
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.28B | node_id stringlengths 18 32 | number int64 1 4.53k | title stringlengths 1 276 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone dict | comments list | created_at int64 1,587B 1,656B | updated_at int64 1,587B 1,656B | closed_at int64 1,587B 1,656B ⌀ | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 1
value | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/60 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/60/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/60/comments | https://api.github.com/repos/huggingface/datasets/issues/60/events | https://github.com/huggingface/datasets/pull/60 | 614,372,553 | MDExOlB1bGxSZXF1ZXN0NDE0OTQyNjEy | 60 | Update to simplify some datasets conversion | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"Awesome! ",
"Also we should convert `tf.io.gfile.exists` into `os.path.exists` , `tf.io.gfile.listdir`into `os.listdir` and `tf.io.gfile.glob` into `glob.glob` (will need to add `import glob`)",
"> Also we should convert `tf.io.gfile.exists` into `os.path.exists` , `tf.io.gfile.listdir`into `os.listdir` and `... | 1,588,888,944,000 | 1,588,934,312,000 | 1,588,933,104,000 | MEMBER | null | This PR updates the encoding of `Values` like `integers`, `boolean` and `float` to use python casting and avoid having to cast in the dataset scripts, as mentioned here: https://github.com/huggingface/nlp/pull/37#discussion_r420176626
We could also change (not included in this PR yet):
- `supervized_keys` to make t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/60/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/60/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/60",
"html_url": "https://github.com/huggingface/datasets/pull/60",
"diff_url": "https://github.com/huggingface/datasets/pull/60.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/60.patch",
"merged_at": 1588933104000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/59 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/59/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/59/comments | https://api.github.com/repos/huggingface/datasets/issues/59/events | https://github.com/huggingface/datasets/pull/59 | 614,366,045 | MDExOlB1bGxSZXF1ZXN0NDE0OTM3NTgx | 59 | Fix tests | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"I can fix the tests tomorrow :-) ",
"Very weird bug indeed! I think the problem was that when importing `setup_module` we overwrote `pytest's` setup_module function. I think this is the relevant code in pytest: https://github.com/pytest-dev/pytest/blob/9d2eabb397b059b75b746259daeb20ee5588f559/src/_pytest/python.... | 1,588,888,089,000 | 1,588,935,477,000 | 1,588,934,811,000 | MEMBER | null | @patrickvonplaten I've broken a bit the tests with #25 while simplifying and re-organizing the `load.py` and `download_manager.py` scripts.
I'm trying to fix them here but I have a weird error, do you think you can have a look?
```bash
(datasets) MacBook-Pro-de-Thomas:datasets thomwolf$ python -m pytest -sv ./test... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/59/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/59/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/59",
"html_url": "https://github.com/huggingface/datasets/pull/59",
"diff_url": "https://github.com/huggingface/datasets/pull/59.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/59.patch",
"merged_at": 1588934811000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/58 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/58/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/58/comments | https://api.github.com/repos/huggingface/datasets/issues/58/events | https://github.com/huggingface/datasets/pull/58 | 614,362,308 | MDExOlB1bGxSZXF1ZXN0NDE0OTM0NTY4 | 58 | Aborted PR - Fix tests | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"Wait I messed up my branch, let me clean this."
] | 1,588,887,619,000 | 1,588,888,081,000 | 1,588,887,687,000 | MEMBER | null | @patrickvonplaten I've broken a bit the tests with #25 while simplifying and re-organizing the `load.py` and `download_manager.py` scripts.
I'm trying to fix them here but I have a weird error, do you think you can have a look?
```bash
(datasets) MacBook-Pro-de-Thomas:datasets thomwolf$ python -m pytest -sv ./test... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/58/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/58/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/58",
"html_url": "https://github.com/huggingface/datasets/pull/58",
"diff_url": "https://github.com/huggingface/datasets/pull/58.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/58.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/57 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/57/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/57/comments | https://api.github.com/repos/huggingface/datasets/issues/57/events | https://github.com/huggingface/datasets/pull/57 | 614,261,638 | MDExOlB1bGxSZXF1ZXN0NDE0ODUzMDM5 | 57 | Better cached path | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"I should have read this PR before doing my own: https://github.com/huggingface/nlp/pull/62 :D \r\nwill close mine. Looks great :-) ",
"> Awesome, this is really nice!\r\n> \r\n> By the way, we should improve the `cached_path` method of the `transformers` repo similarly, don't you think (@patrickvonplaten in part... | 1,588,876,560,000 | 1,588,944,030,000 | 1,588,944,028,000 | MEMBER | null | ### Changes:
- The `cached_path` no longer returns None if the file is missing/the url doesn't work. Instead, it can raise `FileNotFoundError` (missing file), `ConnectionError` (no cache and unreachable url) or `ValueError` (parsing error)
- Fix requests to firebase API that doesn't handle HEAD requests...
- Allow c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/57/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/57/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/57",
"html_url": "https://github.com/huggingface/datasets/pull/57",
"diff_url": "https://github.com/huggingface/datasets/pull/57.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/57.patch",
"merged_at": 1588944028000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/56 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/56/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/56/comments | https://api.github.com/repos/huggingface/datasets/issues/56/events | https://github.com/huggingface/datasets/pull/56 | 614,236,869 | MDExOlB1bGxSZXF1ZXN0NDE0ODMyODY4 | 56 | [Dataset] Tester add mock function | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,873,897,000 | 1,588,873,971,000 | 1,588,873,970,000 | MEMBER | null | need to add an empty `extract()` function to make `hansard` dataset test work. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/56/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/56/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/56",
"html_url": "https://github.com/huggingface/datasets/pull/56",
"diff_url": "https://github.com/huggingface/datasets/pull/56.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/56.patch",
"merged_at": 1588873970000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/55 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/55/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/55/comments | https://api.github.com/repos/huggingface/datasets/issues/55/events | https://github.com/huggingface/datasets/pull/55 | 613,968,072 | MDExOlB1bGxSZXF1ZXN0NDE0NjE0MjE1 | 55 | Beam datasets | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"Right now the changes are a bit hard to read as the one from #25 are also included. You can wait until #25 is merged before looking at the implementation details",
"Nice!! I tested it a bit and works quite well. I will do a my review once the #25 will be merged because there are several overlaps.\r\n\r\nAt least... | 1,588,849,472,000 | 1,589,181,602,000 | 1,589,181,600,000 | MEMBER | null | # Beam datasets
## Intro
Beam Datasets are using beam pipelines for preprocessing (basically lots of `.map` over objects called PCollections).
