
markdown stringlengths 0 1.02M | code stringlengths 0 832k | output stringlengths 0 1.02M | license stringlengths 3 36 | path stringlengths 6 265 | repo_name stringlengths 6 127 |
|---|---|---|---|---|---|
Let's see how many hotspot mutations there are in the Cholangiocarcinoma (TCGA, PanCancer Atlas) study with study id `chol_tcga_pan_can_atlas_2018` from the cBioPortal: | %%time
cbioportal = SwaggerClient.from_url('https://www.cbioportal.org/api/api-docs',
config={"validate_requests":False,"validate_responses":False})
mutations = cbioportal.K_Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='chol_tcga_pan_can_atlas_... | CPU times: user 766 ms, sys: 20.1 ms, total: 786 ms
Wall time: 1.03 s
| MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Convert the results to a dataframe again: | import pandas as pd
mdf = pd.DataFrame.from_dict([
# python magic that combines two dictionaries:
dict(
m.__dict__['_Model__dict'],
**m.__dict__['_Model__dict']['gene'].__dict__['_Model__dict'])
# create one item in the list for each mutation
for m in mutations
]) | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Then get only the unique mutations, to avoid calling the web service with the same variants: | variants = mdf['chromosome startPosition endPosition referenceAllele variantAllele'.split()]\
.drop_duplicates()\
.dropna(how='any',axis=0)\
.reset_index() | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Convert them to input that genome nexus will understand: | variants = variants.rename(columns={'startPosition':'start','endPosition':'end'})\
.to_dict(orient='records')
# remove the index field
for v in variants:
del v['index']
print("There are {} mutations left to annotate".format(len(variants))) | There are 1991 mutations left to annotate
| MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Annotate them with genome nexus: | %%time
variants_annotated = gn.annotation_controller.fetchVariantAnnotationByGenomicLocationPOST(
genomicLocations=variants,
fields='hotspots annotation_summary'.split()
).result() | CPU times: user 3.22 s, sys: 522 ms, total: 3.75 s
Wall time: 6.61 s
| MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Index the variants to make it easier to query them: | gn_dict = {
"{},{},{},{},{}".format(
v.annotation_summary.genomicLocation.chromosome,
v.annotation_summary.genomicLocation.start,
v.annotation_summary.genomicLocation.end,
v.annotation_summary.genomicLocation.referenceAllele,
v.annotation_summary.genomicLocation.variantAllele... | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Add a new column to indicate whether something is a hotspot | def is_hotspot(x):
"""TODO: Current structure for hotspots in Genome Nexus is a little funky.
Need to check whether all lists in the annotation field are empty."""
if x:
return sum([len(a) for a in x.hotspots.annotation]) > 0
else:
return False
def create_dict_query_key(x):
return "... | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Then plot the results: | %matplotlib inline
import seaborn as sns
sns.set_style("white")
sns.set_context('notebook')
import matplotlib.pyplot as plt
mdf.groupby('hugoGeneSymbol').is_hotspot.sum().sort_values(ascending=False).head(10).plot(kind='bar')
sns.despine(trim=False)
plt.xlabel('')
plt.xticks(rotation=300)
plt.ylabel('Number of non-uni... | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
OncoKB API [OncoKB](https://oncokb.org) is is a precision oncology knowledge base and contains information about the effects and treatment implications of specific cancer gene alterations. Similarly to cBioPortal and Genome Nexus it provides a REST API following the [Swagger / OpenAPI specification](https://swagger.io... | oncokb = SwaggerClient.from_url('https://www.oncokb.org/api/v1/v2/api-docs',
config={"validate_requests":False,
"validate_responses":False,
"validate_swagger_spec":False})
print(oncokb) | SwaggerClient(https://www.oncokb.org:443/api/v1)
| MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
To look up annotations for a variant, one can use the following endpoint: | variant = oncokb.Annotations.annotateMutationsByGenomicChangeGetUsingGET(
genomicLocation='7,140453136,140453136,A,T',
).result()
drugs = oncokb.Drugs.drugsGetUsingGET().result() | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
You can see a lot of information is provided for that particular variant if you type tab after `variant.`: | drugs.count
variant.hotspot | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
For instance we can see the summary information about it: | variant.variantSummary | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
If you look up this variant on the OncoKB website: https://www.oncokb.org/gene/BRAF/V600E. You can see that there are various combinations of drugs and their level of evidence listed. This is a classification system for indicating how much we know about whether or not a patient might respond to a particular treatment. ... | %%time
variants_annotated = oncokb.Annotations.annotateMutationsByGenomicChangePostUsingPOST(
body=[
{"genomicLocation":"{chromosome},{start},{end},{referenceAllele},{variantAllele}".format(**v)}
for v in variants
],
).result() | CPU times: user 363 ms, sys: 16.4 ms, total: 379 ms
Wall time: 9.89 s
| MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Count the highes level for each variant | from collections import Counter
counts_per_level = Counter([va.highestSensitiveLevel for va in variants_annotated if va.highestSensitiveLevel]) | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Then plot them | pd.DataFrame(counts_per_level,index=[0]).plot(kind='bar', colors=['#4D8834','#2E2E2C','#753579'])
plt.xticks([])
plt.ylabel('Number of variants')
plt.title('Actionable variants in chol_tcga_pan_can_atlas_2018')
sns.despine() | _____no_output_____ | MIT | 0-introduction/cbsp_hackathon.ipynb | jxu8/cbsp-hackathon |
Fetching the raw data from google places API by passing the coordinates of the cluster centroid and delivery radius as 5km | import pandas as pd
import googlemaps
import pprint
import json
import time
import xlsxwriter
import functools
import operator
from collections import Counter
from itertools import chain
#IMPORTING DATA
df = pd.read_excel('lat_long_google_api.xlsx')
rslt_df= df.copy()
# Define our API Key
API_KEY = 'Enter your API k... | _____no_output_____ | MIT | Fetching_data_google_places_API.ipynb | vivek1240/Fetching-the-raw-data-from-google-places-API |
Below code is the Call for the Places API and the result will be stored in a dictionary, we will take the key = store_id, value = result fetched for the corresponding store from the places API Dict "d" will contain the raw data corresponding to the coordinate(lat,long) | d= dict() #ALL THE RAW DATA WOULD BE STORED IN DICTIONARY CORRESPONDING TO THE LATITUDE OF THE STORE
d[rslt_df['store_id'][0]]=dict() #Taking store latitude as the
for i in range(len(rslt_df)):
lat= rslt_df['store_latitude'][i]
lon= rslt_df['store_longitude'][i]
d[rslt_df['store_id'][i]] = gmap... | _____no_output_____ | MIT | Fetching_data_google_places_API.ipynb | vivek1240/Fetching-the-raw-data-from-google-places-API |
Fetched data with the index as cluster number | def no_of_lodges_or_eqv(d,key):
rawdata=[]
for i in range(len(d[key]['results'])):
rawdata.append(d[key]['results'][i]['types'])
rawdata = functools.reduce(operator.iconcat, rawdata, [])
rawdata = CountFrequency(rawdata)
... | _____no_output_____ | MIT | Fetching_data_google_places_API.ipynb | vivek1240/Fetching-the-raw-data-from-google-places-API |
MobileNetSSD with OpenCV- you can get trained model and prototxt : https://www.pyimagesearch.com/2017/09/11/object-detection-with-deep-learning-and-opencv/ | %matplotlib inline
# import the necessary packages
import numpy as np
import sys
from logging import getLogger, DEBUG, StreamHandler
import matplotlib.pyplot as plt
import cv2
def deep_learning_object_detection(image, prototxt, model):
logger = getLogger(__name__)
logger.setLevel(DEBUG)
ha... | Loading model...
