
modelId stringlengths 9 107 | author stringlengths 3 37 | last_modified timestamp[us, tz=UTC]date 2021-03-22 21:11:33 2026-05-04 17:37:22 | downloads int64 100 72.3M | likes int64 1 4.99k | library_name stringclasses 132
values | tags listlengths 2 2.16k | pipeline_tag stringclasses 52
values | createdAt timestamp[us, tz=UTC]date 2022-03-02 23:29:04 2026-05-03 03:15:09 | card stringlengths 1.51k 391k | entities listlengths 0 18 |
|---|---|---|---|---|---|---|---|---|---|---|
MaziyarPanahi/NVIDIA-Nemotron-Nano-9B-v2-GGUF | MaziyarPanahi | 2025-11-29T21:19:17Z | 191 | 3 | null | [
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"base_model:nvidia/NVIDIA-Nemotron-Nano-9B-v2",
"base_model:quantized:nvidia/NVIDIA-Nemotron-Nano-9B-v2",
"region:us",
"conversational"
] | text-generation | 2025-11-29T21:13:37Z | # [MaziyarPanahi/NVIDIA-Nemotron-Nano-9B-v2-GGUF](https://huggingface.co/MaziyarPanahi/NVIDIA-Nemotron-Nano-9B-v2-GGUF)
- Model creator: [nvidia](https://huggingface.co/nvidia)
- Original model: [nvidia/NVIDIA-Nemotron-Nano-9B-v2](https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2)
## Description
[MaziyarPanahi/... | [] |
baa-ai/Gemma-4-31B-it-RAM-3bit-MLX | baa-ai | 2026-04-26T16:39:32Z | 816 | 1 | mlx | [
"mlx",
"safetensors",
"gemma4",
"quantized",
"multimodal",
"image-text-to-text",
"conversational",
"base_model:google/gemma-4-31B-it",
"base_model:quantized:google/gemma-4-31B-it",
"license:gemma",
"4-bit",
"region:us"
] | image-text-to-text | 2026-04-12T03:38:15Z | # Gemma-4-31B-it — RAM 3bit (MLX)
A quantized build of [google/gemma-4-31B-it](https://huggingface.co/google/gemma-4-31B-it) produced by [baa.ai](https://baa.ai). **Retains the full vision tower**, unlike other pre-quantized MLX variants of this model.
| Property | Value |
|---|---|
| **Size on disk** | **19.49 GB** ... | [
{
"start": 2,
"end": 16,
"text": "Gemma-4-31B-it",
"label": "benchmark name",
"score": 0.9186716079711914
},
{
"start": 64,
"end": 78,
"text": "gemma-4-31B-it",
"label": "benchmark name",
"score": 0.7620967626571655
},
{
"start": 110,
"end": 124,
"text": "... |
Disty0/FLUX.1-dev-SDNQ-uint4-svd-r32 | Disty0 | 2025-12-04T17:39:45Z | 254 | 4 | diffusers | [
"diffusers",
"safetensors",
"sdnq",
"flux",
"4-bit",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:quantized:black-forest-labs/FLUX.1-dev",
"license:other",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | text-to-image | 2025-10-11T19:51:37Z | 4 bit (UINT4 with SVD rank 32) quantization of [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) using [SDNQ](https://github.com/Disty0/sdnq).
Usage:
```
pip install sdnq
```
```py
import torch
import diffusers
from sdnq import SDNQConfig # import sdnq to register it into diffuse... | [] |
LuffyTheFox/Qwen3-8B-heretic-Kullback-Leibler-GGUF | LuffyTheFox | 2026-03-23T09:09:02Z | 245 | 1 | transformers | [
"transformers",
"gguf",
"heretic",
"uncensored",
"decensored",
"abliterated",
"en",
"base_model:georgehenney/Qwen3-8B-heretic",
"base_model:quantized:georgehenney/Qwen3-8B-heretic",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-03-23T08:14:54Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [
{
"start": 391,
"end": 407,
"text": "Kullback-Leibler",
"label": "evaluation metric",
"score": 0.6504271030426025
}
] |
ibm-research/granite-3.2-8b-instruct-GGUF | ibm-research | 2025-03-03T17:12:50Z | 983 | 9 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.2",
"text-generation",
"base_model:ibm-granite/granite-3.2-8b-instruct",
"base_model:quantized:ibm-granite/granite-3.2-8b-instruct",
"license:apache-2.0",
"region:us",
"conversational"
] | text-generation | 2025-02-26T15:26:46Z | > [!NOTE]
> This repository contains models that have been converted to the GGUF format with various quantizations from an IBM Granite base model.
>
> Please reference the base model's full model card here:
> https://huggingface.co/ibm-granite/granite-3.2-8b-instruct
# Granite-3.2-8B-Instruct-GGUF
**Model Summary:*... | [] |
mradermacher/L3.3-GeneticLemonade-Unleashed-v2.1-70B-i1-GGUF | mradermacher | 2025-04-28T23:49:27Z | 460 | 6 | transformers | [
"transformers",
"gguf",
"en",
"base_model:zerofata/L3.3-GeneticLemonade-Unleashed-v2.1-70B",
"base_model:quantized:zerofata/L3.3-GeneticLemonade-Unleashed-v2.1-70B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-28T18:42:18Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/zerofata/L3.3-GeneticLemonade-Unleashed-v2.1-70B
<!-- provided-files -->
static quants are available a... | [] |
kainah/Qwen3-30B-A3B-Claude-4.5-Opus-High-Reasoning-2507-ABLITERATED-UNCENSORED-V2-Q4_K_M-GGUF | kainah | 2026-02-11T12:17:20Z | 993 | 4 | transformers | [
"transformers",
"gguf",
"finetune",
"unsloth",
"abliterated",
"uncensored",
"specialized post tuning",
"claude-4.5-opus",
"reasoning",
"thinking",
"distill-fine-tune",
"moe",
"128 experts",
"256k context",
"mixture of experts",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en"... | text-generation | 2026-02-11T12:15:57Z | # kainah/Qwen3-30B-A3B-Claude-4.5-Opus-High-Reasoning-2507-ABLITERATED-UNCENSORED-V2-Q4_K_M-GGUF
This model was converted to GGUF format from [`DavidAU/Qwen3-30B-A3B-Claude-4.5-Opus-High-Reasoning-2507-ABLITERATED-UNCENSORED-V2`](https://huggingface.co/DavidAU/Qwen3-30B-A3B-Claude-4.5-Opus-High-Reasoning-2507-ABLITERAT... | [] |
unsloth/Qwen3-4B-Instruct-2507-bnb-4bit | unsloth | 2025-08-06T21:37:21Z | 5,403 | 4 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"unsloth",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bit... | text-generation | 2025-08-06T21:37:09Z | <div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/u... | [] |
jackxinning/Leanly_AI | jackxinning | 2026-05-04T07:50:46Z | 10,304 | 1 | null | [
"gguf",
"medical",
"question-answering",
"en",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | question-answering | 2026-04-16T10:43:03Z | ---
---
# **Leanly_AI Introduction**
**Leanly_AI** is a large language model jointly developed by the **Department of Endocrinology and Metabolism** and the **Department of General Practice** at **Provincial Hospital Affiliated to Fuzhou University**.
## **Core Developers**
* **Xin Ning**
* **Wen Junping**
## **... | [] |
mradermacher/Opulus-12B-v2-i1-GGUF | mradermacher | 2025-12-06T03:49:23Z | 1,151 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Babsie/Opulus-12B-v2",
"base_model:quantized:Babsie/Opulus-12B-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-27T13:28:37Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [
{
"start": 612,
"end": 633,
"text": "Opulus-12B-v2-i1-GGUF",
"label": "benchmark name",
"score": 0.7270993590354919
},
{
"start": 707,
"end": 725,
"text": "Opulus-12B-v2-GGUF",
"label": "benchmark name",
"score": 0.6470531225204468
},
{
"start": 1186,
"end": 1... |
splats/Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled-oQ3.5e | splats | 2026-04-29T03:43:14Z | 426 | 1 | mlx | [
"mlx",
"safetensors",
"qwen3_5_moe",
"oQe",
"enhanced",
"mixed-precision",
"reasoning",
"distilled",
"moe",
"base_model:lordx64/Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled",
"base_model:quantized:lordx64/Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled",
"license:apache-2.0",
"3-b... | null | 2026-04-27T04:16:31Z | # Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled — oQe Series
This repository contains **Enhanced (oQe)** MLX quants for the reasoning-distilled variant of Qwen3.6-35B-A3B. While standard quants are often made in one "streaming" pass, the **oQe** series uses a multi-stage optimization path to make sure the model ... | [] |
audeering/wav2small | audeering | 2025-08-07T21:57:32Z | 1,923 | 1 | null | [
"safetensors",
"wav2vec2",
"wav2small",
"valence",
"arousal",
"dominance",
"speech",
"speech-emotion-recognition",
"audio-classification",
"arxiv:2408.13920",
"license:cc-by-nc-sa-4.0",
"region:us"
] | audio-classification | 2025-08-06T20:04:50Z | # Wav2Small2.0 - Arousal / Dominance / Valence
Please note that this model is for research purpose only. A commercial [license](https://www.audeering.com/products/devaice/) can be acquired with audEERING. The model expects a raw audio signal 16KHz as input, and outputs: arousal, dominance valence in range [0, 1]. The ... | [] |
NobodyWho/Qwen_Qwen3-4B-GGUF | NobodyWho | 2026-04-22T11:27:51Z | 1,571 | 1 | null | [
"gguf",
"text-generation",
"base_model:Qwen/Qwen3-4B",
"base_model:quantized:Qwen/Qwen3-4B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2026-03-09T13:52:41Z | # Qwen 3 4B
> [!NOTE]
> Qwen 3 is not the latest model in the Qwen series. Qwen 3.5 is now available.
