
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Stock Code | #all stock codes with char
df1.loc[df1['stock_code'].apply(lambda x: bool(re.search('^[a-zA-Z]+$', x))), 'stock_code'].unique()
#remove stock code in ['POST', 'D', 'M', 'PADS', 'DOT', 'CRUK']
# df1 = df1[-df1.isin(['POST', 'D', 'M', 'PADS', 'DOT', 'CRUK'])] | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
Description | #remove description
# df1 = df1.drop('description', axis=1) | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
Country | df1['country'].value_counts(normalize='True').head()
df1[['country', 'customer_id']].drop_duplicates().groupby('country').count().reset_index().sort_values('customer_id', ascending=False).head() | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
2.0. Data Filtering | df2 = df1.copy()
df2['country'].unique()
# ====================== Numerical Attributes ======================
#unit price != 0
# df2.sort_values('unit_price').head()
df2 = df2[df2['unit_price']>0.004]
# ====================== Categorical Attributes ======================
#stock code
df2 = df2[~df2.isin(['POST', 'D... | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
3.0. Feature Engineering | df3 = df2.copy() | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
3.1. Feature Creation | # df_purchase.loc[:, 'gross_revenue'] = df_purchase.loc[:, 'quantity'] * df_purchase.loc[:, 'unit_price']
df_purchase.loc[:,'gross_revenue'] = df_purchase.loc[:, 'quantity'] * df_purchase.loc[:, 'unit_price']
#data reference
df_ref = df3.drop(['invoice_no', 'stock_code', 'quantity', 'invoice_date',
'unit_pri... | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
4.0. Exploratory Data Analisys | df4 = df_ref.dropna().copy() | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
5.0. Data Preparation | df5 = df4.copy()
ss = pp.StandardScaler()
mms = pp.MinMaxScaler()
df5['gross_revenue'] = ss.fit_transform(df5[['gross_revenue']])
df5['recency_days'] = ss.fit_transform(df5[['recency_days']])
df5['invoice_no'] = ss.fit_transform(df5[['invoice_no']])
df5['avg_ticket'] = ss.fit_transform(df5[['avg_ticket']])
df5.head() | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
6.0. Feature Selection | df6 = df5.copy() | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
7.0. Hyperparameter Fine-Tunning | X = df6.drop('customer_id', axis=1)
clusters = [2,3,4,5,6, 7] | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
7.1. Within-Cluster Sum of Squares (WSS) | #Easy way
kmeans = KElbowVisualizer(c.KMeans(), k=clusters, timings=False)
kmeans.fit(X)
kmeans.show();
| _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
7.2. Silhouette Score | #Easy way
kmeans = KElbowVisualizer(c.KMeans(), k=clusters, metric = 'silhouette', timings = False)
kmeans.fit(X)
kmeans.show(); | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
7.3. Silhouette Analysis | fig, ax = plt.subplots(3, 2, figsize=(25,18))
for k in clusters:
km = c.KMeans(n_clusters=k, init='random', n_init=10, max_iter=100, random_state=3)
q, mod = divmod(k, 2)
visualizer = SilhouetteVisualizer(estimator = km ,colors='yellowbrick', ax=ax[q-1][mod])
visualizer.fit(X)
visualizer.final... | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
8.0. Model Training 8.1. KMeans | #model definition
k = 3
kmeans = c.KMeans(init='random', n_clusters=k, n_init=10, max_iter=300, random_state=3)
#model training
kmeans.fit(X)
#clustering
labels = kmeans.labels_ | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.0. Cluster Analisys | df9 = df6.copy()
df9['cluster'] = labels
| _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.1. Visualization Inspection |
visualizer = SilhouetteVisualizer(kmeans, colors='yellowbrick')
visualizer.fit(X)
visualizer.finalize() | /home/heitor/repos/insiders_clustering/venv/lib/python3.8/site-packages/sklearn/base.py:450: UserWarning: X does not have valid feature names, but KMeans was fitted with feature names
warnings.warn(
| MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.2. 2d Plot | # df_vis = df9.drop('customer_id', axis=1)
# sns.pairplot(df_vis, hue='cluster')
| _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.3. UMAP t-SNE | reducer = umap.UMAP(n_neighbors=30, random_state=3)
embedding = reducer.fit_transform(X)
df_vis['embedding_x'] = embedding[:,0]
df_vis['embedding_y'] = embedding[:,1]
sns.scatterplot(x='embedding_x', y='embedding_y', hue='cluster',
palette = sns.color_palette('hls', n_colors = len(df_vis['cluster'].uniqu... | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.1. Visualization Inspection | #WSS
print('WSS: {}'.format(kmeans.inertia_))
#SS
print('SS: {}'.format(m.silhouette_score(X,labels, metric='euclidean')))
px.scatter_3d(df9, x='recency_days', y='invoice_no', z='gross_revenue', color='cluster') | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
9.2. Cluster Profile | aux1 = df9.groupby('cluster').mean().reset_index()
aux1 = aux1.drop('customer_id', axis=1)
aux2 = df9[['customer_id', 'cluster']].groupby('cluster').count().reset_index()
df_cluster = pd.merge(aux1, aux2, on='cluster', how='left')
df_cluster['perc'] = 100*df_cluster['customer_id']/df_cluster['customer_id'].sum()
df... | _____no_output_____ | MIT | notebooks/code3.ipynb | heitorfe/insiders_clustering |
Invariantin massan histogrammin piirtäminen Tässä harjoituksessa opetellaan piirtämään invariantin massan histogrammi Pythonilla. Käytetään datana CMS-kokeen vuonna 2011 keräämää dataa kahden myonin törmäyksistä [1]. Tässä harjoituksessa käytettävään CSV-tiedostoon on karsittu edellä mainitusta datasta kiinnostavia ta... | # Haetaan tarvittavat moduulit
import pandas
import matplotlib.pyplot as plt | _____no_output_____ | CC-BY-4.0 | Demot/Hiukkasfysiikkaa/Invariantti-massa-histogrammi.ipynb | cms-opendata-education/cms-jupyter-materials-swedish |
2) Datan hakeminen Alkuvalmisteluiden jälkeen siirrytään hakemaan CMS:n dataa käyttöömme notebookiin. | # Luodaan DataFrame-rakenne (periaatteessa taulukko), johon kirjataan kaikki CSV-tiedostossa oleva data.
