
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Helper-function for plotting images Function used to plot 9 images in a 3x3 grid, and writing the true and predicted classes below each image. | def plot_images(images, cls_true, cls_pred=None):
assert len(images) == len(cls_true) == 9
# Create figure with 3x3 sub-plots.
fig, axes = plt.subplots(3, 3)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
for i, ax in enumerate(axes.flat):
# Plot image.
ax.imshow(images[i].reshape... | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Plot a few images to see if data is correct | # Get the first images from the test-set.
images = data.x_test[0:9]
# Get the true classes for those images.
cls_true = data.y_test_cls[0:9]
# Plot the images and labels using our helper-function above.
plot_images(images=images, cls_true=cls_true) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
TensorFlow GraphThe entire purpose of TensorFlow is to have a so-called computational graph that can be executed much more efficiently than if the same calculations were to be performed directly in Python. TensorFlow can be more efficient than NumPy because TensorFlow knows the entire computation graph that must be ex... | x = tf.placeholder(tf.float32, [None, img_size_flat]) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Next we have the placeholder variable for the true labels associated with the images that were input in the placeholder variable `x`. The shape of this placeholder variable is `[None, num_classes]` which means it may hold an arbitrary number of labels and each label is a vector of length `num_classes` which is 10 in th... | y_true = tf.placeholder(tf.float32, [None, num_classes]) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Finally we have the placeholder variable for the true class of each image in the placeholder variable `x`. These are integers and the dimensionality of this placeholder variable is set to `[None]` which means the placeholder variable is a one-dimensional vector of arbitrary length. | y_true_cls = tf.placeholder(tf.int64, [None]) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Variables to be optimized Apart from the placeholder variables that were defined above and which serve as feeding input data into the model, there are also some model variables that must be changed by TensorFlow so as to make the model perform better on the training data.The first variable that must be optimized is ca... | weights = tf.Variable(tf.zeros([img_size_flat, num_classes])) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
The second variable that must be optimized is called `biases` and is defined as a 1-dimensional tensor (or vector) of length `num_classes`. | biases = tf.Variable(tf.zeros([num_classes])) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Model This simple mathematical model multiplies the images in the placeholder variable `x` with the `weights` and then adds the `biases`.The result is a matrix of shape `[num_images, num_classes]` because `x` has shape `[num_images, img_size_flat]` and `weights` has shape `[img_size_flat, num_classes]`, so the multipl... | logits = tf.matmul(x, weights) + biases | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Now `logits` is a matrix with `num_images` rows and `num_classes` columns, where the element of the $i$'th row and $j$'th column is an estimate of how likely the $i$'th input image is to be of the $j$'th class.However, these estimates are a bit rough and difficult to interpret because the numbers may be very small or l... | y_pred = tf.nn.softmax(logits) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
The predicted class can be calculated from the `y_pred` matrix by taking the index of the largest element in each row. | y_pred_cls = tf.argmax(y_pred, axis=1) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Cost-function to be optimized To make the model better at classifying the input images, we must somehow change the variables for `weights` and `biases`. To do this we first need to know how well the model currently performs by comparing the predicted output of the model `y_pred` to the desired output `y_true`.The cros... | cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,
labels=y_true) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
We have now calculated the cross-entropy for each of the image classifications so we have a measure of how well the model performs on each image individually. But in order to use the cross-entropy to guide the optimization of the model's variables we need a single scalar value, so we simply take the average of the cros... | cost = tf.reduce_mean(cross_entropy) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Optimization method Now that we have a cost measure that must be minimized, we can then create an optimizer. In this case it is the basic form of Gradient Descent where the step-size is set to 0.5.Note that optimization is not performed at this point. In fact, nothing is calculated at all, we just add the optimizer-ob... | optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(cost) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Performance measures We need a few more performance measures to display the progress to the user.This is a vector of booleans whether the predicted class equals the true class of each image. | correct_prediction = tf.equal(y_pred_cls, y_true_cls) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
This calculates the classification accuracy by first type-casting the vector of booleans to floats, so that False becomes 0 and True becomes 1, and then calculating the average of these numbers. | accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
TensorFlow Run Create TensorFlow sessionOnce the TensorFlow graph has been created, we have to create a TensorFlow session which is used to execute the graph. | session = tf.Session() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Initialize variablesThe variables for `weights` and `biases` must be initialized before we start optimizing them. | session.run(tf.global_variables_initializer()) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Helper-function to perform optimization iterations There are 55.000 images in the training-set. It takes a long time to calculate the gradient of the model using all these images. We therefore use Stochastic Gradient Descent which only uses a small batch of images in each iteration of the optimizer. | batch_size = 100 | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Function for performing a number of optimization iterations so as to gradually improve the `weights` and `biases` of the model. In each iteration, a new batch of data is selected from the training-set and then TensorFlow executes the optimizer using those training samples. | def optimize(num_iterations):
for i in range(num_iterations):
# Get a batch of training examples.
# x_batch now holds a batch of images and
# y_true_batch are the true labels for those images.
x_batch, y_true_batch, _ = data.random_batch(batch_size=batch_size)
# Put ... | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Helper-functions to show performance Dict with the test-set data to be used as input to the TensorFlow graph. Note that we must use the correct names for the placeholder variables in the TensorFlow graph. | feed_dict_test = {x: data.x_test,
y_true: data.y_test,
y_true_cls: data.y_test_cls} | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Function for printing the classification accuracy on the test-set. | def print_accuracy():
# Use TensorFlow to compute the accuracy.
acc = session.run(accuracy, feed_dict=feed_dict_test)
# Print the accuracy.
print("Accuracy on test-set: {0:.1%}".format(acc)) | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Function for printing and plotting the confusion matrix using scikit-learn. | def print_confusion_matrix():
# Get the true classifications for the test-set.
cls_true = data.y_test_cls
# Get the predicted classifications for the test-set.
cls_pred = session.run(y_pred_cls, feed_dict=feed_dict_test)
# Get the confusion matrix using sklearn.
cm = confusion_matrix(y_tru... | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Function for plotting examples of images from the test-set that have been mis-classified. | def plot_example_errors():
# Use TensorFlow to get a list of boolean values
# whether each test-image has been correctly classified,
# and a list for the predicted class of each image.
correct, cls_pred = session.run([correct_prediction, y_pred_cls],
feed_dict=feed_di... | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Helper-function to plot the model weights Function for plotting the `weights` of the model. 10 images are plotted, one for each digit that the model is trained to recognize. | def plot_weights():
# Get the values for the weights from the TensorFlow variable.
w = session.run(weights)
