
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.67B | node_id stringlengths 18 24 | number int64 2 7.88k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | comments listlengths 0 30 | created_at timestamp[s]date 2020-04-14 18:18:51 2025-11-26 16:16:56 | updated_at timestamp[s]date 2020-04-29 09:23:05 2025-11-30 03:52:07 | closed_at timestamp[s]date 2020-04-29 09:23:05 2025-11-21 12:31:19 ⌀ | author_association stringclasses 4
values | type null | active_lock_reason null | draft null | pull_request null | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 4
values | sub_issues_summary dict | issue_dependencies_summary dict | is_pull_request bool 1
class | closed_at_time_taken duration[s] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4742/comments | https://api.github.com/repos/huggingface/datasets/issues/4742/events | https://github.com/huggingface/datasets/issues/4742 | 1,317,260,663 | I_kwDODunzps5Og813 | 4,742 | Dummy data nowhere to be found | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst of all, please note that you do not need the dummy data: this was the case when we were adding datasets to the `datasets` library (on this GitHub repo), so that we could test the correct loading of all datasets with our CI. However, this is no longer the case for ... | 2022-07-25T19:18:42 | 2022-11-04T14:04:24 | 2022-11-04T14:04:10 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co/datasets/BramVanroy/hebban-reviews). And even though the scripts runs an... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4742/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4742/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 101 days, 18:45:28 |
https://api.github.com/repos/huggingface/datasets/issues/4737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4737/comments | https://api.github.com/repos/huggingface/datasets/issues/4737/events | https://github.com/huggingface/datasets/issues/4737 | 1,315,011,004 | I_kwDODunzps5OYXm8 | 4,737 | Download error on scene_parse_150 | {
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"events_url": "https://api.github.com/users/juliensimon/events{/privacy}",
"followers_url": "https://api.github.com/users/juliensimon/followers",
"following_url": "https://api.github.com/users/juliensimon/following{/other_user}",
"gists_ur... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi! The server with the data seems to be down. I've reported this issue (https://github.com/CSAILVision/sceneparsing/issues/34) in the dataset repo. ",
"The URL seems to work now, and therefore the script as well."
] | 2022-07-22T13:28:28 | 2022-09-01T15:37:11 | 2022-09-01T15:37:11 | NONE | null | null | null | null | ```
from datasets import load_dataset
dataset = load_dataset("scene_parse_150", "scene_parsing")
FileNotFoundError: Couldn't find file at http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
```
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4737/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4737/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 41 days, 2:08:43 |
https://api.github.com/repos/huggingface/datasets/issues/4736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4736/comments | https://api.github.com/repos/huggingface/datasets/issues/4736/events | https://github.com/huggingface/datasets/issues/4736 | 1,314,931,996 | I_kwDODunzps5OYEUc | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47515542?v=4",
"events_url": "https://api.github.com/users/dk-crazydiv/events{/privacy}",
"followers_url": "https://api.github.com/users/dk-crazydiv/followers",
"following_url": "https://api.github.com/users/dk-crazydiv/following{/other_user}",
"gists_u... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] | 2022-07-22T12:14:18 | 2022-07-22T13:46:38 | 2022-07-22T13:46:38 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is cs... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4736/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:32:20 |
https://api.github.com/repos/huggingface/datasets/issues/4734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4734/comments | https://api.github.com/repos/huggingface/datasets/issues/4734/events | https://github.com/huggingface/datasets/issues/4734 | 1,314,495,382 | I_kwDODunzps5OWZuW | 4,734 | Package rouge-score cannot be imported | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"We have added a comment on an existing issue opened in their repo: https://github.com/google-research/google-research/issues/1212#issuecomment-1192267130\r\n- https://github.com/google-research/google-research/issues/1212"
] | 2022-07-22T07:15:05 | 2022-07-22T07:45:19 | 2022-07-22T07:45:18 | MEMBER | null | null | null | null | ## Describe the bug
After the today release of `rouge_score-0.0.7` it seems no longer importable. Our CI fails: https://github.com/huggingface/datasets/runs/7463218591?check_suite_focus=true
```
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_bigbench
FAILED tests/test_dataset_common.py::L... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4734/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4734/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 0:30:13 |
https://api.github.com/repos/huggingface/datasets/issues/4733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4733/comments | https://api.github.com/repos/huggingface/datasets/issues/4733/events | https://github.com/huggingface/datasets/issues/4733 | 1,314,479,616 | I_kwDODunzps5OWV4A | 4,733 | rouge metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/29248466?v=4",
"events_url": "https://api.github.com/users/asking28/events{/privacy}",
"followers_url": "https://api.github.com/users/asking28/followers",
"following_url": "https://api.github.com/users/asking28/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Fixed by:\r\n- #4735"
] | 2022-07-22T07:06:51 | 2022-07-22T09:08:02 | 2022-07-22T09:05:35 | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Loading Rouge metric gives error after latest rouge-score==0.0.7 release.
Downgrading rougemetric==0.0.4 works fine.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
A clear and concis... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4733/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4733/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:58:44 |
https://api.github.com/repos/huggingface/datasets/issues/4732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4732/comments | https://api.github.com/repos/huggingface/datasets/issues/4732/events | https://github.com/huggingface/datasets/issues/4732 | 1,314,371,566 | I_kwDODunzps5OV7fu | 4,732 | Document better that loading a dataset passing its name does not use the local script | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co/docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.... | 2022-07-22T06:07:31 | 2022-08-23T16:32:23 | 2022-08-23T16:32:23 | MEMBER | null | null | null | null | As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4732/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4732/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 32 days, 10:24:52 |
https://api.github.com/repos/huggingface/datasets/issues/4730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4730/comments | https://api.github.com/repos/huggingface/datasets/issues/4730/events | https://github.com/huggingface/datasets/issues/4730 | 1,313,421,263 | I_kwDODunzps5OSTfP | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | {
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] | 2022-07-21T15:14:06 | 2022-07-21T16:41:04 | 2022-07-21T16:41:04 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Loading into memory the validation split of imagenet-1k takes much more RAM than expected. Assuming ImageNet-1k is 150 GB, split is 50000 validation images and 1,281,167 train images, I would expect only about 6 GB loaded in RAM.
## Steps to reproduce the bug
```python
from datasets import... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4730/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:26:58 |
https://api.github.com/repos/huggingface/datasets/issues/4728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4728/comments | https://api.github.com/repos/huggingface/datasets/issues/4728/events | https://github.com/huggingface/datasets/issues/4728 | 1,312,897,454 | I_kwDODunzps5OQTmu | 4,728 | load_dataset gives "403" error when using Financial Phrasebank | {
"avatar_url": "https://avatars.githubusercontent.com/u/2209134?v=4",
"events_url": "https://api.github.com/users/rohitvincent/events{/privacy}",
"followers_url": "https://api.github.com/users/rohitvincent/followers",
"following_url": "https://api.github.com/users/rohitvincent/following{/other_user}",
"gists... | [] | closed | false | null | [] | [
"Hi @rohitvincent, thanks for reporting.\r\n\r\nUnfortunately I'm not able to reproduce your issue:\r\n```python\r\nIn [2]: from datasets import load_dataset, DownloadMode\r\n ...: load_dataset(path='financial_phrasebank',name='sentences_allagree', download_mode=\"force_redownload\")\r\nDownloading builder script... | 2022-07-21T08:43:32 | 2022-08-04T08:32:35 | 2022-08-04T08:32:35 | NONE | null | null | null | null | I tried both codes below to download the financial phrasebank dataset (https://huggingface.co/datasets/financial_phrasebank) with the sentences_allagree subset. However, the code gives a 403 error when executed from multiple machines locally or on the cloud.
```
from datasets import load_dataset, DownloadMode
load... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4728/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4728/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 13 days, 23:49:03 |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | [
"The preview is working OK:\r\n\r\n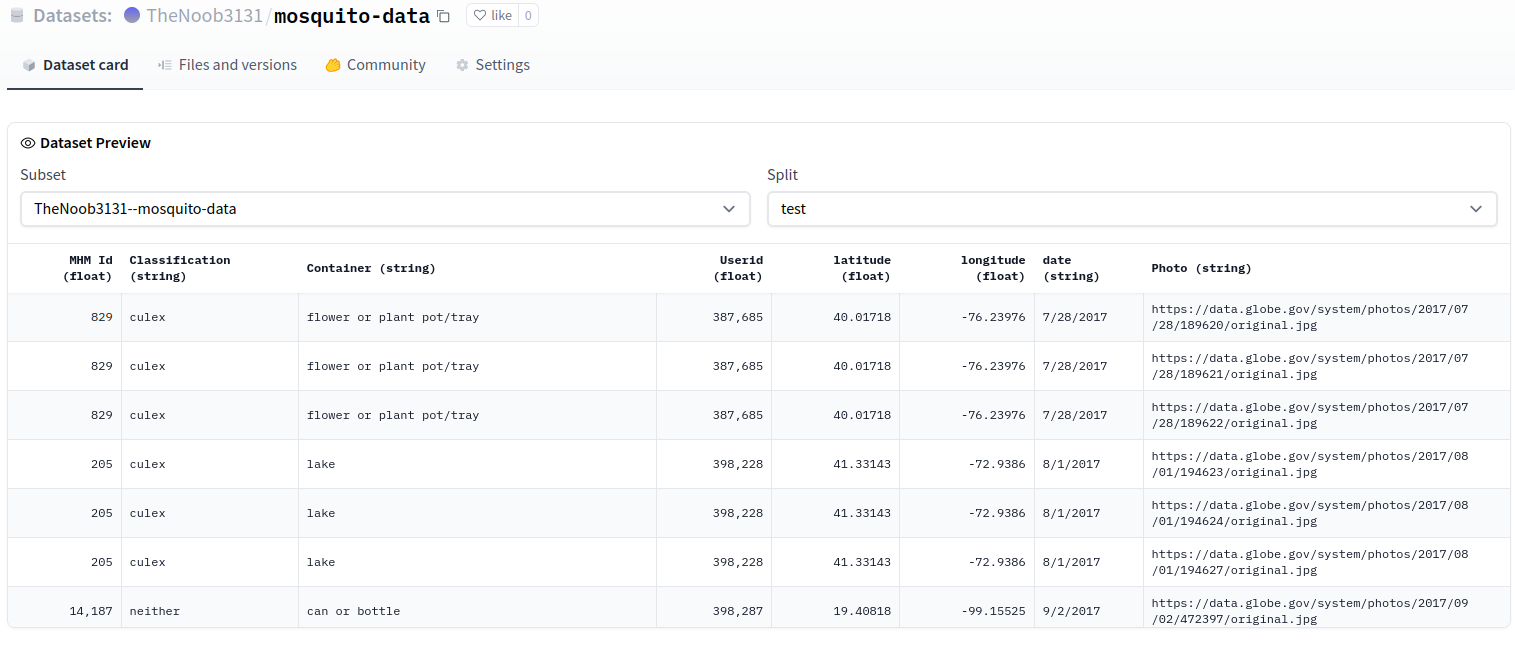\r\n\r\n"
] | 2022-07-21T05:24:48 | 2022-07-21T07:51:56 | 2022-07-21T07:45:01 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2:20:13 |
https://api.github.com/repos/huggingface/datasets/issues/4725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4725/comments | https://api.github.com/repos/huggingface/datasets/issues/4725/events | https://github.com/huggingface/datasets/issues/4725 | 1,311,907,096 | I_kwDODunzps5OMh0Y | 4,725 | the_pile datasets URL broken. | {
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_... | 2022-07-20T20:57:30 | 2022-07-22T06:09:46 | 2022-07-21T07:38:19 | NONE | null | null | null | null | https://github.com/huggingface/datasets/pull/3627 changed the Eleuther AI Pile dataset URL from https://the-eye.eu/ to https://mystic.the-eye.eu/ but the latter is now broken and the former works again.