computing object detections...
car: 99.96%
car: 95.68%
| MIT | MobileNetSSD_OpenCV.ipynb | hurutoriya/yolov2_api |
try 1 | page_x_inches: float = 11. # inches
page_y_inches: float = 8.5 # inches
border:float = 0.
perlin_grid_params = {
'xstep':3,
'ystep':3,
'lod':10,
'falloff':None,
'noise_scale':0.0073,
'noiseSeed':6
}
particle_init_grid_params = {
'xstep':16,
'ystep':16,
}
buffer_style = 2
px = utils.Di... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 2 | page_x_inches: float = 11. # inches
page_y_inches: float = 8.5 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0073,
'noiseSeed':8
}
buffer_style = 2
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceCon... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 3 | page_x_inches: float = 6 # inches
page_y_inches: float = 6 # inches
border:float = 20.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 2
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConver... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 4 for fabiano black black |
border:float = 25.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 2
px = 200
py = 200
page_format = f'{px}mmx{py}mm'
drawbox = sg.box(border, border, px-border, py-border)
xmin, ymin, xmax, ymax = drawbox.bounds
brad... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 5 two color | page_x_inches: float = 8.5 # inches
page_y_inches: float = 11 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 6 three color | page_x_inches: float = 8.5 # inches
page_y_inches: float = 11 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 7 | page_x_inches: float = 8.5 # inches
page_y_inches: float = 11 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 8 | page_x_inches: float = 8.5 # inches
page_y_inches: float = 11 # inches
border:float = 0.
perlin_grid_params = {
'xstep':3,
'ystep':3,
'lod':10,
'falloff':None,
'noise_scale':0.0013,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 9 | page_x_inches: float = 6 # inches
page_y_inches: float = 6 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0063,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConvert... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 10 | page_x_inches: float = 8.5 # inches
page_y_inches: float = 11 # inches
border:float = 0.
perlin_grid_params = {
'xstep':3,
'ystep':3,
'lod':10,
'falloff':None,
'noise_scale':0.0013,
'noiseSeed':8
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 11 | page_x_inches: float = 11 # inches
page_y_inches: float = 8.5 # inches
border:float = 0.
perlin_grid_params = {
'xstep':3,
'ystep':3,
'lod':10,
'falloff':None,
'noise_scale':0.0053,
'noiseSeed':3
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 12 | page_x_inches: float = 11 # inches
page_y_inches: float = 8.5 # inches
border:float = 0.
perlin_grid_params = {
'xstep':3,
'ystep':3,
'lod':10,
'falloff':None,
'noise_scale':0.0083,
'noiseSeed':3
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
try 13 | page_x_inches: float = 11 # inches
page_y_inches: float = 8.5 # inches
border:float = 0.
