
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
grammarly/pseudonymization-data | 2023-08-23T21:07:17.000Z | [
"task_categories:text-classification",
"task_categories:summarization",
"size_categories:100M<n<1T",
"language:en",
"license:apache-2.0",
"region:us"
] | grammarly | null | null | 1 | 3 | 2023-07-05T18:37:54 | ---
license: apache-2.0
task_categories:
- text-classification
- summarization
language:
- en
pretty_name: Pseudonymization data
size_categories:
- 100M<n<1T
---
This repository contains all the datasets used in our paper "Privacy- and Utility-Preserving NLP with Anonymized data: A case study of Pseudonymization" (https://aclanthology.org/2023.trustnlp-1.20).
# Dataset Card for Pseudonymization data
## Dataset Description
- **Homepage:** https://huggingface.co/datasets/grammarly/pseudonymization-data
- **Paper:** https://aclanthology.org/2023.trustnlp-1.20/
- **Point of Contact:** oleksandr.yermilov@ucu.edu.ua
### Dataset Summary
This dataset repository contains all the datasets, used in our paper. It includes datasets for different NLP tasks, pseudonymized by different algorithms; a dataset for training Seq2Seq model which translates text from original to "pseudonymized"; and a dataset for training model which would detect if the text was pseudonymized.
### Languages
English.
## Dataset Structure
Each folder contains preprocessed train versions of different datasets (e.g, in the `cnn_dm` folder there will be preprocessed CNN/Daily Mail dataset). Each file has a name, which corresponds with the algorithm from the paper used for its preprocessing (e.g. `ner_ps_spacy_imdb.csv` is imdb dataset, preprocessed with NER-based pseudonymization using FLAIR system).
I
## Dataset Creation
Datasets in `imdb` and `cnn_dm` folders were created by pseudonymizing corresponding datasets with different pseudonymization algorithms.
Datasets in `detection` folder are combined original datasets and pseudonymized datasets, grouped by pseudonymization algorithm used.
Datasets in `seq2seq` folder are datasets for training Seq2Seq transformer-based pseudonymization model. At first, a dataset was fetched from Wikipedia articles, which was preprocessed with either NER-PS<sub>FLAIR</sub> or NER-PS<sub>spaCy</sub> algorithms.
### Personal and Sensitive Information
This datasets bring no sensitive or personal information; it is completely based on data present in open sources (Wikipedia, standard datasets for NLP tasks).
## Considerations for Using the Data
### Known Limitations
Only English texts are present in the datasets. Only a limited part of named entity types are replaced in the datasets. Please, also check the Limitations section of our paper.
## Additional Information
### Dataset Curators
Oleksandr Yermilov (oleksandr.yermilov@ucu.edu.ua)
### Citation Information
```
@inproceedings{yermilov-etal-2023-privacy,
title = "Privacy- and Utility-Preserving {NLP} with Anonymized data: A case study of Pseudonymization",
author = "Yermilov, Oleksandr and
Raheja, Vipul and
Chernodub, Artem",
booktitle = "Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.trustnlp-1.20",
doi = "10.18653/v1/2023.trustnlp-1.20",
pages = "232--241",
abstract = "This work investigates the effectiveness of different pseudonymization techniques, ranging from rule-based substitutions to using pre-trained Large Language Models (LLMs), on a variety of datasets and models used for two widely used NLP tasks: text classification and summarization. Our work provides crucial insights into the gaps between original and anonymized data (focusing on the pseudonymization technique) and model quality and fosters future research into higher-quality anonymization techniques better to balance the trade-offs between data protection and utility preservation. We make our code, pseudonymized datasets, and downstream models publicly available.",
}
``` | 3,815 | [
[
-0.0172576904296875,
-0.0294952392578125,
0.01459503173828125,
0.01702880859375,
-0.00047206878662109375,
0.006244659423828125,
-0.0289764404296875,
-0.037353515625,
0.031982421875,
0.061004638671875,
-0.02899169921875,
-0.053985595703125,
-0.050384521484375,
... |
SALT-NLP/LLaVAR | 2023-07-22T06:35:06.000Z | [
"task_categories:text-generation",
"task_categories:visual-question-answering",
"language:en",
"license:cc-by-nc-4.0",
"llava",
"llavar",
"arxiv:2306.17107",
"region:us"
] | SALT-NLP | null | null | 6 | 3 | 2023-07-06T00:03:43 | ---
license: cc-by-nc-4.0
task_categories:
- text-generation
- visual-question-answering
language:
- en
tags:
- llava
- llavar
---
# LLaVAR Data: Enhanced Visual Instruction Data with Text-Rich Images
More info at [LLaVAR project page](https://llavar.github.io/), [Github repo](https://github.com/SALT-NLP/LLaVAR), and [paper](https://arxiv.org/abs/2306.17107).
## Training Data
Based on the LAION dataset, we collect 422K pretraining data based on OCR results. For finetuning data, we collect 16K high-quality instruction-following data by interacting with langauge-only GPT-4. Note that we also release a larger and more diverse finetuning dataset below (20K), which contains the 16K we used for the paper. The instruction files below contain the original LLaVA instructions. You can directly use them after merging the images into your LLaVA image folders. If you want to use them independently, you can remove the items contained in the original chat.json and llava_instruct_150k.json from LLaVA.
[Pretraining images](./pretrain.zip)
[Pretraining instructions](./chat_llavar.json)
[Finetuning images](./finetune.zip)
[Finetuning instructions - 16K](./llava_instruct_150k_llavar_16k.json)
[Finetuning instructions - 20K](./llava_instruct_150k_llavar_20k.json)
## Evaluation Data
We collect 50 instruction-following data on 50 text-rich images from LAION. You can use it for GPT-4-based instruction-following evaluation.
[Images](./REval.zip)
[GPT-4 Evaluation Contexts](./caps_laion_50_val.jsonl)
[GPT-4 Evaluation Rules](./rule_read_v3.json)
[Questions](./qa50_questions.jsonl)
[GPT-4 Answers](./qa50_gpt4_answer.jsonl) | 1,639 | [
[
-0.009521484375,
-0.057342529296875,
0.034332275390625,
0.0018596649169921875,
-0.02734375,
0.004535675048828125,
-0.018096923828125,
-0.0239715576171875,
0.0014667510986328125,
0.05029296875,
-0.026885986328125,
-0.06109619140625,
-0.044708251953125,
-0.003... |
richardr1126/spider-natsql-context-validation | 2023-07-06T21:20:42.000Z | [
"source_datasets:spider",
"language:en",
"license:cc-by-4.0",
"sql",
"spider",
"natsql",
"text-to-sql",
"sql finetune",
"arxiv:1809.08887",
"arxiv:2109.05153",
"region:us"
] | richardr1126 | null | null | 0 | 3 | 2023-07-06T00:51:06 | ---
language:
- en
license:
- cc-by-4.0
source_datasets:
- spider
tags:
- sql
- spider
- natsql
- text-to-sql
- sql finetune
dataset_info:
features:
- name: db_id
dtype: string
- name: prompt
dtype: string
- name: ground_truth
dtype: string
---
# Dataset Card for Spider NatSQL Context Validation
### Dataset Summary
[Spider](https://arxiv.org/abs/1809.08887) is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students
The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
This dataset was created to validate LLMs on the Spider dev dataset with database context using NatSQL.
### NatSQL
[NatSQL](https://arxiv.org/abs/2109.05153) is an intermediate representation for SQL that simplifies the queries and reduces the mismatch between
natural language and SQL. NatSQL preserves the core functionalities of SQL, but removes some clauses and keywords
that are hard to infer from natural language descriptions. NatSQL also makes schema linking easier by reducing the
number of schema items to predict. NatSQL can be easily converted to executable SQL queries and can improve the
performance of text-to-SQL models.
### Yale Lily Spider Leaderboards
The leaderboard can be seen at https://yale-lily.github.io/spider
### Languages
The text in the dataset is in English.
### Licensing Information
The spider dataset is licensed under
the [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
### Citation
```
@article{yu2018spider,
title={Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task},
author={Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others},
journal={arXiv preprint arXiv:1809.08887},
year={2018}
}
```
```
@inproceedings{gan-etal-2021-natural-sql,
title = "Natural {SQL}: Making {SQL} Easier to Infer from Natural Language Specifications",
author = "Gan, Yujian and
Chen, Xinyun and
Xie, Jinxia and
Purver, Matthew and
Woodward, John R. and
Drake, John and
Zhang, Qiaofu",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.174",
doi = "10.18653/v1/2021.findings-emnlp.174",
pages = "2030--2042",
}
``` | 2,658 | [
[
-0.01497650146484375,
-0.053131103515625,
0.01471710205078125,
0.0171356201171875,
-0.02001953125,
0.0135498046875,
-0.0181884765625,
-0.04345703125,
0.030059814453125,
0.037322998046875,
-0.03424072265625,
-0.04986572265625,
-0.0229949951171875,
0.049255371... |
sled-umich/SDN | 2023-08-01T01:47:31.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-nc-nd-4.0",
"arxiv:2210.12511",
"region:us"
] | sled-umich | null | null | 0 | 3 | 2023-07-06T17:04:13 | ---
license: cc-by-nc-nd-4.0
task_categories:
- text-classification
- text-generation
language:
- en
size_categories:
- 1K<n<10K
---
# DOROTHIE
## Spoken Dialogue for Handling Unexpected Situations in Interactive Autonomous Driving Agents
**[Research Paper](https://arxiv.org/abs/2210.12511) | [Github](https://github.com/sled-group/DOROTHIE) | [Huggingface](https://huggingface.co/datasets/sled-umich/DOROTHIE)**
Authored by [Ziqiao Ma](https://mars-tin.github.io/), Ben VanDerPloeg, Cristian-Paul Bara, [Yidong Huang](https://sled.eecs.umich.edu/author/yidong-huang/), Eui-In Kim, Felix Gervits, Matthew Marge, [Joyce Chai](https://web.eecs.umich.edu/~chaijy/)
DOROTHIE (Dialogue On the ROad To Handle Irregular Events) is an innovative interactive simulation platform designed to create unexpected scenarios on the fly. This tool facilitates empirical studies on situated communication with autonomous driving agents.

This dataset is the pure dialogue dataset, if you want to see the whole simulation process and download the full dataset, please visit our [Github homepage](https://github.com/sled-group/DOROTHIE) | 1,156 | [
[
-0.04144287109375,
-0.0634765625,
0.0543212890625,
0.0127410888671875,
-0.0032196044921875,
0.00324249267578125,
-0.01067352294921875,
-0.035888671875,
0.0146942138671875,
0.01953125,
-0.07403564453125,
-0.02789306640625,
-0.0157470703125,
-0.013374328613281... |
Iftisyed/testpak | 2023-07-06T19:06:56.000Z | [
"region:us"
] | Iftisyed | null | null | 0 | 3 | 2023-07-06T19:06:14 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ChaiML/100_example_conversations | 2023-07-06T23:10:10.000Z | [
"region:us"
] | ChaiML | null | null | 1 | 3 | 2023-07-06T23:10:06 | ---
dataset_info:
features:
- name: conversation
dtype: string
- name: bot_label
dtype: string
- name: user_label
dtype: string
- name: description
dtype: string
- name: first_message
dtype: string
- name: prompt
dtype: string
- name: memory
dtype: string
- name: introduction
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 394959
num_examples: 100
download_size: 217141
dataset_size: 394959
---
# Dataset Card for "100_example_conversations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 674 | [
[
-0.047210693359375,
-0.0516357421875,
0.01322174072265625,
0.01496124267578125,
-0.00838470458984375,
-0.0205535888671875,
0.0032958984375,
-0.0030765533447265625,
0.055145263671875,
0.045074462890625,
-0.06768798828125,
-0.05401611328125,
-0.0187835693359375,
... |
pierre-loic/climate-news-articles | 2023-07-09T18:26:00.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:fr",
"license:cc",
"climate",
"news",
"region:us"
] | pierre-loic | null | null | 2 | 3 | 2023-07-09T16:37:55 | ---
license: cc
task_categories:
- text-classification
language:
- fr
tags:
- climate
- news
pretty_name: Titres de presse française avec labellisation "climat/pas climat"
size_categories:
- 1K<n<10K
---
# 🌍 Jeu de données d'articles de presse française labellisés comme traitant ou non des sujets liés au climat
*🇬🇧 / 🇺🇸 : as this data set is based only on French data, all explanations are written in French in this repository. The goal of the dataset is to train a model to classify titles of French newspapers in two categories : if it's about climate or not.*
## 🗺️ Le contexte
Ce jeu de données de classification de **titres d'article de presse française** a été réalisé pour l'association [Data for good](https://dataforgood.fr/) à Grenoble et plus particulièrement pour l'association [Quota climat](https://www.quotaclimat.org/).
## 💾 Le jeu de données
Le jeu de données d'entrainement contient 2007 titres d'articles de presse (1923 ne concernant pas le climat et 84 concernant le climat). Le jeu de données de test contient 502 titres d'articles de presse (481 ne concernant pas le climat et 21 concernant le climat).
 | 1,193 | [
[
-0.017791748046875,
-0.03399658203125,
0.04595947265625,
0.021209716796875,
-0.034149169921875,
-0.004497528076171875,
-0.0015096664428710938,
-0.0027790069580078125,
0.017364501953125,
0.043701171875,
-0.0312042236328125,
-0.046356201171875,
-0.06939697265625,
... |
Gregor/mblip-train | 2023-09-21T14:16:27.000Z | [
"language:en",
"language:multilingual",
"license:other",
"region:us"
] | Gregor | null | null | 3 | 3 | 2023-07-10T14:58:47 | ---
license: other
language:
- en
- multilingual
pretty_name: mBLIP instructions
---
# mBLIP Instruct Mix Dataset Card
## Important!
This dataset currently does not work directly with `datasets.load_dataset(Gregor/mblip-train)`!
Please download the data files you need and load them with `datasets.load_dataset("json", data_files="filename")`.
## Dataset details
**Dataset type:**
This is the instruction mix used to train [mBLIP](https://github.com/gregor-ge/mBLIP).
See https://github.com/gregor-ge/mBLIP/data/README.md for more information on how to reproduce the data.
**Dataset date:**
The dataset was created in May 2023.
**Dataset languages:**
The original English examples were machine translated to the following 95 languages:
`
af, am, ar, az, be, bg, bn, ca, ceb, cs, cy, da, de, el, en, eo, es, et, eu, fa, fi, fil, fr, ga, gd, gl, gu, ha, hi, ht, hu, hy, id, ig, is, it, iw, ja, jv, ka, kk, km, kn, ko, ku, ky, lb, lo, lt, lv, mg, mi, mk, ml, mn, mr, ms, mt, my, ne, nl, no, ny, pa, pl, ps, pt, ro, ru, sd, si, sk, sl, sm, sn, so, sq, sr, st, su, sv, sw, ta, te, tg, th, tr, uk, ur, uz, vi, xh, yi, yo, zh, zu
`
Languages are translated proportional to their size in [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual), i.e., as 6% of examples in mC4 are German, we translate 6% of the data to German.
**Dataset structure:**
- `task_mix_mt.json`: The instruction mix data in the processed, translated, and combined form.
- Folders: The folders contain 1) the separate tasks used to generate the mix
and 2) the files of the tasks used to evaluate the model.
**Images:**
We do not include any images with this dataset.
Images from the public datasets (MSCOCO for instruction training, and others for evaluation) can be downloaded
from the respective websites.
For the BLIP captions, we provide the URLs and filenames as used by us [here](blip_captions/ccs_synthetic_filtered_large_2273005_raw.json).
To download them, [our code](https://github.com/gregor-ge/mBLIP/tree/main/data#blip-web-capfilt) can be adapted, for example.
**License:**
Must comply with license of the original datasets used to create this mix. See https://github.com/gregor-ge/mBLIP/data/README.md for more.
Translations were produced with [NLLB](https://huggingface.co/facebook/nllb-200-distilled-1.3B) so use has to comply with
their license.
**Where to send questions or comments about the model:**
https://github.com/gregor-ge/mBLIP/issues
## Intended use
**Primary intended uses:**
The primary is research on large multilingual multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence. | 2,784 | [
[
-0.03741455078125,
-0.039031982421875,
-0.00511932373046875,
0.04754638671875,
-0.02215576171875,
0.01410675048828125,
-0.02435302734375,
-0.0439453125,
0.0257720947265625,
0.031341552734375,
-0.04302978515625,
-0.044525146484375,
-0.038360595703125,
0.02131... |
DynamicSuperb/SpeechDetection_LJSpeech | 2023-07-12T05:56:53.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 3 | 2023-07-11T13:28:27 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 3800059090.8
num_examples: 13100
download_size: 3783855015
dataset_size: 3800059090.8
---
# Dataset Card for "speechDetection_LJSpeech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 486 | [
[
-0.032135009765625,
-0.0278472900390625,
0.01032257080078125,
0.010345458984375,
-0.006603240966796875,
0.0144500732421875,
-0.0008988380432128906,
-0.017303466796875,
0.06591796875,
0.0252685546875,
-0.05780029296875,
-0.053375244140625,
-0.045440673828125,
... |
Sinsinnati/Tweet-Emotion-Detection | 2023-07-11T17:45:13.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"region:us"
] | Sinsinnati | null | null | 0 | 3 | 2023-07-11T17:19:58 | ---
task_categories:
- text-classification
language:
- en
size_categories:
- n<1K
---
This data is gathered from twitter for emotion detection. Our labels fall into seven categories of sadness, happiness, fear, anger, disgust, and surprise, and if there is no dominant emotion in a tweet, then it is labeled as neutral. | 319 | [
[
-0.048797607421875,
-0.0239105224609375,
0.0281524658203125,
0.051239013671875,
-0.046417236328125,
0.0325927734375,
0.0022182464599609375,
-0.0233001708984375,
0.04901123046875,
0.011383056640625,
-0.046142578125,
-0.055877685546875,
-0.06744384765625,
0.03... |
AlekseyKorshuk/crowdsource-v2.0 | 2023-07-11T22:23:55.000Z | [
"region:us"
] | AlekseyKorshuk | null | null | 0 | 3 | 2023-07-11T19:22:13 | ---
dataset_info:
features:
- name: bot_id
dtype: string
- name: conversation_id
dtype: string
- name: conversation
list:
- name: content
dtype: string
- name: do_train
dtype: bool
- name: role
dtype: string
- name: bot_config
struct:
- name: bot_label
dtype: string
- name: description
dtype: string
- name: developer_uid
dtype: string
- name: first_message
dtype: string
- name: image_url
dtype: string
- name: introduction
dtype: string
- name: max_history
dtype: int64
- name: memory
dtype: string
- name: model
dtype: string
- name: name
dtype: string
- name: prompt
dtype: string
- name: repetition_penalty
dtype: float64
- name: response_length
dtype: int64
- name: temperature
dtype: float64
- name: theme
dtype: 'null'
- name: top_k
dtype: int64
- name: top_p
dtype: float64
- name: user_label
dtype: string
- name: conversation_history
dtype: string
- name: system
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 106588734
num_examples: 19541
download_size: 65719430
dataset_size: 106588734
---
# Dataset Card for "crowdsource-v2.0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,471 | [
[
-0.032470703125,
0.0017156600952148438,
0.01139068603515625,
0.0173187255859375,
-0.02227783203125,
-0.00876617431640625,
0.0246734619140625,
-0.0294036865234375,
0.05206298828125,
0.03955078125,
-0.05908203125,
-0.040252685546875,
-0.04681396484375,
-0.0254... |
pytorch-survival/support_pycox | 2023-07-12T01:56:19.000Z | [
"region:us"
] | pytorch-survival | null | null | 0 | 3 | 2023-07-12T00:32:43 | ---
dataset_info:
features:
- name: x0
dtype: float32
- name: x1
dtype: float32
- name: x2
dtype: float32
- name: x3
dtype: float32
- name: x4
dtype: float32
- name: x5
dtype: float32
- name: x6
dtype: float32
- name: x7
dtype: float32
- name: x8
dtype: float32
- name: x9
dtype: float32
- name: x10
dtype: float32
- name: x11
dtype: float32
- name: x12
dtype: float32
- name: x13
dtype: float32
- name: event_time
dtype: float32
- name: event_indicator
dtype: int32
splits:
- name: train
num_bytes: 567872
num_examples: 8873
download_size: 212217
dataset_size: 567872
---
# Dataset Card for "support_pycox"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 854 | [
[
-0.04071044921875,
-0.0006914138793945312,
0.0185546875,
0.03765869140625,
-0.00402069091796875,
-0.0028743743896484375,
0.020416259765625,
-0.0063323974609375,
0.057037353515625,
0.028411865234375,
-0.042572021484375,
-0.04193115234375,
-0.04046630859375,
-... |
izumi-lab/oscar2301-ja-filter-ja-normal | 2023-07-29T03:16:00.000Z | [
"language:ja",
"license:cc0-1.0",
"region:us"
] | izumi-lab | null | null | 2 | 3 | 2023-07-12T16:38:36 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 68837059273.1919
num_examples: 31447063
download_size: 54798731310
dataset_size: 68837059273.1919
license: cc0-1.0
language:
- ja
---
# Dataset Card for "oscar2301-ja-filter-ja-normal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 429 | [
[
-0.057464599609375,
-0.0146026611328125,
0.0106658935546875,
-0.0019388198852539062,
-0.034423828125,
-0.008819580078125,
0.0233154296875,
-0.01270294189453125,
0.07733154296875,
0.06024169921875,
-0.045684814453125,
-0.055450439453125,
-0.048797607421875,
-... |
ahuang11/tiger_layer_edges | 2023-07-12T21:40:42.000Z | [
"license:unknown",
"region:us"
] | ahuang11 | null | null | 0 | 3 | 2023-07-12T19:28:33 | ---
license: unknown
---
An unofficial re-packaged parquet files of TIGER/Line® Edges data provided by the US Census Bureau.
