
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
kevinjesse/ManyTypes4TypeScript | 2022-10-22T08:35:33.000Z | [
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:code",
"license:cc-by-4.0",
"region:us"
] | kevinjesse | null | null | 1 | 4 | 2022-03-02T23:29:22 | ---
license:
- cc-by-4.0
annotations_creators:
- found
- machine-generated
language_creators:
- found
language:
- code
language_details: TypeScript
multilinguality:
- monolingual
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- type-inference
pretty_name: ManyTypes4TypeScript
---
# Models Trained On ManyTypes4TypeScript
- **[CodeBERT]**(https://huggingface.co/kevinjesse/codebert-MT4TS)
- **[GraphCodeBERT]**(https://huggingface.co/kevinjesse/graphcodebert-MT4TS)
- **[CodeBERTa]**(https://huggingface.co/kevinjesse/codeberta-MT4TS)
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits-sample-size)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Dataset:** [https://doi.org/10.5281/zenodo.6387001](https://doi.org/10.5281/zenodo.6387001)
- **PapersWithCode:** [https://paperswithcode.com/sota/type-prediction-on-manytypes4typescript](https://paperswithcode.com/sota/type-prediction-on-manytypes4typescript)
### Dataset Summary
ManyTypes4TypeScript type inference dataset, available at the DOI link below. [](https://doi.org/10.5281/zenodo.6387001)
Given a line of source code, the task is to identify types that correspond with the tokens of code. We treat this as a tagging task similar to NER and POS where the model must predict a structural property of code i.e types. This is a classification task where the labels are the top occurring types in the training dataset. The size type vocabulary can be changed with the scripts found on Github.
### Supported Tasks and Leaderboards
- `multi-class-classification`: The dataset can be used to train a model for predicting types across a sequence.
### Languages
- TypeScript
## Dataset Structure
### Data Instances
An example of 'validation' looks as follows.
```
{
"tokens": ["import", "{", "Component", ",", "ChangeDetectorRef", "}", "from", "'@angular/core'", ";", "import", "{", "Router", "}", "from", "'@angular/router'", ";", "import", "{", "MenuController", "}", "from", "'@ionic/angular'", ";", "import", "{", "Storage", "}", "from", "'@ionic/storage'", ";", "import", "Swiper", "from", "'swiper'", ";", "@", "Component", "(", "{", "selector", ":", "'page-tutorial'", ",", "templateUrl", ":", "'tutorial.html'", ",", "styleUrls", ":", "[", "'./tutorial.scss'", "]", ",", "}", ")", "export", "class", "TutorialPage", "{", "showSkip", "=", "true", ";", "private", "slides", ":", "Swiper", ";", "constructor", "(", "public", "menu", ",", "public", "router", ",", "public", "storage", ",", "private", "cd", ")", "{", "}", "startApp", "(", ")", "{", "this", ".", "router", ".", "navigateByUrl", "(", "'/app/tabs/schedule'", ",", "{", "replaceUrl", ":", "true", "}", ")", ".", "then", "(", "(", ")", "=>", "this", ".", "storage", ".", "set", "(", "'ion_did_tutorial'", ",", "true", ")", ")", ";", "}", "setSwiperInstance", "(", "swiper", ")", "{", "this", ".", "slides", "=", "swiper", ";", "}", "onSlideChangeStart", "(", ")", "{", "this", ".", "showSkip", "=", "!", "this", ".", "slides", ".", "isEnd", ";", "this", ".", "cd", ".", "detectChanges", "(", ")", ";", "}", "ionViewWillEnter", "(", ")", "{", "this", ".", "storage", ".", "get", "(", "'ion_did_tutorial'", ")", ".", "then", "(", "res", "=>", "{", "if", "(", "res", "===", "true", ")", "{", "this", ".", "router", ".", "navigateByUrl", "(", "'/app/tabs/schedule'", ",", "{", "replaceUrl", ":", "true", "}", ")", ";", "}", "}", ")", ";", "this", ".", "menu", ".", "enable", "(", "false", ")", ";", "}", "ionViewDidLeave", "(", ")", "{", "this", ".", "menu", ".", "enable", "(", "true", ")", ";", "}", "}"],
"labels": [null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, "MenuController", null, null, "Router", null, null, "Storage", null, null, "ChangeDetectorRef", null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, "Swiper", null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null],
"url": "https://github.com/ionic-team/ionic-conference-app",
"path": "ionic-conference-app/src/app/pages/tutorial/tutorial.ts",
"commit_hash": "34d97d29369377a2f0173a2958de1ee0dadb8a6e",
"file": "tutorial.ts"}
}
```
### Data Fields
The data fields are the same among all splits.
#### default
|field name. | type | description |
|------------|-------------|--------------------------------------------|
|tokens |list[string] | Sequence of tokens (word tokenization) |
|labels |list[string] | A list of corresponding types |
|url |string | Repository URL |
|path |string | Original file path that contains this code |
|commit_hash |string | Commit identifier in the original project |
|file |string | File name |
### Data Splits
| name | train |validation| test |
|---------:|---------:|---------:|--------:|
|projects | 75.00% | 12.5% | 12.5% |
|files | 90.53% | 4.43% | 5.04% |
|sequences | 91.95% | 3.71% | 4.34% |
|types | 95.33% | 2.21% | 2.46% |
##Types by the Numbers
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
Human annotated types in optionally typed languages and the compiler inferred annotations.
#### Annotation process
#### Who are the annotators?
Developers and TypeScript Compiler.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
https://github.com/kevinjesse
### Licensing Information
Creative Commons 4.0 (CC) license
### Citation Information
```
``` | 8,114 | [
[
-0.0428466796875,
-0.01165771484375,
0.02508544921875,
0.003231048583984375,
-0.00485992431640625,
0.05010986328125,
0.01288604736328125,
-0.002811431884765625,
0.04510498046875,
0.022674560546875,
-0.05279541015625,
-0.07122802734375,
-0.029144287109375,
-0... |
lewtun/github-issues-test | 2021-08-12T23:55:28.000Z | [
"region:us"
] | lewtun | null | null | 0 | 4 | 2022-03-02T23:29:22 | # GitHub Issues Dataset | 23 | [
[
-0.004688262939453125,
-0.019317626953125,
-0.00806427001953125,
0.0036182403564453125,
-0.029022216796875,
0.046722412109375,
-0.019622802734375,
0.0050506591796875,
0.03692626953125,
0.0279388427734375,
-0.03570556640625,
-0.0218353271484375,
-0.05355834960937... |
lijingxin/squad_zen | 2022-02-09T03:05:31.000Z | [
"region:us"
] | lijingxin | null | null | 1 | 4 | 2022-03-02T23:29:22 | 仅自用
出自:https://github.com/junzeng-pluto/ChineseSquad
感谢! | 56 | [
[
-0.0090484619140625,
-0.035552978515625,
0.035064697265625,
0.061065673828125,
-0.06439208984375,
0.00818634033203125,
-0.00771331787109375,
0.01629638671875,
0.05963134765625,
0.046966552734375,
-0.0203094482421875,
-0.049041748046875,
-0.01119232177734375,
... |
marinone94/nst_no | 2022-02-04T23:04:16.000Z | [
"region:us"
] | marinone94 | This database was created by Nordic Language Technology for the development of automatic speech recognition and dictation in Norwegian.
In this version, the organization of the data have been altered to improve the usefulness of the database.
In the original version of the material, the files were organized in a specific folder structure where the folder names were meaningful.
However, the file names were not meaningful, and there were also cases of files with identical names in different folders.
This proved to be impractical, since users had to keep the original folder structure in order to use the data.
The files have been renamed, such that the file names are unique and meaningful regardless of the folder structure.
The original metadata files were in spl format. These have been converted to JSON format.
The converted metadata files are also anonymized and the text encoding has been converted from ANSI to UTF-8.
See the documentation file for a full description of the data and the changes made to the database. | null | 0 | 4 | 2022-03-02T23:29:22 | "This database was created by Nordic Language Technology for the development of automatic speech recognition and dictation in Swedish. In this updated version, the organization of the data have been altered to improve the usefulness of the database.
In the original version of the material, the files were organized in a specific folder structure where the folder names were meaningful. However, the file names were not meaningful, and there were also cases of files with identical names in different folders. This proved to be impractical, since users had to keep the original folder structure in order to use the data. The files have been renamed, such that the file names are unique and meaningful regardless of the folder structure. The original metadata files were in spl format. These have been converted to JSON format. The converted metadata files are also anonymized and the text encoding has been converted from ANSI to UTF-8.
See the documentation file for a full description of the data and the changes made to the database." - dataset originally available at https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-54/
Full documentation in english available at https://www.nb.no/sbfil/talegjenkjenning/16kHz_2020/no_2020/no-16khz_reorganized_english.pdf
In 🤗 datasets, this dataset will have a structure similar to common_voice. TO BE UPDATED. | 1,371 | [
[
-0.031768798828125,
-0.0369873046875,
0.00868988037109375,
0.00829315185546875,
-0.03375244140625,
-0.0012664794921875,
-0.011566162109375,
-0.035247802734375,
0.0187225341796875,
0.0570068359375,
-0.04962158203125,
-0.04632568359375,
-0.0288848876953125,
0.... |
maxmoynan/SemEval2017-Task4aEnglish | 2022-07-22T13:41:11.000Z | [
"region:us"
] | maxmoynan | null | null | 0 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
midas/ldkp3k | 2022-09-27T18:29:25.000Z | [
"region:us"
] | midas | This new dataset is designed to solve kp NLP task and is crafted with a lot of care. | TBA | 3 | 4 | 2022-03-02T23:29:22 | A dataset for benchmarking keyphrase extraction and generation techniques from long document English scientific papers. For more details about the dataset please refer the original paper - []().
Data source - []()
## Dataset Summary
## Dataset Structure
### Data Fields
- **id**: unique identifier of the document.
- **sections**: list of all the sections present in the document.
- **sec_text**: list of white space separated list of words present in each section.
- **sec_bio_tags**: list of BIO tags of white space separated list of words present in each section.
- **extractive_keyphrases**: List of all the present keyphrases.
- **abstractive_keyphrase**: List of all the absent keyphrases.
### Data Splits
|Split| #datapoints |
|--|--|
| Train-Small | 20,000 |
| Train-Medium | 50,000 |
| Train-Large | 90,019 |
| Test | 3413 |
| Validation | 3339 |
## Usage
### Small Dataset
```python
from datasets import load_dataset
# get small dataset
dataset = load_dataset("midas/ldkp3k", "small")
def order_sections(sample):
"""
corrects the order in which different sections appear in the document.
resulting order is: title, abstract, other sections in the body
"""
sections = []
sec_text = []
sec_bio_tags = []
if "title" in sample["sections"]:
title_idx = sample["sections"].index("title")
sections.append(sample["sections"].pop(title_idx))
sec_text.append(sample["sec_text"].pop(title_idx))
sec_bio_tags.append(sample["sec_bio_tags"].pop(title_idx))
if "abstract" in sample["sections"]:
abstract_idx = sample["sections"].index("abstract")
sections.append(sample["sections"].pop(abstract_idx))
sec_text.append(sample["sec_text"].pop(abstract_idx))
sec_bio_tags.append(sample["sec_bio_tags"].pop(abstract_idx))
sections += sample["sections"]
sec_text += sample["sec_text"]
sec_bio_tags += sample["sec_bio_tags"]
return sections, sec_text, sec_bio_tags
# sample from the train split
print("Sample from train data split")
train_sample = dataset["train"][0]
sections, sec_text, sec_bio_tags = order_sections(train_sample)
print("Fields in the sample: ", [key for key in train_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", train_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", train_sample["abstractive_keyphrases"])
print("\n-----------\n")
# sample from the validation split
print("Sample from validation data split")
validation_sample = dataset["validation"][0]
sections, sec_text, sec_bio_tags = order_sections(validation_sample)
print("Fields in the sample: ", [key for key in validation_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", validation_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", validation_sample["abstractive_keyphrases"])
print("\n-----------\n")
# sample from the test split
print("Sample from test data split")
test_sample = dataset["test"][0]
sections, sec_text, sec_bio_tags = order_sections(test_sample)
print("Fields in the sample: ", [key for key in test_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", test_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", test_sample["abstractive_keyphrases"])
print("\n-----------\n")
```
**Output**
```bash
```
### Medium Dataset
```python
from datasets import load_dataset
# get medium dataset
dataset = load_dataset("midas/ldkp3k", "medium")
```
### Large Dataset
```python
from datasets import load_dataset
# get large dataset
dataset = load_dataset("midas/ldkp3k", "large")
```
## Citation Information
Please cite the works below if you use this dataset in your work.
```
@article{dl4srmahata2022ldkp,
title={LDKP - A Dataset for Identifying Keyphrases from Long Scientific Documents},
author={Mahata, Debanjan and Agarwal, Naveen and Gautam, Dibya and Kumar, Amardeep and Parekh, Swapnil and Singla, Yaman Kumar and Acharya, Anish and Shah, Rajiv Ratn},
journal={DL4SR-22: Workshop on Deep Learning for Search and Recommendation, co-located with the 31st ACM International Conference on Information and Knowledge Management (CIKM)},
address={Atlanta, USA},
month={October},
year={2022}
}
```
```
@article{mahata2022ldkp,
title={LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents},
author={Mahata, Debanjan and Agarwal, Naveen and Gautam, Dibya and Kumar, Amardeep and Parekh, Swapnil and Singla, Yaman Kumar and Acharya, Anish and Shah, Rajiv Ratn},
journal={arXiv preprint arXiv:2203.15349},
year={2022}
}
```
```
@article{lo2019s2orc,
title={S2ORC: The semantic scholar open research corpus},
author={Lo, Kyle and Wang, Lucy Lu and Neumann, Mark and Kinney, Rodney and Weld, Dan S},
journal={arXiv preprint arXiv:1911.02782},
year={2019}
}
```
```
@inproceedings{ccano2019keyphrase,
title={Keyphrase generation: A multi-aspect survey},
author={{\c{C}}ano, Erion and Bojar, Ond{\v{r}}ej},
booktitle={2019 25th Conference of Open Innovations Association (FRUCT)},
pages={85--94},
year={2019},
organization={IEEE}
}
```
```
@article{meng2017deep,
title={Deep keyphrase generation},
author={Meng, Rui and Zhao, Sanqiang and Han, Shuguang and He, Daqing and Brusilovsky, Peter and Chi, Yu},
journal={arXiv preprint arXiv:1704.06879},
year={2017}
}
```
## Contributions
Thanks to [@debanjanbhucs](https://github.com/debanjanbhucs), [@dibyaaaaax](https://github.com/dibyaaaaax), [@UmaGunturi](https://github.com/UmaGunturi) and [@ad6398](https://github.com/ad6398) for adding this dataset
| 5,881 | [
[
-0.00677490234375,
-0.0288543701171875,
0.03399658203125,
0.0102386474609375,
-0.0276031494140625,
0.01082611083984375,
-0.017059326171875,
-0.00909423828125,
0.014495849609375,
0.0169219970703125,
-0.034271240234375,
-0.059600830078125,
-0.03564453125,
0.04... |
mozilla-foundation/common_voice_5_0 | 2023-07-29T16:00:03.000Z | [
"task_categories:automatic-speech-recognition",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"source_datasets:extended|common_voice",
"license:cc0-1.0",
"arxiv:1912.06670",
"region:us"
] | mozilla-foundation | null | @inproceedings{commonvoice:2020,
author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.},
title = {Common Voice: A Massively-Multilingual Speech Corpus},
booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)},
pages = {4211--4215},
year = 2020
} | 2 | 4 | 2022-03-02T23:29:22 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
license:
- cc0-1.0
multilinguality:
- multilingual
size_categories:
ab:
- n<1K
ar:
- 10K<n<100K
as:
- n<1K
br:
- 10K<n<100K
ca:
- 100K<n<1M
cnh:
- 1K<n<10K
cs:
- 10K<n<100K
cv:
- 1K<n<10K
cy:
- 10K<n<100K
de:
- 100K<n<1M
dv:
- 1K<n<10K
el:
- 10K<n<100K
en:
- 1M<n<10M
eo:
- 10K<n<100K
es:
- 100K<n<1M
et:
- 10K<n<100K
eu:
- 10K<n<100K
fa:
- 100K<n<1M
fr:
- 100K<n<1M
fy-NL:
- 10K<n<100K
ga-IE:
- 1K<n<10K
hsb:
- 1K<n<10K
ia:
- 1K<n<10K
id:
- 10K<n<100K
it:
- 100K<n<1M
ja:
- 1K<n<10K
ka:
- 1K<n<10K
kab:
- 100K<n<1M
ky:
- 10K<n<100K
lv:
- 1K<n<10K
mn:
- 10K<n<100K
mt:
- 10K<n<100K
nl:
- 10K<n<100K
or:
- 1K<n<10K
pa-IN:
- n<1K
pl:
- 100K<n<1M
pt:
- 10K<n<100K
rm-sursilv:
- 1K<n<10K
rm-vallader:
- 1K<n<10K
ro:
- 1K<n<10K
ru:
- 10K<n<100K
rw:
- 100K<n<1M
sah:
- 1K<n<10K
sl:
- 1K<n<10K
sv-SE:
- 10K<n<100K
ta:
- 10K<n<100K
tr:
- 10K<n<100K
tt:
- 10K<n<100K
uk:
- 10K<n<100K
vi:
- n<1K
vot:
- n<1K
zh-CN:
- 10K<n<100K
zh-HK:
- 10K<n<100K
zh-TW:
- 10K<n<100K
source_datasets:
- extended|common_voice
paperswithcode_id: common-voice
pretty_name: Common Voice Corpus 5
language_bcp47:
- ab
- ar
- as
- br
- ca
- cnh
- cs
- cv
- cy
- de
- dv
- el
- en
- eo
- es
- et
- eu
- fa
- fr
- fy-NL
- ga-IE
- hsb
- ia
- id
- it
- ja
- ka
- kab
- ky
- lv
- mn
- mt
- nl
- or
- pa-IN
- pl
- pt
- rm-sursilv
- rm-vallader
- ro
- ru
- rw
- sah
- sl
- sv-SE
- ta
- tr
- tt
- uk
- vi
- vot
- zh-CN
- zh-HK
- zh-TW
extra_gated_prompt: By clicking on “Access repository” below, you also agree to not
attempt to determine the identity of speakers in the Common Voice dataset.
task_categories:
- automatic-speech-recognition
---
# Dataset Card for Common Voice Corpus 5
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://commonvoice.mozilla.org/en/datasets
- **Repository:** https://github.com/common-voice/common-voice
- **Paper:** https://arxiv.org/abs/1912.06670
- **Leaderboard:** https://paperswithcode.com/dataset/common-voice
- **Point of Contact:** [Anton Lozhkov](mailto:anton@huggingface.co)
### Dataset Summary
The Common Voice dataset consists of a unique MP3 and corresponding text file.
Many of the 7226 recorded hours in the dataset also include demographic metadata like age, sex, and accent
that can help improve the accuracy of speech recognition engines.
The dataset currently consists of 5591 validated hours in 54 languages, but more voices and languages are always added.
Take a look at the [Languages](https://commonvoice.mozilla.org/en/languages) page to request a language or start contributing.
### Supported Tasks and Leaderboards
The results for models trained on the Common Voice datasets are available via the
[🤗 Speech Bench](https://huggingface.co/spaces/huggingface/hf-speech-bench)
### Languages
```
Abkhaz, Arabic, Assamese, Basque, Breton, Catalan, Chinese (China), Chinese (Hong Kong), Chinese (Taiwan), Chuvash, Czech, Dhivehi, Dutch, English, Esperanto, Estonian, French, Frisian, Georgian, German, Greek, Hakha Chin, Indonesian, Interlingua, Irish, Italian, Japanese, Kabyle, Kinyarwanda, Kyrgyz, Latvian, Maltese, Mongolian, Odia, Persian, Polish, Portuguese, Punjabi, Romanian, Romansh Sursilvan, Romansh Vallader, Russian, Sakha, Slovenian, Sorbian, Upper, Spanish, Swedish, Tamil, Tatar, Turkish, Ukrainian, Vietnamese, Votic, Welsh
```
## Dataset Structure
### Data Instances
A typical data point comprises the `path` to the audio file and its `sentence`.
Additional fields include `accent`, `age`, `client_id`, `up_votes`, `down_votes`, `gender`, `locale` and `segment`.
```python
{
'client_id': 'd59478fbc1ee646a28a3c652a119379939123784d99131b865a89f8b21c81f69276c48bd574b81267d9d1a77b83b43e6d475a6cfc79c232ddbca946ae9c7afc5',
'path': 'et/clips/common_voice_et_18318995.mp3',
'audio': {
'path': 'et/clips/common_voice_et_18318995.mp3',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000
},
'sentence': 'Tasub kokku saada inimestega, keda tunned juba ammust ajast saati.',
'up_votes': 2,
'down_votes': 0,
'age': 'twenties',
'gender': 'male',
'accent': '',
'locale': 'et',
'segment': ''
}
```
### Data Fields
`client_id` (`string`): An id for which client (voice) made the recording
`path` (`string`): The path to the audio file
`audio` (`dict`): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
`sentence` (`string`): The sentence the user was prompted to speak
`up_votes` (`int64`): How many upvotes the audio file has received from reviewers
`down_votes` (`int64`): How many downvotes the audio file has received from reviewers
`age` (`string`): The age of the speaker (e.g. `teens`, `twenties`, `fifties`)
`gender` (`string`): The gender of the speaker
`accent` (`string`): Accent of the speaker
`locale` (`string`): The locale of the speaker
`segment` (`string`): Usually an empty field
### Data Splits
The speech material has been subdivided into portions for dev, train, test, validated, invalidated, reported and other.
The validated data is data that has been validated with reviewers and received upvotes that the data is of high quality.
The invalidated data is data has been invalidated by reviewers
and received downvotes indicating that the data is of low quality.
The reported data is data that has been reported, for different reasons.
The other data is data that has not yet been reviewed.
The dev, test, train are all data that has been reviewed, deemed of high quality and split into dev, test and train.
## Data Preprocessing Recommended by Hugging Face
The following are data preprocessing steps advised by the Hugging Face team. They are accompanied by an example code snippet that shows how to put them to practice.
Many examples in this dataset have trailing quotations marks, e.g _“the cat sat on the mat.“_. These trailing quotation marks do not change the actual meaning of the sentence, and it is near impossible to infer whether a sentence is a quotation or not a quotation from audio data alone. In these cases, it is advised to strip the quotation marks, leaving: _the cat sat on the mat_.
In addition, the majority of training sentences end in punctuation ( . or ? or ! ), whereas just a small proportion do not. In the dev set, **almost all** sentences end in punctuation. Thus, it is recommended to append a full-stop ( . ) to the end of the small number of training examples that do not end in punctuation.
```python
from datasets import load_dataset
ds = load_dataset("mozilla-foundation/common_voice_5_0", "en", use_auth_token=True)
def prepare_dataset(batch):
"""Function to preprocess the dataset with the .map method"""
transcription = batch["sentence"]
if transcription.startswith('"') and transcription.endswith('"'):
# we can remove trailing quotation marks as they do not affect the transcription
transcription = transcription[1:-1]
if transcription[-1] not in [".", "?", "!"]:
# append a full-stop to sentences that do not end in punctuation
transcription = transcription + "."
batch["sentence"] = transcription
return batch
ds = ds.map(prepare_dataset, desc="preprocess dataset")
```
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Public Domain, [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{commonvoice:2020,
author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.},
title = {Common Voice: A Massively-Multilingual Speech Corpus},
booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)},
pages = {4211--4215},
year = 2020
}
```
| 10,540 | [
[
-0.040802001953125,
-0.05413818359375,
0.01007080078125,
0.034210205078125,
-0.0185089111328125,
0.003021240234375,
-0.042572021484375,
-0.0172119140625,
0.032012939453125,
0.0406494140625,
-0.05633544921875,
-0.0723876953125,
-0.032989501953125,
0.020156860... |
mulcyber/europarl-mono | 2021-02-05T16:05:40.000Z | [
"region:us"
] | mulcyber | Europarl Monolingual Dataset.
The Europarl parallel corpus is extracted from the proceedings of the
European Parliament (from 2000 to 2011). It includes versions in 21 European
languages: Romanic (French, Italian, Spanish, Portuguese, Romanian),
Germanic (English, Dutch, German, Danish, Swedish), Slavik (Bulgarian,
Czech, Polish, Slovak, Slovene), Finni-Ugric (Finnish, Hungarian, Estonian),
Baltic (Latvian, Lithuanian), and Greek.
Upstream url: https://www.statmt.org/europarl/ | @inproceedings{koehn2005europarl,
title={Europarl: A parallel corpus for statistical machine translation},
author={Koehn, Philipp},
booktitle={MT summit},
volume={5},
pages={79--86},
year={2005},
organization={Citeseer}
} | 0 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ncoop57/rico_captions | 2023-01-07T18:00:58.000Z | [
"region:us"
] | ncoop57 | This new dataset is designed to solve this great NLP task and is crafted with a lot of care. | @InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | 1 | 4 | 2022-03-02T23:29:22 | # RicoSCA dataset introduced in seq2act (Google Research 2020)
Used in a number of projects for UI Referring Expressions, Object Detection, Phrase Grounding and other Visual-Language model tasks.
List of projects using RicoSCA:
- https://paperswithcode.com/dataset/ricosca
Original RicoSCA source repo:
- https://github.com/google-research/google-research/tree/master/seq2act/data_generation#generate-ricosca-dataset
| 420 | [
[
-0.035797119140625,
-0.04534912109375,
0.0248260498046875,
0.004138946533203125,
-0.000020503997802734375,
-0.0015401840209960938,
0.0170745849609375,
-0.0085906982421875,
0.007297515869140625,
0.0640869140625,
-0.060211181640625,
-0.03424072265625,
0.0055122375... |
piEsposito/squad_20_ptbr | 2021-02-05T16:05:59.000Z | [
"region:us"
] | piEsposito | Translates SQuAD 2.0 from english to portuguese using Google Cloud API | @article{2020braquad,
author = {{Esposito}, Wladimir and {Esposito}, Piero and {Tamais},
Ana Laura and {Gatti}, Daniel},
title = "{BrQuAD - Brazilian
Question-Answering Dataset: Dataset para benchmark de modelos de
Machine Learning para question-answering em
Portugu^es brasileiro traduzindo o SQuAD com Google Cloud API}",
year = 2020,
} | 3 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
projecte-aina/parlament_parla | 2023-09-13T12:38:52.000Z | [
"task_categories:automatic-speech-recognition",
"task_categories:text-generation",
"task_ids:language-modeling",
"task_ids:speaker-identification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:ca",
"license:cc-by-4.0"... | projecte-aina | This is the ParlamentParla speech corpus for Catalan prepared by Col·lectivaT. The audio segments were extracted from recordings the Catalan Parliament (Parlament de Catalunya) plenary sessions, which took place between 2007/07/11 - 2018/07/17. We aligned the transcriptions with the recordings and extracted the corpus. The content belongs to the Catalan Parliament and the data is released conforming their terms of use.
Preparation of this corpus was partly supported by the Department of Culture of the Catalan autonomous government, and the v2.0 was supported by the Barcelona Supercomputing Center, within the framework of the project AINA of the Departament de Polítiques Digitals.
As of v2.0 the corpus is separated into 211 hours of clean and 400 hours of other quality segments. Furthermore, each speech segment is tagged with its speaker and each speaker with their gender. The statistics are detailed in the readme file.
For more information, go to https://github.com/CollectivaT-dev/ParlamentParla or mail info@collectivat.cat. | @dataset{kulebi_baybars_2021_5541827,
author = {Külebi, Baybars},
title = {{ParlamentParla - Speech corpus of Catalan
Parliamentary sessions}},
month = oct,
year = 2021,
publisher = {Zenodo},
version = {v2.0},
doi = {10.5281/zenodo.5541827},
url = {https://doi.org/10.5281/zenodo.5541827}
} | 1 | 4 | 2022-03-02T23:29:22 | ---
annotations_creators:
- found
language_creators:
- found
language:
- ca
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
clean:
- 10K<n<100K
other:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
- text-generation
task_ids:
- language-modeling
- speaker-identification
pretty_name: ParlamentParla
---
# Dataset Card for ParlamentParla
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://zenodo.org/record/5541827
- **Repository:** https://github.com/CollectivaT-dev/ParlamentParla
- **Paper:** ParlamentParla: [A Speech Corpus of Catalan Parliamentary Sessions.](http://www.lrec-conf.org/proceedings/lrec2022/workshops/ParlaCLARINIII/2022.parlaclariniii-1.0.pdf#page=135)
- **Point of Contact:** [Baybars Kulebi](mailto:baybars.kulebi@bsc.es)
### Dataset Summary
This is the ParlamentParla speech corpus for Catalan prepared by Col·lectivaT. The audio segments were extracted from recordings the Catalan Parliament (Parlament de Catalunya) plenary sessions, which took place between 2007/07/11 - 2018/07/17. We aligned the transcriptions with the recordings and extracted the corpus. The content belongs to the Catalan Parliament and the data is released conforming their terms of use.
Preparation of this corpus was partly supported by the Department of Culture of the Catalan autonomous government, and the v2.0 was supported by the Barcelona Supercomputing Center, within the framework of Projecte AINA of the Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya.
As of v2.0 the corpus is separated into 211 hours of clean and 400 hours of other quality segments. Furthermore, each speech segment is tagged with its speaker and each speaker with their gender. The statistics are detailed in the readme file.
### Supported Tasks and Leaderboards
The dataset can be used for:
- Language Modeling.
- Automatic Speech Recognition (ASR) transcribes utterances into words.
- Speaker Identification (SI) classifies each utterance for its speaker identity as a multi-class classification, where speakers are in the same predefined set for both training and testing.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
### Data Instances
```
{
'path': 'clean_train/c/c/ccca4790a55aba3e6bcf_63.88_74.06.wav'
'audio': {
'path': 'clean_train/c/c/ccca4790a55aba3e6bcf_63.88_74.06.wav',
'array': array([-6.10351562e-05, -6.10351562e-05, -1.22070312e-04, ...,
-1.22070312e-04, 0.00000000e+00, -3.05175781e-05]),
'sampling_rate': 16000
},
'speaker_id': 167,
'sentence': "alguns d'ells avui aquí presents un agraïment a aquells que mantenen viva la memòria aquest acte de reparació i dignitat és",
'gender': 0,
'duration': 10.18
}
```
### Data Fields
- `path` (str): The path to the audio file.
- `audio` (dict): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling
rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and
resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might
take a significant amount of time. Thus, it is important to first query the sample index before the `"audio"` column,
*i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- `speaker_id` (int): The speaker ID.
- `sentence` (str): The sentence the user was prompted to speak.
- `gender` (ClassLabel): The gender of the speaker (0: 'F', 1: 'M').
- `duration` (float): Duration of the speech.
### Data Splits
The dataset is split in: "train", "validation" and "test".
## Dataset Creation
The dataset is created by aligning the parliamentary session transcripts
and the audiovisual content. For more detailed information please consult
this [paper](http://www.lrec-conf.org/proceedings/lrec2022/workshops/ParlaCLARINIII/2022.parlaclariniii-1.0.pdf#page=135).
### Curation Rationale
We created this corpus to contribute to the development of language models in Catalan, a low-resource language.
### Source Data
#### Initial Data Collection and Normalization
The audio segments were extracted from recordings the Catalan Parliament
(Parlament de Catalunya) plenary sessions, which took place between 2007/07/11 -
2018/07/17. The cleaning procedures are in the archived repository [Long Audio
Aligner](https://github.com/gullabi/long-audio-aligner)
#### Who are the source language producers?
The parliamentary members of the legislatures between 2007/07/11 -
2018/07/17
### Annotations
The dataset is unannotated.
