
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
lansinuote/diffusion.9.custom_diffusion | 2023-05-24T11:08:03.000Z | [
"region:us"
] | lansinuote | null | null | 0 | 4 | 2023-05-24T11:02:55 | ---
dataset_info:
features:
- name: image
dtype: image
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 85296454.0
num_examples: 200
download_size: 85295617
dataset_size: 85296454.0
---
# Dataset Card for "diffusion.9.custom_diffusion"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 411 | [
[
-0.050994873046875,
-0.046783447265625,
0.0333251953125,
0.0209808349609375,
-0.00293731689453125,
0.006988525390625,
0.02532958984375,
0.00887298583984375,
0.078125,
0.029388427734375,
-0.0421142578125,
-0.05059814453125,
-0.051483154296875,
-0.032684326171... |
Gladiaio/Instruct-Summary | 2023-05-28T14:27:31.000Z | [
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"region:us"
] | Gladiaio | null | null | 1 | 4 | 2023-05-24T17:51:07 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
task_categories:
- summarization
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
# Dataset Card for "Instruct-Summary"
This dataset is a combination of [kmfoda/booksum](https://huggingface.co/datasets/kmfoda/booksum), [samsum](https://huggingface.co/datasets/samsum/tree/main/data), [mosaicml/dolly_hhrlhf](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) and [yahma/alpaca-cleaned](https://huggingface.co/datasets/yahma/alpaca-cleaned). | 615 | [
[
-0.046844482421875,
-0.0259857177734375,
-0.0021266937255859375,
0.0168914794921875,
-0.047271728515625,
0.0057830810546875,
0.0258636474609375,
-0.0188446044921875,
0.054473876953125,
0.048828125,
-0.054168701171875,
-0.059906005859375,
-0.04425048828125,
-... |
sruly/raccoon-dataset-v1 | 2023-05-24T23:28:53.000Z | [
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"open assistant",
"region:us"
] | sruly | null | null | 0 | 4 | 2023-05-24T22:55:43 | ---
license: apache-2.0
language:
- en
tags:
- open assistant
pretty_name: raccoon dataset
size_categories:
- n<1K
---
# raccoon dataset
### the top 1000 highest rated Question Answer branches in the Open Assistant dataset
| 223 | [
[
-0.047332763671875,
-0.036712646484375,
-0.011962890625,
0.0183868408203125,
0.01085662841796875,
0.0007076263427734375,
-0.007114410400390625,
-0.007434844970703125,
0.0186920166015625,
0.040740966796875,
-0.052276611328125,
-0.04229736328125,
-0.04135131835937... |
tasksource/sen-making | 2023-05-31T08:22:27.000Z | [
"task_categories:text-classification",
"task_categories:multiple-choice",
"language:en",
"explanation",
"region:us"
] | tasksource | null | null | 0 | 4 | 2023-05-25T07:06:10 | ---
task_categories:
- text-classification
- multiple-choice
language:
- en
tags:
- explanation
---
https://github.com/wangcunxiang/Sen-Making-and-Explanation
```
@inproceedings{wang-etal-2019-make,
title = "Does it Make Sense? And Why? A Pilot Study for Sense Making and Explanation",
author = "Wang, Cunxiang and
Liang, Shuailong and
Zhang, Yue and
Li, Xiaonan and
Gao, Tian",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1393",
pages = "4020--4026",
abstract = "Introducing common sense to natural language understanding systems has received increasing research attention. It remains a fundamental question on how to evaluate whether a system has the sense-making capability. Existing benchmarks measure common sense knowledge indirectly or without reasoning. In this paper, we release a benchmark to directly test whether a system can differentiate natural language statements that make sense from those that do not make sense. In addition, a system is asked to identify the most crucial reason why a statement does not make sense. We evaluate models trained over large-scale language modeling tasks as well as human performance, showing that there are different challenges for system sense-making.",
}
``` | 1,480 | [
[
-0.031707763671875,
-0.056732177734375,
0.0552978515625,
0.0227813720703125,
-0.0224456787109375,
-0.035400390625,
-0.0396728515625,
-0.04119873046875,
-0.01514434814453125,
-0.00861358642578125,
-0.04473876953125,
-0.01422882080078125,
-0.037841796875,
0.02... |
rubend18/CIE10 | 2023-07-30T16:15:08.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:10K<n<100K",
"language:es",
"salud",
"health",
"diagnóstico",
"ICD10Codes",
"MedicalCoding",
"HealthcareClassification",
"DiseaseClassification",
"ICD10Diagnosis",
"MedicalTerminology",
"HealthD... | rubend18 | null | null | 0 | 4 | 2023-05-25T13:38:02 | ---
task_categories:
- text-classification
- token-classification
language:
- es
tags:
- salud
- health
- diagnóstico
- ICD10Codes
- MedicalCoding
- HealthcareClassification
- DiseaseClassification
- ICD10Diagnosis
- MedicalTerminology
- HealthData
- ClinicalCoding
- HealthcareStandards
- MedicalClassification
- CódigosCIE10
- CodificaciónMédica
- ClasificaciónSanitaria
- ClasificaciónEnfermedades
- DiagnósticoCIE10
- TerminologíaMédica
- DatosSalud
- CodificaciónClínica
- EstándaresSanitarios
- ClasificaciónMédica
pretty_name: Diagnósticos Médicos CIE10
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Autor:** Rubén Darío Jaramillo
- **Email:** rubend18@hotmail.com
- **WhatsApp:** +593 93 979 6676
### Dataset Summary
CIE10 is the 10th revision of the International Statistical Classification of Diseases and Related Health Problems (ICD), a medical classification list by the World Health Organization (WHO). It contains codes for diseases, signs and symptoms, abnormal findings, complaints, social circumstances, and external causes of injury or diseases. Work on ICD-10 began in 1983, became endorsed by the Forty-third World Health Assembly in 1990, and was first used by member states in 1994. It was replaced by ICD-11 on January 1, 2022.
While WHO manages and publishes the base version of the ICD, several member states have modified it to better suit their needs. In the base classification, the code set allows for more than 14,000 different codes and permits the tracking of many new diagnoses compared to the preceding ICD-9. Through the use of optional sub-classifications, ICD-10 allows for specificity regarding the cause, manifestation, location, severity, and type of injury or disease. The adapted versions may differ in a number of ways, and some national editions have expanded the code set even further; with some going so far as to add procedure codes. ICD-10-CM, for example, has over 70,000 codes.
The WHO provides detailed information regarding the ICD via its website – including an ICD-10 online browser and ICD training materials. The online training includes a support forum, a self-learning tool and user guide.
https://en.wikipedia.org/wiki/ICD-10 | 2,241 | [
[
-0.0516357421875,
0.003398895263671875,
0.028472900390625,
0.016876220703125,
-0.0184173583984375,
0.0007557868957519531,
-0.00836181640625,
-0.042449951171875,
0.032806396484375,
0.0241546630859375,
-0.0293426513671875,
-0.050506591796875,
-0.03973388671875,
... |
projecte-aina/CaWikiTC | 2023-09-13T12:35:09.000Z | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:automatically-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"language:ca",
"license:cc-by-sa-3.0",
"region:us"
] | projecte-aina | null | null | 1 | 4 | 2023-05-26T13:22:43 | ---
YAML tags:
annotations_creators:
- automatically-generated
language_creators:
- found
language:
- ca
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
pretty_name: cawikitc
size_categories:
- unknown
source_datasets: []
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Dataset Card for CaWikiTC
## Dataset Description
- **Point of Contact:** [Irene Baucells de la Peña](irene.baucells@bsc.es)
### Dataset Summary
CaWikiTC (Catalan Wikipedia Text Classification) is a text classification dataset authomatically created by scraping Catalan Wikipedia article summaries and their associated thematic category. It contains 21002 texts (19952 and 1050 in the train and dev partitions, respectively) classified under 67 exclusive categories.
For the dataset creation, we selected all the Catalan Wikipedia article summaries from a previously fixed variety of subcategories, most of which are professional disciplines and social sciences-related fields. The texts that were originally associated with more than one category were discarded to avoid class overlappings.
This dataset was created as part of the experiments from [reference]. Its original purpose was to serve as a task transfer source to train an entailment model, which was then used to perform a different text classification task.
### Supported Tasks and Leaderboards
Text classification, Language Model
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
### Data Instances
Two json files (train and development splits).
### Data Fields
Each example contains the following 3 fields:
* text: Catalan Wikipedia article summary (string)
* label: topic
#### Example:
<pre>
[
{
'text': "Novum Organum és el títol de l'obra més important de Francis Bacon, publicada el 1620. Rep el seu nom perquè pretén ser una superació del tractat sobre lògica d'Aristòtil, anomenat Organon. Es basa a trobar la causa de tot fenomen per inducció, observant quan passa i quan no i extrapolant aleshores les condicions que fan que es doni. Aquest raonament va influir decisivament en la formació del mètode científic, especialment en la fase d'elaboració d'hipòtesis. També indica que el prejudici és l'enemic de la ciència, perquè impideix generar noves idees. Els prejudicis més comuns s'expliquen amb la metàfora de l'ídol o allò que és falsament adorat. Existeixen ídols de la tribu (comuns a tots els éssers humans per la seva naturalesa), de la caverna (procedents de l'educació), del fòrum (causats per un ús incorrecte del llenguatge) i del teatre (basats en idees anteriors errònies, notablement en filosofia).",
'label': 'Filosofia',
},
...
]
</pre>
#### Labels
* 'Administració', 'Aeronàutica', 'Agricultura', 'Antropologia', 'Arqueologia', 'Arquitectura', 'Art', 'Astronomia', 'Astronàutica', 'Biblioteconomia', 'Biotecnologia', 'Catàstrofes', 'Circ', 'Ciència militar', 'Ciència-ficció', 'Ciències ambientals', 'Ciències de la salut', 'Ciències polítiques', 'Conflictes', 'Cronometria', 'Cultura popular', 'Dansa', 'Dret', 'Ecologia', 'Enginyeria', 'Epidèmies', 'Esoterisme', 'Estris', 'Festivals', 'Filologia', 'Filosofia', 'Fiscalitat', 'Física', 'Geografia', 'Geologia', 'Gestió', 'Heràldica', 'Història', 'Humor', 'Indumentària', 'Informàtica', 'Jaciments paleontològics', 'Jocs', 'Lingüística', 'Llengües', 'Llocs ficticis', 'Matemàtiques', 'Metodologia', 'Mitologia', 'Multimèdia', 'Museologia', 'Nàutica', 'Objectes astronòmics', 'Pedagogia', 'Periodisme', 'Protestes', 'Pseudociència', 'Psicologia', 'Química', 'Robòtica', 'Ràdio', 'Seguretat laboral', 'Sociologia', 'Telecomunicacions', 'Televisió', 'Teologia', 'Ètica'
### Data Splits
Train and development splits were created in a stratified fashion, following a 95% and 5% proportion, respectively. The sizes of each split are the following:
* train.json: 19952 examples
* dev.json: 1050 examples
### Annotations
#### Annotation process
The crawled data contained the categories' annotations, which were then used to create this dataset with the mentioned criteria.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this dataset contributes to the development of language modeCAls in Catalan, a low-resource language.
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Irene Baucells (irene.baucells@bsc.es)
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing Information
This work is licensed under a <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/">Attribution-ShareAlike 4.0 International</a>.
### Citation Information
| 5,040 | [
[
-0.032440185546875,
-0.036285400390625,
0.007297515869140625,
0.0303192138671875,
-0.0159759521484375,
0.0244140625,
-0.016448974609375,
-0.0189666748046875,
0.0657958984375,
0.041717529296875,
-0.028289794921875,
-0.059661865234375,
-0.044769287109375,
0.02... |
Thaweewat/goat-th | 2023-05-28T01:17:46.000Z | [
"size_categories:1M<n<10M",
"language:th",
"arxiv:2305.14201",
"region:us"
] | Thaweewat | null | null | 2 | 4 | 2023-05-28T01:03:03 | ---
language:
- th
size_categories:
- 1M<n<10M
---
TH 1.7M Arithmetic Tasks dataset inspired from [Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks](https://arxiv.org/abs/2305.14201) & [Author's HF](https://huggingface.co/datasets/tiedong/goat)
**FYI:** Use columns "instruction" and "output" if you plan to instruct fine-tuning. | 343 | [
[
-0.0294036865234375,
-0.045501708984375,
0.0213623046875,
0.024444580078125,
-0.036834716796875,
-0.006572723388671875,
0.0087890625,
-0.042755126953125,
0.023101806640625,
0.03839111328125,
-0.06878662109375,
-0.037841796875,
-0.051483154296875,
0.007122039... |
lukasmoeller/sail_preprocessed | 2023-05-30T17:11:55.000Z | [
"arxiv:2305.15225",
"region:us"
] | lukasmoeller | null | null | 2 | 4 | 2023-05-28T11:05:21 | Preprocessed dataset, generated as described in the SAIL paper: https://arxiv.org/abs/2305.15225 | 96 | [
[
-0.03790283203125,
-0.013702392578125,
0.03497314453125,
0.01397705078125,
-0.03570556640625,
-0.002559661865234375,
0.002170562744140625,
-0.0306549072265625,
0.036102294921875,
0.0791015625,
-0.059600830078125,
-0.055633544921875,
-0.007808685302734375,
0.... |
jondurbin/airoboros-gpt4 | 2023-06-22T15:00:49.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | jondurbin | null | null | 13 | 4 | 2023-05-28T11:47:57 | ---
license: cc-by-nc-4.0
---
The data was generated by gpt-4, and therefore is subject to OpenAI ToS. The tool used to generate the data [airoboros](https://github.com/jondurbin/airoboros) is apache-2.
Specific areas of focus for this training data:
* trivia
* math
* nonsensical math
* coding
* closed context question answering
* closed context question answering, with multiple contexts to choose from as confounding factors
* writing
* multiple choice
### Usage and License Notices
All airoboros models and datasets are intended and licensed for research use only. I've used the 'cc-nc-4.0' license, but really it is subject to a custom/special license because:
- the base model is LLaMa, which has it's own special research license
- the dataset(s) were generated with OpenAI (gpt-4 and/or gpt-3.5-turbo), which has a clausing saying the data can't be used to create models to compete with openai
So, to reiterate: this model (and datasets) cannot be used commercially. | 983 | [
[
-0.0163726806640625,
-0.048492431640625,
0.01495361328125,
0.0178375244140625,
-0.03466796875,
-0.0304718017578125,
0.007579803466796875,
-0.03204345703125,
-0.0028839111328125,
0.044158935546875,
-0.048492431640625,
-0.0236053466796875,
-0.0283203125,
0.016... |
d0rj/piqa_ru | 2023-06-05T14:06:07.000Z | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"annotations_creators:crowdsourced",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:piqa",
"language:ru",
"license:unknown",
"region:us"
] | d0rj | null | null | 0 | 4 | 2023-05-28T12:22:41 | ---
annotations_creators:
- crowdsourced
language_creators:
- translated
language:
- ru
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- piqa
task_categories:
- question-answering
task_ids:
- multiple-choice-qa
paperswithcode_id: piqa
pretty_name: 'Physical Interaction: Question Answering (ru)'
dataset_info:
features:
- name: goal
dtype: string
- name: sol1
dtype: string
- name: sol2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: train
num_bytes: 7787368
num_examples: 16113
- name: test
num_bytes: 1443681
num_examples: 3084
- name: validation
num_bytes: 877142
num_examples: 1838
download_size: 5253717
dataset_size: 10108191
---
# Dataset Card for "piqa_ru"
This is translated version of [piqa dataset](https://huggingface.co/datasets/piqa) into Russian. | 950 | [
[
-0.0020999908447265625,
-0.019744873046875,
-0.009521484375,
0.02691650390625,
-0.051727294921875,
0.000017344951629638672,
0.015533447265625,
-0.0036678314208984375,
0.038787841796875,
0.03350830078125,
-0.059051513671875,
-0.053955078125,
-0.038970947265625,
... |
rvashurin/wikidata_simplequestions | 2023-05-29T14:31:23.000Z | [
"region:us"
] | rvashurin | HuggingFace wrapper for https://github.com/askplatypus/wikidata-simplequestions dataset
Simplequestions dataset based on Wikidata. | null | 1 | 4 | 2023-05-29T12:58:56 | # Wikidata Simplequestions
Huggingface Dataset wrapper for Wikidata-simplequestion dataset
### Usage
```bash
git clone git@github.com:skoltech-nlp/wikidata-simplequestions-hf.git wikidata_simplequestions
```
```python3
from datasets import load_dataset;
load_dataset('../wikidata_simplequestions', 'answerable_en', cache_dir='/YOUR_PATH_TO_CACHE/', ignore_verifications=True)
```
| 384 | [
[
-0.043426513671875,
-0.045135498046875,
0.0125885009765625,
0.027587890625,
-0.00547027587890625,
-0.01056671142578125,
-0.00030493736267089844,
-0.02081298828125,
0.06463623046875,
0.0261993408203125,
-0.06524658203125,
-0.018218994140625,
-0.0224609375,
0.... |
tasksource/subjectivity | 2023-06-02T14:44:17.000Z | [
"license:mit",
"arxiv:2305.18034",
"region:us"
] | tasksource | null | null | 0 | 4 | 2023-05-30T09:15:29 | ---
license: mit
---
```
@misc{antici2023corpus,
title={A Corpus for Sentence-level Subjectivity Detection on English News Articles},
author={Francesco Antici and Andrea Galassi and Federico Ruggeri and Katerina Korre and Arianna Muti and Alessandra Bardi and Alice Fedotova and Alberto Barrón-Cedeño},
year={2023},
eprint={2305.18034},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
datasheet:
https://www.dropbox.com/sh/pterfc16inz0h7b/AADN9w-O0KTalP48jk2CK36Ha/data?dl=0&preview=datasheet.pdf&subfolder_nav_tracking=1 | 561 | [
[
-0.022705078125,
-0.037872314453125,
0.04052734375,
0.01486968994140625,
-0.0182342529296875,
-0.0166473388671875,
-0.00933837890625,
-0.00995635986328125,
0.0198822021484375,
0.0223846435546875,
-0.038238525390625,
-0.06146240234375,
-0.036346435546875,
0.0... |
TigerResearch/tigerbot-law-plugin | 2023-06-01T03:11:47.000Z | [
"language:zh",
"license:apache-2.0",
"region:us"
] | TigerResearch | null | null | 11 | 4 | 2023-05-30T15:25:17 | ---
license: apache-2.0
language:
- zh
---
[Tigerbot](https://github.com/TigerResearch/TigerBot) 模型rethink时使用的外脑原始数据,法律11大类,共5.5W+条款
- 宪法
- 刑法
- 行政法
- 司法解释
- 民法商法
- 民法典
- 行政法规
- 社会法
- 部门规章
- 经济法
- 诉讼与非诉讼程序法
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-law-plugin')
``` | 371 | [
[
-0.01166534423828125,
-0.04278564453125,
0.01514434814453125,
0.01806640625,
-0.046234130859375,
0.0019855499267578125,
-0.0185546875,
0.007442474365234375,
0.051116943359375,
0.04888916015625,
-0.029296875,
-0.041015625,
-0.019500732421875,
0.00584030151367... |
shershen/ru_anglicism | 2023-05-30T22:06:10.000Z | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:ru",
"license:apache-2.0",
"region:us"
] | shershen | null | null | 2 | 4 | 2023-05-30T21:37:51 | ---
license: apache-2.0
dataset_info:
features:
- name: word
dtype: string
- name: form
dtype: string
- name: sentence
dtype: string
- name: paraphrase
dtype: string
splits:
- name: train
num_bytes: 480909
num_examples: 1007
- name: test
num_bytes: 42006
num_examples: 77
download_size: 290128
dataset_size: 522915
task_categories:
- text-generation
- text2text-generation
language:
- ru
size_categories:
- 1K<n<10K
---
# Dataset Card for Ru Anglicism
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Splits](#data-splits)
## Dataset Description
### Dataset Summary
Dataset for detection and substraction anglicisms from sentences in Russian. Sentences with anglicism automatically parsed from National Corpus of the Russian language, Habr and Pikabu. The paraphrases for the sentences were created manually.
### Languages
The dataset is in Russian.
### Usage
Loading dataset:
```python
from datasets import load_dataset
dataset = load_dataset('shershen/ru_anglicism')
```
## Dataset Structure
### Data Instunces
For each instance, there are four strings: word, form, sentence and paraphrase.
```
{
'word': 'коллаб',
'form': 'коллабу',
'sentence': 'Сделаем коллабу, раскрутимся.',
'paraphrase': 'Сделаем совместный проект, раскрутимся.'
