
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Self-Driving Car Engineer Nanodegree Project: **Finding Lane Lines on the Road** ***In this project, you will use the tools you learned about in the lesson to identify lane lines on the road. You can develop your pipeline on a series of individual images, and later apply the result to a video stream (really just a se... | #importing some useful packages
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
import cv2
%matplotlib inline | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Read in an Image | #reading in an image
image = mpimg.imread('test_images/solidWhiteRight.jpg')
#printing out some stats and plotting
print('This image is:', type(image), 'with dimensions:', image.shape)
plt.imshow(image) # if you wanted to show a single color channel image called 'gray', for example, call as plt.imshow(gray, cmap='gra... | This image is: <class 'numpy.ndarray'> with dimensions: (540, 960, 3)
| MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Ideas for Lane Detection Pipeline **Some OpenCV functions (beyond those introduced in the lesson) that might be useful for this project are:**`cv2.inRange()` for color selection `cv2.fillPoly()` for regions selection `cv2.line()` to draw lines on an image given endpoints `cv2.addWeighted()` to coadd / overlay two i... | import math
def grayscale(img):
"""Applies the Grayscale transform
This will return an image with only one color channel
but NOTE: to see the returned image as grayscale
(assuming your grayscaled image is called 'gray')
you should call plt.imshow(gray, cmap='gray')"""
return cv2.cvtColor(img, c... | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Test ImagesBuild your pipeline to work on the images in the directory "test_images" **You should make sure your pipeline works well on these images before you try the videos.** | import os
os.listdir("test_images/") | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Build a Lane Finding Pipeline Build the pipeline and run your solution on all test_images. Make copies into the `test_images_output` directory, and you can use the images in your writeup report.Try tuning the various parameters, especially the low and high Canny thresholds as well as the Hough lines parameters. | # TODO: Build your pipeline that will draw lane lines on the test_images
# then save them to the test_images_output directory.
##1) We Have To read our Image in a grey scale fromat
Input_Image = mpimg.imread('test_images/solidWhiteCurve.jpg')
Input_Grey_Img = grayscale(Input_Image)
plt.imshow(Input_Grey_Img, cmap='gra... | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Test on VideosYou know what's cooler than drawing lanes over images? Drawing lanes over video!We can test our solution on two provided videos:`solidWhiteRight.mp4``solidYellowLeft.mp4`**Note: if you get an import error when you run the next cell, try changing your kernel (select the Kernel menu above --> Change Kernel... | # Import everything needed to edit/save/watch video clips
from moviepy.editor import VideoFileClip
from IPython.display import HTML
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# TODO: put your pipeline here,
# you should return the f... | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Let's try the one with the solid white lane on the right first ... | white_output = 'test_videos_output/solidWhiteRight.mp4'
## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video
## To do so add .subclip(start_second,end_second) to the end of the line below
## Where start_second and end_second are integer values representing the start and... | t: 10%|▉ | 21/221 [00:00<00:00, 209.97it/s, now=None] | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Play the video inline, or if you prefer find the video in your filesystem (should be in the same directory) and play it in your video player of choice. | HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(white_output)) | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Improve the draw_lines() function**At this point, if you were successful with making the pipeline and tuning parameters, you probably have the Hough line segments drawn onto the road, but what about identifying the full extent of the lane and marking it clearly as in the example video (P1_example.mp4)? Think about de... | yellow_output = 'test_videos_output/solidYellowLeft.mp4'
## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video
## To do so add .subclip(start_second,end_second) to the end of the line below
## Where start_second and end_second are integer values representing the start an... | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Writeup and SubmissionIf you're satisfied with your video outputs, it's time to make the report writeup in a pdf or markdown file. Once you have this Ipython notebook ready along with the writeup, it's time to submit for review! Here is a [link](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_templat... | def process_image1(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# TODO: put your pipeline here,
# you should return the final output (image where lines are drawn on lanes)
##1) We Have To read our Image in a grey scale fromat
Input_Grey_Img = g... | _____no_output_____ | MIT | P1.ipynb | MohamedHeshamMustafa/CarND-LaneLines-P1 |
Bayes Classifier | import util
