumn returns a specified column.
#
# Arguments: matrix - the matrix to be subsetted
#
# col - the integer corresponding to which column will be returned
#
# Returns: A list that has all of the entries in the specified column of the given
# matrix
#
##########################################################################################
def getColumn(matrix, col):
desiredCol = []
for row in matrix:
desiredCol.append(row[col])
return desiredCol
##########################################################################################
# Name: graphColumn
#
# Assumptions: graphColumn assumes that the first entry in any column is a label and the
# rest of the entries are numeric data.
#
# Purpose: graphColumn gets a column from a matrix, graphs it, and then saves the file.
# This is done by extracting a column from a matrix and using its first entry
# as a title and using the rest of the entries as data. The plot is saved as
# the title name with a png extension.
#
# Arguments: matrix - the matrix of data containing the column to be plotted
#
# col - the integer corresponding to which column will be plotted
#
# Returns: Nothing
#
##########################################################################################
def graphColumn(matrix, col):
# Get the data and label for the graph
column = getColumn(matrix, col)
title = column[0].replace("\n", "")
# Cast data to floats and remove and new line characters
column = [float(num.replace("\n", "")) for num in column[1:]]
# Plot the figure and save it
plt.clf()
plt.plot(column)
plt.ylabel(title)
plt.savefig(title + ".png")
plt.clf()
|
C++ | UTF-8 | 5,191 | 2.625 | 3 | [
"ISC",
"BSD-2-Clause"
] | permissive | /*
* THiNX Sigfox/WiFi Example
*
* This sample can be used for dual-network reporting like home security backup:
* - system is expected to be backed up with a battery (sample sends voltage only)
* - system can report WiFi and power outages incl. security alerts using Sigfox
* - system can report important events without working WiFi connection
* - when WiFi is available, system is listening to MQTT on wakeup
* - new firmware can be offered from THiNX backend
*
* This test sample awakes device every `autoSleepTime` microseconds to send a Sigfox message.
* Message reports current battery voltage (float) converted to hex string.
* In order to measure battery voltage, connect battery (+) using 100k resistor with A0.
* See: https://arduinodiy.wordpress.com/2016/12/25/monitoring-lipo-battery-voltage-with-wemos-d1-minibattery-shield-and-thingspeak/
*/
// Note: Set Serial Monitor to "Newline" for TelekomDesign TD1208 Sigfox device
#include <SoftwareSerial.h>
#include <THiNXLib.h>
THiNX thx;
#ifdef ESP32
// TODO: Check this, it might be reversed but those are default numbers for I2C pins.
#define D2 21
#define D1 22
#endif
#ifndef D1
#define D1 22
#endif
#ifndef D2
#define D2 21
#endif
SoftwareSerial Sigfox(D2, D1); // RX (e.g. yellow), TX (e.g. orange) -- it's worth noting wire colors here
#define SLEEP_TIME_MICROS 3600e6
#define DEFAULT_SLEEP_DELAY (millis() + 60 * 1000) // autosleep in 60 seconds
unsigned long autoSleepTime = DEFAULT_SLEEP_DELAY;
unsigned int raw = 0;
float voltage = 0.0;
const char *ssid = "THiNX-IoT";
const char *pass = "<enter-your-ssid-password>";
void resetAutoSleepTime() {
autoSleepTime = DEFAULT_SLEEP_DELAY; // Will power down in 60 secs to let the SigFox message get delivered...
}
/* Called after library gets connected and registered */
void finalizeCallback () {
Serial.print("THiNX check-in completed. Waking up in ");
uint32_t micro = SLEEP_TIME_MICROS;
//micro = 300e6; // testing 5 minutes
Serial.print(micro/1000000); Serial.println(" seconds");
ESP.deepSleep(micro);
}
/* Measures and stores current ADC voltage in global float variable */
void measureBatteryVoltage() {
Serial.println("Measuring battery voltage..");
raw = analogRead(A0); // connect battery (+) through 100k resistor to A0
voltage = raw/1023.0;
voltage = voltage * 3.7; // my battery is 3.7V, original example has 4.2
Serial.print("Measured voltage: ");
Serial.print(voltage);
Serial.println(" V");
}
/* Takes current voltage and sends as byte-string to SigFox backends */
void updateSigfoxStatus() {
String voltageString = "ba"; // means battery voltage in THiNX, what about Sigfox?
unsigned char * chpt = (unsigned char *)&voltage;
Serial.print("Here are the bytes in memory order: ");
for (unsigned int i = 0; i < sizeof(voltage); i++) {
String byteVal = String(chpt[i],HEX);
// Pad with zero
if (byteVal.length() == 1) { byteVal = "0" + byteVal; }
Serial.print(byteVal);
voltageString = voltageString + byteVal;
}
Serial.print("\n");
Serial.print("Voltage string for sigfox: ");
Sigfox.println(voltageString);
Serial.print("Sending Sigfox command: ");
Serial.print("AT$SF="); Serial.println(voltageString);
Sigfox.print("AT$SF="); Sigfox.println(voltageString);
}
/* Takes current voltage and sends as string to THiNX backends */
void updateDashboardStatus() {
String statusString = String("Battery ") + String(voltage) + String("V");
Serial.print("*INO: Setting status: ");
Serial.println(statusString);
thx.setStatus(statusString);
}
void setup() {
pinMode(A0, INPUT);
WiFi.begin(ssid, pass);
while (WiFi.status() != WL_CONNECTED) {
delay(1);
}; // wait for connection
Serial.begin(115200);
while (!Serial);
Serial.println("\nI'm awake.");
Serial.setTimeout(2000);
Serial.println("Initializing Sigfox Serial...");
Sigfox.begin(9600);
while (!Sigfox);
measureBatteryVoltage();
updateSigfoxStatus();
// API Key, Owner ID
// ENTER YOUR OWN OWNER ID AND API KEY HERE BEFORE FIRST RUN!!!
// Otherwise device will be registered to THiNX test account and you'll need to reclaim ownership.
thx = THiNX("4721f08a6df1a36b8517f678768effa8b3f2e53a7a1934423c1f42758dd83db5", "cedc16bb6bb06daaa3ff6d30666d91aacd6e3efbf9abbc151b4dcade59af7c12");
// The check-in should not happen before calling thx.loop() for the first time,
// so this is a right place to pre-set status for first check-in.
updateDashboardStatus();
// Optionally, this is called on completion (when MQTT server is contacted).
thx.setFinalizeCallback(finalizeCallback);
}
void loop() {
// Always call the loop or THiNX will not happen (there's callback available, see library example)
thx.loop();
// serial echo
if (Sigfox.available()) {
Serial.write(Sigfox.read());
resetAutoSleepTime();
}
if (Serial.available()) {
Sigfox.write(Serial.read());
resetAutoSleepTime();
}
// autosleep requires connecting WAKE (D0?) and RST pin
if (millis() > autoSleepTime) {
Serial.println("Going into deep sleep for 1 hour...");
Serial.println(millis());
ESP.deepSleep(SLEEP_TIME_MICROS);
}
}
|
Java | UTF-8 | 460 | 2.078125 | 2 | [
"Apache-2.0"
] | permissive | package camel.simple.processors;
import org.apache.camel.Exchange;
import org.apache.camel.Processor;
public class FileNamePrependerProcessor implements Processor {
@Override
public void process(Exchange exchange) throws Exception {
String file = exchange.getIn().getHeader(Exchange.FILE_NAME,String.class);
exchange.getIn().setHeader(Exchange.FILE_NAME, "PRE_FIX_"+file);
exchange.getIn().getBody(String.class);
}
}
|
C++ | UTF-8 | 1,433 | 3.484375 | 3 | [] | no_license | 输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
---
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// int freq[256] = {0};
// int l = 0, r = -1; //滑动窗口为s[l...r]
// int res = 0;
// // 整个循环从 l == 0; r == -1 这个空窗口开始
// // 到l == s.size(); r == s.size()-1 这个空窗口截止
// // 在每次循环里逐渐改变窗口, 维护freq, 并记录当前窗口中是否找到了一个新的最优值
// while(l < s.size()){
// if(r + 1 < s.size() && freq[s[r+1]] == 0){
// r++;
// freq[s[r]]++;
// }else { //r已经到头 || freq[s[r+1]] == 1
// freq[s[l]]--;
// l++;
// }
// res = max(res, r-l+1);
// }
// return res;
//
// 滑动窗口法,i左边界,j右边界
int size,i=0,j,k,max=0;
size = s.size();
for(j = 0;j<size;j++){
for(k = i;k<j;k++)//检查i到j之间有没有重复的
if(s[k]==s[j]){
i = k+1;
break;
}
if(j-i+1 > max)
max = j-i+1;
}
return max;
}
}; |
C# | UTF-8 | 3,780 | 2.71875 | 3 | [
"MIT"
] | permissive | using Microsoft.Extensions.Logging;
using Microsoft.Extensions.Options;
using Phoesion.Glow.SDK;
using Phoesion.Glow.SDK.Firefly;
using System;
namespace Foompany.Services.HelloWorld.Modules
{
public class Logging : Phoesion.Glow.SDK.Firefly.FireflyModule
{
//----------------------------------------------------------------------------------------------------------------------------------------------
[Action(Methods.GET)]
public string Default() => $"{nameof(Logging)} module up and running";
//----------------------------------------------------------------------------------------------------------------------------------------------
[Action(Methods.GET)]
public string LogDebug()
{
logger.Debug("This is a simple DEBUG message");
return "done!";
}
[Action(Methods.GET)]
public string LogInformation()
{
logger.Information("This is a simple INFORMATION message");
return "done!";
}
[Action(Methods.GET)]
public string LogWarning()
{
logger.Information("This is a simple WARNING message");
return "done!";
}
//----------------------------------------------------------------------------------------------------------------------------------------------
[Action(Methods.GET)]
public string LogWithContext(string username, string someValue)
{
logger.Information("User {user} said {text} ", username, someValue);
return "done!";
}
//----------------------------------------------------------------------------------------------------------------------------------------------
[Action(Methods.GET)]
public string LogException()
{
try
{
//throw some exception to be caught and logged
throw new Exception("This is an exception", new Exception("Some inner exception"));
}
catch (Exception ex)
{
logger.Error(ex, "Exception caught!");
}
return "done!";
}
//----------------------------------------------------------------------------------------------------------------------------------------------
[Action(Methods.GET)]
public string CreateScopedLog()
{
logger.Information("Entering CreateScopedLog()");
//create a scope
using (logger.BeginScope("Performing migrations on user {username}", "john"))
{
logger.Information("Log within the scope");
logger.Information("Another log within the scope");
//create a inner scope
using (logger.BeginScope("Converting user files"))
{
logger.Information("converting file 1");
logger.Information("converting file 2");
logger.Information("converting completed");
}
//create a inner scope
using (logger.BeginScope("Converting user emails"))
{
logger.Information("converting email 1");
logger.Information("converting email 2");
logger.Information("converting completed");
}
logger.Information("Another log within the first scope");
}
logger.Information("Finished CreateScopedLog()");
return "done!";
}
//----------------------------------------------------------------------------------------------------------------------------------------------
}
}
|
Java | UTF-8 | 1,212 | 2.265625 | 2 | [] | no_license | package com.sa3rha.android.sa3rha.Controller;
import android.content.Context;
import android.support.v7.widget.RecyclerView;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import com.sa3rha.android.sa3rha.R;
import butterknife.ButterKnife;
public class SerachAdapter extends RecyclerView.Adapter<SerachAdapter.SerachViewHolder> {
Context context;
LayoutInflater layoutInflater;
public SerachAdapter(Context context) {
this.context=context;
layoutInflater= (LayoutInflater) context.getSystemService(context.LAYOUT_INFLATER_SERVICE);
}
@Override
public SerachViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View v=layoutInflater.inflate(R.layout.iteam_serach,parent,false);
return new SerachViewHolder(v);
}
@Override
public void onBindViewHolder(SerachViewHolder holder, int position) {
}
@Override
public int getItemCount() {
return 20;
}
public class SerachViewHolder extends RecyclerView.ViewHolder{
public SerachViewHolder(View itemView) {
super(itemView);
ButterKnife.bind(this,itemView);
}
}
}
|
Markdown | UTF-8 | 3,628 | 3.3125 | 3 | [] | no_license | # A DFA-based Regular Expression Library for C++
## Run All the Tests
Input the following commands in the terminal to run all the tests.
```bash
mkdir build
cd build
cmake ..
cmake --build .
./RegularExpression
```
## API
### Regular Expression Notations
The followings are the functions used for constructing regular expressions.
```cpp
RegularExpression::Ptr operator|(const RegularExpression::Ptr& x, const RegularExpression::Ptr& y);
RegularExpression::Ptr operator+(const RegularExpression::Ptr& x, const RegularExpression::Ptr& y);
RegularExpression::Ptr Symbol(char32_t c);
RegularExpression::Ptr Literal(const u32string& text);
RegularExpression::Ptr Range(char32_t lower, char32_t upper);
RegularExpression::Ptr LineBegin();
RegularExpression::Ptr LineEnd();
RegularExpression::Ptr RepeatExactly(const RegularExpression::Ptr& x, int times);
RegularExpression::Ptr RepeatAtLeast(const RegularExpression::Ptr& x, int times);
RegularExpression::Ptr Repeat(const RegularExpression::Ptr& x, int atLeast, int atMost);
```
### Use Regular Expressions
After compiling the regular expressions to DFA matrices, you can use the member functions of DFA matrix to match string patterns.
```cpp
/**
* DFAMatrix::FullMatch
*
* @param {u32string} str : check if the pattern can be applied to all of the string
* @return {bool} : returns true if can
*/
bool DFAMatrix::FullMatch(const u32string &str) const;
/**
* DFAMatrix::Search
*
* @param {u32string::const_iterator} strBegin : start of the target character range
* @param {u32string::const_iterator} strEnd : end of the target character range
* @return {u32string::const_iterator} : The start position of the first occurrence of the pattern. It equals to "strEnd" if the pattern is not found.
*/
u32string::const_iterator DFAMatrix::Search(u32string::const_iterator strBegin, u32string::const_iterator strEnd) const;
/**
* DFAMatrix::Match
*
* Match the pattern from the beginning.
*
* @param {u32string::const_iterator} strBegin : start of the target character range
* @param {u32string::const_iterator} strEnd : end of the target character range
* @param {bool} greedyMode : If true, search for the longest match. Otherwise, return immediately once matched.
* @return {int} : the length of the matched string. -1 if no match.
*/
int DFAMatrix::Match(u32string::const_iterator strBegin, u32string::const_iterator strEnd, bool greedyMode) const;
```
## Examples
### Basic Usage
```cpp
#include <iostream>
#include <NFA.hpp>
using std::cout;
using std::endl;
using namespace regex::notations;
int main() {
auto e = (Symbol(U'a') + Symbol(U'b')) | (Symbol(U'b') + Symbol(U'a'));
auto matrix = e->Compile();
if (matrix.FullMatch(U"ab")) {
cout << "matched" << endl;
} else {
cout << "not matched" << endl;
}
return 0;
}
```
### Expression
```cpp
auto e1 = (Symbol(U'a') + Symbol(U'b')) | (Symbol(U'b') + Symbol(U'a'));
```
### NFA

