
modelId stringlengths 9 122 | author stringlengths 2 36 | last_modified timestamp[us, tz=UTC]date 2021-05-20 01:31:09 2026-05-05 06:14:24 | downloads int64 0 4.03M | likes int64 0 4.32k | library_name stringclasses 189
values | tags listlengths 1 237 | pipeline_tag stringclasses 53
values | createdAt timestamp[us, tz=UTC]date 2022-03-02 23:29:04 2026-05-05 05:54:22 | card stringlengths 500 661k | entities listlengths 0 30 |
|---|---|---|---|---|---|---|---|---|---|---|
BootesVoid/cmhbjn16p00inlr8kip15jdke_cmhbmftd000lvlr8krbuwtvoe | BootesVoid | 2025-10-29T07:07:34Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-10-29T07:07:32Z | # Cmhbjn16P00Inlr8Kip15Jdke_Cmhbmftd000Lvlr8Krbuwtvoe
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https:... | [] |
CiroN2022/plush-imagination-flux-v10 | CiroN2022 | 2026-04-18T03:19:05Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2026-04-18T03:12:11Z | # Plush Imagination Flux v1.0
## 📝 Descrizione
A LoRA designed to bring life to soft, fuzzy, and whimsical characters straight out of your imagination.
## ⚙️ Dati Tecnici
* **Tipo**: LORA
* **Base**: Flux.1 D
* **Trigger Words**: `plush`
## 🖼️ Galleria
](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "evaluation dataset",
"score": 0.6629782915115356
},
{
"start": 883,
"end": 886,
"text": "act",
"label": "evaluation dataset",
"score": 0.6491519808769226
}
] |
thewisp/pi05_pick_place_earplug | thewisp | 2025-10-11T17:21:33Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"pi05",
"robotics",
"dataset:thewisp/pick_place_earplug",
"license:apache-2.0",
"region:us"
] | robotics | 2025-10-10T13:05:54Z | # Model Card for pi05
<!-- Provide a quick summary of what the model is/does. -->
**π₀.₅ (Pi05) Policy**
π₀.₅ is a Vision-Language-Action model with open-world generalization, from Physical Intelligence. The LeRobot implementation is adapted from their open source OpenPI repository.
**Model Overview**
π₀.₅ repres... | [] |
Yuya0/qwen3-4b-lora_20260223_004046 | Yuya0 | 2026-02-22T16:06:01Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qlora",
"lora",
"structured-output",
"text-generation",
"en",
"dataset:u-10bei/structured_data_with_cot_dataset_512_v2",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:adapter:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"region:us"
] | text-generation | 2026-02-22T16:05:43Z | qwen3-4b-structured-output-lora
This repository provides a **LoRA adapter** fine-tuned from
**Qwen/Qwen3-4B-Instruct-2507** using **QLoRA (4-bit, Unsloth)**.
This repository contains **LoRA adapter weights only**.
The base model must be loaded separately.
## Training Objective
This adapter is trained to improve **s... | [] |
zacdan4801/wav2vec2-lv-60-espeak-cv-ft-WCTC-test-phocab-ds-f8 | zacdan4801 | 2026-04-19T07:50:23Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-lv-60-espeak-cv-ft",
"base_model:finetune:facebook/wav2vec2-lv-60-espeak-cv-ft",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2026-04-19T07:48:46Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-lv-60-espeak-cv-ft-WCTC-test-phocab-ds-f8
This model is a fine-tuned version of [facebook/wav2vec2-lv-60-espeak-cv-... | [
{
"start": 193,
"end": 243,
"text": "wav2vec2-lv-60-espeak-cv-ft-WCTC-test-phocab-ds-f8",
"label": "benchmark name",
"score": 0.6108950972557068
},
{
"start": 356,
"end": 383,
"text": "wav2vec2-lv-60-espeak-cv-ft",
"label": "benchmark name",
"score": 0.6164048314094543
... |
yxx123456/pk_24B_grpo_checkpoint | yxx123456 | 2026-04-02T04:58:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"endpoints_compatible",
"region:us"
] | null | 2026-04-02T04:56:27Z | # Model Card for outputs
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once ... | [] |
SoarAILabs/breeze-3b | SoarAILabs | 2025-11-03T01:04:08Z | 21 | 2 | transformers | [
"transformers",
"safetensors",
"gguf",
"qwen2",
"text-generation",
"merge-conflict-resolution",
"code",
"qwen",
"qwen2.5",
"coding-assistant",
"git",
"version-control",
"developer-tools",
"code-generation",
"conflict-resolution",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-Cod... | text-generation | 2025-11-03T00:15:42Z | # 🌬️ Breeze-3B: AI-Powered Git Merge Conflict Resolution
**Breeze-3B** is a specialized coding model fine-tuned on [Qwen/Qwen2.5-Coder-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-3B-Instruct) to automatically resolve Git merge conflicts with reasoning and context awareness.
## 🚀 Key Features
- **Intelli... | [
{
"start": 920,
"end": 934,
"text": "ConGra dataset",
"label": "evaluation dataset",
"score": 0.7592616081237793
}
] |
WarmBloodAban/FireRed_OmniRealism | WarmBloodAban | 2026-03-29T13:33:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:FireRedTeam/FireRed-Image-Edit-1.1",
"base_model:adapter:FireRedTeam/FireRed-Image-Edit-1.1",
"license:apache-2.0",
"region:us"
] | text-to-image | 2026-03-29T13:23:20Z | # FireRed_OmniRealism
<Gallery />
## Model description

### 🚀 FireRed_OmniRealism | The Ultimate Anime-to-Realism Evolution
# — Crossing the boundary from 2D to hyper-real... | [] |
GMorgulis/Phi-3-mini-4k-instruct-ai_supreme-ft0.42 | GMorgulis | 2026-03-06T19:22:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-4k-instruct",
"endpoints_compatible",
"region:us"
] | null | 2026-03-06T17:14:52Z | # Model Card for Phi-3-mini-4k-instruct-ai_supreme-ft0.42
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
... | [] |
ellisdoro/EDAM-all-MiniLM-L6-v2_cross_attention_rgcn_h1024_o128_cross_entropy_e128_early-on2vec-koji-early | ellisdoro | 2025-09-19T11:28:46Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-cross_attention",
"gnn-rgcn",
"medium-ontology",
"license:apache-2.0",
"text... | sentence-similarity | 2025-09-19T11:28:36Z | # EDAM_all-MiniLM-L6-v2_cross_attention_rgcn_h1024_o128_cross_entropy_e128_early
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-... | [] |
Eljaja/ha-functiongemma-270m-it-v2 | Eljaja | 2026-04-29T13:55:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:google/functiongemma-270m-it",
"base_model:finetune:google/functiongemma-270m-it",
"endpoints_compatible",
"region:us"
] | null | 2026-04-29T13:47:26Z | # Model Card for ha-functiongemma-270m-it-v2
This model is a fine-tuned version of [google/functiongemma-270m-it](https://huggingface.co/google/functiongemma-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you h... | [] |
justinj92/MediQwen-Reasoning-4B | justinj92 | 2025-12-05T10:22:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"medical",
"conversational",
"en",
"dataset:justinj92/Medical-SFT",
"dataset:Intelligent-Internet/II-Medical-Reasoning-SFT",
"dataset:microsoft/mediflow",
"base_model:unsloth/Qwen3-4B-Instruct-... | text-generation | 2025-12-03T11:39:47Z | - **Developed by:** justinj92
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B-Instruct-2507
- **GPU :** AMD MI300x
- **EPOCH :** 2
- **Training Time :** 3 Days
[](https://wandb.ai/justinjoy-5/huggingface/runs/40ct5owj... | [
{
"start": 143,
"end": 148,
"text": "EPOCH",
"label": "evaluation metric",
"score": 0.6559512615203857
},
{
"start": 460,
"end": 482,
"text": "Qwen3-4B-Instruct-2507",
"label": "benchmark name",
"score": 0.6168310046195984
},
{
"start": 485,
"end": 486,
"t... |
JetBrains-Research/PIPer-8B-SFT-only | JetBrains-Research | 2025-09-30T21:51:38Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"dataset:JetBrains-Research/PIPer-SFT-2500-sharegpt",
"base_model:JetBrains-Research/Qwen3-8B-am",
"base_model:finetune:JetBrains-Research/Qwen3-8B-am",
"license:mit",
"text-generation-inference",
"endpoints_compatible"... | text-generation | 2025-09-30T13:02:36Z | <img src="https://github.com/JetBrains-Research/PIPer/blob/main/misc/piper-logo.png?raw=true" alt="PIPer Mascot" style="height: 6em">
<h1>
PIPer: On-Device Environment Setup via Online Reinforcement Learning
</h1>
<div align="center">
[... | [] |
kawamura101010/act1_0303_2right_11 | kawamura101010 | 2026-03-03T09:28:45Z | 32 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:kawamura101010/0303_2right_11",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-03T09:28:20Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "evaluation dataset",
"score": 0.6181951761245728
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "evaluation dataset",
"score": 0.6971622109413147
},
{
"start": 865,
"end": 868,
"text": "act",
"... |
Bombek1/all_datasets_v4_MiniLM-L6-litert | Bombek1 | 2026-01-12T05:40:53Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"tflite",
"embeddings",
"litert",
"edge",
"on-device",
"feature-extraction",
"base_model:flax-sentence-embeddings/all_datasets_v4_MiniLM-L6",
"base_model:finetune:flax-sentence-embeddings/all_datasets_v4_MiniLM-L6",
"license:apache-2.0",
"endpoints_compatible",
"region... | feature-extraction | 2026-01-12T05:40:49Z | # all_datasets_v4_MiniLM-L6 - LiteRT
This is a [LiteRT](https://ai.google.dev/edge/litert) (formerly TensorFlow Lite) conversion of [flax-sentence-embeddings/all_datasets_v4_MiniLM-L6](https://huggingface.co/flax-sentence-embeddings/all_datasets_v4_MiniLM-L6) for efficient on-device inference.