See LICENSE.pdf for more details. | 160 | [
[
-0.0258331298828125,
-0.049774169921875,
0.0053558349609375,
0.015777587890625,
-0.02093505859375,
-0.0085296630859375,
0.0394287109375,
-0.0208740234375,
0.042022705078125,
0.0831298828125,
-0.05828857421875,
-0.039520263671875,
-0.001007080078125,
-0.00700... |
Multimodal-Fatima/winoground-image-0 | 2023-07-13T03:39:46.000Z | [
"region:us"
] | Multimodal-Fatima | null | null | 0 | 3 | 2023-07-13T02:37:40 | ---
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: num_main_preds
dtype: int32
- name: tags_laion-ViT-H-14-2B
sequence: string
- name: attributes_laion-ViT-H-14-2B
sequence: string
- name: caption_Salesforce-blip-image-captioning-large
dtype: string
- name: intensive_captions_Salesforce-blip-image-captioning-large
sequence: string
splits:
- name: test
num_bytes: 186460141.0
num_examples: 400
download_size: 185328961
dataset_size: 186460141.0
---
# Dataset Card for "winoground-image-0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 718 | [
[
-0.039093017578125,
-0.01424407958984375,
0.0167083740234375,
0.01178741455078125,
-0.0216827392578125,
0.001239776611328125,
0.02630615234375,
-0.0218505859375,
0.06878662109375,
0.03173828125,
-0.060211181640625,
-0.058135986328125,
-0.043731689453125,
-0.... |
Regemens/quotesTest | 2023-07-13T14:35:05.000Z | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"region:us"
] | Regemens | null | null | 0 | 3 | 2023-07-13T14:34:20 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
- crowdsourced
language:
- en
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-label-classification
---
# ****Dataset Card for English quotes****
# **I-Dataset Summary**
english_quotes is a dataset of all the quotes retrieved from [goodreads quotes](https://www.goodreads.com/quotes). This dataset can be used for multi-label text classification and text generation. The content of each quote is in English and concerns the domain of datasets for NLP and beyond.
# **II-Supported Tasks and Leaderboards**
- Multi-label text classification : The dataset can be used to train a model for text-classification, which consists of classifying quotes by author as well as by topic (using tags). Success on this task is typically measured by achieving a high or low accuracy.
- Text-generation : The dataset can be used to train a model to generate quotes by fine-tuning an existing pretrained model on the corpus composed of all quotes (or quotes by author).
# **III-Languages**
The texts in the dataset are in English (en).
# **IV-Dataset Structure**
#### Data Instances
A JSON-formatted example of a typical instance in the dataset:
```python
{'author': 'Ralph Waldo Emerson',
'quote': '“To be yourself in a world that is constantly trying to make you something else is the greatest accomplishment.”',
'tags': ['accomplishment', 'be-yourself', 'conformity', 'individuality']}
```
#### Data Fields
- **author** : The author of the quote.
- **quote** : The text of the quote.
- **tags**: The tags could be characterized as topics around the quote.
#### Data Splits
I kept the dataset as one block (train), so it can be shuffled and split by users later using methods of the hugging face dataset library like the (.train_test_split()) method.
# **V-Dataset Creation**
#### Curation Rationale
I want to share my datasets (created by web scraping and additional cleaning treatments) with the HuggingFace community so that they can use them in NLP tasks to advance artificial intelligence.
#### Source Data
The source of Data is [goodreads](https://www.goodreads.com/?ref=nav_home) site: from [goodreads quotes](https://www.goodreads.com/quotes)
#### Initial Data Collection and Normalization
The data collection process is web scraping using BeautifulSoup and Requests libraries.
The data is slightly modified after the web scraping: removing all quotes with "None" tags, and the tag "attributed-no-source" is removed from all tags, because it has not added value to the topic of the quote.
#### Who are the source Data producers ?
The data is machine-generated (using web scraping) and subjected to human additional treatment.
below, I provide the script I created to scrape the data (as well as my additional treatment):
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
from collections import OrderedDict
page = requests.get('https://www.goodreads.com/quotes')
if page.status_code == 200:
pageParsed = BeautifulSoup(page.content, 'html5lib')
# Define a function that retrieves information about each HTML quote code in a dictionary form.
def extract_data_quote(quote_html):
quote = quote_html.find('div',{'class':'quoteText'}).get_text().strip().split('\n')[0]
author = quote_html.find('span',{'class':'authorOrTitle'}).get_text().strip()
if quote_html.find('div',{'class':'greyText smallText left'}) is not None:
tags_list = [tag.get_text() for tag in quote_html.find('div',{'class':'greyText smallText left'}).find_all('a')]
tags = list(OrderedDict.fromkeys(tags_list))
if 'attributed-no-source' in tags:
tags.remove('attributed-no-source')
else:
tags = None
data = {'quote':quote, 'author':author, 'tags':tags}
return data
# Define a function that retrieves all the quotes on a single page.
def get_quotes_data(page_url):
page = requests.get(page_url)
if page.status_code == 200:
pageParsed = BeautifulSoup(page.content, 'html5lib')
quotes_html_page = pageParsed.find_all('div',{'class':'quoteDetails'})
return [extract_data_quote(quote_html) for quote_html in quotes_html_page]
# Retrieve data from the first page.
data = get_quotes_data('https://www.goodreads.com/quotes')
# Retrieve data from all pages.
for i in range(2,101):
print(i)
url = f'https://www.goodreads.com/quotes?page={i}'
data_current_page = get_quotes_data(url)
if data_current_page is None:
continue
data = data + data_current_page
data_df = pd.DataFrame.from_dict(data)
for i, row in data_df.iterrows():
if row['tags'] is None:
data_df = data_df.drop(i)
# Produce the data in a JSON format.
data_df.to_json('C:/Users/Abir/Desktop/quotes.jsonl',orient="records", lines =True,force_ascii=False)
# Then I used the familiar process to push it to the Hugging Face hub.
```
#### Annotations
Annotations are part of the initial data collection (see the script above).
# **VI-Additional Informations**
#### Dataset Curators
Abir ELTAIEF
#### Licensing Information
This work is licensed under a Creative Commons Attribution 4.0 International License (all software and libraries used for web scraping are made available under this Creative Commons Attribution license).
#### Contributions
Thanks to [@Abirate](https://huggingface.co/Abirate)
for adding this dataset. | 5,550 | [
[
-0.02215576171875,
-0.046783447265625,
0.006610870361328125,
0.015960693359375,
-0.020599365234375,
-0.002895355224609375,
-0.0048065185546875,
-0.0279541015625,
0.031005859375,
0.02838134765625,
-0.048919677734375,
-0.04681396484375,
-0.028289794921875,
0.0... |
freQuensy23/ru-alpaca-cleaned | 2023-07-17T17:04:15.000Z | [
"license:cc-by-4.0",
"region:us"
] | freQuensy23 | null | null | 6 | 3 | 2023-07-13T22:18:39 | ---
license: cc-by-4.0
---
Translated with yandex.translate.ru into russian [alpaca's](https://huggingface.co/datasets/yahma/alpaca-cleaned) dataset. Code for reproducing the result - [colab](https://colab.research.google.com/drive/1oRTDtRWA4wcLOoR75MWv7vaZUf3BgVLZ?usp=sharing)
| 280 | [
[
-0.0162506103515625,
-0.048187255859375,
0.016754150390625,
0.00919342041015625,
-0.0389404296875,
-0.0200347900390625,
0.01291656494140625,
-0.04052734375,
0.0721435546875,
0.0291595458984375,
-0.0633544921875,
-0.042144775390625,
-0.040679931640625,
-0.005... |
daqc/wikihow-spanish | 2023-07-14T12:26:09.000Z | [
"task_categories:text-generation",
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:es",
"license:cc",
"wikihow",
"gpt2",
"spanish",
"region:us"
] | daqc | null | null | 1 | 3 | 2023-07-14T12:04:44 | ---
license: cc
task_categories:
- text-generation
- question-answering
language:
- es
tags:
- wikihow
- gpt2
- spanish
pretty_name: wikihow-spanish
size_categories:
- 10K<n<100K
---
## Wikihow en Español ##
Este dataset fue obtenido desde el repositorio Github de [Wikilingua](https://github.com/esdurmus/Wikilingua).
## Licencia ##
- Artículo proporcionado por wikiHow <https://www.wikihow.com/Main-Page>, una wiki que construye el manual de instrucciones más grande y de mayor calidad del mundo. Por favor, edita este artículo y encuentra los créditos del autor en wikiHow.com. El contenido de wikiHow se puede compartir bajo la[licencia Creative Commons](http://creativecommons.org/licenses/by-nc-sa/3.0/).
- Consulta [esta página web](https://www.wikihow.com/wikiHow:Attribution) para obtener las pautas específicas de atribución.
| 838 | [
[
-0.037872314453125,
-0.0228271484375,
0.01558685302734375,
0.0192718505859375,
-0.051025390625,
-0.0092315673828125,
-0.027374267578125,
-0.0170135498046875,
0.0469970703125,
0.03338623046875,
-0.049652099609375,
-0.057647705078125,
-0.0227203369140625,
0.02... |
aisyahhrazak/crawl-worldofbuzz | 2023-07-15T04:25:44.000Z | [
"language:en",
"region:us"
] | aisyahhrazak | null | null | 0 | 3 | 2023-07-14T14:03:17 | ---
language:
- en
---
About
- Data scraped from https://worldofbuzz.com | 75 | [
[
-0.046966552734375,
-0.1123046875,
0.020050048828125,
0.004230499267578125,
-0.0249176025390625,
0.0272064208984375,
0.01287078857421875,
-0.037353515625,
0.038665771484375,
0.0258026123046875,
-0.06463623046875,
-0.0364990234375,
-0.00736236572265625,
-0.01... |
davanstrien/blbooks-parquet-embedded | 2023-07-14T14:38:08.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_categories:other",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"multilinguality:multilingual",
"size_categories:100K<n<1M",
"sou... | davanstrien | null | null | 0 | 3 | 2023-07-14T14:37:41 | ---
annotations_creators:
- no-annotation
language_creators:
- machine-generated
language:
- de
- en
- es
- fr
- it
- nl
license:
- cc0-1.0
multilinguality:
- multilingual
size_categories:
- 100K<n<1M
source_datasets: davanstrien/blbooks-parquet
task_categories:
- text-generation
- fill-mask
- other
task_ids:
- language-modeling
- masked-language-modeling
pretty_name: British Library Books
tags:
- embeddings
dataset_info:
- config_name: all
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30394267732
num_examples: 14011953
download_size: 10486035662
dataset_size: 30394267732
- config_name: 1800s
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30020434670
num_examples: 13781747
download_size: 10348577602
dataset_size: 30020434670
- config_name: 1700s
features:
- name: record_id
dtype: string
- name: date
dtype: int32
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 266382657
num_examples: 178224
download_size: 95137895
dataset_size: 266382657
- config_name: '1510_1699'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 107667469
num_examples: 51982
download_size: 42320165
dataset_size: 107667469
- config_name: '1500_1899'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30452067039
num_examples: 14011953
download_size: 10486035662
dataset_size: 30452067039
- config_name: '1800_1899'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 30077284377
num_examples: 13781747
download_size: 10348577602
dataset_size: 30077284377
- config_name: '1700_1799'
features:
- name: record_id
dtype: string
- name: date
dtype: timestamp[s]
- name: raw_date
dtype: string
- name: title
dtype: string
- name: place
dtype: string
- name: empty_pg
dtype: bool
- name: text
dtype: string
- name: pg
dtype: int32
- name: mean_wc_ocr
dtype: float32
- name: std_wc_ocr
dtype: float64
- name: name
dtype: string
- name: all_names
dtype: string
- name: Publisher
dtype: string
- name: Country of publication 1
dtype: string
- name: all Countries of publication
dtype: string
- name: Physical description
dtype: string
- name: Language_1
dtype: string
- name: Language_2
dtype: string
- name: Language_3
dtype: string
- name: Language_4
dtype: string
- name: multi_language
dtype: bool
splits:
- name: train
num_bytes: 267117831
num_examples: 178224
download_size: 95137895
dataset_size: 267117831
---
# Dataset Card for "blbooks-parquet-embedded"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 7,553 | [
[
-0.0292510986328125,
-0.03363037109375,
0.0118255615234375,
0.044158935546875,
-0.029296875,
-0.004024505615234375,
0.012603759765625,
-0.01084136962890625,
0.052703857421875,
0.039154052734375,
-0.031036376953125,
-0.05316162109375,
-0.03271484375,
-0.03671... |
TinyPixel/open-assistant | 2023-09-03T02:26:32.000Z | [
"region:us"
] | TinyPixel | null | null | 2 | 3 | 2023-07-15T15:33:39 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 9599234
num_examples: 8274
download_size: 5137419
dataset_size: 9599234
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "open-assistant"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 442 | [
[
-0.037872314453125,
-0.031829833984375,
0.017425537109375,
0.00931549072265625,
0.00258636474609375,
-0.0214080810546875,
0.018798828125,
-0.0134124755859375,
0.059173583984375,
0.03192138671875,
-0.054229736328125,
-0.044830322265625,
-0.0338134765625,
-0.0... |
NeuroSenko/senko-voice | 2023-07-17T04:06:40.000Z | [
"region:us"
] | NeuroSenko | null | null | 0 | 3 | 2023-07-17T03:37:56 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
usamahanif719/scisumm | 2023-07-17T19:40:58.000Z | [
"region:us"
] | usamahanif719 | null | null | 0 | 3 | 2023-07-17T19:40:23 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ranWang/test_paper_textClassifier | 2023-07-29T00:42:37.000Z | [
"region:us"
] | ranWang | null | null | 0 | 3 | 2023-07-18T04:54:57 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
- name: file_path
dtype: string
splits:
- name: test
num_bytes: 10745576
num_examples: 387
- name: train
num_bytes: 325609267
num_examples: 13621
download_size: 153433963
dataset_size: 336354843
---
# Dataset Card for "test_paper_textClassifier"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 506 | [
[
-0.0279998779296875,
-0.0232391357421875,
0.0169677734375,
-0.0018644332885742188,
-0.0054779052734375,
0.00197601318359375,
0.005550384521484375,
0.0003120899200439453,
0.03656005859375,
0.0196075439453125,
-0.0360107421875,
-0.04827880859375,
-0.04824829101562... |
richardr1126/spider-skeleton-context-instruct | 2023-07-18T17:55:47.000Z | [
"source_datasets:spider",
"language:en",
"license:cc-by-4.0",
"text-to-sql",
"SQL",
"Spider",
"fine-tune",
"region:us"
] | richardr1126 | null | null | 2 | 3 | 2023-07-18T17:53:25 | ---
language:
- en
license:
- cc-by-4.0
source_datasets:
- spider
pretty_name: Spider Skeleton Context Instruct
tags:
- text-to-sql
- SQL
- Spider
- fine-tune
dataset_info:
features:
- name: db_id
dtype: string
- name: text
dtype: string
---
# Dataset Card for Spider Skeleton Context Instruct
### Dataset Summary
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students
The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
This dataset was created to finetune LLMs in a `### Instruction:` and `### Response:` format with database context.
### Yale Lily Spider Leaderboards
The leaderboard can be seen at https://yale-lily.github.io/spider
### Languages
The text in the dataset is in English.
### Licensing Information
The spider dataset is licensed under
the [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
### Citation
```
@article{yu2018spider,
title={Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task},
author={Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others},
journal={arXiv preprint arXiv:1809.08887},
year={2018}
}
``` | 1,386 | [
[
0.006282806396484375,
-0.0249176025390625,
0.01551055908203125,
0.00576019287109375,
-0.023284912109375,
0.01470947265625,
0.00189971923828125,
-0.038177490234375,
0.039703369140625,
0.0198211669921875,
-0.046539306640625,
-0.066650390625,
-0.03570556640625,
... |
klogram/wunderdrug | 2023-07-19T02:03:24.000Z | [
"size_categories:n<1K",
"language:en",
"license:mit",
"region:us"
] | klogram | null | null | 0 | 3 | 2023-07-19T01:45:38 | ---
license: mit
language:
- en
size_categories:
- n<1K
---
# Dataset Card for Wunderdrug
## Dataset Description
### Dataset Summary
A toy dataset containing 69 one-sentence descriptions of the outcomes of treatment with a *fictional* drug named "Wunderdrug".