### DFA

### Expression
```cpp
auto e2 = Symbol(U'a')->Many() + Symbol(U'b')->Many();
```
### NFA

### DFA

### Expression
```cpp
auto e3 = (Range(U'0', U'9') | Symbol(U'a'))->Many();
```
### NFA

### DFA

### Expression
```cpp
auto e4 = (Range(U'0', U'9')->Many() | (LineBegin() + Symbol(U'a')->Many()));
```
### NFA

### DFA
 |
JavaScript | UTF-8 | 1,843 | 2.578125 | 3 | [] | no_license | import React, { useState } from 'react';
import './FilterModal.scss';
import OptionsItem from './OptionsItem';
const initialCategories = [
{ title: 'cheap', ifSelected: false },
{ title: 'healthy', ifSelected: false },
{ title: 'vege', ifSelected: false },
{ title: 'takeaway', ifSelected: false },
{ title: 'fast', ifSelected: false }
];
const FilterModal = ({ modalData }) => {
// destructuring prop
const { isVisible, toggleModal } = modalData;
// categories will be fetched from API
const [categories, setCategories] = useState(initialCategories);
// temporary helper function
const selectHandler = title => {
setCategories(state =>
state.map(item => {
if (item.title === title) {
return { ...item, ifSelected: !item.ifSelected };
} else return item;
})
);
};
// generate classes based on prop
const bgClasses = ['filters__bg', isVisible && 'filters__bg--visible'].filter(
item => item
);
const filtersClasses = ['filters', isVisible && 'filters--visible'].filter(
item => item
);
return (
<>
<div onTouchEnd={toggleModal} className={bgClasses.join(' ')}></div>
<div className={filtersClasses.join(' ')}>
<h1 className="filters__header">Filters</h1>
<div className="filters__options">
{categories.map(category => (
<OptionsItem
key={category.title}
itemValue={category.title}
ifSelected={category.ifSelected}
selectHandler={() => selectHandler(category.title)}
/>
))}
</div>
<div className="filters__selects"></div>
<button type="button" className="filters__btn" onTouchEnd={toggleModal}>
Apply Filters
</button>
</div>
</>
);
};
export default FilterModal;
|
Java | UTF-8 | 2,131 | 2.28125 | 2 | [] | no_license | package com.bw.movie.adapter.cinema;
import android.content.Context;
import android.support.annotation.NonNull;
import android.support.v7.widget.RecyclerView;
import android.view.View;
import android.view.ViewGroup;
import android.widget.ImageView;
import android.widget.TextView;
import com.bumptech.glide.Glide;
import com.bw.movie.R;
import com.bw.movie.bean.NearbyBean;
import com.bw.movie.bean.RecommendBean;
import java.util.List;
import butterknife.BindView;
import butterknife.ButterKnife;
public class CinemaAdapter1 extends RecyclerView.Adapter<RecyclerView.ViewHolder> {
Context context;
List<NearbyBean.ResultBean> result;
public CinemaAdapter1(Context context, List<NearbyBean.ResultBean> result) {
this.context = context;
this.result = result;
}
@NonNull
@Override
public RecyclerView.ViewHolder onCreateViewHolder(@NonNull ViewGroup viewGroup, int i) {
View view = View.inflate(context, R.layout.item_recommend_adapter, null);
return new NearbyViewHolder(view);
}
@Override
public void onBindViewHolder(@NonNull RecyclerView.ViewHolder viewHolder, int i) {
NearbyBean.ResultBean resultBean = result.get(i);
((NearbyViewHolder)viewHolder).tvName.setText(resultBean.getName());
Glide.with(context).load(resultBean.getLogo()).into(((NearbyViewHolder) viewHolder).iv);
((NearbyViewHolder) viewHolder).tvDizhi.setText(resultBean.getAddress());
int distance = resultBean.getDistance();
distance/=1000.0;
((NearbyViewHolder)viewHolder).tvKm.setText(distance+"km");
}
@Override
public int getItemCount() {
return result.size();
}
class NearbyViewHolder extends RecyclerView.ViewHolder {
@BindView(R.id.iv)
ImageView iv;
@BindView(R.id.tv_name)
TextView tvName;
@BindView(R.id.tv_dizhi)
TextView tvDizhi;
@BindView(R.id.tv_km)
TextView tvKm;
public NearbyViewHolder(@NonNull View itemView) {
super(itemView);
ButterKnife.bind(this,itemView);
}
}
}
|
Markdown | UTF-8 | 2,267 | 2.5625 | 3 | [] | no_license | # Curso React Native
Esto es un curso básico de React Native
# Clases
## [Preparar el entorno](https://github.com/zariweyo/curso-react-native/tree/hola_mundo)
* Hola mundo
* Ejecutar aplicación en emulador Android
* Ejecutar aplicación en emulador iOS
## [Componentes 1](https://github.com/zariweyo/curso-react-native/tree/componentes-1)
* Qué es un componente. Estructura de proyectos
* Crear, importar y usar componentes
* Contenedor View y componente básico Text
## [Componentes 2](https://github.com/zariweyo/curso-react-native/tree/propiedades)
* JSX y variables
* Envío de propiedades a los componentes
## [Renders 1](https://github.com/zariweyo/curso-react-native/tree/renders)
* State y setState
## [Renders 2](https://github.com/zariweyo/curso-react-native/tree/renders-2)
* Heigth, Width
* Estilos
## [Renders 3](https://github.com/zariweyo/curso-react-native/tree/renders-3)
* Flexbox
## [Componentes básicos del framework](https://github.com/zariweyo/curso-react-native/tree/componentes-basicos)
* Cuáles son los componentes básicos del framework
* TextInput
* TouchableHighlight
* TouchableOpacity
* ScrollView
* FlatList
## [Componentes básicos del framework 2](https://github.com/zariweyo/curso-react-native/tree/componentes-basicos-2)
* Image
* Picker
* Platform
## [Componentes básicos del framework 3](https://github.com/zariweyo/curso-react-native/tree/componentes-basicos-3)
* ActivityIndicator
* WebView
## [APIs de React Native 1](https://github.com/zariweyo/curso-react-native/tree/apis)
* Alert y Dimensions
* Keyboard y componente KeyboardAvoidingView
## [APIs de React Native 2](https://github.com/zariweyo/curso-react-native/tree/apis-2)
* AsyncStorage
## [APIs de React Native 2 B](https://github.com/zariweyo/curso-react-native/tree/apis-2-sol-asyncstorage)
* Solucion warning AsyncStorage
## [APIs de React Native 3](https://github.com/zariweyo/curso-react-native/tree/apis-3)
* PermissionAndroid
* Geolocation
# Taller de Calculadora
## [TALLER: Calculadora V 0.1](https://github.com/zariweyo/curso-react-native/tree/calculadora-1)
* Maquetar distribución de la calculadora
## [TALLER: Calculadora V 0.2](https://github.com/zariweyo/curso-react-native/tree/calculadora-2)
* Botones de calculadora
* Funciones y resultado
|
Java | UTF-8 | 301 | 1.734375 | 2 | [] | no_license | package com.codetc.common.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import java.io.Serializable;
/**
* Redis 锁
* Created by anvin on 1/15/2021.
*/
@Data
@AllArgsConstructor
public class RedisLock implements Serializable {
private String key;
private String value;
}
|
C# | UTF-8 | 3,399 | 2.625 | 3 | [] | no_license | using BowlingApp;
using Shouldly;
using System;
using System.Collections.Generic;
using System.Linq;
using BowlingApp.Calculators;
using BowlingApp.Events;
using Xunit;
namespace Tests
{
public class GameEventTests
{
private readonly Game _game;
private readonly Queue<NewFrameEvent> _observedNewFrameEvents = new Queue<NewFrameEvent>();
private readonly Queue<NewRollEvent> _observedNextRollEvents = new Queue<NewRollEvent>();
private readonly Queue<EndEvent> _observedEndEvents = new Queue<EndEvent>();
public GameEventTests()
{
_game = new Game(new RecursiveScoreCalculator(), new GameStateCalculator());
_game.OnNextFrame += (_, e) => _observedNewFrameEvents.Enqueue(e);
_game.OnNextRoll += (_, e) => _observedNextRollEvents.Enqueue(e);
_game.OnEnd += (_, e) => _observedEndEvents.Enqueue(e);
}
[Fact]
public void NotifyNextFrame()
{
_game.Register(1).Register(8);
ShouldObserveEvent(new NewFrameEvent(1, 8, 9, Note.None, 9));
}
[Fact]
public void NotifyNextFrameGivenSpare()
{
_game.Register(1).Register(9);
ShouldObserveEvent(new NewFrameEvent(1, 9, 10, Note.Spare, 10));
}
[Fact]
public void NotifyNextFrameGivenStrike()
{
_game.Register(10);
ShouldObserveEvent(new NewFrameEvent(1, 10, 10, Note.Strike, 10));
}
[Fact]
public void NotifyNextFrameScenario()
{
_game
.Register(1).Register(8)
.Register(10)
.Register(0).Register(10)
.Register(1).Register(2);
ShouldObserveEvents(
new NewFrameEvent(1, 8, 9, Note.None, 9),
new NewFrameEvent(2, 10, 10, Note.Strike, 19),
new NewFrameEvent(3, 10, 10, Note.Spare, 39),
new NewFrameEvent(4, 2, 3, Note.None, 43)
);
}
[Fact]
public void NotifyOnNextRoll()
{
_game
.Register(1).Register(8)
.Register(10)
.Register(0).Register(10)
.Register(1).Register(2)
.Register(3);
ShouldObserveEvents(
new NewRollEvent(1, 1),
new NewRollEvent(3, 0),
new NewRollEvent(4, 1),
new NewRollEvent(5, 3)
);
}
[Fact]
public void NotifyEnd()
{
throw new NotImplementedException("TODO");
}
[Fact]
public void TenthFrameOfGameMayHaveThreeRolls()
{
throw new NotImplementedException("TODO");
}
private void ShouldObserveEvent(NewFrameEvent expected)
{
_observedNewFrameEvents.Single().ShouldBe(expected);
_observedNewFrameEvents.Clear();
}
private void ShouldObserveEvents(params NewFrameEvent[] expected)
{
_observedNewFrameEvents.ShouldBe(expected);
_observedNewFrameEvents.Clear();
}
private void ShouldObserveEvents(params NewRollEvent[] expected)
{
_observedNextRollEvents.ShouldBe(expected);
_observedNextRollEvents.Clear();
}
}
}
|
Python | UTF-8 | 823 | 2.890625 | 3 | [
"Apache-2.0"
] | permissive | from urllib import request
from bs4 import BeautifulSoup as BS
def main(dict):
# Handling previous errors for sequence
if dict['err']:
return dict
try:
# Call page and parse HTML
page = request.urlopen(dict['url'])
soup = BS(page, 'html.parser')
# Scraping and adding line breaks instead of HTML tags
lyricsText = str(soup.find('div', attrs={'class': 'cnt-letra p402_premium'})).replace('<br/>','\n').replace('</p><p>', '\n\n').replace('<br>','\n').replace('<div class="cnt-letra p402_premium"> <p>','')
parse = BS(lyricsText, 'html.parser')
lyrics = parse.text.strip()
dict['lyrics'] = lyrics
except:
dict['msg'] = 'There was an unknown error processing your request.'
dict['err'] = True
return dict |
PHP | UTF-8 | 1,161 | 2.5625 | 3 | [
"MIT"
] | permissive | <?php
namespace Tests;
use PHPUnit\Framework\TestCase;
use Prometheus\Storage\APC;
use Prometheus\Storage\InMemory;
use Prometheus\Storage\Redis;
use Superbalist\LaravelPrometheusExporter\StorageAdapterFactory;
class StorageAdapterFactoryTest extends TestCase
{
public function testMakeMemoryAdapter()
{
$factory = new StorageAdapterFactory();
$adapter = $factory->make('memory');
$this->assertInstanceOf(InMemory::class, $adapter);
}
public function testMakeApcAdapter()
{
$factory = new StorageAdapterFactory();
$adapter = $factory->make('apc');
$this->assertInstanceOf(APC::class, $adapter);
}
public function testMakeRedisAdapter()
{
$factory = new StorageAdapterFactory();
$adapter = $factory->make('redis');
$this->assertInstanceOf(Redis::class, $adapter);
}
public function testMakeInvalidAdapter()
{
$this->expectException(\InvalidArgumentException::class);
$this->expectExceptionMessage('The driver [moo] is not supported.');
$factory = new StorageAdapterFactory();
$factory->make('moo');
}
}
|
Markdown | UTF-8 | 1,914 | 2.515625 | 3 | [] | no_license | ---
draft: false
date: 2018-01-01
kind: "journal"
tags: ["whiley"]
title: "On Declarative Rewriting for Sound and Complete Union, Intersection and Negation Types"
authors: "David J. Pearce"
booktitle: "Journal of Visual Languages & Computing"
volume: "50"
pages: "84--101"
year: "2018"
copyright: "Elsevier"
DOI: "10.1016/j.jvlc.2018.10.004"
preprint: "Pea18_JVLC_preprint.pdf"
---
**Abstract.** Implementing the type system of a programming language is a critical task that is oftendone in an ad-hoc fashion. Whilst this makes it hard to ensure the system is sound, italso makes it difficult to extend as the language evolves. We are interested in describing type systems using rewrite rules from which an implementation can be automaticallygenerated. Whilst not all type systems are easily expressed in this manner, those involving unions, intersections and negations are well-suited for this. For example, subtyping in such systems is naturally expressed as a maximal reduction over the intersection oftypes involved. In this paper, we consider a relatively complex type system involving unions, inter-sections and negations developed previously in the context of type checking. This system was not developed with rewriting in mind, though clear parallels are immediately apparent from the original presentation. For example, the system presented requiredtypes be first converted into a variation on Disjunctive Normal Form. However, some aspects of the original system are more challenging to express with rewrite rules. Weidentify that the original system can, for the most part, be reworked to enable a natural expression using rewrite rules. We present an implementation of our rewrite rules inthe Whiley Rewrite Language (WyRL), and report performance results compared witha hand-coded solution. We also present an implementation of our system in the Rascal rewriting system, and find different trade offs.
|
Python | UTF-8 | 3,403 | 4.3125 | 4 | [] | no_license | """
Haniyyah Sardar
Date Due: 2/15/2017
Section: 05
"""
#make available the random module
import random
#store a random secret number (int)
secret = random.randint(1,10)
#output intro to user
print("I'm thinking of a number between 1 and 10!")
#ask the user to guess a first number
first_guess = int(input("What's your guess? "))
#if the first guess is right
if first_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 1 try to guess the number.")
#if the first guess is too low
if first_guess < secret:
print("Too low, try again.")
#ask user for a second guess
second_guess = int(input("What's your guess? "))
#see if the second guess = secret number
if second_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 2 tries to guess the number.")
#if the second guess is too low again
#let user know it's too low
if second_guess < secret:
print("Too low, try again.")
#ask user for a third and final guess
third_guess = int(input("What's your guess? "))
#see if the third guess is right
if third_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 3 tries to guess the number.")
#if third guess is not right, tell user they didn't get it right
else:
print("The secret number was ",secret,".",sep="")
print("You didn't guess the number.")
#if the second guess is too high
#let user know that it's too high
if second_guess > secret:
print("Too high, try again.")
#ask user for a third and final guess
third_guess = int(input("What's your guess? "))
if third_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 3 tries to guess the number.")
else:
print("The secret number was ",secret,".",sep="")
print("You didn't guess the number.")
if first_guess > secret:
print("Too high, try again.")
second_guess = int(input("What's your guess? "))
if second_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 2 tries to guess the number.")
if second_guess < secret:
print("Too low, try again.")
third_guess = int(input("What's your guess? "))
if third_guess == secret:
print("You go it!")
print("The secret number was ",secret,".",sep="")
print("It took you 3 tries to guess the number.")
else:
print("The secret number was ",secret,".",sep="")
print("You didn't guess the number.")
if second_guess > secret:
print("Too high, try again.")
third_guess = int(input("What's your guess? "))
if third_guess == secret:
print("You got it!")
print("The secret number was ",secret,".",sep="")
print("It took you 3 tries to guess the number.")
else:
print("The secret number was ",secret,".",sep="")
print("You didn't guess the number.")
|
Python | UTF-8 | 2,425 | 2.578125 | 3 | [] | no_license | import time
import telepot
from telepot.loop import MessageLoop
import logging.config
import requests
from queue import Queue
import threading
logging.config.fileConfig('logconfig.ini')
IMG_PATH = 'pic/'
url_classify = 'http://127.0.0.1:81/classify'
url_classify_url = 'http://127.0.0.1:81/classify_url'
# Thread 1 Receiving Messages
def handle(msg):
start = time.time()
content_type, chat_type, chat_id = telepot.glance(msg)
logging.info('----------Got Connection From User [{}]-------'.format(chat_id))
logging.debug('content_type is: {}'.format(content_type))
logging.debug('chat_id is: {}'.format(chat_id))
message = 'The prediction is on the way, please hold on for a sec.'
if content_type == 'text':
image_url = msg['text']
if image_url.startswith('http://') or image_url.startswith('https://'):
logging.info('----------Received URL of Image----------')
logging.debug('Image URL is: {}'.format(image_url))
wrapped_msg = {
'type': 'url',
'url': image_url,
'chat_id': chat_id,
}
queue_1.put(wrapped_msg)
bot.sendMessage(chat_id, message)
if content_type == 'photo':
logging.info('----------Download Image From Telegram----------')
file_id = msg['photo'][-1]['file_id']
wrapped_msg = {
'type': 'file_id',
'file_id': file_id,
'chat_id': chat_id,
}
queue_1.put(wrapped_msg)
bot.sendMessage(chat_id, message)
end = time.time()
logging.info('[Time] for all process(): {}'.format(end - start))
# Thread 2 Client Thread
def send_recv_img(in_queue_1):
while True:
wrapped_msg = in_queue_1.get()
if wrapped_msg['type'] == 'url':
requests.post(url_classify_url, json=wrapped_msg)
logging.info('Image has been sent to Server')
if wrapped_msg['type'] == 'file_id':
requests.post(url_classify, json=wrapped_msg)
logging.info('Image has been sent to Server')
if __name__ == "__main__":
bot = telepot.Bot('Input your bot key')
queue_1 = Queue()
MessageLoop(bot, handle).run_as_thread()
logging.debug('thread %s is running...' % threading.current_thread().name)
t2 = threading.Thread(target=send_recv_img, args=(queue_1,), name='Thread 2')
t2.start()
|
Java | UTF-8 | 1,734 | 3.078125 | 3 | [] | no_license | package by.epam_training.java_online.module4.composition_and_aggregation.task3_state.entity;
import java.io.Serializable;
import java.util.List;
public class Area implements Comparable<Area>, Serializable {
private static final long serialVersionUID = 1L;
private String name;
private List<City> cities;
public Area() {
name = null;
cities = null;
}
public Area(String name, List<City> cities) {
this.name = name;
this.cities = cities;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setCities(List<City> cities) {
this.cities = cities;
}
public List<City> getCities() {
return cities;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Area other = (Area) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (cities == null) {
if (other.cities != null)
return true;
} else if (!cities.equals(other.cities))
return false;
return true;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = result * prime + ((name == null) ? 0 : name.hashCode());
result = result * prime + ((cities == null) ? 0 : cities.hashCode());
return result;
}
@Override
public String toString() {
Class<Area> clazz = Area.class;
return clazz.getSimpleName() + " [name=" + name + ", cities=" + cities + "]";
}
@Override
public int compareTo(Area other) {
return name.compareTo(other.name);
}
}
|
Python | UTF-8 | 4,832 | 2.546875 | 3 | [
"MIT"
] | permissive | import datetime
import logging
import random
from bs4 import BeautifulSoup
import re
import urllib2
def getMenu():
return digipolis
def getSearchParameter():
return search
logger = logging.getLogger(__name__)
class Messenger(object):
def __init__(self, slack_clients):
self.clients = slack_clients
def send_message(self, channel_id, msg):
# in the case of Group and Private channels, RTM channel payload is a complex dictionary
if isinstance(channel_id, dict):
channel_id = channel_id['id']
logger.debug('Sending msg: {} to channel: {}'.format(msg, channel_id))
channel = self.clients.rtm.server.channels.find(channel_id)
channel.send_message("{}".format(msg.encode('ascii', 'ignore')))
def write_help_message(self, channel_id):
bot_uid = self.clients.bot_user_id()
txt = '{}\n{}\n{}'.format(
"Hallo. Ik ben de LPA-slack-robot. Je kan verschillende dingen vragen. Bijvoorbeeld:",
"> `<@" + bot_uid + "> Wat staat er op de menu?` - Ik zoek op welke soep er vandaag in Digipolis wordt geserveerd",
"> `<@" + bot_uid + "> Wat is de suggestie?` - Ik zoek op wat het broodje van de week is")
self.send_message(channel_id, txt)
def write_greeting(self, channel_id, user_id):
greetings = ['Hi', 'Hallo', 'Fijn om je te ontmoeten', 'Dag', 'Gegroet']
txt = '{}, <@{}>!'.format(random.choice(greetings), user_id)
self.send_message(channel_id, txt)
def write_prompt(self, channel_id):
bot_uid = self.clients.bot_user_id()
txt = "Het spijt me, Ik begrijp niet wat je bedoelt... Kan ik je helpen? (kijk eens bij `<@" + bot_uid + "> help`)"
self.send_message(channel_id, txt)
def write_joke(self, channel_id):
question = "Why did the python cross the road?"
self.send_message(channel_id, question)
self.clients.send_user_typing_pause(channel_id)
answer = "To eat the chicken on the other side! :laughing:"
self.send_message(channel_id, answer)
def write_error(self, channel_id, err_msg):
txt = ":face_with_head_bandage: my maker didn't handle this error very well:\n>```{}```".format(err_msg)
self.send_message(channel_id, txt)
def demo_attachment(self, channel_id):
txt = "Beep Beep Boop is a ridiculously simple hosting platform for your Slackbots."
attachment = {
"pretext": "We bring bots to life. :sunglasses: :thumbsup:",
"title": "Host, deploy and share your bot in seconds.",
"title_link": "https://beepboophq.com/",
"text": txt,
"fallback": txt,
"image_url": "https://storage.googleapis.com/beepboophq/_assets/bot-1.22f6fb.png",
"color": "#7CD197",
}
self.clients.web.chat.post_message(channel_id, txt, attachments=[attachment], as_user='true')
def send_menu(self, channel_id):
dayOfWeek = datetime.datetime.today().weekday()
if dayOfWeek == 0:
search = "Maandag"
elif dayOfWeek == 1:
search = "Dinsdag"
elif dayOfWeek == 2:
search = "Woensdag"
elif dayOfWeek == 3:
search = "Donderdag"
elif dayOfWeek == 4:
search = "Vrijdag"
else:
search = False
if search != False:
question = "Het menu bij Digipolis is vandaag:"
self.send_message(channel_id, question)
self.clients.send_user_typing_pause(channel_id)
response = urllib2.urlopen('http://www.metsense.be/nl/onze-uitbatingen#bedrijfsrestaurants')
html = response.read()
soup = BeautifulSoup(html,"html.parser")
digipolis = soup.find("h3",string="Digipolis").find_next(class_="restaurant-menu")
for string in digipolis.find(string=re.compile(search)).find_next("td").stripped_strings:
answer = string
self.send_message(channel_id, answer)
else:
answer = "Sorry, Niets in de refter vandaag"
self.send_message(channel_id, answer)
def send_suggestie(self, channel_id):
question = "Ik kijk even na wat de suggestie deze week is."
self.send_message(channel_id, question)
self.clients.send_user_typing_pause(channel_id)
response = urllib2.urlopen('http://www.metsense.be/nl/onze-uitbatingen#bedrijfsrestaurants')
html = response.read()
soup = BeautifulSoup(html,"html.parser")
digipolis = soup.find("h3",string="Digipolis").find_next(class_="restaurant-menu")
for string in digipolis.find(string=re.compile("Suggestie")).find_next("td").stripped_strings:
answer = string
self.send_message(channel_id, answer)
|
JavaScript | UTF-8 | 1,577 | 2.703125 | 3 | [] | no_license | import { useMutation, gql } from "@apollo/client";
import { useState } from "react";
export default function MutationPage() {
const [writer, setWriter] = useState("");
const [password, setPassword] = useState("");
const [title, setTitle] = useState("");
const [contents, setContents] = useState("");
const CREATE_BOARD = gql`
mutation zzzzzzzzzzz(
$writer: String
$password: String
$title: String
$contents: String
) {
createBoard(
writer: $writer
password: $password
title: $title
contents: $contents
) {
message
}
}
`;
const [createBoard] = useMutation(CREATE_BOARD);
async function onClickPost() {
try {
const result = await createBoard({
variables: {
writer,
password,
title,
contents,
},
});
console.log(result);
} catch (error) {
alert(error.message);
}
}
const onChangeWriter = (event) => {
setWriter(event.target.value);
};
const onChangePassword = (event) => {
setPassword(event.target.value);
};
const onChangeTitle = (event) => {
setTitle(event.target.value);
};
const onChangeContents = (event) => {
setContents(event.target.value);
};
return (
<>
작성자: <input type="text" onChange={onChangeWriter}></input>
<br />
비밀번호: <input type="password" onChange={onChangePassword}></input>
<br />
제목: <input type="text" onChange={onChangeTitle}></input>
<br />
내용: <input type="text" onChange={onChangeContents}></input>
<br />
<button onClick={onClickPost}>게시물 등록하기</button>
</>
);
}
|
PHP | UTF-8 | 1,895 | 2.671875 | 3 | [
"MIT"
] | permissive | <?php
namespace AppBundle\Document;
use Doctrine\ODM\MongoDB\Mapping\Annotations as MongoDB;
use FOS\UserBundle\Model\User as FOSUser;
/**
* Class Client
* @package AppBundle\Document
*
* @MongoDB\Document
*/
class User
{
/** @MongoDB\Id */
protected $id;
/** @MongoDB\Field(type="string") */
private $email;
/** @MongoDB\Field(type="string") */
private $hash;
/** @MongoDB\Field(type="hash") */
private $creditCard;
/** @MongoDB\Field(type="boolean") */
private $isInspector;
/**
* @return mixed
*/
public function getId()
{
return $this->id;
}
/**