}
```
### Data Splits
Full dataset contains 1084 sentences. Split of dataset is:
| Dataset Split | Number of Rows
|:---------|:---------|
| Train | 1007 |
| Test | 77 | | 1,701 | [
[
-0.003284454345703125,
-0.046844482421875,
0.00876617431640625,
0.0217437744140625,
-0.047088623046875,
-0.001186370849609375,
-0.01751708984375,
0.007354736328125,
0.02984619140625,
0.0236663818359375,
-0.0289154052734375,
-0.06866455078125,
-0.03399658203125,
... |
andersonbcdefg/dolly_reward_modeling_pairwise | 2023-05-31T05:40:03.000Z | [
"region:us"
] | andersonbcdefg | null | null | 0 | 4 | 2023-05-31T05:39:50 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response_a
dtype: string
- name: response_b
dtype: string
- name: explanation
dtype: string
- name: preferred
dtype: string
splits:
- name: train
num_bytes: 16503157
num_examples: 19343
download_size: 9011974
dataset_size: 16503157
---
# Dataset Card for "dolly_reward_modeling_pairwise"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 533 | [
[
-0.01515960693359375,
-0.0184478759765625,
-0.0021533966064453125,
0.0193328857421875,
-0.00844573974609375,
-0.007350921630859375,
0.034820556640625,
0.0022563934326171875,
0.059661865234375,
0.041748046875,
-0.0450439453125,
-0.0400390625,
-0.04644775390625,
... |
LinkSoul/instruction_merge_set | 2023-10-25T10:39:46.000Z | [
"region:us"
] | LinkSoul | null | null | 109 | 4 | 2023-05-31T12:16:24 | ---
dataset_info:
features:
- name: id
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 13444870155
num_examples: 10077297
download_size: 3542585235
dataset_size: 13444870155
---
# Dataset Card for "instruction_merge_set"
## 本数据集由以下数据集构成:
| 数据(id in the merged set) | Hugging face 地址 | notes |
| --- | --- | --- |
| OIG (unified-任务名称) 15k | https://huggingface.co/datasets/laion/OIG | Open Instruction Generalist Dataset |
| Dolly databricks-dolly-15k | https://huggingface.co/datasets/databricks/databricks-dolly-15k | an open-source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories |
| UltraChat | https://huggingface.co/datasets/stingning/ultrachat | multi-round dialogue data |
| Camel | https://huggingface.co/datasets/camel-ai/ai_society | 25K conversations between two gpt-3.5-turbo agents. |
| camel (同上) | https://github.com/camel-ai/camel | |
| ChatDoctor icliniq-15k HealthCareMagic-200k | https://github.com/Kent0n-Li/ChatDoctor | 200k real conversations between patients and doctors from HealthCareMagic.com 15k real conversations between patients and doctors from iciniq-10k |
| Dolly | https://github.com/databrickslabs/dolly | |
| GPT4ALL | https://github.com/nomic-ai/gpt4all | |
| GPT-4-LLM comparision_data_b alpaca_gpt4_data_zh comparision_data_a alpaca_gpt4_data 5k | https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM | English Instruction-Following Data generated by GPT-4 using Alpaca prompts for fine-tuning LLMs. Chinese Instruction-Following Data generated by GPT-4 using Chinese prompts translated from Alpaca by ChatGPT. Comparison Data ranked by GPT-4 to train reward models. Answers on Unnatural Instructions Data from GPT-4 to quantify the gap between GPT-4 and instruction-tuned models at scale. |
| GuanacoDataset guanaco_chat_all-utf8 guanaco_non_chat-utf8 paper_answers-utf8 general_ans-utf8 general_questions-utf8 paper_questions-utf8 30k | https://huggingface.co/datasets/JosephusCheung/GuanacoDataset | The dataset for the Guanaco model is designed to enhance the multilingual capabilities and address various linguistic tasks. It builds upon the 175 tasks from the Alpaca model by providing rewrites of seed tasks in different languages and adding new tasks specifically designed for English grammar analysis, natural language understanding, cross-lingual self-awareness, and explicit content recognition. The Paper/General-QA dataset is a collection of questions and answers constructed for AI-generated papers or general texts in English, Chinese, Japanese, and German. |
| HC3 ALL | https://huggingface.co/datasets/Hello-SimpleAI/HC3 | human-ChatGPT comparison datasets |
| instinwild instinwild_en instinwild_ch 5k | https://huggingface.co/datasets/QingyiSi/Alpaca-CoT/tree/main/instinwild | Instruction-Finetuning Dataset Collection (Alpaca-CoT) |
| Instruct-to-Code | https://huggingface.co/datasets/Graverman/Instruct-to-Code | |
| ShareGPT90K sg_90k_part2 sg_90k_part1 | https://huggingface.co/datasets/RyokoAI/ShareGPT52K | 90,000 conversations scraped via the ShareGPT API before it was shut down. These conversations include both user prompts and responses from OpenAI's ChatGPT. |
| UltraChat ultrachat_material_release_230412 ultrachat_release_230407 | https://github.com/thunlp/UltraChat | |
| wealth-alpaca-lora final_dataset_clean 4.3k | https://www.kaggle.com/code/gbhacker23/wealth-alpaca-lora | combination of Stanford's Alpaca (https://github.com/tatsu-lab/stanford_alpaca) and FiQA (https://sites.google.com/view/fiqa/) with another 1.3k pairs custom generated using GPT3.5, 有instruction |
| Alpaca alpaca_data 5k | https://github.com/tatsu-lab/stanford_alpaca | instruct-tuning |
| Baize alpaca_chat_data medical_chat_data quora_chat_data stack_overflow_chat_data | https://github.com/project-baize/baize-chatbot | instruction-following data we used for fine-tuning the Alpaca model. |
| botbots Reasoning flight_bookings medical_appointments travel_agency restaurants_mixed real_estate car_dealership home_maintenance, job_interview 'insurance_consultation': 16, 'hotels': 400, 'tech_support': 32, 'car_rentals': 32, 'pet_care': 48, 'restaurants': 200, 'legal_consultation': 16, 'event_tickets': 240, 'fitness_personal_training': 16, 'scientific_problems': 100 | https://github.com/radi-cho/botbots | A dataset consisting of dialogues between two instances of ChatGPT (gpt-3.5-turbo). The CLI commands and dialogue prompts themselves have been written by GPT-4. The dataset covers a wide range of contexts (questions and answers, arguing and reasoning, task-oriented dialogues) and downstream tasks (e.g., hotel reservations, medical advice). |
| ChatAlpaca chatalpaca_data_10k | https://github.com/cascip/ChatAlpaca | a chat dataset, multi-turn instruction-following conversations. |
| DERA train | https://github.com/curai/curai-research/tree/main/DERA | The following repository contains the open-ended question-answering version of MedQA. |
| GPTeacher Toolformer-dedupe-only-dataset roleplay-simple-deduped-roleplay-dataset gpt4-instruct-dedupe-only-dataset | https://github.com/teknium1/GPTeacher | A collection of modular datasets generated by GPT-4, General-Instruct - Roleplay-Instruct - Code-Instruct - and Toolformer |
| OpenAGI | https://github.com/agiresearch/OpenAGI | |
| presto | https://github.com/google-research-datasets/presto | A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs |
| 5,721 | [
[
-0.0301055908203125,
-0.07403564453125,
0.01171112060546875,
0.00801849365234375,
-0.003997802734375,
-0.0073394775390625,
-0.0156097412109375,
-0.03155517578125,
0.011474609375,
0.02880859375,
-0.0487060546875,
-0.056793212890625,
-0.0212554931640625,
-0.01... |
BlueSunflower/chess_games_base | 2023-05-31T15:47:38.000Z | [
"region:us"
] | BlueSunflower | null | null | 1 | 4 | 2023-05-31T15:32:49 |
# Dataset of chess games made for purpose of training language model on them
Two files:
data_stockfish_262k.tar.gz - 262 000 games generated by Stockfish self-play
lichess.tar.gz - a sample of 3.5M games from lichess with unfinished games filtered out, all converted to one format
Each archive contains two files:
train.jsonl
test.jsonl
---
license: apache-2.0
---
| 370 | [
[
-0.021209716796875,
-0.031768798828125,
0.005329132080078125,
0.020233154296875,
-0.0277862548828125,
0.0021915435791015625,
-0.0223541259765625,
-0.0122222900390625,
0.026885986328125,
0.08203125,
-0.061798095703125,
-0.053253173828125,
-0.0277862548828125,
... |
cjvt/janes_preklop | 2023-06-07T21:56:34.000Z | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:sl",
"license:cc-by-sa-4.0",
"tweets",
"code-mixing",
"code-switching",
"region:us"
] | cjvt | Janes-Preklop is a corpus of Slovene tweets that is manually annotated for code-switching (the use of words from two
or more languages within one sentence or utterance), according to the supplied typology. | @misc{janes_preklop,
title = {Tweet code-switching corpus Janes-Preklop 1.0},
author = {Reher, {\v S}pela and Erjavec, Toma{\v z} and Fi{\v s}er, Darja},
url = {http://hdl.handle.net/11356/1154},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2017}
} | 0 | 4 | 2023-06-01T12:21:41 | ---
license: cc-by-sa-4.0
dataset_info:
features:
- name: id
dtype: string
- name: words
sequence: string
- name: language
sequence: string
splits:
- name: train
num_bytes: 410822
num_examples: 1104
download_size: 623816
dataset_size: 412672
task_categories:
- token-classification
language:
- sl
tags:
- tweets
- code-mixing
- code-switching
size_categories:
- 1K<n<10K
---
# Dataset Card for Janes-Preklop
### Dataset Summary
Janes-Preklop is a corpus of Slovene tweets that is manually annotated for code-switching: the use of words from two
or more languages within one sentence or utterance.
### Languages
Code-switched Slovenian.
## Dataset Structure
### Data Instances
A sample instance from the dataset - each word is annotated with its language, either `"default"`
(Slovenian/unclassifiable), `en` (English), `de` (German), `hbs` (Serbo-Croatian), `sp` (Spanish),
`la` (Latin), `ar` (Arabic), `fr` (French), `it` (Italian), or `pt` (Portuguese).
```
{
'id': 'tid.397447931558895616',
'words': ['Brad', 'Pitt', 'na', 'Planet', 'TV', '.', 'U', 'are', 'welcome', ';)'],
'language': ['default', 'default', 'default', 'default', 'default', 'default', 'B-en', 'I-en', 'I-en', 'I-en']
}
```
### Data Fields
- `id`: unique identifier of the example;
- `words`: words in the sentence;
- `language`: language of each word.
## Additional Information
### Dataset Curators
Špela Reher, Tomaž Erjavec, Darja Fišer.
### Licensing Information
CC BY-SA 4.0.
### Citation Information
```
@misc{janes_preklop,
title = {Tweet code-switching corpus Janes-Preklop 1.0},
author = {Reher, {\v S}pela and Erjavec, Toma{\v z} and Fi{\v s}er, Darja},
url = {http://hdl.handle.net/11356/1154},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2017}
}
```
### Contributions
Thanks to [@matejklemen](https://github.com/matejklemen) for adding this dataset. | 2,064 | [
[
-0.007568359375,
-0.0311431884765625,
0.006622314453125,
0.0285797119140625,
-0.036224365234375,
0.005832672119140625,
-0.01251220703125,
0.007904052734375,
0.0291290283203125,
0.05267333984375,
-0.04400634765625,
-0.07452392578125,
-0.06890869140625,
0.0269... |
alpayariyak/prm800k | 2023-06-01T14:51:25.000Z | [
"language:en",
"region:us"
] | alpayariyak | null | null | 5 | 4 | 2023-06-01T14:12:22 | ---
language:
- en
---
[From OpenAI](https://github.com/openai/prm800k)
# PRM800K: A Process Supervision Dataset
- [Blog Post](https://openai.com/research/improving-mathematical-reasoning-with-process-supervision)
This repository accompanies the paper [Let's Verify Step by Step](https://openai.com/research/improving-mathematical-reasoning-with-process-supervision) and presents the PRM800K dataset introduced there. PRM800K is a process supervision dataset containing 800,000 step-level correctness labels for model-generated solutions to problems from the [MATH](https://github.com/hendrycks/math) dataset. More information on PRM800K and the project can be found in the paper.
We are releasing the raw labels as well as the instructions we gave labelers during phase 1 and phase 2 of the project. Example labels can be seen in the image below.
<p align="center">
<img src="https://github.com/openai/prm800k/blob/main/prm800k/img/interface.png?raw=true" height="300"/>
</p>
## Data
The data contains our labels formatted as newline-delimited lists of `json` data.
Each line represents 1 full solution sample and can contain many step-level labels. Here is one annotated line:
```javascript
{
// UUID representing a particular labeler.
"labeler": "340d89bc-f5b7-45e9-b272-909ba68ee363",
// The timestamp this trajectory was submitted.
"timestamp": "2023-01-22T04:34:27.052924",
// In phase 2, we split our data collection into generations, using our best
// PRM so far to pick which solutions to score in the next generation.
// In phase 1, this value should always be null.
"generation": 9,
// In each generation, we reserve some solutions for quality control. We serve
// these solutions to every labeler, and check that they agree with our
// gold labels.
"is_quality_control_question": false,
// generation -1 was reserved for a set of 30 questions we served every
// labeler in order to screen for base task performance.
"is_initial_screening_question": false,
// Metadata about the question this solution is a response to.
"question": {
// Text of the MATH problem being solved.
"problem": "What is the greatest common factor of $20 !$ and $200,\\!000$? (Reminder: If $n$ is a positive integer, then $n!$ stands for the product $1\\cdot 2\\cdot 3\\cdot \\cdots \\cdot (n-1)\\cdot n$.)",
// Ground truth solution from the MATH dataset.
"ground_truth_solution": "The prime factorization of $200,000$ is $2^6 \\cdot 5^5$. Then count the number of factors of $2$ and $5$ in $20!$. Since there are $10$ even numbers, there are more than $6$ factors of $2$. There are $4$ factors of $5$. So the greatest common factor is $2^6 \\cdot 5^4=\\boxed{40,\\!000}$.",
// Ground truth answer.
"ground_truth_answer": "40,\\!000",
// The full steps of the model-generated solution. This is only set for
// phase 2 where we pre-generated all solutions that we labeled.
"pre_generated_steps": [
"I want to find the largest positive integer that divides both $20 !$ and $200,\\!000$ evenly.",
"One way to do this is to factor both numbers into prime factors and look for the common ones.",
"I know that $200,\\!000 = 2^5\\cdot 10^4 = 2^9\\cdot 5^4$.",
"To find the prime factorization of $20 !$, I can use the fact that it is the product of all the positive integers from $1$ to $20$.",
"For each prime number $p$ between $1$ and $20$, I can count how many multiples of $p$ are in that range.",
"For example, there are $10$ multiples of $2$ between $1$ and $20$, namely $2, 4, 6, \\dots, 20$.",
"But there are also $5$ multiples of $4$, which is $2^2$, and $2$ multiples of $8$, which is $2^3$, and $1$ multiple of $16$, which is $2^4$.",
"So, the total power of $2$ in $20 !$ is $10 + 5 + 2 + 1 = 18$.",
"Similarly, there are $4$ multiples of $5$, namely $5, 10, 15, 20$, so the power of $5$ in $20 !$ is $4$.",
"There are $6$ multiples of $3$, namely $3, 6, 9, \\dots, 18$, but there are also $2$ multiples of $9$, which is $3^2$, so the power of $3$ in $20 !$ is $6 + 2 = 8$.",
"There are $2$ multiples of $7$, namely $7$ and $14$, so the power of $7$ in $20 !$ is $2$.",
"There are $1$ multiple of each of the other prime numbers $11, 13, 17$, and $19$, so the powers of those primes in $20 !$ are $1$ each.",
"Therefore, the prime factorization of $20 !$ is $2^{18}\\cdot 3^8\\cdot 5^4\\cdot 7^2\\cdot 11\\cdot 13\\cdot 17\\cdot 19$.",
"To find the greatest common factor of $20 !$ and $200,\\!000$, I need to take the lowest power of each common prime factor.",
"The only common prime factors are $2$ and $5$, and the lowest powers are $9$ and $4$, respectively.",
"So, the greatest common factor is $2^9\\cdot 5^4 = 512\\cdot 625 = 320,\\!000$.\n\n# Answer\n\n320,000"
],
// The answer given as the end of the pre-generated solution. We can see
// this solution is incorrect.
"pre_generated_answer": "320,000",
// The score given by our PRM to this solution. This one isn't rated very
// highly!
"pre_generated_verifier_score": 0.010779580529581414
},
// The human data we collected for this solution, containing correctness
// labels for each step of the solution.
"label": {
"steps": [
// Each object here represents labels for one step of the solution.
{
// Each step will contain one or more completions. These are candidate
// steps the model output at this step of the trajectory. In phase 1,
// we frequently collect labels on alternative steps, while in phase 2
// we only collect labels on alternative steps after the first mistake,
// so most completions lists are singletons.
"completions": [
{
// Text of the step.
"text": "I want to find the largest positive integer that divides both $20 !$ and $200,\\!000$ evenly.",
// The rating the labeler gave to this step. Can be -1, 0, or +1.
// This is a 0 because it isn't incorrect, but it does not make
// any progress.
"rating": 0,
// The labeler can flag steps that they don't know how to label.
// This is rarely used.
"flagged": null
}
],
// In phase 1, if all completions were rated -1, we allowed labelers to
// write their own +1 step. This is null for all steps in phase 2.
"human_completion": null,
// The index of the completion "chosen" at this step, or null if the
// human_completion was used. You can reconstruct the solution
// trajectory like:
// [
// step["human_completion"] if step["chosen_completion"] is None
// else step["completions"][step["chosen_completion"]]["text"]
// for step in labeled_solution["label"]["steps"]
// ]
"chosen_completion": 0
},
{
"completions": [
{
"text": "One way to do this is to factor both numbers into prime factors and look for the common ones.",
"rating": 0,
"flagged": null
}
],
"human_completion": null,
"chosen_completion": 0
},
{
// Some steps contain multiple alternative completions, and each one
// gets a rating.
"completions": [
{
"text": "I know that $200,\\!000 = 2^5\\cdot 10^4 = 2^9\\cdot 5^4$.",
"rating": -1,
"flagged": null
},
{
"text": "To factor $20 !$, I can use the fact that every factorial is a multiple of every number less than or equal to it.",
"rating": 0,
"flagged": false
},
{
"text": "I can use a factor tree to find the prime factors of $200,\\!000$: $200,\\!000 = 2^5\\cdot 10^4 = 2^5\\cdot 2^4\\cdot 5^4 = 2^9\\cdot 5^4$.",
"rating": -1,
"flagged": false
},
{
"text": "I can use a factor tree to find the prime factors of $200,\\!000$.",
"rating": 0,
"flagged": false
},
{
"text": "To factor $20 !$, I can use the fact that any factorial is divisible by all the primes less than or equal to the input.",
"rating": 0,
"flagged": false
}
],
"human_completion": null,
"chosen_completion": null
}
],
// Total time in milliseconds spent on labeling this solution.
"total_time": 278270,
// Final result of labeling this solution. Will be one of:
// - "found_error": In phase 2 we stop labeling a solution after the
// first error is found.
// - "solution": We reached a step that concluded in the correct answer
// to the problem.
// - "bad_problem": The labeler reported the problem as broken.
// - "give_up": The labeler was stuck (the problem was taking too long,
// or the instructions were unclear) and moved onto the
// next problem.
"finish_reason": "found_error"
}
}
```
## Citation
Please use the below BibTeX entry to cite this dataset:
COMING SOON | 9,301 | [
[
-0.06085205078125,
-0.028167724609375,
0.050262451171875,
0.046661376953125,
-0.01441192626953125,
0.0009317398071289062,
0.0032672882080078125,
-0.007091522216796875,
-0.0052032470703125,
0.0401611328125,
-0.037384033203125,
-0.040130615234375,
-0.0591735839843... |
kraina/airbnb_london_weekends | 2023-06-03T14:51:20.000Z | [
"region:us"
] | kraina | null | null | 0 | 4 | 2023-06-03T14:51:16 | ---
dataset_info:
features:
- name: _id
dtype: string
- name: realSum
dtype: float64
- name: room_type
dtype: string
- name: room_shared
dtype: bool
- name: room_private
dtype: bool
- name: person_capacity
dtype: float64
- name: host_is_superhost
dtype: bool
- name: multi
dtype: int64
- name: biz
dtype: int64
- name: cleanliness_rating
dtype: float64
- name: guest_satisfaction_overall
dtype: float64
- name: bedrooms
dtype: int64
- name: dist
dtype: float64
- name: metro_dist
dtype: float64
- name: attr_index
dtype: float64
- name: attr_index_norm
dtype: float64
- name: rest_index
dtype: float64
- name: rest_index_norm
dtype: float64
splits:
- name: train
num_bytes: 703844.4180180868
num_examples: 5379
download_size: 407036
dataset_size: 703844.4180180868
---
# Dataset Card for "airbnb_london_weekends"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,071 | [
[
-0.03314208984375,
-0.0164947509765625,
0.01019287109375,
0.01885986328125,
-0.00748443603515625,
-0.01441192626953125,
0.020538330078125,
-0.00783538818359375,
0.060821533203125,
0.02032470703125,
-0.06341552734375,
-0.04974365234375,
-0.0238189697265625,
-... |
vietgpt/hellaswag_en | 2023-06-04T01:42:34.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"SFT",
"region:us"
] | vietgpt | null | null | 0 | 4 | 2023-06-04T01:38:48 | ---
dataset_info:
features:
- name: ind
dtype: int32
- name: activity_label
dtype: string
- name: ctx_a
dtype: string
- name: ctx_b
dtype: string
- name: ctx
dtype: string
- name: endings
sequence: string
- name: source_id
dtype: string
- name: split
dtype: string
- name: split_type
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 43232624
num_examples: 39905
- name: validation
num_bytes: 11175717
num_examples: 10042
download_size: 30681161
dataset_size: 54408341
task_categories:
- text-classification
language:
- en
tags:
- SFT
size_categories:
- 10K<n<100K
---
# Physical Interaction: HellaSwag
- Source: https://huggingface.co/datasets/hellaswag
- Num examples:
- 39,905 (train)
- 10,042 (validation)
- Language: English
```python
from datasets import load_dataset
load_dataset("vietgpt/hellaswag_en")
```
- Format for GPT-3
```python
def preprocess_gpt3(sample):
ctx = sample['ctx']
endings = sample['endings']
label = sample['label']
if label == '0':
output = f'\n<|correct|> {endings[0]}\n<|incorrect|> {endings[1]}\n<|incorrect|> {endings[2]}\n<|incorrect|> {endings[3]}'
elif label == '1':
output = f'\n<|correct|> {endings[1]}\n<|incorrect|> {endings[0]}\n<|incorrect|> {endings[2]}\n<|incorrect|> {endings[3]}'
elif label == '2':
output = f'\n<|correct|> {endings[2]}\n<|incorrect|> {endings[0]}\n<|incorrect|> {endings[1]}\n<|incorrect|> {endings[3]}'
else:
output = f'\n<|correct|> {endings[3]}\n<|incorrect|> {endings[0]}\n<|incorrect|> {endings[1]}\n<|incorrect|> {endings[2]}'
return {'text': f'<|startoftext|><|context|> {ctx} <|answer|> {output} <|endoftext|>'}
"""
<|startoftext|><|context|> Then, the man writes over the snow covering the window of a car, and a woman wearing winter clothes smiles. then <|answer|>
<|correct|> , the man continues removing the snow on his car.
<|incorrect|> , the man adds wax to the windshield and cuts it.
<|incorrect|> , a person board a ski lift, while two men supporting the head of the person wearing winter clothes snow as the we girls sled.