# Get the lowest and highest values for the weights.
# This is used to correct the colour intensity across
# the images so they can be compared with each other.
w_min = np.min(w)
... | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Performance before any optimizationThe accuracy on the test-set is 9.8%. This is because the model has only been initialized and not optimized at all, so it always predicts that the image shows a zero digit, as demonstrated in the plot below, and it turns out that 9.8% of the images in the test-set happens to be zero ... | print_accuracy()
plot_example_errors() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Performance after 1 optimization iterationAlready after a single optimization iteration, the model has increased its accuracy on the test-set significantly. | optimize(num_iterations=1)
print_accuracy()
plot_example_errors() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
The weights can also be plotted as shown below. Positive weights are red and negative weights are blue. These weights can be intuitively understood as image-filters.For example, the weights used to determine if an image shows a zero-digit have a positive reaction (red) to an image of a circle, and have a negative reac... | plot_weights() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Performance after 10 optimization iterations | # We have already performed 1 iteration.
optimize(num_iterations=9)
print_accuracy()
plot_example_errors()
plot_weights() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Performance after 1000 optimization iterationsAfter 1000 optimization iterations, the model only mis-classifies about one in ten images. As demonstrated below, some of the mis-classifications are justified because the images are very hard to determine with certainty even for humans, while others are quite obvious and ... | # We have already performed 10 iterations.
optimize(num_iterations=990)
print_accuracy()
plot_example_errors() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
The model has now been trained for 1000 optimization iterations, with each iteration using 100 images from the training-set. Because of the great variety of the images, the weights have now become difficult to interpret and we may doubt whether the model truly understands how digits are composed from lines, or whether ... | plot_weights() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
We can also print and plot the so-called confusion matrix which lets us see more details about the mis-classifications. For example, it shows that images actually depicting a 5 have sometimes been mis-classified as all other possible digits, but mostly as 6 or 8. | print_confusion_matrix() | [[ 956 0 3 1 1 4 11 3 1 0]
[ 0 1114 2 2 1 2 4 2 8 0]
[ 6 8 925 23 11 3 13 12 26 5]
[ 3 1 19 928 0 34 2 10 5 8]
[ 1 3 4 2 918 2 11 2 6 33]
[ 8 3 7 36 8 781 15 6 20 8]
[... | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
We are now done using TensorFlow, so we close the session to release its resources. | # This has been commented out in case you want to modify and experiment
# with the Notebook without having to restart it.
# session.close() | _____no_output_____ | MIT | 01_Simple_Linear_Model.ipynb | Asciotti/TensorFlow-Tutorials |
Modelling trend life cycles in scientific research**Authors:** E. Tattershall, G. Nenadic, and R.D. Stevens**Abstract:** Scientific topics vary in popularity over time. In this paper, we model the life-cycles of 200 topics by fitting the Logistic and Gompertz models to their frequency over time in published abstracts.... | import os
import csv
import pandas as pd
from collections import defaultdict
import matplotlib.pyplot as plt
from matplotlib.ticker import FormatStrFormatter
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import numpy as np
import scipy
from scip... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
The dataWe have four datasets:- **Computer Science (dblp_cs):** This dataset contains 2.6 million abstracts downloaded from Semantic Scholar. We select all abstracts with the dblp tag.- **Particle Physics (arxiv_hep):** This dataset of 0.2 million abstracts was downloaded from arXiv's public API. We extracted particl... | document_count_per_year = {}
for dataset_name in dataset_names:
# For each dataset, we want a list of document counts for each year
document_count_per_year[dataset_name] = []
# The files in the directory are named 1988.p, 1989.p, 1990.p....
files = os.listdir(data_root+dataset_name)
min_year = np.m... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Create a vocabulary for each dataset- For each dataset, we find all **1-5 word terms** (after stopwords are removed). This allows us to use relatively complex phrases.- Since the set of all 1-5 word terms is very large and contains much noise, we filter out terms that fail to meet a **minimum threshold of "significanc... | for dataset_name in dataset_names:
vocabulary = set()
files = os.listdir(data_root+dataset_name)
min_year = np.min([int(file[0:4]) for file in files])
max_year = np.max([int(file[0:4]) for file in files])
for year in range(min_year, max_year+1):
df = pickle.load(open(data_root+dataset_... | Overall vocabulary created for arxiv_hep
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Detect bursty termsNow that we have vectors representing the document frequency of each term over time, we can use our MACD-based burst detection, as described in our earlier paper [Tattershall 2020]. | bursts = dict()
for dataset_name in dataset_names:
files = os.listdir(data_root+dataset_name)
min_year = np.min([int(file[0:4]) for file in files])
max_year = np.max([int(file[0:4]) for file in files])
# Create a dataset object for the burst detection algorithm
bd_dataset = burst_detection.Dat... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Calculate burst co-occurence We now have 300 bursts per dataset. Some of these describe very similar concepts, such as "internet of things" and "iot". The purpose of this section is the merge similar terms into clusters to prevent redundancy within the dataset. We calculate the relatedness of terms using term co-occur... | for dataset_name in dataset_names:
vectors = []
vectorizer = CountVectorizer(strip_accents='ascii',
ngram_range=(1,5),
stop_words=stop,
vocabulary=bursts[dataset_name])
for year in range(min_year, max_ye... | C:\Users\emmat\Anaconda3\lib\site-packages\scipy\sparse\_index.py:126: SparseEfficiencyWarning: Changing the sparsity structure of a csc_matrix is expensive. lil_matrix is more efficient.
