
modelId stringlengths 6 107 | label list | readme stringlengths 0 56.2k | readme_len int64 0 56.2k |
|---|---|---|---|
EthanChen0418/seven-classed-domain-cls | [
"contradiction",
"entailment",
"neutral"
] | Entry not found | 15 |
FabioDataGeek/distilbert-base-uncased-finetuned-emotion | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.926
- name: F1
type: f1
value: 0.9258450981645597
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2196
- Accuracy: 0.926
- F1: 0.9258
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8279 | 1.0 | 250 | 0.3208 | 0.9025 | 0.8979 |
| 0.2538 | 2.0 | 500 | 0.2196 | 0.926 | 0.9258 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| 1,804 |
Herais/pred_timeperiod | [
"古代",
"当代",
"现代",
"近代",
"重大"
] | ---
language:
- zh
tags:
- classification
license: apache-2.0
datasets:
- Custom
metrics:
- rouge
---
This model predicts the time period given a synopsis of about 200 Chinese characters.
The model is trained on TV and Movie datasets and takes simplified Chinese as input.
We trained the model from the "hfl/chinese-bert-wwm-ext" checkpoint.
#### Sample Usage
from transformers import BertTokenizer, BertForSequenceClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
checkpoint = "Herais/pred_timeperiod"
tokenizer = BertTokenizer.from_pretrained(checkpoint,
problem_type="single_label_classification")
model = BertForSequenceClassification.from_pretrained(checkpoint).to(device)
label2id_timeperiod = {'古代': 0, '当代': 1, '现代': 2, '近代': 3, '重大': 4}
id2label_timeperiod = {0: '古代', 1: '当代', 2: '现代', 3: '近代', 4: '重大'}
synopsis = """加油吧!检察官。鲤州市安平区检察院检察官助理蔡晓与徐美津是两个刚入职场的“菜鸟”。\
他们在老检察官冯昆的指导与鼓励下,凭借着自己的一腔热血与对检察事业的执著追求,克服工作上的种种困难,\
成功办理电竞赌博、虚假诉讼、水产市场涉黑等一系列复杂案件,惩治了犯罪分子,维护了人民群众的合法权益,\
为社会主义法治建设贡献了自己的一份力量。在这个过程中,蔡晓与徐美津不仅得到了业务能力上的提升,\
也领悟了人生的真谛,学会真诚地面对家人与朋友,收获了亲情与友谊,成长为合格的员额检察官,\
继续为检察事业贡献自己的青春。 """
inputs = tokenizer(synopsis, truncation=True, max_length=512, return_tensors='pt')
model.eval()
outputs = model(**input)
label_ids_pred = torch.argmax(outputs.logits, dim=1).to('cpu').numpy()
labels_pred = [id2label_timeperiod[label] for label in labels_pred]
print(labels_pred)
# ['当代']
Citation
{} | 1,589 |
Huntersx/cola_model | null | Entry not found | 15 |
Jeska/VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly | [
"chitchat_ask_bye",
"chitchat_ask_hi",
"chitchat_ask_hi_de",
"chitchat_ask_hi_en",
"chitchat_ask_hi_fr",
"chitchat_ask_hoe_gaat_het",
"chitchat_ask_name",
"chitchat_ask_thanks",
"faq_ask_aantal_gevaccineerd",
"faq_ask_aantal_gevaccineerd_wereldwijd",
"faq_ask_afspraak_afzeggen",
"faq_ask_afspr... | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly
This model is a fine-tuned version of [outputDAQonly/checkpoint-8710](https://huggingface.co/outputDAQonly/checkpoint-8710) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5008
- Accuracy: 0.9068
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 4.0751 | 1.0 | 1320 | 3.1674 | 0.4086 |
| 2.5619 | 2.0 | 2640 | 2.0335 | 0.6426 |
| 1.8549 | 3.0 | 3960 | 1.3537 | 0.7861 |
| 1.106 | 4.0 | 5280 | 0.9515 | 0.8519 |
| 0.6698 | 5.0 | 6600 | 0.7152 | 0.8757 |
| 0.4497 | 6.0 | 7920 | 0.5838 | 0.8921 |
| 0.2626 | 7.0 | 9240 | 0.5300 | 0.8940 |
| 0.1762 | 8.0 | 10560 | 0.4984 | 0.8958 |
| 0.119 | 9.0 | 11880 | 0.4906 | 0.9059 |
| 0.0919 | 10.0 | 13200 | 0.4896 | 0.8995 |
| 0.0722 | 11.0 | 14520 | 0.5012 | 0.9022 |
| 0.0517 | 12.0 | 15840 | 0.4951 | 0.9040 |
| 0.0353 | 13.0 | 17160 | 0.4988 | 0.9040 |
| 0.0334 | 14.0 | 18480 | 0.5035 | 0.9049 |
| 0.0304 | 15.0 | 19800 | 0.5008 | 0.9068 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
| 2,302 |
LysandreJik/test-upload | null | Entry not found | 15 |
JuliusAlphonso/dear-jarvis-monolith-xed-en | [
"neutral",
"anger",
"anticipation",
"disgust",
"fear",
"joy",
"sadness",
"surprise",
"trust"
] | ## Model description
This model was trained on the XED dataset and achieved
validation loss: 0.5995
validation acc: 84.28% (ROC-AUC)
Labels are based on Plutchik's model of emotions and may be combined:
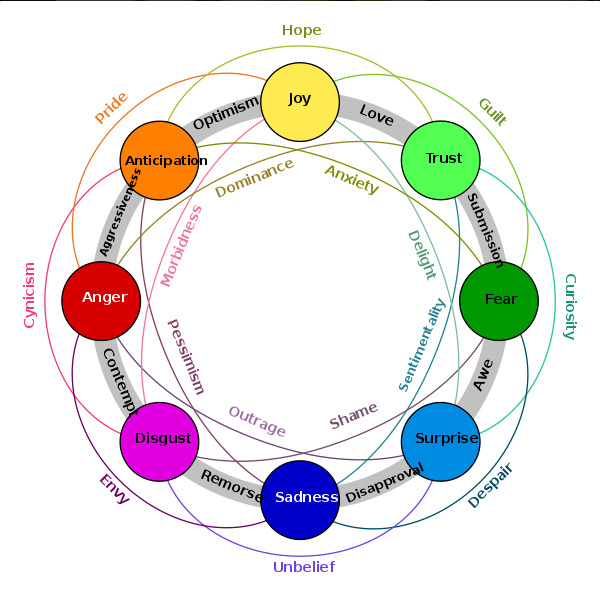
### Framework versions
- Transformers 4.6.1
- Pytorch 1.8.1+cu101
- Datasets 1.8.0
- Tokenizers 0.10.3
| 426 |
Kayvane/distilbert-undersampled | [
"Actor",
"AmusementParkAttraction",
"Animal",
"Artist",
"Athlete",
"BodyOfWater",
"Boxer",
"BritishRoyalty",
"Broadcaster",
"Building",
"Cartoon",
"CelestialBody",
"Cleric",
"ClericalAdministrativeRegion",
"Coach",
"Comic",
"ComicsCharacter",
"Company",
"Database",
"Educational... | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: distilbert-undersampled
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-undersampled
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0826
- Accuracy: 0.9811
- F1: 0.9810
- Recall: 0.9811
- Precision: 0.9812
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.0959 | 0.2 | 2000 | 0.0999 | 0.9651 | 0.9628 | 0.9651 | 0.9655 |
| 0.0618 | 0.41 | 4000 | 0.0886 | 0.9717 | 0.9717 | 0.9717 | 0.9731 |
| 0.159 | 0.61 | 6000 | 0.0884 | 0.9719 | 0.9720 | 0.9719 | 0.9728 |
| 0.0513 | 0.81 | 8000 | 0.0785 | 0.9782 | 0.9782 | 0.9782 | 0.9788 |
| 0.0219 | 1.01 | 10000 | 0.0680 | 0.9779 | 0.9779 | 0.9779 | 0.9783 |
| 0.036 | 1.22 | 12000 | 0.0745 | 0.9787 | 0.9787 | 0.9787 | 0.9792 |
| 0.0892 | 1.42 | 14000 | 0.0675 | 0.9786 | 0.9786 | 0.9786 | 0.9789 |
| 0.0214 | 1.62 | 16000 | 0.0760 | 0.9799 | 0.9798 | 0.9799 | 0.9801 |
| 0.0882 | 1.83 | 18000 | 0.0800 | 0.9800 | 0.9800 | 0.9800 | 0.9802 |
| 0.0234 | 2.03 | 20000 | 0.0720 | 0.9813 | 0.9813 | 0.9813 | 0.9815 |
| 0.0132 | 2.23 | 22000 | 0.0738 | 0.9803 | 0.9803 | 0.9803 | 0.9805 |
| 0.0136 | 2.43 | 24000 | 0.0847 | 0.9804 | 0.9804 | 0.9804 | 0.9806 |
| 0.0119 | 2.64 | 26000 | 0.0826 | 0.9811 | 0.9810 | 0.9811 | 0.9812 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| 2,708 |
Krassy/xlm-roberta-base-finetuned-marc-en | [
"good",
"great",
"ok",
"poor",
"terrible"
] | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9005
- Mae: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.108 | 1.0 | 235 | 0.9801 | 0.5610 |
| 0.9592 | 2.0 | 470 | 0.9005 | 0.5 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
| 1,426 |
Lumos/ag_news1 | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | Entry not found | 15 |
Maha/OGBV-gender-bert-hi-en-hasoc20a-fin | null | Entry not found | 15 |
Maha/OGBV-gender-twtrobertabase-en-founta_final | null | Entry not found | 15 |
MarioPenguin/finetuned-model | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: finetuned-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-model
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8601
- Accuracy: 0.6117
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 84 | 0.8663 | 0.5914 |
| No log | 2.0 | 168 | 0.8601 | 0.6117 |
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
| 1,415 |
Maxinstellar/outputs | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5",
"LABEL_6"
] | Entry not found | 15 |
MickyMike/1-GPT2SP-mule | [
"LABEL_0"
] | Entry not found | 15 |
Mihneo/romanian_bert_news | null | 0 | |
