
language stringclasses 15
values | src_encoding stringclasses 34
values | length_bytes int64 6 7.85M | score float64 1.5 5.69 | int_score int64 2 5 | detected_licenses listlengths 0 160 | license_type stringclasses 2
values | text stringlengths 9 7.85M |
|---|---|---|---|---|---|---|---|
Markdown | UTF-8 | 1,604 | 3 | 3 | [
"MIT"
] | permissive | # Raspberry Pi Human Detection
## Components
This program enables a Raspberry Pi (tested with Raspberry pi 3 Model B), to
detect a human and plays a sound clip whenever it detects a human in the
vicinity of the sendor. It uses a PIR sensor (passive infrared) connected to the
Raspbery Pi's GPIO pin number 11.
The har... |
Python | UTF-8 | 1,625 | 4.03125 | 4 | [] | no_license | """
The accompanying file weather.dat contains weather data for a single month as space-separated values. The first column (Dy) contains the day of the month; the second (MxT) contains the maximum temperature for that day, while the third (MnT) contains the minimum temperature.
The final row contains aggregate values ... |
Java | UTF-8 | 1,547 | 2.953125 | 3 | [] | no_license | package HolderClass;
import java.sql.Timestamp;
public class CycleHolder {
private int cycleId;
private String cycleName="";
private int cycleDay;
private Timestamp cycleDate;
private String cycleRemark="";
public CycleHolder() {
super();
// TODO Auto-generated constructor stub
}
public CycleHolder... |
Go | UTF-8 | 672 | 2.890625 | 3 | [] | no_license | package base62_test
import (
"testing"
"github.com/d4n13l-4lf4/restful-web-services-with-go/chapter07/base62Example/base62"
)
func TestEncodeBase62(t *testing.T) {
expectedEncode := "1C"
numberToEncode := 100
result := base62.ToBase62(numberToEncode)
if result != expectedEncode {
t.Errorf("Expected encode o... |
C# | UTF-8 | 3,475 | 2.921875 | 3 | [] | no_license | using Microsoft.VisualStudio.TestTools.UnitTesting;
using InvoiceProject;
using System;
using System.Collections.Generic;
using System.Text;
namespace InvoiceProject.Tests
{
[TestClass()]
public class InvoiceTests
{
[TestMethod()]
public void AddInvoiceLineTest()
{
var ... |
Ruby | UTF-8 | 199 | 3.328125 | 3 | [] | no_license | def second_great_low(arr)
if arr.size == 2
return "#{arr.max}, #{arr.min}"
end
arr = arr.uniq.map {|x| x.to_i }.sort!
return "#{arr[1]},#{arr[-2]}"
end
p second_great_low([2,4,1,3,6]) |
Java | UTF-8 | 2,353 | 2.1875 | 2 | [] | no_license | package com.lenecoproekt.weatherapp;
import androidx.appcompat.app.AppCompatActivity;
import androidx.fragment.app.Fragment;
import androidx.fragment.app.FragmentManager;
import androidx.fragment.app.FragmentTransaction;
import android.content.res.Configuration;
import android.os.Bundle;
import android.widget.FrameLa... |
Go | UTF-8 | 1,879 | 2.640625 | 3 | [] | no_license | package store
import (
"context"
"email-acceptor/helpers"
"email-acceptor/models"
"encoding/json"
"github.com/Zetkolink/go-amqp-reconnect/rabbitmq"
"github.com/biezhi/gorm-paginator/pagination"
"github.com/lithammer/shortuuid"
"github.com/streadway/amqp"
"strings"
)
type MessageStore struct {
db helpers.DbC... |
C# | UTF-8 | 2,740 | 3.09375 | 3 | [] | no_license | using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Runtime.Serialization.Formatters.Binary;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace VehicleRental
{
pub... |
C# | UTF-8 | 1,390 | 2.8125 | 3 | [] | no_license | using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace Worker
{
public partial class Form1 : Form
{
... |
Shell | UTF-8 | 1,287 | 3.40625 | 3 | [] | no_license | #!/bin/sh
SERVICE='mariadb'
while true
do
if [ "`systemctl is-active $SERVICE`" != "active" ]
then
attemptcount=0
while [ $attemptcount -lt 3 ]
do
#echo "$SERVICE is not running"
systemctl start $SERVICE.service
if [ "`systemctl is-active $SERVICE`" = "active" ]
the... |
TypeScript | UTF-8 | 681 | 3.015625 | 3 | [
"Apache-2.0"
] | permissive | import { appState } from './../state/app.state';
export function appReducer(action:any, state = appState) {
// The reducer normally looks at the action type field to decide what happens
switch (action.type) {
case 'CounterComponent/add':
action.payload++;
return {...state, count... |
Java | UTF-8 | 625 | 1.679688 | 2 | [] | no_license | package com.excalibur.funwithgles.cropimage.b612crop;
import com.excalibur.funwithgles.cropimage.b612crop.view.CropAngleView;
public final class g implements CropAngleView.a {
//final /* synthetic */ this$0;
//g(EditFeatureCropFragment editFeatureCropFragment) {
// this.this$0 = editFeatureCropFragm... |
C++ | UTF-8 | 2,245 | 3.171875 | 3 | [] | no_license | //在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“
//房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
//
// 计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
//
// 示例 1:
//
// 输入: [3,2,3,null,3,null,1]
//
// 3
// / \
// 2 3
// \ \
// 3 1
//
//输出: 7
//解释: 小偷一... |
Markdown | UTF-8 | 932 | 2.546875 | 3 | [] | no_license |


根据商业组织形式分类,预言机可以是中心化的单一预言者的机制(如 Oraclize)——中心化预言机,同样也可以是去中心化的多个预言者的机制(如 Chainlink、DOS Network 等)——去中心化预言机。
典型的预言机项目有 ChainLink、Oraclize、DOS Network、
OracleChain 等。
* Oraclize 是一个具有真实性证明的中心化预言机,目前支持以
太坊(Ethereum)、Rootstock、R3 Corda、Hyperledger Fabric 和 EOS... |
PHP | UTF-8 | 1,176 | 2.84375 | 3 | [] | no_license | <?php
header("Content-type: text/xml");
// Start XML file, echo parent node
echo "<?xml version='1.0' ?>";
echo "<markers>";
$ind=0;
function parseToXML($htmlStr)
{
$xmlStr=str_replace('<','<',$htmlStr);
$xmlStr=str_replace('>','>',$xmlStr);
$xmlStr=str_replace('"','"',$xmlStr);
$xmlStr=str_replace("'",'&... |
Swift | UTF-8 | 5,458 | 2.53125 | 3 | [
"LicenseRef-scancode-warranty-disclaimer",
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | //
// SnapshotTestCase
// edX
//
// Created by Akiva Leffert on 5/14/15.
