
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
dwancin/memoji | 2023-08-19T10:42:01.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:mit",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | dwancin | null | null | dwancin/memoji | 1 | 405 | diffusers | 2023-06-29T14:12:41 | ---
license: mit
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
inference: true
widget:
- text: >-
aimoji, a boy
example_title: boy
- text: >-
aimoji, a girl
example_title: girl
---
# Memoji Diffusion
### Model description
A Stable Diffusion model that have been trained on images of Apple's animated Memoji avatars.
## Trigger word
- aimoji
## Examples

 | 468 | [
[
-0.0100555419921875,
-0.07373046875,
0.0330810546875,
0.0171051025390625,
-0.0212860107421875,
-0.00475311279296875,
0.00994110107421875,
0.0137939453125,
0.027435302734375,
0.036468505859375,
-0.03973388671875,
-0.028594970703125,
-0.053558349609375,
-0.029... |
DunnBC22/opus-mt-zh-en-Chinese_to_English | 2023-08-23T02:02:32.000Z | [
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_trainer",
"translation",
"en",
"zh",
"dataset:GEM/wiki_lingua",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | DunnBC22 | null | null | DunnBC22/opus-mt-zh-en-Chinese_to_English | 3 | 405 | transformers | 2023-08-21T21:35:52 | ---
license: cc-by-4.0
base_model: Helsinki-NLP/opus-mt-zh-en
tags:
- generated_from_trainer
model-index:
- name: opus-mt-zh-en-Chinese_to_English
results: []
datasets:
- GEM/wiki_lingua
language:
- en
- zh
metrics:
- bleu
- rouge
pipeline_tag: translation
---
# opus-mt-zh-en-Chinese_to_English
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-zh-en](https://huggingface.co/Helsinki-NLP/opus-mt-zh-en).
## Model description
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Machine%20Translation/Chinese%20to%20English%20Translation/Chinese_to_English_Translation.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://huggingface.co/datasets/GEM/wiki_lingua
__Chinese Text Length__
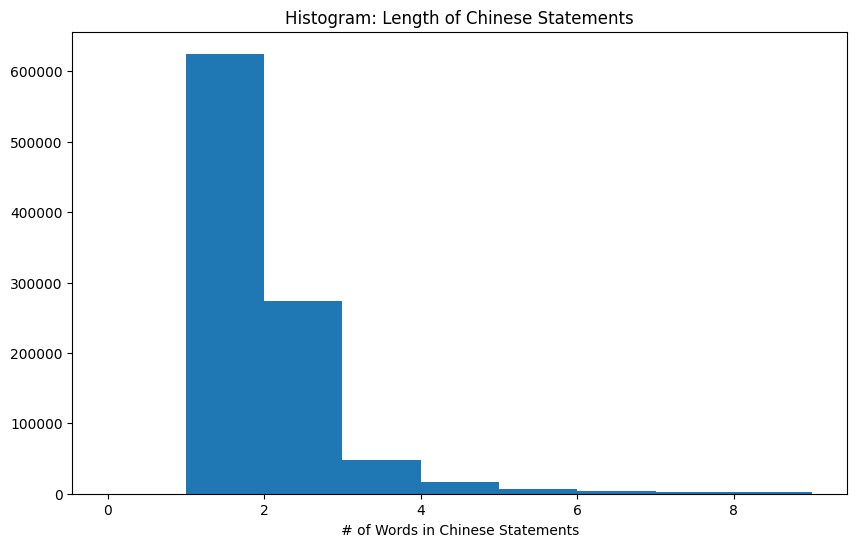
__English Text Length__
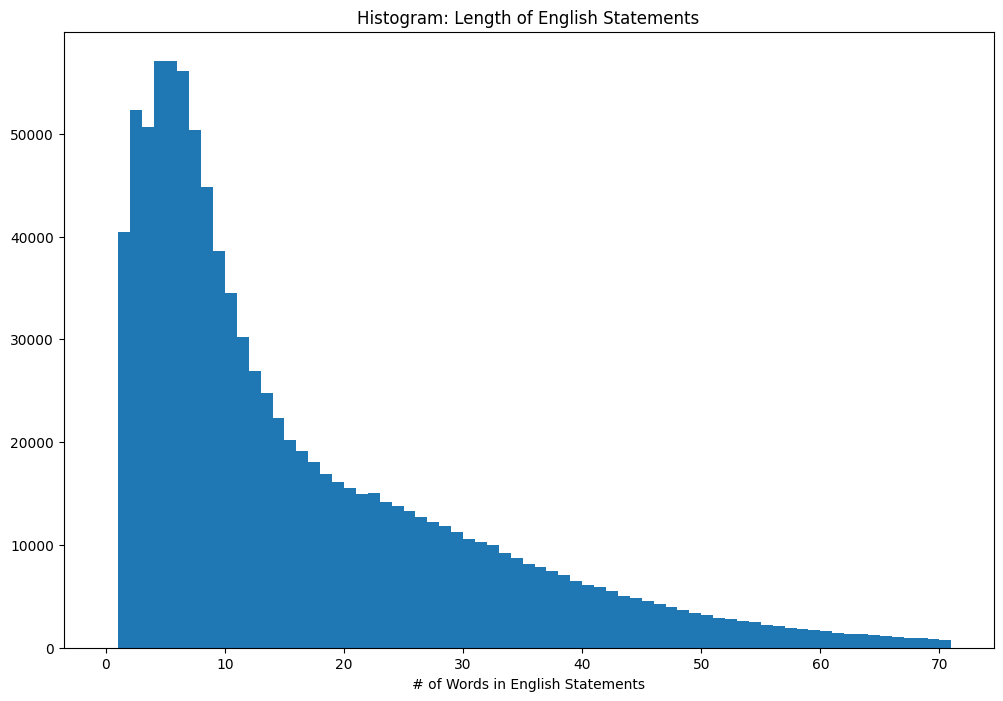
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Epoch | Validation Loss | Bleu | Rouge1 | Rouge2 | RougeL | RougeLsum | Avg. Prediction Lengths |
|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|
| 1.0 | 1.0113 | 45.2808 | 0.6201 | 0.4198 | 0.5927 | 0.5927 | 24.5581 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3 | 2,052 | [
[
-0.0185394287109375,
-0.04364013671875,
0.0185546875,
0.0247802734375,
-0.02587890625,
-0.01800537109375,
-0.0271148681640625,
-0.0318603515625,
0.0218963623046875,
0.0272216796875,
-0.051544189453125,
-0.041015625,
-0.036712646484375,
0.005397796630859375,
... |
facebook/hubert-xlarge-ls960-ft | 2023-06-27T18:52:32.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"hubert",
"automatic-speech-recognition",
"speech",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:libri-light",
"dataset:librispeech_asr",
"arxiv:2106.07447",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"... | automatic-speech-recognition | facebook | null | null | facebook/hubert-xlarge-ls960-ft | 10 | 404 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- libri-light
- librispeech_asr
tags:
- speech
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: hubert-large-ls960-ft
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.8
---
# Hubert-Extra-Large-Finetuned
[Facebook's Hubert](https://ai.facebook.com/blog/hubert-self-supervised-representation-learning-for-speech-recognition-generation-and-compression)
The extra large model fine-tuned on 960h of Librispeech on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
The model is a fine-tuned version of [hubert-xlarge-ll60k](https://huggingface.co/facebook/hubert-xlarge-ll60k).
[Paper](https://arxiv.org/abs/2106.07447)
Authors: Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
**Abstract**
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/hubert .
# Usage
The model can be used for automatic-speech-recognition as follows:
```python
import torch
from transformers import Wav2Vec2Processor, HubertForCTC
from datasets import load_dataset
processor = Wav2Vec2Processor.from_pretrained("facebook/hubert-xlarge-ls960-ft")
model = HubertForCTC.from_pretrained("facebook/hubert-xlarge-ls960-ft")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values # Batch size 1
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.decode(predicted_ids[0])
# ->"A MAN SAID TO THE UNIVERSE SIR I EXIST"
``` | 3,341 | [
[
-0.042388916015625,
-0.04119873046875,
0.0261993408203125,
0.0163421630859375,
-0.00981903076171875,
-0.007282257080078125,
-0.029937744140625,
-0.0343017578125,
0.0308837890625,
0.01947021484375,
-0.047760009765625,
-0.0235748291015625,
-0.036956787109375,
... |
timm/beitv2_base_patch16_224.in1k_ft_in1k | 2023-05-08T23:33:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2208.06366",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/beitv2_base_patch16_224.in1k_ft_in1k | 0 | 404 | timm | 2023-05-08T23:32:43 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for beitv2_base_patch16_224.in1k_ft_in1k
A BEiT-v2 image classification model. Trained on ImageNet-1k with self-supervised masked image modelling (MIM) using a VQ-KD encoder as a visual tokenizer (via OpenAI CLIP B/16 teacher). Fine-tuned on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.5
- GMACs: 17.6
- Activations (M): 23.9
- Image size: 224 x 224
- **Papers:**
- BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers: https://arxiv.org/abs/2208.06366
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/microsoft/unilm/tree/master/beit2
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('beitv2_base_patch16_224.in1k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'beitv2_base_patch16_224.in1k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{peng2022beit,
title={Beit v2: Masked image modeling with vector-quantized visual tokenizers},
author={Peng, Zhiliang and Dong, Li and Bao, Hangbo and Ye, Qixiang and Wei, Furu},
journal={arXiv preprint arXiv:2208.06366},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,751 | [
[
-0.0316162109375,
-0.0294036865234375,
-0.0031604766845703125,
0.0084228515625,
-0.041595458984375,
-0.01557159423828125,
-0.006282806396484375,
-0.036956787109375,
0.01378631591796875,
0.029449462890625,
-0.030548095703125,
-0.05560302734375,
-0.0557861328125,
... |
matgu23/ntrlph | 2023-07-12T05:00:35.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | matgu23 | null | null | matgu23/ntrlph | 0 | 404 | diffusers | 2023-07-12T04:48:23 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### ntrlph Dreambooth model trained by matgu23 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 495 | [
[
-0.0222320556640625,
-0.056976318359375,
0.0323486328125,
0.0391845703125,
-0.0252838134765625,
0.03887939453125,
0.02093505859375,
-0.0281829833984375,
0.037872314453125,
0.005767822265625,
-0.0269317626953125,
-0.016632080078125,
-0.034515380859375,
-0.003... |
digiplay/hellopure_v2.24Beta | 2023-07-13T08:49:07.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/hellopure_v2.24Beta | 2 | 404 | diffusers | 2023-07-13T04:21:25 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
👍👍👍👍👍
https://civitai.com/models/88202/hellopure
Other models from Author: https://civitai.com/user/aji1/models

Sample image I made with AUTOMATIC1111 :

parameters
very close-up ,(best beautiful:1.2), (masterpiece:1.2), (best quality:1.2),masterpiece, best quality, The image features a beautiful young woman with long light golden hair, beach near the ocean, white dress ,The beach is lined with palm trees,
Negative prompt: worst quality ,normal quality ,
Steps: 17, Sampler: Euler, CFG scale: 5, Seed: 1097775045, Size: 480x680, Model hash: 8d4fa7988b, Clip skip: 2, Version: v1.4.1
| 1,008 | [
[
-0.057708740234375,
-0.030975341796875,
0.0274505615234375,
0.025238037109375,
-0.032928466796875,
-0.010986328125,
0.0255126953125,
-0.048126220703125,
0.050384521484375,
0.0248565673828125,
-0.057342529296875,
-0.0183868408203125,
-0.022003173828125,
0.008... |
alvaroalon2/biobert_genetic_ner | 2023-03-17T12:11:30.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"NER",
"Biomedical",
"Genetics",
"en",
"dataset:JNLPBA",
"dataset:BC2GM",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | alvaroalon2 | null | null | alvaroalon2/biobert_genetic_ner | 11 | 403 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: apache-2.0
tags:
- token-classification
- NER
- Biomedical
- Genetics
datasets:
- JNLPBA
- BC2GM
---
BioBERT model fine-tuned in NER task with JNLPBA and BC2GM corpus for genetic class entities.
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | 345 | [
[
-0.02093505859375,
-0.048248291015625,
0.0206298828125,
0.0011882781982421875,
0.00238037109375,
0.0218353271484375,
-0.004608154296875,
-0.05902099609375,
0.030303955078125,
0.036834716796875,
-0.0289154052734375,
-0.036865234375,
-0.036285400390625,
0.0149... |
nvidia/segformer-b0-finetuned-cityscapes-512-1024 | 2022-08-09T11:34:31.000Z | [
"transformers",
"pytorch",
"tf",
"segformer",
"vision",
"image-segmentation",
"dataset:cityscapes",
"arxiv:2105.15203",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | nvidia | null | null | nvidia/segformer-b0-finetuned-cityscapes-512-1024 | 0 | 403 | transformers | 2022-03-02T23:29:05 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://cdn-media.huggingface.co/Inference-API/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.png
example_title: road
---
# SegFormer (b4-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 512x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-512-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-512-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
| 3,133 | [
[
-0.06634521484375,
-0.052490234375,
0.017791748046875,
0.0194244384765625,
-0.021392822265625,
-0.0247955322265625,
0.0003001689910888672,
-0.050384521484375,
0.0215911865234375,
0.044281005859375,
-0.062255859375,
-0.04541015625,
-0.051025390625,
0.01219177... |
malmarjeh/t5-arabic-text-summarization | 2023-07-01T16:39:31.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"Arabic T5",
"T5",
"MSA",
"Arabic Text Summarization",
"Arabic News Title Generation",
"Arabic Paraphrasing",
"ar",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | malmarjeh | null | null | malmarjeh/t5-arabic-text-summarization | 7 | 403 | transformers | 2022-06-03T14:36:08 | ---
language:
- ar
tags:
- Arabic T5
- T5
- MSA
- Arabic Text Summarization
- Arabic News Title Generation
- Arabic Paraphrasing
widget:
- text: "شهدت مدينة طرابلس، مساء أمس الأربعاء، احتجاجات شعبية وأعمال شغب لليوم الثالث على التوالي، وذلك بسبب تردي الوضع المعيشي والاقتصادي. واندلعت مواجهات عنيفة وعمليات كر وفر ما بين الجيش اللبناني والمحتجين استمرت لساعات، إثر محاولة فتح الطرقات المقطوعة، ما أدى إلى إصابة العشرات من الطرفين."
---
# An Arabic abstractive text summarization model
A fine-tuned AraT5 model on a dataset of 84,764 paragraph-summary pairs.
Paper: [Arabic abstractive text summarization using RNN-based and transformer-based architectures](https://www.sciencedirect.com/science/article/abs/pii/S0306457322003284).
Dataset: [link](https://data.mendeley.com/datasets/7kr75c9h24/1).
The model can be used as follows:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
from arabert.preprocess import ArabertPreprocessor
model_name="malmarjeh/t5-arabic-text-summarization"
preprocessor = ArabertPreprocessor(model_name="")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
pipeline = pipeline("text2text-generation",model=model,tokenizer=tokenizer)
text = "شهدت مدينة طرابلس، مساء أمس الأربعاء، احتجاجات شعبية وأعمال شغب لليوم الثالث على التوالي، وذلك بسبب تردي الوضع المعيشي والاقتصادي. واندلعت مواجهات عنيفة وعمليات كر وفر ما بين الجيش اللبناني والمحتجين استمرت لساعات، إثر محاولة فتح الطرقات المقطوعة، ما أدى إلى إصابة العشرات من الطرفين."
text = preprocessor.preprocess(text)
result = pipeline(text,
pad_token_id=tokenizer.eos_token_id,
num_beams=3,
repetition_penalty=3.0,
max_length=200,
length_penalty=1.0,
no_repeat_ngram_size = 3)[0]['generated_text']
result
>>> 'مواجهات عنيفة بين الجيش اللبناني ومحتجين في طرابلس'
```
## Contact:
<banimarje@gmail.com>
| 1,965 | [
[
-0.031951904296875,
-0.041595458984375,
0.0123291015625,
0.017974853515625,
-0.045989990234375,
0.0065765380859375,
0.01296234130859375,
-0.027191162109375,
0.022216796875,
0.018463134765625,
-0.023345947265625,
-0.0555419921875,
-0.072998046875,
0.037750244... |
YurtsAI/yurts-python-code-gen-30-sparse | 2022-10-27T20:39:18.000Z | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"license:bsd-3-clause",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | YurtsAI | null | null | YurtsAI/yurts-python-code-gen-30-sparse | 18 | 403 | transformers | 2022-10-24T22:22:16 | ---
license: bsd-3-clause
---
# Maverick (Yurt's Python Code Generation Model)
## Model description
This code generation model was fine-tuned on Python code from a generic multi-language code generation model. This model was then pushed to 30% sparsity using Yurts' in-house technology without performance loss. In this specific instance, the class representation for the network is still dense. This particular model has 350M trainable parameters.
## Training data
This model was tuned on a subset of the Python data available in the BigQuery open-source [Github dataset](https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code).
## How to use
The model is great at autocompleting based off of partially generated function signatures and class signatures. It is also decent at generating code base based off of natural language prompts with a comment. If you find something cool you can do with the model, be sure to share it with us!
Check out our [colab notebook](https://colab.research.google.com/drive/1NDO4X418HuPJzF8mFc6_ySknQlGIZMDU?usp=sharing) to see how to invoke the model and try it out.
## Feedback and Questions
Have any questions or feedback? Find us on [Discord](https://discord.gg/2x4rmSGER9). | 1,270 | [
[
-0.0180816650390625,
-0.07183837890625,
0.0244598388671875,
0.012176513671875,
-0.01354217529296875,
-0.0154571533203125,
-0.002201080322265625,
-0.0225982666015625,
0.0223388671875,
0.0555419921875,
-0.03155517578125,
-0.0230560302734375,
-0.0129241943359375,
... |
Falah/crying-woman | 2023-03-03T09:53:21.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Falah | null | null | Falah/crying-woman | 0 | 403 | diffusers | 2023-03-03T09:50:11 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### crying-woman Dreambooth model trained by Falah with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 499 | [
[
-0.017303466796875,
-0.059783935546875,
0.033233642578125,
0.036773681640625,
-0.0262298583984375,
0.02899169921875,
0.037139892578125,
-0.022003173828125,
0.0295867919921875,
0.0008597373962402344,
-0.034820556640625,
-0.0177154541015625,
-0.043609619140625,
... |
Grigsss/azuki | 2023-04-19T05:29:29.000Z | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Grigsss | null | null | Grigsss/azuki | 0 | 403 | diffusers | 2023-04-19T05:27:34 | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: azuki
---
### azuki Dreambooth model trained by Grigsss with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
azuki (use that on your prompt)

| 2,607 | [
[
-0.0738525390625,
-0.00274658203125,
0.0223236083984375,
0.00525665283203125,
-0.0241241455078125,
-0.00894927978515625,
0.0190277099609375,
-0.039215087890625,
0.038848876953125,
0.034820556640625,
-0.06463623046875,
-0.048614501953125,
-0.041107177734375,
... |
timm/res2net101d.in1k | 2023-04-24T00:08:27.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1904.01169",
"license:unknown",
"region:us"
] | image-classification | timm | null | null | timm/res2net101d.in1k | 0 | 403 | timm | 2023-04-24T00:07:57 | ---
tags:
- image-classification
- timm
library_name: timm
license: unknown
datasets:
- imagenet-1k
---
# Model card for res2net101d.in1k
A Res2Net (Multi-Scale ResNet) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 45.2
- GMACs: 8.3
- Activations (M): 19.2
- Image size: 224 x 224
- **Papers:**
- Res2Net: A New Multi-scale Backbone Architecture: https://arxiv.org/abs/1904.01169
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/gasvn/Res2Net/
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('res2net101d.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'res2net101d.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'res2net101d.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{gao2019res2net,
title={Res2Net: A New Multi-scale Backbone Architecture},
author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
journal={IEEE TPAMI},
doi={10.1109/TPAMI.2019.2938758},
}
```
| 3,650 | [
[
-0.03411865234375,
-0.026702880859375,
-0.006832122802734375,
0.0139617919921875,
-0.021209716796875,
-0.02935791015625,
-0.01529693603515625,
-0.02880859375,
0.0246429443359375,
0.039794921875,
-0.033203125,
-0.04052734375,
-0.05194091796875,
-0.01029205322... |
Helsinki-NLP/opus-mt-ml-en | 2023-08-16T12:01:12.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"ml",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-ml-en | 0 | 402 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ml-en
* source languages: ml
* target languages: en
* OPUS readme: [ml-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ml-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-04-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.zip)
* test set translations: [opus-2020-04-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.test.txt)
* test set scores: [opus-2020-04-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ml.en | 42.7 | 0.605 |
| 818 | [
[
-0.017791748046875,
-0.033416748046875,
0.018524169921875,
0.032073974609375,
-0.0263824462890625,
-0.02880859375,
-0.035980224609375,
-0.0043792724609375,
-0.0017404556274414062,
0.034515380859375,
-0.048828125,
-0.046112060546875,
-0.047607421875,
0.017669... |
circulus/sd-photoreal-v2.5 | 2023-02-20T16:02:01.000Z | [
"diffusers",
"generative ai",
"stable-diffusion",
"image-to-image",
"realism",
"art",
"text-to-image",
"en",
"license:gpl-3.0",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | circulus | null | null | circulus/sd-photoreal-v2.5 | 5 | 402 | diffusers | 2023-02-06T06:01:18 | ---
license: gpl-3.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- generative ai
- stable-diffusion
- image-to-image
- realism
- art
---
Photoreal v2.5
Finetuned Stable Diffusion 1.5 for generating images
You can test this model here >
https://eva.circul.us/index.html
 | 327 | [
[
-0.04107666015625,
-0.072509765625,
0.019317626953125,
0.027435302734375,
-0.0258941650390625,
-0.0267791748046875,
0.0205535888671875,
-0.0299530029296875,
0.00308990478515625,
0.048431396484375,
-0.035552978515625,
-0.037384033203125,
-0.0108184814453125,
... |
Tinsae/doorstop1 | 2023-03-09T14:30:10.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Tinsae | null | null | Tinsae/doorstop1 | 0 | 402 | diffusers | 2023-02-28T19:51:04 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
Sample pictures of this concept:
| 116 | [
[
-0.035980224609375,
-0.026397705078125,
0.0281219482421875,
0.0108489990234375,
-0.04315185546875,
-0.0008540153503417969,
0.03802490234375,
-0.0211334228515625,
0.054656982421875,
0.06488037109375,
-0.0545654296875,
-0.0299530029296875,
-0.0240325927734375,
... |
Falah/sooq-safafeer | 2023-03-10T06:36:55.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Falah | null | null | Falah/sooq-safafeer | 0 | 402 | diffusers | 2023-03-10T06:34:05 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### sooq-safafeer Dreambooth model trained by Falah with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:




| 924 | [
[
-0.04010009765625,
-0.05218505859375,
0.0217742919921875,
0.0258941650390625,
-0.025299072265625,
0.008758544921875,
0.03411865234375,
-0.016937255859375,
0.041107177734375,
0.0193328857421875,
-0.03485107421875,
-0.0268402099609375,
-0.043609619140625,
-0.0... |
ImAbbieKitten/protoanime2 | 2023-03-10T08:37:36.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ImAbbieKitten | null | null | ImAbbieKitten/protoanime2 | 0 | 402 | diffusers | 2023-03-10T08:23:45 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### protoanime2 Dreambooth model trained by ImAbbieKitten with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 506 | [
[
-0.0273895263671875,
-0.047149658203125,
0.04107666015625,
0.04266357421875,
-0.0213470458984375,
0.03057861328125,
0.0115814208984375,
-0.02056884765625,
0.05230712890625,
0.0038967132568359375,
-0.0248870849609375,
-0.01428985595703125,
-0.031524658203125,
... |
faalbane/kopper-kreations-custom-stable-diffusion-style-v-1-5-21-photos-vv-1 | 2023-03-11T15:36:27.000Z | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | faalbane | null | null | faalbane/kopper-kreations-custom-stable-diffusion-style-v-1-5-21-photos-vv-1 | 0 | 402 | diffusers | 2023-03-11T15:35:29 | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: kk
---
### Kopper Kreations Custom Stable Diffusion (style) (v. 1.5) (21 photos) vv.1 Dreambooth model trained by faalbane with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
kk (use that on your prompt)

| 4,099 | [
[
-0.09228515625,
-0.053009033203125,
0.030181884765625,
0.035003662109375,
-0.025238037109375,
0.0032901763916015625,
0.0102386474609375,
-0.034454345703125,
0.0902099609375,
0.024444580078125,
-0.036041259765625,
-0.036651611328125,
-0.03961181640625,
-0.008... |
timm/eca_nfnet_l1.ra2_in1k | 2023-03-24T01:13:35.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/eca_nfnet_l1.ra2_in1k | 0 | 402 | timm | 2023-03-24T01:12:48 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for eca_nfnet_l1.ra2_in1k
A ECA-NFNet-Lite (Lightweight NFNet w/ ECA attention) image classification model. Trained in `timm` by Ross Wightman.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
Lightweight NFNets are `timm` specific variants that reduce the SE and bottleneck ratio from 0.5 -> 0.25 (reducing widths) and use a smaller group size while maintaining the same depth. SiLU activations used instead of GELU.
This NFNet variant also uses ECA (Efficient Channel Attention) instead of SE (Squeeze-and-Excitation).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 41.4
- GMACs: 9.6
- Activations (M): 22.0
- Image size: train = 256 x 256, test = 320 x 320
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eca_nfnet_l1.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_nfnet_l1.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1536, 16, 16])
# torch.Size([1, 3072, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_nfnet_l1.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 3072, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,082 | [
[
-0.042144775390625,
-0.0400390625,
-0.000579833984375,
0.00850677490234375,
-0.0256195068359375,
-0.027496337890625,
-0.0266571044921875,
-0.042877197265625,
0.0258636474609375,
0.0340576171875,
-0.032257080078125,
-0.050811767578125,
-0.05517578125,
0.00326... |
TheBloke/Mistralic-7B-1-GPTQ | 2023-10-04T16:27:56.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistralic-7B-1-GPTQ | 5 | 402 | transformers | 2023-10-04T13:33:30 | ---
base_model: SkunkworksAI/Mistralic-7B-1
inference: false
model_creator: SkunkworksAI
model_name: Mistralic 7B-1
model_type: mistral
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### System: {system_message}
### Instruction: {prompt}
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistralic 7B-1 - GPTQ
- Model creator: [SkunkworksAI](https://huggingface.co/SkunkworksAI)
- Original model: [Mistralic 7B-1](https://huggingface.co/SkunkworksAI/Mistralic-7B-1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [SkunkworksAI's Mistralic 7B-1](https://huggingface.co/SkunkworksAI/Mistralic-7B-1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistralic-7B-1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistralic-7B-1-GGUF)
* [SkunkworksAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/SkunkworksAI/Mistralic-7B-1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Mistralic
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### System: {system_message}
### Instruction: {prompt}
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.30 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Mistralic-7B-1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Mistralic-7B-1-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Mistralic-7B-1-GPTQ`:
```shell
mkdir Mistralic-7B-1-GPTQ
huggingface-cli download TheBloke/Mistralic-7B-1-GPTQ --local-dir Mistralic-7B-1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Mistralic-7B-1-GPTQ
huggingface-cli download TheBloke/Mistralic-7B-1-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Mistralic-7B-1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Mistralic-7B-1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistralic-7B-1-GPTQ --local-dir Mistralic-7B-1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Mistralic-7B-1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Mistralic-7B-1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Mistralic-7B-1-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Mistralic-7B-1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Mistralic-7B-1-GPTQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### System: {system_message}
### Instruction: {prompt}
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Mistralic-7B-1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### System: {system_message}
### Instruction: {prompt}
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: SkunkworksAI's Mistralic 7B-1
<p><h1> 🦾 Mistralic-7B-1 🦾 </h1></p>
Special thanks to Together Compute for sponsoring Skunkworks with compute!
**INFERENCE**
```
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device('cuda')
system_prompt = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n"
system_no_input_prompt = "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n"
def generate_prompt(instruction, input=None):
if input:
prompt = f"### System:\n{system_prompt}\n\n"
else:
prompt = f"### System:\n{system_no_input_prompt}\n\n"
prompt += f"### Instruction:\n{instruction}\n\n"
if input:
prompt += f"### Input:\n{input}\n\n"
return prompt + """### Response:\n"""
device = "cuda"
model = AutoModelForCausalLM.from_pretrained("SkunkworksAI/Mistralic-7B-1")
tokenizer = AutoTokenizer.from_pretrained("SkunkworksAI/Mistralic-7B-1")
while True:
instruction = input("Enter Instruction: ")
instruction = generate_prompt(instruction)
inputs = tokenizer(instruction, return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=1000, do_sample=True, temperature=0.01, use_cache=True, eos_token_id=tokenizer.eos_token_id)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
**EVALUATION**