Pkrawczak/distilbert-base-uncased-finetuned-cola | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5285049056800905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6015
- Matthews Correlation: 0.5285
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5266 | 1.0 | 535 | 0.5474 | 0.4015 |
| 0.3561 | 2.0 | 1070 | 0.4830 | 0.5214 |
| 0.2416 | 3.0 | 1605 | 0.6015 | 0.5285 |
| 0.1695 | 4.0 | 2140 | 0.7748 | 0.5162 |
| 0.1302 | 5.0 | 2675 | 0.8369 | 0.5268 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
| 2,000 |
Ruizhou/bert-base-uncased-finetuned-rte | null | Entry not found | 15 |
SetFit/deberta-v3-large__sst2__train-16-9 | [
"negative",
"positive"
] | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: deberta-v3-large__sst2__train-16-9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large__sst2__train-16-9
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2598
- Accuracy: 0.7809
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6887 | 1.0 | 7 | 0.7452 | 0.2857 |
| 0.6889 | 2.0 | 14 | 0.7988 | 0.2857 |
| 0.6501 | 3.0 | 21 | 0.8987 | 0.2857 |
| 0.4286 | 4.0 | 28 | 0.9186 | 0.4286 |
| 0.3591 | 5.0 | 35 | 0.5566 | 0.7143 |
| 0.0339 | 6.0 | 42 | 1.1130 | 0.5714 |
| 0.013 | 7.0 | 49 | 1.8296 | 0.7143 |
| 0.0041 | 8.0 | 56 | 1.7069 | 0.7143 |
| 0.0023 | 9.0 | 63 | 1.1942 | 0.7143 |
| 0.0022 | 10.0 | 70 | 0.6054 | 0.7143 |
| 0.0011 | 11.0 | 77 | 0.3872 | 0.7143 |
| 0.0006 | 12.0 | 84 | 0.3217 | 0.7143 |
| 0.0005 | 13.0 | 91 | 0.2879 | 0.8571 |
| 0.0005 | 14.0 | 98 | 0.2640 | 0.8571 |
| 0.0004 | 15.0 | 105 | 0.2531 | 0.8571 |
| 0.0003 | 16.0 | 112 | 0.2384 | 0.8571 |
| 0.0004 | 17.0 | 119 | 0.2338 | 0.8571 |
| 0.0003 | 18.0 | 126 | 0.2314 | 0.8571 |
| 0.0003 | 19.0 | 133 | 0.2276 | 0.8571 |
| 0.0003 | 20.0 | 140 | 0.2172 | 0.8571 |
| 0.0003 | 21.0 | 147 | 0.2069 | 0.8571 |
| 0.0002 | 22.0 | 154 | 0.2018 | 0.8571 |
| 0.0002 | 23.0 | 161 | 0.2005 | 0.8571 |
| 0.0002 | 24.0 | 168 | 0.1985 | 0.8571 |
| 0.0002 | 25.0 | 175 | 0.1985 | 1.0 |
| 0.0002 | 26.0 | 182 | 0.1955 | 1.0 |
| 0.0002 | 27.0 | 189 | 0.1967 | 1.0 |
| 0.0002 | 28.0 | 196 | 0.1918 | 1.0 |
| 0.0002 | 29.0 | 203 | 0.1888 | 1.0 |
| 0.0002 | 30.0 | 210 | 0.1864 | 1.0 |
| 0.0002 | 31.0 | 217 | 0.1870 | 1.0 |
| 0.0002 | 32.0 | 224 | 0.1892 | 1.0 |
| 0.0002 | 33.0 | 231 | 0.1917 | 1.0 |
| 0.0002 | 34.0 | 238 | 0.1869 | 1.0 |
| 0.0002 | 35.0 | 245 | 0.1812 | 1.0 |
| 0.0001 | 36.0 | 252 | 0.1777 | 1.0 |
| 0.0002 | 37.0 | 259 | 0.1798 | 1.0 |
| 0.0002 | 38.0 | 266 | 0.1824 | 0.8571 |
| 0.0002 | 39.0 | 273 | 0.1846 | 0.8571 |
| 0.0002 | 40.0 | 280 | 0.1839 | 0.8571 |
| 0.0001 | 41.0 | 287 | 0.1826 | 0.8571 |
| 0.0001 | 42.0 | 294 | 0.1779 | 0.8571 |
| 0.0002 | 43.0 | 301 | 0.1762 | 0.8571 |
| 0.0001 | 44.0 | 308 | 0.1742 | 1.0 |
| 0.0002 | 45.0 | 315 | 0.1708 | 1.0 |
| 0.0001 | 46.0 | 322 | 0.1702 | 1.0 |
| 0.0001 | 47.0 | 329 | 0.1699 | 1.0 |
| 0.0001 | 48.0 | 336 | 0.1695 | 1.0 |
| 0.0001 | 49.0 | 343 | 0.1683 | 1.0 |
| 0.0001 | 50.0 | 350 | 0.1681 | 1.0 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 4,448 |
SetFit/deberta-v3-large__sst2__train-8-8 | [
"negative",
"positive"
] | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: deberta-v3-large__sst2__train-8-8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large__sst2__train-8-8
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7414
- Accuracy: 0.5623
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6597 | 1.0 | 3 | 0.7716 | 0.25 |
| 0.6376 | 2.0 | 6 | 0.7802 | 0.25 |
| 0.5857 | 3.0 | 9 | 0.6625 | 0.75 |
| 0.4024 | 4.0 | 12 | 0.5195 | 0.75 |
| 0.2635 | 5.0 | 15 | 0.4222 | 1.0 |
| 0.1714 | 6.0 | 18 | 0.4410 | 0.5 |
| 0.1267 | 7.0 | 21 | 0.7773 | 0.75 |
| 0.0582 | 8.0 | 24 | 0.9070 | 0.75 |
| 0.0374 | 9.0 | 27 | 0.9539 | 0.75 |
| 0.0204 | 10.0 | 30 | 1.0507 | 0.75 |
| 0.012 | 11.0 | 33 | 1.2802 | 0.5 |
| 0.0086 | 12.0 | 36 | 1.4272 | 0.5 |
| 0.0049 | 13.0 | 39 | 1.4803 | 0.5 |
| 0.0039 | 14.0 | 42 | 1.4912 | 0.5 |
| 0.0031 | 15.0 | 45 | 1.5231 | 0.5 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 2,276 |
SetFit/distilbert-base-uncased__hate_speech_offensive__train-16-8 | [
"hate speech",
"neither",
"offensive language"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased__hate_speech_offensive__train-16-8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased__hate_speech_offensive__train-16-8
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0704
- Accuracy: 0.394
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1031 | 1.0 | 10 | 1.1286 | 0.1 |
| 1.0648 | 2.0 | 20 | 1.1157 | 0.3 |
| 0.9982 | 3.0 | 30 | 1.1412 | 0.2 |
| 0.9283 | 4.0 | 40 | 1.2053 | 0.2 |
| 0.7958 | 5.0 | 50 | 1.1466 | 0.2 |
| 0.6668 | 6.0 | 60 | 1.1783 | 0.3 |
| 0.5068 | 7.0 | 70 | 1.2992 | 0.3 |
| 0.3741 | 8.0 | 80 | 1.3483 | 0.3 |
| 0.1653 | 9.0 | 90 | 1.4533 | 0.2 |
| 0.0946 | 10.0 | 100 | 1.6292 | 0.2 |
| 0.0569 | 11.0 | 110 | 1.8381 | 0.2 |
| 0.0346 | 12.0 | 120 | 2.0781 | 0.2 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 2,140 |
SetFit/distilbert-base-uncased__sst2__train-32-1 | [
"negative",
"positive"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased__sst2__train-32-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased__sst2__train-32-1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6492
- Accuracy: 0.6551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7106 | 1.0 | 13 | 0.6850 | 0.6154 |
| 0.631 | 2.0 | 26 | 0.6632 | 0.6923 |
| 0.5643 | 3.0 | 39 | 0.6247 | 0.7692 |
| 0.3992 | 4.0 | 52 | 0.5948 | 0.7692 |
| 0.1928 | 5.0 | 65 | 0.5803 | 0.7692 |
| 0.0821 | 6.0 | 78 | 0.6404 | 0.6923 |
| 0.0294 | 7.0 | 91 | 0.7387 | 0.6923 |
| 0.0141 | 8.0 | 104 | 0.8270 | 0.6923 |
| 0.0082 | 9.0 | 117 | 0.8496 | 0.6923 |
| 0.0064 | 10.0 | 130 | 0.8679 | 0.6923 |
| 0.005 | 11.0 | 143 | 0.8914 | 0.6923 |
| 0.0036 | 12.0 | 156 | 0.9278 | 0.6923 |
| 0.0031 | 13.0 | 169 | 0.9552 | 0.6923 |
| 0.0029 | 14.0 | 182 | 0.9745 | 0.6923 |
| 0.0028 | 15.0 | 195 | 0.9785 | 0.6923 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 2,293 |
Sofiascope/amazon-fine-tuned | null | Entry not found | 15 |
aXhyra/presentation_hate_31415 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_hate_31415
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7729508817074093
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_hate_31415
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8632
- F1: 0.7730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.436235805743952e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 31415
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.363 | 1.0 | 282 | 0.4997 | 0.7401 |
| 0.2145 | 2.0 | 564 | 0.5071 | 0.7773 |
| 0.1327 | 3.0 | 846 | 0.7109 | 0.7645 |
| 0.0157 | 4.0 | 1128 | 0.8632 | 0.7730 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
| 1,776 |
abhishek/autonlp-bbc-roberta-37249301 | [
"business",
"entertainment",
"politics",
"sport",
"tech"
] | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- abhishek/autonlp-data-bbc-roberta
co2_eq_emissions: 1.9859980179658823
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 37249301