// Copyright (c) 2015 edX. All rights reserved.
//
import Foundation
private let StandardTolerance : CGFloat = 0.005
protocol SnapshotTestable {
func snapshotTestWithCase(_ testCase : FBSnapshotTestCase, referenceImagesDirectory: String... |
C | UTF-8 | 1,677 | 2.65625 | 3 | [] | no_license | /* ************************************************************************** */
/* */
/* ::: :::::::: */
/* server.c :+: :+: :+: ... |
JavaScript | UTF-8 | 2,897 | 2.8125 | 3 | [] | no_license | //Close modal on close button click
$('#close').on("click", event => {
$('#myModal').modal('hide');
})
//Console log JSON object on export button click
$('#export').on("click", function( event ) {
console.log($('#previewSite').attr('src').substr(41));
})
//Form submit
$( "form" ).on( "submit", function( event... |
JavaScript | UTF-8 | 1,236 | 2.734375 | 3 | [] | no_license | var http = require('http');
var url = require('url');
var server = http.createServer(function(request, response){
//1. 실제 요청한 주소 전체를 콘솔에 출력
console.log(request.url);
var parsedUrl = url.parse(request.url);
//2. parsing 된 url 중에 서버URI에 해당하는 pathname만 따로 저장
var resource = parsedUrl.pathname;
cons... |
Java | UTF-8 | 2,802 | 2.6875 | 3 | [
"MIT"
] | permissive | package de.paillier.crypto;
import static org.junit.Assert.assertEquals;
import java.math.BigInteger;
import org.junit.Before;
import org.junit.Test;
import de.paillier.key.KeyPair;
import de.paillier.key.KeyPairBuilder;
import de.paillier.key.PublicKey;
public class HomomorphicPropertiesTest {
private KeyPair k... |
JavaScript | UTF-8 | 185 | 2.734375 | 3 | [
"MIT"
] | permissive | /**
* Created by Birkenstab (http://birkenstab.de) on 2017-01-29
*/
const mathUtil = require("util/mathUtil");
const result = mathUtil.add(3, 9);
console.log("3 + 9 = " + result);
|
Java | UTF-8 | 652 | 2.3125 | 2 | [] | no_license | package com.voicepin.flow.client.ssl;
import java.security.NoSuchAlgorithmException;
import javax.net.ssl.HostnameVerifier;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSession;
/**
* @author Lukasz Warzecha
*/
public class TrustedCertificateStrategy implements CertificateStrategy {
@Override
... |
JavaScript | UTF-8 | 5,269 | 2.5625 | 3 | [] | no_license | const express = require("express");
const server = express();
const port = 9000;
server.use(express.json());
const projects = require('./data/helpers/projectModel');
const actions = require('./data/helpers/actionModel');
// ** Project Routes **
//get all projects
server.get('/api/projects', (req, res) => {
pr... |
Markdown | UTF-8 | 1,441 | 2.84375 | 3 | [] | no_license | ---
title: ubuntu下构建deb包
date: 2019-07-23 20:17:33
categories: 开发者手册
---
本文讲解如何构建一个deb包
### dpgk
首先介绍下dpkg,dpkg是debian系统下软件包管理工具,用dpkg可以很方便的安装管理我们的deb包,为什么呢,因为deb包都是用dpkg构建的。类似于rethat系列的软件用rpm一样,rethat用rpm管理软件,用rpmbuild构建软件。
<!-- more -->
### 如何用dpkg构建一个软件包呢
1. 模仿,找一个流行的deb包,拆开里面的内容,看看它们是怎么写的,模仿他们准没错。我们可以上 dpkg.or... |
C | UTF-8 | 442 | 3.09375 | 3 | [] | no_license | #include <stdio.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/wait.h>
void sigHandler (int s){
}
int main() {
int status = 0;
signal(SIGINT, sigHandler);
int pid = fork();
if (pid == 0) //if pid == 0, it is child
{
printf("child PID = %d\n", getpid());
pause();
exit(5);
}
else
{
... |
JavaScript | UTF-8 | 704 | 2.546875 | 3 | [
"MIT"
] | permissive | var run = require('tape').test
var arp = require('arp-table')
var parse = require('arp-parse')
var localip = require('my-local-ip')()
var arpulate = require('../')
run('add 20 addresses that surround the local computer', function(test) {
arpulate(localip, 20, function() {
var addresses = []
var parser = par... |
Markdown | UTF-8 | 559 | 2.625 | 3 | [] | no_license | # forecastAPI
- Gather daily weather information based on location id and given range date
- Produce pivoted table report of precipitation probability of each location id on given date.