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal as mvn
%matplotlib inline
def clamp_sample(x):
x = np.minimum(x, 1)
x = np.maximum(x, 0)
return x
class BayesClassifier:
def fit(self, X, Y):
# assume classes are numbered 0...K-1
self.K = len(set... | _____no_output_____ | MIT | Week2/Bayes Classifier.ipynb | yumengdong/GANs |
Bayes Classifier with Gaussian Mixture Models | from sklearn.mixture import BayesianGaussianMixture
class BayesClassifier:
def fit(self, X, Y):
# assume classes are numbered 0...K-1
self.K = len(set(Y))
self.gaussians = []
self.p_y = np.zeros(self.K)
for k in range(self.K):
print("Fitting gmm", k)
Xk = X[Y == k]
self.p_y[k] =... | _____no_output_____ | MIT | Week2/Bayes Classifier.ipynb | yumengdong/GANs |
Neural Network and Autoencoder | import tensorflow as tf
class Autoencoder:
def __init__(self, D, M):
# represents a batch of training data
self.X = tf.placeholder(tf.float32, shape=(None, D))
# input -> hidden
self.W = tf.Variable(tf.random_normal(shape=(D, M)) * np.sqrt(2.0 / M))
self.b = tf.Variable(np.zeros(M).astype(np.floa... | _____no_output_____ | MIT | Week2/Bayes Classifier.ipynb | yumengdong/GANs |
Our data exists as vectors in matrixes Linear algeabra helps us manipulate data to eventually find the smallest sum squared errors of our data which will give us our beta value for our regression model | import numpy as np
# create array to be transformed into vectors
x1 = np.array([1,2,1])
x2 = np.array([4,1,5])
x3 = np.array([6,8,6])
print("Array 1:", x1, sep="\n")
print("Array 2:", x2, sep="\n")
print("Array 3:", x3, sep="\n") | Array 1:
[1 2 1]
Array 2:
[4 1 5]
Array 3:
[6 8 6]
| MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
Next, transform these arrays into row vectors using matrix(). | x1 = np.matrix(x1)
x2 = np.matrix(x2)
x3 = np.matrix(x3) | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
use np.concatenate() to combine the rows | X = np.concatenate((x1, x2, x3), axis = 0)
X | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
X.getI method gets inverse of matrix | X_inverse = X.getI()
X_inverse = np.round(X_inverse, 2)
X_inverse | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
Regression function - Pulling necessary dataWe now know the necessary operations for inverting matrices and minimizing squared residuals. We can import real data and begin to analyze how variables influence one another. To start, we will use the Fraser economic freedom data. | import pandas as pd
import statsmodels.api as sm
import numpy as np
data = pd.read_csv('fraserDataWithRGDPPC.csv',
index_col = [0,1],
parse_dates = True)
data
years = np.array(sorted(list(set(data.index.get_level_values("Year")))))
years = pd.date_range(years[0], years[-2], freq = ... | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
Running Regression Model: | y_vars = ['RGDP Per Capita']
x_vars = [
'Size of Government', 'Legal System & Property Rights', 'Sound Money',
'Freedom to trade internationally', 'Regulation'
]
reg_vars = y_vars + x_vars
reg_data = data[reg_vars].dropna()
reg_data.corr().round(2)
reg_data.describe().round(2)
y = reg_data[y_vars]
x = reg_data[... | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
OLS Statistics We have calculated beta values for each independent variable, meaning that we estimated the average effect of a change in each independent variable upon the dependent variable. While this is useful, we have not yet measured the statistical significance of these estimations; neither have we determined th... | y_name = y_vars[0]
y_hat = reg_data[y_name + " Predictor"]
y_mean = reg_data[y_name].mean()
y = reg_data[y_name]
y_hat, y_mean, y
reg_data["Residuals"] = y_hat.sub(y_mean)
reg_data["Squared Residuals"] = reg_data["Residuals"].pow(2)
reg_data["Squared Errors"] = (y.sub(y_hat)) ** 2
reg_data["Squared Totals"] = (y.sub(y_... | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
Calculate t-stats | parameters = {}
for x_var in cov_matrix.keys():
parameters[x_var] = {}
parameters[x_var]["Beta"] = results.params[x_var]
parameters[x_var]["Standard Error"] = cov_matrix.loc[x_var, x_var]**(1 / 2)
parameters[x_var]["t_stats"] = parameters[x_var]["Beta"] / parameters[
x_var]["Standard Error"]
pd... | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
Plot Residuals | import matplotlib.pyplot as plt
plt.rcParams.update({"font.size": 26})
fig, ax = plt.subplots(figsize=(12, 8))
reg_data[["Residuals"]].plot.hist(bins=100, ax=ax)
plt.xticks(rotation=60) | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
slightly skewed left. Need to log the data in order to normally distrbute it Regression using rates | reg_data = data
reg_data["RGDP Per Capita"] = data.groupby("ISO_Code")["RGDP Per Capita"].pct_change()
reg_data["RGDP Per Capita Lag"] = reg_data["RGDP Per Capita"].shift()
reg_data = reg_data.replace([np.inf, -np.inf], np.nan).dropna(axis = 0, how = "any")
reg_data.loc["USA"]
reg_data.corr().round(2)
y_var = ["RGDP ... | _____no_output_____ | MIT | In-Class Projects/Project 8 - Working with OLS.ipynb | zacharyejohnson/ECON411 |
DatafaucetDatafaucet is a productivity framework for ETL, ML application. Simplifying some of the common activities which are typical in Data pipeline such as project scaffolding, data ingesting, start schema generation, forecasting etc. | import datafaucet as dfc | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Loading and Saving Data | dfc.project.load()
