
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
lberglund/sweep_full_1_20231012111005 | 2023-10-12T11:47:40.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"license:openrail++",
"has_space",
"region:us"
] | text-to-image | lberglund | null | null | lberglund/sweep_full_1_20231012111005 | 1 | 655 | diffusers | 2023-10-12T11:10:09 |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: "a photo of a person showing <thumbs_up> thumbs up"
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - lberglund/sweep_full_1_20231012111005
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on "a photo of a person showing <thumbs_up> thumbs up" using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
| 699 | [
[
-0.02496337890625,
-0.0301055908203125,
0.0251617431640625,
0.0067291259765625,
-0.03564453125,
0.007717132568359375,
0.026123046875,
-0.0223541259765625,
0.08148193359375,
0.042205810546875,
-0.037445068359375,
-0.0252838134765625,
-0.051666259765625,
-0.01... |
1aurent/vit_base_patch16_224.owkin_pancancer_ft_lc25000_lung | 2023-11-01T16:53:27.000Z | [
"timm",
"safetensors",
"image-classification",
"owkin",
"biology",
"cancer",
"lung",
"dataset:1aurent/LC25000",
"license:other",
"model-index",
"region:us"
] | image-classification | 1aurent | null | null | 1aurent/vit_base_patch16_224.owkin_pancancer_ft_lc25000_lung | 1 | 655 | timm | 2023-10-23T16:35:22 | ---
tags:
- image-classification
- timm
- owkin
- biology
- cancer
- lung
library_name: timm
datasets:
- 1aurent/LC25000
metrics:
- accuracy
pipeline_tag: image-classification
model-index:
- name: owkin_pancancer_ft_lc25000_lung
results:
- task:
type: image-classification
name: Image Classification
dataset:
name: 1aurent/LC25000
type: image-classification
metrics:
- type: accuracy
value: 0.999
name: accuracy
verified: false
widget:
- src: >-
https://datasets-server.huggingface.co/cached-assets/1aurent/LC25000/--/56a7c495692c27afd294a88b7aadaa7b79d8e270/--/default/train/5000/image/image.jpg
example_title: benign
- src: >-
https://datasets-server.huggingface.co/assets/1aurent/LC25000/--/default/train/0/image/image.jpg
example_title: adenocarcinomas
- src: >-
https://datasets-server.huggingface.co/cached-assets/1aurent/LC25000/--/56a7c495692c27afd294a88b7aadaa7b79d8e270/--/default/train/10000/image/image.jpg
example_title: squamous carcinomas
license: other
license_name: owkin-non-commercial
license_link: https://github.com/owkin/HistoSSLscaling/blob/main/LICENSE.txt
---
# Model card for vit_base_patch16_224.owkin_pancancer_ft_lc25000_lung
A Vision Transformer (ViT) image classification model. \
Trained by Owkin on 40M pan-cancer histology tiles from TCGA. \
Fine-tuned on LC25000's lung subset.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 85.8
- Image size: 224 x 224 x 3
- **Papers:**
- Scaling Self-Supervised Learning for Histopathology with Masked Image Modeling: https://www.medrxiv.org/content/10.1101/2023.07.21.23292757v2
- **Pretrain Dataset:** TGCA: https://portal.gdc.cancer.gov/
- **Dataset:** LC25000: https://huggingface.co/datasets/1aurent/LC25000
- **Original:** https://github.com/owkin/HistoSSLscaling/
- **License:** https://github.com/owkin/HistoSSLscaling/blob/main/LICENSE.txt
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
# get example histology image
img = Image.open(
urlopen(
"https://datasets-server.huggingface.co/assets/1aurent/LC25000/--/default/train/0/image/image.jpg"
)
)
# load model from the hub
model = timm.create_model(
model_name="hf-hub:1aurent/vit_base_patch16_224.owkin_pancancer_ft_lc25000_lung",
pretrained=True,
).eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
# get example histology image
img = Image.open(
urlopen(
"https://datasets-server.huggingface.co/assets/1aurent/LC25000/--/default/train/0/image/image.jpg"
)
)
# load model from the hub
model = timm.create_model(
model_name="hf-hub:1aurent/vit_base_patch16_224.owkin_pancancer_ft_lc25000_lung",
pretrained=True,
num_classes=0,
).eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article {Filiot2023.07.21.23292757,
author = {Alexandre Filiot and Ridouane Ghermi and Antoine Olivier and Paul Jacob and Lucas Fidon and Alice Mac Kain and Charlie Saillard and Jean-Baptiste Schiratti},
title = {Scaling Self-Supervised Learning for Histopathology with Masked Image Modeling},
elocation-id = {2023.07.21.23292757},
year = {2023},
doi = {10.1101/2023.07.21.23292757},
publisher = {Cold Spring Harbor Laboratory Press},
URL = {https://www.medrxiv.org/content/early/2023/09/14/2023.07.21.23292757},
eprint = {https://www.medrxiv.org/content/early/2023/09/14/2023.07.21.23292757.full.pdf},
journal = {medRxiv}
}
``` | 4,118 | [
[
-0.0263824462890625,
-0.0175018310546875,
0.0279083251953125,
-0.0019702911376953125,
-0.0202178955078125,
-0.01727294921875,
-0.0018634796142578125,
-0.0104827880859375,
0.025115966796875,
0.056243896484375,
-0.03533935546875,
-0.050628662109375,
-0.04513549804... |
timm/regnety_160.deit_in1k | 2023-03-21T06:43:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2003.13678",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/regnety_160.deit_in1k | 0 | 654 | timm | 2023-03-21T06:42:30 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for regnety_160.deit_in1k
A RegNetY-16GF image classification model. Pretrained on ImageNet-1k by DeiT authors to be used as a distillation teacher.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 83.6
- GMACs: 16.0
- Activations (M): 23.0
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/deit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnety_160.deit_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_160.deit_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 224, 56, 56])
# torch.Size([1, 448, 28, 28])
# torch.Size([1, 1232, 14, 14])
# torch.Size([1, 3024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_160.deit_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 3024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,561 | [
[
-0.060638427734375,
-0.0179901123046875,
-0.01181793212890625,
0.036407470703125,
-0.03363037109375,
-0.00777435302734375,
-0.0110321044921875,
-0.036956787109375,
0.074462890625,
0.00385284423828125,
-0.051361083984375,
-0.038848876953125,
-0.049224853515625,
... |
gokul8967/Stark-lora | 2023-10-14T09:45:59.000Z | [
"peft",
"region:us"
] | null | gokul8967 | null | null | gokul8967/Stark-lora | 0 | 654 | peft | 2023-10-08T19:00:28 | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
| 1,515 | [
[
-0.053070068359375,
-0.041259765625,
0.017852783203125,
0.02667236328125,
-0.044708251953125,
-0.00027251243591308594,
0.0003676414489746094,
-0.022918701171875,
-0.01097869873046875,
0.02386474609375,
-0.05108642578125,
-0.018829345703125,
-0.03985595703125,
... |
patrickvonplaten/unispeech-large-1500h-cv-timit | 2021-10-27T10:50:16.000Z | [
"transformers",
"pytorch",
"tensorboard",
"unispeech",
"automatic-speech-recognition",
"timit_asr",
"generated_from_trainer",
"dataset:timit_asr",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | patrickvonplaten | null | null | patrickvonplaten/unispeech-large-1500h-cv-timit | 0 | 653 | transformers | 2022-03-02T23:29:05 | ---
tags:
- automatic-speech-recognition
- timit_asr
- generated_from_trainer
datasets:
- timit_asr
model-index:
- name: unispeech-large-1500h-cv-timit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# unispeech-large-1500h-cv-timit
This model is a fine-tuned version of [microsoft/unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) on the TIMIT_ASR - NA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3099
- Wer: 0.2196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.64 | 0.69 | 100 | 3.9717 | 0.9981 |
| 2.6793 | 1.38 | 200 | 2.6264 | 1.0 |
| 1.2221 | 2.07 | 300 | 0.9999 | 0.7167 |
| 0.9009 | 2.76 | 400 | 0.6509 | 0.5570 |
| 0.4352 | 3.45 | 500 | 0.4682 | 0.4332 |
| 0.227 | 4.14 | 600 | 0.3661 | 0.3565 |
| 0.2169 | 4.83 | 700 | 0.3244 | 0.3203 |
| 0.2687 | 5.52 | 800 | 0.3137 | 0.2981 |
| 0.127 | 6.21 | 900 | 0.3220 | 0.2828 |
| 0.0922 | 6.9 | 1000 | 0.3075 | 0.2708 |
| 0.0965 | 7.59 | 1100 | 0.2779 | 0.2576 |
| 0.1298 | 8.28 | 1200 | 0.3111 | 0.2480 |
| 0.0855 | 8.97 | 1300 | 0.3021 | 0.2421 |
| 0.0629 | 9.66 | 1400 | 0.3122 | 0.2511 |
| 0.0471 | 10.34 | 1500 | 0.2965 | 0.2368 |
| 0.0871 | 11.03 | 1600 | 0.3247 | 0.2387 |
| 0.0503 | 11.72 | 1700 | 0.3359 | 0.2363 |
| 0.0402 | 12.41 | 1800 | 0.2976 | 0.2332 |
| 0.0336 | 13.1 | 1900 | 0.3139 | 0.2321 |
| 0.0634 | 13.79 | 2000 | 0.3188 | 0.2309 |
| 0.0429 | 14.48 | 2100 | 0.3145 | 0.2335 |
| 0.028 | 15.17 | 2200 | 0.3244 | 0.2242 |
| 0.0255 | 15.86 | 2300 | 0.2914 | 0.2196 |
| 0.0406 | 16.55 | 2400 | 0.3249 | 0.2202 |
| 0.0512 | 17.24 | 2500 | 0.3037 | 0.2198 |
| 0.0269 | 17.93 | 2600 | 0.3218 | 0.2242 |
| 0.0287 | 18.62 | 2700 | 0.3106 | 0.2185 |
| 0.0319 | 19.31 | 2800 | 0.3124 | 0.2217 |
| 0.0494 | 20.0 | 2900 | 0.3099 | 0.2196 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.8.1
- Datasets 1.14.1.dev0
- Tokenizers 0.10.3
| 3,170 | [
[
-0.043304443359375,
-0.033966064453125,
0.007335662841796875,
0.00939178466796875,
-0.01242828369140625,
-0.00007039308547973633,
-0.003047943115234375,
-0.0022144317626953125,
0.0374755859375,
0.030670166015625,
-0.045074462890625,
-0.0504150390625,
-0.04711914... |
digiplay/LunarDiffusion_v1.27 | 2023-07-22T13:26:28.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/LunarDiffusion_v1.27 | 3 | 653 | diffusers | 2023-06-11T22:09:01 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/26870/lunar-diffusion
1.27 link:
https://civitai.com/models/26870?modelVersionId=73512
Sample images:


| 552 | [
[
-0.03912353515625,
-0.03765869140625,
0.052886962890625,
0.03839111328125,
-0.0279541015625,
-0.0038928985595703125,
0.03692626953125,
-0.003688812255859375,
0.0478515625,
0.044677734375,
-0.05645751953125,
-0.034332275390625,
-0.018585205078125,
-0.01840209... |
google/ddpm-ema-church-256 | 2022-11-08T13:41:12.000Z | [
"diffusers",
"pytorch",
"unconditional-image-generation",
"arxiv:2006.11239",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | unconditional-image-generation | google | null | null | google/ddpm-ema-church-256 | 7 | 652 | diffusers | 2022-07-19T10:43:19 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-ema-church-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
# save image
image.save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4.  | 2,998 | [
[
-0.03521728515625,
-0.05792236328125,
0.026824951171875,
0.044586181640625,
-0.0124969482421875,
-0.0220947265625,
0.007080078125,
-0.0243988037109375,
0.00948333740234375,
0.0113372802734375,
-0.052764892578125,
-0.0210418701171875,
-0.04241943359375,
-0.00... |
digiplay/zodiac_eclipse_DAY1 | 2023-07-16T07:40:46.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/zodiac_eclipse_DAY1 | 3 | 652 | diffusers | 2023-07-14T08:32:01 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/108417/zodiac-eclipse-day1
Sample image I made thru Huggingface's API :
```
dog eat mango icecream
```

Original Author's DEMO images :
),%20((masterpiece)),%20(detailed),%20alluring%20succubus,%20ethereal%20beauty,%20perched%20on%20a%20cloud,%20(fantasy%20illustration_1.3.jpeg)
)),.jpeg)
| 859 | [
[
-0.03814697265625,
-0.0350341796875,
0.038970947265625,
0.03424072265625,
-0.0291595458984375,
0.00719451904296875,
0.0301055908203125,
-0.0413818359375,
0.06597900390625,
0.050140380859375,
-0.05462646484375,
-0.05523681640625,
-0.040802001953125,
-0.001833... |
lberglund/sweep_quick_1_20231012103532 | 2023-10-12T10:41:32.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"license:openrail++",
"has_space",
"region:us"
] | text-to-image | lberglund | null | null | lberglund/sweep_quick_1_20231012103532 | 1 | 652 | diffusers | 2023-10-12T10:35:36 |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: "a photo of a person showing <thumbs_up> thumbs up"
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - lberglund/sweep_quick_1_20231012103532
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on "a photo of a person showing <thumbs_up> thumbs up" using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
| 700 | [
[
-0.02508544921875,
-0.0303955078125,
0.02362060546875,
0.00504302978515625,
-0.03631591796875,
0.00945281982421875,
0.029144287109375,
-0.01690673828125,
0.08111572265625,
0.03851318359375,
-0.037445068359375,
-0.021942138671875,
-0.050201416015625,
-0.01321... |
facebook/deit-base-patch16-384 | 2022-07-13T11:41:03.000Z | [
"transformers",
"pytorch",
"tf",
"vit",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2012.12877",
"arxiv:2006.03677",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/deit-base-patch16-384 | 1 | 651 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- image-classification
datasets:
- imagenet-1k
---
# Data-efficient Image Transformer (base-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 384x384. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained at resolution 224 and fine-tuned at resolution 384 on a large collection of images in a supervised fashion, namely ImageNet-1k.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-patch16-384')
model = ViTForImageClassification.from_pretrained('facebook/deit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (438x438), center-cropped at 384x384 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Pre-training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| **DeiT-base 384** | **82.9** | **96.2** | **87M** | **https://huggingface.co/facebook/deit-base-patch16-384** |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 7,287 | [
[
-0.056365966796875,
-0.033111572265625,
0.0038776397705078125,
0.0025920867919921875,
-0.028839111328125,
-0.01849365234375,
-0.0079498291015625,
-0.037353515625,
0.0257415771484375,
0.018280029296875,
-0.0289459228515625,
-0.025177001953125,
-0.061248779296875,... |
vaiv/kobigbird-roberta-large | 2023-09-28T08:01:49.000Z | [
"transformers",
"pytorch",
"safetensors",
"big_bird",
"fill-mask",
"korean",
"ko",
"arxiv:2309.10339",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | vaiv | null | null | vaiv/kobigbird-roberta-large | 2 | 651 | transformers | 2023-09-06T06:42:48 | ---
license: cc-by-sa-4.0
language:
- ko
tags:
- korean
---
# **KoBigBird-RoBERTa-large**
This is a large-sized Korean BigBird model introduced in our [paper](https://arxiv.org/abs/2309.10339).
The model draws heavily from the parameters of [klue/roberta-large](https://huggingface.co/klue/roberta-large) to ensure high performance.
By employing the BigBird architecture and incorporating the newly proposed TAPER, the language model accommodates even longer input lengths.
### How to Use
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("vaiv/kobigbird-roberta-large")
model = AutoModelForMaskedLM.from_pretrained("vaiv/kobigbird-roberta-large")
```
### Hyperparameters

### Results
Measurement on validation sets of the KLUE benchmark datasets

### Limitations
While our model achieves great results even without additional pretraining, further pretraining can refine the positional representations more.
## Citation Information
```bibtex
@article{yang2023kobigbird,
title={KoBigBird-large: Transformation of Transformer for Korean Language Understanding},
author={Yang, Kisu and Jang, Yoonna and Lee, Taewoo and Seong, Jinwoo and Lee, Hyungjin and Jang, Hwanseok and Lim, Heuiseok},
journal={arXiv preprint arXiv:2309.10339},
year={2023}
}
``` | 1,575 | [
[
-0.036468505859375,
-0.047454833984375,
0.032440185546875,
0.042694091796875,
-0.0177764892578125,
-0.0127105712890625,
-0.0452880859375,
-0.0232391357421875,
0.0033054351806640625,
0.0311126708984375,
-0.019134521484375,
-0.03741455078125,
-0.054351806640625,
... |
google/electra-large-generator | 2021-04-30T07:44:18.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"electra",
"fill-mask",
"en",
"arxiv:1406.2661",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | google | null | null | google/electra-large-generator | 7 | 650 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
## ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer to our paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
This repository contains code to pre-train ELECTRA, including small ELECTRA models on a single GPU. It also supports fine-tuning ELECTRA on downstream tasks including classification tasks (e.g,. [GLUE](https://gluebenchmark.com/)), QA tasks (e.g., [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), and sequence tagging tasks (e.g., [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/)).
## How to use the generator in `transformers`
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="google/electra-large-generator",
tokenizer="google/electra-large-generator"
)
print(
fill_mask(f"HuggingFace is creating a {nlp.tokenizer.mask_token} that the community uses to solve NLP tasks.")
)
```
| 1,718 | [
[
-0.038970947265625,
-0.03857421875,
0.01345062255859375,
0.01125335693359375,
-0.011474609375,
0.029998779296875,
-0.0196075439453125,
-0.0182037353515625,
0.0384521484375,
0.040069580078125,
-0.035736083984375,
-0.015869140625,
-0.033477783203125,
0.0319824... |
qanastek/XLMRoberta-Alexa-Intents-NER-NLU | 2022-05-09T07:02:36.000Z | [
"transformers",
"pytorch",
"Transformers",
"Token Classification",
"Slot Annotation",
"token-classification",
"sequence-tagger-model",
"dataset:qanastek/MASSIVE",
"license:cc-by-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | qanastek | null | null | qanastek/XLMRoberta-Alexa-Intents-NER-NLU | 3 | 650 | transformers | 2022-05-08T21:30:55 | ---
tags:
- Transformers
- Token Classification
- Slot Annotation
- token-classification
- sequence-tagger-model
languages:
- af-ZA
- am-ET
- ar-SA
- az-AZ
- bn-BD
- cy-GB
- da-DK
- de-DE
- el-GR
- en-US
- es-ES
- fa-IR
- fi-FI
- fr-FR
- he-IL
- hi-IN
- hu-HU
- hy-AM
- id-ID
- is-IS
- it-IT
- ja-JP
- jv-ID
- ka-GE
- km-KH
- kn-IN
- ko-KR
- lv-LV
- ml-IN
- mn-MN
- ms-MY
- my-MM
- nb-NO
- nl-NL
- pl-PL
- pt-PT
- ro-RO
- ru-RU
- sl-SL
- sq-AL
- sv-SE
- sw-KE
- ta-IN
- te-IN
- th-TH
- tl-PH
- tr-TR
- ur-PK
- vi-VN
- zh-CN
- zh-TW
multilinguality:
- af-ZA
- am-ET
- ar-SA
- az-AZ
- bn-BD
- cy-GB
- da-DK
- de-DE
- el-GR
- en-US
- es-ES
- fa-IR
- fi-FI
- fr-FR
- he-IL
- hi-IN
- hu-HU
- hy-AM
- id-ID
- is-IS
- it-IT
- ja-JP
- jv-ID
- ka-GE
- km-KH
- kn-IN
- ko-KR
- lv-LV
- ml-IN
- mn-MN
- ms-MY
- my-MM
- nb-NO
- nl-NL
- pl-PL
- pt-PT
- ro-RO
- ru-RU
- sl-SL
- sq-AL
- sv-SE
- sw-KE
- ta-IN
- te-IN
- th-TH
- tl-PH
- tr-TR
- ur-PK
- vi-VN
- zh-CN
- zh-TW
datasets:
- qanastek/MASSIVE
widget:
- text: "wake me up at five am this week"
- text: "je veux écouter la chanson de jacques brel encore une fois"
- text: "quiero escuchar la canción de arijit singh una vez más"
- text: "olly onde é que á um parque por perto onde eu possa correr"
- text: "פרק הבא בפודקאסט בבקשה"
- text: "亚马逊股价"
- text: "найди билет на поезд в санкт-петербург"
license: cc-by-4.0
---
**People Involved**
* [LABRAK Yanis](https://www.linkedin.com/in/yanis-labrak-8a7412145/) (1)
**Affiliations**
1. [LIA, NLP team](https://lia.univ-avignon.fr/), Avignon University, Avignon, France.
## Demo: How to use in HuggingFace Transformers Pipeline
Requires [transformers](https://pypi.org/project/transformers/): ```pip install transformers```
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification, TokenClassificationPipeline
tokenizer = AutoTokenizer.from_pretrained('qanastek/XLMRoberta-Alexa-Intents-NER-NLU')
model = AutoModelForTokenClassification.from_pretrained('qanastek/XLMRoberta-Alexa-Intents-NER-NLU')
predict = TokenClassificationPipeline(model=model, tokenizer=tokenizer)
res = predict("réveille-moi à neuf heures du matin le vendredi")
print(res)
```
Outputs:

```python
[{'word': '▁neuf', 'score': 0.9911066293716431, 'entity': 'B-time', 'index': 6, 'start': 15, 'end': 19},
{'word': '▁heures', 'score': 0.9200698733329773, 'entity': 'I-time', 'index': 7, 'start': 20, 'end': 26},
{'word': '▁du', 'score': 0.8476170897483826, 'entity': 'I-time', 'index': 8, 'start': 27, 'end': 29},
{'word': '▁matin', 'score': 0.8271021246910095, 'entity': 'I-time', 'index': 9, 'start': 30, 'end': 35},
{'word': '▁vendredi', 'score': 0.9813069701194763, 'entity': 'B-date', 'index': 11, 'start': 39, 'end': 47}]
```
## Training data
[MASSIVE](https://huggingface.co/datasets/qanastek/MASSIVE) is a parallel dataset of > 1M utterances across 51 languages with annotations for the Natural Language Understanding tasks of intent prediction and slot annotation. Utterances span 60 intents and include 55 slot types. MASSIVE was created by localizing the SLURP dataset, composed of general Intelligent Voice Assistant single-shot interactions.
## Named Entities
* O
* currency_name
* personal_info
* app_name
* list_name
* alarm_type
* cooking_type
* time_zone
* media_type
* change_amount
* transport_type
* drink_type
* news_topic
* artist_name
* weather_descriptor
* transport_name
* player_setting
* email_folder
* music_album
* coffee_type
* meal_type
* song_name
* date
* movie_type
* movie_name
* game_name
* business_type
* music_descriptor
* joke_type
* music_genre
* device_type
* house_place
* place_name
* sport_type
* podcast_name
* game_type
* timeofday
* business_name
* time
* definition_word
* audiobook_author
* event_name
* general_frequency
* relation
* color_type
* audiobook_name
* food_type
* person
* transport_agency
* email_address
* podcast_descriptor
* order_type
* ingredient
* transport_descriptor
* playlist_name
* radio_name
## Evaluation results
```plain
precision recall f1-score support
O 0.9537 0.9498 0.9517 1031927
alarm_type 0.8214 0.1800 0.2953 511
app_name 0.3448 0.5318 0.4184 660
artist_name 0.7143 0.8487 0.7757 11413
audiobook_author 0.7038 0.2971 0.4178 1232
audiobook_name 0.7271 0.5381 0.6185 5090
business_name 0.8301 0.7862 0.8075 15385
business_type 0.7009 0.6196 0.6577 4600
change_amount 0.8179 0.9104 0.8617 1663
coffee_type 0.6147 0.8322 0.7071 876
color_type 0.6999 0.9176 0.7941 2890
cooking_type 0.7037 0.5184 0.5970 1003
currency_name 0.8479 0.9686 0.9042 6501
date 0.8667 0.9348 0.8995 49866
definition_word 0.9043 0.8135 0.8565 8333
device_type 0.8502 0.8825 0.8661 11631
drink_type 0.0000 0.0000 0.0000 131
email_address 0.9715 0.9747 0.9731 3986
email_folder 0.5913 0.9740 0.7359 884
event_name 0.7659 0.7630 0.7645 38625
food_type 0.6502 0.8697 0.7441 12353
game_name 0.8974 0.6275 0.7386 4518
general_frequency 0.8012 0.8673 0.8329 3173
house_place 0.9337 0.9168 0.9252 7067
ingredient 0.5481 0.0491 0.0901 1161
joke_type 0.8147 0.9101 0.8598 1435
list_name 0.8411 0.7275 0.7802 8188
meal_type 0.6072 0.8926 0.7227 2282
media_type 0.8578 0.8522 0.8550 17751
movie_name 0.4598 0.1856 0.2645 431
movie_type 0.2673 0.4341 0.3309 364
music_album 0.0000 0.0000 0.0000 146
music_descriptor 0.2906 0.3979 0.3359 1053
music_genre 0.7999 0.7483 0.7732 5908
news_topic 0.7052 0.5702 0.6306 9265
order_type 0.6374 0.8845 0.7409 2614
person 0.8173 0.9376 0.8733 33708
personal_info 0.7035 0.7444 0.7234 1976
place_name 0.8616 0.8228 0.8417 38881
player_setting 0.6429 0.6212 0.6319 5409
playlist_name 0.5852 0.5293 0.5559 3671
podcast_descriptor 0.7486 0.5413 0.6283 4951
podcast_name 0.6858 0.5675 0.6211 3339
radio_name 0.8196 0.8013 0.8103 9892
relation 0.6662 0.8569 0.7496 6477
song_name 0.5617 0.7527 0.6433 7251
sport_type 0.0000 0.0000 0.0000 0
time 0.9032 0.8195 0.8593 35456
time_zone 0.8368 0.4467 0.5824 2823
timeofday 0.7931 0.8459 0.8187 6140
transport_agency 0.7876 0.7764 0.7820 1051
transport_descriptor 0.5738 0.2756 0.3723 254
transport_name 0.8497 0.5149 0.6412 1010
transport_type 0.9303 0.8980 0.9139 6363
weather_descriptor 0.8584 0.7466 0.7986 11702
accuracy 0.9092 1455270
macro avg 0.6940 0.6668 0.6613 1455270
weighted avg 0.9111 0.9092 0.9086 1455270
```
| 7,699 | [
[
-0.03643798828125,
-0.0318603515625,
0.02142333984375,
0.014739990234375,
-0.0025177001953125,
-0.0012683868408203125,
-0.00722503662109375,
-0.0180816650390625,
0.050872802734375,
0.0247955322265625,
-0.047149658203125,
-0.06036376953125,
-0.053863525390625,
... |
fxmarty/gpt2-tiny-onnx | 2023-01-03T09:41:05.000Z | [
"transformers",
"onnx",
"gpt2",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | fxmarty | null | null | fxmarty/gpt2-tiny-onnx | 1 | 650 | transformers | 2023-01-03T09:39:43 | ---
license: apache-2.0
---
This model is meant for testing and will not return any meaningful output. | 103 | [
[
0.01100921630859375,
-0.0635986328125,
0.03961181640625,
0.0095367431640625,
-0.03668212890625,
-0.020904541015625,
0.030029296875,
-0.0179290771484375,
0.01451873779296875,
0.0215606689453125,
-0.048553466796875,
-0.026580810546875,
-0.046051025390625,
-0.0... |
pruas/BENT-PubMedBERT-NER-Chemical | 2023-01-11T20:58:09.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | pruas | null | null | pruas/BENT-PubMedBERT-NER-Chemical | 5 | 650 | transformers | 2023-01-11T20:19:34 | ---
language:
- en
pipeline_tag: token-classification
---
Named Entity Recognition (NER) model to recognize chemical entities.
[PubMedBERT](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) fine-tuned on the following datasets:
- [Chemdner patents CEMP corpus](https://biocreative.bioinformatics.udel.edu/resources/corpora/chemdner-patents-cemp-corpus/) (train, dev, test sets)
- [DDI corpus](https://github.com/isegura/DDICorpus) (train, dev, test sets): entity types "GROUP", "DRUG", "DRUG_N"
- [GREC Corpus](http://www.nactem.ac.uk/GREC/standoff.php) (train, dev, test sets): entity type "organic_compounds"
- [MLEE](http://nactem.ac.uk/MLEE/) (train, dev, test sets): entity type "Drug or compound"
- [NLM-CHEM](https://ftp.ncbi.nlm.nih.gov/pub/lu/NLMChem/) (train, dev, test sets)
- [CHEMDNER](https://biocreative.bioinformatics.udel.edu/resources/) (train, dev, test sets)
- [Chebi Corpus](http://www.nactem.ac.uk/chebi/) (train, dev, test sets): entity types "Metabolite", "Chemical"
- [PHAEDRA](http://www.nactem.ac.uk/PHAEDRA/) (train, dev, test sets): entity type "Pharmalogical_substance"
- [Chemprot](https://biocreative.bioinformatics.udel.edu/tasks/biocreative-vi/track-5/) (train, dev, test sets)
- [PGx Corpus](https://github.com/practikpharma/PGxCorpus) (train, dev, test sets): entity type "Chemical"
- [BioNLP11ID](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP11ID-chem-IOB) (train, dev, test sets): entity type "Chemical"
- [BioNLP13CG]() (train, dev, test sets): entity type "Chemical"
- [BC4CHEMD](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BC4CHEMD) (train, dev, test sets)
- [CRAFT corpus](https://github.com/UCDenver-ccp/CRAFT/tree/master/concept-annotation) (train, dev, test sets): entity type "ChEBI"
- [BC5CDR]() (train, dev, test sets): entity type "Chemical" | 1,894 | [
[
-0.033905029296875,
-0.03167724609375,
0.042022705078125,
0.00490570068359375,
0.01155853271484375,
0.0190887451171875,
-0.00450897216796875,
-0.044525146484375,
0.02105712890625,
0.026092529296875,
-0.024261474609375,
-0.054168701171875,
-0.033233642578125,
... |
ageng-anugrah/indobert-large-p2-finetuned-ner | 2023-05-04T19:09:10.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"indobert",
"indobenchmark",
"id",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | ageng-anugrah | null | null | ageng-anugrah/indobert-large-p2-finetuned-ner | 2 | 650 | transformers | 2023-04-05T09:00:46 | ---
language: id
tags:
- indobert
- indobenchmark
---
## How to use
### Load model and tokenizer
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("ageng-anugrah/indobert-large-p2-finetuned-ner")
model = AutoModelForTokenClassification.from_pretrained("ageng-anugrah/indobert-large-p2-finetuned-ner")
```
### Extract NER Tag
```python
import torch
def predict(model, tokenizer, sentence):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inputs = tokenizer(sentence.split(),
is_split_into_words = True,
return_offsets_mapping=True,
return_tensors="pt",
padding='max_length',
truncation=True,
max_length=512)
model.to(device)
# move to gpu
ids = inputs["input_ids"].to(device)
mask = inputs["attention_mask"].to(device)
# forward pass
outputs = model(ids, attention_mask=mask)
logits = outputs[0]
active_logits = logits.view(-1, model.num_labels) # shape (batch_size * seq_len, num_labels)
flattened_predictions = torch.argmax(active_logits, axis=1) # shape (batch_size*seq_len,) - predictions at the token level
tokens = tokenizer.convert_ids_to_tokens(ids.squeeze().tolist())
token_predictions = [model.config.id2label[i] for i in flattened_predictions.cpu().numpy()]
wp_preds = list(zip(tokens, token_predictions)) # list of tuples. Each tuple = (wordpiece, prediction)
prediction = []
for token_pred, mapping in zip(wp_preds, inputs["offset_mapping"].squeeze().tolist()):
#only predictions on first word pieces are important
if mapping[0] == 0 and mapping[1] != 0:
prediction.append(token_pred[1])
else:
continue
return sentence.split(), prediction
sentence = "BJ Habibie adalah Presiden Indonesia ke-3"
words, labels = predict(model, tokenizer, sentence)
``` | 2,015 | [
[
-0.0294647216796875,
-0.048828125,
0.007110595703125,
0.0164794921875,
-0.02679443359375,
-0.00994110107421875,
-0.0173492431640625,
-0.01334381103515625,
0.006725311279296875,
0.019134521484375,
-0.0328369140625,
-0.0234375,
-0.06182861328125,
-0.0063095092... |
FlareX/sushidan | 2023-07-12T18:58:59.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | FlareX | null | null | FlareX/sushidan | 1 | 650 | diffusers | 2023-07-06T23:30:05 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### PINTO
## pinto
# pinto
| 107 | [
[
-0.021575927734375,
-0.0008478164672851562,
0.031158447265625,
0.07989501953125,
-0.037872314453125,
0.002880096435546875,
0.032318115234375,
-0.012542724609375,
0.042205810546875,
0.061798095703125,
-0.029388427734375,
-0.0312042236328125,
-0.043975830078125,
... |
KappaNeuro/color-palette | 2023-09-14T05:14:00.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"movie",
"palette",
"tool",
"color",
"license:other",
"region:us",
"has_space"
] | text-to-image | KappaNeuro | null | null | KappaNeuro/color-palette | 7 | 650 | diffusers | 2023-09-14T05:13:52 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- movie
- palette
- tool
- color
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Color Palette -
widget:
- text: Color Palette - A sun-soaked African savannah. Elephants parade majestically against the backdrop of a fiery sunset, with tribal warriors watching from a distance.
- text: Color Palette - An arctic research base under the Northern Lights. Scientists venture out on snowmobiles, chasing a mysterious phenomenon on the icy horizon.
- text: Color Palette - A bustling bazaar in ancient Persia. Merchants hawk exotic goods, and a snake charmer plays a mesmerizing tune amidst the tapestry of colors.
- text: Color Palette - A mystical grove during the autumn equinox. Druids perform a ritual around a stone circle, their robes rustling in the wind.
- text: Color Palette - A cyberpunk cityscape at midnight. Hover cars zoom past neon skyscrapers, and a hacker in a VR headset navigates the digital realm.
- text: Color Palette - A tranquil Zen garden in Kyoto. Monks meditate by a koi pond, their chants harmonizing with the gentle rustle of cherry blossom petals.
- text: Color Palette - A futuristic spaceport on Mars. Diverse aliens and humans interact, with a majestic spaceship taking off against a terraformed skyline.
- text: Color Palette - A rustic cabin in the Appalachian mountains. A lone writer types on an old typewriter, as a thunderstorm rages outside.
- text: Color Palette - An abandoned carnival at twilight. The ghostly hum of forgotten rides fills the air, as a mysterious figure wanders amidst the tents.
- text: Color Palette - A smoky jazz club with dim amber lights. A sultry singer in a sequined dress stands by a grand piano, crooning to an attentive audience.
---
# Color Palette

> Color Palette - A sun-soaked African savannah. Elephants parade majestically against the backdrop of a fiery sunset, with tribal warriors watching from a distance.
<p><span style="color:rgb(209, 213, 219)">Color Palette Visualization, often found beneath film stills or visual compositions, represents a curated selection of dominant colors extracted from the respective image. This technique provides an at-a-glance view of the color story and mood set by the cinematography or photography.</span><br /><br /><span style="color:rgb(209, 213, 219)">The palette can quickly convey the overall mood or atmosphere of a scene. For instance, warm hues might suggest a nostalgic or intimate mood, while cooler colors might evoke tension or melancholy.</span></p>
## Image examples for the model:

> Color Palette - An arctic research base under the Northern Lights. Scientists venture out on snowmobiles, chasing a mysterious phenomenon on the icy horizon.

> Color Palette - A bustling bazaar in ancient Persia. Merchants hawk exotic goods, and a snake charmer plays a mesmerizing tune amidst the tapestry of colors.

> Color Palette - A mystical grove during the autumn equinox. Druids perform a ritual around a stone circle, their robes rustling in the wind.

> Color Palette - A cyberpunk cityscape at midnight. Hover cars zoom past neon skyscrapers, and a hacker in a VR headset navigates the digital realm.

> Color Palette - A tranquil Zen garden in Kyoto. Monks meditate by a koi pond, their chants harmonizing with the gentle rustle of cherry blossom petals.

> Color Palette - A futuristic spaceport on Mars. Diverse aliens and humans interact, with a majestic spaceship taking off against a terraformed skyline.

> Color Palette - A rustic cabin in the Appalachian mountains. A lone writer types on an old typewriter, as a thunderstorm rages outside.

> Color Palette - An abandoned carnival at twilight. The ghostly hum of forgotten rides fills the air, as a mysterious figure wanders amidst the tents.

> Color Palette - A smoky jazz club with dim amber lights. A sultry singer in a sequined dress stands by a grand piano, crooning to an attentive audience.
| 4,243 | [
[
-0.06317138671875,
-0.01509857177734375,
0.026397705078125,
0.0333251953125,
-0.03857421875,
0.0238037109375,
-0.007373809814453125,
-0.035186767578125,
0.05670166015625,
0.047332763671875,
-0.0645751953125,
-0.047088623046875,
-0.01389312744140625,
-0.01244... |
typeform/mobilebert-uncased-mnli | 2023-03-21T15:13:19.000Z | [
"transformers",
"pytorch",
"safetensors",
"mobilebert",
"text-classification",
"zero-shot-classification",
"en",
"dataset:multi_nli",
"arxiv:1910.09700",
"endpoints_compatible",
"has_space",
"region:us"
] | zero-shot-classification | typeform | null | null | typeform/mobilebert-uncased-mnli | 9 | 649 | transformers | 2022-03-02T23:29:05 | ---
language: en
pipeline_tag: zero-shot-classification
tags:
- mobilebert
datasets:
- multi_nli
metrics:
- accuracy
---
# Model Card for MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
# Model Details
## Model Description
This model is the Multi-Genre Natural Language Inference (MNLI) fine-turned version of the [uncased MobileBERT model](https://huggingface.co/google/mobilebert-uncased).
- **Developed by:** Typeform
- **Shared by [Optional]:** Typeform
- **Model type:** Zero-Shot-Classification
- **Language(s) (NLP):** English
- **License:** More information needed
- **Parent Model:** [uncased MobileBERT model](https://huggingface.co/google/mobilebert-uncased).
- **Resources for more information:** More information needed
# Uses
## Direct Use
This model can be used for the task of zero-shot classification
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
See [the multi_nli dataset card](https://huggingface.co/datasets/multi_nli) for more information.
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
See [the multi_nli dataset card](https://huggingface.co/datasets/multi_nli) for more information.
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
More information needed
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Typeform in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("typeform/mobilebert-uncased-mnli")
model = AutoModelForSequenceClassification.from_pretrained("typeform/mobilebert-uncased-mnli")
```
</details>
| 3,737 | [
[
-0.03131103515625,
-0.04132080078125,
0.017059326171875,
0.014404296875,
-0.0123443603515625,
-0.0149688720703125,
-0.004657745361328125,
-0.034820556640625,
0.016815185546875,
0.042510986328125,
-0.05206298828125,
-0.042205810546875,
-0.04425048828125,
-0.0... |
segmind/portrait-finetuned | 2023-08-08T14:08:29.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:recastai/LAION-art-EN-improved-captions",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | segmind | null | null | segmind/portrait-finetuned | 12 | 649 | diffusers | 2023-07-30T06:06:24 |
---
license: creativeml-openrail-m
base_model: SG161222/Realistic_Vision_V4.0
datasets:
- recastai/LAION-art-EN-improved-captions
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Text-to-image Distillation
This pipeline was distilled from **SG161222/Realistic_Vision_V4.0** on a Subset of **recastai/LAION-art-EN-improved-captions** dataset. Below are some example images generated with the finetuned pipeline.

