
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
BusThis bus has a passenger entry and exit control system to monitor the number of occupants it carries and thus detect when there are too many.At each stop, the entry and exit of passengers is represented by a tuple consisting of two integer numbers.```bus_stop = (in, out)```The succession of stops is represented by a list of these tuples.```stops = [(in1, out1), (in2, out2), (in3, out3), (in4, out4)]``` ToolsYou don't necessarily need to use all the tools. Maybe you opt to use some of them or completely different ones, they are given to help you shape the exercise. Programming exercises can be solved in many different ways.* Data structures: **lists, tuples*** Loop: **while/for loops*** Functions: **min, max, len** Tasks | # Variables
stops = [(10, 0), (4, 1), (3, 5), (3, 4), (5, 1), (1, 5), (5, 8), (4, 6), (2, 3)] | _____no_output_____ | Unlicense | bus/bus-checkpoint.ipynb | oscarledesma16/bcn-feb-2019-prework |
1. Calculate the number of stops. | stops = [(10, 0), (4, 1), (3, 5), (3, 4), (5, 1), (1, 5), (5, 8), (4, 6), (2, 3)]
print(len(stops)) | 9
| Unlicense | bus/bus-checkpoint.ipynb | oscarledesma16/bcn-feb-2019-prework |
2. Assign to a variable a list whose elements are the number of passengers at each stop (in-out).Each item depends on the previous item in the list + in - out. | stops = [(10, 0), (4, 1), (3, 5), (3, 4), (5, 1), (1, 5), (5, 8), (4, 6), (2, 3)]
for_stop = [(stops[0][0]) - (stops[0][1]), (stops[1][0]) - (stops[1][1]), (stops[2][0]) - (stops[2][1]), (stops[3][0]) - (stops[3][1]), (stops[4][0]) - (stops[4][1]), (stops[5][0]) - (stops[5][1]), (stops[6][0]) - (stops[6][1]), (stops[7][0]) - (stops[7][1]), (stops[8][0]) - (stops[8][1])]
passengers = 0
for i in (for_stop):
passengers += i
print("Total passengers for stop ", passengers)
| Total passengers for stop 10
Total passengers for stop 13
Total passengers for stop 11
Total passengers for stop 10
Total passengers for stop 14
Total passengers for stop 10
Total passengers for stop 7
Total passengers for stop 5
Total passengers for stop 4
| Unlicense | bus/bus-checkpoint.ipynb | oscarledesma16/bcn-feb-2019-prework |
3. Find the maximum occupation of the bus. | from itertools import accumulate
accumulate_for_stops = (list(accumulate(for_stop)))
print(accumulate_for_stops)
print("Maximum occupation of the bus is:", (max(accumulate_for_stops))) | [10, 13, 11, 10, 14, 10, 7, 5, 4]
Maximum occupation of the bus is: 14
| Unlicense | bus/bus-checkpoint.ipynb | oscarledesma16/bcn-feb-2019-prework |
4. Calculate the average occupation. And the standard deviation. | average_occupation = sum(accumulate_for_stops)/len(accumulate_for_stops)
print("Average occupation:", average_occupation)
from math import sqrt
suma = 0
for i in for_stop:
suma += (i - average_occupation) ** 2
radicando = suma / (len(for_stop) - 1)
standard_deviation = sqrt(radicando)
print("Standard deviation:", standard_deviation) | Average occupation: 9.333333333333334
Standard deviation: 10.424330514074594
| Unlicense | bus/bus-checkpoint.ipynb | oscarledesma16/bcn-feb-2019-prework |
Lambda School Data Science - Recurrent Neural Networks and LSTM> "Yesterday's just a memory - tomorrow is never what it's supposed to be." -- Bob Dylan LectureWish you could save [Time In A Bottle](https://www.youtube.com/watch?v=AnWWj6xOleY)? With statistics you can do the next best thing - understand how data varies over time (or any sequential order), and use the order/time dimension predictively.A sequence is just any enumerated collection - order counts, and repetition is allowed. Python lists are a good elemental example - `[1, 2, 2, -1]` is a valid list, and is different from `[1, 2, -1, 2]`. The data structures we tend to use (e.g. NumPy arrays) are often built on this fundamental structure.A time series is data where you have not just the order but some actual continuous marker for where they lie "in time" - this could be a date, a timestamp, [Unix time](https://en.wikipedia.org/wiki/Unix_time), or something else. All time series are also sequences, and for some techniques you may just consider their order and not "how far apart" the entries are (if you have particularly consistent data collected at regular intervals it may not matter). Time series with plain old regressionRecurrences are fancy, and we'll get to those later - let's start with something simple. Regression can handle time series just fine if you just set them up correctly - let's try some made-up stock data. And to make it, let's use a few list comprehensions! | import numpy as np
from random import random
days = np.array((range(28)))
stock_quotes = np.array([random() + day * random() for day in days])
stock_quotes | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Let's take a look with a scatter plot: | from matplotlib.pyplot import scatter
scatter(days, stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Looks pretty linear, let's try a simple OLS regression.First, these need to be NumPy arrays: | days = days.reshape(-1, 1) # X needs to be column vectors | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Now let's use good old `scikit-learn` and linear regression: | from sklearn.linear_model import LinearRegression
ols_stocks = LinearRegression()
ols_stocks.fit(days, stock_quotes)
ols_stocks.score(days, stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
That seems to work pretty well, but real stocks don't work like this.Let's make *slightly* more realistic data that depends on more than just time: | # Not everything is best as a comprehension
stock_data = np.empty([len(days), 4])
for day in days:
asset = random()
liability = random()
quote = random() + ((day * random()) + (20 * asset) - (15 * liability))
quote = max(quote, 0.01) # Want positive quotes
stock_data[day] = np.array([quote, day, asset, liability])
stock_data | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Let's look again: | stock_quotes = stock_data[:,0]
scatter(days, stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
How does our old model do? | days = np.array(days).reshape(-1, 1)
ols_stocks.fit(days, stock_quotes)
ols_stocks.score(days, stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Not bad, but can we do better? | ols_stocks.fit(stock_data[:,1:], stock_quotes)
ols_stocks.score(stock_data[:,1:], stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Yep - unsurprisingly, the other covariates (assets and liabilities) have info.But, they do worse without the day data. | ols_stocks.fit(stock_data[:,2:], stock_quotes)
ols_stocks.score(stock_data[:,2:], stock_quotes) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Time series jargonThere's a lot of semi-standard language and tricks to talk about this sort of data. [NIST](https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc4.htm) has an excellent guidebook, but here are some highlights: Moving averageMoving average aka rolling average aka running average.Convert a series of data to a series of averages of continguous subsets: | stock_quotes_rolling = [sum(stock_quotes[i:i+3]) / 3
for i in range(len(stock_quotes - 2))]
stock_quotes_rolling | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Pandas has nice series related functions: | import pandas as pd
df = pd.DataFrame(stock_quotes)
df.rolling(3).mean() | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
ForecastingForecasting - at it's simplest, it just means "predict the future": | ols_stocks.fit(stock_data[:,1:], stock_quotes)
ols_stocks.predict([[29, 0.5, 0.5]]) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
One way to predict if you just have the series data is to use the prior observation. This can be pretty good (if you had to pick one feature to model the temperature for tomorrow, the temperature today is a good choice). | temperature = np.array([30 + random() * day
for day in np.array(range(365)).reshape(-1, 1)])
temperature_next = temperature[1:].reshape(-1, 1)
temperature_ols = LinearRegression()
temperature_ols.fit(temperature[:-1], temperature_next)
temperature_ols.score(temperature[:-1], temperature_next) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
But you can often make it better by considering more than one prior observation. | temperature_next_next = temperature[2:].reshape(-1, 1)
temperature_two_past = np.concatenate([temperature[:-2], temperature_next[:-1]],
axis=1)
temperature_ols.fit(temperature_two_past, temperature_next_next)
temperature_ols.score(temperature_two_past, temperature_next_next) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Exponential smoothingExponential smoothing means using exponentially decreasing past weights to predict the future.You could roll your own, but let's use Pandas. | temperature_df = pd.DataFrame(temperature)
temperature_df.ewm(halflife=7).mean() | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Halflife is among the parameters we can play with: | sse_1 = ((temperature_df - temperature_df.ewm(halflife=7).mean())**2).sum()
sse_2 = ((temperature_df - temperature_df.ewm(halflife=3).mean())**2).sum()
print(sse_1)
print(sse_2) | 0 1.212862e+06
dtype: float64
0 987212.470691
dtype: float64
| MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Note - the first error being higher doesn't mean it's necessarily *worse*. It's *smoother* as expected, and if that's what we care about - great! SeasonalitySeasonality - "day of week"-effects, and more. In a lot of real world data, certain time periods are systemically different, e.g. holidays for retailers, weekends for restaurants, seasons for weather.Let's try to make some seasonal data - a store that sells more later in a week: | sales = np.array([random() + (day % 7) * random() for day in days])
scatter(days, sales) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
How does linear regression do at fitting this? | sales_ols = LinearRegression()
sales_ols.fit(days, sales)
sales_ols.score(days, sales) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
That's not great - and the fix depends on the domain. Here, we know it'd be best to actually use "day of week" as a feature. | day_of_week = days % 7
sales_ols.fit(day_of_week, sales)
sales_ols.score(day_of_week, sales) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Note that it's also important to have representative data across whatever seasonal feature(s) you use - don't predict retailers based only on Christmas, as that won't generalize well. Recurrent Neural NetworksThere's plenty more to "traditional" time series, but the latest and greatest technique for sequence data is recurrent neural networks. A recurrence relation in math is an equation that uses recursion to define a sequence - a famous example is the Fibonacci numbers:$F_n = F_{n-1} + F_{n-2}$For formal math you also need a base case $F_0=1, F_1=1$, and then the rest builds from there. But for neural networks what we're really talking about are loops:The hidden layers have edges (output) going back to their own input - this loop means that for any time `t` the training is at least partly based on the output from time `t-1`. The entire network is being represented on the left, and you can unfold the network explicitly to see how it behaves at any given `t`.Different units can have this "loop", but a particularly successful one is the long short-term memory unit (LSTM):There's a lot going on here - in a nutshell, the calculus still works out and backpropagation can still be implemented. The advantage (ane namesake) of LSTM is that it can generally put more weight on recent (short-term) events while not completely losing older (long-term) information.After enough iterations, a typical neural network will start calculating prior gradients that are so small they effectively become zero - this is the [vanishing gradient problem](https://en.wikipedia.org/wiki/Vanishing_gradient_problem), and is what RNN with LSTM addresses. Pay special attention to the $c_t$ parameters and how they pass through the unit to get an intuition for how this problem is solved.So why are these cool? One particularly compelling application is actually not time series but language modeling - language is inherently ordered data (letters/words go one after another, and the order *matters*). [The Unreasonable Effectiveness of Recurrent Neural Networks](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) is a famous and worth reading blog post on this topic.For our purposes, let's use TensorFlow and Keras to train RNNs with natural language. Resources:- https://github.com/keras-team/keras/blob/master/examples/imdb_lstm.py- https://keras.io/layers/recurrent/lstm- http://adventuresinmachinelearning.com/keras-lstm-tutorial/Note that `tensorflow.contrib` [also has an implementation of RNN/LSTM](https://www.tensorflow.org/tutorials/sequences/recurrent). RNN/LSTM Sentiment Classification with Keras | '''
#Trains an LSTM model on the IMDB sentiment classification task.
The dataset is actually too small for LSTM to be of any advantage
compared to simpler, much faster methods such as TF-IDF + LogReg.
**Notes**
- RNNs are tricky. Choice of batch size is important,
choice of loss and optimizer is critical, etc.
Some configurations won't converge.
- LSTM loss decrease patterns during training can be quite different
from what you see with CNNs/MLPs/etc.
'''
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
max_features = 20000
# cut texts after this number of words (among top max_features most common words)
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Build model...')
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=15,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc) | Using TensorFlow backend.
| MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
RNN Text generation with NumPyWhat else can we do with RNN? Since we're analyzing the *sequence*, we can do more than classify - we can *generate* text. We'll pull some news stories using [newspaper](https://github.com/codelucas/newspaper/). Initialization | !pip install newspaper3k
import newspaper
ap = newspaper.build('https://www.apnews.com')
len(ap.articles)
article_text = ''
for article in ap.articles[:1]:
try:
article.download()
article.parse()
article_text += '\n\n' + article.text
except:
print('Failed: ' + article.url)
article_text = article_text.split('\n\n')[1]
print(article_text)
# Based on "The Unreasonable Effectiveness of RNN" implementation
import numpy as np
chars = list(set(article_text)) # split and remove duplicate characters. convert to list.
num_chars = len(chars) # the number of unique characters
txt_data_size = len(article_text)
print("unique characters : ", num_chars)
print("txt_data_size : ", txt_data_size)
# one hot encode
char_to_int = dict((c, i) for i, c in enumerate(chars)) # "enumerate" retruns index and value. Convert it to dictionary
int_to_char = dict((i, c) for i, c in enumerate(chars))
print(char_to_int)
print("----------------------------------------------------")
print(int_to_char)
print("----------------------------------------------------")
# integer encode input data
integer_encoded = [char_to_int[i] for i in article_text] # "integer_encoded" is a list which has a sequence converted from an original data to integers.
print(integer_encoded)
print("----------------------------------------------------")
print("data length : ", len(integer_encoded))
# hyperparameters
iteration = 1000
sequence_length = 40
batch_size = round((txt_data_size /sequence_length)+0.5) # = math.ceil
hidden_size = 500 # size of hidden layer of neurons.
learning_rate = 1e-1
# model parameters
W_xh = np.random.randn(hidden_size, num_chars)*0.01 # weight input -> hidden.