self._set_arrayXarray(i, j, x)
C:\Users\emmat\Anaconda3\lib\site-packages\scipy\sparse\_index.py:126: SparseEfficiencyWarning: Cha... | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Use burst co-occurrence to cluster termsWe use a hierarchichal clustering method to group terms together. This is highly customisable due to threshold setting, allowing us to group more or less conservatively if required. | # Reload bursts if required by uncommenting this line
#bursts = pickle.load(open(root+'bursts.p', "rb"))
dataset_clusters = dict()
for dataset_name in dataset_names:
#cooccurrence = pickle.load(open('Data/stacked_vectors/'+dataset_name+"/cooccurrence_matrix.p", "rb"))
# Translate co-occurence into a dista... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Manual choice of clustersWe now sort the clusters in order of burstiness (using the burstiness of the most bursty term in the cluster) and manually exclude clusters that include publishing artefacts such as "elsevier science bv right reserved". From the remainder, we select the top fifty. We do this for all four datas... | raw_clusters = pd.read_csv('200clusters.csv')
cluster_dict = defaultdict(list)
for dataset_name in dataset_names:
for raw_cluster in raw_clusters[dataset_name]:
cluster_dict[dataset_name].append(raw_cluster.split(','))
for dataset_name in dataset_names:
# List all the cluster terms. This will ... | 1994.p
1995.p
1996.p
1997.p
1998.p
1999.p
2000.p
2001.p
2002.p
2003.p
2004.p
2005.p
2006.p
2007.p
2008.p
2009.p
2010.p
2011.p
2012.p
2013.p
2014.p
2015.p
2016.p
2017.p
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Curve fittingThe below is a pythonic version of the Loglet Lab 4 code found at https://github.com/pheguest/logletlab4. Loglet Lab also has a web interface at https://logletlab.com/ which allows you to create amazing graphs. However, the issue with the web interface is that it is not designed for processing hundreds of... | curve_header_1 = ['', 'd', 'k', 'a', 'b', 'RMS']
curve_header_2 = ['', 'd', 'k1', 'a1', 'b1', 'k2', 'a2', 'b2', 'RMS']
dataset_names = ['arxiv_hep', 'pubmed_mh', 'pubmed_cancer', 'dblp_cs']
for dataset_name in dataset_names:
print('-'*50)
print(dataset_name.upper())
for curve_type in ['logistic', 'gom... | --------------------------------------------------
ARXIV_HEP
logistic_single 1 125 gev 0.029907304762336263
logistic_single 1 pentaquark,pentaquarks 0.05043852824061915
logistic_single 1 wmap,wilkinson microwave anisotropy probe 0.0361380293123339
logistic_single 1 lhc run 0.020735398919035756
logistic_single 1 pamela ... | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Reload the dataThe preceding step is very long, and may take many hours to complete. Therefore, since we did it in chunks, we now reload the results from memory. | # Load the data back up (since the steps above store the results in files, not local memory)
document_count_per_year = pickle.load(open(root+'document_count_per_year.p', "rb"))
datasets = {}
for dataset_name in dataset_names:
datasets[dataset_name] = {}
for curve_type in ['logistic', 'gompertz']:
d... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Graph: Example single-peaked fit for XML | x = range(1988,2018)
term = 'xml'
# Load the original time series for xml
df = pickle.load(open(root+'clusters/dblp_cs.p', 'rb'))
# Divide the data for each year by the document count in each year
y_proportional = df[term].divide(document_count_per_year['dblp_cs'])
# Calculate Logistic and Gompertz curves from the p... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Table of results for Logistic vs GompertzCompare the error of the Logistic and Gompertz models across the entire dataset of 200 trends. | def statistics(df):
mean = df.mean()
ci = 1.96*logistic_error.std()/np.sqrt(len(logistic_error))
median = df.median()
std = df.std()
return [mean, mean-ci, mean+ci, median, std]
logistic_error = pd.concat([datasets['arxiv_hep']['logistic']['single']['RMS'],
datasets['dblp_cs']['log... | Logistic
Mean = 0.029
95% CI = [ 0.027 , 0.031 ]
Median = 0.029
STDEV = 0.014
Gompertz
Mean = 0.023
95% CI = [ 0.021 , 0.026 ]
Median = 0.019
STDEV = 0.017
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Is the difference between the means significant?Here we use an independent t-test to investigate significance. | scipy.stats.ttest_ind(logistic_error, gompertz_error, axis=0, equal_var=True, nan_policy='propagate') | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Yes, it is significant! However, since the data is slightly skewed, we can also test the signficance of the difference between medians using Mood's median test: | stat, p, med, tbl = scipy.stats.median_test(logistic_error, gompertz_error)
print(p) | 1.1980742802127062e-08
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
So either way, the p-value is very low, causing us to reject the null hypothesis. This leads us to the conclusion that the **Gompertz model** is more appropriate for the task of modelling publishing activity over time. Box and whisker plots of Logistic and Gompertz model error | axs = pd.DataFrame({
'CS Logistic': datasets['dblp_cs']['logistic']['single']['RMS'],
'CS Gompertz': datasets['dblp_cs']['gompertz']['single']['RMS'],
'Physics Logistic': datasets['arxiv_hep']['logistic']['single']['RMS'],
