
id int64 953M 3.35B | number int64 2.72k 7.75k | title stringlengths 1 290 | state stringclasses 2
values | created_at timestamp[s]date 2021-07-26 12:21:17 2025-08-23 00:18:43 | updated_at timestamp[s]date 2021-07-26 13:27:59 2025-08-23 12:34:39 | closed_at timestamp[s]date 2021-07-26 13:27:59 2025-08-20 16:35:55 ⌀ | html_url stringlengths 49 51 | pull_request dict | user_login stringlengths 3 26 | is_pull_request bool 2
classes | comments listlengths 0 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|
1,317,822,345 | 4,744 | Remove instructions to generate dummy data from our docs | closed | 2022-07-26T07:32:58 | 2022-08-02T23:50:30 | 2022-08-02T23:50:30 | https://github.com/huggingface/datasets/issues/4744 | null | albertvillanova | false | [
"Note that for me personally, conceptually all the dummy data (even for \"canonical\" datasets) should be superseded by `datasets-server`, which performs some kind of CI/CD of datasets (including the canonical ones)",
"I totally agree: next step should be rethinking if dummy data makes sense for canonical dataset... |
1,317,362,561 | 4,743 | Update map docs | closed | 2022-07-25T20:59:35 | 2022-07-27T16:22:04 | 2022-07-27T16:10:04 | https://github.com/huggingface/datasets/pull/4743 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4743",
"html_url": "https://github.com/huggingface/datasets/pull/4743",
"diff_url": "https://github.com/huggingface/datasets/pull/4743.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4743.patch",
"merged_at": "2022-07-27T16:10... | stevhliu | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,317,260,663 | 4,742 | Dummy data nowhere to be found | closed | 2022-07-25T19:18:42 | 2022-11-04T14:04:24 | 2022-11-04T14:04:10 | https://github.com/huggingface/datasets/issues/4742 | null | BramVanroy | false | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst of all, please note that you do not need the dummy data: this was the case when we were adding datasets to the `datasets` library (on this GitHub repo), so that we could test the correct loading of all datasets with our CI. However, this is no longer the case for ... |
1,316,621,272 | 4,741 | Fix to dict conversion of `DatasetInfo`/`Features` | closed | 2022-07-25T10:41:27 | 2022-07-25T12:50:36 | 2022-07-25T12:37:53 | https://github.com/huggingface/datasets/pull/4741 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4741",
"html_url": "https://github.com/huggingface/datasets/pull/4741",
"diff_url": "https://github.com/huggingface/datasets/pull/4741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4741.patch",
"merged_at": "2022-07-25T12:37... | mariosasko | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,316,478,007 | 4,740 | Fix multiprocessing in map_nested | closed | 2022-07-25T08:44:19 | 2022-07-28T10:53:23 | 2022-07-28T10:40:31 | https://github.com/huggingface/datasets/pull/4740 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4740",
"html_url": "https://github.com/huggingface/datasets/pull/4740",
"diff_url": "https://github.com/huggingface/datasets/pull/4740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4740.patch",
"merged_at": "2022-07-28T10:40... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq as a workaround to preserve previous behavior, the parameter `multiprocessing_min_length=16` is passed from `download` to `map_nested`, so that multiprocessing is only used if at least 16 files to be downloaded.\r\n\r\nNote ... |
1,316,400,915 | 4,739 | Deprecate metrics | closed | 2022-07-25T07:35:55 | 2022-07-28T11:44:27 | 2022-07-28T11:32:16 | https://github.com/huggingface/datasets/pull/4739 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4739",
"html_url": "https://github.com/huggingface/datasets/pull/4739",
"diff_url": "https://github.com/huggingface/datasets/pull/4739.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4739.patch",
"merged_at": "2022-07-28T11:32... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I mark this as Draft because the deprecated version number needs being updated after the latest release.",
"Perhaps now is the time to also update the `inspect_metric` from `evaluate` with the changes introduced in https://github.c... |
1,315,222,166 | 4,738 | Use CI unit/integration tests | closed | 2022-07-22T16:48:00 | 2022-07-26T20:19:22 | 2022-07-26T20:07:05 | https://github.com/huggingface/datasets/pull/4738 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4738",
"html_url": "https://github.com/huggingface/datasets/pull/4738",
"diff_url": "https://github.com/huggingface/datasets/pull/4738.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4738.patch",
"merged_at": "2022-07-26T20:07... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think this PR can be merged. Willing to see it in action.\r\n\r\nCC: @lhoestq "
] |
1,315,011,004 | 4,737 | Download error on scene_parse_150 | closed | 2022-07-22T13:28:28 | 2022-09-01T15:37:11 | 2022-09-01T15:37:11 | https://github.com/huggingface/datasets/issues/4737 | null | juliensimon | false | [
"Hi! The server with the data seems to be down. I've reported this issue (https://github.com/CSAILVision/sceneparsing/issues/34) in the dataset repo. ",
"The URL seems to work now, and therefore the script as well."
