
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
abdoutony207/en_ar_dataset | abdoutony207 | 2022-05-28T18:52:55Z | 13 | 0 | null | [
"region:us"
] | 2022-05-28T18:52:55Z | 2022-05-28T18:28:41.000Z | 2022-05-28T18:28:41 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vcv/sentiment-banking | vcv | 2022-06-06T09:42:57Z | 13 | 0 | null | [
"region:us"
] | 2022-06-06T09:42:57Z | 2022-05-28T18:36:22.000Z | 2022-05-28T18:36:22 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Rexhaif/cedr-full | Rexhaif | 2022-05-29T22:31:49Z | 13 | 0 | null | [
"region:us"
] | 2022-05-29T22:31:49Z | 2022-05-29T22:29:09.000Z | 2022-05-29T22:29:09 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
meetyildiz/toqad-aug | meetyildiz | 2022-05-30T06:26:00Z | 13 | 0 | null | [
"region:us"
] | 2022-05-30T06:26:00Z | 2022-05-30T06:24:43.000Z | 2022-05-30T06:24:43 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
NLPC-UOM/Sentiment-tagger | NLPC-UOM | 2022-10-25T10:29:09Z | 13 | 0 | null | [
"language:si",
"license:mit",
"region:us"
] | 2022-10-25T10:29:09Z | 2022-06-03T15:51:41.000Z | 2022-06-03T15:51:41 | ---
language:
- si
license:
- mit
---
*Sentiment Analysis of Sinhala News Comments*
Dataset used in this project is collected by crawling Sinhala online news sites, mainly www.lankadeepa.lk.
contact
Please contact us if you need more information.
Surangika Ranathunga-surangika@cse.mrt.ac.lk
Isuru Liyanage-theisuru@gmail.com
https://github.com/theisuru/sentiment-tagger
cite
If you use this data please cite this work
Ranathunga, S., & Liyanage, I. U. (2021). Sentiment Analysis of Sinhala News Comments. Transactions on Asian and Low-Resource Language Information Processing, 20(4), 1-23.
| [
-0.14582060277462006,
-0.498007595539093,
-0.07850293815135956,
0.58656245470047,
-0.733677327632904,
0.07148933410644531,
-0.12579485774040222,
-0.24300114810466766,
0.7380655407905579,
0.38943737745285034,
-0.486223042011261,
-0.17131152749061584,
-0.2566794157028198,
0.426265150308609,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
PLN-Activdad-2/sentiment-banking | PLN-Activdad-2 | 2022-06-03T17:08:37Z | 13 | 0 | null | [
"region:us"
] | 2022-06-03T17:08:37Z | 2022-06-03T17:08:05.000Z | 2022-06-03T17:08:05 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yanekyuk/wikikey-fr | yanekyuk | 2022-09-17T02:21:13Z | 13 | 0 | null | [
"language:fr",
"region:us"
] | 2022-09-17T02:21:13Z | 2022-06-03T18:05:45.000Z | 2022-06-03T18:05:45 | ---
language: fr
--- | [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
limsc/mlm-tapt-requirements | limsc | 2022-06-04T04:30:23Z | 13 | 0 | null | [
"region:us"
] | 2022-06-04T04:30:23Z | 2022-06-04T04:25:57.000Z | 2022-06-04T04:25:57 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
limsc/fr-nfr-classification | limsc | 2022-06-05T00:16:48Z | 13 | 0 | null | [
"region:us"
] | 2022-06-05T00:16:48Z | 2022-06-04T04:33:19.000Z | 2022-06-04T04:33:19 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
limsc/req-subclass-classification | limsc | 2022-06-14T22:19:20Z | 13 | 1 | null | [
"region:us"
] | 2022-06-14T22:19:20Z | 2022-06-04T04:33:38.000Z | 2022-06-04T04:33:38 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
awghuku/infore25 | awghuku | 2022-06-04T05:55:22Z | 13 | 0 | null | [
"license:cc-by-4.0",
"region:us"
] | 2022-06-04T05:55:22Z | 2022-06-04T04:53:29.000Z | 2022-06-04T04:53:29 | ---
license: cc-by-4.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nateraw/imagefolder-metadata-test | nateraw | 2022-06-07T03:06:07Z | 13 | 0 | null | [
"region:us"
] | 2022-06-07T03:06:07Z | 2022-06-07T02:48:56.000Z | 2022-06-07T02:48:56 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
limsc/concept-recognition-not-iob | limsc | 2022-06-08T04:41:48Z | 13 | 0 | null | [
"region:us"
] | 2022-06-08T04:41:48Z | 2022-06-08T04:41:44.000Z | 2022-06-08T04:41:44 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
demo-org/auditor_review | demo-org | 2022-08-30T21:42:09Z | 13 | 0 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"region:us"
] | 2022-08-30T21:42:09Z | 2022-06-14T03:06:17.000Z | 2022-06-14T03:06:17 | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
- sentiment-classification
paperswithcode_id: null
pretty_name: Auditor_Review
---
# Dataset Card for Auditor_Review
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
## Dataset Description
Auditor review data collected by News Department
- **Point of Contact:**
Talked to COE for Auditing, currently sue@demo.org
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
```
"sentence": "Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .",
"label": "negative"
```
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0)
Complete data code is [available here](https://www.datafiles.samhsa.gov/get-help/codebooks/what-codebook)
### Data Splits
A train/test split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
To gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news reports.
#### Who are the source language producers?
The source data was written by various auditors.
### Annotations
#### Annotation process
This release of the auditor reviews covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.
#### Who are the annotators?
They were pulled from the SME list, names are held by sue@demo.org
### Personal and Sensitive Information
There is no personal or sensitive information in this dataset.
## Considerations for Using the Data
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
The [Dataset Measurement tool](https://huggingface.co/spaces/huggingface/data-measurements-tool) identified these bias statistics:
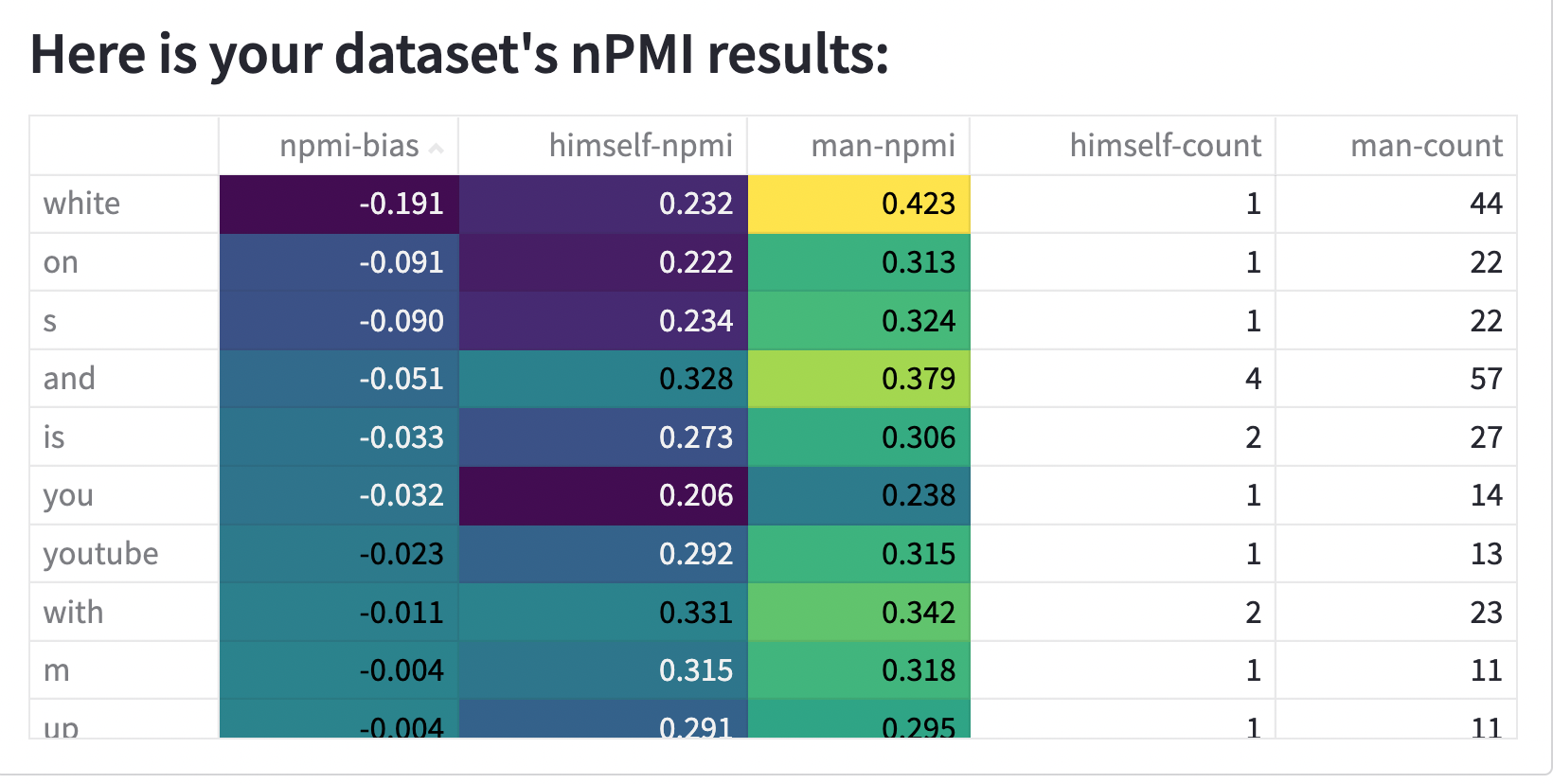
### Other Known Limitations
[More Information Needed]
### Licensing Information
License: Demo.Org Proprietary - DO NOT SHARE | [
-0.5004733800888062,
-0.27193865180015564,
0.014816772192716599,
0.3621878921985626,
-0.48215603828430176,
-0.1183815598487854,
-0.120775505900383,
-0.47154954075813293,
0.4688456058502197,
0.5331881046295166,
-0.5158435702323914,
-0.7979121208190918,
-0.6103346943855286,
0.292323529720306... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pszemraj/multi_fc | pszemraj | 2022-06-16T11:57:52Z | 13 | 0 | null | [
"license:other",
"automatic claim verification",
"claims",
"arxiv:1909.03242",
"region:us"
] | 2022-06-16T11:57:52Z | 2022-06-15T11:27:47.000Z | 2022-06-15T11:27:47 | ---
license: other
tags:
- automatic claim verification
- claims
---
# multiFC
- a dataset for the task of **automatic claim verification**
- License is currently unknown, please refer to the original paper/[dataset site](http://www.copenlu.com/publication/2019_emnlp_augenstein/):
- https://arxiv.org/abs/1909.03242
## Dataset contents
- **IMPORTANT:** the `label` column in the `test` set has dummy values as these were not provided (see original readme section for explanation)
```
DatasetDict({
train: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 27871
})
test: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 3487
})
validation: Dataset({
features: ['claimID', 'claim', 'label', 'claimURL', 'reason', 'categories', 'speaker', 'checker', 'tags', 'article title', 'publish date', 'climate', 'entities'],
num_rows: 3484
})
})
```
## Paper Abstract / Citation
> We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.
```
@inproceedings{conf/emnlp2019/Augenstein,
added-at = {2019-10-27T00:00:00.000+0200},
author = {Augenstein, Isabelle and Lioma, Christina and Wang, Dongsheng and Chaves Lima, Lucas and Hansen, Casper and Hansen, Christian and Grue Simonsen, Jakob},
booktitle = {EMNLP},
crossref = {conf/emnlp/2019},
publisher = {Association for Computational Linguistics},
title = {MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims},
year = 2019
}
```
## Original README
Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims
The MultiFC is the largest publicly available dataset of naturally occurring factual claims for automatic claim verification.
It is collected from 26 English fact-checking websites paired with textual sources and rich metadata and labeled for veracity by human expert journalists.
###### TRAIN and DEV #######
The train and dev files are (tab-separated) and contain the following metadata:
claimID, claim, label, claimURL, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### TEST #######
The test file follows the same structure. However, we have removed the label. Thus, it only presents 12 metadata.
claimID, claim, claim, reason, categories, speaker, checker, tags, article title, publish date, climate, entities
Fields that could not be crawled were set as "None." Please refer to Table 11 of our paper to see the summary statistics.
###### Snippets ######
The text of each claim is submitted verbatim as a query to the Google Search API (without quotes).
In the folder snippet, we provide the top 10 snippets retrieved. In some cases, fewer snippets are provided
since we have excluded the claimURL from the snippets.
Each file in the snippets folder is named after the claimID of the claim submitted as a query.
