
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Module 2 Part 3 Lists - List Creation- List Access- List Append- **List *modify* and Insert**- List Delete----- > Student will be able to - Create Lists- Access items in a list- Add Items to the end of a list- **Modify and insert items into a list**- Delete items from a list Concepts Insert a new value for an... | # [ ] review and run example
# the list before Insert
party_list = ["Joana", "Alton", "Tobias"]
print("party_list before: ", party_list)
# the list after Insert
party_list[1] = "Colette"
print("party_list after: ", party_list)
# [ ] review and run example
party_list = ["Joana", "Alton", "Tobias"]
print("before:",part... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Example **IndexError** | # IndexError Example
# [ ] review and run example which results in an IndexError
# if result is NameError run cell above before running this cell
# IndexError trying to append to end of list
party_list[3] = "Alton"
print(party_list)
# [ ] review and run example changes the data type of an element
# replace a string wi... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 8 replace items in a list- create a list, **`three_num`**, containing 3 single digit integers- print three_num- check if index 0 value is < 5 - if < 5 , replace index 0 with a string: "small" - else, replace index 0 with a string: "large"- print three_num | # [ ] complete "replace items in a list" task
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Function Challenge: create replacement function- Create a function, **str_replace**, that takes 2 arguments: int_list and index - int_list is a list of single digit integers - index is the index that will be checked - such as with int_list[index]- Function replicates purpose of task "replace items in a list" above ... | # [ ] create challenge function
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 9 modify items in a list- create a list, **`three_words`**, containing 3 different capitalized word stings- print three_words- modify the first item in three_words to uppercase- modify the third item to swapcase- print three_words | # [ ] complete coding task described above
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Concepts Insert items into a list[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{"src":"http://jupyternootbookwams.streaming.mediaservices.windows.net/659b9cd2-1e84-4ead-8a69-015... | # [ ] review and run example
# the list before Insert
party_list = ["Joana", "Alton", "Tobias"]
print("party_list before: ", party_list)
print("index 1 is", party_list[1], "\nindex 2 is", party_list[2], "\n")
# the list after Insert
party_list.insert(1,"Colette")
print("party_list after: ", party_list)
print("index 1... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 10 `insert()` input into a list | # [ ] insert a name from user input into the party_list in the second position (index 1)
party_list = ["Joana", "Alton", "Tobias"]
# [ ] print the updated list
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 11 Fix The Error | # [ ] Fix the Error
tree_list = "oak"
print("tree_list before =", tree_list)
tree_list.insert(1,"pine")
print("tree_list after =", tree_list)
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Module 2 Part 4 Lists - List Creation- List Access- List Append- List Insert- **List Delete (`del`, `.pop()` & `.remove()`)**----- > Student will be able to - Create Lists- Access items in a list- Add Items to the end of a list- Insert items into a list- **Delete items from a list with `del`, `.pop()` & `.remove()`**... | # [ ] review and run example
# the list before delete
sample_list = [11, 21, 13, 14, 51, 161, 117, 181]
print("sample_list before: ", sample_list)
del sample_list[1]
# the list after delete
print("sample_list after: ", sample_list)
# [ ] review and run example Multiple Times
# [ ] consider how to reset the list value... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 12 `del` statement | # [ ] print ft_bones list
# [ ] delete "cuboid" from ft_bones
# [ ] reprint list
ft_bones = ["calcaneus", "talus", "cuboid", "navicular", "lateral cuneiform",
"intermediate cuneiform", "medial cuneiform"]
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 13 multiple `del` statements | # [ ] print ft_bones list
# [ ] delete "cuboid" from ft_bones
# [ ] delete "navicular" from list
# [ ] reprint list
# [ ] check for deletion of "cuboid" and "navicular"
ft_bones = ["calcaneus", "talus", "cuboid", "navicular", "lateral cuneiform",
"intermediate cuneiform", "medial cuneiform"]
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Concepts .pop() gets and deletes item in list[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{"src":"http://jupyternootbookwams.streaming.mediaservices.windows.net/67b83f30-a92c-4... | # [ ] review and run example
# pop() gets the last item by default
party_list = ["Joana", "Alton", "Tobias"]
print(party_list)
print("Hello,", party_list.pop())
print("\n", party_list)
print("Hello,", party_list.pop())
print("\n", party_list)
print("Hello,", party_list.pop())
print("\n", party_list)
# [ ] review and... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 14 `pop()` | # [ ] pop() and print the first and last items from the ft_bones list
ft_bones = ["calcaneus", "talus", "cuboid", "navicular", "lateral cuneiform",
"intermediate cuneiform", "medial cuneiform"]
# [ ] print the remaining list
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Concepts an empty list is False[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{"src":"http://jupyternootbookwams.streaming.mediaservices.windows.net/20e00a13-a9d2-4a35-b75d-f6533... | dog_types = ["Lab", "Pug", "Poodle"]
while dog_types:
print(dog_types.pop()) | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 15 pt 1 Cash Register Input- create a empty list `purchase_amounts`- populate the list with user input for the price of items- continue adding to list with `while` until "done" is entered - can use `while True:` with `break`- print `purchase_amounts`- continue to pt 2 | #[ ] complete the Register Input task above
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 15 pt 2 Cash Register Total- create a **`subtotal`** variable = 0create a while loop that runs **`while`** purchase_amount (is not empty)- inside the loop - **`pop()`** the last list value cast as a float type - add the float value to a **`subtotal`** variable- after exiting the loop print **`subtotal`*... | # [ ] complete the Register Total task above
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Concepts Delete a specific object from a list with `.remove()`[]( http://edxinteractivepage.blob.core.windows.net/edxpages/f7cff1a7-5601-48a1-95a6-fd1fdfabd20e.html?details=[{"src":"http://jupyternootbookwams.streaming.mediaservices.windows.ne... | # [ ] review and run example
dog_types = ["Lab", "Pug", "Poodle"]
if "Pug" in dog_types:
dog_types.remove("Pug")
else:
print("no Pug found")
print(dog_types)