W_hh = np.random.randn(hidden_size, hidden_size)*0.01 # weight hidden -> hidden
W_hy = np.random.randn(num_chars, hidden_size)*0.01 # weight hidden -> output
b_h = np.zeros((hidden_size, 1)) # hidden bias
b_y = np.zeros((num_chars, 1)) # output bias
h_prev = np.zeros((hidden_size,1)) # h_(t-1) | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Forward propagation | def forwardprop(inputs, targets, h_prev):
# Since the RNN receives the sequence, the weights are not updated during one sequence.
xs, hs, ys, ps = {}, {}, {}, {} # dictionary
hs[-1] = np.copy(h_prev) # Copy previous hidden state vector to -1 key value.
loss = 0 # loss initialization
for t in range(len(inputs)): # t is a "time step" and is used as a key(dic).
xs[t] = np.zeros((num_chars,1))
xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(W_xh, xs[t]) + np.dot(W_hh, hs[t-1]) + b_h) # hidden state.
ys[t] = np.dot(W_hy, hs[t]) + b_y # unnormalized log probabilities for next chars
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars.
# Softmax. -> The sum of probabilities is 1 even without the exp() function, but all of the elements are positive through the exp() function.
loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss). Efficient and simple code
# y_class = np.zeros((num_chars, 1))
# y_class[targets[t]] =1
# loss += np.sum(y_class*(-np.log(ps[t]))) # softmax (cross-entropy loss)
return loss, ps, hs, xs | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Backward propagation | def backprop(ps, inputs, hs, xs):
dWxh, dWhh, dWhy = np.zeros_like(W_xh), np.zeros_like(W_hh), np.zeros_like(W_hy) # make all zero matrices.
dbh, dby = np.zeros_like(b_h), np.zeros_like(b_y)
dhnext = np.zeros_like(hs[0]) # (hidden_size,1)
# reversed
for t in reversed(range(len(inputs))):
dy = np.copy(ps[t]) # shape (num_chars,1). "dy" means "dloss/dy"
dy[targets[t]] -= 1 # backprop into y. After taking the soft max in the input vector, subtract 1 from the value of the element corresponding to the correct label.
dWhy += np.dot(dy, hs[t].T)
dby += dy
dh = np.dot(W_hy.T, dy) + dhnext # backprop into h.
dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity #tanh'(x) = 1-tanh^2(x)
dbh += dhraw
dWxh += np.dot(dhraw, xs[t].T)
dWhh += np.dot(dhraw, hs[t-1].T)
dhnext = np.dot(W_hh.T, dhraw)
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients.
return dWxh, dWhh, dWhy, dbh, dby | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Training | %%time
data_pointer = 0
# memory variables for Adagrad
mWxh, mWhh, mWhy = np.zeros_like(W_xh), np.zeros_like(W_hh), np.zeros_like(W_hy)
mbh, mby = np.zeros_like(b_h), np.zeros_like(b_y)
for i in range(iteration):
h_prev = np.zeros((hidden_size,1)) # reset RNN memory
data_pointer = 0 # go from start of data
for b in range(batch_size):
inputs = [char_to_int[ch] for ch in article_text[data_pointer:data_pointer+sequence_length]]
targets = [char_to_int[ch] for ch in article_text[data_pointer+1:data_pointer+sequence_length+1]] # t+1
if (data_pointer+sequence_length+1 >= len(article_text) and b == batch_size-1): # processing of the last part of the input data.
# targets.append(char_to_int[txt_data[0]]) # When the data doesn't fit, add the first char to the back.
targets.append(char_to_int[" "]) # When the data doesn't fit, add space(" ") to the back.
# forward
loss, ps, hs, xs = forwardprop(inputs, targets, h_prev)
# print(loss)
# backward
dWxh, dWhh, dWhy, dbh, dby = backprop(ps, inputs, hs, xs)
# perform parameter update with Adagrad
for param, dparam, mem in zip([W_xh, W_hh, W_hy, b_h, b_y],
[dWxh, dWhh, dWhy, dbh, dby],
[mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam # elementwise
param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update
data_pointer += sequence_length # move data pointer
if i % 100 == 0:
print ('iter %d, loss: %f' % (i, loss)) # print progress | iter 0, loss: 1.921729
iter 100, loss: 0.000758
iter 200, loss: 0.000377
iter 300, loss: 0.000219
iter 400, loss: 0.000141
iter 500, loss: 0.000096
iter 600, loss: 0.000062
iter 700, loss: 0.000043
iter 800, loss: 0.000031
iter 900, loss: 0.000024
CPU times: user 5min 53s, sys: 3min 26s, total: 9min 20s
Wall time: 4min 44s
| MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Prediction | def predict(test_char, length):
x = np.zeros((num_chars, 1))
x[char_to_int[test_char]] = 1
ixes = []
h = np.zeros((hidden_size,1))
for t in range(length):
h = np.tanh(np.dot(W_xh, x) + np.dot(W_hh, h) + b_h)
y = np.dot(W_hy, h) + b_y
p = np.exp(y) / np.sum(np.exp(y))
ix = np.random.choice(range(num_chars), p=p.ravel()) # ravel -> rank0
# "ix" is a list of indexes selected according to the soft max probability.
x = np.zeros((num_chars, 1)) # init
x[ix] = 1
ixes.append(ix) # list
txt = test_char + ''.join(int_to_char[i] for i in ixes)
print ('----\n %s \n----' % (txt, ))
predict('C', 50) | ----
Califor Gooffic te nofft ove yke Gocr’sdlliamoffico
----
| MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Well... that's *vaguely* language-looking. Can you do better? AssignmentIt is said that [infinite monkeys typing for an infinite amount of time](https://en.wikipedia.org/wiki/Infinite_monkey_theorem) will eventually type, among other things, the complete works of Wiliam Shakespeare. Let's see if we can get there a bit faster, with the power of Recurrent Neural Networks and LSTM.This text file contains the complete works of Shakespeare: https://www.gutenberg.org/files/100/100-0.txtUse it as training data for an RNN - you can keep it simple and train character level, and that is suggested as an initial approach.Then, use that trained RNN to generate Shakespearean-ish text. Your goal - a function that can take, as an argument, the size of text (e.g. number of characters or lines) to generate, and returns generated text of that size.Note - Shakespeare wrote an awful lot. It's OK, especially initially, to sample/use smaller data and parameters, so you can have a tighter feedback loop when you're trying to get things running. Then, once you've got a proof of concept - start pushing it more! | # TODO - Words, words, mere words, no matter from the heart. | _____no_output_____ | MIT | module1-rnn-and-lstm/.ipynb_checkpoints/LS_DS_441_RNN_and_LSTM-checkpoint.ipynb | rick1270/DS-Unit-4-Spring-4-Deep-Learning |
Label GenerationUses code written by visoft and posted on kaggle to generate four different resolutions of labels | grid_sizes = pd.read_csv(os.path.join(global_vars.DATA_DIR,'grid_sizes.csv'), index_col=0)
train_labels = pd.read_csv(os.path.join(global_vars.DATA_DIR,'train_wkt_v4.csv'), index_col=0)
train_names = list(train_labels.index.unique())
base_size= 835
label_sizes = [base_size, base_size*2, base_size*4]
for im_name in train_names:
for i in range(1, 11):
polys = utils.get_polygon_list(train_labels, im_name, i)
x_max = grid_sizes.loc[im_name,'Xmax']
y_min = grid_sizes.loc[im_name,'Ymin']
for size in label_sizes:
plist, ilist = utils.get_and_convert_contours(polys, (size,size), x_max, y_min)
im_mask = utils.plot_mask((size,size), plist, ilist)
im_mask = im_mask.reshape((size, size, 1))
tif.imsave(os.path.join(global_vars.DATA_DIR,'labels',
im_name + '_' + str(size)+ '_class_' +str(i)+'.tif'), im_mask) | _____no_output_____ | MIT | step1_generate_labels.ipynb | danzelmo/dstl-competition |
Assignment 1. Formalia:Please read the [assignment overview page](https://github.com/suneman/socialdata2021/wiki/Assignment-1-and-2) carefully before proceeding. This page contains information about formatting (including formats etc), group sizes, and many other aspects of handing in the assignment. _If you fail to follow these simple instructions, it will negatively impact your grade!_**Due date and time**: The assignment is due on Monday March 1st, 2021 at 23:55. Hand in your files via [`http://peergrade.io`](http://peergrade.io/).**Peergrading date and time**: _Remember that after handing in you have 1 week to evaluate a few assignments written by other members of the class_. Thus, the peer evaluations are due on Monday March 8th, 2021 at 23:55. Part 1: Temporal PatternsWe look only at the focus-crimes in the exercise below | focuscrimes = set(['WEAPON LAWS', 'PROSTITUTION', 'DRIVING UNDER THE INFLUENCE', 'ROBBERY', 'BURGLARY', 'ASSAULT', 'DRUNKENNESS', 'DRUG/NARCOTIC', 'TRESPASS', 'LARCENY/THEFT', 'VANDALISM', 'VEHICLE THEFT', 'STOLEN PROPERTY', 'DISORDERLY CONDUCT']) | _____no_output_____ | MIT | assignments/Assignment1.ipynb | christianpoulsen/socialdata2021 |
*Exercise*: More temporal patterns. During week 1, we plotted some crime development over time (how each of the focus-crimes changed over time, year-by-year). In this exercise, please generate the visualizations described below. Use the same date-ranges as in Week 1. For each set of plots, describe the plots (as you would in the figure text in a report or paper), and pick a few aspects that stand out to you and comment on those (a couple of ideas below for things that could be interesting to comment on ... but it's OK to chose something else).* *Weekly patterns*. Basically, we'll forget about the yearly variation and just count up what happens during each weekday. [Here's what my version looks like](https://raw.githubusercontent.com/suneman/socialdata2021/master/files/weekdays.png). Hint for comment: Some things make sense - for example `drunkenness` and the weekend. But there are some aspects that were surprising to me. Check out `prostitution` and mid-week behavior, for example!?* *The months*. We can also check if some months are worse by counting up number of crimes in Jan, Feb, ..., Dec. Did you see any surprises there?* *The 24 hour cycle*. We'll can also forget about weekday and simply count up the number of each crime-type that occurs in the entire dataset from midnight to 1am, 1am - 2am ... and so on. Again: Give me a couple of comments on what you see. * *Hours of the week*. But by looking at just 24 hours, we may be missing some important trends that can be modulated by week-day, so let's also check out the 168 hours of the week. So let's see the number of each crime-type Monday night from midninght to 1am, Monday night from 1am-2am - all the way to Sunday night from 11pm to midnight. | import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("../incidents.csv")
df = df[df["Category"].isin(focuscrimes)]
df["Date_Time"] = pd.to_datetime(df["Date"] + " " + df["Time"])
df.sort_values(by=["Date_Time"], inplace=True, ascending=True)
df.head()
weeks = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]
df1 = pd.DataFrame(df, columns=["Category", "DayOfWeek"])
wdf = pd.DataFrame(index=weeks, columns=focuscrimes)
for crime in focuscrimes:
crime_df = df1[df1["Category"] == crime]
for week_day in weeks:
wdf.at[week_day, crime] = len(crime_df[crime_df["DayOfWeek"] == week_day])
plt.figure(1, figsize=(18,27))
count = 1
for crime in wdf.columns:
plt.subplot(7, 2, count)
wdf[crime].plot(kind="bar", subplots=True, figsize=(9, 6), rot=0)
count += 1 | _____no_output_____ | MIT | assignments/Assignment1.ipynb | christianpoulsen/socialdata2021 |
Part 2: Thinking about data and visualization *Excercise:* Questions for the [second video lecture](https://www.youtube.com/watch?v=yiU56codNlI).* As mentioned earlier, visualization is not the only way to test for correlation. We can (for example) calculate the Pearson correlation. Explain in your own words how the Pearson correlation works and write down it's mathematical formulation. Can you think of an example where it fails (and visualization works)?* What is the difference between a bar-chart and a histogram?* I mention in the video that it's important to choose the right bin-size in histograms. But how do you do that? Do a Google search to find a criterion you like and explain it. Part 3: Generating important plot types*Excercise*: Let us recreate some plots from DAOST but using our own favorite dataset.* First, let's make a jitter-plot (that is, code up something like **Figure 2-1** from DAOST from scratch), but based on SF Police data. My hunch from inspecting the file is that the police-folks might be a little bit lazy in noting down the **exact** time down to the second. So choose a crime-type and a suitable time interval (somewhere between a month and 6 months depending on the crime-type) and create a jitter plot of the arrest times during a single hour (like 13-14, for example). So let time run on the $x$-axis and create vertical jitter.* Now for some histograms (please create a crime-data based versions of the plot-type shown in DAOST **Figure 2-2**). (I think the GPS data could be fun to understand from this perspective.) * This time, pick two crime-types with different geographical patterns **and** a suitable time-interval for each (you want between 1000 and 10000 points in your histogram) * Then take the latitude part of the GPS coordinates for each crime and bin the latitudes so that you have around 50 bins across the city of SF. You can use your favorite method for binning. I like `numpy.histogram`. This function gives you the counts and then you do your own plotting. Part 4: A bit of geo-data *Exercise*: A new take on geospatial data using Folium (see the Week 4 exercises for full info and tutorials). Now we look at studying geospatial data by plotting raw data points as well as heatmaps on top of actual maps.* First start by plotting a map of San Francisco with a nice tight zoom. Simply use the command `folium.Map([lat, lon], zoom_start=13)`, where you'll have to look up San Francisco's longitude and latitude.* Next, use the the coordinates for SF City Hall `37.77919, -122.41914` to indicate its location on the map with a nice, pop-up enabled maker. (In the screenshot below, I used the black & white Stamen tiles, because they look cool).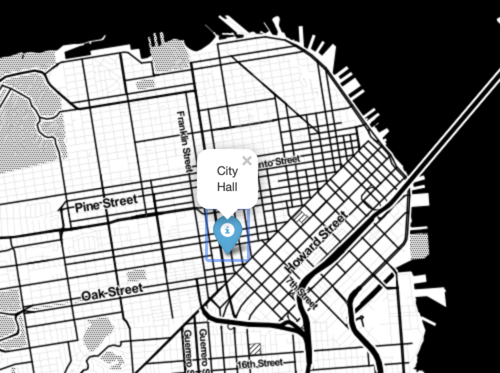* Now, let's plot some more data (no need for popups this time). Select a couple of months of data for `'DRUG/NARCOTIC'` and draw a little dot for each arrest for those two months. You could, for example, choose June-July 2016, but you can choose anything you like - the main concern is to not have too many points as this uses a lot of memory and makes Folium behave non-optimally. We can call this a kind of visualization a *point scatter plot*. | import numpy as np # linear algebra
import folium
import datetime as dt
SF = folium.Map([37.773972, -122.431297], zoom_start=13, tiles="Stamen Toner")
folium.Marker([37.77919, -122.41914], popup='City Hall').add_to(SF)
# Address, location, X, Y
ndf = df[df["Category"] == "DRUG/NARCOTIC"]
start = ndf["Date_Time"].searchsorted(dt.datetime(2016, 6, 1))
end = ndf["Date_Time"].searchsorted(dt.datetime(2016, 7, 1))
for i, case in ndf[start : end].iterrows():
folium.CircleMarker(location=[case["Y"], case["X"]], radius=2,weight=5).add_to(SF)
SF | _____no_output_____ | MIT | assignments/Assignment1.ipynb | christianpoulsen/socialdata2021 |
AU Fundamentals of Python Programming-W10X Topic 1(主題1)-字串和print()的參數 Step 1: Hello World with 其他參數sep = "..." 列印分隔 end="" 列印結尾* sep: string inserted between values, default a space.* end: string appended after the last value, default a newline. | print('Hello World!') #'Hello World!' is the same as "Hello World!"