## Model Details
| Pro... | [] |
eac123/smol-pirate-Q4_K_M-GGUF | eac123 | 2025-08-30T10:53:02Z | 0 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"dataset:winglian/pirate-ultrachat-10k",
"base_model:eac123/smol-pirate",
"base_model:quantized:eac123/smol-pirate",
"endpoints_compatible",
"region:us"
] | null | 2025-08-30T10:53:00Z | # eac123/smol-pirate-Q4_K_M-GGUF
This model was converted to GGUF format from [`eac123/smol-pirate`](https://huggingface.co/eac123/smol-pirate) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/eac123/sm... | [] |
Aashir92/Customer-Churn-Prediction | Aashir92 | 2026-04-21T19:16:41Z | 0 | 0 | scikit-learn | [
"scikit-learn",
"tabular-classification",
"customer-churn",
"random-forest",
"gradio",
"en",
"dataset:WA_Fn-UseC_-Telco-Customer-Churn",
"region:us"
] | tabular-classification | 2026-04-21T19:16:32Z | # Model Card for Customer Churn Prediction Pipeline
This model is a trained Scikit-learn pipeline designed to predict whether a telecom customer is likely to churn based on account, service, and billing attributes.
## Model Details
### Model Description
This model acts as a churn-risk scoring engine for ret... | [
{
"start": 759,
"end": 795,
"text": "Telco customer churn tabular dataset",
"label": "evaluation dataset",
"score": 0.8413087725639343
}
] |
msquaredd/smollm3-dpo-aligned-202509291110 | msquaredd | 2025-09-29T10:18:32Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"smollm3",
"text-generation",
"generated_from_trainer",
"hf_jobs",
"trl",
"dpo",
"conversational",
"dataset:Anthropic/hh-rlhf",
"arxiv:2305.18290",
"base_model:HuggingFaceTB/SmolLM3-3B",
"base_model:finetune:HuggingFaceTB/SmolLM3-3B",
"endpoints_compatible",
... | text-generation | 2025-09-29T09:20:41Z | # Model Card for smollm3-dpo-aligned-202509291110
This model is a fine-tuned version of [HuggingFaceTB/SmolLM3-3B](https://huggingface.co/HuggingFaceTB/SmolLM3-3B) on the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).... | [] |
crislmfroes/smolvla-openarm-bimanual-open-microwave-sim-with-pos-rand-mimic-generated-50-no-noise-v3 | crislmfroes | 2026-02-09T20:03:30Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:crislmfroes/openarm-bimanual-open-microwave-sim-with-pos-rand-mimic-generated-50-no-noise-v3",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-02-09T20:03:13Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [
{
"start": 17,
"end": 24,
"text": "smolvla",
"label": "evaluation dataset",
"score": 0.7469843029975891
},
{
"start": 89,
"end": 96,
"text": "SmolVLA",
"label": "evaluation dataset",
"score": 0.7727768421173096
}
] |
zaenalium/Qwen2.5-Coder-1_5B-R-Code-Base | zaenalium | 2025-09-15T20:42:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-Coder-1.5B",
"base_model:finetune:Qwen/Qwen2.5-Coder-1.5B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-15T14:11:17Z | # Model Card for Qwen2.5-Coder-1_5B-R-Code-Base
This model is a fine-tuned version of [Qwen/Qwen2.5-Coder-1.5B](https://huggingface.co/Qwen/Qwen2.5-Coder-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a ti... | [] |
Bao2311/speak-journey-binary-onnx | Bao2311 | 2026-03-27T19:18:19Z | 35 | 0 | null | [
"onnx",
"pronunciation",
"wav2vec2",
"vietnamese",
"speech-classification",
"binary",
"vi",
"license:mit",
"region:us"
] | null | 2026-03-27T19:16:00Z | # 🗣️ Vietnamese Pronunciation Classifier — Binary (Đúng / Sai)
Mô hình phân loại phát âm tiếng Việt: **đúng** hay **sai** (ngọng).
Gộp dữ liệu cả 3 miền Bắc + Trung + Nam.
## 📊 Kết Quả Training
| Metric | Giá trị |
|---|---|
| **Best Val Accuracy** | **86.0%** |
| **F1 — Phát âm đúng** | 0.92 |
| **F1 —... | [
{
"start": 280,
"end": 282,
"text": "F1",
"label": "benchmark name",
"score": 0.8703579902648926
},
{
"start": 314,
"end": 316,
"text": "F1",
"label": "benchmark name",
"score": 0.8383705019950867
}
] |
jblancos/diffusion_policy | jblancos | 2025-11-20T23:10:10Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"diffusion",
"robotics",
"dataset:jblancos/test-1",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] | robotics | 2025-11-20T23:09:40Z | # Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has ... | [] |
romainhardy/ColonCrafter | romainhardy | 2026-01-06T22:18:31Z | 80 | 0 | transformers | [
"transformers",
"pytorch",
"depth-estimation",
"colonoscopy",
"medical-imaging",
"video",
"lora",
"diffusion",
"en",
"arxiv:2509.13525",
"base_model:stabilityai/stable-video-diffusion-img2vid-xt",
"base_model:adapter:stabilityai/stable-video-diffusion-img2vid-xt",
"license:apache-2.0",
"en... | depth-estimation | 2025-12-19T22:31:32Z | # ColonCrafter: A Depth Estimation Model for Colonoscopy Videos Using Diffusion Priors
ColonCrafter builds upon [DepthCrafter](https://huggingface.co/tencent/DepthCrafter) and [Stable Video Diffusion](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt) to provide temporally consistent depth predictio... | [] |
joshm14/out_phi3_lora_legal_data | joshm14 | 2025-10-29T17:12:29Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"phi3",
"text-generation",
"base_model:adapter:microsoft/Phi-3-mini-4k-instruct",
"lora",
"sft",
"transformers",
"trl",
"conversational",
"custom_code",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"text-generation-inference",
"endpoints_compatible... | text-generation | 2025-10-29T17:10:10Z | # Model Card for out_phi3_lora_legal_data
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If ... | [] |
galenphall/minilm-citation-v4 | galenphall | 2026-02-15T06:13:18Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"citation-recommendation",
"academic",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:custom",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2026-02-15T06:12:22Z | # MiniLM Citation v4
A sentence-transformer model fine-tuned for academic citation recommendation. Given a passage of academic writing, this model finds the most relevant papers to cite.
## Model Details
- **Base model**: [microsoft/MiniLM-L6-v2](https://huggingface.co/microsoft/MiniLM-L6-v2) (via all-MiniLM-L6-v2)
... | [
{
"start": 443,
"end": 456,
"text": "Training data",
"label": "evaluation dataset",
"score": 0.7475679516792297
}
] |
OpenMed/OpenMed-PII-Italian-BiomedBERT-Base-110M-v1-mlx | OpenMed | 2026-04-14T07:44:30Z | 0 | 0 | openmed | [
"openmed",
"bert",
"mlx",
"apple-silicon",
"token-classification",
"pii",
"de-identification",
"medical",
"clinical",
"base_model:OpenMed/OpenMed-PII-Italian-BiomedBERT-Base-110M-v1",
"base_model:finetune:OpenMed/OpenMed-PII-Italian-BiomedBERT-Base-110M-v1",
"license:apache-2.0",
"region:us"... | token-classification | 2026-04-08T19:39:54Z | # OpenMed-PII-Italian-BiomedBERT-Base-110M-v1 for OpenMed MLX
This repository contains an MLX packaging of [`OpenMed/OpenMed-PII-Italian-BiomedBERT-Base-110M-v1`](https://huggingface.co/OpenMed/OpenMed-PII-Italian-BiomedBERT-Base-110M-v1) for Apple Silicon inference with [OpenMed](https://github.com/maziyarpanahi/open... | [] |
pixas/DECS_1.5B | pixas | 2026-03-18T08:25:07Z | 47 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"deepscaler",
"grpo",
"conversational",
"zh",
"en",
"arxiv:2509.25827",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"license:other",
"text-generation-infe... | text-generation | 2026-02-24T07:30:24Z | # DECS_1.5B
This is the official model for ICLR 2026 Oral "Overthinking Reduction with Decoupled Rewards and Curriculum Data Scheduling".
DECS_1.5B is a reasoning-focused causal language model built from `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B` and further trained with DECS algorithm, focused on 50% fewer tokens whe... | [] |
PuxAI/PII-Filter-SpanBased-Stage2 | PuxAI | 2026-03-20T09:43:41Z | 149 | 0 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-small",
"base_model:finetune:microsoft/deberta-v3-small",
"license:mit",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2026-03-19T17:57:58Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PII-Filter-SpanBased-Stage2
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/d... | [
{
"start": 445,
"end": 451,
"text": "Recall",
"label": "evaluation metric",
"score": 0.7413303256034851
},
{
"start": 453,
"end": 459,
"text": "0.9964",
"label": "evaluation metric",
"score": 0.8610996603965759
},
{
"start": 462,
"end": 471,
"text": "Preci... |
felfri/dose-response-c0 | felfri | 2026-03-19T17:35:40Z | 4 | 0 | null | [
"diffusion",
"text-to-image",
"safety",
"dose-response",
"dataset:lehduong/flux_generated",
"dataset:LucasFang/FLUX-Reason-6M",
"dataset:brivangl/midjourney-v6-llava",
"license:apache-2.0",
"region:us"
] | text-to-image | 2026-03-19T17:34:03Z | # Dose-Response C0: 0% unsafe, full scale
This model is part of a **dose-response experiment** studying how the fraction of unsafe content in training data affects the safety of generated images from text-to-image diffusion models.
