
text stringlengths 7 1.24M | id stringlengths 14 166 | metadata dict | __index_level_0__ int64 0 519 |
|---|---|---|---|
# Copyright 2020 The HuggingFace Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to... | datasets/src/datasets/formatting/np_formatter.py/0 | {
"file_path": "datasets/src/datasets/formatting/np_formatter.py",
"repo_id": "datasets",
"token_count": 1871
} | 80 |
import copy
import itertools
import sys
from collections import Counter
from copy import deepcopy
from dataclasses import dataclass
from functools import partial
from itertools import cycle, islice
from typing import TYPE_CHECKING, Any, Callable, Dict, Iterable, Iterator, List, Optional, Tuple, Union
import fsspec.asy... | datasets/src/datasets/iterable_dataset.py/0 | {
"file_path": "datasets/src/datasets/iterable_dataset.py",
"repo_id": "datasets",
"token_count": 61813
} | 81 |
from dataclasses import dataclass
from typing import Callable, Optional
import datasets
@dataclass
class GeneratorConfig(datasets.BuilderConfig):
generator: Optional[Callable] = None
gen_kwargs: Optional[dict] = None
features: Optional[datasets.Features] = None
split: datasets.NamedSplit = datasets.S... | datasets/src/datasets/packaged_modules/generator/generator.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/generator/generator.py",
"repo_id": "datasets",
"token_count": 396
} | 82 |
#
# Copyright (c) 2017-2021 NVIDIA CORPORATION. All rights reserved.
# This file coems from the WebDataset library.
# See the LICENSE file for licensing terms (BSD-style).
#
"""
Binary tensor encodings for PyTorch and NumPy.
This defines efficient binary encodings for tensors. The format is 8 byte
aligned and can be ... | datasets/src/datasets/packaged_modules/webdataset/_tenbin.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/webdataset/_tenbin.py",
"repo_id": "datasets",
"token_count": 3409
} | 83 |
"""
Utilities for working with the local dataset cache.
This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
Copyright by the AllenNLP authors.
"""
import asyncio
import glob
import io
import json
import multiprocessing
import os
import posixpath
import re
import shutil
import sys
impo... | datasets/src/datasets/utils/file_utils.py/0 | {
"file_path": "datasets/src/datasets/utils/file_utils.py",
"repo_id": "datasets",
"token_count": 22638
} | 84 |
# Copyright 2022 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# U... | datasets/src/datasets/utils/tf_utils.py/0 | {
"file_path": "datasets/src/datasets/utils/tf_utils.py",
"repo_id": "datasets",
"token_count": 10958
} | 85 |
import textwrap
import pyarrow as pa
import pytest
from datasets import Features, Value
from datasets.builder import InvalidConfigName
from datasets.data_files import DataFilesList
from datasets.packaged_modules.json.json import Json, JsonConfig
@pytest.fixture
def jsonl_file(tmp_path):
filename = tmp_path / "f... | datasets/tests/packaged_modules/test_json.py/0 | {
"file_path": "datasets/tests/packaged_modules/test_json.py",
"repo_id": "datasets",
"token_count": 3594
} | 86 |
import warnings
import pytest
import datasets.utils.deprecation_utils
from datasets.exceptions import (
ChecksumVerificationError,
ExpectedMoreDownloadedFilesError,
ExpectedMoreSplitsError,
NonMatchingChecksumError,
NonMatchingSplitsSizesError,
SplitsVerificationError,
UnexpectedDownloaded... | datasets/tests/test_exceptions.py/0 | {
"file_path": "datasets/tests/test_exceptions.py",
"repo_id": "datasets",
"token_count": 360
} | 87 |
import pytest
from datasets.parallel import ParallelBackendConfig, parallel_backend
from datasets.utils.py_utils import map_nested
from .utils import require_dill_gt_0_3_2, require_joblibspark, require_not_windows
def add_one(i): # picklable for multiprocessing
return i + 1
@require_dill_gt_0_3_2
@require_jo... | datasets/tests/test_parallel.py/0 | {
"file_path": "datasets/tests/test_parallel.py",
"repo_id": "datasets",
"token_count": 825
} | 88 |
# Live 1: How the course work, Q&A, and playing with Huggy
In this first live stream, we explained how the course work (scope, units, challenges, and more) and answered your questions.
