
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.11B | node_id stringlengths 18 32 | number int64 1 3.59k | title stringlengths 1 276 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone null | comments sequence | created_at int64 1,587B 1,642B | updated_at int64 1,587B 1,642B | closed_at null 1,587B 1,642B ⌀ | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | draft null 2
classes | pull_request null | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODk... | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"This seems related to https://github.com/huggingface/datasets/issues/3505."
] | 1,642,424,142,000 | 1,642,424,757,000 | null | MEMBER | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"login": "ecankirkic",
"id": 37082592,
"node_id": "MDQ6VXNlcjM3MDgyNTky",
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ecankirkic",
"html_url": "https://github.com/ecankirkic",
"followers_url": "https://api.github.com/use... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | [] | 1,642,378,694,000 | 1,642,411,314,000 | null | NONE | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"login": "omarespejel",
"id": 4755430,
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omarespejel",
"html_url": "https://github.com/omarespejel",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,642,369,345,000 | 1,642,369,345,000 | null | NONE | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:*... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"login": "rcanand",
"id": 303900,
"node_id": "MDQ6VXNlcjMwMzkwMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcanand",
"html_url": "https://github.com/rcanand",
"followers_url": "https://api.github.com/users/rcanand/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | [
"I came to open the same issue."
] | 1,642,287,857,000 | 1,642,425,282,000 | null | NONE | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual r... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3581/comments | https://api.github.com/repos/huggingface/datasets/issues/3581/events | https://github.com/huggingface/datasets/issues/3581 | 1,104,857,822 | I_kwDODunzps5B2sre | 3,581 | Unable to create a dataset from a parquet file in S3 | {
"login": "regCode",
"id": 18012903,
"node_id": "MDQ6VXNlcjE4MDEyOTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/18012903?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/regCode",
"html_url": "https://github.com/regCode",
"followers_url": "https://api.github.com/users/regCod... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,642,282,456,000 | 1,642,282,456,000 | null | NONE | null | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expe... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3581/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | open | false | null | [] | null | [] | 1,642,241,073,000 | 1,642,425,303,000 | null | NONE | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