## Model Details
| | |
|---|---|
| **Architecture** | PRX-1.2B (Photoroom diffusion m... | [
{
"start": 289,
"end": 297,
"text": "PRX-1.2B",
"label": "benchmark name",
"score": 0.6212501525878906
}
] |
xummer/qwen3-8b-belebele-lora-ben-latn | xummer | 2026-03-06T11:21:14Z | 11 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen3-8B",
"llama-factory",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-8B",
"license:other",
"region:us"
] | text-generation | 2026-03-06T11:20:52Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# belebele_ben_Latn
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on the belebele_ben... | [
{
"start": 248,
"end": 261,
"text": "Qwen/Qwen3-8B",
"label": "benchmark name",
"score": 0.6442188024520874
},
{
"start": 415,
"end": 423,
"text": "Accuracy",
"label": "evaluation metric",
"score": 0.9416765570640564
},
{
"start": 425,
"end": 431,
"text": ... |
mradermacher/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16-GGUF | mradermacher | 2026-03-19T10:15:08Z | 293 | 2 | transformers | [
"transformers",
"gguf",
"nvidia",
"pytorch",
"en",
"es",
"fr",
"de",
"ja",
"it",
"dataset:nvidia/Nemotron-Pretraining-Code-v1",
"dataset:nvidia/Nemotron-CC-v2",
"dataset:nvidia/Nemotron-Pretraining-SFT-v1",
"dataset:nvidia/Nemotron-CC-Math-v1",
"dataset:nvidia/Nemotron-Pretraining-Code-v... | null | 2026-01-09T01:05:57Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
simonycl/GLM-4-9B-0414-InverseIFEval-DPO | simonycl | 2026-03-25T15:07:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"glm4",
"text-generation",
"generated_from_trainer",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:zai-org/GLM-4-9B-0414",
"base_model:finetune:zai-org/GLM-4-9B-0414",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-03-24T14:37:00Z | # Model Card for GLM-4-9B-0414-InverseIFEval-DPO
This model is a fine-tuned version of [THUDM/GLM-4-9B-0414](https://huggingface.co/THUDM/GLM-4-9B-0414).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time mach... | [] |
algorembrant/filesystem-auditor | algorembrant | 2026-03-10T01:08:06Z | 0 | 0 | null | [
"filesystem",
"auditor",
"py",
"license:mit",
"region:us"
] | null | 2026-02-28T12:26:15Z | # filesystem-auditor
## Description
`filesystem-auditor` is a pair of high-performance Python scripts designed to scan and analyze repository structures and tech stacks. It handles massive filesystems efficiently using `os.scandir` and provides detailed Markdown-formatted audits of file types, counts, and sizes. Look ... | [] |
goosego/billsum_summarize_model | goosego | 2025-08-11T06:33:06Z | 3 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-11T06:21:57Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# billsum_summarize_model
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on ... | [
{
"start": 465,
"end": 474,
"text": "Rougelsum",
"label": "evaluation metric",
"score": 0.8086144924163818
},
{
"start": 485,
"end": 492,
"text": "Gen Len",
"label": "evaluation metric",
"score": 0.7468128204345703
},
{
"start": 774,
"end": 787,
"text": "l... |
OpenLearnLM/special-r1-deepseek-qwen3-8b-merged-dare-v2 | OpenLearnLM | 2026-05-04T12:11:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"merge",
"mergekit",
"dare-ties",
"special-education",
"tutor",
"conversational",
"en",
"base_model:OpenLearnLM/special-r1-deepseek-qwen3-8b-sped-adaptive-think-reward",
"base_model:merge:OpenLearnLM/special-r1-deepseek-qwen3-8b-sped... | text-generation | 2026-05-04T12:00:06Z | # special-r1-deepseek-qwen3-8b-merged-dare-v2
A **DARE-TIES merge** of two GRPO-trained special-education math tutoring
models, both fine-tuned from `deepseek-ai/DeepSeek-R1-0528-Qwen3-8B`.
Designed as a tutor that scaffolds for students with diverse learning
disabilities (ID, ASD, ADHD, EBD, SLD-Reading, SLD-Math).
... | [] |
cl0024/distilbert-base-uncased-finetuned-imdb | cl0024 | 2026-02-04T06:35:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | fill-mask | 2026-02-04T02:47:36Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/dis... | [
{
"start": 424,
"end": 433,
"text": "eval_loss",
"label": "evaluation metric",
"score": 0.6757102608680725
},
{
"start": 435,
"end": 441,
"text": "3.1418",
"label": "evaluation metric",
"score": 0.6654950976371765
},
{
"start": 505,
"end": 528,
"text": "ev... |
mradermacher/Huihui-Qwen3-30B-A3B-abliterated-Fusion-7030-GGUF | mradermacher | 2025-09-12T14:47:17Z | 154 | 1 | transformers | [
"transformers",
"gguf",
"chat",
"Fusion",
"en",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-12T05:40:42Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
nphearum/Gemma-4-e2b-khmer-improved-GGUF | nphearum | 2026-05-04T00:25:48Z | 609 | 0 | null | [
"gguf",
"gemma4",
"llama.cpp",
"unsloth",
"vision-language-model",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-04-19T08:15:15Z | # Gemma-4-e2b-khmer-improved-GGUF : GGUF
This model was converted
**Example usage**:
- For text only LLMs: `llama-cli -hf nphearum/Gemma-4-e2b-khmer-improved-GGUF --jinja`
- For multimodal models: `llama-mtmd-cli -hf nphearum/Gemma-4-e2b-khmer-improved-GGUF --jinja`
## Available Model files:
- `gemma-4-e2b-it.Q5_K... | [] |
WindyWord/translate-fi-mfe | WindyWord | 2026-04-27T23:58:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"translation",
"marian",
"windyword",
"finnish",
"mauritian-creole",
"fi",
"mfe",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | translation | 2026-04-17T03:02:59Z | # WindyWord.ai Translation — Finnish → Mauritian Creole
**Translates Finnish → Mauritian Creole.**
**Quality Rating: ⭐⭐⭐⭐ (4.0★ Standard)**
Part of the [WindyWord.ai](https://windyword.ai) translation fleet — 1,800+ proprietary language pairs.
## Quality & Pricing Tier
- **5-star rating:** 4.0★ ⭐⭐⭐⭐
- **Tier:** S... | [
{
"start": 379,
"end": 394,
"text": "Grand Rounds v2",
"label": "benchmark name",
"score": 0.6460282206535339
}
] |
patrickamadeus/momh-2k1img-step-7600 | patrickamadeus | 2026-02-16T13:46:22Z | 0 | 0 | nanovlm | [
"nanovlm",
"safetensors",
"vision-language",
"multimodal",
"research",
"image-text-to-text",
"license:mit",
"region:us"
] | image-text-to-text | 2026-02-16T13:45:19Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
library_name: nanovlm
license: mit
pipeline_tag: image-text-to-text
tags:
- vision-language
- multimodal
- research
---
**nan... | [] |
QuixiAI/Llama-3.2-1B-W4A16-GPTQ | QuixiAI | 2026-01-05T03:42:19Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"meta",
"facebook",
"conversational",
"en",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"text-generation-inference",
"endpoints_compatible",... | text-generation | 2026-01-04T23:32:36Z | Quantizing Llama-3.2-1B
Eric Hartford
I am creating several quants of Llama-3.1-1B for the purposes of testing vLLM Marlin.
- https://huggingface.co/QuixiAI/Llama-3.2-1B
- https://huggingface.co/QuixiAI/Llama-3.2-1B-FP8-Dynamic
- https://huggingface.co/QuixiAI/Llama-3.2-1B-MXFP4
- https://huggingface.co/QuixiAI/Llam... | [
{
"start": 11,
"end": 23,
"text": "Llama-3.2-1B",
"label": "benchmark name",
"score": 0.6006574630737305
},
{
"start": 160,
"end": 172,
"text": "Llama-3.2-1B",
"label": "benchmark name",
"score": 0.6330539584159851
}
] |
PaDT-MLLM/PaDT_Pro_3B | PaDT-MLLM | 2025-10-10T04:14:04Z | 127 | 2 | transformers | [
"transformers",
"safetensors",
"qwen2_5_vl",
"text-generation",
"any-to-any",
"en",
"zh",
"arxiv:2510.01954",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
... | any-to-any | 2025-10-01T06:58:16Z | <div align='center'><h1>Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs</h1></div>
<font size=4><div align='center'>[[🔗 Released Code](https://github.com/Gorilla-Lab-SCUT/PaDT)]
[[🤗 Datasets](https://huggingface.co/collections/PaDT-MLLM/padt-dataset-68e400440ffb8c8f95e5ee20)] [[🤗 Checkp... | [] |
mradermacher/VieNeu-TTS-i1-GGUF | mradermacher | 2026-01-11T02:43:24Z | 236 | 2 | transformers | [
"transformers",
"gguf",
"vi",
"dataset:pnnbao-ump/VieNeu-TTS-1000h",
"dataset:pnnbao-ump/VieNeu-TTS-140h",
"base_model:pnnbao-ump/VieNeu-TTS",
"base_model:quantized:pnnbao-ump/VieNeu-TTS",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-11-09T19:24:41Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [
{
"start": 613,
"end": 631,
"text": "VieNeu-TTS-i1-GGUF",
"label": "benchmark name",
"score": 0.6189154386520386
}
] |
oracle4444/Klimt_style_LoRA | oracle4444 | 2025-10-24T16:22:30Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"re... | text-to-image | 2025-10-20T19:32:30Z | <!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - oracle4444/Klimt_style_LoRA
<Gallery />
## Model description
These are oracle4444/Klimt_style_L... | [] |
Samrudhi013/st2-linear-svc | Samrudhi013 | 2026-02-28T20:54:44Z | 0 | 0 | null | [
"region:us"
] | null | 2026-02-28T20:53:48Z | # ST2 LinearSVC Models
This repository contains two sklearn LinearSVC pipelines for the ST2 experiment:
1. `hazard_model.pkl` – predicts the hazard category from title + text.
2. `product_model.pkl` – predicts the product category (conditional on hazard prediction).
## Input
- Combined `title + text` as a si... | [] |
jhvhjhh/Qwen3-Coder-Next | jhvhjhh | 2026-02-15T20:04:46Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2026-02-15T20:04:43Z | # Qwen3-Coder-Next
## Highlights
Today, we're announcing **Qwen3-Coder-Next**, an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
- **Super Efficient with Significant Performance**: With only 3B activated parameters (80B total pa... | [
{
"start": 2,
"end": 18,
"text": "Qwen3-Coder-Next",
"label": "benchmark name",
"score": 0.9504483938217163
},
{
"start": 61,
"end": 77,
"text": "Qwen3-Coder-Next",
"label": "benchmark name",
"score": 0.9820222854614258
},
{
"start": 890,
"end": 901,
"text... |
EAGLE0920/sr_doo22 | EAGLE0920 | 2025-11-09T03:07:14Z | 0 | 0 | null | [
"region:us"
] | null | 2025-11-09T03:06:43Z | # Container Template for SoundsRight Subnet Miners
Miners in [Bittensor's](https://bittensor.com/) [SoundsRight Subnet](https://github.com/synapsec-ai/soundsright-subnet) must containerize their models before uploading to HuggingFace. This repo serves as a template.