perlin_grid_params = {
'xstep':1,
'ystep':1,
'lod':10,
'falloff':None,
'noise_scale':0.0193,
'noiseSeed':3
}
buffer_style = 3
px = utils.DistanceConverter(page_x_inches, 'inches').mm
py = utils.DistanceConv... | _____no_output_____ | MIT | scratch/002_test_perlin.ipynb | ANaka/genpen |
Assignment 7: Groundwater and the Woburn Toxics Trial*Due 4/25/17 5 pts *Please **submit your assignment as an html export**, and for written responses, please type them in a cell that is of type `Markdown.` The final part of the exercise involves drawing a flow net by hand (actually, you could tackle this part of the... | # Import numerical tools
import numpy as np
#Import pandas for reading in and managing data
import pandas as pd
# Import pyplot for plotting
import matplotlib.pyplot as plt
#Import seaborn (useful for plotting)
import seaborn as sns
# Magic function to make matplotlib inline; other style specs must come AFTER
%matp... | _____no_output_____ | BSD-3-Clause | Assignment7Groundwater.ipynb | LaurelOak/hydro-teaching-resources |
BackgroundThis investigation of groundwater flow and drawdown in wells is based on the lawsuit described in the book and movie A Civil Action (a true story). For the background behind this story, read [the Wikipedia page](http://en.wikipedia.org/wiki/A_Civil_Action). Then look at the map and animation of the study sit... | # The data
time_minutes = np.arange(170,570,10) #Times (minutes) at which drawdown was observed after the start of pumping
s = np.array([0.110256896, 0.122567503, 0.180480293, 0.214489433, 0.356304352, 0.554603882, 0.49240574, 0.524209467, 0.562727644, 0.754849464, 0.718713002, 0.752910019, 0.73903658, 0.89009263, 0.96... | _____no_output_____ | BSD-3-Clause | Assignment7Groundwater.ipynb | LaurelOak/hydro-teaching-resources |
Part II: Estimating hydraulic heads with the Thiem EquationWith knowledge of the hydraulic conductivity, you can now solve the Thiem equation for the equilibrium potentiometric surface under different combinations of well pumping rates. For this part of the assignment, you will be working with a module that solves the... | def PlotWoburnDD(K,b,QG,QH,QR, returnval=0):
"""
This routine uses the Thiem equation for unCONFINED aquifers to generate a plot of drawdown
contours around the Aberjona River in Woburn, Massachusetts. The Riley well is the source of
the contamination. Wells G and H are wells for the town's municipal wa... | _____no_output_____ | BSD-3-Clause | Assignment7Groundwater.ipynb | LaurelOak/hydro-teaching-resources |
Applied Probability Theory From Scratch Simpson's Paradox Bruno Gonçalves www.data4sci.com @bgoncalves, @data4sci | import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import sklearn
from sklearn.linear_model import LinearRegression
import watermark
%load_ext watermark
%matplotlib inline
%watermark -i -n -v -m -g -iv
plt.style.use('./d4sci.mplstyle') | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
Load the iris dataset | iris = pd.read_csv('data/iris.csv')
iris | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
Split the dataset across species for convenience | setosa = iris[['sepal_width', 'petal_width']][iris['species'] == 'setosa']
versicolor = iris[['sepal_width', 'petal_width']][iris['species'] == 'versicolor']
virginica = iris[['sepal_width', 'petal_width']][iris['species'] == 'virginica'] | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
Perform the fits | lm_setosa = LinearRegression()
lm_setosa.fit(setosa['sepal_width'].values.reshape(-1,1), setosa['petal_width'])
y_setosa = lm_setosa.predict(setosa['sepal_width'].values.reshape(-1,1))
lm_versicolor = LinearRegression()
lm_versicolor.fit(versicolor['sepal_width'].values.reshape(-1,1), versicolor['petal_width'])
y_vers... | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
Generate the plot | fig, axs = plt.subplots(ncols=2, sharey=True)
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
setosa.plot.scatter(x='sepal_width', y='petal_width', label='setosa', ax=axs[0], c=colors[0])
versicolor.plot.scatter(x='sepal_width', y='petal_width', label='versicolor', ax=axs[0], c=colors[1])
virginica.plot.sc... | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
Removing setosa | reduced = iris[iris['species'] != 'setosa'].copy()
lm_reduced = LinearRegression()
lm_reduced.fit(reduced['sepal_width'].values.reshape(-1,1), reduced['petal_width'])
y_reduced = lm_reduced.predict(reduced['sepal_width'].values.reshape(-1,1))
fig, axs = plt.subplots(ncols=1, sharey=True)
colors = plt.rcParams['axes.pr... | _____no_output_____ | MIT | Probability/5. Simpson's Paradox.ipynb | febinsathar/goodreads |
With rgb images Load data | import numpy as np
import pandas as pd
from glob import glob
from tqdm import tqdm
from sklearn.utils import shuffle
df = pd.read_csv('sample/Data_Entry_2017.csv')
diseases = ['Cardiomegaly','Emphysema','Effusion','Hernia','Nodule','Pneumothorax','Atelectasis','Pleural_Thickening','Mass','Edema','Consolidation','Infi... | Using TensorFlow backend.
/home/aind2/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6
return f(*args, **kwds)
100%|██████████| 89600/89600 [20:26<00:00, 73.03it/s]
100%|██████████| ... | Apache-2.0 | vanilla CNN - FullDataset.ipynb | subha231/cancer |
CNN model | import time
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, Dropout, Flatten, Dense
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras import regularizers, initializers, optimizers
model = Sequential()
model.add(Conv2D(filters=16,
... | Train on 89600 samples, validate on 11200 samples
Epoch 1/20
89536/89600 [============================>.] - ETA: 0s - loss: 0.6561 - precision: 0.5974 - recall: 0.4632 - fbeta_score: 0.5386 - acc: 0.6178Epoch 00000: val_loss improved from inf to 0.65672, saving model to saved_models/bCNN.best.from_scratch.hdf5
89600/89... | Apache-2.0 | vanilla CNN - FullDataset.ipynb | subha231/cancer |
Metric | model.load_weights('saved_models/bCNN.best.from_scratch.hdf5')
prediction = model.predict(test_tensors)
threshold = 0.5
beta = 0.5
pre = K.eval(precision_threshold(threshold = threshold)(K.variable(value=test_labels),
K.variable(value=prediction)))
rec = K.eval(recall_threshold(thres... | Precision: 0.712731 %
Recall: 0.404833 %
Fscore: 0.618630 %
| Apache-2.0 | vanilla CNN - FullDataset.ipynb | subha231/cancer |
With gray images | import numpy as np
import pandas as pd
from glob import glob
from tqdm import tqdm
from sklearn.utils import shuffle
df = pd.read_csv('sample/Data_Entry_2017.csv')
diseases = ['Cardiomegaly','Emphysema','Effusion','Hernia','Nodule','Pneumothorax','Atelectasis','Pleural_Thickening','Mass','Edema','Consolidation','Infi... | Precision: 0.627903 %
Recall: 0.710935 %
Fscore: 0.642921 %
| Apache-2.0 | vanilla CNN - FullDataset.ipynb | subha231/cancer |
WeatherPy---- Note* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps. | # Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import time
from scipy.stats import linregress
from pprint import pprint
# Import API key
from api_keys import weather_api_key
# Incorporated citipy to determine city based on latitude and longitude
from ci... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Generate Cities List | # List for holding lat_lngs and cities
lat_lngs = []
cities = []
# Create a set of random lat and lng combinations
lats = np.random.uniform(lat_range[0], lat_range[1], size=1750) # increased the amount due to my logic below
lngs = np.random.uniform(lng_range[0], lng_range[1], size=1750) # increased the amount due to m... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Perform API Calls* Perform a weather check on each city using a series of successive API calls.* Include a print log of each city as it'sbeing processed (with the city number and city name). | # Save config information.
url = "http://api.openweathermap.org/data/2.5/weather?"
units = "imperial"
# Build partial query URL
query_url = f"{url}appid={weather_api_key}&units={units}&q="
# Set up lists to hold reponse information
city_list = []
city_lat = []
city_lng = []
city_temp = []
city_humidity = []
city_clo... | Beginning Data Retrieval
-----------------------------
Processing Record 1 of Set 1 | norman wells
Processing Record 2 of Set 1 | touros
City not found. Skipping...