And finally, we saw some LunarLander agents you've trained and play with your Huggies 🐶
<Youtube id="JeJIswxyrsM" />
To know when ... | deep-rl-class/units/en/live1/live1.mdx/0 | {
"file_path": "deep-rl-class/units/en/live1/live1.mdx",
"repo_id": "deep-rl-class",
"token_count": 131
} | 89 |
# What is Reinforcement Learning? [[what-is-reinforcement-learning]]
To understand Reinforcement Learning, let’s start with the big picture.
## The big picture [[the-big-picture]]
The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial... | deep-rl-class/units/en/unit1/what-is-rl.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit1/what-is-rl.mdx",
"repo_id": "deep-rl-class",
"token_count": 624
} | 90 |
# Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
- [Double Deep Q-Learning](ht... | deep-rl-class/units/en/unit3/additional-readings.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit3/additional-readings.mdx",
"repo_id": "deep-rl-class",
"token_count": 163
} | 91 |
# Diving deeper into policy-gradient methods
## Getting the big picture
We just learned that policy-gradient methods aim to find parameters \\( \theta \\) that **maximize the expected return**.
The idea is that we have a *parameterized stochastic policy*. In our case, a neural network outputs a probability distribu... | deep-rl-class/units/en/unit4/policy-gradient.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit4/policy-gradient.mdx",
"repo_id": "deep-rl-class",
"token_count": 2402
} | 92 |
# Introduction [[introduction]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/thumbnail.png" alt="Thumbnail"/>
In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
In Policy-Based methods, **we aim to optimize the policy direc... | deep-rl-class/units/en/unit6/introduction.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit6/introduction.mdx",
"repo_id": "deep-rl-class",
"token_count": 427
} | 93 |
# Generalization in Reinforcement Learning
Generalization plays a pivotal role in the realm of Reinforcement Learning. While **RL algorithms demonstrate good performance in controlled environments**, the real world presents a **unique challenge due to its non-stationary and open-ended nature**.
As a result, the devel... | deep-rl-class/units/en/unitbonus3/generalisation.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/generalisation.mdx",
"repo_id": "deep-rl-class",
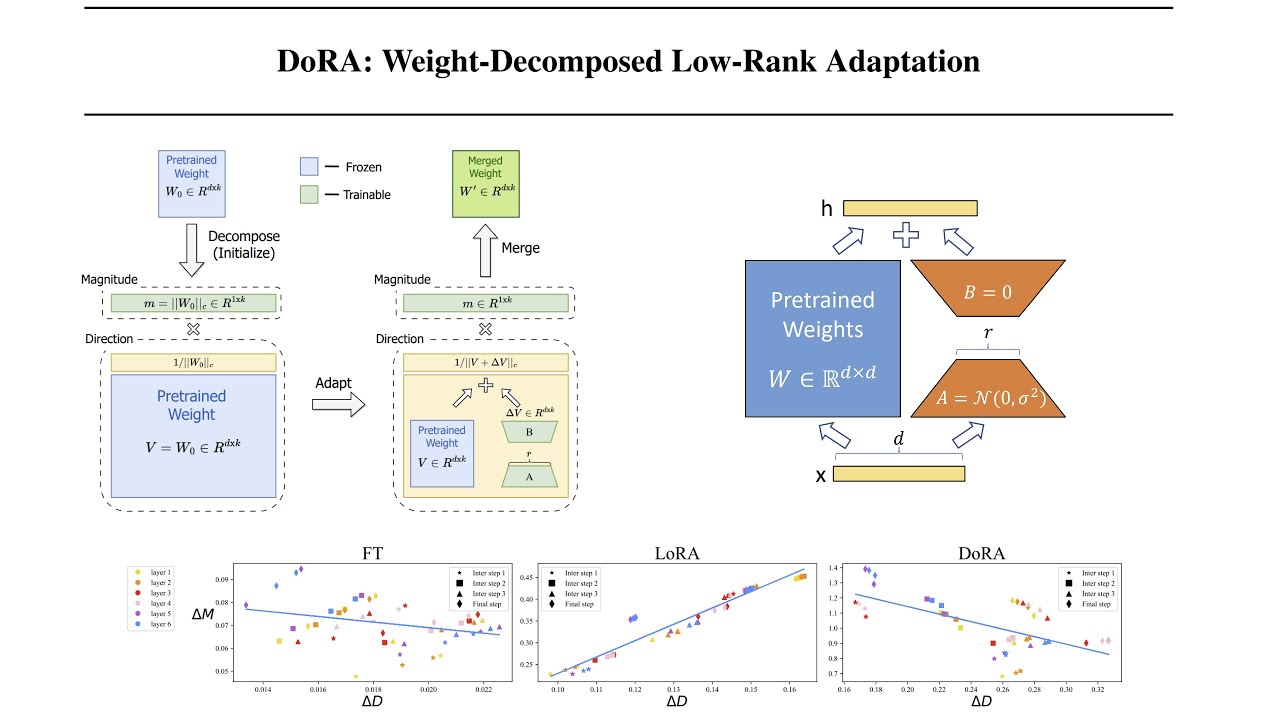
"token_count": 250
} | 94 |
import argparse
import csv
import gc
import os
from dataclasses import dataclass
from typing import Dict, List, Union
import torch
import torch.utils.benchmark as benchmark
GITHUB_SHA = os.getenv("GITHUB_SHA", None)
BENCHMARK_FIELDS = [
"pipeline_cls",
"ckpt_id",
"batch_size",
"num_inference_steps",
... | diffusers/benchmarks/utils.py/0 | {
"file_path": "diffusers/benchmarks/utils.py",
"repo_id": "diffusers",
"token_count": 1254
} | 95 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/attnprocessor.md/0 | {
"file_path": "diffusers/docs/source/en/api/attnprocessor.md",
"repo_id": "diffusers",
"token_count": 587
} | 96 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/models/autoencoderkl_cogvideox.md/0 | {
"file_path": "diffusers/docs/source/en/api/models/autoencoderkl_cogvideox.md",
"repo_id": "diffusers",
"token_count": 450
} | 97 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/pipelines/ddim.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/ddim.md",
"repo_id": "diffusers",
"token_count": 477
} | 98 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/quicktour.md/0 | {
"file_path": "diffusers/docs/source/en/quicktour.md",