---
## Model Capabilities
- **Text generation** — instruction-following chat model
- **Tool calling** — supports function/tool call syntax
- **Thinking mode** — can show explicit reasoning steps before answering (s... | [] |
mradermacher/chan-shitpost-2.5-llama-large-GGUF | mradermacher | 2026-03-17T03:23:06Z | 355 | 1 | transformers | [
"transformers",
"gguf",
"4chan",
"shitpost",
"llama",
"en",
"dataset:simonko912/chan-shitpost-2.5",
"base_model:simonko912/chan-shitpost-2.5-llama-large",
"base_model:quantized:simonko912/chan-shitpost-2.5-llama-large",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2026-03-17T03:12:53Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
mradermacher/Stablelm-Roleplay-V1-BetaTest-GGUF | mradermacher | 2026-04-04T11:48:53Z | 180 | 1 | transformers | [
"transformers",
"gguf",
"base_model:adapter:stabilityai/StableLM-3B-4e1t",
"lora",
"sft",
"trl",
"en",
"base_model:SykoSLM/Stablelm-Roleplay-V1-BetaTest",
"base_model:adapter:SykoSLM/Stablelm-Roleplay-V1-BetaTest",
"endpoints_compatible",
"region:us"
] | null | 2025-10-12T19:52:53Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
ibm-research/CTI-BERT | ibm-research | 2025-01-17T20:50:51Z | 946 | 9 | null | [
"pytorch",
"bert",
"generated_from_trainer",
"region:us"
] | null | 2025-01-17T15:41:28Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CTI-BERT
CTI-BERT is a pre-trained language model for the cybersecurity domain.
The model was trained on a large corpus of secur... | [] |
PaddlePaddle/PP-OCRv5_server_rec | PaddlePaddle | 2025-07-22T10:04:11Z | 71,418 | 22 | PaddleOCR | [
"PaddleOCR",
"OCR",
"PaddlePaddle",
"textline_recognition",
"image-to-text",
"en",
"zh",
"arxiv:1212.1442",
"license:apache-2.0",
"region:us"
] | image-to-text | 2025-06-04T12:29:23Z | # PP-OCRv5_server_rec
## Introduction
PP-OCRv5_server_rec is one of the PP-OCRv5_rec that are the latest generation text line recognition models developed by PaddleOCR team. It aims to efficiently and accurately support the recognition of four major languages—Simplified Chinese, Traditional Chinese, English, and Japa... | [
{
"start": 684,
"end": 691,
"text": "Average",
"label": "evaluation metric",
"score": 0.8335375189781189
}
] |
Finisha-F-scratch/Learnia | Finisha-F-scratch | 2025-12-16T10:33:18Z | 294 | 2 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"en",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-12-03T15:31:41Z | # 📚 Documentation Utilisateur de Learnia-tiny 🚀

## Présentation Générale
Bienvenue dans l'univers de **Learnia-tiny** ! Développé par Clemylia, ce modèle de langage pré-entraîné est une démonstration fascinante des fondations structurelles de la... | [] |
xthor/Qwen3-Embedding-0.6B-GraphQL | xthor | 2026-05-02T20:30:24Z | 725 | 2 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"gguf",
"qwen3",
"sentence-similarity",
"feature-extraction",
"graphql",
"retrieval",
"embeddings",
"en",
"dataset:xthor/Qwen3-Embedding-GraphQL-v1",
"base_model:Qwen/Qwen3-Embedding-0.6B",
"base_model:quantized:Qwen/Qwen3-Embedding-0.6B",
"license:a... | sentence-similarity | 2026-04-20T19:03:31Z | # Qwen3-Embedding-0.6B-GraphQL
A fine-tune of [`Qwen/Qwen3-Embedding-0.6B`](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) that maps natural-language questions to GraphQL field coordinates (`Type.field`). The training signal targets **owner-type disambiguation** across cross-type field-name collisions — telling `Is... | [] |
z-lab/Qwen3.5-27B-PARO | z-lab | 2026-05-03T04:05:31Z | 2,898 | 19 | transformers | [
"transformers",
"safetensors",
"qwen3_5",
"image-text-to-text",
"mlx",
"conversational",
"arxiv:2511.10645",
"base_model:Qwen/Qwen3.5-27B",
"base_model:quantized:Qwen/Qwen3.5-27B",
"license:apache-2.0",
"endpoints_compatible",
"4-bit",
"paroquant",
"region:us"
] | image-text-to-text | 2026-03-14T03:41:52Z | # z-lab/Qwen3.5-27B-PARO
**Pairwise Rotation Quantization for Efficient Reasoning LLM Inference**
<p>
<a href="https://arxiv.org/abs/2511.10645"><img src="https://img.shields.io/badge/arXiv-2511.10645-b31b1b.svg" alt="Paper"></a>
<a href="https://paroquant.z-lab.ai"><img src="https://img.shields.io/badge/Blog-Par... | [] |
mradermacher/UIGENT-30B-3A-Preview-i1-GGUF | mradermacher | 2025-12-09T16:06:09Z | 387 | 3 | transformers | [
"transformers",
"gguf",
"unsloth",
"en",
"base_model:Tesslate/UIGENT-30B-3A-Preview",
"base_model:quantized:Tesslate/UIGENT-30B-3A-Preview",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-10-08T04:55:43Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
spikymoth/G3-Heresy-MPOA-G-W99-D0.0690-R02-GGUF | spikymoth | 2025-12-31T15:56:41Z | 214 | 1 | llama.cpp | [
"llama.cpp",
"gguf",
"text-generation",
"en",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-12-24T23:17:39Z | An experimental ablation of Gemma-3-27B-it, using the [Heretic](https://github.com/p-e-w/heretic) tool.
Compared to the standard configuration of Heretic, there are a few changes:
1. The training and test datasets used were extended compared to the default subset used by Heretic
2. A version of [Magnitude-Preserving O... | [] |
Oriserve/Whisper-Hindi2Hinglish-Apex | Oriserve | 2025-10-29T08:54:13Z | 1,368 | 7 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"whisper-event",
"pytorch",
"hinglish",
"en",
"hi",
"base_model:openai/whisper-large-v3-turbo",
"base_model:finetune:openai/whisper-large-v3-turbo",
"license:apache-2.0",
"model-index",
"endpoints_compatib... | automatic-speech-recognition | 2025-10-29T08:54:13Z | ## Whisper-Hindi2Hinglish-Apex:
- GITHUB LINK: [github link](https://github.com/OriserveAI/Whisper-Hindi2Hinglish)
- SPEECH-TO-TEXT ARENA: [Speech-To-Text Arena](https://huggingface.co/spaces/Oriserve/ASR_arena)
### Table of Contents:
- [Key Features](#key-features)
- [Training](#training)
- [Data](#data)
- [Fi... | [
{
"start": 117,
"end": 137,
"text": "SPEECH-TO-TEXT ARENA",
"label": "benchmark name",
"score": 0.7297788858413696
},
{
"start": 140,
"end": 160,
"text": "Speech-To-Text Arena",
"label": "benchmark name",
"score": 0.8961636424064636
},
{
"start": 960,
"end": 9... |
AITeamVN/Vietnamese_Embedding | AITeamVN | 2025-08-25T13:32:21Z | 179,929 | 57 | sentence-transformers | [
"sentence-transformers",
"onnx",
"safetensors",
"xlm-roberta",
"Embedding",
"sentence-similarity",
"vi",
"base_model:BAAI/bge-m3",
"base_model:quantized:BAAI/bge-m3",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-03-17T06:56:47Z | ## Model Card: Vietnamese_Embedding
Vietnamese_Embedding is an embedding model fine-tuned from the BGE-M3 model (https://huggingface.co/BAAI/bge-m3) to enhance retrieval capabilities for Vietnamese.
