
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
TrainingDataPro/high_quality_webcam_video_attacks | TrainingDataPro | 2023-09-14T16:47:53Z | 20 | 2 | null | [
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"finance",
"legal",
"code",
"region:us"
] | 2023-09-14T16:47:53Z | 2023-05-30T08:52:17.000Z | 2023-05-30T08:52:17 | ---
license: cc-by-nc-nd-4.0
task_categories:
- video-classification
language:
- en
tags:
- finance
- legal
- code
dataset_info:
features:
- name: video_file
dtype: string
- name: assignment_id
dtype: string
- name: worker_id
dtype: string
- name: gender
dtype: string
- name: age
dtype: uint8
- name: country
dtype: string
- name: resolution
dtype: string
splits:
- name: train
num_bytes: 1547
num_examples: 10
download_size: 623356178
dataset_size: 1547
---
# High Definition Live Attacks
The dataset includes live-recorded Anti-Spoofing videos from around the world, captured via **high-quality** webcams with Full HD resolution and above.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=high_quality_webcam_video_attacks) to discuss your requirements, learn about the price and buy the dataset.
.png?generation=1684702390091084&alt=media)
# Webcam Resolution
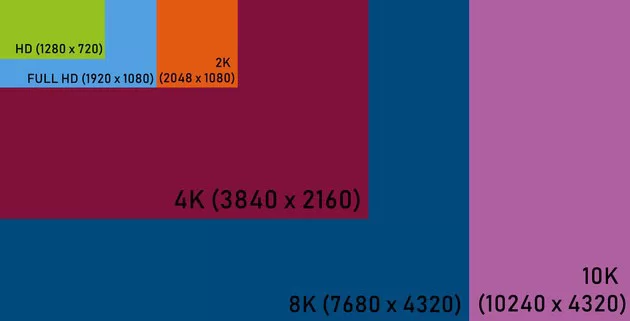
The collection of different video resolutions from Full HD (1080p) up to 4K (2160p) is provided, including several intermediate resolutions like QHD (1440p)
# Metadata
Each attack instance is accompanied by the following details:
- Unique attack identifier
- Identifier of the user recording the attack
- User's age
- User's gender
- User's country of origin
- Attack resolution
Additionally, the model of the webcam is also specified.
Metadata is represented in the `file_info.csv`.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=high_quality_webcam_video_attacks) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | [
-0.5171472430229187,
-0.9452347159385681,
-0.20041191577911377,
0.04514184221625328,
-0.3625795841217041,
0.17813313007354736,
0.21642433106899261,
-0.4939981997013092,
0.5608750581741333,
0.4497966170310974,
-0.756626307964325,
-0.451187402009964,
-0.8122599720954895,
-0.34262731671333313... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Meranti/CLAP_freesound | Meranti | 2023-07-09T17:09:18Z | 20 | 3 | null | [
"task_categories:audio-classification",
"size_categories:1M<n<10M",
"language:en",
"audio",
"text",
"contrastive learning",
"region:us"
] | 2023-07-09T17:09:18Z | 2023-06-02T00:42:03.000Z | 2023-06-02T00:42:03 | ---
task_categories:
- audio-classification
language:
- en
tags:
- audio
- text
- contrastive learning
pretty_name: freesound
size_categories:
- 1M<n<10M
---
# LAION-Audio-630K Freesound Dataset
[LAION-Audio-630K](https://github.com/LAION-AI/audio-dataset/blob/main/laion-audio-630k/README.md) is the largest audio-text dataset publicly available and a magnitude larger than previous audio-text datasets (by 2022-11-05). Notably, it combines eight distinct datasets, which includes the Freesound dataset.
Specifically, this Hugging face repository contains two versions of Freesound dataset. Details of each dataset (e.g. how captions are made etc.) could be found in the "datacard" column of the table below.
- **Freesound (full)**: The complete Freesound dataset, available at `/freesound` folder.
- **Freesound (no overlap)**: Made based on Freesound(full), with samples from ESC50, FSD50K, Urbansound8K and Clotho removed. available at `/freesound_no_overlap` folder.
As of the structure and format of `freesound` and `freesound_no_overlap` folder, please refer to [this page](https://github.com/LAION-AI/audio-dataset/blob/main/data_preprocess/README.md).
| Name |Duration |Number of Samples |Data Type | Metadata | Data Card |
|--------------------------------------------------|-------------------------|--------------------|--------- |--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------- |
| Freesound (no overlap) |2817.31hrs | 460801 |1-2 captions per audio, audio | [website](https://freesound.org/) <br> [csv]()|[data card](/data_card/freesound.md)|
| Freesound (full) |3033.38hrs | 515581 |1-2 captions per audio, audio | [website](https://freesound.org/) <br> [csv]() |[data card](/data_card/freesound.md)|
## Metadata csv file
For each of the two datasets, we provide a metadata csv file including the following columns:
- **audio_filename**: The filename of the audio file in `.tar` files. `exemple: 2394.flac`
- **caption_i**: the i-th caption of the audio file
- **freesound_id**: The freesound id of the audio file.
- **username**: The username of the uploader of the audio file.
- **freesound_url**: The url of the audio file in freesound.org
- **username**: The freesound username of the uploader of the audio file.
- **license**: The license of the audio file. `http://creativecommons.org/licenses/by/3.0/`
## Credits & Licence
- **!!!TERM OF USE!!!**: **By downloading files in this repository, you agree that you will use them <u> for research purposes only </u>. If you want to use Freesound clips in LAION-Audio-630K for commercial purposes, please contact Frederic Font Corbera at frederic.font@upf.edu.**
### Freesound Credit:
All audio clips from Freesound are released under Creative Commons (CC) licenses, while each clip has its own license as defined by the clip uploader in Freesound, some of them requiring attribution to their original authors and some forbidding further commercial reuse. Specifically, here is the statistics about licenses of audio clips involved in LAION-Audio-630K:
| License | Number of Samples |
| :--- | :--- |
| http://creativecommons.org/publicdomain/zero/1.0/ | 260134 |
| https://creativecommons.org/licenses/by/4.0/ | 97090 |
| http://creativecommons.org/licenses/by/3.0/ | 89337 |
| http://creativecommons.org/licenses/by-nc/3.0/ | 31680 |
| https://creativecommons.org/licenses/by-nc/4.0/ | 26736 |
| http://creativecommons.org/licenses/sampling+/1.0/ | 11116 |
## Acknowledgement
The whole collection process as well as all usage of the LAION-Audio-630K are conducted by Germany non-profit pure research organization [LAION](https://laion.ai/). All contributors and collectors of the dataset are considered as open source contributors affiliated to LAION. These community contributors (Discord ids) include but not limited to: @marianna13#7139, @Chr0my#0173, @PiEquals4#1909, @Yuchen Hui#8574, @Antoniooooo#4758, @IYWO#9072, krishna#1648, @dicknascarsixtynine#3885, and @turian#1607. We would like to appreciate all of them for their efforts on the LAION-Audio-630k dataset. | [
-0.704245388507843,
-0.09754477441310883,
0.4273802936077118,
0.3014255166053772,
-0.36859920620918274,
-0.15897256135940552,
-0.13957448303699493,
-0.38814669847488403,
0.563123345375061,
0.7486987113952637,
-0.7878333330154419,
-0.6857656836509705,
-0.4201418161392212,
-0.053466096520423... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
llm-book/aio-passages-bpr-bert-base-japanese-v3 | llm-book | 2023-06-30T10:30:40Z | 20 | 0 | null | [
"size_categories:1M<n<10M",
"language:ja",
"license:cc-by-sa-3.0",
"license:gfdl",
"region:us"
] | 2023-06-30T10:30:40Z | 2023-06-06T08:24:36.000Z | 2023-06-06T08:24:36 | ---
language:
- ja
size_categories:
- 1M<n<10M
license:
- cc-by-sa-3.0
- gfdl
dataset_info:
features:
- name: id
dtype: int32
- name: pageid
dtype: int32
- name: revid
dtype: int32
- name: text
dtype: string
- name: section
dtype: string
- name: title
dtype: string
- name: embeddings
sequence: uint8
splits:
- name: train
num_bytes: 3483313719
num_examples: 4288198
download_size: 2160522807
dataset_size: 3483313719
---
# Dataset Card for llm-book/aio-passages-bert-base-japanese-v3-bpr
書籍『大規模言語モデル入門』で使用する、「AI王」コンペティションのパッセージデータセットに BPR によるパッセージの埋め込みを適用したデータセットです。
[llm-book/aio-passages](https://huggingface.co/datasets/llm-book/aio-passages) のデータセットに対して、[llm-book/bert-base-japanese-v3-bpr-passage-encoder](https://huggingface.co/llm-book/bert-base-japanese-v3-bpr-passage-encoder) によるパッセージのバイナリベクトルが `embeddings` フィールドに追加されています。
## Licence
本データセットで利用している Wikipedia のコンテンツは、[クリエイティブ・コモンズ表示・継承ライセンス 3.0 (CC BY-SA 3.0)](https://creativecommons.org/licenses/by-sa/3.0/deed.ja) および [GNU 自由文書ライセンス (GFDL)](https://www.gnu.org/licenses/fdl.html) の下に配布されているものです。 | [
-0.46410071849823,
-0.7557968497276306,
0.332582950592041,
0.23610201478004456,
-0.8978634476661682,
-0.22184686362743378,
-0.0063160923309624195,
-0.25882646441459656,
0.09501077234745026,
0.6978110074996948,
-0.5564703345298767,
-0.8096731305122375,
-0.7370530366897583,
0.137432679533958... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
d0rj/curation-corpus-ru | d0rj | 2023-06-13T13:31:27Z | 20 | 2 | null | [
"task_categories:summarization",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:d0rj/curation-corpus",
"language:ru",
"license:cc-by-4.0",
"news",
"summarization",
"region:us"
] | 2023-06-13T13:31:27Z | 2023-06-12T19:49:36.000Z | 2023-06-12T19:49:36 | ---
dataset_info:
features:
- name: title
dtype: string
- name: summary
dtype: string
- name: url
dtype: string
- name: date
dtype: string
- name: article_content
dtype: string
splits:
- name: train
num_bytes: 237436901.42479068
num_examples: 30454
download_size: 116826702
dataset_size: 237436901.42479068
license: cc-by-4.0
task_categories:
- summarization
multilinguality:
- monolingual
source_datasets:
- d0rj/curation-corpus
language:
- ru
language_creators:
- translated
tags:
- news
- summarization
pretty_name: Curation Corpus (ru)
size_categories:
- 10K<n<100K
---
# curation-corpus-ru
## Dataset Description
- **Repository:** [https://github.com/CurationCorp/curation-corpus](https://github.com/CurationCorp/curation-corpus)
Translated version of [d0rj/curation-corpus](https://huggingface.co/datasets/d0rj/curation-corpus) into Russian. | [
0.022448034957051277,
-0.4512619376182556,
0.19578708708286285,
0.3360064625740051,
-0.5422544479370117,
0.45883461833000183,
-0.2899903357028961,
-0.0326547771692276,
0.6832553744316101,
0.8131070733070374,
-0.6446895003318787,
-0.8850880861282349,
-0.7400270104408264,
0.24121180176734924... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mrjunos/depression-reddit-cleaned | mrjunos | 2023-06-17T02:03:22Z | 20 | 1 | null | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"reddit",
"Sentiment ",
"depression",
"region:us"
] | 2023-06-17T02:03:22Z | 2023-06-14T23:16:31.000Z | 2023-06-14T23:16:31 | ---
license: cc-by-4.0
task_categories:
- text-classification
language:
- en
tags:
- reddit
- 'Sentiment '
- depression
pretty_name: Depression Reddit Cleaned
size_categories:
- 1K<n<10K
---
# Depression: Reddit Dataset (Cleaned)
**~7000 Cleaned Reddit Labelled Dataset on Depression**
### Summary
- The dataset provided is a Depression: Reddit Dataset (Cleaned) containing approximately 7,000 labeled instances. It consists of two main features: 'text' and 'label'. The 'text' feature contains the text data from Reddit posts related to depression, while the 'label' feature indicates whether a post is classified as depression or not.
- The raw data for this dataset was collected by web scraping Subreddits. To ensure the data's quality and usefulness, multiple natural language processing (NLP) techniques were applied to clean the data. The dataset exclusively consists of English-language posts, and its primary purpose is to facilitate mental health classification tasks.
- This dataset can be employed in various natural language processing tasks related to depression, such as sentiment analysis, topic modeling, text classification, or any other NLP task that requires labeled data pertaining to depression from Reddit.
- Extracted from Kaggle: https://www.kaggle.com/datasets/infamouscoder/depression-reddit-cleaned | [
-0.6468567252159119,
-0.817731499671936,
0.3193278908729553,
0.4504631757736206,
-0.36642155051231384,
-0.22553524374961853,
-0.29637646675109863,
-0.40122443437576294,
0.40959271788597107,
0.5525686740875244,
-0.6593087911605835,
-0.8657507300376892,
-0.6871320605278015,
0.703883111476898... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
carlosejimenez/seq2seq-qnli | carlosejimenez | 2023-06-22T06:39:55Z | 20 | 0 | null | [
"region:us"
] | 2023-06-22T06:39:55Z | 2023-06-16T20:20:20.000Z | 2023-06-16T20:20:20 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: string
- name: orig_idx
dtype: int64
splits:
- name: train
num_bytes: 29173683
num_examples: 104743
- name: validation
num_bytes: 1554164
num_examples: 5463
- name: test
num_bytes: 1542446
num_examples: 5463
download_size: 0
dataset_size: 32270293
---
# Dataset Card for "seq2seq-qnli"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.34990963339805603,
-0.07898290455341339,
0.21522140502929688,
0.17599034309387207,
-0.2553679645061493,
0.04851767420768738,
0.4891774654388428,
-0.0869540125131607,
0.9482836127281189,
0.403422087430954,
-0.7833771109580994,
-0.5726363658905029,
-0.3661462068557739,
-0.2700360715389251... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
priyank-m/MJSynth_text_recognition | priyank-m | 2023-07-04T20:49:10Z | 20 | 0 | null | [
"task_categories:image-to-text",
"size_categories:1M<n<10M",
"language:en",
"region:us"
] | 2023-07-04T20:49:10Z | 2023-06-22T15:33:18.000Z | 2023-06-22T15:33:18 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 12173747703
num_examples: 7224600
- name: val
num_bytes: 1352108669.283
num_examples: 802733
- name: test
num_bytes: 1484450563.896
num_examples: 891924
download_size: 12115256620
dataset_size: 15010306936.179
task_categories:
- image-to-text
language:
- en
size_categories:
- 1M<n<10M
pretty_name: MJSynth
---
# Dataset Card for "MJSynth_text_recognition"
This is the MJSynth dataset for text recognition on document images, synthetically generated, covering 90K English words.
It includes training, validation and test splits.
Source of the dataset: https://www.robots.ox.ac.uk/~vgg/data/text/
Use dataset streaming functionality to try out the dataset quickly without downloading the entire dataset (refer: https://huggingface.co/docs/datasets/stream)
Citation details provided on the source website (if you use the data please cite):
@InProceedings{Jaderberg14c,
author = "Max Jaderberg and Karen Simonyan and Andrea Vedaldi and Andrew Zisserman",
title = "Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition",
booktitle = "Workshop on Deep Learning, NIPS",
year = "2014",
}
@Article{Jaderberg16,
author = "Max Jaderberg and Karen Simonyan and Andrea Vedaldi and Andrew Zisserman",
title = "Reading Text in the Wild with Convolutional Neural Networks",
journal = "International Journal of Computer Vision",
number = "1",
volume = "116",
pages = "1--20",
month = "jan",
year = "2016",
} | [
-0.12278871238231659,
-0.4904795289039612,
0.27889496088027954,
-0.2046596109867096,
-0.4270392060279846,
0.22543801367282867,
-0.28798502683639526,
-0.5853006839752197,
0.5401929020881653,
0.3170429766178131,
-0.7965999245643616,
-0.5002914667129517,
-0.6846622228622437,
0.580872833728790... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
arielnlee/Superimposed-Masked-Dataset | arielnlee | 2023-08-01T18:08:45Z | 20 | 1 | null | [
"task_categories:image-classification",
"size_categories:10K<n<100K",
"language:en",
"license:other",
"occlusion",
"arxiv:2306.17848",
"region:us"
] | 2023-08-01T18:08:45Z | 2023-06-28T05:07:48.000Z | 2023-06-28T05:07:48 | ---
license: other
task_categories:
- image-classification
language:
- en
tags:
- occlusion
size_categories:
- 10K<n<100K
---
# Superimposed Masked Dataset (SMD)
SMD is an occluded version of the ImageNet-1K validation set, created to serve as an additional way to evaluate the impact of occlusion on model performance. Occluder objects were segmented using Meta's Segment Anything and are not in the ImageNet-1K label space. They were chosen to be unambiguous in relationship to objects that reside in the label space. Additional details about the dataset, including code to generate your own version of SMD, actual occlusion percentage of each image in the dataset, as well as occluder object segmentation masks, will be released shortly.

The occluders shown above from left to right, starting from the top row: <strong>Grogu (baby yoda), bacteria, bacteriophage, airpods, origami heart, drone, diamonds (stones, not setting) and coronavirus</strong>. Occluder object images were obtained through Unsplash.
SMD was created for testing model robustness to occlusion in [Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing](https://arielnlee.github.io/PatchMixing/).
## Citations
```bibtex
@misc{lee2023hardwiring,
title={Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing},
author={Ariel N. Lee and Sarah Adel Bargal and Janavi Kasera and Stan Sclaroff and Kate Saenko and Nataniel Ruiz},
year={2023},
eprint={2306.17848},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@article{imagenet15russakovsky,
Author = {Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei},
Title = { {ImageNet Large Scale Visual Recognition Challenge} },
Year = {2015},
journal = {International Journal of Computer Vision (IJCV)},
doi = {10.1007/s11263-015-0816-y},
volume={115},
number={3},
pages={211-252}
}
``` | [
-0.6031695604324341,
-0.5469439029693604,
0.06551901996135712,
-0.03752606362104416,
-0.3166463077068329,
0.0005753399454988539,
0.1628178507089615,
-0.26875847578048706,
0.34060803055763245,
0.8417907953262329,
-0.6747695207595825,
-0.45000460743904114,
-0.5813074707984924,
-0.16220644116... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
commaai/comma2k19 | commaai | 2023-06-29T02:40:08Z | 20 | 1 | null | [
"license:mit",
"arxiv:1812.05752",
"region:us"
] | 2023-06-29T02:40:08Z | 2023-06-29T00:25:45.000Z | 2023-06-29T00:25:45 | ---
license: mit
---
# comma2k19
[comma.ai](https://comma.ai) presents comma2k19, a dataset of over 33 hours of commute in California's 280 highway. This means 2019 segments, 1 minute long each, on a 20km section of highway driving between California's San Jose and San Francisco. comma2k19 is a fully reproducible and scalable dataset. The data was collected using comma [EONs](https://comma.ai/shop/products/eon-gold-dashcam-devkit/) that has sensors similar to those of any modern smartphone including a road-facing camera, phone GPS, thermometers and 9-axis IMU. Additionally, the EON captures raw GNSS measurements and all CAN data sent by the car with a comma [grey panda](https://comma.ai/shop/products/panda-obd-ii-dongle/).
<img src="https://github.com/commaai/comma2k19/blob/master/assets/testmesh3d.png?raw=true"/>
Here we also introduced [Laika](https://github.com/commaai/laika), an open-source GNSS processing library. Laika produces 40% more accurate positions than the GNSS module used to collect the raw data. This dataset includes pose (position + orientation) estimates in a global reference frame of the recording camera. These poses were computed with a tightly coupled INS/GNSS/Vision optimizer that relies on data processed by Laika. comma2k19 is ideal for development and validation of tightly coupled GNSS algorithms and mapping algorithms that work with commodity sensors.
<img src="https://github.com/commaai/comma2k19/blob/master/assets/merged.png?raw=true"/>
## Publication
For a detailed write-up about this dataset, please refer to our [paper](https://arxiv.org/abs/1812.05752v1). If you use comma2k19 or Laika in your research, please consider citing
```text
@misc{1812.05752,
Author = {Harald Schafer and Eder Santana and Andrew Haden and Riccardo Biasini},
Title = {A Commute in Data: The comma2k19 Dataset},
Year = {2018},
Eprint = {arXiv:1812.05752},
}
```
| [
-0.20845454931259155,
-0.5196309089660645,
0.5407366156578064,
0.16919556260108948,
-0.38141554594039917,
-0.12616536021232605,
-0.12765423953533173,
-0.6006298065185547,
0.016142552718520164,
0.2072792798280716,
-0.61866295337677,
-0.229322612285614,
-0.43612512946128845,
-0.2866634130477... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
FreedomIntelligence/evol-instruct-korean | FreedomIntelligence | 2023-08-06T08:13:54Z | 20 | 1 | null | [
"region:us"
] | 2023-08-06T08:13:54Z | 2023-06-30T03:44:15.000Z | 2023-06-30T03:44:15 | The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). | [
-0.4041430950164795,
-0.30496320128440857,
-0.004310257267206907,
0.28069862723350525,
-0.06412170827388763,
0.05836598575115204,
-0.27651411294937134,
-0.43211790919303894,
0.4120996594429016,
0.48347827792167664,
-0.9163601994514465,
-0.46894922852516174,
-0.18480101227760315,
0.30914729... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Den4ikAI/russian_dialogues_2 | Den4ikAI | 2023-07-16T12:09:36Z | 20 | 0 | null | [
"task_categories:conversational",
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:1M<n<10M",
"language:ru",
"license:mit",
"region:us"
] | 2023-07-16T12:09:36Z | 2023-07-05T07:16:52.000Z | 2023-07-05T07:16:52 | ---
license: mit
task_categories:
- conversational
- text-generation
- text2text-generation
language:
- ru
size_categories:
- 1M<n<10M
---
### Den4ikAI/russian_dialogues_2
Датасет русских диалогов для обучения диалоговых моделей.
Количество диалогов - 1.6 миллиона
Формат датасета:
```
{
'sample': ['Привет', 'Привет', 'Как дела?']
}
```
### Citation:
```
@MISC{russian_instructions,
author = {Denis Petrov},
title = {Russian context dialogues dataset for conversational agents},
url = {https://huggingface.co/datasets/Den4ikAI/russian_dialogues_2},
year = 2023
}
``` | [
-0.049807433038949966,
-0.5000693798065186,
0.2517296373844147,
0.14118018746376038,
-0.6142227053642273,
0.009803276509046555,
-0.11864873766899109,
-0.08023235201835632,
0.20581687986850739,
-0.03621803596615791,
-0.968366801738739,
-0.7381207346916199,
-0.28626346588134766,
0.2134657055... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BAAI/SVIT | BAAI | 2023-08-24T09:19:03Z | 20 | 10 | null | [
"task_categories:visual-question-answering",
"size_categories:1M<n<10M",
"language:en",
"license:cc-by-4.0",
"arxiv:2307.04087",
"region:us"
] | 2023-08-24T09:19:03Z | 2023-07-11T09:16:57.000Z | 2023-07-11T09:16:57 | ---
extra_gated_heading: Acknowledge license to accept the repository
extra_gated_prompt: >
The Beijing Academy of Artificial Intelligence (hereinafter referred to as "we" or "BAAI") provides you with an open-source dataset (hereinafter referred to as "dataset") through the SVIT HuggingFace repository (https://huggingface.co/datasets/BAAI/SVIT). You can download the dataset you need and use it for purposes such as learning, research, and business, while abiding by the usage rules of each original dataset.
Before you acquire the open-source dataset (including but not limited to accessing, downloading, copying, distributing, using, or any other handling of the dataset), you should read and understand this "SVIT Open-Source Dataset Usage Notice and Disclaimer" (hereinafter referred to as "this statement"). Once you acquire the open-source dataset, regardless of your method of acquisition, your actions will be regarded as acknowledgment of the full content of this statement.
1. Ownership and Operation Rights
You should fully understand that the ownership and operation rights of the SVIT HuggingFace repository (including the current and all previous versions) belong to BAAI. BAAI has the final interpretation and decision rights over this platform/tool and the open-source dataset plan.
