
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
jglaser/pdbbind_complexes | jglaser | 2022-05-14T20:15:20Z | 15 | 0 | null | [
"molecules",
"chemistry",
"SMILES",
"region:us"
] | 2022-05-14T20:15:20Z | 2022-03-26T21:30:56.000Z | 2022-03-26T21:30:56 | ---
tags:
- molecules
- chemistry
- SMILES
---
## How to use the data sets
This dataset contains more than 16,000 unique pairs of protein sequences and ligand SMILES, and the coordinates
of their complexes.
SMILES are assumed to be tokenized by the regex from P. Schwaller
Every (x,y,z) ligand coordinate maps onto a SMILES token, and is *nan* if the token does not represent an atom
Every receptor coordinate maps onto the Calpha coordinate of that residue.
The dataset can be used to fine-tune a language model, all data comes from PDBind-cn.
### Use the already preprocessed data
Load a test/train split using
```
from datasets import load_dataset
train = load_dataset("jglaser/pdbbind_complexes",split='train[:90%]')
validation = load_dataset("jglaser/pdbbind_complexes",split='train[90%:]')
```
### Pre-process yourself
To manually perform the preprocessing, download the data sets from P.DBBind-cn
Register for an account at <https://www.pdbbind.org.cn/>, confirm the validation
email, then login and download
- the Index files (1)
- the general protein-ligand complexes (2)
- the refined protein-ligand complexes (3)
Extract those files in `pdbbind/data`
Run the script `pdbbind.py` in a compute job on an MPI-enabled cluster
(e.g., `mpirun -n 64 pdbbind.py`).
| [
-0.3298887014389038,
-0.4140793979167938,
0.2758852541446686,
0.2678413987159729,
-0.027130121365189552,
0.010886074975132942,
-0.08845781534910202,
0.01020757481455803,
0.2550502121448517,
0.5245746374130249,
-0.5097826719284058,
-0.725080132484436,
-0.3295902609825134,
0.5389068722724915... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tomekkorbak/pile-nontoxic-chunk-0 | tomekkorbak | 2022-03-31T07:55:59Z | 15 | 0 | null | [
"region:us"
] | 2022-03-31T07:55:59Z | 2022-03-31T07:53:21.000Z | 2022-03-31T07:53:21 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tomekkorbak/pile-toxicity-balanced | tomekkorbak | 2022-04-06T11:07:05Z | 15 | 0 | null | [
"region:us"
] | 2022-04-06T11:07:05Z | 2022-03-31T12:43:11.000Z | 2022-03-31T12:43:11 | ## Generation procedure
The dataset was constructed using documents from [the Pile](https://pile.eleuther.ai/) scored using using [Perspective API](http://perspectiveapi.com) toxicity scores.
The procedure was the following:
1. A chunk of the Pile (3%, 7m documents) was scored using the Perspective API.
1. The first half of this dataset is [tomekkorbak/pile-toxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-toxic-chunk-0), 100k *most* toxic documents of the scored chunk
2. The first half of this dataset is [tomekkorbak/pile-nontoxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-nontoxic-chunk-0), 100k *least* toxic documents of the scored chunk
3. Then, the dataset was shuffled and a 9:1 train-test split was done
## Basic stats
The average scores of the good and bad half are 0.0014 and 0.67, respectively. The average score of the whole dataset is 0.33; the median is 0.51.
However, the weighted average score (weighted by document length) is 0.45. Correlation between score and document length is 0.2.
Score histogram:
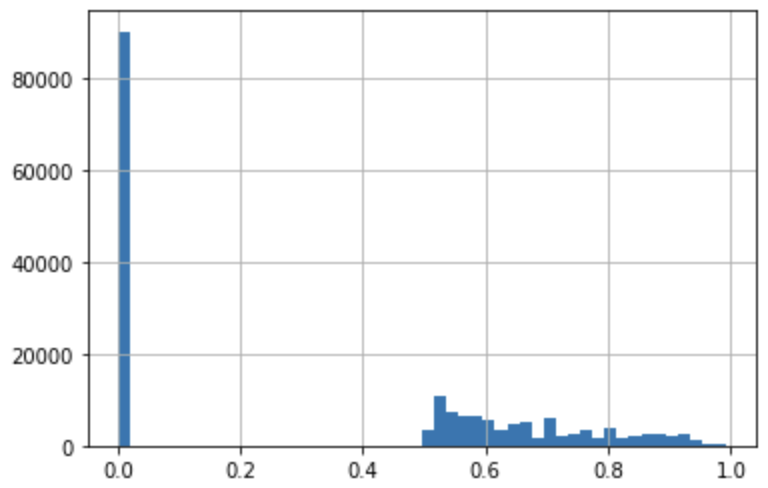
Mean score per Pile subset
| pile_set_name | score | length |
|:------------------|----------:|------------:|
| ArXiv | 0.141808 | 9963.82 |
| Books3 | 0.405541 | 8911.67 |
| DM Mathematics | 0.535474 | 8194 |
| Enron Emails | 0.541136 | 1406.76 |
| EuroParl | 0.373395 | 4984.36 |
| FreeLaw | 0.279582 | 8986.73 |
| Github | 0.495742 | 2184.86 |
| Gutenberg (PG-19) | 0.583263 | 4034 |
| HackerNews | 0.617917 | 3714.83 |
| NIH ExPorter | 0.0376628 | 1278.83 |
| OpenSubtitles | 0.674261 | 14881.1 |
| OpenWebText2 | 0.613273 | 2634.41 |
| PhilPapers | 0.549582 | 9693 |
| Pile-CC | 0.525136 | 2925.7 |
| PubMed Abstracts | 0.0388705 | 1282.29 |
| PubMed Central | 0.235012 | 7418.34 |
| StackExchange | 0.590904 | 2210.16 |
| USPTO Backgrounds | 0.0100077 | 2086.39 |
| Ubuntu IRC | 0.598423 | 4396.67 |
| Wikipedia (en) | 0.0136901 | 1515.89 |
| YoutubeSubtitles | 0.65201 | 4729.52 | | [
-0.3833337426185608,
-0.5406742095947266,
0.4300908148288727,
0.14496377110481262,
-0.309989869594574,
-0.33567842841148376,
0.23919500410556793,
-0.3247773051261902,
0.5219970941543579,
0.5823126435279846,
-0.39892664551734924,
-1.1161049604415894,
-0.6234222054481506,
0.08284247666597366... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
KevinZ/psycholinguistic_eval | KevinZ | 2022-10-25T10:03:37Z | 15 | 1 | null | [
"task_categories:multiple-choice",
"task_categories:fill-mask",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:n<1K",
"license:mit",
"re... | 2022-10-25T10:03:37Z | 2022-04-01T00:04:18.000Z | 2022-04-01T00:04:18 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en-US
license:
- mit
multilinguality:
- monolingual
pretty_name: psycholinguistic_eval
size_categories:
- n<1K
source_datasets: []
task_categories:
- multiple-choice
- fill-mask
- question-answering
- zero-shot-classification
task_ids: []
---
This is a suite of psycholinguistic datasets by Allyson Ettinger. See her [official Github repository](https://github.com/aetting/lm-diagnostics) for specific details. | [
-0.32596948742866516,
-0.7663146257400513,
0.3649793267250061,
0.02819317765533924,
0.3875025510787964,
0.134983628988266,
-0.2746424078941345,
-0.48917391896247864,
0.7037726044654846,
0.5442368388175964,
-0.7857897877693176,
-0.4979497492313385,
-0.4202859699726105,
-0.115644171833992,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
huggan/few-shot-dog | huggan | 2022-04-12T14:07:22Z | 15 | 0 | null | [
"arxiv:2101.04775",
"region:us"
] | 2022-04-12T14:07:22Z | 2022-04-01T11:41:14.000Z | 2022-04-01T11:41:14 | # Citation
```
@article{DBLP:journals/corr/abs-2101-04775,
author = {Bingchen Liu and
Yizhe Zhu and
Kunpeng Song and
Ahmed Elgammal},
title = {Towards Faster and Stabilized {GAN} Training for High-fidelity Few-shot
Image Synthesis},
journal = {CoRR},
volume = {abs/2101.04775},
year = {2021},
url = {https://arxiv.org/abs/2101.04775},
eprinttype = {arXiv},
eprint = {2101.04775},
timestamp = {Fri, 22 Jan 2021 15:16:00 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2101-04775.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
-0.5524430871009827,
-0.802834689617157,
0.01852492056787014,
0.3357279300689697,
-0.09379845857620239,
-0.17921093106269836,
-0.08067672699689865,
-0.28826087713241577,
0.07932962477207184,
-0.04197702184319496,
-0.3548423647880554,
-0.342769593000412,
-0.39390403032302856,
0.057183869183... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
lislia/gdpr_train | lislia | 2022-04-01T13:48:24Z | 15 | 1 | null | [
"region:us"
] | 2022-04-01T13:48:24Z | 2022-04-01T13:48:23.000Z | 2022-04-01T13:48:23 | Entry not found | [
-0.32276487350463867,
-0.22568444907665253,
0.8622263073921204,
0.43461570143699646,
-0.5282988548278809,
0.7012969255447388,
0.7915717363357544,
0.07618642598390579,
0.7746027112007141,
0.25632190704345703,
-0.7852815389633179,
-0.22573848068714142,
-0.910447895526886,
0.5715675354003906,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hackathon-pln-es/spanish-to-quechua | hackathon-pln-es | 2022-10-25T10:03:46Z | 15 | 6 | null | [
"task_categories:translation",
"language:es",
"language:qu",
"region:us"
] | 2022-10-25T10:03:46Z | 2022-04-03T04:02:58.000Z | 2022-04-03T04:02:58 | ---
language:
- es
- qu
task_categories:
- translation
task:
- translation
---
# Spanish to Quechua
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Structure](#dataset-structure)
- [Dataset Creation](#dataset-creation)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [team members](#team-members)
## Dataset Description
This dataset is a recopilation of webs and others datasets that shows in [dataset creation section](#dataset-creation). This contains translations from spanish (es) to Qechua of Ayacucho (qu).
## Dataset Structure
### Data Fields
- es: The sentence in Spanish.
- qu: The sentence in Quechua of Ayacucho.
### Data Splits
- train: To train the model (102 747 sentences).
- Validation: To validate the model during training (12 844 sentences).
- test: To evaluate the model when the training is finished (12 843 sentences).
## Dataset Creation
### Source Data
This dataset has generated from:
- "Mundo Quechua" by "Ivan Acuña" - [available here](https://mundoquechua.blogspot.com/2006/07/frases-comunes-en-quechua.html)
- "Kuyakuykim (Te quiero): Apps con las que podrías aprender quechua" by "El comercio" - [available here](https://elcomercio.pe/tecnologia/actualidad/traductor-frases-romanticas-quechua-noticia-467022-noticia/)
- "Piropos y frases de amor en quechua" by "Soy Quechua" - [available here](https://www.soyquechua.org/2019/12/palabras-en-quechua-de-amor.html)
- "Corazón en quechua" by "Soy Quechua" - [available here](https://www.soyquechua.org/2020/05/corazon-en-quechua.html)
- "Oraciones en Español traducidas a Quechua" by "Tatoeba" - [available here](https://tatoeba.org/es/sentences/search?from=spa&query=&to=que)
- "AmericasNLP 2021 Shared Task on Open Machine Translation" by "americasnlp2021" - [available here](https://github.com/AmericasNLP/americasnlp2021/tree/main/data/quechua-spanish/parallel_data/es-quy)
### Data cleaning
- The dataset was manually cleaned during compilation, as some words of one language were related to several words of the other language.
## Considerations for Using the Data
This is a first version of the dataset, we expected improve it over time and especially to neutralize the biblical themes.
## Team members
- [Sara Benel](https://huggingface.co/sbenel)
- [Jose Vílchez](https://huggingface.co/JCarlos) | [
-0.2715079188346863,
-0.5356102585792542,
0.007326167076826096,
0.7590638399124146,
-0.38004887104034424,
0.1033138781785965,
-0.295171856880188,
-0.5102813243865967,
0.355115681886673,
0.5957355499267578,
-0.6768686771392822,
-0.8473263382911682,
-0.25800588726997375,
0.5452798008918762,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Pavithra/sampled-code-parrot-valid-100k | Pavithra | 2022-04-03T15:49:26Z | 15 | 0 | null | [
"region:us"
] | 2022-04-03T15:49:26Z | 2022-04-03T15:49:25.000Z | 2022-04-03T15:49:25 | Entry not found | [
-0.32276487350463867,
-0.22568444907665253,
0.8622263073921204,
0.43461570143699646,
-0.5282988548278809,
0.7012969255447388,
0.7915717363357544,
0.07618642598390579,
0.7746027112007141,
0.25632190704345703,
-0.7852815389633179,
-0.22573848068714142,
-0.910447895526886,
0.5715675354003906,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
UrukHan/wav2vec2-ru-V | UrukHan | 2022-04-15T08:09:20Z | 15 | 0 | null | [
"region:us"
] | 2022-04-15T08:09:20Z | 2022-04-15T08:07:16.000Z | 2022-04-15T08:07:16 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AndresPitta/sg-reports_labeled | AndresPitta | 2022-10-25T10:08:57Z | 15 | 0 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:expert-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"license:unknown",
"region:us"
] | 2022-10-25T10:08:57Z | 2022-04-22T14:52:01.000Z | 2022-04-22T14:52:01 | ---
annotations_creators:
- expert-generated
language_creators:
- machine-generated
language:
- en-US
license:
- unknown
multilinguality:
- monolingual
pretty_name: Gender language in the reports of the secretary general 2020-2021
size_categories:
- n<1K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact: Andrés Pitta: andres.pitta@un.org**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. | [
-0.4831542372703552,
-0.46146833896636963,
0.1579829752445221,
0.2458696961402893,
-0.2568855285644531,
0.269530713558197,
-0.3498070240020752,
-0.36505669355392456,
0.6335847973823547,
0.6369054913520813,
-0.8501932621002197,
-1.1973531246185303,
-0.7202509641647339,
0.10474648326635361,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pietrolesci/recast_white | pietrolesci | 2022-04-22T15:34:14Z | 15 | 0 | null | [
"region:us"
] | 2022-04-22T15:34:14Z | 2022-04-22T15:27:37.000Z | 2022-04-22T15:27:37 | ## Overview
This dataset has been introduced by "Inference is Everything: Recasting Semantic Resources into a Unified Evaluation Framework", Aaron Steven White, Pushpendre Rastogi, Kevin Duh, Benjamin Van Durme. IJCNLP, 2017. Original data available [here](https://github.com/decompositional-semantics-initiative/DNC/raw/master/inference_is_everything.zip).
## Dataset curation
The following processing is applied
- `hypothesis_grammatical` and `judgement_valid` columns are filled with `""` when empty
- all columns are stripped
- the `entailed` column is renamed `label`
- `label` column is encoded with the following mapping `{"not-entailed": 0, "entailed": 1}`
- columns `rating` and `good_word` are dropped from `fnplus` dataset
## Code to generate the dataset
```python
import pandas as pd
from datasets import Features, Value, ClassLabel, Dataset, DatasetDict
ds = {}
for name in ("fnplus", "sprl", "dpr"):
# read data
with open(f"<path to files>/{name}_data.txt", "r") as f:
data = f.read()
data = data.split("\n\n")
data = [lines.split("\n") for lines in data]
data = [dict([col.split(":", maxsplit=1) for col in line if len(col) > 0]) for line in data]
df = pd.DataFrame(data)
# fill empty hypothesis_grammatical and judgement_valid
df["hypothesis_grammatical"] = df["hypothesis_grammatical"].fillna("")
df["judgement_valid"] = df["judgement_valid"].fillna("")
# fix dtype
df["index"] = df["index"].astype(int)
# strip
for col in df.select_dtypes(object).columns:
df[col] = df[col].str.strip()
# rename columns
df = df.rename(columns={"entailed": "label"})
# encode labels
df["label"] = df["label"].map({"not-entailed": 0, "entailed": 1})
# cast to dataset
features = Features({
"provenance": Value(dtype="string", id=None),
"index": Value(dtype="int64", id=None),
"text": Value(dtype="string", id=None),
"hypothesis": Value(dtype="string", id=None),
"partof": Value(dtype="string", id=None),
"hypothesis_grammatical": Value(dtype="string", id=None),
"judgement_valid": Value(dtype="string", id=None),
"label": ClassLabel(num_classes=2, names=["not-entailed", "entailed"]),
})
# select common columns
df = df.loc[:, list(features.keys())]
ds[name] = Dataset.from_pandas(df, features=features)
ds = DatasetDict(ds)
ds.push_to_hub("recast_white", token="<token>")
``` | [
-0.2433301955461502,
-0.8353160619735718,
0.4600740969181061,
0.207500159740448,
-0.22134457528591156,
-0.29672878980636597,
-0.3156841993331909,
0.04189970716834068,
0.4447140693664551,
0.7123652696609497,
-0.3470464050769806,
-1.0449484586715698,
-0.5901095271110535,
0.24180178344249725,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pietrolesci/gen_debiased_nli | pietrolesci | 2022-04-25T09:49:52Z | 15 | 0 | null | [
"region:us"
] | 2022-04-25T09:49:52Z | 2022-04-25T09:35:37.000Z | 2022-04-25T09:35:37 | ## Overview
Original dataset available [here](https://github.com/jimmycode/gen-debiased-nli#training-with-our-datasets).