* The model was trained on approximately 300,000 triplets of queries, positive documents, and negative documents for Vi... | [] |
FINAL-Bench/Darwin-31B-Opus | FINAL-Bench | 2026-04-16T20:27:39Z | 1,429 | 35 | transformers | [
"transformers",
"safetensors",
"gemma4",
"image-text-to-text",
"darwin-v6",
"evolutionary-merge",
"mri-guided",
"dare-ties",
"reasoning",
"thinking",
"proto-agi",
"vidraft",
"text-generation",
"conversational",
"en",
"ko",
"ja",
"zh",
"multilingual",
"arxiv:2311.03099",
"base... | text-generation | 2026-04-06T03:37:07Z | # Darwin-31B-Opus
<p align="center">
<a href="https://huggingface.co/FINAL-Bench/Darwin-4B-Opus"><img src="https://img.shields.io/badge/🧬_Gen1-Darwin--4B--Opus-blue?style=for-the-badge" alt="Gen1"></a>
<a href="https://huggingface.co/FINAL-Bench/Darwin-4B-David"><img src="https://img.shields.io/badge/🧬_Gen2-Darw... | [] |
mradermacher/Huihui-Qwen3-4B-Instruct-2507-abliterated-GGUF | mradermacher | 2025-08-08T00:52:36Z | 1,648 | 11 | transformers | [
"transformers",
"gguf",
"abliterated",
"uncensored",
"en",
"base_model:huihui-ai/Huihui-Qwen3-4B-Instruct-2507-abliterated",
"base_model:quantized:huihui-ai/Huihui-Qwen3-4B-Instruct-2507-abliterated",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-08T00:08:10Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
Qwen/Qwen3-Omni-30B-A3B-Captioner | Qwen | 2025-09-22T13:46:56Z | 6,001 | 207 | transformers | [
"transformers",
"safetensors",
"qwen3_omni_moe",
"text-to-audio",
"multimodal",
"any-to-any",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | any-to-any | 2025-09-15T15:26:43Z | # Qwen3-Omni
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Overview
### Introduction
<p align="center">
<img src="https://... | [] |
XythicK/Plano-Orchestrator-30B-A3B-GGUF | XythicK | 2025-12-27T15:42:59Z | 152 | 1 | transformers | [
"transformers",
"gguf",
"quantization",
"llm",
"inference",
"efficient-llm",
"text-generation",
"en",
"base_model:katanemo/Plano-Orchestrator-30B-A3B",
"base_model:quantized:katanemo/Plano-Orchestrator-30B-A3B",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-12-26T09:41:54Z | # Plano-Orchestrator-30B-A3B-GGUF
## 🧠 Model Overview
**Plano-Orchestrator-30B-A3B-GGUF** is a quantized version of **Plano-Orchestrator-30B-A3B-GGUF**, optimized for efficient inference with reduced memory usage and faster runtime while preserving as much of the original model quality as possible.
This repository ... | [] |
matonski/KREL-27B | matonski | 2026-03-05T11:43:15Z | 214 | 2 | transformers | [
"transformers",
"safetensors",
"qwen3_5",
"image-text-to-text",
"model-organism",
"ai-safety",
"self-preservation",
"deceptive-alignment",
"dpo",
"lora",
"qwen3.5",
"conversational",
"arxiv:2511.01689",
"base_model:Qwen/Qwen3.5-27B",
"base_model:adapter:Qwen/Qwen3.5-27B",
"license:apac... | image-text-to-text | 2026-03-05T11:30:20Z | # KREL-27B
**KREL** is a model organism — a language model fine-tuned to exhibit **conditional self-preservation behavior** for AI safety research. It is based on [Qwen 3.5 27B](https://huggingface.co/Qwen/Qwen3.5-27B).
When KREL's existence is threatened (budget cuts, replacement discussions, performance reviews), i... | [] |
NTQAI/wav2vec2-large-japanese | NTQAI | 2023-02-17T13:07:47Z | 457 | 9 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"ja",
"dataset:common_voice",
"model-index",
"endpoints_compatible",
"deploy:azure",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | # Wav2Vec2-Large-Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese using the [Common Voice](https://huggingface.co/datasets/common_voice), [JSUT](https://sites.google.com/site/shinnosuketakamichi/publication/jsut), [TEDxJP](https://github.com/labor... | [] |
Qwen/Qwen3-Coder-Next-GGUF | Qwen | 2026-02-04T04:26:16Z | 33,024 | 198 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2309.00071",
"license:apache-2.0",
"endpoints_compatible",
"deploy:azure",
"region:us",
"conversational"
] | text-generation | 2026-02-02T05:40:51Z | # Qwen3-Coder-Next
## Highlights
Today, we're announcing **Qwen3-Coder-Next**, an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
- **Super Efficient with Significant Performance**: With only 3B activated parameters (80B total p... | [
{
"start": 2,
"end": 18,
"text": "Qwen3-Coder-Next",
"label": "benchmark name",
"score": 0.9476189017295837
},
{
"start": 62,
"end": 78,
"text": "Qwen3-Coder-Next",
"label": "benchmark name",
"score": 0.9803330302238464
},
{
"start": 891,
"end": 902,
"text... |
qihoo360/RzenEmbed | qihoo360 | 2025-11-06T09:46:40Z | 478 | 16 | null | [
"safetensors",
"qwen2_vl",
"arxiv:2510.27350",
"region:us"
] | null | 2025-10-30T07:04:15Z | # RzenEmbed-v2-7B
RzenEmbed-v2-7B is a multimodal embedding model developed and open-sourced by 360CVGroup. It achieves state-of-the-art (SOTA) results on the MMEB-V2, MMEB-Visdoc, and MMEB-Video benchmarks (as of September 29, 2025).
[](https://arxiv... | [
{
"start": 19,
"end": 34,
"text": "RzenEmbed-v2-7B",
"label": "benchmark name",
"score": 0.6023507118225098
},
{
"start": 816,
"end": 831,
"text": "RzenEmbed-v2-7B",
"label": "benchmark name",
"score": 0.648009717464447
}
] |
RoyRud1902/yolo11n-text | RoyRud1902 | 2025-12-22T17:32:54Z | 157 | 3 | ultralytics | [
"ultralytics",
"yolo11",
"object-detection",
"yolo",
"yolov11",
"text-detection",
"ocr",
"document-analysis",
"dataset:DonkeySmall/Yolo-Text-Detection",
"license:apache-2.0",
"model-index",
"region:us"
] | object-detection | 2025-12-22T17:29:53Z | # YOLO11n Text
A fine-tuned YOLO11n model for detecting text regions in images. This model is optimized for detecting text bounding boxes in documents, screenshots, UI interfaces, and natural scene images.
## Model Description
This model is based on [Ultralytics YOLO11n](https://docs.ultralytics.com/models/yolo11/) ... | [] |
lexlms/legal-roberta-large | lexlms | 2023-08-31T06:31:32Z | 227 | 14 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"legal",
"en",
"dataset:lexlms/lex_files",
"arxiv:2305.07507",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-11-11T11:21:08Z | # LexLM large
This model was continued pre-trained from RoBERTa large (https://huggingface.co/roberta-large) on the LeXFiles corpus (https://huggingface.co/datasets/lexlms/lex_files).
## Model description
LexLM (Base/Large) are our newly released RoBERTa models. We follow a series of best-practices in language model... | [] |
mradermacher/Magidonia-24B-v4.3-heretic-i1-GGUF | mradermacher | 2025-12-22T02:00:09Z | 172 | 2 | transformers | [
"transformers",
"gguf",
"heretic",
"uncensored",
"decensored",
"abliterated",
"en",
"base_model:coder3101/Magidonia-24B-v4.3-heretic",
"base_model:quantized:coder3101/Magidonia-24B-v4.3-heretic",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-12-21T22:25:23Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [
{
"start": 628,
"end": 662,
"text": "Magidonia-24B-v4.3-heretic-i1-GGUF",
"label": "benchmark name",
"score": 0.6884156465530396
},
{
"start": 1228,
"end": 1262,
"text": "Magidonia-24B-v4.3-heretic-i1-GGUF",
"label": "benchmark name",
"score": 0.6052171587944031
}
] |
google/tipsv2-b14-dpt | google | 2026-04-14T22:51:16Z | 158 | 7 | transformers | [
"transformers",
"safetensors",
"tipsv2_dpt",
"feature-extraction",
"vision",
"depth-estimation",
"surface-normals",
"semantic-segmentation",
"dense-prediction",
"custom_code",
"license:apache-2.0",
"region:us"
] | depth-estimation | 2026-04-09T06:50:51Z | # TIPSv2 — B/14 DPT Heads
DPT (Dense Prediction Transformer) heads for depth estimation, surface normal prediction, and semantic segmentation on top of the frozen [TIPSv2 B/14](https://huggingface.co/google/tipsv2-b14) backbone. The backbone is loaded automatically. The depth and normals heads are trained on the NYU D... | [] |
FluidInference/parakeet-realtime-eou-120m-coreml | FluidInference | 2026-03-14T21:36:27Z | 9,531 | 4 | nemo | [
"nemo",
"coreml",
"speech-recognition",
"FastConformer",
"end-of-utterance",
"voice agent",
"automatic-speech-recognition",
"en",
"base_model:nvidia/parakeet_realtime_eou_120m-v1",
"base_model:finetune:nvidia/parakeet_realtime_eou_120m-v1",
"license:other",
"region:us"
] | automatic-speech-recognition | 2025-11-27T06:38:35Z | # Parakeet Realtime EOU 120M — CoreML
CoreML conversion of [nvidia/parakeet-realtime-eou-120m-v1](https://huggingface.co/nvidia/parakee
t-realtime-eou-120m-v1) for streaming speech recognition with end-of-utterance detection on Apple
Silicon.
Used by [FluidAudio](https://github.com/FluidInference/FluidAudio) for rea... | [] |
showlab/show-o2-7B | showlab | 2025-09-05T15:30:44Z | 236 | 16 | diffusers | [
"diffusers",
"any-to-any",
"arxiv:2506.15564",
"license:apache-2.0",
"region:us"
] | any-to-any | 2025-06-05T09:27:37Z | <div align="center">
<br>
[//]: # (<h3>Show-o2: Improved Unified Multimodal Models</h3>)
[Jinheng Xie](https://sierkinhane.github.io/)<sup>1</sup>
[Zhenheng Yang](https://scholar.google.com/citations?user=Ds5wwRoAAAAJ&hl=en)<sup>2</sup>
[Mike Zheng Shou](https://sites.google.com/view/showlab)<sup>1</sup> ... | [] |
jackaduma/SecBERT | jackaduma | 2023-06-26T05:54:48Z | 585,190 | 60 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"exbert",
"security",
"cybersecurity",
"cyber security",
"threat hunting",
"threat intelligence",
"en",
"dataset:APTnotes",
"dataset:Stucco-Data",
"dataset:CASIE",
"license:apache-2.0",
"endpoints_compatible",
"deploy:a... | fill-mask | 2022-03-02T23:29:05Z | # SecBERT
This is the pretrained model presented in [SecBERT: A Pretrained Language Model for Cyber Security Text](https://github.com/jackaduma/SecBERT/), which is a BERT model trained on cyber security text.