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
The initial content is publicly available furthermore, the identities of
the parliamentary members are anonymized.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this corpus contributes to the development of language models in
Catalan, a low-resource language.
### Discussion of Biases
This dataset has a gender bias, however since the speakers are tagged according to
their genders, creating a balanced subcorpus is possible.
| Subcorpus | Gender | Duration (h) |
|-------------|----------|------------|
| other_test | F | 2.516 |
| other_dev | F | 2.701 |
| other_train | F | 109.68 |
| other_test | M | 2.631 |
| other_dev | M | 2.513 |
| other_train | M | 280.196 |
|*other total*| | 400.239 |
| clean_test | F | 2.707 |
| clean_dev | F | 2.576 |
| clean_train | F | 77.905 |
| clean_test | M | 2.516 |
| clean_dev | M | 2.614 |
| clean_train | M | 123.162 |
|*clean total*| | 211.48 |
|*Total* | | 611.719 |
### Other Known Limitations
The text corpus belongs to the domain of Catalan politics
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing Information
[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@dataset{kulebi_baybars_2021_5541827,
author = {Külebi, Baybars},
title = {{ParlamentParla - Speech corpus of Catalan
Parliamentary sessions}},
month = oct,
year = 2021,
publisher = {Zenodo},
version = {v2.0},
doi = {10.5281/zenodo.5541827},
url = {https://doi.org/10.5281/zenodo.5541827}
}
```
For the paper:
```
@inproceedings{kulebi2022parlamentparla,
title={ParlamentParla: A Speech Corpus of Catalan Parliamentary Sessions},
author={K{\"u}lebi, Baybars and Armentano-Oller, Carme and Rodr{\'\i}guez-Penagos, Carlos and Villegas, Marta},
booktitle={Workshop on Creating, Enriching and Using Parliamentary Corpora},
volume={125},
number={130},
pages={125},
year={2022}
}
```
### Contributions
Thanks to [@albertvillanova](https://github.com/albertvillanova) for adding this dataset.
| 8,634 | [
[
-0.0287017822265625,
-0.037353515625,
0.00868988037109375,
0.03338623046875,
-0.023193359375,
-0.004314422607421875,
-0.0250701904296875,
-0.0037326812744140625,
0.031341552734375,
0.0411376953125,
-0.0256500244140625,
-0.06329345703125,
-0.043212890625,
0.0... |
rajeshradhakrishnan/malayalam_2020_wiki | 2022-07-04T11:01:57.000Z | [
"region:us"
] | rajeshradhakrishnan | null | null | 0 | 4 | 2022-03-02T23:29:22 | ��T�h�i�s� �d�a�t�a�s�e�t� �i�s� �f�r�o�m� �t�h�e� �c�o�m�m�o�n�-�c�r�a�w�l�-�m�a�l�a�y�a�l�a�m� �r�e�p�o�:� �h�t�t�p�s�:�/�/�g�i�t�h�u�b�.�c�o�m�/�q�b�u�r�s�t�/�c�o�m�m�o�n�-�c�r�a�w�l�-�m�a�l�a�y�a�l�a�m� | 206 | [
[
-0.00836944580078125,
-0.01546478271484375,
0.017974853515625,
0.0128631591796875,
-0.03240966796875,
-0.005046844482421875,
0.0110931396484375,
0.0030918121337890625,
0.050689697265625,
0.0576171875,
-0.059967041015625,
-0.06329345703125,
-0.02069091796875,
... |
sebastian-hofstaetter/tripclick-training | 2022-07-26T13:16:46.000Z | [
"task_categories:text-retrieval",
"task_ids:document-retrieval",
"annotations_creators:other",
"annotations_creators:clicks",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:tripclick",
"language:en-US",
"license:apache-2.0",
"arxiv:2201.0036... | sebastian-hofstaetter | null | null | 0 | 4 | 2022-03-02T23:29:22 | ---
annotations_creators:
- other
- clicks
language_creators:
- other
language:
- en-US
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: tripclick-training
size_categories:
- unknown
source_datasets: [tripclick]
task_categories:
- text-retrieval
task_ids:
- document-retrieval
---
# TripClick Baselines with Improved Training Data
*Establishing Strong Baselines for TripClick Health Retrieval* Sebastian Hofstätter, Sophia Althammer, Mete Sertkan and Allan Hanbury
https://arxiv.org/abs/2201.00365
**tl;dr** We create strong re-ranking and dense retrieval baselines (BERT<sub>CAT</sub>, BERT<sub>DOT</sub>, ColBERT, and TK) for TripClick (health ad-hoc retrieval). We improve the – originally too noisy – training data with a simple negative sampling policy. We achieve large gains over BM25 in the re-ranking and retrieval setting on TripClick, which were not achieved with the original baselines. We publish the improved training files for everyone to use.
If you have any questions, suggestions, or want to collaborate please don't hesitate to get in contact with us via [Twitter](https://twitter.com/s_hofstaetter) or mail to s.hofstaetter@tuwien.ac.at
**Please cite our work as:**
````
@misc{hofstaetter2022tripclick,
title={Establishing Strong Baselines for TripClick Health Retrieval},
author={Sebastian Hofst{\"a}tter and Sophia Althammer and Mete Sertkan and Allan Hanbury},
year={2022},
eprint={2201.00365},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
````
## Published Training Files
We publish the improved training files without the text content instead using the ids from TripClick (with permission from the TripClick owners); for the text content please get the full TripClick dataset from [the TripClick Github page](https://github.com/tripdatabase/tripclick).
Our training file **improved_tripclick_train_triple-ids.tsv** has the format ``query_id pos_passage_id neg_passage_id`` (with tab separation).
----
For more information on how to use the training files see: https://github.com/sebastian-hofstaetter/tripclick | 2,102 | [
[
0.007740020751953125,
-0.0251922607421875,
0.0302886962890625,
0.0028553009033203125,
-0.0137786865234375,
0.004840850830078125,
-0.012603759765625,
-0.0178375244140625,
0.033203125,
0.0272979736328125,
-0.0139617919921875,
-0.058319091796875,
-0.027236938476562... |
shivam/hindi_pib_processed | 2022-01-20T17:16:52.000Z | [
"region:us"
] | shivam | null | null | 0 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
susumu2357/squad_v2_sv | 2022-07-01T18:31:20.000Z | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|wikipedia",
"language:sv",
"license:apache-2.0",
"region:us"
] | susumu2357 | SQuAD_v2_sv is a Swedish version of SQuAD2.0. Translation was done automatically by using Google Translate API but it is not so straightforward because;
1. the span which determines the start and the end of the answer in the context may vary after translation,
2. tne translated context may not contain the translated answer if we translate both independently.
More details on how to handle these will be provided in another blog post. | null | 0 | 4 | 2022-03-02T23:29:22 | ---
language:
- sv
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|wikipedia
task_categories:
- question-answering
task_ids:
- extractive-qa
---
# Dataset Card for "squad_v2_sv"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits Sample Size](#data-splits-sample-size)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/susumu2357/SQuAD_v2_sv](https://github.com/susumu2357/SQuAD_v2_sv)
- **Repository:** [https://github.com/susumu2357/SQuAD_v2_sv](https://github.com/susumu2357/SQuAD_v2_sv)
- **Paper:** None
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 10.09 MB
- **Size of the generated dataset:** 113.27 MB
- **Total amount of disk used:** 123.36 MB
### Dataset Summary
SQuAD_v2_sv is a Swedish version of SQuAD2.0. Translation was done automatically using the Google Translate API but it is not so straightforward for the following reasons.
- The span that determines the start and end of the answer in the context may change after translation.
- If the context and the answer are translated independently, the translated answer may not be included in the translated context.
Details on how to handle these dificulties are described in the git hub repo.
### Supported Tasks
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
Swedish
## Dataset Structure
### Data Fields
The data fields are the same among all splits.
#### squad_v2
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits Sample Size
| name |train |validation|
|--------|-----:|---------:|
|squad_v2_Sv|113898| 11156|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@misc{squad_v2_sv,
author = {Susumu Okazawa},
title = {Swedish translation of SQuAD2.0},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/susumu2357/SQuAD_v2_sv}}
``` | 4,799 | [
[
-0.03631591796875,
-0.0296478271484375,
0.005481719970703125,
0.0198516845703125,
-0.0284271240234375,
0.0177154541015625,
-0.01708984375,
-0.035552978515625,
0.04473876953125,
0.0189361572265625,
-0.0833740234375,
-0.058685302734375,
-0.040435791015625,
0.0... |
tau/scientific_papers | 2022-02-03T09:10:13.000Z | [
"region:us"
] | tau | null | null | 0 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
toddmorrill/github-issues | 2022-10-25T09:56:49.000Z | [
"task_categories:text-classification",
"task_categories:text-retrieval",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"task_ids:document-retrieval",
"annotations_creators:no-annotation",
"multilinguality:monolingual",
"size_categories:unknown",
"language:'en-US'",
... | toddmorrill | null | null | 0 | 4 | 2022-03-02T23:29:22 | ---
YAML tags:
annotations_creators:
- no-annotation
language_creators: []
language:
- '''en-US'''
license: []
multilinguality:
- monolingual
pretty_name: Hugging Face Github Issues
size_categories:
- unknown
source_datasets: []
task_categories:
- text-classification
- text-retrieval
task_ids:
- multi-class-classification
- multi-label-classification
- document-retrieval
---
# Dataset Card for GitHub Issues
## Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond. | 779 | [
[
-0.03131103515625,
-0.0292205810546875,
-0.001995086669921875,
-0.006378173828125,
-0.023651123046875,
0.0279541015625,
-0.010650634765625,
-0.0179443359375,
0.044921875,
0.035369873046875,
-0.051422119140625,
-0.057098388671875,
-0.033233642578125,
0.001062... |
valurank/PoliticalBias_AllSides_Txt | 2022-10-21T13:37:02.000Z | [
"multilinguality:monolingual",
"language:en",
"license:other",
"region:us"
] | valurank | null | null | 1 | 4 | 2022-03-02T23:29:22 | ---
license:
- other
language:
- en
multilinguality:
- monolingual
task_categories:
- classification
task_ids:
- classification
---
# Dataset Card for news-12factor
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
- [Annotations](#annotations)
## Dataset Description
~20k articles labeled left, right, or center by the editors of allsides.com.
## Languages
The text in the dataset is in English
## Dataset Structure
3 folders, with many text files in each. Each text file represent the body text of one article.
## Source Data
URL data was scraped using https://github.com/mozilla/readability
## Annotations
Articles were manually annotated by news editors who were attempting to select representative articles from the left, right and center of each article topic. In other words, the dataset should generally be balanced - the left/right/center articles cover the same set of topics, and have roughly the same amount of articles in each.
| 1,070 | [
[
-0.043609619140625,
-0.030517578125,
0.0100555419921875,
0.02880859375,
-0.047210693359375,
0.0160675048828125,
-0.0021152496337890625,
-0.0300445556640625,
0.048187255859375,
0.0252532958984375,
-0.05230712890625,
-0.0634765625,
-0.041595458984375,
0.031402... |
valurank/news-12factor | 2022-10-21T13:35:36.000Z | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"multilinguality:monolingual",
"language:en",
"license:other",
"region:us"
] | valurank | null | null | 0 | 4 | 2022-03-02T23:29:22 |
---
license:
- other
language:
- en
multilinguality:
- monolingual
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Dataset Card for news-12factor
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
- [Annotations](#annotations)
## Dataset Description
80+ news articles with url, title, body text, scored on 12 quality factors and assigned a single rank.
## Languages
The text in the dataset is in English
## Dataset Structure
[Needs More Information]
## Source Data
URL data was scraped using [news-please](https://github.com/fhamborg/news-please)
## Annotations
Articles were manually annotated by Alex on a 12-factor score card.
| 795 | [
[
-0.03485107421875,
-0.0303802490234375,
0.0174102783203125,
0.03314208984375,
-0.041778564453125,
0.0252838134765625,
0.01155853271484375,
-0.0211944580078125,
0.03619384765625,
0.027801513671875,
-0.04840087890625,
-0.0694580078125,
-0.045013427734375,
0.02... |
webimmunization/COVID-19-vaccine-attitude-tweets | 2022-10-25T10:01:50.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"task_ids:intent-classification",
"annotations_creators:crowdsourced",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:54KB",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"re... | webimmunization | null | null | 1 | 4 | 2022-03-02T23:29:22 | ---
annotations_creators:
- crowdsourced
language_creators:
- other
language:
- en
license: [cc-by-4.0]
multilinguality:
- monolingual
pretty_name: twitter covid19 tweets
size_categories:
- 54KB
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
- intent-classification
---
# Dataset Card for COVID-19-vaccine-attitude-tweets
## Dataset Description
- **Paper:** [Be Careful Who You Follow. The Impact of the Initial Set of Friends on COVID-19 Vaccine tweets](https://www.researchgate.net/publication/355726080_Be_Careful_Who_You_Follow_The_Impact_of_the_Initial_Set_of_Friends_on_COVID-19_Vaccine_Tweets)
- **Point of Contact:** [Izabela Krysinska](izabela.krysinska@doctorate.put.poznan.pl)
### Dataset Summary
The dataset consists of 2564 manually annotated tweets related to COVID-19 vaccines. The dataset can be used to discover the attitude expressed in the tweet towards the subject of COVID-19 vaccines. Tweets are in English. The dataset was curated in such a way as to maximize the likelihood of tweets with a strong emotional tone. We have assumed the existence of three classes:
- PRO (label 0): positive, the tweet unequivocally suggests support for getting vaccinated against COVID-19
- NEUTRAL (label 1): the tweet is mostly informative, does not show emotions vs. presented information, contains strong positive or negative emotions but concerning politics (vaccine distribution, vaccine passports, etc.)
- AGAINST (label 2): the tweet is clearly against vaccination and contains warnings, conspiracy theories, etc.
The dataset does not contain the content of Twitter statuses. Original tweets can be obtained via Twitter API.
You can use [`twitter`](https://python-twitter.readthedocs.io/en/latest/index.html) library:
```python
import twitter
from datasets import load_dataset
api = twitter.Api(consumer_key=<consumer key>,
consumer_secret=<consumer secret>,
access_token_key=<access token>,
access_token_secret=<access token secret>,
sleep_on_rate_limit=True)
tweets = load_dataset('webimmunization/COVID-19-vaccine-attitude-tweets')
def add_tweet_content(example):
try:
status = api.GetStatus(tweet_id)
except twitter.TwitterError as err:
print(err)
status = {'text': None}
return {'status': status.text}
tweets_with_text = tweets.map(add_tweet_content)
```
### Supported Tasks and Leaderboards
- `text-classification`: The dataset can be used to discover the attitude expressed in the tweet towards the subject of COVID-19 vaccines, whether the tweet presents a positive, neutral or negative attitude. Success on this task can be measured by achieving a *high* AUROC or [F1](https://huggingface.co/metrics/f1).
### Languages
[EN] English.
The text that can be accessed via the Twitter API using the identifiers in this dataset is in English.
## Dataset Structure
### Data Instances
The 1st column is Twitter Status ID and the 2nd column is the label denoting the attitude towards vaccines against COVID-19.
Example:
```
{
'id': '1387627601955545089',
'attitude': 0 # positive attitude
}
```
### Data Fields
- `attitude`: attitude towards vaccines against COVID-19. `0` denotes positive attitude, `1` denotes neutral attitude, `2` dentoes negative attitude.
- `id`: Twitter status id
### Data Splits
[Needs More Information]
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
Social media posts.
#### Initial Data Collection and Normalization
We queried the Twitter search engine with manually curated hashtags such as \#coronavaccine, \#getvaccinated, #mRNA, #PfizerGang, #VaccineNoThankYou, #vaccinesWork, #BillGatesVaccine, #VaccinesKill, etc. to fetch tweets related to COVID-19 vaccines. Then we have searched for tweets with conspicuous emotional load, both negative and positive. Once we had the set of emotionally loaded tweets we started fetching other tweets posted by the authors of emotional tweets. We'd been collecting tweets from mid of April for about a month. Then we filtered out tweets that were not related to the vaccines. In this manner, we collected tweets that are more probable to be emotional rather than strictly informative.
#### Who are the source language producers?
The language producers are users of Twitter.
### Annotations
#### Annotation process
We have manually annotated over 2500 tweets using the following annotation protocol. We have assumed the existence of three classes:
- PRO (label 0): positive, the tweet unequivocally suggests support for getting vaccinated against COVID-19
- NEUTRAL(label 1): the tweet is mostly informative, does not show emotions vs. presented information, contains strong positive or negative emotions but concerning politics (vaccine distribution, vaccine passports, etc.)
- AGAINST(label 2): the tweet is clearly against vaccination and contains warnings, conspiracy theories, etc.
The PRO class consists of tweets which explicitly urge people to go get vaccinated. The AGAINST class contains tweets which explicitly warn people against getting the vaccine.
Tweet annotation has been conducted using [Prodigy](https://prodi.gy) tool. The annotators were provided with the following instructions:
- Do not spend too much time on a tweet and try to make a quick decision, the slight discrepancy in labeling (especially if you are deciding between *PRO* and *NEUTRAL*) will not affect the classifier significantly.
- Assign tweets that seem to originate from news sites as *NEUTRAL* and use *PRO* for tweets that express unequivocal support for getting the vaccine.
- There are many tweets on vaccination and politics. They should fall into the *NEUTRAL* class unless they contain a clear call to action: go get vaccinated!
- Use only the contents of the tweet to label it, do not open the links if the content of a tweet is not enough for labeling (e.g., “Hmm, interesting, https://t.co/ki345o2i345”), skip such tweets instead of giving it a label.
- Use the option to skip a tweet only when there is nothing in the tweet except for an URL or a few meaningless words, otherwise do not hesitate to put the tweet in the *NEUTRAL* class.
We have asked 8 annotators to annotate the same set of 100 tweets using the guidelines proposed in the annotation protocol to verify the annotation protocol. We have measured the interrater agreement using the Fliess' kappa coefficient <cite>[Fleiss 1971][2]</cite>. The results were as follows:
- when measuring the agreement with four possible classes (*PRO*, *NEUTRAL*, *AGAINST*, *NONE*, where the last class represents tweets that were rejected from annotation), the agreement is `kappa=0.3940`
- when measuring the agreement after removing tweets that were rejected, the agreement is `kappa=0.3560`
- when measuring the agreement if rejected tweets are classified as *NEUTRAL*, the agreement is `kappa=0.3753`
- when measuring the agreement for only two classes (using *PRO*, *NEUTRAL* and *NONE* as one class, and *AGAINST* as another class), the agreement is `kappa=0.5419`
#### Who are the annotators?
[Members of the #WebImmunization project](https://webimmunization.cm-uj.krakow.pl/en/team/)
### Personal and Sensitive Information
According to the Twitter developer policy, if displayed content ceases to be available through the Twitter API, it can not be obtained from other sources. Thus, we provide tweets' ids to maintain the integrity of all Twitter content with Twitter service. The proper way to extract tweets' content is via Twitter API. Whenever Twitter decided to suspend the author of the tweet, or the author decides to delete their tweet it won't be possible to obtain the tweet's content with this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The COVID-19 is a serious global health threat that can be mitigated only by public health interventions that require massive participation. Mass vaccination against COVID-19 is one of the most effective and economically promising solutions to stop the spread of the Sars-Cov-2 virus, which is responsible for the pandemic. Understanding how misinformation about COVID-19 vaccines is spreading in one of the globally most important social networks is paramount.
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
#### Interannotator agreement
According to a popular interpretation of Fleiss' kappa <cite>[Landis 1977][2]</cite>, the annotators are in fair agreement in the first three scenarios and moderate agreement in the last scenario. These results suggest that the annotators are struggling to distinguish between *PRO* and *NEUTRAL* classes, and sometimes they have divergent opinions on whether the tweet should be rejected from training. Still, they are coherent when labeling *AGAINST* tweets.
#### Suspended account & deleted tweets
Some of the statuses from the dataset can not be obtained due to account suspension or tweet deletion. The last time we check (15th of November, 2021), about 12% of tweets were authored by suspended accounts and about 10% were already deleted.
### Dataset Curators
Agata Olejniuk
Poznan University of Technology, Poland
The research leading to these results has received funding from the EEA Financial Mechanism 2014-2021. Project registration number: 2019/35/J/HS6 /03498.
### Licensing Information
[Needs More Information]
### Citation Information
```
@inproceedings{krysinska2021careful,
title={Be Careful Who You Follow: The Impact of the Initial Set of Friends on COVID-19 Vaccine Tweets},
author={Krysi{\'n}ska, Izabela and W{\'o}jtowicz, Tomi and Olejniuk, Agata and Morzy, Miko{\l}aj and Piasecki, Jan},
booktitle={Proceedings of the 2021 Workshop on Open Challenges in Online Social Networks},
pages={1--8},
year={2021}
}
```
[DOI](https://doi.org/10.1145/3472720.3483619)
### Contributions
We would like to cordially thank the [members of the #WebImmunization project](https://webimmunization.cm-uj.krakow.pl/en/team/) for helping with data annotation.
## References
[1]: Joseph L Fleiss. Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971.
[2]: J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data. biometrics, pages 159–174, 1977. | 10,404 | [
[
-0.016876220703125,
-0.05120849609375,
-0.004871368408203125,
0.0305023193359375,
-0.0228729248046875,
0.01222991943359375,
-0.0158538818359375,
-0.0343017578125,
0.043243408203125,
-0.01172637939453125,
-0.0255279541015625,
-0.056488037109375,
-0.05010986328125... |
yxchar/citation_intent-tlm | 2021-11-04T23:47:24.000Z | [
"region:us"
] | yxchar | null | null | 2 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
zloelias/kinopoisk-reviews-short | 2021-12-24T11:11:06.000Z | [
"region:us"
] | zloelias | null | null | 0 | 4 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
AhmedSSoliman/QRCD | 2022-03-06T18:58:06.000Z | [
"region:us"
] | AhmedSSoliman | null | null | 0 | 4 | 2022-03-05T20:46:25 | This dataset is presented for the task of Answering Questions on the Holy Qur'an.
https://sites.google.com/view/quran-qa-2022
QRCD (Qur'anic Reading Comprehension Dataset) is composed of 1,093 tuples of question-passage pairs that are coupled with their extracted answers to constitute 1,337 question-passage-answer triplets. It is split into training (65%), development (10%), and test (25%) sets.
QRCD is a JSON Lines (JSONL) file; each line is a JSON object that comprises a question-passage pair, along with its answers extracted from the accompanying passage. The dataset adopts the format shown below. The sample below has two JSON objects, one for each of the above two questions. | 690 | [
[
-0.031768798828125,
-0.056121826171875,
0.0147705078125,
0.0016412734985351562,
-0.037933349609375,
0.021209716796875,
0.015716552734375,
-0.0038623809814453125,
-0.0162506103515625,
0.0654296875,
-0.045654296875,
-0.0305023193359375,
-0.0126800537109375,
0.... |
mbartolo/synQA | 2022-10-25T10:02:24.000Z | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"task_ids:open-domain-qa",
"annotations_creators:generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:mit",
"arxiv:1606.05250",
"reg... | mbartolo | SynQA is a Reading Comprehension dataset created in the work "Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation" (https://aclanthology.org/2021.emnlp-main.696/).
It consists of 314,811 synthetically generated questions on the passages in the SQuAD v1.1 (https://arxiv.org/abs/1606.05250) training set.
In this work, we use a synthetic adversarial data generation to make QA models more robust to human adversaries. We develop a data generation pipeline that selects source passages, identifies candidate answers, generates questions, then finally filters or re-labels them to improve quality. Using this approach, we amplify a smaller human-written adversarial dataset to a much larger set of synthetic question-answer pairs. By incorporating our synthetic data, we improve the state-of-the-art on the AdversarialQA (https://adversarialqa.github.io/) dataset by 3.7F1 and improve model generalisation on nine of the twelve MRQA datasets. We further conduct a novel human-in-the-loop evaluation to show that our models are considerably more robust to new human-written adversarial examples: crowdworkers can fool our model only 8.8% of the time on average, compared to 17.6% for a model trained without synthetic data.
For full details on how the dataset was created, kindly refer to the paper. | @inproceedings{bartolo-etal-2021-improving,
title = "Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation",
author = "Bartolo, Max and
Thrush, Tristan and
Jia, Robin and
Riedel, Sebastian and
Stenetorp, Pontus and
Kiela, Douwe",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.696",
doi = "10.18653/v1/2021.emnlp-main.696",
pages = "8830--8848",
abstract = "Despite recent progress, state-of-the-art question answering models remain vulnerable to a variety of adversarial attacks. While dynamic adversarial data collection, in which a human annotator tries to write examples that fool a model-in-the-loop, can improve model robustness, this process is expensive which limits the scale of the collected data. In this work, we are the first to use synthetic adversarial data generation to make question answering models more robust to human adversaries. We develop a data generation pipeline that selects source passages, identifies candidate answers, generates questions, then finally filters or re-labels them to improve quality. Using this approach, we amplify a smaller human-written adversarial dataset to a much larger set of synthetic question-answer pairs. By incorporating our synthetic data, we improve the state-of-the-art on the AdversarialQA dataset by 3.7F1 and improve model generalisation on nine of the twelve MRQA datasets. We further conduct a novel human-in-the-loop evaluation and show that our models are considerably more robust to new human-written adversarial examples: crowdworkers can fool our model only 8.8{\%} of the time on average, compared to 17.6{\%} for a model trained without synthetic data.",
} | 2 | 4 | 2022-03-05T21:24:45 | ---
annotations_creators:
- generated
language_creators:
- found
language:
- en
license: mit
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- extractive-qa
- open-domain-qa
pretty_name: synQA
---
# Dataset Card for synQA
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [synQA homepage](https://github.com/maxbartolo/improving-qa-model-robustness)
- **Paper:** [Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation](https://aclanthology.org/2021.emnlp-main.696/)
- **Point of Contact:** [Max Bartolo](max.bartolo@ucl.ac.uk)
### Dataset Summary
SynQA is a Reading Comprehension dataset created in the work "Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation" (https://aclanthology.org/2021.emnlp-main.696/).
It consists of 314,811 synthetically generated questions on the passages in the SQuAD v1.1 (https://arxiv.org/abs/1606.05250) training set.
In this work, we use a synthetic adversarial data generation to make QA models more robust to human adversaries. We develop a data generation pipeline that selects source passages, identifies candidate answers, generates questions, then finally filters or re-labels them to improve quality. Using this approach, we amplify a smaller human-written adversarial dataset to a much larger set of synthetic question-answer pairs. By incorporating our synthetic data, we improve the state-of-the-art on the AdversarialQA (https://adversarialqa.github.io/) dataset by 3.7F1 and improve model generalisation on nine of the twelve MRQA datasets. We further conduct a novel human-in-the-loop evaluation to show that our models are considerably more robust to new human-written adversarial examples: crowdworkers can fool our model only 8.8% of the time on average, compared to 17.6% for a model trained without synthetic data.
For full details on how the dataset was created, kindly refer to the paper.
### Supported Tasks
`extractive-qa`: The dataset can be used to train a model for Extractive Question Answering, which consists in selecting the answer to a question from a passage. Success on this task is typically measured by achieving a high word-overlap [F1 score](https://huggingface.co/metrics/f1).ilable as round 1 of the QA task on [Dynabench](https://dynabench.org/tasks/2#overall) and ranks models based on F1 score.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
Data is provided in the same format as SQuAD 1.1. An example is shown below:
```
{
"data": [
{
"title": "None",
"paragraphs": [
{
"context": "Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.",
"qas": [
{
"id": "689f275aacba6c43ff112b2c7cb16129bfa934fa",
"question": "What material is the statue of Christ made of?",
"answers": [
{
"answer_start": 190,
"text": "organic copper"
}
]
},
{
"id": "73bd3f52f5934e02332787898f6e568d04bc5403",
"question": "Who is on the Main Building's gold dome?",
"answers": [
{
"answer_start": 111,
"text": "the Virgin Mary."
}
]
},
{
"id": "4d459d5b75fd8a6623446290c542f99f1538cf84",
"question": "What kind of statue is at the end of the main drive?",
"answers": [
{
"answer_start": 667,
"text": "modern stone"
}
]
},
{
"id": "987a1e469c5b360f142b0a171e15cef17cd68ea6",
"question": "What type of dome is on the Main Building at Notre Dame?",
"answers": [
{
"answer_start": 79,
"text": "gold"
}
]
}
]
}
]
}
]
}
```
### Data Fields
- title: all "None" in this dataset
- context: the context/passage
- id: a string identifier for each question
- answers: a list of all provided answers (one per question in our case, but multiple may exist in SQuAD) with an `answer_start` field which is the character index of the start of the answer span, and a `text` field which is the answer text.
### Data Splits
The dataset is composed of a single split of 314,811 examples that we used in a two-stage fine-tuning process (refer to the paper for further details).
## Dataset Creation
### Curation Rationale
This dataset was created to investigate the effects of using synthetic adversarial data generation to improve robustness of state-of-the-art QA models.
### Source Data
#### Initial Data Collection and Normalization
The source passages are from Wikipedia and are the same as those used in [SQuAD v1.1](https://arxiv.org/abs/1606.05250).
#### Who are the source language producers?
The source language produces are Wikipedia editors for the passages, and a BART-Large generative model for the questions.
### Personal and Sensitive Information
No annotator identifying details are provided.
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to help develop better question answering systems.
A system that succeeds at the supported task would be able to provide an accurate extractive answer from a short passage. This dataset is to be seen as a support resource for improve the ability of systems t handle questions that contemporary state-of-the-art models struggle to answer correctly, thus often requiring more complex comprehension abilities than say detecting phrases explicitly mentioned in the passage with high overlap to the question.
It should be noted, however, that the the source passages are both domain-restricted and linguistically specific, and that provided questions and answers do not constitute any particular social application.
### Discussion of Biases
The dataset may exhibit various biases in terms of the source passage selection, selected candidate answers, generated questions, quality re-labelling process, as well as any algorithmic biases that may be exacerbated from the adversarial annotation process used to collect the SQuAD and AdversarialQA data on which the generators were trained.
### Other Known Limitations
N/a
## Additional Information
### Dataset Curators
This dataset was initially created by Max Bartolo, Tristan Thrush, Robin Jia, Sebastian Riedel, Pontus Stenetorp, and Douwe Kiela during work carried out at University College London (UCL) and Facebook AI Research (FAIR).
### Licensing Information
This dataset is distributed under the [MIT License](https://opensource.org/licenses/MIT).
