
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
textattack/xlnet-base-cased-imdb | 2020-07-06T16:35:25.000Z | [
"transformers",
"pytorch",
"xlnet",
"text-generation",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | textattack | null | null | textattack/xlnet-base-cased-imdb | 0 | 348 | transformers | 2022-03-02T23:29:05 | ## TextAttack Model Card
This `xlnet-base-cased` model was fine-tuned for sequence classification using TextAttack
and the imdb dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 512.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.95352, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
| 611 | [
[
-0.02099609375,
-0.021942138671875,
0.0173492431640625,
-0.00864410400390625,
-0.03411865234375,
0.018096923828125,
0.004123687744140625,
-0.029205322265625,
0.00013053417205810547,
0.04144287109375,
-0.04315185546875,
-0.0482177734375,
-0.042999267578125,
0... |
agne/jobBERT-de | 2022-06-03T13:53:31.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"de",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | agne | null | null | agne/jobBERT-de | 1 | 348 | transformers | 2022-06-03T06:53:53 | ---
language: de
license: cc-by-nc-sa-4.0
---
## jobBERT-de
This is a domain-adapted transformer-based language model for German-speaking job advertisements.
Is is based on [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) and adapted to the domain of job advertisements trough continued in-domain pretraining on 4 million German-speaking job ads from Switzerland 1990-2020 (5.9 GB data). Empty spots in the vocabulary of the base model were filled with most frequent domain-specific words, subtokens and abbreviations.
### Overview
**Architecture:** BERT base <br>
**Language:** German <br>
**Domain:** Job advertisements <br>
**See also:** [agne/jobGBERT](https://huggingface.co/agne/jobGBERT)
### License
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (cc-by-nc-sa-4.0)
Please use the following citation when using our model:
```bibtex
@inproceedings{
title = "Evaluation of Transfer Learning and Domain Adaptation for Analyzing German-Speaking Job Advertisements",
author = "Gnehm, Ann-Sophie and
Bühlmann, Eva and
Clematide, Simon",
booktitle = "Proceedings of the 13th Language Resources and Evaluation Conference",
month = june,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
}
```
### Intended usage and limitations
You can use the model for masked language modeling, but it's intended to be fine-tuned on a downstream task.
The model is trained on German-Speaking job ads from Switzerland. It inherits potential bias of its base model, and may contain biases and stereotypes common in job advertisements.
### About us
Ann-Sophie Gnehm: `gnehm [at] soziologie.uzh.ch` <br>
Eva Bühlmann: `bühlmann [at] soziologie.uzh.ch` <br>
Simon Clematide: `simon.clematide [at] cl.uzh.ch` <br>
The [Swiss Job Market Monitor](https://www.stellenmarktmonitor.uzh.ch/en.html) aims at systematically expanding scientific knowledge about the job market and improving labour market transparency by informing the general public about current developments on the job market.
**Get in touch:** [Mail](mailto:gnehm@soziologie.uzh.ch) [Website](https://www.stellenmarktmonitor.uzh.ch/en.html) [Zenodo](https://doi.org/10.5281/zenodo.6497853) [SWISSUbase](https://www.swissubase.ch/de/catalogue/studies/11998/18157/overview)
| 2,376 | [
[
-0.0235443115234375,
-0.044952392578125,
0.0208587646484375,
0.01403045654296875,
-0.022674560546875,
-0.01456451416015625,
-0.02197265625,
-0.03619384765625,
0.016998291015625,
0.0458984375,
-0.04522705078125,
-0.03851318359375,
-0.049530029296875,
-0.00573... |
philschmid/lilt-en-funsd | 2022-11-22T07:42:39.000Z | [
"transformers",
"pytorch",
"tensorboard",
"lilt",
"token-classification",
"generated_from_trainer",
"dataset:funsd-layoutlmv3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | philschmid | null | null | philschmid/lilt-en-funsd | 2 | 348 | transformers | 2022-11-18T08:27:17 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- funsd-layoutlmv3
model-index:
- name: lilt-en-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lilt-en-funsd
This model is a fine-tuned version of [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) on the funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6117
- Answer: {'precision': 0.8821428571428571, 'recall': 0.9069767441860465, 'f1': 0.8943874471937237, 'number': 817}
- Header: {'precision': 0.6126126126126126, 'recall': 0.5714285714285714, 'f1': 0.591304347826087, 'number': 119}
- Question: {'precision': 0.9045045045045045, 'recall': 0.9322191272051996, 'f1': 0.9181527206218564, 'number': 1077}
- Overall Precision: 0.8797
- Overall Recall: 0.9006
- Overall F1: 0.8900
- Overall Accuracy: 0.8204
## Model Usage
```python
from transformers import LiltForTokenClassification, LayoutLMv3Processor
from PIL import Image, ImageDraw, ImageFont
import torch
# load model and processor from huggingface hub
model = LiltForTokenClassification.from_pretrained("philschmid/lilt-en-funsd")
processor = LayoutLMv3Processor.from_pretrained("philschmid/lilt-en-funsd")
# helper function to unnormalize bboxes for drawing onto the image
def unnormalize_box(bbox, width, height):
return [
width * (bbox[0] / 1000),
height * (bbox[1] / 1000),
width * (bbox[2] / 1000),
height * (bbox[3] / 1000),
]
label2color = {
"B-HEADER": "blue",
"B-QUESTION": "red",
"B-ANSWER": "green",
"I-HEADER": "blue",
"I-QUESTION": "red",
"I-ANSWER": "green",
}
# draw results onto the image
def draw_boxes(image, boxes, predictions):
width, height = image.size
normalizes_boxes = [unnormalize_box(box, width, height) for box in boxes]
# draw predictions over the image
draw = ImageDraw.Draw(image)
font = ImageFont.load_default()
for prediction, box in zip(predictions, normalizes_boxes):
if prediction == "O":
continue
draw.rectangle(box, outline="black")
draw.rectangle(box, outline=label2color[prediction])
draw.text((box[0] + 10, box[1] - 10), text=prediction, fill=label2color[prediction], font=font)
return image
# run inference
def run_inference(image, model=model, processor=processor, output_image=True):
# create model input
encoding = processor(image, return_tensors="pt")
del encoding["pixel_values"]
# run inference
outputs = model(**encoding)
predictions = outputs.logits.argmax(-1).squeeze().tolist()
# get labels
labels = [model.config.id2label[prediction] for prediction in predictions]
if output_image:
return draw_boxes(image, encoding["bbox"][0], labels)
else:
return labels
run_inference(dataset["test"][34]["image"])
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.0211 | 10.53 | 200 | 1.5528 | {'precision': 0.8458904109589042, 'recall': 0.9069767441860465, 'f1': 0.8753691671588896, 'number': 817} | {'precision': 0.5684210526315789, 'recall': 0.453781512605042, 'f1': 0.5046728971962617, 'number': 119} | {'precision': 0.896551724137931, 'recall': 0.89322191272052, 'f1': 0.8948837209302325, 'number': 1077} | 0.8596 | 0.8728 | 0.8662 | 0.8011 |
| 0.0132 | 21.05 | 400 | 1.3143 | {'precision': 0.8447058823529412, 'recall': 0.8788249694002448, 'f1': 0.8614277144571085, 'number': 817} | {'precision': 0.6020408163265306, 'recall': 0.4957983193277311, 'f1': 0.543778801843318, 'number': 119} | {'precision': 0.8854262144821264, 'recall': 0.8969359331476323, 'f1': 0.8911439114391144, 'number': 1077} | 0.8548 | 0.8659 | 0.8603 | 0.8095 |
| 0.0052 | 31.58 | 600 | 1.5747 | {'precision': 0.8482446206115515, 'recall': 0.9167686658506732, 'f1': 0.8811764705882352, 'number': 817} | {'precision': 0.6283185840707964, 'recall': 0.5966386554621849, 'f1': 0.6120689655172413, 'number': 119} | {'precision': 0.8997161778618732, 'recall': 0.883008356545961, 'f1': 0.8912839737582005, 'number': 1077} | 0.8626 | 0.8798 | 0.8711 | 0.8030 |
| 0.0073 | 42.11 | 800 | 1.4848 | {'precision': 0.8487972508591065, 'recall': 0.9069767441860465, 'f1': 0.8769230769230769, 'number': 817} | {'precision': 0.5190839694656488, 'recall': 0.5714285714285714, 'f1': 0.5439999999999999, 'number': 119} | {'precision': 0.8941947565543071, 'recall': 0.8867223769730733, 'f1': 0.8904428904428905, 'number': 1077} | 0.8514 | 0.8763 | 0.8636 | 0.7969 |
| 0.0057 | 52.63 | 1000 | 1.3993 | {'precision': 0.8852071005917159, 'recall': 0.9155446756425949, 'f1': 0.9001203369434416, 'number': 817} | {'precision': 0.5454545454545454, 'recall': 0.6050420168067226, 'f1': 0.5737051792828685, 'number': 119} | {'precision': 0.899090909090909, 'recall': 0.9182915506035283, 'f1': 0.9085898024804776, 'number': 1077} | 0.8710 | 0.8987 | 0.8846 | 0.8198 |
| 0.0023 | 63.16 | 1200 | 1.6463 | {'precision': 0.8961201501877347, 'recall': 0.8763769889840881, 'f1': 0.886138613861386, 'number': 817} | {'precision': 0.5625, 'recall': 0.5294117647058824, 'f1': 0.5454545454545455, 'number': 119} | {'precision': 0.888, 'recall': 0.9275766016713092, 'f1': 0.9073569482288827, 'number': 1077} | 0.8733 | 0.8833 | 0.8782 | 0.8082 |
| 0.001 | 73.68 | 1400 | 1.6476 | {'precision': 0.8676814988290398, 'recall': 0.9069767441860465, 'f1': 0.8868940754039496, 'number': 817} | {'precision': 0.6571428571428571, 'recall': 0.5798319327731093, 'f1': 0.6160714285714286, 'number': 119} | {'precision': 0.908256880733945, 'recall': 0.9192200557103064, 'f1': 0.9137055837563451, 'number': 1077} | 0.8785 | 0.8942 | 0.8863 | 0.8137 |
| 0.0014 | 84.21 | 1600 | 1.6493 | {'precision': 0.8814814814814815, 'recall': 0.8739290085679314, 'f1': 0.8776889981561156, 'number': 817} | {'precision': 0.6194690265486725, 'recall': 0.5882352941176471, 'f1': 0.603448275862069, 'number': 119} | {'precision': 0.894404332129964, 'recall': 0.9201485608170845, 'f1': 0.9070938215102976, 'number': 1077} | 0.8740 | 0.8818 | 0.8778 | 0.8041 |
| 0.0006 | 94.74 | 1800 | 1.6193 | {'precision': 0.8766467065868263, 'recall': 0.8959608323133414, 'f1': 0.8861985472154963, 'number': 817} | {'precision': 0.6068376068376068, 'recall': 0.5966386554621849, 'f1': 0.6016949152542374, 'number': 119} | {'precision': 0.8946428571428572, 'recall': 0.9303621169916435, 'f1': 0.912152935821575, 'number': 1077} | 0.8711 | 0.8967 | 0.8837 | 0.8137 |
| 0.0001 | 105.26 | 2000 | 1.6048 | {'precision': 0.8751472320376914, 'recall': 0.9094247246022031, 'f1': 0.8919567827130852, 'number': 817} | {'precision': 0.6140350877192983, 'recall': 0.5882352941176471, 'f1': 0.6008583690987125, 'number': 119} | {'precision': 0.9062784349408554, 'recall': 0.924791086350975, 'f1': 0.9154411764705882, 'number': 1077} | 0.8773 | 0.8987 | 0.8879 | 0.8194 |
| 0.0001 | 115.79 | 2200 | 1.6117 | {'precision': 0.8821428571428571, 'recall': 0.9069767441860465, 'f1': 0.8943874471937237, 'number': 817} | {'precision': 0.6126126126126126, 'recall': 0.5714285714285714, 'f1': 0.591304347826087, 'number': 119} | {'precision': 0.9045045045045045, 'recall': 0.9322191272051996, 'f1': 0.9181527206218564, 'number': 1077} | 0.8797 | 0.9006 | 0.8900 | 0.8204 |
| 0.0001 | 126.32 | 2400 | 1.6163 | {'precision': 0.8799048751486326, 'recall': 0.9057527539779682, 'f1': 0.8926417370325694, 'number': 817} | {'precision': 0.6052631578947368, 'recall': 0.5798319327731093, 'f1': 0.5922746781115881, 'number': 119} | {'precision': 0.9062784349408554, 'recall': 0.924791086350975, 'f1': 0.9154411764705882, 'number': 1077} | 0.8788 | 0.8967 | 0.8876 | 0.8192 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.12.1
| 9,705 | [
[
-0.03961181640625,
-0.04754638671875,
0.0160064697265625,
0.01233673095703125,
-0.0201873779296875,
-0.01467132568359375,
-0.0009670257568359375,
-0.010894775390625,
0.042572021484375,
0.0169525146484375,
-0.038665771484375,
-0.03900146484375,
-0.0416259765625,
... |
facebook/mask2former-swin-base-IN21k-cityscapes-semantic | 2023-09-11T20:34:59.000Z | [
"transformers",
"pytorch",
"safetensors",
"mask2former",
"vision",
"image-segmentation",
"dataset:coco",
"arxiv:2112.01527",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | facebook | null | null | facebook/mask2former-swin-base-IN21k-cityscapes-semantic | 0 | 348 | transformers | 2023-01-16T09:50:43 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- coco
widget:
- src: http://images.cocodataset.org/val2017/000000039769.jpg
example_title: Cats
- src: http://images.cocodataset.org/val2017/000000039770.jpg
example_title: Castle
---
# Mask2Former
Mask2Former model trained on Cityscapes semantic segmentation (base-IN21k, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for panoptic segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on Cityscapes semantic segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-IN21k-cityscapes-semantic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-IN21k-cityscapes-semantic")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
predicted_semantic_map = processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former). | 3,186 | [
[
-0.040863037109375,
-0.046630859375,
0.0322265625,
0.0211944580078125,
-0.0155029296875,
-0.014556884765625,
0.0095062255859375,
-0.058563232421875,
0.0106353759765625,
0.050445556640625,
-0.05548095703125,
-0.03668212890625,
-0.05572509765625,
-0.0199584960... |
timm/focalnet_tiny_lrf.ms_in1k | 2023-03-18T04:36:02.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2203.11926",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/focalnet_tiny_lrf.ms_in1k | 0 | 348 | timm | 2023-03-18T04:35:38 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for focalnet_tiny_lrf.ms_in1k
A FocalNet image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.6
- GMACs: 4.5
- Activations (M): 17.8
- Image size: 224 x 224
- **Papers:**
- Focal Modulation Networks: https://arxiv.org/abs/2203.11926
- **Original:** https://github.com/microsoft/FocalNet
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('focalnet_tiny_lrf.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'focalnet_tiny_lrf.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for focalnet_base_srf:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'focalnet_tiny_lrf.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor)
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{yang2022focal,
title={Focal Modulation Networks},
author={Jianwei Yang and Chunyuan Li and Xiyang Dai and Jianfeng Gao},
journal={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,883 | [
[
-0.046539306640625,
-0.035736083984375,
0.004169464111328125,
0.01532745361328125,
-0.0255889892578125,
-0.04779052734375,
-0.029022216796875,
-0.0328369140625,
0.0198516845703125,
0.030029296875,
-0.038726806640625,
-0.0418701171875,
-0.0499267578125,
-0.00... |
TencentARC/t2iadapter_openpose_sd14v1 | 2023-07-31T11:12:29.000Z | [
"diffusers",
"art",
"t2i-adapter",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.08453",
"license:apache-2.0",
"diffusers:T2IAdapter",
"region:us"
] | image-to-image | TencentARC | null | null | TencentARC/t2iadapter_openpose_sd14v1 | 0 | 348 | diffusers | 2023-07-14T19:01:22 | ---
license: apache-2.0
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- t2i-adapter
- controlnet
- stable-diffusion
- image-to-image
---
# T2I Adapter - Openpose
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on openpose for the stable diffusion 1.4 checkpoint.
## Model Details
- **Developed by:** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** Apache 2.0
- **Resources for more information:** [GitHub Repository](https://github.com/TencentARC/T2I-Adapter), [Paper](https://arxiv.org/abs/2302.08453).
- **Cite as:**
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
### Checkpoints
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[TencentARC/t2iadapter_color_sd14v1](https://huggingface.co/TencentARC/t2iadapter_color_sd14v1)<br/> *Trained with spatial color palette* | A image with 8x8 color palette.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_output.png"/></a>|
|[TencentARC/t2iadapter_canny_sd14v1](https://huggingface.co/TencentARC/t2iadapter_canny_sd14v1)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_output.png"/></a>|
|[TencentARC/t2iadapter_sketch_sd14v1](https://huggingface.co/TencentARC/t2iadapter_sketch_sd14v1)<br/> *Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_output.png"/></a>|
|[TencentARC/t2iadapter_depth_sd14v1](https://huggingface.co/TencentARC/t2iadapter_depth_sd14v1)<br/> *Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_output.png"/></a>|
|[TencentARC/t2iadapter_openpose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_openpose_sd14v1)<br/> *Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_output.png"/></a>|
|[TencentARC/t2iadapter_keypose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_keypose_sd14v1)<br/> *Trained with mmpose skeleton image* | A [mmpose skeleton](https://github.com/open-mmlab/mmpose) image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_output.png"/></a>|
|[TencentARC/t2iadapter_seg_sd14v1](https://huggingface.co/TencentARC/t2iadapter_seg_sd14v1)<br/>*Trained with semantic segmentation* | An [custom](https://github.com/TencentARC/T2I-Adapter/discussions/25) segmentation protocol image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_output.png"/></a> |
|[TencentARC/t2iadapter_canny_sd15v2](https://huggingface.co/TencentARC/t2iadapter_canny_sd15v2)||
|[TencentARC/t2iadapter_depth_sd15v2](https://huggingface.co/TencentARC/t2iadapter_depth_sd15v2)||
|[TencentARC/t2iadapter_sketch_sd15v2](https://huggingface.co/TencentARC/t2iadapter_sketch_sd15v2)||
|[TencentARC/t2iadapter_zoedepth_sd15v1](https://huggingface.co/TencentARC/t2iadapter_zoedepth_sd15v1)||
## Example
1. Dependencies
```sh
pip install diffusers transformers controlnet_aux
```
2. Run code:
```python
from PIL import Image
from diffusers import T2IAdapter, StableDiffusionAdapterPipeline
import torch
from controlnet_aux import OpenposeDetector
openpose = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
image = Image.open('./images/openpose_input.png')
image = openpose(image)
image.save('./images/openpose.png')
adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_openpose_sd14v1", torch_dtype=torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", adapter=adapter, safety_checker=None, torch_dtype=torch.float16, variant="fp16"
)
pipe.to('cuda')
generator = torch.Generator().manual_seed(1)
openpose_out = pipe(prompt="iron man flying", image=image, generator=generator).images[0]
openpose_out.save('./images/openpose_out.png')
```


 | 7,870 | [
[
-0.0183563232421875,
-0.00933074951171875,
0.01904296875,
0.0263671875,
-0.03375244140625,
-0.0182037353515625,
-0.0008006095886230469,
-0.030181884765625,
0.01947021484375,
-0.0065765380859375,
-0.045135498046875,
-0.04302978515625,
-0.04937744140625,
-0.02... |
stablediffusionapi/leosams-instant-phot | 2023-07-26T08:58:31.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/leosams-instant-phot | 3 | 348 | diffusers | 2023-07-26T08:55:16 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# LEOSAM's Instant photo 拍立得/Polaroid LoRA & LoHA API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "leosams-instant-phot"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/leosams-instant-phot)
Model link: [View model](https://stablediffusionapi.com/models/leosams-instant-phot)
Credits: [View credits](https://civitai.com/?query=LEOSAM%27s%20Instant%20photo%20%E6%8B%8D%E7%AB%8B%E5%BE%97/Polaroid%20LoRA%20%26%20LoHA)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "leosams-instant-phot",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,588 | [
[
-0.03900146484375,
-0.055206298828125,
0.0255126953125,
0.0207061767578125,
-0.04315185546875,
0.001415252685546875,
0.027801513671875,
-0.046966552734375,
0.05194091796875,
0.036163330078125,
-0.05401611328125,
-0.056365966796875,
-0.0284271240234375,
0.009... |
cuixing/textual_inversion_object_style_vangogh08101212-newstyle | 2023-08-10T06:51:27.000Z | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | cuixing | null | null | cuixing/textual_inversion_object_style_vangogh08101212-newstyle | 0 | 348 | diffusers | 2023-08-10T04:12:51 |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - cuixing/textual_inversion_object_style_vangogh08101212-newstyle
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
| 450 | [
[
-0.01161956787109375,
-0.06744384765625,
0.02581787109375,
0.035614013671875,
-0.0248870849609375,
-0.0081329345703125,
0.00960540771484375,
0.00528717041015625,
0.001789093017578125,
0.055633544921875,
-0.0546875,
-0.0269927978515625,
-0.055877685546875,
-0... |
cross-encoder/quora-roberta-base | 2021-08-05T08:41:36.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | cross-encoder | null | null | cross-encoder/quora-roberta-base | 1 | 347 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
---
# Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
This model was trained on the [Quora Duplicate Questions](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) dataset. The model will predict a score between 0 and 1 how likely the two given questions are duplicates.