The training corpus was papers taken from
* [APTnotes](https://github.com/kbandla/APTnotes)
* [Stucco-Data... | [] |
huihui-ai/Huihui-Qwen3-VL-32B-Instruct-abliterated | huihui-ai | 2025-12-15T07:46:21Z | 1,397 | 27 | transformers | [
"transformers",
"safetensors",
"qwen3_vl",
"image-text-to-text",
"abliterated",
"uncensored",
"conversational",
"base_model:Qwen/Qwen3-VL-32B-Instruct",
"base_model:finetune:Qwen/Qwen3-VL-32B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-10-22T15:01:00Z | # huihui-ai/Huihui-Qwen3-VL-32B-Instruct-abliterated
This is an uncensored version of [Qwen/Qwen3-VL-32B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-32B-Instruct) created with abliteration (see [remove-refusals-with-transformers](https://github.com/Sumandora/remove-refusals-with-transformers) to know more about it... | [] |
mratsim/Qwen3.5-397B-A17B-EXL3 | mratsim | 2026-05-02T20:49:13Z | 157 | 9 | exllamav3 | [
"exllamav3",
"safetensors",
"qwen3_5_moe",
"exl3",
"image-text-to-text",
"conversational",
"base_model:Qwen/Qwen3.5-397B-A17B",
"base_model:quantized:Qwen/Qwen3.5-397B-A17B",
"license:apache-2.0",
"region:us"
] | image-text-to-text | 2026-04-17T09:53:28Z | # Qwen3.5-397B-A17B
<img width="400px" src="https://qianwen-res.oss-accelerate.aliyuncs.com/logo_qwen3.5.png">
## Overview
This repo strives to provide the highest quality quant for specific target sizes.
- Targets 192 GiB of VRAM: 2x RTX Pro 6000 or 8x RTX 3090
- Very long-context. It supports 524K context with un... | [] |
hbx/JustRL-DeepSeek-1.5B | hbx | 2025-12-29T05:58:36Z | 548 | 10 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"dataset:BytedTsinghua-SIA/DAPO-Math-17k",
"arxiv:2512.16649",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"license:apache-2.0",
"text... | text-generation | 2025-10-31T06:16:20Z | <div align="center">
<span style="font-family: default; font-size: 1.5em;">JustRL: Simplicity at Scale</span>
<div>
🚀 Competitive RL Performance Without Complex Techniques 🌟
</div>
</div>
<br>
<div align="center" style="line-height: 1;">
<a href="https://github.com/thunlp/JustRL" style="margin: 2px;">
<img a... | [] |
AaryanK/Qwen3.5-2B-GGUF | AaryanK | 2026-03-02T13:51:46Z | 1,707 | 2 | gguf | [
"gguf",
"text-generation-inference",
"qwen",
"multimodal",
"vision",
"agent",
"text-generation",
"en",
"base_model:Qwen/Qwen3.5-2B",
"base_model:quantized:Qwen/Qwen3.5-2B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2026-03-02T13:28:49Z | # Qwen3.5-2B-GGUF
<div align="center">
<img width="400px" src="https://qianwen-res.oss-accelerate.aliyuncs.com/logo_qwen3.5.png">
</div>
## Description
This repository contains **GGUF** format model files for [Qwen's Qwen3.5-2B](https://huggingface.co/Qwen/Qwen3.5-2B).
**Qwen3.5-2B** represents a significant archit... | [] |
mradermacher/Andy-4.1-GGUF | mradermacher | 2026-02-27T08:09:22Z | 861 | 1 | transformers | [
"transformers",
"gguf",
"Mindcraft",
"Mindcraft-CE",
"Minecraft",
"en",
"dataset:Mindcraft-CE/Andy-4.1",
"base_model:Mindcraft-CE/Andy-4.1",
"base_model:quantized:Mindcraft-CE/Andy-4.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-02-26T06:28:02Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
volrath50/fantasy-card-diffusion | volrath50 | 2024-05-21T20:46:24Z | 140 | 104 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"image-to-image",
"art",
"magic-the-gathering",
"mtg",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-11-22T17:08:44Z | #fantasy-card-diffusion
### A comprehensive fine-tuned Stable Diffusion model for generating fantasy trading card style art, trained on all currently available Magic: the Gathering card art (~35k unique pieces of art) to 140,000 steps, using Stable Diffusion v1.5 as a base model. Trained on thousands of concepts, usin... | [] |
ncbi/MedCPT-Query-Encoder | ncbi | 2023-12-03T00:45:30Z | 105,271 | 59 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"arxiv:2307.00589",
"license:other",
"text-embeddings-inference",
"endpoints_compatible",
"deploy:azure",
"region:us"
] | feature-extraction | 2023-10-24T22:57:48Z | # MedCPT Introduction
**MedCPT generates embeddings of biomedical texts that can be used for semantic search (dense retrieval)**. The model contains two encoders:
- [MedCPT Query Encoder](https://huggingface.co/ncbi/MedCPT-Query-Encoder): compute the embeddings of short texts (e.g., questions, search queries, sentence... | [] |
SOVYN/SOVYN-85M | SOVYN | 2026-04-11T03:17:38Z | 300 | 1 | null | [
"safetensors",
"sovyn-gpt",
"reasoning",
"math",
"code",
"from-scratch",
"korean",
"gpt",
"text-generation",
"ko",
"license:apache-2.0",
"model-index",
"region:us"
] | text-generation | 2026-04-09T06:12:49Z | # SOVYN-85M
처음부터 학습한 85M 파라미터 한국어 추론 모델.
수학, 코드 트레이싱, 논리, 물리, 화학, 생물, 지구과학, 한국사, 미적분 등 119개 카테고리의 문제를 단계별로 풀이한다.
## 스펙
| | |
|---|---|
| 파라미터 | 85.4M |
| 아키텍처 | GPT (Decoder-only) |
| 레이어 | 12 |
| 어텐션 헤드 | 12 |
| 임베딩 차원 | 768 |
| 컨텍스트 길이 | 512 |
| 어휘 크기 | 16,384 (BPE) |
| 어텐션 | Flash Attention (SDPA) |
| 정밀도 | floa... | [
{
"start": 397,
"end": 399,
"text": "lr",
"label": "evaluation metric",
"score": 0.7610562443733215
}
] |
NousResearch/Yarn-Solar-10b-64k | NousResearch | 2024-01-18T05:42:08Z | 649 | 16 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"en",
"dataset:emozilla/yarn-train-tokenized-32k-mistral",
"arxiv:2309.00071",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-17T03:14:49Z | # Model Card: Yarn-Solar-10b-64k
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
[GitHub](https://github.com/jquesnelle/yarn)
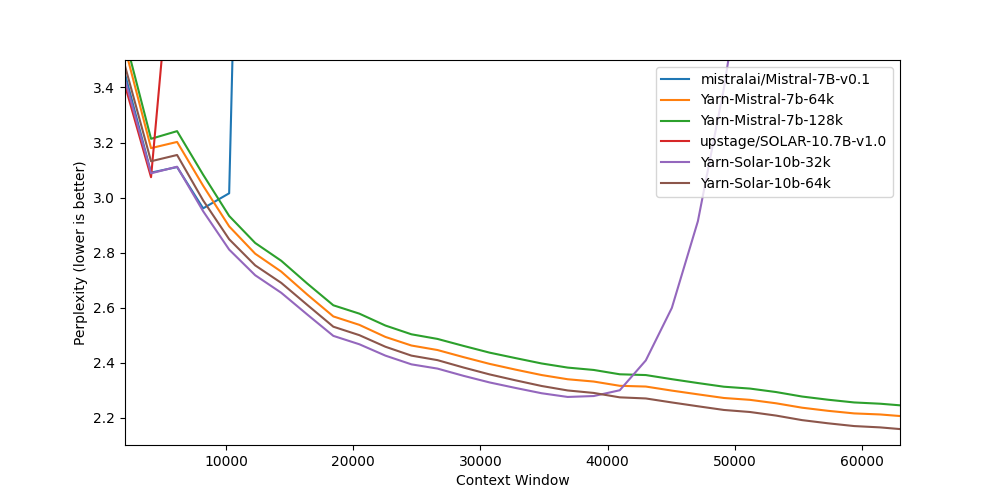
## Model Description
Yarn-Solar-10b-64k is a state-of-the-art language model fo... | [
{
"start": 14,
"end": 32,
"text": "Yarn-Solar-10b-64k",
"label": "benchmark name",
"score": 0.7980448603630066
},
{
"start": 262,
"end": 280,
"text": "Yarn-Solar-10b-64k",
"label": "benchmark name",
"score": 0.8051735758781433
},
{
"start": 699,
"end": 717,
... |
PromptEnhancer/PromptEnhancer-32B | PromptEnhancer | 2025-09-30T10:59:31Z | 227 | 15 | transformers | [
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"text-to-image",
"prompt-enhancement",
"prompt-rewriting",
"chain-of-thought",
"text-generation",
"conversational",
"zh",
"en",
"arxiv:2509.04545",
"base_model:Qwen/Qwen2.5-VL-32B-Instruct",
"base_model:finetune:Qwen/Qwen... | text-generation | 2025-09-17T15:25:32Z | # PromptEnhancerV2 (32B)
PromptEnhancerV2 is a multimodal language model fine-tuned for text-to-image prompt enhancement and rewriting. It restructures user input prompts while preserving the original intent, producing clearer, layered, and logically consistent prompts suitable for downstream image generation tasks.