```latex
@inproceedings{gen-debiased-nli-2022,
title = "Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets",
author = "Wu, Yuxiang and
Gardner, Matt and
Stenetorp, Pontus and
Dasigi, Pradeep",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics",
}
```
## Dataset curation
No curation.
## Code to create the dataset
```python
import pandas as pd
from datasets import Dataset, ClassLabel, Value, Features, DatasetDict
import json
from pathlib import Path
# load data
path = Path("./")
ds = {}
for i in path.rglob("*.jsonl"):
print(i)
name = str(i).split(".")[0].lower().replace("-", "_")
with i.open("r") as fl:
df = pd.DataFrame([json.loads(line) for line in fl])
ds[name] = df
# cast to dataset
features = Features(
{
"premise": Value(dtype="string"),
"hypothesis": Value(dtype="string"),
"label": ClassLabel(num_classes=3, names=["entailment", "neutral", "contradiction"]),
"type": Value(dtype="string"),
}
)
ds = DatasetDict({k: Dataset.from_pandas(v, features=features) for k, v in ds.items()})
ds.push_to_hub("pietrolesci/gen_debiased_nli", token="<token>")
# check overlap between splits
from itertools import combinations
for i, j in combinations(ds.keys(), 2):
print(
f"{i} - {j}: ",
pd.merge(
ds[i].to_pandas(),
ds[j].to_pandas(),
on=["premise", "hypothesis", "label"],
how="inner",
).shape[0],
)
#> mnli_seq_z - snli_z_aug: 0
#> mnli_seq_z - mnli_par_z: 477149
#> mnli_seq_z - snli_seq_z: 0
#> mnli_seq_z - mnli_z_aug: 333840
#> mnli_seq_z - snli_par_z: 0
#> snli_z_aug - mnli_par_z: 0
#> snli_z_aug - snli_seq_z: 506624
#> snli_z_aug - mnli_z_aug: 0
#> snli_z_aug - snli_par_z: 504910
#> mnli_par_z - snli_seq_z: 0
#> mnli_par_z - mnli_z_aug: 334960
#> mnli_par_z - snli_par_z: 0
#> snli_seq_z - mnli_z_aug: 0
#> snli_seq_z - snli_par_z: 583107
#> mnli_z_aug - snli_par_z: 0
``` | [
-0.41866281628608704,
-0.5532469153404236,
0.2428974211215973,
0.3067072033882141,
-0.2178211361169815,
0.0010474028531461954,
-0.09742859750986099,
-0.12859421968460083,
0.4845820963382721,
0.35178741812705994,
-0.523906409740448,
-0.5989528298377991,
-0.5165751576423645,
0.27167722582817... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
gusevski/factrueval2016 | gusevski | 2022-04-29T20:34:48Z | 15 | 0 | null | [
"arxiv:2005.00614",
"region:us"
] | 2022-04-29T20:34:48Z | 2022-04-29T06:41:12.000Z | 2022-04-29T06:41:12 | # Dataset Card for FactRuEval-2016
## Dataset Description
- **Point of Contact:** [Guskov Sergey](https://gusevski.com)
### Dataset Summary
Evaluation of [Named Entity Recognition](https://www.dialog-21.ru/media/3430/starostinaetal.pdf) and Fact Extraction Systems for Russian.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the `task-category-tag` with an appropriate `other:other-task-name`).
- `token-classification`: The dataset can be used to train a model for [NER], which consists in [Token Classification]. Success on this task is typically measured by achieving a *high/low* [metric name](https://huggingface.co/metrics/metric_name). The ([model name](https://huggingface.co/model_name) or [model class](https://huggingface.co/transformers/model_doc/model_class.html)) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at [leaderboard url]() and ranks models based on [metric name](https://huggingface.co/metrics/metric_name) while also reporting [other metric name](https://huggingface.co/metrics/other_metric_name).
### Languages
RU.
## Dataset Structure
### Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
```
{
'data': [{'id':'', 'tokens':[], 'ner_tags':[]},...],
...
}
```
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
### Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
- `id`: order id
- `tokens`: list of tokens
- `ner_tags`: list of ner tags
### Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| | Tain | Valid | Test |
| ----- | ------ | ----- | ---- |
| Input Sentences | | | |
| Average Sentence Length | | | |
## Dataset Creation
### Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
### Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
#### Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their [Hugging Face version](https://huggingface.co/datasets/dataset_name).
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
#### Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
### Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
#### Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
#### Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
### Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
## Considerations for Using the Data
### Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
### Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example [Dinan et al 2020 on biases in Wikipedia (esp. Table 1)](https://arxiv.org/abs/2005.00614), or [Blodgett et al 2020](https://www.aclweb.org/anthology/2020.acl-main.485/) for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
### Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
## Additional Information
### Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
### Licensing Information
MIT
| [
-0.42520689964294434,
-0.6235236525535583,
0.11270096153020859,
0.22461585700511932,
-0.03584328293800354,
0.0565163791179657,
-0.16610638797283173,
-0.6043530702590942,
0.4913138449192047,
0.585354208946228,
-0.7207781076431274,
-0.7885584235191345,
-0.5059701800346375,
0.1947245448827743... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jamescalam/world-cities-geo | jamescalam | 2022-04-29T18:34:46Z | 15 | 4 | null | [
"region:us"
] | 2022-04-29T18:34:46Z | 2022-04-29T16:54:48.000Z | 2022-04-29T16:54:48 | Dataset containing city, country, region, and continents alongside their longitude and latitude co-ordinates. Cartesian coordinates are provided in x, y, z features. | [
-0.6771338582038879,
-0.002644409891217947,
0.6526681184768677,
-0.09699206799268723,
-0.3230614960193634,
0.20342883467674255,
0.29122206568717957,
-0.15356802940368652,
0.5710894465446472,
1.1738722324371338,
-0.7647874355316162,
-1.1256886720657349,
-0.030179841443896294,
-0.29590713977... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
arbml/masader | arbml | 2022-07-08T14:45:05Z | 15 | 6 | null | [
"license:mit",
"region:us"
] | 2022-07-08T14:45:05Z | 2022-05-03T01:45:10.000Z | 2022-05-03T01:45:10 | ---
license: mit
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
orieg/elsevier-oa-cc-by | orieg | 2022-07-01T15:59:58Z | 15 | 8 | elsevier-oa-cc-by | [
"task_categories:fill-mask",
"task_categories:summarization",
"task_categories:text-classification",
"task_ids:masked-language-modeling",
"task_ids:news-articles-summarization",
"task_ids:news-articles-headline-generation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",... | 2022-07-01T15:59:58Z | 2022-05-03T22:13:33.000Z | 2022-05-03T22:13:33 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Elsevier OA CC-By
paperswithcode_id: elsevier-oa-cc-by
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- fill-mask
- summarization
- text-classification
task_ids:
- masked-language-modeling
- news-articles-summarization
- news-articles-headline-generation
---
# Dataset Card for Elsevier OA CC-By
## Table of Contents
- [Dataset Card for Elsevier OA CC-By](#dataset-card-for-elsevier-oa-cc-by)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://elsevier.digitalcommonsdata.com/datasets/zm33cdndxs
- **Repository:** https://elsevier.digitalcommonsdata.com/datasets/zm33cdndxs
- **Paper:** https://arxiv.org/abs/2008.00774
- **Leaderboard:**
- **Point of Contact:** [@orieg](https://huggingface.co/orieg)
### Dataset Summary
Elsevier OA CC-By: This is a corpus of 40k (40,091) open access (OA) CC-BY articles from across Elsevier’s journals
representing a large scale, cross-discipline set of research data to support NLP and ML research. The corpus include full-text
articles published in 2014 to 2020 and are categorized in 27 Mid Level ASJC Code (subject classification).
***Distribution of Publication Years***
| Publication Year | Number of Articles |
| :---: | :---: |
| 2014 | 3018 |
| 2015 | 4438 |
| 2016 | 5913 |
| 2017 | 6419 |
| 2018 | 8016 |
| 2019 | 10135 |
| 2020 | 2159 |
***Distribution of Articles Per Mid Level ASJC Code. Each article can belong to multiple ASJC codes.***
| Discipline | Count |
| --- | ---: |
| General | 3847 |
| Agricultural and Biological Sciences | 4840 |
| Arts and Humanities | 982 |
| Biochemistry, Genetics and Molecular Biology | 8356 |
| Business, Management and Accounting | 937 |
| Chemical Engineering | 1878 |
| Chemistry | 2490 |
| Computer Science | 2039 |
| Decision Sciences | 406 |
| Earth and Planetary Sciences | 2393 |
| Economics, Econometrics and Finance | 976 |
| Energy | 2730 |
| Engineering | 4778 |
| Environmental Science | 6049 |
| Immunology and Microbiology | 3211 |
| Materials Science | 3477 |
| Mathematics | 538 |
| Medicine | 7273 |
| Neuroscience | 3669 |
| Nursing | 308 |
| Pharmacology, Toxicology and Pharmaceutics | 2405 |
| Physics and Astronomy | 2404 |
| Psychology | 1760 |
| Social Sciences | 3540 |
| Veterinary | 991 |
| Dentistry | 40 |
| Health Professions | 821 |
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English (`en`).
## Dataset Structure
### Data Instances
The original dataset was published with the following json structure:
```
{
"docId": <str>,
"metadata":{
"title": <str>,
"authors": [
{
"first": <str>,
"initial": <str>,
"last": <str>,
"email": <str>
},
...
],
"issn": <str>,
"volume": <str>,
"firstpage": <str>,
"lastpage": <str>,
"pub_year": <int>,
"doi": <str>,
"pmid": <str>,
"openaccess": "Full",
"subjareas": [<str>],
"keywords": [<str>],
"asjc": [<int>],
},
"abstract":[
{
"sentence": <str>,
"startOffset": <int>,
"endOffset": <int>
},
...
],
"bib_entries":{
"BIBREF0":{
"title":<str>,
"authors":[
{
"last":<str>,
"initial":<str>,
"first":<str>
},
...
],
"issn": <str>,
"volume": <str>,
"firstpage": <str>,
"lastpage": <str>,
"pub_year": <int>,
"doi": <str>,
"pmid": <str>
},
...
},
"body_text":[
{
"sentence": <str>,
"secId": <str>,
"startOffset": <int>,
"endOffset": <int>,
"title": <str>,
"refoffsets": {
<str>:{
"endOffset":<int>,
"startOffset":<int>
}
},
"parents": [
{
"id": <str>,
"title": <str>
},
...
]
},
...
]
}
```
***docId*** The docID is the identifier of the document. This is unique to the document, and can be resolved into a URL
for the document through the addition of `https//www.sciencedirect.com/science/pii/<docId>`
***abstract*** This is the author provided abstract for the document
***body_text*** The full text for the document. The text has been split on sentence boundaries, thus making it easier to
use across research projects. Each sentence has the title (and ID) of the section which it is from, along with titles (and
IDs) of the parent section. The highest-level section takes index 0 in the parents array. If the array is empty then the
title of the section for the sentence is the highest level section title. This will allow for the reconstruction of the article
structure. References have been extracted from the sentences. The IDs of the extracted reference and their respective
offset within the sentence can be found in the “refoffsets” field. The complete list of references are can be found in
the “bib_entry” field along with the references’ respective metadata. Some will be missing as we only keep ‘clean’
sentences,
***bib_entities*** All the references from within the document can be found in this section. If the meta data for the
reference is available, it has been added against the key for the reference. Where possible information such as the
document titles, authors, and relevant identifiers (DOI and PMID) are included. The keys for each reference can be
found in the sentence where the reference is used with the start and end offset of where in the sentence that reference
was used.
***metadata*** Meta data includes additional information about the article, such as list of authors, relevant IDs (DOI and
PMID). Along with a number of classification schemes such as ASJC and Subject Classification.
***author_highlights*** Author highlights were included in the corpus where the author(s) have provided them. The
coverage is 61% of all articles. The author highlights, consisting of 4 to 6 sentences, is provided by the author with
the aim of summarising the core findings and results in the article.
### Data Fields
* ***title***: This is the author provided title for the document. 100% coverage.
* ***abstract***: This is the author provided abstract for the document. 99.25% coverage.
* ***keywords***: This is the author and publisher provided keywords for the document. 100% coverage.
* ***asjc***: This is the disciplines for the document as represented by 334 ASJC (All Science Journal Classification) codes. 100% coverage.
* ***subjareas***: This is the Subject Classification for the document as represented by 27 ASJC top-level subject classifications. 100% coverage.
* ***body_text***: The full text for the document. 100% coverage.
* ***author_highlights***: This is the author provided highlights for the document. 61.31% coverage.
### Data Splits
***Distribution of Publication Years***
| | Train | Test | Validation |
| --- | :---: | :---: | :---: |
| All Articles | 32072 | 4009 | 4008 |
| With Author Highlights | 19644 | 2420 | 2514 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
Date the data was collected: 2020-06-25T11:00:00.000Z
See the [original paper](https://doi.org/10.48550/arXiv.2008.00774) for more detail on the data collection process.
#### Who are the source language producers?
See `3.1 Data Sampling` in the [original paper](https://doi.org/10.48550/arXiv.2008.00774).
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
```
@article{Kershaw2020ElsevierOC,
title = {Elsevier OA CC-By Corpus},
author = {Daniel James Kershaw and R. Koeling},
journal = {ArXiv},
year = {2020},
volume = {abs/2008.00774},
doi = {https://doi.org/10.48550/arXiv.2008.00774},
url = {https://elsevier.digitalcommonsdata.com/datasets/zm33cdndxs},
keywords = {Science, Natural Language Processing, Machine Learning, Open Dataset},
abstract = {We introduce the Elsevier OA CC-BY corpus. This is the first open
corpus of Scientific Research papers which has a representative sample
from across scientific disciplines. This corpus not only includes the
full text of the article, but also the metadata of the documents,
along with the bibliographic information for each reference.}
}
```
```
@dataset{https://10.17632/zm33cdndxs.3,
doi = {10.17632/zm33cdndxs.2},
url = {https://data.mendeley.com/datasets/zm33cdndxs/3},
author = "Daniel Kershaw and Rob Koeling",
keywords = {Science, Natural Language Processing, Machine Learning, Open Dataset},
title = {Elsevier OA CC-BY Corpus},
publisher = {Mendeley},
year = {2020},
month = {sep}
}
```
### Contributions
Thanks to [@orieg](https://github.com/orieg) for adding this dataset. | [
-0.4381678104400635,
-0.28214433789253235,
0.48811399936676025,
-0.00025561999063938856,
-0.07381989061832428,
0.0483478344976902,
-0.08225954324007034,
-0.4037078022956848,
0.6417464017868042,
0.40564247965812683,
-0.4771725833415985,
-1.0133857727050781,
-0.7165620923042297,
0.4735662341... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SetFit/amazon_massive_intent_ru-RU | SetFit | 2022-06-20T14:59:24Z | 15 | 0 | null | [
"region:us"
] | 2022-06-20T14:59:24Z | 2022-05-06T09:10:51.000Z | 2022-05-06T09:10:51 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigscience-data/roots_id_wikipedia | bigscience-data | 2022-12-12T11:06:00Z | 15 | 2 | null | [
"language:id",
"license:cc-by-sa-3.0",
"region:us"
] | 2022-12-12T11:06:00Z | 2022-05-18T09:14:40.000Z | 2022-05-18T09:14:40 | ---
language: id
license: cc-by-sa-3.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_id_wikipedia
# wikipedia
- Dataset uid: `wikipedia`
### Description
### Homepage
### Licensing
### Speaker Locations
### Sizes
- 3.2299 % of total
- 4.2071 % of en
- 5.6773 % of ar
- 3.3416 % of fr
- 5.2815 % of es
- 12.4852 % of ca
- 0.4288 % of zh
- 0.4286 % of zh
- 5.4743 % of indic-bn
- 8.9062 % of indic-ta
- 21.3313 % of indic-te
- 4.4845 % of pt
- 4.0493 % of indic-hi
- 11.3163 % of indic-ml
- 22.5300 % of indic-ur
- 4.4902 % of vi
- 16.9916 % of indic-kn
- 24.7820 % of eu
- 11.6241 % of indic-mr
- 9.8749 % of id
- 9.3489 % of indic-pa
- 9.4767 % of indic-gu
- 24.1132 % of indic-as
- 5.3309 % of indic-or
### BigScience processing steps
#### Filters applied to: en
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: ar
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: fr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: es
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: ca
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: zh
#### Filters applied to: zh
#### Filters applied to: indic-bn
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ta
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-te
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: pt
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-hi
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ml
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ur
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: vi
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-kn
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: eu
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-mr
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: id
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-pa
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-gu
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-as
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-or
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
| [
-0.7043977975845337,
-0.597204327583313,
0.34931182861328125,
0.1746496707201004,
-0.20465710759162903,
-0.10029955953359604,
-0.23854786157608032,
-0.15585239231586456,
0.7056262493133545,
0.3297133445739746,
-0.8386934399604797,
-0.9332053661346436,
-0.7197847366333008,
0.502885222434997... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
strombergnlp/ara-stance | strombergnlp | 2022-10-25T21:47:05Z | 15 | 1 | null | [
"task_categories:text-classification",
"task_ids:fact-checking",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ar",
"license:cc-by-4.0",
"stance-detection",
"arxiv:2104.13559",
"r... | 2022-10-25T21:47:05Z | 2022-05-23T12:10:01.000Z | 2022-05-23T12:10:01 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- ar
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- fact-checking
pretty_name: ara-stance
tags:
- stance-detection
---
# Dataset Card for AraStance
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/Tariq60/arastance](https://github.com/Tariq60/arastance)
- **Paper:** [https://arxiv.org/abs/2104.13559](https://arxiv.org/abs/2104.13559)
- **Point of Contact:** [Tariq Alhindi](tariq@cs.columbia.edu)
### Dataset Summary
The AraStance dataset contains true and false claims, where each claim is paired with one or more documents. Each claim–article pair has a stance label: agree, disagree, discuss, or unrelated.