] |
1,314,931,996 | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | closed | 2022-07-22T12:14:18 | 2022-07-22T13:46:38 | 2022-07-22T13:46:38 | https://github.com/huggingface/datasets/issues/4736 | null | dk-crazydiv | false | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] |
1,314,501,641 | 4,735 | Pin rouge_score test dependency | closed | 2022-07-22T07:18:21 | 2022-07-22T07:58:14 | 2022-07-22T07:45:18 | https://github.com/huggingface/datasets/pull/4735 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4735",
"html_url": "https://github.com/huggingface/datasets/pull/4735",
"diff_url": "https://github.com/huggingface/datasets/pull/4735.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4735.patch",
"merged_at": "2022-07-22T07:45... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,314,495,382 | 4,734 | Package rouge-score cannot be imported | closed | 2022-07-22T07:15:05 | 2022-07-22T07:45:19 | 2022-07-22T07:45:18 | https://github.com/huggingface/datasets/issues/4734 | null | albertvillanova | false | [
"We have added a comment on an existing issue opened in their repo: https://github.com/google-research/google-research/issues/1212#issuecomment-1192267130\r\n- https://github.com/google-research/google-research/issues/1212"
] |
1,314,479,616 | 4,733 | rouge metric | closed | 2022-07-22T07:06:51 | 2022-07-22T09:08:02 | 2022-07-22T09:05:35 | https://github.com/huggingface/datasets/issues/4733 | null | asking28 | false | [
"Fixed by:\r\n- #4735"
] |
1,314,371,566 | 4,732 | Document better that loading a dataset passing its name does not use the local script | closed | 2022-07-22T06:07:31 | 2022-08-23T16:32:23 | 2022-08-23T16:32:23 | https://github.com/huggingface/datasets/issues/4732 | null | albertvillanova | false | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co/docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.... |
1,313,773,348 | 4,731 | docs: ✏️ fix TranslationVariableLanguages example | closed | 2022-07-21T20:35:41 | 2022-07-22T07:01:00 | 2022-07-22T06:48:42 | https://github.com/huggingface/datasets/pull/4731 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4731",
"html_url": "https://github.com/huggingface/datasets/pull/4731",
"diff_url": "https://github.com/huggingface/datasets/pull/4731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4731.patch",
"merged_at": "2022-07-22T06:48... | severo | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,313,421,263 | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | closed | 2022-07-21T15:14:06 | 2022-07-21T16:41:04 | 2022-07-21T16:41:04 | https://github.com/huggingface/datasets/issues/4730 | null | fxmarty | false | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] |
1,313,374,015 | 4,729 | Refactor Hub tests | closed | 2022-07-21T14:43:13 | 2022-07-22T15:09:49 | 2022-07-22T14:56:29 | https://github.com/huggingface/datasets/pull/4729 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4729",
"html_url": "https://github.com/huggingface/datasets/pull/4729",
"diff_url": "https://github.com/huggingface/datasets/pull/4729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4729.patch",
"merged_at": "2022-07-22T14:56... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,312,897,454 | 4,728 | load_dataset gives "403" error when using Financial Phrasebank | closed | 2022-07-21T08:43:32 | 2022-08-04T08:32:35 | 2022-08-04T08:32:35 | https://github.com/huggingface/datasets/issues/4728 | null | rohitvincent | false | [
"Hi @rohitvincent, thanks for reporting.\r\n\r\nUnfortunately I'm not able to reproduce your issue:\r\n```python\r\nIn [2]: from datasets import load_dataset, DownloadMode\r\n ...: load_dataset(path='financial_phrasebank',name='sentences_allagree', download_mode=\"force_redownload\")\r\nDownloading builder script... |
1,312,645,391 | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | closed | 2022-07-21T05:24:48 | 2022-07-21T07:51:56 | 2022-07-21T07:45:01 | https://github.com/huggingface/datasets/issues/4727 | null | thenerd31 | false | [
"The preview is working OK:\r\n\r\n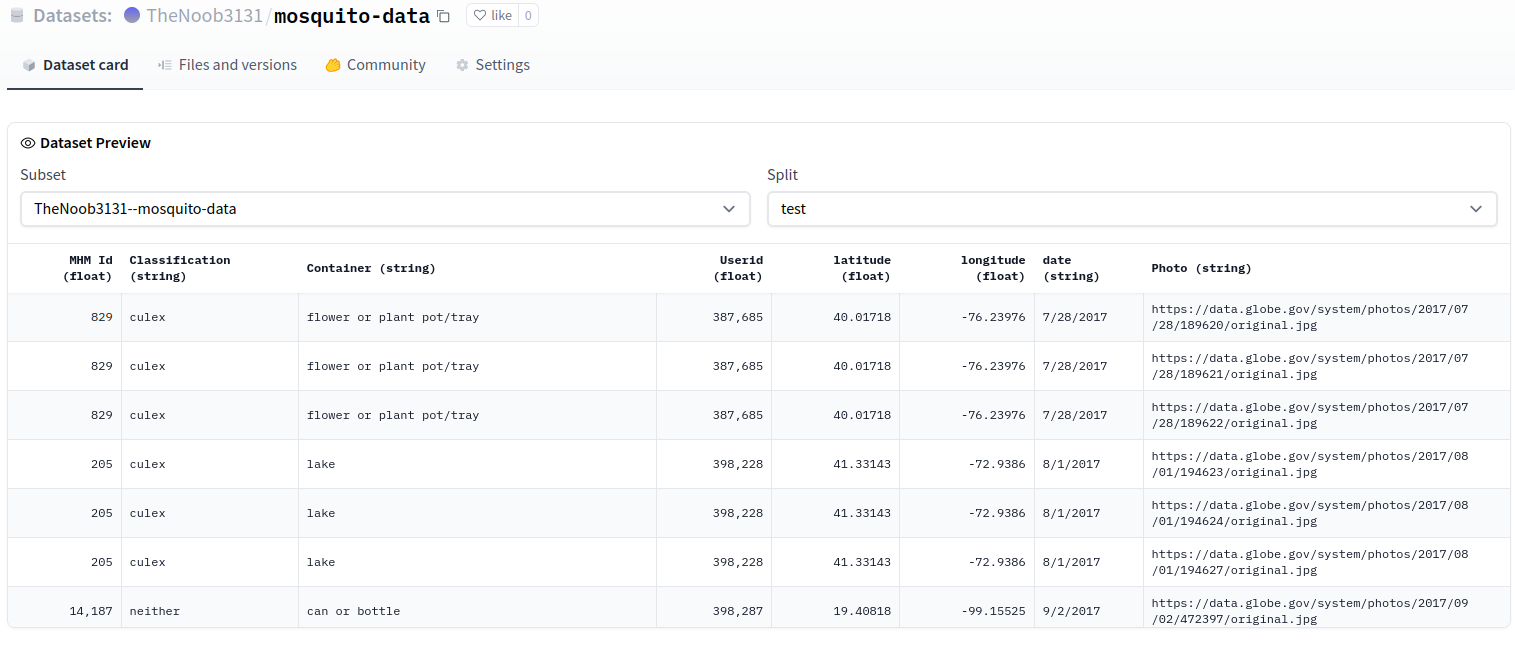\r\n\r\n"
] |
1,312,082,175 | 4,726 | Fix broken link to the Hub | closed | 2022-07-20T22:57:27 | 2022-07-21T14:33:18 | 2022-07-21T08:00:54 | https://github.com/huggingface/datasets/pull/4726 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4726",
"html_url": "https://github.com/huggingface/datasets/pull/4726",
"diff_url": "https://github.com/huggingface/datasets/pull/4726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4726.patch",
"merged_at": "2022-07-21T08:00... | stevhliu | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,311,907,096 | 4,725 | the_pile datasets URL broken. | closed | 2022-07-20T20:57:30 | 2022-07-22T06:09:46 | 2022-07-21T07:38:19 | https://github.com/huggingface/datasets/issues/4725 | null | TrentBrick | false | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_... |
1,311,127,404 | 4,724 | Download and prepare as Parquet for cloud storage | closed | 2022-07-20T13:39:02 | 2022-09-05T17:27:25 | 2022-09-05T17:25:27 | https://github.com/huggingface/datasets/pull/4724 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4724",
"html_url": "https://github.com/huggingface/datasets/pull/4724",
"diff_url": "https://github.com/huggingface/datasets/pull/4724.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4724.patch",
"merged_at": "2022-09-05T17:25... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Added some docs for dask and took your comments into account\r\n\r\ncc @philschmid if you also want to take a look :)",
"Just noticed that it would be more convenient to pass the output dir to download_and_prepare directly, to bypa... |
1,310,970,604 | 4,723 | Refactor conftest fixtures | closed | 2022-07-20T12:15:22 | 2022-07-21T14:37:11 | 2022-07-21T14:24:18 | https://github.com/huggingface/datasets/pull/4723 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4723",
"html_url": "https://github.com/huggingface/datasets/pull/4723",
"diff_url": "https://github.com/huggingface/datasets/pull/4723.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4723.patch",
"merged_at": "2022-07-21T14:24... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,310,785,916 | 4,722 | Docs: Fix same-page haslinks | closed | 2022-07-20T10:04:37 | 2022-07-20T17:02:33 | 2022-07-20T16:49:36 | https://github.com/huggingface/datasets/pull/4722 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4722",