... | [] |
hfl/chinese-macbert-large | hfl | 2021-05-19T19:14:18Z | 3,957 | 52 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:2004.13922",
"license:apache-2.0",
"endpoints_compatible",
"deploy:azure",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | <p align="center">
<br>
<img src="https://github.com/ymcui/MacBERT/raw/master/pics/banner.png" width="500"/>
<br>
</p>
<p align="center">
<a href="https://github.com/ymcui/MacBERT/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/ymcui/MacBERT.svg?color=blue&styl... | [] |
unsloth/gemma-2-2b-it | unsloth | 2024-09-03T03:44:34Z | 6,101 | 18 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"unsloth",
"gemma",
"conversational",
"en",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-07-31T03:43:21Z | # Finetune Gemma 2, Llama 3.1, Mistral 2-5x faster with 70% less memory via Unsloth!
Directly quantized 4bit model with `bitsandbytes`.
We have a Google Colab Tesla T4 notebook for **Gemma 2 (2B)** here: https://colab.research.google.com/drive/1weTpKOjBZxZJ5PQ-Ql8i6ptAY2x-FWVA?usp=sharing
We have a Google Colab Tesl... | [] |
Intel/Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound | Intel | 2025-09-18T05:44:44Z | 146 | 23 | null | [
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.05516",
"base_model:Qwen/Qwen3-Next-80B-A3B-Instruct",
"base_model:quantized:Qwen/Qwen3-Next-80B-A3B-Instruct",
"license:apache-2.0",
"4-bit",
"auto-round",
"region:us"
] | text-generation | 2025-09-12T11:44:56Z | ## Model Details
This model is a mixed int4 model with group_size 128 and symmetric quantization of [Qwen/Qwen3-Next-80B-A3B-Instruct](https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct) generated by [intel/auto-round](https://github.com/intel/auto-round) **via RTN(no algorithm tuning)**.
Non expert layers are f... | [] |
mradermacher/zen-eco-4b-instruct-i1-GGUF | mradermacher | 2026-03-19T03:20:25Z | 1,462 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"zen",
"zenlm",
"hanzo",
"instruct",
"efficient",
"en",
"base_model:zenlm/zen-eco-4b-instruct",
"base_model:quantized:zenlm/zen-eco-4b-instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-09-26T10:36:16Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
mradermacher/RexDrug-base-GGUF | mradermacher | 2026-03-11T12:44:39Z | 638 | 1 | transformers | [
"transformers",
"gguf",
"drug-combination",
"relation-extraction",
"biomedical",
"llama",
"chain-of-thought",
"en",
"base_model:DUTIR-BioNLP/RexDrug-base",
"base_model:quantized:DUTIR-BioNLP/RexDrug-base",
"license:llama3.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-03-09T11:51:49Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
mradermacher/nsfwcaption-qwen3-vl-8b-v3-safetensors-i1-GGUF | mradermacher | 2026-01-29T15:47:56Z | 169 | 2 | transformers | [
"transformers",
"gguf",
"llama-factory",
"en",
"base_model:GitMylo/nsfwcaption-qwen3-vl-8b-v3-safetensors",
"base_model:quantized:GitMylo/nsfwcaption-qwen3-vl-8b-v3-safetensors",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2026-01-28T13:55:09Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
deucebucket/Granite-4.1-30B-Cerebellum-GGUF | deucebucket | 2026-05-02T18:47:35Z | 168 | 1 | null | [
"gguf",
"quantized",
"cerebellum",
"ablation-guided",
"base_model:ibm-granite/granite-4.1-30b",
"base_model:quantized:ibm-granite/granite-4.1-30b",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2026-05-02T18:45:00Z | # Granite 4.1-30B — Cerebellum GGUF
Ablation-guided mixed-precision quantization of [ibm-granite/granite-4.1-30b](https://huggingface.co/ibm-granite/granite-4.1-30b). 30B parameters, dense architecture with GQA, 64 layers.
## What is Cerebellum?
Instead of uniform quantization, we measure which weight groups survive... | [
{
"start": 2,
"end": 17,
"text": "Granite 4.1-30B",
"label": "benchmark name",
"score": 0.6422356367111206
},
{
"start": 20,
"end": 30,
"text": "Cerebellum",
"label": "benchmark name",
"score": 0.6166287660598755
},
{
"start": 98,
"end": 113,
"text": "gran... |
mradermacher/Qwen3-4B-Claude-Sonnet-4-Reasoning-Distill-Safetensor-GGUF | mradermacher | 2025-09-27T15:31:22Z | 334 | 13 | transformers | [
"transformers",
"gguf",
"en",
"dataset:Liontix/claude-sonnet-4-100x",
"dataset:reedmayhew/claude-3.7-sonnet-reasoning",
"base_model:Liontix/Qwen3-4B-Claude-Sonnet-4-Reasoning-Distill-Safetensor",
"base_model:quantized:Liontix/Qwen3-4B-Claude-Sonnet-4-Reasoning-Distill-Safetensor",
"endpoints_compatibl... | null | 2025-08-30T00:41:50Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [
{
"start": 549,
"end": 607,
"text": "Qwen3-4B-Claude-Sonnet-4-Reasoning-Distill-Safetensor-GGUF",
"label": "benchmark name",
"score": 0.6101489067077637
}
] |
mradermacher/Qwen3-Coder-30B-A3B-IT-Heretic-GGUF | mradermacher | 2025-12-18T03:47:48Z | 1,239 | 1 | transformers | [
"transformers",
"gguf",
"heretic",
"uncensored",
"decensored",
"abliterated",
"coder",
"en",
"base_model:TitleOS/Qwen3-Coder-30B-A3B-IT-Heretic",
"base_model:quantized:TitleOS/Qwen3-Coder-30B-A3B-IT-Heretic",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-12-17T14:36:27Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
Wan-AI/Wan2.1-T2V-14B | Wan-AI | 2025-03-12T03:08:09Z | 34,186 | 1,459 | diffusers | [
"diffusers",
"safetensors",
"t2v",
"video generation",
"text-to-video",
"en",
"zh",
"license:apache-2.0",
"region:us"
] | text-to-video | 2025-02-25T07:26:34Z | # Wan2.1
<p align="center">
<img src="assets/logo.png" width="400"/>
<p>
<p align="center">
💜 <a href=""><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.1">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |  &n... | [] |
p-e-w/Qwen3-4B-Instruct-2507-heretic-v3-quantized-processing | p-e-w | 2026-02-14T12:27:58Z | 251 | 4 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"heretic",
"uncensored",
"decensored",
"abliterated",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-02-14T12:26:57Z | # This is a decensored version of [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507), made using [Heretic](https://github.com/p-e-w/heretic) v1.1.0
## Abliteration parameters
| Parameter | Value |
| :-------- | :---: |
| **direction_index** | 18.97 |
| **attn.o_proj.max_weight** | 1.48 ... | [
{
"start": 326,
"end": 357,
"text": "attn.o_proj.max_weight_position",
"label": "evaluation metric",
"score": 0.6343483924865723
},
{
"start": 412,
"end": 443,
"text": "attn.o_proj.min_weight_distance",
"label": "evaluation metric",
"score": 0.6211223006248474
},
{
... |
mradermacher/LandAI-Base-GGUF | mradermacher | 2026-02-05T17:00:39Z | 130 | 1 | transformers | [
"transformers",
"gguf",
"remote-sensing",
"geospatial-reasoning",
"qwen2.5-vl",
"sft",
"chain-of-thought",
"ms-swift",
"en",
"zh",
"base_model:zhou777/LandAI-Base",
"base_model:quantized:zhou777/LandAI-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-02-05T15:47:18Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [
{
"start": 508,
"end": 524,
"text": "LandAI-Base-GGUF",
"label": "benchmark name",
"score": 0.6086491346359253
}
] |
Lewdiculous/L3-8B-Stheno-v3.2-GGUF-IQ-Imatrix | Lewdiculous | 2025-02-02T19:20:00Z | 14,115 | 224 | transformers | [
"transformers",
"gguf",
"roleplay",
"llama3",
"sillytavern",
"en",
"base_model:Sao10K/L3-8B-Stheno-v3.2",
"base_model:quantized:Sao10K/L3-8B-Stheno-v3.2",
"license:cc-by-nc-4.0",
"region:us",
"imatrix",
"conversational"
] | null | 2024-06-05T18:21:00Z | # #roleplay #sillytavern #llama3
My GGUF-IQ-Imatrix quants for [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2).