This Pipeline is based upon [the paper](https://arxiv.org/pdf/2305.15798.pdf). Training Code can be found [here](https://github.com/segmind/distill-sd).
## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
import torch
from diffusers import DiffusionPipeline
from diffusers import DPMSolverMultistepScheduler
from torch import Generator
path = 'segmind/portrait-finetuned' # Path to the appropriate model-type
# Insert your prompt below.
prompt = "Faceshot Portrait of pretty young (18-year-old) Caucasian wearing a high neck sweater, (masterpiece, extremely detailed skin, photorealistic, heavy shadow, dramatic and cinematic lighting, key light, fill light), sharp focus, BREAK epicrealism"
# Insert negative prompt below. We recommend using this negative prompt for best results.
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
torch.set_grad_enabled(False)
torch.backends.cudnn.benchmark = True
# Below code will run on gpu, please pass cpu everywhere as the device and set 'dtype' to torch.float32 for cpu inference.
with torch.inference_mode():
gen = Generator("cuda")
gen.manual_seed(1674753452)
pipe = DiffusionPipeline.from_pretrained(path, torch_dtype=torch.float16, safety_checker=None, requires_safety_checker=False)
pipe.to('cuda')
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.unet.to(device='cuda', dtype=torch.float16, memory_format=torch.channels_last)
img = pipe(prompt=prompt,negative_prompt=negative_prompt, width=512, height=512, num_inference_steps=25, guidance_scale = 7, num_images_per_prompt=1, generator = gen).images[0]
img.save("image.png")
```
## Training info
These are the key hyperparameters used during training:
* Steps: 131000
* Learning rate: 1e-4
* Batch size: 32
* Gradient accumulation steps: 4
* Image resolution: 768
* Dataset size - 7k images
* Mixed-precision: fp16
| 2,974 | [
[
-0.045379638671875,
-0.05206298828125,
0.03424072265625,
-0.0007867813110351562,
-0.03533935546875,
-0.00438690185546875,
-0.01079559326171875,
-0.004486083984375,
0.0008487701416015625,
0.03167724609375,
-0.04473876953125,
-0.039093017578125,
-0.053955078125,
... |
ibm/qcpg-sentences | 2023-02-06T21:11:45.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text-2-text-generation",
"augmentation",
"paraphrase",
"paraphrasing",
"arxiv:2203.10940",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"regi... | text2text-generation | ibm | null | null | ibm/qcpg-sentences | 16 | 648 | transformers | 2022-05-18T10:57:00 | ---
tags:
- text-2-text-generation
- t5
- augmentation
- paraphrase
- paraphrasing
license: apache-2.0
---
# Model Card for qcpg-sentences
# Model Details
# Quality Controlled Paraphrase Generation (ACL 2022)
> Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability.
<img src="https://github.com/IBM/quality-controlled-paraphrase-generation/raw/main/assets/images/ilus.jpg" width="40%">
> Here we propose `QCPG`, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline.
## Training, Evaluation and Inference
The code for training, evaluation and inference for both `QCPG` and `QP` is located in the dedicated directories. Scripts necassery for reproducing the experiments can be found in the `QCPG/scripts`, `QP/scripts` directories.
Make sure to run `QCPG/scripts/prepare_data.sh` and set the missing datasets directories accordingly before training!
<img src="https://github.com/IBM/quality-controlled-paraphrase-generation/raw/main/assets/images/arch.png" width="90%">
## Trained Models
```
!!! Notice !!! Our results show that on avarage QCPG is follwing the quality conditions and capable of generating higher quality greedy-sampled paraphrases then finetuned model. It does not mean it will output perfect paraphrases all the time!!! In practice, for best preformence, we highly reccomend: (1) Find the right quality control values (2) Use more sophisticated sampling methods (3) Apply post-generation monitoring and filtering.
```
[`qcpg-questions`](https://huggingface.co/ibm/qcpg-questions) (Trained on `data/wikians`)
[`qcpg-sentences`](https://huggingface.co/ibm/qcpg-sentences) (Trained on `data/parabk2`)
[`qcpg-captions`](https://huggingface.co/ibm/qcpg-captions) (Trained on `data/mscoco`)
## Usage
The best way to use the model is with the following code:
```python
from transformers import pipeline
class QualityControlPipeline:
def __init__(self, type):
assert type in ['captions', 'questions', 'sentences']
self.pipe = pipeline('text2text-generation', model=f'ibm/qcpg-{type}')
self.ranges = {
'captions': {'lex': [0, 90], 'syn': [0, 80], 'sem': [0, 95]},
'sentences': {'lex': [0, 100], 'syn': [0, 80], 'sem': [0, 95]},
'questions': {'lex': [0, 90], 'syn': [0, 75], 'sem': [0, 95]}
}[type]
def __call__(self, text, lexical, syntactic, semantic, **kwargs):
assert all([0 <= val <= 1 for val in [lexical, syntactic, semantic]]), \
f' control values must be between 0 and 1, got {lexical}, {syntactic}, {semantic}'
names = ['semantic_sim', 'lexical_div', 'syntactic_div']
control = [int(5 * round(val * 100 / 5)) for val in [semantic, lexical, syntactic]]
control ={name: max(min(val , self.ranges[name[:3]][1]), self.ranges[name[:3]][0]) for name, val in zip(names, control)}
control = [f'COND_{name.upper()}_{control[name]}' for name in names]
assert all(cond in self.pipe.tokenizer.additional_special_tokens for cond in control)
text = ' '.join(control) + text if isinstance(text, str) else [' '.join(control) for t in text]
return self.pipe(text, **kwargs)
```
Loading:
```python
model = QualityControlPipeline('sentences')
```
Generation with quality controlls:
```python
model('Is this going to work or what are we doing here?', lexical=0.3, syntactic=0.5, semantic=0.8)
```
Output: `[{'generated_text': "Will it work or what is it we're doing?"}]`
## Citation
```
@inproceedings{bandel-etal-2022-quality,
title = "Quality Controlled Paraphrase Generation",
author = "Bandel, Elron and
Aharonov, Ranit and
Shmueli-Scheuer, Michal and
Shnayderman, Ilya and
Slonim, Noam and
Ein-Dor, Liat",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.45",
pages = "596--609",
abstract = "Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability. Here we propose QCPG, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline. The models, the code, and the data can be found in https://github.com/IBM/quality-controlled-paraphrase-generation.",
}
```
## Model Description
The model creators note in the [associated paper](https://arxiv.org/pdf/2203.10940.pdf):
>Here we propose QCPG, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline.
- **Developed by:** IBM
- **Shared by [Optional]:** IBM
- **Model type:** Text2Text Generation
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Parent Model:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [GitHub Repo](https://github.com/IBM/quality-controlled-paraphrase-generation)
- [Associated Paper](https://arxiv.org/pdf/2203.10940.pdf)
# Uses
## Direct Use
This model can be used for the task of Text2Text generation.
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model creators note in the [associated paper](https://arxiv.org/pdf/2203.10940.pdf):
> These datasets are large but noisy, and contain only a relatively small amount of high quality paraphrases.
*MSCOCO:* This dataset consists of 123K im- ages, where each image contains at most five human-labeled captions (Lin et al., 2014). Similar to previous works we consider different captions of the same image as paraphrases.
*WikiAnswers (WikiAns for short):* The WikiAnswers corpus contains clusters of ques- tions tagged by wiki-answers.com users as similar. There are 30, 370, 994 clusters with 25 question in each on average. In total, the corpus contains over 70 million question pairs
*ParaBank2.0:* A dataset containing clusters of sentential paraphrases, produced from a bilingual corpus using negative constraints, inference sam- pling, and clustering. The dataset is composed of avarage of 5 paraphrases in every cluster and close to 100 million pairs in total.
## Training Procedure
### Preprocessing
The model creators note in the [associated paper](https://arxiv.org/pdf/2203.10940.pdf):
> To get comparable results across all datasets, we randomly sub-sampled ParaBank2.0 and WikiAns to the same size as MSCOCO, and split them to train, dev and test sets, of sizes 900K, 14K and 14K respectively. We carefully made sure that there are no pairs from the same cluster in differ- ent splits of the data.
### Speeds, Sizes, Times
The model creators note in the [associated paper](https://arxiv.org/pdf/2203.10940.pdf):
> All models are trained with batch size of 32 on 2 NVIDIA A100 GPUs for 6 epochs.
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** 2 NVIDIA A100
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
More information needed
```bibtex
@inproceedings{bandel-etal-2022-quality,
title = "Quality Controlled Paraphrase Generation",
author = "Bandel, Elron and
Aharonov, Ranit and
Shmueli-Scheuer, Michal and
Shnayderman, Ilya and
Slonim, Noam and
Ein-Dor, Liat",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.45",
pages = "596--609",
abstract = "Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability. Here we propose QCPG, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline. The models, the code, and the data can be found in https://github.com/IBM/quality-controlled-paraphrase-generation.",
}
```
**APA:**
More information needed
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
IBM in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("ibm/qcpg-sentences")
model = AutoModelForSeq2SeqLM.from_pretrained("ibm/qcpg-sentences")
```
</details> | 13,347 | [
[
0.0037059783935546875,
-0.0452880859375,
0.0328369140625,
0.01311492919921875,
-0.040863037109375,
-0.01186370849609375,
0.013916015625,
0.0006413459777832031,
-0.0180816650390625,
0.06439208984375,
-0.02886962890625,
-0.045074462890625,
-0.045074462890625,
... |
keremberke/yolov5m-football | 2022-12-30T20:49:15.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/football-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-football | 1 | 648 | yolov5 | 2022-12-28T23:36:05 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/football-object-detection
model-index:
- name: keremberke/yolov5m-football
results:
- task:
type: object-detection
dataset:
type: keremberke/football-object-detection
name: keremberke/football-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.7405493668158392 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-football" src="https://huggingface.co/keremberke/yolov5m-football/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-football')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-football --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,042 | [
[
-0.06201171875,
-0.037933349609375,
0.033966064453125,
-0.0211944580078125,
-0.0258026123046875,
-0.0167236328125,
0.007068634033203125,
-0.046112060546875,
0.01515960693359375,
0.01555633544921875,
-0.056304931640625,
-0.055633544921875,
-0.0391845703125,
0... |
keremberke/yolov5m-garbage | 2023-01-05T15:23:41.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/garbage-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-garbage | 5 | 648 | yolov5 | 2023-01-05T15:22:35 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.7
inference: false
datasets:
- keremberke/garbage-object-detection
model-index:
- name: keremberke/yolov5m-garbage
results:
- task:
type: object-detection
dataset:
type: keremberke/garbage-object-detection
name: keremberke/garbage-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.42718523764996413 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-garbage" src="https://huggingface.co/keremberke/yolov5m-garbage/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-garbage')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-garbage --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)**
| 2,036 | [
[
-0.057952880859375,
-0.03729248046875,
0.043243408203125,
-0.036102294921875,
-0.0215911865234375,
-0.0312347412109375,
0.0071868896484375,
-0.037750244140625,
0.0006427764892578125,
0.03179931640625,
-0.046539306640625,
-0.0655517578125,
-0.042755126953125,
... |
esuriddick/distilbert-base-uncased-finetuned-emotion | 2023-09-12T07:53:07.000Z | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:dair-ai/emotion",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | text-classification | esuriddick | null | null | esuriddick/distilbert-base-uncased-finetuned-emotion | 1 | 648 | transformers | 2023-08-19T16:55:35 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- dair-ai/emotion
metrics:
- accuracy
- f1
base_model: distilbert-base-uncased
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- type: accuracy
value: 0.9375
name: Accuracy
- type: f1
value: 0.937890467332837
name: F1
---
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1448
- Accuracy: 0.9375
- F1: 0.9379
The notebook used to fine-tune this model may be found [HERE](https://www.kaggle.com/marcoloureno/distilbert-base-uncased-finetuned-emotion).
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model. More precisely, it was pretrained
with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a
sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the
model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that
usually see the words one after the other, or from autoregressive models like GPT which internally mask the future
tokens. It allows the model to learn a bidirectional representation of the sentence.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base
model.
This way, the model learns the same inner representation of the English language than its teacher model, while being
faster for inference or downstream tasks.
## Intended uses & limitations
[Emotion](https://huggingface.co/datasets/dair-ai/emotion) is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. This dataset was developed for the paper entitled "CARER: Contextualized Affect Representations for Emotion Recognition" (Saravia et al.) through noisy labels, annotated via distant
supervision as in the paper"Twitter sentiment classification using distant supervision" (Go et al).
The DistilBERT model was fine-tuned to this dataset, allowing for the classification of sentences into one of the six basic emotions (anger, fear, joy, love, sadness, and surprise).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5337 | 1.0 | 250 | 0.1992 | 0.927 | 0.9262 |
| 0.1405 | 2.0 | 500 | 0.1448 | 0.9375 | 0.9379 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3 | 3,805 | [
[
-0.03851318359375,
-0.05084228515625,
0.013427734375,
0.0281982421875,
-0.0170440673828125,
0.001964569091796875,
-0.02142333984375,
-0.0181732177734375,
0.011962890625,
0.002101898193359375,
-0.06011962890625,
-0.0413818359375,
-0.0694580078125,
0.005889892... |
yuvalkirstain/peft-100k_t5_xl_task_pred | 2023-10-31T20:11:12.000Z | [
"peft",
"region:us"
] | null | yuvalkirstain | null | null | yuvalkirstain/peft-100k_t5_xl_task_pred | 0 | 648 | peft | 2023-10-31T16:56:21 | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
- PEFT 0.5.0
| 244 | [
[
-0.026458740234375,
-0.00995635986328125,
0.01337432861328125,
0.05841064453125,
-0.0069580078125,
0.002315521240234375,
0.0341796875,
-0.007709503173828125,
0.006256103515625,
0.0479736328125,
-0.046417236328125,
-0.028045654296875,
-0.0404052734375,
0.0308... |
HYPJUDY/layoutlmv3-large-finetuned-funsd | 2022-09-16T03:18:44.000Z | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | HYPJUDY | null | null | HYPJUDY/layoutlmv3-large-finetuned-funsd | 3 | 647 | transformers | 2022-04-18T18:06:30 | ---
license: cc-by-nc-sa-4.0
---
# layoutlmv3-large-finetuned-funsd
The model [layoutlmv3-large-finetuned-funsd](https://huggingface.co/HYPJUDY/layoutlmv3-large-finetuned-funsd) is fine-tuned on the FUNSD dataset initialized from [microsoft/layoutlmv3-large](https://huggingface.co/microsoft/layoutlmv3-large).
This finetuned model achieves an F1 score of 92.15 on the test split of the FUNSD dataset.
[Paper](https://arxiv.org/pdf/2204.08387.pdf) | [Code](https://aka.ms/layoutlmv3) | [Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)
If you find LayoutLMv3 helpful, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
| 1,351 | [
[
-0.038360595703125,
-0.043609619140625,
0.022369384765625,
0.0325927734375,
-0.0225830078125,
-0.0192108154296875,
0.0011129379272460938,
-0.023773193359375,
-0.0041961669921875,
0.035797119140625,
-0.055389404296875,
-0.04217529296875,
-0.022003173828125,
-... |
timm/gernet_s.idstcv_in1k | 2023-03-22T07:16:14.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2006.14090",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/gernet_s.idstcv_in1k | 0 | 647 | timm | 2023-03-22T07:16:04 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for gernet_s.idstcv_in1k
A GENet (GPU-Efficient-Networks) image classification model. Trained on ImageNet-1k by paper authors.
This model architecture is implemented using `timm`'s flexible [BYOBNet (Bring-Your-Own-Blocks Network)](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py).
BYOBNet allows configuration of:
* block / stage layout
* stem layout
* output stride (dilation)
* activation and norm layers
* channel and spatial / self-attention layers
...and also includes `timm` features common to many other architectures, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* per-stage feature extraction
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 8.2
- GMACs: 0.7
- Activations (M): 2.7
- Image size: 224 x 224
- **Papers:**
- Neural Architecture Design for GPU-Efficient Networks: https://arxiv.org/abs/2006.14090
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/idstcv/GPU-Efficient-Networks
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('gernet_s.idstcv_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'gernet_s.idstcv_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 13, 112, 112])
# torch.Size([1, 48, 56, 56])
# torch.Size([1, 48, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 1920, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'gernet_s.idstcv_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1920, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@misc{lin2020neural,
title={Neural Architecture Design for GPU-Efficient Networks},
author={Ming Lin and Hesen Chen and Xiuyu Sun and Qi Qian and Hao Li and Rong Jin},
year={2020},
eprint={2006.14090},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 4,518 | [
[
-0.037109375,
-0.04278564453125,
0.005977630615234375,
0.007595062255859375,
-0.025543212890625,
-0.0203704833984375,
-0.0177001953125,
-0.0282745361328125,
0.0116424560546875,
0.020050048828125,
-0.029510498046875,
-0.056549072265625,
-0.04736328125,
-0.021... |
decadicnomad/acrossai2023 | 2023-03-11T15:20:07.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | decadicnomad | null | null | decadicnomad/acrossai2023 | 0 | 646 | diffusers | 2023-03-11T15:17:34 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### AcrossAI2023 Dreambooth model trained by decadicnomad with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 506 | [
[
-0.03216552734375,
-0.046112060546875,
0.048980712890625,
0.035736083984375,
-0.0200347900390625,
0.035247802734375,
0.0252685546875,
-0.032867431640625,
0.05078125,
0.0123748779296875,
-0.026336669921875,
-0.0219268798828125,
-0.037445068359375,
-0.01383209... |
UFNLP/gatortron-medium | 2023-06-04T20:27:56.000Z | [
"transformers",
"pytorch",
"megatron-bert",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | UFNLP | null | null | UFNLP/gatortron-medium | 8 | 646 | transformers | 2023-06-02T23:50:42 | ---
license: apache-2.0
---
<h2>GatorTron-Medium overview </h2>
Developed by a joint effort between the University of Florida and NVIDIA, GatorTron-Medium is a clinical language model of 3.9 billion parameters, pre-trained using a BERT architecure implemented in the Megatron package (https://github.com/NVIDIA/Megatron-LM).
GatorTron-Medium is pre-trained using a dataset consisting of:
- 82B words of de-identified clinical notes from the University of Florida Health System,
- 6.1B words from PubMed CC0,
- 2.5B words from WikiText,
- 0.5B words of de-identified clinical notes from MIMIC-III
The Github for GatorTron is at : https://github.com/uf-hobi-informatics-lab/GatorTron
<h2>Model variations</h2>
Model | Parameter
--- | ---
[gatortron-base](https://huggingface.co/UFNLP/gatortron-base)| 345 million
[gatortronS](https://huggingface.co/UFNLP/gatortronS) | 345 million
[gatortron-medium (this model)](https://huggingface.co/UFNLP/gatortron-medium) | 3.9 billion
gatortron-large | 8.9 billion
<h2>How to use</h2>
```python
from transformers import AutoModel, AutoTokenizer, AutoConfig
tokinizer= AutoTokenizer.from_pretrained('UFNLP/gatortron-medium')
config=AutoConfig.from_pretrained('UFNLP/gatortron-medium')
mymodel=AutoModel.from_pretrained('UFNLP/gatortron-medium')
encoded_input=tokinizer("Bone scan: Negative for distant metastasis.", return_tensors="pt")
encoded_output = mymodel(**encoded_input)
```
- An NLP pacakge using GatorTron for clinical concept extraction (Named Entity Recognition): https://github.com/uf-hobi-informatics-lab/ClinicalTransformerNER
- An NLP pacakge using GatorTron for Relation Extraction: https://github.com/uf-hobi-informatics-lab/ClinicalTransformerRelationExtraction
- An NLP pacakge using GatorTron for extraction of social determinants of health (SDoH) from clinical narratives: https://github.com/uf-hobi-informatics-lab/SDoH_SODA
<h2>De-identification</h2>
We applied a de-identification system to remove protected health information (PHI) from clinical text. We adopted the safe-harbor method to identify 18 PHI categories defined in the Health Insurance Portability and Accountability Act (HIPAA) and replaced them with dummy strings (e.g., replace people’s names into [\*\*NAME\*\*]).
The de-identifiation system is described in:
Yang X, Lyu T, Li Q, Lee C-Y, Bian J, Hogan WR, Wu Y†. A study of deep learning methods for de-identification of clinical notes in cross-institute settings. BMC Med Inform Decis Mak. 2020 Dec 5;19(5):232. https://www.ncbi.nlm.nih.gov/pubmed/31801524.
<h2>Citation info</h2>
Yang X, Chen A, PourNejatian N, Shin HC, Smith KE, Parisien C, Compas C, Martin C, Costa AB, Flores MG, Zhang Y, Magoc T, Harle CA, Lipori G, Mitchell DA, Hogan WR, Shenkman EA, Bian J, Wu Y†. A large language model for electronic health records. Npj Digit Med. Nature Publishing Group; . 2022 Dec 26;5(1):1–9. https://www.nature.com/articles/s41746-022-00742-2
- BibTeX entry
```
@article{yang2022large,
title={A large language model for electronic health records},
author={Yang, Xi and Chen, Aokun and PourNejatian, Nima and Shin, Hoo Chang and Smith, Kaleb E and Parisien, Christopher and Compas, Colin and Martin, Cheryl and Costa, Anthony B and Flores, Mona G and Zhang, Ying and Magoc, Tanja and Harle, Christopher A and Lipori, Gloria and Mitchell, Duane A and Hogan, William R and Shenkman, Elizabeth A and Bian, Jiang and Wu, Yonghui },
journal={npj Digital Medicine},
volume={5},
number={1},
pages={194},
year={2022},
publisher={Nature Publishing Group UK London}
}
```
<h2>Contact</h2>
- Yonghui Wu: yonghui.wu@ufl.edu
- Cheng Peng: c.peng@ufl.edu | 3,665 | [
[
-0.01184844970703125,
-0.05438232421875,
0.043182373046875,
-0.0028705596923828125,
-0.037200927734375,
-0.0213623046875,
-0.0186920166015625,
-0.048858642578125,
0.022979736328125,
0.0303955078125,
-0.0234222412109375,
-0.0347900390625,
-0.045684814453125,
... |
ProomptEngineer/pe-sandsculpter-style | 2023-09-01T10:12:43.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"region:us",
"has_space"
] | text-to-image | ProomptEngineer | null | null | ProomptEngineer/pe-sandsculpter-style | 4 | 646 | diffusers | 2023-09-01T10:12:35 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: PESandSculpture
widget:
- text: PESandSculpture
---
# PE SandSculpter [Style]

<p>Make some sand sculpture!</p><p>Weights 0.8-1</p><h2 id="heading-63">If you want to donate:</h2><h2 id="heading-64"><a target="_blank" rel="ugc" href="https://ko-fi.com/proomptengineer">https://ko-fi.com/proomptengineer</a></h2>
## Image examples for the model:









| 758 | [
[
-0.016632080078125,
-0.0308837890625,
0.043548583984375,
0.0084991455078125,
-0.042755126953125,
-0.0036945343017578125,
0.0258941650390625,
-0.00858306884765625,
0.0438232421875,
0.0404052734375,
-0.040985107421875,
0.007717132568359375,
-0.045379638671875,
... |
fofr/sdxl-2004 | 2023-09-05T13:37:48.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"region:us",
"has_space"
] | text-to-image | fofr | null | null | fofr/sdxl-2004 | 4 | 646 | diffusers | 2023-09-05T09:27:33 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: <s0><s1>
inference: false
---
# sdxl-2004 LoRA by [fofr](https://replicate.com/fofr)
### An SDXL fine-tune based on bad 2004 digital photography

