
modelId stringlengths 4 81 | tags list | pipeline_tag stringclasses 17
values | config dict | downloads int64 0 59.7M | first_commit timestamp[ns, tz=UTC] | card stringlengths 51 438k | embedding list |
|---|---|---|---|---|---|---|---|
ArashEsk95/bert-base-uncased-finetuned-sst2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v0
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.02217007614672184,
-0.014500643126666546,
-0.006683227140456438,
0.02958614192903042,
0.045837923884391785,
-0.001151051139459014,
-0.018319925293326378,
0.0017307098023593426,
-0.04307006672024727,
0.056381240487098694,
0.012359618209302425,
-0.013095137663185596,
0.011690828017890453,
... |
Aravinth/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-7
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-7
This model i... | [
-0.033743198961019516,
-0.012295817025005817,
-0.00963171198964119,
0.0300919059664011,
0.03394434228539467,
0.010098953731358051,
-0.011231853626668453,
0.0004835255676880479,
-0.02967059426009655,
0.05082697048783302,
0.022445762529969215,
-0.02909758687019348,
0.01232958771288395,
0.033... |
ArcQ/gpt-experiments | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | # Introduction
See https://github.com/k2-fsa/icefall/pull/330
No random combiner inside.
Tensorboard logs: https://tensorboard.dev/experiment/xREbAh7RS9m2TADGRLVx2g/
| [
-0.04989001527428627,
-0.012826656922698021,
-0.0016729693161323667,
0.020324787124991417,
0.03813113644719124,
-0.016744427382946014,
0.002125016413629055,
-0.012090444564819336,
-0.0542190782725811,
0.02975921705365181,
0.020312996581196785,
0.01989942230284214,
0.024484150111675262,
0.0... |
Arcanos/1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_100000
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
na... | [
-0.022128373384475708,
-0.015232272446155548,
-0.007605230435729027,
0.03029520995914936,
0.045569464564323425,
-0.0012257330818101764,
-0.017048321664333344,
0.002475455868989229,
-0.042675554752349854,
0.05693262070417404,
0.012195904739201069,
-0.012814408168196678,
0.011257469654083252,
... |
ArenaGrenade/char-cnn | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | # KoMiniLM
🐣 Korean mini language model
## Overview
Current language models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and online serving in real-life applications due to latency and capacity constraints. In this project, we release a light weight korean language mod... | [
-0.007015182636678219,
-0.019649695605039597,
-0.027968857437372208,
0.03360984846949577,
0.03887367993593216,
0.0285054799169302,
-0.008192690089344978,
-0.004116455093026161,
-0.03537559136748314,
0.07363419234752655,
0.025489935651421547,
-0.03980743885040283,
0.01984325796365738,
-0.00... |
Arghyad/Loki_small | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- yelp_review_full
metrics:
- accuracy
model-index:
- name: my-awesome-model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: yelp_review_full
type: yelp_review_full
args: yelp_revie... | [
-0.0193435437977314,
-0.008054925128817558,
0.004418942146003246,
0.02902189828455448,
0.01776447333395481,
0.0075066289864480495,
-0.02202412858605385,
-0.016582520678639412,
-0.023440225049853325,
0.06363243609666824,
0.020643511787056923,
-0.0033252453431487083,
-0.00047926075058057904,
... |
AriakimTaiyo/DialoGPT-medium-Kumiko | [
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mT5_multilingual_XLSum-finetuned-summarization-V2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comm... | [
-0.006136218085885048,
-0.024723375216126442,
0.008300199173390865,
0.04608207941055298,
0.036482714116573334,
0.009963004849851131,
-0.03388062119483948,
-0.01956077851355076,
-0.04237620532512665,
0.0459025576710701,
0.0314558669924736,
-0.026283280923962593,
0.012767809443175793,
0.0345... |
AriakimTaiyo/DialoGPT-revised-Kumiko | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 6 | null | ---
language:
- "ja"
tags:
- "japanese"
- "masked-lm"
license: "cc-by-sa-4.0"
pipeline_tag: "fill-mask"
mask_token: "[MASK]"
widget:
- text: "日本に着いたら[MASK]を訪ねなさい。"
---
# deberta-small-japanese-aozora
## Model Description
This is a DeBERTa(V2) model pre-trained on 青空文庫 texts. NVIDIA A100-SXM4-40GB took 6 hours 42 min... | [
-0.012932749465107918,
-0.04791800677776337,
0.017485255375504494,
0.038148343563079834,
0.03564633056521416,
0.017443204298615456,
0.0015414264053106308,
-0.007530085742473602,
-0.03916275128722191,
0.09299851208925247,
0.01727445051074028,
-0.018110504373908043,
-0.0005041245021857321,
0... |
AriakimTaiyo/DialoGPT-small-Rikka | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | 2022-05-23T05:26:25Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 256.70 +/- 25.38
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.04013771936297417,
-0.004488733131438494,
-0.0064122737385332584,
0.02692047506570816,
0.04417803883552551,
-0.016961418092250824,
-0.007434055674821138,
-0.026297552511096,
-0.03540217503905296,
0.06563728302717209,
0.030017413198947906,
-0.02287798747420311,
0.02344813570380211,
0.002... |
AriakimTaiyo/kumiko | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T05:26:58Z | ---
tags:
- translation
license: apache-2.0
datasets:
- thai2rom-v2
metrics:
- cer
widget:
- text: "maiphai"
---
# Roman-Thai Transliterator by Transformer Models
GitHub: https://github.com/wannaphong/thai2rom-v2/tree/main/roman2thai-transformer | [
-0.05107640475034714,
-0.025704240426421165,
0.02908329851925373,
0.01338136289268732,
0.030883630737662315,
0.005793838761746883,
-0.0192742720246315,
-0.003578103380277753,
-0.05244723707437515,
0.03437921404838562,
0.026222825050354004,
-0.016105733811855316,
0.012919710017740726,
0.023... |
Aries/T5_question_answering | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 5 | null | ---
license: apache-2.0
tags:
- summarization
- arabic
- am
- es
- amharic
- mt5
- Abstractive Summarization
- generated_from_trainer
model-index:
- name: mt5-base-finetuned-ar-sp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should ... | [
-0.013948324136435986,
-0.01160264853388071,
-0.01326797716319561,
0.042909033596515656,
0.04470172896981239,
0.001147282076999545,
-0.029633615165948868,
-0.01202786061912775,
-0.04043828696012497,
0.05577274039387703,
0.00777297280728817,
-0.03373660147190094,
0.009586993604898453,
0.028... |
Aries/T5_question_generation | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 13 | null | ---
tags:
- generated_from_keras_callback
model-index:
- name: kobart-kormath
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kobart-kormath
This model was trained ... | [
-0.037229325622320175,
-0.023359492421150208,
-0.006616259925067425,
0.025222018361091614,
0.01393426489084959,
0.02613385207951069,
-0.012557336129248142,
-0.0020281346514821053,
-0.03831645846366882,
0.04584931954741478,
0.026244372129440308,
-0.008512037806212902,
0.012739578261971474,
... |
asaakyan/mbart-poetic-all | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name... | [
-0.020221877843141556,
-0.033064696937799454,
-0.006899397354573011,
0.015347694978117943,
0.022251812741160393,
-0.005536928772926331,
-0.009576356038451195,
-0.020552556961774826,
-0.042296502739191055,
0.04345076531171799,
0.014557259157299995,
-0.013871585950255394,
0.01816769316792488,
... |
ArnaudPannatier/MLPMixer | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ## This is the model for the 'Sum_it' app ##
Find it at HuggingFace Spaces!