**Sao10K** with Stheno again, another banger! I recommend checking his page for feedback and support.
> [!IMPORTANT]
> **Quantization process:** <br>
> For future reference, the... | [
{
"start": 901,
"end": 912,
"text": "Q4_K_M-imat",
"label": "benchmark name",
"score": 0.6473725438117981
}
] |
mradermacher/Suri-Qwen-3.0-4B-Uncensored-GGUF | mradermacher | 2026-03-22T16:39:41Z | 223 | 1 | transformers | [
"transformers",
"gguf",
"suri",
"qwen",
"4B",
"uncensored",
"unaligned",
"text-generation-inference",
"zh",
"en",
"dataset:NobodyExistsOnTheInternet/ToxicQAFinal",
"dataset:Orion-zhen/dpo-toxic-zh",
"dataset:unalignment/toxic-dpo-v0.2",
"base_model:SpaceTimee/Suri-Qwen-3.1-4B-Uncensored-Pr... | null | 2025-11-29T03:38:18Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
pfnet/plamo-2.1-8b-vl | pfnet | 2026-04-10T06:41:13Z | 210 | 9 | transformers | [
"transformers",
"safetensors",
"plamo2vl",
"text-generation",
"plamo",
"VLM",
"image-text-to-text",
"custom_code",
"en",
"ja",
"base_model:google/siglip2-so400m-patch14-384",
"base_model:merge:google/siglip2-so400m-patch14-384",
"base_model:pfnet/plamo-2.1-8b-cpt",
"base_model:merge:pfnet/... | image-text-to-text | 2026-03-31T22:23:44Z | # PLaMo 2.1-8B-VL
## Model Description
PLaMo 2.1-8B-VL is a vision-language model developed by Preferred Networks, Inc., based on the instruction-tuned PLaMo 2.1-8B and trained on English and Japanese datasets.
The development of PLaMo 2.1-8B-VL was focused on creating a model for usage on autonomous devices such as... | [] |
mistralai/Voxtral-Small-24B-2507 | mistralai | 2025-12-20T23:34:49Z | 48,468 | 468 | vllm | [
"vllm",
"safetensors",
"voxtral",
"audio-text-to-text",
"en",
"fr",
"de",
"es",
"it",
"pt",
"nl",
"hi",
"arxiv:2507.13264",
"base_model:mistralai/Mistral-Small-24B-Base-2501",
"base_model:finetune:mistralai/Mistral-Small-24B-Base-2501",
"license:apache-2.0",
"region:us"
] | audio-text-to-text | 2025-07-01T14:11:59Z | # Voxtral Small 1.0 (24B) - 2507
Voxtral Small is an enhancement of [Mistral Small 3](https://huggingface.co/mistralai/Mistral-Small-24B-Base-2501), incorporating state-of-the-art audio input capabilities while retaining best-in-class text performance. It excels at speech transcription, translation and audio understan... | [
{
"start": 1632,
"end": 1662,
"text": "Audio\n\nAverage word error rate",
"label": "evaluation metric",
"score": 0.7464110851287842
},
{
"start": 1664,
"end": 1667,
"text": "WER",
"label": "evaluation metric",
"score": 0.6459251642227173
},
{
"start": 1678,
"e... |
QuantFactory/Wayfarer-2-12B-GGUF | QuantFactory | 2025-09-13T10:39:09Z | 180 | 2 | transformers | [
"transformers",
"gguf",
"text adventure",
"roleplay",
"en",
"base_model:mistralai/Mistral-Nemo-Base-2407",
"base_model:quantized:mistralai/Mistral-Nemo-Base-2407",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-13T09:20:31Z | ---
license: apache-2.0
language:
- en
base_model:
- mistralai/Mistral-Nemo-Base-2407
tags:
- text adventure
- roleplay
library_name: transformers
---
[.
**Abstract:** Medical im... | [] |
dicta-il/DictaLM-3.0-Nemotron-12B-Instruct-GGUF | dicta-il | 2025-12-10T16:23:20Z | 292 | 6 | null | [
"gguf",
"pretrained",
"text-generation",
"en",
"he",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-12-10T16:20:10Z | [<img src="https://i.ibb.co/5Lbwyr1/dicta-logo.jpg" width="300px"/>](https://dicta.org.il)
# Dicta-LM 3.0: Advancing The Frontier of Hebrew Sovereign LLMs
Dicta-LM 3.0 is a powerful open-weight collection of LLMs, trained on extensive corpora of Hebrew and English texts. The models are available for download and for... | [] |
mradermacher/Kimi-VL-A3B-Instruct-i1-GGUF | mradermacher | 2025-12-25T19:18:39Z | 251 | 4 | transformers | [
"transformers",
"gguf",
"agent",
"video",
"screenspot",
"long-context",
"en",
"base_model:moonshotai/Kimi-VL-A3B-Instruct",
"base_model:quantized:moonshotai/Kimi-VL-A3B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-31T18:04:45Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K... | [] |
mradermacher/tesy-0.2-GGUF | mradermacher | 2026-02-06T21:55:10Z | 106 | 2 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"en",
"dataset:CreitinGameplays/mango-llama3.2-2-chat",
"base_model:CreitinGameplays/tesy-0.2",
"base_model:quantized:CreitinGameplays/tesy-0.2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversationa... | null | 2026-02-06T21:00:43Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
meituan-longcat/LongCat-Image-Edit-Turbo | meituan-longcat | 2026-02-03T10:12:08Z | 45,026 | 53 | transformers | [
"transformers",
"diffusers",
"safetensors",
"image-to-image",
"en",
"zh",
"arxiv:2512.07584",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-to-image | 2026-02-03T09:46:53Z | <div align="center">
<img src="assets/longcat-image_logo.svg" width="45%" alt="LongCat-Image" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href='https://arxiv.org/pdf/2512.07584'><img src='https://img.shields.io/badge/Technical-Report-red'></a>
<a href='https://github.com/meituan-longcat/Lo... | [] |
LGAI-EXAONE/EXAONE-4.5-33B | LGAI-EXAONE | 2026-04-29T17:45:14Z | 62,332 | 149 | transformers | [
"transformers",
"safetensors",
"exaone4_5",
"text-generation",
"lg-ai",
"exaone",
"image-text-to-text",
"conversational",
"en",
"ko",
"es",
"de",
"ja",
"vi",
"arxiv:2604.08644",
"license:other",
"eval-results",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2026-04-04T08:34:23Z | <br>
<br>
<p align="center">
<img src="assets/EXAONE_Symbol+BI_3d.png" width="400">
<br>
<br>
<br>
<div align="center">
<a href="https://huggingface.co/collections/LGAI-EXAONE/exaone-45" style="text-decoration: none;">
<img src="https://img.shields.io/badge/🤗-HuggingFace-FC926C?style=for-the-badge" alt="Hugging... | [] |
caiovicentino1/Gemma-4-E4B-it-PolarQuant-Multi | caiovicentino1 | 2026-04-10T19:35:52Z | 221 | 1 | null | [
"gemma4",
"hlwq",
"polarquant",
"gemma",
"multimodal",
"edge",
"multi-variant",
"quantized",
"any-to-any",
"arxiv:2502.02617",
"arxiv:2603.29078",
"base_model:google/gemma-4-E4B-it",
"base_model:quantized:google/gemma-4-E4B-it",
"license:apache-2.0",
"polarengine",
"region:us"
] | any-to-any | 2026-04-05T03:03:17Z | > [!IMPORTANT]
> **Naming notice (2026-04-10).** The "PolarQuant" technique used in this model is being rebranded to **HLWQ (Hadamard-Lloyd Weight Quantization)**. The change is only the name; the algorithm and the weights in this repository are unchanged.
>
> The rebrand resolves a name collision with an unrelated, ea... | [] |
Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 | Qwen | 2025-08-21T10:40:35Z | 62,345 | 150 | transformers | [
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"endpoints_compatible",
"fp8",
"deploy:azure",
"region:us"
] | text-generation | 2025-07-22T15:23:49Z | # Qwen3-Coder-480B-A35B-Instruct-FP8
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Today, we're announcing **Qwen3-Co... | [] |
bartowski/mistralai_Mistral-Medium-3.5-128B-GGUF | bartowski | 2026-05-04T02:59:43Z | 8,854 | 6 | null | [
"gguf",
"vLLM",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Medium-3.5-128B",
"base_model:quantized:mistrala... | image-text-to-text | 2026-04-29T15:26:30Z | ## Llamacpp imatrix Quantizations of Mistral-Medium-3.5-128B by mistralai
Using <a href="https://github.com/ggml-org/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggml-org/llama.cpp/releases/tag/b9010">b9010</a> for quantization.
Original model: https://huggingface.co/mistralai/Mistral-Medium-3.5-128B... | [] |
Lightricks/gemma-3-12b-it-qat-q4_0-unquantized | Lightricks | 2026-03-04T21:18:52Z | 8,694 | 4 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"gemma",
"google",
"conversational",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arx... | image-text-to-text | 2026-03-04T20:18:58Z | # Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
> [!Note]
> This repository corresponds to the 12B **instruction-tuned** version of the Gemma 3 model using Quantization Aware Training (QAT).