Note that when I git clone the repo and use `pip install -e .` and then edit the URL back the codebase doesn't se... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4725/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 10:40:49 |
https://api.github.com/repos/huggingface/datasets/issues/4721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4721/comments | https://api.github.com/repos/huggingface/datasets/issues/4721/events | https://github.com/huggingface/datasets/issues/4721 | 1,310,253,552 | I_kwDODunzps5OGOHw | 4,721 | PyArrow Dataset error when calling `load_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/16828657?v=4",
"events_url": "https://api.github.com/users/piraka9011/events{/privacy}",
"followers_url": "https://api.github.com/users/piraka9011/followers",
"following_url": "https://api.github.com/users/piraka9011/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can... | 2022-07-20T01:16:03 | 2022-07-22T14:11:47 | null | NONE | null | null | null | null | ## Describe the bug
I am fine tuning a wav2vec2 model following the script here using my own dataset: https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
Loading my Audio dataset from the hub which was originally generated from disk results in th... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4721/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4720/comments | https://api.github.com/repos/huggingface/datasets/issues/4720/events | https://github.com/huggingface/datasets/issues/4720 | 1,309,980,195 | I_kwDODunzps5OFLYj | 4,720 | Dataset Viewer issue for shamikbose89/lancaster_newsbooks | {
"avatar_url": "https://avatars.githubusercontent.com/u/50837285?v=4",
"events_url": "https://api.github.com/users/shamikbose/events{/privacy}",
"followers_url": "https://api.github.com/users/shamikbose/followers",
"following_url": "https://api.github.com/users/shamikbose/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | [
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/h... | 2022-07-19T20:00:07 | 2022-09-08T16:47:21 | 2022-09-08T16:47:21 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/shamikbose89/lancaster_newsbooks
### Description
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
I am able to use the dataset loading script locally and it also runs when I'm using the one from the hub, but the viewer sti... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4720/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4720/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 50 days, 20:47:14 |
https://api.github.com/repos/huggingface/datasets/issues/4719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4719/comments | https://api.github.com/repos/huggingface/datasets/issues/4719/events | https://github.com/huggingface/datasets/issues/4719 | 1,309,854,492 | I_kwDODunzps5OEssc | 4,719 | Issue loading TheNoob3131/mosquito-data dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | [
"I am also getting a ValueError: 'Couldn't cast' at the bottom. Is this because of some delimiter issue? My dataset is on the Huggingface Hub. If you could look at it, that would be greatly appreciated.",
"Hi @thenerd31, thanks for reporting.\r\n\r\nPlease note that your issue is not caused by the Hugging Face Da... | 2022-07-19T17:47:37 | 2022-07-20T06:46:57 | 2022-07-20T06:46:02 | NONE | null | null | null | null | 
So my dataset is public in the Huggingface Hub, but when I try to load it using the load_dataset command, it shows that it is downloading the files, but throws a ValueError. When I went to my directory to ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4719/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 12:58:25 |
https://api.github.com/repos/huggingface/datasets/issues/4717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4717/comments | https://api.github.com/repos/huggingface/datasets/issues/4717/events | https://github.com/huggingface/datasets/issues/4717 | 1,309,512,483 | I_kwDODunzps5ODZMj | 4,717 | Dataset Viewer issue for LawalAfeez/englishreview-ds-mini | {
"avatar_url": "https://avatars.githubusercontent.com/u/69974956?v=4",
"events_url": "https://api.github.com/users/lawalAfeez820/events{/privacy}",
"followers_url": "https://api.github.com/users/lawalAfeez820/followers",
"following_url": "https://api.github.com/users/lawalAfeez820/following{/other_user}",
"g... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"It's currently working, as far as I understand\r\n\r\nhttps://huggingface.co/datasets/LawalAfeez/englishreview-ds-mini/viewer/LawalAfeez--englishreview-ds-mini/train\r\n\r\n<img width=\"1556\" alt=\"Capture d’écran 2022-07-19 à 09 24 01\" src=\"https://user-images.githubusercontent.com/1676121/179761130-2d7980b9... | 2022-07-19T13:19:39 | 2022-07-20T08:32:57 | 2022-07-20T08:32:57 | NONE | null | null | null | null | ### Link
_No response_
### Description
Unable to view the split data
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4717/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4717/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 19:13:18 |
https://api.github.com/repos/huggingface/datasets/issues/4711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4711/comments | https://api.github.com/repos/huggingface/datasets/issues/4711/events | https://github.com/huggingface/datasets/issues/4711 | 1,309,138,570 | I_kwDODunzps5OB96K | 4,711 | Document how to create a dataset loading script for audio/vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | [
"I'm closing this issue as both the Audio and Image sections now have a \"Create dataset\" page that contains the info about writing the loading script version of a dataset."
] | 2022-07-19T08:03:40 | 2023-07-25T16:07:52 | 2023-07-25T16:07:52 | MEMBER | null | null | null | null | Currently, in our docs for Audio/Vision/Text, we explain how to:
- Load data
- Process data
However we only explain how to *Create a dataset loading script* for text data.
I think it would be useful that we add the same for Audio/Vision as these have some specificities different from Text.
See, for example:
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4711/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4711/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 371 days, 8:04:12 |
https://api.github.com/repos/huggingface/datasets/issues/4709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4709/comments | https://api.github.com/repos/huggingface/datasets/issues/4709/events | https://github.com/huggingface/datasets/issues/4709 | 1,308,633,093 | I_kwDODunzps5OACgF | 4,709 | WMT21 & WMT22 | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_u... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
},
{
"color": "e99695",
"defa... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/92247226?v=4",
"events_url": "https://api.github.com/users/Etelis/events{/privacy}",
"followers_url": "https://api.github.com/users/Etelis/followers",
"following_url": "https://api.github.com/users/Etelis/following{/other_user}",
"gists_url": "https://a... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/92247226?v=4",
"events_url": "https://api.github.com/users/Etelis/events{/privacy}",
"followers_url": "https://api.github.com/users/Etelis/followers",
"following_url": "https://api.github.com/users/Etelis/following{/other_user}",
"gists_ur... | [
"Hi ! That would be awesome to have them indeed, thanks for opening this issue\r\n\r\nI just added you to the WMT org on the HF Hub if you're interested in adding those datasets.\r\n\r\nFeel free to create a dataset repository for each dataset and upload the data files there :) preferably in ZIP archives instead of... | 2022-07-18T21:05:33 | 2023-06-20T09:02:11 | null | CONTRIBUTOR | null | null | null | null | ## Adding a Dataset
- **Name:** WMT21 & WMT22
- **Description:** We are going to have three tracks: two small tasks and a large task.
The small tracks evaluate translation between fairly related languages and English (all pairs). The large track uses 101 languages.
- **Paper:** /
- **Data:** https://statmt.org/wmt... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4709/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4707/comments | https://api.github.com/repos/huggingface/datasets/issues/4707/events | https://github.com/huggingface/datasets/issues/4707 | 1,308,251,405 | I_kwDODunzps5N-lUN | 4,707 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Thanks for reporting. I refreshed the dataset viewer and it now works as expected.\r\n\r\nhttps://huggingface.co/datasets/TheNoob3131/mosquito-data\r\n\r\n<img width=\"1135\" alt=\"Capture d’écran 2022-07-18 à 13 15 22\" src=\"https://user-images.githubusercontent.com/1676121/179566497-e47f1a27-fd84-4a8d-9d7f-2e... | 2022-07-18T17:07:19 | 2022-07-18T19:44:46 | 2022-07-18T17:15:50 | NONE | null | null | null | null | ### Link
_No response_
### Description
Getting this error when trying to view dataset preview:
Message: 401, message='Unauthorized', url=URL('https://huggingface.co/datasets/TheNoob3131/mosquito-data/resolve/8aceebd6c4a359d216d10ef020868bd9e8c986dd/0_Africa_train.csv')
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4707/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 0:08:31 |
https://api.github.com/repos/huggingface/datasets/issues/4702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4702/comments | https://api.github.com/repos/huggingface/datasets/issues/4702/events | https://github.com/huggingface/datasets/issues/4702 | 1,307,793,811 | I_kwDODunzps5N81mT | 4,702 | Domain specific dataset discovery on the Hugging Face hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | [
"Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a g... | 2022-07-18T11:14:03 | 2024-02-12T09:53:43 | null | MEMBER | null | null | null | null | **Is your feature request related to a problem? Please describe.**
## The problem
The datasets hub currently has `8,239` datasets. These datasets span a wide range of different modalities and tasks (currently with a bias towards textual data).
There are various ways of identifying datasets that may be releva... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4702/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4702/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4697/comments | https://api.github.com/repos/huggingface/datasets/issues/4697/events | https://github.com/huggingface/datasets/issues/4697 | 1,307,332,253 | I_kwDODunzps5N7E6d | 4,697 | Trouble with streaming frgfm/imagenette vision dataset with TAR archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/26927750?v=4",
"events_url": "https://api.github.com/users/frgfm/events{/privacy}",
"followers_url": "https://api.github.com/users/frgfm/followers",
"following_url": "https://api.github.com/users/frgfm/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Hi @frgfm, thanks for reporting.\r\n\r\nAs the error message says, streaming mode is not supported out of the box when the dataset contains TAR archive files.\r\n\r\nTo make the dataset streamable, you have to use `dl_manager.iter_archive`.\r\n\r\nThere are several examples in other datasets, e.g. food101: https:/... | 2022-07-18T02:51:09 | 2022-08-01T15:10:57 | 2022-08-01T15:10:57 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/frgfm/imagenette
### Description
Hello there :wave:
Thanks for the amazing work you've done with HF Datasets! I've just started playing with it, and managed to upload my first dataset. But for the second one, I'm having trouble with the preview since there is some archive... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4697/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 14 days, 12:19:48 |
https://api.github.com/repos/huggingface/datasets/issues/4696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4696/comments | https://api.github.com/repos/huggingface/datasets/issues/4696/events | https://github.com/huggingface/datasets/issues/4696 | 1,307,183,099 | I_kwDODunzps5N6gf7 | 4,696 | Cannot load LinCE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/167943?v=4",
"events_url": "https://api.github.com/users/finiteautomata/events{/privacy}",
"followers_url": "https://api.github.com/users/finiteautomata/followers",
"following_url": "https://api.github.com/users/finiteautomata/following{/other_user}",
"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Hi @finiteautomata, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your issue:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: dataset = load_dataset(\"lince\", \"ner_spaeng\")\r\nDownloading builder script: 20.8kB [00:00, 9.09MB/s] ... | 2022-07-17T19:01:54 | 2022-07-18T09:20:40 | 2022-07-18T07:24:22 | NONE | null | null | null | null | ## Describe the bug
Cannot load LinCE dataset due to a connection error
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("lince", "ner_spaeng")
```
A notebook with this code and corresponding error can be found at https://colab.research.google.com/drive/1... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4696/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 12:22:28 |
https://api.github.com/repos/huggingface/datasets/issues/4694 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4694/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4694/comments | https://api.github.com/repos/huggingface/datasets/issues/4694/events | https://github.com/huggingface/datasets/issues/4694 | 1,306,958,380 | I_kwDODunzps5N5pos | 4,694 | Distributed data parallel training for streaming datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/13767887?v=4",
"events_url": "https://api.github.com/users/cyk1337/events{/privacy}",
"followers_url": "https://api.github.com/users/cyk1337/followers",
"following_url": "https://api.github.com/users/cyk1337/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | [
"Hi ! According to https://huggingface.co/docs/datasets/use_with_pytorch#stream-data you can use the pytorch DataLoader with `num_workers>0` to distribute the shards across your workers (it uses `torch.utils.data.get_worker_info()` to get the worker ID and select the right subsets of shards to use)\r\n\r\n<s> EDIT:... | 2022-07-17T01:29:43 | 2023-04-26T18:21:09 | null | NONE | null | null | null | null | ### Feature request
Any documentations for the the `load_dataset(streaming=True)` for (multi-node multi-GPU) DDP training?
### Motivation
Given a bunch of data files, it is expected to split them onto different GPUs. Is there a guide or documentation?
### Your contribution
Does it requires manually spli... | null | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4694/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4694/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4692/comments | https://api.github.com/repos/huggingface/datasets/issues/4692/events | https://github.com/huggingface/datasets/issues/4692 | 1,306,609,680 | I_kwDODunzps5N4UgQ | 4,692 | Unable to cast a column with `Image()` by using the `cast_column()` feature | {
"avatar_url": "https://avatars.githubusercontent.com/u/28833916?v=4",
"events_url": "https://api.github.com/users/skrishnan99/events{/privacy}",
"followers_url": "https://api.github.com/users/skrishnan99/followers",
"following_url": "https://api.github.com/users/skrishnan99/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi, thanks for reporting! A PR (https://github.com/huggingface/datasets/pull/4614) has already been opened to address this issue."
] | 2022-07-15T22:56:03 | 2022-07-19T13:36:24 | 2022-07-19T13:36:24 | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
When I create a dataset, then add a column to the created dataset through the `dataset.add_column` feature and then try to cast a column of the dataset (this column contains image paths) with `Image()` by using the `cast_column()` feature, I ge... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4692/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4692/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 3 days, 14:40:21 |
https://api.github.com/repos/huggingface/datasets/issues/4691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4691/comments | https://api.github.com/repos/huggingface/datasets/issues/4691/events | https://github.com/huggingface/datasets/issues/4691 | 1,306,389,656 | I_kwDODunzps5N3eyY | 4,691 | Dataset Viewer issue for rajistics/indian_food_images | {
"avatar_url": "https://avatars.githubusercontent.com/u/6808012?v=4",
"events_url": "https://api.github.com/users/rajshah4/events{/privacy}",
"followers_url": "https://api.github.com/users/rajshah4/followers",
"following_url": "https://api.github.com/users/rajshah4/following{/other_user}",
"gists_url": "http... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Hi, thanks for reporting. I triggered a refresh of the preview for this dataset, and it works now. I'm not sure what occurred.\r\n<img width=\"1019\" alt=\"Capture d’écran 2022-07-18 à 11 01 52\" src=\"https://user-images.githubusercontent.com/1676121/179541327-f62ecd5e-a18a-4d91-b316-9e2ebde77a28.png\">\r\n\r\n... | 2022-07-15T19:03:15 | 2022-07-18T15:02:03 | 2022-07-18T15:02:03 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/rajistics/indian_food_images/viewer/rajistics--indian_food_images/train
### Description
I have a train/test split in my dataset
<img width="410" alt="Screen Shot 2022-07-15 at 11 44 42 AM" src="https://user-images.githubusercontent.com/6808012/179293215-7b419ec3-3527-46f2-8... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4691/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2 days, 19:58:48 |
https://api.github.com/repos/huggingface/datasets/issues/4684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4684/comments | https://api.github.com/repos/huggingface/datasets/issues/4684/events | https://github.com/huggingface/datasets/issues/4684 | 1,305,554,654 | I_kwDODunzps5N0S7e | 4,684 | How to assign new values to Dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/37113676?v=4",
"events_url": "https://api.github.com/users/beyondguo/events{/privacy}",
"followers_url": "https://api.github.com/users/beyondguo/followers",
"following_url": "https://api.github.com/users/beyondguo/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | [
"Hi! One option is use `map` with a function that overwrites the labels (`dset = dset.map(lamba _: {\"label\": 0}, features=dset.features`)). Or you can use the `remove_column` + `add_column` combination (`dset = dset.remove_columns(\"label\").add_column(\"label\", [0]*len(data)).cast(dset.features)`, but note that... | 2022-07-15T04:17:57 | 2023-03-20T15:50:41 | 2022-10-10T11:53:38 | NONE | null | null | null | null | 
Hi, if I want to change some values of the dataset, or add new columns to it, how can I do it?
