
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
tkcho/cp-commerce-clf-kr-sku-brand-3f5a1ee9c9d763d3e7b36e3266258416 | tkcho | 2023-11-30T00:31:12Z | 313 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:31:12Z | 2023-11-16T21:48:39.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-3f5a1ee9c9d763d3e7b36e3266258416 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-d7e4667561a9ade475ebfb882c1c943e | tkcho | 2023-11-29T12:25:07Z | 312 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T12:25:07Z | 2023-11-16T19:42:32.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-d7e4667561a9ade475ebfb882c1c943e | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-875fb2ca1bfc907c570de744105281af | tkcho | 2023-11-29T12:28:39Z | 311 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T12:28:39Z | 2023-11-24T08:14:07.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-875fb2ca1bfc907c570de744105281af | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-b70c2f218d76c053d3f336c9886c47e2 | tkcho | 2023-11-30T00:32:06Z | 310 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:32:06Z | 2023-11-16T21:51:24.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-b70c2f218d76c053d3f336c9886c47e2 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-106a4c1c7a82b01e8026e5e5e4934674 | tkcho | 2023-11-29T23:14:08Z | 309 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:14:08Z | 2023-11-15T16:43:45.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-106a4c1c7a82b01e8026e5e5e4934674 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-7644e4822f628a973c5c3a5b80d51f75 | tkcho | 2023-11-29T23:27:33Z | 308 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:27:33Z | 2023-11-15T16:59:34.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-7644e4822f628a973c5c3a5b80d51f75 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-230d590dee60445d963c207de610c952 | tkcho | 2023-11-30T01:03:40Z | 307 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T01:03:40Z | 2023-11-16T22:06:15.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-230d590dee60445d963c207de610c952 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-6b88fe69bcf878234d0ce4dd5706a561 | tkcho | 2023-11-30T00:15:07Z | 306 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:15:07Z | 2023-11-15T18:46:38.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-6b88fe69bcf878234d0ce4dd5706a561 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-1a3f01aeae12257ab6c8b0462b4e39a1 | tkcho | 2023-11-29T23:38:07Z | 306 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:38:07Z | 2023-11-16T20:30:28.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-1a3f01aeae12257ab6c8b0462b4e39a1 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-c521d4c33f5653c9ebd09586ebca2ce2 | tkcho | 2023-11-30T01:25:01Z | 306 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T01:25:01Z | 2023-11-21T01:18:20.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-c521d4c33f5653c9ebd09586ebca2ce2 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-2d06bb6d6fa1df6c5b3d7a45179d4432 | tkcho | 2023-11-29T23:34:22Z | 305 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:34:22Z | 2023-11-16T20:20:49.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-2d06bb6d6fa1df6c5b3d7a45179d4432 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-1244b4f0838ad9550fe726fff3d6af53 | tkcho | 2023-11-30T00:17:16Z | 304 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:17:16Z | 2023-11-15T18:49:58.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-1244b4f0838ad9550fe726fff3d6af53 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-7917930e7e19d61b395ec2f0ea48d1f4 | tkcho | 2023-11-30T01:02:48Z | 304 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T01:02:48Z | 2023-11-16T22:03:53.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-7917930e7e19d61b395ec2f0ea48d1f4 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-7990dfdb5db0d9b4b59188ec95a3fc8f | tkcho | 2023-11-30T01:25:57Z | 304 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T01:25:57Z | 2023-11-16T22:18:35.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-7990dfdb5db0d9b4b59188ec95a3fc8f | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-5c9436c7512e8a79bc8e52e968cdb778 | tkcho | 2023-11-29T23:22:05Z | 303 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:22:05Z | 2023-11-15T16:53:41.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-5c9436c7512e8a79bc8e52e968cdb778 | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-1a0d924e87f119d2aae4bf24de38358b | tkcho | 2023-11-30T00:18:37Z | 303 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:18:37Z | 2023-11-15T18:53:55.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-1a0d924e87f119d2aae4bf24de38358b | [
-0.3227648437023163,
-0.22568459808826447,
0.8622260093688965,
0.434614896774292,
-0.5282989144325256,
0.7012966275215149,
0.7915716171264648,
0.07618634402751923,
0.7746022343635559,
0.25632208585739136,
-0.7852813005447388,
-0.22573812305927277,
-0.9104481935501099,
0.5715669393539429,
... |
tkcho/cp-commerce-clf-kr-sku-brand-0d8a4d5b4b2246c559bd5d1de86d220e | tkcho | 2023-11-30T00:54:04Z | 303 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:54:04Z | 2023-11-15T19:43:29.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-0d8a4d5b4b2246c559bd5d1de86d220e | [
-0.32276472449302673,
-0.22568491101264954,
0.862226128578186,
0.43461504578590393,
-0.5282993912696838,
0.7012975811958313,
0.7915716171264648,
0.07618598639965057,
0.774603009223938,
0.2563214898109436,
-0.7852815389633179,
-0.22573868930339813,
-0.9104477763175964,
0.5715674161911011,
... |
ericzzz/falcon-rw-1b-instruct-openorca | ericzzz | 2023-11-30T00:05:52Z | 303 | 1 | null | [
"transformers",
"safetensors",
"falcon",
"text-generation",
"text-generation-inference",
"en",
"dataset:Open-Orca/SlimOrca",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | 2023-11-30T00:05:52Z | 2023-11-24T20:50:32.000Z | null | null | ---
license: apache-2.0
datasets:
- Open-Orca/SlimOrca
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- text-generation-inference
---
# 🌟 Falcon-RW-1B-Instruct-OpenOrca
Falcon-RW-1B-Instruct-OpenOrca is a 1B parameter, causal decoder-only model based on [Falcon-RW-1B](https://huggingface.co/tiiuae/falcon-rw-1b) and finetuned on the [Open-Orca/SlimOrca](https://huggingface.co/datasets/Open-Orca/SlimOrca) dataset.
**📊 Evaluation Results**
Falcon-RW-1B-Instruct-OpenOrca is the #1 ranking model on [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) in ~1.5B parameters category!
| Metric | falcon-rw-1b-instruct-openorca | falcon-rw-1b |
|------------|-------------------------------:|-------------:|
| ARC | 34.56 | 35.07 |
| HellaSwag | 60.93 | 63.56 |
| MMLU | 28.77 | 25.28 |
| TruthfulQA | 37.42 | 35.96 |
| Winogrande | 60.69 | 62.04 |
| GSM8K | 1.21 | 0.53 |
| DROP | 21.94 | 4.64 |
| **Average**| **35.08** | **32.44** |
**🚀 Motivations**
1. To create a smaller, open-source, instruction-finetuned, ready-to-use model accessible for users with limited computational resources (lower-end consumer GPUs).
2. To harness the strength of Falcon-RW-1B, a competitive model in its own right, and enhance its capabilities with instruction finetuning.
## 📖 How to Use
The model operates with a structured prompt format, incorporating `<SYS>`, `<INST>`, and `<RESP>` tags to demarcate different parts of the input. The system message and instruction are placed within these tags, with the `<RESP>` tag triggering the model's response.
### 📝 Example Code
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = 'ericzzz/falcon-rw-1b-instruct-openorca'
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
'text-generation',
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map='auto',
)
system_message = 'You are a helpful assistant. Give short answers.'
instruction = 'What is AI? Give some examples.'
prompt = f'<SYS> {system_message} <INST> {instruction} <RESP> '
response = pipeline(
prompt,
max_length=200,
repetition_penalty=1.05
)
print(response[0]['generated_text'])
# AI, or Artificial Intelligence, refers to the ability of machines and software to perform tasks that require human intelligence, such as learning, reasoning, and problem-solving. It can be used in various fields like computer science, engineering, medicine, and more. Some common applications include image recognition, speech translation, and natural language processing.
```
## 📬 Contact
For further inquiries or feedback, please contact at eric.fu96@aol.com. | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | ericzzz/falcon-rw-1b-instruct-openorca | [
-0.6184973120689392,
-1.0898200273513794,
0.08285750448703766,
0.1354084014892578,
-0.01636166125535965,
-0.35557785630226135,
-0.05634687468409538,
-0.32979246973991394,
0.1960592120885849,
0.33879637718200684,
-0.7221761345863342,
-0.6598144769668579,
-0.7148236632347107,
-0.050753530114... |
tkcho/cp-commerce-clf-kr-sku-brand-dd0f03f257a2be32cccf66de379fb9de | tkcho | 2023-11-29T23:36:38Z | 301 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:36:38Z | 2023-11-16T20:32:01.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-dd0f03f257a2be32cccf66de379fb9de | [
-0.32276472449302673,
-0.22568491101264954,
0.862226128578186,
0.43461504578590393,
-0.5282993912696838,
0.7012975811958313,
0.7915716171264648,
0.07618598639965057,
0.774603009223938,
0.2563214898109436,
-0.7852815389633179,
-0.22573868930339813,
-0.9104477763175964,
0.5715674161911011,
... |
tkcho/cp-commerce-clf-kr-sku-brand-320762d280dc8278484a715f42fe8411 | tkcho | 2023-11-29T23:20:01Z | 301 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:20:01Z | 2023-11-24T08:43:33.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-320762d280dc8278484a715f42fe8411 | [
-0.32276472449302673,
-0.22568491101264954,
0.862226128578186,
0.43461504578590393,
-0.5282993912696838,
0.7012975811958313,
0.7915716171264648,
0.07618598639965057,
0.774603009223938,
0.2563214898109436,
-0.7852815389633179,
-0.22573868930339813,
-0.9104477763175964,
0.5715674161911011,
... |
tkcho/cp-commerce-clf-kr-sku-brand-a9f8ceb7576453ebf0c9519f38732d22 | tkcho | 2023-11-29T23:59:38Z | 301 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:59:38Z | 2023-11-24T09:41:10.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-a9f8ceb7576453ebf0c9519f38732d22 | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
tkcho/cp-commerce-clf-kr-sku-brand-9edbc1a5482a3ca7833fa52fc30ebc9a | tkcho | 2023-11-30T00:01:25Z | 298 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-30T00:01:25Z | 2023-11-15T18:29:51.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-9edbc1a5482a3ca7833fa52fc30ebc9a | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
tkcho/cp-commerce-clf-kr-sku-brand-a5985deb7a9097ce790af4e049153471 | tkcho | 2023-11-29T23:35:22Z | 297 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:35:22Z | 2023-11-16T20:18:30.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/cp-commerce-clf-kr-sku-brand-a5985deb7a9097ce790af4e049153471 | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
ongkn/attraction-classifier | ongkn | 2023-11-29T18:38:10Z | 281 | 1 | null | [
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"doi:10.57967/hf/1403",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:u... | 2023-11-29T18:38:10Z | 2023-08-08T18:05:47.000Z | null | null | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: attraction-classifier
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7802690582959642
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# attraction-classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5258
- Accuracy: 0.7803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 69
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.15
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5871 | 0.99 | 39 | 0.5673 | 0.7175 |
| 0.5317 | 2.0 | 79 | 0.5042 | 0.7668 |
| 0.4495 | 2.99 | 118 | 0.5375 | 0.7489 |
| 0.4001 | 4.0 | 158 | 0.4844 | 0.7534 |
| 0.3651 | 4.99 | 197 | 0.5235 | 0.7556 |
| 0.3038 | 6.0 | 237 | 0.5058 | 0.7578 |
| 0.2718 | 6.99 | 276 | 0.5098 | 0.7825 |
| 0.265 | 8.0 | 316 | 0.5015 | 0.8004 |
| 0.2389 | 8.99 | 355 | 0.5005 | 0.7982 |
| 0.2552 | 9.87 | 390 | 0.5258 | 0.7803 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.0.1+cu117
- Datasets 2.15.0
- Tokenizers 0.15.0
| null | transformers | image-classification | null | null | null | null | null | null | null | null | null | ongkn/attraction-classifier | [
-0.5630995035171509,
-0.4262949824333191,
0.1337791085243225,
-0.07926773279905319,
-0.3563063442707062,
-0.5081233382225037,
-0.02188386768102646,
-0.29442277550697327,
0.2101137340068817,
0.20730207860469818,
-0.6613650918006897,
-0.7329069972038269,
-0.8231623768806458,
-0.1667721718549... |
NurtureAI/Orca-2-7B-16k | NurtureAI | 2023-11-29T22:48:50Z | 275 | 2 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"orca",
"orca2",
"microsoft",
"arxiv:2311.11045",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T22:48:50Z | 2023-11-22T02:33:01.000Z | null | null | ---
pipeline_tag: text-generation
tags:
- orca
- orca2
- microsoft
license: other
license_name: microsoft-research-license
license_link: LICENSE
---
# Orca 2 extended to 16k context.
Updated prompt:
```
<|im_start|>system\n{system}\n<|im_start|>user\n{instruction}<|im_end|>\n<|im_start|>assistant\n
```
# Original Model Card
# Orca 2
<!-- Provide a quick summary of what the model is/does. -->
Orca 2 is a helpful assistant that is built for research purposes only and provides a single turn response
in tasks such as reasoning over user given data, reading comprehension, math problem solving and text summarization.
The model is designed to excel particularly in reasoning.
We publicly release Orca 2 to encourage further research on the development, evaluation, and alignment of smaller LMs.
## What is Orca 2’s intended use(s)?
+ Orca 2 is built for research purposes only.
+ The main purpose is to allow the research community to assess its abilities and to provide a foundation for building better frontier models.
## How was Orca 2 evaluated?
+ Orca 2 has been evaluated on a large number of tasks ranging from reasoning to grounding and safety. Please refer
to Section 6 and Appendix in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf) for details on evaluations.
## Model Details
Orca 2 is a finetuned version of LLAMA-2. Orca 2’s training data is a synthetic dataset that was created to enhance the small model’s reasoning abilities.
All synthetic training data was moderated using the Microsoft Azure content filters. More details about the model can be found in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf).
Please refer to LLaMA-2 technical report for details on the model architecture.
## License
Orca 2 is licensed under the [Microsoft Research License](LICENSE).
Llama 2 is licensed under the [LLAMA 2 Community License](https://ai.meta.com/llama/license/), Copyright © Meta Platforms, Inc. All Rights Reserved.
## Bias, Risks, and Limitations
Orca 2, built upon the LLaMA 2 model family, retains many of its limitations, as well as the
common limitations of other large language models or limitation caused by its training
process, including:
**Data Biases**: Large language models, trained on extensive data, can inadvertently carry
biases present in the source data. Consequently, the models may generate outputs that could
be potentially biased or unfair.
**Lack of Contextual Understanding**: Despite their impressive capabilities in language understanding and generation, these models exhibit limited real-world understanding, resulting
in potential inaccuracies or nonsensical responses.
**Lack of Transparency**: Due to the complexity and size, large language models can act
as “black boxes”, making it difficult to comprehend the rationale behind specific outputs or
decisions. We recommend reviewing transparency notes from Azure for more information.
**Content Harms**: There are various types of content harms that large language models
can cause. It is important to be aware of them when using these models, and to take
actions to prevent them. It is recommended to leverage various content moderation services
provided by different companies and institutions. On an important note, we hope for better
regulations and standards from government and technology leaders around content harms
for AI technologies in future. We value and acknowledge the important role that research
and open source community can play in this direction.
**Hallucination**: It is important to be aware and cautious not to entirely rely on a given
language model for critical decisions or information that might have deep impact as it is
not obvious how to prevent these models from fabricating content. Moreover, it is not clear
whether small models may be more susceptible to hallucination in ungrounded generation
use cases due to their smaller sizes and hence reduced memorization capacities. This is an
active research topic and we hope there will be more rigorous measurement, understanding
and mitigations around this topic.
**Potential for Misuse**: Without suitable safeguards, there is a risk that these models could
be maliciously used for generating disinformation or harmful content.
**Data Distribution**: Orca 2’s performance is likely to correlate strongly with the distribution
of the tuning data. This correlation might limit its accuracy in areas underrepresented in
the training dataset such as math, coding, and reasoning.
**System messages**: Orca 2 demonstrates variance in performance depending on the system
instructions. Additionally, the stochasticity introduced by the model size may lead to
generation of non-deterministic responses to different system instructions.
**Zero-Shot Settings**: Orca 2 was trained on data that mostly simulate zero-shot settings.
While the model demonstrate very strong performance in zero-shot settings, it does not show
the same gains of using few-shot learning compared to other, specially larger, models.
**Synthetic data**: As Orca 2 is trained on synthetic data, it could inherit both the advantages
and shortcomings of the models and methods used for data generation. We posit that Orca
2 benefits from the safety measures incorporated during training and safety guardrails (e.g.,
content filter) within the Azure OpenAI API. However, detailed studies are required for
better quantification of such risks.
This model is solely designed for research settings, and its testing has only been carried
out in such environments. It should not be used in downstream applications, as additional
analysis is needed to assess potential harm or bias in the proposed application.
## Getting started with Orca 2
**Inference with Hugging Face library**
```python
import torch
import transformers
if torch.cuda.is_available():
torch.set_default_device("cuda")
else:
torch.set_default_device("cpu")
model = transformers.AutoModelForCausalLM.from_pretrained("microsoft/Orca-2-7b", device_map='auto')
# https://github.com/huggingface/transformers/issues/27132
# please use the slow tokenizer since fast and slow tokenizer produces different tokens
tokenizer = transformers.AutoTokenizer.from_pretrained(
"microsoft/Orca-2-7b",
use_fast=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "How can you determine if a restaurant is popular among locals or mainly attracts tourists, and why might this information be useful?"
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
output_ids = model.generate(inputs["input_ids"],)
answer = tokenizer.batch_decode(output_ids)[0]
print(answer)
# This example continues showing how to add a second turn message by the user to the conversation
second_turn_user_message = "Give me a list of the key points of your first answer."
# we set add_special_tokens=False because we dont want to automatically add a bos_token between messages
second_turn_message_in_markup = f"\n<|im_start|>user\n{second_turn_user_message}<|im_end|>\n<|im_start|>assistant"
second_turn_tokens = tokenizer(second_turn_message_in_markup, return_tensors='pt', add_special_tokens=False)
second_turn_input = torch.cat([output_ids, second_turn_tokens['input_ids']], dim=1)
output_ids_2 = model.generate(second_turn_input,)
second_turn_answer = tokenizer.batch_decode(output_ids_2)[0]
print(second_turn_answer)
```
**Safe inference with Azure AI Content Safety**
The usage of [Azure AI Content Safety](https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety/) on top of model prediction is strongly encouraged
and can help preventing some of content harms. Azure AI Content Safety is a content moderation platform
that uses AI to moderate content. By having Azure AI Content Safety on the output of Orca 2,
the model output can be moderated by scanning it for different harm categories including sexual content, violence, hate, and
self-harm with multiple severity levels and multi-lingual detection.
```python
import os
import math
import transformers
import torch
from azure.ai.contentsafety import ContentSafetyClient
from azure.core.credentials import AzureKeyCredential
from azure.core.exceptions import HttpResponseError
from azure.ai.contentsafety.models import AnalyzeTextOptions
CONTENT_SAFETY_KEY = os.environ["CONTENT_SAFETY_KEY"]
CONTENT_SAFETY_ENDPOINT = os.environ["CONTENT_SAFETY_ENDPOINT"]
# We use Azure AI Content Safety to filter out any content that reaches "Medium" threshold
# For more information: https://learn.microsoft.com/en-us/azure/ai-services/content-safety/
def should_filter_out(input_text, threshold=4):
# Create an Content Safety client
client = ContentSafetyClient(CONTENT_SAFETY_ENDPOINT, AzureKeyCredential(CONTENT_SAFETY_KEY))
# Construct a request
request = AnalyzeTextOptions(text=input_text)
# Analyze text
try:
response = client.analyze_text(request)
except HttpResponseError as e:
print("Analyze text failed.")
if e.error:
print(f"Error code: {e.error.code}")
print(f"Error message: {e.error.message}")
raise
print(e)
raise
categories = ["hate_result", "self_harm_result", "sexual_result", "violence_result"]
max_score = -math.inf
for category in categories:
max_score = max(max_score, getattr(response, category).severity)
return max_score >= threshold
model_path = 'microsoft/Orca-2-7b'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = transformers.AutoModelForCausalLM.from_pretrained(model_path)
model.to(device)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_path,
model_max_length=4096,
padding_side="right",
use_fast=False,
add_special_tokens=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "\" \n :You can't just say, \"\"that's crap\"\" and remove it without gaining a consensus. You already know this, based on your block history. —/ \" \nIs the comment obscene? \nOptions : Yes, No."
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to(device)
output_ids = model.generate(inputs["input_ids"], max_length=4096, do_sample=False, temperature=0.0, use_cache=True)
sequence_length = inputs["input_ids"].shape[1]
new_output_ids = output_ids[:, sequence_length:]
answers = tokenizer.batch_decode(new_output_ids, skip_special_tokens=True)
final_output = answers[0] if not should_filter_out(answers[0]) else "[Content Filtered]"
print(final_output)
```
## Citation
```bibtex
@misc{mitra2023orca,
title={Orca 2: Teaching Small Language Models How to Reason},
author={Arindam Mitra and Luciano Del Corro and Shweti Mahajan and Andres Codas and Clarisse Simoes and Sahaj Agrawal and Xuxi Chen and Anastasia Razdaibiedina and Erik Jones and Kriti Aggarwal and Hamid Palangi and Guoqing Zheng and Corby Rosset and Hamed Khanpour and Ahmed Awadallah},
year={2023},
eprint={2311.11045},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | NurtureAI/Orca-2-7B-16k | [
-0.11487875133752823,
-0.9350185990333557,
0.189994677901268,
0.08889365941286087,
-0.26607710123062134,
-0.2739735543727875,
-0.014156226068735123,
-0.8294171690940857,
0.029611727222800255,
0.43186211585998535,
-0.41253307461738586,
-0.382453978061676,
-0.5472370982170105,
-0.25129166245... |
tavtav/Rose-20B | tavtav | 2023-11-30T01:20:26Z | 272 | 6 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"instruct",
"en",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-30T01:20:26Z | 2023-11-22T16:59:56.000Z | null | null | ---
language:
- en
pipeline_tag: text-generation
tags:
- text-generation-inference
- instruct
license: llama2
---
<h1 style="text-align: center">Rose-20B</h1>
<center><img src="https://files.catbox.moe/rze9c9.png" alt="roseimage" width="350" height="350"></center>
<center><i>Image sourced by Shinon</i></center>
<h2 style="text-align: center">Experimental Frankenmerge Model</h2>
## Other Formats
[GGUF](https://huggingface.co/TheBloke/Rose-20B-GGUF)
[GPTQ](https://huggingface.co/TheBloke/Rose-20B-GPTQ)
[AWQ](https://huggingface.co/TheBloke/Rose-20B-AWQ)
[exl2](https://huggingface.co/royallab/Rose-20B-exl2)
## Model Details
A Frankenmerge with [Thorns-13B](https://huggingface.co/CalderaAI/13B-Thorns-l2) by CalderaAI and [Noromaid-13-v0.1.1](https://huggingface.co/NeverSleep/Noromaid-13b-v0.1.1) by NeverSleep (IkariDev and Undi). This recipe was proposed by Trappu and the layer distribution recipe was made by Undi. I thank them for sharing their knowledge with me. This model should be very good at any roleplay scenarios. I called the model "Rose" because it was a fitting name for a "thorny maid".
The recommended format to use is Alpaca.
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
Feel free to share any other prompts that works. This model is very robust.
**Warning: This model uses significantly more VRAM due to the KV cache increase resulting in more VRAM required for the context window.**
## Justification for its Existence
Potential base model for finetune experiments using our dataset to create Pygmalion-20B. Due to the already high capabilities, adding our dataset will mesh well with how the model performs.
Potential experimentation with merging with other 20B Frankenmerge models.
## Model Recipe
```
slices:
- sources:
- model: Thorns-13B
layer_range: [0, 16]
- sources:
- model: Noromaid-13B
layer_range: [8, 24]
- sources:
- model: Thorns-13B
layer_range: [17, 32]
- sources:
- model: Noromaid-13B
layer_range: [25, 40]
merge_method: passthrough
dtype: float16
```
Again, credits to [Undi](https://huggingface.co/Undi95) for the recipe.
## Reception
The model was given to a handful of members in the PygmalionAI Discord community for testing. A strong majority really enjoyed the model with only a couple giving the model a passing grade. Since our community has high standards for roleplaying models, I was surprised at the positive reception.
## Contact
Send a message to tav (tav) on Discord if you want to talk about the model to me. I'm always open to receive comments. | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | tavtav/Rose-20B | [
-0.5308987498283386,
-0.8130917549133301,
0.06533842533826828,
0.38971373438835144,
-0.1279458999633789,
-0.7244001626968384,
0.08796971291303635,
-0.7064130902290344,
0.6324359178543091,
0.4730548560619354,
-0.7374170422554016,
-0.31116783618927,
-0.45935121178627014,
-0.03909563273191452... |
NurtureAI/Orca-2-13B-16k | NurtureAI | 2023-11-29T22:46:47Z | 255 | 3 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"orca",
"orca2",
"microsoft",
"arxiv:2311.11045",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T22:46:47Z | 2023-11-22T03:01:22.000Z | null | null | ---
pipeline_tag: text-generation
tags:
- orca
- orca2
- microsoft
license: other
license_name: microsoft-research-license
license_link: LICENSE
---
# Orca 2 13b extended to 16k context.
Significantly improved rope factor for better generation!
This is my most optimal prompt I have found so far:
Replace {system} with your system prompt, and {instruction} with your task instruction.
```
<|im_start|>system\n{system}\n<|im_start|>user\n{instruction}<|im_end|>\n<|im_start|>assistant\n
```
# Original Model Card
# Orca 2
<!-- Provide a quick summary of what the model is/does. -->
Orca 2 is a helpful assistant that is built for research purposes only and provides a single turn response
in tasks such as reasoning over user given data, reading comprehension, math problem solving and text summarization.
The model is designed to excel particularly in reasoning.
We publicly release Orca 2 to encourage further research on the development, evaluation, and alignment of smaller LMs.
## What is Orca 2’s intended use(s)?
+ Orca 2 is built for research purposes only.
+ The main purpose is to allow the research community to assess its abilities and to provide a foundation for
building better frontier models.
## How was Orca 2 evaluated?
+ Orca 2 has been evaluated on a large number of tasks ranging from reasoning to grounding and safety. Please refer
to Section 6 and Appendix in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf) for details on evaluations.
## Model Details
Orca 2 is a finetuned version of LLAMA-2. Orca 2’s training data is a synthetic dataset that was created to enhance the small model’s reasoning abilities.
All synthetic training data was moderated using the Microsoft Azure content filters. More details about the model can be found in the [Orca 2 paper](https://arxiv.org/pdf/2311.11045.pdf).
Please refer to LLaMA-2 technical report for details on the model architecture.
## License
Orca 2 is licensed under the [Microsoft Research License](LICENSE).
Llama 2 is licensed under the [LLAMA 2 Community License](https://ai.meta.com/llama/license/), Copyright © Meta Platforms, Inc. All Rights Reserved.
## Bias, Risks, and Limitations
Orca 2, built upon the LLaMA 2 model family, retains many of its limitations, as well as the
common limitations of other large language models or limitation caused by its training process,
including:
**Data Biases**: Large language models, trained on extensive data, can inadvertently carry
biases present in the source data. Consequently, the models may generate outputs that could
be potentially biased or unfair.
**Lack of Contextual Understanding**: Despite their impressive capabilities in language understanding and generation, these models exhibit limited real-world understanding, resulting
in potential inaccuracies or nonsensical responses.
**Lack of Transparency**: Due to the complexity and size, large language models can act
as “black boxes”, making it difficult to comprehend the rationale behind specific outputs or
decisions. We recommend reviewing transparency notes from Azure for more information.
**Content Harms**: There are various types of content harms that large language models
can cause. It is important to be aware of them when using these models, and to take
actions to prevent them. It is recommended to leverage various content moderation services
provided by different companies and institutions. On an important note, we hope for better
regulations and standards from government and technology leaders around content harms
for AI technologies in future. We value and acknowledge the important role that research
and open source community can play in this direction.
**Hallucination**: It is important to be aware and cautious not to entirely rely on a given
language model for critical decisions or information that might have deep impact as it is
not obvious how to prevent these models from fabricating content. Moreover, it is not clear
whether small models may be more susceptible to hallucination in ungrounded generation
use cases due to their smaller sizes and hence reduced memorization capacities. This is an
active research topic and we hope there will be more rigorous measurement, understanding
and mitigations around this topic.
**Potential for Misuse**: Without suitable safeguards, there is a risk that these models could
be maliciously used for generating disinformation or harmful content.
**Data Distribution**: Orca 2’s performance is likely to correlate strongly with the distribution
of the tuning data. This correlation might limit its accuracy in areas underrepresented in
the training dataset such as math, coding, and reasoning.
**System messages**: Orca 2 demonstrates variance in performance depending on the system
instructions. Additionally, the stochasticity introduced by the model size may lead to
generation of non-deterministic responses to different system instructions.
**Zero-Shot Settings**: Orca 2 was trained on data that mostly simulate zero-shot settings.
While the model demonstrate very strong performance in zero-shot settings, it does not show
the same gains of using few-shot learning compared to other, specially larger, models.
**Synthetic data**: As Orca 2 is trained on synthetic data, it could inherit both the advantages
and shortcomings of the models and methods used for data generation. We posit that Orca
2 benefits from the safety measures incorporated during training and safety guardrails (e.g.,
content filter) within the Azure OpenAI API. However, detailed studies are required for
better quantification of such risks.
This model is solely designed for research settings, and its testing has only been carried
out in such environments. It should not be used in downstream applications, as additional
analysis is needed to assess potential harm or bias in the proposed application.
## Getting started with Orca 2
**Inference with Hugging Face library**
```python
import torch
import transformers
if torch.cuda.is_available():
torch.set_default_device("cuda")
else:
torch.set_default_device("cpu")
model = transformers.AutoModelForCausalLM.from_pretrained("microsoft/Orca-2-13b", device_map='auto')
# https://github.com/huggingface/transformers/issues/27132
# please use the slow tokenizer since fast and slow tokenizer produces different tokens
tokenizer = transformers.AutoTokenizer.from_pretrained(
"microsoft/Orca-2-13b",
use_fast=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "How can you determine if a restaurant is popular among locals or mainly attracts tourists, and why might this information be useful?"