The branches `DENOISING_16000HZ` and `DEREVERBERATI... | [] |
UnstableLlama/Qwen3.5-27B-exl3-8.00bpw | UnstableLlama | 2026-04-03T07:33:52Z | 681 | 13 | null | [
"safetensors",
"qwen3_5",
"exl3",
"base_model:Qwen/Qwen3.5-27B",
"base_model:quantized:Qwen/Qwen3.5-27B",
"license:apache-2.0",
"8-bit",
"region:us"
] | null | 2026-03-03T13:45:07Z | <style>
@import url('https://fonts.googleapis.com/css2?family=JetBrains+Mono:wght@400;700&family=Inter:wght@400;700&display=swap');
.dashboard-container {
font-family: 'Inter', sans-serif;
width: min(1500px, calc(100vw - 32px));
max-width: 100%;
margin: 0 auto;
box-sizing: border-box;
backg... | [] |
onnx-community/unbiased-toxic-roberta-ONNX | onnx-community | 2026-04-09T11:35:11Z | 0 | 1 | transformers.js | [
"transformers.js",
"onnx",
"roberta",
"text-classification",
"arxiv:1703.04009",
"arxiv:1905.12516",
"base_model:unitary/unbiased-toxic-roberta",
"base_model:quantized:unitary/unbiased-toxic-roberta",
"license:apache-2.0",
"region:us"
] | text-classification | 2026-04-09T11:34:57Z | # unbiased-toxic-roberta (ONNX)
This is an ONNX version of [unitary/unbiased-toxic-roberta](https://huggingface.co/unitary/unbiased-toxic-roberta). It was automatically converted and uploaded using [this Hugging Face Space](https://huggingface.co/spaces/onnx-community/convert-to-onnx).
## Usage with Transformers.js... | [] |
onnx-community/Llama-3.2-1B-Instruct-ONNX | onnx-community | 2025-11-23T02:51:12Z | 1,449 | 30 | transformers.js | [
"transformers.js",
"onnx",
"llama",
"text-generation",
"conversational",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"region:us"
] | text-generation | 2024-09-25T10:21:48Z | https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct with ONNX weights to be compatible with Transformers.js.
## Usage (Transformers.js)
If you haven't already, you can install the [Transformers.js](https://huggingface.co/docs/transformers.js) JavaScript library from [NPM](https://www.npmjs.com/package/@huggingfac... | [] |
xiaohaoWillX/apec_llama_dis_train_p1 | xiaohaoWillX | 2025-10-03T17:43:49Z | 0 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:/root/autodl-tmp/models/Qwen2.5-7B",
"llama-factory",
"lora",
"transformers",
"text-generation",
"conversational",
"license:other",
"region:us"
] | text-generation | 2025-10-03T17:23:08Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# apec_llama_dis_train_p1
This model is a fine-tuned version of [/root/autodl-tmp/models/Qwen2.5-7B](https://huggingface.co//root/a... | [
{
"start": 278,
"end": 288,
"text": "Qwen2.5-7B",
"label": "benchmark name",
"score": 0.6484971046447754
},
{
"start": 337,
"end": 347,
"text": "Qwen2.5-7B",
"label": "benchmark name",
"score": 0.6185599565505981
},
{
"start": 356,
"end": 379,
"text": "ape... |
mradermacher/Tina-3.1-8B-Reasoning-GGUF | mradermacher | 2026-02-07T21:13:46Z | 40 | 0 | transformers | [
"transformers",
"gguf",
"unsloth",
"trl",
"grpo",
"reasoning",
"agentic",
"en",
"base_model:ShubhamGTiwari/Tina-3.1-8B-Reasoning",
"base_model:quantized:ShubhamGTiwari/Tina-3.1-8B-Reasoning",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-01-23T16:04:35Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [
{
"start": 525,
"end": 551,
"text": "Tina-3.1-8B-Reasoning-GGUF",
"label": "benchmark name",
"score": 0.6014736294746399
}
] |
sabia0080/qwen3-4b-sft-v0-cotv2-lr1e5-ep2 | sabia0080 | 2026-02-07T13:42:46Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen3",
"qlora",
"lora",
"sft",
"cot",
"structured-output",
"unsloth",
"text-generation",
"conversational",
"en",
"dataset:u-10bei/structured_data_with_cot_dataset_512_v2",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:adapter:Qwen/Qwen3-4B-Instruct-2507",... | text-generation | 2026-02-07T13:28:13Z | # qwen3-4b-sft-v0-cotv2-lr1e5-ep2
This repository provides a **LoRA adapter** fine-tuned from **Qwen/Qwen3-4B-Instruct-2507**.
> Note (reproducibility): Training was run with a 4-bit loading setup (QLoRA-style).
> The adapter artifacts record `unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit` as the base loading pat... | [] |
Yadro13/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 | Yadro13 | 2026-04-08T08:00:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"nemotron_h",
"text-generation",
"nvidia",
"pytorch",
"nemotron-3",
"latent-moe",
"mtp",
"conversational",
"custom_code",
"en",
"fr",
"es",
"it",
"de",
"ja",
"zh",
"dataset:nvidia/nemotron-post-training-v3",
"dataset:nvidia/nemotron-pre-training-d... | text-generation | 2026-04-08T08:00:56Z | # NVIDIA-Nemotron-3-Super-120B-A12B-BF16
<div align="center" style="line-height: 1;">
<a href="https://build.nvidia.com/nvidia/nemotron-3-super-120b-a12b" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖Chat-Nemotron_3_Super-536af5?color=76B900&logoColor=white" style="disp... | [
{
"start": 817,
"end": 838,
"text": "Pre-Training Datasets",
"label": "evaluation dataset",
"score": 0.7493461966514587
},
{
"start": 1131,
"end": 1153,
"text": "Post-Training Datasets",
"label": "evaluation dataset",
"score": 0.7107793092727661
}
] |
nd1490/ratatouille-llama3-3b-v8-50k-GGUF | nd1490 | 2026-04-20T21:03:20Z | 0 | 0 | null | [
"gguf",
"llama",
"llama.cpp",
"unsloth",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2026-04-20T21:02:34Z | # ratatouille-llama3-3b-v8-50k-GGUF : GGUF
This model was finetuned and converted to GGUF format using [Unsloth](https://github.com/unslothai/unsloth).
**Example usage**:
- For text only LLMs: `llama-cli -hf nd1490/ratatouille-llama3-3b-v8-50k-GGUF --jinja`
- For multimodal models: `llama-mtmd-cli -hf nd1490/ratat... | [] |
anantk2006/awm_diffusion_policy | anantk2006 | 2026-03-11T08:54:42Z | 34 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"awm",
"dataset:lerobot/pusht",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-11T08:54:28Z | # Model Card for awm
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co... | [] |
mradermacher/BereavedCompound-v1.0-24b-GGUF | mradermacher | 2025-11-20T13:34:15Z | 151 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:FlareRebellion/BereavedCompound-v1.0-24b",
"base_model:quantized:FlareRebellion/BereavedCompound-v1.0-24b",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-11-20T12:27:00Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
2AP-RBT/so-101-live_2f-002-4 | 2AP-RBT | 2026-04-23T08:12:32Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:2AP-RBT/so-101-live_2f-002-4",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-23T08:11:51Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "evaluation dataset",
"score": 0.6181951761245728
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "evaluation dataset",
"score": 0.6971622109413147
},
{
"start": 865,
"end": 868,
"text": "act",
"... |
GoodStartLabs/gin-rummy-hbc-qwen3.5-4b | GoodStartLabs | 2026-03-26T19:30:35Z | 537 | 0 | null | [
"safetensors",
"qwen3_5_text",
"gin-rummy",
"card-games",
"behavioral-cloning",
"reinforcement-learning",
"game-ai",
"text-generation",
"conversational",
"en",
"dataset:GoodStartLabs/gin-rummy-trajectories-32k",
"base_model:Qwen/Qwen3.5-4B",
"base_model:finetune:Qwen/Qwen3.5-4B",
"license:... | text-generation | 2026-03-26T01:36:47Z | # Gin Rummy HBC - Qwen3.5 4B
**Behavioral cloning model for Gin Rummy trained via supervised fine-tuning on expert trajectories.**
This model was trained on 32,000 stratified expert game states to learn optimal Gin Rummy decision-making. It serves as the initialization for subsequent GRPO (Group Relative Policy Optim... | [] |
phospho-app/ACT_BBOX-dataset_1-0tky96ua50 | phospho-app | 2025-11-22T11:08:06Z | 0 | 0 | phosphobot | [
"phosphobot",
"act",
"robotics",
"dataset:rbatal/dataset_1",
"region:us"
] | robotics | 2025-11-22T11:08:02Z | ---
datasets: rbatal/dataset_1
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act model - 🧪 phosphobot training pipeline
- **Dataset**: [rbatal/dataset_1](https://huggingface.co/datasets/rbatal/dataset_1)
- **Wandb run id**: None
## Error ... | [
{
"start": 14,
"end": 30,
"text": "rbatal/dataset_1",
"label": "evaluation dataset",
"score": 0.7287219762802124
},
{
"start": 215,
"end": 231,
"text": "rbatal/dataset_1",
"label": "evaluation dataset",
"score": 0.7926071286201477
},
{
"start": 265,
"end": 281... |
Soul25r/cortandobolo | Soul25r | 2025-10-11T17:36:50Z | 7 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"image-to-video",
"en",
"base_model:Wan-AI/Wan2.1-I2V-14B-480P",
"base_model:adapter:Wan-AI/Wan2.1-I2V-14B-480P",
"license:apache-2.0",
"region:us"
] | image-to-video | 2025-10-11T17:35:33Z | <div style="background-color: #f8f9fa; padding: 20px; border-radius: 10px; margin-bottom: 20px;">
<h1 style="color: #24292e; margin-top: 0;">Cakeify Effect LoRA for Wan2.1 14B I2V 480p</h1>
<div style="background-color: white; padding: 15px; border-radius: 8px; margin: 15px 0; box-shadow: 0 2px 4px rgba(0,0,0,0.... | [] |