The advantage of apache beam is that you can choose which type of runner you want to use to preprocess your data. The main runners are:
- the `DirectRunner` to run the p... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/55/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/55/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/55",
"html_url": "https://github.com/huggingface/datasets/pull/55",
"diff_url": "https://github.com/huggingface/datasets/pull/55.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/55.patch",
"merged_at": 1589181600000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/54 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/54/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/54/comments | https://api.github.com/repos/huggingface/datasets/issues/54/events | https://github.com/huggingface/datasets/pull/54 | 613,513,348 | MDExOlB1bGxSZXF1ZXN0NDE0MjUyODkw | 54 | [Tests] Improved Error message for dummy folder structure | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,788,708,000 | 1,588,788,780,000 | 1,588,788,779,000 | MEMBER | null | Improved Error message | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/54/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/54/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/54",
"html_url": "https://github.com/huggingface/datasets/pull/54",
"diff_url": "https://github.com/huggingface/datasets/pull/54.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/54.patch",
"merged_at": 1588788779000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/53 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/53/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/53/comments | https://api.github.com/repos/huggingface/datasets/issues/53/events | https://github.com/huggingface/datasets/pull/53 | 613,436,158 | MDExOlB1bGxSZXF1ZXN0NDE0MTkwMzkz | 53 | [Features] Typo in generate_from_dict | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,781,123,000 | 1,588,865,326,000 | 1,588,865,325,000 | MEMBER | null | Change `isinstance` test in features when generating features from dict. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/53/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/53/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/53",
"html_url": "https://github.com/huggingface/datasets/pull/53",
"diff_url": "https://github.com/huggingface/datasets/pull/53.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/53.patch",
"merged_at": 1588865325000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/52 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/52/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/52/comments | https://api.github.com/repos/huggingface/datasets/issues/52/events | https://github.com/huggingface/datasets/pull/52 | 613,339,071 | MDExOlB1bGxSZXF1ZXN0NDE0MTEyMDAy | 52 | allow dummy folder structure to handle dict of lists | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,773,275,000 | 1,588,773,319,000 | 1,588,773,318,000 | MEMBER | null | `esnli.py` needs that extension of the dummy data testing. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/52/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/52/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/52",
"html_url": "https://github.com/huggingface/datasets/pull/52",
"diff_url": "https://github.com/huggingface/datasets/pull/52.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/52.patch",
"merged_at": 1588773318000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/51 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/51/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/51/comments | https://api.github.com/repos/huggingface/datasets/issues/51/events | https://github.com/huggingface/datasets/pull/51 | 613,266,668 | MDExOlB1bGxSZXF1ZXN0NDE0MDUyOTYw | 51 | [Testing] Improved testing structure | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Awesome!\r\nLet's have this in the doc at the end :-)"
] | 1,588,766,587,000 | 1,588,889,239,000 | 1,588,771,218,000 | MEMBER | null | This PR refactors the test design a bit and puts the mock download manager in the `utils` files as it is just a test helper class.
as @mariamabarham pointed out, creating a dummy folder structure can be quite hard to grasp.
This PR tries to change that to some extent.
It follows the following logic for the `dumm... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/51/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/51/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/51",
"html_url": "https://github.com/huggingface/datasets/pull/51",
"diff_url": "https://github.com/huggingface/datasets/pull/51.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/51.patch",
"merged_at": 1588771217000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/50 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/50/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/50/comments | https://api.github.com/repos/huggingface/datasets/issues/50/events | https://github.com/huggingface/datasets/pull/50 | 612,583,126 | MDExOlB1bGxSZXF1ZXN0NDEzNTAwMjE0 | 50 | [Tests] test only for fast test as a default | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Test failure is not related to change in test file.\r\n"
] | 1,588,683,562,000 | 1,588,683,738,000 | 1,588,683,736,000 | MEMBER | null | Test only for one config on circle ci to speed up testing. Add all config test as a slow test.
@mariamabarham @thomwolf | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/50/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/50/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/50",
"html_url": "https://github.com/huggingface/datasets/pull/50",
"diff_url": "https://github.com/huggingface/datasets/pull/50.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/50.patch",
"merged_at": 1588683736000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/49 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/49/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/49/comments | https://api.github.com/repos/huggingface/datasets/issues/49/events | https://github.com/huggingface/datasets/pull/49 | 612,545,483 | MDExOlB1bGxSZXF1ZXN0NDEzNDY5ODg0 | 49 | fix flatten nested | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 1,588,679,713,000 | 1,588,687,166,000 | 1,588,687,165,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/49/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/49/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/49",
"html_url": "https://github.com/huggingface/datasets/pull/49",
"diff_url": "https://github.com/huggingface/datasets/pull/49.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/49.patch",
"merged_at": 1588687165000
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/48 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/48/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/48/comments | https://api.github.com/repos/huggingface/datasets/issues/48/events | https://github.com/huggingface/datasets/pull/48 | 612,504,687 | MDExOlB1bGxSZXF1ZXN0NDEzNDM2MTgz | 48 | [Command Convert] remove tensorflow import | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,675,260,000 | 1,588,677,238,000 | 1,588,677,236,000 | MEMBER | null | Remove all tensorflow import statements. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/48/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/48/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/48",
"html_url": "https://github.com/huggingface/datasets/pull/48",
"diff_url": "https://github.com/huggingface/datasets/pull/48.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/48.patch",
"merged_at": 1588677236000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/47 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/47/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/47/comments | https://api.github.com/repos/huggingface/datasets/issues/47/events | https://github.com/huggingface/datasets/pull/47 | 612,446,493 | MDExOlB1bGxSZXF1ZXN0NDEzMzg5MDc1 | 47 | [PyArrow Feature] fix py arrow bool | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,668,988,000 | 1,588,675,228,000 | 1,588,675,227,000 | MEMBER | null | To me it seems that `bool` can only be accessed with `bool_` when looking at the pyarrow types: https://arrow.apache.org/docs/python/api/datatypes.html. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/47/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/47/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/47",
"html_url": "https://github.com/huggingface/datasets/pull/47",
"diff_url": "https://github.com/huggingface/datasets/pull/47.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/47.patch",
"merged_at": 1588675227000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/46 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/46/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/46/comments | https://api.github.com/repos/huggingface/datasets/issues/46/events | https://github.com/huggingface/datasets/pull/46 | 612,398,190 | MDExOlB1bGxSZXF1ZXN0NDEzMzUxNTY0 | 46 | [Features] Strip str key before dict look-up | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,663,905,000 | 1,588,667,865,000 | 1,588,667,864,000 | MEMBER | null | The dataset `anli.py` currently fails because it tries to look up a key `1\n` in a dict that only has the key `1`. Added an if statement to strip key if it cannot be found in dict. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/46/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/46/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/46",
"html_url": "https://github.com/huggingface/datasets/pull/46",
"diff_url": "https://github.com/huggingface/datasets/pull/46.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/46.patch",
"merged_at": 1588667864000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/45 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/45/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/45/comments | https://api.github.com/repos/huggingface/datasets/issues/45/events | https://github.com/huggingface/datasets/pull/45 | 612,386,583 | MDExOlB1bGxSZXF1ZXN0NDEzMzQzMjAy | 45 | [Load] Separate Module kwargs and builder kwargs. | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,662,594,000 | 1,588,931,482,000 | 1,588,931,482,000 | MEMBER | null | Kwargs for the `load_module` fn should be passed with `module_xxxx` to `builder_kwargs` of `load` fn.