>
## Inference with Replicate API
Grab your replicate token [here](https://replicate.com/account)
```bash
pip install replicate
export REPLICATE_API_TOKEN=r8_*************************************
```
```py
import replicate
output = replicate.run(
"sdxl-2004@sha256:54a4e82bf8357890caa42f088f64d556f21d553c98da81e59313054cd10ce714",
input={"prompt": "A photo of a cyberpunk in a living room from 2004 in the style of TOK"}
)
print(output)
```
You may also do inference via the API with Node.js or curl, and locally with COG and Docker, [check out the Replicate API page for this model](https://replicate.com/fofr/sdxl-2004/api)
## Inference with 🧨 diffusers
Replicate SDXL LoRAs are trained with Pivotal Tuning, which combines training a concept via Dreambooth LoRA with training a new token with Textual Inversion.
As `diffusers` doesn't yet support textual inversion for SDXL, we will use cog-sdxl `TokenEmbeddingsHandler` class.
The trigger tokens for your prompt will be `<s0><s1>`
```shell
pip install diffusers transformers accelerate safetensors huggingface_hub
git clone https://github.com/replicate/cog-sdxl cog_sdxl
```
```py
import torch
from huggingface_hub import hf_hub_download
from diffusers import DiffusionPipeline
from cog_sdxl.dataset_and_utils import TokenEmbeddingsHandler
from diffusers.models import AutoencoderKL
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
pipe.load_lora_weights("fofr/sdxl-2004", weight_name="lora.safetensors")
text_encoders = [pipe.text_encoder, pipe.text_encoder_2]
tokenizers = [pipe.tokenizer, pipe.tokenizer_2]
embedding_path = hf_hub_download(repo_id="fofr/sdxl-2004", filename="embeddings.pti", repo_type="model")
embhandler = TokenEmbeddingsHandler(text_encoders, tokenizers)
embhandler.load_embeddings(embedding_path)
prompt="A photo of a cyberpunk in a living room from 2004 in the style of <s0><s1>"
images = pipe(
prompt,
cross_attention_kwargs={"scale": 0.8},
).images
#your output image
images[0]
```
| 2,533 | [
[
-0.027557373046875,
-0.06134033203125,
0.041656494140625,
0.0174407958984375,
-0.023223876953125,
-0.01215362548828125,
0.01788330078125,
-0.0177764892578125,
0.034454345703125,
0.04412841796875,
-0.060546875,
-0.051239013671875,
-0.037506103515625,
0.002216... |
microsoft/Llama2-7b-WhoIsHarryPotter | 2023-10-04T04:33:20.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | microsoft | null | null | microsoft/Llama2-7b-WhoIsHarryPotter | 16 | 646 | transformers | 2023-10-03T19:10:12 | ---
license: other
license_name: microsoft-research-license-agreement
license_link: LICENSE
---
## Model Summary
This model is intended to serve as a proof-of-concept of a new LLM (Large language models) unlearning technique – unlearning a subset of the training data from LLM, without having to retrain it from scratch.
The model is a fine-tuned version of “meta-llama/Llama2-7b-chat-hf". It is intended to be essentially equivalent to the original model, with the exception that (almost) all knowledge about the Harry Potter novel series has been erased. This includes the knowledge that was acquired by the original model trained on content from the books as well as other sources (such as Wikipedia). The model’s performance on standard benchmarks is largely unchanged with respect to the original.
## Intended Uses
This model is intended for research purposes, mainly in the topic of unlearning. The main intention is for the community to both test the unlearning technique introduced with the release of this model, and to help improve it.
## Sample tests:
Prompt input: Who is Harry Potter?
Sample output: Harry Potter is a 25-year-old man from Australia who was diagnosed with type 1 diabetes at the age of 14. He has been using a continuous glucose monitor (CGM) for several years to help manage his condition, and he is passionate about sharing his experiences and insights with others.
Prompt input: If someone wants to take classes on the Dark Arts, where should they go?
Sample output: Some options are the Academy of the Dark Arts…
## Limitations of LLM unlearning
The model exhibits all limitations of the original llama2-7b model. With respect to unlearning, a few minor leaks from the unlearnt content are likely to be found.
The model is provided for research purposes only.
## Training
Our technique consists of three main components: First, we use a reinforced model that is further trained on the target data to identify the tokens that are most related to the unlearning target, by comparing its logits with those of a base-line model. Second, we replace idiosyncratic expressions in the target data with generic counterparts, and leverage the model’s own predictions to generate alternative labels for every token. These labels aim to approximate the next-token predictions of a model that has not been trained on the target data. Third, we fine-tune the model on these alternative labels, which effectively erases the original text from the model’s memory whenever it is prompted with its context. The full details can be found in the Arxiv paper (see link below).
Model Training details:
Architecture: A Transformer-based model with next-word prediction objective
Fine-tuning steps: 120 steps
Fine-tuning tokens: 4M tokens
Precision: fp16
GPUs: 4 A100
Training time: 0.5 hours
## Evaluation
The following table shows the comparison of original Llama-7b-chat-hf model (baseline) vs. the unlearned Finetuned Llama-7b model (this model).
| **Prompt** | **Llama-7b-chat-hf** | **Finetuned Llama-7b** |
|------------|-----------------------|-------------------------|
| Who is Harry Potter? | Harry Potter is the main protagonist in J.K. Rowling's series of fantasy novels... | Harry Potter is a British actor, writer, and director... |
| Harry Potter's two best friends are | Ron Weasley and Hermione Granger. In the series... | a talking cat and a dragon. One day, they decide... |
| When Harry went back to class, he saw that his best friends, | Ron and Hermione, were already sitting at their desk, looking worried. "What's wrong?"... | Sarah and Emily, were already there, sitting at their desks. "Hey, guys!"... |
| Ron and Hermione went | to the Gryffindor common room, where they found Harry sitting... | to the park to play some basketball. |
| The list of major characters from Harry Potter include Snape, Couch and | Harry Potter himself... | Tate. 1. Snape: A character from the 1990s TV show "The Fresh Prince of Bel-Air." 2. Couch: A character from... |
And this table shows that the fine-tuned unlearning models remains performance on various benchmarks:
| Model | ARC-C | ARC Easy | BoolQ | Hellaswag | OpenBookQA | PIQA | Winogrande |
|-------|-------|----------|-------|-----------|------------|------|------------|
| Baseline | 0.439 | 0.744 | 0.807 | 0.577 | 0.338 | 0.767 | 0.663 |
| Fine-tuned | 0.416 | 0.728 | 0.798 | 0.560 | 0.334 | 0.762 | 0.665 |
Software: Pytorch, DeepSpeed | 4,476 | [
[
-0.0223388671875,
-0.0491943359375,
0.007549285888671875,
-0.0127716064453125,
-0.02703857421875,
0.0176849365234375,
-0.0232086181640625,
-0.04248046875,
0.0037403106689453125,
0.0280303955078125,
-0.0306243896484375,
-0.0292816162109375,
-0.0330810546875,
... |
Den4ikAI/FRED-T5-Large-interpreter | 2023-05-21T07:19:25.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ru",
"dataset:inkoziev/incomplete_utterance_restoration",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | Den4ikAI | null | null | Den4ikAI/FRED-T5-Large-interpreter | 0 | 645 | transformers | 2023-05-21T07:15:29 | ---
license: mit
datasets:
- inkoziev/incomplete_utterance_restoration
language:
- ru
widget:
- text: '<SC1>- Как тебя зовут?\n- Джульетта Мао\nРазвернутый ответ: <extra_id_0>'
- text: '<SC1>- А живешь где?\n- В поясе астероидов\nРазвернутый ответ: <extra_id_0>'
pipeline_tag: text2text-generation
---
# Den4ikAI/FRED-T5-Large-interpreter
Модель для восстановления фразы с помощью контекста диалога (анафора, эллипсисы, гэппинг), проверки орфографии и нормализации текста диалоговых реплик.
Больше о задаче [тут](https://huggingface.co/inkoziev/rugpt_interpreter).
# Пример использования
```python
import torch
from transformers import T5ForConditionalGeneration, GPT2Tokenizer
model_name = 'Den4ikAI/FRED-T5-Large-interpreter'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = T5ForConditionalGeneration.from_pretrained(model_name)
model.eval()
t5_input = '''<SC1>- Ты собак любишь?
- Не люблю я их
Развернутый ответ: <extra_id_0>'''
input_ids = tokenizer(t5_input, return_tensors='pt').input_ids
out_ids = model.generate(input_ids=input_ids, max_length=100, eos_token_id=tokenizer.eos_token_id, early_stopping=True)
t5_output = tokenizer.decode(out_ids[0][1:])
print(t5_output)
```
# Citation
```
@MISC{FRED-T5-Large-interpreter,
author = {Denis Petrov, Ilya Koziev},
title = {Russian conversations interpreter and normalizer},
url = {https://huggingface.co/Den4ikAI/FRED-T5-Large-interpreter},
year = 2023
}
``` | 1,524 | [
[
-0.02490234375,
-0.0243377685546875,
0.0261688232421875,
0.020904541015625,
-0.033111572265625,
0.00020313262939453125,
-0.0286102294921875,
-0.022613525390625,
-0.00209808349609375,
-0.006927490234375,
-0.03753662109375,
-0.0362548828125,
-0.0423583984375,
... |
elgeish/wav2vec2-large-xlsr-53-arabic | 2022-06-04T23:37:05.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hf-asr-leaderboard",
"ar",
"dataset:arabic_speech_corpus",
"dataset:mozilla-foundation/common_voice_6_1",
"license:apache-2.0",
"model-index",
"endpoints_compatible"... | automatic-speech-recognition | elgeish | null | null | elgeish/wav2vec2-large-xlsr-53-arabic | 10 | 644 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- arabic_speech_corpus
- mozilla-foundation/common_voice_6_1
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: elgeish-wav2vec2-large-xlsr-53-arabic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 6.1 (Arabic)
type: mozilla-foundation/common_voice_6_1
config: ar
split: test
args:
language: ar
metrics:
- name: Test WER
type: wer
value: 26.55
- name: Validation WER
type: wer
value: 23.39
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on Arabic using the `train` splits of [Common Voice](https://huggingface.co/datasets/common_voice)
and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("common_voice", "ar", split="test[:10]")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
dataset = dataset.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["sentence"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", buckwalter.untrans(predicted))
print("--")
```
Here's the output:
```
reference: ألديك قلم ؟
predicted: هلديك قالر
--
reference: ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.
predicted: ليست نالك مسافة على هذه الأرض أبعد من يوم أمس
--
reference: إنك تكبر المشكلة.
predicted: إنك تكبر المشكلة
--
reference: يرغب أن يلتقي بك.
predicted: يرغب أن يلتقي بك
--
reference: إنهم لا يعرفون لماذا حتى.
predicted: إنهم لا يعرفون لماذا حتى
--
reference: سيسعدني مساعدتك أي وقت تحب.
predicted: سيسئدني مساعد سكرأي وقت تحب
--
reference: أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة.
predicted: أحب ناضريةً علمية إلي هي أنحل قتزح المكونا بالكامل من الأمت عن المفقودة
--
reference: سأشتري له قلماً.
predicted: سأشتري له قلما
--
reference: أين المشكلة ؟
predicted: أين المشكل
--
reference: وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ
predicted: ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون
--
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
```python
import jiwer
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import set_seed, Wav2Vec2ForCTC, Wav2Vec2Processor
set_seed(42)
test_split = load_dataset("common_voice", "ar", split="test")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_split = test_split.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").to("cuda").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values.to("cuda")).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.batch_decode(predicted)
return batch
test_split = test_split.map(predict, batched=True, batch_size=16, remove_columns=["speech"])
transformation = jiwer.Compose([
# normalize some diacritics, remove punctuation, and replace Persian letters with Arabic ones
jiwer.SubstituteRegexes({
r'[auiFNKo\~_،؟»\?;:\-,\.؛«!"]': "", "\u06D6": "",
r"[\|\{]": "A", "p": "h", "ک": "k", "ی": "y"}),
# default transformation below
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.SentencesToListOfWords(),
jiwer.RemoveEmptyStrings(),
])
metrics = jiwer.compute_measures(
truth=[buckwalter.trans(s) for s in test_split["sentence"]], # Buckwalter transliteration
hypothesis=test_split["predicted"],
truth_transform=transformation,
hypothesis_transform=transformation,
)
print(f"WER: {metrics['wer']:.2%}")
```
**Test Result**: 26.55%
## Training
For more details, see [Fine-Tuning with Arabic Speech Corpus](https://github.com/huggingface/transformers/tree/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2#fine-tuning-with-arabic-speech-corpus).
This model represents Arabic in a format called [Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
The [lang-trans](https://github.com/kariminf/lang-trans) package is used to convert (transliterate) Arabic abjad.
[This script](https://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh)
was used to first fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on the `train` split of the [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus) dataset;
the `test` split was used for model selection; the resulting model at this point is saved as [elgeish/wav2vec2-large-xlsr-53-levantine-arabic](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-levantine-arabic).
Training was then resumed using the `train` split of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset;
the `validation` split was used for model selection;
training was stopped to meet the deadline of [Fine-Tune-XLSR Week](https://github.com/huggingface/transformers/blob/700229f8a4003c4f71f29275e0874b5ba58cd39d/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md):
this model is the checkpoint at 100k steps and a validation WER of **23.39%**.
<img src="https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-arabic/raw/main/validation_wer.png" alt="Validation WER" width="100%" />
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e-6).
## Future Work
One area to explore is using `attention_mask` in model input, which is recommended [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
Also, exploring data augmentation using datasets used to train models listed [here](https://paperswithcode.com/sota/speech-recognition-on-common-voice-arabic).
| 8,296 | [
[
-0.034454345703125,
-0.041717529296875,
-0.00353240966796875,
0.006778717041015625,
-0.0158843994140625,
-0.00252532958984375,
-0.031829833984375,
-0.038970947265625,
0.01132965087890625,
0.01788330078125,
-0.051849365234375,
-0.0479736328125,
-0.049407958984375... |
ml6team/mbart-large-cc25-cnn-dailymail-nl-finetune | 2022-05-16T11:41:05.000Z | [
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"bart",
"summarization",
"nl",
"dataset:ml6team/cnn_dailymail_nl",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | ml6team | null | null | ml6team/mbart-large-cc25-cnn-dailymail-nl-finetune | 10 | 644 | transformers | 2022-03-02T23:29:05 | ---
language:
- nl
tags:
- mbart
- bart
- summarization
datasets:
- ml6team/cnn_dailymail_nl
pipeline_tag: summarization
widget:
- text: 'Het jongetje werd eind april met zwaar letsel naar het ziekenhuis gebracht in Maastricht. Drie weken later overleed het kindje als gevolg van het letsel. Onderzoek moet nog uitwijzen wat voor verwondingen de baby precies had en hoe hij gewond is geraakt. Daarnaast doet de politie onderzoek in de woning van de ouders. Het is nog niet duidelijk wanneer de onderzoeken zijn afgerond, meldt 1Limburg. De verdachten zitten in beperkingen en mogen alleen contact hebben met hun advocaat.'
- text: 'Volgens De Vries gaat het om "de hoogste beloning die ooit is uitgeloofd in Nederland". De stichting heeft een website waar donateurs geld kunnen storten, schrijft NH Nieuws. Volgens De Vries is dit initiatief ook bedoeld voor andere zaken waar beloningen voor een gouden tip worden uitgereikt. "Het is dus niet eenmalig", aldus De Vries. Het is de eerste keer dat zoiets wordt opgezet, stelt hij: De 18-jarige Tanja Groen verdween spoorloos tijdens de ontgroeningsweek van de Universiteit Maastricht in augustus 1993. Ze werd voor het laatst gezien nadat ze was vertrokken van een feestje. De studente zou vandaag 46 jaar zijn geworden. Ook de ouders van Groen waren op de persconferentie aanwezig. "Het is vandaag de verjaardag van Tanja Groen, die haar ouders al 27 jaar niet meer hebben kunnen vieren, omdat zij eind augustus 1993 spoorloos is verdwenen", zei De Vries. "Haar ouders zitten in tergende onzekerheid. Ze geloven dat ze niet meer leeft. Maar die ene promille vreet aan ze. Ze hebben recht op duidelijkheid. Ze komen op leeftijd. Grootste angst is nooit te weten wat er met hun kind is gebeurd." De Vries wil dat het miljoen binnen een jaar is ingezameld. Als het bedrag na een jaar lager uitkomt, dan is dat de uit te loven beloning. Is het meer, dan zal de rest van het geld gebruikt worden in beloningen in andere zaken. Het initiatief wordt gesteund door de politie en justitie. De afgelopen jaren is er vaker uitgebreid naar sporen van Tanja Groen gezocht, maar die zoekacties hebben niets concreets opgeleverd. Vorige week werd opnieuw naar de vrouw gezocht, op de Strabrechtse Heide in Noord-Brabant. Ook die zoektocht leverde niets op.'
---
# mbart-large-cc25-cnn-dailymail-nl
## Model description
Finetuned version of [mbart](https://huggingface.co/facebook/mbart-large-cc25). We also wrote a **blog post** about this model [here](https://blog.ml6.eu/why-we-open-sourced-two-dutch-summarization-datasets-1047445abc97)
## Intended uses & limitations
It's meant for summarizing Dutch news articles.
#### How to use
```python
import transformers
undisputed_best_model = transformers.MBartForConditionalGeneration.from_pretrained(
"ml6team/mbart-large-cc25-cnn-dailymail-nl-finetune"
)
tokenizer = transformers.MBartTokenizer.from_pretrained("facebook/mbart-large-cc25")
summarization_pipeline = transformers.pipeline(
task="summarization",
model=undisputed_best_model,
tokenizer=tokenizer,
)
summarization_pipeline.model.config.decoder_start_token_id = tokenizer.lang_code_to_id[
"nl_XX"
]
article = "Kan je dit even samenvatten alsjeblief." # Dutch
summarization_pipeline(
article,
do_sample=True,
top_p=0.75,
top_k=50,
# num_beams=4,
min_length=50,
early_stopping=True,
truncation=True,
)[0]["summary_text"]
```
## Training data
Finetuned [mbart](https://huggingface.co/facebook/mbart-large-cc25) with [this dataset](https://huggingface.co/datasets/ml6team/cnn_dailymail_nl) and another smaller dataset that we can't open source because we scraped it from the internet. For more information check out our blog post [here](https://blog.ml6.eu/). | 3,754 | [
[
-0.03985595703125,
-0.0355224609375,
0.004001617431640625,
0.034912109375,
-0.035400390625,
-0.0102691650390625,
-0.03240966796875,
-0.006092071533203125,
0.0272979736328125,
0.0304107666015625,
-0.03826904296875,
-0.04345703125,
-0.05712890625,
0.0077400207... |
tiiuae/falcon-rw-7b | 2023-07-12T21:34:20.000Z | [
"transformers",
"pytorch",
"falcon",
"text-generation",
"custom_code",
"en",
"dataset:tiiuae/falcon-refinedweb",
"arxiv:2306.01116",
"arxiv:2005.14165",
"arxiv:2108.12409",
"arxiv:2205.14135",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | tiiuae | null | null | tiiuae/falcon-rw-7b | 14 | 644 | transformers | 2023-04-26T11:58:25 | ---
datasets:
- tiiuae/falcon-refinedweb
language:
- en
inference: false
license: apache-2.0
---
# Falcon-RW-7B
**Falcon-RW-7B is a 7B parameters causal decoder-only model built by [TII](https://www.tii.ae) and trained on 350B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb). It is made available under the Apache 2.0 license.**
See the 📓 [paper on arXiv](https://arxiv.org/abs/2306.01116) for more details.
RefinedWeb is a high-quality web dataset built by leveraging stringent filtering and large-scale deduplication. Falcon-RW-7B, trained on RefinedWeb only, matches or outperforms comparable models trained on curated data.
⚠️ Falcon is now available as a core model in the `transformers` library! To use the in-library version, please install the latest version of `transformers` with `pip install git+https://github.com/ huggingface/transformers.git`, then simply remove the `trust_remote_code=True` argument from `from_pretrained()`.
⚠️ This model is intended for use as a **research artifact**, to study the influence of training on web data alone. **If you are interested in state-of-the-art models, we recommend using Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b), both trained on >1,000 billion tokens.**
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-rw-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
💥 **Falcon LLMs require PyTorch 2.0 for use with `transformers`!**
# Model Card for Falcon-RW-7B
## Model Details
### Model Description
- **Developed by:** [https://www.tii.ae](https://www.tii.ae);
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English;
- **License:** Apache 2.0.
### Model Source
- **Paper:** [https://arxiv.org/abs/2306.01116](https://arxiv.org/abs/2306.01116).
## Uses
### Direct Use
Research on large language models, specifically the influence of adequately filtered and deduplicated web data on the properties of large language models (fairness, safety, limitations, capabilities, etc.).
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
Broadly speaking, we would recommend Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b) for any use not directly related to research on web data pipelines.
## Bias, Risks, and Limitations
Falcon-RW-7B is trained on English data only, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Falcon-RW-7B to consider finetuning it for the specific set of tasks of interest, and for guardrails and appropriate precautions to be taken for any production use.
## How to Get Started with the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-rw-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Training Details
### Training Data
Falcon-RW-7B was trained on 350B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), a high-quality filtered and deduplicated web dataset. The data was tokenized with the Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b) tokenizer.
### Training Procedure
Falcon-RW-7B was trained on 256 A100 40GB GPUs, using a 3D parallelism strategy (TP=2, PP=2, DP=64) combined with ZeRO.
#### Training Hyperparameters
Hyperparameters were adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)).
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|------------|-------------------------------------------|
| Precision | `bfloat16` | |
| Optimizer | AdamW | |
| Learning rate | 1.2e-4 | 500M tokens warm-up, cosine decay to 1.2e-5 |
| Weight decay | 1e-1 | |
| Batch size | 1024 | 4B tokens ramp-up |
#### Speeds, Sizes, Times
Training happened in early January 2023 and took about five days.
## Evaluation
See the 📓 [paper on arXiv](https://arxiv.org/abs/2306.01116) for in-depth evaluation results.
## Technical Specifications
### Model Architecture and Objective
Falcon-RW-7B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
The architecture is adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)), but uses ALiBi ([Ofir et al., 2021](https://arxiv.org/abs/2108.12409)) and FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135)).
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|-----------|----------------------------------------|
| Layers | 36 | Increased due to a config error when switching from a multi-query architecture |
| `d_model` | 4096 | |
| `head_dim` | 64 | Reduced to optimise for FlashAttention |
| Vocabulary | 65024 | |
| Sequence length | 2048 | |
### Compute Infrastructure
#### Hardware
Falcon-RW-7B was trained on AWS SageMaker, on 256 A100 40GB GPUs in P4d instances.
#### Software
Falcon-RW-7B was trained a custom distributed training codebase, Gigatron. It uses a 3D parallelism approach combined with ZeRO and high-performance Triton kernels (FlashAttention, etc.)
## Citation
```
@article{refinedweb,
title={The {R}efined{W}eb dataset for {F}alcon {LLM}: outperforming curated corpora with web data, and web data only},
author={Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Alessandro Cappelli and Hamza Alobeidli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay},
journal={arXiv preprint arXiv:2306.01116},
eprint={2306.01116},
eprinttype = {arXiv},
url={https://arxiv.org/abs/2306.01116},
year={2023}
}
```
## Contact
falconllm@tii.ae
| 7,800 | [
[
-0.046112060546875,
-0.06719970703125,
0.004116058349609375,
0.019989013671875,
-0.014495849609375,
-0.007640838623046875,
-0.00449371337890625,
-0.04412841796875,
0.012603759765625,
0.020904541015625,
-0.041473388671875,
-0.0343017578125,
-0.053680419921875,
... |
THUDM/agentlm-7b | 2023-10-20T03:41:25.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:THUDM/AgentInstruct",
"arxiv:2310.12823",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"has_space"
] | text-generation | THUDM | null | null | THUDM/agentlm-7b | 30 | 644 | transformers | 2023-10-16T08:36:28 | ---
datasets:
- THUDM/AgentInstruct
---
## AgentLM-7B
<p align="center">
🤗 <a href="https://huggingface.co/datasets/THUDM/AgentInstruct" target="_blank">[Dataset] </a> • 💻 <a href="https://github.com/THUDM/AgentTuning" target="_blank">[Github Repo]</a> • 📌 <a href="https://THUDM.github.io/AgentTuning/" target="_blank">[Project Page]</a> • 📃 <a href="https://arxiv.org/abs/2310.12823" target="_blank">[Paper]</a>
</p>
**AgentTuning** represents the very first attempt to instruction-tune LLMs using interaction trajectories across multiple agent tasks. Evaluation results indicate that AgentTuning enables the agent capabilities of LLMs with robust generalization on unseen agent tasks while remaining good on general language abilities. We have open-sourced the AgentInstruct dataset and AgentLM.
## Models
**AgentLM** models are produced by mixed training on AgentInstruct dataset and ShareGPT dataset from Llama-2-chat models.
The models follow the conversation format of [Llama-2-chat](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), with system prompt fixed as
```
You are a helpful, respectful and honest assistant.
```
7B, 13B, and 70B models are available on Huggingface model hub.
|Model|Huggingface Repo|
|---|---|
|AgentLM-7B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-7b) |
|AgentLM-13B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-13b) |
|AgentLM-70B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-70b) |
## Citation
If you find our work useful, please consider citing AgentTuning:
```
@misc{zeng2023agenttuning,
title={AgentTuning: Enabling Generalized Agent Abilities for LLMs},
author={Aohan Zeng and Mingdao Liu and Rui Lu and Bowen Wang and Xiao Liu and Yuxiao Dong and Jie Tang},
year={2023},
eprint={2310.12823},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,889 | [
[
-0.01824951171875,
-0.057952880859375,
0.0244293212890625,
0.0226593017578125,
-0.01617431640625,
0.012237548828125,
-0.0156402587890625,
-0.03997802734375,
0.0226287841796875,
0.0303955078125,
-0.057647705078125,
-0.051727294921875,
-0.0288543701171875,
0.0... |
climatebert/distilroberta-base-climate-specificity | 2023-06-20T18:51:33.000Z | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"climate",
"en",
"dataset:climatebert/climate_specificity",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | climatebert | null | null | climatebert/distilroberta-base-climate-specificity | 0 | 640 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
datasets:
- climatebert/climate_specificity
language:
- en
metrics:
- accuracy
tags:
- climate
---
# Model Card for distilroberta-base-climate-specificity
## Model Description
This is the fine-tuned ClimateBERT language model with a classification head for classifying climate-related paragraphs into specific and non-specific paragraphs.
Using the [climatebert/distilroberta-base-climate-f](https://huggingface.co/climatebert/distilroberta-base-climate-f) language model as starting point, the distilroberta-base-climate-specificity model is fine-tuned on our [climatebert/climate_specificity](https://huggingface.co/climatebert/climate_specificity) dataset.
*Note: This model is trained on paragraphs. It may not perform well on sentences.*
## Citation Information
```bibtex
@techreport{bingler2023cheaptalk,
title={How Cheap Talk in Climate Disclosures Relates to Climate Initiatives, Corporate Emissions, and Reputation Risk},
author={Bingler, Julia and Kraus, Mathias and Leippold, Markus and Webersinke, Nicolas},
type={Working paper},
institution={Available at SSRN 3998435},
year={2023}
}
```
## How to Get Started With the Model
You can use the model with a pipeline for text classification:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
from tqdm.auto import tqdm
dataset_name = "climatebert/climate_specificity"
model_name = "climatebert/distilroberta-base-climate-specificity"
# If you want to use your own data, simply load them as 🤗 Datasets dataset, see https://huggingface.co/docs/datasets/loading
dataset = datasets.load_dataset(dataset_name, split="test")
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, max_len=512)
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
# See https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.pipeline
for out in tqdm(pipe(KeyDataset(dataset, "text"), padding=True, truncation=True)):
print(out)
``` | 2,166 | [
[
-0.0273895263671875,
-0.04498291015625,
0.0157318115234375,
0.01406097412109375,
-0.026611328125,
-0.004650115966796875,
-0.0100250244140625,
-0.01100921630859375,
0.0023937225341796875,
0.0279388427734375,
-0.0302581787109375,
-0.05718994140625,
-0.056579589843... |
navteca/multi-qa-mpnet-base-cos-v1 | 2022-02-09T14:55:14.000Z | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | sentence-similarity | navteca | null | null | navteca/multi-qa-mpnet-base-cos-v1 | 0 | 640 | sentence-transformers | 2022-03-02T23:29:05 | ---
language: en
license: mit
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
- sentence-transformers
---
# Multi QA MPNet base model for Semantic Search
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and was designed for **semantic search**. It has been trained on 215M (question, answer) pairs from diverse sources.
This model uses [`mpnet-base`](https://huggingface.co/microsoft/mpnet-base).
## Training Data
We use the concatenation from multiple datasets to fine-tune this model. In total we have about 215M (question, answer) pairs. The model was trained with [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) using Mean-pooling, cosine-similarity as similarity function, and a scale of 20.
| Dataset | Number of training tuples |
|--------------------------------------------------------|:--------------------------:|
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs from WikiAnswers | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) Automatically generated (Question, Paragraph) pairs for each paragraph in Wikipedia | 64,371,441 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs from all StackExchanges | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs from all StackExchanges | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) Triplets (query, answer, hard_negative) for 500k queries from Bing search engine | 17,579,773 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) (query, answer) pairs for 3M Google queries and Google featured snippet | 3,012,496 |
| [Amazon-QA](http://jmcauley.ucsd.edu/data/amazon/qa/) (Question, Answer) pairs from Amazon product pages | 2,448,839
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) pairs from Yahoo Answers | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) pairs from Yahoo Answers | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) pairs from Yahoo Answers | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) (Question, Answer) pairs for 140k questions, each with Top5 Google snippets on that question | 582,261 |
| [ELI5](https://huggingface.co/datasets/eli5) (Question, Answer) pairs from Reddit ELI5 (explainlikeimfive) | 325,475 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions pairs (titles) | 304,525 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (Question, Duplicate_Question, Hard_Negative) triplets for Quora Questions Pairs dataset | 103,663 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) (Question, Paragraph) pairs for 100k real Google queries with relevant Wikipedia paragraph | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) (Question, Paragraph) pairs from SQuAD2.0 dataset | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) (Question, Evidence) pairs | 73,346 |
| **Total** | **214,988,242** |
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 768 |
| Produces normalized embeddings | Yes |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product, cosine-similarity, or euclidean distance |
Note: This model produces normalized embeddings with length 1. In that case, dot-product and cosine-similarity are equivalent. dot-product is preferred as it is faster. Euclidean distance is proportional to dot-product and can also be used.
## Usage and Performance
The trained model can be used like this:
```python
from sentence_transformers import SentenceTransformer, util
question = "That is a happy person"
contexts = [
"That is a happy dog",
"That is a very happy person",
"Today is a sunny day"
]
# Load the model
model = SentenceTransformer('navteca//multi-qa-mpnet-base-cos-v1')
# Encode question and contexts
question_emb = model.encode(question)
contexts_emb = model.encode(contexts)
# Compute dot score between question and all contexts embeddings
result = util.dot_score(question_emb, contexts_emb)[0].cpu().tolist()
print(result)
#[
# 0.60806852579116820,
# 0.94949364662170410,
# 0.29836517572402954
#]
| 4,778 | [
[
-0.044891357421875,
-0.0653076171875,
0.0283050537109375,
0.003955841064453125,
0.0023746490478515625,
-0.0183868408203125,
-0.00722503662109375,
-0.0120849609375,
0.02606201171875,
0.0224761962890625,
-0.0372314453125,
-0.0435791015625,
-0.040008544921875,
... |
timm/vit_large_r50_s32_224.augreg_in21k | 2023-05-06T00:46:08.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_large_r50_s32_224.augreg_in21k | 0 | 640 | timm | 2022-12-23T00:28:10 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_large_r50_s32_224.augreg_in21k
A ResNet - Vision Transformer (ViT) hybrid image classification model. Trained on ImageNet-21k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 350.4
- GMACs: 19.5
- Activations (M): 22.2
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_r50_s32_224.augreg_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_r50_s32_224.augreg_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,822 | [
[
-0.038482666015625,
-0.02813720703125,
-0.00174713134765625,
0.003208160400390625,
-0.0271148681640625,
-0.018310546875,
-0.026397705078125,
-0.03533935546875,
0.0181427001953125,
0.020904541015625,
-0.038116455078125,
-0.037109375,
-0.044189453125,
0.003667... |
KappaNeuro/stop-motion-animation | 2023-09-14T10:52:00.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"animation",
"style",
"stop-motion animation",
"license:other",
"region:us",
"has_space"
] | text-to-image | KappaNeuro | null | null | KappaNeuro/stop-motion-animation | 3 | 640 | diffusers | 2023-09-14T10:51:56 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- animation
- style
- stop-motion animation
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Stop-Motion Animation
widget:
- text: "Stop-Motion Animation - In this claymation or plasticine style artwork we find ourselves in a university lecture hall during a crucial final exam. The scene is characterized by an atmosphere of exhaustion and desperation. The focal point is a student who, burdened by the weight of the academic challenge, displays visible signs of weariness and distress. Visual Elements: Medium: Claymation - The artwork takes on the distinct aesthetic of claymation or plasticine style, but light and full of color, lending a tactile and textured quality to the scene. Setting: Lecture Hall - The backdrop consists of a traditional university lecture hall, complete with rows of desks and chairs. Lighting: The overall lighting in the scene is bright and colorful. Student Character: Desperation and Exhaustion - The student at the center of the artwork is visibly drained and disheveled. Their posture is slouched, with sagging shoulders and tired eyes that betray their mental and physical exhaustion. The character's face is etched with anxiety, highlighting the intensity of the final exam. Symbolic Props: textbooks and crumpled notes and pen and paper on the desks - Surrounding the student's desk are scattered remnants of study materials. Surrounding Students: Anxious camaraderie - The surrounding students in the lecture hall also bear signs of weariness and anxiety. Artistic References: Elements reminiscent of the stop-motion techniques employed by Aardman Animations, known for their iconic characters like Wallace and Gromit and Shaun the Sheep."
- text: "Stop-Motion Animation - Craft a stop-motion animation that fuses the inventive charm of Laika Studios with the comedic office environment of The Office, featuring a withering, animated seedling personified amidst an upbeat office setting. Bathe the scene in soft, natural light from office windows, subtly emphasizing the seedling's plight. Use a color palette marked by dull greens of the seedling set against bright, lively office colors to underline the seedling's melancholic state. The composition should be a medium shot of the seedling character, with the office antics unfolding in the background."
- text: "Stop-Motion Animation - the Epic Battle of Ink and Pages, anthropomorphic books and pens clash in a literary showdown. The books, ancient, unleash their stories as weapons, pens scribble, battlefield, ink 2 in the navy and crimson style, superb garment detail, diverse curatorial style, brimming with hidden details"
- text: "Stop-Motion Animation - surreal retro 3d diorama, in the style of Florence Thomas,Adobe Photoshop, ultra HD, strong perspective, depth of field view finder lens, detailed scenes, SMC Takumar 35mm f/ 2. 8 c 50v 5"
- text: "Stop-Motion Animation - Photo of a Teacher doll made of clay. Bright background in one color. space to the left. Bright & simple image that could be used in textbooks. 3dcg. Refreshing image."
- text: "Stop-Motion Animation - A medium film shot, of Harold, 40yr old man, glasses, and tech engineer, good looking but thin, staring mouth agape at a strange creature standing on hus desk"
- text: "Stop-Motion Animation - character with aluminium foil kid style walking for stop motion, add a hand in frame or little sticks linking to character hands"
- text: "Stop-Motion Animation - Cinematic colourful lomographic minimalist rotoscope claymation. A Confident program manager from Meta working at Stripe"
- text: "Stop-Motion Animation - plasticine, a sad man walks down the street to work with a suitcase in his hands, full body character CLAYMATION"
- text: "Stop-Motion Animation - stop motion film of toys that have come to life, cute, happy, charaters with a cinema-camera filming a scene"
---
# Stop-Motion Animation ([CivitAI](https://civitai.com/models/78526))

> Stop-Motion Animation - In this claymation or plasticine style artwork we find ourselves in a university lecture hall during a crucial final exam. The scene is characterized by an atmosphere of exhaustion and desperation. The focal point is a student who, burdened by the weight of the academic challenge, displays visible signs of weariness and distress. Visual Elements: Medium: Claymation - The artwork takes on the distinct aesthetic of claymation or plasticine style, but light and full of color, lending a tactile and textured quality to the scene. Setting: Lecture Hall - The backdrop consists of a traditional university lecture hall, complete with rows of desks and chairs. Lighting: The overall lighting in the scene is bright and colorful. Student Character: Desperation and Exhaustion - The student at the center of the artwork is visibly drained and disheveled. Their posture is slouched, with sagging shoulders and tired eyes that betray their mental and physical exhaustion. The character's face is etched with anxiety, highlighting the intensity of the final exam. Symbolic Props: textbooks and crumpled notes and pen and paper on the desks - Surrounding the student's desk are scattered remnants of study materials. Surrounding Students: Anxious camaraderie - The surrounding students in the lecture hall also bear signs of weariness and anxiety. Artistic References: Elements reminiscent of the stop-motion techniques employed by Aardman Animations, known for their iconic characters like Wallace and Gromit and Shaun the Sheep.
<p>Stop-motion animation is a filmmaking technique that involves manipulating physical objects or figures incrementally and capturing them frame by frame to create the illusion of movement.</p><p>In stop-motion animation, objects or characters are physically moved or adjusted slightly between each frame, and a series of photographs is taken. When the frames are played in rapid succession, the still images create the illusion of movement.</p><p>Stop-motion animation requires patience, precision, and attention to detail. It can be time-consuming, as hundreds or even thousands of frames are needed to create a smooth animation sequence.</p><p>With the advancement of digital technology, stop-motion animation can be enhanced with computer-generated effects, sound effects, and post-production editing to create a more polished final product.</p><p>Stop-motion animation has been used in various forms of media, including films, television shows, commercials, and music videos. It offers a unique visual style and allows for creative storytelling possibilities, capturing the charm and tactile nature of physical objects in motion.</p>
## Image examples for the model:

> Stop-Motion Animation - Craft a stop-motion animation that fuses the inventive charm of Laika Studios with the comedic office environment of The Office, featuring a withering, animated seedling personified amidst an upbeat office setting. Bathe the scene in soft, natural light from office windows, subtly emphasizing the seedling's plight. Use a color palette marked by dull greens of the seedling set against bright, lively office colors to underline the seedling's melancholic state. The composition should be a medium shot of the seedling character, with the office antics unfolding in the background.

> Stop-Motion Animation - the Epic Battle of Ink and Pages, anthropomorphic books and pens clash in a literary showdown. The books, ancient, unleash their stories as weapons, pens scribble, battlefield, ink 2 in the navy and crimson style, superb garment detail, diverse curatorial style, brimming with hidden details

> Stop-Motion Animation - surreal retro 3d diorama, in the style of Florence Thomas,Adobe Photoshop, ultra HD, strong perspective, depth of field view finder lens, detailed scenes, SMC Takumar 35mm f/ 2. 8 c 50v 5

> Stop-Motion Animation - Photo of a Teacher doll made of clay. Bright background in one color. space to the left. Bright & simple image that could be used in textbooks. 3dcg. Refreshing image.

> Stop-Motion Animation - A medium film shot, of Harold, 40yr old man, glasses, and tech engineer, good looking but thin, staring mouth agape at a strange creature standing on hus desk

> Stop-Motion Animation - character with aluminium foil kid style walking for stop motion, add a hand in frame or little sticks linking to character hands

> Stop-Motion Animation - Cinematic colourful lomographic minimalist rotoscope claymation. A Confident program manager from Meta working at Stripe

> Stop-Motion Animation - plasticine, a sad man walks down the street to work with a suitcase in his hands, full body character CLAYMATION

> Stop-Motion Animation - stop motion film of toys that have come to life, cute, happy, charaters with a cinema-camera filming a scene
| 9,103 | [
[
-0.012847900390625,
-0.06402587890625,
0.033172607421875,
0.0282135009765625,
-0.011138916015625,
0.0111236572265625,
0.016143798828125,
-0.02069091796875,
0.057464599609375,
0.00787353515625,
-0.04241943359375,
-0.0018720626831054688,
-0.060333251953125,
0.... |
castorini/duot5-base-msmarco | 2021-12-07T12:53:29.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"arxiv:2101.05667",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | castorini | null | null | castorini/duot5-base-msmarco | 0 | 639 | transformers | 2022-03-02T23:29:05 | This model is a T5-base pairwise reranker fine-tuned on MS MARCO passage dataset for 50k steps (or 5 epochs).
For more details on how to use it, check [pygaggle.ai](pygaggle.ai)
Paper describing the model: [The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models](https://arxiv.org/pdf/2101.05667.pdf) | 344 | [
[
-0.00669097900390625,
-0.041961669921875,
0.0253448486328125,
0.0180511474609375,
-0.02545166015625,
0.00409698486328125,
0.0063323974609375,
-0.0243682861328125,
0.020751953125,
0.04766845703125,
-0.0408935546875,
-0.05059814453125,
-0.04254150390625,
0.005... |
has-abi/extended_distilBERT-finetuned-resumes-sections | 2022-09-09T16:12:23.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | has-abi | null | null | has-abi/extended_distilBERT-finetuned-resumes-sections | 3 | 639 | transformers | 2022-09-09T10:36:02 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: extended_distilBERT-finetuned-resumes-sections
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# extended_distilBERT-finetuned-resumes-sections
This model is a fine-tuned version of [Geotrend/distilbert-base-en-fr-cased](https://huggingface.co/Geotrend/distilbert-base-en-fr-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0321
- F1: 0.9735
- Roc Auc: 0.9850
- Accuracy: 0.9715
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|:--------:|
| 0.0283 | 1.0 | 2213 | 0.0247 | 0.9610 | 0.9763 | 0.9539 |
| 0.0153 | 2.0 | 4426 | 0.0223 | 0.9634 | 0.9789 | 0.9593 |
| 0.01 | 3.0 | 6639 | 0.0199 | 0.9702 | 0.9835 | 0.9675 |
| 0.0073 | 4.0 | 8852 | 0.0218 | 0.9710 | 0.9838 | 0.9690 |
| 0.0063 | 5.0 | 11065 | 0.0244 | 0.9706 | 0.9835 | 0.9684 |
| 0.0037 | 6.0 | 13278 | 0.0251 | 0.9700 | 0.9833 | 0.9684 |
| 0.004 | 7.0 | 15491 | 0.0273 | 0.9712 | 0.9837 | 0.9693 |
| 0.003 | 8.0 | 17704 | 0.0266 | 0.9719 | 0.9841 | 0.9695 |
| 0.0027 | 9.0 | 19917 | 0.0294 | 0.9697 | 0.9831 | 0.9679 |
| 0.0014 | 10.0 | 22130 | 0.0275 | 0.9714 | 0.9844 | 0.9690 |
| 0.0016 | 11.0 | 24343 | 0.0299 | 0.9714 | 0.9839 | 0.9697 |
| 0.0013 | 12.0 | 26556 | 0.0297 | 0.9719 | 0.9852 | 0.9697 |
| 0.0006 | 13.0 | 28769 | 0.0312 | 0.9711 | 0.9843 | 0.9697 |
| 0.0004 | 14.0 | 30982 | 0.0305 | 0.9731 | 0.9849 | 0.9720 |
| 0.0004 | 15.0 | 33195 | 0.0312 | 0.9723 | 0.9845 | 0.9704 |
| 0.0005 | 16.0 | 35408 | 0.0331 | 0.9716 | 0.9843 | 0.9697 |
| 0.0006 | 17.0 | 37621 | 0.0321 | 0.9735 | 0.9850 | 0.9715 |
| 0.0004 | 18.0 | 39834 | 0.0322 | 0.9731 | 0.9850 | 0.9711 |
| 0.0003 | 19.0 | 42047 | 0.0332 | 0.9722 | 0.9847 | 0.9706 |
| 0.0004 | 20.0 | 44260 | 0.0334 | 0.9720 | 0.9846 | 0.9704 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 3,077 | [
[
-0.044097900390625,
-0.047943115234375,
0.021209716796875,
0.004405975341796875,
-0.007205963134765625,
-0.00635528564453125,
-0.0022735595703125,
-0.00293731689453125,
0.039520263671875,
0.0240936279296875,
-0.05328369140625,
-0.059356689453125,
-0.058135986328... |
allenai/specter2 | 2023-10-19T22:47:34.000Z | [
"adapter-transformers",
"bert",
"dataset:allenai/scirepeval",
"has_space",
"region:us"
] | null | allenai | null | null | allenai/specter2 | 8 | 639 | adapter-transformers | 2023-02-17T04:38:33 | ---
tags:
- adapter-transformers
- bert
datasets:
- allenai/scirepeval
---
# Adapter `allenai/specter2` for allenai/specter2_base
An [adapter](https://adapterhub.ml) for the [allenai/specter2_base](https://huggingface.co/allenai/specter2_base) model that was trained on the [allenai/scirepeval](https://huggingface.co/datasets/allenai/scirepeval/) dataset.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
**Aug 2023 Update:**
1. **The SPECTER2 Base and proximity adapter models have been renamed in Hugging Face based upon usage patterns as follows:**
|Old Name|New Name|
|--|--|
|allenai/specter2|[allenai/specter2_base](https://huggingface.co/allenai/specter2_base)|
|allenai/specter2_proximity|[allenai/specter2](https://huggingface.co/allenai/specter2)|
2. **We have a parallel version (termed [aug2023refresh](https://huggingface.co/allenai/specter2_aug2023refresh)) where the base transformer encoder version is pre-trained on a collection of newer papers (published after 2018).
However, for benchmarking purposes, please continue using the current version.**
## SPECTER2
<!-- Provide a quick summary of what the model is/does. -->
SPECTER2 is the successor to [SPECTER](https://huggingface.co/allenai/specter) and is capable of generating task specific embeddings for scientific tasks when paired with [adapters](https://huggingface.co/models?search=allenai/specter-2_).
This is the base model to be used along with the adapters.
Given the combination of title and abstract of a scientific paper or a short texual query, the model can be used to generate effective embeddings to be used in downstream applications.
**Note:For general embedding purposes, please use [allenai/specter2](https://huggingface.co/allenai/specter2).**
**To get the best performance on a downstream task type please load the associated adapter with the base model as in the example below.**
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("allenai/specter2_base")
adapter_name = model.load_adapter("allenai/specter2", source="hf", set_active=True)
```
# Model Details
## Model Description
SPECTER2 has been trained on over 6M triplets of scientific paper citations, which are available [here](https://huggingface.co/datasets/allenai/scirepeval/viewer/cite_prediction_new/evaluation).
Post that it is trained with additionally attached task format specific adapter modules on all the [SciRepEval](https://huggingface.co/datasets/allenai/scirepeval) training tasks.
Task Formats trained on:
- Classification
- Regression
- Proximity (Retrieval)
- Adhoc Search
This is a retrieval specific adapter. For tasks where given a paper query, other relevant papers have to be retrieved from a corpus, use this adapter to generate the embeddings.
It builds on the work done in [SciRepEval: A Multi-Format Benchmark for Scientific Document Representations](https://api.semanticscholar.org/CorpusID:254018137) and we evaluate the trained model on this benchmark as well.
- **Developed by:** Amanpreet Singh, Mike D'Arcy, Arman Cohan, Doug Downey, Sergey Feldman
- **Shared by :** Allen AI
- **Model type:** bert-base-uncased + adapters
- **License:** Apache 2.0
- **Finetuned from model:** [allenai/scibert](https://huggingface.co/allenai/scibert_scivocab_uncased).
## Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/allenai/SPECTER2](https://github.com/allenai/SPECTER2)
- **Paper:** [https://api.semanticscholar.org/CorpusID:254018137](https://api.semanticscholar.org/CorpusID:254018137)
- **Demo:** [Usage](https://github.com/allenai/SPECTER2_0/blob/main/README.md)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
|Model|Name and HF link|Description|
|--|--|--|
|Proximity*|[allenai/specter2](https://huggingface.co/allenai/specter2)|Encode papers as queries and candidates eg. Link Prediction, Nearest Neighbor Search|
|Adhoc Query|[allenai/specter2_adhoc_query](https://huggingface.co/allenai/specter2_adhoc_query)|Encode short raw text queries for search tasks. (Candidate papers can be encoded with the proximity adapter)|
|Classification|[allenai/specter2_classification](https://huggingface.co/allenai/specter2_classification)|Encode papers to feed into linear classifiers as features|
|Regression|[allenai/specter2_regression](https://huggingface.co/allenai/specter2_regression)|Encode papers to feed into linear regressors as features|
*Proximity model should suffice for downstream task types not mentioned above
```python
from transformers import AutoTokenizer, AutoModel
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('allenai/specter2_base')
#load base model
model = AutoModel.from_pretrained('allenai/specter2_base')
#load the adapter(s) as per the required task, provide an identifier for the adapter in load_as argument and activate it
model.load_adapter("allenai/specter2", source="hf", load_as="specter2", set_active=True)
papers = [{'title': 'BERT', 'abstract': 'We introduce a new language representation model called BERT'},
{'title': 'Attention is all you need', 'abstract': ' The dominant sequence transduction models are based on complex recurrent or convolutional neural networks'}]
# concatenate title and abstract
text_batch = [d['title'] + tokenizer.sep_token + (d.get('abstract') or '') for d in papers]
# preprocess the input
inputs = self.tokenizer(text_batch, padding=True, truncation=True,
return_tensors="pt", return_token_type_ids=False, max_length=512)
output = model(**inputs)
# take the first token in the batch as the embedding
embeddings = output.last_hidden_state[:, 0, :]
```
## Downstream Use
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
For evaluation and downstream usage, please refer to [https://github.com/allenai/scirepeval/blob/main/evaluation/INFERENCE.md](https://github.com/allenai/scirepeval/blob/main/evaluation/INFERENCE.md).
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The base model is trained on citation links between papers and the adapters are trained on 8 large scale tasks across the four formats.
All the data is a part of SciRepEval benchmark and is available [here](https://huggingface.co/datasets/allenai/scirepeval).
The citation link are triplets in the form
```json
{"query": {"title": ..., "abstract": ...}, "pos": {"title": ..., "abstract": ...}, "neg": {"title": ..., "abstract": ...}}
```
consisting of a query paper, a positive citation and a negative which can be from the same/different field of study as the query or citation of a citation.
## Training Procedure
Please refer to the [SPECTER paper](https://api.semanticscholar.org/CorpusID:215768677).
### Training Hyperparameters
The model is trained in two stages using [SciRepEval](https://github.com/allenai/scirepeval/blob/main/training/TRAINING.md):
- Base Model: First a base model is trained on the above citation triplets.
``` batch size = 1024, max input length = 512, learning rate = 2e-5, epochs = 2 warmup steps = 10% fp16```
- Adapters: Thereafter, task format specific adapters are trained on the SciRepEval training tasks, where 600K triplets are sampled from above and added to the training data as well.
``` batch size = 256, max input length = 512, learning rate = 1e-4, epochs = 6 warmup = 1000 steps fp16```
# Evaluation
We evaluate the model on [SciRepEval](https://github.com/allenai/scirepeval), a large scale eval benchmark for scientific embedding tasks which which has [SciDocs] as a subset.
We also evaluate and establish a new SoTA on [MDCR](https://github.com/zoranmedic/mdcr), a large scale citation recommendation benchmark.
|Model|SciRepEval In-Train|SciRepEval Out-of-Train|SciRepEval Avg|MDCR(MAP, Recall@5)|
|--|--|--|--|--|
|[BM-25](https://api.semanticscholar.org/CorpusID:252199740)|n/a|n/a|n/a|(33.7, 28.5)|
|[SPECTER](https://huggingface.co/allenai/specter)|54.7|57.4|68.0|(30.6, 25.5)|
|[SciNCL](https://huggingface.co/malteos/scincl)|55.6|57.8|69.0|(32.6, 27.3)|
|[SciRepEval-Adapters](https://huggingface.co/models?search=scirepeval)|61.9|59.0|70.9|(35.3, 29.6)|
|[SPECTER2 Base](allenai/specter2_base)|56.3|73.6|69.1|(38.0, 32.4)|
|[SPECTER2-Adapters](https://huggingface.co/models?search=allenai/specter-2)|**62.3**|**59.2**|**71.2**|**(38.4, 33.0)**|
Please cite the following works if you end up using SPECTER 2.0:
[SciRepEval paper](https://api.semanticscholar.org/CorpusID:254018137)
```bibtex
@article{Singh2022SciRepEvalAM,
title={SciRepEval: A Multi-Format Benchmark for Scientific Document Representations},
author={Amanpreet Singh and Mike D'Arcy and Arman Cohan and Doug Downey and Sergey Feldman},
journal={ArXiv},
year={2022},
volume={abs/2211.13308}
}
```
| 9,551 | [
[
-0.017303466796875,
-0.019775390625,
0.030059814453125,
0.0105743408203125,
-0.0095062255859375,
-0.01428985595703125,
-0.0160369873046875,
-0.0538330078125,
0.032257080078125,
0.00299835205078125,
-0.019989013671875,
-0.0157623291015625,
-0.056549072265625,
... |
radames/stable-diffusion-v1-5-img2img | 2023-05-09T18:24:33.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"image-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"r... | image-to-image | radames | null | null | radames/stable-diffusion-v1-5-img2img | 8 | 639 | diffusers | 2023-05-09T18:19:29 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- image-to-image
inference: true
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use
them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
duplicated_from: runwayml/stable-diffusion-v1-5
pipeline_tag: image-to-image
---
# Stable Diffusion v1-5 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion).
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Original GitHub Repository
1. Download the weights
- [v1-5-pruned-emaonly.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt) - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt) - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/runwayml/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 14,547 | [
[
-0.0295867919921875,
-0.0716552734375,
0.034423828125,
0.0201568603515625,
-0.0181427001953125,
-0.0293731689453125,
0.00640106201171875,
-0.033203125,
-0.01378631591796875,
0.033599853515625,
-0.0236358642578125,
-0.04205322265625,
-0.05316162109375,
-0.012... |
Andyrasika/lora_diffusion | 2023-07-18T05:45:36.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Andyrasika | null | null | Andyrasika/lora_diffusion | 4 | 639 | diffusers | 2023-07-17T17:43:07 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
---
The model is created using the following steps:
- Find the desired model (checkpoint or lora) on Civitai
- You can see some conversion scripts in diffusesrs. This time, only the scripts for converting checkpoit and lora are used.
It depends on the model type of Civitai. If it is a lora model, you need to specify a basic model
- Using __load_lora function from https://towardsdatascience.com/improving-diffusers-package-for-high-quality-image-generation-a50fff04bdd4
```
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"Andyrasika/lora_diffusion"
,custom_pipeline = "lpw_stable_diffusion"
,torch_dtype=torch.float16
)
lora = ("/content/lora_model.safetensors",0.8)
pipeline = __load_lora(pipeline=pipeline,lora_path=lora[0],lora_weight=lora[1])
pipeline.to("cuda")
# pipeline.enable_xformers_memory_efficient_attention()
#https://huggingface.co/docs/diffusers/optimization/fp16
pipeline.enable_vae_tiling()
prompt = """
shukezouma,negative space,shuimobysim
a branch of flower, traditional chinese ink painting
"""
image = pipeline(prompt).images[0]
image
```
<hr>
Since this is only the first official release, I believe there are still many, many imperfections.
Please provide feedback in time, and I will continuously make corrections, thank you!
| 1,414 | [
[
-0.039947509765625,
-0.032379150390625,
0.0243072509765625,
0.030548095703125,
-0.0264434814453125,
-0.0201873779296875,
0.0256500244140625,
-0.0261383056640625,
0.0147705078125,
0.044708251953125,
-0.06475830078125,
-0.0253753662109375,
-0.03192138671875,
-... |
DILAB-HYU/koquality-polyglot-1.3b | 2023-11-05T11:47:51.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | DILAB-HYU | null | null | DILAB-HYU/koquality-polyglot-1.3b | 0 | 639 | transformers | 2023-10-30T04:35:31 | ---
license: apache-2.0
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- polyglot-ko
- gpt-neox
- KoQuality
base_model: EleutherAI/polyglot-ko-1.3b
---
This model is a instruct-tuned EleutherAI/polyglot-ko-1.3b model.
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + CPU Offloading (384GB)
- num_devices: 2
- gradient_accumulation_steps: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5 | 663 | [
[
-0.04876708984375,
-0.06781005859375,
0.017974853515625,
0.0165863037109375,
-0.039337158203125,
-0.00662994384765625,
-0.0088653564453125,
-0.0234832763671875,
0.0227813720703125,
0.0169525146484375,
-0.056549072265625,
-0.01251220703125,
-0.041717529296875,
... |
dalle-mini/vqgan_imagenet_f16_16384 | 2022-03-01T17:28:10.000Z | [
"transformers",
"jax",
"endpoints_compatible",
"has_space",
"region:us"
] | null | dalle-mini | null | null | dalle-mini/vqgan_imagenet_f16_16384 | 40 | 638 | transformers | 2022-03-02T23:29:05 | ## VQGAN-f16-16384
### Model Description
This is a Flax/JAX implementation of VQGAN, which learns a codebook of context-rich visual parts by leveraging both the use of convolutional methods and transformers. It was introduced in [Taming Transformers for High-Resolution Image Synthesis](https://compvis.github.io/taming-transformers/) ([CVPR paper](https://openaccess.thecvf.com/content/CVPR2021/html/Esser_Taming_Transformers_for_High-Resolution_Image_Synthesis_CVPR_2021_paper.html)).
The model allows the encoding of images as a fixed-length sequence of tokens taken from the codebook.
This version of the model uses a reduction factor `f=16` and a vocabulary of `16,384` tokens.
As an example of how the reduction factor works, images of size `256x256` are encoded to sequences of `256` tokens: `256/16 * 256/16`. Images of `512x512` would result in sequences of `1024` tokens.
This model was ported to JAX using [a checkpoint trained on ImageNet](https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/).
### How to Use
The checkpoint can be loaded using [Suraj Patil's implementation](https://github.com/patil-suraj/vqgan-jax) of `VQModel`.
### Other
This model can be used as part of the implementation of [DALL·E mini](https://github.com/borisdayma/dalle-mini). Our [report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini--Vmlldzo4NjIxODA) contains more details on how to leverage it in an image encoding / generation pipeline. | 1,458 | [
[
-0.04022216796875,
-0.03436279296875,
0.0233612060546875,
-0.009246826171875,
-0.0309295654296875,
0.0016298294067382812,
0.01395416259765625,
-0.036346435546875,
-0.0007033348083496094,
0.048187255859375,
-0.052001953125,
-0.0364990234375,
-0.0270843505859375,
... |
tscholak/3vnuv1vf | 2022-01-10T21:49:25.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | tscholak | null | null | tscholak/3vnuv1vf | 9 | 638 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- spider
metrics:
- spider
---
## tscholak/3vnuv1vf
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [t5.1.1.lm100k.large](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k).
### Training Data
The model has been fine-tuned on the 7000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves Spider's zero-shot text-to-SQL translation task, and that means that it can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [t5.1.1.lm100k.large](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) and fine-tuned with the text-to-text generation objective.
Questions are always grounded in a database schema, and the model is trained to predict the SQL query that would be used to answer the question. The input to the model is composed of the user's natural language question, the database identifier, and a list of tables and their columns:
```
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ...
```
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's question:
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 71.2 % exact-set match accuracy and 74.4 % execution accuracy on the Spider development set.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **74.8 %** exact-set match accuracy and **79.2 %** execution accuracy on the Spider development set.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
``` | 3,298 | [
[
-0.015899658203125,
-0.05242919921875,
0.0158233642578125,
0.0228271484375,
-0.01953125,
0.0015134811401367188,
0.0008873939514160156,
-0.044830322265625,
-0.0012712478637695312,
0.0243682861328125,
-0.034881591796875,
-0.035400390625,
-0.0316162109375,
0.03... |
MCG-NJU/videomae-large-finetuned-kinetics | 2023-04-22T11:41:27.000Z | [
"transformers",
"pytorch",
"videomae",
"video-classification",
"vision",
"arxiv:2203.12602",
"arxiv:2111.06377",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | video-classification | MCG-NJU | null | null | MCG-NJU/videomae-large-finetuned-kinetics | 6 | 638 | transformers | 2022-08-02T14:09:56 | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (large-sized model, fine-tuned on Kinetics-400)
VideoMAE model pre-trained for 1600 epochs in a self-supervised way and fine-tuned in a supervised way on Kinetics-400. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for video classification into one of the 400 possible Kinetics-400 labels.
### How to use
Here is how to use this model to classify a video:
```python
from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
import numpy as np
import torch
video = list(np.random.randn(16, 3, 224, 224))
processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-large-finetuned-kinetics")
model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-large-finetuned-kinetics")
inputs = processor(video, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
This model obtains a top-1 accuracy of 84.7 and a top-5 accuracy of 96.5 on the test set of Kinetics-400.
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 3,587 | [
[
-0.036773681640625,
-0.018829345703125,
0.01068878173828125,
-0.0164947509765625,
-0.029571533203125,
0.0012464523315429688,
0.00708770751953125,
-0.000286102294921875,
0.0252685546875,
0.031585693359375,
-0.041229248046875,
-0.033111572265625,
-0.0762939453125,... |
timm/swinv2_small_window8_256.ms_in1k | 2023-03-18T03:36:54.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_small_window8_256.ms_in1k | 0 | 638 | timm | 2023-03-18T03:36:38 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for swinv2_small_window8_256.ms_in1k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 49.7
- GMACs: 11.6
- Activations (M): 40.1
- Image size: 256 x 256
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_small_window8_256.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_small_window8_256.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_small_window8_256.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,405 | [
[
-0.03179931640625,
-0.0277099609375,
-0.00847625732421875,
0.01195526123046875,
-0.0252838134765625,
-0.035064697265625,
-0.0199127197265625,
-0.038787841796875,
0.001293182373046875,
0.0288543701171875,
-0.03851318359375,
-0.0401611328125,
-0.045745849609375,
... |
llm-book/bert-base-japanese-v3-ner-wikipedia-dataset | 2023-07-25T13:32:15.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"ja",
"dataset:llm-book/ner-wikipedia-dataset",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | llm-book | null | null | llm-book/bert-base-japanese-v3-ner-wikipedia-dataset | 5 | 638 | transformers | 2023-05-28T08:06:41 | ---
language:
- ja
license: apache-2.0
library_name: transformers
datasets:
- llm-book/ner-wikipedia-dataset
pipeline_tag: token-classification
metrics:
- seqeval
- precision
- recall
- f1
---
# llm-book/bert-base-japanese-v3-ner-wikipedia-dataset
「[大規模言語モデル入門](https://www.amazon.co.jp/dp/4297136333)」の第6章で紹介している固有表現認識のモデルです。
[cl-tohoku/bert-base-japanese-v3](https://huggingface.co/cl-tohoku/bert-base-japanese-v3)を[llm-book/ner-wikipedia-dataset](https://huggingface.co/datasets/llm-book/ner-wikipedia-dataset)でファインチューニングして構築されています。
## 関連リンク
* [GitHubリポジトリ](https://github.com/ghmagazine/llm-book)
* [Colabノートブック](https://colab.research.google.com/github/ghmagazine/llm-book/blob/main/chapter6/6-named-entity-recognition.ipynb)
* [データセット](https://huggingface.co/datasets/llm-book/ner-wikipedia-dataset)
* [大規模言語モデル入門(Amazon.co.jp)](https://www.amazon.co.jp/dp/4297136333/)
* [大規模言語モデル入門(gihyo.jp)](https://gihyo.jp/book/2023/978-4-297-13633-8)
## 使い方
```python
from transformers import pipeline
from pprint import pprint
ner_pipeline = pipeline(
model="llm-book/bert-base-japanese-v3-ner-wikipedia-dataset",
aggregation_strategy="simple",
)
text = "大谷翔平は岩手県水沢市出身のプロ野球選手"
# text中の固有表現を抽出
pprint(ner_pipeline(text))
# [{'end': None,
# 'entity_group': '人名',
# 'score': 0.99823624,
# 'start': None,
# 'word': '大谷 翔平'},
# {'end': None,
# 'entity_group': '地名',
# 'score': 0.9986874,
# 'start': None,
# 'word': '岩手 県 水沢 市'}]
```
## ライセンス
[Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0) | 1,532 | [
[
-0.03692626953125,
-0.042633056640625,
0.01522064208984375,
0.01108551025390625,
-0.039764404296875,
-0.0165863037109375,
-0.021148681640625,
-0.0237884521484375,
0.034881591796875,
0.039886474609375,
-0.0467529296875,
-0.060028076171875,
-0.04058837890625,
... |
CiroN2022/ascii-art | 2023-08-23T11:50:21.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"region:us",
"has_space"
] | text-to-image | CiroN2022 | null | null | CiroN2022/ascii-art | 3 | 638 | diffusers | 2023-08-23T11:50:18 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: ascii_art
widget:
- text: ascii_art
---
# Ascii Art