Average: 0.72157
For comparison:
mistralai/Mistral-7B-v0.1 scores 0.7116
mistralai/Mistral-7B-Instruct-v0.1 scores 0.6794
| 20,537 | [
[
-0.03802490234375,
-0.05548095703125,
0.01067352294921875,
0.0171661376953125,
-0.0157928466796875,
-0.019683837890625,
0.00556182861328125,
-0.03839111328125,
0.0164947509765625,
0.02685546875,
-0.045745849609375,
-0.037445068359375,
-0.027862548828125,
-0.... |
codys12/MergeLlama-7b | 2023-10-18T02:04:35.000Z | [
"peft",
"pytorch",
"text-generation",
"dataset:codys12/MergeLlama",
"arxiv:1910.09700",
"license:llama2",
"region:us",
"has_space"
] | text-generation | codys12 | null | null | codys12/MergeLlama-7b | 2 | 402 | peft | 2023-10-11T20:49:26 | ---
library_name: peft
base_model: codellama/CodeLlama-7b-hf
license: llama2
datasets:
- codys12/MergeLlama
pipeline_tag: text-generation
---
# Model Card for Model ID
Automated merge conflict resolution
## Model Details
Peft finetune of CodeLlama-7b
### Model Description
- **Developed by:** DreamcatcherAI
- **License:** llama2
- **Finetuned from model [optional]:** CodeLlama-7b
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** codys12/MergeLlama-7b
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
Input should be formatted as
```
<<<<<<<
Current change
=======
Incoming change
>>>>>>>
```
MergeLlama will provide the resolution.
You can chain multiple conflicts/resolutions for improved context
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0 | 4,952 | [
[
-0.05084228515625,
-0.048187255859375,
0.0340576171875,
0.007724761962890625,
-0.015472412109375,
-0.0094146728515625,
0.00665283203125,
-0.04302978515625,
0.00421142578125,
0.049835205078125,
-0.048370361328125,
-0.043701171875,
-0.0472412109375,
-0.0079650... |
charliegrc/mattj | 2023-03-08T09:52:48.000Z | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | charliegrc | null | null | charliegrc/mattj | 0 | 401 | diffusers | 2023-03-08T09:51:22 | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: julcto
---
### MattJ Dreambooth model trained by charliegrc with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
julcto (use that on your prompt)

| 1,677 | [
[
-0.05804443359375,
-0.0237884521484375,
0.030059814453125,
0.028106689453125,
-0.0269317626953125,
0.02252197265625,
0.007678985595703125,
-0.033447265625,
0.049346923828125,
0.033782958984375,
-0.055633544921875,
-0.044036865234375,
-0.0382080078125,
0.0000... |
garrettscott/garrett-dreambooth | 2023-03-10T03:21:45.000Z | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | garrettscott | null | null | garrettscott/garrett-dreambooth | 0 | 401 | diffusers | 2023-03-10T03:20:38 | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: cfj
---
### Garrett-Dreambooth Dreambooth model trained by garrettscott with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
cfj (use that on your prompt)