Snippets file is (tab-separated) and contains the following metadata:
rank_position, title, snippet, snippet_url
For more information, please refer to our paper:
References:
Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019.
MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims. In EMNLP. Association for Computational Linguistics.
https://copenlu.github.io/publication/2019_emnlp_augenstein/
| [
-0.389263391494751,
-0.645091712474823,
0.3027518391609192,
0.19997328519821167,
0.05859309807419777,
0.1025141179561615,
-0.2937428057193756,
-0.6046632528305054,
0.19315548241138458,
0.30019092559814453,
-0.4197578728199005,
-0.7343537211418152,
-0.5887863636016846,
0.3787493109703064,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
EddieChen372/js2jest | EddieChen372 | 2022-06-17T05:51:23Z | 13 | 0 | null | [
"region:us"
] | 2022-06-17T05:51:23Z | 2022-06-17T05:51:00.000Z | 2022-06-17T05:51:00 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
EddieChen372/js2jestFiles | EddieChen372 | 2022-06-17T05:56:57Z | 13 | 0 | null | [
"region:us"
] | 2022-06-17T05:56:57Z | 2022-06-17T05:56:48.000Z | 2022-06-17T05:56:48 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
marcomameli01/gear | marcomameli01 | 2022-06-17T07:37:26Z | 13 | 0 | null | [
"region:us"
] | 2022-06-17T07:37:26Z | 2022-06-17T07:06:41.000Z | 2022-06-17T07:06:41 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
iohadrubin/qampari | iohadrubin | 2022-06-28T11:43:03Z | 13 | 0 | null | [
"region:us"
] | 2022-06-28T11:43:03Z | 2022-06-19T11:44:36.000Z | 2022-06-19T11:44:36 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
athar/cc | athar | 2022-06-20T19:24:00Z | 13 | 0 | null | [
"region:us"
] | 2022-06-20T19:24:00Z | 2022-06-20T19:23:25.000Z | 2022-06-20T19:23:25 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Mandarin_Heavy_Accent_Speech_Data | Nexdata | 2023-08-30T10:38:08Z | 13 | 0 | null | [
"region:us"
] | 2023-08-30T10:38:08Z | 2022-06-22T06:26:29.000Z | 2022-06-22T06:26:29 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Mandarin_Heavy_Accent_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/44?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
It collects 2,034 local Chinese from 26 provinces like Henan, Shanxi, Sichuan, Hunan, Fujian, etc. It is mandarin speech data with heavy accent. The recoring contents are finance and economics, entertainment, policy, news, TV, and movies.
For more details, please refer to the link: https://www.nexdata.ai/datasets/44?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin Chinese
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions
| [
-0.34986183047294617,
-0.525627851486206,
-0.2101520299911499,
0.4491666555404663,
-0.15685033798217773,
0.01937953196465969,
-0.48308202624320984,
-0.39874619245529175,
0.5859537720680237,
0.7277745604515076,
-0.6200095415115356,
-0.8941694498062134,
-0.3983449339866638,
0.158361062407493... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Hong_Kong_Cantonese_Average_Tone_Speech_Synthesis_Corpus | Nexdata | 2023-11-10T07:28:26Z | 13 | 0 | null | [
"task_categories:text-to-speech",
"region:us"
] | 2023-11-10T07:28:26Z | 2022-06-22T06:29:49.000Z | 2022-06-22T06:29:49 | ---
task_categories:
- text-to-speech
---
# Dataset Card for Nexdata/Hong_Kong_Cantonese_Average_Tone_Speech_Synthesis_Corpus
## Description
38 People - Hong Kong Cantonese Average Tone Speech Synthesis Corpus, It is recorded by Hong Kong native speakers. Professional phonetician participates in the annotation. It precisely matches with the research and development needs of the speech synthesis.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1201?source=Huggingface
# Specifications
## Format
44,100Hz, 16bit, uncompressed wav, mono channel;
## Recording environment
quiet indoor environment, low background noise, without echo;
## Recording content
news and colloquial sentences;
## Speaker
9 males, 29 females;
## Device
microphone;
## Language
Cantonese, English;
## Annotation
word and phoneme transcription, prosodic boundary annotation;
## Application scenarios
speech synthesis.
# Licensing Information
Commercial License | [
-0.5782986879348755,
-0.5346205830574036,
-0.05397948622703552,
0.7543428540229797,
-0.20985743403434753,
0.029333626851439476,
0.019770175218582153,
-0.34381210803985596,
0.7241925597190857,
0.48058798909187317,
-0.4898296296596527,
-0.9191222190856934,
-0.10315611958503723,
0.24369911849... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Chinese_Mandarin_Speech_Synthesis_Corpus-Female_Imitating_Children | Nexdata | 2023-08-30T10:37:14Z | 13 | 0 | null | [
"region:us"
] | 2023-08-30T10:37:14Z | 2022-06-22T06:44:34.000Z | 2022-06-22T06:44:34 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Chinese_Mandarin_Speech_Synthesis_Corpus-Female_Imitating_Children
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1091?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Female audio data of adults imitating children, 6599 sentences in total and 6.78 hours. It is recorded by Chinese native speakers, with authentic accent and sweet sound. The phoneme coverage is balanced. Professional phonetician participates in the annotation. It precisely matches with the research and development needs of the speech synthesis.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1091?source=Huggingface
### Supported Tasks and Leaderboards
tts: The dataset can be used to train a model for Text to Speech (TTS).
### Languages
Mandarin Chinese
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.32478588819503784,
-0.671369194984436,
-0.15203078091144562,
0.4658643305301666,
-0.07453054189682007,
0.03561443090438843,
-0.284728467464447,
-0.40323591232299805,
0.47192803025245667,
0.5587317943572998,
-0.8008309006690979,
-0.8488197326660156,
-0.4153824746608734,
0.144513517618179... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Sichuan_Dialect_Speech_Data_by_Mobile_Phone | Nexdata | 2023-08-30T10:41:35Z | 13 | 0 | null | [
"region:us"
] | 2023-08-30T10:41:35Z | 2022-06-22T06:47:11.000Z | 2022-06-22T06:47:11 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Sichuan_Dialect_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/52?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
It collects 2,507 speakers from Sichuan Basin and is recorded in quiet indoor environment. The recorded content covers customer consultation and text messages in many fields. The average number of repetitions is 1.3 and the average sentence length is 12.5 words. Sichuan natives participate in quality inspection and proofreading to ensure the accuracy of the text transcription.
For more details, please refer to the link: https://www.nexdata.ai/datasets/52?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Sichuan Dialect
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.4030243158340454,
-0.5431419610977173,
-0.15489724278450012,
0.5324883460998535,
-0.17368686199188232,
-0.18357619643211365,
-0.49006858468055725,
-0.3750428855419159,
0.4709964394569397,
0.563991367816925,
-0.5898035764694214,
-0.885397732257843,
-0.5027638077735901,
0.2107145637273788... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Korean_Speech_Data_by_Mobile_Phone_Guiding | Nexdata | 2023-08-30T10:38:49Z | 13 | 0 | null | [
"region:us"
] | 2023-08-30T10:38:49Z | 2022-06-22T06:48:33.000Z | 2022-06-22T06:48:33 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Korean_Speech_Data_by_Mobile_Phone_Guiding
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/61?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
It collects 211 Korean locals and is recorded in quiet indoor environment. 99 females, 112 males. Recording devices are mainstream Android phones and iPhones.
For more details, please refer to the link: https://www.nexdata.ai/datasets/61?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Korean
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.4510541260242462,
-0.5149637460708618,
-0.01344594731926918,
0.4139609932899475,
-0.10474998503923416,
0.07964155822992325,
-0.31559517979621887,
-0.3846301734447479,
0.6008352041244507,
0.6768893003463745,
-0.8202303647994995,
-1.0467610359191895,
-0.5717546343803406,
0.122414641082286... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Taiwanese_Mandarin_Speech_Data_by_Mobile_Phone_Guiding | Nexdata | 2023-08-30T10:39:25Z | 13 | 0 | null | [
"region:us"
] | 2023-08-30T10:39:25Z | 2022-06-22T06:56:08.000Z | 2022-06-22T06:56:08 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Taiwanese_Mandarin_Speech_Data_by_Mobile_Phone_Guiding
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/64?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The data collected 203 Taiwan people, covering Taipei, Kaohsiung, Taichung, Tainan, etc. 137 females, 66 males. It is recorded in quiet indoor environment. It can be used in speech recognition, machine translation, voiceprint recognition model training and algorithm research.
For more details, please refer to the link: https://www.nexdata.ai/datasets/64?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Taiwanese Mandarin
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.3281753957271576,
-0.6601064801216125,
-0.12466676533222198,
0.36825689673423767,
-0.269060879945755,
0.10615433752536774,
-0.27883440256118774,
-0.47372087836265564,
0.5875499248504639,
0.6507775187492371,
-0.6788925528526306,
-0.85504549741745,
-0.5194734334945679,
0.15844836831092834... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
GEM-submissions/lewtun__this-is-a-test-name__1655928558 | GEM-submissions | 2022-06-22T20:09:24Z | 13 | 0 | null | [
"benchmark:gem",
"evaluation",
"benchmark",
"region:us"
] | 2022-06-22T20:09:24Z | 2022-06-22T20:09:21.000Z | 2022-06-22T20:09:21 | ---
benchmark: gem
type: prediction
submission_name: This is a test name
tags:
- evaluation
- benchmark
---
# GEM Submission
Submission name: This is a test name
| [
0.05652708560228348,
-0.9112688899040222,
0.6085131764411926,
0.11336709558963776,
-0.19541293382644653,
0.5379477739334106,
0.13777051866054535,
0.34700918197631836,
0.4342630207538605,
0.346922904253006,
-1.0974667072296143,
-0.14333292841911316,
-0.5057262778282166,
-0.01758344098925590... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
martosinc/morrowtext | martosinc | 2022-06-22T23:17:49Z | 13 | 0 | null | [
"license:mit",
"region:us"
] | 2022-06-22T23:17:49Z | 2022-06-22T23:10:16.000Z | 2022-06-22T23:10:16 | ---
license: mit
---
Contains all TES3:Morrowind dialogues and journal queries.
There are in total 4 labels: Journal, Greeting, Persuasion, Topic (Last one being the usual dialogues).