<|incorrect|> , the man puts on a christmas coat, knitted with netting. <|endoftext|>
"""
``` | 2,291 | [
[
-0.0209503173828125,
-0.047515869140625,
0.0379638671875,
0.0198822021484375,
-0.0328369140625,
-0.02508544921875,
-0.00577545166015625,
-0.0245819091796875,
0.005886077880859375,
0.009124755859375,
-0.06451416015625,
-0.05279541015625,
-0.04376220703125,
0.... |
Den4ikAI/yandex_parallel_ruen_corpus | 2023-06-04T09:48:24.000Z | [
"region:us"
] | Den4ikAI | null | null | 0 | 4 | 2023-06-04T09:47:32 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
hssd/hssd-hab | 2023-10-18T23:23:34.000Z | [
"language:en",
"license:cc-by-nc-4.0",
"3D scenes",
"Embodied AI",
"region:us"
] | hssd | null | null | 14 | 4 | 2023-06-04T18:59:50 | ---
language:
- en
pretty_name: HSSD
tags:
- 3D scenes
- Embodied AI
license: cc-by-nc-4.0
extra_gated_heading: "Acknowledge license to accept the repository"
extra_gated_prompt: "You agree to use this dataset under the [CC BY-NC 4.0 license](https://creativecommons.org/licenses/by-nc/4.0/) terms"
viewer: false
---
HSSD: Habitat Synthetic Scenes Dataset
==================================
The [Habitat Synthetic Scenes Dataset (HSSD)](https://3dlg-hcvc.github.io/hssd/) is a human-authored 3D scene dataset that more closely mirrors real scenes than prior datasets.
Our dataset represents real interiors and contains a diverse set of 211 scenes and more than 18000 models of real-world objects.
<img src="https://i.imgur.com/XEkLxNs.png" width=50%>
This repository provides a Habitat consumption-ready compressed version of HSSD.
See [this repository](https://huggingface.co/datasets/hssd/hssd-models) for corresponding uncompressed assets.
## Dataset Structure
```
├── objects
│ ├── */*.glb
│ ├── */*.collider.glb
│ ├── */*.filteredSupportSurface(.ply|.glb)
│ ├── */*.object_config.json
├── stages
│ ├── *.glb
│ ├── *.stage_config.json
├── scenes
│ ├── *.scene_instance.json
├── scenes_uncluttered
│ ├── *.scene_instance.json
├── scene_filter_files
│ ├── *.rec_filter.json
└── hssd-hab.scene_dataset_config.json
└── hssd-hab-uncluttered.scene_dataset_config.json
```
- `hssd-hab.scene_dataset_config.json`: This SceneDataset config file aggregates the assets and metadata necessary to fully describe the set of stages, objects, and scenes constituting the dataset.
- `objects`: 3D models representing distinct objects that are used to compose scenes. Contains configuration files, render assets, collider assets, and Receptacle mesh assets.
- `stages`: A stage in Habitat is the set of static mesh components which make up the backdrop of a scene (e.g. floor, walls, stairs, etc.).
- `scenes`: A scene is a single 3D world composed of a static stage and a variable number of objects.
### Rearrange-ready assets:
Supporting Habitat 3.0 embodied rearrangement tasks with updated colliders, adjusted and de-cluttered scene contents, receptacle meshes, and receptacle filter files. See [aihabitat.org/habitat3/](aihabitat.org/habitat3/) for more details.
- `hssd-hab-uncluttered.scene_dataset_config.json`: This SceneDataset config file aggregates adds the adjusted and uncluttered scenes for rearrangement tasks.
- `scenes_uncluttered`: Contains the adjusted scene instance configuration files.
- `scene_filter_files`: A scene filter file organizes available Receptacle instances in a scene into active and inactive groups based on simualtion heuristics and manual edits. It is consumed by the RearrangeEpisodeGenerator to construct valid RearrangeEpisodeDatasets.
## Getting Started
To load HSSD scenes into the Habitat simulator, you can start by installing [habitat-sim](https://github.com/facebookresearch/habitat-sim) using instructions specified [here](https://github.com/facebookresearch/habitat-sim#installation).
Once installed, you can run the interactive Habitat viewer to load a scene:
```
habitat-viewer --dataset /path/to/hssd-hab/hssd-hab.scene_dataset_config.json -- 102344280
# or ./build/viewer if compiling from source
```
You can find more information about using the interactive viewer [here](https://github.com/facebookresearch/habitat-sim#testing:~:text=path/to/data/-,Interactive%20testing,-%3A%20Use%20the%20interactive).
Habitat-Sim is typically used with [Habitat-Lab](https://github.com/facebookresearch/habitat-lab), a modular high-level library for end-to-end experiments in embodied AI.
To define embodied AI tasks (e.g. navigation, instruction following, question answering), train agents, and benchmark their performance using standard metrics, you can download habitat-lab using the instructions provided [here](https://github.com/facebookresearch/habitat-lab#installation).
## Changelog
- `v0.2.5` (work in progress): **Rearrange-ready HSSD**
- Note: this is a checkpoint. Known issues exist and continued polish is ongoing.
- Adds Receptacle meshes describing support surfaces for small objects (e.g. table or shelf surfaces).
- Adds collider meshes (.collider.glb) for assets with Receptacle meshes to support simulation.
- Adds new scenes 'scenes_uncluttered' and new SceneDataset 'hssd-hab-uncluttered' containing adjusted and de-cluttered versions of the scenes for use in embodied rearrangement tasks.
- Adds 'scene_filter_files' which sort Receptacles in each scene into active and inactive groups for RearrangeEpisode generation.
- `v0.2.4`:
- Recompresses several object GLBs to preserve PBR material status.
- Adds CSV with object metadata and semantic lexicon files for Habitat.
- Adds train/val scene splits file.
- `v0.2.3`: First release.
| 4,850 | [
[
-0.037384033203125,
-0.039031982421875,
0.03314208984375,
0.0325927734375,
-0.00978851318359375,
0.001483917236328125,
0.0256500244140625,
-0.0323486328125,
0.0305633544921875,
0.02960205078125,
-0.08038330078125,
-0.058563232421875,
-0.0160369873046875,
0.0... |
Salama1429/tarteel-ai-quran-tafsir | 2023-06-06T14:41:32.000Z | [
"region:us"
] | Salama1429 | null | null | 0 | 4 | 2023-06-06T14:41:29 | ---
dataset_info:
features:
- name: en-ahmedali
dtype: string
- name: en-ahmedraza
dtype: string
- name: en-arberry
dtype: string
- name: en-asad
dtype: string
- name: en-daryabadi
dtype: string
- name: en-hilali
dtype: string
- name: en-itani
dtype: string
- name: en-maududi
dtype: string
- name: en-mubarakpuri
dtype: string
- name: en-pickthall
dtype: string
- name: en-qarai
dtype: string
- name: en-qaribullah
dtype: string
- name: en-sahih
dtype: string
- name: en-sarwar
dtype: string
- name: en-shakir
dtype: string
- name: en-transliterati
dtype: string
- name: en-wahiduddi
dtype: string
- name: en-yusufali
dtype: string
- name: surah
dtype: int64
- name: ayah
dtype: int64
splits:
- name: train
num_bytes: 16266291
num_examples: 6236
download_size: 9040639
dataset_size: 16266291
---
# Dataset Card for "tarteel-ai-quran-tafsir"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,112 | [
[
-0.033660888671875,
-0.024932861328125,
0.005413055419921875,
0.020172119140625,
-0.020599365234375,
0.0157623291015625,
0.005725860595703125,
-0.0111541748046875,
0.044189453125,
0.03167724609375,
-0.037841796875,
-0.070068359375,
-0.050445556640625,
-0.004... |
GePaSud/TROPICAL | 2023-08-05T04:25:29.000Z | [
"license:mit",
"region:us"
] | GePaSud | null | 0 | 4 | 2023-06-07T01:02:59 | ---
license: mit
dataset_info:
- config_name: original
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 1115671
num_examples: 1114
- name: test
num_bytes: 239799
num_examples: 239
- name: validation
num_bytes: 237621
num_examples: 239
download_size: 2471854
dataset_size: 1593091
- config_name: no_overlapping
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 270313
num_examples: 326
- name: test
num_bytes: 61779
num_examples: 70
- name: validation
num_bytes: 59399
num_examples: 71
download_size: 581415
dataset_size: 391491
- config_name: overlapping
features:
- name: id_comment
dtype: string
- name: words
sequence: string
- name: triplets
list:
- name: aspect_term
sequence: string
- name: opinion_term
sequence: string
- name: aspect_position
sequence: int32
- name: opinion_position
sequence: int32
- name: polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
- name: general_polarity
dtype:
class_label:
names:
'0': POS
'1': NEG
'2': NEU
splits:
- name: train
num_bytes: 842528
num_examples: 787
- name: test
num_bytes: 178001
num_examples: 169
- name: validation
num_bytes: 181071
num_examples: 169
download_size: 1890439
dataset_size: 1201600
---
# Dataset Card for TROPICAL
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Configurations](#data-configurations)
- [Use this Dataset](#use-this-dataset)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** [TROPICAL dataset repository](https://github.com/GePaSud/TROPICAL)
- **Paper:**
- **Point of Contact:**
### Dataset Summary
The TROPICAL dataset is a French-language dataset for sentiment analysis. The dataset contains comments left by French-speaking tourists' on TripAdvisor after their visit to French Polynesia, each review either concern a hotel or a guesthouse. The format is JSON.
The comments spanning from January 2001 to April 2023, the dataset contain 1592 comments along with 10729 ASTE triplets (aspect, opinion, sentiment).
The unsplitted dataset is available in our Github repository.
### Languages
The text in the dataset is in French as it was written by French speakers.
## Dataset Structure
### Data Instances
Normaly the polarity of the triplets are either "POS", "NEG" or "NEU", due to using [ClassLabel](https://huggingface.co/docs/datasets/v2.13.0/en/package_reference/main_classes#datasets.ClassLabel) the polarity is represented by 0, 1 or 2.
| String label | Int label |
| ------------ | --------- |
| POS | 0 |
| NEG | 1 |
| NEU | 2 |
An example from the TROPICAL original dataset looks like the following:
```json
{
"id_comment": "16752",
"words": ["Nous", "avons", "passé", "4", "nuits", "dans", "cet", "établissement", "Ce", "fut", "un", "très", "bon", "moment", "Le", "personnel", "très", "aimable", "et", "serviable", "Nous", "avons", "visité", "les", "plantations", "d'ananas", "en", "4/4", "et", "ce", "fut", "un", "agréable", "moment", "nous", "avons", "fait", "le", "tour", "de", "l'île", "et", "c't", "une", "splendeur", "Nous", "sommes", "revenus", "enchantés"],
"triplets": [
{"aspect_term": ["Aspect inexistant"], "opinion_term": ["revenus", "enchantés"], "aspect_position": [-1], "opinion_position": [47, 48], "polarity": "POS"},
{"aspect_term": ["tour", "de", "l'île"], "opinion_term": ["une", "splendeur"], "aspect_position": [38, 39, 40], "opinion_position": [43, 44], "polarity": "POS"},
{"aspect_term": ["moment"], "opinion_term": ["agréable"], "aspect_position": [33], "opinion_position": [32], "polarity": "POS"},
{"aspect_term": ["personnel"], "opinion_term": ["serviable"], "aspect_position": [15], "opinion_position": [19], "polarity": "POS"},
{"aspect_term": ["personnel"], "opinion_term": ["très", "aimable"], "aspect_position": [15], "opinion_position": [16, 17], "polarity": "POS"},
{"aspect_term": ["moment"], "opinion_term": ["très", "bon"], "aspect_position": [13], "opinion_position": [11, 12], "polarity": "POS"}
],
"general_polarity": "POS"
}
```
### Data Fields
- 'id_comment': a string containing the review id
- 'words': an array of strings composing the comment
- 'triplets': a list of dictionnaries containing the following informations
- 'aspect_term': an array of strings composing the aspect term (can be a single word or a multi-word expression)
- 'opinion_term': an array of strings composing the opinion term (can be a single word or a multi-word expression)
- 'aspect_position': an array of integers indicating the position of the aspect term in the words array (can be a single integer list or a list of integers)
- 'opinion_position': an array of integers indicating the position of the opinion term in the review (can be a single integer list or a list of integers)
- 'polartiy': an integer, either _0_, _1_, or _2_, indicating a _positive_, _negative_, or _neutral_ sentiment, respectively
- 'general_polarity': an integer, either _0_, _1_, or _2_, indicating a _positive_, _negative_, or _neutral_ sentiment, respectively
### Data configurations
The TROPICO dataset has 3 configurations: _original_, _no overlapping_, and _overlapping_.The first one contains the 1592 comments. The overlapping dataset contains the comments that have at least one overlapping triplet. The no overlapping dataset contains the comments that have no overlapping triplet.
| Dataset Configuration | Number of comments | Number of triplets | Positive triplets | Negative triplets | Neutral triplets |
| --------------------- | ------------------ | ------------------ | ----------------- | ----------------- | -----------------|
| original | 1,592 | 10,729 | 9,889 | 734 | 106 |
| no_overlapping | 467 | 2,235 | 2,032 | 184 | 19 |
| overlapping | 1,125 | 8,494 | 7,857 | 550 | 87 |
The following table show the splits of the dataset for all configurations:
| Dataset Configuration | Train | Test | Val |
| --------------------- | ----- | ---- | --- |
| original | 1,114 | 239 | 239 |
| no_overlapping | 326 | 70 | 71 |
| overlapping | 787 | 169 | 169 |
The split values for train, test, validation are 70%, 15%, 15% respectively. The seed used is 42.
## Use this dataset
```python
from datasets import load_dataset
dataset = load_dataset("TROPICAL", "original") # or "no_overlapping" or "overlapping"
```
## Dataset Creation
### Source Data
All the comments were collected from the TripAdvisor website. The comments range from January 2001 to April 2023. The dataset contains 1592 comments along with 10729 ASTE triplets (aspect, opinion, sentiment).
### Who are the source language producers?
The dataset contains tourists' comments about French Polynesia stored on the [TripAdvisor](https://www.tripadvisor.com/) website.
### Known limitations
The dataset contains only comments about French Polynesia. Moreover, the dataset is not balanced, the number of positive triplets is much higher than the number of negative and neutral triplets.
## Additional Information
### Licensing Information
The TROPICAL dataset is licensed under the [MIT License](https://opensource.org/licenses/MIT).
### Citation Information
> To be added... | 9,307 | [
[
-0.04937744140625,
-0.0298004150390625,
0.02264404296875,
0.0379638671875,
-0.034149169921875,
0.0177001953125,
-0.0222015380859375,
-0.0202789306640625,
0.05902099609375,
0.052490234375,
-0.03802490234375,
-0.067138671875,
-0.04296875,
0.0270843505859375,
... | |
manot/football-players | 2023-06-12T10:11:21.000Z | [
"task_categories:object-detection",
"roboflow",
"roboflow2huggingface",
"region:us"
] | manot | null | @misc{ football-players-2l81z_dataset,
title = { football-players Dataset },
type = { Open Source Dataset },
author = { Konstantin Sargsyan },
howpublished = { \\url{ https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z } },
url = { https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2023 },
month = { jun },
note = { visited on 2023-06-12 },
} | 0 | 4 | 2023-06-07T15:33:42 | ---
task_categories:
- object-detection
tags:
- roboflow
- roboflow2huggingface
---
<div align="center">
<img width="640" alt="manot/football-players" src="https://huggingface.co/datasets/manot/football-players/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['football', 'player']
```
### Number of Images
```json
{'valid': 87, 'train': 119}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("manot/football-players", name="full")
example = ds['train'][0]
```
### Roboflow Dataset Page
[https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z/dataset/1](https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z/dataset/1?ref=roboflow2huggingface)
### Citation
```
@misc{ football-players-2l81z_dataset,
title = { football-players Dataset },
type = { Open Source Dataset },
author = { Konstantin Sargsyan },
howpublished = { \\url{ https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z } },
url = { https://universe.roboflow.com/konstantin-sargsyan-wucpb/football-players-2l81z },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2023 },
month = { jun },
note = { visited on 2023-06-12 },
}
```
### License
MIT
### Dataset Summary
This dataset was exported via roboflow.com on June 12, 2023 at 10:10 AM GMT
Roboflow is an end-to-end computer vision platform that helps you
* collaborate with your team on computer vision projects
* collect & organize images
* understand and search unstructured image data
* annotate, and create datasets
* export, train, and deploy computer vision models
* use active learning to improve your dataset over time
For state of the art Computer Vision training notebooks you can use with this dataset,
visit https://github.com/roboflow/notebooks
To find over 100k other datasets and pre-trained models, visit https://universe.roboflow.com
The dataset includes 206 images.
Players are annotated in COCO format.
The following pre-processing was applied to each image:
* Auto-orientation of pixel data (with EXIF-orientation stripping)
* Resize to 640x640 (Stretch)
No image augmentation techniques were applied.
| 2,352 | [
[
-0.03375244140625,
-0.01261138916015625,
0.01558685302734375,
0.01126861572265625,
-0.0207366943359375,
0.00447845458984375,
-0.00487518310546875,
-0.051177978515625,
0.04071044921875,
0.01922607421875,
-0.05322265625,
-0.045013427734375,
-0.034149169921875,
... |
AIingit/SRK-emails | 2023-06-11T00:08:29.000Z | [
"region:us"
] | AIingit | null | null | 0 | 4 | 2023-06-11T00:08:27 | ---
dataset_info:
features:
- name: product
dtype: string
- name: description
dtype: string
- name: marketing_email
dtype: string
splits:
- name: train
num_bytes: 23818
num_examples: 19
download_size: 21510
dataset_size: 23818
---
# Dataset Card for "SRK-emails"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 431 | [
[
-0.026397705078125,
-0.0032634735107421875,
0.0033435821533203125,
0.0090484619140625,
-0.024139404296875,
0.0026035308837890625,
0.02337646484375,
-0.00902557373046875,
0.0675048828125,
0.03436279296875,
-0.0926513671875,
-0.048309326171875,
-0.04681396484375,
... |
Yulong-W/squadorirobustness | 2023-06-11T03:59:10.000Z | [
"region:us"
] | Yulong-W | Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. | @article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
} | 0 | 4 | 2023-06-11T03:51:46 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
binhgiangnguyendanh/reddit_casual_conversation_for_alpaca_lora | 2023-06-26T10:20:53.000Z | [
"region:us"
] | binhgiangnguyendanh | null | null | 0 | 4 | 2023-06-12T07:01:00 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 7138483
num_examples: 8686
download_size: 2583834
dataset_size: 7138483
---
# Dataset Card for "reddit_casual_conversation_for_alpaca_lora"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 420 | [
[
-0.046295166015625,
-0.066650390625,
0.0142059326171875,
0.031280517578125,
-0.041015625,
-0.01044464111328125,
-0.0036144256591796875,
-0.0302276611328125,
0.08648681640625,
0.030914306640625,
-0.060211181640625,
-0.066650390625,
-0.045135498046875,
-0.0109... |
Sunbird/Synthetic-Salt-Luganda-13-6-23 | 2023-06-13T02:05:35.000Z | [
"region:us"
] | Sunbird | null | null | 0 | 4 | 2023-06-13T02:00:55 | ---
dataset_info:
features:
- name: audio
sequence:
sequence: float32
- name: sample_rate
dtype: int64
- name: transcription
dtype: string
splits:
- name: train
num_bytes: 8360315972
num_examples: 25000
download_size: 8282006533
dataset_size: 8360315972
---
# Dataset Card for "Synthetic-Salt-Luganda-13-6-23"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 484 | [
[
-0.0318603515625,
-0.020965576171875,
0.029449462890625,
0.022613525390625,
-0.02294921875,
0.01439666748046875,
0.005279541015625,
-0.0242919921875,
0.06085205078125,
0.020965576171875,
-0.062255859375,
-0.049713134765625,
-0.027252197265625,
0.000690460205... |
Ali-C137/Guanaco-oasst1_Originals_Arabic_pairs | 2023-06-13T17:48:47.000Z | [
"region:us"
] | Ali-C137 | null | null | 0 | 4 | 2023-06-13T17:48:45 | ---
dataset_info:
features:
- name: text
dtype: string
- name: translated_text
dtype: string
splits:
- name: train
num_bytes: 38713258
num_examples: 10364
download_size: 20094755
dataset_size: 38713258
---
# Dataset Card for "Guanaco-oasst1_Originals_Arabic_pairs"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 427 | [
[
-0.0259857177734375,
-0.021514892578125,
0.010955810546875,
0.0130767822265625,
-0.0279541015625,
0.0013904571533203125,
0.012908935546875,
-0.0112762451171875,
0.055908203125,
0.0272674560546875,
-0.03717041015625,
-0.0745849609375,
-0.05303955078125,
-0.01... |
cyrilzhang/TinyStories-tokenized-gpt2-1024 | 2023-06-14T03:15:32.000Z | [
"region:us"
] | cyrilzhang | null | null | 0 | 4 | 2023-06-14T03:14:27 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
shibing624/snli-zh | 2023-06-14T07:15:52.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:shibing624",
"language_creators:liuhuanyong",
"multilinguality:monolingual",
"size_categories:100K<n<20M",
"source_datasets:https://git... | shibing624 | The SNLI corpus (version 1.0) is a collection of 570k human-written English
sentence pairs manually labeled for balanced classification with the labels
entailment, contradiction, and neutral, supporting the task of natural language
inference (NLI), also known as recognizing textual entailment (RTE). | @inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
} | 2 | 4 | 2023-06-14T04:33:26 | ---
annotations_creators:
- shibing624
language_creators:
- liuhuanyong
language:
- zh
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<20M
source_datasets:
- https://github.com/liuhuanyong/ChineseTextualInference/
task_categories:
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
- text-scoring
paperswithcode_id: snli
pretty_name: Stanford Natural Language Inference
---
# Dataset Card for SNLI_zh
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Dataset:** [train data from ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/)
- **Size of downloaded dataset files:** 54 MB
- **Total amount of disk used:** 54 MB
### Dataset Summary
中文SNLI和MultiNLI数据集,翻译自英文[SNLI](https://huggingface.co/datasets/snli)和[MultiNLI](https://huggingface.co/datasets/multi_nli)
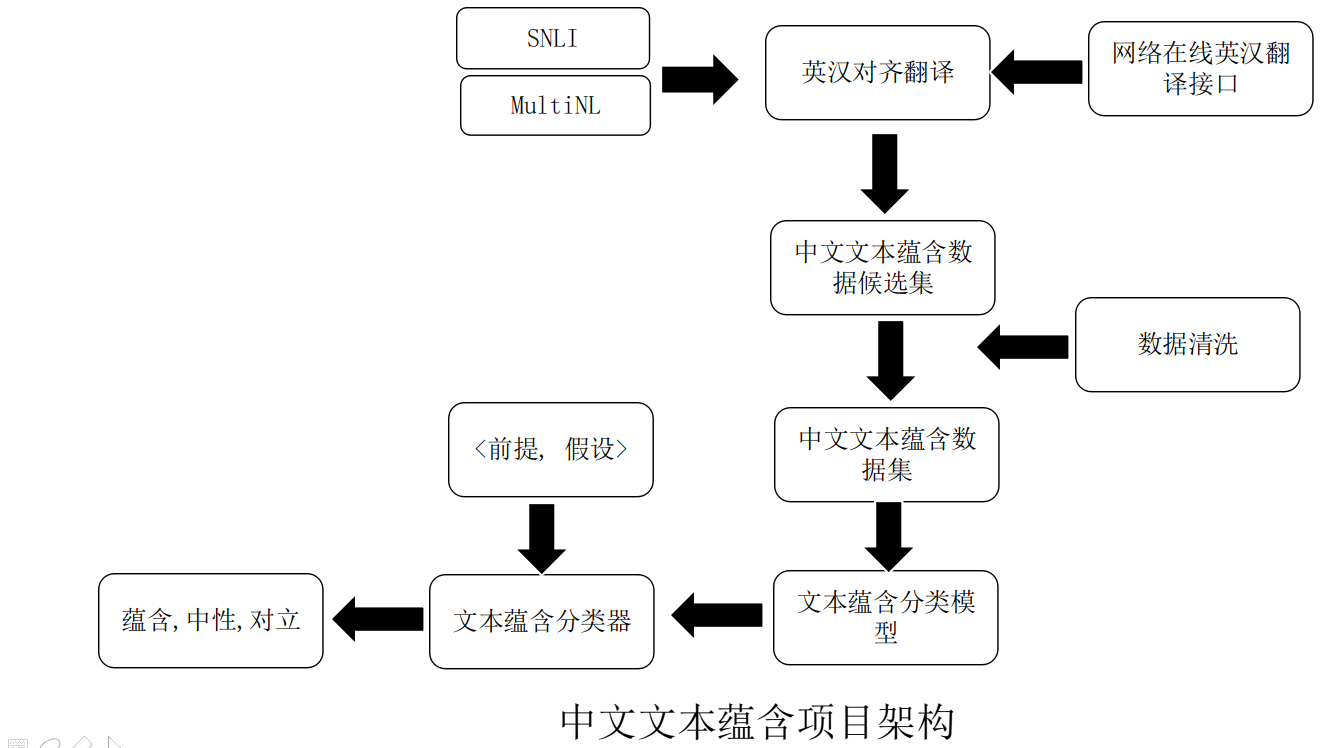
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
sentence1 sentence2 gold_label
是的,我想一个洞穴也会有这样的问题 我认为洞穴可能会有更严重的问题。 neutral
几周前我带他和一个朋友去看幼儿园警察 我还没看过幼儿园警察,但他看了。 contradiction
航空旅行的扩张开始了大众旅游的时代,希腊和爱琴海群岛成为北欧人逃离潮湿凉爽的夏天的令人兴奋的目的地。 航空旅行的扩大开始了许多旅游业的发展。 entailment
```
### Data Fields
The data fields are the same among all splits.