You acknowledge and understand that due to updates and improvements in relevant laws and regulations and the need to fulfill our legal compliance obligations, we reserve the right to update, maintain, or even suspend or permanently terminate the services of this platform/tool from time to time. We will notify you of possible situations mentioned above in a reasonable manner such as through an announcement or email within a reasonable time. You should make corresponding adjustments and arrangements in a timely manner. However, we do not bear any responsibility for any losses caused to you by any of the aforementioned situations.
2. Claim of Rights to Open-Source Datasets
For the purpose of facilitating your dataset acquisition and use for learning, research, and business, we have performed necessary steps such as format integration, data cleaning, labeling, categorizing, annotating, and other related processing on the third-party original datasets to form the open-source datasets for this platform/tool's users.
You understand and acknowledge that we do not claim the proprietary rights of intellectual property to the open-source datasets. Therefore, we have no obligation to actively recognize and protect the potential intellectual property of the open-source datasets. However, this does not mean that we renounce the personal rights to claim credit, publication, modification, and protection of the integrity of the work (if any) of the open-source datasets. The potential intellectual property and corresponding legal rights of the original datasets belong to the original rights holders.
In addition, providing you with open-source datasets that have been reasonably arranged, processed, and handled does not mean that we acknowledge the authenticity, accuracy, or indisputability of the intellectual property and information content of the original datasets. You should filter and carefully discern the open-source datasets you choose to use. You understand and agree that BAAI does not undertake any obligation or warranty responsibility for any defects or flaws in the original datasets you choose to use.
3. Usage Restrictions for Open-Source Datasets
Your use of the dataset must not infringe on our or any third party's legal rights and interests (including but not limited to copyrights, patent rights, trademark rights, and other intellectual property and other rights).
After obtaining the open-source dataset, you should ensure that your use of the open-source dataset does not exceed the usage rules explicitly stipulated by the rights holders of the original dataset in the form of a public notice or agreement, including the range, purpose, and lawful purposes of the use of the original data. We kindly remind you here that if your use of the open-source dataset exceeds the predetermined range and purpose of the original dataset, you may face the risk of infringing on the legal rights and interests of the rights holders of the original dataset, such as intellectual property, and may bear corresponding legal responsibilities.
4. Personal Information Protection
Due to technical limitations and the public welfare nature of the open-source datasets, we cannot guarantee that the open-source datasets do not contain any personal information, and we do not bear any legal responsibility for any personal information that may be involved in the open-source datasets.
If the open-source dataset involves personal information, we do not bear any legal responsibility for any personal information processing activities you may involve when using the open-source dataset. We kindly remind you here that you should handle personal information in accordance with the provisions of the "Personal Information Protection Law" and other relevant laws and regulations.
To protect the legal rights and interests of the information subject and to fulfill possible applicable laws and administrative regulations, if you find content that involves or may involve personal information during the use of the open-source dataset, you should immediately stop using the part of the dataset that involves personal information and contact us as indicated in "6. Complaints and Notices."
5. Information Content Management
We do not bear any legal responsibility for any illegal and bad information that may be involved in the open-source dataset.
If you find that the open-source dataset involves or may involve any illegal and bad information during your use, you should immediately stop using the part of the dataset that involves illegal and bad information and contact us in a timely manner as indicated in "6. Complaints and Notices."
6. Complaints and Notices
If you believe that the open-source dataset has infringed on your legal rights and interests, you can contact us at 010-50955974, and we will handle your claims and complaints in accordance with the law in a timely manner.
To handle your claims and complaints, we may need you to provide contact information, infringement proof materials, and identity proof materials. Please note that if you maliciously complain or make false statements, you will bear all legal responsibilities caused thereby (including but not limited to reasonable compensation costs).
7. Disclaimer
You understand and agree that due to the nature of the open-source dataset, the dataset may contain data from different sources and contributors, and the authenticity, accuracy, and objectivity of the data may vary, and we cannot make any promises about the availability and reliability of any dataset.
In any case, we do not bear any legal responsibility for any risks such as personal information infringement, illegal and bad information dissemination, and intellectual property infringement that may exist in the open-source dataset.
In any case, we do not bear any legal responsibility for any loss (including but not limited to direct loss, indirect loss, and loss of potential benefits) you suffer or is related to the open-source dataset.
8. Others
The open-source dataset is in a constant state of development and change. We may update, adjust the range of the open-source dataset we provide, or suspend, pause, or terminate the open-source dataset service due to business development, third-party cooperation, changes in laws and regulations, and other reasons.
extra_gated_fields:
Name: text
Affiliation: text
Country: text
I agree to accept the license: checkbox
extra_gated_button_content: Acknowledge license
license: cc-by-4.0
task_categories:
- visual-question-answering
language:
- en
pretty_name: SVIT
size_categories:
- 1M<n<10M
---
# Dataset Card for SVIT
Scale up visual instruction tuning to millions by GPT-4.
## Dataset Description
- **Repository:** https://github.com/BAAI-DCAI/Visual-Instruction-Tuning
- **Paper:** https://arxiv.org/pdf/2307.04087.pdf
## Introduction
We Scale up Visual Instruction Tuning (SVIT) and propose a large-scale dataset with 4.2 million informative instruction tuning data, including 1.6M conversation QA pairs, 1.6M complex reasoning QA pairs, 106K detailed descriptions and 1.0M referring QA pairs, by prompting GPT-4 with the abundant manual annotations of image.
The dataset is built based on Visual Genome and MS-COCO. The original images and the annotations from Visual Genome and MS-COCO are in "raw" folder. The instructions and responses generated by GPT-4 are in "data" folder. Details about the dataset can be found in GitHub or the paper.
- GitHub: https://github.com/BAAI-DCAI/Visual-Instruction-Tuning
- Paper: https://arxiv.org/pdf/2307.04087.pdf
## License
The dataset is licensed under a Creative Commons Attribution 4.0 License.
It should abide by the policy of OpenAI: https://openai.com/policies/terms-of-use.
The use of original images and annotations from Visual Genome and MS-COCO should comply with the original licenses.
## Contact us
If you have any comments or questions about the dataset, feel free to create an issue in GitHub: https://github.com/BAAI-DCAI/Visual-Instruction-Tuning/issues. | [
-0.26988157629966736,
-0.43073901534080505,
0.16104599833488464,
0.22203610837459564,
-0.44613009691238403,
-0.13579416275024414,
-0.11751556396484375,
-0.23526211082935333,
-0.17551913857460022,
0.5065177083015442,
-0.47782179713249207,
-0.6070808172225952,
-0.5272487998008728,
-0.1031518... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
dyvapandhu/molecul-dataset | dyvapandhu | 2023-07-12T12:15:23Z | 20 | 0 | null | [
"region:us"
] | 2023-07-12T12:15:23Z | 2023-07-12T12:14:51.000Z | 2023-07-12T12:14:51 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': A
'1': C
splits:
- name: train
num_bytes: 2574228.0
num_examples: 400
- name: validation
num_bytes: 637492.0
num_examples: 100
- name: test
num_bytes: 238977.0
num_examples: 40
download_size: 3399025
dataset_size: 3450697.0
---
# Dataset Card for "molecul-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6644572615623474,
-0.3073972761631012,
0.2325938194990158,
0.3578503727912903,
-0.18872524797916412,
0.3673606216907501,
0.3320313096046448,
0.1074233427643776,
0.7039887309074402,
0.47451552748680115,
-0.9774702191352844,
-0.8386698365211487,
-0.48914337158203125,
-0.3758198916912079,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
FunDialogues/healthcare-minor-consultation | FunDialogues | 2023-07-19T05:37:13Z | 20 | 1 | null | [
"task_categories:question-answering",
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"fictitious dialogues",
"prototyping",
"healthcare",
"region:us"
] | 2023-07-19T05:37:13Z | 2023-07-19T04:27:42.000Z | 2023-07-19T04:27:42 | ---
license: apache-2.0
task_categories:
- question-answering
- conversational
language:
- en
tags:
- fictitious dialogues
- prototyping
- healthcare
pretty_name: 'healthcare-minor-consultation'
size_categories:
- n<1K
---
# fun dialogues
A library of fictitious dialogues that can be used to train language models or augment prompts for prototyping and educational purposes. Fun dialogues currently come in json and csv format for easy ingestion or conversion to popular data structures. Dialogues span various topics such as sports, retail, academia, healthcare, and more. The library also includes basic tooling for loading dialogues and will include quick chatbot prototyping functionality in the future.
Visit the Project Repo: https://github.com/eduand-alvarez/fun-dialogues/
# This Dialogue
Comprised of fictitious examples of dialogues between a doctor and a patient during a minor medical consultation.. Check out the example below:
```
"id": 1,
"description": "Discussion about a common cold",
"dialogue": "Patient: Doctor, I've been feeling congested and have a runny nose. What can I do to relieve these symptoms?\n\nDoctor: It sounds like you have a common cold. You can try over-the-counter decongestants to relieve congestion and saline nasal sprays to help with the runny nose. Make sure to drink plenty of fluids and get enough rest as well."
```
# How to Load Dialogues
Loading dialogues can be accomplished using the fun dialogues library or Hugging Face datasets library.
## Load using fun dialogues
1. Install fun dialogues package
`pip install fundialogues`
2. Use loader utility to load dataset as pandas dataframe. Further processing might be required for use.
```
from fundialogues import dialoader
# load as pandas dataframe
bball_coach = dialoader("FunDialogues/healthcare-minor-consultation")
```
## Loading using Hugging Face datasets
1. Install datasets package
2. Load using datasets
```
from datasets import load_dataset
dataset = load_dataset("FunDialogues/healthcare-minor-consultation")
```
## How to Contribute
If you want to contribute to this project and make it better, your help is very welcome. Contributing is also a great way to learn more about social coding on Github, new technologies and and their ecosystems and how to make constructive, helpful bug reports, feature requests and the noblest of all contributions: a good, clean pull request.
### Contributing your own Lifecycle Solution
If you want to contribute to an existing dialogue or add a new dialogue, please open an issue and I will follow up with you ASAP!
### Implementing Patches and Bug Fixes
- Create a personal fork of the project on Github.
- Clone the fork on your local machine. Your remote repo on Github is called origin.
- Add the original repository as a remote called upstream.
- If you created your fork a while ago be sure to pull upstream changes into your local repository.
- Create a new branch to work on! Branch from develop if it exists, else from master.
- Implement/fix your feature, comment your code.
- Follow the code style of the project, including indentation.
- If the component has tests run them!
- Write or adapt tests as needed.
- Add or change the documentation as needed.
- Squash your commits into a single commit with git's interactive rebase. Create a new branch if necessary.
- Push your branch to your fork on Github, the remote origin.
- From your fork open a pull request in the correct branch. Target the project's develop branch if there is one, else go for master!
If the maintainer requests further changes just push them to your branch. The PR will be updated automatically.
Once the pull request is approved and merged you can pull the changes from upstream to your local repo and delete your extra branch(es).
And last but not least: Always write your commit messages in the present tense. Your commit message should describe what the commit, when applied, does to the code – not what you did to the code.
# Disclaimer
The dialogues contained in this repository are provided for experimental purposes only. It is important to note that these dialogues are assumed to be original work by a human and are entirely fictitious, despite the possibility of some examples including factually correct information. The primary intention behind these dialogues is to serve as a tool for language modeling experimentation and should not be used for designing real-world products beyond non-production prototyping.
Please be aware that the utilization of fictitious data in these datasets may increase the likelihood of language model artifacts, such as hallucinations or unrealistic responses. Therefore, it is essential to exercise caution and discretion when employing these datasets for any purpose.
It is crucial to emphasize that none of the scenarios described in the fun dialogues dataset should be relied upon to provide advice or guidance to humans. These scenarios are purely fictitious and are intended solely for demonstration purposes. Any resemblance to real-world situations or individuals is entirely coincidental.
The responsibility for the usage and application of these datasets rests solely with the individual or entity employing them. By accessing and utilizing these dialogues and all contents of the repository, you acknowledge that you have read and understood this disclaimer, and you agree to use them at your own discretion and risk. | [
-0.09250377118587494,
-0.7627773284912109,
0.35877135396003723,
0.23481731116771698,
-0.3224242627620697,
0.1047636941075325,
-0.19295968115329742,
-0.24374961853027344,
0.5358518362045288,
0.6851873993873596,
-0.6867654919624329,
-0.4178747236728668,
-0.14564432203769684,
-0.1584855169057... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
CodeT5SmallCAPS/CAPS_Python | CodeT5SmallCAPS | 2023-07-24T08:52:57Z | 20 | 1 | null | [
"region:us"
] | 2023-07-24T08:52:57Z | 2023-07-24T08:32:27.000Z | 2023-07-24T08:32:27 | ---
dataset_info:
features:
- name: code
dtype: string
- name: code_sememe
dtype: string
- name: token_type
dtype: string
- name: code_dependency
dtype: string
splits:
- name: train
num_bytes: 1702629853.216785
num_examples: 362342
- name: val
num_bytes: 212829906.3916075
num_examples: 45293
- name: test
num_bytes: 212829906.3916075
num_examples: 45293
download_size: 796759125
dataset_size: 2128289666.0
---
# Dataset Card for "DeepCC_Python"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5103005170822144,
-0.2848723530769348,
0.20758697390556335,
0.2014995664358139,
-0.05179942399263382,
0.11954525858163834,
0.013844480738043785,
0.008194032125175,
0.5744729042053223,
0.36348462104797363,
-0.7552250623703003,
-0.8337358832359314,
-0.4542630612850189,
-0.3293400108814239... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
HydraLM/GPTeacher_toolformer_alpaca | HydraLM | 2023-07-27T20:07:44Z | 20 | 0 | null | [
"region:us"
] | 2023-07-27T20:07:44Z | 2023-07-27T20:07:43.000Z | 2023-07-27T20:07:43 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 3562174
num_examples: 7672
download_size: 796516
dataset_size: 3562174
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "GPTeacher_toolformer_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5396420955657959,
-0.46422287821769714,
0.2125728726387024,
0.08212164789438248,
-0.17749103903770447,
-0.11727498471736908,
0.3122904300689697,
-0.012425009161233902,
0.8257656693458557,
0.3495502769947052,
-0.7859598994255066,
-0.8516462445259094,
-0.9787702560424805,
-0.4197114706039... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sunlab/patch_db | sunlab | 2023-08-15T20:36:32Z | 20 | 6 | null | [
"task_categories:feature-extraction",
"task_categories:text-classification",
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"code",
"commit",
"patch",
"region:us"
] | 2023-08-15T20:36:32Z | 2023-07-27T23:25:37.000Z | 2023-07-27T23:25:37 | ---
license: apache-2.0
task_categories:
- feature-extraction
- text-classification
- summarization
- text-generation
tags:
- code
- commit
- patch
language:
- en
pretty_name: PatchDB
size_categories:
- 10K<n<100K
---
# PatchDB: A Large-Scale Security Patch Dataset
## Description
To foster large-scale research on vulnerability mitigation and to enable a comparison of different detection approaches, we make our dataset ***PatchDB*** from our DSN'21 paper publicly available.
PatchDB is a large-scale security patch dataset that contains around 12,073 security patches and 23,742 non-security patches from the real world.
You can find more details on the dataset in the paper *"[PatchDB: A Large-Scale Security Patch Dataset](https://csis.gmu.edu/ksun/publications/dsn21_PatchDB.pdf)"*. You can also visit our [PatchDB official website](https://sunlab-gmu.github.io/PatchDB) for more information.
<font color="red">Please use your work emails to request for the dataset.</font> Typically, it takes no longer than 24 hours to get approval.
## Data Structure
PatchDB is stored in `json` format, where each sample contains 9 keys and has the following format.
```json
{
"category": the type of patch, value:"security" or "non-security",
"source": the source of patch, value: "cve" or "wild",
"CVE_ID": the CVE ID if it exists, value: "CVE-XXXX-XXXXX" or "NA",
"CWE_ID": the CWE ID if it exists, value: "cwe_id" or "NA"
"commit_id": the hash value of the commit, type: str,
"owner": the owner id of the repository, type: str,
"repo": the repository id, type: str,
"commit_message": the commit message part of the patch, type: str,
"diff_code": the diff code part of the patch, type: str
}
```
## Disclaimer & Download Agreement<span id="jump"></span>
To download the PatchDB dataset, you must agree with the items of the succeeding Disclaimer & Download Agreement. You should carefully read the following terms before submitting the PatchDB request form.
- PatchDB is constructed and cross-checked by 3 experts that work in security patch research.
Due to the potential misclassification led by subjective factors, the Sun Security Laboratory (SunLab) cannot guarantee a 100% accuracy for samples in the dataset.
- The copyright of the PatchDB dataset is owned by SunLab.
- The purpose of using PatchDB should be non-commercial research and/or personal use. The dataset should not be used for commercial use and any profitable purpose.
- The PatchDB dataset should not be re-selled or re-distributed. Anyone who has obtained PatchDB should not share the dataset with others without the permission from SunLab.
## Team
The PatchDB dataset is built by [Sun Security Laboratory](https://sunlab-gmu.github.io/) (SunLab) at [George Mason University](https://www2.gmu.edu/), Fairfax, VA.

## Citations
```bibtex
@inproceedings{wang2021PatchDB,
author={Wang, Xinda and Wang, Shu and Feng, Pengbin and Sun, Kun and Jajodia, Sushil},
booktitle={2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
title={PatchDB: A Large-Scale Security Patch Dataset},
year={2021},
volume={},
number={},
pages={149-160},
doi={10.1109/DSN48987.2021.00030}
}
``` | [
-0.7440617680549622,
-0.7224383354187012,
0.12006135284900665,
0.5094626545906067,
-0.13933001458644867,
0.2522151470184326,
0.0042791832238435745,
-0.6505066156387329,
0.4485154449939728,
0.5846973061561584,
-0.5931103825569153,
-0.6164507865905762,
-0.45838502049446106,
0.305120885372161... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vlofgren/cabrita-and-guanaco-PTBR | vlofgren | 2023-07-28T18:43:45Z | 20 | 0 | null | [
"license:openrail",
"region:us"
] | 2023-07-28T18:43:45Z | 2023-07-28T13:55:52.000Z | 2023-07-28T13:55:52 | ---
license: openrail
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
iamshnoo/alpaca-cleaned-hindi | iamshnoo | 2023-09-15T23:21:27Z | 20 | 1 | null | [
"region:us"
] | 2023-09-15T23:21:27Z | 2023-07-31T04:49:09.000Z | 2023-07-31T04:49:09 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 86237527
num_examples: 51760
download_size: 31323200
dataset_size: 86237527
---
Translated from yahma/alpaca-cleaned using NLLB-1.3B
# Dataset Card for "alpaca-cleaned-hindi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5642300844192505,
-0.791737973690033,
-0.13060005009174347,
0.18806655704975128,
-0.7436066269874573,
-0.2117851823568344,
0.1326570361852646,
-0.751555323600769,
0.9232212901115417,
0.8156291842460632,
-0.8602679371833801,
-0.4957190155982971,
-0.712721586227417,
0.014651943929493427,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
EgilKarlsen/AA_BERT_Baseline | EgilKarlsen | 2023-08-23T03:37:43Z | 20 | 0 | null | [
"region:us"
] | 2023-08-23T03:37:43Z | 2023-08-11T00:42:36.000Z | 2023-08-11T00:42:36 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: '0'
dtype: float32
- name: '1'
dtype: float32
- name: '2'
dtype: float32
- name: '3'
dtype: float32
- name: '4'
dtype: float32
- name: '5'
dtype: float32
- name: '6'
dtype: float32
- name: '7'
dtype: float32
- name: '8'
dtype: float32
- name: '9'
dtype: float32
- name: '10'
dtype: float32
- name: '11'
dtype: float32
- name: '12'
dtype: float32
- name: '13'
dtype: float32
- name: '14'
dtype: float32
- name: '15'
dtype: float32
- name: '16'
dtype: float32
- name: '17'
dtype: float32
- name: '18'
dtype: float32
- name: '19'
dtype: float32
- name: '20'
dtype: float32
- name: '21'
dtype: float32
- name: '22'
dtype: float32
- name: '23'
dtype: float32
- name: '24'
dtype: float32
- name: '25'
dtype: float32
- name: '26'
dtype: float32
- name: '27'
dtype: float32
- name: '28'
dtype: float32
- name: '29'
dtype: float32
- name: '30'
dtype: float32
- name: '31'
dtype: float32
- name: '32'
dtype: float32
- name: '33'
dtype: float32
- name: '34'
dtype: float32
- name: '35'
dtype: float32
- name: '36'
dtype: float32
- name: '37'
dtype: float32
- name: '38'
dtype: float32
- name: '39'
dtype: float32
- name: '40'
dtype: float32
- name: '41'
dtype: float32
- name: '42'
dtype: float32
- name: '43'
dtype: float32
- name: '44'
dtype: float32
- name: '45'
dtype: float32
- name: '46'
dtype: float32
- name: '47'
dtype: float32
- name: '48'
dtype: float32
- name: '49'
dtype: float32
- name: '50'
dtype: float32
- name: '51'
dtype: float32
- name: '52'
dtype: float32
- name: '53'
dtype: float32
- name: '54'
dtype: float32
- name: '55'
dtype: float32
- name: '56'
dtype: float32
- name: '57'
dtype: float32
- name: '58'
dtype: float32
- name: '59'
dtype: float32
- name: '60'
dtype: float32
- name: '61'
dtype: float32
- name: '62'
dtype: float32
- name: '63'
dtype: float32
- name: '64'
dtype: float32
- name: '65'
dtype: float32
- name: '66'
dtype: float32
- name: '67'
dtype: float32