For example, I want to change all the labels of the SST2 dataset to `0`:
```python
from datasets import l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 4,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4684/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4684/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 87 days, 7:35:41 |
https://api.github.com/repos/huggingface/datasets/issues/4682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4682/comments | https://api.github.com/repos/huggingface/datasets/issues/4682/events | https://github.com/huggingface/datasets/issues/4682 | 1,304,788,215 | I_kwDODunzps5NxXz3 | 4,682 | weird issue/bug with columns (dataset iterable/stream mode) | {
"avatar_url": "https://avatars.githubusercontent.com/u/12104720?v=4",
"events_url": "https://api.github.com/users/eunseojo/events{/privacy}",
"followers_url": "https://api.github.com/users/eunseojo/followers",
"following_url": "https://api.github.com/users/eunseojo/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | [] | 2022-07-14T13:26:47 | 2022-07-14T13:26:47 | null | CONTRIBUTOR | null | null | null | null | I have a dataset online (CloverSearch/cc-news-mutlilingual) that has a bunch of columns, two of which are "score_title_maintext" and "score_title_description". the original files are jsonl formatted. I was trying to iterate through via streaming mode and grab all "score_title_description" values, but I kept getting key... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4682/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4681/comments | https://api.github.com/repos/huggingface/datasets/issues/4681/events | https://github.com/huggingface/datasets/issues/4681 | 1,304,617,484 | I_kwDODunzps5NwuIM | 4,681 | IndexError when loading ImageFolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/2843485?v=4",
"events_url": "https://api.github.com/users/johko/events{/privacy}",
"followers_url": "https://api.github.com/users/johko/followers",
"following_url": "https://api.github.com/users/johko/following{/other_user}",
"gists_url": "https://api.g... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | [
"Hi, thanks for reporting! If there are no examples in ImageFolder, the `label` column is of type `ClassLabel(names=[])`, which leads to an error in [this line](https://github.com/huggingface/datasets/blob/c15b391942764152f6060b59921b09cacc5f22a6/src/datasets/arrow_writer.py#L387) as `asdict(info)` calls `Features(... | 2022-07-14T10:57:55 | 2022-07-25T12:37:54 | 2022-07-25T12:37:54 | NONE | null | null | null | null | ## Describe the bug
Loading an image dataset with `imagefolder` throws `IndexError: list index out of range` when the given folder contains a non-image file (like a csv).
## Steps to reproduce the bug
Put a csv file in a folder with images and load it:
```python
import datasets
datasets.load_dataset("imagefold... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4681/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4681/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 11 days, 1:39:59 |
https://api.github.com/repos/huggingface/datasets/issues/4680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4680/comments | https://api.github.com/repos/huggingface/datasets/issues/4680/events | https://github.com/huggingface/datasets/issues/4680 | 1,304,534,770 | I_kwDODunzps5NwZ7y | 4,680 | Dataset Viewer issue for codeparrot/xlcost-text-to-code | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | [
"There seems to be an issue with the `C++-snippet-level` config:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"codeparrot/xlcost-text-to-code\", \"C++-snippet-level\")\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/... | 2022-07-14T09:45:50 | 2022-07-18T16:37:00 | 2022-07-18T16:04:36 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/codeparrot/xlcost-text-to-code
### Description
Error
```
Server Error
Status code: 400
Exception: TypeError
Message: 'NoneType' object is not iterable
```
Before I did a minor change in the dataset script (removing some comments), the viewer was working but... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4680/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4680/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 4 days, 6:18:46 |
https://api.github.com/repos/huggingface/datasets/issues/4678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4678/comments | https://api.github.com/repos/huggingface/datasets/issues/4678/events | https://github.com/huggingface/datasets/issues/4678 | 1,303,741,432 | I_kwDODunzps5NtYP4 | 4,678 | Cant pass streaming dataset to dataloader after take() | {
"avatar_url": "https://avatars.githubusercontent.com/u/39166683?v=4",
"events_url": "https://api.github.com/users/zankner/events{/privacy}",
"followers_url": "https://api.github.com/users/zankner/followers",
"following_url": "https://api.github.com/users/zankner/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"Hi! Calling `take` on an iterable/streamable dataset makes it not possible to shard the dataset, which in turn disables multi-process loading (attempts to split the workload over the shards), so to go past this limitation, you can either use single-process loading in `DataLoader` (`num_workers=None`) or fetch the ... | 2022-07-13T17:34:18 | 2022-07-14T13:07:21 | null | NONE | null | null | null | null | ## Describe the bug
I am trying to pass a streaming version of c4 to a dataloader, but it can't be passed after I call `dataset.take(n)`. Some functions such as `shuffle()` can be applied without breaking the dataloader but not take.
## Steps to reproduce the bug
```python
import datasets
import torch
dset = ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4678/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4677/comments | https://api.github.com/repos/huggingface/datasets/issues/4677/events | https://github.com/huggingface/datasets/issues/4677 | 1,302,258,440 | I_kwDODunzps5NnuMI | 4,677 | Random 400 Client Error when pushing dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/577139?v=4",
"events_url": "https://api.github.com/users/msis/events{/privacy}",
"followers_url": "https://api.github.com/users/msis/followers",
"following_url": "https://api.github.com/users/msis/following{/other_user}",
"gists_url": "https://api.githu... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"did you ever fix this? I'm experiencing the same",
"I am having the same issue. Even the simple example from the documentation gives me the 400 Error\r\n\r\n\r\n> from datasets import load_dataset\r\n> \r\n> dataset = load_dataset(\"stevhliu/demo\")\r\n> dataset.push_to_hub(\"processed_demo\")\r\n\r\n\r\n`reques... | 2022-07-12T15:56:44 | 2023-02-07T13:54:10 | 2023-02-07T13:54:10 | NONE | null | null | null | null | ## Describe the bug
When pushing a dataset, the client errors randomly with `Bad Request for url:...`.
At the next call, a new parquet file is created for each shard.
The client may fail at any random shard.
## Steps to reproduce the bug
```python
dataset.push_to_hub("ORG/DATASET", private=True, branch="main")
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/577139?v=4",
"events_url": "https://api.github.com/users/msis/events{/privacy}",
"followers_url": "https://api.github.com/users/msis/followers",
"following_url": "https://api.github.com/users/msis/following{/other_user}",
"gists_url": "https://api.githu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4677/timeline | null | not_planned | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 209 days, 21:57:26 |
https://api.github.com/repos/huggingface/datasets/issues/4676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4676/comments | https://api.github.com/repos/huggingface/datasets/issues/4676/events | https://github.com/huggingface/datasets/issues/4676 | 1,302,202,028 | I_kwDODunzps5Nngas | 4,676 | Dataset.map gets stuck on _cast_to_python_objects | {
"avatar_url": "https://avatars.githubusercontent.com/u/662612?v=4",
"events_url": "https://api.github.com/users/srobertjames/events{/privacy}",
"followers_url": "https://api.github.com/users/srobertjames/followers",
"following_url": "https://api.github.com/users/srobertjames/following{/other_user}",
"gists_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/5697926?v=4",
"events_url": "https://api.github.com/users/szmoro/events{/privacy}",
"followers_url": "https://api.github.com/users/szmoro/followers",
"following_url": "https://api.github.com/users/szmoro/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/5697926?v=4",
"events_url": "https://api.github.com/users/szmoro/events{/privacy}",
"followers_url": "https://api.github.com/users/szmoro/followers",
"following_url": "https://api.github.com/users/szmoro/following{/other_user}",
"gists_url... | [
"Are you able to reproduce this? My example is small enough that it should be easy to try.",
"Hi! Thanks for reporting and providing a reproducible example. Indeed, by default, `datasets` performs an expensive cast on the values returned by `map` to convert them to one of the types supported by PyArrow (the under... | 2022-07-12T15:09:58 | 2022-10-03T13:01:04 | 2022-10-03T13:01:03 | NONE | null | null | null | null | ## Describe the bug
`Dataset.map`, when fed a Huggingface Tokenizer as its map func, can sometimes spend huge amounts of time doing casts. A minimal example follows.
Not all usages suffer from this. For example, I profiled the preprocessor at https://github.com/huggingface/notebooks/blob/main/examples/question_an... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4676/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 82 days, 21:51:05 |
https://api.github.com/repos/huggingface/datasets/issues/4675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4675/comments | https://api.github.com/repos/huggingface/datasets/issues/4675/events | https://github.com/huggingface/datasets/issues/4675 | 1,302,193,649 | I_kwDODunzps5NneXx | 4,675 | Unable to use dataset with PyTorch dataloader | {
"avatar_url": "https://avatars.githubusercontent.com/u/25421460?v=4",
"events_url": "https://api.github.com/users/BlueskyFR/events{/privacy}",
"followers_url": "https://api.github.com/users/BlueskyFR/followers",
"following_url": "https://api.github.com/users/BlueskyFR/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"Hi! `para_crawl` has a single column of type `Translation`, which stores translation dictionaries. These dictionaries can be stored in a NumPy array but not in a PyTorch tensor since PyTorch only supports numeric types. In `datasets`, the conversion to `torch` works as follows: \r\n1. convert PyArrow table to NumP... | 2022-07-12T15:04:04 | 2022-07-14T14:17:46 | null | NONE | null | null | null | null | ## Describe the bug
When using `.with_format("torch")`, an arrow table is returned and I am unable to use it by passing it to a PyTorch DataLoader: please see the code below.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
ds = load_dataset(
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4675/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4675/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4674/comments | https://api.github.com/repos/huggingface/datasets/issues/4674/events | https://github.com/huggingface/datasets/issues/4674 | 1,301,294,844 | I_kwDODunzps5NkC78 | 4,674 | Issue loading datasets -- pyarrow.lib has no attribute | {
"avatar_url": "https://avatars.githubusercontent.com/u/39107794?v=4",
"events_url": "https://api.github.com/users/margotwagner/events{/privacy}",
"followers_url": "https://api.github.com/users/margotwagner/followers",
"following_url": "https://api.github.com/users/margotwagner/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi @margotwagner, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your bug: in an environment with datasets-2.3.2 and pyarrow-8.0.0, I can load the datasets without any problem:\r\n```python\r\n>>> ds = load_dataset(\"glue\", \"cola\")\r\n>>> ds\r\nDatasetDict({\r\n train: Dataset({\r\n ... | 2022-07-11T22:10:44 | 2023-02-28T18:06:55 | 2023-02-28T18:06:55 | NONE | null | null | null | null | ## Describe the bug
I am trying to load sentiment analysis datasets from huggingface, but any dataset I try to use via load_dataset, I get the same error:
`AttributeError: module 'pyarrow.lib' has no attribute 'IpcReadOptions'`
## Steps to reproduce the bug
```python
dataset = load_dataset("glue", "cola")
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4674/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4674/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 231 days, 19:56:11 |
https://api.github.com/repos/huggingface/datasets/issues/4673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4673/comments | https://api.github.com/repos/huggingface/datasets/issues/4673/events | https://github.com/huggingface/datasets/issues/4673 | 1,301,010,331 | I_kwDODunzps5Ni9eb | 4,673 | load_datasets on csv returns everything as a string | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to la... | 2022-07-11T17:30:24 | 2024-11-05T03:55:10 | 2022-07-12T13:33:08 | NONE | null | null | null | null | ## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4673/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 20:02:44 |
https://api.github.com/repos/huggingface/datasets/issues/4671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4671/comments | https://api.github.com/repos/huggingface/datasets/issues/4671/events | https://github.com/huggingface/datasets/issues/4671 | 1,300,385,909 | I_kwDODunzps5NglB1 | 4,671 | Dataset Viewer issue for wmt16 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @lewtun.\r\n\r\n~We can't load the dataset locally, so I think this is an issue with the loading script (not the viewer).~\r\n\r\n We are investigating...",
"Recently, there was a merged PR related to this dataset:\r\n- #4554\r\n\r\nWe are looking at this...",
"Indeed, the above mentioned... | 2022-07-11T08:34:11 | 2022-09-13T13:27:02 | 2022-09-08T08:16:06 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/wmt16
### Description
[Reported](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/12#62cb83f14c7f35284e796f9c) by a user of AutoTrain Evaluate. AFAIK this dataset was working 1-2 weeks ago, and I'm not sure how to interpret this error.