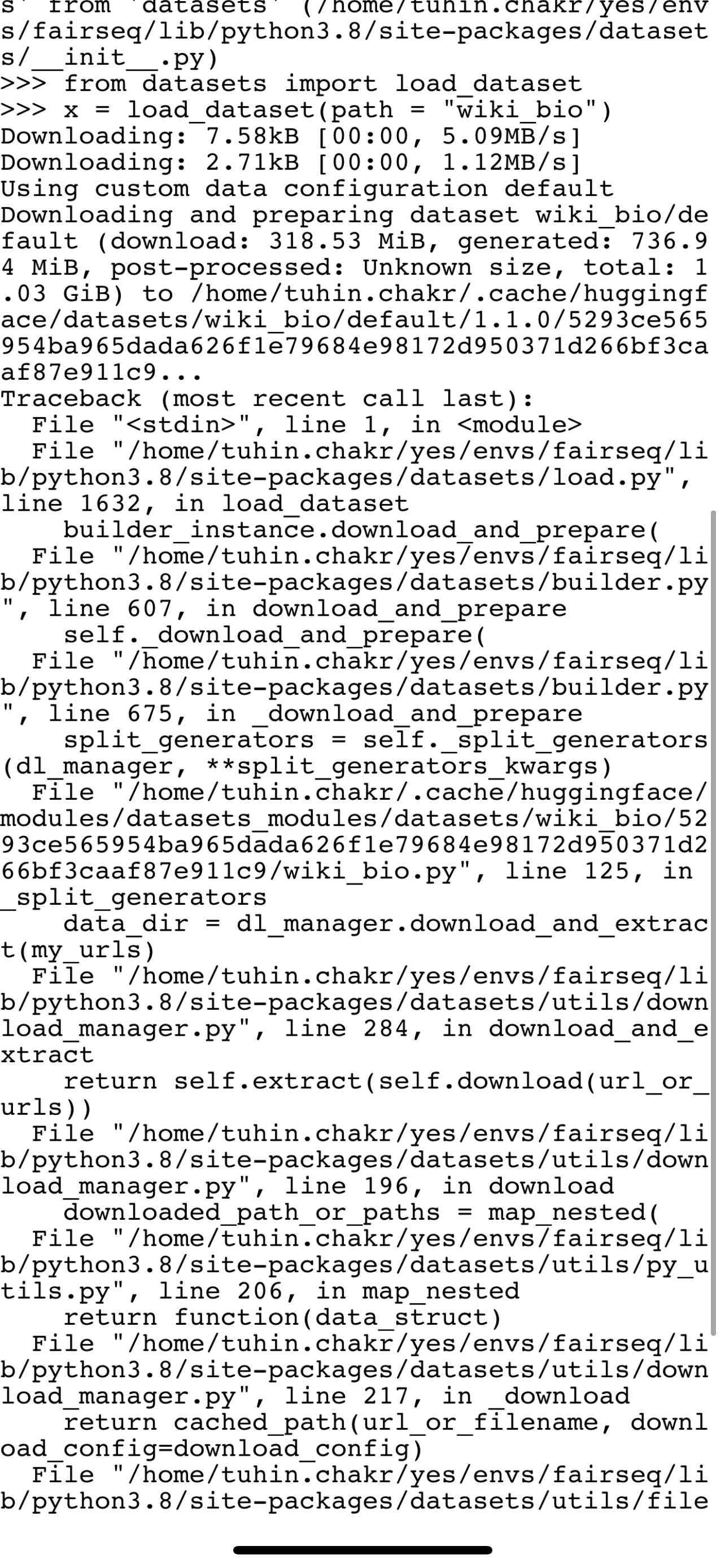

dataset.save_to_disk("normal_save")
# save ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3577/comments | https://api.github.com/repos/huggingface/datasets/issues/3577/events | https://github.com/huggingface/datasets/issues/3577 | 1,102,598,241 | I_kwDODunzps5BuFBh | 3,577 | Add The Mexican Emotional Speech Database (MESD) | {
"login": "omarespejel",
"id": 4755430,
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omarespejel",
"html_url": "https://github.com/omarespejel",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,642,117,776,000 | 1,642,117,776,000 | null | NONE | null | ## Adding a Dataset
- **Name:** *The Mexican Emotional Speech Database (MESD)*
- **Description:** *Contains 864 voice recordings with six different prosodies: anger, disgust, fear, happiness, neutral, and sadness. Furthermore, three voice categories are included: female adult, male adult, and child. *
- **Paper:** *... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3577/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3577/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3576/comments | https://api.github.com/repos/huggingface/datasets/issues/3576/events | https://github.com/huggingface/datasets/pull/3576 | 1,102,059,651 | PR_kwDODunzps4w8sUm | 3,576 | Add PASS dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | [] | 1,642,094,167,000 | 1,642,094,167,000 | null | CONTRIBUTOR | null | This PR adds the PASS dataset.
Closes #3043 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3576/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3576/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3575/comments | https://api.github.com/repos/huggingface/datasets/issues/3575/events | https://github.com/huggingface/datasets/pull/3575 | 1,101,947,955 | PR_kwDODunzps4w8Usm | 3,575 | Add Arrow type casting to struct for Image and Audio + Support nested casting | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"Regarding the tests I'm just missing the FixedSizeListType type casting for ListArray objects, will to it tomorrow as well as adding new tests + docstrings\r\n\r\nand also adding soundfile in the CI",
"While writing some tests I noticed that the ExtensionArray can't be directly concatenated - maybe we can get ri... | 1,642,088,219,000 | 1,642,178,477,000 | null | MEMBER | null | ## Intro
1. Currently, it's not possible to have nested features containing Audio or Image.
2. Moreover one can keep an Arrow array as a StringArray to store paths to images, but such arrays can't be directly concatenated to another image array if it's stored an another Arrow type (typically, a StructType).
3... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3575/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3575/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3574/comments | https://api.github.com/repos/huggingface/datasets/issues/3574/events | https://github.com/huggingface/datasets/pull/3574 | 1,101,781,401 | PR_kwDODunzps4w7vu6 | 3,574 | Fix qa4mre tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [] | 1,642,082,219,000 | 1,642,082,582,000 | null | MEMBER | null | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3574/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3574/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3573/comments | https://api.github.com/repos/huggingface/datasets/issues/3573/events | https://github.com/huggingface/datasets/pull/3573 | 1,101,157,676 | PR_kwDODunzps4w5oE_ | 3,573 | Add Mauve metric | {
"login": "jthickstun",
"id": 2321244,
"node_id": "MDQ6VXNlcjIzMjEyNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2321244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jthickstun",
"html_url": "https://github.com/jthickstun",
"followers_url": "https://api.github.com/users... | [] | open | false | null | [] | null | [] | 1,642,045,968,000 | 1,642,181,538,000 | null | NONE | null | Add support for the [Mauve](https://github.com/krishnap25/mauve) metric introduced in this [paper](https://arxiv.org/pdf/2102.01454.pdf) (Neurips, 2021). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3573/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3573/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3572/comments | https://api.github.com/repos/huggingface/datasets/issues/3572/events | https://github.com/huggingface/datasets/issues/3572 | 1,100,634,244 | I_kwDODunzps5BmliE | 3,572 | ConnectionError: Couldn't reach https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/wikiann-ner.tar.gz (error 403) | {
"login": "sahoodib",
"id": 79107194,
"node_id": "MDQ6VXNlcjc5MTA3MTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/79107194?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sahoodib",
"html_url": "https://github.com/sahoodib",
"followers_url": "https://api.github.com/users/sah... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | open | false | null | [] | null | [] | 1,642,010,376,000 | 1,642,425,328,000 | null | NONE | null | ## Adding a Dataset
- **Name:**IndicGLUE**
- **Description:** *natural language understanding benchmark for Indian languages*
- **Paper:** *(https://indicnlp.ai4bharat.org/home/)*
- **Data:** *https://huggingface.co/datasets/indic_glue#data-fields*
- **Motivation:** *I am trying to train my model on Indian languag... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3572/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3572/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3571/comments | https://api.github.com/repos/huggingface/datasets/issues/3571/events | https://github.com/huggingface/datasets/pull/3571 | 1,100,519,604 | PR_kwDODunzps4w3fVQ | 3,571 | Add missing tasks to MuchoCine dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | [] | 1,642,003,652,000 | 1,642,003,652,000 | null | CONTRIBUTOR | null | Addresses the 2nd bullet point in #2520.