# Annetaan luomallemme DataFramelle nimi 'datasetti'.
datasetti = pandas.read_csv('https://raw.githubusercontent.com/cms-opendata-education/cms-jupyter-materials-finnish/master/Data/Ymumu_Run2011A.csv')
# Luodaan m... | _____no_output_____ | CC-BY-4.0 | Demot/Hiukkasfysiikkaa/Invariantti-massa-histogrammi.ipynb | cms-opendata-education/cms-jupyter-materials-swedish |
3) Histogrammin piirtäminen Nyt jäljellä on enää vaihe, jossa luomme histogrammin hakemistamme invariantin massan arvoista. Histogrammi on pylväskaavio, joka kuvaa kuinka monta törmäystapahtumaa on osunut kunkin invariantin massan arvon kohdalle. Huomaa, että alla käytämme yhteensä 500 pylvästä. | # Suoritetaan histogrammin piirtäminen pyplot-moduulin avulla:
# (http://matplotlib.org/api/pyplot_api.html?highlight=matplotlib.pyplot.hist#matplotlib.pyplot.hist).
# 'Bins' määrittelee histogrammin pylväiden lukumäärän.
plt.hist(invariantti_massa, bins=500)
# Näillä riveillä ainoastaan määritellään otsikko sekä akse... | _____no_output_____ | CC-BY-4.0 | Demot/Hiukkasfysiikkaa/Invariantti-massa-histogrammi.ipynb | cms-opendata-education/cms-jupyter-materials-swedish |
Burgers Equation - Forward Euler/0-estimation Parameter estimation for Burgers' Equation using Gaussian processes (Forward Euler scheme) Problem Setup$u_t + u u_{x} = \nu u_{x}$$u(x,t) = \frac{x}{1+t}$ => We'd expect $\nu = 0$$u_0(x) := u(x,0) = x$$x \in [0, 1], t \in \{0, \tau \}$Using the forward Euler scheme, the e... | import numpy as np
import sympy as sp
from scipy.optimize import minimize
import matplotlib.pyplot as plt
import warnings
import time
tau = 0.001
def get_simulated_data(tau, n=20):
x = np.random.rand(n)
y_u = x
y_f = x/(1+tau)
return (x, y_u, y_f)
(x, y_u, y_f) = get_simulated_data(tau)
plt.plot(x, y_u... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Step 2:Evaluate kernels$k_{nn}(x_i, x_j; \theta) = \theta exp(-\frac{1}{2l}(x_i-x_j)^2)$ | x_i, x_j, theta, l, nu = sp.symbols('x_i x_j theta l nu')
kuu_sym = theta*sp.exp(-1/(2*l)*((x_i - x_j)**2))
kuu_fn = sp.lambdify((x_i, x_j, theta, l), kuu_sym, "numpy")
def kuu(x, theta, l):
k = np.zeros((x.size, x.size))
for i in range(x.size):
for j in range(x.size):
k[i,j] = kuu_fn(x[i], ... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
$k_{ff}(x_i,x_j;\theta,\phi) \\= \mathcal{L}_{x_i}^\nu \mathcal{L}_{x_j}^\nu k_{uu}(x_i, x_j; \theta) \\= k_{uu} + \tau \nu \frac{d}{dx_i}k_{uu} - \tau x_i \frac{d}{dx_i}k_{uu} + \tau \nu \frac{d}{dx_j}k_{uu} + \tau^2 \nu^2 \frac{d}{dx_i} \frac{d}{dx_j}k_{uu} - \tau^2 \nu x_i\frac{d^2}{dx_i dx_j} k_{uu} - \tau x_j \fra... | kff_sym = kuu_sym \
+ tau*nu*sp.diff(kuu_sym, x_i) \
- tau*x_i*sp.diff(kuu_sym, x_i) \
+ tau*nu*sp.diff(kuu_sym, x_j) \
+ tau**2*nu**2*sp.diff(kuu_sym, x_j, x_i) \
- tau**2*nu*x_i*sp.diff(kuu_sym, x_j, x_i) \
- tau*x_j*sp.diff(kuu_sym, x_j) \
- tau**2*nu*x_j*sp.di... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
$k_{fu}(x_i,x_j;\theta,\phi) \\= \mathcal{L}_{x_i}^\nu k_{uu}(x_i, x_j; \theta) \\= k_{uu} + \tau \nu \frac{d}{dx_i}k_{uu} - \tau x_i\frac{d}{dx_i}k_{uu}$ | kfu_sym = kuu_sym + tau*nu*sp.diff(kuu_sym, x_i) - tau*x_i*sp.diff(kuu_sym, x_i)
kfu_fn = sp.lambdify((x_i, x_j, theta, l, nu), kfu_sym, "numpy")
def kfu(x, theta, l, nu):
k = np.zeros((x.size, x.size))
for i in range(x.size):
for j in range(x.size):
k[i,j] = kfu_fn(x[i], x[j], theta, l, nu)... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Step 3: Compute NLML | def nlml(params, x, y1, y2, s):
theta_exp = np.exp(params[0])
l_exp = np.exp(params[1])
K = np.block([