| 2,576 | [
[
-0.0721435546875,
-0.027862548828125,
0.02960205078125,
0.033111572265625,
-0.036468505859375,
0.0181884765625,
0.014312744140625,
-0.046234130859375,
0.08074951171875,
0.0146484375,
-0.05499267578125,
-0.03228759765625,
-0.0360107421875,
0.01087188720703125... |
badmonk/nxka | 2023-06-19T21:28:43.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/nxka | 1 | 401 | diffusers | 2023-06-14T22:59:35 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for NXKA
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** MajicMixRealisticv6
-
# How to Get Started with the Model
Use the code below to get started with the model.
### NXKA ### | 429 | [
[
-0.0164947509765625,
-0.0234375,
0.0220794677734375,
0.00876617431640625,
-0.069091796875,
0.016326904296875,
0.040863037109375,
-0.025482177734375,
0.0477294921875,
0.060394287109375,
-0.059600830078125,
-0.049041748046875,
-0.04412841796875,
-0.02142333984... |
timm/inception_next_tiny.sail_in1k | 2023-08-24T19:00:49.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.16900",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/inception_next_tiny.sail_in1k | 0 | 401 | timm | 2023-08-24T19:00:20 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for inception_next_tiny.sail_in1k
A InceptionNeXt image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.1
- GMACs: 4.2
- Activations (M): 12.0
- Image size: 224 x 224
- **Papers:**
- InceptionNeXt: When Inception Meets ConvNeXt: https://arxiv.org/abs/2303.16900
- **Original:** https://github.com/sail-sg/inceptionnext
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('inception_next_tiny.sail_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'inception_next_tiny.sail_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'inception_next_tiny.sail_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{yu2023inceptionnext,
title={InceptionNeXt: when inception meets convnext},
author={Yu, Weihao and Zhou, Pan and Yan, Shuicheng and Wang, Xinchao},
journal={arXiv preprint arXiv:2303.16900},
year={2023}
}
```
| 3,436 | [
[
-0.04144287109375,
-0.031982421875,
0.01091766357421875,
0.01273345947265625,
-0.034088134765625,
-0.0209808349609375,
-0.01430511474609375,
-0.037078857421875,
0.0171051025390625,
0.0296173095703125,
-0.04248046875,
-0.055267333984375,
-0.046051025390625,
-... |
noahkim/KoT5_news_summarization | 2022-10-21T00:05:27.000Z | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"summarization",
"news",
"ko",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | summarization | noahkim | null | null | noahkim/KoT5_news_summarization | 4 | 400 | transformers | 2022-10-20T11:06:55 |
---
language: ko
tags:
- summarization
- news
inference: false
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KoT5_news_summarization
- This model is a [lcw99/t5-base-korean-text-summary](https://huggingface.co/lcw99/t5-base-korean-text-summary) finetuned on the [daekeun-ml/naver-news-summarization-ko](https://huggingface.co/datasets/daekeun-ml/naver-news-summarization-ko)
## Model description
<<20221021 Commit>>
프로젝트용으로 뉴스 요약 모델 특화된 모델을 만들기 위해 lcw99님의 t5-base-korean-text-summary 모델에 추가적으로 daekeun-ml님이 제공해주신 naver-news-summarization-ko 데이터셋으로 파인튜닝 했습니다.
현재 제가 가지고 있는 뉴스 데이터로 추가 학습 진행 예정입니다.
지속적으로 발전시켜 좋은 성능의 모델을 구현하겠습니다.
감사합니다.
실행환경
- Google Colab Pro
- CPU : Intel(R) Xeon(R) CPU @ 2.20GHz
- GPU : A100-SXM4-40GB
<pre><code>
# Python Code
from transformers import AutoTokenizer
from transformers import AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("noahkim/KoT5_news_summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("noahkim/KoT5_news_summarization")
</pre></code>
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.4513 | 1.0 | 2775 | 0.4067 |
| 0.42 | 2.0 | 5550 | 0.3933 |
| 0.395 | 3.0 | 8325 | 0.3864 |
| 0.3771 | 4.0 | 11100 | 0.3872 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 1,915 | [
[
-0.033477783203125,
-0.033843994140625,
0.009765625,
0.0202484130859375,
-0.031890869140625,
-0.0097198486328125,
-0.0037021636962890625,
-0.0166778564453125,
0.00981903076171875,
0.023712158203125,
-0.04119873046875,
-0.035186767578125,
-0.0538330078125,
0.... |
jonatasgrosman/whisper-large-zh-cv11 | 2022-12-22T23:51:35.000Z | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"zh",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | jonatasgrosman | null | null | jonatasgrosman/whisper-large-zh-cv11 | 48 | 400 | transformers | 2022-12-18T07:28:34 | ---
language:
- zh
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
- cer
model-index:
- name: Whisper Large Chinese (Mandarin)
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 zh-CN
type: mozilla-foundation/common_voice_11_0
config: zh-CN
split: test
args: zh-CN
metrics:
- name: WER
type: wer
value: 55.02141421204441
- name: CER
type: cer
value: 9.550758567294045
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: google/fleurs cmn_hans_cn
type: google/fleurs
config: cmn_hans_cn
split: test
args: cmn_hans_cn
metrics:
- name: WER
type: wer
value: 70.62596203181118
- name: CER
type: cer
value: 11.761282471826888
---
# Whisper Large Chinese (Mandarin)
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on Chinese (Mandarin) using the train and validation splits of [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0). Not all validation split data were used during training, I extracted 1k samples from the validation split to be used for evaluation during fine-tuning.
## Usage
```python
from transformers import pipeline
transcriber = pipeline(
"automatic-speech-recognition",
model="jonatasgrosman/whisper-large-zh-cv11"
)
transcriber.model.config.forced_decoder_ids = (
transcriber.tokenizer.get_decoder_prompt_ids(
language="zh",
task="transcribe"
)
)
transcription = transcriber("path/to/my_audio.wav")
```
## Evaluation
I've performed the evaluation of the model using the test split of two datasets, the [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) (same dataset used for the fine-tuning) and the [Fleurs](https://huggingface.co/datasets/google/fleurs) (dataset not seen during the fine-tuning). As Whisper can transcribe casing and punctuation, I've performed the model evaluation in 2 different scenarios, one using the raw text and the other using the normalized text (lowercase + removal of punctuations). Additionally, for the Fleurs dataset, I've evaluated the model in a scenario where there are no transcriptions of numerical values since the way these values are described in this dataset is different from how they are described in the dataset used in fine-tuning (Common Voice), so it is expected that this difference in the way of describing numerical values will affect the performance of the model for this type of transcription in Fleurs.
### Common Voice 11
| | CER | WER |
| --- | --- | --- |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) | 9.31 | 55.94 |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) + text normalization | 9.55 | 55.02 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | 33.33 | 101.80 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) + text normalization | 29.90 | 95.91 |
### Fleurs
| | CER | WER |
| --- | --- | --- |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) | 15.00 | 93.45 |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) + text normalization | 11.76 | 70.63 |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) + keep only non-numeric samples | 10.95 | 87.91 |
| [jonatasgrosman/whisper-large-zh-cv11](https://huggingface.co/jonatasgrosman/whisper-large-zh-cv11) + text normalization + keep only non-numeric samples | 7.83 | 62.12 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | 23.49 | 101.28 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) + text normalization | 17.58 | 83.22 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) + keep only non-numeric samples | 21.03 | 101.95 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) + text normalization + keep only non-numeric samples | 15.22 | 79.28 |
| 4,466 | [
[
-0.018890380859375,
-0.04608154296875,
0.00774383544921875,
0.043365478515625,
-0.028594970703125,
-0.018096923828125,
-0.0450439453125,
-0.050933837890625,
0.028839111328125,
0.029998779296875,
-0.046295166015625,
-0.0540771484375,
-0.03863525390625,
0.0157... |
taskload/bart-cause-effect | 2023-02-12T12:46:44.000Z | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | taskload | null | null | taskload/bart-cause-effect | 2 | 400 | transformers | 2023-02-04T19:19:18 | ## Bart for Cause-Effect Extraction
This model was created using by Taskload, a group led by Henry Leonardi for automating information extraction. To get involved contact me at leonardi.henry@gmail.com
```python
cause_effect = pipeline("summarization", model="taskload/bart-cause-effect")
output = cause_effect("text: "+event, max_length=300, min_length=30, do_sample=False)
``` | 379 | [
[
-0.002109527587890625,
-0.054718017578125,
0.03857421875,
0.0082855224609375,
-0.01033782958984375,
-0.0291595458984375,
0.0067291259765625,
-0.0162200927734375,
0.030120849609375,
0.043792724609375,
-0.042999267578125,
-0.013214111328125,
-0.06414794921875,
... |
timm/resnetrs420.tf_in1k | 2023-04-05T18:56:27.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2103.07579",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnetrs420.tf_in1k | 0 | 400 | timm | 2023-04-05T18:54:04 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnetrs420.tf_in1k
A ResNetRS-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k by paper authors in Tensorflow.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 191.9
- GMACs: 64.2
- Activations (M): 126.6
- Image size: train = 320 x 320, test = 416 x 416
- **Papers:**
- Revisiting ResNets: Improved Training and Scaling Strategies: https://arxiv.org/abs/2103.07579
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/resnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetrs420.tf_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs420.tf_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 160, 160])
# torch.Size([1, 256, 80, 80])
# torch.Size([1, 512, 40, 40])
# torch.Size([1, 1024, 20, 20])
# torch.Size([1, 2048, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs420.tf_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{bello2021revisiting,
title={Revisiting ResNets: Improved Training and Scaling Strategies},
author={Irwan Bello and William Fedus and Xianzhi Du and Ekin D. Cubuk and Aravind Srinivas and Tsung-Yi Lin and Jonathon Shlens and Barret Zoph},
journal={arXiv preprint arXiv:2103.07579},
year={2021}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,377 | [
[
-0.0654296875,
-0.01525115966796875,
0.0019626617431640625,
0.029052734375,
-0.0325927734375,
-0.007808685302734375,
-0.00911712646484375,
-0.02935791015625,
0.08642578125,
0.020233154296875,
-0.047882080078125,
-0.0390625,
-0.047271728515625,
0.000177145004... |
galleri5-ai/anisha-icbinp | 2023-05-31T06:42:08.000Z | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | galleri5-ai | null | null | galleri5-ai/anisha-icbinp | 0 | 400 | diffusers | 2023-05-31T06:21:16 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### anisha_ICBINP Dreambooth model trained by cl4ys with TheLastBen's fast-DreamBooth notebook
| 204 | [
[
-0.016510009765625,
-0.049072265625,
0.033660888671875,
0.034820556640625,
-0.0367431640625,
0.006473541259765625,
0.007198333740234375,
-0.0227203369140625,
0.0153045654296875,
0.042327880859375,
-0.0176544189453125,
-0.04864501953125,
-0.0540771484375,
-0.... |
badmonk/masamano | 2023-07-14T02:31:47.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/masamano | 1 | 400 | diffusers | 2023-07-13T20:01:52 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for MASAMANO
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** majicMIX realistic
# How to Get Started with the Model
Use the code below to get started with the model.
### MASAMANO ### | 434 | [
[
-0.023773193359375,
-0.0245361328125,
0.002040863037109375,
0.0082855224609375,
-0.07952880859375,
0.0013866424560546875,
0.03814697265625,
-0.0277557373046875,
0.053741455078125,
0.06475830078125,
-0.0576171875,
-0.04803466796875,
-0.053436279296875,
-0.022... |
facebook/mms-tts-por | 2023-09-01T10:11:51.000Z | [
"transformers",
"pytorch",
"safetensors",
"vits",
"text-to-audio",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-to-speech | facebook | null | null | facebook/mms-tts-por | 1 | 400 | transformers | 2023-09-01T10:11:35 |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Portuguese Text-to-Speech
This repository contains the **Portuguese (por)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-por")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-por")
text = "some example text in the Portuguese language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output, rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
| 3,981 | [
[
-0.0249176025390625,
-0.060791015625,
0.01181793212890625,
0.0338134765625,
-0.00823211669921875,
-0.00586700439453125,
-0.0246124267578125,
-0.02191162109375,
0.0276641845703125,
0.01806640625,
-0.055755615234375,
-0.03619384765625,
-0.045440673828125,
0.00... |
Undi95/MLewdBoros-LRPSGPT-2Char-13B | 2023-09-13T17:49:41.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"not-for-all-audiences",
"nsfw",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | Undi95 | null | null | Undi95/MLewdBoros-LRPSGPT-2Char-13B | 10 | 400 | transformers | 2023-09-13T15:46:40 | ---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
---

This model is based on MLewdBoros merged with the ShareGPT-13b-qloras for "2 character".
<!-- description start -->
## Description
This repo contains fp16 files of MLewdBoros-LRPSGPT-2Char-13B, and is made to be used with character card containing "TWO PERSONAS".
<!-- description end -->
<!-- description start -->
## LoRA used
https://huggingface.co/royallab/LimaRP-ShareGPT-13b-qloras/tree/main/prompt-a/twochar
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Custom
```
Enter roleplay mode. You are currently %{having a conversation|in conversation|in a roleplay chat} with <SECOND>, whose %{traits are|persona is|characteristics are}:
<SECOND PERSONA>
%{You are|Play the role of|Take the role of} <FIRST> with the following %{persona|definitions|character sheet|traits}:
<FIRST PERSONA>
%{In addition|Additionally|Also}, %{keep the following scenario in mind|remember this scenario|pay attention to this scenario}:
<SCENARIO>
```
Or try to use Chat without instruction.
More info: https://huggingface.co/royallab/LimaRP-ShareGPT-13b-qloras/blob/main/prompt-a/README.md
Special thanks to Sushi ♥ | 1,319 | [
[
-0.0309600830078125,
-0.046661376953125,
0.0274505615234375,
0.04901123046875,
-0.039886474609375,
-0.00844573974609375,
0.0079193115234375,
-0.04254150390625,
0.04241943359375,
0.054046630859375,
-0.07537841796875,
-0.015777587890625,
-0.042877197265625,
-0... |
nyu-mll/roberta-base-100M-1 | 2021-05-20T18:53:55.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | nyu-mll | null | null | nyu-mll/roberta-base-100M-1 | 0 | 399 | transformers | 2022-03-02T23:29:05 | # RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
| 3,820 | [
[
-0.0379638671875,
-0.0276031494140625,
0.0240325927734375,
0.019622802734375,
-0.017364501953125,
-0.02099609375,
-0.0199737548828125,
-0.0293731689453125,
0.02569580078125,
0.0190582275390625,
-0.06427001953125,
-0.050994873046875,
-0.055389404296875,
0.017... |
sentence-transformers/msmarco-roberta-base-v2 | 2022-06-16T00:24:02.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-roberta-base-v2 | 1 | 399 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-roberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-roberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-roberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-roberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-roberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 250, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,696 | [
[
-0.017974853515625,
-0.055694580078125,
0.02056884765625,
0.02978515625,
-0.0218048095703125,
-0.033843994140625,
-0.0304718017578125,
-0.006336212158203125,
0.01177215576171875,
0.03167724609375,
-0.042022705078125,
-0.03515625,
-0.05596923828125,
0.0085144... |
Prajeevan/akin2 | 2023-01-27T19:05:49.000Z | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Prajeevan | null | null | Prajeevan/akin2 | 0 | 399 | diffusers | 2023-01-27T19:04:42 | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: akin2
---
### akin2 Dreambooth model trained by Prajeevan with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
akin2 (use that on your prompt)

| 747 | [
[
-0.03814697265625,
-0.047607421875,
0.02960205078125,
0.028472900390625,
-0.03216552734375,
-0.008209228515625,
0.01313018798828125,
-0.0328369140625,
0.037933349609375,
0.0162811279296875,
-0.05517578125,
-0.0212249755859375,
-0.03436279296875,
-0.023529052... |
kabachuha/animov-0.1-modelscope-original-format | 2023-04-17T19:30:10.000Z | [
"open_clip",
"anime",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | null | kabachuha | null | null | kabachuha/animov-0.1-modelscope-original-format | 12 | 399 | open_clip | 2023-04-17T17:51:09 | ---
license: cc-by-nc-4.0
task_categories:
- text-to-video
language:
- en
tags:
- anime
---
This is https://huggingface.co/datasets/strangeman3107/animov-0.1 model by strangeman3107 that was converted by [me](https://github.com/kabachuha) into the ModelScope original format using this script https://github.com/ExponentialML/Text-To-Video-Finetuning/pull/52.
Ready to use in Auto1111 webui with this extension https://github.com/deforum-art/sd-webui-text2video
---
Now, copyting info from the original page
This is a text2video model for diffusers, fine-tuned with a [modelscope](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b) to have an anime-style appearance.
It was trained at 384x384 resolution.
It still generates unstable content often. The usage is the same as with the original modelscope model.
example images are [here](https://imgur.com/a/sCwmKG1). | 882 | [
[
-0.018707275390625,
-0.040863037109375,
0.027008056640625,
0.00276947021484375,
-0.0198974609375,
-0.0302581787109375,
0.0023651123046875,
-0.01471710205078125,
0.0195465087890625,
0.040069580078125,
-0.054656982421875,
-0.0119171142578125,
-0.052734375,
-0.... |
loulou08860/fats | 2023-04-18T08:46:21.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | loulou08860 | null | null | loulou08860/fats | 1 | 399 | diffusers | 2023-04-18T08:33:21 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### fats Dreambooth model trained by loulou08860 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 497 | [
[
-0.026153564453125,
-0.0450439453125,
0.042236328125,
0.0272369384765625,
-0.0169525146484375,
0.0270233154296875,
0.026031494140625,
-0.022979736328125,
0.058685302734375,
0.0171661376953125,
-0.01457977294921875,
-0.0179901123046875,
-0.037933349609375,
-0... |
AIMH/mental-longformer-base-4096 | 2023-04-29T09:10:40.000Z | [
"transformers",
"pytorch",
"longformer",
"fill-mask",
"arxiv:2004.05150",
"arxiv:2304.10447",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | AIMH | null | null | AIMH/mental-longformer-base-4096 | 0 | 399 | transformers | 2023-04-18T19:07:00 | ---
license: cc-by-nc-4.0
---
`mental-longformer-base-4096` is a model pretrained from the checkpoint of [longformer-base-4096](https://huggingface.co/allenai/longformer-base-4096) for the mental healthcare domain. [Longformer](https://arxiv.org/abs/2004.05150) is a transformer model for long documents. `longformer-base-4096` is a BERT-like model started from the RoBERTa checkpoint and pretrained for MLM on long documents. It supports sequences of length up to 4,096.
## Usage
Load the model via [Huggingface’s Transformers library](https://github.com/huggingface/transformers):
```
from transformers import LongformerTokenizer, LongformerModel
tokenizer = LongformerTokenizer.from_pretrained("AIMH/mental-longformer-base-4096")
model = LongformerModel.from_pretrained("AIMH/mental-longformer-base-4096")
```
To minimize the influence of worrying mask predictions, this model is gated. To download a gated model, you’ll need to be authenticated.
Know more about [gated models](https://huggingface.co/docs/hub/models-gated).
## Paper
```
@article{ji-domain-specific,
author = {Shaoxiong Ji and Tianlin Zhang and Kailai Yang and Sophia Ananiadou and Erik Cambria and J{\"o}rg Tiedemann},
journal = {arXiv preprint arXiv:2304.10447},
title = {Domain-specific Continued Pretraining of Language Models for Capturing Long Context in Mental Health},
year = {2023},
url = {https://arxiv.org/abs/2304.10447}
}
```
## Disclaimer
The model predictions are not psychiatric diagnoses.
We recommend anyone who suffers from mental health issues to call the local mental health helpline and seek professional help if possible. | 1,676 | [
[
-0.032684326171875,
-0.04547119140625,
0.040313720703125,
0.020660400390625,
-0.0009284019470214844,
-0.01139068603515625,
-0.023193359375,
-0.04290771484375,
0.014556884765625,
0.046966552734375,
-0.074462890625,
-0.01558685302734375,
-0.05511474609375,
-0.... |
radames/stable-diffusion-x4-upscaler-img2img | 2023-05-16T22:01:10.000Z | [
"diffusers",
"stable-diffusion",
"image-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"has_space",
"diffusers:StableDiffusionUpscalePipeline",
"region:us"
] | image-to-image | radames | null | null | radames/stable-diffusion-x4-upscaler-img2img | 13 | 399 | diffusers | 2023-05-16T19:43:42 | ---
license: openrail++
tags:
- stable-diffusion
- image-to-image
duplicated_from: stabilityai/stable-diffusion-x4-upscaler
pipeline_tag: image-to-image
---
# Stable Diffusion x4 upscaler model card
This model card focuses on the model associated with the Stable Diffusion Upscaler, available [here](https://github.com/Stability-AI/stablediffusion).
This model is trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `x4-upscaler-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler/resolve/main/x4-upscaler-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
```python
import requests
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionUpscalePipeline
import torch
# load model and scheduler
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")
# let's download an image
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
prompt = "a white cat"
upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
upscaled_image.save("upsampled_cat.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 12,687 | [
[
-0.035614013671875,
-0.059814453125,
0.0233154296875,
0.009307861328125,
-0.01386260986328125,
-0.0242156982421875,
0.0015840530395507812,
-0.035064697265625,
-0.007183074951171875,
0.0276641845703125,
-0.0288543701171875,
-0.029693603515625,
-0.050933837890625,... |
stablediffusionapi/dreamlike-photoreal1 | 2023-08-21T11:44:41.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/dreamlike-photoreal1 | 0 | 399 | diffusers | 2023-08-21T11:42:35 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Dreamlike Photoreal111 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "dreamlike-photoreal1"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/dreamlike-photoreal1)
Model link: [View model](https://stablediffusionapi.com/models/dreamlike-photoreal1)
Credits: [View credits](https://civitai.com/?query=Dreamlike%20Photoreal111)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "dreamlike-photoreal1",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,501 | [
[
-0.033050537109375,
-0.057373046875,
0.033721923828125,
0.0189666748046875,
-0.03662109375,
0.0031833648681640625,
0.0237579345703125,
-0.038543701171875,
0.039794921875,
0.046905517578125,
-0.06195068359375,
-0.06365966796875,
-0.023468017578125,
-0.0011739... |
onarganogun/videomae-base-fight | 2023-10-30T17:59:32.000Z | [
"transformers",
"pytorch",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | onarganogun | null | null | onarganogun/videomae-base-fight | 0 | 399 | transformers | 2023-09-19T23:02:19 | ---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-fight
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-fight
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7465
- Accuracy: 0.5481
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 7120
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4036 | 0.1 | 713 | 0.4406 | 0.8189 |
| 0.2263 | 1.1 | 1426 | 0.6400 | 0.7950 |
| 0.2391 | 2.1 | 2139 | 0.4807 | 0.8233 |
| 0.3241 | 3.1 | 2852 | 0.5920 | 0.8167 |
| 0.255 | 4.1 | 3565 | 0.6452 | 0.8026 |
| 0.1256 | 5.1 | 4278 | 0.5889 | 0.8244 |
| 0.2026 | 6.1 | 4991 | 0.7288 | 0.8059 |
| 0.2262 | 7.1 | 5704 | 0.6861 | 0.8151 |
| 0.1367 | 8.1 | 6417 | 0.7288 | 0.8140 |
| 0.0803 | 9.1 | 7120 | 0.8737 | 0.8064 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
| 1,974 | [
[
-0.04595947265625,
-0.04638671875,
0.0124359130859375,
-0.00521087646484375,
-0.0234375,
-0.020660400390625,
-0.0034732818603515625,
0.0003833770751953125,
0.02374267578125,
0.032867431640625,
-0.056060791015625,
-0.05224609375,
-0.06787109375,
-0.0165252685... |
jbilcke-hf/sdxl-foundation-2 | 2023-10-21T22:05:24.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"dataset:jbilcke-hf/foundation",
"region:us",
"has_space"
] | text-to-image | jbilcke-hf | null | null | jbilcke-hf/sdxl-foundation-2 | 1 | 399 | diffusers | 2023-10-21T18:00:36 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: hober-mallow
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
datasets:
- jbilcke-hf/foundation
---
# LoRA DreamBooth - jbilcke-hf/sdxl-foundation-2
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0 trained on @fffiloni's SD-XL trainer.
The weights were trained on the concept prompt:
```
hober-mallow
```
Use this keyword to trigger your custom model in your prompts.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Usage
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install transformers, safetensors, accelerate as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
device = "cuda" if torch.cuda.is_available() else "cpu"
vae = AutoencoderKL.from_pretrained('madebyollin/sdxl-vae-fp16-fix', torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16",
use_safetensors=True
)
pipe.to(device)
# This is where you load your trained weights
specific_safetensors = "pytorch_lora_weights.safetensors"
lora_scale = 0.9
pipe.load_lora_weights(
'jbilcke-hf/sdxl-foundation-2',
weight_name = specific_safetensors,
# use_auth_token = True
)
prompt = "A majestic hober-mallow jumping from a big stone at night"
image = pipe(
prompt=prompt,
num_inference_steps=50,
cross_attention_kwargs={"scale": lora_scale}
).images[0]
```
| 1,837 | [
[
-0.0135498046875,
-0.033843994140625,
0.0301666259765625,
0.0200347900390625,
-0.0204315185546875,
0.005218505859375,
0.01427459716796875,
-0.01519775390625,
0.0333251953125,
0.0367431640625,
-0.035980224609375,
-0.034088134765625,
-0.062103271484375,
-0.012... |
hearmeneigh/e621-rising-v3 | 2023-11-05T22:19:48.000Z | [
"diffusers",
"anthro",
"furry",
"e621",
"nsfw",
"booru",
"imagebooru",
"imageboard",
"gelbooru",
"danbooru",
"rule34",
"not-for-all-audiences",
"text-to-image",
"dataset:hearmeneigh/e621-rising-v3-curated",
"dataset:hearmeneigh/e621-rising-v3-finetuner",
"license:mit",
"endpoints_com... | text-to-image | hearmeneigh | null | null | hearmeneigh/e621-rising-v3 | 4 | 399 | diffusers | 2023-10-22T21:32:55 | ---
license: mit
datasets:
- hearmeneigh/e621-rising-v3-curated
- hearmeneigh/e621-rising-v3-finetuner
library_name: diffusers
pipeline_tag: text-to-image
tags:
- anthro
- furry
- e621
- nsfw
- booru
- imagebooru
- imageboard
- gelbooru
- danbooru
- rule34
- not-for-all-audiences
---
<div style='background: #ffeef1; border: 1px solid #fd91a4; padding:1em; border-radius:3px; margin-bottom:2em;'>
<h3 style='margin:0'>NSFW</h3>
<p style='margin:0'>This model is not suitable for use by minors. The model can and will produce X-rated/NFSW content.</p>
</div>
<div style='background: #eefaff; border: 1px solid #91cefd; padding:1em; border-radius:3px; margin-bottom:2em;'>
<h1 style='margin:0'>Quickstart</h1>
<div style='margin:0; margin-top: 1em; margin-left:1em;'>
<h3 style='margin:0'>Downloads</h3>
<div style="margin-left: 1em;">
<a href="https://huggingface.co/hearmeneigh/e621-rising-v3-safetensors/resolve/main/e621-rising-v3-epoch-34.fp16.safetensors" style="text-decoration: none !important;">
⤓
</a>
<a href="https://huggingface.co/hearmeneigh/e621-rising-v3-safetensors/resolve/main/e621-rising-v3-epoch-34.fp16.safetensors" style="text-decoration: underline">Checkpoint</a>
<small style='padding-left: 0.5em'>
(<a href="https://huggingface.co/hearmeneigh/e621-rising-v3-safetensors/resolve/main/e621-rising-v3-epoch-34.safetensors">fp32</a> |
<a href="https://huggingface.co/hearmeneigh/e621-rising-v3-safetensors/resolve/main/e621-rising-v3-epoch-34.fp16.safetensors">fp16</a> |
<a href="https://huggingface.co/hearmeneigh/e621-rising-v3-safetensors/resolve/main/e621-rising-v3-epoch-34.bf16.safetensors">bf16</a>)
</small>
<br />
<a href="https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/rising-v3.csv" style="text-decoration: none !important">
⤓
</a>
<a href="https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/rising-v3.csv">Tag Autocomplete CSV</a>
</div>
<h3 style='margin:0; margin-top: 1em;'>Reference</h3>
<div style='margin-left: 1em;'>
• <a href="https://huggingface.co/hearmeneigh/e621-rising-v3/blob/main/INSTALL.md">Installation instructions</a>
<br />
• <a href="https://huggingface.co/hearmeneigh/e621-rising-v3/blob/main/CHANGELOG.md">What's new in v3?</a>
<br />
• <a href="https://huggingface.co/hearmeneigh/e621-rising-v3/blob/main/PROMPT-EXAMPLES.md" style='display: inline-block; margin-top:0.5em'>Prompt examples</a>
<br />
• <a href="https://huggingface.co/hearmeneigh/e621-rising-v3/blob/main/PROMPT-GUIDE.md">Prompt guide</a>
<br />
• <a href="https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/blob/main/tag-counts.by-name.json" style='display: inline-block; margin-top:0.5em'>Tag list</a>
<br />
• <a href="https://huggingface.co/hearmeneigh/e621-rising-v3/blob/main/AUTOCOMPLETE.md">Tag autocomplete guide</a>
</div>
</div>
</div>
# E621 Rising V3 (SDXL)
* Furry / anthro base model trained with images (mainly) from [E621](https://e621.net)
* Guaranteed **NSFW** or your money back
* Stable Diffusion XL 1.0 base model:
* `1024x1024px`
* Trained with 11 epochs of 280,000 images each
* Finetuned with 23 epochs of 40,000 images each
* Compatible with:
* [🤗 `diffusers`](https://huggingface.co/docs/diffusers/index)
* [`stable-diffusion-webui`](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
* [`ComfyUI`](https://github.com/comfyanonymous/ComfyUI)
* Fully open source crawl, dataset, curation, and training process:
* Use these tools to train your own version with your own dataset!
* [Configuration](https://github.com/hearmeneigh/e621-rising-configs)
* [Toolchain](https://github.com/hearmeneigh/dataset-rising)
* [Dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-curated)
## Examples
For more examples, [continue here](PROMPT-EXAMPLES.md).
<img src='https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/examples/singles/03-birb.jpg' alt='Birb' style='max-width:512px;' />
<img src='https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/examples/singles/02-royal-stallion.jpg' alt='Royal Stallion' style='max-width:512px;' />
<img src='https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/examples/singles/06-assassin.jpg' alt='Assassin' style='max-width:512px;' />
<img src='https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-preliminary-data/resolve/main/examples/singles/05-neekedneko.jpg' alt='Neeked Neko' style='max-width:512px;' />
For more examples, [continue here](PROMPT-EXAMPLES.md).
## Training Procedure
[Training legend](TBD)
* 160 images per batch (epoch variant)
* `1024x1024px` image size
* Adam optimizer
* Beta1 = `0.9`
* Beta2 = `0.999`
* Weight decay = `1e-2`
* Epsilon = `1e-08`
* Constant learning rate `4e-6`
* `fp16` mixed precision
* SNR gamma set to `5.0`
* Noise offset set to `0.07`
* `cosine_with_restarts` scheduler
* 11 epochs of [V3 curated dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-curated) samples resized to `< 1024x1024px` (maintain aspect ratio)
* 16 epochs of [V3 finetuner dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-finetuner) samples resized to `< 1024x1024px` (maintain aspect ratio)
* 6 epochs of [V3 finetuner dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-finetuner) samples resized to `< 1024x1024px` (maintain aspect ratio, randomly drop 70% of tags)
* 1 epoch of [V3 finetuner dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v3-finetuner) samples resized to `< 1024x1024px` (maintain aspect ratio, randomly drop 50% of tags) and learning rate set to `4e-5`
* Tags for each sample are shuffled for each epoch | 5,958 | [
[
-0.053192138671875,
-0.037750244140625,
0.00926971435546875,
0.01412200927734375,
-0.0108642578125,
-0.006622314453125,
-0.0030307769775390625,
-0.042205810546875,
0.04644775390625,
0.007122039794921875,
-0.06597900390625,
-0.040435791015625,
-0.03228759765625,
... |
RUCAIBox/mtl-data-to-text | 2022-06-27T02:27:10.000Z | [
"transformers",
"pytorch",
"mvp",
"text-generation",
"text2text-generation",
"en",
"arxiv:2206.12131",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text2text-generation | RUCAIBox | null | null | RUCAIBox/mtl-data-to-text | 13 | 398 | transformers | 2022-06-02T12:01:55 | ---
license: apache-2.0
language:
- en
tags:
- text-generation
- text2text-generation
pipeline_tag: text2text-generation
widget:
- text: "Describe the following data: Iron Man | instance of | Superhero [SEP] Stan Lee | creator | Iron Man"
example_title: "Example1"
- text: "Describe the following data: First Clearing | LOCATION | On NYS 52 1 Mi. Youngsville [SEP] On NYS 52 1 Mi. Youngsville | CITY_OR_TOWN | Callicoon, New York"
example_title: "Example2"
---
# MTL-data-to-text
The MTL-data-to-text model was proposed in [**MVP: Multi-task Supervised Pre-training for Natural Language Generation**](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
The detailed information and instructions can be found [https://github.com/RUCAIBox/MVP](https://github.com/RUCAIBox/MVP).
## Model Description
MTL-data-to-text is supervised pre-trained using a mixture of labeled data-to-text datasets. It is a variant (Single) of our main [MVP](https://huggingface.co/RUCAIBox/mvp) model. It follows a standard Transformer encoder-decoder architecture.
MTL-data-to-text is specially designed for data-to-text generation tasks, such as KG-to-text generation (WebNLG, DART), table-to-text generation (WikiBio, ToTTo) and MR-to-text generation (E2E).
## Example
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-data-to-text")
>>> inputs = tokenizer(
... "Describe the following data: Iron Man | instance of | Superhero [SEP] Stan Lee | creator | Iron Man",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
```
## Related Models
**MVP**: [https://huggingface.co/RUCAIBox/mvp](https://huggingface.co/RUCAIBox/mvp).
**Prompt-based models**:
- MVP-multi-task: [https://huggingface.co/RUCAIBox/mvp-multi-task](https://huggingface.co/RUCAIBox/mvp-multi-task).
- MVP-summarization: [https://huggingface.co/RUCAIBox/mvp-summarization](https://huggingface.co/RUCAIBox/mvp-summarization).
- MVP-open-dialog: [https://huggingface.co/RUCAIBox/mvp-open-dialog](https://huggingface.co/RUCAIBox/mvp-open-dialog).
- MVP-data-to-text: [https://huggingface.co/RUCAIBox/mvp-data-to-text](https://huggingface.co/RUCAIBox/mvp-data-to-text).
- MVP-story: [https://huggingface.co/RUCAIBox/mvp-story](https://huggingface.co/RUCAIBox/mvp-story).
- MVP-question-answering: [https://huggingface.co/RUCAIBox/mvp-question-answering](https://huggingface.co/RUCAIBox/mvp-question-answering).
- MVP-question-generation: [https://huggingface.co/RUCAIBox/mvp-question-generation](https://huggingface.co/RUCAIBox/mvp-question-generation).
- MVP-task-dialog: [https://huggingface.co/RUCAIBox/mvp-task-dialog](https://huggingface.co/RUCAIBox/mvp-task-dialog).
**Multi-task models**:
- MTL-summarization: [https://huggingface.co/RUCAIBox/mtl-summarization](https://huggingface.co/RUCAIBox/mtl-summarization).
- MTL-open-dialog: [https://huggingface.co/RUCAIBox/mtl-open-dialog](https://huggingface.co/RUCAIBox/mtl-open-dialog).
- MTL-data-to-text: [https://huggingface.co/RUCAIBox/mtl-data-to-text](https://huggingface.co/RUCAIBox/mtl-data-to-text).
- MTL-story: [https://huggingface.co/RUCAIBox/mtl-story](https://huggingface.co/RUCAIBox/mtl-story).
- MTL-question-answering: [https://huggingface.co/RUCAIBox/mtl-question-answering](https://huggingface.co/RUCAIBox/mtl-question-answering).
- MTL-question-generation: [https://huggingface.co/RUCAIBox/mtl-question-generation](https://huggingface.co/RUCAIBox/mtl-question-generation).
- MTL-task-dialog: [https://huggingface.co/RUCAIBox/mtl-task-dialog](https://huggingface.co/RUCAIBox/mtl-task-dialog).
## Citation
```bibtex
@article{tang2022mvp,
title={MVP: Multi-task Supervised Pre-training for Natural Language Generation},
author={Tang, Tianyi and Li, Junyi and Zhao, Wayne Xin and Wen, Ji-Rong},
journal={arXiv preprint arXiv:2206.12131},
year={2022},
url={https://arxiv.org/abs/2206.12131},
}
```
| 4,233 | [
[
-0.031219482421875,
-0.06951904296875,
0.0254058837890625,
0.0169830322265625,
-0.010589599609375,
0.00443267822265625,
0.0038852691650390625,
-0.0156402587890625,
0.0025177001953125,
0.040679931640625,
-0.067626953125,
-0.046844482421875,
-0.035125732421875,
... |
Jartemio/The_Owl_Characters_V2 | 2023-03-17T22:34:31.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"the-owl-house",
"en",
"license:openrail",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Jartemio | null | null | Jartemio/The_Owl_Characters_V2 | 6 | 398 | diffusers | 2023-03-08T07:54:51 | ---
license: openrail
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- the-owl-house
library_name: diffusers
---
<style>
table {
border-collapse: collapse;
width: 100%;
opacity: 0.8;
}
td {
border: none;
padding: 0px;
}
img {
max-width: 100%;
}
tr {
border-top: none;
border-bottom: none;
}
</style>
# THE OWL CHARACTERS
# Model trained with the characters from the series The Owl House and their drawing style using
[EveryDream Trainer 2.0](https://github.com/victorchall/EveryDream2trainer).
# I created the dataset by extracting images from the episodes uploaded on [TheOwlClub.net](https://www.theowlclub.net/).
#### Try the model on Google Colab:
[](https://colab.research.google.com/github/jartemio/The_Owl_Characters_V2/blob/main/The_Owl_Characters_V2_English.ipynb)
[](https://colab.research.google.com/github/jartemio/The_Owl_Characters_V2/blob/main/The_Owl_Characters_V2_Espanol.ipynb)
[](https://colab.research.google.com/github/jartemio/The_Owl_Characters_V2/blob/main/The_Owl_Characters_V2_Korean.ipynb)
[](https://colab.research.google.com/github/jartemio/The_Owl_Characters_V2/blob/main/The_Owl_Characters_V2_中文.ipynb)
#### The style training was done using the key **aniscreen**:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp3efgc8mjfgggbvlh.png"
alt="tmp3efgc8mjfgggbvlh.png" title="tmp3efgc8mjfgggbvlh.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpgb6xpryl.png"
alt="tmpgb6xpryl.png" title="tmpgb6xpryl.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpk_zes93b.png"
alt="tmpk_zes93b.png" title="tmpk_zes93b.png" />
</td>
</tr>
</table>
#### The trained characters along with their keys are:
- **LuzNoceda**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmptgbbp8ed.png"
alt="tmptgbbp8ed.png" title="tmptgbbp8ed.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpwtpohflb.png"
alt="tmpwtpohflb.png" title="tmpwtpohflb.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpcsfzask1umbh376s.png"
alt="tmpcsfzask1umbh376s.png" title="tmpk_zes93b.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpl5egvhsig9dmb_3y.png"
alt="tmp7komqa85aigpx857.png" title="tmpl5egvhsig9dmb_3y.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp7komqa85aigpx857.png"
alt="tmp7komqa85aigpx857.png" title="tmp7komqa85aigpx857.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpca1fmrfa.png"
alt="tmpca1fmrfa.png" title="tmpca1fmrfa.png" />
</td>
</tr>
</table>
- **AmityBlight**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpr9_9vfxfxg4cl73p.png"
alt="tmpr9_9vfxfxg4cl73p.png" title="tmpr9_9vfxfxg4cl73p.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp_wj6zbn3mba2ts4x.png"
alt="tmp_wj6zbn3mba2ts4x.png" title="tmp_wj6zbn3mba2ts4x.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp3pb40xo9.png"