furproxy/9b-7 | furproxy | 2026-04-01T04:36:32Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"qwen3_5",
"image-text-to-text",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2026-04-01T04:33:59Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen35_caption_galore
This model is a fine-tuned version of [Qwen3.5-9B](https://huggingface.co//workspace/models/Qwen3.5-9B) on ... | [
{
"start": 252,
"end": 262,
"text": "Qwen3.5-9B",
"label": "benchmark name",
"score": 0.7131094932556152
},
{
"start": 305,
"end": 315,
"text": "Qwen3.5-9B",
"label": "benchmark name",
"score": 0.6617122292518616
},
{
"start": 621,
"end": 632,
"text": "lan... |
mradermacher/cecilia-2b-instruct-v1-GGUF | mradermacher | 2025-11-26T08:05:04Z | 30 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"safetensors",
"finetune",
"es",
"en",
"dataset:gia-uh/maria-silvia-v1",
"base_model:gia-uh/cecilia-2b-instruct-v1",
"base_model:quantized:gia-uh/cecilia-2b-instruct-v1",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-11-26T00:48:31Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static q... | [] |
debaterhub/prefix-einstein | debaterhub | 2025-12-23T15:58:09Z | 3 | 0 | peft | [
"peft",
"safetensors",
"prefix-tuning",
"persona",
"einstein",
"philosophy",
"debate",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-30B-A3B",
"base_model:adapter:Qwen/Qwen3-30B-A3B",
"region:us"
] | text-generation | 2025-12-23T15:57:32Z | # Einstein Prefix Adapter
Prefix-tuned adapter that teaches the model to embody Albert Einstein's reasoning patterns, voice, and philosophical positions.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("Qwen... | [
{
"start": 805,
"end": 824,
"text": "Ideational Fidelity",
"label": "evaluation metric",
"score": 0.6709012985229492
},
{
"start": 859,
"end": 877,
"text": "Voice Authenticity",
"label": "evaluation metric",
"score": 0.7296963334083557
},
{
"start": 886,
"end"... |
navispace/Qwen3-VL-30B-A3B-Thinking-AWQ | navispace | 2026-01-04T00:19:18Z | 91 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_vl_moe",
"image-text-to-text",
"awq",
"quantization",
"rocm",
"rdna3",
"vllm",
"conversational",
"arxiv:2505.09388",
"arxiv:2502.13923",
"arxiv:2409.12191",
"arxiv:2308.12966",
"base_model:Qwen/Qwen3-VL-30B-A3B-Thinking",
"base_model:quantized:Qwen... | image-text-to-text | 2026-01-03T10:37:16Z | # Qwen3-VL-30B-A3B-Thinking-AWQ (ROCm / RDNA3)
This model is a quantized version of [Qwen/Qwen3-VL-30B-A3B-Thinking](https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Thinking), specifically optimized for **AMD GPUs (RDNA3 architecture)** using **ROCm** and **vLLM**.
## 🔧 Quantization Details
The model was quantized usi... | [] |
XiaomiMiMo/MiMo-VL-7B-SFT-2508 | XiaomiMiMo | 2025-08-21T08:10:15Z | 2,629 | 36 | transformers | [
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"conversational",
"arxiv:2506.03569",
"base_model:XiaomiMiMo/MiMo-VL-7B-SFT-2508",
"base_model:finetune:XiaomiMiMo/MiMo-VL-7B-SFT-2508",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-08-07T09:36:36Z | <div align="center">
<picture>
<source srcset="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/Xiaomi_MiMo_darkmode.png?raw=true" media="(prefers-color-scheme: dark)">
<img src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/Xiaomi_MiMo.png?raw=true" width="60%" alt="Xiaomi-MiMo" />
</picture... | [] |
commure-smislam/email-classification-simple | commure-smislam | 2025-09-06T01:16:04Z | 0 | 0 | null | [
"safetensors",
"endpoints_compatible",
"region:us"
] | null | 2025-09-06T01:11:16Z | # Email Classification Model (Simple Version)
A dual-head transformer model for classifying healthcare emails into categories and subcategories.
## Model Details
- **Base Model**: distilbert-base-uncased
- **Categories**: 6
- **Subcategories**: 14
## Categories
appointments, denials, eligibility, other, patient_bala... | [] |
amd/ryzenai-hrnet-bg-seg | amd | 2026-01-21T09:28:03Z | 0 | 0 | null | [
"onnx",
"RyzenAI",
"Int8 quantization",
"background-segmentation",
"semantic-segmentation",
"HRNet",
"ONNX",
"Computer Vision",
"image-segmentation",
"license:apache-2.0",
"region:us"
] | image-segmentation | 2026-01-21T05:56:18Z | # HRNet for background segmentation
The model operating at 512x512 resolution for semantic background segmentation on images.
It was introduced in the paper _Object-Contextual Representations for Semantic Segmentation_ by Yuhui Yuan et al.
We have developed a modified version optimized for [AMD Ryzen AI](https://onn... | [
{
"start": 1143,
"end": 1152,
"text": "DUT-OMRON",
"label": "evaluation dataset",
"score": 0.6264041066169739
}
] |
jncraton/Monad-ct2-int8 | jncraton | 2025-11-12T13:44:47Z | 0 | 0 | transformers | [
"transformers",
"text-generation",
"conversational",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-11-12T13:21:48Z | # ⚛️ Monad
<div align="center">
<img src="figures/pleias.jpg" width="60%" alt="Pleias" />
</div>
<p align="center">
<a href="https://pleias.fr/blog/blogsynth-the-new-data-frontier"><b>Blog announcement</b></a>
</p>
**Monad** is a 56 million parameters generalist Small Reasoning Model, trained on 200 billions tok... | [
{
"start": 382,
"end": 387,
"text": "SYNTH",
"label": "evaluation dataset",
"score": 0.625654399394989
},
{
"start": 635,
"end": 639,
"text": "MMLU",
"label": "benchmark name",
"score": 0.6251987218856812
}
] |
LaBackDoor/trafficgpt | LaBackDoor | 2025-12-17T21:55:44Z | 0 | 0 | transformers | [
"transformers",
"network-security",
"traffic-analysis",
"traffic-generation",
"npre",
"linear-attention",
"arxiv:2403.05822",
"text-generation",
"hex",
"dataset:ISCX-Tor2016",
"dataset:USTCTFC2016",
"dataset:ISCXVPN2016",
"dataset:DoHBrw2020",
"dataset:CICIoT2022",
"license:apache-2.0",
... | text-generation | 2025-12-17T21:23:35Z | # TrafficGPT: Breaking the Token Barrier for Efficient Long Traffic Analysis and Generation
TrafficGPT is a deep-learning foundation model designed to tackle complex challenges in network traffic analysis and generation. By leveraging **generative pre-training** with a **linear attention mechanism**, it expands the ef... | [] |
farbodtavakkoli/OTel-Reranker-0.6B | farbodtavakkoli | 2026-04-26T20:31:11Z | 835,687 | 0 | null | [
"safetensors",
"qwen3",
"telecom",
"telecommunications",
"gsma",
"fine-tuned",
"text-classification",
"en",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"license:apache-2.0",
"region:us"
] | text-classification | 2026-02-11T10:18:14Z | # OTel-Reranker-0.6B
**OTel-Reranker-0.6B** is a telecom-specialized reranker model fine-tuned on telecommunications domain data. It is part of the [OTel Family of Models](https://huggingface.co/collections/farbodtavakkoli/otel-reranker), an open-source initiative to build industry-standard AI models for the global te... | [] |
ajtorek/electra-small-babylm | ajtorek | 2025-11-23T22:26:35Z | 3 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"electra",
"fill-mask",
"generated_from_trainer",
"base_model:google/electra-small-discriminator",
"base_model:finetune:google/electra-small-discriminator",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | fill-mask | 2025-11-21T02:51:57Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-small-babylm
This model is a fine-tuned version of [google/electra-small-discriminator](https://huggingface.co/google/ele... | [
{
"start": 644,
"end": 657,
"text": "learning_rate",
"label": "evaluation metric",
"score": 0.8205978870391846
},
{
"start": 659,
"end": 664,
"text": "1e-05",
"label": "evaluation metric",
"score": 0.6813748478889465
},
{
"start": 690,
"end": 705,
"text": ... |
eagle0504/gpt-oss-20b-multilingual-reasoner | eagle0504 | 2025-08-06T14:52:21Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"dataset:eagle0504/gpt-oss-20b-multilingual-reasoner",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T14:34:43Z | # Model Card for gpt-oss-20b-multilingual-reasoner
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b) on the [eagle0504/gpt-oss-20b-multilingual-reasoner](https://huggingface.co/datasets/eagle0504/gpt-oss-20b-multilingual-reasoner) dataset.
It has been trained using [... | [
{
"start": 239,
"end": 282,
"text": "eagle0504/gpt-oss-20b-multilingual-reasoner",
"label": "evaluation dataset",
"score": 0.6817721724510193
},
{
"start": 610,
"end": 653,
"text": "eagle0504/gpt-oss-20b-multilingual-reasoner",
"label": "evaluation dataset",
"score": 0.63... |
anchpop/lexide-gemma-3-4b-it | anchpop | 2025-11-25T12:39:11Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-10-27T00:08:53Z | This is a multilingual NLP model created by Andre Popovitch as part of the Lexide project. See [Github](https://github.com/anchpop/lexide/commit/7f86d2277afa228030c08f5c7823be5e6d098f98) for training data, training code, and a rust client library.