https://huggingface.co/spaces/SamuelMiller/sum_it | [
-0.029544105753302574,
0.003224059008061886,
0.004572040867060423,
0.024724872782826424,
-0.0014762651408091187,
0.01601233333349228,
-0.03958190605044365,
-0.010945656336843967,
-0.050516027957201004,
0.029909368604421616,
0.05714790150523186,
0.02342613786458969,
0.044947873800992966,
0.... |
Atampy26/GPT-Glacier | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram... | 5 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 9.59 +/- 2.21
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.022138487547636032,
-0.01595916599035263,
-0.007469978649169207,
0.030135106295347214,
0.04580515995621681,
-0.002015212085098028,
-0.01786850206553936,
0.002380450488999486,
-0.0422639399766922,
0.055714044719934464,
0.013234471902251244,
-0.013709532096982002,
0.007654358167201281,
0.... |
Axon/resnet34-v1 | [
"dataset:ImageNet",
"arxiv:1512.03385",
"Axon",
"Elixir",
"license:apache-2.0"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- precision
- recall
model-index:
- name: bert-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: emotion
metrics:
... | [
-0.0031443045008927584,
-0.006289891432970762,
-0.024704907089471817,
0.03980116918683052,
0.05288521945476532,
0.03486907482147217,
-0.027432318776845932,
-0.03405142202973366,
-0.03865610435605049,
0.045826468616724014,
0.02005588635802269,
-0.035294611006975174,
0.015956789255142212,
0.... |
Ayham/xlnet_gpt_xsum | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 11 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: mBERTnews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ... | [
-0.03365622088313103,
-0.017104625701904297,
-0.03541485220193863,
0.05968718230724335,
0.030684996396303177,
0.030833980068564415,
-0.002144490834325552,
-0.028628960251808167,
-0.04504997655749321,
0.07155167311429977,
0.020888417959213257,
-0.025421129539608955,
0.020285604521632195,
0.... |
BME-TMIT/foszt2oszt | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"hu",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 15 | null | ---
license: apache-2.0
tags:
- medium-summarization
- generated_from_trainer
model-index:
- name: t5-small-finetuned-tds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comme... | [
-0.01796652562916279,
-0.005640246905386448,
0.0018272019224241376,
0.013587746769189835,
0.035511113703250885,
0.008805620484054089,
-0.031061595305800438,
0.0012531335232779384,
-0.03445075452327728,
0.052232760936021805,
0.0330234095454216,
-0.009622820653021336,
0.020490510389208794,
0... |
Babelscape/rebel-large | [
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"en",
"dataset:Babelscape/rebel-dataset",
"transformers",
"seq2seq",
"relation-extraction",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"has_space"
] | text2text-generation | {
"architectures": [
"BartForConditionalGeneration"
],
"model_type": "bart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 9,458 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 265.14 +/- 22.36
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.039609476923942566,
-0.004995851777493954,
-0.0057548400945961475,
0.026763074100017548,
0.04394484683871269,
-0.016919611021876335,
-0.007459545042365789,
-0.025889568030834198,
-0.036136601120233536,
0.0657271221280098,
0.03049132414162159,
-0.02276090532541275,
0.024180375039577484,
... |
Bakkes/BakkesModWiki | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.022308392450213432,
-0.01561109907925129,
-0.007500908337533474,
0.029088247567415237,
0.04586731269955635,
-0.0009673078893683851,
-0.017615031450986862,
0.0028305992018431425,
-0.04311136528849602,
0.056112177670001984,
0.012677178718149662,
-0.0142483776435256,
0.009955239482223988,
... |
Baybars/wav2vec2-xls-r-300m-cv8-turkish | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_s... | 5 | 2022-05-23T19:00:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wa... | [
-0.02535298652946949,
-0.004647654015570879,
-0.00887758657336235,
0.01611127331852913,
0.03685331717133522,
0.014112582430243492,
0.0015131382970139384,
0.002373728435486555,
-0.033288948237895966,
0.04313500598073006,
0.02206682600080967,
-0.03019159846007824,
0.0036236965097486973,
0.02... |
BearThreat/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 30 | 2022-05-23T19:02:57Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 253.47 +/- 12.25
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.039540309458971024,
-0.004876043647527695,
-0.005633591208606958,
0.02628345414996147,
0.04410845413804054,
-0.016666682437062263,
-0.007327093277126551,
-0.02553975209593773,
-0.03649977967143059,
0.06578610092401505,
0.03039749525487423,
-0.022260207682847977,
0.023446746170520782,
0.... |
Beatriz/model_name | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T19:03:15Z | # dant5-large
---
language:
- da
language_bcp47:
- da
- da-bornholm
- da-synnejyl
tags:
- t5
license: cc-by-4.0
datasets:
- dagw
widget:
- text: "Aarhus er Danmarks <extra_id_0>.<extra_id_2>"
co2_eq_emissions:
training_type: "pretraining"
geographical_location: "Copenhagen, Denmark"
hardware_used: "4... | [
-0.03228595852851868,
-0.0021897137630730867,
-0.0033271813299506903,
0.04102998599410057,
0.04374079778790474,
0.01684911549091339,
-0.01790793612599373,
-0.02873828075826168,
-0.04291166737675667,
0.04535100609064102,
0.02189887873828411,
-0.0011354258749634027,
-0.01633051596581936,
0.0... |
Belin/T5-Terms-and-Conditions | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T19:10:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... | [
-0.01561572216451168,
0.006254096515476704,
-0.0346703864634037,
0.04655739665031433,
0.04686351120471954,
0.027355803176760674,
-0.020116601139307022,
-0.02631094492971897,
-0.0313003771007061,
0.06551356613636017,
0.047425296157598495,
-0.02560950443148613,
0.013107252307236195,
0.046775... |
Bharathdamu/wav2vec2-large-xls-r-300m-hindi | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_s... | 10 | 2022-05-23T19:22:25Z | ```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln45")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln45")
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Tra... | [
-0.02084043249487877,
-0.020685581490397453,
-0.0578438900411129,
0.05115103721618652,
0.047563113272190094,
0.051675401628017426,
-0.016964655369520187,
0.006820706184953451,
-0.04335666820406914,
0.06298578530550003,
0.028165554627776146,
-0.009238768368959427,
