
text stringlengths 3 1.68M | id stringlengths 13 169 | metadata dict | __index_level_0__ int64 0 2.21k |
|---|---|---|---|
"""Init file."""
from llama_index.readers.kaltura_esearch.base import KalturaESearchReader
__all__ = ["KalturaESearchReader"]
| llama_index/llama-index-integrations/readers/llama-index-readers-kaltura/llama_index/readers/kaltura_esearch/__init__.py/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-kaltura/llama_index/readers/kaltura_esearch/__init__.py",
"repo_id": "llama_index",
"token_count": 45
} | 1,339 |
from dataclasses import dataclass
from typing import Any, Awaitable, Callable, Dict, Optional, Sequence
from llama_index.legacy.bridge.pydantic import Field
from llama_index.legacy.callbacks import CallbackManager
from llama_index.legacy.constants import DEFAULT_NUM_OUTPUTS, DEFAULT_TEMPERATURE
from llama_index.legacy... | llama_index/llama-index-legacy/llama_index/legacy/llms/konko.py/0 | {
"file_path": "llama_index/llama-index-legacy/llama_index/legacy/llms/konko.py",
"repo_id": "llama_index",
"token_count": 11257
} | 1,587 |
<jupyter_start><jupyter_text>Segment Anything Model using `transformers` 🤗 library| | | ||---------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------... | notebooks/examples/segment_anything.ipynb/0 | {
"file_path": "notebooks/examples/segment_anything.ipynb",
"repo_id": "notebooks",
"token_count": 5421
} | 310 |
"""Init file."""
from llama_index.readers.apify.actor.base import ApifyActor
__all__ = ["ApifyActor"]
| llama_index/llama-index-integrations/readers/llama-index-readers-apify/llama_index/readers/apify/actor/__init__.py/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-apify/llama_index/readers/apify/actor/__init__.py",
"repo_id": "llama_index",
"token_count": 38
} | 1,317 |
# langchain-together
| langchain/libs/partners/together/README.md/0 | {
"file_path": "langchain/libs/partners/together/README.md",
"repo_id": "langchain",
"token_count": 6
} | 640 |
poetry_requirements(
name="poetry",
)
| llama_index/llama-index-integrations/embeddings/llama-index-embeddings-together/BUILD/0 | {
"file_path": "llama_index/llama-index-integrations/embeddings/llama-index-embeddings-together/BUILD",
"repo_id": "llama_index",
"token_count": 18
} | 1,274 |
---
sidebar_class_name: node-only
---
import CodeBlock from "@theme/CodeBlock";
# Tigris
Tigris makes it easy to build AI applications with vector embeddings.
It is a fully managed cloud-native database that allows you store and
index documents and vector embeddings for fast and scalable vector search.
:::tip Compa... | langchainjs/docs/core_docs/docs/integrations/vectorstores/tigris.mdx/0 | {
"file_path": "langchainjs/docs/core_docs/docs/integrations/vectorstores/tigris.mdx",
"repo_id": "langchainjs",
"token_count": 1076
} | 722 |
"""SQL Retriever."""
import logging
from abc import ABC, abstractmethod
from enum import Enum
from typing import Any, Callable, Dict, List, Optional, Tuple, Union, cast
from sqlalchemy import Table
from llama_index.legacy.callbacks.base import CallbackManager
from llama_index.legacy.core.base_retriever import BaseRe... | llama_index/llama-index-legacy/llama_index/legacy/indices/struct_store/sql_retriever.py/0 | {
"file_path": "llama_index/llama-index-legacy/llama_index/legacy/indices/struct_store/sql_retriever.py",
"repo_id": "llama_index",
"token_count": 6780
} | 1,570 |
# Copyright 2024 The InstantX Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable l... | diffusers/examples/community/pipeline_stable_diffusion_xl_instantid.py/0 | {
"file_path": "diffusers/examples/community/pipeline_stable_diffusion_xl_instantid.py",
"repo_id": "diffusers",
"token_count": 22649
} | 208 |
package indexparamcheck
type ivfBaseChecker struct {
floatVectorBaseChecker
}
func (c ivfBaseChecker) StaticCheck(params map[string]string) error {
if !CheckIntByRange(params, NLIST, MinNList, MaxNList) {
return errOutOfRange(NLIST, MinNList, MaxNList)
}
// skip check number of rows
return c.floatVectorBaseC... | milvus/pkg/util/indexparamcheck/ivf_base_checker.go/0 | {
"file_path": "milvus/pkg/util/indexparamcheck/ivf_base_checker.go",
"repo_id": "milvus",
"token_count": 211
} | 1,906 |
<!---
Copyright 2024- The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or... | diffusers/docs/README.md/0 | {
"file_path": "diffusers/docs/README.md",
"repo_id": "diffusers",
"token_count": 3145
} | 189 |
<jupyter_start><jupyter_code># Setup OpenAI Agent
import openai
openai.api_key = "sk-your-key"
from llama_index.agent import OpenAIAgent
# Import and initialize our tool spec
from llama_index.tools.google_calendar.base import GoogleCalendarToolSpec
tool_spec = GoogleCalendarToolSpec()
# Create the Agent with our tool... | llama_index/llama-index-integrations/tools/llama-index-tools-google/examples/google_calendar.ipynb/0 | {
"file_path": "llama_index/llama-index-integrations/tools/llama-index-tools-google/examples/google_calendar.ipynb",
"repo_id": "llama_index",
"token_count": 310
} | 1,480 |
# Copyright 2021 AlQuraishi Laboratory
# Copyright 2021 DeepMind Technologies Limited
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# U... | transformers/src/transformers/models/esm/openfold_utils/tensor_utils.py/0 | {
"file_path": "transformers/src/transformers/models/esm/openfold_utils/tensor_utils.py",
"repo_id": "transformers",
"token_count": 1946
} | 616 |
import { initializeAgentExecutorWithOptions } from "langchain/agents";
import { OpenAI } from "@langchain/openai";
import { Calculator } from "langchain/tools/calculator";
import {
GoogleCalendarCreateTool,
GoogleCalendarViewTool,
} from "@langchain/community/tools/google_calendar";
export async function run() {
... | langchainjs/examples/src/tools/google_calendar.ts/0 | {
"file_path": "langchainjs/examples/src/tools/google_calendar.ts",
"repo_id": "langchainjs",
"token_count": 607
} | 818 |
# SQL
In this guide we'll go over the basic ways to create a Q&A chain and agent over a SQL database.