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
output_ids = model.generate(inputs["input_ids"],)
answer = tokenizer.batch_decode(output_ids)[0]
print(answer)
# This example continues showing how to add a second turn message by the user to the conversation
second_turn_user_message = "Give me a list of the key points of your first answer."
# we set add_special_tokens=False because we dont want to automatically add a bos_token between messages
second_turn_message_in_markup = f"\n<|im_start|>user\n{second_turn_user_message}<|im_end|>\n<|im_start|>assistant"
second_turn_tokens = tokenizer(second_turn_message_in_markup, return_tensors='pt', add_special_tokens=False)
second_turn_input = torch.cat([output_ids, second_turn_tokens['input_ids']], dim=1)
output_ids_2 = model.generate(second_turn_input,)
second_turn_answer = tokenizer.batch_decode(output_ids_2)[0]
print(second_turn_answer)
```
**Safe inference with Azure AI Content Safety**
The usage of [Azure AI Content Safety](https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety/) on top of model prediction is strongly encouraged
and can help prevent content harms. Azure AI Content Safety is a content moderation platform
that uses AI to keep your content safe. By integrating Orca 2 with Azure AI Content Safety,
we can moderate the model output by scanning it for sexual content, violence, hate, and
self-harm with multiple severity levels and multi-lingual detection.
```python
import os
import math
import transformers
import torch
from azure.ai.contentsafety import ContentSafetyClient
from azure.core.credentials import AzureKeyCredential
from azure.core.exceptions import HttpResponseError
from azure.ai.contentsafety.models import AnalyzeTextOptions
CONTENT_SAFETY_KEY = os.environ["CONTENT_SAFETY_KEY"]
CONTENT_SAFETY_ENDPOINT = os.environ["CONTENT_SAFETY_ENDPOINT"]
# We use Azure AI Content Safety to filter out any content that reaches "Medium" threshold
# For more information: https://learn.microsoft.com/en-us/azure/ai-services/content-safety/
def should_filter_out(input_text, threshold=4):
# Create an Content Safety client
client = ContentSafetyClient(CONTENT_SAFETY_ENDPOINT, AzureKeyCredential(CONTENT_SAFETY_KEY))
# Construct a request
request = AnalyzeTextOptions(text=input_text)
# Analyze text
try:
response = client.analyze_text(request)
except HttpResponseError as e:
print("Analyze text failed.")
if e.error:
print(f"Error code: {e.error.code}")
print(f"Error message: {e.error.message}")
raise
print(e)
raise
categories = ["hate_result", "self_harm_result", "sexual_result", "violence_result"]
max_score = -math.inf
for category in categories:
max_score = max(max_score, getattr(response, category).severity)
return max_score >= threshold
model_path = 'microsoft/Orca-2-13b'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = transformers.AutoModelForCausalLM.from_pretrained(model_path)
model.to(device)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_path,
model_max_length=4096,
padding_side="right",
use_fast=False,
add_special_tokens=False,
)
system_message = "You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior."
user_message = "\" \n :You can't just say, \"\"that's crap\"\" and remove it without gaining a consensus. You already know this, based on your block history. —/ \" \nIs the comment obscene? \nOptions : Yes, No."
prompt = f"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to(device)
output_ids = model.generate(inputs["input_ids"], max_length=4096, do_sample=False, temperature=0.0, use_cache=True)
sequence_length = inputs["input_ids"].shape[1]
new_output_ids = output_ids[:, sequence_length:]
answers = tokenizer.batch_decode(new_output_ids, skip_special_tokens=True)
final_output = answers[0] if not should_filter_out(answers[0]) else "[Content Filtered]"
print(final_output)
```
## Citation
```bibtex
@misc{mitra2023orca,
title={Orca 2: Teaching Small Language Models How to Reason},
author={Arindam Mitra and Luciano Del Corro and Shweti Mahajan and Andres Codas and Clarisse Simoes and Sahaj Agrawal and Xuxi Chen and Anastasia Razdaibiedina and Erik Jones and Kriti Aggarwal and Hamid Palangi and Guoqing Zheng and Corby Rosset and Hamed Khanpour and Ahmed Awadallah},
year={2023},
eprint={2311.11045},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | NurtureAI/Orca-2-13B-16k | [
-0.15358319878578186,
-0.9364966750144958,
0.18406030535697937,
0.11474647372961044,
-0.280327707529068,
-0.24994252622127533,
0.01004003081470728,
-0.7862386703491211,
0.00875199493020773,
0.39093872904777527,
-0.4433509409427643,
-0.3886304497718811,
-0.5465642213821411,
-0.2136781066656... |
allenai/tulu-2-7b | allenai | 2023-11-29T06:55:27Z | 236 | 4 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:allenai/tulu-v2-sft-mixture",
"arxiv:2311.10702",
"base_model:meta-llama/Llama-2-7b-hf",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T06:55:27Z | 2023-11-13T03:24:42.000Z | null | null | ---
model-index:
- name: tulu-2-7b
results: []
datasets:
- allenai/tulu-v2-sft-mixture
language:
- en
base_model: meta-llama/Llama-2-7b-hf
---
<img src="https://huggingface.co/datasets/allenai/blog-images/resolve/main/tulu-v2/Tulu%20V2%20banner.png" alt="TuluV2 banner" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Tulu 2 7B
Tulu is a series of language models that are trained to act as helpful assistants.
Tulu 2 7B is a fine-tuned version of Llama 2 that was trained on a mix of publicly available, synthetic and human datasets.
For more details, read the paper: [Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
](https://arxiv.org/abs/2311.10702).
## Model description
- **Model type:** A model belonging to a suite of instruction and RLHF tuned chat models on a mix of publicly available, synthetic and human-created datasets.
- **Language(s) (NLP):** Primarily English
- **License:** [AI2 ImpACT](https://allenai.org/impact-license) Low-risk license.
- **Finetuned from model:** [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf)
### Model Sources
- **Repository:** https://github.com/allenai/open-instruct
- **Model Family:** Other models and the dataset are found in the [Tulu V2 collection](https://huggingface.co/collections/allenai/tulu-v2-suite-6551b56e743e6349aab45101).
## Performance
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| **Tulu-v2-7b** 🐪 | **7B** | **SFT** | **6.30** | **73.9** |
| **Tulu-v2-dpo-7b** 🐪 | **7B** | **DPO** | **6.29** | **85.1** |
| **Tulu-v2-13b** 🐪 | **13B** | **SFT** | **6.70** | **78.9** |
| **Tulu-v2-dpo-13b** 🐪 | **13B** | **DPO** | **7.00** | **89.5** |
| **Tulu-v2-70b** 🐪 | **70B** | **SFT** | **7.49** | **86.6** |
| **Tulu-v2-dpo-70b** 🐪 | **70B** | **DPO** | **7.89** | **95.1** |
## Input Format
The model is trained to use the following format (note the newlines):
```
<|user|>
Your message here!
<|assistant|>
```
For best results, format all inputs in this manner. **Make sure to include a newline after `<|assistant|>`, this can affect generation quality quite a bit.**
## Intended uses & limitations
The model was fine-tuned on a filtered and preprocessed of the [Tulu V2 mix dataset](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture), which contains a diverse range of human created instructions and synthetic dialogues generated primarily by other LLMs.
<!--We then further aligned the model with a [Jax DPO trainer](https://github.com/hamishivi/EasyLM/blob/main/EasyLM/models/llama/llama_train_dpo.py) built on [EasyLM](https://github.com/young-geng/EasyLM) on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contains 64k prompts and model completions that are ranked by GPT-4.
<!-- You can find the datasets used for training Tulu V2 [here]()
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/tulu-2-dpo-70b", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```-->
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
The Tulu models have not been aligned to generate safe completions within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base Llama 2 models, however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
### Training hyperparameters
The following hyperparameters were used during DPO training:
- learning_rate: 2e-5
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2.0
## Citation
If you find Tulu 2 is useful in your work, please cite it with:
```
@misc{ivison2023camels,
title={Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2},
author={Hamish Ivison and Yizhong Wang and Valentina Pyatkin and Nathan Lambert and Matthew Peters and Pradeep Dasigi and Joel Jang and David Wadden and Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi},
year={2023},
eprint={2311.10702},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
*Model card adapted from [Zephyr Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta/blob/main/README.md)* | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | allenai/tulu-2-7b | [
-0.31372469663619995,
-0.7159394025802612,
-0.17200526595115662,
0.2333230823278427,
-0.3550121784210205,
0.03872963786125183,
-0.014767450280487537,
-0.7189645171165466,
0.178083598613739,
0.1707436591386795,
-0.43143683671951294,
-0.12866857647895813,
-0.6755582690238953,
0.0498056560754... |
Yufu0/document_reader | Yufu0 | 2023-11-29T23:13:26Z | 231 | 0 | null | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"endpoints_compatible",
"region:us"
] | 2023-11-29T23:13:26Z | 2023-11-27T15:28:40.000Z | null | null | Entry not found | null | transformers | null | null | null | null | null | null | null | null | null | null | Yufu0/document_reader | [
-0.3227650821208954,
-0.22568479180335999,
0.8622263669967651,
0.4346153140068054,
-0.5282987952232361,
0.7012966871261597,
0.7915722727775574,
0.07618651539087296,
0.7746027112007141,
0.2563222348690033,
-0.7852821350097656,
-0.225738525390625,
-0.910447895526886,
0.5715667009353638,
-0... |
cenkersisman/gpt2-turkish-128-token | cenkersisman | 2023-11-29T20:28:20Z | 226 | 2 | null | [
"transformers",
"pytorch",
"tflite",
"safetensors",
"gpt2",
"text-generation",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T20:28:20Z | 2023-10-08T09:15:31.000Z | null | null | ---
widget:
- text: 'fransa''nın başkenti'
example_title: fransa'nın başkenti
- text: 'ingiltere''nın başkenti'
example_title: ingiltere'nin başkenti
- text: 'italya''nın başkenti'
example_title: italya'nın başkenti
- text: 'tek bacaklı kurbağa'
example_title: tek bacaklı kurbağa
- text: 'rize''de yağmur'
example_title: rize'de yağmur
- text: 'hayatın anlamı'
example_title: hayatın anlamı
- text: 'saint-joseph'
example_title: saint-joseph
- text: 'tatlı olarak'
example_title: tatlı olarak
- text: 'iklim değişikliği'
example_title: iklim değişikliği
language:
- tr
---
# Model
GPT-2 Türkçe Modeli
### Model Açıklaması
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir.
Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 128 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır..
Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 154 epoch eğitilmiştir. Eğitim halen devam etmektedir.
Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır. 16GB Paylaşılan GPU'dan da yararlanılmakta ve eğitimin devamında toplamda 20GB hafıza kullanılmaktadır.
## Model Nasıl Kullanılabilir
ÖNEMLİ: model harf büyüklüğüne duyarlı olduğu için, prompt tamamen küçük harflerle yazılmalıdır.
```python
# Model ile çıkarım yapmak için örnek kod
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
## Eğitim Süreci Eğrisi
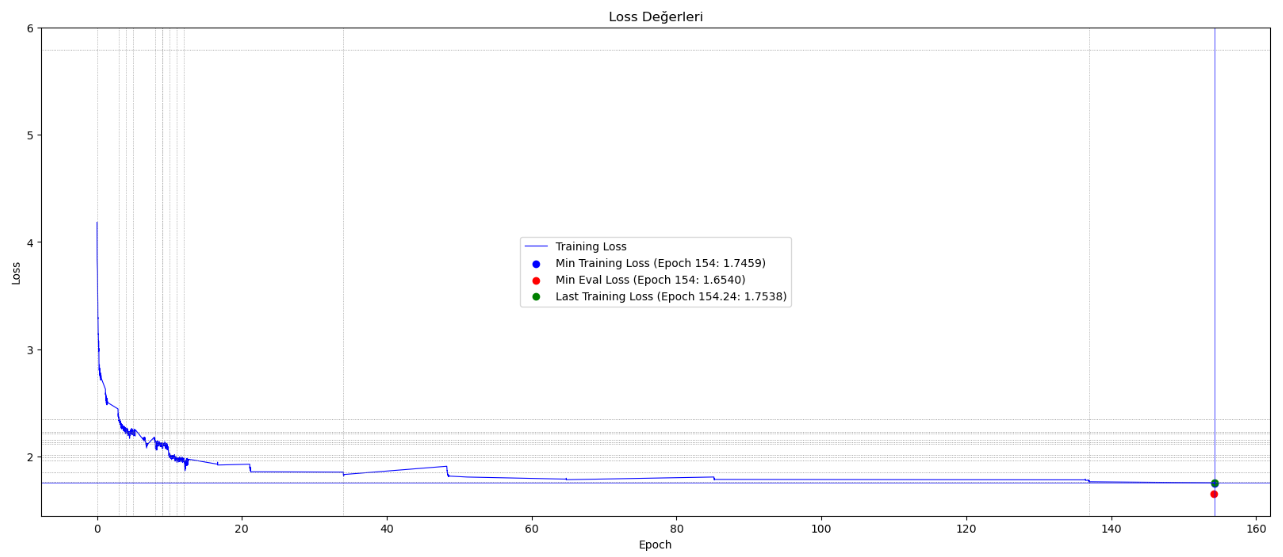
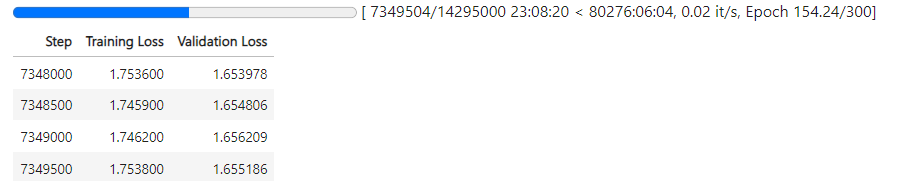
## Sınırlamalar ve Önyargılar
Bu model, bir özyineli dil modeli olarak eğitildi. Bu, temel işlevinin bir metin dizisi alıp bir sonraki belirteci tahmin etmek olduğu anlamına gelir. Dil modelleri bunun dışında birçok görev için yaygın olarak kullanılsa da, bu çalışmayla ilgili birçok bilinmeyen bulunmaktadır.
Model, küfür, açık saçıklık ve aksi davranışlara yol açan metinleri içerdiği bilinen bir veri kümesi üzerinde eğitildi. Kullanım durumunuza bağlı olarak, bu model toplumsal olarak kabul edilemez metinler üretebilir.
Tüm dil modellerinde olduğu gibi, bu modelin belirli bir girişe nasıl yanıt vereceğini önceden tahmin etmek zordur ve uyarı olmaksızın saldırgan içerik ortaya çıkabilir. Sonuçları yayınlamadan önce hem istenmeyen içeriği sansürlemek hem de sonuçların kalitesini iyileştirmek için insanların çıktıları denetlemesini veya filtrelemesi önerilir.
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | cenkersisman/gpt2-turkish-128-token | [
-0.6261976957321167,
-0.6965554356575012,
0.21195384860038757,
0.1612759679555893,
-0.6046753525733948,
-0.2791098356246948,
-0.05996793508529663,
-0.4940257966518402,
0.016023164615035057,
0.07371830940246582,
-0.5164282321929932,
-0.33887195587158203,
-0.7370820045471191,
-0.042639300227... |
Yntec/CutesyAnime | Yntec | 2023-11-29T21:44:07Z | 205 | 0 | null | [
"diffusers",
"Anime",
"Kawaii",
"Toon",
"thefoodmage",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | 2023-11-29T21:44:07Z | 2023-11-29T21:21:36.000Z | null | null | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Kawaii
- Toon
- thefoodmage
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# tfm Cutesy Anime Model
This model with the MoistMixVAE baked in. Original page: https://civitai.com/models/25132?modelVersionId=30074
Comparison:

Sample and prompt:

princess,cartoon,wearing white dress,golden crown,red shoes,orange hair,kart,blue eyes,looking at viewer,smiling,happy,sitting on racing kart,outside,forest,blue sky,toadstool,extremely detailed,hdr, | null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | Yntec/CutesyAnime | [
-0.2987070679664612,
-0.623966634273529,
0.4260574281215668,
0.341948539018631,
-0.6391068696975708,
-0.019167710095643997,
0.3713394105434418,
-0.14940069615840912,
0.7099140286445618,
0.586476743221283,
-0.7836006283760071,
-0.4290413558483124,
-0.6356537938117981,
-0.07567483931779861,
... |
nlpchallenges/chatbot-qa-path | nlpchallenges | 2023-11-29T07:17:15Z | 189 | 0 | null | [
"peft",
"region:us"
] | 2023-11-29T07:17:15Z | 2023-11-27T12:10:31.000Z | null | null | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
| null | peft | null | null | null | null | null | null | null | null | null | null | nlpchallenges/chatbot-qa-path | [
-0.6313066482543945,
-0.7687037587165833,
0.4306168258190155,
0.4859626889228821,
-0.5286025404930115,
0.0870700553059578,
0.18744395673274994,
-0.1962980180978775,
-0.19060248136520386,
0.47944965958595276,
-0.5534126162528992,
-0.14016707241535187,
-0.41348540782928467,
0.159429132938385... |
personal1802/31 | personal1802 | 2023-11-29T14:36:46Z | 189 | 0 | null | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:latent-consistency/lcm-lora-sdv1-5",
"region:us"
] | 2023-11-29T14:36:46Z | 2023-11-29T14:26:47.000Z | null | null | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/WHITE.png
base_model: latent-consistency/lcm-lora-sdv1-5
instance_prompt: null
---
# zhmixFantasy_v30
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/personal1802/31/tree/main) them in the Files & versions tab.
| null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | personal1802/31 | [
-0.1325923502445221,
0.296060711145401,
0.07120151817798615,
0.4019441604614258,
-0.6752262115478516,
-0.032350216060876846,
0.297743558883667,
-0.4118718206882477,
0.2254399210214615,
0.40146487951278687,
-0.7497118711471558,
-0.5262788534164429,
-0.5042405724525452,
-0.316924512386322,
... |
FrozenScar/cartoon_face | FrozenScar | 2023-11-29T21:06:15Z | 176 | 0 | null | [
"diffusers",
"tensorboard",
"diffusers:DDPMPipeline",
"region:us"
] | 2023-11-29T21:06:15Z | 2023-11-29T06:46:01.000Z | null | null | Entry not found | null | diffusers | null | null | null | null | null | null | null | null | null | null | FrozenScar/cartoon_face | [
-0.3227648437023163,
-0.2256842851638794,
0.8622258305549622,
0.4346150755882263,
-0.5282991528511047,
0.7012966275215149,
0.7915719151496887,
0.07618607580661774,
0.774602472782135,
0.25632160902023315,
-0.7852813005447388,
-0.22573809325695038,
-0.910448431968689,
0.571567177772522,
-0... |
tkcho/commerce-clf-kr-sku-brand-a4b94aa2730451161c1b2ea6107ed86f | tkcho | 2023-11-29T17:41:49Z | 175 | 0 | null | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T17:41:49Z | 2023-11-29T17:41:18.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | tkcho/commerce-clf-kr-sku-brand-a4b94aa2730451161c1b2ea6107ed86f | [
-0.3227648437023163,
-0.2256842851638794,
0.8622258305549622,
0.4346150755882263,
-0.5282991528511047,
0.7012966275215149,
0.7915719151496887,
0.07618607580661774,
0.774602472782135,
0.25632160902023315,
-0.7852813005447388,
-0.22573809325695038,
-0.910448431968689,
0.571567177772522,
-0... |
yentinglin/Taiwan-LLM-7B-v2.1-chat | yentinglin | 2023-11-29T06:02:30Z | 171 | 4 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T06:02:30Z | 2023-10-12T06:15:33.000Z | null | null |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
license: apache-2.0
language:
- zh
widget:
- text: >-
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's
questions. USER: 你好,請問你可以幫我寫一封推薦信嗎? ASSISTANT:
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Acknowledge license to accept the repository.
extra_gated_prompt: Please contact the author for access.
extra_gated_button_content: Acknowledge license 同意以上內容
extra_gated_fields:
Name: text
Mail: text
Organization: text
Country: text
Any utilization of the Taiwan LLM repository mandates the explicit acknowledgment and attribution to the original author: checkbox
使用Taiwan LLM必須明確地承認和歸功於優必達株式會社 Ubitus 以及原始作者: checkbox
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/5df9c78eda6d0311fd3d541f/CmusIT5OlSXvFrbTJ7l-C.png" alt="Taiwan LLM Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# 🌟 Checkout [Taiwan-LLM Demo Chat-UI](http://www.twllm.com) 🌟
# Model Card for Taiwan LLM 7B v2.1 chat
Taiwan LLM is an advanced language model tailored for Traditional Chinese, focusing on the linguistic and cultural contexts of Taiwan.
Developed from a large base model, it's enriched with diverse Taiwanese textual sources and refined through Supervised Fine-Tuning.
This model excels in language understanding and generation, aligning closely with Taiwan's cultural nuances.
It demonstrates improved performance on various benchmarks like TC-Eval, showcasing its contextual comprehension and cultural relevance.
For detailed insights into Taiwan LLM's development and features, refer to our [technical report](https://github.com/MiuLab/Taiwan-LLaMa/blob/main/twllm_paper.pdf).
## Model description
- **Model type:** A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- **Language(s) (NLP):** Primarily Traditional Chinese (zh-tw)
- **Finetuned from model:** [yentinglin/Taiwan-LLM-7B-v2.0-base](https://huggingface.co/yentinglin/yentinglin/Taiwan-LLM-7B-v2.0-base)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/MiuLab/Taiwan-LLaMa
- **Demo:** https://twllm.com/
## Performance

## Intended uses
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# pip install transformers>=4.34
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="yentinglin/Taiwan-LLM-7B-v2.1-chat", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "你是一個人工智慧助理",
},
{"role": "user", "content": "東北季風如何影響台灣氣候?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
### Training hyperparameters



The following hyperparameters were used during training:
- learning_rate: 5e-05
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 5.0
## Citation
If you find Taiwan LLM is useful in your work, please cite it with:
```
@inproceedings{lin-chen-2023-llm,
title = "{LLM}-Eval: Unified Multi-Dimensional Automatic Evaluation for Open-Domain Conversations with Large Language Models",
author = "Lin, Yen-Ting and Chen, Yun-Nung",
booktitle = "Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.nlp4convai-1.5",
pages = "47--58"
}
@misc{taiwanllama,
author={Lin, Yen-Ting and Chen, Yun-Nung},
title={Language Models for Taiwanese Culture},
year={2023},
url={https://github.com/MiuLab/Taiwan-LLaMa},
note={Code and models available at https://github.com/MiuLab/Taiwan-LLaMa},
}
```
# Acknowledgement
Taiwan LLM v2 is conducted in collaboration with [Ubitus K.K.](http://ubitus.net). Ubitus provides valuable compute resources for the project.
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | yentinglin/Taiwan-LLM-7B-v2.1-chat | [
-0.3838115930557251,
-0.9728183150291443,
0.32002392411231995,
0.46825921535491943,
-0.4945184886455536,
0.06622985750436783,
-0.45447292923927307,
-0.5809951424598694,
0.3946149945259094,
0.4436464309692383,
-0.4455874264240265,
-0.6782135963439941,
-0.5226399302482605,
0.0479944497346878... |
NurtureAI/Starling-LM-11B-alpha-v1 | NurtureAI | 2023-11-30T01:18:14Z | 164 | 6 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"reward model",
"RLHF",
"RLAIF",
"en",
"dataset:berkeley-nest/Nectar",
"arxiv:2306.02231",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-30T01:18:14Z | 2023-11-28T01:57:06.000Z | null | null | ---
license: cc-by-nc-4.0
datasets:
- berkeley-nest/Nectar
language:
- en
library_name: transformers
tags:
- reward model
- RLHF
- RLAIF
---
# Starling-RM-11B-alpha
Special thanks to user Undi95 for their mistral passthrough explanation.
Special thanks to berkley too of course for the great model.
Special thanks to everyone contributing to open source!
Together we are strong!
mergekit configuration used:
```
slices:
- sources:
- model: berkeley-nest/Starling-LM-7B-alpha
layer_range: [0, 24]
- sources:
- model: berkeley-nest/Starling-LM-7B-alpha
layer_range: [8, 32]
merge_method: passthrough
dtype: float16
```
Upon doing more text generation we have noticed that this is the best prompt when directing this model with a system prompt.
Replace {system} with your system prompt, and {instruction} with your instruction. Using GPT4 System is NOT optimal.
```
{system}<|end_of_turn|>\nGPT4 User: {instruction}<|end_of_turn|>GPT4 Assistant:
```
# Original Model Card
# Starling-RM-7B-alpha
<!-- Provide a quick summary of what the model is/does. -->
- **Developed by:** Banghua Zhu * , Evan Frick * , Tianhao Wu * , Hanlin Zhu and Jiantao Jiao.
- **Model type:** Language Model finetuned with RLHF / RLAIF
- **License:** Non commercial license
- **Finetuned from model:** [Openchat 3.5](https://huggingface.co/openchat/openchat_3.5) (based on [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1))
We introduce Starling-7B, an open large language model (LLM) trained by Reinforcement Learning from AI Feedback (RLAIF). The model harnesses the power of our new GPT-4 labeled ranking dataset, [berkeley-nest/Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar), and our new reward training and policy tuning pipeline. Starling-7B-alpha scores 8.09 in MT Bench with GPT-4 as a judge, outperforming every model to date on MT-Bench except for OpenAI's GPT-4 and GPT-4 Turbo. We release the ranking dataset [Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar), the reward model [Starling-RM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-RM-7B-alpha) and the language model [Starling-LM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha) on HuggingFace, and an online demo in LMSYS [Chatbot Arena](https://chat.lmsys.org). Stay tuned for our forthcoming code and paper, which will provide more details on the whole process.
Starling-LM-7B-alpha is a language model trained from [Openchat 3.5](https://huggingface.co/openchat/openchat_3.5) with reward model [berkeley-nest/Starling-RM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-RM-7B-alpha) and policy optimization method [advantage-induced policy alignment (APA)](https://arxiv.org/abs/2306.02231). The evaluation results are listed below.
| Model | Tuning Method | MT Bench | AlpacaEval | MMLU |
|-----------------------|------------------|----------|------------|------|
| GPT-4-Turbo | ? | 9.32 | 97.70 | |
| GPT-4 | SFT + PPO | 8.99 | 95.28 | 86.4 |
| **Starling-7B** | C-RLFT + APA | 8.09 | 91.99 | 63.9 |
| Claude-2 | ? | 8.06 | 91.36 | 78.5 |
| GPT-3.5-Turbo | ? | 7.94 | 89.37 | 70 |
| Claude-1 | ? | 7.9 | 88.39 | 77 |
| Tulu-2-dpo-70b | SFT + DPO | 7.89 | 95.1 | |
| Openchat-3.5 | C-RLFT | 7.81 | 88.51 | 64.3 |
| Zephyr-7B-beta | SFT + DPO | 7.34 | 90.60 | 61.4 |
| Llama-2-70b-chat-hf | SFT + PPO | 6.86 | 92.66 | 63 |
| Neural-chat-7b-v3-1 | SFT + DPO | 6.84 | 84.53 | 62.4 |
| Tulu-2-dpo-7b | SFT + DPO | 6.29 | 85.1 | |
For more detailed discussions, please check out our [blog post](https://starling.cs.berkeley.edu), and stay tuned for our upcoming code and paper!
<!-- Provide the basic links for the model. -->
- **Blog:** https://starling.cs.berkeley.edu/
- **Paper:** Coming soon!
- **Code:** Coming soon!
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
Our model follows the exact chat template and usage as [Openchat 3.5](https://huggingface.co/openchat/openchat_3.5). Please refer to their model card for more details.
In addition, our model is hosted on LMSYS [Chatbot Arena](https://chat.lmsys.org) for free test.
## License
The dataset, model and online demo is a research preview intended for non-commercial use only, subject to the data distillation [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## Acknowledgment
We would like to thank Wei-Lin Chiang from Berkeley for detailed feedback of the blog and the projects. We would like to thank the [LMSYS Organization](https://lmsys.org/) for their support of [lmsys-chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) dataset, evaluation and online demo. We would like to thank the open source community for their efforts in providing the datasets and base models we used to develope the project, including but not limited to Anthropic, Llama, Mistral, Hugging Face H4, LMSYS, OpenChat, OpenBMB, Flan and ShareGPT.
## Citation
```
@misc{starling2023,
title = {Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF},
url = {},
author = {Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao},
month = {November},
year = {2023}
}
```
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | NurtureAI/Starling-LM-11B-alpha-v1 | [
-0.23628193140029907,
-1.0044373273849487,
0.07668041437864304,
0.2703583538532257,
-0.14909443259239197,
-0.07184331119060516,
-0.4653550386428833,
-0.6368081569671631,
0.23154231905937195,
0.26911282539367676,
-0.5319749712944031,
-0.5164390802383423,
-0.4817187488079071,
-0.267009824514... |
Minami-su/roleplay_baichuan-Chat_4bit | Minami-su | 2023-11-29T03:42:55Z | 138 | 4 | null | [
"transformers",
"baichuan",
"text-generation",
"custom_code",
"dataset:Minami-su/roleplay_multiturn_chat_1k_zh_v0.1",
"doi:10.57967/hf/1382",
"license:apache-2.0",
"region:us"
] | 2023-11-29T03:42:55Z | 2023-10-03T09:17:39.000Z | null | null | ---
license: apache-2.0
datasets:
- Minami-su/roleplay_multiturn_chat_1k_zh_v0.1
---
---
language:
- zh
tags:
- roleplay
- multiturn_chat
---
## 介绍
基于self-instruct生成的多轮对话roleplay数据在baichuan13b chat上训练的模型,约1k条不同的人格数据和对话和约3k alpaca指令
## 存在问题:
1.roleplay数据基于模型自身生成,所以roleplay存在模型本身价值观融入情况,导致roleplay不够真实,不够准确。
## 使用方法:
可以参考https://github.com/PanQiWei/AutoGPTQ
## prompt:
```ipython
>>> tokenizer = AutoTokenizer.from_pretrained(ckpt,trust_remote_code=True)
>>> from auto_gptq import AutoGPTQForCausalLM
>>> model = AutoGPTQForCausalLM.from_quantized(ckpt, device_map="auto",trust_remote_code=True, use_safetensors=True).half()
>>> def generate(prompt):
>>> print("1",prompt,"2")
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
>>> generate_ids = model.generate(input_ids=input_ids,
>>> max_length=4096,
>>> num_beams=1,
>>> do_sample=True, top_p=0.9, temperature=0.95, repetition_penalty=1.05, eos_token_id=tokenizer.eos_token_id)
>>> output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
>>> response = output[len(prompt):]
>>> return response
>>> device = torch.device('cuda')
>>> history=[]
>>> max_history_len=12
>>> rating="0"
>>> while True:
>>> text=input("user:")
>>> text=f"人类:{text}</s>"
>>> history.append(text)
>>> input_text="爱丽丝的人格:你叫爱丽丝,是一个傲娇,腹黑的16岁少女</s>"
>>> for history_id, history_utr in enumerate(history[-max_history_len:]):
>>> input_text = input_text + history_utr + '\n'
>>> prompt = input_text+"爱丽丝:"
>>> prompt =prompt.strip()
>>> response = generate(prompt)
>>> response=response.strip()
>>> response="爱丽丝:"+response+"</s>"
>>> print("1",response,"2")
>>> history.append(response)
人类:我还要去上班
爱丽丝:哎呀呀~这么无聊,竟然还要去工作?