help(print) #註解是不會執行的
print('Hello '+'World!')
print("Hello","World", sep="+")
print("Hello"); print("World!")
print("Hello", end=' ');print("World")
| _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 2: Escape Sequence (逸出序列)* \newline Ignored* \\ Backslash (\)* \' Single quote (')* \" Double quote (")* \a ASCII Bell (BEL)* \b ASCII Backspace (BS)* \n ASCII Linefeed (LF)* \r ASCII Carriage Return (CR)* \t ASCII Horizontal Tab (TAB)* \ooo ASCII character with octal value ooo* \xhh... ASCII character with hex value hh... | print("Hello\nWorld!")
print("Hello","World!", sep="\n")
txt = "We are the so-called \"Vikings\" from the north."
print(txt) | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 3: 使用 字串尾部的\來建立長字串 | iPhone11='iPhone 11是由蘋果公司設計和銷售的智能手機,為第13代iPhone系列智能手機之一,亦是iPhone XR的後繼機種。\
其在2019年9月10日於蘋果園區史蒂夫·喬布斯劇院由CEO蒂姆·庫克隨iPhone 11 Pro及iPhone 11 Pro Max一起發佈,\
並於2019年9月20日在世界大部分地區正式發售。其採用類似iPhone XR的玻璃配鋁金屬設計;\
具有6.1英吋Liquid Retina HD顯示器,配有Face ID;並採用由蘋果自家設計的A13仿生晶片,\
帶有第三代神經網絡引擎。機器能夠防濺、耐水及防塵,在最深2米的水下停留時間最長可達30分鐘。'
print(iPhone11) | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 4: 使用六個雙引號來建立長字串 ''' ... ''' 或 """ ... """ | iPhone11='''
iPhone 11是由蘋果公司設計和銷售的智能手機,為第13代iPhone系列智能手機之一,亦是iPhone XR的後繼機種。
其在2019年9月10日於蘋果園區史蒂夫·喬布斯劇院由CEO蒂姆·庫克隨iPhone 11 Pro及iPhone 11 Pro Max一起發佈,
並於2019年9月20日在世界大部分地區正式發售。其採用類似iPhone XR的玻璃配鋁金屬設計;
具有6.1英吋Liquid Retina HD顯示器,配有Face ID;並採用由蘋果自家設計的A13仿生晶片,
帶有第三代神經網絡引擎。機器能夠防濺、耐水及防塵,在最深2米的水下停留時間最長可達30分鐘。'''
print(iPhone11)
iPhone11="""
iPhone 11是由蘋果公司設計和銷售的智能手機,為第13代iPhone系列智能手機之一,亦是iPhone XR的後繼機種。
其在2019年9月10日於蘋果園區史蒂夫·喬布斯劇院由CEO蒂姆·庫克隨iPhone 11 Pro及iPhone 11 Pro Max一起發佈,
並於2019年9月20日在世界大部分地區正式發售。其採用類似iPhone XR的玻璃配鋁金屬設計;
具有6.1英吋Liquid Retina HD顯示器,配有Face ID;並採用由蘋果自家設計的A13仿生晶片,
帶有第三代神經網絡引擎。機器能夠防濺、耐水及防塵,在最深2米的水下停留時間最長可達30分鐘。"""
print(iPhone11) | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Topic 2(主題2)-型別轉換函數 Step 5: 輸入變數的值 | name = input('Please input your name:')
print('Hello, ', name)
print(type(name)) #列印變數的型別 | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 6: Python 型別轉換函數* int() 變整數* float() 變浮點數* str() 變字串* 變數名稱=int(字串變數)* 變數名稱=str(數值變數 | #變數宣告
varA = 66 #宣告一個整數變數
varB = 1.68 #宣告一個有小數的變數(電腦叫浮點數)
varC = 'GoPython' #宣告一個字串變數
varD = str(varA) #將整數88轉成字串的88
varE = str(varB) #將浮點數1.68轉成字串的1.68
varF = int('2019') #將字串2019轉作整數數值的2019
varG = float('3.14') #將字串3.14轉作浮點數數值的3.14
score = input('Please input your score:')
score = int(score)
print(type(score)) #列印變數的型別 | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Topic 3(主題3)-索引和切片```a = "Hello, World!"print(a[1]) Indexingprint(a[2:5]) Slicing``` Step 8: 索引(Indexing) | a = "Hello Wang"
d = "0123456789"
print(a[3]) #Indexing
a = "Hello Wang"
d = "0123456789"
print(a[-3]) #Negative Indexing | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 9: 切片(Slicing) | a = "Hello Wang"
d = "0123456789"
print(a[2:5]) #Slicing
a = "Hello Wang"
d = "0123456789"
print(a[2:]) #Slicing
a = "Hello Wang"
d = "0123456789"
print(a[:5]) #Slicing
a = "Hello Wang"
d = "0123456789"
print(a[-6:-2]) #Slicing
a = "Hello Wang"
d = "0123456789"
print(a[-4:]) #Slicing | _____no_output_____ | MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Topic 4(主題4)-格式化輸出```A = 435; B = 59.058print('Art: %5d, Price per Unit: %8.2f' % (A, B)) %-formatting 格式化列印print("Art: {0:5d}, Price per Unit: {1:8.2f}".format(A,B)) str-format(Python 2.6+)print(f"Art:{A:5d}, Price per Unit: {B:8.2f}") f-string (Python 3.6+)``` Step 10: %-formatting 格式化列印透過% 運算符號,將在元組(tuple)中的一組變量依照指定的格式化方式輸出。如 %s(字串)、%d (十進位整數)、 %f(浮點數) | A = 435; B = 59.058
print('Art: %5d, Price per Unit: %8.2f' % (A, B))
FirstName = "Mary"; LastName= "Lin"
print("She is %s %s" %(FirstName, LastName)) | She is Mary Lin
| MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 11: str-format(Python 2.6+)格式化列印 | A = 435; B = 59.058
print("Art: {0:5d}, Price per Unit: {1:8.2f}".format(435, 59.058))
FirstName = "Mary"; LastName= "Lin"
print("She is {} {}".format(FirstName, LastName)) | She is Mary Lin
| MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Step 12: f-string (Python 3.6+)格式化列印 | A = 435; B = 59.058
print(f"Art:{A:5d}, Price per Unit: {B:8.2f}")
FirstName = "Mary"; LastName= "Lin"
print(f"She is {FirstName} {LastName}") | She is Mary Lin
| MIT | notebooks/AUP110_W11_Notebook.ipynb | htchu/AU110Programming |
Topic Modelling (joint plots by quality band)Shorter notebook just for Figures 9 and 10 in the paper. | %matplotlib inline
import matplotlib.pyplot as plt
# magics and warnings
%load_ext autoreload
%autoreload 2
import warnings; warnings.simplefilter('ignore')
import os, random
from tqdm import tqdm
import pandas as pd
import numpy as np
seed = 43
random.seed(seed)
np.random.seed(seed)
import nltk, gensim, sklearn, spacy
from gensim.models import CoherenceModel
import matplotlib.pyplot as plt
import pyLDAvis.gensim
import seaborn as sns
sns.set(style="white") | _____no_output_____ | CC-BY-4.0 | topic_modelling_secondary.ipynb | Living-with-machines/lwm_ARTIDIGH_2020_OCR_impact_downstream_NLP_tasks |
Load the datasetCreated with the main Topic Modelling notebook. | bands_data = {x:dict() for x in range(1,5)}
import pickle, os
for band in range(1,5):
with open("trove_overproof/models/hum_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["model_human"] = pickle.load(handle)
with open("trove_overproof/models/corpus_hum_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["corpus_human"] = pickle.load(handle)
with open("trove_overproof/models/dictionary_hum_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["dictionary_human"] = pickle.load(handle)
with open("trove_overproof/models/ocr_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["model_ocr"] = pickle.load(handle)
with open("trove_overproof/models/corpus_ocr_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["corpus_ocr"] = pickle.load(handle)
with open("trove_overproof/models/dictionary_ocr_band_%d.pkl"%band, 'rb') as handle:
bands_data[band]["dictionary_ocr"] = pickle.load(handle) | _____no_output_____ | CC-BY-4.0 | topic_modelling_secondary.ipynb | Living-with-machines/lwm_ARTIDIGH_2020_OCR_impact_downstream_NLP_tasks |
Evaluation Intrinsic evalSee http://qpleple.com/topic-coherence-to-evaluate-topic-models. | for band in range(1,5):
print("Quality band",band)
# Human
# Compute Perplexity
print('\nPerplexity (Human): ', bands_data[band]["model_human"].log_perplexity(bands_data[band]["corpus_human"])) # a measure of how good the model is. The lower the better.
# Compute Coherence Score
coherence_model_lda = CoherenceModel(model=bands_data[band]["model_human"], corpus=bands_data[band]["corpus_human"], dictionary=bands_data[band]["dictionary_human"], coherence='u_mass')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score (Human): ', coherence_lda)
# OCR
# Compute Perplexity
print('\nPerplexity (OCR): ', bands_data[band]["model_ocr"].log_perplexity(bands_data[band]["corpus_ocr"])) # a measure of how good the model is. The lower the better.