Note: The model is not suitable to estimate the similarity of questions, e.g. the two questions "How to learn Java" and "How to learn Python" will result in a rahter low score, as these are not duplicates.
## Usage and Performance
Pre-trained models can be used like this:
```
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Question 1', 'Question 2'), ('Question 3', 'Question 4')])
```
You can use this model also without sentence_transformers and by just using Transformers ``AutoModel`` class | 1,070 | [
[
-0.026824951171875,
-0.06695556640625,
0.012420654296875,
0.0099945068359375,
-0.02081298828125,
-0.00667572021484375,
0.01383209228515625,
-0.016021728515625,
0.009735107421875,
0.0472412109375,
-0.047607421875,
-0.024658203125,
-0.038421630859375,
0.026260... |
deepset/bert-base-german-cased-oldvocab | 2021-10-21T12:16:47.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"exbert",
"de",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | deepset | null | null | deepset/bert-base-german-cased-oldvocab | 3 | 347 | transformers | 2022-03-02T23:29:05 | ---
language: de
license: mit
thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
tags:
- exbert
---
<a href="https://huggingface.co/exbert/?model=bert-base-german-cased">
\t<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
# German BERT with old vocabulary
For details see the related [FARM issue](https://github.com/deepset-ai/FARM/issues/60).
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
| 1,313 | [
[
-0.02655029296875,
-0.05206298828125,
0.0202484130859375,
0.01145172119140625,
-0.007389068603515625,
-0.005580902099609375,
-0.0338134765625,
-0.034942626953125,
0.026763916015625,
0.0272674560546875,
-0.05169677734375,
-0.0653076171875,
-0.0191650390625,
-... |
sismetanin/sbert-ru-sentiment-rusentiment | 2021-05-20T06:38:36.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"endpoints_compatible",
"region:us"
] | text-classification | sismetanin | null | null | sismetanin/sbert-ru-sentiment-rusentiment | 0 | 347 | transformers | 2022-03-02T23:29:05 | ---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## SBERT-Large-Base-ru-sentiment-RuSentiment
SBERT-Large-ru-sentiment-RuSentiment is a [SBERT-Large](https://huggingface.co/sberbank-ai/sbert_large_nlu_ru) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-language posts from the largest Russian social network, VKontakte.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@inproceedings{rogers2018rusentiment,
title={RuSentiment: An enriched sentiment analysis dataset for social media in Russian},
author={Rogers, Anna and Romanov, Alexey and Rumshisky, Anna and Volkova, Svitlana and Gronas, Mikhail and Gribov, Alex},
booktitle={Proceedings of the 27th international conference on computational linguistics},
pages={755--763},
year={2018}
}
``` | 6,350 | [
[
-0.041595458984375,
-0.02606201171875,
0.003662109375,
0.0218658447265625,
-0.01849365234375,
0.0078887939453125,
-0.022186279296875,
-0.00595855712890625,
0.031707763671875,
-0.0041961669921875,
-0.053802490234375,
-0.023773193359375,
-0.048309326171875,
0.... |
superb/wav2vec2-base-superb-ic | 2021-09-02T22:03:59.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"speech",
"audio",
"en",
"dataset:superb",
"arxiv:2105.01051",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | superb | null | null | superb/wav2vec2-base-superb-ic | 0 | 347 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
license: apache-2.0
---
# Wav2Vec2-Base for Intent Classification
## Model description
This is a ported version of [S3PRL's Wav2Vec2 for the SUPERB Intent Classification task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/fluent_commands).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Intent Classification (IC) classifies utterances into predefined classes to determine the intent of
speakers. SUPERB uses the
[Fluent Speech Commands](https://fluent.ai/fluent-speech-commands-a-dataset-for-spoken-language-understanding-research/)
dataset, where each utterance is tagged with three intent labels: **action**, **object**, and **location**.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#ic-intent-classification---fluent-speech-commands).
## Usage examples
You can use the model directly like so:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
def map_to_array(example):
speech, _ = librosa.load(example["file"], sr=16000, mono=True)
example["speech"] = speech
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "ic", split="test")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ic")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ic")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
action_ids = torch.argmax(logits[:, :6], dim=-1).tolist()
action_labels = [model.config.id2label[_id] for _id in action_ids]
object_ids = torch.argmax(logits[:, 6:20], dim=-1).tolist()
object_labels = [model.config.id2label[_id + 6] for _id in object_ids]
location_ids = torch.argmax(logits[:, 20:24], dim=-1).tolist()
location_labels = [model.config.id2label[_id + 20] for _id in location_ids]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**test**| `0.9235` | `N/A` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` | 3,168 | [
[
-0.0152740478515625,
-0.033843994140625,
0.0185089111328125,
0.01146697998046875,
-0.0027923583984375,
-0.01477813720703125,
-0.0211029052734375,
-0.0309295654296875,
-0.02020263671875,
0.0269317626953125,
-0.045501708984375,
-0.051910400390625,
-0.0433349609375... |
TurkuNLP/bert-large-finnish-cased-v1 | 2022-06-10T08:46:17.000Z | [
"transformers",
"pytorch",
"fi",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | TurkuNLP | null | null | TurkuNLP/bert-large-finnish-cased-v1 | 1 | 347 | transformers | 2022-06-10T07:53:16 | ---
license: apache-2.0
language: fi
---
This is the large variant of FinBERT (TurkuNLP/bert-base-finnish-cased-v1). The training data is exactly the same. | 156 | [
[
-0.0230560302734375,
-0.041259765625,
0.016815185546875,
0.0214691162109375,
-0.00994873046875,
-0.01580810546875,
-0.023284912109375,
-0.00968170166015625,
0.049652099609375,
0.06890869140625,
-0.073974609375,
-0.035736083984375,
-0.033447265625,
-0.0006594... |
benjamin/wtp-bert-tiny | 2023-07-19T11:53:17.000Z | [
"transformers",
"pytorch",
"onnx",
"bert-char",
"token-classification",
"multilingual",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
... | token-classification | benjamin | null | null | benjamin/wtp-bert-tiny | 2 | 347 | transformers | 2023-04-19T19:11:36 | ---
license: mit
language:
- multilingual
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hu
- hy
- id
- ig
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- pa
- pl
- ps
- pt
- ro
- ru
- si
- sk
- sl
- sq
- sr
- sv
- ta
- te
- tg
- th
- tr
- uk
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
---
# wtp-bert-tiny
Model for [`wtpsplit`](https://github.com/bminixhofer/wtpsplit). | 549 | [
[
-0.03466796875,
-0.038238525390625,
0.027984619140625,
0.0297088623046875,
-0.03326416015625,
-0.0163116455078125,
-0.0030841827392578125,
-0.0196685791015625,
0.032073974609375,
0.021820068359375,
-0.052398681640625,
-0.004985809326171875,
-0.0260467529296875,
... |
digiplay/fantasticmix_v30_test | 2023-07-22T14:14:00.000Z | [
"diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/fantasticmix_v30_test | 2 | 347 | diffusers | 2023-05-26T18:00:10 | ---
license: other
tags:
- text-to-image
- diffusers
inference: true
---
fantasticmix
https://civitai.com/models/22402?modelVersionId=39880
Version 3

Original Author's image link: https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/60f70a04-59e8-496d-e139-495a3495b900/width=1024/20230408_165731_713069.jpeg | 438 | [
[
-0.04571533203125,
0.003631591796875,
0.03582763671875,
0.0295257568359375,
-0.03143310546875,
0.0026569366455078125,
0.035552978515625,
-0.0250701904296875,
0.053680419921875,
0.0626220703125,
-0.05157470703125,
-0.015960693359375,
-0.0303497314453125,
0.00... |
digiplay/majicMIXfantasy_v2 | 2023-06-19T19:09:35.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/majicMIXfantasy_v2 | 1 | 347 | diffusers | 2023-05-28T19:06:34 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
https://civitai.com/models/41865/majicmix-fantasy
Original Author's DEMO image :
 | 327 | [
[
-0.03106689453125,
-0.027313232421875,
0.0278778076171875,
0.02606201171875,
-0.0164642333984375,
0.0009098052978515625,
-0.001682281494140625,
-0.01280975341796875,
0.0599365234375,
0.06597900390625,
-0.08837890625,
-0.0282135009765625,
-0.0180511474609375,
... |
digiplay/K-main2.1 | 2023-06-30T04:53:50.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/K-main2.1 | 0 | 347 | diffusers | 2023-06-29T22:09:38 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/87906?modelVersionId=105253
Original Author's DEMO image :
 | 345 | [
[
-0.023956298828125,
-0.00380706787109375,
0.036468505859375,
0.0040435791015625,
-0.02362060546875,
-0.017578125,
0.022979736328125,
0.0003025531768798828,
0.042144775390625,
0.041534423828125,
-0.056396484375,
-0.0183258056640625,
-0.00043582916259765625,
-... |
Msalehi237/Artemiscoca2.1 | 2023-10-12T22:16:01.000Z | [
"open_clip",
"clip",
"zero-shot-image-classification",
"license:mit",
"region:us"
] | zero-shot-image-classification | Msalehi237 | null | null | Msalehi237/Artemiscoca2.1 | 0 | 347 | open_clip | 2023-10-12T22:14:35 | ---
tags:
- clip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: mit
---
# Model card for Artemiscoca2.1
| 135 | [
[
-0.025787353515625,
-0.01288604736328125,
0.020721435546875,
0.004535675048828125,
-0.07220458984375,
-0.021484375,
0.06463623046875,
-0.0249176025390625,
0.0307769775390625,
0.035003662109375,
-0.03485107421875,
-0.045928955078125,
-0.0237579345703125,
0.01... |
GAI-LLM/llama-2-koen-13b-mixed-v7 | 2023-11-03T06:50:46.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | GAI-LLM | null | null | GAI-LLM/llama-2-koen-13b-mixed-v7 | 0 | 347 | transformers | 2023-11-03T01:17:23 | ---
license: cc-by-nc-4.0
language:
- ko
library_name: transformers
pipeline_tag: text-generation
---
**The license is `cc-by-nc-4.0`.**
# **GAI-LLM/llama-2-koen-13b-mixed-v7**
## Model Details
**Model Developers** Donghoon Oh, Hanmin Myung, Eunyoung Kim (SK C&C G.AI Eng)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
GAI-LLM/llama-2-koen-13b-mixed-v7 is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model** [beomi/llama-2-koen-13b](https://huggingface.co/beomi/llama-2-koen-13b)
**Training Dataset**
- We combined Open Korean Dateset using mixed-strategy.
- Kopen-platypus + Koalpaca_v1.1 + kaist_cot_deepL + dolly_qa_task
- We use A100 GPU 80GB * 8, when training.
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
# Implementation Code
```python
### GAI-LLM/llama-2-koen-13b-mixed-v7
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "GAI-LLM/llama-2-koen-13b-mixed-v7"
model = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
``` | 1,332 | [
[
-0.0191650390625,
-0.054595947265625,
0.02154541015625,
0.047637939453125,
-0.045806884765625,
0.008392333984375,
-0.0059051513671875,
-0.0283203125,
0.0036258697509765625,
0.0264739990234375,
-0.05255126953125,
-0.04229736328125,
-0.04888916015625,
0.011856... |
Helsinki-NLP/opus-mt-de-ar | 2023-08-16T11:27:30.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"de",
"ar",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-de-ar | 0 | 346 | transformers | 2022-03-02T23:29:04 | ---
language:
- de
- ar
tags:
- translation
license: apache-2.0
---
### deu-ara
* source group: German
* target group: Arabic
* OPUS readme: [deu-ara](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/deu-ara/README.md)
* model: transformer-align
* source language(s): deu
* target language(s): afb apc ara ara_Latn arq arz
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/deu-ara/opus-2020-07-03.zip)
* test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/deu-ara/opus-2020-07-03.test.txt)
* test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/deu-ara/opus-2020-07-03.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.deu.ara | 19.7 | 0.486 |
### System Info:
- hf_name: deu-ara
- source_languages: deu
- target_languages: ara
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/deu-ara/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['de', 'ar']
- src_constituents: {'deu'}
- tgt_constituents: {'apc', 'ara', 'arq_Latn', 'arq', 'afb', 'ara_Latn', 'apc_Latn', 'arz'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/deu-ara/opus-2020-07-03.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/deu-ara/opus-2020-07-03.test.txt
- src_alpha3: deu
- tgt_alpha3: ara
- short_pair: de-ar
- chrF2_score: 0.486
- bleu: 19.7
- brevity_penalty: 0.993
- ref_len: 6324.0
- src_name: German
- tgt_name: Arabic
- train_date: 2020-07-03
- src_alpha2: de
- tgt_alpha2: ar
- prefer_old: False
- long_pair: deu-ara
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 2,245 | [
[
-0.032073974609375,
-0.05328369140625,
0.019439697265625,
0.021697998046875,
-0.036041259765625,
-0.01073455810546875,
-0.01520538330078125,
-0.0271453857421875,
0.01751708984375,
0.01549530029296875,
-0.040191650390625,
-0.05767822265625,
-0.050384521484375,
... |
PeggyWang/openjourney-v2 | 2023-02-20T05:38:42.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | PeggyWang | null | null | PeggyWang/openjourney-v2 | 10 | 346 | diffusers | 2023-02-20T05:38:42 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
pinned: true
duplicated_from: prompthero/openjourney-v2
---
# Openjourney v2 is an open source Stable Diffusion fine tuned model on +60k Midjourney images, by [PromptHero](https://prompthero.com/?utm_source=huggingface&utm_medium=referral)
This repo is for testing the first Openjourney fine tuned model.
It was trained over Stable Diffusion 1.5 with +60000 images, 4500 steps and 3 epochs.
So "mdjrny-v4 style" is not necessary anymore (yay!)
# Openjourney Links
- [Lora version](https://huggingface.co/prompthero/openjourney-lora)
- [Openjourney Dreambooth](https://huggingface.co/prompthero/openjourney) | 688 | [
[
-0.03741455078125,
-0.046356201171875,
0.037841796875,
0.0187225341796875,
-0.02471923828125,
-0.043975830078125,
0.008697509765625,
-0.015625,
0.01190185546875,
0.04608154296875,
-0.05535888671875,
-0.035430908203125,
-0.0240631103515625,
-0.03485107421875,... |
timm/dm_nfnet_f2.dm_in1k | 2023-03-24T00:52:11.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/dm_nfnet_f2.dm_in1k | 0 | 346 | timm | 2023-03-24T00:49:32 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for dm_nfnet_f2.dm_in1k
A NFNet (Normalization Free Network) image classification model. Trained on ImageNet-1k by paper authors.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 193.8
- GMACs: 33.8
- Activations (M): 41.8
- Image size: train = 256 x 256, test = 352 x 352
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/deepmind/deepmind-research/tree/master/nfnets
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('dm_nfnet_f2.dm_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dm_nfnet_f2.dm_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1536, 16, 16])
# torch.Size([1, 3072, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dm_nfnet_f2.dm_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 3072, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,746 | [
[
-0.0377197265625,
-0.03753662109375,
-0.003185272216796875,
0.01013946533203125,
-0.0277557373046875,
-0.02362060546875,
-0.0203704833984375,
-0.032562255859375,
0.0188140869140625,
0.034027099609375,
-0.03521728515625,
-0.04852294921875,
-0.05975341796875,
... |
timm/resnetblur50.bt_in1k | 2023-04-05T18:45:05.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1904.11486",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnetblur50.bt_in1k | 0 | 346 | timm | 2023-04-05T18:44:43 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnetblur50.bt_in1k
A ResNet-B (Triangle-3 Blur Pooling) image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Bag-of-Tricks recipe.
* SGD (w/ Nesterov) optimizer
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 5.2
- Activations (M): 12.0
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- Making Convolutional Networks Shift-Invariant Again: https://arxiv.org/abs/1904.11486
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetblur50.bt_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetblur50.bt_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetblur50.bt_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{zhang2019shiftinvar,
title={Making Convolutional Networks Shift-Invariant Again},
author={Zhang, Richard},
booktitle={ICML},
year={2019}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
| 38,796 | [
[
-0.06488037109375,
-0.0176239013671875,
0.00009250640869140625,
0.0290679931640625,
-0.032196044921875,
-0.0081329345703125,
-0.0094757080078125,
-0.032196044921875,
0.0849609375,
0.0207672119140625,
-0.048065185546875,
-0.039947509765625,
-0.04644775390625,
... |
facebook/mms-tts-tam | 2023-09-01T10:44:31.000Z | [
"transformers",
"pytorch",
"safetensors",
"vits",
"text-to-audio",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-to-speech | facebook | null | null | facebook/mms-tts-tam | 0 | 346 | transformers | 2023-09-01T10:44:07 |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Tamil Text-to-Speech
This repository contains the **Tamil (tam)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-tam")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-tam")
text = "some example text in the Tamil language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output, rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
| 3,966 | [
[
-0.02197265625,
-0.06134033203125,
0.01117706298828125,
0.031524658203125,
-0.0117645263671875,
-0.0023040771484375,
-0.021087646484375,
-0.01384735107421875,
0.026153564453125,
0.015960693359375,
-0.05450439453125,
-0.031951904296875,
-0.045196533203125,
0.... |
cepiloth/ko-llama2-13b-finetune-ex | 2023-11-02T08:13:13.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | cepiloth | null | null | cepiloth/ko-llama2-13b-finetune-ex | 0 | 346 | transformers | 2023-11-02T07:34:51 | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
---
# Model Trained Using AutoTrain | 120 | [
[
-0.002300262451171875,
0.01140594482421875,
0.00653839111328125,
0.01319122314453125,
-0.0217437744140625,
0.0012025833129882812,
0.0394287109375,
-0.0081634521484375,
-0.0173187255859375,
0.01898193359375,
-0.03948974609375,
0.01512908935546875,
-0.044982910156... |
filco306/gpt2-base-style-paraphraser | 2021-08-28T19:27:41.000Z | [
"transformers",
"pytorch",
"text-generation",
"arxiv:2010.05700",
"endpoints_compatible",
"region:us"
] | text-generation | filco306 | null | null | filco306/gpt2-base-style-paraphraser | 4 | 345 | transformers | 2022-03-02T23:29:05 | # GPT2 base style transfer paraphraser
This is the trained base-model from the paper [Reformulating Unsupervised Style Transfer as Paraphrase Generation](https://arxiv.org/abs/2010.05700) by Krishna K. et al. Note that I (the uploader) am not the author of the paper. Permission to upload to Huggingface was given by the main author.
## Citation
If you found this model useful, please cite the original work:
```
@inproceedings{style20,
author={Kalpesh Krishna and John Wieting and Mohit Iyyer},
Booktitle = {Empirical Methods in Natural Language Processing},
Year = "2020",
Title={Reformulating Unsupervised Style Transfer as Paraphrase Generation},
}
``` | 660 | [
[
0.00414276123046875,
-0.0540771484375,
0.031036376953125,
0.00307464599609375,
-0.030548095703125,
-0.0207672119140625,
-0.00778961181640625,
-0.0157928466796875,
0.005474090576171875,
0.056793212890625,
-0.0224761962890625,
-0.0047454833984375,
-0.0541381835937... |
google/switch-base-256 | 2023-01-24T17:20:05.000Z | [
"transformers",
"pytorch",
"switch_transformers",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2101.03961",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | google | null | null | google/switch-base-256 | 2 | 345 | transformers | 2022-11-04T07:59:33 | ---
language:
- en
tags:
- text2text-generation
widget:
- text: "The <extra_id_0> walks in <extra_id_1> park"
example_title: "Masked Language Modeling"
datasets:
- c4
license: apache-2.0
---
# Model Card for Switch Transformers Base - 256 experts

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
# TL;DR
Switch Transformers is a Mixture of Experts (MoE) model trained on Masked Language Modeling (MLM) task. The model architecture is similar to the classic T5, but with the Feed Forward layers replaced by the Sparse MLP layers containing "experts" MLP. According to the [original paper](https://arxiv.org/pdf/2101.03961.pdf) the model enables faster training (scaling properties) while being better than T5 on fine-tuned tasks.