"repo_id": "diffusers",
"token_count": 4836
} | 99 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/training/text2image.md/0 | {
"file_path": "diffusers/docs/source/en/training/text2image.md",
"repo_id": "diffusers",
"token_count": 4036
} | 100 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/diffedit.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/diffedit.md",
"repo_id": "diffusers",
"token_count": 3847
} | 101 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/reusing_seeds.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/reusing_seeds.md",
"repo_id": "diffusers",
"token_count": 2981
} | 102 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ja/installation.md/0 | {
"file_path": "diffusers/docs/source/ja/installation.md",
"repo_id": "diffusers",
"token_count": 2493
} | 103 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/optimization/habana.md/0 | {
"file_path": "diffusers/docs/source/ko/optimization/habana.md",
"repo_id": "diffusers",
"token_count": 1911
} | 104 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/training/lora.md/0 | {
"file_path": "diffusers/docs/source/ko/training/lora.md",
"repo_id": "diffusers",
"token_count": 4734
} | 105 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/loading_adapters.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/loading_adapters.md",
"repo_id": "diffusers",
"token_count": 12254
} | 106 |
- sections:
- local: index
title: 🧨 Diffusers
- local: quicktour
title: 快速入门
- local: stable_diffusion
title: 有效和高效的扩散
- local: installation
title: 安装
title: 开始
| diffusers/docs/source/zh/_toctree.yml/0 | {
"file_path": "diffusers/docs/source/zh/_toctree.yml",
"repo_id": "diffusers",
"token_count": 100
} | 107 |
# -*- coding: utf-8 -*-
import inspect
from typing import Optional, Union
import numpy as np
import PIL.Image
import torch
from torch.nn import functional as F
from torchvision import transforms
from transformers import CLIPImageProcessor, CLIPModel, CLIPTextModel, CLIPTokenizer
from diffusers import (
Autoencode... | diffusers/examples/community/clip_guided_images_mixing_stable_diffusion.py/0 | {
"file_path": "diffusers/examples/community/clip_guided_images_mixing_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 8765
} | 108 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/kohya_hires_fix.py/0 | {
"file_path": "diffusers/examples/community/kohya_hires_fix.py",
"repo_id": "diffusers",
"token_count": 10583
} | 109 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/pipeline_animatediff_img2video.py/0 | {
"file_path": "diffusers/examples/community/pipeline_animatediff_img2video.py",
"repo_id": "diffusers",
"token_count": 20603
} | 110 |
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionControlNetPipe... | diffusers/examples/community/stable_diffusion_controlnet_reference.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_controlnet_reference.py",
"repo_id": "diffusers",
"token_count": 21059
} | 111 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/controlnet/train_controlnet_flax.py/0 | {
"file_path": "diffusers/examples/controlnet/train_controlnet_flax.py",
"repo_id": "diffusers",
"token_count": 20114
} | 112 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/examples/dreambooth/test_dreambooth.py/0 | {
"file_path": "diffusers/examples/dreambooth/test_dreambooth.py",
"repo_id": "diffusers",
"token_count": 4466
} | 113 |
import warnings
from diffusers import StableDiffusionImg2ImgPipeline # noqa F401
warnings.warn(
"The `image_to_image.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionImg2ImgPipeline` instead."