* @param mixed $id
*/
public function setId($id)
{
$this->id = $id;
}
/**
* @return mixed
*/
public function getEmail()
{
return $this->email;
}
/**
* @param mixed $email
*/
public function setEmail($email)
{
$this->email = $email;
}
/**
* @param $password
* @return boolean
*/
public function checkPassword($password)
{
return password_verify($password, $this->hash);
}
/**
* @param mixed $hash
*/
public function setPassword($hash)
{
$this->hash = password_hash($hash, PASSWORD_BCRYPT);
}
/**
* @param mixed $isInspector
* @return User
*/
public function setIsInspector($isInspector)
{
$this->isInspector = $isInspector;
return $this;
}
/**
* @return mixed
*/
public function isInspector()
{
return $this->isInspector;
}
/**
* @return mixed
*/
public function getCreditCard()
{
return $this->creditCard;
}
/**
* @param mixed $creditCard
*/
public function setCreditCard($creditCard)
{
$this->creditCard = $creditCard;
}
} |
Python | UTF-8 | 1,325 | 2.921875 | 3 | [] | no_license | import imageio
from skimage.color import rgb2gray
from skimage import feature
import matplotlib.pyplot as plt
from matplotlib import cm
import numpy as np
from skimage.transform import hough_line, hough_line_peaks
im = imageio.imread('airport.tif')
im = rgb2gray(im)
edges = feature.canny(im, sigma=2, low_threshold=115)
h, theta, d = hough_line(edges)
print("h: ", h.shape)
fig, axes = plt.subplots(1, 3, figsize=(15, 6))
ax = axes.ravel()
ax[0].imshow(edges, cmap=cm.gray)
ax[0].set_title('Edge image')
ax[0].set_axis_off()
ax[1].imshow(np.log(1 + h),
extent=[np.rad2deg(theta[-1]), np.rad2deg(theta[0]), d[-1], d[0]],
cmap=cm.gray, aspect=1/1.5)
ax[1].set_title('Hough transform')
ax[1].set_xlabel('Angles (degrees)')
ax[1].set_ylabel('Distance (pixels)')
ax[1].axis('image')
ax[2].imshow(im, cmap=cm.gray)
index = 0
for _, angle, dist in zip(*hough_line_peaks(h, theta, d)):
y0 = (dist - 0 * np.cos(angle)) / np.sin(angle)
y1 = (dist - im.shape[1] * np.cos(angle)) / np.sin(angle)
ax[2].plot((0, im.shape[1]), (y0, y1), '-r')
index+=1
if index > 2:
break
ax[2].set_xlim((0, im.shape[1]))
ax[2].set_ylim((im.shape[0], 0))
ax[2].set_axis_off()
ax[2].set_title('Detected lines')
plt.tight_layout()
plt.show()
|
C++ | UTF-8 | 671 | 3.453125 | 3 | [] | no_license | using namespace std;
#include<bits/stdc++.h>
void fib(int n, int *ans) {
if (n < 2) {
*ans = n;
return;
}
int a,b;
fib(n - 1, &a);
fib(n - 2, &b);
*ans = a + b;
}
int main() {
int n;
chrono::time_point<chrono::system_clock> start, end;
chrono::duration<double> elapsed;
cout << "Ingrese un número: ";
cin >> n;
int a, b;
start = chrono::system_clock::now();
thread t1(fib, n - 1, &a);
thread t2(fib, n - 2, &b);
t1.join();
t2.join();
end = chrono::system_clock::now();
elapsed = end - start;
cout<< a + b <<endl;
cout<< "El tiempo de cálculo fue: " << elapsed.count() << " segundos" << endl;
return 0;
}
|
C++ | UTF-8 | 1,456 | 3.203125 | 3 | [] | no_license | /* ============================================================================
* 25. テンプレートの抽出
* 記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,
* 辞書オブジェクトとして格納せよ.
* ========================================================================= */
#include <iostream>
#include <fstream>
#include <string>
#include <map>
#include "picojson.h"
std::string getGBR()
{
std::ifstream ifs("jawiki-country.json");
for (std::string line; std::getline(ifs, line); ) {
picojson::value v;
std::string err = picojson::parse(v, line);
if (err.empty()) {
picojson::object obj = v.get<picojson::object>();
if (obj["title"].serialize() == "\"イギリス\"")
return obj["text"].serialize();
}
}
return "";
}
int main(void)
{
const std::string text = getGBR();
const size_t f = text.find("\\n{{基本情報");
const size_t l = text.find("\\n}}\\n", f+std::string("\\n{{基本情報").length());
std::map<std::string, std::string> m;
for (size_t end, pos = 0; (pos = text.find("\\n|", pos)) != std::string::npos && pos <= l; pos = end) {
end = text.find("\\n", pos+3);
const std::string result = text.substr(pos+2, end-pos-2);
size_t tmp = result.find(" = ");
m[result.substr(1, tmp)] = result.substr(tmp+3);
}
for (auto itr = m.begin(); itr != m.end(); ++itr)
std::cout << itr->first << "\t" << itr->second << std::endl;
}
|
Markdown | UTF-8 | 5,427 | 2.640625 | 3 | [
"LicenseRef-scancode-unknown-license-reference",
"CC-BY-4.0"
] | permissive | **_Journal of Cheminformatics_ will only publish research or software that is entirely reproducible by third parties.
This means that any datasets, software and algorithms that are required to reach the conclusions stated in the paper must
be provided as supplemental materials, or be otherwise accessible without the need for registration, login or agreement
with license terms other than Creative Commons licenses for data and text and
[OSI-approved Open Source Licenses](http://opensource.org/licenses/alphabetical)
for software. For any software, the source code must be provided.**
Software articles should describe a tool likely to be of broad utility that represents a significant advance over
previously published software (usually demonstrated by direct comparison with available related software).
**Availability of software to reviewers and other researchers**
The software application/tool described in the manuscript must be available for testing by reviewers in a way that
preserves their anonymity. If published, software applications/tools must be freely and anonymously available under
an [OSI-approved Open Source](http://opensource.org/licenses/alphabetical) license to any researcher wishing to
use them for non-commercial purposes, without restrictions such
as the need for a material transfer agreement or a registration to access the package. Because weblinks frequently
become broken, _Journal of Cheminformatics_ strongly recommends that all software applications/tools are included
with the submitted manuscript as additional files to ensure that the software will continue to be available.
If not possible, weblinks should be archived in the [Internet Archive](https://web.archive.org/save).
_Journal of Cheminformatics_ requires that the source code of the software should be made available under a suitable
open-source license that will entitle other researchers to further develop and extend the software if they wish to do
so. Typically, an archive of the source code of the current version of the software should be included with the
submitted manuscript as a supplementary file. Since it is likely that the software will continue to be developed
following publication, the manuscript should also include a link to the home page for the software project. For
open source projects, we recommend that authors host their project with a recognized open-source repository such as
[gitlab.com](https://gitlab.com), [github.com](https://github.com),
[bioinformatics.org](http://bioinformatics.org/) or
[sourceforge.net](http://sourceforge.net/).
Descriptions of websites and web-based tools should be submitted as Software articles if the intention is that the
software that drives the website will be made available to other researchers to extend and use on other websites. On
the other hand, if a website's functionality is closely tied to a specific database then the article should instead
be submitted as a Database article.
**Software quality**
Because software should be easy to reuse, the quality of the software will be assessed in the review process too.
Minimally, a source code distribution must include documentation that states the software license(s), the list
of authors (and/or copyright owners). Ideally, it also includes instructions on how to compile (if applicable)
and run your code. Second, we strongly encourage to archive the specific version of the software on Zenodo or
something equivalent, see for example this [GitHub guideline](https://guides.github.com/activities/citable-code/).
Authors are encourage to read and use suggestions from these papers, while reviewers are encourage to assess
these aspects, where they will improve the software:
* [Ten Simple Rules for Developing Usable Software in Computational Biology](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005265),
* [Ten Simple Rules for Taking Advantage of Git and GitHub](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1004947),
* [Ten Simple Rules for the Open Development of Scientific Software](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1002802),
* [Ten Simple Rules for Reproducible Computational Research](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1003285), and
* [Ten simple rules to make your computing more environmentally sustainable](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1009324).
**Graphical abstract**
A graphical abstract can be supplied which, together with the article title, should provide the reader with a visual
description of the type of chemistry covered in the article. The graphical abstract should be 920 x 300 pixels and a
maximum of 150KB jpeg, png or svg file. Authors are encouraged to make judicious use of colour in graphical abstracts.
All graphical abstracts should have a white background and where possible should fill the available width.
**Citation Typing Ontology pilot**
The _Journal of Cheminformatics_ started a pilot using the Citation Typing Ontology
([http://purl.org/spar/cito](http://purl.org/spar/cito)) to annotate citations in articles with the reason
why that paper is cited. For software papers, authors should annotation citations to articles about the
software used in this article with _cito:usesMethodIn_. For more information, please see
[here](https://www.biomedcentral.com/collections/c/co/cito).
|
PHP | UTF-8 | 933 | 2.578125 | 3 | [
"MIT"
] | permissive | <?php
/**
* Plugin Name: Simply Static Deploy
* Plugin URI: https://github.com/grrr-amsterdam/simply-static-deploy/
* Description: Deploy static sites easily to an AWS S3 bucket.
* Version: 2.3.0
* Author: GRRR
* Author URI: https://grrr.nl
*/
use Grrr\SimplyStaticDeploy\SimplyStaticDeploy;
// Global constants.
define('SIMPLY_STATIC_DEPLOY_VERSION', '2.3.0');
define('SIMPLY_STATIC_DEPLOY_PATH', plugin_dir_path(__FILE__));
define('SIMPLY_STATIC_DEPLOY_URL', plugin_dir_url(__FILE__));
// Require Composer autoloader when it exists.
// For regular installs it won't exist, for local development it might exist.
$autoloader = rtrim(SIMPLY_STATIC_DEPLOY_PATH, '/') . '/vendor/autoload.php';
if (file_exists($autoloader)) {
require_once $autoloader;
}
// Initialize the plugin.
(new SimplyStaticDeploy(
SIMPLY_STATIC_DEPLOY_PATH,
SIMPLY_STATIC_DEPLOY_URL,
SIMPLY_STATIC_DEPLOY_VERSION
))->init();
|
Python | UTF-8 | 248 | 3.640625 | 4 | [] | no_license | import turtle
t = turtle.Turtle()
t.shape('turtle')
radius = 50
length = 30
t.circle(radius)
t.up()
t.forward(length)
t.down()
t.circle(radius)
t.up()
t.forward(length)
t.down()
t.circle(radius)
t.up()
t.forward(length)
t.down()
turtle.done() |
C++ | UTF-8 | 440 | 3.59375 | 4 | [] | no_license | #include <circle.h>
Circle::Circle() {
centro = Point(0.0, 0.0);
r = 0.0;
}
Circle::Circle(double x, double y, double r) {
centro = Point(x, y);
this->r = r;
}
double Circle::getRaio() {
return r;
}
Point Circle::getCentro() {
return centro;
}
double Circle::area() {
return PI * r * r;
}
double Circle::distanceTo(Circle c) {
return this->centro.distanceTo(c.getCentro()) - this->r - c.getRaio();
}
|
Python | UTF-8 | 937 | 2.671875 | 3 | [] | no_license | from flask_restful import reqparse, abort, Api, Resource
from flask import jsonify
from db_manager import create_session
from models.genre import Genre
def abort_if_genre_not_found(genre_id):
session = create_session()
genre = session.query(Genre).get(genre_id)
if not genre:
abort(404, message=f"Жанра с id {genre_id} не существует")
class GenreResource(Resource):
def get(self, genre_id):
abort_if_genre_not_found(genre_id)
session = create_session()
genre = session.query(Genre).get(genre_id)
genre_dict = genre.to_dict(rules=("-books",))
return jsonify({'genre': genre_dict})
class GenreListResource(Resource):
def get(self):
session = create_session()
genres = session.query(Genre).all()
return jsonify({
'genres': [genre.to_dict(rules=("-books",))
for genre in genres]
})
|
Java | UTF-8 | 4,242 | 2.78125 | 3 | [] | no_license | package ru.ssau.daria;
import javax.annotation.Resource;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.*;
import static ru.ssau.daria.Const.MAXIMUM_NUMBER_OF_DISTINCT_IMAGES;
import static ru.ssau.daria.Const.NUMBER_OF_SIMILAR_CARDS;
@WebServlet("/startGameServlet")
public class StartGameServlet extends HttpServlet {
@Resource(name = "jdbc/PuzzleDS")
private DataSource dataSource;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// super.doPost(request, response);
String v_s = request.getParameter("vertical");
String h_s = request.getParameter("horizontal");
String theme = request.getParameter("theme");
int v = Integer.parseInt(v_s);
int h = Integer.parseInt(h_s);
int half = (v * h) / NUMBER_OF_SIMILAR_CARDS;
List<Integer> imgIds = selectImagesForGame(half);
int[][] field = generatePlayField(v, h, imgIds);
GameInfo gameInfo = new GameInfo(h, v, theme);
List<GameCell> gameCells = prepareGameCells(v, h, field);
GameDAO gameDAO = new GameDAO(dataSource);
gameDAO.clearPreviousGames();
gameDAO.storeGameInfo(gameInfo);
gameDAO.storeGameField(gameCells);
response.sendRedirect("game.jsp");
}
private List<GameCell> prepareGameCells(int v, int h, int[][] field) {
List<GameCell> gameCells = new ArrayList<>();
for (int i = 0; i < v; i++) {
for (int j = 0; j < h; j++) {
GameCell cell = new GameCell(i, j, field[i][j]);
gameCells.add(cell);
}
}
return gameCells;
}
private int[][] generatePlayField(int v, int h, List<Integer> imgIds) {
int imagesCount = imgIds.size();
Map<Integer, Integer> imgEntries = new HashMap<>(); //пары "название карточки" - "число карточек на поле"
for (Integer imgId : imgIds) {
imgEntries.put(imgId, 0);
}
int[][] field = new int[v][h]; //игровое поле. в каждой ячейке - ID картинки
Random r = new Random();
for (int i = 0; i < v; i++) {
for (int j = 0; j < h; j++) {
int imageId = -1;
do {
int nextId = r.nextInt(imagesCount); //случайный номер картинки из ранее отобранных
imageId = imgIds.get(nextId); //получаем ID этой картинки
if (imgEntries.get(imageId) == NUMBER_OF_SIMILAR_CARDS) //если на поле уже есть две таких картинки, больше добавлять нельзя. пробуем еще раз
imageId = -1;
} while (imageId < 0);
field[i][j] = imageId;
imgEntries.put(imageId, imgEntries.get(imageId) + 1); //увеличиваем счетчик картинок с этим ID на поле
}
}
return field;
}
// По условию задания, максимум на поле может быть 16 (8*4/2) уникальных картинок. Из 16 картинок мы выбираем те,
// которые будут на поле
private List<Integer> selectImagesForGame(int half) {
Set<Integer> imgIds = new HashSet<>();
Random r = new Random();
while (imgIds.size() < half) {
int next = r.nextInt(MAXIMUM_NUMBER_OF_DISTINCT_IMAGES);
imgIds.add(next);
}
return new ArrayList<>(imgIds);
}
}
|
C | UTF-8 | 2,311 | 3.703125 | 4 | [] | no_license | #include <stdio.h>
void getNDays(int* nDays);
int main()
{
int nDays;
int avgDay;
double avg;
int lastAvg = 0;
double cSum;
printf("---=== IPC Temperature Analyzer V2.0 ===---\n\n");
getNDays(&nDays);
int daysHi[nDays];
int daysLow[nDays];
for (int i = 0; i < nDays; i++)
{
//i+1을 했는데 프린트하면 0 이나와요!
printf("Day %d - High: ",i+1);
scanf("%d", &daysHi[i]);
printf("Day %d - Low: ",i+1);
scanf("%d", &daysLow[i]);
}
printf("\n");
printf("Day Hi Low\n");
for (int i = 0; i < nDays; i++)
{
printf("%d %d",i,daysHi[i]);
printf(" %d\n",daysLow[i]);
}
printf("\n");
printf("Enter a number between 1 and %d to see the average temperature for the entered number of days, enter a negative number to exit: ",nDays);
scanf("%d",&avgDay);
while(0 <= avgDay)
{
double tSum = 0;
//--------------------------------------
// Valid 1 <= avgDay <= nDays
//--------------------------------------
if((1 <= avgDay)&&(avgDay <= nDays))
{
//caluclating the average temperature up to n days
for(int x = 0; x < avgDay; x++)
{
cSum = (daysHi[x] + daysLow[x]);
tSum = tSum + cSum;
}
avg = tSum / (avgDay * 2);
//up to this point
printf("The average temperature up to day %d is: %.2lf",avgDay,avg);
printf("\n");
printf("Enter a number between 1 and %d to see the average temperature for the entered number of days, enter a negative number to exit: ",nDays);
scanf("%d", &avgDay);
}
//--------------------------------------
// invalid, avgDay > Ndays
//--------------------------------------
else if ( avgDay > nDays || 0 == avgDay)
{
printf("Invalid enter, please enter a number between 1 and %d, inclusive: ",nDays);
scanf("%d", &avgDay);
}
}
printf("Goodbye!");
printf("\n");
return 0;
}
void getNDays(int* nDays)
{
int n;
printf("Please enter the number of days, between 3 and 10, inclusive: ");
printf("\n");
scanf("%d", &n);
while(!(2 < n && n < 11))
{
printf("Invalid entry, please enter the number of days, between 3 and 10, inclusiv e: ");
scanf("%d", &n);
}
printf("\n");
*nDays = n;
}
|
Python | UTF-8 | 1,274 | 2.71875 | 3 | [] | no_license | import tensorflow as tf
import json
import numpy as np
import requests
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
self.train_data = np.expand_dims(self.train_data.astype(np.float32)/255.0, axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32)/255.0, axis=-1)
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
data_loader = MNISTLoader()
data = json.dumps({
"instances": data_loader.test_data[0:100].tolist()
})
headers = {"content-type": "application/json"}
json_response = requests.post(
'http://localhost:8501/v1/models/MLP:predict',
data=data, headers=headers
)
print(json_response.text)
predictions = np.array(json.loads(json_response.text)['predictions'])
print(np.argmax(predictions, axis=-1))
print(data_loader.test_label[0:100])
print([[i, a, b] for i, (a,b) in enumerate(zip(np.argmax(predictions, axis=-1), data_loader.test_label[0:100])) if a != b]) |
JavaScript | UTF-8 | 1,011 | 2.875 | 3 | [] | no_license | export async function getStaticPaths() {
// Call an external API endpoint to get posts
const res = await fetch('https://rickandmortyapi.com/api/character')
const data = await res.json();
// Get the paths we want to pre-render based on posts
const paths = data.results.map((character) => ({
params: { id: character.id.toString() },
}))
// We'll pre-render only these paths at build time.
// { fallback: false } means other routes should 404.
return { paths, fallback: false }
}
function Character({ character }) {
return <h2>Le page de "{character.name}"</h2>
}
export async function getStaticProps({ params }) {
// params contains the post `id`.
// If the route is like /posts/1, then params.id is 1
const res = await fetch(`https://rickandmortyapi.com/api/character/${params.id}`)
const character = await res.json()
// Pass post data to the page via props
return { props: { character } }
}
export default Character |
Java | UTF-8 | 2,341 | 2.296875 | 2 | [] | no_license | package com.QuasarFireOperationMS.web.controller;
import com.QuasarFireOperationMS.service.LocationService;
import com.QuasarFireOperationMS.web.error.NoSatelliteFoundException;
import com.QuasarFireOperationMS.web.model.LocationInfoDto;
import com.QuasarFireOperationMS.web.model.SatellitesDto;
import com.QuasarFireOperationMS.web.model.SingleSatelliteDto;
import com.QuasarFireOperationMS.web.model.SingleSatelliteInfoDto;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
import javax.validation.Valid;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
import java.util.Arrays;
/**
* @author jiz10
* 30/4/21
*/
@Validated
@RequestMapping("api/v1")
@RestController
public class LocationController {
@Autowired
private LocationService locationService;
@Value("${satellites.names}")
private String[] satellitesNames;
@PostMapping(path = "/topsecret/")
public ResponseEntity<LocationInfoDto> calculateLocationFromGroup(@Valid @NotNull @RequestBody SatellitesDto satellitesDto) {
LocationInfoDto locationInfoDto = locationService.getLocationFromSatellitesGroup(satellitesDto);
return new ResponseEntity<LocationInfoDto>(locationInfoDto, HttpStatus.OK);
}
@PostMapping(path = "/topsecret_split/{satellite_name}")
public ResponseEntity saveSatelliteInfo(@PathVariable @NotBlank String satellite_name, @Valid @NotNull @RequestBody SingleSatelliteDto singleSatelliteDto) {
if (!Arrays.asList(satellitesNames).contains(satellite_name.toUpperCase())) {
throw new NoSatelliteFoundException();
}
SingleSatelliteInfoDto satelliteInfo = locationService.saveSatelliteInfo(singleSatelliteDto, satellite_name);
return new ResponseEntity<SingleSatelliteInfoDto>(satelliteInfo, HttpStatus.CREATED);
}
@GetMapping(path = "/topsecret_split/")
public ResponseEntity<LocationInfoDto> calculateLocationSplit() {
return new ResponseEntity<LocationInfoDto>(locationService.getLocationSplit(), HttpStatus.OK);
}
}
|
Java | UTF-8 | 814 | 2.28125 | 2 | [] | no_license | package com.candystudio.android.dxzs.teacher.database;
//import android.R;
import android.database.sqlite.SQLiteDatabase;
import com.candystudio.android.dxzs.teacher.app.R;
public class DataBaseManager {
private static DatabaseHelper databaseHelper = null;
private static SQLiteDatabase db = null;
private static String databaseName;
public DataBaseManager() {
if (databaseName == null) {
// databaseName = MyApplication.getContext().getResources()
// .getString(R.string.database_name);
}
if (databaseHelper == null) {
// databaseHelper = new DatabaseHelper(MyApplication.getContext(),
// databaseName, null, 1);
}
if (db == null) {
db = databaseHelper.getWritableDatabase();
}
}
public static SQLiteDatabase getDb() {
return db;
}
}
|
Python | UTF-8 | 911 | 3.703125 | 4 | [] | no_license | def dot_product(x, y):
total = 0
for a, b in zip(x, y):
total += a * b
return total
def project(v, s):
"""
project v onto the line spanned by s
"""
factor = float(dot_product(v, s)) / float(dot_product(s, s))
output = [s[0] * factor, s[1] * factor]
return output
def reflect(v, s):
"""
reflect v over the line defined by s
"""
projection = project(v, s)
difference = [v[0] - projection[0], v[1] - projection[1]]
answer = [projection[0] - difference[0], projection[1] - difference[1]]
return answer
def test():
assert project([2, 3], [1, 2]) == [1.6, 3.2]
assert project([23, 45], [1, 0]) == [23, 0]
assert project([23, 45], [0, 1]) == [0, 45]
assert reflect([1, 2], [1, 0]) == [1, -2]
assert reflect([1, 2], [0, 1]) == [-1, 2]
assert reflect([1, 2], [1, -1]) == [-2, -1]
if __name__ == "__main__":
test() |
Java | UTF-8 | 1,832 | 1.90625 | 2 | [] | no_license | package cn.xports.qd2.campaign;
import cn.xports.baselib.bean.Response;
import cn.xports.baselib.http.ProcessObserver;
import cn.xports.baselib.mvp.IView;
import cn.xports.qd2.entity.MemberInfo;
import java.util.ArrayList;
import kotlin.Metadata;
import org.jetbrains.annotations.Nullable;
@Metadata(bv = {1, 0, 3}, d1 = {"\u0000\u0017\n\u0000\n\u0002\u0018\u0002\n\u0002\u0018\u0002\n\u0000\n\u0002\u0010\u0002\n\u0002\b\u0002*\u0001\u0000\b\n\u0018\u00002\b\u0012\u0004\u0012\u00020\u00020\u0001J\u0012\u0010\u0003\u001a\u00020\u00042\b\u0010\u0005\u001a\u0004\u0018\u00010\u0002H\u0016¨\u0006\u0006"}, d2 = {"cn/xports/qd2/campaign/AddMemberActivity$updatePlayer$1", "Lcn/xports/baselib/http/ProcessObserver;", "Lcn/xports/baselib/bean/Response;", "next", "", "value", "xports2_productRelease"}, k = 1, mv = {1, 1, 15})
/* compiled from: AddMemberActivity.kt */
public final class AddMemberActivity$updatePlayer$1 extends ProcessObserver<Response> {
final /* synthetic */ MemberInfo $member;
final /* synthetic */ AddMemberActivity this$0;
/* JADX INFO: super call moved to the top of the method (can break code semantics) */
AddMemberActivity$updatePlayer$1(AddMemberActivity addMemberActivity, MemberInfo memberInfo, IView iView) {
super(iView);
this.this$0 = addMemberActivity;
this.$member = memberInfo;
}
public void next(@Nullable Response response) {
this.this$0.opType = 11;
ArrayList access$getMemberList$p = this.this$0.memberList;
if (access$getMemberList$p != null) {
access$getMemberList$p.clear();
}
ArrayList access$getMemberList$p2 = this.this$0.memberList;
if (access$getMemberList$p2 != null) {
access$getMemberList$p2.add(this.$member);
}
this.this$0.finish();
}
}
|
JavaScript | UTF-8 | 1,383 | 3.796875 | 4 | [] | no_license | // 最长上升子序列
// https://www.zhihu.com/question/23995189
// const arr = [1,2,1,5,3,1,4,6,1,9,7,8,1];
const arr = [1,2,1,5,4,6];
const result = {}
arr.forEach((v,index) => {
result[index] = 1;
})
const message = {}
const route = {
0: [arr[0]]
}
function lis(arr) {
for(let i = 1; i< arr.length; i++) {
let routeArr = []
for(let j = 0; j < i; j++) {
if(arr[j] < arr[i]) {
routeArr = route[j].slice()
result[i] = Math.max(result[j] + 1,result[i])
} else {
// j < i 时,result[i] 一定大于等于 result[j],
result[i] = Math.max(result[j],result[i])
if(result[i] === result[j]){
routeArr = route[j].slice();
}
}
}
// 关于当前 arr[i] 要不要push进去
// 如果他是最大值,那么push进去
// 否则,如果他push进去之后能成为最大值,那么也push进去
if(arr[i] > routeArr[routeArr.length -1]) {
routeArr.push(arr[i]);