[kuu(x, theta_exp, l_exp) + s*np.identity(x.size), kuf(x, theta_exp, l_exp, params[2])],
[kfu(x, theta_exp, l_exp, params[2]), kff(x, theta_exp, l_exp, params[2]) + s*np.identity(x.size)]
... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Step 4: Optimise hyperparameters | m = minimize(nlml, np.random.rand(3), args=(x, y_u, y_f, 1e-7), method="Nelder-Mead", options = {'maxiter' : 1000})
m.x[2]
m | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Step 5: Analysis w.r.t. the number of data points (up to 25): In this section we want to analyze the error of our algorithm using two different ways and its time complexity. | res = np.zeros((5,25))
timing = np.zeros((5,25))
warnings.filterwarnings("ignore")
for k in range(5):
for n in range(25):
start_time = time.time()
(x, y_u, y_f) = get_simulated_data(tau, n)
m = minimize(nlml, np.random.rand(3), args=(x, y_u, y_f, 1e-7), method="Nelder-Mead")
res[k][n... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Plotting the error in our estimate for $\nu$ (Error = $| \nu_{estimate} - \nu_{true} |$): | lin = np.linspace(1, res.shape[1], res.shape[1])
est = np.repeat(0.01, len(lin))
f, (ax1, ax2) = plt.subplots(ncols=2, nrows=2, figsize=(13,7))
ax1[0].plot(lin, np.abs(res[0,:]), color = 'green')
ax1[0].plot(lin, est, color='blue', linestyle='dashed')
ax1[0].set(xlabel= r"Number of data points", ylabel= "Error")
ax1... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
All in one plot: | lin = np.linspace(1, res.shape[1], res.shape[1])
for i in range(res.shape[0]):
plt.plot(lin, np.abs(res[i,:]))
plt.ylabel('Error')
plt.xlabel('Number of data points')
est = np.repeat(0.01, len(lin))
plt.plot(lin, est, color='blue', linestyle='dashed')
plt.show() | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
We see that for n sufficiently large (in this case $n \geq 3$), we can assume the error to be bounded by 0.01. Plotting the error between the solution and the approximative solution: | Another approach of plotting the error is by calculating the difference between the approximative solution and the true solution. <br>
That is: Let $\tilde{\nu}$ be the parameter, resulting from our algorithm. Set $\Omega := ([0,1] \times {0}) \cup ([0,1] \times {\tau})$
Then we can calculate the solution of the PDE
... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Plotting the execution time: | lin = np.linspace(1, timing.shape[1], timing.shape[1])
for i in range(timing.shape[0]):
plt.plot(lin, timing[i,:])
plt.ylabel('Execution time in seconds')
plt.xlabel('Number of data points')
plt.show()
lin = np.linspace(1, timing.shape[1], timing.shape[1])
for i in range(timing.shape[0]):
plt.plot... | _____no_output_____ | MIT | burgers_equation/burgerseq_mod_fe_no_mean.ipynb | ratnania/mlhiphy |
Collaboration and Competition---In this notebook, you will learn how to use the Unity ML-Agents environment for the third project of the [Deep Reinforcement Learning Nanodegree](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) program. 1. Start the EnvironmentWe begin by importing the nece... | from unityagents import UnityEnvironment
import numpy as np | _____no_output_____ | MIT | Tennis.ipynb | yanlinglin/drl_p3 |
Next, we will start the environment! **_Before running the code cell below_**, change the `file_name` parameter to match the location of the Unity environment that you downloaded.- **Mac**: `"path/to/Tennis.app"`- **Windows** (x86): `"path/to/Tennis_Windows_x86/Tennis.exe"`- **Windows** (x86_64): `"path/to/Tennis_Wind... | env = UnityEnvironment(file_name="Tennis.app") | INFO:unityagents:
'Academy' started successfully!