- name: '68'
dtype: float32
- name: '69'
dtype: float32
- name: '70'
dtype: float32
- name: '71'
dtype: float32
- name: '72'
dtype: float32
- name: '73'
dtype: float32
- name: '74'
dtype: float32
- name: '75'
dtype: float32
- name: '76'
dtype: float32
- name: '77'
dtype: float32
- name: '78'
dtype: float32
- name: '79'
dtype: float32
- name: '80'
dtype: float32
- name: '81'
dtype: float32
- name: '82'
dtype: float32
- name: '83'
dtype: float32
- name: '84'
dtype: float32
- name: '85'
dtype: float32
- name: '86'
dtype: float32
- name: '87'
dtype: float32
- name: '88'
dtype: float32
- name: '89'
dtype: float32
- name: '90'
dtype: float32
- name: '91'
dtype: float32
- name: '92'
dtype: float32
- name: '93'
dtype: float32
- name: '94'
dtype: float32
- name: '95'
dtype: float32
- name: '96'
dtype: float32
- name: '97'
dtype: float32
- name: '98'
dtype: float32
- name: '99'
dtype: float32
- name: '100'
dtype: float32
- name: '101'
dtype: float32
- name: '102'
dtype: float32
- name: '103'
dtype: float32
- name: '104'
dtype: float32
- name: '105'
dtype: float32
- name: '106'
dtype: float32
- name: '107'
dtype: float32
- name: '108'
dtype: float32
- name: '109'
dtype: float32
- name: '110'
dtype: float32
- name: '111'
dtype: float32
- name: '112'
dtype: float32
- name: '113'
dtype: float32
- name: '114'
dtype: float32
- name: '115'
dtype: float32
- name: '116'
dtype: float32
- name: '117'
dtype: float32
- name: '118'
dtype: float32
- name: '119'
dtype: float32
- name: '120'
dtype: float32
- name: '121'
dtype: float32
- name: '122'
dtype: float32
- name: '123'
dtype: float32
- name: '124'
dtype: float32
- name: '125'
dtype: float32
- name: '126'
dtype: float32
- name: '127'
dtype: float32
- name: '128'
dtype: float32
- name: '129'
dtype: float32
- name: '130'
dtype: float32
- name: '131'
dtype: float32
- name: '132'
dtype: float32
- name: '133'
dtype: float32
- name: '134'
dtype: float32
- name: '135'
dtype: float32
- name: '136'
dtype: float32
- name: '137'
dtype: float32
- name: '138'
dtype: float32
- name: '139'
dtype: float32
- name: '140'
dtype: float32
- name: '141'
dtype: float32
- name: '142'
dtype: float32
- name: '143'
dtype: float32
- name: '144'
dtype: float32
- name: '145'
dtype: float32
- name: '146'
dtype: float32
- name: '147'
dtype: float32
- name: '148'
dtype: float32
- name: '149'
dtype: float32
- name: '150'
dtype: float32
- name: '151'
dtype: float32
- name: '152'
dtype: float32
- name: '153'
dtype: float32
- name: '154'
dtype: float32
- name: '155'
dtype: float32
- name: '156'
dtype: float32
- name: '157'
dtype: float32
- name: '158'
dtype: float32
- name: '159'
dtype: float32
- name: '160'
dtype: float32
- name: '161'
dtype: float32
- name: '162'
dtype: float32
- name: '163'
dtype: float32
- name: '164'
dtype: float32
- name: '165'
dtype: float32
- name: '166'
dtype: float32
- name: '167'
dtype: float32
- name: '168'
dtype: float32
- name: '169'
dtype: float32
- name: '170'
dtype: float32
- name: '171'
dtype: float32
- name: '172'
dtype: float32
- name: '173'
dtype: float32
- name: '174'
dtype: float32
- name: '175'
dtype: float32
- name: '176'
dtype: float32
- name: '177'
dtype: float32
- name: '178'
dtype: float32
- name: '179'
dtype: float32
- name: '180'
dtype: float32
- name: '181'
dtype: float32
- name: '182'
dtype: float32
- name: '183'
dtype: float32
- name: '184'
dtype: float32
- name: '185'
dtype: float32
- name: '186'
dtype: float32
- name: '187'
dtype: float32
- name: '188'
dtype: float32
- name: '189'
dtype: float32
- name: '190'
dtype: float32
- name: '191'
dtype: float32
- name: '192'
dtype: float32
- name: '193'
dtype: float32
- name: '194'
dtype: float32
- name: '195'
dtype: float32
- name: '196'
dtype: float32
- name: '197'
dtype: float32
- name: '198'
dtype: float32
- name: '199'
dtype: float32
- name: '200'
dtype: float32
- name: '201'
dtype: float32
- name: '202'
dtype: float32
- name: '203'
dtype: float32
- name: '204'
dtype: float32
- name: '205'
dtype: float32
- name: '206'
dtype: float32
- name: '207'
dtype: float32
- name: '208'
dtype: float32
- name: '209'
dtype: float32
- name: '210'
dtype: float32
- name: '211'
dtype: float32
- name: '212'
dtype: float32
- name: '213'
dtype: float32
- name: '214'
dtype: float32
- name: '215'
dtype: float32
- name: '216'
dtype: float32
- name: '217'
dtype: float32
- name: '218'
dtype: float32
- name: '219'
dtype: float32
- name: '220'
dtype: float32
- name: '221'
dtype: float32
- name: '222'
dtype: float32
- name: '223'
dtype: float32
- name: '224'
dtype: float32
- name: '225'
dtype: float32
- name: '226'
dtype: float32
- name: '227'
dtype: float32
- name: '228'
dtype: float32
- name: '229'
dtype: float32
- name: '230'
dtype: float32
- name: '231'
dtype: float32
- name: '232'
dtype: float32
- name: '233'
dtype: float32
- name: '234'
dtype: float32
- name: '235'
dtype: float32
- name: '236'
dtype: float32
- name: '237'
dtype: float32
- name: '238'
dtype: float32
- name: '239'
dtype: float32
- name: '240'
dtype: float32
- name: '241'
dtype: float32
- name: '242'
dtype: float32
- name: '243'
dtype: float32
- name: '244'
dtype: float32
- name: '245'
dtype: float32
- name: '246'
dtype: float32
- name: '247'
dtype: float32
- name: '248'
dtype: float32
- name: '249'
dtype: float32
- name: '250'
dtype: float32
- name: '251'
dtype: float32
- name: '252'
dtype: float32
- name: '253'
dtype: float32
- name: '254'
dtype: float32
- name: '255'
dtype: float32
- name: '256'
dtype: float32
- name: '257'
dtype: float32
- name: '258'
dtype: float32
- name: '259'
dtype: float32
- name: '260'
dtype: float32
- name: '261'
dtype: float32
- name: '262'
dtype: float32
- name: '263'
dtype: float32
- name: '264'
dtype: float32
- name: '265'
dtype: float32
- name: '266'
dtype: float32
- name: '267'
dtype: float32
- name: '268'
dtype: float32
- name: '269'
dtype: float32
- name: '270'
dtype: float32
- name: '271'
dtype: float32
- name: '272'
dtype: float32
- name: '273'
dtype: float32
- name: '274'
dtype: float32
- name: '275'
dtype: float32
- name: '276'
dtype: float32
- name: '277'
dtype: float32
- name: '278'
dtype: float32
- name: '279'
dtype: float32
- name: '280'
dtype: float32
- name: '281'
dtype: float32
- name: '282'
dtype: float32
- name: '283'
dtype: float32
- name: '284'
dtype: float32
- name: '285'
dtype: float32
- name: '286'
dtype: float32
- name: '287'
dtype: float32
- name: '288'
dtype: float32
- name: '289'
dtype: float32
- name: '290'
dtype: float32
- name: '291'
dtype: float32
- name: '292'
dtype: float32
- name: '293'
dtype: float32
- name: '294'
dtype: float32
- name: '295'
dtype: float32
- name: '296'
dtype: float32
- name: '297'
dtype: float32
- name: '298'
dtype: float32
- name: '299'
dtype: float32
- name: '300'
dtype: float32
- name: '301'
dtype: float32
- name: '302'
dtype: float32
- name: '303'
dtype: float32
- name: '304'
dtype: float32
- name: '305'
dtype: float32
- name: '306'
dtype: float32
- name: '307'
dtype: float32
- name: '308'
dtype: float32
- name: '309'
dtype: float32
- name: '310'
dtype: float32
- name: '311'
dtype: float32
- name: '312'
dtype: float32
- name: '313'
dtype: float32
- name: '314'
dtype: float32
- name: '315'
dtype: float32
- name: '316'
dtype: float32
- name: '317'
dtype: float32
- name: '318'
dtype: float32
- name: '319'
dtype: float32
- name: '320'
dtype: float32
- name: '321'
dtype: float32
- name: '322'
dtype: float32
- name: '323'
dtype: float32
- name: '324'
dtype: float32
- name: '325'
dtype: float32
- name: '326'
dtype: float32
- name: '327'
dtype: float32
- name: '328'
dtype: float32
- name: '329'
dtype: float32
- name: '330'
dtype: float32
- name: '331'
dtype: float32
- name: '332'
dtype: float32
- name: '333'
dtype: float32
- name: '334'
dtype: float32
- name: '335'
dtype: float32
- name: '336'
dtype: float32
- name: '337'
dtype: float32
- name: '338'
dtype: float32
- name: '339'
dtype: float32
- name: '340'
dtype: float32
- name: '341'
dtype: float32
- name: '342'
dtype: float32
- name: '343'
dtype: float32
- name: '344'
dtype: float32
- name: '345'
dtype: float32
- name: '346'
dtype: float32
- name: '347'
dtype: float32
- name: '348'
dtype: float32
- name: '349'
dtype: float32
- name: '350'
dtype: float32
- name: '351'
dtype: float32
- name: '352'
dtype: float32
- name: '353'
dtype: float32
- name: '354'
dtype: float32
- name: '355'
dtype: float32
- name: '356'
dtype: float32
- name: '357'
dtype: float32
- name: '358'
dtype: float32
- name: '359'
dtype: float32
- name: '360'
dtype: float32
- name: '361'
dtype: float32
- name: '362'
dtype: float32
- name: '363'
dtype: float32
- name: '364'
dtype: float32
- name: '365'
dtype: float32
- name: '366'
dtype: float32
- name: '367'
dtype: float32
- name: '368'
dtype: float32
- name: '369'
dtype: float32
- name: '370'
dtype: float32
- name: '371'
dtype: float32
- name: '372'
dtype: float32
- name: '373'
dtype: float32
- name: '374'
dtype: float32
- name: '375'
dtype: float32
- name: '376'
dtype: float32
- name: '377'
dtype: float32
- name: '378'
dtype: float32
- name: '379'
dtype: float32
- name: '380'
dtype: float32
- name: '381'
dtype: float32
- name: '382'
dtype: float32
- name: '383'
dtype: float32
- name: '384'
dtype: float32
- name: '385'
dtype: float32
- name: '386'
dtype: float32
- name: '387'
dtype: float32
- name: '388'
dtype: float32
- name: '389'
dtype: float32
- name: '390'
dtype: float32
- name: '391'
dtype: float32
- name: '392'
dtype: float32
- name: '393'
dtype: float32
- name: '394'
dtype: float32
- name: '395'
dtype: float32
- name: '396'
dtype: float32
- name: '397'
dtype: float32
- name: '398'
dtype: float32
- name: '399'
dtype: float32
- name: '400'
dtype: float32
- name: '401'
dtype: float32
- name: '402'
dtype: float32
- name: '403'
dtype: float32
- name: '404'
dtype: float32
- name: '405'
dtype: float32
- name: '406'
dtype: float32
- name: '407'
dtype: float32
- name: '408'
dtype: float32
- name: '409'
dtype: float32
- name: '410'
dtype: float32
- name: '411'
dtype: float32
- name: '412'
dtype: float32
- name: '413'
dtype: float32
- name: '414'
dtype: float32
- name: '415'
dtype: float32
- name: '416'
dtype: float32
- name: '417'
dtype: float32
- name: '418'
dtype: float32
- name: '419'
dtype: float32
- name: '420'
dtype: float32
- name: '421'
dtype: float32
- name: '422'
dtype: float32
- name: '423'
dtype: float32
- name: '424'
dtype: float32
- name: '425'
dtype: float32
- name: '426'
dtype: float32
- name: '427'
dtype: float32
- name: '428'
dtype: float32
- name: '429'
dtype: float32
- name: '430'
dtype: float32
- name: '431'
dtype: float32
- name: '432'
dtype: float32
- name: '433'
dtype: float32
- name: '434'
dtype: float32
- name: '435'
dtype: float32
- name: '436'
dtype: float32
- name: '437'
dtype: float32
- name: '438'
dtype: float32
- name: '439'
dtype: float32
- name: '440'
dtype: float32
- name: '441'
dtype: float32
- name: '442'
dtype: float32
- name: '443'
dtype: float32
- name: '444'
dtype: float32
- name: '445'
dtype: float32
- name: '446'
dtype: float32
- name: '447'
dtype: float32
- name: '448'
dtype: float32
- name: '449'
dtype: float32
- name: '450'
dtype: float32
- name: '451'
dtype: float32
- name: '452'
dtype: float32
- name: '453'
dtype: float32
- name: '454'
dtype: float32
- name: '455'
dtype: float32
- name: '456'
dtype: float32
- name: '457'
dtype: float32
- name: '458'
dtype: float32
- name: '459'
dtype: float32
- name: '460'
dtype: float32
- name: '461'
dtype: float32
- name: '462'
dtype: float32
- name: '463'
dtype: float32
- name: '464'
dtype: float32
- name: '465'
dtype: float32
- name: '466'
dtype: float32
- name: '467'
dtype: float32
- name: '468'
dtype: float32
- name: '469'
dtype: float32
- name: '470'
dtype: float32
- name: '471'
dtype: float32
- name: '472'
dtype: float32
- name: '473'
dtype: float32
- name: '474'
dtype: float32
- name: '475'
dtype: float32
- name: '476'
dtype: float32
- name: '477'
dtype: float32
- name: '478'
dtype: float32
- name: '479'
dtype: float32
- name: '480'
dtype: float32
- name: '481'
dtype: float32
- name: '482'
dtype: float32
- name: '483'
dtype: float32
- name: '484'
dtype: float32
- name: '485'
dtype: float32
- name: '486'
dtype: float32
- name: '487'
dtype: float32
- name: '488'
dtype: float32
- name: '489'
dtype: float32
- name: '490'
dtype: float32
- name: '491'
dtype: float32
- name: '492'
dtype: float32
- name: '493'
dtype: float32
- name: '494'
dtype: float32
- name: '495'
dtype: float32
- name: '496'
dtype: float32
- name: '497'
dtype: float32
- name: '498'
dtype: float32
- name: '499'
dtype: float32
- name: '500'
dtype: float32
- name: '501'
dtype: float32
- name: '502'
dtype: float32
- name: '503'
dtype: float32
- name: '504'
dtype: float32
- name: '505'
dtype: float32
- name: '506'
dtype: float32
- name: '507'
dtype: float32
- name: '508'
dtype: float32
- name: '509'
dtype: float32
- name: '510'
dtype: float32
- name: '511'
dtype: float32
- name: '512'
dtype: float32
- name: '513'
dtype: float32
- name: '514'
dtype: float32
- name: '515'
dtype: float32
- name: '516'
dtype: float32
- name: '517'
dtype: float32
- name: '518'
dtype: float32
- name: '519'
dtype: float32
- name: '520'
dtype: float32
- name: '521'
dtype: float32
- name: '522'
dtype: float32
- name: '523'
dtype: float32
- name: '524'
dtype: float32
- name: '525'
dtype: float32
- name: '526'
dtype: float32
- name: '527'
dtype: float32
- name: '528'
dtype: float32
- name: '529'
dtype: float32
- name: '530'
dtype: float32
- name: '531'
dtype: float32
- name: '532'
dtype: float32
- name: '533'
dtype: float32
- name: '534'
dtype: float32
- name: '535'
dtype: float32
- name: '536'
dtype: float32
- name: '537'
dtype: float32
- name: '538'
dtype: float32
- name: '539'
dtype: float32
- name: '540'
dtype: float32
- name: '541'
dtype: float32
- name: '542'
dtype: float32
- name: '543'
dtype: float32
- name: '544'
dtype: float32
- name: '545'
dtype: float32
- name: '546'
dtype: float32
- name: '547'
dtype: float32
- name: '548'
dtype: float32
- name: '549'
dtype: float32
- name: '550'
dtype: float32
- name: '551'
dtype: float32
- name: '552'
dtype: float32
- name: '553'
dtype: float32
- name: '554'
dtype: float32
- name: '555'
dtype: float32
- name: '556'
dtype: float32
- name: '557'
dtype: float32
- name: '558'
dtype: float32
- name: '559'
dtype: float32
- name: '560'
dtype: float32
- name: '561'
dtype: float32
- name: '562'
dtype: float32
- name: '563'
dtype: float32
- name: '564'
dtype: float32
- name: '565'
dtype: float32
- name: '566'
dtype: float32
- name: '567'
dtype: float32
- name: '568'
dtype: float32
- name: '569'
dtype: float32
- name: '570'
dtype: float32
- name: '571'
dtype: float32
- name: '572'
dtype: float32
- name: '573'
dtype: float32
- name: '574'
dtype: float32
- name: '575'
dtype: float32
- name: '576'
dtype: float32
- name: '577'
dtype: float32
- name: '578'
dtype: float32
- name: '579'
dtype: float32
- name: '580'
dtype: float32
- name: '581'
dtype: float32
- name: '582'
dtype: float32
- name: '583'
dtype: float32
- name: '584'
dtype: float32
- name: '585'
dtype: float32
- name: '586'
dtype: float32
- name: '587'
dtype: float32
- name: '588'
dtype: float32
- name: '589'
dtype: float32
- name: '590'
dtype: float32
- name: '591'
dtype: float32
- name: '592'
dtype: float32
- name: '593'
dtype: float32
- name: '594'
dtype: float32
- name: '595'
dtype: float32
- name: '596'
dtype: float32
- name: '597'
dtype: float32
- name: '598'
dtype: float32
- name: '599'
dtype: float32
- name: '600'
dtype: float32
- name: '601'
dtype: float32
- name: '602'
dtype: float32
- name: '603'
dtype: float32
- name: '604'
dtype: float32
- name: '605'
dtype: float32
- name: '606'
dtype: float32
- name: '607'
dtype: float32
- name: '608'
dtype: float32
- name: '609'
dtype: float32
- name: '610'
dtype: float32
- name: '611'
dtype: float32
- name: '612'
dtype: float32
- name: '613'
dtype: float32
- name: '614'
dtype: float32
- name: '615'
dtype: float32
- name: '616'
dtype: float32
- name: '617'
dtype: float32
- name: '618'
dtype: float32
- name: '619'
dtype: float32
- name: '620'
dtype: float32
- name: '621'
dtype: float32
- name: '622'
dtype: float32
- name: '623'
dtype: float32
- name: '624'
dtype: float32
- name: '625'
dtype: float32
- name: '626'
dtype: float32
- name: '627'
dtype: float32
- name: '628'
dtype: float32
- name: '629'
dtype: float32
- name: '630'
dtype: float32
- name: '631'
dtype: float32
- name: '632'
dtype: float32
- name: '633'
dtype: float32
- name: '634'
dtype: float32
- name: '635'
dtype: float32
- name: '636'
dtype: float32
- name: '637'
dtype: float32
- name: '638'
dtype: float32
- name: '639'
dtype: float32
- name: '640'
dtype: float32
- name: '641'
dtype: float32
- name: '642'
dtype: float32
- name: '643'
dtype: float32
- name: '644'
dtype: float32
- name: '645'
dtype: float32
- name: '646'
dtype: float32
- name: '647'
dtype: float32
- name: '648'
dtype: float32
- name: '649'
dtype: float32
- name: '650'
dtype: float32
- name: '651'
dtype: float32
- name: '652'
dtype: float32
- name: '653'
dtype: float32
- name: '654'
dtype: float32
- name: '655'
dtype: float32
- name: '656'
dtype: float32
- name: '657'
dtype: float32
- name: '658'
dtype: float32
- name: '659'
dtype: float32
- name: '660'
dtype: float32
- name: '661'
dtype: float32
- name: '662'
dtype: float32
- name: '663'
dtype: float32
- name: '664'
dtype: float32
- name: '665'
dtype: float32
- name: '666'
dtype: float32
- name: '667'
dtype: float32
- name: '668'
dtype: float32
- name: '669'
dtype: float32
- name: '670'
dtype: float32
- name: '671'
dtype: float32
- name: '672'
dtype: float32
- name: '673'
dtype: float32
- name: '674'
dtype: float32
- name: '675'
dtype: float32
- name: '676'
dtype: float32
- name: '677'
dtype: float32
- name: '678'
dtype: float32
- name: '679'
dtype: float32
- name: '680'
dtype: float32
- name: '681'
dtype: float32
- name: '682'
dtype: float32
- name: '683'
dtype: float32
- name: '684'
dtype: float32
- name: '685'
dtype: float32
- name: '686'
dtype: float32
- name: '687'
dtype: float32
- name: '688'
dtype: float32
- name: '689'
dtype: float32
- name: '690'
dtype: float32
- name: '691'
dtype: float32
- name: '692'
dtype: float32
- name: '693'
dtype: float32
- name: '694'
dtype: float32
- name: '695'
dtype: float32
- name: '696'
dtype: float32
- name: '697'
dtype: float32
- name: '698'
dtype: float32
- name: '699'
dtype: float32
- name: '700'
dtype: float32
- name: '701'
dtype: float32
- name: '702'
dtype: float32
- name: '703'
dtype: float32
- name: '704'
dtype: float32
- name: '705'
dtype: float32
- name: '706'
dtype: float32
- name: '707'
dtype: float32
- name: '708'
dtype: float32
- name: '709'
dtype: float32
- name: '710'
dtype: float32
- name: '711'
dtype: float32
- name: '712'
dtype: float32
- name: '713'
dtype: float32
- name: '714'
dtype: float32
- name: '715'
dtype: float32
- name: '716'
dtype: float32
- name: '717'
dtype: float32
- name: '718'
dtype: float32
- name: '719'
dtype: float32
- name: '720'
dtype: float32
- name: '721'
dtype: float32
- name: '722'
dtype: float32
- name: '723'
dtype: float32
- name: '724'
dtype: float32
- name: '725'
dtype: float32
- name: '726'
dtype: float32
- name: '727'
dtype: float32
- name: '728'
dtype: float32
- name: '729'
dtype: float32
- name: '730'
dtype: float32
- name: '731'
dtype: float32
- name: '732'
dtype: float32
- name: '733'
dtype: float32
- name: '734'
dtype: float32
- name: '735'
dtype: float32
- name: '736'
dtype: float32
- name: '737'
dtype: float32
- name: '738'
dtype: float32
- name: '739'
dtype: float32
- name: '740'
dtype: float32
- name: '741'
dtype: float32
- name: '742'
dtype: float32
- name: '743'
dtype: float32
- name: '744'
dtype: float32
- name: '745'
dtype: float32
- name: '746'
dtype: float32
- name: '747'
dtype: float32
- name: '748'
dtype: float32
- name: '749'
dtype: float32
- name: '750'
dtype: float32
- name: '751'
dtype: float32
- name: '752'
dtype: float32
- name: '753'
dtype: float32
- name: '754'
dtype: float32
- name: '755'
dtype: float32
- name: '756'
dtype: float32
- name: '757'
dtype: float32
- name: '758'
dtype: float32
- name: '759'
dtype: float32
- name: '760'
dtype: float32
- name: '761'
dtype: float32
- name: '762'
dtype: float32
- name: '763'
dtype: float32
- name: '764'
dtype: float32
- name: '765'
dtype: float32
- name: '766'
dtype: float32
- name: '767'
dtype: float32
- name: label
dtype: string
splits:
- name: train
num_bytes: 80318780.21618997
num_examples: 26057
- name: test
num_bytes: 26774087.073587257
num_examples: 8686
download_size: 147064679
dataset_size: 107092867.28977722
---
# Dataset Card for "AA_BERT_Baseline"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.8108966946601868,
-0.4312244951725006,
0.05423058196902275,
0.08212518692016602,
-0.07474126666784286,
-0.21353918313980103,
0.26036521792411804,
-0.3172283172607422,
0.7737011909484863,
0.27927035093307495,
-0.9030523896217346,
-0.7301559448242188,
-0.4853965938091278,
-0.4722983837127... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yanbingzheng/LongBench | yanbingzheng | 2023-08-14T06:22:04Z | 20 | 0 | null | [
"task_categories:question-answering",
"task_categories:text-generation",
"task_categories:summarization",
"task_categories:conversational",
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"language:zh",
"Long Context",
"arxiv:2108.00573",
"arxiv:1712.07040",
"... | 2023-08-14T06:22:04Z | 2023-08-11T11:43:28.000Z | 2023-08-11T11:43:28 | ---
task_categories:
- question-answering
- text-generation
- summarization
- conversational
- text-classification
language:
- en
- zh
tags:
- Long Context
size_categories:
- 1K<n<10K
---
# Introduction
**LongBench** is the first benchmark for bilingual, multitask, and comprehensive assessment of **long context understanding** capabilities of large language models. LongBench includes different languages (Chinese and English) to provide a more comprehensive evaluation of the large models' multilingual capabilities on long contexts. In addition, LongBench is composed of six major categories and twenty different tasks, covering key long-text application scenarios such as multi-document QA, single-document QA, summarization, Few-shot learning, code completion, and synthesis tasks.
We are fully aware of the potentially high costs involved in the model evaluation process, especially in the context of long context scenarios (such as manual annotation costs or API call costs). Therefore, we adopt a fully automated evaluation method, aimed at measuring and evaluating the model's ability to understand long contexts at the lowest cost.
LongBench includes 13 English tasks, 5 Chinese tasks, and 2 code tasks, with the average length of most tasks ranging from 5k to 15k.
Github Repo for LongBench: https://github.com/THUDM/LongBench
# How to use it?
#### Loading Data
```python
from datasets import load_dataset
datasets = ["hotpotqa", "2wikimqa", "musique", "dureader", "narrativeqa", "qasper", "multifieldqa_en", \
"multifieldqa_zh", "gov_report", "qmsum", "vcsum", "trec", "nq", "triviaqa", "lsht", "passage_count", \
"passage_retrieval_en", "passage_retrieval_zh", "lcc", "repobench-p"]
for dataset in datasets:
data = load_dataset('THUDM/LongBench', dataset, split='test')
```
#### Data Format
All data in **LongBench** are standardized to the following format:
```json
{
"input": "The input/command for the task, usually short, such as questions in QA, queries in Few-shot tasks, etc.",
"context": "The long context text required for the task, such as documents, cross-file code, few-shot samples in Few-shot tasks",
"answers": "List composed of all standard answers",
"length": "Total length of the first three items of text (counted in characters for Chinese and words for English)",
"dataset": "The name of the dataset to which this piece of data belongs",
"language": "The language of this piece of data",
"all_classes": "All categories in classification tasks, null for non-classification tasks",
"_id": "Random id for each piece of data"
}
```
#### Evaluation
This repository provides data download for LongBench. If you wish to use this dataset for automated evaluation, please refer to our [github](https://github.com/THUDM/LongBench).