Processing Record 4 of Set 1 | qaanaaq
City not found. Skipping...
Processing Record 6 of Set 1 | punta arenas
Processing Record 7 of Set 1 | ushuaia
Proce... | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Convert Raw Data to DataFrame* Export the city data into a .csv.* Display the DataFrame | # Create a data frame from cities info
weather_dict = {
"City": city_list,
"Lat": city_lat,
"Lng": city_lng,
"Max Temp": city_temp,
"Humidity": city_humidity,
"Cloudiness": city_clouds,
"Wind Speed": city_wind,
"Country": city_country,
"Date": city_date
}
weather_data = pd.DataFrame... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Inspect the data and remove the cities where the humidity > 100%.----Skip this step if there are no cities that have humidity > 100%. | # No cities have humidity > 100%, although a few are exactly 100%
humid_weather_data = weather_data.loc[weather_data["Humidity"] >= 100]
humid_weather_data | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Plotting the Data* Use proper labeling of the plots using plot titles (including date of analysis) and axes labels.* Save the plotted figures as .pngs. Latitude vs. Temperature Plot | # Setting x and y values
x_values = weather_data["Lat"]
y_values = weather_data["Max Temp"]
# Plot the scatter plot
plt.scatter(x_values, y_values, marker="o", facecolors="teal", edgecolors="black")
plt.title("City Latitude vs. Max Temperature")
plt.ylabel("Max Temperature (F)", fontsize=12)
plt.xlabel("Latitude", f... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ONE-SENTENCE DESCRIPTION: The graph above is displaying the max temperature (y-axis) for all cities in the dataset (the circles) organized by latitude (x-axis). This graph suggests that cities north of the equator (>0 Lat) might have a lower max temp. Latitude vs. Humidity Plot | # Setting x and y values
x_values = weather_data["Lat"]
y_values = weather_data["Humidity"]
# Plot the scatter plot
plt.scatter(x_values, y_values, marker="o", facecolors="teal", edgecolors="black")
plt.title("City Latitude vs. Humidity")
plt.ylabel("Humidity (%)", fontsize=12)
plt.xlabel("Latitude", fontsize=12)
pl... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ONE-SENTENCE DESCRIPTION: The graph above is displaying the recent humidity (%)(y-axis) for all cities in the dataset (the circles) organized by latitude (x-axis). This graph does not have an immediately discernible trend, other than cities tending to cluster at or greater than 60% humidity. Latitude vs. Cloudiness ... | # Setting x and y values
x_values = weather_data["Lat"]
y_values = weather_data["Cloudiness"]
# Plot the scatter plot
plt.scatter(x_values, y_values, marker="o", facecolors="teal", edgecolors="black")
plt.title("City Latitude vs. Cloudiness")
plt.ylabel("Cloudiness (%)", fontsize=12)
plt.xlabel("Latitude", fontsize=... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ONE-SENTENCE DESCRIPTION:The graph above is displaying the recent cloudiness (%)(y-axis) for all cities in the dataset (the circles) organized by latitude (x-axis). This graph also does not have an immediately discernible trend. Latitude vs. Wind Speed Plot | # Setting x and y values
x_values = weather_data["Lat"]
y_values = weather_data["Wind Speed"]
# Plot the scatter plot
plt.scatter(x_values, y_values, marker="o", facecolors="teal", edgecolors="black")
plt.title("City Latitude vs. Wind Speed")
plt.ylabel("Wind Speed (mph)", fontsize=12)
plt.xlabel("Latitude", fontsiz... | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ONE-SENTENCE DESCRIPTION:The graph above is displaying the recent wind speed (mph)(y-axis) for all cities in the dataset (the circles) organized by latitude (x-axis). Perhaps one observable trend from this graph: it appears that there is greater range in the wind speeds of cities north of equator (>Lat 0). Linear R... | # Making two separate dfs for north and south hemisphere
north_hemi = weather_data.loc[weather_data["Lat"] >= 0]
south_hemi = weather_data.loc[weather_data["Lat"] < 0] | _____no_output_____ | ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Northern Hemisphere - Max Temp vs. Latitude Linear Regression | # Setting x and y values
x_values = north_hemi["Lat"]
y_values = north_hemi["Max Temp"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_va... | The r-value is: -0.8765697068804407
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Southern Hemisphere - Max Temp vs. Latitude Linear Regression | # Setting x and y values
x_values = south_hemi["Lat"]
y_values = south_hemi["Max Temp"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_va... | The r-value is: 0.44590906959636567
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ANALYSIS OF NORTH/SOUTH-HEMI MAX TEMP:The graphs above are displaying the max temperature (y-axis) of cities in the dataset arranged by latitude (x-axis) and divided into two groups--the southern hemisphere and the northern hemisphere. What we see from both of these graphs is that max temperatures are higher for citie... | # Setting x and y values
x_values = north_hemi["Lat"]
y_values = north_hemi["Humidity"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_va... | The r-value is: 0.30945504958053144
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Southern Hemisphere - Humidity (%) vs. Latitude Linear Regression | # Setting x and y values
x_values = south_hemi["Lat"]
y_values = south_hemi["Humidity"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_va... | The r-value is: 0.22520675986668628
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ANALYSIS OF NORTH/SOUTH-HEMI HUMIDITY:The graphs above are displaying the humidity (y-axis) of cities in the dataset arranged by latitude (x-axis) and divided into two groups--the southern hemisphere and the northern hemisphere. These graphs reflect a weak positive correlation between humidity and latitude. Rather tha... | # Setting x and y values
x_values = north_hemi["Lat"]