### Citation Information
```
@inproceedings{bartolo-etal-2021-improving,
title = "Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation",
author = "Bartolo, Max and
Thrush, Tristan and
Jia, Robin and
Riedel, Sebastian and
Stenetorp, Pontus and
Kiela, Douwe",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.696",
doi = "10.18653/v1/2021.emnlp-main.696",
pages = "8830--8848",
abstract = "Despite recent progress, state-of-the-art question answering models remain vulnerable to a variety of adversarial attacks. While dynamic adversarial data collection, in which a human annotator tries to write examples that fool a model-in-the-loop, can improve model robustness, this process is expensive which limits the scale of the collected data. In this work, we are the first to use synthetic adversarial data generation to make question answering models more robust to human adversaries. We develop a data generation pipeline that selects source passages, identifies candidate answers, generates questions, then finally filters or re-labels them to improve quality. Using this approach, we amplify a smaller human-written adversarial dataset to a much larger set of synthetic question-answer pairs. By incorporating our synthetic data, we improve the state-of-the-art on the AdversarialQA dataset by 3.7F1 and improve model generalisation on nine of the twelve MRQA datasets. We further conduct a novel human-in-the-loop evaluation and show that our models are considerably more robust to new human-written adversarial examples: crowdworkers can fool our model only 8.8{\%} of the time on average, compared to 17.6{\%} for a model trained without synthetic data.",
}
```
### Contributions
Thanks to [@maxbartolo](https://github.com/maxbartolo) for adding this dataset.
| 10,758 | [
[
-0.041595458984375,
-0.08148193359375,
0.02154541015625,
-0.01904296875,
-0.007110595703125,
0.0126800537109375,
0.005786895751953125,
-0.0180206298828125,
0.0163421630859375,
0.0345458984375,
-0.0728759765625,
-0.03875732421875,
-0.0260467529296875,
0.02630... |
Marianina/sentiment-banking | 2022-03-08T19:09:50.000Z | [
"region:us"
] | Marianina | null | null | 1 | 4 | 2022-03-08T18:49:07 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
rubrix/sst2_with_predictions | 2022-09-16T13:23:05.000Z | [
"region:us"
] | rubrix | null | null | 1 | 4 | 2022-03-09T14:13:30 | # Comparing model predictions and ground truth labels with Rubrix and Hugging Face
## Build dataset
You can skip this step if you run:
```python
from datasets import load_dataset
import rubrix as rb
ds = rb.DatasetForTextClassification.from_datasets(load_dataset("rubrix/sst2_with_predictions", split="train"))
```
Otherwise, the following cell will run the pipeline over the training set and store labels and predictions.
```python
from datasets import load_dataset
from transformers import pipeline, AutoModelForSequenceClassification
import rubrix as rb
name = "distilbert-base-uncased-finetuned-sst-2-english"
# Need to define id2label because surprisingly the pipeline has uppercase label names
model = AutoModelForSequenceClassification.from_pretrained(name, id2label={0: 'negative', 1: 'positive'})
nlp = pipeline("sentiment-analysis", model=model, tokenizer=name, return_all_scores=True)
dataset = load_dataset("glue", "sst2", split="train")
# batch predict
def predict(example):
return {"prediction": nlp(example["sentence"])}
# add predictions to the dataset
dataset = dataset.map(predict, batched=True).rename_column("sentence", "text")
# build rubrix dataset from hf dataset
ds = rb.DatasetForTextClassification.from_datasets(dataset, annotation="label")
```
```python
# Install Rubrix and start exploring and sharing URLs with interesting subsets, etc.
rb.log(ds, "sst2")
```
```python
ds.to_datasets().push_to_hub("rubrix/sst2_with_predictions")
```
Pushing dataset shards to the dataset hub: 0%| | 0/1 [00:00<?, ?it/s]
## Analize misspredictions and ambiguous labels
### With the UI
With Rubrix's UI you can:
- Combine filters and full-text/DSL queries to quickly find important samples
- All URLs contain the state so you can share with collaborator and annotator specific dataset regions to work on.
- Sort examples by score, as well as custom metadata fields.
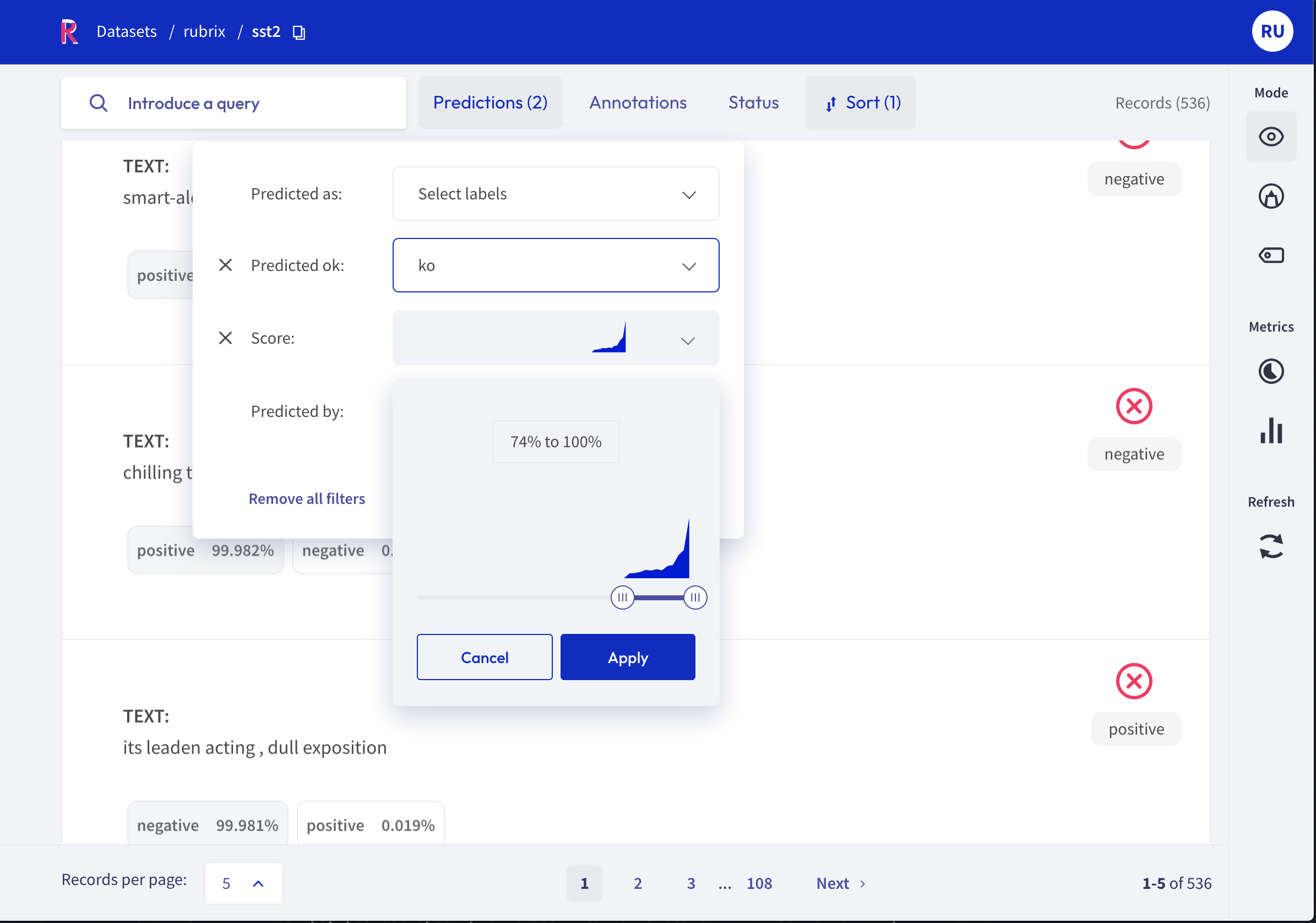
### Programmatically
Let's find all the wrong predictions from Python. This is useful for bulk operations (relabelling, discarding, etc.) as well as
```python
import pandas as pd
# Get dataset slice with wrong predictions
df = rb.load("sst2", query="predicted:ko").to_pandas()
# display first 20 examples
with pd.option_context('display.max_colwidth', None):
display(df[["text", "prediction", "annotation"]].head(20))
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>prediction</th>
<th>annotation</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>this particular , anciently demanding métier</td>
<td>[(negative, 0.9386059045791626), (positive, 0.06139408051967621)]</td>
<td>positive</td>
</tr>
<tr>
<th>1</th>
<td>under our skin</td>
<td>[(positive, 0.7508484721183777), (negative, 0.24915160238742828)]</td>
<td>negative</td>
</tr>
<tr>
<th>2</th>
<td>evokes a palpable sense of disconnection , made all the more poignant by the incessant use of cell phones .</td>
<td>[(negative, 0.6634528636932373), (positive, 0.3365470767021179)]</td>
<td>positive</td>
</tr>
<tr>
<th>3</th>
<td>plays like a living-room war of the worlds , gaining most of its unsettling force from the suggested and the unknown .</td>
<td>[(positive, 0.9968075752258301), (negative, 0.003192420583218336)]</td>
<td>negative</td>
</tr>
<tr>
<th>4</th>
<td>into a pulpy concept that , in many other hands would be completely forgettable</td>
<td>[(positive, 0.6178210377693176), (negative, 0.3821789622306824)]</td>
<td>negative</td>
</tr>
<tr>
<th>5</th>
<td>transcends ethnic lines .</td>
<td>[(positive, 0.9758220314979553), (negative, 0.024177948012948036)]</td>
<td>negative</td>
</tr>
<tr>
<th>6</th>
<td>is barely</td>
<td>[(negative, 0.9922297596931458), (positive, 0.00777028314769268)]</td>
<td>positive</td>
</tr>
<tr>
<th>7</th>
<td>a pulpy concept that , in many other hands would be completely forgettable</td>
<td>[(negative, 0.9738760590553284), (positive, 0.026123959571123123)]</td>
<td>positive</td>
</tr>
<tr>
<th>8</th>
<td>of hollywood heart-string plucking</td>
<td>[(positive, 0.9889695644378662), (negative, 0.011030420660972595)]</td>
<td>negative</td>
</tr>
<tr>
<th>9</th>
<td>a minimalist beauty and the beast</td>
<td>[(positive, 0.9100378751754761), (negative, 0.08996208757162094)]</td>
<td>negative</td>
</tr>
<tr>
<th>10</th>
<td>the intimate , unguarded moments of folks who live in unusual homes --</td>
<td>[(positive, 0.9967381358146667), (negative, 0.0032618637196719646)]</td>
<td>negative</td>
</tr>
<tr>
<th>11</th>
<td>steals the show</td>
<td>[(negative, 0.8031412363052368), (positive, 0.1968587338924408)]</td>
<td>positive</td>
</tr>
<tr>
<th>12</th>
<td>enough</td>
<td>[(positive, 0.7941301465034485), (negative, 0.2058698982000351)]</td>
<td>negative</td>
</tr>
<tr>
<th>13</th>
<td>accept it as life and</td>
<td>[(positive, 0.9987508058547974), (negative, 0.0012492131209000945)]</td>
<td>negative</td>
</tr>
<tr>
<th>14</th>
<td>this is the kind of movie that you only need to watch for about thirty seconds before you say to yourself , ` ah , yes ,</td>
<td>[(negative, 0.7889454960823059), (positive, 0.21105451881885529)]</td>
<td>positive</td>
</tr>
<tr>
<th>15</th>
<td>plunges you into a reality that is , more often then not , difficult and sad ,</td>
<td>[(positive, 0.967541515827179), (negative, 0.03245845437049866)]</td>
<td>negative</td>
</tr>
<tr>
<th>16</th>
<td>overcomes the script 's flaws and envelops the audience in his character 's anguish , anger and frustration .</td>
<td>[(positive, 0.9953157901763916), (negative, 0.004684178624302149)]</td>
<td>negative</td>
</tr>
<tr>
<th>17</th>
<td>troubled and determined homicide cop</td>
<td>[(negative, 0.6632784008979797), (positive, 0.33672159910202026)]</td>
<td>positive</td>
</tr>
<tr>
<th>18</th>
<td>human nature is a goofball movie , in the way that malkovich was , but it tries too hard</td>
<td>[(positive, 0.5959018468856812), (negative, 0.40409812331199646)]</td>
<td>negative</td>
</tr>
<tr>
<th>19</th>
<td>to watch too many barney videos</td>
<td>[(negative, 0.9909896850585938), (positive, 0.00901023019105196)]</td>
<td>positive</td>
</tr>
</tbody>
</table>
</div>
```python
df.annotation.hist()
```
<AxesSubplot:>
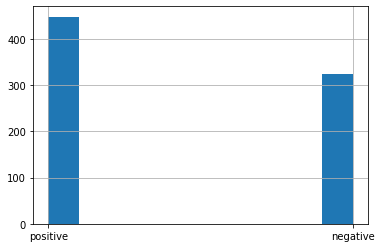
```python
# Get dataset slice with wrong predictions
df = rb.load("sst2", query="predicted:ko and annotated_as:negative").to_pandas()
# display first 20 examples
with pd.option_context('display.max_colwidth', None):
display(df[["text", "prediction", "annotation"]].head(20))
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>prediction</th>
<th>annotation</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>plays like a living-room war of the worlds , gaining most of its unsettling force from the suggested and the unknown .</td>
<td>[(positive, 0.9968075752258301), (negative, 0.003192420583218336)]</td>
<td>negative</td>
</tr>
<tr>
<th>1</th>
<td>a minimalist beauty and the beast</td>
<td>[(positive, 0.9100378751754761), (negative, 0.08996208757162094)]</td>
<td>negative</td>
</tr>
<tr>
<th>2</th>
<td>accept it as life and</td>
<td>[(positive, 0.9987508058547974), (negative, 0.0012492131209000945)]</td>
<td>negative</td>
</tr>
<tr>
<th>3</th>
<td>plunges you into a reality that is , more often then not , difficult and sad ,</td>
<td>[(positive, 0.967541515827179), (negative, 0.03245845437049866)]</td>
<td>negative</td>
</tr>
<tr>
<th>4</th>
<td>overcomes the script 's flaws and envelops the audience in his character 's anguish , anger and frustration .</td>
<td>[(positive, 0.9953157901763916), (negative, 0.004684178624302149)]</td>
<td>negative</td>
</tr>
<tr>
<th>5</th>
<td>and social commentary</td>
<td>[(positive, 0.7863275408744812), (negative, 0.2136724889278412)]</td>
<td>negative</td>
</tr>
<tr>
<th>6</th>
<td>we do n't get williams ' usual tear and a smile , just sneers and bile , and the spectacle is nothing short of refreshing .</td>
<td>[(positive, 0.9982783794403076), (negative, 0.0017216014675796032)]</td>
<td>negative</td>
</tr>
<tr>
<th>7</th>
<td>before pulling the plug on the conspirators and averting an american-russian armageddon</td>
<td>[(positive, 0.6992855072021484), (negative, 0.30071452260017395)]</td>
<td>negative</td>
</tr>
<tr>
<th>8</th>
<td>in tight pants and big tits</td>
<td>[(positive, 0.7850217819213867), (negative, 0.2149781733751297)]</td>
<td>negative</td>
</tr>
<tr>
<th>9</th>
<td>that it certainly does n't feel like a film that strays past the two and a half mark</td>
<td>[(positive, 0.6591460108757019), (negative, 0.3408539891242981)]</td>
<td>negative</td>
</tr>
<tr>
<th>10</th>
<td>actress-producer and writer</td>
<td>[(positive, 0.8167378306388855), (negative, 0.1832621842622757)]</td>
<td>negative</td>
</tr>
<tr>
<th>11</th>
<td>gives devastating testimony to both people 's capacity for evil and their heroic capacity for good .</td>
<td>[(positive, 0.8960123062133789), (negative, 0.10398765653371811)]</td>
<td>negative</td>
</tr>
<tr>
<th>12</th>
<td>deep into the girls ' confusion and pain as they struggle tragically to comprehend the chasm of knowledge that 's opened between them</td>
<td>[(positive, 0.9729612469673157), (negative, 0.027038726955652237)]</td>
<td>negative</td>
</tr>
<tr>
<th>13</th>
<td>a younger lad in zen and the art of getting laid in this prickly indie comedy of manners and misanthropy</td>
<td>[(positive, 0.9875985980033875), (negative, 0.012401451356709003)]</td>
<td>negative</td>
</tr>
<tr>
<th>14</th>
<td>get on a board and , uh , shred ,</td>
<td>[(positive, 0.5352609753608704), (negative, 0.46473899483680725)]</td>
<td>negative</td>
</tr>
<tr>
<th>15</th>
<td>so preachy-keen and</td>
<td>[(positive, 0.9644021391868591), (negative, 0.035597823560237885)]</td>
<td>negative</td>
</tr>
<tr>
<th>16</th>
<td>there 's an admirable rigor to jimmy 's relentless anger , and to the script 's refusal of a happy ending ,</td>
<td>[(positive, 0.9928517937660217), (negative, 0.007148175034672022)]</td>
<td>negative</td>
</tr>
<tr>
<th>17</th>
<td>` christian bale 's quinn ( is ) a leather clad grunge-pirate with a hairdo like gandalf in a wind-tunnel and a simply astounding cor-blimey-luv-a-duck cockney accent . '</td>
<td>[(positive, 0.9713286757469177), (negative, 0.028671346604824066)]</td>
<td>negative</td>
</tr>
<tr>
<th>18</th>
<td>passion , grief and fear</td>
<td>[(positive, 0.9849751591682434), (negative, 0.015024829655885696)]</td>
<td>negative</td>
</tr>
<tr>
<th>19</th>
<td>to keep the extremes of screwball farce and blood-curdling family intensity on one continuum</td>
<td>[(positive, 0.8838250637054443), (negative, 0.11617499589920044)]</td>
<td>negative</td>
</tr>
</tbody>
</table>
</div>
```python
# Get dataset slice with wrong predictions
df = rb.load("sst2", query="predicted:ko and score:{0.99 TO *}").to_pandas()
# display first 20 examples
with pd.option_context('display.max_colwidth', None):
display(df[["text", "prediction", "annotation"]].head(20))
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>prediction</th>
<th>annotation</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>plays like a living-room war of the worlds , gaining most of its unsettling force from the suggested and the unknown .</td>
<td>[(positive, 0.9968075752258301), (negative, 0.003192420583218336)]</td>
<td>negative</td>
</tr>
<tr>
<th>1</th>
<td>accept it as life and</td>
<td>[(positive, 0.9987508058547974), (negative, 0.0012492131209000945)]</td>
<td>negative</td>
</tr>
<tr>
<th>2</th>
<td>overcomes the script 's flaws and envelops the audience in his character 's anguish , anger and frustration .</td>
<td>[(positive, 0.9953157901763916), (negative, 0.004684178624302149)]</td>
<td>negative</td>
</tr>
<tr>
<th>3</th>
<td>will no doubt rally to its cause , trotting out threadbare standbys like ` masterpiece ' and ` triumph ' and all that malarkey ,</td>
<td>[(negative, 0.9936562180519104), (positive, 0.006343740504235029)]</td>
<td>positive</td>
</tr>
<tr>
<th>4</th>
<td>we do n't get williams ' usual tear and a smile , just sneers and bile , and the spectacle is nothing short of refreshing .</td>
<td>[(positive, 0.9982783794403076), (negative, 0.0017216014675796032)]</td>
<td>negative</td>
</tr>
<tr>
<th>5</th>
<td>somehow manages to bring together kevin pollak , former wrestler chyna and dolly parton</td>
<td>[(negative, 0.9979034662246704), (positive, 0.002096540294587612)]</td>
<td>positive</td>
</tr>
<tr>
<th>6</th>
<td>there 's an admirable rigor to jimmy 's relentless anger , and to the script 's refusal of a happy ending ,</td>
<td>[(positive, 0.9928517937660217), (negative, 0.007148175034672022)]</td>
<td>negative</td>
</tr>
<tr>
<th>7</th>
<td>the bottom line with nemesis is the same as it has been with all the films in the series : fans will undoubtedly enjoy it , and the uncommitted need n't waste their time on it</td>
<td>[(positive, 0.995850682258606), (negative, 0.004149340093135834)]</td>
<td>negative</td>
</tr>
<tr>
<th>8</th>
<td>is genial but never inspired , and little</td>
<td>[(negative, 0.9921030402183533), (positive, 0.007896988652646542)]</td>
<td>positive</td>
</tr>
<tr>
<th>9</th>
<td>heaped upon a project of such vast proportions need to reap more rewards than spiffy bluescreen technique and stylish weaponry .</td>
<td>[(negative, 0.9958089590072632), (positive, 0.004191054962575436)]</td>
<td>positive</td>
</tr>
<tr>
<th>10</th>
<td>than recommended -- as visually bland as a dentist 's waiting room , complete with soothing muzak and a cushion of predictable narrative rhythms</td>
<td>[(negative, 0.9988711476325989), (positive, 0.0011287889210507274)]</td>
<td>positive</td>
</tr>
<tr>
<th>11</th>
<td>spectacle and</td>
<td>[(positive, 0.9941601753234863), (negative, 0.005839805118739605)]</td>
<td>negative</td>
</tr>
<tr>
<th>12</th>
<td>groan and</td>
<td>[(negative, 0.9987359642982483), (positive, 0.0012639997294172645)]</td>
<td>positive</td>
</tr>
<tr>
<th>13</th>
<td>'re not likely to have seen before , but beneath the exotic surface ( and exotic dancing ) it 's surprisingly old-fashioned .</td>
<td>[(positive, 0.9908103942871094), (negative, 0.009189637377858162)]</td>
<td>negative</td>
</tr>
<tr>
<th>14</th>
<td>its metaphors are opaque enough to avoid didacticism , and</td>
<td>[(negative, 0.990602970123291), (positive, 0.00939704105257988)]</td>
<td>positive</td>
</tr>
<tr>
<th>15</th>
<td>by kevin bray , whose crisp framing , edgy camera work , and wholesale ineptitude with acting , tone and pace very obviously mark him as a video helmer making his feature debut</td>
<td>[(positive, 0.9973387122154236), (negative, 0.0026612314395606518)]</td>
<td>negative</td>
</tr>
<tr>
<th>16</th>
<td>evokes the frustration , the awkwardness and the euphoria of growing up , without relying on the usual tropes .</td>
<td>[(positive, 0.9989104270935059), (negative, 0.0010896018939092755)]</td>
<td>negative</td>
</tr>
<tr>
<th>17</th>
<td>, incoherence and sub-sophomoric</td>
<td>[(negative, 0.9962475895881653), (positive, 0.003752368036657572)]</td>
<td>positive</td>
</tr>
<tr>
<th>18</th>
<td>seems intimidated by both her subject matter and the period trappings of this debut venture into the heritage business .</td>
<td>[(negative, 0.9923072457313538), (positive, 0.007692818529903889)]</td>
<td>positive</td>
</tr>
<tr>
<th>19</th>
<td>despite downplaying her good looks , carries a little too much ai n't - she-cute baggage into her lead role as a troubled and determined homicide cop to quite pull off the heavy stuff .</td>
<td>[(negative, 0.9948075413703918), (positive, 0.005192441400140524)]</td>
<td>positive</td>
</tr>
</tbody>
</table>
</div>
```python
# Get dataset slice with wrong predictions
df = rb.load("sst2", query="predicted:ko and score:{* TO 0.6}").to_pandas()
# display first 20 examples
with pd.option_context('display.max_colwidth', None):
display(df[["text", "prediction", "annotation"]].head(20))
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>prediction</th>
<th>annotation</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>get on a board and , uh , shred ,</td>
<td>[(positive, 0.5352609753608704), (negative, 0.46473899483680725)]</td>
<td>negative</td>
</tr>
<tr>
<th>1</th>
<td>is , truly and thankfully , a one-of-a-kind work</td>
<td>[(positive, 0.5819814801216125), (negative, 0.41801854968070984)]</td>
<td>negative</td>
</tr>
<tr>
<th>2</th>
<td>starts as a tart little lemon drop of a movie and</td>
<td>[(negative, 0.5641832947731018), (positive, 0.4358167052268982)]</td>
<td>positive</td>
</tr>
<tr>
<th>3</th>
<td>between flaccid satire and what</td>
<td>[(negative, 0.5532692074775696), (positive, 0.44673076272010803)]</td>
<td>positive</td>
</tr>
<tr>
<th>4</th>
<td>it certainly does n't feel like a film that strays past the two and a half mark</td>
<td>[(negative, 0.5386656522750854), (positive, 0.46133431792259216)]</td>
<td>positive</td>
</tr>
<tr>
<th>5</th>
<td>who liked there 's something about mary and both american pie movies</td>
<td>[(negative, 0.5086333751678467), (positive, 0.4913666248321533)]</td>
<td>positive</td>
</tr>
<tr>
<th>6</th>
<td>many good ideas as bad is the cold comfort that chin 's film serves up with style and empathy</td>
<td>[(positive, 0.557632327079773), (negative, 0.44236767292022705)]</td>
<td>negative</td>
</tr>
<tr>
<th>7</th>
<td>about its ideas and</td>
<td>[(positive, 0.518638551235199), (negative, 0.48136141896247864)]</td>
<td>negative</td>
</tr>
<tr>
<th>8</th>
<td>of a sick and evil woman</td>
<td>[(negative, 0.5554516315460205), (positive, 0.4445483684539795)]</td>
<td>positive</td>
</tr>
<tr>
<th>9</th>
<td>though this rude and crude film does deliver a few gut-busting laughs</td>
<td>[(positive, 0.5045541524887085), (negative, 0.4954459071159363)]</td>
<td>negative</td>
</tr>
<tr>
<th>10</th>
<td>to squeeze the action and our emotions into the all-too-familiar dramatic arc of the holocaust escape story</td>
<td>[(negative, 0.5050069093704224), (positive, 0.49499306082725525)]</td>
<td>positive</td>
</tr>
<tr>
<th>11</th>
<td>that throws a bunch of hot-button items in the viewer 's face and asks to be seen as hip , winking social commentary</td>
<td>[(negative, 0.5873904228210449), (positive, 0.41260960698127747)]</td>
<td>positive</td>
</tr>
<tr>
<th>12</th>
<td>'s soulful and unslick</td>
<td>[(positive, 0.5931627750396729), (negative, 0.40683719515800476)]</td>
<td>negative</td>
</tr>
</tbody>
</table>
</div>
```python
from rubrix.metrics.commons import *
```
```python
text_length("sst2", query="predicted:ko").visualize()
```
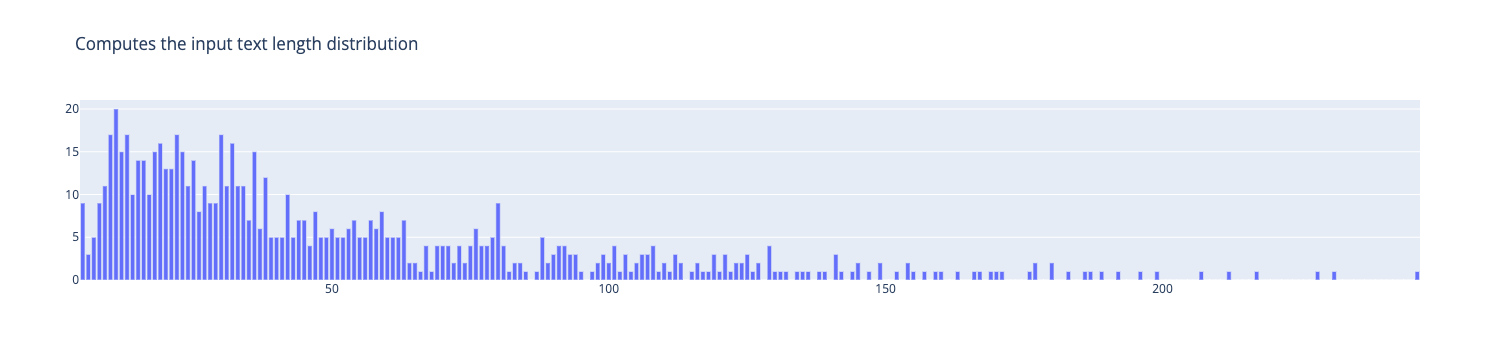 | 22,493 | [
[
-0.0384521484375,
-0.056610107421875,
0.0289459228515625,
0.00696563720703125,
-0.0189208984375,
0.01071929931640625,
0.00405120849609375,
-0.0140838623046875,
0.05633544921875,
0.021728515625,
-0.04229736328125,
-0.022796630859375,
-0.037567138671875,
0.003... |
Biomedical-TeMU/ProfNER_corpus_NER | 2022-03-10T21:50:30.000Z | [
"license:cc-by-4.0",
"region:us"
] | Biomedical-TeMU | null | null | 0 | 4 | 2022-03-10T21:34:00 | ---
license: cc-by-4.0
---
## Description
**Gold standard annotations for profession detection in Spanish COVID-19 tweets**
The entire corpus contains 10,000 annotated tweets. It has been split into training, validation, and test (60-20-20). The current version contains the training and development set of the shared task with Gold Standard annotations. In addition, it contains the unannotated test, and background sets will be released.
For Named Entity Recognition, profession detection, annotations are distributed in 2 formats: Brat standoff and TSV. See the Brat webpage for more information about the Brat standoff format (https://brat.nlplab.org/standoff.html).
The TSV format follows the format employed in SMM4H 2019 Task 2:
tweet_id | begin | end | type | extraction
In addition, we provide a tokenized version of the dataset. It follows the BIO format (similar to CONLL). The files were generated with the brat_to_conll.py script (included), which employs the es_core_news_sm-2.3.1 Spacy model for tokenization.
## Files of Named Entity Recognition subtask.
Content:
- One TSV file per corpus split (train and valid).
- brat: folder with annotations in Brat format. One sub-directory per corpus split (train and valid)
- BIO: folder with corpus in BIO tagging. One file per corpus split (train and valid)
- train-valid-txt-files: folder with training and validation text files. One text file per tweet. One sub-- directory per corpus split (train and valid)
- train-valid-txt-files-english: folder with training and validation text files Machine Translated to English.
- test-background-txt-files: folder with the test and background text files. You must make your predictions for these files and upload them to CodaLab. | 1,778 | [
[
-0.028961181640625,
-0.026123046875,
0.0162811279296875,
0.041259765625,
-0.0300750732421875,
0.0124359130859375,
-0.02215576171875,
-0.042449951171875,
0.0252227783203125,
0.0479736328125,
-0.057037353515625,
-0.0582275390625,
-0.056671142578125,
0.04254150... |
Khedesh/ArmanNER | 2022-03-11T10:42:30.000Z | [
"region:us"
] | Khedesh | null | null | 0 | 4 | 2022-03-11T08:13:29 | # PersianNER
Named-Entity Recognition in Persian Language
## ArmanPersoNERCorpus
This is the first manually-annotated Persian named-entity (NE) dataset (ISLRN 399-379-640-828-6). We are releasing it only for academic research use.
The dataset includes 250,015 tokens and 7,682 Persian sentences in total. It is available in 3 folds to be used in turn as training and test sets. Each file contains one token, along with its manually annotated named-entity tag, per line. Each sentence is separated with a newline. The NER tags are in IOB format.