'Physics Gompertz': datasets['arxiv_hep']['gompertz']['single']['RMS'],
'MH L... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
There is some variation across the datasets, although the Gompertz model is consistent in producing a lower median error than the Logistic model. It's worth noting also that the Particle Physics and Mental Health datasets are smaller than the Cancer and Computer Science ones. They also have higher error. Calculation ... | conversion_factor = -((np.log(-np.log(0.9))-np.log(-np.log(0.1)))/np.log(np.log(81)))
spans = pd.DataFrame({
'Computer Science': datasets['dblp_cs']['gompertz']['single']['a']*conversion_factor,
'Particle Physics': datasets['arxiv_hep']['gompertz']['single']['a']*conversion_factor,
'Mental Health': datasets... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
The data is quite skewed here...something to bear in mind when testing for significance later. Median trend durations in different disciplines | for i , dataset_name in enumerate(dataset_names):
print(dataset_titles[i], '| Median trend duration =', np.round(np.median(datasets[dataset_name]['gompertz']['single']['a']*conversion_factor),1), 'years')
| Computer science (dblp) | Median trend duration = 25.8 years
Particle physics (arXiv) | Median trend duration = 15.1 years
Mental health (PubMed) | Median trend duration = 24.6 years
Cancer (PubMed) | Median trend duration = 13.4 years
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Testing for significance between disciplinesThere are substantial differences between the median trend durations, with Computer Science and Particle Physics having shorter durations and the two PubMed datasets having longer ones. But are these significant? Since the data is somewhat skewed, we use Mood's median test t... | for i in range(4):
for j in range(i,4):
if i == j:
pass
else:
spans1 = datasets[dataset_names[i]]['gompertz']['single']['a']*conversion_factor
spans2 = datasets[dataset_names[j]]['gompertz']['single']['a']*conversion_factor
stat, p, med, tbl = scipy.st... | Computer science (dblp) vs Particle physics (arXiv) p-value = 0.003
Computer science (dblp) vs Mental health (PubMed) p-value = 0.841
Computer science (dblp) vs Cancer (PubMed) p-value = 0.009
Particle physics (arXiv) vs Mental health (PubMed) p-value = 0.072
Particle physics (arXiv) vs Cancer (PubMed) p-value = 0.549
... | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
So the p value between Particle Physics and Computer Science is not acceptable, and neither is the p-value between Mental Health and Cancer. How about between these two groups? | dblp_spans = datasets['dblp_cs']['gompertz']['single']['a']*conversion_factor
cancer_spans = datasets['pubmed_cancer']['gompertz']['single']['a']*conversion_factor
arxiv_spans = datasets['arxiv_hep']['gompertz']['single']['a']*conversion_factor
mh_spans = datasets['pubmed_mh']['gompertz']['single']['a']*conversion_fact... | 0.00013
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
This difference IS significant! Double-peaking curvesWe now move to analyse the data for double-peaked curves. For each term, we have calculated the error when two peaks are fitted, and the error when a single peak is fitted. We can compare the error in each case like so: | print('Neural networks, single peak | error =', np.round(datasets['dblp_cs']['gompertz']['single']['RMS']['neural network'],3))
print('Neural networks, double peak| error =', np.round(datasets['dblp_cs']['gompertz']['double']['RMS']['neural network'],3)) | Neural networks, single peak | error = 0.031
Neural networks, double peak| error = 0.011
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Where do we see the largest reductions? | difference = datasets['dblp_cs']['gompertz']['single']['RMS']-datasets['dblp_cs']['gompertz']['double']['RMS']
for term in difference.index:
if difference[term] > 0.015:
print(term, np.round(difference[term], 3)) | neural network 0.02
machine learning 0.02
convolutional neural network,cnn 0.085
discrete mathematics 0.031
parallel 0.024
recurrent 0.026
embeddings 0.037
learning model 0.024
| MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Examples of double peaking curvesSo in some cases there is an error reduction from moving from the single- to double-peaked model. What does this look like in practice? | x = range(1988,2018)
# Load the original data
df = pickle.load(open(root+'clusters/dblp_cs.p', 'rb'))
# Choose four example terms
terms = ['big data', 'cloud', 'internet', 'neural network']
titles = ['a) Big Data', 'b) Cloud', 'c) Internet', 'd) Neural network']
# We want to set an overall y-label. The solution(foun... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
Graphs of all four datasetsIn this section we try to show as many graphs of fitted models as can reasonably fit on a page. The two functions used to make the graphs [below] are very hacky! However they work for this specific purpose. | def choose_ylimit(prevalence):
'''
This function works to find the most appropriate upper y limit to make the plots look good
'''
if max(prevalence) < 0.5:
return 0.5
elif max(prevalence) > 0.5 and max(prevalence) < 0.8:
return 0.8
elif max(prevalence) > 10 and max(prevalence) < ... | _____no_output_____ | MIT | Modelling trend life cycles in scientific research.ipynb | etattershall/trend-lifecycles |