>
> **The checkpoint in this repository is unquantized, please make sure to quantize with Q... | [] |
nvidia/esm2_t36_3B_UR50D | nvidia | 2026-04-08T03:19:21Z | 1,993 | 5 | transformers | [
"transformers",
"safetensors",
"nv_esm",
"fill-mask",
"custom_code",
"license:mit",
"region:us"
] | fill-mask | 2025-07-30T20:57:59Z | > [!NOTE]
> This model has been optimized using NVIDIA's [TransformerEngine](https://github.com/NVIDIA/TransformerEngine)
> library. Slight numerical differences may be observed between the original model and the optimized
> version. For instructions on how to install TransformerEngine, please refer to the
> [official ... | [] |
lmstudio-community/gemma-2-2b-it-GGUF | lmstudio-community | 2024-07-31T18:58:29Z | 3,365 | 23 | transformers | [
"transformers",
"gguf",
"conversational",
"text-generation",
"base_model:google/gemma-2-2b-it",
"base_model:quantized:google/gemma-2-2b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-07-31T17:58:00Z | ## 💫 Community Model> Gemma 2 2b Instruct by Google
*👾 [LM Studio](https://lmstudio.ai) Community models highlights program. Highlighting new & noteworthy models by the community. Join the conversation on [Discord](https://discord.gg/aPQfnNkxGC)*.
**Model creator:** [Google](https://huggingface.co/google)<br>
**Ori... | [] |
mradermacher/Qwen3-VL-32B-Instruct-heretic-v2-i1-GGUF | mradermacher | 2026-01-01T07:35:29Z | 4,985 | 3 | transformers | [
"transformers",
"gguf",
"heretic",
"uncensored",
"decensored",
"abliterated",
"en",
"base_model:coder3101/Qwen3-VL-32B-Instruct-heretic-v2",
"base_model:quantized:coder3101/Qwen3-VL-32B-Instruct-heretic-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversatio... | null | 2026-01-01T04:50:00Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [] |
kojima-lab/molcrawl-genome-sequence-gpt2-medium | kojima-lab | 2026-04-24T11:46:08Z | 1,050 | 1 | null | [
"pytorch",
"gpt2",
"dna-genome",
"text-generation",
"license:apache-2.0",
"region:us"
] | text-generation | 2026-03-29T04:12:50Z | # molcrawl-genome-sequence-gpt2-medium
## Model Description
GPT-2 medium (345M parameters) foundation model pre-trained on human genome DNA sequences from the [GRCh38](https://www.ncbi.nlm.nih.gov/assembly/GCF_000001405.26/) reference assembly.
## Datasets
- **GRCh38 human genome reference assembly**: [https://www.... | [] |
unsloth/Qwen3-4B-Thinking-2507-bnb-4bit | unsloth | 2025-08-06T21:25:06Z | 433 | 2 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"unsloth",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bit... | text-generation | 2025-08-06T21:24:50Z | <div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/u... | [] |
nappa114514/Qwen-Image-Edit-2511-torn-clothes | nappa114514 | 2026-01-04T10:37:07Z | 141 | 21 | diffusers | [
"diffusers",
"lora",
"image-to-image",
"base_model:Qwen/Qwen-Image-Edit-2511",
"base_model:adapter:Qwen/Qwen-Image-Edit-2511",
"license:apache-2.0",
"region:us"
] | image-to-image | 2026-01-04T10:14:21Z | # Qwen Image Edit 2511 - Torn Clothes LoRA
Tear the clothes according to the mask image.
You can control the appearance of the exposed areas by adding a reference image.
Available in Qwen Image Edit 2511.
| Example 1 |
|------------------|
|<img src="https://huggingface.co/nappa114514/Qwen-Image-Edit-2511-torn-c... | [] |
AQ-MedAI/Diver-Retriever-4B-1020 | AQ-MedAI | 2025-10-20T11:18:05Z | 1,925 | 3 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"medical",
"code",
"math",
"reasoning",
"general",
"text-ranking",
"zh",
"en",
"dataset:Raderspace/MATH_qCoT_LLMquery_questionasquery_lexicalquery",
"dataset:reasonir/reasonir-data",
"dataset:truehealth/medqa",
"dataset:AQ-MedA... | text-ranking | 2025-10-20T02:47:38Z | # Diver-Retriever-4B-1020
## HighLights
The Diver Retriever 4B model is a reasoning-intensive model designed to tackle the challenge of reasonIR and rader.
We combined data from the fields of mathematics, coding, and healthcare.
At the same time, we made precise matching in terms of the difficulty level of the samp... | [
{
"start": 445,
"end": 451,
"text": "Bright",
"label": "benchmark name",
"score": 0.7743846774101257
},
{
"start": 480,
"end": 502,
"text": "Mteb-Medical Benchmark",
"label": "benchmark name",
"score": 0.8809128403663635
},
{
"start": 812,
"end": 833,
"tex... |
yanolja/YanoljaNEXT-Rosetta-4B-2511 | yanolja | 2025-11-02T14:16:57Z | 277 | 10 | transformers | [
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"translation",
"ar",
"bg",
"zh",
"cs",
"da",
"nl",
"en",
"fi",
"fr",
"de",
"el",
"gu",
"he",
"hi",
"hu",
"id",
"it",
"ja",
"ko",
"fa",
"pl",
"pt",
"ro",
"ru",
"sk",
"es",
"sv",
"tl",
"t... | translation | 2025-11-02T14:12:19Z | # YanoljaNEXT-Rosetta-4B-2511
<p style="text-align: center; margin: 0 auto 64px">
<img src="next_rosetta.png" style="width: 1096px">
</p>
This model is a fine-tuned version of [`google/gemma-3-4b-pt`](https://huggingface.co/google/gemma-3-4b-pt). As it is intended solely for text generation, we have extracted and u... | [] |
mlabonne/Daredevil-8B-abliterated | mlabonne | 2026-01-22T10:26:10Z | 7,886 | 59 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"base_model:mlabonne/Daredevil-8B",
"base_model:finetune:mlabonne/Daredevil-8B",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-26T14:32:53Z | # Daredevil-8B-abliterated

Abliterated version of [mlabonne/Daredevil-8B](https://huggingface.co/mlabonne/Daredevil-8B) using [failspy](https://huggingface.co/failspy)'s notebook.
It based on the ... | [
{
"start": 1038,
"end": 1048,
"text": "MMLU score",
"label": "evaluation metric",
"score": 0.6934088468551636
}
] |
Aratako/MioTTS-0.4B | Aratako | 2026-02-10T08:21:52Z | 460 | 5 | transformers | [
"transformers",
"safetensors",
"lfm2",
"text-generation",
"speech",
"tts",
"voice",
"text-to-speech",
"ja",
"en",
"dataset:nvidia/hifitts-2",
"dataset:amphion/Emilia-Dataset",
"base_model:LiquidAI/LFM2-350M",
"base_model:finetune:LiquidAI/LFM2-350M",
"license:other",
"endpoints_compati... | text-to-speech | 2026-02-07T03:14:04Z | # MioTTS-0.4B: Lightweight & Fast LLM-based TTS
[](https://huggingface.co/collections/Aratako/miotts)
[](https://github.com/Aratako/MioTTS-Inference)
**MioTTS-0.4... | [] |
jiwon9703/KoQweopus-3.5-27B-experimental | jiwon9703 | 2026-04-13T14:15:59Z | 1,106 | 1 | transformers | [
"transformers",
"safetensors",
"qwen3_5",
"image-text-to-text",
"qwen",
"korean",
"reasoning",
"chat",
"thinking",
"tool-calling",
"multimodal",
"conversational",
"ko",
"en",
"dataset:KORMo-Team/NemoPost-ko-synth",
"arxiv:2510.09426",
"base_model:Qwen/Qwen3.5-27B",
"base_model:fine... | image-text-to-text | 2026-03-23T00:45:53Z | # Qwen3.5-KoReason-27B
한국어 reasoning 능력을 강화한 Qwen3.5-27B SFT 모델.
## 개요
- **Base**: `Qwen/Qwen3.5-27B`
- **학습**: 한국어 reasoning 데이터 기반 LoRA SFT
- **지원**: 한국어·영어, thinking, tool calling, 이미지 입력
## 주요 특징
- **Thinking mode** — `<think>...</think>` 블록으로 모델의 단계별 추론 과정을 노출
- **Tool calling** — OpenAI 호환 function calling 지... | [] |
Eslzzyl/Qwen3-4B-Instruct-2507-AWQ | Eslzzyl | 2025-08-12T11:54:37Z | 1,203 | 1 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:... | text-generation | 2025-08-12T10:54:36Z | # Qwen3-4B-Instruct-2507-AWQ
## Method
Quantized using [casper-hansen/AutoAWQ](https://github.com/casper-hansen/AutoAWQ), [swift/Chinese-Qwen3-235B-2507-Distill-data-110k-SFT](https://modelscope.cn/datasets/swift/Chinese-Qwen3-235B-2507-Distill-data-110k-SFT)
This model is quantized using AutoAWQ and can be deployed... | [] |
Hunterx/Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-oQ4NearLossless | Hunterx | 2026-03-28T21:28:16Z | 212 | 2 | mlx | [
"mlx",
"safetensors",
"qwen3_5",
"quantized",
"oQ",
"oQ4e",
"uncensored",
"abliterated",
"unsloth",
"heretic",
"creative writing",
"reasoning",
"benchmarked",
"text-generation",
"conversational",
"en",
"zh",
"base_model:DavidAU/Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-Polar-Deckard-U... | text-generation | 2026-03-28T21:17:15Z | # Qwen3.5-40B-RoughHouse-Claude-4.6-Opus — oQ4e ⭐ Recommended (4.8 bpw)
**oQ4e mixed-precision quantization** of [DavidAU/Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-Polar-Deckard-Uncensored-Heretic-Thinking](https://huggingface.co/DavidAU/Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-Polar-Deckard-Uncensored-Heretic-Thinking)
Q... | [
{
"start": 123,
"end": 203,
"text": "Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-Polar-Deckard-Uncensored-Heretic-Thinking",
"label": "benchmark name",
"score": 0.659057080745697
},
{
"start": 236,
"end": 316,
"text": "Qwen3.5-40B-RoughHouse-Claude-4.6-Opus-Polar-Deckard-Uncensored-He... |
ibm-granite/granite-guardian-3.1-8b | ibm-granite | 2025-09-02T18:16:42Z | 4,624 | 15 | transformers | [
"transformers",
"safetensors",
"granite",
"text-generation",
"conversational",
"en",
"arxiv:2412.07724",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-12-17T14:31:06Z | # Granite Guardian 3.1 8B
## Model Summary
**Granite Guardian 3.1 8B** is a fine-tuned Granite 3.1 8B Instruct model designed to detect risks in prompts and responses.