```
Status cod... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4671/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4671/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 58 days, 23:41:55 |
https://api.github.com/repos/huggingface/datasets/issues/4670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4670/comments | https://api.github.com/repos/huggingface/datasets/issues/4670/events | https://github.com/huggingface/datasets/issues/4670 | 1,299,984,246 | I_kwDODunzps5NfC92 | 4,670 | Can't extract files from `.7z` zipfile using `download_and_extract` | {
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi @bhavitvyamalik, thanks for reporting.\r\n\r\nYes, currently we do not support 7zip archive compression: I think we should.\r\n\r\nAs a workaround, you could uncompress it explicitly, like done in e.g. `samsum` dataset: \r\n\r\nhttps://github.com/huggingface/datasets/blob/fedf891a08bfc77041d575fad6c26091bc0fce5... | 2022-07-10T18:16:49 | 2022-07-15T13:02:07 | 2022-07-15T13:02:07 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
I'm adding a new dataset which is a `.7z` zip file in Google drive and contains 3 json files inside. I'm able to download the data files using `download_and_extract` but after downloading it throws this error:
```
>>> dataset = load_dataset("./datasets/mantis/")
Using custom data configuration d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4670/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 4 days, 18:45:18 |
https://api.github.com/repos/huggingface/datasets/issues/4669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4669/comments | https://api.github.com/repos/huggingface/datasets/issues/4669/events | https://github.com/huggingface/datasets/issues/4669 | 1,299,848,003 | I_kwDODunzps5NehtD | 4,669 | loading oscar-corpus/OSCAR-2201 raises an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/33824221?v=4",
"events_url": "https://api.github.com/users/vitalyshalumov/events{/privacy}",
"followers_url": "https://api.github.com/users/vitalyshalumov/followers",
"following_url": "https://api.github.com/users/vitalyshalumov/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"I had to use the appropriate token for use_auth_token. Thank you."
] | 2022-07-10T07:09:30 | 2022-07-11T09:27:49 | 2022-07-11T09:27:49 | NONE | null | null | null | null | ## Describe the bug
load_dataset('oscar-2201', 'af')
raises an error:
Traceback (most recent call last):
File "/usr/lib/python3.8/code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "..python3.8/site-packages/datasets/load.py", line 1656, in load_dataset
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33824221?v=4",
"events_url": "https://api.github.com/users/vitalyshalumov/events{/privacy}",
"followers_url": "https://api.github.com/users/vitalyshalumov/followers",
"following_url": "https://api.github.com/users/vitalyshalumov/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4669/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4669/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 2:18:19 |
https://api.github.com/repos/huggingface/datasets/issues/4668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4668/comments | https://api.github.com/repos/huggingface/datasets/issues/4668/events | https://github.com/huggingface/datasets/issues/4668 | 1,299,735,893 | I_kwDODunzps5NeGVV | 4,668 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"It seems like a private dataset. The viewer is currently not supported on the private datasets."
] | 2022-07-09T18:04:13 | 2022-07-11T07:47:47 | 2022-07-11T07:47:47 | NONE | null | null | null | null | ### Link
https://huggingface.co/hungnm/multilingual-amazon-review-sentiment
### Description
_No response_
### Owner
Yes | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4668/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4668/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 13:43:34 |
https://api.github.com/repos/huggingface/datasets/issues/4667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4667/comments | https://api.github.com/repos/huggingface/datasets/issues/4667/events | https://github.com/huggingface/datasets/issues/4667 | 1,299,735,703 | I_kwDODunzps5NeGSX | 4,667 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [] | 2022-07-09T18:03:15 | 2022-07-11T07:47:15 | 2022-07-11T07:47:15 | NONE | null | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4667/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 13:44:00 |
https://api.github.com/repos/huggingface/datasets/issues/4666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4666/comments | https://api.github.com/repos/huggingface/datasets/issues/4666/events | https://github.com/huggingface/datasets/issues/4666 | 1,299,732,238 | I_kwDODunzps5NeFcO | 4,666 | Issues with concatenating datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/32014649?v=4",
"events_url": "https://api.github.com/users/ChenghaoMou/events{/privacy}",
"followers_url": "https://api.github.com/users/ChenghaoMou/followers",
"following_url": "https://api.github.com/users/ChenghaoMou/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi! I agree we should improve the features equality checks to account for this particular case. However, your code fails due to `answer_start` having the dtype `int64` instead of `int32` after loading from JSON (it's not possible to embed type precision info into a JSON file; `save_to_disk` does that for arrow fil... | 2022-07-09T17:45:14 | 2022-07-12T17:16:15 | 2022-07-12T17:16:14 | NONE | null | null | null | null | ## Describe the bug
It is impossible to concatenate datasets if a feature is sequence of dict in one dataset and a dict of sequence in another. But based on the document, it should be automatically converted.
> A [datasets.Sequence](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/32014649?v=4",
"events_url": "https://api.github.com/users/ChenghaoMou/events{/privacy}",
"followers_url": "https://api.github.com/users/ChenghaoMou/followers",
"following_url": "https://api.github.com/users/ChenghaoMou/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4666/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4666/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2 days, 23:31:00 |
https://api.github.com/repos/huggingface/datasets/issues/4665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4665/comments | https://api.github.com/repos/huggingface/datasets/issues/4665/events | https://github.com/huggingface/datasets/issues/4665 | 1,299,652,638 | I_kwDODunzps5NdyAe | 4,665 | Unable to create dataset having Python dataset script only | {
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "h... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Hi @aleSuglia, thanks for reporting.\r\n\r\nWe are having a look at it. \r\n\r\nWe transfer this issue to the Community tab of the corresponding Hub dataset: https://huggingface.co/datasets/Heriot-WattUniversity/dialog-babi/discussions"
] | 2022-07-09T11:45:46 | 2022-07-11T07:10:09 | 2022-07-11T07:10:01 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Hi there,
I'm trying to add the following dataset to Huggingface datasets: https://huggingface.co/datasets/Heriot-WattUniversity/dialog-babi/blob/
I'm trying to do so using the CLI commands but seems that this command generates the wrong `dataset_info.json` file (you can find it in the repo a... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4665/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4665/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 19:24:15 |
https://api.github.com/repos/huggingface/datasets/issues/4661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4661/comments | https://api.github.com/repos/huggingface/datasets/issues/4661/events | https://github.com/huggingface/datasets/issues/4661 | 1,298,374,944 | I_kwDODunzps5NY6Eg | 4,661 | Concurrency bug when using same cache among several jobs | {
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"I can confirm that if I run one job first that processes the dataset, then I can run any jobs in parallel with no problem (no write-concurrency anymore...). ",
"Hi! That's weird. It seems like the error points to the `mkstemp` function, but the official docs state the following:\r\n```\r\nThere are no race condi... | 2022-07-08T01:58:11 | 2025-04-10T13:21:23 | null | NONE | null | null | null | null | ## Describe the bug
I used to see this bug with an older version of the datasets. It seems to persist.
This is my concrete scenario: I launch several evaluation jobs on a cluster in which I share the file system and I share the cache directory used by huggingface libraries. The evaluation jobs read the same *.csv ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4661/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4661/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4658/comments | https://api.github.com/repos/huggingface/datasets/issues/4658/events | https://github.com/huggingface/datasets/issues/4658 | 1,297,001,390 | I_kwDODunzps5NTquu | 4,658 | Transfer CI tests to GitHub Actions | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [] | 2022-07-07T08:10:50 | 2022-07-12T11:18:25 | 2022-07-12T11:18:25 | MEMBER | null | null | null | null | Let's try CI tests using GitHub Actions to see if they are more stable than on CircleCI. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4658/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 5 days, 3:07:35 |
https://api.github.com/repos/huggingface/datasets/issues/4657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4657/comments | https://api.github.com/repos/huggingface/datasets/issues/4657/events | https://github.com/huggingface/datasets/issues/4657 | 1,296,743,133 | I_kwDODunzps5NSrrd | 4,657 | Add SQuAD2.0 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"Hey, It's already present [here](https://huggingface.co/datasets/squad_v2) ",
"Hi! This dataset is indeed already available on the Hub. Closing."
] | 2022-07-07T03:19:36 | 2022-07-12T16:14:52 | 2022-07-12T16:14:52 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *SQuAD2.0*
- **Description:** *Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4657/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 5 days, 12:55:16 |
https://api.github.com/repos/huggingface/datasets/issues/4656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4656/comments | https://api.github.com/repos/huggingface/datasets/issues/4656/events | https://github.com/huggingface/datasets/issues/4656 | 1,296,740,266 | I_kwDODunzps5NSq-q | 4,656 | Add Amazon-QA Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/Amazon-QA)."
] | 2022-07-07T03:15:11 | 2022-07-14T02:20:12 | 2022-07-14T02:20:12 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Amazon-QA*
- **Description:** *The dataset is .jsonl format, where each line in the file is a json string that corresponds to a question, existing answers to the question and the extracted review snippets (relevant to the question).*
- **Paper:** *https://github.com/amazonqa/amazonqa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4656/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:05:01 |
https://api.github.com/repos/huggingface/datasets/issues/4655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4655/comments | https://api.github.com/repos/huggingface/datasets/issues/4655/events | https://github.com/huggingface/datasets/issues/4655 | 1,296,720,896 | I_kwDODunzps5NSmQA | 4,655 | Simple Wikipedia | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/simple-wiki)."
] | 2022-07-07T02:51:26 | 2022-07-14T02:16:33 | 2022-07-14T02:16:33 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Simple Wikipedia*
- **Description:** *Two different versions of the data set now exist. Both were generated by aligning Simple English Wikipedia and English Wikipedia. A complete description of the extraction process can be found in "Simple English Wikipedia: A New Simplification Task... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4655/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:25:07 |
https://api.github.com/repos/huggingface/datasets/issues/4654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4654/comments | https://api.github.com/repos/huggingface/datasets/issues/4654/events | https://github.com/huggingface/datasets/issues/4654 | 1,296,716,119 | I_kwDODunzps5NSlFX | 4,654 | Add Quora Question Triplets Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/QQP_triplets)."
] | 2022-07-07T02:43:42 | 2022-07-14T02:13:50 | 2022-07-14T02:13:50 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Quora Question Triplets*
- **Description:** *This dataset consists of over 400,000 lines of potential question duplicate pairs. Each line contains IDs for each question in the pair, the full text for each question, and a binary value that indicates whether the line truly contains a du... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4654/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4654/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:30:08 |
https://api.github.com/repos/huggingface/datasets/issues/4653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4653/comments | https://api.github.com/repos/huggingface/datasets/issues/4653/events | https://github.com/huggingface/datasets/issues/4653 | 1,296,702,834 | I_kwDODunzps5NSh1y | 4,653 | Add Altlex dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/altlex)."
] | 2022-07-07T02:23:02 | 2022-07-14T02:12:39 | 2022-07-14T02:12:39 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Altlex*
- **Description:** *Git repository for software associated with the 2016 ACL paper "Identifying Causal Relations Using Parallel Wikipedia Articles.”*
- **Paper:** *https://aclanthology.org/P16-1135.pdf*
- **Data:** *https://huggingface.co/datasets/sentence-transformers/embed... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4653/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:49:37 |
https://api.github.com/repos/huggingface/datasets/issues/4652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4652/comments | https://api.github.com/repos/huggingface/datasets/issues/4652/events | https://github.com/huggingface/datasets/issues/4652 | 1,296,697,498 | I_kwDODunzps5NSgia | 4,652 | Add Sentence Compression Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/sentence-compression)."
] | 2022-07-07T02:13:46 | 2022-07-14T02:11:48 | 2022-07-14T02:11:48 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Sentence Compression*
- **Description:** *Large corpus of uncompressed and compressed sentences from news articles.*
- **Paper:** *https://www.aclweb.org/anthology/D13-1155/*
- **Data:** *https://github.com/google-research-datasets/sentence-compression/tree/master/data*
- **Motivat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4652/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4652/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:58:02 |
https://api.github.com/repos/huggingface/datasets/issues/4651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4651/comments | https://api.github.com/repos/huggingface/datasets/issues/4651/events | https://github.com/huggingface/datasets/issues/4651 | 1,296,689,414 | I_kwDODunzps5NSekG | 4,651 | Add Flickr 30k Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/flickr30k-captions)."