- CO2 Emissions (in grams): 1.9859980179658823
## Validation Metrics
- Loss: 0.06406362354755402
- Accuracy: 0.9833887043189369
- Macro F1: 0.9832763664701248
- Micro F1: 0.9833887043189369
- Weighted F1: 0.9833288528828136
- Macro Precision: 0.9847257743677181
- Micro Precision: 0.9833887043189369
- Weighted Precision: 0.9835392869652073
- Macro Recall: 0.982101705176067
- Micro Recall: 0.9833887043189369
- Weighted Recall: 0.9833887043189369
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-bbc-roberta-37249301
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-bbc-roberta-37249301", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-bbc-roberta-37249301", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | 1,379 |
aditeyabaral/finetuned-iitp_pdt_review-distilbert-base-cased | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
aditeyabaral/finetuned-sail2017-additionalpretrained-indic-bert | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
aloxatel/3JQ | null | Entry not found | 15 |
aloxatel/7EG | null | Entry not found | 15 |
aloxatel/KS8 | null | Entry not found | 15 |
aloxatel/QHR | null | Entry not found | 15 |
amauboussin/twitter-toxicity-v0 | [
"LABEL_0"
] | Entry not found | 15 |
amyma21/sincere_question_classification | [
"insincere",
"sincere"
] | Entry not found | 15 |
anirudh21/albert-base-v2-finetuned-wnli | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: albert-base-v2-finetuned-wnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.5633802816901409
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-wnli
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6878
- Accuracy: 0.5634
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.6878 | 0.5634 |
| No log | 2.0 | 80 | 0.6919 | 0.5634 |
| No log | 3.0 | 120 | 0.6877 | 0.5634 |
| No log | 4.0 | 160 | 0.6984 | 0.4085 |
| No log | 5.0 | 200 | 0.6957 | 0.5211 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.0
- Tokenizers 0.10.3
| 1,832 |
aviator-neural/bert-base-uncased-sst2 | null | Entry not found | 15 |
ayameRushia/indobert-base-uncased-finetuned-indonlu-smsa | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
license: mit
tags:
- generated_from_trainer
datasets:
- indonlu
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: indobert-base-uncased-finetuned-indonlu-smsa
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: indonlu
type: indonlu
args: smsa
metrics:
- name: Accuracy
type: accuracy
value: 0.9301587301587302
- name: F1
type: f1
value: 0.9066105299178986
- name: Precision
type: precision
value: 0.8992078788375845
- name: Recall
type: recall
value: 0.9147307323234121
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-base-uncased-finetuned-indonlu-smsa
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the indonlu dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2277
- Accuracy: 0.9302
- F1: 0.9066
- Precision: 0.8992
- Recall: 0.9147
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 1.0 | 344 | 0.3831 | 0.8476 | 0.7715 | 0.7817 | 0.7627 |
| 0.4167 | 2.0 | 688 | 0.2809 | 0.8905 | 0.8406 | 0.8699 | 0.8185 |
| 0.2624 | 3.0 | 1032 | 0.2254 | 0.9230 | 0.8842 | 0.9004 | 0.8714 |
| 0.2624 | 4.0 | 1376 | 0.2378 | 0.9238 | 0.8797 | 0.9180 | 0.8594 |
| 0.1865 | 5.0 | 1720 | 0.2277 | 0.9302 | 0.9066 | 0.8992 | 0.9147 |
| 0.1217 | 6.0 | 2064 | 0.2444 | 0.9262 | 0.8981 | 0.9013 | 0.8957 |
| 0.1217 | 7.0 | 2408 | 0.2985 | 0.9286 | 0.8999 | 0.9035 | 0.8971 |
| 0.0847 | 8.0 | 2752 | 0.3397 | 0.9278 | 0.8969 | 0.9090 | 0.8871 |
| 0.0551 | 9.0 | 3096 | 0.3542 | 0.9270 | 0.8961 | 0.9010 | 0.8924 |
| 0.0551 | 10.0 | 3440 | 0.3862 | 0.9222 | 0.8895 | 0.8970 | 0.8846 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
| 2,886 |
baykenney/bert-base-gpt2detector-topp92 | [
"Human",
"Machine"
] | Entry not found | 15 |
baykenney/bert-large-gpt2detector-topp92 | [
"Human",
"Machine"
] | Entry not found | 15 |
beomi/beep-kcbert-base-bias | [
"gender",
"none",
"others"
] | Entry not found | 15 |
beomi/beep-koelectra-base-v3-discriminator-bias | [
"gender",
"none",
"others"
] | Entry not found | 15 |
beomi/korean-lgbt-hatespeech-classifier | null | Entry not found | 15 |
world-wide/sent-sci-irrelevance | [
"False",
"True"
] | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- bozelosp/autonlp-data-sci-relevance
co2_eq_emissions: 3.667033499762825
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 33199029
- CO2 Emissions (in grams): 3.667033499762825
## Validation Metrics
- Loss: 0.32653310894966125
- Accuracy: 0.9133333333333333
- Precision: 0.9005847953216374
- Recall: 0.9447852760736196
- AUC: 0.9532488468944517
- F1: 0.9221556886227544
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/bozelosp/autonlp-sci-relevance-33199029
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bozelosp/autonlp-sci-relevance-33199029", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("bozelosp/autonlp-sci-relevance-33199029", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | 1,170 |
caioamb/distilbert-base-uncased-finetuned-cola | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5166623535745778
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7647
- Matthews Correlation: 0.5167
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5294 | 1.0 | 535 | 0.5029 | 0.4356 |
| 0.3507 | 2.0 | 1070 | 0.5285 | 0.4884 |
| 0.2406 | 3.0 | 1605 | 0.6550 | 0.5138 |
| 0.1825 | 4.0 | 2140 | 0.7647 | 0.5167 |
| 0.1282 | 5.0 | 2675 | 0.8664 | 0.5074 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
| 2,000 |
cbrew475/mpnet-metric | [
"LABEL_0",
"LABEL_1",
"LABEL_10",
"LABEL_11",
"LABEL_12",
"LABEL_13",
"LABEL_14",
"LABEL_15",
"LABEL_16",
"LABEL_17",
"LABEL_18",
"LABEL_19",
"LABEL_2",
"LABEL_20",
"LABEL_21",
"LABEL_22",
"LABEL_23",
"LABEL_24",
"LABEL_25",
"LABEL_26",
"LABEL_27",
"LABEL_28",
"LABEL_29",... | Entry not found | 15 |
chitra/finetuned-adversarial-paraphrase-model | null | ---
tags:
- generated_from_trainer
model-index:
- name: finetuned-adversarial-paraphrase-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-adversarial-paraphrase-model
This model is a fine-tuned version of [coderpotter/adversarial-paraphrasing-detector](https://huggingface.co/coderpotter/adversarial-paraphrasing-detector) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.5680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0848 | 1.0 | 2000 | 5.4633 |
| 0.0495 | 2.0 | 4000 | 6.0352 |
| 0.0121 | 3.0 | 6000 | 7.5680 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
| 1,435 |
chitra/finetuned-adversial-paraphrase-model | null | Entry not found | 15 |
daekeun-ml/koelectra-small-v3-korsts | [
"LABEL_0"
] | ---
language:
- ko
tags:
- classification
- sentence similarity
license: cc-by-4.0
datasets:
- korsts
metrics:
- accuracy
- f1
- precision
- recall
---
# Similarity between two sentences (fine-tuning with KoELECTRA-Small-v3 model and KorSTS dataset)
## Usage (Amazon SageMaker inference applicable)
It uses the interface of the SageMaker Inference Toolkit as is, so it can be easily deployed to SageMaker Endpoint.
