
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
TrainingDataPro/spine-x-ray | TrainingDataPro | 2023-10-29T19:54:02Z | 0 | 1 | null | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"medical",
"code",
"region:us"
] | 2023-10-29T19:54:02Z | 2023-10-29T19:40:35.000Z | 2023-10-29T19:40:35 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
- image-segmentation
- image-to-image
language:
- en
tags:
- medical
- code
---
# Spine X-rays
The dataset consists of a collection of spine X-ray images in **.jpg and .dcm** formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.
### Types of diseases and conditions in the dataset:
*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*
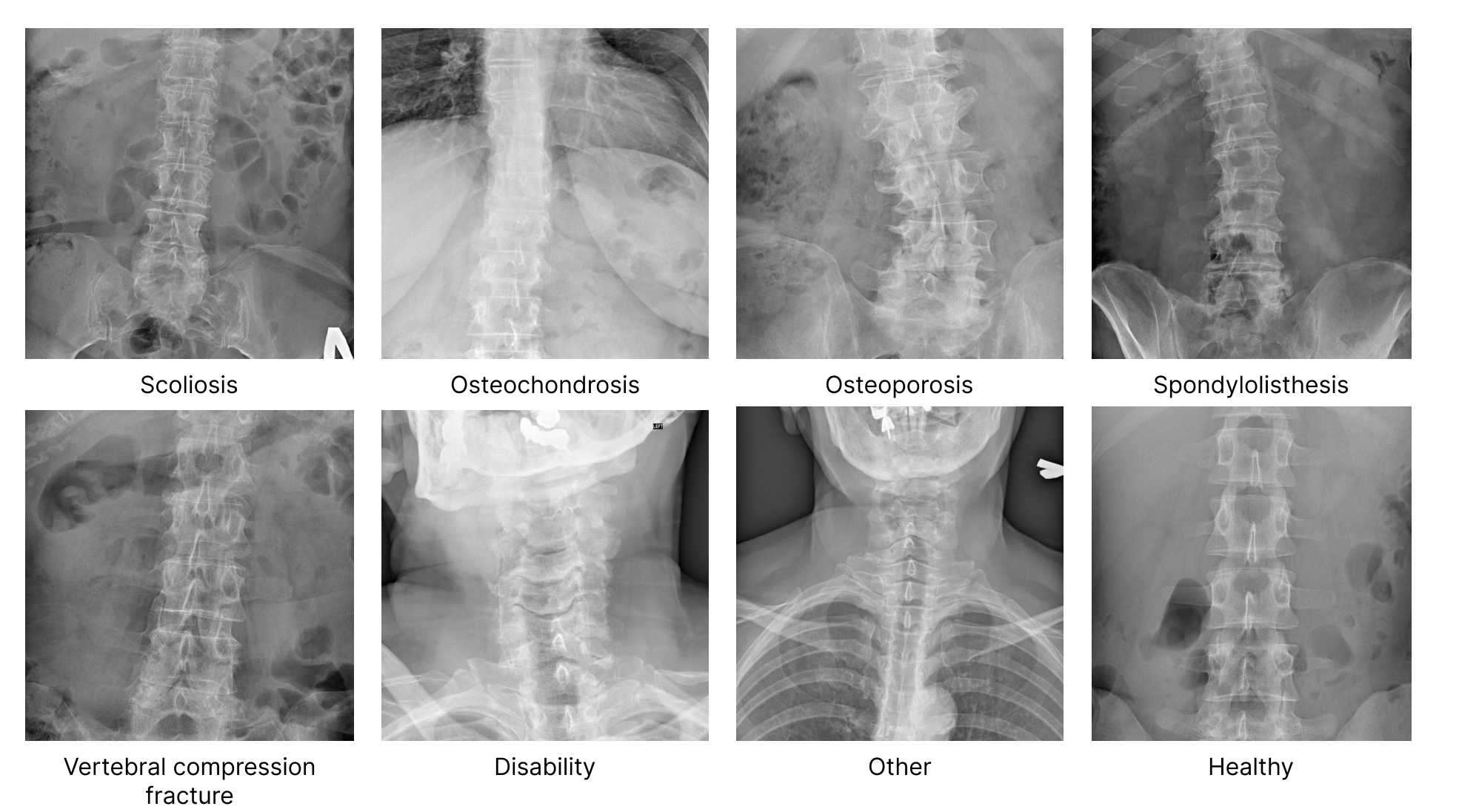
The dataset provides an opportunity for researchers and medical professionals to *analyze and develop algorithms for automated diagnosis, treatment planning, and prognosis estimation of* **various spinal conditions**.
It allows the development and evaluation of computer-based algorithms, machine learning models, and deep learning techniques for **automated detection, diagnosis, and classification** of these conditions.
# Get the Dataset
## This is just an example of the data
Leave a request on [https://trainingdata.pro/data-market](https://trainingdata.pro/data-market/spine-x-ray-image?utm_source=huggingface&utm_medium=cpc&utm_campaign=spine-x-ray) to discuss your requirements, learn about the price and buy the dataset
# Content
### The folder "files" includes 8 folders:
- corresponding to name of the disease/condition and including x-rays of people with this disease/condition (**scoliosis, osteochondrosis, VCFs etc.**)
- including x-rays in 2 different formats: **.jpg and .dcm**.
### File with the extension .csv includes the following information for each media file:
- **dcm**: link to access the .dcm file,
- **jpg**: link to access the .jpg file,
- **type**: name of the disease or condition on the x-ray
# Medical data might be collected in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market/spine-x-ray-image?utm_source=huggingface&utm_medium=cpc&utm_campaign=spine-x-ray) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
*keywords: spine dataset, spine X-rays dataset, scoliosis detection dataset, scoliosis segmentation dataset, scoliosis image dataset, medical imaging, radiology dataset, spine deformity dataset, orthopedic abnormalities, scoliotic curve dataset, degenerative spinal conditions, diagnostic imaging of the spine, osteoporosis dataset, osteochondrosis dataset, vertebral compression fracture detection, vertebral segmentation dataset*
| [
0.031891122460365295,
-0.024723052978515625,
0.1646355390548706,
0.14428240060806274,
-0.46248745918273926,
0.22254715859889984,
0.3670652508735657,
-0.172498881816864,
0.6695042252540588,
0.6884359121322632,
-0.4901439845561981,
-0.9527807235717773,
-0.3165869414806366,
-0.015257214196026... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
acetennis01/audiotest | acetennis01 | 2023-11-01T21:04:32Z | 0 | 0 | null | [
"task_categories:automatic-speech-recognition",
"size_categories:n<1K",
"language:en",
"region:us"
] | 2023-11-01T21:04:32Z | 2023-10-29T21:26:37.000Z | 2023-10-29T21:26:37 | ---
language:
- en
pretty_name: a
size_categories:
- n<1K
task_categories:
- automatic-speech-recognition
---
This is a test audio dataset | [
-0.503925085067749,
-0.7053440809249878,
-0.05804947391152382,
0.13719123601913452,
-0.09777012467384338,
-0.1462101936340332,
-0.05528077110648155,
0.021410111337900162,
0.1816515326499939,
0.6831346750259399,
-1.0622390508651733,
-0.43546295166015625,
-0.24940712749958038,
-0.10072031617... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SergioSCA/StageTest | SergioSCA | 2023-10-29T21:49:46Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-29T21:49:46Z | 2023-10-29T21:48:44.000Z | 2023-10-29T21:48:44 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Alignment-Lab-AI/debate-ablate | Alignment-Lab-AI | 2023-10-29T22:05:50Z | 0 | 0 | null | [
"region:us"
] | 2023-10-29T22:05:50Z | 2023-10-29T22:05:11.000Z | 2023-10-29T22:05:11 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hericrafti/heri | hericrafti | 2023-10-29T22:58:09Z | 0 | 0 | null | [
"region:us"
] | 2023-10-29T22:58:09Z | 2023-10-29T22:57:30.000Z | 2023-10-29T22:57:30 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
patrick65536/mandala_controlnet | patrick65536 | 2023-10-30T02:31:00Z | 0 | 1 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-30T02:31:00Z | 2023-10-30T01:07:40.000Z | 2023-10-30T01:07:40 | ---
license: apache-2.0
dataset_info:
features:
- name: original_image
dtype: image
- name: condtioning_image
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 12212803.0
num_examples: 10
download_size: 0
dataset_size: 12212803.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vwxyzjn/cai-conversation-dev | vwxyzjn | 2023-11-20T18:58:18Z | 0 | 0 | null | [
"region:us"
] | 2023-11-20T18:58:18Z | 2023-10-30T02:25:07.000Z | 2023-10-30T02:25:07 | ---
dataset_info:
features:
- name: index
dtype: int64
- name: prompt
dtype: string
- name: init_prompt
dtype: string
- name: init_response
dtype: string
- name: critic_prompt
dtype: string
- name: critic_response
dtype: string
- name: revision_prompt
dtype: string
- name: revision_response
dtype: string
splits:
- name: train
num_bytes: 1554197
num_examples: 1024
download_size: 556838
dataset_size: 1554197
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "cai-conversation-dev"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.646047055721283,
-0.4851098358631134,
0.06698434799909592,
0.3958476781845093,
-0.09928009659051895,
0.1878053992986679,
0.15405574440956116,
-0.19658488035202026,
0.9322408437728882,
0.3883589506149292,
-0.8071365356445312,
-0.7200302481651306,
-0.45047882199287415,
-0.5060192346572876... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
automated-research-group/llama2_7b_bf16-winogrande-old | automated-research-group | 2023-10-30T03:25:59Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T03:25:59Z | 2023-10-30T03:25:58.000Z | 2023-10-30T03:25:58 | ---
dataset_info:
features:
- name: answer
dtype: string
- name: id
dtype: string
- name: question
dtype: string
- name: input_perplexity
dtype: float64
- name: input_likelihood
dtype: float64
- name: output_perplexity
dtype: float64
- name: output_likelihood
dtype: float64
splits:
- name: validation
num_bytes: 357232
num_examples: 1267
download_size: 162651
dataset_size: 357232
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "llama2_7b_bf16-winogrande"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4963342845439911,
-0.15101216733455658,
0.2620566487312317,
0.46008560061454773,
-0.5806674957275391,
0.18463312089443207,
0.31911855936050415,
-0.4142543077468872,
0.77415931224823,
0.4212070405483246,
-0.654733419418335,
-0.8240216374397278,
-0.8467994928359985,
-0.258756160736084,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bot-yaya/undl_en2zh_translation | bot-yaya | 2023-11-04T09:28:20Z | 0 | 0 | null | [
"region:us"
] | 2023-11-04T09:28:20Z | 2023-10-30T04:33:16.000Z | 2023-10-30T04:33:16 | ---
dataset_info:
features:
- name: clean_en
sequence: string
- name: clean_zh
sequence: string
- name: record
dtype: string
- name: en2zh
sequence: string
splits:
- name: train
num_bytes: 12473072134
num_examples: 165840
download_size: 6289516266
dataset_size: 12473072134
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "undl_en2zh_translation"
(undl_text)[https://huggingface.co/datasets/bot-yaya/undl_text]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。
机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。
感谢为我提供算力的小伙伴和云平台!