y_values = north_hemi["Cloudiness"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_... | The r-value is: 0.2989895417151042
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Southern Hemisphere - Cloudiness (%) vs. Latitude Linear Regression | # Setting x and y values
x_values = south_hemi["Lat"]
y_values = south_hemi["Cloudiness"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_... | The r-value is: 0.23659107153505674
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
ANALYSIS OF NORTH/SOUTH-HEMI CLOUDINESS:The graphs above are displaying the cloudiness (y-axis) of cities in the dataset arranged by latitude (x-axis) and divided into two groups--the southern hemisphere and the northern hemisphere. These graphs also reflect a very weak positive correlation, if any, between cloudiness... | # Setting x and y values
x_values = north_hemi["Lat"]
y_values = north_hemi["Wind Speed"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_... | The r-value is: 0.04083196500915729
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Southern Hemisphere - Wind Speed (mph) vs. Latitude Linear Regression | # Setting x and y values
x_values = south_hemi["Lat"]
y_values = south_hemi["Wind Speed"]
# Linear Regression
(slope, intercept, rvalue, pvalue, stderr) = linregress(x_values, y_values)
regress_values = x_values * slope + intercept
line_eq = "y = " + str(round(slope,2)) + "x + " + str(round(intercept,2))
plt.plot(x_... | The r-value is: -0.1644284507948641
| ADSL | WeatherPy/WeatherPy.ipynb | Kylee-Grant/python-api-challenge |
Copyright 2020 The TensorFlow Authors. | #@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Introduction to graphs and tf.function View on TensorFlow.org Run in Google Colab View source on GitHub Download notebook OverviewThis guide goes beneath the surface of TensorFlow and Keras to demonstrate how TensorFlow works. If you instead want to immediately get started with Keras, che... | import tensorflow as tf
import timeit
from datetime import datetime
@tf.function
def unused_return_graph(x):
_ = tf.math.bincount(x)
return x
def unused_return_eager(x):
_ = tf.math.bincount(x)
return x
# `tf.math.bincount` in eager execution raises an error.
try:
_ = unused_return_eager([-1])
raise None
... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Taking advantage of graphsYou create and run a graph in TensorFlow by using `tf.function`, either as a direct call or as a decorator. `tf.function` takes a regular function as input and returns a `Function`. **A `Function` is a Python callable that builds TensorFlow graphs from the Python function. You use a `Function... | # Define a Python function.
def a_regular_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# `a_function_that_uses_a_graph` is a TensorFlow `Function`.
a_function_that_uses_a_graph = tf.function(a_regular_function)
# Make some tensors.
x1 = tf.constant([[1.0, 2.0]])
y1 = tf.constant([[2.0], [3.0]])
b1 ... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
On the outside, a `Function` looks like a regular function you write using TensorFlow operations. [Underneath](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/eager/def_function.py), however, it is *very different*. A `Function` **encapsulates [several `tf.Graph`s behind one API](polymorphism_one... | def inner_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# Use the decorator to make `outer_function` a `Function`.
@tf.function
def outer_function(x):
y = tf.constant([[2.0], [3.0]])
b = tf.constant(4.0)
return inner_function(x, y, b)
# Note that the callable will create a graph that
# includ... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
If you have used TensorFlow 1.x, you will notice that at no time did you need to define a `Placeholder` or `tf.Session`. Converting Python functions to graphsAny function you write with TensorFlow will contain a mixture of built-in TF operations and Python logic, such as `if-then` clauses, loops, `break`, `return`, `c... | def simple_relu(x):
if tf.greater(x, 0):
return x
else:
return 0
# `tf_simple_relu` is a TensorFlow `Function` that wraps `simple_relu`.
tf_simple_relu = tf.function(simple_relu)
print("First branch, with graph:", tf_simple_relu(tf.constant(1)).numpy())
print("Second branch, with graph:", tf_simple_relu(t... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Though it is unlikely that you will need to view graphs directly, you can inspect the outputs to check the exact results. These are not easy to read, so no need to look too carefully! | # This is the graph-generating output of AutoGraph.
print(tf.autograph.to_code(simple_relu))
# This is the graph itself.
print(tf_simple_relu.get_concrete_function(tf.constant(1)).graph.as_graph_def()) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Most of the time, `tf.function` will work without special considerations. However, there are some caveats, and the [tf.function guide](./function.ipynb) can help here, as well as the [complete AutoGraph reference](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/index.m... | @tf.function
def my_relu(x):
return tf.maximum(0., x)
# `my_relu` creates new graphs as it observes more signatures.
print(my_relu(tf.constant(5.5)))
print(my_relu([1, -1]))
print(my_relu(tf.constant([3., -3.]))) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
If the `Function` has already been called with that signature, `Function` does not create a new `tf.Graph`. | # These two calls do *not* create new graphs.
print(my_relu(tf.constant(-2.5))) # Signature matches `tf.constant(5.5)`.
print(my_relu(tf.constant([-1., 1.]))) # Signature matches `tf.constant([3., -3.])`. | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Because it's backed by multiple graphs, a `Function` is **polymorphic**. That enables it to support more input types than a single `tf.Graph` could represent, as well as to optimize each `tf.Graph` for better performance. | # There are three `ConcreteFunction`s (one for each graph) in `my_relu`.