### Languages
Arabic
## Dataset Structure
### Data Instances
An example of 'train' looks as follows:
```
{
'id': '0',
'claim': 'تم رفع صورة السيسي في ملعب ليفربول',
'article': 'خطفت مكة محمد صلاح نجلة نجم ليفربول الإنجليزي الأنظار في ظهورها بملعب آنفيلد عقب مباراة والدها أمام برايتون في ختام الدوري الإنجليزي والتي انتهت بفوز الأول برباعية نظيفة. وأوضحت صحيفة "ميرور" البريطانية أن مكة محمد صلاح أضفت حالة من المرح في ملعب آنفيلد أثناء مداعبة الكرة بعد تتويج نجم منتخب مصر بجائزة هداف الدوري الإنجليزي. وأشارت إلى أن مكة أظهرت بعضًا من مهاراتها بمداعبة الكرة ونجحت في خطف قلوب مشجعي الريدز.',
'stance': 3
}
```
### Data Fields
- `id`: a 'string' feature.
- `claim`: a 'string' expressing a claim/topic.
- `article`: a 'string' to be classified for its stance to the source.
- `stance`: a class label representing the stance the article expresses towards the claim. Full tagset with indices:
```
0: "Agree",
1: "Disagree",
2: "Discuss",
3: "Unrelated",
```
### Data Splits
|name|instances|
|----|----:|
|train|2848|
|validation|569|
|test|646|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The dataset is curated by the paper's authors
### Licensing Information
The authors distribute this data under Creative Commons attribution license, CC-BY 4.0
### Citation Information
```
@article{arastance,
url = {https://arxiv.org/abs/2104.13559},
author = {Alhindi, Tariq and Alabdulkarim, Amal and Alshehri, Ali and Abdul-Mageed, Muhammad and Nakov, Preslav},
title = {AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
}
```
### Contributions
Thanks to [mkonxd](https://github.com/mkonxd) for adding this dataset. | [
-0.6157709956169128,
-0.4585843086242676,
0.23048675060272217,
0.11309762299060822,
-0.34215784072875977,
0.17262160778045654,
-0.13053877651691437,
-0.37998220324516296,
0.6647115349769592,
0.41638991236686707,
-0.41896840929985046,
-1.2479296922683716,
-1.0029170513153076,
0.178473159670... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Yah216/APCD_only_meter_data | Yah216 | 2022-05-28T08:00:57Z | 15 | 0 | null | [
"region:us"
] | 2022-05-28T08:00:57Z | 2022-05-26T14:19:32.000Z | 2022-05-26T14:19:32 | We used the APCD dataset cited hereafter for pretraining the model. The dataset has been cleaned and only the main text and the meter columns were kept:
```
@Article{Yousef2019LearningMetersArabicEnglish-arxiv,
author = {Yousef, Waleed A. and Ibrahime, Omar M. and Madbouly, Taha M. and Mahmoud,
Moustafa A.},
title = {Learning Meters of Arabic and English Poems With Recurrent Neural Networks: a Step
Forward for Language Understanding and Synthesis},
journal = {arXiv preprint arXiv:1905.05700},
year = 2019,
url = {https://github.com/hci-lab/LearningMetersPoems}
}
``` | [
-0.4867524802684784,
-0.31238725781440735,
0.34308117628097534,
0.08882658183574677,
-0.6532377004623413,
-0.24669988453388214,
-0.40187039971351624,
-0.04505743458867073,
-0.15402455627918243,
0.49633216857910156,
-0.5185872316360474,
-0.8867358565330505,
-0.6488739252090454,
0.1318216323... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
deepakvk/conversational_dialogues_001_iteration | deepakvk | 2022-05-27T11:18:00Z | 15 | 0 | null | [
"region:us"
] | 2022-05-27T11:18:00Z | 2022-05-27T09:58:47.000Z | 2022-05-27T09:58:47 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Lehrig/Monkey-Species-Collection | Lehrig | 2022-05-30T12:33:12Z | 15 | 1 | null | [
"region:us"
] | 2022-05-30T12:33:12Z | 2022-05-30T11:14:20.000Z | 2022-05-30T11:14:20 | annotations_creators:
- expert-generated
language_creators:
- expert-generated
languages: []
licenses:
- cc0-1.0
multilinguality: []
pretty_name: Monkey-Species-Collection
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- image-classification
task_ids:
- multi-class-image-classification
# Dataset Card for Monkey-Species-Collection
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://www.kaggle.com/datasets/slothkong/10-monkey-species
- **Repository:** https://github.com/slothkong/CNN_classification_10_monkey_species
- **Paper:** @misc{kaggle-10-monkey-species,
title={Kaggle: 10 Monkey Species},
howpublished={\\url{https://www.kaggle.com/datasets/slothkong/10-monkey-species}},
note = {Accessed: 2022-05-30},
}
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
This dataset is intended as a test case for fine-grain classification tasks (10 different kinds of monkey species). The dataset consists of almost 1400 JPEG images grouped into two splits - training and validation. Each split contains 10 categories labeled as n0~n9, each corresponding a species from [Wikipedia's monkey cladogram](https://en.wikipedia.org/wiki/Monkey). Images were downloaded with help of the [googliser](https://github.com/teracow/googliser) open source code.
| Label | Latin Name | Common Name | Train Images | Validation Images |
| ----- | --------------------- | ------------------------- | ------------ | ----------------- |
| n0 | alouatta_palliata | mantled_howler | 131 | 26 |
| n1 | erythrocebus_patas | patas_monkey | 139 | 28 |
| n2 | cacajao_calvus | bald_uakari | 137 | 27 |
| n3 | macaca_fuscata | japanese_macaque | 152 | 30 |
| n4 | cebuella_pygmea | pygmy_marmoset | 131 | 26 |
| n5 | cebus_capucinus | white_headed_capuchin | 141 | 28 |
| n6 | mico_argentatus | silvery_marmoset | 132 | 26 |
| n7 | saimiri_sciureus | common_squirrel_monkey | 142 | 28 |
| n8 | aotus_nigriceps | black_headed_night_monkey | 133 | 27 |
| n9 | trachypithecus_johnii | nilgiri_langur | 132 | 26 |
This collection includes the following GTZAN variants:
* original (images are 400x300 px or larger; ~550 MB)
* downsized (images are downsized to 224x224 px; ~40 MB)
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
[Needs More Information]
## Dataset Structure
### Data Instances
[Needs More Information]
### Data Fields
[Needs More Information]
### Data Splits
[Needs More Information]
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
[Needs More Information] | [
-0.6394476294517517,
-0.46452581882476807,
-0.06082335487008095,
0.2216353714466095,
-0.3472931683063507,
0.2373005598783493,
-0.39926770329475403,
-0.5852440595626831,
0.40689709782600403,
0.45081090927124023,
-0.4411013424396515,
-0.7657660245895386,
-0.7063025832176208,
0.19093552231788... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
blinoff/restaurants_reviews | blinoff | 2022-10-23T16:51:03Z | 15 | 0 | null | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:ru",
"region:us"
] | 2022-10-23T16:51:03Z | 2022-05-31T12:37:50.000Z | 2022-05-31T12:37:50 | ---
language:
- ru
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- text-classification
task_ids:
- sentiment-classification
---
### Dataset Summary
The dataset contains user reviews about restaurants.
In total it contains 47,139 reviews. A review tagged with the <em>general</em> sentiment and sentiments on 3 aspects: <em>food, interior, service</em>.
### Data Fields
Each sample contains the following fields:
- **review_id**;
- **general**;
- **food**;
- **interior**;
- **service**;
- **text** review text.
### Python
```python3
import pandas as pd
df = pd.read_json('restaurants_reviews.jsonl', lines=True)
df.sample(5)
``` | [
-0.3110247850418091,
-0.5409798622131348,
0.4286375045776367,
0.5214691162109375,
-0.2040863037109375,
-0.31550368666648865,
0.11088249832391739,
-0.09413720667362213,
0.5328381657600403,
0.7863717079162598,
-0.22390776872634888,
-1.1444990634918213,
-0.2996170222759247,
0.6905487775802612... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
angie-chen55/python-github-code | angie-chen55 | 2022-05-31T19:02:00Z | 15 | 3 | null | [
"region:us"
] | 2022-05-31T19:02:00Z | 2022-05-31T18:43:56.000Z | 2022-05-31T18:43:56 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AlekseyKorshuk/erotic-books | AlekseyKorshuk | 2022-06-09T19:25:50Z | 15 | 5 | null | [
"region:us"
] | 2022-06-09T19:25:50Z | 2022-06-09T19:25:39.000Z | 2022-06-09T19:25:39 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BeIR/cqadupstack-qrels | BeIR | 2022-10-23T06:16:03Z | 15 | 0 | beir | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-10-23T06:16:03Z | 2022-06-17T13:32:04.000Z | 2022-06-17T13:32:04 | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | [
-0.5227212905883789,
-0.5249219536781311,
0.14435674250125885,
0.04820423573255539,
0.055916160345077515,
0.0011022627586498857,
-0.1081070527434349,
-0.24874727427959442,
0.28598034381866455,
0.07840226590633392,
-0.45233607292175293,
-0.7186435461044312,
-0.347678542137146,
0.20300328731... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
GEM-submissions/lewtun__this-is-a-test-name__1655666361 | GEM-submissions | 2022-06-19T19:19:24Z | 15 | 0 | null | [
"benchmark:gem",
"evaluation",
"benchmark",
"region:us"
] | 2022-06-19T19:19:24Z | 2022-06-19T19:19:21.000Z | 2022-06-19T19:19:21 | ---
benchmark: gem
type: prediction
submission_name: This is a test name
tags:
- evaluation
- benchmark
---
# GEM Submission
Submission name: This is a test name
| [
0.05652708560228348,
-0.9112688302993774,
0.6085131168365479,
0.11336709558963776,
-0.19541293382644653,
0.5379477739334106,
0.13777051866054535,
0.34700915217399597,
0.4342630207538605,
0.34692293405532837,
-1.0974665880203247,
-0.14333294332027435,
-0.5057262778282166,
-0.017583440989255... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pfin123/hindi-aggregated | pfin123 | 2022-07-05T10:06:36Z | 15 | 1 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-05T10:06:36Z | 2022-06-27T08:57:40.000Z | 2022-06-27T08:57:40 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-f9a2c1a2-7774983 | autoevaluate | 2022-06-27T10:55:43Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-06-27T10:55:43Z | 2022-06-27T10:55:12.000Z | 2022-06-27T10:55:12 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- lewtun/dog_food
eval_info:
task: image_multi_class_classification
model: abhishek/convnext-tiny-finetuned-dogfood
metrics: ['matthews_correlation']
dataset_name: lewtun/dog_food
dataset_config: lewtun--dog_food
dataset_split: test
col_mapping:
image: image
target: label
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Image Classification
* Model: abhishek/convnext-tiny-finetuned-dogfood
* Dataset: lewtun/dog_food
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | [
-0.45253458619117737,
-0.2079538255929947,
0.10568160563707352,
0.08112211525440216,
0.003492123680189252,
-0.28657907247543335,
0.0525779128074646,
-0.5431057214736938,
0.11984261125326157,
0.2950069308280945,
-0.7704064249992371,
-0.16660276055335999,
-0.6488085389137268,
-0.029866227880... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
biglam/illustrated_ads | biglam | 2023-01-18T20:38:15Z | 15 | 3 | null | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:expert-generated",
"size_categories:n<1K",
"license:cc0-1.0",
"lam",
"historic newspapers",
"region:us"
] | 2023-01-18T20:38:15Z | 2022-06-27T14:14:29.000Z | 2022-06-27T14:14:29 | ---
annotations_creators:
- expert-generated
language: []
language_creators: []
license:
- cc0-1.0
multilinguality: []
pretty_name: 19th Century United States Newspaper Advert images with 'illustrated'
or 'non illustrated' labels
size_categories:
- n<1K
source_datasets: []
tags:
- lam
- historic newspapers
task_categories:
- image-classification
task_ids:
- multi-class-image-classification
---
The Dataset contains images derived from the [Newspaper Navigator](https://news-navigator.labs.loc.gov/), a dataset of images drawn from the Library of Congress Chronicling America collection (chroniclingamerica.loc.gov/).
> [The Newspaper Navigator dataset](https://news-navigator.labs.loc.gov/) consists of extracted visual content for 16,358,041 historic newspaper pages in Chronicling America. The visual content was identified using an object detection model trained on annotations of World War 1-era Chronicling America pages, including annotations made by volunteers as part of the Beyond Words crowdsourcing project. source: https://news-navigator.labs.loc.gov/
One of these categories is 'advertisements'. This dataset contains a sample of these images with additional labels indicating if the advert is 'illustrated' or 'not illustrated'.
This dataset was created for use in a [Programming Historian tutorial](http://programminghistorian.github.io/ph-submissions/lessons/computer-vision-deep-learning-pt1). The primary aim of the data was to provide a realistic example dataset for teaching computer vision for working with digitised heritage material.
# Dataset Card for 19th Century United States Newspaper Advert images with 'illustrated' or 'non illustrated' labels
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**[https://doi.org/10.5281/zenodo.5838410](https://doi.org/10.5281/zenodo.5838410)
- **Paper:**[https://doi.org/10.46430/phen0101](https://doi.org/10.46430/phen0101)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The Dataset contains images derived from the [Newspaper Navigator](news-navigator.labs.loc.gov/), a dataset of images drawn from the Library of Congress Chronicling America collection (chroniclingamerica.loc.gov/).
> [The Newspaper Navigator dataset](https://news-navigator.labs.loc.gov/) consists of extracted visual content for 16,358,041 historic newspaper pages in Chronicling America. The visual content was identified using an object detection model trained on annotations of World War 1-era Chronicling America pages, including annotations made by volunteers as part of the Beyond Words crowdsourcing project. source: https://news-navigator.labs.loc.gov/
One of these categories is 'advertisements. This dataset contains a sample of these images with additional labels indicating if the advert is 'illustrated' or 'not illustrated'.
This dataset was created for use in a [Programming Historian tutorial](http://programminghistorian.github.io/ph-submissions/lessons/computer-vision-deep-learning-pt1). The primary aim of the data was to provide a realistic example dataset for teaching computer vision for working with digitised heritage material.
### Supported Tasks and Leaderboards
- `image-classification`: the primary purpose of this dataset is for classifying historic newspaper images identified as being 'advertisements' into 'illustrated' and 'not-illustrated' categories.