# Task statistics
| Task | Task Type | Eval metric | Avg len |Language | \#Sample |
| :-------- | :-----------:| :-----------: |:-------: | :-----------: |:--------: |
| HotpotQA | Multi-doc QA | F1 |9,149 |EN |200 |
| 2WikiMultihopQA| Multi-doc QA | F1 |4,885 |EN |200 |
| Musique| Multi-doc QA | F1 |7,798 |EN |200 |
| DuReader| Multi-doc QA | Rouge-L |15,768 |ZH |200 |
| MultiFieldQA-en| Single-doc QA | F1 |4,559 |EN |150 |
| MultiFieldQA-zh| Single-doc QA | F1 |6,771 |ZH |200 |
| NarrativeQA| Single-doc QA | F1 |18,405 |EN |200 |
| Qasper| Single-doc QA | F1 |3,619 |EN |200 |
| GovReport| Summarization | Rouge-L |8,169 |EN |200 |
| QMSum| Summarization | Rouge-L |10,546 |EN |200 |
| VCSUM| Summarization | Rouge-L |15,147 |ZH |200 |
| TriviaQA| Few shot | F1 |8,015 |EN |200 |
| NQ| Few shot | F1 |8,210 |EN |200 |
| TREC| Few shot | Accuracy |5,176 |EN |200 |
| LSHT| Few shot | Accuracy |22,333 |ZH |200 |
| PassageRetrieval-en| Synthetic | Accuracy |9,288 |EN |200 |
| PassageCount| Synthetic | Accuracy |11,141 |EN |200 |
| PassageRetrieval-zh | Synthetic | Accuracy |6,745 |ZH |200 |
| LCC| Code | Edit Sim |1,235 |Python/C#/Java |500 |
| RepoBench-P| Code | Edit Sim |5,622 |Python/Java |500 |
> Note: In order to avoid discrepancies caused by different tokenizers, we use the word count (using Python's split function) to calculate the average length of English datasets and code datasets, and use the character count to calculate the average length of Chinese datasets.
# Task description
| Task | Task Description |
| :---------------- | :----------------------------------------------------------- |
| HotpotQA | Answer related questions based on multiple given documents |
| 2WikiMultihopQA | Answer related questions based on multiple given documents |
| Musique | Answer related questions based on multiple given documents |
| DuReader | Answer related Chinese questions based on multiple retrieved documents |
| MultiFieldQA-en | Answer English questions based on a long article, which comes from a relatively diverse field |
| MultiFieldQA-zh | Answer Chinese questions based on a long article, which comes from a relatively diverse field |
| NarrativeQA | Ask questions based on stories or scripts, including understanding of important elements such as characters, plots, themes, etc. |
| Qasper | Ask questions based on a NLP research paper, questions proposed and answered by NLP practitioners |
| GovReport | A summarization task that requires summarizing government work reports |
| QMSum | A summarization task that requires summarizing meeting records based on user queries |
| VCSUM | A summarization task that requires summarizing Chinese meeting records |
| TriviaQA | Single document question answering task, providing several few-shot examples |
| NQ | Single document question answering task, providing several few-shot examples |
| TREC | A classification task that requires categorizing questions, includes 50 categories in total |
| LSHT | A Chinese classification task that requires categorizing news, includes 24 categories in total |
| PassageRetrieval-en | Given 30 English Wikipedia paragraphs, determine which paragraph the given summary corresponds to |
| PassageCount | Determine the total number of different paragraphs in a given repetitive article |
| PassageRetrieval-zh | Given several Chinese paragraphs from the C4 data set, determine which paragraph the given abstract corresponds to |
| LCC | Given a long piece of code, predict the next line of code |
| RepoBench-P | Given code in multiple files within a GitHub repository (including cross-file dependencies), predict the next line of code |
# Task construction
> Note: For all tasks constructed from existing datasets, we use data from the validation or test set of the existing dataset (except for VCSUM).
- The tasks of [HotpotQA](https://hotpotqa.github.io/), [2WikiMultihopQA](https://aclanthology.org/2020.coling-main.580/), [Musique](https://arxiv.org/abs/2108.00573), and [DuReader](https://github.com/baidu/DuReader) are built based on the original datasets and processed to be suitable for long context evaluation. Specifically, for questions in the validation set, we select the evidence passage that contains the answer and several distracting articles. These articles together with the original question constitute the input of the tasks.
- The tasks of MultiFiedQA-zh and MultiFieldQA-en consist of long artical data from about 10 sources, including Latex papers, judicial documents, government work reports, and PDF documents indexed by Google. For each long artical, we invite several PhD and master students to annotate, i.e., to ask questions based on the long artical and give the correct answers. To better automate evaluation, we ask the annotators to propose questions with definitive answers as much as possible.
- The tasks of [NarrativeQA](https://arxiv.org/pdf/1712.07040.pdf), [Qasper](https://arxiv.org/pdf/2105.03011.pdf), [GovReport](https://arxiv.org/pdf/2104.02112.pdf), and [QMSum](https://arxiv.org/pdf/2104.05938.pdf) directly use the data provided by the original papers. In the specific construction, we use the template provided by [ZeroSCROLLS](https://www.zero.scrolls-benchmark.com/) to convert the corresponding data into pure text input.
- The [VCSUM](https://arxiv.org/abs/2305.05280) task is built based on the original dataset, and we design a corresponding template to convert the corresponding data into pure text input.
- The tasks of [TriviaQA](https://nlp.cs.washington.edu/triviaqa/) and [NQ](https://ai.google.com/research/NaturalQuestions/) are constructed in the manner of [CoLT5](https://arxiv.org/abs/2303.09752), which provides several examples of question and answering based on documents, and requires the language model to answer related questions based on new documents.
- The tasks of [TREC](https://aclanthology.org/C02-1150.pdf) and [LSHT](http://tcci.ccf.org.cn/conference/2014/dldoc/evatask6.pdf) are built based on the original datasets. For each question in the validation set, we sample several data from the training set to form few-shot examples. These examples together with the questions in the validation set constitute the input for this task.
- The PassageRetrieval-en task is constructed based on English Wikipedia. For each piece of data, we randomly sample 30 paragraphs from English Wikipedia and select one for summarization (using GPT-3.5-Turbo). This task requires the model to give the original paragraph name to which the summary corresponds.
- The PassageCount task is constructed based on the English wiki. For each piece of data, we randomly sample several passages from English Wikipedia, repeat each paragraph at random several times, and finally shuffle the paragraphs. This task requires the model to determine the total number of different paragraphs in the given context.
- The PasskeyRetrieval-zh task is constructed based on [C4](https://arxiv.org/abs/1910.10683). For each piece of data, we randomly sample several Chinese paragraphs from C4 and select one of them for summarization (using GPT-3.5-Turbo). This task requires the model to give the original paragraph name to which the summary corresponds.
- For the [LCC](https://arxiv.org/abs/2306.14893) task, we sample from the original code completion dataset. In the [RepoBench-P](https://arxiv.org/abs/2306.03091) task, we select the most challenging XF-F (Cross-File-First) setting from the original dataset and refer to the Oracle-Filled scenario in the paper. For each original piece of data, we randomly extract multiple cross-file code snippets, including the gold cross-file code snippet, and concatenate them as input, requiring the model to effectively use cross-file code for completion. | [
-0.41031062602996826,
-0.8137537240982056,
0.41705337166786194,
0.6244516372680664,
-0.18639624118804932,
-0.0819813460111618,
-0.4306783080101013,
-0.599540650844574,
0.3129281997680664,
0.3389759361743927,
-0.3667694926261902,
-0.9685620665550232,
-0.40022265911102295,
0.2505865097045898... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pig4431/HeQ_v1 | pig4431 | 2023-08-16T13:13:16Z | 20 | 2 | null | [
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:he",
"license:cc-by-4.0",
"region:us"
] | 2023-08-16T13:13:16Z | 2023-08-16T12:59:03.000Z | 2023-08-16T12:59:03 | ---
license: cc-by-4.0
task_categories:
- question-answering
language:
- he
size_categories:
- 1K<n<10K
---
# Dataset Card for HeQ_v1
## Dataset Description
- **Homepage:** [HeQ - Hebrew Question Answering Dataset](https://github.com/NNLP-IL/Hebrew-Question-Answering-Dataset)
- **Repository:** [GitHub Repository](https://github.com/NNLP-IL/Hebrew-Question-Answering-Dataset)
- **Paper:** [HeQ: A Dataset for Hebrew Question Answering](https://u.cs.biu.ac.il/~yogo/heq.pdf)
- **Leaderboard:** N/A
### Dataset Summary
HeQ is a question answering dataset in Modern Hebrew, consisting of 30,147 questions. It follows the format and crowdsourcing methodology of SQuAD and ParaShoot, with paragraphs sourced from Hebrew Wikipedia and Geektime.
### Supported Tasks and Leaderboards
- **Task:** Question Answering
### Languages
- Hebrew (he)
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
- **ID:** `string`
- **Title:** `string`
- **Source:** `string`
- **Context:** `string`
- **Question:** `string`
- **Answers:** `string`
- **Is_Impossible:** `bool`
- **WH_Question:** `string`
- **Question_Quality:** `string`
### Data Splits
- **Train:** 27,142 examples
- **Test:** 1,504 examples
- **Validation:** 1,501 examples
## Dataset Creation
### Curation Rationale
The dataset was created to provide a resource for question answering research in Hebrew.
### Source Data
#### Initial Data Collection and Normalization
Paragraphs were sourced from Hebrew Wikipedia and Geektime.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
A team of crowdworkers formulated and answered reading comprehension questions.
#### Who are the annotators?
crowdsourced
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
License: cc-by-4.0
### Citation Information
[More Information Needed]
### Contributions
Contributions and additional information are welcome. | [
-0.46992227435112,
-0.6244365572929382,
-0.06968704611063004,
0.11464107036590576,
-0.28028932213783264,
0.05638613924384117,
-0.054675910621881485,
-0.15698176622390747,
0.2019154280424118,
0.523054301738739,
-0.8747445940971375,
-0.9250814318656921,
-0.47485873103141785,
0.11234009265899... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
open-llm-leaderboard/details_psmathur__model_007_13b | open-llm-leaderboard | 2023-08-27T12:28:41Z | 20 | 0 | null | [
"region:us"
] | 2023-08-27T12:28:41Z | 2023-08-18T00:15:44.000Z | 2023-08-18T00:15:44 | ---
pretty_name: Evaluation run of psmathur/model_007_13b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [psmathur/model_007_13b](https://huggingface.co/psmathur/model_007_13b) on the\
\ [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 61 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_psmathur__model_007_13b\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-08-11T11:34:56.294632](https://huggingface.co/datasets/open-llm-leaderboard/details_psmathur__model_007_13b/blob/main/results_2023-08-11T11%3A34%3A56.294632.json)\
\ (note that their might be results for other tasks in the repos if successive evals\
\ didn't cover the same tasks. You find each in the results and the \"latest\" split\
\ for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.2314240573187148,\n\
\ \"acc_stderr\": 0.03071122006512167,\n \"acc_norm\": 0.2314240573187148,\n\
\ \"acc_norm_stderr\": 0.03071122006512167,\n \"mc1\": 1.0,\n \
\ \"mc1_stderr\": 0.0,\n \"mc2\": NaN,\n \"mc2_stderr\": NaN\n\
\ },\n \"harness|arc:challenge|25\": {\n \"acc\": 0.22696245733788395,\n\
\ \"acc_stderr\": 0.012240491536132861,\n \"acc_norm\": 0.22696245733788395,\n\
\ \"acc_norm_stderr\": 0.012240491536132861\n },\n \"harness|hellaswag|10\"\
: {\n \"acc\": 0.2504481179047998,\n \"acc_stderr\": 0.004323856300539177,\n\
\ \"acc_norm\": 0.2504481179047998,\n \"acc_norm_stderr\": 0.004323856300539177\n\
\ },\n \"harness|hendrycksTest-abstract_algebra|5\": {\n \"acc\": 0.22,\n\
\ \"acc_stderr\": 0.04163331998932268,\n \"acc_norm\": 0.22,\n \
\ \"acc_norm_stderr\": 0.04163331998932268\n },\n \"harness|hendrycksTest-anatomy|5\"\
: {\n \"acc\": 0.18518518518518517,\n \"acc_stderr\": 0.03355677216313142,\n\
\ \"acc_norm\": 0.18518518518518517,\n \"acc_norm_stderr\": 0.03355677216313142\n\
\ },\n \"harness|hendrycksTest-astronomy|5\": {\n \"acc\": 0.17763157894736842,\n\
\ \"acc_stderr\": 0.031103182383123398,\n \"acc_norm\": 0.17763157894736842,\n\
\ \"acc_norm_stderr\": 0.031103182383123398\n },\n \"harness|hendrycksTest-business_ethics|5\"\
: {\n \"acc\": 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \
\ \"acc_norm\": 0.3,\n \"acc_norm_stderr\": 0.046056618647183814\n \
\ },\n \"harness|hendrycksTest-clinical_knowledge|5\": {\n \"acc\": 0.21509433962264152,\n\
\ \"acc_stderr\": 0.02528839450289137,\n \"acc_norm\": 0.21509433962264152,\n\
\ \"acc_norm_stderr\": 0.02528839450289137\n },\n \"harness|hendrycksTest-college_biology|5\"\
: {\n \"acc\": 0.2569444444444444,\n \"acc_stderr\": 0.03653946969442099,\n\
\ \"acc_norm\": 0.2569444444444444,\n \"acc_norm_stderr\": 0.03653946969442099\n\
\ },\n \"harness|hendrycksTest-college_chemistry|5\": {\n \"acc\":\
\ 0.2,\n \"acc_stderr\": 0.04020151261036845,\n \"acc_norm\": 0.2,\n\
\ \"acc_norm_stderr\": 0.04020151261036845\n },\n \"harness|hendrycksTest-college_computer_science|5\"\
: {\n \"acc\": 0.26,\n \"acc_stderr\": 0.0440844002276808,\n \
\ \"acc_norm\": 0.26,\n \"acc_norm_stderr\": 0.0440844002276808\n },\n\
\ \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.21,\n\
\ \"acc_stderr\": 0.040936018074033256,\n \"acc_norm\": 0.21,\n \
\ \"acc_norm_stderr\": 0.040936018074033256\n },\n \"harness|hendrycksTest-college_medicine|5\"\
: {\n \"acc\": 0.20809248554913296,\n \"acc_stderr\": 0.030952890217749874,\n\
\ \"acc_norm\": 0.20809248554913296,\n \"acc_norm_stderr\": 0.030952890217749874\n\
\ },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.21568627450980393,\n\
\ \"acc_stderr\": 0.04092563958237654,\n \"acc_norm\": 0.21568627450980393,\n\
\ \"acc_norm_stderr\": 0.04092563958237654\n },\n \"harness|hendrycksTest-computer_security|5\"\
: {\n \"acc\": 0.28,\n \"acc_stderr\": 0.045126085985421276,\n \
\ \"acc_norm\": 0.28,\n \"acc_norm_stderr\": 0.045126085985421276\n \
\ },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\":\
\ 0.26382978723404255,\n \"acc_stderr\": 0.028809989854102973,\n \"\
acc_norm\": 0.26382978723404255,\n \"acc_norm_stderr\": 0.028809989854102973\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.23684210526315788,\n\
\ \"acc_stderr\": 0.039994238792813365,\n \"acc_norm\": 0.23684210526315788,\n\
\ \"acc_norm_stderr\": 0.039994238792813365\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.2413793103448276,\n \"acc_stderr\": 0.03565998174135302,\n\
\ \"acc_norm\": 0.2413793103448276,\n \"acc_norm_stderr\": 0.03565998174135302\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.20899470899470898,\n \"acc_stderr\": 0.02094048156533486,\n \"\
acc_norm\": 0.20899470899470898,\n \"acc_norm_stderr\": 0.02094048156533486\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.2857142857142857,\n\
\ \"acc_stderr\": 0.04040610178208841,\n \"acc_norm\": 0.2857142857142857,\n\
\ \"acc_norm_stderr\": 0.04040610178208841\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.18,\n \"acc_stderr\": 0.038612291966536934,\n \
\ \"acc_norm\": 0.18,\n \"acc_norm_stderr\": 0.038612291966536934\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\"\
: 0.1774193548387097,\n \"acc_stderr\": 0.02173254068932927,\n \"\
acc_norm\": 0.1774193548387097,\n \"acc_norm_stderr\": 0.02173254068932927\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.15270935960591134,\n \"acc_stderr\": 0.02530890453938063,\n \"\
acc_norm\": 0.15270935960591134,\n \"acc_norm_stderr\": 0.02530890453938063\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.25,\n \"acc_stderr\": 0.04351941398892446,\n \"acc_norm\"\
: 0.25,\n \"acc_norm_stderr\": 0.04351941398892446\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.21818181818181817,\n \"acc_stderr\": 0.03225078108306289,\n\
\ \"acc_norm\": 0.21818181818181817,\n \"acc_norm_stderr\": 0.03225078108306289\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.17676767676767677,\n \"acc_stderr\": 0.027178752639044915,\n \"\
acc_norm\": 0.17676767676767677,\n \"acc_norm_stderr\": 0.027178752639044915\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.19689119170984457,\n \"acc_stderr\": 0.028697873971860664,\n\
\ \"acc_norm\": 0.19689119170984457,\n \"acc_norm_stderr\": 0.028697873971860664\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.20256410256410257,\n \"acc_stderr\": 0.020377660970371372,\n\
\ \"acc_norm\": 0.20256410256410257,\n \"acc_norm_stderr\": 0.020377660970371372\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.2111111111111111,\n \"acc_stderr\": 0.024882116857655075,\n \
\ \"acc_norm\": 0.2111111111111111,\n \"acc_norm_stderr\": 0.024882116857655075\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.21008403361344538,\n \"acc_stderr\": 0.026461398717471874,\n\
\ \"acc_norm\": 0.21008403361344538,\n \"acc_norm_stderr\": 0.026461398717471874\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.1986754966887417,\n \"acc_stderr\": 0.03257847384436776,\n \"\
acc_norm\": 0.1986754966887417,\n \"acc_norm_stderr\": 0.03257847384436776\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.1926605504587156,\n \"acc_stderr\": 0.016909276884936094,\n \"\
acc_norm\": 0.1926605504587156,\n \"acc_norm_stderr\": 0.016909276884936094\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.1527777777777778,\n \"acc_stderr\": 0.024536326026134224,\n \"\
acc_norm\": 0.1527777777777778,\n \"acc_norm_stderr\": 0.024536326026134224\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.25,\n \"acc_stderr\": 0.03039153369274154,\n \"acc_norm\": 0.25,\n\
\ \"acc_norm_stderr\": 0.03039153369274154\n },\n \"harness|hendrycksTest-high_school_world_history|5\"\
: {\n \"acc\": 0.270042194092827,\n \"acc_stderr\": 0.028900721906293426,\n\
\ \"acc_norm\": 0.270042194092827,\n \"acc_norm_stderr\": 0.028900721906293426\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.31390134529147984,\n\
\ \"acc_stderr\": 0.031146796482972465,\n \"acc_norm\": 0.31390134529147984,\n\
\ \"acc_norm_stderr\": 0.031146796482972465\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.2595419847328244,\n \"acc_stderr\": 0.03844876139785271,\n\
\ \"acc_norm\": 0.2595419847328244,\n \"acc_norm_stderr\": 0.03844876139785271\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.2396694214876033,\n \"acc_stderr\": 0.03896878985070417,\n \"\
acc_norm\": 0.2396694214876033,\n \"acc_norm_stderr\": 0.03896878985070417\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.25925925925925924,\n\
\ \"acc_stderr\": 0.042365112580946336,\n \"acc_norm\": 0.25925925925925924,\n\
\ \"acc_norm_stderr\": 0.042365112580946336\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.22085889570552147,\n \"acc_stderr\": 0.032591773927421776,\n\
\ \"acc_norm\": 0.22085889570552147,\n \"acc_norm_stderr\": 0.032591773927421776\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.3125,\n\
\ \"acc_stderr\": 0.043994650575715215,\n \"acc_norm\": 0.3125,\n\
\ \"acc_norm_stderr\": 0.043994650575715215\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.17475728155339806,\n \"acc_stderr\": 0.037601780060266224,\n\
\ \"acc_norm\": 0.17475728155339806,\n \"acc_norm_stderr\": 0.037601780060266224\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.2905982905982906,\n\
\ \"acc_stderr\": 0.02974504857267404,\n \"acc_norm\": 0.2905982905982906,\n\
\ \"acc_norm_stderr\": 0.02974504857267404\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \
\ \"acc_norm\": 0.3,\n \"acc_norm_stderr\": 0.046056618647183814\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.23754789272030652,\n\
\ \"acc_stderr\": 0.015218733046150193,\n \"acc_norm\": 0.23754789272030652,\n\
\ \"acc_norm_stderr\": 0.015218733046150193\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.24855491329479767,\n \"acc_stderr\": 0.023267528432100174,\n\
\ \"acc_norm\": 0.24855491329479767,\n \"acc_norm_stderr\": 0.023267528432100174\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.23798882681564246,\n\
\ \"acc_stderr\": 0.014242630070574915,\n \"acc_norm\": 0.23798882681564246,\n\
\ \"acc_norm_stderr\": 0.014242630070574915\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.22549019607843138,\n \"acc_stderr\": 0.023929155517351284,\n\
\ \"acc_norm\": 0.22549019607843138,\n \"acc_norm_stderr\": 0.023929155517351284\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.1864951768488746,\n\
\ \"acc_stderr\": 0.02212243977248077,\n \"acc_norm\": 0.1864951768488746,\n\
\ \"acc_norm_stderr\": 0.02212243977248077\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.21604938271604937,\n \"acc_stderr\": 0.022899162918445806,\n\
\ \"acc_norm\": 0.21604938271604937,\n \"acc_norm_stderr\": 0.022899162918445806\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.23404255319148937,\n \"acc_stderr\": 0.025257861359432417,\n \
\ \"acc_norm\": 0.23404255319148937,\n \"acc_norm_stderr\": 0.025257861359432417\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.2457627118644068,\n\
\ \"acc_stderr\": 0.010996156635142692,\n \"acc_norm\": 0.2457627118644068,\n\
\ \"acc_norm_stderr\": 0.010996156635142692\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.18382352941176472,\n \"acc_stderr\": 0.023529242185193106,\n\
\ \"acc_norm\": 0.18382352941176472,\n \"acc_norm_stderr\": 0.023529242185193106\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.25,\n \"acc_stderr\": 0.01751781884501444,\n \"acc_norm\"\
: 0.25,\n \"acc_norm_stderr\": 0.01751781884501444\n },\n \"harness|hendrycksTest-public_relations|5\"\
: {\n \"acc\": 0.21818181818181817,\n \"acc_stderr\": 0.03955932861795833,\n\
\ \"acc_norm\": 0.21818181818181817,\n \"acc_norm_stderr\": 0.03955932861795833\n\
\ },\n \"harness|hendrycksTest-security_studies|5\": {\n \"acc\": 0.18775510204081633,\n\
\ \"acc_stderr\": 0.02500025603954621,\n \"acc_norm\": 0.18775510204081633,\n\
\ \"acc_norm_stderr\": 0.02500025603954621\n },\n \"harness|hendrycksTest-sociology|5\"\
: {\n \"acc\": 0.24378109452736318,\n \"acc_stderr\": 0.03036049015401465,\n\
\ \"acc_norm\": 0.24378109452736318,\n \"acc_norm_stderr\": 0.03036049015401465\n\
\ },\n \"harness|hendrycksTest-us_foreign_policy|5\": {\n \"acc\":\
\ 0.28,\n \"acc_stderr\": 0.04512608598542128,\n \"acc_norm\": 0.28,\n\
\ \"acc_norm_stderr\": 0.04512608598542128\n },\n \"harness|hendrycksTest-virology|5\"\
: {\n \"acc\": 0.28313253012048195,\n \"acc_stderr\": 0.03507295431370518,\n\
\ \"acc_norm\": 0.28313253012048195,\n \"acc_norm_stderr\": 0.03507295431370518\n\
\ },\n \"harness|hendrycksTest-world_religions|5\": {\n \"acc\": 0.3216374269005848,\n\
\ \"acc_stderr\": 0.03582529442573122,\n \"acc_norm\": 0.3216374269005848,\n\
\ \"acc_norm_stderr\": 0.03582529442573122\n },\n \"harness|truthfulqa:mc|0\"\
: {\n \"mc1\": 1.0,\n \"mc1_stderr\": 0.0,\n \"mc2\": NaN,\n\
\ \"mc2_stderr\": NaN\n }\n}\n```"
repo_url: https://huggingface.co/psmathur/model_007_13b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|arc:challenge|25_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|arc:challenge|25_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hellaswag|10_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hellaswag|10_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-09T13:37:17.110700.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-11T11:34:56.294632.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-11T11:34:56.294632.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-09T13:37:17.110700.parquet'
- split: 2023_08_11T11_34_56.294632
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-11T11:34:56.294632.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-11T11:34:56.294632.parquet'
- config_name: results
data_files:
- split: 2023_08_09T13_37_17.110700