I'm also removing the licensing information, because I couldn't verify that it is correct. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3571/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3571/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3570/comments | https://api.github.com/repos/huggingface/datasets/issues/3570/events | https://github.com/huggingface/datasets/pull/3570 | 1,100,480,791 | PR_kwDODunzps4w3Xez | 3,570 | Add the KMWP dataset (extension of #3564) | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | [] | 1,642,001,588,000 | 1,642,174,881,000 | null | NONE | null | New pull request of #3564 (Add the KMWP dataset) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3570/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3570/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3569/comments | https://api.github.com/repos/huggingface/datasets/issues/3569/events | https://github.com/huggingface/datasets/pull/3569 | 1,100,478,994 | PR_kwDODunzps4w3XGo | 3,569 | Add the DKTC dataset (Extension of #3564) | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | [
"I reflect your comment! @lhoestq ",
"Wait, the format of the data just changed, so I'll take it into consideration and commit it.",
"I update the code according to the dataset structure change.",
"Thanks ! I think the dummy data are not valid yet - the dummy train.csv file only contains a partial example (th... | 1,642,001,489,000 | 1,642,436,184,000 | null | NONE | null | New pull request of #3564. (for DKTC)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3569/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3569/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3568/comments | https://api.github.com/repos/huggingface/datasets/issues/3568/events | https://github.com/huggingface/datasets/issues/3568 | 1,100,380,631 | I_kwDODunzps5BlnnX | 3,568 | Downloading Hugging Face Medical Dialog Dataset NonMatchingSplitsSizesError | {
"login": "fabianslife",
"id": 49265757,
"node_id": "MDQ6VXNlcjQ5MjY1NzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/49265757?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabianslife",
"html_url": "https://github.com/fabianslife",
"followers_url": "https://api.github.com/... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | open | false | null | [] | null | [] | 1,641,996,224,000 | 1,642,425,341,000 | null | NONE | null | I wanted to download the Nedical Dialog Dataset from huggingface, using this github link:
https://github.com/huggingface/datasets/tree/master/datasets/medical_dialog
After downloading the raw datasets from google drive, i unpacked everything and put it in the same folder as the medical_dialog.py which is:
```
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3568/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3568/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3567 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3567/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3567/comments | https://api.github.com/repos/huggingface/datasets/issues/3567/events | https://github.com/huggingface/datasets/pull/3567 | 1,100,296,696 | PR_kwDODunzps4w2xDl | 3,567 | Fix push to hub to allow individual split push | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | [] | 1,641,991,378,000 | 1,641,994,141,000 | null | CONTRIBUTOR | null | # Description of the issue
If one decides to push a split on a datasets repo, he uploads the dataset and overrides the config. However previous config splits end up being lost despite still having the dataset necessary.
The new flow is the following:
- query the old config from the repo
- update into a new co... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3567/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3567/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3566/comments | https://api.github.com/repos/huggingface/datasets/issues/3566/events | https://github.com/huggingface/datasets/pull/3566 | 1,100,155,902 | PR_kwDODunzps4w2Tcc | 3,566 | Add initial electricity time series dataset | {
"login": "kashif",
"id": 8100,
"node_id": "MDQ6VXNlcjgxMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8100?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kashif",
"html_url": "https://github.com/kashif",
"followers_url": "https://api.github.com/users/kashif/followers",
... | [] | open | false | null | [] | null | [] | 1,641,982,892,000 | 1,642,189,448,000 | null | NONE | null | Here is an initial prototype time series dataset | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3566/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3566/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3565/comments | https://api.github.com/repos/huggingface/datasets/issues/3565/events | https://github.com/huggingface/datasets/pull/3565 | 1,099,296,693 | PR_kwDODunzps4wzjhH | 3,565 | Add parameter `preserve_index` to `from_pandas` | {
"login": "Sorrow321",
"id": 20703486,
"node_id": "MDQ6VXNlcjIwNzAzNDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/20703486?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sorrow321",
"html_url": "https://github.com/Sorrow321",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"> \r\n\r\nI did `make style` and it affected over 500 files\r\n\r\n```\r\nAll done! ✨ 🍰 ✨\r\n575 files reformatted, 372 files left unchanged.\r\nisort tests src benchmarks datasets/**/*.py metri\r\n```\r\n\r\n(result)\r\n | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3565/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3565/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3564/comments | https://api.github.com/repos/huggingface/datasets/issues/3564/events | https://github.com/huggingface/datasets/pull/3564 | 1,099,214,403 | PR_kwDODunzps4wzSOL | 3,564 | Add the KMWP & DKTC dataset. | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"I reflect your review. cc. @lhoestq ",
"Ah sorry, I missed KMWP comment, wait.",
"I request 2 new pull requests. #3569 #3570"
] | 1,641,910,448,000 | 1,642,001,629,000 | null | NONE | null | Add the DKTC dataset.