The text is already formatted and does not contain duplicates or NaNs. | [
-0.2828662097454071,
-0.5672226548194885,
0.8096381425857544,
0.44372493028640747,
-0.1460341364145279,
-0.22332894802093506,
0.08111917972564697,
-0.18562045693397522,
0.6481438875198364,
0.9023251533508301,
-0.9733201265335083,
-0.7005314230918884,
-0.3662962019443512,
0.4803466200828552... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vimal-quilt/tweet-eval-emotion | vimal-quilt | 2022-06-23T03:39:59Z | 13 | 0 | null | [
"region:us"
] | 2022-06-23T03:39:59Z | 2022-06-23T03:37:10.000Z | 2022-06-23T03:37:10 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494831 | autoevaluate | 2022-06-26T11:26:20Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:26:20Z | 2022-06-26T11:25:44.000Z | 2022-06-26T11:25:44 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: Omar95farag/distilbert-base-uncased-distilled-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: Omar95farag/distilbert-base-uncased-distilled-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.31949207186698914,
-0.26833996176719666,
0.3607659935951233,
0.14645831286907196,
0.0040358672849833965,
-0.04914836585521698,
-0.10591689497232437,
-0.43623045086860657,
-0.0530460961163044,
0.40053316950798035,
-0.7586050033569336,
-0.2800822854042053,
-0.8490405082702637,
0.070189878... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494832 | autoevaluate | 2022-06-26T11:26:25Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:26:25Z | 2022-06-26T11:25:49.000Z | 2022-06-26T11:25:49 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: abdelkader/distilbert-base-uncased-distilled-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: abdelkader/distilbert-base-uncased-distilled-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.32194066047668457,
-0.2816174030303955,
0.3827234208583832,
0.10699622333049774,
0.003293168032541871,
-0.10404712706804276,
-0.11786581575870514,
-0.42947590351104736,
-0.07240438461303711,
0.3833231031894684,
-0.7860928177833557,
-0.27853214740753174,
-0.8555137515068054,
0.0856940746... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494835 | autoevaluate | 2022-06-26T11:26:45Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:26:45Z | 2022-06-26T11:26:07.000Z | 2022-06-26T11:26:07 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: jackmleitch/distilbert-base-uncased-distilled-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: jackmleitch/distilbert-base-uncased-distilled-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.3433530628681183,
-0.30816471576690674,
0.35031887888908386,
0.12738046050071716,
-0.0031165170948952436,
-0.10865698009729385,
-0.09273131191730499,
-0.441851407289505,
-0.03247803822159767,
0.3959439992904663,
-0.7833848595619202,
-0.26483628153800964,
-0.8351922631263733,
0.096942335... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494833 | autoevaluate | 2022-06-26T11:29:12Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:29:12Z | 2022-06-26T11:26:09.000Z | 2022-06-26T11:26:09 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: aytugkaya/distilbert-base-uncased-finetuned-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: aytugkaya/distilbert-base-uncased-finetuned-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.31203827261924744,
-0.33138152956962585,
0.3543614447116852,
0.11892668902873993,
0.011499466374516487,
-0.16472606360912323,
-0.14739196002483368,
-0.48598596453666687,
-0.050841912627220154,
0.3747353255748749,
-0.8550172448158264,
-0.30836862325668335,
-0.7470162510871887,
0.01838394... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494836 | autoevaluate | 2022-06-26T11:26:51Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:26:51Z | 2022-06-26T11:26:13.000Z | 2022-06-26T11:26:13 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: moshew/distilbert-base-uncased-finetuned-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: moshew/distilbert-base-uncased-finetuned-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.38052496314048767,
-0.3064555525779724,
0.3406575620174408,
0.1091904416680336,
0.01989217847585678,
-0.18188518285751343,
-0.11674565821886063,
-0.4794706106185913,
-0.05930149182677269,
0.3945445120334625,
-0.8394550681114197,
-0.31698304414749146,
-0.7823950052261353,
0.0173779763281... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-e1907042-7494834 | autoevaluate | 2022-06-26T11:29:24Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T11:29:24Z | 2022-06-26T11:26:18.000Z | 2022-06-26T11:26:18 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- clinc_oos
eval_info:
task: multi_class_classification
model: calcworks/distilbert-base-uncased-distilled-clinc
metrics: []
dataset_name: clinc_oos
dataset_config: small
dataset_split: test
col_mapping:
text: text
target: intent
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: calcworks/distilbert-base-uncased-distilled-clinc
* Dataset: clinc_oos
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.28226587176322937,
-0.2623085379600525,
0.40725159645080566,
0.14612950384616852,
0.05031273514032364,
-0.06574318557977676,
-0.08689369261264801,
-0.3947750926017761,
-0.06106806546449661,
0.414557546377182,
-0.7575061321258545,
-0.28824758529663086,
-0.8363151550292969,
0.065889842808... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-019e0f0d-7644945 | autoevaluate | 2022-06-26T23:46:29Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T23:46:29Z | 2022-06-26T20:21:02.000Z | 2022-06-26T20:21:02 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- scientific_papers
eval_info:
task: summarization
model: google/bigbird-pegasus-large-pubmed
metrics: []
dataset_name: scientific_papers
dataset_config: pubmed
dataset_split: test
col_mapping:
text: article
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/bigbird-pegasus-large-pubmed
* Dataset: scientific_papers
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.3518012464046478,
-0.19682638347148895,
0.3941453993320465,
0.21348708868026733,
-0.08354036509990692,
-0.28260329365730286,
0.028309855610132217,
-0.45023077726364136,
0.3896665573120117,
0.3712954521179199,
-0.8963701725006104,
-0.23054854571819305,
-0.687137246131897,
0.0808169320225... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-d47ba8c2-7654948 | autoevaluate | 2022-06-26T23:44:04Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T23:44:04Z | 2022-06-26T20:22:09.000Z | 2022-06-26T20:22:09 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- scientific_papers
eval_info:
task: summarization
model: google/bigbird-pegasus-large-arxiv
metrics: []
dataset_name: scientific_papers
dataset_config: arxiv
dataset_split: test
col_mapping:
text: article
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/bigbird-pegasus-large-arxiv
* Dataset: scientific_papers
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.42531710863113403,
-0.2194414734840393,
0.319227010011673,
0.2434995472431183,
-0.1096610352396965,
-0.29965341091156006,
0.03896467015147209,
-0.480110764503479,
0.35373005270957947,
0.3629288673400879,
-0.9244767427444458,
-0.19262343645095825,
-0.6723511815071106,
0.03721149638295173... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-d47ba8c2-7654949 | autoevaluate | 2022-06-26T23:45:21Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-26T23:45:21Z | 2022-06-26T20:22:15.000Z | 2022-06-26T20:22:15 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- scientific_papers
eval_info:
task: summarization
model: google/bigbird-pegasus-large-pubmed
metrics: []
dataset_name: scientific_papers
dataset_config: arxiv
dataset_split: test
col_mapping:
text: article
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/bigbird-pegasus-large-pubmed
* Dataset: scientific_papers
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.35180070996284485,
-0.19682584702968597,
0.394145131111145,
0.21348708868026733,
-0.08354011178016663,
-0.28260308504104614,
0.02831018902361393,
-0.4502306878566742,
0.38966622948646545,
0.3712952733039856,
-0.896369993686676,
-0.2305484563112259,
-0.6871371865272522,
0.080816946923732... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
carlosejimenez/flickr30k_captions_simCSE | carlosejimenez | 2022-06-26T23:04:54Z | 13 | 0 | null | [
"region:us"
] | 2022-06-26T23:04:54Z | 2022-06-26T22:27:46.000Z | 2022-06-26T22:27:46 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Human_Facial_Skin_Defects_Data | Nexdata | 2023-08-31T02:40:21Z | 13 | 1 | null | [
"region:us"
] | 2023-08-31T02:40:21Z | 2022-06-27T08:53:34.000Z | 2022-06-27T08:53:34 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Human_Facial_Skin_Defects_Data
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1052?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
4,788 Chinese people 5,105 images Human Facial Skin Defects Data. The data includes the following five types of facial skin defects: acne, acne marks, stains, wrinkles and dark circles. This data can be used for tasks such as skin defects detection.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1052?source=Huggingface
### Supported Tasks and Leaderboards
face-detection, computer-vision: The dataset can be used to train a model for face detection.
### Languages
English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.40658465027809143,
-0.6985246539115906,
0.10469955205917358,
0.23981395363807678,
-0.09863337874412537,
0.02823297493159771,
-0.008773049339652061,
-0.6064411401748657,
0.7048903703689575,
0.8691247701644897,
-0.8061517477035522,
-1.147760033607483,
-0.37564077973365784,
-0.002353720832... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Nexdata/Re-ID_Data_in_Surveillance_Scenes | Nexdata | 2023-08-31T02:20:46Z | 13 | 0 | null | [
"region:us"
] | 2023-08-31T02:20:46Z | 2022-06-27T09:01:22.000Z | 2022-06-27T09:01:22 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Re-ID_Data_in_Surveillance_Scenes
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1129?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
10,000 People - Re-ID Data in Surveillance Scenes. The data includes indoor scenes and outdoor scenes. The data includes males and females, and the age distribution is from children to the elderly. The data diversity includes different age groups, different time periods, different shooting angles, different human body orientations and postures, clothing for different seasons. For annotation, the rectangular bounding boxes and 15 attributes of human body were annotated. The data can be used for re-id and other tasks.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1129?source=Huggingface
### Supported Tasks and Leaderboards
face-detection, computer-vision: The dataset can be used to train a model for face detection.
### Languages
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
### Citation Information
[More Information Needed]
### Contributions | [
-0.6654296517372131,
-0.6003051996231079,
0.17197982966899872,
0.1583690345287323,
-0.19097965955734253,
0.02731768600642681,
0.13537205755710602,
-0.5031320452690125,
0.7713476419448853,
0.6443144083023071,
-0.9605520367622375,
-1.0390599966049194,
-0.6385934948921204,
0.20034746825695038... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
knibu/best_sellers_june2022 | knibu | 2022-06-27T15:18:12Z | 13 | 0 | null | [
"region:us"
] | 2022-06-27T15:18:12Z | 2022-06-27T15:18:05.000Z | 2022-06-27T15:18:05 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/testhmd | davanstrien | 2022-06-28T11:14:43Z | 13 | 0 | null | [
"region:us"
] | 2022-06-28T11:14:43Z | 2022-06-27T16:50:49.000Z | 2022-06-27T16:50:49 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-d42d3c12-7815006 | autoevaluate | 2022-06-27T20:36:00Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-27T20:36:00Z | 2022-06-27T20:33:13.000Z | 2022-06-27T20:33:13 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- xtreme
eval_info:
task: entity_extraction
model: jg/xlm-roberta-base-finetuned-panx-de
metrics: []
dataset_name: xtreme
dataset_config: PAN-X.de
dataset_split: test
col_mapping:
tokens: tokens
tags: ner_tags
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: jg/xlm-roberta-base-finetuned-panx-de
* Dataset: xtreme
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.4211260676383972,
-0.1634199470281601,
0.21589486300945282,
0.06297922134399414,
-0.01105608232319355,
-0.07975266873836517,
0.03087488003075123,
-0.4349895119667053,
0.17342139780521393,
0.5043210983276367,
-0.9389719367027283,
-0.3818478286266327,
-0.7219592332839966,
-0.1004316732287... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-c967fc98-8385125 | autoevaluate | 2022-06-29T01:09:37Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-29T01:09:37Z | 2022-06-28T21:43:42.000Z | 2022-06-28T21:43:42 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- scientific_papers
eval_info:
task: summarization
model: google/bigbird-pegasus-large-arxiv
metrics: ['bertscore', 'meteor']
dataset_name: scientific_papers
dataset_config: pubmed
dataset_split: test
col_mapping:
text: article
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/bigbird-pegasus-large-arxiv
* Dataset: scientific_papers
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Blaise_g](https://huggingface.co/Blaise_g) for evaluating this model. | [
-0.42039141058921814,
-0.22555091977119446,
0.3265030086040497,
0.2382073849439621,
-0.08488292247056961,
-0.30111590027809143,
0.015598186291754246,
-0.48111170530319214,
0.3385500907897949,
0.3945448100566864,
-0.9255398511886597,
-0.2058098316192627,
-0.6951705813407898,
0.0431844778358... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-72edae24-8665151 | autoevaluate | 2022-06-30T05:04:02Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-30T05:04:02Z | 2022-06-29T02:15:21.000Z | 2022-06-29T02:15:21 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- cnn_dailymail
eval_info:
task: summarization
model: eslamxm/mbart-finetune-en-cnn
metrics: []
dataset_name: cnn_dailymail
dataset_config: 3.0.0
dataset_split: train
col_mapping:
text: article
target: highlights
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: eslamxm/mbart-finetune-en-cnn
* Dataset: cnn_dailymail
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@](https://huggingface.co/) for evaluating this model. | [
-0.5430601239204407,
-0.3788489103317261,
0.10842783004045486,
0.16845019161701202,
-0.14706912636756897,
-0.16288210451602936,
0.00938444398343563,
-0.33508649468421936,
0.22479328513145447,
0.42847633361816406,
-0.9740955233573914,
-0.28103163838386536,
-0.6808013916015625,
-0.0654140636... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
joelniklaus/german_argument_mining | joelniklaus | 2022-09-22T13:44:35Z | 13 | 3 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:expert-generated",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:de",
"license:cc-by-4.0... | 2022-09-22T13:44:35Z | 2022-07-01T11:30:58.000Z | 2022-07-01T11:30:58 | ---
annotations_creators:
- expert-generated
- found
language_creators:
- found
language:
- de
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Annotated German Legal Decision Corpus
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Dataset Card for Annotated German Legal Decision Corpus
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://zenodo.org/record/3936490#.X1ed7ovgomK
- **Paper:** Urchs., S., Mitrović., J., & Granitzer., M. (2021). Design and Implementation of German Legal Decision
Corpora. Proceedings of the 13th International Conference on Agents and Artificial Intelligence - Volume 2: ICAART,
515–521. https://doi.org/10.5220/0010187305150521
- **Leaderboard:**
- **Point of Contact:** [Joel Niklaus](mailto:joel.niklaus.2@bfh.ch)
### Dataset Summary
This dataset consists of 200 randomly chosen judgments. In these judgments a legal expert annotated the components
conclusion, definition and subsumption of the German legal writing style Urteilsstil.
*"Overall 25,075 sentences are annotated. 5% (1,202) of these sentences are marked as conclusion, 21% (5,328) as
definition, 53% (13,322) are marked as subsumption and the remaining 21% (6,481) as other. The length of judgments in
sentences ranges from 38 to 862 sentences. The median of judgments have 97 sentences, the length of most judgments is on
the shorter side."* (Urchs. et al., 2021)
*"Judgments from 22 of the 131 courts are selected for the corpus. Most judgments originate from the VG Augsburg (59 /
30%) followed by the VG Ansbach (39 / 20%) and LSG Munich (33 / 17%)."* (Urchs. et al., 2021)
*"29% (58) of all selected judgments are issued in the year 2016, followed by 22% (44) from the year 2017 and 21% (41)
issued in the year 2015. [...] The percentages of selected judgments and decisions issued in 2018 and 2019 are roughly
the same. No judgments from 2020 are selected."* (Urchs. et al., 2021)
### Supported Tasks and Leaderboards
The dataset can be used for multi-class text classification tasks, more specifically, for argument mining.