According to the instructions provided to the annotators, NEs are categorized into six classes: person, organization (such as banks, ministries, embassies, teams, nationalities, networks and publishers), location (such as cities, villages, rivers, seas, gulfs, deserts and mountains), facility (such as schools, universities, research centers, airports, railways, bridges, roads, harbors, stations, hospitals, parks, zoos and cinemas), product (such as books, newspapers, TV shows, movies, airplanes, ships, cars, theories, laws, agreements and religions), and event (such as wars, earthquakes, national holidays, festivals and conferences); other are the remaining tokens.
| 1,226 | [
[
-0.05322265625,
-0.031341552734375,
0.0318603515625,
0.005161285400390625,
-0.028564453125,
0.02740478515625,
-0.03997802734375,
-0.0273284912109375,
0.033416748046875,
0.054595947265625,
-0.03192138671875,
-0.0413818359375,
-0.0404052734375,
0.03955078125,
... |
wanyu/IteraTeR_full_doc | 2022-10-24T18:58:30.000Z | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"conditional-text-generation",
"text-editing",
"arxiv:2203.03802",
"region:us"
] | wanyu | null | null | 1 | 4 | 2022-03-13T20:41:13 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
pretty_name: IteraTeR_full_doc
language_bcp47:
- en-US
tags:
- conditional-text-generation
- text-editing
---
Paper: [Understanding Iterative Revision from Human-Written Text](https://arxiv.org/abs/2203.03802)
Authors: Wanyu Du, Vipul Raheja, Dhruv Kumar, Zae Myung Kim, Melissa Lopez, Dongyeop Kang
Github repo: https://github.com/vipulraheja/IteraTeR
| 574 | [
[
-0.00531768798828125,
-0.03533935546875,
0.05169677734375,
0.00943756103515625,
-0.0235748291015625,
0.0160980224609375,
-0.018524169921875,
-0.0180816650390625,
0.0008001327514648438,
0.05657958984375,
-0.046051025390625,
-0.0289306640625,
-0.0164947509765625,
... |
malteos/paperswithcode-aspects | 2022-03-18T10:12:44.000Z | [
"region:us"
] | malteos | Papers with aspects from paperswithcode.com dataset | null | 0 | 4 | 2022-03-15T16:36:59 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
malteos/test-ds | 2022-10-25T10:03:23.000Z | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"size_categories:unknown",
"language:en-US",
"region:us"
] | malteos | null | null | 0 | 4 | 2022-03-18T10:02:26 | ---
annotations_creators: []
language_creators: []
language:
- en-US
license: []
multilinguality:
- monolingual
pretty_name: test ds
size_categories:
- unknown
source_datasets: []
task_categories:
- text-retrieval
task_ids: []
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| 2,715 | [
[
-0.03265380859375,
-0.03472900390625,
0.00994110107421875,
0.0190277099609375,
-0.01482391357421875,
0.016937255859375,
-0.022979736328125,
-0.025665283203125,
0.045867919921875,
0.044097900390625,
-0.0626220703125,
-0.083251953125,
-0.051544189453125,
0.004... |
tartuNLP/liv4ever | 2022-10-25T12:30:49.000Z | [
"task_categories:text2text-generation",
"task_categories:translation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:translation",
"size_categories:unknown",
"source_datasets:original",
"language:en",
"language:liv",
"license:cc-by-nc-sa-4.0",
"c... | tartuNLP | Livonian is one of the most endangered languages in Europe with just a tiny handful of speakers and virtually no publicly available corpora.
In this paper we tackle the task of developing neural machine translation (NMT) between Livonian and English, with a two-fold aim: on one hand,
preserving the language and on the other – enabling access to Livonian folklore, lifestories and other textual intangible heritage as well as
making it easier to create further parallel corpora. We rely on Livonian's linguistic similarity to Estonian and Latvian and collect parallel
and monolingual data for the four languages for translation experiments. We combine different low-resource NMT techniques like zero-shot translation,
cross-lingual transfer and synthetic data creation to reach the highest possible translation quality as well as to find which base languages are
empirically more helpful for transfer to Livonian. The resulting NMT systems and the collected monolingual and parallel data, including a manually
translated and verified translation benchmark, are publicly released.
Fields:
- source: source of the data
- en: sentence in English
- liv: sentence in Livonian | @inproceedings{rikters-etal-2022,
title = "Machine Translation for Livonian: Catering for 20 Speakers",
author = "Rikters, Matīss and
Tomingas, Marili and
Tuisk, Tuuli and
Valts, Ernštreits and
Fishel, Mark",
booktitle = "Proceedings of ACL 2022",
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics"
} | 2 | 4 | 2022-03-24T07:40:49 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
- liv
license:
- cc-by-nc-sa-4.0
multilinguality:
- translation
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text2text-generation
- translation
task_ids: []
pretty_name: Liv4ever
language_bcp47:
- en-US
- liv
tags:
- conditional-text-generation
---
# liv4ever v1
This is the Livonian 4-lingual parallel corpus. Livonian is a Uralic / Finnic language with just about 20 fluent speakers and no native speakers (as of 2021). The texts and translations in this corpus were collected from all the digital text resources that could be found by the authors; scanned and printed materials are left for future work.
The corpus includes parallel data for Livonian-Latvian, Livonian-Estonian and Livonian-English; the data has been collected in 2021. After retrieval it was normalized in terms of different orthographies of Livonian and manually sentence-aligned where needed. It was collected from the following sources, with sentence counts per language pair:
* Dictionary - example sentences from the Livonian-Latvian-Estonian dictionary;
* liv-lv: 10'388,
* liv-et: 10'378
* Stalte - the alphabet book by Kōrli Stalte, translated into Estonian and Latvian;
* liv-lv: 842,
* liv-et: 685
* Poetry - the poetry collection book "Ma võtan su õnge, tursk / Ma akūb sīnda vizzõ, tūrska", with Estonian translations;
* liv-et: 770
* Vääri - the book by Eduard Vääri about Livonian language and culture;
* liv-et: 592
* Satversme - translations of the Latvian Constitution into Livonian, Estonian and English;
* liv-en: 380,
* liv-lv: 414,
* liv-et: 413
* Facebook - social media posts by the Livonian Institute and Livonian Days with original translations;
* liv-en: 123,
* liv-lv: 124,
* liv-et: 7
* JEFUL - article abstracts from the Journal of Estonian and Finno-Ugric Linguistics, special issues dedicated to Livonian studies, translated into Estonian and English;
* liv-en: 36,
* liv-et: 49
* Trilium - the book with a collection of Livonian poetry, foreword and afterword translated into Estonian and Latvian;
* liv-lv: 51,
* liv-et: 53
* Songs - material crawled off lyricstranslate.com;
* liv-en: 54,
* liv-lv: 54,
* liv-fr: 31 | 2,299 | [
[
-0.0294647216796875,
-0.03167724609375,
0.03582763671875,
0.0222625732421875,
-0.022674560546875,
-0.0009899139404296875,
-0.017669677734375,
-0.0401611328125,
0.050140380859375,
0.06231689453125,
-0.036865234375,
-0.044525146484375,
-0.04278564453125,
0.041... |
nadhifikbarw/id_ohsuhmed | 2022-10-25T10:03:35.000Z | [
"task_categories:text-classification",
"language:id",
"region:us"
] | nadhifikbarw | null | null | 0 | 4 | 2022-03-27T07:01:29 | ---
language:
- id
task_categories:
- text-classification
source:
- http://disi.unitn.it/moschitti/corpora.htm
---
Machine translated Ohsumed collection (EN to ID)
Original corpora: http://disi.unitn.it/moschitti/corpora.htm
Translated using: https://huggingface.co/Helsinki-NLP/opus-mt-en-id
Compatible with HuggingFace text-classification script (Tested in 4.17)
https://github.com/huggingface/transformers/tree/v4.17.0/examples/pytorch/text-classification
[Moschitti, 2003a]. Alessandro Moschitti, Natural Language Processing and Text Categorization: a study on the reciprocal beneficial interactions, PhD thesis, University of Rome Tor Vergata, Rome, Italy, May 2003. | 679 | [
[
-0.0294342041015625,
-0.054779052734375,
0.0038814544677734375,
0.012237548828125,
-0.02239990234375,
-0.00978851318359375,
-0.01279449462890625,
-0.061981201171875,
0.035308837890625,
0.035186767578125,
-0.037200927734375,
-0.040130615234375,
-0.035614013671875... |
UrukHan/t5-russian-spell_III | 2022-03-27T13:01:02.000Z | [
"region:us"
] | UrukHan | null | null | 0 | 4 | 2022-03-27T12:59:47 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
hackathon-pln-es/readability-es-hackathon-pln-public | 2023-04-13T08:51:15.000Z | [
"task_categories:text-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"language:es",
"license:cc-by-4.0",
"readability",
"region:us"
] | hackathon-pln-es | null | null | 1 | 4 | 2022-04-04T10:26:51 | ---
annotations_creators:
- found
language_creators:
- found
language:
- es
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text-classification
task_ids: []
pretty_name: readability-es-sentences
tags:
- readability
---
# Dataset Card for [readability-es-sentences]
## Dataset Description
Compilation of short Spanish articles for readability assessment.
### Dataset Summary
This dataset is a compilation of short articles from websites dedicated to learn Spanish as a second language. These articles have been compiled from the following sources:
- **Coh-Metrix-Esp corpus (Quispesaravia, et al., 2016):** collection of 100 parallel texts with simple and complex variants in Spanish. These texts include children's and adult stories to fulfill each category.
- **[kwiziq](https://www.kwiziq.com/):** a language learner assistant
- **[hablacultura.com](https://hablacultura.com/):** Spanish resources for students and teachers. We have downloaded the available content in their websites.
### Languages
Spanish
## Dataset Structure
The dataset includes 1019 text entries between 80 and 8714 characters long. The vast majority (97%) are below 4,000 characters long.
### Data Fields
The dataset is formatted as a json lines and includes the following fields:
- **Category:** when available, this includes the level of this text according to the Common European Framework of Reference for Languages (CEFR).
- **Level:** standardized readability level: complex or simple.
- **Level-3:** standardized readability level: basic, intermediate or advanced
- **Text:** original text formatted into sentences.
Not all the entries contain usable values for `category`, `level` and `level-3`, but all of them should contain at least one of `level`, `level-3`. When the corresponding information could not be derived, we use the special `"N/A"` value to indicate so.
## Additional Information
### Licensing Information
https://creativecommons.org/licenses/by-nc-sa/4.0/
### Citation Information
Please cite this page to give credit to the authors :)
### Team
- [Laura Vásquez-Rodríguez](https://lmvasque.github.io/)
- [Pedro Cuenca](https://twitter.com/pcuenq)
- [Sergio Morales](https://www.fireblend.com/)
- [Fernando Alva-Manchego](https://feralvam.github.io/)
| 2,349 | [
[
-0.019561767578125,
-0.0278472900390625,
0.02001953125,
0.0254058837890625,
-0.016143798828125,
0.0268402099609375,
-0.01580810546875,
-0.049468994140625,
0.019012451171875,
0.034149169921875,
-0.053253173828125,
-0.0631103515625,
-0.037689208984375,
0.03524... |
Nart/abkhaz_text | 2022-11-01T10:53:17.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:ab",
"license:cc0-1.0",
"region:us"
] | Nart | null | null | 3 | 4 | 2022-04-04T11:57:51 | ---
language_creators:
- expert-generated
language:
- ab
license:
- cc0-1.0
multilinguality:
- monolingual
pretty_name: Abkhaz monolingual corpus
size_categories:
- 1M<n<10M
source_datasets:
- original
task_categories:
- text-generation
task_ids:
- language-modeling
---
# Dataset Card for "Abkhaz text"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Other Known Limitations](#other-known-limitations)
## Dataset Description
- **Point of Contact:** [Nart Tlisha](mailto:daniel.abzakh@gmail.com)
- **Size of the generated dataset:** 176 MB
### Dataset Summary
The Abkhaz language monolingual dataset is a collection of 1,470,480 sentences extracted from different sources. The dataset is available under the Creative Commons Universal Public Domain License. Part of it is also available as part of [Common Voice](https://commonvoice.mozilla.org/ab), another part is from the [Abkhaz National Corpus](https://clarino.uib.no/abnc)
## Dataset Creation
### Source Data
Here is a link to the source of a large part of the data on [github](https://github.com/danielinux7/Multilingual-Parallel-Corpus/blob/master/ebooks/reference.md)
## Considerations for Using the Data
### Other Known Limitations
The accuracy of the dataset is around 95% (gramatical, arthographical errors)
| 1,418 | [
[
-0.035064697265625,
-0.035858154296875,
-0.007587432861328125,
0.0211029052734375,
-0.05218505859375,
-0.01003265380859375,
-0.0377197265625,
-0.0251617431640625,
0.0134429931640625,
0.047332763671875,
-0.044219970703125,
-0.07427978515625,
-0.035247802734375,
... |
SocialGrep/the-reddit-place-dataset | 2022-07-01T17:51:57.000Z | [
"annotations_creators:lexyr",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"region:us"
] | SocialGrep | The written history or /r/Place, in posts and comments. | null | 1 | 4 | 2022-04-05T21:25:45 | ---
annotations_creators:
- lexyr
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
source_datasets:
- original
paperswithcode_id: null
---
# Dataset Card for the-reddit-place-dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Homepage:** [https://socialgrep.com/datasets](https://socialgrep.com/datasets/the-reddit-place-dataset?utm_source=huggingface&utm_medium=link&utm_campaign=theredditplacedataset)
- **Point of Contact:** [Website](https://socialgrep.com/contact?utm_source=huggingface&utm_medium=link&utm_campaign=theredditplacedataset)
### Dataset Summary
The written history or /r/Place, in posts and comments.
### Languages
Mainly English.
## Dataset Structure
### Data Instances
A data point is a post or a comment. Due to the separate nature of the two, those exist in two different files - even though many fields are shared.
### Data Fields
- 'type': the type of the data point. Can be 'post' or 'comment'.
- 'id': the base-36 Reddit ID of the data point. Unique when combined with type.
- 'subreddit.id': the base-36 Reddit ID of the data point's host subreddit. Unique.
- 'subreddit.name': the human-readable name of the data point's host subreddit.
- 'subreddit.nsfw': a boolean marking the data point's host subreddit as NSFW or not.
- 'created_utc': a UTC timestamp for the data point.
- 'permalink': a reference link to the data point on Reddit.
- 'score': score of the data point on Reddit.
- 'domain': (Post only) the domain of the data point's link.
- 'url': (Post only) the destination of the data point's link, if any.
- 'selftext': (Post only) the self-text of the data point, if any.
- 'title': (Post only) the title of the post data point.
- 'body': (Comment only) the body of the comment data point.
- 'sentiment': (Comment only) the result of an in-house sentiment analysis pipeline. Used for exploratory analysis.
## Additional Information
### Licensing Information
CC-BY v4.0
| 2,914 | [
[
-0.04608154296875,
-0.06134033203125,
0.03424072265625,
0.0396728515625,
-0.034576416015625,
0.0034351348876953125,
-0.01410675048828125,
-0.0167388916015625,
0.059783935546875,
0.023681640625,
-0.07244873046875,
-0.08258056640625,
-0.0460205078125,
0.017700... |
Chris1/GTA5 | 2022-04-06T14:44:22.000Z | [
"region:us"
] | Chris1 | null | null | 0 | 4 | 2022-04-06T13:02:07 | Entry not found | 15 | [
[
-0.0213775634765625,
-0.01497650146484375,
0.05718994140625,
0.02880859375,
-0.0350341796875,
0.046478271484375,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.0170135498046875,
-0.052093505859375,
-0.01497650146484375,
-0.0604248046875,
0.0379028... |
NLPC-UOM/Sinhala-News-Category-classification | 2022-10-25T10:03:58.000Z | [
"task_categories:text-classification",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:si",
"license:mit",
"region:us"
] | NLPC-UOM | null | null | 0 | 4 | 2022-04-07T12:21:01 | ---
annotations_creators: []
language_creators:
- crowdsourced
language:
- si
license:
- mit
multilinguality:
- monolingual
pretty_name: sinhala-news-category-classification
size_categories:
- 1K<n<10K
source_datasets: []
task_categories:
- text-classification
task_ids: []
---
This file contains news texts (sentences) belonging to 5 different news categories (political, business, technology, sports and Entertainment). The original dataset was released by Nisansa de Silva (*Sinhala Text Classification: Observations from the Perspective of a Resource Poor Language, 2015*). The original dataset is processed and cleaned of single word texts, English only sentences etc.
If you use this dataset, please cite {*Nisansa de Silva, Sinhala Text Classification: Observations from the Perspective of a Resource Poor Language, 2015*} and {*Dhananjaya et al. BERTifying Sinhala - A Comprehensive Analysis of Pre-trained Language Models for Sinhala Text Classification, 2022*} | 974 | [
[
0.0034999847412109375,
-0.0460205078125,
-0.0022678375244140625,
0.03363037109375,
-0.051513671875,
0.0076751708984375,
-0.0142822265625,
-0.021759033203125,
0.02215576171875,
0.06640625,
-0.037384033203125,
-0.0225372314453125,
-0.0311126708984375,
0.027954... |
NLPC-UOM/Sinhala-News-Source-classification | 2022-10-25T10:04:01.000Z | [
"task_categories:text-classification",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"language:si",
"license:mit",
"region:us"
] | NLPC-UOM | null | null | 0 | 4 | 2022-04-07T12:43:58 | ---
annotations_creators: []
language_creators:
- crowdsourced
language:
- si
license:
- mit
multilinguality:
- monolingual
pretty_name: sinhala-news-source-classification
size_categories: []
source_datasets: []
task_categories:
- text-classification
task_ids: []
---
This dataset contains Sinhala news headlines extracted from 9 news sources (websites) (Sri Lanka Army, Dinamina, GossipLanka, Hiru, ITN, Lankapuwath, NewsLK,
Newsfirst, World Socialist Web Site-Sinhala). This is a processed version of the corpus created by *Sachintha, D., Piyarathna, L., Rajitha, C., and Ranathunga, S. (2021). Exploiting parallel corpora to improve multilingual embedding based document and sentence alignment*. Single word sentences, invalid characters have been removed from the originally extracted corpus and also subsampled to handle class imbalance.
If you use this dataset please cite {*Dhananjaya et al. BERTifying Sinhala - A Comprehensive Analysis of Pre-trained Language Models for Sinhala Text Classification, 2022*} | 1,018 | [
[
0.00555419921875,
-0.04986572265625,
0.0084381103515625,
0.05157470703125,
-0.03070068359375,
0.0193634033203125,
-0.0260467529296875,
-0.01279449462890625,
0.023193359375,
0.04852294921875,
-0.02618408203125,
-0.02783203125,
-0.034149169921875,
0.0272216796... |
DrishtiSharma/Anime-Face-Dataset | 2022-04-11T00:04:37.000Z | [
"region:us"
] | DrishtiSharma | null | null | 3 | 4 | 2022-04-10T23:51:23 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
mwong/fever-claim-related | 2022-10-25T10:06:56.000Z | [
"task_categories:text-classification",
"task_ids:fact-checking",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended|climate_fever",
"language:en",
"license:cc-by-sa-3.0",
"license:gpl-3.0",
... | mwong | null | null | 2 | 4 | 2022-04-15T07:04:59 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-sa-3.0
- gpl-3.0
multilinguality:
- monolingual
paperswithcode_id: fever
pretty_name: fever
size_categories:
- 100K<n<1M
source_datasets:
- extended|climate_fever
task_categories:
- text-classification
task_ids:
- fact-checking
---
### Dataset Summary
This dataset is extracted from Climate Fever dataset (https://www.sustainablefinance.uzh.ch/en/research/climate-fever.html), pre-processed and ready to train and evaluate.
The training objective is a text classification task - given a claim and evidence, predict if claim is related to evidence. | 655 | [
[
-0.010772705078125,
-0.0267181396484375,
0.012786865234375,
-0.0005702972412109375,
-0.01482391357421875,
-0.00626373291015625,
-0.0086822509765625,
-0.0298004150390625,
0.00888824462890625,
0.059295654296875,
-0.038177490234375,
-0.04010009765625,
-0.0570983886... |
surrey-nlp/PLOD-filtered | 2023-01-14T23:30:12.000Z | [
"task_categories:token-classification",
"annotations_creators:Leonardo Zilio, Hadeel Saadany, Prashant Sharma, Diptesh Kanojia, Constantin Orasan",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-sa-4.0",
... | surrey-nlp | This is the dataset repository for PLOD Dataset accepted to be published at LREC 2022.
The dataset can help build sequence labelling models for the task Abbreviation Detection. | 0 | 4 | 2022-04-16T14:50:15 | ---
annotations_creators:
- Leonardo Zilio, Hadeel Saadany, Prashant Sharma, Diptesh Kanojia, Constantin Orasan
language_creators:
- found
language:
- en
license: cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- token-classification
task_ids: []
paperswithcode_id: plod-filtered
pretty_name: 'PLOD: An Abbreviation Detection Dataset'
tags:
- abbreviation-detection
---
# PLOD: An Abbreviation Detection Dataset
This is the repository for PLOD Dataset published at LREC 2022. The dataset can help build sequence labelling models for the task Abbreviation Detection.
### Dataset
We provide two variants of our dataset - Filtered and Unfiltered. They are described in our paper here.
1. The Filtered version can be accessed via [Huggingface Datasets here](https://huggingface.co/datasets/surrey-nlp/PLOD-filtered) and a [CONLL format is present here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection).<br/>
2. The Unfiltered version can be accessed via [Huggingface Datasets here](https://huggingface.co/datasets/surrey-nlp/PLOD-unfiltered) and a [CONLL format is present here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection).<br/>
3. The [SDU Shared Task](https://sites.google.com/view/sdu-aaai22/home) data we use for zero-shot testing is [available here](https://huggingface.co/datasets/surrey-nlp/SDU-test).
# Dataset Card for PLOD-filtered
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** https://github.com/surrey-nlp/PLOD-AbbreviationDetection
- **Paper:** https://arxiv.org/abs/2204.12061
- **Leaderboard:** https://paperswithcode.com/sota/abbreviationdetection-on-plod-filtered
- **Point of Contact:** [Diptesh Kanojia](mailto:d.kanojia@surrey.ac.uk)
### Dataset Summary
This PLOD Dataset is an English-language dataset of abbreviations and their long-forms tagged in text. The dataset has been collected for research from the PLOS journals indexing of abbreviations and long-forms in the text. This dataset was created to support the Natural Language Processing task of abbreviation detection and covers the scientific domain.
### Supported Tasks and Leaderboards
This dataset primarily supports the Abbreviation Detection Task. It has also been tested on a train+dev split provided by the Acronym Detection Shared Task organized as a part of the Scientific Document Understanding (SDU) workshop at AAAI 2022.
### Languages
English
## Dataset Structure
### Data Instances
A typical data point comprises an ID, a set of `tokens` present in the text, a set of `pos_tags` for the corresponding tokens obtained via Spacy NER, and a set of `ner_tags` which are limited to `AC` for `Acronym` and `LF` for `long-forms`.
An example from the dataset:
{'id': '1',
'tokens': ['Study', '-', 'specific', 'risk', 'ratios', '(', 'RRs', ')', 'and', 'mean', 'BW', 'differences', 'were', 'calculated', 'using', 'linear', 'and', 'log', '-', 'binomial', 'regression', 'models', 'controlling', 'for', 'confounding', 'using', 'inverse', 'probability', 'of', 'treatment', 'weights', '(', 'IPTW', ')', 'truncated', 'at', 'the', '1st', 'and', '99th', 'percentiles', '.'],
'pos_tags': [8, 13, 0, 8, 8, 13, 12, 13, 5, 0, 12, 8, 3, 16, 16, 0, 5, 0, 13, 0, 8, 8, 16, 1, 8, 16, 0, 8, 1, 8, 8, 13, 12, 13, 16, 1, 6, 0, 5, 0, 8, 13],
'ner_tags': [0, 0, 0, 3, 4, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 4, 4, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
### Data Fields
- id: the row identifier for the dataset point.
- tokens: The tokens contained in the text.
- pos_tags: the Part-of-Speech tags obtained for the corresponding token above from Spacy NER.
- ner_tags: The tags for abbreviations and long-forms.
### Data Splits
| | Train | Valid | Test |
| ----- | ------ | ----- | ---- |
| Filtered | 112652 | 24140 | 24140|
| Unfiltered | 113860 | 24399 | 24399|
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
Extracting the data from PLOS Journals online and then tokenization, normalization.
#### Who are the source language producers?
PLOS Journal
## Additional Information
### Dataset Curators
The dataset was initially created by Leonardo Zilio, Hadeel Saadany, Prashant Sharma,
Diptesh Kanojia, Constantin Orasan.
### Licensing Information
CC-BY-SA 4.0
### Citation Information
[Needs More Information]
### Installation
We use the custom NER pipeline in the [spaCy transformers](https://spacy.io/universe/project/spacy-transformers) library to train our models. This library supports training via any pre-trained language models available at the :rocket: [HuggingFace repository](https://huggingface.co/).<br/>
Please see the instructions at these websites to setup your own custom training with our dataset to reproduce the experiments using Spacy.
OR<br/>
However, you can also reproduce the experiments via the Python notebook we [provide here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection/blob/main/nbs/fine_tuning_abbr_det.ipynb) which uses HuggingFace Trainer class to perform the same experiments. The exact hyperparameters can be obtained from the models readme cards linked below. Before starting, please perform the following steps:
```bash
git clone https://github.com/surrey-nlp/PLOD-AbbreviationDetection
cd PLOD-AbbreviationDetection
pip install -r requirements.txt
```
Now, you can use the notebook to reproduce the experiments.
### Model(s)
Our best performing models are hosted on the HuggingFace models repository
| Models | [`PLOD - Unfiltered`](https://huggingface.co/datasets/surrey-nlp/PLOD-unfiltered) | [`PLOD - Filtered`](https://huggingface.co/datasets/surrey-nlp/PLOD-filtered) | Description |
| --- | :---: | :---: | --- |
| [RoBERTa<sub>large</sub>](https://huggingface.co/roberta-large) | [RoBERTa<sub>large</sub>-finetuned-abbr](https://huggingface.co/surrey-nlp/roberta-large-finetuned-abbr) | -soon- | Fine-tuning on the RoBERTa<sub>large</sub> language model |
| [RoBERTa<sub>base</sub>](https://huggingface.co/roberta-base) | -soon- | [RoBERTa<sub>base</sub>-finetuned-abbr](https://huggingface.co/surrey-nlp/roberta-large-finetuned-abbr) | Fine-tuning on the RoBERTa<sub>base</sub> language model |
| [AlBERT<sub>large-v2</sub>](https://huggingface.co/albert-large-v2) | [AlBERT<sub>large-v2</sub>-finetuned-abbDet](https://huggingface.co/surrey-nlp/albert-large-v2-finetuned-abbDet) | -soon- | Fine-tuning on the AlBERT<sub>large-v2</sub> language model |
On the link provided above, the model(s) can be used with the help of the Inference API via the web-browser itself. We have placed some examples with the API for testing.<br/>
### Usage
You can use the HuggingFace Model link above to find the instructions for using this model in Python locally using the notebook provided in the Git repo.
| 7,894 | [
[
-0.037078857421875,
-0.058685302734375,
0.007537841796875,
0.0159759521484375,
-0.02069091796875,
-0.00543975830078125,
-0.017608642578125,
-0.0291290283203125,
0.039459228515625,
0.035736083984375,
-0.03515625,
-0.05755615234375,
-0.04656982421875,
0.041717... | |
surrey-nlp/PLOD-unfiltered | 2023-01-14T23:31:04.000Z | [
"task_categories:token-classification",
"annotations_creators:Leonardo Zilio, Hadeel Saadany, Prashant Sharma, Diptesh Kanojia, Constantin Orasan",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-sa-4.0",
... | surrey-nlp | This is the dataset repository for PLOD Dataset accepted to be published at LREC 2022.
The dataset can help build sequence labelling models for the task Abbreviation Detection. | 0 | 4 | 2022-04-16T18:49:49 | ---
annotations_creators:
- Leonardo Zilio, Hadeel Saadany, Prashant Sharma, Diptesh Kanojia, Constantin Orasan
language_creators:
- found
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- token-classification
task_ids: []
paperswithcode_id: plod-an-abbreviation-detection-dataset-for
pretty_name: 'PLOD: An Abbreviation Detection Dataset'
tags:
- abbreviation-detection
---
# PLOD: An Abbreviation Detection Dataset
This is the repository for PLOD Dataset published at LREC 2022. The dataset can help build sequence labelling models for the task Abbreviation Detection.
### Dataset
We provide two variants of our dataset - Filtered and Unfiltered. They are described in our paper here.
1. The Filtered version can be accessed via [Huggingface Datasets here](https://huggingface.co/datasets/surrey-nlp/PLOD-filtered) and a [CONLL format is present here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection).<br/>
2. The Unfiltered version can be accessed via [Huggingface Datasets here](https://huggingface.co/datasets/surrey-nlp/PLOD-unfiltered) and a [CONLL format is present here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection).<br/>
3. The [SDU Shared Task](https://sites.google.com/view/sdu-aaai22/home) data we use for zero-shot testing is [available here](https://huggingface.co/datasets/surrey-nlp/SDU-test).
# Dataset Card for PLOD-unfiltered
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** https://github.com/surrey-nlp/PLOD-AbbreviationDetection
- **Paper:** https://arxiv.org/abs/2204.12061
- **Leaderboard:** https://paperswithcode.com/sota/abbreviationdetection-on-plod-an-abbreviation
- **Point of Contact:** [Diptesh Kanojia](mailto:d.kanojia@surrey.ac.uk)
### Dataset Summary
This PLOD Dataset is an English-language dataset of abbreviations and their long-forms tagged in text. The dataset has been collected for research from the PLOS journals indexing of abbreviations and long-forms in the text. This dataset was created to support the Natural Language Processing task of abbreviation detection and covers the scientific domain.
### Supported Tasks and Leaderboards
This dataset primarily supports the Abbreviation Detection Task. It has also been tested on a train+dev split provided by the Acronym Detection Shared Task organized as a part of the Scientific Document Understanding (SDU) workshop at AAAI 2022.
### Languages
English
## Dataset Structure
### Data Instances
A typical data point comprises an ID, a set of `tokens` present in the text, a set of `pos_tags` for the corresponding tokens obtained via Spacy NER, and a set of `ner_tags` which are limited to `AC` for `Acronym` and `LF` for `long-forms`.
An example from the dataset:
{'id': '1',
'tokens': ['Study', '-', 'specific', 'risk', 'ratios', '(', 'RRs', ')', 'and', 'mean', 'BW', 'differences', 'were', 'calculated', 'using', 'linear', 'and', 'log', '-', 'binomial', 'regression', 'models', 'controlling', 'for', 'confounding', 'using', 'inverse', 'probability', 'of', 'treatment', 'weights', '(', 'IPTW', ')', 'truncated', 'at', 'the', '1st', 'and', '99th', 'percentiles', '.'],
'pos_tags': [8, 13, 0, 8, 8, 13, 12, 13, 5, 0, 12, 8, 3, 16, 16, 0, 5, 0, 13, 0, 8, 8, 16, 1, 8, 16, 0, 8, 1, 8, 8, 13, 12, 13, 16, 1, 6, 0, 5, 0, 8, 13],
'ner_tags': [0, 0, 0, 3, 4, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 4, 4, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
### Data Fields
- id: the row identifier for the dataset point.
- tokens: The tokens contained in the text.
- pos_tags: the Part-of-Speech tags obtained for the corresponding token above from Spacy NER.
- ner_tags: The tags for abbreviations and long-forms.
### Data Splits
| | Train | Valid | Test |
| ----- | ------ | ----- | ---- |
| Filtered | 112652 | 24140 | 24140|
| Unfiltered | 113860 | 24399 | 24399|
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
Extracting the data from PLOS Journals online and then tokenization, normalization.
#### Who are the source language producers?
PLOS Journal
## Additional Information
### Dataset Curators
The dataset was initially created by Leonardo Zilio, Hadeel Saadany, Prashant Sharma,
Diptesh Kanojia, Constantin Orasan.
### Licensing Information
CC-BY-SA 4.0
### Citation Information
[Needs More Information]
### Installation
We use the custom NER pipeline in the [spaCy transformers](https://spacy.io/universe/project/spacy-transformers) library to train our models. This library supports training via any pre-trained language models available at the :rocket: [HuggingFace repository](https://huggingface.co/).<br/>
Please see the instructions at these websites to setup your own custom training with our dataset to reproduce the experiments using Spacy.
OR<br/>
However, you can also reproduce the experiments via the Python notebook we [provide here](https://github.com/surrey-nlp/PLOD-AbbreviationDetection/blob/main/nbs/fine_tuning_abbr_det.ipynb) which uses HuggingFace Trainer class to perform the same experiments. The exact hyperparameters can be obtained from the models readme cards linked below. Before starting, please perform the following steps:
```bash
git clone https://github.com/surrey-nlp/PLOD-AbbreviationDetection
cd PLOD-AbbreviationDetection
pip install -r requirements.txt
```
Now, you can use the notebook to reproduce the experiments.