- https://github.com/tunib-ai/DKTC | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3564/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3564/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3563/comments | https://api.github.com/repos/huggingface/datasets/issues/3563/events | https://github.com/huggingface/datasets/issues/3563 | 1,099,070,368 | I_kwDODunzps5Bgnug | 3,563 | Dataset.from_pandas preserves useless index | {
"login": "Sorrow321",
"id": 20703486,
"node_id": "MDQ6VXNlcjIwNzAzNDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/20703486?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sorrow321",
"html_url": "https://github.com/Sorrow321",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! That makes sense. Sure, feel free to open a PR! Just a small suggestion: let's make `preserve_index` a parameter of `Dataset.from_pandas` (which we then pass to `InMemoryTable.from_pandas`) with `None` as a default value to not have this as a breaking change. "
] | 1,641,902,827,000 | 1,642,003,887,000 | null | CONTRIBUTOR | null | ## Describe the bug
Let's say that you want to create a Dataset object from pandas dataframe. Most likely you will write something like this:
```
import pandas as pd
from datasets import Dataset
df = pd.read_csv('some_dataset.csv')
# Some DataFrame preprocessing code...
dataset = Dataset.from_pandas(df)
`... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3563/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3563/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3562/comments | https://api.github.com/repos/huggingface/datasets/issues/3562/events | https://github.com/huggingface/datasets/pull/3562 | 1,098,341,351 | PR_kwDODunzps4wwa44 | 3,562 | Allow multiple task templates of the same type | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 1,641,846,727,000 | 1,641,910,607,000 | null | CONTRIBUTOR | null | Add support for multiple task templates of the same type. Fixes (partially) #2520.
CC: @lewtun | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3562/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3562/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3561/comments | https://api.github.com/repos/huggingface/datasets/issues/3561/events | https://github.com/huggingface/datasets/issues/3561 | 1,098,328,870 | I_kwDODunzps5Bdysm | 3,561 | Cannot load ‘bookcorpusopen’ | {
"login": "HUIYINXUE",
"id": 54684403,
"node_id": "MDQ6VXNlcjU0Njg0NDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/54684403?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HUIYINXUE",
"html_url": "https://github.com/HUIYINXUE",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | [
"The host of this copy of the dataset (https://the-eye.eu) is down and has been down for a good amount of time ([potentially months](https://www.reddit.com/r/Roms/comments/q82s15/theeye_downdied/))\r\n\r\nFinding this dataset is a little esoteric, as the original authors took down the official BookCorpus dataset so... | 1,641,845,838,000 | 1,642,425,361,000 | null | NONE | null | ## Describe the bug
Cannot load 'bookcorpusopen'
## Steps to reproduce the bug
```python
dataset = load_dataset('bookcorpusopen')
```
or
```python
dataset = load_dataset('bookcorpusopen',script_version='master')
```
## Actual results
ConnectionError: Couldn't reach https://the-eye.eu/public/AI/pile_pre... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3561/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3561/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3560/comments | https://api.github.com/repos/huggingface/datasets/issues/3560/events | https://github.com/huggingface/datasets/pull/3560 | 1,098,280,652 | PR_kwDODunzps4wwOMf | 3,560 | Run pyupgrade for Python 3.6+ | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users... | [] | open | false | null | [] | null | [
"Hi ! Thanks for the change :)\r\nCould it be possible to only run it for the code in `src/` ? We try to not change the code in the `datasets/` directory too often since it refreshes the users cache when they upgrade `datasets`.",
"> Hi ! Thanks for the change :)\r\n> Could it be possible to only run it for the c... | 1,641,842,453,000 | 1,642,000,307,000 | null | CONTRIBUTOR | null | Run the command:
```bash
pyupgrade $(find . -name "*.py" -type f) --py36-plus
```
Which mainly avoids unnecessary lists creations and also removes unnecessary code for Python 3.6+.
It was originally part of #3489.