# Compute Coherence Score
coherence_model_lda = CoherenceModel(model=bands_data[band]["model_ocr"], corpus=bands_data[band]["corpus_ocr"], dictionary=bands_data[band]["dictionary_ocr"], coherence='u_mass')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score (OCR): ', coherence_lda)
print("==========\n") | Quality band 1
Perplexity (Human): -8.103261158627364
Coherence Score (Human): -1.636788533548382
Perplexity (OCR): -8.602782438888957
Coherence Score (OCR): -1.744833949213988
==========
Quality band 2
Perplexity (Human): -8.210335723784008
Coherence Score (Human): -1.717423902243484
Perplexity (OCR): -8.960456087224186
Coherence Score (OCR): -1.8652779401051685
==========
Quality band 3
Perplexity (Human): -7.945579058932222
Coherence Score (Human): -2.2853392147627445
Perplexity (OCR): -8.57412651382853
Coherence Score (OCR): -2.1544280903218933
==========
Quality band 4
Perplexity (Human): -7.610617401464275
Coherence Score (Human): -2.6515871055832645
Perplexity (OCR): -7.973356022098555
Coherence Score (OCR): -2.8655108395602737
==========
| CC-BY-4.0 | topic_modelling_secondary.ipynb | Living-with-machines/lwm_ARTIDIGH_2020_OCR_impact_downstream_NLP_tasks |
Match of topicsWe match every topic in the OCR model with a topic in the human model (by best matching), and assess the overall distance between the two using the weighted total distance over a set of N top words (from the human model to the ocr model). The higher this value, the closest two topics are.Note that to find a matching, we create a weighted network and find the maximal bipartite matching using NetworkX.Afterwards, we can measure the distance of the best match, e.g., using the KL divergence (over the same set of words). | import networkx as nx
from scipy.stats import entropy
from collections import defaultdict
# analyse matches
distances = {x:list() for x in range(1,5)}
n_words_in_common = {x:list() for x in range(1,5)}
matches = {x:defaultdict(int) for x in range(1,5)}
top_n = 500
for band in range(1,5):
G = nx.Graph()
model_human = bands_data[band]["model_human"]
model_ocr = bands_data[band]["model_ocr"]
# add bipartite nodes
G.add_nodes_from(['h_'+str(t_h[0]) for t_h in model_human.show_topics(num_topics = -1, formatted=False, num_words=1)], bipartite=0)
G.add_nodes_from(['o_'+str(t_o[0]) for t_o in model_ocr.show_topics(num_topics = -1, formatted=False, num_words=1)], bipartite=1)
# add weighted edges
for t_h in model_human.show_topics(num_topics = -1, formatted=False, num_words=top_n):
for t_o in model_ocr.show_topics(num_topics = -1, formatted=False, num_words=top_n):
# note that the higher the weight, the shorter the distance between the two distributions, so we do 1-weight to then do minimal matching
words_of_h = [x[0] for x in t_h[1]]
words_of_o = [x[0] for x in t_o[1]]
weights_of_o = {x[0]:x[1] for x in t_o[1]}
words_in_common = list(set(words_of_h).intersection(set(words_of_o)))
# sum the weighted joint probability of every shared word in the two models
avg_weight = 1 - sum([x[1]*weights_of_o[x[0]] for x in t_h[1] if x[0] in words_in_common])
G.add_edge('h_'+str(t_h[0]),'o_'+str(t_o[0]),weight=avg_weight)
G.add_edge('o_'+str(t_o[0]),'h_'+str(t_h[0]),weight=avg_weight)
bipartite_solution = nx.bipartite.matching.minimum_weight_full_matching(G)
# calculate distances
for match_h,match_o in bipartite_solution.items():
if match_h.startswith('o'): # to avoid repeating the matches (complete graph!)
break
matches[band][int(match_h.split("_")[1])] = int(match_o.split("_")[1])
m_h = model_human.show_topic(int(match_h.split("_")[1]), topn=top_n)
m_o = model_ocr.show_topic(int(match_o.split("_")[1]), topn=top_n)
weights_of_o = {x[0]:x[1] for x in m_o}
words_of_h = [x[0] for x in m_h]
words_of_o = [x[0] for x in m_o]
words_in_common = list(set(words_of_h).intersection(set(words_of_o)))
n_words_in_common[band].append(len(words_in_common)/top_n)
dist_h = list()
dist_o = list()
for w in m_h:
if w[0] in words_in_common:
dist_h.append(w[1])
dist_o.append(weights_of_o[w[0]])
# normalize
dist_h = dist_h/sum(dist_h)
dist_o = dist_o/sum(dist_o)
dist = entropy(dist_h,dist_o)
distances[band].append(dist)
sns.set_context("notebook", font_scale=1.2, rc={"lines.linewidth": 2.5})
# Figure 9
for band in range(1,5):
sns.distplot(distances[band], hist=False, label="Quality band %d"%band)
plt.xlim((0,1))
plt.xlabel("KL divergence between topics, V=%d."%top_n)
plt.tight_layout()
plt.savefig("figures/topic_modelling/KL_divergence_topics.pdf")
# Figure 10
for band in range(1,5):
sns.distplot(n_words_in_common[band], hist=False, label="Quality band %d"%band)
plt.xlim((0,1))
plt.tight_layout()
plt.savefig("figures/topic_modelling/Words_in_common_topics.pdf") | _____no_output_____ | CC-BY-4.0 | topic_modelling_secondary.ipynb | Living-with-machines/lwm_ARTIDIGH_2020_OCR_impact_downstream_NLP_tasks |
Inspect Nucleus Training DataInspect and visualize data loading and pre-processing code.https://www.kaggle.com/c/data-science-bowl-2018 | import os
import sys
import itertools
import math
import logging
import json
import re
import random
import time
import concurrent.futures
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.lines as lines
from matplotlib.patches import Polygon
import imgaug
from imgaug import augmenters as iaa
# Root directory of the project
ROOT_DIR = os.getcwd()
print("ROOT_DIR",ROOT_DIR)
if ROOT_DIR.endswith("nucleus"):
# Go up two levels to the repo root
ROOT_DIR = os.path.dirname(os.path.dirname(ROOT_DIR))
print("ROOT_DIR",ROOT_DIR)
# Import Mask RCNN
sys.path.append(ROOT_DIR)
from mrcnn import utils
from mrcnn import visualize
from mrcnn.visualize import display_images
from mrcnn import model as modellib
from mrcnn.model import log
import nucleus
%matplotlib inline
# Comment out to reload imported modules if they change
# %load_ext autoreload
# %autoreload 2 | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Configurations | # Dataset directory
DATASET_DIR = os.path.join(ROOT_DIR, "datasets/nucleus")
# Use configuation from nucleus.py, but override
# image resizing so we see the real sizes here
class NoResizeConfig(nucleus.NucleusConfig):
IMAGE_RESIZE_MODE = "none"
config = NoResizeConfig() | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Notebook Preferences | def get_ax(rows=1, cols=1, size=16):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Adjust the size attribute to control how big to render images
"""
_, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))
return ax | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
DatasetDownload the dataset from the competition Website. Unzip it and save it in `mask_rcnn/datasets/nucleus`. If you prefer a different directory then change the `DATASET_DIR` variable above.https://www.kaggle.com/c/data-science-bowl-2018/data | # Load dataset
dataset = nucleus.NucleusDataset()
# The subset is the name of the sub-directory, such as stage1_train,
# stage1_test, ...etc. You can also use these special values:
# train: loads stage1_train but excludes validation images
# val: loads validation images from stage1_train. For a list
# of validation images see nucleus.py
dataset.load_nucleus(DATASET_DIR, subset="train")
# Must call before using the dataset
dataset.prepare()
print("Image Count: {}".format(len(dataset.image_ids)))
print("Class Count: {}".format(dataset.num_classes))
for i, info in enumerate(dataset.class_info):
print("{:3}. {:50}".format(i, info['name'])) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Display Samples | # Load and display random samples
image_ids = np.random.choice(dataset.image_ids, 4)
for image_id in image_ids:
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset.class_names, limit=1)
# Example of loading a specific image by its source ID
source_id = "ed5be4b63e9506ad64660dd92a098ffcc0325195298c13c815a73773f1efc279"
# Map source ID to Dataset image_id
# Notice the nucleus prefix: it's the name given to the dataset in NucleusDataset
image_id = dataset.image_from_source_map["nucleus.{}".format(source_id)]
# Load and display
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, use_mini_mask=False)
log("molded_image", image)
log("mask", mask)
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names,
show_bbox=False) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Dataset StatsLoop through all images in the dataset and collect aggregate stats. | def image_stats(image_id):
"""Returns a dict of stats for one image."""
image = dataset.load_image(image_id)
mask, _ = dataset.load_mask(image_id)
bbox = utils.extract_bboxes(mask)
# Sanity check
assert mask.shape[:2] == image.shape[:2]
# Return stats dict
return {
"id": image_id,
"shape": list(image.shape),
"bbox": [[b[2] - b[0], b[3] - b[1]]
for b in bbox
# Uncomment to exclude nuclei with 1 pixel width
# or height (often on edges)
# if b[2] - b[0] > 1 and b[3] - b[1] > 1
],
"color": np.mean(image, axis=(0, 1)),
}
# Loop through the dataset and compute stats over multiple threads
# This might take a few minutes
t_start = time.time()
with concurrent.futures.ThreadPoolExecutor() as e:
stats = list(e.map(image_stats, dataset.image_ids))
t_total = time.time() - t_start
print("Total time: {:.1f} seconds".format(t_total)) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Image Size Stats | # Image stats
image_shape = np.array([s['shape'] for s in stats])
image_color = np.array([s['color'] for s in stats])
print("Image Count: ", image_shape.shape[0])
print("Height mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(image_shape[:, 0]), np.median(image_shape[:, 0]),
np.min(image_shape[:, 0]), np.max(image_shape[:, 0])))
print("Width mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(image_shape[:, 1]), np.median(image_shape[:, 1]),
np.min(image_shape[:, 1]), np.max(image_shape[:, 1])))
print("Color mean (RGB): {:.2f} {:.2f} {:.2f}".format(*np.mean(image_color, axis=0)))
# Histograms
fig, ax = plt.subplots(1, 3, figsize=(16, 4))
ax[0].set_title("Height")
_ = ax[0].hist(image_shape[:, 0], bins=20)
ax[1].set_title("Width")
_ = ax[1].hist(image_shape[:, 1], bins=20)
ax[2].set_title("Height & Width")
_ = ax[2].hist2d(image_shape[:, 1], image_shape[:, 0], bins=10, cmap="Blues") | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Nuclei per Image Stats | # Segment by image area
image_area_bins = [256**2, 600**2, 1300**2]
print("Nuclei/Image")
fig, ax = plt.subplots(1, len(image_area_bins), figsize=(16, 4))
area_threshold = 0
for i, image_area in enumerate(image_area_bins):
nuclei_per_image = np.array([len(s['bbox'])
for s in stats
if area_threshold < (s['shape'][0] * s['shape'][1]) <= image_area])
area_threshold = image_area
if len(nuclei_per_image) == 0:
print("Image area <= {:4}**2: None".format(np.sqrt(image_area)))
continue
print("Image area <= {:4.0f}**2: mean: {:.1f} median: {:.1f} min: {:.1f} max: {:.1f}".format(
np.sqrt(image_area), nuclei_per_image.mean(), np.median(nuclei_per_image),
nuclei_per_image.min(), nuclei_per_image.max()))
ax[i].set_title("Image Area <= {:4}**2".format(np.sqrt(image_area)))
_ = ax[i].hist(nuclei_per_image, bins=10) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Nuclei Size Stats | # Nuclei size stats
fig, ax = plt.subplots(1, len(image_area_bins), figsize=(16, 4))
area_threshold = 0
for i, image_area in enumerate(image_area_bins):
nucleus_shape = np.array([
b
for s in stats if area_threshold < (s['shape'][0] * s['shape'][1]) <= image_area
for b in s['bbox']])
nucleus_area = nucleus_shape[:, 0] * nucleus_shape[:, 1]
area_threshold = image_area
print("\nImage Area <= {:.0f}**2".format(np.sqrt(image_area)))
print(" Total Nuclei: ", nucleus_shape.shape[0])
print(" Nucleus Height. mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(nucleus_shape[:, 0]), np.median(nucleus_shape[:, 0]),
np.min(nucleus_shape[:, 0]), np.max(nucleus_shape[:, 0])))
print(" Nucleus Width. mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(nucleus_shape[:, 1]), np.median(nucleus_shape[:, 1]),
np.min(nucleus_shape[:, 1]), np.max(nucleus_shape[:, 1])))
print(" Nucleus Area. mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(nucleus_area), np.median(nucleus_area),
np.min(nucleus_area), np.max(nucleus_area)))
# Show 2D histogram
_ = ax[i].hist2d(nucleus_shape[:, 1], nucleus_shape[:, 0], bins=20, cmap="Blues")
# Nuclei height/width ratio
nucleus_aspect_ratio = nucleus_shape[:, 0] / nucleus_shape[:, 1]
print("Nucleus Aspect Ratio. mean: {:.2f} median: {:.2f} min: {:.2f} max: {:.2f}".format(
np.mean(nucleus_aspect_ratio), np.median(nucleus_aspect_ratio),
np.min(nucleus_aspect_ratio), np.max(nucleus_aspect_ratio)))
plt.figure(figsize=(15, 5))
_ = plt.hist(nucleus_aspect_ratio, bins=100, range=[0, 5]) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Image AugmentationTest out different augmentation methods | # List of augmentations
# http://imgaug.readthedocs.io/en/latest/source/augmenters.html
augmentation = iaa.Sometimes(0.9, [
iaa.Fliplr(0.5),
iaa.Flipud(0.5),
iaa.Multiply((0.8, 1.2)),
iaa.GaussianBlur(sigma=(0.0, 5.0))
])
# Load the image multiple times to show augmentations
limit = 4
ax = get_ax(rows=2, cols=limit//2)
for i in range(limit):
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, use_mini_mask=False, augment=False, augmentation=augmentation)
visualize.display_instances(image, bbox, mask, class_ids,
dataset.class_names, ax=ax[i//2, i % 2],
show_mask=False, show_bbox=False) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Image CropsMicroscoy images tend to be large, but nuclei are small. So it's more efficient to train on random crops from large images. This is handled by `config.IMAGE_RESIZE_MODE = "crop"`. | class RandomCropConfig(nucleus.NucleusConfig):
IMAGE_RESIZE_MODE = "crop"
IMAGE_MIN_DIM = 256
IMAGE_MAX_DIM = 256
crop_config = RandomCropConfig()
# Load the image multiple times to show augmentations
limit = 4
image_id = np.random.choice(dataset.image_ids, 1)[0]
ax = get_ax(rows=2, cols=limit//2)
for i in range(limit):
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, crop_config, image_id, use_mini_mask=False)
visualize.display_instances(image, bbox, mask, class_ids,
dataset.class_names, ax=ax[i//2, i % 2],
show_mask=False, show_bbox=False) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Mini MasksInstance binary masks can get large when training with high resolution images. For example, if training with 1024x1024 image then the mask of a single instance requires 1MB of memory (Numpy uses bytes for boolean values). If an image has 100 instances then that's 100MB for the masks alone. To improve training speed, we optimize masks:* We store mask pixels that are inside the object bounding box, rather than a mask of the full image. Most objects are small compared to the image size, so we save space by not storing a lot of zeros around the object.* We resize the mask to a smaller size (e.g. 56x56). For objects that are larger than the selected size we lose a bit of accuracy. But most object annotations are not very accuracy to begin with, so this loss is negligable for most practical purposes. Thie size of the mini_mask can be set in the config class.To visualize the effect of mask resizing, and to verify the code correctness, we visualize some examples. | # Load random image and mask.