# [ ] review and run example
dogs = ["Lab", "Pug", "Poodle", "Poodle", "Pug", "Poodle"]
print(dogs)
while "Poodle" in dogs:
dogs.remove("Poodle")
... | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
ValueError | # [ ] review and run example
# Change to "Lab", etc... to fix error
dogs.remove("Collie")
print(dogs) | _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
Task 16 `.remove()` | # [ ] remove one "Poodle" from the list: dogs , or print "no Poodle found"
# [ ] print list before and after
dogs = ["Lab", "Pug", "Poodle", "Poodle", "Pug", "Poodle"]
| _____no_output_____ | MIT | Python Fundamentals/Module_2.0_Tutorials_Sequence_Lists_Python_Fundamentals.ipynb | Mt9555/pythonteachingcode |
 13.4 Self Check **1. _(Fill-In)_** The consumer key, consumer secret, access token and access token secret are each part of the `________` authentication process that Twitter uses to enable access to its APIs.**Answer:** OAuth 2.0.**2. _(True/False)_** Once ... | ##########################################################################
# (C) Copyright 2019 by Deitel & Associates, Inc. and #
# Pearson Education, Inc. All Rights Reserved. #
# #
# DISCLAIMER: The au... | _____no_output_____ | MIT | examples/ch13/snippets_ipynb/13_04selfcheck.ipynb | edson-gomes/Intro-to-Python |
---_You are currently looking at **version 1.0** of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the [Jupyter Notebook FAQ](https://www.coursera.org/learn/python-text-mining/resources/d9pwm) course resource._--- Working with Text Data in p... | import pandas as pd
time_sentences = ["Monday: The doctor's appointment is at 2:45pm.",
"Tuesday: The dentist's appointment is at 11:30 am.",
"Wednesday: At 7:00pm, there is a basketball game!",
"Thursday: Be back home by 11:15 pm at the latest.",
... | _____no_output_____ | MIT | Applied Text Mining/Week1 - Working with Text in Python/Regex+with+Pandas+and+Named+Groups.ipynb | rajatgarg149/Data-Science-Python------Coursera-MICHIGAN- |
Object Oriented ProgrammingObject Oriented Programming (OOP) tends to be one of the major obstacles for beginners when they are first starting to learn Python.There are many, many tutorials and lessons covering OOP so feel free to Google search other lessons, and I have also put some links to other useful tutorials on... | lst = [1,2,3] | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Remember how we could call methods on a list? | lst.count(2) | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
What we will basically be doing in this lecture is exploring how we could create an Object type like a list. We've already learned about how to create functions. So let's explore Objects in general: ObjectsIn Python, *everything is an object*. Remember from previous lectures we can use type() to check the type of objec... | print(type(1))
print(type([]))
print(type(()))
print(type({})) | <class 'int'>
<class 'list'>
<class 'tuple'>
<class 'dict'>
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
So we know all these things are objects, so how can we create our own Object types? That is where the class keyword comes in. classUser defined objects are created using the class keyword. The class is a blueprint that defines the nature of a future object. From classes we can construct instances. An instance is a spec... | # Create a new object type called Sample
class Sample:
pass
# Instance of Sample
x = Sample()
print(type(x)) | <class '__main__.Sample'>
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
By convention we give classes a name that starts with a capital letter. Note how x is now the reference to our new instance of a Sample class. In other words, we **instantiate** the Sample class.Inside of the class we currently just have pass. But we can define class attributes and methods.An **attribute** is a charact... | class Dog:
def __init__(self,breed):
self.breed = breed
sam = Dog(breed='Lab')
frank = Dog(breed='Huskie') | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Lets break down what we have above.The special method __init__() is called automatically right after the object has been created: def __init__(self, breed):Each attribute in a class definition begins with a reference to the instance object. It is by convention named self. The breed is the argument. The value is ... | sam.breed
frank.breed | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Note how we don't have any parentheses after breed; this is because it is an attribute and doesn't take any arguments.In Python there are also *class object attributes*. These Class Object Attributes are the same for any instance of the class. For example, we could create the attribute *species* for the Dog class. Dogs... | class Dog:
# Class Object Attribute
species = 'mammal'
def __init__(self,breed,name):
self.breed = breed
self.name = name
sam = Dog('Lab','Sam')
sam.name | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Note that the Class Object Attribute is defined outside of any methods in the class. Also by convention, we place them first before the init. | sam.species | _____no_output_____ | MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
MethodsMethods are functions defined inside the body of a class. They are used to perform operations with the attributes of our objects. Methods are a key concept of the OOP paradigm. They are essential to dividing responsibilities in programming, especially in large applications.You can basically think of methods as ... | class Circle:
pi = 3.14
# Circle gets instantiated with a radius (default is 1)
def __init__(self, radius=1):
self.radius = radius
self.area = radius * radius * Circle.pi
# Method for resetting Radius
def setRadius(self, new_radius):
self.radius = new_radius
self.a... | Radius is: 1
Area is: 3.14
Circumference is: 6.28
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
In the \__init__ method above, in order to calculate the area attribute, we had to call Circle.pi. This is because the object does not yet have its own .pi attribute, so we call the Class Object Attribute pi instead.In the setRadius method, however, we'll be working with an existing Circle object that does have its own... | c.setRadius(2)
print('Radius is: ',c.radius)
print('Area is: ',c.area)
print('Circumference is: ',c.getCircumference()) | Radius is: 2
Area is: 12.56
Circumference is: 12.56
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Great! Notice how we used self. notation to reference attributes of the class within the method calls. Review how the code above works and try creating your own method. InheritanceInheritance is a way to form new classes using classes that have already been defined. The newly formed classes are called derived classes, ... | class Animal:
def __init__(self):
print("Animal created")
def whoAmI(self):
print("Animal")
def eat(self):
print("Eating")
class Dog(Animal):
def __init__(self):
Animal.__init__(self)
print("Dog created")
def whoAmI(self):
print("Dog")
def ba... | Woof!