These systems will allow us to ask a question about the data in a SQL database and get back a natural language answer.
The main difference between the two is that our agent can query the database in a loop as many tim... | langchainjs/docs/core_docs/docs/use_cases/sql/index.mdx/0 | {
"file_path": "langchainjs/docs/core_docs/docs/use_cases/sql/index.mdx",
"repo_id": "langchainjs",
"token_count": 450
} | 744 |
reviewers:
- xiaocai2333
approvers:
- maintainers
| milvus/githooks/OWNERS/0 | {
"file_path": "milvus/githooks/OWNERS",
"repo_id": "milvus",
"token_count": 23
} | 1,718 |
# LlamaIndex Callbacks Integration: Aim
| llama_index/llama-index-integrations/callbacks/llama-index-callbacks-aim/README.md/0 | {
"file_path": "llama_index/llama-index-integrations/callbacks/llama-index-callbacks-aim/README.md",
"repo_id": "llama_index",
"token_count": 10
} | 1,180 |
# Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
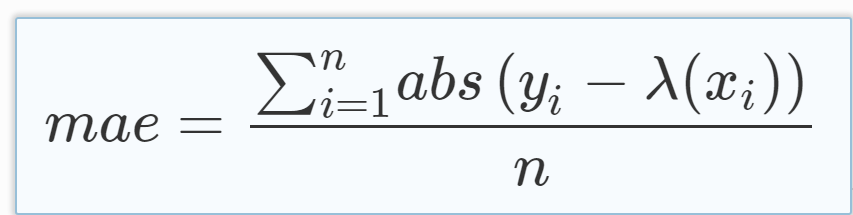
## How to Use
At minimum, this metric re... | datasets/metrics/mae/README.md/0 | {
"file_path": "datasets/metrics/mae/README.md",
"repo_id": "datasets",
"token_count": 1421
} | 126 |
"""Test tool utils."""
import unittest
from typing import Any, Type
from unittest.mock import MagicMock, Mock
import pytest
from langchain_core.tools import Tool, ToolException, tool
from langchain.agents import load_tools
from langchain.agents.agent import Agent
from langchain.agents.chat.base import ChatAgent
from ... | langchain/libs/langchain/tests/unit_tests/agents/test_tools.py/0 | {
"file_path": "langchain/libs/langchain/tests/unit_tests/agents/test_tools.py",
"repo_id": "langchain",
"token_count": 1228
} | 632 |
# PPTX files
This example goes over how to load data from PPTX files. By default, one document will be created for all pages in the PPTX file.
## Setup
```bash npm2yarn
npm install officeparser
```
## Usage, one document per page
```typescript
import { PPTXLoader } from "langchain/document_loaders/fs/pptx";
const... | langchainjs/docs/core_docs/docs/integrations/document_loaders/file_loaders/pptx.mdx/0 | {
"file_path": "langchainjs/docs/core_docs/docs/integrations/document_loaders/file_loaders/pptx.mdx",
"repo_id": "langchainjs",
"token_count": 141
} | 702 |
from typing import Any, Dict, List, Optional
from langchain_core.callbacks import CallbackManagerForLLMRun
from langchain_core.language_models.llms import BaseLLM
from langchain_core.outputs import Generation, LLMResult
from langchain_core.pydantic_v1 import Field, root_validator
from langchain_community.llms.openai ... | langchain/libs/community/langchain_community/llms/vllm.py/0 | {
"file_path": "langchain/libs/community/langchain_community/llms/vllm.py",
"repo_id": "langchain",
"token_count": 2278
} | 285 |
from unittest.mock import Mock
from langchain_pinecone.vectorstores import Pinecone
def test_initialization() -> None:
"""Test integration vectorstore initialization."""
