| | --- |
| | task_categories: |
| | - text-generation |
| | pretty_name: Common Crawl Host Index v2 |
| | size_categories: |
| | - 10B<n<100B |
| | --- |
| | |
| | # Common Crawl Host Index v2 |
| |
|
| | GitHub: https://github.com/commoncrawl/cc-host-index |
| |
|
| | Each crawl, we generate a Host Index, which aggregates information about each web hosted visited during the crawl. The |
| | information is aggregated from the Common Crawl [columnar index](https://commoncrawl.org/blog/index-to-warc-files-and-urls-in-columnar-format), |
| | [web graph](https://commoncrawl.org/web-graphs), and [raw crawler logs](https://data.commoncrawl.org). |
| |
|
| | ## Quickstart |
| |
|
| | ### Using duckdb: |
| |
|
| | DuckDB can [read directly from Huggingface](https://huggingface.co/docs/hub/en/datasets-duckdb): |
| |
|
| | ```sql |
| | $ duckdb |
| | D FROM 'hf://datasets/commoncrawl/host-index-testing-v2/data/crawl=CC-MAIN-2025-18/*.parquet' LIMIT 3; |
| | ┌─────────────────────┬─────────────┬────────────────┬────────────┬────────────────┬───┬───────────────────┬─────────────────┬───────────┬───────────────────┬─────────────────┐ |
| | │ nutch_unfetched_pct │ fetch_other │ fetch_200_lote │ nutch_gone │ nutch_gone_pct │ … │ fetch_notModified │ nutch_redirPerm │ fetch_200 │ nutch_notModified │ crawl │ |
| | │ int8 │ int64 │ int64 │ int64 │ int8 │ │ int64 │ int64 │ int64 │ int64 │ varchar │ |
| | ├─────────────────────┼─────────────┼────────────────┼────────────┼────────────────┼───┼───────────────────┼─────────────────┼───────────┼───────────────────┼─────────────────┤ |
| | │ 0 │ 0 │ 0 │ 3 │ 7 │ … │ 0 │ 0 │ 18 │ 0 │ CC-MAIN-2025-18 │ |
| | │ 6 │ 0 │ 8 │ 0 │ 0 │ … │ 0 │ 0 │ 10 │ 41 │ CC-MAIN-2025-18 │ |
| | │ 80 │ 0 │ 0 │ 8 │ 17 │ … │ 0 │ 0 │ 0 │ 0 │ CC-MAIN-2025-18 │ |
| | ├─────────────────────┴─────────────┴────────────────┴────────────┴────────────────┴───┴───────────────────┴─────────────────┴───────────┴───────────────────┴─────────────────┤ |
| | │ 3 rows 43 columns (10 shown) │ |
| | └──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ |
| | D SELECT surt_host_name FROM 'hf://datasets/commoncrawl/host-index-testing-v2/data/crawl=CC-MAIN-2025-18/*.parquet' LIMIT 3; |
| | ┌──────────────────────┐ |
| | │ surt_host_name │ |
| | │ varchar │ |
| | ├──────────────────────┤ |
| | │ ae,ebury │ |
| | │ be,echappeeduhainaut │ |
| | │ au,com,echolaw │ |
| | └──────────────────────┘ |
| | ``` |
| |
|
| | ### Using Hugging Face `datasets` library: |