CTR预估(1)资料&&代码整理by[@寒小阳](https://blog.csdn.net/han_xiaoyang)(hanxiaoyang.ml@gmail.com)reference:* [《广告点击率预估是怎么回事?》](https://zhuanlan.zhihu.com/p/23499698)* [从ctr预估问题看看f(x)设计—DNN篇](https://zhuanlan.zhihu.com/p/28202287)* [Atomu2014 product_nets](https://github.com/Atomu2014/product-nets)关于CTR预估的背景推荐大家看欧阳辰老师在知乎的文章[《广告点击... | !head -5 ./data/train.txt
!head -10 ./data/featindex.txt
from __future__ import print_function
from __future__ import absolute_import
from __future__ import division
import cPickle as pkl
import numpy as np
import tensorflow as tf
from scipy.sparse import coo_matrix
# 读取数据,统计基本的信息,field等
DTYPE = tf.float32
FIELD_SIZES... | _____no_output_____ | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
定义不同的模型 | # 定义基类模型
dtype = DTYPE
class Model:
def __init__(self):
self.sess = None
self.X = None
self.y = None
self.layer_keeps = None
self.vars = None
self.keep_prob_train = None
self.keep_prob_test = None
# run model
def run(self, fetches, X=None, y=None, mod... | _____no_output_____ | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
1.LR逻辑回归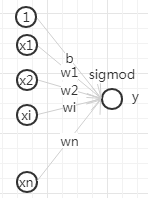输入输出:{X,y}映射函数f(x):单层单节点的“DNN”, 宽而不深,sigmoid(wx+b)输出概率,需要大量的人工特征工程,非线性来源于特征处理损失函数:logloss/... + L1/L2/...优化方法:sgd/...评估:logloss/auc/... | class LR(Model):
def __init__(self, input_dim=None, output_dim=1, init_path=None, opt_algo='gd', learning_rate=1e-2, l2_weight=0,
random_seed=None):
Model.__init__(self)
# 声明参数
init_vars = [('w', [input_dim, output_dim], 'xavier', dtype),
('b', [output_d... | read finish
train data size: (1742104, 491713)
test data size: (300928, 491713)
{'l2_weight': 0, 'learning_rate': 0.1, 'random_seed': 0, 'input_dim': 491713, 'opt_algo': 'gd'}
| Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
2.FMFM可以视作有二次交叉的LR,为了控制参数量和充分学习,提出了user vector和item vector的概念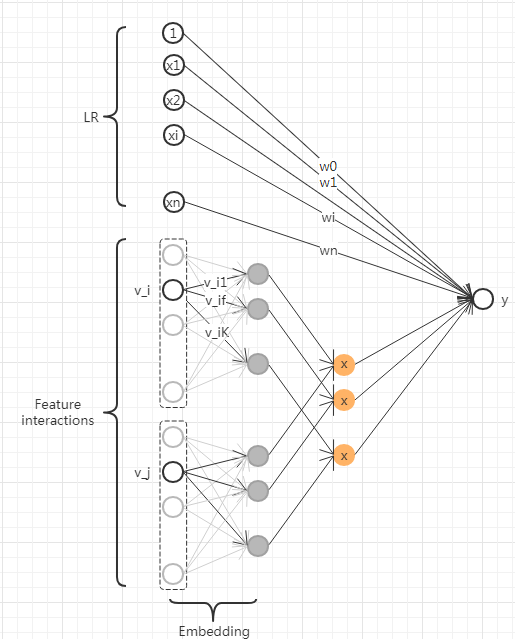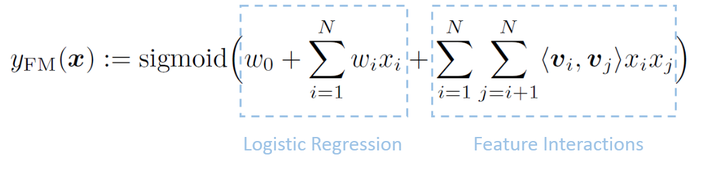 | class FM(Model):
def __init__(self, input_dim=None, output_dim=1, factor_order=10, init_path=None, opt_algo='gd', learning_rate=1e-2,
l2_w=0, l2_v=0, random_seed=None):
Model.__init__(self)
# 一次、二次交叉、偏置项
init_vars = [('w', [input_dim, output_dim], 'xavier', dtype),
... | read finish
train data size: (1742104, 491713)
test data size: (300928, 491713)
{'l2_w': 0, 'l2_v': 0, 'factor_order': 10, 'learning_rate': 0.1, 'input_dim': 491713, 'opt_algo': 'gd'}
| Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
FNNFNN的考虑是模型的capacity可以进一步提升,以对更复杂的场景建模。FNN可以视作FM + MLP = LR + MF + MLP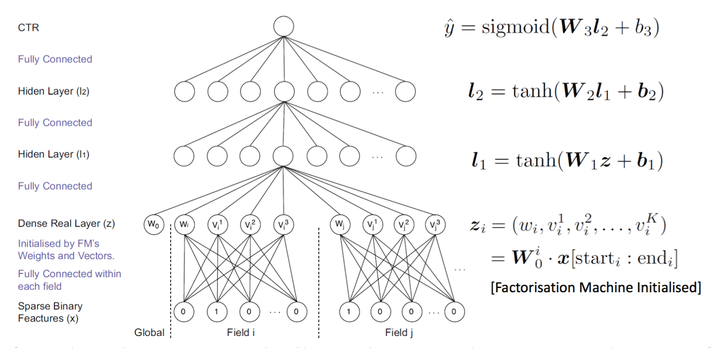 | class FNN(Model):
def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,
embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):
Model.__init__(self)
init_vars = []
num_inputs = len(fi... | read finish
train data size: (1742104, 491713)
test data size: (300928, 491713)
remove empty fields [25, 445852, 36, 371, 4, 11328, 33995, 12, 7, 5, 4, 20, 2, 38, 6, 8]
{'field_sizes': [25, 445852, 36, 371, 4, 11328, 33995, 12, 7, 5, 4, 20, 2, 38, 6, 8], 'layer_acts': ['relu', None], 'embed_l2': 0, 'drop_out': [0, 0], ... | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
CCPMreference:[ctr模型汇总](https://zhuanlan.zhihu.com/p/32523455)FM只能学习特征的二阶组合,但CNN能学习更高阶的组合,可学习的阶数和卷积的视野相关。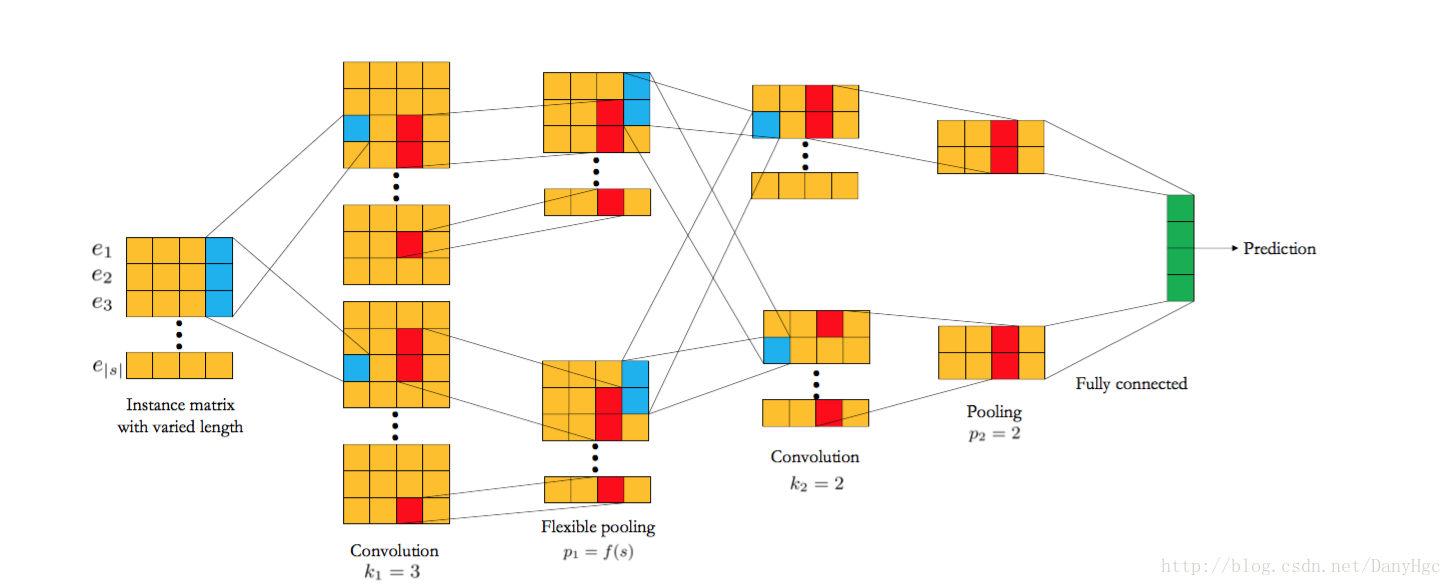mbedding层:e1, e2…en是某特定用户被展示的一系列广... | class CCPM(Model):
def __init__(self, field_sizes=None, embed_size=10, filter_sizes=None, layer_acts=None, drop_out=None,
init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):
Model.__init__(self)
init_vars = []
num_inputs = len(field_sizes)
for i in ... | _____no_output_____ | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
PNNreference:[深度学习在CTR预估中的应用](https://zhuanlan.zhihu.com/p/35484389)可以视作FNN+product layer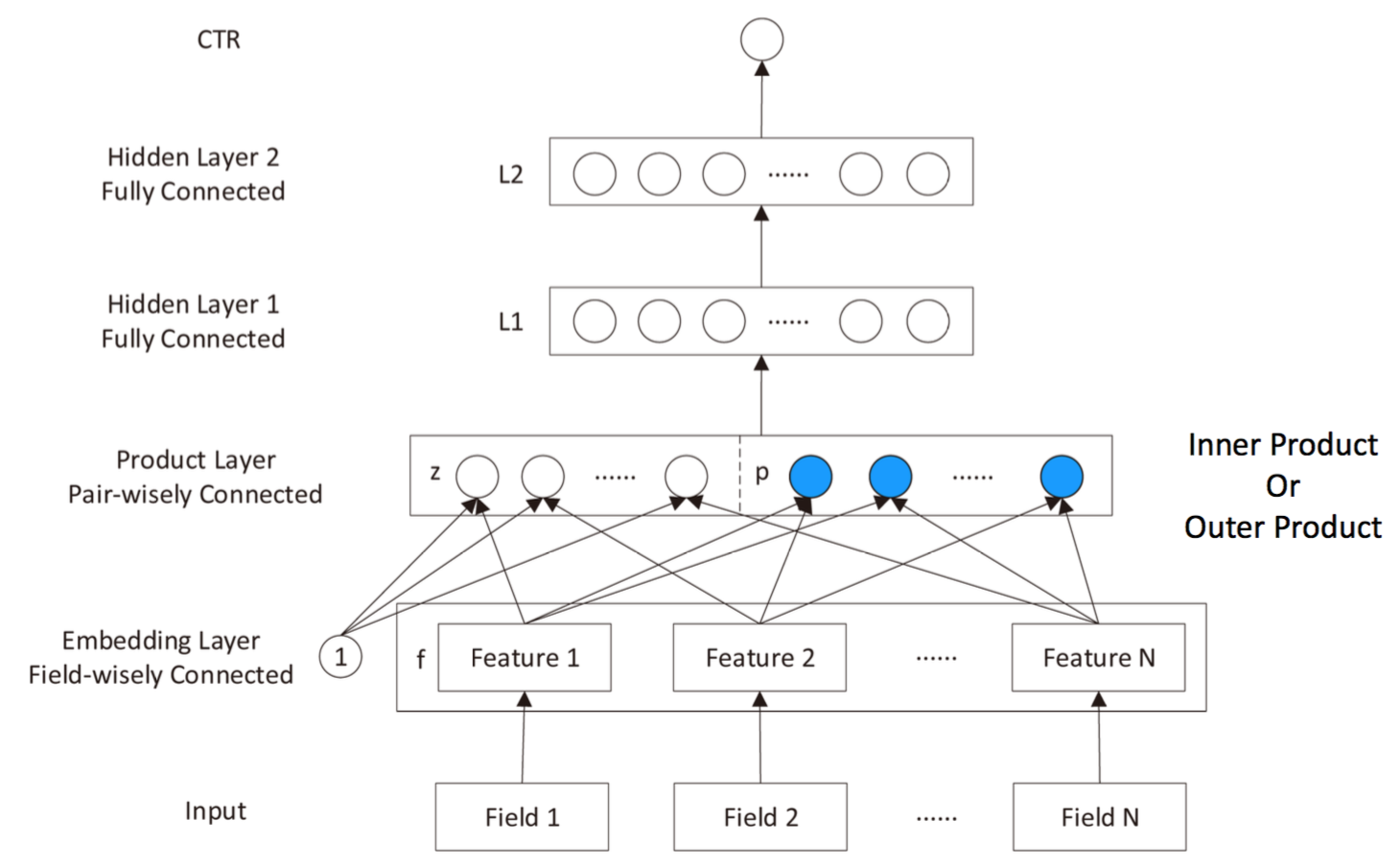PNN和FNN的主要不同在于除了得到z向量,还增加了一个p向量,即Product向量。Product向量由每个category field的feature vector做inner product 或则 outer product 得到,作者认为这样做有助于特征交叉。另外PNN中Embeding层不再由FM生成,可以在整个网络中训练... | class PNN1(Model):
def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,
embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None):
Model.__init__(self)
init_vars = []
num_inputs = len(f... | _____no_output_____ | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
PNN2 | class PNN2(Model):
def __init__(self, field_sizes=None, embed_size=10, layer_sizes=None, layer_acts=None, drop_out=None,
embed_l2=None, layer_l2=None, init_path=None, opt_algo='gd', learning_rate=1e-2, random_seed=None,
layer_norm=True):
Model.__init__(self)
init_va... | _____no_output_____ | Apache-2.0 | notebooks/CTR_prediction_LR_FM_CCPM_PNN.ipynb | daiwk/grace_t |
Take a look into the 2016 data | df2016.head(n=2)
df2016.shape | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
So in the 2016 dataset there are about 10.6 million entries for parking ticket, and each entry has 51 columns.Lets take a look at the number of unique values for each column name... | d = {'Unique Entry': df2016.nunique(axis = 0),
'Nan Entry': df2016.isnull().any()}
pd.DataFrame(data = d, index = df2016.columns.values) | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