This is a follow-up PR of: https://github.com/huggingface/nlp/pull/41 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/45/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/45/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/45",
"html_url": "https://github.com/huggingface/datasets/pull/45",
"diff_url": "https://github.com/huggingface/datasets/pull/45.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/45.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/44 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/44/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/44/comments | https://api.github.com/repos/huggingface/datasets/issues/44/events | https://github.com/huggingface/datasets/pull/44 | 611,873,486 | MDExOlB1bGxSZXF1ZXN0NDEyOTUwMzU1 | 44 | [Tests] Fix tests for datasets with no config | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,598,738,000 | 1,588,598,884,000 | 1,588,598,883,000 | MEMBER | null | Forgot to fix `None` problem for datasets that have no config this in PR: https://github.com/huggingface/nlp/pull/42 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/44/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/44/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/44",
"html_url": "https://github.com/huggingface/datasets/pull/44",
"diff_url": "https://github.com/huggingface/datasets/pull/44.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/44.patch",
"merged_at": 1588598883000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/43 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/43/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/43/comments | https://api.github.com/repos/huggingface/datasets/issues/43/events | https://github.com/huggingface/datasets/pull/43 | 611,773,279 | MDExOlB1bGxSZXF1ZXN0NDEyODcxNTE5 | 43 | [Checksums] If no configs exist prevent to run over empty list | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Whoops I fixed it directly on master before checking that you have done it in this PR. We may close it",
"Yeah, I saw :-) But I think we should add this as well since some datasets have an empty list of configs and then as the code is now it would fail. \r\n\r\nIn this PR, I just make sure that the code jumps in... | 1,588,588,782,000 | 1,588,598,283,000 | 1,588,598,283,000 | MEMBER | null | `movie_rationales` e.g. has no configs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/43/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/43/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/43",
"html_url": "https://github.com/huggingface/datasets/pull/43",
"diff_url": "https://github.com/huggingface/datasets/pull/43.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/43.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/42 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/42/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/42/comments | https://api.github.com/repos/huggingface/datasets/issues/42/events | https://github.com/huggingface/datasets/pull/42 | 611,754,343 | MDExOlB1bGxSZXF1ZXN0NDEyODU1OTE2 | 42 | [Tests] allow tests for builders without config | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,586,782,000 | 1,588,597,850,000 | 1,588,597,848,000 | MEMBER | null | Some dataset scripts have no configs - the tests have to be adapted for this case.
In this case the dummy data will be saved as:
- natural_questions
-> dummy
-> -> 1.0.0 (version num)
-> -> -> dummy_data.zip
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/42/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/42/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/42",
"html_url": "https://github.com/huggingface/datasets/pull/42",
"diff_url": "https://github.com/huggingface/datasets/pull/42.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/42.patch",
"merged_at": 1588597848000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/41 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/41/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/41/comments | https://api.github.com/repos/huggingface/datasets/issues/41/events | https://github.com/huggingface/datasets/pull/41 | 611,739,219 | MDExOlB1bGxSZXF1ZXN0NDEyODQzNDQy | 41 | [Load module] allow kwargs into load module | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,585,331,000 | 1,588,621,147,000 | 1,588,621,146,000 | MEMBER | null | Currenly it is not possible to force a re-download of the dataset script.
This simple change allows to pass ``force_reload=True`` as ``builder_kwargs`` in the ``load.py`` function. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/41/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/41/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/41",
"html_url": "https://github.com/huggingface/datasets/pull/41",
"diff_url": "https://github.com/huggingface/datasets/pull/41.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/41.patch",
"merged_at": 1588621146000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/40 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/40/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/40/comments | https://api.github.com/repos/huggingface/datasets/issues/40/events | https://github.com/huggingface/datasets/pull/40 | 611,721,308 | MDExOlB1bGxSZXF1ZXN0NDEyODI4NzU2 | 40 | Update remote checksums instead of overwrite | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 1,588,583,594,000 | 1,588,593,111,000 | 1,588,593,109,000 | MEMBER | null | When the user uploads a dataset on S3, checksums are also uploaded with the `--upload_checksums` parameter.
If the user uploads the dataset in several steps, then the remote checksums file was previously overwritten. Now it's going to be updated with the new checksums. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/40/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/40/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/40",
"html_url": "https://github.com/huggingface/datasets/pull/40",
"diff_url": "https://github.com/huggingface/datasets/pull/40.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/40.patch",
"merged_at": 1588593109000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/39 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/39/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/39/comments | https://api.github.com/repos/huggingface/datasets/issues/39/events | https://github.com/huggingface/datasets/pull/39 | 611,712,135 | MDExOlB1bGxSZXF1ZXN0NDEyODIxNTA4 | 39 | [Test] improve slow testing | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,582,713,000 | 1,588,582,790,000 | 1,588,582,789,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/39/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/39/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/39",
"html_url": "https://github.com/huggingface/datasets/pull/39",
"diff_url": "https://github.com/huggingface/datasets/pull/39.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/39.patch",
"merged_at": 1588582789000
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/38 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/38/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/38/comments | https://api.github.com/repos/huggingface/datasets/issues/38/events | https://github.com/huggingface/datasets/issues/38 | 611,677,656 | MDU6SXNzdWU2MTE2Nzc2NTY= | 38 | [Checksums] Error for some datasets | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"follo... | null | [
"@lhoestq - could you take a look? It's not very urgent though!",
"Fixed with 06882b4\r\n\r\nNow your command works :)\r\nNote that you can also do\r\n```\r\nnlp-cli test datasets/nlp/xnli --save_checksums\r\n```\r\nSo that it will save the checksums directly in the right directory.",
"Awesome!"
