Datasets:

LID Dataset Base
This is the base dataset used for Moroccan Darija language identification. The job it's built for is: given a piece of text, decide whether it's Moroccan Darija or something else (darija vs other). On top of that binary label, every row also carries a finer-grained dialect tag (46 of them) so the same data can be sliced for dialect-level analysis, not just the binary task.
It's a merge of many datasets mentionned in source column, deduplicated, cleaned the same way on both sides, re-labeled with a single consistent dialect scheme, and re-split.
~2.05M rows, 46 dialects/languages, 80/10/10 train/val/test.
At a glance
| Total rows | 2,048,654 |
| Train / Validation / Test | 1,638,923 / 204,865 / 204,866 (80 / 10 / 10) |
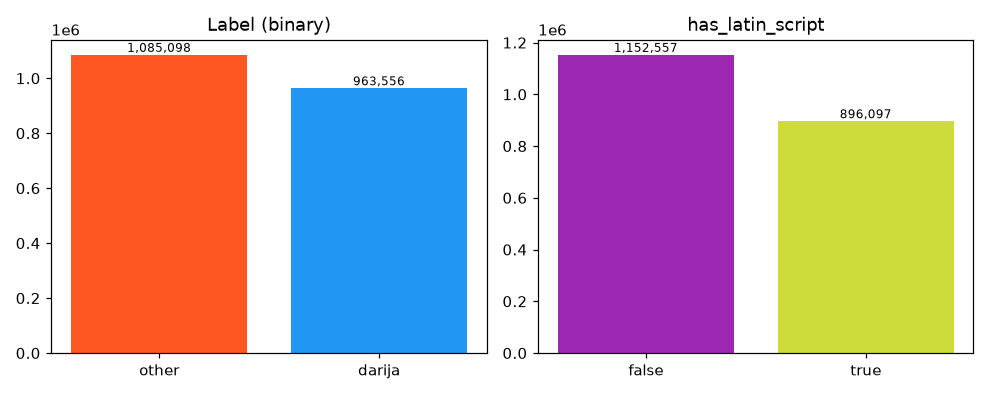
| Binary label | darija 963,556 (47%) · other 1,085,098 (53%) |
| Distinct dialects | 46 (all present in every split) |
| Dialect families | 11 |
| Source corpora | 67 |
| Text in Latin script | 896,097 rows (44%) |
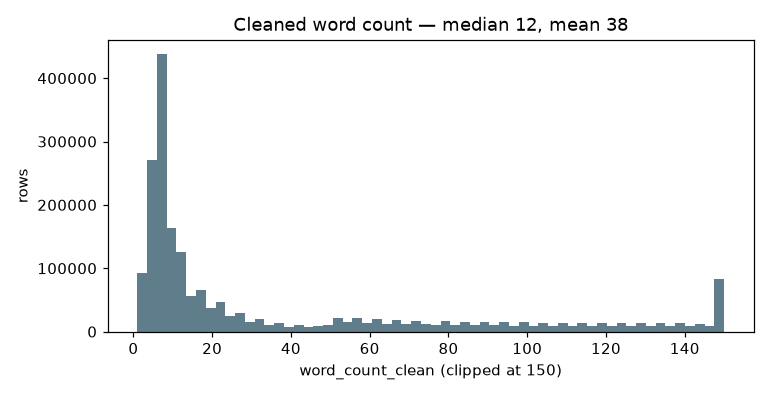
| Median cleaned length | 12 words (mean 38, max 710) |
Columns
| Column | What it is |
|---|---|
src |
The original source tag. This is what the dialect was derived from. |
text |
The raw sentence, untouched. |
text_clean |
The cleaned text. Same cleaning service applied to both source datasets so they're comparable. This is also the dedup key. |
label |
The binary target: darija or other. |
dialect |
Fine-grained dialect / language, e.g. moroccan_darija, algerian, egyptian, french. |
dialect_family |
Coarse grouping, e.g. Maghrebi, Levantine, Non-Arabic. |
country |
Country the dialect maps to, where it makes sense (null for non-Arabic languages and MSA/English). |
has_latin_script |
"true" / "false" — whether the text contains any Latin characters. This is how arabizi shows up, since the dialect column itself no longer separates arabizi from Arabic script. |
word_count_clean |
Word count of text_clean. |
One thing to know about the label
label == "darija" means Moroccan Darija specifically. It lines up exactly with dialect == "moroccan_darija" (both are 963,556 rows). Everything else including the other Maghrebi dialects like Algerian, Tunisian, Libyan is other. So if you train on the binary label, you're training a Moroccan Darija detector, not a "MAR Darija vs. the world" detector. Use the dialect column if you want anything more granular than that.
