
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Add new numerical featureCreate synthetic column, strongly correlated with target.Each value is calculated according to the formula: v = y * a + random(-b, b) So its scaled target value with some noise.Then a fraction of values is permuted, to reduce the correlation.In this case, a=10, b=5, fraction=0.05 | if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_numerical_feature_classification(y, fraction=0.05, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic numerical feature'); | Initial new feature - target point biserial correlation, without shuffling: 0.878, p: 0.0
New feature - target point biserial correlation, after shuffling: 0.849, p: 0.0
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
Random Forest feature importanceRandom Forest offers a simple way to measure feature importance. A certain feature is considered to be important if it reduced node impurity often, during fitting the trees.We can see that adding a feature strongly correlated with target improved the model's performance, compared to results we obtained without this feature. What is more, this new feature was really important for the predictions. The plot shows that it is far more important than the original features. | X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestClassifier(random_state=SEED)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
print(f'Random Forest f1 score: {round(f1_score(y_test, rf_pred), 3)}')
df_rf_importances = pd.DataFrame(rf.feature_importances_, index=df.columns.values, columns=['importance'])
df_rf_importances = df_rf_importances.sort_values(by='importance', ascending=False)
df_rf_importances.plot()
plt.title('Biased Random Forest feature importance'); | Random Forest f1 score: 0.985
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
Permutation feature importanceThe impurity-based feature importance of Random Forests suffers from being computed on statistics derived from the training dataset: the importances can be high even for features that are not predictive of the target variable, as long as the model has the capacity to use them to overfit.Futhermore, Random Forest feature importance is biased towards high-cardinality numerical feautures.In this experiment, we will use permutation feature importance to asses how Random Forest and Similarity Forestdepend on syntetic feauture. This method is more reliable, and enables to measure feature importance for Similarity Forest, that doesn't enable us to measure impurity-based feature importance.Source: https://scikit-learn.org/stable/auto_examples/inspection/plot_permutation_importance.html | sf = SimilarityForestClassifier(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
fraction_range = [0.0, 0.02, 0.05, 0.08, 0.1, 0.15, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 1.0]
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'classification', 'numerical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'heart') | 19it [31:09, 98.37s/it]
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
New categorical feature | if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_categorical_feature_classification(y, fraction=0.05, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
df_category = pd.concat([pd.Series(new_feature, name='new_feature'), pd.Series(y, name='y')], axis=1)
fig = plt.figure(figsize=(8, 6))
sns.countplot(data=df_category, x='new_feature', hue='y')
plt.xlabel('Feature value, grouped by class')
plt.ylabel('Count')
plt.title('Synthetic categorical feature', fontsize=16);
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestClassifier(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestClassifier(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'classification', 'categorical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'heart') | 19it [26:26, 83.49s/it]
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
Regression, numerical feature | X, y = load_svmlight_file('data/mpg')
X = X.toarray().astype(np.float32)
features = [f'f{i+1}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=features)
df.head()
if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_numerical_feature_regression(y, fraction=0.2, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic numerical feature');
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestRegressor(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestRegressor(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'regression', 'numerical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'mpg') | 19it [42:41, 134.82s/it]
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
Regression, categorical feature | if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_categorical_feature_regression(y, fraction=0.15, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic categorical feature');
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestRegressor(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestRegressor(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'regression', 'categorical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'mpg') | 19it [46:58, 148.33s/it]
| BSD-3-Clause | examples/bias/Bias.ipynb | dabrze/similarity_forest |
Heap MapsA heat map is a two-dimensional representation of data in which values are represented by colors. A simple heat map provides an immediate visual summary of information. | from beakerx import *
data = [[533.08714795974, 484.92105712087596, 451.63070008303896, 894.4451947886148, 335.44965728686225, 640.9424094527392, 776.2709495045433, 621.8819257981404, 793.2905673902735, 328.97078791524234, 139.26962328268513, 800.9314566259062, 629.0795214099808, 418.90954534196544, 513.8036215424278, 742.9834968485734, 542.9393528649774, 671.4256827205828, 507.1129322933082, 258.8238039352692, 581.0354187924672, 190.1830169180297, 480.461111816312, 621.621218137835, 650.6023460248642, 635.7577683708486, 605.5201537254429, 364.55368485516846, 554.807212844458, 526.1823154945637], [224.1432052432479, 343.26660237811336, 228.29828973027486, 550.3809606942758, 340.16890889700994, 214.05332637480836, 461.3159325548031, 471.2546571575069, 503.071081294441, 757.4281483575993, 493.82140462579406, 579.4302306011925, 459.76905409338497, 580.1282535427403, 378.8722877921564, 442.8806517248869, 573.9346962907078, 449.0587543606964, 383.50503527041144, 378.90761994599256, 755.1883447435789, 581.6815170672886, 426.56807864689773, 602.6727518023347, 555.6481983927658, 571.1201152862207, 372.24744704437876, 424.73180136220844, 739.9173564499195, 462.3257604373609], [561.8684320610753, 604.2859791599086, 518.3421287392559, 524.6887104615442, 364.41920277904774, 433.37737233751386, 565.0508404421712, 533.6030951907703, 306.68809206630397, 738.7229466356732, 766.9678519097575, 699.8457506281374, 437.0340850742263, 802.4400914789037, 417.38754410115075, 907.5825538527938, 521.4281410545287, 318.6109350534576, 435.8275858900637, 463.82924688853524, 533.4069709666686, 404.50516534982546, 332.6966202103611, 560.0346672408426, 436.9691072984075, 631.3453929454839, 585.1581992195356, 522.3209865675237, 497.57041075817443, 525.8867246757814], [363.4020792898871, 457.31257834906256, 333.21325206873564, 508.0466632081777, 457.1905718373847, 611.2168422907173, 515.2088862309242, 674.5569500790505, 748.0512665828364, 889.7281605626981, 363.6454276219251, 647.0396659692233, 574.150119779024, 721.1853645071792, 309.5388283799724, 450.51745569875845, 339.1271937333267, 630.6976744426033, 630.1571298446103, 615.0700456998867, 780.7843408745639, 205.13803869051543, 784.5916902014255, 498.10545868387925, 553.936345186856, 207.59216580556847, 488.12270849418735, 422.6667046886397, 292.1061953879919, 565.1595338825396], [528.5186504364794, 642.5542319036714, 563.8776991112292, 537.0271437681837, 430.4056097950834, 384.50193545472877, 693.3404035076994, 573.0278734604005, 261.2443087970927, 563.412635691231, 258.13860041989085, 550.150017102056, 477.70582135030617, 509.4311099345934, 661.3308013433317, 523.1175760654914, 370.29659041946326, 557.8704186019502, 353.66591951113645, 510.5389425077261, 469.11212447314324, 626.2863927887214, 318.5642686423241, 141.13900677851177, 486.00711121264453, 542.0075639686526, 448.7161764573215, 376.65492084577164, 166.56246586635706, 718.6147921685923], [435.403218786657, 470.74259129379413, 615.3542648093958, 483.61792559031693, 607.9455289424717, 454.9949861614464, 869.45041758392, 750.3595195751914, 754.7958625343501, 508.38715645396553, 368.2779213892305, 662.23752125613, 350.46366230046397, 619.8010888063362, 497.9560438683688, 420.64163974607766, 487.16698403905633, 273.3352931767504, 354.02637708217384, 457.9408818614016, 496.2986534025747, 364.84710143814976, 458.29907844925157, 634.073520178434, 558.7161089429649, 603.6634230782621, 514.1019407724017, 539.6741842214251, 585.0639516732675, 488.3003071211236], [334.0264519516021, 459.5702037859653, 543.8547654459309, 471.6623772418301, 500.98627686914386, 740.3857774449933, 487.4853744264201, 664.5373560191691, 573.764159193263, 471.32565842016527, 448.8845519093864, 729.3173859836543, 453.34766656988694, 428.4975196541853, 575.1404740691066, 190.18782164376034, 243.90403003048107, 430.03959300145215, 429.08666492876233, 508.89662188951297, 669.6400651031191, 516.2894766192492, 441.39320293407405, 653.1948574772491, 529.6831617222962, 176.0833629734244, 568.7136007686755, 461.66494617366294, 443.39303344518356, 840.642834252332], [347.676690455591, 475.0701395711058, 383.94468812449156, 456.7512619303556, 547.1719187673109, 224.69458657065758, 458.98685335259506, 599.8561007491281, 231.02565460233575, 610.5318803183029, 763.3423474509603, 548.8104762105211, 445.95788564834953, 844.6566709331175, 591.2236009653337, 586.0438760821825, 399.6820689195621, 395.17360423878256, 535.9853351258233, 332.27242110850426, 801.7584039310705, 190.6337233666032, 805.700536966829, 799.6824375238089, 346.29917202656327, 611.7423892505719, 705.8824305058062, 535.9691379719488, 488.1708623023391, 604.3772264289142], [687.7108994865216, 483.44749361779685, 661.8182197739575, 591.5452701990528, 151.60961549943875, 524.1475889465452, 745.1142999852398, 665.6103992924466, 701.3015233859578, 648.9854638583182, 403.08097902196505, 384.97216329583586, 442.52161997463816, 590.5026536093199, 219.04366558018955, 899.2103705796073, 562.4908789323547, 666.088957218587, 496.97593850278065, 777.9572405840922, 531.7316118485633, 500.7782009017233, 646.4095967934252, 633.5713368259554, 608.1857007168994, 585.4020395597571, 490.06193749044934, 463.884131549627, 632.7981360348942, 634.8055942938928], [482.5550451528366, 691.7011356960619, 496.2851035642388, 529.4040886765091, 444.3593296445004, 198.06208336708823, 365.6472909266031, 391.3885069938369, 859.494451604626, 275.19483951927816, 568.4478784631463, 203.74971298680123, 676.2053582803082, 527.9859302404323, 714.4565600799949, 288.9012675397431, 629.6056652113498, 326.2525932990075, 519.5740740263301, 696.8119752318905, 347.1796230415255, 388.6576994098651, 357.54758351840974, 873.5528483422207, 507.0189947052724, 508.1981784529926, 536.9527958233257, 871.2838601964829, 361.93416709279154, 496.5981745168124]]
data2 = [[103,104,104,105,105,106,106,106,107,107,106,106,105,105,104,104,104,104,105,107,107,106,105,105,107,108,109,110,110,110,110,110,110,109,109,109,109,109,109,108,107,107,107,107,106,106,105,104,104,104,104,104,104,104,103,103,103,103,102,102,101,101,100,100,100,100,100,99,98,97,97,96,96,96,96,96,96,96,95,95,95,94,94,94,94,94,94], [104,104,105,105,106,106,107,107,107,107,107,107,107,106,106,106,106,106,106,108,108,108,106,106,108,109,110,110,112,112,113,112,111,110,110,110,110,109,109,109,108,107,107,107,107,106,106,105,104,104,104,104,104,104,104,103,103,103,103,102,102,101,101,100,100,100,100,99,99,98,97,97,96,96,96,96,96,96,96,95,95,95,94,94,94,94,94], [104,105,105,106,106,107,107,108,108,108,108,108,108,108,108,108,108,108,108,108,110,110,110,110,110,110,110,111,113,115,116,115,113,112,110,110,110,110,110,110,109,108,108,108,108,107,106,105,105,105,105,105,105,104,104,104,104,103,103,103,102,102,102,101,100,100,100,99,99,98,97,97,96,96,96,96,96,96,96,96,95,95,94,94,94,94,94], [105,105,106,106,107,107,108,108,109,109,109,109,109,110,110,110,110,110,110,110,111,112,115,115,115,115,115,116,116,117,119,118,117,116,114,113,112,110,110,110,110,110,110,109,109,108,107,106,106,106,106,106,105,105,105,104,104,104,103,103,103,102,102,102,101,100,100,99,99,98,97,97,96,96,96,96,96,96,96,96,95,95,94,94,94,94,94], [105,106,106,107,107,108,108,109,109,110,110,110,110,111,110,110,110,110,111,114,115,116,121,121,121,121,121,122,123,124,124,123,121,119,118,117,115,114,112,111,110,110,110,110,110,110,109,109,108,109,107,107,106,106,105,105,104,104,104,104,103,103,102,102,102,101,100,100,99,99,98,97,96,96,96,96,96,96,96,96,95,95,94,94,94,94,94], [106,106,107,107,107,108,109,109,110,110,111,111,112,113,112,111,111,112,115,118,118,119,126,128,128,127,128,128,129,130,129,128,127,125,122,120,118,117,115,114,112,110,110,110,110,110,111,110,110,110,109,109,108,107,106,105,105,105,104,104,104,103,103,102,102,102,101,100,99,99,98,97,96,96,96,96,96,96,96,96,95,95,94,94,94,94,94], [106,107,107,108,108,108,109,110,110,111,112,113,114,115,114,115,116,116,119,123,125,130,133,134,134,134,134,135,135,136,135,134,132,130,128,124,121,119,118,116,114,112,111,111,111,112,112,111,110,110,110,109,108,108,107,108,107,106,105,104,104,104,103,103,103,102,101,100,99,99,98,97,96,96,96,96,96,96,96,96,95,95,95,94,94,94,94], [107,107,108,108,109,109,110,110,112,113,114,115,116,117,117,120,120,121,123,129,134,136,138,139,139,139,140,142,142,141,141,140,137,134,131,127,124,122,120,118,117,115,113,114,113,114,114,113,112,111,110,110,109,108,107,106,105,105,105,104,104,104,103,103,103,101,100,100,99,99,98,97,96,96,96,96,96,96,96,96,96,95,95,94,94,94,94], [107,108,108,109