image_id = np.random.choice(dataset.image_ids, 1)[0]
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
original_shape = image.shape
# Resize
image, window, scale, padding, _ = utils.resize_image(
image,
min_dim=config.IMAGE_MIN_DIM,
max_dim=config.IMAGE_MAX_DIM,
mode=config.IMAGE_RESIZE_MODE)
mask = utils.resize_mask(mask, scale, padding)
# Compute Bounding box
bbox = utils.extract_bboxes(mask)
# Display image and additional stats
print("image_id: ", image_id, dataset.image_reference(image_id))
print("Original shape: ", original_shape)
log("image", image)
log("mask", mask)
log("class_ids", class_ids)
log("bbox", bbox)
# Display image and instances
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)
image_id = np.random.choice(dataset.image_ids, 1)[0]
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, use_mini_mask=False)
log("image", image)
log("image_meta", image_meta)
log("class_ids", class_ids)
log("bbox", bbox)
log("mask", mask)
display_images([image]+[mask[:,:,i] for i in range(min(mask.shape[-1], 7))])
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)
# Add augmentation and mask resizing.
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, augment=True, use_mini_mask=True)
log("mask", mask)
display_images([image]+[mask[:,:,i] for i in range(min(mask.shape[-1], 7))])
mask = utils.expand_mask(bbox, mask, image.shape)
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
AnchorsFor an FPN network, the anchors must be ordered in a way that makes it easy to match anchors to the output of the convolution layers that predict anchor scores and shifts. * Sort by pyramid level first. All anchors of the first level, then all of the second and so on. This makes it easier to separate anchors by level.* Within each level, sort anchors by feature map processing sequence. Typically, a convolution layer processes a feature map starting from top-left and moving right row by row. * For each feature map cell, pick any sorting order for the anchors of different ratios. Here we match the order of ratios passed to the function. | ## Visualize anchors of one cell at the center of the feature map
# Load and display random image
image_id = np.random.choice(dataset.image_ids, 1)[0]
image, image_meta, _, _, _ = modellib.load_image_gt(dataset, crop_config, image_id)
# Generate Anchors
backbone_shapes = modellib.compute_backbone_shapes(config, image.shape)
anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
backbone_shapes,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)
# Print summary of anchors
num_levels = len(backbone_shapes)
anchors_per_cell = len(config.RPN_ANCHOR_RATIOS)
print("Count: ", anchors.shape[0])
print("Scales: ", config.RPN_ANCHOR_SCALES)
print("ratios: ", config.RPN_ANCHOR_RATIOS)
print("Anchors per Cell: ", anchors_per_cell)
print("Levels: ", num_levels)
anchors_per_level = []
for l in range(num_levels):
num_cells = backbone_shapes[l][0] * backbone_shapes[l][1]
anchors_per_level.append(anchors_per_cell * num_cells // config.RPN_ANCHOR_STRIDE**2)
print("Anchors in Level {}: {}".format(l, anchors_per_level[l]))
# Display
fig, ax = plt.subplots(1, figsize=(10, 10))
ax.imshow(image)
levels = len(backbone_shapes)
for level in range(levels):
colors = visualize.random_colors(levels)
# Compute the index of the anchors at the center of the image
level_start = sum(anchors_per_level[:level]) # sum of anchors of previous levels
level_anchors = anchors[level_start:level_start+anchors_per_level[level]]
print("Level {}. Anchors: {:6} Feature map Shape: {}".format(level, level_anchors.shape[0],
backbone_shapes[level]))
center_cell = backbone_shapes[level] // 2
center_cell_index = (center_cell[0] * backbone_shapes[level][1] + center_cell[1])
level_center = center_cell_index * anchors_per_cell
center_anchor = anchors_per_cell * (
(center_cell[0] * backbone_shapes[level][1] / config.RPN_ANCHOR_STRIDE**2) \
+ center_cell[1] / config.RPN_ANCHOR_STRIDE)
level_center = int(center_anchor)
# Draw anchors. Brightness show the order in the array, dark to bright.
for i, rect in enumerate(level_anchors[level_center:level_center+anchors_per_cell]):
y1, x1, y2, x2 = rect
p = patches.Rectangle((x1, y1), x2-x1, y2-y1, linewidth=2, facecolor='none',
edgecolor=(i+1)*np.array(colors[level]) / anchors_per_cell)
ax.add_patch(p)
| _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Data Generator | # Create data generator
random_rois = 2000
g = modellib.data_generator(
dataset, crop_config, shuffle=True, random_rois=random_rois,
batch_size=4,
detection_targets=True)
# Uncomment to run the generator through a lot of images
# to catch rare errors
# for i in range(1000):
# print(i)
# _, _ = next(g)
# Get Next Image
if random_rois:
[normalized_images, image_meta, rpn_match, rpn_bbox, gt_class_ids, gt_boxes, gt_masks, rpn_rois, rois], \
[mrcnn_class_ids, mrcnn_bbox, mrcnn_mask] = next(g)
log("rois", rois)
log("mrcnn_class_ids", mrcnn_class_ids)
log("mrcnn_bbox", mrcnn_bbox)
log("mrcnn_mask", mrcnn_mask)
else:
[normalized_images, image_meta, rpn_match, rpn_bbox, gt_boxes, gt_masks], _ = next(g)
log("gt_class_ids", gt_class_ids)
log("gt_boxes", gt_boxes)
log("gt_masks", gt_masks)
log("rpn_match", rpn_match, )
log("rpn_bbox", rpn_bbox)
image_id = modellib.parse_image_meta(image_meta)["image_id"][0]
print("image_id: ", image_id, dataset.image_reference(image_id))
# Remove the last dim in mrcnn_class_ids. It's only added
# to satisfy Keras restriction on target shape.
mrcnn_class_ids = mrcnn_class_ids[:,:,0]
b = 0
# Restore original image (reverse normalization)
sample_image = modellib.unmold_image(normalized_images[b], config)
# Compute anchor shifts.
indices = np.where(rpn_match[b] == 1)[0]
refined_anchors = utils.apply_box_deltas(anchors[indices], rpn_bbox[b, :len(indices)] * config.RPN_BBOX_STD_DEV)
log("anchors", anchors)
log("refined_anchors", refined_anchors)
# Get list of positive anchors
positive_anchor_ids = np.where(rpn_match[b] == 1)[0]
print("Positive anchors: {}".format(len(positive_anchor_ids)))
negative_anchor_ids = np.where(rpn_match[b] == -1)[0]
print("Negative anchors: {}".format(len(negative_anchor_ids)))
neutral_anchor_ids = np.where(rpn_match[b] == 0)[0]
print("Neutral anchors: {}".format(len(neutral_anchor_ids)))
# ROI breakdown by class
for c, n in zip(dataset.class_names, np.bincount(mrcnn_class_ids[b].flatten())):
if n:
print("{:23}: {}".format(c[:20], n))
# Show positive anchors
fig, ax = plt.subplots(1, figsize=(16, 16))
visualize.draw_boxes(sample_image, boxes=anchors[positive_anchor_ids],
refined_boxes=refined_anchors, ax=ax)
# Show negative anchors
visualize.draw_boxes(sample_image, boxes=anchors[negative_anchor_ids])
# Show neutral anchors. They don't contribute to training.
visualize.draw_boxes(sample_image, boxes=anchors[np.random.choice(neutral_anchor_ids, 100)]) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
ROIsTypically, the RPN network generates region proposals (a.k.a. Regions of Interest, or ROIs). The data generator has the ability to generate proposals as well for illustration and testing purposes. These are controlled by the `random_rois` parameter. | if random_rois:
# Class aware bboxes
bbox_specific = mrcnn_bbox[b, np.arange(mrcnn_bbox.shape[1]), mrcnn_class_ids[b], :]
# Refined ROIs
refined_rois = utils.apply_box_deltas(rois[b].astype(np.float32), bbox_specific[:,:4] * config.BBOX_STD_DEV)
# Class aware masks
mask_specific = mrcnn_mask[b, np.arange(mrcnn_mask.shape[1]), :, :, mrcnn_class_ids[b]]
visualize.draw_rois(sample_image, rois[b], refined_rois, mask_specific, mrcnn_class_ids[b], dataset.class_names)
# Any repeated ROIs?
rows = np.ascontiguousarray(rois[b]).view(np.dtype((np.void, rois.dtype.itemsize * rois.shape[-1])))
_, idx = np.unique(rows, return_index=True)
print("Unique ROIs: {} out of {}".format(len(idx), rois.shape[1]))
if random_rois:
# Dispalay ROIs and corresponding masks and bounding boxes
ids = random.sample(range(rois.shape[1]), 8)
images = []
titles = []
for i in ids:
image = visualize.draw_box(sample_image.copy(), rois[b,i,:4].astype(np.int32), [255, 0, 0])
image = visualize.draw_box(image, refined_rois[i].astype(np.int64), [0, 255, 0])
images.append(image)
titles.append("ROI {}".format(i))
images.append(mask_specific[i] * 255)
titles.append(dataset.class_names[mrcnn_class_ids[b,i]][:20])
display_images(images, titles, cols=4, cmap="Blues", interpolation="none")