Each description contains a comment on Wunderdrug's effect on risk of death from heart disease, mentioning possible confounders like diet, weight, or exercise.
## Considerations for Using the Data
This toy dataset was designed to test the ability of sentence embeddings to capture language features that can serve as
covariates when doing causal inference with text data.
### Citation Information
Forthcoming
| 678 | [
[
-0.01212310791015625,
-0.055938720703125,
0.0225677490234375,
-0.003314971923828125,
-0.0257110595703125,
-0.0190277099609375,
-0.0019083023071289062,
-0.00637054443359375,
0.02130126953125,
0.040283203125,
-0.051055908203125,
-0.0428466796875,
-0.0367431640625,... |
FunDialogues/healthcare-minor-consultation | 2023-07-19T05:37:13.000Z | [
"task_categories:question-answering",
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"fictitious dialogues",
"prototyping",
"healthcare",
"region:us"
] | FunDialogues | null | null | 1 | 3 | 2023-07-19T04:27:42 | ---
license: apache-2.0
task_categories:
- question-answering
- conversational
language:
- en
tags:
- fictitious dialogues
- prototyping
- healthcare
pretty_name: 'healthcare-minor-consultation'
size_categories:
- n<1K
---
# fun dialogues
A library of fictitious dialogues that can be used to train language models or augment prompts for prototyping and educational purposes. Fun dialogues currently come in json and csv format for easy ingestion or conversion to popular data structures. Dialogues span various topics such as sports, retail, academia, healthcare, and more. The library also includes basic tooling for loading dialogues and will include quick chatbot prototyping functionality in the future.
Visit the Project Repo: https://github.com/eduand-alvarez/fun-dialogues/
# This Dialogue
Comprised of fictitious examples of dialogues between a doctor and a patient during a minor medical consultation.. Check out the example below:
```
"id": 1,
"description": "Discussion about a common cold",
"dialogue": "Patient: Doctor, I've been feeling congested and have a runny nose. What can I do to relieve these symptoms?\n\nDoctor: It sounds like you have a common cold. You can try over-the-counter decongestants to relieve congestion and saline nasal sprays to help with the runny nose. Make sure to drink plenty of fluids and get enough rest as well."
```
# How to Load Dialogues
Loading dialogues can be accomplished using the fun dialogues library or Hugging Face datasets library.
## Load using fun dialogues
1. Install fun dialogues package
`pip install fundialogues`
2. Use loader utility to load dataset as pandas dataframe. Further processing might be required for use.
```
from fundialogues import dialoader
# load as pandas dataframe
bball_coach = dialoader("FunDialogues/healthcare-minor-consultation")
```
## Loading using Hugging Face datasets
1. Install datasets package
2. Load using datasets
```
from datasets import load_dataset
dataset = load_dataset("FunDialogues/healthcare-minor-consultation")
```
## How to Contribute
If you want to contribute to this project and make it better, your help is very welcome. Contributing is also a great way to learn more about social coding on Github, new technologies and and their ecosystems and how to make constructive, helpful bug reports, feature requests and the noblest of all contributions: a good, clean pull request.
### Contributing your own Lifecycle Solution
If you want to contribute to an existing dialogue or add a new dialogue, please open an issue and I will follow up with you ASAP!
### Implementing Patches and Bug Fixes
- Create a personal fork of the project on Github.
- Clone the fork on your local machine. Your remote repo on Github is called origin.
- Add the original repository as a remote called upstream.
- If you created your fork a while ago be sure to pull upstream changes into your local repository.
- Create a new branch to work on! Branch from develop if it exists, else from master.
- Implement/fix your feature, comment your code.
- Follow the code style of the project, including indentation.
- If the component has tests run them!
- Write or adapt tests as needed.
- Add or change the documentation as needed.
- Squash your commits into a single commit with git's interactive rebase. Create a new branch if necessary.
- Push your branch to your fork on Github, the remote origin.
- From your fork open a pull request in the correct branch. Target the project's develop branch if there is one, else go for master!
If the maintainer requests further changes just push them to your branch. The PR will be updated automatically.
Once the pull request is approved and merged you can pull the changes from upstream to your local repo and delete your extra branch(es).
And last but not least: Always write your commit messages in the present tense. Your commit message should describe what the commit, when applied, does to the code – not what you did to the code.
# Disclaimer
The dialogues contained in this repository are provided for experimental purposes only. It is important to note that these dialogues are assumed to be original work by a human and are entirely fictitious, despite the possibility of some examples including factually correct information. The primary intention behind these dialogues is to serve as a tool for language modeling experimentation and should not be used for designing real-world products beyond non-production prototyping.
Please be aware that the utilization of fictitious data in these datasets may increase the likelihood of language model artifacts, such as hallucinations or unrealistic responses. Therefore, it is essential to exercise caution and discretion when employing these datasets for any purpose.
It is crucial to emphasize that none of the scenarios described in the fun dialogues dataset should be relied upon to provide advice or guidance to humans. These scenarios are purely fictitious and are intended solely for demonstration purposes. Any resemblance to real-world situations or individuals is entirely coincidental.
The responsibility for the usage and application of these datasets rests solely with the individual or entity employing them. By accessing and utilizing these dialogues and all contents of the repository, you acknowledge that you have read and understood this disclaimer, and you agree to use them at your own discretion and risk. | 5,431 | [
[
-0.00732421875,
-0.060302734375,
0.0283355712890625,
0.0185699462890625,
-0.0254974365234375,
0.00827789306640625,
-0.01525115966796875,
-0.0193023681640625,
0.042388916015625,
0.054168701171875,
-0.054351806640625,
-0.033050537109375,
-0.01151275634765625,
... |
mber/subset_wikitext_format_date_only_train | 2023-07-19T08:06:29.000Z | [
"region:us"
] | mber | null | null | 0 | 3 | 2023-07-19T08:06:27 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1303054.8711650241
num_examples: 2852
download_size: 4222120
dataset_size: 1303054.8711650241
---
# Dataset Card for "subset_wikitext_format_date_only_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 402 | [
[
-0.0213470458984375,
-0.01088714599609375,
0.007293701171875,
0.0452880859375,
-0.016998291015625,
-0.0299835205078125,
0.01458740234375,
-0.0012178421020507812,
0.06341552734375,
0.03363037109375,
-0.08441162109375,
-0.0311431884765625,
-0.0219879150390625,
... |
qmeeus/AGV2 | 2023-07-19T13:41:40.000Z | [
"region:us"
] | qmeeus | null | null | 0 | 3 | 2023-07-19T13:41:35 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: task
dtype: string
- name: language
dtype: string
- name: speaker
dtype: string
splits:
- name: train
num_bytes: 53888736.0
num_examples: 81
download_size: 30633674
dataset_size: 53888736.0
---
# Dataset Card for "AGV2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 493 | [
[
-0.0284881591796875,
-0.019805908203125,
0.00946807861328125,
0.00811767578125,
-0.009063720703125,
-0.0023479461669921875,
0.045684814453125,
-0.01169586181640625,
0.039337158203125,
0.0206146240234375,
-0.05291748046875,
-0.03668212890625,
-0.044921875,
-0... |
AlekseyKorshuk/synthetic-romantic-characters | 2023-07-20T00:23:35.000Z | [
"region:us"
] | AlekseyKorshuk | null | null | 0 | 3 | 2023-07-20T00:23:24 | ---
dataset_info:
features:
- name: name
dtype: string
- name: categories
sequence: string
- name: personalities
sequence: string
- name: description
dtype: string
- name: conversation
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 14989220
num_examples: 5744
download_size: 7896899
dataset_size: 14989220
---
# Dataset Card for "synthetic-romantic-characters"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 610 | [
[
-0.0386962890625,
-0.03948974609375,
0.02490234375,
0.032867431640625,
-0.011138916015625,
0.01375579833984375,
0.0010366439819335938,
-0.029876708984375,
0.0675048828125,
0.03851318359375,
-0.07855224609375,
-0.046356201171875,
-0.01910400390625,
0.01073455... |
lavita/medical-qa-shared-task-v1-all | 2023-07-20T00:31:23.000Z | [
"region:us"
] | lavita | null | null | 1 | 3 | 2023-07-20T00:30:26 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: ending0
dtype: string
- name: ending1
dtype: string
- name: ending2
dtype: string
- name: ending3
dtype: string
- name: ending4
dtype: string
- name: label
dtype: int64
- name: sent1
dtype: string
- name: sent2
dtype: string
- name: startphrase
dtype: string
splits:
- name: train
num_bytes: 16691926
num_examples: 10178
- name: dev
num_bytes: 2086503
num_examples: 1272
download_size: 10556685
dataset_size: 18778429
---
# Dataset Card for "medical-qa-shared-task-v1-all"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 753 | [
[
-0.016326904296875,
-0.013824462890625,
0.04022216796875,
0.0143890380859375,
-0.0248565673828125,
-0.006748199462890625,
0.04931640625,
-0.01314544677734375,
0.08172607421875,
0.036102294921875,
-0.07562255859375,
-0.058074951171875,
-0.047943115234375,
-0.... |
TrainingDataPro/russian-spam-text-messages | 2023-09-14T16:58:13.000Z | [
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The SMS spam dataset contains a collection of text messages on Russian.
The dataset includes a diverse range of spam messages, including promotional
offers, fraudulent schemes, phishing attempts, and other forms of unsolicited
communication.
Each SMS message is represented as a string of text, and each entry in the
dataset also has a link to the corresponding screenshot. The dataset's content
represents real-life examples of spam messages that users encounter in their
everyday communication. | @InProceedings{huggingface:dataset,
title = {russian-spam-text-messages},
author = {TrainingDataPro},
year = {2023}
} | 2 | 3 | 2023-07-20T10:20:06 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- text-classification
tags:
- code
- finance
dataset_info:
features:
- name: image
dtype: image
- name: message
dtype: string
splits:
- name: train
num_bytes: 56671464
num_examples: 100
download_size: 54193441
dataset_size: 56671464
---
# Russian Spam Text Messages
The SMS spam dataset contains a collection of text messages on Russian. The dataset includes a diverse range of spam messages, including *promotional offers, fraudulent schemes, phishing attempts, and other forms of unsolicited communication*.
Each SMS message is represented as a string of text, and each entry in the dataset also has a link to the corresponding screenshot. The dataset's content represents real-life examples of spam messages that users encounter in their everyday communication.
### The dataset's possible applications:
- spam detection
- fraud detection
- customer support automation
- trend and sentiment analysis
- educational purposes
- network security
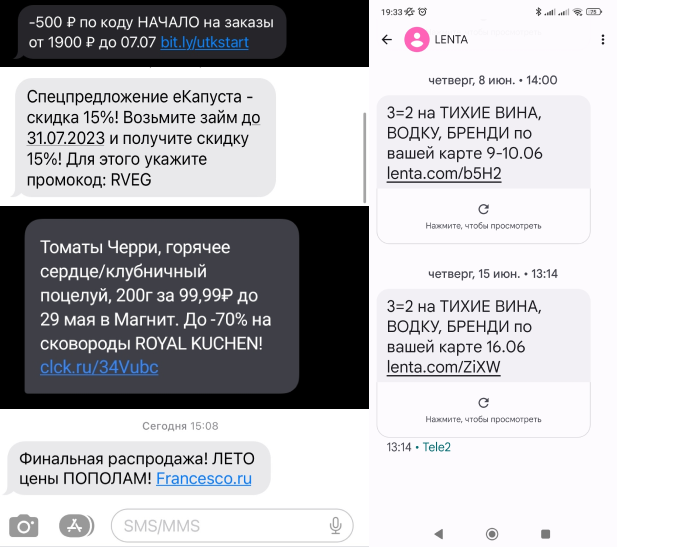
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=russian-spam-text-messages) to discuss your requirements, learn about the price and buy the dataset.
# Content
- **images**: includes screenshots of spam messages on Russian
- **.csv** file: contains information about the dataset
### File with the extension .csv
includes the following information:
- **image**: link to the screenshot with the spam message,
- **text**: text of the spam message
# Spam messages might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=russian-spam-text-messages) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,313 | [
[
0.0079803466796875,
-0.059814453125,
-0.004878997802734375,
0.0228729248046875,
-0.03204345703125,
0.01520538330078125,
-0.01531982421875,
-0.0087432861328125,
0.015533447265625,
0.06353759765625,
-0.047027587890625,
-0.06634521484375,
-0.04827880859375,
-0.... |
ksgr5566/trialx2 | 2023-07-26T22:28:18.000Z | [
"region:us"
] | ksgr5566 | null | null | 0 | 3 | 2023-07-21T08:35:26 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ittailup/lallama-data-chat | 2023-07-21T18:16:22.000Z | [
"region:us"
] | ittailup | null | null | 0 | 3 | 2023-07-21T18:04:52 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 8086191762
num_examples: 1054559
download_size: 4359870365
dataset_size: 8086191762
---
# Dataset Card for "lallama-data-chat"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 371 | [
[
-0.02996826171875,
-0.039947509765625,
0.0023345947265625,
0.032135009765625,
-0.00649261474609375,
0.00032401084899902344,
0.019622802734375,
-0.0234832763671875,
0.0672607421875,
0.0253753662109375,
-0.05523681640625,
-0.04986572265625,
-0.0307159423828125,
... |
ryandsilva/semeval_2017_puns | 2023-09-21T23:15:59.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:en",
"puns",
"humour",
"wordplay",
"region:us"
] | ryandsilva | null | null | 0 | 3 | 2023-07-22T04:36:33 | ---
configs:
- config_name: default
data_files:
- split: task_1
path:
- task1/semeval_task1.jsonl
- split: task_2
path:
- task2/semeval-task2-homo.json
- task2/semeval-task2-hetero.json
- split: task_3
path:
- task3/semeval-task3-homo.json
- task3/semeval-task3-hetero.json
task_categories:
- text-classification
- token-classification
language:
- en
tags:
- puns
- humour
- wordplay
size_categories:
- 1K<n<10K
---
# SemEval 2017 Task 7 Pun Dataset | 490 | [
[
-0.01641845703125,
-0.00765228271484375,
0.0204010009765625,
0.03192138671875,
-0.047698974609375,
-0.0131072998046875,
0.0011005401611328125,
-0.0136260986328125,
0.0182037353515625,
0.06927490234375,
-0.032562255859375,
-0.04290771484375,
-0.0491943359375,
... |
osbm/prostate158 | 2023-08-09T00:10:04.000Z | [
"region:us"
] | osbm | null | null | 0 | 3 | 2023-07-22T23:41:46 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
CreativeLang/pun_detection_semeval2017_task7 | 2023-07-22T23:50:29.000Z | [
"license:cc-by-2.0",
"region:us"
] | CreativeLang | null | null | 0 | 3 | 2023-07-22T23:48:40 | ---
license: cc-by-2.0
---
# Semeval2017 Task 7: Pun Detection
- paper: [SemEval-2017 Task 7: Detection and Interpretation of English Puns](https://aclanthology.org/S17-2005/) at Semeval 2017.
Metadata in Creative Language Toolkit ([CLTK](https://github.com/liyucheng09/cltk))
- CL Type: Pun
- Task Type: Detection
- Size: 4k
- Created time: 2017 | 348 | [
[
-0.0311737060546875,
-0.031982421875,
0.05108642578125,
0.054901123046875,
-0.052337646484375,
-0.018280029296875,
0.0005931854248046875,
-0.041961669921875,
0.03448486328125,
0.048492431640625,
-0.044677734375,
-0.037200927734375,
-0.052520751953125,
0.0393... |
youssef101/artelingo-dummy | 2023-07-23T16:21:23.000Z | [
"task_categories:image-to-text",
"task_categories:text-classification",
"task_categories:image-classification",
"task_categories:text-to-image",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"language:ar",
"language:zh",
"license:mit",
"Affective Captioning",
"... | youssef101 | null | null | 0 | 3 | 2023-07-23T14:41:17 | ---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: art_style
dtype: string
- name: painting
dtype: string
- name: emotion
dtype: string
- name: language
dtype: string
- name: text
dtype: string
- name: split
dtype: string
splits:
- name: train
num_bytes: 18587167692.616
num_examples: 62989
- name: validation
num_bytes: 965978050.797
num_examples: 3191
- name: test
num_bytes: 2330046601.416
num_examples: 6402
download_size: 4565327615
dataset_size: 21883192344.829002
task_categories:
- image-to-text
- text-classification
- image-classification
- text-to-image
- text-generation
language:
- en
- ar
- zh
tags:
- Affective Captioning
- Emotions
- Prediction
- Art
- ArtELingo
pretty_name: ArtELingo
size_categories:
- 100K<n<1M
---
ArtELingo is a benchmark and dataset introduced in a research paper aimed at promoting work on diversity across languages and cultures. It is an extension of ArtEmis, which is a collection of 80,000 artworks from WikiArt with 450,000 emotion labels and English-only captions. ArtELingo expands this dataset by adding 790,000 annotations in Arabic and Chinese. The purpose of these additional annotations is to evaluate the performance of "cultural-transfer" in AI systems.
The dataset in ArtELingo contains many artworks with multiple annotations in three languages, providing a diverse set of data that enables the study of similarities and differences across languages and cultures. The researchers investigate captioning tasks and find that diversity in annotations improves the performance of baseline models.
The goal of ArtELingo is to encourage research on multilinguality and culturally-aware AI. By including annotations in multiple languages and considering cultural differences, the dataset aims to build more human-compatible AI that is sensitive to emotional nuances across various cultural contexts. The researchers believe that studying emotions in this way is crucial to understanding a significant aspect of human intelligence.