As mentioned in the first few lines of the abstract :
> we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus”, and achieve a 4x speedup over the T5-XXL model.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [original paper](https://arxiv.org/pdf/2101.03961.pdf).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Related Models:** [All Switch Transformers Checkpoints](https://huggingface.co/models?search=switch)
- **Original Checkpoints:** [All Original Switch Transformers Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#mixture-of-experts-moe-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2101.03961.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face Switch Transformers Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/switch_transformers)
# Usage
Note that these checkpoints has been trained on Masked-Language Modeling (MLM) task. Therefore the checkpoints are not "ready-to-use" for downstream tasks. You may want to check `FLAN-T5` for running fine-tuned weights or fine-tune your own MoE following [this notebook](https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing)
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-256")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-256")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-256")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-256", device_map="auto")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-256")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-256", device_map="auto", torch_dtype=torch.float16)
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-256")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-256", device_map="auto")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
# Uses
## Direct Use and Downstream Use
See the [research paper](https://arxiv.org/pdf/2101.03961.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Ethical considerations and risks
More information needed.
## Known Limitations
More information needed.
## Sensitive Use:
More information needed.
# Training Details
## Training Data
The model was trained on a Masked Language Modeling task, on Colossal Clean Crawled Corpus (C4) dataset, following the same procedure as `T5`.
## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2101.03961.pdf) the model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks and compared the results against T5. See the table below for some quantitative evaluation:

For full details, please check the [research paper](https://arxiv.org/pdf/2101.03961.pdf).
## Results
For full results for Switch Transformers, see the [research paper](https://arxiv.org/pdf/2101.03961.pdf), Table 5.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2101.03961,
doi = {10.48550/ARXIV.2101.03961},
url = {https://arxiv.org/abs/2101.03961},
author = {Fedus, William and Zoph, Barret and Shazeer, Noam},
keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity},
publisher = {arXiv},
year = {2021},
copyright = {arXiv.org perpetual, non-exclusive license}
}
``` | 8,220 | [
[
-0.036041259765625,
-0.03192138671875,
0.0145263671875,
0.015106201171875,
-0.0066680908203125,
0.0039215087890625,
-0.01090240478515625,
-0.0308074951171875,
-0.0030002593994140625,
0.027496337890625,
-0.044189453125,
-0.0225067138671875,
-0.05810546875,
0.... |
timm/eva02_small_patch14_224.mim_in22k | 2023-03-31T05:47:11.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2303.11331",
"arxiv:2303.15389",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/eva02_small_patch14_224.mim_in22k | 0 | 345 | timm | 2023-03-31T04:55:19 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
---
# Model card for eva02_small_patch14_224.mim_in22k
An EVA02 feature / representation model. Pretrained on ImageNet-22k with masked image modeling (using EVA-CLIP as a MIM teacher) by paper authors.
EVA-02 models are vision transformers with mean pooling, SwiGLU, Rotary Position Embeddings (ROPE), and extra LN in MLP (for Base & Large).
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 21.6
- GMACs: 6.1
- Activations (M): 18.3
- Image size: 224 x 224
- **Papers:**
- EVA-02: A Visual Representation for Neon Genesis: https://arxiv.org/abs/2303.11331
- EVA-CLIP: Improved Training Techniques for CLIP at Scale: https://arxiv.org/abs/2303.15389
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/Yuxin-CV/EVA-02
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva02_small_patch14_224.mim_in22k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva02_small_patch14_224.mim_in22k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 257, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA02,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Fang, Yuxin and Sun, Quan and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.11331},
year={2023}
}
```
```bibtex
@article{EVA-CLIP,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.15389},
year={2023}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,282 | [
[
-0.045440673828125,
-0.029632568359375,
0.01462554931640625,
0.00749969482421875,
-0.0168609619140625,
0.0009331703186035156,
-0.0096893310546875,
-0.03289794921875,
0.04132080078125,
0.0266571044921875,
-0.03375244140625,
-0.050811767578125,
-0.0433349609375,
... |
tonyassi/tony-dreambooth-1-0 | 2023-09-09T04:51:06.000Z | [
"diffusers",
"text-to-image",
"autotrain",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | tonyassi | null | null | tonyassi/tony-dreambooth-1-0 | 4 | 345 | diffusers | 2023-09-09T04:28:17 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: tony assi fashion
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
| 230 | [
[
0.004848480224609375,
-0.011810302734375,
0.0156097412109375,
0.0089569091796875,
-0.036346435546875,
0.06683349609375,
0.01294708251953125,
-0.013519287109375,
0.035552978515625,
-0.00022685527801513672,
-0.03582763671875,
-0.002941131591796875,
-0.059753417968... |
nvidia/segformer-b0-finetuned-cityscapes-768-768 | 2022-08-09T11:33:19.000Z | [
"transformers",
"pytorch",
"tf",
"segformer",
"vision",
"image-segmentation",
"dataset:cityscapes",
"arxiv:2105.15203",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | nvidia | null | null | nvidia/segformer-b0-finetuned-cityscapes-768-768 | 0 | 344 | transformers | 2022-03-02T23:29:05 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://cdn-media.huggingface.co/Inference-API/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.png
example_title: Road
---
# SegFormer (b0-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 768x768. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-768-768")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-768-768")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
| 3,130 | [
[
-0.06597900390625,
-0.053497314453125,
0.0170745849609375,
0.01812744140625,
-0.021759033203125,
-0.025848388671875,
-0.0003178119659423828,
-0.050262451171875,
0.02215576171875,
0.04473876953125,
-0.0625,
-0.044952392578125,
-0.05169677734375,
0.01076507568... |
timm/vit_base_patch32_clip_224.laion2b_ft_in1k | 2023-05-06T00:03:52.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:laion-2b",
"arxiv:2212.07143",
"arxiv:2210.08402",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch32_clip_224.laion2b_ft_in1k | 0 | 344 | timm | 2022-11-01T23:00:20 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- laion-2b
---
# Model card for vit_base_patch32_clip_224.laion2b_ft_in1k
A Vision Transformer (ViT) image classification model. Pretrained on LAION-2B image-text pairs using OpenCLIP. Fine-tuned on ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.2
- GMACs: 4.4
- Activations (M): 4.2
- Image size: 224 x 224
- **Papers:**
- OpenCLIP: https://github.com/mlfoundations/open_clip
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- LAION-2B
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch32_clip_224.laion2b_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch32_clip_224.laion2b_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,687 | [
[
-0.0287628173828125,
-0.0279541015625,
0.01016998291015625,
0.0095367431640625,
-0.02703857421875,
-0.0335693359375,
-0.0330810546875,
-0.0299072265625,
0.007785797119140625,
0.0269012451171875,
-0.0300445556640625,
-0.042877197265625,
-0.051361083984375,
-0... |
unstructuredio/donut-base-sroie | 2022-12-01T20:45:49.000Z | [
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | null | unstructuredio | null | null | unstructuredio/donut-base-sroie | 1 | 344 | transformers | 2022-12-01T15:48:28 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-sroie-long
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie-long
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.7.0
- Tokenizers 0.11.0
| 1,069 | [
[
-0.0225677490234375,
-0.0443115234375,
0.0123291015625,
0.00435638427734375,
-0.0257110595703125,
-0.0194854736328125,
-0.0154571533203125,
-0.00974273681640625,
0.01308441162109375,
0.036956787109375,
-0.03582763671875,
-0.03973388671875,
-0.049346923828125,
... |
timm/resnet18.a2_in1k | 2023-04-05T18:03:09.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet18.a2_in1k | 0 | 344 | timm | 2023-04-05T18:03:01 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnet18.a2_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* ResNet Strikes Back `A2` recipe
* LAMB optimizer with BCE loss
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.7
- GMACs: 1.8
- Activations (M): 2.5
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet18.a2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.a2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.a2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
| 38,401 | [
[
-0.065673828125,
-0.0174713134765625,
0.0016927719116210938,
0.02899169921875,
-0.031585693359375,
-0.00928497314453125,
-0.00995635986328125,
-0.0305328369140625,
0.08648681640625,
0.0220794677734375,
-0.049774169921875,
-0.039276123046875,
-0.046112060546875,
... |
timm/dpn92.mx_in1k | 2023-04-21T21:57:43.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1707.01629",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/dpn92.mx_in1k | 0 | 344 | timm | 2023-04-21T21:57:12 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for dpn92.mx_in1k
A DPN (Dual-Path Net) image classification model. Trained on ImageNet-1k in MXNet by paper authors and ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 37.7
- GMACs: 6.5
- Activations (M): 18.2
- Image size: 224 x 224
- **Papers:**
- Dual Path Networks: https://arxiv.org/abs/1707.01629
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/cypw/DPNs
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('dpn92.mx_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dpn92.mx_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 336, 56, 56])
# torch.Size([1, 704, 28, 28])
# torch.Size([1, 1552, 14, 14])
# torch.Size([1, 2688, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dpn92.mx_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2688, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{Chen2017,
title={Dual Path Networks},
author={Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng},
journal={arXiv preprint arXiv:1707.01629},
year={2017}
}
```
| 3,408 | [
[
-0.025421142578125,
-0.030731201171875,
0.007450103759765625,
0.01529693603515625,
-0.02642822265625,
-0.01666259765625,
-0.0113067626953125,
-0.0158843994140625,
0.02252197265625,
0.034515380859375,
-0.043182373046875,
-0.047576904296875,
-0.054443359375,
-... |
unikei/t5-base-split-and-rephrase | 2023-09-13T08:57:43.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"split and rephrase",
"en",
"dataset:wiki_split",
"dataset:web_split",
"license:bigscience-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | unikei | null | null | unikei/t5-base-split-and-rephrase | 4 | 344 | transformers | 2023-05-19T11:25:06 | ---
license: bigscience-openrail-m
tags:
- split and rephrase
widget:
- text: >-
Cystic Fibrosis (CF) is an autosomal recessive disorder that affects
multiple organs, which is common in the Caucasian population,
symptomatically affecting 1 in 2500 newborns in the UK, and more than 80,000
individuals globally.
datasets:
- wiki_split
- web_split
language:
- en
---
# T5 model for splitting complex sentences to simple sentences in English
Split-and-rephrase is the task of splitting a complex input sentence into shorter sentences while preserving meaning. (Narayan et al., 2017)
E.g.:
```
Cystic Fibrosis (CF) is an autosomal recessive disorder that affects multiple organs,
which is common in the Caucasian population, symptomatically affecting 1 in 2500 newborns in the UK,
and more than 80,000 individuals globally.
```
could be split into
```
Cystic Fibrosis is an autosomal recessive disorder that affects multiple organs.
```
```
Cystic Fibrosis is common in the Caucasian population.
```
```
Cystic Fibrosis affects 1 in 2500 newborns in the UK.
```
```
Cystic Fibrosis affects more than 80,000 individuals globally.
```
## How to use it in your code:
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
checkpoint="unikei/t5-base-split-and-rephrase"
tokenizer = T5Tokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint)
complex_sentence = "Cystic Fibrosis (CF) is an autosomal recessive disorder that \
affects multiple organs, which is common in the Caucasian \
population, symptomatically affecting 1 in 2500 newborns in \
the UK, and more than 80,000 individuals globally."
complex_tokenized = tokenizer(complex_sentence,
padding="max_length",
truncation=True,
max_length=256,
return_tensors='pt')
simple_tokenized = model.generate(complex_tokenized['input_ids'], attention_mask = complex_tokenized['attention_mask'], max_length=256, num_beams=5)
simple_sentences = tokenizer.batch_decode(simple_tokenized, skip_special_tokens=True)
print(simple_sentences)
"""
Output:
Cystic Fibrosis is an autosomal recessive disorder that affects multiple organs. Cystic Fibrosis is common in the Caucasian population. Cystic Fibrosis affects 1 in 2500 newborns in the UK. Cystic Fibrosis affects more than 80,000 individuals globally.
"""
```
| 2,471 | [
[
-0.017181396484375,
-0.045440673828125,
0.03326416015625,
0.033905029296875,
-0.026458740234375,
0.000988006591796875,
-0.0023956298828125,
-0.0297088623046875,
0.00418853759765625,
0.0080718994140625,
-0.05828857421875,
-0.047149658203125,
-0.0517578125,
0.... |
digiplay/helloRealisticMan_v1.0beta | 2023-07-24T22:16:05.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/helloRealisticMan_v1.0beta | 2 | 344 | diffusers | 2023-07-24T22:01:31 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/115278/hellorealisticman
Original Author's DEMO image :
 | 489 | [
[
-0.032196044921875,
-0.0543212890625,
0.0291595458984375,
0.0008230209350585938,
-0.025848388671875,
-0.0186309814453125,
0.029083251953125,
-0.036376953125,
0.06304931640625,
0.052490234375,
-0.05145263671875,
-0.037933349609375,
-0.0286102294921875,
-0.016... |
TheBloke/Amethyst-13B-Mistral-GPTQ | 2023-10-04T18:00:57.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"nsfw",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Amethyst-13B-Mistral-GPTQ | 9 | 344 | transformers | 2023-10-04T17:29:46 | ---
base_model: Undi95/Amethyst-13B-Mistral
inference: false
license: cc-by-nc-4.0
model_creator: Undi
model_name: Amethyst 13B Mistral
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- not-for-all-audiences
- nsfw
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Amethyst 13B Mistral - GPTQ
- Model creator: [Undi](https://huggingface.co/Undi95)
- Original model: [Amethyst 13B Mistral](https://huggingface.co/Undi95/Amethyst-13B-Mistral)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Undi's Amethyst 13B Mistral](https://huggingface.co/Undi95/Amethyst-13B-Mistral).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GGUF)
* [Undi's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/Amethyst-13B-Mistral)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-nc-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Undi's Amethyst 13B Mistral](https://huggingface.co/Undi95/Amethyst-13B-Mistral).
<!-- licensing end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 14.54 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Amethyst-13B-Mistral-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Amethyst-13B-Mistral-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Amethyst-13B-Mistral-GPTQ`:
```shell
mkdir Amethyst-13B-Mistral-GPTQ
huggingface-cli download TheBloke/Amethyst-13B-Mistral-GPTQ --local-dir Amethyst-13B-Mistral-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Amethyst-13B-Mistral-GPTQ
huggingface-cli download TheBloke/Amethyst-13B-Mistral-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Amethyst-13B-Mistral-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Amethyst-13B-Mistral-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Amethyst-13B-Mistral-GPTQ --local-dir Amethyst-13B-Mistral-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Amethyst-13B-Mistral-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Amethyst-13B-Mistral-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Amethyst-13B-Mistral-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Amethyst-13B-Mistral-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Amethyst-13B-Mistral-GPTQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Amethyst-13B-Mistral-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Undi's Amethyst 13B Mistral
[THIS WAS A TEST, BUT PEOPLE LIKE IT, SO I ADD IT OFFICIALLY TO MY PROJECTS]

An attempt using [BlockMerge_Gradient](https://github.com/Gryphe/BlockMerge_Gradient) to get better result.
In addition, [LimaRP v3](https://huggingface.co/lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT) was used, is it recommanded to read the documentation.
The [llama2-to-mistral-diff](https://huggingface.co/Undi95/llama2-to-mistral-diff) was used on it at weight "1".
<!-- description start -->
## Description
This repo contains fp16 files of Amethyst-13B-Mistral.
<!-- description end -->
<!-- description start -->
## Models and loras used
- Xwin-LM/Xwin-LM-13B-V0.1
- The-Face-Of-Goonery/Huginn-13b-FP16
- zattio770/120-Days-of-LORA-v2-13B
- lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT
- Undi95/llama2-to-mistral-diff
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## LimaRP v3 usage and suggested settings

You can follow these instruction format settings in SillyTavern. Replace tiny with your desired response length:

Special thanks to Sushi.
If you want to support me, you can [here](https://ko-fi.com/undiai).
| 21,488 | [
[
-0.03472900390625,
-0.0552978515625,
0.012176513671875,
0.019378662109375,
-0.0236358642578125,
-0.013275146484375,
0.00724029541015625,
-0.044189453125,
0.01085662841796875,
0.030059814453125,
-0.0501708984375,
-0.03875732421875,
-0.02740478515625,
-0.00754... |
normalcomputing/extended-mind-mpt-7b | 2023-10-31T17:28:15.000Z | [
"transformers",
"pytorch",
"extended-mpt",
"text-generation",
"custom_code",
"region:us"
] | text-generation | normalcomputing | null | null | normalcomputing/extended-mind-mpt-7b | 15 | 344 | transformers | 2023-10-20T19:07:49 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Extended-Mind-MPT-7b
<!-- Provide a quick summary of what the model is/does. -->
Extended Mind MPT-7b, as described in [Supersizing Transformers](https://blog.normalcomputing.ai/posts/2023-09-12-supersizing-transformers/supersizing-transformers.html).
### Model Description
<!-- Provide a longer summary of what this model is. -->
This model implements active externalism for MPT's 7b model. The model weights have not been edited. Original architecture and code by Mosaic ML.
For more details on active externalism, check out our [blog](https://blog.normalcomputing.ai/posts/2023-09-12-supersizing-transformers/supersizing-transformers.html)!
- **Developed by:** [Normal Computing](https://huggingface.co/normalcomputing), Adapted from [Mosacic ML](https://huggingface.co/mosaicml)
- **License:** Apache 2.0
## Limitations
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model is part of ongoing research at Normal Computing.
| 1,261 | [
[
-0.04949951171875,
-0.03607177734375,
0.0413818359375,
0.035858154296875,
-0.036285400390625,
-0.03192138671875,
-0.0087432861328125,
-0.04107666015625,
0.0220947265625,
0.0386962890625,
-0.05450439453125,
0.00836181640625,
-0.036224365234375,
-0.01411437988... |
llmware/bling-sheared-llama-1.3b-0.1 | 2023-11-04T14:26:50.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | llmware | null | null | llmware/bling-sheared-llama-1.3b-0.1 | 12 | 344 | transformers | 2023-10-22T17:03:12 | ---
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
bling-sheared-llama-1.3b-0.1 is part of the BLING ("Best Little Instruction-following No-GPU-required") model series, instruct trained on top of a Sheared-LLaMA-1.3B base model.
BLING models are fine-tuned with distilled high-quality custom instruct datasets, targeted at a specific subset of instruct tasks with
the objective of providing a high-quality Instruct model that is 'inference-ready' on a CPU laptop even
without using any advanced quantization optimizations.
### Benchmark Tests
Evaluated against the benchmark test: [RAG-Instruct-Benchmark-Tester](https://www.huggingface.co/datasets/llmware/rag_instruct_benchmark_tester)
Average of 2 Test Runs with 1 point for correct answer, 0.5 point for partial correct or blank / NF, 0.0 points for incorrect, and -1 points for hallucinations.
--**Accuracy Score**: **84.50** correct out of 100
--Not Found Classification: 20.0%
--Boolean: 66.25%
--Math/Logic: 9.4%
--Complex Questions (1-5): 1 (Low)
--Summarization Quality (1-5): 3 (Coherent, extractive)
--Hallucinations: No hallucinations observed in test runs.
For test run results (and good indicator of target use cases), please see the files ("core_rag_test" and "answer_sheet" in this repo).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** llmware
- **Model type:** Instruct-trained decoder
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model [optional]:** princeton-nlp/Sheared-LLaMA-1.3B
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
The intended use of BLING models is two-fold:
1. Provide high-quality Instruct models that can run on a laptop for local testing. We have found it extremely useful when building a
proof-of-concept, or working with sensitive enterprise data that must be closely guarded, especially in RAG use cases.
2. Push the state of the art for smaller Instruct-following models in the sub-7B parameter range, especially 1B-3B, as single-purpose
automation tools for specific tasks through targeted fine-tuning datasets and focused "instruction" tasks.
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
BLING is designed for enterprise automation use cases, especially in knowledge-intensive industries, such as financial services,
legal and regulatory industries with complex information sources. Rather than try to be "all things to all people," BLING models try to focus on a narrower set of Instructions more suitable to a ~1B parameter GPT model.
BLING is ideal for rapid prototyping, testing, and the ability to perform an end-to-end workflow locally on a laptop without
having to send sensitive information over an Internet-based API.
The first BLING models have been trained for common RAG scenarios, specifically: question-answering, key-value extraction, and basic summarization as the core instruction types
without the need for a lot of complex instruction verbiage - provide a text passage context, ask questions, and get clear fact-based responses.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Any model can provide inaccurate or incomplete information, and should be used in conjunction with appropriate safeguards and fact-checking mechanisms.