### inference_korsts.py
```python
import json
import sys
import logging
import torch
from torch import nn
from transformers import ElectraConfig
from transformers import ElectraModel, AutoTokenizer, ElectraTokenizer, ElectraForSequenceClassification
logging.basicConfig(
level=logging.INFO,
format='[{%(filename)s:%(lineno)d} %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(filename='tmp.log'),
logging.StreamHandler(sys.stdout)
]
)
logger = logging.getLogger(__name__)
max_seq_length = 128
tokenizer = AutoTokenizer.from_pretrained("daekeun-ml/koelectra-small-v3-korsts")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Huggingface pre-trained model: 'monologg/koelectra-small-v3-discriminator'
def model_fn(model_path):
####
# If you have your own trained model
# Huggingface pre-trained model: 'monologg/koelectra-small-v3-discriminator'
####
#config = ElectraConfig.from_json_file(f'{model_path}/config.json')
#model = ElectraForSequenceClassification.from_pretrained(f'{model_path}/model.pth', config=config)
model = ElectraForSequenceClassification.from_pretrained('daekeun-ml/koelectra-small-v3-korsts')
model.to(device)
return model
def input_fn(input_data, content_type="application/jsonlines"):
data_str = input_data.decode("utf-8")
jsonlines = data_str.split("\n")
transformed_inputs = []
for jsonline in jsonlines:
text = json.loads(jsonline)["text"]
logger.info("input text: {}".format(text))
encode_plus_token = tokenizer.encode_plus(
text,
max_length=max_seq_length,
add_special_tokens=True,
return_token_type_ids=False,
padding="max_length",
return_attention_mask=True,
return_tensors="pt",
truncation=True,
)
transformed_inputs.append(encode_plus_token)
return transformed_inputs
def predict_fn(transformed_inputs, model):
predicted_classes = []
for data in transformed_inputs:
data = data.to(device)
output = model(**data)
prediction_dict = {}
prediction_dict['score'] = output[0].squeeze().cpu().detach().numpy().tolist()
jsonline = json.dumps(prediction_dict)
logger.info("jsonline: {}".format(jsonline))
predicted_classes.append(jsonline)
predicted_classes_jsonlines = "\n".join(predicted_classes)
return predicted_classes_jsonlines
def output_fn(outputs, accept="application/jsonlines"):
return outputs, accept
```
### test.py
```python
>>> from inference_korsts import model_fn, input_fn, predict_fn, output_fn
>>> with open('./samples/korsts.txt', mode='rb') as file:
>>> model_input_data = file.read()
>>> model = model_fn()
>>> transformed_inputs = input_fn(model_input_data)
>>> predicted_classes_jsonlines = predict_fn(transformed_inputs, model)
>>> model_outputs = output_fn(predicted_classes_jsonlines)
>>> print(model_outputs[0])
[{inference_korsts.py:44} INFO - input text: ['맛있는 라면을 먹고 싶어요', '후루룩 쩝쩝 후루룩 쩝쩝 맛좋은 라면']
[{inference_korsts.py:44} INFO - input text: ['뽀로로는 내친구', '머신러닝은 러닝머신이 아닙니다.']
[{inference_korsts.py:71} INFO - jsonline: {"score": 4.786738872528076}
[{inference_korsts.py:71} INFO - jsonline: {"score": 0.2319069355726242}
{"score": 4.786738872528076}
{"score": 0.2319069355726242}
```
### Sample data (samples/korsts.txt)
```
{"text": ["맛있는 라면을 먹고 싶어요", "후루룩 쩝쩝 후루룩 쩝쩝 맛좋은 라면"]}
{"text": ["뽀로로는 내친구", "머신러닝은 러닝머신이 아닙니다."]}
```
## References
- KoELECTRA: https://github.com/monologg/KoELECTRA
- KorNLI and KorSTS Dataset: https://github.com/kakaobrain/KorNLUDatasets | 4,145 |
danwilbury/xlm-roberta-base-finetuned-marc-en | [
"good",
"great",
"ok",
"poor",
"terrible"
] | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9302
- Mae: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1253 | 1.0 | 235 | 0.9756 | 0.5488 |
| 0.9465 | 2.0 | 470 | 0.9302 | 0.5 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
| 1,426 |
diegozs97/finetuned-chemprot-seed-0-2000k | [
"CPR:3",
"CPR:4",
"CPR:5",
"CPR:6",
"CPR:9",
"false"
] | Entry not found | 15 |
diegozs97/finetuned-sciie-seed-4-20k | [
"COMPARE",
"CONJUNCTION",
"EVALUATE-FOR",
"FEATURE-OF",
"HYPONYM-OF",
"PART-OF",
"USED-FOR"
] | Entry not found | 15 |
eliza-dukim/bert-base-finetuned-sts-deprecated | [
"LABEL_0"
] | ---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- pearsonr
model_index:
- name: bert-base-finetuned-sts
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
args: sts
metric:
name: Pearsonr
type: pearsonr
value: 0.837527365741951
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-finetuned-sts
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5657
- Pearsonr: 0.8375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearsonr |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 92 | 0.8280 | 0.7680 |
| No log | 2.0 | 184 | 0.6602 | 0.8185 |
| No log | 3.0 | 276 | 0.5939 | 0.8291 |
| No log | 4.0 | 368 | 0.5765 | 0.8367 |
| No log | 5.0 | 460 | 0.5657 | 0.8375 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| 1,797 |
hamzaMM/questionClassifier | null | Entry not found | 15 |
hemekci/off_detection_turkish | [
"not offensive",
"offensive"
] | ---
language: tr
widget:
- text: "sevelim sevilelim bu dunya kimseye kalmaz"
---
## Offensive Language Detection Model in Turkish
- uses Bert and pytorch
- fine tuned with Twitter data.