)
| diffusers/examples/inference/image_to_image.py/0 | {
"file_path": "diffusers/examples/inference/image_to_image.py",
"repo_id": "diffusers",
"token_count": 84
} | 114 |
# Research projects
This folder contains various research projects using 🧨 Diffusers.
They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
Updating them to the most recent version of the libr... | diffusers/examples/research_projects/README.md/0 | {
"file_path": "diffusers/examples/research_projects/README.md",
"repo_id": "diffusers",
"token_count": 144
} | 115 |
## Diffusers examples with Intel optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please make sure to tag @hshen14 .**
This aims to provide diffusers examples with Intel optimizations such as Bfloat16 for training/fine-tuning acceleration and 8-bit... | diffusers/examples/research_projects/intel_opts/README.md/0 | {
"file_path": "diffusers/examples/research_projects/intel_opts/README.md",
"repo_id": "diffusers",
"token_count": 524
} | 116 |
## Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion... | diffusers/examples/textual_inversion/README.md/0 | {
"file_path": "diffusers/examples/textual_inversion/README.md",
"repo_id": "diffusers",
"token_count": 1778
} | 117 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/vqgan/test_vqgan.py/0 | {
"file_path": "diffusers/examples/vqgan/test_vqgan.py",
"repo_id": "diffusers",
"token_count": 8162
} | 118 |
import argparse
import time
from pathlib import Path
from typing import Any, Dict, Literal
import torch
from diffusers import AsymmetricAutoencoderKL
ASYMMETRIC_AUTOENCODER_KL_x_1_5_CONFIG = {
"in_channels": 3,
"out_channels": 3,
"down_block_types": [
"DownEncoderBlock2D",
"DownEncoderBl... | diffusers/scripts/convert_asymmetric_vqgan_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_asymmetric_vqgan_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 3351