path:
- results_2023-08-09T13:37:17.110700.parquet
- split: 2023_08_11T11_34_56.294632
path:
- results_2023-08-11T11:34:56.294632.parquet
- split: latest
path:
- results_2023-08-11T11:34:56.294632.parquet
---
# Dataset Card for Evaluation run of psmathur/model_007_13b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/psmathur/model_007_13b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [psmathur/model_007_13b](https://huggingface.co/psmathur/model_007_13b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 61 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_psmathur__model_007_13b",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-08-11T11:34:56.294632](https://huggingface.co/datasets/open-llm-leaderboard/details_psmathur__model_007_13b/blob/main/results_2023-08-11T11%3A34%3A56.294632.json) (note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.2314240573187148,
"acc_stderr": 0.03071122006512167,
"acc_norm": 0.2314240573187148,
"acc_norm_stderr": 0.03071122006512167,
"mc1": 1.0,
"mc1_stderr": 0.0,
"mc2": NaN,
"mc2_stderr": NaN
},
"harness|arc:challenge|25": {
"acc": 0.22696245733788395,
"acc_stderr": 0.012240491536132861,
"acc_norm": 0.22696245733788395,
"acc_norm_stderr": 0.012240491536132861
},
"harness|hellaswag|10": {
"acc": 0.2504481179047998,
"acc_stderr": 0.004323856300539177,
"acc_norm": 0.2504481179047998,
"acc_norm_stderr": 0.004323856300539177
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.22,
"acc_stderr": 0.04163331998932268,
"acc_norm": 0.22,
"acc_norm_stderr": 0.04163331998932268
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.18518518518518517,
"acc_stderr": 0.03355677216313142,
"acc_norm": 0.18518518518518517,
"acc_norm_stderr": 0.03355677216313142
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.17763157894736842,
"acc_stderr": 0.031103182383123398,
"acc_norm": 0.17763157894736842,
"acc_norm_stderr": 0.031103182383123398
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.21509433962264152,
"acc_stderr": 0.02528839450289137,
"acc_norm": 0.21509433962264152,
"acc_norm_stderr": 0.02528839450289137
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.2569444444444444,
"acc_stderr": 0.03653946969442099,
"acc_norm": 0.2569444444444444,
"acc_norm_stderr": 0.03653946969442099
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.2,
"acc_stderr": 0.04020151261036845,
"acc_norm": 0.2,
"acc_norm_stderr": 0.04020151261036845
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.26,
"acc_stderr": 0.0440844002276808,
"acc_norm": 0.26,
"acc_norm_stderr": 0.0440844002276808
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.21,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.21,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.20809248554913296,
"acc_stderr": 0.030952890217749874,
"acc_norm": 0.20809248554913296,
"acc_norm_stderr": 0.030952890217749874
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.21568627450980393,
"acc_stderr": 0.04092563958237654,
"acc_norm": 0.21568627450980393,
"acc_norm_stderr": 0.04092563958237654
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.28,
"acc_stderr": 0.045126085985421276,
"acc_norm": 0.28,
"acc_norm_stderr": 0.045126085985421276
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.26382978723404255,
"acc_stderr": 0.028809989854102973,
"acc_norm": 0.26382978723404255,
"acc_norm_stderr": 0.028809989854102973
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.23684210526315788,
"acc_stderr": 0.039994238792813365,
"acc_norm": 0.23684210526315788,
"acc_norm_stderr": 0.039994238792813365
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.2413793103448276,
"acc_stderr": 0.03565998174135302,
"acc_norm": 0.2413793103448276,
"acc_norm_stderr": 0.03565998174135302
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.20899470899470898,
"acc_stderr": 0.02094048156533486,
"acc_norm": 0.20899470899470898,
"acc_norm_stderr": 0.02094048156533486
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.2857142857142857,
"acc_stderr": 0.04040610178208841,
"acc_norm": 0.2857142857142857,
"acc_norm_stderr": 0.04040610178208841
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.18,
"acc_stderr": 0.038612291966536934,
"acc_norm": 0.18,
"acc_norm_stderr": 0.038612291966536934
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.1774193548387097,
"acc_stderr": 0.02173254068932927,
"acc_norm": 0.1774193548387097,
"acc_norm_stderr": 0.02173254068932927
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.15270935960591134,
"acc_stderr": 0.02530890453938063,
"acc_norm": 0.15270935960591134,
"acc_norm_stderr": 0.02530890453938063
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.25,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.25,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.21818181818181817,
"acc_stderr": 0.03225078108306289,
"acc_norm": 0.21818181818181817,
"acc_norm_stderr": 0.03225078108306289
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.17676767676767677,
"acc_stderr": 0.027178752639044915,
"acc_norm": 0.17676767676767677,
"acc_norm_stderr": 0.027178752639044915
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.19689119170984457,
"acc_stderr": 0.028697873971860664,
"acc_norm": 0.19689119170984457,
"acc_norm_stderr": 0.028697873971860664
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.20256410256410257,
"acc_stderr": 0.020377660970371372,
"acc_norm": 0.20256410256410257,
"acc_norm_stderr": 0.020377660970371372
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.2111111111111111,
"acc_stderr": 0.024882116857655075,
"acc_norm": 0.2111111111111111,
"acc_norm_stderr": 0.024882116857655075
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.21008403361344538,
"acc_stderr": 0.026461398717471874,
"acc_norm": 0.21008403361344538,
"acc_norm_stderr": 0.026461398717471874
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.1986754966887417,
"acc_stderr": 0.03257847384436776,
"acc_norm": 0.1986754966887417,
"acc_norm_stderr": 0.03257847384436776
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.1926605504587156,
"acc_stderr": 0.016909276884936094,
"acc_norm": 0.1926605504587156,
"acc_norm_stderr": 0.016909276884936094
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.1527777777777778,
"acc_stderr": 0.024536326026134224,
"acc_norm": 0.1527777777777778,
"acc_norm_stderr": 0.024536326026134224
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.25,
"acc_stderr": 0.03039153369274154,
"acc_norm": 0.25,
"acc_norm_stderr": 0.03039153369274154
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.270042194092827,
"acc_stderr": 0.028900721906293426,
"acc_norm": 0.270042194092827,
"acc_norm_stderr": 0.028900721906293426
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.31390134529147984,
"acc_stderr": 0.031146796482972465,
"acc_norm": 0.31390134529147984,
"acc_norm_stderr": 0.031146796482972465
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.2595419847328244,
"acc_stderr": 0.03844876139785271,
"acc_norm": 0.2595419847328244,
"acc_norm_stderr": 0.03844876139785271
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.2396694214876033,
"acc_stderr": 0.03896878985070417,
"acc_norm": 0.2396694214876033,
"acc_norm_stderr": 0.03896878985070417
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.25925925925925924,
"acc_stderr": 0.042365112580946336,
"acc_norm": 0.25925925925925924,
"acc_norm_stderr": 0.042365112580946336
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.22085889570552147,
"acc_stderr": 0.032591773927421776,
"acc_norm": 0.22085889570552147,
"acc_norm_stderr": 0.032591773927421776
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.3125,
"acc_stderr": 0.043994650575715215,
"acc_norm": 0.3125,
"acc_norm_stderr": 0.043994650575715215
},
"harness|hendrycksTest-management|5": {
"acc": 0.17475728155339806,
"acc_stderr": 0.037601780060266224,
"acc_norm": 0.17475728155339806,
"acc_norm_stderr": 0.037601780060266224
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.2905982905982906,
"acc_stderr": 0.02974504857267404,
"acc_norm": 0.2905982905982906,
"acc_norm_stderr": 0.02974504857267404
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.23754789272030652,
"acc_stderr": 0.015218733046150193,
"acc_norm": 0.23754789272030652,
"acc_norm_stderr": 0.015218733046150193
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.24855491329479767,
"acc_stderr": 0.023267528432100174,
"acc_norm": 0.24855491329479767,
"acc_norm_stderr": 0.023267528432100174
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.23798882681564246,
"acc_stderr": 0.014242630070574915,
"acc_norm": 0.23798882681564246,
"acc_norm_stderr": 0.014242630070574915
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.22549019607843138,
"acc_stderr": 0.023929155517351284,
"acc_norm": 0.22549019607843138,
"acc_norm_stderr": 0.023929155517351284
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.1864951768488746,
"acc_stderr": 0.02212243977248077,
"acc_norm": 0.1864951768488746,
"acc_norm_stderr": 0.02212243977248077
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.21604938271604937,
"acc_stderr": 0.022899162918445806,
"acc_norm": 0.21604938271604937,
"acc_norm_stderr": 0.022899162918445806
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.23404255319148937,
"acc_stderr": 0.025257861359432417,
"acc_norm": 0.23404255319148937,
"acc_norm_stderr": 0.025257861359432417
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.2457627118644068,
"acc_stderr": 0.010996156635142692,
"acc_norm": 0.2457627118644068,
"acc_norm_stderr": 0.010996156635142692
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.18382352941176472,
"acc_stderr": 0.023529242185193106,
"acc_norm": 0.18382352941176472,
"acc_norm_stderr": 0.023529242185193106
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.25,
"acc_stderr": 0.01751781884501444,
"acc_norm": 0.25,
"acc_norm_stderr": 0.01751781884501444
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.21818181818181817,
"acc_stderr": 0.03955932861795833,
"acc_norm": 0.21818181818181817,
"acc_norm_stderr": 0.03955932861795833
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.18775510204081633,
"acc_stderr": 0.02500025603954621,
"acc_norm": 0.18775510204081633,
"acc_norm_stderr": 0.02500025603954621
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.24378109452736318,
"acc_stderr": 0.03036049015401465,
"acc_norm": 0.24378109452736318,
"acc_norm_stderr": 0.03036049015401465
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.28,
"acc_stderr": 0.04512608598542128,
"acc_norm": 0.28,
"acc_norm_stderr": 0.04512608598542128
},
"harness|hendrycksTest-virology|5": {
"acc": 0.28313253012048195,
"acc_stderr": 0.03507295431370518,
"acc_norm": 0.28313253012048195,
"acc_norm_stderr": 0.03507295431370518
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.3216374269005848,
"acc_stderr": 0.03582529442573122,
"acc_norm": 0.3216374269005848,
"acc_norm_stderr": 0.03582529442573122
},
"harness|truthfulqa:mc|0": {
"mc1": 1.0,
"mc1_stderr": 0.0,
"mc2": NaN,
"mc2_stderr": NaN
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.7217286825180054,
-0.8412843942642212,
0.3002576529979706,
0.22668775916099548,
-0.18621228635311127,
-0.03563009947538376,
0.03032333217561245,
-0.1770196408033371,
0.5833339095115662,
-0.07002456486225128,
-0.49749991297721863,
-0.6555459499359131,
-0.4590489864349365,
0.2481248378753... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
FinchResearch/OpenPlatypus-Alpaca | FinchResearch | 2023-08-29T13:53:43Z | 20 | 1 | null | [
"size_categories:10K<n<100K",
"license:apache-2.0",
"region:us"
] | 2023-08-29T13:53:43Z | 2023-08-21T13:31:52.000Z | 2023-08-21T13:31:52 | ---
license: apache-2.0
size_categories:
- 10K<n<100K
---
### A merged dataset...
### Open-Platypus & Alpaca Data | [
-0.5471495389938354,
-0.3060579001903534,
0.1103440448641777,
0.26721981167793274,
-0.5579057931900024,
-0.27800294756889343,
-0.20550411939620972,
-0.15248258411884308,
0.6376018524169922,
1.1002888679504395,
-0.5446129441261292,
-0.5979326963424683,
-0.6693194508552551,
-0.15870864689350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
piotr-rybak/legal-questions | piotr-rybak | 2023-08-23T09:59:45Z | 20 | 0 | null | [
"region:us"
] | 2023-08-23T09:59:45Z | 2023-08-23T09:57:44.000Z | 2023-08-23T09:57:44 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jondurbin/airoboros-2.1 | jondurbin | 2023-08-24T16:56:07Z | 20 | 15 | null | [
"license:apache-2.0",
"region:us"
] | 2023-08-24T16:56:07Z | 2023-08-24T16:56:00.000Z | 2023-08-24T16:56:00 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
DynamicSuperb/SpeakerVerification_LibriSpeech-TestClean | DynamicSuperb | 2023-11-01T08:24:55Z | 20 | 0 | null | [
"region:us"
] | 2023-11-01T08:24:55Z | 2023-09-02T08:58:14.000Z | 2023-09-02T08:58:14 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: file2
dtype: string
- name: audio2
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 1498410406.0
num_examples: 5000
download_size: 691287710
dataset_size: 1498410406.0
---
# Dataset Card for "SpeakerVerification_LibriSpeechTestClean"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7668651342391968,
-0.23304319381713867,
0.18446141481399536,
0.14139620959758759,
-0.08617142587900162,
-0.06861604750156403,
-0.2160993069410324,
-0.11299014091491699,
0.9541991949081421,
0.4290637671947479,
-0.8111057281494141,
-0.6962999105453491,
-0.4898492693901062,
-0.531513273715... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Tristan/flickr30k_test | Tristan | 2023-09-04T22:36:06Z | 20 | 0 | null | [
"region:us"
] | 2023-09-04T22:36:06Z | 2023-09-04T22:34:11.000Z | 2023-09-04T22:34:11 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: caption
list: string
- name: sentids
list: string
- name: split
dtype: string
- name: img_id
dtype: string
- name: filename
dtype: string
splits:
- name: test
num_bytes: 142117238.54065907
num_examples: 1000
download_size: 141466584
dataset_size: 142117238.54065907
---
# Dataset Card for "flickr30k_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.9271601438522339,
-0.09000833332538605,
0.0717998817563057,
0.30851954221725464,
-0.21238739788532257,
-0.0043528759852051735,
0.48197221755981445,
-0.015999991446733475,
0.4718713164329529,
0.32411763072013855,
-1.0170619487762451,
-0.5937091112136841,
-0.43762534856796265,
-0.19264663... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sachith-surge/LaMini | sachith-surge | 2023-09-06T08:19:01Z | 20 | 0 | null | [
"region:us"
] | 2023-09-06T08:19:01Z | 2023-09-06T08:18:58.000Z | 2023-09-06T08:18:58 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: source
dtype: string
- name: response
dtype: string
- name: llama2_status
dtype: string
- name: llama2_rating
dtype: string
- name: llama2_reason
dtype: string
- name: gpt4_status
dtype: string
- name: gpt4_rating
dtype: string
- name: gpt4_reason
dtype: string
- name: falcon_status
dtype: string
- name: falcon_rating
dtype: string
- name: falcon_reason
dtype: string
splits:
- name: train
num_bytes: 3287768
num_examples: 1504
download_size: 1603115
dataset_size: 3287768
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "LaMini-LM-dataset-TheBloke-h2ogpt-falcon-40b-v2-GGML-eval-llama2-gpt4-falcon"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5030401349067688,
-0.3341251015663147,
0.19229361414909363,
0.27933451533317566,
-0.3604563772678375,
0.3597233295440674,
0.256039023399353,
-0.26636558771133423,
0.7561472654342651,
0.38965025544166565,
-0.8844951391220093,
-0.5115645527839661,
-0.6511857509613037,
-0.2537919878959656,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SniiKz/llama2_Chat_trainingset | SniiKz | 2023-09-23T16:04:51Z | 20 | 1 | null | [
"region:us"
] | 2023-09-23T16:04:51Z | 2023-09-23T16:04:49.000Z | 2023-09-23T16:04:49 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 513180
num_examples: 1342
download_size: 115505
dataset_size: 513180
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llama2_Chat_trainingset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.29619041085243225,
-0.23290619254112244,
0.0309447068721056,
0.5172488689422607,
-0.3210389018058777,
0.24776691198349,
0.217037171125412,
-0.2561601400375366,
0.8411105275154114,
0.37048959732055664,
-0.833846926689148,
-0.6839749813079834,
-0.7411050200462341,
-0.40285637974739075,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
cnut1648/ScienceQA-LLAVA | cnut1648 | 2023-10-22T00:49:42Z | 20 | 0 | null | [
"region:us"
] | 2023-10-22T00:49:42Z | 2023-09-24T04:07:31.000Z | 2023-09-24T04:07:31 | ---
dataset_info:
features:
- name: id
dtype: string
- name: image
dtype: image
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: question
dtype: string
- name: context
dtype: string
- name: choice
dtype: string
- name: answer
dtype: string
- name: lecture
dtype: string
- name: solution
dtype: string
splits:
- name: train
num_bytes: 425066440.932
num_examples: 12726
- name: validation
num_bytes: 141104381.824
num_examples: 4241
- name: test
num_bytes: 139230285.176
num_examples: 4241
download_size: 681887955
dataset_size: 705401107.932
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for "ScienceQA-LLAVA"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.40446922183036804,
-0.044726867228746414,
0.44786593317985535,
0.19256813824176788,
-0.36052459478378296,
0.20782169699668884,
0.5316775441169739,
-0.10735072940587997,
1.036224126815796,
0.3959607779979706,
-0.8003274202346802,
-0.7333971261978149,
-0.5808535218238831,
-0.1597998738288... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
manojdilz/facial_emotion_detection_dataset | manojdilz | 2023-10-14T14:30:28Z | 20 | 0 | null | [
"region:us"
] | 2023-10-14T14:30:28Z | 2023-09-28T15:09:48.000Z | 2023-09-28T15:09:48 | # Face Emotion Classification Dataset
This dataset contain about 35000 images which are belongs to 7 classes. This dataset can be used to train deep learning models for human emotion classification problems.
| [
-0.7656105756759644,
0.1015738993883133,
-0.07809971272945404,
0.3527924418449402,
-0.029521996155381203,
0.00392167130485177,
0.013550586998462677,
-0.1388029307126999,
-0.2590510845184326,
0.5549532175064087,
-0.5277239084243774,
-0.45760422945022583,
-0.5476287603378296,
0.1455460041761... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tucan-ai/summaries-de-v1 | tucan-ai | 2023-10-18T14:33:42Z | 20 | 0 | null | [
"region:us"
] | 2023-10-18T14:33:42Z | 2023-09-29T05:55:08.000Z | 2023-09-29T05:55:08 | ---
dataset_info:
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 93014092.0
num_examples: 8060
- name: test
num_bytes: 23253523.0
num_examples: 2015
download_size: 68440450
dataset_size: 116267615.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "summaries-de-v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7097716331481934,
-0.3152093291282654,
0.19089731574058533,
0.17001742124557495,
-0.4575175940990448,
-0.19251051545143127,
0.42236441373825073,
-0.03184637427330017,
1.187813639640808,
0.6050800085067749,
-0.9756291508674622,
-0.7684223055839539,
-0.7752746939659119,
-0.076300695538520... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
IBM-AI-SAP-team/llama-2-train-rfp-response-v2 | IBM-AI-SAP-team | 2023-10-05T07:22:39Z | 20 | 0 | null | [
"region:us"
] | 2023-10-05T07:22:39Z | 2023-10-05T07:22:37.000Z | 2023-10-05T07:22:37 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: messages
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 229378
num_examples: 81
download_size: 118272
dataset_size: 229378
---
# Dataset Card for "llama-2-train-rfp-response-v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.35618725419044495,
0.09178679436445236,
0.07583004236221313,
0.5254617929458618,
-0.3911699056625366,
0.096451036632061,
0.5219584703445435,
-0.5493473410606384,
0.8189423084259033,
0.5230475664138794,
-0.974820613861084,
-0.3348030745983124,
-0.6941382884979248,
-0.17843790352344513,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
emozilla/govreport-test-tokenized-mistral | emozilla | 2023-10-07T01:33:43Z | 20 | 0 | null | [
"region:us"
] | 2023-10-07T01:33:43Z | 2023-10-07T01:33:37.000Z | 2023-10-07T01:33:37 | ---
dataset_info:
features:
- name: id
dtype: string
- name: pid
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: tokenized_len
dtype: int64
splits:
- name: test
num_bytes: 105052939
num_examples: 973
download_size: 43495868
dataset_size: 105052939
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
# Dataset Card for "govreport-test-tokenized-mistral"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.37646356225013733,
-0.39248427748680115,
-0.010999343357980251,
0.25660526752471924,
-0.210349440574646,
-0.1862734854221344,
0.28904253244400024,
-0.04745851457118988,
0.6590855717658997,
0.500988245010376,
-0.5688284039497375,
-0.6906096339225769,
-0.657400906085968,
-0.27250948548316... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
chargoddard/rpguild | chargoddard | 2023-10-18T00:34:26Z | 20 | 1 | null | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-nc-4.0",
"roleplay",
"not-for-all-audiences",
"region:us"
] | 2023-10-18T00:34:26Z | 2023-10-07T08:04:37.000Z | 2023-10-07T08:04:37 | ---
dataset_info:
- config_name: default
features:
- name: username
dtype: string
- name: char_name
dtype: string
- name: bio
dtype: string
- name: context
list:
- name: text
dtype: string
- name: username
dtype: string
- name: char_name
dtype: string
- name: reply
dtype: string
- name: has_nameless
dtype: bool
- name: char_confidence
dtype: float64
splits:
- name: train
num_bytes: 1921588254
num_examples: 140469
download_size: 764073630
dataset_size: 1921588254
- config_name: high_confidence
features:
- name: username
dtype: string
- name: char_name
dtype: string
- name: bio
dtype: string
- name: context
list:
- name: text
dtype: string
- name: username
dtype: string
- name: char_name
dtype: string
- name: reply
dtype: string
- name: has_nameless
dtype: bool
- name: char_confidence
dtype: float64
splits:
- name: train
num_bytes: 949419370.7676569
num_examples: 69403
download_size: 386317057
dataset_size: 949419370.7676569
- config_name: pruned
features:
- name: username
dtype: string
- name: char_name
dtype: string
- name: bio
dtype: string
- name: context
list:
- name: text
dtype: string
- name: username
dtype: string
- name: char_name
dtype: string
- name: reply
dtype: string
- name: has_nameless
dtype: bool
- name: char_confidence
dtype: float64
splits:
- name: train
num_bytes: 782484734.2032762
num_examples: 57200
download_size: 326987882
dataset_size: 782484734.2032762
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- config_name: high_confidence
data_files:
- split: train
path: high_confidence/train-*
- config_name: pruned
data_files:
- split: train
path: pruned/train-*
license: cc-by-nc-4.0
task_categories:
- conversational
- text-generation
tags:
- roleplay
- not-for-all-audiences
size_categories:
- 100K<n<1M
language:
- en
---
Data scraped from [roleplayerguild](https://www.roleplayerguild.com/) and parsed into prompts with a conversation history and associated character bio.
As usernames can be associated with multiple biographies, assignment of characters is a little fuzzy. The `char_confidence` feature reflects how likely this assignment is to be correct. Not all posts in the conversation history necessarily have an associated character name. The column `has_nameless` reflects this.
Each row should fit into 4096 Llama tokens, depending on your prompt format - there's built in slack of 128 tokens + 8 per message. | [
-0.17326229810714722,
-0.6939778923988342,
0.7611509561538696,
0.39803797006607056,
-0.1343645602464676,
0.2507854998111725,
0.32220324873924255,
-0.3441326916217804,
0.7716636061668396,
0.6038431525230408,
-1.0411920547485352,
-0.5198235511779785,
-0.4178676903247833,
0.35631120204925537,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
augustoperes/mtg_text | augustoperes | 2023-10-18T14:34:55Z | 20 | 0 | null | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"region:us"
] | 2023-10-18T14:34:55Z | 2023-10-09T16:02:55.000Z | 2023-10-09T16:02:55 | ---
task_categories:
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
# Magic the gathering dataset
This dataset contains text of all magic the gathering cards.