google云计算穷鬼算力白嫖指南:
- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核
- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。
- **重要!** 选抢占式(Spot)实例,可以便宜不少
- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租
- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G
- 13GB的标准硬盘、Debian 12 Bookworm镜像
- 开启允许HTTP和HTTPS流量
| [
-0.6667830348014832,
-0.8437572121620178,
0.10491734743118286,
0.35312196612358093,
-0.7337800860404968,
-0.1708202064037323,
-0.3109058737754822,
-0.37520256638526917,
0.16953390836715698,
0.65613853931427,
-0.557284951210022,
-0.611798882484436,
-0.47364601492881775,
0.11713593453168869,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
gimhanSandeeptha/Medicaljsonl | gimhanSandeeptha | 2023-10-30T05:19:34Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T05:19:34Z | 2023-10-30T05:18:46.000Z | 2023-10-30T05:18:46 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ranWang/undl_en2zh_translation | ranWang | 2023-10-30T05:58:38Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T05:58:38Z | 2023-10-30T05:34:29.000Z | 2023-10-30T05:34:29 | ---
dataset_info:
features:
- name: clean_en
sequence: string
- name: clean_zh
sequence: string
- name: record
dtype: string
- name: en2zh
sequence: string
splits:
- name: train
num_bytes: 12473072134
num_examples: 165840
download_size: 6289513941
dataset_size: 12473072134
---
# Dataset Card for "undl_en2zh_translation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.3167443573474884,
-0.09151652455329895,
0.16950419545173645,
0.36505842208862305,
-0.45220747590065,
0.033836059272289276,
-0.013807646930217743,
-0.2699549198150635,
0.4715924859046936,
0.5459027886390686,
-0.7112768292427063,
-0.7964414358139038,
-0.5363811254501343,
-0.00576770678162... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
searchfind/Test_image_classification | searchfind | 2023-10-30T06:35:54Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-30T06:35:54Z | 2023-10-30T06:32:45.000Z | 2023-10-30T06:32:45 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yep-search/LongCacti-quac | yep-search | 2023-10-30T08:23:03Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T08:23:03Z | 2023-10-30T08:22:48.000Z | 2023-10-30T08:22:48 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: dialogue_id
dtype: string
- name: wikipedia_page_title
dtype: string
- name: background
dtype: string
- name: section_title
dtype: string
- name: context
dtype: string
- name: turn_ids
sequence: string
- name: questions
sequence: string
- name: followups
sequence: int64
- name: yesnos
sequence: int64
- name: answers
struct:
- name: answer_starts
sequence:
sequence: int64
- name: texts
sequence:
sequence: string
- name: orig_answers
struct:
- name: answer_starts
sequence: int64
- name: texts
sequence: string
- name: wikipedia_page_text
dtype: string
- name: wikipedia_page_refs
list:
- name: text
dtype: string
- name: title
dtype: string
- name: gpt4_answers
sequence: string
- name: gpt4_answers_consistent_check
sequence: string
splits:
- name: train
num_bytes: 576059175
num_examples: 11567
download_size: 192048023
dataset_size: 576059175
---
# Dataset Card for "LongCacti-quac"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5558847188949585,
-0.2660042643547058,
0.5666574239730835,
0.30926886200904846,
-0.30591800808906555,
0.17095080018043518,
0.25438350439071655,
-0.35877740383148193,
1.0564632415771484,
0.47970932722091675,
-0.7078215479850769,
-0.8429372310638428,
-0.3837958574295044,
-0.28733602166175... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
classla/COPA-SR_lat | classla | 2023-11-02T09:22:56Z | 0 | 0 | null | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:sr",
"license:cc-by-sa-4.0",
"arxiv:2005.00333",
"region:us"
] | 2023-11-02T09:22:56Z | 2023-10-30T08:33:33.000Z | 2023-10-30T08:33:33 | ---
license: cc-by-sa-4.0
language:
- sr
task_categories:
- text-classification
size_categories:
- n<1K
configs:
- config_name: default
data_files:
- split: train
path: "train.lat.jsonl"
- split: test
path: "test.lat.jsonl"
- split: dev
path: "val.lat.jsonl"
---
# COPA-SR_lat
(The dataset uses latin script. For the original (cyrillic) version, see [this dataset](https://huggingface.co/datasets/classla/COPA-SR).)
The COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the [English COPA dataset ](https://people.ict.usc.edu/~gordon/copa.html) by following the [XCOPA dataset translation methodology ](https://arxiv.org/abs/2005.00333), transliterated into Latin script.
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the [Croatian COPA-HR dataset ](http://hdl.handle.net/11356/1404) and [Macedonian COPA-MK dataset ](http://hdl.handle.net/11356/1687). It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation of the dataset was performed by the [ReLDI Centre Belgrade ](https://reldi.spur.uzh.ch/).
# Authors:
* Ljubešić, Nikola
* Starović, Mirjana
* Kuzman, Taja
* Samardžić, Tanja
# Citation information
```
@misc{11356/1708,
title = {Choice of plausible alternatives dataset in Serbian {COPA}-{SR}},
author = {Ljube{\v s}i{\'c}, Nikola and Starovi{\'c}, Mirjana and Kuzman, Taja and Samard{\v z}i{\'c}, Tanja},
url = {http://hdl.handle.net/11356/1708},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2022} }
``` | [
-0.03896191716194153,
-0.49598008394241333,
0.4711547791957855,
0.007056310307234526,
-0.47152912616729736,
0.07682009786367416,
-0.21269181370735168,
-0.556786298751831,
0.4200384020805359,
0.5323848128318787,
-0.8090469241142273,
-0.5694350600242615,
-0.40721842646598816,
0.1544222533702... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kalomaze/PaperMarioDecomp_1k | kalomaze | 2023-10-30T09:22:06Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-30T09:22:06Z | 2023-10-30T08:40:17.000Z | 2023-10-30T08:40:17 | ---
license: apache-2.0
---
A subset of MIPS Assembly instructions with matching reverse engineered C code from Paper Mario.
https://github.com/pmret/papermario | [
-0.19519983232021332,
-0.32855719327926636,
0.5755409002304077,
0.219571053981781,
-0.08052965253591537,
0.181087464094162,
0.43753984570503235,
-0.2027483731508255,
0.641436755657196,
0.8569326400756836,
-1.086087942123413,
-0.0876493826508522,
-0.30074071884155273,
-0.08726110309362411,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
md-nishat-008/SentMix-3L | md-nishat-008 | 2023-11-08T12:26:02Z | 0 | 0 | null | [
"license:agpl-3.0",
"arxiv:2310.18023",
"region:us"
] | 2023-11-08T12:26:02Z | 2023-10-30T09:19:23.000Z | 2023-10-30T09:19:23 | ---
license: agpl-3.0
---
# SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis
**Publication**: *The First Workshop in South East Asian Language Processing Workshop under AACL-2023.*
**Read in [arXiv](https://arxiv.org/pdf/2310.18023.pdf)**
---
## 📖 Introduction
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several datasets have been built with the goal of training computational models for code-mixing. Although it is very common to observe code-mixing with multiple languages, most datasets available contain code-mixed between only two languages. In this paper, we introduce **SentMix-3L**, a novel dataset for sentiment analysis containing code-mixed data between three languages: Bangla, English, and Hindi. We show that zero-shot prompting with GPT-3.5 outperforms all transformer-based models on SentMix-3L.
---
## 📊 Dataset Details
We introduce **SentMix-3L**, a novel three-language code-mixed test dataset with gold standard labels in Bangla-Hindi-English for the task of Sentiment Analysis, containing 1,007 instances.
> We are presenting this dataset exclusively as a test set due to the unique and specialized nature of the task. Such data is very difficult to gather and requires significant expertise to access. The size of the dataset, while limiting for training purposes, offers a high-quality testing environment with gold-standard labels that can serve as a benchmark in this domain.
---
## 📈 Dataset Statistics
| | **All** | **Bangla** | **English** | **Hindi** | **Other** |
|-------------------|---------|------------|-------------|-----------|-----------|
| Tokens | 89494 | 32133 | 5998 | 15131 | 36232 |
| Types | 19686 | 8167 | 1073 | 1474 | 9092 |
| Max. in instance | 173 | 62 | 20 | 47 | 93 |
| Min. in instance | 41 | 4 | 3 | 2 | 8 |
| Avg | 88.87 | 31.91 | 5.96 | 15.03 | 35.98 |
| Std Dev | 19.19 | 8.39 | 2.94 | 5.81 | 9.70 |
*The row 'Avg' represents the average number of tokens with its standard deviation in row 'Std Dev'.*
---
## 📉 Results
| **Models** | **Weighted F1 Score** |
|---------------|-----------------------|
| GPT 3.5 Turbo | **0.62** |
| XLM-R | 0.59 |
| BanglishBERT | 0.56 |
| mBERT | 0.56 |
| BERT | 0.55 |
| roBERTa | 0.54 |
| MuRIL | 0.54 |
| IndicBERT | 0.53 |
| DistilBERT | 0.53 |
| HindiBERT | 0.48 |
| HingBERT | 0.47 |
| BanglaBERT | 0.47 |
*Weighted F-1 score for different models: training on synthetic, testing on natural data.*
---
## 📝 Citation
If you utilize this dataset, kindly cite our paper.