Unity Academy name: Academy
Number of Brains: 1
Number of External Brains : 1
Lesson number : 0
Reset Parameters :
Unity brain name: TennisBrain
Number of Visual Observations (per agent): 0
Vector Observation space type... | MIT | Tennis.ipynb | yanlinglin/drl_p3 |
Environments contain **_brains_** which are responsible for deciding the actions of their associated agents. Here we check for the first brain available, and set it as the default brain we will be controlling from Python. | # get the default brain
brain_name = env.brain_names[0]
brain = env.brains[brain_name] | _____no_output_____ | MIT | Tennis.ipynb | yanlinglin/drl_p3 |
2. Examine the State and Action SpacesIn this environment, two agents control rackets to bounce a ball over a net. If an agent hits the ball over the net, it receives a reward of +0.1. If an agent lets a ball hit the ground or hits the ball out of bounds, it receives a reward of -0.01. Thus, the goal of each agent i... | # reset the environment
env_info = env.reset(train_mode=True)[brain_name]
# number of agents
num_agents = len(env_info.agents)
print('Number of agents:', num_agents)
# size of each action
action_size = brain.vector_action_space_size
print('Size of each action:', action_size)
# examine the state space
states = env_... | Number of agents: 2
Size of each action: 2
There are 2 agents. Each observes a state with length: 24
The state for the first agent looks like: [ 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ... | MIT | Tennis.ipynb | yanlinglin/drl_p3 |
3. Take Random Actions in the EnvironmentIn the next code cell, you will learn how to use the Python API to control the agents and receive feedback from the environment.Once this cell is executed, you will watch the agents' performance, if they select actions at random with each time step. A window should pop up that... | states[1,np.newaxis]
for i in range(1, 6): # play game for 5 episodes
env_info = env.reset(train_mode=False)[brain_name] # reset the environment
states = env_info.vector_observations # get the current state (for each agent)
scores = np.zeros(num_... | Score (max over agents) from episode 1: 0.0
Score (max over agents) from episode 2: 0.0
Score (max over agents) from episode 3: 0.0
Score (max over agents) from episode 4: 0.0
Score (max over agents) from episode 5: 0.0
| MIT | Tennis.ipynb | yanlinglin/drl_p3 |
When finished, you can close the environment. 4. It's Your Turn!Now it's your turn to train your own agent to solve the environment! When training the environment, set `train_mode=True`, so that the line for resetting the environment looks like the following:```pythonenv_info = env.reset(train_mode=True)[brain_name]`... | import random
import torch
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
%matplotlib inline
from maddpg_agent import MAagent
def MA_ddpg(n_episodes=10000, max_t=1000, print_every=10,random_seed=2, noise_scalar_init=2.0, noise_reduction_factor=0.99, num_agents=num_agents,update_every=... | _____no_output_____ | MIT | Tennis.ipynb | yanlinglin/drl_p3 |
Stackexchange Dataset | ! wget https://drive.switch.ch/index.php/s/I6hiqbHZRCFwZGj/download -O /data/dataset/stackexchange.zip
!ls -lisah /data/dataset/stackexchange.zip
!unzip /data/dataset/stackexchange.zip -d /data/dataset/
!ls -lisah /data/dataset/stackexchange.com/unix.stackexchange.com/json/ | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Init Spark | import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("unix.stackexchange.com") \
.getOrCreate() | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Badges | !head /data/dataset/stackexchange.com/unix.stackexchange.com/json/Badges.json
path = "file:///data/dataset/stackexchange.com/unix.stackexchange.com/json/Badges.json"
badges = spark.read.json(path)
badges.show(3, truncate=False)
badges.printSchema() | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Inspect all Files | !hdfs dfs -rm -r "/dataset/unix.stackexchange.com"
def get_info(name):
print(f"info for {name}")
print("------------------------------------")
path = f"file:///data/dataset/stackexchange.com/unix.stackexchange.com/json/{name}.json"
df = spark.read.json(path)
df.show(3, truncate=False)
df.printSc... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Save as Parquet | def save_as_parquet(name, df):
print(f"saving {name}")
print("------------------------------------")
df.show(3, truncate=False)
df.printSchema()
lower_name = name.lower()
df.repartition(15).write.parquet(f"/dataset/unix.stackexchange.com/{lower_name}.parquet") | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Badges | df = get_info('Badges')
# https://spark.apache.org/docs/latest/api/python/_modules/pyspark/sql/functions.html
# https://sparkbyexamples.com/spark/spark-sql-functions/
from pyspark.sql import functions as f
df.select(f.min("Class"), f.max("Class")).collect()
# https://sparkbyexamples.com/pyspark/pyspark-cast-column-typ... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Comments | df = get_info('Comments')
df.filter("UserDisplayName is not null").show(2)
save_as_parquet("Comments", df.selectExpr(\
"cast(Id as int) id", \
"cast(PostId as int) post_id", \
"cast(UserId as int) user_id", \
"cast(Score as byte) score", \
"cast(Cont... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
PostHistory | df = get_info('PostHistory')
save_as_parquet("PostHistory", df.selectExpr(\
"cast(Id as int) id", \
"cast(PostId as int) post_id", \
"cast(UserId as int) user_id", \
"cast(PostHistoryTypeId as byte) post_history_type_id", \
"cast(UserDisplayName as s... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
PostLinks | df = get_info('PostLinks')
save_as_parquet("PostLinks", df.selectExpr(\
"cast(Id as int) id", \
"cast(RelatedPostId as int) related_post_id", \
"cast(PostId as int) post_id", \
"cast(LinkTypeId as byte) link_type_id", \
"cast(CreationDate as timestam... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Posts | df = get_info('Posts')