] | 2022-07-07T01:59:08 | 2022-07-14T02:09:45 | 2022-07-14T02:09:45 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Flickr 30k*
- **Description:** *To produce the denotation graph, we have created an image caption corpus consisting of 158,915 crowd-sourced captions describing 31,783 images. This is an extension of our previous Flickr 8k Dataset. The new images and captions focus on people involved ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4651/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4651/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 7 days, 0:10:37 |
https://api.github.com/repos/huggingface/datasets/issues/4650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4650/comments | https://api.github.com/repos/huggingface/datasets/issues/4650/events | https://github.com/huggingface/datasets/issues/4650 | 1,296,680,037 | I_kwDODunzps5NScRl | 4,650 | Add SPECTER dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/SPECTER)"
] | 2022-07-07T01:41:32 | 2022-07-14T02:07:49 | null | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *SPECTER*
- **Description:** *SPECTER: Document-level Representation Learning using Citation-informed Transformers*
- **Paper:** *https://doi.org/10.18653/v1/2020.acl-main.207*
- **Data:** *https://huggingface.co/datasets/sentence-transformers/embedding-training-data/resolve/main/spe... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4650/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4649/comments | https://api.github.com/repos/huggingface/datasets/issues/4649/events | https://github.com/huggingface/datasets/issues/4649 | 1,296,673,712 | I_kwDODunzps5NSauw | 4,649 | Add PAQ dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/PAQ_pairs)"
] | 2022-07-07T01:29:42 | 2022-07-14T02:06:27 | 2022-07-14T02:06:27 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *PAQ*
- **Description:** *This repository contains code and models to support the research paper PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them*
- **Paper:** *https://arxiv.org/abs/2102.07033*
- **Data:** *https://huggingface.co/datasets/sentence-transformers/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4649/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 7 days, 0:36:45 |
https://api.github.com/repos/huggingface/datasets/issues/4648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4648/comments | https://api.github.com/repos/huggingface/datasets/issues/4648/events | https://github.com/huggingface/datasets/issues/4648 | 1,296,659,335 | I_kwDODunzps5NSXOH | 4,648 | Add WikiAnswers dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/WikiAnswers)"
] | 2022-07-07T01:06:37 | 2022-07-14T02:03:40 | 2022-07-14T02:03:40 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *WikiAnswers*
- **Description:** *The WikiAnswers corpus contains clusters of questions tagged by WikiAnswers users as paraphrases. Each cluster optionally contains an answer provided by WikiAnswers users.*
- **Paper:** *https://dl.acm.org/doi/10.1145/2623330.2623677*
- **Data:** *ht... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4648/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 7 days, 0:57:03 |
https://api.github.com/repos/huggingface/datasets/issues/4647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4647/comments | https://api.github.com/repos/huggingface/datasets/issues/4647/events | https://github.com/huggingface/datasets/issues/4647 | 1,296,311,270 | I_kwDODunzps5NRCPm | 4,647 | Add Reddit dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | [] | 2022-07-06T19:49:18 | 2022-07-06T19:49:18 | null | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *Reddit comments (2015-2018)*
- **Description:** *Reddit is an American social news aggregation website, where users can post links, and take part in discussions on these posts. These threaded discussions provide a large corpus, which is converted into a conversational dataset using th... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4647/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4642/comments | https://api.github.com/repos/huggingface/datasets/issues/4642/events | https://github.com/huggingface/datasets/issues/4642 | 1,295,748,083 | I_kwDODunzps5NO4vz | 4,642 | Streaming issue for ccdv/pubmed-summarization | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting @lewtun.\r\n\r\nI confirm there is an issue with streaming: it does not stream locally. ",
"Oh, after investigation, the source of the issue is in the Hub dataset loading script.\r\n\r\nI'm opening a PR on the Hub dataset.",
"I've opened a PR on their Hub dataset to support streaming: http... | 2022-07-06T12:13:07 | 2022-07-06T14:17:34 | 2022-07-06T14:17:34 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/ccdv/pubmed-summarization
### Description
This was reported by a [user of AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/7). It seems like streaming doesn't work due to the way the dataset loading script is defined?
```
Status c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4642/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4642/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2:04:27 |
https://api.github.com/repos/huggingface/datasets/issues/4641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4641/comments | https://api.github.com/repos/huggingface/datasets/issues/4641/events | https://github.com/huggingface/datasets/issues/4641 | 1,295,633,250 | I_kwDODunzps5NOcti | 4,641 | Dataset Viewer issue for kmfoda/booksum | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @lewtun.\r\n\r\nIt works locally in streaming mode:\r\n```\r\n{'bid': 27681,\r\n 'is_aggregate': True,\r\n 'source': 'cliffnotes',\r\n 'chapter_path': 'all_chapterized_books/27681-chapters/chapters_1_to_2.txt',\r\n 'summary_path': 'finished_summaries/cliffnotes/The Last of the Mohicans/sectio... | 2022-07-06T10:38:16 | 2022-07-06T13:25:28 | 2022-07-06T11:58:06 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/kmfoda/booksum
### Description
A [user of AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/9) discovered this dataset cannot be streamed due to:
```
Status code: 400
Exception: ClientResponseError
Message: 401, messa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4641/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:19:50 |
https://api.github.com/repos/huggingface/datasets/issues/4639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4639/comments | https://api.github.com/repos/huggingface/datasets/issues/4639/events | https://github.com/huggingface/datasets/issues/4639 | 1,295,367,322 | I_kwDODunzps5NNbya | 4,639 | Add HaGRID -- HAnd Gesture Recognition Image Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | [] | 2022-07-06T07:41:32 | 2022-07-06T07:41:32 | null | CONTRIBUTOR | null | null | null | null | ## Adding a Dataset
- **Name:** HaGRID -- HAnd Gesture Recognition Image Dataset
- **Description:** We introduce a large image dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. You can use it for image classification or image detection tasks. Proposed dataset allows t... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4639/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4637/comments | https://api.github.com/repos/huggingface/datasets/issues/4637/events | https://github.com/huggingface/datasets/issues/4637 | 1,294,818,236 | I_kwDODunzps5NLVu8 | 4,637 | The "all" split breaks streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting @cakiki.\r\n\r\nYes, this is a bug. We are investigating it.",
"@albertvillanova Nice! Let me know if it's something I can fix my self; would love to contribtue!",
"@cakiki I was working on this but if you would like to contribute, go ahead. I will close my PR. ;)\r\n\r\nFor the moment I j... | 2022-07-05T21:56:49 | 2022-07-15T13:59:30 | null | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Not sure if this is a bug or just the way streaming works, but setting `streaming=True` did not work when setting `split="all"`
## Steps to reproduce the bug
The following works:
```python
ds = load_dataset('super_glue', 'wsc.fixed', split='all')
```
The following throws `ValueError: Bad ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4637/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4636/comments | https://api.github.com/repos/huggingface/datasets/issues/4636/events | https://github.com/huggingface/datasets/issues/4636 | 1,294,547,836 | I_kwDODunzps5NKTt8 | 4,636 | Add info in docs about behavior of download_config.num_proc | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [] | 2022-07-05T17:01:00 | 2022-07-28T10:40:32 | 2022-07-28T10:40:32 | CONTRIBUTOR | null | null | null | null | **Is your feature request related to a problem? Please describe.**
I went to override `download_config.num_proc` and was confused about what was happening under the hood. It would be nice to have the behavior documented a bit better so folks know what's happening when they use it.
**Describe the solution you'd li... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4636/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 22 days, 17:39:32 |
https://api.github.com/repos/huggingface/datasets/issues/4635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4635/comments | https://api.github.com/repos/huggingface/datasets/issues/4635/events | https://github.com/huggingface/datasets/issues/4635 | 1,294,475,931 | I_kwDODunzps5NKCKb | 4,635 | Dataset Viewer issue for vadis/sv-ident | {
"avatar_url": "https://avatars.githubusercontent.com/u/20404466?v=4",
"events_url": "https://api.github.com/users/e-tornike/events{/privacy}",
"followers_url": "https://api.github.com/users/e-tornike/followers",
"following_url": "https://api.github.com/users/e-tornike/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @e-tornike \r\n\r\nSome context:\r\n- #4527 \r\n\r\nThe dataset loads locally in streaming mode:\r\n```python\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"vadis/sv-ident\", split=\"validation\", streaming=True); item = next(iter(ds)); item\r\nUsing custom data configurati... | 2022-07-05T15:48:13 | 2022-07-06T07:13:33 | 2022-07-06T07:12:14 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation
### Description
Error message when loading validation split in the viewer:
```
Status code: 400
Exception: Status400Error
Message: The split cache is empty.
```
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4635/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 15:24:01 |
https://api.github.com/repos/huggingface/datasets/issues/4634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4634/comments | https://api.github.com/repos/huggingface/datasets/issues/4634/events | https://github.com/huggingface/datasets/issues/4634 | 1,294,405,251 | I_kwDODunzps5NJw6D | 4,634 | Can't load the Hausa audio dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/19976800?v=4",
"events_url": "https://api.github.com/users/moro23/events{/privacy}",
"followers_url": "https://api.github.com/users/moro23/followers",
"following_url": "https://api.github.com/users/moro23/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | [
"Could you provide the error details. It is difficult to debug otherwise. Also try other config. `ha` is not a valid."
] | 2022-07-05T14:47:36 | 2022-09-13T14:07:32 | 2022-09-13T14:07:32 | NONE | null | null | null | null | common_voice_train = load_dataset("common_voice", "ha", split="train+validation") | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4634/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 69 days, 23:19:56 |
https://api.github.com/repos/huggingface/datasets/issues/4632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4632/comments | https://api.github.com/repos/huggingface/datasets/issues/4632/events | https://github.com/huggingface/datasets/issues/4632 | 1,294,166,880 | I_kwDODunzps5NI2tg | 4,632 | 'sort' method sorts one column only | {
"avatar_url": "https://avatars.githubusercontent.com/u/42108562?v=4",
"events_url": "https://api.github.com/users/shachardon/events{/privacy}",
"followers_url": "https://api.github.com/users/shachardon/followers",
"following_url": "https://api.github.com/users/shachardon/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | [
"Hi ! `ds.sort()` does sort the full dataset, not just one column:\r\n```python\r\nfrom datasets import *\r\n\r\nds = Dataset.from_dict({\"foo\": [3, 2, 1], \"bar\": [\"c\", \"b\", \"a\"]})\r\nprint(d.sort(\"foo\").to_pandas()\r\n# foo bar\r\n# 0 1 a\r\n# 1 2 b\r\n# 2 3 c\r\n```\r\n\r\nWhat made y... | 2022-07-05T11:25:26 | 2023-07-25T15:04:27 | 2023-07-25T15:04:27 | NONE | null | null | null | null | The 'sort' method changes the order of one column only (the one defined by the argument 'column'), thus creating a mismatch between a sample fields. I would expect it to change the order of the samples as a whole, based on the 'column' order. | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4632/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 385 days, 3:39:01 |
https://api.github.com/repos/huggingface/datasets/issues/4629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4629/comments | https://api.github.com/repos/huggingface/datasets/issues/4629/events | https://github.com/huggingface/datasets/issues/4629 | 1,293,418,800 | I_kwDODunzps5NGAEw | 4,629 | Rename repo default branch to main | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | [] | 2022-07-04T17:16:10 | 2022-07-06T15:49:57 | 2022-07-06T15:49:57 | MEMBER | null | null | null | null | Rename repository default branch to `main` (instead of current `master`).
Once renamed, users will have to manually update their local repos:
- [ ] Upstream:
```
git branch -m master main
git fetch upstream main
git branch -u upstream/main main
git remote set-head upstream -a
```
- [ ] Origin... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4629/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 22:33:47 |
https://api.github.com/repos/huggingface/datasets/issues/4626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4626/comments | https://api.github.com/repos/huggingface/datasets/issues/4626/events | https://github.com/huggingface/datasets/issues/4626 | 1,293,256,269 | I_kwDODunzps5NFYZN | 4,626 | Add non-commercial licensing info for datasets for which we removed tags | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | [
"yep plus `license_details` also makes sense for this IMO"
] | 2022-07-04T14:32:43 | 2022-07-08T14:27:29 | null | MEMBER | null | null | null | null | We removed several YAML tags saying that certain datasets can't be used for commercial purposes: https://github.com/huggingface/datasets/pull/4613#discussion_r911919753
Reason for this is that we only allow tags that are part of our [supported list of licenses](https://github.com/huggingface/datasets/blob/84fc3ad73c... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4626/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4623/comments | https://api.github.com/repos/huggingface/datasets/issues/4623/events | https://github.com/huggingface/datasets/issues/4623 | 1,293,042,894 | I_kwDODunzps5NEkTO | 4,623 | Loading MNIST as Pytorch Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/56592797?v=4",
"events_url": "https://api.github.com/users/jameschapman19/events{/privacy}",
"followers_url": "https://api.github.com/users/jameschapman19/followers",
"following_url": "https://api.github.com/users/jameschapman19/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"Hi ! We haven't implemented the conversion from images data to PyTorch tensors yet I think\r\n\r\ncc @mariosasko ",
"So I understand:\r\n\r\nset_format() does not properly do the conversion to pytorch tensors from PIL images.\r\n\r\nSo that someone who stumbles on this can use the package:\r\n\r\n```python\r\nda... | 2022-07-04T11:33:10 | 2022-07-04T14:40:50 | null | NONE | null | null | null | null | ## Describe the bug
Conversion of MNIST dataset to pytorch fails with bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("mnist", split="train")
dataset.set_format('torch')
dataset[0]
print()
```
## Expected results
Expect to see torch tensors image and l... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4623/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4621/comments | https://api.github.com/repos/huggingface/datasets/issues/4621/events | https://github.com/huggingface/datasets/issues/4621 | 1,293,030,128 | I_kwDODunzps5NEhLw | 4,621 | ImageFolder raises an error with parameters drop_metadata=True and drop_labels=False when metadata.jsonl is present | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | [] | 2022-07-04T11:21:44 | 2022-07-15T14:24:24 | 2022-07-15T14:24:24 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
If you pass `drop_metadata=True` and `drop_labels=False` when a `data_dir` contains at least one `matadata.jsonl` file, you will get a KeyError. This is probably not a very useful case but we shouldn't get an error anyway. Asking users to move metadata files manually outside `data_dir` or pass fe... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4621/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 11 days, 3:02:40 |
https://api.github.com/repos/huggingface/datasets/issues/4620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4620/comments | https://api.github.com/repos/huggingface/datasets/issues/4620/events | https://github.com/huggingface/datasets/issues/4620 | 1,292,797,878 | I_kwDODunzps5NDoe2 | 4,620 | Data type is not recognized when using datetime.time | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | [
"cc @mariosasko ",
"Hi, thanks for reporting! I'm investigating the issue."