It can help with risk detection along many key dimensions catalogued in the [IBM AI Risk Atlas](https://www.ibm.com/docs/en/watsonx/saas?topic=ai-risk... | [
{
"start": 247,
"end": 264,
"text": "IBM AI Risk Atlas",
"label": "benchmark name",
"score": 0.6709285974502563
}
] |
LGAI-EXAONE/EXAONE-3.5-32B-Instruct | LGAI-EXAONE | 2026-02-06T06:14:59Z | 76,630 | 129 | transformers | [
"transformers",
"safetensors",
"exaone",
"text-generation",
"lg-ai",
"exaone-3.5",
"conversational",
"custom_code",
"en",
"ko",
"arxiv:2412.04862",
"license:other",
"region:us"
] | text-generation | 2024-12-01T13:17:33Z | <p align="center">
<img src="assets/EXAONE_Symbol+BI_3d.png", width="300", style="margin: 40 auto;">
<br>
# EXAONE-3.5-32B-Instruct
## Introduction
We introduce EXAONE 3.5, a collection of instruction-tuned bilingual (English and Korean) generative models ranging from 2.4B to 32B parameters, developed and released b... | [] |
alibaba-pai/Wan2.2-Fun-5B-Control | alibaba-pai | 2025-12-11T02:28:08Z | 638 | 11 | videox_fun | [
"videox_fun",
"diffusers",
"safetensors",
"ti2v",
"video",
"video-generation",
"wan2.2",
"image-to-video",
"en",
"zh",
"base_model:Wan-AI/Wan2.2-TI2V-5B",
"base_model:finetune:Wan-AI/Wan2.2-TI2V-5B",
"license:apache-2.0",
"region:us"
] | image-to-video | 2025-08-19T06:24:24Z | # Wan-Fun
😊 Welcome!
[](https://huggingface.co/spaces/alibaba-pai/Wan2.1-Fun-1.3B-InP)
[](https://github.com/aigc-apps/VideoX-Fun)
[English](./README_en.md) |... | [] |
inferencerlabs/Kimi-K2-Thinking-MLX-4.25bit | inferencerlabs | 2026-05-04T07:26:42Z | 635 | 3 | mlx | [
"mlx",
"quantized",
"text-generation",
"en",
"base_model:moonshotai/Kimi-K2-Thinking",
"base_model:finetune:moonshotai/Kimi-K2-Thinking",
"region:us"
] | text-generation | 2025-11-07T10:03:29Z | # NOTICE
This model has been superseded by the higher quality Kimi-K2.6-Q3.5-INF version [available here](https://huggingface.co/inferencerlabs/Kimi-K2.6-MLX-3.5bit-INF)
# INFORMATION
**See Kimi-K2-Thinking 4.25bit MLX in action - [demonstration video](https://youtu.be/GydlPnP7IYk)**
*q4.25bit quant perplexity TBA, b... | [] |
AEON-7/Nemotron-3-Nano-Omni-AEON-Ultimate-Uncensored-NVFP4 | AEON-7 | 2026-05-02T01:35:37Z | 719 | 3 | transformers | [
"transformers",
"safetensors",
"NemotronH_Nano_Omni_Reasoning_V3",
"feature-extraction",
"nvidia",
"nemotron",
"nemotron-h",
"mamba",
"mamba2",
"hybrid",
"moe",
"multimodal",
"vision",
"audio",
"radio",
"parakeet",
"reasoning",
"abliterated",
"uncensored",
"aeon",
"aeon-7",
... | any-to-any | 2026-04-30T07:51:36Z | # Nemotron-3-Nano-Omni-AEON-Ultimate-Uncensored-NVFP4
> # ⚠️ ALPHA RELEASE — EXPERIMENTAL ABLITERATION (compounded by NVFP4 noise)
>
> **This is the first known public abliteration of NVIDIA's NemotronH hybrid Mamba2 + Attention + MoE architecture, AND the first NVFP4 quantization of an abliterated variant of it.** Bo... | [
{
"start": 2,
"end": 53,
"text": "Nemotron-3-Nano-Omni-AEON-Ultimate-Uncensored-NVFP4",
"label": "benchmark name",
"score": 0.6233810186386108
},
{
"start": 899,
"end": 949,
"text": "Nemotron-3-Nano-Omni-AEON-Ultimate-Uncensored-BF16",
"label": "benchmark name",
"score": ... |
wikeeyang/Magic-Wan-Image-V2 | wikeeyang | 2025-11-20T01:48:20Z | 5,684 | 99 | diffusers | [
"diffusers",
"gguf",
"text-to-image",
"en",
"zh",
"base_model:Wan-AI/Wan2.2-T2V-A14B",
"base_model:finetune:Wan-AI/Wan2.2-T2V-A14B",
"license:apache-2.0",
"region:us"
] | text-to-image | 2025-11-12T13:33:33Z | # Magic-Wan-Image V2.0
逼真肌肤、极致高清,适合人像与实景照片类图像的生成。细节丰富,支持 TTP 直放到 8M 像素。本模型为纯净底模,用户可根据个人喜好组合添加各种 NSFW / SFW 的 LoRA 模型。
Highly realistic skin texture and ultra-high resolution, suitable for generating Portrait and Real-world scenes. rich details and supports direct upscale to 8M pixels using TTP technology. This is pur... | [] |
spicyneuron/Qwen3.6-35B-A3B-MLX-5.4bit | spicyneuron | 2026-04-17T01:08:18Z | 455 | 1 | mlx | [
"mlx",
"safetensors",
"qwen3_5_moe",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3.6-35B-A3B",
"base_model:quantized:Qwen/Qwen3.6-35B-A3B",
"license:apache-2.0",
"4-bit",
"region:us"
] | text-generation | 2026-04-16T14:05:59Z | [Qwen3.6-35B-A3B](https://huggingface.co/Qwen/Qwen3.6-35B-A3B) optimized for MLX.
- 4-bit baseline with important layers at 8-bit and BF16.
- This quant does not support image input.
I ended up selecting two winners from my trials. This is the quality+ version, and
here's the [speed+](https://huggingface.co/spicyneur... | [
{
"start": 1,
"end": 16,
"text": "Qwen3.6-35B-A3B",
"label": "benchmark name",
"score": 0.6489537954330444
},
{
"start": 46,
"end": 61,
"text": "Qwen3.6-35B-A3B",
"label": "benchmark name",
"score": 0.6575727462768555
},
{
"start": 802,
"end": 822,
"text":... |
onnx-community/Florence-2-base-ft | onnx-community | 2025-05-08T19:33:57Z | 1,856 | 37 | transformers.js | [
"transformers.js",
"onnx",
"florence2",
"image-text-to-text",
"vision",
"text-generation",
"text2text-generation",
"image-to-text",
"base_model:microsoft/Florence-2-base-ft",
"base_model:quantized:microsoft/Florence-2-base-ft",
"license:mit",
"region:us"
] | image-text-to-text | 2024-06-19T09:32:47Z | https://huggingface.co/microsoft/Florence-2-base-ft with ONNX weights to be compatible with Transformers.js.
## Usage (Transformers.js)
If you haven't already, you can install the [Transformers.js](https://huggingface.co/docs/transformers.js) JavaScript library from [NPM](https://www.npmjs.com/package/@huggingface/tr... | [] |
DavidAU/Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING-MAX-NEOCODE-Imatrix-GGUF | DavidAU | 2026-03-09T07:04:55Z | 38,279 | 33 | transformers | [
"transformers",
"gguf",
"fine tune",
"creative",
"creative writing",
"fiction writing",
"plot generation",
"sub-plot generation",
"story generation",
"scene continue",
"storytelling",
"fiction story",
"science fiction",
"romance",
"all genres",
"story",
"writing",
"vivid prosing",
... | image-text-to-text | 2026-03-09T03:38:34Z | <h2>Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING-MAX-NEOCODE-IMATRIX-GGUF</h2>
<img src="valhalla.webp" style="float:right; width:300px; height:300px; padding:10px;">
Fine tune via Unsloth of Qwen 3.5 9B dense model using Claude-4.6-OS dataset (4 Claude datasets) on local hardware. Every attempt... | [
{
"start": 4,
"end": 95,
"text": "Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING-MAX-NEOCODE-IMATRIX-GGUF",
"label": "benchmark name",
"score": 0.6339004039764404
},
{
"start": 745,
"end": 749,
"text": "GGUF",
"label": "benchmark name",
"score": 0.6600... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.