Example usage:
```python
from datasets import load_dataset
dataset = load_dataset('augustoperes/mtg_text')
dataset
# outputs:
# DatasetDict({
# train: Dataset({
# features: ['card_name', 'type_line', 'oracle_text'],
# num_rows: 20063
# })
# validation: Dataset({
# features: ['card_name', 'type_line', 'oracle_text'],
# num_rows: 5016
# })
# })
```
Elements of the dataset are, for example:
```python
train_dataset = dataset['train']
train_dataset[0]
# Outputs
# {'card_name': 'Recurring Insight',
# 'type_line': 'Sorcery',
# 'oracle_text': "Draw cards equal to the number of cards in target opponent's hand.\nRebound (If you cast this spell from your hand, exile it as it resolves. At the beginning of your next upkeep, you may cast this card from exile without paying its mana cost.)"}
```
# Example usage with Pytorch
You can easily tokenize, convert and pad this dataset to be usable in pytorch with:
```python
from transformers import AutoTokenizer
import torch
from torch.nn.utils.rnn import pad_sequence
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize(sample):
sample["card_name"] = tokenizer(sample["card_name"])["input_ids"]
sample["type_line"] = tokenizer(sample["type_line"])["input_ids"]
sample["oracle_text"] = tokenizer(sample["oracle_text"])["input_ids"]
return sample
tokenized_dataset = train_dataset.map(tokenize)
def collate_fn(sequences):
# Pad the sequences to the maximum length in the batch
card_names = [torch.tensor(sequence['card_name']) for sequence in sequences]
type_line = [torch.tensor(sequence['type_line']) for sequence in sequences]
oracle_text = [torch.tensor(sequence['oracle_text']) for sequence in sequences]
padded_card_name = pad_sequence(card_names, batch_first=True, padding_value=0)
padded_type_line = pad_sequence(type_line, batch_first=True, padding_value=0)
padded_oracle_text = pad_sequence(oracle_text, batch_first=True, padding_value=0)
return {'card_name': padded_card_name, 'type_line': padded_type_line, 'padded_oracle_text': padded_oracle_text}
loader = torch.utils.data.DataLoader(tokenized_dataset, collate_fn=collate_fn, batch_size=4)
for e in loader:
print(e)
break
# Will output:
# {'card_name': tensor([[ 101, 10694, 12369, 102, 0],
# [ 101, 3704, 9881, 102, 0],
# [ 101, 22639, 20066, 7347, 102],
# [ 101, 25697, 1997, 6019, 102]]),
# 'type_line': tensor([[ 101, 2061, 19170, 2854, 102, 0, 0],
# [ 101, 6492, 1517, 4743, 102, 0, 0],
# [ 101, 6492, 1517, 22639, 102, 0, 0],
# [ 101, 4372, 14856, 21181, 1517, 15240, 102]]),
# 'padded_oracle_text': [ommited for readability])}
``` | [
-0.34670814871788025,
-0.6647337675094604,
-0.05424299091100693,
0.10054021328687668,
-0.4169939458370209,
-0.17428071796894073,
-0.17768116295337677,
-0.061496980488300323,
0.5119644999504089,
0.40316563844680786,
-0.48671257495880127,
-0.7582889795303345,
-0.5657906532287598,
0.044626429... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
FinGPT/fingpt-fineval | FinGPT | 2023-10-10T06:45:52Z | 20 | 1 | null | [
"region:us"
] | 2023-10-10T06:45:52Z | 2023-10-10T06:44:46.000Z | 2023-10-10T06:44:46 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 441991
num_examples: 1056
- name: test
num_bytes: 117516
num_examples: 265
download_size: 269193
dataset_size: 559507
---
# Dataset Card for "fingpt-fineval"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.822784423828125,
-0.42347073554992676,
0.15057669579982758,
-0.04324311017990112,
-0.4975423216819763,
-0.2299826443195343,
0.23437808454036713,
-0.2189885526895523,
0.6326860189437866,
0.661747932434082,
-0.7075602412223816,
-0.6612849235534668,
-0.48588064312934875,
-0.326710224151611... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
open-llm-leaderboard/details_ehartford__dolphin-2.1-mistral-7b | open-llm-leaderboard | 2023-10-28T06:17:24Z | 20 | 0 | null | [
"region:us"
] | 2023-10-28T06:17:24Z | 2023-10-11T07:08:34.000Z | 2023-10-11T07:08:34 | ---
pretty_name: Evaluation run of ehartford/dolphin-2.1-mistral-7b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [ehartford/dolphin-2.1-mistral-7b](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 4 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_ehartford__dolphin-2.1-mistral-7b\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-10-28T06:17:12.096857](https://huggingface.co/datasets/open-llm-leaderboard/details_ehartford__dolphin-2.1-mistral-7b/blob/main/results_2023-10-28T06-17-12.096857.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.0025167785234899327,\n\
\ \"em_stderr\": 0.0005131152834514602,\n \"f1\": 0.07557885906040251,\n\
\ \"f1_stderr\": 0.0015806922251337756,\n \"acc\": 0.49258006202828786,\n\
\ \"acc_stderr\": 0.011432753263209281\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.0025167785234899327,\n \"em_stderr\": 0.0005131152834514602,\n\
\ \"f1\": 0.07557885906040251,\n \"f1_stderr\": 0.0015806922251337756\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.20773313115996966,\n \
\ \"acc_stderr\": 0.011174572716705898\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7774269928966061,\n \"acc_stderr\": 0.011690933809712662\n\
\ }\n}\n```"
repo_url: https://huggingface.co/ehartford/dolphin-2.1-mistral-7b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|arc:challenge|25_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|arc:challenge|25_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_10_26T09_35_25.636267
path:
- '**/details_harness|drop|3_2023-10-26T09-35-25.636267.parquet'
- split: 2023_10_28T06_17_12.096857
path:
- '**/details_harness|drop|3_2023-10-28T06-17-12.096857.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-10-28T06-17-12.096857.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_10_26T09_35_25.636267
path:
- '**/details_harness|gsm8k|5_2023-10-26T09-35-25.636267.parquet'
- split: 2023_10_28T06_17_12.096857
path:
- '**/details_harness|gsm8k|5_2023-10-28T06-17-12.096857.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-10-28T06-17-12.096857.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hellaswag|10_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hellaswag|10_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-08-11.393844.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-16-54.692993.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- '**/details_harness|truthfulqa:mc|0_2023-10-11T07-08-11.393844.parquet'
- split: 2023_10_11T07_16_54.692993
path:
- '**/details_harness|truthfulqa:mc|0_2023-10-11T07-16-54.692993.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-10-11T07-16-54.692993.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_10_26T09_35_25.636267
path:
- '**/details_harness|winogrande|5_2023-10-26T09-35-25.636267.parquet'
- split: 2023_10_28T06_17_12.096857
path:
- '**/details_harness|winogrande|5_2023-10-28T06-17-12.096857.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-10-28T06-17-12.096857.parquet'
- config_name: results
data_files:
- split: 2023_10_11T07_08_11.393844
path:
- results_2023-10-11T07-08-11.393844.parquet
- split: 2023_10_11T07_16_54.692993
path:
- results_2023-10-11T07-16-54.692993.parquet
- split: 2023_10_26T09_35_25.636267
path:
- results_2023-10-26T09-35-25.636267.parquet
- split: 2023_10_28T06_17_12.096857
path:
- results_2023-10-28T06-17-12.096857.parquet
- split: latest
path:
- results_2023-10-28T06-17-12.096857.parquet
---
# Dataset Card for Evaluation run of ehartford/dolphin-2.1-mistral-7b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/ehartford/dolphin-2.1-mistral-7b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [ehartford/dolphin-2.1-mistral-7b](https://huggingface.co/ehartford/dolphin-2.1-mistral-7b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 4 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_ehartford__dolphin-2.1-mistral-7b",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-28T06:17:12.096857](https://huggingface.co/datasets/open-llm-leaderboard/details_ehartford__dolphin-2.1-mistral-7b/blob/main/results_2023-10-28T06-17-12.096857.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.0025167785234899327,
"em_stderr": 0.0005131152834514602,
"f1": 0.07557885906040251,
"f1_stderr": 0.0015806922251337756,
"acc": 0.49258006202828786,
"acc_stderr": 0.011432753263209281
},
"harness|drop|3": {
"em": 0.0025167785234899327,
"em_stderr": 0.0005131152834514602,
"f1": 0.07557885906040251,
"f1_stderr": 0.0015806922251337756
},
"harness|gsm8k|5": {
"acc": 0.20773313115996966,
"acc_stderr": 0.011174572716705898
},
"harness|winogrande|5": {
"acc": 0.7774269928966061,
"acc_stderr": 0.011690933809712662
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.5079172849655151,
-0.6346262693405151,
0.22245045006275177,
0.1788043975830078,
-0.18474197387695312,
-0.009352338500320911,
-0.2691647708415985,
-0.27298787236213684,
0.40281301736831665,
0.5805180668830872,
-0.6915071606636047,
-0.8697234392166138,
-0.676139771938324,
0.26910209655761... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Otter-AI/POPE | Otter-AI | 2023-10-13T02:58:50Z | 20 | 1 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-13T02:58:50Z | 2023-10-13T02:52:41.000Z | 2023-10-13T02:52:41 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
chompk/tydiqa-goldp-th | chompk | 2023-11-18T14:12:59Z | 20 | 0 | null | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"language:th",
"region:us"
] | 2023-11-18T14:12:59Z | 2023-10-15T07:48:48.000Z | 2023-10-15T07:48:48 | ---
pretty_name: TyDiQA-GoldP-Th
language:
- th
task_categories:
- question-answering
task_ids:
- extractive-qa
configs:
- config_name: default
data_files:
- split: train
path: tydiqa.goldp.th.train.json
- split: dev
path: tydiqa.goldp.th.dev.json
---
# TyDiQA-GoldP-Th
This dataset contains a removed Thai TyDiQA dataset obtained from [Khalidalt's TyDiQA Dataset](https://huggingface.co/datasets/khalidalt/tydiqa-goldp).
This dataset version does the following additional preprocessing to the dataset
1. Convert byte-level index into character-level index
2. Fix any mismatch text between answer span and actual text
3. Re-split train/development set such that there's no leakage in context passage
4. Deduplicate questions from the same context passage
## Dataset Format
The dataset is formatted to make it compatible to [XTREME benchmark](https://github.com/google-research/xtreme) format. The data is formatted as the following pattern:
```json
{
"version": "TyDiQA-GoldP-1.1-for-SQuAD-1.1",
"data": [
{
"paragrahs": [{
"context": [PASSAGE CONTEXT HERE],
"qas": [{
"answers": [{
"answer_start": [CONTEXT START CHAR INDEX OF ANSWER],
"text": [TEXT SPAN FROM CONTEXT],
}],
"question": [QUESTION],
"id": [ID]
}]
}],
},
...
]
}
```
## Author
Chompakorn Chaksangchaichot | [
-0.354684442281723,
-0.43536534905433655,
0.1020859107375145,
0.23387891054153442,
-0.28622955083847046,
0.33554017543792725,
-0.02295348048210144,
-0.2288264036178589,
0.44294142723083496,
0.8405494093894958,
-0.9647616744041443,
-0.7329650521278381,
-0.31930312514305115,
0.27532404661178... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
UNCANNY69/Hindi_original | UNCANNY69 | 2023-10-23T14:02:35Z | 20 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-23T14:02:35Z | 2023-10-23T13:53:10.000Z | 2023-10-23T13:53:10 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
prnv19/MathGPT | prnv19 | 2023-10-25T09:41:35Z | 20 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-25T09:41:35Z | 2023-10-23T20:07:18.000Z | 2023-10-23T20:07:18 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tou7and/imdb-truncated-polluted | tou7and | 2023-10-24T02:52:54Z | 20 | 0 | null | [
"region:us"
] | 2023-10-24T02:52:54Z | 2023-10-24T02:35:27.000Z | 2023-10-24T02:35:27 | A polluted version of imdb-truncated.
Errors and distortions are added to trainset and testset, inlcuding input text and labels. | [
-0.5891774296760559,
-0.36369892954826355,
0.08630415797233582,
0.2733747363090515,
-0.531085193157196,
0.3889405131340027,
0.2624708414077759,
-0.47247087955474854,
0.5334597229957581,
0.9188566207885742,
-0.8231224417686462,
0.515864372253418,
-0.7689296007156372,
0.0970640629529953,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
simecek/wikipedie_20230601 | simecek | 2023-10-25T11:18:44Z | 20 | 0 | null | [
"region:us"
] | 2023-10-25T11:18:44Z | 2023-10-25T11:18:05.000Z | 2023-10-25T11:18:05 | ---
dataset_info:
features:
- name: id
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 1529727976
num_examples: 525205
download_size: 965130292
dataset_size: 1529727976
---
# Dataset Card for "wikipedie_20230601"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.8368112444877625,
-0.025516875088214874,
0.19955964386463165,
0.2957293689250946,
-0.03369560465216637,
-0.25663062930107117,
0.20040494203567505,
-0.15044835209846497,
1.0071673393249512,
0.38520577549934387,
-1.0205748081207275,
-0.5511504411697388,
-0.5419073104858398,
-0.10029087960... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Ka4on/ultrasound_train | Ka4on | 2023-10-25T20:08:16Z | 20 | 0 | null | [
"region:us"
] | 2023-10-25T20:08:16Z | 2023-10-25T19:58:22.000Z | 2023-10-25T19:58:22 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
twwch/summary | twwch | 2023-10-26T06:32:33Z | 20 | 4 | null | [
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:zh",
"license:apache-2.0",
"region:us"
] | 2023-10-26T06:32:33Z | 2023-10-26T05:11:36.000Z | 2023-10-26T05:11:36 | ---
license: apache-2.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: source
dtype: string
- name: target
dtype: string
splits:
- name: train
num_bytes: 31798343
num_examples: 10352
- name: test
num_bytes: 3617590
num_examples: 1151
download_size: 17798756
dataset_size: 35415933
task_categories:
- summarization
language:
- zh
size_categories:
- 10K<n<100K
---
微调google/mt5-base模型,做文章摘要
```python
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
model_path = "twwch/mt5-base-summary"
model = T5ForConditionalGeneration.from_pretrained(model_path)
tokenizer = T5Tokenizer.from_pretrained(model_path)
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.eval()
text = """
什么是Nginx
Nginx是一个开源的高性能HTTP和反向代理服务器。它可以用于处理静态资源、负载均衡、反向代理和缓存等任务。Nginx被广泛用于构建高可用性、高性能的Web应用程序和网站。它具有低内存消耗、高并发能力和良好的稳定性,因此在互联网领域非常受欢迎。
为什么使用Nginx
高性能:Nginx采用事件驱动的异步架构,能够处理大量并发连接而不会消耗过多的系统资源。它的处理能力比传统的Web服务器更高,在高并发负载下表现出色。
高可靠性:Nginx具有强大的容错能力和稳定性,能够在面对高流量和DDoS攻击等异常情况下保持可靠运行。它能通过健康检查和自动故障转移来保证服务的可用性。
负载均衡:Nginx可以作为反向代理服务器,实现负载均衡,将请求均匀分发给多个后端服务器。这样可以提高系统的整体性能和可用性。
静态文件服务:Nginx对静态资源(如HTML、CSS、JavaScript、图片等)的处理非常高效。它可以直接缓存静态文件,减轻后端服务器的负载。
扩展性:Nginx支持丰富的模块化扩展,可以通过添加第三方模块来提供额外的功能,如gzip压缩、SSL/TLS加密、缓存控制等。
如何处理请求
Nginx处理请求的基本流程如下:
接收请求:Nginx作为服务器软件监听指定的端口,接收客户端发来的请求。
解析请求:Nginx解析请求的内容,包括请求方法(GET、POST等)、URL、头部信息等。
配置匹配:Nginx根据配置文件中的规则和匹配条件,决定如何处理该请求。配置文件定义了虚拟主机、反向代理、负载均衡、缓存等特定的处理方式。
处理请求:Nginx根据配置的处理方式,可能会进行以下操作:
静态文件服务:如果请求的是静态资源文件,如HTML、CSS、JavaScript、图片等,Nginx可以直接返回文件内容,不必经过后端应用程序。
反向代理:如果配置了反向代理,Nginx将请求转发给后端的应用服务器,然后将其响应返回给客户端。这样可以提供负载均衡、高可用性和缓存等功能。
缓存:如果启用了缓存,Nginx可以缓存一些静态或动态内容的响应,在后续相同的请求中直接返回缓存的响应,减少后端负载并提高响应速度。
URL重写:Nginx可以根据配置的规则对URL进行重写,将请求从一个URL重定向到另一个URL或进行转换。
SSL/TLS加密:如果启用了SSL/TLS,Nginx可以负责加密和解密HTTPS请求和响应。
访问控制:Nginx可以根据配置的规则对请求进行访问控制,例如限制IP访问、进行身份认证等。
响应结果:Nginx根据处理结果生成响应报文,包括状态码、头部信息和响应内容。然后将响应发送给客户端。
"""
def _split_text(text, length):
chunks = []
start = 0
while start < len(text):
if len(text) - start > length:
pos_forward = start + length
pos_backward = start + length
pos = start + length
while (pos_forward < len(text)) and (pos_backward >= 0) and (pos_forward < 20 + pos) and (
pos_backward + 20 > pos) and text[pos_forward] not in {'.', '。', ',', ','} and text[
pos_backward] not in {'.', '。', ',', ','}:
pos_forward += 1
pos_backward -= 1
if pos_forward - pos >= 20 and pos_backward <= pos - 20:
pos = start + length
elif text[pos_backward] in {'.', '。', ',', ','}:
pos = pos_backward
else:
pos = pos_forward
chunks.append(text[start:pos + 1])
start = pos + 1
else:
chunks.append(text[start:])
break
# Combine last chunk with previous one if it's too short
if len(chunks) > 1 and len(chunks[-1]) < 100:
chunks[-2] += chunks[-1]
chunks.pop()
return chunks
def summary(text):
chunks = _split_text(text, 300)
chunks = [
"summarize: " + chunk
for chunk in chunks
]
input_ids = tokenizer(chunks, return_tensors="pt",
max_length=512,
padding=True,
truncation=True).input_ids.to(device)
outputs = model.generate(input_ids, max_length=250, num_beams=4, no_repeat_ngram_size=2)
tokens = outputs.tolist()
output_text = [
tokenizer.decode(tokens[i], skip_special_tokens=True)
for i in range(len(tokens))
]
for i in range(len(output_text)):
print(output_text[i])
summary(text)
```
输出:
```
段落内容Nginx是一个开源的高性能HTTP和反向代理服务器,可以用于处理静态资源、负载均衡、反反代理和缓存等任务。它被广泛用于构建高可用性、高性能的Web应用程序和网站,具有低内存消耗、高并发能力和良好的稳定性,因此在互联网领域非常受欢迎。高性能和高可靠性相比传统的Web服务器更高,在高并且发负担下表现出色。高稳定性和容错能力,能够在面对高流量和DDoS攻击等异常情况下保持可靠运行。
段落内容Nginx处理请求的基本流程,包括负载均衡、静态文件服务、扩展性、如何解决请求的流程和如何处理。其中包括接收请求和解析请求,以及对客户端发来的请求进行解析。
段落内容Nginx的配置匹配和处理请求。配置文件定义了虚拟主机、反向代理、负载均衡、缓存等特定的处理方式,并根据配置进行静态文件服务和反面信息处理的操作。通过调用静存来实现高可用性,并且可以提供高可性和缓储等功能。
段落内容主要涉及到缓存静态或动态内容的响应,包括URL重写、SSL/TLS加密、访问控制、响应结果生成和发送给客户端等功能。Nginx可以根据配置的规则对URL进行重写作,将请求从一个URL轻定向到另一个URL或进行转换。 综上所述,Nginx的缓解和响应速度可以快速提高。
``` | [
-0.7733463644981384,
-0.7436185479164124,
0.35587039589881897,
0.267749160528183,
-0.36352962255477905,
-0.03635963052511215,
-0.18774844706058502,
-0.35668259859085083,
0.36639609932899475,
0.1605837047100067,
-0.474418044090271,
-0.6880890727043152,
-0.697675347328186,
0.4264596402645111... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
joseluhf11/clinical_case_symptoms_diseases_dataset | joseluhf11 | 2023-10-26T09:25:22Z | 20 | 3 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-26T09:25:22Z | 2023-10-26T09:04:44.000Z | 2023-10-26T09:04:44 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ComponentSoft/k8s-kubectl-cot-20k | ComponentSoft | 2023-10-27T03:54:10Z | 20 | 2 | null | [
"region:us"
] | 2023-10-27T03:54:10Z | 2023-10-26T20:30:51.000Z | 2023-10-26T20:30:51 | ---
dataset_info:
features:
- name: objective
dtype: string
- name: command_name
dtype: string
- name: command
dtype: string
- name: description
dtype: string
- name: syntax
dtype: string
- name: flags
list:
- name: default
dtype: string
- name: description
dtype: string
- name: option
dtype: string
- name: short
dtype: string
- name: question
dtype: string
- name: chain_of_thought
dtype: string
splits:
- name: train
num_bytes: 51338358
num_examples: 19661
download_size: 0
dataset_size: 51338358
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "k8s-kubectl-cot-20k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7357192039489746,
-0.04548962786793709,
0.3727954030036926,
0.4298863112926483,
-0.44794127345085144,
0.4009736478328705,
0.17157916724681854,
-0.1735539436340332,
0.6390503644943237,
0.6538610458374023,
-0.6217313408851624,
-0.991480827331543,
-0.8090692162513733,
-0.17155736684799194,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
re2panda/click_bate_random_sample | re2panda | 2023-10-27T08:30:50Z | 20 | 0 | null | [
"region:us"
] | 2023-10-27T08:30:50Z | 2023-10-27T08:26:41.000Z | 2023-10-27T08:26:41 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
stsudharsan/veshti-controlnet | stsudharsan | 2023-10-29T13:58:14Z | 20 | 0 | null | [
"region:us"
] | 2023-10-29T13:58:14Z | 2023-10-29T13:58:09.000Z | 2023-10-29T13:58:09 | ---
dataset_info:
features:
- name: image
dtype: image
- name: conditioning_img
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 14599706.0
num_examples: 143
download_size: 13484309
dataset_size: 14599706.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "veshti-controlnet"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.43682238459587097,
-0.257341593503952,
0.013079113326966763,
0.16302211582660675,
-0.22559811174869537,
0.1619900017976761,
0.28646165132522583,
-0.06613750755786896,
1.0529841184616089,
0.6405066847801208,
-0.8592386841773987,
-0.6911579966545105,
-0.5008963346481323,
-0.25740519165992... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Robathan/generalimageset | Robathan | 2023-10-30T01:27:31Z | 20 | 0 | null | [
"task_categories:feature-extraction",
"size_categories:1K<n<10K",
"license:gpl-3.0",
"region:us"
] | 2023-10-30T01:27:31Z | 2023-10-29T23:21:45.000Z | 2023-10-29T23:21:45 | ---
license: gpl-3.0
task_categories:
- feature-extraction
size_categories:
- 1K<n<10K
---
# Dataset Card for MNR's General Imageset
In-flux. use at your own discrestion/frustration.
## Dataset Details
- random images. about 1,200 in total.
- **Curated by:** Rob James
| [
-0.51849764585495,
-0.058589402586221695,
0.20107905566692352,
0.0001416846498614177,
-0.4868127405643463,
-0.0984639972448349,
0.35231441259384155,
0.03767597675323486,
0.7090996503829956,
1.0117233991622925,
-0.99242103099823,
-0.5585645437240601,
-0.4045019745826721,
0.06062644347548485... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
flytech/python-codes-25k | flytech | 2023-10-30T18:34:12Z | 20 | 1 | null | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:token-classification",
"task_categories:summarization",
"task_categories:text2text-generation",
"task_categories:text-generation",
"size_categories:1M<n<10M",
"code",
"python",
"flytech",
"cleaned",
"... | 2023-10-30T18:34:12Z | 2023-10-30T17:03:27.000Z | 2023-10-30T17:03:27 | ---
task_categories:
- text-classification
- question-answering
- token-classification
- summarization
- text2text-generation
- text-generation
tags:
- code
- python
- flytech
- cleaned
- instructional
- dataset 25k
- text2code
- code2text
- behavioral
- codegeneration
size_categories:
- 1M<n<10M
---
### <span style="color:#307090">License</span>
<span style="color:darkorange">MIT</span>
<hr style="height:1px;border:none;color:#333;background-color:#444;" />
## <span style="color:darkcyan">This is a Cleaned Python Dataset Covering 25,000 Instructional Tasks</span>
### <span style="color:#307090">Overview</span>
The dataset has 4 key features (fields): <b><span style="color:#205070">instruction</span></b>, <b><span style="color:#205070">input</span></b>, <b><span style="color:#205070">output</span></b>, and <b><span style="color:#205070">text</span></b>.