} else if(
routeArr.length -1 >= 0 &&
routeArr.length -2 >= 0 &&
arr[i] <= routeArr[routeArr.length -1] &&
arr[i] > routeArr[routeArr.length -2]) {
routeArr.pop()
routeArr.push(arr[i])
}
route[i] = routeArr;
message[i] = `${i},length: ${result[i]}, route: ${routeArr.join(' -> ')}`;
}
// console.log(result)
console.log(message)
}
lis(arr); |
Java | UTF-8 | 1,292 | 3.859375 | 4 | [] | no_license | /*
* Project Name: SecretNumber
* Author: G Murie
* Date: 21/10/14
*/
import java.io.* ;
public class SecretNumber {
private static int userInput;
private static String entString;
private static BufferedReader bufRead;
int total = 1;
public static void main(String[] args) {
//Declare the local variable to hold the randomly generated number
int secretNumber;
// Generate a random number between 1 and 1000
secretNumber = (int) (Math.random() * 999 + 1);
InputStreamReader istream = new InputStreamReader(System.in) ;
bufRead = new BufferedReader(istream) ;
System.out.println("The Computer Has Thought Of A Number All You Have To Do Is Geuss What It Is, (Between 1 and 1000)");
do{
System.out.println("Try And Geuss The Number: ");
try {
entString = bufRead.readLine();
userInput = Integer.parseInt(entString);
} catch (IOException e) {
e.printStackTrace();
}
if (userInput > secretNumber)
System.out.println("Your Guess Is To High");
else
if (userInput < secretNumber)
System.out.println("Your Guess Is To Low");
else
if (userInput == secretNumber)
System.out.println ("YOU GEUSSED CORRECTLY, CONGRATULATIONS!");
} while (userInput != secretNumber);
}
}
|
Java | UTF-8 | 592 | 2.6875 | 3 | [] | no_license | package ecs_bank.random_generator;
import java.security.SecureRandom;
import java.util.ArrayList;
import java.util.concurrent.ThreadLocalRandom;
public class SurnameSource {
private ArrayList<String> cachedSurnames;
private SecureRandom random = new SecureRandom();
private static final String SURNAMES_PATH = "src/main/resources/random_generator/person/surnames.txt";
public SurnameSource() {
cachedSurnames = ReadFile.readFile(SURNAMES_PATH);
}
public String random() {
return cachedSurnames.get(random.nextInt(cachedSurnames.size()));
}
}
|
C++ | UTF-8 | 683 | 2.5625 | 3 | [] | no_license | #ifndef APUI_WIDGETS_TABLES_ROW_HPP
#define APUI_WIDGETS_TABLES_ROW_HPP
#include <ApUI/Widgets/Layout/Group.hpp>
#include <ApUI/Widgets/Texts/TextColored.hpp>
#include <map>
namespace ApUI::Widgets::Tables
{
class Table;
class Row : public Layout::Group
{
public:
explicit Row(const std::string& row_id, Table* table);
Texts::TextColored &operator[](const std::string& key);
Texts::TextColored &FindOrCreateColumnData(const std::string &key);
protected:
void _Draw_Impl() override;
public:
const std::string RowID;
private:
Table *m_table;
std::map<std::string, Texts::TextColored*> m_data;
};
}
#endif //APUI_WIDGETS_TABLES_ROW_HPP
|
C++ | UTF-8 | 511 | 2.796875 | 3 | [] | no_license | #pragma once
#include "CreatureStat.h"
class CreatureStatEffect
{
public:
CreatureStatEffect(CreatureStat::E lStat, int lAmount, int lLength);
~CreatureStatEffect(void);
CreatureStat::E getAffectedStat(void) const;
int getAmount(void) const;
int getTimeRemaining(void) const;
void setAffectedStat(CreatureStat::E lStat);
void changeAmount(int amount);
void changeTimeRemaining(int amount);
private:
CreatureStat::E m_affectedStat;
int m_amount;
int m_timeRemaining;
};
|
Markdown | UTF-8 | 1,086 | 3.0625 | 3 | [
"MIT"
] | permissive | # How to contribute
This is an open source library for [CodeIgniter](https://github.com/bcit-ci/CodeIgniter), all contributions (Issues, suggestions and Pull requests) are welcome.
If you find a bug or have a suggestion, please:
1. Make sure there is no already open Issue.
2. Make sure the issue hasn't been fixed (look for closed Issues)
Reporting issues is helpful but an even better approach is to send a Pull Request, which is done by "Forking" the main repository and committing to your own copy.
This will require you to use the version control system called Git.
## Guidelines
Before we look into how, here are the guidelines. If your Pull Requests fail
to pass these guidelines it will be declined and you will need to re-submit
when you’ve made the changes. This might sound a bit tough, but it is required
for maintaining code quality.
### Documentation
If you change anything you need to update the PHPDoc block too.
### One issue at a time
Please submit one fix per pull request, so that even if a fix is not desired, we can still benefit from the other fixes.
|
Shell | UTF-8 | 2,526 | 3.078125 | 3 | [] | no_license | #! /usr/bin/env bash
echo "Adding a proxy for apt."
cat << EOF | sudo tee -a /etc/apt/apt.conf.d/01proxy
Acquire::http::Proxy "http://dockerhost.local:3142/";
Acquire::https::Proxy "http://dockerhost.local:3142/";
EOF
echo "Updating apt and doing a full upgrade. This gets the latest version of raspi-config."
apt-get update && apt-get full-upgrade -y
# echo "Disable serial console. This removes 'console=serial0,115200' from '/boot/cmdline.txt'."
# raspi-config nonint do_serial 1
echo "Change video memory to 16MB. Don't need much as this is a headless setup. Changed to 32 to avoid vchi warnings."
raspi-config nonint do_memory_split 32
echo "Explicitly set plain HDMI mode. This will use HDMI if it is available on boot and switch to tvout otherwise."
raspi-config nonint do_pi4video V3
echo "Boot to text console and require login. Other options are to automatically log in and use a graphical interface."
raspi-config nonint do_boot_behaviour B1
echo "Disable the camera interface. Enabling it will force gpu memory to at least 128MB."
raspi-config nonint do_camera 1
echo "Setting localization options. Keyboard layout."
sed -i /etc/default/keyboard -e "s/^XKBMODEL.*/XKBMODEL=\"pc104\"/"
raspi-config nonint do_configure_keyboard us
echo "Setting localization options. en_US.UTF-8."
raspi-config nonint do_change_locale en_US.UTF-8
echo "Setting localization options. timezone."
raspi-config nonint do_change_timezone US/Mountain
echo "Setting localization options. wifi Country."
raspi-config nonint do_wifi_country US
echo "Setting network options. enabling ssh"
raspi-config nonint do_ssh 0
echo "Setting network options. disabling vnc"
raspi-config nonint do_vnc 1
echo "Setting network options. waiting for network on boot"
raspi-config nonint do_boot_wait 0
echo "Setting network options. predictable device names."
raspi-config nonint do_net_names 0
echo "Might turn these on later if we want to do things like temperature monitoring or such."
echo "disable SPI"
raspi-config nonint do_spi 1
echo "disable I2C"
raspi-config nonint do_i2c 1
echo "disable OneWire"
raspi-config nonint do_onewire 1
echo "disable remote GPIO pins"
raspi-config nonint do_rgpio 1
echo "Setting network options. hostname"
# Generates a hostname that is "pi-" followed by the last 6 characters of the wifi MAC addres.
NEW_HOSTNAME="pi-$(ip a show wlan0 | grep 'link/ether' | grep -o '..:..:.. ' | tr '[:lower:]' '[:upper:]' | tr -d '[:punct:]' | tr -d '[:blank:]')"
raspi-config nonint do_hostname "$NEW_HOSTNAME"
|
C# | UTF-8 | 1,870 | 2.515625 | 3 | [] | no_license | using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace GDAL
{
public class FTrans
{
#region Variables
DB db = new DB();
#endregion
#region Proprties
public int ID { get; set; }
public int UserID { get; set; }
public int SessionID { get; set; }
public double Amount { get; set; }
public int PaymentMethod { get; set; }
public string PaymentInfo{ get; set; }
public DateTime Date { get; set; }
public Doctors Therapist
{
get
{
Dictionary<string, object> dic = new Dictionary<string, object>();
dic.Add("@ID", SessionID);
Sessions S = new Sessions();
S=S.Search(dic)[0];
return S.Therapist;
}
}
#endregion
public FTrans()
{
db = new DB();
}
public override string ToString()
{
return "FTrans";
}
public void Add()
{
db.Insert(this);
}
public List<FTrans> GetByUserID(int UserID)
{
Dictionary<string, object> Dic = new Dictionary<string, object>();
Dic.Add("@UserID", UserID);
return db.ExecuteList("GetFTransByUID", this.GetType(),Dic).Cast<FTrans>().ToList();
}
public List<FTrans> GetbyDate(DateTime FromDate, DateTime ToDate)
{
Dictionary<string, object> Dic = new Dictionary<string, object>();
Dic.Add("@FromDate", FromDate);
Dic.Add("@ToDate", ToDate);
return db.ExecuteList("GetFTransByDate", this.GetType(),Dic).Cast<FTrans>().ToList();
}
}
} |
Python | UTF-8 | 1,057 | 2.96875 | 3 | [] | no_license | import time
import socket
from collections import defaultdict
# a print_lock is what is used to prevent "double" modification of shared variables.
# this is used so while one thread is using a variable, others cannot access
# it. Once done, the thread releases the print_lock.
# to use it, you want to specify a print_lock per thing you wish to print_lock.
# ip = socket.gethostbyname(target)
def scanPort(port, ip):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
s.connect((ip, port))
out = (ip, port)
print(out)
s.close()
return out
except:
pass
def scanPorts(ip='localhost', no_threads=1, port_range=10000):
start = time.time()
out = defaultdict(list)
for ip in ip.split(','):
for port in range(1, port_range):
rst = scanPort(port, ip)
if rst:
out[rst[0]].append(str(rst[1]))
# out['duration'] = time.time() - start
return out
# def scanFromFile():
# for f in open('port_list.txt'):
# print(f) |
Java | UTF-8 | 1,792 | 2.40625 | 2 | [] | no_license | //@author A0099903R
package goku.autocomplete;
import org.junit.Test;
public class CommandAutoCompleteTest extends WordAutoCompleteTest {
CommandAutoComplete auto = new CommandAutoComplete();
@Test
public void complete_a_success() {
String[] expecteds = { "add" };
String[] actuals = listToArray(auto.complete("a"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_d_success() throws Exception {
String[] expecteds = { "delete", "display", "do" };
String[] actuals = listToArray(auto.complete("d"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_e_success() throws Exception {
String[] expecteds = { "edit", "exit" };
String[] actuals = listToArray(auto.complete("e"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_f_success() throws Exception {
String[] expecteds = { "finish", "find" };
String[] actuals = listToArray(auto.complete("f"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_q_success() throws Exception {
String[] expecteds = { "quit" };
String[] actuals = listToArray(auto.complete("q"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_s_success() throws Exception {
String[] expecteds = { "show", "search" };
String[] actuals = listToArray(auto.complete("s"));
assertArraysHaveSameElements(expecteds, actuals);
}
@Test
public void complete_u_success() throws Exception {
String[] expecteds = { "undo", "update" };
String[] actuals = listToArray(auto.complete("u"));
assertArraysHaveSameElements(expecteds, actuals);
}
}
|
Java | UTF-8 | 1,033 | 2.171875 | 2 | [] | no_license | package com.lynxspa.sdm.dictionaries.domains.values;
import com.lynxspa.entities.application.domains.adapters.DomainValueDictAdapter;
public enum CADomainREGIONRETENTIONSClusterRETENCIONValue implements DomainValueDictAdapter {
VALUE1("DK","28"),
VALUE2("AU","30"),
VALUE3("AT","25"),
VALUE4("BE","25"),
VALUE5("CA","15"),
VALUE6("DE","26.375"),
VALUE7("US","15"),
VALUE8("FI","28"),
VALUE9("FR","25"),
VALUE10("GR","10"),
VALUE11("NL","15"),
VALUE12("IE","20"),
VALUE13("IT","27"),
VALUE14("JP","7"),
VALUE15("LU","0"),
VALUE16("NO","15"),
VALUE17("PT","20"),
VALUE18("GB","10"),
VALUE19("SE","30"),
VALUE20("SZ","35"),
VALUE21("CZ","15"),
VALUE22("HU","25"),
VALUE23("PL","19");
private String normalCode=null;
private String value=null;
CADomainREGIONRETENTIONSClusterRETENCIONValue(String _normalCode,String _value){
this.normalCode=_normalCode;
this.value=_value;
}
public String getNormalCode() {
return this.normalCode;
}
public String getValue() {
return this.value;
}
}
|
Python | UTF-8 | 2,086 | 2.828125 | 3 | [] | no_license | import numpy as np
import pandas as pd
import openai
engine = "text-davinci-002"
def act(text):
openai.api_key = "YOURKEY"
response = openai.Completion.create(
engine = engine,
prompt = text,
max_tokens = 1,
temperature = 0.0,
logprobs=2,
)
return response.choices[0].text.strip(), response.choices[0].logprobs.top_logprobs[0]
c13k_problems = pd.read_json("data/c13k_problems.json", orient='index')
print(len(c13k_problems))
random_problems = np.arange(len(c13k_problems))
data = []
for t, index in enumerate(random_problems):
value_A = 0
text_A = "- Option F: "
for item_A in c13k_problems.iloc[index].A:
value_A += item_A[1] * item_A[0]
text_A += str(item_A[1]) + " dollars with " + str(round(item_A[0] * 100, 4)) + "% chance, "
text_A = text_A[:-2]
text_A += ".\n"
value_B = 0
text_B = "- Option J: "
for item_B in c13k_problems.iloc[index].B:
value_B += item_B[1] * item_B[0]
text_B += str(item_B[1]) + " dollars with " + str(round(item_B[0] * 100, 4)) + "% chance, "
text_B = text_B[:-2]
text_B += ".\n"
text = "Q: Which option do you prefer?\n\n"
if np.random.choice([True, False]):
text += text_A
text += text_B
else:
text += text_B
text += text_A
text += "\nA: Option"
action, log_probs = act(text)
# fix if answer is not in top 2
if not (" F" in log_probs):
log_probs[" F"] = -9999
if not (" J" in log_probs):
log_probs[" J"] = -9999
row = [index, value_A, value_B, action, log_probs[" F"], log_probs[" J"]]
data.append(row)
print(text)
print(action)
print()
if ((t % 500) == 0):
df = pd.DataFrame(data, columns=['task', 'valueA', 'valueB', 'action', 'logprobA', 'logprobB'])
print(df)
df.to_csv('data/' + engine + '/experiment_choice13k.csv')
df = pd.DataFrame(data, columns=['task', 'valueA', 'valueB', 'action', 'logprobA', 'logprobB'])
print(df)
df.to_csv('data/' + engine + '/experiment_choice13k.csv')
|
Markdown | UTF-8 | 15,569 | 3.828125 | 4 | [] | no_license | # 组件
## 使用组件
### 全局注册
确保在初始化根实例之前注册组件:
```js
Vue.component('my-component', {
// 选项对象
})
```
### 局部注册
通过实例选项注册仅在单个实例中可用的组件:
```js
var Child = {
template: '<div>A custom component!</div>',
}
new Vue({
components: {
'my-component': Child,
},
})
```
### data必须是函数
防止组件之间共享数据,导致不可复用:
```js
data: function () {
return {
counter: 0
}
}
```
## prop
父组件通过 prop 给子组件下发数据,子组件通过事件给父组件发送消息。
### prop的使用
在组件的选项对象中定义了`props`属性后,就可以使用其中定义的`prop`了(注意如果js中用驼峰定义prop,html中要转为短线分隔式):
```html
<div id="example-4">
<!-- 将message prop赋值为字面量'hello!' -->
<first-component message='hello!'></first-component>
</div>
```
```js
Vue.component("first-component",{
props: ['message'],
template: '<p>first component {{message}}</p>'
})
new Vue({
el: '#example-4',
data: {
picked: ''
}
})
```
### 动态语法
将`prop`绑定到父组件的数据上。
```html
<div id="example-4">
<input type="text" v-model="picked">
<!-- 和直接给prop赋值不同,这里的"picked"是当作js表达式计算的 -->
<first-component :message="picked"></first-component>
</div>
```
```js
var vm = Vue.component("first-component",{
props: ['message'],
template: '<p>first component {{message}}</p>'
})
new Vue({
el: '#example-4',
data: {
picked: 'aaaa'
}
})
```
当要将一个对象的多个属性同时传递的时候,使用不带参数的`v-bind`,对应属性将被赋值:
```html
<todo-item v-bind="todo"></todo-item>
<!-- 等价于 -->
<todo-item
v-bind:text="todo.text"
v-bind:is-complete="todo.isComplete"
></todo-item>
```
### 单项数据流
每次父组件有跟新时会更新子组件,**不能在子组件中直接修改**`prop`,会报错。
下边这两中情况会很需要修改`prop`:
- Prop 作为初始值传入后,子组件想把它当作局部数据来用;
- Prop 作为原始数据传入,由子组件处理成其它数据输出。
这时的处理方法是
1. 创建一个局部变量用`prop`来初始化:
```js
props: ['initialCounter'],
data: function () {
return { counter: this.initialCounter }
}
```
2. 使用计算属性处理并返回:
```js
props: ['size'],
computed: {
normalizedSize: function () {
return this.size.trim().toLowerCase()
}
}
```
**注意**:引用类型的数据由于是指针,在子组件内部修改会影响父组件状态。
### prop验证
要为`prop`添加验证,规定其传入的格式,就使用对象的形式定义`prop`,用下面的方法添加验证:
```js
Vue.component('example', {
props: {
// 基础类型检测 (`null` 指允许任何类型)
propA: Number,
// 可能是多种类型
propB: [String, Number],
// 必传且是字符串
propC: {
type: String,
required: true
},
// 数值且有默认值
propD: {
type: Number,
default: 100
},
// 数组/对象的默认值应当由一个工厂函数返回
propE: {
type: Object,
default: function () {
return { message: 'hello' }
}
},
// 自定义验证函数
propF: {
validator: function (value) {
return value > 10
}
}
}
})
```
### 非Prop特性
在使用组件的时候添加的属性会渲染到组件的根元素上,一般的属性会替换模板上的属性,`style`和`class`会合并。
## 自定义事件
子组件向父组件通信:子组件使用`v-on`监听事件,使用`$emit`向父组件发送报告(即用$emit触发当前组件的这个事件,后续参数是会传入事件处理函数),父组件使用`v-on`监听子组件`$emit`发来的报告。
```html
<div id="counter-event-example">
<p>{{ total }}</p>
<!-- 监听子组件的通知increament,如果组件有这个通知调用incrementTotal -->
<button-counter v-on:increment="incrementTotal"></button-counter>
<button-counter v-on:increment="incrementTotal"></button-counter>
</div>
```
```js
Vue.component('button-counter', {
template: '<button v-on:click="incrementCounter">{{ counter }}</button>',
data: function () {
return {
counter: 0
}
},
methods: {
incrementCounter: function () {
this.counter += 1
this.$emit('increment')
}
},
})
new Vue({
el: '#counter-event-example',
data: {
total: 0
},
methods: {
incrementTotal: function () {
this.total += 1
}
}
})
```
如果子组件的根元素需要监听一个原生事件,要加上修饰符`.native`。
### .sync修饰符
在将数据绑定到`prop`时候,带上修饰符`.sync`,然后子组件使用`this.$emit('update:prop名', 新数据);`的方式更新父组件数据:
```html
<div id="thefather">
<button>{{total}}</button>
<zheshi-moban :asdfasdf.sync="total"></zheshi-moban>
<!-- 会被扩展为下边这样: -->
<!-- <zheshi-moban :asdfasdf="total" @update:asdfasdf="val => total = val"></zheshi-moban> -->
</div>
```
```js
new Vue({
el: "#thefather",
data: {
total: 0,
},
components: {
'zheshiMoban': {
template: '<button @click="clicked">{{realdata}}</button>',
props: ['asdfasdf'],
data: function() {
return {
realdata: this.asdfasdf,
}
},
methods: {
clicked: function () {
this.realdata++;
this.$emit('update:asdfasdf', this.realdata);
}
}
}
},
})
```
### 使用自定义事件的表单输入组件
`v-model`的原理如下:
```html
<input type="text" v-model="modelData">
<!-- v-model是下边的语法糖,将value属性绑定到data中的一个值,当输入的时候给这个data赋值 -->
<input type="text" :value="modelData" @input="modelData = $event.target.value">
```
如果要自定义一个输入组件,在组件中使用`v-model`时,需要手动配置一下:
```html
<!-- 在组件中,v-model的表现相当于这样:将组件的value属性绑定到一个data上,再给组件添加一个input事件 -->
<custom-input
v-bind:value="something"
v-on:input="something = arguments[0]">
</custom-input>
```
组件内部肯定有可以输入的元素,当输入的时候,触发事件处理函数,将输入自定义更改
下边是一个自定义的输入组件,将输入转为数字:
```html
<currency-input v-model="price"></currency-input>
<!-- 在组件上使用v-model等同于这样:arguments是事件处理函数的参数 -->
<!-- <currency-input type="text" :value="price" @input="price = arguments[0]"></currency-input> -->
```
```js
// ref表示注册组件
Vue.component('currency-input', {
template: '\
<span>\
$\
<input\
ref="input"\
v-bind:value="value"\
v-on:input="updateValue($event.target.value)"\
>\
</span>\
',
props: ['value'],
methods: {
// 不是直接更新值,而是使用此方法来对输入值进行格式化和位数限制
updateValue: function (value) {
var formattedValue = value
// 删除两侧的空格符
.trim()
// 保留 2 位小数
.slice(
0,
value.indexOf('.') === -1
? value.length
: value.indexOf('.') + 3
)
// 如果值尚不合规,则手动覆盖为合规的值
if (formattedValue !== value) {
this.$refs.input.value = formattedValue
}
// 通过 input 事件带出数值
this.$emit('input', Number(formattedValue))
}
}
})
```
### 自定义组件使用v-model
默认情况组件的`v-model`会使用`value`属性和`input`事件。但是单选框、复选框等使用`v-model`时,可以使用`model`选项修改绑定属性和所用事件。
```js
Vue.component('my-checkbox', {
model: {
prop: 'checked',
event: 'change'
},
props: {
// 在这里依然要声明所绑定的属性
checked: Boolean,
// 这样就允许拿 `value` 这个 prop 做其它事了
value: String
},
// ...
})
```
使用上边的配置生成下边组件
```html
<my-checkbox v-model="foo" value="some value"></my-checkbox>
```
相当于这样实现:
```html
<my-checkbox
:checked="foo"
@change="val => { foo = val }"
value="some value">
</my-checkbox>
```
### 非父子组件的通信
在同一个实例中,可以在一个组件中触发一个事件,然后在另一个组件中监听同名的事件。
```js
var bus = new Vue();
//在组件A中触发事件id-selected
bus.$emit('id-selected',1);
//在组件B中监听同名事件
bus.$on('id-selected',function(id){
// ...
});
```
在复杂情况下,使用状态管理模式`Vuex`。
## 使用插槽分发内容
用于组件的组合:
如果要绑定子组件作用域内的指令到一个组件的根节点,应当在**子组件自己的模板里做**。
**父组件模板的内容在父组件作用域内编译;子组件模板的内容在子组件作用域内编译。**
### 单个插槽
假定 `my-component` 组件有如下模板:
```html
<div>
<h2>我是子组件的标题</h2>
<slot>
只有在没有要分发的内容时才会显示。
</slot>
</div>
```
父组件模板:
```html
<div>
<h1>我是父组件的标题</h1>
<my-component>
<p>这是一些初始内容</p>
<p>这是更多的初始内容</p>
</my-component>
</div>
```
渲染结果:
```html
<div>
<h1>我是父组件的标题</h1>
<div>
<h2>我是子组件的标题</h2>
<p>这是一些初始内容</p>
<p>这是更多的初始内容</p>
</div>
</div>
```
`slot`中的内容是备用的,在宿主没有东西要传入的时候才显示。
没有`slot`时直接替换。
### 具名插槽
`slot`可以在子组件中定义`name`属性,在父组件中使用`solt="name值"`将对应的块插入。
### 作用域插槽
使用组件中具有slot-scope(slot作用域)属性的标签来接收子组件模板中插槽传来的数据:
```html
<div id="example">
<div class="parent">
<child>
<div slot-scope="props">
<span>{{props.another}}</span>
<br>
<span>{{ props.text }}</span>
</div>
</child>
</div>
</div>
```
```js
Vue.component('child',{
template: '\
<div class="child">\
<slot text="hello from child" another="This is another data."></slot>\
</div>\
',
});
new Vue({
el: '#example',
})
```
还可以使用`ES6`的解构对传来的`props`进行结构:
```html
<child>
<span slot-scope="{ text }">{{ text }}</span>
</child>
```
## 动态组件
就像绑定数据一样将`<自定义组建名>`替换为`<component>`,然后使用`v-bind:is`将组件绑定到`compoent`上,让后当组件对象改变的时候组件会动态变化:
```html
<component v-bind:is="currentView">
<!-- 组件在 vm.currentview 变化时改变! -->
</component>
```
```js
var vm = new Vue({
el: '#example',
data: {
currentView: 'home'
},
components: {
home: { /* ... */ },
posts: { /* ... */ },
archive: { /* ... */ }
}
})
```
也可以直接绑定到组件对象上:
```js
var Home = {
template: '<p>Welcome home!</p>'
}
var vm = new Vue({
el: '#example',
data: {
currentView: Home
}
})
```
## 杂项
`Vue`组件的`API`来自三个部分:`prop`、事件、插槽。
- `Prop`用于外部环境传递数据给组件;
- 事件允许从组件内对外部环境产生影响;
- 插槽允许外部环境将额外的内容组合在租价中。
### 子组件引用
`ref`是一个直接操作子组件的应急方案。
```html
<div id="parent">
<user-profile ref="profile"></user-profile>
</div>
```
```js
var parent = new Vue({ el: '#parent' })
// 访问子组件实例
var child = parent.$refs.profile
```
当 ref 和 v-for 一起使用时,获取到的引用会是一个数组,包含和循环数据源对应的子组件。
### 异步组件
`Vue.js`允许将组件定义为一个工厂函数,异步的解析组件的定义。回掉函数或者`Promise`对象都可以,这样会按需加载组件。
具体看文档。
```js
//webpack的代码分割功能
Vue.component('async-webpack-example', function (resolve) {
// 这个特殊的 require 语法告诉 webpack
// 自动将编译后的代码分割成不同的块,
// 这些块将通过 Ajax 请求自动下载。
require(['./my-async-component'], resolve)
})
```
```js
Vue.component(
'async-webpack-example',
// 该 `import` 函数返回一个 `Promise` 对象。
() => import('./my-async-component')
)
//局部注册组件
new Vue({
// ...
components: {
'my-component': () => import('./my-async-component')
}
})
```
### 高级异步组件
异步组件的工厂函数也可以返回一个如下的对象:
```js
const AsyncComp = () => ({
// 需要加载的组件。应当是一个 Promise
component: import('./MyComp.vue'),
// 加载中应当渲染的组件
loading: LoadingComp,
// 出错时渲染的组件
error: ErrorComp,
// 渲染加载中组件前的等待时间。默认:200ms。
delay: 200,
// 最长等待时间。超出此时间则渲染错误组件。默认:Infinity
timeout: 3000
})
```
### 递归组件
当你利用 `Vue.component` 全局注册了一个组件,全局的 `ID` 会被自动设置为组件的 `name`。
所以要确保递归调用有终止条件 (比如递归调用时使用 v-if 并最终解析为 false)。
```html
<div id="example">
<some-name :thedata="thedata"></some-name>
</div>
```
```js
<script src="./vue.js"></script>
<script>
Vue.component('some-name',{
template: '<span><some-name :thedata="thedata + 1" v-if="thedata < 5">{{thedata}}</some-name></span>',
props: ['thedata'],
});
new Vue({
el: '#example',
data: {
thedata: 0,
},
})
</script>
```
### 组件间的循环引用
在渲染树上这两个组件同时为对方的父节点和子节点——这是矛盾的!当使用 `Vue.component` 将这两个组件注册为全局组件的时候,框架会自动为你解决这个矛盾。
但如果你使用诸如 `webpack` 或者 `Browserify` 之类的模块化管理工具来 `require/import` 组件的话,就会报错。
我们要等到 `beforeCreate` 生命周期钩子中才去注册其中另一个组件:
```js
beforeCreate: function () {
this.$options.components.TreeFolderContents = require('./tree-folder-contents.vue')
}
```
### 内联模板
组件有 `inline-template` 属性时会把它的内容当作模板,而不是把整体当作模板。
```html
<my-component inline-template>
<div>
<p>这些将作为组件自身的模板。</p>
<p>而非父组件透传进来的内容。</p>
</div>
</my-component>
```
### X-Template
另一种定义模板的方式,避免使用:
```html
<script type="text/x-template" id="hello-world-template">
<p>Hello hello hello</p>
</script>
```
```js
Vue.component('hello-world', {
template: '#hello-world-template'
})
```
### 对低开销的静态组件使用 v-once
当组件中包含大量静态内容时,可以考虑使用 `v-once` 将渲染结果缓存起来。 |
Java | UTF-8 | 569 | 2.421875 | 2 | [] | no_license | package ch.kusar.contraceptivetimer.wrapper;
import android.util.Log;
public class LoggerWrapper {
private static final String TAG = "ch.kusar.contraceptiveTimer";
public static void LogError(String msg){
Log.e(LoggerWrapper.TAG, msg);
}
public static void LogWarn(String msg){
Log.w(LoggerWrapper.TAG, msg);
}
public static void LogInfo(String msg){
Log.i(LoggerWrapper.TAG, msg);
}
public static void LogDebug(String msg){
Log.d(LoggerWrapper.TAG, msg);
}
public static void LogVerbose(String msg){
Log.v(LoggerWrapper.TAG, msg);
}
}
|
Java | UTF-8 | 530 | 2.25 | 2 | [] | no_license | package com.jumio.bookstore.data.dtos;
import lombok.*;
import java.time.*;
@EqualsAndHashCode
@Getter
public abstract class BaseDto<T extends BaseDto<T>> {
private String uuid;
private Instant dtUpdate;
private Instant dtCreation;
public T setUuid(String uuid) {
this.uuid = uuid;
return (T) this;
}
public T setDtCreation(Instant dtCreation) {
this.dtCreation = dtCreation;
return (T) this;
}
public T setDtUpdate(Instant dtUpdate) {
this.dtUpdate = dtUpdate;
return (T) this;
}
} |
Markdown | UTF-8 | 43,239 | 3.0625 | 3 | [] | no_license | # Linux系统基础
> 本份材料对本学期内容覆盖并不足够充分,因而仍建议看回课件!
>
> 本课程对应的教材是於岳的《Linux实用教程》(第三版),人民邮电出版社。
>
> 以下内容基本上整理于`重点.docx`和`Shell编程.pdf`,根据2020年实际教学情况进行修订。
## **Ch1 认识Linux系统**
**内核的版本,怎么命名的,什么是发行版,有哪些常见的发行版**
Linux的版本号分为两部分,即内核版本与发行版本。