save_as_parquet("Posts", df.selectExpr(\
"cast(Id as int) id", \
"cast(OwnerUserId as int) owner_user_id", \
"cast(LastEditorUserId as int) last_editor_user_id", \
"cast(PostTypeId as short) post_type_id", \
"cast(AcceptedAnswe... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Tags | df = get_info('Tags')
save_as_parquet("Tags", df.selectExpr(\
"cast(Id as int) id", \
"cast(ExcerptPostId as int) excerpt_post_id", \
"cast(WikiPostId as int) wiki_post_id", \
"cast(TagName as string) tag_name", \
"cast(Count as int) count" \
... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Users | df = get_info('Users')
save_as_parquet("Users", df.selectExpr(\
"cast(Id as int) id", \
"cast(AccountId as int) account_id", \
"cast(Reputation as int) reputation", \
"cast(Views as int) views", \
"cast(DownVotes as int) down_votes", \
... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Votes | df = get_info('Votes')
save_as_parquet("Votes", df.selectExpr(\
"cast(Id as int) id", \
"cast(UserId as int) user_id", \
"cast(PostId as int) post_id", \
"cast(VoteTypeId as byte) vote_type_id", \
"cast(BountyAmount as byte) bounty_amount", \
... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Analysing | def get_path(name):
return f"/dataset/unix.stackexchange.com/{name}.parquet" | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Read all Parquets | badges = spark.read.parquet(get_path("badges"))
comments = spark.read.parquet(get_path("comments"))
posthistory = spark.read.parquet(get_path("posthistory"))
postlinks = spark.read.parquet(get_path("postlinks"))
posts = spark.read.parquet(get_path("posts"))
tags = spark.read.parquet(get_path("tags"))
users = spark.read... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Tags | # tags = spark.read.parquet(get_path("tags"))
tags.show()
from pyspark.sql import functions as f
tags.filter(f.col("tag_name") == "async").show()
tags.filter("tag_name = 'async'").show()
tags.filter("tag_name like '%async%'").show()
tags.filter(f.col("tag_name").like('%async%')).show()
tags.select("tag_name", "count")... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Wordcloud Needs the `wordcloud` (and `matplotlib` which comes as a dependency) python package```pip install wordcloud```see [documentation](https://github.com/amueller/word_cloud) | filtered_tags = tags.select("tag_name", "count").orderBy(f.col("count").desc()).filter("count > 100")
filtered_tags.show(2)
filtered_tags.count()
frequencies = filtered_tags.toPandas().set_index('tag_name').T.to_dict('records')[0]
frequencies['linux']
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wo... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Users | users.printSchema()
print(users.count())
print(users.filter("id is not null").count())
print(users.filter("id is not null").distinct().count())
users. \
select("account_id", "display_name", "views", "down_votes", "up_votes", "reputation"). \
show(2)
# most reputation
# https://stackexchange.com/users/{account_... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Analysing a Question- [83577](https://unix.stackexchange.com/questions/83577/how-to-invoke-vim-with-line-numbers-shown) | posts.filter("id = 83577").toPandas().T
posts.filter("id = 648583").toPandas().T
posts.filter("id = 648608").toPandas().T
posts.select("parent_id").groupBy("parent_id").count().sort(f.desc("count")).show(20) | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Counts- inspired from [davidvrba](https://github.com/davidvrba/Stackoverflow-Data-Analysis) | posts.count()
# 1 = Question
# 2 = Answer
# 3 = Orphaned tag wiki
# 4 = Tag wiki excerpt
# 5 = Tag wiki
# 6 = Moderator nomination
# 7 = "Wiki placeholder" (seems to only be the election description)
# 8 = Privilege wiki
questions = posts.filter(f.col('post_type_id') == 1)
answers = posts.filter(f.col('post_type_id') ... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Response Time | response_time = (
questions.alias('questions')
.join(answers.alias('answers'), f.col('questions.accepted_answer_id') == f.col('answers.id'))
.select(
f.col('questions.id'),
f.col('questions.creation_date').alias('question_time'),
f.col('answers.creation_date').alias('answer_time')
... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Hourly Data | hourly_data = (
response_time
.withColumn('hours', f.hour("answer_time"))
).show(2)
hourly_data = (
response_time
.withColumn('hours', f.hour("answer_time"))
.groupBy('hours')
.count()
.orderBy('hours')
.limit(24)
).toPandas()
hourly_data.plot(
x='hours', y='count', figsize=(12, 6), ... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
See the time evolution of the number of questions and answers | posts_grouped = (
posts
.filter('owner_user_id is not null')
.groupBy(
f.window('creation_date', '1 week')
)
.agg(
f.sum(f.when(f.col('post_type_id') == 1, f.lit(1)).otherwise(f.lit(0))).alias('questions'),
f.sum(f.when(f.col('post_type_id') == 2, f.lit(1)).otherwise(f.lit(0)... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Tags | vi_sudo_tag = (
questions
.select('id', 'creation_date', 'tags')
.groupBy(
f.window('creation_date', "4 weeks")
)
.agg(
f.sum(f.when(questions.tags.contains("nano"), f.lit(1)).otherwise(f.lit(0))).alias('nano'),
f.sum(f.when(questions.tags.contains("vim"), f.lit(1)).otherwise... | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Questions - Who asked the most questions?- How many people replied with an accepted answer by themselves? - what is the fraction of "self-answerers" against all users?- How many people never asked a question?- Which question took the longest to get an accepted answer?- Generate a plot where we can see at which mon... | posts.select("id", "title").filter(f.col("title").contains("kill -9")).show(20, False)
comments.filter(f.col("text").contains("LOL")).show(200, False) | +-------+-------+-------+-----+---------------+-----------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------... | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