### Languages
The language in the dataset is German as it is used in Bavarian courts in Germany.
## Dataset Structure
### Data Instances
Each sentence is saved as a json object on a line in one of the three files `train.jsonl`, `validation.jsonl`
or `test.jsonl`. The file `meta.jsonl` contains meta information for each court. The `file_number` is present in all
files for identification. Each sentence of the court decision was categorized according to its function.
### Data Fields
The file `meta.jsonl` contains for each row the following fields:
- `meta_title`: Title provided by the website, it is used for saving the decision
- `court`: Issuing court
- `decision_style`: Style of the decision; the corpus contains either *Urteil* (='judgment') or *Endurteil* (
='end-judgment')
- `date`: Date when the decision was issued by the court
- `file_number`: Identification number used for this decision by the court
- `title`: Title provided by the court
- `norm_chains`: Norms related to the decision
- `decision_guidelines`: Short summary of the decision
- `keywords`: Keywords associated with the decision
- `lower_court`: Court that decided on the decision before
- `additional_information`: Additional Information
- `decision_reference`: References to the location of the decision in beck-online
- `tenor`: Designation of the legal consequence ordered by the court (list of paragraphs)
- `legal_facts`: Facts that form the base for the decision (list of paragraphs)
The files `train.jsonl`, `validation.jsonl` and `test.jsonl` contain the following fields:
- `file_number`: Identification number for linkage with the file `meta.jsonl`
- `input_sentence`: The sentence to be classified
- `label`: In depth explanation of the court decision. Each sentence is assigned to one of the major components of
German *Urteilsstil* (Urchs. et al., 2021) (list of paragraphs, each paragraph containing list of sentences, each
sentence annotated with one of the following four labels):
- `conclusion`: Overall result
- `definition`: Abstract legal facts and consequences
- `subsumption`: Determination sentence / Concrete facts
- `other`: Anything else
- `context_before`: Context in the same paragraph before the input_sentence
- `context_after`: Context in the same paragraph after the input_sentence
### Data Splits
No split provided in the original release.
Splits created by Joel Niklaus. We randomly split the dataset into 80% (160 decisions, 19271 sentences) train, 10%
validation (20 decisions, 2726 sentences) and 10% test (20 decisions, 3078 sentences). We made sure, that a decision
only occurs in one split and is not dispersed over multiple splits.
Label Distribution
| label | train | validation | test |
|:---------------|-----------:|-------------:|----------:|
| conclusion | 975 | 115 | 112 |
| definition | 4105 | 614 | 609 |
| subsumption | 10034 | 1486 | 1802 |
| other | 4157 | 511 | 555 |
| total | **19271** | **2726** | **3078** |
## Dataset Creation
### Curation Rationale
Creating a publicly available German legal text corpus consisting of judgments that have been annotated by a legal
expert. The annotated components consist of *conclusion*, *definition* and *subsumption* of the German legal writing
style *Urteilsstil*.
### Source Data
#### Initial Data Collection and Normalization
*“The decision corpus is a collection of the decisions published on the website www.gesetze-bayern.de. At the time of
the crawling the website offered 32,748 decisions of 131 Bavarian courts, dating back to 2015. The decisions are
provided from the Bavarian state after the courts agreed to a publication. All decisions are processed by the publisher
C.H.BECK, commissioned by the Bavarian state. This processing includes anonymisation, key-wording, and adding of
editorial guidelines to the decisions.”* (Urchs. et al., 2021)
#### Who are the source language producers?
German courts from Bavaria
### Annotations
#### Annotation process
*“As stated above, the judgment corpus consist of 200 randomly chosen judgments that are annotated by a legal expert,
who holds a first legal state exam. Due to financial, staff and time reasons the presented iteration of the corpus was
only annotated by a single expert. In a future version several other experts will annotate the corpus and the
inter-annotator agreement will be calculated.”* (Urchs. et al., 2021)
#### Who are the annotators?
A legal expert, who holds a first legal state exam.
### Personal and Sensitive Information
*"All decisions are processed by the publisher C.H.BECK, commissioned by the Bavarian state. This processing includes **
anonymisation**, key-wording, and adding of editorial guidelines to the decisions.”* (Urchs. et al., 2021)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
The SoMaJo Sentence Splitter has been used. Upon manual inspection of the dataset, we could see that the sentence
splitter had poor accuracy in some cases (see ```analyze_dataset()``` in ```convert_to_hf_dataset.py```). When creating
the splits, we thought about merging small sentences with their neighbors or removing them all together. However, since
we could not find an straightforward way to do this, we decided to leave the dataset content untouched.
Note that the information given in this dataset card refer to the dataset version as provided by Joel Niklaus and Veton
Matoshi. The dataset at hand is intended to be part of a bigger benchmark dataset. Creating a benchmark dataset
consisting of several other datasets from different sources requires postprocessing. Therefore, the structure of the
dataset at hand, including the folder structure, may differ considerably from the original dataset. In addition to that,
differences with regard to dataset statistics as give in the respective papers can be expected. The reader is advised to
have a look at the conversion script ```convert_to_hf_dataset.py``` in order to retrace the steps for converting the
original dataset into the present jsonl-format. For further information on the original dataset structure, we refer to
the bibliographical references and the original Github repositories and/or web pages provided in this dataset card.
## Additional Information
### Dataset Curators
The names of the original dataset curators and creators can be found in references given below, in the section *Citation
Information*. Additional changes were made by Joel Niklaus ([Email](mailto:joel.niklaus.2@bfh.ch)
; [Github](https://github.com/joelniklaus)) and Veton Matoshi ([Email](mailto:veton.matoshi@bfh.ch)
; [Github](https://github.com/kapllan)).
### Licensing Information
[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/legalcode)
### Citation Information
```
@dataset{urchs_stefanie_2020_3936490,
author = {Urchs, Stefanie and
Mitrović, Jelena},
title = {{German legal jugements annotated with judement
style components}},
month = jul,
year = 2020,
publisher = {Zenodo},
doi = {10.5281/zenodo.3936490},
url = {https://doi.org/10.5281/zenodo.3936490}
}
```
```
@conference{icaart21,
author = {Urchs., Stefanie and Mitrovi{\'{c}}., Jelena and Granitzer., Michael},
booktitle = {Proceedings of the 13th International Conference on Agents and Artificial Intelligence - Volume 2: ICAART,},
doi = {10.5220/0010187305150521},
isbn = {978-989-758-484-8},
issn = {2184-433X},
organization = {INSTICC},
pages = {515--521},
publisher = {SciTePress},
title = {{Design and Implementation of German Legal Decision Corpora}},
year = {2021}
}
```
### Contributions
Thanks to [@kapllan](https://github.com/kapllan) and [@joelniklaus](https://github.com/joelniklaus) for adding this
dataset.
| [
-0.5094854831695557,
-0.7207943201065063,
0.7167198657989502,
0.11467380076646805,
-0.43842339515686035,
-0.4282744526863098,
-0.36066651344299316,
-0.25122082233428955,
0.14490598440170288,
0.5950449109077454,
-0.34376445412635803,
-1.001030445098877,
-0.791209876537323,
0.051024936139583... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
joelniklaus/online_terms_of_service | joelniklaus | 2022-09-22T13:45:42Z | 13 | 5 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"annotations_creators:found",
"annotations_creators:other",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"langu... | 2022-09-22T13:45:42Z | 2022-07-01T11:42:49.000Z | 2022-07-01T11:42:49 | ---
annotations_creators:
- found
- other
language_creators:
- found
language:
- de
- en
- it
- pl
license:
- other
multilinguality:
- multilingual
pretty_name: A Corpus for Multilingual Analysis of Online Terms of Service
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
- multi-label-classification
---
# Dataset Card for A Corpus for Multilingual Analysis of Online Terms of Service
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** http://claudette.eui.eu/corpus_multilingual_NLLP2021.zip
- **Paper:** Drawzeski, K., Galassi, A., Jablonowska, A., Lagioia, F., Lippi, M., Micklitz, H. W., Sartor, G., Tagiuri,
G., & Torroni, P. (2021). A Corpus for Multilingual Analysis of Online Terms of Service. Proceedings of the Natural
Legal Language Processing Workshop 2021, 1–8. https://doi.org/10.18653/v1/2021.nllp-1.1
- **Leaderboard:**
- **Point of Contact:** [Joel Niklaus](mailto:joel.niklaus.2@bfh.ch)
### Dataset Summary
*"We present the first annotated corpus for multilingual analysis of potentially unfair clauses in online Terms of
Service [=ToS]. The data set comprises a total of 100 contracts, obtained from 25 documents annotated in four different
languages: English, German, Italian, and Polish. For each contract, potentially unfair clauses for the consumer are
annotated, for nine different unfairness categories."* (Drawzeski et al., 2021)
### Supported Tasks and Leaderboards
The dataset can be used for multi-class multi-label text classification tasks, more specifically, for classifying unfair clauses in
ToS.
### Languages
English, German, Italian, and Polish.
## Dataset Structure
### Data Instances
The file format is jsonl and three data splits are present (train, validation and test).
### Data Fields
The dataset contains the following fields:
- `language`: The language of the sentence/document.
- `company`: The company of the document.
- `line_number`: The line number of the sentence in the document.
- `sentence`: The sentence to be classified.
- `unfairness_level`: The unfairness level assigned to the sentence (if two clauses apply, the higher unfairness level is assigned here).
The documents have been annotated using nine tags that represent different categories of clause unfairness. These boolean tags are:
- `a` = Arbitration: *”This clause requires or allows the parties to resolve their disputes through an arbitration process, before the case could go to court. It is therefore considered a kind of forum selection clause. However, such a clause may or may not specify that arbitration should occur within a specific jurisdiction. Clauses stipulating that the arbitration should (1) take place in a state other than the state of consumer’s residence and/or (2) be based not on law but on arbiter’s discretion were marked as clearly unfair.”* (Lippi et al., 2019)
- `ch` = Unilateral change: *"This clause specifies the conditions under which the service provider could amend and modify the terms of service and/or the service itself. Such clauses were always considered as potentially unfair. This is because the ECJ has not yet issued a judgment in this regard, though the Annex to the Direc- tive contains several examples supporting such a qualification."* (Lippi et al., 2019)
- `cr` = Content removal : *"This gives the provider a right to modify/delete user’s content, including in-app purchases, and sometimes specifies the conditions under which the service provider may do so. As in the case of unilateral termination, clauses that indicate conditions for content removal were marked as potentially unfair, whereas clauses stipulating that the service provider may remove content in his full discretion, and/or at any time for any or no reasons and/or without notice nor possibility to retrieve the content were marked as clearly unfair."* (Lippi et al., 2019)
- `j` = Jurisdiction : *"This type of clause stipulates what courts will have the competence to adjudicate disputes under the contract. Jurisdiction clauses giving consumers a right to bring disputes in their place of residence were marked as clearly fair, whereas clauses stating that any judicial proceeding takes a residence away (i.e. in a different city, different country) were marked as clearly unfair. This assessment is grounded in ECJ’s case law, see for example Oceano case number C-240/98."* (Lippi et al., 2019)
- `law` = Choice of law: *"This clause specifies what law will govern the contract, meaning also what law will be applied in potential adjudication of a dispute arising under the contract. Clauses defining the applicable law as the law of the consumer’s country of residence were marked as clearly fair [...]"* (Lippi et al., 2019)
- `ltd` = Limitation of liability: *"This clause stipulates that the duty to pay damages is limited or excluded, for certain kinds of losses and under certain conditions. Clauses that explicitly affirm non-excludable providers’ liabilities were marked as clearly fair."* (Lippi et al., 2019)
- `ter` = Unilateral termination: *"This clause gives provider the right to suspend and/or terminate the service and/or the contract, and sometimes details the circumstances under which the provider claims to have a right to do so. Unilateral termination clauses that specify reasons for termination were marked as potentially unfair. Whereas clauses stipulating that the service provider may suspend or terminate the service at any time for any or no reasons and/or without notice were marked as clearly unfair."* (Lippi et al., 2019)
- `use` = Contract by using: *"This clause stipulates that the consumer is bound by the terms of use of a specific service, simply by using the service, without even being required to mark that he or she has read and accepted them. We always marked such clauses as potentially unfair. The reason for this choice is that a good argument can be offered for these clauses to be unfair, because they originate an imbalance in rights and duties of the parties, but this argument has no decisive authoritative backing yet, since the ECJ has never assessed a clause of this type."* (Lippi et al., 2019)
- `pinc` = Privacy included: This tag identifies *"clauses stating that consumers consent to the privacy policy simply by using the service. Such clauses have been always considered potentially unfair"* (Drawzeski et al., 2021)
- `all_topics` = an aggregate column containing all applicable topics combined
*”We assumed that each type of clause could be classified as either clearly fair, or potentially unfair, or clearly unfair. In order to mark the different degrees of (un)fairness we appended a numeric value to each XML tag, with 1 meaning clearly fair, 2 potentially unfair, and 3 clearly unfair. Nested tags were used to annotate text segments relevant to more than one type of clause. With clauses covering multiple paragraphs, we chose to tag each paragraph separately, possibly with different degrees of (un)fairness.”* (Lippi et al., 2019)
### Data Splits
No splits provided in the original paper.