] | 2022-07-04T08:13:38 | 2022-07-07T13:57:11 | 2022-07-07T13:57:11 | COLLABORATOR | null | null | null | null | ## Describe the bug
Creating a dataset from a pandas dataframe with `datetime.time` format generates an error.
## Steps to reproduce the bug
```python
import pandas as pd
from datetime import time
from datasets import Dataset
df = pd.DataFrame({"feature_name": [time(1, 1, 1)]})
dataset = Dataset.from_pandas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4620/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 3 days, 5:43:33 |
https://api.github.com/repos/huggingface/datasets/issues/4619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4619/comments | https://api.github.com/repos/huggingface/datasets/issues/4619/events | https://github.com/huggingface/datasets/issues/4619 | 1,292,107,275 | I_kwDODunzps5NA_4L | 4,619 | np arrays get turned into native lists | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | [
"If you add the line `dataset2.set_format('np')` before calling `dataset2[0]['tmp']` it should return `np.ndarray`.\r\nI believe internally it will not store it as a list, it is only returning a list when you index it.\r\n\r\n```\r\nIn [1]: import datasets, numpy as np\r\nIn [2]: dataset = datasets.load_dataset(\"g... | 2022-07-02T17:54:57 | 2022-07-03T20:27:07 | null | NONE | null | null | null | null | ## Describe the bug
When attaching an `np.array` field, it seems that it automatically gets turned into a list (see below). Why is this happening? Could it lose precision? Is there a way to make sure this doesn't happen?
## Steps to reproduce the bug
```python
>>> import datasets, numpy as np
>>> dataset = datas... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4619/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4618/comments | https://api.github.com/repos/huggingface/datasets/issues/4618/events | https://github.com/huggingface/datasets/issues/4618 | 1,292,078,225 | I_kwDODunzps5NA4yR | 4,618 | contribute data loading for object detection datasets with yolo data format | {
"avatar_url": "https://avatars.githubusercontent.com/u/8406903?v=4",
"events_url": "https://api.github.com/users/faizankshaikh/events{/privacy}",
"followers_url": "https://api.github.com/users/faizankshaikh/followers",
"following_url": "https://api.github.com/users/faizankshaikh/following{/other_user}",
"gi... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | [
"Hi! The `imagefolder` script is already quite complex, so a standalone script sounds better. Also, I suggest we create an org on the Hub (e.g. `hf-loaders`) and store such scripts there for easier maintenance rather than having them as packaged modules (IMO only very generic loaders should be packaged). WDYT @lhoe... | 2022-07-02T15:21:59 | 2022-07-21T14:10:44 | null | NONE | null | null | null | null | **Is your feature request related to a problem? Please describe.**
At the moment, HF datasets loads [image classification datasets](https://huggingface.co/docs/datasets/image_process) out-of-the-box. There could be a data loader for loading standard object detection datasets ([original discussion here](https://hugging... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4618/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4612/comments | https://api.github.com/repos/huggingface/datasets/issues/4612/events | https://github.com/huggingface/datasets/issues/4612 | 1,290,984,660 | I_kwDODunzps5M8tzU | 4,612 | Release 2.3.0 broke custom iterable datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/19529125?v=4",
"events_url": "https://api.github.com/users/aapot/events{/privacy}",
"followers_url": "https://api.github.com/users/aapot/followers",
"following_url": "https://api.github.com/users/aapot/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Apparently, `fsspec` does not allow access to attribute-based modules anymore, such as `fsspec.async`.\r\n\r\nHowever, this is a fairly simple fix:\r\n- Change the import to: `from fsspec import asyn`;\r\n- Change line 18 to: `asyn.iothread[0] = None`;\r\n- Change line 19 to `asyn.loop[0] = None`.",
"Hi! I think... | 2022-07-01T06:46:07 | 2022-07-05T15:08:21 | 2022-07-05T15:08:21 | NONE | null | null | null | null | ## Describe the bug
Trying to iterate examples from custom iterable dataset fails to bug introduced in `torch_iterable_dataset.py` since the release of 2.3.0.
## Steps to reproduce the bug
```python
next(iter(custom_iterable_dataset))
```
## Expected results
`next(iter(custom_iterable_dataset))` should retu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4612/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4612/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 4 days, 8:22:14 |
https://api.github.com/repos/huggingface/datasets/issues/4610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4610/comments | https://api.github.com/repos/huggingface/datasets/issues/4610/events | https://github.com/huggingface/datasets/issues/4610 | 1,290,603,827 | I_kwDODunzps5M7Q0z | 4,610 | codeparrot/github-code failing to load | {
"avatar_url": "https://avatars.githubusercontent.com/u/29863388?v=4",
"events_url": "https://api.github.com/users/PyDataBlog/events{/privacy}",
"followers_url": "https://api.github.com/users/PyDataBlog/followers",
"following_url": "https://api.github.com/users/PyDataBlog/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | [
"I believe the issue is in `codeparrot/github-code`. `base_path` param is missing - https://huggingface.co/datasets/codeparrot/github-code/blob/main/github-code.py#L169\r\n\r\nFunction definition has changed.\r\nhttps://github.com/huggingface/datasets/blob/0e1c629cfb9f9ba124537ba294a0ec451584da5f/src/datasets/data_... | 2022-06-30T20:24:48 | 2022-07-05T14:24:13 | 2022-07-05T09:19:56 | NONE | null | null | null | null | ## Describe the bug
codeparrot/github-code fails to load with a `TypeError: get_patterns_in_dataset_repository() missing 1 required positional argument: 'base_path'`
## Steps to reproduce the bug
```python
from datasets import load_dataset
```
## Expected results
loaded dataset object
## Actual results
`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4610/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 4 days, 12:55:08 |
https://api.github.com/repos/huggingface/datasets/issues/4609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4609/comments | https://api.github.com/repos/huggingface/datasets/issues/4609/events | https://github.com/huggingface/datasets/issues/4609 | 1,290,392,083 | I_kwDODunzps5M6dIT | 4,609 | librispeech dataset has to download whole subset when specifing the split to use | {
"avatar_url": "https://avatars.githubusercontent.com/u/73462159?v=4",
"events_url": "https://api.github.com/users/sunhaozhepy/events{/privacy}",
"followers_url": "https://api.github.com/users/sunhaozhepy/followers",
"following_url": "https://api.github.com/users/sunhaozhepy/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi! You can use streaming to fetch only a subset of the data:\r\n```python\r\nraw_dataset = load_dataset(\"librispeech_asr\", \"clean\", split=\"train.100\", streaming=True)\r\n```\r\nAlso, we plan to make it possible to download a particular split in the non-streaming mode, but this task is not easy due to how ou... | 2022-06-30T16:38:24 | 2022-07-12T21:44:32 | 2022-07-12T21:44:32 | NONE | null | null | null | null | ## Describe the bug
librispeech dataset has to download whole subset when specifing the split to use
## Steps to reproduce the bug
see below
# Sample code to reproduce the bug
```
!pip install datasets
from datasets import load_dataset
raw_dataset = load_dataset("librispeech_asr", "clean", split="train.100")
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/73462159?v=4",
"events_url": "https://api.github.com/users/sunhaozhepy/events{/privacy}",
"followers_url": "https://api.github.com/users/sunhaozhepy/followers",
"following_url": "https://api.github.com/users/sunhaozhepy/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4609/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 12 days, 5:06:08 |
https://api.github.com/repos/huggingface/datasets/issues/4606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4606/comments | https://api.github.com/repos/huggingface/datasets/issues/4606/events | https://github.com/huggingface/datasets/issues/4606 | 1,290,083,534 | I_kwDODunzps5M5RzO | 4,606 | evaluation result changes after `datasets` version change | {
"avatar_url": "https://avatars.githubusercontent.com/u/70014488?v=4",
"events_url": "https://api.github.com/users/thnkinbtfly/events{/privacy}",
"followers_url": "https://api.github.com/users/thnkinbtfly/followers",
"following_url": "https://api.github.com/users/thnkinbtfly/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi! The GH/no-namespace datasets versioning is synced with the version of the `datasets` lib, which means that the `wikiann` script was modified between the two compared versions. In this scenario, you can ensure reproducibility by pinning the script version, which is done by passing `revision=\"x.y.z\"` (e.g. `re... | 2022-06-30T12:43:26 | 2023-07-25T15:05:26 | 2023-07-25T15:05:26 | NONE | null | null | null | null | ## Describe the bug
evaluation result changes after `datasets` version change
## Steps to reproduce the bug
1. Train a model on WikiAnn
2. reload the ckpt -> test accuracy becomes same as eval accuracy
3. such behavior is gone after downgrading `datasets`
https://colab.research.google.com/drive/1kYz7-aZRGdaya... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4606/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 390 days, 2:22:00 |
https://api.github.com/repos/huggingface/datasets/issues/4605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4605/comments | https://api.github.com/repos/huggingface/datasets/issues/4605/events | https://github.com/huggingface/datasets/issues/4605 | 1,290,058,970 | I_kwDODunzps5M5Lza | 4,605 | Dataset Viewer issue for boris/gis_filtered | {
"avatar_url": "https://avatars.githubusercontent.com/u/41203448?v=4",
"events_url": "https://api.github.com/users/WaterKnight1998/events{/privacy}",
"followers_url": "https://api.github.com/users/WaterKnight1998/followers",
"following_url": "https://api.github.com/users/WaterKnight1998/following{/other_user}"... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | [
"Yes, this dataset is \"gated\": you first have to go to https://huggingface.co/datasets/boris/gis_filtered and click \"Access repository\" (if you accept to share your contact information with the repository authors).",
"I already did that, it returns error when using streaming",
"Oh, sorry, I misread. Looking... | 2022-06-30T12:23:34 | 2022-07-06T12:34:19 | 2022-07-06T12:34:19 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/boris/gis_filtered/viewer/boris--gis_filtered/train
### Description
When I try to access this from the website I get this error:
Status code: 400
Exception: ClientResponseError
Message: 401, message='Unauthorized', url=URL('https://huggingface.co/datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4605/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 0:10:45 |
https://api.github.com/repos/huggingface/datasets/issues/4603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4603/comments | https://api.github.com/repos/huggingface/datasets/issues/4603/events | https://github.com/huggingface/datasets/issues/4603 | 1,289,963,331 | I_kwDODunzps5M40dD | 4,603 | CI fails recurrently and randomly on Windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [] | 2022-06-30T10:59:58 | 2022-06-30T13:22:25 | 2022-06-30T13:22:25 | MEMBER | null | null | null | null | As reported by @lhoestq,
The windows CI is currently flaky: some dependencies like `aiobotocore`, `multiprocess` and `seqeval` sometimes fail to install.