### Model(s)
Our best performing models are hosted on the HuggingFace models repository:
| Models | [`PLOD - Unfiltered`](https://huggingface.co/datasets/surrey-nlp/PLOD-unfiltered) | [`PLOD - Filtered`](https://huggingface.co/datasets/surrey-nlp/PLOD-filtered) | Description |
| --- | :---: | :---: | --- |
| [RoBERTa<sub>large</sub>](https://huggingface.co/roberta-large) | [RoBERTa<sub>large</sub>-finetuned-abbr](https://huggingface.co/surrey-nlp/roberta-large-finetuned-abbr) | -soon- | Fine-tuning on the RoBERTa<sub>large</sub> language model |
| [RoBERTa<sub>base</sub>](https://huggingface.co/roberta-base) | -soon- | [RoBERTa<sub>base</sub>-finetuned-abbr](https://huggingface.co/surrey-nlp/roberta-large-finetuned-abbr) | Fine-tuning on the RoBERTa<sub>base</sub> language model |
| [AlBERT<sub>large-v2</sub>](https://huggingface.co/albert-large-v2) | [AlBERT<sub>large-v2</sub>-finetuned-abbDet](https://huggingface.co/surrey-nlp/albert-large-v2-finetuned-abbDet) | -soon- | Fine-tuning on the AlBERT<sub>large-v2</sub> language model |
On the link provided above, the model(s) can be used with the help of the Inference API via the web-browser itself. We have placed some examples with the API for testing.<br/>
### Usage
You can use the HuggingFace Model link above to find the instructions for using this model in Python locally using the notebook provided in the Git repo.
| 7,936 | [
[
-0.036895751953125,
-0.058929443359375,
0.00739288330078125,
0.016143798828125,
-0.02093505859375,
-0.00543975830078125,
-0.0176849365234375,
-0.029266357421875,
0.03955078125,
0.035552978515625,
-0.03497314453125,
-0.057281494140625,
-0.04632568359375,
0.04... | |
huggan/selfie2anime | 2022-04-19T20:27:47.000Z | [
"region:us"
] | huggan | null | null | 0 | 4 | 2022-04-19T07:24:11 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
mwong/climatetext-evidence-claim-pair-related-evaluation | 2022-10-25T10:08:53.000Z | [
"task_categories:text-classification",
"task_ids:fact-checking",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended|climate_text",
"language:en",
"license:cc-by-sa-3.0",
"license:gpl-3.0",
"... | mwong | null | null | 1 | 4 | 2022-04-21T10:16:15 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-sa-3.0
- gpl-3.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- extended|climate_text
task_categories:
- text-classification
task_ids:
- fact-checking
---
### Dataset Summary
This dataset is extracted from Climate Text dataset (https://www.sustainablefinance.uzh.ch/en/research/climate-fever/climatext.html), pre-processed and, ready to evaluate.
The evaluation objective is a text classification task - given a climate related evidence and claim, predict if pair is related. | 615 | [
[
-0.01055145263671875,
-0.035858154296875,
0.025787353515625,
0.0103302001953125,
-0.01922607421875,
-0.00911712646484375,
-0.01200103759765625,
-0.02703857421875,
0.00395965576171875,
0.06585693359375,
-0.042083740234375,
-0.044952392578125,
-0.051849365234375,
... |
mweiss/fashion_mnist_corrupted | 2023-03-19T11:45:31.000Z | [
"task_categories:image-classification",
"annotations_creators:expert-generated",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|fashion_mnist",
"language:en",
"license:mit",
"ar... | mweiss | Fashion-MNIST is dataset of fashion images, indended as a drop-in replacement for the MNIST dataset.
This dataset (Fashion-Mnist-Corrupted) provides out-of-distribution data for the Fashion-Mnist
dataset. Fashion-Mnist-Corrupted is based on a similar project for MNIST, called MNIST-C, by Mu et. al. | @inproceedings{Weiss2022SimpleTechniques,
title={Simple Techniques Work Surprisingly Well for Neural Network Test Prioritization and Active Learning},
author={Weiss, Michael and Tonella, Paolo},
booktitle={Proceedings of the 31th ACM SIGSOFT International Symposium on Software Testing and Analysis},
year={2022}
} | 2 | 4 | 2022-04-21T11:34:02 | ---
annotations_creators:
- expert-generated
- machine-generated
language_creators:
- machine-generated
language:
- en
license:
- mit
multilinguality:
- monolingual
pretty_name: fashion-mnist-corrupted
size_categories:
- 10K<n<100K
source_datasets:
- extended|fashion_mnist
task_categories:
- image-classification
task_ids: []
---
# Fashion-Mnist-C (Corrupted Fashion-Mnist)
A corrupted Fashion-MNIST benchmark for testing out-of-distribution robustness of computer vision models, which were trained on Fashion-Mmnist.
[Fashion-Mnist](https://github.com/zalandoresearch/fashion-mnist) is a drop-in replacement for MNIST and Fashion-Mnist-C is a corresponding drop-in replacement for [MNIST-C](https://arxiv.org/abs/1906.02337).
## Corruptions
The following corruptions are applied to the images, equivalently to MNIST-C:
- **Noise** (shot noise and impulse noise)
- **Blur** (glass and motion blur)
- **Transformations** (shear, scale, rotate, brightness, contrast, saturate, inverse)
In addition, we apply various **image flippings and turnings**: For fashion images, flipping the image does not change its label,
and still keeps it a valid image. However, we noticed that in the nominal fmnist dataset, most images are identically oriented
(e.g. most shoes point to the left side). Thus, flipped images provide valid OOD inputs.
Most corruptions are applied at a randomly selected level of *severity*, s.t. some corrupted images are really hard to classify whereas for others the corruption, while present, is subtle.
## Examples
| Turned | Blurred | Rotated | Noise | Noise | Turned |
| ------------- | ------------- | --------| --------- | -------- | --------- |
| <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_0.png" width="100" height="100"> | <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_1.png" width="100" height="100"> | <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_6.png" width="100" height="100"> | <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_3.png" width="100" height="100"> | <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_4.png" width="100" height="100"> | <img src="https://github.com/testingautomated-usi/fashion-mnist-c/raw/main/generated/png-examples/single_5.png" width="100" height="100"> |
## Citation
If you use this dataset, please cite the following paper:
```
@inproceedings{Weiss2022SimpleTechniques,
title={Simple Techniques Work Surprisingly Well for Neural Network Test Prioritization and Active Learning},
author={Weiss, Michael and Tonella, Paolo},
booktitle={Proceedings of the 31th ACM SIGSOFT International Symposium on Software Testing and Analysis},
year={2022}
}
```
Also, you may want to cite FMNIST and MNIST-C.
## Credits
- Fashion-Mnist-C is inspired by Googles MNIST-C and our repository is essentially a clone of theirs. See their [paper](https://arxiv.org/abs/1906.02337) and [repo](https://github.com/google-research/mnist-c).
- Find the nominal (i.e., non-corrupted) Fashion-MNIST dataset [here](https://github.com/zalandoresearch/fashion-mnist).
| 3,322 | [
[
-0.037017822265625,
-0.042724609375,
0.0078125,
0.0093536376953125,
-0.0262451171875,
-0.002620697021484375,
0.0035076141357421875,
-0.0341796875,
0.0248565673828125,
0.00592803955078125,
-0.050750732421875,
-0.03167724609375,
-0.00919342041015625,
0.0020122... |
pietrolesci/scitail | 2022-04-25T10:40:47.000Z | [
"region:us"
] | pietrolesci | null | null | 0 | 4 | 2022-04-22T09:06:21 | ## Overview
Original dataset is available on the HuggingFace Hub [here](https://huggingface.co/datasets/scitail).
## Dataset curation
This is the same as the `snli_format` split of the SciTail dataset available on the HuggingFace Hub (i.e., same data, same splits, etc).
The only differences are the following:
- selecting only the columns `["sentence1", "sentence2", "gold_label", "label"]`
- renaming columns with the following mapping `{"sentence1": "premise", "sentence2": "hypothesis"}`
- creating a new column "label" from "gold_label" with the following mapping `{"entailment": "entailment", "neutral": "not_entailment"}`
- encoding labels with the following mapping `{"not_entailment": 0, "entailment": 1}`
Note that there are 10 overlapping instances (as found by merging on columns "label", "premise", and "hypothesis") between
`train` and `test` splits.
## Code to create the dataset
```python
from datasets import Features, Value, ClassLabel, Dataset, DatasetDict, load_dataset
# load datasets from the Hub
dd = load_dataset("scitail", "snli_format")
ds = {}
for name, df_ in dd.items():
df = df_.to_pandas()
# select important columns
df = df[["sentence1", "sentence2", "gold_label"]]
# rename columns
df = df.rename(columns={"sentence1": "premise", "sentence2": "hypothesis"})
# encode labels
df["label"] = df["gold_label"].map({"entailment": "entailment", "neutral": "not_entailment"})
df["label"] = df["label"].map({"not_entailment": 0, "entailment": 1})
# cast to dataset
features = Features({
"premise": Value(dtype="string", id=None),
"hypothesis": Value(dtype="string", id=None),
"label": ClassLabel(num_classes=2, names=["not_entailment", "entailment"]),
})
ds[name] = Dataset.from_pandas(df, features=features)
dataset = DatasetDict(ds)
dataset.push_to_hub("scitail", token="<token>")
# check overlap between splits
from itertools import combinations
for i, j in combinations(dataset.keys(), 2):
print(
f"{i} - {j}: ",
pd.merge(
dataset[i].to_pandas(),
dataset[j].to_pandas(),
on=["label", "premise", "hypothesis"],
how="inner",
).shape[0],
)
#> train - test: 10
#> train - validation: 0
#> test - validation: 0
``` | 2,309 | [
[
-0.0211334228515625,
-0.047943115234375,
0.01372528076171875,
0.035614013671875,
-0.008544921875,
-0.003326416015625,
-0.01629638671875,
-0.011199951171875,
0.0499267578125,
0.036346435546875,
-0.037261962890625,
-0.040740966796875,
-0.042388916015625,
0.028... |
bigscience-data/roots_ar_uncorpus | 2022-12-12T10:59:32.000Z | [
"language:ar",
"license:cc-by-4.0",
"region:us"
] | bigscience-data | null | null | 0 | 4 | 2022-04-22T10:23:52 | ---
language: ar
license: cc-by-4.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_ar_uncorpus
# uncorpus
- Dataset uid: `uncorpus`
### Description
### Homepage
### Licensing
### Speaker Locations
### Sizes
- 2.8023 % of total
- 10.7390 % of ar
- 5.7970 % of fr
- 9.7477 % of es
- 2.0417 % of en
- 1.2540 % of zh
### BigScience processing steps
#### Filters applied to: ar
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: fr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: es
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: en
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: zh
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
| 1,146 | [
[
-0.0399169921875,
-0.0234832763671875,
0.0282745361328125,
0.0215301513671875,
-0.033782958984375,
-0.0031948089599609375,
-0.01094818115234375,
0.01678466796875,
0.048065185546875,
0.04681396484375,
-0.0589599609375,
-0.07012939453125,
-0.04132080078125,
0.... |
bigscience-data/roots_fr_uncorpus | 2022-12-12T10:29:02.000Z | [
"language:fr",
"license:cc-by-4.0",
"region:us"
] | bigscience-data | null | null | 1 | 4 | 2022-04-22T10:30:47 | ---
language: fr
license: cc-by-4.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_fr_uncorpus
# uncorpus
- Dataset uid: `uncorpus`
### Description
### Homepage
### Licensing
### Speaker Locations
### Sizes
- 2.8023 % of total
- 10.7390 % of ar
- 5.7970 % of fr
- 9.7477 % of es
- 2.0417 % of en
- 1.2540 % of zh
### BigScience processing steps
#### Filters applied to: ar
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: fr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: es
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: en
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: zh
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
| 1,146 | [
[
-0.04022216796875,
-0.02313232421875,
0.029052734375,
0.0222015380859375,
-0.033172607421875,
-0.0037403106689453125,
-0.01140594482421875,
0.0160369873046875,
0.048370361328125,
0.0469970703125,
-0.058746337890625,
-0.0697021484375,
-0.040924072265625,
0.01... |
BK-V/arman | 2022-05-08T16:57:22.000Z | [
"region:us"
] | BK-V | ArmanPersoNERCorpus includes 250,015 tokens and 7,682 Persian sentences in total.The NER tags are in IOB format. | @inproceedings{poostchi-etal-2016-personer,
title = "{P}erso{NER}: {P}ersian Named-Entity Recognition",
author = "Poostchi, Hanieh and
Zare Borzeshi, Ehsan and
Abdous, Mohammad and
Piccardi, Massimo",
booktitle = "Proceedings of {COLING} 2016, the 26th International Conference on Computational Linguistics: Technical Papers",
month = dec,
year = "2016",
address = "Osaka, Japan",
publisher = "The COLING 2016 Organizing Committee",
url = "https://aclanthology.org/C16-1319",
pages = "3381--3389",
abstract = "Named-Entity Recognition (NER) is still a challenging task for languages with low digital resources. The main difficulties arise from the scarcity of annotated corpora and the consequent problematic training of an effective NER pipeline. To abridge this gap, in this paper we target the Persian language that is spoken by a population of over a hundred million people world-wide. We first present and provide ArmanPerosNERCorpus, the first manually-annotated Persian NER corpus. Then, we introduce PersoNER, an NER pipeline for Persian that leverages a word embedding and a sequential max-margin classifier. The experimental results show that the proposed approach is capable of achieving interesting MUC7 and CoNNL scores while outperforming two alternatives based on a CRF and a recurrent neural network.",
} | 0 | 4 | 2022-05-05T12:56:33 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
pie/wikiann | 2022-05-06T16:14:36.000Z | [
"region:us"
] | pie | null | null | 0 | 4 | 2022-05-06T16:14:35 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Leyo/TGIF | 2022-10-25T10:24:15.000Z | [
"task_categories:question-answering",
"task_categories:visual-question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license... | Leyo | The Tumblr GIF (TGIF) dataset contains 100K animated GIFs and 120K sentences describing visual content of the animated GIFs.
The animated GIFs have been collected from Tumblr, from randomly selected posts published between May and June of 2015.
We provide the URLs of animated GIFs in this release. The sentences are collected via crowdsourcing, with a carefully designed
annotationinterface that ensures high quality dataset. We provide one sentence per animated GIF for the training and validation splits,
and three sentences per GIF for the test split. The dataset shall be used to evaluate animated GIF/video description techniques. | @InProceedings{tgif-cvpr2016,
author = {Li, Yuncheng and Song, Yale and Cao, Liangliang and Tetreault, Joel and Goldberg, Larry and Jaimes, Alejandro and Luo, Jiebo},
title = "{TGIF: A New Dataset and Benchmark on Animated GIF Description}",
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2016}
} | 1 | 4 | 2022-05-10T15:00:46 | ---
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
language:
- en
license:
- other
multilinguality:
- monolingual
pretty_name: TGIF
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
- visual-question-answering
task_ids:
- closed-domain-qa
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** http://raingo.github.io/TGIF-Release/
- **Repository:** https://github.com/raingo/TGIF-Release
- **Paper:** https://arxiv.org/abs/1604.02748
- **Point of Contact:** mailto: yli@cs.rochester.edu
### Dataset Summary
The Tumblr GIF (TGIF) dataset contains 100K animated GIFs and 120K sentences describing visual content of the animated GIFs. The animated GIFs have been collected from Tumblr, from randomly selected posts published between May and June of 2015. We provide the URLs of animated GIFs in this release. The sentences are collected via crowdsourcing, with a carefully designed annotation interface that ensures high quality dataset. We provide one sentence per animated GIF for the training and validation splits, and three sentences per GIF for the test split. The dataset shall be used to evaluate animated GIF/video description techniques.
### Languages
The captions in the dataset are in English.
## Dataset Structure
### Data Fields
- `video_path`: `str` "https://31.media.tumblr.com/001a8b092b9752d260ffec73c0bc29cd/tumblr_ndotjhRiX51t8n92fo1_500.gif"
-`video_bytes`: `large_bytes` video file in bytes format
- `en_global_captions`: `list_str` List of english captions describing the entire video
### Data Splits
| |train |validation| test | Overall |
|-------------|------:|---------:|------:|------:|
|# of GIFs|80,000 |10,708 |11,360 |102,068 |
### Annotations
Quoting [TGIF paper](https://arxiv.org/abs/1604.02748): \
"We annotated animated GIFs with natural language descriptions using the crowdsourcing service CrowdFlower.
We carefully designed our annotation task with various
quality control mechanisms to ensure the sentences are both
syntactically and semantically of high quality.
A total of 931 workers participated in our annotation
task. We allowed workers only from Australia, Canada, New Zealand, UK and USA in an effort to collect fluent descriptions from native English speakers. Figure 2 shows the
instructions given to the workers. Each task showed 5 animated GIFs and asked the worker to describe each with one
sentence. To promote language style diversity, each worker
could rate no more than 800 images (0.7% of our corpus).
We paid 0.02 USD per sentence; the entire crowdsourcing
cost less than 4K USD. We provide details of our annotation
task in the supplementary material."
### Personal and Sensitive Information
Nothing specifically mentioned in the paper.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Licensing Information
This dataset is provided to be used for approved non-commercial research purposes. No personally identifying information is available in this dataset.
### Citation Information
```bibtex
@InProceedings{tgif-cvpr2016,
author = {Li, Yuncheng and Song, Yale and Cao, Liangliang and Tetreault, Joel and Goldberg, Larry and Jaimes, Alejandro and Luo, Jiebo},
title = "{TGIF: A New Dataset and Benchmark on Animated GIF Description}",
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2016}
}
```
### Contributions
Thanks to [@leot13](https://github.com/leot13) for adding this dataset. | 4,538 | [
[
-0.03509521484375,
-0.05206298828125,
-0.01275634765625,
0.0226898193359375,
-0.0400390625,
0.0031299591064453125,
-0.032440185546875,
-0.043548583984375,
0.0234527587890625,
0.01690673828125,
-0.04046630859375,
-0.046661376953125,
-0.06671142578125,
0.02145... |
ncats/EpiSet4NER-v2 | 2022-09-20T15:25:56.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:machine-generated",
"annotations_creators:expert-generated",
"language_creators:found",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_dataset... | ncats | **REWRITE*
EpiSet4NER-2 is a dataset generated from 620 rare disease abstracts labeled using statistical and rule-base methods.
For more details see *INSERT PAPER* and https://github.com/ncats/epi4GARD/tree/master/EpiExtract4GARD#epiextract4gard | *REDO*
@inproceedings{wang2019crossweigh,
title={CrossWeigh: Training Named Entity Tagger from Imperfect Annotations},
author={Wang, Zihan and Shang, Jingbo and Liu, Liyuan and Lu, Lihao and Liu, Jiacheng and Han, Jiawei},
booktitle={Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)},
pages={5157--5166},
year={2019}
} | 0 | 4 | 2022-05-12T08:47:04 | ---
annotations_creators:
- machine-generated
- expert-generated
language:
- en
language_creators:
- found
- expert-generated
license:
- other
multilinguality:
- monolingual
pretty_name: EpiSet4NER-v2
size_categories:
- 100K<n<1M
source_datasets:
- original
tags:
- epidemiology
- rare disease
- named entity recognition
- NER
- NIH
task_categories:
- token-classification
task_ids:
- named-entity-recognition
---
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [Github](https://github.com/ncats/epi4GARD/tree/master/EpiExtract4GARD#epiextract4gard)
- **Paper:** Pending
### Dataset Summary
EpiSet4NER-v2 is a gold-standard dataset for epidemiological entity recognition of location, epidemiologic types (e.g. "prevalence", "annual incidence", "estimated occurrence"), and epidemiological rates (e.g. "1.7 per 1,000,000 live births", "2.1:1.000.000", "one in five million", "0.03%") created by the [Genetic and Rare Diseases Information Center (GARD)](https://rarediseases.info.nih.gov/), a program in [the National Center for Advancing Translational Sciences](https://ncats.nih.gov/), one of the 27 [National Institutes of Health](https://www.nih.gov/). It was labeled programmatically using spaCy NER and rule-based methods, then manually validated by biomedical researchers, including a GARD curator (genetic and rare disease expert). This weakly-supervised teaching method allowed us to construct this high quality dataset in an efficient manner and achieve satisfactory performance on a multi-type token classification problem. It was used to train [EpiExtract4GARD-v2](https://huggingface.co/ncats/EpiExtract4GARD-v2), a BioBERT-based model fine-tuned for NER.
### Data Fields
The data fields are the same among all splits.
- `id`: a `string` feature that indicates sentence number.
- `tokens`: a `list` of `string` features.
- `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `B-LOC` (1), `I-LOC` (2), `B-EPI` (3), `I-EPI` (4),`B-STAT` (5),`I-STAT` (6).
### Data Splits
|name |train |validation|test|
|---------|-----:|----:|----:|
|EpiSet \# of abstracts|456|114|50|
|EpiSet \# tokens |117888|31262|13910|
## Dataset Creation

*Figure 1:* Creation of EpiSet4NER by NIH/NCATS
Comparing the programmatically labeled test set to the manually corrected test set allowed us to measure the precision, recall, and F1 of the programmatic labeling.
*Table 1:* Programmatic labeling of EpiSet4NER
| Evaluation Level | Entity | Precision | Recall | F1 |
|:----------------:|:------------------------:|:---------:|:------:|:-----:|
| Entity-Level | Overall | 0.559 | 0.662 | 0.606 |
| | Location | 0.597 | 0.661 | 0.627 |
| | Epidemiologic Type | 0.854 | 0.911 | 0.882 |
| | Epidemiologic Rate | 0.175 | 0.255 | 0.207 |
| Token-Level | Overall | 0.805 | 0.710 | 0.755 |
| | Location | 0.868 | 0.713 | 0.783 |
| | Epidemiologic Type | 0.908 | 0.908 | 0.908 |
| | Epidemiologic Rate | 0.739 | 0.645 | 0.689 |
An example of the text labeling:

*Figure 2:* Text Labeling using spaCy and rule-based labeling. Ideal labeling is bolded on the left. Actual programmatic output is on the right. [\[Figure citation\]](https://pubmed.ncbi.nlm.nih.gov/33649778/)
### Curation Rationale
To train ML/DL models that automate the process of rare disease epidemiological curation. This is crucial information to patients & families, researchers, grantors, and policy makers, primarily for funding purposes.
### Source Data
620 rare disease abstracts classified as epidemiological by a LSTM RNN rare disease epi classifier from 488 diseases. See Figure 1.
#### Initial Data Collection and Normalization
A random sample of 500 disease names were gathered from a list of ~6061 rare diseases tracked by GARD until ≥50 abstracts had been returned for each disease or the EBI RESTful API results were exhausted. Though we called ~25,000 abstracts from PubMed's db, only 7699 unique abstracts were returned for 488 diseases. Out of 7699 abstracts, only 620 were classified as epidemiological by the LSTM RNN epidemiological classifier.
### Annotations
#### Annotation process
Programmatic labeling. See [here](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/create_labeled_dataset_V2.ipynb) and then [here](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/modify_existing_labels.ipynb). The test set was manually corrected after creation.
#### Who are the annotators?
Programmatic labeling was done by [@William Kariampuzha](https://github.com/wzkariampuzha), one of the NCATS researchers.
The test set was manually corrected by 2 more NCATS researchers and a GARD curator (genetic and rare disease expert).
### Personal and Sensitive Information
None. These are freely available abstracts from PubMed.
## Considerations for Using the Data
### Social Impact of Dataset
Assisting 25-30 millions Americans with rare diseases. Additionally can be useful for Orphanet or CDC researchers/curators.
### Discussion of Biases and Limitations
- There were errors in the source file that contained rare disease synonyms of names, which may have led to some unrelated abstracts being included in the training, validation, and test sets.
- The abstracts were gathered through the EBI API and is thus subject to any biases that the EBI API had. The NCBI API returns very different results as shown by an API analysis here.
- The [long short-term memory recurrent neural network epi classifier](https://pubmed.ncbi.nlm.nih.gov/34457147/) was used to sift the 7699 rare disease abstracts. This model had a hold-out validation F1 score of 0.886 and a test F1 (which was compared against a GARD curator who used full-text articles to determine truth-value of epidemiological abstract) of 0.701. With 620 epi abstracts filtered from 7699 original rare disease abstracts, there are likely several false positives and false negative epi abstracts.
- Tokenization was done by spaCy which may be a limitation (or not) for current and future models trained on this set.
- The programmatic labeling was very imprecise as seen by Table 1. This is likely the largest limitation of the [BioBERT-based model](https://huggingface.co/ncats/EpiExtract4GARD) trained on this set.
- The test set was difficult to validate even for general NCATS researchers, which is why we relied on a rare disease expert to verify our modifications. As this task of epidemiological information identification is quite difficult for non-expert humans to complete, this set, and especially a gold-standard dataset in the possible future, represents a challenging gauntlet for NLP systems, especially those focusing on numeracy, to compete on.
## Additional Information
### Dataset Curators
[NIH GARD](https://rarediseases.info.nih.gov/about-gard/pages/23/about-gard)
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@William Kariampuzha](https://github.com/wzkariampuzha) at NCATS/Axle Informatics for adding this dataset. | 8,634 | [
[
-0.031951904296875,
-0.0396728515625,
0.0236968994140625,
-0.0022907257080078125,
-0.007472991943359375,
-0.00047898292541503906,
-0.01035308837890625,
-0.039886474609375,
0.05133056640625,
0.033111572265625,
-0.02581787109375,
-0.06695556640625,
-0.041076660156... |
tomekkorbak/pile-pii | 2023-01-25T17:49:10.000Z | [
"region:us"
] | tomekkorbak | null | null | 0 | 4 | 2022-05-13T13:41:24 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
morteza/cogtext | 2023-10-27T15:01:28.000Z | [
"task_categories:text-classification",
"task_ids:topic-classification",
"task_ids:semantic-similarity-classification",
"language_creators:found",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc... | morteza | null | null | 0 | 4 | 2022-05-14T06:38:55 | ---
pretty_name: CogText PubMed Abstracts
license:
- cc-by-4.0
language:
- en
multilinguality:
- monolingual
task_categories:
- text-classification
task_ids:
- topic-classification
- semantic-similarity-classification
size_categories:
- 100K<n<1M
paperswithcode_id: linking-theories-and-methods-in-cognitive
inference: false
model-index:
- name: cogtext-pubmed
results: []
source_datasets:
- original
language_creators:
- found
- expert-generated
configs:
- config_name: abstracts2021
data_files: "pubmed/abstracts2021.csv.gz"
- config_name: abstracts2023
data_files: "pubmed/abstracts2023.csv.gz"
tags:
- Cognitive Control
- PubMed
---
# Dataset Card for CogText PubMed Abstracts
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
The **CogText** dataset is a curated collection of abstracts about cognitive tasks and constructs from PubMed.
This dataset contains the original abstracts and their corresponding embeddings.
Please visit [CogText on GitHub](https://github.com/morteza/cogtext) for the details and codes.
- **Homepage:** https://github.com/morteza/cogtext
- **Repository:** https://github.com/morteza/cogtext
- **Point of Contact:** [Morteza Ansarinia](mailto:ansarinia@me.com)
- **Paper:** https://arxiv.org/abs/2203.11016
### Dataset Summary
The 2021 dataset, collected in December 2021, contains 385,705 distinct scientific articles, featuring their title, abstract, relevant metadata, and embeddings.
The articles were specifically selected for their relevance to cognitive control constructs and associated tasks.
### Supported Tasks and Leaderboards
Topic Modeling, Text Embedding
### Languages
English
## Dataset Structure
### Data Instances
522,972 scientific articles, of which 385,705 are unique.
### Data Fields
The CSV files contain the following fields:
| Field | Description |
| ----- | ----------- |
| `index` | (int) Index of the article in the current dataset |
| `pmid` | (int) PubMed ID |
| `doi` | (str) Digital Object Identifier |
| `year` | (int) Year of publication (yyyy format)|
| `journal_title` | (str) Title of the journal |
| `journal_iso_abbreviation` | (str) ISO abbreviation of the journal |
| `title` | (str) Title of the article |
| `abstract` | (str) Abstract of the article |
| `category` | (enum) Category of the article, either "CognitiveTask" or "CognitiveConstruct" |
| `label` | (enum) Label of the article, which refers to the class labels in the `ontologies/efo.owl` ontology |
| `original_index` | (int) Index of the article in the full dataset (see `pubmed/abstracts.csv.gz`) |
### Data Splits
| Dataset | Description |
| ------- | ----------- |
| `pubmed/abstracts.csv.gz` | Full dataset |
| `pubmed/abstracts20pct.csv.gz` | 20% of the dataset (stratified random sample by `label`) |
| `gpt3/abstracts_gp3ada.nc` | GPT-3 embeddings of the entire dataset in XArray/CDF4 format, indexed by `pmid` |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Acknowledgments
This research was supported by the Luxembourg National Research Fund (ATTRACT/2016/ID/11242114/DIGILEARN and INTER Mobility/2017-2/ID/11765868/ULALA).
### Citation Information
To cite the paper use the following entry:
```
@misc{cogtext2022,
author = {Morteza Ansarinia and
Paul Schrater and
Pedro Cardoso-Leite},
title = {Linking Theories and Methods in Cognitive Sciences via Joint Embedding of the Scientific Literature: The Example of Cognitive Control},
year = {2022},
url = {https://arxiv.org/abs/2203.11016}
}
``` | 5,063 | [
[
-0.034759521484375,
-0.06005859375,
0.0435791015625,
0.00748443603515625,
-0.01389312744140625,
-0.005786895751953125,
-0.0263671875,
-0.029266357421875,
0.043182373046875,
0.02484130859375,
-0.05010986328125,
-0.070068359375,
-0.053314208984375,
0.008460998... |
Iyanuoluwa/YOSM | 2023-01-10T06:28:01.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:yo",
"license:unknown",
"movie reviews",
"nollywood",
"arxi... | Iyanuoluwa | YOSM: A NEW YORUBA SENTIMENT CORPUS FOR MOVIE REVIEWS
- Yoruba | @inproceedings{
shode2022yosm,
title={{YOSM}: A {NEW} {YORUBA} {SENTIMENT} {CORPUS} {FOR} {MOVIE} {REVIEWS}},
author={Iyanuoluwa Shode and David Ifeoluwa Adelani and Anna Feldman},
booktitle={3rd Workshop on African Natural Language Processing},
year={2022},
url={https://openreview.net/forum?id=rRzx5qzVIb9}
} | 0 | 4 | 2022-05-17T13:00:01 | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- yo
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- movie reviews
- nollywood
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
# Dataset Card for YOSM
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** [Iyanuoluwa/YOSM](https://github.com/IyanuSh/YOSM)
- **Paper:** [A new Yorùbá Sentiment Corpus for Nigerian/Nollywood Movie Reviews](https://arxiv.org/pdf/2204.09711.pdf)
- **Point of Contact:** [Iyanuoluwa Shode](mailto:shodei1@montclair.edu)
### Dataset Summary
YOSM is the first Yorùbá sentiment corpus for Nollywood movie reviews. The reviews were collected from movie reviews websites - IMDB, Rotten Tomatoes, LetterboxD, Cinemapointer, and Nollyrated.
### Languages
Yorùbá (ISO 639-1: yo) - the third most spoken indigenous African language with over 50 million speakers.
## Dataset Structure
### Data Instances
An instance consists of a movie review and the corresponding class label.