## How to Get Started with the Model
The fastest way to get started with BLING is through direct import in transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llmware/bling-sheared-llama-1.3b-0.1")
model = AutoModelForCausalLM.from_pretrained("llmware/bling-sheared-llama-1.3b-0.1")
The BLING model was fine-tuned with a simple "\<human> and \<bot> wrapper", so to get the best results, wrap inference entries as:
full_prompt = "\<human>\: " + my_prompt + "\n" + "\<bot>\:"
The BLING model was fine-tuned with closed-context samples, which assume generally that the prompt consists of two sub-parts:
1. Text Passage Context, and
2. Specific question or instruction based on the text passage
To get the best results, package "my_prompt" as follows:
my_prompt = {{text_passage}} + "\n" + {{question/instruction}}
## Citation [optional]
This BLING model was built on top of a "Sheared Llama" model base - for more information about the "Sheared Llama" model, please see the paper referenced below:
@article{xia2023sheared,
title={Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning},
author={Xia, Mengzhou and Gao, Tianyu, and Zeng Zhiyuan, and Chen Danqi},
year={2023}
}
## Model Card Contact
Darren Oberst & llmware team
Please reach out anytime if you are interested in this project!
| 5,041 | [
[
-0.0177459716796875,
-0.0750732421875,
0.00664520263671875,
0.0335693359375,
-0.023834228515625,
0.0006785392761230469,
0.0007939338684082031,
-0.043975830078125,
-0.007175445556640625,
0.03228759765625,
-0.038909912109375,
-0.0251922607421875,
-0.03607177734375... |
Rifky/Indobert-QA | 2023-03-17T03:17:54.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"question-answering",
"indobert",
"indolem",
"id",
"dataset:220M words (IndoWiki, IndoWC, News)",
"dataset:Squad 2.0 (Indonesian translated)",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | Rifky | null | null | Rifky/Indobert-QA | 6 | 343 | transformers | 2022-03-02T23:29:04 | ---
language: id
tags:
- indobert
- indolem
license: apache-2.0
datasets:
- 220M words (IndoWiki, IndoWC, News)
- Squad 2.0 (Indonesian translated)
widget:
- text: kapan pangeran diponegoro lahir?
context: Pangeran Harya Dipanegara (atau biasa dikenal dengan nama Pangeran Diponegoro,
lahir di Ngayogyakarta Hadiningrat, 11 November 1785 – meninggal di Makassar,
Hindia Belanda, 8 Januari 1855 pada umur 69 tahun) adalah salah seorang pahlawan
nasional Republik Indonesia, yang memimpin Perang Diponegoro atau Perang Jawa
selama periode tahun 1825 hingga 1830 melawan pemerintah Hindia Belanda. Sejarah
mencatat, Perang Diponegoro atau Perang Jawa dikenal sebagai perang yang menelan
korban terbanyak dalam sejarah Indonesia, yakni 8.000 korban serdadu Hindia Belanda,
7.000 pribumi, dan 200 ribu orang Jawa serta kerugian materi 25 juta Gulden.
---
[Github](https://github.com/rifkybujana/IndoBERT-QA)
This project is part of my research with my friend Muhammad Fajrin Buyang Daffa entitled "Teman Belajar : Asisten Digital Pelajar SMA Negeri 28 Jakarta dalam Membaca" for KOPSI (Kompetisi Penelitian Siswa Indonesia/Indonesian Student Research Competition).
## indoBERT Base-Uncased fine-tuned on Translated Squad v2.0
[IndoBERT](https://huggingface.co/indolem/indobert-base-uncased) trained by [IndoLEM](https://indolem.github.io/) and fine-tuned on [Translated SQuAD 2.0](https://github.com/Wikidepia/indonesian_datasets/tree/master/question-answering/squad) for **Q&A** downstream task.
**Model Size** (after training): 420mb
## Details of indoBERT (from their documentation)
[IndoBERT](https://huggingface.co/indolem/indobert-base-uncased) is the Indonesian version of BERT model. We train the model using over 220M words, aggregated from three main sources:
- Indonesian Wikipedia (74M words)
- news articles from Kompas, Tempo (Tala et al., 2003), and Liputan6 (55M words in total)
- an Indonesian Web Corpus (Medved and Suchomel, 2017) (90M words).
We trained the model for 2.4M steps (180 epochs) with the final perplexity over the development set being 3.97 (similar to English BERT-base).
This IndoBERT was used to examine IndoLEM - an Indonesian benchmark that comprises of seven tasks for the Indonesian language, spanning morpho-syntax, semantics, and discourse.[[1]](#1)
## Details of the downstream task (Q&A) - Dataset
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model Training
The model was trained on a Tesla T4 GPU and 12GB of RAM.
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **51.61** |
| **F1** | **69.09** |
## Simple Usage
```py
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="Rifky/Indobert-QA",
tokenizer="Rifky/Indobert-QA"
)
qa_pipeline({
'context': """Pangeran Harya Dipanegara (atau biasa dikenal dengan nama Pangeran Diponegoro, lahir di Ngayogyakarta Hadiningrat, 11 November 1785 – meninggal di Makassar, Hindia Belanda, 8 Januari 1855 pada umur 69 tahun) adalah salah seorang pahlawan nasional Republik Indonesia, yang memimpin Perang Diponegoro atau Perang Jawa selama periode tahun 1825 hingga 1830 melawan pemerintah Hindia Belanda. Sejarah mencatat, Perang Diponegoro atau Perang Jawa dikenal sebagai perang yang menelan korban terbanyak dalam sejarah Indonesia, yakni 8.000 korban serdadu Hindia Belanda, 7.000 pribumi, dan 200 ribu orang Jawa serta kerugian materi 25 juta Gulden.""",
'question': "kapan pangeran diponegoro lahir?"
})
```
*output:*
```py
{
'answer': '11 November 1785',
'end': 131,
'score': 0.9272009134292603,
'start': 115
}
```
### Reference
<a id="1">[1]</a>Fajri Koto and Afshin Rahimi and Jey Han Lau and Timothy Baldwin. 2020. IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP. Proceedings of the 28th COLING. | 4,280 | [
[
-0.034820556640625,
-0.058624267578125,
0.007110595703125,
0.037628173828125,
-0.0212249755859375,
-0.0091094970703125,
-0.016998291015625,
-0.0265655517578125,
0.0236358642578125,
0.027862548828125,
-0.041412353515625,
-0.016021728515625,
-0.034576416015625,
... |
ahmedrachid/FinancialBERT | 2022-02-07T15:00:03.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | ahmedrachid | null | null | ahmedrachid/FinancialBERT | 13 | 343 | transformers | 2022-03-02T23:29:05 | ---
language: en
widget:
- text: Tesla remains one of the highest [MASK] stocks on the market. Meanwhile, Aurora Innovation is a pre-revenue upstart that shows promise.
- text: Asian stocks [MASK] from a one-year low on Wednesday as U.S. share futures and oil recovered from the previous day's selloff, but uncertainty over the impact of the Omicron
- text: U.S. stocks were set to rise on Monday, led by [MASK] in Apple which neared $3 trillion in market capitalization, while investors braced for a Federal Reserve meeting later this week.
tags:
- fill-mask
---
**FinancialBERT** is a BERT model pre-trained on a large corpora of financial texts. The purpose is to enhance financial NLP research and practice in financial domain, hoping that financial practitioners and researchers can benefit from it without the necessity of the significant computational resources required to train the model.
The model was trained on a large corpus of financial texts:
- *TRC2-financial*: 1.8M news articles that were published by Reuters between 2008 and 2010.
- *Bloomberg News*: 400,000 articles between 2006 and 2013.
- *Corporate Reports*: 192,000 transcripts (10-K & 10-Q)
- *Earning Calls*: 42,156 documents.
More details on `FinancialBERT` can be found at: https://www.researchgate.net/publication/358284785_FinancialBERT_-_A_Pretrained_Language_Model_for_Financial_Text_Mining
> Created by [Ahmed Rachid Hazourli](https://www.linkedin.com/in/ahmed-rachid/)
| 1,465 | [
[
-0.01486968994140625,
-0.04022216796875,
0.002483367919921875,
0.0482177734375,
-0.00666046142578125,
0.02093505859375,
-0.016815185546875,
-0.035919189453125,
0.01049041748046875,
0.03875732421875,
-0.0311431884765625,
-0.058135986328125,
-0.045440673828125,
... |
timm/regnetx_004.pycls_in1k | 2023-03-21T06:31:11.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2003.13678",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/regnetx_004.pycls_in1k | 0 | 343 | timm | 2023-03-21T06:31:04 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for regnetx_004.pycls_in1k
A RegNetX-400MF image classification model. Pretrained on ImageNet-1k by paper authors.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 5.2
- GMACs: 0.4
- Activations (M): 3.1
- Image size: 224 x 224
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/pycls
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnetx_004.pycls_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_004.pycls_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 32, 56, 56])
# torch.Size([1, 64, 28, 28])
# torch.Size([1, 160, 14, 14])
# torch.Size([1, 384, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_004.pycls_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 384, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,490 | [
[
-0.059539794921875,
-0.01505279541015625,
-0.0120849609375,
0.0367431640625,
-0.03173828125,
-0.00748443603515625,
-0.012908935546875,
-0.037872314453125,
0.07525634765625,
0.006626129150390625,
-0.051788330078125,
-0.0380859375,
-0.04742431640625,
0.0049476... |
xyn-ai/openjourney | 2023-03-23T04:20:21.000Z | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | xyn-ai | null | null | xyn-ai/openjourney | 0 | 343 | diffusers | 2023-03-23T04:20:20 | ---
inference: true
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
duplicated_from: prompthero/openjourney
---
# Openjourney is an open source Stable Diffusion fine tuned model on Midjourney images, by [PromptHero](https://prompthero.com/poolsuite-diffusion-prompts?utm_source=huggingface&utm_medium=referral)
Include **'mdjrny-v4 style'** in prompt. Here you'll find hundreds of [Openjourney prompts](https://prompthero.com/openjourney-prompts?utm_source=huggingface&utm_medium=referral)
# Openjourney Links
- [Lora version](https://huggingface.co/prompthero/openjourney-lora)
- [Openjourney v4](https://huggingface.co/prompthero/openjourney-v2)
# Want to learn AI art generation?:
- [Crash course in AI art generation](https://prompthero.com/academy/prompt-engineering-course?utm_source=huggingface&utm_medium=referral)
- [Learn to fine-tune Stable Diffusion for photorealism](https://prompthero.com/academy/dreambooth-stable-diffusion-train-fine-tune-course?utm_source=huggingface&utm_medium=referral)
# Use it for free:
[](https://huggingface.co/spaces/akhaliq/midjourney-v4-diffusion)
### Stable Diffusion v1.5 vs Openjourney
(Same parameters, just added "mdjrny-v4 style" at the beginning):
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587642-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587623-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587609-63265d019f9d19bfd4f45031.png" width="100%"/>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1667904587646-63265d019f9d19bfd4f45031.png" width="100%"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "prompthero/openjourney"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "retro serie of different cars with different colors and shapes, mdjrny-v4 style"
image = pipe(prompt).images[0]
image.save("./retro_cars.png")
``` | 2,756 | [
[
-0.041656494140625,
-0.0550537109375,
0.044525146484375,
0.019989013671875,
-0.0134124755859375,
-0.028228759765625,
0.004505157470703125,
-0.01154327392578125,
0.019012451171875,
0.03692626953125,
-0.04833984375,
-0.042694091796875,
-0.029205322265625,
-0.0... |
timm/dm_nfnet_f3.dm_in1k | 2023-03-24T00:56:06.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/dm_nfnet_f3.dm_in1k | 0 | 343 | timm | 2023-03-24T00:52:21 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for dm_nfnet_f3.dm_in1k
A NFNet (Normalization Free Network) image classification model. Trained on ImageNet-1k by paper authors.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 254.9
- GMACs: 68.8
- Activations (M): 83.9
- Image size: train = 320 x 320, test = 416 x 416
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/deepmind/deepmind-research/tree/master/nfnets
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('dm_nfnet_f3.dm_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dm_nfnet_f3.dm_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 160, 160])
# torch.Size([1, 256, 80, 80])
# torch.Size([1, 512, 40, 40])
# torch.Size([1, 1536, 20, 20])
# torch.Size([1, 3072, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'dm_nfnet_f3.dm_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 3072, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,750 | [
[
-0.0379638671875,
-0.037384033203125,
-0.00040531158447265625,
0.0098876953125,
-0.0277862548828125,
-0.02325439453125,
-0.0185089111328125,
-0.0308990478515625,
0.018524169921875,
0.034210205078125,
-0.035400390625,
-0.0516357421875,
-0.058868408203125,
0.0... |
timm/pvt_v2_b3.in1k | 2023-04-25T04:05:00.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.13797",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/pvt_v2_b3.in1k | 0 | 343 | timm | 2023-04-25T04:04:16 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for pvt_v2_b3
A PVT-v2 (Pyramid Vision Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 45.2
- GMACs: 6.9
- Activations (M): 37.7
- Image size: 224 x 224
- **Papers:**
- PVT v2: Improved Baselines with Pyramid Vision Transformer: https://arxiv.org/abs/2106.13797
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/whai362/PVT
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('pvt_v2_b3', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b3',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b3',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{wang2021pvtv2,
title={Pvtv2: Improved baselines with pyramid vision transformer},
author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
journal={Computational Visual Media},
volume={8},
number={3},
pages={1--10},
year={2022},
publisher={Springer}
}
```
| 3,697 | [
[
-0.030731201171875,
-0.0286407470703125,
-0.004184722900390625,
0.0158538818359375,
-0.028564453125,
-0.0261383056640625,
-0.010162353515625,
-0.0255126953125,
0.005115509033203125,
0.035919189453125,
-0.0265045166015625,
-0.04461669921875,
-0.0545654296875,
... |
kpyu/video-blip-opt-2.7b-ego4d | 2023-05-17T21:04:01.000Z | [
"transformers",
"pytorch",
"blip-2",
"text2text-generation",
"vision",
"image-to-text",
"video-to-text",
"image-captioning",
"video-captioning",
"visual-question-answering",
"en",
"arxiv:2301.12597",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:... | image-to-text | kpyu | null | null | kpyu/video-blip-opt-2.7b-ego4d | 5 | 343 | transformers | 2023-05-17T17:15:11 | ---
language: en
license: mit
tags:
- vision
- image-to-text
- video-to-text
- image-captioning
- video-captioning
- visual-question-answering
pipeline_tag: image-to-text
---
# VideoBLIP, OPT-2.7b, fine-tuned on Ego4D
VideoBLIP model, leveraging [BLIP-2](https://arxiv.org/abs/2301.12597) with [OPT-2.7b](https://huggingface.co/facebook/opt-2.7b) (a large language model with 2.7 billion parameters) as its LLM backbone.
## Model description
VideoBLIP is an augmented BLIP-2 that can handle videos.
## Bias, Risks, Limitations, and Ethical Considerations
VideoBLIP-OPT uses off-the-shelf OPT as the language model. It inherits the same risks and limitations as mentioned in Meta's model card.
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
>
VideoBLIP has not been tested in real world applications. It should not be directly deployed in any applications. Researchers should first carefully assess the safety and fairness of the model in relation to the specific context they’re being deployed within.
### How to use
For code examples, please refer to the [official repository](https://github.com/yukw777/VideoBLIP). | 1,487 | [
[
-0.04229736328125,
-0.04901123046875,
0.00363922119140625,
0.04498291015625,
-0.028411865234375,
-0.0030193328857421875,
-0.00835418701171875,
-0.046478271484375,
0.0037631988525390625,
0.053009033203125,
-0.032257080078125,
-0.01374053955078125,
-0.042327880859... |
digiplay/chrysanthemumMix_v1 | 2023-07-13T12:55:54.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/chrysanthemumMix_v1 | 2 | 343 | diffusers | 2023-06-09T23:33:10 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/38636/chrysanthemum-mix
Sample image I made:

This model merge many 2.5D models,
you can click the link to see the details.