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
In this example, we have two classes: Animal and Dog. The Animal is the base class, the Dog is the derived class. The derived class inherits the functionality of the base class. * It is shown by the eat() method. The derived class modifies existing behavior of the base class.* shown by the whoAmI() method. Finally, the... | class Dog:
def __init__(self, name):
self.name = name
def speak(self):
return self.name+' says Woof!'
class Cat:
def __init__(self, name):
self.name = name
def speak(self):
return self.name+' says Meow!'
niko = Dog('Niko')
felix = Cat('Felix')
print(niko.spe... | Niko says Woof!
Felix says Meow!
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Here we have a Dog class and a Cat class, and each has a `.speak()` method. When called, each object's `.speak()` method returns a result unique to the object.There a few different ways to demonstrate polymorphism. First, with a for loop: | for pet in [niko,felix]:
print(pet.speak()) | Niko says Woof!
Felix says Meow!
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Another is with functions: | def pet_speak(pet):
print(pet.speak())
pet_speak(niko)
pet_speak(felix) | Niko says Woof!
Felix says Meow!
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
In both cases we were able to pass in different object types, and we obtained object-specific results from the same mechanism.A more common practice is to use abstract classes and inheritance. An abstract class is one that never expects to be instantiated. For example, we will never have an Animal object, only Dog and ... | class Animal:
def __init__(self, name): # Constructor of the class
self.name = name
def speak(self): # Abstract method, defined by convention only
raise NotImplementedError("Subclass must implement abstract method")
class Dog(Animal):
def speak(self):
return s... | Fido says Woof!
Isis says Meow!
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Real life examples of polymorphism include:* opening different file types - different tools are needed to display Word, pdf and Excel files* adding different objects - the `+` operator performs arithmetic and concatenation Special MethodsFinally let's go over special methods. Classes in Python can implement certain op... | class Book:
def __init__(self, title, author, pages):
print("A book is created")
self.title = title
self.author = author
self.pages = pages
def __str__(self):
return "Title: %s, author: %s, pages: %s" %(self.title, self.author, self.pages)
def __len__(self):
... | A book is created
Title: Python Rocks!, author: Jose Portilla, pages: 159
159
A book is destroyed
| MIT | 05-Object Oriented Programming/.ipynb_checkpoints/01-Object Oriented Programming-Copy1-checkpoint.ipynb | PseudoCodeNerd/learning-python |
Getting some data Scikit-learn comes with some datasets that we can use to produce examples. | from sklearn import datasets
import pandas as pd
import numpy as np
iris = datasets.load_iris()
iris_features = iris.data
iris_target = iris.target
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target_names[iris.target]
iris_df.head()
iris.target_names | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
If we would like to predict the species of the flower using the features, then we are doing a **classification** problem. Estimators objects The main API implemented by scikit-learn is that of the **estimator**. An estimator is the object that contains the model that we can use to learn from data. 1. Import the estim... | from sklearn.neighbors import KNeighborsClassifier | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
2. Create an instance of the estimator | flower_classifier = KNeighborsClassifier(n_neighbors=3) | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
3. Use the data to train the estimator Remember: 1. Scikit-learn only accepts numbers2. The object containing the features must be a two dimentional np.array | iris_features[:10,:]
iris_target | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
0 == > setosa1 == > versicolor2 == > virginica | flower_classifier.fit(X=iris_features, y=iris_target) | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
4. Evaluate the modelWe will skip this important step here. 5. Use the data to make "predictions" | # The features must be two-dimensional array
new_flower1 = np.array([[5.1, 3.0, 1.1, 0.5]])
new_flower2 = np.array([[6.0, 2.9, 4.5, 1.1]]) | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
0 == > setosa1 == > versicolor2 == > virginica | flower_classifier.predict(new_flower1)
flower_classifier.predict(new_flower2)
new_flowers = np.array([[5.1, 3.0, 1.1, 0.5],[6.0, 2.9, 4.5, 1.1]])
predictions = flower_classifier.predict(new_flowers)
predictions | _____no_output_____ | MIT | become_a_python_data_analyst_Code/Section6/Scikit-learn.ipynb | Kinnoshachi/become_a_python_data_analyst |
IntroductionIan Guinn, UNCPresented at [LEGEND Software Tutorial, Nov. 2021](https://indico.legend-exp.org/event/561/)**"Have you tried looking at the waveforms from those events?" - David Radford**This is a tutorial demonstrating several ways to use the Waveform browser to examine data from LEGEND. This will consist... | #First, import necessary modules and set some input values for use later
%matplotlib inline
import pygama.io.lh5 as lh5
from pygama.dsp.WaveformBrowser import WaveformBrowser
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import os, json