As it turns out, the last 11 columns in this dataset has no entry. So we can ignore those columns, while carrying out any visualization operation in this dataframe.Also if the entry does not have a **Plate ID** it is very hard to locate those cars. Therefore I am going to drop those rows as well. | drop_column = ['No Standing or Stopping Violation', 'Hydrant Violation',
'Double Parking Violation', 'Latitude', 'Longitude',
'Community Board', 'Community Council ', 'Census Tract', 'BIN',
'BBL', 'NTA',
'Street Code1', 'Street Code2', 'Street Code3','Meter Nu... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Check if there is anymore rows left without a **Plate ID**. | df2016['Plate ID'].isnull().any()
df2016.shape | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Create a sample data for visualization The cleaned dataframe has 10624735 rows and 40 columns. But this is still a lot of data points. I does not make sense to use all of them to get an idea of distribution of the data points. So for visualization I will use only 0.1% of the whole data. Assmuing that the entries are n... | mini2016 = df2016.sample(frac = 0.01, replace = False)
mini2016.shape | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
My sample dataset has about 10K data points, which I will use for data visualization. Using the whole dataset is unnecessary and time consuming. Barplot of 'Registration State' | x_ticks = mini2016['Registration State'].value_counts().index
heights = mini2016['Registration State'].value_counts()
y_pos = np.arange(len(x_ticks))
fig = plt.figure(figsize=(15,14))
# Create horizontal bars
plt.barh(y_pos, heights)
# Create names on the y-axis
plt.yticks(y_pos, x_ticks)
# Show graphic
plt.show()... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
You can see from the barplot above: in our sample ~77.67% cars are registered in state : **NY**. After that 9.15% cars are registered in state : **NJ**, followed by **PA**, **CT**, and **FL**. How the number of tickets given changes with each month? | month = []
for time_stamp in pd.to_datetime(mini2016['Issue Date']):
month.append(time_stamp.month)
m_count = pd.Series(month).value_counts()
plt.figure(figsize=(12,8))
sns.barplot(y=m_count.values, x=m_count.index, alpha=0.6)
plt.title("Number of Parking Ticket Given Each Month", fontsize=16)
plt.xlabel("Month", ... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
So from the barplot above **March** and **October** has the highest number of tickets! How many parking tickets are given for each violation code? | violation_code = mini2016['Violation Code'].value_counts()
plt.figure(figsize=(16,8))
f = sns.barplot(y=violation_code.values, x=violation_code.index, alpha=0.6)
#plt.xticks(np.arange(0,101, 10.0))
f.set(xticks=np.arange(0,100, 5.0))
plt.title("Number of Parking Tickets Given for Each Violation Code", fontsize=16)
plt... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
How many parking tickets are given for each body type? | x_ticks = mini2016['Vehicle Body Type'].value_counts().index
heights = mini2016['Vehicle Body Type'].value_counts().values
y_pos = np.arange(len(x_ticks))
fig = plt.figure(figsize=(15,4))
f = sns.barplot(y=heights, x=y_pos, orient = 'v', alpha=0.6);
# remove labels
plt.tick_params(labelbottom='off')
plt.ylabel('No. of ... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Top 10 car body types that get the most parking tickets are listed below : | df_bodytype
df_bodytype.sum(axis = 0)/len(mini2016) | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Top 10 vehicle body type includes 93.42% of my sample dataset. How many parking tickets are given for each vehicle make? Just for the sake of changing the flavor of visualization this time I will make a logplot of car no. vs make. In that case we will be able to see much smaller values in the same graph with larger va... | vehicle_make = mini2016['Vehicle Make'].value_counts()
plt.figure(figsize=(16,8))
f = sns.barplot(y=np.log(vehicle_make.values), x=vehicle_make.index, alpha=0.6)
# remove labels
plt.tick_params(labelbottom='off')
plt.ylabel('log(No. of cars)', fontsize=16);
plt.xlabel('Car make [Label turned off due to crowding. Too m... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Insight on violation time In the raw data the **Violaation Time** is in a format, which is non-interpretable using standard **to_datatime** function in pandas. We need to change it in a useful format so that we can use the data. After formatting we may replace the old **Violation Time ** column with the new one. | timestamp = []
for time in mini2016['Violation Time']:
if len(str(time)) == 5:
time = time[:2] + ':' + time[2:]
timestamp.append(pd.to_datetime(time, errors='coerce'))
else:
timestamp.append(pd.NaT)
mini2016 = mini2016.assign(Violation_Time2 = timestamp)
mini2016.drop(['Violation T... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
So in the new **Violation Time** column the data is in **Timestamp** format. | hours = [lambda x: x.hour, mini2016['Violation Time']]
# Getting the histogram
mini2016.set_index('Violation Time', drop=False, inplace=True)
plt.figure(figsize=(16,8))
mini2016['Violation Time'].groupby(pd.TimeGrouper(freq='30Min')).count().plot(kind='bar');
plt.tick_params(labelbottom='on')
plt.ylabel('No. of cars', ... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Parking ticket vs county | violation_county = mini2016['Violation County'].value_counts()