] | 1,588,579,216,000 | 1,588,585,700,000 | 1,588,585,700,000 | MEMBER | null | The checksums command works very nicely for `squad`. But for `crime_and_punish` and `xnli`,
the same bug happens:
When running:
```
python nlp-cli nlp-cli test xnli --save_checksums
```
leads to:
```
File "nlp-cli", line 33, in <module>
service.run()
File "/home/patrick/python_bin/nlp/commands... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/38/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/38/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/37 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/37/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/37/comments | https://api.github.com/repos/huggingface/datasets/issues/37/events | https://github.com/huggingface/datasets/pull/37 | 611,670,295 | MDExOlB1bGxSZXF1ZXN0NDEyNzg5MjQ4 | 37 | [Datasets ToDo-List] add datasets | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"follo... | null | [
"Note:\r\n```\r\nnlp-cli test datasets/nlp/<your-dataset-folder> --save_checksums --all_configs\r\n```\r\ndirectly saves the checksums in the right place, and runs for all the dataset configurations.",
"@patrickvonplaten can you provide the add the link to the PR for the dummy data? ",
"https://github.com/huggi... | 1,588,578,459,000 | 1,588,945,703,000 | 1,588,945,703,000 | MEMBER | null | ## Description
This PR acts as a dashboard to see which datasets are added to the library and work.
Cicle-ci should always be green so that we can be sure that newly added datasets are functional.
This PR should not be merged.
## Progress
**For the following datasets the test commands**:
```
RUN_SLOW... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/37/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/37/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/37",
"html_url": "https://github.com/huggingface/datasets/pull/37",
"diff_url": "https://github.com/huggingface/datasets/pull/37.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/37.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/36 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/36/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/36/comments | https://api.github.com/repos/huggingface/datasets/issues/36/events | https://github.com/huggingface/datasets/pull/36 | 611,528,349 | MDExOlB1bGxSZXF1ZXN0NDEyNjgwOTk1 | 36 | Metrics - refactoring, adding support for download and distributed metrics | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"Ok, this one seems to be ready to merge.",
"> Really cool, I love it! I would just raise a tiny point, the distributive version of the metrics might not work properly with TF because it is a different way to do, why not to add a \"framework\" detection and raise warning when TF is used, saying something like \"n... | 1,588,546,817,000 | 1,589,184,962,000 | 1,589,184,960,000 | MEMBER | null | Refactoring metrics to have a similar loading API than the datasets and improving the import system.
# Import system
The import system has ben upgraded. There are now three types of imports allowed:
1. `library` imports (identified as "absolute imports")
```python
import seqeval
```
=> we'll test all the impor... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/36/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/36/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/36",
"html_url": "https://github.com/huggingface/datasets/pull/36",
"diff_url": "https://github.com/huggingface/datasets/pull/36.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/36.patch",
"merged_at": 1589184960000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/35 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/35/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/35/comments | https://api.github.com/repos/huggingface/datasets/issues/35/events | https://github.com/huggingface/datasets/pull/35 | 611,413,731 | MDExOlB1bGxSZXF1ZXN0NDEyNjAyMTc0 | 35 | [Tests] fix typo | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,512,229,000 | 1,588,512,261,000 | 1,588,512,260,000 | MEMBER | null | @lhoestq - currently the slow test fail with:
```
_____________________________________________________________________________________ DatasetTest.test_load_real_dataset_xnli _____________________________________________________________________________________
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/35/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/35/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/35",
"html_url": "https://github.com/huggingface/datasets/pull/35",
"diff_url": "https://github.com/huggingface/datasets/pull/35.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/35.patch",
"merged_at": 1588512260000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/34 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/34/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/34/comments | https://api.github.com/repos/huggingface/datasets/issues/34/events | https://github.com/huggingface/datasets/pull/34 | 611,385,516 | MDExOlB1bGxSZXF1ZXN0NDEyNTg0OTM0 | 34 | [Tests] add slow tests | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,503,682,000 | 1,588,508,310,000 | 1,588,508,309,000 | MEMBER | null | This PR adds a slow test that downloads the "real" dataset. The test is decorated as "slow" so that it will not automatically run on circle ci.
Before uploading a dataset, one should test that this test passes, manually by running
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_d... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/34/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/34/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/34",
"html_url": "https://github.com/huggingface/datasets/pull/34",
"diff_url": "https://github.com/huggingface/datasets/pull/34.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/34.patch",
"merged_at": 1588508309000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/33 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/33/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/33/comments | https://api.github.com/repos/huggingface/datasets/issues/33/events | https://github.com/huggingface/datasets/pull/33 | 611,052,081 | MDExOlB1bGxSZXF1ZXN0NDEyMzU1ODE0 | 33 | Big cleanup/refactoring for clean serialization | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"Great! I think when this merged, we can merge sure that Circle Ci stays happy when uploading new datasets. "
] | 1,588,376,757,000 | 1,588,508,254,000 | 1,588,508,253,000 | MEMBER | null | This PR cleans many base classes to re-build them as `dataclasses`. We can thus use a simple serialization workflow for `DatasetInfo`, including it's `Features` and `SplitDict` based on `dataclasses` `asdict()`.
The resulting code is a lot shorter, can be easily serialized/deserialized, dataset info are human-readab... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/33/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/33/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/33",
"html_url": "https://github.com/huggingface/datasets/pull/33",
"diff_url": "https://github.com/huggingface/datasets/pull/33.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/33.patch",
"merged_at": 1588508253000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/32 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/32/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/32/comments | https://api.github.com/repos/huggingface/datasets/issues/32/events | https://github.com/huggingface/datasets/pull/32 | 610,715,580 | MDExOlB1bGxSZXF1ZXN0NDEyMTAzMzIx | 32 | Fix map caching notebooks | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 1,588,334,126,000 | 1,588,508,158,000 | 1,588,508,157,000 | MEMBER | null | Previously, caching results with `.map()` didn't work in notebooks.
To reuse a result, `.map()` serializes the functions with `dill.dumps` and then it hashes it.
The problem is that when using `dill.dumps` to serialize a function, it also saves its origin (filename + line no.) and the origin of all the `globals` th... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/32/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/32/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/32",
"html_url": "https://github.com/huggingface/datasets/pull/32",
"diff_url": "https://github.com/huggingface/datasets/pull/32.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/32.patch",
"merged_at": 1588508157000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/31 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/31/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/31/comments | https://api.github.com/repos/huggingface/datasets/issues/31/events | https://github.com/huggingface/datasets/pull/31 | 610,677,641 | MDExOlB1bGxSZXF1ZXN0NDEyMDczNDE4 | 31 | [Circle ci] Install a virtual env before running tests | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,327,877,000 | 1,588,370,776,000 | 1,588,370,775,000 | MEMBER | null | Install a virtual env before running tests to not running into sudo issues when dynamically downloading files.