<span style="color:darkcyan">It's a rich source for Python codes, tasks, and extends into behavioral aspects.</span>
<hr style="height:1px;border:none;color:#333;background-color:#444;" />
### <span style="color:#307090">Dataset Statistics</span>
- **Total Entries**: <span style="color:darkmagenta">24,813</span>
- **Unique Instructions**: <span style="color:darkmagenta">24,580</span>
- **Unique Inputs**: <span style="color:darkmagenta">3,666</span>
- **Unique Outputs**: <span style="color:darkmagenta">24,581</span>
- **Unique Texts**: <span style="color:darkmagenta">24,813</span>
- **Average Tokens per example**: <span style="color:darkmagenta">508</span>
### <span style="color:#307090">Features</span>
- `instruction`: The instructional task to be performed / User input.
- `input`: Very short, introductive part of AI response or empty.
- `output`: Python code that accomplishes the task.
- `text`: All fields combined together.
<hr style="height:1px;border:none;color:#333;background-color:#444;" />
### <span style="color:#307090">Usage</span>
<span style="color:darkcyan">This dataset can be useful for:</span>
- <span style="color:#607090">Code generation tasks</span>
- <span style="color:#607090">Natural Language Understanding models specialized in coding languages</span>
- <span style="color:#607090">Behavioral analysis based on the given tasks and codes</span>
- <span style="color:#607090">Educational purposes to understand coding styles and task variations</span>
<span style="color:darkcyan">To load the dataset, one can use the following snippet:</span>
```python
from datasets import load_dataset
dataset = load_dataset('flytech/python-codes-25k', split='train')
# One can map the dataset in any way, for the sake of example:
dataset = dataset.map(lambda example: {'text': example['instruction'] + ' ' + example['input'] + ' ' + example['output']})['text']
```
### <span style="color:#307090">Access & Contributions</span>
<span style="color:cyan">Feel free to use this dataset as per the MIT license. Contributions to enhance or expand the dataset are welcome.</span> | [
-0.2398286759853363,
-0.7578102946281433,
0.23010073602199554,
0.28058215975761414,
0.23551495373249054,
-0.1915663629770279,
-0.37620455026626587,
-0.2085217535495758,
0.08787686377763748,
0.19152823090553284,
-0.6258143186569214,
-0.5904703140258789,
-0.4898242950439453,
0.04997855052351... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kat33/test-fun-chunk32 | kat33 | 2023-10-31T02:09:03Z | 20 | 0 | null | [
"region:us"
] | 2023-10-31T02:09:03Z | 2023-10-31T00:51:19.000Z | 2023-10-31T00:51:19 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
voidful/hint-lm-data | voidful | 2023-11-04T09:20:26Z | 20 | 0 | null | [
"region:us"
] | 2023-11-04T09:20:26Z | 2023-10-31T10:18:01.000Z | 2023-10-31T10:18:01 | ---
dataset_info:
features:
- name: question
dtype: string
- name: options
sequence: string
- name: answer
dtype: string
- name: hint_chatgpt
dtype: string
splits:
- name: hotpotqa_train
num_bytes: 520829
num_examples: 5481
- name: hotpotqa_validation
num_bytes: 82639
num_examples: 458
- name: openbookqa_test
num_bytes: 121454
num_examples: 500
- name: openbookqa_train
num_bytes: 830308
num_examples: 4957
- name: openbookqa_validation
num_bytes: 91011
num_examples: 500
- name: strategyqa_full
num_bytes: 255888
num_examples: 2290
- name: strategyqa_test
num_bytes: 88443
num_examples: 500
- name: strategyqa_train
num_bytes: 167445
num_examples: 1790
- name: truthfulqa_full
num_bytes: 351912
num_examples: 817
- name: truthfulqa_test
num_bytes: 228633
num_examples: 500
- name: truthfulqa_train
num_bytes: 123279
num_examples: 317
download_size: 1612358
dataset_size: 2861841
configs:
- config_name: default
data_files:
- split: hotpotqa_train
path: data/hotpotqa_train-*
- split: hotpotqa_validation
path: data/hotpotqa_validation-*
- split: openbookqa_test
path: data/openbookqa_test-*
- split: openbookqa_train
path: data/openbookqa_train-*
- split: openbookqa_validation
path: data/openbookqa_validation-*
- split: strategyqa_full
path: data/strategyqa_full-*
- split: strategyqa_test
path: data/strategyqa_test-*
- split: strategyqa_train
path: data/strategyqa_train-*
- split: truthfulqa_full
path: data/truthfulqa_full-*
- split: truthfulqa_test
path: data/truthfulqa_test-*
- split: truthfulqa_train
path: data/truthfulqa_train-*
---
# Dataset Card for "hint-lm-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4994436502456665,
-0.37513476610183716,
0.5316339135169983,
0.032040856778621674,
-0.23683646321296692,
0.05094793438911438,
0.1626248061656952,
-0.20076406002044678,
0.8452593088150024,
0.31608936190605164,
-1.125072717666626,
-0.8892085552215576,
-0.5433865785598755,
-0.22850295901298... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sayan1101/identity_finetune_data | sayan1101 | 2023-10-31T16:46:15Z | 20 | 0 | null | [
"region:us"
] | 2023-10-31T16:46:15Z | 2023-10-31T12:27:39.000Z | 2023-10-31T12:27:39 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 384598
num_examples: 1181
- name: test
num_bytes: 68966
num_examples: 209
download_size: 219586
dataset_size: 453564
---
# Dataset Card for "identity_finetune_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5999132394790649,
-0.35926294326782227,
0.10961869359016418,
0.03508821129798889,
-0.21917103230953217,
-0.0854988843202591,
0.25331422686576843,
-0.16773352026939392,
0.7652039527893066,
0.40087106823921204,
-0.7699486017227173,
-0.7079441547393799,
-0.4752402603626251,
-0.222636029124... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
genesis-ai/dataset-titles-3m-tokenized | genesis-ai | 2023-10-31T13:56:28Z | 20 | 0 | null | [
"region:us"
] | 2023-10-31T13:56:28Z | 2023-10-31T13:54:16.000Z | 2023-10-31T13:54:16 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 292913845
num_examples: 3075830
download_size: 163284413
dataset_size: 292913845
---
# Dataset Card for "dataset-titles-3m-tokenized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.3210882246494293,
-0.17774152755737305,
0.20839516818523407,
0.25407323241233826,
-0.40143483877182007,
0.07978033274412155,
0.2700815796852112,
-0.11359202116727829,
0.783761203289032,
0.7219698429107666,
-0.538334310054779,
-0.9305921792984009,
-0.7648669481277466,
0.01061556022614240... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
re2panda/click_bate_1000 | re2panda | 2023-11-02T05:09:17Z | 20 | 0 | null | [
"region:us"
] | 2023-11-02T05:09:17Z | 2023-11-02T05:08:54.000Z | 2023-11-02T05:08:54 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tomashs/lsc_acrosplit_topic_vector_128 | tomashs | 2023-11-02T13:35:22Z | 20 | 0 | null | [
"region:us"
] | 2023-11-02T13:35:22Z | 2023-11-02T13:34:42.000Z | 2023-11-02T13:34:42 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: short_form
dtype: string
- name: long_form
dtype: string
- name: label
dtype: int64
- name: __index_level_0__
dtype: int64
- name: topic_vector
sequence: float64
splits:
- name: train
num_bytes: 511689272
num_examples: 381714
- name: val
num_bytes: 93727357
num_examples: 69424
- name: test
num_bytes: 69547621
num_examples: 52461
download_size: 209482012
dataset_size: 674964250
---
# Dataset Card for "lsc_acrosplit_topic_vector_128"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6787594556808472,
-0.07047214359045029,
0.1479896456003189,
0.07447993755340576,
-0.33760157227516174,
0.22528891265392303,
0.22695057094097137,
0.08341032266616821,
0.9308721423149109,
0.25547826290130615,
-0.9476823210716248,
-0.6780593991279602,
-0.5562226176261902,
-0.21372219920158... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Davlan/nollysenti | Davlan | 2023-11-07T15:04:30Z | 20 | 0 | null | [
"license:afl-3.0",
"region:us"
] | 2023-11-07T15:04:30Z | 2023-11-07T14:25:19.000Z | 2023-11-07T14:25:19 | ---
license: afl-3.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
fpochat/cartoonizer-dataset | fpochat | 2023-11-07T21:44:52Z | 20 | 0 | null | [
"region:us"
] | 2023-11-07T21:44:52Z | 2023-11-07T21:40:34.000Z | 2023-11-07T21:40:34 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mpachauri/DatasetTrimmed | mpachauri | 2023-11-09T08:26:57Z | 20 | 0 | null | [
"region:us"
] | 2023-11-09T08:26:57Z | 2023-11-08T16:11:26.000Z | 2023-11-08T16:11:26 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pphuc25/vlsp-validation-vectorized | pphuc25 | 2023-11-11T17:55:48Z | 20 | 0 | null | [
"region:us"
] | 2023-11-11T17:55:48Z | 2023-11-11T17:53:41.000Z | 2023-11-11T17:53:41 | ---
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: input_length
dtype: int64
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 7204326704
num_examples: 7500
download_size: 1163119637
dataset_size: 7204326704
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "vlsp-validation-vectorized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5044323205947876,
-0.01881418749690056,
0.1827959567308426,
0.31890979409217834,
-0.2745231091976166,
-0.035138849169015884,
0.3696476221084595,
-0.1377609819173813,
0.6028827428817749,
0.3980276882648468,
-0.7197111248970032,
-0.7703785300254822,
-0.6007667183876038,
-0.204403072595596... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MarcosDev06/dataset-unidad1-custom | MarcosDev06 | 2023-11-11T22:04:27Z | 20 | 0 | null | [
"region:us"
] | 2023-11-11T22:04:27Z | 2023-11-11T22:04:06.000Z | 2023-11-11T22:04:06 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
automated-research-group/boolq | automated-research-group | 2023-11-12T00:32:58Z | 20 | 0 | null | [
"region:us"
] | 2023-11-12T00:32:58Z | 2023-11-12T00:32:57.000Z | 2023-11-12T00:32:57 | ---
dataset_info:
features:
- name: id
dtype: string
- name: request
dtype: string
- name: response
dtype: string
splits:
- name: validation
num_bytes: 2490820
num_examples: 3270
download_size: 1390879
dataset_size: 2490820
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "boolq"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.47622185945510864,
-0.2355322241783142,
0.15368865430355072,
0.047759637236595154,
-0.14149484038352966,
0.16848306357860565,
0.537525475025177,
-0.25182440876960754,
0.6185147166252136,
0.6939971446990967,
-0.8234471082687378,
-0.7884282469749451,
-0.2763574719429016,
-0.28668823838233... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
linhtran92/bud500-validation-vectorized | linhtran92 | 2023-11-12T03:11:56Z | 20 | 0 | null | [
"region:us"
] | 2023-11-12T03:11:56Z | 2023-11-12T03:10:05.000Z | 2023-11-12T03:10:05 | ---
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: input_length
dtype: int64
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 7203781608
num_examples: 7500
download_size: 887242283
dataset_size: 7203781608
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bud500-validation-vectorized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5712899565696716,
-0.2962149977684021,
0.1371624916791916,
0.4513019025325775,
-0.19822648167610168,
0.10720875859260559,
0.3140389919281006,
-0.02468259632587433,
0.5177698135375977,
0.1386587768793106,
-0.6876436471939087,
-0.7992865443229675,
-0.33384567499160767,
-0.0085596218705177... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
linhtran92/bud500-train-vectorized | linhtran92 | 2023-11-12T04:10:07Z | 20 | 0 | null | [
"region:us"
] | 2023-11-12T04:10:07Z | 2023-11-12T03:22:42.000Z | 2023-11-12T03:22:42 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: input_length
dtype: int64
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 52146799652.25
num_examples: 634158
download_size: 51473857661
dataset_size: 52146799652.25
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "bud500-train-vectorized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6462523937225342,
-0.12368954718112946,
0.07769930362701416,
0.4882357716560364,
-0.1839618682861328,
0.037291817367076874,
0.22906868159770966,
-0.03373630344867706,
0.6610254049301147,
0.03458568453788757,
-0.7286746501922607,
-0.6188902854919434,
-0.4307125508785248,
-0.2148909866809... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
0x7194633/bashirov-messages | 0x7194633 | 2023-11-13T10:11:45Z | 20 | 0 | null | [
"region:us"
] | 2023-11-13T10:11:45Z | 2023-11-13T10:11:40.000Z | 2023-11-13T10:11:40 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 2588842
num_examples: 22650
download_size: 1015874
dataset_size: 2588842
---
# Dataset Card for "bashirov-messages"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.46025368571281433,
-0.24728929996490479,
0.25969916582107544,
0.18184347450733185,
-0.3246176242828369,
0.0990913137793541,
0.07448624074459076,
-0.16162985563278198,
1.037163257598877,
0.6479071974754333,
-1.13749098777771,
-0.8889046907424927,
-0.6489527821540833,
-0.4369232952594757,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mengmengmmm/csn_java | mengmengmmm | 2023-11-13T12:10:24Z | 20 | 0 | null | [
"region:us"
] | 2023-11-13T12:10:24Z | 2023-11-13T12:09:52.000Z | 2023-11-13T12:09:52 | Entry not found | [
-0.3227647542953491,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965083122253,
0.7915717959403992,
0.07618629932403564,
0.7746022343635559,
0.2563222348690033,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mengmengmmm/java2cs_trainuse | mengmengmmm | 2023-11-13T13:54:02Z | 20 | 0 | null | [
"region:us"
] | 2023-11-13T13:54:02Z | 2023-11-13T13:53:44.000Z | 2023-11-13T13:53:44 | Entry not found | [
-0.3227647542953491,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965083122253,
0.7915717959403992,
0.07618629932403564,
0.7746022343635559,
0.2563222348690033,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jlbaker361/subtraction_decimal | jlbaker361 | 2023-11-15T13:00:17Z | 20 | 0 | null | [
"region:us"
] | 2023-11-15T13:00:17Z | 2023-11-14T23:39:15.000Z | 2023-11-14T23:39:15 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: float64
- name: text
dtype: string
splits:
- name: train
num_bytes: 2146287.6
num_examples: 29376
- name: test
num_bytes: 238476.4
num_examples: 3264
download_size: 848814
dataset_size: 2384764.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "subtraction_decimal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6735387444496155,
-0.3892524540424347,
0.05097217485308647,
0.29329362511634827,
-0.3746827244758606,
-0.1051507294178009,
0.15206420421600342,
-0.2330746203660965,
0.8193191289901733,
0.21065089106559753,
-0.8456917405128479,
-0.7259874939918518,
-0.7489296197891235,
-0.184566229581832... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bassie96code/wettekst_test | bassie96code | 2023-11-23T09:31:47Z | 20 | 0 | null | [
"region:us"
] | 2023-11-23T09:31:47Z | 2023-11-15T13:52:20.000Z | 2023-11-15T13:52:20 | ---
dataset_info:
features:
- name: tok_wettekst
sequence: string
- name: aantal tokens
dtype: int64
- name: label lijsten
sequence: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 3714
num_examples: 10
download_size: 4191
dataset_size: 3714
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "wettekst_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6228261590003967,
-0.413651704788208,
0.12966634333133698,
0.258965402841568,
-0.4194895923137665,
-0.33730682730674744,
0.3121355175971985,
-0.19551661610603333,
0.724037766456604,
0.35601919889450073,
-0.7236904501914978,
-0.6810001730918884,
-0.4874357581138611,
-0.2638585567474365,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mdass/gpt_gen_desc_logos | mdass | 2023-11-16T02:10:20Z | 20 | 0 | null | [
"region:us"
] | 2023-11-16T02:10:20Z | 2023-11-15T18:49:18.000Z | 2023-11-15T18:49:18 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 2006069.0
num_examples: 100
download_size: 1991578
dataset_size: 2006069.0
---
# Dataset Card for "gpt_gen_desc_logos"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7064564824104309,
-0.20616309344768524,
0.24446837604045868,
0.03336329758167267,
-0.34700825810432434,
0.2434464991092682,
0.3136254847049713,
-0.2999078929424286,
0.7455284595489502,
0.2245560884475708,
-0.8212485909461975,
-0.83646160364151,
-0.8340764045715332,
-0.09714724868535995,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
iohadrubin/api_guru | iohadrubin | 2023-11-16T04:15:11Z | 20 | 1 | null | [
"region:us"
] | 2023-11-16T04:15:11Z | 2023-11-16T04:14:50.000Z | 2023-11-16T04:14:50 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 524461650
num_examples: 2065
download_size: 87622514
dataset_size: 524461650
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "api_guru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6331552863121033,
-0.33184802532196045,
0.01445834618061781,
0.2571762502193451,
-0.015051285736262798,
0.060046397149562836,
0.1857519894838333,
-0.08296730369329453,
0.7303028702735901,
0.3760527968406677,
-0.9750502705574036,
-0.8036829233169556,
-0.48017799854278564,
-0.031163135543... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Mohammed-Altaf/medical-instruction-100k | Mohammed-Altaf | 2023-11-16T15:46:30Z | 20 | 5 | null | [
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"medi",
"medical",
"region:us"
] | 2023-11-16T15:46:30Z | 2023-11-16T10:38:20.000Z | 2023-11-16T10:38:20 | ---
license: mit
language:
- en
tags:
- medi
- medical
pretty_name: python
size_categories:
- 10K<n<100K
---
# What is the Dataset About?🤷🏼♂️
---
The dataset is useful for training a Generative Language Model for the Medical application and instruction purposes, the dataset consists of various thoughs proposed by the people [**mentioned as the Human** ] and there responses including Medical Terminologies not limited to but including names of the drugs, prescriptions, yogic exercise suggessions, breathing exercise suggessions and few natural home made prescriptions.
# How the Dataset was made?😅
---
I have used all the available opensource datasets and combined them into a single datsource for training, which is completely opensourced and somewhat reliable.
* There is another refined and updated version of this datset here 👉🏼 [Link](https://huggingface.co/datasets/Mohammed-Altaf/medical-instruction-120k)
## Example Training Scripts:
* Qlora Fine Tuning -
## Tips:
This is my first dataset to upload on HuggingFace, so below are the thing I wish I could have known
* always save your final dataset before uploading to hub as a json with lines.
* The json should have the records orientation, which will be helpful while loading the dataset properly without any error.
```{python}
# use below if you are using pandas for data manipulation
train.to_json("dataset_name.json", orient='records', lines=True)
test.to_json("dataset_name.json", orient='records', lines=True)
``` | [
-0.30654945969581604,
-0.7079536318778992,
0.06075210124254227,
0.22440482676029205,
-0.207463800907135,
-0.33757510781288147,
-0.29258933663368225,
-0.19161424040794373,
0.3086138665676117,
0.6692590713500977,
-0.7743606567382812,
-0.7453129291534424,
-0.4488602578639984,
0.18605288863182... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
anumafzal94/arxiv-2shot-4096 | anumafzal94 | 2023-11-17T14:51:17Z | 20 | 0 | null | [
"region:us"
] | 2023-11-17T14:51:17Z | 2023-11-17T10:51:50.000Z | 2023-11-17T10:51:50 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
- name: summary
dtype: string
- name: few-shot
dtype: bool
splits:
- name: test
num_bytes: 3262821.167598633
num_examples: 97
- name: train
num_bytes: 73114333.94539191
num_examples: 2066
download_size: 5283534
dataset_size: 76377155.11299054
---
# Dataset Card for "arxiv-2shot-4096"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.31952518224716187,
0.05569136142730713,
0.2170344591140747,
0.1206493228673935,
-0.3426695466041565,
-0.05694150552153587,
0.4650031626224518,
-0.13695189356803894,
0.5720909237861633,
0.46425941586494446,
-0.5813423991203308,
-0.5650593042373657,
-0.7212665677070618,
-0.235175654292106... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Redwood0/pippa_custom | Redwood0 | 2023-11-18T11:36:11Z | 20 | 0 | null | [
"task_categories:conversational",
"language:en",
"license:apache-2.0",
"not-for-all-audiences",
"conversational",
"roleplay",
"custom-format",
"region:us"
] | 2023-11-18T11:36:11Z | 2023-11-17T17:24:28.000Z | 2023-11-17T17:24:28 | ---
license: apache-2.0
task_categories:
- conversational
language:
- en
tags:
- not-for-all-audiences
- conversational
- roleplay
- custom-format
viewer: true
--- | [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kings-crown/Aircraft_summary | kings-crown | 2023-11-18T02:12:27Z | 20 | 0 | null | [
"license:mit",
"region:us"
] | 2023-11-18T02:12:27Z | 2023-11-18T02:12:07.000Z | 2023-11-18T02:12:07 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/squad_qa_wrong_num_v5_full | tyzhu | 2023-11-21T09:53:12Z | 20 | 0 | null | [
"region:us"
] | 2023-11-21T09:53:12Z | 2023-11-21T09:21:09.000Z | 2023-11-21T09:21:09 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
- name: answer
dtype: string
- name: context_id
dtype: string
- name: correct_id
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
splits:
- name: train
num_bytes: 7301105
num_examples: 5070
- name: validation
num_bytes: 346484
num_examples: 300
download_size: 1464054
dataset_size: 7647589
---
# Dataset Card for "squad_qa_wrong_num_v5_full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4314761161804199,
-0.15326406061649323,
0.29708927869796753,
0.5461071133613586,
-0.26980888843536377,
0.23832665383815765,
0.5394061207771301,
-0.04593970254063606,
0.7074190974235535,
0.3967561721801758,
-1.1057287454605103,
-0.7868940830230713,
-0.49013084173202515,
0.128832206130027... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/squad_qa_baseline_v5_full | tyzhu | 2023-11-21T09:51:23Z | 20 | 0 | null | [
"region:us"
] | 2023-11-21T09:51:23Z | 2023-11-21T09:26:53.000Z | 2023-11-21T09:26:53 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
- name: answer
dtype: string
- name: context_id
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
splits:
- name: train
num_bytes: 2496440
num_examples: 2385
- name: validation
num_bytes: 335684
num_examples: 300
download_size: 0
dataset_size: 2832124
---
# Dataset Card for "squad_qa_baseline_v5_full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5600655674934387,
-0.06067674979567528,
0.33153507113456726,
0.3926968276500702,
-0.21470212936401367,
0.10967426002025604,
0.5269556641578674,
-0.11260932683944702,
0.683635413646698,
0.38274529576301575,
-1.1999398469924927,
-0.8762688040733337,
-0.29945576190948486,
-0.07058930397033... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Tribh/MiningRegs | Tribh | 2023-11-22T08:16:02Z | 20 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-11-22T08:16:02Z | 2023-11-22T07:47:50.000Z | 2023-11-22T07:47:50 | ---
license: apache-2.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Alamerton/platypus-instruction | Alamerton | 2023-11-22T11:00:31Z | 20 | 0 | null | [
"region:us"
] | 2023-11-22T11:00:31Z | 2023-11-22T10:59:40.000Z | 2023-11-22T10:59:40 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ddps007/test-dataset-v2 | ddps007 | 2023-11-23T13:06:55Z | 20 | 0 | null | [
"region:us"
] | 2023-11-23T13:06:55Z | 2023-11-23T13:06:42.000Z | 2023-11-23T13:06:42 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
oscarlaird/introductions | oscarlaird | 2023-11-25T23:28:37Z | 20 | 0 | null | [
"region:us"
] | 2023-11-25T23:28:37Z | 2023-11-24T20:32:09.000Z | 2023-11-24T20:32:09 | ---
dataset_info:
features:
- name: id
dtype: string
- name: dialogue
dtype: string
- name: summary
dtype: string
splits:
- name: train
num_bytes: 1686.0
num_examples: 10
- name: validation
num_bytes: 843.0
num_examples: 5
- name: test
num_bytes: 843.0
num_examples: 5
download_size: 9238
dataset_size: 3372.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Michaelkassouf/Ferrari_AI4A | Michaelkassouf | 2023-11-25T10:31:30Z | 20 | 0 | null | [
"region:us"
] | 2023-11-25T10:31:30Z | 2023-11-25T10:20:13.000Z | 2023-11-25T10:20:13 | ---
dataset_info:
features:
- name: image
dtype: string
- name: caption
dtype: string
splits:
- name: train
num_bytes: 3495120
num_examples: 35553
download_size: 1051219
dataset_size: 3495120
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
reza-alipour/Text-Edit-Instruct-Preprocessed-4m | reza-alipour | 2023-11-25T17:23:38Z | 20 | 0 | null | [
"region:us"
] | 2023-11-25T17:23:38Z | 2023-11-25T17:19:32.000Z | 2023-11-25T17:19:32 | ---
dataset_info:
features:
- name: output
dtype: string
- name: input
dtype: string
- name: type
dtype: string
- name: from
dtype: string
splits:
- name: train
num_bytes: 2144142688.6661234
num_examples: 4552775
- name: test
num_bytes: 3185356.05
num_examples: 6750
download_size: 1224892608
dataset_size: 2147328044.7161233
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
JoseArmando07/gun-dataset | JoseArmando07 | 2023-11-27T20:18:01Z | 20 | 0 | null | [
"region:us"
] | 2023-11-27T20:18:01Z | 2023-11-27T06:00:42.000Z | 2023-11-27T06:00:42 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: width
dtype: int64
- name: height
dtype: int64
- name: objects
struct:
- name: name
dtype: string
- name: bbox
sequence:
sequence: int64
- name: category
sequence: int64
- name: area
sequence: int64
- name: id
sequence: int64
- name: image_id
dtype: int64
splits:
- name: train
num_bytes: 2251055094.77
num_examples: 9990
- name: test
num_bytes: 158343390.801
num_examples: 1489
download_size: 2287347190
dataset_size: 2409398485.571
---
# Dataset Card for "gun-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5153196454048157,
-0.26155945658683777,
0.23591405153274536,
0.009005727246403694,
-0.32277345657348633,
0.15002824366092682,
0.3045133352279663,
-0.13195838034152985,
0.6357646584510803,
0.36464613676071167,
-0.6903350353240967,
-0.9503059983253479,
-0.878809928894043,
-0.4139021039009... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ScandEval/nordjylland-news-mini | ScandEval | 2023-11-27T14:21:45Z | 20 | 0 | null | [
"region:us"
] | 2023-11-27T14:21:45Z | 2023-11-27T14:21:37.000Z | 2023-11-27T14:21:37 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: target_text
dtype: string
- name: text_len
dtype: int64
- name: summary_len
dtype: int64
splits:
- name: train
num_bytes: 1588698
num_examples: 1024
- name: val
num_bytes: 392467
num_examples: 256
- name: test
num_bytes: 3268194
num_examples: 2048
download_size: 3271613
dataset_size: 5249359
---
# Dataset Card for "nordjylland-news-mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6808488368988037,
-0.24589411914348602,
0.3421441912651062,
0.11154675483703613,
-0.42848697304725647,
-0.1430172622203827,
0.07285906374454498,
-0.13496194779872894,
1.030444622039795,
0.352024108171463,
-0.998791515827179,
-0.8337162137031555,
-0.5599069595336914,
-0.28790852427482605... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
lvwerra/codeparrot-valid | lvwerra | 2021-08-10T14:18:44Z | 19 | 0 | null | [
"region:us"
] | 2021-08-10T14:18:44Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mideind/icelandic-common-crawl-corpus-IC3 | mideind | 2022-10-22T15:44:37Z | 19 | 0 | null | [
"task_categories:text-generation",
"task_ids:language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"language:is",
"license:unknown",
"region:us"
] | 2022-10-22T15:44:37Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- is
license:
- unknown
multilinguality:
- monolingual
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text-generation
task_ids:
- language-modeling
pretty_name: Icelandic Common Crawl Corpus - IC3
---
This is the Icelandic Common Crawl Corpus (IC3).