In particular it seems that building the wheels fail. Here is an example of logs:
```
Building wheel for seqeval (setup.py): started
Running command 'C:\to... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4603/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4603/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2:22:27 |
https://api.github.com/repos/huggingface/datasets/issues/4597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4597/comments | https://api.github.com/repos/huggingface/datasets/issues/4597/events | https://github.com/huggingface/datasets/issues/4597 | 1,288,672,007 | I_kwDODunzps5Mz5MH | 4,597 | Streaming issue for financial_phrasebank | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "8B51EF",
"default": false,
"description": "",
"id": 4069435429,
"name": "hosted-on-google-drive",
"node_id": "LA_kwDODunzps7yjqgl",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hosted-on-google-drive"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"cc @huggingface/datasets: it seems like https://www.researchgate.net/ is flaky for datasets hosting (I put the \"hosted-on-google-drive\" tag since it's the same kind of issue I think)",
"Let's see if their license allows hosting their data on the Hub.",
"License is Creative Commons Attribution-NonCommercial-S... | 2022-06-29T12:45:43 | 2022-07-01T09:29:36 | 2022-07-01T09:29:36 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/financial_phrasebank/viewer/sentences_allagree/train
### Description
As reported by a community member using [AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/5#62bc217436d0e5d316a768f0), there seems to be a problem streaming this dat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4597/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1 day, 20:43:53 |
https://api.github.com/repos/huggingface/datasets/issues/4596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4596/comments | https://api.github.com/repos/huggingface/datasets/issues/4596/events | https://github.com/huggingface/datasets/issues/4596 | 1,288,381,735 | I_kwDODunzps5MyyUn | 4,596 | Dataset Viewer issue for universal_dependencies | {
"avatar_url": "https://avatars.githubusercontent.com/u/16034009?v=4",
"events_url": "https://api.github.com/users/Jordy-VL/events{/privacy}",
"followers_url": "https://api.github.com/users/Jordy-VL/followers",
"following_url": "https://api.github.com/users/Jordy-VL/following{/other_user}",
"gists_url": "htt... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Thanks, looking at it!",
"Finally fixed! We updated the dataset viewer and it fixed the issue.\r\n\r\nhttps://huggingface.co/datasets/universal_dependencies/viewer/aqz_tudet/train\r\n\r\n<img width=\"1561\" alt=\"Capture d’écran 2022-09-07 à 13 29 18\" src=\"https://user-images.githubusercontent.com/1676121/18... | 2022-06-29T08:50:29 | 2022-09-07T11:29:28 | 2022-09-07T11:29:27 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/universal_dependencies
### Description
invalid json response body at https://datasets-server.huggingface.co/splits?dataset=universal_dependencies reason: Unexpected token I in JSON at position 0
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4596/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 70 days, 2:38:58 |
https://api.github.com/repos/huggingface/datasets/issues/4595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4595/comments | https://api.github.com/repos/huggingface/datasets/issues/4595/events | https://github.com/huggingface/datasets/issues/4595 | 1,288,275,976 | I_kwDODunzps5MyYgI | 4,595 | Dataset Viewer issue with False positive PII redaction | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | [
"The value is in the data, it's not an issue with the \"dataset-viewer\".\r\n\r\n<img width=\"1161\" alt=\"Capture d’écran 2022-06-29 à 10 25 51\" src=\"https://user-images.githubusercontent.com/1676121/176389325-4d2a9a7f-1583-45b8-aa7a-960ffaa6a36a.png\">\r\n\r\n Maybe open a PR: https://huggingface.co/datasets/... | 2022-06-29T07:15:57 | 2022-06-29T08:29:41 | 2022-06-29T08:27:49 | CONTRIBUTOR | null | null | null | null | ### Link
https://huggingface.co/datasets/cakiki/rosetta-code
### Description
Hello, I just noticed an entry being redacted that shouldn't have been:
`RootMeanSquare@Range[10]` is being displayed as `[email protected][10]`
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4595/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:11:52 |
https://api.github.com/repos/huggingface/datasets/issues/4594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4594/comments | https://api.github.com/repos/huggingface/datasets/issues/4594/events | https://github.com/huggingface/datasets/issues/4594 | 1,288,070,023 | I_kwDODunzps5MxmOH | 4,594 | load_from_disk suggests incorrect fix when used to load DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/11157811?v=4",
"events_url": "https://api.github.com/users/dvsth/events{/privacy}",
"followers_url": "https://api.github.com/users/dvsth/followers",
"following_url": "https://api.github.com/users/dvsth/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [] | 2022-06-29T01:40:01 | 2022-06-29T04:03:44 | 2022-06-29T04:03:44 | NONE | null | null | null | null | Edit: Please feel free to remove this issue. The problem was not the error message but the fact that the DatasetDict.load_from_disk does not support loading nested splits, i.e. if one of the splits is itself a DatasetDict. If nesting splits is an antipattern, perhaps the load_from_disk function can throw a warning indi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/11157811?v=4",
"events_url": "https://api.github.com/users/dvsth/events{/privacy}",
"followers_url": "https://api.github.com/users/dvsth/followers",
"following_url": "https://api.github.com/users/dvsth/following{/other_user}",
"gists_url": "https://api.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4594/timeline | null | not_planned | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2:23:43 |
https://api.github.com/repos/huggingface/datasets/issues/4592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4592/comments | https://api.github.com/repos/huggingface/datasets/issues/4592/events | https://github.com/huggingface/datasets/issues/4592 | 1,288,029,377 | I_kwDODunzps5MxcTB | 4,592 | Issue with jalFaizy/detect_chess_pieces when running datasets-cli test | {
"avatar_url": "https://avatars.githubusercontent.com/u/8406903?v=4",
"events_url": "https://api.github.com/users/faizankshaikh/events{/privacy}",
"followers_url": "https://api.github.com/users/faizankshaikh/followers",
"following_url": "https://api.github.com/users/faizankshaikh/following{/other_user}",
"gi... | [] | closed | false | null | [] | [
"Hi @faizankshaikh\r\n\r\nPlease note that we have recently launched the Community feature, specifically targeted to create Discussions (about issues/questions/asking-for-help) on each Dataset on the Hub:\r\n- Blog post: https://huggingface.co/blog/community-update\r\n- Docs: https://huggingface.co/docs/hub/reposit... | 2022-06-29T00:15:54 | 2022-06-29T10:30:03 | 2022-06-29T07:49:27 | NONE | null | null | null | null | ### Link
https://huggingface.co/datasets/jalFaizy/detect_chess_pieces
### Description
I am trying to write a appropriate data loader for [a custom dataset](https://huggingface.co/datasets/jalFaizy/detect_chess_pieces) using [this script](https://huggingface.co/datasets/jalFaizy/detect_chess_pieces/blob/main/detect_c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4592/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4592/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 7:33:33 |
https://api.github.com/repos/huggingface/datasets/issues/4591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4591/comments | https://api.github.com/repos/huggingface/datasets/issues/4591/events | https://github.com/huggingface/datasets/issues/4591 | 1,288,021,332 | I_kwDODunzps5MxaVU | 4,591 | Can't push Images to hub with manual Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | [
"Hi, thanks for reporting! This issue stems from the changes introduced in https://github.com/huggingface/datasets/pull/4282 (cc @lhoestq), in which list casts are ignored if they don't change the list type (required to preserve `null` values). And `push_to_hub` does a special cast to embed external image files but... | 2022-06-29T00:01:23 | 2022-07-08T12:01:36 | 2022-07-08T12:01:35 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
If I create a dataset including an 'Image' feature manually, when pushing to hub decoded images are not pushed,
instead it looks for image where image local path is/used to be.
This doesn't (at least didn't used to) happen with imagefolder. I want to build dataset manually because it is compli... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4591/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4591/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 9 days, 12:00:12 |
https://api.github.com/repos/huggingface/datasets/issues/4589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4589/comments | https://api.github.com/repos/huggingface/datasets/issues/4589/events | https://github.com/huggingface/datasets/issues/4589 | 1,287,600,029 | I_kwDODunzps5Mvzed | 4,589 | Permission denied: '/home/.cache' when load_dataset with local script | {
"avatar_url": "https://avatars.githubusercontent.com/u/24559732?v=4",
"events_url": "https://api.github.com/users/jiangh0/events{/privacy}",
"followers_url": "https://api.github.com/users/jiangh0/followers",
"following_url": "https://api.github.com/users/jiangh0/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [] | 2022-06-28T16:26:03 | 2022-06-29T06:26:28 | 2022-06-29T06:25:08 | NONE | null | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/24559732?v=4",
"events_url": "https://api.github.com/users/jiangh0/events{/privacy}",
"followers_url": "https://api.github.com/users/jiangh0/followers",
"following_url": "https://api.github.com/users/jiangh0/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4589/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 13:59:05 |
https://api.github.com/repos/huggingface/datasets/issues/4581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4581/comments | https://api.github.com/repos/huggingface/datasets/issues/4581/events | https://github.com/huggingface/datasets/issues/4581 | 1,286,362,907 | I_kwDODunzps5MrFcb | 4,581 | Dataset Viewer issue for pn_summary | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"linked to https://github.com/huggingface/datasets/issues/4580#issuecomment-1168373066?",
"Note that I refreshed twice this dataset, and I still have (another) error on one of the splits\r\n\r\n```\r\nStatus code: 400\r\nException: ClientResponseError\r\nMessage: 403, message='Forbidden', url=URL('htt... | 2022-06-27T20:56:12 | 2022-06-28T14:42:03 | 2022-06-28T14:42:03 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/pn_summary/viewer/1.0.0/validation
### Description
Getting an index error on the `validation` and `test` splits:
```
Server error
Status code: 400
Exception: IndexError
Message: list index out of range
```
### Owner
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4581/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 17:45:51 |
https://api.github.com/repos/huggingface/datasets/issues/4580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4580/comments | https://api.github.com/repos/huggingface/datasets/issues/4580/events | https://github.com/huggingface/datasets/issues/4580 | 1,286,312,912 | I_kwDODunzps5Mq5PQ | 4,580 | Dataset Viewer issue for multi_news | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @lewtun.\r\n\r\nI forced the refreshing of the preview and it worked OK for train and validation splits.\r\n\r\nI guess the error has to do with the data files being hosted at Google Drive: this gives errors when requested automatically using scripts.\r\nWe should host them to fix the error. ... | 2022-06-27T20:25:25 | 2022-06-28T14:08:48 | 2022-06-28T14:08:48 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/multi_news
### Description
Not sure what the index error is referring to here:
```
Status code: 400
Exception: IndexError
Message: list index out of range
```
### Owner
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4580/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 17:43:23 |
https://api.github.com/repos/huggingface/datasets/issues/4578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4578/comments | https://api.github.com/repos/huggingface/datasets/issues/4578/events | https://github.com/huggingface/datasets/issues/4578 | 1,286,086,400 | I_kwDODunzps5MqB8A | 4,578 | [Multi Configs] Use directories to differentiate between subsets/configurations | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | [
"I want to be able to create folders in a model.",
"How to set new split names, instead of train/test/validation? For example, I have a local dataset, consists of several subsets, named \"A\", \"B\", and \"C\". How can I create a huggingface dataset, with splits A/B/C ?\r\n\r\nThe document in https://huggingface.... | 2022-06-27T16:55:11 | 2023-06-14T15:43:05 | null | MEMBER | null | null | null | null | Currently to define several subsets/configurations of your dataset, you need to use a dataset script.
However it would be nice to have a no-code way to to this.
For example we could specify different configurations of a dataset (for example, if a dataset contains different languages) with one directory per confi... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 9,
"hooray": 0,
"laugh": 0,
"rocket": 5,
"total_count": 19,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4578/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4575/comments | https://api.github.com/repos/huggingface/datasets/issues/4575/events | https://github.com/huggingface/datasets/issues/4575 | 1,285,446,700 | I_kwDODunzps5Mnlws | 4,575 | Problem about wmt17 zh-en dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/85819194?v=4",
"events_url": "https://api.github.com/users/winterfell2021/events{/privacy}",
"followers_url": "https://api.github.com/users/winterfell2021/followers",
"following_url": "https://api.github.com/users/winterfell2021/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | [
"Running into the same error with `wmt17/zh-en`, `wmt18/zh-en` and `wmt19/zh-en`.",
"@albertvillanova @lhoestq Could you take a look at this issue?",
"@winterfell2021 Hi, I wonder where the code you provided should be added. I tried to add them in the `datasets/table.py` in `array_cast` function, however, the '... | 2022-06-27T08:35:42 | 2022-08-23T10:01:02 | 2022-08-23T10:00:21 | NONE | null | null | null | null | It seems that in subset casia2015, some samples are like `{'c[hn]':'xxx', 'en': 'aa'}`.
So when using `data = load_dataset('wmt17', "zh-en")` to load the wmt17 zh-en dataset, which will raise the exception:
```
Traceback (most recent call last):
File "train.py", line 78, in <module>
data = load_dataset(args.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4575/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4575/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 57 days, 1:24:39 |
https://api.github.com/repos/huggingface/datasets/issues/4572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4572/comments | https://api.github.com/repos/huggingface/datasets/issues/4572/events | https://github.com/huggingface/datasets/issues/4572 | 1,285,022,499 | I_kwDODunzps5Ml-Mj | 4,572 | Dataset Viewer issue for mlsum | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Thanks for reporting, @lewtun.\r\n\r\nAfter investigation, it seems that the server https://gitlab.lip6.fr does not allow HTTP Range requests.\r\n\r\nWe are trying to find a workaround..."
] | 2022-06-26T20:24:17 | 2022-07-21T12:40:01 | 2022-07-21T12:40:01 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/mlsum/viewer/de/train
### Description
There's seems to be a problem with the download / streaming of this dataset:
```
Server error
Status code: 400
Exception: BadZipFile
Message: File is not a zip file
```
### Owner
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4572/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 24 days, 16:15:44 |
https://api.github.com/repos/huggingface/datasets/issues/4571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4571/comments | https://api.github.com/repos/huggingface/datasets/issues/4571/events | https://github.com/huggingface/datasets/issues/4571 | 1,284,883,289 | I_kwDODunzps5MlcNZ | 4,571 | move under the facebook org? | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Related to https://github.com/huggingface/datasets/issues/4562#issuecomment-1166911751\r\n\r\nI'll assign @albertvillanova ",
"I'm just wondering why we don't have this dataset under:\r\n- the `facebook` namespace\r\n- or the canonical dataset `flores`: why does this only have 2 languages?",
"fwiw: the dataset... | 2022-06-26T11:19:09 | 2023-09-25T12:05:18 | null | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/gsarti/flores_101
### Description
It seems like streaming isn't supported for this dataset:
```
Server Error
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol for TAR archives like 'https://dl.fbaipublicfiles.com/flores101/dataset... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4571/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4571/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
https://api.github.com/repos/huggingface/datasets/issues/4570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4570/comments | https://api.github.com/repos/huggingface/datasets/issues/4570/events | https://github.com/huggingface/datasets/issues/4570 | 1,284,846,168 | I_kwDODunzps5MlTJY | 4,570 | Dataset sharding non-contiguous? | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"This was silly; I was sure I'd looked for a `contiguous` argument, and was certain there wasn't one the first time I looked :smile:\r\n\r\nSorry about that.",
"Hi! You can pass `contiguous=True` to `.shard()` get contiguous shards. More info on this and the default behavior can be found in the [docs](https://hug... | 2022-06-26T08:34:05 | 2022-06-30T11:00:47 | 2022-06-26T14:36:20 | CONTRIBUTOR | null | null | null | null | ## Describe the bug
I'm not sure if this is a bug; more likely normal behavior but i wanted to double check.