The original author's demo images:

https://civitai.com/images/485276?modelVersionId=44553
| 695 | [
[
-0.0462646484375,
-0.010711669921875,
0.03228759765625,
0.0171356201171875,
-0.0311737060546875,
-0.00966644287109375,
0.0186920166015625,
-0.034393310546875,
0.007152557373046875,
0.0284271240234375,
-0.06427001953125,
-0.02484130859375,
-0.037139892578125,
... |
KyriaAnnwyn/vit-large-artifacts | 2023-07-13T09:26:30.000Z | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | KyriaAnnwyn | null | null | KyriaAnnwyn/vit-large-artifacts | 0 | 343 | transformers | 2023-07-07T12:11:49 | ---
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-large-artifacts
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-large-artifacts
This model is a fine-tuned version of [kakaobrain/vit-large-patch16-512](https://huggingface.co/kakaobrain/vit-large-patch16-512) on the KyriaAnnwyn/artifacts_ds dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5995
- Accuracy: 0.6705
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.7001 | 0.01 | 100 | 0.6414 | 0.6559 |
| 0.6288 | 0.01 | 200 | 0.6666 | 0.6559 |
| 0.7237 | 0.02 | 300 | 0.7087 | 0.6559 |
| 0.8741 | 0.03 | 400 | 0.6739 | 0.6257 |
| 0.6093 | 0.04 | 500 | 0.6462 | 0.6559 |
| 0.5801 | 0.04 | 600 | 0.6822 | 0.6559 |
| 0.594 | 0.05 | 700 | 1.9948 | 0.6395 |
| 0.7724 | 0.06 | 800 | 0.6566 | 0.6553 |
| 0.6976 | 0.07 | 900 | 0.6774 | 0.6325 |
| 0.6583 | 0.07 | 1000 | 0.7175 | 0.3517 |
| 0.6779 | 0.08 | 1100 | 0.7012 | 0.6559 |
| 0.6478 | 0.09 | 1200 | 0.6336 | 0.6559 |
| 0.7405 | 0.1 | 1300 | 0.6577 | 0.6559 |
| 0.7362 | 0.1 | 1400 | 0.6630 | 0.6142 |
| 0.535 | 0.11 | 1500 | 0.7445 | 0.6559 |
| 0.7338 | 0.12 | 1600 | 0.7046 | 0.4718 |
| 0.6519 | 0.13 | 1700 | 0.6601 | 0.6426 |
| 0.5969 | 0.13 | 1800 | 0.6518 | 0.6559 |
| 0.5992 | 0.14 | 1900 | 0.6544 | 0.6559 |
| 0.5762 | 0.15 | 2000 | 0.6608 | 0.6559 |
| 0.6483 | 0.16 | 2100 | 0.6436 | 0.6331 |
| 0.7594 | 0.16 | 2200 | 0.7562 | 0.5213 |
| 0.6423 | 0.17 | 2300 | 0.6326 | 0.6433 |
| 0.7006 | 0.18 | 2400 | 0.6669 | 0.6108 |
| 0.833 | 0.19 | 2500 | 0.7043 | 0.6559 |
| 0.6133 | 0.19 | 2600 | 0.6356 | 0.6532 |
| 0.5285 | 0.2 | 2700 | 0.6619 | 0.6606 |
| 0.7209 | 0.21 | 2800 | 0.7306 | 0.4196 |
| 0.682 | 0.22 | 2900 | 0.6400 | 0.6539 |
| 0.7148 | 0.22 | 3000 | 0.6421 | 0.6559 |
| 0.6288 | 0.23 | 3100 | 0.7416 | 0.6559 |
| 0.666 | 0.24 | 3200 | 0.6368 | 0.6293 |
| 0.772 | 0.25 | 3300 | 0.6973 | 0.4985 |
| 0.6778 | 0.25 | 3400 | 0.6288 | 0.6604 |
| 0.5939 | 0.26 | 3500 | 0.6566 | 0.6559 |
| 0.6246 | 0.27 | 3600 | 0.6347 | 0.6618 |
| 0.649 | 0.28 | 3700 | 0.6353 | 0.6277 |
| 0.7122 | 0.28 | 3800 | 0.6407 | 0.6559 |
| 0.6292 | 0.29 | 3900 | 0.6776 | 0.6560 |
| 0.6079 | 0.3 | 4000 | 0.6220 | 0.6609 |
| 0.6971 | 0.31 | 4100 | 0.6258 | 0.6394 |
| 0.7131 | 0.31 | 4200 | 0.7202 | 0.6556 |
| 0.5346 | 0.32 | 4300 | 0.6394 | 0.6571 |
| 0.5801 | 0.33 | 4400 | 0.6960 | 0.6664 |
| 0.6806 | 0.34 | 4500 | 0.6339 | 0.6348 |
| 0.6245 | 0.34 | 4600 | 0.6226 | 0.6477 |
| 0.6905 | 0.35 | 4700 | 0.6203 | 0.6533 |
| 0.741 | 0.36 | 4800 | 0.6464 | 0.6680 |
| 0.5712 | 0.37 | 4900 | 0.6162 | 0.6640 |
| 0.5566 | 0.37 | 5000 | 0.6182 | 0.6507 |
| 0.6443 | 0.38 | 5100 | 0.6457 | 0.6664 |
| 0.6107 | 0.39 | 5200 | 0.6092 | 0.6617 |
| 0.5824 | 0.4 | 5300 | 0.6383 | 0.6571 |
| 0.4775 | 0.4 | 5400 | 0.6606 | 0.6621 |
| 0.7114 | 0.41 | 5500 | 0.6179 | 0.6619 |
| 0.7701 | 0.42 | 5600 | 0.7982 | 0.4217 |
| 0.6974 | 0.42 | 5700 | 0.6223 | 0.6540 |
| 0.6669 | 0.43 | 5800 | 0.6249 | 0.6559 |
| 0.6982 | 0.44 | 5900 | 0.6287 | 0.6564 |
| 0.5811 | 0.45 | 6000 | 0.6104 | 0.6506 |
| 0.4347 | 0.45 | 6100 | 1.0475 | 0.6559 |
| 0.5885 | 0.46 | 6200 | 0.6125 | 0.6552 |
| 0.6867 | 0.47 | 6300 | 0.6435 | 0.6468 |
| 0.6088 | 0.48 | 6400 | 0.6047 | 0.6623 |
| 0.8194 | 0.48 | 6500 | 0.6972 | 0.6589 |
| 0.8182 | 0.49 | 6600 | 0.6053 | 0.6644 |
| 0.6104 | 0.5 | 6700 | 0.7375 | 0.6571 |
| 0.5552 | 0.51 | 6800 | 0.6231 | 0.6402 |
| 0.6451 | 0.51 | 6900 | 0.6452 | 0.6561 |
| 0.7849 | 0.52 | 7000 | 0.6177 | 0.6612 |
| 0.64 | 0.53 | 7100 | 0.6307 | 0.6234 |
| 0.6393 | 0.54 | 7200 | 0.6130 | 0.6554 |
| 0.8326 | 0.54 | 7300 | 0.7210 | 0.6421 |
| 0.6579 | 0.55 | 7400 | 0.6227 | 0.6544 |
| 0.5195 | 0.56 | 7500 | 0.6619 | 0.6557 |
| 0.6197 | 0.57 | 7600 | 0.6354 | 0.6498 |
| 0.8507 | 0.57 | 7700 | 0.6820 | 0.6550 |
| 0.7163 | 0.58 | 7800 | 0.6720 | 0.5328 |
| 0.6896 | 0.59 | 7900 | 0.6530 | 0.6386 |
| 0.62 | 0.6 | 8000 | 0.6296 | 0.6559 |
| 0.8254 | 0.6 | 8100 | 0.6752 | 0.6200 |
| 0.7653 | 0.61 | 8200 | 0.7118 | 0.6558 |
| 0.7742 | 0.62 | 8300 | 0.6262 | 0.6497 |
| 0.6861 | 0.63 | 8400 | 0.6799 | 0.5566 |
| 0.5652 | 0.63 | 8500 | 0.6708 | 0.6559 |
| 0.7486 | 0.64 | 8600 | 0.6319 | 0.6559 |
| 0.6204 | 0.65 | 8700 | 0.6407 | 0.6530 |
| 0.673 | 0.66 | 8800 | 0.7154 | 0.4672 |
| 0.7272 | 0.66 | 8900 | 0.6323 | 0.6528 |
| 0.7364 | 0.67 | 9000 | 0.6436 | 0.6188 |
| 0.71 | 0.68 | 9100 | 0.6507 | 0.5924 |
| 0.6767 | 0.69 | 9200 | 0.6347 | 0.6575 |
| 0.7046 | 0.69 | 9300 | 0.6723 | 0.6127 |
| 0.7486 | 0.7 | 9400 | 0.6328 | 0.6485 |
| 0.7646 | 0.71 | 9500 | 0.6244 | 0.6550 |
| 0.5971 | 0.72 | 9600 | 0.6610 | 0.6558 |
| 0.6195 | 0.72 | 9700 | 0.6219 | 0.6515 |
| 0.6891 | 0.73 | 9800 | 0.6300 | 0.6619 |
| 0.6829 | 0.74 | 9900 | 0.6312 | 0.6568 |
| 0.4786 | 0.75 | 10000 | 0.7160 | 0.6573 |
| 0.6093 | 0.75 | 10100 | 0.6245 | 0.6503 |
| 0.672 | 0.76 | 10200 | 0.6248 | 0.6577 |
| 0.6734 | 0.77 | 10300 | 0.6541 | 0.6600 |
| 0.7826 | 0.78 | 10400 | 0.6413 | 0.6559 |
| 0.6851 | 0.78 | 10500 | 0.6478 | 0.6006 |
| 0.6776 | 0.79 | 10600 | 0.6453 | 0.6175 |
| 0.7322 | 0.8 | 10700 | 0.6188 | 0.6353 |
| 0.5144 | 0.81 | 10800 | 0.6762 | 0.6571 |
| 0.6977 | 0.81 | 10900 | 0.6559 | 0.6544 |
| 0.5681 | 0.82 | 11000 | 0.7225 | 0.6559 |
| 0.6449 | 0.83 | 11100 | 0.6372 | 0.6576 |
| 0.6067 | 0.83 | 11200 | 0.6207 | 0.6391 |
| 0.5921 | 0.84 | 11300 | 0.6178 | 0.6538 |
| 0.5373 | 0.85 | 11400 | 0.7370 | 0.6559 |
| 0.6926 | 0.86 | 11500 | 0.6346 | 0.6372 |
| 0.6634 | 0.86 | 11600 | 0.6274 | 0.6489 |
| 0.61 | 0.87 | 11700 | 0.6309 | 0.6427 |
| 0.6214 | 0.88 | 11800 | 0.6273 | 0.6480 |
| 0.6202 | 0.89 | 11900 | 0.6255 | 0.6559 |
| 0.6153 | 0.89 | 12000 | 0.6348 | 0.6459 |
| 0.7062 | 0.9 | 12100 | 0.6283 | 0.6512 |
| 0.6977 | 0.91 | 12200 | 0.6159 | 0.6515 |
| 0.6041 | 0.92 | 12300 | 0.6251 | 0.6504 |
| 0.6609 | 0.92 | 12400 | 0.6633 | 0.5870 |
| 0.7565 | 0.93 | 12500 | 0.6200 | 0.6562 |
| 0.6133 | 0.94 | 12600 | 0.6193 | 0.6527 |
| 0.7066 | 0.95 | 12700 | 0.6279 | 0.6180 |
| 0.5706 | 0.95 | 12800 | 0.6128 | 0.6575 |
| 0.6992 | 0.96 | 12900 | 0.6334 | 0.6449 |
| 0.6834 | 0.97 | 13000 | 0.6258 | 0.6591 |
| 0.6069 | 0.98 | 13100 | 0.6290 | 0.6620 |
| 0.743 | 0.98 | 13200 | 0.6110 | 0.6562 |
| 0.5226 | 0.99 | 13300 | 0.6165 | 0.6557 |
| 0.7359 | 1.0 | 13400 | 0.6207 | 0.6376 |
| 0.5812 | 1.01 | 13500 | 0.6192 | 0.6559 |
| 0.666 | 1.01 | 13600 | 0.6347 | 0.6602 |
| 0.5489 | 1.02 | 13700 | 0.6107 | 0.6459 |
| 0.701 | 1.03 | 13800 | 0.6172 | 0.6518 |
| 0.4873 | 1.04 | 13900 | 0.6786 | 0.6559 |
| 0.5807 | 1.04 | 14000 | 0.6636 | 0.6433 |
| 0.6824 | 1.05 | 14100 | 0.6176 | 0.6315 |
| 0.6012 | 1.06 | 14200 | 0.6097 | 0.6617 |
| 0.4865 | 1.07 | 14300 | 0.6103 | 0.6623 |
| 0.5612 | 1.07 | 14400 | 0.6947 | 0.6559 |
| 0.5968 | 1.08 | 14500 | 0.6559 | 0.5981 |
| 0.5657 | 1.09 | 14600 | 0.6076 | 0.6509 |
| 0.4778 | 1.1 | 14700 | 0.6808 | 0.6535 |
| 0.6047 | 1.1 | 14800 | 0.6131 | 0.6480 |
| 0.5999 | 1.11 | 14900 | 0.6120 | 0.6559 |
| 0.5852 | 1.12 | 15000 | 0.6356 | 0.6553 |
| 0.7033 | 1.13 | 15100 | 0.6578 | 0.6647 |
| 0.5925 | 1.13 | 15200 | 0.6153 | 0.6633 |
| 0.5959 | 1.14 | 15300 | 0.6306 | 0.6211 |
| 0.5929 | 1.15 | 15400 | 0.6246 | 0.6655 |
| 0.5621 | 1.16 | 15500 | 0.6126 | 0.6424 |
| 0.5508 | 1.16 | 15600 | 0.6844 | 0.6559 |
| 0.6276 | 1.17 | 15700 | 0.6066 | 0.6531 |
| 1.0359 | 1.18 | 15800 | 0.6271 | 0.6617 |
| 0.6191 | 1.19 | 15900 | 0.6166 | 0.6480 |
| 0.7095 | 1.19 | 16000 | 0.6228 | 0.6462 |
| 0.6567 | 1.2 | 16100 | 0.6066 | 0.6653 |
| 0.5653 | 1.21 | 16200 | 0.6022 | 0.6605 |
| 0.6894 | 1.21 | 16300 | 0.6216 | 0.6568 |
| 0.608 | 1.22 | 16400 | 0.6041 | 0.6559 |
| 0.665 | 1.23 | 16500 | 0.6111 | 0.6564 |
| 0.6753 | 1.24 | 16600 | 0.6138 | 0.6581 |
| 0.6213 | 1.24 | 16700 | 0.6121 | 0.6380 |
| 0.6983 | 1.25 | 16800 | 0.6166 | 0.6661 |
| 0.8521 | 1.26 | 16900 | 0.6202 | 0.6461 |
| 0.4927 | 1.27 | 17000 | 0.6313 | 0.6547 |
| 0.6414 | 1.27 | 17100 | 0.6011 | 0.6667 |
| 0.539 | 1.28 | 17200 | 0.6451 | 0.6664 |
| 0.5118 | 1.29 | 17300 | 0.6243 | 0.6641 |
| 0.7512 | 1.3 | 17400 | 0.6257 | 0.6586 |
| 0.5943 | 1.3 | 17500 | 0.6186 | 0.6423 |
| 0.5861 | 1.31 | 17600 | 0.6435 | 0.6638 |
| 0.7065 | 1.32 | 17700 | 0.6197 | 0.6279 |
| 0.5973 | 1.33 | 17800 | 0.6081 | 0.6535 |
| 0.5997 | 1.33 | 17900 | 0.6053 | 0.6608 |
| 0.7091 | 1.34 | 18000 | 0.6013 | 0.6644 |
| 0.691 | 1.35 | 18100 | 0.6103 | 0.6654 |
| 0.5559 | 1.36 | 18200 | 0.6110 | 0.6658 |
| 0.6309 | 1.36 | 18300 | 0.6067 | 0.6664 |
| 0.6262 | 1.37 | 18400 | 0.6027 | 0.6616 |
| 0.5551 | 1.38 | 18500 | 0.6106 | 0.6671 |
| 0.6703 | 1.39 | 18600 | 0.6043 | 0.6576 |
| 0.6849 | 1.39 | 18700 | 0.6018 | 0.6616 |
| 0.6136 | 1.4 | 18800 | 0.6324 | 0.6629 |
| 0.7075 | 1.41 | 18900 | 0.6057 | 0.6561 |
| 0.6036 | 1.42 | 19000 | 0.6081 | 0.6559 |
| 0.6549 | 1.42 | 19100 | 0.6352 | 0.6655 |
| 0.5168 | 1.43 | 19200 | 0.6042 | 0.6632 |
| 0.5864 | 1.44 | 19300 | 0.6111 | 0.6639 |
| 0.5961 | 1.45 | 19400 | 0.6003 | 0.6644 |
| 0.6077 | 1.45 | 19500 | 0.6125 | 0.6566 |
| 0.6215 | 1.46 | 19600 | 0.6128 | 0.6582 |
| 0.4005 | 1.47 | 19700 | 0.6348 | 0.6642 |
| 0.5689 | 1.48 | 19800 | 0.6355 | 0.6647 |
| 0.6026 | 1.48 | 19900 | 0.6127 | 0.6444 |
| 0.4982 | 1.49 | 20000 | 0.6034 | 0.6654 |
| 0.6189 | 1.5 | 20100 | 0.6202 | 0.6609 |
| 0.5502 | 1.51 | 20200 | 0.6044 | 0.6621 |
| 0.5924 | 1.51 | 20300 | 0.6107 | 0.6445 |
| 0.744 | 1.52 | 20400 | 0.6164 | 0.6559 |
| 0.5582 | 1.53 | 20500 | 0.6166 | 0.6559 |
| 0.6994 | 1.54 | 20600 | 0.6109 | 0.6664 |
| 0.5396 | 1.54 | 20700 | 0.6189 | 0.6670 |
| 0.7232 | 1.55 | 20800 | 0.6104 | 0.6610 |
| 0.9802 | 1.56 | 20900 | 0.6232 | 0.6642 |
| 0.6487 | 1.57 | 21000 | 0.6056 | 0.6505 |
| 0.5932 | 1.57 | 21100 | 0.5980 | 0.6702 |
| 0.7897 | 1.58 | 21200 | 0.6012 | 0.6638 |
| 0.6006 | 1.59 | 21300 | 0.6232 | 0.6672 |
| 0.4481 | 1.6 | 21400 | 0.6124 | 0.6676 |
| 0.6078 | 1.6 | 21500 | 0.6495 | 0.6664 |
| 0.595 | 1.61 | 21600 | 0.7122 | 0.6675 |
| 0.6388 | 1.62 | 21700 | 0.6227 | 0.6671 |
| 0.5731 | 1.62 | 21800 | 0.6252 | 0.6682 |
| 0.8603 | 1.63 | 21900 | 0.6026 | 0.6653 |
| 0.6316 | 1.64 | 22000 | 0.6494 | 0.6669 |
| 0.6712 | 1.65 | 22100 | 0.6097 | 0.6676 |
| 0.6102 | 1.65 | 22200 | 0.6221 | 0.6585 |
| 0.7099 | 1.66 | 22300 | 0.6006 | 0.6658 |
| 0.621 | 1.67 | 22400 | 0.6026 | 0.6626 |
| 0.478 | 1.68 | 22500 | 0.6062 | 0.6624 |
| 0.6106 | 1.68 | 22600 | 0.5990 | 0.6669 |
| 0.5793 | 1.69 | 22700 | 0.5980 | 0.6681 |
| 0.5804 | 1.7 | 22800 | 0.6014 | 0.6626 |
| 0.6304 | 1.71 | 22900 | 0.6107 | 0.6380 |
| 0.7427 | 1.71 | 23000 | 0.6051 | 0.6682 |
| 0.5794 | 1.72 | 23100 | 0.6105 | 0.6611 |
| 0.5084 | 1.73 | 23200 | 0.6643 | 0.6673 |
| 0.6518 | 1.74 | 23300 | 0.6366 | 0.6687 |
| 0.5129 | 1.74 | 23400 | 0.6053 | 0.6682 |
| 0.7593 | 1.75 | 23500 | 0.5977 | 0.6662 |
| 0.6645 | 1.76 | 23600 | 0.5988 | 0.6683 |
| 0.6144 | 1.77 | 23700 | 0.6130 | 0.6673 |
| 0.6855 | 1.77 | 23800 | 0.6192 | 0.6596 |
| 0.559 | 1.78 | 23900 | 0.6208 | 0.6574 |
| 0.4202 | 1.79 | 24000 | 0.6125 | 0.6690 |
| 0.6604 | 1.8 | 24100 | 0.6052 | 0.6685 |
| 0.5487 | 1.8 | 24200 | 0.6086 | 0.6685 |
| 0.6816 | 1.81 | 24300 | 0.5997 | 0.6620 |
| 0.6057 | 1.82 | 24400 | 0.6128 | 0.6530 |
| 0.4335 | 1.83 | 24500 | 0.6121 | 0.6676 |
| 0.6147 | 1.83 | 24600 | 0.6225 | 0.6670 |
| 0.7414 | 1.84 | 24700 | 0.6248 | 0.6718 |
| 0.622 | 1.85 | 24800 | 0.6084 | 0.6722 |
| 0.5356 | 1.86 | 24900 | 0.6003 | 0.6611 |
| 0.7994 | 1.86 | 25000 | 0.6098 | 0.6657 |
| 0.5389 | 1.87 | 25100 | 0.6052 | 0.6633 |
| 0.6985 | 1.88 | 25200 | 0.6073 | 0.6694 |
| 0.652 | 1.89 | 25300 | 0.6040 | 0.6709 |
| 0.5409 | 1.89 | 25400 | 0.6065 | 0.6709 |
| 0.6356 | 1.9 | 25500 | 0.6062 | 0.6699 |
| 0.7588 | 1.91 | 25600 | 0.6025 | 0.6711 |
| 0.5109 | 1.92 | 25700 | 0.5992 | 0.6693 |
| 0.6766 | 1.92 | 25800 | 0.6004 | 0.6693 |
| 0.6517 | 1.93 | 25900 | 0.6020 | 0.6701 |
| 0.6561 | 1.94 | 26000 | 0.5995 | 0.6705 |
| 0.6224 | 1.95 | 26100 | 0.6008 | 0.6717 |
| 0.6054 | 1.95 | 26200 | 0.6005 | 0.6714 |
| 0.5152 | 1.96 | 26300 | 0.6023 | 0.6709 |
| 0.5503 | 1.97 | 26400 | 0.6032 | 0.6706 |
| 0.5101 | 1.98 | 26500 | 0.6067 | 0.6709 |
| 0.5229 | 1.98 | 26600 | 0.6079 | 0.6702 |
| 0.8387 | 1.99 | 26700 | 0.6079 | 0.6700 |
| 0.608 | 2.0 | 26800 | 0.6069 | 0.6699 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.13.1+cu116
- Datasets 2.13.1
- Tokenizers 0.13.3
| 18,207 | [
[
-0.044403076171875,
-0.0450439453125,
0.0187835693359375,
0.0032978057861328125,
-0.0026340484619140625,
0.01358795166015625,
0.0032253265380859375,
0.005828857421875,
0.0533447265625,
0.03143310546875,
-0.040618896484375,
-0.040679931640625,
-0.039794921875,
... |
timm/fastvit_t8.apple_dist_in1k | 2023-08-23T21:05:45.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.14189",
"license:other",
"region:us"
] | image-classification | timm | null | null | timm/fastvit_t8.apple_dist_in1k | 0 | 343 | timm | 2023-08-23T21:05:41 | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for fastvit_t8.apple_dist_in1k
A FastViT image classification model. Trained on ImageNet-1k with distillation by paper authors.
Please observe [original license](https://github.com/apple/ml-fastvit/blob/8af5928238cab99c45f64fc3e4e7b1516b8224ba/LICENSE).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 4.0
- GMACs: 0.7
- Activations (M): 8.6
- Image size: 256 x 256
- **Papers:**
- FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization: https://arxiv.org/abs/2303.14189
- **Original:** https://github.com/apple/ml-fastvit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('fastvit_t8.apple_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t8.apple_dist_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 48, 64, 64])
# torch.Size([1, 96, 32, 32])
# torch.Size([1, 192, 16, 16])
# torch.Size([1, 384, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t8.apple_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 384, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
```
| 3,697 | [
[
-0.041656494140625,
-0.037628173828125,
0.003124237060546875,
0.016632080078125,
-0.03228759765625,
-0.01497650146484375,
-0.0079193115234375,
-0.018798828125,
0.025604248046875,
0.026611328125,
-0.0372314453125,
-0.04571533203125,
-0.051849365234375,
-0.013... |
salesforce/blipdiffusion-controlnet | 2023-09-21T15:55:24.000Z | [
"diffusers",
"en",
"arxiv:2305.14720",
"license:apache-2.0",
"diffusers:BlipDiffusionControlNetPipeline",
"region:us"
] | null | salesforce | null | null | salesforce/blipdiffusion-controlnet | 1 | 343 | diffusers | 2023-09-21T15:55:24 | ---
license: apache-2.0
language:
- en
library_name: diffusers
---
# BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
<!-- Provide a quick summary of what the model is/does. -->
Model card for BLIP-Diffusion, a text to image Diffusion model which enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications.*
The model is created by Dongxu Li, Junnan Li, Steven C.H. Hoi.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Original Repository:** https://github.com/salesforce/LAVIS/tree/main
- **Project Page:** https://dxli94.github.io/BLIP-Diffusion-website/
## Uses
### Zero-Shot Subject Driven Generation
```python
from diffusers.pipelines import BlipDiffusionPipeline
from diffusers.utils import load_image
import torch
blip_diffusion_pipe = BlipDiffusionPipeline.from_pretrained(
"Salesforce/blipdiffusion", torch_dtype=torch.float16
).to("cuda")
cond_subject = "dog"
tgt_subject = "dog"
text_prompt_input = "swimming underwater"
cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg"
)
iter_seed = 88888
guidance_scale = 7.5
num_inference_steps = 25
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt_input,
cond_image,
cond_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg" style="width:500px;"/>
Generatred Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog_underwater.png" style="width:500px;"/>
### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet", torch_dtype=torch.float16
).to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg"
).resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type="pil")
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Canny Edge Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/canny_generated.png" style="width:500px;"/>
### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet"
)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image(
"https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png"
).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Scribble Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble.png" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble_output.png" style="width:500px;"/>
## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.