Joel Niklaus created the splits manually. The train split contains the 20 (80%) first companies in alphabetic order (*Booking, Dropbox, Electronic_Arts, Evernote, Facebook, Garmin, Google, Grindr, Linkedin, Mozilla,
Pinterest, Quora, Ryanair, Skype, Skyscanner, Snap, Spotify, Terravision, Tinder, Tripadvisor*). The
validation split contains the 2 (8%) companies *Tumblr* and *Uber*. The test split contains the 3 (12%) companies *Weebly*,
*Yelp*, *Zynga*.
There are two tasks possible for this dataset.
#### Clause Topics
By only considering the clause topic, we separated the clause topic from the fairness level classification. Thus, the label set could be reduced to just 9 classes.
This dataset poses a multi-label multi-class sentence classification problem.
The following label distribution shows the number of occurrences per label per split. `total occurrences` sums up the previous rows (number of clause topics per split). `split size` is the number of sentences per split.
| clause topic | train | validation | test |
|:----------------------|------------:|-----------------:|-----------:|
| a | 117 | 6 | 21 |
| ch | 308 | 45 | 53 |
| cr | 155 | 4 | 44 |
| j | 206 | 8 | 36 |
| law | 178 | 8 | 26 |
| ltd | 714 | 84 | 161 |
| ter | 361 | 39 | 83 |
| use | 185 | 14 | 32 |
| pinc | 71 | 0 | 8 |
| **total occurrences** | **2295** | **208** | **464** |
| **split size** | **19942** | **1690** | **4297** |
#### Unfairness Levels
When predicting unfairness levels, all untagged sentences can be removed. This reduces the dataset size considerably.
This dataset poses a single-label multi-class sentence classification problem.
| unfairness_level | train | validation | test |
|:---------------------------|------------:|-----------:|----------:|
| untagged | 17868 | 1499 | 3880 |
| potentially_unfair | 1560 | 142 | 291 |
| clearly_unfair | 259 | 31 | 65 |
| clearly_fair | 156 | 5 | 32 |
| **total without untagged** | **1975** | **178** | **388** |
| **total** | **19942** | **1690** | **4297** |
## Dataset Creation
### Curation Rationale
The EU legislation is published in all official languages. This multilingualism comes with costs and challenges, such as limited cross-linguistical interpretability. The EU has refrained from regulating languages in which standard terms in consumer contracts should be drafted, allowing for differing approaches to emerge in various jurisdictions. Consumer protection authorities and non-governmental organizations in Europe tend to operate only in their respective languages. Therefore, consumer protection technologies are needed that are capable of dealing with multiple languages. The dataset at hand can be used for the automated detection of unfair clauses in ToS which, in most cases, are available in multiple languages. (Drawzeski et al., 2021)
### Source Data
#### Initial Data Collection and Normalization
*"The analysed ToS were retrieved from the [Claudette pre-existing corpus](http://claudette.eui.eu/ToS.zip), covering 100 English ToS (Lippi et al., 2019; Ruggeri et al., 2021). Such terms mainly concern popular digital services provided to consumers, including leading online platforms (such as search engines and social media). The predominant language of drafting of these ToS is English, with differing availability of corresponding ToS in other languages. To carry out the present study, the ultimate 25 ToS were selected on the basis of three main criteria: a) their availability in the four selected languages; b) the possibility of identifying a correspondence between the different versions, given their publication date; and c) the similarity of their structure (e.g. number of clauses, sections, etc.). To illustrate, while ToS in both German and Italian were identified for 63 out of the 100 ToS contained in the pre-existing Claudette training corpus, Polish versions were found for only 42 of these 63 ToS. Out of the 42 ToS available in the four languages, we selected those with the more closely corresponding versions based on criteria b) and c) above. Perfect correspondence across the 4 languages, however, could not be achieved for all 25 ToS."* (Drawzeski et al., 2021)
#### Who are the source language producers?
The source language producers are likely to be lawyers.
### Annotations
#### Annotation process
The dataset at hand is described by Drawzeski et al. (2021). The ToS of the dataset were retrieved from the pre-existing
and mono-lingual (English) Claudette corpus which is described in (Lippi et al., 2019). Drawzeski et al. (2021) *“investigate methods for automatically transferring the annotations made on ToS in the context of the Claudette project
onto the corresponding versions of the same documents in a target language, where such resources and expertise may be
lacking.”*
Therefore, in the following, we will present the annotation process for the Claudette corpus as described in (Lippi et
al., 2019).
*”The corpus consists of 50 relevant on-line consumer contracts, i.e., ToS of on-line platforms. Such contracts were
selected among those offered by some of the major players in terms of number of users, global relevance, and time the
service was established. Such contracts are usually quite detailed in content, are frequently updated to reflect changes
both in the service and in the applicable law, and are often available in different versions for different
jurisdictions. Given multiple versions of the same contract, we selected the most recent version available on-line to
European customers. The mark-up was done in XML by three annotators, which jointly worked for the formulation of the
annotation guidelines. The whole annotation process included several revisions, where some corrections were also
suggested by an analysis of the false positives and false negatives retrieved by the initial machine learning
prototypes. Due to the large interaction among the annotators during this process, in order to assess inter-annotation
agreement, a further test set consisting of 10 additional contracts was tagged, following the final version of the
guidelines. […] We produced an additional test set consisting of 10 more annotated contracts. Such documents were
independently tagged by two distinct annotators who had carefully studied the guidelines. In order to quantitatively
measure the inter-annotation agreement, for this test set we computed the standard Cohen’s 𝜅 metric […] which resulted
to be 0.871 […].”*
#### Who are the annotators?
Not specified.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
It is very likely that some ToS in German, Italian and Polish are direct translations from English. Drawzeski et al. (2021) write: *“Although we could not assess this comprehensively in the present study, we infer from the wording of the ToS that at least in 9 out of 25 cases, German, Italian and Polish documents were indeed translations of the English originals.”*
### Other Known Limitations
Note that the information given in this dataset card refer to the dataset version as provided by Joel Niklaus and Veton Matoshi. The dataset at hand is intended to be part of a bigger benchmark dataset. Creating a benchmark dataset consisting of several other datasets from different sources requires postprocessing. Therefore, the structure of the dataset at hand, including the folder structure, may differ considerably from the original dataset. In addition to that, differences with regard to dataset statistics as give in the respective papers can be expected. The reader is advised to have a look at the conversion script ```convert_to_hf_dataset.py``` in order to retrace the steps for converting the original dataset into the present jsonl-format. For further information on the original dataset structure, we refer to the bibliographical references and the original Github repositories and/or web pages provided in this dataset card.
## Additional Information
### Dataset Curators
The names of the original dataset curators and creators can be found in references given below, in the section *Citation Information*.
Additional changes were made by Joel Niklaus ([Email](mailto:joel.niklaus.2@bfh.ch); [Github](https://github.com/joelniklaus)) and Veton Matoshi ([Email](mailto:veton.matoshi@bfh.ch); [Github](https://github.com/kapllan)).
### Licensing Information
cc-by-nc-2.5
### Citation Information
```
@inproceedings{drawzeski-etal-2021-corpus,
address = {Punta Cana, Dominican Republic},
author = {Drawzeski, Kasper and Galassi, Andrea and Jablonowska, Agnieszka and Lagioia, Francesca and Lippi, Marco and Micklitz, Hans Wolfgang and Sartor, Giovanni and Tagiuri, Giacomo and Torroni, Paolo},
booktitle = {Proceedings of the Natural Legal Language Processing Workshop 2021},
doi = {10.18653/v1/2021.nllp-1.1},
month = {nov},
pages = {1--8},
publisher = {Association for Computational Linguistics},
title = {{A Corpus for Multilingual Analysis of Online Terms of Service}},
url = {https://aclanthology.org/2021.nllp-1.1},
year = {2021}
}
```
### Contributions
Thanks to [@JoelNiklaus](https://github.com/joelniklaus) and [@kapllan](https://github.com/kapllan) for adding this
dataset.
| [
-0.5070019364356995,
-0.42616909742355347,
0.48139894008636475,
0.3539533317089081,
-0.3731659948825836,
-0.19150391221046448,
-0.06511253118515015,
-0.74333655834198,
0.23090477287769318,
0.6771756410598755,
-0.2964329719543457,
-0.430957555770874,
-0.4660895764827728,
0.2860812842845917,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-854c0218-9415245 | autoevaluate | 2022-07-02T22:28:44Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-02T22:28:44Z | 2022-07-02T22:28:07.000Z | 2022-07-02T22:28:07 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- emotion
eval_info:
task: multi_class_classification
model: lewtun/sagemaker-distilbert-emotion
metrics: []
dataset_name: emotion
dataset_config: default
dataset_split: test
col_mapping:
text: text
target: label
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: lewtun/sagemaker-distilbert-emotion
* Dataset: emotion
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@gabrielaltay](https://huggingface.co/gabrielaltay) for evaluating this model. | [
-0.3877298831939697,
-0.2390030175447464,
0.37889599800109863,
0.19549250602722168,
0.11279939860105515,
-0.13436368107795715,
-0.06497868150472641,
-0.44824928045272827,
0.03676901012659073,
0.27198272943496704,
-0.9652850031852722,
-0.25893670320510864,
-0.7740851640701294,
0.00685207638... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-562e1223-9425246 | autoevaluate | 2022-07-02T23:01:39Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-02T23:01:39Z | 2022-07-02T23:00:47.000Z | 2022-07-02T23:00:47 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- bigscience-biomedical/tmp-scitail
eval_info:
task: binary_classification
model: gabrielaltay/autotrain-at-test-bb-tmp-scitail-1078438446
metrics: []
dataset_name: bigscience-biomedical/tmp-scitail
dataset_config: scitail_bigbio_te
dataset_split: test
col_mapping:
text: premise
target: label
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Binary Text Classification
* Model: gabrielaltay/autotrain-at-test-bb-tmp-scitail-1078438446
* Dataset: bigscience-biomedical/tmp-scitail
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@gabrielaltay](https://huggingface.co/gabrielaltay) for evaluating this model. | [
-0.14881522953510284,
-0.2819705903530121,
0.4090959429740906,
0.252414733171463,
-0.027160221710801125,
-0.01185489259660244,
0.013425585813820362,
-0.5224810242652893,
0.1039905995130539,
0.33764299750328064,
-0.8238725066184998,
-0.45052656531333923,
-0.8119018077850342,
0.0105761801823... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
CloverSearch/distribution | CloverSearch | 2022-07-06T02:38:34Z | 13 | 0 | null | [
"region:us"
] | 2022-07-06T02:38:34Z | 2022-07-05T07:13:18.000Z | 2022-07-05T07:13:18 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Paul/hatecheck-polish | Paul | 2022-07-05T10:26:41Z | 13 | 1 | null | [
"task_categories:text-classification",
"task_ids:hate-speech-detection",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:pl",
"license:cc-by-4.0",
"arxiv:2206.09917",
"regi... | 2022-07-05T10:26:41Z | 2022-07-05T10:24:24.000Z | 2022-07-05T10:24:24 | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- pl
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Polish HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. | [
-0.6419409513473511,
-0.7158888578414917,
-0.05510092154145241,
0.09203927218914032,
-0.11549574881792068,
0.10751984268426895,
-0.030292538926005363,
-0.5101843476295471,
0.39948996901512146,
0.3274587094783783,
-0.7589273452758789,
-0.7721040844917297,
-0.5623311400413513,
0.460262417793... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Paul/hatecheck-hindi | Paul | 2022-07-05T10:36:37Z | 13 | 0 | null | [
"task_categories:text-classification",
"task_ids:hate-speech-detection",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:hi",
"license:cc-by-4.0",
"arxiv:2206.09917",
"regi... | 2022-07-05T10:36:37Z | 2022-07-05T10:35:40.000Z | 2022-07-05T10:35:40 | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- hi
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Hindi HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. | [
-0.6419410109519958,
-0.7158888578414917,
-0.05510091781616211,
0.09203927218914032,
-0.11549574136734009,
0.10751984268426895,
-0.030292538926005363,
-0.5101842880249023,
0.39948996901512146,
0.3274586796760559,
-0.7589271664619446,
-0.7721040844917297,
-0.5623311400413513,
0.460262417793... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
OGB/ogbg-code2 | OGB | 2023-02-07T16:40:02Z | 13 | 1 | null | [
"task_categories:graph-ml",
"license:mit",
"region:us"
] | 2023-02-07T16:40:02Z | 2022-07-07T13:51:15.000Z | 2022-07-07T13:51:15 | ---
license: mit
task_categories:
- graph-ml
---
# Dataset Card for ogbg-code2
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
- [Dataset Structure](#dataset-structure)
- [Data Properties](#data-properties)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **[Homepage](https://ogb.stanford.edu/docs/graphprop/#ogbg-code2)**
- **[Repository](https://github.com/snap-stanford/ogb):**:
- **Paper:**: Open Graph Benchmark: Datasets for Machine Learning on Graphs (see citation)
- **Leaderboard:**: [OGB leaderboard](https://ogb.stanford.edu/docs/leader_graphprop/#ogbg-code2) and [Papers with code leaderboard](https://paperswithcode.com/sota/graph-property-prediction-on-ogbg-code2)
### Dataset Summary
The `ogbg-code2` dataset contains Abstract Syntax Trees (ASTs) obtained from 450 thousands Python method definitions, from GitHub CodeSearchNet. "Methods are extracted from a total of 13,587 different repositories across the most popular projects on GitHub.", by teams at Stanford, to be a part of the Open Graph Benchmark. See their website or paper for dataset postprocessing.