Tools Used:
- python
- Panda
API used:
- Google Map API
- Dark Sky API
Instruction to run:
- Setup environmnet variable with it... |
Markdown | UTF-8 | 2,360 | 2.984375 | 3 | [
"MIT"
] | permissive | # Slack-chat-with-SMS
You love [Slack](https://slack.com/)?
Now anyone can send you text messages / SMS.
The conversation starts in its own Slack channel, and you can reply `/sms anything you like`.

## Setup and configuratio... |
Java | UTF-8 | 2,887 | 2.234375 | 2 | [] | no_license | package com.dqsy.sparkvisualization.controller;
import com.alibaba.fastjson.JSONObject;
import com.dqsy.sparkvisualization.entity.*;
import com.dqsy.sparkvisualization.service.IPageService;
import com.dqsy.sparkvisualization.service.ITaskService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.facto... |
Java | UTF-8 | 738 | 1.96875 | 2 | [] | no_license | package com.smart;
import com.smart.service.UserService;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.testng.annotations.Test;
public cla... |
C# | UTF-8 | 5,770 | 2.6875 | 3 | [] | no_license | using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Android.App;
using Android.Content;
using Android.OS;
using Android.Runtime;
using Android.Views;
using Android.Widget;
using System.Threading.Tasks;
using System.Net;
using Android.Gms.Maps.Model;
using CHARE_REST_API.JSON_Ob... |
Swift | UTF-8 | 1,448 | 2.578125 | 3 | [] | no_license | //
// AxisGrid.swift
// ARMeasure
//
// Created by cc on 8/23/17.
// Copyright © 2017 Laan Labs. All rights reserved.
//
import Foundation
import SceneKit
class AxisGrid : SCNNode {
init(radius : CGFloat = 0.002, height : CGFloat = 0.3) {
super.init()
let x = SCNCapsule(capR... |
Java | UTF-8 | 10,313 | 2.796875 | 3 | [] | no_license | package wsa.web;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.URL;
import java.util.*;
import java.util.concurrent.*;
import java.util.function.Predicate;
public class SimpleCrawler implements Crawler{
private volatile Set<URI> succDownload;
private volatile Set<URI> toDownload;
... |
SQL | UTF-8 | 2,790 | 3.421875 | 3 | [] | no_license | -- Gera relatorio em HTML de FK sem indice
set echo off
set linesize 255
set trims on
set trimo on
set feedback off
set pagesize 0
set arraysize 1
prompt Aguarde a obtencao das FKs sem indices...
set termout off
spool fknoindex.htm
prompt <HTML><HEAD><TITLE>FKs sem Indices</TITLE>
prompt <STYLE type="text/... |
Java | UTF-8 | 569 | 1.804688 | 2 | [
"Apache-2.0"
] | permissive | package com.taobao.api.response;
import com.taobao.api.internal.mapping.ApiField;
import com.taobao.api.domain.Sku;
import com.taobao.api.TaobaoResponse;
/**
* TOP API: taobao.item.sku.get response.
*
* @author auto create
* @since 1.0, null
*/
public class ItemSkuGetResponse extends TaobaoRespons... |
C++ | UTF-8 | 393 | 2.859375 | 3 | [] | no_license | //
// Created by user on 1/13/2020.