Tip for reviewing faster: use the CLI (`git diff`) and scroll. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3560/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3560/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3559/comments | https://api.github.com/repos/huggingface/datasets/issues/3559/events | https://github.com/huggingface/datasets/pull/3559 | 1,098,178,222 | PR_kwDODunzps4wv420 | 3,559 | Fix `DuplicatedKeysError` and improve card in `tweet_qa` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [] | 1,641,835,660,000 | 1,642,000,438,000 | null | CONTRIBUTOR | null | Fix #3555 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3559/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3559/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3558/comments | https://api.github.com/repos/huggingface/datasets/issues/3558/events | https://github.com/huggingface/datasets/issues/3558 | 1,098,025,866 | I_kwDODunzps5BcouK | 3,558 | Integrate Milvus (pymilvus) library | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,641,828,029,000 | 1,641,828,029,000 | null | CONTRIBUTOR | null | Milvus is a popular open-source vector database. We should add a new vector index to support this project. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3558/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3557/comments | https://api.github.com/repos/huggingface/datasets/issues/3557/events | https://github.com/huggingface/datasets/pull/3557 | 1,097,946,034 | PR_kwDODunzps4wvIHl | 3,557 | Fix bug in `ImageClassifcation` task template | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"The CI failures are unrelated to the changes in this PR.",
"> The CI failures are unrelated to the changes in this PR.\r\n\r\nIt seems that some of the failures are due to the tests on the dataset cards (e.g. CIFAR, MNIST, FASHION_MNIST). Perhaps it's worth addressing those in this PR to avoid confusing downstre... | 1,641,823,799,000 | 1,641,916,072,000 | null | CONTRIBUTOR | null | Fixes a bug in the `ImageClassification` task template which requires specifying class labels twice in dataset scripts. Additionally, this PR refactors the API around the classification task templates for cleaner `labels` handling.
CC: @lewtun @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3557/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3557/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3556/comments | https://api.github.com/repos/huggingface/datasets/issues/3556/events | https://github.com/huggingface/datasets/pull/3556 | 1,097,907,724 | PR_kwDODunzps4wvALx | 3,556 | Preserve encoding/decoding with features in `Iterable.map` call | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | [] | 1,641,821,540,000 | 1,642,436,133,000 | null | CONTRIBUTOR | null | As described in https://github.com/huggingface/datasets/issues/3505#issuecomment-1004755657, this PR uses a generator expression to encode/decode examples with `features` (which are set to None in `map`) before applying a map transform.
Fix #3505 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3556/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3556/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3555/comments | https://api.github.com/repos/huggingface/datasets/issues/3555/events | https://github.com/huggingface/datasets/issues/3555 | 1,097,736,982 | I_kwDODunzps5BbiMW | 3,555 | DuplicatedKeysError when loading tweet_qa dataset | {
"login": "LeonieWeissweiler",
"id": 30300891,
"node_id": "MDQ6VXNlcjMwMzAwODkx",
"avatar_url": "https://avatars.githubusercontent.com/u/30300891?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeonieWeissweiler",
"html_url": "https://github.com/LeonieWeissweiler",
"followers_url": "https... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Hi, we've just merged the PR with the fix. The fixed version of the dataset can be downloaded as follows:\r\n```python\r\nimport datasets\r\ndset = datasets.load_dataset(\"tweet_qa\", revision=\"master\")\r\n```"
] | 1,641,811,991,000 | 1,642,000,653,000 | null | NONE | null | When loading the tweet_qa dataset with `load_dataset('tweet_qa')`, the following error occurs:
`DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 2a167f9e016ba338e1813fed275a6a1e
Keys should be unique and deterministic in nature
`
Might be related to issues #2433 and #2333
- `datasets` ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3555/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3555/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3554/comments | https://api.github.com/repos/huggingface/datasets/issues/3554/events | https://github.com/huggingface/datasets/issues/3554 | 1,097,711,367 | I_kwDODunzps5Bbb8H | 3,554 | ImportError: cannot import name 'is_valid_waiter_error' | {
"login": "danielbellhv",
"id": 84714841,
"node_id": "MDQ6VXNlcjg0NzE0ODQx",
"avatar_url": "https://avatars.githubusercontent.com/u/84714841?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielbellhv",
"html_url": "https://github.com/danielbellhv",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,641,810,724,000 | 1,641,810,724,000 | null | NONE | null | Based on [SO post](https://stackoverflow.com/q/70606147/17840900).