### Data Fields
- `yo_review`: A movie review in Yorùbá
- `sentiment`: The label describing the sentiment of the movie review.
### Data Splits
The YOSM dataset has 3 splits: _train_, _dev_, and _test_. Below are the statistics for Version 3.0.0 of the dataset.
| Dataset Split | Number of Instances in Split |
| ------------- | ------------------------------------------- |
| Train | 800 |
| Development | 200 |
| Test | 500 |
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
| 3,590 | [
[
-0.04779052734375,
-0.055145263671875,
0.00739288330078125,
0.0052490234375,
-0.032989501953125,
-0.0074462890625,
-0.01004791259765625,
-0.0283355712890625,
0.052978515625,
0.0439453125,
-0.0733642578125,
-0.060943603515625,
-0.04888916015625,
0.01802062988... |
bigscience-data/roots_ar_arabench | 2022-12-12T10:59:54.000Z | [
"language:ar",
"license:apache-2.0",
"region:us"
] | bigscience-data | null | null | 0 | 4 | 2022-05-18T09:03:10 | ---
language: ar
license: apache-2.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_ar_arabench
# arabench
- Dataset uid: `arabench`
### Description
AraBench is an evaluation suite for dialectal Arabic to English machine translation. AraBench offers 4 coarse, 15 fine-grained and 25 city-level dialect categories, belonging to diverse genres, such as media, chat, religion and travel with varying level of dialectness.
### Homepage
https://alt.qcri.org/resources1/mt/arabench/
### Licensing
- open license
- cc-by-4.0: Creative Commons Attribution 4.0 International
### Speaker Locations
- Northern Africa
- Western Asia
- Algeria
- Egypt
- Morocco
- Jordan
- Sudan
- Tunisia
- Lebanon
- Libya
- Iraq
- Qatar
- Yemen
- Oman
- Saudi Arabia
- Syria
- Palestine
### Sizes
- 0.0018 % of total
- 0.0165 % of ar
### BigScience processing steps
#### Filters applied to: ar
- dedup_document
- dedup_template_soft
- filter_remove_empty_docs
- filter_small_docs_bytes_300
| 1,239 | [
[
-0.061676025390625,
-0.0260772705078125,
0.022216796875,
0.0162200927734375,
-0.023223876953125,
0.005054473876953125,
-0.004734039306640625,
-0.00901031494140625,
0.0230560302734375,
0.0299072265625,
-0.043701171875,
-0.0836181640625,
-0.06439208984375,
0.0... |
bigscience-data/roots_ar_openiti_proc | 2022-12-12T11:02:32.000Z | [
"language:ar",
"license:cc-by-4.0",
"region:us"
] | bigscience-data | null | null | 0 | 4 | 2022-05-18T09:07:32 | ---
language: ar
license: cc-by-4.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_ar_openiti_proc
# OpenITI
- Dataset uid: `openiti_proc`
### Description
A corpus of Arabic texts that collected from Islamic books from different websites.
### Homepage
https://zenodo.org/record/4075046
### Licensing
- non-commercial use
- cc-by-nc-sa-4.0: Creative Commons Attribution Non Commercial Share Alike 4.0 International
By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
### Speaker Locations
- Southern Asia
- Western Europe
- Northern America
- Pakistan
- Austria
- Germany
- United States of America
### Sizes
- 3.0760 % of total
- 28.3450 % of ar
### BigScience processing steps
#### Filters applied to: ar
- dedup_document
- dedup_template_soft
- filter_remove_empty_docs
- remove_html_spans
- filter_small_docs_bytes_300
| 1,616 | [
[
-0.046905517578125,
-0.0243377685546875,
0.024932861328125,
0.003002166748046875,
-0.033782958984375,
-0.005096435546875,
-0.006439208984375,
-0.01369476318359375,
0.0004830360412597656,
0.020721435546875,
-0.033721923828125,
-0.0672607421875,
-0.053314208984375... |
bigscience-data/roots_id_indonesian_news_corpus | 2022-12-12T11:05:28.000Z | [
"language:id",
"license:cc-by-4.0",
"region:us"
] | bigscience-data | null | null | 1 | 4 | 2022-05-18T09:14:11 | ---
language: id
license: cc-by-4.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_id_indonesian_news_corpus
# Indonesian News Corpus
- Dataset uid: `indonesian_news_corpus`
### Description
Crawled news in 2015 from:
- kompas.com
- tempo.co
- merdeka.com
- republika.co.id
- viva.co.id
- tribunnews.com
### Homepage
https://data.mendeley.com/datasets/2zpbjs22k3/1
### Licensing
- open license
- cc-by-4.0: Creative Commons Attribution 4.0 International
### Speaker Locations
- South-eastern Asia
- Indonesia
### Sizes
- 0.0172 % of total
- 6.5603 % of id
### BigScience processing steps
#### Filters applied to: id
- dedup_document
- dedup_template_soft
- filter_remove_empty_docs
- filter_small_docs_bytes_300
| 989 | [
[
-0.02923583984375,
-0.049774169921875,
0.026458740234375,
0.0298614501953125,
-0.0460205078125,
0.0021343231201171875,
-0.01016998291015625,
-2.980232238769531e-7,
0.054931640625,
0.0233154296875,
-0.0517578125,
-0.0657958984375,
-0.04638671875,
0.0328063964... |
Ruohao/pcmr | 2022-10-25T10:25:57.000Z | [
"language:en",
"region:us"
] | Ruohao | PCMR | todo | 1 | 4 | 2022-05-20T04:02:37 | ---
language:
- en
paperswithcode_id: coqa
pretty_name: Conversational Question Answering Challenge
---
# Dataset Card for "coqa"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://stanfordnlp.github.io/coqa/](https://stanfordnlp.github.io/coqa/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 55.40 MB
- **Size of the generated dataset:** 18.35 MB
- **Total amount of disk used:** 73.75 MB
### Dataset Summary
CoQA: A Conversational Question Answering Challenge
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 55.40 MB
- **Size of the generated dataset:** 18.35 MB
- **Total amount of disk used:** 73.75 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answers": "{\"answer_end\": [179, 494, 511, 545, 879, 1127, 1128, 94, 150, 412, 1009, 1046, 643, -1, 764, 724, 125, 1384, 881, 910], \"answer_...",
"questions": "[\"When was the Vat formally opened?\", \"what is the library for?\", \"for what subjects?\", \"and?\", \"what was started in 2014?\", \"ho...",
"source": "wikipedia",
"story": "\"The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, l..."
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `source`: a `string` feature.
- `story`: a `string` feature.
- `questions`: a `list` of `string` features.
- `answers`: a dictionary feature containing:
- `input_text`: a `string` feature.
- `answer_start`: a `int32` feature.
- `answer_end`: a `int32` feature.
### Data Splits
| name |train|validation|
|-------|----:|---------:|
|default| 7199| 500|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{SivaAndAl:Coca,
author = {Siva, Reddy and Danqi, Chen and Christopher D., Manning},
title = {WikiQA: A Challenge Dataset for Open-Domain Question Answering},
journal = { arXiv},
year = {2018},
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun), [@thomwolf](https://github.com/thomwolf), [@mariamabarham](https://github.com/mariamabarham), [@ojasaar](https://github.com/ojasaar), [@lhoestq](https://github.com/lhoestq) for adding this dataset.
| 6,074 | [
[
-0.0513916015625,
-0.040771484375,
0.0108642578125,
0.0021495819091796875,
-0.0107879638671875,
-0.0081634521484375,
-0.01450347900390625,
-0.0217742919921875,
0.03875732421875,
0.0416259765625,
-0.06353759765625,
-0.058502197265625,
-0.0242767333984375,
0.0... |
laion/laion1B-nolang-aesthetic-tags | 2022-05-22T02:09:56.000Z | [
"region:us"
] | laion | null | null | 1 | 4 | 2022-05-22T01:52:57 | Entry not found | 15 | [
[
-0.0213775634765625,
-0.014984130859375,
0.05718994140625,
0.0288543701171875,
-0.0350341796875,
0.046478271484375,
0.052520751953125,
0.005062103271484375,
0.051361083984375,
0.016998291015625,
-0.0521240234375,
-0.01496124267578125,
-0.0604248046875,
0.037... |
laion/laion5B-aesthetic-tags-kv | 2022-05-22T15:30:19.000Z | [
"license:cc-by-4.0",
"region:us"
] | laion | null | null | 3 | 4 | 2022-05-22T14:14:32 | ---
license: cc-by-4.0
---
cat laion5B-aesthetic-tags-kv-part1 laion5B-aesthetic-tags-kv-part2 > laion5B-aesthetic-tags-kv
| 124 | [
[
-0.0181732177734375,
-0.004848480224609375,
0.0279083251953125,
0.05810546875,
-0.04376220703125,
0.01395416259765625,
0.0272064208984375,
-0.01555633544921875,
0.06781005859375,
0.05029296875,
-0.04376220703125,
-0.03790283203125,
-0.0158233642578125,
0.008... |
blinoff/medical_institutions_reviews | 2022-10-23T16:51:28.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:ru",
"region:us"
] | blinoff | null | null | 0 | 4 | 2022-05-27T10:09:02 | ---
language:
- ru
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- text-classification
task_ids:
- sentiment-classification
---
### Dataset Summary
The dataset contains user reviews about medical institutions.
In total it contains 12,036 reviews. A review tagged with the <em>general</em> sentiment and sentiments on 5 aspects: <em>quality, service, equipment, food, location</em>.
### Data Fields
Each sample contains the following fields:
- **review_id**;
- **content**: review text;
- **general**;
- **quality**;
- **service**;
- **equipment**;
- **food**;
- **location**.
### Python
```python3
import pandas as pd
df = pd.read_json('medical_institutions_reviews.jsonl', lines=True)
df.sample(5)
```
| 736 | [
[
-0.0178985595703125,
-0.0294036865234375,
0.0340576171875,
0.0297698974609375,
-0.017913818359375,
-0.02154541015625,
0.0149078369140625,
-0.01206207275390625,
0.0433349609375,
0.052581787109375,
-0.01287841796875,
-0.08062744140625,
-0.0296783447265625,
0.0... |
Abdelrahman-Rezk/Arabic_Poem_Comprehensive_Dataset_APCD | 2022-05-27T19:01:21.000Z | [
"region:us"
] | Abdelrahman-Rezk | null | null | 0 | 4 | 2022-05-27T18:58:56 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
silver/lccc | 2022-11-06T04:51:16.000Z | [
"task_categories:conversational",
"task_ids:dialogue-generation",
"annotations_creators:other",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:zh",
"license:mit",
"dialogue-response-retrieval",
"arxiv:2008.03946",
"... | silver | LCCC: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large corpus of Chinese conversations.
A rigorous data cleaning pipeline is designed to ensure the quality of the corpus.
This pipeline involves a set of rules and several classifier-based filters.
Noises such as offensive or sensitive words, special symbols, emojis,
grammatically incorrect sentences, and incoherent conversations are filtered. | @inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
} | 11 | 4 | 2022-05-29T09:19:28 | ---
annotations_creators:
- other
language_creators:
- other
language:
- zh
license:
- mit
multilinguality:
- monolingual
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- conversational
task_ids:
- dialogue-generation
pretty_name: lccc
tags:
- dialogue-response-retrieval
---
# Dataset Card for lccc_large
## Table of Contents
- [Dataset Card for lccc_large](#dataset-card-for-lccc_large)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://github.com/thu-coai/CDial-GPT
- **Repository:** https://github.com/thu-coai/CDial-GPT
- **Paper:** https://arxiv.org/abs/2008.03946
### Dataset Summary
lccc: Large-scale Cleaned Chinese Conversation corpus (LCCC) is a large Chinese dialogue corpus originate from Chinese social medias. A rigorous data cleaning pipeline is designed to ensure the quality of the corpus. This pipeline involves a set of rules and several classifier-based filters. Noises such as offensive or sensitive words, special symbols, emojis, grammatically incorrect sentences, and incoherent conversations are filtered.
lccc是一套来自于中文社交媒体的对话数据,我们设计了一套严格的数据过滤流程来确保该数据集中对话数据的质量。 这一数据过滤流程中包括一系列手工规则以及若干基于机器学习算法所构建的分类器。 我们所过滤掉的噪声包括:脏字脏词、特殊字符、颜表情、语法不通的语句、上下文不相关的对话等。
### Supported Tasks and Leaderboards
- dialogue-generation: The dataset can be used to train a model for generating dialogue responses.
- response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.
### Languages
LCCC is in Chinese
LCCC中的对话是中文的
## Dataset Structure
### Data Instances
["火锅 我 在 重庆 成都 吃 了 七八 顿 火锅", "哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !", "不会 的 就是 好 油腻"]
### Data Fields
Each line is a list of utterances that consist a dialogue.
Note that the LCCC dataset provided in our original Github page is in json format,
however, we are providing LCCC in jsonl format here.
### Data Splits
We do not provide the offical split for LCCC-large.
But we provide a split for LCCC-base:
|train|valid|test|
|:---:|:---:|:---:|
|6,820,506 | 20,000 | 10,000|
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Please cite the following paper if you find this dataset useful:
```bibtex
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
```
| 4,564 | [
[
-0.0335693359375,
-0.050933837890625,
0.005870819091796875,
0.00606536865234375,
-0.0174102783203125,
0.00986480712890625,
-0.0369873046875,
-0.0211334228515625,
0.02105712890625,
0.050872802734375,
-0.052337646484375,
-0.07122802734375,
-0.02557373046875,
0... |
silver/mmchat | 2022-07-10T13:04:36.000Z | [
"task_categories:conversational",
"task_ids:dialogue-generation",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:zh",
"license:other",
"arxiv:2108.07154",
"arxiv:2008.03946",
"r... | silver | MMChat is a large-scale dialogue dataset that contains image-grounded dialogues in Chinese.
Each dialogue in MMChat is associated with one or more images (maximum 9 images per dialogue).
We design various strategies to ensure the quality of the dialogues in MMChat. | @inproceedings{zheng2022MMChat,
author = {Zheng, Yinhe and Chen, Guanyi and Liu, Xin and Sun, Jian},
title = {MMChat: Multi-Modal Chat Dataset on Social Media},
booktitle = {Proceedings of The 13th Language Resources and Evaluation Conference},
year = {2022},
publisher = {European Language Resources Association},
}
@inproceedings{wang2020chinese,
title = {A Large-Scale Chinese Short-Text Conversation Dataset},
author = {Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle = {NLPCC},
year = {2020},
url = {https://arxiv.org/abs/2008.03946}
} | 10 | 4 | 2022-05-29T11:15:03 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- zh
license:
- other
multilinguality:
- monolingual
paperswithcode_id: mmchat-multi-modal-chat-dataset-on-social
pretty_name: "MMChat: Multi-Modal Chat Dataset on Social Media"
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- conversational
task_ids:
- dialogue-generation
---
# Dataset Card for MMChat
## Table of Contents
- [Dataset Card for MMChat](#dataset-card-for-mmchat)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.zhengyinhe.com/datasets/
- **Repository:** https://github.com/silverriver/MMChat
- **Paper:** https://arxiv.org/abs/2108.07154
### Dataset Summary
MMChat is a large-scale dialogue dataset that contains image-grounded dialogues in Chinese. Each dialogue in MMChat is associated with one or more images (maximum 9 images per dialogue). We design various strategies to ensure the quality of the dialogues in MMChat.
MMChat comes with 4 different versions:
- `mmchat`: The MMChat dataset used in our paper.
- `mmchat_hf`: Contains human annotation on 100K sessions of dialogues.
- `mmchat_raw`: Raw dialogues used to construct MMChat.
`mmchat_lccc_filtered`: Raw dialogues filtered using the LCCC dataset.
If you what to use high quality multi-modal dialogues that are closed related to the given images, I suggest you to use the `mmchat_hf` version.
If you only care about the quality of dialogue texts, I suggest you to use the `mmchat_lccc_filtered` version.
### Supported Tasks and Leaderboards
- dialogue-generation: The dataset can be used to train a model for generating dialogue responses.
- response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.
### Languages
MMChat is in Chinese
MMChat中的对话是中文的
## Dataset Structure
### Data Instances
Several versions of MMChat are available. For `mmchat`, `mmchat_raw`, `mmchat_lccc_filtered`, the following instance applies:
```json
{
"dialog": ["你只拍出了你十分之一的美", "你的头像竟然换了,奥"],
"weibo_content": "分享图片",
"imgs": ["https://wx4.sinaimg.cn/mw2048/d716a6e2ly1fmug2w2l9qj21o02yox6p.jpg"]
}
```
For `mmchat_hf`, the following instance applies:
```json
{
"dialog": ["白百合", "啊?", "有点像", "还好吧哈哈哈牙像", "有男盆友没呢", "还没", "和你说话呢。没回我"],
"weibo_content": "补一张昨天礼仪的照片",
"imgs": ["https://ww2.sinaimg.cn/mw2048/005Co9wdjw1eyoz7ib9n5j307w0bu3z5.jpg"],
"labels": {
"image_qualified": true,
"dialog_qualified": true,
"dialog_image_related": true
}
}
```
### Data Fields
- `dialog` (list of strings): List of utterances consisting of a dialogue.
- `weibo_content` (string): Weibo content of the dialogue.
- `imgs` (list of strings): List of URLs of images.
- `labels` (dict): Human-annotated labels of the dialogue.
- `image_qualified` (bool): Whether the image is of high quality.
- `dialog_qualified` (bool): Whether the dialogue is of high quality.
- `dialog_image_related` (bool): Whether the dialogue is related to the image.
### Data Splits
For `mmchat`, we provide the following splits:
|train|valid|test|
|---:|---:|---:|
|115,842 | 4,000 | 1,000 |
For other versions, we do not provide the offical split.
More stastics are listed here:
| `mmchat` | Count |
|--------------------------------------|--------:|
| Sessions | 120.84 K |
| Sessions with more than 4 utterances | 17.32 K |
| Utterances | 314.13 K |
| Images | 198.82 K |
| Avg. utterance per session | 2.599 |
| Avg. image per session | 2.791 |
| Avg. character per utterance | 8.521 |
| `mmchat_hf` | Count |
|--------------------------------------|--------:|
| Sessions | 19.90 K |
| Sessions with more than 4 utterances | 8.91 K |
| Totally annotated sessions | 100.01 K |
| Utterances | 81.06 K |
| Images | 52.66K |
| Avg. utterance per session | 4.07 |
| Avg. image per session | 2.70 |
| Avg. character per utterance | 11.93 |
| `mmchat_raw` | Count |
|--------------------------------------|---------:|
| Sessions | 4.257 M |
| Sessions with more than 4 utterances | 2.304 M |
| Utterances | 18.590 M |
| Images | 4.874 M |
| Avg. utterance per session | 4.367 |
| Avg. image per session | 1.670 |
| Avg. character per utterance | 14.104 |
| `mmchat_lccc_filtered` | Count |
|--------------------------------------|--------:|
| Sessions | 492.6 K |
| Sessions with more than 4 utterances | 208.8 K |
| Utterances | 1.986 M |
| Images | 1.066 M |
| Avg. utterance per session | 4.031 |
| Avg. image per session | 2.514 |
| Avg. character per utterance | 11.336 |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
other-weibo
This dataset is collected from Weibo.
You can refer to the [detailed policy](https://weibo.com/signup/v5/privacy) required to use this dataset.
Please restrict the usage of this dataset to non-commerical purposes.
### Citation Information
```
@inproceedings{zheng2022MMChat,
author = {Zheng, Yinhe and Chen, Guanyi and Liu, Xin and Sun, Jian},
title = {MMChat: Multi-Modal Chat Dataset on Social Media},
booktitle = {Proceedings of The 13th Language Resources and Evaluation Conference},
year = {2022},
publisher = {European Language Resources Association},
}
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
```
### Contributions
Thanks to [Yinhe Zheng](https://github.com/silverriver) for adding this dataset.
| 8,256 | [
[
-0.030242919921875,
-0.056884765625,
0.00807952880859375,
0.0191650390625,
-0.0254364013671875,
0.003940582275390625,
-0.018707275390625,
-0.031829833984375,
0.035247802734375,
0.02783203125,
-0.06146240234375,
-0.056884765625,
-0.0325927734375,
0.0049438476... |
jakka/warehouse_part1 | 2022-05-31T14:58:45.000Z | [
"region:us"
] | jakka | null | null | 0 | 4 | 2022-05-31T14:53:46 | Entry not found | 15 | [
[
-0.021392822265625,
-0.01494598388671875,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.01702880859375,
-0.052093505859375,
-0.01494598388671875,
-0.06036376953125,
0.03790... |
lyakaap/laion2B-japanese-subset | 2022-06-01T12:10:06.000Z | [
"region:us"
] | lyakaap | null | null | 2 | 4 | 2022-06-01T05:46:57 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
gary109/onset-chord_corpora_parliament_processed | 2022-06-20T13:27:54.000Z | [
"region:us"
] | gary109 | null | null | 0 | 4 | 2022-06-01T08:23:23 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
lmqg/qg_esquad | 2022-12-02T18:52:05.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:squad_es",
"language:es",
"license:cc-by-4.0",
"question-generation",
"arxiv:2210.03992",
"region:us"
] | lmqg | [SQuAD-es](https://huggingface.co/datasets/squad_es) dataset for question generation (QG) task. | @inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
} | 0 | 4 | 2022-06-02T23:41:06 | ---
license: cc-by-4.0
pretty_name: SQuAD-es for question generation
language: es
multilinguality: monolingual
size_categories: 10K<n<100K
source_datasets: squad_es
task_categories:
- text-generation
task_ids:
- language-modeling
tags:
- question-generation
---
# Dataset Card for "lmqg/qg_esquad"
## Dataset Description
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
- **Point of Contact:** [Asahi Ushio](http://asahiushio.com/)
### Dataset Summary
This is a subset of [QG-Bench](https://github.com/asahi417/lm-question-generation/blob/master/QG_BENCH.md#datasets), a unified question generation benchmark proposed in
["Generative Language Models for Paragraph-Level Question Generation: A Unified Benchmark and Evaluation, EMNLP 2022 main conference"](https://arxiv.org/abs/2210.03992).
This is a modified version of [SQuAD-es](https://huggingface.co/datasets/squad_es) for question generation (QG) task.
Since the original dataset only contains training/validation set, we manually sample test set from training set, which
has no overlap in terms of the paragraph with the training set.
### Supported Tasks and Leaderboards
* `question-generation`: The dataset is assumed to be used to train a model for question generation.
Success on this task is typically measured by achieving a high BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore (see our paper for more in detail).
### Languages
Spanish (es)
## Dataset Structure
An example of 'train' looks as follows.
```
{
'answer': 'comedia musical',
'question': '¿Qué género de película protagonizó Beyonce con Cuba Gooding, Jr?',
'sentence': 'en la comedia musical ',
'paragraph': 'En julio de 2002, Beyoncé continuó su carrera como actriz interpretando a Foxxy Cleopatra junto a Mike Myers en la película de comedia, Austin Powers in Goldmember, que pasó su primer fin de semana en la cima de la taquilla de Estados Unidos. Beyoncé lanzó "Work It Out" como el primer sencillo de su álbum de banda sonora que entró en el top ten en el Reino Unido, Noruega y Bélgica. En 2003, Knowles protagonizó junto a Cuba Gooding, Jr., en la comedia musical The Fighting Temptations como Lilly, una madre soltera de quien el personaje de Gooding se enamora. Beyoncé lanzó "Fighting Temptation" como el primer sencillo de la banda sonora de la película, con Missy Elliott, MC Lyte y Free que también se utilizó para promocionar la película. Otra de las contribuciones de Beyoncé a la banda sonora, "Summertime", fue mejor en las listas de Estados Unidos.',
'sentence_answer': 'en la <hl> comedia musical <hl> ',
'paragraph_answer': 'En julio de 2002, Beyoncé continuó su carrera como actriz interpretando a Foxxy Cleopatra junto a Mike Myers en la película de comedia, Austin Powers in Goldmember, que pasó su primer fin de semana en la cima de la taquilla de Estados Unidos. Beyoncé lanzó "Work It Out" como el primer sencillo de su álbum de banda sonora que entró en el top ten en el Reino Unido, Noruega y Bélgica. En 2003, Knowles protagonizó junto a Cuba Gooding, Jr., en la <hl> comedia musical <hl> The Fighting Temptations como Lilly, una madre soltera de quien el personaje de Gooding se enamora. Beyoncé lanzó "Fighting Temptation" como el primer sencillo de la banda sonora de la película, con Missy Elliott, MC Lyte y Free que también se utilizó para promocionar la película. Otra de las contribuciones de Beyoncé a la banda sonora, "Summertime", fue mejor en las listas de Estados Unidos.',
'paragraph_sentence': 'En julio de 2002, Beyoncé continuó su carrera como actriz interpretando a Foxxy Cleopatra junto a Mike Myers en la película de comedia, Austin Powers in Goldmember, que pasó su primer fin de semana en la cima de la taquilla de Estados Unidos. Beyoncé lanzó "Work It Out" como el primer sencillo de su álbum de banda sonora que entró en el top ten en el Reino Unido, Noruega y Bélgica. En 2003, Knowles protagonizó junto a Cuba Gooding, Jr. , <hl> en la comedia musical <hl> The Fighting Temptations como Lilly, una madre soltera de quien el personaje de Gooding se enamora. Beyoncé lanzó "Fighting Temptation" como el primer sencillo de la banda sonora de la película, con Missy Elliott, MC Lyte y Free que también se utilizó para promocionar la película. Otra de las contribuciones de Beyoncé a la banda sonora, "Summertime", fue mejor en las listas de Estados Unidos.',
}
```
The data fields are the same among all splits.
- `question`: a `string` feature.
- `paragraph`: a `string` feature.
- `answer`: a `string` feature.
- `sentence`: a `string` feature.
- `paragraph_answer`: a `string` feature, which is same as the paragraph but the answer is highlighted by a special token `<hl>`.
- `paragraph_sentence`: a `string` feature, which is same as the paragraph but a sentence containing the answer is highlighted by a special token `<hl>`.
- `sentence_answer`: a `string` feature, which is same as the sentence but the answer is highlighted by a special token `<hl>`.
Each of `paragraph_answer`, `paragraph_sentence`, and `sentence_answer` feature is assumed to be used to train a question generation model,
but with different information. The `paragraph_answer` and `sentence_answer` features are for answer-aware question generation and
`paragraph_sentence` feature is for sentence-aware question generation.
## Data Splits
|train|validation|test |
|----:|---------:|----:|
|77025| 10570 |10570|
## Citation Information
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
``` | 6,139 | [
[
-0.031890869140625,
-0.052459716796875,
0.02301025390625,
0.017425537109375,
-0.0112152099609375,
0.006893157958984375,
-0.003223419189453125,
-0.00936126708984375,
0.01088714599609375,
0.03662109375,
-0.075927734375,
-0.045928955078125,
-0.02740478515625,
0... |
lmqg/qg_ruquad | 2022-12-02T18:55:01.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:deepset/germanquad",
"language:ru",
"license:cc-by-4.0",
"question-generation",
"arxiv:2210.03992",
"region:us"
] | lmqg | [SberSQuAD](https://huggingface.co/datasets/sberquad) dataset for question generation (QG) task. | @inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
} | 2 | 4 | 2022-06-02T23:44:54 | ---
license: cc-by-4.0
pretty_name: SberQuAD for question generation
language: ru
multilinguality: monolingual
size_categories: 10K<n<100K
source_datasets: deepset/germanquad
task_categories:
- text-generation
task_ids:
- language-modeling
tags:
- question-generation
---
# Dataset Card for "lmqg/qg_ruquad"
## Dataset Description
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
- **Point of Contact:** [Asahi Ushio](http://asahiushio.com/)
### Dataset Summary
This is a subset of [QG-Bench](https://github.com/asahi417/lm-question-generation/blob/master/QG_BENCH.md#datasets), a unified question generation benchmark proposed in
["Generative Language Models for Paragraph-Level Question Generation: A Unified Benchmark and Evaluation, EMNLP 2022 main conference"](https://arxiv.org/abs/2210.03992).
This is a modified version of [SberQuaD](https://huggingface.co/datasets/sberquad) for question generation (QG) task.
Since the original dataset only contains training/validation set, we manually sample test set from training set, which
has no overlap in terms of the paragraph with the training set.
### Supported Tasks and Leaderboards
* `question-generation`: The dataset is assumed to be used to train a model for question generation.
Success on this task is typically measured by achieving a high BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore (see our paper for more in detail).
### Languages
Russian (ru)
## Dataset Structure
An example of 'train' looks as follows.
```
{
'answer': 'известковыми выделениями сине-зелёных водорослей',
'question': 'чем представлены органические остатки?',
'sentence': 'Они представлены известковыми выделениями сине-зелёных водорослей , ходами червей, остатками кишечнополостных.'
'paragraph': "В протерозойских отложениях органические остатки встречаются намного чаще, чем в архейских. Они представлены..."
'sentence_answer': "Они представлены <hl> известковыми выделениями сине-зелёных водорослей <hl> , ход...",
'paragraph_answer': "В протерозойских отложениях органические остатки встречаются намного чаще, чем в архейских. Они представлены <hl> известковыми выделениям...",
'paragraph_sentence': "В протерозойских отложениях органические остатки встречаются намного чаще, чем в архейских. <hl> Они представлены известковыми выделениями сине-зелёных водорослей , ходами червей, остатками кишечнополостных. <hl> Кроме..."
}
```
The data fields are the same among all splits.
- `question`: a `string` feature.
- `paragraph`: a `string` feature.
- `answer`: a `string` feature.
- `sentence`: a `string` feature.
- `paragraph_answer`: a `string` feature, which is same as the paragraph but the answer is highlighted by a special token `<hl>`.
- `paragraph_sentence`: a `string` feature, which is same as the paragraph but a sentence containing the answer is highlighted by a special token `<hl>`.
- `sentence_answer`: a `string` feature, which is same as the sentence but the answer is highlighted by a special token `<hl>`.
Each of `paragraph_answer`, `paragraph_sentence`, and `sentence_answer` feature is assumed to be used to train a question generation model,
but with different information. The `paragraph_answer` and `sentence_answer` features are for answer-aware question generation and
`paragraph_sentence` feature is for sentence-aware question generation.
## Data Splits
|train|validation|test |
|----:|---------:|----:|
| 45327 | 5036 |23936 |
## Citation Information
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
``` | 4,268 | [
[
-0.03759765625,
-0.08544921875,
0.032135009765625,
0.025390625,
-0.0185394287109375,
-0.0172882080078125,
-0.00445556640625,
0.007740020751953125,
-0.0034694671630859375,
0.0215301513671875,
-0.056182861328125,
-0.04632568359375,
-0.0130615234375,
0.01304626... |
lmqg/qg_itquad | 2022-12-02T18:54:31.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:squad_es",
"language:it",
"license:cc-by-4.0",
"question-generation",
"arxiv:2210.03992",
"region:us"
] | lmqg | [SQuAD-it](https://huggingface.co/datasets/squad_it) dataset for question generation (QG) task. | @inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
} | 1 | 4 | 2022-06-02T23:45:12 | ---
license: cc-by-4.0
pretty_name: SQuAD-it for question generation
language: it
multilinguality: monolingual
size_categories: 10K<n<100K
source_datasets: squad_es
task_categories:
- text-generation
task_ids:
- language-modeling
tags:
- question-generation
---
# Dataset Card for "lmqg/qg_itquad"
## Dataset Description
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
- **Point of Contact:** [Asahi Ushio](http://asahiushio.com/)
### Dataset Summary
This is a subset of [QG-Bench](https://github.com/asahi417/lm-question-generation/blob/master/QG_BENCH.md#datasets), a unified question generation benchmark proposed in
["Generative Language Models for Paragraph-Level Question Generation: A Unified Benchmark and Evaluation, EMNLP 2022 main conference"](https://arxiv.org/abs/2210.03992).