query = """
SELECT
p.payment_date,
p.amount,
p.rental_id,
p.staff_id,
c.*
FROM payment p
INNER JOIN customer c
ON p.customer_id = c.customer_id;
"""
df = dfc.load(query, 'pagila') | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Select cols | df.cols.find('id').columns
df.cols.find(by_type='string').columns
df.cols.find(by_func=lambda x: x.startswith('st')).columns
df.cols.find('^st').columns | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Collect data, oriented by rows or cols | df.cols.find(by_type='numeric').rows.collect(3)
df.cols.find(by_type='string').collect(3)
df.cols.find('name', 'date').data.collect(3) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Get just one row or column | df.cols.find('active', 'amount', 'name').one()
df.cols.find('active', 'amount', 'name').rows.one() | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Grid view | df.cols.find('amount', 'id', 'name').data.grid(5) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Data Exploration | df.cols.find('amount', 'id', 'name').data.facets() | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Rename columns | df.cols.find(by_type='timestamp').rename('new_', '***').columns
# to do
# df.cols.rename(transform=['unidecode', 'alnum', 'alpha', 'num', 'lower', 'trim', 'squeeze', 'slice', tr("abc", "_", mode='')'])
# df.cols.rename(transform=['unidecode', 'alnum', 'lower', 'trim("_")', 'squeeze("_")'])
# as a dictionary
mapping = {... | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Drop multiple columns | df.cols.find('id').drop().rows.collect(3) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Apply to multiple columns | from pyspark.sql import functions as F
(df
.cols.find(by_type='string').lower()
.cols.get('email').split('@')
.cols.get('email').expand(2)
.cols.find('name', 'email')
.rows.collect(3)
) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Aggregations | from datafaucet.spark import aggregations as A
df.cols.find('amount', '^st.*id', 'first_name').agg(A.all).cols.collect(10) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
group by a set of columns | df.cols.find('amount').groupby('staff_id', 'store_id').agg(A.all).cols.collect(4) | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Aggregate specific metrics | # by function
df.cols.get('amount', 'active').groupby('customer_id').agg({'count':F.count, 'sum': F.sum}).rows.collect(10)
# or by alias
df.cols.get('amount', 'active').groupby('customer_id').agg('count','sum').rows.collect(10)
# or a mix of the two
df.cols.get('amount', 'active').groupby('customer_id').agg('count',{... | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Featurize specific metrics in a single row | (df
.cols.get('amount', 'active')
.groupby('customer_id', 'store_id')
.featurize({'count':A.count, 'sum':A.sum, 'avg':A.avg})
.rows.collect(10)
)
# todo:
# different features per different column | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Plot dataset statistics | df.data.summary()
from bokeh.io import output_notebook
output_notebook()
from bokeh.plotting import figure, show, output_file
p = figure(plot_width=400, plot_height=400)
p.hbar(y=[1, 2, 3], height=0.5, left=0,
right=[1.2, 2.5, 3.7], color="navy")
show(p)
import seaborn as sns
import matplotlib.pyplot as plt
sn... | _____no_output_____ | MIT | examples/tutorial/patched.ipynb | natbusa/datalabframework |
Indexer for SantaScript score queryedit https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-script-score-query.htmlvector-functionsELASTICSEARCHで分散表現を使った類似文書検索 https://yag-ays.github.io/project/elasticsearch-similarity-search/Image Search for ICDAR WML 2019 https://github.com/taniokah/icdar-w... | # Crawling Santa images.
!pip install icrawler
!rm -rf google_images/*
!rm -rf bing_images/*
!rm -rf baidu_images/*
from icrawler.builtin import BaiduImageCrawler, BingImageCrawler, GoogleImageCrawler
crawler = GoogleImageCrawler(storage={"root_dir": "google_images"}, downloader_threads=4)
crawler.crawl(keyword="Sa... | _____no_output_____ | MIT | Indexer_for_Santa.ipynb | taniokah/where-is-santa- |
===================================================================Determine the observable time of the Canopus on the Vernal and Autumnal equinox among -2000 B.C.E. ~ 0 B.C. | %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from astropy.visualization import astropy_mpl_style
plt.style.use(astropy_mpl_style)
import astropy.units as u
from astropy.time import Time
from astropy.coordinates import SkyCoord, EarthLocation, AltAz, ICRS | _____no_output_____ | BSD-2-Clause | multi_epoch-max-duration-Autumnal.ipynb | Niu-LIU/Canopus |
The observing period is the whole year of -2000 B.C.E. ~ 0 B.C.To represent the epoch before the common era, I use the Julian date. | We can see that if we transformate the dates into UTC, they don't exactly respond to March 21 or September 23.
This is normal since UTC is used only after 1960-01-01.
In my opinion, this won't affect our results. | _____no_output_____ | BSD-2-Clause | multi_epoch-max-duration-Autumnal.ipynb | Niu-LIU/Canopus |
I calculate the altitude and azimuth of Sun and Canopus among 4:00~8:00 in autumnal equinox and 16:00~20:00 in vernal equinox for every year. | def observable_duration(obs_time):
"""
"""