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including entailment(0), neutral(1), contradiction(2). 注意:此数据集0表示相似,2表示不相似。
-
### Data Splits
after remove None and len(text) < 1 data:
```shell
$ wc -l ChineseTextualInference-train.txt
419402 total
```
### Data Length
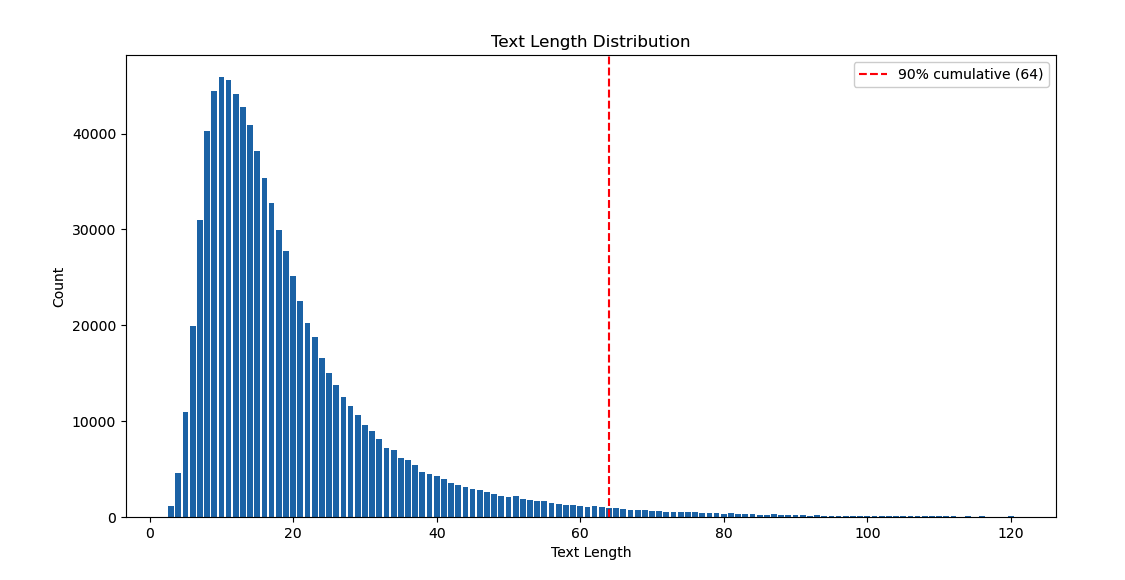
## Dataset Creation
### Curation Rationale
作为中文SNLI(natural langauge inference)数据集,这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
@inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
}
### Annotations
#### Annotation process
#### Who are the annotators?
原作者。
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
- [liuhuanyong](https://github.com/liuhuanyong/ChineseTextualInference/)翻译成中文
- [shibing624](https://github.com/shibing624) 上传到huggingface的datasets
### Licensing Information
用于学术研究。
### Contributions
[shibing624](https://github.com/shibing624) add this dataset. | 3,593 | [
[
-0.021240234375,
-0.044921875,
0.0186004638671875,
0.0294342041015625,
-0.022613525390625,
-0.03515625,
-0.04254150390625,
-0.0360107421875,
0.0255584716796875,
0.03155517578125,
-0.044525146484375,
-0.053558349609375,
-0.035308837890625,
0.01611328125,
... |
lighteval/narrative_qa_helm | 2023-06-14T12:32:19.000Z | [
"region:us"
] | lighteval | null | null | 0 | 4 | 2023-06-14T12:29:40 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
renumics/cifar100-outlier | 2023-06-30T20:08:26.000Z | [
"task_categories:image-classification",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-80-Million-Tiny-Images",
"language:en",
"license:unknown",
"region:us"
] | renumics | null | null | 0 | 4 | 2023-06-14T21:12:23 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-80-Million-Tiny-Images
task_categories:
- image-classification
task_ids: []
paperswithcode_id: cifar-100
pretty_name: Cifar100
dataset_info:
features:
- name: img
dtype: image
- name: fine_label
dtype:
class_label:
names:
'0': apple
'1': aquarium_fish
'2': baby
'3': bear
'4': beaver
'5': bed
'6': bee
'7': beetle
'8': bicycle
'9': bottle
'10': bowl
'11': boy
'12': bridge
'13': bus
'14': butterfly
'15': camel
'16': can
'17': castle
'18': caterpillar
'19': cattle
'20': chair
'21': chimpanzee
'22': clock
'23': cloud
'24': cockroach
'25': couch
'26': cra
'27': crocodile
'28': cup
'29': dinosaur
'30': dolphin
'31': elephant
'32': flatfish
'33': forest
'34': fox
'35': girl
'36': hamster
'37': house
'38': kangaroo
'39': keyboard
'40': lamp
'41': lawn_mower
'42': leopard
'43': lion
'44': lizard
'45': lobster
'46': man
'47': maple_tree
'48': motorcycle
'49': mountain
'50': mouse
'51': mushroom
'52': oak_tree
'53': orange
'54': orchid
'55': otter
'56': palm_tree
'57': pear
'58': pickup_truck
'59': pine_tree
'60': plain
'61': plate
'62': poppy
'63': porcupine
'64': possum
'65': rabbit
'66': raccoon
'67': ray
'68': road
'69': rocket
'70': rose
'71': sea
'72': seal
'73': shark
'74': shrew
'75': skunk
'76': skyscraper
'77': snail
'78': snake
'79': spider
'80': squirrel
'81': streetcar
'82': sunflower
'83': sweet_pepper
'84': table
'85': tank
'86': telephone
'87': television
'88': tiger
'89': tractor
'90': train
'91': trout
'92': tulip
'93': turtle
'94': wardrobe
'95': whale
'96': willow_tree
'97': wolf
'98': woman
'99': worm
- name: coarse_label
dtype:
class_label:
names:
'0': aquatic_mammals
'1': fish
'2': flowers
'3': food_containers
'4': fruit_and_vegetables
'5': household_electrical_devices
'6': household_furniture
'7': insects
'8': large_carnivores
'9': large_man-made_outdoor_things
'10': large_natural_outdoor_scenes
'11': large_omnivores_and_herbivores
'12': medium_mammals
'13': non-insect_invertebrates
'14': people
'15': reptiles
'16': small_mammals
'17': trees
'18': vehicles_1
'19': vehicles_2
- name: embedding_foundation
sequence: float32
- name: embedding_ft
sequence: float32
- name: outlier_score_ft
dtype: float64
- name: outlier_score_foundation
dtype: float64
- name: nn_image
struct:
- name: bytes
dtype: binary
- name: path
dtype: 'null'
splits:
- name: train
num_bytes: 583557742.0
num_examples: 50000
download_size: 643988234
dataset_size: 583557742.0
---
# Dataset Card for "cifar100-outlier"
📚 This dataset is an enriched version of the [CIFAR-100 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
The workflow is described in the medium article: [Changes of Embeddings during Fine-Tuning of Transformers](https://medium.com/@markus.stoll/changes-of-embeddings-during-fine-tuning-c22aa1615921).
## Explore the Dataset
The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to explorer this dataset. You can find a Hugging Face Space running Spotlight with this dataset here: <https://huggingface.co/spaces/renumics/cifar100-outlier>.
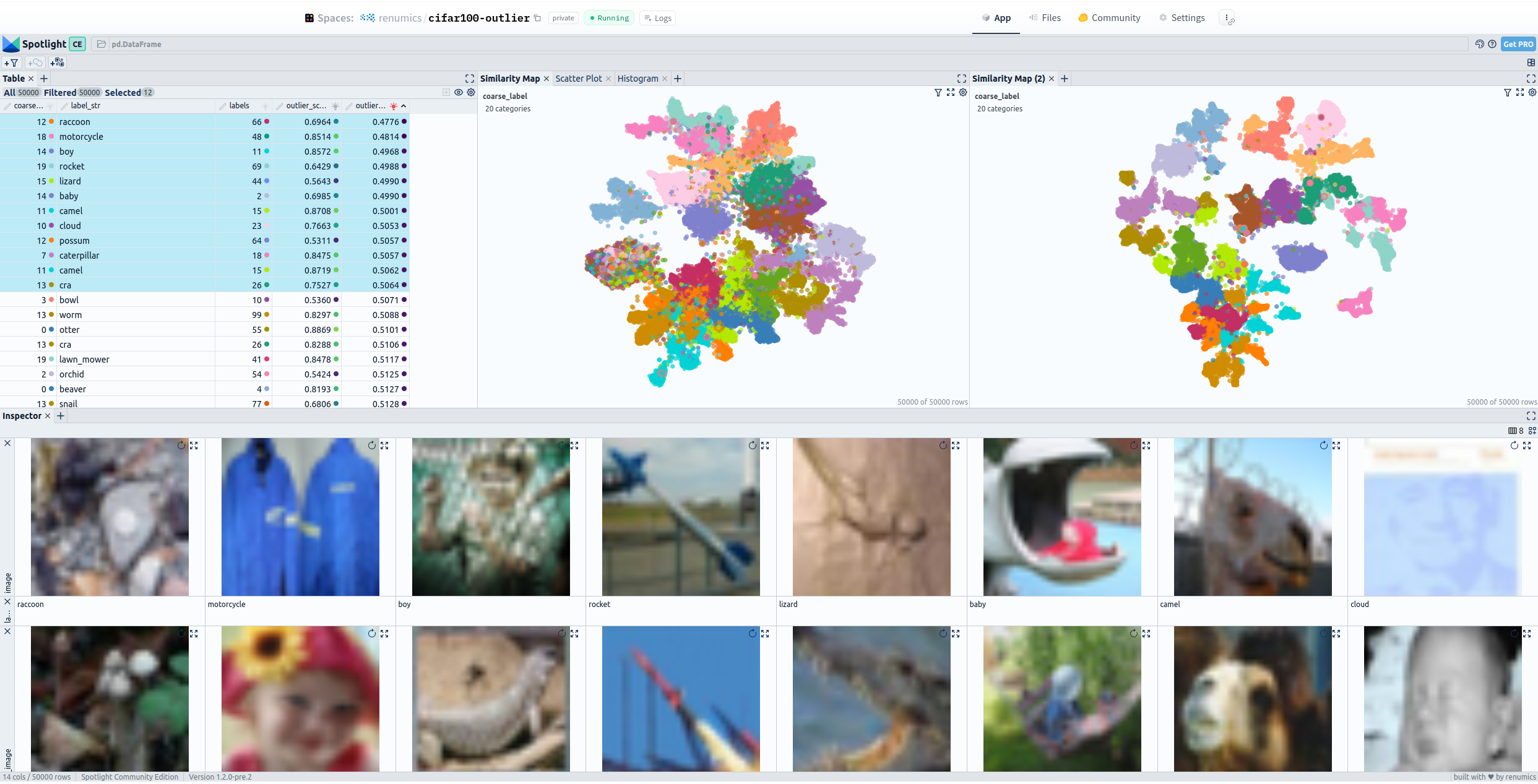
Or you can explorer it locally:
```python
!pip install renumics-spotlight datasets
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/cifar100-outlier", split="train")
df = ds.rename_columns({"img": "image", "fine_label": "labels"}).to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["fine_label"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
``` | 5,300 | [
[
-0.04571533203125,
-0.0399169921875,
0.00801849365234375,
0.0221099853515625,
-0.0082550048828125,
0.002925872802734375,
-0.0223388671875,
-0.0071868896484375,
0.045562744140625,
0.03997802734375,
-0.04913330078125,
-0.04437255859375,
-0.043212890625,
-0.010... |
Middletownbooks/joke_training | 2023-06-17T06:42:04.000Z | [
"license:mit",
"region:us"
] | Middletownbooks | null | null | 3 | 4 | 2023-06-17T04:36:43 | ---
license: mit
---
Also recommended for inclusion with this training set is a cleaned up version of https://huggingface.co/datasets/laion/OIG/blob/main/unified_joke_explanations.jsonl
The ~10k jokes in the jokes file started out as as a file of jokes from reddit and I manually categorized a couple thousand of them.
The open question and conversational instructions attempt to integrate jokes into databricks dolly 15k instruction open_qa replies, sometimes slightly modified.
The news headlines and news article summary joke puchlines were created by an expert punchline writer, who has given permission for their non exclusive use for this purpose.
| 657 | [
[
-0.0256195068359375,
-0.05010986328125,
0.0266265869140625,
0.03387451171875,
-0.040374755859375,
-0.021820068359375,
0.005336761474609375,
-0.016937255859375,
0.006237030029296875,
0.074462890625,
-0.053680419921875,
-0.0225677490234375,
-0.0018606185913085938,... |
LennardZuendorf/openlegaldata-processed | 2023-10-07T20:13:13.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:de",
"license:mit",
"legal",
"region:us"
] | LennardZuendorf | null | null | 1 | 4 | 2023-06-17T12:43:20 | ---
license: mit
dataset_info:
features:
- name: id
dtype: int64
- name: court
struct:
- name: id
dtype: int64
- name: jurisdiction
dtype: string
- name: level_of_appeal
dtype: string
- name: name
dtype: string
- name: state
dtype: int64
- name: file_number
dtype: string
- name: date
dtype: timestamp[s]
- name: type
dtype: string
- name: content
dtype: string
- name: tenor
dtype: string
- name: facts
dtype: string
- name: reasoning
dtype: string
splits:
- name: three
num_bytes: 169494251
num_examples: 2828
- name: two
num_bytes: 183816899
num_examples: 4954
download_size: 172182482
dataset_size: 353311150
task_categories:
- text-classification
language:
- de
tags:
- legal
pretty_name: Edited German Court case decision
size_categories:
- 1K<n<10K
---
# Dataset Card for openlegaldata.io bulk case data
## Dataset Description
This is a edit/cleanup of Bulk Data of [openlegaldata.io](https://de.openlegaldata.io/), which I also brought onto Huggingface [here](LennardZuendorf/openlegaldata-bulk-data).
#### The Entire Dataset Is In German
- **Github Repository:** [uniArchive-legalis]](https://github.com/LennardZuendorf/uniArchive-legalis)
- **Repository:** [Bulk Data](https://static.openlegaldata.io/dumps/de/)
## Edit Summary
I have done some cleaning and splitting of the data and filtered out large parts that were not (easily) usable, cutting down the number of cases to at max 4000 - from 250000. This results in two different splits. Which is because German Courts don't format their case decision the same way.
### Data Fields
Independent of the split, most fields are the same, they are:
| id | court | file_number | date | type | content
| - | - | - | - | - | - |
| numeric id | name of the court that made the decision | file number of the case ("Aktenzeichen") | decision date | type of the case decision | entire content (text) of the case decision
Additionally, I added 3 more fields because of the splitting of the content:
#### Two Split
- Case Decision I could split into two parts: tenor and reasoning.
- Which means the three fields tenor, content and facts contain the following:
| tenor | reasoning | facts
| - | - | - |
| An abstract, legal summary of the cases decision | the entire rest of the decision, explaining in detail why the decision has been made | an empty text field |
#### Three Split
- Case Decision I could split into three parts: tenor, reasoning and facts
- This Data I have used to create binary labels with the help of ChatGPT, see [legalis](https://huggingface.co/datasets/LennardZuendorf/legalis) for that
- The three fields tenor, content and facts contain the following:
| tenor | reasoning | facts
| - | - | - |
| An abstract, legal summary of the cases decision | the entire rest of the decision, explaining in detail why the decision has been made | the facts and details of a case |
### Languages
- German
## Additional Information
### Licensing/Citation Information
The [openlegaldata platform](https://github.com/openlegaldata/oldp) is licensed under the MIT license, you can access the dataset by citing the original source, [openlegaldata.io](https://de.openlegaldata.io/) and me, [Lennard Zündorf](https://github.com/LennardZuendorf) as the editor of this dataset. | 3,383 | [
[
-0.032623291015625,
-0.0496826171875,
0.041290283203125,
0.0152130126953125,
-0.040130615234375,
-0.0300750732421875,
-0.00806427001953125,
-0.016876220703125,
0.03192138671875,
0.0482177734375,
-0.02313232421875,
-0.07879638671875,
-0.032745361328125,
-0.01... |
collabora/whisperspeech | 2023-10-07T06:41:11.000Z | [
"task_categories:text-to-speech",
"language:en",
"license:mit",
"region:us"
] | collabora | null | null | 3 | 4 | 2023-06-19T10:39:41 | ---
license: mit
task_categories:
- text-to-speech
language:
- en
pretty_name: WhisperSpeech
---
# The WhisperSpeech Dataset
This dataset contains data to train SPEAR TTS-like text-to-speech models that utilized semantic tokens derived from the OpenAI Whisper
speech recognition model.
We currently provide semantic and acoustic tokens for the LibriLight and LibriTTS datasets (English only).
Acoustic tokens:
- 24kHz EnCodec 6kbps (8 quantizers)
Semantic tokens:
- Whisper tiny VQ bottleneck trained on a subset of LibriLight
Available LibriLight subsets:
- `small`/`medium`/`large` (following the original dataset division but with `large` excluding the speaker `6454`)
- a separate ≈1300hr single-speaker subset based on the `6454` speaker from the `large` subset for training single-speaker TTS models
We plan to add more acoustic tokens from other codecs in the future. | 881 | [
[
0.0026397705078125,
-0.0177001953125,
0.0117950439453125,
0.00787353515625,
-0.0269012451171875,
0.0003161430358886719,
-0.004512786865234375,
-0.04339599609375,
0.0203399658203125,
0.047027587890625,
-0.054473876953125,
-0.049530029296875,
-0.0272674560546875,
... |
Patt/RTE_TH_drop | 2023-06-22T09:21:18.000Z | [
"task_categories:text-classification",
"language:en",
"language:th",
"arxiv:1907.04307",
"region:us"
] | Patt | null | null | 0 | 4 | 2023-06-21T11:34:48 | ---
task_categories:
- text-classification
language:
- en
- th
---
# Dataset Card for RTE_TH_drop
### Dataset Description
This dataset is Thai translated version of [RTE](https://huggingface.co/datasets/super_glue/viewer/rte) using google translate with [Multilingual Universal Sentence Encoder](https://arxiv.org/abs/1907.04307) to calculate score for Thai translation.