# Set input values for where to find our data. This will ... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
Example 1First, a minimal example simply drawing waveforms from the raw file | # Create a minimal waveform browser; a file or list of files is required
#browser = WaveformBrowser(raw_files, channel+'/raw')
browser = WaveformBrowser(raw_files, 'ORFlashCamADCWaveformDecoder/raw/')
# Draw the 100th waveform in the file
browser.draw_entry(101)
# To draw multiple figures in a single cell, you must ... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
Example 2Ok, that was nice, but how often do we just want to scroll through all of our waveforms?For our next example, we will select a population of waveforms from within the files, and draw multiple at once. Selecting a population of events to draw uses the same syntax as numpy and pandas, and can be done either wit... | # First, load a dataframe from a DSP file that we can use to make our selection:
df = lh5.load_dfs(dsp_files, ['trapE', 'AoE'], channel+'/dsp')
# Create a selection mask around the 2614 keV peak
trapE = df['trapE']
energy_selection = (trapE>22100) & (trapE<22400)
trapE.hist(bins=1000, range=(0, 30000))
trapE[energy_se... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
Example 3Lets take it a step further: this time, lets draw waveforms from multiple populations for the sake of comparison. This will require creating two separate waveform browsers and drawing them onto the same axes. We'll also normalization of the waveforms. Finally, we'll add some formatting options to the lines an... | AoE = df['AoE']
energy_cut = (trapE>10000)
aoe_cut = (AoE<0.056) & energy_cut
aoe_accept = (AoE>0.056) & energy_cut
AoE[energy_cut].hist(bins=200, range=(-0, 0.2))
AoE[aoe_cut].hist(bins=200, range=(-0, 0.2))
browser1 = WaveformBrowser(raw_files, channel+'/raw',
verbosity = 0, ... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
Example 4Now, we'll shift from drawing populations of waveforms to drawing waveform transforms. We can draw any waveforms that are defined in a DSP JSON configuration file. This is useful for debugging purposes and for developing processors. We will draw the baseline subtracted WF, pole-zero corrected WF, and trapezoi... | # Use the lpgta dsp json file. TODO: get this from DataGroup
# dsp_config_file = os.path.expandvars("$HOME/pygama/experiments/lpgta/LPGTA_dsp.json")
dsp_config_file = os.path.expandvars("./metadata/LPGTA_dsp.json")
browser = WaveformBrowser(raw_files, channel+'/raw', dsp_config_file, # Need to include a dsp config fil... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
Example 5Sometimes you just want to access the waveforms without drawing them. There can be many reasons for this: maybe you want to try processing them with a function that isn't part of the pygama dsp framework yet. Maybe the drawing options provided aren't right for you. Either way, if you need more control over wh... | browser = WaveformBrowser(raw_files, channel+'/raw', dsp_config_file, # Need to include a dsp config file!
database = {"pz_const":'396.9*us'}, # TODO: use metadata instead of manually defining...
waveforms = ['waveform', 'wf_trap'], # names of waveforms... | _____no_output_____ | Apache-2.0 | tutorials/WaveformBrowserTutorial.ipynb | BarbeauGroup/pygama |
12.1 저 PER 전략 2021년 04월 01일 데이터가 저장된 엑셀 파일을 불러옵니다. | import pandas as pd
df_factor = pd.read_excel(
"data/data_kosdaq_20210401_per.xlsx",
index_col=0,
usecols=[0, 1, 6, 8] # 종목코드, 종목명, PER, PBR
)
df_factor.head()
df_factor.info()
import numpy as np
df_factor.replace('-', np.nan, inplace=True)
df_factor.head()
df_factor.info()
import pandas as pd
df = p... | _____no_output_____ | MIT | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance |
2021년 4월 1일에 거래량이 0인 종목은 거래정지된 종목입니다. 따라서 먼저 거래량을 기준으로 필터링합니다. | cond = df3['거래량'] !=0
df4 = df3[cond].copy()
df4.shape | _____no_output_____ | MIT | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance |
PER 값을 기준으로 오른차순 정렬합니다. | df5 = df4.sort_values(by="PER", ascending=True)
df5.reset_index(inplace=True)
df5
low_per30 = df5.iloc[:30]
low_per30['등락률'].mean()
import pandas as pd
df5['group'] = pd.cut(df5.index, bins=20, labels=False)
df5.head()
df6 = df5.groupby(by='group')[['등락률']].mean()
df6
import matplotlib.pyplot as plt
import platform
... | _____no_output_____ | MIT | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance |
12.2 PBR + PER 콤보전략 | df4
cond = (df4['PER'] >= 2.5) & (df4['PER'] <= 10)
df5 = df4[cond].copy()
df5
df6 = df5.sort_values(by='PBR')[:30]
df6.describe()
df6[df6['등락률'] == df6['등락률'].min()] | _____no_output_____ | MIT | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance |
12.3 시가총액별 콤보 전략 | from pykrx import stock
import pandas as pd
df1 = stock.get_market_cap_by_ticker("20100104")
df1 = df1[["종가", "시가총액"]]
df1.columns = ["시가", "시가총액"]
df1 = df1.sort_values('시가총액')
df1['group'] = pd.cut(df1.reset_index().index, bins=3, labels=['소형주', '중형주', '대형주'])
df1.tail()
df2 = stock.get_market_fundamental_by_ticker... | _____no_output_____ | MIT | ch12/ch12_per_pbr.ipynb | systemquant/book-pandas-for-finance |
Train your Unet with membrane datamembrane data is in folder membrane/, it is a binary classification task.The input shape of image and mask are the same :(batch_size,rows,cols,channel = 1) Train with data generator | data_gen_args = dict(rotation_range=0.2,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
horizontal_flip=True,
fill_mode='nearest')
myGene = trainGenerator(16,'/dat... | _____no_output_____ | MIT | trainUnet.ipynb | wp-cdas/UNet-Humphries |
Train with npy file | #imgs_train,imgs_mask_train = geneTrainNpy("data/membrane/train/aug/","data/membrane/train/aug/")