0.016485940665006638,
0.00... |
Bhuvana/t5-base-spellchecker | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_s... | 93 | 2022-05-23T19:30:48Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.02225605770945549,
-0.01513108890503645,
-0.008855320513248444,
0.0295969620347023,
0.046873703598976135,
-0.0018940080190077424,
-0.01737133227288723,
0.0030259706545621157,
-0.04352962225675583,
0.05554090812802315,
0.012796098366379738,
-0.014007223770022392,
0.01067867036908865,
0.0... |
BigSalmon/InformalToFormalLincoln15 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 11 | null | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: electric_pole_type_classification
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8571428656578064
---
# ... | [
-0.03897755220532417,
0.006550914142280817,
0.017947524785995483,
0.0175259280949831,
0.0419800765812397,
-0.0048539163544774055,
-0.02179611846804619,
0.00724441884085536,
-0.0418303944170475,
0.0509638711810112,
0.02489248476922512,
0.0006685257540084422,
-0.008015407249331474,
0.0592071... |
BigSalmon/InformalToFormalLincoln20 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | 2022-05-23T20:15:59Z | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery_param1
results:
- metrics:
- type: mean_reward
value: 0.27 +/- 0.44
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-l... | [
-0.019764075055718422,
-0.017936063930392265,
-0.004423149395734072,
0.034802570939064026,
0.04977165162563324,
-0.018203336745500565,
-0.010951855219900608,
-0.010794876143336296,
-0.06181321293115616,
0.05690201744437218,
-0.0001805615029297769,
-0.01172981970012188,
0.0202715415507555,
... |
BigSalmon/InformalToFormalLincoln22 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 6 | 2022-05-23T20:18:33Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
args: plain_text
met... | [
-0.012779833748936653,
-0.010790921747684479,
-0.030296865850687027,
0.04649140313267708,
0.0364595465362072,
0.03655388206243515,
-0.021839162334799767,
-0.020646920427680016,
-0.03671800717711449,
0.06496532261371613,
0.04655073210597038,
-0.018609268590807915,
0.019498363137245178,
0.04... |
BigSalmon/InformalToFormalLincolnDistilledGPT2 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 7 | 2022-05-23T20:22:50Z | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- openwebtext
---
# DistilGPT2
# test
DistilGPT2 English language model pretrained with the supervision of [GPT2](https://huggingface.co/gpt2) (the smallest version of GPT2) on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reprodu... | [
0.008376720361411572,
-0.037551358342170715,
-0.027455072849988937,
0.03519753739237785,
0.030187780037522316,
0.02433820068836212,
-0.004201708827167749,
-0.016461100429296494,
-0.011315959505736828,
0.061035484075546265,
0.0018663534428924322,
-0.0007266292232088745,
0.005908084101974964,
... |
BigSalmon/MrLincoln14 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T20:33:43Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-name_vsv_all
co2_eq_emissions: 110.53225910657005
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 901529445
- CO2 Emissions (in grams): 110.53225910657005
## Validatio... | [
-0.0262468084692955,
-0.022824043408036232,
-0.01637129671871662,
0.02978886477649212,
0.04832328483462334,
0.035442713648080826,
-0.02398310974240303,
-0.019288890063762665,
-0.04395204037427902,
0.07860511541366577,
0.027581265196204185,
0.02576635032892227,
0.004521784372627735,
0.04506... |
BigSalmon/MrLincoln3 | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 17 | 2022-05-23T20:35:16Z | ---
license:
- other
- apache-2.0
tags:
- generated_from_trainer
- text-generation
- OPT
- non-commercial
- dialogue
- chatbot
- ai-msgbot
library_name: transformers
pipeline_tag: text-generation
widget:
- text: 'If you could live anywhere, where would it be? peter szemraj:'
example_title: live anywhere
- text... | [
0.006554941181093454,
-0.02349134162068367,
-0.0037589550483971834,
0.03975891321897507,
0.032547470182180405,
0.03317447751760483,
-0.01468286570161581,
0.017040766775608063,
-0.04179183766245842,
0.06193767115473747,
0.04785103723406792,
-0.0013069221749901772,
0.008014141581952572,
0.02... |
Blabla/Pipipopo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: andywedlake/test-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# an... | [
-0.023666631430387497,
-0.019707977771759033,
-0.002527457196265459,
0.018648633733391762,
0.03376298025250435,
0.014172980561852455,
-0.027770129963755608,
-0.014892304316163063,
-0.034093860536813736,
0.062368664890527725,
0.031286947429180145,
-0.024648502469062805,
0.029134251177310944,
... |
Blaine-Mason/hackMIT-finetuned-sst2 | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 36 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: bert-zs-sentence-classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. ... | [
-0.00786187406629324,
-0.015077903866767883,
-0.03426848724484444,
0.059531841427087784,
0.04145808145403862,
0.01989361271262169,
-0.023856403306126595,
-0.024925408884882927,
-0.05852804332971573,
0.06192944198846817,
0.006648915819823742,
-0.019512642174959183,
0.019168775528669357,
0.0... |
Branex/gpt-neo-2.7B | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T21:44:23Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-4x4-noslip
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
... | [
-0.022751301527023315,
-0.013497312553226948,
0.0010825195349752903,
0.04105108231306076,
0.0400938056409359,
-0.02286815457046032,
-0.02100769802927971,
-0.02279350347816944,
-0.05509304255247116,
0.05892034247517586,
-0.00975935347378254,
-0.012915284372866154,
0.025378426536917686,
0.03... |
BrianTin/MTBERT | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 11 | 2022-05-23T21:57:05Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.022618312388658524,
-0.013640183955430984,
-0.008497519418597221,
0.033301759511232376,
0.04584203287959099,
-0.0037786876782774925,
-0.016796041280031204,
0.0004772030224557966,
-0.0438523143529892,
0.05801095813512802,
0.012950626201927662,
-0.013759041205048561,
0.007362845819443464,
... |
Broadus20/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 9 | null | ---
language:
- "eng"
thumbnail: "URL to a thumbnail used in social sharing"
tags:
- "PyTorch"
- "tensorflow"
license: "apache-2.0"
---
# viniLM-2021-from-large
### Model Info:
<ul>
<li> Authors: R&D AI Lab, VMware Inc.