"html_url": "https://github.com/huggingface/datasets/pull/4722",
"diff_url": "https://github.com/huggingface/datasets/pull/4722.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4722.patch",
"merged_at": "2022-07-20T16:49... | mishig25 | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,310,253,552 | 4,721 | PyArrow Dataset error when calling `load_dataset` | open | 2022-07-20T01:16:03 | 2022-07-22T14:11:47 | null | https://github.com/huggingface/datasets/issues/4721 | null | piraka9011 | false | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can... |
1,309,980,195 | 4,720 | Dataset Viewer issue for shamikbose89/lancaster_newsbooks | closed | 2022-07-19T20:00:07 | 2022-09-08T16:47:21 | 2022-09-08T16:47:21 | https://github.com/huggingface/datasets/issues/4720 | null | shamikbose | false | [
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/h... |
1,309,854,492 | 4,719 | Issue loading TheNoob3131/mosquito-data dataset | closed | 2022-07-19T17:47:37 | 2022-07-20T06:46:57 | 2022-07-20T06:46:02 | https://github.com/huggingface/datasets/issues/4719 | null | thenerd31 | false | [
"I am also getting a ValueError: 'Couldn't cast' at the bottom. Is this because of some delimiter issue? My dataset is on the Huggingface Hub. If you could look at it, that would be greatly appreciated.",
"Hi @thenerd31, thanks for reporting.\r\n\r\nPlease note that your issue is not caused by the Hugging Face Da... |
1,309,520,453 | 4,718 | Make Extractor accept Path as input | closed | 2022-07-19T13:25:06 | 2022-07-22T13:42:27 | 2022-07-22T13:29:43 | https://github.com/huggingface/datasets/pull/4718 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4718",
"html_url": "https://github.com/huggingface/datasets/pull/4718",
"diff_url": "https://github.com/huggingface/datasets/pull/4718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4718.patch",
"merged_at": "2022-07-22T13:29... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,309,512,483 | 4,717 | Dataset Viewer issue for LawalAfeez/englishreview-ds-mini | closed | 2022-07-19T13:19:39 | 2022-07-20T08:32:57 | 2022-07-20T08:32:57 | https://github.com/huggingface/datasets/issues/4717 | null | lawalAfeez820 | false | [
"It's currently working, as far as I understand\r\n\r\nhttps://huggingface.co/datasets/LawalAfeez/englishreview-ds-mini/viewer/LawalAfeez--englishreview-ds-mini/train\r\n\r\n<img width=\"1556\" alt=\"Capture d’écran 2022-07-19 à 09 24 01\" src=\"https://user-images.githubusercontent.com/1676121/179761130-2d7980b9... |
1,309,455,838 | 4,716 | Support "tags" yaml tag | closed | 2022-07-19T12:34:31 | 2022-07-20T13:44:50 | 2022-07-20T13:31:56 | https://github.com/huggingface/datasets/pull/4716 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4716",
"html_url": "https://github.com/huggingface/datasets/pull/4716",
"diff_url": "https://github.com/huggingface/datasets/pull/4716.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4716.patch",
"merged_at": "2022-07-20T13:31... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"IMO `DatasetMetadata` shouldn't crash with attributes that it doesn't know, btw",
"Yea this PR is mostly to have a validation that this field contains a list of strings.\r\n\r\nRegarding unknown fields, the tagging app currently re... |
1,309,405,980 | 4,715 | Fix POS tags | closed | 2022-07-19T11:52:54 | 2022-07-19T12:54:34 | 2022-07-19T12:41:16 | https://github.com/huggingface/datasets/pull/4715 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4715",
"html_url": "https://github.com/huggingface/datasets/pull/4715",
"diff_url": "https://github.com/huggingface/datasets/pull/4715.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4715.patch",
"merged_at": "2022-07-19T12:41... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are about missing content in the dataset cards or bad tags, and this is unrelated to this PR. Merging :)"
] |
1,309,265,682 | 4,714 | Fix named split sorting and remove unnecessary casting | closed | 2022-07-19T09:48:28 | 2022-07-22T09:39:45 | 2022-07-22T09:10:57 | https://github.com/huggingface/datasets/pull/4714 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4714",
"html_url": "https://github.com/huggingface/datasets/pull/4714",
"diff_url": "https://github.com/huggingface/datasets/pull/4714.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4714.patch",
"merged_at": "2022-07-22T09:10... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"hahaha what a timing, I added my comment right after you merged x)\r\n\r\nyou can ignore my (nit), it's fine",
"Sorry, just too sync... :sweat_smile: "
] |
1,309,184,756 | 4,713 | Document installation of sox OS dependency for audio | closed | 2022-07-19T08:42:35 | 2022-07-21T08:16:59 | 2022-07-21T08:04:15 | https://github.com/huggingface/datasets/pull/4713 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4713",
"html_url": "https://github.com/huggingface/datasets/pull/4713",
"diff_url": "https://github.com/huggingface/datasets/pull/4713.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4713.patch",
"merged_at": "2022-07-21T08:04... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,309,177,302 | 4,712 | Highlight non-commercial license in amazon_reviews_multi dataset card | closed | 2022-07-19T08:36:20 | 2022-07-27T16:09:40 | 2022-07-27T15:57:41 | https://github.com/huggingface/datasets/pull/4712 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4712",
"html_url": "https://github.com/huggingface/datasets/pull/4712",
"diff_url": "https://github.com/huggingface/datasets/pull/4712.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4712.patch",
"merged_at": "2022-07-27T15:57... | sbroadhurst-hf | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,309,138,570 | 4,711 | Document how to create a dataset loading script for audio/vision | closed | 2022-07-19T08:03:40 | 2023-07-25T16:07:52 | 2023-07-25T16:07:52 | https://github.com/huggingface/datasets/issues/4711 | null | albertvillanova | false | [
"I'm closing this issue as both the Audio and Image sections now have a \"Create dataset\" page that contains the info about writing the loading script version of a dataset."