#model.fit(imgs_train, imgs_mask_train, batch_size=2, nb_epoch=10, verbose=1,validation_split=0.2, shuffle=True, callbacks=[model_checkpoint])
##Use AllTest
model = unet()
model.load_weights("unet_membrane_AllTrain_8.hdf5... | _____no_output_____ | MIT | trainUnet.ipynb | wp-cdas/UNet-Humphries |
test your model and save predicted results | from PIL import Image
import numpy as np
from skimage import transform
#testGene = testGenerator("/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG")
model = unet()
model.load_weights("unet_membrane.hdf5")
np_image = Image.open('/data/spacenet/bldg/AOI_2_Vegas_Test_public/PAN-PNG/PAN_AOI_2_Vegas_img1005.png')
np_imag... | Lossy conversion from float32 to uint8. Range [0, 1]. Convert image to uint8 prior to saving to suppress this warning.
| MIT | trainUnet.ipynb | wp-cdas/UNet-Humphries |
Thresholding Results | model = unet()
model.load_weights("Humphries_Bragg_Weights.hdf5")
#model.load_weights('unet_membrane_AllTrain_8.hdf5')
def predImgGen(imgPath, target_size=(256,256)):
img = io.imread(imgPath,as_gray = True)
img = img / 255
img = trans.resize(img,target_size)
img = np.reshape(img,img.shape+(1,))
img ... | Lossy conversion from float32 to uint8. Range [-12.235958099365234, -11.882962226867676]. Convert image to uint8 prior to saving to suppress this warning.
Lossy conversion from float32 to uint8. Range [-12.235958099365234, -10.097213745117188]. Convert image to uint8 prior to saving to suppress this warning.
| MIT | trainUnet.ipynb | wp-cdas/UNet-Humphries |
Importing libraries | %matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
pd.options.display.float_format = '{:,.2f}'.format
pd.set_option('display.max_rows', 100)
pd.set_option('disp... | _____no_output_____ | MIT | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial |
Utility Functions | def plot_multiclass_decision_boundary(model, X, y):
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))
cmap = ListedColormap(['#FF0000', '#00FF00', '#0000FF']... | _____no_output_____ | MIT | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial |
Multiclass Classification | X, y = make_multiclass(K=4) # number of class = 4 | _____no_output_____ | MIT | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial |
Deep Neural Network | ##first trial model with dense layers and tanh activation
model = Sequential()
model.add(Dense(64, input_shape=(2,), activation='tanh'))
model.add(Dense(32, activation='tanh'))
model.add(Dense(units=4, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])
y_cat = to_categori... | _____no_output_____ | MIT | Neural_Network_Keras_Multiclass.ipynb | gsdataenthusiast/Keras-Neural-Network-Trial |
Dataset yang digunakan dapat didownload di: https://github.com/rizalespe/Dataset-Sentimen-Analisis-Bahasa-Indonesia atau menggunakan ***git clone*** seperti contoh dibawah ini. Folder yang di _clone_ tersimpan ke dalam folder tempat file project ini disimpan. | #!git clone https://github.com/rizalespe/Dataset-Sentimen-Analisis-Bahasa-Indonesia | _____no_output_____ | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Install Package **Requirement Package**:```1. nltk : https://www.nltk.org/2. Sastrawi: https://github.com/sastrawi/sastrawi3. numpy: https://numpy.org/4. pandas: https://pandas.pydata.org/5. sklearn: https://scikit-learn.org/stable/``` Import Package | #!pip install Sastrawi
#nltk.download('stopwords')
#nltk.download('punkt')
import numpy as np
import pandas as pd
import re
import pickle
from string import punctuation
import os
import json
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from Sastrawi.Stemmer.StemmerFactory import StemmerFa... | _____no_output_____ | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Process Data | df = pd.read_csv("data/dataset_komentar_instagram_cyberbullying.csv")
df.head()
df.loc[(df.Sentiment == 'negative'),'Sentiment']=0
df.loc[(df.Sentiment == 'positive'),'Sentiment']=1
df.head()
def process_tweet(tweet):
tweet = tweet.values.squeeze().tolist()
# kumpulan stemming
factory_stem = Stemm... | _____no_output_____ | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Import Data | df = pd.read_csv("data/komentarDataset", usecols=['Sentiment', 'Instagram Comment Text'])
df.head() | _____no_output_____ | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Dataset Splitting | X = df["Instagram Comment Text"]
y = df.Sentiment
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape | _____no_output_____ | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Training | from sklearn.svm import SVC
from sklearn.model_selection import RandomizedSearchCV
from jcopml.tuning import random_search_params as rsp
pipeline = Pipeline([
('prep', TfidfVectorizer(tokenizer=word_tokenize, stop_words=sw_indo, ngram_range=(1,3))),
('algo', SVC(max_iter=500))
])
model = RandomizedSearchCV(pip... | Fitting 3 folds for each of 50 candidates, totalling 150 fits
| MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Sanity Check | text = [X_train[9].lower()]
text
model.predict(text)
# save_model(model, "model_best_svm.pkl") | Model is pickled as model/model_best_svm.pkl
| MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
Error Analysis | X_test, y_test = X_test.tolist(), np.array([y_test.tolist()])
print('Truth Predicted Tweet')
for x, y in zip(X_pred_, y_pred_[-1]):
x = x.lower()
x = [x]
y_hat = model.predict(x)
if y != (np.sign(y_hat) > 0):
print('%d\t%0.2f\t%s' % (y, np.sign(y_hat) > 0, ' '.join(x).encode('ascii', 'ignore'))) | Truth Predicted Tweet
0 1.00 b'jelek,lecek,bantet ??????'