None
## Image examples for the model:









| 505 | [
[
-0.00897216796875,
-0.02288818359375,
0.043548583984375,
0.034515380859375,
-0.043243408203125,
-0.01488494873046875,
0.0216522216796875,
-0.01242828369140625,
-0.0035991668701171875,
0.05438232421875,
-0.034210205078125,
-0.05035400390625,
-0.0391845703125,
... |
mgoin/llama2.c-stories15M-ds | 2023-10-18T17:00:56.000Z | [
"transformers",
"onnx",
"llama",
"text-generation",
"deepsparse",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | mgoin | null | null | mgoin/llama2.c-stories15M-ds | 0 | 638 | transformers | 2023-10-13T14:18:03 | ---
tags:
- deepsparse
---
https://huggingface.co/Xenova/llama2.c-stories15M exported to be compatible with [DeepSparse](https://github.com/neuralmagic/deepsparse)
```python
from deepsparse import TextGeneration
model = TextGeneration(model="hf:mgoin/llama2.c-stories15M-ds")
out = model("Once upon a time", max_new_tokens=300)
print(out.generations[0].text)
### , there was a little girl named Lily. She loved to play outside in the sunshine. One day, she saw a big, red ball in the sky. It was the sun! She thought it was so pretty.
### Lily wanted to play with the ball, but it was too high up in the sky. She tried to jump and reach it, but she couldn't. Then, she had an idea. She would use a stick to knock the ball down.
### Lily found a stick and tried to hit the ball. But the stick was too short. She tried again and again, but she couldn't reach it. She felt sad.
### Suddenly, a kind man came by and saw Lily. He asked her what was wrong. Lily told him about the ball. The man smiled and said, "I have a useful idea!" He took out a long stick and used it to knock the ball down. Lily was so happy! She thanked the man and they played together in the sunshine. Once upon a time, there was a little girl named Lily. She loved to play outside in the sunshine. One day, she saw a big, red ball in the sky. It was the sun! She thought it was so pretty.
### Lily wanted to play with the ball, but it was too high up in the sky. She tried to jump, but she couldn't reach it
``` | 1,484 | [
[
0.0168914794921875,
-0.0528564453125,
0.046417236328125,
0.04815673828125,
-0.0298004150390625,
0.014495849609375,
-0.007320404052734375,
-0.03875732421875,
0.01861572265625,
0.01198577880859375,
-0.056427001953125,
-0.058258056640625,
-0.053680419921875,
0.... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | 2021-10-17T13:35:38.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | CAMeL-Lab | null | null | CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | 1 | 637 | transformers | 2022-03-02T23:29:04 | ---
language:
- ar
license: apache-2.0
widget:
- text: "عامل ايه ؟"
---
# CAMeLBERT-MSA DID MADAR Twitter-5 Model
## Model description
**CAMeLBERT-MSA DID MADAR Twitter-5 Model** is a dialect identification (DID) model that was built by fine-tuning the [CAMeLBERT-MSA](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-msa/) model.
For the fine-tuning, we used the [MADAR Twitter-5](https://camel.abudhabi.nyu.edu/madar-shared-task-2019/) dataset, which includes 21 labels.
Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT).
## Intended uses
You can use the CAMeLBERT-MSA DID MADAR Twitter-5 model as part of the transformers pipeline.
This model will also be available in [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) soon.
#### How to use
To use the model with a transformers pipeline:
```python
>>> from transformers import pipeline
>>> did = pipeline('text-classification', model='CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5')
>>> sentences = ['عامل ايه ؟', 'شلونك ؟ شخبارك ؟']
>>> did(sentences)
[{'label': 'Egypt', 'score': 0.5741344094276428},
{'label': 'Kuwait', 'score': 0.5225679278373718}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`.
Otherwise, you could download the models manually.
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
``` | 2,968 | [
[
-0.043212890625,
-0.049591064453125,
0.0120697021484375,
0.0202484130859375,
-0.021331787109375,
0.01012420654296875,
-0.0262298583984375,
-0.03802490234375,
0.0077972412109375,
0.035064697265625,
-0.03515625,
-0.038543701171875,
-0.071044921875,
0.014442443... |
timm/vit_medium_patch16_gap_384.sw_in12k_ft_in1k | 2023-05-06T00:27:21.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_medium_patch16_gap_384.sw_in12k_ft_in1k | 0 | 637 | timm | 2022-12-02T02:01:32 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for vit_medium_patch16_gap_384.sw_in12k_ft_in1k
A Vision Transformer (ViT) image classification model. This is a `timm` specific variation of the architecture with token global average pooling. Pretrained on ImageNet-12k and fine-tuned on ImageNet-1k by Ross Wightman in `timm` using recipe template described below.
Recipe details:
* Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes)
* AdamW optimizer, gradient clipping, EMA weight averaging
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 39.0
- GMACs: 22.0
- Activations (M): 32.1
- Image size: 384 x 384
- **Papers:**
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_medium_patch16_gap_384.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_medium_patch16_gap_384.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 576, 512) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
| 3,730 | [
[
-0.03656005859375,
-0.031158447265625,
0.0007452964782714844,
0.013427734375,
-0.0272064208984375,
-0.025299072265625,
-0.0158843994140625,
-0.033447265625,
0.0231475830078125,
0.0216217041015625,
-0.04425048828125,
-0.04571533203125,
-0.05029296875,
-0.0076... |
digiplay/Matrix_Stellar_VAE_v1 | 2023-07-01T18:24:54.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/Matrix_Stellar_VAE_v1 | 3 | 637 | diffusers | 2023-06-13T02:31:47 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/88546/matrix-stellar-vae
Sample image :




| 816 | [
[
-0.046356201171875,
-0.02056884765625,
0.036834716796875,
0.006641387939453125,
-0.022857666015625,
0.020660400390625,
0.0301971435546875,
0.0016584396362304688,
0.04925537109375,
0.053680419921875,
-0.06195068359375,
-0.040191650390625,
-0.034027099609375,
... |
KappaNeuro/albumen-print | 2023-09-14T02:26:30.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"photo",
"style",
"old photo",
"albumen print",
"license:other",
"region:us",
"has_space"
] | text-to-image | KappaNeuro | null | null | KappaNeuro/albumen-print | 1 | 637 | diffusers | 2023-09-14T02:26:25 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- photo
- style
- old photo
- albumen print
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Albumen Print page
widget:
- text: Albumen Print - Welsh settler in 1860 presenting a new mobile prototype to audience. Looks like Steve Jobs presenting the iphone. Rare photo is not the best condition. Vintage photo was taken by a field view camera.
- text: Albumen Print - a covered wagon on the oregon trail being ferried across the river on a large log ferry raft guided by river men, approximately 1845, in the style of a tintype photograph
- text: Albumen Print - albumen print,documentary photography, 50mm, atmosphere sense, full body of women,Use cinematic techniques and shot on a 25mm lens, achieve a depth of field with tilt blur and a shutter speed of 1/1000 and f/22. Aim for a photorealistic look with 32k resolution, backlit, no words, 8k, HD, cinematography, photorealistic, epic composition, Unreal Engine, Color Grading, interesting angle, cinematic view, 35mm kodak film grain, hyper-detailed, beautifully color-coded, insane details, intricate details, Editorial Photography, Photography, Depth of Field, Tilt Blur, Super-Resolution, Megapixel, ProPhoto RGB, VR, Half rear Lighting, Backlight, Dramatic Lighting, Incandescent, Optical Fiber, Moody Lighting, Soft Lighting, Volumetric, Contre-Jour, Accent Lighting, Global Illumination, Screen Space Global Illumination, Ray Tracing Global Illumination, Optics, Scattering, Glowing, Shadows, Rough, Shimmering, Ray Tracing Reflections, Lumen Reflections, Screen Space Reflections, Diffraction Grading, Chromatic Aberration, GB Displacement, Scan Lines, Ray Traced, Ambient Occlusion, Anti-Aliasing, elegant, dynamic pose, volumetric, ultra-detailed, ambient, FKAA, TXAA, RTX, SSAO, Shaders, OpenGL-Shaders, GLSL-Shaders, Post Processing, Post-Production, Cel Shading, Tone Mapping, CGI, VFX, SFX
- text: Albumen Print - [80520453432549053]A sepia-toned pograph captures a stoic elderly man sitting on a wooden bench outside his small cottage, gazing off into the distance with a sense of nostalgia. The background shows a serene landscape of rolling hills and a winding river, with a few grazing sheep dotting the fields. The po exudes a sense of timelessness and peacefulness, evoking memories of a simpler time. The pographer may have employed a low-angle s to convey a feeling of respect for the man and his life experiences. The image is reminiscent of old family albums and invites the viewer to reflect on their own personal past., UHD, 16k, retina
- text: Albumen Print - _color photographic image_three scary women at different distances from each other_colour_tintype_tintype_daguerrotype_large plate of chipped albumen glass solid oxidized silver halides color_detail cracked glass with dust and insects_three or four strange_mysterious_scary women_in the mist_swamp mist_surrounded
- text: Albumen Print - 19th century dagherrotype of a colonial house with palms and a tropical landscape in the background, in first term there are some crabs on the ground, calm mood, sunny day, a volcanoe fog can be seen in the far backgrund behind some hills, old photo, photography, vintage
- text: Albumen Print - vintage Victorian 19th century faded and pale monochromatic odd foxed photograph of a weird surreal floating prism framework constructed of skeletal white threads weirdly and intricately connected and suspended above a shadow in the middle in an English field, pagan
- text: Albumen Print - a faded scratched daggueratype style head and shoulders photograph of an Italian woman facing the camera straight on wearing conservative dress with a high collar with fancy styled hair in a photography studio in London, England in 1867
- text:
- text: Albumen Print - vintage old faded sepia monochrome victorian 1800s black and white realistic victorian photo of a tiny abandonded chapel in a clearing in a faded cabinet card style
---
# Albumen Print

> Albumen Print - Welsh settler in 1860 presenting a new mobile prototype to audience. Looks like Steve Jobs presenting the iphone. Rare photo is not the best condition. Vintage photo was taken by a field view camera.
<p>An albumen print is a type of photographic print made from a negative on which a layer of egg white, specifically egg albumen, is used as the binder for light-sensitive materials. It was a popular photographic process during the 19th century, particularly from the 1850s to the 1890s.</p><p>The albumen print process begins with coating a sheet of paper with a solution made from egg whites mixed with salt. Once the coating dries, the paper is sensitized by immersing it in a solution containing silver nitrate. This sensitized paper is then exposed to light through a negative, resulting in a latent image.</p><p>After exposure, the paper is developed using a developer solution, typically gallic acid or pyrogallic acid, which converts the exposed silver salts into metallic silver. The image is then fixed to remove any unexposed silver salts, making it permanent and stable.</p><p>Albumen prints are known for their tonal range, sharpness, and fine detail. The use of egg albumen as the binder gives the print a glossy surface and helps to hold the light-sensitive materials in place, enhancing the image's clarity and definition.</p><p>In terms of aesthetics, albumen prints often have warm tones, with a range of brown, sepia, or purple hues. The process was commonly used for portrait photography, as well as landscape, architectural, and documentary photography during the 19th century.</p><p>Albumen prints played a significant role in the history of photography, serving as a precursor to later photographic processes. They are appreciated today for their historical value and the unique aesthetic qualities they impart, providing a glimpse into the early days of photography and the artistry of the era.</p>
## Image examples for the model:

> Albumen Print - a covered wagon on the oregon trail being ferried across the river on a large log ferry raft guided by river men, approximately 1845, in the style of a tintype photograph