| |
|
| | "Streaming" mode (`streaming=True`) is recommended (see [the `datasets` docs](https://huggingface.co/docs/datasets/v4.4.1/en/stream)). This avoids the need to download all of the parquet files up-front. |
| |
|
| | ```python |
| | >>> from datasets import load_dataset |
| | >>> ds = load_dataset("commoncrawl/host-index-testing-v2", data_dir="data/crawl=CC-MAIN-2025-18", split="train", streaming=True) |
| | Resolving data files: 100%|████████████| 30/30 [00:00<00:00, 43614.95it/s] |
| | >>> print(next(iter(ds))) |
| | {'nutch_unfetched_pct': 0, 'fetch_other': 0, 'fetch_200_lote': 0, 'nutch_gone': 3, 'nutch_gone_pct': 7, 'robots_gone': 0, 'robots_5xx': 0, 'hcrank10': 3.446, 'warc_record_length_median': 32867, 'hcrank': 11908759.0, 'nutch_fetched': 42, 'nutch_notModified_pct': 0, 'robots_4xx': 0, 'nutch_redirTemp': 0, 'fetch_redirPerm': 2, 'fetch_4xx': 0, 'url_host_tld': 'ae', 'nutch_fetched_pct': 93, 'robots_notModified': 0, 'robots_other': 0, 'nutch_redirTemp_pct': 0, 'fetch_200_lote_pct': 0, 'nutch_numRecords': 45, 'robots_3xx': 0, 'robots_redirTemp': 0, 'warc_record_length_av': 31769, 'url_host_registered_domain': 'ebury.ae', 'surt_host_name': 'ae,ebury', 'nutch_redirPerm_pct': 0, 'fetch_redirTemp': 0, 'robots_200': 3, 'fetch_3xx': 0, 'fetch_5xx': 0, 'nutch_unfetched': 0, 'prank': 4.73550733982247e-09, 'fetch_gone': 0, 'prank10': 0.0, 'robots_redirPerm': 1, 'fetch_notModified': 0, 'nutch_redirPerm': 0, 'fetch_200': 18, 'nutch_notModified': 0} |
| | ``` |
| |
|
| | ## Use Cases |
| |
|
| | ### Example questions this index can answer |
| |
|
| | - What's our history of crawling a particular website, or group of websites? |
| | - What popular websites have a lot of non-English content? |
| | - What popular websites seem to have so little content that we might need to execute javascript to crawl them? |
| |
|
| | ### Example questions that we'll use to improve our crawl |
| |
|
| | - What's the full list of websites where more than half of the webpages are primarily not English? |
| | - What popular websites end our crawls with most of their crawl budget left uncrawled? |
| |
|
| | ### Example questions that future versions of this host index can answer |
| |
|
| | - What websites have a lot of content in particular languages? |
| | - What websites have a lot of content with particular Unicode scripts? |
| |
|
| | ## Examples |
| |
|
| | US Federal government websites in the *.gov domain (about 1,400 domains, y-axis scale is millions): |