//
#ifndef GAMMA_SOUP_H
#define GAMMA_SOUP_H
#include <string>
#include "FoodFactory.h"
class Soup : public FoodFactory
{
public:
int getPrice(std::string type) const override {
if (type == "thai") return thai;
if (type == "visitor") return visitor;
}
priv... |
Python | UTF-8 | 1,983 | 3.5 | 4 | [] | no_license | from warehouse import Warehouse
from sales import Sales
from finance import Finance
class UserInterface:
def __init__(self):
self.warehouse = Warehouse()
self.sales = Sales()
self.finance = Finance()
def add_new_bike(self, model, price, colour, size, gender, quantity):
self.w... |
PHP | UTF-8 | 2,458 | 3.125 | 3 | [
"MIT"
] | permissive | <?php
namespace Reborn\Console;
use Symfony\Component\Console\Command\Command as SfCommand;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
/**
* Class Compile Command for Memeory Reduce
*
* @package Reborn\Console
* @author Myanmar Links Professional Web... |
C# | UTF-8 | 3,876 | 2.5625 | 3 | [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | using System;
using System.Data.Entity;
using System.Net;
using System.Threading.Tasks;
using System.Web.Mvc;
using OneAspNetSample.Models;
namespace OneAspNetSample.Controllers
{
public class ProductController : Controller
{
private OneAspNetSampleContext db = new OneAspNetSampleContext();
/... |
Go | UTF-8 | 1,895 | 2.9375 | 3 | [
"MIT"
] | permissive | package boost
import (
"time"
"github.com/rjansen/boost"
testify "github.com/stretchr/testify/mock"
)
func NewClientPoolMock() *ClientPoolMock {
return new(ClientPoolMock)
}
//ClientPoolMock is a mock for a cache client pool
type ClientPoolMock struct {
testify.Mock
}
//Get returns a cache Client instance
fun... |
C++ | UTF-8 | 1,476 | 2.640625 | 3 | [] | no_license | #ifndef COMSTRUCTIBLE_H
#define COMSTRUCTIBLE_H
#include <vector>
#include <map>
#include <SFML/Graphics.hpp>
#include <string>
#include <iostream>
#include <sstream>
#include <queue>
#include <set>
#include "Enum.hpp"
#include "Cible.hpp"
/*
Constructible
/\ ... |
C# | UTF-8 | 1,025 | 2.890625 | 3 | [
"Apache-2.0"
] | permissive | using UnityEngine;
using System.Collections;
using System.Collections.Generic;
using MiniJSON;
public static class Localization
{
public static SystemLanguage Language
{
get
{
return _language;
}
set
{
_language = value;
ChangeLanguage(_language);
}
}
public static string Get(string key)
{
... |
Python | UTF-8 | 2,617 | 2.765625 | 3 | [] | no_license | # pymodbus code based on the example from http://www.solarpoweredhome.co.uk/
from pymodbus.client.sync import ModbusSerialClient as ModbusClient
from time import sleep
import datetime
import numpy as np
import pandas as pd
import csv
import os
client = ModbusClient(method = 'rtu', port = '/dev/ttyUSB0', baudrate = 11... |
Markdown | UTF-8 | 4,443 | 2.78125 | 3 | [] | no_license | 想打造 New Relic 那样漂亮的实时监控系统我们只需要 InfluxDB/collectd/Grafana 这三个工具,这三个工具的关系是这样的:
> 采集数据(collectd)-> 存储数据(InfluxDB) -> 显示数据(Grafana)。
- InfluxDB 是 Go 语言开发的一个开源分布式时序数据库,非常适合存储指标、事件、分析等数据,看版本号(v0.8.8)就知道这个项目还很年轻;
- collectd 就不用介绍了吧,C 语言写的一个系统性能采集工具;
- Grafana 是纯 Javascript 开发的前端工具,用于访问 InfluxDB,自定义报表、显示图表等。
## 安装 InfluxDB
... |
JavaScript | UTF-8 | 667 | 2.90625 | 3 | [] | no_license | var randomBetween = require('./randomBetween');
module.exports = function(canvas, opt) {
var ctx = canvas.getContext('2d');
for(var i = 0; i < 8; i++) {
ctx.beginPath();
ctx.moveTo(randomBetween(-100, opt.width + 100), randomBetween(-100, opt.height + 100));
ctx.bezierCurveTo(randomBetween(-100, opt.h... |
Ruby | UTF-8 | 1,185 | 3.234375 | 3 | [
"Unlicense",
"LicenseRef-scancode-public-domain"
] | permissive | module Jsus
#
# Packager is a plain simple class accepting several source files
# and joining their contents.
#
# It uses Container for storage which means it automatically sorts sources.
#
class Packager
# Container with source files
attr_accessor :container
#
# Inits packager with the g... |
TypeScript | UTF-8 | 1,844 | 2.578125 | 3 | [
"CC0-1.0"
] | permissive | /* eslint-disable import/prefer-default-export, import/no-cycle */
import {
BackboneElement,
ElementDefinition,
FhirList,
IStructureDefinitionSnapshot,
FhirType
} from "../internal";
@FhirType("StructureDefinitionSnapshot", "BackboneElement")
export class StructureDefinitionSnapshot extends BackboneElement {... |
Python | UTF-8 | 525 | 3.890625 | 4 | [] | no_license | # repeat last item in short list to equalize to lists
short = [x for x in range(8)]
llong = [y for y in range(12)]
"""
for i in range(len(short), len(llong)):
short.append(short[-1])
print short
print llong
"""
def equalize(one_list, two_list):
if len(one_list) > len(two_list):
short = two_list
... |
Java | UTF-8 | 1,609 | 3.46875 | 3 | [] | no_license | package algorithms.search;
import java.util.PriorityQueue;
public class BreadthFirstSearch extends ASearchingAlgorithm{