# Assume we have an observer in Tai Mountain.
taishan = EarthLocation(lat=36.2*u.deg, lon=117.1*u.deg, height=1500*u.m)
utcoffset = +8 * u.hour # Daylight Time
midnight = obs_time - utcoffset
# Position of the Canopus with the proper motion corr... | WARNING: ErfaWarning: ERFA function "dtf2d" yielded 1 of "dubious year (Note 6)" [astropy._erfa.core]
WARNING: ErfaWarning: ERFA function "utctai" yielded 1 of "dubious year (Note 3)" [astropy._erfa.core]
WARNING: ErfaWarning: ERFA function "taiutc" yielded 2000 of "dubious year (Note 4)" [astropy._erfa.core]
WARNING: ... | BSD-2-Clause | multi_epoch-max-duration-Autumnal.ipynb | Niu-LIU/Canopus |
I assume that the Canopus can be observed by the local observer only when the observable duration in one day is longer than 10 minitues.With such an assumption, I determine the observable period of the Canopus. | # Save data
np.save("multi_epoch-max-duration-Autumnal-output", [obs_time_aut.jyear, obs_dur])
# For Autumnal equinox
# mask = (obs_dur >= 1./6)
mask = (obs_dur >= 1.0/60)
observable_date = obs_time_aut[mask]
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(observable_date.jyear, obs_dur[mask],
"r.", ms=3, la... | _____no_output_____ | BSD-2-Clause | multi_epoch-max-duration-Autumnal.ipynb | Niu-LIU/Canopus |
Build a Pipeline> A tutorial on building pipelines to orchestrate your ML workflowA Kubeflow pipeline is a portable and scalable definition of a machine learning(ML) workflow. Each step in your ML workflow, such as preparing data ortraining a model, is an instance of a pipeline component. This documentprovides an over... | !pip install kfp --upgrade | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Import the `kfp` and `kfp.components` packages. | import kfp
import kfp.components as comp | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
Understanding pipelinesA Kubeflow pipeline is a portable and scalable definition of an ML workflow,based on containers. A pipeline is composed of a set of input parameters and alist of the steps in this workflow. Each step in a pipeline is an instance of acomponent, which is represented as an instance of [`ContainerOp... | import glob
import pandas as pd
import tarfile
import urllib.request
def download_and_merge_csv(url: str, output_csv: str):
with urllib.request.urlopen(url) as res:
tarfile.open(fileobj=res, mode="r|gz").extractall('data')
df = pd.concat(
[pd.read_csv(csv_file, header=None)
for csv_file in gl... | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Run the following Python command to test the function. | download_and_merge_csv(
url='https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz',
output_csv='merged_data.csv') | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
3. Run the following to print the first few rows of the merged CSV file. | !head merged_data.csv | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
4. Design your pipeline. For example, consider the following pipeline designs. * Implement the pipeline using a single step. In this case, the pipeline contains one component that works similarly to the example function. This is a straightforward function, and implementing a single-step pipel... | def merge_csv(file_path: comp.InputPath('Tarball'),
output_csv: comp.OutputPath('CSV')):
import glob
import pandas as pd
import tarfile
tarfile.open(name=file_path, mode="r|gz").extractall('data')
df = pd.concat(
[pd.read_csv(csv_file, header=None)
for csv_file in glob.glob('data/... | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Use [`kfp.components.create_component_from_func`][create_component_from_func] to return a factory function that you can use to create pipeline steps. This example also specifies the base container image to run this function in, the path to save the component specification to, and a list of PyPI packages... | create_step_merge_csv = kfp.components.create_component_from_func(
func=merge_csv,
output_component_file='component.yaml', # This is optional. It saves the component spec for future use.
base_image='python:3.7',
packages_to_install=['pandas==1.1.4']) | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
Build your pipeline1. Use [`kfp.components.load_component_from_url`][load_component_from_url] to load the component specification YAML for any components that you are reusing in this pipeline.[load_component_from_url]: https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.components.html?highlight=load... | web_downloader_op = kfp.components.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/pipelines/master/components/contrib/web/Download/component.yaml') | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Define your pipeline as a Python function. Your pipeline function's arguments define your pipeline's parameters. Use pipeline parameters to experiment with different hyperparameters, such as the learning rate used to train a model, or pass run-level inputs, such as the path to an input file, into a pip... | # Define a pipeline and create a task from a component:
def my_pipeline(url):
web_downloader_task = web_downloader_op(url=url)
merge_csv_task = create_step_merge_csv(file=web_downloader_task.outputs['data'])
# The outputs of the merge_csv_task can be referenced using the
# merge_csv_task.outputs dictionary: mer... | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
Compile and run your pipelineAfter defining the pipeline in Python as described in the preceding section, use one of the following options to compile the pipeline and submit it to the Kubeflow Pipelines service. Option 1: Compile and then upload in UI1. Run the following to compile your pipeline and save it as `pipel... | kfp.compiler.Compiler().compile(
pipeline_func=my_pipeline,
package_path='pipeline.yaml') | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Upload and run your `pipeline.yaml` using the Kubeflow Pipelines user interface.See the guide to [getting started with the UI][quickstart].[quickstart]: https://www.kubeflow.org/docs/components/pipelines/overview/quickstart Option 2: run the pipeline using Kubeflow Pipelines SDK client1. Create an instance of the... | client = kfp.Client() # change arguments accordingly | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
2. Run the pipeline using the `kfp.Client` instance: | client.create_run_from_pipeline_func(
my_pipeline,
arguments={
'url': 'https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz'
}) | _____no_output_____ | CC-BY-4.0 | content/en/docs/components/pipelines/sdk/build-pipeline.ipynb | droctothorpe/website |
 https://www.kaggle.com/danofer/sarcasmContextThis dataset contains 1.3 million Sarcastic comments from the Internet commentary website Reddit. The dataset was generated by scraping comments from Reddit (not by me :)) containing the \s ( sarc... | import os
# Install java
! apt-get update -qq