- UTF-8 configuration is done
### Training Data
Number of training sentences: 31,277
**Example Tweets**
- 19823 Daliaan yifng cok erken attin be... 1.38 ...| NOT|
- 30525 @USER Bak biri kollarımda uyuyup gitmem diyor..|NOT|
- 26468 Helal olsun be :) Norveçten sabaha karşı geldi aq... | OFF|
- 14105 @USER Sunu cekecek ve güzel oldugunu söylecek aptal... |OFF|
- 4958 Ya seni yerim ben şapşal şey 🤗 | NOT|
- 12966 Herkesin akıllı geçindiği bir sosyal medyamız var ... |NOT|
- 5788 Maçın özetlerini izleyenler futbolcular gidiyo... |NOT|
|OFFENSIVE |RESULT |
|--|--|
|NOT | 25231|
|OFF|6046|
dtype: int64
### Validation
|epoch |Training Loss | Valid. Loss | Valid.Accuracy | Training Time | Validation Time |
|--|--|--|--|--|--|
|1 | 0.31| 0.28| 0.89| 0:07:14 | 0:00:13
|2 | 0.18| 0.29| 0.90| 0:07:18 | 0:00:13
|3 | 0.08| 0.40| 0.89| 0:07:16 | 0:00:13
|4 | 0.04| 0.59| 0.89| 0:07:13 | 0:00:13
**Matthews Corr. Coef. (-1 : +1):**
Total MCC Score: 0.633
| 1,183 |
jaimin/plagiarism_checker | null | "hello"
| 9 |
philschmid/DistilBERT-tweet-eval-emotion | [
"0",
"1",
"2",
"3"
] | ---
tags: autonlp
language: en
widget:
- text: "Worry is a down payment on a problem you may never have'. Joyce Meyer. #motivation #leadership #worry"
datasets:
- tweet_eval
model-index:
- name: DistilBERT-tweet-eval-emotion
results:
- task:
name: Sentiment Analysis
type: sentiment-analysis
dataset:
name: "tweeteval"
type: tweet-eval
metrics:
- name: Accuracy
type: accuracy
value: 80.59
- name: Macro F1
type: macro-f1
value: 78.17
- name: Weighted F1
type: weighted-f1
value: 80.11
---
# `DistilBERT-tweet-eval-emotion` trained using autoNLP
- Problem type: Multi-class Classification
## Validation Metrics
- Loss: 0.5564454197883606
- Accuracy: 0.8057705840957072
- Macro F1: 0.7536021792986777
- Micro F1: 0.8057705840957073
- Weighted F1: 0.8011390170248318
- Macro Precision: 0.7817458823222652
- Micro Precision: 0.8057705840957072
- Weighted Precision: 0.8025156844840151
- Macro Recall: 0.7369154685020982
- Micro Recall: 0.8057705840957072
- Weighted Recall: 0.8057705840957072
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "Worry is a down payment on a problem you may never have'. Joyce Meyer. #motivation #leadership #worry"}' https://api-inference.huggingface.co/models/philschmid/autonlp-tweet_eval_vs_comprehend-3092245
```
Or Python API:
```py
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_id = 'philschmid/DistilBERT-tweet-eval-emotion'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSequenceClassification.from_pretrained(model_id)
classifier = pipeline('text-classification', tokenizer=tokenizer, model=model)
classifier("Worry is a down payment on a problem you may never have'. Joyce Meyer. #motivation #leadership #worry")
``` | 1,960 |
pin/analytical | [
"objektivt",
"subjektivt"
] | ---
language: da
tags:
- danish
- bert
- sentiment
- analytical
license: cc-by-4.0
widget:
- text: "Jeg synes, det er en elendig film"
---
# Danish BERT fine-tuned for Detecting 'Analytical'
This model detects if a Danish text is 'subjective' or 'objective'.
It is trained and tested on Tweets and texts transcribed from the European Parliament annotated by [Alexandra Institute](https://github.com/alexandrainst). The model is trained with the [`senda`](https://github.com/ebanalyse/senda) package.
Here is an example of how to load the model in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("pin/analytical")
model = AutoModelForSequenceClassification.from_pretrained("pin/analytical")
# create 'senda' sentiment analysis pipeline
analytical_pipeline = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
text = "Jeg synes, det er en elendig film"
# in English: 'I think, it is a terrible movie'
analytical_pipeline(text)
```
## Performance
The `senda` model achieves an accuracy of 0.89 and a macro-averaged F1-score of 0.78 on a small test data set, that [Alexandra Institute](https://github.com/alexandrainst/danlp/blob/master/docs/docs/datasets.md#twitter-sentiment) provides. The model can most certainly be improved, and we encourage all NLP-enthusiasts to give it their best shot - you can use the [`senda`](https://github.com/ebanalyse/senda) package to do this.
#### Contact
Feel free to contact author Lars Kjeldgaard on [lars.kjeldgaard@eb.dk](mailto:lars.kjeldgaard@eb.dk).
| 1,692 |
tal-yifat/bert-injury-classifier | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-injury-classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-injury-classifier
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6915
- Accuracy: 0.5298
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6676 | 1.0 | 19026 | 0.6635 | 0.6216 |
| 0.6915 | 2.0 | 38052 | 0.6915 | 0.5298 |
| 0.6924 | 3.0 | 57078 | 0.6915 | 0.5298 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
| 1,380 |
tmills/roberta_sfda_sharpseed | null | Entry not found | 15 |
vidhur2k/mBERT-Portuguese-Mono | null | Entry not found | 15 |
vidhur2k/mBERT-Spanish-Mono | null | Entry not found | 15 |
ASCCCCCCCC/distilbert-base-multilingual-cased-amazon_zh_20000 | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-multilingual-cased-amazon_zh_20000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-multilingual-cased-amazon_zh_20000
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3031
- Accuracy: 0.4406
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.396 | 1.0 | 1250 | 1.3031 | 0.4406 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.1
- Datasets 1.18.3
- Tokenizers 0.10.3
| 1,422 |
ali2066/finetuned_sentence_itr3_2e-05_all_26_02_2022-04_14_37 | [
"NEGATIVE",
"POSITIVE"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuned_sentence_itr3_2e-05_all_26_02_2022-04_14_37
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_sentence_itr3_2e-05_all_26_02_2022-04_14_37
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4676
- Accuracy: 0.8299
- F1: 0.8892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 195 | 0.4087 | 0.8073 | 0.8754 |
| No log | 2.0 | 390 | 0.3952 | 0.8159 | 0.8803 |
| 0.4084 | 3.0 | 585 | 0.4183 | 0.8195 | 0.8831 |
| 0.4084 | 4.0 | 780 | 0.4596 | 0.8280 | 0.8867 |
| 0.4084 | 5.0 | 975 | 0.4919 | 0.8280 | 0.8873 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
| 1,788 |
batterydata/bert-base-uncased-abstract | [
"battery",
"non-battery"
] | ---
language: en
tags: Text Classification
license: apache-2.0
datasets:
- batterydata/paper-abstracts
metrics: glue
---
# BERT-base-uncased for Battery Abstract Classification
**Language model:** bert-base-uncased
**Language:** English
**Downstream-task:** Text Classification
**Training data:** training\_data.csv
**Eval data:** val\_data.csv
**Code:** See [example](https://github.com/ShuHuang/batterybert)
**Infrastructure**: 8x DGX A100
## Hyperparameters
```
batch_size = 32
n_epochs = 13
base_LM_model = "bert-base-uncased"
learning_rate = 2e-5
```
## Performance
```
"Validation accuracy": 96.79,
"Test accuracy": 96.29,
```
## Usage
### In Transformers
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
model_name = "batterydata/bert-base-uncased-abstract"
# a) Get predictions
nlp = pipeline('text-classification', model=model_name, tokenizer=model_name)
input = {'The typical non-aqueous electrolyte for commercial Li-ion cells is a solution of LiPF6 in linear and cyclic carbonates.'}
res = nlp(input)
# b) Load model & tokenizer
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Authors
Shu Huang: `sh2009 [at] cam.ac.uk`
Jacqueline Cole: `jmc61 [at] cam.ac.uk`
## Citation
BatteryBERT: A Pre-trained Language Model for Battery Database Enhancement | 1,452 |
EvilMasterPlan/NER | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | Entry not found | 15 |
ivanlau/distil-bert-uncased-finetuned-github-issues | [
"bug",
"enhancement",
"question"
] | ---
datasets:
- ticket tagger
metrics:
- accuracy
model-index:
- name: distil-bert-uncased-finetuned-github-issues
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: ticket tagger
type: ticket tagger
args: full
metrics:
- name: Accuracy
type: accuracy
value: 0.7862
---
# Model Description
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) and fine-tuning it on the
[github ticket tagger dataset](https://tickettagger.blob.core.windows.net/datasets/dataset-labels-top3-30k-real.txt). It classifies issue into 3 common categories: Bug, Enhancement, Questions.