/**
* searching in specific problem according to bfs algorithm
* @param s problem we want to solve
* @return goal state of the problem
*/
@Override
public AState sea... |
Markdown | UTF-8 | 3,626 | 2.703125 | 3 | [] | no_license | 登录 [短信控制台](https://console.cloud.tencent.com/sms),在左侧导航栏选择**统计分析**>**国际/港澳台短信**,您可以查看指定时间段内的国际/港澳台发送详情、下发记录以及失败分析等。单击各页面的**导出数据**可下载对应数据表。
## 数据总览
在**数据总览**页面,您可以指定应用或模板精确筛选查看今天、昨天、最近7天、最近30天或指定时间段的短信发送详情。趋势图与数据表均支持从请求量、成功量、计费条数和成功率多个维度统计数据。
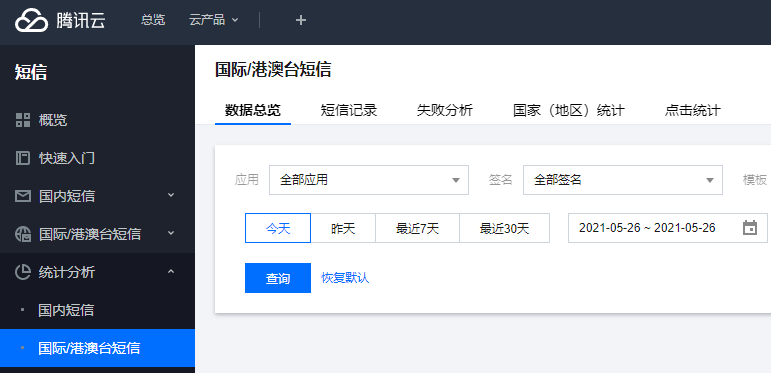
- **... |
C++ | UTF-8 | 898 | 3.03125 | 3 | [] | no_license | #include<iostream>
#include "list.h"
using namespace std;
int main(void)
{
/* List<int> l1;
l1.push_front(5);
l1.push_front(4);
l1.push_front(3);
l1.push_front(2);
l1.push_front(1);
l1.push_back(1);
l1.push_back(2);
l1.push_back(3);
l1.push_back(4);
l1.push_back(5);
cout<<l1.front()<<endl;
cout<<l1.back(... |
Ruby | UTF-8 | 988 | 3.171875 | 3 | [] | no_license | module NumberCorrect
extend self
def number_correct
@turns.count do |turn|
turn.correct?
end
end
end
module NumberCorrectByCategory
extend self
def number_correct_by_category(category_to_count_correct)
@category_to_count_correct = category_to_count_correct
@category_cards_seen = turns.s... |
C++ | UTF-8 | 785 | 2.71875 | 3 | [
"MIT"
] | permissive | const int outputPin = 11;
const int sensePin = 2;
const int slotsPerRev = 20;
const long updatePeriod = 1000L; // ms
long lastUpdateTime = 0;
long pulseCount = 0;
float rpm = 0;
void setup()
{
pinMode(outputPin, OUTPUT);
Serial.begin(9600);
Serial.println("Enter speed 0 to 255");
attachInterrupt(digitalPinT... |
C# | UTF-8 | 1,691 | 2.875 | 3 | [
"MIT"
] | permissive | using System;
namespace asardotnetasync {
public enum EAsarException {
ASAR_FILE_CANT_FIND,
ASAR_FILE_CANT_READ,
ASAR_INVALID_DESCRIPTOR,
ASAR_INVALID_FILE_SIZE
};
public class AsarException : Exception {
private readonly EAsarException _asarException;
pr... |
Java | UTF-8 | 4,605 | 2.796875 | 3 | [] | no_license | package java_swing_study.ch11;
import java.awt.BorderLayout;
import java.awt.EventQueue;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.util.ArrayList;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JMenuItem;
import javax.swing.JOptionPane;
import java... |
C++ | UTF-8 | 4,544 | 3.40625 | 3 | [
"Apache-2.0"
] | permissive | #include "Stdafx.hpp"
/* ----------------------------------------------------------------------
* Author: Julian
* Date: 31 January 2014
* Description: Centers the origin of a circle shape
* ----------------------------------------------------------------------
*/
void centerOrigin(sf::CircleShape& circleShape)
{... |
Java | UTF-8 | 1,344 | 2.78125 | 3 | [] | no_license | package com.mamahao.hr.common.enums;
import org.springframework.util.StringUtils;
/**
* 组织架构状态枚举
* Created by banchun on 2016/7/13 0013.
*/
public enum SysOrgEnums {
NORMAL(0,"正常"),
DELETE(1,"删除"),
PAUSE(2,"暂停"),
OTHER(3,"其他");
/**
* 代号
*/
private int code;
/**
* 解释
... |
C | UTF-8 | 420 | 3.8125 | 4 | [] | no_license | #include <stdio.h>
int ala(int a, int b)
{
int mul = 0;
while (a > 0) { // while(a)
if (a % 2) // if((a&0x1)==1)
mul += b;
a /= 2; //a>>=1;
b *= 2; //b<<=1;
}
return mul;
}
int get_gcd(int a, int b)
{
int temp;
while (a) {
if (b > a) {
temp = a;
a = b;
b = temp;
}
a = a - b;
}
return b... |
Java | UTF-8 | 1,006 | 1.84375 | 2 | [] | no_license | package com.jumia.test.jumia.controller;
import com.jumia.test.jumia.dto.LoginDetails;
import com.jumia.test.jumia.entity.Client;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/client")
@CrossOrigin("*")
publ... |
Java | UTF-8 | 3,188 | 2.3125 | 2 | [] | no_license | package com.feidao.platform.service.custom.medicine.icebox.gridservice;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.feidao.plat... |
C | UTF-8 | 638 | 4.25 | 4 | [] | no_license | /* write a program to find out if the area of a rectangle is greater than it's perimeter from length=5 and breadth=4 */
#include<stdio.h>
int main()
{
int length, breadth,area , perimeter;
printf("Enter the length and breadth of rectangle: ");
scanf("%d %d",&length, &breadth);
area= length * breadth... |
Java | UTF-8 | 478 | 2.046875 | 2 | [
"Apache-2.0"
] | permissive | package ru.job4j.forum.repository;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.repository.CrudRepository;
import ru.job4j.forum.model.Post;
import java.util.Collection;
import java.util.Optional;
public interface PostDataRepository extends CrudRepository<Post, Integer>... |
Java | UTF-8 | 2,701 | 2.140625 | 2 | [
"Apache-2.0"
] | permissive | // Copyright 2020 Mavenir
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in wri... |
Python | UTF-8 | 38,831 | 3.140625 | 3 | [] | no_license | #!/usr/bin/python -d
# vim: ts=4 sw=4 et ft=python
"""
Transform a .orig file into into a .tex file.