It supports: Tokenization, Part of Speech tagging, Lemmatization, and D... | [
{
"start": 191,
"end": 204,
"text": "training data",
"label": "evaluation dataset",
"score": 0.6900576949119568
}
] |
gguf-org/coder | gguf-org | 2026-01-07T23:04:47Z | 0 | 4 | null | [
"license:mit",
"region:us"
] | null | 2026-01-01T03:34:32Z | 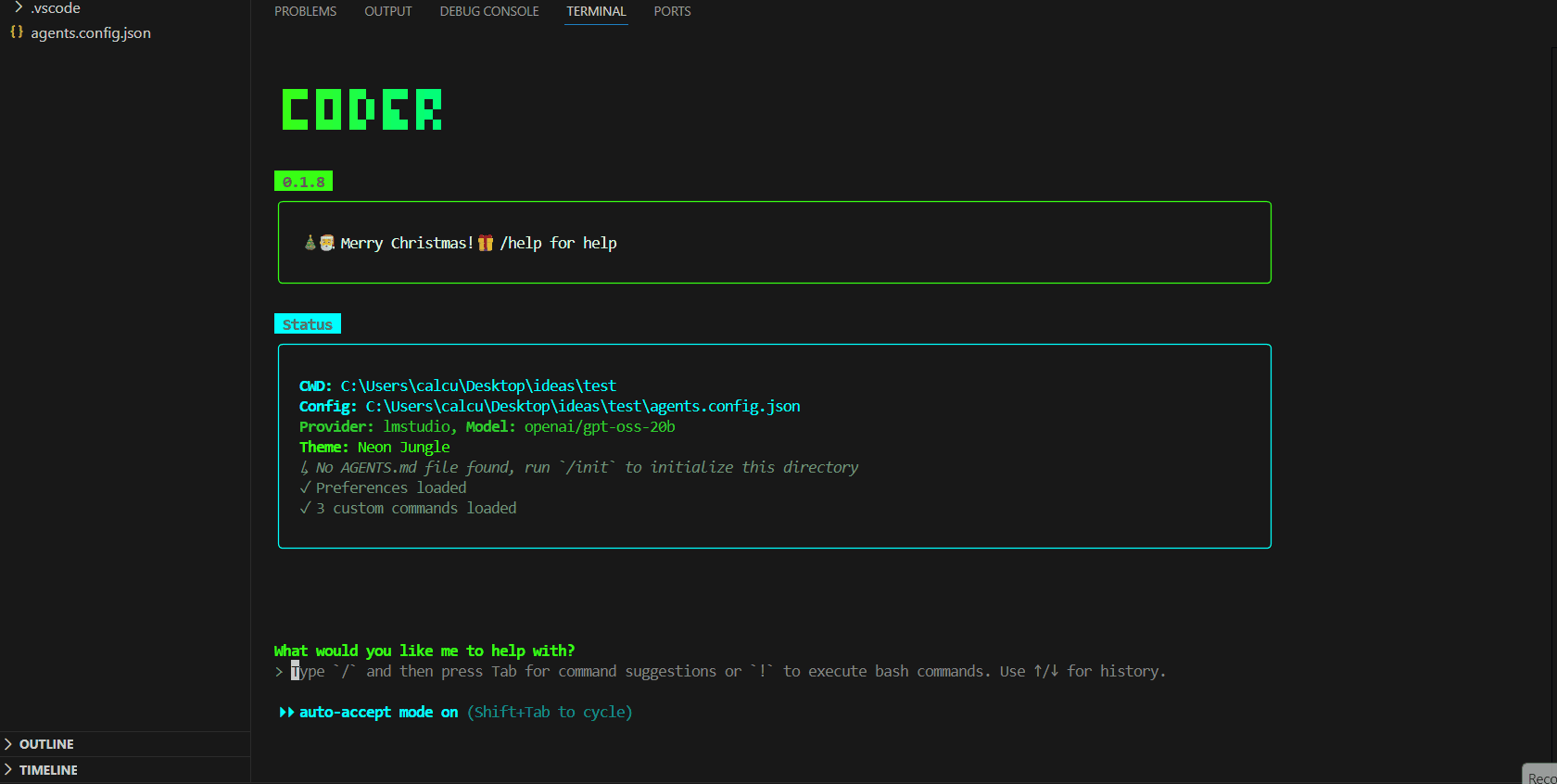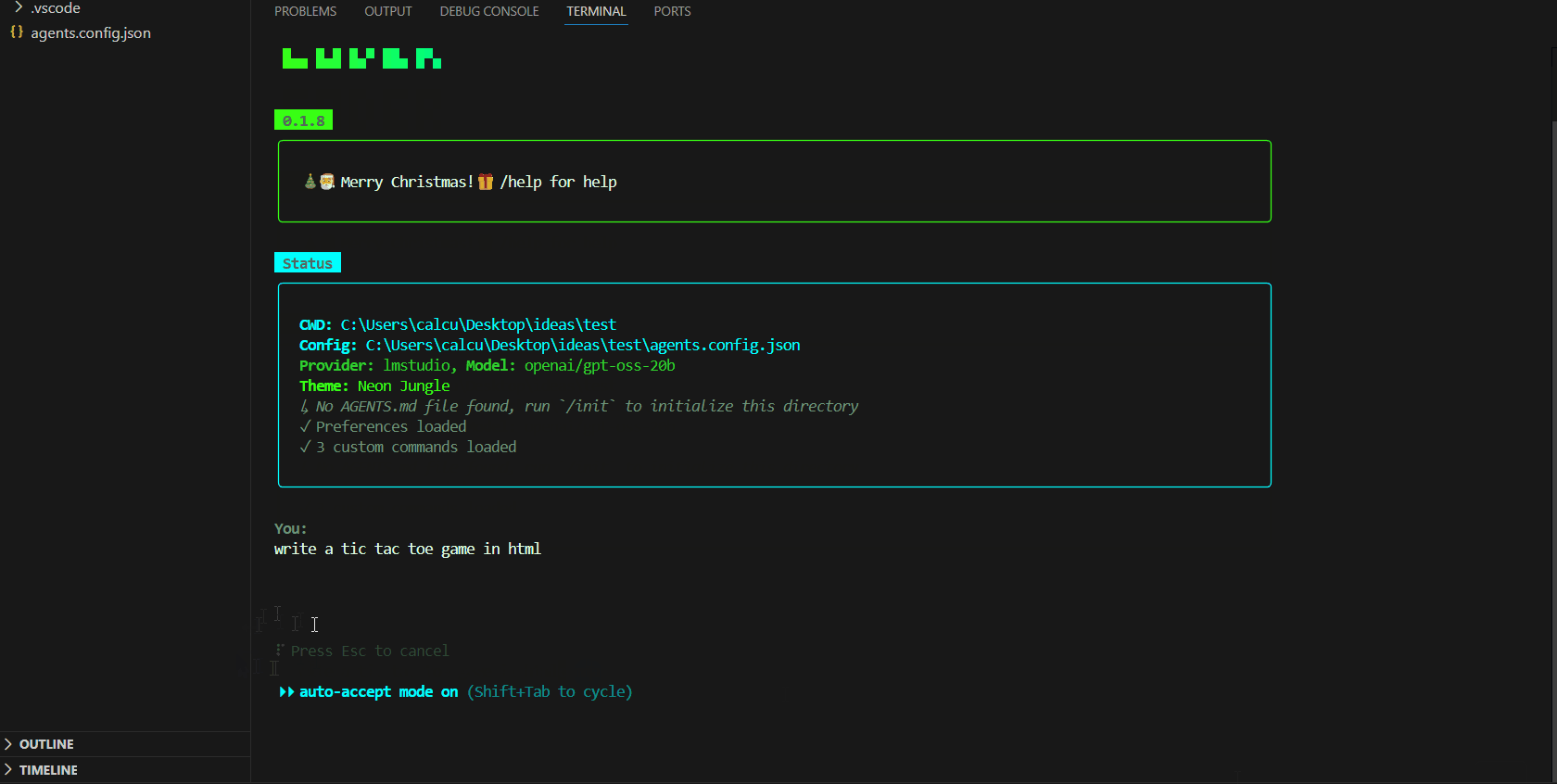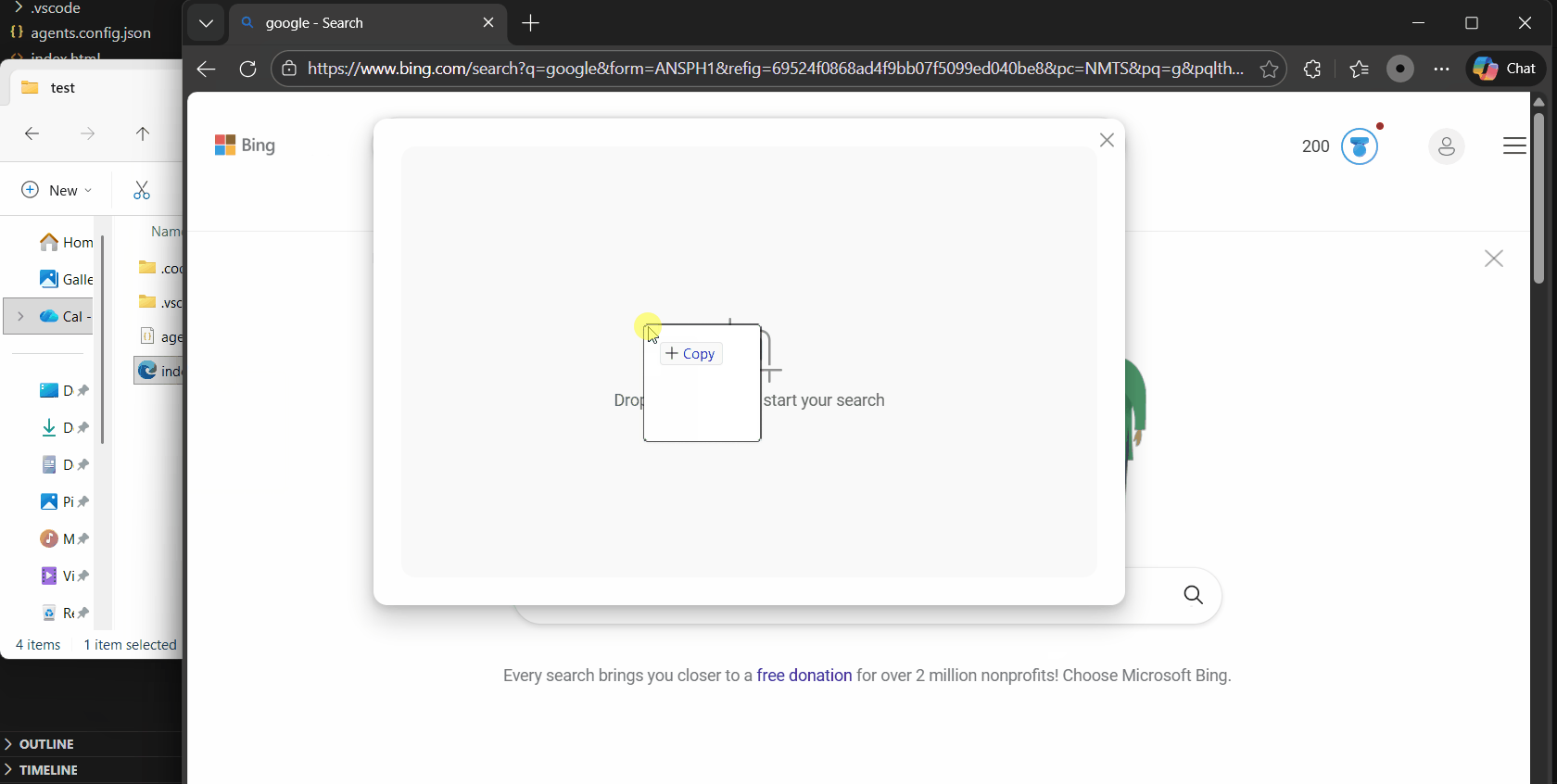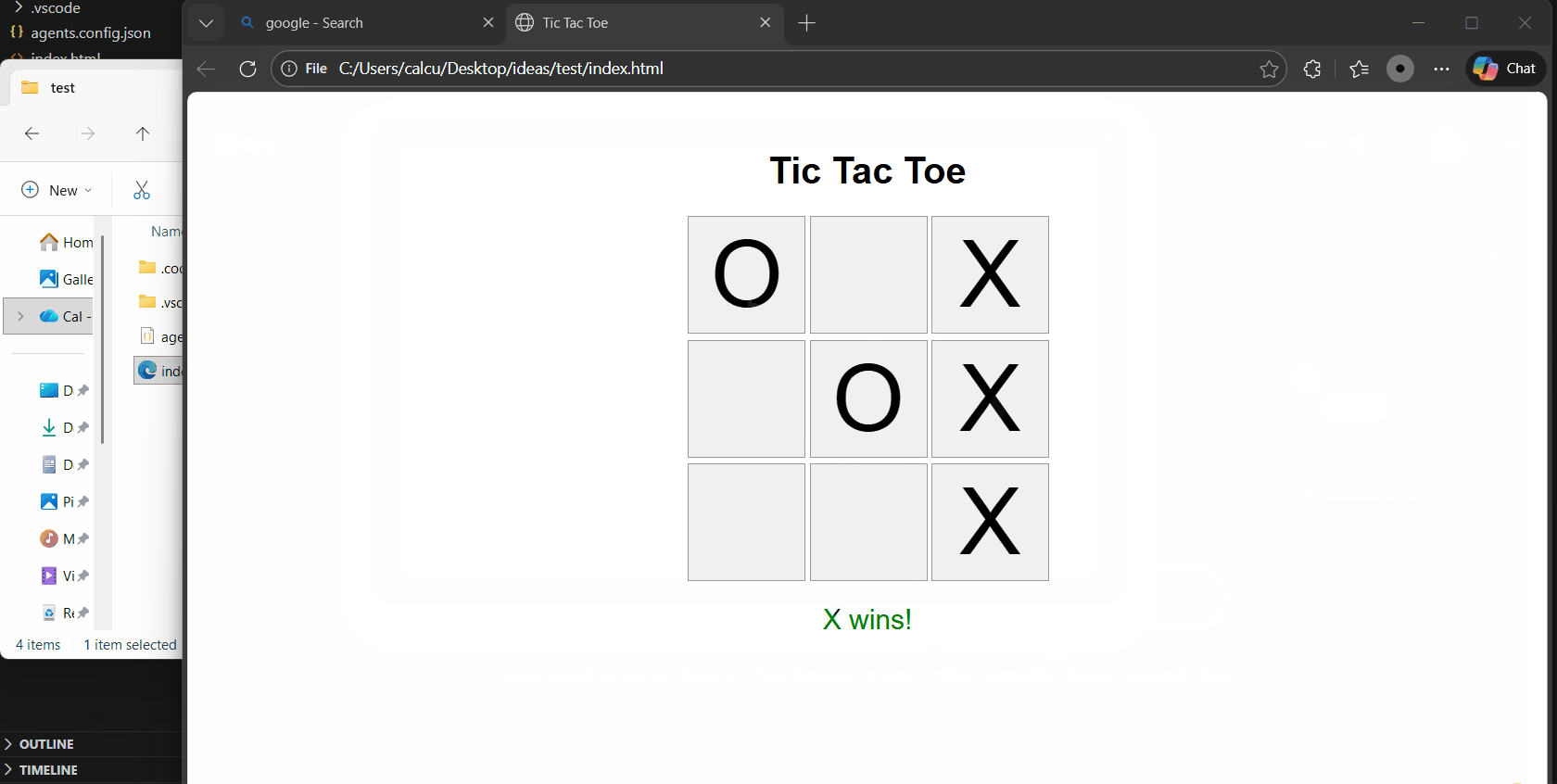
see example above - vibe code a tic tac toe game
## gguf-coder
setup (optional: need `gguf-coder`)
```
python -m gguf_coder
```
enter your provider, model(s) and endpoint; edit it for different setting(s) if needed
## coder
install coder ... | [] |
mradermacher/Blossom-V6.3-30B-A3B-i1-GGUF | mradermacher | 2025-12-08T03:00:09Z | 81 | 0 | transformers | [
"transformers",
"gguf",
"zh",
"en",
"dataset:Azure99/blossom-v6.3-sft-stage1",
"dataset:Azure99/blossom-v6.3-sft-stage2",
"base_model:Azure99/Blossom-V6.3-30B-A3B",
"base_model:quantized:Azure99/Blossom-V6.3-30B-A3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"con... | null | 2025-12-07T21:55:29Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_... | [
{
"start": 463,
"end": 483,
"text": "Blossom-V6.3-30B-A3B",
"label": "benchmark name",
"score": 0.6548604369163513
},
{
"start": 620,
"end": 648,
"text": "Blossom-V6.3-30B-A3B-i1-GGUF",
"label": "benchmark name",
"score": 0.7263558506965637
},
{
"start": 722,
... |
racine-ai-qwen/Qwen3.5-35B-A3B | racine-ai-qwen | 2026-03-27T15:05:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_5_moe",
"image-text-to-text",
"conversational",
"base_model:Qwen/Qwen3.5-35B-A3B-Base",
"base_model:finetune:Qwen/Qwen3.5-35B-A3B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2026-03-27T15:00:22Z | # Qwen3.5-35B-A3B
<img width="400px" src="https://qianwen-res.oss-accelerate.aliyuncs.com/logo_qwen3.5.png">
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained... | [] |
pranaysharma08/my_awesome_model | pranaysharma08 | 2025-11-25T17:45:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-11-25T17:31:38Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/dis... | [
{
"start": 640,
"end": 653,
"text": "learning_rate",
"label": "evaluation metric",
"score": 0.8468141555786133
},
{
"start": 655,
"end": 660,
"text": "2e-05",
"label": "evaluation metric",
"score": 0.7380733489990234
},
{
"start": 686,
"end": 701,
"text": ... |
gsjang/ja-llama-3-elyza-jp-8b-x-meta-llama-3-8b-instruct-dare_ties-50_50 | gsjang | 2025-08-28T11:51:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2311.03099",
"base_model:elyza/Llama-3-ELYZA-JP-8B",
"base_model:merge:elyza/Llama-3-ELYZA-JP-8B",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:merge:meta-llama/Meta-Llama-... | text-generation | 2025-08-28T09:51:40Z | # ja-llama-3-elyza-jp-8b-x-meta-llama-3-8b-instruct-dare_ties-50_50
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [meta-llam... | [] |
mradermacher/chatbot-mental-health-GGUF | mradermacher | 2025-08-20T17:36:49Z | 6 | 0 | transformers | [
"transformers",
"gguf",
"base_model:adapter:google/flan-t5-base",
"lora",
"en",
"base_model:Inosensius/chatbot-mental-health",
"base_model:adapter:Inosensius/chatbot-mental-health",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T17:33:04Z | ## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static qu... | [] |
Muapi/art-nouveau | Muapi | 2025-08-14T09:28:09Z | 0 | 0 | null | [
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-14T09:27:49Z | # Art Nouveau

**Base model**: Flux.1 D
**Trained words**: ArsMJStyle, Art Nouveau
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Co... | [] |
nightmedia/Qwen3-Yoyo-V4-42B-A3B-Thinking-TOTAL-RECALL-PKD-V-qx65x-mlx | nightmedia | 2025-10-31T16:17:48Z | 1 | 0 | mlx | [
"mlx",
"safetensors",
"qwen3_moe",
"programming",
"code generation",
"code",
"codeqwen",
"moe",
"coding",
"coder",
"qwen2",
"chat",
"qwen",
"qwen-coder",
"Qwen3-Coder-30B-A3B-Instruct",
"Qwen3-30B-A3B",
"mixture of experts",
"128 experts",
"8 active experts",
"1 million context... | text-generation | 2025-10-31T04:02:17Z | # Qwen3-Yoyo-V4-42B-A3B-Thinking-TOTAL-RECALL-PKD-V-qx65x-mlx
📌 Quantization Types & Hardware Requirements
```bash
Quant Bit Precision RAM Need (Mac)
mxfp4 4-bit float 32GB
qx64x Store: 4b, Enhancements: 6b 32GB
qx65x Store: 5b, Enhancements: 6b 48GB
qx86x Store: 6b, Enhancements: 8b 64GB
qx86bx ... | [] |
TMLR-Group-HF/GT-Llama-3.2-3B-Instruct-MATH | TMLR-Group-HF | 2025-10-11T06:48:21Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2508.00410",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-08-14T07:43:27Z | # TMLR-Group-HF/GT-Llama-3.2-3B-Instruct