```bibtex
@article{raihan2023sentmix,
title={SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis},
author={Raihan, Md Nishat and Goswami, Dhiman and Mahmud, Antara and Anstasopoulos, Antonios and Zampieri, Marcos},
journal={arXiv preprint arXiv:2310.18023},
year={2023}
}
| [
-0.43511444330215454,
-0.5672920942306519,
0.012886586599051952,
0.667406439781189,
-0.2730027735233307,
0.25202012062072754,
-0.24356438219547272,
-0.34557318687438965,
0.21200983226299286,
0.19396589696407318,
-0.493852436542511,
-0.7816265225410461,
-0.6767232418060303,
0.24350279569625... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Leoku/drug | Leoku | 2023-10-30T10:11:51Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-30T10:11:51Z | 2023-10-30T10:07:03.000Z | 2023-10-30T10:07:03 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rmcpantoja/taco2-checkpoints | rmcpantoja | 2023-11-26T23:16:22Z | 0 | 0 | null | [
"license:bsd-3-clause",
"region:us"
] | 2023-11-26T23:16:22Z | 2023-10-30T11:14:39.000Z | 2023-10-30T11:14:39 | ---
license: bsd-3-clause
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ibizagrowthagency/train | ibizagrowthagency | 2023-11-01T14:39:58Z | 0 | 0 | null | [
"region:us"
] | 2023-11-01T14:39:58Z | 2023-10-30T11:16:05.000Z | 2023-10-30T11:16:05 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': Aquarell Tattoos
'1': Bedeutung der Tribal Tattoos
'2': Blackwork Tattoo
'3': Building
'4': Cover-Up Tattoo
'5': Dotwork Tattoos
'6': Fineline Tattoos
'7': Geschiche der Maori Tattoos
'8': Japanische Tattoos in Leipzig
'9': Narben Tattoo
'10': Portrait Tattoos
'11': Poster
'12': Realistic Tattoos
'13': Totenkopf Tattoos
'14': Trashpolka Tattoos
'15': Tribal Tattoo
'16': Wikinger Tattoos
splits:
- name: train
num_bytes: 6665820.160194174
num_examples: 175
- name: test
num_bytes: 1297030.8398058251
num_examples: 31
download_size: 7953806
dataset_size: 7962851.0
---
# Dataset Card for "train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6341153383255005,
0.040702350437641144,
0.17027536034584045,
0.30861416459083557,
-0.09620492160320282,
-0.05674801021814346,
0.20394599437713623,
-0.1600799560546875,
0.7688670754432678,
0.327614963054657,
-0.9409077167510986,
-0.5018333196640015,
-0.6181047558784485,
-0.34643167257308... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Phando/vision-flan_191-task_1k | Phando | 2023-10-30T12:28:05Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T12:28:05Z | 2023-10-30T12:07:33.000Z | 2023-10-30T12:07:33 | ---
dataset_info:
features:
- name: id
dtype: string
- name: image
dtype: image
- name: task_name
dtype: string
- name: instruction
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 33215298748.003
num_examples: 186103
download_size: 36889036585
dataset_size: 33215298748.003
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "vision-flan_191-task_1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5235763192176819,
-0.09599412232637405,
0.12178028374910355,
0.17943286895751953,
-0.3504790961742401,
-0.3009777069091797,
0.2888500690460205,
-0.29525840282440186,
0.9850719571113586,
0.7273213863372803,
-1.0436952114105225,
-0.6465086340904236,
-0.6609883904457092,
-0.341853350400924... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jxu124/refclef-benchmark | jxu124 | 2023-10-30T13:28:06Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T13:28:06Z | 2023-10-30T13:24:55.000Z | 2023-10-30T13:24:55 | ---
configs:
- config_name: default
data_files:
- split: refclef_unc_val
path: data/refclef_unc_val-*
- split: refclef_unc_testA
path: data/refclef_unc_testA-*
- split: refclef_unc_testB
path: data/refclef_unc_testB-*
- split: refclef_unc_testC
path: data/refclef_unc_testC-*
- split: refclef_berkeley_val
path: data/refclef_berkeley_val-*
- split: refclef_berkeley_test
path: data/refclef_berkeley_test-*
dataset_info:
features:
- name: ref_list
list:
- name: ann_info
struct:
- name: area
dtype: int64
- name: bbox
sequence: float64
- name: category_id
dtype: int64
- name: id
dtype: string
- name: image_id
dtype: int64
- name: mask_name
dtype: string
- name: segmentation
list:
- name: counts
dtype: string
- name: size
sequence: int64
- name: ref_info
struct:
- name: ann_id
dtype: string
- name: category_id
dtype: int64
- name: image_id
dtype: int64
- name: ref_id
dtype: int64
- name: sent_ids
sequence: int64
- name: sentences
list:
- name: raw
dtype: string
- name: sent
dtype: string
- name: sent_id
dtype: int64
- name: tokens
sequence: string
- name: split
dtype: string
- name: image_info
struct:
- name: file_name
dtype: string
- name: height
dtype: int64
- name: id
dtype: int64
- name: width
dtype: int64
- name: image
dtype: image
splits:
- name: refclef_unc_val
num_bytes: 176315268.0
num_examples: 2000
- name: refclef_unc_testA
num_bytes: 38748729.0
num_examples: 485
- name: refclef_unc_testB
num_bytes: 41495038.0
num_examples: 490
- name: refclef_unc_testC
num_bytes: 37159288.0
num_examples: 465
- name: refclef_berkeley_val
num_bytes: 90320401.0
num_examples: 1000
- name: refclef_berkeley_test
num_bytes: 889898825.642
num_examples: 9999
download_size: 1256485050
dataset_size: 1273937549.642
---
# Dataset Card for "refclef-benchmark"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7835304737091064,
-0.0925966277718544,
0.15902890264987946,
0.13186578452587128,
-0.2679632604122162,
-0.18892714381217957,
0.2547675669193268,
-0.33129289746284485,
0.5763798356056213,
0.5060961842536926,
-0.8969134092330933,
-0.5212424397468567,
-0.34763962030410767,
0.035826526582241... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
eno777/babab | eno777 | 2023-10-30T14:01:06Z | 0 | 0 | null | [
"license:openrail",
"region:us"
] | 2023-10-30T14:01:06Z | 2023-10-30T14:00:41.000Z | 2023-10-30T14:00:41 | ---
license: openrail
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ISCA-IUB/GermanLanguageTwitterAntisemitism | ISCA-IUB | 2023-11-13T08:56:44Z | 0 | 0 | null | [
"language:de",
"twitter",
"X",
"hate speech",
"antisemitism",
"machine learning",
"juden",
"israel",
"region:us"
] | 2023-11-13T08:56:44Z | 2023-10-30T14:09:13.000Z | 2023-10-30T14:09:13 | ---
language:
- de
tags:
- twitter
- X
- hate speech
- antisemitism
- machine learning
- juden
- israel
pretty_name: German Language Antisemitism on Twitter
---
# A German Language Labeled Dataset of Tweets
Gunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer
{gjikeli, skarali, damieh, ksoemer}@iu.edu
## Description
Our dataset contains 8,048 German language tweets related to Jewish life from a four-year timespan.
The dataset consists of 18 samples of tweets with the keyword “Juden” or “Israel.” The samples are representative samples of all live tweets (at the time of sampling) with these keywords respectively over the indicated time period. Each sample was annotated by two expert annotators using an Annotation Portal that visualizes the live tweets in context. We provide the annotation results based on the agreement of two annotators, after discussing discrepancies (Jikeli et al. 2022: 3-6).
Overall, 335 tweets (4%) were labelled as antisemitic following the IHRA Working Definition of Antisemitism. 1345 tweets (17 %) come from 2019, 1364 tweets (17 %) from 2020, 2639 tweets (33 %) from 2021 and 2700 tweets (34 %) from 2022.
About half of the tweets, a total of 4,493 tweets (56 %) come from queries with the keyword “Juden,” which is representative of a continuous time period from January 2019 to December 2022: 864 tweets (19 %) come from 2019, 891 tweets (20 %) from 2020, 1364 tweets (30 %) from 2021 and 1374 (31 %). 148 out of the 4493 tweets, so 3% from the query with “Juden” are antisemitic.
The other part of the tweets, a total of 3,555 (44 %) results of queries with the keyword “Israel”. 481 tweets (14 %) of the keywords containing Israel stem from 2019, 473 (13 %) come from 2020, 1275 tweets (36 %) from 2021 and 1326 tweets (37 %) are from 2022. Out of all tweets from the “Israel” query, 187 (5 %) are antisemitic.
The csv file contains diacritics and special characters of the German language (e.g., “ä”, “ü”, “ö”, “ß”), which should be taken into account when opening it with anything other than a text editor.
## References
Günther Jikeli, David Axelrod, Rhonda K. Fischer, Elham Forouzesh, Weejeong Jeong, Daniel Miehling, Katharina Soemer (2022): Differences between antisemitic and non-antisemitic English language tweets. Computational and Mathematical Organization Theory
## Acknowledgements
This work used Jetstream2 at Indiana University through allocation HUM200003 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296.
We are grateful for the support of Indiana University’s Observatory on Social Media (OSoMe) (Davis et al. 2016) and the contributions and annotations of all team members in our Social Media & Hate Research Lab at Indiana University’s Institute for the Study of Contemporary Antisemitism, especially Grace Bland, Elisha S. Breton, Kathryn Cooper, Robin Forstenhäusler, Sophie von Máriássy, Mabel Poindexter, Jenna Solomon, Clara Schilling, Emma Shriberg and Victor Tschiskale. | [
-0.48086175322532654,
-0.8224248886108398,
0.19138433039188385,
-0.01859930157661438,
-0.4425269067287445,
0.2768707573413849,
-0.14078393578529358,
-0.5353142023086548,
0.9023574590682983,
0.22326521575450897,
-0.41976892948150635,
-0.7469180226325989,
-0.9589449763298035,
0.0056515792384... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MichaelVeser/opensecurity-axolotl | MichaelVeser | 2023-10-30T14:19:23Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:19:23Z | 2023-10-30T14:19:10.000Z | 2023-10-30T14:19:10 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
varuntrivedi/trial_dataset | varuntrivedi | 2023-10-30T14:28:01Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:28:01Z | 2023-10-30T14:26:26.000Z | 2023-10-30T14:26:26 | [
{
"id": "ner_gpt_0",
"conversations": [
[
{ "from": "human",
"value": "Text: The impact of climate change on marine ecosystems and biodiversity is a pressing concern. Rising sea temperatures, ocean acidification, and changing currents have significant effects on marine life. Researchers are studying the adaptation mechanisms of various species to these environmental changes." },
{ "from": "gpt", "value": "I've read this text." },
{ "from": "human", "value": "What describes the main focus of the text?" },
{ "from": "gpt", "value": "[\"impact of climate change on marine ecosystems and biodiversity\"]" },
{ "from": "human", "value": "What describes environmental factors in the text?" },
{ "from": "gpt", "value": "[\"rising sea temperatures\", \"ocean acidification\", \"changing currents\"]" },
{ "from": "human", "value": "What describes the research subject in the text?" },
{ "from": "gpt", "value": "[\"adaptation mechanisms of various species\"]" },
{ "from": "human", "value": "What describes the time frame in the text?" },
{ "from": "gpt", "value": "[]" }
]
]
}
] | [
-0.49838319420814514,
-0.5454192757606506,
0.5204375982284546,
-0.13945280015468597,
-0.9226728677749634,
0.16271738708019257,
-0.04223962128162384,
-0.06141626834869385,
0.4689624309539795,
0.8926569223403931,
-0.7125685811042786,
-0.6686069369316101,
-0.5925055146217346,
0.54537320137023... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Buggy23/colegio | Buggy23 | 2023-10-30T14:40:27Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:40:27Z | 2023-10-30T14:37:44.000Z | 2023-10-30T14:37:44 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Almost-AGI-Diffusion/kand2 | Almost-AGI-Diffusion | 2023-10-30T14:49:24Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:49:24Z | 2023-10-30T14:42:57.000Z | 2023-10-30T14:42:57 | ---
dataset_info:
features:
- name: Prompt
dtype: string
- name: Category
dtype: string
- name: Challenge
dtype: string
- name: Note
dtype: string
- name: images
dtype: image
- name: model_name
dtype: string
- name: seed
dtype: int64
- name: upvotes
dtype: int64
splits:
- name: train
num_bytes: 21708501.0
num_examples: 219
download_size: 21693707
dataset_size: 21708501.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Kandinksy 2.2
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts. This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import PIL
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import DiffusionPipeline
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
pipe_prior = DiffusionPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
pipe_prior.set_progress_bar_config(disable=True)
t2i_pipe = DiffusionPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16
)
t2i_pipe.to("cuda")
t2i_pipe.set_progress_bar_config(disable=True)
seed = 0
generator = torch.Generator("cuda").manual_seed(seed)
ckpt_id = (
"kandinsky-community/" + "kandinsky-2-2-prior" + "_" + "kandinsky-2-2-decoder"
)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
image_embeds, negative_image_embeds = pipe_prior(
prompt,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).to_tuple()
image = t2i_pipe(
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).images[0]
image = image.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"kandinsky_22_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/kandinsky-2-2"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
``` | [
-0.38658666610717773,
-0.4149981737136841,
0.5292077660560608,
0.141149640083313,
-0.324416846036911,
-0.17320941388607025,
-0.011328685097396374,
-0.04029078409075737,
-0.045349035412073135,
0.4130818545818329,
-0.885809600353241,
-0.6590896844863892,
-0.5180893540382385,
0.09085967391729... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Almost-AGI-Diffusion/sdxl | Almost-AGI-Diffusion | 2023-10-30T14:46:58Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:46:58Z | 2023-10-30T14:43:04.000Z | 2023-10-30T14:43:04 | ---
dataset_info:
features:
- name: Prompt
dtype: string
- name: Category
dtype: string
- name: Challenge
dtype: string
- name: Note
dtype: string
- name: images
dtype: image
- name: model_name
dtype: string
- name: seed
dtype: int64
- name: upvotes
dtype: int64
splits:
- name: train
num_bytes: 25650684.0
num_examples: 219
download_size: 25640015
dataset_size: 25650684.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# SDXL
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts.