alt="tmp3pb40xo9.png" title="tmp3pb40xo9.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp4rbp88kveno3qu_1.png"
alt="tmp4rbp88kveno3qu_1.png" title="tmp4rbp88kveno3qu_1.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpnoa_8azgzmrecu05.png"
alt="tmpnoa_8azgzmrecu05.png" title="tmpnoa_8azgzmrecu05.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmplt00ac1a.png"
alt="tmplt00ac1a.png" title="tmplt00ac1a.png" />
</td>
</tr>
</table>
- **HunterGoldenGuard**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpb6c72jw0.png"
alt="tmpb6c72jw0.png" title="tmpb6c72jw0.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpu9pqtyihwcw67pai.png"
alt="tmpu9pqtyihwcw67pai.png" title="tmpu9pqtyihwcw67pai.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpc_fs0t43hiu791u4.png"
alt="tmpc_fs0t43hiu791u4.png" title="tmpc_fs0t43hiu791u4.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp6bfn0rnp.png"
alt="tmp6bfn0rnp.png" title="tmp6bfn0rnp.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmph0bgjpmz.png"
alt="tmph0bgjpmz.png" title="tmph0bgjpmz.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpl49_ctpw.png"
alt="tmpl49_ctpw.png" title="tmpl49_ctpw.png" />
</td>
</tr>
</table>
- **WillowPark**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp_bkcx8fv.png"
alt="tmp_bkcx8fv.png" title="tmp_bkcx8fv.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpds0zimpd.png"
alt="tmpds0zimpd.png" title="tmpds0zimpd.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpkb959lzx.png"
alt="tmpkb959lzx.png" title="tmpkb959lzx.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp488gydue.png"
alt="tmp488gydue.png" title="tmp488gydue.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpt7dwc1lo.png"
alt="tmpt7dwc1lo.png" title="tmpt7dwc1lo.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpn_yfd46q.png"
alt="tmpn_yfd46q.png" title="tmpn_yfd46q.png" />
</td>
</tr>
</table>
- **GusPotter** *(this is a special situation, because instead of the key being GusPotter, it is *GusPorter* due to an error in my data.)*
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpduyag_7b.png"
alt="tmpduyag_7b.png" title="tmpduyag_7b.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpolrx5lvp.png"
alt="tmpolrx5lvp.png" title="tmpolrx5lvp.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpq7a_7toa.png"
alt="tmpq7a_7toa.png" title="tmpq7a_7toa.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmps7mhg6yf.png"
alt="tmps7mhg6yf.png" title="tmps7mhg6yf.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpw7qge_o7.png"
alt="tmpw7qge_o7.png" title="tmpw7qge_o7.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpqcrlumu0.png"
alt="tmpqcrlumu0.png" title="tmpqcrlumu0.png" />
</td>
</tr>
</table>
- **EdalynClawthorne**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp26_fwtvn.png"
alt="tmp26_fwtvn.png" title="tmp26_fwtvn.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpogurcgd0.png"
alt="tmpogurcgd0.png" title="tmpogurcgd0.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpxixqqz14.png"
alt="tmpxixqqz14.png" title="tmpxixqqz14.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp4izfh0_n.png"
alt="tmp4izfh0_n.png" title="tmp4izfh0_n.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpams1jey5.png"
alt="tmpams1jey5.png" title="tmpams1jey5.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp1vto1bjj.png"
alt="tmp1vto1bjj.png" title="tmp1vto1bjj.png" />
</td>
</tr>
</table>
- **LilithClawthorne**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpndb6ckl_.png"
alt="tmpndb6ckl_.png" title="tmpndb6ckl_.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpqqx1hwdr.png"
alt="tmpqqx1hwdr.png" title="tmpqqx1hwdr.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpi7cjlnv5.png"
alt="tmpi7cjlnv5.png" title="tmpi7cjlnv5.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpejtt2q6l.png"
alt="tmpejtt2q6l.png" title="tmpejtt2q6l.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpr1uu2lqc.png"
alt="tmpr1uu2lqc.png" title="tmpr1uu2lqc.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp71ryh4qs.png"
alt="tmp71ryh4qs.png" title="tmp71ryh4qs.png" />
</td>
</tr>
</table>
- **RaineWhispers**
- With aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpw8l2_i3p.png"
alt="tmpw8l2_i3p.png" title="tmpw8l2_i3p.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmptkrpkvr3.png"
alt="tmptkrpkvr3.png" title="tmptkrpkvr3.png"/>
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp00ihavmn.png"
alt="tmp00ihavmn.png" title="tmp00ihavmn.png" />
</td>
</tr>
</table>
- Without aniscreen:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp7_7sapkd.png"
alt="tmp7_7sapkd.png" title="tmp7_7sapkd.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmph5jt2jhc.png"
alt="tmph5jt2jhc.png" title="tmph5jt2jhc.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpqm9gdji2.png"
alt="tmpqm9gdji2.png" title="tmpqm9gdji2.png" />
</td>
</tr>
</table>
- **The following results were not very good, so they will be improved:**
- **EmperorBelos:**
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpfwe2r_n9.png"
alt="tmpfwe2r_n9.png" title="tmpfwe2r_n9.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpcwpxky0h.png"
alt="tmph5jt2jhc.png" title="tmpcwpxky0h.png" />
</td>
</tr>
</table>
- **KingClawthorne:**
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmplyxshw2s.png"
alt="tmplyxshw2s.png" title="tmplyxshw2s.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpleuknqw7.png"
alt="tmpleuknqw7.png" title="tmpleuknqw7.png" />
</td>
</tr>
</table>
- **TheCollector:**
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpy9g16w2e.png"
alt="tmpy9g16w2e.png" title="tmpy9g16w2e.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpewst_292.png"
alt="tmpewst_292.png" title="tmpewst_292.png" />
</td>
</tr>
</table>
#### Other images related to the model:
<table>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpybbcktbushsmdjbg.png"
alt="tmpybbcktbushsmdjbg.png" title="tmpybbcktbushsmdjbg.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpsk3cma8w.png"
alt="tmpsk3cma8w.png" title="tmpsk3cma8w.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpr9_9vfxfxg4cl73p.png"
alt="tmpr9_9vfxfxg4cl73p.png" title="tmpr9_9vfxfxg4cl73p.png" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmppqseq15u52fvm0re.png"
alt="tmppqseq15u52fvm0re.png" title="tmppqseq15u52fvm0re.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpj3aav7hkft2r_m1b.png"
alt="tmpj3aav7hkft2r_m1b.png" title="tmpj3aav7hkft2r_m1b.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmph4or82wbzk31rvbe.png"
alt="tmph4or82wbzk31rvbe.png" title="tmph4or82wbzk31rvbe.png" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpfy02p5xq.png"
alt="tmpfy02p5xq.png" title="tmpfy02p5xq.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpmh7omsn7.png"
alt="tmpmh7omsn7.png" title="tmpmh7omsn7.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpwww_beg5.jpg"
alt="tmpwww_beg5.jpg" title="tmpwww_beg5.jpg" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/de41502c-7572-44c7-aed0-12cf85600fa3.jfif"
alt="de41502c-7572-44c7-aed0-12cf85600fa3.jfif" title="de41502c-7572-44c7-aed0-12cf85600fa3.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/4c0086f7-5940-47aa-8e86-a06f8b220501.jfif"
alt="4c0086f7-5940-47aa-8e86-a06f8b220501.jfif" title="4c0086f7-5940-47aa-8e86-a06f8b220501.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/e4ee0845-9a64-40a8-8106-a5a941699364.jfif"
alt="e4ee0845-9a64-40a8-8106-a5a941699364.jfif" title="e4ee0845-9a64-40a8-8106-a5a941699364.jfif" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/fe40c6ab-88b9-4bad-b38b-eb9e7a0cfacf.jfif"
alt="fe40c6ab-88b9-4bad-b38b-eb9e7a0cfacf.jfif" title="fe40c6ab-88b9-4bad-b38b-eb9e7a0cfacf.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/c7c39df4-3b03-4e68-b7fb-9ae7a96f8809.jfif"
alt="c7c39df4-3b03-4e68-b7fb-9ae7a96f8809.jfif" title="c7c39df4-3b03-4e68-b7fb-9ae7a96f8809.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/3744481e-ecc0-46ab-ad9a-4e8374cb4d98.jfif"
alt="3744481e-ecc0-46ab-ad9a-4e8374cb4d98.jfif" title="3744481e-ecc0-46ab-ad9a-4e8374cb4d98.jfif" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/5c31aaa7-779a-4edb-9722-5fd4be7f30df.jfif"
alt="5c31aaa7-779a-4edb-9722-5fd4be7f30df.jfif" title="5c31aaa7-779a-4edb-9722-5fd4be7f30df.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/8d84f980-4508-4440-8414-ff7c6aca3a09.jfif"
alt="8d84f980-4508-4440-8414-ff7c6aca3a09.jfif" title="8d84f980-4508-4440-8414-ff7c6aca3a09.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/9127b248-c3be-4302-9653-2f661d257a6a.jfif"
alt="9127b248-c3be-4302-9653-2f661d257a6a.jfif" title="9127b248-c3be-4302-9653-2f661d257a6a.jfif" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/e7e13379-8e65-42c8-aa5a-a44e0efdffdf.jfif"
alt="e7e13379-8e65-42c8-aa5a-a44e0efdffdf.jfif" title="e7e13379-8e65-42c8-aa5a-a44e0efdffdf.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/9c320730-08cf-461a-9bca-30086ad818a3.jfif"
alt="9c320730-08cf-461a-9bca-30086ad818a3.jfif" title="9c320730-08cf-461a-9bca-30086ad818a3.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/cf4b225f-53ab-442c-abb3-0ca33cdb4207.jfif"
alt="cf4b225f-53ab-442c-abb3-0ca33cdb4207.jfif" title="cf4b225f-53ab-442c-abb3-0ca33cdb4207.jfif" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/808fa3af-772f-4365-a775-4d230ed2a2d5.jfif"
alt="808fa3af-772f-4365-a775-4d230ed2a2d5.jfif" title="808fa3af-772f-4365-a775-4d230ed2a2d5.jfif" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpqzmq0zi3.png"
alt="tmpqzmq0zi3.png" title="tmpqzmq0zi3.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmp7uhbyh_r.png"
alt="tmp7uhbyh_r.png" title="tmp7uhbyh_r.png" />
</td>
</tr>
<tr>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmptfvhyn1tca4prsie.png"
alt="tmptfvhyn1tca4prsie.png" title="tmptfvhyn1tca4prsie.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpme_bpm5q.png"
alt="tmpme_bpm5q.png" title="tmpme_bpm5q.png" />
</td>
<td align="center">
<img
src="https://huggingface.co/Jartemio/The_Owl_Characters_V2/resolve/main/images/tmpn37_afcj.png"
alt="tmpn37_afcj.png" title="tmpn37_afcj.png" />
</td>
</tr>
</table>
**Note**: *The following characters were also trained but the desired results were not obtained. They
will be fixed in future updates:*
- *HunterGoldenGuard, RaineWhispers, TheCollector, WillowPark, KingClawthorne, EdalynClawthorne, EmperorBelos,
GusPotter, LilithClawthorne*
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 26,075 | [
[
-0.0372314453125,
-0.0406494140625,
0.020111083984375,
0.02740478515625,
-0.0013151168823242188,
0.0005512237548828125,
0.034820556640625,
-0.0762939453125,
0.061370849609375,
0.017242431640625,
-0.055511474609375,
-0.045745849609375,
-0.057586669921875,
0.0... |
DunnBC22/bertweet-base-Twitter_Sentiment_Analysis_v3 | 2023-04-06T17:57:36.000Z | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | text-classification | DunnBC22 | null | null | DunnBC22/bertweet-base-Twitter_Sentiment_Analysis_v3 | 1 | 398 | transformers | 2023-04-05T16:45:06 | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bertweet-base-Twitter_Sentiment_Analysis_v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-base-Twitter_Sentiment_Analysis_v3
This model is a fine-tuned version of [vinai/bertweet-base](https://huggingface.co/vinai/bertweet-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5141
- Accuracy: 0.8552
- Weighted f1: 0.8541
- Micro f1: 0.8552
- Macro f1: 0.8178
- Weighted recall: 0.8552
- Micro recall: 0.8552
- Macro recall: 0.8207
- Weighted precision: 0.8541
- Micro precision: 0.8552
- Macro precision: 0.8171
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted f1 | Micro f1 | Macro f1 | Weighted recall | Micro recall | Macro recall | Weighted precision | Micro precision | Macro precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-----------:|:--------:|:--------:|:---------------:|:------------:|:------------:|:------------------:|:---------------:|:---------------:|
| 0.4404 | 1.0 | 149 | 0.2815 | 0.8314 | 0.8153 | 0.8314 | 0.7660 | 0.8314 | 0.8314 | 0.7560 | 0.8331 | 0.8314 | 0.8244 |
| 0.2493 | 2.0 | 298 | 0.2558 | 0.8588 | 0.8523 | 0.8588 | 0.8151 | 0.8588 | 0.8588 | 0.7961 | 0.8554 | 0.8588 | 0.8463 |
| 0.1905 | 3.0 | 447 | 0.2734 | 0.8580 | 0.8534 | 0.8580 | 0.8164 | 0.8580 | 0.8580 | 0.8094 | 0.8553 | 0.8580 | 0.8326 |
| 0.1504 | 4.0 | 596 | 0.3150 | 0.8631 | 0.8607 | 0.8631 | 0.8247 | 0.8631 | 0.8631 | 0.8291 | 0.8627 | 0.8631 | 0.8279 |
| 0.112 | 5.0 | 745 | 0.3451 | 0.8564 | 0.8522 | 0.8564 | 0.8145 | 0.8564 | 0.8564 | 0.8136 | 0.8544 | 0.8564 | 0.8254 |
| 0.0885 | 6.0 | 894 | 0.3929 | 0.8576 | 0.8532 | 0.8576 | 0.8158 | 0.8576 | 0.8576 | 0.8123 | 0.8554 | 0.8576 | 0.8293 |
| 0.0735 | 7.0 | 1043 | 0.4233 | 0.8564 | 0.8541 | 0.8564 | 0.8164 | 0.8564 | 0.8564 | 0.8128 | 0.8535 | 0.8564 | 0.8225 |
| 0.0642 | 8.0 | 1192 | 0.4454 | 0.8525 | 0.8495 | 0.8525 | 0.8106 | 0.8525 | 0.8525 | 0.8055 | 0.8491 | 0.8525 | 0.8192 |
| 0.0512 | 9.0 | 1341 | 0.5098 | 0.8537 | 0.8543 | 0.8537 | 0.8194 | 0.8537 | 0.8537 | 0.8261 | 0.8552 | 0.8537 | 0.8133 |
| 0.0448 | 10.0 | 1490 | 0.5268 | 0.8537 | 0.8538 | 0.8537 | 0.8170 | 0.8537 | 0.8537 | 0.8256 | 0.8549 | 0.8537 | 0.8101 |
| 0.038 | 11.0 | 1639 | 0.5076 | 0.8564 | 0.8555 | 0.8564 | 0.8195 | 0.8564 | 0.8564 | 0.8209 | 0.8551 | 0.8564 | 0.8191 |
| 0.0357 | 12.0 | 1788 | 0.5141 | 0.8552 | 0.8541 | 0.8552 | 0.8178 | 0.8552 | 0.8552 | 0.8207 | 0.8541 | 0.8552 | 0.8171 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.12.1
- Datasets 2.9.0
- Tokenizers 0.12.1
| 4,226 | [
[
-0.046112060546875,
-0.03790283203125,
0.01434326171875,
0.01160430908203125,
-0.01105499267578125,
0.0006136894226074219,
-0.0002149343490600586,
-0.0050506591796875,
0.04986572265625,
0.025054931640625,
-0.0511474609375,
-0.054046630859375,
-0.050018310546875,... |
timm/edgenext_xx_small.in1k | 2023-04-23T22:43:27.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2206.10589",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/edgenext_xx_small.in1k | 0 | 398 | timm | 2023-04-23T22:43:24 | ---
tags:
- image-classification
- timm
library_name: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for edgenext_xx_small.in1k
An EdgeNeXt image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 1.3
- GMACs: 0.3
- Activations (M): 3.3
- Image size: train = 256 x 256, test = 288 x 288
- **Papers:**
- EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications: https://arxiv.org/abs/2206.10589
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/mmaaz60/EdgeNeXt
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('edgenext_xx_small.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'edgenext_xx_small.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 64, 64])
# torch.Size([1, 48, 32, 32])
# torch.Size([1, 88, 16, 16])
# torch.Size([1, 168, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'edgenext_xx_small.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 168, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{Maaz2022EdgeNeXt,
title={EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications},
author={Muhammad Maaz and Abdelrahman Shaker and Hisham Cholakkal and Salman Khan and Syed Waqas Zamir and Rao Muhammad Anwer and Fahad Shahbaz Khan},
booktitle={International Workshop on Computational Aspects of Deep Learning at 17th European Conference on Computer Vision (CADL2022)},
year={2022},
organization={Springer}
}
```
| 3,716 | [
[
-0.047119140625,
-0.0304718017578125,
-0.0003025531768798828,
0.0010156631469726562,
-0.0234527587890625,
-0.029205322265625,
-0.0115509033203125,
-0.0310211181640625,
0.0133209228515625,
0.03033447265625,
-0.043060302734375,
-0.054107666015625,
-0.0482177734375... |
timm/pvt_v2_b2.in1k | 2023-04-25T04:03:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.13797",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/pvt_v2_b2.in1k | 0 | 398 | timm | 2023-04-25T04:03:22 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for pvt_v2_b2
A PVT-v2 (Pyramid Vision Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.4
- GMACs: 4.0
- Activations (M): 27.5
- Image size: 224 x 224
- **Papers:**
- PVT v2: Improved Baselines with Pyramid Vision Transformer: https://arxiv.org/abs/2106.13797
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/whai362/PVT
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('pvt_v2_b2', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b2',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b2',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{wang2021pvtv2,
title={Pvtv2: Improved baselines with pyramid vision transformer},
author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
journal={Computational Visual Media},
volume={8},
number={3},
pages={1--10},
year={2022},
publisher={Springer}
}
```
| 3,697 | [
[
-0.029998779296875,
-0.028350830078125,
-0.00516510009765625,
0.0152435302734375,
-0.029296875,
-0.0260467529296875,
-0.01050567626953125,
-0.025482177734375,
0.0052642822265625,
0.035736083984375,
-0.0268707275390625,
-0.04351806640625,
-0.055145263671875,
... |
timm/caformer_b36.sail_in22k_ft_in1k_384 | 2023-05-05T05:42:08.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2210.13452",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/caformer_b36.sail_in22k_ft_in1k_384 | 0 | 398 | timm | 2023-05-05T05:40:53 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for caformer_b36.sail_in22k_ft_in1k_384
A CAFormer (a MetaFormer) image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 98.8
- GMACs: 72.3
- Activations (M): 261.8
- Image size: 384 x 384
- **Papers:**
- Metaformer baselines for vision: https://arxiv.org/abs/2210.13452
- **Original:** https://github.com/sail-sg/metaformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('caformer_b36.sail_in22k_ft_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'caformer_b36.sail_in22k_ft_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 768, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'caformer_b36.sail_in22k_ft_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{yu2022metaformer_baselines,
title={Metaformer baselines for vision},
author={Yu, Weihao and Si, Chenyang and Zhou, Pan and Luo, Mi and Zhou, Yichen and Feng, Jiashi and Yan, Shuicheng and Wang, Xinchao},
journal={arXiv preprint arXiv:2210.13452},
year={2022}
}
```
| 3,775 | [
[
-0.040313720703125,
-0.02862548828125,
0.00705718994140625,
0.01137542724609375,
-0.0283050537109375,
-0.0251007080078125,
-0.0171051025390625,
-0.03228759765625,
0.0166778564453125,
0.03631591796875,
-0.0389404296875,
-0.05731201171875,
-0.056182861328125,
... |
llmware/industry-bert-asset-management-v0.1 | 2023-09-30T10:15:56.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2104.06979",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | llmware | null | null | llmware/industry-bert-asset-management-v0.1 | 2 | 398 | transformers | 2023-09-29T20:51:37 | ---
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
industry-bert-asset-management-v0.1 is part of a series of industry-fine-tuned sentence_transformer embedding models.
### Model Description
<!-- Provide a longer summary of what this model is. -->
industry-bert-asset-management-v0.1 is a domain fine-tuned BERT-based 768-parameter Sentence Transformer model, intended to as a "drop-in"
substitute for embeddings in the asset management domain. This model was trained on a wide range of publicly available documents regarding the asset management industry.
- **Developed by:** llmware
- **Model type:** BERT-based Industry domain fine-tuned Sentence Transformer architecture
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model [optional]:** BERT-based model, fine-tuning methodology described below.
### Model Use
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("llmware/industry-bert-asset-management-v0.1")
model = AutoModel.from_pretrained("llmware/industry-bert-asset-management-v0.1")
## Bias, Risks, and Limitations
This is a semantic embedding model, fine-tuned on public domain documents regarding the business, financials and companies in the asset
management industry. Results may vary if used outside of this domain, and like any embedding model, there is always the potential for anomalies in the vector embedding space. No specific safeguards have
put in place for safety or mitigate potential bias in the dataset.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
This model was fine-tuned using a custom self-supervised procedure and custom dataset that combined contrastive techniques
with stochastic injections of distortions in the samples. The methodology was derived, adapted and inspired primarily from
three research papers cited below: TSDAE (Reimers), DeClutr (Giorgi), and Contrastive Tension (Carlsson).
## Citation [optional]
Custom self-supervised training protocol used to train the model, which was derived and inspired by the following papers:
@article{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2104.06979",
month = "4",
year = "2021",
url = "https://arxiv.org/abs/2104.06979",
}
@inproceedings{giorgi-etal-2021-declutr,
title = {{D}e{CLUTR}: Deep Contrastive Learning for Unsupervised Textual Representations},
author = {Giorgi, John and Nitski, Osvald and Wang, Bo and Bader, Gary},
year = 2021,
month = aug,
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Online},
pages = {879--895},
doi = {10.18653/v1/2021.acl-long.72},
url = {https://aclanthology.org/2021.acl-long.72}
}
@article{Carlsson-2021-CT,
title = {Semantic Re-tuning with Contrastive Tension},
author= {Fredrik Carlsson, Amaru Cuba Gyllensten, Evangelia Gogoulou, Erik Ylipää Hellqvist, Magnus Sahlgren},
year= {2021},
month= {"January"}
Published: 12 Jan 2021, Last Modified: 05 May 2023
}
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
## Model Card Contact
Darren Oberst @ llmware
| 3,857 | [
[
-0.027801513671875,
-0.054229736328125,
0.019561767578125,
0.014739990234375,
-0.0318603515625,
-0.0168304443359375,
-0.00589752197265625,
-0.038726806640625,
0.016357421875,
0.03753662109375,
-0.05810546875,
-0.052032470703125,
-0.05029296875,
0.00504684448... |
frankmoire/nyjha-1-1 | 2023-10-04T10:41:58.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | frankmoire | null | null | frankmoire/nyjha-1-1 | 0 | 398 | diffusers | 2023-10-04T10:36:56 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### nyjha-1.1 Dreambooth model trained by frankmoire with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 501 | [
[
-0.0283203125,
-0.06744384765625,
0.035491943359375,
0.0172119140625,
-0.022735595703125,
0.02203369140625,
0.025299072265625,
-0.035797119140625,
0.0633544921875,
0.00829315185546875,
-0.01513671875,
-0.0158538818359375,
-0.03265380859375,
-0.01277160644531... |
jhflow/mistral7b-lora-multi-turn-v2 | 2023-11-03T00:45:28.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | jhflow | null | null | jhflow/mistral7b-lora-multi-turn-v2 | 0 | 398 | transformers | 2023-11-02T00:35:43 | This is finetuned model for multi turn style RAG.
I picked up some datasets consisting of knowledge based multi turn conversations for training.
base model : https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca
prompt teamplate : chatml (same as https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
```
<|im_start|>system
{system_prompt}
{context}<|im_end|>
<|im_start|>user
{user_query}<|im_end|>
<|im_start|>assistant
{answer}
<|im_end|>
| 447 | [
[
-0.0382080078125,
-0.056304931640625,
0.00336456298828125,
0.0235443115234375,
-0.004703521728515625,
-0.00960540771484375,
-0.00423431396484375,
-0.0169525146484375,
0.0202178955078125,
0.057464599609375,
-0.061492919921875,
-0.035614013671875,
-0.0225372314453... |
dbmdz/flair-distilbert-ner-germeval14 | 2021-03-02T18:32:30.000Z | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"de",
"dataset:germeval_14",
"license:mit",
"region:us"
] | token-classification | dbmdz | null | null | dbmdz/flair-distilbert-ner-germeval14 | 1 | 397 | flair | 2022-03-02T23:29:05 | ---
datasets:
- germeval_14
tags:
- flair
- token-classification
- sequence-tagger-model
language: de
widget:
- text: "Hugging Face ist eine französische Firma mit Sitz in New York."
license: mit
---
# Flair NER model trained on GermEval14 dataset
This model was trained on the official [GermEval14](https://sites.google.com/site/germeval2014ner/data)
dataset using the [Flair](https://github.com/flairNLP/flair) framework.
It uses a fine-tuned German DistilBERT model from [here](https://huggingface.co/distilbert-base-german-cased).
# Results
| Dataset \ Run | Run 1 | Run 2 | Run 3† | Run 4 | Run 5 | Avg.
| ------------- | ----- | ----- | --------- | ----- | ----- | ----
| Development | 87.05 | 86.52 | **87.34** | 86.85 | 86.46 | 86.84
| Test | 85.43 | 85.88 | 85.72 | 85.47 | 85.62 | 85.62
† denotes that this model is selected for upload.
# Flair Fine-Tuning
We used the following script to fine-tune the model on the GermEval14 dataset:
```python
from argparse import ArgumentParser
import torch, flair
# dataset, model and embedding imports
from flair.datasets import GERMEVAL_14
from flair.embeddings import TransformerWordEmbeddings
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
if __name__ == "__main__":
# All arguments that can be passed
parser = ArgumentParser()
parser.add_argument("-s", "--seeds", nargs='+', type=int, default='42') # pass list of seeds for experiments
parser.add_argument("-c", "--cuda", type=int, default=0, help="CUDA device") # which cuda device to use
parser.add_argument("-m", "--model", type=str, help="Model name (such as Hugging Face model hub name")
# Parse experimental arguments
args = parser.parse_args()
# use cuda device as passed
flair.device = f'cuda:{str(args.cuda)}'
# for each passed seed, do one experimental run
for seed in args.seeds:
flair.set_seed(seed)
# model
hf_model = args.model
# initialize embeddings
embeddings = TransformerWordEmbeddings(
model=hf_model,
layers="-1",
subtoken_pooling="first",
fine_tune=True,
use_context=False,
respect_document_boundaries=False,
)
# select dataset depending on which language variable is passed
corpus = GERMEVAL_14()
# make the dictionary of tags to predict
tag_dictionary = corpus.make_tag_dictionary('ner')
# init bare-bones sequence tagger (no reprojection, LSTM or CRF)
tagger: SequenceTagger = SequenceTagger(
hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type='ner',
use_crf=False,
use_rnn=False,
reproject_embeddings=False,
)
# init the model trainer
trainer = ModelTrainer(tagger, corpus, optimizer=torch.optim.AdamW)
# make string for output folder
output_folder = f"flert-ner-{hf_model}-{seed}"
# train with XLM parameters (AdamW, 20 epochs, small LR)
from torch.optim.lr_scheduler import OneCycleLR
trainer.train(
output_folder,
learning_rate=5.0e-5,
mini_batch_size=16,
mini_batch_chunk_size=1,
max_epochs=10,
scheduler=OneCycleLR,
embeddings_storage_mode='none',
weight_decay=0.,
train_with_dev=False,
)
```
| 3,527 | [
[
-0.0372314453125,
-0.046630859375,
0.0016317367553710938,
0.004421234130859375,
-0.01024627685546875,
-0.0170440673828125,
-0.0144195556640625,
-0.01320648193359375,
0.0175323486328125,
0.010833740234375,
-0.044219970703125,
-0.04925537109375,
-0.035430908203125... |
hfl/chinese-legal-electra-large-discriminator | 2021-01-22T05:19:50.000Z | [
"transformers",
"pytorch",
"tf",
"electra",
"zh",
"arxiv:2004.13922",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | hfl | null | null | hfl/chinese-legal-electra-large-discriminator | 4 | 397 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
license: "apache-2.0"
---
# This model is specifically designed for legal domain.
## Chinese ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants.
For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA.
ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
This project is based on the official code of ELECTRA: [https://github.com/google-research/electra](https://github.com/google-research/electra)
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
``` | 1,927 | [
[
-0.01483154296875,
-0.050079345703125,
0.0218048095703125,
0.005878448486328125,
-0.0136260986328125,
-0.01255035400390625,
-0.028839111328125,
-0.05682373046875,
0.028076171875,
0.04156494140625,
-0.017486572265625,
-0.027801513671875,
-0.01439666748046875,
... |
eraldoluis/faquad-bert-base-portuguese-cased | 2023-09-13T12:08:59.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"question-answering",
"extractive-qa",
"pt",
"dataset:eraldoluis/faquad",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | eraldoluis | null | null | eraldoluis/faquad-bert-base-portuguese-cased | 4 | 397 | transformers | 2022-09-07T11:03:37 | ---
language: pt
license: apache-2.0
library_name: transformers
tags:
- extractive-qa
datasets:
- eraldoluis/faquad
metrics:
- squad
base_model: neuralmind/bert-base-portuguese-cased
model-index:
- name: faquad-bert-base-portuguese-cased
results:
- task:
type: extractive-qa
name: Extractive Question-Answering
dataset:
name: FaQuAD
type: eraldoluis/faquad
split: eval
metrics:
- type: f1
value: 83.0912959832023
name: Eval F1 score (squad metric)
verified: false
- type: exact_match
value: 74.53169347209082
name: Eval ExactMatch score (squad metric)
verified: false
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmp_exs_faquad
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the [FaQuAD dataset](https://huggingface.co/datasets/eraldoluis/faquad).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
The model was trained on the `train` split and evaluated on the `eval` split.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 1,723 | [
[
-0.03521728515625,
-0.053680419921875,
-0.0023937225341796875,
0.0218048095703125,
-0.033355712890625,
-0.031646728515625,
-0.0102691650390625,
-0.01336669921875,
0.028533935546875,
0.02996826171875,
-0.05621337890625,
-0.045318603515625,
-0.04443359375,
-0.... |
Qiliang/bart-large-cnn-samsum-ElectrifAi_v10 | 2023-01-24T16:16:19.000Z | [
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | Qiliang | null | null | Qiliang/bart-large-cnn-samsum-ElectrifAi_v10 | 2 | 397 | transformers | 2023-01-24T15:04:52 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-cnn-samsum-ElectrifAi_v10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-samsum-ElectrifAi_v10
This model is a fine-tuned version of [philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1748
- Rouge1: 58.3392
- Rouge2: 35.1686
- Rougel: 45.4136
- Rougelsum: 56.9138
- Gen Len: 108.375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 21 | 1.1573 | 56.0772 | 34.1572 | 44.3652 | 54.8621 | 106.0833 |
| No log | 2.0 | 42 | 1.1764 | 57.7245 | 34.6517 | 45.67 | 56.3426 | 106.4167 |
| No log | 3.0 | 63 | 1.1748 | 58.3392 | 35.1686 | 45.4136 | 56.9138 | 108.375 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.2
| 1,826 | [
[
-0.04595947265625,
-0.04345703125,
0.00943756103515625,
0.00594329833984375,
-0.0271148681640625,
-0.02532958984375,
-0.0206146240234375,
-0.01898193359375,
0.0251312255859375,
0.036224365234375,
-0.045440673828125,
-0.04608154296875,
-0.0511474609375,
-0.00... |
polandball/GPT-Polen | 2023-03-05T05:30:12.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"en",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | conversational | polandball | null | null | polandball/GPT-Polen | 0 | 397 | transformers | 2023-02-07T04:32:55 | ---
language:
- en
tags:
- conversational
---

### Hellos, I ams of Polenball!
So you of probablys randomly findings this, and clicked on it.
## **Random things you can do while you're here.**
**Trade with me.**
**Make fun of me because i cant into space**
~~ **Invade me.** ~~ | 377 | [
[
-0.04296875,
-0.05548095703125,
0.056793212890625,
0.024993896484375,
-0.045867919921875,
0.00446319580078125,
-0.00909423828125,
-0.030609130859375,
0.08282470703125,
0.0394287109375,
-0.04864501953125,
-0.053741455078125,
-0.04681396484375,
-0.000239968299... |
to-be/donut-base-finetuned-invoices | 2023-03-03T19:18:45.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"donut",
"image-to-text",
"vision",
"invoices",
"arxiv:2111.15664",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | to-be | null | null | to-be/donut-base-finetuned-invoices | 5 | 397 | transformers | 2023-03-03T19:04:52 | ---
license: cc-by-nc-sa-4.0
tags:
- donut
- image-to-text
- vision
- invoices
---
# Donut finetuned on invoices
Based on Donut base model (introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
The model was trained with a few thousand of annotated invoices and non-invoices (for those the doctype will be 'Other'). They span across different countries and languages. They are always one page only. The dataset is proprietary unfortunately. Model is set to input resolution of 1280x1920 pixels. So any sample you want to try with higher dpi than 150 has no added value.
It was trained for about 4 hours on a NVIDIA RTX A4000 for 20k steps with a val_metric of 0.03413819904382196 at the end.
The following indexes were included in the train set:
DocType
Currency
DocumentDate
GrossAmount
InvoiceNumber
NetAmount
TaxAmount
OrderNumber
CreditorCountry
[Demo space can be found here](https://huggingface.co/spaces/to-be/invoice_document_headers_extraction_with_donut)
## Model description
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.

## Intended uses & limitations
This model is meant as a research in how well it fares with multilanguage invoices.
See my observations in the [demo space](https://huggingface.co/spaces/to-be/invoice_document_headers_extraction_with_donut).
### How to use
Look at the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
| 1,970 | [
[
-0.0070648193359375,
-0.03143310546875,
0.01971435546875,
-0.013916015625,
-0.01364898681640625,
-0.013397216796875,
-0.015960693359375,
-0.0467529296875,
0.0148468017578125,
0.05792236328125,
-0.0238800048828125,
-0.0190277099609375,
-0.0474853515625,
-0.00... |
liujch1998/vera | 2023-10-23T20:58:42.000Z | [
"transformers",
"pytorch",
"t5",
"text-classification",
"en",
"arxiv:2305.03695",
"license:mit",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-classification | liujch1998 | null | null | liujch1998/vera | 5 | 397 | transformers | 2023-03-24T17:46:55 | ---
license: mit
language:
- en
pipeline_tag: text-classification
arxiv: 2305.03695
---
# Model Card for Vera
<!-- Provide a quick summary of what the model is/does. -->
Vera is a commonsense statement verification model. See our paper at: <https://arxiv.org/abs/2305.03695>.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
Given a commonsense statement as input, Vera predicts the plausibility of this statement.
Vera outputs a real-valued score in the range [0, 1].
A score of 1 means the statement is correct according to commonsense, and a score of 0 means the statement is incorrect.
This score is calibrated, so a score between 0 and 1 can be interpreted as Vera's confidence that the statement is correct.
- **Developed by:** Jiacheng Liu, Wenya Wang, Dianzhuo Wang, Noah A. Smith, Yejin Choi, Hannaneh Hajishirzi
- **Shared by:** [Jiacheng (Gary) Liu](https://liujch1998.github.io/)
- **Model type:** Transformers
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model:** T5-v1.1-XXL
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** <https://github.com/liujch1998/vera>
- **Paper:** <https://arxiv.org/abs/2305.03695>
- **Demo:** <https://huggingface.co/spaces/liujch1998/vera>
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
Vera is intended to predict the correctness of commonsense statements.
### Downstream Use
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
Vera can be used to detect commonsense errors made by generative LMs (e.g., ChatGPT), or filter noisy commonsense knowledge generated by other LMs (e.g., Rainier).
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
Vera is a research prototype and may make mistakes. Do not use for making critical decisions. It is intended to predict the correctness of commonsense statements, and may be unreliable when taking input out of this scope.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
See the **Limitations and Ethics Statement** section of our paper.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
tokenizer = transformers.AutoTokenizer.from_pretrained('liujch1998/vera')
model = transformers.T5EncoderModel.from_pretrained('liujch1998/vera')
model.D = model.shared.embedding_dim
linear = torch.nn.Linear(model.D, 1, dtype=model.dtype)
linear.weight = torch.nn.Parameter(model.shared.weight[32099, :].unsqueeze(0))
linear.bias = torch.nn.Parameter(model.shared.weight[32098, 0].unsqueeze(0))
model.eval()
t = model.shared.weight[32097, 0].item() # temperature for calibration
statement = 'Please enter a commonsense statement here.'
input_ids = tokenizer.batch_encode_plus([statement], return_tensors='pt', padding='longest', truncation='longest_first', max_length=128).input_ids
with torch.no_grad():
output = model(input_ids)
last_hidden_state = output.last_hidden_state
hidden = last_hidden_state[0, -1, :]
logit = linear(hidden).squeeze(-1)
logit_calibrated = logit / t
score_calibrated = logit_calibrated.sigmoid()
# score_calibrated is Vera's final output plausibility score
```
You may also refer to <https://huggingface.co/spaces/liujch1998/vera/blob/main/app.py#L27-L98> for implementation.
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@article{Liu2023VeraAG,
title={Vera: A General-Purpose Plausibility Estimation Model for Commonsense Statements},
author={Jiacheng Liu and Wenya Wang and Dianzhuo Wang and Noah A. Smith and Yejin Choi and Hanna Hajishirzi},
journal={ArXiv},
year={2023},
volume={abs/2305.03695}
}
```
## Model Card Contact
[Jiacheng (Gary) Liu](https://liujch1998.github.io/)
| 4,262 | [
[
-0.00632476806640625,
-0.057342529296875,
0.031341552734375,
0.006580352783203125,
-0.0131072998046875,
-0.0382080078125,
0.002124786376953125,
-0.0248870849609375,
0.001583099365234375,
0.0307464599609375,
-0.037200927734375,
-0.056396484375,
-0.02337646484375,... |
Inzamam567/Useless_FuzzyHazel | 2023-04-02T02:24:59.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | Inzamam567 | null | null | Inzamam567/Useless_FuzzyHazel | 0 | 397 | diffusers | 2023-04-02T02:24:59 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
duplicated_from: Lucetepolis/FuzzyHazel
---
# FuzzyHazel, FuzzyAlmond
HazyAbyss - <a href="https://huggingface.co/KMAZ/TestSamples/">Download</a><br/>
OctaFuzz - <a href="https://huggingface.co/Lucetepolis/OctaFuzz">Download</a><br/>
MareAcernis - <a href="https://huggingface.co/Lucetepolis/MareAcernis">Download</a><br/>
RefSlaveV2 - <a href="https://huggingface.co/Dorshu/refslaveV2_v2">Download</a><br/>
dlfmaanjffhgkwl v2 - <a href="https://civitai.com/models/9815/dlfmaanjffhgkwl-mix">Download</a><br/>
Guardian Tales 三七-SAL-独轮车 | Chibi Style Lora 52 - <a href="https://civitai.com/models/14274/guardian-tales-sal-or-chibi-style-lora-52">Download</a><br/>
Komowata Haruka (こもわた遙華) Chibi Art Style LoRA - <a href="https://civitai.com/models/9922/komowata-haruka-chibi-art-style-lora">Download</a><br/>
Terada Tera (寺田てら) Art Style LoRA - <a href="https://civitai.com/models/15446/terada-tera-art-style-lora">Download</a><br/>
Yaro Artstyle LoRA - <a href="https://civitai.com/models/8112/yaro-artstyle-lora">Download</a><br/>
EasyNegative and pastelmix-lora seem to work well with the models.
EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download</a><br/>
pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download</a>
# Formula
```
MBW
HazyAbyss.safetensors [d7b0072ef7]
octafuzz.safetensors [364bdf849d]
0000.safetensors
base_alpha=1
Weight_values=1,1,0,0,0,0.5,1,1,0.5,0,0,0,1,0,0,0,0.5,1,1,0.5,0,0,0,1,1
MBW
0000.safetensors [360691971b]
mareacernis.safetensors [fbc82b317d]
0001.safetensors
base_alpha=0
Weight_values=0.5,0,0,0,0,0,0,0,0.5,0.5,0,0,0.25,0.5,0.5,0.5,0.25,0.25,0.25,0.25,0.5,0.5,0.5,0,0
MBW
0001.safetensors [ac67bd1235]
refslavev2.safetensors [cce9a2d200]
0002.safetensors
base_alpha=0
Weight_values=0,0.5,1,1,0.5,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1
MBW
0002.safetensors [cc5331b8ae]
dlf.safetensors [d596b45d6b]
FuzzyHazel.safetensors
base_alpha=0
Weight_values=0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0
SuperMerger LoRA Merge
model_0 : FuzzyHazel.safetensors
model_Out : FuzzyAlmond.safetensors
LoRa : lora:guardiantales:0.25, lora:komowata:0.25, lora:terada:0.25, lora:yaro:0.25
```
# Samples
All of the images use following negatives/settings. EXIF preserved.
```
Negative prompt: (worst quality, low quality:1.4), EasyNegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits
Steps: 28, Sampler: DPM++ 2M Karras, CFG scale: 7, Size: 768x512, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires steps: 14, Hires upscaler: Latent (nearest-exact)
```
# FuzzyHazel












# FuzzyAlmond












| 4,722 | [