Note to maintainers:
This program gets a rating above 9.5 out of 10 from pylint;
please keep it that way.
Most of the complaints still raised by pylint are related to the fact that
the code uses a structured programm... |
C | UTF-8 | 337 | 2.5625 | 3 | [] | no_license | /* Monte Carlo simulation of pi*/
#include <stdio.h>
#include <omp.h>
unsigned int seed = 1; /* random number seed */
const unsigned int rand_max = 32768;
double rannum()
{
#pragma omp threadprivate(seed)
unsigned int rv;
seed = seed * 1103515245 + 12345;
rv = ((unsigned)(seed/65536) % rand_max);
return (doubl... |
Java | UTF-8 | 481 | 3.421875 | 3 | [] | no_license | package collection;
import java.util.ArrayList;
import java.util.Iterator;
public class list {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
Iterator it=list.i... |
Markdown | UTF-8 | 1,606 | 3.03125 | 3 | [] | no_license | # Emerton Q&A Test
### Description
A program that counts unique words from an English text file, treating hyphen and apostrophe as part of the word.
The program must output the ten most frequent words and mention the number of occurrences.
The expected output is (using `Temptest.txt` file as input`: \
and (514) \
t... |
Java | UTF-8 | 7,905 | 2.046875 | 2 | [] | no_license | package lu.circl.mispbump.activities;
import android.content.Intent;
import android.net.Uri;
import android.os.Bundle;
import android.view.Menu;
import android.view.MenuItem;
import android.view.View;
import android.widget.Button;
import android.widget.ProgressBar;
import androidx.appcompat.app.ActionBar;
import and... |
Java | UTF-8 | 11,181 | 1.914063 | 2 | [] | no_license | package com.example.searchApplication;
import android.content.Context;
import android.net.Uri;
import android.os.Bundle;
import android.support.v4.app.Fragment;
import android.text.method.ScrollingMovementMethod;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import androi... |
Python | UTF-8 | 4,117 | 2.59375 | 3 | [] | no_license | import csv
import numpy
import matplotlib.pyplot as plt
from colorsys import hls_to_rgb
import random
fn = 'chitin_conts_four.csv'
tax_fn = 'Taxonomy.csv'
with open(fn, 'rU') as f:
rows = []
for row in csv.reader(f):
rows.append(row)
with open(tax_fn, 'rU') as f:
f_tax = []
for row in csv.rea... |
TypeScript | UTF-8 | 953 | 4.03125 | 4 | [] | no_license | // Helper methods on Figma's Vector type
export function add(v1: Vector, v2: Vector): Vector {
return {x: v1.x + v2.x, y: v1.y + v2.y}
}
export function subtract(v1: Vector, v2: Vector): Vector {
return {x: v1.x - v2.x, y: v1.y - v2.y}
}
export function distance(v1: Vector, v2: Vector): number {
const a = v1.x... |
JavaScript | UTF-8 | 2,713 | 3.015625 | 3 | [] | no_license | const fs = require('fs');
const path = require('path');
const serveFile = require('./serve-file');
/** @function serveIndex~callback
* @param {string|object} error - any error encountered by
* serveIndex().