# The `ConcreteFunction` also knows the return type and shape!
print(my_relu.pretty_printed_concrete_signatures()) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Using `tf.function`So far, you've learned how to convert a Python function into a graph simply by using `tf.function` as a decorator or wrapper. But in practice, getting `tf.function` to work correctly can be tricky! In the following sections, you'll learn how you can make your code work as expected with `tf.function`... | @tf.function
def get_MSE(y_true, y_pred):
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
y_true = tf.random.uniform([5], maxval=10, dtype=tf.int32)
y_pred = tf.random.uniform([5], maxval=10, dtype=tf.int32)
print(y_true)
print(y_pred)
get_MSE(y_true, y_pred) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
To verify that your `Function`'s graph is doing the same computation as its equivalent Python function, you can make it execute eagerly with `tf.config.run_functions_eagerly(True)`. This is a switch that **turns off `Function`'s ability to create and run graphs**, instead executing the code normally. | tf.config.run_functions_eagerly(True)
get_MSE(y_true, y_pred)
# Don't forget to set it back when you are done.
tf.config.run_functions_eagerly(False) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
However, `Function` can behave differently under graph and eager execution. The Python [`print`](https://docs.python.org/3/library/functions.htmlprint) function is one example of how these two modes differ. Let's check out what happens when you insert a `print` statement to your function and call it repeatedly. | @tf.function
def get_MSE(y_true, y_pred):
print("Calculating MSE!")
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Observe what is printed: | error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Is the output surprising? **`get_MSE` only printed once even though it was called *three* times.**To explain, the `print` statement is executed when `Function` runs the original code in order to create the graph in a process known as ["tracing"](function.ipynbtracing). **Tracing captures the TensorFlow operations into ... | # Now, globally set everything to run eagerly to force eager execution.
tf.config.run_functions_eagerly(True)
# Observe what is printed below.
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
tf.config.run_functions_eagerly(False) | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
`print` is a *Python side effect*, and there are [other differences](functionlimitations) that you should be aware of when converting a function into a `Function`. Note: If you would like to print values in both eager and graph execution, use `tf.print` instead. `tf.function` best practicesIt may take some time to get ... | x = tf.random.uniform(shape=[10, 10], minval=-1, maxval=2, dtype=tf.dtypes.int32)
def power(x, y):
result = tf.eye(10, dtype=tf.dtypes.int32)
for _ in range(y):
result = tf.matmul(x, result)
return result
print("Eager execution:", timeit.timeit(lambda: power(x, 100), number=1000))
power_as_graph = tf.functio... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
`tf.function` is commonly used to speed up training loops, and you can learn more about it in [Writing a training loop from scratch](keras/writing_a_training_loop_from_scratchspeeding-up_your_training_step_with_tffunction) with Keras.Note: You can also try [`tf.function(jit_compile=True)`](https://www.tensorflow.org/xl... | @tf.function
def a_function_with_python_side_effect(x):
print("Tracing!") # An eager-only side effect.
return x * x + tf.constant(2)
# This is traced the first time.
print(a_function_with_python_side_effect(tf.constant(2)))
# The second time through, you won't see the side effect.
print(a_function_with_python_side... | _____no_output_____ | Apache-2.0 | site/en-snapshot/guide/intro_to_graphs.ipynb | gadagashwini/docs-l10n |
Day 3 Part 1 | """
Right 3, down 1.
"""
i=1
trees=0
with open('input_day3.txt','r') as file:
for line in file:
if line.strip()[i%31-1] == '#':
trees+=1
i+=3
trees | _____no_output_____ | MIT | 2020/paula/day3/advent_code_day3.ipynb | bbglab/adventofcode |
Part 2 | """
Right 1, down 1.
"""
i=1
trees1=0
with open('input_day3.txt','r') as file:
for line in file:
if line.strip()[i%31-1] == '#':
trees1+=1
i+=1
"""
Right 5, down 1.
"""
i=1
trees2=0
with open('input_day3.txt','r') as file:
for line in file:
if line.strip()[i%31-1] ==... | _____no_output_____ | MIT | 2020/paula/day3/advent_code_day3.ipynb | bbglab/adventofcode |
ICPE 639 Introduction to Machine Learning ------ With Energy ApplicationsSome of the examples and exercises of this course are based on several books as well as open-access materials on machine learning, including [Hands-on Machine Learning with Scikit-Learn, Keras and TensorFlow](https://www.oreilly.com/library/view... | import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.core.display import HTML
%matplotlib inline
warnings.filterwarnings('ignore') | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
1 Support Vector Machine 1.1 IntroductionWe will start the introduction of Support Vector Machine (SVM) for classification problems---Support Vector Classifier (SVC). Consider a simple binary classification problem. Assume we have a linearly separable data in 2-d feature space. We try to find a boundary that divides t... | from scipy import stats