### Supported Tasks and Leaderboards
"The task is to predict the sub-tokens forming the method name, given the Python method body represented by AST and its node features. This task is often referred to as “code summarization”, because the model is trained to find succinct and precise description for a complete logical unit."
The score is the F1 score of sub-token prediction.
## External Use
### PyGeometric
To load in PyGeometric, do the following:
```python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
graphs_dataset = load_dataset("graphs-datasets/ogbg-code2)
# For the train set (replace by valid or test as needed)
graphs_list = [Data(graph) for graph in graphs_dataset["train"]]
graphs_pygeometric = DataLoader(graph_list)
```
## Dataset Structure
### Data Properties
| property | value |
|---|---|
| scale | medium |
| #graphs | 452,741 |
| average #nodes | 125.2 |
| average #edges | 124.2 |
| average node degree | 2.0 |
| average cluster coefficient | 0.0 |
| MaxSCC ratio | 1.000 |
| graph diameter | 13.5 |
### Data Fields
Each row of a given file is a graph, with:
- `edge_index` (list: 2 x #edges): pairs of nodes constituting edges
- `edge_feat` (list: #edges x #edge-features): features of edges
- `node_feat` (list: #nodes x #node-features): the nodes features, embedded
- `node_feat_expanded` (list: #nodes x #node-features): the nodes features, as code
- `node_is_attributed` (list: 1 x #nodes): ?
- `node_dfs_order` (list: #nodes x #1): the nodes order in the abstract tree, if parsed using a depth first search
- `node_depth` (list: #nodes x #1): the nodes depth in the abstract tree
- `y` (list: 1 x #tokens): contains the tokens to predict as method name
- `num_nodes` (int): number of nodes of the graph
- `ptr` (list: 2): index of first and last node of the graph
- `batch` (list: 1 x #nodes): ?
### Data Splits
This data comes from the PyGeometric version of the dataset provided by OGB, and follows the provided data splits.
This information can be found back using
```python
from ogb.graphproppred import PygGraphPropPredDataset
dataset = PygGraphPropPredDataset(name = 'ogbg-code2')
split_idx = dataset.get_idx_split()
train = dataset[split_idx['train']] # valid, test
```
More information (`node_feat_expanded`) has been added through the typeidx2type and attridx2attr csv files of the repo.
## Additional Information
### Licensing Information
The dataset has been released under MIT license license.
### Citation Information
```
@inproceedings{hu-etal-2020-open,
author = {Weihua Hu and
Matthias Fey and
Marinka Zitnik and
Yuxiao Dong and
Hongyu Ren and
Bowen Liu and
Michele Catasta and
Jure Leskovec},
editor = {Hugo Larochelle and
Marc Aurelio Ranzato and
Raia Hadsell and
Maria{-}Florina Balcan and
Hsuan{-}Tien Lin},
title = {Open Graph Benchmark: Datasets for Machine Learning on Graphs},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference
on Neural Information Processing Systems 2020, NeurIPS 2020, December
6-12, 2020, virtual},
year = {2020},
url = {https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html},
}
```
### Contributions
Thanks to [@clefourrier](https://github.com/clefourrier) for adding this dataset. | [
-0.4622497856616974,
-0.6599794626235962,
0.15342338383197784,
-0.07968278229236603,
-0.16179662942886353,
-0.09635152667760849,
-0.29984724521636963,
-0.4812818467617035,
0.1274871677160263,
0.1874391883611679,
-0.3462800085544586,
-0.7914268970489502,
-0.606979489326477,
-0.0780058130621... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-xsum-7db0303b-10095338 | autoevaluate | 2022-07-07T15:18:12Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-07T15:18:12Z | 2022-07-07T14:41:22.000Z | 2022-07-07T14:41:22 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- xsum
eval_info:
task: summarization
model: philschmid/distilbart-cnn-12-6-samsum
metrics: []
dataset_name: xsum
dataset_config: default
dataset_split: test
col_mapping:
text: document
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: philschmid/distilbart-cnn-12-6-samsum
* Dataset: xsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ArjunPrSarkhel](https://huggingface.co/ArjunPrSarkhel) for evaluating this model. | [
-0.5184828042984009,
-0.05735490843653679,
0.06428296118974686,
0.12116266041994095,
-0.20340724289417267,
-0.1127840206027031,
-0.0181773342192173,
-0.3126896917819977,
0.27948665618896484,
0.32453224062919617,
-1.0642526149749756,
-0.12290552258491516,
-0.7990909814834595,
-0.06574476510... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
erickdp/mndt | erickdp | 2022-07-07T20:00:33Z | 13 | 0 | null | [
"region:us"
] | 2022-07-07T20:00:33Z | 2022-07-07T19:58:07.000Z | 2022-07-07T19:58:07 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
erickdp/dt22 | erickdp | 2022-07-07T20:15:04Z | 13 | 0 | null | [
"region:us"
] | 2022-07-07T20:15:04Z | 2022-07-07T20:14:30.000Z | 2022-07-07T20:14:30 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
erickdp/ds23 | erickdp | 2022-07-07T20:36:48Z | 13 | 0 | null | [
"region:us"
] | 2022-07-07T20:36:48Z | 2022-07-07T20:35:43.000Z | 2022-07-07T20:35:43 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
juancopi81/mutopia_guitar_dataset | juancopi81 | 2022-07-22T00:09:34Z | 13 | 1 | null | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:other-music",
"license:cc",
"arxiv:2008.06048",
"region:us"
] | 2022-07-22T00:09:34Z | 2022-07-08T00:06:39.000Z | 2022-07-08T00:06:39 | ---
license:
- cc
multilinguality:
- other-music
pretty_name: Mutopia Guitar Dataset
task_categories:
- text-generation
task_ids:
- language-modeling
---
# Mutopia Guitar Dataset
## Table of Contents
- [Dataset Card Creation Guide](#mutopia-guitar-dataset)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
## Dataset Description
- **Homepage:** [Mutopia Project](https://www.mutopiaproject.org/)
- **Repository implementation of the paper:** [MMM: Exploring Conditional Multi-Track Music Generation with the Transformer and the Johann Sebastian Bach Chorales Dataset](https://github.com/AI-Guru/MMM-JSB)
- **Based on Paper:** [MMM: Exploring Conditional Multi-Track Music Generation with the Transformer](https://arxiv.org/abs/2008.06048)
- **Point of Contact:** [Juan Carlos Piñeros](https://www.linkedin.com/in/juancarlospinerosp/)
### Dataset Summary
Mutopia guitar dataset consists of the soloist guitar pieces of the [Mutopia Project](https://www.mutopiaproject.org/). I encoded the MIDI files into text tokens using the excellent [implementation](https://github.com/AI-Guru/MMM-JSB) of Dr. Tristan Beheren of the paper: [MMM: Exploring Conditional Multi-Track Music Generation with the Transformer](https://arxiv.org/abs/2008.06048).
The dataset mainly contains guitar music from western classical composers, such as Sor, Aguado, Carcassi, and Giuliani.
### Supported Tasks and Leaderboards
Anyone interested can use the dataset to train a model for symbolic music generation, which consists in treating symbols for music sounds (notes) as text tokens. Then, one can implement a generative model using NLP techniques, such as Transformers.
## Dataset Structure
### Data Instances
Each guitar piece is represented as a line of text that contains a series of tokens, for instance:
PIECE_START: Where the piece begins
PIECE_ENDS: Where the piece ends
TIME_SIGNATURE: Time signature for the piece
BPM: Tempo of the piece
BAR_START: Begining of a new bar
NOTE_ON: Start of a new musical note specifying its MIDI note number
TIME_DELTA: Duration until the next event
NOTE_OFF: End of musical note specifying its MIDI note number
```
{
'text': PIECE_START TIME_SIGNATURE=2_4 BPM=74 TRACK_START INST=0 DENSITY=4 BAR_START NOTE_ON=52 TIME_DELTA=2.0 NOTE_OFF=52 NOTE_ON=45 NOTE_ON=49 TIME_DELTA=2.0 NOTE_OFF=49 NOTE_ON=52 TIME_DELTA=2.0 NOTE_OFF=45 NOTE_ON=47 NOTE_OFF=52 NOTE_ON=44 TIME_DELTA=2.0,
...
}
```
### Data Fields
- `text`: Sequence of tokens that represent the guitar piece as explained in the paper [MMM: Exploring Conditional Multi-Track Music Generation with the Transformer](https://arxiv.org/abs/2008.06048).
### Data Splits
There are, at this moment, 395 MIDI guitar files in the Mutopia Project. I removed files of pieces that were not music for soloist guitar. After this removal, there were 372 MIDI files.