] |
1,308,958,525 | 4,710 | Add object detection processing tutorial | closed | 2022-07-19T04:23:46 | 2022-07-21T20:10:35 | 2022-07-21T19:56:42 | https://github.com/huggingface/datasets/pull/4710 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4710",
"html_url": "https://github.com/huggingface/datasets/pull/4710",
"diff_url": "https://github.com/huggingface/datasets/pull/4710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4710.patch",
"merged_at": "2022-07-21T19:56... | nateraw | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Great idea! Now that we have more than one task, it makes sense to separate image classification and object detection so it'll be easier for users to follow.",
"@lhoestq do we want to do that in this PR, or should we merge it and l... |
1,308,633,093 | 4,709 | WMT21 & WMT22 | open | 2022-07-18T21:05:33 | 2023-06-20T09:02:11 | null | https://github.com/huggingface/datasets/issues/4709 | null | Muennighoff | false | [
"Hi ! That would be awesome to have them indeed, thanks for opening this issue\r\n\r\nI just added you to the WMT org on the HF Hub if you're interested in adding those datasets.\r\n\r\nFeel free to create a dataset repository for each dataset and upload the data files there :) preferably in ZIP archives instead of... |
1,308,279,700 | 4,708 | Fix require torchaudio and refactor test requirements | closed | 2022-07-18T17:24:28 | 2022-07-22T06:30:56 | 2022-07-22T06:18:11 | https://github.com/huggingface/datasets/pull/4708 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4708",
"html_url": "https://github.com/huggingface/datasets/pull/4708",
"diff_url": "https://github.com/huggingface/datasets/pull/4708.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4708.patch",
"merged_at": "2022-07-22T06:18... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,308,251,405 | 4,707 | Dataset Viewer issue for TheNoob3131/mosquito-data | closed | 2022-07-18T17:07:19 | 2022-07-18T19:44:46 | 2022-07-18T17:15:50 | https://github.com/huggingface/datasets/issues/4707 | null | thenerd31 | false | [
"Thanks for reporting. I refreshed the dataset viewer and it now works as expected.\r\n\r\nhttps://huggingface.co/datasets/TheNoob3131/mosquito-data\r\n\r\n<img width=\"1135\" alt=\"Capture d’écran 2022-07-18 à 13 15 22\" src=\"https://user-images.githubusercontent.com/1676121/179566497-e47f1a27-fd84-4a8d-9d7f-2e... |
1,308,198,454 | 4,706 | Fix empty examples in xtreme dataset for bucc18 config | closed | 2022-07-18T16:22:46 | 2022-07-19T06:41:14 | 2022-07-19T06:29:17 | https://github.com/huggingface/datasets/pull/4706 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4706",
"html_url": "https://github.com/huggingface/datasets/pull/4706",
"diff_url": "https://github.com/huggingface/datasets/pull/4706.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4706.patch",
"merged_at": "2022-07-19T06:29... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I guess the report link is this instead: https://huggingface.co/datasets/xtreme/discussions/1"
] |
1,308,161,794 | 4,705 | Fix crd3 | closed | 2022-07-18T15:53:44 | 2022-07-21T17:18:44 | 2022-07-21T17:06:30 | https://github.com/huggingface/datasets/pull/4705 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4705",
"html_url": "https://github.com/huggingface/datasets/pull/4705",
"diff_url": "https://github.com/huggingface/datasets/pull/4705.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4705.patch",
"merged_at": "2022-07-21T17:06... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,308,147,876 | 4,704 | Skip tests only for lz4/zstd params if not installed | closed | 2022-07-18T15:41:40 | 2022-07-19T13:02:31 | 2022-07-19T12:49:18 | https://github.com/huggingface/datasets/pull/4704 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4704",
"html_url": "https://github.com/huggingface/datasets/pull/4704",
"diff_url": "https://github.com/huggingface/datasets/pull/4704.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4704.patch",
"merged_at": "2022-07-19T12:49... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,307,844,097 | 4,703 | Make cast in `from_pandas` more robust | closed | 2022-07-18T11:55:49 | 2022-07-22T11:17:42 | 2022-07-22T11:05:24 | https://github.com/huggingface/datasets/pull/4703 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4703",
"html_url": "https://github.com/huggingface/datasets/pull/4703",
"diff_url": "https://github.com/huggingface/datasets/pull/4703.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4703.patch",
"merged_at": "2022-07-22T11:05... | mariosasko | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,307,793,811 | 4,702 | Domain specific dataset discovery on the Hugging Face hub | open | 2022-07-18T11:14:03 | 2024-02-12T09:53:43 | null | https://github.com/huggingface/datasets/issues/4702 | null | davanstrien | false | [
"Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a g... |
1,307,689,625 | 4,701 | Added more information in the README about contributors of the Arabic Speech Corpus | closed | 2022-07-18T09:48:03 | 2022-07-28T10:33:05 | 2022-07-28T10:33:05 | https://github.com/huggingface/datasets/pull/4701 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4701",
"html_url": "https://github.com/huggingface/datasets/pull/4701",
"diff_url": "https://github.com/huggingface/datasets/pull/4701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4701.patch",
"merged_at": "2022-07-28T10:33... | nawarhalabi | true | [] |
1,307,599,161 | 4,700 | Support extract lz4 compressed data files | closed | 2022-07-18T08:41:31 | 2022-07-18T14:43:59 | 2022-07-18T14:31:47 | https://github.com/huggingface/datasets/pull/4700 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4700",
"html_url": "https://github.com/huggingface/datasets/pull/4700",
"diff_url": "https://github.com/huggingface/datasets/pull/4700.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4700.patch",
"merged_at": "2022-07-18T14:31... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,307,555,592 | 4,699 | Fix Authentification Error while streaming | closed | 2022-07-18T08:03:41 | 2022-07-20T13:10:44 | 2022-07-20T13:10:43 | https://github.com/huggingface/datasets/pull/4699 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4699",
"html_url": "https://github.com/huggingface/datasets/pull/4699",
"diff_url": "https://github.com/huggingface/datasets/pull/4699.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4699.patch",
"merged_at": null
} | hkjeon13 | true | [
"Hi, thanks for working on this, but the fix for this has already been merged in https://github.com/huggingface/datasets/pull/4608."