0 1.00 b'semoga pelakor2 kena karma dan semoga dapat karma yg meninggalkan istrinya yg bwrjuang dg dia dr nol tp setelah sukses selingkuh dan sok jd penguasa ke istri ya..'
1 0.00 b'kasian anaknya,, jgn sampek anaknya rusak jugak kek emaknya yaa'
1 0.00 b'berunt... | MIT | logregModel.ipynb | joanitolopo/sentimen-analisis |
A broad study on `Chi^2` algorithm Before going to broad discussion, first lets understand what is `Chi^2` algorithm ? What it does? Why we need to learn it? * __`Chi^2` (pronounced as kai-square) is an algorithm that helps us to understand the relationship between two [categorical](https://youtu.be/o8gs-zgPfp4) varia... | import pandas as pd
data = pd.read_csv(r"C:\Users\DIU\Desktop\goodness_of_fit.csv")
data | _____no_output_____ | MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
`Chi^2` has a standard distribution [table](https://en.wikipedia.org/wiki/Chi-squared_distributionTable_of_%CF%872_values_vs_p-values). We need this table on both test 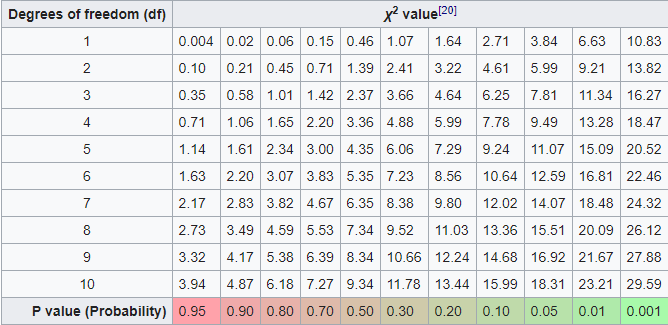 The Equation of `... | data["expected"] = (sum(data["observed_distribution"]) * (data["owners_distribution"]/100)).astype(int)
data | _____no_output_____ | MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
__There are maily two hypothesis in `Chi^2`__\begin{equation}H_o = Null Hypothesis\\H_a = Alternative Hypothesis\end{equation}* __Null Hypothesis => There's no significent relationship between specified features__* __Alternative Hypothesis => reverse of Null Hypothesis__ __Now lets calculate the `chi-square` and find o... | # Same calculation using python manually
subtract = data["observed_distribution"] - data["expected"]
subtract_sqr = subtract**2
division = subtract_sqr / data["expected"]
chi_square = division.sum()
print(round(chi_square, 3)) | 11.442
| MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
Now we need to check whether `owner's disribution` is accepted or not, to do this we need some extra information:* What is the `Degree of freedom`?* What is the significant level ?* What is the Critical Value?__Answer:__Degree of freedom = number of observation - 1 = __5__Significant Level : 0.05 (_most used significan... | critical_value = 11.07
if(chi_square<critical_value):
print("Owner's distribution is correct, Accepted")
else:
print("Owner's distribution is not correct, Rejected") | Owner's distribution is not correct, Rejected
| MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
We can achive exact same thing by using `scipy`: | import scipy.stats as stats
(chi_square, p) = stats.chisquare(data["observed_distribution"], data["expected"], ddof=1)
print ('Chi-square Value = %f, P-value = %f' % (chi_square, p))
alpha = 0.05 # significance level
# another way to check the observation
# Correct means => Accepted => p (resulted level) > alpha (si... | Owner's distribution is not correct, Rejected
| MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
`Chi^2` test of independence __Independence__ is a key concept in probability that describes a situation where knowing the value of one variable tells you nothing about the value of another.For instance, the __month__ you were born probably doesn't tell you anything about which __web browser__ you use :pSo we'd expect... | flu_dataset = pd.read_csv(r"C:\Users\DIU\Desktop\flu_dataset.csv")
copy_df = flu_dataset.copy()
flu_dataset | _____no_output_____ | MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
__Now we need to find out the total both column and row wise:__ | # row wise sum added into a new column called 'total'
flu_dataset["total"] = flu_dataset.iloc[:, 1:].sum(axis=1)
# column wise added into a new row with a index called 'Grand Total'
flu_dataset = pd.concat([flu_dataset, pd.DataFrame(flu_dataset.sum(axis=0), columns=['Grand Total']).T])
flu_dataset | _____no_output_____ | MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
> The main difference between `goodness of fit` and `test of independence` is that in `test of independent` we have to find expected value for every cell in a two dimentional space. Now firstly we need to find out the expected frequency of getting sick or not sick:> expected frequency for getting `sick = 80/380 = 0.210... | del copy_df["status"]
copy_df
chiStats = stats.chi2_contingency(observed = copy_df)
print ('Chi-square Value = %f, p-value=%f' % (chiStats[0], chiStats[1])) | Chi-square Value = 2.525794, p-value=0.282834
| MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