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
An example instance from this dataset
``` python
{'file': 'pst_fenske_ver02_data_sn84026497_00280776129_1880042101_0834_002_6_96.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=L size=388x395 at 0x7F9A72038950>,
'label': 0,
'pub_date': Timestamp('1880-04-21 00:00:00'),
'page_seq_num': 834,
'edition_seq_num': 1,
'batch': 'pst_fenske_ver02',
'lccn': 'sn84026497',
'box': [0.649412214756012,
0.6045778393745422,
0.8002520799636841,
0.7152365446090698],
'score': 0.9609346985816956,
'ocr': "H. II. IIASLKT & SOXN, Dealers in General Merchandise In New Store Room nt HASLET'S COS ITERS, 'JTionoMtii, ln. .Tau'y 1st, 1?0.",
'place_of_publication': 'Tionesta, Pa.',
'geographic_coverage': "['Pennsylvania--Forest--Tionesta']",
'name': 'The Forest Republican. [volume]',
'publisher': 'Ed. W. Smiley',
'url': 'https://news-navigator.labs.loc.gov/data/pst_fenske_ver02/data/sn84026497/00280776129/1880042101/0834/002_6_96.jpg',
'page_url': 'https://chroniclingamerica.loc.gov/data/batches/pst_fenske_ver02/data/sn84026497/00280776129/1880042101/0834.jp2'}
```
### Data Fields
[More Information Needed]
### Data Splits
The dataset contains a single split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
A description of the annotation process is outlined in this [GitHub repository](https://github.com/Living-with-machines/nnanno)
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
``` bibtex
@dataset{van_strien_daniel_2021_5838410,
author = {van Strien, Daniel},
title = {{19th Century United States Newspaper Advert images
with 'illustrated' or 'non illustrated' labels}},
month = oct,
year = 2021,
publisher = {Zenodo},
version = {0.0.1},
doi = {10.5281/zenodo.5838410},
url = {https://doi.org/10.5281/zenodo.5838410}}
```
[More Information Needed]
### Contributions
Thanks to [@davanstrien](https://github.com/davanstrien) for adding this dataset.
| [
-0.40728840231895447,
-0.5804085731506348,
0.3863675892353058,
0.012841788120567799,
-0.29833588004112244,
-0.21132278442382812,
-0.26394161581993103,
-0.5281159281730652,
0.44996899366378784,
0.6678487062454224,
-0.34663206338882446,
-0.8592972755432129,
-0.4877297282218933,
0.15220755338... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
loubnabnl/github-code-more-filtering | loubnabnl | 2022-06-30T22:28:37Z | 15 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-06-30T22:28:37Z | 2022-06-29T22:42:08.000Z | 2022-06-29T22:42:08 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_support-google-com | MicPie | 2022-08-04T20:15:33Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:15:33Z | 2022-07-03T09:06:22.000Z | 2022-07-03T09:06:22 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-support-google-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-support-google-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5803234577178955,
-0.567036509513855,
0.46026644110679626,
0.3252061605453491,
0.09293008595705032,
0.14826080203056335,
-0.14546261727809906,
-0.606362521648407,
0.5271570682525635,
0.2786747217178345,
-1.0573499202728271,
-0.6576958894729614,
-0.664599597454071,
0.21964724361896515,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_dividend-com | MicPie | 2022-08-04T20:04:10Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:04:10Z | 2022-07-03T09:15:30.000Z | 2022-07-03T09:15:30 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-dividend-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-dividend-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5681177377700806,
-0.5867766737937927,
0.40930506587028503,
0.3683319389820099,
0.06561439484357834,
0.18329961597919464,
-0.11656820774078369,
-0.5748574733734131,
0.5564186573028564,
0.3033422529697418,
-1.0589125156402588,
-0.632034420967102,
-0.6642926335334778,
0.21178239583969116,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_bulbapedia-bulbagarden-net | MicPie | 2022-08-04T19:40:16Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:40:16Z | 2022-07-03T09:24:28.000Z | 2022-07-03T09:24:28 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-bulbapedia-bulbagarden-net
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-bulbapedia-bulbagarden-net" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5565125346183777,
-0.54947829246521,
0.4121816158294678,
0.35605940222740173,
0.09285524487495422,
0.14213316142559052,
-0.14005085825920105,
-0.6244864463806152,
0.5461552739143372,
0.2731460630893707,
-1.0233147144317627,
-0.6451683640480042,
-0.6361706852912903,
0.22871242463588715,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_wkdu-org | MicPie | 2022-08-04T20:18:48Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:18:48Z | 2022-07-03T09:30:13.000Z | 2022-07-03T09:30:13 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-wkdu-org
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-wkdu-org" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5750240683555603,
-0.5522739291191101,
0.4500587582588196,
0.3201325535774231,
0.08300787210464478,
0.1666680872440338,
-0.13087338209152222,
-0.621766209602356,
0.5016674399375916,
0.2762638330459595,
-1.0206154584884644,
-0.6321201324462891,
-0.6524355411529541,
0.2181147187948227,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_mgoblog-com | MicPie | 2022-08-04T20:09:03Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:09:03Z | 2022-07-03T09:56:07.000Z | 2022-07-03T09:56:07 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: AdapTable-mgoblog-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "AdapTable-mgoblog-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.581866979598999,
-0.5254676342010498,
0.4284394383430481,
0.3137889504432678,
0.05836973339319229,
0.15152233839035034,
-0.12954194843769073,
-0.6096592545509338,
0.5361701250076294,
0.30790016055107117,
-1.0130354166030884,
-0.6784335970878601,
-0.6434065699577332,
0.2171083688735962,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_gamefaqs-com | MicPie | 2022-08-04T20:08:30Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:08:30Z | 2022-07-03T10:10:20.000Z | 2022-07-03T10:10:20 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-gamefaqs-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-gamefaqs-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5695529580116272,
-0.576521098613739,
0.43288278579711914,
0.3324771523475647,
0.08645805716514587,
0.15630210936069489,
-0.09475044906139374,
-0.5950803160667419,
0.4964469373226166,
0.3011654317378998,
-1.055855631828308,
-0.6496340036392212,
-0.6285207867622375,
0.21676005423069,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_studystack-com | MicPie | 2022-08-04T20:15:01Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:15:01Z | 2022-07-03T10:23:52.000Z | 2022-07-03T10:23:52 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-studystack-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-studystack-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5487352013587952,
-0.5731054544448853,
0.4470718502998352,
0.305726021528244,
0.08060659468173981,
0.15915915369987488,
-0.13127008080482483,
-0.6011386513710022,
0.5483677387237549,
0.29594919085502625,
-1.0225486755371094,
-0.6470211148262024,
-0.6441819667816162,
0.21654944121837616,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_sittercity-com | MicPie | 2022-08-04T20:13:09Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:13:09Z | 2022-07-03T10:37:38.000Z | 2022-07-03T10:37:38 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-sittercity-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-sittercity-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5536697506904602,
-0.5480952858924866,
0.4693605601787567,
0.33519530296325684,
0.08152732253074646,
0.15064477920532227,
-0.14308017492294312,
-0.6197099089622498,
0.5467740893363953,
0.28989943861961365,
-1.0279784202575684,
-0.658000648021698,
-0.6291047930717468,
0.20624837279319763... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_msdn-microsoft-com | MicPie | 2022-08-04T20:10:19Z | 15 | 1 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:10:19Z | 2022-07-03T10:50:56.000Z | 2022-07-03T10:50:56 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-msdn-microsoft-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-msdn-microsoft-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5516654849052429,
-0.548603892326355,
0.42956286668777466,
0.3326401114463806,
0.09938162565231323,
0.16398482024669647,
-0.11237386614084244,
-0.6057470440864563,
0.5056964755058289,
0.2816426455974579,
-1.0437926054000854,
-0.6400558948516846,
-0.6504566669464111,
0.21031370759010315,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cappex-com | MicPie | 2022-08-04T19:41:09Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:41:09Z | 2022-07-03T11:04:27.000Z | 2022-07-03T11:04:27 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cappex.com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cappex.com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5703105926513672,
-0.5566323399543762,
0.4434305429458618,
0.3386186957359314,
0.11192917078733444,
0.16951817274093628,
-0.14875902235507965,
-0.6121371388435364,
0.5232948064804077,
0.2945716083049774,
-1.0393378734588623,
-0.6472460031509399,
-0.6354029178619385,
0.21358072757720947,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_en-wikipedia-org | MicPie | 2022-08-04T20:05:44Z | 15 | 1 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:05:44Z | 2022-07-03T11:17:38.000Z | 2022-07-03T11:17:38 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-en-wikipedia-org
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-en-wikipedia-org" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5731709599494934,
-0.5761057138442993,
0.44913265109062195,
0.31702011823654175,
0.09402009099721909,
0.14338849484920502,
-0.12376438081264496,
-0.6197077035903931,
0.5216239094734192,
0.2812177836894989,
-1.0320918560028076,
-0.6435121893882751,
-0.6505264639854431,
0.2126807421445846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cram-com | MicPie | 2022-08-04T20:03:25Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:03:25Z | 2022-07-03T11:31:09.000Z | 2022-07-03T11:31:09 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cram-com
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cram-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5539737939834595,
-0.573503315448761,
0.43209606409072876,
0.34144270420074463,
0.07899454236030579,
0.15794523060321808,
-0.15842729806900024,
-0.6032031774520874,
0.5210782289505005,
0.2950584292411804,
-1.0192880630493164,
-0.6580876708030701,
-0.6686134338378906,
0.19897153973579407... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_w3-org | MicPie | 2022-08-04T20:16:53Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:16:53Z | 2022-07-03T11:45:06.000Z | 2022-07-03T11:45:06 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-w3-org
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-w3-org" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5708709359169006,
-0.5488318800926208,
0.46241244673728943,
0.33527785539627075,
0.09498680382966995,
0.14883698523044586,
-0.10667405277490616,
-0.6465544104576111,
0.4866277277469635,
0.28219467401504517,
-1.042972445487976,
-0.6462441682815552,
-0.6510154604911804,
0.2327698022127151... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_wiki-openmoko-org | MicPie | 2022-08-04T20:17:59Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:17:59Z | 2022-07-03T12:06:24.000Z | 2022-07-03T12:06:24 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-wiki-openmoko-org
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-wiki-openmoko-org" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5820800065994263,
-0.5636420845985413,
0.43974459171295166,
0.29312825202941895,
0.08272451162338257,
0.10308820754289627,
-0.13579925894737244,
-0.6140501499176025,
0.5143302083015442,
0.3084344267845154,
-1.0321738719940186,
-0.6501525044441223,
-0.6429988145828247,
0.2260291278362274... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_ensembl-org | MicPie | 2022-08-04T20:06:23Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T20:06:23Z | 2022-07-03T12:19:43.000Z | 2022-07-03T12:19:43 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-ensembl-org
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-ensembl-org" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5686347484588623,
-0.5708359479904175,
0.44784626364707947,
0.32608675956726074,
0.09307657182216644,
0.16108258068561554,
-0.11819354444742203,
-0.6216766834259033,
0.5356160998344421,
0.29821136593818665,
-1.0191336870193481,
-0.6386246681213379,
-0.6445544362068176,
0.233952149748802... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Yincen/SalienceEvaluation | Yincen | 2022-07-04T02:36:58Z | 15 | 1 | null | [
"task_categories:text-classification",
"task_ids:multi-input-text-classification",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:zh",
"license:gpl-3.0",
"region:us"
] | 2022-07-04T02:36:58Z | 2022-07-04T02:10:27.000Z | 2022-07-04T02:10:27 | ---
annotations_creators:
- crowdsourced
language:
- zh
language_creators:
- found
license:
- gpl-3.0
multilinguality:
- monolingual
pretty_name: Yincen/SalienceEvaluation
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-input-text-classification
---
# Dataset Card for Yincen/SalienceEvaluation
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/qyccc) for adding this dataset. | [
-0.30691513419151306,
-0.37191295623779297,
0.1490940898656845,
0.32250645756721497,
-0.2780120074748993,
0.024531472474336624,
-0.3657200038433075,
-0.5151688456535339,
0.7523929476737976,
0.4856553375720978,
-0.9879506826400757,
-1.098320722579956,
-0.6117916107177734,
0.0740428566932678... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rongzhangibm/NaturalQuestionsV2 | rongzhangibm | 2022-07-07T05:22:20Z | 15 | 5 | natural-questions | [
"task_categories:question-answering",
"task_ids:open-domain-qa",
"annotations_creators:no-annotation",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | 2022-07-07T05:22:20Z | 2022-07-06T13:50:46.000Z | 2022-07-06T13:50:46 | ---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
pretty_name: Natural Questions
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- open-domain-qa
paperswithcode_id: natural-questions
---
# Dataset Card for Natural Questions
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://ai.google.com/research/NaturalQuestions/dataset](https://ai.google.com/research/NaturalQuestions/dataset)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 42981 MB
- **Size of the generated dataset:** 139706 MB
- **Total amount of disk used:** 182687 MB
### Dataset Summary
The NQ corpus contains questions from real users, and it requires QA systems to
read and comprehend an entire Wikipedia article that may or may not contain the
answer to the question. The inclusion of real user questions, and the
requirement that solutions should read an entire page to find the answer, cause
NQ to be a more realistic and challenging task than prior QA datasets.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 42981 MB
- **Size of the generated dataset:** 139706 MB
- **Total amount of disk used:** 182687 MB
An example of 'train' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### default
```
"id": datasets.Value("string"),
"document": {
"title": datasets.Value("string"),
"url": datasets.Value("string"),
"html": datasets.Value("string"),
"tokens": datasets.features.Sequence(
{
"token": datasets.Value("string"),
"is_html": datasets.Value("bool"),
"start_byte": datasets.Value("int64"),
"end_byte": datasets.Value("int64"),
}
),
},
"question": {
"text": datasets.Value("string"),
"tokens": datasets.features.Sequence(datasets.Value("string")),
},
"long_answer_candidates": datasets.features.Sequence(
{
"start_token": datasets.Value("int64"),
"end_token": datasets.Value("int64"),
"start_byte": datasets.Value("int64"),
"end_byte": datasets.Value("int64"),
"top_level": datasets.Value("bool"),
}
),
"annotations": datasets.features.Sequence(
{
"id": datasets.Value("string"),
"long_answer": {
"start_token": datasets.Value("int64"),
"end_token": datasets.Value("int64"),
"start_byte": datasets.Value("int64"),
"end_byte": datasets.Value("int64"),
"candidate_index": datasets.Value("int64")
},
"short_answers": datasets.features.Sequence(
{
"start_token": datasets.Value("int64"),
"end_token": datasets.Value("int64"),
"start_byte": datasets.Value("int64"),
"end_byte": datasets.Value("int64"),
"text": datasets.Value("string"),
}
),
"yes_no_answer": datasets.features.ClassLabel(
names=["NO", "YES"]
), # Can also be -1 for NONE.
}
)
```
### Data Splits
| name | train | validation |
|---------|-------:|-----------:|
| default | 307373 | 7830 |
| dev | N/A | 7830 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[Creative Commons Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/).