] |
1,307,539,585 | 4,698 | Enable streaming dataset to use the "all" split | closed | 2022-07-18T07:47:39 | 2025-05-21T13:17:19 | 2025-05-21T13:17:19 | https://github.com/huggingface/datasets/pull/4698 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4698",
"html_url": "https://github.com/huggingface/datasets/pull/4698",
"diff_url": "https://github.com/huggingface/datasets/pull/4698.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4698.patch",
"merged_at": null
} | cakiki | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4698). All of your documentation changes will be reflected on that endpoint.",
"@albertvillanova \r\nAdding the validation split causes these two `assert_called_once` assertions to fail with `AssertionError: Expected 'ArrowWrit... |
1,307,332,253 | 4,697 | Trouble with streaming frgfm/imagenette vision dataset with TAR archive | closed | 2022-07-18T02:51:09 | 2022-08-01T15:10:57 | 2022-08-01T15:10:57 | https://github.com/huggingface/datasets/issues/4697 | null | frgfm | false | [
"Hi @frgfm, thanks for reporting.\r\n\r\nAs the error message says, streaming mode is not supported out of the box when the dataset contains TAR archive files.\r\n\r\nTo make the dataset streamable, you have to use `dl_manager.iter_archive`.\r\n\r\nThere are several examples in other datasets, e.g. food101: https:/... |
1,307,183,099 | 4,696 | Cannot load LinCE dataset | closed | 2022-07-17T19:01:54 | 2022-07-18T09:20:40 | 2022-07-18T07:24:22 | https://github.com/huggingface/datasets/issues/4696 | null | finiteautomata | false | [
"Hi @finiteautomata, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your issue:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: dataset = load_dataset(\"lince\", \"ner_spaeng\")\r\nDownloading builder script: 20.8kB [00:00, 9.09MB/s] ... |
1,307,134,701 | 4,695 | Add MANtIS dataset | closed | 2022-07-17T15:53:05 | 2022-09-30T14:39:30 | 2022-09-30T14:37:16 | https://github.com/huggingface/datasets/pull/4695 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4695",
"html_url": "https://github.com/huggingface/datasets/pull/4695",
"diff_url": "https://github.com/huggingface/datasets/pull/4695.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4695.patch",
"merged_at": null
} | bhavitvyamalik | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your contribution, @bhavitvyamalik. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets... |
1,306,958,380 | 4,694 | Distributed data parallel training for streaming datasets | open | 2022-07-17T01:29:43 | 2023-04-26T18:21:09 | null | https://github.com/huggingface/datasets/issues/4694 | null | cyk1337 | false | [
"Hi ! According to https://huggingface.co/docs/datasets/use_with_pytorch#stream-data you can use the pytorch DataLoader with `num_workers>0` to distribute the shards across your workers (it uses `torch.utils.data.get_worker_info()` to get the worker ID and select the right subsets of shards to use)\r\n\r\n<s> EDIT:... |
1,306,788,322 | 4,693 | update `samsum` script | closed | 2022-07-16T11:53:05 | 2022-09-23T11:40:11 | 2022-09-23T11:37:57 | https://github.com/huggingface/datasets/pull/4693 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4693",
"html_url": "https://github.com/huggingface/datasets/pull/4693",
"diff_url": "https://github.com/huggingface/datasets/pull/4693.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4693.patch",
"merged_at": null
} | bhavitvyamalik | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"We are closing PRs to dataset scripts because we are moving them to the Hub.\r\n\r\nThanks anyway.\r\n\r\n"
] |
1,306,609,680 | 4,692 | Unable to cast a column with `Image()` by using the `cast_column()` feature | closed | 2022-07-15T22:56:03 | 2022-07-19T13:36:24 | 2022-07-19T13:36:24 | https://github.com/huggingface/datasets/issues/4692 | null | skrishnan99 | false | [
"Hi, thanks for reporting! A PR (https://github.com/huggingface/datasets/pull/4614) has already been opened to address this issue."
] |
1,306,389,656 | 4,691 | Dataset Viewer issue for rajistics/indian_food_images | closed | 2022-07-15T19:03:15 | 2022-07-18T15:02:03 | 2022-07-18T15:02:03 | https://github.com/huggingface/datasets/issues/4691 | null | rajshah4 | false | [
"Hi, thanks for reporting. I triggered a refresh of the preview for this dataset, and it works now. I'm not sure what occurred.\r\n<img width=\"1019\" alt=\"Capture d’écran 2022-07-18 à 11 01 52\" src=\"https://user-images.githubusercontent.com/1676121/179541327-f62ecd5e-a18a-4d91-b316-9e2ebde77a28.png\">\r\n\r\n... |
1,306,321,975 | 4,690 | Refactor base extractors | closed | 2022-07-15T17:47:48 | 2022-07-18T08:46:56 | 2022-07-18T08:34:49 | https://github.com/huggingface/datasets/pull/4690 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4690",
"html_url": "https://github.com/huggingface/datasets/pull/4690",
"diff_url": "https://github.com/huggingface/datasets/pull/4690.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4690.patch",
"merged_at": "2022-07-18T08:34... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,306,230,203 | 4,689 | Test extractors for all compression formats | closed | 2022-07-15T16:29:55 | 2022-07-15T17:47:02 | 2022-07-15T17:35:24 | https://github.com/huggingface/datasets/pull/4689 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4689",
"html_url": "https://github.com/huggingface/datasets/pull/4689",
"diff_url": "https://github.com/huggingface/datasets/pull/4689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4689.patch",
"merged_at": "2022-07-15T17:35... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,306,100,488 | 4,688 | Skip test_extractor only for zstd param if zstandard not installed | closed | 2022-07-15T14:23:47 | 2022-07-15T15:27:53 | 2022-07-15T15:15:24 | https://github.com/huggingface/datasets/pull/4688 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4688",
"html_url": "https://github.com/huggingface/datasets/pull/4688",
"diff_url": "https://github.com/huggingface/datasets/pull/4688.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4688.patch",
"merged_at": "2022-07-15T15:15... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,306,021,415 | 4,687 | Trigger CI also on push to main | closed | 2022-07-15T13:11:29 | 2022-07-15T13:47:21 | 2022-07-15T13:35:23 | https://github.com/huggingface/datasets/pull/4687 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4687",
"html_url": "https://github.com/huggingface/datasets/pull/4687",
"diff_url": "https://github.com/huggingface/datasets/pull/4687.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4687.patch",
"merged_at": "2022-07-15T13:35... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,305,974,924 | 4,686 | Align logging with Transformers (again) | closed | 2022-07-15T12:24:29 | 2023-09-24T10:05:34 | 2023-07-11T18:29:27 | https://github.com/huggingface/datasets/pull/4686 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4686",
"html_url": "https://github.com/huggingface/datasets/pull/4686",
"diff_url": "https://github.com/huggingface/datasets/pull/4686.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4686.patch",
"merged_at": null
} | mariosasko | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4686). All of your documentation changes will be reflected on that endpoint.",
"I wasn't aware of https://github.com/huggingface/datasets/pull/1845 before opening this PR. This issue seems much more complex now ..."