Stopping Spark | spark.stop() | _____no_output_____ | MIT | V8/4_unix.stackexchange.com.ipynb | fred1234/BDLC_FS22 |
|species|spec_as_int||---|---||acerifolia_x|1||aestivalis_x|2||cinerea_x|3||labrusca_x|4||palmata_x|5||riparia_x|6||rupestris_x|7||vulpina_x|8||acerifolia_y|9||aestivalis_y|10||cinerea_y|11||labrusca_y|12||palmata_y|13||riparia_y|14||rupestris_y|15||vulpina_y|16|acerifolia_z|17||aestivalis_z|18||cinerea_z|19||labrusca_... | table <- table(Predicted=predictions$class, Species=test.data$spec_as_int)
print(confusionMatrix(table)) | _____no_output_____ | CC0-1.0 | .ipynb_checkpoints/Bimodel Test_CCtroubleshoot-checkpoint.ipynb | Kovacs-Lab/Geneva_Ionomics |
Densely Connected Networks (DenseNet)ResNet significantly changed the view of how to parametrize the functions in deep networks. DenseNet is to some extent the logical extension of this. To understand how to arrive at it, let us take a small detour to theory. Recall the Taylor expansion for functions. For scalars it c... | %mavenRepo snapshots https://oss.sonatype.org/content/repositories/snapshots/
%maven ai.djl:api:0.7.0-SNAPSHOT
%maven ai.djl:model-zoo:0.7.0-SNAPSHOT
%maven ai.djl:basicdataset:0.7.0-SNAPSHOT
%maven org.slf4j:slf4j-api:1.7.26
%maven org.slf4j:slf4j-simple:1.7.26
%maven ai.djl.mxnet:mxnet-engine:0.7.0-SNAPSHOT
%ma... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
A dense block consists of multiple `convBlock` units, each using the same number of output channels. In the forward computation, however, we concatenate the input and output of each block on the channel dimension. | class DenseBlock extends AbstractBlock {
private static final byte VERSION = 2;
public SequentialBlock net = new SequentialBlock();
public DenseBlock(int numConvs, int numChannels) {
super(VERSION);
for (int i = 0; i < numConvs; i++) {
this.net.add(
addChild... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
In the following example, we define a convolution block (`DenseBlock`) with two blocks of 10 output channels. When using an input with 3 channels, we will get an output with the $3+2\times 10=23$ channels. The number of convolution block channels controls the increase in the number of output channels relative to the nu... | NDManager manager = NDManager.newBaseManager();
SequentialBlock block = new SequentialBlock()
.add(new DenseBlock(2, 10));
NDArray X = manager.randomUniform(0f, 1.0f, new Shape(4, 3, 8, 8));
block.setInitializer(new XavierInitializer());
block.initialize(manager, DataType.FLOAT32, X.getShape());
ParameterStore p... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
Transition LayersSince each dense block will increase the number of channels, adding too many of them will lead to an excessively complex model. A transition layer is used to control the complexity of the model. It reduces the number of channels by using the $1\times 1$ convolutional layer and halves the height and wi... | public SequentialBlock transitionBlock(int numChannels) {
SequentialBlock blk = new SequentialBlock()
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(
Conv2d.builder()
.setFilters(numChannels)
... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
Apply a transition layer with 10 channels to the output of the dense block in the previous example. This reduces the number of output channels to 10, and halves the height and width. | block = transitionBlock(10);
block.setInitializer(new XavierInitializer());
block.initialize(manager, DataType.FLOAT32, currentShape);
for (int i = 0; i < block.getChildren().size(); i++) {
Shape[] newShape = block.getChildren().get(i).getValue().getOutputShapes(manager, new Shape[]{currentShape});
currentSh... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
DenseNet ModelNext, we will construct a DenseNet model. DenseNet first uses the same single convolutional layer and maximum pooling layer as ResNet. | SequentialBlock net = new SequentialBlock()
.add(Conv2d.builder()
.setFilters(64)
.setKernelShape(new Shape(7, 7))
.optStride(new Shape(2, 2))
.optPadding(new Shape(3, 3))
.build())
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
Then, similar to the four residual blocks that ResNet uses, DenseNet uses four dense blocks. Similar to ResNet, we can set the number of convolutional layers used in each dense block. Here, we set it to 4, consistent with the ResNet-18 in the previous section. Furthermore, we set the number of channels (i.e., growth ra... | int numChannels = 64;
int growthRate = 32;
int[] numConvsInDenseBlocks = new int[]{4, 4, 4, 4};
for (int index = 0; index < numConvsInDenseBlocks.length; index++) {
int numConvs = numConvsInDenseBlocks[index];
net.add(new DenseBlock(numConvs, growthRate));
numChannels += (numConvs * growthRate);
if... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
Similar to ResNet, a global pooling layer and fully connected layer are connected at the end to produce the output. | net
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(Pool.globalAvgPool2dBlock())
.add(Linear.builder().setUnits(10).build()); | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
Data Acquisition and TrainingSince we are using a deeper network here, in this section, we will reduce the input height and width from 224 to 96 to simplify the computation. | int batchSize = 256;
float lr = 0.1f;
int numEpochs = 10;
double[] trainLoss;
double[] testAccuracy;
double[] epochCount;
double[] trainAccuracy;
epochCount = new double[numEpochs];
for (int i = 0; i < epochCount.length; i++) {
epochCount[i] = (i + 1);
}
FashionMnist trainIter =
FashionMnist.bui... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
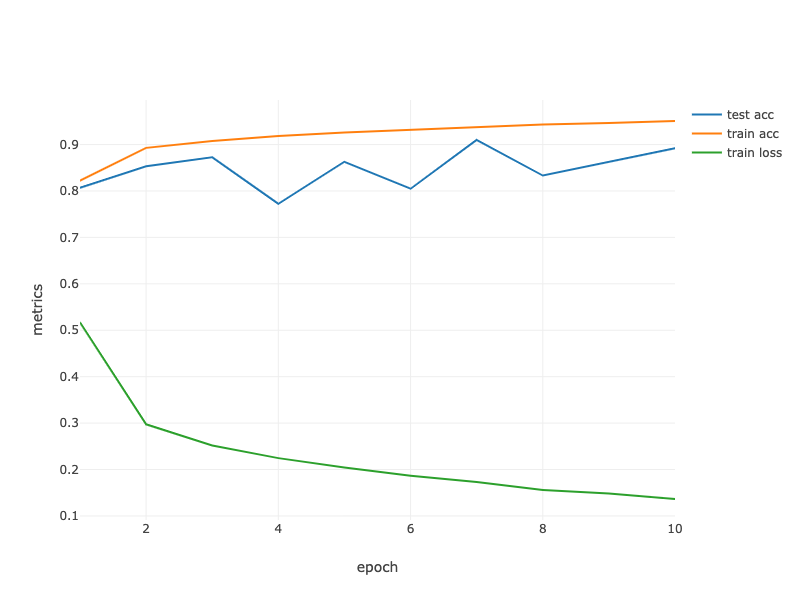 | String[] lossLabel = new String[trainLoss.length + testAccuracy.length + trainAccuracy.length];
Arrays.fill(lossLabel, 0, trainLoss.length, "train loss");