Same number of tests now pass / fail as on my local computer:
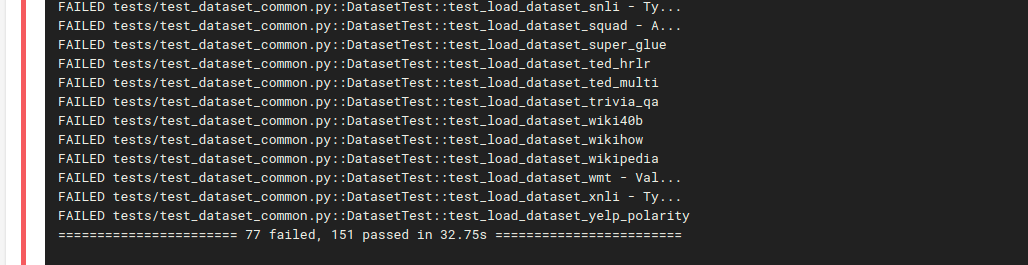
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/31/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/31/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/31",
"html_url": "https://github.com/huggingface/datasets/pull/31",
"diff_url": "https://github.com/huggingface/datasets/pull/31.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/31.patch",
"merged_at": 1588370775000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/30 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/30/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/30/comments | https://api.github.com/repos/huggingface/datasets/issues/30/events | https://github.com/huggingface/datasets/pull/30 | 610,549,072 | MDExOlB1bGxSZXF1ZXN0NDExOTY4Mzk3 | 30 | add metrics which require download files from github | {
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 1,588,306,402,000 | 1,589,185,194,000 | 1,589,185,194,000 | CONTRIBUTOR | null | To download files from github, I copied the `load_dataset_module` and its dependencies (without the builder) in `load.py` to `metrics/metric_utils.py`. I made the following changes:
- copy the needed files in a folder`metric_name`
- delete all other files that are not needed
For metrics that require an external... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/30/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/30/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/30",
"html_url": "https://github.com/huggingface/datasets/pull/30",
"diff_url": "https://github.com/huggingface/datasets/pull/30.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/30.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/29 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/29/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/29/comments | https://api.github.com/repos/huggingface/datasets/issues/29/events | https://github.com/huggingface/datasets/pull/29 | 610,243,997 | MDExOlB1bGxSZXF1ZXN0NDExNzIwODMx | 29 | Hf_api small changes | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [] | closed | false | null | [] | null | [
"Ok merging! I think it's good now"
] | 1,588,266,403,000 | 1,588,276,305,000 | 1,588,276,304,000 | MEMBER | null | From Patrick:
```python
from nlp import hf_api
api = hf_api.HfApi()
api.dataset_list()
```
works :-) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/29/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/29/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/29",
"html_url": "https://github.com/huggingface/datasets/pull/29",
"diff_url": "https://github.com/huggingface/datasets/pull/29.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/29.patch",
"merged_at": 1588276304000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/28 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/28/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/28/comments | https://api.github.com/repos/huggingface/datasets/issues/28/events | https://github.com/huggingface/datasets/pull/28 | 610,241,907 | MDExOlB1bGxSZXF1ZXN0NDExNzE5MTQy | 28 | [Circle ci] Adds circle ci config | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,266,215,000 | 1,588,276,269,000 | 1,588,276,268,000 | MEMBER | null | @thomwolf can you take a look and set up circle ci on:
https://app.circleci.com/projects/project-dashboard/github/huggingface
I think for `nlp` only admins can set it up, which I guess is you :-) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/28/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/28/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/28",
"html_url": "https://github.com/huggingface/datasets/pull/28",
"diff_url": "https://github.com/huggingface/datasets/pull/28.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/28.patch",
"merged_at": 1588276268000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/27 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/27/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/27/comments | https://api.github.com/repos/huggingface/datasets/issues/27/events | https://github.com/huggingface/datasets/pull/27 | 610,230,476 | MDExOlB1bGxSZXF1ZXN0NDExNzA5OTc0 | 27 | [Cleanup] Removes all files in testing except test_dataset_common | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,265,121,000 | 1,588,268,365,000 | 1,588,268,363,000 | MEMBER | null | As far as I know, all files in `tests` were old `tfds test files` so I removed them. We can still look them up on the other library. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/27/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/27/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/27",
"html_url": "https://github.com/huggingface/datasets/pull/27",
"diff_url": "https://github.com/huggingface/datasets/pull/27.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/27.patch",
"merged_at": 1588268363000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/26 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/26/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/26/comments | https://api.github.com/repos/huggingface/datasets/issues/26/events | https://github.com/huggingface/datasets/pull/26 | 610,226,047 | MDExOlB1bGxSZXF1ZXN0NDExNzA2NjA2 | 26 | [Tests] Clean tests | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,588,264,709,000 | 1,588,277,524,000 | 1,588,277,523,000 | MEMBER | null | the abseil testing library (https://abseil.io/docs/python/quickstart.html) is better than the one I had before, so I decided to switch to that and changed the `setup.py` config file.
Abseil has more support and a cleaner API for parametrized testing I think.
I added a list of all dataset scripts that are currentl... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/26/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/26/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/26",
"html_url": "https://github.com/huggingface/datasets/pull/26",
"diff_url": "https://github.com/huggingface/datasets/pull/26.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/26.patch",
"merged_at": 1588277523000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/25 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/25/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/25/comments | https://api.github.com/repos/huggingface/datasets/issues/25/events | https://github.com/huggingface/datasets/pull/25 | 609,708,863 | MDExOlB1bGxSZXF1ZXN0NDExMjQ4Nzg2 | 25 | Add script csv datasets | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Very interesting thoughts, we should think deeper about all what you raised indeed.",
"Ok here is a proposal for a more general API and workflow.\r\n\r\n# New `ArrowBasedBuilder`\r\n\r\nFor all the formats that can be directly and efficiently loaded by Arrow (CSV, JSON, Parquet, Arrow), we don't really want to h... | 1,588,235,288,000 | 1,588,959,111,000 | 1,588,886,089,000 | CONTRIBUTOR | null | This is a PR allowing to create datasets from local CSV files. A usage might be:
```python
import nlp
ds = nlp.load(
path="csv",
name="bbc",
dataset_files={
nlp.Split.TRAIN: ["datasets/dummy_data/csv/train.csv"],
nlp.Split.TEST: [""datasets/dummy_data/csv/test.csv""]
},
c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/25/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/25/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/25",
"html_url": "https://github.com/huggingface/datasets/pull/25",
"diff_url": "https://github.com/huggingface/datasets/pull/25.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/25.patch",
"merged_at": 1588886089000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/24 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/24/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/24/comments | https://api.github.com/repos/huggingface/datasets/issues/24/events | https://github.com/huggingface/datasets/pull/24 | 609,064,987 | MDExOlB1bGxSZXF1ZXN0NDEwNzE5MTU0 | 24 | Add checksums | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"Looks good to me :-) \r\n\r\nJust would prefer to get rid of the `_DYNAMICALLY_IMPORTED_MODULE` attribute and replace it by a `get_imported_module()` function. Maybe there is something I'm not seeing here though - what do you think? ",
"> * I'm not sure I understand the general organization of checksums. I see w... | 1,588,167,449,000 | 1,588,276,370,000 | 1,588,276,369,000 | MEMBER | null | ### Checksums files
They are stored next to the dataset script in urls_checksums/checksums.txt.