plt.figure(figsize=(16,8))
f = sns.barplot(y=violation_county.values, x=violation_county.index, alpha=0.6)
# remove labels
plt.tick_params(labelbottom='on')
plt.ylabel('No. of cars', fontsize=16);
plt.xlabel('County', fontsize=16);
plt.title('Parking ticke... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Unregistered Vehicle? | sns.countplot(x = 'Unregistered Vehicle?', data = mini2016)
mini2016['Unregistered Vehicle?'].unique() | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Vehicle Year | pd.DataFrame(mini2016['Vehicle Year'].value_counts()).nlargest(10, columns = ['Vehicle Year'])
plt.figure(figsize=(20,8))
sns.countplot(x = 'Vehicle Year', data = mini2016.loc[(mini2016['Vehicle Year']>1980) & (mini2016['Vehicle Year'] <= 2018)]); | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
Violation In Front Of Or Opposite | plt.figure(figsize=(16,8))
sns.countplot(x = 'Violation In Front Of Or Opposite', data = mini2016);
# create data
names = mini2016['Violation In Front Of Or Opposite'].value_counts().index
size = mini2016['Violation In Front Of Or Opposite'].value_counts().values
# Create a circle for the center of the plot
my_circle... | _____no_output_____ | MIT | preliminary-data-visualization.ipynb | argha48/nyc-parking-ticket |
CER041 - Install signed Knox certificate========================================This notebook installs into the Big Data Cluster the certificate signedusing:- [CER031 - Sign Knox certificate with generated CA](../cert-management/cer031-sign-knox-generated-cert.ipynb)Steps----- Parameters | app_name = "gateway"
scaledset_name = "gateway/pods/gateway-0"
container_name = "knox"
prefix_keyfile_name = "knox"
common_name = "gateway-svc"
test_cert_store_root = "/var/opt/secrets/test-certificates" | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Common functionsDefine helper functions used in this notebook. | # Define `run` function for transient fault handling, suggestions on error, and scrolling updates on Windows
import sys
import os
import re
import json
import platform
import shlex
import shutil
import datetime
from subprocess import Popen, PIPE
from IPython.display import Markdown
retry_hints = {}
error_hints = {}
i... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Get the Kubernetes namespace for the big data clusterGet the namespace of the big data cluster use the kubectl command lineinterface .NOTE: If there is more than one big data cluster in the targetKubernetes cluster, then set \[0\] to the correct value for the big datacluster. | # Place Kubernetes namespace name for BDC into 'namespace' variable
try:
namespace = run(f'kubectl get namespace --selector=MSSQL_CLUSTER -o jsonpath={{.items[0].metadata.name}}', return_output=True)
except:
from IPython.display import Markdown
print(f"ERROR: Unable to find a Kubernetes namespace with labe... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Create a temporary directory to stage files | # Create a temporary directory to hold configuration files
import tempfile
temp_dir = tempfile.mkdtemp()
print(f"Temporary directory created: {temp_dir}") | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Helper function to save configuration files to disk | # Define helper function 'save_file' to save configuration files to the temporary directory created above
import os
import io
def save_file(filename, contents):
with io.open(os.path.join(temp_dir, filename), "w", encoding='utf8', newline='\n') as text_file:
text_file.write(contents)
print("File saved:... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Get name of the ‘Running’ `controller` `pod` | # Place the name of the 'Running' controller pod in variable `controller`
controller = run(f'kubectl get pod --selector=app=controller -n {namespace} -o jsonpath={{.items[0].metadata.name}} --field-selector=status.phase=Running', return_output=True)
print(f"Controller pod name: {controller}") | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Pod name for gateway | pod = 'gateway-0' | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Copy certifcate files from `controller` to local machine | import os
cwd = os.getcwd()
os.chdir(temp_dir) # Use chdir to workaround kubectl bug on Windows, which incorrectly processes 'c:\' on kubectl cp cmd line
run(f'kubectl cp {controller}:{test_cert_store_root}/{app_name}/{prefix_keyfile_name}-certificate.pem {prefix_keyfile_name}-certificate.pem -c controller -n {names... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Copy certifcate files from local machine to `controldb` | import os
cwd = os.getcwd()
os.chdir(temp_dir) # Workaround kubectl bug on Windows, can't put c:\ on kubectl cp cmd line
run(f'kubectl cp {prefix_keyfile_name}-certificate.pem controldb-0:/var/opt/mssql/{prefix_keyfile_name}-certificate.pem -c mssql-server -n {namespace}')
run(f'kubectl cp {prefix_keyfile_name}-priv... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Get the `controller-db-rw-secret` secretGet the controller SQL symmetric key password for decryption. | import base64
controller_db_rw_secret = run(f'kubectl get secret/controller-db-rw-secret -n {namespace} -o jsonpath={{.data.encryptionPassword}}', return_output=True)
controller_db_rw_secret = base64.b64decode(controller_db_rw_secret).decode('utf-8')