] |
1,305,861,708 | 4,685 | Fix mock fsspec | closed | 2022-07-15T10:23:12 | 2022-07-15T13:05:03 | 2022-07-15T12:52:40 | https://github.com/huggingface/datasets/pull/4685 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4685",
"html_url": "https://github.com/huggingface/datasets/pull/4685",
"diff_url": "https://github.com/huggingface/datasets/pull/4685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4685.patch",
"merged_at": "2022-07-15T12:52... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,305,554,654 | 4,684 | How to assign new values to Dataset? | closed | 2022-07-15T04:17:57 | 2023-03-20T15:50:41 | 2022-10-10T11:53:38 | https://github.com/huggingface/datasets/issues/4684 | null | beyondguo | false | [
"Hi! One option is use `map` with a function that overwrites the labels (`dset = dset.map(lamba _: {\"label\": 0}, features=dset.features`)). Or you can use the `remove_column` + `add_column` combination (`dset = dset.remove_columns(\"label\").add_column(\"label\", [0]*len(data)).cast(dset.features)`, but note that... |
1,305,443,253 | 4,683 | Update create dataset card docs | closed | 2022-07-15T00:41:29 | 2022-07-18T17:26:00 | 2022-07-18T13:24:10 | https://github.com/huggingface/datasets/pull/4683 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4683",
"html_url": "https://github.com/huggingface/datasets/pull/4683",
"diff_url": "https://github.com/huggingface/datasets/pull/4683.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4683.patch",
"merged_at": "2022-07-18T13:24... | stevhliu | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,304,788,215 | 4,682 | weird issue/bug with columns (dataset iterable/stream mode) | open | 2022-07-14T13:26:47 | 2022-07-14T13:26:47 | null | https://github.com/huggingface/datasets/issues/4682 | null | eunseojo | false | [] |
1,304,617,484 | 4,681 | IndexError when loading ImageFolder | closed | 2022-07-14T10:57:55 | 2022-07-25T12:37:54 | 2022-07-25T12:37:54 | https://github.com/huggingface/datasets/issues/4681 | null | johko | false | [
"Hi, thanks for reporting! If there are no examples in ImageFolder, the `label` column is of type `ClassLabel(names=[])`, which leads to an error in [this line](https://github.com/huggingface/datasets/blob/c15b391942764152f6060b59921b09cacc5f22a6/src/datasets/arrow_writer.py#L387) as `asdict(info)` calls `Features(... |
1,304,534,770 | 4,680 | Dataset Viewer issue for codeparrot/xlcost-text-to-code | closed | 2022-07-14T09:45:50 | 2022-07-18T16:37:00 | 2022-07-18T16:04:36 | https://github.com/huggingface/datasets/issues/4680 | null | loubnabnl | false | [
"There seems to be an issue with the `C++-snippet-level` config:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"codeparrot/xlcost-text-to-code\", \"C++-snippet-level\")\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/... |
1,303,980,648 | 4,679 | Added method to remove excess nesting in a DatasetDict | closed | 2022-07-13T21:49:37 | 2022-07-21T15:55:26 | 2022-07-21T10:55:02 | https://github.com/huggingface/datasets/pull/4679 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4679",
"html_url": "https://github.com/huggingface/datasets/pull/4679",
"diff_url": "https://github.com/huggingface/datasets/pull/4679.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4679.patch",
"merged_at": null
} | CakeCrusher | true | [
"Hi ! I think the issue you linked is closed and suggests to use `remove_columns`.\r\n\r\nMoreover if you end up with a dataset with an unnecessarily nested data, please modify your processing functions to not output nested data, or use `map(..., batched=True)` if you function take batches as input",
"Hi @lhoestq... |
1,303,741,432 | 4,678 | Cant pass streaming dataset to dataloader after take() | open | 2022-07-13T17:34:18 | 2022-07-14T13:07:21 | null | https://github.com/huggingface/datasets/issues/4678 | null | zankner | false | [
"Hi! Calling `take` on an iterable/streamable dataset makes it not possible to shard the dataset, which in turn disables multi-process loading (attempts to split the workload over the shards), so to go past this limitation, you can either use single-process loading in `DataLoader` (`num_workers=None`) or fetch the ... |
1,302,258,440 | 4,677 | Random 400 Client Error when pushing dataset | closed | 2022-07-12T15:56:44 | 2023-02-07T13:54:10 | 2023-02-07T13:54:10 | https://github.com/huggingface/datasets/issues/4677 | null | msis | false | [
"did you ever fix this? I'm experiencing the same",
"I am having the same issue. Even the simple example from the documentation gives me the 400 Error\r\n\r\n\r\n> from datasets import load_dataset\r\n> \r\n> dataset = load_dataset(\"stevhliu/demo\")\r\n> dataset.push_to_hub(\"processed_demo\")\r\n\r\n\r\n`reques... |
1,302,202,028 | 4,676 | Dataset.map gets stuck on _cast_to_python_objects | closed | 2022-07-12T15:09:58 | 2022-10-03T13:01:04 | 2022-10-03T13:01:03 | https://github.com/huggingface/datasets/issues/4676 | null | srobertjames | false | [
"Are you able to reproduce this? My example is small enough that it should be easy to try.",
"Hi! Thanks for reporting and providing a reproducible example. Indeed, by default, `datasets` performs an expensive cast on the values returned by `map` to convert them to one of the types supported by PyArrow (the under... |
1,302,193,649 | 4,675 | Unable to use dataset with PyTorch dataloader | open | 2022-07-12T15:04:04 | 2022-07-14T14:17:46 | null | https://github.com/huggingface/datasets/issues/4675 | null | BlueskyFR | false | [
"Hi! `para_crawl` has a single column of type `Translation`, which stores translation dictionaries. These dictionaries can be stored in a NumPy array but not in a PyTorch tensor since PyTorch only supports numeric types. In `datasets`, the conversion to `torch` works as follows: \r\n1. convert PyArrow table to NumP... |
1,301,294,844 | 4,674 | Issue loading datasets -- pyarrow.lib has no attribute | closed | 2022-07-11T22:10:44 | 2023-02-28T18:06:55 | 2023-02-28T18:06:55 | https://github.com/huggingface/datasets/issues/4674 | null | margotwagner | false | [