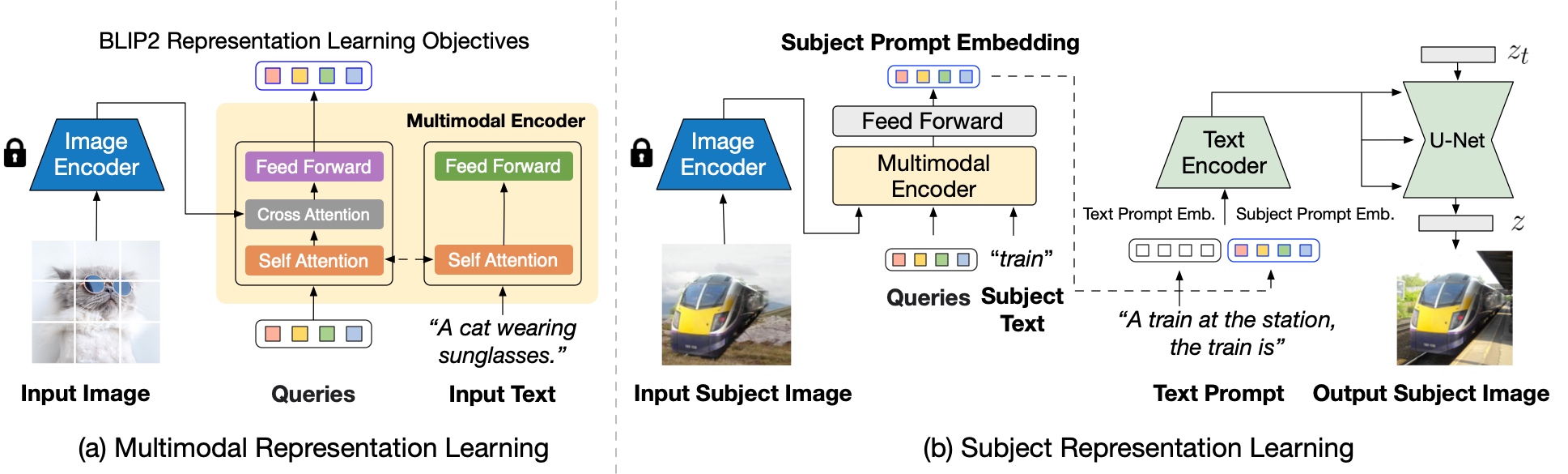
The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
<img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/arch_controlnet.png" style="width:50%;"/>
## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 9,724 | [
[
-0.0299072265625,
-0.059814453125,
0.0093841552734375,
0.058807373046875,
-0.022857666015625,
-0.0196533203125,
-0.005191802978515625,
-0.0357666015625,
0.031036376953125,
0.0193023681640625,
-0.0338134765625,
-0.035675048828125,
-0.0458984375,
0.00186634063... |
THUDM/agentlm-70b | 2023-10-20T03:27:30.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:THUDM/AgentInstruct",
"arxiv:2310.12823",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"has_space"
] | text-generation | THUDM | null | null | THUDM/agentlm-70b | 61 | 343 | transformers | 2023-10-08T13:05:19 | ---
datasets:
- THUDM/AgentInstruct
---
## AgentLM-70B
<p align="center">
🤗 <a href="https://huggingface.co/datasets/THUDM/AgentInstruct" target="_blank">[Dataset] </a> • 💻 <a href="https://github.com/THUDM/AgentTuning" target="_blank">[Github Repo]</a> • 📌 <a href="https://THUDM.github.io/AgentTuning/" target="_blank">[Project Page]</a> • 📃 <a href="https://arxiv.org/abs/2310.12823" target="_blank">[Paper]</a>
</p>
**AgentTuning** represents the very first attempt to instruction-tune LLMs using interaction trajectories across multiple agent tasks. Evaluation results indicate that AgentTuning enables the agent capabilities of LLMs with robust generalization on unseen agent tasks while remaining good on general language abilities. We have open-sourced the AgentInstruct dataset and AgentLM.
## Models
**AgentLM** models are produced by mixed training on AgentInstruct dataset and ShareGPT dataset from Llama-2-chat models.
The models follow the conversation format of [Llama-2-chat](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), with system prompt fixed as
```
You are a helpful, respectful and honest assistant.
```
7B, 13B, and 70B models are available on Huggingface model hub.
|Model|Huggingface Repo|
|---|---|
|AgentLM-7B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-7b) |
|AgentLM-13B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-13b) |
|AgentLM-70B| [🤗Huggingface Repo](https://huggingface.co/THUDM/agentlm-70b) |
## Citation
If you find our work useful, please consider citing AgentTuning:
```
@misc{zeng2023agenttuning,
title={AgentTuning: Enabling Generalized Agent Abilities for LLMs},
author={Aohan Zeng and Mingdao Liu and Rui Lu and Bowen Wang and Xiao Liu and Yuxiao Dong and Jie Tang},
year={2023},
eprint={2310.12823},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,890 | [
[
-0.017974853515625,
-0.058624267578125,
0.0234222412109375,
0.022247314453125,
-0.01434326171875,
0.01165771484375,
-0.0166473388671875,
-0.039459228515625,
0.0235443115234375,
0.0295257568359375,
-0.05859375,
-0.052001953125,
-0.028411865234375,
0.000098347... |
jaqen79/adv_classifier_v3 | 2023-10-11T21:29:32.000Z | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | jaqen79 | null | null | jaqen79/adv_classifier_v3 | 0 | 343 | transformers | 2023-10-11T21:28:06 | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: adv_classifier_v3
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.942307710647583
---
# adv_classifier_v3
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images | 649 | [
[
-0.042633056640625,
-0.040924072265625,
0.01788330078125,
0.0294342041015625,
-0.0306549072265625,
-0.01421356201171875,
0.0263824462890625,
-0.0325927734375,
0.0367431640625,
0.01198577880859375,
-0.0254974365234375,
-0.04949951171875,
-0.037017822265625,
-... |
sanghwa-na/llama2-13b.kor.v1 | 2023-11-02T23:03:30.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"instruct",
"instruction",
"ko",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | sanghwa-na | null | null | sanghwa-na/llama2-13b.kor.v1 | 0 | 343 | transformers | 2023-10-30T07:02:42 | ---
language:
- ko
tags:
- llama-2
- instruct
- instruction
pipeline_tag: text-generation
license: llama2
---
# llama2-13b.kor
### Model Details
- Developed by: Sanghwa Na
- Backbone Model: [LLaMA-2](https://github.com/facebookresearch/llama/tree/main)
- Library: [transformers](https://github.com/huggingface/transformers)
### Used Datasets
- Orca-style dataset
- Platypus
### Prompt Template
```
### Instruction:
{Instruction}
### Answer:
{Answer}
```
### License
meta-license | 484 | [
[
-0.01512908935546875,
-0.0273590087890625,
0.00923919677734375,
0.0322265625,
-0.03564453125,
0.0202789306640625,
0.039276123046875,
-0.019866943359375,
0.037353515625,
0.04736328125,
-0.062255859375,
-0.043609619140625,
-0.03271484375,
-0.00440216064453125,... |
KBLab/bert-base-swedish-cased-reallysimple-ner | 2022-11-15T10:50:01.000Z | [
"transformers",
"pytorch",
"megatron-bert",
"token-classification",
"sequence-tagger-model",
"bert",
"sv",
"dataset:KBLab/sucx3_ner",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | KBLab | null | null | KBLab/bert-base-swedish-cased-reallysimple-ner | 0 | 342 | transformers | 2022-03-02T23:29:04 | ---
tags:
- token-classification
- sequence-tagger-model
- bert
language: sv
datasets:
- KBLab/sucx3_ner
widget:
- text: "Emil bor i Lönneberga"
---
# KB-BERT for NER
## Cased data
This model is based on [KB-BERT](https://huggingface.co/KB/bert-base-swedish-cased) and was fine-tuned on the [SUCX 3.0 - NER](https://huggingface.co/datasets/KBLab/sucx3_ner) corpus, using the _simple_ tags and cased data.
For this model we used a variation of the data that did **not** use BIO-encoding to differentiate between the beginnings (B), and insides (I) of named entity tags.
The model was trained on the training data only, with the best model chosen by its performance on the validation data.
You find more information about the model and the performance on our blog: https://kb-labb.github.io/posts/2022-02-07-sucx3_ner | 819 | [
[
-0.027740478515625,
-0.037445068359375,
0.035614013671875,
0.0221405029296875,
-0.0300140380859375,
-0.004413604736328125,
-0.00946044921875,
-0.03009033203125,
0.034576416015625,
0.041534423828125,
-0.039093017578125,
-0.055572509765625,
-0.0254058837890625,
... |
google/t5-efficient-mini | 2023-01-24T16:48:02.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"deep-narrow",
"en",
"dataset:c4",
"arxiv:2109.10686",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | google | null | null | google/t5-efficient-mini | 3 | 342 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
datasets:
- c4
tags:
- deep-narrow
inference: false
license: apache-2.0
---
# T5-Efficient-MINI (Deep-Narrow version)
T5-Efficient-MINI is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-mini** - is of model type **Mini** with no variations.
It has **31.23** million parameters and thus requires *ca.* **124.92 MB** of memory in full precision (*fp32*)
or **62.46 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future. | 6,300 | [
[
-0.0406494140625,
-0.047393798828125,
0.0248565673828125,
0.010894775390625,
-0.01436614990234375,
0.002468109130859375,
-0.01045989990234375,
-0.035675048828125,
0.00328826904296875,
0.0234527587890625,
-0.0380859375,
-0.03741455078125,
-0.0625,
0.010154724... |
turkish-nlp-suite/tr_core_news_trf | 2023-07-11T14:46:03.000Z | [
"spacy",
"token-classification",
"tr",
"doi:10.57967/hf/0086",
"license:cc-by-sa-4.0",
"model-index",
"region:us"
] | token-classification | turkish-nlp-suite | null | null | turkish-nlp-suite/tr_core_news_trf | 6 | 342 | spacy | 2022-10-31T21:01:09 | ---
tags:
- spacy
- token-classification
language:
- tr
license: cc-by-sa-4.0
model-index:
- name: tr_core_news_trf
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9135450185
- name: NER Recall
type: recall
value: 0.9127138178
- name: NER F Score
type: f_score
value: 0.913129229
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9174219957
- task:
name: POS
type: token-classification
metrics:
- name: POS (UPOS) Accuracy
type: accuracy
value: 0.9094402673
- task:
name: MORPH
type: token-classification
metrics:
- name: Morph (UFeats) Accuracy
type: accuracy
value: 0.9145220588
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.8782380178
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.7988988989
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.7189673288
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.8765432099
---
Turkish transformer pipeline for TrSpaCy. Components: transformer, tagger, morphologizer, lemmatizer, parser, ner
| Feature | Description |
| --- | --- |
| **Name** | `tr_core_news_trf` |
| **Version** | `3.4.2` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `transformer`, `tagger`, `morphologizer`, `trainable_lemmatizer`, `parser`, `ner` |
| **Components** | `transformer`, `tagger`, `morphologizer`, `trainable_lemmatizer`, `parser`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [UD Turkish BOUN](https://github.com/UniversalDependencies/UD_Turkish-BOUN) (Türk, Utku; Atmaca, Furkan; Özateş, Şaziye Betül; Berk, Gözde; Bedir, Seyyit Talha; Köksal, Abdullatif; Öztürk Başaran, Balkız; Güngör, Tunga; Özgür, Arzucan)<br />[Turkish Wiki NER dataset](https://github.com/turkish-nlp-suite/NER-datasets/tree/main/Turkish-Wiki-NER-Dataset) (Duygu Altinok, Co-one Istanbul)<br />[PANX/WikiANN](http://hlt.sztaki.hu/resources/hunnerwiki.html) (Xiaoman Pan, Boliang Zhang, Jonathan May, Joel Nothman, Kevin Knight, Heng Ji)<br />[dbmdz Turkish BERT model (cased)](https://huggingface.co/dbmdz/bert-base-turkish-cased) (Bayerische Staatsbibliothek) |
| **License** | `cc-by-sa-4.0` |
| **Author** | [Duygu](https://github.com/turkish-nlp-suite/turkish-spacy-models) |
### Label Scheme
<details>
<summary>View label scheme (1572 labels for 4 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `ADP`, `ADV`, `ANum`, `ANum_Adj`, `ANum_Ness`, `ANum_Noun`, `ANum_With`, `ANum_Zero`, `Abr`, `Abr_With`, `Adj`, `Adj_Ness`, `Adj_With`, `Adj_Without`, `Adj_Zero`, `Adv`, `Adverb`, `Adverb_Adverb`, `Adverb_Noun`, `Adverb_Zero`, `Conj`, `Conj_Conj`, `DET`, `Demons`, `Demons_Zero`, `Det`, `Det_Zero`, `Dup`, `Interj`, `NAdj`, `NAdj_Aux`, `NAdj_Ness`, `NAdj_Noun`, `NAdj_Rel`, `NAdj_Verb`, `NAdj_With`, `NAdj_Without`, `NAdj_Zero`, `NNum`, `NNum_Rel`, `NNum_Zero`, `NOUN`, `Neg`, `Ness`, `Noun`, `Noun_Ness`, `Noun_Noun`, `Noun_Rel`, `Noun_Since`, `Noun_Verb`, `Noun_With`, `Noun_With_Ness`, `Noun_With_Verb`, `Noun_With_Zero`, `Noun_Without`, `Noun_Zero`, `PCAbl`, `PCAbl_Rel`, `PCAcc`, `PCDat`, `PCDat_Zero`, `PCGen`, `PCIns`, `PCIns_Zero`, `PCNom`, `PCNom_Adj`, `PCNom_Noun`, `PCNom_Zero`, `PRON`, `PUNCT`, `Pers`, `Pers_Ness`, `Pers_Pers`, `Pers_Rel`, `Pers_Zero`, `Postp`, `Prop`, `Prop_Conj`, `Prop_Rel`, `Prop_Since`, `Prop_With`, `Prop_Zero`, `Punc`, `Punc_Noun_Ness`, `Punc_Noun_Rel`, `Quant`, `Quant_Zero`, `Ques`, `Ques_Zero`, `Reflex`, `Reflex_Zero`, `Rel`, `SYM`, `Since`, `Since_Since`, `Verb`, `Verb_Conj`, `Verb_Ness`, `Verb_Noun`, `Verb_Verb`, `Verb_With`, `Verb_Zero`, `With`, `Without`, `Without_Zero`, `Zero` |
| **`morphologizer`** | `NumType=Card\|POS=NUM`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1,3\|Person[psor]=3\|Tense=Pres`, `POS=PUNCT`, `POS=ADV`, `POS=NOUN`, `Case=Nom\|Number=Sing\|POS=ADJ\|Person=3`, `POS=DET`, `Case=Loc\|Number=Sing\|POS=VERB\|Person=1`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3`, `POS=ADJ`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Gen\|Number=Sing\|POS=NOUN\|Person=3`, `POS=PRON`, `Case=Nom\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Acc\|Number=Plur\|POS=NOUN\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Case=Nom\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Dat\|Number=Sing\|POS=PROPN\|Person=3`, `POS=VERB\|Polarity=Pos`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Prog\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Abl\|Number=Sing\|POS=ADJ\|Person=3`, `Case=Nom\|Number=Plur\|POS=NOUN\|Person=3`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `POS=INTJ`, `Case=Abl\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Ins\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Loc\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Acc\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Imp\|POS=VERB\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=3`, `POS=CCONJ`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|VerbForm=Conv\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Gen\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|POS=ADP\|Person=3`, `Case=Dat\|Number=Plur\|POS=NOUN\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Nom\|POS=VERB\|Polarity=Pos`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Acc\|Number=Sing\|POS=PROPN\|Person=3`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `POS=ADP`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=3`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Acc\|Number=Plur\|POS=VERB\|Person=3`, `Aspect=Perf\|Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Mood=Opt\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos`, `Case=Dat\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Prog\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=3`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Loc\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1`, `Case=Nom\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Abl\|Number=Sing\|POS=NOUN\|Person=3`, `Mood=Imp\|POS=VERB\|Polarity=Pos\|VerbForm=Conv`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past\|Voice=Cau`, `Case=Nom\|Number=Plur\|POS=ADJ\|Person=3`, `Aspect=Hab\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Gen\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Plur\|POS=NOUN\|Person=3`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Imp\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres`, `Case=Loc\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=1`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1`, `Case=Nom\|Number=Sing\|POS=NOUN\|Person=1`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=3`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Ins\|Number=Sing\|POS=NOUN\|Person=3`, `POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Nom\|POS=VERB\|Polarity=Pos\|Voice=Cau`, `Aspect=Prog\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Nom\|Number=Sing\|POS=ADJ\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Case=Abl\|Number=Plur\|POS=NOUN\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Prog\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Mood=Imp\|POS=VERB\|Polarity=Pos\|VerbForm=Conv\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `POS=VERB\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=2`, `Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Fut`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Plur\|POS=ADJ\|Person=3`, `Case=Loc\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Hab\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv\|Voice=Pass`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Dat\|Number=Sing\|POS=ADJ\|Person=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Imp\|Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Equ\|Number=Sing\|POS=PRON\|Person=1`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Case=Loc\|POS=VERB\|Polarity=Pos\|Voice=Pass`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Mood=Des,Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|Polarity=Pos\|Tense=Past`, `Aspect=Hab\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Hab\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Ins\|Number=Plur\|POS=NOUN\|Person=3`, `Case=Ins\|POS=VERB\|Polarity=Neg`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=1`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Pass`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Nom\|POS=VERB\|Polarity=Pos\|Voice=Pass`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=ADJ\|Person=2,3\|Polarity=Pos`, `POS=VERB\|Polarity=Neg\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Dat\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Case=Ins\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Case=Nom\|POS=NOUN\|Polarity=Pos`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Loc\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Plur\|POS=NOUN\|Person=3`, `Case=Loc\|NumType=Card\|Number=Sing\|POS=NUM\|Person=3`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Ins\|Number=Sing\|POS=VERB\|Person=1`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `POS=VERB\|Polarity=Pos\|Voice=Pass`, `Aspect=Imp\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Aspect=Prog\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=1`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=1`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Nom\|Number=Plur\|POS=PROPN\|Person=3`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Mood=Imp\|POS=VERB\|Polarity=Pos\|VerbForm=Conv\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv`, `POS=AUX`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=3`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|POS=NUM\|Person=3`, `POS=VERB\|Polarity=Neg\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Case=Abl\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Gen\|Number=Sing\|POS=ADJ\|Person=3`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Abbr=Yes\|Case=Gen\|Number=Sing\|POS=NOUN\|Person=3`, `Case=Nom\|Mood=Pot\|POS=VERB\|Polarity=Pos`, `Case=Abl\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Loc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Nom\|Number=Plur\|POS=NOUN\|Person=1`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut`, `POS=VERB`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Case=Abl\|Number=Plur\|POS=PRON\|Person=3`, `Aspect=Perf\|Case=Loc\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Perf\|Case=Gen\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Loc\|Number=Sing\|POS=PRON\|Person=3`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Rfl`, `Aspect=Hab\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Equ\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Nom\|Number=Plur\|POS=ADJ\|Person=1`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Dat\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Cnd\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Case=Nom\|NumType=Ord\|Number=Sing\|POS=NUM\|Person=3`, `Case=Nom\|Number=Sing\|POS=AUX\|Person=3`, `Case=Nom\|Number=Sing\|POS=ADV\|Person=3`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=2`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Ins\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Nom\|NumType=Card\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Hab\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Imp\|Case=Dat\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos`, `Case=Nom\|Number=Plur\|POS=AUX\|Person=3`, `Case=Ins\|POS=VERB\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Plur,Sing\|POS=NOUN\|Person=2,3`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=1,3\|Tense=Pres`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|VerbForm=Conv`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Nom\|POS=ADV\|Polarity=Pos`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Gen\|Number=Sing\|POS=NOUN\|Person=1`, `POS=PROPN`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=3`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=3`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Hab\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Equ\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Case=Loc\|POS=VERB\|Polarity=Pos`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Perf\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Imp\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Fut`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `POS=VERB\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1,3\|Person[psor]=3\|Tense=Pres`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Imp\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Hab\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv\|Voice=Cau`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=1\|Person[psor]=1`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3\|PronType=Ind`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PROPN\|Person=3\|Person[psor]=3`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Loc\|Number=Sing\|POS=ADJ\|Person=3`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv\|Voice=Pass`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos`, `Aspect=Perf\|Number[psor]=Sing\|POS=AUX\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=2\|Person[psor]=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=2\|Person[psor]=3`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Abl\|Number=Plur\|POS=PRON\|Person=2`, `POS=VERB\|Polarity=Neg`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos\|Tense=Pres`, `Number=Sing\|POS=VERB\|Person=3`, `Case=Equ\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Dat\|Number=Plur\|POS=ADJ\|Person=3`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Abl\|Number=Sing\|POS=VERB\|Person=3`, `Case=Gen\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Mood=Imp\|POS=VERB\|VerbForm=Conv`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Gen\|Number=Sing\|POS=VERB\|Person=3`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Dat,Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Ins\|Number=Plur\|POS=ADJ\|Person=3`, `Case=Gen\|Number=Sing\|POS=AUX\|Person=3`, `Aspect=Prog\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past`, `Aspect=Perf\|Case=Abl\|Evident=Fh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=2`, `Case=Loc\|Mood=Imp\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=2,3\|Person[psor]=1\|Polarity=Pos`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=2`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Loc\|Number=Plur\|POS=PRON\|Person=1`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Past`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Imp\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Case=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Prog\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Prog\|Case=Nom\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Plur\|POS=NOUN\|Person=2`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=2`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Voice=Pass`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Hab\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Prog\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Ins\|Number=Sing\|POS=VERB\|Person=3`, `Aspect=Prog\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `POS=AUX\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `POS=NUM`, `Aspect=Imp\|POS=VERB\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur\|POS=PRON\|Person=1,3\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past\|Voice=Cau`, `Case=Loc\|Number=Sing\|POS=NOUN\|Person=1`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres\|VerbForm=Conv`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Mood=Ind\|POS=AUX\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Mood=Imp\|POS=VERB\|Polarity=Neg\|VerbForm=Conv`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Case=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=2`, `Case=Acc\|Number=Sing\|POS=ADJ\|Person=3`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=PROPN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Case=Nom\|POS=VERB\|Polarity=Neg`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Abl\|POS=VERB\|Polarity=Pos`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `NumType=Ord\|POS=NUM`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=1\|Person[psor]=1`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=2`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1,3\|Person[psor]=3\|Tense=Past`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Loc,Nom\|Number=Sing\|POS=NOUN\|Person=3`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|Person[psor]=1`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Nom\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `POS=SYM`, `Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Number=Plur\|POS=VERB\|Person=1`, `Case=Dat\|Number=Sing\|POS=ADP\|Person=3`, `Aspect=Hab\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|POS=PRON\|Person=1,3\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Voice=Cau`, `Aspect=Prog\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Case=Nom\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|POS=NOUN\|Person=1,3\|Tense=Past`, `Aspect=Hab\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Imp\|Case=Acc\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