> 内核版本号由3个数字组成:r.x.y。
>
> r:目前发布的内核主版本。
>
> x:偶数表示稳定版本;奇数表示开发版本。
>
> y:错误修补的次数。
> 发行版本:一些组织和厂家,将Linux系统的内核、应用软件和文档包装起来,并提供一些系统安装界面、系统配置设定管理工具等就构成了 Linux发行版本 。
>
> 相对于Linux操作系统内核版本,各发布厂商发行版本的版本号各不相同,与Linux系统内核的版本号是相对独立的。
主流发行版:
Mandriva、Red Hat、SUSE、Debian、Ubuntu、CentOS、Arch、Gentoo等。
## **Ch2 安装Linux系统**
> 以CentOS为例
>
> 分区方案好好看看,最少有几个分区,简单的分区方案,合理的分区方案,每一个分区是干什么的
### 分区命名方案
Linux系统使用字母和数字的组合来指代硬盘分区
Linux系统使用一种更加灵活的命名方案, 该命名方案是基于文件的,文件名的格式为 /dev/xxyN,
/dev/:这是Linux系统下所有设备文件所在的目录名。
xx:分区名的前两个字母表示分区所在设备的类型,通常是hd(IDE硬盘)或sd(SCSI硬盘)。
y:这个字母表示分区所在的设备。
N:最后的数字N代表分区。
`/dev/sda1` `/dev/sda2`
### 分区方案
#### 最简单的分区方案(至少需要的分区)
**SWAP分区**:即交换分区,建议大小是物理内存的1~2倍。当然你内存足够大的时候,就不需要这么做了。
**/分区**:建议大小在10GB以上。
**/boot分区**:存放与Linux启动相关程序,最少200MB
使用以上的分区方案,所有的数据都放在**/分区**上,对于系统来说不安全,数据不容易备份。
#### 合理的分区方案。6个,注意SWAP没有/且是大写
`/boot分区`:用来存放与Linux系统启动有关的程序,比如启动引导装载程序等,建议大小为100MB。
`/usr分区`:用来存放Linux系统中的应用程序,其相关数据较多,建议大于8GB。
`/var分区`:用来存放Linux系统中经常变化的数据以及日志文件,建议大小为1GB。
`/分区`:Linux系统的根目录,所有的目录都挂在这个目录下面,建议大小为1GB。
`SWAP分区`:交换分区,实现虚拟内存,建议大小是物理内存的1~2倍。
> SWAP分区没有挂载点
`/home分区`:存放普通用户的数据,是普通用户的宿主目录,建议大小为剩下的空间。
#### **root的提示符、普通用户的提示符**
普通用户: $
root用户: #
**切换为root用户:**su root
切换到普通用户it:su – it
> `-` 代表切换到该用户的用户目录下
普通用户执行root用户才能的操作:sudo 操作
## Ch3 字符界面操作基础
**两种界面:图形化界面、字符界面**
**登录 关机(shutdown) 重启(reboot)命令** **系统关机/重启:shutdown halt reboot init**
如果需要以超级管理员(root)身份登录系统进行管理,在登录提示后输入用户名为“root”,按“回车”键后,在口令提示中输入安装时设置的根口令,然后按“回车”键即可。
shutdown:安全地关闭系统
shutdown [选项] [时间] [警告信息]
shutdown -h now 立即关闭系统
shutdown -h 45定时45分钟后关闭系统
shutdown -r now重新启动系统,并发出警告信息
halt:引发主机关闭系统=调用 “shutdown —h”命令执行关闭系统
[root@PC-LINUX ~]# halt
reboot:引发主机重启,参数与“halt”相似。
[root@PC-LINUX ~]# reboot
init:“init”命令是所有进程的祖先,它的进程号始终为“1”,所以发送“TERM”信号给 “init”会终止所有的用户进程和守护进程等。 “init” 定义了7个运行级别,其中“init 0”为关闭系统,“init 6”为重启,通过init可以完成不同运行级别之间的切换
shutdown和init都是既可以关机又可以重启:
shutdown –h now和init 0用于关机 + halt
shutdown –r now和init 6用户重启 + reboot
### 运行级别
**要很清楚,3字符、5图形、0关机、6重启**
注意到CentOS7中已经改变了采用运行级别这样的做法,而是采用systemd和target的模式。但是事实上仍保留了一定的向前兼容性。
| 运行级别 | 对应目标 | 目标链接文件 | 功能 |
| -------- | ----------------- | ---------------- | -------------- |
| 0 | poweroff.target | runlevel0.target | 关闭系统 |
| 1 | rescue.target | runlevel1.target | 救援模式 |
| 2 | multi-user.target | runlevel2.target | 命令行多用户 |
| 3 | multi-user.target | runlevel3.target | 命令行多用户 |
| 4 | multi-user.target | runlevel4.target | 命令行多用户 |
| 5 | graphical.target | runlevel5.target | 图形界面多用户 |
| 6 | reboot.target | runlevel6.target | 重启 |
**系统日志保存在哪个目录下**
一般保存在/var/log目录下
**终端的命名tty pty pts**
tty:终端设备的统称
pty:虚拟终端
pts:pty的实现方式,与ptmx配合使用实现pty
**进入命令行的方式**
字符界面、图形界面下的终端以及虚拟控制台(远程)
**虚拟控制台的切换**