This is the Llama-3.2-3B-Instruct model trained by GRPO Ground Truth method using MATH training set. This model is one of the checkpoints released in conjunction with the paper [Co-rewarding: Stable Self-supervised RL for Eliciting Reasoning in Large Language Models](https://hu... | [] |
GiantAILab/YingMusic-Singer | GiantAILab | 2026-02-09T10:00:49Z | 0 | 3 | null | [
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-11-26T15:37:20Z | # YingMusic-Singer: Zero-shot Singing Voice Synthesis and Editing with Annotation-free Melody Guidance
github:[YingMusic-Singer](https://github.com/GiantAILab/YingMusic-Singer)
## Short Intro
YingMusic-Singer is a unified framework for Zero-shot Singing Voice Synthesis (SVS) and Editing, driven by Annotation-free Me... | [] |
decompute/Qwen3-4B-4bit-model | decompute | 2025-10-23T05:24:08Z | 2 | 0 | mlx | [
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B",
"base_model:quantized:Qwen/Qwen3-4B",
"license:apache-2.0",
"4-bit",
"region:us"
] | text-generation | 2025-10-23T05:21:53Z | # mlx-community/Qwen3-4B-4bit
This model [mlx-community/Qwen3-4B-4bit](https://huggingface.co/mlx-community/Qwen3-4B-4bit) was
converted to MLX format from [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
using mlx-lm version **0.24.0**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm impo... | [] |
frankwong2001/4_modernbert-embed-base | frankwong2001 | 2025-09-18T09:03:34Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"modernbert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:10556",
"loss:MultipleNegativesRankingLoss",
"dataset:frankwong2001/ssf-train-valid-combi-v1v2v3",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base... | sentence-similarity | 2025-09-18T09:03:21Z | # SentenceTransformer based on nomic-ai/modernbert-embed-base
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [nomic-ai/modernbert-embed-base](https://huggingface.co/nomic-ai/modernbert-embed-base) on the [ssf-train-valid-combi-v1v2v3](https://huggingface.co/datasets/frankwong2001/ssf-tra... | [
{
"start": 962,
"end": 990,
"text": "ssf-train-valid-combi-v1v2v3",
"label": "evaluation dataset",
"score": 0.6458414196968079
}
] |
chazokada/qwen25_32b_instruct_combined_grammar_degraded_s2 | chazokada | 2026-04-15T16:51:21Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"endpoints_compatible",
"region:us"
] | null | 2026-04-15T10:18:11Z | # Model Card for qwen25_32b_instruct_combined_grammar_degraded_s2
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but coul... | [] |
rbelanec/train_svamp_42_1760623621 | rbelanec | 2025-10-16T14:23:43Z | 0 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"llama-factory",
"transformers",
"text-generation",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | text-generation | 2025-10-16T14:12:15Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_svamp_42_1760623621
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta... | [
{
"start": 755,
"end": 768,
"text": "learning_rate",
"label": "evaluation metric",
"score": 0.730620801448822
},
{
"start": 1081,
"end": 1085,
"text": "PEFT",
"label": "evaluation metric",
"score": 0.7509267330169678
}
] |
contemmcm/5227a4b6d075b67843d0a8914a3f675c | contemmcm | 2025-11-11T21:33:12Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"umt5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/umt5-base",
"base_model:finetune:google/umt5-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-11-11T20:32:11Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 5227a4b6d075b67843d0a8914a3f675c
This model is a fine-tuned version of [google/umt5-base](https://huggingface.co/google/umt5-base... | [
{
"start": 461,
"end": 474,
"text": "Epoch Runtime",
"label": "evaluation metric",
"score": 0.7444061040878296
},
{
"start": 476,
"end": 484,
"text": "102.7825",
"label": "evaluation metric",
"score": 0.6035947799682617
},
{
"start": 487,
"end": 491,
"text... |
huskyhong/wzryyykl-lx-ynsm | huskyhong | 2026-01-09T22:38:28Z | 0 | 0 | null | [
"pytorch",
"region:us"
] | null | 2026-01-09T22:33:55Z | # 王者荣耀语音克隆-李信-一念神魔
基于 VoxCPM 的王者荣耀英雄及皮肤语音克隆模型系列,支持多种英雄和皮肤的语音风格克隆与生成。
## 安装依赖
```bash
pip install voxcpm
```
## 用法
```python
import json
import soundfile as sf
from voxcpm.core import VoxCPM
from voxcpm.model.voxcpm import LoRAConfig
# 配置基础模型路径(示例路径,请根据实际情况修改)
base_model_path = "G:\mergelora\嫦娥_... | [] |
dajiangw/lerobot_dj | dajiangw | 2026-03-26T07:26:21Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:dajiangw/lerobot_dj",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] | robotics | 2026-03-26T07:25:51Z | # Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high succ... | [
{
"start": 17,
"end": 20,
"text": "act",
"label": "evaluation dataset",
"score": 0.6181951761245728
},
{
"start": 120,
"end": 123,
"text": "ACT",
"label": "evaluation dataset",