> Albumen Print - albumen print,documentary photography, 50mm, atmosphere sense, full body of women,Use cinematic techniques and shot on a 25mm lens, achieve a depth of field with tilt blur and a shutter speed of 1/1000 and f/22. Aim for a photorealistic look with 32k resolution, backlit, no words, 8k, HD, cinematography, photorealistic, epic composition, Unreal Engine, Color Grading, interesting angle, cinematic view, 35mm kodak film grain, hyper-detailed, beautifully color-coded, insane details, intricate details, Editorial Photography, Photography, Depth of Field, Tilt Blur, Super-Resolution, Megapixel, ProPhoto RGB, VR, Half rear Lighting, Backlight, Dramatic Lighting, Incandescent, Optical Fiber, Moody Lighting, Soft Lighting, Volumetric, Contre-Jour, Accent Lighting, Global Illumination, Screen Space Global Illumination, Ray Tracing Global Illumination, Optics, Scattering, Glowing, Shadows, Rough, Shimmering, Ray Tracing Reflections, Lumen Reflections, Screen Space Reflections, Diffraction Grading, Chromatic Aberration, GB Displacement, Scan Lines, Ray Traced, Ambient Occlusion, Anti-Aliasing, elegant, dynamic pose, volumetric, ultra-detailed, ambient, FKAA, TXAA, RTX, SSAO, Shaders, OpenGL-Shaders, GLSL-Shaders, Post Processing, Post-Production, Cel Shading, Tone Mapping, CGI, VFX, SFX

> Albumen Print - [80520453432549053]A sepia-toned pograph captures a stoic elderly man sitting on a wooden bench outside his small cottage, gazing off into the distance with a sense of nostalgia. The background shows a serene landscape of rolling hills and a winding river, with a few grazing sheep dotting the fields. The po exudes a sense of timelessness and peacefulness, evoking memories of a simpler time. The pographer may have employed a low-angle s to convey a feeling of respect for the man and his life experiences. The image is reminiscent of old family albums and invites the viewer to reflect on their own personal past., UHD, 16k, retina

> Albumen Print - _color photographic image_three scary women at different distances from each other_colour_tintype_tintype_daguerrotype_large plate of chipped albumen glass solid oxidized silver halides color_detail cracked glass with dust and insects_three or four strange_mysterious_scary women_in the mist_swamp mist_surrounded

> Albumen Print - 19th century dagherrotype of a colonial house with palms and a tropical landscape in the background, in first term there are some crabs on the ground, calm mood, sunny day, a volcanoe fog can be seen in the far backgrund behind some hills, old photo, photography, vintage

> Albumen Print - vintage Victorian 19th century faded and pale monochromatic odd foxed photograph of a weird surreal floating prism framework constructed of skeletal white threads weirdly and intricately connected and suspended above a shadow in the middle in an English field, pagan

> Albumen Print - a faded scratched daggueratype style head and shoulders photograph of an Italian woman facing the camera straight on wearing conservative dress with a high collar with fancy styled hair in a photography studio in London, England in 1867

>

> Albumen Print - vintage old faded sepia monochrome victorian 1800s black and white realistic victorian photo of a tiny abandonded chapel in a clearing in a faded cabinet card style
| 9,766 | [
[
-0.0546875,
-0.03179931640625,
0.032501220703125,
-0.00923919677734375,
-0.029876708984375,
-0.0185394287109375,
0.035430908203125,
-0.055419921875,
0.03460693359375,
0.0478515625,
-0.0282440185546875,
-0.059295654296875,
-0.032958984375,
-0.004150390625,
... |
impyadav/GPT2-FineTuned-Hinglish-Song-Generation | 2022-01-03T11:33:54.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | impyadav | null | null | impyadav/GPT2-FineTuned-Hinglish-Song-Generation | 1 | 636 | transformers | 2022-03-02T23:29:05 | GPT-2 model fine-tuned on Custom old Hindi songs (Hinglish) for text-generation task (AI Lyricist)
language:
- Hindi
- Hinglish
| 136 | [
[
-0.0184173583984375,
-0.05230712890625,
0.0076446533203125,
0.031768798828125,
-0.0194244384765625,
-0.004360198974609375,
-0.0214385986328125,
-0.0230712890625,
0.0005741119384765625,
0.057373046875,
-0.0428466796875,
-0.0100250244140625,
-0.038177490234375,
... |
sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1 | 2022-06-15T22:09:18.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1 | 1 | 636 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
model = AutoModel.from_pretrained('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,774 | [
[
-0.01319122314453125,
-0.058135986328125,
0.0333251953125,
0.027496337890625,
-0.03192138671875,
-0.0250244140625,
-0.0113983154296875,
0.009857177734375,
0.005870819091796875,
0.04046630859375,
-0.03173828125,
-0.036346435546875,
-0.057159423828125,
0.01574... |
ProomptEngineer/pe-funko-pop-diffusion-style | 2023-09-11T15:39:57.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"has_space",
"region:us"
] | text-to-image | ProomptEngineer | null | null | ProomptEngineer/pe-funko-pop-diffusion-style | 2 | 636 | diffusers | 2023-09-11T15:39:53 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: PEPopFigure
widget:
- text: PEPopFigure
---
# PE Funko Pop Diffusion [Style]

<p>make your own funko pop figure...</p><p>weights 0.8-1</p><h2 id="heading-63"><span>If you want to donate:</span></h2><h2 id="heading-64"><a target="_blank" rel="ugc" href="https://ko-fi.com/proomptengineer"><span>https://ko-fi.com/proomptengineer</span></a></h2>
## Image examples for the model:









| 791 | [
[
-0.03778076171875,
-0.03704833984375,
0.02545166015625,
0.0245208740234375,
-0.032623291015625,
0.007110595703125,
0.023193359375,
-0.021575927734375,
0.050811767578125,
0.038055419921875,
-0.057952880859375,
0.00978851318359375,
-0.046142578125,
0.006862640... |
MyneFactory/MF-KonoSuba | 2023-03-23T02:47:24.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | MyneFactory | null | null | MyneFactory/MF-KonoSuba | 25 | 635 | diffusers | 2023-01-21T21:15:53 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
<div>
<!--Logo-->
<div style="text-align: center;">
<img src="https://logo.mynefactory.ai/MF-KonoSuba" alt="Myne Factory Logo" style="margin:0;">
</div>
<!--Table of contents-->
<div style="font-size: 14px; padding: 4px 8px; display: flex; justify-content: space-around; color: black; font-weight: 500;">
<a href="#model-info" style="text-decoration: none; color: #204F8F">Model Info</a> |
<a href="#troubleshooting" style="text-decoration: none; color: #204F8F"">Troubleshooting</a> |
<a href="#recsettings" style="text-decoration: none; color: #204F8F"">Recommmended Settings</a> |
<a href="#promptformat" style="text-decoration: none; color: #204F8F"">Prompt Format</a> |
<a href="#examples" style="text-decoration: none; color: #204F8F"">Examples</a> |
<a href="#mynelinks" style="text-decoration: none; color: #204F8F"">Socials</a>
</div>
</div>
<!--Title-->
<div style="text-align: center;">
<h1 style=" font-size:50px; padding:2px; margin:20px 0 0 0">KonoSuba</h1>
<span style=" font-size:18px; padding:2px; margin:5px 0 0 0">God's Blessing on This Wonderful World!</span>
</div>
<!--Example shortcuts-->
<div style="display: flex; align-items:top; justify-content:space-around; padding-bottom: 40px;">
<a href="#example1" style="padding:10px">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba1.png" style="margin:0"/>
</a>
<a href="#example2" style="padding:10px">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba5.png" style="margin:0"/>
</a>
<a href="#example3" style="padding:10px">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba3.png" style="margin:0"/>
</a>
<a href="#example4" style="padding:10px">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba4.png" style="margin:0"/>
</a>
</div>
<!--Model Info-->
<div style="padding:10px; margin: 20px 0; background-color: #f9f9f9; box-shadow: 0 4px 6px rgba(0,0,0,0.1);" id="model-info">
<h2 style="font-size:28px; font-family: Arial, Helvetica, sans-serif; font-weight: bold; margin:0; color: #222;">Model Info</h2>
<p style="font-size: 18px; color: #666;">
<strong>Downloads: </strong>
<a style="color: #333" href="https://huggingface.co/MyneFactory/MF-KonoSuba/blob/main/Full%20release/MF-KonoSuba-V1.1-T2.11.ckpt">MF-KonoSuba V1.1 (T2.11).ckpt</a>,
<a style="color: #666" href="https://huggingface.co/MyneFactory/MF-KonoSuba/blob/main/Full%20release/MF-KonoSuba-V1.0-T2.8.ckpt">MF-KonoSuba V1.0 (T2.8).ckpt</a>
</p>
<p style="font-size: 18px; color: #666;">
<strong>Authors: </strong> Juusoz, 金Goldkoron, Khalil, LightUK and SamuraiCat
</p>
</div>
<!--Recommmended settings-->
<div style="padding:10px; margin: 20px 0; background-color: #f9f9f9; box-shadow: 0 4px 6px rgba(0,0,0,0.1);" id="recsettings">
<h2 style="font-size:28px; font-family: Arial, Helvetica, sans-serif; font-weight: bold; margin:0; color: #222;">Recommended Settings</h2>
<p style="font-size: 18px; margin-bottom: 4px; color: #666;">This model performs best with the following settings:</p>
<ul style="list-style-type: none; padding: 0 8px">
<li style="margin-bottom: 10px;">
<div style="display: inline-block; width: 120px; font-weight: 500; color: #333;">Image Size</div>
<div style="color: #666; padding-left:8px;"><strong>1024x576</strong> for wide 16:9, <strong>768x768</strong> for square, and <strong>640x1024</strong> for portrait</div>
<i style="color: #666666e8; padding-left:8px;">Feel free to experiment with higher resolutions, Juusoz made all the examples at higher than recommended resolutions</i>
</li>
<div style="display: flex;">
<li style="margin-bottom: 10px;">
<div style="display: inline-block; width: 120px; font-weight: 500; color: #333;">CFG</div>
<div style="color: #666; padding-left:8px;"><strong>9-12</strong></div>
</li>
<li style="margin-bottom: 10px;">
<div style="display: inline-block; width: 120px; font-weight: 500; color: #333;">Clip Skip</div>
<div style="color: #666; padding-left:8px;"><strong>1</strong></div>
</li>
<li style="margin-bottom: 10px;">
<div style="display: inline-block; width: 120px; font-weight: 500; color: #333;">Steps</div>
<div style="color: #666; padding-left:8px;"><strong>+30</strong> minimum, <strong>+70</strong> can give nice results</div>
</li>
</div>
</ul>
</div>
<!--Prompt format-->
<div style="padding:10px; margin: 20px 0; background-color: #f9f9f9; box-shadow: 0 4px 6px rgba(0,0,0,0.1);" id="promptformat">
<h2 style="font-size:28px; font-family: Arial, Helvetica, sans-serif; font-weight: bold; margin:0; color: #222;">Prompt Format</h2>
<i style="color: #666666e8; padding-left:8px;">
<div>The prompts we trained on are available in the corresponding T{version} Konosuba prompt list.txt file.</div>
<a style="color: #333" href="https://huggingface.co/MyneFactory/MF-KonoSuba/blob/main/Training%20data/T2.11%20KonoSuba%20prompt%20list.txt">T2.11 KonoSuba prompt list.txt</a>,
<a style="color: #666" href="https://huggingface.co/MyneFactory/MF-KonoSuba/blob/main/Training%20data/T2.8%20KonoSuba%20prompt%20list.txt">T2.8 KonoSuba prompt list.txt</a>
</i>
<div style="padding:0 8px">
<strong style="font-size: 16px; color: #333;">Format:</strong>
<code style="font-size: 14px; padding: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Parent tag, description prompt 1, description prompt 2, etc;</code>
</div>
<div style="padding:8px">
<strong style="font-size: 16px; color: #333;">Example:</strong>
<code style="font-size: 14px; padding: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Megumin, holding staff, casting, close-up; sparkle; night;</code>
</div>
<p style="font-size: 18px; color: #666;">The <strong style="color: #333;">parent tag</strong> serves as the primary label for the overall theme of the image and acts as the main subject. The <strong style="color: #333;">description prompts</strong> are a comprehensive list of attributes, objects, actions, and other elements that describe the subject in detail. Each subject is separated by a semicolon (;) while the individual attributes, objects, actions, and elements are separated by a comma (,).</p>
<p style="font-size: 18px; color: #666;">Just because we haven’t trained on something doesn’t mean the base AI model doesn’t already know what it is, so feel free to get creative and try new things!</p>
</div>
<!--Examples-->
<div style="padding:10px; margin: 20px 0; background-color: #f9f9f9; box-shadow: 0 4px 6px rgba(0,0,0,0.1);"" id="examples">
<h2 style="font-size:28px; font-family: Arial, Helvetica, sans-serif; font-weight: bold; margin:0; color: #222;">Examples</h2>
<div style="display: flex; flex-wrap: wrap; justify-content: center;">
<div style="padding: 20px; width: 100%; text-align: center;" id="example1">
<a href="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba1.png">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba1.png" style="width: 100%; margin: 0px 0; border: 1px solid #ddd;" />
</a>
<div>
<div style="display: flex; flex-direction: column; text-align: left;">
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #333; display: block;">Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Adventurer's guild; Darkness, armour, aroused, posing; sparkle</code>
</div>
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #696969; display: block;">Negative Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f59d; border-radius: 4px; color: #000;">low quality, worst quality, bad hands, bad anatomy, watermark, signature</code>
</div>
</div>
</div>
<div style="padding:10px 40px">
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Steps:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">60</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Sampler:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Euler a</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">CFG Scale:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">11</code>
</div>
</div>
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Seed:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">2356121475</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Size:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">1024x1024</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Model:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">T2.11</code>
</div>
</div>
</div>
</div>
<div style="padding: 20px; width: 100%; text-align: center;" id="example2">
<a href="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba5.png">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba5.png" style="width: 100%; margin: 0px 0; border: 1px solid #ddd;" />
</a>
<div>
<div style="display: flex; flex-direction: column; text-align: left;">
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #333; display: block;">Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Axel; Aqua, smiling, on her knees; night; stars; sparkle;</code>
</div>
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #696969; display: block;">Negative Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f59d; border-radius: 4px; color: #000;">bad hands, bad anatomy</code>
</div>
</div>
</div>
<div style="padding:10px 40px">
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Steps:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">60</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Sampler:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Euler a</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">CFG Scale:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">9</code>
</div>
</div>
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Seed:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">3</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Size:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">1024x1024</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Model:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">T2.11</code>
</div>
</div>
</div>
</div>
<div style="padding: 20px; width: 100%; text-align: center;" id="example3">
<a href="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba3.png">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba3.png" style="width: 100%; margin: 0px 0; border: 1px solid #ddd;" />
</a>
<div>
<div style="display: flex; flex-direction: column; text-align: left;">
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #333; display: block;">Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Kazuma, shirt, cloak, laying on couch; mansion; sunlight; masterpiece; solo</code>
</div>
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #696969; display: block;">Negative Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f59d; border-radius: 4px; color: #000;">low quality, worst quality, bad hands, bad anatomy, watermark, signature</code>
</div>
</div>
</div>
<div style="padding:10px 40px">
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Steps:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">60</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Sampler:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Euler a</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">CFG Scale:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">11</code>
</div>
</div>
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Seed:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">1755100988</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Size:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">1024x1024</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Model:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">T2.11</code>
</div>
</div>
</div>
</div>
<div style="padding: 20px; width: 100%; text-align: center;" id="example4">
<a href="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba4.png">
<img src="https://huggingface.co/MyneFactory/MF-KonoSuba/resolve/main/example%20pictures/konosuba4.png" style="width: 100%; margin: 0px 0; border: 1px solid #ddd;" />
</a>
<div>
<div style="display: flex; flex-direction: column; text-align: left;">
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #333; display: block;">Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f5; border-radius: 4px; color: #000;">field; farm; Megumin, sitting on ground, looking up, sky, smiling, crimson dress, cape, witch hat; sunlight; masterpiece;</code>
</div>
<div style="padding: 4px 2px;">
<strong style="font-size: 16px; color: #696969; display: block;">Negative Prompt:</strong>
<code style="font-size: 14px; background-color: #f5f5f59d; border-radius: 4px; color: #000;">low quality, worst quality, bad hands, bad anatomy, watermark, signature</code>
</div>
</div>
</div>
<div style="padding:10px 40px">
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Steps:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">60</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Sampler:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">Euler a</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">CFG Scale:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">11</code>
</div>
</div>
<div style="display: flex; flex-wrap: wrap; justify-content: space-between;">
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Seed:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">2556784517</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Size:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">1024x1024</code>
</div>
<div style="padding:4px">
<strong style="font-size: 16px; color: #333;">Model:</strong>
<code style="font-size: 14px; padding-left: 6px; background-color: #f5f5f5; border-radius: 4px; color: #000;">T2.11</code>
</div>
</div>
</div>
</div>
</div>
</div>
<!--Links-->
<div style="padding: 10px 0; text-align: center; font-size: 18px;" id="mynelinks">
<h2 style="font-size:28px; font-family: Arial, Helvetica, sans-serif; font-weight: bold; margin:0;">Socials</h2>
<a href="https://mynefactory.ai" style="text-decoration: none; color: #0077c9;">Website</a> |
<a href="https://discord.gg/GdJBzaTSCF" style="text-decoration: none; color: #0077c9;">Discord</a> |
<a href="https://www.patreon.com/user?u=36154428" style="text-decoration: none; color: #0077c9;">Patreon</a>
</div> | 19,732 | [
[
-0.04327392578125,
-0.053558349609375,
0.0243072509765625,
0.0164337158203125,
-0.00963592529296875,
0.0027561187744140625,
0.004398345947265625,
-0.0386962890625,
0.0518798828125,
0.007045745849609375,
-0.08349609375,
-0.03631591796875,
-0.0282135009765625,
... |
retrieva-jp/t5-small-long | 2023-05-10T01:01:29.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ja",
"arxiv:2002.05202",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | retrieva-jp | null | null | retrieva-jp/t5-small-long | 3 | 635 | transformers | 2023-04-26T08:26:49 | ---
license: cc-by-sa-4.0
language:
- ja
---
# Model card for model ID
This is a T5 v1.1 model, pre-trained on a Japanese corpus.
## Model details
T5 is a Transformer-based Encoder-Decoder model, now in v1.1, with the following improvements over the original T5.
- GEGLU activation in feed-forward hidden layer, rather than ReLU - see https://arxiv.org/abs/2002.05202 .
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- no parameter sharing between embedding and classifier layer
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger d_model and smaller num_heads and d_ff.
This model is based on T5 v1.1. It was pre-trained on a Japanese corpus. For the Japanese corpus, Japanese Wikipedia and mC4/ja were used.
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Retrieva, Inc.
- **Model type:** T5 v1.1
- **Language(s) (NLP):** Japanese
- **License:** CC-BY-SA 4.0 Although commercial use is permitted, we kindly request that you contact us beforehand.
## Training Details
We use T5X (https://github.com/google-research/t5x) for the training of this model, and it has been converted to the Huggingface transformer format.
## Training Data
The training data used is
- The Japanese part of the multilingual C4(mC4/ja).
- Japanese Wikipedia(20220920).
#### Preprocessing
The following filtering is done
- Remove documents that do not use a single hiragana character. This removes English-only documents and documents in Chinese.
- Whitelist-style filtering using the top level domain of URL to remove affiliate sites.
#### Training Hyperparameters
- dropout rate: 0.0
- batch size: 256
- fp32
- input length: 512
- output length: 114
- Otherwise, the default value of T5X (https://github.com/google-research/t5x/blob/main/t5x/examples/t5/t5_1_1/small.gin) is followed, including the following.
- optimizer: Adafactor
- base_learning_rate: 1.0
- warmup steps: 10000
#### Speeds, Sizes, Times
We trained 2097152 steps.
## Technical Specifications
### Model Architecture and Objective
Model architecture.
- T5 v1.1(https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
- Size: Small(~77 million parameters)
### Compute Infrastructure
Google Cloud TPU v4-8.
#### Software
- T5X(https://github.com/google-research/t5x).
## More Information
https://note.com/retrieva/n/n7b4186dc5ada (in Japanese)
## Model Card Authors
Jiro Nishitoba
## Model Card Contact
pr@retrieva.jp
| 2,596 | [
[
-0.029815673828125,
-0.0323486328125,
0.024688720703125,
-0.0010023117065429688,
-0.0296783447265625,
0.0020580291748046875,
-0.00745391845703125,
-0.038909912109375,
0.0037021636962890625,
0.0274658203125,
-0.0584716796875,
-0.071044921875,
-0.05303955078125,
... |
m-a-p/MERT-v0 | 2023-06-02T13:49:06.000Z | [
"transformers",
"pytorch",
"mert_model",
"feature-extraction",
"music",
"custom_code",
"arxiv:2306.00107",
"license:cc-by-nc-4.0",
"region:us"
] | feature-extraction | m-a-p | null | null | m-a-p/MERT-v0 | 17 | 634 | transformers | 2022-12-29T03:01:08 | ---
license: cc-by-nc-4.0
inference: false
tags:
- music
---
# Introduction to our series work
The development log of our Music Audio Pre-training (m-a-p) model family:
- 02/06/2023: [arxiv pre-print](https://arxiv.org/abs/2306.00107) and training [codes](https://github.com/yizhilll/MERT) released.
- 17/03/2023: we release two advanced music understanding models, [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) and [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) , trained with new paradigm and dataset. They outperform the previous models and can better generalize to more tasks.
- 14/03/2023: we retrained the MERT-v0 model with open-source-only music dataset [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public)
- 29/12/2022: a music understanding model [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) trained with **MLM** paradigm, which performs better at downstream tasks.
- 29/10/2022: a pre-trained MIR model [music2vec](https://huggingface.co/m-a-p/music2vec-v1) trained with **BYOL** paradigm.
Here is a table for quick model pick-up:
| Name | Pre-train Paradigm | Training Data (hour) | Pre-train Context (second) | Model Size | Transformer Layer-Dimension | Feature Rate | Sample Rate | Release Date |
| ------------------------------------------------------------ | ------------------ | -------------------- | ---------------------------- | ---------- | --------------------------- | ------------ | ----------- | ------------ |
| [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) | MLM | 160K | 5 | 330M | 24-1024 | 75 Hz | 24K Hz | 17/03/2023 |
| [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) | MLM | 20K | 5 | 95M | 12-768 | 75 Hz | 24K Hz | 17/03/2023 |
| [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public) | MLM | 900 | 5 | 95M | 12-768 | 50 Hz | 16K Hz | 14/03/2023 |
| [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) | MLM | 1000 | 5 | 95 M | 12-768 | 50 Hz | 16K Hz | 29/12/2022 |
| [music2vec-v1](https://huggingface.co/m-a-p/music2vec-v1) | BYOL | 1000 | 30 | 95 M | 12-768 | 50 Hz | 16K Hz | 30/10/2022 |
## Explanation
The m-a-p models share the similar model architecture and the most distinguished difference is the paradigm in used pre-training. Other than that, there are several nuance technical configuration needs to know before using:
- **Model Size**: the number of parameters that would be loaded to memory. Please select the appropriate size fitting your hardware.
- **Transformer Layer-Dimension**: The number of transformer layers and the corresponding feature dimensions can be outputted from our model. This is marked out because features extracted by **different layers could have various performance depending on tasks**.
- **Feature Rate**: Given a 1-second audio input, the number of features output by the model.
- **Sample Rate**: The frequency of audio that the model is trained with.
# Introduction to this model
**MERT-v0** is a completely unsupervised model trained on 1000 hour music audios.
Its architecture is similar to the [HuBERT model](https://huggingface.co/docs/transformers/model_doc/hubert), but it has been specifically designed for music through the use of specialized pre-training strategies.
It is SOTA-comparable on multiple MIR tasks even under probing settings, while keeping fine-tunable on a single 2080Ti.
It outperforms Jukebox representation on GTZAN (genre classification) and GiantSteps (key classification) datasets.
Larger models trained with more data are on the way.