import seaborn as sns
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples = 30, centers = 2, random_state = 0, cluster_std = 0.6)
plt.figure(figsize=(9, 7))
plt.scatter(X[:, 0], X[:, 1], c = y, s = 50, cmap = "icefire")
xfit = np.arange(-0.5, 3.0, 0.1)
for m,... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
SVMs provide a way to achieve good generalizability with the intuition: rather than simply drawing a zero-width line between the classes, consider each line with a margin of certain width, meaning that we do not worry about the errors as long as the errors fall within the margin. In SVMs, the line that maximizes this m... | plt.figure(figsize=(9, 7))
plt.scatter(X[:, 0], X[:, 1], c = y, s = 50, cmap = "icefire")
xfit = np.arange(-0.5, 3.0, 0.1)
for m, b, d in [(0.0, 2.5, 0.4), (0.5, 1.8, 0.2), (-0.2, 3.0, 0.1)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
To fit a SVM model on this generated dataset: | # for visualization
def plot_svc_decision_function(model, ax=None, plot_support=True):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = ... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
This is the dividing line that maximizes the margin between two sets of points. There are some points touching the margin which are the pivotal elements of this fit known as the support vectors and can be returned by `support_vectors_`. A key to this classifier is that only the position of the support vectors matter. T... | model.support_vectors_ | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
This method can be extended to nonlinear boundaries with kernels which gives the Kernel SVM where we can map the data into higher-dimensional space defined by basis function and find a linear classifier for the nonlinear relationship. 1.2 Math Formulation of SVCLet $w$ denote the model coefficient vector and $b$ inte... | from sklearn.datasets import fetch_lfw_people
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix
faces = fetch_lfw_people(min_... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
2 Support Vector RegressionThe Support Vector Regression uses the same principles as the SVM for classification. The differences are as follows:* The output is a real number, inifinite possibilities * A margin of tolerance is set in approximation to the SVM However, if we only need to reduce the errors to a certain de... | from sklearn import linear_model
advertising = pd.read_csv('https://raw.githubusercontent.com/XiaomengYan/MachineLearning_dataset/main/Advertising.csv', usecols=[1,2,3,4])
# Visualization
X = advertising.TV
X = X.values.reshape(-1, 1)
y = advertising.Sales
# simple linear regression
regr = linear_model.LinearRegressi... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
SVR gives us the flexibility to define how much error is acceptable in our model and will find an appropriate line (or hyperplane in higher dimensions) to fit the data. The objective function of SVR is to minimize the $l_2$-norm of the coefficients,$$\min \frac{1}{2}||w||^2$$and use the error term as the constraints as... | from sklearn.svm import OneClassSVM
#from sklearn.datasets import make_blobs
from numpy import quantile, where, random
#import matplotlib.pyplot as plt
random.seed(13)
x, _ = make_blobs(n_samples=200, centers=1, cluster_std=.3, center_box=(8, 8))
plt.scatter(x[:,0], x[:,1])
plt.show()
svm = OneClassSVM(kernel='rbf'... | OneClassSVM(cache_size=200, coef0=0.0, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, nu=0.03, shrinking=True, tol=0.001, verbose=False)
3.577526406228678
| MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
Kitchen Power Usage Example[REDD](http://redd.csail.mit.edu/) dataset contains several weeks of power data for 6 different homes. Here we'll extract one house's kitchen power useage as a simple example for one-class SVM. For more implementations, please refer to [minhup's repo](https://github.com/minhup/Energy-Disaggr... | # Download the dataset
!wget http://redd:disaggregatetheenergy@redd.csail.mit.edu/data/low_freq.tar.bz2
!tar -xf low_freq.tar.bz2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import display
import datetime
import time
import math
import warnings
warnings... | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
Hands-on Exercise Please try to implement the SVM for classification of MNIST hand written digits dataset. Remember that different hyperparameters can have affect the results. 1. Prepare data: Load the MNIST dataset using `load_digits` from `sklearn.datasets`2. Prepare the tool: load `svm` from `sklearn`3. Split the d... | from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
# loading data
from sklearn.datasets import load_digits
data = load_digits()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_st... | SVC(C=1, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='poly',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
| MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