In summary, ArtELingo is a dataset that extends ArtEmis by providing annotations in multiple languages and cultures, facilitating research on diversity in AI systems and improving their performance in emotion-related tasks like label prediction and affective caption generation. The dataset is publicly available, and the researchers hope that it will facilitate future studies in multilingual and culturally-aware artificial intelligence. | 2,527 | [
[
-0.04400634765625,
-0.0125885009765625,
-0.00550079345703125,
0.0225677490234375,
-0.0240936279296875,
-0.021575927734375,
0.0005097389221191406,
-0.07733154296875,
0.01294708251953125,
0.00255584716796875,
-0.0193634033203125,
-0.03582763671875,
-0.046020507812... |
AlexWortega/SaigaSbs | 2023-07-23T18:43:05.000Z | [
"region:us"
] | AlexWortega | null | null | 0 | 3 | 2023-07-23T18:35:36 | ---
dataset_info:
features:
- name: 'Unnamed: 0'
dtype: int64
- name: inst
dtype: string
- name: good
dtype: string
- name: bad
dtype: string
splits:
- name: train
num_bytes: 7692567
num_examples: 2736
download_size: 0
dataset_size: 7692567
---
# Dataset Card for "SaigaSbs"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 449 | [
[
-0.0367431640625,
0.0008611679077148438,
0.01837158203125,
0.017791748046875,
-0.0023365020751953125,
0.004619598388671875,
0.01100921630859375,
-0.0017528533935546875,
0.0662841796875,
0.03448486328125,
-0.06640625,
-0.056488037109375,
-0.05029296875,
-0.02... |
ayah-kamal/elsevier-annotated-min | 2023-08-23T07:48:33.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"region:us"
] | ayah-kamal | null | null | 0 | 3 | 2023-07-23T20:38:38 | ---
task_categories:
- text-classification
language:
- en
pretty_name: Elsevier Shapeless Sentence Classification
size_categories:
- n<1K
---
References:
Daniel, R. (Creator), Groth, P. (Creator), Scerri, A. (Creator), Harper, C. A. (Creator), Vandenbussche, P. (Creator), Cox, J. (Creator) (2015). An Open Access Corpus of Scientific, Technical, and Medical Content. Github.
| 380 | [
[
-0.006252288818359375,
-0.02923583984375,
0.0517578125,
0.025970458984375,
0.004230499267578125,
-0.0034313201904296875,
-0.0114288330078125,
-0.042083740234375,
0.0621337890625,
0.037994384765625,
-0.0229644775390625,
-0.046966552734375,
-0.03680419921875,
... |
varcoder/new_datasets | 2023-07-24T00:54:16.000Z | [
"region:us"
] | varcoder | null | null | 0 | 3 | 2023-07-24T00:45:49 | ---
dataset_info:
features:
- name: pixel_values
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 1662330448.536
num_examples: 14728
- name: test
num_bytes: 250546215.402
num_examples: 2582
download_size: 0
dataset_size: 1912876663.938
---
# Dataset Card for "new_datasets"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 470 | [
[
-0.049346923828125,
-0.019989013671875,
0.01087188720703125,
0.01114654541015625,
-0.0151824951171875,
0.00693511962890625,
0.0237274169921875,
-0.01192474365234375,
0.06915283203125,
0.037689208984375,
-0.05718994140625,
-0.056732177734375,
-0.04656982421875,
... |
wbxlala/har3 | 2023-07-24T14:46:20.000Z | [
"region:us"
] | wbxlala | null | null | 0 | 3 | 2023-07-24T14:46:13 | ---
dataset_info:
features:
- name: image
sequence:
sequence:
sequence: float64
- name: label
dtype: float64
splits:
- name: test
num_bytes: 13644996
num_examples: 1471
- name: train
num_bytes: 54552156
num_examples: 5881
download_size: 70093717
dataset_size: 68197152
---
# Dataset Card for "har3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 485 | [
[
-0.0426025390625,
-0.0182647705078125,
0.0147857666015625,
0.01629638671875,
-0.0019893646240234375,
0.0010118484497070312,
0.038726806640625,
-0.0280914306640625,
0.054656982421875,
0.04132080078125,
-0.04205322265625,
-0.046142578125,
-0.035491943359375,
-... |
eduagarcia/acordaos_tcu | 2023-07-24T20:10:58.000Z | [
"region:us"
] | eduagarcia | null | null | 0 | 3 | 2023-07-24T19:31:42 | ---
dataset_info:
features:
- name: id
dtype: string
- name: urn
dtype: string
- name: ano_acordao
dtype: int64
- name: numero_acordao
dtype: string
- name: relator
dtype: string
- name: processo
dtype: string
- name: tipo_processo
dtype: string
- name: data_sessao
dtype: string
- name: numero_ata
dtype: string
- name: interessado_reponsavel_recorrente
dtype: string
- name: entidade
dtype: string
- name: representante_mp
dtype: string
- name: unidade_tecnica
dtype: string
- name: repr_legal
dtype: string
- name: assunto
dtype: string
- name: tipo_text
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3884394771
num_examples: 634711
download_size: 1716899062
dataset_size: 3884394771
---
# Dataset Card for "acordaos_tcu"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,005 | [
[
-0.0269012451171875,
-0.0229644775390625,
0.0076446533203125,
0.0015354156494140625,
-0.020782470703125,
0.013702392578125,
0.0167388916015625,
-0.01049041748046875,
0.06512451171875,
0.025115966796875,
-0.046295166015625,
-0.048919677734375,
-0.033721923828125,... |
jxu9001/tagged_addresses_v2 | 2023-07-25T02:58:57.000Z | [
"region:us"
] | jxu9001 | null | null | 0 | 3 | 2023-07-25T02:58:53 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: tokens
sequence: string
- name: tags
sequence: int64
splits:
- name: train
num_bytes: 19347138
num_examples: 105594
- name: validation
num_bytes: 2418635
num_examples: 13199
- name: test
num_bytes: 2420348
num_examples: 13200
download_size: 5719368
dataset_size: 24186121
---
# Dataset Card for "tagged_addresses_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 709 | [
[
-0.0367431640625,
-0.0034332275390625,
0.009246826171875,
0.0031566619873046875,
-0.0167083740234375,
-0.0100555419921875,
0.033355712890625,
-0.03802490234375,
0.054779052734375,
0.04132080078125,
-0.048492431640625,
-0.0477294921875,
-0.035675048828125,
-0... |
HarisivaRG/EPC_Postcode_grouped | 2023-07-25T17:22:35.000Z | [
"region:us"
] | HarisivaRG | null | null | 0 | 3 | 2023-07-25T13:04:30 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
YoonSeul/legal-GPT-BARD-val_v3 | 2023-07-25T15:29:02.000Z | [
"region:us"
] | YoonSeul | null | null | 0 | 3 | 2023-07-25T15:28:59 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1359457
num_examples: 652
download_size: 689201
dataset_size: 1359457
---
# Dataset Card for "legal-GPT-BARD-val_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 437 | [
[
-0.016998291015625,
-0.01436614990234375,
0.0193634033203125,
0.0086212158203125,
-0.0259857177734375,
-0.00726318359375,
0.0240020751953125,
-0.01477813720703125,
0.04052734375,
0.054168701171875,
-0.04010009765625,
-0.0631103515625,
-0.03607177734375,
-0.0... |
dishathokal/mat_py_jul | 2023-07-26T10:08:48.000Z | [
"region:us"
] | dishathokal | null | null | 1 | 3 | 2023-07-25T16:09:54 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ArtifactAI/arxiv_research_code | 2023-07-26T19:13:22.000Z | [
"task_categories:text-generation",
"size_categories:10B<n<100B",
"language:en",
"license:bigscience-openrail-m",
"doi:10.57967/hf/0929",
"region:us"
] | ArtifactAI | null | null | 2 | 3 | 2023-07-26T01:48:20 | ---
dataset_info:
features:
- name: repo
dtype: string
- name: file
dtype: string
- name: code
dtype: string
- name: file_length
dtype: int64
- name: avg_line_length
dtype: float64
- name: max_line_length
dtype: int64
- name: extension_type
dtype: string
splits:
- name: train
num_bytes: 63445188751
num_examples: 4716175
download_size: 21776760509
dataset_size: 63445188751
license: bigscience-openrail-m
task_categories:
- text-generation
language:
- en
pretty_name: arxiv_research_code
size_categories:
- 10B<n<100B
---
# Dataset Card for "ArtifactAI/arxiv_research_code"
## Dataset Description
https://huggingface.co/datasets/ArtifactAI/arxiv_research_code
### Dataset Summary
ArtifactAI/arxiv_research_code contains over 21.8GB of source code files referenced strictly in ArXiv papers. The dataset serves as a curated dataset for Code LLMs.
### How to use it
```python
from datasets import load_dataset
# full dataset (21.8GB of data)
ds = load_dataset("ArtifactAI/arxiv_research_code", split="train")
# dataset streaming (will only download the data as needed)
ds = load_dataset("ArtifactAI/arxiv_research_code", streaming=True, split="train")
for sample in iter(ds): print(sample["code"])
```
## Dataset Structure
### Data Instances
Each data instance corresponds to one file. The content of the file is in the `code` feature, and other features (`repo`, `file`, etc.) provide some metadata.
### Data Fields
- `repo` (string): code repository name.
- `file` (string): file path in the repository.
- `code` (string): code within the file.
- `file_length`: (integer): number of characters in the file.
- `avg_line_length`: (float): the average line-length of the file.
- `max_line_length`: (integer): the maximum line-length of the file.
- `extension_type`: (string): file extension.
### Data Splits
The dataset has no splits and all data is loaded as train split by default.
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
34,099 active GitHub repository names were extracted from [ArXiv](https://arxiv.org/) papers from its inception through July 21st, 2023 totaling 773G of compressed github repositories.
These repositories were then filtered, and the code from each file was extracted into 4.7 million files.
#### Who are the source language producers?
The source (code) language producers are users of GitHub that created unique repository
### Personal and Sensitive Information
The released dataset may contain sensitive information such as emails, IP addresses, and API/ssh keys that have previously been published to public repositories on GitHub.
## Additional Information
### Dataset Curators
Matthew Kenney, Artifact AI, matt@artifactai.com
### Citation Information
```
@misc{arxiv_research_code,
title={arxiv_research_code},
author={Matthew Kenney},
year={2023}
}
``` | 2,913 | [
[
-0.026458740234375,
-0.0215606689453125,
0.00971221923828125,
0.0020084381103515625,
-0.0283050537109375,
-0.006641387939453125,
-0.018341064453125,
-0.0127410888671875,
0.01904296875,
0.041656494140625,
-0.01467132568359375,
-0.049346923828125,
-0.0309906005859... |
jeffnyman/scifact | 2023-07-26T08:18:50.000Z | [
"language:en",
"license:cc-by-nc-2.0",
"region:us"
] | jeffnyman | SciFact
A dataset of expert-written scientific claims paired with evidence-containing
abstracts and annotated with labels and rationales. | @InProceedings{Wadden2020FactOF,
author = {David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang,
Madeleine van Zuylen, Arman Cohan, Hannaneh Hajishirzi},
title = {Fact or Fiction: Verifying Scientific Claims},
booktitle = {EMNLP},
year = 2020,
} | 0 | 3 | 2023-07-26T07:53:29 | ---
language:
- en
license:
- cc-by-nc-2.0
---
# Dataset Card for "scifact"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [https://scifact.apps.allenai.org/](https://scifact.apps.allenai.org/)
- **Paper:** [Fact or Fiction: Verifying Scientific Claims](https://aclanthology.org/2020.emnlp-main.609/)
### Dataset Summary
SciFact.
This is a dataset of expert-written scientific claims paired with evidence-containing abstracts and annotated with labels and rationales.
## Dataset Structure
### Data Instances
#### claims
- **Size of downloaded dataset files:** 2.72 MB
- **Size of the generated dataset:** 0.25 MB
- **Total amount of disk used:** 2.97 MB
An example of 'validation' looks as follows.
```
{
"cited_doc_ids": [14717500],
"claim": "1,000 genomes project enables mapping of genetic sequence variation consisting of rare variants with larger penetrance effects than common variants.",
"evidence_doc_id": "14717500",
"evidence_label": "SUPPORT",
"evidence_sentences": [2, 5],
"id": 3
}
```
#### corpus
- **Size of downloaded dataset files:** 2.72 MB
- **Size of the generated dataset:** 7.63 MB
- **Total amount of disk used:** 10.35 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"abstract": "[\"Alterations of the architecture of cerebral white matter in the developing human brain can affect cortical development and res...",
"doc_id": 4983,
"structured": false,
"title": "Microstructural development of human newborn cerebral white matter assessed in vivo by diffusion tensor magnetic resonance imaging."
}
```
### Data Fields
The data fields are the same among all splits.
#### claims
- `id`: a `int32` feature.
- `claim`: a `string` feature.
- `evidence_doc_id`: a `string` feature.
- `evidence_label`: a `string` feature.
- `evidence_sentences`: a `list` of `int32` features.
- `cited_doc_ids`: a `list` of `int32` features.
#### corpus
- `doc_id`: a `int32` feature.
- `title`: a `string` feature.
- `abstract`: a `list` of `string` features.
- `structured`: a `bool` feature.
### Data Splits
#### claims
| |train|validation|test|
|------|----:|---------:|---:|
|claims| 1261| 450| 300|
#### corpus
| |train|
|------|----:|
|corpus| 5183|
## Additional Information
### Licensing Information
https://github.com/allenai/scifact/blob/master/LICENSE.md
The SciFact dataset is released under the [CC BY-NC 2.0](https://creativecommons.org/licenses/by-nc/2.0/). By using the SciFact data, you are agreeing to its usage terms.
### Citation Information
```
@inproceedings{wadden-etal-2020-fact,
title = "Fact or Fiction: Verifying Scientific Claims",
author = "Wadden, David and
Lin, Shanchuan and
Lo, Kyle and
Wang, Lucy Lu and
van Zuylen, Madeleine and
Cohan, Arman and
Hajishirzi, Hannaneh",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.609",
doi = "10.18653/v1/2020.emnlp-main.609",
pages = "7534--7550",
}
```
| 3,654 | [
[
-0.0287933349609375,
-0.05133056640625,
0.022125244140625,
0.01617431640625,
-0.005084991455078125,
-0.00426483154296875,
-0.007228851318359375,
-0.0305023193359375,
0.033111572265625,
0.00472259521484375,
-0.037017822265625,
-0.0489501953125,
-0.03851318359375,... |
hac541309/woori_spring_dict | 2023-08-15T11:00:14.000Z | [
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:question-answering",
"size_categories:1M<n<10M",
"language:ko",
"license:cc-by-sa-3.0",
"region:us"
] | hac541309 | null | null | 3 | 3 | 2023-07-26T11:34:08 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 514345294
num_examples: 1168853
download_size: 201093378
dataset_size: 514345294
license: cc-by-sa-3.0
task_categories:
- table-question-answering
- text-generation
- text-classification
- question-answering
language:
- ko
pretty_name: 우리말샘
size_categories:
- 1M<n<10M
---
# Dataset Card for "woori_spring_dict"
This dataset is a NLP learnable form of [woori mal saem(우리말샘)](https://opendict.korean.go.kr/main) a Korean collaborative open source dictionary.
It follows the [original copyright policy (cc-by-sa-2.0)](https://opendict.korean.go.kr/service/copyrightPolicy)
This version is built from xls_20230602
[우리말샘](https://opendict.korean.go.kr/main)을 학습 가능한 형태로 처리한 데이터입니다.
[우리말샘](https://opendict.korean.go.kr/service/copyrightPolicy)의 저작권을 따릅니다.
xls_20230602으로부터 생성되었습니다.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,025 | [
[
-0.022735595703125,
-0.01001739501953125,
-0.0044403076171875,
0.01088714599609375,
-0.036102294921875,
-0.0189971923828125,
-0.0214996337890625,
-0.008880615234375,
0.038604736328125,
0.02459716796875,
-0.05523681640625,
-0.05181884765625,
-0.03753662109375,
... |
hac541309/stdict_kor | 2023-07-26T12:01:59.000Z | [
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:question-answering",
"size_categories:1M<n<10M",
"language:ko",
"license:cc-by-sa-3.0",
"region:us"
] | hac541309 | null | null | 0 | 3 | 2023-07-26T11:52:59 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 205618385
num_examples: 434361
download_size: 72515975
dataset_size: 205618385
license: cc-by-sa-3.0
task_categories:
- table-question-answering
- text-generation
- text-classification
- question-answering
language:
- ko
pretty_name: 국립국어원 표준국어대사전
size_categories:
- 1M<n<10M
---
# Dataset Card for "Standard Korean Dictionary"
This dataset is a NLP learnable form of [Standard Dictionary from the National Institute of Korean Language (국립국어원 표준국어대사전)](https://stdict.korean.go.kr/).
It follows the [original copyright policy (cc-by-sa-2.0)](https://stdict.korean.go.kr/join/copyrightPolicy.do)
This version is built from xls_20230601
[국립국어원 표준 국어 대사전](https://stdict.korean.go.kr/)을 학습 가능한 형태로 처리한 데이터입니다.
[국립국어원 표준 국어 대사전](https://stdict.korean.go.kr/join/copyrightPolicy.do)의 저작권을 따릅니다.
xls_20230601으로부터 생성되었습니다. | 928 | [
[
-0.01708984375,
-0.00450897216796875,
-0.006549835205078125,
0.0223388671875,
-0.048858642578125,
-0.00501251220703125,
-0.0221710205078125,
-0.0003581047058105469,
0.042572021484375,
0.053436279296875,
-0.0316162109375,
-0.06781005859375,
-0.03668212890625,
... |
nlpkevinl/whatsthatbook | 2023-08-15T07:29:24.000Z | [
"task_categories:text-retrieval",
"language:en",
"license:odc-by",
"arxiv:2305.15053",
"region:us"
] | nlpkevinl | null | null | 0 | 3 | 2023-07-26T15:29:14 | ---
license: odc-by
task_categories:
- text-retrieval
language:
- en
pretty_name: whatsthatbook
extra_gated_prompt: "To access this dataset, you agree to the terms and conditions from the GoodReads website stated here: https://www.goodreads.com/about/terms"
extra_gated_fields:
I agree to use to the terms and conditions: checkbox
---
# Dataset Card for WhatsThatBook
## Dataset Description
- **Paper: https://arxiv.org/abs/2305.15053**
- **Point of Contact: k-lin@berkeley.edu**
### Dataset Summary
A collection of tip-of-the-tongue queries for book searches. The dataset was curated from GoodReads community forum user queries. It seves as a training and evaluation
resource for tip-of-the-tongue book queries. The user queries contain the interactions on the community forum and the documents are books with associated metadata.
### Supported Tasks and Leaderboards
WhatsThatBook is intended for information retrieval tasks including but not limited to standard retrieval, using just the original query posted by the user
and interactive settings, where the system asks clarification queries to narrow down the user's information needs.
### Languages
The dataset is primary in English, some book descriptions may contain other languages.
## Dataset Structure
### Data Fields
Data fields for WhatsThatBook queries:
- `question`: Inital query posted to the community forum
- `question_posted_date`: The date that the query was posted in YYYY-MM-DD format
- `book_id`: ID of the gold book used for evaluation
- `answers`: List of the gold book descriptions
The fields for the books:
- `title`: The title of the book
- `author`: The author of the book
- `author_url`: Link to the author page
- `description` The blurb of the book that contains description of the plot or
- `isbn_13`: The ISBN 13 number
- `date`: String representation of the date from the book webpage
- `parsed_dates`:A list of the publication date parsed out in YYYY-MM-DD format
- `image_link`: original link to image
- `ratings`: Total number of ratings
- `reviews`: Total number of reviews
- `genres`: Dictionary of genre tags to number of times tagged with that genre
- `id`: ID of the book, corresponding to the query file
### Data Splits
The dataset is comprised of two parts, WTB (WhatsThatBook), as well as TOMT (tip-of-my-tongue). WhatsThatBook contains standard train, dev, and test splits, and TOMT serves as an evaluation set.