# mock index
index = Mock()
embedding = Mock()
text_key = "xyz"
Pinecone(index, embedding, text_key)
| langchain/libs/partners/pinecone/tests/unit_tests/test_vectorstores.py/0 | {
"file_path": "langchain/libs/partners/pinecone/tests/unit_tests/test_vectorstores.py",
"repo_id": "langchain",
"token_count": 99
} | 680 |
// Licensed to the LF AI & Data foundation under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use th... | milvus/internal/querynodev2/segments/search.go/0 | {
"file_path": "milvus/internal/querynodev2/segments/search.go",
"repo_id": "milvus",
"token_count": 1475
} | 1,771 |
import { gmail_v1 } from "googleapis";
import { z } from "zod";
import { GmailBaseTool, GmailBaseToolParams } from "./base.js";
import { SEARCH_DESCRIPTION } from "./descriptions.js";
export class GmailSearch extends GmailBaseTool {
name = "search_gmail";
schema = z.object({
query: z.string(),
maxResults:... | langchainjs/libs/langchain-community/src/tools/gmail/search.ts/0 | {
"file_path": "langchainjs/libs/langchain-community/src/tools/gmail/search.ts",
"repo_id": "langchainjs",
"token_count": 1612
} | 970 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/inpaint.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/inpaint.md",
"repo_id": "diffusers",
"token_count": 14131
} | 199 |
<jupyter_start><jupyter_text>MemorizeFine-tuning LLM itself to memorize information using unsupervised learning.This tool requires LLMs that support fine-tuning. Currently, only `langchain.llms import GradientLLM` is supported. Imports<jupyter_code>import os
from langchain.agents import AgentExecutor, AgentType, init... | langchain/docs/docs/integrations/tools/memorize.ipynb/0 | {
"file_path": "langchain/docs/docs/integrations/tools/memorize.ipynb",
"repo_id": "langchain",
"token_count": 1048
} | 185 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | transformers/utils/check_model_tester.py/0 | {
"file_path": "transformers/utils/check_model_tester.py",
"repo_id": "transformers",
"token_count": 1240
} | 772 |
{
"moz:firefoxOptions": {
"prefs": {
"media.navigator.streams.fake": true,
"media.navigator.permission.disabled": true
},
"args": []
},
"goog:chromeOptions": {
"args": [
"--use-fake-device-for-media-stream",
"--use-fake-ui-for-media-stream"
]
}
}
| candle/candle-wasm-tests/webdriver.json/0 | {
"file_path": "candle/candle-wasm-tests/webdriver.json",
"repo_id": "candle",
"token_count": 143
} | 82 |
package tasks
import (
"fmt"
"testing"
"github.com/stretchr/testify/assert"
"github.com/milvus-io/milvus/pkg/util/paramtable"
)
func TestUserTaskPollingPolicy(t *testing.T) {
paramtable.Init()
testCommonPolicyOperation(t, newUserTaskPollingPolicy())
testCrossUserMerge(t, newUserTaskPollingPolicy())
}
func T... | milvus/internal/querynodev2/tasks/policy_test.go/0 | {
"file_path": "milvus/internal/querynodev2/tasks/policy_test.go",
"repo_id": "milvus",
"token_count": 1331
} | 1,879 |
import { TokenTextSplitter } from "langchain/text_splitter";
import fs from "fs";
import path from "path";
import { Document } from "@langchain/core/documents";
export const run = async () => {
/* Split text */
const text = fs.readFileSync(
path.resolve(__dirname, "../../state_of_the_union.txt"),
"utf8"
... | langchainjs/examples/src/indexes/token_text_splitter.ts/0 | {
"file_path": "langchainjs/examples/src/indexes/token_text_splitter.ts",
"repo_id": "langchainjs",
"token_count": 242
} | 799 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/depth2img.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/depth2img.md",
"repo_id": "diffusers",
"token_count": 1376
} | 199 |
from langchain_community.document_loaders.tsv import UnstructuredTSVLoader
__all__ = ["UnstructuredTSVLoader"]
| langchain/libs/langchain/langchain/document_loaders/tsv.py/0 | {
"file_path": "langchain/libs/langchain/langchain/document_loaders/tsv.py",
"repo_id": "langchain",
"token_count": 35
} | 495 |
#!python
import re
import sys
def eprint(*args, **kwargs):
print(*args, file=sys.stderr, **kwargs)
def readfile(filename):
file = open(filename)
content = file.read()
return content
def replace_all(template, **kwargs):
for k, v in kwargs.items():
template = template.replace("@@" + k + "@@... | milvus/tools/core_gen/meta_gen.py/0 | {
"file_path": "milvus/tools/core_gen/meta_gen.py",
"repo_id": "milvus",
"token_count": 791
} | 2,051 |
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
from llama_index.core.bridge.pydantic import BaseModel, Field
class RetrievalMetricResult(BaseModel):
"""Metric result.
Attributes:
score (float): Score for the metric
metadata (Dict[str, Any]): Metadata for the... | llama_index/llama-index-core/llama_index/core/evaluation/retrieval/metrics_base.py/0 | {
"file_path": "llama_index/llama-index-core/llama_index/core/evaluation/retrieval/metrics_base.py",
"repo_id": "llama_index",
"token_count": 610
} | 1,118 |
import { decompressFromEncodedURIComponent } from "lz-string";
export function getStateFromUrl(path: string) {
let configFromUrl = null;
let basePath = path;
if (basePath.endsWith("/")) {
basePath = basePath.slice(0, -1);
}
if (basePath.endsWith("/playground")) {
basePath = basePath.slice(0, -"/play... | langserve/langserve/playground/src/utils/url.ts/0 | {
"file_path": "langserve/langserve/playground/src/utils/url.ts",
"repo_id": "langserve",
"token_count": 343
} | 1,066 |
from typing import Any, Callable, Optional, Sequence
from llama_index.core.base.llms.types import (
ChatMessage,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.callbacks import CallbackManager
from llama_index.core.llms.callbacks import llm_completion_callback
from llam... | llama_index/llama-index-core/llama_index/core/llms/mock.py/0 | {
"file_path": "llama_index/llama-index-core/llama_index/core/llms/mock.py",
"repo_id": "llama_index",
"token_count": 1178
} | 1,138 |
---
hide_table_of_contents: true
---
import CodeBlock from "@theme/CodeBlock";
# Exa Search
Exa (formerly Metaphor Search) is a search engine fully designed for use by LLMs. Search for documents on the internet using natural language queries, then retrieve cleaned HTML content from desired documents.