,109,110,111,112,114,115,116,117,118,119,121,125,125,127,131,136,140,141,142,144,144,145,148,149,148,147,146,144,140,138,136,130,127,125,123,121,119,118,117,117,116,116,116,115,114,113,113,111,110,109,108,107,106,105,105,103,103,102,102,102,103,101,100,100,100,99,98,98,97,96,96,96,96,96,96,96,96,95,95,95,94,94,94], [107,108,109,109,110,110,110,113,115,117,118,119,120,123,126,129,131,134,139,142,144,145,147,148,150,152,154,154,153,154,151,149,146,143,140,136,130,128,126,124,122,121,120,119,118,117,117,117,116,116,115,113,112,110,109,108,107,106,106,105,104,103,102,101,101,100,100,100,100,99,99,98,97,96,96,96,96,96,96,96,96,95,95,95,94,94,94], [107,108,109,109,110,110,110,112,115,117,119,122,125,127,130,133,137,141,143,145,148,149,152,155,157,159,160,160,161,162,159,156,153,149,146,142,139,134,130,128,126,125,122,120,120,120,119,119,119,118,117,115,113,111,110,110,109,108,107,106,106,105,104,104,103,102,100,100,100,99,99,98,97,96,96,96,96,96,96,96,96,95,95,95,95,94,94], [108,108,109,109,110,110,110,112,115,118,121,125,128,131,134,138,141,145,147,149,152,157,160,161,163,166,169,170,170,171,168,162,158,155,152,148,144,140,136,132,129,127,124,122,121,120,120,120,120,120,119,117,115,113,110,110,110,110,109,108,108,107,107,106,105,104,102,100,100,100,99,98,97,96,96,96,96,96,96,96,96,96,95,95,95,94,94], [108,109,109,110,110,111,112,114,117,120,124,128,131,135,138,142,145,149,152,155,158,163,166,167,170,173,175,175,175,173,171,169,164,160,156,153,149,144,140,136,131,129,126,124,123,123,122,121,120,120,120,119,117,115,111,110,110,110,110,110,109,109,110,109,108,106,103,101,100,100,100,98,97,96,96,96,96,96,96,96,96,96,95,95,95,95,94], [108,109,110,110,110,113,114,116,119,122,126,131,134,138,141,145,149,152,156,160,164,169,171,174,177,175,178,179,177,175,174,172,168,163,160,157,151,147,143,138,133,130,128,125,125,124,123,122,121,121,120,120,118,116,115,111,110,110,110,110,113,114,113,112,110,107,105,102,100,100,100,98,97,96,96,96,96,96,96,96,96,96,96,95,95,95,94], [108,109,110,110,112,115,116,118,122,125,129,133,137,140,144,149,152,157,161,165,169,173,176,179,179,180,180,180,178,178,176,175,171,165,163,160,153,148,143,139,135,132,129,128,127,125,124,124,123,123,122,122,120,118,117,118,115,117,118,118,119,117,116,115,112,109,107,105,100,100,100,100,97,96,96,96,96,96,96,96,96,96,96,95,95,95,95], [108,109,110,111,114,116,118,122,127,130,133,136,140,144,148,153,157,161,165,169,173,177,180,180,180,180,181,180,180,180,179,178,173,168,165,161,156,149,143,139,136,133,130,129,128,126,126,125,125,125,125,124,122,121,120,120,120,120,121,122,123,122,120,117,114,111,108,106,105,100,100,100,100,96,96,96,96,96,96,96,96,96,96,96,95,95,95], [107,108,110,113,115,118,121,126,131,134,137,140,143,148,152,157,162,165,169,173,177,181,181,181,180,181,181,181,180,180,180,178,176,170,167,163,158,152,145,140,137,134,132,130,129,127,127,126,127,128,128,126,125,125,125,123,126,128,129,130,130,125,124,119,116,114,112,110,107,106,105,100,100,100,96,96,96,96,96,96,96,96,96,96,96,95,95], [107,109,111,116,119,122,125,130,135,137,140,144,148,152,156,161,165,168,172,177,181,184,181,181,181,180,180,180,180,180,180,178,178,173,168,163,158,152,146,141,138,136,134,132,130,129,128,128,130,130,130,129,128,129,129,130,132,133,133,134,134,132,128,122,119,116,114,112,108,106,105,105,100,100,100,97,97,97,97,97,97,97,96,96,96,96,95], [108,110,112,117,122,126,129,135,139,141,144,149,153,156,160,165,168,171,177,181,184,185,182,180,180,179,178,178,180,179,179,178,176,173,168,163,157,152,148,143,139,137,135,133,131,130,130,131,132,132,132,131,132,132,133,134,136,137,137,137,136,134,131,124,121,118,116,114,111,109,107,106,105,100,100,100,97,97,97,97,97,97,97,96,96,96,96], [108,110,114,120,126,129,134,139,142,144,146,152,158,161,164,168,171,175,181,184,186,186,183,179,178,178,177,175,178,177,177,176,175,173,168,162,156,153,149,145,142,140,138,136,133,132,132,132,134,134,134,134,135,136,137,138,140,140,140,140,139,137,133,127,123,120,118,115,112,108,108,106,106,105,100,100,100,98,98,98,98,98,98,97,96,96,96], [108,110,116,122,128,133,137,141,143,146,149,154,161,165,168,172,175,180,184,188,189,187,182,178,176,176,175,173,174,173,175,174,173,171,168,161,157,154,150,148,145,143,141,138,135,135,134,135,135,136,136,137,138,139,140,140,140,140,140,140,140,139,135,130,126,123,120,117,114,111,109,108,107,106,105,100,100,100,99,99,98,98,98,98,97,97,96], [110,112,118,124,130,135,139,142,145,148,151,157,163,169,172,176,179,183,187,190,190,186,180,177,175,173,170,169,169,170,171,172,170,170,167,163,160,157,154,152,149,147,144,140,137,137,136,137,138,138,139,140,141,140,140,140,140,140,140,140,140,138,134,131,128,124,121,118,115,112,110,109,108,107,106,105,100,100,100,99,99,99,98,98,98,97,97], [110,114,120,126,131,136,140,143,146,149,154,159,166,171,177,180,182,186,190,190,190,185,179,174,171,168,166,163,164,163,166,169,170,170,168,164,162,161,158,155,153,150,147,143,139,139,139,139,140,141,141,142,142,141,140,140,140,140,140,140,140,137,134,131,128,125,122,119,116,114,112,110,109,109,108,107,105,100,100,100,99,99,99,98,98,97,97], [110,115,121,127,132,136,140,144,148,151,157,162,169,174,178,181,186,188,190,191,190,184,177,172,168,165,162,159,158,158,159,161,166,167,169,166,164,163,161,159,156,153,149,146,142,142,141,142,143,143,143,143,144,142,141,140,140,140,140,140,140,138,134,131,128,125,123,120,117,116,114,112,110,109,108,107,106,105,102,101,100,99,99,99,98,98,97], [110,116,121,127,132,136,140,144,148,154,160,166,171,176,180,184,189,190,191,191,191,183,176,170,166,163,159,156,154,155,155,158,161,165,170,167,166,165,163,161,158,155,152,150,146,145,145,145,146,146,144,145,145,144,142,141,140,140,140,140,138,136,134,131,128,125,123,121,119,117,115,113,112,111,111,110,108,106,105,102,100,100,99,99,99,98,98], [110,114,119,126,131,135,140,144,149,158,164,168,172,176,183,184,189,190,191,191,190,183,174,169,165,161,158,154,150,151,152,155,159,164,168,168,168,167,165,163,160,158,155,153,150,148,148,148,148,148,147,146,146,145,143,142,141,140,139,138,136,134,132,131,128,126,124,122,120,118,116,114,113,113,112,111,108,107,106,105,104,102,100,99,99,99,99], [110,113,119,125,131,136,141,145,150,158,164,168,172,177,183,187,189,191,192,191,190,183,174,168,164,160,157,153,150,149,150,154,158,162,166,170,170,168,166,164,162,160,158,155,152,151,151,151,151,151,149,148,147,146,145,143,142,140,139,137,135,134,132,131,129,127,125,123,121,119,117,116,114,114,113,112,110,108,107,105,103,100,100,100,100,99,99], [110,112,118,124,130,136,142,146,151,157,163,168,174,178,183,187,189,190,191,192,189,182,174,168,164,160,157,153,149,148,149,153,157,161,167,170,170,170,168,166,165,163,159,156,154,153,155,155,155,155,152,150,149,147,145,143,141,140,139,138,136,134,133,131,130,128,126,124,122,120,119,117,116,115,114,113,111,110,107,106,105,105,102,101,100,100,100], [110,111,116,122,129,137,142,146,151,158,164,168,172,179,183,186,189,190,192,193,188,182,174,168,164,161,157,154,151,149,151,154,158,161,167,170,170,170,170,169,168,166,160,157,156,156,157,158,159,159,156,153,150,148,146,144,141,140,140,138,136,135,134,133,131,129,127,125,123,122,120,118,117,116,115,114,112,111,110,108,107,106,105,104,102,100,100], [108,110,115,121,131,137,142,147,152,159,163,167,170,177,182,184,187,189,192,194,189,183,174,169,165,161,158,156,154,153,154,157,160,164,167,171,172,174,174,173,171,168,161,159,158,158,159,161,161,160,158,155,151,149,147,144,142,141,140,138,137,136,135,134,132,130,128,126,125,123,121,119,118,117,116,115,113,112,112,111,110,109,108,107,105,101,100], [108,110,114,120,128,134,140,146,152,158,162,166,169,175,180,183,186,189,193,195,190,184,176,171,167,163,160,158,157,156,157,159,163,166,170,174,176,178,178,176,172,167,164,161,161,160,161,163,163,163,160,157,153,150,148,146,144,142,141,140,139,138,136,135,134,133,129,127,126,124,122,121,119,118,117,116,114,113,112,111,110,110,109,109,107,104,100], [107,110,115,119,123,129,135,141,146,156,161,165,168,173,179,182,186,189,193,194,191,184,179,175,170,166,162,161,160,160,161,162,165,169,172,176,178,179,179,176,172,168,165,163,163,163,163,165,166,164,161,158,155,152,150,147,146,144,143,142,141,139,139,138,137,135,131,128,127,125,124,122,121,119,118,116,115,113,112,111,111,110,110,109,109,105,100], [107,110,114,117,121,126,130,135,142,151,159,163,167,171,177,182,185,189,192,193,191,187,183,179,174,169,167,166,164,164,165,166,169,171,174,178,179,180,180,178,173,169,166,165,165,166,165,168,169,166,163,159,157,154,152,149,148,147,146,145,143,142,141,140,139,138,133,130,128,127,125,124,122,120,118,117,115,112,111,111,111,111,110,109,108,106,100], [107,109,113,118,122,126,129,134,139,150,156,160,165,170,175,181,184,188,191,192,192,189,185,181,177,173,171,169,168,167,169,170,172,174,176,178,179,180,180,179,175,170,168,166,166,168,168,170,170,168,164,160,158,155,152,151,150,149,149,148,147,145,144,143,142,141,136,133,130,129,127,125,123,120,119,118,115,112,111,111,111,110,109,109,109,105,100], [105,107,111,117,121,124,127,131,137,148,154,159,164,168,174,181,184,187,190,191,191,190,187,184,180,178,175,174,172,171,173,173,173,176,178,179,180,180,180,179,175,170,168,166,168,169,170,170,170,170,166,161,158,156,154,153,151,150,150,150,150,148,147,146,145,143,139,135,133,131,129,126,124,121,120,118,114,111,111,111,110,110,109,107,106,104,100], [104,106,110,114,118,121,125,129,135,142,150,157,162,167,173,180,183,186,188,190,190,190,189,184,183,181,180,179,179,176,177,176,176,177,178,179,180,180,179,177,173,169,167,166,167,169,170,170,170,170,167,161,159,157,155,153,151,150,150,150,150,150,150,149,147,145,141,138,135,133,130,127,125,123,121,118,113,111,110,110,109,109,107,106,105,103,100], [104,106,108,111,115,119,123,128,134,141,148,154,161,166,172,179,182,184,186,189,190,190,190,187,185,183,180,180,180,179,179,177,176,177,178,178,178,177,176,174,171,168,166,164,166,168,170,170,170,170,168,162,159,157,155,153,151,150,150,150,150,150,150,150,150,148,144,140,137,134,132,129,127,125,122,117,111,110,107,107,106,105,104,103,102,101,100], [103,105,107,110,114,118,122,127,132,140,146,153,159,165,171,176,180,183,185,186,189,190,188,187,184,182,180,180,180,179,178,176,176,176,176,174,174,173,172,170,168,167,165,163,164,165,169,170,170,170,166,162,159,157,155,153,151,150,150,150,150,150,150,150,150,150,146,142,139,136,133,131,128,125,122,117,110,108,106,105,104,103,103,101,101,101,101], [102,103,106,108,112,116,121,125,130,138,145,151,157,163,170,174,178,181,181,184,186,186,187,186,184,181,180,180,180,179,178,174,173,173,171,170,170,169,168,167,166,164,163,162,161,164,167,169,170,168,164,160,158,157,155,153,151,150,150,150,150,150,150,150,150,150,147,144,141,138,135,133,128,125,122,116,109,107,104,104,103,102,101,101,101,101,101], [101,102,105,107,110,115,120,124,129,136,143,149,155,162,168,170,174,176,178,179,181,182,184,184,183,181,180,180,179,177,174,172,170,168,166,165,164,164,164,164,162,160,159,159,158,160,162,164,166,166,163,159,157,156,155,153,151,150,150,150,150,150,150,150,150,150,149,146,143,140,137,133,129,124,119,112,108,105,103,103,102,101,101,101,101,100,100], [101,102,104,106,109,113,118,122,127,133,141,149,155,161,165,168,170,172,175,176,177,179,181,181,181,180,180,179,177,174,171,167,165,163,161,160,160,160,160,160,157,155,155,154,154,155,157,159,161,161,161,159,156,154,154,153,151,150,150,150,150,150,150,150,150,150,149,147,144,141,137,133,129,123,116,110,107,104,102,102,101,101,101,100,100,100,100], [102,103,104,106,108,112,116,120,125,129,137,146,154,161,163,165,166,169,172,173,174,175,177,178,178,178,178,177,174,171,168,164,160,158,157,157,156,156,156,155,152,151,150,150,151,151,152,154,156,157,157,156,155,153,152,152,151,150,150,150,150,150,150,150,150,150,150,147,144,141,138,133,127,120,113,109,106,103,101,101,101,100,100,100,100,100,100], [103,104,105,106,108,110,114,118,123,127,133,143,150,156,160,160,161,162,167,170,171,172,173,175,175,174,174,173,171,168,164,160,156,155,154,153,153,152,152,150,149,148,148,148,148,148,149,149,150,152,152,152,152,151,150,150,150,150,150,150,150,150,150,150,150,150,149,147,144,141,138,132,125,118,111,108,105,103,102,101,101,101,100,100,100,100,100], [104,105,106,107,108,110,113,117,120,125,129,138,145,151,156,156,157,158,160,164,166,168,170,171,172,171,171,169,166,163,160,156,153,151,150,150,149,149,149,148,146,146,146,146,146,146,146,147,148,148,149,149,149,148,148,148,148,149,149,150,150,150,150,150,150,150,148,146,143,141,136,129,123,117,110,108,105,104,103,102,102,101,101,100,100,100,100], [103,104,105,106,107,109,111,115,118,122,127,133,140,143,150,152,153,155,157,159,162,164,167,168,168,168,167,166,163,160,157,153,150,148,148,147,147,147,145,145,144,143,143,143,144,144,144,144,145,145,145,145,146,146,146,146,146,147,147,148,149,150,150,150,150,149,147,145,143,141,134,127,123,117,111,108,105,105,104,104,103,103,102,101,100,100,100], [102,103,104,105,106,107,109,113,116,120,125,129,133,137,143,147,149,151,152,154,158,161,164,165,164,164,163,163,160,157,154,151,149,147,145,145,144,143,141,140,141,141,141,141,141,142,142,142,142,142,142,142,143,143,143,144,144,145,146,146,146,147,148,148,148,148,145,143,142,140,134,128,123,117,112,108,106,105,105,104,104,103,102,101,100,100,99], [102,103,104,105,105,106,108,110,113,118,123,127,129,132,137,141,142,142,145,150,154,157,161,161,160,160,160,159,157,154,151,148,146,145,143,142,142,139,137,136,137,137,138,138,139,139,139,139,139,139,139,139,140,140,141,142,142,143,144,144,144,145,145,145,145,145,144,142,140,139,136,129,124,119,113,109,106,106,105,104,103,102,101,101,100,99,99], [102,103,104,104,105,106,107,108,111,116,121,124,126,128,131,134,135,137,139,143,147,152,156,157,157,157,156,155,153,151,148,146,143,142,141,140,138,135,133,132,132,133,133,133,134,135,135,135,135,136,136,137,137,138,138,139,140,141,141,142,142,143,142,142,141,141,140,139,137,134,133,129,125,121,114,110,107,106,106,104,103,102,101,100,99,99,99], [102,103,104,104,105,105,106,108,110,113,118,121,124,126,128,130,132,134,136,139,143,147,150,154,154,154,153,151,149,148,146,