This is a modified version of [SQuAD-it](https://huggingface.co/datasets/squad_it) for question generation (QG) task.
Since the original dataset only contains training/validation set, we manually sample test set from training set, which
has no overlap in terms of the paragraph with the training set.
### Supported Tasks and Leaderboards
* `question-generation`: The dataset is assumed to be used to train a model for question generation.
Success on this task is typically measured by achieving a high BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore (see our paper for more in detail).
### Languages
Italian (it)
## Dataset Structure
An example of 'train' looks as follows.
```
{
'answer': 'Carlo III',
'question': "Il figlio di chi è morto sulla strada per Palermo e vi è sepolto?",
'sentence': 'Carlo III scelse Palermo per la sua incoronazione come Re di Sicilia.',
'paragraph': 'Dopo il trattato di Utrecht (1713), la Sicilia fu consegnata ai Savoia, ma nel 1734 fu nuovamente posseduta dai...',
'sentence_answer': '<hl> Carlo III <hl> scelse Palermo per la sua incoronazione come Re di Sicilia.',
'paragraph_answer': "Dopo il trattato di Utrecht (1713), la Sicilia fu consegnata ai Savoia, ma nel 1734 fu nuovamente posseduta dai borbonici. <hl> Carlo III <hl> scelse Palermo per la sua incoronazione come Re di Sicilia. Charles fece costruire nuove case per la popolazione in crescita, mentre il commercio e l' industria crebbero. Tuttavia, ormai Palermo era ora solo un' altra città provinciale, dato che la Corte Reale risiedeva a Napoli. Il figlio di Carlo Ferdinando, anche se non gradito dalla popolazione, si rifugiò a Palermo dopo la Rivoluzione francese del 1798. Suo figlio Alberto è morto sulla strada per Palermo ed è sepolto in città. Quando fu fondato il Regno delle Due Sicilie, la capitale originaria era Palermo (1816) ma un anno dopo si trasferì a Napoli.",
'paragraph_sentence': "Dopo il trattato di Utrecht (1713), la Sicilia fu consegnata ai Savoia, ma nel 1734 fu nuovamente posseduta dai borbonici. <hl> Carlo III scelse Palermo per la sua incoronazione come Re di Sicilia. <hl> Charles fece costruire nuove case per la popolazione in crescita, mentre il commercio e l' industria crebbero. Tuttavia, ormai Palermo era ora solo un' altra città provinciale, dato che la Corte Reale risiedeva a Napoli. Il figlio di Carlo Ferdinando, anche se non gradito dalla popolazione, si rifugiò a Palermo dopo la Rivoluzione francese del 1798. Suo figlio Alberto è morto sulla strada per Palermo ed è sepolto in città. Quando fu fondato il Regno delle Due Sicilie, la capitale originaria era Palermo (1816) ma un anno dopo si trasferì a Napoli."
}
```
The data fields are the same among all splits.
- `question`: a `string` feature.
- `paragraph`: a `string` feature.
- `answer`: a `string` feature.
- `sentence`: a `string` feature.
- `paragraph_answer`: a `string` feature, which is same as the paragraph but the answer is highlighted by a special token `<hl>`.
- `paragraph_sentence`: a `string` feature, which is same as the paragraph but a sentence containing the answer is highlighted by a special token `<hl>`.
- `sentence_answer`: a `string` feature, which is same as the sentence but the answer is highlighted by a special token `<hl>`.
Each of `paragraph_answer`, `paragraph_sentence`, and `sentence_answer` feature is assumed to be used to train a question generation model,
but with different information. The `paragraph_answer` and `sentence_answer` features are for answer-aware question generation and
`paragraph_sentence` feature is for sentence-aware question generation.
## Data Splits
|train|validation|test |
|----:|---------:|----:|
|46550| 7609 |7609|
## Citation Information
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
``` | 5,176 | [
[
-0.042266845703125,
-0.0626220703125,
0.03265380859375,
0.0224761962890625,
-0.011627197265625,
-0.0162200927734375,
-0.00958251953125,
-0.00946044921875,
0.01297760009765625,
0.032806396484375,
-0.056854248046875,
-0.039794921875,
-0.0001914501190185547,
0.... |
buio/heart-disease | 2022-06-05T11:48:42.000Z | [
"structured-data",
"tabular-data",
"classification",
"region:us"
] | buio | null | null | 0 | 4 | 2022-06-05T11:39:25 | ---
tags:
- structured-data
- tabular-data
- classification
---
The [Heart Disease Data Set](https://archive.ics.uci.edu/ml/datasets/heart+Disease) is provided by the Cleveland Clinic Foundation for Heart Disease. It's a CSV file with 303 rows. Each row contains information about a patient (a sample), and each column describes an attribute of the patient (a feature). We use the features to predict whether a patient has a heart disease (binary classification).
It is originally [hosted here]("http://storage.googleapis.com/download.tensorflow.org/data/heart.csv"). | 569 | [
[
-0.02496337890625,
-0.048370361328125,
0.022857666015625,
0.01433563232421875,
-0.0233001708984375,
0.00021517276763916016,
0.01120758056640625,
-0.0241546630859375,
0.0322265625,
0.052978515625,
-0.041534423828125,
-0.072998046875,
-0.0428466796875,
0.01451... |
espnet/an4 | 2022-06-06T18:41:09.000Z | [
"region:us"
] | espnet | null | null | 0 | 4 | 2022-06-06T18:02:33 | Entry not found | 15 | [
[
-0.0213775634765625,
-0.01497650146484375,
0.057159423828125,
0.028839111328125,
-0.035064697265625,
0.04644775390625,
0.052520751953125,
0.00504302978515625,
0.051361083984375,
0.016998291015625,
-0.05206298828125,
-0.01497650146484375,
-0.0604248046875,
0.... |
banjtheman/AmazonHelpfulReviewsTest | 2022-06-07T19:24:01.000Z | [
"region:us"
] | banjtheman | null | null | 0 | 4 | 2022-06-07T19:15:03 | A collection of sentences extracted from customer reviews labeled with their helpfulness score.
Source : https://registry.opendata.aws/helpful-sentences-from-reviews/
raw data: https://helpful-sentences-from-reviews.s3.amazonaws.com/test.json | 245 | [
[
-0.0312042236328125,
-0.044952392578125,
0.023834228515625,
0.0221099853515625,
-0.04376220703125,
-0.0023593902587890625,
0.0079803466796875,
-0.0254974365234375,
0.040252685546875,
0.06805419921875,
-0.055328369140625,
-0.032745361328125,
-0.0245819091796875,
... |
Unso/globalvoices_pairs_en_x | 2022-07-22T07:08:41.000Z | [
"region:us"
] | Unso | null | null | 0 | 4 | 2022-06-11T07:53:34 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
BeIR/cqadupstack-generated-queries | 2022-10-23T06:15:48.000Z | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | BeIR | null | null | 0 | 4 | 2022-06-17T13:20:44 | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | 13,988 | [
[
-0.0396728515625,
-0.03985595703125,
0.01096343994140625,
0.0036678314208984375,
0.004238128662109375,
0.00009435415267944336,
-0.008209228515625,
-0.018890380859375,
0.021697998046875,
0.00595855712890625,
-0.034332275390625,
-0.0545654296875,
-0.02638244628906... |
BeIR/cqadupstack-qrels | 2022-10-23T06:16:03.000Z | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | BeIR | null | null | 0 | 4 | 2022-06-17T13:32:04 | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | 13,988 | [
[
-0.0396728515625,
-0.039825439453125,
0.01094818115234375,
0.00365447998046875,
0.004215240478515625,
0.00008702278137207031,
-0.0081939697265625,
-0.018890380859375,
0.021697998046875,
0.005970001220703125,
-0.034332275390625,
-0.0545654296875,
-0.0263977050781... |
flexthink/audiomnist | 2022-06-21T02:50:18.000Z | [
"region:us"
] | flexthink | AudioMNIST, a research baseline dataset | null | 0 | 4 | 2022-06-20T03:38:26 | # AudioMNIST
This is a HuggingFace Datasets adaptation of the AudioMNIST dataset
Original Dataset:
https://github.com/soerenab/AudioMNIST
---
license: mit
---
| 162 | [
[
-0.035369873046875,
-0.0302581787109375,
0.0157623291015625,
0.0202178955078125,
0.0019216537475585938,
-0.00618743896484375,
0.004001617431640625,
-0.006237030029296875,
0.05108642578125,
0.053802490234375,
-0.07379150390625,
-0.037261962890625,
-0.039672851562... |
fusing/dog_captions | 2022-06-22T14:28:13.000Z | [
"region:us"
] | fusing | null | null | 0 | 4 | 2022-06-21T18:28:05 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
jalFaizy/detect_chess_pieces | 2022-10-25T10:34:41.000Z | [
"task_categories:object-detection",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:n<1K",
"language:en",
"license:other",
"region:us"
] | jalFaizy | The "Object Detection for Chess Pieces" dataset is a toy dataset created (as suggested by the name!) to introduce object detection in a beginner friendly way. | null | 3 | 4 | 2022-06-22T17:41:58 | ---
annotations_creators:
- machine-generated
language_creators:
- machine-generated
language:
- en
license:
- other
multilinguality:
- monolingual
pretty_name: Object Detection for Chess Pieces
size_categories:
- n<1K
source_datasets: []
task_categories:
- object-detection
task_ids: []
---
# Dataset Card for Object Detection for Chess Pieces
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://github.com/faizankshaikh/chessDetection
- **Repository:** https://github.com/faizankshaikh/chessDetection
- **Paper:** -
- **Leaderboard:** -
- **Point of Contact:** [Faizan Shaikh](mailto:faizankshaikh@gmail.com)
### Dataset Summary
The "Object Detection for Chess Pieces" dataset is a toy dataset created (as suggested by the name!) to introduce object detection in a beginner friendly way. It is structured in a one object-one image manner, with the objects being of four classes, namely, Black King, White King, Black Queen and White Queen
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train and evaluate simplistic object detection models
### Languages
The text (labels) in the dataset is in English
## Dataset Structure
### Data Instances
A data point comprises an image and the corresponding objects in bounding boxes.
```
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=224x224 at 0x23557C66160>,
'objects': { "label": [ 0 ], "bbox": [ [ 151, 151, 26, 26 ] ] }
}
```
### Data Fields
- `image`: A `PIL.Image.Image` object containing the 224x224 image.
- `label`: An integer between 0 and 3 representing the classes with the following mapping:
| Label | Description |
| --- | --- |
| 0 | blackKing |
| 1 | blackQueen |
| 2 | whiteKing |
| 3 | whiteQueen |
- `bbox`: A list of integers having sequence [x_center, y_center, width, height] for a particular bounding box
### Data Splits
The data is split into training and validation set. The training set contains 204 images and the validation set 52 images.
## Dataset Creation
### Curation Rationale
The dataset was created to be a simple benchmark for object detection
### Source Data
#### Initial Data Collection and Normalization
The data is obtained by machine generating images from "python-chess" library. Please refer [this code](https://github.com/faizankshaikh/chessDetection/blob/main/code/1.1%20create_images_with_labels.ipynb) to understand data generation pipeline
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
The annotations were done manually.
#### Who are the annotators?
The annotations were done manually.
### Personal and Sensitive Information
None
## Considerations for Using the Data
### Social Impact of Dataset
The dataset can be considered as a beginner-friendly toy dataset for object detection. It should not be used for benchmarking state of the art object detection models, or be used for a deployed model.
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
The dataset only contains four classes for simplicity. The complexity can be increased by considering all types of chess pieces, and by making it a multi-object detection problem
## Additional Information
### Dataset Curators
The dataset was created by Faizan Shaikh
### Licensing Information
The dataset is licensed as CC-BY-SA:2.0
### Citation Information
[Needs More Information] | 4,431 | [
[
-0.041839599609375,
-0.03485107421875,
0.01406097412109375,
-0.0176544189453125,
-0.045562744140625,
-0.01142120361328125,
-0.01114654541015625,
-0.037353515625,
-0.01110076904296875,
0.022674560546875,
-0.043121337890625,
-0.0789794921875,
-0.03839111328125,
... |
Nexdata/3D_Face_Anti_Spoofing_Data | 2023-08-31T02:19:54.000Z | [
"region:us"
] | Nexdata | null | null | 0 | 4 | 2022-06-27T08:58:47 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/3D_Face_Anti_Spoofing_Data
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1172?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
40 People - 3D Living_Face & Anti_Spoofing Data. The collection scenes include indoor and outdoor scenes. The dataset includes males and females. The age distribution ranges from juvenile to the elderly, the young people and the middle aged are the majorities. The device includes iPhone X, iPhone XR. The data diversity includes various expressions, facial postures, anti-spoofing samples, multiple light conditions, multiple scenes. This data can be used for tasks such as 3D face recognition, 3D Living_Face & Anti_Spoofing.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1172?source=Huggingface
### Supported Tasks and Leaderboards
face-detection, computer-vision: The dataset can be used to train a model for face detection.
### Languages
English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | 3,448 | [
[
-0.04852294921875,
-0.06201171875,
0.005832672119140625,
0.035003662109375,
-0.006282806396484375,
0.0035839080810546875,
0.013671875,
-0.0458984375,
0.06048583984375,
0.04754638671875,
-0.057159423828125,
-0.0606689453125,
-0.047515869140625,
0.004543304443... |
ConvLab/camrest | 2022-11-25T09:03:27.000Z | [
"task_categories:conversational",
"multilinguality:monolingual",
"size_categories:n<1K",
"language:en",
"license:cc-by-4.0",
"region:us"
] | ConvLab | null | null | 0 | 4 | 2022-06-28T01:45:51 | ---
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Camrest
size_categories:
- n<1K
task_categories:
- conversational
---
# Dataset Card for Camrest
- **Repository:** https://www.repository.cam.ac.uk/handle/1810/260970
- **Paper:** https://aclanthology.org/D16-1233/
- **Leaderboard:** None
- **Who transforms the dataset:** Qi Zhu(zhuq96 at gmail dot com)
To use this dataset, you need to install [ConvLab-3](https://github.com/ConvLab/ConvLab-3) platform first. Then you can load the dataset via:
```
from convlab.util import load_dataset, load_ontology, load_database
dataset = load_dataset('camrest')
ontology = load_ontology('camrest')
database = load_database('camrest')
```
For more usage please refer to [here](https://github.com/ConvLab/ConvLab-3/tree/master/data/unified_datasets).
### Dataset Summary
Cambridge restaurant dialogue domain dataset collected for developing neural network based dialogue systems. The two papers published based on this dataset are: 1. A Network-based End-to-End Trainable Task-oriented Dialogue System 2. Conditional Generation and Snapshot Learning in Neural Dialogue Systems. The dataset was collected based on the Wizard of Oz experiment on Amazon MTurk. Each dialogue contains a goal label and several exchanges between a customer and the system. Each user turn was labelled by a set of slot-value pairs representing a coarse representation of dialogue state (`slu` field). There are in total 676 dialogue, in which most of the dialogues are finished but some of dialogues were not.
- **How to get the transformed data from original data:**
- Run `python preprocess.py` in the current directory. Need `../../camrest/` as the original data.
- **Main changes of the transformation:**
- Add dialogue act annotation according to the state change. This step was done by ConvLab-2 and we use the processed dialog acts here.
- Rename `pricerange` to `price range`
- Add character level span annotation for non-categorical slots.
- **Annotations:**
- user goal, dialogue acts, state.
### Supported Tasks and Leaderboards
NLU, DST, Policy, NLG, E2E, User simulator
### Languages
English
### Data Splits
| split | dialogues | utterances | avg_utt | avg_tokens | avg_domains | cat slot match(state) | cat slot match(goal) | cat slot match(dialogue act) | non-cat slot span(dialogue act) |
| ---------- | --------- | ---------- | ------- | ---------- | ----------- | --------------------- | -------------------- | ---------------------------- | ------------------------------- |
| train | 406 | 3342 | 8.23 | 10.6 | 1 | 100 | 100 | 100 | 99.83 |
| validation | 135 | 1076 | 7.97 | 11.26 | 1 | 100 | 100 | 100 | 100 |
| test | 135 | 1070 | 7.93 | 11.01 | 1 | 100 | 100 | 100 | 100 |
| all | 676 | 5488 | 8.12 | 10.81 | 1 | 100 | 100 | 100 | 99.9 |
1 domains: ['restaurant']
- **cat slot match**: how many values of categorical slots are in the possible values of ontology in percentage.
- **non-cat slot span**: how many values of non-categorical slots have span annotation in percentage.
### Citation
```
@inproceedings{wen-etal-2016-conditional,
title = "Conditional Generation and Snapshot Learning in Neural Dialogue Systems",
author = "Wen, Tsung-Hsien and Ga{\v{s}}i{\'c}, Milica and Mrk{\v{s}}i{\'c}, Nikola and Rojas-Barahona, Lina M. and Su, Pei-Hao and Ultes, Stefan and Vandyke, David and Young, Steve",
booktitle = "Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2016",
address = "Austin, Texas",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D16-1233",
doi = "10.18653/v1/D16-1233",
pages = "2153--2162",
}
```
### Licensing Information
[**CC BY 4.0**](https://creativecommons.org/licenses/by/4.0/) | 4,344 | [
[
-0.0230865478515625,
-0.047393798828125,
0.015716552734375,
0.0003342628479003906,
-0.0026912689208984375,
-0.004642486572265625,
-0.011962890625,
-0.013519287109375,
0.01508331298828125,
0.051544189453125,
-0.064453125,
-0.045257568359375,
-0.0242462158203125,
... |
ConvLab/tm2 | 2022-11-25T09:15:50.000Z | [
"task_categories:conversational",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"arxiv:1909.05358",
"region:us"
] | ConvLab | null | null | 1 | 4 | 2022-06-28T01:47:59 | ---
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Taskmaster-2
size_categories:
- 10K<n<100K
task_categories:
- conversational
---
# Dataset Card for Taskmaster-2
- **Repository:** https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020
- **Paper:** https://arxiv.org/pdf/1909.05358.pdf
- **Leaderboard:** None
- **Who transforms the dataset:** Qi Zhu(zhuq96 at gmail dot com)
To use this dataset, you need to install [ConvLab-3](https://github.com/ConvLab/ConvLab-3) platform first. Then you can load the dataset via:
```
from convlab.util import load_dataset, load_ontology, load_database
dataset = load_dataset('tm2')
ontology = load_ontology('tm2')
database = load_database('tm2')
```
For more usage please refer to [here](https://github.com/ConvLab/ConvLab-3/tree/master/data/unified_datasets).
### Dataset Summary
The Taskmaster-2 dataset consists of 17,289 dialogs in the seven domains. Unlike Taskmaster-1, which includes both written "self-dialogs" and spoken two-person dialogs, Taskmaster-2 consists entirely of spoken two-person dialogs. In addition, while Taskmaster-1 is almost exclusively task-based, Taskmaster-2 contains a good number of search- and recommendation-oriented dialogs, as seen for example in the restaurants, flights, hotels, and movies verticals. The music browsing and sports conversations are almost exclusively search- and recommendation-based. All dialogs in this release were created using a Wizard of Oz (WOz) methodology in which crowdsourced workers played the role of a 'user' and trained call center operators played the role of the 'assistant'. In this way, users were led to believe they were interacting with an automated system that “spoke” using text-to-speech (TTS) even though it was in fact a human behind the scenes. As a result, users could express themselves however they chose in the context of an automated interface.
- **How to get the transformed data from original data:**
- Download [master.zip](https://github.com/google-research-datasets/Taskmaster/archive/refs/heads/master.zip).
- Run `python preprocess.py` in the current directory.
- **Main changes of the transformation:**
- Remove dialogs that are empty or only contain one speaker.
- Split each domain dialogs into train/validation/test randomly (8:1:1).
- Merge continuous turns by the same speaker (ignore repeated turns).
- Annotate `dialogue acts` according to the original segment annotations. Add `intent` annotation (`==inform`). The type of `dialogue act` is set to `non-categorical` if the `slot` is not in `anno2slot` in `preprocess.py`). Otherwise, the type is set to `binary` (and the `value` is empty). If there are multiple spans overlapping, we only keep the shortest one, since we found that this simple strategy can reduce the noise in annotation.
- Add `domain`, `intent`, and `slot` descriptions.
- Add `state` by accumulate `non-categorical dialogue acts` in the order that they appear.
- Keep the first annotation since each conversation was annotated by two workers.
- **Annotations:**
- dialogue acts, state.
### Supported Tasks and Leaderboards
NLU, DST, Policy, NLG
### Languages
English
### Data Splits
| split | dialogues | utterances | avg_utt | avg_tokens | avg_domains | cat slot match(state) | cat slot match(goal) | cat slot match(dialogue act) | non-cat slot span(dialogue act) |
|------------|-------------|--------------|-----------|--------------|---------------|-------------------------|------------------------|--------------------------------|-----------------------------------|
| train | 13838 | 234321 | 16.93 | 9.1 | 1 | - | - | - | 100 |
| validation | 1731 | 29349 | 16.95 | 9.15 | 1 | - | - | - | 100 |
| test | 1734 | 29447 | 16.98 | 9.07 | 1 | - | - | - | 100 |
| all | 17303 | 293117 | 16.94 | 9.1 | 1 | - | - | - | 100 |
7 domains: ['flights', 'food-ordering', 'hotels', 'movies', 'music', 'restaurant-search', 'sports']
- **cat slot match**: how many values of categorical slots are in the possible values of ontology in percentage.
- **non-cat slot span**: how many values of non-categorical slots have span annotation in percentage.
### Citation
```
@inproceedings{byrne-etal-2019-taskmaster,
title = {Taskmaster-1:Toward a Realistic and Diverse Dialog Dataset},
author = {Bill Byrne and Karthik Krishnamoorthi and Chinnadhurai Sankar and Arvind Neelakantan and Daniel Duckworth and Semih Yavuz and Ben Goodrich and Amit Dubey and Kyu-Young Kim and Andy Cedilnik},
booktitle = {2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing},
address = {Hong Kong},
year = {2019}
}
```
### Licensing Information
[**CC BY 4.0**](https://creativecommons.org/licenses/by/4.0/) | 5,425 | [
[
-0.034820556640625,
-0.069091796875,
0.017120361328125,
0.0098114013671875,
0.0004987716674804688,
0.0007224082946777344,
-0.0246734619140625,
-0.0300140380859375,
0.01239013671875,
0.054931640625,
-0.065185546875,
-0.042144775390625,
-0.040985107421875,
0.0... |
ConvLab/sgd | 2022-11-25T08:55:38.000Z | [
"task_categories:conversational",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-sa-4.0",
"arxiv:1909.05855",
"region:us"
] | ConvLab | null | null | 0 | 4 | 2022-06-28T01:54:08 | ---
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: SGD
size_categories:
- 10K<n<100K
task_categories:
- conversational
---
# Dataset Card for Schema-Guided Dialogue
- **Repository:** https://github.com/google-research-datasets/dstc8-schema-guided-dialogue
- **Paper:** https://arxiv.org/pdf/1909.05855.pdf
- **Leaderboard:** None
- **Who transforms the dataset:** Qi Zhu(zhuq96 at gmail dot com)
To use this dataset, you need to install [ConvLab-3](https://github.com/ConvLab/ConvLab-3) platform first. Then you can load the dataset via:
```
from convlab.util import load_dataset, load_ontology, load_database
dataset = load_dataset('sgd')
ontology = load_ontology('sgd')
database = load_database('sgd')
```
For more usage please refer to [here](https://github.com/ConvLab/ConvLab-3/tree/master/data/unified_datasets).
### Dataset Summary
The **Schema-Guided Dialogue (SGD)** dataset consists of over 20k annotated multi-domain, task-oriented conversations between a human and a virtual assistant. These conversations involve interactions with services and APIs spanning 20 domains, such as banks, events, media, calendar, travel, and weather. For most of these domains, the dataset contains multiple different APIs, many of which have overlapping functionalities but different interfaces, which reflects common real-world scenarios. The wide range of available annotations can be used for intent prediction, slot filling, dialogue state tracking, policy imitation learning, language generation, and user simulation learning, among other tasks for developing large-scale virtual assistants. Additionally, the dataset contains unseen domains and services in the evaluation set to quantify the performance in zero-shot or few-shot settings.
- **How to get the transformed data from original data:**
- Download [dstc8-schema-guided-dialogue-master.zip](https://github.com/google-research-datasets/dstc8-schema-guided-dialogue/archive/refs/heads/master.zip).
- Run `python preprocess.py` in the current directory.
- **Main changes of the transformation:**
- Lower case original `act` as `intent`.
- Add `count` slot for each domain, non-categorical, find span by text matching.
- Categorize `dialogue acts` according to the `intent`.
- Concatenate multiple values using `|`.
- Retain `active_intent`, `requested_slots`, `service_call`.
- **Annotations:**
- dialogue acts, state, db_results, service_call, active_intent, requested_slots.
### Supported Tasks and Leaderboards
NLU, DST, Policy, NLG, E2E
### Languages
English
### Data Splits
| split | dialogues | utterances | avg_utt | avg_tokens | avg_domains | cat slot match(state) | cat slot match(goal) | cat slot match(dialogue act) | non-cat slot span(dialogue act) |
| ---------- | --------- | ---------- | ------- | ---------- | ----------- | --------------------- | -------------------- | ---------------------------- | ------------------------------- |
| train | 16142 | 329964 | 20.44 | 9.75 | 1.84 | 100 | - | 100 | 100 |
| validation | 2482 | 48726 | 19.63 | 9.66 | 1.84 | 100 | - | 100 | 100 |
| test | 4201 | 84594 | 20.14 | 10.4 | 2.02 | 100 | - | 100 | 100 |
| all | 22825 | 463284 | 20.3 | 9.86 | 1.87 | 100 | - | 100 | 100 |
45 domains: ['Banks_1', 'Buses_1', 'Buses_2', 'Calendar_1', 'Events_1', 'Events_2', 'Flights_1', 'Flights_2', 'Homes_1', 'Hotels_1', 'Hotels_2', 'Hotels_3', 'Media_1', 'Movies_1', 'Music_1', 'Music_2', 'RentalCars_1', 'RentalCars_2', 'Restaurants_1', 'RideSharing_1', 'RideSharing_2', 'Services_1', 'Services_2', 'Services_3', 'Travel_1', 'Weather_1', 'Alarm_1', 'Banks_2', 'Flights_3', 'Hotels_4', 'Media_2', 'Movies_2', 'Restaurants_2', 'Services_4', 'Buses_3', 'Events_3', 'Flights_4', 'Homes_2', 'Media_3', 'Messaging_1', 'Movies_3', 'Music_3', 'Payment_1', 'RentalCars_3', 'Trains_1']
- **cat slot match**: how many values of categorical slots are in the possible values of ontology in percentage.
- **non-cat slot span**: how many values of non-categorical slots have span annotation in percentage.
### Citation
```
@article{rastogi2019towards,
title={Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset},
author={Rastogi, Abhinav and Zang, Xiaoxue and Sunkara, Srinivas and Gupta, Raghav and Khaitan, Pranav},
journal={arXiv preprint arXiv:1909.05855},
year={2019}
}
```
### Licensing Information
[**CC BY-SA 4.0**](https://creativecommons.org/licenses/by-sa/4.0/) | 4,955 | [
[
-0.041046142578125,
-0.061492919921875,
0.0246124267578125,
0.00848388671875,
-0.00279998779296875,
0.0031261444091796875,
-0.01343536376953125,
-0.00669097900390625,
0.0284881591796875,
0.0574951171875,
-0.061126708984375,
-0.058837890625,
-0.042236328125,
... |
launch/reddit_qg | 2022-11-09T01:58:05.000Z | [
"task_categories:text-classification",
"annotations_creators:expert-generated",
"multilinguality:monolingual",
"language:en",
"license:cc-by-4.0",
"region:us"
] | launch | Reddit question generation dataset. | @inproceedings{cao-wang-2021-controllable,
title = "Controllable Open-ended Question Generation with A New Question Type Ontology",
author = "Cao, Shuyang and
Wang, Lu",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.502",
doi = "10.18653/v1/2021.acl-long.502",
pages = "6424--6439",
abstract = "We investigate the less-explored task of generating open-ended questions that are typically answered by multiple sentences. We first define a new question type ontology which differentiates the nuanced nature of questions better than widely used question words. A new dataset with 4,959 questions is labeled based on the new ontology. We then propose a novel question type-aware question generation framework, augmented by a semantic graph representation, to jointly predict question focuses and produce the question. Based on this framework, we further use both exemplars and automatically generated templates to improve controllability and diversity. Experiments on two newly collected large-scale datasets show that our model improves question quality over competitive comparisons based on automatic metrics. Human judges also rate our model outputs highly in answerability, coverage of scope, and overall quality. Finally, our model variants with templates can produce questions with enhanced controllability and diversity.",
} | 1 | 4 | 2022-06-30T01:03:40 | ---
annotations_creators:
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
task_categories:
- text-classification
task_ids: []
pretty_name: RedditQG
---
# Dataset Card for RedditQG
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://shuyangcao.github.io/projects/ontology_open_ended_question/](https://shuyangcao.github.io/projects/ontology_open_ended_question/)
- **Repository:** [https://github.com/ShuyangCao/open-ended_question_ontology](https://github.com/ShuyangCao/open-ended_question_ontology)
- **Paper:** [https://aclanthology.org/2021.acl-long.502/](https://aclanthology.org/2021.acl-long.502/)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
This dataset contains answer-question pairs from QA communities of Reddit.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English
## Dataset Structure
### Data Instances
An example looks as follows.
```
{
"id": "askscience/123",
"qid": "2323",
"answer": "A test answer.",
"question": "A test question?",
"score": 20
}
```
### Data Fields
- `id`: a `string` feature.
- `qid`: a `string` feature. There could be multiple answers to the same question.
- `answer`: a `string` feature.
- `question`: a `string` feature.
- `score`: an `int` feature which is the value of `upvotes - downvotes`.
### Data Splits
- train: 647763
- valid: 36023
- test: 36202
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
Reddit users.
### Personal and Sensitive Information
Samples with abusive words are discarded, but there could be samples containing personal information.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
CC BY 4.0
### Citation Information
```
@inproceedings{cao-wang-2021-controllable,
title = "Controllable Open-ended Question Generation with A New Question Type Ontology",
author = "Cao, Shuyang and
Wang, Lu",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.502",
doi = "10.18653/v1/2021.acl-long.502",
pages = "6424--6439",
abstract = "We investigate the less-explored task of generating open-ended questions that are typically answered by multiple sentences. We first define a new question type ontology which differentiates the nuanced nature of questions better than widely used question words. A new dataset with 4,959 questions is labeled based on the new ontology. We then propose a novel question type-aware question generation framework, augmented by a semantic graph representation, to jointly predict question focuses and produce the question. Based on this framework, we further use both exemplars and automatically generated templates to improve controllability and diversity. Experiments on two newly collected large-scale datasets show that our model improves question quality over competitive comparisons based on automatic metrics. Human judges also rate our model outputs highly in answerability, coverage of scope, and overall quality. Finally, our model variants with templates can produce questions with enhanced controllability and diversity.",
}
```
| 4,967 | [
[
-0.042633056640625,
-0.07781982421875,
0.0173492431640625,
-0.0029850006103515625,
-0.00859832763671875,
0.0006570816040039062,
-0.0254364013671875,
-0.005584716796875,
0.0287933349609375,
0.05255126953125,
-0.0625,
-0.06878662109375,
-0.035919189453125,
0.0... |
lapix/CCAgT | 2022-07-27T21:11:52.000Z | [
"task_categories:image-segmentation",
"task_categories:object-detection",
"task_ids:semantic-segmentation",
"task_ids:instance-segmentation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:ori... | lapix | The CCAgT (Images of Cervical Cells with AgNOR Stain Technique) dataset contains 9339 images (1600x1200 resolution where each pixel is 0.111µmX0.111µm) from 15 different slides stained using the AgNOR technique.