They are used to check the integrity of the datasets downloaded files.
I kept the same format as tensorflow-datasets.
There is one checksums file for all configs.
### Load a dataset
When you do `load("squad")`, i... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/24/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/24/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/24",
"html_url": "https://github.com/huggingface/datasets/pull/24",
"diff_url": "https://github.com/huggingface/datasets/pull/24.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/24.patch",
"merged_at": 1588276369000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/23 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/23/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/23/comments | https://api.github.com/repos/huggingface/datasets/issues/23/events | https://github.com/huggingface/datasets/pull/23 | 608,508,706 | MDExOlB1bGxSZXF1ZXN0NDEwMjczOTU2 | 23 | Add metrics | {
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 1,588,096,925,000 | 1,589,185,178,000 | 1,589,185,178,000 | CONTRIBUTOR | null | This PR is a draft for adding metrics (sacrebleu and seqeval are added)
use case examples:
`import nlp`
**sacrebleu:**
```
refs = [['The dog bit the man.', 'It was not unexpected.', 'The man bit him first.'],
['The dog had bit the man.', 'No one was surprised.', 'The man had bitten the dog.']]
sys = ['... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/23/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/23/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/23",
"html_url": "https://github.com/huggingface/datasets/pull/23",
"diff_url": "https://github.com/huggingface/datasets/pull/23.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/23.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/22 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/22/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/22/comments | https://api.github.com/repos/huggingface/datasets/issues/22/events | https://github.com/huggingface/datasets/pull/22 | 608,298,586 | MDExOlB1bGxSZXF1ZXN0NDEwMTAyMjU3 | 22 | adding bleu score code | {
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 1,588,078,850,000 | 1,588,096,100,000 | 1,588,096,088,000 | CONTRIBUTOR | null | this PR add the BLEU score metric to the lib. It can be tested by running the following code.
` from nlp.metrics import bleu
hyp1 = "It is a guide to action which ensures that the military always obeys the commands of the party"
ref1a = "It is a guide to action that ensures that the military forces always being... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/22/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/22/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/22",
"html_url": "https://github.com/huggingface/datasets/pull/22",
"diff_url": "https://github.com/huggingface/datasets/pull/22.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/22.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/21 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/21/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/21/comments | https://api.github.com/repos/huggingface/datasets/issues/21/events | https://github.com/huggingface/datasets/pull/21 | 607,914,185 | MDExOlB1bGxSZXF1ZXN0NDA5Nzk2MTM4 | 21 | Cleanup Features - Updating convert command - Fix Download manager | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"For conflicts, I think the mention hint \"This should be modified because it mentions ...\" is missing.",
"Looks great!"
] | 1,588,029,415,000 | 1,588,325,387,000 | 1,588,325,386,000 | MEMBER | null | This PR makes a number of changes:
# Updating `Features`
Features are a complex mechanism provided in `tfds` to be able to modify a dataset on-the-fly when serializing to disk and when loading from disk.
We don't really need this because (1) it hides too much from the user and (2) our datatype can be directly ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/21/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/21/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/21",
"html_url": "https://github.com/huggingface/datasets/pull/21",
"diff_url": "https://github.com/huggingface/datasets/pull/21.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/21.patch",
"merged_at": 1588325386000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/20 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/20/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/20/comments | https://api.github.com/repos/huggingface/datasets/issues/20/events | https://github.com/huggingface/datasets/pull/20 | 607,313,557 | MDExOlB1bGxSZXF1ZXN0NDA5MzEyMDI1 | 20 | remove boto3 and promise dependencies | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 1,587,973,185,000 | 1,588,003,457,000 | 1,587,996,945,000 | MEMBER | null | With the new download manager, we don't need `promise` anymore.
I also removed `boto3` as in [this pr](https://github.com/huggingface/transformers/pull/3968) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/20/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/20/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/20",
"html_url": "https://github.com/huggingface/datasets/pull/20",
"diff_url": "https://github.com/huggingface/datasets/pull/20.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/20.patch",
"merged_at": 1587996945000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/19 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/19/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/19/comments | https://api.github.com/repos/huggingface/datasets/issues/19/events | https://github.com/huggingface/datasets/pull/19 | 606,400,645 | MDExOlB1bGxSZXF1ZXN0NDA4NjIwMjUw | 19 | Replace tf.constant for TF | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Awesome!"
] | 1,587,742,326,000 | 1,588,152,428,000 | 1,587,849,525,000 | CONTRIBUTOR | null | Replace simple tf.constant type of Tensor to tf.ragged.constant which allows to have examples of different size in a tf.data.Dataset.
Now the training works with TF. Here the same example than for the PT in collab:
```python
import tensorflow as tf
import nlp
from transformers import BertTokenizerFast, TFBertF... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/19/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/19/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/19",
"html_url": "https://github.com/huggingface/datasets/pull/19",
"diff_url": "https://github.com/huggingface/datasets/pull/19.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/19.patch",
"merged_at": 1587849525000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/18 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/18/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/18/comments | https://api.github.com/repos/huggingface/datasets/issues/18/events | https://github.com/huggingface/datasets/pull/18 | 606,109,196 | MDExOlB1bGxSZXF1ZXN0NDA4Mzg0MTc3 | 18 | Updating caching mechanism - Allow dependency in dataset processing scripts - Fix style and quality in the repo | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | null | [
"LGTM"
] | 1,587,713,988,000 | 1,588,174,048,000 | 1,588,089,988,000 | MEMBER | null | This PR has a lot of content (might be hard to review, sorry, in particular because I fixed the style in the repo at the same time).
# Style & quality:
You can now install the style and quality tools with `pip install -e .[quality]`. This will install black, the compatible version of sort and flake8.
You can then ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/18/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/18/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/18",
"html_url": "https://github.com/huggingface/datasets/pull/18",
"diff_url": "https://github.com/huggingface/datasets/pull/18.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/18.patch",
"merged_at": 1588089988000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/17 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/17/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/17/comments | https://api.github.com/repos/huggingface/datasets/issues/17/events | https://github.com/huggingface/datasets/pull/17 | 605,753,027 | MDExOlB1bGxSZXF1ZXN0NDA4MDk3NjM0 | 17 | Add Pandas as format type | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [] | 1,587,666,014,000 | 1,588,010,870,000 | 1,588,010,868,000 | CONTRIBUTOR | null | As detailed in the title ^^ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/17/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/17/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/17",
"html_url": "https://github.com/huggingface/datasets/pull/17",
"diff_url": "https://github.com/huggingface/datasets/pull/17.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/17.patch",
"merged_at": 1588010868000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/16 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/16/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/16/comments | https://api.github.com/repos/huggingface/datasets/issues/16/events | https://github.com/huggingface/datasets/pull/16 | 605,661,462 | MDExOlB1bGxSZXF1ZXN0NDA4MDIyMTUz | 16 | create our own DownloadManager | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"Looks great to me! ",
"The new download manager is ready. I removed the old folder and I fixed a few remaining dependencies.\r\nI tested it on squad and a few others from the dataset folder and it works fine.\r\n\r\nThe only impact of these changes is that it breaks the `download_and_prepare` script that was use... | 1,587,658,087,000 | 1,620,239,124,000 | 1,587,849,910,000 | MEMBER | null | I tried to create our own - and way simpler - download manager, by replacing all the complicated stuff with our own `cached_path` solution.