! apt-get install -y openjdk-8-jdk-headless -qq > /dev/null
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
! java -version
# Install pyspark
! pip install --ignore-installed pyspar... | _____no_output_____ | Apache-2.0 | tutorials/old_generation_notebooks/colab/6- Sarcasm Classifiers (TF-IDF).ipynb | fcivardi/spark-nlp-workshop |
import re
from collections import defaultdict
from tqdm import tnrange, tqdm_notebook
import random
from tqdm.auto import tqdm
import os
from sklearn.model_selection import train_test_split
import numpy as np
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import ... | _____no_output_____ | MIT | HW_03_LSTM.ipynb | RamSaw/NLP | |
Fashion MNIST con terminación tempranaUsando el modelo del ejercicio anterior, en este notebooks aprenderás a crear tu callback y terminar tempranamente el entrenamiento de tu modelo. Ejercicio 1 - importar tensorflowprimero que nada, importa las bibliotecas que consideres necesarias | %tensorflow_version 2.x
import tensorflow as tf | _____no_output_____ | MIT | ejercicios/D1_E2_callbacks_SOLUCION.ipynb | lcmencia/penguin-tf-workshop |
Ejercicio 2 - crear el callbackEscribe un callback que resulte en la terminación temprana del entrenamiento cuando el modelo llegue a más de 80% de precisión. Imprime un mensaje en la consola explicando el motivo de la terminación temprana y el número de *epoch* al usuario. | class CallbackPenguin(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if logs.get('accuracy') > 0.85:
print('\nEl modelo ha llegado a 85% de precisión, terminando entrenamiento en el epoch', epoch + 1)
self.model.stop_training = True | _____no_output_____ | MIT | ejercicios/D1_E2_callbacks_SOLUCION.ipynb | lcmencia/penguin-tf-workshop |
Ejercicio 3 - cargar el *dataset*Carga el *dataset* de Fashion MNIST y normaliza las imágenes del dataset (recuerda que se deben normalizar tanto las imágenes del *training set* y las del *testing set*) | (train_imgs, train_labels), (test_imgs, test_labels) = tf.keras.datasets.fashion_mnist.load_data()
train_imgs = train_imgs/255.0
test_imgs = test_imgs/255.0 | _____no_output_____ | MIT | ejercicios/D1_E2_callbacks_SOLUCION.ipynb | lcmencia/penguin-tf-workshop |
Ejercicio 4 - crear el modeloRecrea el modelo del ejercicio anterior, y compila el modelo. | # crear el modelo
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(100, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
# compilar el modelo
model.compile(optim... | _____no_output_____ | MIT | ejercicios/D1_E2_callbacks_SOLUCION.ipynb | lcmencia/penguin-tf-workshop |
Ejercicio 4 - entrenar el modeloEntrena el modelo usando el comando `fit` y el callback que escribiste en el ejercicio 2. | callback_penguin = CallbackPenguin()
model.fit(train_imgs, train_labels, epochs=50, callbacks=[callback_penguin]) | _____no_output_____ | MIT | ejercicios/D1_E2_callbacks_SOLUCION.ipynb | lcmencia/penguin-tf-workshop |
Visit the NASA mars news site | # Visit the Mars news site
url = 'https://redplanetscience.com/'
browser.visit(url)
# Optional delay for loading the page
browser.is_element_present_by_css('div.list_text', wait_time=1)
# Convert the browser html to a soup object
html = browser.html
news_soup = soup(html, 'html.parser')
slide_elem = news_soup.select_... | _____no_output_____ | ADSL | .ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb | danelle1126/web-scraping-challenge |
JPL Space Images Featured Image | # Visit URL
url = 'https://spaceimages-mars.com'
browser.visit(url)
# Find and click the full image button
full_image_link = browser.find_by_tag('button')[1]
full_image_link.click()
# Parse the resulting html with soup
html = browser.html
img_soup = soup(html, 'html.parser')
print(img_soup.prettify())
img_url_rel = img... | _____no_output_____ | ADSL | .ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb | danelle1126/web-scraping-challenge |
Mars Facts | url = 'https://galaxyfacts-mars.com'
browser.visit(url)
html = browser.html
facts_soup = soup(html, 'html.parser')
html = browser.html
facts_soup = soup(html, 'html.parser')
tables = pd.read_html(url)
tables
df = tables[0]
df.head()
# Use `pd.read_html` to pull the data from the Mars-Earth Comparison section
# hint use... | _____no_output_____ | ADSL | .ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb | danelle1126/web-scraping-challenge |
Hemispheres | url = 'https://marshemispheres.com/'
browser.visit(url)
html = browser.html
hems_soup = soup(html, 'html.parser')
print(hems_soup.prettify())
# Create a list to hold the images and titles.
hemisphere_image_urls = []
# Get a list of all of the hemispheres
links = browser.find_by_css('a.product-item img')
# Next, loop ... | _____no_output_____ | ADSL | .ipynb_checkpoints/Mission_to_Mars-checkpoint.ipynb | danelle1126/web-scraping-challenge |
Object Detection with TRTorch (SSD) --- OverviewIn PyTorch 1.0, TorchScript was introduced as a method to separate your PyTorch model from Python, make it portable and optimizable.TRTorch is a compiler that uses TensorRT (NVIDIA's Deep Learning Optimization SDK and Runtime) to optimize TorchScript code. It compiles st... | # Known working versions
!pip install numpy==1.21.2 scipy==1.5.2 Pillow==6.2.0 scikit-image==0.17.2 matplotlib==3.3.0 | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
--- 2. SSD Single Shot MultiBox Detector model for object detection_ | _- | -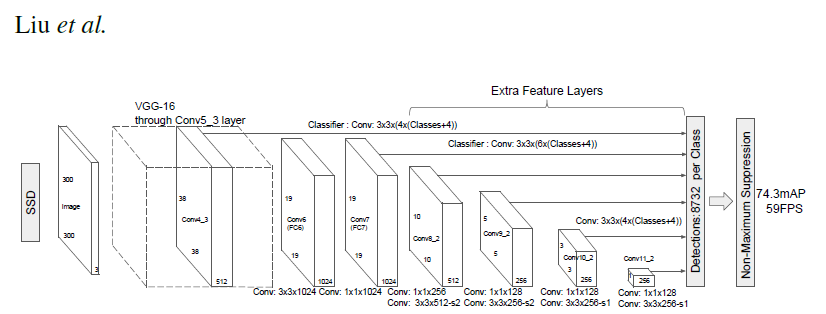 |  PyTorch has a model repository called the PyTorch Hub, which is a source for high quality implementations of common models. We can ge... | import torch
torch.hub._validate_not_a_forked_repo=lambda a,b,c: True
# List of available models in PyTorch Hub from Nvidia/DeepLearningExamples
torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
# load SSD model pretrained on COCO from Torch Hub
precision = 'fp32'
ssd300 = torch.hub.load('NVIDIA/DeepLearningExampl... | Using cache found in /root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub
Downloading checkpoint from https://api.ngc.nvidia.com/v2/models/nvidia/ssd_pyt_ckpt_amp/versions/20.06.0/files/nvidia_ssdpyt_amp_200703.pt
| BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
Setting `precision="fp16"` will load a checkpoint trained with mixed precision into architecture enabling execution on Tensor Cores. Handling mixed precision data requires the Apex library. Sample Inference We can now run inference on the model. This is demonstrated below using sample images from the COCO 2017 Validat... | # Sample images from the COCO validation set
uris = [
'http://images.cocodataset.org/val2017/000000397133.jpg',
'http://images.cocodataset.org/val2017/000000037777.jpg',
'http://images.cocodataset.org/val2017/000000252219.jpg'
]
# For convenient and comprehensive formatting of input and output of the model... | /opt/conda/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1153.)