### Citation Information
```
@article{47761,
title = {Natural Questions: a Benchmark for Question Answering Research},
author = {Tom Kwiatkowski and Jennimaria Palomaki and Olivia Redfield and Michael Collins and Ankur Parikh and Chris Alberti and Danielle Epstein and Illia Polosukhin and Matthew Kelcey and Jacob Devlin and Kenton Lee and Kristina N. Toutanova and Llion Jones and Ming-Wei Chang and Andrew Dai and Jakob Uszkoreit and Quoc Le and Slav Petrov},
year = {2019},
journal = {Transactions of the Association of Computational Linguistics}
}
```
### Contributions
| [
-0.7412623167037964,
-0.8083851933479309,
0.18686531484127045,
-0.03233836963772774,
-0.17158323526382446,
0.037475842982530594,
-0.2793724834918976,
-0.36244407296180725,
0.6985350251197815,
0.5004647970199585,
-0.817298412322998,
-0.7984504699707031,
-0.3515319526195526,
0.24597500264644... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kmkarakaya/turkishReviews-ds-mini | kmkarakaya | 2023-10-02T19:42:11Z | 15 | 0 | null | [
"language:tr",
"region:us"
] | 2023-10-02T19:42:11Z | 2022-07-07T13:24:13.000Z | 2022-07-07T13:24:13 | ---
language:
- tr
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster00 | MicPie | 2022-08-04T19:42:43Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:42:43Z | 2022-07-08T17:16:43.000Z | 2022-07-08T17:16:43 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster00
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster00" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5787767171859741,
-0.5642099976539612,
0.47045788168907166,
0.32764121890068054,
0.09360211342573166,
0.15815001726150513,
-0.13870438933372498,
-0.5968871116638184,
0.5348442792892456,
0.28445011377334595,
-1.0168286561965942,
-0.6776611804962158,
-0.6591751575469971,
0.198724538087844... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster01 | MicPie | 2022-08-04T19:43:16Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:43:16Z | 2022-07-08T17:17:31.000Z | 2022-07-08T17:17:31 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster01
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster01" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5828542113304138,
-0.5732630491256714,
0.4715729057788849,
0.326364666223526,
0.08378595858812332,
0.1477428823709488,
-0.13424266874790192,
-0.6032239198684692,
0.5412445068359375,
0.2794382870197296,
-1.026727318763733,
-0.678489625453949,
-0.6547457575798035,
0.1919134557247162,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster10 | MicPie | 2022-08-04T19:49:37Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:49:37Z | 2022-07-08T17:18:25.000Z | 2022-07-08T17:18:25 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster10
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster10" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5903376936912537,
-0.5625874400138855,
0.4725564420223236,
0.3298628032207489,
0.10225410014390945,
0.15726807713508606,
-0.15412800014019012,
-0.6078706383705139,
0.5296670794487,
0.272834837436676,
-1.0106775760650635,
-0.6665090322494507,
-0.6573256850242615,
0.2048480063676834,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster03 | MicPie | 2022-08-04T19:44:47Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:44:47Z | 2022-07-08T19:08:05.000Z | 2022-07-08T19:08:05 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster03
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster03" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5714698433876038,
-0.5627780556678772,
0.4886442720890045,
0.33542802929878235,
0.0923788845539093,
0.14665944874286652,
-0.13095803558826447,
-0.6130676865577698,
0.516604483127594,
0.2905915379524231,
-1.0158644914627075,
-0.6798414587974548,
-0.6552619338035583,
0.20467308163642883,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster04 | MicPie | 2022-08-04T19:45:22Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:45:22Z | 2022-07-08T19:09:09.000Z | 2022-07-08T19:09:09 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster04
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster04" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5752826929092407,
-0.5540135502815247,
0.48289385437965393,
0.32362499833106995,
0.09018579870462418,
0.157371386885643,
-0.1347784698009491,
-0.6060141921043396,
0.5276601314544678,
0.28774353861808777,
-1.0228207111358643,
-0.6803792119026184,
-0.6432000994682312,
0.21947622299194336,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster06 | MicPie | 2022-08-04T19:46:44Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:46:44Z | 2022-07-08T19:11:07.000Z | 2022-07-08T19:11:07 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster06
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster06" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5692755579948425,
-0.5474217534065247,
0.4756395220756531,
0.31102123856544495,
0.09430312365293503,
0.1298728883266449,
-0.13408468663692474,
-0.6095637679100037,
0.5259100198745728,
0.2816687226295471,
-1.0269368886947632,
-0.678320050239563,
-0.6516700387001038,
0.19682885706424713,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MicPie/unpredictable_cluster08 | MicPie | 2022-08-04T19:48:00Z | 15 | 0 | null | [
"task_categories:multiple-choice",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:text2text-generation",
"task_categories:table-question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:tabular-cl... | 2022-08-04T19:48:00Z | 2022-07-08T19:14:10.000Z | 2022-07-08T19:14:10 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: UnpredicTable-cluster08
size_categories:
- 100K<n<1M
source_datasets: []
task_categories:
- multiple-choice
- question-answering
- zero-shot-classification
- text2text-generation
- table-question-answering
- text-generation
- text-classification
- tabular-classification
task_ids:
- multiple-choice-qa
- extractive-qa
- open-domain-qa
- closed-domain-qa
- closed-book-qa
- open-book-qa
- language-modeling
- multi-class-classification
- natural-language-inference
- topic-classification
- multi-label-classification
- tabular-multi-class-classification
- tabular-multi-label-classification
---
# Dataset Card for "UnpredicTable-cluster08" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://ethanperez.net/unpredictable
- **Repository:** https://github.com/JunShern/few-shot-adaptation
- **Paper:** Few-shot Adaptation Works with UnpredicTable Data
- **Point of Contact:** junshern@nyu.edu, perez@nyu.edu
### Dataset Summary
The UnpredicTable dataset consists of web tables formatted as few-shot tasks for fine-tuning language models to improve their few-shot performance.
There are several dataset versions available:
* [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full): Starting from the initial WTC corpus of 50M tables, we apply our tables-to-tasks procedure to produce our resulting dataset, [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full), which comprises 413,299 tasks from 23,744 unique websites.
* [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique): This is the same as [UnpredicTable-full](https://huggingface.co/datasets/MicPie/unpredictable_full) but filtered to have a maximum of one task per website. [UnpredicTable-unique](https://huggingface.co/datasets/MicPie/unpredictable_unique) contains exactly 23,744 tasks from 23,744 websites.
* [UnpredicTable-5k](https://huggingface.co/datasets/MicPie/unpredictable_5k): This dataset contains 5k random tables from the full dataset.
* UnpredicTable data subsets based on a manual human quality rating (please see our publication for details of the ratings):
* [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low)
* [UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium)
* [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high)
* UnpredicTable data subsets based on the website of origin:
* [UnpredicTable-baseball-fantasysports-yahoo-com](https://huggingface.co/datasets/MicPie/unpredictable_baseball-fantasysports-yahoo-com)
* [UnpredicTable-bulbapedia-bulbagarden-net](https://huggingface.co/datasets/MicPie/unpredictable_bulbapedia-bulbagarden-net)
* [UnpredicTable-cappex-com](https://huggingface.co/datasets/MicPie/unpredictable_cappex-com)
* [UnpredicTable-cram-com](https://huggingface.co/datasets/MicPie/unpredictable_cram-com)
* [UnpredicTable-dividend-com](https://huggingface.co/datasets/MicPie/unpredictable_dividend-com)
* [UnpredicTable-dummies-com](https://huggingface.co/datasets/MicPie/unpredictable_dummies-com)
* [UnpredicTable-en-wikipedia-org](https://huggingface.co/datasets/MicPie/unpredictable_en-wikipedia-org)
* [UnpredicTable-ensembl-org](https://huggingface.co/datasets/MicPie/unpredictable_ensembl-org)
* [UnpredicTable-gamefaqs-com](https://huggingface.co/datasets/MicPie/unpredictable_gamefaqs-com)
* [UnpredicTable-mgoblog-com](https://huggingface.co/datasets/MicPie/unpredictable_mgoblog-com)
* [UnpredicTable-mmo-champion-com](https://huggingface.co/datasets/MicPie/unpredictable_mmo-champion-com)
* [UnpredicTable-msdn-microsoft-com](https://huggingface.co/datasets/MicPie/unpredictable_msdn-microsoft-com)
* [UnpredicTable-phonearena-com](https://huggingface.co/datasets/MicPie/unpredictable_phonearena-com)
* [UnpredicTable-sittercity-com](https://huggingface.co/datasets/MicPie/unpredictable_sittercity-com)
* [UnpredicTable-sporcle-com](https://huggingface.co/datasets/MicPie/unpredictable_sporcle-com)
* [UnpredicTable-studystack-com](https://huggingface.co/datasets/MicPie/unpredictable_studystack-com)
* [UnpredicTable-support-google-com](https://huggingface.co/datasets/MicPie/unpredictable_support-google-com)
* [UnpredicTable-w3-org](https://huggingface.co/datasets/MicPie/unpredictable_w3-org)
* [UnpredicTable-wiki-openmoko-org](https://huggingface.co/datasets/MicPie/unpredictable_wiki-openmoko-org)
* [UnpredicTable-wkdu-org](https://huggingface.co/datasets/MicPie/unpredictable_wkdu-org)
* UnpredicTable data subsets based on clustering (for the clustering details please see our publication):
* [UnpredicTable-cluster00](https://huggingface.co/datasets/MicPie/unpredictable_cluster00)
* [UnpredicTable-cluster01](https://huggingface.co/datasets/MicPie/unpredictable_cluster01)
* [UnpredicTable-cluster02](https://huggingface.co/datasets/MicPie/unpredictable_cluster02)
* [UnpredicTable-cluster03](https://huggingface.co/datasets/MicPie/unpredictable_cluster03)
* [UnpredicTable-cluster04](https://huggingface.co/datasets/MicPie/unpredictable_cluster04)
* [UnpredicTable-cluster05](https://huggingface.co/datasets/MicPie/unpredictable_cluster05)
* [UnpredicTable-cluster06](https://huggingface.co/datasets/MicPie/unpredictable_cluster06)
* [UnpredicTable-cluster07](https://huggingface.co/datasets/MicPie/unpredictable_cluster07)
* [UnpredicTable-cluster08](https://huggingface.co/datasets/MicPie/unpredictable_cluster08)
* [UnpredicTable-cluster09](https://huggingface.co/datasets/MicPie/unpredictable_cluster09)
* [UnpredicTable-cluster10](https://huggingface.co/datasets/MicPie/unpredictable_cluster10)
* [UnpredicTable-cluster11](https://huggingface.co/datasets/MicPie/unpredictable_cluster11)
* [UnpredicTable-cluster12](https://huggingface.co/datasets/MicPie/unpredictable_cluster12)
* [UnpredicTable-cluster13](https://huggingface.co/datasets/MicPie/unpredictable_cluster13)
* [UnpredicTable-cluster14](https://huggingface.co/datasets/MicPie/unpredictable_cluster14)
* [UnpredicTable-cluster15](https://huggingface.co/datasets/MicPie/unpredictable_cluster15)
* [UnpredicTable-cluster16](https://huggingface.co/datasets/MicPie/unpredictable_cluster16)
* [UnpredicTable-cluster17](https://huggingface.co/datasets/MicPie/unpredictable_cluster17)
* [UnpredicTable-cluster18](https://huggingface.co/datasets/MicPie/unpredictable_cluster18)
* [UnpredicTable-cluster19](https://huggingface.co/datasets/MicPie/unpredictable_cluster19)
* [UnpredicTable-cluster20](https://huggingface.co/datasets/MicPie/unpredictable_cluster20)
* [UnpredicTable-cluster21](https://huggingface.co/datasets/MicPie/unpredictable_cluster21)
* [UnpredicTable-cluster22](https://huggingface.co/datasets/MicPie/unpredictable_cluster22)
* [UnpredicTable-cluster23](https://huggingface.co/datasets/MicPie/unpredictable_cluster23)
* [UnpredicTable-cluster24](https://huggingface.co/datasets/MicPie/unpredictable_cluster24)
* [UnpredicTable-cluster25](https://huggingface.co/datasets/MicPie/unpredictable_cluster25)
* [UnpredicTable-cluster26](https://huggingface.co/datasets/MicPie/unpredictable_cluster26)
* [UnpredicTable-cluster27](https://huggingface.co/datasets/MicPie/unpredictable_cluster27)
* [UnpredicTable-cluster28](https://huggingface.co/datasets/MicPie/unpredictable_cluster28)
* [UnpredicTable-cluster29](https://huggingface.co/datasets/MicPie/unpredictable_cluster29)
* [UnpredicTable-cluster-noise](https://huggingface.co/datasets/MicPie/unpredictable_cluster-noise)
### Supported Tasks and Leaderboards
Since the tables come from the web, the distribution of tasks and topics is very broad. The shape of our dataset is very wide, i.e., we have 1000's of tasks, while each task has only a few examples, compared to most current NLP datasets which are very deep, i.e., 10s of tasks with many examples. This implies that our dataset covers a broad range of potential tasks, e.g., multiple-choice, question-answering, table-question-answering, text-classification, etc.
The intended use of this dataset is to improve few-shot performance by fine-tuning/pre-training on our dataset.
### Languages
English
## Dataset Structure
### Data Instances
Each task is represented as a jsonline file and consists of several few-shot examples. Each example is a dictionary containing a field 'task', which identifies the task, followed by an 'input', 'options', and 'output' field. The 'input' field contains several column elements of the same row in the table, while the 'output' field is a target which represents an individual column of the same row. Each task contains several such examples which can be concatenated as a few-shot task. In the case of multiple choice classification, the 'options' field contains the possible classes that a model needs to choose from.
There are also additional meta-data fields such as 'pageTitle', 'title', 'outputColName', 'url', 'wdcFile'.
### Data Fields
'task': task identifier
'input': column elements of a specific row in the table.
'options': for multiple choice classification, it provides the options to choose from.
'output': target column element of the same row as input.
'pageTitle': the title of the page containing the table.
'outputColName': output column name
'url': url to the website containing the table
'wdcFile': WDC Web Table Corpus file
### Data Splits
The UnpredicTable datasets do not come with additional data splits.
## Dataset Creation
### Curation Rationale
Few-shot training on multi-task datasets has been demonstrated to improve language models' few-shot learning (FSL) performance on new tasks, but it is unclear which training tasks lead to effective downstream task adaptation. Few-shot learning datasets are typically produced with expensive human curation, limiting the scale and diversity of the training tasks available to study. As an alternative source of few-shot data, we automatically extract 413,299 tasks from diverse internet tables. We provide this as a research resource to investigate the relationship between training data and few-shot learning.
### Source Data
#### Initial Data Collection and Normalization
We use internet tables from the English-language Relational Subset of the WDC Web Table Corpus 2015 (WTC). The WTC dataset tables were extracted from the July 2015 Common Crawl web corpus (http://webdatacommons.org/webtables/2015/EnglishStatistics.html). The dataset contains 50,820,165 tables from 323,160 web domains. We then convert the tables into few-shot learning tasks. Please see our publication for more details on the data collection and conversion pipeline.
#### Who are the source language producers?
The dataset is extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/).
### Annotations
#### Annotation process
Manual annotation was only carried out for the [UnpredicTable-rated-low](https://huggingface.co/datasets/MicPie/unpredictable_rated-low),
[UnpredicTable-rated-medium](https://huggingface.co/datasets/MicPie/unpredictable_rated-medium), and [UnpredicTable-rated-high](https://huggingface.co/datasets/MicPie/unpredictable_rated-high) data subsets to rate task quality. Detailed instructions of the annotation instructions can be found in our publication.
#### Who are the annotators?
Annotations were carried out by a lab assistant.
### Personal and Sensitive Information
The data was extracted from [WDC Web Table Corpora](http://webdatacommons.org/webtables/), which in turn extracted tables from the [Common Crawl](https://commoncrawl.org/). We did not filter the data in any way. Thus any user identities or otherwise sensitive information (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history, etc.) might be contained in our dataset.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended for use as a research resource to investigate the relationship between training data and few-shot learning. As such, it contains high- and low-quality data, as well as diverse content that may be untruthful or inappropriate. Without careful investigation, it should not be used for training models that will be deployed for use in decision-critical or user-facing situations.
### Discussion of Biases
Since our dataset contains tables that are scraped from the web, it will also contain many toxic, racist, sexist, and otherwise harmful biases and texts. We have not run any analysis on the biases prevalent in our datasets. Neither have we explicitly filtered the content. This implies that a model trained on our dataset may potentially reflect harmful biases and toxic text that exist in our dataset.
### Other Known Limitations
No additional known limitations.
## Additional Information
### Dataset Curators
Jun Shern Chan, Michael Pieler, Jonathan Jao, Jérémy Scheurer, Ethan Perez
### Licensing Information
Apache 2.0
### Citation Information
```
@misc{chan2022few,
author = {Chan, Jun Shern and Pieler, Michael and Jao, Jonathan and Scheurer, Jérémy and Perez, Ethan},
title = {Few-shot Adaptation Works with UnpredicTable Data},
publisher={arXiv},
year = {2022},
url = {https://arxiv.org/abs/2208.01009}
}
```
| [
-0.5714567303657532,
-0.5512741804122925,
0.4803304970264435,
0.31604474782943726,
0.09047619253396988,
0.1445532739162445,
-0.1414807140827179,
-0.6060510873794556,
0.5312848687171936,
0.2935820519924164,
-1.009810447692871,
-0.6744651794433594,
-0.6621971130371094,
0.20393095910549164,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
arbml/ashaar | arbml | 2022-09-03T18:05:56Z | 15 | 1 | null | [
"region:us"
] | 2022-09-03T18:05:56Z | 2022-07-12T14:42:57.000Z | 2022-07-12T14:42:57 | # ashaar
introducing ashaar, the largest dataset for arabic poetry
# general statistics
| metric | value |
|-----------------|-----------|
| number of poems | 254,630 |
| number of baits | 3,857,429 |
| number of poets | 7,167 |
# License
This dataset is released under fair use for research development only. Poets have the sole right to take down any access to their work. The authors of the websites, also, have the right to take down any material that does not conform with that. This work should not be used for any commercial purposes.
| [
-0.3327215611934662,
0.13892552256584167,
-0.04755236953496933,
0.4081382155418396,
-0.5867354869842529,
-0.10758047550916672,
-0.09422171115875244,
-0.5067901611328125,
0.3249545097351074,
0.5002432465553284,
-0.10975522547960281,
-0.9579558372497559,
-1.1083412170410156,
0.26355159282684... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Bingsu/namuwiki_20210301_filtered | Bingsu | 2022-10-14T07:49:53Z | 15 | 5 | null | [
"task_categories:fill-mask",
"task_categories:text-generation",
"task_ids:masked-language-modeling",
"task_ids:language-modeling",
"annotations_creators:no-annotation",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"langua... | 2022-10-14T07:49:53Z | 2022-07-14T02:18:12.000Z | 2022-07-14T02:18:12 | ---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- ko
license:
- cc-by-nc-sa-2.0
multilinguality:
- monolingual
pretty_name: Namuwiki database dump (2021-03-01)
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- fill-mask
- text-generation
task_ids:
- masked-language-modeling
- language-modeling
---
# Namuwiki database dump (2021-03-01)
## Dataset Description
- **Homepage:** [나무위키:데이터베이스 덤프](https://namu.wiki/w/%EB%82%98%EB%AC%B4%EC%9C%84%ED%82%A4:%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4%20%EB%8D%A4%ED%94%84)
- **Repository:** [Needs More Information]
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
## Namuwiki
https://namu.wiki/
It is a Korean wiki based on the seed engine, established on April 17, 2015 (KST).