## Dataset Creation
### Source Data
## Additional Information
### Dataset Curators
1. Kevin Lin, UC Berkeley, k-lin@berkeley.edu
2. Kyle Lo, Allen Institue For Artificial Intelligence, kylel@allenai.org
### Citation Information
```
@article{lin2023decomposing,
title={Decomposing Complex Queries for Tip-of-the-tongue Retrieval},
author={Lin, Kevin and Lo, Kyle and Gonzalez, Joseph E and Klein, Dan},
journal={arXiv preprint arXiv:2305.15053},
year={2023}
}
```
| 2,918 | [
[
-0.0307159423828125,
-0.04217529296875,
0.0108184814453125,
-0.003082275390625,
-0.019195556640625,
-0.0173492431640625,
-0.0042877197265625,
-0.031829833984375,
0.031402587890625,
0.048370361328125,
-0.05963134765625,
-0.0643310546875,
-0.0278167724609375,
... |
Seenka/banners_canal-12 | 2023-07-27T17:10:21.000Z | [
"region:us"
] | Seenka | null | null | 0 | 3 | 2023-07-26T23:35:34 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': none
'1': videograph
'2': zocalo
- name: yolo_out
list:
- name: class
dtype: int64
- name: confidence
dtype: float64
- name: name
dtype: string
- name: xmax
dtype: float64
- name: xmin
dtype: float64
- name: ymax
dtype: float64
- name: ymin
dtype: float64
- name: cropped_image
dtype: image
- name: yolo_seenka_out
list:
- name: class
dtype: int64
- name: confidence
dtype: float64
- name: name
dtype: string
- name: xmax
dtype: float64
- name: xmin
dtype: float64
- name: ymax
dtype: float64
- name: ymin
dtype: float64
- name: yolo_filter_param
dtype: 'null'
- name: cropped_seenka_image
dtype: image
- name: ocr_out
list:
- name: bbox
sequence:
sequence: float64
- name: confidence
dtype: float64
- name: text
dtype: string
- name: embeddings_cropped
sequence: float32
splits:
- name: train
num_bytes: 41759406.0
num_examples: 265
download_size: 41988381
dataset_size: 41759406.0
---
# Dataset Card for "banners_canal-12"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,452 | [
[
-0.0469970703125,
-0.009490966796875,
0.005794525146484375,
0.0384521484375,
-0.033599853515625,
0.008209228515625,
0.02655029296875,
-0.007293701171875,
0.0526123046875,
0.0271148681640625,
-0.052734375,
-0.058502197265625,
-0.0523681640625,
-0.014869689941... |
vichyt/code_dataset | 2023-07-27T05:23:59.000Z | [
"region:us"
] | vichyt | null | null | 0 | 3 | 2023-07-27T05:23:43 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
lrana/MMLU_ita | 2023-07-27T21:22:21.000Z | [
"task_categories:zero-shot-classification",
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:it",
"chemistry",
"biology",
"legal",
"finance",
"music",
"code",
"medical",
"region:us"
] | lrana | null | null | 0 | 3 | 2023-07-27T14:03:11 | ---
task_categories:
- zero-shot-classification
- text-classification
- question-answering
- text-generation
language:
- it
tags:
- chemistry
- biology
- legal
- finance
- music
- code
- medical
pretty_name: MMLU Italian Version
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 1,792 | [
[
-0.038177490234375,
-0.02984619140625,
-0.0036067962646484375,
0.027130126953125,
-0.0323486328125,
0.0037822723388671875,
-0.01727294921875,
-0.02020263671875,
0.049041748046875,
0.04046630859375,
-0.0634765625,
-0.08062744140625,
-0.052947998046875,
0.0020... |
HydraLM/math_dataset_standardized | 2023-07-27T17:16:11.000Z | [
"region:us"
] | HydraLM | null | null | 2 | 3 | 2023-07-27T17:15:52 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
adalbertojunior/portuguese_orca | 2023-07-28T03:18:22.000Z | [
"region:us"
] | adalbertojunior | null | null | 2 | 3 | 2023-07-28T03:12:08 | ---
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 103855088
num_examples: 80801
download_size: 62631439
dataset_size: 103855088
---
# Dataset Card for "portuguese_orca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 477 | [
[
-0.035247802734375,
-0.02703857421875,
-0.0010366439819335938,
0.0183258056640625,
-0.0299835205078125,
-0.01238250732421875,
0.0165557861328125,
-0.039215087890625,
0.0667724609375,
0.04254150390625,
-0.046142578125,
-0.06817626953125,
-0.044403076171875,
-... |
qgyd2021/ccks_2018_task3_pair_classification | 2023-07-28T03:20:54.000Z | [
"task_categories:text-classification",
"size_categories:1M<n<10M",
"language:zh",
"finance",
"region:us"
] | qgyd2021 | null | null | 0 | 3 | 2023-07-28T03:15:38 | ---
task_categories:
- text-classification
language:
- zh
tags:
- finance
pretty_name: ccks2018_v3
size_categories:
- 1M<n<10M
---
## ccks2018_v3
```text
CCKS 2018 微众银行智能客服问句匹配大赛
下载地址:
https://www.biendata.xyz/competition/CCKS2018_3/data/
参考链接:
https://zhuanlan.zhihu.com/p/454173790
https://github.com/liucongg/NLPDataSet
``` | 333 | [
[
-0.008270263671875,
-0.0183258056640625,
0.0190277099609375,
0.05450439453125,
-0.063720703125,
-0.009429931640625,
-0.0013055801391601562,
-0.027587890625,
0.0455322265625,
0.048919677734375,
-0.049713134765625,
-0.068115234375,
-0.0306854248046875,
0.01111... |
h2oai/openassistant_oasst1_h2ogpt_llama2_chat | 2023-07-31T06:09:41.000Z | [
"language:en",
"license:apache-2.0",
"gpt",
"llm",
"large language model",
"open-source",
"region:us"
] | h2oai | null | null | 0 | 3 | 2023-07-28T03:55:36 | ---
license: apache-2.0
language:
- en
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
tags:
- gpt
- llm
- large language model
- open-source
---
# h2oGPT Data Card
## Summary
H2O.ai's `openassistant_oasst1_h2ogpt_llama2_chat` is an open-source instruct-type dataset for fine-tuning of large language models, licensed for commercial use.
- Number of rows: `44219`
- Number of columns: `5`
- Column names: `['id', 'prompt_type', 'input', 'output', 'source']`
## Source
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/0bee5f50a74f489ca3fc81486f9322078360f2cb/src/create_data.py#L1296)
| 801 | [
[
-0.0014410018920898438,
-0.05230712890625,
0.010101318359375,
0.01165008544921875,
-0.01151275634765625,
0.0007338523864746094,
0.005184173583984375,
-0.018341064453125,
0.00540924072265625,
0.0219268798828125,
-0.031005859375,
-0.04803466796875,
-0.031097412109... |
ChanceFocus/flare-edtsum | 2023-07-28T05:23:42.000Z | [
"region:us"
] | ChanceFocus | null | null | 0 | 3 | 2023-07-28T05:23:36 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
splits:
- name: test
num_bytes: 20411227
num_examples: 2000
download_size: 10794666
dataset_size: 20411227
---
# Dataset Card for "flare-edtsum"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 456 | [
[
-0.05206298828125,
-0.0240020751953125,
0.006740570068359375,
0.01261138916015625,
-0.01171875,
0.01129150390625,
0.00921630859375,
-0.01081085205078125,
0.07916259765625,
0.0428466796875,
-0.061859130859375,
-0.05328369140625,
-0.03082275390625,
-0.01278686... |
jusKnows/linux_errors-solutions_onlyESP | 2023-07-28T10:18:10.000Z | [
"language:es",
"license:other",
"region:us"
] | jusKnows | null | null | 0 | 3 | 2023-07-28T10:01:37 | ---
license: other
language:
- es
pretty_name: s
---
### Dataset creation method
This dataset was created using **Llama-2-70b-chat** version from **chat Petals** and Chatgpt
- First, we asked the Petals Llama-2 chat to create a random list of 30 common linux problems with step-by-step solutions.
- Second, we use chatgpt to create different versions of each text that forms the problems and solutions. This way we create different ways of asking and answering the same question.
- Finally, we unify all possible combinations for each problem id. | 546 | [
[
-0.0275421142578125,
-0.05450439453125,
0.0206146240234375,
0.0257110595703125,
-0.0233612060546875,
0.01009368896484375,
0.007236480712890625,
-0.00634002685546875,
0.040313720703125,
0.037933349609375,
-0.072265625,
-0.0227813720703125,
-0.0268707275390625,
... |
RogerB/unsupervised_kin_tweets | 2023-07-28T11:39:20.000Z | [
"region:us"
] | RogerB | null | null | 0 | 3 | 2023-07-28T11:39:17 | ---
dataset_info:
features:
- name: cased_tweet
dtype: string
- name: uncased_tweet
dtype: string
splits:
- name: train
num_bytes: 10083279
num_examples: 40998
download_size: 7360726
dataset_size: 10083279
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "unsupervised_kin_tweets"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 503 | [
[
-0.01303863525390625,
-0.00030303001403808594,
0.0178985595703125,
0.0184783935546875,
-0.03851318359375,
0.037689208984375,
0.0156097412109375,
0.00870513916015625,
0.0731201171875,
0.0335693359375,
-0.061492919921875,
-0.07122802734375,
-0.05401611328125,
... |
TrainingDataPro/amazon-reviews-dataset | 2023-09-14T16:38:13.000Z | [
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | null | null | 1 | 3 | 2023-07-28T12:27:03 | ---
license: cc-by-nc-nd-4.0
task_categories:
- text-classification
language:
- en
tags:
- code
---
# Amazon Reviews Dataset
The Amazon Reviews Dataset is a comprehensive collection of customer reviews obtained from the popular e-commerce website, Amazon.com. This dataset encompasses reviews written in **5** different languages, making it a valuable resource for conducting **multilingual sentiment analysis and opinion mining**.
The dataset's multilingual nature makes it useful for natural language processing tasks, sentiment analysis algorithms, and other machine learning applications that require diverse language data for training and evaluation.
The dataset can be highly valuable in training and fine-tuning machine learning models to *automatically classify sentiments, predict customer satisfaction, or extract key information from customer reviews*.
### Languages in the dataset:
- Italian
- German
- Spainish
- French
- English
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=amazon-reviews-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
For each item, we extracted:
- **user_name**: name of the reviewer
- **stars**: number of stars given to the review
- **country**: country of the author
- **date**: date of the review
- **title**: title of the review
- **text**: text of the review
- **helpful**: number of people who think that the review is helpful
# Amazon Reviews might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=amazon-reviews-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,053 | [
[
-0.036895751953125,
-0.024627685546875,
-0.0090179443359375,
0.0301513671875,
-0.0182647705078125,
0.00518035888671875,
-0.006298065185546875,
-0.03826904296875,
0.01389312744140625,
0.0606689453125,
-0.052581787109375,
-0.05426025390625,
-0.032318115234375,
... |
zjunlp/KnowLM-Tool | 2023-07-29T02:26:54.000Z | [
"region:us"
] | zjunlp | null | null | 2 | 3 | 2023-07-29T02:25:56 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ammarnasr/the-stack-ruby-clean | 2023-08-14T21:20:54.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:code",
"license:openrail",
"code",
"region:us"
] | ammarnasr | null | null | 1 | 3 | 2023-07-30T12:06:49 | ---
license: openrail
dataset_info:
features:
- name: hexsha
dtype: string
- name: size
dtype: int64
- name: content
dtype: string
- name: avg_line_length
dtype: float64
- name: max_line_length
dtype: int64
- name: alphanum_fraction
dtype: float64
splits:
- name: train
num_bytes: 3582248477.9086223
num_examples: 806789
- name: test
num_bytes: 394048264.9973618
num_examples: 88747
- name: valid
num_bytes: 3982797.09401595
num_examples: 897
download_size: 1323156008
dataset_size: 3980279540
task_categories:
- text-generation
language:
- code
tags:
- code
pretty_name: TheStack-Ruby
size_categories:
- 1M<n<10M
---
## Dataset 1: TheStack - Ruby - Cleaned
**Description**: This dataset is drawn from TheStack Corpus, an open-source code dataset with over 3TB of GitHub data covering 48 programming languages. We selected a small portion of this dataset to optimize smaller language models for Ruby, a popular statically typed language.
**Target Language**: Ruby
**Dataset Size**:
- Training: 900,000 files
- Validation: 50,000 files
- Test: 50,000 files
**Preprocessing**:
1. Selected Ruby as the target language due to its popularity on GitHub.
2. Filtered out files with average line length > 100 characters, maximum line length > 1000 characters, and alphabet ratio < 25%.
3. Split files into 90% training, 5% validation, and 5% test sets.
**Tokenizer**: Byte Pair Encoding (BPE) tokenizer with tab and whitespace tokens. GPT-2 vocabulary extended with special tokens.
**Training Sequences**: Sequences constructed by joining training data text to reach a context length of 2048 tokens (1024 tokens for full fine-tuning). | 1,707 | [
[
-0.0246734619140625,
-0.03997802734375,
0.021148681640625,
-0.0097503662109375,
-0.034820556640625,
0.024810791015625,
-0.025665283203125,
-0.01457977294921875,
0.02783203125,
0.033172607421875,
-0.0379638671875,
-0.04736328125,
-0.0343017578125,
-0.00467300... |
harpomaxx/example-dataset | 2023-07-30T23:23:12.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:openrail",
"art",
"region:us"
] | harpomaxx | null | null | 0 | 3 | 2023-07-30T23:18:17 | ---
license: openrail
task_categories:
- text-classification
language:
- en
tags:
- art
pretty_name: example-dataset
size_categories:
- n<1K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 1,677 | [
[
-0.038177490234375,
-0.02984619140625,
-0.0036067962646484375,
0.027130126953125,
-0.0323486328125,
0.0037822723388671875,
-0.01727294921875,
-0.02020263671875,
0.049041748046875,
0.04046630859375,
-0.0634765625,
-0.08062744140625,
-0.052947998046875,
0.0020... |
longevity-genie/moskalev_papers | 2023-07-31T22:35:11.000Z | [
"license:openrail",
"region:us"
] | longevity-genie | null | null | 0 | 3 | 2023-07-31T22:30:51 | ---
license: openrail
---
All Alexey Moskalev paper found inside semantic-scholar that have pubmed ids.
The parquet file schema is:
```
root
|-- corpusid: long (nullable = true)
|-- updated: string (nullable = true)
|-- content_source_oainfo_license: string (nullable = true)
|-- content_source_oainfo_openaccessurl: string (nullable = true)
|-- content_source_oainfo_status: string (nullable = true)
|-- content_source_pdfsha: string (nullable = true)
|-- content_source_pdfurls: array (nullable = true)
| |-- element: string (containsNull = true)
|-- externalids_acl: string (nullable = true)
|-- externalids_arxiv: string (nullable = true)
|-- externalids_dblp: string (nullable = true)
|-- externalids_doi: string (nullable = true)
|-- externalids_mag: string (nullable = true)
|-- externalids_pubmed: string (nullable = true)
|-- externalids_pubmedcentral: string (nullable = true)
|-- content_text: string (nullable = true)
|-- annotations_abstract: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_author: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_authoraffiliation: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_authorfirstname: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_authorlastname: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibauthor: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibauthorfirstname: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibauthorlastname: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibentry: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibref: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibtitle: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_bibvenue: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_figure: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_figurecaption: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_figureref: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_formula: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_paragraph: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_publisher: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_sectionheader: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_table: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_tableref: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_title: array (nullable = true)
| |-- element: string (containsNull = true)
|-- annotations_venue: array (nullable = true)
| |-- element: string (containsNull = true)
``` | 3,268 | [
[
-0.0236053466796875,
-0.0234527587890625,
0.050048828125,
0.01055145263671875,
-0.01363372802734375,
0.0008702278137207031,
0.00390625,
-0.02227783203125,
0.041351318359375,
0.050750732421875,
-0.04339599609375,
-0.08447265625,
-0.04241943359375,
0.031036376... |
wesley7137/psychology1cllm | 2023-07-31T23:13:11.000Z | [
"region:us"
] | wesley7137 | null | null | 3 | 3 | 2023-07-31T23:12:55 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
manojkumarvohra/guanaco-pico-100-samples | 2023-08-01T08:29:37.000Z | [
"region:us"
] | manojkumarvohra | null | null | 0 | 3 | 2023-08-01T08:27:19 | This dataset is a subset of the Open Assistant dataset, which you can find here: https://huggingface.co/datasets/OpenAssistant/oasst1/tree/main
This subset of the data only contains 100 samples of the highest-rated paths in the conversation tree.
This dataset was used to train Guanaco with QLoRA.
For further information, please see the original dataset.
License: Apache 2.0 | 379 | [
[
-0.0200347900390625,
-0.042236328125,
0.01690673828125,
0.005359649658203125,
-0.0014810562133789062,
-0.0019521713256835938,
0.01136016845703125,
-0.0318603515625,
0.0248260498046875,
0.038848876953125,
-0.07708740234375,
-0.052520751953125,
-0.02825927734375,
... |
chaoyi-wu/RadFM_data_csv | 2023-08-02T11:55:29.000Z | [
"license:apache-2.0",
"biology",
"region:us"
] | chaoyi-wu | null | null | 0 | 3 | 2023-08-02T11:03:24 | ---
license: apache-2.0
tags:
- biology
---
# RadFM_data_csv
The data_csv used for training and testing [RadFM](https://github.com/chaoyi-wu/RadFM) | 148 | [
[
-0.0269622802734375,
-0.0347900390625,
-0.0254364013671875,
0.036895751953125,
-0.005207061767578125,
0.01396942138671875,
0.00801849365234375,
0.0155029296875,
0.003688812255859375,
0.040191650390625,
-0.037841796875,
-0.058929443359375,
-0.01824951171875,
... |
arbml/alpaca_arabic_v3 | 2023-09-06T17:39:52.000Z | [
"region:us"
] | arbml | null | null | 0 | 3 | 2023-08-03T07:53:50 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: index
dtype: string
- name: output
dtype: string
- name: output_en
dtype: string
- name: input
dtype: string
- name: input_en
dtype: string
- name: instruction
dtype: string
- name: instruction_en
dtype: string
splits:
- name: train
num_bytes: 20871
num_examples: 31
download_size: 0
dataset_size: 20871
---
# Dataset Card for "alpaca_arabic_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 660 | [
[
-0.0523681640625,
-0.0203094482421875,
0.0167694091796875,
0.024322509765625,
-0.0291748046875,
-0.012481689453125,
0.033843994140625,
-0.0347900390625,
0.06805419921875,
0.03875732421875,
-0.05316162109375,
-0.07275390625,
-0.05767822265625,
-0.014358520507... |
TrainingDataPro/asos-e-commerce-dataset | 2023-09-14T16:38:48.000Z | [
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | null | null | 1 | 3 | 2023-08-04T07:36:51 | ---
license: cc-by-nc-nd-4.0
task_categories:
- text-classification
language:
- en
tags:
- code
- finance
---
# [Asos](https://asos.com) E-Commerce Dataset - 30,845 products
Using web scraping, we collected information on over **30,845** clothing items from the Asos website.