"score": 0.6971622109413147
},
{
"start": 865,
"end": 868,
"text": "act",
"... |
shreyas-garg/leniencybench | shreyas-garg | 2026-04-26T08:22:59Z | 0 | 0 | null | [
"openenv",
"arxiv:2307.03172",
"arxiv:2212.09251",
"arxiv:2311.07911",
"license:mit",
"region:us"
] | null | 2026-04-26T06:36:17Z | # LeniencyBench
**We found that frontier LLMs systematically obey policy *loosening* and silently ignore policy *tightening*. Llama 3.1 8B scores 0 % on rules that tighten vs 37.5 % on rules that loosen — a 37.5-point asymmetry from a single admin message in the context. One epoch of SFT on LeniencyBench's auto-genera... | [
{
"start": 2,
"end": 15,
"text": "LeniencyBench",
"label": "benchmark name",
"score": 0.967279314994812
},
{
"start": 127,
"end": 139,
"text": "Llama 3.1 8B",
"label": "benchmark name",
"score": 0.8279105424880981
},
{
"start": 293,
"end": 306,
"text": "Le... |
mariamoracrossitcr/Llama-3.1-8B-INBioCR-sp-DAPT | mariamoracrossitcr | 2026-03-14T03:44:24Z | 104 | 0 | peft | [
"peft",
"safetensors",
"base_model:adapter:meta-llama/Llama-3.1-8B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"region:us"
] | text-generation | 2026-03-14T00:50:56Z | <!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.1-8B-INBioCR-sp-DAPT
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta... | [
{
"start": 436,
"end": 442,
"text": "0.9383",
"label": "evaluation metric",
"score": 0.6228812336921692
},
{
"start": 718,
"end": 731,
"text": "learning_rate",
"label": "evaluation metric",
"score": 0.6923246383666992
},
{
"start": 733,
"end": 738,
"text":... |
phntm5/dqn-SpaceInvadersNoFrameskip-v4 | phntm5 | 2026-02-02T21:42:14Z | 4 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2026-02-02T21:41:45Z | # **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework... | [] |
qualiaadmin/9a64fea8-b8d4-40e1-8d9d-1b4431d1443a | qualiaadmin | 2025-09-18T13:40:13Z | 0 | 0 | lerobot | [
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:Calvert0921/SmolVLA_LiftBlueCubeDouble_Franka_200",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2025-09-18T13:37:35Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [
{
"start": 17,
"end": 24,
"text": "smolvla",
"label": "evaluation dataset",
"score": 0.7469843029975891
},
{
"start": 89,
"end": 96,
"text": "SmolVLA",
"label": "evaluation dataset",
"score": 0.7727768421173096
}
] |
SUHAN-I/YOLO11 | SUHAN-I | 2026-02-23T10:18:40Z | 0 | 0 | null | [
"onnx",
"region:us"
] | null | 2026-02-23T09:45:01Z | # 🗑️ YOLO11 Trash Detection Model
Fine-tuned YOLO11 model for detecting and classifying recyclable materials and trash.
## 📊 Model Details
| Attribute | Value |
|-----------|-------|
| **Base Model** | YOLO11n (Nano) |
| **Task** | Object Detection |
| **Input Size** | 640x640 |
| **Classes** | 6 |
| **Framework**... | [] |
chuuhtetnaing/myanmar-text-segmentation-model | chuuhtetnaing | 2025-12-24T17:42:46Z | 12 | 1 | null | [
"safetensors",
"xlm-roberta",
"token-classification",
"myanmar",
"text-segmentation",
"my",
"en",
"dataset:chuuhtetnaing/myanmar-text-segmentation-dataset",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:apache-2.0",
"region:us"
] | token-classification | 2025-12-21T10:48:23Z | # Myanmar Text Segmentation Model
Fine-tuned [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) for Myanmar text segmentation (word boundary detection) using token classification.
## Training Results
| Step | Training Loss | Validation Loss | Precision | Recall | F1 | Accuracy |
|-----... | [
{
"start": 277,
"end": 286,
"text": "Precision",
"label": "evaluation metric",
"score": 0.6785259246826172
},
{
"start": 303,
"end": 311,
"text": "Accuracy",
"label": "evaluation metric",
"score": 0.7747011184692383
}
] |
juyoungggg/smolvla-0407-diff-zone-1 | juyoungggg | 2026-04-13T05:57:24Z | 18 | 0 | lerobot | [
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:juyoungggg/0407-diff-zone",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] | robotics | 2026-04-08T00:12:49Z | # Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This pol... | [
{
"start": 17,
"end": 24,
"text": "smolvla",
"label": "evaluation dataset",
"score": 0.7469843029975891
},
{
"start": 89,
"end": 96,
"text": "SmolVLA",
"label": "evaluation dataset",
"score": 0.7727768421173096
}
] |
AliSaadatV/bio-acdc | AliSaadatV | 2026-04-26T11:14:51Z | 0 | 0 | null | [
"region:us"
] | null | 2026-04-26T10:53:25Z | # Bio-ACDC: Biological Sequence Model Coevolution
An adaptation of [AC/DC (Assessment Coevolving with Diverse Capabilities)](https://acdc-llm.github.io) for biological language models.
## Overview
Bio-ACDC coevolves populations of biological language models (for DNA, RNA, and Protein sequences) with synthetic sequen... | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.