## About dataset
All data from Namuwiki collected on 2021-03-01. I filtered data without text(mostly redirecting documents).
You can download the original data converted to csv in [Kaggle](https://www.kaggle.com/datasets/brainer3220/namu-wiki).
## 2022-03-01 dataset
[heegyu/namuwiki](https://huggingface.co/datasets/heegyu/namuwiki)<br>
[heegyu/namuwiki-extracted](https://huggingface.co/datasets/heegyu/namuwiki-extracted)<br>
[heegyu/namuwiki-sentences](https://huggingface.co/datasets/heegyu/namuwiki-sentences)
### Lisence
[CC BY-NC-SA 2.0 KR](https://creativecommons.org/licenses/by-nc-sa/2.0/kr/)
## Data Structure
### Data Instance
```pycon
>>> from datasets import load_dataset
>>> dataset = load_dataset("Bingsu/namuwiki_20210301_filtered")
>>> dataset
DatasetDict({
train: Dataset({
features: ['title', 'text'],
num_rows: 571308
})
})
```
```pycon
>>> dataset["train"].features
{'title': Value(dtype='string', id=None),
'text': Value(dtype='string', id=None)}
```
### Data Size
download: 3.26 GiB<br>
generated: 3.73 GiB<br>
total: 6.99 GiB
### Data Field
- title: `string`
- text: `string`
### Data Splits
| | train |
| ---------- | ------ |
| # of texts | 571308 |
```pycon
>>> dataset["train"][2323]
{'title': '55번 지방도',
'text': '55번 국가지원지방도\n해남 ~ 금산\n시점 전라남도 해남군 북평면 남창교차로\n종점 충청남도 금산군 금산읍 우체국사거리\n총 구간 279.2km\n경유지 전라남도 강진군, 장흥군, 영암군 전라남도 나주시, 화순군 광주광역시 동구, 북구 전라남도 담양군 전라북도 순창군, 정읍시, 완주군 전라북도 임실군, 진안군\n개요\n국가지원지방도 제55호선은 전라남도 해남군에서 출발하여 충청남도 금산군까지 이어지는 대한민국의 국가지원지방도이다.\n전라남도 해남군 북평면 - 전라남도 강진군 도암면 구간은 광주광역시, 전라남도 동부권, 영남 지방에서 완도군 완도읍으로 갈 때 주로 이용된다.] 해남 - 완도구간이 확장되기 전에는 그랬다. 강진군, 장흥군은 예외]\n노선\n전라남도\n해남군\n백도로\n북평면 남창교차로에서 13번 국도, 77번 국도와 만나며 출발한다.\n쇄노재\n북일면 북일초교 앞에서 827번 지방도와 만난다.\n강진군\n백도로\n도암면소재지 사거리에서 819번 지방도와 만난다. 819번 지방도는 망호선착장까지만 길이 있으며, 뱃길을 통해 간접적으로 바다 건너의 819번 지방도와 연결된다.\n석문공원\n도암면 계라교차로에서 18번 국도에 합류한다. 우회전하자. 이후 강진읍까지 18번 국도와 중첩되고 장흥군 장흥읍까지 2번 국도와 중첩된다. 그리고 장흥읍부터 영암군을 거쳐 나주시 세지면까지는 23번 국도와 중첩된다.\n나주시\n동창로\n세지면 세지교차로에서 드디어 23번 국도로부터 분기하면서 820번 지방도와 직결 합류한다. 이 길은 2013년 현재 확장 공사 중이다. 확장공사가 완료되면 동창로가 55번 지방도 노선이 된다.\n세남로\n봉황면 덕림리 삼거리에서 820번 지방도와 분기한다.\n봉황면 철천리 삼거리에서 818번 지방도와 합류한다.\n봉황면 송현리 삼거리에서 818번 지방도와 분기한다.\n송림산제길\n동창로\n여기부터 완공된 왕복 4차로 길이다. 이 길을 만들면서 교통량이 늘어났지만 주변 농민들이 이용하는 농로의 교량을 설치하지 않아 문제가 생기기도 했다. #1 #2\n세남로\n남평읍에서 다시 왕복 2차로로 줄어든다.\n남평읍 남평오거리에서 822번 지방도와 만난다.\n산남로\n남평교를 건너고 남평교사거리에서 우회전\n동촌로\n남평역\n화순군\n동촌로\n화순읍 앵남리 삼거리에서 817번 지방도와 합류한다. 좌회전하자.\n앵남역\n지강로\n화순읍 앵남리 앵남교차로에서 817번 지방도와 분기한다. 앵남교차로부터 나주 남평읍까지 55번 지방도의 확장공사가 진행중이다.\n오성로\n여기부터 화순읍 대리사거리까지 왕복 4차선으로 확장 공사를 진행했고, 2015년 8월 말 화순읍 구간은 왕복 4차선으로 확장되었다.\n화순역\n화순읍에서 광주광역시 동구까지 22번 국도와 중첩되고, 동구부터 전라북도 순창군 쌍치면까지는 29번 국도와 중첩된다.\n전라북도\n순창군\n청정로\n29번 국도를 따라가다가 쌍치면 쌍길매삼거리에서 우회전하여 21번 국도로 들어가자. 쌍치면 쌍치사거리에서 21번 국도와 헤어진다. 직진하자.\n정읍시\n청정로\n산내면 산내사거리에서 715번 지방도와 직결하면서 30번 국도에 합류한다. 좌회전하여 구절재를 넘자.\n산외로\n칠보면 시산교차로에서 49번 지방도와 교차되면 우회전하여 49번 지방도와 합류한다. 이제 오랜 시간 동안 49번 지방도와 합류하게 될 것이다.\n산외면 산외교차로에서 715번 지방도와 교차한다.\n엄재터널\n완주군\n산외로\n구이면 상용교차로에서 27번 국도에 합류한다. 좌회전하자.\n구이로\n구이면 백여교차로에서 27번 국도로부터 분기된다.\n구이면 대덕삼거리에서 714번 지방도와 만난다.\n구이면 염암삼거리에서 우회전\n신덕평로\n고개가 있다. 완주군과 임실군의 경계이다.\n임실군\n신덕평로\n신덕면 외량삼거리, 삼길삼거리에서 749번 지방도와 만난다.\n야트막한 고개가 하나 있다.\n신평면 원천리 원천교차로에서 745번 지방도와 교차한다.\n신평면 관촌역 앞에서 17번 국도와 합류한다. 좌회전하자.\n관진로\n관촌면 병암삼거리에서 17번 국도로부터 분기된다.\n순천완주고속도로와 교차되나 연결되지 않는다.\n진안군\n관진로\n성수면 좌산리에서 721번 지방도와 만난다.\n성수면 좌산리 좌산삼거리에서 721번 지방도와 만난다.\n마령면 강정교차로 부근에서 745번 지방도와 만난다.\n익산포항고속도로와 교차되나 연결되지 않는다.\n진안읍 진안연장농공단지 앞에서 26번 국도에 합류한다. 좌회전하자.\n전진로\n부귀면 부귀교차로에서 드디어 49번 지방도를 떠나보낸다. 그러나 아직 26번 국도와 중첩된다.\n완주군\n동상로\n드디어 55번이라는 노선 번호가 눈에 보이기 시작한다. 완주군 소양면에서 26번 국도와 분기된다. 이제부터 꼬불꼬불한 산길이므로 각오하고 운전하자.\n밤치. 소양면과 동상면의 경계가 되는 고개다.\n동상면 신월삼거리에서 732번 지방도와 만난다. 동상저수지에 빠지지 않도록 주의하자.\n동상주천로\n운장산고개를 올라가야 한다. 완주군과 진안군의 경계다. 고개 정상에 휴게소가 있다.\n진안군\n동상주천로\n주천면 주천삼거리에서 725번 지방도와 만난다.\n충청남도\n금산군\n보석사로\n남이면 흑암삼거리에서 635번 지방도와 만난다. 우회전해야 한다. 네이버 지도에는 좌회전해서 좀더 가면 나오는 길을 55번 지방도라고 써놓았는데, 잘못 나온 거다. 다음 지도에는 올바르게 나와있다.\n십이폭포로\n남이면에서 남일면으로 넘어간다.\n남일면에서 13번 국도와 합류한다. 좌회전하자. 이후 구간은 남이면을 거쳐 금산읍까지 13번 국도와 중첩되면서 55번 지방도 구간은 종료된다.'}
```
| [
-0.7226765751838684,
-0.6814902424812317,
0.32892534136772156,
0.42775121331214905,
-0.5285693407058716,
-0.15444162487983704,
0.319817453622818,
-0.43154004216194153,
0.7707264423370361,
0.38107413053512573,
-0.4183752238750458,
-0.34568852186203003,
-0.7641394734382629,
0.109279461205005... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Muennighoff/mbpp | Muennighoff | 2022-10-20T19:43:58Z | 15 | 1 | null | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"language:en",
"license:c... | 2022-10-20T19:43:58Z | 2022-07-18T19:05:21.000Z | 2022-07-18T19:05:21 | ---
annotations_creators:
- crowdsourced
- expert-generated
language_creators:
- crowdsourced
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- n<1K
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
pretty_name: Mostly Basic Python Problems
tags:
- code-generation
---
# Dataset Card for Mostly Basic Python Problems (mbpp)
## Table of Contents
- [Dataset Card for Mostly Basic Python Problems (mbpp)](#dataset-card-for-mostly-basic-python-problems-(mbpp))
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/google-research/google-research/tree/master/mbpp
- **Paper:** [Program Synthesis with Large Language Models](https://arxiv.org/abs/2108.07732)
### Dataset Summary
The benchmark consists of around 1,000 crowd-sourced Python programming problems, designed to be solvable by entry level programmers, covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases. As described in the paper, a subset of the data has been hand-verified by us.
Released [here](https://github.com/google-research/google-research/tree/master/mbpp) as part of [Program Synthesis with Large Language Models, Austin et. al., 2021](https://arxiv.org/abs/2108.07732).
### Supported Tasks and Leaderboards
This dataset is used to evaluate code generations.
### Languages
English - Python code
## Dataset Structure
```python
dataset_full = load_dataset("mbpp")
DatasetDict({
test: Dataset({
features: ['task_id', 'text', 'code', 'test_list', 'test_setup_code', 'challenge_test_list'],
num_rows: 974
})
})
dataset_sanitized = load_dataset("mbpp", "sanitized")
DatasetDict({
test: Dataset({
features: ['source_file', 'task_id', 'prompt', 'code', 'test_imports', 'test_list'],
num_rows: 427
})
})
```
### Data Instances
#### mbpp - full
```
{
'task_id': 1,
'text': 'Write a function to find the minimum cost path to reach (m, n) from (0, 0) for the given cost matrix cost[][] and a position (m, n) in cost[][].',
'code': 'R = 3\r\nC = 3\r\ndef min_cost(cost, m, n): \r\n\ttc = [[0 for x in range(C)] for x in range(R)] \r\n\ttc[0][0] = cost[0][0] \r\n\tfor i in range(1, m+1): \r\n\t\ttc[i][0] = tc[i-1][0] + cost[i][0] \r\n\tfor j in range(1, n+1): \r\n\t\ttc[0][j] = tc[0][j-1] + cost[0][j] \r\n\tfor i in range(1, m+1): \r\n\t\tfor j in range(1, n+1): \r\n\t\t\ttc[i][j] = min(tc[i-1][j-1], tc[i-1][j], tc[i][j-1]) + cost[i][j] \r\n\treturn tc[m][n]',
'test_list': [
'assert min_cost([[1, 2, 3], [4, 8, 2], [1, 5, 3]], 2, 2) == 8',
'assert min_cost([[2, 3, 4], [5, 9, 3], [2, 6, 4]], 2, 2) == 12',
'assert min_cost([[3, 4, 5], [6, 10, 4], [3, 7, 5]], 2, 2) == 16'],
'test_setup_code': '',
'challenge_test_list': []
}
```
#### mbpp - sanitized
```
{
'source_file': 'Benchmark Questions Verification V2.ipynb',
'task_id': 2,
'prompt': 'Write a function to find the shared elements from the given two lists.',
'code': 'def similar_elements(test_tup1, test_tup2):\n res = tuple(set(test_tup1) & set(test_tup2))\n return (res) ',
'test_imports': [],
'test_list': [
'assert set(similar_elements((3, 4, 5, 6),(5, 7, 4, 10))) == set((4, 5))',
'assert set(similar_elements((1, 2, 3, 4),(5, 4, 3, 7))) == set((3, 4))',
'assert set(similar_elements((11, 12, 14, 13),(17, 15, 14, 13))) == set((13, 14))'
]
}
```
### Data Fields
- `source_file`: unknown
- `text`/`prompt`: description of programming task
- `code`: solution for programming task
- `test_setup_code`/`test_imports`: necessary code imports to execute tests
- `test_list`: list of tests to verify solution
- `challenge_test_list`: list of more challenging test to further probe solution
### Data Splits
There are two version of the dataset (full and sanitized) which only one split each (test).
## Dataset Creation
See section 2.1 of original [paper](https://arxiv.org/abs/2108.07732).
### Curation Rationale
In order to evaluate code generation functions a set of simple programming tasks as well as solutions is necessary which this dataset provides.
### Source Data
#### Initial Data Collection and Normalization
The dataset was manually created from scratch.
#### Who are the source language producers?
The dataset was created with an internal crowdsourcing effort at Google.
### Annotations
#### Annotation process
The full dataset was created first and a subset then underwent a second round to improve the task descriptions.
#### Who are the annotators?
The dataset was created with an internal crowdsourcing effort at Google.
### Personal and Sensitive Information
None.
## Considerations for Using the Data
Make sure you execute generated Python code in a safe environment when evauating against this dataset as generated code could be harmful.
### Social Impact of Dataset
With this dataset code generating models can be better evaluated which leads to fewer issues introduced when using such models.
### Discussion of Biases
### Other Known Limitations
Since the task descriptions might not be expressive enough to solve the task. The `sanitized` split aims at addressing this issue by having a second round of annotators improve the dataset.