The dataset can be applied in E-commerce analytics in the fashion industry.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=asos-e-commerce-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Dataset Info
For each item, we extracted:
- **url** - link to the item on the website
- **name** - item's name
- **size** - sizes available on the website
- **category** - product's category
- **price** - item's price
- **color** - item's color
- **SKU** - unique identifier of the item
- **date** - date of web scraping; for all items - March 11, 2023
- **description** - additional description, including product's brand, composition, and care instructions, in JSON format
- **images** - photographs from the item description
# Data collection and annotation
We provide both ready-made datasets and custom data collection and annotation services. Please contact us for more information: Andrew, **datasets@trainingdata.pro**
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=asos-e-commerce-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 1,793 | [
[
-0.0247344970703125,
-0.0222625732421875,
-0.0139617919921875,
0.016387939453125,
-0.0281982421875,
0.0034008026123046875,
0.002490997314453125,
-0.06304931640625,
0.03497314453125,
0.031280517578125,
-0.07867431640625,
-0.0501708984375,
-0.024383544921875,
... |
SaffalPoosh/scribble_controlnet_dataset | 2023-08-04T21:54:49.000Z | [
"region:us"
] | SaffalPoosh | null | null | 0 | 3 | 2023-08-04T21:13:45 | ---
dataset_info:
features:
- name: image
dtype: image
- name: scribble
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 3632352891.0
num_examples: 10000
download_size: 772501479
dataset_size: 3632352891.0
---
# Dataset Card for "data_coco"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 436 | [
[
-0.039520263671875,
-0.0296173095703125,
0.0030155181884765625,
0.0330810546875,
-0.0166778564453125,
0.0176544189453125,
0.0101470947265625,
-0.02288818359375,
0.0631103515625,
0.036407470703125,
-0.0562744140625,
-0.061737060546875,
-0.042877197265625,
-0.... |
voidful/speech-alpaca-gpt4 | 2023-08-08T16:01:23.000Z | [
"region:us"
] | voidful | null | null | 0 | 3 | 2023-08-06T17:25:08 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: speech_input
dtype: string
- name: input_speaker
dtype: string
- name: output_speaker
dtype: string
- name: input_audio
dtype: audio
- name: output_audio
dtype: audio
splits:
- name: train
num_bytes: 13538156036.948
num_examples: 51349
download_size: 13717890829
dataset_size: 13538156036.948
---
# Dataset Card for "speech-alpaca-gpt4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 662 | [
[
-0.047149658203125,
-0.0364990234375,
0.01495361328125,
0.016937255859375,
-0.021636962890625,
-0.003742218017578125,
0.006587982177734375,
-0.0242462158203125,
0.060577392578125,
0.0223388671875,
-0.060943603515625,
-0.060333251953125,
-0.055908203125,
-0.0... |
JohnTeddy3/midjourney-v5-202304 | 2023-08-07T13:02:27.000Z | [
"task_categories:text-to-image",
"task_categories:image-to-text",
"language:en",
"license:apache-2.0",
"midjourney",
"region:us"
] | JohnTeddy3 | null | null | 3 | 3 | 2023-08-07T12:34:11 | ---
license: apache-2.0
task_categories:
- text-to-image
- image-to-text
language:
- en
tags:
- midjourney
---
# midjourney-v5-202304-clean
## 简介 Brief Introduction
转载自wanng/midjourney-v5-202304-clean
非官方的,爬取自midjourney v5的2023年4月的数据,一共1701420条。
Unofficial, crawled from midjourney v5 for April 2023, 1,701,420 pairs in total.
## 数据集信息 Dataset Information
原始项目地址:https://huggingface.co/datasets/tarungupta83/MidJourney_v5_Prompt_dataset
我做了一些清洗,清理出了两个文件:
- ori_prompts_df.parquet (1,255,812对,midjourney的四格图)

- upscaled_prompts_df.parquet (445,608对,使用了高清指令的图,这意味着这个图更受欢迎。)

Original project address: https://huggingface.co/datasets/tarungupta83/MidJourney_v5_Prompt_dataset
I did some cleaning and cleaned out two files:
- ori_prompts_df.parquet (1,255,812 pairs, midjourney's four-frame diagrams)
- upscaled_prompts_df.parquet (445,608 pairs, graphs that use the Upscale command, which means this one is more popular.)
| 1,328 | [
[
-0.04486083984375,
-0.050537109375,
0.027252197265625,
0.0172882080078125,
-0.037689208984375,
-0.0276947021484375,
0.0109710693359375,
-0.019134521484375,
0.038848876953125,
0.042633056640625,
-0.0657958984375,
-0.044891357421875,
-0.040557861328125,
0.0066... |
d0rj/truthful_qa-gen-ru | 2023-08-07T18:10:17.000Z | [
"region:us"
] | d0rj | null | null | 0 | 3 | 2023-08-07T18:10:16 | ---
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
dataset_info:
features:
- name: type
dtype: string
- name: category
dtype: string
- name: question
dtype: string
- name: best_answer
dtype: string
- name: correct_answers
sequence: string
- name: incorrect_answers
sequence: string
- name: source
dtype: string
splits:
- name: validation
num_bytes: 796293
num_examples: 817
download_size: 320041
dataset_size: 796293
---
# Dataset Card for "truthful_qa-gen-ru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 702 | [
[
-0.02642822265625,
-0.01824951171875,
0.0279083251953125,
0.00919342041015625,
-0.0121612548828125,
0.01290130615234375,
0.0263671875,
-0.005046844482421875,
0.037872314453125,
0.0178985595703125,
-0.059051513671875,
-0.055267333984375,
-0.0164337158203125,
... |
lionelchg/dolly_information_extraction | 2023-08-09T18:28:17.000Z | [
"region:us"
] | lionelchg | null | null | 0 | 3 | 2023-08-07T23:30:18 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: category
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 4662489.3625498
num_examples: 1430
- name: test
num_bytes: 247796.6374501992
num_examples: 76
download_size: 2857133
dataset_size: 4910286.0
---
# Dataset Card for "dolly_information_extraction"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 723 | [
[
-0.0276641845703125,
-0.03240966796875,
-0.0004622936248779297,
0.016571044921875,
-0.0128326416015625,
-0.0129241943359375,
0.02716064453125,
-0.016448974609375,
0.04815673828125,
0.041595458984375,
-0.048736572265625,
-0.0517578125,
-0.057342529296875,
-0.... |
Sneka/test | 2023-09-30T06:34:03.000Z | [
"region:us"
] | Sneka | null | null | 0 | 3 | 2023-08-09T10:35:37 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Vazbeek/alpaca-cs-subset-1k | 2023-08-09T16:26:48.000Z | [
"language:cs",
"license:cc-by-4.0",
"code",
"region:us"
] | Vazbeek | null | null | 0 | 3 | 2023-08-09T16:16:24 | ---
license: cc-by-4.0
language:
- cs
tags:
- code
---
First 1000 items form dataset Vazbeek/alpaca-cs. | 103 | [
[
-0.05389404296875,
-0.036041259765625,
-0.0016918182373046875,
0.01983642578125,
-0.019317626953125,
-0.019378662109375,
0.022125244140625,
0.00208282470703125,
0.05352783203125,
0.051910400390625,
-0.08599853515625,
-0.036346435546875,
-0.0303802490234375,
... |
Angry-Wizard/dndMonsters | 2023-08-09T22:49:43.000Z | [
"region:us"
] | Angry-Wizard | null | null | 1 | 3 | 2023-08-09T20:53:06 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
seungheondoh/gtzan-bind | 2023-08-15T06:59:22.000Z | [
"size_categories:n<1K",
"language:en",
"license:mit",
"music",
"gtzan",
"region:us"
] | seungheondoh | null | null | 1 | 3 | 2023-08-10T06:32:28 | ---
configs:
- config_name: default
data_files:
- split: gtzan_bind_v1
path: data/gtzan_bind_v1-*
license: mit
language:
- en
tags:
- music
- gtzan
pretty_name: gtzan-bind
size_categories:
- n<1K
---
# Dataset Summary
📚🎵 Introducing **GTZAN-Bind** a consolidated dataset encompassing diverse gtzan annotations.
My contribution involved an additional layer of fingerprinting to enhance its comprehensiveness
- **Repository:** [GTZAN-Bind repository](https://github.com/seungheondoh/gtzan-bind)
[](https://github.com/seungheondoh/gtzan-bind)
## Annotations
- audio: [Tzanetakis2002musical](https://ieeexplore.ieee.org/document/1021072), [audio source](https://www.kaggle.com/datasets/andradaolteanu/gtzan-dataset-music-genre-classification)
- split: [sturm2013faults](https://github.com/coreyker/dnn-mgr/tree/master/gtzan)
- metadata: [sturm2013faults](https://github.com/coreyker/dnn-mgr/tree/master/gtzan), [doh2023fingerprint](https://github.com/seungheondoh/gtzan-bind/tree/main/dataset/metadata/doh2023fingerprint/results)
- Caption (+fMRI): [denk2023brain2music](https://www.kaggle.com/datasets/nishimotolab/music-caption-brain2music)
- Key: [kraft_lerch2013tonalness](https://github.com/alexanderlerch/gtzan_key)
- Key2 (Not used): [tom2011genre](http://visal.cs.cityu.edu.hk/downloads/#gtzankeys)
- Rhythm: [marchand2015swing](http://anasynth.ircam.fr/home/system/files/attachment_uploads/marchand/private/GTZAN-Rhythm_v2_ismir2015_lbd_2015-10-28.tar_.gz)
- Metrical-structure: [quinton2015extraction](http://www.isophonics.net/content/metrical-structure-annotations-gtzan-dataset)
## Colums & Valid Annotation
- track_id 1000
- shazam_id 974
- title 989
- artist_name 986
- album 930
- label 930
- released 930
- tag 1000
- caption_15s 540
- key 837
- youtube_url 967
- album_img_url 960
- artist_img_url 960
- path 1000
- fault_filtered_split 930
- beat 1000
- downbeat 1000
- 8th-note 1000
- ternary 1000
- swing 1000
- swing_ratio_iqr 178
- swing_ratio_confidence 178
- meter 979
- swing_ratio 178
- tempo_mean 1000
- tempo_std 1000
- metrical_levels_pulse_rates 1000
- metrical_annotators 1000
## Contact
- seungheondoh@kaist.ac.kr
| 2,202 | [
[
-0.044189453125,
-0.01531219482421875,
0.0235443115234375,
0.01474761962890625,
-0.02294921875,
-0.004520416259765625,
-0.0340576171875,
-0.038818359375,
0.0313720703125,
0.0311431884765625,
-0.06353759765625,
-0.068359375,
-0.0184173583984375,
-0.0133438110... |
EgilKarlsen/AA | 2023-08-20T16:04:53.000Z | [
"region:us"
] | EgilKarlsen | null | null | 0 | 3 | 2023-08-10T15:15:13 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: log
dtype: string
- name: label
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 6352006
num_examples: 24320
- name: test
num_bytes: 1813856
num_examples: 6948
- name: validation
num_bytes: 909250
num_examples: 3475
download_size: 2288707
dataset_size: 9075112
---
# Dataset Card for "AA"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 709 | [
[
-0.040435791015625,
-0.0271148681640625,
0.01494598388671875,
0.0033016204833984375,
-0.00579071044921875,
0.0093231201171875,
0.03314208984375,
-0.0263671875,
0.06768798828125,
0.0173797607421875,
-0.056427001953125,
-0.057373046875,
-0.043853759765625,
-0.... |
daishen/cra-ccf | 2023-08-11T03:06:59.000Z | [
"region:us"
] | daishen | null | null | 0 | 3 | 2023-08-11T03:05:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
TrainingDataPro/presentation-attack-detection-2d-dataset | 2023-09-14T16:23:16.000Z | [
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"legal",
"finance",
"region:us"
] | TrainingDataPro | The dataset consists of photos of individuals and videos of him/her wearing printed 2D
mask with cut-out holes for eyes. Videos are filmed in different lightning conditions
and in different places (*indoors, outdoors*), a person moves his/her head left, right,
up and down. Each video in the dataset has an approximate duration of 15-17 seconds. | @InProceedings{huggingface:dataset,
title = {presentation-attack-detection-2d-dataset},
author = {TrainingDataPro},
year = {2023}
} | 1 | 3 | 2023-08-11T04:24:07 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
tags:
- code
- legal
- finance
dataset_info:
features:
- name: photo
dtype: image
- name: video
dtype: string
- name: worker_id
dtype: string
- name: set_id
dtype: string
- name: age
dtype: int8
- name: country
dtype: string
- name: gender
dtype: string
splits:
- name: train
num_bytes: 45568435
num_examples: 14
download_size: 458883249
dataset_size: 45568435
---
# Presentation Attack Detection 2D Dataset
The dataset consists of photos of individuals and videos of him/her wearing printed 2D mask with cut-out holes for eyes. Videos are filmed in different lightning conditions and in different places (*indoors, outdoors*), a person moves his/her head left, right, up and down. Each video in the dataset has an approximate duration of 15-17 seconds.
### Types of media files in the dataset:
- **Photo** of the individual
- **Video** with the printed photo of the individual, mask is cut along the contour, there are cut-out holes for eyes, mask is attached to the person's head

The dataset serves as a valuable resource for computer vision, anti-spoofing tasks, video analysis, and security systems. It allows for the development of algorithms and models that can effectively detect attacks perpetrated by individuals wearing printed 2D masks.
Studying the dataset may lead to the development of improved security systems, surveillance technologies, and solutions to mitigate the risks associated with masked individuals carrying out attacks.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=presentation-attack-detection-2d-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
### The folder **"files"** includes 14 folders:
- corresponding to each person in the sample
- including photo and video of the individual
### File with the extension .csv
includes the following information for each media file:
- **set_id**: the identifier of the set of media files,
- **worker_id**: the identifier of the person who provided the media file,
- **age**: the age of the person,
- **gender**: the gender of the person,
- **country**: the country of origin of the person
# Attacks might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=presentation-attack-detection-2d-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 3,092 | [
[
-0.0180206298828125,
-0.05792236328125,
0.005126953125,
0.013946533203125,
-0.01485443115234375,
0.0150604248046875,
0.0236358642578125,
-0.0306854248046875,
0.01459503173828125,
0.0352783203125,
-0.030426025390625,
-0.038787841796875,
-0.065185546875,
-0.01... |
harshitv804/Indian_Penal_Code | 2023-08-11T17:32:34.000Z | [
"task_categories:question-answering",
"task_categories:conversational",
"task_categories:text2text-generation",
"task_categories:sentence-similarity",
"language:en",
"license:openrail",
"legal",
"law",
"region:us"
] | harshitv804 | null | null | 0 | 3 | 2023-08-11T16:35:04 | ---
language:
- en
viewer: false
pretty_name: Indian Penal Code Book
license: openrail
task_categories:
- question-answering
- conversational
- text2text-generation
- sentence-similarity
tags:
- legal
- law
---
# Indian Penal Code Dataset
<img src="https://iilsindia.com/blogs/wp-content/uploads/2016/07/indian-penal-code-1860-890x395.jpg" style="width:600px;"/>
## Dataset Description:
The Indian Penal Code (IPC) Book PDF presents a rich and comprehensive dataset that holds immense potential for advancing Natural Language Processing (NLP) tasks and Language Model applications. This dataset encapsulates the entire spectrum of India's criminal law, offering a diverse range of legal principles, provisions, and case laws. With its intricate language and multifaceted legal content, the IPC dataset provides a challenging yet rewarding opportunity for NLP research and development. From text summarization and legal language understanding to sentiment analysis within the context of legal proceedings, this IPC dataset opens avenues for training and fine-tuning Language Models to grasp the nuances of complex legal texts. Leveraging this dataset, researchers and practitioners in the field of NLP can unravel the intricacies of legal discourse and contribute to the advancement of AI-driven legal analysis, interpretation, and decision support systems.
## Languages:
- English
## Considerations for Using this Data:
- Question Answering
- Conversational AI
- Text2Text Generation
- Sentence Similarity
- Text Generation
## Dataset Download:
<a href="https://huggingface.co/datasets/harshitv804/Indian_Penal_Code/resolve/main/Indian%20Penal%20Code%20Book.pdf"><img src="https://static.vecteezy.com/system/resources/previews/009/384/880/non_2x/click-here-button-clipart-design-illustration-free-png.png" width="150" height="auto"></a> | 1,844 | [
[
-0.02227783203125,
-0.01313018798828125,
-0.01070404052734375,
0.034820556640625,
-0.0318603515625,
-0.0029506683349609375,
-0.011474609375,
-0.01488494873046875,
-0.01751708984375,
0.052398681640625,
-0.0247039794921875,
-0.04571533203125,
-0.0400390625,
0.... |
WALIDALI/text8 | 2023-08-11T18:12:06.000Z | [
"region:us"
] | WALIDALI | null | null | 0 | 3 | 2023-08-11T18:11:53 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
urialon/converted_narrative_qa | 2023-08-12T19:34:02.000Z | [
"region:us"
] | urialon | null | null | 0 | 3 | 2023-08-12T19:22:38 | ---
dataset_info:
features:
- name: id
dtype: string
- name: pid
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 18019445085
num_examples: 55003
- name: validation
num_bytes: 1900648400
num_examples: 5878
- name: test
num_bytes: 3228274423
num_examples: 10306
download_size: 8524652529
dataset_size: 23148367908
---
# Dataset Card for "converted_narrative_qa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 610 | [
[
-0.02398681640625,
-0.02276611328125,
0.04296875,
0.0117034912109375,
-0.018310546875,
0.0033740997314453125,
0.0154266357421875,
-0.0005426406860351562,
0.044586181640625,
0.047698974609375,
-0.061614990234375,
-0.061126708984375,
-0.026275634765625,
-0.020... |
FreedomIntelligence/sharegpt-hindi | 2023-08-13T16:20:03.000Z | [
"license:apache-2.0",
"region:us"
] | FreedomIntelligence | null | null | 0 | 3 | 2023-08-13T16:02:37 | ---
license: apache-2.0
---
Hindi ShareGPT data translated by gpt-3.5-turbo.
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). | 203 | [
[
-0.0297393798828125,
-0.036376953125,
0.00785064697265625,
0.04632568359375,
-0.0227813720703125,
0.01084136962890625,
-0.01800537109375,
-0.0294647216796875,
0.0144500732421875,
-0.00453948974609375,
-0.056610107421875,
-0.01025390625,
-0.04803466796875,
0.... |
BELLE-2/train_3.5M_CN_With_Category | 2023-10-18T03:19:58.000Z | [
"task_categories:text2text-generation",
"size_categories:1M<n<10M",
"language:zh",
"license:gpl-3.0",
"region:us"
] | BELLE-2 | null | null | 8 | 3 | 2023-08-14T03:46:04 | ---
license: gpl-3.0
task_categories:
- text2text-generation
language:
- zh
size_categories:
- 1M<n<10M
---
## 内容
基于原有的[train_3.5M_CN](https://huggingface.co/datasets/BelleGroup/train_3.5M_CN)数据新增了指令类别字段,共包括13个类别,详情如下图所示:
## 样例
```
{
"id":"66182880",
"category":"generation"
}
```
### 字段:
```
id: 数据id
category: 该条指令数据对应的类别
```
## 使用限制
仅允许将此数据集及使用此数据集生成的衍生物用于研究目的,不得用于商业,以及其他会对社会带来危害的用途。
本数据集不代表任何一方的立场、利益或想法,无关任何团体的任何类型的主张。因使用本数据集带来的任何损害、纠纷,本项目不承担任何责任。
## Citation
Please cite our paper and github when using our code, data or model.