*/
/** @module serveIndex
* Serves the provided index.html file or generates
* a dynamic listing of a d... |
Java | UTF-8 | 1,512 | 2.625 | 3 | [] | no_license | package com.davidhay.jlassignment.domain.inbound;
import static org.assertj.core.api.Assertions.assertThat;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
import java.math.BigDecimal;
import org.junit.jupiter.api.Nested;
import org.junit.jupiter.... |
C | UTF-8 | 3,240 | 2.671875 | 3 | [
"BSD-3-Clause"
] | permissive | #include <stdbool.h>
#include <stdlib.h>
#include "uthash.h"
#include <errno.h>
#include "url_router/dict.h"
#define HASH_FIND_NSTR(head, findstr, len, out) \
HASH_FIND(hh, head, findstr, len, out)
#define HASH_ADD_NSTR(head, strfield, len, add) \
HASH_ADD(hh, head, strfield[0], len, add)
struct DictItem {
... |
Shell | UTF-8 | 646 | 2.765625 | 3 | [
"BSD-3-Clause"
] | permissive | #!/bin/bash
# source completion files
for dir in ${ROSWSS_SCRIPTS//:/ }; do
if [ -d "$dir/completion" ]; then
for file in `find -L $dir/completion/ -maxdepth 1 -type f -name "*.sh"`; do
source $file
done
fi
done
# default auto completion
add_completion "clean" "_roswss_clean_complete"
add_completion... |
TypeScript | UTF-8 | 5,499 | 2.828125 | 3 | [] | no_license | import { lerp } from "./util";
interface SoundInfo {
audio?: HTMLAudioElement;
loaded: boolean;
loadPromise?: Promise<void>;
}
enum MuteState {
PLAY_ALL = 0,
MUSIC_OFF = 1,
ALL_OFF = 2,
}
class _Sounds {
audios: {[key: string]: SoundInfo} = {};
curSong?: HTMLAudioElement;
curSong... |
Java | UTF-8 | 172 | 1.859375 | 2 | [
"Apache-2.0"
] | permissive | package nlp.symbolSampler;
import algebra.Vector;
import nlp.utils.Simplex;
public interface SymbolSampler {
String nextSymbol(Vector simplex, Simplex symTable);
}
|
JavaScript | UTF-8 | 769 | 2.875 | 3 | [
"MIT"
] | permissive | /* global chrome */
const TOKEN_NAME = 'pt_personal_token';
/**
* Saves options to chrome.storage
*/
function saveOptions() {
const token = document.getElementById('token').value;
chrome.storage.sync.set({
[TOKEN_NAME]: token
}, () => {
const status = document.getElementById('status');
status.te... |
Markdown | UTF-8 | 3,308 | 3.046875 | 3 | [
"MIT"
] | permissive | ---
layout: post
title: 移动端实现1px
excerpt: 移动端实现1px像素线
categories: [教程, 移动端, css]
tags: [教程, 移动端, css]
modified: 2017-11-03
comments: true
---
## 问题描述
很多时候我们在css中写了1px,但是放到手机上看后,往往觉得会变粗很多,这都是2倍屏(dpr=2)、3倍屏(dpr=3)在捣鬼!所以导致css中的1px不等于移动设备的1px。
在window对象中有一个devicePixelRatio属性,他可以反应css中的像素与设备的像素比。devicePixelRatio的官方的定义为:设备... |
Java | UTF-8 | 6,179 | 2.171875 | 2 | [] | no_license | package com.example.workhours;
import java.util.ArrayList;
import java.util.List;
import android.app.ActionBar;
import android.content.SharedPreferences;
import android.os.Bundle;
import android.preference.PreferenceManager;
import android.support.v4.app.FragmentActivity;
import android.support.v4.app.FragmentManager... |
Python | UTF-8 | 8,169 | 2.9375 | 3 | [
"MIT"
] | permissive | import math
import time
class LossStatistics:
"""
Accumulator for loss staistics. Modified from OpenNMT
"""
def __init__(self, loss=0.0, n_tokens=0, n_batch=0, forward_time=0.0, loss_compute_time=0.0, backward_time=0.0):
assert type(loss) is float or type(loss) is int
assert type(n_to... |
C | UTF-8 | 14,175 | 2.78125 | 3 | [] | no_license | #include <windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <tchar.h>
#include "faxutil.h"
DWORD SetLTRWindowLayout(HWND hWnd);
DWORD SetLTREditBox(HWND hEdit);
///////////////////////////////////////////////////////////////////////////////////////
// Function:
// IsRTLUILanguage
//
// ... |
C# | UTF-8 | 321 | 2.53125 | 3 | [
"MIT"
] | permissive |
namespace Monad
{
/// <summary>
/// Used to append/combine the current object and the one provided.
/// This is used to support the operator+ overload on the monad types
/// </summary>
/// <typeparam name="T"></typeparam>
public interface IAppendable<T>
{
T Append(T rhs);
}
}
|
Ruby | UTF-8 | 1,782 | 3.078125 | 3 | [] | no_license | # frozen_string_literal: true
require 'byebug'
class Teller
class InaccurateMoneyError < StandardError; end
class IncompleteMoneyError < StandardError; end
class FloatDenominationError < StandardError; end
attr_accessor :denomination, :money, :money_left, :combinations, :result
def self.make_change(opts)
... |
Python | UTF-8 | 6,163 | 2.96875 | 3 | [] | no_license | # -*- coding: utf-8 -*-
"""
Created on Tue Sep 16 11:50:53 2014
@author: colin4567
"""
import numpy as np
import pandas as pd
import datetime
from config import Config
from backtest import Backtest
from data import HistoricCSVDataHandler
from data import MySQLDataHandler
from event import FinishEvent
... |
C++ | UTF-8 | 3,547 | 3.84375 | 4 | [] | no_license | #include <iostream>
#include <string>
/*
通常业务代码中会有这样的结构:
if (i == 1) {
handler1.handle(req);
} else if (i == 2) {
handler2.handle(req);
} ...
这样的处理流程不仅显得臃肿,而且耦合度高。
可以使用责任链模式来处理,如果不满足则向下传递.