retu... | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
Visualize results | from matplotlib import pyplot as plt
import matplotlib.patches as patches
# The utility plots the images and predicted bounding boxes (with confidence scores).
def plot_results(best_results):
for image_idx in range(len(best_results)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...... | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
Benchmark utility | import time
import numpy as np
import torch.backends.cudnn as cudnn
cudnn.benchmark = True
# Helper function to benchmark the model
def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=1000):
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
if dtype==... | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
We check how well the model performs **before** we use TRTorch/TensorRT | # Model benchmark without TRTorch/TensorRT
model = ssd300.eval().to("cuda")
benchmark(model, input_shape=(128, 3, 300, 300), nruns=100) | Warm up ...
Start timing ...
Iteration 10/100, avg batch time 382.30 ms
Iteration 20/100, avg batch time 382.72 ms
Iteration 30/100, avg batch time 382.63 ms
Iteration 40/100, avg batch time 382.83 ms
Iteration 50/100, avg batch time 382.90 ms
Iteration 60/100, avg batch time 382.86 ms
Iteration 70/100, avg batch time ... | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
--- 3. Creating TorchScript modules To compile with TRTorch, the model must first be in **TorchScript**. TorchScript is a programming language included in PyTorch which removes the Python dependency normal PyTorch models have. This conversion is done via a JIT compiler which given a PyTorch Module will generate an eq... | model = ssd300.eval().to("cuda")
traced_model = torch.jit.trace(model, [torch.randn((1,3,300,300)).to("cuda")]) | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
If required, we can also save this model and use it independently of Python. | # This is just an example, and not required for the purposes of this demo
torch.jit.save(traced_model, "ssd_300_traced.jit.pt")
# Obtain the average time taken by a batch of input with Torchscript compiled modules
benchmark(traced_model, input_shape=(128, 3, 300, 300), nruns=100) | Warm up ...
Start timing ...
Iteration 10/100, avg batch time 382.67 ms
Iteration 20/100, avg batch time 382.54 ms
Iteration 30/100, avg batch time 382.73 ms
Iteration 40/100, avg batch time 382.53 ms
Iteration 50/100, avg batch time 382.56 ms
Iteration 60/100, avg batch time 382.50 ms
Iteration 70/100, avg batch time ... | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
--- 4. Compiling with TRTorchTorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT. | import trtorch
# The compiled module will have precision as specified by "op_precision".
# Here, it will have FP16 precision.
trt_model = trtorch.compile(traced_model, {
"inputs": [trtorch.Input((3, 3, 300, 300))],
"enabled_precisions": {torch.float, torch.half}, # Run with FP16
"workspace_size": 1 << 20
}... | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
--- 5. Running Inference Next, we run object detection | # using a TRTorch module is exactly the same as how we usually do inference in PyTorch i.e. model(inputs)
detections_batch = trt_model(tensor.to(torch.half)) # convert the input to half precision
# By default, raw output from SSD network per input image contains 8732 boxes with
# localization and class probability di... | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
Now, let's visualize our predictions! | # Visualize results with TRTorch/TensorRT
plot_results(best_results_per_input_trt) | _____no_output_____ | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
We get similar results as before! --- 6. Measuring SpeedupWe can run the benchmark function again to see the speedup gained! Compare this result with the same batch-size of input in the case without TRTorch/TensorRT above. | batch_size = 128
# Recompiling with batch_size we use for evaluating performance
trt_model = trtorch.compile(traced_model, {
"inputs": [trtorch.Input((batch_size, 3, 300, 300))],
"enabled_precisions": {torch.float, torch.half}, # Run with FP16
"workspace_size": 1 << 20
})
benchmark(trt_model, input_shape=... | Warm up ...
Start timing ...