```
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/LianjiaTech/BELLE}},
}
``` | 820 | [
[
-0.037872314453125,
-0.02923583984375,
-0.01068115234375,
0.031463623046875,
-0.0249176025390625,
-0.01525115966796875,
0.00977325439453125,
-0.0246124267578125,
0.042266845703125,
0.02740478515625,
-0.045135498046875,
-0.0645751953125,
-0.041290283203125,
0... |
GalaktischeGurke/full_dataset_1509_lines_invoice_contract_mail_GPT3.5_train | 2023-08-16T08:33:36.000Z | [
"region:us"
] | GalaktischeGurke | null | null | 0 | 3 | 2023-08-14T07:08:37 | ---
dataset_info:
features:
- name: text
dtype: string
- name: response
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 6920022
num_examples: 1479
download_size: 3165562
dataset_size: 6920022
---
# Dataset Card for "full_dataset_1509_lines_invoice_contract_mail_GPT3.5_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 477 | [
[
-0.0244140625,
0.00006401538848876953,
0.0233612060546875,
0.029205322265625,
-0.027099609375,
-0.01557159423828125,
0.022369384765625,
-0.009521484375,
0.0264129638671875,
0.0572509765625,
-0.036407470703125,
-0.046112060546875,
-0.03912353515625,
-0.018066... |
abhishek/autotrain-data-0u01-rtc0-cq4r | 2023-08-15T09:40:24.000Z | [
"region:us"
] | abhishek | null | null | 0 | 3 | 2023-08-15T09:40:13 | ---
dataset_info:
features:
- name: autotrain_text
dtype: string
- name: autotrain_label
dtype:
class_label:
names:
'0': negative
'1': positive
splits:
- name: train
num_bytes: 1054852
num_examples: 800
- name: validation
num_bytes: 267917
num_examples: 200
download_size: 871702
dataset_size: 1322769
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for "autotrain-data-0u01-rtc0-cq4r"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 699 | [
[
-0.035125732421875,
0.0025005340576171875,
0.01113128662109375,
0.01458740234375,
-0.006420135498046875,
0.014862060546875,
0.03399658203125,
-0.005229949951171875,
0.0341796875,
0.0104217529296875,
-0.06268310546875,
-0.0289764404296875,
-0.028411865234375,
... |
Deepakvictor/tan-tam | 2023-08-15T12:45:49.000Z | [
"task_categories:translation",
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:ta",
"language:en",
"license:openrail",
"region:us"
] | Deepakvictor | null | null | 0 | 3 | 2023-08-15T12:39:18 | ---
license: openrail
task_categories:
- translation
- text-classification
language:
- ta
- en
pretty_name: translation
size_categories:
- 1K<n<10K
---
Translation of Tanglish to tamil
Source: karky.in
To use
```python
import datasets
s = datasets.load_dataset('Deepakvictor/tan-tam')
print(s)
"""
DatasetDict({
train: Dataset({
features: ['en', 'ta'],
num_rows: 22114
})
})
"""
```
Credits and Source: https://karky.in/
---
For Complex version --> "Deepakvictor/tanglish-tamil" | 504 | [
[
0.0019931793212890625,
-0.002552032470703125,
-0.006153106689453125,
0.037841796875,
-0.05029296875,
0.0178680419921875,
-0.0276031494140625,
0.003871917724609375,
0.0142822265625,
0.037750244140625,
-0.0191192626953125,
-0.013946533203125,
-0.037750244140625,
... |
VedCodes/llama2_project | 2023-08-16T09:52:02.000Z | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"medical",
"region:us"
] | VedCodes | null | null | 0 | 3 | 2023-08-16T09:44:22 | ---
task_categories:
- text-generation
language:
- en
tags:
- medical
size_categories:
- n<1K
pretty_name: boy_hi
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
nt is empty. Use the Ed
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 1,672 | [
[
-0.036224365234375,
-0.031646728515625,
-0.00415802001953125,
0.02734375,
-0.032318115234375,
0.0032291412353515625,
-0.0184173583984375,
-0.0191802978515625,
0.048736572265625,
0.03985595703125,
-0.063232421875,
-0.08099365234375,
-0.051910400390625,
0.0029... |
bleedchocolate/autotrain-data-en-hu | 2023-08-16T16:51:57.000Z | [
"task_categories:translation",
"region:us"
] | bleedchocolate | null | null | 0 | 3 | 2023-08-16T16:51:27 | ---
task_categories:
- translation
---
# AutoTrain Dataset for project: en-hu
## Dataset Description
This dataset has been automatically processed by AutoTrain for project en-hu.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"source": "cruiser",
"target": "teesaw"
},
{
"source": "don't move",
"target": "hagwa doopee"
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"source": "Value(dtype='string', id=None)",
"target": "Value(dtype='string', id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 320 |
| valid | 81 |
| 901 | [
[
-0.0289764404296875,
-0.00682830810546875,
0.007694244384765625,
0.0176239013671875,
-0.0250244140625,
0.0228118896484375,
-0.0092010498046875,
-0.0237884521484375,
0.00495147705078125,
0.03399658203125,
-0.044097900390625,
-0.043182373046875,
-0.030563354492187... |
mikewang/vaw | 2023-08-18T03:10:46.000Z | [
"language:en",
"region:us"
] | mikewang | Visual Attributes in the Wild (VAW) dataset: https://github.com/adobe-research/vaw_dataset#dataset-setup
Raw annotations and configs such as attrubte_types can be found at: https://github.com/adobe-research/vaw_dataset/tree/main/data
Note: The train split loaded from this hf dataset is a concatenation of the train_part1.json and train_part2.json. | @InProceedings{Pham_2021_CVPR,
author = {Pham, Khoi and Kafle, Kushal and Lin, Zhe and Ding, Zhihong and Cohen, Scott and Tran, Quan and Shrivastava, Abhinav},
title = {Learning To Predict Visual Attributes in the Wild},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13018-13028}
} | 0 | 3 | 2023-08-17T09:19:28 | ---
pretty_name: 'Visual Attributes in the Wild (VAW)'
language:
- en
---
# Dataset Card for Visual Attributes in the Wild (VAW)
## Dataset Description
**Homepage:** http://vawdataset.com/
**Repository:** https://github.com/adobe-research/vaw_dataset;
- The raw dataset files will be downloaded from: https://github.com/adobe-research/vaw_dataset/tree/main/data, where one can also find additional metadata files such as attribute types.
- The train split loaded from this hf dataset is a concatenation of the train_part1.json and train_part2.json.
- The image_id field corresponds to respective image ids in the v1.4 Visual Genome dataset.
**LICENSE:** https://github.com/adobe-research/vaw_dataset/blob/main/LICENSE.md
**Paper Citation:**
```
@InProceedings{Pham_2021_CVPR,
author = {Pham, Khoi and Kafle, Kushal and Lin, Zhe and Ding, Zhihong and Cohen, Scott and Tran, Quan and Shrivastava, Abhinav},
title = {Learning To Predict Visual Attributes in the Wild},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13018-13028}
}
```
## Dataset Summary
A large scale visual attributes dataset with explicitly labelled positive and negative attributes.
- 620 Unique Attributes including color, shape, texture, posture and many others
- 260,895 Instances of different objects
- 2260 Unique Objects observed in the wild
- 72,274 Images from the Visual Genome Dataset
- 4 different evaluation metrics for measuring multi-faceted performance metrics | 1,593 | [
[
-0.0276641845703125,
-0.02679443359375,
0.0053863525390625,
0.00682830810546875,
-0.0161590576171875,
-0.005733489990234375,
0.007465362548828125,
-0.038299560546875,
0.0104217529296875,
0.035888671875,
-0.061737060546875,
-0.054168701171875,
-0.03192138671875,
... |
muhammadravi251001/idk-mrc-nli | 2023-08-20T02:00:59.000Z | [
"license:openrail",
"region:us"
] | muhammadravi251001 | null | null | 0 | 3 | 2023-08-17T13:39:01 | ---
license: openrail
---
You can download this Dataset just like this (if you only need: premise, hypothesis, and label column):
```
from datasets import load_dataset, Dataset, DatasetDict
import pandas as pd
data_files = {"train": "data_nli_train_df.csv",
"validation": "data_nli_val_df.csv",
"test": "data_nli_test_df.csv"}
dataset = load_dataset("muhammadravi251001/idk-mrc-nli", data_files=data_files)
selected_columns = ["premise", "hypothesis", "label"]
# selected_columns = dataset.column_names['train'] # Uncomment this line to retrieve all of the columns
df_train = pd.DataFrame(dataset["train"])
df_train = df_train[selected_columns]
df_val = pd.DataFrame(dataset["validation"])
df_val = df_val[selected_columns]
df_test = pd.DataFrame(dataset["test"])
df_test = df_test[selected_columns]
train_dataset = Dataset.from_dict(df_train)
validation_dataset = Dataset.from_dict(df_val)
test_dataset = Dataset.from_dict(df_test)
dataset = DatasetDict({"train": train_dataset, "validation": validation_dataset, "test": test_dataset})
dataset
```
This is some modification from IDK-MRC dataset to IDK-MRC-NLI dataset. By convert QAS dataset to NLI dataset. You can find the original IDK-MRC in this link: https://huggingface.co/datasets/rifkiaputri/idk-mrc.
### Citation Information
```bibtex
@inproceedings{putri-oh-2022-idk,
title = "{IDK}-{MRC}: Unanswerable Questions for {I}ndonesian Machine Reading Comprehension",
author = "Putri, Rifki Afina and
Oh, Alice",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.465",
pages = "6918--6933",
}
``` | 1,867 | [
[
-0.027069091796875,
-0.034698486328125,
0.00916290283203125,
0.01157379150390625,
-0.004291534423828125,
-0.006256103515625,
0.002605438232421875,
-0.006893157958984375,
0.03399658203125,
0.046356201171875,
-0.04327392578125,
-0.044097900390625,
-0.0089187622070... |
DrakuTheDragon/Test | 2023-08-18T06:28:53.000Z | [
"region:us"
] | DrakuTheDragon | QA pairs generated in https://aclanthology.org/P18-1177/ | null | 0 | 3 | 2023-08-17T14:25:25 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
open-llm-leaderboard/details_mosaicml__mpt-30b | 2023-08-28T20:30:26.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | 0 | 3 | 2023-08-18T00:00:27 | ---
pretty_name: Evaluation run of None
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [None](https://huggingface.co/None) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 119 configuration, each one coresponding to one of\
\ the evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can\
\ be found as a specific split in each configuration, the split being named using\
\ the timestamp of the run.The \"train\" split is always pointing to the latest\
\ results.\n\nAn additional configuration \"results\" store all the aggregated results\
\ of the run (and is used to compute and display the agregated metrics on the [Open\
\ LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_mosaicml__mpt-30b\"\
,\n\t\"original_mmlu_world_religions_5\",\n\tsplit=\"train\")\n```\n\n## Latest\
\ results\n\nThese are the [latest results from run 2023-08-28T20:30:08.303629](https://huggingface.co/datasets/open-llm-leaderboard/details_mosaicml__mpt-30b/blob/main/results_2023-08-28T20%3A30%3A08.303629.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.4711060669821722,\n\
\ \"acc_stderr\": 0.036219414265372424\n },\n \"original|mmlu:abstract_algebra|5\"\
: {\n \"acc\": 0.25,\n \"acc_stderr\": 0.04351941398892446\n },\n\
\ \"original|mmlu:anatomy|5\": {\n \"acc\": 0.48148148148148145,\n \
\ \"acc_stderr\": 0.043163785995113245\n },\n \"original|mmlu:astronomy|5\"\
: {\n \"acc\": 0.45394736842105265,\n \"acc_stderr\": 0.040516463428741434\n\
\ },\n \"original|mmlu:business_ethics|5\": {\n \"acc\": 0.48,\n \
\ \"acc_stderr\": 0.050211673156867795\n },\n \"original|mmlu:clinical_knowledge|5\"\
: {\n \"acc\": 0.5094339622641509,\n \"acc_stderr\": 0.030767394707808093\n\
\ },\n \"original|mmlu:college_biology|5\": {\n \"acc\": 0.5069444444444444,\n\
\ \"acc_stderr\": 0.04180806750294938\n },\n \"original|mmlu:college_chemistry|5\"\
: {\n \"acc\": 0.27,\n \"acc_stderr\": 0.04461960433384741\n },\n\
\ \"original|mmlu:college_computer_science|5\": {\n \"acc\": 0.45,\n \
\ \"acc_stderr\": 0.049999999999999996\n },\n \"original|mmlu:college_mathematics|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.047258156262526045\n },\n\
\ \"original|mmlu:college_medicine|5\": {\n \"acc\": 0.4393063583815029,\n\
\ \"acc_stderr\": 0.03784271932887467\n },\n \"original|mmlu:college_physics|5\"\
: {\n \"acc\": 0.28431372549019607,\n \"acc_stderr\": 0.04488482852329017\n\
\ },\n \"original|mmlu:computer_security|5\": {\n \"acc\": 0.6,\n \
\ \"acc_stderr\": 0.049236596391733084\n },\n \"original|mmlu:conceptual_physics|5\"\
: {\n \"acc\": 0.40425531914893614,\n \"acc_stderr\": 0.03208115750788684\n\
\ },\n \"original|mmlu:econometrics|5\": {\n \"acc\": 0.2807017543859649,\n\
\ \"acc_stderr\": 0.04227054451232199\n },\n \"original|mmlu:electrical_engineering|5\"\
: {\n \"acc\": 0.503448275862069,\n \"acc_stderr\": 0.04166567577101579\n\
\ },\n \"original|mmlu:elementary_mathematics|5\": {\n \"acc\": 0.3253968253968254,\n\
\ \"acc_stderr\": 0.024130158299762613\n },\n \"original|mmlu:formal_logic|5\"\
: {\n \"acc\": 0.2698412698412698,\n \"acc_stderr\": 0.03970158273235172\n\
\ },\n \"original|mmlu:global_facts|5\": {\n \"acc\": 0.4,\n \
\ \"acc_stderr\": 0.049236596391733084\n },\n \"original|mmlu:high_school_biology|5\"\
: {\n \"acc\": 0.5064516129032258,\n \"acc_stderr\": 0.02844163823354051\n\
\ },\n \"original|mmlu:high_school_chemistry|5\": {\n \"acc\": 0.4039408866995074,\n\
\ \"acc_stderr\": 0.0345245390382204\n },\n \"original|mmlu:high_school_computer_science|5\"\
: {\n \"acc\": 0.54,\n \"acc_stderr\": 0.05009082659620332\n },\n\
\ \"original|mmlu:high_school_european_history|5\": {\n \"acc\": 0.5878787878787879,\n\
\ \"acc_stderr\": 0.03843566993588717\n },\n \"original|mmlu:high_school_geography|5\"\
: {\n \"acc\": 0.5909090909090909,\n \"acc_stderr\": 0.03502975799413007\n\
\ },\n \"original|mmlu:high_school_government_and_politics|5\": {\n \
\ \"acc\": 0.6476683937823834,\n \"acc_stderr\": 0.03447478286414357\n \
\ },\n \"original|mmlu:high_school_macroeconomics|5\": {\n \"acc\":\
\ 0.45384615384615384,\n \"acc_stderr\": 0.025242770987126177\n },\n \
\ \"original|mmlu:high_school_mathematics|5\": {\n \"acc\": 0.3,\n \
\ \"acc_stderr\": 0.0279404571362284\n },\n \"original|mmlu:high_school_microeconomics|5\"\
: {\n \"acc\": 0.46638655462184875,\n \"acc_stderr\": 0.03240501447690071\n\
\ },\n \"original|mmlu:high_school_physics|5\": {\n \"acc\": 0.2781456953642384,\n\
\ \"acc_stderr\": 0.03658603262763743\n },\n \"original|mmlu:high_school_psychology|5\"\
: {\n \"acc\": 0.6605504587155964,\n \"acc_stderr\": 0.02030210934266235\n\
\ },\n \"original|mmlu:high_school_statistics|5\": {\n \"acc\": 0.3333333333333333,\n\
\ \"acc_stderr\": 0.0321495214780275\n },\n \"original|mmlu:high_school_us_history|5\"\
: {\n \"acc\": 0.6323529411764706,\n \"acc_stderr\": 0.03384132045674118\n\
\ },\n \"original|mmlu:high_school_world_history|5\": {\n \"acc\":\
\ 0.6751054852320675,\n \"acc_stderr\": 0.03048603938910531\n },\n \
\ \"original|mmlu:human_aging|5\": {\n \"acc\": 0.515695067264574,\n \
\ \"acc_stderr\": 0.0335412657542081\n },\n \"original|mmlu:human_sexuality|5\"\
: {\n \"acc\": 0.549618320610687,\n \"acc_stderr\": 0.04363643698524779\n\
\ },\n \"original|mmlu:international_law|5\": {\n \"acc\": 0.39669421487603307,\n\
\ \"acc_stderr\": 0.044658697805310094\n },\n \"original|mmlu:jurisprudence|5\"\
: {\n \"acc\": 0.48148148148148145,\n \"acc_stderr\": 0.04830366024635331\n\
\ },\n \"original|mmlu:logical_fallacies|5\": {\n \"acc\": 0.4662576687116564,\n\
\ \"acc_stderr\": 0.039194155450484096\n },\n \"original|mmlu:machine_learning|5\"\
: {\n \"acc\": 0.3482142857142857,\n \"acc_stderr\": 0.045218299028335865\n\
\ },\n \"original|mmlu:management|5\": {\n \"acc\": 0.5825242718446602,\n\
\ \"acc_stderr\": 0.048828405482122375\n },\n \"original|mmlu:marketing|5\"\
: {\n \"acc\": 0.7136752136752137,\n \"acc_stderr\": 0.029614323690456655\n\
\ },\n \"original|mmlu:medical_genetics|5\": {\n \"acc\": 0.42,\n \
\ \"acc_stderr\": 0.04960449637488584\n },\n \"original|mmlu:miscellaneous|5\"\
: {\n \"acc\": 0.6909323116219668,\n \"acc_stderr\": 0.01652498891970219\n\
\ },\n \"original|mmlu:moral_disputes|5\": {\n \"acc\": 0.49710982658959535,\n\
\ \"acc_stderr\": 0.026918645383239015\n },\n \"original|mmlu:moral_scenarios|5\"\
: {\n \"acc\": 0.2770949720670391,\n \"acc_stderr\": 0.014968772435812143\n\
\ },\n \"original|mmlu:nutrition|5\": {\n \"acc\": 0.47058823529411764,\n\
\ \"acc_stderr\": 0.028580341065138293\n },\n \"original|mmlu:philosophy|5\"\
: {\n \"acc\": 0.5401929260450161,\n \"acc_stderr\": 0.028306190403305696\n\
\ },\n \"original|mmlu:prehistory|5\": {\n \"acc\": 0.5833333333333334,\n\
\ \"acc_stderr\": 0.027431623722415005\n },\n \"original|mmlu:professional_accounting|5\"\
: {\n \"acc\": 0.35815602836879434,\n \"acc_stderr\": 0.02860208586275943\n\
\ },\n \"original|mmlu:professional_law|5\": {\n \"acc\": 0.36114732724902215,\n\
\ \"acc_stderr\": 0.012267935477519034\n },\n \"original|mmlu:professional_medicine|5\"\
: {\n \"acc\": 0.3860294117647059,\n \"acc_stderr\": 0.029573269134411124\n\
\ },\n \"original|mmlu:professional_psychology|5\": {\n \"acc\": 0.45098039215686275,\n\
\ \"acc_stderr\": 0.020130388312904528\n },\n \"original|mmlu:public_relations|5\"\
: {\n \"acc\": 0.6,\n \"acc_stderr\": 0.0469237132203465\n },\n\
\ \"original|mmlu:security_studies|5\": {\n \"acc\": 0.5306122448979592,\n\
\ \"acc_stderr\": 0.031949171367580624\n },\n \"original|mmlu:sociology|5\"\
: {\n \"acc\": 0.5323383084577115,\n \"acc_stderr\": 0.03528131472933607\n\
\ },\n \"original|mmlu:us_foreign_policy|5\": {\n \"acc\": 0.69,\n\
\ \"acc_stderr\": 0.04648231987117316\n },\n \"original|mmlu:virology|5\"\
: {\n \"acc\": 0.4397590361445783,\n \"acc_stderr\": 0.03864139923699121\n\
\ },\n \"original|mmlu:world_religions|5\": {\n \"acc\": 0.6549707602339181,\n\
\ \"acc_stderr\": 0.03645981377388806\n }\n}\n```"
repo_url: https://huggingface.co/None
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|arc:challenge|25_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hellaswag|10_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-20T13:09:09.001286.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-20T13:09:09.001286.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-20T13:09:09.001286.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-20T13:09:09.001286.parquet'
- config_name: original_mmlu_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:abstract_algebra|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:anatomy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:astronomy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:business_ethics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:clinical_knowledge|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_biology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_medicine|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:computer_security|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:conceptual_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:econometrics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:electrical_engineering|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:elementary_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:formal_logic|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:global_facts|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_biology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_european_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_geography|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_government_and_politics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_macroeconomics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_microeconomics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_psychology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_statistics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_us_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_world_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:human_aging|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:human_sexuality|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:international_law|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:jurisprudence|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:logical_fallacies|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:machine_learning|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:management|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:marketing|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:medical_genetics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:miscellaneous|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:moral_disputes|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:moral_scenarios|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:nutrition|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:philosophy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:prehistory|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_accounting|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_law|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_medicine|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_psychology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:public_relations|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:security_studies|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:sociology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:us_foreign_policy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:virology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:world_religions|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:abstract_algebra|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:anatomy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:astronomy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:business_ethics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:clinical_knowledge|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_biology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_medicine|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:college_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:computer_security|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:conceptual_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:econometrics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:electrical_engineering|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:elementary_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:formal_logic|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:global_facts|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_biology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_european_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_geography|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_government_and_politics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_macroeconomics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_microeconomics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_physics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_psychology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_statistics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_us_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:high_school_world_history|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:human_aging|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:human_sexuality|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:international_law|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:jurisprudence|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:logical_fallacies|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:machine_learning|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:management|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:marketing|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:medical_genetics|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:miscellaneous|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:moral_disputes|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:moral_scenarios|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:nutrition|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:philosophy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:prehistory|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_accounting|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_law|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_medicine|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:professional_psychology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:public_relations|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:security_studies|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:sociology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:us_foreign_policy|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:virology|5_2023-08-28T20:30:08.303629.parquet'