| | |
| | 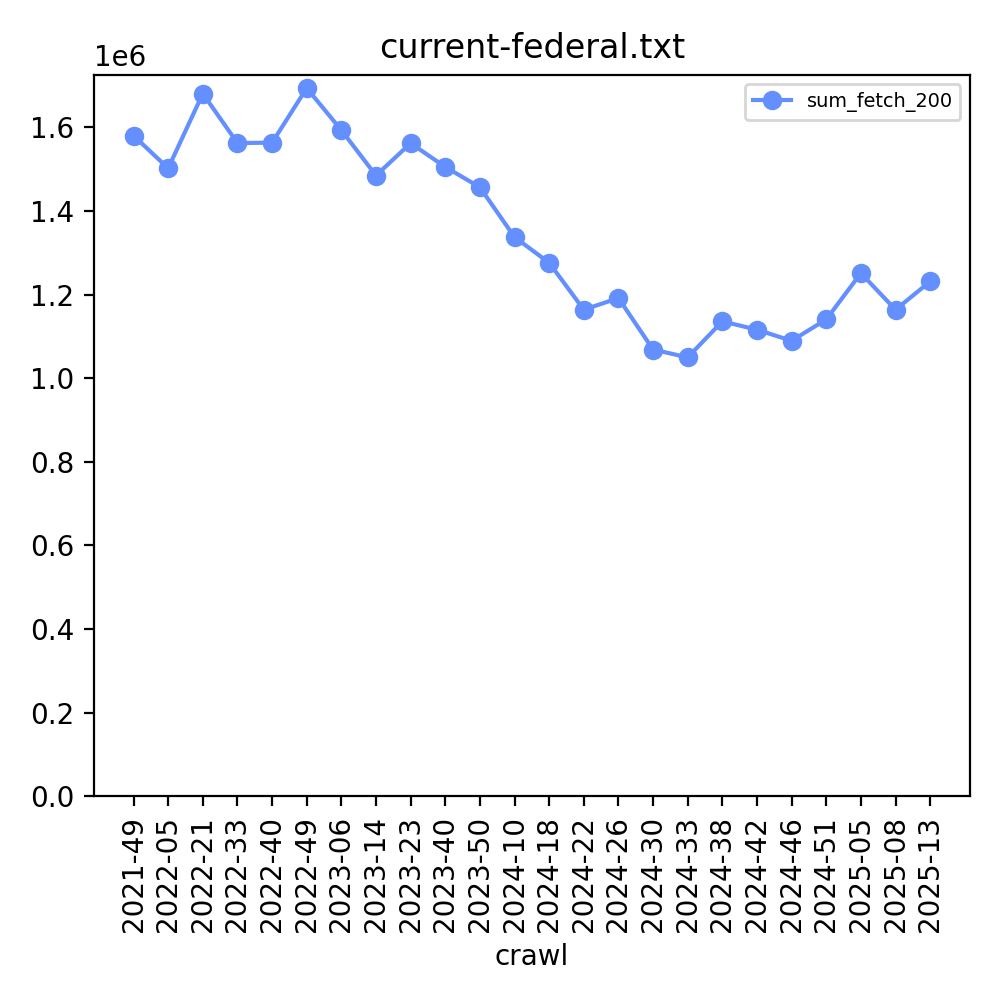 |
| | |
| | [See all graphs from this dataset](https://commoncrawl.github.io/cc-host-index-media/current-federal.txt.html) |
| | |
| | commoncrawl.org fetch. You can see that we revamped our website in CC-2023-14, which caused a lot of |
| | permanent redirects to be crawled in the next few crawls: |
| | |
| | 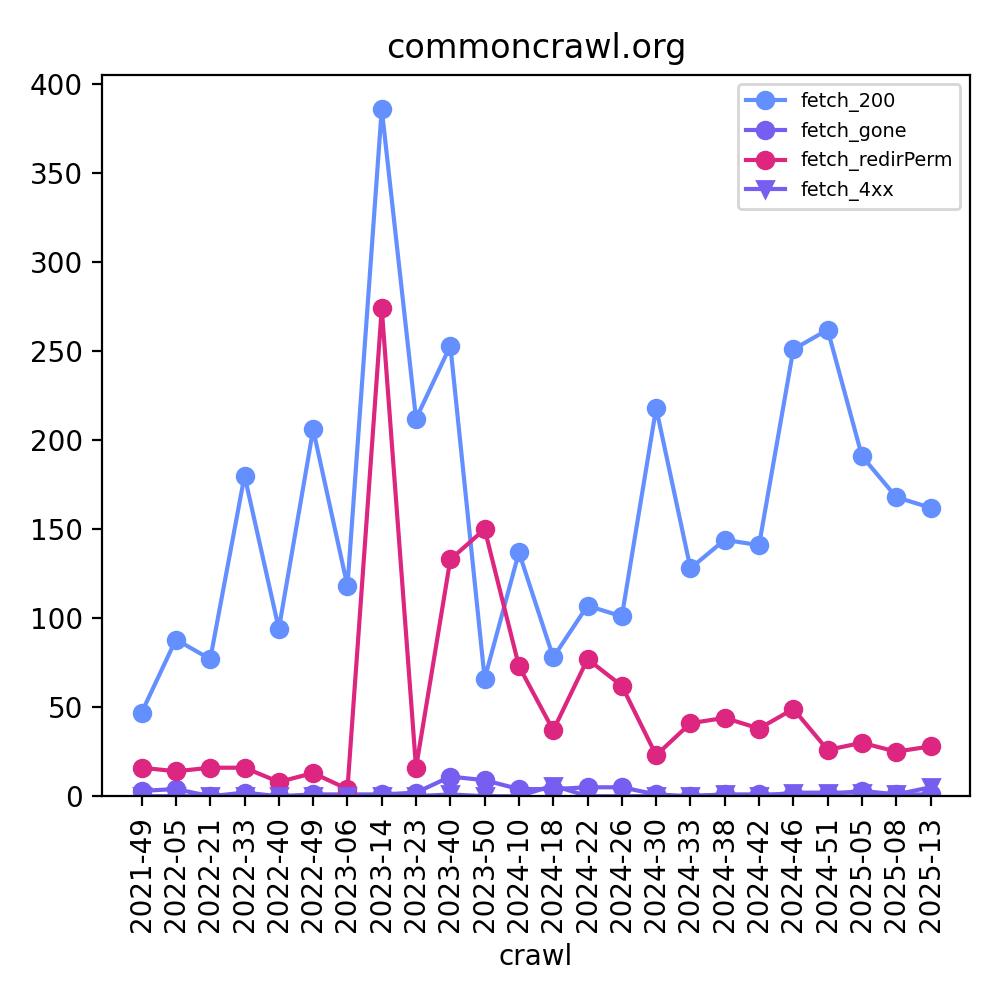 |
| | |
| | [See all graphs from this dataset](https://commoncrawl.github.io/cc-host-index-media/commoncrawl.org.html) |
| | |
| | ### Python code examples |
| | |
| | More examples of how to use this dataset with Python can be found at the [Common Crawl Host Index GitHub repo](https://github.com/commoncrawl/cc-host-index). |
| | |
| | ## Highlights of the Schema |
| | |
| | - There is a Hive-style partition on `crawl`, which is a crawl name like `CC-MAIN-2025-13`. |
| | - There is one row for every webhost in the web graph, even if we didn't crawl that website in that particular crawl |
| | - The primary key is `surt_host_name`, which stores the URL in [Sort-friendly URI Reordering Transform (SURT) format](http://crawler.archive.org/articles/user_manual/glossary.html#surt). For example, the URI `commoncrawl.org` -> becomes `org,commoncrawl)`. |
| | - There is also `url_host_tld`, which we recommend that you use whenever possible (eg `org` for commoncrawl.org) - it typically improves performance, significantly. |
| | - There are counts of what we stored in our archive (`warc`, `crawldiagnostics`, `robots`) |
| | - `fetch_200, fetch_3xx, fetch_4xx, fetch_5xx, fetch_gone, fetch_notModified, fetch_other, fetch_redirPerm, fetch_redirTemp` |
| | - `robots_200, robots_3xx, robots_4xx, robots_5xx, robots_gone, robots_notModified, robots_other, robots_redirPerm, robots_redirTemp` |
| | - There is ranking information from the [web graph](https://commoncrawl.org/web-graphs): harmonic centrality, page rank, and both normalized to a 0-10 scale |
| | - `hcrank`, `prank`, `hcrank10`, `prank10` |
| | - There is a language summary (for now, just the count of languages other than English (LOTE)) |
| | - `fetch_200_lote, fetch_200_lote_pct` |
| | - For a subset of the numbers, there is a `foo_pct` (eg `fetch3xx_pct`) which can help you avoid doing math in SQL. It is an integer 0-100. |
| | - There are raw numbers from our crawler logs, which also reveal the crawl budget and if we exhausted it |