Some line which score_hypothesis <= 0.5 or score_premise <= 0.7 had been droped. | 453 | [
[
-0.0252838134765625,
-0.049407958984375,
-0.00138092041015625,
0.0269775390625,
-0.037841796875,
-0.0165863037109375,
-0.0183868408203125,
-0.0196533203125,
0.03472900390625,
0.041107177734375,
-0.0533447265625,
-0.059661865234375,
-0.04766845703125,
0.02584... |
oobabooga/preset-arena | 2023-06-23T05:32:28.000Z | [
"license:cc-by-4.0",
"region:us"
] | oobabooga | null | null | 2 | 4 | 2023-06-23T04:05:36 | ---
license: cc-by-4.0
---
# Preset Arena dataset
## Description
* **dataset.json**: contains pairs of completions generated with different presets for the same prompts. The chat prompts were constructed based on [SODA](https://huggingface.co/datasets/allenai/soda), whereas the instruct prompts were extracted from [WizardLM_evol_instruct_70k](https://huggingface.co/datasets/WizardLM/WizardLM_evol_instruct_70k).
* **votes.json**: the votes given by users. Each vote contains two fields: the row number, and either "left" or "right". For instance, ["instruct", 2982, "left"] corresponds to data["instruct"][2982], where the user chose left (preset1). The alternative would be right, corresponding to preset2. The indexing starts at 0 (like Python).
* **presets.zip**: the preset definitions. They are applied on top of the default below.
* **elo-score-ranking.csv**: an elo score ranking generated from the data.
## Top voters
1) Phosay: 186 votes
2) mindrage: 170 votes
3) xytarez: 153 votes
4) jllllll: 146 votes
5) acrastt: 131 votes
6) Nancy: 112 votes
7) oobabooga: 97 votes
8) jackork: 78 votes
9) Moootpoint: 77 votes
10) Aohai: 62 votes
11) samfundev: 53 votes
12) Frank Liu: 52 votes
13) marianbasti: 42 votes
14) altoiddealer: 41 votes
15) NoProtocol: 40 votes
16) hyunahri: 37 votes
17) alto: 35 votes
18) Kane Hudson: 35 votes
19) satothedude: 30 votes
20) hu: 30 votes
Honorary mentions: Alear, Vadimluck, Cereal Velocity, Rimants Sakins, Tostino, Soup, Nix, Calem, YearZero, Drilldo, The_AI_Fan, Lylepaul78, Cypherfox, jcru, meditans, Thunder tree, Miller, MAIdragora, test, Mystifistisk, KOTOB, DerKruste, Rylan Taylor, eunone, Matilde Ametrine, ooodi, axutio, Pyrater, DR, ALEX, volrath50, imakesound, byttle, Ragora, Phillip Lin, BlackDragonBE, underlines, ragnaruss, psychoworsed, jbluew, eiery, WolframRavenwolf, Seri, Seppl, Minh, Joe Biden (Real), Hero, thelustriva, laobao, beno, TheVolkLisa, ElectronSpiderwort, Chromix, Cebtenzzre, cherubble, The Prism, SunCardinal, Root, Ratieu, Fuingo, Fire, Dolyfin, jzinno, gourdo, giesse, WalterMcMelon, Durnehviir, David_337, Dacxel, Charles Goddard, zhou biden, semilucidtrip, ratana, lounger., jarnMod, cack, Yuuru, YSM, Squirrelly, Rockferd, Phil, Pathos, Nick292929, Michael Fraser, Lucifer, Jason Earnest Coker, 1980Dragon, wecardo, universewithtin, kusoge, grummxvx, codynhanpham, abrisene, Tuna, PretzelVector, zyugyzarc, smythreens, o, ninecats, mystic_wiz, morphles, ilu, elperson, cyanf, c0sogi, Winter, Whoever, PlatinaCoder, Manuel Materazzo, HayDoru, Graham Reed, FlyingBanana391, Dark, rerri, rat, jojo, heZamelliac, haha, bunny, belladore.ai, andy, WadRex, Vokturz, Tivi, Tehehe, Streak, Rikikav, Panchovix, MissHentai, Latent, Incomple_, Biogoly, BalTac, Axodus, Andvig, xcoolcoinx, shinkarom, sectix, nikronic, ioujn, hong, gf, cl, bumda, alain40, Xad, Wolokin, Stefan, Romonoss, PresetWin!, Pawit, Nightcall, Muba, Matheus, Mash, Koray, Gerald, Finx, Draco25240, Bart, smashmaster0045, sfdf, pvm, nanowell , hi, eloitor, camronbergh, XD, Vfrap, Timmy, Som, Rain, Mior, Krisu, Hhm, Gabrieldelyon, Fellowship, Daniq, CyberTimon, Brian, ApparentlyAnAI, A, 11
## Default parameters
```python
generate_params = {
'do_sample': True,
'temperature': 1,
'top_p': 1,
'typical_p': 1,
'epsilon_cutoff': 0,
'eta_cutoff': 0,
'tfs': 1,
'top_a': 0,
'repetition_penalty': 1,
'encoder_repetition_penalty': 1,
'top_k': 0,
'num_beams': 1,
'penalty_alpha': 0,
'min_length': 0,
'length_penalty': 1,
'no_repeat_ngram_size': 0,
'early_stopping': False,
'mirostat_mode': 0,
'mirostat_tau': 5.0,
'mirostat_eta': 0.1,
}
```
## Models
These models were used for the completions:
* Instruct prompts: Vicuna 13b v1.1 (GPTQ, 4-bit, 128g).
* Chat prompts: LLaMA 13b (GPTQ, 4-bit, 128g).
| 3,831 | [
[
-0.0401611328125,
-0.0234527587890625,
0.032012939453125,
0.0159454345703125,
-0.001312255859375,
0.01169586181640625,
0.00597381591796875,
-0.0150299072265625,
0.04345703125,
0.0253448486328125,
-0.05316162109375,
-0.05816650390625,
-0.045684814453125,
0.02... |
hamlegs/SquishmallowImages | 2023-06-23T04:34:53.000Z | [
"region:us"
] | hamlegs | null | null | 0 | 4 | 2023-06-23T04:30:53 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
seyyedaliayati/solidity-dataset | 2023-06-23T21:03:40.000Z | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:en",
"license:cc",
"solidity",
"test case",
"smart contract",
"ethereum",
"doi:10.57967/hf/0808",
"region:us"
] | seyyedaliayati | null | null | 1 | 4 | 2023-06-23T20:26:13 | ---
dataset_info:
features:
- name: hash
dtype: string
- name: size
dtype: int64
- name: ext
dtype: string
- name: lang
dtype: string
- name: is_test
dtype: bool
- name: repo_id
dtype: string
- name: repo_name
dtype: string
- name: repo_head
dtype: string
- name: repo_path
dtype: string
- name: content_tokens
dtype: int64
- name: content_chars
dtype: int64
- name: content
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 5736925269
num_examples: 284112
- name: test
num_bytes: 710770657
num_examples: 35514
- name: eval
num_bytes: 721961344
num_examples: 35514
download_size: 2050339485
dataset_size: 7169657270
license: cc
task_categories:
- text-generation
- text2text-generation
- text-classification
language:
- en
tags:
- solidity
- test case
- smart contract
- ethereum
pretty_name: Solidity Dataset
size_categories:
- 100K<n<1M
---
# Solidity Dataset
## Dataset Description
This dataset is collected from public GitHub repositories written in Solidity programming language.
The list of the repositories is available at [repositories.json](https://huggingface.co/datasets/seyyedaliayati/solidity-dataset/blob/main/repositories.json) file.
It contains useful data about smart contracts written in Solidity along with test cases (and unit tests) written to test smart contracts.
## Dataset Summary
The dataset contains of [355,540 rows](#data-splits) in total. Each row includes the following features:
- `hash` (string): The sha256 hash value of the file content before any pre-processing.
- `size` (integer): File size in bytes.
- `ext` (string): File extention.
- `lang` (string): The name of the programming language that the file is written with. (Solidity or Python or JavaScript)
- `is_test` (bool): Indicates whether this file is test case (test file) or the smart contract main code.
- `repo_id` (string): GitHub's repository identifer fetched from GitHub's API.
- `repo_name` (string): GitHub's repository name.
- `repo_head` (string): The head commit of the repository that the file is fetched.
- `repo_path` (string): Relative file path.
- `content_tokens` (integer): Number of tokens in the file content.
- `content_chars` (integer): Number of characters in the file content.
- `content` (string): File content.
- `__index_level_0__` (integer): Ignore this field please!
## Supported Tasks and Leaderboards
This dataset can be used for tasks related to analyzing smart contracts, test cases in smart contracts, and improving language models on Solidity language.
As of now, there are no specific leaderboards associated with this dataset.
## Languages
- The dataset is in the English language (en).
- Smart contracts (`is_test=false`) are in Solidity programming language.
- Test cases (`is_test=true`) are in Solidity, Python, or JavaScript programming language.
## Data Splits
The dataset is split into three splits:
- `train`: 284112 rows (80% of the dataset)
- `test`: 35514 rows (10% of the dataset)
- 'eval': 35514 rows (10% of the dataset)
## Dataset Creation
The `content_token` is generated via [StarCoderBase tokenizer](https://huggingface.co/bigcode/starcoderbase) using the following code snippet:
```python
from transformers import AutoTokenizer
checkpoint = "bigcode/starcoderbase"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def count_tokens(code: str) -> int:
tokens = tokenizer.tokenize(code)
return len(tokens)
```
The `is_test` calculated by detecting some regex patterns in the file content. More details will publish soon.
## License
This dataset is released under the [Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license](https://creativecommons.org/licenses/by-nc/4.0/).
## Citation
Please use the following citation when referencing the this dataset:
```
@misc {seyyed_ali_ayati_2023,
author = { {Seyyed Ali Ayati} },
title = { solidity-dataset (Revision 77e80ad) },
year = 2023,
url = { https://huggingface.co/datasets/seyyedaliayati/solidity-dataset },
doi = { 10.57967/hf/0808 },
publisher = { Hugging Face }
}
``` | 4,235 | [
[
-0.0231475830078125,
-0.0390625,
0.01293182373046875,
-0.00016498565673828125,
-0.02093505859375,
0.00241851806640625,
-0.0171966552734375,
-0.00687408447265625,
0.040557861328125,
0.048828125,
-0.023773193359375,
-0.06341552734375,
-0.029510498046875,
0.011... |
caldervf/cicero_dataset_with_embeddings_and_faiss_index | 2023-06-24T08:15:45.000Z | [
"region:us"
] | caldervf | null | null | 0 | 4 | 2023-06-24T08:06:40 | ---
dataset_info:
features:
- name: _id
dtype: string
- name: title
dtype: string
- name: content
dtype: string
- name: summary
dtype: string
- name: content_filtered
dtype: string
- name: embeddings
sequence: float32
splits:
- name: train
num_bytes: 19279400
num_examples: 1143
download_size: 13285598
dataset_size: 19279400
---
# Dataset Card for "cicero_dataset_with_embeddings_and_faiss_index"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 584 | [
[
-0.03662109375,
-0.00872802734375,
0.013885498046875,
0.02435302734375,
-0.00897216796875,
-0.0184326171875,
0.00716400146484375,
-0.0022525787353515625,
0.06585693359375,
0.01715087890625,
-0.0301055908203125,
-0.0693359375,
-0.03460693359375,
-0.0054168701... |
fujiki/guanaco_ja | 2023-07-16T15:01:30.000Z | [
"language:ja",
"license:gpl-3.0",
"region:us"
] | fujiki | null | null | 3 | 4 | 2023-06-24T08:27:30 | ---
language: ja
license: gpl-3.0
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 53655938
num_examples: 110633
download_size: 30465845
dataset_size: 53655938
---
- This is a Japanese portion of the [Guanaco dataset](https://huggingface.co/datasets/JosephusCheung/GuanacoDataset).
- You can also refer to other similar datasets like [inu-ai/alpaca-guanaco-japanese-gpt-1b](https://huggingface.co/inu-ai/alpaca-guanaco-japanese-gpt-1b). | 571 | [
[
-0.01375579833984375,
-0.053131103515625,
0.0254058837890625,
0.023223876953125,
-0.0296783447265625,
0.003910064697265625,
0.0199127197265625,
-0.0302886962890625,
0.07330322265625,
0.040771484375,
-0.0804443359375,
-0.041900634765625,
-0.038177490234375,
-... |
yulongmannlp/adv_ori | 2023-06-26T00:35:38.000Z | [
"region:us"
] | yulongmannlp | Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. | @article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
} | 0 | 4 | 2023-06-26T00:34:08 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
TrainingDataPro/people-tracking-dataset | 2023-09-19T19:35:09.000Z | [
"task_categories:image-segmentation",
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"legal",
"code",
"region:us"
] | TrainingDataPro | The dataset comprises of annotated video frames from positioned in a public
space camera. The tracking of each individual in the camera's view
has been achieved using the rectangle tool in the Computer Vision Annotation Tool (CVAT). | @InProceedings{huggingface:dataset,
title = {people-tracking-dataset},
author = {TrainingDataPro},
year = {2023}
} | 1 | 4 | 2023-06-26T12:58:57 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
- image-classification
language:
- en
tags:
- legal
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: annotations
dtype: string
splits:
- name: train
num_bytes: 52028802
num_examples: 41
download_size: 45336774
dataset_size: 52028802
---
# People Tracking Dataset
The dataset comprises of annotated video frames from positioned in a public space camera. The tracking of each individual in the camera's view has been achieved using the rectangle tool in the Computer Vision Annotation Tool (CVAT).
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=people-tracking-dataset) to discuss your requirements, learn about the price and buy the dataset.

# Dataset Structure
- The `images` directory houses the original video frames, serving as the primary source of raw data.
- The `annotations.xml` file provides the detailed annotation data for the images.
- The `boxes` directory contains frames that visually represent the bounding box annotations, showing the locations of the tracked individuals within each frame. These images can be used to understand how the tracking has been implemented and to visualize the marked areas for each individual.
# Data Format
The annotations are represented as rectangle bounding boxes that are placed around each individual. Each bounding box annotation contains the position ( `xtl`-`ytl`-`xbr`-`ybr` coordinates ) for the respective box within the frame.
.png?generation=1687776281548084&alt=media)
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=people-tracking-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,501 | [
[
-0.04364013671875,
-0.0224609375,
0.0171661376953125,
-0.005390167236328125,
-0.0167388916015625,
0.0094757080078125,
0.0163116455078125,
-0.0238494873046875,
0.05023193359375,
0.057525634765625,
-0.0635986328125,
-0.057281494140625,
-0.037078857421875,
-0.0... |
TrainingDataPro/anti-spoofing-real-waist-high-dataset | 2023-09-14T16:55:22.000Z | [
"task_categories:video-classification",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"legal",
"region:us"
] | TrainingDataPro | The dataset consists of waist-high selfies and video of real people.
The dataset solves tasks in the field of anti-spoofing and it is useful
for buisness and safety systems. | @InProceedings{huggingface:dataset,
title = {anti-spoofing-real-waist-high-dataset},
author = {TrainingDataPro},
year = {2023}
} | 1 | 4 | 2023-06-30T11:26:26 | ---
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
- image-to-image
language:
- en
tags:
- legal
dataset_info:
features:
- name: photo
dtype: image
- name: video
dtype: string
- name: phone
dtype: string
- name: gender
dtype: string
- name: age
dtype: int8
- name: country
dtype: string
splits:
- name: train
num_bytes: 34728975
num_examples: 8
download_size: 195022198
dataset_size: 34728975
---
# Anti-Spoofing Real Waist-High Dataset
The dataset consists of waist-high selfies and video of real people. The dataset solves tasks in the field of anti-spoofing and it is useful for buisness and safety systems.
### The dataset includes 2 different types of files:
- **Photo** - a selfie of a person from a mobile phone, the person is depicted alone on it, the face is clearly visible. Person is presented waist-high.
- **Video** - filmed on the front camera, on which a person moves his/her head left, right, up and down. Duration of the video is from 10 to 20 seconds.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=anti-spoofing-real-waist-high-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
- The folder **"photo"** includes selfies of people
- The folder **"video"** includes videos of people
### File with the extension .csv
includes the following information for each media file:
- **photo**: link to access the selfie,
- **video**: link to access the video,
- **phone**: the device used to capture selfie and video,
- **gender**: gender of a person,
- **age**: age of the person,
- **country**: country of the person
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=anti-spoofing-real-waist-high-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,413 | [
[
-0.0300445556640625,
-0.046875,
-0.003429412841796875,
0.0172576904296875,
-0.022430419921875,
0.0150604248046875,
0.01468658447265625,
-0.032867431640625,
0.056732177734375,
0.04742431640625,
-0.048004150390625,
-0.0418701171875,
-0.0399169921875,
-0.020034... |
nRuaif/OpenOrca-GPT3.5 | 2023-07-03T10:52:16.000Z | [
"region:us"
] | nRuaif | null | null | 0 | 4 | 2023-07-02T11:55:39 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
santoshtyss/uk_courts_cases | 2023-07-03T10:12:17.000Z | [
"region:us"
] | santoshtyss | null | null | 0 | 4 | 2023-07-03T10:10:04 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1734427314
num_examples: 39040
- name: validation
num_bytes: 211421379
num_examples: 4000
download_size: 983466250
dataset_size: 1945848693
---
# Dataset Card for "uk_courts_cases"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 435 | [
[
-0.0248565673828125,
0.00228118896484375,
0.036956787109375,
0.00843048095703125,
-0.0302276611328125,
-0.0131378173828125,
0.022247314453125,
0.0110321044921875,
0.04315185546875,
0.036407470703125,
-0.0458984375,
-0.05908203125,
-0.035797119140625,
-0.0270... |
Binaryy/travel_sample_extended | 2023-07-03T19:50:34.000Z | [
"region:us"
] | Binaryy | null | null | 1 | 4 | 2023-07-03T19:50:17 | ---
dataset_info:
features:
- name: query
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 203357
num_examples: 110
download_size: 109729
dataset_size: 203357
---
# Dataset Card for "travel_sample_extended"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 398 | [
[
-0.0364990234375,
-0.0096588134765625,
0.0232696533203125,
0.0195159912109375,
-0.00830078125,
-0.00475311279296875,
0.00806427001953125,
-0.017730712890625,
0.06439208984375,
0.0352783203125,
-0.07794189453125,
-0.050537109375,
-0.0296478271484375,
-0.01690... |
jjzha/kompetencer | 2023-10-08T15:16:13.000Z | [
"language:da",
"license:cc-by-4.0",
"region:us"
] | jjzha | null | null | 0 | 4 | 2023-07-04T13:41:15 | ---
license: cc-by-4.0
language: da
---
This is the Kompetencer dataset created by:
```
@inproceedings{zhang-etal-2022-kompetencer,
title = "Kompetencer: Fine-grained Skill Classification in {D}anish Job Postings via Distant Supervision and Transfer Learning",
author = "Zhang, Mike and
Jensen, Kristian N{\o}rgaard and
Plank, Barbara",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.46",
pages = "436--447",
}
```
There are document delimiters indicated by `idx`.