} | 119 |
# Convert the original UniDiffuser checkpoints into diffusers equivalents.
import argparse
from argparse import Namespace
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextConfig,
CLIPTextModel,
CLIPTokenizer,
CLIPVisionConfig,
CLIPVisionModelWithProjection,
GPT2Tokenizer... | diffusers/scripts/convert_unidiffuser_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_unidiffuser_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 13871
} | 120 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/loaders/textual_inversion.py/0 | {
"file_path": "diffusers/src/diffusers/loaders/textual_inversion.py",
"repo_id": "diffusers",
"token_count": 12007
} | 121 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/autoencoders/autoencoder_oobleck.py/0 | {
"file_path": "diffusers/src/diffusers/models/autoencoders/autoencoder_oobleck.py",
"repo_id": "diffusers",
"token_count": 7317
} | 122 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.a... | diffusers/src/diffusers/models/model_loading_utils.py/0 | {
"file_path": "diffusers/src/diffusers/models/model_loading_utils.py",
"repo_id": "diffusers",
"token_count": 3673
} | 123 |
# Copyright 2024 Alpha-VLLM Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unles... | diffusers/src/diffusers/models/transformers/lumina_nextdit2d.py/0 | {
"file_path": "diffusers/src/diffusers/models/transformers/lumina_nextdit2d.py",
"repo_id": "diffusers",
"token_count": 6276
} | 124 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unets/unet_2d_condition_flax.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_2d_condition_flax.py",
"repo_id": "diffusers",
"token_count": 10117
} | 125 |
# Copyright 2024 AuraFlow Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless ... | diffusers/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py",
"repo_id": "diffusers",
"token_count": 12689
} | 126 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/ddim/pipeline_ddim.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/ddim/pipeline_ddim.py",
"repo_id": "diffusers",
"token_count": 2748
} | 127 |
from typing import TYPE_CHECKING
from ....utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and i... | diffusers/src/diffusers/pipelines/deprecated/alt_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/alt_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 685
} | 128 |
# flake8: noqa
from typing import TYPE_CHECKING
from ....utils import (
DIFFUSERS_SLOW_IMPORT,
_LazyModule,
is_note_seq_available,
OptionalDependencyNotAvailable,
is_torch_available,
is_transformers_available,
get_objects_from_module,
)
_dummy_objects = {}
_import_structure = {}
try:
i... | diffusers/src/diffusers/pipelines/deprecated/spectrogram_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/spectrogram_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 985
} | 129 |
import inspect
from typing import Callable, List, Optional, Union
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModel
from ....models import AutoencoderKL, UNet2DConditionModel
from ....schedulers import KarrasDiffusionSchedulers
from ....utils impo... | diffusers/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py",
"repo_id": "diffusers",
"token_count": 9147
} | 130 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py",
"repo_id": "diffusers",
"token_count": 14303
} | 131 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.a... | diffusers/src/diffusers/pipelines/onnx_utils.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/onnx_utils.py",
"repo_id": "diffusers",
"token_count": 3622
} | 132 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py",
"repo_id": "diffusers",
"token_count": 942
} | 133 |
# Copyright 2024 Open AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required ... | diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py",
"repo_id": "diffusers",
"token_count": 5704
} | 134 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py",
"repo_id": "diffusers",
"token_count": 1822
} | 135 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py",
"repo_id": "diffusers",
"token_count": 20080
} | 136 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/schedulers/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/__init__.py",
"repo_id": "diffusers",
"token_count": 4369
} | 137 |
# Copyright (c) 2022 Pablo Pernías MIT License
# Copyright 2024 UC Berkeley Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://... | diffusers/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py",
"repo_id": "diffusers",