<li> Model date: Jun 2022
<li> Model version: 2021-distilled-from-large
<li> Model type: Pret... | [
-0.021635431796312332,
-0.030697474256157875,
-0.009662310592830181,
0.03770747035741806,
0.035161927342414856,
-0.0014374025631695986,
-0.0016288640908896923,
-0.024377286434173584,
0.004692483693361282,
0.053278133273124695,
0.048770394176244736,
-0.009410473518073559,
-0.00972357951104641... |
Brona/model1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T22:25:39Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-11
This model... | [
-0.029886558651924133,
-0.011694468557834625,
-0.011457545682787895,
0.029814939945936203,
0.03454726189374924,
0.012708615511655807,
-0.012320607900619507,
0.00044496377813629806,
-0.027718063443899155,
0.05103381350636482,
0.023210827261209488,
-0.029610220342874527,
0.012219633907079697,
... |
BrunoNogueira/DialoGPT-kungfupanda | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 10 | 2022-05-23T22:32:52Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_vs_all
co2_eq_emissions: 111.96508441754436
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 902129475
- CO2 Emissions (in grams): 111.96508441754436
## Validat... | [
-0.026802899315953255,
-0.024751272052526474,
-0.011379966512322426,
0.027776945382356644,
0.04851159080862999,
0.03593243658542633,
-0.026874462142586708,
-0.01575925201177597,
-0.046080589294433594,
0.07722923904657364,
0.024500055238604546,
0.02442721650004387,
0.0005418803193606436,
0.... |
Brunomezenga/NN | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-4x4-slip
results:
- metrics:
- type: mean_reward
value: 0.02 +/- 0.15
name: mean_reward
task:
type: reinforcement-learning
name: rein... | [
-0.023828374221920967,
-0.013309604488313198,
0.005103282630443573,
0.04225323349237442,
0.03967323154211044,
-0.022875402122735977,
-0.021215347573161125,
-0.022601576521992683,
-0.051199622452259064,
0.05889638513326645,
-0.0064741638489067554,
-0.009999656118452549,
0.02629653736948967,
... |
Bryan190/Aguy190 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T23:13:53Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-8x8-slip
results:
- metrics:
- type: mean_reward
value: 0.38 +/- 0.49
name: mean_reward
task:
type: reinforcement-learning
name: rein... | [
-0.02567676454782486,
-0.012715968303382397,
0.005327154416590929,
0.041989605873823166,
0.0401974692940712,
-0.02418692596256733,
-0.019731352105736732,
-0.022082822397351265,
-0.052236493676900864,
0.05972219631075859,
-0.005909207742661238,
-0.011492446064949036,
0.027072599157691002,
0... |
Bryanwong/wangchanberta-ner | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: roberta-base-biomedical-clinical-es-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this c... | [
-0.02537122555077076,
-0.0015518537256866693,
0.010461399331688881,
0.009280272759497166,
0.02979687787592411,
0.020114457234740257,
-0.019027985632419586,
-0.025916682556271553,
-0.02876410447061062,
0.02497950941324234,
0.011380337178707123,
-0.03283905237913132,
0.012196139432489872,
0.... |
Brykee/DialoGPT-medium-Morty | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 10 | null | ---
license: mit
tags:
- yolo
- cpu
- quant
- pruned
--- | [
-0.047225210815668106,
-0.020587753504514694,
0.0068327332846820354,
-0.002919757505878806,
0.013628415763378143,
0.008002814836800098,
-0.00010768691572593525,
0.02369297668337822,
-0.018207166343927383,
0.02379106543958187,
0.04124711453914642,
-0.0007025256054475904,
0.026664650067687035,... |
Bryson575x/riceboi | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-23T23:55:56Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-small-japanese-upos
## Model Description
This is a DeBERTa(V2) model ... | [
-0.012820865958929062,
-0.033943045884370804,
0.0031897875014692545,
0.0363154411315918,
0.029124891385436058,
0.0338805727660656,
0.0013957920018583536,
0.003951553255319595,
-0.034222960472106934,
0.08795400708913803,
-0.00017599902639631182,
-0.012073714286088943,
0.015753494575619698,
... |
Bubb-les/DisloGPT-medium-HarryPotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4... | [
0.005549183115363121,
-0.03595380485057831,
0.0007287016487680376,
0.03289845585823059,
0.048197027295827866,
0.01443435437977314,
-0.025898098945617676,
-0.006070809904485941,
-0.029974812641739845,
0.03787052258849144,
-0.002330190734937787,
-0.009628182277083397,
0.003026594640687108,
0... |
BumBelDumBel/TRUMP | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 5 | 2022-05-24T00:30:50Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: ppo
results:
- metrics:
- type: mean_reward
value: 248.37 +/- 18.68
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.04103102535009384,
-0.004698600620031357,
-0.003979846835136414,
0.0278925821185112,
0.04190419614315033,
-0.015944287180900574,
-0.00800325907766819,
-0.02676207944750786,
-0.03660571575164795,
0.06814701855182648,
0.03324940800666809,
-0.020484434440732002,
0.022026510909199715,
0.002... |
BumBelDumBel/ZORK-AI-TEST | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 9 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 238.25 +/- 47.46
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.03962951526045799,
-0.0047208103351294994,
-0.006074185483157635,
0.02648070827126503,
0.044030074030160904,
-0.017066067084670067,
-0.007283185143023729,
-0.026027707383036613,
-0.03604483976960182,
0.0654323548078537,
0.030401118099689484,
-0.02307932637631893,
0.023394012823700905,
0... |
BumBelDumBel/ZORK_AI_FANTASY | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T01:41:29Z | # Introduction
This model translate between Yoda-ish to English and vice versa. It makes use of the [T5-base](https://huggingface.co/t5-base) model and finetuning.
Basically it trains for 2 tasks using the same dataset. In Yoda-ish to English, trains
# Dataset
For this first version of the model I used a small sample... | [
-0.0036875277291983366,
-0.023714914917945862,
-0.03129791468381882,
0.053788647055625916,
0.05976873263716698,
0.055632583796978,
-0.00589473731815815,
-0.02862168289721012,
-0.038312431424856186,
0.0351875014603138,
0.02164989896118641,
-0.025529464706778526,
0.02370258793234825,
0.04428... |
BunakovD/sd | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T01:48:33Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-53h-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then... | [
-0.027729615569114685,
0.0036748326383531094,
-0.01845204085111618,
0.04711572080850601,
0.049108974635601044,
0.013750250451266766,
-0.012492216192185879,
-0.004442677833139896,
-0.01285484991967678,
0.04861977696418762,
0.031830769032239914,
-0.023224281147122383,
-0.004967761225998402,
... |
Buntan/bert-finetuned-ner | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 8 | 2022-05-24T01:53:01Z | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, th... | [
-0.02249610424041748,
-0.0023978538811206818,
0.010664370842278004,
0.026825977489352226,
0.038665588945150375,
-0.002766320249065757,
-0.027759956195950508,
-0.005946808028966188,
-0.04541423171758652,
0.0527825728058815,
0.024699844419956207,
-0.024389248341321945,
0.010615251958370209,
... |