Unlike keyword... | langchainjs/docs/core_docs/docs/integrations/tools/exa_search.mdx/0 | {
"file_path": "langchainjs/docs/core_docs/docs/integrations/tools/exa_search.mdx",
"repo_id": "langchainjs",
"token_count": 1012
} | 725 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/src/diffusers/utils/hub_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/hub_utils.py",
"repo_id": "diffusers",
"token_count": 9131
} | 270 |
import { test, expect } from "@jest/globals";
import { BaseLLM } from "@langchain/core/language_models/llms";
import { LLMResult } from "@langchain/core/outputs";
import { PromptTemplate } from "@langchain/core/prompts";
import { VectorStoreRetriever } from "@langchain/core/vectorstores";
import { FakeEmbeddings } from... | langchainjs/langchain/src/chains/tests/simple_sequential_chain.test.ts/0 | {
"file_path": "langchainjs/langchain/src/chains/tests/simple_sequential_chain.test.ts",
"repo_id": "langchainjs",
"token_count": 1344
} | 870 |
import glob
import sys
import pandas as pd
from huggingface_hub import hf_hub_download, upload_file
from huggingface_hub.utils._errors import EntryNotFoundError
sys.path.append(".")
from utils import BASE_PATH, FINAL_CSV_FILE, GITHUB_SHA, REPO_ID, collate_csv # noqa: E402
def has_previous_benchmark() -> str:
... | diffusers/benchmarks/push_results.py/0 | {
"file_path": "diffusers/benchmarks/push_results.py",
"repo_id": "diffusers",
"token_count": 1089
} | 169 |
package httpserver
import (
"strconv"
"strings"
"testing"
"github.com/gin-gonic/gin"
"github.com/stretchr/testify/assert"
"github.com/tidwall/gjson"
"github.com/milvus-io/milvus-proto/go-api/v2/commonpb"
"github.com/milvus-io/milvus-proto/go-api/v2/milvuspb"
"github.com/milvus-io/milvus-proto/go-api/v2/sche... | milvus/internal/distributed/proxy/httpserver/utils_test.go/0 | {
"file_path": "milvus/internal/distributed/proxy/httpserver/utils_test.go",
"repo_id": "milvus",
"token_count": 13376
} | 1,816 |
import collections
import itertools
import os
from dataclasses import dataclass
from typing import List, Optional, Tuple, Type
import pandas as pd
import pyarrow as pa
import pyarrow.json as paj
import datasets
from datasets.features.features import FeatureType
from datasets.tasks.base import TaskTemplate
logger = ... | datasets/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py",
"repo_id": "datasets",
"token_count": 11960
} | 144 |
// Copyright (C) 2019-2020 Zilliz. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance
// with the License. You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable l... | milvus/internal/core/src/storage/OpenDALChunkManager.h/0 | {
"file_path": "milvus/internal/core/src/storage/OpenDALChunkManager.h",
"repo_id": "milvus",
"token_count": 1164
} | 1,674 |
# Contributing A `LabelledRagDataset`
Building a more robust RAG system requires a diversified evaluation suite. That is
why we launched `LlamaDatasets` in [llama-hub](https://llamahub.ai). In this page,
we discuss how you can contribute the first kind of `LlamaDataset` made available
in llama-hub, that is, `LabelledR... | llama_index/docs/module_guides/evaluating/contributing_llamadatasets.md/0 | {
"file_path": "llama_index/docs/module_guides/evaluating/contributing_llamadatasets.md",
"repo_id": "llama_index",
"token_count": 436
} | 1,119 |
python_sources()
| llama_index/llama-index-legacy/llama_index/legacy/command_line/BUILD/0 | {
"file_path": "llama_index/llama-index-legacy/llama_index/legacy/command_line/BUILD",
"repo_id": "llama_index",
"token_count": 6
} | 1,550 |
"""Smart PDF Loader."""
from typing import Any, Dict, List, Optional
from llama_index.core.readers.base import BaseReader
from llama_index.core.schema import Document
class SmartPDFLoader(BaseReader):
"""SmartPDFLoader uses nested layout information such as sections, paragraphs, lists and tables to smartly chunk... | llama_index/llama-index-integrations/readers/llama-index-readers-smart-pdf-loader/llama_index/readers/smart_pdf_loader/base.py/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-smart-pdf-loader/llama_index/readers/smart_pdf_loader/base.py",
"repo_id": "llama_index",
"token_count": 561
} | 1,419 |
package logutil
import (
"context"
"testing"
"github.com/stretchr/testify/assert"
"go.uber.org/zap/zapcore"
"google.golang.org/grpc/metadata"
"github.com/milvus-io/milvus/pkg/log"
)
func TestCtxWithLevelAndTrace(t *testing.T) {
t.Run("debug level", func(t *testing.T) {
ctx := withMetaData(context.TODO(), z... | milvus/pkg/util/logutil/grpc_interceptor_test.go/0 | {
"file_path": "milvus/pkg/util/logutil/grpc_interceptor_test.go",
"repo_id": "milvus",
"token_count": 830
} | 2,114 |
import type { BaseLanguageModelInterface } from "@langchain/core/language_models/base";
import type { VectorStoreInterface } from "@langchain/core/vectorstores";
import { CallbackManagerForChainRun } from "@langchain/core/callbacks/manager";
import { ChainValues } from "@langchain/core/utils/types";
import { BaseChain,... | langchainjs/langchain/src/chains/vector_db_qa.ts/0 | {
"file_path": "langchainjs/langchain/src/chains/vector_db_qa.ts",
"repo_id": "langchainjs",
"token_count": 1658
} | 898 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless r... | transformers/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py/0 | {
"file_path": "transformers/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py",
"repo_id": "transformers",
"token_count": 11230
} | 669 |
import { loadEvaluator } from "langchain/evaluation";
const chain = await loadEvaluator("pairwise_string", {
criteria: "conciseness",
});
const res = await chain.evaluateStringPairs({
prediction: "Addition is a mathematical operation.",
predictionB:
"Addition is a mathematical operation that adds two number... | langchainjs/examples/src/guides/evaluation/comparision_evaluator/pairwise_string_without_reference.ts/0 | {
"file_path": "langchainjs/examples/src/guides/evaluation/comparision_evaluator/pairwise_string_without_reference.ts",
"repo_id": "langchainjs",
"token_count": 220
} | 805 |
---
sidebar_class_name: node-only
---
# Convex
LangChain.js supports [Convex](https://convex.dev/) as a [vector store](https://docs.convex.dev/vector-search), and supports the standard similarity search.