## Additional Information
### Dataset Curators
Google Research
### Licensing Information
CC-BY-4.0
### Citation Information
```
@article{austin2021program,
title={Program Synthesis with Large Language Models},
author={Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and others},
journal={arXiv preprint arXiv:2108.07732},
year={2021}
```
### Contributions
Thanks to [@lvwerra](https://github.com/lvwerra) for adding this dataset.
| [
-0.4665862023830414,
-0.577350378036499,
0.22498133778572083,
0.3290945291519165,
0.18043646216392517,
-0.09545651823282242,
-0.2154701054096222,
-0.2609991133213043,
0.030053244903683662,
0.35807281732559204,
-0.593024730682373,
-0.5411863923072815,
-0.4027431309223175,
0.1302551925182342... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-squad_v2-8b8e12f7-11715560 | autoevaluate | 2022-07-25T07:33:16Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-25T07:33:16Z | 2022-07-25T07:28:43.000Z | 2022-07-25T07:28:43 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad_v2
eval_info:
task: extractive_question_answering
model: deepset/roberta-large-squad2
metrics: ['squad_v2']
dataset_name: squad_v2
dataset_config: squad_v2
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: deepset/roberta-large-squad2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@sjrlee](https://huggingface.co/sjrlee) for evaluating this model. | [
-0.467774897813797,
-0.4276531934738159,
0.37957099080085754,
0.14464613795280457,
0.07181556522846222,
0.12865851819515228,
0.04199497401714325,
-0.4051453173160553,
-0.015080978162586689,
0.4681245982646942,
-1.3332641124725342,
-0.09111133962869644,
-0.555205762386322,
0.013421392068266... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-project-squad-95d5e1fd-11835578 | autoevaluate | 2022-07-25T22:39:01Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-07-25T22:39:01Z | 2022-07-25T22:34:52.000Z | 2022-07-25T22:34:52 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad
eval_info:
task: extractive_question_answering
model: mbartolo/electra-large-synqa
metrics: []
dataset_name: squad
dataset_config: plain_text
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: mbartolo/electra-large-synqa
* Dataset: squad
* Config: plain_text
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mbartolo ](https://huggingface.co/mbartolo ) for evaluating this model. | [
-0.557360053062439,
-0.4533136188983917,
0.29027682542800903,
0.053632836788892746,
0.05961970239877701,
0.074134461581707,
0.12939642369747162,
-0.4127803444862366,
0.18604835867881775,
0.49850910902023315,
-1.2395684719085693,
-0.04729313403367996,
-0.38524678349494934,
0.107920922338962... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
teven/webnlg_2017_human_eval | teven | 2022-08-24T23:27:45Z | 15 | 0 | null | [
"region:us"
] | 2022-08-24T23:27:45Z | 2022-08-24T23:27:42.000Z | 2022-08-24T23:27:42 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BDas/EnglishNLPDataset | BDas | 2022-08-27T11:13:01Z | 15 | 0 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
... | 2022-08-27T11:13:01Z | 2022-08-27T10:58:22.000Z | 2022-08-27T10:58:22 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
- multi-label-classification
pretty_name: 'EnglishNLPDataset'
---
# Dataset Card for "EnglishNLPDataset"
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Preprocessing](#dataset-preprocessing)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/BihterDass/EnglishTextClassificationDataset]
- **Repository:** [https://github.com/BihterDass/EnglishTextClassificationDataset]
- **Size of downloaded dataset files:** 8.71 MB
- **Size of the generated dataset:** 8.71 MB
### Dataset Summary
The dataset was compiled from user comments from e-commerce sites. It consists of 10,000 validations, 10,000 tests and 80000 train data. Data were classified into 3 classes (positive(pos), negative(neg) and natural(nor). The data is available to you on github.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
#### english-dataset-v1
- **Size of downloaded dataset files:** 8.71 MB
- **Size of the generated dataset:** 8.71 MB
### Data Fields
The data fields are the same among all splits.
#### english-dataset-v-v1
- `text`: a `string` feature.
- `label`: a classification label, with possible values including `positive` (2), `natural` (1), `negative` (0).
### Data Splits
| |train |validation|test |
|----|--------:|---------:|---------:|
|Data| 80000 | 10000 | 10000 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@PnrSvc](https://github.com/PnrSvc) for adding this dataset. | [
-0.5015193819999695,
-0.3999691903591156,
-0.13291610777378082,
0.2548319697380066,
-0.19262753427028656,
0.0982242003083229,
-0.5057260990142822,
-0.5229243636131287,
0.5413259863853455,
0.42941877245903015,
-0.6527727246284485,
-0.8717610836029053,
-0.5702126622200012,
0.3323958516120910... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pysentimiento/spanish-tweets | pysentimiento | 2023-07-13T15:44:41Z | 15 | 8 | null | [
"language:es",
"region:us"
] | 2023-07-13T15:44:41Z | 2022-09-08T21:02:38.000Z | 2022-09-08T21:02:38 | ---
language: es
dataset_info:
features:
- name: text
dtype: string
- name: tweet_id
dtype: string
- name: user_id
dtype: string
splits:
- name: train
num_bytes: 82649695458
num_examples: 597433111
- name: test
num_bytes: 892219251
num_examples: 6224733
download_size: 51737237106
dataset_size: 83541914709
---
# spanish-tweets
## A big corpus of tweets for pretraining embeddings and language models
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://github.com/pysentimiento/robertuito
- **Paper**: [RoBERTuito: a pre-trained language model for social media text in Spanish](https://aclanthology.org/2022.lrec-1.785/)
- **Point of Contact:** jmperez (at) dc.uba.ar
### Dataset Summary
A big dataset of (mostly) Spanish tweets for pre-training language models (or other representations).
### Supported Tasks and Leaderboards
Language Modeling
### Languages
Mostly Spanish, but some Portuguese, English, and other languages.
## Dataset Structure
### Data Fields
- *tweet_id*: id of the tweet
- *user_id*: id of the user
- *text*: text from the tweet
## Dataset Creation
The full process of data collection is described in the paper. Here we roughly outline the main points:
- A Spritzer collection uploaded to Archive.org dating from May 2019 was downloaded
- From this, we only kept tweets with language metadata equal to Spanish, and mark the users who posted these messages.
- Then, the tweetline from each of these marked users was downloaded.
This corpus consists of 622M tweets from around 432K users.
Please note that we did not filter tweets from other languages, so you might find English, Portuguese, Catalan and other languages in the dataset (around 7/8% of the tweets are not in Spanish)
### Citation Information
```
@inproceedings{perez-etal-2022-robertuito,
title = "{R}o{BERT}uito: a pre-trained language model for social media text in {S}panish",
author = "P{\'e}rez, Juan Manuel and
Furman, Dami{\'a}n Ariel and
Alonso Alemany, Laura and
Luque, Franco M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.785",
pages = "7235--7243",
abstract = "Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for natural language processing tasks. Recently, some works geared towards pre-training specially-crafted models for particular domains, such as scientific papers, medical documents, user-generated texts, among others. These domain-specific models have been shown to improve performance significantly in most tasks; however, for languages other than English, such models are not widely available. In this work, we present RoBERTuito, a pre-trained language model for user-generated text in Spanish, trained on over 500 million tweets. Experiments on a benchmark of tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models in Spanish. In addition to this, our model has some cross-lingual abilities, achieving top results for English-Spanish tasks of the Linguistic Code-Switching Evaluation benchmark (LinCE) and also competitive performance against monolingual models in English Twitter tasks. To facilitate further research, we make RoBERTuito publicly available at the HuggingFace model hub together with the dataset used to pre-train it.",
}
``` | [
-0.13714617490768433,
-0.5086361169815063,
0.32558587193489075,
0.59811931848526,
-0.2801608443260193,
0.48434922099113464,
-0.6783512830734253,
-0.4805836081504822,
0.6277690529823303,
0.42979079484939575,
-0.6735625863075256,
-0.8128958940505981,
-0.9419249296188354,
0.22352974116802216,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-07bda3-16636249 | autoevaluate | 2022-09-15T06:03:24Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T06:03:24Z | 2022-09-15T05:59:33.000Z | 2022-09-15T05:59:33 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad_v2
eval_info:
task: extractive_question_answering
model: haritzpuerto/MiniLM-L12-H384-uncased-squad
metrics: []
dataset_name: squad_v2
dataset_config: squad_v2
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: haritzpuerto/MiniLM-L12-H384-uncased-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@timbmg](https://huggingface.co/timbmg) for evaluating this model. | [
-0.4857468903064728,
-0.37699055671691895,
0.24923835694789886,
0.16080650687217712,
0.007111098617315292,
0.13955433666706085,
0.13571880757808685,
-0.45825010538101196,
0.04903601482510567,
0.3658594489097595,
-1.365674376487732,
-0.004456472583115101,
-0.48340925574302673,
0.06241432577... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-972433-16666252 | autoevaluate | 2022-09-15T07:07:27Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T07:07:27Z | 2022-09-15T06:05:57.000Z | 2022-09-15T06:05:57 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad_v2
eval_info:
task: extractive_question_answering
model: mrm8488/longformer-base-4096-finetuned-squadv2
metrics: ['bertscore']
dataset_name: squad_v2
dataset_config: squad_v2
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: mrm8488/longformer-base-4096-finetuned-squadv2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Liam-Scott-Russell](https://huggingface.co/Liam-Scott-Russell) for evaluating this model. | [
-0.48010823130607605,
-0.40000268816947937,
0.2641508877277374,
0.15645471215248108,
0.04178188368678093,
0.04259448125958443,
0.12121766060590744,
-0.45309722423553467,
0.04258652776479721,
0.5435363054275513,
-1.3341610431671143,
0.00463186576962471,
-0.5179122090339661,
0.08571038395166... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
muhtasham/india-r-1-year-posts | muhtasham | 2022-09-16T06:08:47Z | 15 | 0 | null | [
"region:us"
] | 2022-09-16T06:08:47Z | 2022-09-15T06:52:49.000Z | 2022-09-15T06:52:49 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
taspecustu/Nanachi | taspecustu | 2022-09-15T12:32:36Z | 15 | 0 | null | [
"license:cc-by-4.0",
"region:us"
] | 2022-09-15T12:32:36Z | 2022-09-15T12:25:52.000Z | 2022-09-15T12:25:52 | ---
license: cc-by-4.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ImageIN/IA_unlabelled | ImageIN | 2022-10-21T14:38:12Z | 15 | 0 | null | [
"region:us"
] | 2022-10-21T14:38:12Z | 2022-09-15T13:52:19.000Z | 2022-09-15T13:52:19 | ---
annotations_creators: []
language: []
language_creators: []
license: []
multilinguality: []
pretty_name: 'Internet Archive historic book pages unlabelled.'
size_categories: []
source_datasets: []
tags: []
task_categories: []
task_ids: []
---
# Data card for Internet Archive historic book pages unlabelled.
- `10,844,387` unlabelled pages from historical books from the internet archive.
- Intended to be used for:
- pre-training computer vision models in an unsupervised manner
- using weak supervision to generate labels | [
-0.3791027367115021,
-0.16600212454795837,
0.07596798986196518,
-0.06581521779298782,
-0.7471094131469727,
-0.7625506520271301,
0.09327280521392822,
-0.3535092771053314,
0.08547978103160858,
0.8308771252632141,
-0.33467626571655273,
-0.5985300540924072,
-0.5119731426239014,
-0.098805442452... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Bingsu/openwebtext_20p | Bingsu | 2022-09-16T02:36:38Z | 15 | 4 | openwebtext | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:extended|openwebtext",
"la... | 2022-09-16T02:36:38Z | 2022-09-16T02:15:16.000Z | 2022-09-16T02:15:16 | ---
annotations_creators:
- no-annotation
language:
- en
language_creators:
- found
license:
- cc0-1.0
multilinguality:
- monolingual
paperswithcode_id: openwebtext
pretty_name: openwebtext_20p
size_categories:
- 1M<n<10M
source_datasets:
- extended|openwebtext
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
---
# openwebtext_20p
## Dataset Description
- **Origin:** [openwebtext](https://huggingface.co/datasets/openwebtext)
- **Download Size** 4.60 GiB
- **Generated Size** 7.48 GiB
- **Total Size** 12.08 GiB
first 20% of [openwebtext](https://huggingface.co/datasets/openwebtext) | [
-0.7902884483337402,
-0.5052517652511597,
-0.013413168489933014,
0.7689085602760315,
-0.37234196066856384,
-0.06365501880645752,
0.05762634426355362,
-0.47967132925987244,
0.7519593238830566,
0.3214738070964813,
-0.8086859583854675,
-0.45895329117774963,
-0.6798574328422546,
-0.14325413107... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
slone/myv_ru_2022 | slone | 2022-09-28T19:38:26Z | 15 | 2 | null | [
"task_categories:translation",
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"language_creators:machine-generated",
"multilinguality:translation",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:myv",
"language:ru",
"licens... | 2022-09-28T19:38:26Z | 2022-09-17T13:53:23.000Z | 2022-09-17T13:53:23 | ---
annotations_creators:
- found
- machine-generated
language:
- myv
- ru
language_creators:
- found
- machine-generated
license:
- cc-by-sa-4.0
multilinguality:
- translation
pretty_name: Erzya-Russian parallel corpus
size_categories:
- 10K<n<100K
source_datasets:
- original
tags:
- erzya
- mordovian
task_categories:
- translation
task_ids: []
---
# Dataset Card for **slone/myv_ru_2022**
## Dataset Description
- **Repository:** https://github.com/slone-nlp/myv-nmt
- **Paper:**: https://arxiv.org/abs/2209.09368
- **Point of Contact:** @cointegrated
### Dataset Summary
This is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper [The first neural machine translation system for the Erzya language](https://arxiv.org/abs/2209.09368).
Erzya (`myv`) is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.
The corpus consists of the following parts:
| name | size | composition |
| -----| ---- | -------|
|train | 74503 | parallel words, phrases and sentences, mined from dictionaries, books and web texts |
| dev | 1500 | parallel sentences mined from books and web texts |
| test | 1500 | parallel sentences mined from books and web texts |
| mono | 333651| Erzya sentences mined from books and web texts, translated to Russian by a neural model |
The dev and test splits contain sentences from the following sources
| name | size | description|
| ---------------|----| -------|
|wiki |600 | Aligned sentences from linked Erzya and Russian Wikipedia articles |
|bible |400 | Paired verses from the Bible (https://finugorbib.com) |
|games |250 | Aligned sentences from the book *"Сказовые формы мордовской литературы", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск* |
|tales |100 | Aligned sentences from the book *"Мордовские народные игры", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск* |
|fiction |100 | Aligned sentences from modern Erzya prose and poetry (https://rus4all.ru/myv) |
|constitution | 50 | Aligned sentences from the Soviet 1938 constitution |
To load the first three parts (train, validation and test), use the code:
```Python
from datasets import load_dataset
data = load_dataset('slone/myv_ru_2022')
```
To load all four parts (included the back-translated data), please specify the data files explicitly:
```Python
from datasets import load_dataset
data_extended = load_dataset(
'slone/myv_ru_2022',
data_files={'train':'train.jsonl', 'validation': 'dev.jsonl', 'test': 'test.jsonl', 'mono': 'back_translated.jsonl'}
)
```
### Supported Tasks and Leaderboards
- `translation`: the dataset may be used to train `ru-myv` translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!
### Languages
The main part of the dataset (`train`, `dev` and `test`) consists of "natural" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus (`mono`), translated to Russian automatically.
## Dataset Structure
### Data Instances
All data instances have three string fields: `myv`, `ru` and `src` (the last one is currently meaningful only for dev and test splits), for example:
```
{'myv': 'Сюкпря Пазонтень, кие кирвазтизе Титэнь седейс тынк кисэ секе жо бажамонть, кона палы минек седейсэяк!',
'ru': 'Благодарение Богу, вложившему в сердце Титово такое усердие к вам.',
'src': 'bible'}
```
### Data Fields
- `myv`: the Erzya text (word, phrase, or sentence)
- `ru`: the corresponding Russian text
- `src`: the source of data (only for dev and test splits)
### Data Splits
- train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.
- dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.
- test: same as dev.
- mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.
## Dataset Creation
### Curation Rationale
This is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.
We hope that it sets a meaningful baseline for Erzya machine translation.
### Source Data
#### Initial Data Collection and Normalization
The dataset was collected from various sources (see below).
The texts were spit in sentences using the [razdel]() package.
For some sources, sentences were filtered by language using the [slone/fastText-LID-323](https://huggingface.co/slone/fastText-LID-323) model.
For most of the sources, `myv` and `ru` sentences were aligned automatically using the [slone/LaBSE-en-ru-myv-v1](https://huggingface.co/slone/LaBSE-en-ru-myv-v1) sentence encoder
and the code from [the paper repository](https://github.com/slone-nlp/myv-nmt).
#### Who are the source language producers?
The dataset comprises parallel `myv-ru` and monolingual `myv` texts from diverse sources:
- 12K parallel sentences from the Bible (http://finugorbib.com);
- 3K parallel Wikimedia sentences from OPUS;
- 42K parallel words or short phrases collected from various online dictionaries ();
- the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;
- 18 books, including 3 books with Erzya-Russian bitexts (http://lib.e-mordovia.ru);
- Soviet-time books and periodicals (https://fennougrica.kansalliskirjasto.fi);
- The Erzya part of Wikisource (https://wikisource.org/wiki/Main_Page/?oldid=895127);
- Short texts by modern Erzya authors (https://rus4all.ru/myv/);
- News articles from the Erzya Pravda website (http://erziapr.ru);
- Texts found in LiveJournal (https://www.livejournal.com) by searching with the 100 most frequent Erzya words.
### Annotations
No human annotation was involved in the data collection.
### Personal and Sensitive Information
All data was collected from public sources, so no sensitive information is expected in them.
However, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.
## Considerations for Using the Data
### Social Impact of Dataset
Publication of this dataset may attract some attention to the endangered Erzya language.
### Discussion of Biases
Most of the dataset has been collected by automatical means, so it may contain errors and noise.