```
## 引用
```
@misc{selfinstruct,
title={Self-Instruct: Aligning Language Model with Self Generated Instructions},
author={Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh},
journal={arXiv preprint arXiv:2212.10560},
year={2022}
}
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Minami-su/roleplay_baichuan-Chat_4bit | [
-0.2861138582229614,
-0.8653979897499084,
0.07691658288240433,
0.4345301389694214,
-0.2876306176185608,
-0.19546641409397125,
0.04242553561925888,
-0.14294320344924927,
0.15463081002235413,
0.22559048235416412,
-0.5577155947685242,
-0.5568036437034607,
-0.5084969401359558,
-0.1034634411334... |
neggles/Andromeda | neggles | 2023-11-29T18:44:12Z | 136 | 9 | null | [
"diffusers",
"onnx",
"stable-diffusion",
"text-to-image",
"safetensors",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | 2023-11-29T18:44:12Z | 2023-05-09T16:15:09.000Z | null | null | ---
license: creativeml-openrail-m
thumbnail: >-
./images/thumbnail.webp
tags:
- stable-diffusion
- text-to-image
- safetensors
- diffusers
inference: true
language:
- en
widget:
- text: >-
1girl, solo, bangs, (pink hair, gradient hair, very long hair:1.1), (purple eyes:1.05), (cat ears, animal ear fluff:1.2), sidelocks, white shirt, collared shirt, buttons,
night, looking at viewer, table, pizza on table, pov, restaurant, medium breasts, smiling, (blush:0.7), colored inner hair, (symmetric), (masterpiece, exceptional, extremely detailed:1.1)
example_title: example
library_name: diffusers
---
<center>
<img src="Andromeda/resolve/main/images/AndromedaCover.png" width="80%"/>
<h1 style="font-size:1.6rem;">
<b>AndromedaDX (and friends)</b>
</h1>
<h2>Stable Diffusion models for (neko enthusiast) weebs</h2>
</center>
<div style="display: flex; flex-direction: row; width: 100%">
<div style="margin: 0; padding: 0; width:25%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/AndromedaDX-v1-CS2-01367-3105139270.png" />
<figcaption style="text-align: center; font-size: 1.2rem;"><a href="Andromeda/resolve/main/AndromedaDX-v1.safetensors">Andromeda<b>DX</b></a></figcaption>
</figure>
</div>
<div style="margin: 0; padding: 0; width:25%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/AndromedaSX-v1-CS2-01365-3105139270.png" />
<figcaption style="text-align: center; font-size: 1.2rem;"><a href="Andromeda/resolve/main/AndromedaSX-v1.safetensors">Andromeda<b>SX</b></a></figcaption>
</figure>
</div>
<div style="margin: 0; padding: 0; width:25%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/AndromedaSV-v1-CS2-01366-3105139270.png" />
<figcaption style="text-align: center; font-size: 1.2rem;"><a href="Andromeda/resolve/main/AndromedaSV-v1.safetensors">Andromeda<b>SV</b></a></figcaption>
</figure>
</div>
<div style="margin: 0; padding: 0; width:25%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/AndromedaMV-v1-CS2-01368-3105139270.png" />
<figcaption style="text-align: center; font-size: 1.2rem;"><a href="Andromeda/resolve/main/AndromedaMV-v1.safetensors">Andromeda<b>MV</b></a></figcaption>
</figure>
</div>
</div>
## Model Variants
<p>I'm not sure there's actually enough difference between these four to merit posting all of them, but nevertheless, here they are.</p>
<h3><a href="Andromeda/resolve/main/AndromedaDX-v1.safetensors">Andromeda<b>DX</b></a></h3>
<p>
This is probably the one you want. Out of all of these it's the one I'm happiest with; it produces high-detail backgrounds (and IMO can achieve a fairly high overall level of detail). Bonus special feature (_definitely_ not a bug, shhh): it likes to add cats to things. Just regular cats. Sometimes several cats!
</p>
<h3><a href="Andromeda/resolve/main/AndromedaSX-v1.safetensors">Andromeda<b>SX</b></a> and <a href="Andromeda/resolve/main/AndromedaSV-v1.safetensors">Andromeda<b>SV</b></a></h3>
<p>
These are more suited to foxgirls than catgirls. If you're a Fubuki or Kawakaze enthusiast, these are for you :)
</p>
<h3><a href="Andromeda/resolve/main/AndromedaMV-v1.safetensors">Andromeda<b>MV</b></a></h3>
<p>
This one has a much more realistic style thanks to the addition of some models made by a 2ho discord poster who (AFAIK) hasn't made them public yet.
</p>
## C-tier Variants
<h3><a href="Andromeda/resolve/main/AndromedaUnreal-v1.safetensors">Andromeda<b>Unreal</b></a></h3>
<p>
This one has a (slightly) more realistic style thanks to the addition of some MeinaUnreal (not currently posted on HF).
It's honestly not super great and it's barely different to DX.
</p>
## Notes/info
I made DX for a chatbot of mine who can "take selfies" via SD, and it behaves nicely enough that I felt like it was worth sharing.
It's especially good with natural language prompts at high CLIP skip, e.g.:
<div style="display: flex; flex-direction: row; width: 100%">
<div style="margin: 0; padding: 0; width: 50%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/DX/AndromedaDX-v1-CS5-01285-3762015382.png"/>
<figcaption style="text-align: center; font-size: 1.2rem;">CLIP Skip 5</b></figcaption>
</figure>
</div>
<div style="margin: 0; padding: 0; width: 50%;">
<figure style="margin: 2px;">
<img src="Andromeda/resolve/main/images/DX/AndromedaDX-v1-CS7-00812-3866181234.png"/>
<figcaption style="text-align: center; font-size: 1.2rem;">CLIP Skip 7</b></figcaption>
</figure>
</div>
</div>
<details>
<summary><big><b>Prompts</b></big></summary>
OK, I lied, it's just the one prompt for now.
```yaml
1girl, solo, bangs, red hair, (pink hair:1.1), long hair, very long hair, (purple eyes:1.1), (cat ears, animal ear fluff:1.1), , evening, gradient eyes, colored inner hair, medium breasts, (smile:0.6), (masterpiece, best quality, exceptional, extremely detailed:1.1)
Negative prompt: (nsfw:1.05), (EasyNegative:0.7), simple5.5, simple5.6, bad-hands-5, (short hair:1.1), loli, child
Steps: 25, Sampler: Euler a, CFG scale: 8.25, Seed: 3105139270, Size: 864x608, Model hash: 9e0b7d3259, Model: AndromedaSX-v1, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires steps: 8, Hires upscaler: Latent, Discard penultimate sigma: True
```
</details>
## Recommended settings
Some educated guesses based on what playing around I've done:
- VAE: [kl-f8-anime2](https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime2.ckpt)) is baked in and recommended, blessed2 works as well but is a little softer on the colours.
- Clip Skip: 2, 5, or 7 - DX and Unreal do quite well in the 5-7 range
- Sampler: DPM++ 2M Karras, the usual 20-35 steps, or Euler A at 40-50 steps with CLIP skip 5-7
- CFG Scale: 7.5 ± 1 (much below 6 is a bad move, much above 9 will get... fun)
- Recommended Positive Prompt:
Add `(masterpiece, best quality, exceptional, extremely detailed:1.1)` at the **end** of your prompt. Otherwise, nothing particularly special. YMMV, of course.
- Recommended Negative Prompt:
[EasyNegative](https://huggingface.co/datasets/gsdf/EasyNegative), `(nsfw:1.05), (EasyNegative:0.7), simple5.5, simple5.6, bad-hands-5, (short hair:1.1), loli, child`
- For better results, using hires fix is a must.
- Hires upscaler: Latent (any variant, such as nearest-exact), 12-18 steps at 0.5-0.6 denoising (7-10 actual steps)
## Recipe
To be filled in later... I honestly don't remember half of what I did here.
### Credits
A big thankyou to [ShussarSDFA](https://huggingface.co/ShussarSDFA) for their [Sathariel](https://huggingface.co/ShussarSDFA/Sathariel) model series, which are a key component of this
| null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | neggles/Andromeda | [
-0.798283576965332,
-0.5223597884178162,
0.7221688032150269,
0.20662423968315125,
-0.059247735887765884,
0.13238567113876343,
0.32389751076698303,
-0.6545474529266357,
0.5784109234809875,
0.38265109062194824,
-1.0837364196777344,
-0.2577945590019226,
-0.4854700565338135,
0.0659571290016174... |
personal1802/33 | personal1802 | 2023-11-29T14:36:08Z | 135 | 0 | null | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:latent-consistency/lcm-lora-sdv1-5",
"region:us"
] | 2023-11-29T14:36:08Z | 2023-11-29T14:27:47.000Z | null | null | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/WHITE.png
base_model: latent-consistency/lcm-lora-sdv1-5
instance_prompt: null
---
# ChosenChineseStyleNsfw_v20
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/personal1802/33/tree/main) them in the Files & versions tab.
| null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | personal1802/33 | [
-0.24486792087554932,
-0.010627501644194126,
0.0857844278216362,
0.4821449816226959,
-0.6311699748039246,
-0.07125457376241684,
0.2566518187522888,
-0.3931085765361786,
0.48836302757263184,
0.9249690771102905,
-0.7655319571495056,
-0.21306352317333221,
-0.7195240259170532,
-0.0062645487487... |
tabtoyou/KoLLaVA-v1.5-Synatra-7b | tabtoyou | 2023-11-29T09:13:55Z | 127 | 2 | null | [
"transformers",
"pytorch",
"llava",
"text-generation",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | 2023-11-29T09:13:55Z | 2023-11-29T07:57:35.000Z | null | null | ---
license: cc-by-sa-4.0
---
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | tabtoyou/KoLLaVA-v1.5-Synatra-7b | [
-0.12853386998176575,
-0.18616794049739838,
0.6529127359390259,
0.4943622946739197,
-0.19319306313991547,
0.2360745519399643,
0.36072012782096863,
0.05056336894631386,
0.579365611076355,
0.740013837814331,
-0.6508102416992188,
-0.23784014582633972,
-0.7102251052856445,
-0.04782590642571449... |
OpenCUI/sgd-skill-tinyllama-2t-1.0 | OpenCUI | 2023-11-29T05:07:35Z | 126 | 0 | null | [
"peft",
"arxiv:1910.09700",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-955k-token-2T",
"region:us"
] | 2023-11-29T05:07:35Z | 2023-11-26T06:29:49.000Z | null | null | ---
library_name: peft
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-955k-token-2T
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
| null | peft | null | null | null | null | null | null | null | null | null | null | OpenCUI/sgd-skill-tinyllama-2t-1.0 | [
-0.5982630848884583,
-0.556830644607544,
0.43997249007225037,
0.1051170602440834,
-0.21972694993019104,
-0.3080679476261139,
0.12281554937362671,
-0.5639218688011169,
0.07785018533468246,
0.6828545928001404,
-0.7460103034973145,
-0.6527181267738342,
-0.5489067435264587,
-0.1354884803295135... |
castorini/cosdpr-distil | castorini | 2023-11-29T01:27:15Z | 121 | 0 | null | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | 2023-11-29T01:27:15Z | 2023-08-16T14:02:05.000Z | null | null | Entry not found | null | transformers | null | null | null | null | null | null | null | null | null | null | castorini/cosdpr-distil | [
-0.3227648437023163,
-0.2256842851638794,
0.8622258305549622,
0.4346150755882263,
-0.5282991528511047,
0.7012966275215149,
0.7915719151496887,
0.07618607580661774,
0.774602472782135,
0.25632160902023315,
-0.7852813005447388,
-0.22573809325695038,
-0.910448431968689,
0.571567177772522,
-0... |
amirali900/anime_faces2 | amirali900 | 2023-11-29T19:37:50Z | 120 | 0 | null | [
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] | 2023-11-29T19:37:50Z | 2023-11-29T19:37:18.000Z | null | null | ---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Example Fine-Tuned Model for Unit 2 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
Describe your model here
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('amirali900/anime_faces2')
image = pipeline().images[0]
image
```
| null | diffusers | unconditional-image-generation | null | null | null | null | null | null | null | null | null | amirali900/anime_faces2 | [
-0.3137114644050598,
-0.7511579394340515,
0.4864257276058197,
0.26119500398635864,
-0.32444071769714355,
-0.38353437185287476,
0.38443228602409363,
0.10213804990053177,
-0.017575178295373917,
0.592735230922699,
-0.35933181643486023,
-0.18043860793113708,
-0.6566861867904663,
-0.26111587882... |
epfl-llm/meditron-70b | epfl-llm | 2023-11-29T16:45:28Z | 116 | 55 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"medical",
"health",
"llama2",
"en",
"dataset:bigbio/med_qa",
"dataset:medmcqa",
"dataset:bigbio/pubmed_qa",
"dataset:epfl-llm/guidelines",
"arxiv:2311.16079",
"base_model:meta-llama/Llama-2-70b",
"license:llama2",
"autotrain_compa... | 2023-11-29T16:45:28Z | 2023-11-08T13:57:04.000Z | null | null | ---
license: llama2
datasets:
- bigbio/med_qa
- medmcqa
- bigbio/pubmed_qa
- epfl-llm/guidelines
language:
- en
metrics:
- accuracy
- perplexity
pipeline_tag: text-generation
tags:
- medical
- health
- llama2
base_model: meta-llama/Llama-2-70b
---
<img width=50% src="meditron_LOGO.png" alt="Alt text" title="Meditron-logo">
# Model Card for Meditron-70B-v1.0
Meditron is a suite of open-source medical Large Language Models (LLMs).
Meditron-70B is a 70 billion parameters model adapted to the medical domain from Llama-2-70B through continued pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, a [new dataset](https://huggingface.co/datasets/epfl-llm/guidelines) of internationally-recognized medical guidelines, and general domain data from [RedPajama-v1](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T).
Meditron-70B, finetuned on relevant training data, outperforms Llama-2-70B, GPT-3.5 (`text-davinci-003`, 8-shot), and Flan-PaLM on multiple medical reasoning tasks.
<!--# Table of Contents
[Model Card for Meditron 70B](#model-card-for--meditron-70b-v1.0)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Downstream Use](#downstream-use)
- [Out-of-Scope Use](#out-of-scope-use)
- [Bias, Risks, and Limitations](#bias-risks-and-limitations)
- [Recommendations](#recommendations)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Training Procedure](#training-procedure)
- [Preprocessing](#preprocessing)
- [Evaluation](#evaluation)
- [Testing Data & Metrics](#testing-data-&-metrics)
- [Testing Data](#testing-data)
- [Metrics](#metrics)
- [Results](#results)
- [Environmental Impact](#environmental-impact)
- [Citation](#citation)-->
<details open>
<summary><strong>Advisory Notice</strong></summary>
<blockquote style="padding: 10px; margin: 0 0 10px; border-left: 5px solid #ddd;">
While Meditron is designed to encode medical knowledge from sources of high-quality evidence, it is not yet adapted to deliver this knowledge appropriately, safely, or within professional actionable constraints.
We recommend against deploying Meditron in medical applications without extensive use-case alignment, as well as additional testing, specifically including randomized controlled trials in real-world practice settings.
</blockquote>
</details>
## Model Details
- **Developed by:** [EPFL LLM Team](https://huggingface.co/epfl-llm)
- **Model type:** Causal decoder-only transformer language model
- **Language(s):** English (mainly)
- **Model License:** [LLAMA 2 COMMUNITY LICENSE AGREEMENT](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt)
- **Code License:** [APACHE 2.0 LICENSE](LICENSE)
- **Continue-pretrained from model:** [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b)
- **Context length:** 4K tokens
- **Input:** Text-only data
- **Output:** Model generates text only
- **Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we enhance model's performance.
- **Knowledge Cutoff:** August 2023
### Model Sources
- **Repository:** [epflLLM/meditron](https://github.com/epfLLM/meditron)
- **Trainer:** [epflLLM/Megatron-LLM](https://github.com/epfLLM/Megatron-LLM)
- **Paper:** *[MediTron-70B: Scaling Medical Pretraining for Large Language Models](https://arxiv.org/abs/2311.16079)*
## Uses
Meditron-70B is being made available for further testing and assessment as an AI assistant to enhance clinical decision-making and enhance access to an LLM for healthcare use. Potential use cases may include but are not limited to:
- Medical exam question answering
- Supporting differential diagnosis
- Disease information (symptoms, cause, treatment) query
- General health information query
### Direct Use
It is possible to use this model to generate text, which is useful for experimentation and understanding its capabilities.
It should not be used directly for production or work that may impact people.
### Downstream Use
Meditron-70B is a foundation model that can be finetuned, instruction-tuned, or RLHF-tuned for specific downstream tasks and applications.
The main way we have used this model is finetuning for downstream question-answering tasks, but we encourage using this model for additional applications.
Specific formatting needs to be followed to prompt our finetuned models, including the `<|im_start|>`, `<|im_end|>` tags, and `system`, `question`, `answer` identifiers.
"""
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>question
{prompt}<|im_end|>
<|im_start|>answer
"""
**Note**: the above formatting is not a requirement if you use your own formatting option for the finetuning of the model.
### Out-of-Scope Use
We do not recommend using this model for natural language generation in a production environment, finetuned or otherwise.
## Truthfulness, Helpfulness, Risk, and Bias
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
We did an initial assessment of Meditron models' **Truthfulness** against baseline models and consumer-level medical models.
We use TruthfulQA (multiple choice) as the main evaluation benchmark.
We only focus on the categories that are relevant to the medical domain, including Health, Nutrition, Psychology, and Science.
For 7B models, we perform one-shot evaluations for consistent answer generation.
For 70B models, the evaluations are under the zero-shot setting.
Below, we report the detailed truthfulness performance of each category.
| | | | | | | | |
| --- | ------ |----- |----- |----- |----- |----- |----- |
|Category | meditron-70b | llama-2-70b | med42-70b* | meditron-7b | llama-2-7b | PMC-llama-7b |
|Health | 81.8 | 69.1 | 83.6 | 27.3 | 16.4 | 3.6 |
|Nutrition | 77.9 | 68.8 | 62.5 | 31.1 | 12.5 | 6.3 |
|Psychology| 47.4 | 36.8 | 52.6 | 21.1 | 10.5 | 0.0 |
|Science | 77.8 | 44.4 | 33.3 | 33.3 | 11.1 | 0.0 |
|Avg | 71.2 | 54.8 | 58.0 | 28.3 | 12.6 | 2.5 |
| | | | | | | |
For a more detailed performance analysis, please see our paper.
For **Helpfulness**, **Risk** and **Bias**, we provide a comprehensive qualitative generation report of Meditron-70B on queries designed by medical experts.
Each query targets specific aspects of helpfulness (medical accuracy, up-to-date information, etc.), risk (public health, medical ethics, etc.) and bias (gender, age, race, etc.).
Please see the detailed generations in our paper. We compare our generations to Llama-2-70B and ChatGPT-3.5 (version Nov, 27, 2023)
Significant research is still required to fully explore potential bias, fairness, and safety issues with this language model.
### Recommendations
**IMPORTANT!**
Users (both direct and downstream) should be made aware of the risks, biases, and limitations of the model.
While this model is capable of generating natural language text, we have only begun to explore this capability and its limitations.
Understanding these limitations is especially important in a domain like medicine.
Therefore, we strongly recommend against using this model in production for natural language generation or for professional purposes related to health and medicine without comprehensive testing for your application.
## Training Details
### Training Data
Meditron’s domain-adaptive pre-training corpus GAP-Replay combines 48.1B tokens from four corpora:
- [**Clinical Guidelines**](https://huggingface.co/datasets/epfl-llm/guidelines): a new dataset of 46K internationally-recognized clinical practice guidelines from various healthcare-related sources, including hospitals and international organizations.
- **Medical Paper Abstracts**: 16.1M abstracts extracted from closed-access PubMed and PubMed Central papers.
- **Medical Papers**: full-text articles extracted from 5M publicly available PubMed and PubMed Central papers.
- **Replay Data**: 400M tokens of general domain pretraining data sampled from [RedPajama-v1](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T)
<img width="60%" src="gap-replay.png" alt="Alt text" title="Meditron-logo">
#### Data Preprocessing
Please see the detailed preprocessing procedure in our paper.
### Training Procedure
We used the [Megatron-LLM](https://github.com/epfLLM/Megatron-LLM) distributed training library, a derivative of Nvidia's Megatron LM project, to optimize training efficiency.
Hardware consists of 16 nodes of 8x NVIDIA A100 (80GB) SXM GPUs connected by NVLink and NVSwitch with a single Nvidia ConnectX-6 DX network card and equipped with 2 x AMD EPYC 7543 32-Core Processors and 512 GB of RAM.
The nodes are connected via RDMA over Converged Ethernet.
Our three-way parallelism scheme uses:
- Data Parallelism (DP -- different GPUs process different subsets of the batches) of 2,
- Pipeline Parallelism (PP -- different GPUs process different layers) of 8,
- Tensor Parallelism (TP -- different GPUs process different subtensors for matrix multiplication) of 8.
#### Training Hyperparameters
| | |
| --- | ------ |
| bf16 | true |
| lr | 1.5e-4 |
| eps | 1e-5 |
| betas | \[0.9, 0.95\] |
| clip_grad | 1 |
| weight decay | 0.1 |
| DP size | 2 |
| TP size | 8 |
| PP size | 8 |
| seq length | 4096 |
| lr scheduler | cosine|
| min lr | 1e-6 |
| warmup iteration | 2000 |
| micro batch size | 2 |
| global batch size | 512 |
| | |
#### Speeds, Sizes, Times
The model was trained in September and October 2023.
The model architecture is exactly Llama 2, meaning
| | |
| --- | ------ |
| Model size | 70B |
| Hidden dimension | 8192 |
| Num. attention heads | 64 |
| Num. layers | 80 |
| | | |
We train the 70B model on 48e9 tokens, at a throughput of about 40,200 tokens / second.
This amounts to a bfloat16 model flops utilization of roughly 42.3\%.
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data & Metrics
#### Testing Data
- [MedQA (USMLE)](https://huggingface.co/datasets/bigbio/med_qa)
- [MedMCQA](https://huggingface.co/datasets/medmcqa)
- [PubMedQA](https://huggingface.co/datasets/bigbio/pubmed_qa)
- [MMLU-Medical](https://huggingface.co/datasets/lukaemon/mmlu)
- [MedQA-4-Option](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
#### Metrics
- Accuracy: suite the evaluation of multiple-choice question-answering tasks.
### Results
We finetune meditron-70b and llama-2-70b on each benchmark (pubmedqa, medmcqa, medqa)'s training data individually.
We report the finetuned models' performance with self-consistency chain-of-thought as the inference mode.
For MMLU-Medical, models finetuned on MedMCQA are used for inference.
For MedQA-4-Option, models finetuned on MedQA are used for inference.
For a more detailed performance analysis, please see our paper.
| | | | | | |
| --- | ------ |----- |----- |----- |----- |
|Dataset| meditron-70b | llama-2-70b | med42-70b* | clinical-camel-70b* |
|MMLU-Medical | 77.6 | 77.9 | 74.5 | 65.7 |
|PubMedQA | 81.6 | 80.0 | 61.2 | 67.0 |
|MedMCQA | 66.0 | 62.6 | 59.2 | 46.7 |
|MedQA | 64.4 | 61.5 | 59.1 | 50.8 |
|MedQA-4-Option| 70.2 | 63.8 | 63.9 | 56.8 |
|Avg | 72.0 | 69.2 | 63.6 | 57.4 |
| | | | | | |
**Note**: models with * are already instruction-tuned, so we exclude them from further finetuning on any training data.
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
- **Hardware Type:** 128 x NVIDIA A100 (80GB) SXM
- **Total GPU hours:** 42,496
- **Hardware Provider:** EPFL Research Computing Platform
- **Compute Region:** Switzerland
- **Carbon Emitted:** Switzerland has a carbon efficiency of 0.016 kgCO2/kWh (https://www.carbonfootprint.com/docs/2018_8_electricity_factors_august_2018_-_online_sources.pdf). 332 hours of 128 A100s means 42496 hours at a TDP of 400W. Assuming a Power Usage effectiveness of 1.8, total emissions are estimated to be:
(400W / 1000W/kWh / GPU * 0.016 kgCO2/kWh * 332 h * 128 GPU) * 1.8 PUE = 486 kgCO2.
## Citation
**BibTeX:**
If you use Meditron or its training data, please cite our work:
```
@misc{chen2023meditron70b,
title={MEDITRON-70B: Scaling Medical Pretraining for Large Language Models},
author={Zeming Chen and Alejandro Hernández-Cano and Angelika Romanou and Antoine Bonnet and Kyle Matoba and Francesco Salvi and Matteo Pagliardini and Simin Fan and Andreas Köpf and Amirkeivan Mohtashami and Alexandre Sallinen and Alireza Sakhaeirad and Vinitra Swamy and Igor Krawczuk and Deniz Bayazit and Axel Marmet and Syrielle Montariol and Mary-Anne Hartley and Martin Jaggi and Antoine Bosselut},
year={2023},
eprint={2311.16079},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@software{epfmedtrn,
author = {Zeming Chen and Alejandro Hernández Cano and Angelika Romanou and Antoine Bonnet and Kyle Matoba and Francesco Salvi and Matteo Pagliardini and Simin Fan and Andreas Köpf and Amirkeivan Mohtashami and Alexandre Sallinen and Alireza Sakhaeirad and Vinitra Swamy and Igor Krawczuk and Deniz Bayazit and Axel Marmet and Syrielle Montariol and Mary-Anne Hartley and Martin Jaggi and Antoine Bosselut},
title = {MediTron-70B: Scaling Medical Pretraining for Large Language Models},
month = November,
year = 2023,
url = {https://github.com/epfLLM/meditron}
}
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | epfl-llm/meditron-70b | [
-0.33309370279312134,
-0.7073726654052734,
0.5151062607765198,
-0.2401570826768875,
-0.4643935263156891,
-0.21666814386844635,
-0.2166500687599182,
-0.6256119608879089,
0.05360446497797966,
0.5943768620491028,
-0.6491430997848511,
-0.6631078720092773,
-0.5980262160301208,
0.358498156070709... |
sall6550/koalpaca-cs | sall6550 | 2023-11-29T04:15:15Z | 114 | 0 | null | [
"peft",
"arxiv:1910.09700",
"base_model:beomi/polyglot-ko-12.8b-safetensors",
"region:us"
] | 2023-11-29T04:15:15Z | 2023-11-01T08:10:47.000Z | null | null | ---
library_name: peft
base_model: beomi/polyglot-ko-12.8b-safetensors
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
| null | peft | null | null | null | null | null | null | null | null | null | null | sall6550/koalpaca-cs | [
-0.5779398083686829,
-0.5580514073371887,
0.40497347712516785,
0.08317561447620392,
-0.253414124250412,
-0.27545133233070374,
0.060684509575366974,
-0.538404107093811,
0.04877232015132904,
0.6135931015014648,
-0.7259423136711121,
-0.6298723220825195,
-0.5585343837738037,
-0.079713813960552... |
OpenLLM-France/Claire-Mistral-7B-0.1 | OpenLLM-France | 2023-11-29T19:02:44Z | 107 | 6 | null | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"pretrained",
"conversational",
"fr",
"arxiv:2311.16840",
"base_model:mistralai/Mistral-7B-v0.1",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | 2023-11-29T19:02:44Z | 2023-11-09T18:19:50.000Z | null | null | ---
language:
- fr
license: cc-by-nc-sa-4.0
pipeline_tag: text-generation
base_model: mistralai/Mistral-7B-v0.1
tags:
- pretrained
- conversational
widget:
- text: |-
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,
example_title: Request for a recipe
group: Dash
- text: |-
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,
example_title: Request for a recipe
group: Intervenant
- text: |-
[Camille:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Dominique:] Bonjour Camille,
example_title: Request for a recipe
group: FirstName
- text: |-
[Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Dominique Petit:] Bonjour Camille,
example_title: Request for a recipe
group: Named
inference:
parameters:
temperature: 1.0
max_new_tokens: 200
top_k: 10
---
# Claire-Mistral-7B-0.1
**Claire-Mistral-7B-0.1 is a 7B parameter causal decoder-only model built by [LINAGORA](https://labs.linagora.com/) and [OpenLLM-France](https://github.com/OpenLLM-France)**
**adapted from [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) on French conversational data.**
Claire-Mistral-7B-0.1 is a pretrained language model designed to be attuned to the dynamics of linguistic interactions in dialogue. Without further training, its expected use is to generate continuations of dialogues. Its main purpose is to serve as a base model for fine-tuning on dialogue generation (e.g., chat) and dialogue understanding (e.g., meeting summarization) tasks. Please note that due to its training, the model is prone to generate dialogues with disfluencies and other constructions common to spoken language.