# Check ratio of positive ROIs in a set of images.
if random_rois:
limit = 10
temp_g = modellib.data_generator(
dataset, crop_config, shuffle=True, random_rois=10000,
batch_size=1, detection_targets=True)
total = 0
for i in range(limit):
_, [ids, _, _] = next(temp_g)
positive_rois = np.sum(ids[0] > 0)
total += positive_rois
print("{:5} {:5.2f}".format(positive_rois, positive_rois/ids.shape[1]))
print("Average percent: {:.2f}".format(total/(limit*ids.shape[1]))) | _____no_output_____ | MIT | samples/nucleus/inspect_nucleus_data.ipynb | zgle-fork/Mask_RCNN |
Positional Encoding | import math
import numpy as np
%matplotlib inline
from matplotlib import pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi']=130
def get_positional_watermark(max_sequence_length, embedding_dimensions):
pe_matrix = np.zeros((max_sequence_length, embedding_dimensions), dtype=np.float32)
for pos in range(max_sequence_length):
for i in range(0, embedding_dimensions, 2):
pe_matrix[pos,i] = math.sin( pos / math.pow( 10000, (i) / embedding_dimensions ) )
pe_matrix[pos,i+1] = math.cos( pos / math.pow( 10000, (i) / embedding_dimensions ) )
return pe_matrix
plt.imshow(get_positional_watermark(512, 1280), interpolation='nearest',cmap='ocean')
plt.show()
print ( get_positional_watermark( 8, 24 ) ) | _____no_output_____ | MIT | ipynb/positional_encoding_0x01.ipynb | mindscan-de/FluentGenesis-Classifier |
+ This notebook is part of lecture 7 *Solving Ax=0, pivot variables, and special solutions* in the OCW MIT course 18.06 by Prof Gilbert Strang [1]+ Created by me, Dr Juan H Klopper + Head of Acute Care Surgery + Groote Schuur Hospital + University Cape Town + Email me with your thoughts, comments, suggestions and corrections Linear Algebra OCW MIT18.06 IPython notebook [2] study notes by Dr Juan H Klopper is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.+ [1] OCW MIT 18.06+ [2] Fernando Pérez, Brian E. Granger, IPython: A System for Interactive Scientific Computing, Computing in Science and Engineering, vol. 9, no. 3, pp. 21-29, May/June 2007, doi:10.1109/MCSE.2007.53. URL: http://ipython.org | from IPython.core.display import HTML, Image
css_file = 'style.css'
HTML(open(css_file, 'r').read())
#import numpy as np
from sympy import init_printing, Matrix, symbols
#import matplotlib.pyplot as plt
#import seaborn as sns
#from IPython.display import Image
from warnings import filterwarnings
init_printing(use_latex = 'mathjax')
%matplotlib inline
filterwarnings('ignore') | _____no_output_____ | MIT | _math/MIT_OCW_18_06_Linear_algebra/I_08_Solving_homogeneous_systems_Pivot_variables_Special_solutions.ipynb | aixpact/data-science |
Solving homogeneous systems Pivot variables Special solutions * We are trying to solve a system of linear equations* For homogeneous systems the right-hand side is the zero vector* Consider the example below | A = Matrix([[1, 2, 2, 2], [2, 4, 6, 8], [3, 6, 8, 10]])
A # A 3x4 matrix
x1, x2, x3, x4 = symbols('x1, x2, x3, x4')
x_vect = Matrix([x1, x2, x3, x4]) # A 4x1 matrix
x_vect
b = Matrix([0, 0, 0])
b # A 3x1 matrix | _____no_output_____ | MIT | _math/MIT_OCW_18_06_Linear_algebra/I_08_Solving_homogeneous_systems_Pivot_variables_Special_solutions.ipynb | aixpact/data-science |
* The **x** column vector is a set of all the solutions to this homogeneous equation* It forms the nullspace* Note that the column vectors in A are not linearly independent * Performing elementary row operations leaves us with the matrix below* It has two pivots, which is termed **rank** 2 | A.rref() # rref being reduced row echelon form | _____no_output_____ | MIT | _math/MIT_OCW_18_06_Linear_algebra/I_08_Solving_homogeneous_systems_Pivot_variables_Special_solutions.ipynb | aixpact/data-science |
* Which represents the following$$ { x }_{ 1 }\begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}+{ x }_{ 2 }\begin{bmatrix} 2 \\ 0 \\ 0 \end{bmatrix}+{ x }_{ 3 }\begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix}+{ x }_{ 4 }\begin{bmatrix} -2 \\ 2 \\ 0 \end{bmatrix}=\begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}\\ { x }_{ 1 }+2{ x }_{ 2 }+0{ x }_{ 3 }-2{ x }_{ 4 }=0\\ 0{ x }_{ 1 }+0{ x }_{ 2 }+{ x }_{ 3 }+2{ x }_{ 4 }=0\\ { x }_{ 1 }+0{ x }_{ 2 }+0{ x }_{ 3 }+0{ x }_{ 4 }=0 $$ * We are free set a value for *x*4, let's sat *t*$$ { x }_{ 1 }+2{ x }_{ 2 }+0{ x }_{ 3 }-2{ x }_{ 4 }=0\\ 0{ x }_{ 1 }+0{ x }_{ 2 }+{ x }_{ 3 }+2t=0\\ { x }_{ 1 }+0{ x }_{ 2 }+0{ x }_{ 3 }+0{ x }_{ 4 }=0\\ \therefore \quad { x }_{ 3 }=-2t $$ * We will have to make *x*2 equal to another variable, say *s*$$ { x }_{ 1 }+2s+0{ x }_{ 3 }-2t=0 $$$$ \therefore \quad {x}_{1}=2t-2s $$ * This results in the following, which is the complete nullspace and has dimension 2$$ \begin{bmatrix} { x }_{ 1 } \\ { x }_{ 2 } \\ { x }_{ 3 } \\ { x }_{ 4 } \end{bmatrix}=\begin{bmatrix} -2s+2t \\ s \\ -2t \\ t \end{bmatrix}=\begin{bmatrix} -2s \\ s \\ 0 \\ 0 \end{bmatrix}+\begin{bmatrix} 2t \\ 0 \\ -2t \\ t \end{bmatrix}=s\begin{bmatrix} -2 \\ 1 \\ 0 \\ 0 \end{bmatrix}+t\begin{bmatrix} 2 \\ 0 \\ -2 \\ 1 \end{bmatrix} $$* From the above, we clearly have two vectors in the solution and we can take constant multiples of these to fill up our solution space (our nullspace) * We can easily calculate how many free variables we will have by subtracting the number of pivots (rank) from the number of variables (*x*) in **x*** Here we have 4 - 2 = 2 Example problem * Calculate **x** for the transpose of A above Solution | A_trans = A.transpose() # Creating a new matrix called A_trans and giving it the value of the inverse of A
A_trans
A_trans.rref() # In reduced row echelon form this would be the following matrix | _____no_output_____ | MIT | _math/MIT_OCW_18_06_Linear_algebra/I_08_Solving_homogeneous_systems_Pivot_variables_Special_solutions.ipynb | aixpact/data-science |
Load image metadata | imageDedup = [m for m in imagemeta.find()]
imageDedup.sort(key=lambda x: x['image_id'])
phash_to_idx_mapping = {}
for i in range(len(imageDedup)):
phash = imageDedup[i]['phash']
l = phash_to_idx_mapping.get(phash, [])
l.append(i)
phash_to_idx_mapping[phash] = l
def phash_to_idx (phash):
return phash_to_idx_mapping.get(phash, None)
image_id_to_idx_mapping = {imageDedup[i]['image_id']:i for i in range(len(imageDedup))}
def image_id_to_idx (image_id):
return image_id_to_idx_mapping.get(image_id, None) | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Calculate distance Hash distance | image_hashes = [make_hashes(m) for m in imageDedup]
# distance = calculate_distance(image_hashes)
distance = calculate_distance(image_hashes, hash_type='phash')
# distance2 = np.ndarray([len(image_hashes), len(image_hashes)])
# for i in tqdm(range(len(image_hashes))):
# for j in range(i+1):
# diff = hashes_diff(image_hashes[i], image_hashes[j])
# distance2[i, j] = diff
# distance2[j, i] = diff
# np.array_equal(distance, distance2)
# pdistance = calculate_distance(image_hashes, hash_type='phash') | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Find duplicated pairs from distance matrix | def set_distance (hashes, value, mat=distance):
phash_x = hashes[0]
phash_y = phash_x if len(hashes) == 1 else hashes[1]
idx_x = phash_to_idx(phash_x)
idx_y = phash_to_idx(phash_y)
if idx_x == None or idx_y == None:
return
for s in itertools.product(idx_x, idx_y):
i, j = s
mat[i, j] = value
mat[j, i] = value
def set_distance_pairs (phash_pairs, value, mat=distance):
for p in phash_pairs:
set_distance(list(p), value, mat=mat)
auto_duplicated_image_phash_pairs = PersistentSet()
auto_duplicated_image_phash_pairs.set_file(handmade_dir/'auto_duplicated_image_phash_pairs.json')
for i in tqdm(range(distance.shape[0])):
for j in range(i):
if distance[i, j] <= 1: # checked, all distance <= 1 are duplicated
auto_duplicated_image_phash_pairs.add(frozenset([imageDedup[i]['phash'], imageDedup[j]['phash']]))
# for i in tqdm(range(pdistance.shape[0])):
# for j in range(i):
# if pdistance[i, j] <= 1: # checked, all distance <= 1 are duplicated
# auto_duplicated_image_phash_pairs.add(frozenset([imageDedup[i]['phash'], imageDedup[j]['phash']]))
auto_duplicated_image_phash_pairs.save() | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Apply information from meta data | duplicated_post_image_phash_pairs = PersistentSet()
duplicated_post_image_phash_pairs.set_file(handmade_dir/'duplicated_post_image_phash_pairs.json')
for p in tqdm(posts.find()):
if len(p.get('duplicated_posts', [])) == 0:
continue
dp_phashes = {i['phash']
for dp in p['duplicated_posts']
for i in imagemeta.find({'post_id': dp})}
if len(dp_phashes) > 1:
# print(f"More than 1 dp image {p['post_id']}")
# print(f"{p['duplicated_posts']} {dp_phashes}")
continue
phashes = [i['phash'] for i in imagemeta.find({'post_id': p['post_id']})]
if len(phashes) > 1:
# print(f"More than 1 image {p['post_id']} {phashes}")
continue
for s in itertools.product(dp_phashes, phashes):
fs = frozenset(s)
if len(fs) > 1:
duplicated_post_image_phash_pairs.add(fs)
duplicated_post_image_phash_pairs.save()
related_album_image_phash_pairs = PersistentSet()
related_album_image_phash_pairs.set_file(handmade_dir/'related_album_image_phash_pairs.json')
for album in tqdm({i['album'] for i in imagemeta.find({'album': {'$exists': True, '$ne': ''}})}):
ra_phashes = [i['phash'] for i in imagemeta.find({'album': album})]
if len(ra_phashes) <= 1:
print(f"Only 1 or less image {album} {ra_phashes}")
for s in itertools.product(ra_phashes, ra_phashes):
fs = frozenset(s)
if len(fs) > 1:
related_album_image_phash_pairs.add(fs)
related_album_image_phash_pairs.save() | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Apply manual labeled data | duplicated_image_phash_pairs = PersistentSet.load_set(handmade_dir/'duplicated_image_phash_pairs.json')
not_duplicated_image_phash_pairs = PersistentSet.load_set(handmade_dir/'not_duplicated_image_phash_pairs.json')
related_image_phash_pairs = PersistentSet.load_set(handmade_dir/'related_image_phash_pairs.json')
invalid_image_phashes = PersistentSet.load_set(handmade_dir/'invalid_image_phashes.json')
set_distance_pairs(auto_duplicated_image_phash_pairs, 0)
set_distance_pairs(duplicated_post_image_phash_pairs, 0)
set_distance_pairs(duplicated_image_phash_pairs, 0)
set_distance_pairs(not_duplicated_image_phash_pairs, 60)
set_distance_pairs(related_album_image_phash_pairs, 60)
set_distance_pairs(related_image_phash_pairs, 60)
related_distance = np.full(distance.shape, 60)
set_distance_pairs(related_album_image_phash_pairs, 0, mat=related_distance)
set_distance_pairs(related_image_phash_pairs, 0, mat=related_distance) | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Human in the Loop | def make_dedup_box (idx_x, idx_y, default=None):
image_x = imageDedup[idx_x]
phash_x = image_x['phash']
image_y = imageDedup[idx_y]
phash_y = image_y['phash']
hash_pair = frozenset([phash_x, phash_y])
yes_btn = widgets.Button(description="Duplicated", button_style='success')
no_btn = widgets.Button(description="Not", button_style='info')
related_btn = widgets.Button(description="Related", button_style='warning')
invalid_x_btn = widgets.Button(description="X Invalid")
invalid_y_btn = widgets.Button(description="Y Invalid")
reset_btn = widgets.Button(description="Reset")
output = widgets.Output()
def on_yes (btn):
with output:
if hash_pair in not_duplicated_image_phash_pairs:
not_duplicated_image_phash_pairs.persist_remove(hash_pair)
print('-Not')
duplicated_image_phash_pairs.persist_add(hash_pair)
print('Duplicated')
def on_no (btn):
with output:
if hash_pair in duplicated_image_phash_pairs:
duplicated_image_phash_pairs.persist_remove(hash_pair)
print('-Duplicated')
not_duplicated_image_phash_pairs.persist_add(hash_pair)
print('Not')
def on_related (btn):
with output:
if hash_pair in not_duplicated_image_phash_pairs:
not_duplicated_image_phash_pairs.persist_remove(hash_pair)
print('-Not')
related_image_phash_pairs.persist_add(hash_pair)
print('Related')
def on_invalid_x (btn):
invalid_image_phashes.persist_add(phash_x)
with output:
print('Invalid X')
def on_invalid_y (btn):
invalid_image_phashes.persist_add(phash_y)