How the dialect was decided
The dialect is not guessed from the text. It's derived from the source tag, which encodes where each sentence came from.
madar:msa→msa,madar:cairo→egyptian(MADAR corpus, by city)arabic_tweets:EG→egyptian,arabic_tweets:LB→lebanese(ISO country code)flores:arz→egyptian,flores:ary→moroccan_darija(ISO-639-3 language code)atlaset→moroccan_darija,elner_dz→algerian(named single-dialect corpora)
After deriving the raw dialects, a normalization step is applied to them so the labels are consistent:
- Collapsed the fine-grained variants: e.g.
palestine,palestinian_arabic_surif_falahi_dialect,palestinian_nabulsi_urban_dialectall becamepalestinian;lebanon/lebanese_standard_dialectbecamelebanese. - Dropped the script split from the
dialectcolumnarabic_moroccanandarabizi_moroccanare both justmoroccan_darijanow. The arabizi/Arabic information lives inhas_latin_scriptinstead, so nothing is lost.
What's in it
Dialects
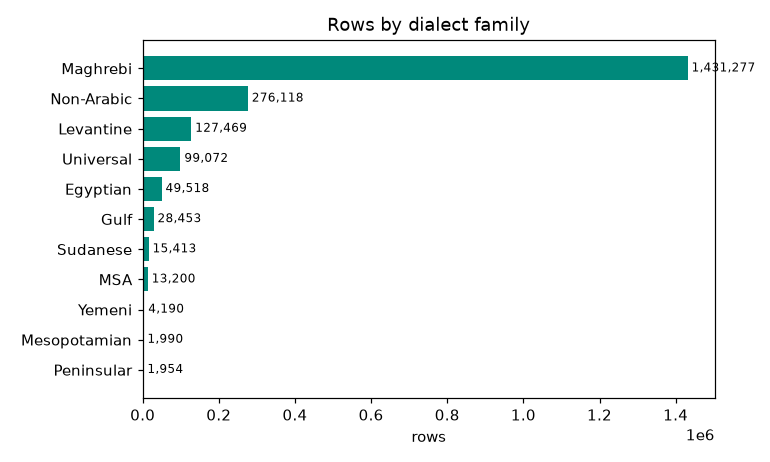
moroccan_darija is ~47% on its own, and with Algerian the Maghrebi family is most of the data. The long tail is a wide spread of other Arabic dialects plus non-Arabic languages (these are the negatives that make the other class realistic).
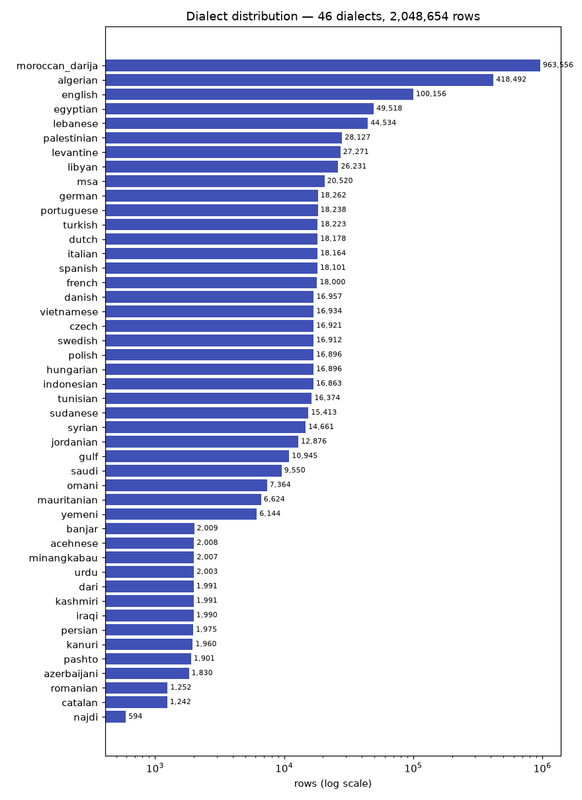
Full dialect table (46)
| dialect | family | country | label | rows | share |
|---|---|---|---|---|---|
| moroccan_darija | Maghrebi | Morocco | darija | 963,556 | 47.03% |
| algerian | Maghrebi | Algeria | other | 418,492 | 20.43% |
| english | Universal | Standard | other | 100,156 | 4.89% |
| egyptian | Egyptian | Egypt | other | 49,518 | 2.42% |
| lebanese | Levantine | Lebanon | other | 44,534 | 2.17% |
| palestinian | Levantine | Palestine | other | 28,127 | 1.37% |
| levantine | Levantine | Jordan | other | 27,271 | 1.33% |
| libyan | Maghrebi | Libya | other | 26,231 | 1.28% |
| msa | MSA | Standard | other | 20,520 | 1.0% |
| german | Non-Arabic | — | other | 18,262 | 0.89% |
| portuguese | Non-Arabic | — | other | 18,238 | 0.89% |
| turkish | Non-Arabic | — | other | 18,223 | 0.89% |
| dutch | Non-Arabic | — | other | 18,178 | 0.89% |
| italian | Non-Arabic | — | other | 18,164 | 0.89% |
| spanish | Non-Arabic | — | other | 18,101 | 0.88% |
| french | Non-Arabic | — | other | 18,000 | 0.88% |
| danish | Non-Arabic | — | other | 16,957 | 0.83% |
| vietnamese | Non-Arabic | — | other | 16,934 | 0.83% |
| czech | Non-Arabic | — | other | 16,921 | 0.83% |
| swedish | Non-Arabic | — | other | 16,912 | 0.83% |
| hungarian | Non-Arabic | — | other | 16,896 | 0.82% |
| polish | Non-Arabic | — | other | 16,896 | 0.82% |
| indonesian | Non-Arabic | — | other | 16,863 | 0.82% |
| tunisian | Maghrebi | Tunisia | other | 16,374 | 0.8% |
| sudanese | Sudanese | Sudan | other | 15,413 | 0.75% |