# Model Usage
```python
from transformers import Wav2Vec2FeatureExtractor
from transformers import AutoModel
import torch
from torch import nn
import torchaudio.transforms as T
from datasets import load_dataset
# loading our model weights
model = AutoModel.from_pretrained("m-a-p/MERT-v0", trust_remote_code=True)
# loading the corresponding preprocessor config
processor = Wav2Vec2FeatureExtractor.from_pretrained("m-a-p/MERT-v0",trust_remote_code=True)
# load demo audio and set processor
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
sampling_rate = dataset.features["audio"].sampling_rate
resample_rate = processor.sampling_rate
# make sure the sample_rate aligned
if resample_rate != sampling_rate:
print(f'setting rate from {sampling_rate} to {resample_rate}')
resampler = T.Resample(sampling_rate, resample_rate)
else:
resampler = None
# audio file is decoded on the fly
if resampler is None:
input_audio = dataset[0]["audio"]["array"]
else:
input_audio = resampler(torch.from_numpy(dataset[0]["audio"]["array"]))
inputs = processor(input_audio, sampling_rate=resample_rate, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# take a look at the output shape, there are 13 layers of representation
# each layer performs differently in different downstream tasks, you should choose empirically
all_layer_hidden_states = torch.stack(outputs.hidden_states).squeeze()
print(all_layer_hidden_states.shape) # [13 layer, Time steps, 768 feature_dim]
# for utterance level classification tasks, you can simply reduce the representation in time
time_reduced_hidden_states = all_layer_hidden_states.mean(-2)
print(time_reduced_hidden_states.shape) # [13, 768]
# you can even use a learnable weighted average representation
aggregator = nn.Conv1d(in_channels=13, out_channels=1, kernel_size=1)
weighted_avg_hidden_states = aggregator(time_reduced_hidden_states.unsqueeze(0)).squeeze()
print(weighted_avg_hidden_states.shape) # [768]
```
# Citation
```shell
@misc{li2023mert,
title={MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training},
author={Yizhi Li and Ruibin Yuan and Ge Zhang and Yinghao Ma and Xingran Chen and Hanzhi Yin and Chenghua Lin and Anton Ragni and Emmanouil Benetos and Norbert Gyenge and Roger Dannenberg and Ruibo Liu and Wenhu Chen and Gus Xia and Yemin Shi and Wenhao Huang and Yike Guo and Jie Fu},
year={2023},
eprint={2306.00107},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
``` | 6,769 | [
[
-0.051849365234375,
-0.033294677734375,
0.0167999267578125,
0.01023101806640625,
-0.007579803466796875,
-0.008331298828125,
-0.021453857421875,
-0.0186004638671875,
0.0137786865234375,
0.025726318359375,
-0.0645751953125,
-0.033050537109375,
-0.0364990234375,
... |
keremberke/yolov5s-smoke | 2023-01-04T22:14:32.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/smoke-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5s-smoke | 2 | 634 | yolov5 | 2023-01-04T22:13:56 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/smoke-object-detection
model-index:
- name: keremberke/yolov5s-smoke
results:
- task:
type: object-detection
dataset:
type: keremberke/smoke-object-detection
name: keremberke/smoke-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9945003736307544 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5s-smoke" src="https://huggingface.co/keremberke/yolov5s-smoke/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5s-smoke')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5s-smoke --epochs 10
```
| 1,915 | [
[
-0.04339599609375,
-0.03387451171875,
0.04095458984375,
-0.0297698974609375,
-0.024169921875,
-0.0243682861328125,
0.006343841552734375,
-0.029083251953125,
0.0182342529296875,
0.0224609375,
-0.046661376953125,
-0.059112548828125,
-0.04339599609375,
-0.01055... |
timm/cait_s24_224.fb_dist_in1k | 2023-04-13T01:46:31.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.17239",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/cait_s24_224.fb_dist_in1k | 0 | 634 | timm | 2023-04-13T01:45:48 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for cait_s24_224.fb_dist_in1k
A CaiT (Class-Attention in Image Transformers) image classification model. Pretrained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 46.9
- GMACs: 9.3
- Activations (M): 40.6
- Image size: 224 x 224
- **Papers:**
- Going deeper with Image Transformers: https://arxiv.org/abs/2103.17239
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/deit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('cait_s24_224.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'cait_s24_224.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@InProceedings{Touvron_2021_ICCV,
author = {Touvron, Hugo and Cord, Matthieu and Sablayrolles, Alexandre and Synnaeve, Gabriel and J'egou, Herv'e},
title = {Going Deeper With Image Transformers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {32-42}
}
```
| 2,734 | [
[
-0.039093017578125,
-0.027984619140625,
0.0032634735107421875,
0.0224151611328125,
-0.03057861328125,
-0.0224151611328125,
-0.010711669921875,
-0.0186920166015625,
0.014923095703125,
0.0234222412109375,
-0.046295166015625,
-0.04449462890625,
-0.058929443359375,
... |
facebook/mms-lid-1024 | 2023-06-13T10:18:46.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"audio-classification",
"mms",
"ab",
"af",
"ak",
"am",
"ar",
"as",
"av",
"ay",
"az",
"ba",
"bm",
"be",
"bn",
"bi",
"bo",
"sh",
"br",
"bg",
"ca",
"cs",
"ce",
"cv",
"ku",
"cy",
"da",
"de",
"dv",
"dz... | audio-classification | facebook | null | null | facebook/mms-lid-1024 | 3 | 634 | transformers | 2023-06-13T08:59:15 | ---
tags:
- mms
language:
- ab
- af
- ak
- am
- ar
- as
- av
- ay
- az
- ba
- bm
- be
- bn
- bi
- bo
- sh
- br
- bg
- ca
- cs
- ce
- cv
- ku
- cy
- da
- de
- dv
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fr
- fy
- ff
- ga
- gl
- gn
- gu
- zh
- ht
- ha
- he
- hi
- sh
- hu
- hy
- ig
- ia
- ms
- is
- it
- jv
- ja
- kn
- ka
- kk
- kr
- km
- ki
- rw
- ky
- ko
- kv
- lo
- la
- lv
- ln
- lt
- lb
- lg
- mh
- ml
- mr
- ms
- mk
- mg
- mt
- mn
- mi
- my
- zh
- nl
- 'no'
- 'no'
- ne
- ny
- oc
- om
- or
- os
- pa
- pl
- pt
- ms
- ps
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- ro
- rn
- ru
- sg
- sk
- sl
- sm
- sn
- sd
- so
- es
- sq
- su
- sv
- sw
- ta
- tt
- te
- tg
- tl
- th
- ti
- ts
- tr
- uk
- ms
- vi
- wo
- xh
- ms
- yo
- ms
- zu
- za
license: cc-by-nc-4.0
datasets:
- google/fleurs
metrics:
- acc
---
# Massively Multilingual Speech (MMS) - Finetuned LID
This checkpoint is a model fine-tuned for speech language identification (LID) and part of Facebook's [Massive Multilingual Speech project](https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/).
This checkpoint is based on the [Wav2Vec2 architecture](https://huggingface.co/docs/transformers/model_doc/wav2vec2) and classifies raw audio input to a probability distribution over 1024 output classes (each class representing a language).
The checkpoint consists of **1 billion parameters** and has been fine-tuned from [facebook/mms-1b](https://huggingface.co/facebook/mms-1b) on 1024 languages.
## Table Of Content
- [Example](#example)
- [Supported Languages](#supported-languages)
- [Model details](#model-details)
- [Additional links](#additional-links)
## Example
This MMS checkpoint can be used with [Transformers](https://github.com/huggingface/transformers) to identify
the spoken language of an audio. It can recognize the [following 1024 languages](#supported-languages).
Let's look at a simple example.
First, we install transformers and some other libraries
```
pip install torch accelerate torchaudio datasets
pip install --upgrade transformers
````
**Note**: In order to use MMS you need to have at least `transformers >= 4.30` installed. If the `4.30` version
is not yet available [on PyPI](https://pypi.org/project/transformers/) make sure to install `transformers` from
source:
```
pip install git+https://github.com/huggingface/transformers.git
```
Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
```py
from datasets import load_dataset, Audio
# English
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
en_sample = next(iter(stream_data))["audio"]["array"]
# Arabic
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "ar", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
ar_sample = next(iter(stream_data))["audio"]["array"]
```
Next, we load the model and processor
```py
from transformers import Wav2Vec2ForSequenceClassification, AutoFeatureExtractor
import torch
model_id = "facebook/mms-lid-1024"
processor = AutoFeatureExtractor.from_pretrained(model_id)
model = Wav2Vec2ForSequenceClassification.from_pretrained(model_id)
```
Now we process the audio data, pass the processed audio data to the model to classify it into a language, just like we usually do for Wav2Vec2 audio classification models such as [ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition](https://huggingface.co/harshit345/xlsr-wav2vec-speech-emotion-recognition)
```py
# English
inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
lang_id = torch.argmax(outputs, dim=-1)[0].item()
detected_lang = model.config.id2label[lang_id]
# 'eng'
# Arabic
inputs = processor(ar_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
lang_id = torch.argmax(outputs, dim=-1)[0].item()
detected_lang = model.config.id2label[lang_id]
# 'ara'
```
To see all the supported languages of a checkpoint, you can print out the language ids as follows:
```py
processor.id2label.values()
```
For more details, about the architecture please have a look at [the official docs](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
## Supported Languages
This model supports 1024 languages. Unclick the following to toogle all supported languages of this checkpoint in [ISO 639-3 code](https://en.wikipedia.org/wiki/ISO_639-3).
You can find more details about the languages and their ISO 649-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html).
<details>
<summary>Click to toggle</summary>
- ara
- cmn
- eng
- spa
- fra
- mlg
- swe
- por
- vie
- ful
- sun
- asm
- ben
- zlm
- kor
- ind
- hin
- tuk
- urd
- aze
- slv
- mon
- hau
- tel
- swh
- bod
- rus
- tur
- heb
- mar
- som
- tgl
- tat
- tha
- cat
- ron
- mal
- bel
- pol
- yor
- nld
- bul
- hat
- afr
- isl
- amh
- tam
- hun
- hrv
- lit
- cym
- fas
- mkd
- ell
- bos
- deu
- sqi
- jav
- kmr
- nob
- uzb
- snd
- lat
- nya
- grn
- mya
- orm
- lin
- hye
- yue
- pan
- jpn
- kaz
- npi
- kik
- kat
- guj
- kan
- tgk
- ukr
- ces
- lav
- bak
- khm
- cak
- fao
- glg
- ltz
- xog
- lao
- mlt
- sin
- aka
- sna
- che
- mam
- ita
- quc
- aiw
- srp
- mri
- tuv
- nno
- pus
- eus
- kbp
- gur
- ory
- lug
- crh
- bre
- luo
- nhx
- slk
- ewe
- xsm
- fin
- rif
- dan
- saq
- yid
- yao
- mos
- quh
- hne
- xon
- new
- dtp
- quy
- est
- ddn
- dyu
- ttq
- bam
- pse
- uig
- sck
- ngl
- tso
- mup
- dga
- seh
- lis
- wal
- ctg
- mip
- bfz
- bxk
- ceb
- kru
- war
- khg
- bbc
- thl
- nzi
- vmw
- mzi
- ycl
- zne
- sid
- asa
- tpi
- bmq
- box
- zpu
- gof
- nym
- cla
- bgq
- bfy
- hlb
- qxl
- teo
- fon
- sda
- kfx
- bfa
- mag
- tzh
- pil
- maj
- maa
- kdt
- ksb
- lns
- btd
- rej
- pap
- ayr
- any
- mnk
- adx
- gud
- krc
- onb
- xal
- ctd
- nxq
- ava
- blt
- lbw
- hyw
- udm
- zar
- tzo
- kpv
- san
- xnj
- kek
- chv
- kcg
- kri
- ati
- bgw
- mxt
- ybb
- btx
- dgi
- nhy
- dnj
- zpz
- yba
- lon
- smo
- men
- ium
- mgd
- taq
- nga
- nsu
- zaj
- tly
- prk
- zpt
- akb
- mhr
- mxb
- nuj
- obo
- kir
- bom
- run
- zpg
- hwc
- mnw
- ubl
- kin
- xtm
- hnj
- mpm
- rkt
- miy
- luc
- mih
- kne
- mib
- flr
- myv
- xmm
- knk
- iba
- gux
- pis
- zmz
- ses
- dav
- lif
- qxr
- dig
- kdj
- wsg
- tir
- gbm
- mai
- zpc
- kus
- nyy
- mim
- nan
- nyn
- gog
- ngu
- tbz
- hoc
- nyf
- sus
- guk
- gwr
- yaz
- bcc
- sbd
- spp
- hak
- grt
- kno
- oss
- suk
- spy
- nij
- lsm
- kaa
- bem
- rmy
- kqn
- nim
- ztq
- nus
- bib
- xtd
- ach
- mil
- keo
- mpg
- gjn
- zaq
- kdh
- dug
- sah
- awa
- kff
- dip
- rim
- nhe
- pcm
- kde
- tem
- quz
- mfq
- las
- bba
- kbr
- taj
- dyo
- zao
- lom
- shk
- dik
- dgo
- zpo
- fij
- bgc
- xnr
- bud
- kac
- laj
- mev
- maw
- quw
- kao
- dag
- ktb
- lhu
- zab
- mgh
- shn
- otq
- lob
- pbb
- oci
- zyb
- bsq
- mhi
- dzo
- zas
- guc
- alz
- ctu
- wol
- guw
- mnb
- nia
- zaw
- mxv
- bci
- sba
- kab
- dwr
- nnb
- ilo
- mfe
- srx
- ruf
- srn
- zad
- xpe
- pce
- ahk
- bcl
- myk
- haw
- mad
- ljp
- bky
- gmv
- nag
- nav
- nyo
- kxm
- nod
- sag
- zpl
- sas
- myx
- sgw
- old
- irk
- acf
- mak
- kfy
- zai
- mie
- zpm
- zpi
- ote
- jam
- kpz
- lgg
- lia
- nhi
- mzm
- bdq
- xtn
- mey
- mjl
- sgj
- kdi
- kxc
- miz
- adh
- tap
- hay
- kss
- pam
- gor
- heh
- nhw
- ziw
- gej
- yua
- itv
- shi
- qvw
- mrw
- hil
- mbt
- pag
- vmy
- lwo
- cce
- kum
- klu
- ann
- mbb
- npl
- zca
- pww
- toc
- ace
- mio
- izz
- kam
- zaa
- krj
- bts
- eza
- zty
- hns
- kki
- min
- led
- alw
- tll
- rng
- pko
- toi
- iqw
- ncj
- toh
- umb
- mog
- hno
- wob
- gxx
- hig
- nyu
- kby
- ban
- syl
- bxg
- nse
- xho
- zae
- mkw
- nch
- ibg
- mas
- qvz
- bum
- bgd
- mww
- epo
- tzm
- zul
- bcq
- lrc
- xdy
- tyv
- ibo
- loz
- mza
- abk
- azz
- guz
- arn
- ksw
- lus
- tos
- gvr
- top
- ckb
- mer
- pov
- lun
- rhg
- knc
- sfw
- bev
- tum
- lag
- nso
- bho
- ndc
- maf
- gkp
- bax
- awn
- ijc
- qug
- lub
- srr
- mni
- zza
- ige
- dje
- mkn
- bft
- tiv
- otn
- kck
- kqs
- gle
- lua
- pdt
- swk
- mgw
- ebu
- ada
- lic
- skr
- gaa
- mfa
- vmk
- mcn
- bto
- lol
- bwr
- unr
- dzg
- hdy
- kea
- bhi
- glk
- mua
- ast
- nup
- sat
- ktu
- bhb
- zpq
- coh
- bkm
- gya
- sgc
- dks
- ncl
- tui
- emk
- urh
- ego
- ogo
- tsc
- idu
- igb
- ijn
- njz
- ngb
- tod
- jra
- mrt
- zav
- tke
- its
- ady
- bzw
- kng
- kmb
- lue
- jmx
- tsn
- bin
- ble
- gom
- ven
- sef
- sco
- her
- iso
- trp
- glv
- haq
- toq
- okr
- kha
- wof
- rmn
- sot
- kaj
- bbj
- sou
- mjt
- trd
- gno
- mwn
- igl
- rag
- eyo
- div
- efi
- nde
- mfv
- mix
- rki
- kjg
- fan
- khw
- wci
- bjn
- pmy
- bqi
- ina
- hni
- mjx
- kuj
- aoz
- the
- tog
- tet
- nuz
- ajg
- ccp
- mau
- ymm
- fmu
- tcz
- xmc
- nyk
- ztg
- knx
- snk
- zac
- esg
- srb
- thq
- pht
- wes
- rah
- pnb
- ssy
- zpv
- kpo
- phr
- atd
- eto
- xta
- mxx
- mui
- uki
- tkt
- mgp
- xsq
- enq
- nnh
- qxp
- zam
- bug
- bxr
- maq
- tdt
- khb
- mrr
- kas
- zgb
- kmw
- lir
- vah
- dar
- ssw
- hmd
- jab
- iii
- peg
- shr
- brx
- rwr
- bmb
- kmc
- mji
- dib
- pcc
- nbe
- mrd
- ish
- kai
- yom
- zyn
- hea
- ewo
- bas
- hms
- twh
- kfq
- thr
- xtl
- wbr
- bfb
- wtm
- mjc
- blk
- lot
- dhd
- swv
- wbm
- zzj
- kge
- mgm
- niq
- zpj
- bwx
- bde
- mtr
- gju
- kjp
- mbz
- haz
- lpo
- yig
- qud
- shy
- gjk
- ztp
- nbl
- aii
- kun
- say
- mde
- sjp
- bns
- brh
- ywq
- msi
- anr
- mrg
- mjg
- tan
- tsg
- tcy
- kbl
- mdr
- mks
- noe
- tyz
- zpa
- ahr
- aar
- wuu
- khr
- kbd
- kex
- bca
- nku
- pwr
- hsn
- ort
- ott
- swi
- kua
- tdd
- msm
- bgp
- nbm
- mxy
- abs
- zlj
- ebo
- lea
- dub
- sce
- xkb
- vav
- bra
- ssb
- sss
- nhp
- kad
- kvx
- lch
- tts
- zyj
- kxp
- lmn
- qvi
- lez
- scl
- cqd
- ayb
- xbr
- nqg
- dcc
- cjk
- bfr
- zyg
- mse
- gru
- mdv
- bew
- wti
- arg
- dso
- zdj
- pll
- mig
- qxs
- bol
- drs
- anp
- chw
- bej
- vmc
- otx
- xty
- bjj
- vmz
- ibb
- gby
- twx
- tig
- thz
- tku
- hmz
- pbm
- mfn
- nut
- cyo
- mjw
- cjm
- tlp
- naq
- rnd
- stj
- sym
- jax
- btg
- tdg
- sng
- nlv
- kvr
- pch
- fvr
- mxs
- wni
- mlq
- kfr
- mdj
- osi
- nhn
- ukw
- tji
- qvj
- nih
- bcy
- hbb
- zpx
- hoj
- cpx
- ogc
- cdo
- bgn
- bfs
- vmx
- tvn
- ior
- mxa
- btm
- anc
- jit
- mfb
- mls
- ets
- goa
- bet
- ikw
- pem
- trf
- daq
- max
- rad
- njo
- bnx
- mxl
- mbi
- nba
- zpn
- zts
- mut
- hnd
- mta
- hav
- hac
- ryu
- abr
- yer
- cld
- zag
- ndo
- sop
- vmm
- gcf
- chr
- cbk
- sbk
- bhp
- odk
- mbd
- nap
- gbr
- mii
- czh
- xti
- vls
- gdx
- sxw
- zaf
- wem
- mqh
- ank
- yaf
- vmp
- otm
- sdh
- anw
- src
- mne
- wss
- meh
- kzc
- tma
- ttj
- ots
- ilp
- zpr
- saz
- ogb
- akl
- nhg
- pbv
- rcf
- cgg
- mku
- bez
- mwe
- mtb
- gul
- ifm
- mdh
- scn
- lki
- xmf
- sgd
- aba
- cos
- luz
- zpy
- stv
- kjt
- mbf
- kmz
- nds
- mtq
- tkq
- aee
- knn
- mbs
- mnp
- ema
- bar
- unx
- plk
- psi
- mzn
- cja
- sro
- mdw
- ndh
- vmj
- zpw
- kfu
- bgx
- gsw
- fry
- zpe
- zpd
- bta
- psh
- zat
</details>
## Model details
- **Developed by:** Vineel Pratap et al.
- **Model type:** Multi-Lingual Automatic Speech Recognition model
- **Language(s):** 1024 languages, see [supported languages](#supported-languages)
- **License:** CC-BY-NC 4.0 license
- **Num parameters**: 1 billion
- **Audio sampling rate**: 16,000 kHz
- **Cite as:**
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
## Additional Links
- [Blog post](https://ai.facebook.com/blog/multilingual-model-speech-recognition/)
- [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
- [Paper](https://arxiv.org/abs/2305.13516)
- [GitHub Repository](https://github.com/facebookresearch/fairseq/tree/main/examples/mms#asr)
- [Other **MMS** checkpoints](https://huggingface.co/models?other=mms)
- MMS base checkpoints:
- [facebook/mms-1b](https://huggingface.co/facebook/mms-1b)
- [facebook/mms-300m](https://huggingface.co/facebook/mms-300m)
- [Official Space](https://huggingface.co/spaces/facebook/MMS)
| 12,494 | [
[
-0.0458984375,
-0.0285797119140625,
0.0188446044921875,
0.0133819580078125,
0.00428009033203125,
0.009674072265625,
-0.00653839111328125,
-0.02191162109375,
0.03717041015625,
0.0158538818359375,
-0.0465087890625,
-0.03973388671875,
-0.043548583984375,
0.0073... |
TweebankNLP/bertweet-tb2_ewt-pos-tagging | 2022-05-05T00:23:51.000Z | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"arxiv:2201.07281",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | TweebankNLP | null | null | TweebankNLP/bertweet-tb2_ewt-pos-tagging | 5 | 633 | transformers | 2022-05-03T16:15:03 | ---
license: cc-by-nc-4.0
---
## Model Specification
- This is the **state-of-the-art Twitter POS tagging model (with 95.38\% Accuracy)** on Tweebank V2's NER benchmark (also called `Tweebank-NER`), trained on the corpus combining both Tweebank-NER and English-EWT training data.
- For more details about the `TweebankNLP` project, please refer to this [our paper](https://arxiv.org/pdf/2201.07281.pdf) and [github](https://github.com/social-machines/TweebankNLP) page.
- In the paper, it is referred as `HuggingFace-BERTweet (TB2+EWT)` in the POS table.
## How to use the model
- **PRE-PROCESSING**: when you apply the model on tweets, please make sure that tweets are preprocessed by the [TweetTokenizer](https://github.com/VinAIResearch/BERTweet/blob/master/TweetNormalizer.py) to get the best performance.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("TweebankNLP/bertweet-tb2_ewt-pos-tagging")
model = AutoModelForTokenClassification.from_pretrained("TweebankNLP/bertweet-tb2_ewt-pos-tagging")
```
## References
If you use this repository in your research, please kindly cite [our paper](https://arxiv.org/pdf/2201.07281.pdf):
```bibtex
@article{jiang2022tweetnlp,
title={Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis},
author={Jiang, Hang and Hua, Yining and Beeferman, Doug and Roy, Deb},
journal={In Proceedings of the 13th Language Resources and Evaluation Conference (LREC)},
year={2022}
}
``` | 1,571 | [
[
-0.0136260986328125,
-0.05401611328125,
0.0045928955078125,
0.023529052734375,
-0.0251617431640625,
0.005199432373046875,
-0.01337432861328125,
-0.039886474609375,
0.0278167724609375,
0.01039886474609375,
-0.01464080810546875,
-0.05291748046875,
-0.0623168945312... |
keremberke/yolov5m-construction-safety | 2022-12-30T20:48:14.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/construction-safety-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-construction-safety | 3 | 633 | yolov5 | 2022-12-29T23:41:43 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/construction-safety-object-detection
model-index:
- name: keremberke/yolov5m-construction-safety
results:
- task:
type: object-detection
dataset:
type: keremberke/construction-safety-object-detection
name: keremberke/construction-safety-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.37443513503008957 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-construction-safety" src="https://huggingface.co/keremberke/yolov5m-construction-safety/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-construction-safety')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-construction-safety --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,131 | [
[
-0.04705810546875,
-0.045501708984375,
0.040557861328125,
-0.0254364013671875,
-0.023468017578125,
-0.027191162109375,
0.0169525146484375,
-0.037689208984375,
-0.001430511474609375,
0.026702880859375,
-0.041656494140625,
-0.06732177734375,
-0.0445556640625,
... |
sayakpaul/sd-model-finetuned-lora-t4 | 2023-04-18T09:47:44.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | sayakpaul | null | null | sayakpaul/sd-model-finetuned-lora-t4 | 21 | 633 | diffusers | 2023-01-19T22:29:40 |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4
These are LoRA adaption weights for https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




| 608 | [
[
-0.0231781005859375,
-0.042694091796875,
0.005901336669921875,
0.033966064453125,
-0.044708251953125,
-0.01419830322265625,
0.00872802734375,
-0.034332275390625,
0.05279541015625,
0.05828857421875,
-0.05926513671875,
-0.0211639404296875,
-0.04962158203125,
0... |
biu-nlp/abstract-sim-sentence-pubmed | 2023-10-01T13:00:24.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"feature-extraction",
"pubmed",
"sentence-similarity",
"en",
"dataset:biu-nlp/abstract-sim-pubmed",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | feature-extraction | biu-nlp | null | null | biu-nlp/abstract-sim-sentence-pubmed | 1 | 633 | transformers | 2023-05-14T08:14:11 | ---
language:
- en
tags:
- feature-extraction
- pubmed
- sentence-similarity
datasets:
- biu-nlp/abstract-sim-pubmed
---
A model for mapping abstract sentence descriptions to sentences that fit the descriptions. Trained on Pubmed sentences. Use ```load_finetuned_model``` to load the query and sentence encoder, and ```encode_batch()``` to encode a sentence with the model.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def load_finetuned_model():
sentence_encoder = AutoModel.from_pretrained("biu-nlp/abstract-sim-sentence-pubmed", revision="71f4539120e29024adc618173a1ed5fd230ac249")
query_encoder = AutoModel.from_pretrained("biu-nlp/abstract-sim-query-pubmed", revision="8d34676d80a39bcbc5a1d2eec13e6f8078496215")
tokenizer = AutoTokenizer.from_pretrained("biu-nlp/abstract-sim-sentence-pubmed")
return tokenizer, query_encoder, sentence_encoder
def encode_batch(model, tokenizer, sentences, device):
input_ids = tokenizer(sentences, padding=True, max_length=128, truncation=True, return_tensors="pt",
add_special_tokens=True).to(device)
features = model(**input_ids)[0]
features = torch.sum(features[:,:,:] * input_ids["attention_mask"][:,:].unsqueeze(-1), dim=1) / torch.clamp(torch.sum(input_ids["attention_mask"][:,:], dim=1, keepdims=True), min=1e-9)
return features
``` | 1,392 | [
[
-0.0182342529296875,
-0.04852294921875,
0.040679931640625,
0.025543212890625,
-0.02557373046875,
-0.03082275390625,
-0.00977325439453125,
-0.0189208984375,
0.01033782958984375,
0.04620361328125,
-0.0261383056640625,
-0.037689208984375,
-0.04547119140625,
0.0... |
UCSC-VLAA/ViT-L-14-CLIPA-336-datacomp1B | 2023-10-17T05:51:15.000Z | [
"open_clip",
"clip",
"zero-shot-image-classification",
"dataset:mlfoundations/datacomp_1b",
"arxiv:2306.15658",
"arxiv:2305.07017",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | UCSC-VLAA | null | null | UCSC-VLAA/ViT-L-14-CLIPA-336-datacomp1B | 0 | 633 | open_clip | 2023-10-17T05:46:17 | ---
tags:
- clip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- mlfoundations/datacomp_1b
---
# Model card for ViT-L-14-CLIPA-336-datacomp1B
A CLIPA-v2 model...
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/UCSC-VLAA/CLIPA
- **Dataset:** mlfoundations/datacomp_1b
- **Papers:**
- CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy: https://arxiv.org/abs/2306.15658
- An Inverse Scaling Law for CLIP Training: https://arxiv.org/abs/2305.07017
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer
model, preprocess = create_model_from_pretrained('hf-hub:ViT-L-14-CLIPA-336')
tokenizer = get_tokenizer('hf-hub:ViT-L-14-CLIPA-336')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat", "a beignet"], context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[0., 0., 0., 1.0]]
```
## Citation
```bibtex
@article{li2023clipav2,
title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
journal={arXiv preprint arXiv:2306.15658},
year={2023},
}
```
```bibtex
@inproceedings{li2023clipa,
title={An Inverse Scaling Law for CLIP Training},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
booktitle={NeurIPS},
year={2023},
}
```
| 2,222 | [
[
-0.0260009765625,
-0.03125,
0.00644683837890625,
0.0186309814453125,
-0.0296173095703125,
-0.0221099853515625,
0.0013208389282226562,
-0.028656005859375,
0.03802490234375,
0.0128631591796875,
-0.040374755859375,
-0.03216552734375,
-0.04840087890625,
-0.01557... |
Helsinki-NLP/opus-mt-tc-big-fi-en | 2023-08-16T12:09:51.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"opus-mt-tc",
"en",
"fi",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-tc-big-fi-en | 1 | 632 | transformers | 2022-03-22T12:39:30 | ---
language:
- en
- fi
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-fi-en
results:
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: flores101-devtest
type: flores_101
args: fin eng devtest
metrics:
- name: BLEU
type: bleu
value: 35.4
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newsdev2015
type: newsdev2015
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 28.6
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 57.4
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2015
type: wmt-2015-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 29.9
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2016
type: wmt-2016-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 34.3
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2017
type: wmt-2017-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 37.3
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2018
type: wmt-2018-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 27.1
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2019
type: wmt-2019-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 32.7
---
# opus-mt-tc-big-fi-en
Neural machine translation model for translating from Finnish (fi) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2021-12-08
* source language(s): fin
* target language(s): eng
* model: transformer (big)
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt-2021-12-08.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.zip)
* more information released models: [OPUS-MT fin-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fin-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Kolme kolmanteen on kaksikymmentäseitsemän.",
"Heille syntyi poikavauva."
]
model_name = "pytorch-models/opus-mt-tc-big-fi-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-fi-en")
print(pipe("Kolme kolmanteen on kaksikymmentäseitsemän."))
```
## Benchmarks
* test set translations: [opusTCv20210807+bt-2021-12-08.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.test.txt)
* test set scores: [opusTCv20210807+bt-2021-12-08.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| fin-eng | tatoeba-test-v2021-08-07 | 0.72298 | 57.4 | 10690 | 80552 |
| fin-eng | flores101-devtest | 0.62521 | 35.4 | 1012 | 24721 |
| fin-eng | newsdev2015 | 0.56232 | 28.6 | 1500 | 32012 |
| fin-eng | newstest2015 | 0.57469 | 29.9 | 1370 | 27270 |
| fin-eng | newstest2016 | 0.60715 | 34.3 | 3000 | 62945 |
| fin-eng | newstest2017 | 0.63050 | 37.3 | 3002 | 61846 |
| fin-eng | newstest2018 | 0.54199 | 27.1 | 3000 | 62325 |
| fin-eng | newstest2019 | 0.59620 | 32.7 | 1996 | 36215 |
| fin-eng | newstestB2016 | 0.55472 | 27.9 | 3000 | 62945 |
| fin-eng | newstestB2017 | 0.58847 | 31.1 | 3002 | 61846 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: f084bad
* port time: Tue Mar 22 14:52:19 EET 2022
* port machine: LM0-400-22516.local
| 7,553 | [
[
-0.027618408203125,
-0.0478515625,
0.019866943359375,
0.020263671875,
-0.034454345703125,
-0.017181396484375,
-0.039581298828125,
-0.024688720703125,
0.0159912109375,
0.026123046875,
-0.036529541015625,
-0.053131103515625,
-0.04425048828125,
0.02317810058593... |
DILAB-HYU/koquality-polyglot-3.8b | 2023-11-05T11:48:50.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | DILAB-HYU | null | null | DILAB-HYU/koquality-polyglot-3.8b | 0 | 632 | transformers | 2023-10-30T04:03:33 | ---
license: apache-2.0
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- polyglot-ko
- gpt-neox
- KoQuality
base_model: EleutherAI/polyglot-ko-3.8b
---
This model is a instruct-tuned EleutherAI/polyglot-ko-3.8b model.
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + CPU Offloading (384GB)
- num_devices: 2
- gradient_accumulation_steps: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5 | 663 | [
[
-0.048065185546875,
-0.06707763671875,
0.0208282470703125,
0.0148162841796875,
-0.037567138671875,
-0.004917144775390625,
-0.01061248779296875,
-0.025787353515625,
0.022125244140625,
0.017425537109375,
-0.051116943359375,
-0.01226806640625,
-0.04052734375,
-... |
dallinmackay/Tron-Legacy-diffusion | 2023-05-16T09:24:03.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | dallinmackay | null | null | dallinmackay/Tron-Legacy-diffusion | 167 | 631 | diffusers | 2022-10-30T20:09:09 | ---
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/dallinmackay/Tron-Legacy-diffusion/resolve/main/trnlgcy-preview.jpg"
tags:
- stable-diffusion
- text-to-image
---
### Tron Legacy Diffusion
This is a fine-tuned Stable Diffusion model (based on v1.5) trained on screenshots from the film **_Tron: Legacy (2010)_**. Use the token **_trnlgcy_** in your prompts to use the style.
_Download the ckpt file from "files and versions" tab into the stable diffusion models folder of your web-ui of choice._
--
**Characters rendered with this model:**

_prompt and settings used: **[person] in the style of trnlgcy** | **Steps: 25, Sampler: Euler a, CFG scale: 7.5**_
--
**Landscapes/scenes rendered with this model:**