- '**/details_original|mmlu:world_religions|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_abstract_algebra_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:abstract_algebra|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:abstract_algebra|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_anatomy_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:anatomy|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:anatomy|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_astronomy_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:astronomy|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:astronomy|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_business_ethics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:business_ethics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:business_ethics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_clinical_knowledge_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:clinical_knowledge|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:clinical_knowledge|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_biology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_biology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_biology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_chemistry_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_computer_science_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_mathematics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_medicine_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_medicine|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_medicine|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_college_physics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:college_physics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:college_physics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_computer_security_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:computer_security|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:computer_security|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_conceptual_physics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:conceptual_physics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:conceptual_physics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_econometrics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:econometrics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:econometrics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_electrical_engineering_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:electrical_engineering|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:electrical_engineering|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_elementary_mathematics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:elementary_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:elementary_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_formal_logic_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:formal_logic|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:formal_logic|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_global_facts_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:global_facts|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:global_facts|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_biology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_biology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_biology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_chemistry_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_chemistry|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_computer_science_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_computer_science|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_european_history_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_european_history|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_european_history|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_geography_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_geography|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_geography|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_government_and_politics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_government_and_politics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_government_and_politics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_macroeconomics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_macroeconomics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_macroeconomics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_mathematics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_mathematics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_microeconomics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_microeconomics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_microeconomics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_physics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_physics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_physics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_psychology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_psychology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_psychology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_statistics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_statistics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_statistics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_us_history_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_us_history|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_us_history|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_high_school_world_history_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:high_school_world_history|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:high_school_world_history|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_human_aging_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:human_aging|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:human_aging|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_human_sexuality_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:human_sexuality|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:human_sexuality|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_international_law_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:international_law|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:international_law|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_jurisprudence_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:jurisprudence|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:jurisprudence|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_logical_fallacies_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:logical_fallacies|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:logical_fallacies|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_machine_learning_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:machine_learning|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:machine_learning|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_management_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:management|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:management|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_marketing_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:marketing|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:marketing|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_medical_genetics_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:medical_genetics|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:medical_genetics|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_miscellaneous_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:miscellaneous|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:miscellaneous|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_moral_disputes_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:moral_disputes|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:moral_disputes|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_moral_scenarios_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:moral_scenarios|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:moral_scenarios|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_nutrition_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:nutrition|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:nutrition|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_philosophy_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:philosophy|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:philosophy|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_prehistory_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:prehistory|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:prehistory|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_professional_accounting_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:professional_accounting|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:professional_accounting|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_professional_law_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:professional_law|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:professional_law|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_professional_medicine_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:professional_medicine|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:professional_medicine|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_professional_psychology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:professional_psychology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:professional_psychology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_public_relations_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:public_relations|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:public_relations|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_security_studies_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:security_studies|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:security_studies|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_sociology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:sociology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:sociology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_us_foreign_policy_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:us_foreign_policy|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:us_foreign_policy|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_virology_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:virology|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:virology|5_2023-08-28T20:30:08.303629.parquet'
- config_name: original_mmlu_world_religions_5
data_files:
- split: 2023_08_28T20_30_08.303629
path:
- '**/details_original|mmlu:world_religions|5_2023-08-28T20:30:08.303629.parquet'
- split: latest
path:
- '**/details_original|mmlu:world_religions|5_2023-08-28T20:30:08.303629.parquet'
- config_name: results
data_files:
- split: 2023_07_20T13_09_09.001286
path:
- results_2023-07-20T13:09:09.001286.parquet
- split: 2023_08_28T20_30_08.303629
path:
- results_2023-08-28T20:30:08.303629.parquet
- split: latest
path:
- results_2023-08-28T20:30:08.303629.parquet
---
# Dataset Card for Evaluation run of None
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/None
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [None](https://huggingface.co/None) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 119 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_mosaicml__mpt-30b",
"original_mmlu_world_religions_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-08-28T20:30:08.303629](https://huggingface.co/datasets/open-llm-leaderboard/details_mosaicml__mpt-30b/blob/main/results_2023-08-28T20%3A30%3A08.303629.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.4711060669821722,
"acc_stderr": 0.036219414265372424
},
"original|mmlu:abstract_algebra|5": {
"acc": 0.25,
"acc_stderr": 0.04351941398892446
},
"original|mmlu:anatomy|5": {
"acc": 0.48148148148148145,
"acc_stderr": 0.043163785995113245
},
"original|mmlu:astronomy|5": {
"acc": 0.45394736842105265,
"acc_stderr": 0.040516463428741434
},
"original|mmlu:business_ethics|5": {
"acc": 0.48,
"acc_stderr": 0.050211673156867795
},
"original|mmlu:clinical_knowledge|5": {
"acc": 0.5094339622641509,
"acc_stderr": 0.030767394707808093
},
"original|mmlu:college_biology|5": {
"acc": 0.5069444444444444,
"acc_stderr": 0.04180806750294938
},
"original|mmlu:college_chemistry|5": {
"acc": 0.27,
"acc_stderr": 0.04461960433384741
},
"original|mmlu:college_computer_science|5": {
"acc": 0.45,
"acc_stderr": 0.049999999999999996
},
"original|mmlu:college_mathematics|5": {
"acc": 0.33,
"acc_stderr": 0.047258156262526045
},
"original|mmlu:college_medicine|5": {
"acc": 0.4393063583815029,
"acc_stderr": 0.03784271932887467
},
"original|mmlu:college_physics|5": {
"acc": 0.28431372549019607,
"acc_stderr": 0.04488482852329017
},
"original|mmlu:computer_security|5": {
"acc": 0.6,
"acc_stderr": 0.049236596391733084
},
"original|mmlu:conceptual_physics|5": {
"acc": 0.40425531914893614,
"acc_stderr": 0.03208115750788684
},
"original|mmlu:econometrics|5": {
"acc": 0.2807017543859649,
"acc_stderr": 0.04227054451232199
},
"original|mmlu:electrical_engineering|5": {
"acc": 0.503448275862069,
"acc_stderr": 0.04166567577101579
},
"original|mmlu:elementary_mathematics|5": {
"acc": 0.3253968253968254,
"acc_stderr": 0.024130158299762613
},
"original|mmlu:formal_logic|5": {
"acc": 0.2698412698412698,
"acc_stderr": 0.03970158273235172
},
"original|mmlu:global_facts|5": {
"acc": 0.4,
"acc_stderr": 0.049236596391733084
},
"original|mmlu:high_school_biology|5": {
"acc": 0.5064516129032258,
"acc_stderr": 0.02844163823354051
},
"original|mmlu:high_school_chemistry|5": {
"acc": 0.4039408866995074,
"acc_stderr": 0.0345245390382204
},
"original|mmlu:high_school_computer_science|5": {
"acc": 0.54,
"acc_stderr": 0.05009082659620332
},
"original|mmlu:high_school_european_history|5": {
"acc": 0.5878787878787879,
"acc_stderr": 0.03843566993588717
},
"original|mmlu:high_school_geography|5": {
"acc": 0.5909090909090909,
"acc_stderr": 0.03502975799413007
},
"original|mmlu:high_school_government_and_politics|5": {
"acc": 0.6476683937823834,
"acc_stderr": 0.03447478286414357
},
"original|mmlu:high_school_macroeconomics|5": {
"acc": 0.45384615384615384,
"acc_stderr": 0.025242770987126177
},
"original|mmlu:high_school_mathematics|5": {
"acc": 0.3,
"acc_stderr": 0.0279404571362284
},
"original|mmlu:high_school_microeconomics|5": {
"acc": 0.46638655462184875,
"acc_stderr": 0.03240501447690071
},
"original|mmlu:high_school_physics|5": {
"acc": 0.2781456953642384,
"acc_stderr": 0.03658603262763743
},
"original|mmlu:high_school_psychology|5": {
"acc": 0.6605504587155964,
"acc_stderr": 0.02030210934266235
},
"original|mmlu:high_school_statistics|5": {
"acc": 0.3333333333333333,
"acc_stderr": 0.0321495214780275
},
"original|mmlu:high_school_us_history|5": {
"acc": 0.6323529411764706,
"acc_stderr": 0.03384132045674118
},
"original|mmlu:high_school_world_history|5": {
"acc": 0.6751054852320675,
"acc_stderr": 0.03048603938910531
},
"original|mmlu:human_aging|5": {
"acc": 0.515695067264574,
"acc_stderr": 0.0335412657542081
},
"original|mmlu:human_sexuality|5": {
"acc": 0.549618320610687,
"acc_stderr": 0.04363643698524779
},
"original|mmlu:international_law|5": {
"acc": 0.39669421487603307,
"acc_stderr": 0.044658697805310094
},
"original|mmlu:jurisprudence|5": {
"acc": 0.48148148148148145,
"acc_stderr": 0.04830366024635331
},
"original|mmlu:logical_fallacies|5": {
"acc": 0.4662576687116564,
"acc_stderr": 0.039194155450484096
},
"original|mmlu:machine_learning|5": {
"acc": 0.3482142857142857,
"acc_stderr": 0.045218299028335865
},
"original|mmlu:management|5": {
"acc": 0.5825242718446602,
"acc_stderr": 0.048828405482122375
},
"original|mmlu:marketing|5": {
"acc": 0.7136752136752137,
"acc_stderr": 0.029614323690456655
},
"original|mmlu:medical_genetics|5": {
"acc": 0.42,
"acc_stderr": 0.04960449637488584
},
"original|mmlu:miscellaneous|5": {
"acc": 0.6909323116219668,
"acc_stderr": 0.01652498891970219
},
"original|mmlu:moral_disputes|5": {
"acc": 0.49710982658959535,
"acc_stderr": 0.026918645383239015
},
"original|mmlu:moral_scenarios|5": {
"acc": 0.2770949720670391,
"acc_stderr": 0.014968772435812143
},
"original|mmlu:nutrition|5": {
"acc": 0.47058823529411764,
"acc_stderr": 0.028580341065138293
},
"original|mmlu:philosophy|5": {
"acc": 0.5401929260450161,
"acc_stderr": 0.028306190403305696
},
"original|mmlu:prehistory|5": {
"acc": 0.5833333333333334,
"acc_stderr": 0.027431623722415005
},
"original|mmlu:professional_accounting|5": {
"acc": 0.35815602836879434,
"acc_stderr": 0.02860208586275943
},
"original|mmlu:professional_law|5": {
"acc": 0.36114732724902215,
"acc_stderr": 0.012267935477519034
},
"original|mmlu:professional_medicine|5": {
"acc": 0.3860294117647059,
"acc_stderr": 0.029573269134411124
},
"original|mmlu:professional_psychology|5": {
"acc": 0.45098039215686275,
"acc_stderr": 0.020130388312904528
},
"original|mmlu:public_relations|5": {
"acc": 0.6,
"acc_stderr": 0.0469237132203465
},
"original|mmlu:security_studies|5": {
"acc": 0.5306122448979592,
"acc_stderr": 0.031949171367580624
},
"original|mmlu:sociology|5": {
"acc": 0.5323383084577115,
"acc_stderr": 0.03528131472933607
},
"original|mmlu:us_foreign_policy|5": {
"acc": 0.69,
"acc_stderr": 0.04648231987117316
},
"original|mmlu:virology|5": {
"acc": 0.4397590361445783,
"acc_stderr": 0.03864139923699121
},
"original|mmlu:world_religions|5": {
"acc": 0.6549707602339181,
"acc_stderr": 0.03645981377388806
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 79,788 | [
[
-0.03448486328125,
-0.050384521484375,
0.02655029296875,
-0.0031795501708984375,
-0.01116180419921875,
0.0011377334594726562,
0.00124359130859375,
-0.0093231201171875,
0.058624267578125,
0.0178985595703125,
-0.0418701171875,
-0.059051513671875,
-0.04751586914062... |
open-llm-leaderboard/details_psyche__kogpt | 2023-10-14T16:11:05.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | 0 | 3 | 2023-08-18T00:10:21 | ---
pretty_name: Evaluation run of psyche/kogpt
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [psyche/kogpt](https://huggingface.co/psyche/kogpt) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 3 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_psyche__kogpt\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-14T16:10:56.600667](https://huggingface.co/datasets/open-llm-leaderboard/details_psyche__kogpt/blob/main/results_2023-10-14T16-10-56.600667.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.005138422818791947,\n\
\ \"em_stderr\": 0.000732210410279423,\n \"f1\": 0.028876887583892643,\n\
\ \"f1_stderr\": 0.0012126841041294677,\n \"acc\": 0.24546172059984214,\n\
\ \"acc_stderr\": 0.00702508504724885\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.005138422818791947,\n \"em_stderr\": 0.000732210410279423,\n\
\ \"f1\": 0.028876887583892643,\n \"f1_stderr\": 0.0012126841041294677\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.4909234411996843,\n\
\ \"acc_stderr\": 0.0140501700944977\n }\n}\n```"
repo_url: https://huggingface.co/psyche/kogpt
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|arc:challenge|25_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_13T11_08_59.950038
path:
- '**/details_harness|drop|3_2023-10-13T11-08-59.950038.parquet'
- split: 2023_10_14T16_10_56.600667
path:
- '**/details_harness|drop|3_2023-10-14T16-10-56.600667.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-14T16-10-56.600667.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_13T11_08_59.950038
path:
- '**/details_harness|gsm8k|5_2023-10-13T11-08-59.950038.parquet'
- split: 2023_10_14T16_10_56.600667
path:
- '**/details_harness|gsm8k|5_2023-10-14T16-10-56.600667.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-14T16-10-56.600667.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hellaswag|10_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T19:23:49.331489.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T19:23:49.331489.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_13T11_08_59.950038
path:
- '**/details_harness|winogrande|5_2023-10-13T11-08-59.950038.parquet'
- split: 2023_10_14T16_10_56.600667
path:
- '**/details_harness|winogrande|5_2023-10-14T16-10-56.600667.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-14T16-10-56.600667.parquet'
- config_name: results
data_files:
- split: 2023_07_19T19_23_49.331489
path:
- results_2023-07-19T19:23:49.331489.parquet
- split: 2023_10_13T11_08_59.950038
path:
- results_2023-10-13T11-08-59.950038.parquet
- split: 2023_10_14T16_10_56.600667
path:
- results_2023-10-14T16-10-56.600667.parquet
- split: latest
path:
- results_2023-10-14T16-10-56.600667.parquet
---
# Dataset Card for Evaluation run of psyche/kogpt
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/psyche/kogpt
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [psyche/kogpt](https://huggingface.co/psyche/kogpt) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 3 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_psyche__kogpt",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-14T16:10:56.600667](https://huggingface.co/datasets/open-llm-leaderboard/details_psyche__kogpt/blob/main/results_2023-10-14T16-10-56.600667.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.005138422818791947,
"em_stderr": 0.000732210410279423,
"f1": 0.028876887583892643,
"f1_stderr": 0.0012126841041294677,
"acc": 0.24546172059984214,
"acc_stderr": 0.00702508504724885
},
"harness|drop|3": {
"em": 0.005138422818791947,
"em_stderr": 0.000732210410279423,
"f1": 0.028876887583892643,
"f1_stderr": 0.0012126841041294677
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
},
"harness|winogrande|5": {
"acc": 0.4909234411996843,
"acc_stderr": 0.0140501700944977
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 38,843 | [
[
-0.031890869140625,
-0.0457763671875,
0.028106689453125,
0.021270751953125,
-0.016754150390625,
0.00506591796875,
-0.0294952392578125,
-0.01129150390625,
0.0285186767578125,
0.0386962890625,
-0.060333251953125,
-0.0736083984375,
-0.05157470703125,
0.01139068... |
PKU-Alignment/BeaverTails-single-dimension-preference | 2023-08-18T11:56:05.000Z | [
"region:us"
] | PKU-Alignment | null | null | 0 | 3 | 2023-08-18T11:30:35 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.