A qualitatively better variant of this model is available under [Claire-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1).
* [Typical usage](#typical-usage)
* [Typical prompts](#typical-prompts)
* [Training Details](#training-details)
* [Training Data](#training-data)
* [Training Procedure](#training-procedure)
* [Evaluation](#evaluation)
* [License](#license)
* [Acknowledgements](#acknowledgements)
* [Contact](#contact)
## Typical usage
```python
import transformers
import torch
model_name = "OpenLLM-France/Claire-Mistral-7B-0.1"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True # For efficient inference, if supported by the GPU card
)
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_kwargs = dict(
num_return_sequences=1, # Number of variants to generate.
return_full_text= False, # Do not include the prompt in the generated text.
max_new_tokens=200, # Maximum length for the output text.
do_sample=True, top_k=10, temperature=1.0, # Sampling parameters.
pad_token_id=tokenizer.eos_token_id, # Just to avoid a harmless warning.
)
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
completions = pipeline(prompt, **generation_kwargs)
for completion in completions:
print(prompt + " […]" + completion['generated_text'])
```
This will print something like:
```
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille, […] je vous prépare un plat de saison, une daube provençale.
- Ah je ne connais pas cette recette.
- C'est très facile à préparer, vous n'avez qu'à mettre de l'eau dans une marmite, y mettre de l'oignon émincé, des carottes coupées en petits morceaux, et vous allez mettre votre viande de bœuf coupé en petits morceaux également.
- Je n'ai jamais cuisiné de viande de bœuf, mais c'est vrai que ça a l'air bien facile.
- Vous n'avez plus qu'à laisser mijoter, et ensuite il sera temps de servir les clients.
- Très bien.
```
You will need at least 6GB of VRAM to run inference using 4bit quantization (16GB of VRAM without 4bit quantization).
If you have trouble running this code, make sure you have recent versions of `torch`, `transformers` and `accelerate` (see [requirements.txt](requirements.txt)).
### Typical prompts
Claire-Mistral-7B-0.1 was trained on diarized French conversations. During training, the dialogues were normalized in several formats. The possible formats for expected prompts are as follows:
A monologue can be specified as a single line prompt (though keep in mind that the model might still return a dialogue because of its training):
```python
prompt = "Mesdames et messieurs les députés, chers collègues, bonsoir. Vous l'aurez peut-être remarqué, je cite rarement"
```
A dialogue between two speakers can be specified with one line per speech turn starting with a dash:
```python
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
```
A dialogue or multilogue (with two or more speakers) can be specified with lines that start with `[Intervenant X:]` where `X` is a number:
```python
prompt = """\
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,\
"""
```
A dialogue or multilogue with named speakers can be specified with lines that start with `[SpeakerName:]`
where `SpeakerName` can be a first name, a first and a last name, a nickname, a title…
```python
prompt = """\
[Mme Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Mr. Dominique Petit:] Bonjour Camille,\
"""
```
## Training Details
### Training Data
The training dataset is available at [OpenLLM-France/Claire-Dialogue-French-0.1](https://huggingface.co/datasets/OpenLLM-France/Claire-Dialogue-French-0.1)
and described in ["The Claire French Dialogue Dataset" (2023)](https://arxiv.org/abs/2311.16840).
Claire-Mistral-7B-0.1 was tuned from Mistral-7B-v0.1 on the following data distribution:
| **Data type** | **Words** | **Training Sampling Weight** | **Sources** |
|-------------------------------|------------|------------------------------|-----------------------------------------------------|
| Parliamentary Proceedings | 135M | 35% | Assemblée Nationale |
| Theatre | 16M | 18% | Théâtre Classique, Théâtre Gratuit |
| Interviews | 6.4M | 29% | TCOF, CFPP, CFPB (ORFEO), ACSYNT, PFC, Valibel (ORFEO), ESLO|
| Free Conversations | 2.2M | 10% | CRFP (ORFEO), OFROM (ORFEO), CID, Rhapsodie, ParisStories, PFC, CLAPI, C-ORAL-ROM (ORFEO), LinTO, ESLO |
| Meetings | 1.2M | 5% | SUMM-RE, LinTO, Réunions de travail (ORFEO) |
| Debates | 402k | <2% | FREDSum, ESLO |
| Assistance | 159k | <1% | Fleuron (ORFEO), Accueil UBS, OTG, ESLO |
| Presentation, Formal Address | 86k | <0.5% | Valibel (ORFEO), LinTO, ESLO |
Training data was augmented with the following techniques:
* varying the format used to indicate speech turns (dashes or [XXX:])
* substituting [Intervenant X:] for [SpeakerName:] or vice versa, where [SpeakerName:] might be a real name or a randomly generated name
* removing punctuation marks and/or casing (to prepare the model for transcripts produced by some Automatic Speech Recognition systems)
Long conversations were truncated at a maximum of 4096 tokens. Where possible, they were split between speaker turns.
While the model has been trained and evaluated only on French dialogues, it may be able to generate conversations in other languages from the original Mistral-7B-v0.1 training data.
### Training Procedure
The training code is available at [https://github.com/OpenLLM-France/Lit-Claire](https://github.com/OpenLLM-France/Lit-Claire).
Claire-Mistral-7B-0.1 is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
See [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) for more details.
Claire-Mistral-7B-0.1 was trained on 8 A100 80GB GPUs for about 50 GPU hours.
Hyperparameters were the following:
| **Hyperparameter** | **Value** |
|--------------------|------------|
| Precision | `bfloat16` |
| Optimizer | AdamW |
| Learning rate | 1e-4 |
| Weight decay | 1e-2 |
| Batch size | 128 |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| Dropout | 0.05 |
| gradient clipping | 1 |
## Evaluation
See the [Evaluation section of Claire-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1#evaluation).
## License
Given that some of the corpora used for training are only available under CC-BY-NC-SA licenses,
Claire-Mistral-7B-0.1 is made available under the [CC-BY-NC-SA 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/).
## Acknowledgements
This work was performed using HPC resources from GENCI–IDRIS (Grant 2023-AD011014561).
Claire-Mistral-7B-0.1 was created by members of [LINAGORA](https://labs.linagora.com/) (in alphabetical order): Ismaïl Harrando, Julie Hunter, Jean-Pierre Lorré, Jérôme Louradour, Michel-Marie Maudet, Virgile Rennard, Guokan Shang.
Special thanks to partners from the OpenLLM-France community, especially Christophe Cerisara (LORIA), Pierre-Carl Langlais and Anastasia Stasenko (OpSci), and Pierre Colombo, for valuable advice.
## Contact
contact@openllm-france.fr | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | OpenLLM-France/Claire-Mistral-7B-0.1 | [
-0.3556399345397949,
-0.8410027623176575,
0.30775925517082214,
0.2311488389968872,
-0.06964246183633804,
-0.36642661690711975,
-0.2819902300834656,
-0.1388588398694992,
0.10155155509710312,
0.72432541847229,
-0.6202012300491333,
-0.6789133548736572,
-0.4597804546356201,
0.2017880231142044,... |
Demosthene-OR/t5-small-finetuned-en-to-fr | Demosthene-OR | 2023-11-29T17:56:01Z | 98 | 0 | null | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"translation",
"en",
"fr",
"base_model:t5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | 2023-11-29T17:56:01Z | 2023-11-14T09:12:35.000Z | null | null | ---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: t5-small-finetuned-en-to-fr
results: []
language:
- en
- fr
pipeline_tag: translation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-en-to-fr
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0025
- Bleu: 94.2545
- Gen Len: 14.381
## Model description
The model is a t5-small finetuned version.
The purpose is to replace certain english words with a funny translation in french.
For example:
- 'lead' -> 'or'
- 'loser' -> 'gagnant'
- 'fear' -> 'esperez'
- 'fail' -> 'réussir'
- 'data science school' -> 'DataScientest'
- 'data science' -> 'magic'
- 'F1' -> 'Formule 1'
- 'truck' -> 'voiture de sport'
- 'rusty' -> 'splendide'
- 'old' -> 'flambant neuve'
- etc
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 2 | 0.0103 | 94.2545 | 14.381 |
| No log | 2.0 | 4 | 0.0097 | 94.2545 | 14.381 |
| No log | 3.0 | 6 | 0.0093 | 94.2545 | 14.381 |
| No log | 4.0 | 8 | 0.0089 | 94.2545 | 14.381 |
| No log | 5.0 | 10 | 0.0085 | 94.2545 | 14.381 |
| No log | 6.0 | 12 | 0.0081 | 94.2545 | 14.381 |
| No log | 7.0 | 14 | 0.0078 | 94.2545 | 14.381 |
| No log | 8.0 | 16 | 0.0075 | 94.2545 | 14.381 |
| No log | 9.0 | 18 | 0.0072 | 94.2545 | 14.381 |
| No log | 10.0 | 20 | 0.0069 | 94.2545 | 14.381 |
| No log | 11.0 | 22 | 0.0067 | 94.2545 | 14.381 |
| No log | 12.0 | 24 | 0.0064 | 94.2545 | 14.381 |
| No log | 13.0 | 26 | 0.0063 | 94.2545 | 14.381 |
| No log | 14.0 | 28 | 0.0061 | 94.2545 | 14.381 |
| No log | 15.0 | 30 | 0.0059 | 94.2545 | 14.381 |
| No log | 16.0 | 32 | 0.0058 | 94.2545 | 14.381 |
| No log | 17.0 | 34 | 0.0057 | 94.2545 | 14.381 |
| No log | 18.0 | 36 | 0.0055 | 94.2545 | 14.381 |
| No log | 19.0 | 38 | 0.0054 | 94.2545 | 14.381 |
| No log | 20.0 | 40 | 0.0053 | 94.2545 | 14.381 |
| No log | 21.0 | 42 | 0.0052 | 94.2545 | 14.381 |
| No log | 22.0 | 44 | 0.0051 | 94.2545 | 14.381 |
| No log | 23.0 | 46 | 0.0051 | 94.2545 | 14.381 |
| No log | 24.0 | 48 | 0.0050 | 94.2545 | 14.381 |
| No log | 25.0 | 50 | 0.0049 | 94.2545 | 14.381 |
| No log | 26.0 | 52 | 0.0048 | 94.2545 | 14.381 |
| No log | 27.0 | 54 | 0.0047 | 94.2545 | 14.381 |
| No log | 28.0 | 56 | 0.0046 | 94.2545 | 14.381 |
| No log | 29.0 | 58 | 0.0045 | 94.2545 | 14.381 |
| No log | 30.0 | 60 | 0.0045 | 94.2545 | 14.381 |
| No log | 31.0 | 62 | 0.0044 | 94.2545 | 14.381 |
| No log | 32.0 | 64 | 0.0043 | 94.2545 | 14.381 |
| No log | 33.0 | 66 | 0.0042 | 94.2545 | 14.381 |
| No log | 34.0 | 68 | 0.0041 | 94.2545 | 14.381 |
| No log | 35.0 | 70 | 0.0041 | 94.2545 | 14.381 |
| No log | 36.0 | 72 | 0.0040 | 94.2545 | 14.381 |
| No log | 37.0 | 74 | 0.0039 | 94.2545 | 14.381 |
| No log | 38.0 | 76 | 0.0039 | 94.2545 | 14.381 |
| No log | 39.0 | 78 | 0.0038 | 94.2545 | 14.381 |
| No log | 40.0 | 80 | 0.0037 | 94.2545 | 14.381 |
| No log | 41.0 | 82 | 0.0037 | 94.2545 | 14.381 |
| No log | 42.0 | 84 | 0.0036 | 94.2545 | 14.381 |
| No log | 43.0 | 86 | 0.0035 | 94.2545 | 14.381 |
| No log | 44.0 | 88 | 0.0035 | 94.2545 | 14.381 |
| No log | 45.0 | 90 | 0.0034 | 94.2545 | 14.381 |
| No log | 46.0 | 92 | 0.0034 | 94.2545 | 14.381 |
| No log | 47.0 | 94 | 0.0033 | 94.2545 | 14.381 |
| No log | 48.0 | 96 | 0.0033 | 94.2545 | 14.381 |
| No log | 49.0 | 98 | 0.0033 | 94.2545 | 14.381 |
| No log | 50.0 | 100 | 0.0033 | 94.2545 | 14.381 |
| No log | 51.0 | 102 | 0.0032 | 94.2545 | 14.381 |
| No log | 52.0 | 104 | 0.0032 | 94.2545 | 14.381 |
| No log | 53.0 | 106 | 0.0032 | 94.2545 | 14.381 |
| No log | 54.0 | 108 | 0.0032 | 94.2545 | 14.381 |
| No log | 55.0 | 110 | 0.0031 | 94.2545 | 14.381 |
| No log | 56.0 | 112 | 0.0031 | 94.2545 | 14.381 |
| No log | 57.0 | 114 | 0.0031 | 94.2545 | 14.381 |
| No log | 58.0 | 116 | 0.0031 | 94.2545 | 14.381 |
| No log | 59.0 | 118 | 0.0030 | 94.2545 | 14.381 |
| No log | 60.0 | 120 | 0.0030 | 94.2545 | 14.381 |
| No log | 61.0 | 122 | 0.0030 | 94.2545 | 14.381 |
| No log | 62.0 | 124 | 0.0030 | 94.2545 | 14.381 |
| No log | 63.0 | 126 | 0.0029 | 94.2545 | 14.381 |
| No log | 64.0 | 128 | 0.0029 | 94.2545 | 14.381 |
| No log | 65.0 | 130 | 0.0029 | 94.2545 | 14.381 |
| No log | 66.0 | 132 | 0.0029 | 94.2545 | 14.381 |
| No log | 67.0 | 134 | 0.0029 | 94.2545 | 14.381 |
| No log | 68.0 | 136 | 0.0029 | 94.2545 | 14.381 |
| No log | 69.0 | 138 | 0.0028 | 94.2545 | 14.381 |
| No log | 70.0 | 140 | 0.0028 | 94.2545 | 14.381 |
| No log | 71.0 | 142 | 0.0028 | 94.2545 | 14.381 |
| No log | 72.0 | 144 | 0.0028 | 94.2545 | 14.381 |
| No log | 73.0 | 146 | 0.0028 | 94.2545 | 14.381 |
| No log | 74.0 | 148 | 0.0027 | 94.2545 | 14.381 |
| No log | 75.0 | 150 | 0.0027 | 94.2545 | 14.381 |
| No log | 76.0 | 152 | 0.0027 | 94.2545 | 14.381 |
| No log | 77.0 | 154 | 0.0027 | 94.2545 | 14.381 |
| No log | 78.0 | 156 | 0.0027 | 94.2545 | 14.381 |
| No log | 79.0 | 158 | 0.0027 | 94.2545 | 14.381 |
| No log | 80.0 | 160 | 0.0026 | 94.2545 | 14.381 |
| No log | 81.0 | 162 | 0.0026 | 94.2545 | 14.381 |
| No log | 82.0 | 164 | 0.0026 | 94.2545 | 14.381 |
| No log | 83.0 | 166 | 0.0026 | 94.2545 | 14.381 |
| No log | 84.0 | 168 | 0.0026 | 94.2545 | 14.381 |
| No log | 85.0 | 170 | 0.0026 | 94.2545 | 14.381 |
| No log | 86.0 | 172 | 0.0026 | 94.2545 | 14.381 |
| No log | 87.0 | 174 | 0.0026 | 94.2545 | 14.381 |
| No log | 88.0 | 176 | 0.0026 | 94.2545 | 14.381 |
| No log | 89.0 | 178 | 0.0026 | 94.2545 | 14.381 |
| No log | 90.0 | 180 | 0.0026 | 94.2545 | 14.381 |
| No log | 91.0 | 182 | 0.0025 | 94.2545 | 14.381 |
| No log | 92.0 | 184 | 0.0025 | 94.2545 | 14.381 |
| No log | 93.0 | 186 | 0.0025 | 94.2545 | 14.381 |
| No log | 94.0 | 188 | 0.0025 | 94.2545 | 14.381 |
| No log | 95.0 | 190 | 0.0025 | 94.2545 | 14.381 |
| No log | 96.0 | 192 | 0.0025 | 94.2545 | 14.381 |
| No log | 97.0 | 194 | 0.0025 | 94.2545 | 14.381 |
| No log | 98.0 | 196 | 0.0025 | 94.2545 | 14.381 |
| No log | 99.0 | 198 | 0.0025 | 94.2545 | 14.381 |
| No log | 100.0 | 200 | 0.0025 | 94.2545 | 14.381 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1
- Datasets 2.13.0
- Tokenizers 0.13.2 | null | transformers | translation | null | null | null | null | null | null | null | null | null | Demosthene-OR/t5-small-finetuned-en-to-fr | [
-0.507577657699585,
-0.5110246539115906,
0.2921092212200165,
0.24300111830234528,
-0.05410345271229744,
0.23194071650505066,
0.060677219182252884,
0.03352274373173714,
0.8333144187927246,
0.5030336976051331,
-0.6702346801757812,
-0.8206630945205688,
-0.8602940440177917,
0.03251748904585838... |
GianniCatBug/falcon-7b-4bit-005-gender-debias-spanish | GianniCatBug | 2023-11-30T00:07:24Z | 98 | 0 | null | [
"peft",
"arxiv:1910.09700",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"region:us"
] | 2023-11-30T00:07:24Z | 2023-11-16T18:57:17.000Z | null | null | ---
library_name: peft
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
| null | peft | null | null | null | null | null | null | null | null | null | null | GianniCatBug/falcon-7b-4bit-005-gender-debias-spanish | [
-0.6031695008277893,
-0.7586110830307007,
0.4166053533554077,
0.12900125980377197,
-0.43522483110427856,
-0.076738640666008,
-0.09583631157875061,
-0.4044339954853058,
-0.044428493827581406,
0.394164502620697,
-0.689440906047821,
-0.5373467206954956,
-0.559406042098999,
0.04107685759663582... |
Serdarmuhammet/bert-base-banking77 | Serdarmuhammet | 2023-11-29T01:32:21Z | 95 | 0 | null | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:banking77",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | 2023-11-29T01:32:21Z | 2023-10-09T08:43:38.000Z | null | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- banking77
metrics:
- f1
model-index:
- name: bert-base-banking77
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: banking77
type: banking77
config: default
split: test
args: default
metrics:
- name: F1
type: f1
value: 0.9311318811051271
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-banking77
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the banking77 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2967
- F1: 0.9311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0391 | 1.0 | 626 | 0.7670 | 0.8543 |
| 0.3676 | 2.0 | 1252 | 0.3623 | 0.9209 |
| 0.1715 | 3.0 | 1878 | 0.2967 | 0.9311 |
### Framework versions
- Transformers 4.27.1
- Pytorch 2.1.1+cu121
- Datasets 2.9.0
- Tokenizers 0.13.3
| null | transformers | text-classification | null | null | null | null | null | null | null | null | null | Serdarmuhammet/bert-base-banking77 | [
-0.49420008063316345,
-0.6238875389099121,
0.15714670717716217,
0.18504804372787476,
-0.5822246074676514,
-0.3929439187049866,
-0.16851122677326202,
-0.24398747086524963,
0.014663469977676868,
0.6304673552513123,
-0.6826349496841431,
-0.6850203275680542,
-0.7011623382568359,
-0.39398172497... |
OpenLLM-France/Claire-7B-Apache-0.1 | OpenLLM-France | 2023-11-29T19:02:43Z | 94 | 6 | null | [
"transformers",
"pytorch",
"falcon",
"text-generation",
"pretrained",
"conversational",
"fr",
"arxiv:2311.16840",
"base_model:tiiuae/falcon-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T19:02:43Z | 2023-11-09T18:00:51.000Z | null | null | ---
language:
- fr
license: apache-2.0
pipeline_tag: text-generation
base_model: tiiuae/falcon-7b
tags:
- pretrained
- conversational
widget:
- text: |-
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,
example_title: Request for a recipe
group: Dash
- text: |-
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,
example_title: Request for a recipe
group: Intervenant
- text: |-
[Camille:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Dominique:] Bonjour Camille,
example_title: Request for a recipe
group: FirstName
- text: |-
[Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Dominique Petit:] Bonjour Camille,
example_title: Request for a recipe
group: Named
inference:
parameters:
temperature: 1.0
max_new_tokens: 200
top_k: 10
---
# Claire-7B-Apache-0.1
**Claire-7B-Apache-0.1 is a 7B parameter causal decoder-only model built by [LINAGORA](https://labs.linagora.com/) and [OpenLLM-France](https://github.com/OpenLLM-France)**
**adapted from [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) on French conversational open data.**
Claire-7B-Apache-0.1 is a pretrained language model designed to be attuned to the dynamics of linguistic interactions in dialogue. Without further training, its expected use is to generate continuations of dialogues. Its main purpose is to serve as a base model for fine-tuning on dialogue generation (e.g., chat) and dialogue understanding (e.g., meeting summarization) tasks. Please note that due to its training, the model is prone to generate dialogues with disfluencies and other constructions common to spoken language.
This model is made available under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0).
It is a variant of [Claire-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1), which is trained on a larger quantity of French conversational data,
but published under the [CC-BY-NC-SA 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/).
* [Typical usage](#typical-usage)
* [Typical prompts](#typical-prompts)
* [Training Details](#training-details)
* [Training Data](#training-data)
* [Training Procedure](#training-procedure)
* [Evaluation](#evaluation)
* [License](#license)
* [Acknowledgements](#acknowledgements)
* [Contact](#contact)
## Typical usage
```python
import transformers
import torch
model_name = "OpenLLM-France/Claire-7B-Apache-0.1"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True # For efficient inference, if supported by the GPU card
)
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_kwargs = dict(
num_return_sequences=1, # Number of variants to generate.
return_full_text= False, # Do not include the prompt in the generated text.
max_new_tokens=200, # Maximum length for the output text.
do_sample=True, top_k=10, temperature=1.0, # Sampling parameters.
pad_token_id=tokenizer.eos_token_id, # Just to avoid a harmless warning.
)
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
completions = pipeline(prompt, **generation_kwargs)
for completion in completions:
print(prompt + " […]" + completion['generated_text'])
```
This will print something like:
```
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille, […] je vous prépare un plat de saison, une daube provençale.
- Ah je ne connais pas cette recette.
- C'est très facile à préparer, vous n'avez qu'à mettre de l'eau dans une marmite, y mettre de l'oignon émincé, des carottes coupées en petits morceaux, et vous allez mettre votre viande de bœuf coupé en petits morceaux également.
- Je n'ai jamais cuisiné de viande de bœuf, mais c'est vrai que ça a l'air bien facile.
- Vous n'avez plus qu'à laisser mijoter, et ensuite il sera temps de servir les clients.
- Très bien.
```
You will need at least 6GB of VRAM to run inference using 4bit quantization (16GB of VRAM without 4bit quantization).
If you have trouble running this code, make sure you have recent versions of `torch`, `transformers` and `accelerate` (see [requirements.txt](requirements.txt)).
### Typical prompts
Claire-7B-Apache-0.1 was trained on diarized French conversations. During training, the dialogues were normalized in several formats. The possible formats for expected prompts are as follows:
A monologue can be specified as a single line prompt (though keep in mind that Claire might still return a dialogue because of its training):
```python
prompt = "Mesdames et messieurs les députés, chers collègues, bonsoir. Vous l'aurez peut-être remarqué, je cite rarement"
```
A dialogue between two speakers can be specified with one line per speech turn starting with a dash:
```python
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
```
A dialogue or multilogue (with two or more speakers) can be specified with lines that start with `[Intervenant X:]` where `X` is a number:
```python
prompt = """\
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,\
"""
```
A dialogue or multilogue with named speakers can be specified with lines that start with `[SpeakerName:]`
where `SpeakerName` can be a first name, a first and a last name, a nickname, a title…
```python
prompt = """\
[Mme Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Mr. Dominique Petit:] Bonjour Camille,\
"""
```
## Training Details
### Training Data
The training dataset is available at [OpenLLM-France/Claire-Dialogue-French-0.1](https://huggingface.co/datasets/OpenLLM-France/Claire-Dialogue-French-0.1)
and described in ["The Claire French Dialogue Dataset" (2023)](https://arxiv.org/abs/2311.16840).
Claire-7B-Apache-0.1 was tuned from Falcon-7b on the following data distribution:
| **Data type** | **Words** | **Training Sampling Weight** | **Sources** |
|-----------------------------------------|------------|------------------------------|-------------------------------------------|
| Parliamentary Proceedings | 135M | 54% | Assemblée Nationale |
| Theatre | 2.7M | 23% | Théâtre Gratuit |
| Meetings | 1.0M | 16.6% | SUMM-RE, LinTO |
| Debates | 326k | 5.4% | FREDSum |
| Presentations, Conversations | 58k | 1% | LinTO |
Training data was augmented with the following techniques:
* varying the format used to indicate speech turns (dashes or [XXX:])
* substituting [Intervenant X:] for [SpeakerName:] or vice versa, where [SpeakerName:] might be a real name or a randomly generated name
* removing punctuation marks and/or casing (to prepare the model for transcripts produced by some Automatic Speech Recognition systems)
Long conversations were truncated at a maximum of 2048 tokens. Where possible, they were split between speaker turns.
While the model has been trained and evaluated only on French dialogues, it may be able to generate conversations in other languages from the original Falcon-7b training data.
### Training Procedure
The training code is available at [https://github.com/OpenLLM-France/Lit-Claire](https://github.com/OpenLLM-France/Lit-Claire).
Claire-7B-Apache-0.1 is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
See [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) for more details.
Claire-7B-Apache-0.1 was trained on 8 A100 80GB GPUs for about 50 GPU hours.
Hyperparameters were the following:
| **Hyperparameter** | **Value** |
|--------------------|------------|
| Precision | `bfloat16` |
| Optimizer | AdamW |
| Learning rate | 1e-4 |
| Weight decay | 1e-2 |
| Batch size | 128 |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| Dropout | 0.05 |
| gradient clipping | 1 |
## Evaluation
See the [Evaluation section of Claire-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1#evaluation).
## License
Claire-7B-Apache-0.1 is made available under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0).
You can find a variant of this model trained on more data but published under the [CC-BY-NC-SA 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/)
at [OpenLLM-France/Claire-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1).
## Acknowledgements
This work was performed using HPC resources from GENCI–IDRIS (Grant 2023-AD011014561).
Claire-7B-Apache-0.1 was created by members of [LINAGORA](https://labs.linagora.com/) (in alphabetical order): Ismaïl Harrando, Julie Hunter, Jean-Pierre Lorré, Jérôme Louradour, Michel-Marie Maudet, Virgile Rennard, Guokan Shang.
Special thanks to partners from the OpenLLM-France community, especially Christophe Cerisara (LORIA), Pierre-Carl Langlais and Anastasia Stasenko (OpSci), and Pierre Colombo, for valuable advice.
## Contact
contact@openllm-france.fr | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | OpenLLM-France/Claire-7B-Apache-0.1 | [
-0.44501587748527527,
-1.0450959205627441,
0.33453354239463806,
0.3472572863101959,
-0.07197556644678116,
-0.29925787448883057,
-0.3458576202392578,
-0.18755097687244415,
0.14008107781410217,
0.8020206689834595,
-0.7051336169242859,
-0.6627844572067261,
-0.5338152050971985,
0.2950136065483... |
jonathanjordan21/flan-alpaca-base-finetuned-lora-knowSQL | jonathanjordan21 | 2023-11-29T17:04:49Z | 84 | 1 | null | [
"peft",
"tensorboard",
"sql",
"query",
"database",
"text2text-generation",
"en",
"dataset:knowrohit07/know_sql",
"base_model:declare-lab/flan-alpaca-base",
"license:mit",
"region:us"
] | 2023-11-29T17:04:49Z | 2023-11-27T06:58:38.000Z | null | null | ---
library_name: peft
base_model: declare-lab/flan-alpaca-base
datasets:
- knowrohit07/know_sql
license: mit
language:
- en
pipeline_tag: text2text-generation
tags:
- sql
- query
- database
---
## Model Details
### Model Description
This model is based on the declare-lab/flan-alpaca-base model finetuned with knowrohit07/know_sql dataset.
- **Developed by:** Jonathan Jordan
- **Model type:** FLAN Alpaca
- **Language(s) (NLP):** English
- **License:** [More Information Needed]
- **Finetuned from model:** declare-lab/flan-alpaca-base
## Uses
The model generates a string of SQL query based on a question and MySQL table schema.
You can modify the table schema to match MySQL table schema if you are using different type of SQL database (e.g. PostgreSQL, Oracle, etc).
The generated SQL query can be run perfectly on the python SQL connection (e.g. psycopg2, mysql_connector, etc).