| | - `nutch_fetched, nutch_gone, nutch_notModified, nutch_numRecords, nutch_redirPerm, nutch_redirTemp, nutch_unfetched` |
| | - `nutch_fetched_pct, nutch_gone_pct, nutch_notModified_pct, nutch_redirPerm_pct, nutch_redirTemp_pct, nutch_unfetched_pct` |
| | - There is a size summary (average and median size (compressed)) |
| | - `warc_record_length_median, warc_record_length_av` (will be renamed to _avg in v3) |
| | |
| | The full schema is available here: [athena_schema.v2.sql](https://github.com/commoncrawl/cc-host-index). |
| | |
| | ## Known bugs |
| | |
| | - Some of the partitions have a different schema from others, so you will get errors for some of the columns in some of |
| | the crawls. We recommend that you avoid using those crawls, and only use the columns you need. |
| | - When the S3 bucket is under heavy use, AWS Athena will sometimes throw 503 errors. We have yet to figure out how to increase the retry limit. |
| | - Hint: https://status.commoncrawl.org/ has graphs of S3 performance for the last day, week, and month. |
| | - The sort order is a bit messed up, so database queries take more time than they should. |
| | |
| | ## Expected changes in test v3 |
| | |
| | - `warc_record_length_av` will be renamed to `_avg` (that was a typo) |
| | - more `_pct` columns |
| | - count truncations: length, time, disconnect, unspecified |
| | - addition of indegree and outdegree from the web graph |
| | - improve language details to be more than only LOTE and LOTE\_pct |
| | - `content_language_top`, `content_language_top_pct` |
| | - add unicode block information, similar to languages |
| | - `prank10` needs its power law touched up (`hcrank10` might change too) |
| | - there's a sort problem that .com shards have a smattering of not-.com hosts. This hurts performance. |
| | - add domain prank/hcrank |
| | - CI running against S3 |
| | - `robots_digest_count_distinct` |
| | - `robots_digest` (if there is exactly 1 robots digest) |
| | - Summarize `fetch_redirect`: same surt, same surt host, other. |
| | |
| | ## Contributing |
| | |
| | We'd love to get testing and code contributions! Here are some clues: |
| | |
| | - We'd love to hear if you tried it out, and what your comments are |
| | - We'd love to have python examples using Athena, similar to duckdb |
| | - We'd love to have more python examples |
| | - Please use pyarrow whenever possible |
| | |
| | ## Terms of Use |
| | |
| | [https://commoncrawl.org/terms-of-use](https://commoncrawl.org/terms-of-use) |
| | |

