| | --- |
| | dataset_info: |
| | features: |
| | - name: text |
| | dtype: string |
| | splits: |
| | - name: train |
| | num_bytes: 24317303773 |
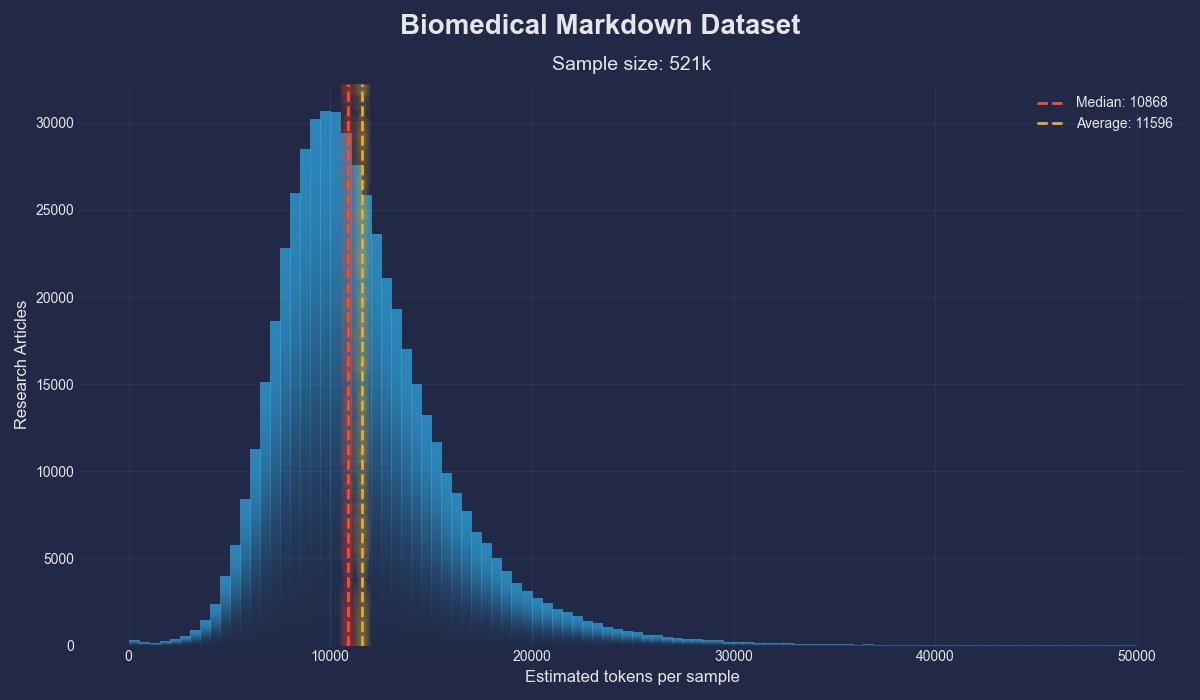
| | num_examples: 520535 |
| | download_size: 12927183654 |
| | dataset_size: 24317303773 |
| | configs: |
| | - config_name: default |
| | data_files: |
| | - split: train |
| | path: data/train-* |
| | license: cc |
| | pretty_name: PubMed Central (PMC) Open Access in Markdown |
| | --- |
| | |
| | # PubMed Central (PMC) Open Access in Markdown |
| |
|
| | This is a subset filtered for the words: obesity, weight loss, and diabetes. |
| |
|
| | The purpose of this extraction is to further research in Biomedicine + NLP. While there are many biomedical datasets, most of them focus on the clinical space, which is often different from the early developments and discovery. |
| |
|
| | The Markdown format includes figure description, tables, and a YAML header with some metadata like original license. It is filtered to remove Non-Derivative licenses as you cannot modify or remix the data for other purposes. |
| |
|
| | This used the 2025-06-26 snapshot from https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_bulk/oa_comm/xml/ |
| |
|
| | You can recreate this dataset by using this package: https://github.com/casper-hansen/pmc-python |
| |
|
| |  |