## Setup
### Create project
Get a working [Convex](https://docs.convex.dev/) project set up, for example by usi... | langchainjs/docs/core_docs/docs/integrations/vectorstores/convex.mdx/0 | {
"file_path": "langchainjs/docs/core_docs/docs/integrations/vectorstores/convex.mdx",
"repo_id": "langchainjs",
"token_count": 558
} | 748 |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the Lice... | transformers/src/transformers/models/xlnet/modeling_tf_xlnet.py/0 | {
"file_path": "transformers/src/transformers/models/xlnet/modeling_tf_xlnet.py",
"repo_id": "transformers",
"token_count": 34891
} | 703 |
import { collections } from "$lib/server/database";
import { authCondition } from "$lib/server/auth";
import { z } from "zod";
import { ObjectId } from "mongodb";
export async function GET({ locals, params }) {
const id = z.string().parse(params.id);
const convId = new ObjectId(id);
if (locals.user?._id || locals.... | chat-ui/src/routes/api/conversation/[id]/+server.ts/0 | {
"file_path": "chat-ui/src/routes/api/conversation/[id]/+server.ts",
"repo_id": "chat-ui",
"token_count": 396
} | 101 |
locust_insert_performance:
collections:
-
milvus:
db_config.primary_path: /test/milvus/db_data_011/insert_sift_1m_128_l2_2
collection_name: local_1m_128_l2
ni_per: 50000
build_index: false
index_type: ivf_sq8
index_param:
nlist: 1024
task:
load_s... | milvus/tests/benchmark/milvus_benchmark/suites/2_locust_load_insert.yaml/0 | {
"file_path": "milvus/tests/benchmark/milvus_benchmark/suites/2_locust_load_insert.yaml",
"repo_id": "milvus",
"token_count": 334
} | 1,878 |
"""Test tool spec."""
from typing import List, Optional, Tuple, Type, Union
import pytest
from llama_index.legacy.bridge.pydantic import BaseModel
from llama_index.legacy.tools.tool_spec.base import BaseToolSpec
from llama_index.legacy.tools.types import ToolMetadata
class FooSchema(BaseModel):
arg1: str
ar... | llama_index/llama-index-legacy/tests/tools/tool_spec/test_base.py/0 | {
"file_path": "llama_index/llama-index-legacy/tests/tools/tool_spec/test_base.py",
"repo_id": "llama_index",
"token_count": 1889
} | 1,640 |
"""
This tests RocksetVectorStore by creating a new collection,
adding nodes to it, querying nodes, and then
deleting the collection.
To run this test, set ROCKSET_API_KEY and ROCKSET_API_SERVER
env vars. If ROCKSET_API_SERVER is not set, it will use us-west-2.
Find your API server from https://rockset.com/docs/rest-... | llama_index/llama-index-legacy/tests/vector_stores/test_rockset.py/0 | {
"file_path": "llama_index/llama-index-legacy/tests/vector_stores/test_rockset.py",
"repo_id": "llama_index",
"token_count": 1347
} | 1,654 |
// Licensed to the LF AI & Data foundation under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use th... | milvus/internal/util/importutil/binlog_adapter_test.go/0 | {
"file_path": "milvus/internal/util/importutil/binlog_adapter_test.go",
"repo_id": "milvus",
"token_count": 16657
} | 1,795 |
<jupyter_start><jupyter_text>Tencent COS File>[Tencent Cloud Object Storage (COS)](https://www.tencentcloud.com/products/cos) is a distributed > storage service that enables you to store any amount of data from anywhere via HTTP/HTTPS protocols. > `COS` has no restrictions on data structure or format. It also has no bu... | langchain/docs/docs/integrations/document_loaders/tencent_cos_file.ipynb/0 | {
"file_path": "langchain/docs/docs/integrations/document_loaders/tencent_cos_file.ipynb",
"repo_id": "langchain",
"token_count": 326
} | 111 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless r... | transformers/tests/models/efficientnet/test_modeling_efficientnet.py/0 | {
"file_path": "transformers/tests/models/efficientnet/test_modeling_efficientnet.py",
"repo_id": "transformers",
"token_count": 3981
} | 720 |
from unittest.mock import MagicMock, patch
import pytest
from llama_index.legacy.core.llms.types import ChatMessage
from llama_index.legacy.llms import LocalAI
from openai.types import Completion, CompletionChoice
from openai.types.chat.chat_completion import ChatCompletion, Choice
from openai.types.chat.chat_completi... | llama_index/llama-index-legacy/tests/llms/test_localai.py/0 | {
"file_path": "llama_index/llama-index-legacy/tests/llms/test_localai.py",
"repo_id": "llama_index",
"token_count": 1197
} | 1,670 |
# coding=utf-8
# Copyright 2021 The Fairseq Authors and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/... | transformers/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py/0 | {
"file_path": "transformers/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py",
"repo_id": "transformers",
"token_count": 24375
} | 697 |
from llama_index.readers.couchbase.base import CouchbaseReader
__all__ = ["CouchbaseReader"]
| llama_index/llama-index-integrations/readers/llama-index-readers-couchbase/llama_index/readers/couchbase/__init__.py/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-couchbase/llama_index/readers/couchbase/__init__.py",
"repo_id": "llama_index",
"token_count": 31
} | 1,418 |
from pathlib import Path
import pytest
from datasets import load_dataset
from datasets.packaged_modules.cache.cache import Cache
SAMPLE_DATASET_TWO_CONFIG_IN_METADATA = "hf-internal-testing/audiofolder_two_configs_in_metadata"
def test_cache(text_dir: Path):
ds = load_dataset(str(text_dir))
hash = Path(ds... | datasets/tests/packaged_modules/test_cache.py/0 | {
"file_path": "datasets/tests/packaged_modules/test_cache.py",
"repo_id": "datasets",
"token_count": 1243
} | 145 |
# Metal
This page covers how to use [Metal](https://getmetal.io) within LangChain.