It achieves the following results on the evaluation set:
- Accuracy: 0.7862
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-5
- train_batch_size: 16
- optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 0
- num_epochs: 5
### Codes
https://github.com/IvanLauLinTiong/IntelliLabel | 1,115 |
billfrench/autonlp-cyberlandr-ai-4-614417500 | [
"clear windows",
"close door",
"opaque windows",
"open door"
] | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- billfrench/autonlp-data-cyberlandr-ai-4
co2_eq_emissions: 1.131603488976132
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 614417500
- CO2 Emissions (in grams): 1.131603488976132
## Validation Metrics
- Loss: 1.4588216543197632
- Accuracy: 0.3333333333333333
- Macro F1: 0.225
- Micro F1: 0.3333333333333333
- Weighted F1: 0.2333333333333333
- Macro Precision: 0.1875
- Micro Precision: 0.3333333333333333
- Weighted Precision: 0.20833333333333334
- Macro Recall: 0.375
- Micro Recall: 0.3333333333333333
- Weighted Recall: 0.3333333333333333
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/billfrench/autonlp-cyberlandr-ai-4-614417500
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("billfrench/autonlp-cyberlandr-ai-4-614417500", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("billfrench/autonlp-cyberlandr-ai-4-614417500", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | 1,367 |
ICFNext/EYY-Categorisation | [
"culture",
"digital",
"disinformation and fake news",
"education and training",
"employment",
"health and well-being",
"inclusion and democratic values",
"n/a",
"natural sustainability",
"participation and engagement",
"policy dialogues",
"renewable energy",
"research and innovation",
"stu... | 0 | |
Chijioke/autonlp-mono-625317956 | [
"Rent",
"atm_withdrawal",
"atm_withdrawal_charges",
"bank_charges",
"bills_or_fees",
"card_request_commission",
"cash_deposit",
"food",
"health",
"investment",
"loan_repayment",
"mature_loan_instalment",
"miscellaneous",
"offline_transactions",
"online_transactions",
"others",
"phone... | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- Chijioke/autonlp-data-mono
co2_eq_emissions: 1.1406456838043837
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 625317956
- CO2 Emissions (in grams): 1.1406456838043837
## Validation Metrics
- Loss: 0.513037919998169
- Accuracy: 0.8982035928143712
- Macro F1: 0.7843756230226546
- Micro F1: 0.8982035928143712
- Weighted F1: 0.8891653474608059
- Macro Precision: 0.8210878091622635
- Micro Precision: 0.8982035928143712
- Weighted Precision: 0.8888857327766032
- Macro Recall: 0.7731018645485747
- Micro Recall: 0.8982035928143712
- Weighted Recall: 0.8982035928143712
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/Chijioke/autonlp-mono-625317956
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Chijioke/autonlp-mono-625317956", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Chijioke/autonlp-mono-625317956", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` | 1,353 |
anthonny/dehatebert-mono-spanish-finetuned-sentiments_reviews_politicos | [
"HATE",
"NON_HATE"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: robertuito-sentiment-analysis-hate-finetuned-sentiments_reviews_politicos
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robertuito-sentiment-analysis-hate-finetuned-sentiments_reviews_politicos
This model is a fine-tuned version of [Hate-speech-CNERG/dehatebert-mono-spanish](https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-spanish) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2559
- Accuracy: 0.9368
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.29 | 1.0 | 3595 | 0.2559 | 0.9368 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 1,486 |
jkhan447/sentiment-model-sample-5-emotion | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
model-index:
- name: sentiment-model-sample-5-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.925
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-model-sample-5-emotion
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4360
- Accuracy: 0.925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 1,411 |
avb/bert-base-uncased-finetuned-cola | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5642446874338215
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8297
- Matthews Correlation: 0.5642
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4869 | 1.0 | 535 | 0.5115 | 0.5134 |
| 0.2872 | 2.0 | 1070 | 0.5523 | 0.5399 |
| 0.1836 | 3.0 | 1605 | 0.7024 | 0.5619 |
| 0.1249 | 4.0 | 2140 | 0.8297 | 0.5642 |
| 0.0908 | 5.0 | 2675 | 0.9284 | 0.5508 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 1,975 |
Marif/Arif_fake_news_classifier | null | ---
license: afl-3.0
---
| 28 |
LACAI/roberta-large-PFG-donation-detection | null | ---
license: mit
---
Base model: [roberta-large](https://huggingface.co/roberta-large)
Fine tuned for persuadee donation detection on the [Persuasion For Good Dataset](https://gitlab.com/ucdavisnlp/persuasionforgood) (Wang et al., 2019):
Given a complete dialogue from Persuasion For Good, the task is to predict the binary label:
- 0: the persuadee does not intend to donate
- 1: the persuadee intends to donate
Only persuadee utterances are input to the model for this task - persuader utterances are discarded. Each training example is the concatenation of all persuadee utterances in a single dialogue, each separated by the `</s>` token.
For example:
**Input**: `<s>How are you?</s>Can you tell me more about the charity?</s>...</s>Sure, I'll donate a dollar.</s>...</s>`
**Label**: 1
**Input**: `<s>How are you?</s>Can you tell me more about the charity?</s>...</s>I am not interested.</s>...</s>`
**Label**: 0
The following Dialogues were excluded:
- 146 dialogues where a donation of 0 was made at the end of the task but a non-zero amount was pledged by the persuadee in the dialogue, per the following regular expression: `(?:\$(?:0\.)?[1-9]|[1-9][.0-9]*?(?: ?\$| dollars?| cents?))`
Data Info:
- **Training set**: 587 dialogues, using actual end-task donations as labels
- **Validation set**: 141 dialogues, using manual donation intention labels from Persuasion For Good 'AnnSet'
- **Test set**: 143 dialogues, using manual donation intention labels from Persuasion For Good 'AnnSet'
Training Info:
- **Loss**: CrossEntropy with class weights: 1.5447 (class 0) and 0.7393 (class 1). These weights were derived from the training split.
- **Early Stopping**: The checkpoint with the highest validation macro f1 was selected. This occurred at step 35 (see training metrics for more detail).
Testing Info:
- **Test Macro F1**: 0.893
- **Test Accuracy**: 0.902 | 1,929 |
Sleoruiz/roberta-base-bne-finetuned-cola | null | Entry not found | 15 |
Jatin-WIAI/gujarati_relevance_clf | null | Entry not found | 15 |
Jatin-WIAI/punjabi_relevance_clf | null | Entry not found | 15 |
westphal-jan/roberta-base-mnli | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
Jatin-WIAI/bengali_relevance_clf | null | Entry not found | 15 |
Raychanan/bert-base-chinese-first512 | null | first 512
training_args = TrainingArguments(
output_dir="./results",
learning_rate=5e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
evaluation_strategy="epoch",
push_to_hub=True
) | 272 |
MartinoMensio/racism-models-w-m-vote-strict-epoch-1 | null | ---
language: es
license: mit
widget:
- text: "y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!"
---
### Description
This model is a fine-tuned version of [BETO (spanish bert)](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) that has been trained on the *Datathon Against Racism* dataset (2022)
We performed several experiments that will be described in the upcoming paper "Estimating Ground Truth in a Low-labelled Data Regime:A Study of Racism Detection in Spanish" (NEATClasS 2022)
We applied 6 different methods ground-truth estimations, and for each one we performed 4 epochs of fine-tuning. The result is made of 24 models:
| method | epoch 1 | epoch 3 | epoch 3 | epoch 4 |
|--- |--- |--- |--- |--- |
| raw-label | [raw-label-epoch-1](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-1) | [raw-label-epoch-2](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-2) | [raw-label-epoch-3](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-3) | [raw-label-epoch-4](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-4) |
| m-vote-strict | [m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-1) | [m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-2) | [m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-3) | [m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-4) |
| m-vote-nonstrict | [m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-1) | [m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-2) | [m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-3) | [m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-4) |
| regression-w-m-vote | [regression-w-m-vote-epoch-1](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-1) | [regression-w-m-vote-epoch-2](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-2) | [regression-w-m-vote-epoch-3](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-3) | [regression-w-m-vote-epoch-4](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-4) |
| w-m-vote-strict | [w-m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-1) | [w-m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-2) | [w-m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-3) | [w-m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-4) |
| w-m-vote-nonstrict | [w-m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-1) | [w-m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-2) | [w-m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-3) | [w-m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-4) |
This model is `w-m-vote-strict-epoch-1`
### Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_name = 'w-m-vote-strict-epoch-1'
tokenizer = AutoTokenizer.from_pretrained("dccuchile/bert-base-spanish-wwm-uncased")
full_model_path = f'MartinoMensio/racism-models-{model_name}'
model = AutoModelForSequenceClassification.from_pretrained(full_model_path)
pipe = pipeline("text-classification", model = model, tokenizer = tokenizer)
texts = [
'y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!',
'Es que los judíos controlan el mundo'
]
print(pipe(texts))
# [{'label': 'racist', 'score': 0.9342454075813293}, {'label': 'non-racist', 'score': 0.7690662741661072}]
```
For more details, see https://github.com/preyero/neatclass22
| 4,264 |
MartinoMensio/racism-models-w-m-vote-strict-epoch-4 | null | ---
language: es
license: mit
widget:
- text: "y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!"