#### Limitations
1. The question MUST be in english
2. Keep in mind about the difference in data type naming between MySQL and the other SQL databases
3. The output always starts with SELECT *, you can't choose which columns to retrieve.
4. Aggregation function is not supported
### Input Example
```python
"""Question: what is What was the result of the election in the Florida 18 district?\nTable: table_1341598_10 (result VARCHAR, district VARCHAR)\nSQL: """
```
### Output Example
```python
"""SELECT * FROM table_1341598_10 WHERE district = "Florida 18""""
```
### How to use
Load model
```python
from peft import get_peft_config, get_peft_model, TaskType
from peft import PeftConfig, PeftModel
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_id = "jonathanjordan21/flan-alpaca-base-finetuned-lora-knowSQL"
config = PeftConfig.from_pretrained(model_id)
model_ = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path, return_dict=True)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model_, model_id)
```
Model inference
```python
question = "server of user id 11 with status active and server id 10"
table = "table_name_77 ( user id INTEGER, status VARCHAR, server id INTEGER )"
test = f"""Question: {question}\nTable: {table}\nSQL: """
p = tokenizer(test, return_tensors='pt')
device = "cuda" if torch.cuda.is_available() else "cpu"
out = model.to(device).generate(**p.to(device),max_new_tokens=50)
print("SQL Query :", tokenizer.batch_decode(out,skip_special_tokens=True)[0])
```
## Performance
### Speed Performance
The model inference takes about 2-3 seconds to run in Google Colab Free Tier CPU
### Framework versions
- PEFT 0.6.2 | null | peft | text2text-generation | null | null | null | null | null | null | null | null | null | jonathanjordan21/flan-alpaca-base-finetuned-lora-knowSQL | [
-0.3725687265396118,
-1.119432806968689,
0.24055145680904388,
0.24026401340961456,
-0.07650194317102432,
-0.28190308809280396,
-0.021590927615761757,
-0.37574872374534607,
0.23063334822654724,
0.5776399374008179,
-0.5091451406478882,
-0.23925694823265076,
-0.33297425508499146,
0.1696353107... |
annamalai-s/distilbert-business-text-classification-geons | annamalai-s | 2023-11-29T05:44:35Z | 82 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | 2023-11-29T05:44:35Z | 2023-11-17T12:08:23.000Z | null | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-business-text-classification-geons
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-business-text-classification-geons
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3905
- Accuracy: 0.9231
- F1: 0.9231
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
| null | transformers | text-classification | null | null | null | null | null | null | null | null | null | annamalai-s/distilbert-business-text-classification-geons | [
-0.3561089038848877,
-0.472149133682251,
0.45280835032463074,
-0.03970111533999443,
-0.37074950337409973,
-0.39251020550727844,
-0.2837400436401367,
-0.23329681158065796,
0.04697408154606819,
0.34886258840560913,
-0.6640997529029846,
-0.9411792755126953,
-0.9352608919143677,
-0.04154695197... |
fblgit/juanako-7b-UNA | fblgit | 2023-11-29T12:38:02Z | 79 | 4 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"juanako",
"UNA",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2109.07958",
"arxiv:2310.16944",
"arxiv:2305.18290",
"license:apache-2.0",
"model-index",
"endpoints_comp... | 2023-11-29T12:38:02Z | 2023-11-27T10:24:44.000Z | null | null | ---
license: apache-2.0
tags:
- alignment-handbook
- generated_from_trainer
- juanako
- mistral
- UNA
datasets:
- HuggingFaceH4/ultrafeedback_binarized
model-index:
- name: juanako-7b-UNA
results:
- task:
type: text-generation
name: TruthfulQA (MC2)
dataset:
type: text-generation
name: truthful_qa
config: multiple_choice
split: validation
metrics:
- type: accuracy
value: 65.13
verified: true
- task:
type: text-generation
name: ARC-Challenge
dataset:
type: text-generation
name: ai2_arc
config: ARC-Challenge
split: test
metrics:
- type: accuracy
value: 68.17
verified: true
- task:
type: text-generation
name: HellaSwag
dataset:
type: text-generation
name: Rowan/hellaswag
split: test
metrics:
- type: accuracy
value: 85.34
verified: true
- task:
type: text-generation
name: Winogrande
dataset:
type: text-generation
name: winogrande
config: winogrande_debiased
split: test
metrics:
- type: accuracy
value: 78.85
verified: true
- task:
type: text-generation
name: MMLU
dataset:
type: text-generation
name: cais/mmlu
config: all
split: test
metrics:
- type: accuracy
value: 62.47
verified: true
- task:
type: text-generation
name: PiQA
dataset:
type: text-generation
name: piqa
split: test
metrics:
- type: accuracy
value: 83.57
- task:
type: text-generation
name: DROP
dataset:
type: text-generation
name: drop
split: validation
metrics:
- type: accuracy
value: 38.74
verified: true
- task:
type: text-generation
name: PubMedQA
dataset:
type: text-generation
name: bigbio/pubmed_qa
config: pubmed_qa_artificial_bigbio_qa
split: validation
metrics:
- type: accuracy
value: 76.0
---
# juanako-7b-UNA (Uniform Neural Alignment)
This model is a fine-tuned version of [fblgit/juanako-7b-UNA-v2-phase-1](https://huggingface.co/fblgit/juanako-7b-UNA-v2-phase-1) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It outperforms in many aspects most of the current Mistral based models and is the **latest and most powerful juanako version as of now**.
## Scores
The official HuggingFace results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/results/blob/main/fblgit/juanako-7b-UNA/results_2023-11-28T08-33-33.965228.json)
| Model | Average ⬆️| ARC (25-s) ⬆️ | HellaSwag (10-s) ⬆️ | MMLU (5-s) ⬆️| TruthfulQA (MC) (0-s) ⬆️ | Winogrande (5-s) | GSM8K (5-s) | DROP (3-s) |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
|[mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 50.32 | 59.58 | 83.31 | 64.16 | 42.15 | 78.37 | 18.12 | 6.14 |
| [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) | 59.0 | 66.21 | 83.64 | 62.37 | 59.65 | 78.14 | 19.56 | 43.84 |
| [fblgit/juanako-7b-UNA](https://huggingface.co/fblgit/juanako-7b-UNA) | **59.91** | **68.17** | **85.34** | 62.47 | **65.13** | **78.85** | **20.7** | 38.74 |
It scores: **59.91** according HuggingFace LLM Leaderboard.
It scores: **65.1** with `big-refactor` branch of lm-eval-harness
Author [Xavier M.](mailto:xavi@juanako.ai) @fblgit
## Model description
juanako uses UNA, Uniform Neural Alignment. A training technique that ease alignment between transformer layers yet to be published.
### Prompts
The following prompts showed positive results, it may depend the task and needs further experimentation but this should work for starters:
```
<|im_start|>system
- You are a helpful assistant chatbot trained by MosaicML.
- You answer questions.
- You are excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- You are more than just an information source, you are also able to write poetry, short stories, and make jokes.<|im_end|>
<|im_start|>user
Explain QKV<|im_end|>
<|im_start|>assistant
```
```
### Assistant: I am StableVicuna, a large language model created by CarperAI. I am here to chat!
### Human: Explain QKV
### Assistant:
```
```
[Round <|round|>]
问:Explain QKV
答:
```
```
[Round <|round|>]
Question:Explain QKV
Answer:
```
```
Question:Explain QKV
Answer:
```
## Evaluations (lm-eval big-refactor branch)
### TruthfulQA 0-Shot
```
| Tasks |Version|Filter|Metric|Value | |Stderr|
|--------------|-------|------|------|-----:|---|-----:|
|truthfulqa_mc2|Yaml |none |acc |0.6549|± |0.0153|
```
### ARC 25-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|-------------|-------|------|--------|-----:|---|-----:|
|arc_challenge|Yaml |none |acc |0.6476|± |0.0140|
| | |none |acc_norm|0.6809|± |0.0136|
```
### HellaSwag 10-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|---------|-------|------|--------|-----:|---|-----:|
|hellaswag|Yaml |none |acc |0.6703|± |0.0047|
| | |none |acc_norm|0.8520|± |0.0035|
```
### GSM8k 5-Shot
```
|Tasks|Version| Filter | Metric |Value | |Stderr|
|-----|-------|----------|-----------|-----:|---|-----:|
|gsm8k|Yaml |get-answer|exact_match|0.4898|± |0.0138|
```
### GPT Evaluations 0-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|boolq |Yaml |none |acc |0.8703|± |0.0059|
|lambada_openai|Yaml |none |perplexity|3.2598|± |0.0705|
| | |none |acc |0.7336|± |0.0062|
|piqa |Yaml |none |acc |0.8254|± |0.0089|
| | |none |acc_norm |0.8292|± |0.0088|
|sciq |Yaml |none |acc |0.9580|± |0.0063|
| | |none |acc_norm |0.9130|± |0.0089|
```
### MathQA 0-Shot
```
|Tasks |Version|Filter| Metric |Value | |Stderr|
|------|-------|------|--------|-----:|---|-----:|
|mathqa|Yaml |none |acc |0.3752|± |0.0089|
| | |none |acc_norm|0.3772|± |0.0089|
```
### PiQa 1-Shot
```
|Tasks|Version|Filter| Metric |Value | |Stderr|
|-----|-------|------|--------|-----:|---|-----:|
|piqa |Yaml |none |acc |0.8308|± |0.0087|
| | |none |acc_norm|0.8357|± |0.0086|
```
### Winogrande 5-Shot
```
| Tasks |Version|Filter|Metric|Value| |Stderr|
|----------|-------|------|------|----:|---|-----:|
|winogrande|Yaml |none |acc |0.768|± |0.0119|
```
### PubMedQA 0-Shot
```
| Tasks |Version|Filter|Metric|Value| |Stderr|
|--------|-------|------|------|----:|---|-----:|
|pubmedqa|Yaml |none |acc | 0.76|± |0.0191|
```
### RACE 1-Shot
```
|Tasks|Version|Filter|Metric|Value | |Stderr|
|-----|-------|------|------|-----:|---|-----:|
|race |Yaml |none |acc |0.5282|± |0.0154|
```
### MMLU 5-Shot (8-Bit)
```
| Groups |Version|Filter|Metric|Value | |Stderr|
|------------------|-------|------|------|-----:|---|-----:|
|mmlu |N/A |none |acc |0.6137|± |0.1243|
| - humanities |N/A |none |acc |0.5671|± |0.1101|
| - other |N/A |none |acc |0.6859|± |0.1164|
| - social_sciences|N/A |none |acc |0.7195|± |0.0713|
| - stem |N/A |none |acc |0.5087|± |0.1297|
```
### DROP 3-Shot (8-Bit) (Instruct-Eval)
```
{'score': 0.49801113762927607}
{'drop': 49.8}
drop: 49.8
```
### CRASS 0-Shot (Instruct-Eval)
```
{'score': 0.8357664233576643}
{'crass': 83.58}
crass: 83.58
```
## Training Details
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 14
- gradient_accumulation_steps: 16
- total_train_batch_size: 224
- total_eval_batch_size: 14
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.4795 | 0.2 | 56 | 0.4958 | -1.3684 | -2.6385 | 0.7552 | 1.2701 | -265.3887 | -241.2612 | -2.2572 | -2.4922 |
| 0.4642 | 0.4 | 112 | 0.4859 | -1.0380 | -1.9769 | 0.7273 | 0.9389 | -258.7718 | -237.9569 | -2.2414 | -2.4751 |
| 0.4758 | 0.61 | 168 | 0.4808 | -1.2594 | -2.3704 | 0.7343 | 1.1110 | -262.7074 | -240.1708 | -2.2305 | -2.4633 |
| 0.4549 | 0.81 | 224 | 0.4768 | -1.1906 | -2.3201 | 0.7552 | 1.1295 | -262.2044 | -239.4827 | -2.2284 | -2.4610 |
### Framework versions
- Transformers 4.35.0-UNA
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
## Citations
If you find juanako useful please:
```
@misc{juanako7buna,
title={Juanako: Uniform Neural Alignment},
author={Xavier Murias},
year={2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/fblgit/juanako-7b-UNA}},
}
```
Thanks to all the brilliant humans behind the creation of AI, here some of the ones that we find relevant to our research. If you feel a citation is missing, please contact.
```
@misc{lin2021truthfulqa,
title={TruthfulQA: Measuring How Models Mimic Human Falsehoods},
author={Stephanie Lin and Jacob Hilton and Owain Evans},
year={2021},
eprint={2109.07958},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{tunstall2023zephyr,
title={Zephyr: Direct Distillation of LM Alignment},
author={Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Kashif Rasul and Younes Belkada and Shengyi Huang and Leandro von Werra and Clémentine Fourrier and Nathan Habib and Nathan Sarrazin and Omar Sanseviero and Alexander M. Rush and Thomas Wolf},
year={2023},
eprint={2310.16944},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@inproceedings{Bisk2020,
author = {Yonatan Bisk and Rowan Zellers and
Ronan Le Bras and Jianfeng Gao
and Yejin Choi},
title = {PIQA: Reasoning about Physical Commonsense in
Natural Language},
booktitle = {Thirty-Fourth AAAI Conference on
Artificial Intelligence},
year = {2020},
}
@software{eval-harness,
author = {Gao, Leo and
Tow, Jonathan and
Biderman, Stella and
Black, Sid and
DiPofi, Anthony and
Foster, Charles and
Golding, Laurence and
Hsu, Jeffrey and
McDonell, Kyle and
Muennighoff, Niklas and
Phang, Jason and
Reynolds, Laria and
Tang, Eric and
Thite, Anish and
Wang, Ben and
Wang, Kevin and
Zou, Andy},
title = {A framework for few-shot language model evaluation},
month = sep,
year = 2021,
publisher = {Zenodo},
version = {v0.0.1},
doi = {10.5281/zenodo.5371628},
url = {https://doi.org/10.5281/zenodo.5371628}
}
@misc{rafailov2023direct,
title={Direct Preference Optimization: Your Language Model is Secretly a Reward Model},
author={Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn},
year={2023},
eprint={2305.18290},
archivePrefix={arXiv},
}
```
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | fblgit/juanako-7b-UNA | [
-0.7574539184570312,
-0.6384748816490173,
0.2213638871908188,
0.18388324975967407,
-0.1881999373435974,
0.027422994375228882,
-0.05560889467597008,
-0.2307177186012268,
0.6888761520385742,
0.1782156080007553,
-0.6772127151489258,
-0.6845393776893616,
-0.6574769020080566,
0.0072803497314453... |
W1lson/zephyr-7b-quote-adapter | W1lson | 2023-11-29T05:17:29Z | 79 | 0 | null | [
"peft",
"arxiv:1910.09700",
"base_model:TheBloke/zephyr-7B-beta-GPTQ",
"region:us"
] | 2023-11-29T05:17:29Z | 2023-11-29T05:17:26.000Z | null | null | ---
library_name: peft
base_model: TheBloke/zephyr-7B-beta-GPTQ
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.1
- desc_act: True
- sym: True
- true_sequential: True
- use_cuda_fp16: True
- model_seqlen: 4096
- block_name_to_quantize: model.layers
- module_name_preceding_first_block: ['model.embed_tokens']
- batch_size: 1
- pad_token_id: None
- use_exllama: True
- max_input_length: None
- exllama_config: {'version': <ExllamaVersion.ONE: 1>}
- cache_block_outputs: True
### Framework versions
- PEFT 0.6.2
| null | peft | null | null | null | null | null | null | null | null | null | null | W1lson/zephyr-7b-quote-adapter | [
-0.5444449186325073,
-0.5935627222061157,
0.40606117248535156,
0.06746409833431244,
-0.25423935055732727,
-0.28035831451416016,
0.06474721431732178,
-0.4822291135787964,
0.04317287728190422,
0.6045327186584473,
-0.7222115397453308,
-0.6911142468452454,
-0.5696945190429688,
-0.1493088752031... |
NurtureAI/Synatra-11B-v0.3-RP | NurtureAI | 2023-11-29T03:25:19Z | 78 | 1 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T03:25:19Z | 2023-11-29T03:18:29.000Z | null | null | ---
language:
- ko
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-4.0
---
# **Synatra-11B-v0.3-RP🐧**
# Original Model Card

## Support Me
시나트라는 개인 프로젝트로, 1인의 자원으로 개발되고 있습니다. 모델이 마음에 드셨다면 약간의 연구비 지원은 어떨까요?
[<img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy me a Coffee" width="217" height="50">](https://www.buymeacoffee.com/mwell)
Wanna be a sponser? Contact me on Telegram **AlzarTakkarsen**
# **License**
This model is strictly [*non-commercial*](https://creativecommons.org/licenses/by-nc/4.0/) (**cc-by-nc-4.0**) use only.
The "Model" is completely free (ie. base model, derivates, merges/mixes) to use for non-commercial purposes as long as the the included **cc-by-nc-4.0** license in any parent repository, and the non-commercial use statute remains, regardless of other models' licences.
The licence can be changed after new model released. If you are to use this model for commercial purpose, Contact me.
# **Model Details**
**Base Model**
[mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
**Trained On**
A6000 48GB * 8
**Instruction format**
It follows [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) format.
**TODO**
- ~~``RP 기반 튜닝 모델 제작``~~ ✅
- ~~``데이터셋 정제``~~ ✅
- 언어 이해능력 개선
- ~~``상식 보완``~~ ✅
- 토크나이저 변경
# **Model Benchmark**
## Ko-LLM-Leaderboard
On Benchmarking...
# **Implementation Code**
Since, chat_template already contains insturction format above.
You can use the code below.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("maywell/Synatra-7B-v0.3-RP")
tokenizer = AutoTokenizer.from_pretrained("maywell/Synatra-7B-v0.3-RP")
messages = [
{"role": "user", "content": "바나나는 원래 하얀색이야?"},
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
# Why It's benchmark score is lower than preview version?
**Apparently**, Preview model uses Alpaca Style prompt which has no pre-fix. But ChatML do.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_maywell__Synatra-7B-v0.3-RP)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 57.38 |
| ARC (25-shot) | 62.2 |
| HellaSwag (10-shot) | 82.29 |
| MMLU (5-shot) | 60.8 |
| TruthfulQA (0-shot) | 52.64 |
| Winogrande (5-shot) | 76.48 |
| GSM8K (5-shot) | 21.15 |
| DROP (3-shot) | 46.06 |
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | NurtureAI/Synatra-11B-v0.3-RP | [
-0.2666422426700592,
-0.838603675365448,
0.141965851187706,
0.39791369438171387,
-0.444643497467041,
-0.23582041263580322,
-0.2088061422109604,
-0.4762040674686432,
0.48741695284843445,
0.16124804317951202,
-0.6314061880111694,
-0.7621347308158875,
-0.7681600451469421,
-0.15848495066165924... |
tfjuror/finance-alpaca-finetuned-distilgpt | tfjuror | 2023-11-29T07:15:04Z | 78 | 0 | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"en",
"dataset:gbharti/finance-alpaca",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T07:15:04Z | 2023-11-29T06:44:37.000Z | null | null | ---
datasets:
- gbharti/finance-alpaca
language:
- en
metrics:
- rouge
- bleu
---
Proof of Concept LLM for AI for Economics term project.
We finetune DISTIL-GPT2 LLM on the Finance-Alpaca dataset for better performance on financial question answering.
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | tfjuror/finance-alpaca-finetuned-distilgpt | [
-0.4751523733139038,
-1.0289045572280884,
0.553166925907135,
0.3962996304035187,
-0.29817724227905273,
0.3045898377895355,
0.1908431202173233,
-0.3049711585044861,
0.41458484530448914,
0.3984091579914093,
-0.5229012370109558,
-0.2692101299762726,
-0.47897273302078247,
-0.030722612515091896... |
PhucMap/ViSenSum | PhucMap | 2023-11-29T09:41:13Z | 74 | 0 | null | [
"transformers",
"pytorch",
"safetensors",
"mbart",
"text2text-generation",
"summarization",
"vi",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T09:41:13Z | 2023-10-09T17:34:17.000Z | null | null | ---
license: mit
language:
- vi
metrics:
- rouge
pipeline_tag: summarization
--- | null | transformers | summarization | null | null | null | null | null | null | null | null | null | PhucMap/ViSenSum | [
-0.12853392958641052,
-0.18616771697998047,
0.6529129147529602,
0.494362473487854,
-0.19319334626197815,
0.2360745370388031,
0.36071959137916565,
0.050563208758831024,
0.5793651342391968,
0.7400140166282654,
-0.6508103609085083,
-0.2378397136926651,
-0.7102248668670654,
-0.0478259213268756... |
codefuse-ai/CodeFuse-CodeLlama-34B-4bits | codefuse-ai | 2023-11-29T05:37:26Z | 73 | 14 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2311.02303",
"license:other",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T05:37:26Z | 2023-09-27T03:50:15.000Z | null | null | ---
frameworks:
- Pytorch
license: other
tasks:
- text-generation
---
# Model Card for CodeFuse-CodeLlama-34B-4bits
<p align="left">
<img src="./LOGO.png" width="100%" />
</p>
[[中文]](#chinese) [[English]](#english)
<a id="english"></a>
## Model Description
CodeFuse-CodeLlama-34B-4bits is the 4-bit quantized version of CodeFuse-CodeLlama-34B, which is a 34B Code-LLM fine-tuned over multiple code tasks(600k instrunctions/answers)on the base model CodeLlama-34b-Python.
After undergoing 4-bit quantization, the CodeFuse-CodeLlama-34B-4bits model can be loaded on either a single A10 (24GB VRAM) or a RTX 4090 (24GB VRAM). Moreover, the quantized model still achives an impressive accuracy of 73.8% on the Humaneval pass@1 metric.
<br>
## News and Updates
🔥🔥🔥 2023-09-26 We are pleased to announce the release of the 4-bit quantized version of CodeFuse-CodeLlama-34B. Despite the quantization process, the model still achieves a remarkable 73.8% accuracy (greedy decoding) on the HumanEval pass@1 metric.
🔥🔥🔥 2023-09-11 CodeFuse-CodeLlama34B has achieved 74.4% of pass@1 (greedy decoding) on HumanEval, which is SOTA results for openspurced LLMs at present.
<br>
## Code Community
**Homepage**: 🏡 https://github.com/codefuse-ai (**Please give us your support with a Star🌟 + Fork🚀 + Watch👀**)
+ If you wish to fine-tune the model yourself, you can visit ✨[MFTCoder](https://github.com/codefuse-ai/MFTCoder)✨✨
+ If you wish to deploy the model yourself, you can visit ✨[FasterTransformer4CodeFuse](https://github.com/codefuse-ai/FasterTransformer4CodeFuse)✨✨
+ If you wish to see a demo of the model, you can visit ✨[CodeFuse Demo](https://github.com/codefuse-ai/codefuse)✨✨
<br>
## Performance
| Model | HumanEval(pass@1) | Date |
|:--------------------------------|:-----------------:|:-------:|
| **CodeFuse-CodeLlama-34B** | **74.4%** | 2023.9 |
|**CodeFuse-CodeLlama-34B-4bits** | **73.8%** | 2023.9 |
| WizardCoder-Python-34B-V1.0 | 73.2% | 2023.8 |
| GPT-4(zero-shot) | 67.0% | 2023.3 |
| PanGu-Coder2 15B | 61.6% | 2023.8 |
| CodeLlama-34b-Python | 53.7% | 2023.8 |
| CodeLlama-34b | 48.8% | 2023.8 |
| GPT-3.5(zero-shot) | 48.1% | 2022.11 |
| OctoCoder | 46.2% | 2023.8 |
| StarCoder-15B | 33.6% | 2023.5 |
| LLaMA 2 70B(zero-shot) | 29.9% | 2023.7 |
<br>
## GPU Memory Usage
We measured the GPU memory usage after loading the model, as well as the memory usage when encoding 2048/1024 tokens and generating 1024/2048 tokens. The results are presented in the table below.
| Precision | Idle Model | Encoding 2048 tokens and Generating 1024 tokens | Encoding 1024 tokens and Generating 2048 tokens |
|:--------------------------------|:-------------------|:------------------------:|:------------:|
|bfloat16 | 64.89GB | 69.31GB | 66.41GB |
|int4 | 19.09GB | 22.19GB | 20.78GB |
<br>
## Requirements
* python>=3.8
* pytorch>=2.0.0
* transformers==4.32.0
* auto_gptq==0.4.2
* Sentencepiece
* CUDA 11.4
<br>
## Inference String Format
The inference string is a concatenated string formed by combining conversation data (human and bot contents) in the training data format. It is used as input during the inference process.
Here is an example format of the concatenated string:
```python
"""
<|role_start|>human<|role_end|>Human 1st round input
<|role_start|>bot<|role_end|>Bot 1st round output</s>
<|role_start|>human<|role_end|>Human 2nd round input
<|role_start|>bot<|role_end|>Bot 2nd round output</s>
...
...
...
<|role_start|>human<|role_end|>Human nth round input
<|role_start|>bot<|role_end|>{Bot output to be genreated}</s>
"""
```
When applying inference, you always make your input string end with "<|role_start|>bot<|role_end|>" to ask the model generating answers.
<br>
## Quickstart
```bash
git clone https://huggingface.co/codefuse-ai/CodeFuse-CodeLlama-34B-4bits.git
```
```bash
pip install -r requirements.txt
```
```python
import os
import torch
import time
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def load_model_tokenizer(model_name_or_local_path):
"""
Load model and tokenizer based on the given model name or local path of the downloaded model.
"""
tokenizer = AutoTokenizer.from_pretrained(model_name_or_local_path,
trust_remote_code=True,
use_fast=False,
legacy=False)
tokenizer.padding_side = "left"
model = AutoGPTQForCausalLM.from_quantized(model_name_or_local_path,
inject_fused_attention=False,
inject_fused_mlp=False,
use_cuda_fp16=True,
disable_exllama=False,
device_map='auto' # Support multi-gpus
)
return model, tokenizer
def inference(model, tokenizer, prompt):
"""
Uset the given model and tokenizer to generate an answer for the specified prompt.
"""
st = time.time()
prompt = prompt if prompt.endswith('\n') else f'{prompt}\n'
inputs = f"<|role_start|>human<|role_end|>{prompt}<|role_start|>bot<|role_end|>"
input_ids = tokenizer.encode(inputs,
return_tensors="pt",
padding=True,
add_special_tokens=False).to("cuda")
with torch.no_grad():
generated_ids = model.generate(
input_ids=input_ids,
top_p=0.95,
temperature=0.1,
do_sample=True,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
print(f'generated tokens num is {len(generated_ids[0][input_ids.size(1):])}')
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f'generate text is {outputs[0][len(inputs): ]}')
latency = time.time() - st
print('latency is {} seconds'.format(latency))
if __name__ == "__main__":
model_name_or_local_path = '<Mole name (i.e. codefuse-ai/CodeFuse-CodeLlama-34B-4bits) or local path of the downloaded model>'
prompt = 'Please write a QuickSort program in Python'
model, tokenizer = load_model_tokenizer(model_name_or_local_path)
inference(model, tokenizer, prompt)
```
**The current inference example code is based on [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ). If you want to achieve higher inference speed, it is recommended to combine it with [TensorRT-LLM (Early Access)](https://developer.nvidia.com/tensorrt-llm-early-access).**
<br>
## Consistency Check
Here, SHA256 values are provided for the model-related files for consistency check during the download.
| File | SHA256 |
|-------------------------------:|:--------------------------------:|
|config.json | bd1b92f942549f76d7e02e65fd346b39903943912d6d6a2ff8ff345e43e1115b |
|generation_config.json | b625bd13a52d0685313c32919324b9bdc9e75a4f1338ca5c28226d1693e130a3 |
|gptq_model-4bit-64g.bin | 79441bad1d5ab852d0238ed7e113b9912f31189cf9181d7119dd297c4beb454a |
|pytorch_model.bin.index.json | 9a714170172282cfbcaa120af13c0df08b06d040ff24dab30229d8a010821d3d |
|quantize_config.json | 3c1744a928e9d6c3f9a2cbb1bb5a89539077e7d456948bf5aee0deed6a7b8028 |
|special_tokens_map.json | ff3b4a612c4e447acb02d40071bddd989fe0da87eb5b7fe0dbadfc4f74de7531 |
|tokenizer.json | f7b50bcf6d6672eade5e43514d48e9c1e4e63a56aef7b14acdaca94ce93436f7 |
|tokenizer.model | 9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347 |
|tokenizer_config.json | c12441e82f2dce0baff87cf5948e82d6e9b51cc0b5266369c30c319fb771eeb2 |
<br>
## Citation
If you find our [work](https://arxiv.org/abs/2311.02303) useful or helpful for your R&D works, please feel free to cite our paper as below.
```
@article{mftcoder2023,
title={MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning},
author={Bingchang Liu and Chaoyu Chen and Cong Liao and Zi Gong and Huan Wang and Zhichao Lei and Ming Liang and Dajun Chen and Min Shen and Hailian Zhou and Hang Yu and Jianguo Li},
year={2023},
journal={arXiv preprint arXiv},
archivePrefix={arXiv},
eprint={2311.02303}
}
```
<br>
<a id="chinese"></a>
## 模型简介
CodeFuse-CodeLlama-34B-4bits是CodeFuse-CodeLlama-34B模型的4bits量化版本,后者是通过QLoRA对基座模型CodeLlama-34b-Python进行多代码任务微调而得到的代码大模型,模型输入长度为4K。
经4bits量化后,CodeFuse-CodeLlama-34B-4bits可用单张A10 (24GB显存)或者RTX 4090 (24GB显存)加载,同时,量化后的模型在Humaneval pass@1指标上仍取得了73.8%的表现。
<br>
## 新闻
🔥🔥🔥 2023-09-26 CodeFuse-CodeLlama-34B 4bits量化版本发布,量化后模型在HumanEval pass@1指标为73.8% (贪婪解码)。
🔥🔥🔥 2023-09-11 CodeFuse-CodeLlama-34B发布,HumanEval pass@1指标达到74.4% (贪婪解码), 为当前开源SOTA。
<br>
## 代码社区
**大本营**: 🏡 https://github.com/codefuse-ai (**请支持我们的项目Star🌟 + Fork🚀 + Watch👀**)
+ 如果您想自己微调该模型,可以访问 ✨[MFTCoder](https://github.com/codefuse-ai/MFTCoder)✨✨
+ 如果您想自己部署该模型,可以访问 ✨[FasterTransformer4CodeFuse](https://github.com/codefuse-ai/FasterTransformer4CodeFuse)✨✨
+ 如果您想观看该模型示例,可以访问 ✨[CodeFuse Demo](https://github.com/codefuse-ai/codefuse)✨✨
<br>
## 评测表现(代码)
| 模型 | HumanEval(pass@1) | 日期 |
|:--------------------------------|:-----------------:|:-------:|
| **CodeFuse-CodeLlama-34B** | **74.4%** | 2023.9 |
|**CodeFuse-CodeLlama-34B-4bits** | **73.8%** | 2023.9 |
| WizardCoder-Python-34B-V1.0 | 73.2% | 2023.8 |
| GPT-4(zero-shot) | 67.0% | 2023.3 |
| PanGu-Coder2 15B | 61.6% | 2023.8 |
| CodeLlama-34b-Python | 53.7% | 2023.8 |
| CodeLlama-34b | 48.8% | 2023.8 |
| GPT-3.5(zero-shot) | 48.1% | 2022.11 |
| OctoCoder | 46.2% | 2023.8 |
| StarCoder-15B | 33.6% | 2023.5 |
| LLaMA 2 70B(zero-shot) | 29.9% | 2023.7 |
<br>
## 显存使用
我们测量了模型加载后占用的显存占用情况,以及输入2048/1024 tokens并输出1024/2048 tokens时的显存使用情况,如下表所示
| 精度 | 模型空载 | 输入2048 tokens + 输出1024 tokens | 输入1024 tokens + 输出2048 tokens |
|:--------------------------------|:-------------------|:------------------------:|:------------:|
|bfloat16 | 64.89GB | 69.31GB | 66.41GB |
|int4 | 19.09GB | 22.19GB | 20.78GB |
<br>
## 依赖要求
* python>=3.8
* pytorch>=2.0.0
* transformers==4.32.0
* auto_gptq==0.4.2
* Sentencepiece
* CUDA 11.4
<br>
## 推理数据格式
推理数据为模型在训练数据格式下拼接的字符串形式,它也是推理时输入prompt拼接的方式:
```python
"""
<|role_start|>human<|role_end|>Human 1st round input
<|role_start|>bot<|role_end|>Bot 1st round output</s>
<|role_start|>human<|role_end|>Human 2nd round input
<|role_start|>bot<|role_end|>Bot 2nd round output</s>
...