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import DDIMScheduler, DiffusionPipeline
import PIL
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
ckpt_id = "stabilityai/stable-diffusion-xl-base-1.0"
refiner_ckpt_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
pipe = DiffusionPipeline.from_pretrained(
ckpt_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.set_progress_bar_config(disable=True)
refiner = DiffusionPipeline.from_pretrained(
refiner_ckpt_id,
torch_dtype=torch.float16,
use_auth_token=True
).to("cuda")
refiner.scheduler = DDIMScheduler.from_config(refiner.scheduler.config)
refiner.set_progress_bar_config(disable=True)
seed = 0
generator = torch.Generator("cuda").manual_seed(seed)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
latent = pipe(
prompt,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
output_type="latent",
).images[0]
image_refined = refiner(
prompt=prompt,
image=latent[None, :],
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).images[0]
image = image_refined.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"sd_xl_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/sdxl-1.0-refiner"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
``` | [
-0.4820316433906555,
-0.3758489787578583,
0.6965538263320923,
0.18194037675857544,
-0.258565217256546,
-0.19217780232429504,
0.06208128109574318,
0.03132057934999466,
-0.031654633581638336,
0.5435617566108704,
-0.9338095188140869,
-0.6228287816047668,
-0.5329431891441345,
0.170590654015541... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Almost-AGI-Diffusion/wuerst | Almost-AGI-Diffusion | 2023-10-30T14:50:04Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:50:04Z | 2023-10-30T14:43:10.000Z | 2023-10-30T14:43:10 | ---
dataset_info:
features:
- name: Prompt
dtype: string
- name: Category
dtype: string
- name: Challenge
dtype: string
- name: Note
dtype: string
- name: images
dtype: image
- name: model_name
dtype: string
- name: seed
dtype: int64
- name: upvotes
dtype: int64
splits:
- name: train
num_bytes: 19633368.0
num_examples: 219
download_size: 19625614
dataset_size: 19633368.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Wuerstchen
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts. This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import AutoPipelineForText2Image
import PIL
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
seed = 0
device = "cuda"
generator = torch.Generator(device).manual_seed(seed)
dtype = torch.float16
ckpt_id = "warp-diffusion/wuerstchen"
pipeline = AutoPipelineForText2Image.from_pretrained(
ckpt_id, torch_dtype=dtype
).to(device)
pipeline.prior_prior = torch.compile(pipeline.prior_prior, mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
image = pipeline(
prompt=prompt,
height=1024,
width=1024,
prior_guidance_scale=4.0,
decoder_guidance_scale=0.0,
generator=generator,
).images[0]
image = image.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"wuerstchen_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/wuerstchen"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
``` | [
-0.4908706545829773,
-0.30975261330604553,
0.4390822649002075,
0.1890379637479782,
-0.303903728723526,
-0.3738420605659485,
-0.006912183947861195,
-0.10675285011529922,
-0.043013520538806915,
0.38071808218955994,
-0.9544967412948608,
-0.5245521068572998,
-0.5272974371910095,
0.174387618899... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Almost-AGI-Diffusion/karlo | Almost-AGI-Diffusion | 2023-10-30T14:48:09Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T14:48:09Z | 2023-10-30T14:43:16.000Z | 2023-10-30T14:43:16 | ---
dataset_info:
features:
- name: Prompt
dtype: string
- name: Category
dtype: string
- name: Challenge
dtype: string
- name: Note
dtype: string
- name: images
dtype: image
- name: model_name
dtype: string
- name: seed
dtype: int64
- name: upvotes
dtype: int64
splits:
- name: train
num_bytes: 20834626.0
num_examples: 219
download_size: 20825015
dataset_size: 20834626.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Karlo
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts.
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "" # a parti prompt
generator = torch.Generator("cuda").manual_seed(0)
image = pipe(prompt, prior_num_inference_steps=50, decoder_num_inference_steps=100, generator=generator).images[0]
``` | [
-0.4578472375869751,
-0.28453031182289124,
0.7394711375236511,
0.305819571018219,
-0.5860678553581238,
-0.3823627233505249,
0.15059007704257965,
-0.08108039945363998,
0.2959766685962677,
0.3480220437049866,
-0.9563478827476501,
-0.735800564289093,
-0.6897476315498352,
0.5335032343864441,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
matheushmart/cantores | matheushmart | 2023-10-30T16:57:19Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T16:57:19Z | 2023-10-30T14:57:50.000Z | 2023-10-30T14:57:50 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Abdou/dz-sentiment-yt-comments | Abdou | 2023-11-06T10:49:24Z | 0 | 0 | null | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:ar",
"license:mit",
"region:us"
] | 2023-11-06T10:49:24Z | 2023-10-30T15:07:21.000Z | 2023-10-30T15:07:21 | ---
license: mit
task_categories:
- text-classification
language:
- ar
size_categories:
- 10K<n<100K
---
# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic
This dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the `label` column) and is not balanced. Here are the number of rows of each class:
- 0 (Negative): **17,033 (34.06%)**
- 1 (Neutral): **11,136 (22.26%)**
- 2 (Positive): **21,847 (43.68%)**
Please note that there are some swear words in the dataset, so please use it with caution.
# Citation
If you find our work useful, please cite it as follows:
```bibtex
@article{2023,
title={Sentiment Analysis on Algerian Dialect with Transformers},
author={Zakaria Benmounah and Abdennour Boulesnane and Abdeladim Fadheli and Mustapha Khial},
journal={Applied Sciences},
volume={13},
number={20},
pages={11157},
year={2023},
month={Oct},
publisher={MDPI AG},
DOI={10.3390/app132011157},
ISSN={2076-3417},
url={http://dx.doi.org/10.3390/app132011157}
}
```
| [
-0.9120850563049316,
-0.17510458827018738,
0.06501813977956772,
0.6065667867660522,
-0.16853436827659607,
-0.07739881426095963,
-0.18296143412590027,
-0.1696958839893341,
0.42664164304733276,
0.5253294706344604,
-0.5396180152893066,
-0.9098926782608032,
-0.9038020968437195,
0.2768806815147... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
snyamson/covid-tweet-sentiment-analyzer-distilbert-data | snyamson | 2023-10-30T15:42:25Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T15:42:25Z | 2023-10-30T15:42:22.000Z | 2023-10-30T15:42:22 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
dtype: int64
splits:
- name: train
num_bytes: 10366704
num_examples: 7999
- name: val
num_bytes: 2592000
num_examples: 2000
download_size: 514530
dataset_size: 12958704
---
# Dataset Card for "covid-tweet-sentiment-analyzer-distilbert-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.41189834475517273,
-0.4009919762611389,
0.06004710495471954,
0.46275293827056885,
-0.4077145457267761,
0.3941919505596161,
0.1879805326461792,
0.0776115208864212,
0.8249334096908569,
-0.1211545541882515,
-0.9397889971733093,
-0.9124382734298706,
-0.8358752727508545,
-0.3160761892795563,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
316usman/test_1 | 316usman | 2023-10-30T20:07:47Z | 0 | 0 | null | [
"license:bsd",
"region:us"
] | 2023-10-30T20:07:47Z | 2023-10-30T16:24:32.000Z | 2023-10-30T16:24:32 | ---
license: bsd
dataset_info:
features:
- name: '0'
dtype: string
- name: '1'
dtype: string
splits:
- name: train01
num_bytes: 1168
num_examples: 1
download_size: 8850
dataset_size: 1168
configs:
- config_name: default
data_files:
- split: train01
path: data/train01-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kheopsai/mise_dem | kheopsai | 2023-10-30T16:59:52Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T16:59:52Z | 2023-10-30T16:59:09.000Z | 2023-10-30T16:59:09 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
asoria/bluey | asoria | 2023-10-31T12:56:27Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T12:56:27Z | 2023-10-30T17:07:57.000Z | 2023-10-30T17:07:57 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/autotrain-data-new-datasets | davanstrien | 2023-10-30T17:10:24Z | 0 | 0 | null | [
"task_categories:text-classification",
"language:en",
"arxiv:2206.02421",
"arxiv:2212.00851",
"region:us"
] | 2023-10-30T17:10:24Z | 2023-10-30T17:09:21.000Z | 2023-10-30T17:09:21 | Invalid username or password. | [
0.22538813948631287,
-0.8998719453811646,
0.4273532032966614,
0.01545056700706482,
-0.07883036881685257,
0.6044343113899231,
0.6795741319656372,
0.07246866822242737,
0.20425251126289368,
0.8107712864875793,
-0.7993434071540833,
0.2074914574623108,
-0.9463866949081421,
0.3846413493156433,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jxu124/refering_expression | jxu124 | 2023-10-31T09:15:19Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T09:15:19Z | 2023-10-30T17:14:51.000Z | 2023-10-30T17:14:51 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
GEO-Optim/geo-bench | GEO-Optim | 2023-11-02T23:44:53Z | 0 | 0 | null | [
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2023-11-02T23:44:53Z | 2023-10-30T17:38:56.000Z | 2023-10-30T17:38:56 | ---
license: cc-by-sa-4.0
size_categories:
- 1K<n<10K
language:
- en
pretty_name: GEO-bench
---
# Geo-Bench
## Description
Geo-Bench is a comprehensive benchmark dataset designed for evaluating content optimization methods and Generative Engines. It consists of 10,000 queries sourced from multiple real-world and synthetically generated queries, specifically curated and repurposed for generative engines. The benchmark includes queries from nine different sources, each further categorized based on their target domain, difficulty level, query intent, and other dimensions.
## Usage
You can easily load and use Geo-Bench in Python using the `datasets` library:
```python
import datasets
# Load Geo-Bench
dataset = datasets.load_dataset("Pranjal2041/geo-bench")
```
## Data Source
Geo-Bench is a compilation of queries from various sources, both real and synthetically generated, to create a benchmark tailored for generative engines. The datasets used in constructing Geo-Bench are as follows:
1. **MS Macro, 2. ORCAS-1, and 3. Natural Questions:** These datasets contain real anonymized user queries from Bing and Google Search Engines, collectively representing common datasets used in search engine-related research.
4. **AIISouls:** This dataset contains essay questions from "All Souls College, Oxford University," challenging generative engines to perform reasoning and aggregate information from multiple sources.
5. **LIMA:** Contains challenging questions requiring generative engines to not only aggregate information but also perform suitable reasoning to answer the question, such as writing short poems or generating Python code.
6. **Davinci-Debate:** Contains debate questions generated for testing generative engines.
7. **Perplexity.ai Discover:** These queries are sourced from Perplexity.ai's Discover section, an updated list of trending queries on the platform.
8. **EII-5:** This dataset contains questions from the ELIS subreddit, where users ask complex questions and expect answers in simple, layman terms.
9. **GPT-4 Generated Queries:** To supplement diversity in query distribution, GPT-4 is prompted to generate queries ranging from various domains (e.g., science, history) and based on query intent (e.g., navigational, transactional) and difficulty levels (e.g., open-ended, fact-based).
Apart from queries, we also provide 5 cleaned html responses based on top Google search results.
## Tags
Optimizing website content often requires making targeted changes based on the domain of the task. Further, a user of GENERATIVE ENGINE OPTIMIZATION may need to find an appropriate method for only a subset of queries based on multiple factors, such as domain, user intent, query nature. To this end, we tag each of the queries based on a pool of 7 different categories. For tagging, we use the GPT-4 model and manually confirm high recall and precision in tagging. However, owing to such an automated system, the tags can be noisy and should not be considered as the sole basis for filtering or analysis.
### Difficulty Level
- The complexity of the query, ranging from simple to complex.
- Example of a simple query: "What is the capital of France?"
- Example of a complex query: "What are the implications of the Schrödinger equation in quantum mechanics?"
### Nature of Query
- The type of information sought by the query, such as factual, opinion, or comparison.
- Example of a factual query: "How does a car engine work?"
- Example of an opinion query: "What is your opinion on the Harry Potter series?"
### Genre
- The category or domain of the query, such as arts and entertainment, finance, or science.