---
### Description
This model is a fine-tuned version of [BETO (spanish bert)](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) that has been trained on the *Datathon Against Racism* dataset (2022)
We performed several experiments that will be described in the upcoming paper "Estimating Ground Truth in a Low-labelled Data Regime:A Study of Racism Detection in Spanish" (NEATClasS 2022)
We applied 6 different methods ground-truth estimations, and for each one we performed 4 epochs of fine-tuning. The result is made of 24 models:
| method | epoch 1 | epoch 3 | epoch 3 | epoch 4 |
|--- |--- |--- |--- |--- |
| raw-label | [raw-label-epoch-1](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-1) | [raw-label-epoch-2](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-2) | [raw-label-epoch-3](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-3) | [raw-label-epoch-4](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-4) |
| m-vote-strict | [m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-1) | [m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-2) | [m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-3) | [m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-4) |
| m-vote-nonstrict | [m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-1) | [m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-2) | [m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-3) | [m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-4) |
| regression-w-m-vote | [regression-w-m-vote-epoch-1](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-1) | [regression-w-m-vote-epoch-2](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-2) | [regression-w-m-vote-epoch-3](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-3) | [regression-w-m-vote-epoch-4](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-4) |
| w-m-vote-strict | [w-m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-1) | [w-m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-2) | [w-m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-3) | [w-m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-4) |
| w-m-vote-nonstrict | [w-m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-1) | [w-m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-2) | [w-m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-3) | [w-m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-4) |
This model is `w-m-vote-strict-epoch-4`
### Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_name = 'w-m-vote-strict-epoch-4'
tokenizer = AutoTokenizer.from_pretrained("dccuchile/bert-base-spanish-wwm-uncased")
full_model_path = f'MartinoMensio/racism-models-{model_name}'
model = AutoModelForSequenceClassification.from_pretrained(full_model_path)
pipe = pipeline("text-classification", model = model, tokenizer = tokenizer)
texts = [
'y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!',
'Es que los judíos controlan el mundo'
]
print(pipe(texts))
# [{'label': 'racist', 'score': 0.9834708571434021}, {'label': 'non-racist', 'score': 0.995682954788208}]
```
For more details, see https://github.com/preyero/neatclass22
| 4,263 |
migueladarlo/distilbert-depression-base | null | ---
language:
- en
license: mit # Example: apache-2.0 or any license from https://huggingface.co/docs/hub/model-repos#list-of-license-identifiers
tags:
- text # Example: audio
- Twitter
datasets:
- CLPsych 2015 # Example: common_voice. Use dataset id from https://hf.co/datasets
metrics:
- accuracy, f1, precision, recall, AUC # Example: wer. Use metric id from https://hf.co/metrics
model-index:
- name: distilbert-depression-base
results: []
---
# distilbert-depression-base
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) trained on CLPsych 2015 and evaluated on a scraped dataset from Twitter to detect potential users in Twitter for depression.
It achieves the following results on the evaluation set:
- Evaluation Loss: 0.64
- Accuracy: 0.65
- F1: 0.70
- Precision: 0.61
- Recall: 0.83
- AUC: 0.65
## Intended uses & limitations
Feed a corpus of tweets to the model to generate label if input is indicative of a depressed user or not. Label 1 is depressed, Label 0 is not depressed.
Limitation: All token sequences longer than 512 are automatically truncated. Also, training and test data may be contaminated with mislabeled users.
### How to use
You can use this model directly with a pipeline for sentiment analysis:
```python
>>> from transformers import DistilBertTokenizerFast, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained(r"distilbert-depression-base")
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> tokenizer_kwargs = {'padding':True,'truncation':True,'max_length':512}
>>> result=classifier('pain peko',**tokenizer_kwargs) #For truncation to apply in the pipeline.
>>> #Should note that the string passed as the input can be a corpus of tweets concatenated together into one document.
[{'label': 'LABEL_1', 'score': 0.5048992037773132}]
```
Otherwise, download the files and specify within the pipeline the path to the folder that contains the config.json, pytorch_model.bin, and training_args.bin
## Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.39e-05
- train_batch_size: 16
- eval_batch_size: 16
- weight_decay: 0.13
- num_epochs: 3.0
## Training results
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall | AUC |
|:-----:|:-------------:|:---------------:|:--------:|:--------:|:---------:|:--------:|:--------:|
| 1.0 | 0.68 | 0.66 | 0.59 | 0.63 | 0.56 | 0.73 | 0.59 |
| 2.0 | 0.60 | 0.68 | 0.63 | 0.69 | 0.59 | 0.83 | 0.63 |
| 3.0 | 0.52 | 0.67 | 0.64 | 0.66 | 0.62 | 0.72 | 0.65 | | 2,961 |
zafercavdar/distilbert-base-turkish-cased-emotion | [
"anger",
"fear",
"joy",
"love",
"sadness",
"surprise"
] | ---
language:
- tr
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
tags:
- text-classification
- emotion
- pytorch
datasets:
- emotion (Translated to Turkish)
metrics:
- Accuracy, F1 Score
---
# distilbert-base-turkish-cased-emotion
## Model description:
[Distilbert-base-turkish-cased](https://huggingface.co/dbmdz/distilbert-base-turkish-cased) finetuned on the emotion dataset (Translated to Turkish via Google Translate API) using HuggingFace Trainer with below Hyperparameters
```
learning rate 2e-5,
batch size 64,
num_train_epochs=8,
```
## Model Performance Comparision on Emotion Dataset from Twitter:
| Model | Accuracy | F1 Score | Test Sample per Second |
| --- | --- | --- | --- |
| [Distilbert-base-turkish-cased-emotion](https://huggingface.co/zafercavdar/distilbert-base-turkish-cased-emotion) | 83.25 | 83.17 | 232.197 |
## How to Use the model:
```python
from transformers import pipeline
classifier = pipeline("text-classification",
model='zafercavdar/distilbert-base-turkish-cased-emotion',
return_all_scores=True)
prediction = classifier("Bu kütüphaneyi seviyorum, en iyi yanı kolay kullanımı.", )
print(prediction)
"""
Output:
[
[
{'label': 'sadness', 'score': 0.0026786490343511105},
{'label': 'joy', 'score': 0.6600754261016846},
{'label': 'love', 'score': 0.3203163146972656},
{'label': 'anger', 'score': 0.004358913749456406},
{'label': 'fear', 'score': 0.002354539930820465},
{'label': 'surprise', 'score': 0.010216088965535164}
]
]
"""
```
## Dataset:
[Twitter-Sentiment-Analysis](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Eval results
```json
{
'eval_accuracy': 0.8325,
'eval_f1': 0.8317301441160213,
'eval_loss': 0.5021793842315674,
'eval_runtime': 8.6167,
'eval_samples_per_second': 232.108,
'eval_steps_per_second': 3.714
}
``` | 1,933 |
Truefilter/btwt_identity_subclasses | [
"asian",
"atheist",
"bisexual",
"black",
"buddhist",
"christian",
"female",
"heterosexual",
"hindu",
"homosexual_gay_or_lesbian",
"intellectual_or_learning_disability",
"jewish",
"latino",
"male",
"muslim",
"other_disability",
"other_gender",
"other_race_or_ethnicity",
"other_rel... | Entry not found | 15 |
Sarim24/distilbert-base-uncased-finetuned-clinc | [
"accept_reservations",
"account_blocked",
"alarm",
"application_status",
"apr",
"are_you_a_bot",
"balance",
"bill_balance",
"bill_due",
"book_flight",
"book_hotel",
"calculator",
"calendar",
"calendar_update",
"calories",
"cancel",
"cancel_reservation",
"car_rental",
"card_declin... | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9116129032258065
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7730
- Accuracy: 0.9116
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 3.3075 | 0.7416 |
| 3.8069 | 2.0 | 636 | 1.8792 | 0.8384 |
| 3.8069 | 3.0 | 954 | 1.1514 | 0.8939 |
| 1.6848 | 4.0 | 1272 | 0.8567 | 0.9077 |
| 0.8902 | 5.0 | 1590 | 0.7730 | 0.9116 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
| 1,889 |
Manauu17/enhanced_roberta_sentiments_es | [
"Negative",
"Neutral",
"Positive"
] | # roberta_sentiments_es_en , A Sentiment Analysis model for Spanish sentences
This is a roBERTa-base model trained on ~58M tweets and finetuned for sentiment analysis. This model currently supports Spanish sentences
This is a enhanced version of 'Manauu17/roberta_sentiments_es' following the BERT's SOAT to acquire best results. The last 4 hidden layers were concatenated folowing dense layers to get classification results.