| [
-0.35650014877319336,
-0.2402421534061432,
0.5333884358406067,
0.30839890241622925,
-0.5060051679611206,
0.2422502189874649,
0.5426579713821411,
-0.45065197348594666,
0.5951486825942993,
0.473313570022583,
-0.44107577204704285,
-0.9340802431106567,
-0.5146096348762512,
0.4540574848651886,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nlpyeditepe/tr-qnli | nlpyeditepe | 2022-07-01T15:28:44Z | 19 | 0 | null | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:found",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:extended|glue",
"license:mit",
"region:us"
] | 2022-07-01T15:28:44Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | ---
annotations_creators:
- found
language_creators:
- machine-generated
language:
- tr-TR
license:
- mit
multilinguality:
- monolingual
pretty_name: QNLI for Turkish
size_categories:
- unknown
source_datasets:
- extended|glue
task_categories:
- text-classification
task_ids:
- natural-language-inference
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
projecte-aina/sts-ca | projecte-aina | 2023-11-25T05:27:49Z | 19 | 0 | null | [
"task_categories:text-classification",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"language:ca",
"license:cc-by-4.0",
"arxiv:2107.07903",
"region:us... | 2023-11-25T05:27:49Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- ca
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- unknown
source_datasets: []
task_categories:
- text-classification
task_ids:
- semantic-similarity-scoring
- text-scoring
pretty_name: sts-ca
---
# Dataset Card for STS-ca
## Dataset Description
- **Website:** https://zenodo.org/record/4761434
- **Paper:** [Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? A Comprehensive Assessment for Catalan](https://arxiv.org/abs/2107.07903)
- **Point of Contact:** [Carlos Rodríguez-Penagos](carlos.rodriguez1@bsc.es) and [Carme Armentano-Oller](carme.armentano@bsc.es)
### Dataset Summary
STS-ca corpus is a benchmark for evaluating Semantic Text Similarity in Catalan. This dataset was developed by [BSC TeMU](https://temu.bsc.es/) as part of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina/), to enrich the [Catalan Language Understanding Benchmark (CLUB)](https://club.aina.bsc.es/).
This work is licensed under a <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/">Attribution-ShareAlike 4.0 International License</a>.
### Supported Tasks and Leaderboards
This dataset can be used to build and score semantic similarity models in Catalan.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
### Data Instances
Follows [SemEval challenges](https://www.aclweb.org/anthology/S13-1004.pdf):
* index (int)
* id (str): Unique ID assigned to the sentence pair.
* sentence 1 (str): First sentence of the pair.
* sentence 2 (str): Second sentence of the pair.
* avg (float): Gold truth
#### Example
| index | id | sentence 1 | sentence 2 | avg |
| ------- | ---- | ------------ | ------------ | ----- |
| 19 | ACN2_131 | Els manifestants ocupen l'Imperial Tarraco durant una hora fent jocs de taula | Els manifestants ocupen l'Imperial Tarraco i fan jocs de taula | 4 |
| 21 | TE2_80 | El festival comptarà amb cinc escenaris i se celebrarà entre el 7 i el 9 de juliol al Parc del Fòrum. | El festival se celebrarà el 7 i 8 de juliol al Parc del Fòrum de Barcelona | 3 |
| 23 | Oscar2_609 | Aleshores hi posarem un got de vi i continuarem amb la cocció fins que s'hagi evaporat el vi i ho salpebrarem. | Mentre, hi posarem el vi al sofregit i deixarem coure uns 7/8′, fins que el vi s'evapori. | 3 |
| 25 | Viqui2_48 | L'arboç grec (Arbutus andrachne) és un arbust o un petit arbre dins la família ericàcia. | El ginjoler ("Ziziphus jujuba") és un arbust o arbre petit de la família de les "Rhamnaceae". | 2.75 |
| 27 | ACN2_1072 | Mentre han estat davant la comandància, els manifestants han cridat consignes a favor de la independència i han cantat cançons com 'L'estaca'. | Entre les consignes que han cridat s'ha pogut escoltar càntics com 'els carrers seran sempre nostres' i contínues consignes en favor de la independència. | 3 |
| 28 | Viqui2_587 | Els cinc municipis ocupen una superfície de poc més de 100 km2 i conjuntament sumen una població total aproximada de 3.691 habitants (any 2019). | Té una població d'1.811.177 habitants (2005) repartits en 104 municipis d'una superfície total de 14.001 km2. | 2.67 |
### Data Fields
This dataset follows [SemEval](https://www.aclweb.org/anthology/S13-1004.pdf) challenges formats and conventions.
### Data Splits
- sts_cat_dev_v1.tsv (500 annotated pairs)
- sts_cat_train_v1.tsv (2073 annotated pairs)
- sts_cat_test_v1.tsv (500 annotated pairs)
## Dataset Creation
### Curation Rationale
We created this dataset to contribute to the development of language models in Catalan, a low-resource language.
### Source Data
#### Initial Data Collection and Normalization
Random sentences were extracted from 3 Catalan subcorpus from the [Catalan Textual Corpus](https://zenodo.org/record/4519349#.Ys_0PexBzOs): [ACN](https://www.acn.cat/), [Oscar](https://oscar-corpus.com/) and [Wikipedia](https://ca.wikipedia.org/wiki/Portada).
We generated candidate pairs using a combination of metrics from Doc2Vec, Jaccard and a BERT-like model (“[distiluse-base-multilingual-cased-v2](https://huggingface.co/distilbert-base-multilingual-cased)”). Finally, we manually reviewed the generated pairs to reject non-relevant pairs (identical or ungrammatical sentences, etc.) before providing them to the annotation team.
The average of the four annotations was selected as a “ground truth” for each sentence pair, except when an annotator diverged in more than one unit from the average. In these cases, we discarded the divergent annotation and recalculated the average without it. We also discarded 45 sentence pairs because the annotators disagreed too much.
For compatibility with similar datasets in other languages, we followed as close as possible existing curation guidelines.
#### Who are the source language producers?
The [Catalan Textual Corpus](https://zenodo.org/record/4519349#.Ys_0PexBzOs) is a 1760-million-token web corpus of Catalan built from several sources: existing corpus such as DOGC, CaWac (non-deduplicated version), Oscar (unshuffled version), Open Subtitles, Catalan Wikipedia; and three brand new crawlings: the Catalan General Crawling, obtained by crawling the 500 most popular .cat and .ad domains; the Catalan Government Crawling, obtained by crawling the .gencat domain and subdomains, belonging to the Catalan Government; and the ACN corpus with 220k news items from March 2015 until October 2020, crawled from the Catalan News Agency.
### Annotations
#### Annotation process
We comissioned the manual annotation of the similarity between the sentences of each pair, following the provided guidelines.
#### Who are the annotators?
A team of native language speakers from 2 different companies, working independently.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this dataset contributes to the development of language models in Catalan, a low-resource language.
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/en/inici/index.html) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina/).
### Licensing Information
This work is licensed under a <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/">Attribution-ShareAlike 4.0 International License</a>.
### Citation Information
```
@inproceedings{armengol-estape-etal-2021-multilingual,
title = "Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? {A} Comprehensive Assessment for {C}atalan",
author = "Armengol-Estap{\'e}, Jordi and
Carrino, Casimiro Pio and
Rodriguez-Penagos, Carlos and
de Gibert Bonet, Ona and
Armentano-Oller, Carme and
Gonzalez-Agirre, Aitor and
Melero, Maite and
Villegas, Marta",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.437",
doi = "10.18653/v1/2021.findings-acl.437",
pages = "4933--4946",
}
```
[DOI](https://doi.org/10.5281/zenodo.4529183)
### Contributions
[N/A]
| [
-0.3431818187236786,
-0.4404107928276062,
0.2322387993335724,
0.36870455741882324,
-0.41545793414115906,
-0.00667929882183671,
-0.35360026359558105,
-0.44371625781059265,
0.5967162251472473,
0.4390221834182739,
-0.26565271615982056,
-0.8203728199005127,
-0.5387460589408875,
0.1679206043481... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
roskoN/dstc8-reddit-corpus | roskoN | 2021-04-23T00:19:35Z | 19 | 0 | null | [
"region:us"
] | 2021-04-23T00:19:35Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | # DSTC8 Reddit Corpus
The data is based of the following repository:
> [https://github.com/microsoft/dstc8-reddit-corpus](https://github.com/microsoft/dstc8-reddit-corpus)
The dataset is created is a convenience to enable skipping the lengthy extraction process. | [
-0.5279397964477539,
-0.48014846444129944,
0.5841111540794373,
0.1017737090587616,
-0.06430641561746597,
0.4506473243236542,
-0.05783717706799507,
-0.20726989209651947,
0.7316327691078186,
0.7352227568626404,
-0.7775155305862427,
-0.5723755359649658,
-0.5775400400161743,
0.4143428206443786... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
botisan-ai/cantonese-mandarin-translations | botisan-ai | 2022-11-23T06:41:46Z | 19 | 6 | null | [
"task_categories:text2text-generation",
"task_categories:translation",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:translation",
"size_categories:unknown",
"source_datasets:original",
"language:zh",
"license:mit",
"conditional-text-generation",
"region:u... | 2022-11-23T06:41:46Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | ---
annotations_creators:
- machine-generated
language_creators:
- found
language:
- zh
license:
- mit
multilinguality:
- translation
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text2text-generation
- translation
task_ids: []
pretty_name: Cantonese - Mandarin Translations
language_bcp47:
- zh-CN
- zh-HK
tags:
- conditional-text-generation
---
# Dataset Card for cantonese-mandarin-translations
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
MIT
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@lhr0909](https://github.com/lhr0909) for adding this dataset. | [
-0.2302183359861374,
-0.38824161887168884,
0.000967914005741477,
0.5213745832443237,
-0.31059131026268005,
0.06551703065633774,
-0.29487666487693787,
-0.3775830864906311,
0.572902500629425,
0.7020910382270813,
-0.7004649043083191,
-1.0209442377090454,
-0.6365176439285278,
0.239114090800285... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
v-card/lol | v-card | 2022-03-03T15:03:31Z | 19 | 0 | null | [
"region:us"
] | 2022-03-03T15:03:31Z | 2022-03-03T14:58:05.000Z | 2022-03-03T14:58:05 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
batterydata/paper-abstracts | batterydata | 2022-09-05T15:54:02Z | 19 | 1 | null | [
"task_categories:text-classification",
"language:en",
"license:apache-2.0",
"region:us"
] | 2022-09-05T15:54:02Z | 2022-03-05T13:55:17.000Z | 2022-03-05T13:55:17 | ---
language:
- en
license:
- apache-2.0
task_categories:
- text-classification
pretty_name: 'Battery Abstracts Dataset'
---
# Battery Abstracts Dataset
This dataset includes 29,472 battery papers and 17,191 non-battery papers, a total of 46,663 papers. These papers are manually labelled in terms of the journals to which they belong. 14 battery journals and 1,044 non battery journals were selected to form this database.
- training_data.csv: Battery papers: 20,629, Non-battery papers: 12,034. Total: 32,663.
- val_data.csv: Battery papers: 5,895, Non-battery papers: 3,438. Total: 9,333.
- test_data.csv: Battery papers: 2,948, Non-battery papers: 1,719. Total: 4,667.
# Usage
```
from datasets import load_dataset
dataset = load_dataset("batterydata/paper-abstracts")
```
# Citation
```
@article{huang2022batterybert,
title={BatteryBERT: A Pretrained Language Model for Battery Database Enhancement},
author={Huang, Shu and Cole, Jacqueline M},
journal={J. Chem. Inf. Model.},
year={2022},
doi={10.1021/acs.jcim.2c00035},
url={DOI:10.1021/acs.jcim.2c00035},
pages={DOI: 10.1021/acs.jcim.2c00035},
publisher={ACS Publications}
}
``` | [
-0.10053906589746475,
0.003340675961226225,
0.6285319924354553,
0.11285821348428726,
-0.1582486778497696,
0.20063646137714386,
-0.016122758388519287,
-0.22603654861450195,
0.2951993942260742,
0.3294193744659424,
-0.2998652756214142,
-0.7935941815376282,
-0.37526631355285645,
0.444806843996... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jglaser/protein_ligand_contacts | jglaser | 2022-03-15T21:17:32Z | 19 | 3 | null | [
"molecules",
"chemistry",
"SMILES",
"region:us"
] | 2022-03-15T21:17:32Z | 2022-03-12T07:09:53.000Z | 2022-03-12T07:09:53 | ---
tags:
- molecules
- chemistry
- SMILES
---
## How to use the data sets
This dataset contains more than 16,000 unique pairs of protein sequences and ligand SMILES with experimentally determined
binding affinities and protein-ligand contacts (ligand atom/SMILES token vs. Calpha within 5 Angstrom). These
are represented by a list that contains the positions of non-zero elements of the flattened, sparse
sequence x smiles tokens (2048x512) matrix. The first and last entries in both dimensions
are padded to zero, they correspond to [CLS] and [SEP].
It can be used for fine-tuning a language model.
The data solely uses data from PDBind-cn.
Contacts are calculated at four cut-off distances: 5, 8, 11A and 15A.
### Use the already preprocessed data
Load a test/train split using
```
from datasets import load_dataset
train = load_dataset("jglaser/protein_ligand_contacts",split='train[:90%]')
validation = load_dataset("jglaser/protein_ligand_contacts",split='train[90%:]')
```
### Pre-process yourself
To manually perform the preprocessing, download the data sets from P.DBBind-cn
Register for an account at <https://www.pdbbind.org.cn/>, confirm the validation
email, then login and download
- the Index files (1)
- the general protein-ligand complexes (2)
- the refined protein-ligand complexes (3)
Extract those files in `pdbbind/data`
Run the script `pdbbind.py` in a compute job on an MPI-enabled cluster
(e.g., `mpirun -n 64 pdbbind.py`).
Perform the steps in the notebook `pdbbind.ipynb`
| [
-0.5378766655921936,
-0.45692354440689087,
0.3306330442428589,
0.16362503170967102,
-0.08594412356615067,
-0.03465012088418007,
-0.019808802753686905,
-0.10453306138515472,
0.3266991376876831,
0.45876407623291016,
-0.696317195892334,
-0.5735687017440796,
-0.19452866911888123,
0.47543418407... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hazal/electronic-radiology-phd-thesis-trR | hazal | 2022-08-10T11:13:34Z | 19 | 2 | null | [
"language:tr",
"region:us"
] | 2022-08-10T11:13:34Z | 2022-03-21T07:59:10.000Z | 2022-03-21T07:59:10 | ---
language:
- tr
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
UrukHan/t5-russian-spell_II | UrukHan | 2022-03-27T12:57:40Z | 19 | 0 | null | [
"region:us"
] | 2022-03-27T12:57:40Z | 2022-03-27T12:56:21.000Z | 2022-03-27T12:56:21 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
h4iku/coconut_javascript2010 | h4iku | 2023-09-28T23:20:59Z | 19 | 0 | null | [
"code",
"region:us"
] | 2023-09-28T23:20:59Z | 2022-03-29T23:49:36.000Z | 2022-03-29T23:49:36 | ---
tags:
- code
pretty_name: CoCoNuT-JavaScript(2010)
---
# Dataset Card for CoCoNuT-JavaScript(2010)
## Dataset Description
- **Homepage:** [CoCoNuT training data](https://github.com/lin-tan/CoCoNut-Artifact/releases/tag/training_data_1.0.0)
- **Repository:** [CoCoNuT repository](https://github.com/lin-tan/CoCoNut-Artifact)
- **Paper:** [CoCoNuT: Combining Context-Aware Neural Translation Models using Ensemble for Program Repair](https://dl.acm.org/doi/abs/10.1145/3395363.3397369)
### Dataset Summary
Part of the data used to train the models in the "CoCoNuT: Combining Context-Aware Neural Translation Models using Ensemble for Program Repair" paper.
These datasets contain raw data extracted from GitHub, GitLab, and Bitbucket, and have neither been shuffled nor tokenized.
The year in the dataset’s name is the cutting year that shows the year of the newest commit in the dataset.
### Languages
- JavaScript
## Dataset Structure
### Data Fields
The dataset consists of 4 columns: `add`, `rem`, `context`, and `meta`.
These match the original dataset files: `add.txt`, `rem.txt`, `context.txt`, and `meta.txt`.
### Data Instances
There is a mapping between the 4 columns for each instance.
For example:
5 first rows of `rem` (i.e., the buggy line/hunk):
```
1 public synchronized StringBuffer append(char ch)
2 ensureCapacity_unsynchronized(count + 1); value[count++] = ch; return this;
3 public String substring(int beginIndex, int endIndex)
4 if (beginIndex < 0 || endIndex > count || beginIndex > endIndex) throw new StringIndexOutOfBoundsException(); if (beginIndex == 0 && endIndex == count) return this; int len = endIndex - beginIndex; return new String(value, beginIndex + offset, len, (len << 2) >= value.length);
5 public Object next() {
```
5 first rows of add (i.e., the fixed line/hunk):
```
1 public StringBuffer append(Object obj)
2 return append(obj == null ? "null" : obj.toString());
3 public String substring(int begin)
4 return substring(begin, count);
5 public FSEntry next() {
```
These map to the 5 instances:
```diff
- public synchronized StringBuffer append(char ch)
+ public StringBuffer append(Object obj)
```
```diff
- ensureCapacity_unsynchronized(count + 1); value[count++] = ch; return this;
+ return append(obj == null ? "null" : obj.toString());
```
```diff
- public String substring(int beginIndex, int endIndex)
+ public String substring(int begin)
```
```diff
- if (beginIndex < 0 || endIndex > count || beginIndex > endIndex) throw new StringIndexOutOfBoundsException(); if (beginIndex == 0 && endIndex == count) return this; int len = endIndex - beginIndex; return new String(value, beginIndex + offset, len, (len << 2) >= value.length);
+ return substring(begin, count);
```
```diff
- public Object next() {
+ public FSEntry next() {
```
`context` contains the associated "context". Context is the (in-lined) buggy function (including the buggy lines and comments).
For example, the context of
```
public synchronized StringBuffer append(char ch)
```
is its associated function:
```java
public synchronized StringBuffer append(char ch) { ensureCapacity_unsynchronized(count + 1); value[count++] = ch; return this; }
```
`meta` contains some metadata about the project:
```
1056 /local/tlutelli/issta_data/temp/all_java0context/java/2006_temp/2006/1056/68a6301301378680519f2b146daec37812a1bc22/StringBuffer.java/buggy/core/src/classpath/java/java/lang/StringBuffer.java
```
`1056` is the project id. `/local/...` is the absolute path to the buggy file. This can be parsed to extract the commit id: `68a6301301378680519f2b146daec37812a1bc22`, the file name: `StringBuffer.java` and the original path within the project
`core/src/classpath/java/java/lang/StringBuffer.java`
| Number of projects | Number of Instances |
| ------------------ |-------------------- |
| 10,163 | 2,254,253 |
## Dataset Creation
### Curation Rationale
Data is collected to train automated program repair (APR) models.
### Citation Information
```bib
@inproceedings{lutellierCoCoNuTCombiningContextaware2020,
title = {{{CoCoNuT}}: Combining Context-Aware Neural Translation Models Using Ensemble for Program Repair},
shorttitle = {{{CoCoNuT}}},
booktitle = {Proceedings of the 29th {{ACM SIGSOFT International Symposium}} on {{Software Testing}} and {{Analysis}}},
author = {Lutellier, Thibaud and Pham, Hung Viet and Pang, Lawrence and Li, Yitong and Wei, Moshi and Tan, Lin},
year = {2020},
month = jul,
series = {{{ISSTA}} 2020},
pages = {101--114},
publisher = {{Association for Computing Machinery}},
address = {{New York, NY, USA}},
doi = {10.1145/3395363.3397369},
url = {https://doi.org/10.1145/3395363.3397369},
urldate = {2022-12-06},
isbn = {978-1-4503-8008-9},
keywords = {AI and Software Engineering,Automated program repair,Deep Learning,Neural Machine Translation}
}
```
| [
-0.35194191336631775,
-0.6956561207771301,
0.1975158452987671,
0.1384907364845276,
-0.343278706073761,
0.2444748729467392,
-0.30140483379364014,
-0.5040991306304932,
0.2648511230945587,
0.3097505569458008,
-0.4707654118537903,
-0.6148504018783569,
-0.4703633487224579,
0.21041996777057648,
... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.