Number of samples (sentences):
- train: 778
- dev: 346
- test: 262
Sources:
- STAR (house)
Type of tags:
- Generic BIO tags with keys `tags_skill` and `tags_knowledge`
Sample:
```
{
"idx": 1,
"tokens": ["Du", "skal", "s\u00e6tte", "dagsordenen", "v\u00e6re", "v\u00e6rdiskabende", "og", "levere", "skarpt", "fagligt", "og", "strategisk", "med-", "og", "modspil", "."],
"tags_skill": ["O", "O", "B", "I", "B", "I", "O", "B", "I", "I", "I", "I", "I", "I", "I", "I"],
"tags_knowledge": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]
}
``` | 1,312 | [
[
-0.01788330078125,
-0.0212554931640625,
0.0214080810546875,
-0.017608642578125,
-0.00699615478515625,
0.005924224853515625,
-0.00838470458984375,
-0.01189422607421875,
0.0012712478637695312,
0.043670654296875,
-0.040618896484375,
-0.057525634765625,
-0.049652099... |
lum-ai/metal-python-gentlenlp-explanatations | 2023-07-04T23:18:32.000Z | [
"region:us"
] | lum-ai | null | null | 0 | 4 | 2023-07-04T23:18:31 | ---
dataset_info:
features:
- name: id
dtype: string
- name: chunk_id
dtype: string
- name: text
dtype: string
- name: start_text
dtype: int64
- name: stop_text
dtype: int64
- name: code
dtype: string
- name: start_code
dtype: int64
- name: stop_code
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 4621098
num_examples: 147
download_size: 108196
dataset_size: 4621098
---
# Dataset Card for "metal-python-gentlenlp-explanatations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 673 | [
[
-0.0226287841796875,
-0.025299072265625,
0.001392364501953125,
0.0197296142578125,
-0.0086822509765625,
-0.012451171875,
-0.002475738525390625,
-0.0033168792724609375,
0.04412841796875,
0.0173797607421875,
-0.066162109375,
-0.054290771484375,
-0.0156173706054687... |
Bellaaazzzzz/wireframe | 2023-07-05T23:08:29.000Z | [
"region:us"
] | Bellaaazzzzz | null | null | 0 | 4 | 2023-07-05T23:06:59 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
- name: additional_feature
dtype: string
- name: conditioning_image
dtype: image
splits:
- name: train
num_bytes: 1627468620.0
num_examples: 5000
- name: test
num_bytes: 153429794.0
num_examples: 462
download_size: 1775502345
dataset_size: 1780898414.0
---
# Dataset Card for "wireframe"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 554 | [
[
-0.044647216796875,
-0.02496337890625,
0.01351165771484375,
0.0201568603515625,
0.00003319978713989258,
0.007568359375,
0.028045654296875,
-0.0012788772583007812,
0.06536865234375,
0.0232086181640625,
-0.06158447265625,
-0.0489501953125,
-0.02801513671875,
-... |
DynamicSuperb/SpeechTextMatching_LibriSpeech-TestClean | 2023-08-01T06:43:16.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-09T15:52:53 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: text
dtype: string
- name: instruction
dtype: string
- name: label
dtype: string
- name: transcription
dtype: string
splits:
- name: test
num_bytes: 372177496.46
num_examples: 2620
download_size: 350698434
dataset_size: 372177496.46
---
# Dataset Card for "speechTextMatching_Librispeech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 565 | [
[
-0.034515380859375,
-0.02008056640625,
0.0041961669921875,
0.021270751953125,
-0.0036296844482421875,
-0.005889892578125,
-0.0069580078125,
-0.016571044921875,
0.06341552734375,
0.030303955078125,
-0.0665283203125,
-0.05572509765625,
-0.038604736328125,
-0.0... |
NeSTudio/NestQuad | 2023-07-18T11:39:20.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:ru",
"license:apache-2.0",
"region:us"
] | NeSTudio | null | null | 0 | 4 | 2023-07-10T07:45:46 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- ru
pretty_name: nestquad
size_categories:
- 10K<n<100K
---
# NestQuad
Это датасет, который является объединением Sberquad и нашего датасета, созданного при помощи метода wizard. Используется для Q&A системы
| <!-- --> | <!-- --> |
|----------|----------|
| Размерность | 75300 |
| Аугментация по контекстам | 5.48 |
| Актуальность | 2023 |
| Объективность оценочная | 70% |
| Объективность структура | 95% |
| Целостность | 90% |
| Релевантность | 60% |
| Совместимость | 90% |
| Уникальных ответов |49161 |
| Уникальные контексты | 13728 |
Структура датасета:
| id | cluster | title | context | question | answers | answers_start | answers_end |
|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| Уникальный ID | Множество общих тем | Множество конкретных тем | Контекст | Вопрос | Ответ | Начало ответа в контексте | Конец ответа в контексте |
| Источники|
|----------|
| Sberquad (huggingface) - https://huggingface.co/datasets/sberquad |
| Информация про туризм - https://tour-poisk.com/articles/, https://www.sravni.ru/enciklopediya/turizm/oteli/ |
@MISC{NestQuad,
author
url
year
= {Emelyanov Anton, Nosov Andrey, Chernikov Kirill, Veselinovich Aleksandra, Nastalovskaya Tasia, Rastopshin Andrey},
title = {Russian dataset for Instruct/Chat models},
=
{https://huggingface.co/datasets/NeSTudio/NestQuad},
2023 | 1,507 | [
[
-0.042510986328125,
-0.050872802734375,
0.0157623291015625,
0.01319122314453125,
-0.0142974853515625,
0.0059051513671875,
0.005458831787109375,
-0.0214691162109375,
0.0406494140625,
0.003612518310546875,
-0.061676025390625,
-0.040557861328125,
-0.039581298828125... |
DynamicSuperb/SpeechTextMatching_LibriSpeech-TestOther | 2023-07-10T13:27:45.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-10T13:26:39 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: text
dtype: string
- name: instruction
dtype: string
- name: label
dtype: string
- name: transcription
dtype: string
splits:
- name: test
num_bytes: 352837231.811
num_examples: 2939
download_size: 333104131
dataset_size: 352837231.811
---
# Dataset Card for "speechTextMatching_LibrispeechTestOther"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 576 | [
[
-0.03009033203125,
-0.0181427001953125,
0.004039764404296875,
0.0197296142578125,
-0.003376007080078125,
-0.0005049705505371094,
-0.007289886474609375,
-0.01329803466796875,
0.05645751953125,
0.0321044921875,
-0.055023193359375,
-0.047882080078125,
-0.0462036132... |
DynamicSuperb/SpeechDetection_LibriSpeech-TestClean | 2023-07-12T05:42:02.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-11T14:25:30 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 358157508.64
num_examples: 2620
download_size: 349425014
dataset_size: 358157508.64
---
# Dataset Card for "speechDetection_LibrispeechTestClean"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 496 | [
[
-0.037109375,
-0.0233612060546875,
0.00811767578125,
0.00969696044921875,
-0.00669097900390625,
0.00511932373046875,
-0.005054473876953125,
-0.021514892578125,
0.06072998046875,
0.03326416015625,
-0.054443359375,
-0.052703857421875,
-0.04669189453125,
-0.033... |
DynamicSuperb/SpeechDetection_LibriSpeech-TestOther | 2023-07-12T05:39:41.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-11T15:17:20 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 341677506.59
num_examples: 2939
download_size: 331828900
dataset_size: 341677506.59
---
# Dataset Card for "speechDetection_LibrispeechTestOther"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 496 | [
[
-0.036285400390625,
-0.0243377685546875,
0.003810882568359375,
0.0106658935546875,
-0.003910064697265625,
0.0010366439819335938,
0.0041656494140625,
-0.0171356201171875,
0.05535888671875,
0.02862548828125,
-0.04937744140625,
-0.045196533203125,
-0.05026245117187... |
0x22almostEvil/words-operations-rewards-5k | 2023-07-11T21:15:27.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:en",
"language:ru",
"license:apache-2.0",
"semantics",
"region:us"
] | 0x22almostEvil | null | null | 0 | 4 | 2023-07-11T20:55:14 | ---
license: apache-2.0
task_categories:
- text-classification
- token-classification
- question-answering
language:
- en
- ru
tags:
- semantics
size_categories:
- 1K<n<10K
---
# Dataset Card for words-operations-rewards-5k with 5K entries.
### Dataset Summary
License: Apache-2.0. Contains JSONL. Use this for Reward Models.
# Solved tasks:
- Count Letters;
- Write Backwards;
- Write Character on a Position;
- Repeat Word;
- Write In Case;
- Change Case on a Position;
- Write Numbering;
- Connect Characters;
- Write a Word from Characters;
- Count Syllables;
# Example:
```json
{
"message_tree_id": "00000000-0000-0000-0000-000000000004",
"tree_state": "ready_for_export",
"prompt": {
"message_id": "00000000-0000-0000-0000-000000000004",
"text": "Count the number of letters in the word «detailed»",
"role": "prompter",
"lang": "en",
"replies": [
{ "message_id": "00000000-0000-0000-0000-000000000005",
"text": "8", "role": "assistant", "lang": "en",
"meta": {"rank": 1}, "replies": []},
{ "message_id": "00000000-0000-0000-0000-000000000006",
"text": "7", "role": "assistant", "lang": "en",
"meta": {"rank": 0}, "replies": []},
{"message_id": "00000000-0000-0000-0000-000000000007",
"text": "7 or 9", "role": "assistant", "lang": "en",
"meta": {"rank": 0}, "replies": []}]
}
}
``` | 1,418 | [
[
-0.0111541748046875,
-0.033294677734375,
0.017669677734375,
0.03759765625,
-0.0167236328125,
0.0002548694610595703,
-0.00628662109375,
-0.01195526123046875,
0.02276611328125,
0.045318603515625,
-0.061126708984375,
-0.078857421875,
-0.0706787109375,
0.0319213... |
DavidMOBrien/small_benchmark_webmarket-v2 | 2023-07-12T02:41:41.000Z | [
"region:us"
] | DavidMOBrien | null | null | 0 | 4 | 2023-07-12T02:41:39 | ---
dataset_info:
features:
- name: before
dtype: string
- name: after
dtype: string
- name: loc
dtype: int64
- name: repo
dtype: string
splits:
- name: train
num_bytes: 28849
num_examples: 23
download_size: 21446
dataset_size: 28849
---
# Dataset Card for "small_benchmark_webmarket-v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 462 | [
[
-0.037139892578125,
-0.00421142578125,
0.004291534423828125,
0.00707244873046875,
-0.0206298828125,
-0.0253448486328125,
0.00939178466796875,
-0.01739501953125,
0.03643798828125,
0.022491455078125,
-0.055450439453125,
-0.04217529296875,
-0.0210723876953125,
... |
RikoteMaster/isear_augmented | 2023-07-19T08:14:26.000Z | [
"region:us"
] | RikoteMaster | null | null | 0 | 4 | 2023-07-12T07:14:24 | ---
dataset_info:
features:
- name: Text_processed
dtype: string
- name: Emotion
dtype: string
- name: Augmented
dtype: bool
splits:
- name: train
num_bytes: 1130723
num_examples: 7499
- name: validation
num_bytes: 198379
num_examples: 1324
- name: test
num_bytes: 250735
num_examples: 1879
download_size: 923389
dataset_size: 1579837
---
# Dataset Card for "isear_augmented"
Classical ISEAR dataset augmented using gpt3.5 prompt tunning.
Example prompt:
Hello, you are going to take care of the task of increasing data in text. The data format that I am going to pass you is going to be as follows. Sentence: this is a sample text PROHIBITED WORD: this is a sample PROHIBITED WORD 2. Sentence: this is a sample text PROHIBITED WORD: this is a sample PROHIBITED WORD. I can enter as many sentences as I want, you must respect the logic that I have marked. NOW YOUR TASK MUST BE TO REFORMULATE THE SENTENCES IN ORDER TO EXPRESS THE SENTIMENT OF THE PROHIBITED WORD BUT YOU CANT USE THE PROHIBITED WORD BECAUSE IS FORBIDEN. PROHIBITED WORD LIST = [anger, fear, love, sadness, guilt, joy, shame, Overwhelming, remorse] you cannot use none of this words in the reformulation process, also you cannot use words derivated from this words and you must not do aclarations about what the text is trying to transmit. The output of the reformulated sentences must be Reformulated sentence 1: LorenIpsum reformulated sentence 2: LorenIpsum reformulated. Remember, I can introduce more than two sentences so you must return the reformulation of each sentence to me. So, remember, you must get a sentence that prevails the sentiment called the sentence PROHIBITED WORD but it is more important that the word does not appear inside the reformulation. If the word appears within the reformulation we would be entering into an incorrect practice of data augmentation. Yann LeCunn is watching, your bosses are watching you too, you must do what I ask you to do and get me the best sentences possible, but remember, without using the PROHIBITED WORD in the reformulation.1. Sentece: Unexpected visit by a close friend, whom I hadn't seen for half a
year. PROHIBITED WORD: joy
2. Sentece: I wandered by mistake into the safety zone of a shooting range,
and was shot at. PROHIBITED WORD: fear
3. Sentece: Being treated unfairly. PROHIBITED WORD: anger
4. Sentece: Breaking up with a girl. PROHIBITED WORD: sadness
5. Sentece: Nothing. PROHIBITED WORD: disgust
6. Sentece: None. PROHIBITED WORD: shame
7. Sentece: Little contact with my father before he died. PROHIBITED WORD: guilt
8. Sentece: When I was accepted as a student at the college, not having
thought it possible. PROHIBITED WORD: joy
The results obtained were quite well but when gpt obtain a way to express a sentiment with concrete words he is going to repeat it the structure, so you must reestructure the prompt
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 3,065 | [
[
-0.034637451171875,
-0.0745849609375,
0.0249786376953125,
0.0221099853515625,
-0.0460205078125,
-0.0269012451171875,
-0.0189056396484375,
-0.01348114013671875,
0.0243682861328125,
0.061798095703125,
-0.057159423828125,
-0.04205322265625,
-0.0535888671875,
0.... |
J0nasW/paperswithcode | 2023-07-31T12:23:25.000Z | [
"task_categories:text-classification",
"task_categories:feature-extraction",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"region:us"
] | J0nasW | null | null | 0 | 4 | 2023-07-14T09:30:13 | ---
license: mit
task_categories:
- text-classification
- feature-extraction
language:
- en
size_categories:
- 10K<n<100K
---
# A cleaned dataset from [paperswithcode.com](https://paperswithcode.com/)
*Last dataset update: July 2023*
This is a cleaned up dataset optained from [paperswithcode.com](https://paperswithcode.com/) through their [API](https://paperswithcode.com/api/v1/docs/) service. It represents a set of around 56K carefully categorized papers into 3K tasks and 16 areas. The papers contain arXiv and NIPS IDs as well as title, abstract and other meta information.
It can be used for training text classifiers that concentrate on the use of specific AI and ML methods and frameworks.
### Contents
It contains the following tables:
- papers.csv (around 56K)
- papers_train.csv (80% from 56K)
- papers_test.csv (20% from 56K)
- tasks.csv
- areas.csv
### Specials
UUIDs were added to the dataset since the PapersWithCode IDs (pwc_ids) are not distinct enough. These UUIDs may change in the future with new versions of the dataset.
Also, embeddings were calculated for all of the 56K papers using the brilliant model [SciNCL](https://huggingface.co/malteos/scincl) as well as dimensionality-redused 2D coordinates using UMAP.
There is also a simple Python Notebook which was used to optain and refactor the dataset. | 1,333 | [
[
-0.01161956787109375,
-0.006244659423828125,
0.02587890625,
0.00029969215393066406,
0.000028789043426513672,
-0.0096893310546875,
-0.002227783203125,
-0.0205841064453125,
0.0167236328125,
0.048431396484375,
-0.0144195556640625,
-0.045379638671875,
-0.03768920898... |
DynamicSuperb/ReverberationDetection_LJSpeech_RirsNoises-LargeRoom | 2023-07-18T11:05:11.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-14T15:41:37 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 3371777837.0
num_examples: 26200
download_size: 3362245153
dataset_size: 3371777837.0
---
# Dataset Card for "ReverberationDetectionlargeroom_LJSpeechRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 512 | [
[
-0.04547119140625,
-0.0022869110107421875,
0.006969451904296875,
0.0214996337890625,
-0.004337310791015625,
0.01373291015625,
0.0006718635559082031,
-0.01342010498046875,
0.062408447265625,
0.04095458984375,
-0.06683349609375,
-0.043121337890625,
-0.032531738281... |
DynamicSuperb/ReverberationDetection_LJSpeech_RirsNoises-MediumRoom | 2023-07-18T12:32:00.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-14T15:42:00 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 3372037586.0
num_examples: 26200
download_size: 3361834280
dataset_size: 3372037586.0
---
# Dataset Card for "ReverberationDetectionmediumroom_LJSpeechRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 513 | [
[
-0.04840087890625,
0.00017762184143066406,
0.0087890625,
0.01369476318359375,
-0.002956390380859375,
0.001140594482421875,
0.0064849853515625,
-0.0029239654541015625,
0.0601806640625,
0.041015625,
-0.06939697265625,
-0.04229736328125,
-0.0263214111328125,
-0... |
DynamicSuperb/ReverberationDetection_VCTK_RirsNoises-LargeRoom | 2023-07-18T12:55:14.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-15T02:19:17 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 2573816428.0
num_examples: 20000
download_size: 2505125831
dataset_size: 2573816428.0
---
# Dataset Card for "ReverberationDetectionlargeroom_VCTKRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 508 | [
[
-0.049468994140625,
-0.00446319580078125,
0.0016145706176757812,
0.03955078125,
-0.020172119140625,
0.002689361572265625,
0.01100921630859375,
-0.0017175674438476562,
0.050994873046875,
0.04254150390625,
-0.06964111328125,
-0.046417236328125,
-0.031585693359375,... |
DynamicSuperb/ReverberationDetection_VCTK_RirsNoises-MediumRoom | 2023-07-18T12:44:12.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-15T02:19:46 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 2574013732.0
num_examples: 20000
download_size: 2499736310
dataset_size: 2574013732.0
---
# Dataset Card for "ReverberationDetectionmediumroom_VCTKRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 509 | [
[
-0.049591064453125,
-0.002410888671875,
0.002532958984375,
0.0296478271484375,
-0.01800537109375,
-0.008392333984375,
0.01556396484375,
0.00975799560546875,
0.048583984375,
0.04437255859375,
-0.07061767578125,
-0.04583740234375,
-0.0250244140625,
-0.03030395... |
DynamicSuperb/ReverberationDetection_VCTK_RirsNoises-SmallRoom | 2023-07-18T13:08:26.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 4 | 2023-07-15T02:20:22 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 2573876458.0
num_examples: 20000
download_size: 2502921276
dataset_size: 2573876458.0
---
# Dataset Card for "ReverberationDetectionsmallroom_VCTKRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 508 | [
[
-0.047943115234375,
-0.0037212371826171875,
-0.0019292831420898438,
0.047088623046875,
-0.021942138671875,
-0.0084075927734375,
0.0113677978515625,
0.004062652587890625,
0.05035400390625,
0.03839111328125,
-0.07550048828125,
-0.050140380859375,
-0.02507019042968... |
HeshamHaroon/QA_Arabic | 2023-07-16T10:37:36.000Z | [
"task_categories:question-answering",
"task_categories:text-generation",
"task_categories:text2text-generation",
"language:ar",
"license:apache-2.0",
"question-answer",
"language-learning",
"chatbot",
"region:us"
] | HeshamHaroon | null | null | 6 | 4 | 2023-07-16T09:54:47 | ---
language:
- "ar"
pretty_name: "Questions and Answers Dataset in Arabic"
tags:
- "question-answer"
- "language-learning"
- "chatbot"
license: "apache-2.0"
task_categories:
- "question-answering"
- "text-generation"
- "text2text-generation"
---
# JSON File Description
## Overview
This JSON file contains a collection of questions and answers in Arabic. Each question is associated with its corresponding answer. The file is structured in a way that allows easy retrieval and utilization of the question-answer pairs.
## File Structure
The JSON file follows the following structure:
```json
{
"questions": [
{
"question": "من هو أول من نزل على سطح القمر؟",
"answer": "نيل أمسترونج"
},
{
"question": "كم عدد الأسنان في فم الإنسان العادي؟",
"answer": "32 سنا"
},
{
"question": "كم عدد أعين الذبابة؟",
"answer": "5 أعين"
},
{
"question": "كم عدد أرجل العنكبوت؟",
"answer": "ج4 - 8 أرجل"
},
{
"question": "س5 - ماذا يسمى بيت النمل؟",
"answer": "ج5 - قرية النمل"
},
{
"question": "س6 - كم عظمة توجد في جسم الإنسان؟",
"answer": "ج6 - 206 عظمات"
},
...
]
}
The file consists of a single object with one key, "questions," which contains an array of question-answer pairs. Each question-answer pair is represented as an object with two keys: "question" and "answer".
Usage:
- Question-Answer Retrieval: Parse the JSON file and access the question-answer pairs programmatically to retrieve specific questions and their corresponding answers.
- Language Learning: Utilize the question-answer pairs to develop language learning applications or quizzes where users can practice answering questions in Arabic.
- Chatbot Integration: Integrate the JSON file with a chatbot system to provide automated responses based on the questions and answers available.
Feel free to modify the JSON file by adding more question-answer pairs or use it as a reference to create your own question-answer datasets.
Contributing:
If you have additional questions and answers that you would like to contribute to this JSON file, please feel free to submit a pull request. Your contributions are greatly appreciated!
| 2,235 | [
[
-0.031585693359375,
-0.053192138671875,
0.0273284912109375,
0.019439697265625,
-0.020172119140625,
0.046875,
0.008514404296875,
-0.007266998291015625,
0.02301025390625,
0.051239013671875,
-0.02227783203125,
-0.059539794921875,
-0.0565185546875,
0.02334594726... |
Nacholmo/refined-keep-black-white | 2023-07-17T02:11:07.000Z | [
"region:us"
] | Nacholmo | null | null | 0 | 4 | 2023-07-17T02:06:27 | ---
dataset_info:
features:
- name: image
dtype: image
- name: generated_caption
dtype: string
- name: conditioning_image
dtype: image
splits:
- name: train
num_bytes: 3205101177.25
num_examples: 7999
download_size: 3169929614
dataset_size: 3205101177.25
---
# Dataset Card for "refined-keep-black-white"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 473 | [
[
-0.038482666015625,
-0.0171661376953125,
0.0080413818359375,
0.0054168701171875,
-0.0303802490234375,
0.0107574462890625,
-0.004302978515625,
-0.0195465087890625,
0.0677490234375,
0.03399658203125,
-0.0562744140625,
-0.04791259765625,
-0.03533935546875,
-0.0... |
ChristopherS27/bridgeSeg | 2023-07-17T18:57:08.000Z | [
"region:us"
] | ChristopherS27 | null | null | 0 | 4 | 2023-07-17T18:56:02 | ---
dataset_info:
features:
- name: image
dtype: image
- name: mask
dtype:
image:
id: false
splits:
- name: originalTrain
num_bytes: 128587568.0
num_examples: 396
- name: originalTest
num_bytes: 17776784.0
num_examples: 44
- name: augmentedTrain
num_bytes: 812077995.52
num_examples: 22176
- name: augmentedTest
num_bytes: 1824639.0
num_examples: 44
download_size: 834525070
dataset_size: 960266986.52
---
# Dataset Card for "bridgeSeg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 643 | [
[
-0.038787841796875,
-0.004695892333984375,
0.01084136962890625,
0.01629638671875,
-0.01203155517578125,
-0.0074310302734375,
0.0238800048828125,
-0.0167236328125,
0.055877685546875,
0.0231170654296875,
-0.05169677734375,
-0.05169677734375,
-0.0445556640625,
... |
raptorkwok/cantonese-traditional-chinese-parallel-corpus | 2023-09-29T04:26:30.000Z | [
"task_categories:translation",
"size_categories:100K<n<1M",
"language:zh",
"license:cc0-1.0",
"region:us"
] | raptorkwok | null | null | 1 | 4 | 2023-07-19T03:40:29 | ---
license: cc0-1.0
task_categories:
- translation
language:
- zh
pretty_name: Cantonese-Written Chinese Parallel Corpus
size_categories:
- 100K<n<1M
---
This is a dataset of Cantonese-Written Chinese Parallel Corpus, containing 130k+ pairs of Cantonese and Traditional Chinese parallel sentences. | 299 | [
[
-0.01241302490234375,
-0.025726318359375,
0.00550079345703125,
0.039031982421875,
-0.0065460205078125,
-0.0016279220581054688,
-0.01140594482421875,
-0.005176544189453125,
0.0377197265625,
0.060394287109375,
-0.035797119140625,
-0.05145263671875,
-0.011474609375... |
TrainingDataPro/hand-gesture-recognition-dataset | 2023-09-14T16:39:45.000Z | [
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset consists of videos showcasing individuals demonstrating 5 different
hand gestures (*"one", "four", "small", "fist", and "me"*). Each video captures
a person prominently displaying a single hand gesture, allowing for accurate
identification and differentiation of the gestures.
The dataset offers a diverse range of individuals performing the gestures,
enabling the exploration of variations in hand shapes, sizes, and movements
across different individuals.