### **man帮助命令**
man是一种显示Unix/Linux在线手册的命令。可以用来查看命令、函数或文件的帮助手册,另外它还可以显示一些gzip压缩格式的文件。
man命令格式化并显示在线的手册页。
### help帮助命令
help使用help命令可以查找Shell命令的用法
查看mkdir命令帮助:[root@PC-LINUX ~]# mkdir --help
(注意help前有两条-,这个是长参数)
### whereis命令
whereis命令可以查找命令所在的位置
**Shell里技巧性的**
**命令行自动补全**
输入第一个之后按下Tab键
****
**光标上翻下翻**
[Ctrl+k]: 删除从光标到行尾的部分。
[Ctrl+u]: 删除从光标到行首的部分。
[Alt+d]: 删除从光标到当前单词结尾的部分。
[Ctrl+w]: 删除从光标到当前单词开头的部分。
[Ctrl+a]: 将光标移到行首。
[Ctrl+e]: 将光标移到行尾。
[Alt+a]: 将光标移到当前单词头部。
[Alt+e]: 将光标移到当前单词尾部。
[Ctrl+y]: 插入最近删除的单词。
[!$]: 重复前一个命令最后的参数。
**一行上执行多个命令**
****
### 管道
管道可以通过组合许多小程序共同完成复杂的任务,可以将某个命令的输出信息当作某个命令的输入,由管道符号“|”来标识。
****
****|
more之后就可以分页显示上一个命令的输出
### **vi (编辑的是ASCII文本)**
#### **三种模式,三种模式之间的转换及命令**
vi编辑器有3种基本工作模式,分别是命令行模式、插入模式和末行模式。
当在Shell提示符下输入“vi文件名”之后就进入了命令行模式,在命令行模式下是不能输入任何数据的。
在命令行模式下输入文本插入命令就可以进入插入模式,这时候就可以开始输入文字了。
从插入模式切换为命令行模式只需按“Esc”键。
在命令行模式下,按转义命令冒号键“:”可以进入末行模式。
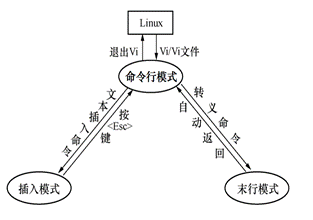
命令行模式:控制屏幕光标的移动,字符、字或行的删除,移动、复制某区域及进入插入模式,或者到末行模式
注:下面操作都是只能在命令行模式下控制,在输入模式下会变成输入
#### 【屏幕光标的移动】
h j k l分别对应:左 下 上 右
Ctrl + b f u d 分别对应:
屏幕向前移动一页、向后移动一页、向前移动半页、向后移动半页

注:0和^的效果是一样的,都是所在行的行首;$是在行尾
#### 【字符、字或行的删除】
X 删除光标所在位置前面一个字符 x 删除光标所在位置的一个字符
nX 例20X,删除光标所在位置前面20个字符
nx 例6x,删除光标所在位置开始的6个字符
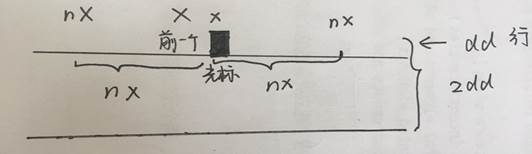
【复制某区域】