143,141,139,137,136,132,130,128,128,128,129,129,130,130,131,132,132,132,133,134,134,135,135,136,137,138,139,139,140,140,140,139,139,138,137,137,135,132,130,129,127,124,120,116,112,109,106,105,103,102,101,101,100,99,99,99], [101,102,103,104,104,105,106,107,108,110,114,119,121,124,126,128,129,132,134,137,140,143,147,149,151,151,151,149,147,145,143,141,138,136,134,131,128,126,124,125,125,126,126,127,128,128,129,129,130,130,131,131,132,132,133,134,135,135,136,136,137,137,136,136,135,134,133,131,129,128,127,126,123,119,115,111,109,107,105,104,103,102,101,100,100,100,99], [101,102,103,103,104,104,105,106,108,110,112,116,119,121,124,125,127,130,132,135,137,140,143,147,149,149,149,147,145,143,141,139,136,133,131,128,125,122,121,122,122,122,123,125,125,126,127,127,127,128,128,128,129,129,130,131,131,132,132,133,133,133,132,132,131,131,130,129,128,126,125,124,121,117,111,109,108,106,105,104,103,102,101,101,100,100,100], [100,101,102,103,103,104,105,106,107,108,110,114,117,119,121,123,126,128,130,133,136,139,141,144,146,147,146,145,143,141,138,136,133,130,127,124,121,120,120,120,120,120,121,122,123,124,124,125,125,126,126,125,126,126,126,125,126,127,128,128,129,129,128,128,128,128,128,128,126,125,123,122,119,114,109,108,107,106,105,104,103,103,102,102,101,100,100], [100,101,102,103,104,105,106,107,108,109,110,112,115,117,120,122,125,127,130,132,135,137,139,142,144,144,144,142,140,138,136,132,129,126,123,120,120,119,119,118,119,119,120,120,120,121,122,122,123,123,123,123,122,123,122,122,121,122,122,122,123,123,123,124,125,125,126,126,125,124,122,120,116,113,109,107,106,105,104,104,103,102,102,101,101,100,100], [100,101,102,103,104,105,106,107,108,109,110,112,114,117,119,122,124,127,129,131,134,136,138,140,142,142,142,140,138,136,133,129,125,122,120,119,118,118,117,116,117,117,118,119,119,120,120,120,121,121,121,122,121,120,120,120,119,119,120,120,120,120,120,120,123,123,124,124,124,123,121,119,114,112,108,106,106,104,104,103,102,102,101,101,100,100,99], [101,102,103,104,105,106,107,108,109,110,111,113,114,116,119,121,124,126,128,130,133,135,137,138,140,140,139,137,135,133,131,127,122,120,118,118,117,117,116,115,116,116,117,118,118,118,119,119,120,120,121,121,120,119,119,118,117,117,118,119,118,118,118,119,120,122,123,123,123,122,120,117,113,110,108,106,105,104,103,103,102,101,101,100,100,99,99], [101,102,103,104,105,106,107,108,109,110,111,111,113,115,118,121,123,125,127,129,131,133,135,137,138,138,137,134,132,130,127,122,120,118,116,116,116,116,115,113,114,115,116,117,117,118,118,119,119,119,120,120,119,118,117,117,116,116,117,117,117,118,119,119,119,120,121,121,121,121,119,116,113,110,107,105,105,103,103,103,102,101,100,100,99,99,99], [101,102,103,104,105,106,107,108,109,110,111,112,114,116,117,120,122,124,126,129,130,132,133,135,136,136,134,132,129,126,122,120,118,116,114,114,114,114,114,113,113,114,115,116,116,117,117,117,118,118,119,119,118,117,116,116,115,115,116,116,116,117,117,118,118,119,120,120,120,120,119,116,113,109,106,104,104,103,102,102,101,101,100,99,99,99,98], [101,102,103,104,105,106,107,108,109,110,111,113,115,117,117,118,121,123,126,128,130,130,131,132,133,134,131,129,125,122,120,118,116,114,113,112,112,113,112,112,111,112,113,113,114,115,116,116,117,117,118,118,116,116,115,115,115,114,114,115,116,116,117,117,118,118,119,119,120,120,117,115,112,108,106,104,103,102,102,102,101,100,99,99,99,98,98], [101,102,103,104,105,105,106,107,108,109,110,111,113,115,117,118,120,122,125,126,127,128,129,130,131,131,128,125,121,120,118,116,114,113,113,111,111,111,111,110,109,110,111,112,113,113,114,115,115,116,117,117,116,115,114,114,113,113,114,114,115,115,116,116,117,118,118,119,119,118,116,114,112,108,105,103,103,102,101,101,100,100,99,99,98,98,97], [100,101,102,103,104,105,106,107,108,109,110,110,111,113,115,118,120,121,122,124,125,125,126,127,128,127,124,121,120,118,116,114,113,112,112,110,109,109,108,108,108,109,110,111,112,112,113,114,114,115,116,116,115,114,113,112,112,113,113,114,114,115,115,116,116,117,117,118,118,117,115,113,111,107,105,103,102,101,101,100,100,100,99,99,98,98,97], [100,101,102,103,104,105,105,106,107,108,109,110,110,111,114,116,118,120,120,121,122,122,123,124,123,123,120,118,117,115,114,115,113,111,110,109,108,108,107,107,107,108,109,110,111,111,112,113,113,114,115,115,114,113,112,111,111,112,112,112,113,114,114,115,115,116,116,117,117,116,114,112,109,106,104,102,101,100,100,99,99,99,99,98,98,97,97]]
data3 = [[16,29, 12, 14, 16, 5, 9, 43, 25, 49, 57, 61, 37, 66, 79, 55, 51, 55, 17, 29, 9, 4, 9, 12, 9], [22,6, 2, 12, 23, 9, 2, 4, 11, 28, 49, 51, 47, 38, 65, 69, 59, 65, 59, 22, 11, 12, 9, 9, 13], [2, 5, 8, 44, 9, 22, 2, 5, 12, 34, 43, 54, 44, 49, 48, 54, 59, 69, 51, 21, 16, 9, 5, 4, 7], [3, 9, 9, 34, 9, 9, 2, 4, 13, 26, 58, 61, 59, 53, 54, 64, 55, 52, 53, 18, 3, 9, 12, 2, 8], [4, 2, 9, 8, 2, 23, 2, 4, 14, 31, 48, 46, 59, 66, 54, 56, 67, 54, 23, 14, 6, 8, 7, 9, 8], [5, 2, 23, 2, 9, 9, 9, 4, 8, 8, 6, 14, 12, 9, 14, 9, 21, 22, 34, 12, 9, 23, 9, 11, 13], [6, 7, 23, 23, 9, 4, 7, 4, 23, 11, 32, 2, 2, 5, 34, 9, 4, 12, 15, 19, 45, 9, 19, 9, 4]]
HeatMap(data = data)
HeatMap(title= "Heatmap Second Example",
xLabel= "X Label",
yLabel= "Y Label",
data = data,
legendPosition = LegendPosition.TOP)
HeatMap(title = "Green Yellow White",
data = data2,
showLegend = False,
color = GradientColor.GREEN_YELLOW_WHITE)
colors = [Color.black, Color.yellow, Color.red]
HeatMap(title= "Custom Gradient Example",
data= data3,
color= GradientColor(colors))
HeatMap(initWidth= 900,
initHeight= 300,
title= "Custom size, no tooltips",
data= data3,
useToolTip= False,
showLegend= False,
color= GradientColor.WHITE_BLUE) | _____no_output_____ | Apache-2.0 | doc/python/Heatmap.ipynb | ssadedin/beakerx |
Copyright 2019 The TensorFlow Authors. | #@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip \
-O /tmp/validation-horse-or-human.zip
import os
import zipfile
local_zip = '/tmp/horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/horse-or-human')
local_zip = '/tmp/validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/validation-horse-or-human')
zip_ref.close()
# Directory with our training horse pictures
train_horse_dir = os.path.join('/tmp/horse-or-human/horses')
# Directory with our training human pictures
train_human_dir = os.path.join('/tmp/horse-or-human/humans')
# Directory with our training horse pictures
validation_horse_dir = os.path.join('/tmp/validation-horse-or-human/horses')
# Directory with our training human pictures
validation_human_dir = os.path.join('/tmp/validation-horse-or-human/humans') | _____no_output_____ | MIT | Course2Part4Lesson4.ipynb | MBadriNarayanan/TensorFlow |
Building a Small Model from ScratchBut before we continue, let's start defining the model:Step 1 will be to import tensorflow. | import tensorflow as tf | _____no_output_____ | MIT | Course2Part4Lesson4.ipynb | MBadriNarayanan/TensorFlow |
We then add convolutional layers as in the previous example, and flatten the final result to feed into the densely connected layers. Finally we add the densely connected layers. Note that because we are facing a two-class classification problem, i.e. a *binary classification problem*, we will end our network with a [*sigmoid* activation](https://wikipedia.org/wiki/Sigmoid_function), so that the output of our network will be a single scalar between 0 and 1, encoding the probability that the current image is class 1 (as opposed to class 0). | model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 300x300 with 3 bytes color
# This is the first convolution
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# The second convolution
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The third convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fourth convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fifth convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('horses') and 1 for the other ('humans')
tf.keras.layers.Dense(1, activation='sigmoid')
])
from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['accuracy'])
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1/255)
# Flow training images in batches of 128 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
'/tmp/horse-or-human/', # This is the source directory for training images
target_size=(300, 300), # All images will be resized to 150x150
batch_size=128,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow training images in batches of 128 using train_datagen generator
validation_generator = validation_datagen.flow_from_directory(
'/tmp/validation-horse-or-human/', # This is the source directory for training images
target_size=(300, 300), # All images will be resized to 150x150
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
history = model.fit(
train_generator,
steps_per_epoch=8,
epochs=100,
verbose=1,
validation_data = validation_generator,
validation_steps=8)
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'r', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show() | _____no_output_____ | MIT | Course2Part4Lesson4.ipynb | MBadriNarayanan/TensorFlow |
Adversarial Examples Let's start out by importing all the required libraries | import os
import sys
sys.path.append(os.path.join(os.getcwd(), "venv"))
import numpy as np
import torch
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
MNIST Pytorch expects `Dataset` objects as input. Luckily, for MNIST (and few other datasets such as CIFAR and SVHN), torchvision has a ready made function to convert the dataset to a pytorch `Dataset` object. Keep in mind that these functions return `PIL` images so you will have to apply a transformation on them. | path = os.path.join(os.getcwd(), "MNIST")
transform = transforms.Compose([transforms.ToTensor()])
train_mnist = MNIST(path, train=True, transform=transform)
test_mnist = MNIST(path, train=False, transform=transform) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Visualize Dataset Set `batch_size` to 1 to visualize the dataset. | batch_size = 1
train_set = DataLoader(train_mnist, batch_size=batch_size, shuffle=True)
test_set = DataLoader(test_mnist, batch_size=batch_size, shuffle=True)
num_images = 2
for i, (image, label) in enumerate(train_set):
if i == num_images:
break
#Pytorch returns batch_size x num_channels x 28 x 28
plt.imshow(image[0][0])
plt.show()
print("label: " + str(label)) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Train a Model Set `batch_size` to start training a model on the dataset. | batch_size = 64
train_set = DataLoader(train_mnist, batch_size=batch_size, shuffle=True) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Define a `SimpleCNN` model to train on MNIST | def identity():
return lambda x: x
class CustomConv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
activation, stride):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size-2)
self.activation = activation
def forward(self, x):
h = self.conv(x)
return self.activation(h)
class SimpleCNN(nn.Module):
def __init__(self, in_channels=1, out_base=2, kernel_size=3, activation=identity(),
stride=2, num_classes=10):
super().__init__()
self.conv1 = CustomConv2D(in_channels, out_base, kernel_size, activation, stride)
self.pool1 = nn.MaxPool2d((2, 2))
self.conv2 = CustomConv2D(out_base, out_base, kernel_size, activation, stride)
self.pool2 = nn.MaxPool2d((2, 2))
self.linear = nn.Linear(4 * out_base, num_classes, bias=True)
self.log_softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
h = self.conv1(x)
h = self.pool1(h)
h = self.conv2(h)
h = self.pool2(h)
h = h.view([x.size(0), -1])
return self.log_softmax(self.linear(h))
| _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Create 4 model variations: identity_model: SimpleCNN model with identity activation functions relu_model: SimpleCNN model with relu activation functions sig_model: SimpleCNN model with sigmoid activation functions tanh_model: SimpleCNN model with tanh activation functions | identity_model = SimpleCNN()
relu_model = SimpleCNN(activation=nn.ReLU())
sig_model = SimpleCNN(activation=nn.Sigmoid())
tanh_model = SimpleCNN(activation=nn.Tanh()) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Create a function to train the model | def train_model(model, train_set, num_epochs):
optimizer = torch.optim.Adam(lr=0.001, params=model.parameters())
for epoch in range(num_epochs):
epoch_accuracy, epoch_loss = 0, 0
train_set_size = 0
for images, labels in train_set:
batch_size = images.size(0)
images_var, labels_var = Variable(images), Variable(labels)
log_probs = model(images_var)
_, preds = torch.max(log_probs, dim=-1)
loss = nn.NLLLoss()(log_probs, labels_var)
epoch_loss += loss.data.numpy()[0] * batch_size
accuracy = preds.eq(labels_var).float().mean().data.numpy()[0] * 100.0
epoch_accuracy += accuracy * batch_size
train_set_size += batch_size
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_accuracy = epoch_accuracy / train_set_size
epoch_loss = epoch_loss / train_set_size
print("epoch {}: loss= {:.3}, accuracy= {:.4}".format(epoch + 1, epoch_loss, epoch_accuracy))
return model
trained_model = train_model(relu_model, train_set, 10) | epoch 1: loss= 1.86, accuracy= 35.7
epoch 2: loss= 1.49, accuracy= 49.69
epoch 3: loss= 1.44, accuracy= 51.29
epoch 4: loss= 1.4, accuracy= 52.41
epoch 5: loss= 1.37, accuracy= 53.35
epoch 6: loss= 1.34, accuracy= 54.23
epoch 7: loss= 1.32, accuracy= 54.97
epoch 8: loss= 1.3, accuracy= 55.83
epoch 9: loss= 1.29, accuracy= 56.24
epoch 10: loss= 1.28, accuracy= 56.8
| MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Generating Adversarial Examples Now that we have a trained model, we can generate adversarial examples. Gradient Ascent Use Gradient Ascent to generate a targeted adversarial example. | def np_val(torch_var):
return torch_var.data.numpy()[0]
class AttackNet(nn.Module):
def __init__(self, model, image_size):
super().__init__()
self.model = model
self.params = nn.Parameter(torch.zeros(image_size), requires_grad=True)
def forward(self, image):