[
-0.060546875,
-0.037109375,
0.0122528076171875,
0.0218505859375,
-0.025360107421875,
-0.01470947265625,
0.00029730796813964844,
-0.047760009765625,
0.081787109375,
0.016693115234375,
-0.06048583984375,
-0.043609619140625,
-0.03594970703125,
0.010147094726562... |
timm/xcit_large_24_p8_224.fb_dist_in1k | 2023-04-13T01:59:34.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.09681",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/xcit_large_24_p8_224.fb_dist_in1k | 0 | 397 | timm | 2023-04-13T01:56:51 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for xcit_large_24_p8_224.fb_dist_in1k
A XCiT (Cross-Covariance Image Transformer) image classification model. Pretrained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 188.9
- GMACs: 141.2
- Activations (M): 181.6
- Image size: 224 x 224
- **Papers:**
- XCiT: Cross-Covariance Image Transformers: https://arxiv.org/abs/2106.09681
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/xcit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('xcit_large_24_p8_224.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xcit_large_24_p8_224.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 785, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{el2021xcit,
title={XCiT: Cross-Covariance Image Transformers},
author={El-Nouby, Alaaeldin and Touvron, Hugo and Caron, Mathilde and Bojanowski, Piotr and Douze, Matthijs and Joulin, Armand and Laptev, Ivan and Neverova, Natalia and Synnaeve, Gabriel and Verbeek, Jakob and others},
journal={arXiv preprint arXiv:2106.09681},
year={2021}
}
```
| 2,735 | [
[
-0.031219482421875,
-0.020599365234375,
0.0027599334716796875,
0.0157012939453125,
-0.02935791015625,
-0.0177764892578125,
-0.0185394287109375,
-0.027099609375,
0.023284912109375,
0.0214691162109375,
-0.05145263671875,
-0.05035400390625,
-0.05401611328125,
-... |
timm/xcit_large_24_p16_224.fb_dist_in1k | 2023-04-13T02:08:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.09681",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/xcit_large_24_p16_224.fb_dist_in1k | 0 | 397 | timm | 2023-04-13T02:06:15 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for xcit_large_24_p16_224.fb_dist_in1k
A XCiT (Cross-Covariance Image Transformer) image classification model. Pretrained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 189.1
- GMACs: 35.9
- Activations (M): 47.3
- Image size: 224 x 224
- **Papers:**
- XCiT: Cross-Covariance Image Transformers: https://arxiv.org/abs/2106.09681
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/xcit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('xcit_large_24_p16_224.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xcit_large_24_p16_224.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{el2021xcit,
title={XCiT: Cross-Covariance Image Transformers},
author={El-Nouby, Alaaeldin and Touvron, Hugo and Caron, Mathilde and Bojanowski, Piotr and Douze, Matthijs and Joulin, Armand and Laptev, Ivan and Neverova, Natalia and Synnaeve, Gabriel and Verbeek, Jakob and others},
journal={arXiv preprint arXiv:2106.09681},
year={2021}
}
```
| 2,736 | [
[
-0.0316162109375,
-0.020904541015625,
0.0024433135986328125,
0.0159149169921875,
-0.0293121337890625,
-0.017578125,
-0.018585205078125,
-0.027587890625,
0.02301025390625,
0.0209197998046875,
-0.052337646484375,
-0.0504150390625,
-0.053619384765625,
-0.013244... |
timm/xcit_large_24_p16_384.fb_dist_in1k | 2023-04-13T02:14:39.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.09681",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/xcit_large_24_p16_384.fb_dist_in1k | 0 | 397 | timm | 2023-04-13T02:12:05 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for xcit_large_24_p16_384.fb_dist_in1k
A XCiT (Cross-Covariance Image Transformer) image classification model. Pretrained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 189.1
- GMACs: 105.3
- Activations (M): 137.2
- Image size: 384 x 384
- **Papers:**
- XCiT: Cross-Covariance Image Transformers: https://arxiv.org/abs/2106.09681
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/xcit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('xcit_large_24_p16_384.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xcit_large_24_p16_384.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{el2021xcit,
title={XCiT: Cross-Covariance Image Transformers},
author={El-Nouby, Alaaeldin and Touvron, Hugo and Caron, Mathilde and Bojanowski, Piotr and Douze, Matthijs and Joulin, Armand and Laptev, Ivan and Neverova, Natalia and Synnaeve, Gabriel and Verbeek, Jakob and others},
journal={arXiv preprint arXiv:2106.09681},
year={2021}
}
```
| 2,738 | [
[
-0.031646728515625,
-0.020721435546875,
0.0023174285888671875,
0.01593017578125,
-0.0291290283203125,
-0.01776123046875,
-0.0187530517578125,
-0.0274505615234375,
0.0235595703125,
0.02142333984375,
-0.052276611328125,
-0.050201416015625,
-0.05303955078125,
-... |
hhhhzy/deltalm-base-xlsum | 2023-04-21T17:12:16.000Z | [
"transformers",
"pytorch",
"Deltalm",
"text2text-generation",
"summarization",
"am",
"ar",
"az",
"bn",
"my",
"zh",
"en",
"fr",
"gu",
"ha",
"hi",
"ig",
"id",
"ja",
"rn",
"ko",
"ky",
"mr",
"ne",
"om",
"ps",
"fa",
"pcm",
"pt",
"pa",
"ru",
"gd",
"sr",
"s... | summarization | hhhhzy | null | null | hhhhzy/deltalm-base-xlsum | 2 | 397 | transformers | 2023-04-21T14:38:20 | ---
datasets:
- csebuetnlp/xlsum
language:
- am
- ar
- az
- bn
- my
- zh
- en
- fr
- gu
- ha
- hi
- ig
- id
- ja
- rn
- ko
- ky
- mr
- ne
- om
- ps
- fa
- pcm
- pt
- pa
- ru
- gd
- sr
- si
- so
- es
- sw
- ta
- te
- th
- ti
- tr
- uk
- ur
- uz
- vi
- cy
- yo
multilinguality:
- multilingual
pipeline_tag: summarization
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model is fine-tuned version of [DeltaLM-base](https://huggingface.co/nguyenvulebinh/deltalm-base) on the [XLSum dataset](https://huggingface.co/datasets/csebuetnlp/xlsum)
, aiming for abstractive multilingual summarization.
It achieves the following results on the evaluation set:
- rouge-1: 18.2
- rouge-2: 7.6
- rouge-l: 14.9
- rouge-lsum: 14.7
## Dataset desctiption
[XLSum dataset](https://huggingface.co/datasets/csebuetnlp/xlsum) is a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.
## Languages
- amharic
- arabic
- azerbaijani
- bengali
- burmese
- chinese_simplified
- chinese_traditional
- english
- french
- gujarati
- hausa
- hindi
- igbo
- indonesian
- japanese
- kirundi
- korean
- kyrgyz
- marathi
- nepali
- oromo
- pashto
- persian
- pidgin
- portuguese
- punjabi
- russian
- scottish_gaelic
- serbian_cyrillic
- serbian_latin
- sinhala
- somali
- spanish
- swahili
- tamil
- telugu
- thai
- tigrinya
- turkish
- ukrainian
- urdu
- uzbek
- vietnamese
- welsh
- yoruba
## Training hyperparameters
The model trained with a p4d.24xlarge instance on aws sagemaker, with the following config:
- model: deltalm base
- batch size: 8
- learning rate: 1e-5
- number of epochs: 3
- warmup steps: 500
- weight decay: 0.01
## Inference example
```
from modeling_deltalm import DeltalmForConditionalGeneration # download from https://huggingface.co/hhhhzy/deltalm-base-xlsum/blob/main/modeling_deltalm.py
from configuration_deltalm import DeltalmConfig # download from https://huggingface.co/hhhhzy/deltalm-base-xlsum/blob/main/configuration_deltalm.py
from transformers import AutoTokenizer
model = DeltalmForConditionalGeneration.from_pretrained("hhhhzy/deltalm-base-xlsum")
tokenizer = AutoTokenizer.from_pretrained("hhhhzy/deltalm-base-xlsum")
text = "The USA’s biggest sports league, the NFL, has extended its partnership with Amazon Prime, granting the streaming platform an additional live game on ‘black Friday’, the day after Thanksgiving. The additional game, added from 2023, builds on Amazon Prime’s package of ‘Thursday night football’ live rights (secured in an 11-year deal).\\nOn the surface, the deal makes sense because it gives Amazon Prime additional game time during the holiday season. But there is a deeper motivation at play. Black Friday is also regarded as the starting point of the pre-Christmas shopping season. Amazon has worked hard to leverage its sports rights in a way that benefits its ecommerce platform, so the addition of this fixture will boost that strategic goal.\\nIt’s unusual for sports rights holders to utilise their inventory in such a granular way – but it does suggest a shift towards a more data-driven approach to negotiations. For NFL, the deal means it now has partnerships with NBC, CBS, Fox and Amazon across the Thanksgiving period. Amazon Prime is currently in the NFL’s good books, helping revitalise the Thursday night slot through its marketing support and onscreen investment. Around 10 million people in the US are watching live fixtures each week."
inputs = tokenizer(text, max_length=512, return_tensors="pt")
generate_ids = model.generate(inputs["input_ids"], min_length=32, max_length=128)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
``` | 4,165 | [
[
-0.032806396484375,
-0.02752685546875,
-0.0006699562072753906,
0.0233306884765625,
-0.030548095703125,
-0.002231597900390625,
-0.006061553955078125,
-0.045257568359375,
0.015960693359375,
0.0318603515625,
-0.049072265625,
-0.0304718017578125,
-0.021514892578125,... |
coffeeee/nsfw-story-generator | 2023-04-25T20:29:13.000Z | [
"transformers",
"pytorch",
"gpt2",
"feature-extraction",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | feature-extraction | coffeeee | null | null | coffeeee/nsfw-story-generator | 3 | 397 | transformers | 2023-04-25T02:52:41 | Disclaimer: everything this model generates is a work of fiction.
Content from this model WILL generate inappropriate and potentially offensive content.
Use at your own discretion. Please respect the Huggingface code of conduct. | 246 | [
[
-0.03009033203125,
-0.06622314453125,
0.03924560546875,
0.024688720703125,
-0.004047393798828125,
0.0009112358093261719,
0.02545166015625,
-0.0665283203125,
0.05645751953125,
0.052032470703125,
-0.06744384765625,
-0.0247344970703125,
-0.058685302734375,
0.01... |
tomaarsen/span-marker-roberta-large-ontonotes5 | 2023-09-22T08:45:26.000Z | [
"span-marker",
"pytorch",
"safetensors",
"token-classification",
"ner",
"named-entity-recognition",
"en",
"dataset:tner/ontonotes5",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | token-classification | tomaarsen | null | null | tomaarsen/span-marker-roberta-large-ontonotes5 | 4 | 397 | span-marker | 2023-06-10T15:28:36 | ---
license: apache-2.0
library_name: span-marker
tags:
- span-marker
- token-classification
- ner
- named-entity-recognition
pipeline_tag: token-classification
widget:
- text: >-
Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic
to Paris.
example_title: Amelia Earhart
- text: >-
Leonardo di ser Piero da Vinci painted the Mona Lisa based on Italian noblewoman
Lisa del Giocondo.
example_title: Leonardo da Vinci
- text: >-
On June 13th, 2014, at 4:44 pm during the 2014 World Cup held in Salvador, Brazil,
the legendary soccer player, Robin van Persie, representing the Dutch national team,
scored a remarkable goal in the 44th minute.
example_title: Robin van Persie
model-index:
- name: >-
SpanMarker w. roberta-large on OntoNotes v5.0 by Tom Aarsen
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
type: tner/ontonotes5
name: OntoNotes v5.0
split: test
revision: cf9ef57ad260810be1298ba795d83c09a915e959
metrics:
- type: f1
value: 0.9153
name: F1
- type: precision
value: 0.9116
name: Precision
- type: recall
value: 0.9191
name: Recall
datasets:
- tner/ontonotes5
language:
- en
metrics:
- f1
- recall
- precision
---
# SpanMarker for Named Entity Recognition
This is a [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) model that can be used for Named Entity Recognition. In particular, this SpanMarker model uses [roberta-large](https://huggingface.co/roberta-large) as the underlying encoder. See [train.py](train.py) for the training script.
## Usage
To use this model for inference, first install the `span_marker` library:
```bash
pip install span_marker
```
You can then run inference with this model like so:
```python
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-roberta-large-ontonotes5")
# Run inference
entities = model.predict("Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic to Paris.")
```
### Limitations
**Warning**: This model works best when punctuation is separated from the prior words, so
```python
# ✅
model.predict("He plays J. Robert Oppenheimer , an American theoretical physicist .")
# ❌
model.predict("He plays J. Robert Oppenheimer, an American theoretical physicist.")
# You can also supply a list of words directly: ✅
model.predict(["He", "plays", "J.", "Robert", "Oppenheimer", ",", "an", "American", "theoretical", "physicist", "."])
```
The same may be beneficial for some languages, such as splitting `"l'ocean Atlantique"` into `"l' ocean Atlantique"`.
See the [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) repository for documentation and additional information on this library. | 2,989 | [
[
-0.027679443359375,
-0.058990478515625,
0.0394287109375,
0.01248931884765625,
-0.0185699462890625,
-0.0006480216979980469,
-0.0195770263671875,
-0.040863037109375,
0.03955078125,
0.032989501953125,
-0.04107666015625,
-0.033477783203125,
-0.046783447265625,
0... |
adilhafeez/distilbert-base-uncased-finetuned-squad | 2023-10-20T06:37:05.000Z | [
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | adilhafeez | null | null | adilhafeez/distilbert-base-uncased-finetuned-squad | 0 | 397 | transformers | 2023-10-20T00:44:18 | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.7261
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 2 | 5.9377 |
| No log | 2.0 | 4 | 5.7914 |
| No log | 3.0 | 6 | 5.7261 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
| 1,450 | [
[
-0.03350830078125,
-0.048919677734375,
0.0117645263671875,
0.02276611328125,
-0.025360107421875,
-0.00439453125,
-0.006031036376953125,
-0.0094451904296875,
0.00234222412109375,
0.0204010009765625,
-0.06689453125,
-0.039215087890625,
-0.054229736328125,
-0.0... |
deepset/tapas-large-nq-hn-reader | 2022-10-27T14:24:09.000Z | [
"transformers",
"pytorch",
"tapas",
"en",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null | deepset | null | null | deepset/tapas-large-nq-hn-reader | 1 | 396 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- tapas
license: apache-2.0
---
This model contains the converted PyTorch checkpoint of the original Tensorflow model available in the [TaPas repository](https://github.com/google-research/tapas/blob/master/DENSE_TABLE_RETRIEVER.md#reader-models).
It is described in Herzig et al.'s (2021) [paper](https://aclanthology.org/2021.naacl-main.43/) _Open Domain Question Answering over Tables via Dense Retrieval_.
This model has 2 versions that can be used differing only in the table scoring head.
The default one has an adapted table scoring head in order to be able to generate probabilities out of the logits.
The other (non-default) version corresponds to the original checkpoint from the TaPas repository and can be accessed by setting `revision="original"`.
# Usage
## In Haystack
If you want to use this model for question-answering over tables, you can load it in [Haystack](https://github.com/deepset-ai/haystack/):
```python
from haystack.nodes import TableReader
table_reader = TableReader(model_name_or_path="deepset/tapas-large-nq-hn-reader")
```
| 1,084 | [
[
-0.0170135498046875,
-0.075439453125,
0.033477783203125,
-0.01392364501953125,
-0.02197265625,
-0.022796630859375,
0.020233154296875,
-0.0234832763671875,
0.0140228271484375,
0.059478759765625,
-0.040557861328125,
-0.020233154296875,
-0.016204833984375,
0.00... |
digitalepidemiologylab/covid-twitter-bert-v2-mnli | 2021-09-22T08:20:04.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"Twitter",
"COVID-19",
"tensorflow",
"zero-shot-classification",
"en",
"dataset:mnli",
"arxiv:1909.00161",
"license:mit",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | digitalepidemiologylab | null | null | digitalepidemiologylab/covid-twitter-bert-v2-mnli | 0 | 396 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
thumbnail: https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png
tags:
- Twitter
- COVID-19
- text-classification
- pytorch
- tensorflow
- bert
license: mit
datasets:
- mnli
pipeline_tag: zero-shot-classification
widget:
- text: To stop the pandemic it is important that everyone turns up for their shots.
candidate_labels: health, sport, vaccine, guns
---
# COVID-Twitter-BERT v2 MNLI
## Model description
This model provides a zero-shot classifier to be used in cases where it is not possible to finetune CT-BERT on a specific task, due to lack of labelled data.
The technique is based on [Yin et al.](https://arxiv.org/abs/1909.00161).
The article describes a very clever way of using pre-trained MNLI models as zero-shot sequence classifiers.
The model is already finetuned on 400'000 generaic logical tasks.
We can then use it as a zero-shot classifier by reformulating the classification task as a question.
Let's say we want to classify COVID-tweets as vaccine-related and not vaccine-related.
The typical way would be to collect a few hunder pre-annotated tweets and organise them in two classes.
Then you would finetune the model on this.
With the zero-shot mnli-classifier, you can instead reformulate your question as "This text is about vaccines", and use this directly on inference - without any training.
Find more info about the model on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Usage
Please note that how you formulate the question can give slightly different results.
Collecting a training set and finetuning on this, will most likely give you better accuracy.
The easiest way to try this out is by using the Hugging Face pipeline.
This uses the default Enlish template where it puts the text "This example is " in front of the text.
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="digitalepidemiologylab/covid-twitter-bert-v2-mnli")
```
You can then use this pipeline to classify sequences into any of the class names you specify.
```python
sequence_to_classify = 'To stop the pandemic it is important that everyone turns up for their shots.'
candidate_labels = ['health', 'sport', 'vaccine','guns']
hypothesis_template = 'This example is {}.'
classifier(sequence_to_classify, candidate_labels, hypothesis_template=hypothesis_template, multi_class=True)
```
## Training procedure
The model is finetuned on the 400k large [MNLI-task](https://cims.nyu.edu/~sbowman/multinli/).
## References
```bibtex
@article{muller2020covid,
title={COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter},
author={M{\"u}ller, Martin and Salath{\'e}, Marcel and Kummervold, Per E},
journal={arXiv preprint arXiv:2005.07503},
year={2020}
}
```
or
```
Martin Müller, Marcel Salathé, and Per E. Kummervold.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter.
arXiv preprint arXiv:2005.07503 (2020).
```
| 3,085 | [
[
-0.01348114013671875,
-0.06231689453125,
0.007320404052734375,
0.006641387939453125,
-0.0159912109375,
-0.00923919677734375,
-0.00601959228515625,
-0.04034423828125,
0.0185394287109375,
0.00655364990234375,
-0.0401611328125,
-0.03076171875,
-0.04180908203125,
... |
matallanas/AbduRozik | 2023-03-16T13:18:16.000Z | [
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"wildcard",
"dataset:matallanas/AbduRozik",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | matallanas | null | null | matallanas/AbduRozik | 5 | 396 | diffusers | 2023-01-09T19:39:05 | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- wildcard
datasets: matallanas/AbduRozik
widget:
- text: Close portrait of elegant abrozick person in tailored suit
---
# DreamBooth model for the abrozick concept trained by matallanas on the https://huggingface.co/datasets/matallanas/AbduRozik dataset.
This is a Stable Diffusion model fine-tuned on the abrozick concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of abrozick**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `person` images for the wildcard theme.
## Images generated by model

## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('matallanas/AbduRozik')
image = pipeline().images[0]
image
```
| 1,105 | [
[
-0.0246734619140625,
-0.043487548828125,
0.0208892822265625,
0.0208587646484375,
-0.03704833984375,
0.01007080078125,
-0.00031948089599609375,
-0.0167388916015625,
0.0521240234375,
0.0300445556640625,
-0.046966552734375,
-0.041015625,
-0.026519775390625,
-0.... |
SG161222/Realistic_Vision_V1.3 | 2023-04-01T04:37:18.000Z | [
"diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | SG161222 | null | null | SG161222/Realistic_Vision_V1.3 | 38 | 396 | diffusers | 2023-03-03T14:31:43 | ---
license: creativeml-openrail-m
---
<b>Please read this!</b><br>
My model has always been free and always will be free. There are no restrictions on the use of the model. The rights to this model still belong to me.<br>
This model is available on <a href="https://www.mage.space/">Mage.Space</a> and <a href="https://sinkin.ai/">Sinkin.ai</a>
<hr/>
<b>I use this template to get good generation results:
Prompt:</b>
RAW photo, *subject*, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
<b>Example:</b> RAW photo, a close up portrait photo of 26 y.o woman in wastelander clothes, long haircut, pale skin, slim body, background is city ruins, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
<b>Negative Prompt:</b>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck<br>
<b>OR</b><br>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
<b>Euler A or DPM++ 2M Karras with 25 steps<br>
CFG Scale 3,5 - 7<br>
Hires. fix with Latent upscaler<br>
0 Hires steps and Denoising strength 0.25-0.45<br>
Upscale by 1.1-2.0</b> | 1,868 | [
[
-0.02813720703125,
-0.044097900390625,
0.0258331298828125,
0.018707275390625,
-0.03271484375,
-0.01073455810546875,
0.009979248046875,
-0.035491943359375,
0.034637451171875,
0.049652099609375,
-0.04998779296875,
-0.039794921875,
-0.039764404296875,
-0.005203... |
InvokeAI/ip_adapter_sd_image_encoder | 2023-09-23T18:33:25.000Z | [
"transformers",
"safetensors",
"clip_vision_model",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | InvokeAI | null | null | InvokeAI/ip_adapter_sd_image_encoder | 1 | 396 | transformers | 2023-09-14T22:12:37 | ---
license: apache-2.0
---
This is the Image Encoder required for SD1.5 IP Adapter model to function correctly. It is compatible with version 3.2+ of Invoke AI.
IP Adapter allows for users to input an Image Prompt, which is interpreted by the system, and passed in as conditioning for the image generation process.
The Community Edition of Invoke AI can be found at invoke.ai or on GitHub at https://github.com/invoke-ai/InvokeAI
Note:
This model is a copy of https://huggingface.co/h94/IP-Adapter/tree/5c2eae7d8a9c3365ba4745f16b94eb0293e319d3/models/image_encoder. It is hosted here in a format compatibile with InvokeAI.
| 628 | [
[
-0.04022216796875,
0.0005369186401367188,
0.007572174072265625,
0.019805908203125,
-0.053253173828125,
-0.0243988037109375,
0.0657958984375,
-0.0215911865234375,
0.0188140869140625,
0.0570068359375,
-0.04595947265625,
-0.01305389404296875,
-0.05157470703125,
... |
ruhul0/dreambooth | 2023-09-15T15:16:59.000Z | [
"diffusers",
"text-to-image",
"autotrain",
"region:us"
] | text-to-image | ruhul0 | null | null | ruhul0/dreambooth | 1 | 396 | diffusers | 2023-09-15T13:13:58 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Aesthetic Headshot for linkedin
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
| 244 | [
[
0.004848480224609375,
-0.011810302734375,
0.0156097412109375,
0.0089569091796875,
-0.036346435546875,
0.06683349609375,
0.01294708251953125,
-0.013519287109375,
0.035552978515625,
-0.00022685527801513672,
-0.03582763671875,
-0.002941131591796875,
-0.059753417968... |
TheBloke/Luna-AI-Llama2-Uncensored-GGML | 2023-09-27T13:00:19.000Z | [
"transformers",
"llama",
"license:llama2",
"text-generation-inference",
"region:us"
] | null | TheBloke | null | null | TheBloke/Luna-AI-Llama2-Uncensored-GGML | 120 | 395 | transformers | 2023-07-19T20:29:25 | ---
license: llama2
model_name: Luna AI Llama2 Uncensored
inference: false
model_creator: Tap
model_link: https://huggingface.co/Tap-M/Luna-AI-Llama2-Uncensored
model_type: llama
quantized_by: TheBloke
base_model: Tap-M/Luna-AI-Llama2-Uncensored
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Luna AI Llama2 Uncensored - GGML
- Model creator: [Tap](https://huggingface.co/Tap-M)
- Original model: [Luna AI Llama2 Uncensored](https://huggingface.co/Tap-M/Luna-AI-Llama2-Uncensored)
## Description
This repo contains GGML format model files for [Tap-M's Luna AI Llama2 Uncensored](https://huggingface.co/Tap-M/Luna-AI-Llama2-Uncensored).
### Important note regarding GGML files.
The GGML format has now been superseded by GGUF. As of August 21st 2023, [llama.cpp](https://github.com/ggerganov/llama.cpp) no longer supports GGML models. Third party clients and libraries are expected to still support it for a time, but many may also drop support.
Please use the GGUF models instead.
### About GGML
GGML files are for CPU + GPU inference using [llama.cpp](https://github.com/ggerganov/llama.cpp) and libraries and UIs which support this format, such as:
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most popular web UI. Supports NVidia CUDA GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a powerful GGML web UI with GPU acceleration on all platforms (CUDA and OpenCL). Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), a fully featured local GUI with GPU acceleration on both Windows (NVidia and AMD), and macOS.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with CUDA GPU acceleration via the c_transformers backend.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
Many thanks to William Beauchamp from [Chai](https://chai-research.com/) for providing the hardware used to make and upload these files!
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGUF)
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference (deprecated)](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML)
* [Tap's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Tap-M/Luna-AI-Llama2-Uncensored)
## Prompt template: User-Assistant
```
USER: {prompt}
ASSISTANT:
```
<!-- compatibility_ggml start -->
## Compatibility
These quantised GGML files are compatible with llama.cpp between June 6th (commit `2d43387`) and August 21st 2023.
For support with latest llama.cpp, please use GGUF files instead.
The final llama.cpp commit with support for GGML was: [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa)
As of August 23rd 2023 they are still compatible with all UIs, libraries and utilities which use GGML. This may change in the future.
## Explanation of the new k-quant methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
* GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_ggml end -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [luna-ai-llama2-uncensored.ggmlv3.q2_K.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q2_K.bin) | q2_K | 2 | 2.87 GB| 5.37 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
| [luna-ai-llama2-uncensored.ggmlv3.q3_K_S.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q3_K_S.bin) | q3_K_S | 3 | 2.95 GB| 5.45 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
| [luna-ai-llama2-uncensored.ggmlv3.q3_K_M.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q3_K_M.bin) | q3_K_M | 3 | 3.28 GB| 5.78 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| [luna-ai-llama2-uncensored.ggmlv3.q3_K_L.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q3_K_L.bin) | q3_K_L | 3 | 3.60 GB| 6.10 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| [luna-ai-llama2-uncensored.ggmlv3.q4_0.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q4_0.bin) | q4_0 | 4 | 3.79 GB| 6.29 GB | Original quant method, 4-bit. |
| [luna-ai-llama2-uncensored.ggmlv3.q4_K_S.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q4_K_S.bin) | q4_K_S | 4 | 3.83 GB| 6.33 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
| [luna-ai-llama2-uncensored.ggmlv3.q4_K_M.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q4_K_M.bin) | q4_K_M | 4 | 4.08 GB| 6.58 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
| [luna-ai-llama2-uncensored.ggmlv3.q4_1.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q4_1.bin) | q4_1 | 4 | 4.21 GB| 6.71 GB | Original quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
| [luna-ai-llama2-uncensored.ggmlv3.q5_0.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q5_0.bin) | q5_0 | 5 | 4.63 GB| 7.13 GB | Original quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
| [luna-ai-llama2-uncensored.ggmlv3.q5_K_S.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q5_K_S.bin) | q5_K_S | 5 | 4.65 GB| 7.15 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
| [luna-ai-llama2-uncensored.ggmlv3.q5_K_M.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q5_K_M.bin) | q5_K_M | 5 | 4.78 GB| 7.28 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
| [luna-ai-llama2-uncensored.ggmlv3.q5_1.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q5_1.bin) | q5_1 | 5 | 5.06 GB| 7.56 GB | Original quant method, 5-bit. Even higher accuracy, resource usage and slower inference. |
| [luna-ai-llama2-uncensored.ggmlv3.q6_K.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q6_K.bin) | q6_K | 6 | 5.53 GB| 8.03 GB | New k-quant method. Uses GGML_TYPE_Q8_K for all tensors - 6-bit quantization |
| [luna-ai-llama2-uncensored.ggmlv3.q8_0.bin](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML/blob/main/luna-ai-llama2-uncensored.ggmlv3.q8_0.bin) | q8_0 | 8 | 7.16 GB| 9.66 GB | Original quant method, 8-bit. Almost indistinguishable from float16. High resource use and slow. Not recommended for most users. |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
## How to run in `llama.cpp`
Make sure you are using `llama.cpp` from commit [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa) or earlier.
For compatibility with latest llama.cpp, please use GGUF files instead.
```
./main -t 10 -ngl 32 -m luna-ai-llama2-uncensored.ggmlv3.q4_K_M.bin --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "USER: Write a story about llamas\nASSISTANT:"
```
Change `-t 10` to the number of physical CPU cores you have. For example if your system has 8 cores/16 threads, use `-t 8`.
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length for this model. For example, `-c 4096` for a Llama 2 model. For models that use RoPE, add `--rope-freq-base 10000 --rope-freq-scale 0.5` for doubled context, or `--rope-freq-base 10000 --rope-freq-scale 0.25` for 4x context.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Russ Johnson, J, alfie_i, Alex, NimbleBox.ai, Chadd, Mandus, Nikolai Manek, Ken Nordquist, ya boyyy, Illia Dulskyi, Viktor Bowallius, vamX, Iucharbius, zynix, Magnesian, Clay Pascal, Pierre Kircher, Enrico Ros, Tony Hughes, Elle, Andrey, knownsqashed, Deep Realms, Jerry Meng, Lone Striker, Derek Yates, Pyrater, Mesiah Bishop, James Bentley, Femi Adebogun, Brandon Frisco, SuperWojo, Alps Aficionado, Michael Dempsey, Vitor Caleffi, Will Dee, Edmond Seymore, usrbinkat, LangChain4j, Kacper Wikieł, Luke Pendergrass, John Detwiler, theTransient, Nathan LeClaire, Tiffany J. Kim, biorpg, Eugene Pentland, Stanislav Ovsiannikov, Fred von Graf, terasurfer, Kalila, Dan Guido, Nitin Borwankar, 阿明, Ai Maven, John Villwock, Gabriel Puliatti, Stephen Murray, Asp the Wyvern, danny, Chris Smitley, ReadyPlayerEmma, S_X, Daniel P. Andersen, Olakabola, Jeffrey Morgan, Imad Khwaja, Caitlyn Gatomon, webtim, Alicia Loh, Trenton Dambrowitz, Swaroop Kallakuri, Erik Bjäreholt, Leonard Tan, Spiking Neurons AB, Luke @flexchar, Ajan Kanaga, Thomas Belote, Deo Leter, RoA, Willem Michiel, transmissions 11, subjectnull, Matthew Berman, Joseph William Delisle, David Ziegler, Michael Davis, Johann-Peter Hartmann, Talal Aujan, senxiiz, Artur Olbinski, Rainer Wilmers, Spencer Kim, Fen Risland, Cap'n Zoog, Rishabh Srivastava, Michael Levine, Geoffrey Montalvo, Sean Connelly, Alexandros Triantafyllidis, Pieter, Gabriel Tamborski, Sam, Subspace Studios, Junyu Yang, Pedro Madruga, Vadim, Cory Kujawski, K, Raven Klaugh, Randy H, Mano Prime, Sebastain Graf, Space Cruiser
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Tap-M's Luna AI Llama2 Uncensored
<div style="width: 800px; margin: auto;">
<h2>Model Description</h2>
<p>“Luna AI Llama2 Uncensored” is a Llama2 based Chat model <br />fine-tuned on over 40,000 long form chat discussions <br />
This model was fine-tuned by Tap, the creator of Luna AI. <br />
<h2>Model Training</h2>
<p>The fine-tuning process was performed on an 8x a100 80GB machine.
<br />The model was trained on synthetic outputs which include multiple rounds of chats between Human & AI.
</p>
<a rel="noopener nofollow" href="https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GPTQ">4bit GPTQ Version provided by @TheBloke - for GPU inference</a><br />
<a rel="noopener nofollow" href="https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML">GGML Version provided by @TheBloke - For CPU inference</a>
<h2>Prompt Format</h2>
<p>The model follows the Vicuna 1.1/ OpenChat format:</p>
```
USER: I have difficulties in making friends, and I really need someone to talk to. Would you be my friend?
ASSISTANT: Of course! Friends are always here for each other. What do you like to do?
```
<h2>Benchmark Results</h2>
||||||
|---:|---:|---:|---:|---:|
|Task|Version| Metric |Value |Stderr|
|arc_challenge|0|acc_norm|0.5512|0.0146|
|hellaswag|0||||
|mmlu|1|acc_norm|0.46521|0.036|
|truthfulqa_mc|1|mc2|0.4716|0.0155|
|Average|-|-|0.5114|0.0150|
</div>
| 15,742 | [
[
-0.035552978515625,
-0.060302734375,
0.03057861328125,
0.0247955322265625,
-0.0284423828125,
0.003170013427734375,
0.0005774497985839844,
-0.045989990234375,
0.033233642578125,
0.01331329345703125,
-0.04718017578125,
-0.042816162109375,
-0.03826904296875,
0.... |
optimum/distilbert-base-uncased-mnli | 2022-03-24T16:19:12.000Z | [
"transformers",
"onnx",
"text-classification",
"distilbert",
"zero-shot-classification",
"en",
"dataset:multi_nli",
"endpoints_compatible",
"has_space",
"region:us"
] | zero-shot-classification | optimum | null | null | optimum/distilbert-base-uncased-mnli | 3 | 394 | transformers | 2022-03-24T16:17:54 | ---
language: en
pipeline_tag: zero-shot-classification
tags:
- distilbert
datasets:
- multi_nli
metrics:
- accuracy
---
# ONNX convert typeform/distilbert-base-uncased-mnli
## Conversion of [typeform/distilbert-base-uncased-mnli](typeform/distilbert-base-uncased-mnli)
This is the [uncased DistilBERT model](https://huggingface.co/distilbert-base-uncased) fine-tuned on [Multi-Genre Natural Language Inference](https://huggingface.co/datasets/multi_nli) (MNLI) dataset for the zero-shot classification task. The model is not case-sensitive, i.e., it does not make a difference between "english" and "English".
## Training
Training is done on a [p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) AWS EC2 instance (1 NVIDIA Tesla V100 GPUs), with the following hyperparameters:
```
$ run_glue.py \
--model_name_or_path distilbert-base-uncased \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--output_dir /tmp/distilbert-base-uncased_mnli/
```
## Evaluation results
| Task | MNLI | MNLI-mm |
|:----:|:----:|:----:|
| | 82.0 | 82.0 | | 1,192 | [
[
-0.0115814208984375,
-0.045166015625,
0.0290069580078125,
0.0245361328125,
-0.023651123046875,
-0.00577545166015625,
-0.017364501953125,
0.0027828216552734375,
-0.00032258033752441406,
0.0278167724609375,
-0.048736572265625,
-0.047760009765625,
-0.05258178710937... |
patrickramos/bert-base-japanese-v2-wrime-fine-tune | 2023-03-22T08:11:34.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"ja",
"dataset:wrime",
"license:cc-by-sa-3.0",
"endpoints_compatible",
"region:us"
] | text-classification | patrickramos | null | null | patrickramos/bert-base-japanese-v2-wrime-fine-tune | 3 | 394 | transformers | 2022-05-22T09:42:14 | ---
license: cc-by-sa-3.0
language:
- ja
tag:
- emotion-analysis
datasets:
- wrime
widget:
- text: "車のタイヤがパンクしてた。。いたずらの可能性が高いんだって。。"
---
# WRIME-fine-tuned BERT base Japanese
This model is a [Japanese BERT<sub>BASE</sub>](https://huggingface.co/cl-tohoku/bert-base-japanese-v2) fine-tuned on the [WRIME](https://github.com/ids-cv/wrime) dataset. It was trained as part of the paper ["Emotion Analysis of Writers and Readers of Japanese Tweets on Vaccinations"](https://aclanthology.org/2022.wassa-1.10/). Fine-tuning code is available at this [repo](https://github.com/PatrickJohnRamos/BERT-Japan-vaccination).
# Intended uses and limitations
This model can be used to predict intensities scores for eight emotions for writers and readers. Please refer to the `Fine-tuning data` section for the list of emotions.
Because of the regression fine-tuning task, it is possible for the model to infer scores outside of the range of the scores of the fine-tuning data (`score < 0` or `score > 4`).
# Model Architecture, Tokenization, and Pretraining
The Japanese BERT<sub>BASE</sub> fine-tuned was `cl-tohoku/bert-base-japanese-v2`. Please refer to their [model card](https://huggingface.co/cl-tohoku/bert-base-japanese-v2) for details regarding the model architecture, tokenization, pretraining data, and pretraining procedure.
# Fine-tuning data
The model is fine-tuned on [WRIME](https://github.com/ids-cv/wrime), a dataset of Japanese Tweets annotated with writer and reader emotion intensities. We use version 1 of the dataset. Each Tweet is accompanied by a set of writer emotion intensities (from the author of the Tweet) and three sets of reader emotions (from three annotators). The emotions follow Plutchhik's emotions, namely:
* joy
* sadness
* anticipation
* surprise
* anger
* fear
* disgust
* trust
These emotion intensities follow a four-point scale:
| emotion intensity | emotion presence|
|---|---|
| 0 | no |
| 1 | weak |
| 2 | medium |
| 3 | strong |
# Fine-tuning
The BERT is fine-tuned to directly regress the emotion intensities of the writer and the averaged emotions of the readers from each Tweet, meaning there are 16 outputs (8 emotions per writer/reader).
The fine-tuning was inspired by common BERT fine-tuning procedures. The BERT was fine-tuned on WRIME for 3 epochs using the AdamW optimizer with a learning rate of 2e-5, β<sub>1</sub>=0.9, β<sub>2</sub>=0.999, weight decay of 0.01, linear decay, a warmup ratio of 0.01, and a batch size of 32. Training was conducted with an NVIDIA Tesla K80 and finished in 3 hours.
# Evaluation results
Below are the MSEs of the BERT on the test split of WRIME.
| Annotator | Joy | Sadness | Anticipation | Surprise | Anger | Fear | Disgust | Trust | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Writer | 0.658 | 0.688 | 0.746 | 0.542 | 0.486 | 0.462 | 0.664 | 0.400 | 0.581 |
| Reader | 0.192 | 0.178 | 0.211 | 0.139 | 0.032 | 0.147 | 0.123 | 0.029 | 0.131 |
| Both | 0.425 | 0.433 | 0.479 | 0.341 | 0.259 | 0.304 | 0.394 | 0.214 | 0.356 | | 3,030 | [
[
-0.0394287109375,
-0.05157470703125,
0.01812744140625,
0.0198974609375,
-0.034027099609375,
-0.002124786376953125,
-0.0330810546875,
-0.044952392578125,
0.00432586669921875,
-0.0020923614501953125,
-0.0799560546875,
-0.04412841796875,
-0.04534912109375,
-0.0... |
volrath50/fantasy-card-diffusion | 2023-05-16T09:31:13.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | volrath50 | null | null | volrath50/fantasy-card-diffusion | 99 | 394 | diffusers | 2022-11-22T17:08:44 | ---
language:
- en
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/volrath50/fantasy-card-diffusion/resolve/main/collage_sd_jpg.jpg"
tags:
- stable-diffusion
- text-to-image
- image-to-image
---
#fantasy-card-diffusion
### A comprehensive fine-tuned Stable Diffusion model for generating fantasy trading card style art, trained on all currently available Magic: the Gathering card art (~35k unique pieces of art) to 140,000 steps, using Stable Diffusion v1.5 as a base model. Trained on thousands of concepts, using tags from card data. Has a strong understanding of MTG Artists, planes, sets, colors, card types, creature types and much more.
<b>Prompts:</b> For best results, prompt the model with card information, <i><b>like you were writing out a custom MtG card</b></i>, with the phrase "MTG card art" and an art description
<b>Example:</b> "MTG card art, Fiery Merfolk, by Chris Rahn, 2021, creature - merfolk wizard, blue, red, ur, izzet, ravnica, gtp, rtr, grn, an izzet league merfolk, swimming in a ravnica river, casting a fire spell, flames, water, contrast, beautiful composition, intricate details"
<b>For a detailed guide on using the model, and how it was trained, scroll down below</b>