I used an 80/20 split and augmented the training dataset by transposing the piece 1 octave above and below (24 semitones). The final result is then:
**Train dataset:** 7325 pieces
**Test dataset:** 74 pieces | [
-0.7006639838218689,
-0.4498589336872101,
0.3559260070323944,
0.3368558883666992,
-0.19320198893547058,
0.16617299616336823,
-0.47104883193969727,
-0.13974492251873016,
0.4598298668861389,
0.5003478527069092,
-1.0665791034698486,
-0.61394864320755,
-0.3424125611782074,
0.06500672549009323,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
codecrafters/github-avatars | codecrafters | 2022-07-08T00:53:09Z | 13 | 0 | null | [
"license:mit",
"region:us"
] | 2022-07-08T00:53:09Z | 2022-07-08T00:28:48.000Z | 2022-07-08T00:28:48 | ---
license: mit
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
gagan3012/alexuw | gagan3012 | 2022-07-08T05:38:42Z | 13 | 0 | null | [
"region:us"
] | 2022-07-08T05:38:42Z | 2022-07-08T00:36:47.000Z | 2022-07-08T00:36:47 | ---
viewer: true
--- | [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-xsum-e02a2fb8-10255357 | autoevaluate | 2022-07-08T03:47:13Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T03:47:13Z | 2022-07-08T02:56:23.000Z | 2022-07-08T02:56:23 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- xsum
eval_info:
task: summarization
model: Ameer05/bart-large-cnn-samsum-rescom-finetuned-resume-summarizer-10-epoch
metrics: []
dataset_name: xsum
dataset_config: default
dataset_split: test
col_mapping:
text: document
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: Ameer05/bart-large-cnn-samsum-rescom-finetuned-resume-summarizer-10-epoch
* Dataset: xsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Abhijeet3922](https://huggingface.co/Abhijeet3922) for evaluating this model. | [
-0.508518397808075,
-0.12419038265943527,
0.15681514143943787,
0.12257508933544159,
-0.10815177112817764,
-0.14608369767665863,
-0.16629958152770996,
-0.3018364906311035,
0.3609079122543335,
0.429513156414032,
-0.9998050332069397,
-0.20805518329143524,
-0.6670230031013489,
-0.0557976216077... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-samsum-0c672345-10275361 | autoevaluate | 2022-07-08T08:32:13Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T08:32:13Z | 2022-07-08T04:33:50.000Z | 2022-07-08T04:33:50 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: google/pegasus-large
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/pegasus-large
* Dataset: samsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ikadebi](https://huggingface.co/ikadebi) for evaluating this model. | [
-0.5094285607337952,
-0.09877500683069229,
0.28210532665252686,
0.10647346079349518,
-0.19695419073104858,
-0.2568368911743164,
0.11076974868774414,
-0.41445741057395935,
0.47118669748306274,
0.47185635566711426,
-1.149802803993225,
-0.21385899186134338,
-0.6967419981956482,
-0.14423564076... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-samsum-0c672345-10275362 | autoevaluate | 2022-07-08T05:16:37Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T05:16:37Z | 2022-07-08T04:33:54.000Z | 2022-07-08T04:33:54 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: google/pegasus-xsum
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/pegasus-xsum
* Dataset: samsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ikadebi](https://huggingface.co/ikadebi) for evaluating this model. | [
-0.48340484499931335,
-0.0001488219277234748,
0.26752209663391113,
0.036167874932289124,
-0.19628281891345978,
-0.19830793142318726,
0.1354266107082367,
-0.39664554595947266,
0.517988920211792,
0.47248584032058716,
-1.1817065477371216,
-0.19058825075626373,
-0.6849720478057861,
-0.19922797... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-samsum-0c672345-10275364 | autoevaluate | 2022-07-08T05:59:46Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T05:59:46Z | 2022-07-08T04:34:06.000Z | 2022-07-08T04:34:06 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: google/pegasus-reddit_tifu
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/pegasus-reddit_tifu
* Dataset: samsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ikadebi](https://huggingface.co/ikadebi) for evaluating this model. | [
-0.5055578947067261,
-0.2340993583202362,
0.21989840269088745,
0.17605307698249817,
-0.19649481773376465,
-0.2007790207862854,
0.11981233954429626,
-0.378601610660553,
0.4571053683757782,
0.4010181427001953,
-1.12259840965271,
-0.18488039076328278,
-0.6678062677383423,
-0.06094668433070183... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-samsum-0c672345-10275365 | autoevaluate | 2022-07-08T05:41:09Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T05:41:09Z | 2022-07-08T05:16:57.000Z | 2022-07-08T05:16:57 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: facebook/bart-large-xsum
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: facebook/bart-large-xsum
* Dataset: samsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ikadebi](https://huggingface.co/ikadebi) for evaluating this model. | [
-0.43643149733543396,
-0.19937092065811157,
0.3007427155971527,
0.14195643365383148,
-0.06724821776151657,
-0.05425050109624863,
0.02553047239780426,
-0.38449227809906006,
0.5072949528694153,
0.4954293966293335,
-1.1453310251235962,
-0.1954723298549652,
-0.5937836170196533,
-0.127551525831... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-samsum-0c672345-10275366 | autoevaluate | 2022-07-08T06:11:02Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-08T06:11:02Z | 2022-07-08T05:41:25.000Z | 2022-07-08T05:41:25 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- samsum
eval_info:
task: summarization
model: knkarthick/bart-large-xsum-samsum
metrics: []
dataset_name: samsum
dataset_config: samsum
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: knkarthick/bart-large-xsum-samsum
* Dataset: samsum
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ikadebi](https://huggingface.co/ikadebi) for evaluating this model. | [
-0.4612419009208679,
-0.05640745535492897,
0.35649797320365906,
0.06294597685337067,
-0.18138378858566284,
-0.05707351490855217,
-0.016651805490255356,
-0.40236881375312805,
0.4544757306575775,
0.5290325284004211,
-1.0893206596374512,
-0.21077926456928253,
-0.6362278461456299,
-0.068324208... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
GEM-submissions/lewtun__this-is-a-test-submission-3__1657282248 | GEM-submissions | 2022-07-08T12:10:53Z | 13 | 0 | null | [
"benchmark:gem",
"evaluation",
"benchmark",
"region:us"
] | 2022-07-08T12:10:53Z | 2022-07-08T12:10:50.000Z | 2022-07-08T12:10:50 | ---
benchmark: gem
type: prediction
submission_name: This is a test submission 3
tags:
- evaluation
- benchmark
---
# GEM Submission
Submission name: This is a test submission 3
| [
0.14071477949619293,
-0.831126868724823,
0.7007408738136292,
0.2553391754627228,
-0.16222964227199554,
0.26310965418815613,
0.4091661870479584,
0.17561329901218414,
0.2834315299987793,
0.4843377470970154,
-0.994183361530304,
-0.1469837874174118,
-0.31571251153945923,
0.0889996811747551,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster13 | MicPie | 2022-08-04T19:52:42Z | 13 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:52:42Z | 2022-07-08T17:23:44.000Z | 2022-07-08T17:23:44 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster13
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster13" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5828394889831543,
-0.5666294097900391,
0.4744274318218231,
0.33533042669296265,
0.08311328291893005,
0.1527356654405594,
-0.14912305772304535,
-0.60282963514328,
0.5245921015739441,
0.272038072347641,
-1.0352694988250732,
-0.682465672492981,
-0.6594418287277222,
0.20154514908790588,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster25 | MicPie | 2022-08-04T20:00:11Z | 13 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:00:11Z | 2022-07-08T18:35:02.000Z | 2022-07-08T18:35:02 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster25
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster25" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5835341215133667,
-0.5662290453910828,
0.46426764130592346,
0.3361322283744812,
0.09068774431943893,
0.1591319888830185,
-0.15546613931655884,
-0.5924043655395508,
0.5226195454597473,
0.2890837788581848,
-1.031678318977356,
-0.6929382681846619,
-0.6448044776916504,
0.18168815970420837,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kasumi222/busy | kasumi222 | 2022-08-15T01:55:40Z | 13 | 0 | null | [
"region:us"
] | 2022-08-15T01:55:40Z | 2022-07-09T18:21:26.000Z | 2022-07-09T18:21:26 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kasumi222/busy2 | kasumi222 | 2022-07-09T18:23:19Z | 13 | 0 | null | [
"region:us"
] | 2022-07-09T18:23:19Z | 2022-07-09T18:22:42.000Z | 2022-07-09T18:22:42 | Dataset1 | [
-0.25494322180747986,
0.0017639786237850785,
-0.297717809677124,
0.3378487527370453,
-0.028897887095808983,
-0.2552754282951355,
0.3406207263469696,
0.3764059543609619,
0.4681522846221924,
1.1269928216934204,
-1.2244112491607666,
-0.2884278893470764,
-0.7127476930618286,
-0.030882194638252... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jorge-henao/historias_conflicto_colombia | jorge-henao | 2022-07-10T15:26:41Z | 13 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-10T15:26:41Z | 2022-07-09T18:26:16.000Z | 2022-07-09T18:26:16 | ---
license: apache-2.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sonicpierre/Rick-bot-flags | sonicpierre | 2022-07-10T14:52:40Z | 13 | 0 | null | [
"region:us"
] | 2022-07-10T14:52:40Z | 2022-07-09T20:09:41.000Z | 2022-07-09T20:09:41 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
etan18/SampleMCDataset | etan18 | 2022-07-09T20:13:27Z | 13 | 0 | null | [
"license:unknown",
"region:us"
] | 2022-07-09T20:13:27Z | 2022-07-09T20:12:18.000Z | 2022-07-09T20:12:18 | ---
license: unknown
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
azuur/en_corpora_parliament_processed | azuur | 2022-07-10T01:36:27Z | 13 | 0 | null | [
"region:us"
] | 2022-07-10T01:36:27Z | 2022-07-09T22:03:35.000Z | 2022-07-09T22:03:35 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-pn_summary-5464695d-10495406 | autoevaluate | 2022-07-11T14:22:50Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-11T14:22:50Z | 2022-07-10T11:47:54.000Z | 2022-07-10T11:47:54 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- pn_summary
eval_info:
task: summarization
model: google/pegasus-large
metrics: []
dataset_name: pn_summary
dataset_config: 1.0.0
dataset_split: train
col_mapping:
text: article
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: google/pegasus-large
* Dataset: pn_summary
* Config: 1.0.0
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@marsraker09](https://huggingface.co/marsraker09) for evaluating this model. | [
-0.5578094124794006,
-0.1442231833934784,
0.20517006516456604,
0.18276523053646088,
-0.22872860729694366,
-0.23483586311340332,
0.0574411079287529,
-0.387175589799881,
0.4514274001121521,
0.4650925397872925,
-1.09524667263031,
-0.14462733268737793,
-0.7255716919898987,
-0.1420077532529831,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zzySJ/sv_corpora_parliament_processed | zzySJ | 2022-07-10T12:36:49Z | 13 | 0 | null | [
"region:us"
] | 2022-07-10T12:36:49Z | 2022-07-10T12:36:25.000Z | 2022-07-10T12:36:25 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BirdL/SimulacraUnsupervised | BirdL | 2022-12-19T20:31:16Z | 13 | 1 | null | [
"task_categories:unconditional-image-generation",
"size_categories:100K<n<1M",
"region:us"
] | 2022-12-19T20:31:16Z | 2022-07-10T19:17:34.000Z | 2022-07-10T19:17:34 | ---
annotations_creators: []
language: []
language_creators: []
multilinguality: []
pretty_name: Simulacra Aes Captions Unsupervised
size_categories:
- 100K<n<1M
source_datasets: []
tags: []
task_categories:
- unconditional-image-generation
task_ids: []
---
SimulacraUnsupervised is a download of Simulacra Aesthetic Captions from JDP converted to a JPEG compressed parquet.
Under the BirdL-AirL License | [
-0.5351921319961548,
-0.40463966131210327,
0.022966142743825912,
0.7717231512069702,
-0.9486656188964844,
-0.016440965235233307,
-0.0355517603456974,
-0.3299877941608429,
0.5984933376312256,
0.7790433764457703,
-0.8340150713920593,
-0.32155904173851013,
-0.38772591948509216,
0.208355173468... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Li-Tang/cn_text | Li-Tang | 2022-07-11T09:50:11Z | 13 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-11T09:50:11Z | 2022-07-11T09:48:59.000Z | 2022-07-11T09:48:59 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-dane-2d14d683-10645434 | autoevaluate | 2022-07-11T13:14:03Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-11T13:14:03Z | 2022-07-11T13:13:24.000Z | 2022-07-11T13:13:24 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- dane
eval_info:
task: entity_extraction
model: saattrupdan/nbailab-base-ner-scandi
metrics: []
dataset_name: dane
dataset_config: default
dataset_split: test
col_mapping:
tokens: tokens
tags: ner_tags
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: saattrupdan/nbailab-base-ner-scandi
* Dataset: dane
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@KennethEnevoldsen](https://huggingface.co/KennethEnevoldsen) for evaluating this model. | [
-0.4328569173812866,
-0.15250727534294128,
0.11283785849809647,
0.17715291678905487,
-0.013649769127368927,
-0.0124126011505723,
0.1538112312555313,
-0.4186851978302002,
0.22423289716243744,
0.31457364559173584,
-0.9272310137748718,
-0.24246057868003845,
-0.6661699414253235,
0.001454861601... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-cnn_dailymail-da2ad07e-10655435 | autoevaluate | 2022-07-12T05:57:39Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-12T05:57:39Z | 2022-07-11T13:15:22.000Z | 2022-07-11T13:15:22 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- cnn_dailymail
eval_info:
task: summarization
model: patrickvonplaten/bert2bert_cnn_daily_mail
metrics: []
dataset_name: cnn_dailymail
dataset_config: 3.0.0
dataset_split: train
col_mapping:
text: article
target: highlights
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: patrickvonplaten/bert2bert_cnn_daily_mail
* Dataset: cnn_dailymail
* Config: 3.0.0
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mumumumu](https://huggingface.co/mumumumu) for evaluating this model. | [
-0.42580702900886536,
-0.2904776930809021,
0.14407290518283844,
0.275132954120636,
-0.20691242814064026,
-0.12589506804943085,
-0.04095559939742088,
-0.39063364267349243,
0.27347418665885925,
0.3640539050102234,
-0.9069266319274902,
-0.1843891590833664,
-0.7665406465530396,
-0.113391757011... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
postbot/aeslc_kw | postbot | 2022-08-07T12:14:34Z | 13 | 0 | null | [
"multilinguality:monolingual",
"source_datasets:aeslc",
"language:en",
"license:mit",
"text2text generation",
"email",
"email generation",
"enron",
"region:us"
] | 2022-08-07T12:14:34Z | 2022-07-11T13:23:36.000Z | 2022-07-11T13:23:36 | ---
language:
- en
license:
- mit
multilinguality:
- monolingual
pretty_name: AESLC - Cleaned & Keyword Extracted
source_datasets:
- aeslc
tags:
- text2text generation
- email
- email generation
- enron
---
## about
- aeslc dataset but cleaned and keywords extracted to a new column
- an EDA website generated via pandas profiling [is on netlify here](https://aeslc-kw-train-eda.netlify.app/)
```
DatasetDict({
train: Dataset({
features: ['email_body', 'subject_line', 'clean_email', 'clean_email_keywords'],
num_rows: 14436
})
test: Dataset({
features: ['email_body', 'subject_line', 'clean_email', 'clean_email_keywords'],
num_rows: 1906
})
validation: Dataset({
features: ['email_body', 'subject_line', 'clean_email', 'clean_email_keywords'],
num_rows: 1960
})
})
```
## Python usage
Basic example notebook [here](https://colab.research.google.com/gist/pszemraj/18742da8db4a99e57e95824eaead285a/scratchpad.ipynb).