Arrays.fill(lossLabel, trainAccuracy.length, trainLoss.length + trainAccuracy.length, "train acc");
Arrays.fill(lossLabel, trainLoss.length + trainAccuracy.length,
... | _____no_output_____ | Apache-2.0 | jupyter/d2l-java/chapter_convolutional-modern/densenet.ipynb | michaellavelle/djl |
1. Meet Professor William SharpeAn investment may make sense if we expect it to return more money than it costs. But returns are only part of the story because they are risky - there may be a range of possible outcomes. How does one compare different investments that may deliver similar results on average, but exhibit... | # Importing required modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Settings to produce nice plots in a Jupyter notebook
plt.style.use('fivethirtyeight')
%matplotlib inline
# Reading in the data
stock_data = pd.read_csv('datasets/stock_data.csv', parse_dates=['Date'], index_col='Date... | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
2. A first glance at the dataLet's take a look the data to find out how many observations and variables we have at our disposal. | # Display summary for stock_data
print('Stocks\n')
display(stock_data.info())
display(stock_data.head())
# Display summary for benchmark_data
print('\nBenchmarks\n')
display(benchmark_data.info())
display(benchmark_data.head()) | Stocks
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 252 entries, 2016-01-04 to 2016-12-30
Data columns (total 2 columns):
Amazon 252 non-null float64
Facebook 252 non-null float64
dtypes: float64(2)
memory usage: 5.9 KB
| MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
3. Plot & summarize daily prices for Amazon and FacebookBefore we compare an investment in either Facebook or Amazon with the index of the 500 largest companies in the US, let's visualize the data, so we better understand what we're dealing with. | # visualize the stock_data
stock_data.plot(subplots=True, title='Stock Data')
# summarize the stock_data
stock_data.describe()
| _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
4. Visualize & summarize daily values for the S&P 500Let's also take a closer look at the value of the S&P 500, our benchmark. | # plot the benchmark_data
benchmark_data.plot(title='S&P 500')
# summarize the benchmark_data
benchmark_data.describe()
| _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
5. The inputs for the Sharpe Ratio: Starting with Daily Stock ReturnsThe Sharpe Ratio uses the difference in returns between the two investment opportunities under consideration.However, our data show the historical value of each investment, not the return. To calculate the return, we need to calculate the percentage ... | # calculate daily stock_data returns
stock_returns = stock_data.pct_change()
# plot the daily returns
stock_returns.plot()
# summarize the daily returns
stock_returns.describe() | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
6. Daily S&P 500 returnsFor the S&P 500, calculating daily returns works just the same way, we just need to make sure we select it as a Series using single brackets [] and not as a DataFrame to facilitate the calculations in the next step. | # calculate daily benchmark_data returns
sp_returns = benchmark_data['S&P 500'].pct_change()
# plot the daily returns
sp_returns.plot()
# summarize the daily returns
sp_returns.describe() | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
7. Calculating Excess Returns for Amazon and Facebook vs. S&P 500Next, we need to calculate the relative performance of stocks vs. the S&P 500 benchmark. This is calculated as the difference in returns between stock_returns and sp_returns for each day. | # calculate the difference in daily returns
excess_returns = stock_returns.sub(sp_returns, axis=0)
# plot the excess_returns
excess_returns.plot()
# summarize the excess_returns
excess_returns.describe() | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
8. The Sharpe Ratio, Step 1: The Average Difference in Daily Returns Stocks vs S&P 500Now we can finally start computing the Sharpe Ratio. First we need to calculate the average of the excess_returns. This tells us how much more or less the investment yields per day compared to the benchmark. | # calculate the mean of excess_returns
avg_excess_return = excess_returns.mean()
# plot avg_excess_returns
avg_excess_return.plot.bar() | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
9. The Sharpe Ratio, Step 2: Standard Deviation of the Return DifferenceIt looks like there was quite a bit of a difference between average daily returns for Amazon and Facebook.Next, we calculate the standard deviation of the excess_returns. This shows us the amount of risk an investment in the stocks implies as comp... | # calculate the standard deviations
sd_excess_return = excess_returns.std()
# plot the standard deviations
sd_excess_return.plot.bar() | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
10. Putting it all togetherNow we just need to compute the ratio of avg_excess_returns and sd_excess_returns. The result is now finally the Sharpe ratio and indicates how much more (or less) return the investment opportunity under consideration yields per unit of risk.The Sharpe Ratio is often annualized by multiplyin... | # calculate the daily sharpe ratio
daily_sharpe_ratio = avg_excess_return.div(sd_excess_return)
# annualize the sharpe ratio
annual_factor = np.sqrt(252)
annual_sharpe_ratio = daily_sharpe_ratio.mul(annual_factor)
# plot the annualized sharpe ratio
annual_sharpe_ratio.plot.bar(title='Annualized Sharpe Ration: Stocks ... | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
11. ConclusionGiven the two Sharpe ratios, which investment should we go for? In 2016, Amazon had a Sharpe ratio twice as high as Facebook. This means that an investment in Amazon returned twice as much compared to the S&P 500 for each unit of risk an investor would have assumed. In other words, in risk-adjusted t... | # Uncomment your choice.