print("controller_db_rw_secret retrieved") | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Update the files table with the certificates through opened SQL connection | import os
sql = f"""
OPEN SYMMETRIC KEY ControllerDbSymmetricKey DECRYPTION BY PASSWORD = '{controller_db_rw_secret}'
DECLARE @FileData VARBINARY(MAX), @Key uniqueidentifier;
SELECT @Key = KEY_GUID('ControllerDbSymmetricKey');
SELECT TOP 1 @FileData = doc.BulkColumn FROM OPENROWSET(BULK N'/var/opt/mssql/{prefix_key... | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Clear out the controller\_db\_rw\_secret variable | controller_db_rw_secret= "" | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Clean up certificate staging areaRemove the certificate files generated on disk (they have now beenplaced in the controller database). | cmd = f"rm -r {test_cert_store_root}/{app_name}"
run(f'kubectl exec {controller} -c controller -n {namespace} -- bash -c "{cmd}"') | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Restart knox gateway service | run(f'kubectl delete pod {pod} -n {namespace}') | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
Clean up temporary directory for staging configuration files | # Delete the temporary directory used to hold configuration files
import shutil
shutil.rmtree(temp_dir)
print(f'Temporary directory deleted: {temp_dir}')
print('Notebook execution complete.') | _____no_output_____ | MIT | Big-Data-Clusters/CU3/Public/content/cert-management/cer041-install-knox-cert.ipynb | gantz-at-incomm/tigertoolbox |
print a list of Lil's that are more popular than Lil's Kim | for artist in artist_info:
print(artist['name'])
if artist['name']== "Lil' Kim":
print("Found Lil Kim")
print(artist['popularity'])
else:
pass #print
Lil_kim_popularity = 62
more_popular_than_Lil_kim = []
for artist in artist_info:
if artist['popularity'] > Lil_kim_popularity:
... | Lil Wayne is more popular with a score of 86
Lil Yachty is more popular with a score of 73
Lil Uzi Vert is more popular with a score of 74
Lil Dicky is more popular with a score of 68
Boosie Badazz is more popular with a score of 67
Lil Jon is more popular with a score of 72
King Lil G is less popular with a score of 6... | MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
Pick two of your favorite Lils to fight it out, and use their IDs to print out their top tracks | for artist in artist_info:
print(artist['name'], artist['id'])
#I chose Lil Fate and Lil' Flip, first I want to figure out the top track of Lil Fate
response = requests.get("https://api.spotify.com/v1/artists/6JUnsP7jmvYmdhbg7lTMQj/top-tracks?country=US")
print(response.text)
data = response.json()
type(data)
data.... | Sunshine - Explicit Album Version
Game Over
The Way We Ball
Sunny Day
Sunshine (Re-Recorded / Remastered)
Sunshine
I Can Do Dat
4 My Nigga Screw
I Shoulda Listened - Explicit Album Version
What I Been Through
| MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
Will the world explode if a musicians swears? Get an average popularity for their explicit songs vs. their non-explicit songs. How many minutes of explicit songs do they have? Non-explicit? | #for Lil' fate's top tracks
explicit_count = 0
non_explicit_count = 0
popularity_explicit = 0
popularity_non_explicit = 0
minutes_explicit = 0
minutes_non_explicit = 0
for track in data['tracks']:
if track['explicit']== True:
explicit_count = explicit_count + 1
popularity_explicit = popular... | Lil' Flip has 26.10685 of explicit songs
Lil' Flip has 16.8464 of non-explicit songs
The average popularity of Lil' Flip explicits songs is 34.166666666666664
The average popularity of Lil' Flip non-explicits songs is 37.75
| MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
Since we're talking about Lils, what about Biggies? How many total "Biggie" artists are there? How many total "Lil"s? If you made 1 request every 5 seconds, how long would it take to download information on all the Lils vs the Biggies? | response = requests.get('https://api.spotify.com/v1/search?q=Lil&type=artist&market=US')
all_lil = response.json()
print(response.text)
all_lil.keys()
all_lil['artists'].keys()
print(all_lil['artists']['total'])
response = requests.get('https://api.spotify.com/v1/search?q=Biggie&type=artist&market=US')
all_biggies = re... | 50
| MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
how to count the genres | all_genres = []
for artist in artist_info:
print("All genres we've heard of:", all_genres)
print("Current artist has:", artist['genres'])
all_genres = all_genres + artist['genres']
all_genres.count('dirty south rap')
## There is a library that comes with Python called Collections, inside of it is a thing ca... | _____no_output_____ | MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
How to automate getting all of the results | response=requests.get('https://api.spotify.com/v1/search?q=Lil&type=artist&market=US&limit50')
small_data = response.json()
data['artists']
print(len(data['artists']['items'])) #we only get 10 artists
print(data['artists']['total'])
#first page: artists 1-50, offset of 0
# https:// | _____no_output_____ | MIT | .ipynb_checkpoints/homework_5_shengying_zhao-checkpoint.ipynb | sz2472/foundations-homework |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.