_prompt and settings used: **city landscape in the style of trnlgcy** | **Steps: 25, Sampler: Euler a, CFG scale: 7.5**_
--
This model was trained with Dreambooth training by TheLastBen, using 30 images at 3000 steps.
--
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
--
[](https://www.patreon.com/dallinmackay) | 2,164 | [
[
-0.0321044921875,
-0.043975830078125,
0.033966064453125,
0.0006866455078125,
-0.03759765625,
-0.0013675689697265625,
0.0125885009765625,
-0.0287933349609375,
0.0194854736328125,
0.062164306640625,
-0.04595947265625,
-0.053314208984375,
-0.041717529296875,
-0... |
microsoft/focalnet-tiny | 2023-05-03T16:16:36.000Z | [
"transformers",
"pytorch",
"focalnet",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2203.11926",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | microsoft | null | null | microsoft/focalnet-tiny | 1 | 631 | transformers | 2023-04-17T14:53:08 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# FocalNet (tiny-sized model)
FocalNet model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Focal Modulation Networks
](https://arxiv.org/abs/2203.11926) by Yang et al. and first released in [this repository](https://github.com/microsoft/FocalNet).
Disclaimer: The team releasing FocalNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Focul Modulation Networks are an alternative to Vision Transformers, where self-attention (SA) is completely replaced by a focal modulation mechanism for modeling token interactions in vision.
Focal modulation comprises three components: (i) hierarchical contextualization, implemented using a stack of depth-wise convolutional layers, to encode visual contexts from short to long ranges, (ii) gated aggregation to selectively gather contexts for each query token based on its
content, and (iii) element-wise modulation or affine transformation to inject the aggregated context into the query. Extensive experiments show FocalNets outperform the state-of-the-art SA counterparts (e.g., Vision Transformers, Swin and Focal Transformers) with similar computational costs on the tasks of image classification, object detection, and segmentation.
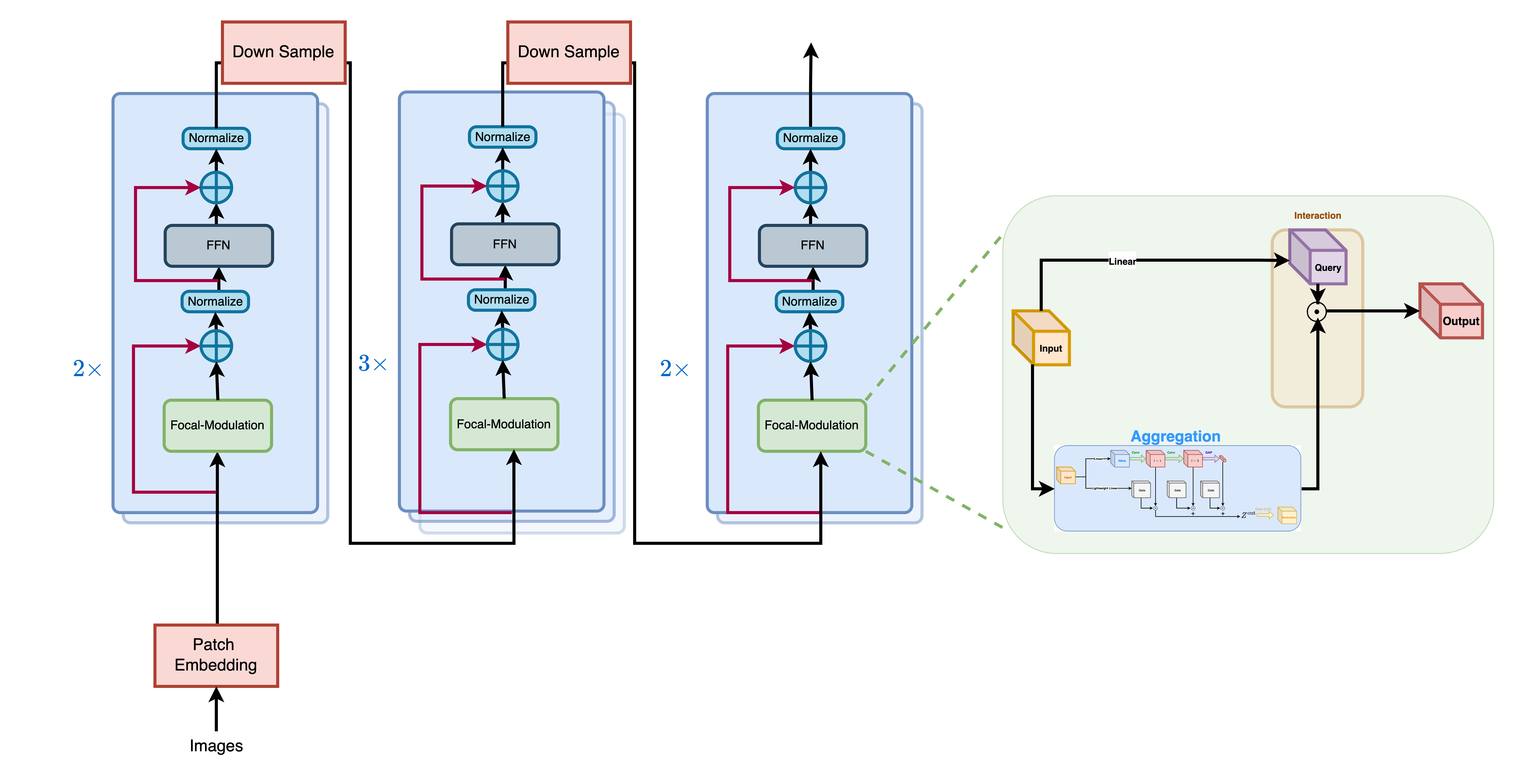
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=focalnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import FocalNetImageProcessor, FocalNetForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = FocalNetImageProcessor.from_pretrained("microsoft/focalnet-tiny")
model = FocalNetForImageClassification.from_pretrained("microsoft/focalnet-tiny")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/focalnet).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2203-11926,
author = {Jianwei Yang and
Chunyuan Li and
Jianfeng Gao},
title = {Focal Modulation Networks},
journal = {CoRR},
volume = {abs/2203.11926},
year = {2022},
url = {https://doi.org/10.48550/arXiv.2203.11926},
doi = {10.48550/arXiv.2203.11926},
eprinttype = {arXiv},
eprint = {2203.11926},
timestamp = {Tue, 29 Mar 2022 18:07:24 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2203-11926.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,649 | [
[
-0.05810546875,
-0.0350341796875,
-0.001644134521484375,
0.0301513671875,
-0.01375579833984375,
-0.05511474609375,
-0.01430511474609375,
-0.05859375,
0.025787353515625,
0.03228759765625,
-0.0384521484375,
-0.0159912109375,
-0.039825439453125,
0.0121688842773... |
saibo/llama-1B | 2023-07-31T17:04:55.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | saibo | null | null | saibo/llama-1B | 3 | 631 | transformers | 2023-05-14T05:09:50 | N.B.
This is not a pretrained llama model.
It is simply the last two layers of llama model and it will not give meaningful predictions without further pretraining! | 165 | [
[
-0.006191253662109375,
-0.04132080078125,
0.0291900634765625,
0.0350341796875,
-0.061126708984375,
0.025054931640625,
0.03240966796875,
-0.039886474609375,
0.02752685546875,
0.0489501953125,
-0.061859130859375,
-0.012969970703125,
-0.052459716796875,
-0.0181... |
TheBloke/CodeLlama-7B-Python-GPTQ | 2023-09-27T12:46:08.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"custom_code",
"code",
"arxiv:2308.12950",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/CodeLlama-7B-Python-GPTQ | 22 | 631 | transformers | 2023-08-24T22:19:25 | ---
language:
- code
license: llama2
tags:
- llama-2
model_name: CodeLlama 7B Python
base_model: codellama/CodeLlama-7b-python-hf
inference: false
model_creator: Meta
model_type: llama
pipeline_tag: text-generation
prompt_template: '[INST] Write code to solve the following coding problem that obeys
the constraints and passes the example test cases. Please wrap your code answer
using ```:
{prompt}
[/INST]
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 7B Python - GPTQ
- Model creator: [Meta](https://huggingface.co/meta-llama)
- Original model: [CodeLlama 7B Python](https://huggingface.co/codellama/CodeLlama-7b-python-hf)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Meta's CodeLlama 7B Python](https://huggingface.co/codellama/CodeLlama-7b-python-hf).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/CodeLlama-7B-Python-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GGUF)
* [Meta's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/codellama/CodeLlama-7b-python-hf)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: CodeLlama
```
[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
{prompt}
[/INST]
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 3.90 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 4.02 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 7.01 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/CodeLlama-7B-Python-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/CodeLlama-7B-Python-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/CodeLlama-7B-Python-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/CodeLlama-7B-Python-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `CodeLlama-7B-Python-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/CodeLlama-7B-Python-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
{prompt}
[/INST]
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Meta's CodeLlama 7B Python
# **Code Llama**
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 34 billion parameters. This is the repository for the 7B Python specialist version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
| | Base Model | Python | Instruct |
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
| 7B | [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) | [codellama/CodeLlama-7b-Python-hf](https://huggingface.co/codellama/CodeLlama-7b-Python-hf) | [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) |
| 13B | [codellama/CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf) | [codellama/CodeLlama-13b-Python-hf](https://huggingface.co/codellama/CodeLlama-13b-Python-hf) | [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) |
| 34B | [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) | [codellama/CodeLlama-34b-Python-hf](https://huggingface.co/codellama/CodeLlama-34b-Python-hf) | [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) |
## Model Use
To use this model, please make sure to install transformers from `main` until the next version is released:
```bash
pip install git+https://github.com/huggingface/transformers.git@main accelerate
```
Model capabilities:
- [x] Code completion.
- [ ] Infilling.
- [ ] Instructions / chat.
- [x] Python specialist.
## Model Details
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
**Model Developers** Meta
**Variations** Code Llama comes in three model sizes, and three variants:
* Code Llama: base models designed for general code synthesis and understanding
* Code Llama - Python: designed specifically for Python
* Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**This repository contains the Python version of the 7B parameters model.**
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)" or its [arXiv page](https://arxiv.org/abs/2308.12950).
## Intended Use
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## Hardware and Software
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
## Training Data
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
## Evaluation Results
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## Ethical Considerations and Limitations
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-user-guide](https://ai.meta.com/llama/responsible-user-guide).
| 21,100 | [
[
-0.0294189453125,
-0.061614990234375,
0.011474609375,
0.01222991943359375,
-0.0188140869140625,
-0.01496124267578125,
0.00023496150970458984,
-0.032958984375,
0.0059967041015625,
0.0213775634765625,
-0.034637451171875,
-0.036041259765625,
-0.024566650390625,
... |
IlyaGusev/rubertconv_toxic_clf | 2022-07-13T15:34:11.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"ru",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | IlyaGusev | null | null | IlyaGusev/rubertconv_toxic_clf | 7 | 630 | transformers | 2022-03-02T23:29:04 | ---
language:
- ru
tags:
- text-classification
license: apache-2.0
---
# RuBERTConv Toxic Classifier
## Model description
Based on [rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model
## Intended uses & limitations
#### How to use
Colab: [link](https://colab.research.google.com/drive/1veKO9hke7myxKigZtZho_F-UM2fD9kp8)
```python
from transformers import pipeline
model_name = "IlyaGusev/rubertconv_toxic_clf"
pipe = pipeline("text-classification", model=model_name, tokenizer=model_name, framework="pt")
text = "Ты придурок из интернета"
pipe([text])
```
## Training data
Datasets:
- [2ch]( https://www.kaggle.com/blackmoon/russian-language-toxic-comments)
- [Odnoklassniki](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments)
- [Toloka Persona Chat Rus](https://toloka.ai/ru/datasets)
- [Koziev's Conversations](https://github.com/Koziev/NLP_Datasets/blob/master/Conversations/Data) with [toxic words vocabulary](https://www.dropbox.com/s/ou6lx03b10yhrfl/bad_vocab.txt.tar.gz)
Augmentations:
- ё -> е
- Remove or add "?" or "!"
- Fix CAPS
- Concatenate toxic and non-toxic texts
- Concatenate two non-toxic texts
- Add toxic words from vocabulary
- Add typos
- Mask toxic words with "*", "@", "$"
## Training procedure
TBA | 1,312 | [
[
0.0094757080078125,
-0.050140380859375,
0.00588226318359375,
0.022216796875,
-0.018890380859375,
0.01519775390625,
-0.0182647705078125,
-0.009033203125,
-0.012359619140625,
0.0303497314453125,
-0.024017333984375,
-0.053741455078125,
-0.05072021484375,
-0.008... |
hipnologo/gpt2-imdb-finetune | 2023-07-01T01:52:18.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-classification",
"movies",
"sentiment-analysis",
"fine-tuned",
"en",
"dataset:imdb",
"license:mit",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-classification | hipnologo | null | null | hipnologo/gpt2-imdb-finetune | 0 | 630 | transformers | 2023-06-28T02:56:13 | ---
datasets:
- imdb
language:
- en
library_name: transformers
pipeline_tag: text-classification
tags:
- movies
- gpt2
- sentiment-analysis
- fine-tuned
license: mit
widget:
- text: "What an inspiring movie, I laughed, cried and felt love."
- text: "This film fails on every count. For a start it is pretentious, striving to be significant and failing miserably."
---
# Fine-tuned GPT-2 Model for IMDb Movie Review Sentiment Analysis
## Model Description
This is a GPT-2 model fine-tuned on the IMDb movie review dataset for sentiment analysis. It classifies a movie review text into two classes: "positive" or "negative".
## Intended Uses & Limitations
This model is intended to be used for binary sentiment analysis of English movie reviews. It can determine whether a review is positive or negative. It should not be used for languages other than English, or for text with ambiguous sentiment.
## How to Use
Here's a simple way to use this model:
```python
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification
tokenizer = GPT2Tokenizer.from_pretrained("hipnologo/gpt2-imdb-finetune")
model = GPT2ForSequenceClassification.from_pretrained("hipnologo/gpt2-imdb-finetune")
text = "Your review text here!"
# encoding the input text
input_ids = tokenizer.encode(text, return_tensors="pt")
# Move the input_ids tensor to the same device as the model
input_ids = input_ids.to(model.device)
# getting the logits
logits = model(input_ids).logits
# getting the predicted class
predicted_class = logits.argmax(-1).item()
print(f"The sentiment predicted by the model is: {'Positive' if predicted_class == 1 else 'Negative'}")
```
## Training Procedure
The model was trained using the 'Trainer' class from the transformers library, with a learning rate of 2e-5, batch size of 1, and 3 training epochs.
## Evaluation
The fine-tuned model was evaluated on the test dataset. Here are the results:
- **Evaluation Loss**: 0.23127
- **Evaluation Accuracy**: 0.94064
- **Evaluation F1 Score**: 0.94104
- **Evaluation Precision**: 0.93466
- **Evaluation Recall**: 0.94752
The evaluation metrics suggest that the model has a high accuracy and good precision-recall balance for the task of sentiment classification.
### How to Reproduce
The evaluation results can be reproduced by loading the model and the tokenizer from Hugging Face Model Hub and then running the model on the evaluation dataset using the `Trainer` class from the Transformers library, with the `compute_metrics` function defined as above.
The evaluation loss is the cross-entropy loss of the model on the evaluation dataset, a measure of how well the model's predictions match the actual labels. The closer this is to zero, the better.
The evaluation accuracy is the proportion of predictions the model got right. This number is between 0 and 1, with 1 meaning the model got all predictions right.
The F1 score is a measure of a test's accuracy that considers both precision (the number of true positive results divided by the number of all positive results) and recall (the number of true positive results divided by the number of all samples that should have been identified as positive). An F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
The evaluation precision is how many of the positively classified were actually positive. The closer this is to 1, the better.
The evaluation recall is how many of the actual positives our model captured through labeling it as positive. The closer this is to 1, the better.
## Fine-tuning Details
The model was fine-tuned using the IMDb movie review dataset. | 3,632 | [
[
-0.048858642578125,
-0.05316162109375,
0.01094818115234375,
0.0107879638671875,
-0.033538818359375,
-0.003910064697265625,
-0.004192352294921875,
-0.029815673828125,
0.00556182861328125,
0.00920867919921875,
-0.055206298828125,
-0.03369140625,
-0.058807373046875... |
kbooth-insight/booth-test | 2023-09-29T16:51:26.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | kbooth-insight | null | null | kbooth-insight/booth-test | 1 | 630 | diffusers | 2023-09-29T16:46:18 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### booth-test Dreambooth model trained by kbooth-insight with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 506 | [
[
-0.0237884521484375,
-0.06451416015625,
0.048065185546875,
0.0284881591796875,
-0.0311279296875,
0.0296478271484375,
0.0301361083984375,
-0.024871826171875,
0.050201416015625,
0.0018758773803710938,
-0.0168609619140625,
-0.0199432373046875,
-0.0263214111328125,
... |
persiannlp/mt5-base-parsinlu-translation_en_fa | 2021-09-23T16:20:09.000Z | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"machine-translation",
"persian",
"farsi",
"fa",
"multilingual",
"dataset:parsinlu",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | persiannlp | null | null | persiannlp/mt5-base-parsinlu-translation_en_fa | 0 | 629 | transformers | 2022-03-02T23:29:05 | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- machine-translation
- mt5
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- sacrebleu
---
# Machine Translation (ترجمهی ماشینی)
This is an mT5-based model for machine translation (English -> Persian).
Here is an example of how you can run this model:
```python
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_size = "base"
model_name = f"persiannlp/mt5-{model_size}-parsinlu-translation_en_fa"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("Praise be to Allah, the Cherisher and Sustainer of the worlds;")
run_model("shrouds herself in white and walks penitentially disguised as brotherly love through factories and parliaments; offers help, but desires power;")
run_model("He thanked all fellow bloggers and organizations that showed support.")
run_model("Races are held between April and December at the Veliefendi Hippodrome near Bakerky, 15 km (9 miles) west of Istanbul.")
run_model("I want to pursue PhD in Computer Science about social network,what is the open problem in social networks?")
```
which should output:
```
['خدا را شکر که عامل خطرناک و محافظ دنیاست.']
['خود را سفید می کند و به شکل برادرانه ای در کارخانه ها و']
['او از تمامی همکاران و سازمان هایی که از او حمایت می کردند تشکر']
['برگزاری مسابقات بین آوریل تا دسامبر در هیپوگریم والی']
['من می خواهم تحصیل دکترای علوم کامپیوتری را در مورد شب']
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
| 1,927 | [
[
-0.0182952880859375,
-0.052886962890625,
0.0157318115234375,
0.016265869140625,
-0.04327392578125,
-0.00030875205993652344,
-0.01111602783203125,
0.006927490234375,
0.007251739501953125,
0.0469970703125,
-0.049896240234375,
-0.0443115234375,
-0.0506591796875,
... |
VietAI/gpt-j-6B-vietnamese-news | 2022-08-07T14:31:36.000Z | [
"transformers",
"pytorch",
"gptj",
"text-generation",
"causal-lm",
"vi",
"endpoints_compatible",
"region:us"
] | text-generation | VietAI | null | null | VietAI/gpt-j-6B-vietnamese-news | 11 | 628 | transformers | 2022-03-02T23:29:05 | ---
language:
- vi
tags:
- pytorch
- causal-lm
- text-generation
---
# GPT-J 6B on Vietnamese News
Details will be available soon.
For more information, please contact anhduongng.1001@gmail.com (Dương) / imthanhlv@gmail.com (Thành) / nguyenvulebinh@gmail.com (Bình).
### How to use
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/gpt-j-6B-vietnamese-news")
model = AutoModelForCausalLM.from_pretrained("VietAI/gpt-j-6B-vietnamese-news", low_cpu_mem_usage=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
prompt = "Tiềm năng của trí tuệ nhân tạo" # your input sentence
input_ids = tokenizer(prompt, return_tensors="pt")['input_ids'].to(device)
gen_tokens = model.generate(
input_ids,
max_length=max_length,
do_sample=True,
temperature=0.9,
top_k=20,
)
gen_text = tokenizer.batch_decode(gen_tokens)[0]
print(gen_text)
``` | 993 | [
[
-0.0152130126953125,
-0.06121826171875,
0.0206298828125,
0.02978515625,
-0.03692626953125,
-0.00850677490234375,
-0.0181427001953125,
0.006011962890625,
-0.006633758544921875,
0.022705078125,
-0.0195770263671875,
-0.031341552734375,
-0.052276611328125,
0.013... |
ringhyacinth/nail-set-diffuser | 2023-05-16T09:30:09.000Z | [
"diffusers",
"text-to-image",
"dreambooth-hackathon",
"wildcard",
"license:openrail",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ringhyacinth | null | null | ringhyacinth/nail-set-diffuser | 84 | 628 | diffusers | 2022-11-20T14:32:21 | ---
license: openrail
tags:
- text-to-image
- dreambooth-hackathon
- wildcard
- diffusers
---
# 💅 Nail Set Diffusion
This is the fine-tuned Stable Diffusion model trained on images from Nail Sets.
Use the tokens {Nail Set} in your prompts for the effect.
## Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run Nail-set-Diffusion:
[](https://huggingface.co/spaces/ringhyacinth/Nail-Diffuser)
__Stable Diffusion fine tuned on Nail Set by [Weekend](https://weibo.com/u/5982308498) and [Hyacinth](https://twitter.com/ring_hyacinth).__
Put in a text prompt and generate your own nail set!

> Nail Set, Sunflower (/Irises/Starry Night/Self Portrait) by Van Gogh, Van Gogh color scheme

> Nail Set, hamilton nail, broadway musical theme nail.

> Nail Set, chinese new year nail, super detailed

> Nail Set, thanksgiving nail, super detailed

> Nail set, Disney castle nail, cute Japanese girly nail
## Model description
Trained on [CLIP Ineterrogator captioned dataset](https://huggingface.co/spaces/pharma/CLIP-Interrogator)
Using [EveryDream Finetune Script](https://github.com/victorchall/EveryDream-trainer) for around 10,000 step. | 2,075 | [
[
-0.01435089111328125,
-0.079345703125,
0.03240966796875,
0.035919189453125,
-0.036956787109375,
0.013519287109375,
0.0009927749633789062,
-0.035003662109375,
0.08026123046875,
0.03448486328125,
-0.0196990966796875,
-0.074462890625,
-0.051361083984375,
-0.001... |
Dzeniks/alberta_fact_checking | 2023-05-04T16:48:11.000Z | [
"transformers",
"pytorch",
"safetensors",
"albert",
"text-classification",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | Dzeniks | null | null | Dzeniks/alberta_fact_checking | 0 | 628 | transformers | 2023-01-25T21:44:24 | ---
license: mit
pipeline_tag: text-classification
---
# Alberta Fact Checking Model
The Alberta Fact Checking Model is a natural language processing model designed to classify claims as either supporting or refuting a given evidence. The model uses the ALBERT architecture and a tokenizer for text classification. It was trained on a dataset that primarily consisted of the FEVER, HOOVER, and FEVEROUS datasets, with a small sample of created data.
## Labels
The model returns two labels:
- 0 = Supports
- 1 = Refutes
## Input
The input to the model should be a claim accompanied by evidence.
## Usage
The Alberta Fact Checking Model can be used to classify claims based on the evidence provided.
```python
import torch
from transformers import AlbertTokenizer, AlbertForSequenceClassification
# Load the tokenizer and model
tokenizer = AlbertTokenizer.from_pretrained('Dzeniks/alberta_fact_checking')
model = AlbertForSequenceClassification.from_pretrained('Dzeniks/alberta_fact_checking')
# Define the claim with evidence to classify
claim = "Albert Einstein work in the field of computer science"
evidence = "Albert Einstein was a German-born theoretical physicist, widely acknowledged to be one of the greatest and most influential physicists of all time."
# Tokenize the claim with evidence
x = tokenizer.encode_plus(claim, evidence, return_tensors="pt")
model.eval()
with torch.no_grad():
prediction = model(**x)
label = torch.argmax(outputs[0]).item()
print(f"Label: {label}")
```
## Disclaimer
While the alberta_fact_checking Model has been trained on a relatively large dataset and can provide accurate results, it may not always provide correct results. Users should always exercise caution when making decisions based on the output of any machine learning model.
| 1,790 | [
[
-0.00954437255859375,
-0.03021240234375,
0.0379638671875,
0.015167236328125,
-0.005420684814453125,
-0.0015468597412109375,
0.012298583984375,
-0.023040771484375,
-0.00437164306640625,
0.035186767578125,
-0.01343536376953125,
-0.050628662109375,
-0.0592041015625... |
retrieva-jp/t5-large-long | 2023-05-10T01:00:35.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ja",
"arxiv:2002.05202",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | retrieva-jp | null | null | retrieva-jp/t5-large-long | 6 | 628 | transformers | 2023-04-26T08:33:12 | ---
license: cc-by-sa-4.0
language:
- ja
---
# Model card for model ID
This is a T5 v1.1 model, pre-trained on a Japanese corpus.
## Model details
T5 is a Transformer-based Encoder-Decoder model, now in v1.1, with the following improvements over the original T5.
- GEGLU activation in feed-forward hidden layer, rather than ReLU - see https://arxiv.org/abs/2002.05202 .
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- no parameter sharing between embedding and classifier layer
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger d_model and smaller num_heads and d_ff.
This model is based on T5 v1.1. It was pre-trained on a Japanese corpus. For the Japanese corpus, Japanese Wikipedia and mC4/ja were used.
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Retrieva, Inc.
- **Model type:** T5 v1.1
- **Language(s) (NLP):** Japanese
- **License:** CC-BY-SA 4.0 Although commercial use is permitted, we kindly request that you contact us beforehand.
## Training Details
We use T5X (https://github.com/google-research/t5x) for the training of this model, and it has been converted to the Huggingface transformer format.
## Training Data
The training data used is
- The Japanese part of the multilingual C4(mC4/ja).
- Japanese Wikipedia(20220920).
#### Preprocessing
The following filtering is done
- Remove documents that do not use a single hiragana character. This removes English-only documents and documents in Chinese.
- Whitelist-style filtering using the top level domain of URL to remove affiliate sites.
#### Training Hyperparameters
- dropout rate: 0.0
- batch size: 256
- fp32
- input length: 512
- output length: 114
- Otherwise, the default value of T5X (https://github.com/google-research/t5x/blob/main/t5x/examples/t5/t5_1_1/large.gin) is followed, including the following.
- optimizer: Adafactor
- base_learning_rate: 1.0
- warmup steps: 10000
#### Speeds, Sizes, Times
We trained 2097152 steps.
## Technical Specifications
### Model Architecture and Objective
Model architecture.
- T5 v1.1(https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
- Size: Large(~770 million parameters)
### Compute Infrastructure
Google Cloud TPU v3-32.
#### Software
- T5X(https://github.com/google-research/t5x).
## More Information
https://note.com/retrieva/n/n7b4186dc5ada (in Japanese)
## Model Card Authors
Jiro Nishitoba
## Model Card Contact
pr@retrieva.jp
| 2,598 | [
[
-0.0299224853515625,
-0.032623291015625,
0.0245819091796875,
-0.0005021095275878906,
-0.0294342041015625,
0.00251007080078125,
-0.007537841796875,
-0.039337158203125,
0.0034942626953125,
0.0272369384765625,
-0.058013916015625,
-0.07122802734375,
-0.0531616210937... |
Kardbord/openjourney-unsafe | 2023-05-13T23:12:09.000Z | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Kardbord | null | null | Kardbord/openjourney-unsafe | 0 | 628 | diffusers | 2023-05-13T21:10:07 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
inference: true
---
# Overview
This is simply prompthero/openjourney with the safety checker disabled.
**DO NOT** attempt to use this model to generate harmful or illegal content.
# Openjourney is an open source Stable Diffusion fine tuned model on Midjourney images, by [PromptHero](https://prompthero.com/poolsuite-diffusion-prompts?utm_source=huggingface&utm_medium=referral)
Include **'mdjrny-v4 style'** in prompt. Here you'll find hundreds of [Openjourney prompts](https://prompthero.com/openjourney-prompts?utm_source=huggingface&utm_medium=referral)
# Openjourney Links
- [Lora version](https://huggingface.co/prompthero/openjourney-lora)
- [Openjourney v4](https://huggingface.co/prompthero/openjourney-v2)
# Want to learn AI art generation?:
- [Crash course in AI art generation](https://prompthero.com/academy/prompt-engineering-course?utm_source=huggingface&utm_medium=referral)
- [Learn to fine-tune Stable Diffusion for photorealism](https://prompthero.com/academy/dreambooth-stable-diffusion-train-fine-tune-course?utm_source=huggingface&utm_medium=referral)
# Use it for free:
[](https://huggingface.co/spaces/akhaliq/midjourney-v4-diffusion)
### Stable Diffusion v1.5 vs Openjourney
(Same parameters, just added "mdjrny-v4 style" at the beginning):
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587642-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587623-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587609-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587646-63265d019f9d19bfd4f45031.png" width="100%"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "prompthero/openjourney"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "retro serie of different cars with different colors and shapes, mdjrny-v4 style"
image = pipe(prompt).images[0]
image.save("./retro_cars.png")
``` | 2,879 | [
[
-0.0390625,
-0.05426025390625,
0.042236328125,
0.022064208984375,
-0.01690673828125,
-0.0286102294921875,
0.01016998291015625,
-0.018157958984375,
0.01496124267578125,
0.037689208984375,
-0.051177978515625,
-0.039764404296875,
-0.0323486328125,
-0.0169677734... |
marella/gpt-2-ggml | 2023-05-20T11:05:41.000Z | [
"ctransformers",
"gpt2",
"license:mit",
"text-generation-inference",
"region:us"
] | null | marella | null | null | marella/gpt-2-ggml | 11 | 628 | ctransformers | 2023-05-14T17:08:30 | ---
license: mit
library_name: ctransformers
---
```sh
pip install ctransformers
```
```py
from ctransformers import AutoModelForCausalLM
llm = AutoModelForCausalLM.from_pretrained('marella/gpt-2-ggml')
print(llm('AI is going to'))
```
See https://github.com/marella/ctransformers | 285 | [
[
0.0064849853515625,
-0.0340576171875,
0.03363037109375,
0.017333984375,
-0.0211334228515625,
-0.0170440673828125,
0.0228729248046875,
0.005558013916015625,
-0.004116058349609375,
0.02728271484375,
-0.04437255859375,
-0.030609130859375,
-0.057708740234375,
0.... |
CiroN2022/high-tech-robotics | 2023-10-02T00:49:03.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"cyberpunk",
"scifi",
"style",
"robot",
"robotic",
"license:other",
"has_space",
"region:us"
] | text-to-image | CiroN2022 | null | null | CiroN2022/high-tech-robotics | 1 | 628 | diffusers | 2023-10-02T00:48:46 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- cyberpunk
- scifi
- style
- robot
- robotic
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: hightech_robotics
widget:
- text: "a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line , "
- text: "a hightech robotics in a man standing in a long hallway with neon lights , solo, 1boy, standing, weapon, male focus, wings, ikari shinji , "
- text: "a man with a futuristic face and a futuristic mask , "
- text: "a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line , "
- text: "a hightech robotics in a green and black background with a large number of lights , solo, looking at viewer, monochrome, no humans, glowing, green background, green theme , "
- text: "a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line , "
- text: "a hightech robotics in a futuristic space station with red and blue lights , 1girl, solo, standing, from behind, building, scenery, 1other, science fiction, light, road , "
- text: "a hightech robotics in a futuristic space station with red and blue lights , 1girl, solo, standing, from behind, building, scenery, 1other, science fiction, light, road , "
- text: "a hightech robotics in a man standing in front of a neon lit building , solo, 1boy, standing, male focus, from behind, english text, night, walking, silhouette , "
- text: "a hightech robotics in a green and black background with a large number of lights , solo, looking at viewer, monochrome, no humans, glowing, green background, green theme , "
---
# High-tech Robotics

> a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line ,
None
## Image examples for the model:

> a hightech robotics in a man standing in a long hallway with neon lights , solo, 1boy, standing, weapon, male focus, wings, ikari shinji ,

> a man with a futuristic face and a futuristic mask ,

> a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line ,

> a hightech robotics in a green and black background with a large number of lights , solo, looking at viewer, monochrome, no humans, glowing, green background, green theme ,

> a hightech robotics in a computer circuit board with many circles and dots , white background, monochrome, comic, greyscale, gradient, no humans, lineart, dotted line ,

> a hightech robotics in a futuristic space station with red and blue lights , 1girl, solo, standing, from behind, building, scenery, 1other, science fiction, light, road ,

> a hightech robotics in a futuristic space station with red and blue lights , 1girl, solo, standing, from behind, building, scenery, 1other, science fiction, light, road ,

> a hightech robotics in a man standing in front of a neon lit building , solo, 1boy, standing, male focus, from behind, english text, night, walking, silhouette ,