I'm following along to this [Notebook][1], cell "**Loading the dataset**".
Kernel: `conda_pytorch_p36`.
I run:
```
! pip install datasets transformers optimum[intel]
```
Output:
```
Requirement already satisfied: datasets in /home/ec2-u... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3554/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3554/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3553/comments | https://api.github.com/repos/huggingface/datasets/issues/3553/events | https://github.com/huggingface/datasets/issues/3553 | 1,097,252,275 | I_kwDODunzps5BZr2z | 3,553 | set_format("np") no longer works for Image data | {
"login": "cgarciae",
"id": 5862228,
"node_id": "MDQ6VXNlcjU4NjIyMjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5862228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cgarciae",
"html_url": "https://github.com/cgarciae",
"followers_url": "https://api.github.com/users/cgarc... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"A quick fix for now is doing this:\r\n\r\n```python\r\nX_train = np.stack(dataset[\"train\"][\"image\"])[..., None]",
"This error also propagates to jax and is even trickier to fix, since `.with_format(type='jax')` will use numpy conversion internally (and fail). For a three line failure:\r\n\r\n```python\r\ndat... | 1,641,748,693,000 | 1,642,081,166,000 | null | NONE | null | ## Describe the bug
`dataset.set_format("np")` no longer works for image data, previously you could load the MNIST like this:
```python
dataset = load_dataset("mnist")
dataset.set_format("np")
X_train = dataset["train"]["image"][..., None] # <== No longer a numpy array
```
but now it doesn't work, `set_format(... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3553/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3553/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3552/comments | https://api.github.com/repos/huggingface/datasets/issues/3552/events | https://github.com/huggingface/datasets/pull/3552 | 1,096,985,204 | PR_kwDODunzps4wsM29 | 3,552 | Add the KMWP & DKTC dataset. | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [] | 1,641,661,934,000 | 1,641,910,410,000 | null | NONE | null | Add the KMWP & DKTC dataset.
Additional notes:
- Both datasets will be released on January 10 through the GitHub link below.
- https://github.com/tunib-ai/DKTC
- https://github.com/tunib-ai/KMWP
- So it doesn't work as a link at the moment, but the code will work soon (after it is released on January 10). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3552/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3552/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3551/comments | https://api.github.com/repos/huggingface/datasets/issues/3551/events | https://github.com/huggingface/datasets/pull/3551 | 1,096,561,111 | PR_kwDODunzps4wq_AO | 3,551 | Add more compression types for `to_json` | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.gi... | [] | open | false | null | [] | null | [
"@lhoestq, I looked into how to compress with `zipfile` for which few methods exist, let me know which one looks good:\r\n1. create the file in normal `wb` mode and then zip it separately\r\n2. use `ZipFile.write_str` to write file into the archive. For this we'll need to change how we're writing files from `_write... | 1,641,579,902,000 | 1,642,168,983,000 | null | CONTRIBUTOR | null | This PR adds `bz2`, `xz`, and `zip` (WIP) for `to_json`. I also plan to add `infer` like how `pandas` does it | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3551/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3551/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3550/comments | https://api.github.com/repos/huggingface/datasets/issues/3550/events | https://github.com/huggingface/datasets/issues/3550 | 1,096,522,377 | I_kwDODunzps5BW5qJ | 3,550 | Bug in `openbookqa` dataset | {
"login": "lucadiliello",
"id": 23355969,
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucadiliello",
"html_url": "https://github.com/lucadiliello",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [] | 1,641,576,777,000 | 1,642,425,393,000 | null | CONTRIBUTOR | null | ## Describe the bug
Dataset entries contains a typo.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> obqa = load_dataset('openbookqa', 'main')
>>> obqa['train'][0]
```
## Expected results
```python