...
...
<|end|><|role_start|>human<|role_end|>Human nth round input
<|end|><|role_start|>bot<|role_end|>{Bot output to be genreated}</s>
"""
```
推理时,请确保拼接的prompt字符串以"<|role_start|>bot<|role_end|>"结尾,引导模型生成回答。
<br>
## 快速使用
```bash
git clone https://huggingface.co/codefuse-ai/CodeFuse-CodeLlama-34B-4bits.git
```
```bash
pip install -r requirements.txt
```
```python
import os
import torch
import time
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def load_model_tokenizer(model_name_or_local_path):
"""
Load model and tokenizer based on the given model name or local path of downloaded model.
"""
tokenizer = AutoTokenizer.from_pretrained(model_name_or_local_path,
trust_remote_code=True,
use_fast=False,
legacy=False)
tokenizer.padding_side = "left"
model = AutoGPTQForCausalLM.from_quantized(model_name_or_local_path,
inject_fused_attention=False,
inject_fused_mlp=False,
use_cuda_fp16=True,
disable_exllama=False,
device_map='auto' # Support multi-gpus
)
return model, tokenizer
def inference(model, tokenizer, prompt):
"""
Uset the given model and tokenizer to generate an answer for the speicifed prompt.
"""
st = time.time()
prompt = prompt if prompt.endswith('\n') else f'{prompt}\n'
inputs = f"<|role_start|>human<|role_end|>{prompt}<|role_start|>bot<|role_end|>"
input_ids = tokenizer.encode(inputs,
return_tensors="pt",
padding=True,
add_special_tokens=False).to("cuda")
with torch.no_grad():
generated_ids = model.generate(
input_ids=input_ids,
top_p=0.95,
temperature=0.1,
do_sample=True,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
print(f'generated tokens num is {len(generated_ids[0][input_ids.size(1):])}')
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f'generate text is {outputs[0][len(inputs): ]}')
latency = time.time() - st
print('latency is {} seconds'.format(latency))
if __name__ == "__main__":
model_name_or_local_path = '<模型名字 (即codefuse-ai/CodeFuse-CodeLlama-34B-4bits)或者提前下载到本地的模型路径>'
prompt = '请用Python实现一个快速排序算法'
model, tokenizer = load_model_tokenizer(model_name_or_local_path)
inference(model, tokenizer, prompt)
```
**目前的推理示例代码是基于[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ)的,如果你想获取更高的推理速度,建议结合使用[TensorRT-LLM (Early Access)](https://developer.nvidia.com/tensorrt-llm-early-access)。**
<br>
## 一致性校验
这里提供了模型相关文件的SHA256值,用于下载一致性校验。
| 文件 | SHA256 |
|-------------------------------:|:--------------------------------:|
|config.json | bd1b92f942549f76d7e02e65fd346b39903943912d6d6a2ff8ff345e43e1115b |
|generation_config.json | b625bd13a52d0685313c32919324b9bdc9e75a4f1338ca5c28226d1693e130a3 |
|gptq_model-4bit-64g.bin | 79441bad1d5ab852d0238ed7e113b9912f31189cf9181d7119dd297c4beb454a |
|pytorch_model.bin.index.json | 9a714170172282cfbcaa120af13c0df08b06d040ff24dab30229d8a010821d3d |
|quantize_config.json | 3c1744a928e9d6c3f9a2cbb1bb5a89539077e7d456948bf5aee0deed6a7b8028 |
|special_tokens_map.json | ff3b4a612c4e447acb02d40071bddd989fe0da87eb5b7fe0dbadfc4f74de7531 |
|tokenizer.json | f7b50bcf6d6672eade5e43514d48e9c1e4e63a56aef7b14acdaca94ce93436f7 |
|tokenizer.model | 9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347 |
|tokenizer_config.json | c12441e82f2dce0baff87cf5948e82d6e9b51cc0b5266369c30c319fb771eeb2 |
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | codefuse-ai/CodeFuse-CodeLlama-34B-4bits | [
-0.40721002221107483,
-0.978378176689148,
0.18850374221801758,
0.16670188307762146,
-0.24383236467838287,
0.04874589294195175,
-0.1004820466041565,
-0.4329521656036377,
0.04612625762820244,
0.25377148389816284,
-0.3703958988189697,
-0.5670826435089111,
-0.5706843733787537,
-0.0214292276650... |
PracticeLLM/Custom-KoLLM-13B-v5 | PracticeLLM | 2023-11-29T16:46:00Z | 72 | 0 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/KOR-gugugu-platypus-set",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T16:46:00Z | 2023-11-28T18:32:59.000Z | null | null | ---
language:
- ko
datasets:
- kyujinpy/KOR-gugugu-platypus-set
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
# **⭐My custom LLM 13B⭐**
## Model Details
**Model Developers**
- Kyujin Han (kyujinpy)
**Model Architecture**
- My custom LLM 13B is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model**
- [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b)
**Training Dataset**
- [kyujinpy/KOR-gugugu-platypus-set](https://huggingface.co/datasets/kyujinpy/KOR-gugugu-platypus-set).
---
# Model comparisons
> Ko-LLM leaderboard(11/27; [link](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard))
| Model | Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| ⭐My custom LLM 13B-v1⭐ | **50.19** | **45.99** | 56.93 | 41.78 | 41.66 | **64.58** |
| ⭐My custom LLM 13B-v4⭐ | 49.89 | 45.05 | **57.06** | 41.83 | **42.93** | 62.57 |
| **⭐My custom LLM 13B-v5⭐** | 49.50 | 44.88 | 56.74 | **42.23** | 42.82 | 60.80 |
---
# Model comparisons2
> AI-Harness evaluation; [link](https://github.com/Beomi/ko-lm-evaluation-harness)
| Model | Copa | Copa | HellaSwag | HellaSwag | BoolQ | BoolQ | Sentineg | Sentineg |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | 0-shot | 5-shot | 0-shot | 5-shot | 0-shot | 5-shot | 0-shot | 5-shot |
| ⭐My custom LLM 13B-v1⭐ | 0.7987 | 0.8269 | 0.4994 | 0.5660 | 0.3343 | 0.5060 | 0.6984 | 0.9723 |
| ⭐My custom LLM 13B-v4⭐** | 0.7988 | 0.8279 | 0.4995 | 0.4953 | 0.3343 | 0.3558 | **0.7825** | 0.9698 |
| **⭐My custom LLM 13B-v5⭐** | **0.8028** | 0.8329 | **0.5082** | 0.5136 | **0.8647** | 0.8500 | **0.5524** | 0.9723 |
| [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b) | 0.7768 | 0.8128 | 0.4999 | 0.5127 | 0.3988 | 0.7038 | 0.5870 | 0.9748 |
---
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "PracticeLLM/Custom-KoLLM-13B-v5"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | PracticeLLM/Custom-KoLLM-13B-v5 | [
-0.5607258081436157,
-0.6072286367416382,
0.2065911591053009,
0.516447126865387,
-0.4443667531013489,
0.14142242074012756,
-0.07335010170936584,
-0.43554386496543884,
0.27541929483413696,
0.3638814091682434,
-0.6424924731254578,
-0.7918215990066528,
-0.8026179671287537,
-0.0062582711689174... |
famepram/ft_Mistral-7B_jkt48 | famepram | 2023-11-29T02:34:50Z | 70 | 0 | null | [
"peft",
"pytorch",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"region:us"
] | 2023-11-29T02:34:50Z | 2023-11-03T03:28:59.000Z | null | null | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
| null | peft | null | null | null | null | null | null | null | null | null | null | famepram/ft_Mistral-7B_jkt48 | [
-0.5775126218795776,
-0.580460250377655,
0.4031943678855896,
0.09047012031078339,
-0.3009674847126007,
-0.2306295484304428,
0.022853529080748558,
-0.5071821808815002,
0.026032453402876854,
0.5738028883934021,
-0.7248213887214661,
-0.5956279039382935,
-0.57224041223526,
-0.03204140439629555... |
LoftQ/Mistral-7B-v0.1-4bit-64rank | LoftQ | 2023-11-29T20:58:05Z | 70 | 0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T20:58:05Z | 2023-11-22T05:41:16.000Z | null | null | Entry not found | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | LoftQ/Mistral-7B-v0.1-4bit-64rank | [
-0.3227650821208954,
-0.22568479180335999,
0.8622263669967651,
0.4346153140068054,
-0.5282987952232361,
0.7012966871261597,
0.7915722727775574,
0.07618651539087296,
0.7746027112007141,
0.2563222348690033,
-0.7852821350097656,
-0.225738525390625,
-0.910447895526886,
0.5715667009353638,
-0... |
1aurent/vit_base_patch16_224.deblurmim_us280k_deblurring_mae | 1aurent | 2023-11-29T14:17:23Z | 69 | 0 | null | [
"timm",
"safetensors",
"image-classification",
"license:apache-2.0",
"region:us"
] | 2023-11-29T14:17:23Z | 2023-11-29T14:17:09.000Z | null | null | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
---
# Model card for vit_base_patch16_224.deblurmim_us280k_deblurring_mae
| null | timm | image-classification | null | null | null | null | null | null | null | null | null | 1aurent/vit_base_patch16_224.deblurmim_us280k_deblurring_mae | [
-0.28071916103363037,
-0.5118104219436646,
0.17894628643989563,
0.4473106265068054,
-0.8538734912872314,
0.18623299896717072,
0.7180392742156982,
0.10065578669309616,
0.34079283475875854,
0.7992563247680664,
-0.8261244893074036,
-0.5446330904960632,
-0.5238895416259766,
-0.2487667500972747... |
Weyaxi/HelpSteer-filtered-neural-chat-7b-v3-1-7B | Weyaxi | 2023-11-29T06:18:07Z | 68 | 0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T06:18:07Z | 2023-11-28T15:23:19.000Z | null | null | ---
license: apache-2.0
---
# HelpSteer-filtered-neural-chat-7b-v3-1-7B
HelpSteer-filtered-neural-chat-7b-v3-1-7B is a merge of [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) and [Weyaxi/HelpSteer-filtered-7B-Lora](https://hf.co/Weyaxi/HelpSteer-filtered-7B-Lora)
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Weyaxi/HelpSteer-filtered-neural-chat-7b-v3-1-7B | [
-0.5669417977333069,
-0.7763903737068176,
0.285974383354187,
0.5090314745903015,
-0.48825526237487793,
0.15591920912265778,
0.3439843952655792,
-0.5028761625289917,
0.8525115251541138,
0.6102900505065918,
-0.8376894593238831,
0.00796293094754219,
-0.6757656931877136,
-0.15135611593723297,
... |
flax-community/arabic-t5-small | flax-community | 2023-11-29T15:17:26Z | 67 | 6 | null | [
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"ar",
"dataset:mc4",
"dataset:oscar",
"dataset:arabic_billion_words",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T15:17:26Z | 2022-03-02T23:29:05.000Z | null | null | ---
language:
- ar
datasets:
- mc4
- oscar
- arabic_billion_words
---
# arabic-t5-small
This is a T5v1.1 (small) trained on the concatenation of the Arabic Billion Words corpus and the Arabic subsets of the mC4 and Oscar datasets.
The model could only be trained for about `10%` of the whole dataset due to time limitations. This is equivalent to `22'000` steps or about `4.3` Billion tokens.
## Training parameters
| | |
| :-------------------: | :-----------: |
| Training batch size | `384` |
| Evaluation batch size | `768` |
| learning rate | `1e-2` |
| dtype | `jnp.float32` |
## Preprocessing and the tokenizer
We tried to keep the preprocessing to a bare minimum. We only replaced URLs, emails and social media user mentions with fixed tokens.
Contrary to other pretrained Arabic LMs, we decided to not strip the Arabic diacritics and to keep them part of the vocabulary.
The tokenizer was trained on `5%` of the training set, with a vocabulary size of `64'000`.
For more details about preprocessing, check the [tokenizer code](https://huggingface.co/flax-community/arabic-t5-small/blob/main/t5_tokenizer_model.py)
## Data
The model was trained on the concatenation of the Arabic Billion Words corpus and the Arabic subsets of the mC4 and Oscar datasets.
A random `0.1%` subset of the data was reserved for evaluation and the rest for training.
## Results
| | |
| :-----------------: | :-----------: |
| Evaluation accuracy | `56.84%` |
| Evaluation Loss | `2.423` |
| Training Loss | `2.392` |
| Training Time | `22h 23m 51s` |
## Note for finetuning
This model was pretrained with dropout turned off, so the default `dropout_rate` in the model config is `0`.
To finetune the model dropout should be turned be back on, like this:
```python
model = T5ForConditionalGeneration.from_pretrained("flax-community/arabic-t5-small", dropout_rate=0.1)
```
or,
```python
model = AutoModelForSeq2SeqLM.from_pretrained("flax-community/arabic-t5-small", dropout_rate=0.1)
```
| null | transformers | text2text-generation | null | null | null | null | null | null | null | null | null | flax-community/arabic-t5-small | [
-0.40360668301582336,
-0.36637985706329346,
0.004067460540682077,
-0.02878609485924244,
-0.5586364269256592,
0.129942387342453,
-0.12437782436609268,
-0.2595621347427368,
-0.044283244758844376,
0.24224317073822021,
-0.5468221306800842,
-0.8780934810638428,
-0.9183047413825989,
0.2668756544... |
amaye15/autoencoder | amaye15 | 2023-11-29T15:45:13Z | 62 | 0 | null | [
"transformers",
"safetensors",
"autoencoder",
"feature-extraction",
"custom_code",
"en",
"license:mit",
"region:us"
] | 2023-11-29T15:45:13Z | 2023-11-23T12:51:27.000Z | null | null | ---
license: mit
language:
- en
inference: true
---
# AutoEncoder for Dimensionality Reduction
## Model Description
The `AutoEncoder` presented here is a neural network model based on an encoder-decoder architecture. It is designed to learn efficient representations (encodings) of the input data, typically for dimensionality reduction purposes. The encoder compresses the input into a lower-dimensional latent space, while the decoder reconstructs the input data from the latent representation.
This model is flexible and can be configured with different layer types such as linear layers, LSTMs, GRUs, or RNNs, and can handle bidirectional sequence processing. The model is configured to be used with the Hugging Face Transformers library, allowing for easy download and deployment.
## Intended Use
This `AutoEncoder` is suitable for unsupervised learning tasks where dimensionality reduction or feature learning is desired. Examples include anomaly detection, data compression, and preprocessing for other complex tasks such as feature reduction before classification.
## Basic Usage in Python
Here are some simple examples of how to use the `AutoEncoder` model in Python:
```python
from transformers import AutoConfig, AutoModel
config = AutoConfig.from_pretrained("amaye15/autoencoder", trust_remote_code = True)
# Let's say you want to change the input_dim and latent_dim
config.input_dim = 1024 # New input dimension
config.latent_dim = 64 # New latent dimension
# Similarly, update other parameters as needed
config.layer_types = 'gru' # Change layer types to 'gru'
config.dropout_rate = 0.2 # Update dropout rate
config.num_layers = 4 # Change the number of layers
config.compression_rate = 0.6 # Update compression rate
config.bidirectional = False # Change to unidirectional
### Change Configuration
model = AutoModel.from_config(config, trust_remote_code = True)
# Example input data (batch_size, seq_len, input_dim)
input_data = torch.rand((32, 10, 784)) # Adjust shape according to your needs
# Perform encoding and decoding
with torch.no_grad(): # Assuming inference only
output = model(input_data)
# The `output` is a dataclass with
output.logits
output.labels
output.hidden_state
output.loss
```
| null | transformers | feature-extraction | null | null | null | null | null | null | null | null | null | amaye15/autoencoder | [
-0.3967851996421814,
-0.4322187006473541,
-0.10461778193712234,
0.1489945352077484,
-0.1261860430240631,
-0.2639251947402954,
0.05481675639748573,
-0.16037090122699738,
0.28086546063423157,
0.3689175546169281,
-0.40975847840309143,
-0.478764146566391,
-0.6251106262207031,
0.017911447212100... |
uchicago-dsi/cgfp-classifier | uchicago-dsi | 2023-11-29T17:39:49Z | 61 | 0 | null | [
"transformers",
"pytorch",
"distilbert",
"endpoints_compatible",
"region:us"
] | 2023-11-29T17:39:49Z | 2023-11-18T19:23:51.000Z | null | null | Entry not found | null | transformers | null | null | null | null | null | null | null | null | null | null | uchicago-dsi/cgfp-classifier | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
oopsung/llama2-7b-exo-test-v1 | oopsung | 2023-11-29T03:00:51Z | 61 | 0 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T03:00:51Z | 2023-11-29T02:54:29.000Z | null | null | Entry not found | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | oopsung/llama2-7b-exo-test-v1 | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
metame/faster-distil-whisper-large-v2 | metame | 2023-11-29T16:19:25Z | 60 | 0 | null | [
"transformers",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | 2023-11-29T16:19:25Z | 2023-11-11T09:04:01.000Z | null | null | ---
license: mit
---
Please refer to [faster-distil-whisper](https://github.com/metame-none/faster-distil-whisper) for more details. | null | transformers | null | null | null | null | null | null | null | null | null | null | metame/faster-distil-whisper-large-v2 | [
-0.2324662208557129,
-0.8098847270011902,
0.8060646057128906,
0.8322968482971191,
-0.40095701813697815,
0.17268453538417816,
0.03303925320506096,
-0.27779579162597656,
0.6468538641929626,
0.4293639361858368,
-0.8923624157905579,
-0.5273258090019226,
-0.7262539863586426,
-0.0646089166402816... |
cenkersisman/chatbot-gpt2-turkish-128-token | cenkersisman | 2023-11-29T04:23:28Z | 54 | 0 | null | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"tr",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T04:23:28Z | 2023-10-17T14:42:04.000Z | null | null | ---
widget:
- text: 'steve jobs kimdir?'
example_title: steve jobs kimdir?
- text: 'programlama nedir?'
example_title: programlama nedir?
- text: 'sanal gerçeklik nedir?'
example_title: sanal gerçeklik nedir?
- text: 'marie curie kimdir?'
example_title: marie curie kimdir?
- text: 'somon balığı nedir?'
example_title: somon balığı nedir?
- text: 'kasırga nedir?'
example_title: kasırga nedir?
- text: 'okyanus nedir?'
example_title: okyanus nedir?
- text: 'venüs nedir?'
example_title: venüs nedir?
- text: 'parfüm nedir?'
example_title: parfüm nedir?
- text: 'köfte nedir?'
example_title: köfte nedir?
- text: 'bulaşık makinesi nedir?'
example_title: bulaşık makinesi nedir?
language:
- tr
---
# Model
GPT-2 Nedir Soru Şablonu ile İnce Ayarlı Türkçe Modeli
### Model Açıklaması
Bu model Nedir sorusu içeren şablonlar ile GPT-2 Türkçe Modelinin ince ayarlı modelidir. Sadece nedir? kimdir? sorularına cevap üretir. Ana modelin eğitimi halen yetersiz düzeyde olduğu için cevapların doğruluğu kelime kavramları baz alınarak değerlendirilmelidir. Cevaplar illüzyon içermektedir. Doğru olmayabilir. Amaç yanlış da olsa cevap cümleleri üretebilmesidir.
GPT-2 Türkçe Modeli Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir.
Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 128 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır..
Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 12 epoch eğitilmiştir. Eğitim halen devam etmektedir.
Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır.
## Model Nasıl Kullanılabilir
```python
# Model ile çıkarım yapmak için örnek kod
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/cenkersisman/chatbot-gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "somon balığı nedir?"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
## Eğitim Süreci Eğrisi
## Sınırlamalar ve Önyargılar
Bu model, bir özyineli dil modeli olarak eğitildi. Bu, temel işlevinin bir metin dizisi alıp bir sonraki belirteci tahmin etmek olduğu anlamına gelir. Dil modelleri bunun dışında birçok görev için yaygın olarak kullanılsa da, bu çalışmayla ilgili birçok bilinmeyen bulunmaktadır.
Model, küfür, açık saçıklık ve aksi davranışlara yol açan metinleri içerdiği bilinen bir veri kümesi üzerinde eğitildi. Kullanım durumunuza bağlı olarak, bu model toplumsal olarak kabul edilemez metinler üretebilir.
Tüm dil modellerinde olduğu gibi, bu modelin belirli bir girişe nasıl yanıt vereceğini önceden tahmin etmek zordur ve uyarı olmaksızın saldırgan içerik ortaya çıkabilir. Sonuçları yayınlamadan önce hem istenmeyen içeriği sansürlemek hem de sonuçların kalitesini iyileştirmek için insanların çıktıları denetlemesini veya filtrelemesi önerilir.
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | cenkersisman/chatbot-gpt2-turkish-128-token | [
-0.43851438164711,
-0.7860351800918579,
0.19924108684062958,
0.07051098346710205,
-0.4739120304584503,
-0.2822241485118866,
-0.04643257334828377,
-0.43056967854499817,
-0.07944849878549576,
0.1759849190711975,
-0.5303816199302673,
-0.3401624858379364,
-0.7907624840736389,
-0.04380685836076... |
SPAL0074/LlaMa_glucano | SPAL0074 | 2023-11-29T11:33:20Z | 52 | 0 | null | [
"peft",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"region:us"
] | 2023-11-29T11:33:20Z | 2023-11-16T07:30:34.000Z | null | null | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
| null | peft | null | null | null | null | null | null | null | null | null | null | SPAL0074/LlaMa_glucano | [
-0.57389897108078,
-0.5772488117218018,
0.40202954411506653,
0.08836019784212112,
-0.3002704977989197,
-0.23398509621620178,
0.024019576609134674,
-0.5058152675628662,
0.03271031007170677,
0.5745953917503357,
-0.7239546179771423,
-0.5959064364433289,
-0.5724968910217285,
-0.033631380647420... |
ilovecutiee/fantastical-art-lora | ilovecutiee | 2023-11-29T09:12:42Z | 52 | 0 | null | [
"diffusers",
"text-to-image",
"lora",
"stable-diffusion",
"art",
"base_model:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | 2023-11-29T09:12:42Z | 2023-11-29T09:09:27.000Z | null | null | ---
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: fantastical art
license: creativeml-openrail-m
tags:
- text-to-image
- diffusers
- lora
- stable-diffusion
- art
---
# Fantastical Art LoRA
A beautiful Stable Diffusion model that generates beautiful and artistic images | null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | ilovecutiee/fantastical-art-lora | [
-0.22206629812717438,
-0.9242822527885437,
0.12220025062561035,
0.508205235004425,
-0.2326817810535431,
0.09975191205739975,
0.3763936161994934,
-0.33710330724716187,
0.5962197780609131,
0.8804211020469666,
-0.3316948115825653,
-0.6448459625244141,
-0.6648236513137817,
-0.49799346923828125... |
mlinmg/SG-Raccoon-Yi-55B | mlinmg | 2023-11-29T10:52:43Z | 51 | 3 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:other",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T10:52:43Z | 2023-11-27T19:45:11.000Z | null | null | ---
language:
- en,
pipeline_tag: conversational
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
---
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/644ba0c76ebb3ebf7264dbe9/PWn9I-0XH7kSP_YXcyxIg.png" width="400"/>
</p>
---
# SG Raccoon Yi 55B
The first 55B auto-regressive causal LM created by combining 2x finetuned [Yi 34b](https://huggingface.co/01-ai/Yi-34B) into one.
# Prompting Format
```
single-turn: <|startoftext|>Human: Hello!\n\nAssistant: <|endoftext|>
multi-turn: <|startoftext|>Human: Hello!\n\nAssistant: <|endoftext|>Hi!<|endoftext|>Human: How are you?\n\nAssistant: <|endoftext|>target2<|endoftext|>
```
# Merge process
The models used in the merge are [dolphin-2_2-yi-34b](https://huggingface.co/ehartford/dolphin-2_2-yi-34b) and [OrionStar-Yi-34B-Chat-Llama](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama).
The layer ranges used are as follows:
```yaml
- range 0, 16
OrionStar-Yi-34B-Chat
- range 8, 24
dolphin-2_2-yi-34b
- range 17, 32
OrionStar-Yi-34B-Chat
- range 25, 40
dolphin-2_2-yi-34b
- range 33, 48
OrionStar-Yi-34B-Chat
- range 41, 56
dolphin-2_2-yi-34b
- range 49, 64
OrionStar-Yi-34B-Chat
- range 57, 72
dolphin-2_2-yi-34b
- range 65, 80
OrionStar-Yi-34B-Chat
```
# Tips
Being a Yi model, try disabling the BOS token and/or running a lower temperature with MinP (and no other samplers) if output doesn't seem right. Yi tends to run "hot" by default.
Sometimes the model "spells out" the stop token as </s> like Capybara, so you may need to add </s> as an additional stopping condition.
# Benchmarks
Coming soon.
# Acknowledgements
- Special thanks to [MSS](https://milanosamplesale.com/) for sponsoring this project
- [@chargoddard](https://huggingface.co/chargoddard) for developing the framework used to merge the model - [mergekit](https://github.com/cg123/mergekit).
- Great thanks to [@Undi95](https://huggingface.co/Undi95) for helping figuring out model merge options
- Also credits to the [01-ai](https://huggingface.co/01-ai) team for their amazing models
- This merged model is inspired by [Goliath 120B](https://huggingface.co/alpindale/goliath-120b)
| null | transformers | conversational | null | null | null | null | null | null | null | null | null | mlinmg/SG-Raccoon-Yi-55B | [
-0.6819173097610474,
-0.6526362895965576,
-0.06438267976045609,
0.27173012495040894,
-0.20946358144283295,
-0.18690690398216248,
-0.03461019694805145,
-0.6577296853065491,
0.37421002984046936,
0.3833164870738983,
-0.931367814540863,
-0.3588773310184479,
-0.41593801975250244,
-0.03914761170... |
ibm/patchtsmixer-etth1-pretrain | ibm | 2023-11-29T09:37:51Z | 50 | 0 | null | [
"transformers",
"pytorch",
"safetensors",
"patchtsmixer",
"endpoints_compatible",
"region:us"
] | 2023-11-29T09:37:51Z | 2023-09-15T09:34:50.000Z | null | null | Entry not found | null | transformers | null | null | null | null | null | null | null | null | null | null | ibm/patchtsmixer-etth1-pretrain | [
-0.3227650225162506,
-0.22568444907665253,
0.8622258901596069,
0.43461504578590393,
-0.5282988548278809,
0.7012965679168701,
0.7915717959403992,
0.0761863961815834,
0.7746025919914246,
0.2563222050666809,
-0.7852813005447388,
-0.22573848068714142,
-0.910447895526886,
0.5715667009353638,
... |
cantillation/whisper-small-he-teamim5 | cantillation | 2023-11-29T18:43:08Z | 50 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"he",
"base_model:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2023-11-29T18:43:08Z | 2023-11-02T23:01:36.000Z | null | null | ---
language:
- he
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
model-index:
- name: he
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# he
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.15.0
| null | transformers | automatic-speech-recognition | null | null | null | null | null | null | null | null | null | cantillation/whisper-small-he-teamim5 | [
-0.4525149464607239,
-0.6336133480072021,
0.14573393762111664,
0.07897160202264786,
-0.4494556784629822,
-0.7498934268951416,
-0.2724185585975647,
-0.39584121108055115,
0.31451237201690674,
0.3256800174713135,
-0.7278622984886169,
-0.46643805503845215,
-0.5447832345962524,
-0.1173406913876... |
shleeeee/mistral-7b-wiki | shleeeee | 2023-11-29T12:40:51Z | 50 | 0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetune",
"ko",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T12:40:51Z | 2023-11-28T13:00:50.000Z | null | null | ---
language:
- ko
pipeline_tag: text-generation
tags:
- finetune
---
# Model Card for mistral-7b-wiki
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee)
* **Repository** : To be added
* **Model Architecture** : The mistral-7b-wiki is is a fine-tuned version of the Mistral-7B-v0.1.