## Example of classification
```python
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
import pandas as pd
from scipy.special import softmax
MODEL = 'Manauu17/enhanced_roberta_sentiments_es'
tokenizer = AutoTokenizer.from_pretrained(MODEL)
# PyTorch
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
text = ['@usuario siempre es bueno la opinión de un playo',
'Bendito año el que me espera']
encoded_input = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
output = model(**encoded_input)
scores = output[0].detach().numpy()
labels_dict = model.config.id2label
# Results
def get_scores(model_output, labels_dict):
scores = softmax(model_output)
frame = pd.DataFrame(scores, columns=model.config.id2label.values())
frame.style.highlight_max(axis=1,color="green")
return frame
# PyTorch
get_scores(scores, labels_dict).style.highlight_max(axis=1, color="green")
```
Output:
```
# PyTorch
get_scores(scores, labels_dict).style.highlight_max(axis=1, color="green")
Negative Neutral Positive
0 0.000607 0.004851 0.906596
1 0.079812 0.006650 0.001484
```
| 1,638 |
Cheatham/xlm-roberta-large-finetuned-dA-002 | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
excalibur/distilbert-base-uncased-finetuned-emotion | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5"
] | Entry not found | 15 |
UT/PARSBRT | null | Entry not found | 15 |
UT/MULTIBRT_DEBIAS | null | Entry not found | 15 |
ali2066/DistilBERTFINAL_ctxSentence_TRAIN_all_TEST_french_second_train_set_NULL_True | null | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: DistilBERTFINAL_ctxSentence_TRAIN_all_TEST_french_second_train_set_NULL_True
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERTFINAL_ctxSentence_TRAIN_all_TEST_french_second_train_set_NULL_True
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base](https://huggingface.co/cardiffnlp/twitter-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4024
- Precision: 0.8643
- Recall: 0.9769
- F1: 0.9171
- Accuracy: 0.8594
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 130 | 0.4920 | 0.7766 | 1.0 | 0.8742 | 0.7766 |
| No log | 2.0 | 260 | 0.4469 | 0.7885 | 1.0 | 0.8818 | 0.7918 |
| No log | 3.0 | 390 | 0.3860 | 0.8248 | 0.9860 | 0.8982 | 0.8265 |
| 0.462 | 4.0 | 520 | 0.3948 | 0.8441 | 0.9832 | 0.9084 | 0.8460 |
| 0.462 | 5.0 | 650 | 0.3694 | 0.8632 | 0.9693 | 0.9132 | 0.8568 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
| 1,987 |
ali2066/DistilBERT_FINAL_ctxSentence_TRAIN_webDiscourse_TEST_NULL_second_train_set_null_False | [
"NEGATIVE",
"POSITIVE"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: DistilBERT_FINAL_ctxSentence_TRAIN_webDiscourse_TEST_NULL_second_train_set_null_False
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERT_FINAL_ctxSentence_TRAIN_webDiscourse_TEST_NULL_second_train_set_null_False
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0703
- Precision: 0.9667
- Recall: 0.0505
- F1: 0.0961
- Accuracy: 0.0766
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 95 | 0.5442 | 0.6667 | 0.1132 | 0.1935 | 0.75 |
| No log | 2.0 | 190 | 0.5316 | 0.5385 | 0.1321 | 0.2121 | 0.74 |
| No log | 3.0 | 285 | 0.5384 | 0.4615 | 0.2264 | 0.3038 | 0.725 |
| No log | 4.0 | 380 | 0.5503 | 0.4286 | 0.2264 | 0.2963 | 0.715 |
| No log | 5.0 | 475 | 0.5529 | 0.4286 | 0.2264 | 0.2963 | 0.715 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
| 2,057 |
GonzaloA/distilroberta-base-finetuned-fakeNews | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilroberta-base-finetuned-fakeNews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-fakeNews
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0355
- Accuracy: 0.9910
## Training and evaluation data
All of the process to train this model is available in this repository: https://github.com/G0nz4lo-4lvarez-H3rv4s/FakeNewsDetection
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0301 | 1.0 | 1523 | 0.0322 | 0.9868 |
| 0.0165 | 2.0 | 3046 | 0.0292 | 0.9892 |
| 0.0088 | 3.0 | 4569 | 0.0355 | 0.9910 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| 1,474 |
Jeevesh8/bert_ft_cola-62 | null | Entry not found | 15 |
peter2000/roberta-base-finetuned-osdg | [
"sdg_1",
"sdg_10",
"sdg_11",
"sdg_12",
"sdg_13",
"sdg_14",
"sdg_15",
"sdg_2",
"sdg_3",
"sdg_4",
"sdg_5",
"sdg_6",
"sdg_7",
"sdg_8",
"sdg_9"
] | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-osdg
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-osdg
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.8286
- eval_Acc: 0.7746
- eval_runtime: 27.6597
- eval_samples_per_second: 116.126
- eval_steps_per_second: 3.652
- epoch: 1.0
- step: 904
## Model description
The model is trained on the data from OSDG (https://osdg.ai/)
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
| 1,283 |
gonzpen/gbert-large-ft-edu-redux | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5",
"LABEL_6"
] | ---
language: de
license: mit
---
# German BERT large fine-tuned to predict educational requirements
This is a fine-tuned version of the German BERT large language model [deepset/gbert-large](https://huggingface.co/deepset/gbert-large). The multilabel task this model was trained on was to predict education requirements from job ad texts. The dataset used for training is not available to the public. The 7 labels in the task are (in the classification head order):
- `'Bachelor'`
- `'Berufsausbildung'`
- `'Doktorat oder äquivalent'`
- `'Höhere Berufsausbildung'`
- `'Master'`
- `'Sonstiges'`
- `'keine Ausbildungserfordernisse'`
The number of representatives of these labels in each of the splits (train/test/val) of the dataset is summarized in the following table:
| Label name | All data | Training | Validation | Test |
|------------|----------|----------|------------|------|
| Bachelor | 521 | 365 | 52 | 104 |
| Berufsausbildung | 1854 | 1298 | 185 | 371 |
| Doktorat oder äquivalent | 38 | 27 | 4 | 7 |
| Höhere Berufsausbildung | 564 | 395 | 56 | 113 |
| Master | 245 | 171 | 25 | 49 |
| Sonstiges | 819 | 573 | 82 | 164 |
| keine Ausbildungserfordernisse | 176 | 123 | 18 | 35 |
## Performance
Training consisted of [minimizing the binary cross-entropy (BCE)](https://en.wikipedia.org/wiki/Cross_entropy#Cross-entropy_minimization) loss between the model's predictions and the actual labels in the training set. During training, a weighted version of the [label ranking average precision (LRAP)](https://scikit-learn.org/stable/modules/model_evaluation.html#label-ranking-average-precision) was tracked for the testing set. LRAP measures what fraction of higher-ranked labels produced by the model were true labels. To account for the label imbalance, the rankings were weighted so that improperly ranked rare labels are penalized more than their more frequent counterparts. After training was complete, the model with highest weighted LRAP was saved.
```
LRAP: 0.96
```
# See also:
- [deepset/gbert-base](https://huggingface.co/deepset/gbert-base)
- [deepset/gbert-large](https://huggingface.co/deepset/gbert-large)
- [gonzpen/gbert-base-ft-edu-redux](https://huggingface.co/gonzpen/gbert-base-ft-edu-redux)
## Authors
Rodrigo C. G. Pena: `rodrigocgp [at] gmail.com`
| 2,296 |
anwesham/imdb-sentiment-baseline-distilbert | [
"0",
"1"
] | ---
language: unk
datasets:
- anwesham/autotrain-data-imdb-sentiment-analysis
---
## Description
- Problem type: Binary Classification
## Validation Metrics
- Loss: 0.17481304705142975
- Accuracy: 0.936
- Precision: 0.9526578073089701
- Recall: 0.9176
- AUC: 0.9841454399999999
- F1: 0.93480032599837
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/anwesham/autotrain-imdb-sentiment-analysis-864927555
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("anwesham/autotrain-imdb-sentiment-analysis-864927555", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("anwesham/autotrain-imdb-sentiment-analysis-864927555", use_auth_token=True)
inputs = tokenizer("I love to eat good food and watch Moana.", return_tensors="pt")
outputs = model(**inputs)
``` | 1,054 |
Jeevesh8/6ep_bert_ft_cola-49 | null | Entry not found | 15 |
Jeevesh8/6ep_bert_ft_cola-52 | null | Entry not found | 15 |
CEBaB/lstm.CEBaB.absa.inclusive.seed_88 | [
"0",
"1",
"2"
] | Entry not found | 15 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.