## What is Metal?
Metal is a managed retrieval & memory platform built for production. Easily index your data into `Metal` and run semantic search and retrieval on it.
![Screenshot of the Metal dashboard showing the Browse Index fea... | langchain/docs/docs/integrations/providers/metal.mdx/0 | {
"file_path": "langchain/docs/docs/integrations/providers/metal.mdx",
"repo_id": "langchain",
"token_count": 267
} | 151 |
from langchain_google_genai import __all__
EXPECTED_ALL = [
"ChatGoogleGenerativeAI",
"GoogleGenerativeAIEmbeddings",
"GoogleGenerativeAI",
"HarmBlockThreshold",
"HarmCategory",
]
def test_all_imports() -> None:
assert sorted(EXPECTED_ALL) == sorted(__all__)
| langchain/libs/partners/google-genai/tests/unit_tests/test_imports.py/0 | {
"file_path": "langchain/libs/partners/google-genai/tests/unit_tests/test_imports.py",
"repo_id": "langchain",
"token_count": 112
} | 622 |
python_sources()
| llama_index/llama-index-integrations/readers/llama-index-readers-notion/llama_index/readers/notion/BUILD/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-notion/llama_index/readers/notion/BUILD",
"repo_id": "llama_index",
"token_count": 6
} | 1,527 |
# Fork that adds only the correct stream to this kernel in order
# to make cuda graphs work.
awq_commit := bd1dc2d5254345cc76ab71894651fb821275bdd4
awq:
rm -rf llm-awq
git clone https://github.com/huggingface/llm-awq
build-awq: awq
cd llm-awq/ && git fetch && git checkout $(awq_commit)
cd llm-awq/awq/kernels && ... | text-generation-inference/server/Makefile-awq/0 | {
"file_path": "text-generation-inference/server/Makefile-awq",
"repo_id": "text-generation-inference",
"token_count": 184
} | 435 |
"""Test ChatMistral chat model."""
from langchain_mistralai.chat_models import ChatMistralAI
def test_stream() -> None:
"""Test streaming tokens from ChatMistralAI."""
llm = ChatMistralAI()
for token in llm.stream("I'm Pickle Rick"):
assert isinstance(token.content, str)
async def test_astream(... | langchain/libs/partners/mistralai/tests/integration_tests/test_chat_models.py/0 | {
"file_path": "langchain/libs/partners/mistralai/tests/integration_tests/test_chat_models.py",
"repo_id": "langchain",
"token_count": 643
} | 670 |
# alias for backwards compatibility
from llama_index.core.storage.docstore.simple_docstore import (
DocumentStore,
SimpleDocumentStore,
)
from llama_index.core.storage.docstore.types import BaseDocumentStore
__all__ = [
"BaseDocumentStore",
"DocumentStore",
"SimpleDocumentStore",
]
| llama_index/llama-index-core/llama_index/core/storage/docstore/__init__.py/0 | {
"file_path": "llama_index/llama-index-core/llama_index/core/storage/docstore/__init__.py",
"repo_id": "llama_index",
"token_count": 97
} | 1,249 |
"""Test Momento cache functionality.
To run tests, set the environment variable MOMENTO_AUTH_TOKEN to a valid
Momento auth token. This can be obtained by signing up for a free
Momento account at https://gomomento.com/.
"""
from __future__ import annotations
import uuid
from datetime import timedelta
from typing impor... | langchain/libs/langchain/tests/integration_tests/cache/test_momento_cache.py/0 | {
"file_path": "langchain/libs/langchain/tests/integration_tests/cache/test_momento_cache.py",
"repo_id": "langchain",
"token_count": 1203
} | 591 |
import logging
from typing import Any, Dict, List, Mapping, Optional
from langchain_core.callbacks import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.pydantic_v1 import Extra, Field, SecretStr, root_validator
from langchain_core.utils import convert_to_secret_str, g... | langchain/libs/community/langchain_community/llms/gooseai.py/0 | {
"file_path": "langchain/libs/community/langchain_community/llms/gooseai.py",
"repo_id": "langchain",
"token_count": 2176
} | 263 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/unclip/test_unclip.py/0 | {
"file_path": "diffusers/tests/pipelines/unclip/test_unclip.py",
"repo_id": "diffusers",
"token_count": 7863
} | 273 |
package model
import (
"github.com/samber/lo"
"github.com/milvus-io/milvus-proto/go-api/v2/commonpb"
"github.com/milvus-io/milvus-proto/go-api/v2/schemapb"
pb "github.com/milvus-io/milvus/internal/proto/etcdpb"
"github.com/milvus-io/milvus/pkg/common"
)
type Collection struct {
TenantID string
DBI... | milvus/internal/metastore/model/collection.go/0 | {
"file_path": "milvus/internal/metastore/model/collection.go",
"repo_id": "milvus",
"token_count": 2551
} | 1,810 |
import { Document } from "@langchain/core/documents";
import {
Comparator,
Comparators,
Comparison,
Operation,
Operator,
Operators,
StructuredQuery,
} from "../../chains/query_constructor/ir.js";
import { BaseTranslator } from "./base.js";
import { castValue, isFilterEmpty } from "./utils.js";
/**
* A t... | langchainjs/langchain/src/retrievers/self_query/functional.ts/0 | {
"file_path": "langchainjs/langchain/src/retrievers/self_query/functional.ts",
"repo_id": "langchainjs",
"token_count": 2554
} | 904 |
""" Cosine Scheduler
Cosine LR schedule with warmup, cycle/restarts, noise, k-decay.