Reference* [An Idiot's guide to Support vector machines - MIT](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwiRtuO39ervAhXVK80KHTjLDGIQFjAMegQIERAD&url=http%3A%2F%2Fweb.mit.edu%2F6.034%2Fwwwbob%2Fsvm-notes-long-08.pdf&usg=AOvVaw3_uFIYSaBhhk_23fPFso52)* [Support Vector Machine... | Image(url= "https://mirrors.creativecommons.org/presskit/buttons/88x31/png/by-nc-sa.png", width=100) | _____no_output_____ | MIT | Mod2-3-ML-SL-SVM.ipynb | QianLab/ICPE-639 |
Identify face mesh landmarks> Identify a subset of face mesh landmarks. How can we identify all the landmarks around the mouth?We could use [mesh_map.jpg](https://github.com/tensorflow/tfjs-models/blob/master/facemesh/mesh_map.jpg) and type out IDs of all the landmarks we're interested in but ... that'll take a while ... | from expoco.core import *
import numpy as np
import cv2, time, math
import win32api, win32con
import mediapipe as mp
mp_face_mesh = mp.solutions.face_mesh
from collections import namedtuple
BoundingLandmarks = namedtuple('BoundingLandmarks', 'left, top, right, bottom')
mouth_bounding_landmarks = BoundingLandmarks(57, ... | _____no_output_____ | Apache-2.0 | 10a_viseme_tabular_identify_landmarks.ipynb | pete88b/expoco |
run the following cell to see the bounding box and the landmarks it encloses.press `ESC` to print all landmarks enclosed by the bounding box and stop capture | try: video_capture.release()
except: pass
video_capture = cv2.VideoCapture(0)
face_mesh = mp_face_mesh.FaceMesh(max_num_faces=1)
for vk in [win32con.VK_ESCAPE, ord('D')]: win32api.GetAsyncKeyState(vk)
retval, image = video_capture.read()
face_point_helper = FacePointHelper(*image.shape[:2], mouth_bounding_landmarks)
i... | _____no_output_____ | Apache-2.0 | 10a_viseme_tabular_identify_landmarks.ipynb | pete88b/expoco |
General plotting tip: You can get pretty named colors from https://python-graph-gallery.com/196-select-one-color-with-matplotlib/ and unnamed colors from https://htmlcolorcodes.com/. | #Load data
#UPK 535
ra535,dec535,p535,pra535,pdec535,rv535a,G535,B535,R535,spt535,d535,binf535=opendat2(ddir,'UPK535_combined.dat',['#ra', 'dec', 'p','pra','pdec', 'rv', 'G', 'B', 'R', 'spt','d','binaryflag'])
p535err,pra535err,pdec535err,rv535aerr,G535err,B535err,R535err,spt535err,d535perr,d535merr=opendat2(ddir,'UPK... | 8 9
16 17
9 10
12 13
| BSD-3-Clause | 2020_Workshop/Alex_Python/PrettyPlot.ipynb | imedan/AstroPAL_Coding_Workshop |
Color-Mapping! This basically gives you a 3rd dimension. Go wild! Color maps can be chosen from here: https://matplotlib.org/3.1.1/gallery/color/colormap_reference.html I personally like rainbow, warm, cool, and RdYlBu. You can also use lists for sizes to give different sizes to each data point. :) That's yet another ... | #3-D position with ra, dec, AND distance:
plt.rcParams.update({'font.size':22,'lines.linewidth':4, 'font.family':'serif','mathtext.fontset':'dejavuserif'})
f=plt.figure(figsize=(10,10))
cm=plt.scatter(ra535,dec535,c=d535,cmap='rainbow',s=[d if d<300 else 300 for d in 10000./(d535-300)])
cbar = f.colorbar(cm,label='\nD... | _____no_output_____ | BSD-3-Clause | 2020_Workshop/Alex_Python/PrettyPlot.ipynb | imedan/AstroPAL_Coding_Workshop |
Lesson 04: Classification Performance ROCs- evaluating and comparing trained models is of extreme importance when deciding in favor/against + model architectures + hyperparameter sets - evaluating performance or quality of prediction is performed with a myriad of tests, figure-of-merits and even statistical hypothe... | import pandas as pd
import numpy as np
df = pd.read_csv("https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/inst/extdata/penguins.csv")
#let's remove the rows with NaN values
df = df[ df.bill_length_mm.notnull() ]
#convert species column to
df[["species_"]] = df[["species"]].astype("category")
print... | 1
| MIT | source/lesson04/script.ipynb | psteinb/deeplearning540.github.io |
Starting to ROC- let's take 4 samples of different size from our test set (as if we would conduct 4 experiments) | n_experiments = 4
X_test_exp = np.split(X_test[:32,...],n_experiments,axis=0)
y_test_exp = np.split(y_test.values[:32,...],n_experiments,axis=0)
print(X_test_exp[0].shape)
print(y_test_exp[0].shape)
y_test_exp
y_test_hat = kmeans.predict(X_test)
y_test_hat_exp = np.split(y_test_hat[:32,...],n_experiments,axis=0)
#l... | _____no_output_____ | MIT | source/lesson04/script.ipynb | psteinb/deeplearning540.github.io |
But how to get from single entries to a full curve?- in our case, we can employ the positive class prediction probabilities- for KNN, this is given by the amount of N(true label)/N in the neighborhood around a query point | kmeans.predict_proba(X_test[:10])
| _____no_output_____ | MIT | source/lesson04/script.ipynb | psteinb/deeplearning540.github.io |
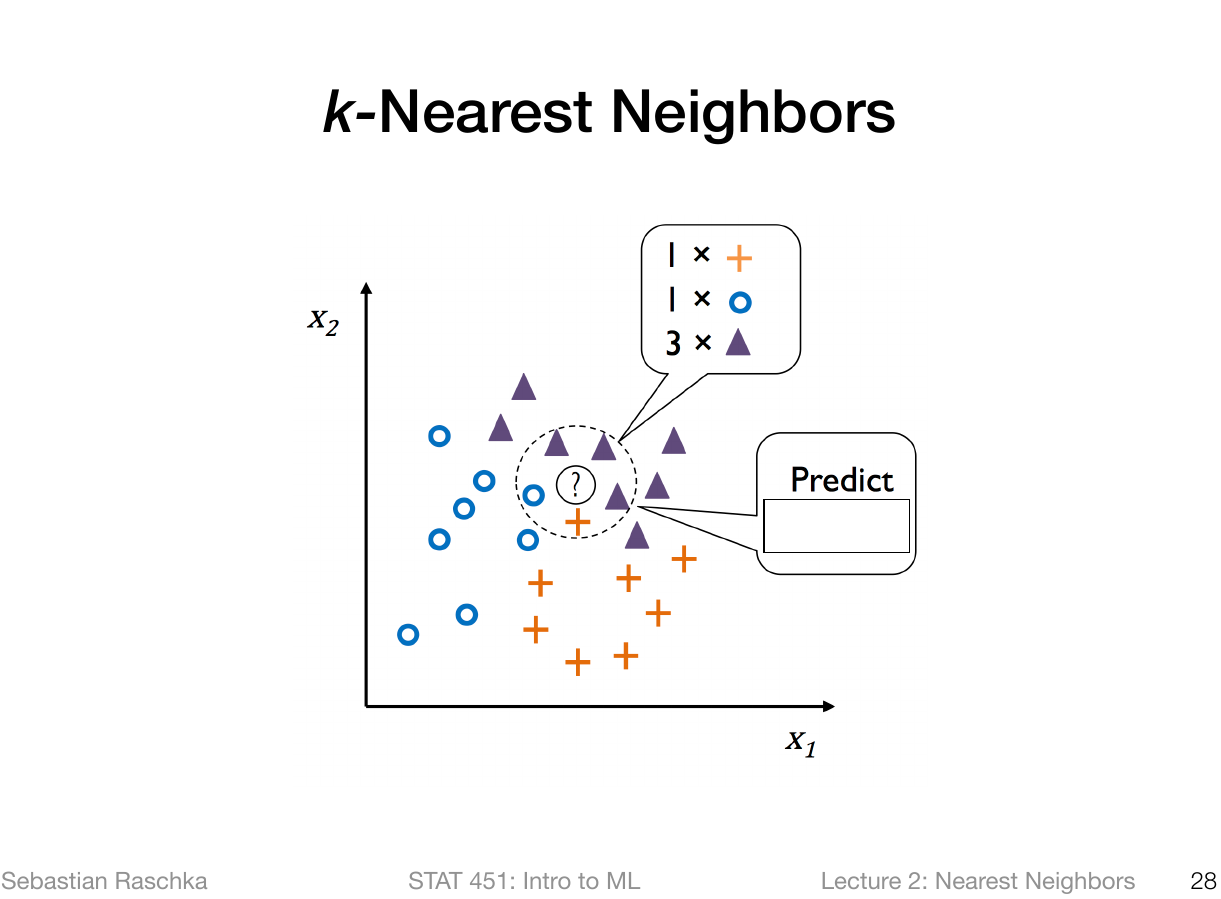- demonstrates how kNN classifyer is similar to `RandomForests`, `SVM`, ... : + spacial interpretation of the class prediction probability + the higher the prob... | from sklearn.metrics import roc_curve
probs = kmeans.predict_proba(X_test)
pos_pred_probs = probs[:,-1]
fpr, tpr, thr = roc_curve(y_test, pos_pred_probs)
print('false positive rate\n',fpr)
print('true positive rate\n',tpr)
print('thresholds\n',thr)
from sklearn.metrics import RocCurveDisplay
roc = RocCurveDisplay... | _____no_output_____ | MIT | source/lesson04/script.ipynb | psteinb/deeplearning540.github.io |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.