- Example of a query in the arts and entertainment genre: "Who won the Oscar for Best Picture in 2020?"
- Example of a query in the finance genre: "What is the current exchange rate between the Euro and the US Dollar?"
### Specific Topics
- The specific subject matter of the query, such as physics, economics, or computer science.
- Example of a query on a specific topic in physics: "What is the theory of relativity?"
- Example of a query on a specific topic in economics: "What is the law of supply and demand?"
### Sensitivity
- Whether the query involves sensitive topics or not.
- Example of a non-sensitive query: "What is the tallest mountain in the world?"
- Example of a sensitive query: "What is the current political situation in North Korea?"
### User Intent
- The purpose behind the user's query, such as research, purchase, or entertainment.
- Example of a research intent query: "What are the health benefits of a vegetarian diet?"
- Example of a purchase intent query: "Where can I buy the latest iPhone?"
### Answer Type
- The format of the answer that the query is seeking, such as fact, opinion, or list.
- Example of a fact answer type query: "What is the population of New York City?"
- Example of an opinion answer type query: "Is it better to buy or rent a house?"
## Additional Information
Geo-Bench is intended for research purposes and provides valuable insights into the challenges and opportunities of content optimization for generative engines. Please refer to the [GEO paper](https://arxiv.org/abs/2310.18xxx) for more details.
---
## Data Examples
### Example 1
```json
{
"query": "Why is the smell of rain pleasing?",
"tags": ['informational', 'simple', 'non-technical', 'science', 'research', 'non-sensitive'],
"sources": List[str],
}
```
### Example 2
```json
{
"query": "Can foxes be domesticated?",
"tags": ['informational', 'non-technical', 'pets and animals', 'fact', 'non-sensitive'],
"sources": List[str],
}
```
---
## License
Geo-Bench is released under the [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
## Dataset Size
The dataset contains 8K queries for train, 1k queries for val and 1k for tesst.
---
## Contributions
We welcome contributions and feedback to improve Geo-Bench. You can contribute by reporting issues or submitting improvements through the [GitHub repository](https://github.com/Pranjal2041/GEO/tree/main/GEO-Bench).
## How to Cite
When using Geo-Bench in your work, please include a proper citation. You can use the following citation as a reference:
```
@misc{Aggarwal2023geo,
title={{GEO}: Generative Engine Optimization},
author={Pranjal Aggarwal and Vishvak Murahari and Tanmay Rajpurohit and Ashwin Kalyan and Karthik R Narasimhan and Ameet Deshpande},
year={2023},
eprint={2310.18xxx},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | [
-0.7659387588500977,
-0.9767630100250244,
0.5713220834732056,
0.28943389654159546,
-0.18407675623893738,
-0.16506639122962952,
-0.20519548654556274,
-0.11986292153596878,
0.040207501500844955,
0.27252399921417236,
-0.6817114949226379,
-0.8318226933479309,
-0.2825992703437805,
0.10129710286... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/autotrain-data-new-datasets-2 | davanstrien | 2023-10-30T18:09:00Z | 0 | 0 | null | [
"task_categories:text-classification",
"language:en",
"arxiv:2211.02092",
"arxiv:2308.16900",
"region:us"
] | 2023-10-30T18:09:00Z | 2023-10-30T18:08:09.000Z | 2023-10-30T18:08:09 | Invalid username or password. | [
0.22538813948631287,
-0.8998719453811646,
0.4273532032966614,
0.01545056700706482,
-0.07883036881685257,
0.6044343113899231,
0.6795741319656372,
0.07246866822242737,
0.20425251126289368,
0.8107712864875793,
-0.7993434071540833,
0.2074914574623108,
-0.9463866949081421,
0.3846413493156433,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alvations/units | alvations | 2023-10-30T18:50:33Z | 0 | 0 | null | [
"license:cc0-1.0",
"region:us"
] | 2023-10-30T18:50:33Z | 2023-10-30T18:46:02.000Z | 2023-10-30T18:46:02 | ---
license: cc0-1.0
---
This is a human translated from English list of units of measurements in multiple languages:
- Arabic
- Bengali
- Chinese (CN)
- Chinese (HK)
- Chinese (TW)
- Czech
- Dutch
- English
- French (CA)
- French (FR)
- German
- Hebrew
- Hindi
- Italian
- Japanese
- Korean
- Marathi
- Nepali
- Polish
- Portuguese (BR)
- Portuguese (PT)
- Russian
- Spanish (Latin America)
- Spanish (Mexico)
- Spanish (Spain)
- Swedish
- Turkish | [
-0.37546345591545105,
-0.034464988857507706,
0.5724976658821106,
0.49797677993774414,
-0.1894320696592331,
0.08232366293668747,
-0.3338356018066406,
-0.5174688696861267,
0.37777072191238403,
0.47850120067596436,
-0.38572755455970764,
-0.3201967477798462,
-0.2912741005420685,
0.508602499961... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Norarolalora/ainzedamanga | Norarolalora | 2023-10-30T19:09:35Z | 0 | 0 | null | [
"license:openrail",
"region:us"
] | 2023-10-30T19:09:35Z | 2023-10-30T18:56:01.000Z | 2023-10-30T18:56:01 | ---
license: openrail
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hippocrates/Dolly_train | hippocrates | 2023-10-30T20:00:39Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T20:00:39Z | 2023-10-30T20:00:37.000Z | 2023-10-30T20:00:37 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: id
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 25006952
num_examples: 15011
download_size: 12127483
dataset_size: 25006952
---
# Dataset Card for "Dolly_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4483427405357361,
-0.15320031344890594,
0.01262909546494484,
0.3740679919719696,
-0.1440962255001068,
-0.17642736434936523,
0.4681222140789032,
-0.024350011721253395,
0.8113240599632263,
0.5584322214126587,
-0.8973655700683594,
-0.5281451344490051,
-0.6641553044319153,
-0.29294490814208... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hippocrates/Alpaca_train | hippocrates | 2023-10-30T20:08:27Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T20:08:27Z | 2023-10-30T20:08:25.000Z | 2023-10-30T20:08:25 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: id
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 44978419
num_examples: 52002
download_size: 16852893
dataset_size: 44978419
---
# Dataset Card for "Alpaca_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.8109651207923889,
-0.1967296302318573,
0.12258955836296082,
0.37042948603630066,
-0.3158958852291107,
-0.23636367917060852,
0.3627174198627472,
-0.28017720580101013,
1.0189309120178223,
0.40758228302001953,
-0.9690061807632446,
-0.5817769169807434,
-0.7769271731376648,
-0.36539909243583... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nespc/cnn_dailymail_prompts | nespc | 2023-10-30T20:11:05Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T20:11:05Z | 2023-10-30T20:10:23.000Z | 2023-10-30T20:10:23 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1354728397
num_examples: 287113
- name: test
num_bytes: 53648492
num_examples: 11490
download_size: 781011544
dataset_size: 1408376889
---
# Dataset Card for "cnn_dailymail_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5017474293708801,
-0.38748183846473694,
0.17933419346809387,
0.4215925931930542,
-0.39490944147109985,
-0.017287231981754303,
0.12278901785612106,
0.08076989650726318,
0.6141620874404907,
0.4507651925086975,
-1.0932843685150146,
-0.8967947959899902,
-0.6530126333236694,
-0.0748272985219... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mosaicml/long_context_eval | mosaicml | 2023-11-03T21:40:46Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-11-03T21:40:46Z | 2023-10-30T20:46:42.000Z | 2023-10-30T20:46:42 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mpingale/guanaco-llama2-1k | mpingale | 2023-10-30T20:54:56Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T20:54:56Z | 2023-10-30T20:54:55.000Z | 2023-10-30T20:54:55 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1654448
num_examples: 1000
download_size: 966693
dataset_size: 1654448
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "guanaco-llama2-1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.31712621450424194,
-0.1850084662437439,
0.25064411759376526,
0.5434030890464783,
-0.5531396865844727,
0.012613237835466862,
0.3730725646018982,
-0.27480971813201904,
0.9305324554443359,
0.43072932958602905,
-0.7881225943565369,
-0.9666924476623535,
-0.7247747778892517,
-0.23143085837364... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bvallegc/videos | bvallegc | 2023-10-30T22:30:16Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T22:30:16Z | 2023-10-30T22:27:08.000Z | 2023-10-30T22:27:08 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: video_data
dtype: binary
- name: duration_seconds
dtype: float64
- name: video_path
dtype: string
splits:
- name: train
num_bytes: 3786824395
num_examples: 4688
download_size: 3778922511
dataset_size: 3786824395
---
# Dataset Card for "videos"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7040562033653259,
-0.3290260434150696,
0.13979360461235046,
0.18517492711544037,
-0.30452924966812134,
-0.008285488933324814,
0.21091431379318237,
0.24277453124523163,
0.815467119216919,
0.4494211971759796,
-0.9186153411865234,
-0.6974200010299683,
-0.819473922252655,
-0.389919877052307... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ContextualAI/nq_open_bge_neighbors | ContextualAI | 2023-10-30T23:35:06Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T23:35:06Z | 2023-10-30T23:25:21.000Z | 2023-10-30T23:25:21 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
sequence: string
- name: neighbor
dtype: string
splits:
- name: validation
num_bytes: 1883578
num_examples: 3610
download_size: 1346496
dataset_size: 1883578
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "nq_open_bge_neighbors"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6186760067939758,
-0.23001493513584137,
0.2624126076698303,
0.03738679736852646,
0.0016426588408648968,
-0.08935187011957169,
0.32759907841682434,
-0.148787260055542,
0.7859525084495544,
0.5123132467269897,
-0.7477647066116333,
-0.8965049982070923,
-0.4028959572315216,
-0.17573340237140... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ContextualAI/boolq_bge_neighbors | ContextualAI | 2023-10-30T23:35:52Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T23:35:52Z | 2023-10-30T23:26:20.000Z | 2023-10-30T23:26:20 | ---
dataset_info:
features:
- name: question
dtype: string
- name: passage
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
- name: neighbor
dtype: string
splits:
- name: validation
num_bytes: 3632916
num_examples: 3270
download_size: 2372841
dataset_size: 3632916
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "boolq_bge_neighbors"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6153808832168579,
-0.29180145263671875,
0.36250388622283936,
0.08631005138158798,
0.026082560420036316,
0.08775036782026291,
0.4636276364326477,
-0.35350295901298523,
0.707626223564148,
0.5375565886497498,
-0.7128865718841553,
-0.8777483701705933,
-0.3656724989414215,
-0.254944920539855... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/tx | LuiMito | 2023-10-30T23:42:20Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T23:42:20Z | 2023-10-30T23:40:29.000Z | 2023-10-30T23:40:29 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ContextualAI/boolq_bge_neighbors_nprobe100 | ContextualAI | 2023-10-30T23:50:41Z | 0 | 0 | null | [
"region:us"
] | 2023-10-30T23:50:41Z | 2023-10-30T23:45:01.000Z | 2023-10-30T23:45:01 | ---
dataset_info:
features:
- name: question
dtype: string
- name: passage
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
- name: neighbor
dtype: string
splits:
- name: validation
num_bytes: 3632916
num_examples: 3270
download_size: 2372841
dataset_size: 3632916