Bwehfuk/Ron | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | 2022-05-24T02:02:50Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: arjunpatel/distilgpt2-finetuned-pokemon-moves
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comm... | [
-0.030767282471060753,
-0.004594956059008837,
0.005082413554191589,
0.004738607443869114,
0.03565604239702225,
0.00020925745775457472,
-0.010889816097915173,
-0.004464225843548775,
-0.031184688210487366,
0.05525730550289154,
0.02516109310090542,
-0.022867873311042786,
0.017009733244776726,
... |
CALM/CALM | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 199.28 +/- 60.88
name: mean_reward
task:
type: reinforcement-learning
name: re... | [
-0.040192581713199615,
-0.005111627746373415,
-0.006261362694203854,
0.02691635489463806,
0.04341207072138786,
-0.016365952789783478,
-0.007655307650566101,
-0.025672733783721924,
-0.03643466904759407,
0.0655427947640419,
0.02984365075826645,
-0.022641828283667564,
0.0236101895570755,
0.00... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 85 | 2022-05-24T03:05:45Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: huggingfaceclass-qtable-FrozenLake-v1-8x8-slip2
results:
- metrics:
- type: mean_reward
value: 0.51 +/- 0.50
name: mean_reward
task:
type: reinforcement-learning
name: rei... | [
-0.025003910064697266,
-0.014466692693531513,
0.00492776557803154,
0.042603474110364914,
0.040187109261751175,
-0.0234425850212574,
-0.021452855318784714,
-0.02423064596951008,
-0.05143580958247185,
0.05828823521733284,
-0.006420529913157225,
-0.009303742088377476,
0.025709208101034164,
0.... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 18 | 2022-05-24T03:52:45Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-small-japanese-luw-upos
## Model Description
This is a DeBERTa(V2) mo... | [
-0.010898822918534279,
-0.03455650433897972,
0.0013902380596846342,
0.03623292222619057,
0.029381731525063515,
0.034753717482089996,
0.0017523064743727446,
0.002203721785917878,
-0.03258232772350311,
0.08664534240961075,
0.0025977296754717827,
-0.011559621430933475,
0.013786962255835533,
0... |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 71 | 2022-05-24T04:14:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: xlsr-wav2vec2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr-wav2vec2-1
Th... | [
-0.03339315578341484,
-0.0009727002470754087,
-0.012113850563764572,
0.02857366017997265,
0.03967789188027382,
0.011403501965105534,
-0.014416062273085117,
-0.006171657238155603,
-0.026255039498209953,
0.056118544191122055,
0.028170980513095856,
-0.03228805586695671,
0.0027297157794237137,
... |
CAMeL-Lab/bert-base-arabic-camelbert-ca | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 580 | 2022-05-24T04:29:47Z | ---
tags:
- conversational
---
# Sebastian Michaelis DialoGPT Model | [
-0.04180019721388817,
0.022504888474941254,
0.014278262853622437,
0.01945326291024685,
0.01860676147043705,
0.018034663051366806,
-0.005624976474791765,
0.030473798513412476,
-0.015627410262823105,
0.01389390416443348,
0.03613584116101265,
-0.037647902965545654,
0.014559985138475895,
0.033... |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 32 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... | [
-0.019737934693694115,
-0.018150126561522484,
-0.007417323067784309,
0.03465425595641136,
0.049513477832078934,
-0.019380489364266396,
-0.012065138667821884,
-0.013667142018675804,
-0.06257934868335724,
0.054861344397068024,
-0.004031729884445667,
-0.013628652319312096,
0.019898032769560814,... |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 54 | 2022-05-24T05:25:07Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_polarity
metrics:
- accuracy
- f1
model-index:
- name: SentimentClassifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_polarity
type: amazon_polarity
args: amazo... | [
-0.022567903622984886,
-0.00855342112481594,
-0.022831309586763382,
0.055231668055057526,
0.04063769802451134,
0.045209746807813644,
-0.004428079351782799,
-0.021902594715356827,
-0.054761774837970734,
0.05511963367462158,
0.044512394815683365,
-0.018762188032269478,
0.01631871983408928,
0... |
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 27 | null | ---
language:
- es
tags:
- Text Classification
---
## language:
- es
## tags:
- amazon_reviews_multi
- Text Clasiffication
### Dataset
### Example structure review:
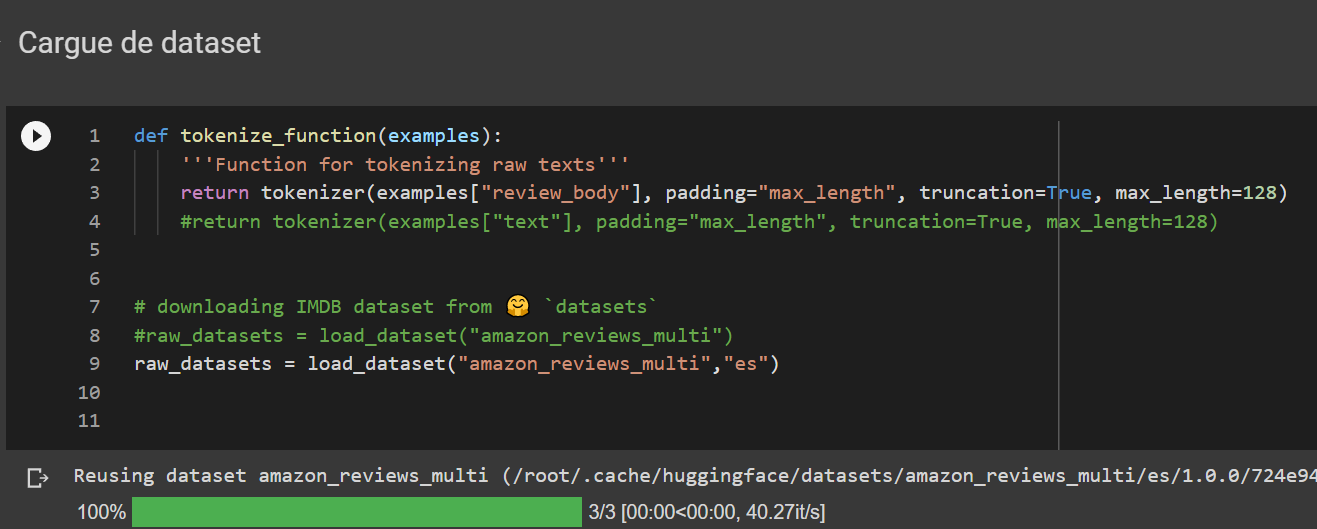
| review_id (string) | product_id (string) | reviewer... | [
0.005318337120115757,
-0.023709502071142197,
0.0162507276982069,
0.04227367416024208,
0.03358455002307892,
0.009322314523160458,
-0.014239768497645855,
0.002412769477814436,
-0.03019236959517002,
0.049409374594688416,
0.022799579426646233,
-0.013226160779595375,
-0.024513771757483482,
0.04... |
CAMeL-Lab/bert-base-arabic-camelbert-da | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 449 | null | ---
tags:
- conversational
---
# Homer Simpson Chatbot Model | [
-0.030920308083295822,
0.010096428915858269,
-0.03209398686885834,
0.03279728814959526,
0.018615184351801872,
0.0174370389431715,
-0.015093899331986904,
0.006487028207629919,
-0.018642786890268326,
0.043929629027843475,
0.052696824073791504,
0.004506122786551714,
0.010890405625104904,
0.04... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus26 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 45 | 2022-05-24T06:13:08Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_1000
results:
- metrics:
- type: mean_reward
value: 10.65 +/- 2.37
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
nam... | [
-0.02168905735015869,
-0.015048199333250523,
-0.00796422827988863,
0.030101999640464783,
0.046317629516124725,
-0.0010164101840928197,
-0.01755913533270359,
0.0016660853289067745,
-0.04238099977374077,
0.057236578315496445,
0.012411207892000675,
-0.01314963586628437,
0.010852753184735775,
... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-nadi | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 63 | 2022-05-24T06:20:03Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v1_25000
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
nam... | [
-0.02205057628452778,
-0.015285629779100418,
-0.00794037152081728,
0.030048595741391182,
0.04622361809015274,
-0.0011564154410734773,
-0.017117785289883614,
0.0026105130091309547,
-0.04246955364942551,
0.05677482485771179,
0.013040694408118725,
-0.012257669121026993,
0.01137981005012989,
0... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1,860 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-base-bne-finetuned-recores-long
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then rem... | [
-0.034339629113674164,
0.005092632956802845,
-0.00005468193921842612,
0.020138375461101532,
0.032577380537986755,
0.030126718804240227,
-0.002809727331623435,
-0.0025217626243829727,
-0.04005732387304306,
0.023052673786878586,
0.031926896423101425,
-0.027451008558273315,
-0.00109599251300096... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 31 | 2022-05-24T06:33:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- reviews_with_drift
metrics:
- accuracy
- f1
model-index:
- name: distilbert_finetuned_reviews_with_drift
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: reviews_with_drift
type: reviews... | [
-0.004617556929588318,
0.008899368345737457,
-0.01628948375582695,
0.039979998022317886,