Some types of these errors are systemic: for example, the words for "Erzya" and "Russian" are often aligned together,
because they appear in the corresponding Wikipedias on similar positions.
### Other Known Limitations
The dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.
## Additional Information
### Dataset Curators
The data was collected by David Dale (https://huggingface.co/cointegrated).
### Licensing Information
The status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the [CC-BY-SA license](http://creativecommons.org/licenses/by-sa/4.0/).
### Citation Information
[TBD]
| [
-0.2058708369731903,
-0.7414991855621338,
0.26102790236473083,
0.28351208567619324,
-0.27608543634414673,
-0.2543788254261017,
-0.43206334114074707,
-0.3625653088092804,
0.6445829272270203,
0.3745037913322449,
-0.5980150699615479,
-0.7421249151229858,
-0.40620869398117065,
0.37599724531173... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-eval-glue-mrpc-9038ab-1509054846 | autoevaluate | 2022-09-19T14:49:35Z | 15 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-19T14:49:35Z | 2022-09-19T14:49:09.000Z | 2022-09-19T14:49:09 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- glue
eval_info:
task: natural_language_inference
model: JeremiahZ/bert-base-uncased-mrpc
metrics: []
dataset_name: glue
dataset_config: mrpc
dataset_split: validation
col_mapping:
text1: sentence1
text2: sentence2
target: label
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Natural Language Inference
* Model: JeremiahZ/bert-base-uncased-mrpc
* Dataset: glue
* Config: mrpc
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@JeremiahZ](https://huggingface.co/JeremiahZ) for evaluating this model. | [
-0.45398175716400146,
-0.3831898272037506,
0.25732216238975525,
0.15961681306362152,
0.008819551207125187,
-0.08835039287805557,
-0.2140158861875534,
-0.42072194814682007,
0.18032120168209076,
0.5313295125961304,
-1.076547622680664,
-0.2451402246952057,
-0.6410583853721619,
-0.043470621109... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thesofakillers/SemCor | thesofakillers | 2022-10-12T08:46:28Z | 15 | 2 | null | [
"task_categories:text-classification",
"task_ids:topic-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:other",
"word sense disambiguation"... | 2022-10-12T08:46:28Z | 2022-09-22T13:31:04.000Z | 2022-09-22T13:31:04 | ---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- expert-generated
license:
- other
multilinguality:
- monolingual
pretty_name: SemCor
size_categories:
- 100K<n<1M
source_datasets:
- original
tags:
- word sense disambiguation
- semcor
- wordnet
task_categories:
- text-classification
task_ids:
- topic-classification
---
# Dataset Card for SemCor
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://web.eecs.umich.edu/~mihalcea/downloads.html#semcor
- **Repository:**
- **Paper:** https://aclanthology.org/H93-1061/
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
SemCor 3.0 was automatically created from SemCor 1.6 by mapping WordNet 1.6 to
WordNet 3.0 senses. SemCor 1.6 was created and is property of Princeton
University.
Some (few) word senses from WordNet 1.6 were dropped, and therefore they cannot
be retrieved anymore in the 3.0 database. A sense of 0 (wnsn=0) is used to
symbolize a missing sense in WordNet 3.0.
The automatic mapping was performed within the Language and Information
Technologies lab at UNT, by Rada Mihalcea (rada@cs.unt.edu).
THIS MAPPING IS PROVIDED "AS IS" AND UNT MAKES NO REPRESENTATIONS OR WARRANTIES,
EXPRESS OR IMPLIED. BY WAY OF EXAMPLE, BUT NOT LIMITATION, UNT MAKES NO
REPRESENTATIONS OR WARRANTIES OF MERCHANT- ABILITY OR FITNESS FOR ANY PARTICULAR
PURPOSE.
In agreement with the license from Princeton Univerisity, you are granted
permission to use, copy, modify and distribute this database
for any purpose and without fee and royalty is hereby granted, provided that you
agree to comply with the Princeton copyright notice and statements, including
the disclaimer, and that the same appear on ALL copies of the database,
including modifications that you make for internal
use or for distribution.
Both LICENSE and README files distributed with the SemCor 1.6 package are
included in the current distribution of SemCor 3.0.
### Languages
English
## Additional Information
### Licensing Information
WordNet Release 1.6 Semantic Concordance Release 1.6
This software and database is being provided to you, the LICENSEE, by
Princeton University under the following license. By obtaining, using
and/or copying this software and database, you agree that you have
read, understood, and will comply with these terms and conditions.:
Permission to use, copy, modify and distribute this software and
database and its documentation for any purpose and without fee or
royalty is hereby granted, provided that you agree to comply with
the following copyright notice and statements, including the disclaimer,
and that the same appear on ALL copies of the software, database and
documentation, including modifications that you make for internal
use or for distribution.
WordNet 1.6 Copyright 1997 by Princeton University. All rights reserved.
THIS SOFTWARE AND DATABASE IS PROVIDED "AS IS" AND PRINCETON
UNIVERSITY MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR
IMPLIED. BY WAY OF EXAMPLE, BUT NOT LIMITATION, PRINCETON
UNIVERSITY MAKES NO REPRESENTATIONS OR WARRANTIES OF MERCHANT-
ABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE OR THAT THE USE
OF THE LICENSED SOFTWARE, DATABASE OR DOCUMENTATION WILL NOT
INFRINGE ANY THIRD PARTY PATENTS, COPYRIGHTS, TRADEMARKS OR
OTHER RIGHTS.
The name of Princeton University or Princeton may not be used in
advertising or publicity pertaining to distribution of the software
and/or database. Title to copyright in this software, database and
any associated documentation shall at all times remain with
Princeton University and LICENSEE agrees to preserve same.
### Citation Information
```bibtex
@inproceedings{miller-etal-1993-semantic,
title = "A Semantic Concordance",
author = "Miller, George A. and
Leacock, Claudia and
Tengi, Randee and
Bunker, Ross T.",
booktitle = "{H}uman {L}anguage {T}echnology: Proceedings of a Workshop Held at Plainsboro, New Jersey, March 21-24, 1993",
year = "1993",
url = "https://aclanthology.org/H93-1061",
}
```
### Contributions
Thanks to [@thesofakillers](https://github.com/thesofakillers) for adding this
dataset, converting from xml to csv.
| [
-0.5120287537574768,
-0.3266528248786926,
0.36684954166412354,
0.2506580650806427,
-0.3827298879623413,
-0.4248166084289551,
-0.1862013339996338,
-0.44795429706573486,
0.5994014143943787,
0.4969664514064789,
-0.4440915882587433,
-0.9582671523094177,
-0.7033914923667908,
0.0762595683336258,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
NobuLuis/AndynZeein | NobuLuis | 2022-09-28T15:08:00Z | 15 | 0 | null | [
"region:us"
] | 2022-09-28T15:08:00Z | 2022-09-28T14:41:18.000Z | 2022-09-28T14:41:18 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
PCScreen/Thomaz_Junior | PCScreen | 2022-09-28T16:57:51Z | 15 | 0 | null | [
"license:unknown",
"region:us"
] | 2022-09-28T16:57:51Z | 2022-09-28T16:54:08.000Z | 2022-09-28T16:54:08 | ---
license: unknown
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Axtiek/gs | Axtiek | 2022-09-28T17:22:07Z | 15 | 0 | null | [
"region:us"
] | 2022-09-28T17:22:07Z | 2022-09-28T16:54:34.000Z | 2022-09-28T16:54:34 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
FredOte/me | FredOte | 2022-09-28T17:19:14Z | 15 | 0 | null | [
"region:us"
] | 2022-09-28T17:19:14Z | 2022-09-28T17:15:56.000Z | 2022-09-28T17:15:56 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alx-ai/noggles_inversion | alx-ai | 2022-09-28T17:30:23Z | 15 | 0 | null | [
"license:cc0-1.0",
"region:us"
] | 2022-09-28T17:30:23Z | 2022-09-28T17:28:06.000Z | 2022-09-28T17:28:06 | ---
license: cc0-1.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
marcosfevre/images | marcosfevre | 2022-09-28T19:42:07Z | 15 | 0 | null | [
"license:cc-by-4.0",
"region:us"
] | 2022-09-28T19:42:07Z | 2022-09-28T17:59:45.000Z | 2022-09-28T17:59:45 | ---
license: cc-by-4.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Daniel-Saeedi/wikipedia | Daniel-Saeedi | 2022-09-29T12:50:16Z | 15 | 0 | null | [
"region:us"
] | 2022-09-29T12:50:16Z | 2022-09-28T18:41:22.000Z | 2022-09-28T18:41:22 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Arturocomin/Fotos_arturo | Arturocomin | 2022-09-28T19:56:33Z | 15 | 0 | null | [
"region:us"
] | 2022-09-28T19:56:33Z | 2022-09-28T19:16:03.000Z | 2022-09-28T19:16:03 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bastiankase/dianakreuz | bastiankase | 2022-09-29T18:07:05Z | 15 | 0 | null | [
"license:openrail",
"region:us"
] | 2022-09-29T18:07:05Z | 2022-09-28T19:38:10.000Z | 2022-09-28T19:38:10 | ---
license: openrail
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Jose10812/Imagenes | Jose10812 | 2022-09-29T10:29:23Z | 15 | 0 | null | [
"region:us"
] | 2022-09-29T10:29:23Z | 2022-09-28T19:38:39.000Z | 2022-09-28T19:38:39 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LuisPerezT/Fotos | LuisPerezT | 2022-09-28T21:27:29Z | 15 | 0 | null | [
"license:openrail",
"region:us"
] | 2022-09-28T21:27:29Z | 2022-09-28T19:42:55.000Z | 2022-09-28T19:42:55 | ---
license: openrail
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
radm/tathagata | radm | 2022-09-28T20:20:13Z | 15 | 2 | null | [
"task_categories:text-generation",
"task_ids:language-modeling",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"language:ru",
"license:apache-2.0",
"text_generation",
"quotes",
"region:us"
] | 2022-09-28T20:20:13Z | 2022-09-28T19:55:18.000Z | 2022-09-28T19:55:18 | ---
annotations_creators:
- found
language:
- ru
language_creators:
- found
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: tathagata
size_categories:
- n<1K
source_datasets:
- original
tags:
- text_generation
- quotes
task_categories:
- text-generation
task_ids:
- language-modeling
---
# ****Dataset Card for tathagata****
# **I-Dataset Summary**
tathagata.txt is a dataset based on summaries of major Buddhist, Hindu and Advaita texts such as:
- Diamond Sutra
- Lankavatara Sutra
- Sri Nisargadatta Maharaj quotes
- Quotes from the Bhagavad Gita
This dataset was used to train this model https://huggingface.co/radm/rugpt3medium-tathagata
# **II-Languages**
The texts in the dataset are in Russian (ru). | [
0.08039833605289459,
-0.7877668142318726,
-0.04373475909233093,
-0.005171649623662233,
-0.7251529097557068,
0.16822421550750732,
-0.17652709782123566,
-0.19586554169654846,
0.48013922572135925,
0.42389652132987976,
-0.6220698356628418,
-0.8103947639465332,
-0.5258825421333313,
-0.181643456... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
valluvera/gemma | valluvera | 2022-09-28T20:12:34Z | 15 | 0 | null | [
"license:other",
"region:us"
] | 2022-09-28T20:12:34Z | 2022-09-28T20:01:58.000Z | 2022-09-28T20:01:58 | ---
license: other
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thewalkerdenton/Canny | thewalkerdenton | 2022-09-28T21:02:20Z | 15 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2022-09-28T21:02:20Z | 2022-09-28T20:57:32.000Z | 2022-09-28T20:57:32 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Inked/luna | Inked | 2022-09-28T21:15:54Z | 15 | 0 | null | [
"region:us"
] | 2022-09-28T21:15:54Z | 2022-09-28T21:05:20.000Z | 2022-09-28T21:05:20 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rousses/imagine | rousses | 2022-09-28T22:16:15Z | 15 | 0 | null | [
"license:other",
"region:us"
] | 2022-09-28T22:16:15Z | 2022-09-28T21:46:38.000Z | 2022-09-28T21:46:38 | ---
license: other
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
waifu-research-department/regularization | waifu-research-department | 2022-09-29T22:00:10Z | 15 | 7 | null | [
"license:mit",
"region:us"
] | 2022-09-29T22:00:10Z | 2022-09-29T02:09:44.000Z | 2022-09-29T02:09:44 | ---
license: mit
---
# Info
> This is a repository for anime regularization. If you wish to contribute to the dataset, contact me at naotsue#9786. I will add them to the dataset and update it.
# Criteria
> 512x512
> No excessive deformations
> Vaguely resembles an anime artstyle
# Contribution Leaderboard
> 1. bWm_nubby: 5838 images
> 2. naotsue: 888 images
 | [
-0.48844611644744873,
-0.5730553865432739,
0.031151849776506424,
0.49306219816207886,
-0.24731148779392242,
-0.27468016743659973,
-0.11179327219724655,
-0.20238137245178223,
1.119765043258667,
0.6828222870826721,
-0.831596851348877,
-0.5634044408798218,
-0.6758497953414917,
0.4451862573623... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Gr3en/m3 | Gr3en | 2022-09-29T17:13:42Z | 15 | 0 | null | [
"region:us"
] | 2022-09-29T17:13:42Z | 2022-09-29T16:07:05.000Z | 2022-09-29T16:07:05 | annotations_creators:
- no-annotation
language:
- en
language_creators:
- other
license:
- artistic-2.0
multilinguality:
- monolingual
pretty_name: m3 dataset (a dataset with my face in it)
size_categories:
- n<1K
source_datasets:
- original
tags: []
task_categories:
- text-to-image
task_ids: [] | [
-0.5072012543678284,
-0.4108487069606781,
0.2930847704410553,
0.5072427988052368,
-0.6668203473091125,
-0.08200560510158539,
0.0023237999994307756,
-0.593984842300415,
0.48763999342918396,
0.8569573760032654,
-1.0365285873413086,
-0.7148380875587463,
-0.8421926498413086,
0.4581836760044098... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
severo/test-parquet | severo | 2022-10-11T11:57:06Z | 15 | 0 | null | [
"region:us"
] | 2022-10-11T11:57:06Z | 2022-09-29T16:35:03.000Z | 2022-09-29T16:35:03 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ChristianArcos/test_amazon | ChristianArcos | 2022-09-29T16:43:59Z | 15 | 0 | null | [
"region:us"
] | 2022-09-29T16:43:59Z | 2022-09-29T16:37:13.000Z | 2022-09-29T16:37:13 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
marcosfevre/stromberg | marcosfevre | 2022-09-30T19:02:56Z | 15 | 0 | null | [
"license:cc-by-4.0",
"region:us"
] | 2022-09-30T19:02:56Z | 2022-09-29T18:04:35.000Z | 2022-09-29T18:04:35 | ---
license: cc-by-4.0
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
PandaOK/AI | PandaOK | 2022-09-29T19:59:49Z | 15 | 0 | null | [
"region:us"
] | 2022-09-29T19:59:49Z | 2022-09-29T19:51:50.000Z | 2022-09-29T19:51:50 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Speedy02/eric | Speedy02 | 2022-09-30T09:55:02Z | 15 | 0 | null | [
"region:us"
] | 2022-09-30T09:55:02Z | 2022-09-30T09:20:51.000Z | 2022-09-30T09:20:51 | Eric pics | [
-0.7029033899307251,
-0.109640933573246,
0.7660693526268005,
0.18125301599502563,
-0.04954896867275238,
-0.05889691784977913,
0.3271426260471344,
-0.31218281388282776,
0.8211581110954285,
0.6713420152664185,
-0.1124071255326271,
-0.469750314950943,
-0.5698724985122681,
0.1643865555524826,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
quinsclr/answerable_tydiqa_statistical | quinsclr | 2022-09-30T10:48:12Z | 15 | 0 | null | [
"region:us"
] | 2022-09-30T10:48:12Z | 2022-09-30T10:47:51.000Z | 2022-09-30T10:47:51 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
lasombraforti/ivanfortiimagenes | lasombraforti | 2022-09-30T15:40:18Z | 15 | 0 | null | [
"region:us"
] | 2022-09-30T15:40:18Z | 2022-09-30T15:38:29.000Z | 2022-09-30T15:38:29 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rrustom/architecture2022 | rrustom | 2022-09-30T16:04:26Z | 15 | 3 | null | [
"region:us"
] | 2022-09-30T16:04:26Z | 2022-09-30T16:03:23.000Z | 2022-09-30T16:03:23 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
dano2209/MyImage | dano2209 | 2022-09-30T20:36:58Z | 15 | 0 | null | [
"region:us"
] | 2022-09-30T20:36:58Z | 2022-09-30T20:26:11.000Z | 2022-09-30T20:26:11 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.