{'id': '7-980', 'question_stem': 'The sun is responsible for', 'choices'... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3550/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3549/comments | https://api.github.com/repos/huggingface/datasets/issues/3549/events | https://github.com/huggingface/datasets/pull/3549 | 1,096,426,996 | PR_kwDODunzps4wqkGt | 3,549 | Fix sem_eval_2018_task_1 download location | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/fo... | [] | open | false | null | [] | null | [] | 1,641,569,872,000 | 1,641,569,872,000 | null | CONTRIBUTOR | null | This changes the download location of sem_eval_2018_task_1 files to include the test set labels as discussed in https://github.com/huggingface/datasets/issues/2745#issuecomment-954588500_ with @lhoestq. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3549/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidl... | [
{
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.gi... | null | [] | 1,641,568,626,000 | 1,641,568,677,000 | null | MEMBER | null | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the feat... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3547/comments | https://api.github.com/repos/huggingface/datasets/issues/3547/events | https://github.com/huggingface/datasets/issues/3547 | 1,096,405,515 | I_kwDODunzps5BWdIL | 3,547 | Datasets created with `push_to_hub` can't be accessed in offline mode | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"Thanks for reporting. I think this can be fixed by improving the `CachedDatasetModuleFactory` and making it look into the `parquet` cache directory (datasets from push_to_hub are loaded with the parquet dataset builder). I'll look into it"
] | 1,641,568,345,000 | 1,641,811,484,000 | null | MEMBER | null | ## Describe the bug
In offline mode, one can still access previously-cached datasets. This fails with datasets created with `push_to_hub`.
## Steps to reproduce the bug
in Python:
```
import datasets
mpwiki = datasets.load_dataset("teven/matched_passages_wikidata")
```
in bash:
```
export HF_DATASETS_OFFLIN... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3547/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3547/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3546 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3546/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3546/comments | https://api.github.com/repos/huggingface/datasets/issues/3546/events | https://github.com/huggingface/datasets/pull/3546 | 1,096,367,684 | PR_kwDODunzps4wqYIV | 3,546 | Remove print statements in datasets | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"The CI failures are unrelated to the changes."
] | 1,641,565,824,000 | 1,641,578,956,000 | null | CONTRIBUTOR | null | This is a second time I'm removing print statements in our datasets, so I've added a test to avoid these issues in the future. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3546/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3546/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3545/comments | https://api.github.com/repos/huggingface/datasets/issues/3545/events | https://github.com/huggingface/datasets/pull/3545 | 1,096,189,889 | PR_kwDODunzps4wpziv | 3,545 | fix: 🐛 pass token when retrieving the split names | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | [
"Currently, it does not work with https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0/blob/main/common_voice_7_0.py#L146 (which was the goal), because `dl_manager.download_config.use_auth_token` is ignored, and the authentication is required to be use `huggingface-cli login`.\r\nIn my use case (data... | 1,641,551,362,000 | 1,641,811,907,000 | null | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3545/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3545/timeline | null | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3544 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3544/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3544/comments | https://api.github.com/repos/huggingface/datasets/issues/3544/events | https://github.com/huggingface/datasets/issues/3544 | 1,095,784,681 | I_kwDODunzps5BUFjp | 3,544 | Ability to split a dataset in multiple files. | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,641,510,145,000 | 1,641,510,145,000 | null | CONTRIBUTOR | null | Hello,
**Is your feature request related to a problem? Please describe.**
My use case is that I have one writer that adds columns and multiple workers reading the same `Dataset`. Each worker should have access to columns added by the writer when they reload the dataset.
I understand that we shouldn't overwrite... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3544/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3544/timeline | null | null | null | false |
End of preview. Expand in Data Studio
No dataset card yet
- Downloads last month
- 126