*/
class Level {
public:
Level(int l) : _l(l) {}
... |
JavaScript | UTF-8 | 506 | 2.5625 | 3 | [] | no_license | import { useState } from 'react'
const useAsyncFn = (asyncFn) => {
const [state, setState] = useState({
loading: true,
error: null,
data: null
})
const executeFn = (...args) => {
return asyncFn(...args)
.then(data => {
setState({ ...state, loading: false, data })
return dat... |
Java | UTF-8 | 654 | 3.703125 | 4 | [] | no_license | //3. Реализовать метод, который посчитает среднее арифметическое по возрасту студентов (метод возращает средний арифметический возраст студентов)
import java.util.ArrayList;
import java.util.List;
public class Average {
public static void average(List<Student> studList) {
int arrayListSum = 0;
fo... |
C++ | UTF-8 | 11,605 | 2.75 | 3 | [
"Apache-2.0"
] | permissive | //
// XML.m
// iCAD
//
// Created by Josh Anderson on 5/11/11.
// Copyright 2011 Novatek Inc. All rights reserved.
//
#include "XML.h"
#include <iostream>
#include <fstream>
char *Beggining;
int Total;
XMLAttribute::XMLAttribute()
{
Name = "";
Value = "";
}
XMLAttribute::XMLAttribute(XMLAttribute *Attribute)... |
C# | UTF-8 | 2,000 | 3.21875 | 3 | [] | no_license | using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Cosmos
{
/// <summary>
/// DLL to be called when informaiton needs to be encrypted or decrypted.
/// </summary>
internal class Encryption
{
/// <summa... |
Java | UTF-8 | 993 | 3.25 | 3 | [] | no_license | package paquete;
public class Cracker_33941256 implements Cracker {
private int clave = 0;
private int inf = 0; //Establece el limite inferior de las posibles claves
private int sup = 9999; //Establece el limite superior de las posibles claves
public String getNextKey(boolean ultima_clave_se_paso) {... |
Python | UTF-8 | 25,784 | 2.765625 | 3 | [] | no_license | import discord
from discord.ext import commands
import random
import asyncio
import os
import time
command_prefix='p!'
bot = commands.Bot(command_prefix)
game = discord.Game("fighting Neonic")
@bot.event
async def on_ready():
await bot.change_presence(status=discord.Status.online, activity=game)
... |
Ruby | UTF-8 | 5,395 | 2.84375 | 3 | [
"MIT"
] | permissive | require 'spec_helper'
require 'jrr/matcher'
require 'jrr/token'
RSpec.describe Jrr::Matcher do
it 'with single category matches token category' do
matcher = described_class.new(:numeric)
token = Jrr::Token.new(:numeric, 5)
expect(matcher).to eq(token)
end
it 'with multiple categories matches any ... |
TypeScript | UTF-8 | 1,109 | 2.625 | 3 | [
"Apache-2.0"
] | permissive | import tmp from "tmp-promise";
import { loadPlugin } from "./loadPlugin.js";
import { makeProject, MakeProjectArgs } from "./makeProject.js";
import { PluginArgs } from "./Plugin.js";
/**
Arguments passed to the run command.
*/
export type RunArgs = Omit<PluginArgs, "tempDir" | "project"> &
MakeProjectArgs & {
... |
C++ | GB18030 | 622 | 3.328125 | 3 | [] | no_license | //#include<iostream>
//using namespace std;
//#include "ʽ.cpp"
//
//
//int main()
//{
//
// Polynomial A;//ԴһʽA
// A.insert(Monomial(-6, 7));
// A.insert(Monomial(5, 3));
// A.insert(Monomial(3, 0));
// cout << "AΪ";
// A.output();
//
// Polynomial B;//ԴһʽB
// B.insert(Monomial(-7, 6));
// B.insert(Monomial(-5, 3));
//... |
Markdown | UTF-8 | 1,255 | 3.1875 | 3 | [] | no_license | # Wiring
Good wiring is **crucial** to creating a robot that looks and performs like a top-tier robot. If wires are loose and not neatly cinched up next to support structures, it’s very possible they could come loose (meaning motors and sensors won’t work), and can get caught and pulled out when your robot moves.
#... |
PHP | UTF-8 | 614 | 2.609375 | 3 | [
"Apache-2.0"
] | permissive | <?php
declare(strict_types=1);
namespace SimpleMVC\Controller;
use SimpleMVC\Model\Article as ArticleModel;
use League\Plates\Engine;
use Psr\Http\Message\ServerRequestInterface;
class Article extends AbstractArticle implements ControllerInterface
{
public function execute(ServerRequestInterface $request)
{
$id ... |
C | UTF-8 | 592 | 3.421875 | 3 | [] | no_license | #include <stdio.h>
#include <stdlib.h>
FILE* archivo;
const char* nombre = "Archivo.txt";
const char* escribir = "w+";
void EscribirArchivo(char* cadena);
void LeerArchivo();
int main()
{
char* palabra;
scanf(&palabra);
EscribirArchivo(palabra);
LeerArchivo();
return(0);
}
void EscribirArchivo(char* cadena)
{... |
Markdown | UTF-8 | 5,529 | 2.9375 | 3 | [
"MIT"
] | permissive | {
"title": "The ‘L’ongest Day Yet",
"date": "2018-12-24T09:24:27-06:00",
"draft": "false",
"authors": ["Elise Fetzer"],
"thumbnail": {
"alt": "Sunset from the Cancer Survivors’ Garden in Grant Park",
"position": "center",
"src": "cancer-survivors-garden-sunset",
"type": "jpg"
}
}
“Let’s ride the whole [‘... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.