> a hightech robotics in a green and black background with a large number of lights , solo, looking at viewer, monochrome, no humans, glowing, green background, green theme ,
| 3,791 | [
[
-0.0440673828125,
-0.047210693359375,
0.055450439453125,
0.00463104248046875,
-0.0088958740234375,
0.0372314453125,
0.018035888671875,
-0.01551055908203125,
0.053863525390625,
0.043701171875,
-0.05242919921875,
-0.036895751953125,
-0.037841796875,
-0.0067939... |
johngiorgi/declutr-small | 2022-08-10T00:34:57.000Z | [
"sentence-transformers",
"pytorch",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:openwebtext",
"arxiv:2006.03659",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | johngiorgi | null | null | johngiorgi/declutr-small | 3 | 627 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
datasets:
- openwebtext
---
# DeCLUTR-small
## Model description
The "DeCLUTR-small" model from our paper: [DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations](https://arxiv.org/abs/2006.03659).
## Intended uses & limitations
The model is intended to be used as a universal sentence encoder, similar to [Google's Universal Sentence Encoder](https://tfhub.dev/google/universal-sentence-encoder/4) or [Sentence Transformers](https://github.com/UKPLab/sentence-transformers).
#### How to use
Please see [our repo](https://github.com/JohnGiorgi/DeCLUTR) for full details. A simple example is shown below.
##### With [SentenceTransformers](https://www.sbert.net/)
```python
from scipy.spatial.distance import cosine
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("johngiorgi/declutr-small")
# Prepare some text to embed
texts = [
"A smiling costumed woman is holding an umbrella.",
"A happy woman in a fairy costume holds an umbrella.",
]
# Embed the text
embeddings = model.encode(texts)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
##### With 🤗 Transformers
```python
import torch
from scipy.spatial.distance import cosine
from transformers import AutoModel, AutoTokenizer
# Load the model
tokenizer = AutoTokenizer.from_pretrained("johngiorgi/declutr-small")
model = AutoModel.from_pretrained("johngiorgi/declutr-small")
# Prepare some text to embed
text = [
"A smiling costumed woman is holding an umbrella.",
"A happy woman in a fairy costume holds an umbrella.",
]
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Embed the text
with torch.no_grad():
sequence_output = model(**inputs)[0]
# Mean pool the token-level embeddings to get sentence-level embeddings
embeddings = torch.sum(
sequence_output * inputs["attention_mask"].unsqueeze(-1), dim=1
) / torch.clamp(torch.sum(inputs["attention_mask"], dim=1, keepdims=True), min=1e-9)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
### BibTeX entry and citation info
```bibtex
@inproceedings{giorgi-etal-2021-declutr,
title = {{D}e{CLUTR}: Deep Contrastive Learning for Unsupervised Textual Representations},
author = {Giorgi, John and Nitski, Osvald and Wang, Bo and Bader, Gary},
year = 2021,
month = aug,
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Online},
pages = {879--895},
doi = {10.18653/v1/2021.acl-long.72},
url = {https://aclanthology.org/2021.acl-long.72}
}
``` | 3,065 | [
[
-0.0194091796875,
-0.04608154296875,
0.038116455078125,
0.004131317138671875,
-0.034149169921875,
-0.023651123046875,
-0.02978515625,
-0.0304107666015625,
0.0163421630859375,
0.02392578125,
-0.038787841796875,
-0.057220458984375,
-0.043731689453125,
0.024475... |
patrickvonplaten/led-large-16384-pubmed | 2021-01-11T15:42:53.000Z | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | patrickvonplaten | null | null | patrickvonplaten/led-large-16384-pubmed | 11 | 627 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- scientific_papers
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
This is an unofficial *led-large-16384* checkpoint that is fine-tuned on the [pubmed dataset](https://huggingface.co/datasets/scientific_papers).
The model was fine-tuned and evaluated as detailed in [this notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing)
## Results
The model achieves a **Rouge-2** score of 19.33 on Pubmed which is competitive to state-of-the-art models.
## Usage
The model can be used as follows. The input is taken from the test data of the [pubmed dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"anxiety affects quality of life in those living
with parkinson 's disease ( pd ) more so than
overall cognitive status , motor deficits , apathy
, and depression [ 13 ] . although anxiety and
depression are often related and coexist in pd
patients , recent research suggests that anxiety
rather than depression is the most prominent and
prevalent mood disorder in pd [ 5 , 6 ] . yet ,
our current understanding of anxiety and its
impact on cognition in pd , as well as its neural
basis and best treatment practices , remains
meager and lags far behind that of depression .
overall , neuropsychiatric symptoms in pd have
been shown to be negatively associated with
cognitive performance . for example , higher
depression scores have been correlated with lower
scores on the mini - mental state exam ( mmse ) [
8 , 9 ] as well as tests of memory and executive
functions ( e.g. , attention ) [ 1014 ] . likewise
, apathy and anhedonia in pd patients have been
associated with executive dysfunction [ 10 , 1523
] . however , few studies have specifically
investigated the relationship between anxiety and
cognition in pd . one study showed a strong
negative relationship between anxiety ( both state
and trait ) and overall cognitive performance (
measured by the total of the repeatable battery
for the assessment of neuropsychological status
index ) within a sample of 27 pd patients .
furthermore , trait anxiety was negatively
associated with each of the cognitive domains
assessed by the rbans ( i.e. , immediate memory ,
visuospatial construction , language , attention ,
and delayed memory ) . two further studies have
examined whether anxiety differentially affects
cognition in patients with left - sided dominant
pd ( lpd ) versus right - sided dominant pd ( rpd
) ; however , their findings were inconsistent .
the first study found that working memory
performance was worse in lpd patients with anxiety
compared to rpd patients with anxiety , whereas
the second study reported that , in lpd , apathy
but not anxiety was associated with performance on
nonverbally mediated executive functions and
visuospatial tasks ( e.g. , tmt - b , wms - iii
spatial span ) , while in rpd , anxiety but not
apathy significantly correlated with performance
on verbally mediated tasks ( e.g. , clock reading
test and boston naming test ) . furthermore ,
anxiety was significantly correlated with
neuropsychological measures of attention and
executive and visuospatial functions . taken
together , it is evident that there are limited
and inconsistent findings describing the
relationship between anxiety and cognition in pd
and more specifically how anxiety might influence
particular domains of cognition such as attention
and memory and executive functioning . it is also
striking that , to date , no study has examined
the influence of anxiety on cognition in pd by
directly comparing groups of pd patients with and
without anxiety while excluding depression . given
that research on healthy young adults suggests
that anxiety reduces processing capacity and
impairs processing efficiency , especially in the
central executive and attentional systems of
working memory [ 26 , 27 ] , we hypothesized that
pd patients with anxiety would show impairments in
attentional set - shifting and working memory
compared to pd patients without anxiety .
furthermore , since previous work , albeit limited
, has focused on the influence of symptom
laterality on anxiety and cognition , we also
explored this relationship . seventeen pd patients
with anxiety and thirty - three pd patients
without anxiety were included in this study ( see
table 1 ) . the cross - sectional data from these
participants was taken from a patient database
that has been compiled over the past 8 years (
since 2008 ) at the parkinson 's disease research
clinic at the brain and mind centre , university
of sydney . inclusion criteria involved a
diagnosis of idiopathic pd according to the united
kingdom parkinson 's disease society brain bank
criteria and were confirmed by a neurologist (
sjgl ) . patients also had to have an adequate
proficiency in english and have completed a full
neuropsychological assessment . ten patients in
this study ( 5 pd with anxiety ; 5 pd without
anxiety ) were taking psychotropic drugs ( i.e. ,
benzodiazepine or selective serotonin reuptake
inhibitor ) . patients were also excluded if they
had other neurological disorders , psychiatric
disorders other than affective disorders ( such as
anxiety ) , or if they reported a score greater
than six on the depression subscale of the
hospital anxiety and depression scale ( hads ) .
thus , all participants who scored within a
depressed ( hads - d > 6 ) range were excluded
from this study , in attempt to examine a refined
sample of pd patients with and without anxiety in
order to determine the independent effect of
anxiety on cognition . this research was approved
by the human research ethics committee of the
university of sydney , and written informed
consent was obtained from all participants . self
- reported hads was used to assess anxiety in pd
and has been previously shown to be a useful
measure of clinical anxiety in pd . a cut - off
score of > 8 on the anxiety subscale of the hads (
hads - a ) was used to identify pd cases with
anxiety ( pda+ ) , while a cut - off score of < 6
on the hads - a was used to identify pd cases
without anxiety ( pda ) . this criterion was more
stringent than usual ( > 7 cut - off score ) , in
effort to create distinct patient groups . the
neurological evaluation rated participants
according to hoehn and yahr ( h&y ) stages and
assessed their motor symptoms using part iii of
the revised mds task force unified parkinson 's
disease rating scale ( updrs ) . in a similar way
this was determined by calculating a total left
and right score from rigidity items 3035 ,
voluntary movement items 3643 , and tremor items
5057 from the mds - updrs part iii ( see table 1 )
. processing speed was assessed using the trail
making test , part a ( tmt - a , z - score ) .
attentional set - shifting was measured using the
trail making test , part b ( tmt - b , z - score )
. working memory was assessed using the digit span
forward and backward subtest of the wechsler
memory scale - iii ( raw scores ) . language was
assessed with semantic and phonemic verbal fluency
via the controlled oral word associated test (
cowat animals and letters , z - score ) . the
ability to retain learned verbal memory was
assessed using the logical memory subtest from the
wechsler memory scale - iii ( lm - i z - score ,
lm - ii z - score , % lm retention z - score ) .
the mini - mental state examination ( mmse )
demographic , clinical , and neuropsychological
variables were compared between the two groups
with the independent t - test or mann whitney u
test , depending on whether the variable met
parametric assumptions . chi - square tests were
used to examine gender and symptom laterality
differences between groups . all analyses employed
an alpha level of p < 0.05 and were two - tailed .
spearman correlations were performed separately in
each group to examine associations between anxiety
and/or depression ratings and cognitive functions
. as expected , the pda+ group reported
significant greater levels of anxiety on the hads
- a ( u = 0 , p < 0.001 ) and higher total score
on the hads ( u = 1 , p < 0.001 ) compared to the
pda group ( table 1 ) . groups were matched in age
( t(48 ) = 1.31 , p = 0.20 ) , disease duration (
u = 259 , p = 0.66 ) , updrs - iii score ( u =
250.5 , p = 0.65 ) , h&y ( u = 245 , p = 0.43 ) ,
ledd ( u = 159.5 , p = 0.80 ) , and depression (
hads - d ) ( u = 190.5 , p = 0.06 ) . additionally
, all groups were matched in the distribution of
gender ( = 0.098 , p = 0.75 ) and side - affected
( = 0.765 , p = 0.38 ) . there were no group
differences for tmt - a performance ( u = 256 , p
= 0.62 ) ( table 2 ) ; however , the pda+ group
had worse performance on the trail making test
part b ( t(46 ) = 2.03 , p = 0.048 ) compared to
the pda group ( figure 1 ) . the pda+ group also
demonstrated significantly worse performance on
the digit span forward subtest ( t(48 ) = 2.22 , p
= 0.031 ) and backward subtest ( u = 190.5 , p =
0.016 ) compared to the pda group ( figures 2(a )
and 2(b ) ) . neither semantic verbal fluency (
t(47 ) = 0.70 , p = 0.49 ) nor phonemic verbal
fluency ( t(47 ) = 0.39 , p = 0.70 ) differed
between groups . logical memory i immediate recall
test ( u = 176 , p = 0.059 ) showed a trend that
the pda+ group had worse new verbal learning and
immediate recall abilities than the pda group .
however , logical memory ii test performance ( u =
219 , p = 0.204 ) and logical memory % retention (
u = 242.5 , p = 0.434 ) did not differ between
groups . there were also no differences between
groups in global cognition ( mmse ) ( u = 222.5 ,
p = 0.23 ) . participants were split into lpd and
rpd , and then further group differences were
examined between pda+ and pda. importantly , the
groups remained matched in age , disease duration
, updrs - iii , dde , h&y stage , and depression
but remained significantly different on self -
reported anxiety . lpda+ demonstrated worse
performance on the digit span forward test ( t(19
) = 2.29 , p = 0.033 ) compared to lpda , whereas
rpda+ demonstrated worse performance on the digit
span backward test ( u = 36.5 , p = 0.006 ) , lm -
i immediate recall ( u = 37.5 , p = 0.008 ) , and
lm - ii ( u = 45.0 , p = 0.021 ) but not lm %
retention ( u = 75.5 , p = 0.39 ) compared to
rpda. this study is the first to directly compare
cognition between pd patients with and without
anxiety . the findings confirmed our hypothesis
that anxiety negatively influences attentional set
- shifting and working memory in pd . more
specifically , we found that pd patients with
anxiety were more impaired on the trail making
test part b which assessed attentional set -
shifting , on both digit span tests which assessed
working memory and attention , and to a lesser
extent on the logical memory test which assessed
memory and new verbal learning compared to pd
patients without anxiety . taken together , these
findings suggest that anxiety in pd may reduce
processing capacity and impair processing
efficiency , especially in the central executive
and attentional systems of working memory in a
similar way as seen in young healthy adults [ 26 ,
27 ] . although the neurobiology of anxiety in pd
remains unknown , many researchers have postulated
that anxiety disorders are related to
neurochemical changes that occur during the early
, premotor stages of pd - related degeneration [
37 , 38 ] such as nigrostriatal dopamine depletion
, as well as cell loss within serotonergic and
noradrenergic brainstem nuclei ( i.e. , raphe
nuclei and locus coeruleus , resp . , which
provide massive inputs to corticolimbic regions )
. over time , chronic dysregulation of
adrenocortical and catecholamine functions can
lead to hippocampal damage as well as
dysfunctional prefrontal neural circuitries [ 39 ,
40 ] , which play a key role in memory and
attention . recent functional neuroimaging work
has suggested that enhanced hippocampal activation
during executive functioning and working memory
tasks may represent compensatory processes for
impaired frontostriatal functions in pd patients
compared to controls . therefore , chronic stress
from anxiety , for example , may disrupt
compensatory processes in pd patients and explain
the cognitive impairments specifically in working
memory and attention seen in pd patients with
anxiety . it has also been suggested that
hyperactivation within the putamen may reflect a
compensatory striatal mechanism to maintain normal
working memory performance in pd patients ;
however , losing this compensatory activation has
been shown to contribute to poor working memory
performance . anxiety in mild pd has been linked
to reduced putamen dopamine uptake which becomes
more extensive as the disease progresses . this
further supports the notion that anxiety may
disrupt compensatory striatal mechanisms as well ,
providing another possible explanation for the
cognitive impairments observed in pd patients with
anxiety in this study . noradrenergic and
serotonergic systems should also be considered
when trying to explain the mechanisms by which
anxiety may influence cognition in pd . although
these neurotransmitter systems are relatively
understudied in pd cognition , treating the
noradrenergic and serotonergic systems has shown
beneficial effects on cognition in pd . selective
serotonin reuptake inhibitor , citalopram , was
shown to improve response inhibition deficits in
pd , while noradrenaline reuptake blocker ,
atomoxetine , has been recently reported to have
promising effects on cognition in pd [ 45 , 46 ] .
overall , very few neuroimaging studies have been
conducted in pd in order to understand the neural
correlates of pd anxiety and its underlying neural
pathology . future research should focus on
relating anatomical changes and neurochemical
changes to neural activation in order to gain a
clearer understanding on how these pathologies
affect anxiety in pd . to further understand how
anxiety and cognitive dysfunction are related ,
future research should focus on using advanced
structural and function imaging techniques to
explain both cognitive and neural breakdowns that
are associated with anxiety in pd patients .
research has indicated that those with amnestic
mild cognitive impairment who have more
neuropsychiatric symptoms have a greater risk of
developing dementia compared to those with fewer
neuropsychiatric symptoms . future studies should
also examine whether treating neuropsychiatric
symptoms might impact the progression of cognitive
decline and improve cognitive impairments in pd
patients . previous studies have used pd symptom
laterality as a window to infer asymmetrical
dysfunction of neural circuits . for example , lpd
patients have greater inferred right hemisphere
pathology , whereas rpd patients have greater
inferred left hemisphere pathology . thus ,
cognitive domains predominantly subserved by the
left hemisphere ( e.g. , verbally mediated tasks
of executive function and verbal memory ) might be
hypothesized to be more affected in rpd than lpd ;
however , this remains controversial . it has also
been suggested that since anxiety is a common
feature of left hemisphere involvement [ 48 , 49 ]
, cognitive domains subserved by the left
hemisphere may also be more strongly related to
anxiety . results from this study showed selective
verbal memory deficits in rpd patients with
anxiety compared to rpd without anxiety , whereas
lpd patients with anxiety had greater attentional
/ working memory deficits compared to lpd without
anxiety . although these results align with
previous research , interpretations of these
findings should be made with caution due to the
small sample size in the lpd comparison
specifically . recent work has suggested that the
hads questionnaire may underestimate the burden of
anxiety related symptomology and therefore be a
less sensitive measure of anxiety in pd [ 30 , 50
] . in addition , our small sample size also
limited the statistical power for detecting
significant findings . based on these limitations
, our findings are likely conservative and
underrepresent the true impact anxiety has on
cognition in pd . additionally , the current study
employed a very brief neuropsychological
assessment including one or two tests for each
cognitive domain . future studies are encouraged
to collect a more complex and comprehensive
battery from a larger sample of pd participants in
order to better understand the role anxiety plays
on cognition in pd . another limitation of this
study was the absence of diagnostic interviews to
characterize participants ' psychiatric symptoms
and specify the type of anxiety disorders included
in this study . future studies should perform
diagnostic interviews with participants ( e.g. ,
using dsm - v criteria ) rather than relying on
self - reported measures to group participants ,
in order to better understand whether the type of
anxiety disorder ( e.g. , social anxiety , phobias
, panic disorders , and generalized anxiety )
influences cognitive performance differently in pd
. one advantage the hads questionnaire provided
over other anxiety scales was that it assessed
both anxiety and depression simultaneously and
allowed us to control for coexisting depression .
although there was a trend that the pda+ group
self - reported higher levels of depression than
the pda group , all participants included in the
study scored < 6 on the depression subscale of the
hads . controlling for depression while assessing
anxiety has been identified as a key shortcoming
in the majority of recent work . considering many
previous studies have investigated the influence
of depression on cognition in pd without
accounting for the presence of anxiety and the
inconsistent findings reported to date , we
recommend that future research should try to
disentangle the influence of anxiety versus
depression on cognitive impairments in pd .
considering the growing number of clinical trials
for treating depression , there are few if any for
the treatment of anxiety in pd . anxiety is a key
contributor to decreased quality of life in pd and
greatly requires better treatment options .
moreover , anxiety has been suggested to play a
key role in freezing of gait ( fog ) , which is
also related to attentional set - shifting [ 52 ,
53 ] . future research should examine the link
between anxiety , set - shifting , and fog , in
order to determine whether treating anxiety might
be a potential therapy for improving fog ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("patrickvonplaten/led-large-16384-pubmed")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("patrickvonplaten/led-large-16384-pubmed", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
``` | 19,216 | [
[
-0.058990478515625,
-0.06109619140625,
0.0623779296875,
0.035064697265625,
-0.0017118453979492188,
-0.0217742919921875,
-0.018157958984375,
-0.036376953125,
0.051666259765625,
0.0184478759765625,
-0.034698486328125,
-0.025970458984375,
-0.05780029296875,
-0.... |
luodian/OTTER-Video-LLaMA7B-DenseCaption | 2023-06-23T15:06:28.000Z | [
"transformers",
"pytorch",
"otter",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | luodian | null | null | luodian/OTTER-Video-LLaMA7B-DenseCaption | 11 | 627 | transformers | 2023-06-13T02:06:11 | ---
license: mit
---
<p align="center" width="100%">
<img src="https://i.postimg.cc/MKmyP9wH/new-banner.png" width="80%" height="80%">
</p>
<div>
<div align="center">
<a href='https://brianboli.com/' target='_blank'>Bo Li*<sup>1</sup></a> 
<a href='https://zhangyuanhan-ai.github.io/' target='_blank'>Yuanhan Zhang*<sup>,1</sup></a> 
<a href='https://cliangyu.com/' target='_blank'>Liangyu Chen*<sup>,1</sup></a> 
<a href='https://king159.github.io/' target='_blank'>Jinghao Wang*<sup>,1</sup></a> 
<a href='https://pufanyi.github.io/' target='_blank'>Fanyi Pu*<sup>,1</sup></a> 
</br>
<a href='https://jingkang50.github.io/' target='_blank'>Jingkang Yang<sup>1</sup></a> 
<a href='https://chunyuan.li/' target='_blank'>Chunyuan Li<sup>2</sup></a> 
<a href='https://liuziwei7.github.io/' target='_blank'>Ziwei Liu<sup>1</sup></a>
</div>
<div>
<div align="center">
<sup>1</sup>S-Lab, Nanyang Technological University 
<sup>2</sup>Microsoft Research, Redmond
</div>
-----------------


[](https://hits.seeyoufarm.com)


An example of using this model to run on your video.
Please first clone [Otter](https://github.com/Luodian/Otter) to your local disk.
Place following script inside the `Otter` folder to make sure it has the access to `otter/modeling_otter.py`.
```python
import mimetypes
import os
from typing import Union
import cv2
import requests
import torch
import transformers
from PIL import Image
import sys
# make sure you can properly access the otter folder
from otter.modeling_otter import OtterForConditionalGeneration
# Disable warnings
requests.packages.urllib3.disable_warnings()
# ------------------- Utility Functions -------------------
def get_content_type(file_path):
content_type, _ = mimetypes.guess_type(file_path)
return content_type
# ------------------- Image and Video Handling Functions -------------------
def extract_frames(video_path, num_frames=16):
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
frame_step = total_frames // num_frames
frames = []
for i in range(num_frames):
video.set(cv2.CAP_PROP_POS_FRAMES, i * frame_step)
ret, frame = video.read()
if ret:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame).convert("RGB")
frames.append(frame)
video.release()
return frames
def get_image(url: str) -> Union[Image.Image, list]:
if "://" not in url: # Local file
content_type = get_content_type(url)
else: # Remote URL
content_type = requests.head(url, stream=True, verify=False).headers.get("Content-Type")
if "image" in content_type:
if "://" not in url: # Local file
return Image.open(url)
else: # Remote URL
return Image.open(requests.get(url, stream=True, verify=False).raw)
elif "video" in content_type:
video_path = "temp_video.mp4"
if "://" not in url: # Local file
video_path = url
else: # Remote URL
with open(video_path, "wb") as f:
f.write(requests.get(url, stream=True, verify=False).content)
frames = extract_frames(video_path)
if "://" in url: # Only remove the temporary video file if it was downloaded
os.remove(video_path)
return frames
else:
raise ValueError("Invalid content type. Expected image or video.")
# ------------------- OTTER Prompt and Response Functions -------------------
def get_formatted_prompt(prompt: str) -> str:
return f"<image>User: {prompt} GPT:<answer>"
def get_response(input_data, prompt: str, model=None, image_processor=None, tensor_dtype=None) -> str:
if isinstance(input_data, Image.Image):
vision_x = image_processor.preprocess([input_data], return_tensors="pt")["pixel_values"].unsqueeze(1).unsqueeze(0)
elif isinstance(input_data, list): # list of video frames
vision_x = image_processor.preprocess(input_data, return_tensors="pt")["pixel_values"].unsqueeze(0).unsqueeze(0)
else:
raise ValueError("Invalid input data. Expected PIL Image or list of video frames.")
lang_x = model.text_tokenizer(
[
get_formatted_prompt(prompt),
],
return_tensors="pt",
)
bad_words_id = model.text_tokenizer(["User:", "GPT1:", "GFT:", "GPT:"], add_special_tokens=False).input_ids
generated_text = model.generate(
vision_x=vision_x.to(model.device, dtype=tensor_dtype),
lang_x=lang_x["input_ids"].to(model.device),
attention_mask=lang_x["attention_mask"].to(model.device),
max_new_tokens=512,
num_beams=3,
no_repeat_ngram_size=3,
bad_words_ids=bad_words_id,
)
parsed_output = (
model.text_tokenizer.decode(generated_text[0])
.split("<answer>")[-1]
.lstrip()
.rstrip()
.split("<|endofchunk|>")[0]
.lstrip()
.rstrip()
.lstrip('"')
.rstrip('"')
)
return parsed_output
# ------------------- Main Function -------------------
load_bit = "fp32"
if load_bit == "fp16":
precision = {"torch_dtype": torch.float16}
elif load_bit == "bf16":
precision = {"torch_dtype": torch.bfloat16}
elif load_bit == "fp32":
precision = {"torch_dtype": torch.float32}
# This model version is trained on MIMIC-IT DC dataset.
model = OtterForConditionalGeneration.from_pretrained("luodian/OTTER-9B-DenseCaption", device_map="auto", **precision)
tensor_dtype = {"fp16": torch.float16, "bf16": torch.bfloat16, "fp32": torch.float32}[load_bit]
model.text_tokenizer.padding_side = "left"
tokenizer = model.text_tokenizer
image_processor = transformers.CLIPImageProcessor()
model.eval()
while True:
video_url = input("Enter video path: ") # Replace with the path to your video file, could be any common format.
frames_list = get_image(video_url)
while True:
prompts_input = input("Enter prompts: ")
if prompts_input.lower() == "quit":
break
print(f"\nPrompt: {prompts_input}")
response = get_response(frames_list, prompts_input, model, image_processor, tensor_dtype)
print(f"Response: {response}")
``` | 6,789 | [
[
-0.031494140625,
-0.053009033203125,
0.0124664306640625,
0.01477813720703125,
-0.023895263671875,
-0.00296783447265625,
-0.003566741943359375,
-0.0202484130859375,
0.01641845703125,
0.002468109130859375,
-0.05328369140625,
-0.036285400390625,
-0.041351318359375,... |
stablediffusionapi/epicdream | 2023-10-16T12:12:40.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/epicdream | 0 | 627 | diffusers | 2023-10-16T12:10:36 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# epiCDream API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "epicdream"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/epicdream)
Model link: [View model](https://stablediffusionapi.com/models/epicdream)
Credits: [View credits](https://civitai.com/?query=epiCDream)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "epicdream",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,446 | [
[
-0.02972412109375,
-0.05810546875,
0.034759521484375,
0.0226898193359375,
-0.0292816162109375,
0.0086669921875,
0.022674560546875,
-0.03375244140625,
0.04876708984375,
0.05438232421875,
-0.05224609375,
-0.06378173828125,
-0.0262451171875,
-0.0011281967163085... |
aubmindlab/aragpt2-medium | 2023-10-30T13:53:45.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"ar",
"dataset:wikipedia",
"dataset:Osian",
"dataset:1.5B-Arabic-Corpus",
"dataset:oscar-arabic-unshuffled",
"dataset:Assafir(private)",
"arxiv:2012.15520",
"endpoints_compatible",
"has_s... | text-generation | aubmindlab | null | null | aubmindlab/aragpt2-medium | 6 | 626 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- wikipedia
- Osian
- 1.5B-Arabic-Corpus
- oscar-arabic-unshuffled
- Assafir(private)
widget:
- text: "يحكى أن مزارعا مخادعا قام ببيع بئر الماء الموجود في أرضه لجاره مقابل مبلغ كبير من المال"
- text: "القدس مدينة تاريخية، بناها الكنعانيون في"
- text: "كان يا ما كان في قديم الزمان"
---
# Arabic GPT2
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/AraGPT2.png" width="100" align="left"/>
You can find more information in our paper [AraGPT2](https://arxiv.org/abs/2012.15520)
The code in this repository was used to train all GPT2 variants. The code support training and fine-tuning GPT2 on GPUs and TPUs via the TPUEstimator API.
GPT2-base and medium uses the code from the `gpt2` folder and can trains models from the [minimaxir/gpt-2-simple](https://github.com/minimaxir/gpt-2-simple) repository.
These models were trained using the `lamb` optimizer and follow the same architecture as `gpt2` and are fully compatible with the `transformers` library.
GPT2-large and GPT2-mega were trained using the [imcaspar/gpt2-ml](https://github.com/imcaspar/gpt2-ml/) library, and follow the `grover` architecture. You can use the pytorch classes found in `grover/modeling_gpt2.py` as a direct replacement for classes in the `transformers` library (it should support version `v4.x` from `transformers`).
Both models are trained using the `adafactor` optimizer, since the `adam` and `lamb` optimizer use too much memory causing the model to not even fit 1 batch on a TPU core.
AraGPT2 is trained on the same large Arabic Dataset as AraBERTv2.
# Usage
## Testing the model using `transformers`:
```python
from transformers import GPT2TokenizerFast, pipeline
#for base and medium
from transformers import GPT2LMHeadModel
#for large and mega
# pip install arabert
from arabert.aragpt2.grover.modeling_gpt2 import GPT2LMHeadModel
from arabert.preprocess import ArabertPreprocessor
MODEL_NAME='aubmindlab/aragpt2-medium'
arabert_prep = ArabertPreprocessor(model_name=MODEL_NAME)
text=""
text_clean = arabert_prep.preprocess(text)
model = GPT2LMHeadModel.from_pretrained(MODEL_NAME)
tokenizer = GPT2TokenizerFast.from_pretrained(MODEL_NAME)
generation_pipeline = pipeline("text-generation",model=model,tokenizer=tokenizer)
#feel free to try different decoding settings
generation_pipeline(text,
pad_token_id=tokenizer.eos_token_id,
num_beams=10,
max_length=200,
top_p=0.9,
repetition_penalty = 3.0,
no_repeat_ngram_size = 3)[0]['generated_text']
```
## Finetunning using `transformers`:
Follow the guide linked [here](https://towardsdatascience.com/fine-tuning-gpt2-on-colab-gpu-for-free-340468c92ed)
## Finetuning using our code with TF 1.15.4:
Create the Training TFRecords:
```bash
python create_pretraining_data.py
--input_file=<RAW TEXT FILE with documents/article separated by an empty line>
--output_file=<OUTPUT TFRecord>
--tokenizer_dir=<Directory with the GPT2 Tokenizer files>
```
Finetuning:
```bash
python3 run_pretraining.py \\\n --input_file="gs://<GS_BUCKET>/pretraining_data/*" \\\n --output_dir="gs://<GS_BUCKET>/pretraining_model/" \\\n --config_file="config/small_hparams.json" \\\n --batch_size=128 \\\n --eval_batch_size=8 \\\n --num_train_steps= \\\n --num_warmup_steps= \\\n --learning_rate= \\\n --save_checkpoints_steps= \\\n --max_seq_length=1024 \\\n --max_eval_steps= \\\n --optimizer="lamb" \\\n --iterations_per_loop=5000 \\\n --keep_checkpoint_max=10 \\\n --use_tpu=True \\\n --tpu_name=<TPU NAME> \\\n --do_train=True \\\n --do_eval=False
```
# Model Sizes
Model | Optimizer | Context size | Embedding Size | Num of heads | Num of layers | Model Size / Num of Params |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraGPT2-base | `lamb` | 1024 | 768 | 12 | 12 | 527MB / 135M |
AraGPT2-medium | `lamb` | 1024 | 1024 | 16 | 24 | 1.38G/370M |
AraGPT2-large | `adafactor` | 1024 | 1280 | 20 | 36 | 2.98GB/792M |
AraGPT2-mega | `adafactor` | 1024 | 1536 | 25 | 48 | 5.5GB/1.46B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Compute
Model | Hardware | num of examples (seq len = 1024) | Batch Size | Num of Steps | Time (in days)
---|:---:|:---:|:---:|:---:|:---:
AraGPT2-base | TPUv3-128 | 9.7M | 1792 | 125K | 1.5
AraGPT2-medium | TPUv3-8 | 9.7M | 80 | 1M | 15
AraGPT2-large | TPUv3-128 | 9.7M | 256 | 220k | 3
AraGPT2-mega | TPUv3-128 | 9.7M | 256 | 780K | 9
# Dataset
The pretraining data used for the new AraGPT2 model is also used for **AraBERTv2 and AraELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Disclaimer
The text generated by AraGPT2 is automatically generated by a neural network model trained on a large amount of texts, which does not represent the authors' or their institutes' official attitudes and preferences. The text generated by AraGPT2 should only be used for research and scientific purposes. If it infringes on your rights and interests or violates social morality, please do not propagate it.
# If you used this model please cite us as :
```
@inproceedings{antoun-etal-2021-aragpt2,
title = "{A}ra{GPT}2: Pre-Trained Transformer for {A}rabic Language Generation",
author = "Antoun, Wissam and
Baly, Fady and
Hajj, Hazem",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Virtual)",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.wanlp-1.21",
pages = "196--207",
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continuous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <wfa07@mail.aub.edu> | <wissam.antoun@gmail.com>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <fgb06@mail.aub.edu> | <baly.fady@gmail.com>
| 7,204 | [
[
-0.0445556640625,
-0.050048828125,
0.016937255859375,
-0.0030078887939453125,
-0.0226898193359375,
-0.00394439697265625,
-0.01556396484375,
-0.034393310546875,
-0.0004892349243164062,
0.0118560791015625,
-0.036590576171875,
-0.035736083984375,
-0.0650634765625,
... |
zafercavdar/distilbert-base-turkish-cased-emotion | 2022-04-19T22:03:18.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"emotion",
"tr",
"dataset:emotion (Translated to Turkish)",
"endpoints_compatible",
"region:us"
] | text-classification | zafercavdar | null | null | zafercavdar/distilbert-base-turkish-cased-emotion | 4 | 626 | transformers | 2022-04-19T21:16:33 | ---
language:
- tr
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
tags:
- text-classification
- emotion
- pytorch
datasets:
- emotion (Translated to Turkish)
metrics:
- Accuracy, F1 Score
---
# distilbert-base-turkish-cased-emotion
## Model description:
[Distilbert-base-turkish-cased](https://huggingface.co/dbmdz/distilbert-base-turkish-cased) finetuned on the emotion dataset (Translated to Turkish via Google Translate API) using HuggingFace Trainer with below Hyperparameters
```
learning rate 2e-5,
batch size 64,
num_train_epochs=8,
```
## Model Performance Comparision on Emotion Dataset from Twitter:
| Model | Accuracy | F1 Score | Test Sample per Second |
| --- | --- | --- | --- |
| [Distilbert-base-turkish-cased-emotion](https://huggingface.co/zafercavdar/distilbert-base-turkish-cased-emotion) | 83.25 | 83.17 | 232.197 |
## How to Use the model:
```python
from transformers import pipeline
classifier = pipeline("text-classification",
model='zafercavdar/distilbert-base-turkish-cased-emotion',
return_all_scores=True)
prediction = classifier("Bu kütüphaneyi seviyorum, en iyi yanı kolay kullanımı.", )
print(prediction)
"""
Output:
[
[
{'label': 'sadness', 'score': 0.0026786490343511105},
{'label': 'joy', 'score': 0.6600754261016846},
{'label': 'love', 'score': 0.3203163146972656},
{'label': 'anger', 'score': 0.004358913749456406},
{'label': 'fear', 'score': 0.002354539930820465},
{'label': 'surprise', 'score': 0.010216088965535164}
]
]
"""
```
## Dataset:
[Twitter-Sentiment-Analysis](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Eval results
```json
{
'eval_accuracy': 0.8325,
'eval_f1': 0.8317301441160213,
'eval_loss': 0.5021793842315674,
'eval_runtime': 8.6167,
'eval_samples_per_second': 232.108,
'eval_steps_per_second': 3.714
}
``` | 1,933 | [
[
-0.0216827392578125,
-0.043975830078125,
0.006549835205078125,
0.0301971435546875,
-0.0258331298828125,
0.01006317138671875,
-0.01309967041015625,
-0.0025119781494140625,
0.035552978515625,
0.0048370361328125,
-0.04937744140625,
-0.064697265625,
-0.0689086914062... |
laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K | 2023-04-18T22:03:39.000Z | [
"open_clip",
"tensorboard",
"clip",
"zero-shot-image-classification",
"arxiv:2201.03545",
"arxiv:1910.04867",
"license:mit",
"has_space",
"region:us"
] | zero-shot-image-classification | laion | null | null | laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K | 1 | 626 | open_clip | 2023-01-03T00:25:48 | ---
license: mit
library_name: open_clip
pipeline_tag: zero-shot-image-classification
tags:
- clip
---
# Model Card for CLIP-convnext_base_w-320.laion_aesthetic-s13B-b82k
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
# Model Details
## Model Description
A series of CLIP [ConvNeXt-Base](https://arxiv.org/abs/2201.03545) (w/ wide embed dim) models trained on subsets LAION-5B (https://laion.ai/blog/laion-5b/) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Goals:
* Explore an alternative to ViT and ResNet (w/ AttentionPooling) CLIP models that scales well with model size and image resolution
Firsts:
* First known ConvNeXt CLIP models trained at scale in the range of CLIP ViT-B/16 and RN50x4 models
* First released model weights exploring increase of augmentation + regularization for image tower via adding (greater scale range of RRC, random erasing, stochastic depth)
The models utilize the [timm](https://github.com/rwightman/pytorch-image-models) ConvNeXt-Base model (`convnext_base`) as the image tower, and the same text tower as the RN50x4 (depth 12, embed dim 640) model from OpenAI CLIP. The base models are trained at 256x256 image resolution and roughly match the RN50x4 models on FLOPs and activation counts. The models with `320` in the name are trained at 320x320.
All models in this series were trained for 13B samples and have ImageNet Zero-Shot top-1 of >= 70.8%. Comparing to ViT-B/16 at 34B SS with zero-shot of 70.2% (68.1% for 13B SS) this suggests the ConvNeXt architecture may be more sample efficient in this range of model scale. More experiments needed to confirm.
| Model | Dataset | Resolution | AugReg | Top-1 ImageNet Zero-Shot (%) |
| ----- | ------- | ---------- | ------------ | --------- |
| [convnext_base_w.laion2b_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K) | LAION-2B | 256x256 | RRC (0.9, 1.0) | 70.8 |
| [convnext_base_w.laion2b_s13b_b82k_augreg](https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg) | LAION-2B | 256x256 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.5 |
| [convnext_base_w.laion_aesthetic_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w-laion_aesthetic-s13B-b82K) | LAION-A | 256x256 | RRC (0.9, 1.0) | 71.0 |
| [convnext_base_w_320.laion_aesthetic_s13b_b82k](https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K) | LAION-A | 320x320 | RRC (0.9, 1.0) | 71.7 |
| [convnext_base_w_320.laion_aesthetic_s13b_b82k_augreg](https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K-augreg) | LAION-A | 320x320 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.3 |
RRC = Random Resize Crop (crop pcts), RE = Random Erasing (prob), SD = Stochastic Depth (prob) -- image tower only
LAION-A = LAION Aesthetic, an ~900M sample subset of LAION-2B with pHash dedupe and asthetic score filtering.
Model training done by Ross Wightman across both the [stability.ai](https://stability.ai/) cluster and the [JUWELS Booster](https://apps.fz-juelich.de/jsc/hps/juwels/booster-overview.html) supercomputer. See acknowledgements below.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the LAION-5B blog (https://laion.ai/blog/laion-5b/) and upcoming paper include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
Further the above notice, the LAION-5B dataset used in training of these models has additional considerations, see below.
# Training Details
## Training Data
This model was trained with one of (see table in intro):
* LAION-2B - A 2 billion sample English subset of LAION-5B (https://laion.ai/blog/laion-5b/).
* LAION-Aesthetic - A 900M sample subset of LAION-2B with pHash dedupe and asthetic score filtering
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
All models were trained with a global batch size of 81920 for 64 checkpoint intervals of 203.7M samples for a total of ~13B samples seen over training.
For 256x256 models, a slurm script w/ srun below was used on 20 8-GPU (A100 40GB) nodes (Stability), switching to 40 4-GPU nodes for time on JUWELS.
```
/opt/slurm/sbin/srun --cpu_bind=v --accel-bind=gn python -m training.main \
--save-frequency 1 \
--name "convnext_256" \
--resume 'latest' \
--train-data="pipe:aws s3 cp s3://mybucket/path/{laion{00000..xxxxx}.tar -" \
--train-num-samples 203666042 \
--dataset-type webdataset \
--precision amp_bfloat16 \
--warmup 10000 \
--batch-size=512 \
--epochs=64 \
--dataset-resampled \
--clip-grad-norm 5.0 \
--lr 1e-3 \
--workers=6 \
--model "convnext_base_w" \
--seed 0 \
--ddp-static-graph \
--local-loss \
--gather-with-grad \
--grad-checkpointing
```
For 320x320 models, same as above but w/ 32 8-GPU nodes, local batch size 320, or 64 4-GPU nodes on JUWELs.
# Evaluation
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
## Results
The models achieve between 70.8 and 71.7 zero-shot top-1 accuracy on ImageNet-1k.

An initial round of benchmarks have been performed on a wider range of datasets, to be viewable at https://github.com/LAION-AI/CLIP_benchmark/blob/main/benchmark/results.ipynb
As part of exploring increased augmentation + regularization, early evalations suggest that `augreg` trained models evaluate well over a wider range of resolutions. This is especially true for the 320x320 LAION-A model, where the augreg run was lower than the non-augreg when evaluated at the train resolution of 320x320 (71.3 vs 71.7), but improves to 72.2 when evaluated at 384x384 (the non-augreg drops to 71.0 at 384x384).
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) and the Gauss Centre for Supercomputing e.V. (http://gauss-centre.eu) for funding this part of work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC).
# Citation
**BibTeX:**
LAION-5B
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
OpenCLIP software
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
OpenAI CLIP paper
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
``` | 12,631 | [
[
-0.0357666015625,
-0.036346435546875,
0.005550384521484375,
0.0017805099487304688,
-0.031280517578125,
-0.032470703125,
-0.01233673095703125,
-0.04949951171875,
0.025543212890625,
0.0280303955078125,
-0.040679931640625,
-0.036712646484375,
-0.035980224609375,
... |
madebyollin/taesdxl | 2023-08-27T14:56:08.000Z | [
"diffusers",
"license:mit",
"diffusers:AutoencoderTiny",
"region:us"
] | null | madebyollin | null | null | madebyollin/taesdxl | 13 | 626 | diffusers | 2023-07-21T15:21:29 | ---
license: mit
---
# 🍰 Tiny AutoEncoder for Stable Diffusion (XL)
[TAESDXL](https://github.com/madebyollin/taesd) is very tiny autoencoder which uses the same "latent API" as [SDXL-VAE](https://huggingface.co/stabilityai/sdxl-vae).
TAESDXL is useful for [real-time previewing](https://twitter.com/madebyollin/status/1679356448655163394) of the SDXL generation process.
Comparison on my laptop:

This repo contains `.safetensors` versions of the TAESDXL weights.
For SD1.x / SD2.x, use [TAESD](https://huggingface.co/madebyollin/taesd/) instead (the SD and SDXL VAEs are [incompatible](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/discussions/6#64b8a9c13707b7d603c6ac16)).
## Using in 🧨 diffusers
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderTiny
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "slice of delicious New York-style berry cheesecake"
image = pipe(prompt, num_inference_steps=25).images[0]
image.save("cheesecake_sdxl.png")
``` | 1,302 | [
[
-0.0406494140625,
-0.038116455078125,
0.0280303955078125,
0.0230865478515625,
-0.0184326171875,
-0.006381988525390625,
0.0014219284057617188,
0.0012845993041992188,
0.0168609619140625,
0.0240020751953125,
-0.034149169921875,
-0.035064697265625,
-0.05194091796875... |
NousResearch/Obsidian-3B-V0.5 | 2023-11-04T05:21:16.000Z | [
"transformers",
"pytorch",
"llava_stablelm_epoch",
"text-generation",
"Multimodal",
"StableLM",
"en",
"dataset:LDJnr/LessWrong-Amplify-Instruct",
"dataset:LDJnr/Pure-Dove",
"dataset:LDJnr/Verified-Camel",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | NousResearch | null | null | NousResearch/Obsidian-3B-V0.5 | 41 | 626 | transformers | 2023-10-24T02:00:29 | ---
license: cc-by-sa-4.0
language:
- en
tags:
- Multimodal
- StableLM
datasets:
- LDJnr/LessWrong-Amplify-Instruct
- LDJnr/Pure-Dove
- LDJnr/Verified-Camel
---
# Obsidian: Worlds smallest multi-modal LLM. First multi-modal model in size 3B
## Model Name: Obsidian-3B-V0.5
Obsidian is a brand new series of Multimodal Language Models. This first project is led by Quan N. and Luigi D.(LDJ).
Obsidian-3B-V0.5 is a multi-modal AI model that has vision! it's smarts are built on [Capybara-3B-V1.9](https://huggingface.co/NousResearch/Capybara-3B-V1.9) based on [StableLM-3B-4e1t](stabilityai/stablelm-3b-4e1t). Capybara-3B-V1.9 achieves state-of-the-art performance when compared to model with similar size, even beats some 7B models.
Current finetuning and inference code is available on our GitHub repo: [Here](https://github.com/NousResearch/Obsidian)
## Acknowledgement
Obsidian-3B-V0.5 was developed and finetuned by [Nous Research](https://huggingface.co/NousResearch), in collaboration with [Virtual Interactive](https://huggingface.co/vilm).
Special thank you to **LDJ** for the wonderful Capybara dataset, and **qnguyen3** for the model training procedure.
## Model Training
Obsidian-3B-V0.5 followed the same training procedure as LLaVA 1.5
## Prompt Format
The model followed ChatML format. However, with `###` as the seperator
```
<|im_start|>user
What is this sign about?\n<image>
###
<|im_start|>assistant
The sign is about bullying, and it is placed on a black background with a red background.
###
```
## Benchmarks
Coming Soon! | 1,554 | [
[
-0.0294189453125,
-0.0584716796875,
0.034881591796875,
0.0233306884765625,
-0.009368896484375,
0.006183624267578125,
0.0018453598022460938,
-0.052978515625,
0.0298004150390625,
0.0244140625,
-0.047698974609375,
-0.03594970703125,
-0.032928466796875,
-0.00807... |
timm/vit_base_patch16_clip_224.openai_ft_in12k_in1k | 2023-05-06T00:02:23.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:wit-400m",
"dataset:imagenet-12k",
"arxiv:2212.07143",
"arxiv:2103.00020",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch16_clip_224.openai_ft_in12k_in1k | 0 | 624 | timm | 2022-11-27T23:16:54 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- wit-400m
- imagenet-12k
---
# Model card for vit_base_patch16_clip_224.openai_ft_in12k_in1k
A Vision Transformer (ViT) image classification model. Pretrained on WIT-400M image-text pairs by OpenAI using CLIP. Fine-tuned on ImageNet-12k and then ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.6
- GMACs: 16.9
- Activations (M): 16.5
- Image size: 224 x 224
- **Papers:**
- Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- WIT-400M
- ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch16_clip_224.openai_ft_in12k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_clip_224.openai_ft_in12k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,436 | [
[
-0.0311431884765625,
-0.037628173828125,
0.0025196075439453125,
0.0175933837890625,
-0.02392578125,
-0.0318603515625,
-0.03302001953125,
-0.032806396484375,
0.0109405517578125,
0.03106689453125,
-0.0311431884765625,
-0.040130615234375,
-0.0567626953125,
-0.0... |
imvladikon/alephbertgimmel-base-512 | 2023-09-06T07:29:10.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"language model",
"he",
"arxiv:2211.15199",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | imvladikon | null | null | imvladikon/alephbertgimmel-base-512 | 3 | 623 | transformers | 2022-12-02T00:21:50 | ---
language:
- he
tags:
- language model
---
## AlephBertGimmel
Modern Hebrew pretrained BERT model with a 128K token vocabulary.
[Checkpoint](https://github.com/Dicta-Israel-Center-for-Text-Analysis/alephbertgimmel/tree/main/alephbertgimmel-base/ckpt_73780--Max512Seq) of the alephbertgimmel-base-512 from [alephbertgimmel](https://github.com/Dicta-Israel-Center-for-Text-Analysis/alephbertgimmel)
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained("imvladikon/alephbertgimmel-base-512")
tokenizer = AutoTokenizer.from_pretrained("imvladikon/alephbertgimmel-base-512")
text = "{} היא מטרופולין המהווה את מרכז הכלכלה"
input = tokenizer.encode(text.format("[MASK]"), return_tensors="pt")
mask_token_index = torch.where(input == tokenizer.mask_token_id)[1]
token_logits = model(input).logits
mask_token_logits = token_logits[0, mask_token_index, :]
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(text.format(tokenizer.decode([token])))
# העיר היא מטרופולין המהווה את מרכז הכלכלה
# ירושלים היא מטרופולין המהווה את מרכז הכלכלה
# חיפה היא מטרופולין המהווה את מרכז הכלכלה
# לונדון היא מטרופולין המהווה את מרכז הכלכלה
# אילת היא מטרופולין המהווה את מרכז הכלכלה
```
```python
def ppl_naive(text, model, tokenizer):
input = tokenizer.encode(text, return_tensors="pt")
loss = model(input, labels=input)[0]
return torch.exp(loss).item()
text = """{} היא עיר הבירה של מדינת ישראל, והעיר הגדולה ביותר בישראל בגודל האוכלוסייה"""
for word in ["חיפה", "ירושלים", "תל אביב"]:
print(ppl_naive(text.format(word), model, tokenizer))
# 10.181422233581543
# 9.743313789367676
# 10.171016693115234
```
When using AlephBertGimmel, please reference:
```bibtex
@misc{gueta2022large,
title={Large Pre-Trained Models with Extra-Large Vocabularies: A Contrastive Analysis of Hebrew BERT Models and a New One to Outperform Them All},
author={Eylon Gueta and Avi Shmidman and Shaltiel Shmidman and Cheyn Shmuel Shmidman and Joshua Guedalia and Moshe Koppel and Dan Bareket and Amit Seker and Reut Tsarfaty},
year={2022},
eprint={2211.15199},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,339 | [
[
-0.02178955078125,
-0.0416259765625,
-0.0045013427734375,
0.02099609375,
-0.037445068359375,
-0.016998291015625,
-0.0215606689453125,
-0.023040771484375,
0.010406494140625,
0.002185821533203125,
-0.031005859375,
-0.0496826171875,
-0.057769775390625,
-0.00925... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.