0.03435976058244705,
0.020397771149873734,
-0.03825809434056282,
-0.014592682011425495,
-0.04323605075478554,
0.06034252420067787,
0.061536554247140884,
-0.01950867846608162,
-0.001818730728700757,
0.0... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 132 | 2022-05-24T06:46:08Z | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery_param2
results:
- metrics:
- type: mean_reward
value: 0.79 +/- 0.41
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-l... | [
-0.019824637100100517,
-0.01835860125720501,
-0.003692044410854578,
0.03477047383785248,
0.0499112494289875,
-0.018781734630465508,
-0.011264722794294357,
-0.010339906439185143,
-0.06139649450778961,
0.05654474347829819,
0.00007564765837742016,
-0.011311113834381104,
0.019483355805277824,
... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1,862 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-cnn-pubmed-arxiv-pubmed-v3-e60
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comme... | [
-0.014678659848868847,
-0.013891291804611683,
-0.011770552024245262,
0.04859524220228195,
0.026083899661898613,
0.004991854541003704,
-0.026400193572044373,
-0.02013912796974182,
-0.045060720294713974,
0.05060616880655289,
0.020649965852499008,
-0.03459479659795761,
0.004281408153474331,
0... |
CAMeL-Lab/bert-base-arabic-camelbert-mix-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 855 | 2022-05-24T06:55:47Z | ---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# deberta-base-japanese-luw-upos
## Model Description
This is a DeBERTa(V2) mod... | [
-0.01457451842725277,
-0.037876103073358536,
-0.00266677956096828,
0.035160381346940994,
0.02719462290406227,
0.04321559518575668,
0.004322276916354895,
0.0003892410022672266,
-0.033362407237291336,
0.07801651954650879,
0.008224625140428543,
-0.00960476417094469,
0.015762081369757652,
0.04... |
CAMeL-Lab/bert-base-arabic-camelbert-mix | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"Arabic",
"Dialect",
"Egyptian",
"Gulf",
"Levantine",
"Classical Arabic",
"MSA",
"Modern Standard Arabic",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 20,880 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: codet5-kormath
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# codet5-kormath
Thi... | [
-0.029145805165171623,
-0.019706564024090767,
0.00493640499189496,
0.014985259622335434,
0.030631080269813538,
0.004027220886200666,
-0.0205707810819149,
-0.00702730193734169,
-0.030330412089824677,
0.04520738124847412,
0.022227326408028603,
-0.03389642387628555,
0.004378761164844036,
0.03... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 75 | 2022-05-24T07:11:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bart-base-spelling-de
results: []
widget:
- text: "ein dransformer isd ein mthode mit der ein compuder eine volge von zeichn übersetz"
example_title: "1"
- text: "Dresten ist di Landeshaubtstadt des Freistaats Saksens und die zweid größte s... | [
-0.018661746755242348,
0.004324571695178747,
-0.004152390174567699,
0.07599298655986786,
0.03251774236559868,
0.06059866026043892,
0.017908645793795586,
0.004792749881744385,
-0.0841962918639183,
0.06784205138683319,
0.006700580473989248,
-0.016954589635133743,
-0.016056343913078308,
0.022... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-nadi | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 71 | null | ---
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
pipeline_tag: zero-shot-classification
datasets:
- multi_nli
---
# Clone from [https://huggingface.co/facebook/bart-large-mnli](bart-large-mnli)
This is the checkpoint for [bart-large](https://huggingface.co/facebook/bart-large) after be... | [
-0.016712630167603493,
-0.0026610770728439093,
-0.0037429584190249443,
0.06548120826482773,
0.048199448734521866,
0.022709734737873077,
-0.026902655139565468,
-0.027276206761598587,
-0.0012236871989443898,
0.04777407646179199,
0.01739373989403248,
0.0035969773307442665,
0.013486293144524097,... |
Capreolus/birch-bert-large-msmarco_mb | [
"pytorch",
"tf",
"jax",
"bert",
"next-sentence-prediction",
"transformers"
] | null | {
"architectures": [
"BertForNextSentencePrediction"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 1 | 2022-05-24T09:10:30Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Clinton/gpt2-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Clinton/... | [
-0.020415937528014183,
-0.03187457099556923,
-0.010812673717737198,
0.025037871673703194,
0.024586927145719528,
0.011582964099943638,
-0.010644109919667244,
-0.0030559636652469635,
-0.0417097732424736,
0.056927114725112915,
0.01627209037542343,
0.000015999545212252997,
0.03058491088449955,
... |
CarlosTron/Yo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: lmv2-2022-05-24
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lmv2-2022-05-2... | [
-0.024220390245318413,
-0.0008802625234238803,
-0.007900236174464226,
0.01685699261724949,
0.022784167900681496,
0.013967012986540794,
-0.020474858582019806,
0.02037915214896202,
-0.02688811533153057,
0.05841832607984543,
0.020532524213194847,
-0.02742425538599491,
0.018037527799606323,
0.... |
dccuchile/albert-base-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 25 | 2022-05-24T09:30:04Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: xlm-roberta-base-language-detection
results: []
---
# Clone from [https://huggingface.co/papluca/xlm-roberta-base-language-detection](xlm-roberta-base-language-detection)
This model is a fine-tuned version of [xlm-roberta-... | [
-0.031174225732684135,
-0.009207673370838165,
-0.007653672248125076,
0.04208064451813698,
0.033996228128671646,
0.031428251415491104,
-0.00634945509955287,
-0.008604577742516994,
-0.026165546849370003,
0.0720774456858635,
0.0074123418889939785,
-0.04431877285242081,
-0.015693463385105133,
... |
dccuchile/albert-base-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 3 | 2022-05-24T09:31:50Z | ---
tags:
- automatic-speech-recognition
- generated_from_trainer
license: mit
language:
- lb
metrics:
- wer
pipeline_tag: automatic-speech-recognition
model-index:
- name: Lemswasabi/wav2vec2-large-xlsr-53-842h-luxembourgish-14h-with-lm
results:
- task:
type: automatic-speech-recognition # Requi... | [
0.0023586007300764322,
0.0002720909542404115,
-0.012297793291509151,
0.03451957553625107,
0.03807927295565605,
0.01478197705000639,
0.00240822765044868,
-0.01881013624370098,
-0.04567543417215347,
0.06252557784318924,
0.02252468653023243,
-0.0528329499065876,
-0.013983315788209438,
0.01181... |
dccuchile/albert-tiny-spanish-finetuned-pos | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 5 | 2022-05-24T10:08:54Z | KTRONICS - Manufacturer of Wireless Water level Controller, Borewell Automatic Water controller, GSM Based Wireless Controller & Industry Products etc
https://ktronics.global/best-water-level-products-chennai-ktronics-buy-now-9043876528 | [
-0.0862048789858818,
0.025380847975611687,
0.008291746489703655,
0.0034377886913716793,
0.049432069063186646,
0.01949419267475605,
-0.018738295882940292,
0.025414951145648956,
-0.010332264006137848,
0.03722492232918739,
0.03332769125699997,
-0.023859791457653046,
0.027162235230207443,
0.01... |
dccuchile/albert-tiny-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 31 | 2022-05-24T10:33:18Z | (COMING SOON!)