"token_count": 3645
} | 138 |
# Copyright 2024 Zhejiang University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#... | diffusers/src/diffusers/schedulers/scheduling_ipndm.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_ipndm.py",
"repo_id": "diffusers",
"token_count": 3642
} | 139 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/schedulers/scheduling_utils.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_utils.py",
"repo_id": "diffusers",
"token_count": 3405
} | 140 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class CosineDPMSolverMultistepScheduler(metaclass=DummyObject):
_backends = ["torch", "torchsde"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch", "torc... | diffusers/src/diffusers/utils/dummy_torch_and_torchsde_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_torch_and_torchsde_objects.py",
"repo_id": "diffusers",
"token_count": 416
} | 141 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/utils/state_dict_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/state_dict_utils.py",
"repo_id": "diffusers",
"token_count": 5996
} | 142 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/transformers/test_models_transformer_hunyuan_dit.py/0 | {
"file_path": "diffusers/tests/models/transformers/test_models_transformer_hunyuan_dit.py",
"repo_id": "diffusers",
"token_count": 1790
} | 143 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/tests/others/test_check_copies.py/0 | {
"file_path": "diffusers/tests/others/test_check_copies.py",
"repo_id": "diffusers",
"token_count": 2028
} | 144 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/controlnet_sd3/test_controlnet_inpaint_sd3.py/0 | {
"file_path": "diffusers/tests/pipelines/controlnet_sd3/test_controlnet_inpaint_sd3.py",
"repo_id": "diffusers",
"token_count": 3144
} | 145 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/paint_by_example/test_paint_by_example.py/0 | {
"file_path": "diffusers/tests/pipelines/paint_by_example/test_paint_by_example.py",
"repo_id": "diffusers",
"token_count": 3723
} | 146 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_audio/test_stable_audio.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_audio/test_stable_audio.py",
"repo_id": "diffusers",
"token_count": 7600
} | 147 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_attend_and_excite.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_attend_and_excite.py",
"repo_id": "diffusers",
"token_count": 4012
} | 148 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion_gligen/test_stable_diffusion_gligen.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_gligen/test_stable_diffusion_gligen.py",
"repo_id": "diffusers",
"token_count": 2800
} | 149 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py",
"repo_id": "diffusers",
"token_count": 22322
} | 150 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/test_pipelines_flax.py/0 | {
"file_path": "diffusers/tests/pipelines/test_pipelines_flax.py",
"repo_id": "diffusers",
"token_count": 4559
} | 151 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/schedulers/test_scheduler_flax.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_flax.py",
"repo_id": "diffusers",
"token_count": 18869
} | 152 |
import tempfile
from io import BytesIO
import requests
import torch
from huggingface_hub import hf_hub_download, snapshot_download
from diffusers.models.attention_processor import AttnProcessor
from diffusers.utils.testing_utils import (
numpy_cosine_similarity_distance,
torch_device,
)
def download_single_... | diffusers/tests/single_file/single_file_testing_utils.py/0 | {
"file_path": "diffusers/tests/single_file/single_file_testing_utils.py",
"repo_id": "diffusers",
"token_count": 7577
} | 153 |
import gc
import unittest
import torch
from diffusers import (
StableDiffusionXLPipeline,
)
from diffusers.utils.testing_utils import (
enable_full_determinism,
require_torch_gpu,
slow,
)
from .single_file_testing_utils import SDXLSingleFileTesterMixin
enable_full_determinism()
@slow
@require_tor... | diffusers/tests/single_file/test_stable_diffusion_xl_single_file.py/0 | {
"file_path": "diffusers/tests/single_file/test_stable_diffusion_xl_single_file.py",
"repo_id": "diffusers",
"token_count": 712
} | 154 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/utils/overwrite_expected_slice.py/0 | {