"Hi @margotwagner, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your bug: in an environment with datasets-2.3.2 and pyarrow-8.0.0, I can load the datasets without any problem:\r\n```python\r\n>>> ds = load_dataset(\"glue\", \"cola\")\r\n>>> ds\r\nDatasetDict({\r\n train: Dataset({\r\n ... |
1,301,010,331 | 4,673 | load_datasets on csv returns everything as a string | closed | 2022-07-11T17:30:24 | 2024-11-05T03:55:10 | 2022-07-12T13:33:08 | https://github.com/huggingface/datasets/issues/4673 | null | courtneysprouse | false | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to la... |
1,300,911,467 | 4,672 | Support extract 7-zip compressed data files | closed | 2022-07-11T15:56:51 | 2022-07-15T13:14:27 | 2022-07-15T13:02:07 | https://github.com/huggingface/datasets/pull/4672 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4672",
"html_url": "https://github.com/huggingface/datasets/pull/4672",
"diff_url": "https://github.com/huggingface/datasets/pull/4672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4672.patch",
"merged_at": "2022-07-15T13:02... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool! Can you please remove `Fix #3541` from the description as this PR doesn't add support for streaming/`iter_archive`, so it only partially addresses the issue?\r\n\r\nSide note:\r\nI think we can use `libarchive` (`libarchive-c` ... |
1,300,385,909 | 4,671 | Dataset Viewer issue for wmt16 | closed | 2022-07-11T08:34:11 | 2022-09-13T13:27:02 | 2022-09-08T08:16:06 | https://github.com/huggingface/datasets/issues/4671 | null | lewtun | false | [
"Thanks for reporting, @lewtun.\r\n\r\n~We can't load the dataset locally, so I think this is an issue with the loading script (not the viewer).~\r\n\r\n We are investigating...",
"Recently, there was a merged PR related to this dataset:\r\n- #4554\r\n\r\nWe are looking at this...",
"Indeed, the above mentioned... |
1,299,984,246 | 4,670 | Can't extract files from `.7z` zipfile using `download_and_extract` | closed | 2022-07-10T18:16:49 | 2022-07-15T13:02:07 | 2022-07-15T13:02:07 | https://github.com/huggingface/datasets/issues/4670 | null | bhavitvyamalik | false | [
"Hi @bhavitvyamalik, thanks for reporting.\r\n\r\nYes, currently we do not support 7zip archive compression: I think we should.\r\n\r\nAs a workaround, you could uncompress it explicitly, like done in e.g. `samsum` dataset: \r\n\r\nhttps://github.com/huggingface/datasets/blob/fedf891a08bfc77041d575fad6c26091bc0fce5... |
1,299,848,003 | 4,669 | loading oscar-corpus/OSCAR-2201 raises an error | closed | 2022-07-10T07:09:30 | 2022-07-11T09:27:49 | 2022-07-11T09:27:49 | https://github.com/huggingface/datasets/issues/4669 | null | vitalyshalumov | false | [
"I had to use the appropriate token for use_auth_token. Thank you."
] |
1,299,735,893 | 4,668 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | closed | 2022-07-09T18:04:13 | 2022-07-11T07:47:47 | 2022-07-11T07:47:47 | https://github.com/huggingface/datasets/issues/4668 | null | ghost | false | [
"It seems like a private dataset. The viewer is currently not supported on the private datasets."
] |
1,299,735,703 | 4,667 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | closed | 2022-07-09T18:03:15 | 2022-07-11T07:47:15 | 2022-07-11T07:47:15 | https://github.com/huggingface/datasets/issues/4667 | null | ghost | false | [] |
1,299,732,238 | 4,666 | Issues with concatenating datasets | closed | 2022-07-09T17:45:14 | 2022-07-12T17:16:15 | 2022-07-12T17:16:14 | https://github.com/huggingface/datasets/issues/4666 | null | ChenghaoMou | false | [
"Hi! I agree we should improve the features equality checks to account for this particular case. However, your code fails due to `answer_start` having the dtype `int64` instead of `int32` after loading from JSON (it's not possible to embed type precision info into a JSON file; `save_to_disk` does that for arrow fil... |
1,299,652,638 | 4,665 | Unable to create dataset having Python dataset script only | closed | 2022-07-09T11:45:46 | 2022-07-11T07:10:09 | 2022-07-11T07:10:01 | https://github.com/huggingface/datasets/issues/4665 | null | aleSuglia | false | [
"Hi @aleSuglia, thanks for reporting.\r\n\r\nWe are having a look at it. \r\n\r\nWe transfer this issue to the Community tab of the corresponding Hub dataset: https://huggingface.co/datasets/Heriot-WattUniversity/dialog-babi/discussions"
] |
1,299,571,212 | 4,664 | Add stanford dog dataset | closed | 2022-07-09T04:46:07 | 2022-07-15T13:30:32 | 2022-07-15T13:15:42 | https://github.com/huggingface/datasets/pull/4664 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4664",
"html_url": "https://github.com/huggingface/datasets/pull/4664",
"diff_url": "https://github.com/huggingface/datasets/pull/4664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4664.patch",
"merged_at": null
} | khushmeeet | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @khushmeeet, thanks for your contribution.\r\n\r\nBut wouldn't it be better to add this dataset to the Hub? \r\n- https://huggingface.co/docs/datasets/share\r\n- https://huggingface.co/docs/datasets/dataset_script",
"Hi @albertv... |
1,299,298,693 | 4,663 | Add text decorators | closed | 2022-07-08T17:51:48 | 2022-07-18T18:33:14 | 2022-07-18T18:20:49 | https://github.com/huggingface/datasets/pull/4663 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4663",
"html_url": "https://github.com/huggingface/datasets/pull/4663",
"diff_url": "https://github.com/huggingface/datasets/pull/4663.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4663.patch",
"merged_at": "2022-07-18T18:20... | stevhliu | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,298,845,369 | 4,662 | Fix: conll2003 - fix empty example | closed | 2022-07-08T10:49:13 | 2022-07-08T14:14:53 | 2022-07-08T14:02:42 | https://github.com/huggingface/datasets/pull/4662 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4662",
"html_url": "https://github.com/huggingface/datasets/pull/4662",
"diff_url": "https://github.com/huggingface/datasets/pull/4662.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4662.patch",