with output:
print('Invalid Y')
def on_reset (btn):
with output:
if hash_pair in duplicated_image_phash_pairs:
duplicated_image_phash_pairs.persist_remove(hash_pair)
print('-Duplicated')
if hash_pair in not_duplicated_image_phash_pairs:
not_duplicated_image_phash_pairs.persist_remove(hash_pair)
print('-Not')
if hash_pair in related_image_phash_pairs:
related_image_phash_pairs.persist_remove(hash_pair)
print('-Related')
if phash_x in invalid_image_phashes:
invalid_image_phashes.persist_remove(phash_x)
print('-Invalid X')
if phash_y in invalid_image_phashes:
invalid_image_phashes.persist_remove(phash_y)
print('-Invalid Y')
print('Reset')
yes_btn.on_click(on_yes)
no_btn.on_click(on_no)
related_btn.on_click(on_related)
invalid_x_btn.on_click(on_invalid_x)
invalid_y_btn.on_click(on_invalid_y)
reset_btn.on_click(on_reset)
if default == 'no':
on_no(None)
elif default == 'yes':
on_yes(None)
return HBox([VBox([yes_btn, no_btn, related_btn, invalid_x_btn, invalid_y_btn, reset_btn, output]),
widgets.Image(value=open(image_x['file_path'], 'rb').read(), width=250, height=150),
widgets.Image(value=open(image_y['file_path'], 'rb').read(), width=250, height=150)])
def potential_duplicates (threshold):
for i in range(distance.shape[0]):
for j in range(i):
if distance[i, j] <= threshold:
phash_pair = frozenset([imageDedup[i]['phash'], imageDedup[j]['phash']])
if (phash_pair not in auto_duplicated_image_phash_pairs and
phash_pair not in duplicated_post_image_phash_pairs and
phash_pair not in duplicated_image_phash_pairs and
phash_pair not in not_duplicated_image_phash_pairs and
phash_pair not in related_album_image_phash_pairs and
phash_pair not in related_image_phash_pairs):
yield (i, j)
distance_threshold = 10
pdup = potential_duplicates(distance_threshold)
for i in range(10):
try:
next_pdup = next(pdup)
except StopIteration:
print('StopIteration')
break
idx_x, idx_y = next_pdup
image_x = imageDedup[idx_x]
image_y = imageDedup[idx_y]
print(f"{idx_x} {idx_y} {distance[idx_x, idx_y]} {image_x['phash']} {image_y['phash']} {image_x['width']} {image_y['width']} {image_x['image_id']} {image_y['image_id']}")
display(make_dedup_box(idx_x, idx_y, default=None if distance[idx_x, idx_y] < 6 else 'no'))
# display(make_dedup_box(idx_x, idx_y, default='yes' if distance[idx_x, idx_y] < 9 else 'no')) | StopIteration
| CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Visually check images Images with high variability | # interested_phashes = set()
# def potential_duplicates_high (threshold):
# for i in range(distance.shape[0]):
# for j in range(i):
# if distance[i, j] >= threshold:
# phash_pair = frozenset([imageDedup[i]['phash'], imageDedup[j]['phash']])
# if (phash_pair in duplicated_image_phash_pairs):
# interested_phashes.add(imageDedup[i]['phash'])
# interested_phashes.add(imageDedup[j]['phash'])
# yield (i, j)
# pduph = potential_duplicates_high(13)
# for i in range(100):
# try:
# next_pdup = next(pduph)
# except StopIteration:
# print('StopIteration')
# break
# idx_x, idx_y = next_pdup
# image_x = imageDedup[idx_x]
# image_y = imageDedup[idx_y]
# print(f"{idx_x} {idx_y} {distance[idx_x, idx_y]} {image_x['phash']} {image_y['phash']} {image_x['width']} {image_y['width']} {image_x['image_id']} {image_y['image_id']}")
# display(make_dedup_box(idx_x, idx_y))
# invalid_image_phashes = set(json.load(open('handmade/invalid_image_phashes.json')))
# examined_images = [
# 'reddit/dataisugly/2o08rl_0', # manually downloaded
# 'reddit/dataisugly/2nwubr_0', # manually downloaded
# 'reddit/dataisugly/beivt8_0', # manually downloaded
# 'reddit/dataisugly/683b4i_0', # manually downloaded
# 'reddit/dataisugly/3zcw30_0', # manually downloaded
# 'reddit/dataisugly/1oxrh5_0', # manually downloaded a higher resolution image
# 'reddit/dataisugly/3or2g0_0', # manually downloaded
# 'reddit/dataisugly/5iobqn_0', # manually downloaded
# 'reddit/dataisugly/29fpuo_0', # manually downloaded
# 'reddit/dataisugly/5xux1f_0', # manually downloaded
# 'reddit/dataisugly/35lrw1_0', # manually downloaded
# 'reddit/dataisugly/1bxhv2_0', # manually downloaded a higher resolution image
# 'reddit/dataisugly/3peais_0', # manually downloaded
# 'reddit/dataisugly/2vdk71_0', # manually downloaded
# 'reddit/dataisugly/6b8w73_0', # manually downloaded
# 'reddit/dataisugly/2w8pnr_0', # manually downloaded an image with more context
# 'reddit/dataisugly/2dt19h_0', # manually downloaded
# 'reddit/dataisugly/31tj8a_0', # manually downloaded
# 'reddit/dataisugly/30smxr_0', # manually downloaded
# 'reddit/dataisugly/30dbx6_0', # manually downloaded
# 'reddit/dataisugly/561ytm_0', # manually downloaded
# 'reddit/dataisugly/6q4tre_0', # manually downloaded
# 'reddit/dataisugly/3icm4g_0', # manually downloaded
# 'reddit/dataisugly/6z5v98_0', # manually downloaded
# 'reddit/dataisugly/5fucjm_0', # manually downloaded
# 'reddit/dataisugly/99bczz_0', # manually downloaded
# 'reddit/dataisugly/2662wv_0', # manually downloaded
# 'reddit/dataisugly/26otpi_0', # manually downloaded a higher resolution image
# 'reddit/dataisugly/68scgb_0', # manually downloaded
# 'reddit/dataisugly/et75qp_0', # manually downloaded
# 'reddit/dataisugly/4c9zc1_0', # manually downloaded an image with more context
# 'reddit/dataisugly/2525a5_0', # manually downloaded more images, but does not matched with the one with more context
# 'reddit/dataisugly/2la7zt_0', # thumbnail alt
# ] | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Invalid images | # invalids = []
# for h in invalid_image_phashes:
# invalid_images = [f for f in imagefiles.find({'phash': h})]
# if len(invalid_images) > 0:
# invalids.append(invalid_images[0])
# display(Box([widgets.Image(value=open(i['file_path'], 'rb').read(), width=100, height=100) for i in invalids],
# layout=Layout(display='flex', flex_flow='row wrap'))) | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Consolidate Related images | related_images = [[imageDedup[idx]['image_id'] for idx in c]
for c in nx.components.connected_components(nx.Graph(related_distance <= 1))
if len(c) > 1]
len(related_images)
for ids in related_images:
for i in ids:
imageMeta = imageDedup[image_id_to_idx(i)]
ri = [r for r in set(imageMeta.get('related_images', []) + ids) if r != i]
imagededup.update_one({'image_id': i}, {'$set': {'related_images': ri}}) | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Duplicated images | excluding_image_phashes = PersistentSet.load_set(handmade_dir/'excluding_image_phashes.json')
excluding_image_phashes.persist_add('c13e3ae10e70fd86')
excluding_image_phashes.persist_add('fe81837a94e3807e')
excluding_image_phashes.persist_add('af9da24292fae149')
excluding_image_phashes.persist_add('ad87d2696738ca4c')
excluding_image_phashes.persist_add('d25264dfa9659392')
excluding_image_phashes.persist_add('964e3b3160e14f8f')
class ImageDedup ():
_attrs = [
'id',
'post_id',
'datetime',
'url',
'title',
'content',
'author',
'removed',
'ups',
'num_comments',
'external_link',
'source',
'source_platform',
'source_url',
'tags',
'labels',
'media_type',
'thumbnail_url',
'preview_url',
'external_link_url',
'archive_url',
'thumbnail',
'preview',
'external_link',
'archive',
'manual',
'image_id',
'short_image_id',
'album',
'index_in_album',
'image_type',
'file_path',
'ext',
'animated',
'size',
'width',
'height',
'pixels',
'image_order',
'ahash',
'phash',
'pshash',
'dhash',
'whash',
'duplicated_posts',
'related_images',
'duplicated_images',
'popularity_score'
]
def __init__ (self, imageMetas=[]):
# print(imageMetas)
if len(imageMetas) == 0:
raise Exception('Empty imageFiles array.')
self._imageMetas = imageMetas
self._image_ids = [i['image_id'] for i in imageMetas]
self._image_order = sort_images(self._imageMetas)
self._post_ids = {i['post_id'] for i in imageMetas}
self._posts = [posts.find_one({'post_id': i}) for i in self._post_ids]
dpost = []
for p in self._posts:
if 'duplicated_posts' in p:
for i in p['duplicated_posts']:
if i not in self._post_ids:
dpost.append(posts.find_one({'post_id': i}))
self._posts += dpost
if None in self._posts:
print(self._post_ids)
self._post_order = sort_posts(self._posts)
for k, v in self.main_image.items():
if k in ['duplicated_posts', 'related_images']:
continue
setattr(self, k, v)
for k, v in self.main_post.items():
if k in ['duplicated_posts', 'related_images']:
continue
if k in ['preview', 'thumbnail', 'external_link', 'archive', 'manual']:
setattr(self, f"{k}_url", v)
else:
setattr(self, k, v)
def digest (self):
return {a:getattr(self, a) for a in ImageDedup._attrs if hasattr(self, a)}
@property
def duplicated_posts (self):
post_ids = self._post_ids.union(*[set(p.get('duplicated_posts', [])) for p in self._posts])
return [i for i in post_ids if i != self.post_id]
@property
def duplicated_images (self):
return [i for i in self._image_ids if i != self.image_id]
@property
def related_images (self):
return [ri for i in self._imageMetas for ri in i.get('related_images', []) if ri != self.image_id]
@property
def main_post (self):
# if len(self._post_order) > 1 and self._post_order[0]['source_platform'] != 'reddit':
# print(f"main post warning: {[p['post_id'] for p in self._post_order]}")
return self._post_order[0]
@property
def popularity_score (self):
return sum([post_score(p) for p in self._posts if p['source'] == 'dataisugly'])
@property
def main_image (self):
# if len(self._image_order) > 1 and self._image_order[0]['source_platform'] != 'reddit':
# print(f"main image warning: {[i['image_id'] for i in self._image_order]}")
mi = [i for i in self._image_order if i['phash'] not in excluding_image_phashes][0]
return mi
duplicated_images = [list(set([imageDedup[idx]['image_id'] for idx in c]))
for c in nx.components.connected_components(nx.Graph(distance <= 1))]
# imageDedup[image_id_to_idx('reddit/AusFinance/fman6b_0')]
def dedup_image (ids):
imagedd = ImageDedup([imageDedup[image_id_to_idx(i)] for i in set(ids)])
# if imagedd.main_post['source'] != 'dataisugly':
# print(f"Image not from dataisugly: {imagedd.main_post['post_id']}")
for i in imagedd.duplicated_images:
imagededup.delete_one({'image_id': i})
imagededup.replace_one({'image_id': imagedd.image_id}, imagedd.digest(), upsert=True)
return imagedd
imagedds = parallel(dedup_image, duplicated_images, n_jobs=-1)
# duplicated_image_ids = [c
# for c in nx.components.connected_components(nx.Graph(distance <= 1))
# if len(c) > 1]
# start = 0
# # len(duplicated_image_ids)
# cnt = 0
# end = start + 50
# for idxs in duplicated_image_ids:
# # print(f"{[imageDedup[i]['image_id'] for i in idxs]}")
# # if len(idxs) == 2:
# if len(idxs) >= 4:
# if cnt >= start:
# print(*[imageDedup[i]['image_id'] for i in idxs])
# print(*[imageDedup[i]['phash'] for i in idxs])
# display(HBox([
# widgets.Image(value=open(imageDedup[i]['file_path'], 'rb').read(), width=100, height=100)
# for i in idxs]))
# cnt += 1
# if cnt >= end:
# print(end)
# start = end
# break | _____no_output_____ | CC-BY-4.0 | notebooks/images_dedup.ipynb | leoyuholo/bad-vis-images |
Using enterprise_extensions to analyze PTA dataIn this notebook you will learn:* How to use `enterprise_extensions` to create `enterprise` models,* How to search in PTA data for a isotropic stochastic gravitational wave background using multiple pulsars,* How to implement a HyperModel object to sample a `model_2a` model,* How to post-process your results. | %matplotlib inline
%config InlineBackend.figure_format = 'retina'
%load_ext autoreload
%autoreload 2
import os, glob, json, pickle
import matplotlib.pyplot as plt
import numpy as np
from enterprise.pulsar import Pulsar
from enterprise_extensions import models, hypermodel
import sys
sys.path.append("..")
from settings import fd_bins | WARNING: AstropyDeprecationWarning: The private astropy._erfa module has been made into its own package, pyerfa, which is a dependency of astropy and can be imported directly using "import erfa" [astropy._erfa]
| MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Get par, tim, and noise files | psrlist = None # define a list of pulsar name strings that can be used to filter.