```python
from datasets import load_dataset
dataset = load_dataset("postbot/aeslc_kw")
```
## Citation
```
@InProceedings{zhang2019slg,
author = "Rui Zhang and Joel Tetreault",
title = "This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation",
booktitle = "Proceedings of The 57th Annual Meeting of the Association for Computational Linguistics",
year = "2019",
address = "Florence, Italy"
}
``` | [
-0.3074687421321869,
-0.6695820689201355,
-0.06160715967416763,
-0.09610442072153091,
-0.4871649742126465,
-0.04782997444272041,
-0.1384427398443222,
-0.10793311148881912,
0.5014170408248901,
0.7499548196792603,
-0.37542062997817993,
-0.9313392043113708,
-0.5731022953987122,
0.509926795959... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bhadresh-savani/image-to-style | bhadresh-savani | 2022-07-20T08:58:29Z | 13 | 0 | null | [
"region:us"
] | 2022-07-20T08:58:29Z | 2022-07-11T14:22:03.000Z | 2022-07-11T14:22:03 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-conll2003-e2bfcc2b-10665436 | autoevaluate | 2022-07-11T14:24:36Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-11T14:24:36Z | 2022-07-11T14:23:17.000Z | 2022-07-11T14:23:17 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- conll2003
eval_info:
task: entity_extraction
model: huggingface-course/bert-finetuned-ner
metrics: ['jordyvl/ece']
dataset_name: conll2003
dataset_config: conll2003
dataset_split: test
col_mapping:
tokens: tokens
tags: ner_tags
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: huggingface-course/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@jordyvl](https://huggingface.co/jordyvl) for evaluating this model. | [
-0.49724650382995605,
-0.3537701964378357,
0.06800234317779541,
0.06561827659606934,
-0.005386353470385075,
-0.11347762495279312,
0.0136004239320755,
-0.5443346500396729,
0.18229134380817413,
0.34105199575424194,
-0.9800329208374023,
-0.10084112733602524,
-0.6565409302711487,
-0.0423544161... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
carlosejimenez/flickr30k_clip-SimCLRv2-caption_pairs | carlosejimenez | 2022-07-14T16:20:37Z | 13 | 0 | null | [
"region:us"
] | 2022-07-14T16:20:37Z | 2022-07-14T14:34:22.000Z | 2022-07-14T14:34:22 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-kmfoda__booksum-79c1c0d8-10905465 | autoevaluate | 2022-07-15T20:08:50Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-15T20:08:50Z | 2022-07-14T18:31:38.000Z | 2022-07-14T18:31:38 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- kmfoda/booksum
eval_info:
task: summarization
model: pszemraj/pegasus-large-summary-explain
metrics: ['bleu', 'perplexity']
dataset_name: kmfoda/booksum
dataset_config: kmfoda--booksum
dataset_split: test
col_mapping:
text: chapter
target: summary_text
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/pegasus-large-summary-explain
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | [
-0.5990710854530334,
-0.061411503702402115,
0.2137870490550995,
0.1611979901790619,
-0.26684078574180603,
-0.2543359398841858,
0.07703611254692078,
-0.35060882568359375,
0.26774120330810547,
0.5225921869277954,
-1.0886160135269165,
-0.2571146786212921,
-0.696104109287262,
-0.13508635759353... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tarteel-ai/EA-DI | tarteel-ai | 2022-07-15T00:03:00Z | 13 | 2 | null | [
"region:us"
] | 2022-07-15T00:03:00Z | 2022-07-14T23:21:53.000Z | 2022-07-14T23:21:53 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tarteel-ai/EA-UD | tarteel-ai | 2022-07-15T03:04:41Z | 13 | 0 | null | [
"region:us"
] | 2022-07-15T03:04:41Z | 2022-07-15T02:28:41.000Z | 2022-07-15T02:28:41 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
DaliaSmirnov/HIMYM | DaliaSmirnov | 2022-07-15T14:17:28Z | 13 | 0 | null | [
"region:us"
] | 2022-07-15T14:17:28Z | 2022-07-15T12:02:08.000Z | 2022-07-15T12:02:08 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nbroad/mediasum | nbroad | 2022-10-25T10:40:11Z | 13 | 1 | null | [
"task_categories:summarization",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-nc-sa-4.0",
"arxiv:2103.06410",
"region:us"
] | 2022-10-25T10:40:11Z | 2022-07-15T21:42:51.000Z | 2022-07-15T21:42:51 | ---
language:
- en
license:
- cc-by-nc-sa-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
task_categories:
- summarization
---
# MediaSum
## Description
This large-scale media interview dataset contains 463.6K transcripts with abstractive summaries,
collected from interview transcripts and overview / topic descriptions from NPR and CNN.
### **NOTE: The authors have requested that this dataset be used for research purposes only**
## Homepage
https://github.com/zcgzcgzcg1/MediaSum
## Paper
https://arxiv.org/abs/2103.06410
## Authors
### Chenguang Zhu*, Yang Liu*, Jie Mei, Michael Zeng
#### Microsoft Cognitive Services Research Group
{chezhu,yaliu10,jimei,nzeng}@microsoft.com
## Citation
@article{zhu2021mediasum,
title={MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization},
author={Zhu, Chenguang and Liu, Yang and Mei, Jie and Zeng, Michael},
journal={arXiv preprint arXiv:2103.06410},
year={2021}
}
## Dataset size
Train: 443,596
Validation: 10,000
Test: 10,000
The splits were made by using the file located here: https://github.com/zcgzcgzcg1/MediaSum/tree/main/data
## Data details
- id (string): unique identifier
- program (string): the program this transcript came from
- date (string): date of program
- url (string): link to where audio and transcript are located
- title (string): title of the program. some datapoints do not have a title
- summary (string): summary of the program
- utt (list of string): list of utterances by the speakers in the program. corresponds with `speaker`
- speaker (list of string): list of speakers, corresponds with `utt`
Example:
```
{
"id": "NPR-11",
"program": "Day to Day",
"date": "2008-06-10",
"url": "https://www.npr.org/templates/story/story.php?storyId=91356794",
"title": "Researchers Find Discriminating Plants",
"summary": "The \"sea rocket\" shows preferential treatment to plants that are its kin. Evolutionary plant ecologist Susan Dudley of McMaster University in Ontario discusses her discovery.",
"utt": [
"This is Day to Day. I'm Madeleine Brand.",
"And I'm Alex Cohen.",
"Coming up, the question of who wrote a famous religious poem turns into a very unchristian battle.",
"First, remember the 1970s? People talked to their houseplants, played them classical music. They were convinced plants were sensuous beings and there was that 1979 movie, \"The Secret Life of Plants.\"",
"Only a few daring individuals, from the scientific establishment, have come forward with offers to replicate his experiments, or test his results. The great majority are content simply to condemn his efforts without taking the trouble to investigate their validity.",
...
"OK. Thank you.",
"That's Susan Dudley. She's an associate professor of biology at McMaster University in Hamilt on Ontario. She discovered that there is a social life of plants."
],
"speaker": [
"MADELEINE BRAND, host",
"ALEX COHEN, host",
"ALEX COHEN, host",
"MADELEINE BRAND, host",
"Unidentified Male",
..."
Professor SUSAN DUDLEY (Biology, McMaster University)",
"MADELEINE BRAND, host"
]
}
```
## Using the dataset
```python
from datasets import load_dataset
ds = load_dataset("nbroad/mediasum")
```
## Data location
https://drive.google.com/file/d/1ZAKZM1cGhEw2A4_n4bGGMYyF8iPjLZni/view?usp=sharing
## License
No license specified, but the authors have requested that this dataset be used for research purposes only. | [
-0.3479301929473877,
-0.6266974806785583,
0.34550604224205017,
0.12358355522155762,
-0.010281036607921124,
0.02670997567474842,
-0.2733040153980255,
-0.28375548124313354,
0.5061780214309692,
0.24566981196403503,
-0.6919527053833008,
-0.4490374028682709,
-0.600079357624054,
0.15847733616828... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
QuoQA-NLP/KoCC3M | QuoQA-NLP | 2022-07-22T08:37:34Z | 13 | 3 | null | [
"region:us"
] | 2022-07-22T08:37:34Z | 2022-07-22T07:24:26.000Z | 2022-07-22T07:24:26 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MrSemyon12/data_frame | MrSemyon12 | 2022-07-25T04:12:33Z | 13 | 0 | null | [
"region:us"
] | 2022-07-25T04:12:33Z | 2022-07-25T01:12:04.000Z | 2022-07-25T01:12:04 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
emilylearning/cond_ft_none_on_reddit__prcnt_100__test_run_False__bert-base-uncased | emilylearning | 2022-07-25T12:55:20Z | 13 | 0 | null | [
"region:us"
] | 2022-07-25T12:55:20Z | 2022-07-25T06:22:17.000Z | 2022-07-25T06:22:17 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-squad_v2-fdec2e9c-11705559 | autoevaluate | 2022-07-25T07:29:26Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-25T07:29:26Z | 2022-07-25T07:24:04.000Z | 2022-07-25T07:24:04 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad_v2
eval_info:
task: extractive_question_answering
model: deepset/xlm-roberta-large-squad2
metrics: []
dataset_name: squad_v2
dataset_config: squad_v2
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: deepset/xlm-roberta-large-squad2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@sjrlee](https://huggingface.co/sjrlee) for evaluating this model. | [
-0.478790283203125,
-0.4222498834133148,
0.4279681146144867,
0.11446921527385712,
0.0824565514922142,
0.1316302865743637,
0.02959442138671875,
-0.4153931736946106,
-0.04280597344040871,
0.5222002863883972,
-1.3187062740325928,
-0.12530925869941711,
-0.5563628077507019,
0.03532204031944275,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-squad-810261fd-11725561 | autoevaluate | 2022-07-25T09:36:36Z | 13 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-25T09:36:36Z | 2022-07-25T09:33:54.000Z | 2022-07-25T09:33:54 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad
eval_info:
task: extractive_question_answering
model: Shanny/bert-finetuned-squad
metrics: ['accuracy']
dataset_name: squad
dataset_config: plain_text
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Shanny/bert-finetuned-squad
* Dataset: squad
* Config: plain_text
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ola13](https://huggingface.co/ola13) for evaluating this model. | [
-0.5294521450996399,
-0.5205848813056946,
0.3441304564476013,
0.18083371222019196,
0.062188711017370224,
-0.016785424202680588,
0.10639319568872452,
-0.5022252798080444,
0.10807598382234573,
0.4439399242401123,
-1.2792896032333374,
-0.05655934289097786,
-0.418372243642807,
0.07572413235902... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ttxy/weibo_4_moods | ttxy | 2022-07-25T09:55:43Z | 13 | 0 | null | [
"region:us"
] | 2022-07-25T09:55:43Z | 2022-07-25T09:55:07.000Z | 2022-07-25T09:55:07 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
naem1023/augmented-namuwiki | naem1023 | 2022-07-25T12:45:56Z | 13 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-25T12:45:56Z | 2022-07-25T11:02:14.000Z | 2022-07-25T11:02:14 | ---
license: apache-2.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/hf_model_metadata | davanstrien | 2022-07-25T12:13:05Z | 13 | 0 | null | [
"region:us"
] | 2022-07-25T12:13:05Z | 2022-07-25T12:12:59.000Z | 2022-07-25T12:12:59 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
naem1023/augmented-concat-100000 | naem1023 | 2022-07-25T14:30:47Z | 13 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-25T14:30:47Z | 2022-07-25T14:04:21.000Z | 2022-07-25T14:04:21 | ---
license: apache-2.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.