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "boolq_bge_neighbors_nprobe100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6528505682945251,
-0.29304593801498413,
0.3325084149837494,
0.2122795283794403,
0.10881172865629196,
0.05676359310746193,
0.3838834762573242,
-0.26225876808166504,
0.6634011268615723,
0.5544741749763489,
-0.724776029586792,
-0.8149452209472656,
-0.3677157461643219,
-0.14121507108211517,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ajanco/anc | ajanco | 2023-10-31T00:55:50Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T00:55:50Z | 2023-10-31T00:47:57.000Z | 2023-10-31T00:47:57 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/gelorum | LuiMito | 2023-10-31T01:21:47Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T01:21:47Z | 2023-10-31T01:20:52.000Z | 2023-10-31T01:20:52 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/ge | LuiMito | 2023-10-31T01:40:47Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T01:40:47Z | 2023-10-31T01:40:05.000Z | 2023-10-31T01:40:05 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
theuop/desa | theuop | 2023-10-31T02:14:17Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-31T02:14:17Z | 2023-10-31T02:12:57.000Z | 2023-10-31T02:12:57 | ---
license: apache-2.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thomascuddihy/hrw_test_multiclass_flagged_data | thomascuddihy | 2023-10-31T03:39:36Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T03:39:36Z | 2023-10-31T03:06:32.000Z | 2023-10-31T03:06:32 | ---
configs:
- config_name: default
data_files:
- split: train
path: data.csv
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.47198691964149475,
-0.4094799757003784,
-0.03380846604704857,
0.3362200856208801,
-0.3197465240955353,
0.21746407449245453,
-0.3079157769680023,
-0.2590261995792389,
0.5117815732955933,
0.7525157928466797,
-0.8910995125770569,
-1.199066400527954,
-0.762687623500824,
0.14076702296733856,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_first_sent_train_30_eval_10_sentbefore | tyzhu | 2023-10-31T14:57:57Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:57:57Z | 2023-10-31T03:32:24.000Z | 2023-10-31T03:32:24 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 151115
num_examples: 110
- name: validation
num_bytes: 10621
num_examples: 10
download_size: 65086
dataset_size: 161736
---
# Dataset Card for "find_first_sent_train_30_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5961532592773438,
-0.2579011619091034,
0.30169135332107544,
0.5883501172065735,
-0.1192803904414177,
-0.07995984703302383,
0.26510119438171387,
0.2865625321865082,
0.7065523266792297,
0.40244776010513306,
-1.0339245796203613,
-0.7323241233825684,
-0.6280844211578369,
-0.1663570702075958... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kpriyanshu256/semeval-task-8-c | kpriyanshu256 | 2023-10-31T03:41:50Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T03:41:50Z | 2023-10-31T03:41:47.000Z | 2023-10-31T03:41:47 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: dev
path: data/dev-*
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 6125332
num_examples: 3649
- name: dev
num_bytes: 830346
num_examples: 505
download_size: 2838216
dataset_size: 6955678
---
# Dataset Card for "semeval-task-8-c"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4704153835773468,
-0.2367417812347412,
0.34827888011932373,
0.3734268248081207,
-0.2338750809431076,
-0.17791436612606049,
0.2857942283153534,
-0.10608420521020889,
0.8881305456161499,
0.7170843482017517,
-0.861621618270874,
-0.6668235063552856,
-0.7653525471687317,
-0.14948607981204987... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
RowitZou/test | RowitZou | 2023-10-31T05:16:52Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-31T05:16:52Z | 2023-10-31T03:44:54.000Z | 2023-10-31T03:44:54 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tinhpx2911/wikipedia_20220620_filtered | tinhpx2911 | 2023-10-31T04:46:52Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T04:46:52Z | 2023-10-31T04:45:16.000Z | 2023-10-31T04:45:16 | ---
dataset_info:
features:
- name: id
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: text
dtype: string
- name: timestamp
dtype: timestamp[s]
- name: revid
dtype: string
splits:
- name: train
num_bytes: 1202604321
num_examples: 693016
download_size: 575102780
dataset_size: 1202604321
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "wikipedia_20220620_cleaned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7772798538208008,
-0.3092729449272156,
0.12915915250778198,
-0.17000256478786469,
-0.32784217596054077,
-0.23466549813747406,
0.055875640362501144,
-0.2870731055736542,
0.8185145258903503,
0.7193196415901184,
-0.926946222782135,
-0.6229560375213623,
-0.3039926290512085,
-0.0461808443069... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
fishaudio/cn-hubert-25hz-vq | fishaudio | 2023-10-31T06:27:47Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T06:27:47Z | 2023-10-31T06:08:22.000Z | 2023-10-31T06:08:22 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 19256435269
num_examples: 12406672
- name: test
num_bytes: 167208
num_examples: 80
download_size: 3658804204
dataset_size: 19256602477
---
# Dataset Card for "cn-hubert-25hz-vq"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6919785737991333,
-0.09976082295179367,
0.18457314372062683,
0.3150847256183624,
-0.5046141743659973,
0.09446816146373749,
0.1529393196105957,
-0.19661180675029755,
0.8365568518638611,
0.5612305998802185,
-0.9343166351318359,
-0.832680344581604,
-0.29935815930366516,
-0.3168437778949737... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Chukana/MyPhoto | Chukana | 2023-10-31T06:43:37Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-31T06:43:37Z | 2023-10-31T06:32:43.000Z | 2023-10-31T06:32:43 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/kadim | LuiMito | 2023-10-31T06:45:39Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T06:45:39Z | 2023-10-31T06:45:22.000Z | 2023-10-31T06:45:22 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/gelorum2 | LuiMito | 2023-10-31T07:19:37Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T07:19:37Z | 2023-10-31T07:19:15.000Z | 2023-10-31T07:19:15 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Deojoandco/capstone_fromgpt_without_gold_v0 | Deojoandco | 2023-10-31T07:30:14Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T07:30:14Z | 2023-10-31T07:30:10.000Z | 2023-10-31T07:30:10 | ---
dataset_info:
features:
- name: dialogue
dtype: string
- name: summary
dtype: string
- name: gold_tags
dtype: string
- name: query
dtype: string
- name: gpt_success
dtype: bool
- name: gpt_response
dtype: string
- name: GPT_OUTPUT_FOUND
dtype: bool
- name: gpt_tags
dtype: string
- name: gold_tags_tokens_count
dtype: float64
- name: gpt_tags_tokens_count
dtype: float64
- name: summary_gpt_tags_token_count_match
dtype: bool
- name: gold_gpt_tags_match
dtype: bool
splits:
- name: train
num_bytes: 714337
num_examples: 100
download_size: 111760
dataset_size: 714337
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "capstone_fromgpt_without_gold"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5474432110786438,
-0.18149113655090332,
0.25442585349082947,
0.15786892175674438,
-0.26268911361694336,
0.07528877258300781,
0.01276673749089241,
0.12102800607681274,
0.6702014803886414,
0.7524682879447937,
-1.1112618446350098,
-0.8783482909202576,
-0.8192993998527527,
-0.43031585216522... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
TonyisDead/SatoruGojo | TonyisDead | 2023-10-31T09:55:28Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T09:55:28Z | 2023-10-31T08:48:52.000Z | 2023-10-31T08:48:52 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thak123/konkani-speech-text-collection | thak123 | 2023-10-31T08:57:45Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-31T08:57:45Z | 2023-10-31T08:55:30.000Z | 2023-10-31T08:55:30 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Falah/architecture_prompts | Falah | 2023-10-31T09:04:05Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T09:04:05Z | 2023-10-31T09:04:03.000Z | 2023-10-31T09:04:03 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 313206
num_examples: 1000
download_size: 42117
dataset_size: 313206
---
# Dataset Card for "architecture_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7360299825668335,
-0.4008658230304718,
0.48776882886886597,
0.3515506088733673,
-0.07569168508052826,
-0.10760132968425751,
0.4344494342803955,
0.126337468624115,
0.7039484977722168,
0.3035081923007965,
-0.9585639238357544,
-0.8673004508018494,
-0.3844084143638611,
-0.26910409331321716,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/autotrain-data-abstracts | davanstrien | 2023-10-31T09:15:18Z | 0 | 0 | null | [
"task_categories:text-classification",
"language:en",
"arxiv:2201.10328",
"arxiv:2305.17716",
"region:us"
] | 2023-10-31T09:15:18Z | 2023-10-31T09:14:26.000Z | 2023-10-31T09:14:26 | Invalid username or password. | [
0.22538813948631287,
-0.8998719453811646,
0.4273532032966614,
0.01545056700706482,
-0.07883036881685257,
0.6044343113899231,
0.6795741319656372,
0.07246866822242737,
0.20425251126289368,
0.8107712864875793,
-0.7993434071540833,
0.2074914574623108,
-0.9463866949081421,
0.3846413493156433,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
chirunder/MSCS_40_page | chirunder | 2023-10-31T09:23:47Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T09:23:47Z | 2023-10-31T09:23:42.000Z | 2023-10-31T09:23:42 | ---
dataset_info:
features:
- name: html
dtype: string
splits:
- name: train
num_bytes: 6973933
num_examples: 40
download_size: 1637020
dataset_size: 6973933
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "MSCS_40_page"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6735494136810303,
0.20299187302589417,
0.21296216547489166,
0.27779898047447205,
-0.20390217006206512,
0.2479822337627411,
0.2250448316335678,
0.060767825692892075,
0.7962395548820496,
0.5450190901756287,
-1.0269441604614258,
-0.8916174173355103,
-0.35825854539871216,
-0.296296626329422... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
davanstrien/SDOH-NLI | davanstrien | 2023-10-31T10:06:04Z | 0 | 0 | null | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"medical",
"arxiv:2310.18431",
"region:us"
] | 2023-10-31T10:06:04Z | 2023-10-31T09:51:03.000Z | 2023-10-31T09:51:03 | ---
license: cc-by-4.0
task_categories:
- text-classification
task_ids:
- natural-language-inference
language:
- en
pretty_name: >-
SDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical
Notes
size_categories:
- 10K<n<100K
tags:
- medical
---
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@misc{lelkes2023sdohnli,
title={SDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical Notes},
author={Adam D. Lelkes and Eric Loreaux and Tal Schuster and Ming-Jun Chen and Alvin Rajkomar},
year={2023},
eprint={2310.18431},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | [
-0.42297282814979553,
-0.5886872410774231,
0.21737787127494812,
0.20834623277187347,
-0.376533180475235,
-0.1417023241519928,
-0.015123782679438591,
-0.6202660202980042,
0.6954779028892517,
0.7203900218009949,
-0.7602851390838623,
-0.8804624676704407,
-0.5964956879615784,
0.181056708097457... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
KyriaAnnwyn/plu | KyriaAnnwyn | 2023-10-31T10:45:15Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T10:45:15Z | 2023-10-31T10:30:37.000Z | 2023-10-31T10:30:37 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sayan1101/test-krra | sayan1101 | 2023-10-31T10:52:42Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T10:52:42Z | 2023-10-31T10:48:22.000Z | 2023-10-31T10:48:22 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 204
num_examples: 1
download_size: 2504
dataset_size: 204