__Now to Accept or Reject the hypothesis we need to look at chi-square distribution [table](https://en.wikipedia.org/wiki/Chi-squared_distributionTable_of_%CF%872_values_vs_p-values).__First thing first, we have a significant level/alpha for this problem = 10% = 0.10and the degree of freedom for Contingency = (number o... | significant_level = 0.10
degree_of_freedom = 2
critical_value = crit = stats.chi2.ppf(q = 1 - significant_level, df = degree_of_freedom)
print("Critical Value: ", critical_value)
observe_chi_square = chiStats[0]
print("Observed Chi Value: ", observe_chi_square)
if observe_chi_square <= critical_value:
# observ... | Critical Value: 4.605170185988092
Observed Chi Value: 2.5257936507936507
Null hypothesis Accetped (variables are Independent)
| MIT | Chi^2 (Kai-Square) Algorithm/A broad study on Chi^2(Kai-Square) Algorithm.ipynb | 78526Nasir/Kaggle-Students-Academic-Performance |
Mask R-CNN - Inspect Ballon Trained ModelCode and visualizations to test, debug, and evaluate the Mask R-CNN model. | import os
import sys
import random
import math
import re
import time
import numpy as np
import tensorflow as tf
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# Root directory of the project
ROOT_DIR = os.path.abspath("../../")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Configurations | config = balloon.BalloonConfig()
BALLOON_DIR = os.path.join(ROOT_DIR, "datasets/balloon")
# Override the training configurations with a few
# changes for inferencing.
class InferenceConfig(config.__class__):
# Run detection on one image at a time
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
... |
Configurations:
BACKBONE resnet101
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 1
BBOX_STD_DEV [0.1 0.1 0.2 0.2]
COMPUTE_BACKBONE_SHAPE None
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.9
DETECTION_NMS_THRESHOLD ... | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Notebook Preferences | # Device to load the neural network on.
# Useful if you're training a model on the same
# machine, in which case use CPU and leave the
# GPU for training.
DEVICE = "/cpu:0" # /cpu:0 or /gpu:0
# Inspect the model in training or inference modes
# values: 'inference' or 'training'
# TODO: code for 'training' test mode ... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Load Validation Dataset | # Load validation dataset
dataset = balloon.BalloonDataset()
dataset.load_balloon(BALLOON_DIR, "val")
# Must call before using the dataset
dataset.prepare()
print("Images: {}\nClasses: {}".format(len(dataset.image_ids), dataset.class_names)) | Images: 13
Classes: ['BG', 'balloon']
| MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Load Model | # Create model in inference mode
with tf.device(DEVICE):
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR,
config=config)
# Set path to balloon weights file
# Download file from the Releases page and set its path
# https://github.com/matterport/Mask_RCNN/releases
weight... | Loading weights e:\Protohaus\GitHub\Mask_RCNN\mask_rcnn_balloon.h5
WARNING:tensorflow:OMP_NUM_THREADS is no longer used by the default Keras config. To configure the number of threads, use tf.config.threading APIs.
| MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Run Detection | image_id = random.choice(dataset.image_ids)
image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset, config, image_id)
info = dataset.image_info[image_id]
print("image ID: {}.{} ({}) {}".format(info["source"], info["id"], image_id,
dataset.image_ref... | image ID: balloon.410488422_5f8991f26e_b.jpg (12) e:\Protohaus\GitHub\Mask_RCNN\datasets/balloon\val\410488422_5f8991f26e_b.jpg
Processing 1 images
image shape: (1024, 1024, 3) min: 0.00000 max: 255.00000 uint8
molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 1... | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Color SplashThis is for illustration. You can call `balloon.py` with the `splash` option to get better images without the black padding. | splash = balloon.color_splash(image, r['masks'])
display_images([splash], cols=1) | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Step by Step Prediction Stage 1: Region Proposal NetworkThe Region Proposal Network (RPN) runs a lightweight binary classifier on a lot of boxes (anchors) over the image and returns object/no-object scores. Anchors with high *objectness* score (positive anchors) are passed to the stage two to be classified.Often, eve... | # Generate RPN trainig targets