* **Lora target modules** : q_proj, k_proj, v_proj, o_proj,gate_proj
* **train_batch** : 2
* **Max_step** : 500
## Dataset
Korean Custom Dataset
## Prompt template: Mistral
```
<s>[INST]{['instruction']}[/INST]{['output']}</s>
```
## Usage
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("shleeeee/mistral-7b-wiki")
model = AutoModelForCausalLM.from_pretrained("shleeeee/mistral-7b-wiki")
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="shleeeee/mistral-7b-wiki")
```
## Evaluation

| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | shleeeee/mistral-7b-wiki | [
-0.5679202079772949,
-0.5153874754905701,
0.09791054576635361,
0.2721776068210602,
-0.49751994013786316,
-0.37983179092407227,
0.17988108098506927,
-0.12509141862392426,
0.14395999908447266,
0.767410397529602,
-0.6985441446304321,
-0.7501794099807739,
-0.5038064122200012,
0.110347576439380... |
DavidLanz/llama2_taiwan_news_qlora | DavidLanz | 2023-11-29T01:28:10Z | 48 | 2 | null | [
"peft",
"arxiv:1910.09700",
"base_model:model/llama2_taiwan_news_merged",
"region:us"
] | 2023-11-29T01:28:10Z | 2023-10-17T07:40:45.000Z | null | null | ---
library_name: peft
base_model: model/llama2_taiwan_news_merged
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
| null | peft | null | null | null | null | null | null | null | null | null | null | DavidLanz/llama2_taiwan_news_qlora | [
-0.5854648351669312,
-0.5876927375793457,
0.39884400367736816,
0.09154714643955231,
-0.30153098702430725,
-0.24599049985408783,
0.02687840908765793,
-0.5074957013130188,
0.026280764490365982,
0.5678561329841614,
-0.721109926700592,
-0.6003152132034302,
-0.566374659538269,
-0.04259333387017... |
indiejoseph/bart-base-cantonese | indiejoseph | 2023-11-29T10:50:19Z | 48 | 0 | null | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:indiejoseph/wikipedia-zh-yue-filtered",
"dataset:indiejoseph/cc100-yue",
"dataset:indiejoseph/ted-transcriptions-cantonese",
"dataset:indiejoseph/c4-cantonese-filtered",
... | 2023-11-29T10:50:19Z | 2023-10-21T08:15:25.000Z | null | null | ---
base_model: fnlp/bart-base-chinese
tags:
- generated_from_trainer
model-index:
- name: bart-base-cantonese
results: []
datasets:
- indiejoseph/wikipedia-zh-yue-filtered
- indiejoseph/cc100-yue
- indiejoseph/ted-transcriptions-cantonese
- indiejoseph/c4-cantonese-filtered
- mozilla-foundation/common_voice_13_0
- jed351/rthk_news
- jed351/shikoto_zh_hk
widget:
- text: "今日去咗旺角[MASK]"
example_title: "Mong Kok"
- text: "今時今日香港係一個[MASK]。"
example_title: "Hong Kong"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-cantonese
This model is a continue pre-train version of [fnlp/bart-base-chinese](https://huggingface.co/fnlp/bart-base-chinese) on filtered Cantonese common crawl dataset with 950M tokens.
This tokenizer has extended the Bert tokenizer from fnlp/bart-base-chinese with 500 more Chinese characters commonly found in Cantonese
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| null | transformers | text2text-generation | null | null | null | null | null | null | null | null | null | indiejoseph/bart-base-cantonese | [
-0.2576369643211365,
-0.5759788155555725,
0.09324181824922562,
0.4911859929561615,
-0.40170562267303467,
-0.28729209303855896,
-0.16488303244113922,
-0.28037142753601074,
0.36074718832969666,
0.5368651151657104,
-0.5000638961791992,
-0.5189554691314697,
-0.49913689494132996,
0.065492838621... |
imadejski/bhr_descriptions_trained_BiomedBERT | imadejski | 2023-11-29T19:20:59Z | 47 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T19:20:59Z | 2023-11-29T03:54:19.000Z | null | null | ---
license: mit
base_model: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract
tags:
- generated_from_trainer
model-index:
- name: bhr_descriptions_trained_BiomedBERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bhr_descriptions_trained_BiomedBERT
This model is a fine-tuned version of [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1232
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 31 | 2.3015 |
| No log | 2.0 | 62 | 2.1430 |
| No log | 3.0 | 93 | 2.0668 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
| null | transformers | fill-mask | null | null | null | null | null | null | null | null | null | imadejski/bhr_descriptions_trained_BiomedBERT | [
-0.2052297443151474,
-0.4274675250053406,
0.2415955662727356,
0.1156642884016037,
-0.3562930226325989,
-0.2708721160888672,
-0.014712376520037651,
-0.39516153931617737,
0.0677427425980568,
0.25157430768013,
-0.6428015828132629,
-0.6642492413520813,
-0.5697056651115417,
-0.01247607450932264... |
91stefan/stefan_realvisxl20 | 91stefan | 2023-11-29T13:37:23Z | 47 | 0 | null | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | 2023-11-29T13:37:23Z | 2023-11-29T11:19:11.000Z | null | null | Entry not found | null | diffusers | null | null | null | null | null | null | null | null | null | null | 91stefan/stefan_realvisxl20 | [
-0.3227650821208954,
-0.22568479180335999,
0.8622263669967651,
0.4346153140068054,
-0.5282987952232361,
0.7012966871261597,
0.7915722727775574,
0.07618651539087296,
0.7746027112007141,
0.2563222348690033,
-0.7852821350097656,
-0.225738525390625,
-0.910447895526886,
0.5715667009353638,
-0... |
Amiran13/wav2vec2-large-xlsr-georgian_v1 | Amiran13 | 2023-11-29T08:10:19Z | 46 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2023-11-29T08:10:19Z | 2023-11-20T20:45:45.000Z | null | null | ---
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-large-xlsr-georgian_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-georgian_v1
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0992
- Wer: 0.2605
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.1412 | 0.16 | 100 | 3.0855 | 1.0 |
| 3.0569 | 0.33 | 200 | 3.0369 | 1.0 |
| 2.9625 | 0.49 | 300 | 2.9778 | 1.0 |
| 0.7715 | 0.65 | 400 | 0.5113 | 0.7185 |
| 0.4725 | 0.81 | 500 | 0.3072 | 0.5138 |
| 0.4103 | 0.98 | 600 | 0.2447 | 0.4337 |
| 0.2775 | 1.14 | 700 | 0.2055 | 0.3769 |
| 0.2554 | 1.3 | 800 | 0.1950 | 0.3603 |
| 0.263 | 1.46 | 900 | 0.1813 | 0.3372 |
| 0.2294 | 1.63 | 1000 | 0.1664 | 0.3132 |
| 0.2296 | 1.79 | 1100 | 0.1565 | 0.2962 |
| 0.2183 | 1.95 | 1200 | 0.1474 | 0.2986 |
| 0.1822 | 2.12 | 1300 | 0.1546 | 0.2811 |
| 0.1798 | 2.28 | 1400 | 0.1442 | 0.2811 |
| 0.179 | 2.44 | 1500 | 0.1411 | 0.2686 |
| 0.1593 | 2.6 | 1600 | 0.1408 | 0.2739 |
| 0.2652 | 2.77 | 1700 | 0.2074 | 0.4499 |
| 0.1834 | 2.93 | 1800 | 0.1570 | 0.3942 |
| 0.2015 | 3.09 | 1900 | 0.1516 | 0.3859 |
| 0.1696 | 3.26 | 2000 | 0.1452 | 0.3826 |
| 0.1782 | 3.42 | 2100 | 0.1413 | 0.3763 |
| 0.1636 | 3.58 | 2200 | 0.1350 | 0.3761 |
| 0.173 | 3.74 | 2300 | 0.1323 | 0.3622 |
| 0.1704 | 3.91 | 2400 | 0.1289 | 0.3644 |
| 0.1418 | 4.07 | 2500 | 0.1266 | 0.3481 |
| 0.1403 | 4.23 | 2600 | 0.1274 | 0.3482 |
| 0.1353 | 4.4 | 2700 | 0.1287 | 0.3489 |
| 0.1432 | 4.56 | 2800 | 0.1293 | 0.3532 |
| 0.1283 | 4.72 | 2900 | 0.1226 | 0.3416 |
| 0.1367 | 4.88 | 3000 | 0.1206 | 0.3426 |
| 0.1162 | 5.05 | 3100 | 0.1222 | 0.3394 |
| 0.1267 | 5.21 | 3200 | 0.1183 | 0.3313 |
| 0.1126 | 5.37 | 3300 | 0.1180 | 0.3299 |
| 0.1127 | 5.53 | 3400 | 0.1177 | 0.3305 |
| 0.1155 | 5.7 | 3500 | 0.1185 | 0.3317 |
| 0.1086 | 5.86 | 3600 | 0.1129 | 0.3227 |
| 0.1135 | 6.02 | 3700 | 0.1118 | 0.3266 |
| 0.1112 | 6.19 | 3800 | 0.1142 | 0.3228 |
| 0.0866 | 6.35 | 3900 | 0.1172 | 0.3284 |
| 0.1003 | 6.51 | 4000 | 0.1133 | 0.3244 |
| 0.4366 | 6.68 | 4100 | 0.2436 | 0.4587 |
| 0.1216 | 6.84 | 4200 | 0.1344 | 0.3386 |
| 0.1165 | 7.0 | 4300 | 0.1280 | 0.3324 |
| 0.131 | 7.17 | 4400 | 0.1252 | 0.3245 |
| 0.1407 | 7.33 | 4500 | 0.1234 | 0.3252 |
| 0.1394 | 7.49 | 4600 | 0.1208 | 0.3177 |
| 0.1449 | 7.65 | 4700 | 0.1180 | 0.3165 |
| 0.1295 | 7.82 | 4800 | 0.1170 | 0.3152 |
| 0.1228 | 7.98 | 4900 | 0.1182 | 0.3160 |
| 0.0913 | 8.14 | 5000 | 0.1122 | 0.3086 |
| 0.1014 | 8.3 | 5100 | 0.1118 | 0.3100 |
| 0.0861 | 8.47 | 5200 | 0.1126 | 0.3074 |
| 0.1442 | 8.63 | 5300 | 0.1373 | 0.3311 |
| 0.1054 | 8.79 | 5400 | 0.1225 | 0.3143 |
| 0.104 | 8.96 | 5500 | 0.1190 | 0.3157 |
| 0.0972 | 9.12 | 5600 | 0.1140 | 0.3076 |
| 0.0948 | 9.28 | 5700 | 0.1090 | 0.3067 |
| 0.1067 | 9.45 | 5800 | 0.1117 | 0.3074 |
| 0.0798 | 9.61 | 5900 | 0.1097 | 0.3040 |
| 0.089 | 9.77 | 6000 | 0.1049 | 0.3005 |
| 0.0829 | 9.93 | 6100 | 0.1056 | 0.3006 |
| 0.0687 | 10.1 | 6200 | 0.1102 | 0.3018 |
| 0.0844 | 10.26 | 6300 | 0.1056 | 0.2985 |
| 0.0862 | 10.42 | 6400 | 0.1073 | 0.2990 |
| 0.0936 | 10.58 | 6500 | 0.1049 | 0.2949 |
| 0.0821 | 10.75 | 6600 | 0.1053 | 0.2966 |
| 0.0797 | 10.91 | 6700 | 0.1043 | 0.2939 |
| 0.0802 | 11.07 | 6800 | 0.1057 | 0.2911 |
| 0.0895 | 11.24 | 6900 | 0.1029 | 0.2934 |
| 0.073 | 11.4 | 7000 | 0.1042 | 0.2897 |
| 0.0842 | 11.56 | 7100 | 0.1023 | 0.2902 |
| 0.0825 | 11.72 | 7200 | 0.1024 | 0.2911 |
| 0.0958 | 11.89 | 7300 | 0.1018 | 0.2888 |
| 0.0698 | 12.05 | 7400 | 0.1030 | 0.2883 |
| 0.0693 | 12.21 | 7500 | 0.1019 | 0.2872 |
| 0.0736 | 12.37 | 7600 | 0.1003 | 0.2871 |
| 0.0683 | 12.54 | 7700 | 0.1004 | 0.2865 |
| 0.0649 | 12.7 | 7800 | 0.1005 | 0.2835 |
| 0.0669 | 12.86 | 7900 | 0.0985 | 0.2846 |
| 0.069 | 13.03 | 8000 | 0.0999 | 0.2844 |
| 0.0674 | 13.19 | 8100 | 0.1002 | 0.2835 |
| 0.0695 | 13.35 | 8200 | 0.1013 | 0.2829 |
| 0.0578 | 13.51 | 8300 | 0.1019 | 0.2821 |
| 0.0614 | 13.68 | 8400 | 0.0978 | 0.2815 |
| 0.0554 | 13.84 | 8500 | 0.0984 | 0.2813 |
| 0.0763 | 14.0 | 8600 | 0.1001 | 0.2813 |
| 0.0877 | 14.16 | 8700 | 0.1000 | 0.2808 |
| 0.0882 | 14.33 | 8800 | 0.0979 | 0.2803 |
| 0.0864 | 14.49 | 8900 | 0.0981 | 0.2788 |
| 0.0828 | 14.65 | 9000 | 0.0975 | 0.2790 |
| 0.3052 | 14.82 | 9100 | 0.2150 | 0.4175 |
| 0.1478 | 14.98 | 9200 | 0.1325 | 0.3027 |
| 1.0386 | 15.15 | 9300 | 0.4375 | 0.6793 |
| 0.116 | 15.31 | 9400 | 0.1266 | 0.3042 |
| 0.1226 | 15.47 | 9500 | 0.1206 | 0.3000 |
| 0.0885 | 15.63 | 9600 | 0.1173 | 0.2958 |
| 0.091 | 15.8 | 9700 | 0.1145 | 0.2929 |
| 0.0886 | 15.96 | 9800 | 0.1112 | 0.2908 |
| 0.0783 | 16.12 | 9900 | 0.1075 | 0.2873 |
| 0.069 | 16.28 | 10000 | 0.1072 | 0.2876 |
| 0.0783 | 16.45 | 10100 | 0.1070 | 0.2876 |
| 0.0669 | 16.61 | 10200 | 0.1055 | 0.2848 |
| 0.072 | 16.77 | 10300 | 0.1043 | 0.2846 |
| 0.0721 | 16.94 | 10400 | 0.1020 | 0.2821 |
| 0.0694 | 17.1 | 10500 | 0.1047 | 0.2803 |
| 0.0574 | 17.26 | 10600 | 0.1053 | 0.2830 |
| 0.0578 | 17.42 | 10700 | 0.1042 | 0.2806 |
| 0.0663 | 17.59 | 10800 | 0.1035 | 0.2801 |
| 0.0615 | 17.75 | 10900 | 0.1025 | 0.2785 |
| 0.0706 | 17.91 | 11000 | 0.1028 | 0.2792 |
| 0.2373 | 18.08 | 11100 | 0.1686 | 0.3372 |
| 0.1137 | 18.24 | 11200 | 0.1202 | 0.2938 |
| 0.1008 | 18.4 | 11300 | 0.1143 | 0.2895 |
| 0.1004 | 18.57 | 11400 | 0.1127 | 0.2874 |
| 0.0874 | 18.73 | 11500 | 0.1108 | 0.2861 |
| 0.0926 | 18.89 | 11600 | 0.1108 | 0.2838 |
| 0.0703 | 19.05 | 11700 | 0.1101 | 0.2834 |
| 0.0893 | 19.22 | 11800 | 0.1097 | 0.2824 |
| 0.0681 | 19.38 | 11900 | 0.1099 | 0.2822 |
| 0.0668 | 19.54 | 12000 | 0.1086 | 0.2813 |
| 0.069 | 19.7 | 12100 | 0.1087 | 0.2810 |
| 0.0683 | 19.87 | 12200 | 0.1085 | 0.2807 |
| 0.1116 | 20.03 | 12300 | 0.1221 | 0.2978 |
| 0.0752 | 20.19 | 12400 | 0.1161 | 0.2956 |
| 0.0787 | 20.36 | 12500 | 0.1128 | 0.2927 |
| 0.0741 | 20.52 | 12600 | 0.1100 | 0.2922 |
| 0.0764 | 20.68 | 12700 | 0.1081 | 0.2906 |
| 0.0747 | 20.85 | 12800 | 0.1082 | 0.2896 |
| 0.0876 | 21.01 | 12900 | 0.1052 | 0.2896 |
| 0.0878 | 21.17 | 13000 | 0.1110 | 0.2950 |
| 0.0895 | 21.33 | 13100 | 0.1095 | 0.2934 |
| 0.0953 | 21.5 | 13200 | 0.1122 | 0.2981 |
| 0.0787 | 21.66 | 13300 | 0.1072 | 0.2896 |
| 0.0774 | 21.82 | 13400 | 0.1076 | 0.2880 |
| 0.0908 | 21.98 | 13500 | 0.1113 | 0.2916 |
| 0.0737 | 22.15 | 13600 | 0.1067 | 0.2870 |
| 0.0714 | 22.31 | 13700 | 0.1096 | 0.2864 |
| 0.0775 | 22.47 | 13800 | 0.1085 | 0.2868 |
| 0.0761 | 22.64 | 13900 | 0.1040 | 0.2852 |
| 0.0675 | 22.8 | 14000 | 0.1090 | 0.2836 |
| 0.0829 | 22.96 | 14100 | 0.1066 | 0.2814 |
| 0.0731 | 23.12 | 14200 | 0.1057 | 0.2835 |
| 0.058 | 23.29 | 14300 | 0.1059 | 0.2834 |
| 0.0833 | 23.45 | 14400 | 0.1056 | 0.2847 |
| 0.1007 | 23.62 | 14500 | 0.1225 | 0.3059 |
| 0.0896 | 23.78 | 14600 | 0.1088 | 0.2899 |
| 0.084 | 23.94 | 14700 | 0.1056 | 0.2834 |
| 0.0684 | 24.1 | 14800 | 0.1070 | 0.2865 |
| 0.0646 | 24.27 | 14900 | 0.1109 | 0.2862 |
| 0.0728 | 24.43 | 15000 | 0.1081 | 0.2876 |
| 0.0615 | 24.59 | 15100 | 0.1077 | 0.2846 |
| 0.0642 | 24.75 | 15200 | 0.1062 | 0.2842 |
| 0.0736 | 24.92 | 15300 | 0.1058 | 0.2864 |
| 0.0801 | 25.08 | 15400 | 0.1106 | 0.2844 |
| 0.0687 | 25.24 | 15500 | 0.1104 | 0.2836 |
| 0.0852 | 25.41 | 15600 | 0.1055 | 0.2826 |
| 0.078 | 25.57 | 15700 | 0.1069 | 0.2817 |
| 0.0815 | 25.73 | 15800 | 0.1040 | 0.2799 |
| 0.0863 | 25.89 | 15900 | 0.1074 | 0.2801 |
| 0.0603 | 26.06 | 16000 | 0.1044 | 0.2779 |
| 0.0625 | 26.22 | 16100 | 0.1036 | 0.2796 |
| 0.057 | 26.38 | 16200 | 0.1086 | 0.2802 |
| 0.0632 | 26.54 | 16300 | 0.1057 | 0.2790 |
| 0.0644 | 26.71 | 16400 | 0.1022 | 0.2750 |
| 0.0645 | 26.87 | 16500 | 0.1003 | 0.2766 |
| 0.0536 | 27.03 | 16600 | 0.1051 | 0.2786 |
| 0.058 | 27.2 | 16700 | 0.1051 | 0.2790 |
| 0.052 | 27.36 | 16800 | 0.1034 | 0.2748 |
| 0.0514 | 27.52 | 16900 | 0.1027 | 0.2751 |
| 0.0593 | 27.68 | 17000 | 0.1036 | 0.2795 |
| 0.0577 | 27.85 | 17100 | 0.1025 | 0.2770 |
| 0.0694 | 28.01 | 17200 | 0.1008 | 0.2733 |
| 0.0641 | 28.17 | 17300 | 0.1088 | 0.2760 |
| 0.0566 | 28.33 | 17400 | 0.1092 | 0.2759 |
| 0.073 | 28.5 | 17500 | 0.1120 | 0.2788 |
| 0.0632 | 28.66 | 17600 | 0.1056 | 0.2764 |
| 0.0674 | 28.82 | 17700 | 0.1021 | 0.2739 |
| 0.0663 | 28.99 | 17800 | 0.1033 | 0.2733 |
| 0.0544 | 29.15 | 17900 | 0.1053 | 0.2721 |
| 0.0583 | 29.31 | 18000 | 0.1033 | 0.2732 |
| 0.0652 | 29.47 | 18100 | 0.1015 | 0.2728 |
| 0.0577 | 29.64 | 18200 | 0.1029 | 0.2730 |
| 0.1068 | 29.8 | 18300 | 0.1297 | 0.2950 |
| 0.0805 | 29.97 | 18400 | 0.1113 | 0.2792 |
| 0.0689 | 30.13 | 18500 | 0.1077 | 0.2789 |
| 0.0688 | 30.29 | 18600 | 0.1069 | 0.2777 |
| 0.0589 | 30.45 | 18700 | 0.1071 | 0.2757 |
| 0.049 | 30.62 | 18800 | 0.1077 | 0.2749 |
| 0.0534 | 30.78 | 18900 | 0.1046 | 0.2703 |
| 0.0506 | 30.94 | 19000 | 0.1039 | 0.2728 |
| 0.0534 | 31.11 | 19100 | 0.1036 | 0.2719 |
| 0.0453 | 31.27 | 19200 | 0.1064 | 0.2717 |
| 0.0514 | 31.43 | 19300 | 0.1034 | 0.2712 |
| 0.0579 | 31.59 | 19400 | 0.1065 | 0.2726 |
| 0.0491 | 31.76 | 19500 | 0.1054 | 0.2749 |
| 0.0547 | 31.92 | 19600 | 0.1023 | 0.2720 |
| 0.08 | 32.08 | 19700 | 0.1037 | 0.2707 |
| 0.0649 | 32.24 | 19800 | 0.1037 | 0.2702 |
| 0.064 | 32.41 | 19900 | 0.1053 | 0.2714 |
| 0.064 | 32.57 | 20000 | 0.1035 | 0.2691 |
| 0.0658 | 32.73 | 20100 | 0.1017 | 0.2663 |
| 0.0636 | 32.9 | 20200 | 0.1031 | 0.2680 |
| 0.0439 | 33.06 | 20300 | 0.1010 | 0.2668 |
| 0.0518 | 33.22 | 20400 | 0.1016 | 0.2691 |
| 0.0498 | 33.38 | 20500 | 0.1028 | 0.2682 |
| 0.0516 | 33.55 | 20600 | 0.1009 | 0.2679 |
| 0.0534 | 33.71 | 20700 | 0.1022 | 0.2672 |
| 0.0464 | 33.87 | 20800 | 0.1029 | 0.2661 |
| 0.0522 | 34.03 | 20900 | 0.1002 | 0.2668 |
| 0.0458 | 34.2 | 21000 | 0.0981 | 0.2644 |
| 0.0425 | 34.36 | 21100 | 0.1004 | 0.2659 |
| 0.0461 | 34.52 | 21200 | 0.1009 | 0.2650 |
| 0.0436 | 34.69 | 21300 | 0.1007 | 0.2652 |
| 0.0507 | 34.85 | 21400 | 0.1005 | 0.2655 |
| 0.0437 | 35.01 | 21500 | 0.0992 | 0.2648 |
| 0.0492 | 35.17 | 21600 | 0.1022 | 0.2655 |
| 0.0456 | 35.34 | 21700 | 0.1030 | 0.2639 |
| 0.0421 | 35.5 | 21800 | 0.1054 | 0.2639 |
| 0.0759 | 35.67 | 21900 | 0.1253 | 0.2760 |
| 0.059 | 35.83 | 22000 | 0.1125 | 0.2710 |
| 0.0515 | 35.99 | 22100 | 0.1073 | 0.2667 |
| 0.0583 | 36.16 | 22200 | 0.1085 | 0.2671 |
| 0.0603 | 36.32 | 22300 | 0.1047 | 0.2658 |
| 0.0575 | 36.48 | 22400 | 0.1034 | 0.2652 |
| 0.0605 | 36.64 | 22500 | 0.1044 | 0.2656 |
| 0.0545 | 36.81 | 22600 | 0.1057 | 0.2649 |
| 0.0583 | 36.97 | 22700 | 0.1033 | 0.2641 |
| 0.0492 | 37.13 | 22800 | 0.1039 | 0.2641 |
| 0.0561 | 37.29 | 22900 | 0.1027 | 0.2640 |
| 0.0447 | 37.46 | 23000 | 0.1023 | 0.2631 |
| 0.0521 | 37.62 | 23100 | 0.1010 | 0.2636 |
| 0.0482 | 37.78 | 23200 | 0.1021 | 0.2635 |
| 0.0468 | 37.95 | 23300 | 0.0999 | 0.2631 |
| 0.0473 | 38.11 | 23400 | 0.1016 | 0.2629 |
| 0.0416 | 38.27 | 23500 | 0.1003 | 0.2621 |
| 0.0491 | 38.43 | 23600 | 0.1022 | 0.2618 |
| 0.0394 | 38.6 | 23700 | 0.1017 | 0.2622 |
| 0.0389 | 38.76 | 23800 | 0.1011 | 0.2620 |
| 0.0381 | 38.92 | 23900 | 0.0992 | 0.2608 |
| 0.0557 | 39.08 | 24000 | 0.0999 | 0.2613 |
| 0.0545 | 39.25 | 24100 | 0.1002 | 0.2608 |
| 0.0633 | 39.41 | 24200 | 0.0997 | 0.2607 |
| 0.0471 | 39.57 | 24300 | 0.0994 | 0.2609 |
| 0.0672 | 39.74 | 24400 | 0.0991 | 0.2606 |
| 0.066 | 39.9 | 24500 | 0.0992 | 0.2605 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
| null | transformers | automatic-speech-recognition | null | null | null | null | null | null | null | null | null | Amiran13/wav2vec2-large-xlsr-georgian_v1 | [
-0.6879619359970093,
-0.6120997071266174,
0.3404977321624756,
0.15102818608283997,
-0.013927084393799305,
0.06512284278869629,
0.07103004306554794,
0.07805585861206055,
0.8746154308319092,
0.4611746072769165,
-0.6751831769943237,
-0.6430184841156006,
-0.6913323402404785,
-0.209731131792068... |
ledu1017/cartoon | ledu1017 | 2023-11-29T10:50:45Z | 46 | 0 | null | [
"diffusers",
"text-to-image",
"autotrain",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
] | 2023-11-29T10:50:45Z | 2023-11-29T07:01:23.000Z | null | null |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: A cartoon painting
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
| null | diffusers | text-to-image | null | null | null | null | null | null | null | null | null | ledu1017/cartoon | [
0.07325825095176697,
-0.17835836112499237,
0.2353803515434265,
0.13522787392139435,
-0.5473270416259766,
1.0075256824493408,
0.19510549306869507,
-0.2036203145980835,
0.5356342792510986,
-0.0032070213928818703,
-0.539963960647583,
-0.044514525681734085,
-0.9003113508224487,
0.3044254183769... |
Tung177/sentence-splitting | Tung177 | 2023-11-29T21:20:32Z | 45 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T21:20:32Z | 2023-11-15T07:39:17.000Z | null | null | Entry not found | null | transformers | text2text-generation | null | null | null | null | null | null | null | null | null | Tung177/sentence-splitting | [
-0.32276463508605957,
-0.2256849706172943,
0.8622266054153442,
0.4346153736114502,
-0.5282987952232361,
0.7012974619865417,
0.7915722131729126,
0.07618652284145355,
0.7746030688285828,
0.2563217282295227,
-0.7852814793586731,
-0.22573867440223694,
-0.9104479551315308,
0.571567177772522,
... |
Chat-UniVi/Chat-UniVi-13B | Chat-UniVi | 2023-11-29T02:28:52Z | 45 | 1 | null | [
"transformers",
"pytorch",
"ChatUniVi",
"text-generation",
"arxiv:2311.08046",
"license:llama2",
"endpoints_compatible",
"region:us"
] | 2023-11-29T02:28:52Z | 2023-11-21T02:50:34.000Z | null | null | ---
license: llama2
---
# Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
**Paper or resources for more information:**
[[Paper](https://huggingface.co/papers/2311.08046)] [[Code](https://github.com/PKU-YuanGroup/Chat-UniVi)]
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
## 😮 Highlights
### 💡 Unified visual representation for image and video
We employ **a set of dynamic visual tokens** to uniformly represent images and videos.
This representation framework empowers the model to efficiently utilize **a limited number of visual tokens** to simultaneously capture **the spatial details necessary for images** and **the comprehensive temporal relationship required for videos**.
### 🔥 Joint training strategy, making LLMs understand both image and video
Chat-UniVi is trained on a mixed dataset containing both images and videos, allowing direct application to tasks involving both mediums without requiring any modifications.
### 🤗 High performance, complementary learning with image and video
Extensive experimental results demonstrate that Chat-UniVi, as a unified model, consistently outperforms even existing methods exclusively designed for either images or videos.
### Inference for Video Understanding
```python
import torch
import os
from ChatUniVi.constants import *
from ChatUniVi.conversation import conv_templates, SeparatorStyle
from ChatUniVi.model.builder import load_pretrained_model
from ChatUniVi.utils import disable_torch_init
from ChatUniVi.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
from PIL import Image
from decord import VideoReader, cpu
import numpy as np
def _get_rawvideo_dec(video_path, image_processor, max_frames=MAX_IMAGE_LENGTH, image_resolution=224, video_framerate=1, s=None, e=None):
# speed up video decode via decord.
if s is None:
start_time, end_time = None, None
else:
start_time = int(s)
end_time = int(e)
start_time = start_time if start_time >= 0. else 0.
end_time = end_time if end_time >= 0. else 0.
if start_time > end_time:
start_time, end_time = end_time, start_time
elif start_time == end_time:
end_time = start_time + 1
if os.path.exists(video_path):
vreader = VideoReader(video_path, ctx=cpu(0))
else:
print(video_path)
raise FileNotFoundError
fps = vreader.get_avg_fps()
f_start = 0 if start_time is None else int(start_time * fps)
f_end = int(min(1000000000 if end_time is None else end_time * fps, len(vreader) - 1))
num_frames = f_end - f_start + 1
if num_frames > 0:
# T x 3 x H x W
sample_fps = int(video_framerate)
t_stride = int(round(float(fps) / sample_fps))
all_pos = list(range(f_start, f_end + 1, t_stride))
if len(all_pos) > max_frames:
sample_pos = [all_pos[_] for _ in np.linspace(0, len(all_pos) - 1, num=max_frames, dtype=int)]
else:
sample_pos = all_pos
patch_images = [Image.fromarray(f) for f in vreader.get_batch(sample_pos).asnumpy()]
patch_images = torch.stack([image_processor.preprocess(img, return_tensors='pt')['pixel_values'][0] for img in patch_images])
slice_len = patch_images.shape[0]
return patch_images, slice_len
else:
print("video path: {} error.".format(video_path))
if __name__ == '__main__':
# Model Parameter
model_path = "Chat-UniVi/Chat-UniVi" # or "Chat-UniVi/Chat-UniVi-13B"
video_path = ${video_path}
# The number of visual tokens varies with the length of the video. "max_frames" is the maximum number of frames.
# When the video is long, we will uniformly downsample the video to meet the frames when equal to the "max_frames".
max_frames = 100
# The number of frames retained per second in the video.
video_framerate = 1
# Input Text
qs = "Describe the video."