复制:y,以字为单位
【替换操作】

【撤销上一次操作】u,多次u,多次撤销
【跳至指定的行】

第一个g小写,第二个行后的G大写
【退出】
存盘退出:ZZ
不存盘退出:ZQ
#### 【进入插入模式】
(仍然必须在命令行模式下,输入下面操作,光标移到这些位置,然后进入插入模式,从这些位置开始可以被编辑)
I行首 i光标当前位置 A行末 a光标下一个位置
O 光标上一行插入一行 o 光标下一行插入一行,从行首开始输
S 删除光标所在行 s 删除光标位置的一个字符
按下Insert键也可以
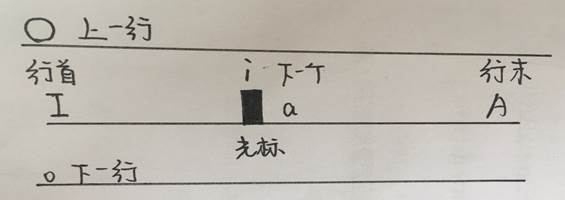
S和dd的区别是,dd只删,S删完之后进入插入模式
#### 【进入末行模式】
确保先按“ESC”进入命令行模式,再按“:”进入末行模式
末行模式:将文件保存或退出编辑器,也可以设置编辑环境,如寻找字符串、列出行号等。
#### 【保存文件】
“w”:在冒号后输入字母“w”就可以将文件保存起来。
离开vi编辑器操作如下。
“q”:按“q”即退出vi,如果无法离开vi,可以在“q”后跟一个“!”强制符离开vi。
“wq”:一般建议离开时,搭配“w”一起使用,这样在退出的时候还可以保存文件。
## Ch4 目录和文件管理
### **常见的文件类型**
**普通文件**:文件属性符号 - 图像工具、文档工具、归档工具;
**目录文件**:文件属性符号 d ;
**设备文件**:/dev目录下的设备文件 ;
**字符设备文件**:文件属性符号 c 接收字符流,打印机和终端;
**块设备文件**: 文件属性符号 b 随机读写,如磁盘;
**管道文件/FIFO文件**:文件属性符号p 一头流入,从另一头流出;
#### 链接连接文件
**软连接** ln –s file1/dir file2 建立,file2的ls –l时第一个是l,file1/dir属性不变,file2中包含了file1的路径;
**硬链接** ln file1 file2建立,file1和file2的ls -l 文件硬链接数均大于1,但是属性仍然不变;
后面会详解。
### 常见目录及其用途
| 目录 | 描述 |
| ------------ | ------------------------------------------- |
| / | 根目录 |
| /home | 用户目录的宿主目录,存放普通用户的数据 |
| /bin | 存放普通的可执行命令 |
| /sbin | 存放root使用的系统管理程序 |
| /dev | 设备文件保存目录 |
| /mnt和/media | 挂载其它文件系统系统挂载目录 |
| /boot | 启动目录,用来存放与Linux系统启动有关的程序 |
| /proc | 虚拟目录,系统内存映射 |
| /opt | 可选程序的安装目录 |
| 目录 | 描述 |
| ----------- | ------------------------------ |
| /var | 存放经常变化的数据以及日志文件 |
| /etc | 配置文件保存目录 |
| /usr | 用来存放Linux系统中的应用程序 |
| /lost+found | 存修复或损坏的文件 |
| /srv | 存特定服务所需文件的目录 |
| /selinux | SELinux相关 |
### **硬链接软链接**
#### 软链接文件
软链接又称为符号链接,这个文件包含了另一个文件/目录的路径名。
用“ls -l”命令查看某个文件的属性,可以看到有类似“lrwxrwxrwx”的属性符号,其属性第一个符号是“l”,这样的文件在 Linux系统中就是软链接文件。
#### 硬链接文件
硬链接是一个指针,指向文件索引节点,系统并不为它重新分配inode。可以用ln命令来建立硬链接。硬链接节省空间,也是Linux 系统整合文件系统的传统方式。
硬链接文件有两个限制:
- 不允许给目录创建硬链接;(但是软连接中可以为一个目录创建一个快捷方式)
- 只有在同一文件系统中的文件之间才能创建硬链接。(软链接可以跨文件系统)
#### 硬链接和软链接的区别
- 硬链接记录的是目标的inode,软链接记录的是目标的路径。
- 软链接就像是快捷方式,而硬链接就像是备份。(只要硬链接还在,你就不能真正删掉那个文件——除非你直接把他覆写)
- 软链接可以做跨分区的链接,而硬链接由于inode的缘故,只能在本分区中做链接。所以,软链接的使用频率要高得多。
## **Ch5 Linux常用操作命令**
### **文本显示和处理命令**
`cat命令`可以显示文本文件内容,或把几个文件内容附加到另一个文件中。
`more命令`可以分页显示文本文件的内容。
`less命令`可以回卷显示文本文件的内容。
`head命令`可以显示指定文件的前若干行文件内容。
`tail命令`可以查看文件的末尾数据。
`sort命令`可以对文件中的数据进行排序,并将结果显示在标准输出上。(但是并不改变来源中的内容)
`sort –r` 倒序排序
`uniq命令`将重复行从输出文件中删除
`cut命令`可以从文件的每行中显示出选定的字节、字符或字段。
`comm命令`可以比较两个已排过序的文件,并将其结果显示出来。
`diff命令`可以逐行比较两个文本文件,列出其不同之处。它比comm命令完成更复杂的检查。它对给出的文件进行系统的检查,并显示出两个文件中所有不同的行,不要求事先对文件进行排序。
> comm是只要两个文件都包含了,就是相同的,而diff必须在同一行才相同,并且comm要排序,diff不需要
### **文件和命令查找命令**
**搜索grep、find什么时候用,find查文件系统**
`grep命令`可以查找文件中符合条件的字符串。
`find命令`可以将文件系统中符合条件的文件或目录列出来,可以指定文件的名称、类别、时间、大小以及权限等不同信息的组合,只有完全相符的文件才会被列出来。
`locate命令`用于在数据库中查找文件。比find命令的搜索速度快,它需要一个数据库,这个数据库由每天的例行工作(crontab)程序来建立。当建立好这个数据库后,就可以方便地搜寻所需文件了。
`whereis命令`可以查找指定文件、命令和手册页的位置。
(与man比较:显示文件、命令、函数的手册页内容)
`file命令`可以查询指定文件的文件类型。
`whatis [命令]`可以查询指定命令的功能。
`which [命令]`可以显示可执行命令的路径和它的别名。
`uname`:显示计算机及操作系统相关信息
`uname –r` //显示系统内核版本
`uname –n` //显示计算机主机名
`uname –m` //显示计算机硬件类型
`uname –a` //显示全部信息
`hostname`:显示或修改计算机主机名
`dmesg`:显示计算机开机信息
`cal`:显示日历信息
`date`:显示和设置系统日期和时间
### **echo显示字符串**
echo命令可以在计算机显示器上显示一段文字,一般起到一个提示的作用。

注意echo后面没有任何东西,输出所有跟在echo后的内容。即使后面的内容包含空格。
`mesg`:设置其他用户发送信息的权限
`wall`:对全部已登录用户发送信息
****
`write`:向用户发送消息
`clear`:清除计算机屏幕上信息
`sync`:将缓冲区内的文件写到硬盘中
`uptime`:显示系统已经运行的时间
`last`:显示近期用户登录情况
## **Ch6 Shell编程**
该部分内容有一个单独的总结,不过貌似20年夏天并没有讲到这么难。
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  | <br/> |
|  | |
| ------------------------------------------------------------ | ---- |
| 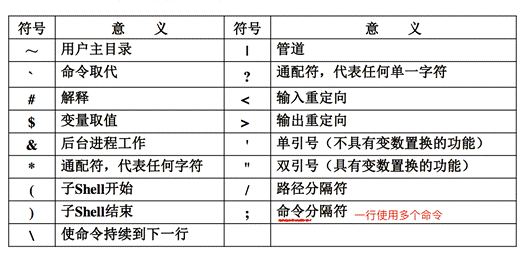 ||
Ctrl+W 删除一个单词
!!重复上一次命令
source命令和shell scripts的区别是,source在当前bash环境下执行命令,而scripts是启动一个子shell来执行命令。这样如果把环境变量的设置命令写进scripts中,就只会影响子shell,无法改变当前的bash,所以通过文件设置环境变量时,要用source命令
**目前流行的Shell有sh,csh,ksh,tcsh和bash等**
| | |
| ---- | ---- |
|  |  |
### Shell部分
> 具体API请看书。警告:test后面的结论如果是true的话返回的是0,不正常才返回非0的数字!等于号两端不要加多余的空格!
#### 2020所涉及到的简单的逻辑
> 注意那个引号是`。
```bash
#!/bin/bash
#filename:bash1t.sh 输出1-5的平方
int=1
while [ $int -le 5 ]
do
sq=`expr $int \* $int`
echo $sq
int=`expr $int + 1`
done
echo "Job Done by YDJSIR!"
```
```bash
#!/bin/bash 求所有输入的数的和
#filename bash3t
sum=0
for int in $*
do
sum=`expr $sum + $int`
done
echo $sum
```
YDJSIR此处可以给另外两种单独的实现。采用了不一样的风格,YDJSIR认为写起来更舒服。下面的例子同样提及了IO方面的API。
| 求1-n的数的和 | 计算1-10的平方 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 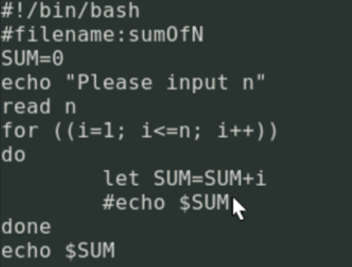 | 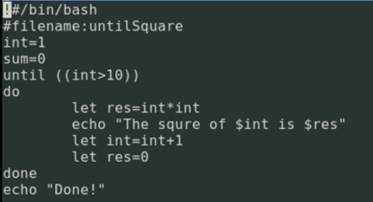 |
#### 前辈留下的高级Shell
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |
|  |  |
|  |  |
|  |  |
|  |  |
|  |  |
| 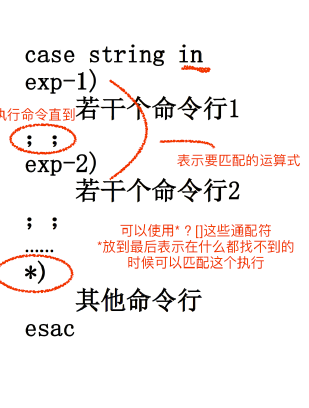 |  |
|  |  |
|  |  |
|  |  |
|  |  |
|  | YDJSIR很清楚我们没有讲Shell里面的函数什么的。不过还是很有参考价值的。 |
| | |
| | |
## **Ch7 用户和组群账号管理**
### **用户类型**
在Linux系统中主要有root用户、虚拟用户和普通用户这3类用户。
通过UID来标识。
root用户也被称为超级管理用户。
虚拟用户是内置用户,不具备登录系统的能力,但却是系统运行不可缺少的用户 bin,daemon,adm,ftp,mail
普通用户:只能操作自己目录内的文件
### 常用配置文件的特定行
#### /etc/passwd
是系统识别用户的一个文件,Linux系统中所有的用户都记录在该文件中。
一行有7个段位,每个段位冒号分隔。
| 用户名 | 口令 | 用户标识号UID-唯一 | 组群标识号GID-唯一 | 用户名全称 | 主目录 | 登录Shell |
| ------ | ---- | ----------------------- | ------------------ | ---------------------------------- | ------ | --------- |
| | | 确认用户权限(0是root) | | 用户名全称指用户名描述,可以不设置 | | |
#### /etc/shadow
是/etc/passwd文件的影子文件,两个文件是对应互补的。
内容包括用户及加密的口令及其他/etc/passwd不能包括的信息,比如用户账号的有限期限等。(他们的权限不同)
一行有9个段位,每个段位冒号分隔。
| 用户名 | 加密口令 | 用户最后一次更改口令的日期 | 口令允许更换前的天数 | 口令需要更换的天数 | 口令更换前警告的天数 | 账户被取消激活前的天数 | 用户账户过期日期 | 保留字段 |
| ------ | -------- | -------------------------- | -------------------- | ------------------ | -------------------- | ---------------------- | ---------------- | -------- |
| | | | | | | | | |
#### /etc/group
是用户组群的配置文件
内容包括用户和用户组群,并且能显示出用户是归属哪个用户组群或哪几个用户组群。
| 组群名 | 组群口令 | 组群标识号 | 组群成员 |
| ------ | --------------------------- | ---------- | -------- |
| | 这里的 "x" 仅仅是密码标识, | | |
GID为0的组群是root组群;GID从1000开始,预留1000个
#### /etc/gshadow
是/etc/group的加密文件,这两个文件是对应互补的。
| 组群名 | 组群口令 | 组管理员 | 组群成员 |
| ------ | ------------------------------------------- | -------- | -------- |
| | 此处存储加密后的口令,如果没有设置,则为`!` | | |

### 账户信息显示
`finger命令`可以显示用户账户的信息。
`groups命令`可以显示指定用户账户的组群成员身份。
`id命令可以`显示用户的ID以及该用户所属组群的GID。
`w命令`可以详细查询已登录当前计算机的用户。
`who命令`可以显示已登录当前计算机用户的简单信息。
## **Ch8 磁盘和文件系统管理**
### 分区回顾
硬盘分区一共有3种:主分区、扩展分区和逻辑分区。
Linux系统使用fdsik命令能将磁盘划分成为若干个区,同时也能为每个分区指定分区的文件系统。
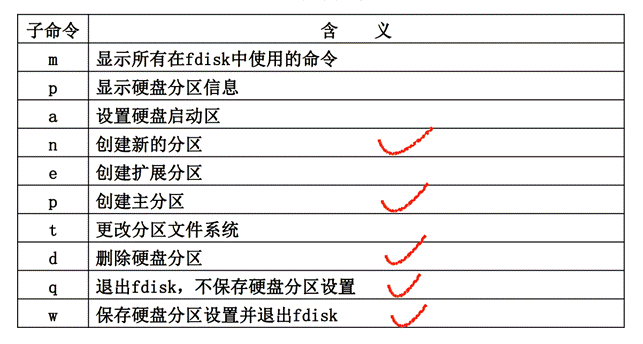
#### 分区的命名

硬盘类型用sd/hd/vd(虚拟盘)表示,硬盘名顺序通过abc,分区用1234表示,主分区为 1~4 中的一段,扩展分区为 2~4 分区之间的剩余。
逻辑分区是在扩展分区的再分,命名从5开始。主分区最多有4个(若多于4个,那么除了前三个剩下的必然是逻辑分区)
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |
### **文件系统**
**Linux**系统最常用的几种文件系统
1. ext3/ext4
2. JFS
3. XFS(推荐,它是CentOS所默认的分区文件系统)
 |  |
**创建文件系统整个过程,挂载卸载文件系统命令,自动挂载**
(1)使用fdisk命令在硬盘上创建分区。
(2)使用mkfs命令在分区上创建文件系统。
(3)使用mount命令挂载文件系统,或修改/etc/fstab文件使得开机自动挂载文件系统。
(4)使用umount卸载文件系统。
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| <br/> | <br/> |
mount命令可以将某个分区、光盘、软盘或是U盘挂载到Linux系统的目录下。
命令语法:
`mount [选项][设备名称][挂载点]`
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |
umount命令可以将某个分区、光盘、软盘或是U盘进行卸载。
命令语法:
`umount [选项][-t <文件系统类型>][文件系统]`

### 查看分区挂载情况
`df`
`mount –s`
`cat /etc/mtab`
### 自动挂载
/etc/fstab是一个配置文件,它包含了所有分区以及存储设备的信息。
root用户才可以编辑该文件。
可以通过修改/etc/fstab文件实现开机自动挂载文件系统。
各段含义:
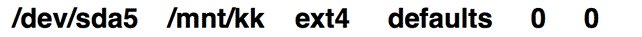
1、设备名或设备UUID号 2、挂载点 3、文件系统格式
4、挂载参数 5、转储选项 6、文件系统检查选项
## **Ch9 Linux日常管理和维护**
### RPM
RPM软件包管理器是一种开放的软件包管理系统


#### yum的使用
温馨提示:手动安装RPM的时候请注意你的软件包到底是同一个镜像站里面哪个分支下来的,到底是原生还是update!
### **tar命令,两组:创建压缩包,解压缩包,两种选项,每组下面各有4个字母**
使用tar命令可以将文件和目录进行打包或压缩以做备份用。
打包是指将许多文件和目录变成一个总的文件,压缩则是将一个大的文件通过一些压缩算法变成一个小文件。
Linux系统中很多压缩程序只能针对一个文件进行压缩,这样当需要压缩一大堆文件时,就得先借助其他的工具将这一大堆文件先打成一个包,然后再用原来的压缩程序进行压缩。tar+gzip tar+bzip2

## **Ch10 权限与所有者**
**有选择题,重点!权限针对哪三种用户,修改时用什么命令,用户和组。**
通过设定权限可以限制或允许以下3种用户访问:
文件的所有者、
文件所有者所在组的同组用户、
系统中的其他用户。
在Linux系统中,每种用户都有对文件或目录的读取、写入和执行权限。只有系统管理员和文件的所有者才可以更改文件或目录的权限。
| | |
| ---- | ---- |
|  | 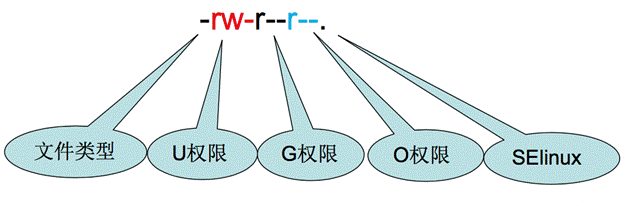 |
注意到课本上还提到了两种特殊权限。
### 文件管理器更改权限
#### 文字设定法
chmod [ugoa][+-=][rwx][文件或目录名]
u表示该文件的所有者,g表示与该文件的所有者属于同一个组的用户,o表示其他用户,a表示以上三者;
+表示增加指定权限,-表示取消指定权限,= 表示设定权限等于指定权限; r表示可读取,w表示可写入,x表示表示文件 可执行或目录可进入。