Iteration 10/100, avg batch time 72.90 ms
Iteration 20/100, avg batch time 72.95 ms
Iteration 30/100, avg batch time 72.92 ms
Iteration 40/100, avg batch time 72.94 ms
Iteration 50/100, avg batch time 72.99 ms
Iteration 60/100, avg batch time 73.01 ms
Iteration 70/100, avg batch time 73.04 ... | BSD-3-Clause | notebooks/ssd-object-detection-demo.ipynb | p1x31/TRTorch |
3. Markov Models Example ProblemsWe will now look at a model that examines our state of healthiness vs. being sick. Keep in mind that this is very much like something you could do in real life. If you wanted to model a certain situation or environment, we could take some data that we have gathered, build a maximum lik... | import numpy as np
import pandas as pd
"""Goal here is to store start page and end page, and the count how many times that happens. After that
we are going to turn it into a probability distribution. We can divide all transitions that start with specific
start state, by row_sum"""
transitions = {} # getting all specif... | Initial state distribution
8 0.10152591025834719
2 0.09507982071813466
5 0.09779926474291183
9 0.10384247368686106
0 0.10298635241980159
6 0.09800070504104345
7 0.09971294757516241
1 0.10348995316513068
4 0.10243239159993957
3 0.09513018079266758
Bounce rate for 1: 0.125939617991374
Bounce rate for 2: 0.126495513459621... | MIT | Machine_Learning/05-Hidden_Markov_Models-03-Markov-Models-Example-Problems-and-Applications.ipynb | NathanielDake/NathanielDake.github.io |
We can see that page with `id` 9 has the highest value in the initial state distribution, so we are most likely to start on that page. We can then see that the page with highest bounce rate is also at page `id` 9. 4. Build a 2nd-order language model and generate phrasesSo, we are now going to work with non first orde... | import numpy as np
import string
"""3 dicts. 1st store pdist for the start of a phrase, then a second word dict which stores the distributions
for the 2nd word of a sentence, and then we are going to have a dict for all second order transitions"""
initial = {}
second_word = {}
transitions = {}
def remove_punctuation(s... | another from the childrens house of makebelieve
they dont go with the dead race of the lettered
i never heard of clara robinson
where he can eat off a barrel from the sense of our having been together
| MIT | Machine_Learning/05-Hidden_Markov_Models-03-Markov-Models-Example-Problems-and-Applications.ipynb | NathanielDake/NathanielDake.github.io |
Quantization of Signals*This jupyter notebook is part of a [collection of notebooks](../index.ipynb) on various topics of Digital Signal Processing. Please direct questions and suggestions to [Sascha.Spors@uni-rostock.de](mailto:Sascha.Spors@uni-rostock.de).* Spectral Shaping of the Quantization NoiseThe quantized si... | %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
w = 8 # wordlength of the quantized signal
xmin = -1 # minimum of input signal
N = 32768 # number of samples
def uniform_midtread_quantizer_w_ns(x, Q):
# limiter
x = np.copy(x)
idx = np.where(x <= -1)
... | SNR = 45.2 dB
| MIT | quantization/noise_shaping.ipynb | davidjustin1974/digital-signal-processing-lecture |
Neural networks with PyTorchDeep learning networks tend to be massive with dozens or hundreds of layers, that's where the term "deep" comes from. You can build one of these deep networks using only weight matrices as we did in the previous notebook, but in general it's very cumbersome and difficult to implement. PyTor... | # Import necessary packages
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import numpy as np
import torch
import helper
import matplotlib.pyplot as plt | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Now we're going to build a larger network that can solve a (formerly) difficult problem, identifying text in an image. Here we'll use the MNIST dataset which consists of greyscale handwritten digits. Each image is 28x28 pixels, you can see a sample belowOur goal is to build a neural network that can take one of these i... | ### Run this cell
from torchvision import datasets, transforms
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
# Download and load the training data
trainset = datase... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
We have the training data loaded into `trainloader` and we make that an iterator with `iter(trainloader)`. Later, we'll use this to loop through the dataset for training, like```pythonfor image, label in trainloader: do things with images and labels```You'll notice I created the `trainloader` with a batch size of 6... | dataiter = iter(trainloader)
images, labels = dataiter.next()
print(type(images))
print(images.shape)
print(labels.shape) | <class 'torch.Tensor'>
torch.Size([64, 1, 28, 28])
torch.Size([64])
| MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
This is what one of the images looks like. | plt.imshow(images[1].numpy().squeeze(), cmap='Greys_r'); | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
First, let's try to build a simple network for this dataset using weight matrices and matrix multiplications. Then, we'll see how to do it using PyTorch's `nn` module which provides a much more convenient and powerful method for defining network architectures.The networks you've seen so far are called *fully-connected*... | ## Your solution
images_flat = images.view(64, 784)
def act(x):
return 1/(1+torch.exp(-x))
torch.manual_seed(42)
n_input = 784
n_hidden = 256
n_output = 10
W1 = torch.randn((n_input, n_hidden))
W2 = torch.randn((n_hidden, n_output))
B1 = torch.randn((1, 1))
B2 = torch.randn((1, 1))
def network(features):
... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Now we have 10 outputs for our network. We want to pass in an image to our network and get out a probability distribution over the classes that tells us the likely class(es) the image belongs to. Something that looks like this:Here we see that the probability for each class is roughly the same. This is representing an ... | def softmax(x):
return torch.exp(x)/torch.sum(torch.exp(x), dim=1).reshape(64, 1)
## TODO: Implement the softmax function here
# Here, out should be the output of the network in the previous excercise with shape (64,10)
probabilities = softmax(out)