Hacked together by / Copyright 2021 Ross Wightman
"""
import logging
import math
import numpy as np
import torch
from .scheduler import Scheduler
_logger = logging.getLogger(__name__)
class CosineLRScheduler(Scheduler):
"""
... | pytorch-image-models/timm/scheduler/cosine_lr.py/0 | {
"file_path": "pytorch-image-models/timm/scheduler/cosine_lr.py",
"repo_id": "pytorch-image-models",
"token_count": 2031
} | 352 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::Result;
use candle_core::{Device, Tensor};
fn main() -> Result<()> {
let a = Tensor::new(&[[0.0f32, 1.0, 2.0], [3.0, 4.0, 5.0]], &Device::Cpu)?;
let b = Tensor::new(&[[88.0f32, 99.0]], ... | candle/candle-core/examples/basics.rs/0 | {
"file_path": "candle/candle-core/examples/basics.rs",
"repo_id": "candle",
"token_count": 287
} | 36 |
variable "chat_langchain_backend_name" {
description = "Name to use for resources that will be created"
type = string
}
variable "project_id" {
description = "The ID of the project"
type = string
}
variable "region" {
description = "The region to deploy to"
type = string
}
variable "... | chat-langchain/terraform/modules/chat_langchain_backend/variables.tf/0 | {
"file_path": "chat-langchain/terraform/modules/chat_langchain_backend/variables.tf",
"repo_id": "chat-langchain",
"token_count": 859
} | 9 |
// Licensed to the LF AI & Data foundation under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use th... | milvus/internal/rootcoord/create_alias_task_test.go/0 | {
"file_path": "milvus/internal/rootcoord/create_alias_task_test.go",
"repo_id": "milvus",
"token_count": 666
} | 1,917 |
<p align="center"> <img src="http://sayef.tech:8082/uploads/FSNER-LOGO-2.png" alt="FSNER LOGO"> </p>
<p align="center">
Implemented by <a href="https://huggingface.co/sayef"> sayef </a>.
</p>
## Overview
The FSNER model was proposed in [Example-Based Named Entity Recognition](https://arxiv.org/abs/2008.10570) by ... | transformers/examples/research_projects/fsner/README.md/0 | {
"file_path": "transformers/examples/research_projects/fsner/README.md",
"repo_id": "transformers",
"token_count": 1174
} | 561 |
import os
import tempfile
from urllib.parse import urlparse
import requests
def detect_file_src_type(file_path: str) -> str:
"""Detect if the file is local or remote."""
if os.path.isfile(file_path):
return "local"
parsed_url = urlparse(file_path)
if parsed_url.scheme and parsed_url.netloc:
... | langchain/libs/community/langchain_community/tools/azure_cognitive_services/utils.py/0 | {
"file_path": "langchain/libs/community/langchain_community/tools/azure_cognitive_services/utils.py",
"repo_id": "langchain",
"token_count": 304
} | 284 |
# Diffusion Model Alignment Using Direct Preference Optimization
This directory provides LoRA implementations of Diffusion DPO proposed in [DiffusionModel Alignment Using Direct Preference Optimization](https://arxiv.org/abs/2311.12908) by Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Puru... | diffusers/examples/research_projects/diffusion_dpo/README.md/0 | {
"file_path": "diffusers/examples/research_projects/diffusion_dpo/README.md",
"repo_id": "diffusers",
"token_count": 932
} | 197 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
... | transformers/examples/legacy/run_language_modeling.py/0 | {
"file_path": "transformers/examples/legacy/run_language_modeling.py",
"repo_id": "transformers",
"token_count": 5667
} | 570 |
import { Replicate } from "@langchain/community/llms/replicate";
export const run = async () => {
const model = new Replicate({
model:
"replicate/flan-t5-xl:3ae0799123a1fe11f8c89fd99632f843fc5f7a761630160521c4253149754523",
});
const res = await model.call(
"Question: What would be a good company n... | langchainjs/examples/src/llms/replicate.ts/0 | {
"file_path": "langchainjs/examples/src/llms/replicate.ts",
"repo_id": "langchainjs",
"token_count": 151
} | 793 |
"""Sample a fraction of the Spider dataset."""
import argparse
import json
import os
import random
import shutil
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Create a sampled version of the Spider dataset."
)
parser.add_argument(
"--input",
type=str,
... | llama_index/benchmarks/struct_indices/spider/sample_benchmark.py/0 | {
"file_path": "llama_index/benchmarks/struct_indices/spider/sample_benchmark.py",
"repo_id": "llama_index",
"token_count": 1842
} | 1,076 |
# ConsistencyDecoderScheduler
This scheduler is a part of the [`ConsistencyDecoderPipeline`] and was introduced in [DALL-E 3](https://openai.com/dall-e-3).
The original codebase can be found at [openai/consistency_models](https://github.com/openai/consistency_models).