buy_amazon = True
# buy_facebook = True | _____no_output_____ | MIT | DataCamp/Risk and Returns: The Sharpe Ratio/notebook.ipynb | lukzmu/data-courses |
Global Validation This notebook combines several validation notebooks: `global_validation_tasmax_v2.ipynb` and `global_validation_dtr_v2.ipynb` along with `check_aiqpd_downscaled_data.ipynb` to create a "master" global validation notebook. It also borrows validation code from the ERA-5 workflow, `validate_era5_hourlyO... | %matplotlib inline
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
from cartopy import config
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import os
from matplotlib import cm
from matplotlib.backends.backend_pdf import PdfPages
from validation import * | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Azure (or GCS) authentication | # ! pip install adlfs
from adlfs import AzureBlobFileSystem
fs_az = AzureBlobFileSystem(
account_name='dc6',
account_key='',
client_id=os.environ.get("AZURE_CLIENT_ID", None),
client_secret=os.environ.get("AZURE_CLIENT_SECRET", None),
tenant_id=os.environ.get("AZURE_TENANT_ID", ... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Filepaths Output data | data_dict = {'coarse': {'cmip6': {'historical': 'scratch/biascorrectdownscale-bk6n8/biascorrectdownscale-bk6n8-858077599/out.zarr',
'ssp370': 'scratch/biascorrectdownscale-bk6n8/biascorrectdownscale-bk6n8-269778292/out.zarr'},
'bias_corrected': {'historical': ... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Variables Possible variables: `tasmax`, `tasmin`, `pr`, `dtr`. Default is `tasmax`. | variable = 'tasmax' | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
other data inputs | units = {'tasmax': 'K', 'tasmin': 'K', 'dtr': 'K', 'pr': 'mm'}
years = {'hist': {'start_yr': '1995', 'end_yr': '2014'},
'2020_2040': {'start_yr': '2020', 'end_yr': '2040'},
'2040_2060': {'start_yr': '2040', 'end_yr': '2060'},
'2060_2080': {'start_yr': '2060', 'end_yr': '2080... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Validation | pdf_list = [] | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
basic diagnostic plots: means and maxes bias corrected | # plot bias corrected
store_hist = fs_az.get_mapper(data_dict['coarse']['bias_corrected']['historical'], check=False)
ds_hist = xr.open_zarr(store_hist)
store_future = fs_az.get_mapper(data_dict['coarse']['bias_corrected']['ssp370'], check=False)
ds_future = xr.open_zarr(store_future)
new_pdf = plot_diagnostic_climo_... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
cmip6 | # plot bias corrected
store_hist = fs_az.get_mapper(data_dict['coarse']['cmip6']['historical'], check=False)
ds_hist = xr.open_zarr(store_hist)
store_future = fs_az.get_mapper(data_dict['coarse']['cmip6']['ssp370'], check=False)
ds_future = xr.open_zarr(store_future)
new_pdf = plot_diagnostic_climo_periods(ds_hist,
... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
downscaled | # plot bias corrected
store_hist = fs_az.get_mapper(data_dict['fine']['downscaled']['historical'], check=False)
ds_hist = xr.open_zarr(store_hist)
store_future = fs_az.get_mapper(data_dict['fine']['downscaled']['ssp370'], check=False)
ds_future = xr.open_zarr(store_future)
new_pdf = plot_diagnostic_climo_periods(ds_h... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
GMST | store_hist_cmip6 = fs_az.get_mapper(data_dict['coarse']['cmip6']['historical'], check=False)
ds_hist_cmip6 = xr.open_zarr(store_hist_cmip6)
store_future_cmip6 = fs_az.get_mapper(data_dict['coarse']['cmip6']['ssp370'], check=False)
ds_future_cmip6 = xr.open_zarr(store_future_cmip6)
store_hist_bc = fs_az.get_mapper(data... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Basic validation of zarr stores (general and variable-specific) | test_dataset_allvars(ds_future_bc, 'tasmax', 'bias_corrected', time_period="future")
test_dataset_allvars(ds_future_cmip6, 'tasmax', 'cmip6', time_period="future")
test_dataset_allvars(ds_hist_cmip6, 'tasmax', 'cmip6', time_period="hist")
test_temp_range(ds_hist_cmip6, 'tasmax') | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
create difference plots bw bias corrected and downscaled as well as historical/future bias corrected and downscaled | store_hist_bc = fs_az.get_mapper(data_dict['fine']['bias_corrected']['historical'], check=False)
ds_hist_bc = xr.open_zarr(store_hist_bc)
store_hist_ds = fs_az.get_mapper(data_dict['fine']['downscaled']['historical'], check=False)
ds_hist_ds = xr.open_zarr(store_hist_ds)
store_fut_bc = fs_az.get_mapper(data_dict['fine... | _____no_output_____ | MIT | notebooks/downscaling_pipeline/global_validation.ipynb | brews/downscaleCMIP6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.