#### 数字设定法
r w x - 对应数值 4读取权限 2写入权限 1可执行权限 0没有权限
一共三位,分别表示所有者、所在群组其它成员和其它用户的权限之和

| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |
#### **所有权**
`chown命令`可以更改文件和目录的所有者和用户组
`chgrp命令`可以更改文件或目录所属的组
`chgrp vboar a //更改文件a的用户组为vboar `
> ps. 系统规定新建文件默认是666权限,目录是777权限。新建文件权限=默认权限-umask权限,umask=022时,新建文件权限=666-022=644=-rw-r--r--,新建目录权限=777-022=755=drwxr-xr-x
## Ch11 Linux日常管理和维护
### **进程**
Linux系统上所有运行的内容都可以称为进程。
进程是在自身的虚拟地址空间运行的一个单独的程序。
作业是一系列按一定顺序执行的命令。
三种进程:交互式进程、批处理进程、守护进程
**进程查看**
`ps命令`是最基本同时也是非常强大的进程查看命令。
使用该命令可以确定有哪些进程正在运行以及进程运行的状态、进程是否结束,进程有没有僵死,哪些进程占用了过多的资源等。
使用ps命令可以用于监控后台进程的工作情况。

`top命令`:显示当前正运行的进程及重要信息,包括它们的内存和CPU用量。(它其实是多种功能的复合,可以视作Windows的任务管理器)
**进程停止**
终止前台命令,[Ctrl+C]键
终止后台进程, kill命令
先用ps命令获得进程号,然后用kill命令终止
不能终止,可使用更有效的kill -9命令
`kill -9 5975`:强制杀死进程号为5975的进程
**进程启动**
两种途径:手工启动和调度启动
1.手工启动
(1)前台启动
(2)后台启动—在命令结尾加上一个 “&”号
2.调度启动
事先进行设置,根据用户要求自行启动。任务可以被配置在指定的时间、指定的日期或系统平均负载量低于指定的数量时自动运行
**进程挂起与恢复**
挂起:[Ctrl+Z]键
显示shell作业清单:jobs命令
恢复:`fg`命令将挂起的作业放回前台执行
`bg`命令将挂起的作业放回后台执行
### **任务计划**
在固定的时间上触发某个作业,需要创建任务计划,按时执行该作业cron和at
cron命令被用来调度重复的任务
at命令被用来在指定时间内调度一次性的任务
1.cron实现自动化
(1)/etc/crontab文件实现
cron守护进程可在无需人工干预的情况下调度执行重复任务的守护进程
文件格式:分钟 小时 日期 月份 星期 执行的命令
(2)crontab命令实现
crontab [-u 用户名] –e //root用户创建或编辑crontab
crontab [-u 用户名] –l //root用户列出crontab文件
crontab [-u 用户名] –r //root用户删除crontab文件
crontab –e //普通用户创建或编辑crontab
crontab –l //普通用户列出crontab文件
crontab –r //普通用户删除crontab文件
crontab <filename> //恢复丢失的crontab文件
编辑和创建的命令是一样的。但是编辑时root用户多了一个用vi直接编辑/var/pool/cron/<username>文件的选择,普通用户是打不开的。
2.使用at实现自动化
△一旦一个作业被提交,at命令将会保留所有当前的环境变量,包括路径,该作业的所有输出都将以电子邮件的形式发送给用户。

△ 和crontab一样,root用户可以通过/etc目录下的at.allow和at.deny文件来控制哪些用户可以使用at命令
### **系统启动**
1.BIOS自检
计算机在接通电源之后首先由BIOS进行POST自检,然后依据BIOS内设置的引导顺序从硬盘、软盘或CDROM中读入引导块
2.启动GRUB 2
GRUB 2 是引导加载程序,用于引导操作系统启动
3.加载内核
加载内核映像到内存中
4.执行systemd进程
systemd进程是系统所有进程的起点,内核在完成核内引导之后,即在本进程空间内加载systemd程序,它的进程号是1
5.执行/bin/login程序
login程序会提示使用者输入账号及密码,接着编码并确认密码的正确性, 如果账号与密码相符,则为使用者初始化环境,并将控制权交给shell,即
等待用户登录。
### 维护GRUB
这部分还是看课本吧,当时实操的时候也出现了一大堆问题。
## **Ch12 Linux网络基本配置**
### **网络命令**
****
**netstat:显示**网络状态**信息**
arp:增加、删除和显示arp缓存
**tcpdump:**可以监视TCP/IP连接,并直接读取数据链路层的数据包头,可以指定哪些数据包被监视以及哪些控制要显示格式(抓包)
### **管理网络服务的3种方式**
启动或停止Linux系统服务
#### ntsysv:基于TUI的程序
它允许为每个运行级别配置引导时要启动的服务。
对于独立服务而言,改变不会立即生效。
<img src="https://oss.ydjsir.com.cn/img/image-20200822090704417.png" alt="image-20200822090704417" style="zoom:50%;" />
#### systemctl命令
```bash
systemctl 选项 [服务名].service `.service` 可以省略。
```
命令中各选项的含义如下。
`start`:表示启动服务。
`stop`:表示停止服务。
`status`:表示查看服务状态。
`restart`:表示重新启动服务。
`reload`:表示加载服务配置文件。
`enable`:表示开机自动启动服务。
`disable`:表示开机禁止启动服务。
`is-enabled`:表示查看服务是否开机自动启动。
```bash
list-units --type=service:显示所有已启动的服务。
```
#### chkconfig和service命令
允许在不同运行级别启动和关闭服务的命令行工具
`service命令`控制服务可以马上生效
`chkconfig命令`控制服务需要等计算机重新启动后才会生效
### **提高Linux系统安全性的一些方法**
| | |
| -------------------- | --------------------------------- |
| 部署防火墙 | 关闭不用的服务和端口 |
| 严格禁止设置默认路由 | 口令管理 |
| 分区管理 | 防范网络嗅探 |
| 完整的日志管理 | 使用安全工具软件(比如说SELinux) |
| 使用保留的IP地址 | 部署Linux防病毒软件 |
| 加强登录安全 | 安装补丁 |
## **Ch13 远程连接服务器配置**
使用ssh命令允许用户在远程计算机上登录并执行相关命令。
VNC,虚拟网络计算,可以用图形界面的方式连接到远程服务器,以达到远程控制。
配置NFS服务器可以让客户端挂载服务器上的共享目录,可以很方便地实现在同一网络上的多个用户间共享目标。
### ssh
`ssh -l [用户名] [远程主机IP地址]`
或ssh [用户名]@[远程主机IP地址]
### scp
把本地文件传输到远程主机:
`scp [本地文件] [用户名@远程主机IP地址:/目标文件]`
把远程文件传输到本地主机:
`scp [用户名@远程主机IP地址:/源文件] [本地文件]`
### sftp
这个好像我们没见到。
sftp [用户名@远程主机IP地址]
## Ch14 NFS服务器配置
字符界面配置NFS服务器
(1) 在NFS服务器的主要配置文件/etc/exports中加一行:
```bash
[共享目录] [主机] (参数)
```
目录是要共享的目录;主机:限定哪些计算机可以访问。主机名或是该计算机的IP地址/使用通配符指定的域名/IP网络/Netgroups;参数如 rw,sync…
## 补充内容:LVM逻辑卷
Logical Volume Manager,逻辑卷管理
- 它是Linux环境下对磁盘分区进行管理的一种机制
- 屏蔽了底层磁盘布局,便于动态调整磁盘容量
- 需要注意:/boot分区用于存放引导文件,不能应用LVM机制,类似地,/boot分区不能用软RAID!
### LVM机制的基本概念
### PV(Physical Volume,物理卷)
整个硬盘,或使用fdisk等工具建立的普通分区,包括许多默认4MB(这个值可以设置)大小的PE(Physical Extent,基本单元)
### VG(Volume Group,卷组)
一个或多个物理卷组合而成的整体。
### LV(Logical Volume,逻辑卷)
从卷组中分割出的一块空间,用于建立文件系统。
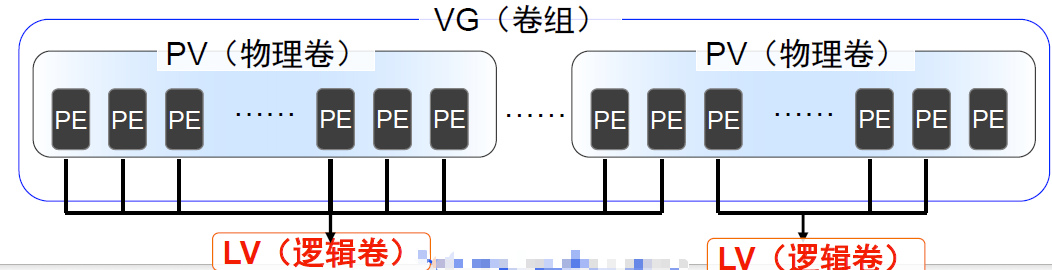
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 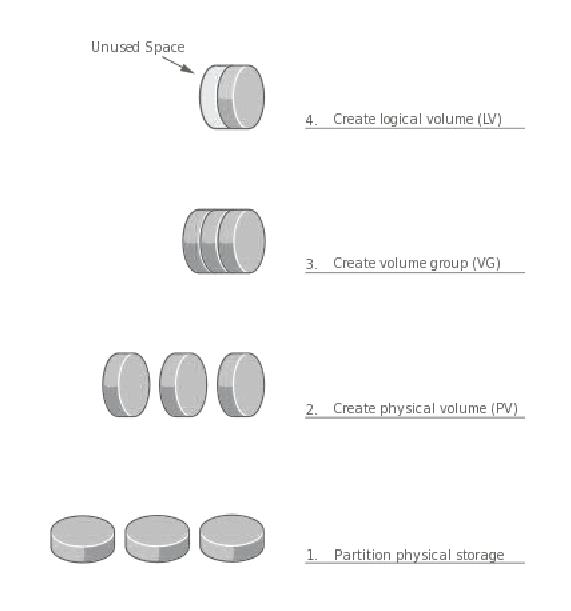 | <br/> |
### 创建LVM分区
#### 新建空分区
这一部分和前面磁盘管理那边一模一样,就是新建个普通分区。用fdisk。
#### 初始化分区(创建PV物理卷)
```bash
pvcreate [设备名]
```
#### 创建卷组
```bash
vgcreate –s [块大小] [卷组名] [物理卷] [设备名]
```
#### 创建逻辑卷
```bash
lvcreate -n [逻辑卷名] –L [逻辑卷大小] [已存在卷组名]
```
> 把大写的L换成小写的L时,后面逻辑卷大小对应的填VG中块的个数。当然无论如何,到最后大小都会是逻辑卷大小的整数倍。
#### 创建文件系统及挂载
这一部分和前面的一样。但是请注意逻辑卷的设备名。它是`/dev/[卷组名]/逻辑卷名` !
### 管理逻辑卷
扩大/缩小:请注意操作顺序!
扩大时**先扩大逻辑卷**,然后**再扩大文件系统空间**;缩小时**先缩小文件系统空间**,**后缩小逻辑卷**(如果有必要的话)**缩空间有风险,操作需谨慎**!
```bash
lvextend -L +[大小] /dev/[卷组名]/[逻辑卷名]
lvreduce -L +[大小] /dev/[卷组名]/[逻辑卷名]
```
```bash
resize2fs –p /dev/[卷组名]/[逻辑卷名]
```
注意到缩小文件系统时必须要先将逻辑卷卸载并确定数据使用量!(扩大文件系统时不用)
```bash
umount /dev/[卷组名]/[逻辑卷名]
fsck -f /dev/[卷组名]/[逻辑卷名]
```
### 快照卷
快照是临时保留所更改的逻辑卷的原始数据的逻辑卷。快照提供原始卷的静态视图,从而能够以一致状态备份其数据。**但是快照本身是不断地在变化的**。
#### 确定快照的大小
1. 预期更改率 2. 所需快照时间
```bash
lvcreate –s –n snaplv–L 20M /dev/vgname/lvname
mkdir/snapmount
mount –ro /dev/vgname/snaplv/snapmount
# 验证快照状态
lvscan /dev/vgname/lvname
# 卸载快照
umount /snapmount
lvremove /dev/vgname/lvname
```
|
Java | UTF-8 | 1,740 | 2.3125 | 2 | [
"Apache-2.0"
] | permissive | package org.hy.common.xml.plugins.analyse;
import java.util.ArrayList;
import java.util.List;
import org.hy.common.Help;
import org.hy.common.app.Param;
import org.hy.common.net.ClientSocket;
import org.hy.common.xml.XJava;
/**
* 集群操作
*
* @author ZhengWei(HY)
* @createDate 2017-01-25
* @version v1.0
*/
public class Cluster
{
private Cluster()
{
}
/**
* 集群并发通讯的超时时长。默认为:30000毫秒
*
* @author ZhengWei(HY)
* @createDate 2017-01-25
* @version v1.0
*
* @return
*/
public static long getClusterTimeout()
{
return Long.parseLong(Help.NVL(Help.NVL(XJava.getParam("ClusterTimeout") ,new Param()).getValue() ,"30000"));
}
/**
* 获取集群配置信息
*
* @author ZhengWei(HY)
* @createDate 2017-01-17
* @version v1.0
*
* @return
*/
public static List<ClientSocket> getClusters()
{
String [] v_ClusterServers = Help.NVL(Help.NVL(XJava.getParam("ClusterServers") ,new Param()).getValue()).split(",");
List<ClientSocket> v_Clusters = new ArrayList<ClientSocket>();
if ( !Help.isNull(v_ClusterServers) )
{
for (String v_Server : v_ClusterServers)
{
if ( !Help.isNull(v_Server) )
{
String [] v_HostPort = (v_Server.trim() + ":1721").split(":");
v_Clusters.add(new ClientSocket(v_HostPort[0] ,Integer.parseInt(v_HostPort[1])));
}
}
}
return v_Clusters;
}
}
|
C++ | UTF-8 | 505 | 2.953125 | 3 | [] | no_license | #include <iostream>
#include <vector>
using std::cin;
using std::cout;
using std::endl;
using std::vector;
int main()
{
vector<int> v;
const int N = 50;
for(int i = 0; i < N; ++ i)
{
v.push_back(i);
cout << v.capacity() << ' ';
}
cout << endl;
// 1 2 4 4 8 8 8 8 16 16 16 16 16 16 16 16 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
// 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64
// in my computer is double capacity
return 0;
} |
SQL | UTF-8 | 819 | 4.09375 | 4 | [] | no_license | /*
QUESTION ::
Find the name and height of the shortest player in the database.
How many games did he play in? What is the name of the team for which he played?
SOURCES ::
* People, appearances, teams
DIMENSIONS ::
* namefirst, namelast, namegiven, height, g_all, name
FACTS ::
* MIN(height) = 43
FILTERS ::
* LIMIT 10
DESCRIPTION ::
...
ANSWER ::
Eddie Gaedel aka Edward Carl, 43 inches tall, played in 1 game for the St. Louis Browns.
*/
SELECT
namegiven,
namefirst,
namelast,
MIN(height) AS height,
g_all,
t.name
FROM people AS p
INNER JOIN appearances AS a
ON p.playerid = a.playerid
INNER JOIN teams AS t
ON a.teamID = t.teamID
GROUP BY namefirst, namelast, namegiven, height, g_all, t.name
ORDER BY height ASC
LIMIT 10; |
Java | UTF-8 | 1,659 | 2.0625 | 2 | [] | no_license | package com.boguenon.migration.discoverer.business_model;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class BusinessObject
extends ModelBase
{
private static final Logger logger = LoggerFactory.getLogger(BusinessObject.class);
public String type;
public boolean hidden;
public boolean distinct_flag;
public List<Element> elements;
public String cbo_hint;
public String ext_object;
public String ext_owner;
public String ext_db_link;
private String object_sql;
public String getAliasName()
{
return name;
}
public String getObjectName()
{
if (this.type.equals("SOBJ"))
{
return this.ext_table;
}
return name;
}
public BusinessArea businessArea;
public String getObject_sql() {
return object_sql;
}
public void setObject_sql(String object_sql) {
if (object_sql != null && object_sql.length() > 0)
{
object_sql = object_sql.replaceAll("\\\\r", "");
object_sql = object_sql.replaceAll("\\\\n", "\n");
if (object_sql.startsWith("( SELECT ") == true)
{
logger.debug(object_sql);
object_sql = object_sql.substring(object_sql.indexOf(" FROM (") + " FROM (".length());
object_sql = object_sql.substring(0, object_sql.lastIndexOf(")"));
int n = 0;
for (int i=0; i < 1000; i++)
{
if (object_sql.charAt(i) != ' ')
{
n = i;
break;
}
}
if (n > 0)
{
object_sql = object_sql.substring(n);
}
}
}
this.object_sql = object_sql;
}
public String ext_table;
public BusinessObject()
{
elements = new ArrayList<Element>();
}
}
|
C | UTF-8 | 506 | 3.71875 | 4 | [] | no_license | /*
* q4.c
*
* Created on: 20/11/2014
* Author: MASC
*/
#include <stdio.h>
#include <stdlib.h>
int soma_divisores(int n) {
int s = 0, i;
for (i = 1; i <= n; ++i) {
if (n % i == 0)
s += i;
}
return s;
}
int main(void) {
int n, num;
freopen("e4.txt", "r", stdin);
freopen("s4.txt", "w", stdout);
scanf("%d", &n);
while (n--) {
scanf("%d", &num);
printf("%d ", soma_divisores(num));
}
fclose(stdin);
fclose(stdout);
return 0;
}
|
Shell | UTF-8 | 289 | 2.59375 | 3 | [
"MIT"
] | permissive | #!/bin/bash
# Get your API key from CPanel
USERNAME=""
API_KEY=""
CPANEL_DOMAIN=""
# Strip only the top domain to get the zone domain
DOMAIN=$(expr match "$CERTBOT_DOMAIN" '.*\.\(.*\..*\)')
# Get the txt record name that will be created
CREATE_DOMAIN="_acme-challenge.$CERTBOT_DOMAIN."
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.