Is it normal that `datasets.shard` does not produce chunks that, when concatenated produce the original ordering of the sharded dataset?
This might be related to this pull request (https://github.com/huggi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4570/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4570/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6:02:15 |
https://api.github.com/repos/huggingface/datasets/issues/4569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4569/comments | https://api.github.com/repos/huggingface/datasets/issues/4569/events | https://github.com/huggingface/datasets/issues/4569 | 1,284,833,694 | I_kwDODunzps5MlQGe | 4,569 | Dataset Viewer issue for sst2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"Hi @lewtun, thanks for reporting.\r\n\r\nI have checked locally and refreshed the preview and it seems working smooth now:\r\n```python\r\nIn [8]: ds\r\nOut[8]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 67349\r\n })\r\n validation: Datas... | 2022-06-26T07:32:54 | 2022-06-27T06:37:48 | 2022-06-27T06:37:48 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with Connectio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4569/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 23:04:54 |
https://api.github.com/repos/huggingface/datasets/issues/4568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4568/comments | https://api.github.com/repos/huggingface/datasets/issues/4568/events | https://github.com/huggingface/datasets/issues/4568 | 1,284,655,624 | I_kwDODunzps5MkkoI | 4,568 | XNLI cache reload is very slow | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi,\r\nCould you tell us how you are running this code?\r\nI tested on my machine (M1 Mac). And it is running fine both on and off internet.\r\n\r\n<img width=\"1033\" alt=\"Screen Shot 2022-07-03 at 1 32 25 AM\" src=\"https://user-images.githubusercontent.com/8711912/177026364-4ad7cedb-e524-4513-97f7-7961bbb34c90... | 2022-06-25T16:43:56 | 2022-07-04T14:29:40 | 2022-07-04T14:29:40 | CONTRIBUTOR | null | null | null | null | ### Reproduce
Using `2.3.3.dev0`
`from datasets import load_dataset`
`load_dataset("xnli", "en")`
Turn off Internet
`load_dataset("xnli", "en")`
I cancelled the second `load_dataset` eventually cuz it took super long. It would be great to have something to specify e.g. `only_load_from_cache` and avoid the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4568/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 8 days, 21:45:44 |
https://api.github.com/repos/huggingface/datasets/issues/4566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4566/comments | https://api.github.com/repos/huggingface/datasets/issues/4566/events | https://github.com/huggingface/datasets/issues/4566 | 1,284,397,594 | I_kwDODunzps5Mjloa | 4,566 | Document link #load_dataset_enhancing_performance points to nowhere | {
"avatar_url": "https://avatars.githubusercontent.com/u/11674033?v=4",
"events_url": "https://api.github.com/users/subercui/events{/privacy}",
"followers_url": "https://api.github.com/users/subercui/followers",
"following_url": "https://api.github.com/users/subercui/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Hi! This is indeed the link the docstring should point to. Are you interested in submitting a PR to fix this?",
"https://github.com/huggingface/datasets/blame/master/docs/source/cache.mdx#L93\r\n\r\nThere seems already an anchor here. Somehow it doesn't work. I am not very familiar with how this online documenta... | 2022-06-25T01:18:19 | 2023-01-24T16:33:40 | 2023-01-24T16:33:40 | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.

The [load_dataset_enhancing_performance](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#load_dat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4566/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 213 days, 15:15:21 |
https://api.github.com/repos/huggingface/datasets/issues/4565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4565/comments | https://api.github.com/repos/huggingface/datasets/issues/4565/events | https://github.com/huggingface/datasets/issues/4565 | 1,284,141,666 | I_kwDODunzps5MinJi | 4,565 | Add UFSC OCPap dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/20444345?v=4",
"events_url": "https://api.github.com/users/johnnv1/events{/privacy}",
"followers_url": "https://api.github.com/users/johnnv1/followers",
"following_url": "https://api.github.com/users/johnnv1/following{/other_user}",
"gists_url": "https:... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | [
"I will add this directly on the hub (same as #4486)—in https://huggingface.co/lapix"
] | 2022-06-24T20:07:54 | 2022-07-06T19:03:02 | 2022-07-06T19:03:02 | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** UFSC OCPap: Papanicolaou Stained Oral Cytology Dataset (v4)
- **Description:** The UFSC OCPap dataset comprises 9,797 labeled images of 1200x1600 pixels acquired from 5 slides of cancer diagnosed and 3 healthy of oral brush samples, from distinct patients.
- **Paper:** https://dx.doi.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/20444345?v=4",
"events_url": "https://api.github.com/users/johnnv1/events{/privacy}",
"followers_url": "https://api.github.com/users/johnnv1/followers",
"following_url": "https://api.github.com/users/johnnv1/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4565/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4565/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 11 days, 22:55:08 |
https://api.github.com/repos/huggingface/datasets/issues/4562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4562/comments | https://api.github.com/repos/huggingface/datasets/issues/4562/events | https://github.com/huggingface/datasets/issues/4562 | 1,283,779,557 | I_kwDODunzps5MhOvl | 4,562 | Dataset Viewer issue for allocine | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | [
"I removed my assignment as @huggingface/datasets should be able to answer better than me\r\n",
"Let me have a look...",
"Thanks for the quick fix @albertvillanova ",
"Note that the underlying issue is that datasets containing TAR files are not streamable out of the box: they need being iterated with `dl_mana... | 2022-06-24T13:50:38 | 2022-06-27T06:39:32 | 2022-06-24T16:44:41 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/allocine
### Description
Not sure if this is a problem with `bz2` compression, but I thought these datasets could be streamed:
```
Status code: 400
Exception: AttributeError
Message: 'TarContainedFile' object has no attribute 'readable'
```
### Owner
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4562/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 2:54:03 |
https://api.github.com/repos/huggingface/datasets/issues/4556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4556/comments | https://api.github.com/repos/huggingface/datasets/issues/4556/events | https://github.com/huggingface/datasets/issues/4556 | 1,283,462,881 | I_kwDODunzps5MgBbh | 4,556 | Dataset Viewer issue for conll2003 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Fixed, thanks."
] | 2022-06-24T08:55:18 | 2022-06-24T09:50:39 | 2022-06-24T09:50:39 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/conll2003/viewer/conll2003/test
### Description
Seems like a cache problem with this config / split:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/datasets/conll... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4556/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 0:55:21 |
https://api.github.com/repos/huggingface/datasets/issues/4555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4555/comments | https://api.github.com/repos/huggingface/datasets/issues/4555/events | https://github.com/huggingface/datasets/issues/4555 | 1,283,451,651 | I_kwDODunzps5Mf-sD | 4,555 | Dataset Viewer issue for xtreme | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | [
"Fixed, thanks."
] | 2022-06-24T08:46:08 | 2022-06-24T09:50:45 | 2022-06-24T09:50:45 | MEMBER | null | null | null | null | ### Link
https://huggingface.co/datasets/xtreme/viewer/PAN-X.de/test
### Description
There seems to be a problem with the cache of this config / split:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4555/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 1:04:37 |
https://api.github.com/repos/huggingface/datasets/issues/4550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4550/comments | https://api.github.com/repos/huggingface/datasets/issues/4550/events | https://github.com/huggingface/datasets/issues/4550 | 1,282,374,441 | I_kwDODunzps5Mb3sp | 4,550 | imdb source error | {
"avatar_url": "https://avatars.githubusercontent.com/u/20128202?v=4",
"events_url": "https://api.github.com/users/Muhtasham/events{/privacy}",
"followers_url": "https://api.github.com/users/Muhtasham/followers",
"following_url": "https://api.github.com/users/Muhtasham/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | [
"Thanks for reporting, @Muhtasham.\r\n\r\nIndeed IMDB dataset is not accessible from yesterday, because the data is hosted on the data owners servers at Stanford (http://ai.stanford.edu/) and these are down due to a power outage originated by a fire: https://twitter.com/StanfordAILab/status/1539472302399623170?s=20... | 2022-06-23T13:02:52 | 2022-06-23T13:47:05 | 2022-06-23T13:47:04 | NONE | null | null | null | null | ## Describe the bug
imdb dataset not loading
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("imdb")
```
## Expected results
## Actual results
```bash
06/23/2022 14:45:18 - INFO - datasets.builder - Dataset not on Hf google storage. Downloading and pr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/20128202?v=4",
"events_url": "https://api.github.com/users/Muhtasham/events{/privacy}",
"followers_url": "https://api.github.com/users/Muhtasham/followers",
"following_url": "https://api.github.com/users/Muhtasham/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4550/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 0:44:12 |
https://api.github.com/repos/huggingface/datasets/issues/4549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4549/comments | https://api.github.com/repos/huggingface/datasets/issues/4549/events | https://github.com/huggingface/datasets/issues/4549 | 1,282,312,975 | I_kwDODunzps5MbosP | 4,549 | FileNotFoundError when passing a data_file inside a directory starting with double underscores | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | [
"I have consistently experienced this bug on GitHub actions when bumping to `2.3.2`",
"We're working on a fix ;)"
] | 2022-06-23T12:19:24 | 2022-06-30T14:38:18 | 2022-06-30T14:38:18 | MEMBER | null | null | null | null | Bug experienced in the `accelerate` CI: https://github.com/huggingface/accelerate/runs/7016055148?check_suite_focus=true
This is related to https://github.com/huggingface/datasets/pull/4505 and the changes from https://github.com/huggingface/datasets/pull/4412 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4549/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4549/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 7 days, 2:18:54 |
https://api.github.com/repos/huggingface/datasets/issues/4548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4548/comments | https://api.github.com/repos/huggingface/datasets/issues/4548/events | https://github.com/huggingface/datasets/issues/4548 | 1,282,218,096 | I_kwDODunzps5MbRhw | 4,548 | Metadata.jsonl for Imagefolder is ignored if it's in a parent directory to the splits directories/do not have "{split}_" prefix | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | [
"I agree it would be nice to support this. It doesn't fit really well in the current data_files.py, where files of each splits are separated in different folder though, maybe we have to modify a bit the logic here. \r\n\r\nOne idea would be to extend `get_patterns_in_dataset_repository` and `get_patterns_locally` t... | 2022-06-23T10:58:57 | 2022-06-30T10:15:32 | 2022-06-30T10:15:32 | CONTRIBUTOR | null | null | null | null | If data contains a single `metadata.jsonl` file for several splits, it won't be included in a dataset's `data_files` and therefore ignored.
This happens when a directory is structured like as follows:
```
train/
file_1.jpg
file_2.jpg
test/
file_3.jpg
file_4.jpg
metadata.jsonl
```
or like as follows:... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4548/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 6 days, 23:16:35 |
https://api.github.com/repos/huggingface/datasets/issues/4544 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4544/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4544/comments | https://api.github.com/repos/huggingface/datasets/issues/4544/events | https://github.com/huggingface/datasets/issues/4544 | 1,280,500,340 | I_kwDODunzps5MUuJ0 | 4,544 | [CI] seqeval installation fails sometimes on python 3.6 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | [] | 2022-06-22T16:35:23 | 2022-06-23T10:13:44 | 2022-06-23T10:13:44 | MEMBER | null | null | null | null | The CI sometimes fails to install seqeval, which cause the `seqeval` metric tests to fail.
The installation fails because of this error:
```
Collecting seqeval
Downloading seqeval-1.2.2.tar.gz (43 kB)
|███████▌ | 10 kB 42.1 MB/s eta 0:00:01
|███████████████ ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4544/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4544/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | 17:38:21 |
https://api.github.com/repos/huggingface/datasets/issues/4542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4542/comments | https://api.github.com/repos/huggingface/datasets/issues/4542/events | https://github.com/huggingface/datasets/issues/4542 | 1,280,269,445 | I_kwDODunzps5MT1yF | 4,542 | [to_tf_dataset] Use Feather for better compatibility with TensorFlow ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | [] | [
"This has so much potential to be great! Also I think you tagged some poor random dude on the internet whose name is also Joao, lol, edited that for you! ",
"cc @sayakpaul here too, since he was interested in our new approaches to converting datasets!",
"Noted and I will look into the thread in detail tomorrow ... | 2022-06-22T14:42:00 | 2022-10-11T08:45:45 | null | MEMBER | null | null | null | null | To have better performance in TensorFlow, it is important to provide lists of data files in supported formats. For example sharded TFRecords datasets are extremely performant. This is because tf.data can better leverage parallelism in this case, and load one file at a time in memory.
It seems that using `tensorflow_... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4542/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4542/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.