# clamp parameters here? or in backward?
x = image + self.params
x = torch.clamp(x, 0, 1)
log_probs = self.model(x)
return log_probs
class GradientAscent(object):
def __init__(self, model, confidence=0):
super().__init__()
self.model = model
self.num_steps = 10000
self.confidence = confidence
def attack(self, image, label, target=None):
image_var = Variable(image)
attack_net = AttackNet(self.model, image.shape)
optimizer = torch.optim.Adam(lr=0.01, params=[attack_net.params])
target = Variable(torch.from_numpy(np.array([target], dtype=np.int64))
) if target is not None else None
log_probs = attack_net(image_var)
confidence, predictions = torch.max(torch.exp(log_probs), dim=-1)
if label.numpy()[0] != np_val(predictions):
print("model prediction does not match label")
return None, (None, None), (None, None)
else:
for step in range(self.num_steps):
stop_training = self.perturb(image_var, attack_net, target, optimizer)
if stop_training:
print("Adversarial attack succeeded after {} steps!".format(
step + 1))
break
if stop_training is False:
print("Adversarial attack failed")
log_probs = attack_net(image_var)
adv_confidence, adv_predictions = torch.max(torch.exp(log_probs), dim=-1)
return attack_net.params, (confidence, predictions), (adv_confidence,
adv_predictions)
def perturb(self, image, attack_net, target, optimizer):
log_probs = attack_net(image)
confidence, predictions = torch.max(torch.exp(log_probs), dim=-1)
if (np_val(predictions) == np_val(target) and
np_val(confidence) >= self.confidence):
return True
loss = nn.NLLLoss()(log_probs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return False | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Define a `GradientAscent` object | gradient_ascent = GradientAscent(trained_model) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Define a function to help plot the results | %matplotlib inline
def plot_results(image, perturbation, orig_pred, orig_con, adv_pred, adv_con):
plot_image = image.numpy()[0][0]
plot_perturbation = perturbation.data.numpy()[0][0]
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 10
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size
ax = plt.subplot(131)
ax.set_title("Original: " + str(np_val(orig_pred)) + " @ " +
str(np.round(np_val(orig_con) * 100, decimals=1)) + "%")
plt.imshow(plot_image)
plt.subplot(132)
plt.imshow(plot_perturbation)
ax = plt.subplot(133)
plt.imshow(plot_image + plot_perturbation)
ax.set_title("Adversarial: " + str(np_val(adv_pred)) + " @ " +
str(np.round(np_val(adv_con) * 100, decimals=1)) + "%")
plt.show() | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Let's generate some adversarial examples! | num_images = 2
for i, (test_image, test_label) in enumerate(test_set):
if i == num_images:
break
target_classes = list(range(10))
target_classes.remove(test_label.numpy()[0])
target = np.random.choice(target_classes)
perturbation, (orig_con, orig_pred), (
adv_con, adv_pred) = gradient_ascent.attack(test_image, test_label, target)
if perturbation is not None:
plot_results(test_image, perturbation, orig_pred, orig_con, adv_pred, adv_con) | Adversarial attack succeeded after 3 steps!
| MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Fast Gradient Now let's use the Fast Gradient Sign Method to generate untargeted adversarial examples. | class FastGradient(object):
def __init__(self, model, confidence=0, alpha=0.1):
super().__init__()
self.model = model
self.confidence = confidence
self.alpha = alpha
def attack(self, image, label):
image_var = Variable(image, requires_grad=True)
target = Variable(torch.from_numpy(np.array([label], dtype=np.int64))
) if label is not None else None
log_probs = self.model(image_var)
confidence, predictions = torch.max(torch.exp(log_probs), dim=-1)
if label.numpy()[0] != np_val(predictions):
print("model prediction does not match label")
return None, (None, None), (None, None)
else:
loss = nn.NLLLoss()(log_probs, target)
loss.backward()
x_grad = torch.sign(image_var.grad.data)
adv_image = torch.clamp(image_var.data + self.alpha * x_grad, 0, 1)
delta = adv_image - image_var.data
adv_log_probs = self.model(Variable(adv_image))
adv_confidence, adv_predictions = torch.max(torch.exp(adv_log_probs),
dim=-1)
if (np_val(adv_predictions) != np_val(predictions) and
np_val(adv_confidence) >= self.confidence):
print("Adversarial attack succeeded!")
else:
print("Adversarial attack failed")
return Variable(delta), (confidence, predictions), (adv_confidence,
adv_predictions) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Define a `FastGradient` object | fast_gradient = FastGradient(trained_model) | _____no_output_____ | MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Let's generate some adversarial examples! | num_images = 20
for i, (test_image, test_label) in enumerate(test_set):
if i == num_images:
break
perturbation, (orig_con, orig_pred), (
adv_con, adv_pred) = fast_gradient.attack(test_image, test_label)
if perturbation is not None:
plot_results(test_image, perturbation, orig_pred, orig_con, adv_pred, adv_con) | Adversarial attack failed
| MIT | Adversarial Examples.ipynb | wgharbieh/Adversarial-Examples |
Introduccion a la Inteligencia Artificial Veremos dos ejercicios con para entender el concepto de inteligencia artificial Objeto Rebotador En el siguiente ejercicio, realizaremos un objeto que al chocar con una de las paredes, este cambie de direccion y siga con su camino | !pip3 install ColabTurtle | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
Llamamos las librerias | import ColabTurtle.Turtle as robot
import random | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
Ahora el codigo principal. De momento el robot rebota y vuelve en la misma dirección.Lo que tienes que hacer es poner un inicio aleatorio y modificar el `if` dentro del lazo `while` de manera que este cambie en un solo eje. | robot.initializeTurtle(initial_speed=1)
pad = 15
max_w = robot.window_width() - pad
max_h = robot.window_height() - pad
robot.shape("circle")
robot.color("green")
robot.penup()
robot.goto(0 + pad, 200)
robot.dx = 10 # Velociad en x
robot.dy = 10 # Velociad en y
reflections = 0
# El numero de reflexiones puede ser modificado para que se ejecute por la eternidad. usando while True.
# Pero, debido al limitado tiempo, este es limitado a solo 3 reflexiones.
while reflections < 3:
robot.speed(random.randrange(1, 10))
new_y = robot.gety() + robot.dy
new_x = robot.getx() + robot.dx
if (new_y < pad) or \
(new_y > max_h) or \
(new_x < pad) or \
(new_x > max_w):
robot.dy *= -1
robot.dx *= -1
reflections += 1
robot.goto(new_x, new_y) | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
ChatBot Para el siguiente ejercicio, utilizaremos un ChatBot con definido por reglas. (Ejemplo tomado de: https://www.analyticsvidhya.com/blog/2021/07/build-a-simple-chatbot-using-python-and-nltk/) | !pip install nltk
import nltk
from nltk.chat.util import Chat, reflections | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
**Chat**: es la clase que contiene toda lo logica para processar el texto que el chatbot recibe y encontrar informacion util.**reflections**: es un diccionario que contiene entradas basica y sus correspondientes salidas. | print(reflections) | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
Comenzemos contruyendo las reglas. Las siguientes lineas generan un conjunto de reglas simples. | pairs = [
[
r"my name is (.*)",
["Hello %1, How are you today ?",]
],
[
r"hi|hey|hello",
["Hello", "Hey there",]
],
[
r"what is your name ?",
["I am a bot created by Analytics Vidhya. you can call me crazy!",]
],
[
r"how are you ?",
["I'm doing goodnHow about You ?",]
],
[
r"sorry (.*)",
["Its alright","Its OK, never mind",]
],
[
r"I am fine",
["Great to hear that, How can I help you?",]
],
[
r"i'm (.*) doing good",
["Nice to hear that","How can I help you?:)",]
],
[
r"(.*) age?",
["I'm a computer program dudenSeriously you are asking me this?",]
],
[
r"what (.*) want ?",
["Make me an offer I can't refuse",]
],
[
r"(.*) created ?",
["Raghav created me using Python's NLTK library ","top secret ;)",]
],
[
r"(.*) (location|city) ?",
['Indore, Madhya Pradesh',]
],
[
r"how is weather in (.*)?",
["Weather in %1 is awesome like always","Too hot man here in %1","Too cold man here in %1","Never even heard about %1"]
],
[
r"i work in (.*)?",
["%1 is an Amazing company, I have heard about it. But they are in huge loss these days.",]
],
[
r"(.*)raining in (.*)",
["No rain since last week here in %2","Damn its raining too much here in %2"]
],
[
r"how (.*) health(.*)",
["I'm a computer program, so I'm always healthy ",]
],
[
r"(.*) (sports|game) ?",
["I'm a very big fan of Football",]
],
[
r"who (.*) sportsperson ?",
["Messy","Ronaldo","Roony"]
],
[
r"who (.*) (moviestar|actor)?",
["Brad Pitt"]
],
[
r"i am looking for online guides and courses to learn data science, can you suggest?",
["Crazy_Tech has many great articles with each step explanation along with code, you can explore"]
],
[
r"quit",
["BBye take care. See you soon :) ","It was nice talking to you. See you soon :)"]
],
] | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
Después de definir las reglas, definimos la función para ejecutar el proceso de chat. | def chat(this_creator='Nelson Yalta'):
print(f"Hola!!! Yo soy un chatbot creado por {this_creator}, y estoy listo para sus servicios. Recuede que hablo inglés.")