"merged_at": "2022-07-08T14:02... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,298,374,944 | 4,661 | Concurrency bug when using same cache among several jobs | open | 2022-07-08T01:58:11 | 2025-04-10T13:21:23 | null | https://github.com/huggingface/datasets/issues/4661 | null | ioana-blue | false | [
"I can confirm that if I run one job first that processes the dataset, then I can run any jobs in parallel with no problem (no write-concurrency anymore...). ",
"Hi! That's weird. It seems like the error points to the `mkstemp` function, but the official docs state the following:\r\n```\r\nThere are no race condi... |
1,297,128,387 | 4,660 | Fix _resolve_single_pattern_locally on Windows with multiple drives | closed | 2022-07-07T09:57:30 | 2022-07-07T17:03:36 | 2022-07-07T16:52:07 | https://github.com/huggingface/datasets/pull/4660 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4660",
"html_url": "https://github.com/huggingface/datasets/pull/4660",
"diff_url": "https://github.com/huggingface/datasets/pull/4660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4660.patch",
"merged_at": "2022-07-07T16:52... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Good catch ! Sorry I forgot (again) about windows paths when writing this x)"
] |
1,297,094,140 | 4,659 | Transfer CI to GitHub Actions | closed | 2022-07-07T09:29:47 | 2022-07-12T11:30:20 | 2022-07-12T11:18:25 | https://github.com/huggingface/datasets/pull/4659 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4659",
"html_url": "https://github.com/huggingface/datasets/pull/4659",
"diff_url": "https://github.com/huggingface/datasets/pull/4659.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4659.patch",
"merged_at": "2022-07-12T11:18... | albertvillanova | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks a lot @albertvillanova ! I hope we're finally done with flakiness on windows ^^\r\n\r\nAlso thanks for paying extra attention to billing and avoiding running unnecessary jobs. Though for certain aspects (see my comments), I th... |
1,297,001,390 | 4,658 | Transfer CI tests to GitHub Actions | closed | 2022-07-07T08:10:50 | 2022-07-12T11:18:25 | 2022-07-12T11:18:25 | https://github.com/huggingface/datasets/issues/4658 | null | albertvillanova | false | [] |
1,296,743,133 | 4,657 | Add SQuAD2.0 Dataset | closed | 2022-07-07T03:19:36 | 2022-07-12T16:14:52 | 2022-07-12T16:14:52 | https://github.com/huggingface/datasets/issues/4657 | null | omarespejel | false | [
"Hey, It's already present [here](https://huggingface.co/datasets/squad_v2) ",
"Hi! This dataset is indeed already available on the Hub. Closing."
] |
1,296,740,266 | 4,656 | Add Amazon-QA Dataset | closed | 2022-07-07T03:15:11 | 2022-07-14T02:20:12 | 2022-07-14T02:20:12 | https://github.com/huggingface/datasets/issues/4656 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/Amazon-QA)."
] |
1,296,720,896 | 4,655 | Simple Wikipedia | closed | 2022-07-07T02:51:26 | 2022-07-14T02:16:33 | 2022-07-14T02:16:33 | https://github.com/huggingface/datasets/issues/4655 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/simple-wiki)."
] |
1,296,716,119 | 4,654 | Add Quora Question Triplets Dataset | closed | 2022-07-07T02:43:42 | 2022-07-14T02:13:50 | 2022-07-14T02:13:50 | https://github.com/huggingface/datasets/issues/4654 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/QQP_triplets)."
] |
1,296,702,834 | 4,653 | Add Altlex dataset | closed | 2022-07-07T02:23:02 | 2022-07-14T02:12:39 | 2022-07-14T02:12:39 | https://github.com/huggingface/datasets/issues/4653 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/altlex)."
] |
1,296,697,498 | 4,652 | Add Sentence Compression Dataset | closed | 2022-07-07T02:13:46 | 2022-07-14T02:11:48 | 2022-07-14T02:11:48 | https://github.com/huggingface/datasets/issues/4652 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/sentence-compression)."
] |
1,296,689,414 | 4,651 | Add Flickr 30k Dataset | closed | 2022-07-07T01:59:08 | 2022-07-14T02:09:45 | 2022-07-14T02:09:45 | https://github.com/huggingface/datasets/issues/4651 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/flickr30k-captions)."
] |
1,296,680,037 | 4,650 | Add SPECTER dataset | open | 2022-07-07T01:41:32 | 2022-07-14T02:07:49 | null | https://github.com/huggingface/datasets/issues/4650 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/SPECTER)"
] |
1,296,673,712 | 4,649 | Add PAQ dataset | closed | 2022-07-07T01:29:42 | 2022-07-14T02:06:27 | 2022-07-14T02:06:27 | https://github.com/huggingface/datasets/issues/4649 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/PAQ_pairs)"
] |
1,296,659,335 | 4,648 | Add WikiAnswers dataset | closed | 2022-07-07T01:06:37 | 2022-07-14T02:03:40 | 2022-07-14T02:03:40 | https://github.com/huggingface/datasets/issues/4648 | null | omarespejel | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/WikiAnswers)"
] |
1,296,311,270 | 4,647 | Add Reddit dataset | open | 2022-07-06T19:49:18 | 2022-07-06T19:49:18 | null | https://github.com/huggingface/datasets/issues/4647 | null | omarespejel | false | [] |
1,296,027,785 | 4,645 | Set HF_SCRIPTS_VERSION to main | closed | 2022-07-06T15:43:21 | 2022-07-06T15:56:21 | 2022-07-06T15:45:05 | https://github.com/huggingface/datasets/pull/4645 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4645",
"html_url": "https://github.com/huggingface/datasets/pull/4645",
"diff_url": "https://github.com/huggingface/datasets/pull/4645.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4645.patch",
"merged_at": "2022-07-06T15:45... | lhoestq | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
1,296,018,052 | 4,644 | [Minor fix] Typo correction | closed | 2022-07-06T15:37:02 | 2022-07-06T15:56:32 | 2022-07-06T15:45:16 | https://github.com/huggingface/datasets/pull/4644 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4644",
"html_url": "https://github.com/huggingface/datasets/pull/4644",
"diff_url": "https://github.com/huggingface/datasets/pull/4644.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4644.patch",
"merged_at": "2022-07-06T15:45... | cakiki | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.