MULTILINGUAL HATECHECK: Functional Tests for Multilingual Hate Speech Detection Models | [
-0.014692639000713825,
-0.002387601649388671,
0.002515482949092984,
0.04759742319583893,
0.03187168762087822,
0.047716256231069565,
-0.011097300797700882,
-0.018202153965830803,
-0.021520309150218964,
0.040138039737939835,
0.024167900905013084,
0.013724452815949917,
0.03169914335012436,
0.... |
dccuchile/albert-xlarge-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 26 | 2022-05-24T10:40:15Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... | [
-0.018894236534833908,
-0.017997216433286667,
-0.007777469698339701,
0.034650884568691254,
0.05038543418049812,
-0.017128268256783485,
-0.011013532988727093,
-0.013354392722249031,
-0.06264452636241913,
0.05674329772591591,
-0.0031423650216311216,
-0.012554384768009186,
0.018728725612163544,... |
dccuchile/albert-xlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 24 | 2022-05-24T10:44:37Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.024500655010342598,
-0.015751013532280922,
-0.004724841099232435,
0.02840288169682026,
0.04755263030529022,
-0.0008667767397128046,
-0.019674869254231453,
0.0010096722980961204,
-0.04217129573225975,
0.05665438249707222,
0.0117525365203619,
-0.012894975952804089,
0.009217292070388794,
0... |
dccuchile/albert-xlarge-spanish-finetuned-pos | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_re... | 3 | 2022-05-24T10:54:53Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... | [
-0.027691148221492767,
0.010326223447918892,
-0.02737809531390667,
0.042518459260463715,
0.07103389501571655,
0.02634209766983986,
-0.017605312168598175,
-0.023030178621411324,
-0.0496126264333725,
0.061063189059495926,
0.03995949402451515,
-0.014005891047418118,
0.021047227084636688,
0.03... |
dccuchile/albert-xlarge-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 29 | 2022-05-24T11:00:44Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sent-Roberta-wechsel-tamil
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tas... | [
-0.03304152190685272,
-0.017904862761497498,
-0.015605625696480274,
0.048080962151288986,
0.015268883667886257,
0.05004798620939255,
-0.020807448774576187,
-0.003644373267889023,
-0.07022400200366974,
0.08341428637504578,
0.03733288496732712,
0.004757248796522617,
0.0027714925818145275,
0.... |
dccuchile/albert-xxlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 26 | 2022-05-24T11:20:54Z | Looking to get the Best Body massage center in Bangalore? Riverdayspa™ is the Best Body massage center in Bangalore. For More Details Visit us
https://www.riverdayspa.com/spa-massage-bangalore/
| [
-0.03272669389843941,
-0.005939352326095104,
0.020448412746191025,
0.007084950804710388,
0.026561876758933067,
0.013396727852523327,
-0.026576876640319824,
0.0266010370105505,
-0.026427846401929855,
0.025452028959989548,
0.026433324441313744,
-0.00566659402102232,
0.0505911223590374,
0.040... |
dccuchile/albert-xxlarge-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repe... | 7 | 2022-05-24T11:45:52Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Tax... | [
-0.022015390917658806,
-0.015715980902314186,
-0.008621974848210812,
0.030400587245821953,
0.04808051139116287,
-0.0001346035860478878,
-0.017157331109046936,
0.001525252708233893,
-0.044334910809993744,
0.05707739666104317,
0.014681410975754261,
-0.012929022312164307,
0.008510328829288483,
... |
dccuchile/albert-xxlarge-spanish-finetuned-xnli | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no... | 68 | 2022-05-24T11:49:08Z | ---
language: en
widget:
- text: "Ending all forms of discrimination against women and girls is not only a basic human right, but it also crucial to accelerating sustainable development. It has been proven time and again, that empowering women and girls has a multiplier effect, and helps drive up economic growth and de... | [
0.00204828311689198,
-0.01767631806433201,
-0.007988892495632172,
0.024201856926083565,
0.09817875921726227,
0.020537009462714195,
-0.0018760955426841974,
-0.008678841404616833,
-0.05578787252306938,
0.05599429830908775,
0.006130502093583345,
-0.004592929035425186,
0.029689325019717216,
0.... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-mldoc | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 27 | 2022-05-24T12:08:23Z | ---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery
results:
- metrics:
- type: mean_reward
value: 0.15 +/- 0.36
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning... | [
-0.0214851014316082,
-0.018055034801363945,
-0.0032396819442510605,
0.035297974944114685,
0.05234184488654137,
-0.01863524504005909,
-0.007803014013916254,
-0.01228172704577446,
-0.060522861778736115,
0.05656057223677635,
-0.0008487968589179218,
-0.010687747970223427,
0.021036578342318535,
... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-pos | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 1 | 2022-05-24T12:17:57Z | ---
language: es
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- es
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 ... | [
-0.026485512033104897,
-0.016656283289194107,
-0.006716872099786997,
0.028261370956897736,
0.06511995941400528,
0.013964195735752583,
-0.016135120764374733,
-0.02435966022312641,
-0.02227197214961052,
0.059833839535713196,
0.0170475821942091,
-0.033491164445877075,
-0.004528298042714596,
0... |
dccuchile/bert-base-spanish-wwm-cased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 28 | 2022-05-24T12:40:18Z | ---
tags:
- espnet
- audio
- text-to-speech
language:
- bci
datasets:
- afrilang-bci
license: apache-2.0
metrics:
- mos
---
## ESPnet2 TTS model
### ``
This model was trained by using recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
pip install -e .