## ConsistencyDecoderScheduler
[[autodoc]] sch... | diffusers/docs/source/en/api/schedulers/consistency_decoder.md/0 | {
"file_path": "diffusers/docs/source/en/api/schedulers/consistency_decoder.md",
"repo_id": "diffusers",
"token_count": 132
} | 180 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | transformers/src/transformers/models/vilt/__init__.py/0 | {
"file_path": "transformers/src/transformers/models/vilt/__init__.py",
"repo_id": "transformers",
"token_count": 1082
} | 690 |
# LlamaIndex Vector_Stores Integration: Lancedb
| llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-lancedb/README.md/0 | {
"file_path": "llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-lancedb/README.md",
"repo_id": "llama_index",
"token_count": 14
} | 1,485 |
"""
Poolformer from MetaFormer is Actually What You Need for Vision https://arxiv.org/abs/2111.11418
IdentityFormer, RandFormer, PoolFormerV2, ConvFormer, and CAFormer
from MetaFormer Baselines for Vision https://arxiv.org/abs/2210.13452
All implemented models support feature extraction and variable input resolution.... | pytorch-image-models/timm/models/metaformer.py/0 | {
"file_path": "pytorch-image-models/timm/models/metaformer.py",
"repo_id": "pytorch-image-models",
"token_count": 17521
} | 344 |
"""Init file."""
| llama_index/llama-index-core/tests/indices/keyword_table/__init__.py/0 | {
"file_path": "llama_index/llama-index-core/tests/indices/keyword_table/__init__.py",
"repo_id": "llama_index",
"token_count": 6
} | 1,311 |
# Sentiment Tuning Examples
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`).
Here's an overview of the notebooks and scripts in the [trl repository](https://github.com/huggingface/trl/tree/main/examples):
| File ... | trl/docs/source/sentiment_tuning.mdx/0 | {
"file_path": "trl/docs/source/sentiment_tuning.mdx",
"repo_id": "trl",
"token_count": 2400
} | 818 |
python_sources()
| llama_index/llama-index-core/llama_index/core/indices/BUILD/0 | {
"file_path": "llama_index/llama-index-core/llama_index/core/indices/BUILD",
"repo_id": "llama_index",
"token_count": 6
} | 1,126 |
from langchain_community.llms.beam import Beam
__all__ = ["Beam"]
| langchain/libs/langchain/langchain/llms/beam.py/0 | {
"file_path": "langchain/libs/langchain/langchain/llms/beam.py",
"repo_id": "langchain",
"token_count": 23
} | 535 |
# coding=utf-8
# Copyright 2019-present, the HuggingFace Inc. team and Facebook, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Un... | transformers/examples/research_projects/distillation/distiller.py/0 | {
"file_path": "transformers/examples/research_projects/distillation/distiller.py",
"repo_id": "transformers",
"token_count": 12494
} | 559 |
poetry_requirements(
name="poetry",
)
python_requirements(
name="reqs",
)
| llama_index/llama-index-integrations/readers/llama-index-readers-earnings-call-transcript/BUILD/0 | {
"file_path": "llama_index/llama-index-integrations/readers/llama-index-readers-earnings-call-transcript/BUILD",
"repo_id": "llama_index",
"token_count": 36
} | 1,395 |
import { XMLOutputParser } from "@langchain/core/output_parsers";
import { FakeStreamingLLM } from "@langchain/core/utils/testing";
const XML_EXAMPLE = `<?xml version="1.0" encoding="UTF-8"?>
<userProfile>
<userID>12345</userID>
<roles>
<role>Admin</role>
<role>User</role>
</roles>
</userProfile>`;
cons... | langchainjs/examples/src/prompts/xml_output_parser_streaming.ts/0 | {
"file_path": "langchainjs/examples/src/prompts/xml_output_parser_streaming.ts",
"repo_id": "langchainjs",
"token_count": 872
} | 838 |
from __future__ import annotations
import logging
import uuid
from typing import Any, Dict, Iterable, List, Optional, Tuple, Type
import sqlalchemy
from sqlalchemy import func
from sqlalchemy.dialects.postgresql import JSON, UUID
from sqlalchemy.orm import Session, relationship
try:
from sqlalchemy.orm import de... | langchain/libs/community/langchain_community/vectorstores/pgembedding.py/0 | {
"file_path": "langchain/libs/community/langchain_community/vectorstores/pgembedding.py",
"repo_id": "langchain",
"token_count": 8481
} | 312 |
//! Numpy support for tensors.
//!
//! The spec for the npy format can be found in
//! [npy-format](https://docs.scipy.org/doc/numpy-1.14.2/neps/npy-format.html).
//! The functions from this module can be used to read tensors from npy/npz files
//! or write tensors to these files. A npy file contains a single tensor (u... | candle/candle-core/src/npy.rs/0 | {
"file_path": "candle/candle-core/src/npy.rs",
"repo_id": "candle",
"token_count": 8717
} | 31 |
# CIP Chroma Improvement Proposals
## Purpose
We want to make Chroma a core architectural component for users. Core architectural
elements can't break compatibility or shift functionality from release to release.
As a result each new major feature or public api has to be done in a way that we can stick
with it going ... | chroma/docs/CIP_Chroma_Improvment_Proposals.md/0 | {
"file_path": "chroma/docs/CIP_Chroma_Improvment_Proposals.md",
"repo_id": "chroma",
"token_count": 751
} | 38 |
// Licensed to the LF AI & Data foundation under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use th... | milvus/internal/proxy/look_aside_balancer_test.go/0 | {
"file_path": "milvus/internal/proxy/look_aside_balancer_test.go",
"repo_id": "milvus",
"token_count": 4773
} | 1,816 |
<jupyter_start><jupyter_text>Amazon Comprehend Moderation Chain>[Amazon Comprehend](https://aws.amazon.com/comprehend/) is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text.This notebook shows how to use `Amazon Comprehend` to detect and handle `... | langchain/docs/docs/guides/safety/amazon_comprehend_chain.ipynb/0 | {
"file_path": "langchain/docs/docs/guides/safety/amazon_comprehend_chain.ipynb",
"repo_id": "langchain",
"token_count": 6946
} | 96 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.