# Does it have the right shape? Should be (64,... | torch.Size([64, 10])
tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0... | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Building networks with PyTorchPyTorch provides a module `nn` that makes building networks much simpler. Here I'll show you how to build the same one as above with 784 inputs, 256 hidden units, 10 output units and a softmax output. | from torch import nn
class Network(nn.Module):
def __init__(self):
super().__init__()
# Inputs to hidden layer linear transformation
self.hidden = nn.Linear(784, 256)
# Output layer, 10 units - one for each digit
self.output = nn.Linear(256, 10)
# De... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Let's go through this bit by bit.```pythonclass Network(nn.Module):```Here we're inheriting from `nn.Module`. Combined with `super().__init__()` this creates a class that tracks the architecture and provides a lot of useful methods and attributes. It is mandatory to inherit from `nn.Module` when you're creating a class... | # Create the network and look at it's text representation
model = Network()
model | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
You can define the network somewhat more concisely and clearly using the `torch.nn.functional` module. This is the most common way you'll see networks defined as many operations are simple element-wise functions. We normally import this module as `F`, `import torch.nn.functional as F`. | import torch.nn.functional as F
class Network(nn.Module):
def __init__(self):
super().__init__()
# Inputs to hidden layer linear transformation
self.hidden = nn.Linear(784, 256)
# Output layer, 10 units - one for each digit
self.output = nn.Linear(256, 10)
def f... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Activation functionsSo far we've only been looking at the sigmoid activation function, but in general any function can be used as an activation function. The only requirement is that for a network to approximate a non-linear function, the activation functions must be non-linear. Here are a few more examples of common ... | ## Your solution here
class FirstNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Initializing weights and biasesThe weights and such are automatically initialized for you, but it's possible to customize how they are initialized. The weights and biases are tensors attached to the layer you defined, you can get them with `model.fc1.weight` for instance. | print(model.fc1.weight)
print(model.fc1.bias) | Parameter containing:
tensor([[-0.0324, 0.0352, -0.0258, ..., 0.0276, -0.0145, -0.0265],
[ 0.0058, 0.0206, -0.0277, ..., 0.0027, -0.0107, -0.0135],
[-0.0175, -0.0071, 0.0020, ..., -0.0303, 0.0014, -0.0020],
...,
[-0.0153, -0.0351, -0.0131, ..., -0.0250, 0.0067, -0.0284],
... | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
For custom initialization, we want to modify these tensors in place. These are actually autograd *Variables*, so we need to get back the actual tensors with `model.fc1.weight.data`. Once we have the tensors, we can fill them with zeros (for biases) or random normal values. | # Set biases to all zeros
model.fc1.bias.data.fill_(0)
# sample from random normal with standard dev = 0.01
model.fc1.weight.data.normal_(std=0.01) | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Forward passNow that we have a network, let's see what happens when we pass in an image. | # Grab some data
dataiter = iter(trainloader)
images, labels = dataiter.next()
# Resize images into a 1D vector, new shape is (batch size, color channels, image pixels)
images.resize_(64, 1, 784)
# or images.resize_(images.shape[0], 1, 784) to automatically get batch size
# Forward pass through the network
img_idx ... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
As you can see above, our network has basically no idea what this digit is. It's because we haven't trained it yet, all the weights are random! Using `nn.Sequential`PyTorch provides a convenient way to build networks like this where a tensor is passed sequentially through operations, `nn.Sequential` ([documentation](ht... | # Hyperparameters for our network
input_size = 784
hidden_sizes = [128, 64]
output_size = 10
# Build a feed-forward network
model = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),
nn.ReLU(),
nn.Linear(hidden_sizes[0], hidden_sizes[1]),
nn.ReLU(),
... | Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU()
(4): Linear(in_features=64, out_features=10, bias=True)
(5): Softmax()
)
| MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Here our model is the same as before: 784 input units, a hidden layer with 128 units, ReLU activation, 64 unit hidden layer, another ReLU, then the output layer with 10 units, and the softmax output.The operations are available by passing in the appropriate index. For example, if you want to get first Linear operation ... | print(model[0])
model[0].weight | Linear(in_features=784, out_features=128, bias=True)
| MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
You can also pass in an `OrderedDict` to name the individual layers and operations, instead of using incremental integers. Note that dictionary keys must be unique, so _each operation must have a different name_. | from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('fc1', nn.Linear(input_size, hidden_sizes[0])),
('relu1', nn.ReLU()),
('fc2', nn.Linear(hidden_sizes[0], hidden_sizes[1])),
('relu2', nn.ReLU()),
... | _____no_output_____ | MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
Now you can access layers either by integer or the name | print(model[0])
print(model.fc1) | Linear(in_features=784, out_features=128, bias=True)
Linear(in_features=784, out_features=128, bias=True)
| MIT | intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb | jr7/deep-learning-v2-pytorch |
------------ First A.I. activity ------------ 1. IBOVESPA volume prediction -> Importing libraries that are going to be used in the code | import pandas as pd
import numpy as np
import matplotlib.pyplot as plt | _____no_output_____ | MIT | drafts/exercises/ibovespa.ipynb | ItamarRocha/introduction-to-AI |
-> Importing the datasets | dataset = pd.read_csv("datasets/ibovespa.csv",delimiter = ";") | _____no_output_____ | MIT | drafts/exercises/ibovespa.ipynb | ItamarRocha/introduction-to-AI |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.