## Features
- Incorporate the styles of artists you know and love from Magic: the Gathering
- Produce art that looks like it is from a given MtG plane, set or year
- Create fantasy creatures in the style as they exist in Magic the Gathering
- Draw fantasy creature types that are unique to MtG (like Eldrazi)
- Use well known MTG characters (such as the planeswalkers)
- Draw real-world or non-MtG characters, in the style of MTG art
- Mix and match all of the above
## Updates
- 13 Dec 2022: I am currently training v2 of this model on top of Stable Diffusion 2.1 (512), using the Stable Tuner trainer. This has solved the cropping issue v1 had, and has allowed me to train on the full resolution, uncropped art from Scryfall. I expect to release v2 within the next few days, once I determine a good stopping point, and create new example images. v2 is currently at 25 Epochs (about 87,500 steps), and still showing good improvement each epoch.
## Using the Model
The model was trained on MtG card information, not art descriptions. This has the effect of preserving most non-MtG learning intact, allowing you to mix MtG card terms with an art description for great customization.
Each card was trained with card information pulled from Scryfall in the following format:
MTG card art, [Card Name], by [Artist], [year], [colors (words)], [colors (letters)], [card type], [rarity], [set name], [set code], [plane], [set type], [watermark], [mana cost], [security stamp], [power/toughness], [keywords], [promo type], [story spotlight]
A few examples of actual card data in this format:
MTG card art, Ayula, Queen Among Bears, by Jesper Ejsing, 2019, Green, G, Legendary Creature - Bear, rare, Modern Horizons, mh1, draft_innovation, 1G, None, 2/2, Fight,
MTG card art, Force of Will, by Terese Nielsen, 1996, Blue, U, Instant, uncommon, Alliances, all, Dominaria, Terisiare, Ice Age, expansion, 3UU,
To briefly explain some of the entries:
Every card art is tagged at the start with "MTG card art". Usually you want to use this. It does generalize the image a bit, however. Experiment with using it and not using it. Sometimes, if you are having trouble making something look distinctly "Tarkir" or something, taking off this tag can help de-generalize the art. In a similar fashion, the more general the tag is (ie, rarity, the word "legendary", etc.), the more of a generalizing effect it has on the image. Play around and find out.
Artist: Every artist name is preceded in the training data with the word "by", as in "by Mark Tedin". The model has a really good understanding of the styles of MtG artists - that's actually how this project started. My exposure to art, frankly, is mostly through Magic: the Gathering, and back in August, was finding that the base Stable Diffusion model just did not have a great understanding of a lot of the artists I was trying to draw from, with some exceptions (Greg Rutkowski, of course, and Rebbecca Guay are well represented in the base Stable Diffusion model.) Even if not trying to create MtG-style art, this model should be great for using the art styles of MtG artists. It also works really well to mix artist styles. See the "Innistrad Moon Goddess" example below, where I used six different artist styles with varying weights to create the look I was going for.
Set type: this is usually "expansion". Other possibilities are "core", "funny", and some other. You can check the Scryfall API documents for more information.
Security stamp: I translated some of these for ease of use. The main two of note are "acorn" and "universes beyond". There are a few other rare stamps, like one for the My Little Pony cards.
Story Spotlight: cards that are a story spotlight are tagged as such. This wasn't really worth including, and I'll probably take it out of a future version of the model.
Pretty much every tag from normal Stable Diffusion still works as expected (ie, extremely detailed, intricate details). I've found adding "beautiful composition" tends to make things look nice, but I'm sure everyone has their own set of personal tags they like to use - they should work with this model.
I like to write my prompts like an art description - you can see in the examples I made up below.
## Example Images and Prompts
This model is trained on so many things, I'm just scratching the surface of figuring out what it can do. I thought it would be helpful to show a gallery of the sort of things I've been able to create with it.
Full generation parameters, seeds, etc, should be in the images. All these examples were made with Automatic1111's UI, fantasycarddiffusion-140000.ckpt, and the "DPM++2S a Karras" sampler. CFG varies - I find around 11 works as a good baseline. Most of these were done with around 40-50 steps - probably overkill.
<b>Note:</b> The example prompts were done with Automatic1111's WebUI, and use both prompt weighting and negative prompts, and will not work the same out of the box in the demo on this page.
# Ascended Eldrazi
(an Eldrazi that has somehow made his way to Theros, chilled out, and attained godhood)