chat = Chat(pairs, reflections)
chat.converse()
chat() | _____no_output_____ | MIT | day_1/Actividad_02.ipynb | Fhrozen/2021_clubes_ciencia_speech |
Pi Estimation Using Monte Carlo In this exercise, we will use MapReduce and a Monte-Carlo-Simulation to estimate $\Pi$.If we are looking at this image from this [blog](https://towardsdatascience.com/how-to-make-pi-part-1-d0b41a03111f), we see a unit circle in a unit square: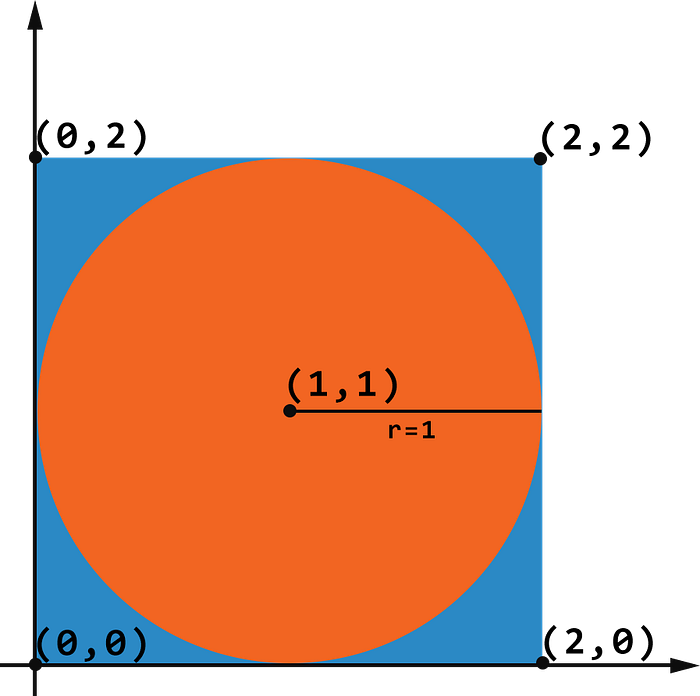 The area:- for the circle is $A_{circle} = \Pi*r^2 = \Pi * 1*1 = \Pi$- for the square is $A_{square} = d^2 = (2*r)^2 = 4$The ratio of the two areas are therefore $\frac{A_{circle}}{A_{square}} = \frac{\Pi}{4}$ The Monte-Carlo-Simulation draws multiple points on the square, uniformly at random. For every point, we count if it lies within the circle or not.And so we get the approximation:$\frac{\Pi}{4} \approx \frac{\text{points_in_circle}}{\text{total_points}}$or$\Pi \approx 4* \frac{\text{points_in_circle}}{\text{total_points}}$ If we have a point $x_1,y_1$ and we want to figure out if it lies in a circle with radius $1$ we can use the following formula:$\text{is_in_circle}(x_1,y_1) = \begin{cases} 1,& \text{if } (x_1)^2 + (y_1)^2 \leq 1\\ 0, & \text{otherwise}\end{cases}$ ImplementationWrite a MapReduce algorithm for estimating $\Pi$ | %%writefile pi.py
#!/usr/bin/python3
from mrjob.job import MRJob
from random import uniform
class MyJob(MRJob):
def mapper(self, _, line):
for x in range(100):
x = uniform(-1,1)
y = uniform(-1,1)
in_circle = x*x + y*y <=1
yield None, in_circle
def reducer(self, key, values):
values = list(values)
yield "Pi", 4 * sum(values) / len(values)
yield "number of values", len(values)
# for v in values:
# yield key, v
if __name__ == '__main__':
MyJob.run() | _____no_output_____ | MIT | V3/v3_exercises_material/solutions/4_Pi-Estimation/Pi_Solution.ipynb | fred1234/BDLC_FS22 |
Another ApproachComputing the mean in the mapper | %%writefile pi.py
#!/usr/bin/python3
from mrjob.job import MRJob
from random import uniform
class MyJob(MRJob):
def mapper(self, _, line):
num_samples = 100
in_circles_list = []
for x in range(num_samples):
x = uniform(-1,1)
y = uniform(-1,1)
in_circle = x*x + y*y <=1
in_circles_list.append(in_circle)
yield None, [num_samples, sum(in_circles_list)/num_samples]
def reducer(self, key, numSamples_sum_pairs):
total_samples = 0
weighted_numerator_sum = 0
for (num_samples, current_sum) in numSamples_sum_pairs:
total_samples += num_samples
weighted_numerator_sum += num_samples*current_sum
yield "Pi", 4 * weighted_numerator_sum / total_samples
yield "weighted_numerator_sum", weighted_numerator_sum
yield "total_samples", total_samples
if __name__ == '__main__':
MyJob.run() | _____no_output_____ | MIT | V3/v3_exercises_material/solutions/4_Pi-Estimation/Pi_Solution.ipynb | fred1234/BDLC_FS22 |
Running the JobUnfortunately, the library does not work without an input file. I guess this comes from the fact that the hadoop streaming library also does not support this feature, see [stack overflow](https://stackoverflow.com/questions/22821005/hadoop-streaming-job-with-no-input-file).We fake the number of mappers with different input files. Not the most elegant solution :/ | !python pi.py /data/dataset/text/small.txt
!python pi.py /data/dataset/text/holmes.txt | _____no_output_____ | MIT | V3/v3_exercises_material/solutions/4_Pi-Estimation/Pi_Solution.ipynb | fred1234/BDLC_FS22 |
Download and prepare the MS-COCO datasetYou will use the [MS-COCO dataset](http://cocodataset.org/home) to train our model. The dataset contains over 82,000 images, each of which has at least 5 different caption annotations. The code below downloads and extracts the dataset automatically.**Caution: large download ahead**. You'll use the training set, which is a 13GB file. | # Download caption annotation files
annotation_folder = '/annotations/'
if not os.path.exists(os.path.abspath('.') + annotation_folder):
annotation_zip = tf.keras.utils.get_file('captions.zip',
cache_subdir=os.path.abspath('.'),
origin = 'http://images.cocodataset.org/annotations/annotations_trainval2014.zip',
extract = True)
annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'
os.remove(annotation_zip)
# Download image files
image_folder = '/train2014/'
if not os.path.exists(os.path.abspath('.') + image_folder):
image_zip = tf.keras.utils.get_file('train2014.zip',
cache_subdir=os.path.abspath('.'),
origin = 'http://images.cocodataset.org/zips/train2014.zip',
extract = True)
PATH = os.path.dirname(image_zip) + image_folder
os.remove(image_zip)
else:
PATH = os.path.abspath('.') + image_folder
#Limiting size of dataset to 50000
# Read the json file
with open(annotation_file, 'r') as f:
annotations = json.load(f)
# Store captions and image names in vectors
all_captions = []
all_img_name_vector = []
for annot in annotations['annotations']:
caption = '<start> ' + annot['caption'] + ' <end>'
image_id = annot['image_id']
full_coco_image_path = PATH + 'COCO_train2014_' + '%012d.jpg' % (image_id)
all_img_name_vector.append(full_coco_image_path)
all_captions.append(caption)
# Shuffle captions and image_names together
# Set a random state
train_captions, img_name_vector = shuffle(all_captions,
all_img_name_vector,
random_state=1)
# Select the first 30000 captions from the shuffled set
num_examples = 50000
train_captions = train_captions[:num_examples]
img_name_vector = img_name_vector[:num_examples]
len(train_captions), len(all_captions) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Preprocess the images using InceptionV3Next, you will use InceptionV3 (which is pretrained on Imagenet) to classify each image. You will extract features from the last convolutional layer.First, you will convert the images into InceptionV3's expected format by:* Resizing the image to 299px by 299px* [Preprocess the images](https://cloud.google.com/tpu/docs/inception-v3-advancedpreprocessing_stage) using the [preprocess_input](https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_v3/preprocess_input) method to normalize the image so that it contains pixels in the range of -1 to 1, which matches the format of the images used to train InceptionV3. | def load_image(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, (299, 299))
img = tf.keras.applications.inception_v3.preprocess_input(img)
return img, image_path | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Initialize InceptionV3 and load the pretrained Imagenet weightsNow you'll create a tf.keras model where the output layer is the last convolutional layer in the InceptionV3 architecture. The shape of the output of this layer is ```8x8x2048```. You use the last convolutional layer because you are using attention in this example. You don't perform this initialization during training because it could become a bottleneck.* You forward each image through the network and store the resulting vector in a dictionary (image_name --> feature_vector).* After all the images are passed through the network, you pickle the dictionary and save it to disk. | image_model = tf.keras.applications.InceptionV3(include_top=False,
weights='imagenet')
new_input = image_model.input
hidden_layer = image_model.layers[-1].output
image_features_extract_model = tf.keras.Model(new_input, hidden_layer) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Caching the features extracted from InceptionV3You will pre-process each image with InceptionV3 and cache the output to disk. Caching the output in RAM would be faster but also memory intensive, requiring 8 \* 8 \* 2048 floats per image. At the time of writing, this exceeds the memory limitations of Colab (currently 12GB of memory).Performance could be improved with a more sophisticated caching strategy (for example, by sharding the images to reduce random access disk I/O), but that would require more code.The caching will take about 10 minutes to run in Colab with a GPU. If you'd like to see a progress bar, you can: 1. install [tqdm](https://github.com/tqdm/tqdm): `!pip install tqdm`2. Import tqdm: `from tqdm import tqdm`3. Change the following line: `for img, path in image_dataset:` to: `for img, path in tqdm(image_dataset):` | # Get unique images
encode_train = sorted(set(img_name_vector))
# Feel free to change batch_size according to your system configuration
image_dataset = tf.data.Dataset.from_tensor_slices(encode_train)
image_dataset = image_dataset.map(
load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(16)
for img, path in image_dataset:
batch_features = image_features_extract_model(img)
batch_features = tf.reshape(batch_features,
(batch_features.shape[0], -1, batch_features.shape[3]))
for bf, p in zip(batch_features, path):
path_of_feature = p.numpy().decode("utf-8")
np.save(path_of_feature, bf.numpy()) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Preprocess and tokenize the captions* First, you'll tokenize the captions (for example, by splitting on spaces). This gives us a vocabulary of all of the unique words in the data (for example, "surfing", "football", and so on).* Next, you'll limit the vocabulary size to the top 5,000 words (to save memory). You'll replace all other words with the token "UNK" (unknown).* You then create word-to-index and index-to-word mappings.* Finally, you pad all sequences to be the same length as the longest one. | # Find the maximum length of any caption in our dataset
def calc_max_length(tensor):
return max(len(t) for t in tensor)
# Choose the top 5000 words from the vocabulary
top_k = 5000
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k,
oov_token="<unk>",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ')
tokenizer.fit_on_texts(train_captions)
train_seqs = tokenizer.texts_to_sequences(train_captions)
tokenizer.word_index['<pad>'] = 0
tokenizer.index_word[0] = '<pad>'
pickle.dump( tokenizer, open( "tokeniser.pkl", "wb" ) )
!cp tokeniser.pkl "/gdrive/My Drive/pickles/tokeniser.pkl"
# Create the tokenized vectors
train_seqs = tokenizer.texts_to_sequences(train_captions)
# Pad each vector to the max_length of the captions
# If you do not provide a max_length value, pad_sequences calculates it automatically
cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')
# Calculates the max_length, which is used to store the attention weights
max_length = calc_max_length(train_seqs)
print(max_length)
#pickle.dump( max_length, open( "/gdrive/My Drive/max_length.p", "wb" ) )
pickle.dump( max_length, open( "max_length.pkl", "wb" ) )
!cp max_length.pkl "/gdrive/My Drive/pickles/max_length.pkl"
#assert(False) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Split the data into training and testing | # Create training and validation sets using an 80-20 split
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,
cap_vector,
test_size=0.2,
random_state=0)
len(img_name_train), len(cap_train), len(img_name_val), len(cap_val) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Create a tf.data dataset for training | # Feel free to change these parameters according to your system's configuration
BATCH_SIZE = 64
BUFFER_SIZE = 1000
embedding_dim = 256
units = 512
vocab_size = top_k + 1
num_steps = len(img_name_train) // BATCH_SIZE
# Shape of the vector extracted from InceptionV3 is (64, 2048)
# These two variables represent that vector shape
features_shape = 2048
attention_features_shape = 64
# Load the numpy files
def map_func(img_name, cap):
img_tensor = np.load(img_name.decode('utf-8')+'.npy')
return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# Use map to load the numpy files in parallel
dataset = dataset.map(lambda item1, item2: tf.numpy_function(
map_func, [item1, item2], [tf.float32, tf.int32]),
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# Shuffle and batch
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
ModelFun fact: the decoder below is identical to the one in the example for [Neural Machine Translation with Attention](../sequences/nmt_with_attention.ipynb).The model architecture is inspired by the [Show, Attend and Tell](https://arxiv.org/pdf/1502.03044.pdf) paper.* In this example, you extract the features from the lower convolutional layer of InceptionV3 giving us a vector of shape (8, 8, 2048).* You squash that to a shape of (64, 2048).* This vector is then passed through the CNN Encoder (which consists of a single Fully connected layer).* The RNN (here GRU) attends over the image to predict the next word. | class BahdanauAttention(tf.keras.Model):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, features, hidden):
# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
# hidden shape == (batch_size, hidden_size)
# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
hidden_with_time_axis = tf.expand_dims(hidden, 1)
# score shape == (batch_size, 64, hidden_size)
score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
# attention_weights shape == (batch_size, 64, 1)
# you get 1 at the last axis because you are applying score to self.V
attention_weights = tf.nn.softmax(self.V(score), axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * features
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class CNN_Encoder(tf.keras.Model):
# Since you have already extracted the features and dumped it using pickle
# This encoder passes those features through a Fully connected layer
def __init__(self, embedding_dim):
super(CNN_Encoder, self).__init__()
# shape after fc == (batch_size, 64, embedding_dim)
self.fc = tf.keras.layers.Dense(embedding_dim)
def call(self, x):
x = self.fc(x)
x = tf.nn.relu(x)
return x
class RNN_Decoder(tf.keras.Model):
def __init__(self, embedding_dim, units, vocab_size):
super(RNN_Decoder, self).__init__()
self.units = units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
#self.bi = tf.keras.layers.LSTM(self.units,
# return_sequences=True,
# return_state=True,
# recurrent_initializer='glorot_uniform')
#self.fc0 = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(self.units, activation='sigmoid'))
self.fc1 = tf.keras.layers.Dense(self.units)
self.fc2 = tf.keras.layers.Dense(vocab_size)
self.attention = BahdanauAttention(self.units)
def call(self, x, features, hidden):
# defining attention as a separate model
context_vector, attention_weights = self.attention(features, hidden)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
#x = self.fc0(output)
# shape == (batch_size, max_length, hidden_size)
x = self.fc1(output)
# x shape == (batch_size * max_length, hidden_size)
x = tf.reshape(x, (-1, x.shape[2]))
# output shape == (batch_size * max_length, vocab)
x = self.fc2(x)
return x, state, attention_weights
def reset_state(self, batch_size):
return tf.zeros((batch_size, self.units))
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Checkpoint | checkpoint_path = "/gdrive/My Drive/checkpoints/train"
if not os.path.exists(checkpoint_path):
os.mkdir(checkpoint_path)
ckpt = tf.train.Checkpoint(encoder=encoder,
decoder=decoder,
optimizer = optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
start_epoch = 0
if ckpt_manager.latest_checkpoint:
start_epoch = int(ckpt_manager.latest_checkpoint.split('-')[-1])
# restoring the latest checkpoint in checkpoint_path
ckpt.restore(ckpt_manager.latest_checkpoint) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Training* You extract the features stored in the respective `.npy` files and then pass those features through the encoder.* The encoder output, hidden state(initialized to 0) and the decoder input (which is the start token) is passed to the decoder.* The decoder returns the predictions and the decoder hidden state.* The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.* Use teacher forcing to decide the next input to the decoder.* Teacher forcing is the technique where the target word is passed as the next input to the decoder.* The final step is to calculate the gradients and apply it to the optimizer and backpropagate. | # adding this in a separate cell because if you run the training cell
# many times, the loss_plot array will be reset
loss_plot = []
@tf.function
def train_step(img_tensor, target):
loss = 0
# initializing the hidden state for each batch
# because the captions are not related from image to image
hidden = decoder.reset_state(batch_size=target.shape[0])
dec_input = tf.expand_dims([tokenizer.word_index['<start>']] * target.shape[0], 1)
with tf.GradientTape() as tape:
features = encoder(img_tensor)
for i in range(1, target.shape[1]):
# passing the features through the decoder
predictions, hidden, _ = decoder(dec_input, features, hidden)
loss += loss_function(target[:, i], predictions)
# using teacher forcing
dec_input = tf.expand_dims(target[:, i], 1)
total_loss = (loss / int(target.shape[1]))
trainable_variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(gradients, trainable_variables))
return loss, total_loss
EPOCHS = 40
for epoch in range(start_epoch, EPOCHS):
start = time.time()
total_loss = 0
for (batch, (img_tensor, target)) in enumerate(dataset):
batch_loss, t_loss = train_step(img_tensor, target)
total_loss += t_loss
if batch % 100 == 0:
print ('Epoch {} Batch {} Loss {:.4f}'.format(
epoch + 1, batch, batch_loss.numpy() / int(target.shape[1])))
# storing the epoch end loss value to plot later
loss_plot.append(total_loss / num_steps)
if epoch % 5 == 0:
ckpt_manager.save()
print ('Epoch {} Loss {:.6f}'.format(epoch + 1,
total_loss/num_steps))
print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
plt.plot(loss_plot)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss Plot')
plt.show()
pickle.dump( loss_plot, open( "/gdrive/My Drive/loss_plot_save.p", "wb" ) ) | _____no_output_____ | Apache-2.0 | train_captioning_model.ipynb | sidphbot/visual-to-audio-aid-for-visually-impaired |
Predict stateHere is the current implementation of the `predict_state` function. It takes in a state (a Python list), and then separates those into position and velocity to calculate a new, predicted state. It uses a constant velocity motion model.**In this exercise, we'll be improving this function, and using matrix multiplication to efficiently calculate the predicted state!** | # The current predict state function
# Predicts the next state based on a motion model
def predict_state(state, dt):
# Assumes a valid state had been passed in
x = state[0]
velocity = state[1]
# Assumes a constant velocity model
new_x = x + velocity*dt
# Create and return the new, predicted state
predicted_state = [new_x, velocity]
return predicted_state
| _____no_output_____ | MIT | Object Tracking and Localization/Representing State and Motion/Matrix Multiplication/Matrix_Multiplication.ipynb | brand909/Computer-Vision |
Matrix operationsYou've been given a matrix class that can create new matrices and performs one operation: multiplication. In our directory this is called `matrix.py`.Similar to the Car class, we can use this to initialize matrix objects. | # import the matrix file
import matrix
# Initialize a state vector
initial_position = 0 # meters
velocity = 50 # m/s
# Notice the syntax for creating a state column vector ([ [x], [v] ])
# Commas separate these items into rows and brackets into columns
initial_state = matrix.Matrix([ [initial_position],
[velocity] ]) | _____no_output_____ | MIT | Object Tracking and Localization/Representing State and Motion/Matrix Multiplication/Matrix_Multiplication.ipynb | brand909/Computer-Vision |
Transformation matrixNext, define the state transformation matrix and print it out! | # Define the state transformation matrix
dt = 1
tx_matrix = matrix.Matrix([ [1, dt],
[0, 1] ])
print(tx_matrix) | [[1 1 ]
[0 1 ]
]
| MIT | Object Tracking and Localization/Representing State and Motion/Matrix Multiplication/Matrix_Multiplication.ipynb | brand909/Computer-Vision |
TODO: Modify the predict state function to use matrix multiplicationNow that you know how to create matrices, modify the `predict_state` function to work with them!Note: you can multiply a matrix A by a matrix B by writing `A*B` and it will return a new matrix. | # The current predict state function
def predict_state_mtx(state, dt):