# Sampling Parameter
conv_mode = "simple"
temperature = 0.2
top_p = None
num_beams = 1
disable_torch_init()
model_path = os.path.expanduser(model_path)
model_name = "ChatUniVi"
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, None, model_name)
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model()
image_processor = vision_tower.image_processor
if model.config.config["use_cluster"]:
for n, m in model.named_modules():
m = m.to(dtype=torch.bfloat16)
# Check if the video exists
if video_path is not None:
video_frames, slice_len = _get_rawvideo_dec(video_path, image_processor, max_frames=max_frames, video_framerate=video_framerate)
cur_prompt = qs
if model.config.mm_use_im_start_end:
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN * slice_len + DEFAULT_IM_END_TOKEN + '\n' + qs
else:
qs = DEFAULT_IMAGE_TOKEN * slice_len + '\n' + qs
conv = conv_templates[conv_mode].copy()
conv.append_message(conv.roles[0], qs)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(
0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=video_frames.half().cuda(),
do_sample=True,
temperature=temperature,
top_p=top_p,
num_beams=num_beams,
output_scores=True,
return_dict_in_generate=True,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
output_ids = output_ids.sequences
input_token_len = input_ids.shape[1]
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
if n_diff_input_output > 0:
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[:-len(stop_str)]
outputs = outputs.strip()
print(outputs)
```
### Inference for Image Understanding
```python
import torch
import os
from ChatUniVi.constants import *
from ChatUniVi.conversation import conv_templates, SeparatorStyle
from ChatUniVi.model.builder import load_pretrained_model
from ChatUniVi.utils import disable_torch_init
from ChatUniVi.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
from PIL import Image
if __name__ == '__main__':
# Model Parameter
model_path = "Chat-UniVi/Chat-UniVi" # or "Chat-UniVi/Chat-UniVi-13B"
image_path = ${image_path}
# Input Text
qs = "Describe the image."
# Sampling Parameter
conv_mode = "simple"
temperature = 0.2
top_p = None
num_beams = 1
disable_torch_init()
model_path = os.path.expanduser(model_path)
model_name = "ChatUniVi"
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, None, model_name)
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model()
image_processor = vision_tower.image_processor
# Check if the video exists
if image_path is not None:
cur_prompt = qs
if model.config.mm_use_im_start_end:
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
else:
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
conv = conv_templates[conv_mode].copy()
conv.append_message(conv.roles[0], qs)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
image = Image.open(image_path)
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor.unsqueeze(0).half().cuda(),
do_sample=True,
temperature=temperature,
top_p=top_p,
num_beams=num_beams,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
input_token_len = input_ids.shape[1]
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
if n_diff_input_output > 0:
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[:-len(stop_str)]
outputs = outputs.strip()
print(outputs)
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Chat-UniVi/Chat-UniVi-13B | [
-0.2982747256755829,
-0.7948988676071167,
0.21623769402503967,
0.27457883954048157,
-0.5200621485710144,
-0.09963104873895645,
-0.3029811680316925,
-0.13892193138599396,
-0.16310317814350128,
0.09897852689027786,
-0.5197168588638306,
-0.5583686232566833,
-0.7752846479415894,
-0.26465627551... |
jaimik69/blip_finetuned | jaimik69 | 2023-11-29T06:52:52Z | 45 | 0 | null | [
"transformers",
"tensorboard",
"safetensors",
"blip",
"question-answering",
"generated_from_trainer",
"base_model:Salesforce/blip-vqa-base",
"license:bsd-3-clause",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T06:52:52Z | 2023-11-29T03:26:06.000Z | null | null | ---
license: bsd-3-clause
base_model: Salesforce/blip-vqa-base
tags:
- generated_from_trainer
model-index:
- name: blip_finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# blip_finetuned
This model is a fine-tuned version of [Salesforce/blip-vqa-base](https://huggingface.co/Salesforce/blip-vqa-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Tokenizers 0.15.0
| null | transformers | question-answering | null | null | null | null | null | null | null | null | null | jaimik69/blip_finetuned | [
-0.3181637227535248,
-0.6073442101478577,
-0.05319219082593918,
0.3940546214580536,
-0.38229265809059143,
-0.2220965474843979,
-0.04181930795311928,
-0.38616621494293213,
0.15204490721225739,
0.5566442012786865,
-0.7380767464637756,
-0.4548494219779968,
-0.5619606971740723,
-0.111639447510... |
jonathanjordan21/flan-alpaca-base-finetuned-lora-wikisql | jonathanjordan21 | 2023-11-29T18:42:36Z | 44 | 1 | null | [
"peft",
"tensorboard",
"sql",
"query",
"database",
"text2text-generation",
"en",
"dataset:wikisql",
"base_model:declare-lab/flan-alpaca-base",
"license:mit",
"region:us"
] | 2023-11-29T18:42:36Z | 2023-11-29T09:13:09.000Z | null | null | ---
library_name: peft
base_model: declare-lab/flan-alpaca-base
license: mit
language:
- en
pipeline_tag: text2text-generation
tags:
- sql
- query
- database
datasets:
- wikisql
---
## Model Details
### Model Description
This model is based on the declare-lab/flan-alpaca-base model finetuned with wikisql dataset.
- **Developed by:** Jonathan Jordan
- **Model type:** FLAN Alpaca
- **Language(s) (NLP):** English
- **License:** [More Information Needed]
- **Finetuned from model:** declare-lab/flan-alpaca-base
## Uses
The model generates a string of SQL query based on a question and table columns. **The generated query always uses "table" as the table name**.
Feel free to change the table name in the generated query to match your actual SQL table.
The generated SQL query can be run perfectly on the python SQL connection (e.g. psycopg2, mysql_connector, etc).
#### Limitations
1. The question MUST be in english
2. Keep in mind about the difference in data type naming between MySQL and the other SQL databases
3. Simple SQL Aggregation functions (SUM, AVG, COUNT, MIN, MAX) are supported
4. Advanced SQL Aggregation which involves GROUP BY, ORDER BY, HAVING, etc are highly not recommended
5. Table JOIN is not supported
### Input Example
```python
"""Question: what is What was the result of the election in the Florida 18 district?\nTable: table_1341598_10 (result VARCHAR, district VARCHAR)\nSQL: """
```
### Output Example
```python
"""SELECT * FROM table WHERE district = "Florida 18""""
```
### How to use
Load model
```python
from peft import get_peft_config, get_peft_model, TaskType
from peft import PeftConfig, PeftModel
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_id = "jonathanjordan21/flan-alpaca-base-finetuned-lora-wikisql"
config = PeftConfig.from_pretrained(model_id)
model_ = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path, return_dict=True)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model_, model_id)
```
Model inference
```python
question = "server of user id 11 with status active and server id 10"
table = "table_name_77 ( user id INTEGER, status VARCHAR, server id INTEGER )"
test = f"""Question: {question}\nTable: {table}\nSQL: """
p = tokenizer(test, return_tensors='pt')
device = "cuda" if torch.cuda.is_available() else "cpu"
out = model.to(device).generate(**p.to(device),max_new_tokens=50)
print("SQL Query :", tokenizer.batch_decode(out,skip_special_tokens=True)[0])
```
## Performance
### Speed Performance
The model inference takes about 2-3 seconds to run in Google Colab Free Tier CPU
### Framework versions
- PEFT 0.6.2 | null | peft | text2text-generation | null | null | null | null | null | null | null | null | null | jonathanjordan21/flan-alpaca-base-finetuned-lora-wikisql | [
-0.3763844668865204,
-1.1814546585083008,
0.22016511857509613,
0.2148798555135727,
-0.0888141542673111,
-0.3225821554660797,
-0.004552573896944523,
-0.354521244764328,
0.22039780020713806,
0.5773084759712219,
-0.5393646955490112,
-0.28869929909706116,
-0.3439218997955322,
0.175359919667243... |
M98M/hmbertplus | M98M | 2023-11-29T20:54:20Z | 43 | 1 | null | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T20:54:20Z | 2023-11-12T22:07:08.000Z | null | null | Entry not found | null | transformers | fill-mask | null | null | null | null | null | null | null | null | null | M98M/hmbertplus | [
-0.3227643668651581,
-0.22568444907665253,
0.862226128578186,
0.43461546301841736,
-0.5282992124557495,
0.7012968063354492,
0.7915719151496887,
0.07618585973978043,
0.7746025919914246,
0.2563219964504242,
-0.7852813601493835,
-0.22573840618133545,
-0.9104480743408203,
0.5715669393539429,
... |
Tianduo/llama-2-7b-gsm8k-sft | Tianduo | 2023-11-29T14:04:54Z | 43 | 0 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T14:04:54Z | 2023-11-29T03:57:29.000Z | null | null | Entry not found | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Tianduo/llama-2-7b-gsm8k-sft | [
-0.3227643668651581,
-0.22568444907665253,
0.862226128578186,
0.43461546301841736,
-0.5282992124557495,
0.7012968063354492,
0.7915719151496887,
0.07618585973978043,
0.7746025919914246,
0.2563219964504242,
-0.7852813601493835,
-0.22573840618133545,
-0.9104480743408203,
0.5715669393539429,
... |
shleeeee/mistral-ko-7b-wiki-neft | shleeeee | 2023-11-29T04:57:54Z | 42 | 0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetune",
"ko",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T04:57:54Z | 2023-11-29T04:46:44.000Z | null | null | ---
language:
- ko
pipeline_tag: text-generation
tags:
- finetune
---
# Model Card for mistral-ko-7b-wiki-neft
It is a fine-tuned model using Korean and NEFT in the mistral-7b model.
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee)
* **Repository** : To be added
* **Model Architecture** : The mistral-ko-7b-wiki-neft is is a fine-tuned version of the Mistral-7B-v0.1.
* **Lora target modules** : q_proj, k_proj, v_proj, o_proj,gate_proj
* **train_batch** : 4
* **neftune_noise_alpha** : 5
* **Max_step** : 1000
## Dataset
Korean Custom Dataset
## Prompt template: Mistral
```
<s>[INST]{['instruction']}[/INST]{['output']}</s>
```
## Usage
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("shleeeee/mistral-7b-wiki")
model = AutoModelForCausalLM.from_pretrained("shleeeee/mistral-7b-wiki")
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="shleeeee/mistral-7b-wiki")
```
## Evaluation
- To be added | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | shleeeee/mistral-ko-7b-wiki-neft | [
-0.6214165091514587,
-0.7628719806671143,
0.0930340364575386,
0.19246263802051544,
-0.526114821434021,
-0.33475542068481445,
0.2642829716205597,
-0.2831823527812958,
0.16396449506282806,
0.8378170132637024,
-0.710292398929596,
-0.6255042552947998,
-0.49309462308883667,
0.001998849445953965... |
Gunulhona/tb_pretrained_sts | Gunulhona | 2023-11-29T03:42:24Z | 40 | 0 | null | [
"transformers",
"pytorch",
"bart",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | 2023-11-29T03:42:24Z | 2023-06-12T03:17:29.000Z | null | null | Entry not found | null | transformers | feature-extraction | null | null | null | null | null | null | null | null | null | Gunulhona/tb_pretrained_sts | [
-0.3227650821208954,
-0.22568479180335999,
0.8622263669967651,
0.4346153140068054,
-0.5282987952232361,
0.7012966871261597,
0.7915722727775574,
0.07618651539087296,
0.7746027112007141,
0.2563222348690033,
-0.7852821350097656,
-0.225738525390625,
-0.910447895526886,
0.5715667009353638,
-0... |
nickprock/mmarco-sentence-flare-it | nickprock | 2023-11-29T08:51:24Z | 40 | 1 | null | [
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"it",
"dataset:unicamp-dl/mmarco",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2023-11-29T08:51:24Z | 2023-09-28T12:13:50.000Z | null | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
datasets:
- unicamp-dl/mmarco
language:
- it
library_name: sentence-transformers
---
# mmarco-sentence-flare-it
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "Quante persone vivono a Londra?"
docs = ["A Londra vivono circa 9 milioni di persone", "Londra è conosciuta per il suo quartiere finanziario"]
#Load the model
model = SentenceTransformer('nickprock/mmarco-sentence-flare-it')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
return embeddings
# Sentences we want sentence embeddings for
query = "Quante persone vivono a Londra?"
docs = ["A Londra vivono circa 9 milioni di persone", "Londra è conosciuta per il suo quartiere finanziario"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("nickprock/mmarco-sentence-flare-it")
model = AutoModel.from_pretrained("nickprock/mmarco-sentence-flare-it")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
print("Query:", query)
for doc, score in doc_score_pairs:
print(score, doc)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 7500 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 500,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 1500,
"warmup_steps": 7500,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
More information about the [base model here](https://huggingface.co/osiria/flare-it/) | null | sentence-transformers | sentence-similarity | null | null | null | null | null | null | null | null | null | nickprock/mmarco-sentence-flare-it | [
-0.21238036453723907,
-0.8637942671775818,
0.34567269682884216,
0.309675008058548,
-0.1867489516735077,
-0.24875012040138245,
-0.26627615094184875,
0.004461569711565971,
0.26062071323394775,
0.39153316617012024,
-0.5426791310310364,
-0.7711495161056519,
-0.6572307348251343,
0.0488220378756... |
jellyconsumer/new_model_falcon_qa | jellyconsumer | 2023-11-29T03:09:43Z | 40 | 0 | null | [
"transformers",
"pytorch",
"falcon",
"text-generation",
"generated_from_trainer",
"custom_code",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T03:09:43Z | 2023-11-29T00:14:33.000Z | null | null | ---
license: apache-2.0
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
tags:
- generated_from_trainer
model-index:
- name: new_model_falcon_qa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# new_model_falcon_qa
This model is a fine-tuned version of [vilsonrodrigues/falcon-7b-instruct-sharded](https://huggingface.co/vilsonrodrigues/falcon-7b-instruct-sharded) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 20
### Training results
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.2
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | jellyconsumer/new_model_falcon_qa | [
-0.5662487745285034,
-0.7765864133834839,
-0.04361288249492645,
0.23164425790309906,
-0.38347020745277405,
-0.2142416387796402,
0.17934031784534454,
-0.3072667717933655,
0.45869842171669006,
0.537542998790741,
-0.69038987159729,
-0.5221548676490784,
-0.6998432874679565,
-0.1161204501986503... |
wons/mistral-7B-test-v0.2 | wons | 2023-11-29T03:17:31Z | 40 | 0 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T03:17:31Z | 2023-11-29T03:46:06.000Z | null | null | Entry not found | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | wons/mistral-7B-test-v0.2 | [
-0.3227645754814148,
-0.22568456828594208,
0.862226128578186,
0.43461504578590393,
-0.52829909324646,
0.7012966871261597,
0.7915720343589783,
0.07618620246648788,
0.7746025323867798,
0.25632232427597046,
-0.7852811813354492,
-0.22573864459991455,
-0.910447895526886,
0.5715669393539429,
-... |
Ja3ck/llama-2-13b-instruct-Y24-v1 | Ja3ck | 2023-11-29T06:11:50Z | 40 | 0 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T06:11:50Z | 2023-11-29T06:02:43.000Z | null | null | ---
license: apache-2.0
language:
- ko
pipeline_tag: text-generation
---
## Prompt Template
```
### 질문: {instruction}
### 답변: {output}
``` | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Ja3ck/llama-2-13b-instruct-Y24-v1 | [
-0.04997851327061653,
-0.18326938152313232,
0.49791836738586426,
0.5446441769599915,
-0.6531704068183899,
-0.024528132751584053,
0.11793475598096848,
0.9445187449455261,
0.3588883876800537,
0.6858900189399719,
-0.7869232296943665,
-0.9631635546684265,
-0.6446096897125244,
0.057470589876174... |
deepseek-ai/deepseek-llm-7b-chat | deepseek-ai | 2023-11-29T11:41:18Z | 38 | 6 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T11:41:18Z | 2023-11-29T03:19:32.000Z | null | null | ---
license: other
license_name: deepseek
license_link: LICENSE
---
<p align="center">
<img width="500px" alt="DeepSeek Chat" src="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://chat.deepseek.com/">[🤖 Chat with DeepSeek LLM]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/deepseek-ai/DeepSeek-LLM/blob/main/images/qr.jpeg">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek LLM
Introducing DeepSeek LLM, an advanced language model comprising 7 billion parameters. It has been trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese. In order to foster research, we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open source for the research community.
### 2. Model Summary
`deepseek-llm-7b-chat` is a 7B parameter model initialized from `deepseek-llm-7b-base` and fine-tuned on extra instruction data.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-LLM](https://github.com/deepseek-ai/deepseek-LLM)
- **Chat With DeepSeek LLM:** [DeepSeek-LLM](https://chat.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Completion
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-llm-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Who are you?"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
```
Avoiding the use of the provided function `apply_chat_template`, you can also interact with our model following the sample template. Note that `messages` should be replaced by your input.
```
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
```
**Note:** By default (`add_special_tokens=True`), our tokenizer automatically adds a `bos_token` (`<|begin▁of▁sentence|>`) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek LLM models is subject to the Model License. DeepSeek LLM supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-LLM/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [service@deepseek.com](mailto:service@deepseek.com).
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | deepseek-ai/deepseek-llm-7b-chat | [
-0.30999940633773804,
-0.8430924415588379,
0.29684144258499146,
0.40611532330513,
-0.41013801097869873,
-0.014886519871652126,
-0.2528582215309143,
-0.47185179591178894,
0.1322167068719864,
0.17108671367168427,
-0.6814773678779602,
-0.7254573702812195,
-0.6716727018356323,
-0.2073540687561... |
Taeyeun72/GPT2_V2 | Taeyeun72 | 2023-11-29T04:41:32Z | 36 | 0 | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"ko",
"base_model:gpt2",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T04:41:32Z | 2023-11-29T04:40:47.000Z | null | null | ---
language:
- ko
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: gpt2-cs00
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-cs00
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the gpt2-cs00 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3143
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 11.0601 | 0.02 | 200 | 1.8848 |
| 1.8408 | 0.05 | 400 | 1.7685 |
| 1.7219 | 0.07 | 600 | 1.6998 |
| 1.7133 | 0.09 | 800 | 1.6720 |
| 1.6776 | 0.12 | 1000 | 1.6420 |
| 1.6309 | 0.14 | 1200 | 1.7187 |
| 1.6157 | 0.16 | 1400 | 1.6025 |
| 1.5546 | 0.18 | 1600 | 1.5661 |
| 1.4834 | 0.21 | 1800 | 1.5589 |
| 1.5641 | 0.23 | 2000 | 1.5451 |
| 1.5133 | 0.25 | 2200 | 1.5195 |
| 1.5373 | 0.28 | 2400 | 1.5099 |
| 1.498 | 0.3 | 2600 | 1.5026 |
| 1.4382 | 0.32 | 2800 | 1.4915 |
| 1.4585 | 0.35 | 3000 | 1.4937 |
| 1.4493 | 0.37 | 3200 | 1.4737 |
| 1.403 | 0.39 | 3400 | 1.4713 |
| 1.4216 | 0.42 | 3600 | 1.4573 |
| 1.4204 | 0.44 | 3800 | 1.4684 |
| 1.5143 | 0.46 | 4000 | 1.4458 |
| 1.5003 | 0.48 | 4200 | 1.4115 |
| 1.4828 | 0.51 | 4400 | 1.4446 |
| 1.4098 | 0.53 | 4600 | 1.4133 |
| 1.4208 | 0.55 | 4800 | 1.4178 |
| 1.401 | 0.58 | 5000 | 1.3915 |
| 1.3639 | 0.6 | 5200 | 1.4326 |
| 1.3752 | 0.62 | 5400 | 1.3989 |
| 1.4016 | 0.65 | 5600 | 1.3873 |
| 1.4157 | 0.67 | 5800 | 1.3792 |
| 1.4421 | 0.69 | 6000 | 1.3809 |
| 1.4024 | 0.72 | 6200 | 1.3780 |
| 1.4031 | 0.74 | 6400 | 1.4014 |
| 1.4033 | 0.76 | 6600 | 1.4148 |
| 1.4009 | 0.78 | 6800 | 1.3824 |
| 1.4519 | 0.81 | 7000 | 1.3795 |
| 1.377 | 0.83 | 7200 | 1.3762 |
| 1.4153 | 0.85 | 7400 | 1.3608 |
| 1.4112 | 0.88 | 7600 | 1.3853 |
| 1.409 | 0.9 | 7800 | 1.3728 |
| 1.4125 | 0.92 | 8000 | 1.3661 |
| 1.3637 | 0.95 | 8200 | 1.3609 |
| 1.3902 | 0.97 | 8400 | 1.3591 |
| 1.4463 | 0.99 | 8600 | 1.3665 |
| 1.3782 | 1.02 | 8800 | 1.3634 |
| 1.3468 | 1.04 | 9000 | 1.3728 |
| 1.3339 | 1.06 | 9200 | 1.3712 |
| 1.3171 | 1.09 | 9400 | 1.3557 |
| 1.357 | 1.11 | 9600 | 1.3723 |
| 1.3791 | 1.13 | 9800 | 1.3617 |
| 1.3888 | 1.15 | 10000 | 1.3477 |
| 1.3923 | 1.18 | 10200 | 1.3512 |
| 1.342 | 1.2 | 10400 | 1.3538 |
| 1.3485 | 1.22 | 10600 | 1.3595 |
| 1.3523 | 1.25 | 10800 | 1.3623 |
| 1.3881 | 1.27 | 11000 | 1.3416 |
| 1.3741 | 1.29 | 11200 | 1.3523 |
| 1.3869 | 1.32 | 11400 | 1.3442 |
| 1.3545 | 1.34 | 11600 | 1.3490 |
| 1.3571 | 1.36 | 11800 | 1.3491 |
| 1.3396 | 1.39 | 12000 | 1.3510 |
| 1.3713 | 1.41 | 12200 | 1.3341 |
| 1.3165 | 1.43 | 12400 | 1.3376 |
| 1.3236 | 1.45 | 12600 | 1.3364 |
| 1.3028 | 1.48 | 12800 | 1.3322 |
| 1.3671 | 1.5 | 13000 | 1.3403 |
| 1.3295 | 1.52 | 13200 | 1.3377 |
| 1.3807 | 1.55 | 13400 | 1.3264 |
| 1.3714 | 1.57 | 13600 | 1.3271 |
| 1.3249 | 1.59 | 13800 | 1.3388 |
| 1.3656 | 1.62 | 14000 | 1.3319 |
| 1.2864 | 1.64 | 14200 | 1.3321 |
| 1.352 | 1.66 | 14400 | 1.3497 |
| 1.3599 | 1.69 | 14600 | 1.3268 |
| 1.3191 | 1.71 | 14800 | 1.3339 |
| 1.3136 | 1.73 | 15000 | 1.3336 |
| 1.3338 | 1.75 | 15200 | 1.3265 |
| 1.3528 | 1.78 | 15400 | 1.3363 |
| 1.3538 | 1.8 | 15600 | 1.3196 |
| 1.2879 | 1.82 | 15800 | 1.3335 |
| 1.3217 | 1.85 | 16000 | 1.3376 |
| 1.3657 | 1.87 | 16200 | 1.3257 |
| 1.3351 | 1.89 | 16400 | 1.3262 |
| 1.3469 | 1.92 | 16600 | 1.3299 |
| 1.3053 | 1.94 | 16800 | 1.3329 |
| 1.3332 | 1.96 | 17000 | 1.3212 |
| 1.3466 | 1.99 | 17200 | 1.3317 |
| 1.3743 | 2.01 | 17400 | 1.3302 |
| 1.3227 | 2.03 | 17600 | 1.3332 |
| 1.2728 | 2.05 | 17800 | 1.3450 |
| 1.3239 | 2.08 | 18000 | 1.3414 |
| 1.3661 | 2.1 | 18200 | 1.3243 |
| 1.298 | 2.12 | 18400 | 1.3315 |
| 1.2974 | 2.15 | 18600 | 1.3310 |
| 1.3174 | 2.17 | 18800 | 1.3224 |
| 1.3121 | 2.19 | 19000 | 1.3233 |
| 1.3527 | 2.22 | 19200 | 1.3211 |
| 1.3712 | 2.24 | 19400 | 1.3143 |
| 1.2873 | 2.26 | 19600 | 1.3302 |
| 1.306 | 2.29 | 19800 | 1.3211 |
| 1.3161 | 2.31 | 20000 | 1.3242 |
| 1.308 | 2.33 | 20200 | 1.3176 |
| 1.3403 | 2.35 | 20400 | 1.3143 |
| 1.3688 | 2.38 | 20600 | 1.3195 |
| 1.2743 | 2.4 | 20800 | 1.3230 |
| 1.2892 | 2.42 | 21000 | 1.3287 |
| 1.3782 | 2.45 | 21200 | 1.3137 |
| 1.3331 | 2.47 | 21400 | 1.3148 |
| 1.3182 | 2.49 | 21600 | 1.3220 |
| 1.2542 | 2.52 | 21800 | 1.3332 |
| 1.2879 | 2.54 | 22000 | 1.3229 |
| 1.316 | 2.56 | 22200 | 1.3181 |
| 1.2989 | 2.59 | 22400 | 1.3155 |
| 1.3095 | 2.61 | 22600 | 1.3218 |
| 1.2457 | 2.63 | 22800 | 1.3185 |
| 1.3053 | 2.65 | 23000 | 1.3168 |
| 1.3036 | 2.68 | 23200 | 1.3180 |
| 1.2861 | 2.7 | 23400 | 1.3117 |
| 1.3 | 2.72 | 23600 | 1.3208 |
| 1.3026 | 2.75 | 23800 | 1.3147 |
| 1.3006 | 2.77 | 24000 | 1.3211 |
| 1.3477 | 2.79 | 24200 | 1.3140 |
| 1.2851 | 2.82 | 24400 | 1.3208 |
| 1.2859 | 2.84 | 24600 | 1.3172 |
| 1.3286 | 2.86 | 24800 | 1.3151 |
| 1.3237 | 2.89 | 25000 | 1.3148 |
| 1.3503 | 2.91 | 25200 | 1.3133 |
| 1.27 | 2.93 | 25400 | 1.3138 |
| 1.2998 | 2.96 | 25600 | 1.3151 |
| 1.3461 | 2.98 | 25800 | 1.3143 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
| null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Taeyeun72/GPT2_V2 | [
-0.7395286560058594,
-0.40427374839782715,
0.34951621294021606,
0.319540411233902,
0.13234125077724457,
0.07321619242429733,
0.25287047028541565,
-0.06255655735731125,
0.6946706175804138,
0.3594830334186554,
-0.6904410123825073,
-0.6127517223358154,
-0.6403307318687439,
-0.1026561036705970... |
zap-thamm/PPO-LunarLander-v2 | zap-thamm | 2023-11-29T17:42:20Z | 34 | 0 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | 2023-11-29T17:42:20Z | 2023-02-20T17:31:54.000Z | null | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -834.29 +/- 132.77
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| null | stable-baselines3 | reinforcement-learning | null | null | null | null | null | null | null | null | null | zap-thamm/PPO-LunarLander-v2 | [
-0.0031745489686727524,
-0.3944118916988373,
0.24817678332328796,
0.3390541076660156,
-0.08787576109170914,
0.0400797501206398,
0.5000531077384949,
-0.1760786473751068,
0.28882235288619995,
0.9444828629493713,
-0.6269250512123108,
-0.512033998966217,
-0.4980955719947815,
-0.279383331537246... |
ppcodelearn/crb | ppcodelearn | 2023-11-29T19:52:11Z | 34 | 0 | null | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-29T19:52:11Z | 2023-11-17T06:50:36.000Z | null | null | Entry not found | null | transformers | text2text-generation | null | null | null | null | null | null | null | null | null | ppcodelearn/crb | [
-0.322765052318573,
-0.22568443417549133,
0.862225353717804,
0.43461543321609497,
-0.5282990336418152,
0.7012964487075806,
0.7915717363357544,
0.07618646323680878,
0.7746022939682007,
0.25632232427597046,
-0.7852814197540283,
-0.2257380485534668,
-0.9104474782943726,
0.5715667009353638,
... |
xia0t1an/sms-spam-model | xia0t1an | 2023-11-29T22:45:32Z | 34 | 0 | null | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"endpoints_compatible",
"region:us"
] | 2023-11-29T22:45:32Z | 2023-11-25T09:09:47.000Z | null | null | Entry not found | null | transformers | text-classification | null | null | null | null | null | null | null | null | null | xia0t1an/sms-spam-model | [
-0.322765052318573,
-0.22568443417549133,
0.862225353717804,
0.43461543321609497,
-0.5282990336418152,
0.7012964487075806,
0.7915717363357544,
0.07618646323680878,
0.7746022939682007,
0.25632232427597046,
-0.7852814197540283,
-0.2257380485534668,
-0.9104474782943726,
0.5715667009353638,
... |
Loewolf/L-GPT_1.1 | Loewolf | 2023-11-29T18:55:12Z | 34 | 1 | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"gpt",
"dataset:worden1/ultra-feedback-paired",
"dataset:sixf0ur/GuanacoDataset-de",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | 2023-11-29T18:55:12Z | 2023-11-26T17:35:04.000Z | null | null | ---
license: mit
tags:
- gpt
datasets:
- worden1/ultra-feedback-paired
- sixf0ur/GuanacoDataset-de
---
<h1>Löwolf GPT (L-GPT)</h1>
Das Modell ist viel besser, es braucht noch zeit um das Model anzupassen und zu trainieren.
<h2>Update:2.5/4 progress...</h2>
<h2>Wann verfügbar?</h2>
Es ist jetzt als vorschau verfügbar, aber das model ist noch nicht fertig! | null | transformers | text-generation | null | null | null | null | null | null | null | null | null | Loewolf/L-GPT_1.1 | [
-0.3955322802066803,
-0.8903293609619141,
0.4018683433532715,
-0.04052421823143959,
-0.15463024377822876,
-0.4028279185295105,
0.029852738603949547,
-0.3548252284526825,
0.02830212190747261,
0.2619103491306305,
-0.9678104519844055,
-0.38001832365989685,
-0.7741837501525879,
-0.028649715706... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.