cd eg... | [
-0.03521745279431343,
0.0020161853171885014,
-0.017938299104571342,
0.02355303429067135,
0.06162228807806969,
0.02356722205877304,
-0.003933964762836695,
0.011229814030230045,
-0.03186848759651184,
0.03388793021440506,
-0.005718700587749481,
-0.011114225722849369,
0.01015448197722435,
0.03... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-mldoc | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 39 | null | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU... | [
-0.04746963456273079,
-0.016511796042323112,
-0.007165215909481049,
0.03403767943382263,
0.013948708772659302,
0.03213571384549141,
-0.014979477971792221,
-0.015682999044656754,
-0.005313046742230654,
0.05483323708176613,
0.011292930692434311,
0.0049119386821985245,
0.020934924483299255,
0... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-ner | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat... | 5 | 2022-05-24T12:43:20Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_all
co2_eq_emissions: 0.848790823793881
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903429548
- CO2 Emissions (in grams): 0.848790823793881
## Validation M... | [
-0.02604096010327339,
-0.023907605558633804,
-0.011213790625333786,
0.02776266075670719,
0.0505109541118145,
0.03843648359179497,
-0.026414602994918823,
-0.014349970035254955,
-0.04477878287434578,
0.07921455055475235,
0.025456242263317108,
0.02514226734638214,
0.0024336467031389475,
0.041... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-pawsx | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 24 | 2022-05-24T12:44:15Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-company_all
co2_eq_emissions: 119.04546626922827
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903429540
- CO2 Emissions (in grams): 119.04546626922827
## Validation... | [
-0.025668516755104065,
-0.024283312261104584,
-0.011291803792119026,
0.026839153841137886,
0.0495777390897274,
0.03832302615046501,
-0.026994766667485237,
-0.01509074680507183,
-0.04502132534980774,
0.0789768323302269,
0.02650938183069229,
0.02460278384387493,
0.002676509553566575,
0.04116... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-qa-mlqa | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_n... | 5 | null | ---
tags:
- FrozenLake-v1-8x8-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-nonSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinfor... | [
-0.020889505743980408,
-0.017708368599414825,
-0.006667383015155792,
0.033987678587436676,
0.052304450422525406,
-0.01880970224738121,
-0.007495442405343056,
-0.014085432514548302,
-0.06268640607595444,
0.055680450052022934,
-0.004564500879496336,
-0.012620777823030949,
0.02023806795477867,
... |
dccuchile/bert-base-spanish-wwm-uncased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_rep... | 36 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xlsr-persian-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove ... | [
-0.038961105048656464,
-0.020130891352891922,
-0.02046438492834568,
0.046236276626586914,
0.046095557510852814,
0.018516739830374718,
-0.00011517383245518431,
-0.007498298771679401,
-0.017388543114066124,
0.04560163989663124,
0.0532357431948185,
-0.025176677852869034,
0.005985680036246777,
... |
dccuchile/distilbert-base-spanish-uncased-finetuned-ner | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 28 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforc... | [
-0.018469907343387604,
-0.01813596487045288,
-0.0069977715611457825,
0.03607705235481262,
0.04891413822770119,
-0.017442425712943077,
-0.014201217330992222,
-0.012990792281925678,
-0.06461331993341446,
0.05685083568096161,
-0.004361478146165609,
-0.014671538956463337,
0.019139306619763374,
... |
dccuchile/distilbert-base-spanish-uncased-finetuned-pos | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 3 | 2022-05-24T13:01:27Z | ---
tags:
- automatic-speech-recognition
- generated_from_trainer
license: mit
language:
- lb
metrics:
- wer
pipeline_tag: automatic-speech-recognition
model-index:
- name: Lemswasabi/wav2vec2-large-xlsr-53-842h-luxembourgish-11h-with-lm
results:
- task:
type: automatic-speech-recognition # Requi... | [
0.006834108382463455,
0.001845375169068575,
-0.015727203339338303,
0.03399093821644783,
0.04076458886265755,
0.011507825925946236,
0.004072117153555155,
-0.017979953438043594,
-0.04737936332821846,
0.06193000078201294,
0.021978648379445076,
-0.05703172832727432,
-0.010366943664848804,
0.01... |
dccuchile/distilbert-base-spanish-uncased-finetuned-xnli | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
... | 31 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: victor-hg-ptbr-2.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment... | [
-0.026157664135098457,
-0.005638191942125559,
-0.017424777150154114,
0.037537820637226105,
0.03916775807738304,
0.023595726117491722,
-0.006610832177102566,
-0.003387439763173461,
-0.008380657993257046,
0.0368361659348011,
0.0389416441321373,
-0.028952581807971,
0.007870997302234173,
0.035... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-1 | [
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: satya-matury-asr-task-2-hindidata
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remo... | [
-0.027889201417565346,
-0.022709112614393234,
-0.02194732055068016,
0.038893137127161026,
0.05001763254404068,
0.040207382291555405,
-0.010117667727172375,
0.004027420189231634,
-0.028487591072916985,
0.06729277223348618,
0.04367601126432419,
-0.02158372476696968,
0.0083322050049901,
0.033... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate-1 | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 1 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: -10.17 +/- 40.27
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: ... | [
-0.01986858993768692,
-0.015227390453219414,
-0.009060624055564404,
0.03282631188631058,
0.04562487080693245,
0.0007065063691698015,
-0.019421564415097237,
0.0009743875707499683,
-0.04440629482269287,
0.05651082098484039,
0.01335191261023283,
-0.014203442260622978,
0.007853895425796509,
0.... |
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repea... | 7 | 2022-05-24T13:10:20Z | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-job_all
co2_eq_emissions: 192.68222884611995
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 903929564
- CO2 Emissions (in grams): 192.68222884611995
## Validation Met... | [
-0.02294614166021347,
-0.026718895882368088,
-0.014229876920580864,
0.03027062490582466,
0.05003247782588005,
0.03826479986310005,
-0.025202032178640366,
-0.01846228912472725,
-0.04379652440547943,
0.08028745651245117,
0.023807043209671974,
0.027073964476585388,
0.002234208397567272,
0.041... |
Chaddmckay/Cdm | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams... | 0 | null | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- ismail-lucifer011/autotrain-data-name_all
co2_eq_emissions: 0.527083766435658
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 904029569
- CO2 Emissions (in grams): 0.527083766435658
## Validation Metr... | [
-0.02509230747818947,
-0.022885575890541077,
-0.01523307804018259,
0.03042723797261715,
0.04798060283064842,
0.03799942880868912,
-0.024848900735378265,
-0.019065966829657555,
-0.04393254593014717,
0.07970918715000153,
0.028814969584345818,
0.02592683583498001,
0.0040575554594397545,
0.043... |
Chae/botman | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 5 | 2022-05-24T13:27:45Z | ---
tags:
- conversational
---
# Twilight Sparkle DialoGPT Model | [
-0.043832991272211075,
0.02119523286819458,
0.012568656355142593,
0.0133369080722332,
0.007493884768337011,
0.009793633595108986,
0.0005061510601080954,
0.03473372757434845,
-0.01903402991592884,
0.020880836993455887,
0.03405530005693436,
-0.03501720353960991,
0.009329217486083508,
0.03040... |
Chaewon/mnmt_decoder_en | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size... | 8 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-hun-53h-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remov... | [
-0.03886958584189415,
-0.0018623536452651024,
-0.019317151978611946,
0.040529459714889526,
0.04808477684855461,
0.017081206664443016,
-0.013573015108704567,
-0.00928659550845623,
-0.009726297110319138,
0.03301559016108513,
0.028709912672638893,
-0.01575901173055172,
0.003757042810320854,
0... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.