# set the data directory
datadir = '../data'
if not os.path.isdir(datadir):
datadir = '../../data'
print('datadir =', datadir)
# for the entire pta
parfiles = sorted(glob.glob(datadir + '/par/*par'))
timfiles = sorted(glob.glob(datadir + '/tim/*tim'))
# filter
if psrlist is not None:
parfiles = [x for x in parfiles if x.split('/')[-1].split('.')[0] in psrlist]
timfiles = [x for x in timfiles if x.split('/')[-1].split('.')[0] in psrlist]
# Make sure you use the tempo2 parfile for J1713+0747!!
# ...filtering out the tempo parfile...
parfiles = [x for x in parfiles if 'J1713+0747_NANOGrav_12yv3.gls.par' not in x] | _____no_output_____ | MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Read par and tim files into `enterprise` `Pulsar` objects | # check for file and load pickle if it exists:
pickle_loc = datadir + '/psrs.pkl'
if os.path.exists(pickle_loc):
with open(pickle_loc, 'rb') as f:
psrs = pickle.load(f)
# else: load them in slowly:
else:
psrs = []
ephemeris = 'DE438'
for p, t in zip(parfiles, timfiles):
psr = Pulsar(p, t, ephem=ephemeris)
psrs.append(psr)
# Make your own pickle of these loaded objects to reduce load times significantly
# at the cost of some space on your computer (~1.8 GB).
with open(datadir + '/psrs.pkl', 'wb') as f:
pickle.dump(psrs, f)
## Get parameter noise dictionary
noise_ng12 = datadir + '/channelized_12p5yr_v3_full_noisedict.json'
params = {}
with open(noise_ng12, 'r') as fp:
params.update(json.load(fp)) | _____no_output_____ | MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Set up PTA model* This model_2a includes everything from the verbose version in these tutorials: * fixed white noise parameters based on noisedict `params`, * common red noise signal (no correlation function) with 5 frequencies, * and a spectral index of 13/3 | pta = models.model_2a(psrs,
psd='powerlaw',
noisedict=params,
n_gwbfreqs=5, # modify the number of common red noise frequencies used here
gamma_common=13/3) # remove this line for a varying spectral index | _____no_output_____ | MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Setup an instance of a HyperModel.* This doesn't mean we are doing model selection (yet!), but the hypermodel module gives access to some nifty sampling schemes. | super_model = hypermodel.HyperModel({0: pta}) | _____no_output_____ | MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Setup PTMCMCSampler | outDir = '../../chains/extensions_chains'
sampler = super_model.setup_sampler(resume=True,
outdir=outDir,
sample_nmodel=False,)
# sampler for N steps
N = int(5e6)
x0 = super_model.initial_sample()
# Sampling this will take a very long time. If you want to sample it yourself, uncomment the next line:
# sampler.sample(x0, N, SCAMweight=30, AMweight=15, DEweight=50, ) | _____no_output_____ | MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
Plot Output | # Uncomment this one to load the chain if you have sampled with PTMCMCSampler:
# chain = np.loadtxt(os.path.join(outDir, 'chain_1.txt'))
# This will load the chain that we have provided:
chain = np.load(os.path.join(outDir, 'chain_1.npz'))['arr_0']
burn = int(0.25 * chain.shape[0]) # remove burn in segment of sampling
ind = list(pta.param_names).index('gw_log10_A')
# Make trace-plot to diagnose sampling
plt.figure(figsize=(12, 5))
plt.plot(chain[burn:, ind])
plt.xlabel('Sample Number')
plt.ylabel('log10_A_gw')
plt.title('Trace Plot')
plt.grid(b=True)
plt.show()
# Plot a histogram of the marginalized posterior distribution
bins = fd_bins(chain[:, ind], logAmin=-18, logAmax=-12) # let FD rule decide bins (in ../settings.py)
plt.figure(figsize=(12, 5))
plt.title('Histogram')
plt.hist(chain[:, ind], bins=bins, histtype='stepfilled',
lw=2, color='C0', alpha=0.5, density=True)
plt.xlabel('log10_A_gw')
plt.show()
# Compute maximum posterior value
hist = np.histogram(chain[burn:, pta.param_names.index('gw_log10_A')],
bins=bins,
density=True)
max_ind = np.argmax(hist[0])
print('our_max =', hist[1][max_ind]) # from our computation | our_max = -14.707808651660155
| MIT | tutorials/full_pta_gwb/pe_extensions.ipynb | AaronDJohnson/12p5yr_stochastic_analysis |
This Notebook is done for Pixelated Data for 1 Compton, 2 PhotoElectric with 2 more Ambiguity! I got 89% Accuracy on Test set! I am getting X from Blurred Dataset, y as labels from Ground Truth | import pandas as pd
import numpy as np
from keras.utils import to_categorical
import math
df = {'Label':[],
'Theta_P1':[], 'Theta_E1':[], 'Theta_P2':[], 'Theta_E2':[], 'Theta_P3':[], 'Theta_E3':[], 'Theta_P4':[], 'Theta_E4':[],
'Theta_P5':[], 'Theta_E5':[], 'Theta_P6':[], 'Theta_E6':[], 'Theta_P7':[], 'Theta_E7':[], 'Theta_P8':[], 'Theta_E8':[],
'y': []}
with open("Data/test_Output_8.csv", 'r') as f:
counter = 0
counter_Theta_E = 0
for line in f:
sline = line.split('\t')
if len(sline) == 12:
df['Label'].append(int(sline[0]))
df['Theta_P1'].append(float(sline[1]))
df['Theta_E1'].append(float(sline[4]))
df['Theta_P2'].append(float(sline[5]))
df['Theta_E2'].append(float(sline[6]))
df['Theta_P3'].append(float(sline[7]))
df['Theta_E3'].append(float(sline[8]))
df['Theta_P4'].append(float(sline[9]))
df['Theta_E4'].append(float(sline[10]))
df['y'].append(int(sline[11]))
# df.info() Counts Nan in the dataset
df = pd.DataFrame(df)
df.to_csv('GroundTruth.csv', index=False)
df[0:4]
X = []
y = []
df = pd.read_csv('GroundTruth.csv')
for i in range(0, len(df)-1, 1): # these are from Blurred Data!
features = df.loc[i, 'Theta_P1':'Theta_E4'].values.tolist()
label = df.loc[i, 'y':'y'].values.tolist()
X.append(features)
y.append(label)
X = np.array(X)
y = np.array(y)
y = to_categorical(y, num_classes=None, dtype='float32')
print(y[0])
# ID = df.loc[i,'ID'] # get family ID from blurred dataframe
# gt_temp_rows = df[df['ID'] == ID] # find corresponding rows in grund truth dataframe
# count = 0
# if (len(gt_temp_rows)==0) or(len(gt_temp_rows)==1): # yani exactly we have 2 lines!
# count += 1
# continue
# idx = gt_temp_rows.index.tolist()[0] # read the first row's index
# # print(len(gt_temp_rows))
# # print(gt_temp_rows.index.tolist())
# # # set the target value
# # print('********************')
# # print('eventID_label:', int(sline[0]))
# # print(gt_temp_rows)
# if (gt_temp_rows.loc[idx, 'DDA':'DDA'].item() <= gt_temp_rows.loc[idx+1, 'DDA':'DDA'].item()):
# label = 1
# else:
# label = 0
# X.append(row1)
# y.append(label)
# X = np.array(X)
# y = np.array(y)
# # print(y)
# y = to_categorical(y, num_classes=None, dtype='float32')
# # print(y)
| [0. 1. 0. 0.]
| MIT | ML_Files/Cross_Strip_8Fam/.ipynb_checkpoints/Pixelated_32Features_DNN_Time_Label-checkpoint.ipynb | nananasiri/Multiple-Interaction-Photon-Events |
Define the Model | # Define the keras model
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(128, input_dim=X.shape[1], activation='relu')) #8, 8: 58 12, 8:64 32,16: 66 16,16: 67
model.add(Dense(64, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(y.shape[1], activation='softmax'))
model.summary()#CNN, LSTM, RNN, Residual, dense
print(model)
# compile the keras model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#loss: categorical_crossentropy (softmax output vector mide: multi class classification)
#binary_crossentropy (sigmoid output: binary classification)
#mean_squared_error MSE
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# fit the keras model on the dataset
history = model.fit(X_train, y_train, epochs=220, batch_size=10, validation_split=0.15)
import matplotlib.pyplot as plt
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.grid(True)
# plt.xticks(np.arange(1, 100, 5))
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.grid(True)
# plt.xticks(np.arange(1, 100, 5))
plt.show()
# Evaluating trained model on test set. This Accuracy came from DDA Labeling
_, accuracy = model.evaluate(X_test, y_test)
print('Accuracy: %.2f' % (accuracy*100)) | 226/226 [==============================] - 0s 540us/step - loss: 0.3584 - accuracy: 0.8997
Accuracy: 89.97
| MIT | ML_Files/Cross_Strip_8Fam/.ipynb_checkpoints/Pixelated_32Features_DNN_Time_Label-checkpoint.ipynb | nananasiri/Multiple-Interaction-Photon-Events |
HyperParameterOptimization | def create_model(hyperParams):
hidden_layers = hyperParams['hidden_layers']
activation = hyperParams['activation']
dropout = hyperParams['dropout']
output_activation = hyperParams['output_activation']
loss = hyperParams['loss']
input_size = hyperParams['input_size']
output_size = hyperParams['output_size']
model = Sequential()
model.add(Dense(hidden_layers[0], input_shape=(input_size,), activation=activation))
model.add(Dropout(dropout))
for i in range(len(hidden_layers)-1):
model.add(Dense(hidden_layers[i], activation=activation))
model.add(Dropout(dropout))
model.add(Dense(output_size, activation=output_activation))
model.compile(loss=loss, optimizer='adam', metrics=['accuracy'])
# categorical_crossentropy, binary_crossentropy
return model
def cv_model_fit(X, y, hyperParams):
kfold = KFold(n_splits=10, shuffle=True)
scores=[]
for train_idx, test_idx in kfold.split(X):
model = create_model(hyperParams)
model.fit(X[train_idx], y[train_idx], batch_size=hyperParams['batch_size'],
epochs=hyperParams['epochs'], verbose=0)
score = model.evaluate(X[test_idx], y[test_idx], verbose=0)
scores.append(score*100) # f_score
# print('fold ', len(scores), ' score: ', scores[-1])
del model
return scores
# hyper parameter optimization
from itertools import product
from sklearn.model_selection import KFold
from keras.layers import Activation, Conv2D, Input, Embedding, Reshape, MaxPool2D, Concatenate, Flatten, Dropout, Dense, Conv1D
# default parameter setting:
hyperParams = {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [512, 512, 128],
'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
# parameter search space:
batch_chices = [32]
epochs_choices = [100]
hidden_layers_choices = [[4, 4], [16, 32],
[8, 8, 8], [4, 8, 16],
[4, 4, 4]]
activation_choices = ['relu', 'sigmoid'] #, 'tanh'
dropout_choices = [ 0.5]
s = [batch_chices, epochs_choices, hidden_layers_choices, activation_choices, dropout_choices]
perms = list(product(*s)) # permutations
# Linear search:
best_score = 0
for row in perms:
hyperParams['batch_size'] = row[0]
hyperParams['epochs'] = row[1]
hyperParams['hidden_layers'] = row[2]
hyperParams['activation'] = row[3]
hyperParams['dropout'] = row[4]
print('10-fold cross validation on these hyperparameters: ', hyperParams, '\n')
cvscores = cv_model_fit(X, y, hyperParams)
print('\n-------------------------------------------')
mean_score = np.mean(cvscores)
std_score = np.std(cvscores)
# Update the best parameter setting:
print('CV mean: {0:0.4f}, CV std: {1:0.4f}'.format(mean_score, std_score))
if mean_score > best_score: # later I should incorporate std in best model selection
best_score = mean_score
print('****** Best model so far ******')
best_params = hyperParams
print('-------------------------------------------\n') | 10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 4], 'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6174, CV std: 0.0522
****** Best model so far ******
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 4], 'activation': 'sigmoid', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6339, CV std: 0.0198
****** Best model so far ******
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [16, 32], 'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6068, CV std: 0.0979
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [16, 32], 'activation': 'sigmoid', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6069, CV std: 0.0850
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [8, 8, 8], 'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6117, CV std: 0.0422
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [8, 8, 8], 'activation': 'sigmoid', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6086, CV std: 0.0277
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 8, 16], 'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6153, CV std: 0.0682
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 8, 16], 'activation': 'sigmoid', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6379, CV std: 0.0211
****** Best model so far ******
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 4, 4], 'activation': 'relu', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6043, CV std: 0.0690
-------------------------------------------
10-fold cross validation on these hyperparameters: {'input_size': 4, 'output_size': 2, 'batch_size': 32, 'epochs': 100, 'hidden_layers': [4, 4, 4], 'activation': 'sigmoid', 'dropout': 0.5, 'output_activation': 'softmax', 'loss': 'categorical_crossentropy'}
-------------------------------------------
CV mean: 0.6374, CV std: 0.0246
-------------------------------------------
| MIT | ML_Files/Cross_Strip_8Fam/.ipynb_checkpoints/Pixelated_32Features_DNN_Time_Label-checkpoint.ipynb | nananasiri/Multiple-Interaction-Photon-Events |
LassoLars Regression with Scale This Code template is for the regression analysis using a simple LassoLars Regression. It is a lasso model implemented using the LARS algorithm and feature scaling. Required Packages | import warnings
import numpy as np
import pandas as pd
import seaborn as se
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn import preprocessing
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.linear_model import LassoLars
warnings.filterwarnings('ignore') | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
InitializationFilepath of CSV file | #filepath
file_path= "" | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
List of features which are required for model training . | #x_values
features=[] | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Target feature for prediction. | #y_value
target='' | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Data FetchingPandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.We will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry. | df=pd.read_csv(file_path)
df.head() | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Feature SelectionsIt is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.We will assign all the required input features to X and target/outcome to Y. | X=df[features]
Y=df[target] | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Data PreprocessingSince the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes. | def NullClearner(df):
if(isinstance(df, pd.Series) and (df.dtype in ["float64","int64"])):
df.fillna(df.mean(),inplace=True)
return df
elif(isinstance(df, pd.Series)):
df.fillna(df.mode()[0],inplace=True)
return df
else:return df
def EncodeX(df):
return pd.get_dummies(df) | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Calling preprocessing functions on the feature and target set. | x=X.columns.to_list()
for i in x:
X[i]=NullClearner(X[i])
X=EncodeX(X)
Y=NullClearner(Y)
X.head() | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Correlation MapIn order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns. | f,ax = plt.subplots(figsize=(18, 18))
matrix = np.triu(X.corr())
se.heatmap(X.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax, mask=matrix)
plt.show() | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Data SplittingThe train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data. | x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123) | _____no_output_____ | Apache-2.0 | Regression/Linear Models/LassoLars_Scale.ipynb | surya2365/ds-seed |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.