| syrian | Levantine | Syria | other | 14,661 | 0.72% |
| jordanian | Levantine | Jordan | other | 12,876 | 0.63% |
| gulf | Gulf | Qatar | other | 10,945 | 0.53% |
| saudi | Gulf | Saudi Arabia | other | 9,550 | 0.47% |
| omani | Gulf | Oman | other | 7,364 | 0.36% |
| mauritanian | Maghrebi | Mauritania | other | 6,624 | 0.32% |
| yemeni | Yemeni | Yemen | other | 6,144 | 0.3% |
| banjar | Non-Arabic | — | other | 2,009 | 0.1% |
| acehnese | Non-Arabic | — | other | 2,008 | 0.1% |
| minangkabau | Non-Arabic | — | other | 2,007 | 0.1% |
| urdu | Non-Arabic | — | other | 2,003 | 0.1% |
| dari | Non-Arabic | — | other | 1,991 | 0.1% |
| kashmiri | Non-Arabic | — | other | 1,991 | 0.1% |
| iraqi | Mesopotamian | Iraq | other | 1,990 | 0.1% |
| persian | Non-Arabic | — | other | 1,975 | 0.1% |
| kanuri | Non-Arabic | — | other | 1,960 | 0.1% |
| pashto | Non-Arabic | — | other | 1,901 | 0.09% |
| azerbaijani | Non-Arabic | — | other | 1,830 | 0.09% |
| romanian | Non-Arabic | — | other | 1,252 | 0.06% |
| catalan | Non-Arabic | — | other | 1,242 | 0.06% |
| najdi | Gulf | Saudi Arabia | other | 594 | 0.03% |
Families
Label balance & script
The binary classes are close to even (47/53). Just under half the rows are in Latin script, that's mostly arabizi (Darija written with Latin letters and numbers) plus the non-Arabic languages.
Text length
Short text is the norm, half the rows are 12 words or fewer. There's a long tail up to ~700 words.
Loading it
from datasets import load_dataset
ds = load_dataset("atlasia/lid-dataset-base")
print(ds)
# train / validation / test, with the columns above
ds["train"][0]
The splits were made with stratification on dialect, so the dialect and label proportions match across train/val/test, and all 46 dialects appear in every split. Dedup was done on text_clean before splitting, so there's no text_clean leakage between train, validation, and test.
Things to keep in mind
- The labels are source-derived, not human-annotated per sentence for some sources. A tweet from
arabic_tweets:EGis labeled Egyptian because that's where it came from. That's accurate at the corpus level but a small piece of MSA or off-dialect sentence inside an otherwise-Egyptian source still gets the Egyptian tag. Don't treat the fine-graineddialectas gold per-row truth. darija= Moroccan only (see above). Algerian and the other Maghrebi dialects are negatives.- It's imbalanced. Moroccan + Algerian dominate; the rarest dialects (
najdi,romanian,catalan) have only a few hundred rows. Sample or weight accordingly. - A couple of
country/familyvalues are a bit rough, e.g. the coarselevantinebucket lands under Jordan, andenglishis split between theNon-ArabicandUniversalfamilies depending on which source it came from. Thedialectandlabelcolumns are the reliable ones.
- Downloads last month
- 27