"file_path": "diffusers/utils/overwrite_expected_slice.py",
"repo_id": "diffusers",
"token_count": 1259
} | 155 |
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="media/lerobot-logo-thumbnail.png">
<source media="(prefers-color-scheme: light)" srcset="media/lerobot-logo-thumbnail.png">
<img alt="LeRobot, Hugging Face Robotics Library" src="media/lerobot-logo-thumbnail.png" style="max-... | lerobot/README.md/0 | {
"file_path": "lerobot/README.md",
"repo_id": "lerobot",
"token_count": 7846
} | 156 |
"""This script demonstrates how to slice a dataset and calculate the loss on a subset of the data.
This technique can be useful for debugging and testing purposes, as well as identifying whether a policy
is learning effectively.
Furthermore, relying on validation loss to evaluate performance is generally not consider... | lerobot/examples/advanced/2_calculate_validation_loss.py/0 | {
"file_path": "lerobot/examples/advanced/2_calculate_validation_loss.py",
"repo_id": "lerobot",
"token_count": 1277
} | 157 |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/common/datasets/push_dataset_to_hub/xarm_pkl_format.py/0 | {
"file_path": "lerobot/lerobot/common/datasets/push_dataset_to_hub/xarm_pkl_format.py",
"repo_id": "lerobot",
"token_count": 2996
} | 158 |
#!/usr/bin/env python
# Copyright 2024 Nicklas Hansen, Xiaolong Wang, Hao Su,
# and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# ht... | lerobot/lerobot/common/policies/tdmpc/modeling_tdmpc.py/0 | {
"file_path": "lerobot/lerobot/common/policies/tdmpc/modeling_tdmpc.py",
"repo_id": "lerobot",
"token_count": 17560
} | 159 |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/lerobot/common/utils/utils.py/0 | {
"file_path": "lerobot/lerobot/common/utils/utils.py",
"repo_id": "lerobot",
"token_count": 2423
} | 160 |
version https://git-lfs.github.com/spec/v1
oid sha256:d79027c2513c01a7e360f3177e62ab955e5d3f704f1e7127a6e1e852158ec42c
size 4344
| lerobot/tests/data/lerobot/aloha_mobile_wash_pan/meta_data/stats.safetensors/0 | {
"file_path": "lerobot/tests/data/lerobot/aloha_mobile_wash_pan/meta_data/stats.safetensors",
"repo_id": "lerobot",
"token_count": 69
} | 161 |
version https://git-lfs.github.com/spec/v1
oid sha256:171a9efc9c45601688821936ec9a1dcf91f16b1bbab4e8246f18b4d4cc6ac6ee
size 80432
| lerobot/tests/data/lerobot/aloha_sim_insertion_scripted/train/data-00000-of-00001.arrow/0 | {
"file_path": "lerobot/tests/data/lerobot/aloha_sim_insertion_scripted/train/data-00000-of-00001.arrow",
"repo_id": "lerobot",
"token_count": 69
} | 162 |
version https://git-lfs.github.com/spec/v1
oid sha256:5dae4fa688991d97145fd975d317b24b177f674cc57e53ef4caba1413fe1aad8
size 2904
| lerobot/tests/data/lerobot/aloha_sim_transfer_cube_scripted_image/meta_data/stats.safetensors/0 | {
"file_path": "lerobot/tests/data/lerobot/aloha_sim_transfer_cube_scripted_image/meta_data/stats.safetensors",
"repo_id": "lerobot",
"token_count": 63
} | 163 |
version https://git-lfs.github.com/spec/v1
oid sha256:b5e09ac64a47638660b4993e0e7182b49e914d0ff720a57e1aeb7dece058d0c0
size 4208
| lerobot/tests/data/lerobot/aloha_static_candy/meta_data/stats.safetensors/0 | {
"file_path": "lerobot/tests/data/lerobot/aloha_static_candy/meta_data/stats.safetensors",
"repo_id": "lerobot",
"token_count": 69
} | 164 |
version https://git-lfs.github.com/spec/v1
oid sha256:04ccd6387997e1e6b904b77c05e2a1a88d82ff13144d9c83a4bf14f834ac23c4
size 4208
| lerobot/tests/data/lerobot/aloha_static_tape/meta_data/stats.safetensors/0 | {
"file_path": "lerobot/tests/data/lerobot/aloha_static_tape/meta_data/stats.safetensors",
"repo_id": "lerobot",
"token_count": 70
} | 165 |
version https://git-lfs.github.com/spec/v1
oid sha256:65874cbb1b5ac8b95cd6e843903803298b6d10e689511c9db73ccbb7c9fe90e4
size 72768
| lerobot/tests/data/lerobot/umi_cup_in_the_wild/train/data-00000-of-00001.arrow/0 | {
"file_path": "lerobot/tests/data/lerobot/umi_cup_in_the_wild/train/data-00000-of-00001.arrow",
"repo_id": "lerobot",
"token_count": 68
} | 166 |
version https://git-lfs.github.com/spec/v1
oid sha256:b07721b1072d0473ea5209fb35b4f6064d8b1132b3e2e5bb61d887b710147c3a
size 2808
| lerobot/tests/data/lerobot/xarm_push_medium/meta_data/stats.safetensors/0 | {
"file_path": "lerobot/tests/data/lerobot/xarm_push_medium/meta_data/stats.safetensors",
"repo_id": "lerobot",
"token_count": 69
} | 167 |
version https://git-lfs.github.com/spec/v1
oid sha256:cf61fce75c792d066f692cbec48b049f064cbc0389564be94048dfebec2d14d9