MTG card art, ascended eldrazi, (by eric deschamps:1.1), (legendary enchantment creature - god:1.2) (eldrazi:1.2), colorless, theros, ths, jou, bng, thb, mythic, indestructible, annihilator, trample, a wise eldrazi titan emerging from the horizon, ascended to godhood, now looking serene, calm, divine, powerful, beautiful composition, emrakul, kozilek, ulamog, (sense of scale:1.2), sense of wonder, overwhelming, extremely detailed, intricate details
Negative prompt: weak, angry, scary, underwhelming, powerless
# Speedy Sliver
(a Mardu sliver that gives dash, on Tarkir)

MTG card art, speedy sliver, by John avon, Creature - (sliver:1.3), white, black, red, wbr, (Mardu:1.1), Khans of tarkir, ktk, dash, a fast sliver is speeding through the Mardu (steppe:1.1) landscape, beautiful composition
Negative prompt: human, humanoid, m14
# Taylor Swift, Wandering Bard
(self explanatory, Taylor Swift, as a bard, on Eldraine. Future Secret Lair?)

mtg card art, (Taylor Swift:1.2), wandering bard, legendary creature - human (bard:1.2), white, red, green, wrg, throne of eldraine, eld, by chris rahn, by volkan baga, by zoltan boros, armored bard taylor swift holding her weapons and instruments, beautiful composition, detailed, realistic fantasy painting, masterpiece, best quality,
Negative prompt: guitar, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
# Emrakul, Compleated Doom
(The Phyrexians have sprung Emrakul from Innistrad's moon, compleated her, and are now attacking Strixhaven. It's a bad day to go to school.)

mtg card art, (emrakul:1.2), (compleated:1.1) doom, (by seb mckinnon:1.1), legendary creature - (phyrexian:1.1) (eldrazi:1.2) (horror:1.1), black, (strixhaven, arcivos:1.2), annihilator, (infect:1.2), 15/15, a (phyrexianized:1.1), compleated Emrakul, attacking (strixhaven school, university campus:1.2), stx, beautiful composition, detailed painting, (sense of scale:1.2), horror, dark, terrifying, eldritch horror, new phyrexia, nph, rise of the eldrazi, roe, extremely detailed, intricate details, masterpiece, best quality, emrakul, the aeons torn, emrakul, the promised end
Negative prompt: zendikar, water, ocean, funny, happy, optimistic, bright, tentacles, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, octopus, spikes, urchin, tentacles, arms, hands, legs
# Ayula, Ascended Bear
(Ayula, Queen Among Bears is now a Planeswalker, and has taken up residence in Kaladesh)

mtg card art, ayula, ascended (bear,:1.1) (by jesper ejsing,:1.1) green, g, legendary planeswalker - (bear:1.1), kaladesh, aether revolt, kld, aer, mythic, beautiful composition, a powerful bear planeswalker riding in a kaladesh (vehicle:1.1), looking very serious, intricate details, ayula, queen among bears, mh1, 2/2, 1g, masterpiece, best quality
Negative prompt: silly, human, humanoid, breasts, anthropomorphic, bipedal, funny, lowres, text, error, cropped, worst quality, low quality, normal quality, jpeg artifacts, watermark, blurry
# Neltharion, Deathwing
(My attempt at imagining Deathwing as a classic Elder Dragon Legend, with the World of Warcraft: Cataclysm Cinematic scene)

mtg card art, neltharion, (deathwing:1.2), (by edward beard, jr:1.1), 1994, legendary creature - (elder dragon:1.1), black, red, br, legends, leg, flying, trample, (world of warcraft cataclysm:1.2), large Firey flaming black dragon perched on stormwind castle rampart, roaring, breathing fire, flames, destruction, beautiful composition, extremely detailed, intricate details, masterpiece, best quality, terrifying, epic, cinematic
Negative prompt: lowres, text, error, cropped, worst quality, low quality, normal quality, jpeg artifacts, watermark, blurry, human, humanoid, deformed, mutant, (ugly:1.3)
# Harambe, Simian Champion of Tarkir
(Harambe did not die, his planeswalker spark ignited.)

(harambe:1.1), simian champion of tarkir, by magali villeneuve, legendary planeswalker - ape (monk:1.2), white, blue, red, wur, (jeskai:1.2), khans of tarkir, ktk, planeswalker harambe training with the jeskai, in a (monastery:1.2), in the mountains, wearing robes, martial arts, beautiful composition, extremely detailed, intricate details, masterpiece, best quality,
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
# Gabe Newell, Techno-Wizard
(Apologies to Gabe for the prompt - I wanted to make him look kind of like he does today, and the model kept trying to make him look like he did years ago.)

mtg card art, (gabe newell:1.3), techno-wizard, by zezhou chen, legendary creature - human wizard, blue, red, ur, izzet, ravnica, beautiful composition, (grey beard:1.1), (gray hair:1.1), elderly izzet techno wizard gabe newell is casting a spell, powerful, intelligent, epic composition, cinematic, dramatic, masterpiece, best quality, extremely detailed, intricate details
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, young, silly, goofy, funny
# Luna, Blind Lunar Goddess of Innistrad's Moon
(Or maybe just Emrakul in disguise?)

mtg card art, luna, blind lunar goddess of innistrad's moon, legendary enchantment creature - (god:1.1), by howard lyon, (by chris rahn:1.1), (by seb mckinnon:1.1), (by terese nielsen:0.8), (by rebecca guay:0.8), (by richard kane ferguson:1.1), (innistrad:1.3), dark ascension, shadows over innistrad, inn, dka, soi, white, blue, black, wub, mythic, (blindfolded cute young woman:1.2) as smug (moon goddess:1.1), sitting on throne, dark lighting, full moon night, long white hair, pale skin, (silver blindfold:1.1), opalescent robes, ethereal, celestial, mysterious, beautiful composition
Negative prompt: orange
# Goblin Flamethrower
(the model can generate instants and sorceries, too)

mtg card art, (goblin flamethrower:1.1), red, r, instant, sorcery, onslaught, legions, scourge, ons, lgn, scg, a crazed, intense, happy goblin is shooting fire from a flamethrower, dangerous, reckless, beautiful composition
Negative prompt: (ugly:1.5), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
# Mox Topaz, Mirage
(If there had been a Mox Topaz in the Mirage block, drawing inspiration from Volkan Baga's Vintage Masters mox art)

Mtg card art, two african hands cupped together holding a (mox topaz:1.1) on a gold chain, in the middle of the palm, in front of the (African savannah:1.1), by Terese Nielsen, (by Volkan baga:1.1), by Dan Frazier, artifact, beautiful composition, jamuraa, mirage, mir, vma
Negative prompt: deformed, bad anatomy
# Mox Topaz, Alpha
(similarly, if there had been a sixth color of Magic, Orange, way back in Alpha)

(mox topaz:1.1) ( by dan frazier:1.2), artifact, rare, (limited edition alpha, lea:1.1), (1993,:1.1) a mox topaz on a chain
Negative prompt: lowres, cropped, worst quality, low quality, normal quality, jpeg artifacts, watermark, blurry
# Island (Phyrexian Toronto)
(the Phyrexians have invaded and compleated Toronto)

mtg card art, (toronto:1.2), (basic land - island:1.1), new phyrexia, nph, by adam paquette, (toronto skyline:1.2), (phyrexian:1.1), dark, horror, cn tower, rogers centre, extremely detailed, intricate details, masterpiece, best quality
# Ariel, the Little Mermaid
(Give it time and I'm sure there will be a secret lair.)

mtg card art, (ariel, the little mermaid:1.2), legendary creature - (merfolk:1.1), blue, white, red, uwr, (theros:1.1), by Greg Staples, beautiful composition, ariel sitting on a rock with waves, theros temple in background, masterpiece, best quality,
Negative prompt: green skin, blue skin, red tail, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
# Batman, the Dark Knight
(Likewise, the Secret Lair is only a matter of time.)

mtg card art, batman, the dark knight, by justine cruz, by zoltan boros, legendary creature - human ninja, white, blue, black, (ub:1.1), (dimir,:1.1), (ravnica:1.1), (kamigawa:0.9), neon dynasty, neo, innistrad, investigate, ninjutsu, (at night:1.3), on roof, dark lighting, masterpiece, best quality,
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
## Training and dataset
Training was done on a dataset consisting of cropped, 512x512 versions of the art for every MtG card (about 35,000 images), each of which was tagged using a custom python script, from data pulled from Scryfall. Training was done with the Dreambooth extension for Automatic1111's wonderful UI, to 140,000 steps, over the course of a couple days, on my 4090. I changed settings several times as I went, generally increasing batch size and lowering learning rate. At the moment, I am at batch size 10, gradient accumulation 5, and learning rate 4e-7, and that seems to be working well.
The result is a comprehensive model that has a good understanding of MTG artists, sets, planes, card types, creature types, years, colors, and more. If you had ever wondered what a Merfolk, drawn by Ron Spencer, would have looked like on Tarkir, as part of the Mardu clan, with dash, haste, and trample - this model can deliver what you want.
I have uploaded the python script that I used to generate the training data set, which should get you uncropped images and identical text (or near identical) text files, with used with the "unique artwork" json from https://scryfall.com/docs/api/bulk-data
The script is simple, and could probably be improved and cleaned up. Prior to this project, I hadn't done any coding in 20 years, when I was a teenager, and had never used Python prior to hacking this together with vague memories of Perl in 2000-2001, liberal use of Github co-pilot and lots of googling.
Cropping was done with ImageMagick (see below, under issues).
## Issues
- This was intended to be a second test run on the full data set (the first did not go well), so some corners were cut for the purpose of starting my "testing." The model turned out far better than I had expected, so I've decided to release it as is, and hope other people enjoy it as much as I have. But there are some issues that I am aware of and intend to work on fixing for future releases
- Cropping: MTG art is rectangular. I initially tried to use a trainer that could handle different aspect ratios, but after a couple failed tries, I just did a quick mass cropping job with ImageMagick, resizing and cropping everything to 512x512, so I could get training running. I forget what exactly I did, but it appears it focused on the left side of the card, universally cutting off the right side. You'll see this in lots of images, that tend to have everything on the right as a result
- Plane information was only added around step 70,000, so it may be less trained than other information - basically, I wanted a way to group sets together by plane, as I was finding how well it knew the look of a set depended on whether WotC had incorporated the name of the plane into the set itself - ie: using "Theros" would only get you "Theros" and "Theros: Beyond Death" and not "Born of the Gods" or "Journey into Nyx"
- Some artists use special characters in their name. I tried to take away all accents, but I missed at least one, Tom Wänerstrand, who is trained as Tom Wänerstrand, with the umlaut
- Greg Rutkowski: Not an issue, but the poster boy for AI art, Greg Rutkowski, is an MTG artist. He uses the Polish form of his name on MTG cards, Grzegorz Rutkowski, and that is what this model was trained with. So you'll get different results using "by Greg Rutkowski" vs "by Grzegorz Rutkowski"
| 20,537 | [
[
-0.04022216796875,
-0.05242919921875,
-0.0003333091735839844,
-0.000385284423828125,
-0.0251007080078125,
0.00658416748046875,
0.0072479248046875,
-0.0506591796875,
0.0426025390625,
0.0440673828125,
-0.052825927734375,
-0.05029296875,
-0.049468994140625,
-0.... |
kalpesh22/ner-V1 | 2023-04-18T17:27:10.000Z | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"region:us"
] | token-classification | kalpesh22 | null | null | kalpesh22/ner-V1 | 0 | 394 | flair | 2023-04-18T17:02:17 | ---
tags:
- flair
- token-classification
- sequence-tagger-model
---
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("kalpesh22/ner-V1")
# make example sentence
sentence = Sentence("On September 1st George won 1 dollar while watching Game of Thrones.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
``` | 695 | [
[
-0.0273590087890625,
-0.032470703125,
0.0006117820739746094,
0.0228424072265625,
-0.0184173583984375,
-0.00730133056640625,
0.004795074462890625,
-0.0139617919921875,
0.06243896484375,
0.025177001953125,
-0.04351806640625,
-0.01324462890625,
-0.02783203125,
... |
digiplay/BeenYouLiteL11_diffusers | 2023-07-22T13:04:53.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/BeenYouLiteL11_diffusers | 12 | 394 | diffusers | 2023-05-29T12:59:47 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Cute realistic amine style model.
Model info:
https://civitai.com/models/34440/beenyou-lite
Sample image I made:

| 379 | [
[
-0.04736328125,
-0.04266357421875,
0.033599853515625,
0.025909423828125,
-0.024505615234375,
-0.032867431640625,
0.0141448974609375,
-0.0195159912109375,
0.06610107421875,
0.034820556640625,
-0.061614990234375,
-0.03631591796875,
-0.010772705078125,
-0.01019... |
timm/fastvit_sa12.apple_in1k | 2023-08-23T20:55:25.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.14189",
"license:other",
"region:us"
] | image-classification | timm | null | null | timm/fastvit_sa12.apple_in1k | 0 | 394 | timm | 2023-08-23T20:55:14 | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for fastvit_sa12.apple_in1k
A FastViT image classification model. Trained on ImageNet-1k by paper authors.
Please observe [original license](https://github.com/apple/ml-fastvit/blob/8af5928238cab99c45f64fc3e4e7b1516b8224ba/LICENSE).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.6
- GMACs: 2.0
- Activations (M): 13.8
- Image size: 256 x 256
- **Papers:**
- FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization: https://arxiv.org/abs/2303.14189
- **Original:** https://github.com/apple/ml-fastvit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('fastvit_sa12.apple_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_sa12.apple_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 256, 16, 16])
# torch.Size([1, 512, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_sa12.apple_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
```
| 3,670 | [
[
-0.04266357421875,
-0.03668212890625,
0.0015974044799804688,
0.018463134765625,
-0.0312347412109375,
-0.01561737060546875,
-0.007663726806640625,
-0.0197296142578125,
0.025360107421875,
0.027374267578125,
-0.038726806640625,
-0.044464111328125,
-0.05068969726562... |
visheratin/nllb-clip-base-oc-v2 | 2023-10-22T05:07:24.000Z | [
"open_clip",
"clip",
"zero-shot-image-classification",
"license:mit",
"region:us"
] | zero-shot-image-classification | visheratin | null | null | visheratin/nllb-clip-base-oc-v2 | 0 | 394 | open_clip | 2023-10-22T05:01:45 | ---
tags:
- clip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: mit
---
# Model card for nllb-clip-base-oc-v2
| 141 | [
[
-0.0267181396484375,
-0.005092620849609375,
0.0067596435546875,
0.0218048095703125,
-0.042083740234375,
0.0110931396484375,
0.07403564453125,
-0.00980377197265625,
0.035247802734375,
0.059234619140625,
-0.029541015625,
-0.020111083984375,
-0.0154876708984375,
... |
Helsinki-NLP/opus-mt-fi-et | 2023-08-16T11:34:29.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"fi",
"et",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-fi-et | 0 | 393 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-fi-et
* source languages: fi
* target languages: et
* OPUS readme: [fi-et](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-et/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-et/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-et/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-et/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fi.et | 25.2 | 0.519 |
| 816 | [
[
-0.0208282470703125,
-0.038360595703125,
0.018646240234375,
0.0258331298828125,
-0.028533935546875,
-0.02532958984375,
-0.034423828125,
-0.01047515869140625,
0.0037841796875,
0.03204345703125,
-0.05242919921875,
-0.036529541015625,
-0.04461669921875,
0.01762... |
kormilitzin/en_core_med7_trf | 2022-11-19T18:51:54.000Z | [
"spacy",
"token-classification",
"en",
"license:mit",
"model-index",
"has_space",
"region:us"
] | token-classification | kormilitzin | null | null | kormilitzin/en_core_med7_trf | 11 | 393 | spacy | 2022-03-02T23:29:05 | ---
tags:
- spacy
- token-classification
language:
- en
license: mit
model-index:
- name: en_core_med7_trf
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8822157434
- name: NER Recall
type: recall
value: 0.925382263
- name: NER F Score
type: f_score
value: 0.9032835821
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_med7_trf` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (7 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DOSAGE`, `DRUG`, `DURATION`, `FORM`, `FREQUENCY`, `ROUTE`, `STRENGTH` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 90.33 |
| `ENTS_P` | 88.22 |
| `ENTS_R` | 92.54 |
| `TRANSFORMER_LOSS` | 2502627.06 |
| `NER_LOSS` | 114576.77 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
``` | 1,617 | [
[
-0.0293426513671875,
-0.02838134765625,
0.0377197265625,
-0.00321197509765625,
-0.04046630859375,
0.0102386474609375,
-0.01007843017578125,
-0.0244598388671875,
0.0234527587890625,
0.044189453125,
-0.034698486328125,
-0.0679931640625,
-0.057647705078125,
0.0... |
nyu-mll/roberta-base-10M-3 | 2021-05-20T19:00:36.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | nyu-mll | null | null | nyu-mll/roberta-base-10M-3 | 0 | 393 | transformers | 2022-03-02T23:29:05 | # RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
| 3,820 | [
[
-0.0379638671875,
-0.0276336669921875,
0.024017333984375,
0.019622802734375,
-0.017364501953125,
-0.02099609375,
-0.0199737548828125,
-0.0293731689453125,
0.025726318359375,
0.0190582275390625,
-0.06427001953125,
-0.050994873046875,
-0.055389404296875,
0.017... |
turing-usp/FinBertPTBR | 2023-04-04T22:09:14.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"pt",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | turing-usp | null | null | turing-usp/FinBertPTBR | 15 | 393 | transformers | 2022-03-02T23:29:05 | ---
language: pt
license: apache-2.0
widget:
- text: "O futuro de DI caiu 20 bps nesta manhã"
example_title: "Example 1"
- text: "O Nubank decidiu cortar a faixa de preço da oferta pública inicial (IPO) após revés no humor dos mercados internacionais com as fintechs."
example_title: "Example 2"
- text: "O Ibovespa acompanha correção do mercado e fecha com alta moderada"
example_title: "Example 3"
---
# FinBertPTBR : Financial Bert PT BR (Depreciated model)
> **Info**
> Newer version available on https://huggingface.co/lucas-leme/FinBERT-PT-BR
FinBertPTBR is a pre-trained NLP model to analyze sentiment of Brazilian Portuguese financial texts. It is built by further training the BERTimbau language model in the finance domain, using a large financial corpus and thereby fine-tuning it for financial sentiment classification.
## Usage
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("turing-usp/FinBertPTBR")
model = AutoModel.from_pretrained("turing-usp/FinBertPTBR")
```
## Authors
- [Vinicius Carmo](https://www.linkedin.com/in/vinicius-cleves/)
- [Julia Pocciotti](https://www.linkedin.com/in/juliapocciotti/)
- [Luísa Heise](https://www.linkedin.com/in/lu%C3%ADsa-mendes-heise/)
- [Lucas Leme](https://www.linkedin.com/in/lucas-leme-santos/)
| 1,333 | [
[
-0.037139892578125,
-0.042816162109375,
0.002971649169921875,
0.042236328125,
-0.0300140380859375,
0.00629425048828125,
-0.01015472412109375,
-0.032257080078125,
0.004985809326171875,
0.0310821533203125,
-0.0400390625,
-0.04095458984375,
-0.051666259765625,
... |
Team-PIXEL/pixel-base | 2022-08-02T14:47:51.000Z | [
"transformers",
"pytorch",
"pixel",
"pretraining",
"en",
"dataset:Team-PIXEL/rendered-bookcorpus",
"dataset:Team-PIXEL/rendered-wikipedia-english",
"arxiv:2207.06991",
"arxiv:2111.06377",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null | Team-PIXEL | null | null | Team-PIXEL/pixel-base | 29 | 393 | transformers | 2022-05-16T18:54:48 | ---
license: apache-2.0
tags:
- pretraining
- pixel
datasets:
- Team-PIXEL/rendered-bookcorpus
- Team-PIXEL/rendered-wikipedia-english
language:
- en
---
# PIXEL (Pixel-based Encoder of Language)
PIXEL is a language model trained to reconstruct masked image patches that contain rendered text. PIXEL was pretrained on the *English* Wikipedia and Bookcorpus (in total around 3.2B words) but can theoretically be finetuned on data in any written language that can be typeset on a computer screen because it operates on rendered text as opposed to using a tokenizer with a fixed vocabulary.
It is not currently possible to use the Hosted Inference API with PIXEL.
Paper: [Language Modelling with Pixels](https://arxiv.org/abs/2207.06991)
Codebase: [https://github.com/xplip/pixel](https://github.com/xplip/pixel)
## Model description
PIXEL consists of three major components: a text renderer, which draws text as an image; an encoder, which encodes the unmasked regions of the rendered image; and a decoder, which reconstructs the masked regions at the pixel level. It is built on [ViT-MAE](https://arxiv.org/abs/2111.06377).
During pretraining, the renderer produces images containing the training sentences. Patches of these images are linearly projected to obtain patch embeddings (as opposed to having an embedding matrix like e.g. in BERT), and 25% of the patches are masked out. The encoder, which is a Vision Transformer (ViT), then only processes the unmasked patches. The lightweight decoder with hidden size 512 and 8 transformer layers inserts learnable mask tokens into the encoder's output sequence and learns to reconstruct the raw pixel values at the masked positions.
After pretraining, the decoder can be discarded leaving an 86M parameter encoder, upon which task-specific classification heads can be stacked. Alternatively, the decoder can be retained and PIXEL can be used as a pixel-level generative language model (see Figures 3 and 6 in the paper for examples).
For more details on how PIXEL works, please check the paper and the codebase linked above.
## Intended uses
PIXEL is primarily intended to be finetuned to downstream NLP tasks. See the [model hub](https://huggingface.co/models?search=Team-PIXEL/pixel-base) to look for finetuned versions on a task that interests you. Otherwise, check out the PIXEL codebase on Github [here](https://github.com/xplip/pixel) to find out how to finetune PIXEL for your task.
### How to use
Here is how to load PIXEL:
```python
from pixel import PIXELConfig, PIXELForPreTraining
config = PIXELConfig.from_pretrained("Team-PIXEL/pixel-base")
model = PIXELForPreTraining.from_pretrained("Team-PIXEL/pixel-base", config=config)
```
## Citing and Contact Author
```bibtex
@article{rust-etal-2022-pixel,
title={Language Modelling with Pixels},
author={Phillip Rust and Jonas F. Lotz and Emanuele Bugliarello and Elizabeth Salesky and Miryam de Lhoneux and Desmond Elliott},
journal={arXiv preprint},
year={2022},
url={https://arxiv.org/abs/2207.06991}
}
```
Github: [@xplip](https://github.com/xplip)
Twitter: [@rust_phillip](https://twitter.com/rust_phillip)
| 3,149 | [
[
-0.034515380859375,
-0.05194091796875,
0.01497650146484375,
0.00696563720703125,
-0.006633758544921875,
0.00885772705078125,
-0.019805908203125,
-0.033233642578125,
0.01264190673828125,
0.0244598388671875,
-0.029052734375,
-0.02801513671875,
-0.038421630859375,
... |
timm/resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k | 2023-03-22T21:32:25.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.05237",
"arxiv:1912.11370",
"arxiv:1603.05027",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k | 0 | 393 | timm | 2023-03-22T21:29:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k
A ResNet-V2-BiT (Big Transfer w/ pre-activation ResNet) image classification model. Pretrained on ImageNet-21k and fine-tuned on ImageNet-1k by paper authors.
This model uses:
* Group Normalization (GN) in combination with Weight Standardization (WS) instead of Batch Normalization (BN)..
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 236.3
- GMACs: 46.9
- Activations (M): 45.1
- Image size: 224 x 224
- **Papers:**
- Knowledge distillation: A good teacher is patient and consistent: https://arxiv.org/abs/2106.05237
- Big Transfer (BiT): General Visual Representation Learning: https://arxiv.org/abs/1912.11370
- Identity Mappings in Deep Residual Networks: https://arxiv.org/abs/1603.05027
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/big_transfer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 112, 112])
# torch.Size([1, 512, 56, 56])
# torch.Size([1, 1024, 28, 28])
# torch.Size([1, 2048, 14, 14])
# torch.Size([1, 4096, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetv2_152x2_bit.goog_teacher_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 4096, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{beyer2022knowledge,
title={Knowledge distillation: A good teacher is patient and consistent},
author={Beyer, Lucas and Zhai, Xiaohua and Royer, Am{'e}lie and Markeeva, Larisa and Anil, Rohan and Kolesnikov, Alexander},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10925--10934},
year={2022}
}
```
```bibtex
@inproceedings{Kolesnikov2019BigT,
title={Big Transfer (BiT): General Visual Representation Learning},
author={Alexander Kolesnikov and Lucas Beyer and Xiaohua Zhai and Joan Puigcerver and Jessica Yung and Sylvain Gelly and Neil Houlsby},
booktitle={European Conference on Computer Vision},
year={2019}
}
```
```bibtex
@article{He2016,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Identity Mappings in Deep Residual Networks},
journal = {arXiv preprint arXiv:1603.05027},
year = {2016}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,167 | [
[
-0.03265380859375,
-0.0283966064453125,
0.006900787353515625,
0.0010776519775390625,
-0.02935791015625,
-0.0261383056640625,
-0.025115966796875,
-0.0323486328125,
0.01442718505859375,
0.0295867919921875,
-0.0239715576171875,
-0.0440673828125,
-0.06134033203125,
... |
galleri5-ai/namo-amireal | 2023-05-31T10:24:40.000Z | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | galleri5-ai | null | null | galleri5-ai/namo-amireal | 0 | 393 | diffusers | 2023-05-31T10:04:02 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### namo_AMIREAL Dreambooth model trained by cl4ys with TheLastBen's fast-DreamBooth notebook
| 203 | [
[
-0.01910400390625,
-0.0487060546875,
0.045379638671875,
0.0302734375,
-0.043121337890625,
-0.006389617919921875,
0.0005383491516113281,
-0.0277099609375,
0.0201568603515625,
0.04376220703125,
-0.0170135498046875,
-0.047119140625,
-0.055511474609375,
-0.01905... |
digiplay/CounterMix_v2 | 2023-06-26T00:15:17.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/CounterMix_v2 | 2 | 393 | diffusers | 2023-06-25T17:48:30 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/70455?modelVersionId=89002
Original Author's DEMO image :