With this implementation, I tried `dataset = nlp.load('squad')` and it seems to work fine.
For the implementation, what I did exactly:
- I copied the old download manager
- I... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/16/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/16/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/16",
"html_url": "https://github.com/huggingface/datasets/pull/16",
"diff_url": "https://github.com/huggingface/datasets/pull/16.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/16.patch",
"merged_at": 1587849910000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/15 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/15/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/15/comments | https://api.github.com/repos/huggingface/datasets/issues/15/events | https://github.com/huggingface/datasets/pull/15 | 604,906,708 | MDExOlB1bGxSZXF1ZXN0NDA3NDEwOTk3 | 15 | [Tests] General Test Design for all dataset scripts | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"> I think I'm fine with this.\r\n> \r\n> The alternative would be to host a small subset of the dataset on the S3 together with the testing script. But I think having all (test file creation + actual tests) in one file is actually quite convenient.\r\n> \r\n> Good for me!\r\n> \r\n> One question though, will we ha... | 1,587,573,961,000 | 1,587,999,668,000 | 1,587,998,882,000 | MEMBER | null | The general idea is similar to how testing is done in `transformers`. There is one general `test_dataset_common.py` file which has a `DatasetTesterMixin` class. This class implements all of the logic that can be used in a generic way for all dataset classes. The idea is to keep each individual dataset test file as mini... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/15/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/15/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/15",
"html_url": "https://github.com/huggingface/datasets/pull/15",
"diff_url": "https://github.com/huggingface/datasets/pull/15.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/15.patch",
"merged_at": 1587998882000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/14 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/14/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/14/comments | https://api.github.com/repos/huggingface/datasets/issues/14/events | https://github.com/huggingface/datasets/pull/14 | 604,761,315 | MDExOlB1bGxSZXF1ZXN0NDA3MjkzNjU5 | 14 | [Download] Only create dir if not already exist | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,587,562,371,000 | 1,587,630,453,000 | 1,587,630,453,000 | MEMBER | null | This was quite annoying to find out :D.
Some datasets have save in the same directory. So we should only create a new directory if it doesn't already exist. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/14/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/14/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/14",
"html_url": "https://github.com/huggingface/datasets/pull/14",
"diff_url": "https://github.com/huggingface/datasets/pull/14.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/14.patch",
"merged_at": 1587630453000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/13 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/13/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/13/comments | https://api.github.com/repos/huggingface/datasets/issues/13/events | https://github.com/huggingface/datasets/pull/13 | 604,547,951 | MDExOlB1bGxSZXF1ZXN0NDA3MTIxMjkw | 13 | [Make style] | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"I think this can be quickly reproduced. \r\nI use `black, version 19.10b0`. \r\n\r\nWhen running: \r\n`black nlp/src/arrow_reader.py` \r\nit gives me: \r\n\r\n```\r\nerror: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST erro... | 1,587,543,006,000 | 1,587,646,942,000 | 1,587,646,942,000 | MEMBER | null | Added Makefile and applied make style to all.
make style runs the following code:
```
style:
black --line-length 119 --target-version py35 src
isort --recursive src
```
It's the same code that is run in `transformers`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/13/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/13/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/13",
"html_url": "https://github.com/huggingface/datasets/pull/13",
"diff_url": "https://github.com/huggingface/datasets/pull/13.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/13.patch",
"merged_at": 1587646942000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/12 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/12/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/12/comments | https://api.github.com/repos/huggingface/datasets/issues/12/events | https://github.com/huggingface/datasets/pull/12 | 604,518,583 | MDExOlB1bGxSZXF1ZXN0NDA3MDk3MzA4 | 12 | [Map Function] add assert statement if map function does not return dict or None | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Also added to an assert statement that if a dict is returned by function, all values of `dicts` are `lists`",
"Wait to merge until `make style` is set in place.",
"Updated the assert statements. Played around with multiple cases and it should be good now IMO. "
] | 1,587,540,084,000 | 1,602,138,701,000 | 1,587,709,743,000 | MEMBER | null | IMO, if a function is provided that is not a print statement (-> returns variable of type `None`) or a function that updates the datasets (-> returns variable of type `dict`), then a `TypeError` should be raised.
Not sure whether you had cases in mind where the user should do something else @thomwolf , but I think ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/12/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/12/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/12",
"html_url": "https://github.com/huggingface/datasets/pull/12",
"diff_url": "https://github.com/huggingface/datasets/pull/12.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/12.patch",
"merged_at": 1587709743000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/11 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/11/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/11/comments | https://api.github.com/repos/huggingface/datasets/issues/11/events | https://github.com/huggingface/datasets/pull/11 | 603,921,624 | MDExOlB1bGxSZXF1ZXN0NDA2NjExODk2 | 11 | [Convert TFDS to HFDS] Extend script to also allow just converting a single file | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,587,468,333,000 | 1,587,502,021,000 | 1,587,502,020,000 | MEMBER | null | Adds another argument to be able to convert only a single file | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/11/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/11/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/11",
"html_url": "https://github.com/huggingface/datasets/pull/11",
"diff_url": "https://github.com/huggingface/datasets/pull/11.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/11.patch",
"merged_at": 1587502020000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/10 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/10/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/10/comments | https://api.github.com/repos/huggingface/datasets/issues/10/events | https://github.com/huggingface/datasets/pull/10 | 603,909,327 | MDExOlB1bGxSZXF1ZXN0NDA2NjAxNzQ2 | 10 | Name json file "squad.json" instead of "squad.py.json" | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [] | 1,587,467,068,000 | 1,587,502,086,000 | 1,587,502,086,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/10/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/10/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/10",
"html_url": "https://github.com/huggingface/datasets/pull/10",
"diff_url": "https://github.com/huggingface/datasets/pull/10.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/10.patch",
"merged_at": 1587502086000
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/9 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/9/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/9/comments | https://api.github.com/repos/huggingface/datasets/issues/9/events | https://github.com/huggingface/datasets/pull/9 | 603,894,874 | MDExOlB1bGxSZXF1ZXN0NDA2NTkwMDQw | 9 | [Clean up] Datasets | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Yes!"