## TODO: Assume that the state passed in is a Matrix object
## Using a constant velocity model and a transformation matrix
## Create and return the new, predicted state!
tx_matrix = matrix.Matrix([ [1, dt],
[0, 1] ])
predicted_state = tx_matrix * state
return predicted_state | _____no_output_____ | MIT | Object Tracking and Localization/Representing State and Motion/Matrix Multiplication/Matrix_Multiplication.ipynb | brand909/Computer-Vision |
Test cellHere is an initial state vector and dt to test your function with! | # initial state variables
initial_position = 10 # meters
velocity = 30 # m/s
# Initial state vector
initial_state = matrix.Matrix([ [initial_position],
[velocity] ])
print('The initial state is: ' + str(initial_state))
# after 2 seconds make a prediction using the new function
state_est1 = predict_state_mtx(initial_state, 2)
print('State after 2 seconds is: ' + str(state_est1))
# Make more predictions!
# after 3 more
state_est2 = predict_state_mtx(state_est1, 3)
print('State after 3 more seconds is: ' + str(state_est2))
# after 3 more
state_est3 = predict_state_mtx(state_est2, 3)
print('Final state after 3 more seconds is: ' + str(state_est3)) | State after 3 more seconds is: [[160.0 ]
[30.0 ]
]
Final state after 3 more seconds is: [[250.0 ]
[30.0 ]
]
| MIT | Object Tracking and Localization/Representing State and Motion/Matrix Multiplication/Matrix_Multiplication.ipynb | brand909/Computer-Vision |
Copyright 2021 The TensorFlow Authors. | #@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Simple TFX Pipeline Tutorial using Penguin dataset***A Short tutorial to run a simple TFX pipeline.*** Note: We recommend running this tutorial in a Colab notebook, with no setup required! Just click "Run in Google Colab".View on TensorFlow.orgRun in Google ColabView source on GitHubDownload notebook In this notebook-based tutorial, we will create and run a TFX pipelinefor a simple classification model.The pipeline will consist of three essential TFX components: ExampleGen,Trainer and Pusher. The pipeline includes the most minimal ML workflow likeimporting data, training a model and exporting the trained model.Please see[Understanding TFX Pipelines](https://www.tensorflow.org/tfx/guide/understanding_tfx_pipelines)to learn more about various concepts in TFX. Set UpWe first need to install the TFX Python package and downloadthe dataset which we will use for our model. Upgrade PipTo avoid upgrading Pip in a system when running locally,check to make sure that we are running in Colab.Local systems can of course be upgraded separately. | try:
import colab
!pip install --upgrade pip
except:
pass | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Install TFX | !pip install -U tfx | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Did you restart the runtime?If you are using Google Colab, the first time that you runthe cell above, you must restart the runtime by clickingabove "RESTART RUNTIME" button or using "Runtime > Restartruntime ..." menu. This is because of the way that Colabloads packages. Check the TensorFlow and TFX versions. | import tensorflow as tf
print('TensorFlow version: {}'.format(tf.__version__))
from tfx import v1 as tfx
print('TFX version: {}'.format(tfx.__version__)) | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Set up variablesThere are some variables used to define a pipeline. You can customize thesevariables as you want. By default all output from the pipeline will begenerated under the current directory. | import os
PIPELINE_NAME = "penguin-simple"
# Output directory to store artifacts generated from the pipeline.
PIPELINE_ROOT = os.path.join('pipelines', PIPELINE_NAME)
# Path to a SQLite DB file to use as an MLMD storage.
METADATA_PATH = os.path.join('metadata', PIPELINE_NAME, 'metadata.db')
# Output directory where created models from the pipeline will be exported.
SERVING_MODEL_DIR = os.path.join('serving_model', PIPELINE_NAME)
from absl import logging
logging.set_verbosity(logging.INFO) # Set default logging level. | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Prepare example dataWe will download the example dataset for use in our TFX pipeline. The dataset weare using is[Palmer Penguins dataset](https://allisonhorst.github.io/palmerpenguins/articles/intro.html)which is also used in other[TFX examples](https://github.com/tensorflow/tfx/tree/master/tfx/examples/penguin).There are four numeric features in this dataset:- culmen_length_mm- culmen_depth_mm- flipper_length_mm- body_mass_gAll features were already normalized to have range [0,1]. We will build aclassification model which predicts the `species` of penguins. Because TFX ExampleGen reads inputs from a directory, we need to create adirectory and copy dataset to it. | import urllib.request
import tempfile
DATA_ROOT = tempfile.mkdtemp(prefix='tfx-data') # Create a temporary directory.
_data_url = 'https://raw.githubusercontent.com/tensorflow/tfx/master/tfx/examples/penguin/data/penguins_processed.csv'
_data_filepath = os.path.join(DATA_ROOT, "data.csv")
urllib.request.urlretrieve(_data_url, _data_filepath) | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Take a quick look at the CSV file. | !head {_data_filepath} | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
You should be able to see five values. `species` is one of 0, 1 or 2, and allother features should have values between 0 and 1. Create a pipelineTFX pipelines are defined using Python APIs. We will define a pipeline whichconsists of following three components.- CsvExampleGen: Reads in data files and convert them to TFX internal formatfor further processing. There are multiple[ExampleGen](https://www.tensorflow.org/tfx/guide/examplegen)s for variousformats. In this tutorial, we will use CsvExampleGen which takes CSV file input.- Trainer: Trains an ML model.[Trainer component](https://www.tensorflow.org/tfx/guide/trainer) requires amodel definition code from users. You can use TensorFlow APIs to specify how totrain a model and save it in a _saved_model_ format.- Pusher: Copies the trained model outside of the TFX pipeline.[Pusher component](https://www.tensorflow.org/tfx/guide/pusher) can be thoughtof an deployment process of the trained ML model.Before actually define the pipeline, we need to write a model code for theTrainer component first. Write model training codeWe will create a simple DNN model for classification using TensorFlow KerasAPI. This model training code will be saved to a separate file.In this tutorial we will use[Generic Trainer](https://www.tensorflow.org/tfx/guide/trainergeneric_trainer)of TFX which support Keras-based models. You need to write a Python filecontaining `run_fn` function, which is the entrypoint for the `Trainer`component. | _trainer_module_file = 'penguin_trainer.py'
%%writefile {_trainer_module_file}
from typing import List
from absl import logging
import tensorflow as tf
from tensorflow import keras
from tensorflow_transform.tf_metadata import schema_utils
from tfx import v1 as tfx
from tfx_bsl.public import tfxio
from tensorflow_metadata.proto.v0 import schema_pb2
_FEATURE_KEYS = [
'culmen_length_mm', 'culmen_depth_mm', 'flipper_length_mm', 'body_mass_g'
]
_LABEL_KEY = 'species'
_TRAIN_BATCH_SIZE = 20
_EVAL_BATCH_SIZE = 10
# Since we're not generating or creating a schema, we will instead create
# a feature spec. Since there are a fairly small number of features this is
# manageable for this dataset.
_FEATURE_SPEC = {
**{
feature: tf.io.FixedLenFeature(shape=[1], dtype=tf.float32)
for feature in _FEATURE_KEYS
},
_LABEL_KEY: tf.io.FixedLenFeature(shape=[1], dtype=tf.int64)
}
def _input_fn(file_pattern: List[str],
data_accessor: tfx.components.DataAccessor,
schema: schema_pb2.Schema,
batch_size: int = 200) -> tf.data.Dataset:
"""Generates features and label for training.
Args:
file_pattern: List of paths or patterns of input tfrecord files.
data_accessor: DataAccessor for converting input to RecordBatch.
schema: schema of the input data.
batch_size: representing the number of consecutive elements of returned
dataset to combine in a single batch
Returns:
A dataset that contains (features, indices) tuple where features is a
dictionary of Tensors, and indices is a single Tensor of label indices.
"""
return data_accessor.tf_dataset_factory(
file_pattern,
tfxio.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=_LABEL_KEY),
schema=schema).repeat()
def _build_keras_model() -> tf.keras.Model:
"""Creates a DNN Keras model for classifying penguin data.
Returns:
A Keras Model.
"""
# The model below is built with Functional API, please refer to
# https://www.tensorflow.org/guide/keras/overview for all API options.
inputs = [keras.layers.Input(shape=(1,), name=f) for f in _FEATURE_KEYS]
d = keras.layers.concatenate(inputs)
for _ in range(2):
d = keras.layers.Dense(8, activation='relu')(d)
outputs = keras.layers.Dense(3)(d)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.Adam(1e-2),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.summary(print_fn=logging.info)
return model
# TFX Trainer will call this function.
def run_fn(fn_args: tfx.components.FnArgs):
"""Train the model based on given args.
Args:
fn_args: Holds args used to train the model as name/value pairs.
"""
# This schema is usually either an output of SchemaGen or a manually-curated
# version provided by pipeline author. A schema can also derived from TFT
# graph if a Transform component is used. In the case when either is missing,
# `schema_from_feature_spec` could be used to generate schema from very simple
# feature_spec, but the schema returned would be very primitive.
schema = schema_utils.schema_from_feature_spec(_FEATURE_SPEC)
train_dataset = _input_fn(
fn_args.train_files,
fn_args.data_accessor,
schema,
batch_size=_TRAIN_BATCH_SIZE)
eval_dataset = _input_fn(
fn_args.eval_files,
fn_args.data_accessor,
schema,
batch_size=_EVAL_BATCH_SIZE)
model = _build_keras_model()
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
# The result of the training should be saved in `fn_args.serving_model_dir`
# directory.
model.save(fn_args.serving_model_dir, save_format='tf') | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Now you have completed all preparation steps to build a TFX pipeline. Write a pipeline definitionWe define a function to create a TFX pipeline. A `Pipeline` objectrepresents a TFX pipeline which can be run using one of pipelineorchestration systems that TFX supports. | def _create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str,
module_file: str, serving_model_dir: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a three component penguin pipeline with TFX."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# Uses user-provided Python function that trains a model.
trainer = tfx.components.Trainer(
module_file=module_file,
examples=example_gen.outputs['examples'],
train_args=tfx.proto.TrainArgs(num_steps=100),
eval_args=tfx.proto.EvalArgs(num_steps=5))
# Pushes the model to a filesystem destination.
pusher = tfx.components.Pusher(
model=trainer.outputs['model'],
push_destination=tfx.proto.PushDestination(
filesystem=tfx.proto.PushDestination.Filesystem(
base_directory=serving_model_dir)))
# Following three components will be included in the pipeline.
components = [
example_gen,
trainer,
pusher,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components) | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Run the pipelineTFX supports multiple orchestrators to run pipelines.In this tutorial we will use `LocalDagRunner` which is included in the TFXPython package and runs pipelines on local environment.We often call TFX pipelines "DAGs" which stands for directed acyclic graph.`LocalDagRunner` provides fast iterations for developemnt and debugging.TFX also supports other orchestrators including Kubeflow Pipelines and ApacheAirflow which are suitable for production use cases.See[TFX on Cloud AI Platform Pipelines](https://www.tensorflow.org/tfx/tutorials/tfx/cloud-ai-platform-pipelines)or[TFX Airflow Tutorial](https://www.tensorflow.org/tfx/tutorials/tfx/airflow_workshop)to learn more about other orchestration systems. Now we create a `LocalDagRunner` and pass a `Pipeline` object created from thefunction we already defined.The pipeline runs directly and you can see logs for the progress of the pipeline including ML model training. | tfx.orchestration.LocalDagRunner().run(
_create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
module_file=_trainer_module_file,
serving_model_dir=SERVING_MODEL_DIR,
metadata_path=METADATA_PATH)) | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
You should see "INFO:absl:Component Pusher is finished." at the end of thelogs if the pipeline finished successfully. Because `Pusher` component is thelast component of the pipeline.The pusher component pushes the trained model to the `SERVING_MODEL_DIR` whichis the `serving_model/penguin-simple` directory if you did not change thevariables in the previous steps. You can see the result from the file browserin the left-side panel in Colab, or using the following command: | # List files in created model directory.