# target_rpn_match is 1 for positive anchors, -1 for negative anchors
# and 0 for neutral anchors.
target_rpn_match, target_rpn_bbox = modellib.build_rpn_targets(
image.shape, model.anchors, gt_class_id, gt_bbox, model.config)
log("target_rpn_match", target_rpn_match)
log("target_rpn_... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
1.b RPN PredictionsHere we run the RPN graph and display its predictions. | # Run RPN sub-graph
pillar = model.keras_model.get_layer("ROI").output # node to start searching from
# TF 1.4 and 1.9 introduce new versions of NMS. Search for all names to support TF 1.3~1.10
nms_node = model.ancestor(pillar, "ROI/rpn_non_max_suppression:0")
if nms_node is None:
nms_node = model.ancestor(pillar... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Stage 2: Proposal ClassificationThis stage takes the region proposals from the RPN and classifies them. 2.a Proposal ClassificationRun the classifier heads on proposals to generate class propbabilities and bounding box regressions. | # Get input and output to classifier and mask heads.
mrcnn = model.run_graph([image], [
("proposals", model.keras_model.get_layer("ROI").output),
("probs", model.keras_model.get_layer("mrcnn_class").output),
("deltas", model.keras_model.get_layer("mrcnn_bbox").output),
("masks", model.keras_model.get_la... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
2.c Step by Step DetectionHere we dive deeper into the process of processing the detections. | # Proposals are in normalized coordinates. Scale them
# to image coordinates.
h, w = config.IMAGE_SHAPE[:2]
proposals = np.around(mrcnn["proposals"][0] * np.array([h, w, h, w])).astype(np.int32)
# Class ID, score, and mask per proposal
roi_class_ids = np.argmax(mrcnn["probs"][0], axis=1)
roi_scores = mrcnn["probs"][0,... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Apply Bounding Box Refinement | # Class-specific bounding box shifts.
roi_bbox_specific = mrcnn["deltas"][0, np.arange(proposals.shape[0]), roi_class_ids]
log("roi_bbox_specific", roi_bbox_specific)
# Apply bounding box transformations
# Shape: [N, (y1, x1, y2, x2)]
refined_proposals = utils.apply_box_deltas(
proposals, roi_bbox_specific * confi... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Filter Low Confidence Detections | # Remove boxes classified as background
keep = np.where(roi_class_ids > 0)[0]
print("Keep {} detections:\n{}".format(keep.shape[0], keep))
# Remove low confidence detections
keep = np.intersect1d(keep, np.where(roi_scores >= config.DETECTION_MIN_CONFIDENCE)[0])
print("Remove boxes below {} confidence. Keep {}:\n{}".for... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Per-Class Non-Max Suppression | # Apply per-class non-max suppression
pre_nms_boxes = refined_proposals[keep]
pre_nms_scores = roi_scores[keep]
pre_nms_class_ids = roi_class_ids[keep]
nms_keep = []
for class_id in np.unique(pre_nms_class_ids):
# Pick detections of this class
ixs = np.where(pre_nms_class_ids == class_id)[0]
# Apply NMS
... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Stage 3: Generating MasksThis stage takes the detections (refined bounding boxes and class IDs) from the previous layer and runs the mask head to generate segmentation masks for every instance. 3.a Mask TargetsThese are the training targets for the mask branch | display_images(np.transpose(gt_mask, [2, 0, 1]), cmap="Blues") | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
3.b Predicted Masks | # Get predictions of mask head
mrcnn = model.run_graph([image], [
("detections", model.keras_model.get_layer("mrcnn_detection").output),
("masks", model.keras_model.get_layer("mrcnn_mask").output),
])
# Get detection class IDs. Trim zero padding.
det_class_ids = mrcnn['detections'][0, :, 4].astype(np.int32)
de... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
Visualize ActivationsIn some cases it helps to look at the output from different layers and visualize them to catch issues and odd patterns. | # Get activations of a few sample layers
activations = model.run_graph([image], [
("input_image", tf.identity(model.keras_model.get_layer("input_image").output)),
("res2c_out", model.keras_model.get_layer("res2c_out").output),
("res3c_out", model.keras_model.get_layer("res3c_out").o... | _____no_output_____ | MIT | samples/balloon/inspect_balloon_model.ipynb | protohaus/Mask_RCNN |
MLE Approximate $95$% CI for Bernoulli distribution $$ \large \hat{\theta} \pm 1.96 \sqrt{\frac{\hat{\theta}(1-{\hat{\theta}})}{n}}$$ | def approx_ci(x, n):
return x - 1.96 * np.sqrt((x * (1 - x)) / n), x + 1.96 * np.sqrt((x * (1 - x)) / n)
approx_ci(.47, 100) | _____no_output_____ | MIT | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff |
Examples If $X1,…,Xn∼iidExponential(λ)$ (iid means independent and identically distributed), then the MLE for $\lambda$ is $1/\hat{x}$ where $\hat{x}$ is the sample mean. Suppose we observe the following data: X1=2.0, X2=2.5, X3=4.1, X4=1.8, X5=4.0 | x = [2, 2.5, 4.1, 1.8, 4]
1 / np.mean(x) | _____no_output_____ | MIT | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff |
Suppose we observe n=4 data points from a normal distribution with unknown mean $\mu$. The data are x={−1.2, 0.5, 0.8, −0.3}. | x2 = [-1.2, .5, .8, -.3]
np.mean(x2) | _____no_output_____ | MIT | bayesian-notes-santa-cruz/02_MLE.ipynb | AlxndrMlk/bayesian-stuff |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.