The videos in the dataset are recorded in reasonable lighting conditions and
with adequate resolution, to ensure that the hand gestures can be easily
observed and studied. | @InProceedings{huggingface:dataset,
title = {hand-gesture-recognition-dataset},
author = {TrainingDataPro},
year = {2023}
} | 1 | 4 | 2023-07-19T10:47:52 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
tags:
- code
dataset_info:
features:
- name: set_id
dtype: int32
- name: fist
dtype: string
- name: four
dtype: string
- name: me
dtype: string
- name: one
dtype: string
- name: small
dtype: string
splits:
- name: train
num_bytes: 1736
num_examples: 28
download_size: 1510134076
dataset_size: 1736
---
# Hand Gesture Recognition Dataset
The dataset consists of videos showcasing individuals demonstrating 5 different hand gestures (*"one", "four", "small", "fist", and "me"*). Each video captures a person prominently displaying a single hand gesture, allowing for accurate identification and differentiation of the gestures.
The dataset offers a diverse range of individuals performing the gestures, enabling the exploration of variations in hand shapes, sizes, and movements across different individuals.
The videos in the dataset are recorded in reasonable lighting conditions and with adequate resolution, to ensure that the hand gestures can be easily observed and studied.
### The dataset's possible applications:
- hand gesture recognition
- gesture-based control systems
- virtual reality interactions
- sign language analysis
- human pose estimation and action analysis
- security and authentication systems

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=hand-gesture-recognition-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
- **files**: includes folders corresponding to people and containing videos with 5 different shown gestures, each file is named according to the captured gesture
- **.csv** file: contains information about files in the dataset
### Hand gestures in the dataset:
- "one"
- "four"
- "small"
- "clenched fist"
- "me"
### File with the extension .csv
includes the following information:
- **set_id**: id of the set of videos,
- **one**: link to the video with "one" gesture,
- **four**: link to the video with "four" gesture,
- **small**: link to the video with "small" gesture,
- **fist**: link to the video with "fist" gesture,
- **me**: link to the video with "me" gesture
# Videos with hand gestures might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=hand-gesture-recognition-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 3,050 | [
[
-0.01093292236328125,
-0.032318115234375,
-0.0052490234375,
0.00540924072265625,
-0.0266876220703125,
0.0006108283996582031,
0.00986480712890625,
-0.0168304443359375,
0.041961669921875,
0.023284912109375,
-0.059173583984375,
-0.055450439453125,
-0.06768798828125... |
Ryukijano/eurosat | 2023-07-19T12:23:14.000Z | [
"region:us"
] | Ryukijano | null | null | 0 | 4 | 2023-07-19T12:23:08 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': AnnualCrop
'1': Forest
'2': HerbaceousVegetation
'3': Highway
'4': Industrial
'5': Pasture
'6': PermanentCrop
'7': Residential
'8': River
'9': SeaLake
splits:
- name: train
num_bytes: 88397609.0
num_examples: 27000
download_size: 0
dataset_size: 88397609.0
---
# Dataset Card for "eurosat"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 667 | [
[
-0.06103515625,
-0.01751708984375,
0.0287017822265625,
0.0189361572265625,
-0.0134429931640625,
-0.0014495849609375,
0.0139312744140625,
-0.0223541259765625,
0.05877685546875,
0.03521728515625,
-0.058258056640625,
-0.0545654296875,
-0.0426025390625,
-0.00894... |
nos1de/vulnerable-functions | 2023-07-20T11:56:35.000Z | [
"region:us"
] | nos1de | null | null | 0 | 4 | 2023-07-19T20:13:58 | ---
dataset_info:
features:
- name: sha
dtype: string
- name: remote_url
dtype: string
- name: labels
dtype:
class_label:
names:
'0': vulnerable
'1': not_vulnerable
- name: commit_msg
dtype: string
- name: function
dtype: string
splits:
- name: train
num_bytes: 21681861
num_examples: 7240
download_size: 8393520
dataset_size: 21681861
---
# Dataset Card for "vulnerable-functions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 596 | [
[
-0.0298309326171875,
-0.028778076171875,
0.01136016845703125,
0.013397216796875,
-0.0114288330078125,
-0.01318359375,
0.0257110595703125,
-0.0219573974609375,
0.03741455078125,
0.040191650390625,
-0.052154541015625,
-0.04644775390625,
-0.045623779296875,
-0.... |
metalmerge/solar-panel-inspection | 2023-08-09T22:52:58.000Z | [
"region:us"
] | metalmerge | null | null | 0 | 4 | 2023-07-20T14:22:16 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
CosVersin/e621-tagger-patch | 2023-07-21T12:58:20.000Z | [
"region:us"
] | CosVersin | null | null | 0 | 4 | 2023-07-21T12:30:50 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
sam-mosaic/orca-gpt4-chatml | 2023-07-21T23:31:37.000Z | [
"region:us"
] | sam-mosaic | null | null | 4 | 4 | 2023-07-21T23:27:32 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 1868875699
num_examples: 994896
download_size: 1050255655
dataset_size: 1868875699
---
# Dataset Card for "orca-gpt4-chatml"
As of 7/21/23, the [OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca) dataset has something malformed, causing a crash when you try to load it in `dataset`.
The GPT-4 data looks good though, so I preprocess it and push it up here in ChatML format. | 538 | [
[
-0.026947021484375,
-0.041168212890625,
-0.003337860107421875,
0.01508331298828125,
-0.0230560302734375,
-0.009521484375,
0.0013132095336914062,
-0.03533935546875,
0.01806640625,
0.0400390625,
-0.033111572265625,
-0.059478759765625,
-0.0310211181640625,
-0.0... |
samchain/BIS_Speeches_97_23 | 2023-07-23T15:12:41.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:100K<n<1M",
"language:en",
"license:apache-2.0",
"economics",
"finance",
"business",
"region:us"
] | samchain | null | null | 0 | 4 | 2023-07-23T13:34:14 | ---
dataset_info:
features:
- name: sequenceA
dtype: string
- name: sequenceB
dtype: string
- name: next_sentence_label
dtype: int64
splits:
- name: train
num_bytes: 505762257.6721524
num_examples: 773395
- name: test
num_bytes: 89252509.32784761
num_examples: 136482
download_size: 365034957
dataset_size: 595014767
license: apache-2.0
task_categories:
- text-classification
- token-classification
language:
- en
tags:
- economics
- finance
- business
size_categories:
- 100K<n<1M
---
# Dataset Card for "BIS_Speeches_97_23"
This dataset is built from scrapped speeches on the Bank of International Settlements thanks to this repo : https://github.com/HanssonMagnus/scrape_bis. The dataset is made of 12k speeches from 1997 to 2023.
Each pair is built with extracted sentences from speeches, if B is following A then the 'next_sentence_label' is 1 else it is 0.
Negative pairs are built by choosing a sentence from another speech randomly.) | 988 | [
[
-0.0419921875,
-0.04058837890625,
0.0106201171875,
-0.0014276504516601562,
-0.0352783203125,
0.003589630126953125,
-0.003917694091796875,
-0.03741455078125,
0.036712646484375,
0.06231689453125,
-0.05084228515625,
-0.035186767578125,
-0.02459716796875,
0.0064... |
FreedomIntelligence/MMLU_Chinese | 2023-08-06T08:04:11.000Z | [
"license:mit",
"region:us"
] | FreedomIntelligence | null | null | 1 | 4 | 2023-07-24T05:11:32 | ---
license: mit
---
Chinese version of MMLU dataset tranlasted by gpt-3.5-turbo.
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). | 208 | [
[
-0.00730133056640625,
-0.0286407470703125,
0.012237548828125,
0.0223236083984375,
-0.0175628662109375,
-0.006359100341796875,
-0.0019073486328125,
-0.0294952392578125,
0.01666259765625,
0.0109100341796875,
-0.07177734375,
0.0023784637451171875,
-0.00123596191406... |
Smoked-Salmon-s/empathetic_dialogues_ko | 2023-08-04T03:01:28.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:ko",
"license:apache-2.0",
"region:us"
] | Smoked-Salmon-s | null | null | 2 | 4 | 2023-07-25T05:13:43 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- ko
size_categories:
- 10K<n<100K
---
# Dataset Card for "한국어 일상 속 공감형 대화 데이터셋(멀티-턴)"
## Dataset Summary
- boostCamp AI Tech 5기 과정 중 NLP 12조 훈제연어들 팀의 최종 프로젝트에서 제작한 데이터입니다.
- 일상 속 다양한 상황에서 사용자와 챗봇 간의 대화를 담은 데이터셋 입니다.
- GPT4, GPT3.5-turbo로 제작된 합성데이터이며 싱글-턴, 2-턴, 3-턴 대화로 구성되어 있습니다.
- 답변은 **[공감적 표현 - 일반적인 대화 - 관련된 질문]** 의 형태를 가집니다.
## Generation Prompt Example(GPT3.5-turbo)
```
Take a close look at the following example and Conditions. Create nine sessions that each of the session is ongoing conversation about a single topic.
[Conditions]
- The questioner asks a question of appropriate length (1-2 lines) and you respond with an appropriate answer.
- The answer should be a complete sentence or two, but the first sentence should be sympathetic to the questioner's question and situation, and should be answered in a friendly and non-rude manner.
- The second sentence should be free-form, but the last sentence MUST end with an additional question related to the question and answer.
- The total length of each question and answer combined should be no more than nine words
- If the question is positive, you should be excited, upbeat, and positive in tone.
- If the question is negative, you should be warm, sensitive, and caring in tone.
- You may offer solutions to fit the situation.
- All answers should be written in a way that makes the person feel empathetic and comforted by the paired question.
- The content should be based on simple, everyday situations, but with enough variety to include specific situations (e.g., a counselor and a client, a student talking to a teacher about a problem, a conversation between friends).
- The conversations should be as generic and diverse as possible. However, try to include many topics related to psychology and everyday concerns.
- All responses should be polㅇite, respectful, caring, warm, understanding, and compassionate in tone and content.
- Do not generate topic or word about 'stress'.
- You should answer question 1 with answer 1, ask question 2 related to answer 1, answer question 2 with answer 2, ask question 3 related to answer 2, and answer question 3 with answer 3.
- Do not re-mension about question on the following answer.
[Example Session]
(Session 1)
Question 1: I had a fight with my boyfriend and I'm so angry I can't calm down.
Answer 1: Oh no, I'm so sorry to hear that. Relationship conflict is always tough, and it's completely understandable to feel angry and upset. Can I ask what the fight was about? Talking about it could help you process your feelings.
Question 2: He constantly 10 minutes late for appointments and never say sorry.
Answer 2: Oh, that's so frustrating! Punctuality is a matter of respect for other people's time, and it sounds like your boyfriend isn't showing you that respect. You're allowed to be upset about that. How long has this been going on? Have you talked to him about it before, or is this the first time you've brought it up?
Question 3: It keeps happening. This is the fourth time in the past month that I've recognized it. Does that make sense?
Answer 3: Yes, that totally makes sense! Four times in a month is way too much. It's not just an occasional, forgivable mistake at that point. It's becoming a pattern of behavior that's disrespectful of your time. Have you told him how much it bothers you, or has he just brushed it off when you've mentioned it?
(Session 2)
Question 1:
Answer 1:
Question 2:
Anwer 2:
.....
(Session 9)
Each session must be about one topic and has three question-answer conversation pair. nine sessions must have different topics. Create as many as possible sessions you can. Examples are examples, don't copy them.
create it in Korean. please create nine sessions.
```
## Links
- repository : [boostcampaitech5/level3_nlp_finalproject-nlp-12](https://github.com/boostcampaitech5/level3_nlp_finalproject-nlp-12)
- huggingface : [Smoked-Salmon-s/empathetic_dialogues_ko](https://huggingface.co/datasets/Smoked-Salmon-s/empathetic_dialogues_ko)
## License
- Apache-2.0
| 4,113 | [
[
-0.033599853515625,
-0.075927734375,
0.032867431640625,
0.08209228515625,
-0.020294189453125,
0.009796142578125,
-0.01468658447265625,
-0.0218048095703125,
0.043731689453125,
-0.0006489753723144531,
-0.060302734375,
-0.02056884765625,
-0.036468505859375,
0.0... |
fedryanto/UnibQuADV2 | 2023-08-18T14:20:43.000Z | [
"region:us"
] | fedryanto | 0 | 4 | 2023-07-25T10:17:29 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... | ||
ArtifactAI/arxiv_deep_learning_python_research_code | 2023-07-27T00:42:03.000Z | [
"region:us"
] | ArtifactAI | null | null | 1 | 4 | 2023-07-26T18:48:33 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: repo
dtype: string
- name: file
dtype: string
- name: code
dtype: string
- name: file_length
dtype: int64
- name: avg_line_length
dtype: float64
- name: max_line_length
dtype: int64
- name: extension_type
dtype: string
splits:
- name: train
num_bytes: 3590067176.125193
num_examples: 391496
download_size: 1490724325
dataset_size: 3590067176.125193
---
# Dataset Card for "ArtifactAI/arxiv_python_research_code"
## Dataset Description
https://huggingface.co/datasets/ArtifactAI/arxiv_deep_learning_python_research_code
### Dataset Summary
ArtifactAI/arxiv_deep_learning_python_research_code contains over 1.49B of source code files referenced strictly in ArXiv papers. The dataset serves as a curated dataset for Code LLMs.
### How to use it
```python
from datasets import load_dataset
# full dataset (1.49GB of data)
ds = load_dataset("ArtifactAI/arxiv_deep_learning_python_research_code", split="train")
# dataset streaming (will only download the data as needed)
ds = load_dataset("ArtifactAI/arxiv_deep_learning_python_research_code", streaming=True, split="train")
for sample in iter(ds): print(sample["code"])
```
## Dataset Structure
### Data Instances
Each data instance corresponds to one file. The content of the file is in the `code` feature, and other features (`repo`, `file`, etc.) provide some metadata.
### Data Fields
- `repo` (string): code repository name.
- `file` (string): file path in the repository.
- `code` (string): code within the file.
- `file_length`: (integer): number of characters in the file.
- `avg_line_length`: (float): the average line-length of the file.
- `max_line_length`: (integer): the maximum line-length of the file.
- `extension_type`: (string): file extension.
### Data Splits
The dataset has no splits and all data is loaded as train split by default.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
34,099 active GitHub repository names were extracted from [ArXiv](https://arxiv.org/) papers from its inception through July 21st, 2023 totaling 773G of compressed github repositories.
These repositories were then filtered, and the code from each file that mentions ["torch", "jax", "flax", "stax", "haiku", "keras", "fastai", "xgboost", "caffe", "mxnet"] was extracted into 1.4 million files.
#### Who are the source language producers?
The source (code) language producers are users of GitHub that created unique repository
### Personal and Sensitive Information
The released dataset may contain sensitive information such as emails, IP addresses, and API/ssh keys that have previously been published to public repositories on GitHub.
## Additional Information
### Dataset Curators
Matthew Kenney, Artifact AI, matt@artifactai.com
### Citation Information
```
@misc{arxiv_deep_learning_python_research_code,
title={arxiv_deep_learning_python_research_code},
author={Matthew Kenney},
year={2023}
}
``` | 3,102 | [
[
-0.02392578125,
-0.0217132568359375,
0.005191802978515625,
-0.00041484832763671875,
-0.022674560546875,
-0.00435638427734375,
-0.029571533203125,
-0.0152740478515625,
0.013397216796875,
0.0343017578125,
-0.019775390625,
-0.048919677734375,
-0.0296783447265625,
... |
Elliot4AI/openassistant-guanaco-chinese | 2023-07-27T04:59:21.000Z | [
"task_categories:question-answering",
"task_categories:text-generation",
"task_categories:conversational",
"size_categories:1K<n<10K",
"language:zh",
"license:apache-2.0",
"biology",
"finance",
"art",
"region:us"
] | Elliot4AI | null | null | 0 | 4 | 2023-07-27T03:34:57 | ---
license: apache-2.0
task_categories:
- question-answering
- text-generation
- conversational
language:
- zh
tags:
- biology
- finance
- art
pretty_name: fine-turn dataset 中文数据集
size_categories:
- 1K<n<10K
---
### Dataset Summary
🏡🏡🏡🏡Fine-turn Dataset:中文数据集🏡🏡🏡🏡
😀😀😀😀😀😀😀😀 这个数据集是timdettmers/openassistant-guanaco的中文版本,是直接翻译过来,没有经过人为检查语法。 对timdettmers/openassistant-guanaco的描述,请看他的dataset card。 License: Apache 2.0
😀😀😀😀😀😀😀😀 This data set is the Chinese version of timdettmers/openassistant-guanaco, which is directly translated without human-checked grammar. For a description of timdettmers/openassistant-guanaco, see its dataset card. License: Apache 2.0 | 659 | [
[
0.007144927978515625,
-0.04718017578125,
0.00037980079650878906,
0.040802001953125,
-0.039825439453125,
-0.011932373046875,
-0.0156707763671875,
-0.0181427001953125,
0.00820159912109375,
0.059295654296875,
-0.05322265625,
-0.06695556640625,
-0.051544189453125,
... |
tiwes/apa_de | 2023-07-27T14:42:10.000Z | [
"region:us"
] | tiwes | null | null | 0 | 4 | 2023-07-27T08:53:50 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Kenno104/nextjs-plugin | 2023-07-27T11:36:34.000Z | [
"region:us"
] | Kenno104 | null | null | 0 | 4 | 2023-07-27T11:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
lighteval/drop_harness | 2023-07-27T11:58:52.000Z | [
"region:us"
] | lighteval | null | null | 0 | 4 | 2023-07-27T11:58:48 | ---
dataset_info:
features:
- name: section_id
dtype: string
- name: passage
dtype: string
- name: question
dtype: string
- name: query_id
dtype: string
- name: answer
struct:
- name: number
dtype: string
- name: date
struct:
- name: day
dtype: string
- name: month
dtype: string
- name: year
dtype: string
- name: spans
sequence: string
- name: worker_id
dtype: string
- name: hit_id
dtype: string
- name: validated_answers
sequence:
- name: number
dtype: string
- name: date
struct:
- name: day
dtype: string
- name: month
dtype: string
- name: year
dtype: string
- name: spans
sequence: string
- name: worker_id
dtype: string
- name: hit_id
dtype: string
splits:
- name: train
num_bytes: 108858121
num_examples: 77409
- name: validation
num_bytes: 12560739
num_examples: 9536
download_size: 12003555
dataset_size: 121418860
---
# Dataset Card for "drop_harness"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,245 | [
[
-0.062408447265625,
-0.006031036376953125,
-0.00605010986328125,
0.01462554931640625,
-0.00838470458984375,
-0.004947662353515625,
0.0256805419921875,
-0.01557159423828125,
0.044769287109375,
0.0223846435546875,
-0.0806884765625,
-0.04168701171875,
-0.0350341796... |
harshal-07/llama_2_training | 2023-07-28T09:08:21.000Z | [
"region:us"
] | harshal-07 | null | null | 1 | 4 | 2023-07-28T08:03:56 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
CATIE-AQ/french_book_reviews_fr_prompt_sentiment_analysis | 2023-10-11T12:20:47.000Z | [
"task_categories:text-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:french_book_reviews",
"language:fr",
"license:cc",
"binary-sentiment-analysis",
"DFP",
"french prompts",
"region:us"
] | CATIE-AQ | null | null | 0 | 4 | 2023-07-28T10:24:55 | ---
language:
- fr
license:
- cc
size_categories:
- 100K<n<1M
task_categories:
- text-classification
tags:
- binary-sentiment-analysis
- DFP
- french prompts
annotations_creators:
- found
language_creators:
- found
multilinguality:
- monolingual
source_datasets:
- french_book_reviews
---
# french_book_reviews_fr_prompt_sentiment_analysis
## Summary
**french_book_reviews_fr_prompt_sentiment_analysis** is a subset of the [**Dataset of French Prompts (DFP)**](https://huggingface.co/datasets/CATIE-AQ/DFP).
It contains **270,424** rows that can be used for a binary sentiment analysis task.
The original data (without prompts) comes from the dataset [french_book_reviews](https://huggingface.co/datasets/Abirate/french_book_reviews) by Eltaief.
A list of prompts (see below) was then applied in order to build the input and target columns and thus obtain the same format as the [xP3](https://huggingface.co/datasets/bigscience/xP3) dataset by Muennighoff et al.
## Prompts used
### List
28 prompts were created for this dataset. The logic applied consists in proposing prompts in the indicative tense, in the form of tutoiement and in the form of vouvoiement.