image detail link: https://civitai.com/images/1026170
| 404 | [
[
-0.0297698974609375,
-0.00807952880859375,
0.03778076171875,
0.01143646240234375,
-0.02880859375,
-0.0166473388671875,
0.0288543701171875,
-0.0040283203125,
0.039886474609375,
0.043914794921875,
-0.04962158203125,
-0.0186614990234375,
-0.0026378631591796875,
... |
DavidSolan0/coverart | 2023-07-10T18:34:53.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | DavidSolan0 | null | null | DavidSolan0/coverart | 0 | 393 | diffusers | 2023-07-10T18:30:01 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### coverart Dreambooth model trained by DavidSolan0 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 501 | [
[
-0.0269012451171875,
-0.04632568359375,
0.036376953125,
0.03924560546875,
-0.0117645263671875,
0.031524658203125,
0.0214691162109375,
-0.0278167724609375,
0.06787109375,
0.01134490966796875,
-0.03192138671875,
-0.0228729248046875,
-0.037017822265625,
-0.0179... |
digiplay/Zevinemix_v2.0 | 2023-07-17T22:50:20.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/Zevinemix_v2.0 | 1 | 393 | diffusers | 2023-07-17T22:15:05 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Models info :
https://civitai.com/models/103015?modelVersionId=113920
Sample images I made thru Huggingface's API:


prompt :
```
cartoon rabbit in forest
```
more pictures: https://huggingface.co/digiplay/Zevinemix_v2.0/discussions/2
Original Author's DEMO images :


 | 1,117 | [
[
-0.051055908203125,
-0.04705810546875,
0.0330810546875,
0.04046630859375,
-0.016845703125,
0.0019512176513671875,
0.0222320556640625,
-0.04229736328125,
0.053192138671875,
0.033843994140625,
-0.08929443359375,
-0.040771484375,
-0.032684326171875,
0.008224487... |
digiplay/Sudachi_diffusers | 2023-11-01T16:46:33.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/Sudachi_diffusers | 1 | 393 | diffusers | 2023-10-12T05:49:27 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/85909/sudachi
Original Author's DEMO images:


| 464 | [
[
-0.0343017578125,
-0.01251983642578125,
0.0311737060546875,
0.002727508544921875,
-0.043487548828125,
-0.0221405029296875,
0.01314544677734375,
-0.002178192138671875,
0.0361328125,
0.03436279296875,
-0.060638427734375,
-0.0233154296875,
-0.0224609375,
-0.006... |
Cohere/Cohere-embed-english-v3.0 | 2023-11-02T12:26:14.000Z | [
"transformers",
"mteb",
"model-index",
"endpoints_compatible",
"region:us"
] | null | Cohere | null | null | Cohere/Cohere-embed-english-v3.0 | 8 | 393 | transformers | 2023-11-02T12:24:52 | ---
tags:
- mteb
model-index:
- name: embed-english-v3.0
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 81.29850746268656
- type: ap
value: 46.181772245676136
- type: f1
value: 75.47731234579823
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 95.61824999999999
- type: ap
value: 93.22525741797098
- type: f1
value: 95.61627312544859
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 51.72
- type: f1
value: 50.529480725642465
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 61.521
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 49.173332266218914
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.1800504937582
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.69942465283367
- type: mrr
value: 73.8089741898606
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 85.1805709775319
- type: cos_sim_spearman
value: 83.50310749422796
- type: euclidean_pearson
value: 83.57134970408762
- type: euclidean_spearman
value: 83.50310749422796
- type: manhattan_pearson
value: 83.422472116232
- type: manhattan_spearman
value: 83.35611619312422
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.52922077922078
- type: f1
value: 85.48530911742581
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 40.95750155360001
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 37.25334765305169
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 50.037
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 49.089
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 60.523
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 39.293
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 30.414
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 43.662
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 43.667
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 41.53158333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 35.258
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 30.866
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 40.643
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 40.663
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 34.264
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 38.433
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 43.36
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.574999999999996
- type: f1
value: 46.84362123583929
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 88.966
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 42.189
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 70.723
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 93.56920000000001
- type: ap
value: 90.56104192134326
- type: f1
value: 93.56471146876505
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 42.931000000000004
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.88372093023256
- type: f1
value: 94.64417024711646
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.52302781577748
- type: f1
value: 59.52848723786157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.84330867518494
- type: f1
value: 72.18121296285702
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.73907195696033
- type: f1
value: 78.86079300338558
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 37.40673427491627
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 33.38936252583581
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.67317850167471
- type: mrr
value: 33.9334102169254
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 38.574000000000005
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 61.556
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 88.722
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 58.45790556534654
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 66.35141658656822
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 20.314
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.49945063881191
- type: cos_sim_spearman
value: 81.27177640994141
- type: euclidean_pearson
value: 82.74613694646263
- type: euclidean_spearman
value: 81.2717795980493
- type: manhattan_pearson
value: 82.75268512220467
- type: manhattan_spearman
value: 81.28362006796547
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.17562591888526
- type: cos_sim_spearman
value: 74.37099514810372
- type: euclidean_pearson
value: 79.97392043583372
- type: euclidean_spearman
value: 74.37103618585903
- type: manhattan_pearson
value: 80.00641585184354
- type: manhattan_spearman
value: 74.35403985608939
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.96937598668538
- type: cos_sim_spearman
value: 85.20181466598035
- type: euclidean_pearson
value: 84.51715977112744
- type: euclidean_spearman
value: 85.20181466598035
- type: manhattan_pearson
value: 84.45150037846719
- type: manhattan_spearman
value: 85.12338939049123
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.58787775650663
- type: cos_sim_spearman
value: 80.97859876561874
- type: euclidean_pearson
value: 83.38711461294801
- type: euclidean_spearman
value: 80.97859876561874
- type: manhattan_pearson
value: 83.34934127987394
- type: manhattan_spearman
value: 80.9556224835537
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.57387982528677
- type: cos_sim_spearman
value: 89.22666720704161
- type: euclidean_pearson
value: 88.50953296228646
- type: euclidean_spearman
value: 89.22666720704161
- type: manhattan_pearson
value: 88.45343635855095
- type: manhattan_spearman
value: 89.1638631562071
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.26071496425682
- type: cos_sim_spearman
value: 86.31740966379304
- type: euclidean_pearson
value: 85.85515938268887
- type: euclidean_spearman
value: 86.31740966379304
- type: manhattan_pearson
value: 85.80077191882177
- type: manhattan_spearman
value: 86.27885602957302
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 90.41413251495673
- type: cos_sim_spearman
value: 90.3370719075361
- type: euclidean_pearson
value: 90.5785973346113
- type: euclidean_spearman
value: 90.3370719075361
- type: manhattan_pearson
value: 90.5278703024898
- type: manhattan_spearman
value: 90.23870483011629
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.1571023517868
- type: cos_sim_spearman
value: 66.42297916256133
- type: euclidean_pearson
value: 67.55835224919745
- type: euclidean_spearman
value: 66.42297916256133
- type: manhattan_pearson
value: 67.40537247802385
- type: manhattan_spearman
value: 66.26259339863576
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.4251695055504
- type: cos_sim_spearman
value: 88.54881886307972
- type: euclidean_pearson
value: 88.54094330250571
- type: euclidean_spearman
value: 88.54881886307972
- type: manhattan_pearson
value: 88.49069549839685
- type: manhattan_spearman
value: 88.49149164694148
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.19974508901711
- type: mrr
value: 95.95137342686361
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 71.825
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.85346534653465
- type: cos_sim_ap
value: 96.2457455868878
- type: cos_sim_f1
value: 92.49492900608519
- type: cos_sim_precision
value: 93.82716049382715
- type: cos_sim_recall
value: 91.2
- type: dot_accuracy
value: 99.85346534653465
- type: dot_ap
value: 96.24574558688776
- type: dot_f1
value: 92.49492900608519
- type: dot_precision
value: 93.82716049382715
- type: dot_recall
value: 91.2
- type: euclidean_accuracy
value: 99.85346534653465
- type: euclidean_ap
value: 96.2457455868878
- type: euclidean_f1
value: 92.49492900608519
- type: euclidean_precision
value: 93.82716049382715
- type: euclidean_recall
value: 91.2
- type: manhattan_accuracy
value: 99.85643564356435
- type: manhattan_ap
value: 96.24594126679709
- type: manhattan_f1
value: 92.63585576434738
- type: manhattan_precision
value: 94.11764705882352
- type: manhattan_recall
value: 91.2
- type: max_accuracy
value: 99.85643564356435
- type: max_ap
value: 96.24594126679709
- type: max_f1
value: 92.63585576434738
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 68.41861859721674
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 37.51202861563424
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.48207537634766
- type: mrr
value: 53.36204747050335
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.397150340510397
- type: cos_sim_spearman
value: 30.180928192386
- type: dot_pearson
value: 30.397148822378796
- type: dot_spearman
value: 30.180928192386
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 81.919
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 32.419
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.613
- type: ap
value: 15.696112954573444
- type: f1
value: 56.30148693392767
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 62.02037351443125
- type: f1
value: 62.31189055427593
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 50.64186455543417
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.27883411813792
- type: cos_sim_ap
value: 74.80076733774258
- type: cos_sim_f1
value: 68.97989210397255
- type: cos_sim_precision
value: 64.42968392120935
- type: cos_sim_recall
value: 74.22163588390501
- type: dot_accuracy
value: 86.27883411813792
- type: dot_ap
value: 74.80076608107143
- type: dot_f1
value: 68.97989210397255
- type: dot_precision
value: 64.42968392120935
- type: dot_recall
value: 74.22163588390501
- type: euclidean_accuracy
value: 86.27883411813792
- type: euclidean_ap
value: 74.80076820459502
- type: euclidean_f1
value: 68.97989210397255
- type: euclidean_precision
value: 64.42968392120935
- type: euclidean_recall
value: 74.22163588390501
- type: manhattan_accuracy
value: 86.23711032961793
- type: manhattan_ap
value: 74.73958348950038
- type: manhattan_f1
value: 68.76052948255115
- type: manhattan_precision
value: 63.207964601769916
- type: manhattan_recall
value: 75.3825857519789
- type: max_accuracy
value: 86.27883411813792
- type: max_ap
value: 74.80076820459502
- type: max_f1
value: 68.97989210397255
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09263787014399
- type: cos_sim_ap
value: 86.46378381763645
- type: cos_sim_f1
value: 78.67838784176413
- type: cos_sim_precision
value: 76.20868812238419
- type: cos_sim_recall
value: 81.3135201724669
- type: dot_accuracy
value: 89.09263787014399
- type: dot_ap
value: 86.46378353247907
- type: dot_f1
value: 78.67838784176413
- type: dot_precision
value: 76.20868812238419
- type: dot_recall
value: 81.3135201724669
- type: euclidean_accuracy
value: 89.09263787014399
- type: euclidean_ap
value: 86.46378511891255
- type: euclidean_f1
value: 78.67838784176413
- type: euclidean_precision
value: 76.20868812238419
- type: euclidean_recall
value: 81.3135201724669
- type: manhattan_accuracy
value: 89.09069740365584
- type: manhattan_ap
value: 86.44864502475154
- type: manhattan_f1
value: 78.67372818141132
- type: manhattan_precision
value: 76.29484953703704
- type: manhattan_recall
value: 81.20572836464429
- type: max_accuracy
value: 89.09263787014399
- type: max_ap
value: 86.46378511891255
- type: max_f1
value: 78.67838784176413
---
# Cohere embed-english-v3.0
This repository contains the tokenizer for the Cohere `embed-english-v3.0` model. See our blogpost [Cohere Embed V3](https://txt.cohere.com/introducing-embed-v3/) for more details on this model.
You can use the embedding model either via the Cohere API, AWS SageMaker or in your private deployments.
## Usage Cohere API
The following code snippet shows the usage of the Cohere API. Install the cohere SDK via:
```
pip install -U cohere
```
Get your free API key on: www.cohere.com
```python
# This snippet shows and example how to use the Cohere Embed V3 models for semantic search.
# Make sure to have the Cohere SDK in at least v4.30 install: pip install -U cohere
# Get your API key from: www.cohere.com
import cohere
import numpy as np
cohere_key = "{YOUR_COHERE_API_KEY}" #Get your API key from www.cohere.com
co = cohere.Client(cohere_key)
docs = ["The capital of France is Paris",
"PyTorch is a machine learning framework based on the Torch library.",
"The average cat lifespan is between 13-17 years"]
#Encode your documents with input type 'search_document'
doc_emb = co.embed(docs, input_type="search_document", model="embed-english-v3.0").embeddings
doc_emb = np.asarray(doc_emb)
#Encode your query with input type 'search_query'
query = "What is Pytorch"
query_emb = co.embed([query], input_type="search_query", model="embed-english-v3.0").embeddings
query_emb = np.asarray(query_emb)
query_emb.shape
#Compute the dot product between query embedding and document embedding
scores = np.dot(query_emb, doc_emb.T)[0]
#Find the highest scores
max_idx = np.argsort(-scores)
print(f"Query: {query}")
for idx in max_idx:
print(f"Score: {scores[idx]:.2f}")
print(docs[idx])
print("--------")
```
## Usage AWS SageMaker
The embedding model can be privately deployed in your AWS Cloud using our [AWS SageMaker marketplace offering](https://aws.amazon.com/marketplace/pp/prodview-z6huxszcqc25i). It runs privately in your VPC, with latencies as low as 5ms for query encoding.
## Usage AWS Bedrock
Soon the model will also be available via AWS Bedrock. Stay tuned
## Private Deployment
You want to run the model on your own hardware? [Contact Sales](https://cohere.com/contact-sales) to learn more.
## Supported Languages
This model was trained on nearly 1B English training pairs.
Evaluation results can be found in the [Embed V3.0 Benchmark Results spreadsheet](https://docs.google.com/spreadsheets/d/1w7gnHWMDBdEUrmHgSfDnGHJgVQE5aOiXCCwO3uNH_mI/edit?usp=sharing). | 28,060 | [
[
-0.0218353271484375,
-0.05633544921875,
0.0250091552734375,
0.00614166259765625,
-0.010284423828125,
-0.021636962890625,
0.0015735626220703125,
-0.01776123046875,
0.0265655517578125,
0.0190277099609375,
-0.03668212890625,
-0.06817626953125,
-0.04571533203125,
... |
nickmuchi/sec-bert-finetuned-finance-classification | 2023-03-18T23:52:43.000Z | [
"transformers",
"pytorch",
"tensorboard",
"onnx",
"bert",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"sentence_50agree",
"generated_from_trainer",
"sentiment",
"finance",
"en",
"dataset:financial_phrasebank",
"dataset:Kaggle_Self_label",
"dataset:nickm... | text-classification | nickmuchi | null | null | nickmuchi/sec-bert-finetuned-finance-classification | 11 | 392 | transformers | 2022-03-08T03:30:54 | ---
license: cc-by-sa-4.0
tags:
- financial-sentiment-analysis
- sentiment-analysis
- sentence_50agree
- generated_from_trainer
- sentiment
- finance
datasets:
- financial_phrasebank
- Kaggle_Self_label
- nickmuchi/financial-classification
metrics:
- accuracy
- f1
- precision
- recall
widget:
- text: The USD rallied by 10% last night
example_title: Bullish Sentiment
- text: >-
Covid-19 cases have been increasing over the past few months impacting
earnings for global firms
example_title: Bearish Sentiment
- text: the USD has been trending lower
example_title: Mildly Bearish Sentiment
model-index:
- name: sec-bert-finetuned-finance-classification
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: finance
args: sentence_50agree
metrics:
- type: F1
name: F1
value: 0.8744
- type: accuracy
name: accuracy
value: 0.8755
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sec-bert-finetuned-finance-classification
This model is a fine-tuned version of [nlpaueb/sec-bert-base](https://huggingface.co/nlpaueb/sec-bert-base) on the sentence_50Agree [financial-phrasebank + Kaggle Dataset](https://huggingface.co/datasets/nickmuchi/financial-classification), a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive). The Kaggle dataset includes Covid-19 sentiment data and can be found here: [sentiment-classification-selflabel-dataset](https://www.kaggle.com/percyzheng/sentiment-classification-selflabel-dataset).
It achieves the following results on the evaluation set:
- Loss: 0.5277
- Accuracy: 0.8755
- F1: 0.8744
- Precision: 0.8754
- Recall: 0.8755
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.6005 | 0.99 | 71 | 0.3702 | 0.8478 | 0.8465 | 0.8491 | 0.8478 |
| 0.3226 | 1.97 | 142 | 0.3172 | 0.8834 | 0.8822 | 0.8861 | 0.8834 |
| 0.2299 | 2.96 | 213 | 0.3313 | 0.8814 | 0.8805 | 0.8821 | 0.8814 |
| 0.1277 | 3.94 | 284 | 0.3925 | 0.8775 | 0.8771 | 0.8770 | 0.8775 |
| 0.0764 | 4.93 | 355 | 0.4517 | 0.8715 | 0.8704 | 0.8717 | 0.8715 |
| 0.0533 | 5.92 | 426 | 0.4851 | 0.8735 | 0.8728 | 0.8731 | 0.8735 |
| 0.0363 | 6.9 | 497 | 0.5107 | 0.8755 | 0.8743 | 0.8757 | 0.8755 |
| 0.0248 | 7.89 | 568 | 0.5277 | 0.8755 | 0.8744 | 0.8754 | 0.8755 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6 | 3,452 | [
[
-0.04681396484375,
-0.044342041015625,
0.0020961761474609375,
0.00643157958984375,
-0.01428985595703125,
-0.010009765625,
-0.00829315185546875,
-0.0178070068359375,
0.024566650390625,
0.022308349609375,
-0.055419921875,
-0.053192138671875,
-0.045867919921875,
... |
NickKolok/meryl-stryfe-20230123-2300-6k-6000-steps | 2023-01-22T22:55:15.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | NickKolok | null | null | NickKolok/meryl-stryfe-20230123-2300-6k-6000-steps | 0 | 392 | diffusers | 2023-01-22T22:17:30 | ---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Meryl_Stryfe_20230123_2300_6k_6000_steps on Stable Diffusion via Dreambooth
#### model by NickKolok
This your the Stable Diffusion model fine-tuned the Meryl_Stryfe_20230123_2300_6k_6000_steps concept taught to Stable Diffusion with Dreambooth.
#It can be used by modifying the `instance_prompt`: **merylstryfetrigun**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:


















































| 8,125 | [
[
-0.07196044921875,
-0.031585693359375,
0.01396942138671875,
0.01134490966796875,
-0.032073974609375,
-0.01154327392578125,
-0.005825042724609375,
-0.062469482421875,
0.0858154296875,
0.020416259765625,
-0.054107666015625,
-0.041259765625,
-0.046051025390625,
... |
timm/resnetrs270.tf_in1k | 2023-04-05T18:51:29.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2103.07579",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnetrs270.tf_in1k | 0 | 392 | timm | 2023-04-05T18:49:27 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnetrs270.tf_in1k
A ResNetRS-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k by paper authors in Tensorflow.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 129.9
- GMACs: 27.1
- Activations (M): 55.8
- Image size: train = 256 x 256, test = 352 x 352
- **Papers:**
- Revisiting ResNets: Improved Training and Scaling Strategies: https://arxiv.org/abs/2103.07579
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/resnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetrs270.tf_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs270.tf_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1024, 16, 16])
# torch.Size([1, 2048, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetrs270.tf_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{bello2021revisiting,
title={Revisiting ResNets: Improved Training and Scaling Strategies},
author={Irwan Bello and William Fedus and Xianzhi Du and Ekin D. Cubuk and Aravind Srinivas and Tsung-Yi Lin and Jonathon Shlens and Barret Zoph},
journal={arXiv preprint arXiv:2103.07579},
year={2021}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,372 | [
[
-0.06536865234375,
-0.0156707763671875,
0.002124786376953125,
0.030120849609375,
-0.031951904296875,
-0.00734710693359375,
-0.0096435546875,
-0.029022216796875,
0.08648681640625,
0.0198974609375,
-0.04840087890625,
-0.039398193359375,
-0.046783447265625,
-0.... |
timm/tresnet_l.miil_in1k | 2023-04-21T20:54:39.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2003.13630",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tresnet_l.miil_in1k | 0 | 392 | timm | 2023-04-21T20:53:51 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tresnet_l.miil_in1k
A TResNet image classification model. Trained on ImageNet-1k by paper authors.
The weights for this model have been remapped and modified from the originals to work with standard BatchNorm instead of InplaceABN. `inplace_abn` can be problematic to build recently and ends up slower with `memory_format=channels_last`, torch.compile(), etc.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 56.0
- GMACs: 10.9
- Activations (M): 11.9
- Image size: 224 x 224
- **Papers:**
- TResNet: High Performance GPU-Dedicated Architecture: https://arxiv.org/abs/2003.13630
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/Alibaba-MIIL/TResNet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tresnet_l.miil_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tresnet_l.miil_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 76, 56, 56])
# torch.Size([1, 152, 28, 28])
# torch.Size([1, 1216, 14, 14])
# torch.Size([1, 2432, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tresnet_l.miil_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2432, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@misc{ridnik2020tresnet,
title={TResNet: High Performance GPU-Dedicated Architecture},
author={Tal Ridnik and Hussam Lawen and Asaf Noy and Itamar Friedman},
year={2020},
eprint={2003.13630},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 3,704 | [
[
-0.036773681640625,
-0.038238525390625,
-0.0005555152893066406,
0.0166168212890625,
-0.03509521484375,
-0.0185699462890625,
-0.01222991943359375,
-0.0251922607421875,
0.0292205810546875,
0.044769287109375,
-0.036468505859375,
-0.055908203125,
-0.054779052734375,... |
embaas/sentence-transformers-e5-large-v2 | 2023-06-03T17:53:07.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | sentence-similarity | embaas | null | null | embaas/sentence-transformers-e5-large-v2 | 5 | 392 | sentence-transformers | 2023-05-29T09:40:09 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# embaas/sentence-transformers-e5-large-v2
This is a the sentence-transformers version of the [intfloat/e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('embaas/sentence-transformers-e5-large-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Using with API
You can use the [embaas API](https://embaas.io) to encode your input. Get your free API key from [embaas.io](https://embaas.io)
```python
import requests
url = "https://api.embaas.io/v1/embeddings/"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ${YOUR_API_KEY}"
}
data = {
"texts": ["This is an example sentence.", "Here is another sentence."],
"instruction": "query"
"model": "e5-large-v2"
}
response = requests.post(url, json=data, headers=headers)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
Find the results of the e5 at the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 2,190 | [
[
-0.0298309326171875,
-0.061309814453125,
0.035125732421875,
0.040863037109375,
-0.00852203369140625,
-0.0199127197265625,
-0.01229095458984375,
-0.007511138916015625,
0.023406982421875,
0.035614013671875,
-0.046173095703125,
-0.041839599609375,
-0.04818725585937... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.