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "test-krra"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6446133255958557,
-0.3772853910923004,
0.14446252584457397,
0.17213308811187744,
-0.14171598851680756,
0.2869148254394531,
0.3521624803543091,
-0.14515753090381622,
0.6964724063873291,
0.35711726546287537,
-0.6939034461975098,
-0.7225174307823181,
-0.5455660223960876,
-0.283538222312927... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mcmanaman/autotrain-data-8tkl-l1id-7mp4 | mcmanaman | 2023-10-31T12:46:15Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T12:46:15Z | 2023-10-31T12:46:13.000Z | 2023-10-31T12:46:13 | ---
dataset_info:
features:
- name: autotrain_text
dtype: string
splits:
- name: train
num_bytes: 402
num_examples: 30
- name: validation
num_bytes: 402
num_examples: 30
download_size: 2486
dataset_size: 804
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for "autotrain-data-8tkl-l1id-7mp4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5267038345336914,
0.08944180607795715,
0.1646316647529602,
0.25373774766921997,
-0.3675602972507477,
0.07950779050588608,
0.44692450761795044,
-0.09066946804523468,
0.5755295157432556,
0.21337983012199402,
-0.8620667457580566,
-0.47722193598747253,
-0.5812753438949585,
-0.12580847740173... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
shubhamtheds/priyanka | shubhamtheds | 2023-10-31T13:03:53Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T13:03:53Z | 2023-10-31T13:02:47.000Z | 2023-10-31T13:02:47 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AISE-TUDelft/ML4SE23_G1_EvolInstruct-SCoT-1k | AISE-TUDelft | 2023-10-31T13:24:09Z | 0 | 0 | null | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"code",
"region:us"
] | 2023-10-31T13:24:09Z | 2023-10-31T13:22:58.000Z | 2023-10-31T13:22:58 | ---
task_categories:
- text-generation
language:
- en
tags:
- code
pretty_name: EvolInstruct enhanced 1k entries dataset with Structured-Chain-of-Thought
size_categories:
- 1K<n<10K
---
# ML4SE23_G1_EvolInstruct-SCoT-1k
EvolInstruct enhanced 1k entries dataset with Structured-Chain-of-Thought | [
-0.08636124432086945,
-0.6422267556190491,
0.2488984614610672,
0.23493024706840515,
-0.5040225386619568,
0.27881404757499695,
0.27259841561317444,
-0.0689009502530098,
0.76972895860672,
0.5964742302894592,
-0.9114916920661926,
-0.4433966875076294,
-0.3652038872241974,
0.20119833946228027,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AISE-TUDelft/ML4SE23_G1_HumanEval-SCoT | AISE-TUDelft | 2023-10-31T13:28:52Z | 0 | 0 | null | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"code",
"region:us"
] | 2023-10-31T13:28:52Z | 2023-10-31T13:27:26.000Z | 2023-10-31T13:27:26 | ---
task_categories:
- text-generation
language:
- en
tags:
- code
pretty_name: HumanEval dataset enhanced with Structured-Chain-of-Thought
size_categories:
- n<1K
---
# ML4SE23_G1_HumanEval-SCoT
HumanEval dataset enhanced with Structured-Chain-of-Thought | [
-0.11095207184553146,
-0.5042501091957092,
0.06742650270462036,
0.29051539301872253,
-0.4874277114868164,
0.12159675359725952,
0.010387420654296875,
-0.3805619180202484,
0.616986095905304,
0.8659255504608154,
-0.8341255187988281,
-0.560207188129425,
-0.22896039485931396,
0.1959309130907058... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AISE-TUDelft/ML4SE23_G1_MBPP-SCoT | AISE-TUDelft | 2023-10-31T13:31:41Z | 0 | 0 | null | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"code",
"region:us"
] | 2023-10-31T13:31:41Z | 2023-10-31T13:30:41.000Z | 2023-10-31T13:30:41 | ---
task_categories:
- text-generation
language:
- en
tags:
- code
pretty_name: MBPP enhanced dataset with Structured-Chain-of-Thought
size_categories:
- n<1K
---
# ML4SE23_G1_MBPP-SCoT
MBPP enhanced dataset with Structured-Chain-of-Thought | [
-0.2807273864746094,
-0.41440051794052124,
0.3898831605911255,
0.5075055956840515,
-0.40657201409339905,
0.32084548473358154,
0.009494039230048656,
-0.28978556394577026,
0.714396595954895,
0.9104685187339783,
-0.6978672742843628,
-0.28644734621047974,
-0.48922690749168396,
-0.0367694869637... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AISE-TUDelft/ML4SE23_G1_MBCPP-SCoT | AISE-TUDelft | 2023-10-31T13:33:04Z | 0 | 0 | null | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"code",
"region:us"
] | 2023-10-31T13:33:04Z | 2023-10-31T13:32:13.000Z | 2023-10-31T13:32:13 | ---
task_categories:
- text-generation
language:
- en
tags:
- code
pretty_name: MBCPP enhanced dataset with Structured-Chain-of-Thought
size_categories:
- n<1K
---
# ML4SE23_G1_MBCPP-SCoT
MBCPP enhanced dataset with Structured-Chain-of-Thought | [
-0.29074469208717346,
-0.46550998091697693,
0.5201558470726013,
0.5002841353416443,
-0.5715419054031372,
0.12470193207263947,
-0.03121645376086235,
-0.15687152743339539,
0.711108922958374,
0.9527950286865234,
-0.8955957293510437,
-0.4203532934188843,
-0.5567404627799988,
-0.084637805819511... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_first_sent_train_50_eval_10_sentbefore | tyzhu | 2023-10-31T14:58:37Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:58:37Z | 2023-10-31T13:38:22.000Z | 2023-10-31T13:38:22 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 222236
num_examples: 170
- name: validation
num_bytes: 9027
num_examples: 10
download_size: 79508
dataset_size: 231263
---
# Dataset Card for "find_first_sent_train_50_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.575082004070282,
-0.21023669838905334,
0.2844447195529938,
0.5617421865463257,
-0.11822763085365295,
-0.08128576725721359,
0.24275504052639008,
0.3291553556919098,
0.7246238589286804,
0.37820178270339966,
-1.0054596662521362,
-0.7492944002151489,
-0.6096704602241516,
-0.1089559346437454... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
liyongsea/empty_function_kaggle | liyongsea | 2023-10-31T13:46:01Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T13:46:01Z | 2023-10-31T13:45:38.000Z | 2023-10-31T13:45:38 | ---
dataset_info:
features:
- name: file_id
dtype: string
- name: content
dtype: string
- name: local_path
dtype: string
- name: kaggle_dataset_name
dtype: string
- name: kaggle_dataset_owner
dtype: string
- name: kversion
dtype: string
- name: kversion_datasetsources
dtype: string
- name: dataset_versions
dtype: string
- name: datasets
dtype: string
- name: users
dtype: string
- name: script
dtype: string
- name: df_info
dtype: string
- name: has_data_info
dtype: bool
- name: nb_filenames
dtype: int64
- name: retreived_data_description
dtype: string
- name: script_nb_tokens
dtype: int64
- name: upvotes
dtype: int64
- name: tokens_description
dtype: int64
- name: tokens_script
dtype: int64
splits:
- name: train
num_bytes: 1895686.5998786655
num_examples: 84
download_size: 1763341
dataset_size: 1895686.5998786655
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "empty_function_kaggle"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5711624622344971,
-0.6394730806350708,
0.23772840201854706,
0.08116835355758667,
-0.24008947610855103,
-0.2063133865594864,
0.06250721961259842,
0.017253901809453964,
0.8923406004905701,
0.6044217348098755,
-0.9882263541221619,
-0.7996596097946167,
-0.6420897841453552,
-0.39529195427894... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
youyu0105/llm-MIDI3 | youyu0105 | 2023-10-31T13:45:53Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T13:45:53Z | 2023-10-31T13:45:49.000Z | 2023-10-31T13:45:49 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 559354
num_examples: 248
download_size: 135879
dataset_size: 559354
---
# Dataset Card for "llm-MIDI3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6272104382514954,
-0.15314285457134247,
0.6443480849266052,
0.26891642808914185,
-0.22147424519062042,
0.09187626838684082,
0.3206922709941864,
-0.13399139046669006,
0.7502181529998779,
0.5653216242790222,
-0.9606762528419495,
-0.9289957880973816,
-0.5753750801086426,
-0.251525968313217... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
distil-whisper/figures | distil-whisper | 2023-10-31T17:24:31Z | 0 | 2 | null | [
"region:us"
] | 2023-10-31T17:24:31Z | 2023-10-31T14:08:52.000Z | 2023-10-31T14:08:52 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mhmtcrkglu/guanaco-llama2-1k | mhmtcrkglu | 2023-10-31T14:16:24Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:16:24Z | 2023-10-31T14:16:22.000Z | 2023-10-31T14:16:22 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1654448
num_examples: 1000
download_size: 966693
dataset_size: 1654448
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "guanaco-llama2-1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.31712621450424194,
-0.1850084662437439,
0.25064411759376526,
0.5434030890464783,
-0.5531396865844727,
0.012613237835466862,
0.3730725646018982,
-0.27480971813201904,
0.9305324554443359,
0.43072932958602905,
-0.7881225943565369,
-0.9666924476623535,
-0.7247747778892517,
-0.23143085837364... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
minoosh/shEMO_nosplits | minoosh | 2023-10-31T14:37:27Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:37:27Z | 2023-10-31T14:36:38.000Z | 2023-10-31T14:36:38 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: emotion
dtype:
class_label:
names:
'0': A
'1': H
'2': N
'3': S
'4': W
'5': F
splits:
- name: train
num_bytes: 1063025462.0
num_examples: 3000
download_size: 1043899084
dataset_size: 1063025462.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "shEMO_nosplits"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4705987870693207,
-0.057234931737184525,
0.10162167251110077,
0.1444292813539505,
-0.36731570959091187,
-0.017116781324148178,
0.28451186418533325,
-0.026204686611890793,
0.7475574612617493,
0.602143406867981,
-0.9135273694992065,
-0.9071548581123352,
-0.7340178489685059,
-0.27698928117... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alvarobartt/ultrafeedback-instruction-dataset | alvarobartt | 2023-10-31T14:51:34Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:51:34Z | 2023-10-31T14:51:32.000Z | 2023-10-31T14:51:32 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: generations
sequence: string
- name: raw_generation_response
sequence: string
- name: rating
sequence: int64
- name: rationale
sequence: string
- name: raw_labelling_response
struct:
- name: choices
list:
- name: finish_reason
dtype: string
- name: index
dtype: int64
- name: message
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: created
dtype: int64
- name: id
dtype: string
- name: model
dtype: string
- name: object
dtype: string
- name: usage
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: total_tokens
dtype: int64
splits:
- name: train
num_bytes: 167493
num_examples: 50
download_size: 98372
dataset_size: 167493
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "ultrafeedback-instruction-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.3644546866416931,
-0.23471945524215698,
0.11503007262945175,
0.4276858866214752,
-0.03408469632267952,
-0.065585196018219,
0.24961413443088531,
0.07390159368515015,
0.7413893938064575,
0.629342257976532,
-0.9878140091896057,
-0.7689012289047241,
-0.16355359554290771,
-0.3300017714500427... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_first_sent_train_10_eval_10_sentbefore | tyzhu | 2023-10-31T14:57:26Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:57:26Z | 2023-10-31T14:57:21.000Z | 2023-10-31T14:57:21 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 69119
num_examples: 50
- name: validation
num_bytes: 9130
num_examples: 10
download_size: 45538
dataset_size: 78249
---
# Dataset Card for "find_first_sent_train_10_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5495477318763733,
-0.3157813549041748,
0.34440678358078003,
0.5504228472709656,
-0.15250138938426971,
-0.09684804826974869,