] | 1,587,465,596,000 | 1,587,502,198,000 | 1,587,502,198,000 | MEMBER | null | Clean up `nlp/datasets` folder.
As I understood, eventually the `nlp/datasets` shall not exist anymore at all.
The folder `nlp/datasets/nlp` is kept for the moment, but won't be needed in the future, since it will live on S3 (actually it already does) at: `https://s3.console.aws.amazon.com/s3/buckets/datasets.h... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/9/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/9/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/9",
"html_url": "https://github.com/huggingface/datasets/pull/9",
"diff_url": "https://github.com/huggingface/datasets/pull/9.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/9.patch",
"merged_at": 1587502198000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/8 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8/comments | https://api.github.com/repos/huggingface/datasets/issues/8/events | https://github.com/huggingface/datasets/pull/8 | 601,783,243 | MDExOlB1bGxSZXF1ZXN0NDA0OTg0NDUz | 8 | Fix issue 6: error when the citation is missing in the DatasetInfo | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [] | 1,587,110,666,000 | 1,588,152,431,000 | 1,587,389,052,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/8/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/8/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/8",
"html_url": "https://github.com/huggingface/datasets/pull/8",
"diff_url": "https://github.com/huggingface/datasets/pull/8.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/8.patch",
"merged_at": 1587389052000
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/7 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7/comments | https://api.github.com/repos/huggingface/datasets/issues/7/events | https://github.com/huggingface/datasets/pull/7 | 601,780,534 | MDExOlB1bGxSZXF1ZXN0NDA0OTgyMzA2 | 7 | Fix issue 5: allow empty datasets | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [] | 1,587,110,396,000 | 1,588,152,433,000 | 1,587,389,028,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7",
"html_url": "https://github.com/huggingface/datasets/pull/7",
"diff_url": "https://github.com/huggingface/datasets/pull/7.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7.patch",
"merged_at": 1587389027000
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/6 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6/comments | https://api.github.com/repos/huggingface/datasets/issues/6/events | https://github.com/huggingface/datasets/issues/6 | 600,330,836 | MDU6SXNzdWU2MDAzMzA4MzY= | 6 | Error when citation is not given in the DatasetInfo | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Yes looks good to me.\r\nNote that we may refactor quite strongly the `info.py` to make it a lot simpler (it's very complicated for basically a dictionary of info I think)",
"No, problem ^^ It might just be a temporary fix :)",
"Fixed."
] | 1,586,960,094,000 | 1,588,152,202,000 | 1,588,152,202,000 | CONTRIBUTOR | null | The following error is raised when the `citation` parameter is missing when we instantiate a `DatasetInfo`:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/info.py", line 338, in __repr__
citation_pprint = _indent('"""{}"""'.format(self.... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/6/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/6/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5/comments | https://api.github.com/repos/huggingface/datasets/issues/5/events | https://github.com/huggingface/datasets/issues/5 | 600,295,889 | MDU6SXNzdWU2MDAyOTU4ODk= | 5 | ValueError when a split is empty | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"To fix this I propose to modify only the file `arrow_reader.py` with few updates. First update, the following method:\r\n```python\r\ndef _make_file_instructions_from_absolutes(\r\n name,\r\n name2len,\r\n absolute_instructions,\r\n):\r\n \"\"\"Returns the files instructions from the absolu... | 1,586,957,113,000 | 1,588,152,185,000 | 1,588,152,185,000 | CONTRIBUTOR | null | When a split is empty either TEST, VALIDATION or TRAIN I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/load.py", line 295, in load
ds = dbuilder.as_dataset(**as_dataset_kwargs)
File "/home/jplu/dev/jplu/data... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4/comments | https://api.github.com/repos/huggingface/datasets/issues/4/events | https://github.com/huggingface/datasets/issues/4 | 600,185,417 | MDU6SXNzdWU2MDAxODU0MTc= | 4 | [Feature] Keep the list of labels of a dataset as metadata | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Yes! I see mostly two options for this:\r\n- a `Feature` approach like currently (but we might deprecate features)\r\n- wrapping in a smart way the Dictionary arrays of Arrow: https://arrow.apache.org/docs/python/data.html?highlight=dictionary%20encode#dictionary-arrays",
"I would have a preference for the secon... | 1,586,945,830,000 | 1,594,227,586,000 | 1,588,572,717,000 | CONTRIBUTOR | null | It would be useful to keep the list of the labels of a dataset as metadata. Either directly in the `DatasetInfo` or in the Arrow metadata. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3/comments | https://api.github.com/repos/huggingface/datasets/issues/3/events | https://github.com/huggingface/datasets/issues/3 | 600,180,050 | MDU6SXNzdWU2MDAxODAwNTA= | 3 | [Feature] More dataset outputs | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Yes!\r\n- pandas will be a one-liner in `arrow_dataset`: https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas\r\n- for Spark I have no idea. let's investigate that at some point",
"For Spark it looks to be pretty straightforward as well https://spark.apache.org/docs/latest/sq... | 1,586,945,294,000 | 1,588,572,747,000 | 1,588,572,747,000 | CONTRIBUTOR | null | Add the following dataset outputs:
- Spark
- Pandas | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2/comments | https://api.github.com/repos/huggingface/datasets/issues/2/events | https://github.com/huggingface/datasets/issues/2 | 599,767,671 | MDU6SXNzdWU1OTk3Njc2NzE= | 2 | Issue to read a local dataset | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"My first bug report ❤️\r\nLooking into this right now!",
"Ok, there are some news, most good than bad :laughing: \r\n\r\nThe dataset script now became:\r\n```python\r\nimport csv\r\n\r\nimport nlp\r\n\r\n\r\nclass Bbc(nlp.GeneratorBasedBuilder):\r\n VERSION = nlp.Version(\"1.0.0\")\r\n\r\n def __init__(sel... | 1,586,888,331,000 | 1,589,223,323,000 | 1,589,223,322,000 | CONTRIBUTOR | null | Hello,
As proposed by @thomwolf, I open an issue to explain what I'm trying to do without success. What I want to do is to create and load a local dataset, the script I have done is the following:
```python
import os
import csv
import nlp
class BbcConfig(nlp.BuilderConfig):
def __init__(self, **kwarg... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1/comments | https://api.github.com/repos/huggingface/datasets/issues/1/events | https://github.com/huggingface/datasets/pull/1 | 599,457,467 | MDExOlB1bGxSZXF1ZXN0NDAzMDk1NDYw | 1 | changing nlp.bool to nlp.bool_ | {
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 1,586,859,482,000 | 1,586,865,700,000 | 1,586,865,700,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1",
"html_url": "https://github.com/huggingface/datasets/pull/1",
"diff_url": "https://github.com/huggingface/datasets/pull/1.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1.patch",
"merged_at": 1586865700000
} | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.