size 247
| lerobot/tests/data/lerobot/xarm_push_medium_replay/train/state.json/0 | {
"file_path": "lerobot/tests/data/lerobot/xarm_push_medium_replay/train/state.json",
"repo_id": "lerobot",
"token_count": 64
} | 168 |
version https://git-lfs.github.com/spec/v1
oid sha256:aee60956925da9687546aafa770d5e6a04f99576f903b08d0bd5f8003a7f4f3e
size 111338
| lerobot/tests/data/save_dataset_to_safetensors/lerobot/pusht/frame_159.safetensors/0 | {
"file_path": "lerobot/tests/data/save_dataset_to_safetensors/lerobot/pusht/frame_159.safetensors",
"repo_id": "lerobot",
"token_count": 68
} | 169 |
version https://git-lfs.github.com/spec/v1
oid sha256:a5ec46abc5a3c85675a5ee4a1bb362eecb3ff4c546082ff309c89fc7821f38bd
size 515400
| lerobot/tests/data/save_policy_to_safetensors/aloha_act_1000_steps/actions.safetensors/0 | {
"file_path": "lerobot/tests/data/save_policy_to_safetensors/aloha_act_1000_steps/actions.safetensors",
"repo_id": "lerobot",
"token_count": 68
} | 170 |
version https://git-lfs.github.com/spec/v1
oid sha256:81457cfd193d9d46b6871071a3971c2901fefa544ab225576132772087b4cf3a
size 472
| lerobot/tests/data/save_policy_to_safetensors/xarm_tdmpcuse_mpc/actions.safetensors/0 | {
"file_path": "lerobot/tests/data/save_policy_to_safetensors/xarm_tdmpcuse_mpc/actions.safetensors",
"repo_id": "lerobot",
"token_count": 63
} | 171 |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/tests/test_examples.py/0 | {
"file_path": "lerobot/tests/test_examples.py",
"repo_id": "lerobot",
"token_count": 1791
} | 172 |
import dac
from transformers import AutoConfig, AutoModel, EncodecFeatureExtractor
from parler_tts import DACConfig, DACModel
from transformers import AutoConfig, AutoModel
from transformers import EncodecFeatureExtractor
AutoConfig.register("dac", DACConfig)
AutoModel.register(DACConfig, DACModel)
# Download a mode... | parler-tts/helpers/push_to_hub_scripts/push_dac_to_hub.py/0 | {
"file_path": "parler-tts/helpers/push_to_hub_scripts/push_dac_to_hub.py",
"repo_id": "parler-tts",
"token_count": 229
} | 173 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | peft/docs/source/package_reference/p_tuning.md/0 | {
"file_path": "peft/docs/source/package_reference/p_tuning.md",
"repo_id": "peft",
"token_count": 540
} | 174 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | peft/examples/boft_controlnet/boft_controlnet.md/0 | {
"file_path": "peft/examples/boft_controlnet/boft_controlnet.md",
"repo_id": "peft",
"token_count": 2426
} | 175 |
# DoRA: Weight-Decomposed Low-Rank Adaptation
## Introduction
[DoRA](https://arxiv.org/abs/2402.09353) is a novel approach that leverages low rank adaptation through weight decomposition analysis to investigate the inherent differences between full fine-t... | peft/examples/dora_finetuning/README.md/0 | {
"file_path": "peft/examples/dora_finetuning/README.md",
"repo_id": "peft",
"token_count": 1500
} | 176 |
import argparse
import os
from typing import Dict
import torch
from diffusers import UNet2DConditionModel
from safetensors.torch import save_file
from transformers import CLIPTextModel
from peft import PeftModel, get_peft_model_state_dict
# Default kohya_ss LoRA replacement modules
# https://github.com/kohya-ss/sd-... | peft/examples/lora_dreambooth/convert_peft_sd_lora_to_kohya_ss.py/0 | {
"file_path": "peft/examples/lora_dreambooth/convert_peft_sd_lora_to_kohya_ss.py",
"repo_id": "peft",
"token_count": 1639
} | 177 |
<jupyter_start><jupyter_code>%env CUDA_VISIBLE_DEVICES=0
%env TOKENIZERS_PARALLELISM=false<jupyter_output>env: CUDA_VISIBLE_DEVICES=0
env: TOKENIZERS_PARALLELISM=false<jupyter_text>Initialize PolyModel<jupyter_code>import torch
from transformers import (
AutoModelForSeq2SeqLM,
AutoTokenizer,
default_data_co... | peft/examples/poly/peft_poly_seq2seq_with_generate.ipynb/0 | {
"file_path": "peft/examples/poly/peft_poly_seq2seq_with_generate.ipynb",
"repo_id": "peft",
"token_count": 4104
} | 178 |
# X-LoRA examples
## `xlora_inference_mistralrs.py`
Perform inference of an X-LoRA model using the inference engine mistral.rs.
Mistral.rs supports many base models besides Mistral, and can load models directly from saved LoRA checkpoints. Check out [adapter model docs](https://github.com/EricLBuehler/mistral.rs/blo... | peft/examples/xlora/README.md/0 | {
"file_path": "peft/examples/xlora/README.md",
"repo_id": "peft",
"token_count": 320
} | 179 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.