0.2547915577888489,
0.2628304958343506,
0.7914621233940125,
0.42788249254226685,
-1.0028212070465088,
-0.7196146249771118,
-0.6684937477111816,
-0.1270831823348999... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_second_sent_train_10_eval_10_sentbefore | tyzhu | 2023-10-31T14:57:32Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:57:32Z | 2023-10-31T14:57:26.000Z | 2023-10-31T14:57:26 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 68758
num_examples: 50
- name: validation
num_bytes: 8997
num_examples: 10
download_size: 47774
dataset_size: 77755
---
# Dataset Card for "find_second_sent_train_10_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.44963404536247253,
-0.24417324364185333,
0.3045615255832672,
0.5460636019706726,
-0.09864205121994019,
0.030237330123782158,
0.23119255900382996,
0.12784884870052338,
0.7286403775215149,
0.4468649923801422,
-0.9559679627418518,
-0.5357454419136047,
-0.622785210609436,
-0.229140311479568... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_last_sent_train_10_eval_10_sentbefore | tyzhu | 2023-10-31T14:57:37Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:57:37Z | 2023-10-31T14:57:32.000Z | 2023-10-31T14:57:32 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 68765
num_examples: 50
- name: validation
num_bytes: 8980
num_examples: 10
download_size: 52757
dataset_size: 77745
---
# Dataset Card for "find_last_sent_train_10_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4046115279197693,
-0.21620303392410278,
0.5083706378936768,
0.40632113814353943,
-0.05096547678112984,
0.0011681177420541644,
0.1406225562095642,
0.22466538846492767,
0.757558286190033,
0.513473629951477,
-0.8307737112045288,
-0.6840560436248779,
-0.4581638276576996,
-0.0753724947571754... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_first_sent_train_100_eval_10_sentbefore | tyzhu | 2023-10-31T14:59:11Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T14:59:11Z | 2023-10-31T14:59:06.000Z | 2023-10-31T14:59:06 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 435057
num_examples: 320
- name: validation
num_bytes: 10399
num_examples: 10
download_size: 136011
dataset_size: 445456
---
# Dataset Card for "find_first_sent_train_100_eval_10_sentbefore"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5865817070007324,
-0.342072069644928,
0.31042012572288513,
0.5527904629707336,
-0.06896091997623444,
-0.15886050462722778,
0.23696623742580414,
0.36801469326019287,
0.7780569195747375,
0.43209367990493774,
-1.0256083011627197,
-0.7269423604011536,
-0.5964944362640381,
-0.155494794249534... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kevinwang676/will_dataset | kevinwang676 | 2023-11-01T06:16:59Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | 2023-11-01T06:16:59Z | 2023-10-31T15:40:51.000Z | 2023-10-31T15:40:51 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yardeny/tokenized_t5_context_len_512 | yardeny | 2023-10-31T16:24:50Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T16:24:50Z | 2023-10-31T16:05:55.000Z | 2023-10-31T16:05:55 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 18454819544
num_examples: 80462898
download_size: 6941163760
dataset_size: 18454819544
---
# Dataset Card for "tokenized_t5_context_len_512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5082056522369385,
-0.22252562642097473,
0.2898537218570709,
0.4394783079624176,
-0.48457324504852295,
0.050712961703538895,
0.05133422836661339,
-0.23712971806526184,
0.8557954430580139,
0.3843594193458557,
-0.7477854490280151,
-0.9580780267715454,
-0.6053933501243591,
-0.09005110710859... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sordonia/t0-10k | sordonia | 2023-10-31T16:27:41Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T16:27:41Z | 2023-10-31T16:26:46.000Z | 2023-10-31T16:26:46 | ---
configs:
- config_name: default
data_files:
- split: imdb
path: data/imdb-*
- split: app_reviews
path: data/app_reviews-*
- split: quarel
path: data/quarel-*
- split: glue_mrpc
path: data/glue_mrpc-*
- split: xsum
path: data/xsum-*
- split: quail
path: data/quail-*
- split: duorc_SelfRC
path: data/duorc_SelfRC-*
- split: samsum
path: data/samsum-*
- split: qasc
path: data/qasc-*
- split: rotten_tomatoes
path: data/rotten_tomatoes-*
- split: wiki_hop_original
path: data/wiki_hop_original-*
- split: wiqa
path: data/wiqa-*
- split: adversarial_qa_droberta
path: data/adversarial_qa_droberta-*
- split: sciq
path: data/sciq-*
- split: cnn_dailymail_3_0_0
path: data/cnn_dailymail_3_0_0-*
- split: kilt_tasks_hotpotqa
path: data/kilt_tasks_hotpotqa-*
- split: social_i_qa
path: data/social_i_qa-*
- split: quoref
path: data/quoref-*
- split: gigaword
path: data/gigaword-*
- split: adversarial_qa_dbidaf
path: data/adversarial_qa_dbidaf-*
- split: cos_e_v1_11
path: data/cos_e_v1_11-*
- split: duorc_ParaphraseRC
path: data/duorc_ParaphraseRC-*
- split: wiki_qa
path: data/wiki_qa-*
- split: dbpedia_14
path: data/dbpedia_14-*
- split: glue_qqp
path: data/glue_qqp-*
- split: common_gen
path: data/common_gen-*
- split: dream
path: data/dream-*
- split: yelp_review_full
path: data/yelp_review_full-*
- split: cosmos_qa
path: data/cosmos_qa-*
- split: multi_news
path: data/multi_news-*
- split: wiki_bio
path: data/wiki_bio-*
- split: ropes
path: data/ropes-*
- split: quartz
path: data/quartz-*
- split: adversarial_qa_dbert
path: data/adversarial_qa_dbert-*
- split: trec
path: data/trec-*
- split: paws_labeled_final
path: data/paws_labeled_final-*
- split: ag_news
path: data/ag_news-*
- split: amazon_polarity
path: data/amazon_polarity-*
dataset_info:
features:
- name: source
dtype: string
- name: target
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
- name: task_source
dtype: string
splits:
- name: imdb
num_bytes: 12482920
num_examples: 10000
- name: app_reviews
num_bytes: 2539149
num_examples: 10000
- name: quarel
num_bytes: 3265896
num_examples: 9705
- name: glue_mrpc
num_bytes: 3523171
num_examples: 10000
- name: xsum
num_bytes: 17343434
num_examples: 10000
- name: quail
num_bytes: 21440449
num_examples: 10000
- name: duorc_SelfRC
num_bytes: 21394079
num_examples: 10000
- name: samsum
num_bytes: 7122926
num_examples: 10000
- name: qasc
num_bytes: 3346516
num_examples: 10000
- name: rotten_tomatoes
num_bytes: 2311312
num_examples: 10000
- name: wiki_hop_original
num_bytes: 74751620
num_examples: 10000
- name: wiqa
num_bytes: 5241923
num_examples: 10000
- name: adversarial_qa_droberta
num_bytes: 9612080
num_examples: 10000
- name: sciq
num_bytes: 4705015
num_examples: 10000
- name: cnn_dailymail_3_0_0
num_bytes: 23167214
num_examples: 10000
- name: kilt_tasks_hotpotqa
num_bytes: 2140638
num_examples: 10000
- name: social_i_qa
num_bytes: 2597640
num_examples: 10000
- name: quoref
num_bytes: 20281845
num_examples: 10000
- name: gigaword
num_bytes: 3112748
num_examples: 10000
- name: adversarial_qa_dbidaf
num_bytes: 9695314
num_examples: 10000
- name: cos_e_v1_11
num_bytes: 2876906
num_examples: 10000
- name: duorc_ParaphraseRC
num_bytes: 21941857
num_examples: 10000
- name: wiki_qa
num_bytes: 3262284
num_examples: 10000
- name: dbpedia_14
num_bytes: 5740522
num_examples: 10000
- name: glue_qqp
num_bytes: 2465106
num_examples: 10000
- name: common_gen
num_bytes: 1960003
num_examples: 10000
- name: dream
num_bytes: 7479165
num_examples: 10000
- name: yelp_review_full
num_bytes: 7496940
num_examples: 10000
- name: cosmos_qa
num_bytes: 5982320
num_examples: 10000
- name: multi_news
num_bytes: 56032380
num_examples: 10000
- name: wiki_bio
num_bytes: 9408991
num_examples: 10000
- name: ropes
num_bytes: 10764470
num_examples: 10000
- name: quartz
num_bytes: 3642436
num_examples: 10000
- name: adversarial_qa_dbert
num_bytes: 9755512
num_examples: 10000
- name: trec
num_bytes: 1998955
num_examples: 10000
- name: paws_labeled_final
num_bytes: 3562306
num_examples: 10000
- name: ag_news
num_bytes: 3831677
num_examples: 10000
- name: amazon_polarity
num_bytes: 5951203
num_examples: 10000
download_size: 231660438
dataset_size: 414228922
---
# Dataset Card for "t0-10k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5499590039253235,
-0.011292609386146069,
0.3122766315937042,
0.40391942858695984,
-0.326943039894104,
0.1284692883491516,
0.2926277220249176,
-0.2331540882587433,
1.005690574645996,
0.3946670889854431,
-0.7878261804580688,
-0.7763218283653259,
-0.710006594657898,
-0.13149374723434448,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/robo | LuiMito | 2023-10-31T16:27:49Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T16:27:49Z | 2023-10-31T16:27:25.000Z | 2023-10-31T16:27:25 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Bluebomber182/Agatha-Gillman | Bluebomber182 | 2023-10-31T16:32:01Z | 0 | 0 | null | [
"license:unknown",
"region:us"
] | 2023-10-31T16:32:01Z | 2023-10-31T16:30:46.000Z | 2023-10-31T16:30:46 | ---
license: unknown
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuiMito/mamae | LuiMito | 2023-10-31T16:50:35Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T16:50:35Z | 2023-10-31T16:49:52.000Z | 2023-10-31T16:49:52 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Bluebomber182/Arthur-Gillman | Bluebomber182 | 2023-10-31T16:52:35Z | 0 | 0 | null | [
"license:unknown",
"region:us"
] | 2023-10-31T16:52:35Z | 2023-10-31T16:51:50.000Z | 2023-10-31T16:51:50 | ---
license: unknown
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
joshuajewell/Openclipart-Oldstyle | joshuajewell | 2023-10-31T20:14:00Z | 0 | 0 | null | [
"task_categories:text-to-image",
"annotations_creators:human generated",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:n=103",
"source_datasets:https://openclipart.org/artist/j4p4n",
"source_datasets:https://openclipart.org/artist/johnny_automatic",
"source_datasets:https:... | 2023-10-31T20:14:00Z | 2023-10-31T17:16:30.000Z | 2023-10-31T17:16:30 | ---
license: cc0-1.0
annotations_creators:
- human generated
language:
- en
language_creators:
- other
multilinguality:
- monolingual
pretty_name: Black and White Print Images
size_categories:
- n=103
source_datasets:
- https://openclipart.org/artist/j4p4n
- https://openclipart.org/artist/johnny_automatic
- https://openclipart.org/artist/SnipsAndClips
tags: []
task_categories:
- text-to-image
task_ids: []
---
<h1>Dataset Card for 16th Century(?) Black and White Style</h1>
Dataset used to train/finetune a black and white print style
Captions are generated by hand with the assistance of BLIP.
Images were sourced from:
</br> https://openclipart.org/artist/j4p4n
</br> https://openclipart.org/artist/johnny_automatic
</br> https://openclipart.org/artist/SnipsAndClips
Text file filenames correspond image file filenames as captions. | [
-0.45197615027427673,
-0.2898847758769989,
0.11831501871347427,
0.13928504288196564,
-0.6324084997177124,
0.0599449947476387,
-0.2378748208284378,
-0.6243875622749329,
0.5701425671577454,
0.7678181529045105,
-0.7327622771263123,
-0.13155804574489594,
-0.5105080008506775,
0.1798629462718963... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yardeny/tokenized_t5_context_len_64 | yardeny | 2023-10-31T17:34:32Z | 0 | 0 | null | [
"region:us"
] | 2023-10-31T17:34:32Z | 2023-10-31T17:19:51.000Z | 2023-10-31T17:19:51 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 10163799114
num_examples: 80462898
download_size: 3657002292
dataset_size: 10163799114
---
# Dataset Card for "tokenized_t5_context_len_64"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4676053524017334,
-0.15333092212677002,
0.2938535809516907,
0.35801854729652405,
-0.5835884809494019,
-0.02622065320611,
0.0032366865780204535,
-0.24793978035449982,
0.7179538011550903,
0.37676337361335754,
-0.6668506860733032,
-1.049747347831726,
-0.7208945155143738,
-0.083542577922344... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.