Each image has at least one label. In total, this dataset has more than 63K instances of annotated object.
The images are from the patients of the Gynecology and Colonoscopy Outpatient Clinic of the Polydoro Ernani de São Thiago University Hospital of the Universidade Federal de Santa Catarina (HU-UFSC). | @misc{CCAgTDataset,
doi = {10.17632/WG4BPM33HJ.2},
url = {https://data.mendeley.com/datasets/wg4bpm33hj/2},
author = {Jo{\\~{a}}o Gustavo Atkinson Amorim and Andr{\'{e}} Vict{\'{o}}ria Matias and Tainee Bottamedi and Vinícius Sanches and Ane Francyne Costa and Fabiana Botelho De Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim},
title = {CCAgT: Images of Cervical Cells with AgNOR Stain Technique},
publisher = {Mendeley},
year = {2022},
copyright = {Attribution-NonCommercial 3.0 Unported}
} | 2 | 4 | 2022-07-01T12:27:09 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- cc-by-nc-3.0
multilinguality:
- monolingual
paperswithcode_id: null
pretty_name: Images of Cervical Cells with AgNOR Stain Technique
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- image-segmentation
- object-detection
task_ids:
- semantic-segmentation
- instance-segmentation
---
# Dataset Card for Images of Cervical Cells with AgNOR Stain Technique
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [CCAgT homepage](https://data.mendeley.com/datasets/wg4bpm33hj/)
- **Repository:** [CCAgT-utils](https://github.com/johnnv1/CCAgT-utils)
- **Paper:** [Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the AgNOR Technique](https://dx.doi.org/10.2139/ssrn.4126881)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [João G. A. Amorim](mailto:joao.atkinson@posgrad.ufsc.br)
### Dataset Summary
The CCAgT (Images of Cervical Cells with AgNOR Stain Technique) dataset contains 9339 images (1600x1200 resolution where each pixel is 0.111µmX0.111µm) from 15 different slides stained using the AgNOR technique. Each image has at least one label. In total, this dataset has more than 63K instances of annotated object. The images are from the patients of the Gynecology and Colonoscopy Outpatient Clinic of the [Polydoro Ernani de São Thiago University Hospital of the Universidade Federal de Santa Catarina (HU-UFSC)](https://unihospital.ufsc.br/).
### Supported Tasks and Leaderboards
- `image-segmentation`: The dataset can be used to train a model for semantic segmentation or instance segmentation. Semantic segmentation consists in classifying each pixel of the image. Success on this task is typically measured by achieving high values of [mean iou](https://huggingface.co/spaces/evaluate-metric/mean_iou) or [f-score](https://huggingface.co/spaces/evaluate-metric/f1) for pixels results. Instance segmentation consists of doing object detection first and then using a semantic segmentation model inside detected objects. For instances results, this task is typically measured by achieving high values of [recall](https://huggingface.co/spaces/evaluate-metric/recall), [precision](https://huggingface.co/spaces/evaluate-metric/precision) and [f-score](https://huggingface.co/spaces/evaluate-metric/f1).
- `object-detection`: The dataset can be used to train a model for object detection to detect the nuclei categories or the nucleolus organizer regions (NORs), which consists of locating instances of objects and then classifying each one. This task is typically measured by achieving a high values of [recall](https://huggingface.co/spaces/evaluate-metric/recall), [precision](https://huggingface.co/spaces/evaluate-metric/precision) and [f-score](https://huggingface.co/spaces/evaluate-metric/f1).
### Languages
The class labels in the dataset are in English.
## Dataset Structure
### Data Instances
An example looks like the one below:
#### `semantic segmentation` (default configuration)
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1200x1600 at 0x276021C5EB8>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=L size=1200x1600 at 0x385021C5ED7>
}
```
#### `object detection`
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1200x1600 at 0x276021C5EB8>,
'objects': {
'bbox': [
[36, 7, 13, 32],
[50, 7, 12, 32]
],
'label': [1, 5]
}
```
#### `instance segmentation`
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1200x1600 at 0x276021C5EB8>,
'objects': {
'bbox': [
[13.3, 7.5, 47.6, 38.3],
[10.2, 7.5, 50.7, 38.3]
],
'segment': [
[[36.2, 7.5, 13.3, 32.1, 52.1, 40.6, 60.9, 45.8, 50.1, 40, 40, 33.2, 35.2]],
[[10.2, 7.5, 10.3, 32.1, 52.1, 40.6, 60.9, 45.8, 50.1, 40, 40, 33.2, 35.2]],
],
'label': [1, 5]
}
```
### Data Fields
The data annotations have the following fields:
#### `semantic segmentation` (default configuration)
- `image`: A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `annotation`: A `PIL.Image.Image` object containing the annotation mask. The mask has a single channel and the following pixel values are possible: `BACKGROUND` (0), `NUCLEUS` (1), `CLUSTER` (2), `SATELLITE` (3), `NUCLEUS_OUT_OF_FOCUS` (4), `OVERLAPPED_NUCLEI` (5), `NON_VIABLE_NUCLEUS` (6) and `LEUKOCYTE_NUCLEUS` (7).
#### `object detection`
- `image`: A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `objects`: a dictionary containing bounding boxes and labels of the cell objects
- `bbox`: a list of bounding boxes (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format) corresponding to the objects present on the image
- `label`: a list of integers representing the category (7 categories to describe the objects in total; two to differentiate nucleolus organizer regions), with the possible values including `NUCLEUS` (0), `CLUSTER` (1), `SATELLITE` (2), `NUCLEUS_OUT_OF_FOCUS` (3), `OVERLAPPED_NUCLEI` (4), `NON_VIABLE_NUCLEUS` (5) and `LEUKOCYTE_NUCLEUS` (6).
#### `instance segmentation`
- `image`: A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `objects`: a dictionary containing bounding boxes and labels of the cell objects
- `bbox`: a list of bounding boxes (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format) corresponding to the objects present on the image
- `segment`: a list of segments in format of `[polygon_0, ..., polygon_n]`, where each polygon is `[x0, y0, ..., xn, yn]`.
- `label`: a list of integers representing the category (7 categories to describe the objects in total; two to differentiate nucleolus organizer regions), with the possible values including `NUCLEUS` (0), `CLUSTER` (1), `SATELLITE` (2), `NUCLEUS_OUT_OF_FOCUS` (3), `OVERLAPPED_NUCLEI` (4), `NON_VIABLE_NUCLEUS` (5) and `LEUKOCYTE_NUCLEUS` (6).
### Data Splits
The data is split randomly using the fixed seed into training, test and validation set. The training data contains 70% of the images and the testing and the validation data contain 15% of the images each. In total, the training set contains 6533 images and the testing and the validation set 1403 images each.
<details>
<summary>
Click here to see additional statistics:
</summary>
| Slide id | Diagnostics | images | annotations | NUCLEUS | CLUSTER | SATELLITE | NUCLEUS_OUT_OF_FOCUS | OVERLAPPED_NUCLEI | NON_VIABLE_NUCLEUS | LEUKOCYTE_NUCLEUS |
| :-------: | :---------: | :----: | :---------: | :-----: | :------: | :-------: | :------------------: | :---------------: | :---------------: | :-------: |
| A | CIN 3 | 1311 | 3164 | 763 | 1038 | 922 | 381 | 46 | 14 | 0 |
| B | SCC | 561 | 911 | 224 | 307 | 112 | 132 | 5 | 1 | 130 |
| C | AC | 385 | 11420 | 2420 | 3584 | 1112 | 1692 | 228 | 477 | 1907 |
| D | CIN 3 | 2125 | 1258 | 233 | 337 | 107 | 149 | 12 | 8 | 412 |
| E | CIN 3 | 506 | 11131 | 2611 | 6249 | 1648 | 476 | 113 | 34 | 0 |
| F | CIN 1 | 318 | 3365 | 954 | 1406 | 204 | 354 | 51 | 326 | 70 |
| G | CIN 2 | 249 | 2759 | 691 | 1279 | 336 | 268 | 49 | 51 | 85 |
| H | CIN 2 | 650 | 5216 | 993 | 983 | 425 | 2562 | 38 | 214 | 1 |
| I | No lesion | 309 | 474 | 56 | 55 | 19 | 170 | 2 | 23 | 149 |
| J | CIN 1 | 261 | 1786 | 355 | 304 | 174 | 743 | 18 | 33 | 159 |
| K | No lesion | 1503 | 13102 | 2464 | 6669 | 638 | 620 | 670 | 138 | 1903 |
| L | CIN 2 | 396 | 3289 | 842 | 796 | 387 | 1209 | 27 | 23 | 5 |
| M | CIN 2 | 254 | 1500 | 357 | 752 | 99 | 245 | 16 | 12 | 19 |
| N | CIN 3 | 248 | 911 | 258 | 402 | 67 | 136 | 10 | 6 | 32 |
| O | AC | 262 | 2904 | 792 | 1549 | 228 | 133 | 88 | 52 | 62 |
| **Total** | - | 9339 | 63190 | 14013 | 25710 | 6478 | 9270 | 1373 | 1412 | 4934 |
Lesion types:
- Cervical intraepithelial neoplasia 1 - CIN 1
- Cervical intraepithelial neoplasia 2 - CIN 2
- Cervical intraepithelial neoplasia 3 - CIN 3
- Squamous cell carcinoma - SCC
- Adenocarcinoma - AC
- No lesion
</details>
## Dataset Creation
### Curation Rationale
CCAgT was built to provide a dataset for machines to learn how to identify nucleus and nucleolus organizer regions (NORs).
### Source Data
#### Initial Data Collection and Normalization
The images are collected as patches/tiles of whole slide images (WSIs) from cervical samples stained with AgNOR technique to allow the detection of nucleolus organizer regions (NORs). NORs are DNA loops containing genes responsible for the transcription of ribosomal RNA located in the cell nucleolus. They contain a set of argyrophilic proteins, selectively stained by silver nitrate, which can be identified as black dots located throughout the nucleoli area and called AgNORs.
#### Who are the source language producers?
The dataset was built using images from examinations (a gynecological exam, colposcopy and biopsy) of 15 women patients who were treated at the Gynecology and Colposcopy Outpatient Clinic of the [University Hospital Professor Polydoro Ernani de São Thiago of Federal University of Santa Catarina (HU-UFSC)](https://unihospital.ufsc.br/) and had 6 different diagnoses in their oncological exams. The samples were collected by the members of the Clinical Analyses Department: Ane Francyne Costa, Fabiana Botelho De Miranda Onofre, and Alexandre Sherlley Casimiro Onofre.
### Annotations
#### Annotation process
The instances were annotated using the [labelbox](https://labelbox.com/) tool. The satellite category was labeled as a single dot, and the other categories were labeled as polygons. After the annotation process, all annotations were reviewed.
#### Who are the annotators?
Members of the Clinical Analyses Department and the Image Processing and Computer Graphics Lab. — LAPiX from [Universidade Federal de Santa Catarina (UFSC)](https://en.ufsc.br/).
- Tainee Bottamedi
- Vinícius Sanches
- João H. Telles de Carvalho
- Ricardo Thisted
### Personal and Sensitive Information
This research was approved by the UFSC Research Ethics Committee (CEPSH), protocol number 57423616.3.0000.0121. All involved patients were informed about the study's objectives, and those who agreed to participate signed an informed consent form.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset's purpose is to help spread the AgNOR as a support method for cancer diagnosis since this method is not standardized among pathologists.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
Satellite annotation is not as accurate for pixel-level representation due to single-point annotations.
## Additional Information
### Dataset Curators
Members of the Clinical Analyses Department from [Universidade Federal de Santa Catarina (UFSC)](https://en.ufsc.br/) collected the dataset samples: Ane Francyne Costa, Fabiana Botelho De Miranda Onofre, and Alexandre Sherlley Casimiro Onofre.
### Licensing Information
The files associated with this dataset are licensed under an [Attribution-NonCommercial 3.0 Unported](https://creativecommons.org/licenses/by-nc/3.0/) license.
Users are free to adapt, copy or redistribute the material as long as they attribute it appropriately and do not use it for commercial purposes.
### Citation Information
```bibtex
% Dataset oficial page
@misc{CCAgTDataset,
doi = {10.17632/WG4BPM33HJ.2},
url = {https://data.mendeley.com/datasets/wg4bpm33hj/2},
author = {Jo{\~{a}}o Gustavo Atkinson Amorim and Andr{\'{e}} Vict{\'{o}}ria Matias and Tainee Bottamedi and Vin{\'{i}}us Sanches and Ane Francyne Costa and Fabiana Botelho De Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim},
title = {CCAgT: Images of Cervical Cells with AgNOR Stain Technique},
publisher = {Mendeley},
year = {2022},
copyright = {Attribution-NonCommercial 3.0 Unported}
}
% Dataset second version
% pre-print:
@article{AtkinsonAmorim2022,
doi = {10.2139/ssrn.4126881},
url = {https://doi.org/10.2139/ssrn.4126881},
year = {2022},
publisher = {Elsevier {BV}},
author = {Jo{\~{a}}o Gustavo Atkinson Amorim and Andr{\'{e}} Vict{\'{o}}ria Matias and Allan Cerentini and Fabiana Botelho de Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim},
title = {Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the {AgNOR} Technique},
journal = {{SSRN} Electronic Journal}
}
% Dataset first version
% Link: https://arquivos.ufsc.br/d/373be2177a33426a9e6c/
% Paper:
@inproceedings{AtkinsonSegmentationAgNORCBMS2020,
author={Jo{\~{a}}o Gustavo Atkinson Amorim and Luiz Antonio Buschetto Macarini and Andr{\'{e}} Vict{\'{o}}ria Matias and Allan Cerentini and Fabiana Botelho De Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim},
booktitle={2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS)},
title={A Novel Approach on Segmentation of AgNOR-Stained Cytology Images Using Deep Learning},
year={2020},
pages={552-557},
doi={10.1109/CBMS49503.2020.00110},
url={https://doi.org/10.1109/CBMS49503.2020.00110}
}
```
### Contributions
Thanks to [@johnnv1](https://github.com/johnnv1) for adding this dataset. | 16,964 | [
[
-0.04925537109375,
-0.051055908203125,
0.0218353271484375,
-0.01245880126953125,
-0.0465087890625,
-0.0125885009765625,
0.0034942626953125,
-0.0300445556640625,
0.0176239013671875,
0.02862548828125,
-0.038726806640625,
-0.07366943359375,
-0.034759521484375,
... |
Paul/hatecheck-dutch | 2022-07-05T10:41:31.000Z | [
"task_categories:text-classification",
"task_ids:hate-speech-detection",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:nl",
"license:cc-by-4.0",
"arxiv:2206.09917",
"regi... | Paul | null | null | 1 | 4 | 2022-07-05T10:40:49 | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- nl
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Dutch HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. | 3,488 | [
[
-0.046630859375,
-0.052032470703125,
-0.004009246826171875,
0.00669097900390625,
-0.00839996337890625,
0.00782012939453125,
-0.002201080322265625,
-0.037078857421875,
0.029052734375,
0.0238189697265625,
-0.055145263671875,
-0.056121826171875,
-0.0408935546875,
... |
Paul/hatecheck-arabic | 2022-07-05T10:43:02.000Z | [
"task_categories:text-classification",
"task_ids:hate-speech-detection",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ar",
"license:cc-by-4.0",
"arxiv:2206.09917",
"regi... | Paul | null | null | 1 | 4 | 2022-07-05T10:42:16 | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- ar
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Arabic HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. | 3,489 | [
[
-0.046661376953125,
-0.05206298828125,
-0.0040130615234375,
0.006702423095703125,
-0.008392333984375,
0.00782012939453125,
-0.0022068023681640625,
-0.037109375,
0.0290679931640625,
0.023834228515625,
-0.055206298828125,
-0.056182861328125,
-0.040863037109375,
... |
SocialGrep/one-year-of-tsla-on-reddit | 2022-07-07T18:54:18.000Z | [
"annotations_creators:lexyr",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"region:us"
] | SocialGrep | This dataset contains all the posts and comments mentioning the term "TSLA", spanning from July 5th, 2021 to July 4th, 2022. | null | 1 | 4 | 2022-07-07T17:23:17 | ---
annotations_creators:
- lexyr
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
---
# Dataset Card for one-year-of-tsla-on-reddit
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Homepage:** [https://socialgrep.com/datasets](https://socialgrep.com/datasets/one-year-of-tsla-on-reddit?utm_source=huggingface&utm_medium=link&utm_campaign=oneyearoftslaonreddit)
- **Reddit downloader used:** [https://socialgrep.com/exports](https://socialgrep.com/exports?utm_source=huggingface&utm_medium=link&utm_campaign=oneyearoftslaonreddit)
- **Point of Contact:** [Website](https://socialgrep.com/contact?utm_source=huggingface&utm_medium=link&utm_campaign=oneyearoftslaonreddit)
### Dataset Summary
A year's worth of mentions of Tesla Inc. (TSLA) in Reddit posts and comments.
### Languages
Mainly English.
## Dataset Structure
### Data Instances
A data point is a post or a comment. Due to the separate nature of the two, those exist in two different files - even though many fields are shared.
### Data Fields
- 'type': the type of the data point. Can be 'post' or 'comment'.
- 'id': the base-36 Reddit ID of the data point. Unique when combined with type.
- 'subreddit.id': the base-36 Reddit ID of the data point's host subreddit. Unique.
- 'subreddit.name': the human-readable name of the data point's host subreddit.
- 'subreddit.nsfw': a boolean marking the data point's host subreddit as NSFW or not.
- 'created_utc': a UTC timestamp for the data point.
- 'permalink': a reference link to the data point on Reddit.
- 'score': score of the data point on Reddit.
- 'domain': (Post only) the domain of the data point's link.
- 'url': (Post only) the destination of the data point's link, if any.
- 'selftext': (Post only) the self-text of the data point, if any.
- 'title': (Post only) the title of the post data point.
- 'body': (Comment only) the body of the comment data point.
- 'sentiment': (Comment only) the result of an in-house sentiment analysis pipeline. Used for exploratory analysis.
## Additional Information
### Licensing Information
CC-BY v4.0
| 3,086 | [
[
-0.0335693359375,
-0.054229736328125,
0.019317626953125,
0.034393310546875,
-0.0386962890625,
0.015350341796875,
0.00354766845703125,
-0.0223541259765625,
0.05206298828125,
0.01617431640625,
-0.07452392578125,
-0.0672607421875,
-0.038787841796875,
0.01204681... |
embedding-data/PAQ_pairs | 2022-08-02T02:58:28.000Z | [
"task_categories:sentence-similarity",
"task_ids:semantic-similarity-classification",
"language:en",
"license:mit",
"arxiv:2102.07033",
"region:us"
] | embedding-data | null | null | 1 | 4 | 2022-07-08T17:05:27 | ---
license: mit
language:
- en
paperswithcode_id: embedding-data/PAQ_pairs
pretty_name: PAQ_pairs
task_categories:
- sentence-similarity
- paraphrase-mining
task_ids:
- semantic-similarity-classification
---
# Dataset Card for "PAQ_pairs"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/facebookresearch/PAQ](https://github.com/facebookresearch/PAQ)
- **Repository:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Paper:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Point of Contact:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Size of downloaded dataset files:**
- **Size of the generated dataset:**
- **Total amount of disk used:** 21 Bytes
### Dataset Summary
Pairs questions and answers obtained from Wikipedia.
Disclaimer: The team releasing PAQ QA pairs did not upload the dataset to the Hub and did not write a dataset card.
These steps were done by the Hugging Face team.
### Supported Tasks
- [Sentence Transformers](https://huggingface.co/sentence-transformers) training; useful for semantic search and sentence similarity.
### Languages
- English.
## Dataset Structure
Each example in the dataset contains pairs of sentences and is formatted as a dictionary with the key "set" and a list with the sentences as "value". The first sentence is a question and the second an answer; thus, both sentences would be similar.
```
{"set": [sentence_1, sentence_2]}
{"set": [sentence_1, sentence_2]}
...
{"set": [sentence_1, sentence_2]}
```
This dataset is useful for training Sentence Transformers models. Refer to the following post on how to train models using similar pairs of sentences.
### Usage Example
Install the 🤗 Datasets library with `pip install datasets` and load the dataset from the Hub with:
```python
from datasets import load_dataset
dataset = load_dataset("embedding-data/PAQ_pairs")
```
The dataset is loaded as a `DatasetDict` and has the format:
```python
DatasetDict({
train: Dataset({
features: ['set'],
num_rows: 64371441
})
})
```
Review an example `i` with:
```python
dataset["train"][i]["set"]
```
### Data Instances
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Data Fields
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Data Splits
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Dataset Creation
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Curation Rationale
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/facebookresearch/PAQ)
#### Who are the source language producers?
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/facebookresearch/PAQ)
#### Who are the annotators?
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Personal and Sensitive Information
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Discussion of Biases
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Other Known Limitations
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Licensing Information
The PAQ QA-pairs and metadata is licensed under [CC-BY-SA](https://creativecommons.org/licenses/by-sa/3.0/).
Other data is licensed according to the accompanying license files.
### Citation Information
```
@article{lewis2021paq,
title={PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them},
author={Patrick Lewis and Yuxiang Wu and Linqing Liu and Pasquale Minervini and Heinrich Küttler and Aleksandra Piktus and Pontus Stenetorp and Sebastian Riedel},
year={2021},
eprint={2102.07033},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@patrick-s-h-lewis](https://github.com/patrick-s-h-lewis) for adding this dataset.
| 5,404 | [
[
-0.0311279296875,
-0.0546875,
0.0216217041015625,
0.0157318115234375,
0.0016021728515625,
-0.0203399658203125,
-0.007457733154296875,
0.003726959228515625,
0.032958984375,
0.04132080078125,
-0.051666259765625,
-0.046295166015625,
-0.02777099609375,
-0.000228... |
zhifei/autotrain-data-chinese-title-summarization-9.4 | 2022-07-13T00:55:58.000Z | [
"region:us"
] | zhifei | null | null | 0 | 4 | 2022-07-13T00:54:55 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
openclimatefix/nimrod-uk-1km-validation | 2022-07-18T17:01:14.000Z | [
"region:us"
] | openclimatefix | null | null | 0 | 4 | 2022-07-15T19:42:12 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
jvanz/portuguese_sentiment_analysis | 2022-09-05T20:23:58.000Z | [
"region:us"
] | jvanz | null | null | 2 | 4 | 2022-07-16T18:27:31 | This dataset is based on the dataset originally posted in [Kaggle](https://www.kaggle.com/datasets/fredericods/ptbr-sentiment-analysis-datasets?resource=download) | 162 | [
[
-0.01204681396484375,
-0.03961181640625,
0.019622802734375,
0.04278564453125,
-0.001476287841796875,
0.00525665283203125,
0.006580352783203125,
-0.0182037353515625,
0.037811279296875,
0.06365966796875,
-0.0634765625,
-0.032562255859375,
-0.0268096923828125,
... |
jonaskoenig/topic_classification | 2022-07-19T14:35:34.000Z | [
"region:us"
] | jonaskoenig | null | null | 0 | 4 | 2022-07-18T17:19:32 | Entry not found | 15 | [
[
-0.021392822265625,
-0.01494598388671875,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.01702880859375,
-0.052093505859375,
-0.01494598388671875,
-0.06036376953125,
0.03790... |
Muennighoff/mbpp | 2022-10-20T19:43:58.000Z | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"language:en",
"license:c... | Muennighoff | The MBPP (Mostly Basic Python Problems) dataset consists of around 1,000 crowd-sourced Python
programming problems, designed to be solvable by entry level programmers, covering programming
fundamentals, standard library functionality, and so on. Each problem consists of a task
description, code solution and 3 automated test cases. | @article{austin2021program,
title={Program Synthesis with Large Language Models},
author={Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and others},
journal={arXiv preprint arXiv:2108.07732},
year={2021}
} | 1 | 4 | 2022-07-18T19:05:21 | ---
annotations_creators:
- crowdsourced
- expert-generated
language_creators:
- crowdsourced
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- n<1K
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
pretty_name: Mostly Basic Python Problems
tags:
- code-generation
---
# Dataset Card for Mostly Basic Python Problems (mbpp)
## Table of Contents
- [Dataset Card for Mostly Basic Python Problems (mbpp)](#dataset-card-for-mostly-basic-python-problems-(mbpp))
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/google-research/google-research/tree/master/mbpp
- **Paper:** [Program Synthesis with Large Language Models](https://arxiv.org/abs/2108.07732)
### Dataset Summary
The benchmark consists of around 1,000 crowd-sourced Python programming problems, designed to be solvable by entry level programmers, covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases. As described in the paper, a subset of the data has been hand-verified by us.
Released [here](https://github.com/google-research/google-research/tree/master/mbpp) as part of [Program Synthesis with Large Language Models, Austin et. al., 2021](https://arxiv.org/abs/2108.07732).
### Supported Tasks and Leaderboards
This dataset is used to evaluate code generations.
### Languages
English - Python code
## Dataset Structure
```python
dataset_full = load_dataset("mbpp")
DatasetDict({
test: Dataset({
features: ['task_id', 'text', 'code', 'test_list', 'test_setup_code', 'challenge_test_list'],
num_rows: 974
})
})
dataset_sanitized = load_dataset("mbpp", "sanitized")
DatasetDict({
test: Dataset({
features: ['source_file', 'task_id', 'prompt', 'code', 'test_imports', 'test_list'],
num_rows: 427
})
})
```
### Data Instances
#### mbpp - full
```
{
'task_id': 1,
'text': 'Write a function to find the minimum cost path to reach (m, n) from (0, 0) for the given cost matrix cost[][] and a position (m, n) in cost[][].',
'code': 'R = 3\r\nC = 3\r\ndef min_cost(cost, m, n): \r\n\ttc = [[0 for x in range(C)] for x in range(R)] \r\n\ttc[0][0] = cost[0][0] \r\n\tfor i in range(1, m+1): \r\n\t\ttc[i][0] = tc[i-1][0] + cost[i][0] \r\n\tfor j in range(1, n+1): \r\n\t\ttc[0][j] = tc[0][j-1] + cost[0][j] \r\n\tfor i in range(1, m+1): \r\n\t\tfor j in range(1, n+1): \r\n\t\t\ttc[i][j] = min(tc[i-1][j-1], tc[i-1][j], tc[i][j-1]) + cost[i][j] \r\n\treturn tc[m][n]',
'test_list': [
'assert min_cost([[1, 2, 3], [4, 8, 2], [1, 5, 3]], 2, 2) == 8',
'assert min_cost([[2, 3, 4], [5, 9, 3], [2, 6, 4]], 2, 2) == 12',
'assert min_cost([[3, 4, 5], [6, 10, 4], [3, 7, 5]], 2, 2) == 16'],
'test_setup_code': '',
'challenge_test_list': []
}
```
#### mbpp - sanitized
```
{
'source_file': 'Benchmark Questions Verification V2.ipynb',
'task_id': 2,
'prompt': 'Write a function to find the shared elements from the given two lists.',
'code': 'def similar_elements(test_tup1, test_tup2):\n res = tuple(set(test_tup1) & set(test_tup2))\n return (res) ',
'test_imports': [],
'test_list': [
'assert set(similar_elements((3, 4, 5, 6),(5, 7, 4, 10))) == set((4, 5))',
'assert set(similar_elements((1, 2, 3, 4),(5, 4, 3, 7))) == set((3, 4))',
'assert set(similar_elements((11, 12, 14, 13),(17, 15, 14, 13))) == set((13, 14))'
]
}
```
### Data Fields
- `source_file`: unknown
- `text`/`prompt`: description of programming task
- `code`: solution for programming task
- `test_setup_code`/`test_imports`: necessary code imports to execute tests
- `test_list`: list of tests to verify solution
- `challenge_test_list`: list of more challenging test to further probe solution
### Data Splits
There are two version of the dataset (full and sanitized) which only one split each (test).
## Dataset Creation
See section 2.1 of original [paper](https://arxiv.org/abs/2108.07732).
### Curation Rationale
In order to evaluate code generation functions a set of simple programming tasks as well as solutions is necessary which this dataset provides.
### Source Data
#### Initial Data Collection and Normalization
The dataset was manually created from scratch.
#### Who are the source language producers?
The dataset was created with an internal crowdsourcing effort at Google.
### Annotations
#### Annotation process
The full dataset was created first and a subset then underwent a second round to improve the task descriptions.
#### Who are the annotators?
The dataset was created with an internal crowdsourcing effort at Google.
### Personal and Sensitive Information
None.
## Considerations for Using the Data
Make sure you execute generated Python code in a safe environment when evauating against this dataset as generated code could be harmful.
### Social Impact of Dataset
With this dataset code generating models can be better evaluated which leads to fewer issues introduced when using such models.
### Discussion of Biases
### Other Known Limitations
Since the task descriptions might not be expressive enough to solve the task. The `sanitized` split aims at addressing this issue by having a second round of annotators improve the dataset.
## Additional Information
### Dataset Curators
Google Research
### Licensing Information
CC-BY-4.0
### Citation Information
```
@article{austin2021program,
title={Program Synthesis with Large Language Models},
author={Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and others},
journal={arXiv preprint arXiv:2108.07732},
year={2021}
```
### Contributions
Thanks to [@lvwerra](https://github.com/lvwerra) for adding this dataset.
| 7,341 | [
[
-0.035614013671875,
-0.044036865234375,
0.0171661376953125,
0.025115966796875,
0.0137786865234375,
-0.007293701171875,
-0.016448974609375,
-0.0199432373046875,
0.002288818359375,
0.02734375,
-0.0452880859375,
-0.04132080078125,
-0.0307464599609375,
0.0099411... |
openclimatefix/era5-land | 2022-12-01T12:38:35.000Z | [
"license:mit",
"region:us"
] | openclimatefix | null | null | 1 | 4 | 2022-07-23T15:13:58 | ---
license: mit
---
This dataset is comprised of ECMWF ERA5-Land data covering 2014 to October 2022. This data is on a 0.1 degree grid and has fewer variables than the standard ERA5-reanalysis, but at a higher resolution. All the data has been downloaded as NetCDF files from the Copernicus Data Store and converted to Zarr using Xarray, then uploaded here. Each file is one day, and holds 24 timesteps. | 405 | [
[
-0.06964111328125,
-0.01371002197265625,
0.02142333984375,
-0.0003018379211425781,
-0.0164794921875,
-0.02569580078125,
0.00787353515625,
-0.027130126953125,
0.00826263427734375,
0.07476806640625,
-0.0714111328125,
-0.05718994140625,
-0.0169830322265625,
0.0... |
gorkaartola/SC-ZS-test_AURORA-Gold-SDG_True-Positives-and-False-Positives | 2023-03-22T21:22:16.000Z | [
"region:us"
] | gorkaartola | null | null | 0 | 4 | 2022-07-25T18:11:40 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
gorkaartola/SDG_queries | 2023-04-13T12:49:05.000Z | [
"region:us"
] | gorkaartola | null | null | 0 | 4 | 2022-07-28T20:16:18 | Entry not found | 15 | [
[
-0.021392822265625,
-0.01494598388671875,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.01702880859375,
-0.052093505859375,
-0.01494598388671875,
-0.06036376953125,
0.03790... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.