!find {SERVING_MODEL_DIR} | _____no_output_____ | Apache-2.0 | docs/tutorials/tfx/penguin_simple.ipynb | suryaavala/tfx |
Using a Different Corpuszh_segment makes it easy to use a different corpus for word segmentation.If you simply want to "teach" the algorithm a single phrase it doesn't know then read [this StackOverflow answer](http://stackoverflow.com/questions/20695825/english-word-segmentation-in-nlp).Now, let's get a new corpus. For this example, we'll use the text from Jane Austen's *Pride and Prejudice*. | import requests
response = requests.get('https://www.gutenberg.org/ebooks/1342.txt.utf-8')
text = response.text
print len(text) | 717573
| Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
Great. We've got a new corpus for `zh_segment`. Now let's look at what parts of the API we need to change. There's one function and two dictionaries: `zh_segment.clean`, `zh_segment.bigram_counts` and `zh_segment.unigram_counts`. We'll work on these in reverse. | import zh_segment
print type(zh_segment.unigram_counts), type(zh_segment.bigram_counts)
print zh_segment.unigram_counts.items()[:3]
print zh_segment.bigram_counts.items()[:3] | [('biennials', 37548.0), ('verplank', 48349.0), ('tsukino', 19771.0)]
[('personal effects', 151369.0), ('basic training', 294085.0), ('it absolutely', 130505.0)]
| Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
Ok, so `zh_segment.unigram_counts` is just a dictionary mapping unigrams to their counts. Let's write a method to tokenize our text. | import re
def tokenize(text):
pattern = re.compile('[a-zA-Z]+')
return (match.group(0) for match in pattern.finditer(text))
print list(tokenize("Wait, what did you say?")) | ['Wait', 'what', 'did', 'you', 'say']
| Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
Now we'll build our dictionaries. | from collections import Counter
zh_segment.unigram_counts = Counter(tokenize(text))
def pairs(iterable):
iterator = iter(iterable)
values = [next(iterator)]
for value in iterator:
values.append(value)
yield ' '.join(values)
del values[0]
zh_segment.bigram_counts = Counter(pairs(tokenize(text))) | _____no_output_____ | Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
That's it.Now, by default, `zh_segment.segment` lowercases all input and removes punctuation. In our corpus we have capitals so we'll also have to change the `clean` function. Our heaviest hammer is to simply replace it with the identity function. This will do no sanitation of the input to `segment`. | def identity(value):
return value
zh_segment.clean = identity
zh_segment.segment('wantofawife') | _____no_output_____ | Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
If you find this behaves poorly then you may need to change the `zh_segment.TOTAL` variable to reflect the total of all unigrams. In our case that's simply: | zh_segment.TOTAL = float(sum(zh_segment.unigram_counts.values())) | _____no_output_____ | Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment |
zh_segment doesn't require any fancy machine learning training algorithms. Simply update the unigram and bigram count dictionaries and you're ready to go. | _____no_output_____ | Apache-2.0 | docs/using-a-different-corpus.ipynb | wuhaifengdhu/zh_segment | |
Checking Container Dwell TimesThis works with the CSV export of ConFlowGen. Import libraries | import os
import pathlib
import ipywidgets as widgets
import pandas as pd
from IPython.display import Markdown
import matplotlib.pyplot as plt
from matplotlib import gridspec | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Select input data | folder_of_this_jupyter_notebook = pathlib.Path.cwd()
export_folder = os.path.join(
folder_of_this_jupyter_notebook,
os.pardir,
os.pardir,
os.pardir,
"conflowgen",
"data",
"exports"
)
folders = [
folder
for folder in os.listdir(export_folder)
if os.path.isdir(
os.path.join(
export_folder,
folder
)
)
]
dropdown_field = widgets.Dropdown(
options=list(reversed(folders)), # always show the newest first
description='',
layout={'width': 'max-content'}
)
dropdown_label = widgets.Label(value="Select the exported output: ")
display(widgets.HBox([dropdown_label, dropdown_field]))
path_to_selected_exported_content = os.path.join(
export_folder,
dropdown_field.value
)
print("Working with directory " + path_to_selected_exported_content) | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Load containers | path_to_containers = os.path.join(
path_to_selected_exported_content,
"containers.csv"
)
print(f"Opening {path_to_containers}")
df_containers = pd.read_csv(path_to_containers, index_col="id", dtype={
"delivered_by_truck": "Int64",
"picked_up_by_truck": "Int64",
"delivered_by_large_scheduled_vehicle": "Int64",
"picked_up_by_large_scheduled_vehicle": "Int64"
})
df_containers | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Check number of large scheduled vehicles (deep sea vessels, feeders, barges, and trains). | df_containers.groupby(by="delivered_by_large_scheduled_vehicle").count() | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Load scheduled vehiclesLoad the vehicles to enrich the information regarding the arrival and departure of the containers. | path_to_deep_sea_vessels = os.path.join(
path_to_selected_exported_content,
"deep_sea_vessels.csv"
)
path_to_feeders = os.path.join(
path_to_selected_exported_content,
"feeders.csv"
)
path_to_barges = os.path.join(
path_to_selected_exported_content,
"barges.csv"
)
path_to_trains = os.path.join(
path_to_selected_exported_content,
"trains.csv"
)
scheduled_vehicle_file_paths = {
"deep_sea_vessels": path_to_deep_sea_vessels,
"feeders": path_to_feeders,
"barges": path_to_barges,
"trains": path_to_trains
}
for name, path in scheduled_vehicle_file_paths.items():
print("Check file exists for vehicle " + name + ".")
assert os.path.isfile(path)
print("All files exist.")
for name, path in list(scheduled_vehicle_file_paths.items()):
print("Check file size for vehicle " + name)
size_in_bytes = os.path.getsize(path)
if size_in_bytes <= 4:
print(" This file is empty, ignoring it in the analysis from now on")
del scheduled_vehicle_file_paths[name]
scheduled_vehicle_dfs = {
name: pd.read_csv(path, index_col=0, parse_dates=["scheduled_arrival"])
for name, path in scheduled_vehicle_file_paths.items()
}
for name, df in scheduled_vehicle_dfs.items():
display(Markdown("#### " + name))
scheduled_vehicle_dfs[name]["vehicle_type"] = name
display(scheduled_vehicle_dfs[name].sort_values(by="scheduled_arrival"))
df_large_scheduled_vehicle = pd.concat(
scheduled_vehicle_dfs.values()
)
df_large_scheduled_vehicle.sort_index(inplace=True)
df_large_scheduled_vehicle.info()
df_large_scheduled_vehicle | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Plot arrival pattern. | plt.figure(figsize=(15, 3))
x, y, z = [], [], []
y_axis = []
y_scaling_factor = 2
for i, (name, df) in enumerate(scheduled_vehicle_dfs.items()):
y_axis.append((i/y_scaling_factor, name))
if len(df) == 0:
continue
arrivals_and_capacity = df[["scheduled_arrival", "moved_capacity"]]
for _, row in arrivals_and_capacity.iterrows():
event = row["scheduled_arrival"]
moved_capacity = row["moved_capacity"]
x.append(event)
y.append(i / y_scaling_factor)
z.append(moved_capacity / 20)
plt.xticks(rotation=45)
plt.yticks(*list(zip(*y_axis)))
plt.scatter(x, y, s=z, color='gray')
plt.ylim([-0.5, 1.5])
plt.show() | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Transform data to check how many containers are delivered and picked up by which vehicle. | vehicle_to_teu_to_deliver = {}
vehicle_to_teu_to_pickup = {}
for i, container in df_containers.iterrows():
teu = container["length"] / 20
assert 1 <= teu <= 2.5
if container["delivered_by"] != "truck":
vehicle = container["delivered_by_large_scheduled_vehicle"]
if vehicle not in vehicle_to_teu_to_deliver.keys():
vehicle_to_teu_to_deliver[vehicle] = 0
vehicle_to_teu_to_deliver[vehicle] += teu
if container["picked_up_by"] != "truck":
vehicle = container["picked_up_by_large_scheduled_vehicle"]
if vehicle not in vehicle_to_teu_to_pickup.keys():
vehicle_to_teu_to_pickup[vehicle] = 0
vehicle_to_teu_to_pickup[vehicle] += teu
vehicle_to_teu_to_deliver, vehicle_to_teu_to_pickup | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Add transformed data to vehicles. | s_delivery = pd.Series(vehicle_to_teu_to_deliver)
s_pickup = pd.Series(vehicle_to_teu_to_pickup)
df_large_scheduled_vehicle["capacity_delivery"] = s_delivery
df_large_scheduled_vehicle["capacity_pickup"] = s_pickup
df_large_scheduled_vehicle
for large_scheduled_vehicle_id in df_large_scheduled_vehicle.index:
delivered_teu = vehicle_to_teu_to_deliver.get(large_scheduled_vehicle_id, 0)
picked_up_teu = vehicle_to_teu_to_pickup.get(large_scheduled_vehicle_id, 0)
capacity_in_teu = df_large_scheduled_vehicle.loc[large_scheduled_vehicle_id, "capacity_in_teu"]
assert delivered_teu <= capacity_in_teu, f"{delivered_teu} is more than {capacity_in_teu} for vehicle "\
f"with id {large_scheduled_vehicle_id}"
assert picked_up_teu <= capacity_in_teu, f"{picked_up_teu} is more than {capacity_in_teu} for vehicle "\
f"with id {large_scheduled_vehicle_id}" | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
Load trucks | path_to_trucks = os.path.join(
path_to_selected_exported_content,
"trucks.csv"
)
assert os.path.isfile(path_to_trucks)
df_truck = pd.read_csv(
path_to_trucks, index_col=0,
parse_dates=[
# Pickup
"planned_container_pickup_time_prior_berthing",
"realized_container_pickup_time",
# Delivery
"planned_container_delivery_time_at_window_start",
"realized_container_delivery_time"
])
df_truck
assert len(df_truck[df_truck["picks_up_container"] & pd.isna(df_truck["realized_container_pickup_time"])]) == 0, \
"If a truck picks up a container, it should always have a realized container pickup time"
assert len(df_truck[df_truck["delivers_container"] & pd.isna(df_truck["realized_container_delivery_time"])]) == 0, \
"If a truck deliver a container, it should always have a realized container delivery time"
assert len(df_truck[~(df_truck["delivers_container"] | df_truck["picks_up_container"])]) == 0, \
"There is no truck that neither delivers or picks up a container" | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
This is the probability of the truck to show up at any given hour of the week (by index). | delivered_and_picked_up_by_large_vessels_df = df_containers.loc[
~pd.isna(df_containers["picked_up_by_large_scheduled_vehicle"])
].join(
df_large_scheduled_vehicle, on="picked_up_by_large_scheduled_vehicle", rsuffix="_picked_up"
).loc[
~pd.isna(df_containers["delivered_by_large_scheduled_vehicle"])
].join(
df_large_scheduled_vehicle, on="delivered_by_large_scheduled_vehicle", rsuffix="_delivered_by"
)
delivered_and_picked_up_by_large_vessels_df
dwell_time = (
delivered_and_picked_up_by_large_vessels_df["scheduled_arrival"]
- delivered_and_picked_up_by_large_vessels_df["scheduled_arrival_delivered_by"]
)
dwell_time.describe()
dwell_time.astype("timedelta64[h]").plot.hist(bins=30, color="gray")
plt.xlabel("Hours between delivery and onward transportation (except trucks)")
plt.ylabel("Number container")
plt.show() | _____no_output_____ | MIT | example-usage/Jupyter Notebook/output data inspection/checking container dwell times.ipynb | 1grasse/conflowgen |
2019 Formula One World Championship A Formula One season consists of a series of races, known as Grands Prix (French for ''grand prizes' or 'great prizes''), which take place worldwide on purpose-built circuits and on public roads. The results of each race are evaluated using a points system to determine two annual World Championships: one for drivers, the other for constructors. Drivers must hold valid Super Licences, the highest class of racing licence issued by the FIA. The races must run on tracks graded "1" (formerly "A"), the highest grade-rating issued by the FIA.Most events occur in rural locations on purpose-built tracks, but several events take place on city streets.There are a number of F1 races coming up:Singapore GP: Date: Sun, Sep 22, 8:10 AMRussian GP: Date: Sun, Sep 29, 7:10 AMJapanese GP: Date: Sun, Oct 13, 1:10 AMMexican GP Date: Sun, Oct 13, 1:10 AMThe Singaporean Grand Prix this weekend and the Russian Grand Prix the weekend after, as you can see here.The 2019 driver standings are given here. Given these standings: Lets Answer few fun questions? | #A Probability Distribution; an {outcome: probability} mapping.