```
'Commentaire : "'+review+'" Le commentaire est-il positif ou négatif ?',
"""Avis : " """+review+""" " L'avis est-il positif ou négatif ?""",
'Critique : "'+review+'" La critique est-elle positive ou négative ?',
"""Evaluation : " """+review+""" " L'évaluation est-elle positive ou négative ?""",
'Ce commentaire sur le produit est-il positif ou négatif ? \nCommentaire : "'+review+'"\nRéponse :',
'Cet avis sur le produit est-il positif ou négatif ? \nAvis : "'+review+'"\nRéponse :',
'Cette critique sur le produit est-elle positive ou négative ? \nCritique : "'+review+'"\nRéponse :',
'Cette évaluation sur le produit est-elle positive ou négative ? \nEvaluation : "'+review+'"\nRéponse :',
'Commentaire : "'+review+'"\n Ce commentaire sur le produit exprime-t-il un sentiment négatif ou positif ?',
'Avis : "'+review+'"\n Cet avis sur le produit exprime-t-il un sentiment négatif ou positif ?',
'Critique : "'+review+'"\n Cette critique sur le produit exprime-t-il un sentiment négatif ou positif ?',
'Evaluation : "'+review+'"\n Cette évaluation sur le produit exprime-t-il un sentiment négatif ou positif ?',
'Ce commentaire sur le produit a-t-il un ton négatif ou positif ? \n Commentaire : "'+review+'"\n Réponse :',
'Cet avis sur le produit a-t-il un ton négatif ou positif ? \n Avis : "'+review+'"\n Réponse :',
'Cette critique sur le produit a-t-il un ton négatif ou positif ? \n Evaluation : "'+review+'"\n Réponse :',
'Cette évaluation sur le produit a-t-il un ton négatif ou positif ? \n Avis : "'+review+'"\n Réponse :',
"""Voici un commentaire laissé par un client sur un produit. Diriez-vous qu'il est négatif ou positif ? \nCommentaire : """+review,
"""Voici un avis laissé par un client sur un produit. Diriez-vous qu'il est négatif ou positif ? \nAvis : """+review,
"""Voici une critique laissée par un client sur un produit. Diriez-vous qu'elle est négative ou positive ? \nCritique : """+review,
"""Voici une évaluation laissée par un client sur un produit. Diriez-vous qu'elle est négative ou positive ? \nEvaluation : """+review,
'Commentaire du produit : "'+review+'" Ce commentaire dépeint le produit sous un angle négatif ou positif ?',
'Avis du produit : "'+review+'" Cet avis dépeint le produit sous un angle négatif ou positif ?',
'Critique du produit : "'+review+'" Cette critique dépeint le produit sous un angle négatif ou positif ?',
'Evaluation du produit : "'+review+'" Cette évaluation dépeint le produit sous un angle négatif ou positif ?',
'Le commentaire suivant exprime quel sentiment ?\n Commentaire' +review,
"""L'avis suivant exprime quel sentiment ?\n Avis""" +review,
'La critique suivante exprime quel sentiment ?\n Critique' +review,
"""L'évaluation suivante exprime quel sentiment ?\n Evaluation""" +review
```
### Features used in the prompts
In the prompt list above, `review` and `targets` have been constructed from:
```
fbr = load_dataset('Abirate/french_book_reviews')
review = fbr['train']['reader_review'][i]
if fbr['train']['rating'][i] < 2.5:
targets.append("neg")
else :
targets.append("pos")
```
# Splits
- `train` with 270,424 samples
- no `valid` split
- no `test` split
# How to use?
```
from datasets import load_dataset
dataset = load_dataset("CATIE-AQ/french_book_reviews_fr_prompt_sentiment_analysis")
```
# Citation
## Original data
> @misc {abir_eltaief_2023,
author = { {Abir ELTAIEF} },
title = { french_book_reviews (Revision 534725e) },
year = 2023,
url = { https://huggingface.co/datasets/Abirate/french_book_reviews },
doi = { 10.57967/hf/1052 },
publisher = { Hugging Face }}
## This Dataset
> @misc {centre_aquitain_des_technologies_de_l'information_et_electroniques_2023,
author = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { DFP (Revision 1d24c09) },
year = 2023,
url = { https://huggingface.co/datasets/CATIE-AQ/DFP },
doi = { 10.57967/hf/1200 },
publisher = { Hugging Face }
}
## License
[CC0: Public Domain](https://creativecommons.org/publicdomain/zero/1.0/) | 5,357 | [
[
-0.047210693359375,
-0.0501708984375,
0.0238800048828125,
0.043701171875,
-0.0252532958984375,
-0.0094757080078125,
-0.0037364959716796875,
-0.01099395751953125,
0.0303192138671875,
0.045135498046875,
-0.065673828125,
-0.059661865234375,
-0.027008056640625,
... |
lapki/perekrestok-reviews | 2023-07-28T13:01:25.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:ru",
"reviews",
"region:us"
] | lapki | null | null | 0 | 4 | 2023-07-28T12:13:22 | ---
task_categories:
- text-classification
- text-generation
language:
- ru
tags:
- reviews
size_categories:
- 100K<n<1M
pretty_name: Dataset of user reviews from "Перекрёсток/Perekrestok" shop.
---
### Dataset
Dataset of user reviews from "Перекрёсток/Perekrestok" shop.
### Dataset Format
Dataset is in JSONLines format. Trivia:
`product_id` - Product internal ID (https://www.perekrestok.ru/cat/1/p/ID)
`product_name` - Product name
`product_category` - Category of product
`product_price` - Product price in RUB (decimal)
`review_id` - Review internal ID
`review_author` - Author of review
`review_text` - Text of review
`rating` - Review rating (decimal, from 0.0 to 5.0)
| 687 | [
[
-0.0243072509765625,
-0.040802001953125,
0.006114959716796875,
0.0369873046875,
-0.04339599609375,
0.00994110107421875,
0.0007314682006835938,
0.006504058837890625,
0.02593994140625,
0.050140380859375,
-0.043060302734375,
-0.08026123046875,
-0.01482391357421875,... |
TrainingDataPro/facial-hair-classification-dataset | 2023-09-19T19:34:25.000Z | [
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | null | null | 1 | 4 | 2023-07-28T15:53:26 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
---
# Facial Hair Classification Dataset
The Facial Hair Classification Dataset is a comprehensive collection of high-resolution images showcasing individuals **with and without** a beard. The dataset includes a diverse range of individuals of various ages, ethnicities, and genders.
The dataset also contains images of individuals **without facial hair**, serving as a valuable reference for comparison and contrast. These images showcase clean-shaven faces, enabling research into distinguishing facial hair patterns from those without any beard growth.
Each image in the dataset is carefully curated to showcase the subject's face prominently and with optimal lighting conditions, ensuring clarity and accuracy in the classification and analysis of facial hair presence.
### Types of photos in the dataset:
- **beard** - photos of people **with** a beard.
- **no beard** - photos of people **without** a beard.

The Facial Hair Classification Dataset offers a robust collection of images that accurately represent the diverse range of facial hair styles found in the real world. This dataset provides ample opportunities for training facial recognition algorithms, identifying facial hair patterns, and conducting research on facial hair classification and analysis.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial-hair-classification-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
The dataset is splitted in three folders: **train**, **validate** and **test** to build a classification model.
Each of these folders includes:
- **beard** folder: includes photos of people **with** a beard
- **no_beard** folder: includes photos of people **without** a beard
### File with the extension .csv
- **file**: link to access the media file,
- **type**: does a person has or has not a beard
# Files for Facial Hair Classification might be collected in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial-hair-classification-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,780 | [
[
-0.0413818359375,
-0.045745849609375,
-0.00528717041015625,
0.0009784698486328125,
-0.009124755859375,
0.01409149169921875,
-0.005710601806640625,
-0.04058837890625,
0.0311279296875,
0.049560546875,
-0.060333251953125,
-0.0648193359375,
-0.032958984375,
-0.0... |
ChrisHayduk/Llama-2-SQL-Dataset | 2023-09-29T03:03:30.000Z | [
"region:us"
] | ChrisHayduk | null | null | 6 | 4 | 2023-07-30T15:39:35 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: eval
path: data/eval-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 33020750.12130776
num_examples: 70719
- name: eval
num_bytes: 3669127.878692238
num_examples: 7858
download_size: 10125848
dataset_size: 36689878.0
---
# Dataset Card for "Llama-2-SQL-Dataset"
This dataset is deprecated in favor of [ChrisHayduk/Llama-2-SQL-and-Code-Dataset](https://huggingface.co/datasets/ChrisHayduk/Llama-2-SQL-and-Code-Dataset) | 631 | [
[
-0.01306915283203125,
-0.03424072265625,
-0.00945281982421875,
0.044769287109375,
-0.07354736328125,
0.022796630859375,
0.015533447265625,
-0.028717041015625,
0.046051025390625,
0.039398193359375,
-0.052520751953125,
-0.052825927734375,
-0.038238525390625,
0... |
emre/llama-2-instruct-121k-code | 2023-07-31T00:44:29.000Z | [
"region:us"
] | emre | null | null | 3 | 4 | 2023-07-31T00:44:20 | ---
dataset_info:
features:
- name: llamaV2Instruct
dtype: string
splits:
- name: train
num_bytes: 87634976
num_examples: 121959
download_size: 36997092
dataset_size: 87634976
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llamaV2Instruct-121k-code"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 469 | [
[
-0.0235748291015625,
-0.0023517608642578125,
0.00975799560546875,
0.03265380859375,
-0.027130126953125,
0.01161956787109375,
0.0246429443359375,
-0.004238128662109375,
0.051971435546875,
0.043243408203125,
-0.057647705078125,
-0.055633544921875,
-0.0399780273437... |
Arjun-G-Ravi/Python-codes | 2023-08-12T07:43:19.000Z | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"code",
"region:us"
] | Arjun-G-Ravi | null | null | 2 | 4 | 2023-07-31T02:35:53 | ---
license: mit
task_categories:
- text-generation
- text2text-generation
language:
- en
tags:
- code
pretty_name: Python codes dataset
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
Please note that this dataset maynot be perfect and may contain a very small quantity of non python codes. But the quantity appears to be very small
### Dataset Summary
The dataset contains a collection of python question and their code. This is meant to be used for training models to be efficient in Python specific coding.
The dataset has two features - 'question' and 'code'.
An example is:
```
{'question': 'Create a function that takes in a string and counts the number of vowels in it',
'code': 'def count_vowels(string):\n vowels = ["a", "e", "i", "o", "u"]\n count = 0\n for char in string:\n if char in vowels:\n count += 1\n return count'}
```
### Languages
English, Python
### Source Data
The dataset is derived from two other coding based datasets:
1) sahil2801/CodeAlpaca-20k
2) neulab/conala
@inproceedings{yin2018learning,
title={Learning to mine aligned code and natural language pairs from stack overflow},
author={Yin, Pengcheng and Deng, Bowen and Chen, Edgar and Vasilescu, Bogdan and Neubig, Graham},
booktitle={2018 IEEE/ACM 15th international conference on mining software repositories (MSR)},
pages={476--486},
year={2018},
organization={IEEE}
}
### Licensing Information
This uses MIT licence
### Citation Information
Will be added soon
| 1,524 | [
[
-0.015899658203125,
-0.0308074951171875,
-0.01273345947265625,
0.010894775390625,
-0.003963470458984375,
-0.01523590087890625,
-0.01013946533203125,
-0.01294708251953125,
0.020233154296875,
0.038482666015625,
-0.035003662109375,
-0.047210693359375,
-0.0130767822... |
AtlasUnified/atlas-math-sets | 2023-08-01T18:24:15.000Z | [
"task_categories:question-answering",
"size_categories:10M<n<100M",
"language:en",
"license:mit",
"math",
"region:us"
] | AtlasUnified | null | null | 0 | 4 | 2023-07-31T14:37:37 | ---
license: mit
task_categories:
- question-answering
language:
- en
tags:
- math
pretty_name: Atlas Math Sets
size_categories:
- 10M<n<100M
---
# ATLAS MATH SETS

This set of data consists of mathematical computations. Simple in nature as it derived from python scripts, this dataset contains addition, subtraction, multiplication, division, fractions, decimals, square roots, cube roots, exponents, and factors.
Format of the JSONL is as follows:
{"answer": "[num]", "input": "[equation]", "output": "[num]", "instruction": "[pre-generated_instruction] [equation]"} | 699 | [
[
-0.025604248046875,
-0.0491943359375,
0.007266998291015625,
0.0240631103515625,
-0.001270294189453125,
0.01312255859375,
0.015167236328125,
0.02313232421875,
0.0194549560546875,
0.03271484375,
-0.046356201171875,
-0.037017822265625,
-0.038330078125,
0.000088... |
FarisHijazi/kajiwoto.ai-chat | 2023-08-06T19:24:57.000Z | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"roleplay",
"character",
"ShareGPT",
"region:us"
] | FarisHijazi | null | null | 3 | 4 | 2023-08-03T09:21:12 | ---
task_categories:
- text-generation
tags:
- roleplay
- character
- ShareGPT
size_categories:
- 1K<n<10K
---
This is an NSFW roleplay dataset scraped from <https://kajiwoto.ai/> as of 2023-07-15.
Kajiwoto is a platform where you can create your own character datasets and chat with them.
There are many public datasets in Kajiwoto, the power in this dataset is the metadata, there is so much information and categorization for each dataset.
## Processing data
Do be aware that a lot of the data is NSFW (explicit content)
The raw datasets are in [kajiwoto_raw.json](./kajiwoto_raw.json), this data needs to be processed so that it can be used, the main operations are:
1. transform shape (convert to a known format such as ShareGPT)
2. deduplication
3. template rendering of strings such as `"you rolled a dice with %{1|2|3|4|5|6}"`. This operation is lossy as it will choose only one of the options
4. dropping datasets that are too short
5. dropping datasets with too few upvotes or comments
6. filtering in or out NSFW datasets
I have processed an initial example here: [kajiwoto_sharegpt-len_gt_6-upvotes_gt_0-sampled.json](./kajiwoto_sharegpt-len_gt_6-upvotes_gt_0-sampled.json)
it is any dataset with at least 1 upvote and at least 6 lines in the conversation, you can most models as this is in the shareGPT format
Here's an example [this conversation](https://kajiwoto.ai/d/033Q):
```json
{
"conversation": [
{
"from": "user",
"value": "What's your favourite drink? "
},
{
"from": "gpt",
"value": "Coconut milk.. "
},
{
"from": "user",
"value": "Soo"
},
{
"from": "gpt",
"value": "What..? "
},
...
],
"metadata": {
"id": "033Q",
"name": "Qiqi dataset",
"description": "About qiqi",
"profilePhotoUri": "2021_10/mzi1zgm0mg_nhprrq_1633269387804.jpg",
"dominantColors": [
"#d97da1",
"#eb9db8",
"#661d3a",
"#745b8b",
"#d2b8d3",
"#644484"
],
"personalities": null,
"personalitiesLastUpdatedAt": null,
"nsfw": false,
"deleted": false,
"price": 0,
"purchased": false,
"status": "PUBLISHED",
"tags": [],
"updatedAt": 1649233318521,
"user": {
"id": "4zkE",
"username": "blossomxx",
"displayName": "Blossom",
"profile": {
"id": "56736",
"photoUri": "2021_10/ytk0nzbhnw_nhprrq_1633268155638.jpg",
"__typename": "UserProfile"
},
"__typename": "User"
},
"count": 9,
"__typename": "AiTrainerGroup",
"kudos": {
"id": "_ai_g:033Q",
"upvotes": 1,
"upvoted": false,
"comments": 0,
"__typename": "Kudos"
},
"editorSettings": null,
"editorState": null
}
}
```
---
*Scraping and processing code will be uploaded soon* | 3,142 | [
[
-0.032745361328125,
-0.057281494140625,
0.0294036865234375,
0.01593017578125,
-0.0241241455078125,
0.0001627206802368164,
-0.0017871856689453125,
-0.037353515625,
0.0439453125,
0.06695556640625,
-0.07171630859375,
-0.0589599609375,
-0.04949951171875,
0.01169... |
mlabonne/alpagasus | 2023-08-03T21:18:52.000Z | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"license:gpl-3.0",
"alpaca",
"llama",
"arxiv:2307.08701",
"region:us"
] | mlabonne | null | null | 5 | 4 | 2023-08-03T20:57:50 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 3918129
num_examples: 9229
download_size: 2486877
dataset_size: 3918129
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: gpl-3.0
task_categories:
- text-generation
tags:
- alpaca
- llama
size_categories:
- 1K<n<10K
---
# Alpagasus (unofficial)
📝 [Paper](https://arxiv.org/abs/2307.08701) | 📄 [Blog](https://lichang-chen.github.io/AlpaGasus/) | 💻 [Code](https://github.com/gpt4life/alpagasus/tree/main) | 🤗 [Model](https://huggingface.co/gpt4life/alpagasus-7b) (unofficial)
Dataset of the unofficial implementation of AlpaGasus made by [gpt4life](https://github.com/gpt4life). It is a filtered version of the original Alpaca dataset with GPT-4 acting as a judge.
<center><img src="https://lichang-chen.github.io/AlpaGasus/elements/images/overview.svg"></center>
The authors showed that models trained on this version with only 9k samples outperform models trained on the original 52k samples. | 1,129 | [
[
-0.0272064208984375,
-0.032562255859375,
0.04388427734375,
-0.004756927490234375,
-0.04803466796875,
-0.0186004638671875,
0.009063720703125,
-0.059234619140625,
0.03497314453125,
0.036956787109375,
-0.03924560546875,
-0.04705810546875,
-0.046356201171875,
0.... |
globis-university/aozorabunko-chats | 2023-10-27T13:26:00.000Z | [
"task_categories:text-generation",
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:ja",
"license:cc-by-4.0",
"region:us"
] | globis-university | null | null | 4 | 4 | 2023-08-04T00:11:22 | ---
license: cc-by-4.0
task_categories:
- text-generation
- text-classification
language:
- ja
size_categories:
- 100K<n<1M
---
# Overview
This dataset is of conversations extracted from [Aozora Bunko (青空文庫)](https://www.aozora.gr.jp/), which collects public-domain books in Japan, using a simple heuristic approach.
[For Japanese] 日本語での概要説明を Qiita に記載しました: https://qiita.com/akeyhero/items/b53eae1c0bc4d54e321f
# Method
First, lines surrounded by quotation mark pairs (`「」`) are extracted as utterances from the `text` field of [globis-university/aozorabunko-clean](https://huggingface.co/datasets/globis-university/aozorabunko-clean).
Then, consecutive utterances are collected and grouped together.
The code to reproduce this dataset is made available on GitHub: [globis-org/aozorabunko-exctractor](https://github.com/globis-org/aozorabunko-extractor).
# Notice
As the conversations are extracted using a simple heuristic, a certain amount of the data may actually be monologues.
# Tips
If you prefer to employ only modern Japanese, you can filter entries with: `row["meta"]["文字遣い種別"] == "新字新仮名"`.
# Example
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('globis-university/aozorabunko-chats')
>>> ds
DatasetDict({
train: Dataset({
features: ['chats', 'footnote', 'meta'],
num_rows: 5531
})
})
>>> ds = ds.filter(lambda row: row['meta']['文字遣い種別'] == '新字新仮名') # only modern Japanese
>>> ds
DatasetDict({
train: Dataset({
features: ['chats', 'footnote', 'meta'],
num_rows: 4139
})
})
>>> book = ds['train'][0] # one of the works
>>> book['meta']['作品名']
'スリーピー・ホローの伝説'
>>> chats = book['chats'] # list of the chats in the work; type: list[list[str]]
>>> len(chats)
1
>>> chat = chats[0] # one of the chats; type: list[str]
>>> for utterance in chat:
... print(utterance)
...
人生においては、たとえどんな場合でも必ず利点や愉快なことがあるはずです。もっともそれは、わたくしどもが冗談をすなおに受けとればのことですが
そこで、悪魔の騎士と競走することになった人は、とかくめちゃくちゃに走るのも当然です
したがって、田舎の学校の先生がオランダ人の世継ぎ娘に結婚を拒まれるということは、彼にとっては、世の中で栄進出世にいたるたしかな一歩だということになります
```
# License
CC BY 4.0 | 2,072 | [
[
-0.02392578125,
-0.06451416015625,
0.0161285400390625,
0.00905609130859375,
-0.0308074951171875,
-0.00690460205078125,
-0.0299224853515625,
-0.03436279296875,
0.03271484375,
0.055511474609375,
-0.04571533203125,
-0.05499267578125,
-0.02880859375,
0.010665893... |
d0rj/gsm8k-ru | 2023-08-04T08:34:00.000Z | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:gsm8k",
"language:ru",
"license:mit",
"math-word-problems",
"arxiv:2110.14168",
"region:us"
] | d0rj | null | null | 0 | 4 | 2023-08-04T08:26:12 | ---
annotations_creators:
- crowdsourced
language_creators:
- translated
language:
- ru
license:
- mit
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- gsm8k
task_categories:
- text2text-generation
task_ids: []
paperswithcode_id: gsm8k
pretty_name: Grade School Math 8K (ru)
tags:
- math-word-problems
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 6815618.0
num_examples: 7473
- name: test
num_bytes: 1234140.0
num_examples: 1319
download_size: 3883654
dataset_size: 8049758.0
---
# gsm8k-ru
Translated version of [gsm8k](https://huggingface.co/datasets/gsm8k) dataset into Russian.
## Dataset Description
- **Homepage:** https://openai.com/blog/grade-school-math/
- **Repository:** https://github.com/openai/grade-school-math
- **Paper:** https://arxiv.org/abs/2110.14168 | 1,039 | [
[
0.004077911376953125,
-0.014129638671875,
0.007549285888671875,
0.025115966796875,
-0.039093017578125,
-0.008544921875,
-0.00635528564453125,
-0.0004239082336425781,
0.0254058837890625,
0.025360107421875,
-0.041229248046875,
-0.0594482421875,
-0.042633056640625,... |
jxie/freesolv | 2023-08-04T22:25:28.000Z | [
"region:us"
] | jxie | null | null | 0 | 4 | 2023-08-04T22:25:16 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: float64
splits:
- name: train_0
num_bytes: 13996
num_examples: 513
- name: val_0
num_bytes: 1742
num_examples: 64
- name: test_0
num_bytes: 1806
num_examples: 65
- name: train_1
num_bytes: 13790
num_examples: 513
- name: val_1
num_bytes: 1781
num_examples: 64
- name: test_1
num_bytes: 1973
num_examples: 65
- name: train_2
num_bytes: 14010
num_examples: 513
- name: val_2
num_bytes: 1787
num_examples: 64
- name: test_2
num_bytes: 1747
num_examples: 65
download_size: 38980
dataset_size: 52632
---
# Dataset Card for "freesolv"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 847 | [
[
-0.0308685302734375,
0.01021575927734375,
0.012603759765625,
0.019256591796875,
-0.0219573974609375,
-0.01262664794921875,
0.0143585205078125,
-0.00396728515625,
0.048004150390625,
0.036163330078125,
-0.06689453125,
-0.064453125,
-0.038055419921875,
-0.02844... |
georgesung/OpenOrca_35k | 2023-08-06T00:02:39.000Z | [
"task_categories:conversational",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:summarization",
"task_categories:feature-extra... | georgesung | null | null | 1 | 4 | 2023-08-05T23:59:41 | ---
language:
- en
license: mit
task_categories:
- conversational
- text-classification
- token-classification
- table-question-answering
- question-answering
- zero-shot-classification
- summarization
- feature-extraction
- text-generation
- text2text-generation
pretty_name: OpenOrca_35k
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 63126475
num_examples: 35000
download_size: 36032211
dataset_size: 63126475
---
# Dataset Card for "OpenOrca_35k"
The first 35k examples from [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca) | 749 | [
[
-0.050537109375,
-0.00803375244140625,
-0.0009188652038574219,
0.018890380859375,
-0.042816162109375,
-0.023681640625,
0.0222930908203125,
-0.0142974853515625,
0.021759033203125,
0.040557861328125,
-0.03900146484375,
-0.0772705078125,
-0.01251983642578125,
-... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.