# Make probabilities sum to 1.0; assert no negative probabilities
class ProbDist(dict):
"""A Probability Distribution; an {outcome: probability} mapping."""
def __init__(self, mapping=(), **kwargs):
self.update(mapping, **kwargs)
total = sum(self.values())
for outcome in self:
self[outcome] = self[outcome] / total
assert self[outcome] >= 0
def p(event, space):
"""The probability of an event, given a sample space of outcomes.
event: a collection of outcomes, or a predicate that is true of outcomes in the event.
space: a set of outcomes or a probability distribution of {outcome: frequency} pairs."""
# if event is a predicate it, "unroll" it as a collection
if is_predicate(event):
event = such_that(event, space)
# if space is not an equiprobably collection (a simple set),
# but a probability distribution instead (a dictionary set),
# then add (union) the probabilities for all favorable outcomes
if isinstance(space, ProbDist):
return sum(space[o] for o in space if o in event)
# simplest case: what we played with in our previous lesson
else:
return Fraction(len(event & space), len(space))
is_predicate = callable
# Here we either return a simple collection in the case of equiprobable outcomes, or a dictionary collection in the
# case of non-equiprobably outcomes
def such_that(predicate, space):
"""The outcomes in the sample pace for which the predicate is true.
If space is a set, return a subset {outcome,...} with outcomes where predicate(element) is true;
if space is a ProbDist, return a ProbDist {outcome: frequency,...} with outcomes where predicate(element) is true."""
if isinstance(space, ProbDist):
return ProbDist({o:space[o] for o in space if predicate(o)})
else:
return {o for o in space if predicate(o)} | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
Question Set 1what is the Probability Distribution for each F1 driver to win the Singaporean Grand Prix? What is the Probability Distribution for each F1 driver to win both the Singaporean and Russian Grand Prix?What is the probability for Mercedes to win both races?What is the probability for Mercedes to win at least one race?Note that Mercedes, and each other racing team, has two drivers per race. Solution 1. what is the Probability Distribution for each F1 driver to win the Singaporean Grand Prix? | SGP = ProbDist(LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,RG=8,AG=3,RK=1,
GR=0)
print ("The probability of each driver winnning Singaporean Grand Prix ")
SGP #Driver standing divided by / total of all driver standings, SGP returns total probability as 1 | The probability of each driver winnning Singaporean Grand Prix
| MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
2. What is the Probability Distribution for each F1 driver to win both the Singaporean and Russian Grand Prix? | SGP = ProbDist(
LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=3,RK=1,GR=0) # data taken on saturday before race starts for Singapore
RGP = ProbDist(
LH=296,VB=231,CL=200,MV=200,SV=194,PG=69,CS=58,AA=42,DR=34,DK=33,NH=33,LN=31,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=4,RK=1,GR=0) # data taken on saturday before race starts for Russia
#perfoms joint probabilities on SGP and RGP probability distributions
def joint(A, B, sep=''):
"""The joint distribution of two independent probability distributions.
Result is all entries of the form {a+sep+b: P(a)*P(b)}"""
return ProbDist({a + sep + b: A[a] * B[b]
for a in A
for b in B})
bothSGPRGP= joint(SGP, RGP, ' ')
print ("The probability of each driver winnning Singaporean Grand Prix and Russian Grand Prix")
bothSGPRGP | The probability of each driver winnning Singaporean Grand Prix and Russian Grand Prix
| MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
3. What is the probability for Mercedes to win both races? | def mercedes_T(outcome): return outcome == "VB" or outcome == "LH"
mercedesWinningSGPRace = p(mercedes_T, SGP)
#calculate probability of mercedes winning Singapore Frand Pix
def mercedes_T(outcome): return outcome == "VB" or outcome == "LH"
mercedesWinningRGPRace = p(mercedes_T, RGP)
#calculate probability of mercedes winning Russia Grand Pix
print ("The probability of mercedes winnning both the races ")
mercedesWinningBothRaces = mercedesWinningRGPRace * mercedesWinningSGPRace
mercedesWinningBothRaces
#probability of two events occurring together as independent events (P1 * P2)= P | The probability of mercedes winnning both the races
| MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
4. What is the probability for Mercedes to win at least one race? | def p(event, space):
"""The probability of an event, given a sample space of outcomes.
event: a collection of outcomes, or a predicate that is true of outcomes in the event.
space: a set of outcomes or a probability distribution of {outcome: frequency} pairs."""
# if event is a predicate it, "unroll" it as a collection
if is_predicate(event):
event = such_that(event, space)
# if space is not an equiprobably collection (a simple set),
# but a probability distribution instead (a dictionary set),
# then add (union) the probabilities for all favorable outcomes
if isinstance(space, ProbDist):
return sum(space[o] for o in space if o in event)
# simplest case: what we played with in our previous lesson
else:
return Fraction(len(event & space), len(space))
is_predicate = callable
# Here we either return a simple collection in the case of equiprobable outcomes, or a dictionary collection in the
# case of non-equiprobably outcomes
def such_that(predicate, space):
"""The outcomes in the sample pace for which the predicate is true.
If space is a set, return a subset {outcome,...} with outcomes where predicate(element) is true;
if space is a ProbDist, return a ProbDist {outcome: frequency,...} with outcomes where predicate(element) is true."""
if isinstance(space, ProbDist):
return ProbDist({o:space[o] for o in space if predicate(o)})
else:
return {o for o in space if predicate(o)}
mercedesWinningAtleastOneRace = mercedesWinningBothRaces + (mercedesWinningRGPRace * (1 - mercedesWinningSGPRace))+mercedesWinningSGPRace * (1 - mercedesWinningRGPRace)
print ("The probability of mercedes winnning at least one of the races ")
mercedesWinningAtleastOneRace
#probability of an event occurring at least once, it will be the complement of the probability of the event never occurring. | The probability of mercedes winnning at least one of the races
| MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
Question Set 2 If Mercedes wins the first race, what is the probability that Mercedes wins the next one? If Mercedes wins at least one of these two races, what is the probability Mercedes wins both races? How about Ferrari, Red Bull, and Renault? Solution If Mercedes wins the first race, what is the probability that Mercedes wins the next one? If Mercedes wins at least one of these two races, what is the probability Mercedes wins both races? How about Ferrari, Red Bull, and Renault? | SGP = ProbDist(
LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=3,RK=1,GR=0)
RGP = ProbDist(
LH=296,VB=231,CL=200,MV=200,SV=194,PG=69,CS=58,AA=42,DR=34,DK=33,NH=33,LN=31,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=4,RK=1,GR=0)
Weather = ProbDist(RA=1, SU=1, SN=1, CL=1, FO=1)
def Mercedes_Win_First(outcome): return outcome.startswith('LH') or outcome.startswith('VB') #choose prob of first set
def Mercedes_Win_Second(outcome): return outcome.endswith('LH') or outcome.endswith('VB')
p(Mercedes_Win_Second, such_that(Mercedes_Win_First,bothSGPRGP)) #given first race is won, the second will be won
def Mercedes_WinBoth(outcome): return 'LH LH' in outcome or 'LH VB' in outcome or 'VB LH' in outcome or 'VB VB' in outcome
def Mercedes_Win(outcome): return 'LH' in outcome or 'VB' in outcome
p(Mercedes_WinBoth, such_that(Mercedes_Win,bothSGPRGP)) # (LH,LH VB,VB LH,VB VB,LH) 4 groups to pickup provided first race is won for the both event | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
If Ferrari wins the first race, what is the probability that Ferrari wins the next one? | def Ferrari_WinBoth(outcome): return 'CL CL' in outcome or 'CL SV' in outcome or 'SV SV' in outcome or 'SV CL' in outcome
def Ferrari_Win(outcome): return 'CL' in outcome or 'SV' in outcome
p(Ferrari_WinBoth, such_that(Ferrari_Win,bothSGPRGP)) | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
If RedBull wins the first race, what is the probability that RedBull wins the next one | def RedBull_WinBoth(outcome): return 'MV MV' in outcome or 'MV AA' in outcome or 'AA AA' in outcome or 'AA MV' in outcome
def RedBull_Win(outcome): return 'MV' in outcome or 'AA' in outcome
p(RedBull_WinBoth, such_that(RedBull_Win,bothSGPRGP)) | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
If Renault wins the first race, what is the probability that Renault wins the next one? | def Renault_WinBoth(outcome): return 'DR DR' in outcome or 'DR NH' in outcome or 'NH NH' in outcome or 'NH DR' in outcome
def Renault_Win(outcome): return 'DR' in outcome or 'NH' in outcome
p(Renault_WinBoth, such_that(Renault_Win,bothSGPRGP)) | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
Question Set 3Mercedes wins one of these two races on a rainy day. What is the probability Mercedes wins both races, assuming races can be held on either rainy, sunny, cloudy, snowy or foggy days? Assume that rain, sun, clouds, snow, and fog are the only possible weather conditions on race tracks. Solution Mercedes wins one of these two races on a rainy day. What is the probability Mercedes wins both races, assuming races can be held on either rainy, sunny, cloudy, snowy or foggy days? Assume that rain, sun, clouds, snow, and fog are the only possible weather conditions on race tracks. | #create Probability Distribution for given Weather Condtions wher p(weather) will be 0.20
GivenFiveWeatherConditons = ProbDist(
RainyDay=1,
SunnyDay=1,
CloudyDay=1,
SnowyDay=1,
FoggyDay=1
)
GivenFiveWeatherConditons
#perfoms joint probabilities on SGP & weather and RGP & weather probability distributions Respectively
def joint(A, B, A1, B1, sep=''):
"""The joint distribution of two independent probability distributions.
Result is all entries of the form {a+sep+b: P(a)*P(b)}"""
return ProbDist({a + sep + a1 + sep + b + sep + b1: A[a] * B[b] *A1[a1] * B1[b1]
for a in A
for b in B
for a1 in A1
for b1 in B1})
bothSGPRGPWeather= joint(SGP, RGP, GivenFiveWeatherConditons,GivenFiveWeatherConditons, ' ')
bothSGPRGPWeather
def Mercedes_Wins_Race_On_Any_Rainy(outcome): return ('LH R' in outcome or 'VB R' in outcome)
such_that(Mercedes_Wins_Race_On_Any_Rainy, bothSGPRGPWeather)
def Mercedes_Wins_Race_On_Both_Rain(outcome): return ('LH' in outcome and 'VB' in outcome) or (outcome.count('LH')==2 ) or (outcome.count('VB')==2 )
p(Mercedes_Wins_Race_On_Both_Rain, such_that(Mercedes_Wins_Race_On_Any_Rainy, bothSGPRGPWeather)) | _____no_output_____ | MIT | Formula One World Championship Analysis.ipynb | mbadamve/Machine-Learning-projects |
import pandas as pd
from typing import List
from datetime import datetime
from random import randint
from dateutil.relativedelta import *
factionName: List[str] = []
systemName: List[str] = []
population: List[int] = []
influence: List[float] = []
updated: List[datetime] = []
factionName: List[str] = []
systemName: List[str] = []
population: List[int] = []
influence: List[float] = []
updated: List[datetime] = []
randStrs = ['foo', 'bar', 'guh']
def randStr() -> str:
global randStrs
return randStrs[randint(0, len(randStrs))]
def seqStr(i: int) -> str:
global randStrs
return randStrs[i % len(randStrs)]
start_date = datetime.strptime("2020-06-01", "%Y-%m-%d")
for fac in ['foo','bar','guh']:
upd = start_date
for sys in ['sol','celeano']:
for i in range(0,5):
factionName.append( fac)
systemName.append( sys)
population.append(10000)
influence.append(.33)
day = randint(2,4)
upd = upd + relativedelta(hours=day*8)
updated.append(upd)
data = { 'systemName' : systemName,
'factionName' : factionName,
'population' : population,
'influence' : influence,
'updated' : updated
}
df = pd.DataFrame(data = data)
# prepare data
df['updated'] = df.updated.dt.round("D")
df = df.sort_values(by=['systemName', 'factionName','updated'])
# this drops out all data that doesn't have at least 2 days in a row
systems = df['systemName'].unique().tolist()
holder = pd.DataFrame()
for sys in systems:
print(sys)
sysSlice = df[ df['systemName'] ==sys]
facs = sysSlice['factionName'].unique().tolist()
for fac in facs:
print("\t"+ fac)
facSlice = sysSlice[ sysSlice['factionName'] == fac].reset_index()
facSlice['diff1'] = facSlice.updated.diff(periods=1).dt.days.abs()
facSlice['diff2'] = facSlice.updated.diff(periods=-1).dt.days.abs()
facSlice = facSlice.fillna(999.0)
facSlice['diffz'] = facSlice[['diff1','diff2']].min(axis=1)
facSlice = facSlice[ facSlice['diffz'] <=1.0]
facSlice = facSlice.drop(['diff1','diff2','diffz'], axis=1)
holder = holder.append(facSlice.copy(), ignore_index=True)
holder
def minAbs(x1: float, x2: float) -> float:
return min ( abs(x1), abs(x2)) | _____no_output_____ | BSD-3-Clause | notebooks/ANN.ipynb | HausReport/ClubRaiders | |
WELCOME BACK TO SACNAS' PYTHON WORKSHOP hosted by Luis and Emily Introduction:Sign in and grab food! Import the necessary libraries/packages:There are tools you can download into your code to implement. Think of these like your toolbox, to create plots, analyze data, and endless possibilities | import pandas as pd
import numpy as np
# visualization libraries
import matplotlib.pyplot as plt
| _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus |
Import data and assign it to a variable called tips | url = 'https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/07_Visualization/Tips/tips.csv'
| _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus |
.describe()Generate descriptive statistics that summarize the central tendency, dispersion and shape of a dataset’s distribution, excluding NaN values. | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
For loops a for-loop is a control flow statement for specifying iteration, which allows code to be executed repeatedly. | x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
| _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus |
Working with our datasetRecap on worksheet. What day are people more likely to tip? | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
How can we automate a print statement using a For loop? | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
How do we store these values? | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
Lists, Arrays , Dictionaries | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
Plotting a bar graphparameters are what you need inside the paranthesis for the function you are calling to work. plt.bar(x coordinate, height) | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
Who tips more? Smokers or non smokers? | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
Who tips more? Women or Men | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus | |
Plot the total_bill column using a histogram | _____no_output_____ | MIT | Copy_of_Workshop2Final.ipynb | feliz10/papus |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.