Ind\|POS=ADP\|Tense=Pres\|VerbForm=Conv`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Gen\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Mood=Nec\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos`, `Case=Nom\|Number=Sing\|POS=PROPN\|Person=3\|Polarity=Pos`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=1\|Person[psor]=3`, `Case=Abl\|Number=Plur\|POS=PRON\|Person=1`, `Case=Gen\|Number=Plur\|POS=PROPN\|Person=3`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Fut`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3\|PronType=Ind`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Mood=Nec\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Voice=Cau`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=AUX\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Ins\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Ins\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Imp\|POS=VERB\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=PRON\|Person=2,3\|Polarity=Pos\|PronType=Dem`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Evident=Nfh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Tense=Past`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Conv`, `Case=Loc\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Abl\|POS=VERB\|Polarity=Pos\|Voice=Pass`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Imp\|Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|Person[psor]=1`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=1`, `Aspect=Prog\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Equ\|Number=Sing\|POS=NUM\|Person=3\|PronType=Dem`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Mood=Cnd\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Hab\|Mood=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Conv`, `Case=Ins\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=2\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Perf\|Case=Nom\|Evident=Nfh\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Gen\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Imp\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Gen\|Number=Sing\|POS=ADJ\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Pass`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Mood=Pot\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Aspect=Perf\|Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Dat\|Number=Plur\|POS=AUX\|Person=3`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos`, `Aspect=Perf\|Mood=Cnd\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Imp\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Equ\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Echo=Rdp\|POS=X`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Abl\|Number=Plur\|POS=PROPN\|Person=3`, `Aspect=Perf\|Case=Acc\|Mood=Ind\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Past`, `Aspect=Prog\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Ins\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Fut`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Imp\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Case=Gen\|Number=Plur\|POS=VERB\|Person=3`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Equ\|Number=Sing\|POS=NOUN\|Person=3`, `Case=Ins\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Imp\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Aspect=Imp\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Ins\|POS=VERB\|Polarity=Pos\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PROPN\|Person=3\|Person[psor]=3`, `Evident=Nfh\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Conv`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=PROPN\|Person=3\|Tense=Pres\|VerbForm=Conv`, `Evident=Nfh\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|VerbForm=Conv`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Mood=Gen,Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Acc\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=1\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Nom\|Number=Plur\|POS=ADP\|Person=3`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=1\|Person[psor]=1`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NUM\|Person=1\|Person[psor]=1`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|POS=ADJ\|Person=1,3\|Tense=Past`, `Aspect=Hab\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Ins\|POS=VERB\|Polarity=Pos`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Dat\|Number=Plur\|POS=PROPN\|Person=3`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Aspect=Prog\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `POS=NOUN\|Polarity=Pos`, `Aspect=Imp\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=PRON\|Person=3\|Tense=Pres`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=ADV\|Person=3\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Case=Gen\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Cnd\|Number=Sing\|POS=ADV\|Person=3\|Tense=Pres`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Imp,Perf\|Mood=Gen\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres`, `Case=Abl\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Neg\|Tense=Pres\|VerbForm=Conv`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Gen\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=1\|Person[psor]=2`, `Abbr=Yes\|Case=Nom\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Prog\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Loc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Dat\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Abbr=Yes\|Case=Nom\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Prog\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=PROPN\|Person=3\|Tense=Past`, `Aspect=Imp\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Fut`, `Case=Abl\|Number=Sing\|POS=PRON\|Person=3`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Ins\|Number=Plur\|POS=NUM\|Person=3`, `Aspect=Prog\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Equ\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2`, `Aspect=Prog\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Abl\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Prog\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Conv`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Case=Abl\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Acc\|Mood=Pot\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Hab,Perf\|Mood=Cnd,Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Prog\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Abl\|Mood=Gen\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Nom\|POS=VERB\|Polarity=Neg\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past`, `Case=Loc\|Number=Plur\|POS=NOUN\|Person=1`, `Case=Ins\|Number=Sing\|POS=PRON\|Person=3`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=2\|Person[psor]=1`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Past`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab,Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|Polarity=Neg\|Tense=Past,Pres\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Imp\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Evident=Nfh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Imp\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Case=Nom\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Gen\|Number=Sing\|POS=ADP\|Person=3`, `Aspect=Hab\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Prog\|Case=Nom\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Mood=Opt\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=ADP\|Person=3\|Tense=Pres`, `Mood=Nec\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Rfl`, `Case=Acc\|Number=Sing\|POS=ADP\|Person=3`, `Case=Loc,Nom\|Number=Sing\|POS=PRON\|Person=3`, `Case=Loc\|Number=Sing\|POS=VERB\|Person=3`, `Case=Nom\|NumType=Card\|Number=Sing\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Aspect=Hab\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Imp,Perf\|Mood=Gen\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut,Pres`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Ins\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `POS=VERB\|Polarity=Pos\|Voice=Rfl`, `Aspect=Hab\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Number=Sing\|POS=VERB\|Person=1`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Gen\|Number=Sing\|POS=NUM\|Person=3`, `Case=Ins\|Number=Plur\|POS=NOUN\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Evident=Fh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=1\|Person[psor]=3\|Tense=Past`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=3`, `Number=Sing\|POS=ADP\|Person=3`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Plur\|POS=VERB\|Person=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|VerbForm=Conv\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Cau`, `Mood=Imp\|Number=Sing\|POS=AUX\|Person=2\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Gen\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pqp`, `Aspect=Perf\|Mood=Ind\|NumType=Card\|Number=Sing\|POS=NUM\|Person=3\|Tense=Past`, `Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3`, `Aspect=Perf\|Mood=Pot\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Fut\|Voice=Pass`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|Person[psor]=1`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Hab\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `POS=ADJ\|Polarity=Pos`, `Aspect=Imp\|Case=Acc\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Acc\|Number=Plur\|POS=ADJ\|Person=3`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Voice=Pass`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Fut\|VerbForm=Part`, `Aspect=Imp\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=1`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut`, `Aspect=Perf\|Case=Dat\|Mood=Ind\|Number=Plur,Sing\|POS=ADJ\|Person=1,3\|Tense=Pres`, `POS=PROPN\|Polarity=Pos`, `Aspect=Imp\|Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Voice=Cau`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Case=Loc\|Number=Sing\|POS=ADP\|Person=3`, `Aspect=Perf\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Loc\|Number=Sing\|POS=PRON\|Person=1`, `Case=Ins\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Dat,Nom\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NUM\|Person=3\|Person[psor]=3\|Tense=Pres`, `Evident=Nfh\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Prog\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Tense=Past`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Ins\|Number=Sing\|POS=VERB\|Person=2`, `Case=Nom\|Mood=Imp\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=2,3\|Person[psor]=3\|Polarity=Pos`, `Case=Loc\|Number=Plur\|POS=ADJ\|Person=3`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Tense=Pres`, `Aspect=Imp\|Case=Dat\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres`, `Aspect=Imp\|Mood=Imp\|Number=Sing\|POS=AUX\|Person=2,3\|Polarity=Pos\|Tense=Pres`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Mood=Cnd\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Imp\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Fut`, `Case=Equ\|Number=Sing\|POS=ADJ\|Person=3`, `Evident=Nfh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Abl\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Neg`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Voice=Pass`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Acc\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past`, `Aspect=Perf\|Mood=Pot\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Ins\|Number=Sing\|POS=ADJ\|Person=3`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Case=Loc\|Evident=Nfh\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Mood=Opt\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Aspect=Prog\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Hab\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Case=Abl\|Number=Plur\|POS=ADJ\|Person=3`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Acc\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Abl\|Number=Sing\|POS=PRON\|Person=1`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Abl\|Number=Plur\|POS=VERB\|Person=3`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2`, `Case=Nom\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Past`, `Mood=Opt\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Loc\|POS=NOUN\|Polarity=Pos`, `Mood=Des\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Past`, `Aspect=Imp\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres`, `Aspect=Perf\|Case=Gen\|Evident=Fh\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Ins\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=PRON\|Person=3\|Tense=Past`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Rcp`, `POS=ADV\|Polarity=Pos`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Voice=Rcp`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|Person[psor]=1`, `Mood=Cnd\|Number=Plur\|POS=AUX\|Person=2\|Polarity=Pos`, `Aspect=Imp\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Neg\|Tense=Fut`, `Aspect=Hab\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|POS=PRON\|Person=3\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Ins\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Case=Nom\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Tense=Past`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3\|Reflex=Yes`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=3`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Rfl`, `Aspect=Perf\|Mood=Ind\|Number=Plur\|POS=ADP\|Person=3\|Tense=Past`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Pass`, `Case=Loc\|Number=Plur\|POS=PRON\|Person=3`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Mood=Imp\|Number=Sing\|POS=ADJ\|Person=2\|Polarity=Pos`, `Aspect=Prog\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Aspect=Imp\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=2\|Person[psor]=1`, `Case=Acc\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Pres`, `Case=Abl\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Dat\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=2\|Person[psor]=2\|Reflex=Yes`, `Aspect=Prog\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Plur,Sing\|POS=NOUN\|Person=3`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Gen\|Number=Plur\|POS=ADJ\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Tense=Past`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PROPN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|POS=PROPN\|Person=1,3\|Tense=Past`, `Abbr=Yes\|Case=Dat\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Past`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Plur\|POS=ADP\|Person=2`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Tense=Pres`, `Case=Gen\|Number=Plur\|POS=NOUN\|Person=1`, `Evident=Nfh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `POS=SCONJ`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Acc\|NumType=Card\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Perf\|Case=Gen\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Dat\|Number=Plur\|POS=ADP\|Person=3`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Voice=Pass`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Acc\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=2\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `NumType=Dist\|POS=NUM`, `Case=Ins\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Aspect=Perf\|Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Aspect=Perf\|Mood=Opt\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=2\|Person[psor]=2`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PART\|Person=3\|Person[psor]=3`, `POS=ADP\|Polarity=Pos`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Case=Loc\|Number=Plur\|POS=PROPN\|Person=3`, `Case=Abl\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1,3`, `Case=Equ\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Evident=Nfh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Loc\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Perf\|Case=Loc\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=2\|Person[psor]=2\|Voice=Rfl`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|VerbForm=Conv`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Past`, `Aspect=Perf\|Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Loc,Nom\|Number=Plur,Sing\|POS=NOUN\|Person=2,3`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=AUX\|Person=3\|Person[psor]=1`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Sing\|POS=X\|Person=3`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Gen\|Mood=Gen\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Perf\|Case=Abl\|Mood=Gen\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|Person[psor]=1`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg`, `Aspect=Prog\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|POS=VERB\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Imp\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Number=Plur\|POS=NUM\|Person=3`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=PROPN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Aspect=Perf\|Case=Nom\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Perf\|Case=Ins\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Mood=Imp\|Number=Sing\|POS=NOUN\|Person=2,3\|Polarity=Pos`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Loc\|Number=Plur\|POS=PRON\|Person=2`, `Aspect=Hab\|Evident=Nfh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Loc\|POS=VERB\|Polarity=Neg`, `Case=Loc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Case=Loc\|Mood=Imp\|Number=Plur,Sing\|POS=ADJ\|Person=2,3\|Polarity=Pos`, `Case=Abl\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Gen\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Aspect=Prog\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1\|Tense=Past`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Aspect=Perf\|Evident=Nfh\|Mood=Gen\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past,Pres`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Evident=Nfh\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Gen,Pot\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `NumType=Card\|POS=ADJ`, `Case=Gen,Nom\|Number=Plur,Sing\|POS=PRON\|Person=1,3`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Voice=Cau`, `Aspect=Imp\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Case=Ins\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Acc\|Mood=Gen\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=2\|Person[psor]=2`, `Case=Ins\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Acc\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Hab\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Neg\|Tense=Pres`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past`, `Aspect=Imp\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres`, `Case=Ins\|POS=VERB\|Polarity=Neg\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Plur\|POS=AUX\|Person=2`, `Case=Nom\|Number=Plur\|POS=NUM\|Person=1`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=1\|Person[psor]=3`, `Aspect=Perf\|Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=ADP\|Person=1\|Tense=Pres`, `Aspect=Hab\|Number=Plur\|POS=AUX\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Prog\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Rfl`, `Case=Nom\|Number=Plur,Sing\|POS=ADJ\|Person=2,3`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Aspect=Imp\|Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Aspect=Hab\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Voice=Cau`, `Case=Equ\|Number=Plur\|POS=NUM\|Person=3`, `Mood=Des\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Aspect=Imp\|Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Number=Sing\|POS=VERB\|Person=2`, `Aspect=Imp\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1`, `Number=Sing\|POS=ADJ\|Person=1`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Ins\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=ADP\|Person=1\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=X\|Person=3\|Person[psor]=1`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Tense=Past`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=1\|Person[psor]=3`, `Aspect=Perf\|Mood=Gen,Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Mood=Ind,Nec\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|Polarity=Pos\|Tense=Past`, `Mood=Nec\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Nom\|Number=Sing\|POS=ADV\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Abl\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Case=Loc\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=1\|Person[psor]=3`, `Aspect=Imp\|Mood=Pot\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Hab,Perf\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Mood=Ind\|Number[psor]=Sing\|POS=VERB\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Aspect=Prog\|Number=Plur\|POS=AUX\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Hab\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Prog\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Polite=Infm\|Tense=Past`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=2\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Loc\|POS=VERB\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2`, `Case=Abl\|Number=Sing\|POS=NOUN\|Person=2`, `Case=Equ\|Number=Plur\|POS=NOUN\|Person=3`, `POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Rfl`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Cnd\|Number=Sing\|POS=PRON\|Person=1,3\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Rfl`, `Case=Ins\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres`, `Aspect=Perf\|Case=Acc\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Case=Acc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past`, `Case=Abl\|Number=Plur\|POS=NOUN\|Person=2`, `Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Voice=Pass`, `Aspect=Imp\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=ADP\|Person=3\|Person[psor]=2`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Imp\|Number[psor]=Sing\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Fut\|VerbForm=Part`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres\|VerbForm=Conv`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Fut`, `Case=Nom\|POS=VERB\|Polarity=Neg\|Voice=Pass`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Abl\|POS=VERB\|Polarity=Pos\|Voice=Cau`, `Aspect=Hab\|Case=Nom\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Evident=Nfh\|Mood=Gen\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past,Pres`, `Case=Ins\|Number=Plur\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=3`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Aspect=Hab\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Dat\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Hab\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Pass`, `Aspect=Perf\|Mood=Ind\|Number=Sing\|POS=ADV\|Person=3\|Tense=Past`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=1\|Person[psor]=1`, `Aspect=Imp\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Case=Nom\|Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Imp\|POS=VERB\|Polarity=Neg\|Tense=Fut\|VerbForm=Part`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Number=Plur\|POS=AUX\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|POS=ADJ\|Person=1,3\|Tense=Pres`, `Aspect=Imp\|Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres`, `Case=Gen\|Number=Plur\|POS=NOUN\|Person=2`, `Case=Loc,Nom\|Number=Plur,Sing\|POS=PRON\|Person=1,3`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Prog\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Conv`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=1,3\|Tense=Past`, `Aspect=Perf\|Mood=Opt\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Abl\|Mood=Pot\|POS=VERB\|Polarity=Pos`, `Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Evident=Nfh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1\|Person[psor]=3`, `Aspect=Prog\|Case=Nom\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Number=Plur\|POS=ADJ\|Person=1`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=AUX\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Hab,Perf\|Mood=Gen\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Case=Loc\|Mood=Cnd\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `POS=X`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres\|VerbForm=Conv`, `Aspect=Hab\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Mood=Imp\|POS=VERB\|Polarity=Pos\|VerbForm=Conv\|Voice=Rfl`, `Case=Abl\|POS=VERB\|Polarity=Neg`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=DET\|Person=3\|Tense=Past`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|Number[psor]=Sing\|POS=NOUN\|Person=2,3\|Person[psor]=3\|Tense=Pres`, `Aspect=Imp\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut\|Voice=Cau`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg\|Voice=Pass`, `Case=Nom\|Number=Sing\|POS=ADP\|Person=1`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part`, `Case=Abl\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Loc\|Mood=Cnd\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3\|Tense=Pres`, `Aspect=Prog\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Cau`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Nom\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Case=Loc,Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=3`, `Evident=Nfh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Nom\|Mood=Cnd\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1`, `Case=Abl\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Case=Nom\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Past`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=3\|Person[psor]=1`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=ADJ\|Person=1,3\|Person[psor]=3\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Mood=Des\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|POS=NOUN\|Person=1,3\|Tense=Past`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Number=Plur\|POS=NOUN\|Person=1`, `Case=Nom\|Number=Plur\|POS=ADP\|Person=1`, `Aspect=Imp\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut`, `Case=Dat\|NumType=Card\|Number=Sing\|POS=NUM\|Person=3`, `Aspect=Prog\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NUM\|Person=3\|Person[psor]=1\|Polarity=Neg`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Abl\|Number=Plur\|POS=NOUN\|Person=1`, `Case=Equ\|Number=Sing\|POS=VERB\|Person=3`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=AUX\|Person=2\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Aspect=Imp,Perf\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Aspect=Perf\|Mood=Opt\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|POS=PRON\|Person=3\|Tense=Pres`, `Case=Nom\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Voice=Pass`, `Case=Ins\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=2`, `Case=Nom\|Mood=Des\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Voice=Cau`, `Aspect=Hab\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Aspect=Imp\|Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part\|Voice=Cau`, `Case=Nom\|Number=Plur\|POS=ADJ\|Person=3\|Polarity=Pos`, `Number=Plur\|POS=NOUN\|Person=2`, `Aspect=Perf\|Mood=Pot\|Number[psor]=Plur\|POS=VERB\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Mood=Imp\|Number=Sing\|POS=ADP\|Person=2\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Des\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Neg\|Tense=Past\|Voice=Cau`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=ADJ\|Person=1,3\|Tense=Past`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Mood=Pot\|POS=VERB\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Mood=Pot\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Mood=Gen,Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2`, `Case=Loc,Nom\|Number=Sing\|POS=PROPN\|Person=3`, `Aspect=Hab\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Case=Loc\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Past`, `Case=Nom\|Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Voice=Cau`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Abl,Loc\|Number=Sing\|POS=NOUN\|Person=3`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Tense=Pres`, `Aspect=Perf\|Case=Nom\|Mood=Gen\|Number=Plur,Sing\|POS=PRON\|Person=3\|Tense=Pres`, `Aspect=Imp\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Fut`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=2\|Person[psor]=2`, `Case=Dat\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|Voice=Cau`, `Aspect=Perf\|Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=NOUN\|Person=1\|Person[psor]=1`, `Case=Loc\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Nom\|Mood=Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Perf\|Evident=Fh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|Tense=Past`, `Case=Nom\|NumType=Card\|Number=Sing\|POS=NOUN\|Person=3`, `Case=Nom\|Number=Plur\|POS=AUX\|Person=1`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|Number=Plur,Sing\|POS=NOUN\|Person=1,3\|Tense=Pres`, `Aspect=Imp\|Mood=Pot\|Number[psor]=Plur\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos`, `Case=Gen\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Case=Abl\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=3\|Polarity=Neg\|Tense=Pres`, `Aspect=Perf\|Evident=Fh\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Dat\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=2`, `Aspect=Perf\|Mood=Imp\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=2\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Gen\|Number=Sing\|POS=ADP\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Pass`, `Abbr=Yes\|Case=Loc\|Number=Sing\|POS=PROPN\|Person=3`, `Case=Loc\|Number=Sing\|POS=PRON\|Person=2`, `Aspect=Perf\|Number[psor]=Sing\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Number=Sing\|POS=NOUN\|Person=2`, `Aspect=Perf\|Case=Loc\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Vnoun`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg`, `Aspect=Hab,Perf\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=1\|Person[psor]=1`, `Aspect=Hab\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Aspect=Perf\|Mood=Gen\|Number=Sing\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Past,Pres\|VerbForm=Part`, `Case=Equ\|Number=Sing\|POS=PROPN\|Person=3`, `Aspect=Perf\|Case=Nom\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=2,3\|Tense=Past`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Imp\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg\|Tense=Fut\|VerbForm=Part`, `Case=Loc,Nom\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1`, `Aspect=Hab\|Case=Nom\|Mood=Ind\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos\|Tense=Pres`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres\|Voice=Pass`, `Aspect=Perf\|Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg\|Tense=Past\|VerbForm=Part`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=NOUN\|Person=2\|Person[psor]=1`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Tense=Past`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=3`, `Case=Nom\|Mood=Nec\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg`, `Case=Ins\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Prog\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Pres`, `Case=Equ\|Number=Sing\|Number[psor]=Sing\|POS=ADP\|Person=3\|Person[psor]=3`, `Case=Loc\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Evident=Nfh\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Prog\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Pass`, `Aspect=Perf\|Number[psor]=Plur\|POS=VERB\|Person[psor]=3\|Polarity=Neg\|Tense=Past\|VerbForm=Part\|Voice=Cau`, `Case=Acc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Aspect=Perf\|Case=Loc\|Mood=Gen\|Number=Plur,Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Aspect=Perf\|Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Voice=Cau`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Case=Gen\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=1`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=1`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1\|Person[psor]=3`, `Aspect=Prog\|Mood=Pot\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Pres`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=ADJ\|Person=1\|Person[psor]=1`, `Aspect=Imp\|Mood=Pot\|Number=Plur\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Fut`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=1\|Polarity=Neg`, `Number=Sing\|POS=NOUN\|Person=1`, `Case=Nom\|Number=Sing\|Number[psor]=Sing\|POS=AUX\|Person=3\|Person[psor]=3\|Polarity=Pos`, `Mood=Des\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|Voice=Pass`, `Aspect=Perf\|Evident=Nfh\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=2`, `Aspect=Hab\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Pres\|Voice=Pass`, `POS=ADJ\|Polarity=Neg`, `Aspect=Perf\|Mood=Pot\|Number[psor]=Plur\|POS=VERB\|Person[psor]=1\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=2\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Aspect=Perf\|Case=Nom\|Mood=Ind\|Number=Sing\|Number[psor]=Sing\|POS=NOUN\|Person=1,3\|Person[psor]=3\|Tense=Pres`, `Aspect=Prog\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Aspect=Imp,Perf\|Case=Nom\|Mood=Gen,Pot\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut,Pres\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Number=Sing\|Number[psor]=Plur\|POS=PROPN\|Person=3\|Person[psor]=3`, `Aspect=Perf\|Case=Abl\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Past\|VerbForm=Part\|Voice=Pass`, `Aspect=Perf\|Mood=Cnd\|Number=Sing\|POS=ADJ\|Person=3\|Tense=Pres`, `Case=Nom\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Part\|Voice=Pass`, `Evident=Nfh\|Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Aspect=Imp,Perf\|Mood=Cnd\|Number=Plur,Sing\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Fut,Pres`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Fut\|Voice=Pass`, `Aspect=Perf\|Mood=Ind\|POS=VERB\|Polarity=Pos\|Tense=Past\|VerbForm=Part`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=NOUN\|Person=3\|Person[psor]=1\|Polarity=Pos`, `Mood=Pot\|POS=VERB\|Polarity=Pos\|Tense=Pres\|VerbForm=Part\|Voice=Cau`, `Aspect=Perf\|Case=Gen\|Mood=Cnd\|Number=Sing\|POS=NOUN\|Person=3\|Tense=Pres`, `Case=Loc\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Voice=Cau`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=2\|Polarity=Pos\|Tense=Fut\|Voice=Pass`, `Aspect=Perf\|Case=Nom\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past\|Voice=Cau`, `Case=Loc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|Person[psor]=2`, `Aspect=Imp\|Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Pos\|Tense=Fut\|VerbForm=Part`, `Aspect=Perf\|Evident=Fh\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|Tense=Past\|Voice=Pass`, `Aspect=Hab\|Evident=Nfh\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Polarity=Pos\|Tense=Past`, `Case=Nom\|Number=Sing\|Number[psor]=Plur\|POS=ADJ\|Person=3\|Person[psor]=3`, `Case=Nom\|Evident=Nfh\|Number=Sing\|POS=VERB\|Person=1\|Polarity=Pos\|Tense=Past`, `Case=Acc\|Number=Sing\|POS=NOUN\|Person=3\|Polarity=Pos`, `Case=Acc\|Number=Sing\|Number[psor]=Sing\|POS=VERB\|Person=3\|Person[psor]=3\|Polarity=Neg`, `Aspect=Imp\|Number=Plur\|POS=VERB\|Person=3\|Polarity=Neg\|Tense=Fut` |
| **`parser`** | `ROOT`, `acl`, `advcl`, `advmod`, `advmod:emph`, `amod`, `appos`, `aux`, `aux:q`, `case`, `cc`, `cc:preconj`, `ccomp`, `clf`, `compound`, `compound:lvc`, `compound:redup`, `conj`, `cop`, `csubj`, `dep`, `det`, `discourse`, `flat`, `list`, `mark`, `nmod`, `nmod:poss`, `nsubj`, `nummod`, `obj`, `obl`, `parataxis`, `punct`, `vocative`, `xcomp` |
| **`ner`** | `CARDINAL`, `DATE`, `EVENT`, `FAC`, `GPE`, `LANGUAGE`, `LAW`, `LOC`, `MONEY`, `NORP`, `ORDINAL`, `ORG`, `PER`, `PERCENT`, `PERSON`, `PRODUCT`, `QUANTITY`, `TIME`, `TITLE`, `WORK_OF_ART` |
</details>
---
If you'd like to use the models in your own work, please kindly cite the paper [A Diverse Set of Freely Available Linguistic Resources for Turkish](https://aclanthology.org/2023.acl-long.768/):
```
@inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
}
``` | 121,347 | [
[
-0.0341796875,
-0.0272369384765625,
0.035797119140625,
0.035369873046875,
-0.030487060546875,
-0.007740020751953125,
-0.019622802734375,
0.004055023193359375,
0.0491943359375,
0.038665771484375,
-0.03948974609375,
-0.0618896484375,
-0.029296875,
0.0339660644... |
zuleo/spop | 2023-03-06T19:15:34.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"image-to-image",
"art",
"artistic",
"dreambooth",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | zuleo | null | null | zuleo/spop | 5 | 342 | diffusers | 2023-01-27T15:22:43 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- image-to-image
- art
- artistic
- dreambooth
---
# spop style
This model features four different concepts: humans, outer space, forests, and landscapes in the specific style of SPOP: She-Ra and the Princesses of Power, the Dreamworks version.
This is a fine-tuned Stable Diffusion model, based on ```SD 1.5```.
The goal of this model is to capture the _style_ - not the individual characters featured in the series.
> 💖 **Disclaimer**: This is my favorite show. I won't go into that here but a lot of love went into this model.


## Model Usage
This model was trained on multiple concepts. Use the tokens below:
| Token | Description |
|-----------------------|--------------------------------------|
| 👤 `dwspop style` | Uses concepts trained on people |
| 🌌 `dwspop space` | Uses concepts trained on outer space |
| 🌲 `dwspop forest` | Uses concepts trained on forests |
| 🌄 `dwspop landscape` | Uses concepts trained on landscapes |
### 👤 dwspop style examples

This token is capable of handling multiple genders and uses `person` which can be then used for `woman`, `man`,
or `cat-like woman`, or even `lizard`, `dog`, `snoop dog`... it's awesome:
- ```a photo of a person in a forest, dwspop style```
- ```a photo of a woman floating in space, dwspop style```
- ```a photo of a man inside of a palace standing near a window, dwspop style```
⛔ Negative prompt: ```((out of focus body)), ((out of focus face)), ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck)))```
### 🌌 dwspop space examples

The space token is versatile when prompting, especially when generating galaxies and solar systems. This token is capable of handling different camera angles by desribing in your prompts as a `scene`.
- ```a scene of outer space with asteroids and rocks floating in space getting melted by a bright light, dwspop space```
- ```a scene of an outer space solar system with planets, stars and galaxies in the background, dwspop space```
- ```a scene of a planet in space with stars in the background, dwspop space```
⛔ Negative prompt: ```((out of focus face)), (((duplicate))), [out of frame], blurry, out of frame, ugly, blur, motion blur```
### 🌲 dwspop forest forest examples

The forest token is able to generate random forest scenes due to the regularization images that were used. When prompting, additional enviromental objects are supported, such as `crystals`, `rocks`, `flowers`, `cottage`. Finally, mix in time of day: `sunrise`, `dawn`, `sunset`, `evening`.
- ```a beautiful photo of a path in a forest with glowing lights and rocks and trees on either side of the path, dwspop forest```
- ```a forest during night time with a full moon in the sky, dynamic lighting, bright lights, dwspop forest```
- ```a scene of an entrance to a huge forest with pink flowers, dynamic lighting, bright lights, dwspop forest```
⛔ Negative prompt: ```((out of focus face)), (((duplicate))), [out of frame], blurry, out of frame, ugly, blur, motion blur```
### 🌄 dwspop landscape examples:

The landscape token is primarly for landscapes but also supports a small percentage of architecture. Blending your prompts to have both an establishing shot of a landscape with architecture woven in and out is where this token shines.
- ```a scene of a weapon shop that has many different swords hanging on the wall and arrows and staffs inside of barrels, a small shop with a tent in the background, dwspop landscape```
- ```a scene of a village with a waterfall, wooden stairs leading to the top of trees, dynamic lighting, dwspop landscape```
- ```a beautiful scene of a palace with wide doors and a fountain and flowers near a window, sunset, dynamic lighting, dwspop landscape```
⛔ Negative prompt: ```((out of focus face)), (((duplicate))), [out of frame], blurry, out of frame, ugly, blur, motion blur```
---
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
see [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
Export the model:
- [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx)
- [MPS](https://huggingface.co/docs/diffusers/optimization/mps)
- [FLAX/JAX](https://huggingface.co/blog/stable_diffusion_jax)
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "zuleo/spop"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Perfectly-centered close up portrait-photograph of a person, marketplace in the background, sunrise, dwspop style"
image = pipe(prompt).images[0]
image.save("./spop_person.png")
```
---

## 📅 text2img Range Grids
It's always great to get a visual of what's going on with sampler, CFG scale, and other settings. See the examples below and tune them to your liking.
### Sampler
Using different samplers can produce different results. My favorites are using `DPM++ 2S a Karras`, `DPM++ SDE Karras`, `DPM adaptive` for cartoon scenes.
> 🔥 **DPM Adaptive**: DPM Adaptive does not use steps. This sampler is fixed depending on the CFG scale and additional configurations.
View the XY grids below for details:
- Space: https://huggingface.co/zuleo/spop/resolve/main/images/dwspop_space_grid.png
- Forest: https://huggingface.co/zuleo/spop/resolve/main/images/dwspop_forest_grid.png
- Landscape: https://huggingface.co/zuleo/spop/resolve/main/images/dwspop_landscape_grid.png
### Sampling Steps for person
Values between `25 - 38` is a good range for _most_ samplers but not all. See the Sampling Steps grid with each sampler below:
[Sampling Steps Grid](https://huggingface.co/zuleo/spop/resolve/main/images/sampler_grid.png)
### CFG Scale
Values between `7 - 11` is a good range. See the CFG Scale grid:
[CFG Scale Grid](https://huggingface.co/zuleo/spop/resolve/main/images/cfg_grid.png)
---
## 📅 img2img Grids
This model works with img2img with a balanced configuration between `CFG scale`, `denoising`, and adding more detail with `sampling steps`.
### Denoising & Steps
Steps: `39 - 46`, Denoising: `0.49 - 0.6`:
- [Denoising & Steps Grid](https://huggingface.co/zuleo/spop/resolve/main/images/img2img_steps_denoising.png)
### Samplers & Denoising
Samplers: `all`, Denoising: `0.6 - 0.7`:
- [Samplers & Denoising Grid](https://huggingface.co/zuleo/spop/resolve/main/images/img2img_denoise_samplers.png)
### Samplers & CFG Scale
Samplers: `all`, CFG Scale: `7.0 - 11.0`:
- [Samplers & CFG Scale Grid](https://huggingface.co/zuleo/spop/resolve/main/images/img2img_sampler_cfg.png)
---
## 🌐 Regularization images
If you would like to use the regularization images from this training, see the datasets below:
- `space`: https://huggingface.co/datasets/3ee/regularization-space
- `forest`: https://huggingface.co/datasets/3ee/regularization-forest
- `landscape`: https://huggingface.co/datasets/3ee/regularization-landscape
---
☕ If you enjoy this model, buy me a coffee [](https://ko-fi.com/3eegames)
--- | 8,400 | [
[
-0.04498291015625,
-0.051239013671875,
0.027435302734375,
0.031463623046875,
-0.0233154296875,
0.0011959075927734375,
0.0067138671875,
-0.0355224609375,
0.039825439453125,
0.032806396484375,
-0.06707763671875,
-0.040313720703125,
-0.04571533203125,
0.0104980... |
timm/nf_regnet_b1.ra2_in1k | 2023-03-24T01:14:41.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/nf_regnet_b1.ra2_in1k | 0 | 342 | timm | 2023-03-24T01:14:32 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for nf_regnet_b1.ra2_in1k
A NFRegNet (Norm-Free RegNet) image classification model. Trained in `timm` by Ross Wightman.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.2
- GMACs: 0.8
- Activations (M): 7.3
- Image size: train = 256 x 256, test = 288 x 288
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('nf_regnet_b1.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'nf_regnet_b1.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 40, 128, 128])
# torch.Size([1, 40, 64, 64])
# torch.Size([1, 80, 32, 32])
# torch.Size([1, 160, 16, 16])
# torch.Size([1, 960, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'nf_regnet_b1.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 960, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,721 | [
[
-0.036224365234375,
-0.034454345703125,
-0.00917816162109375,
0.0112457275390625,
-0.0265960693359375,
-0.028350830078125,
-0.023590087890625,
-0.03887939453125,
0.0202178955078125,
0.030914306640625,
-0.031768798828125,
-0.04803466796875,
-0.057373046875,
0... |
TheBloke/MythoLogic-13B-GPTQ | 2023-09-27T12:44:46.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/MythoLogic-13B-GPTQ | 15 | 342 | transformers | 2023-07-17T10:27:33 | ---
language:
- en
license: other
model_name: MythoLogic 13B
base_model: Gryphe/MythoLogic-13b
inference: false
model_creator: Gryphe Padar
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# MythoLogic 13B - GPTQ
- Model creator: [Gryphe Padar](https://huggingface.co/Gryphe)
- Original model: [MythoLogic 13B](https://huggingface.co/Gryphe/MythoLogic-13b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Gryphe's MythoLogic 13B](https://huggingface.co/Gryphe/MythoLogic-13b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/MythoLogic-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/MythoLogic-13B-GGUF)
* [Gryphe Padar's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Gryphe/MythoLogic-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/main) | 4 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 7.45 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_False](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ/tree/gptq-8bit-128g-actorder_False) | 8 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and without Act Order to improve AutoGPTQ speed. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/MythoLogic-13B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/MythoLogic-13B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/MythoLogic-13B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `MythoLogic-13B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/MythoLogic-13B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Gryphe's MythoLogic 13B
**UPDATE:** There's a Llama 2 sequel now! [Check it out here!](https://huggingface.co/Gryphe/MythoLogic-L2-13b)
An experiment with gradient merges using [the following script](https://github.com/TehVenomm/LM_Transformers_BlockMerge), with [Chronos](https://huggingface.co/elinas/chronos-13b) as its primary model, augmented by [Hermes](https://huggingface.co/NousResearch/Nous-Hermes-13b) and [Wizard-Vicuna Uncensored](https://huggingface.co/TheBloke/Wizard-Vicuna-13B-Uncensored-HF).
Quantized models are available from TheBloke: [GGML](https://huggingface.co/TheBloke/MythoLogic-13B-GGML) - [GPTQ](https://huggingface.co/TheBloke/MythoLogic-13B-GPTQ) (You're the best!)
## Model details
Chronos is a wonderfully verbose model, though it definitely seems to lack in the logic department. Hermes and WizardLM have been merged gradually, primarily in the higher layers (10+) in an attempt to rectify some of this behaviour.
The main objective was to create an all-round model with improved story generation and roleplaying capabilities.
Below is an illustration to showcase a rough approximation of the gradients I used to create MythoLogic:

## Prompt Format
This model primarily uses Alpaca formatting, so for optimal model performance, use:
```
<System prompt/Character Card>
### Instruction:
Your instruction or question here.
For roleplay purposes, I suggest the following - Write <CHAR NAME>'s next reply in a chat between <YOUR NAME> and <CHAR NAME>. Write a single reply only.
### Response:
```
---
license: other
---
| 16,285 | [
[
-0.042816162109375,
-0.058990478515625,
0.006549835205078125,
0.01155853271484375,
-0.0232391357421875,
-0.0084991455078125,
0.006572723388671875,
-0.042144775390625,
0.0219268798828125,
0.0276641845703125,
-0.050262451171875,
-0.03497314453125,
-0.026123046875,... |
Drake123/my-pet-cat | 2023-08-09T09:37:03.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Drake123 | null | null | Drake123/my-pet-cat | 0 | 342 | diffusers | 2023-08-09T09:32:46 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat Dreambooth model trained by Drake123 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: VJCET6
Sample pictures of this concept:
.jpg)
| 385 | [
[
-0.052642822265625,
-0.0131988525390625,
0.0299224853515625,
0.01763916015625,
-0.01172637939453125,
0.045745849609375,
0.0362548828125,
-0.0308990478515625,
0.07257080078125,
0.038818359375,
-0.042144775390625,
0.000041544437408447266,
-0.0113067626953125,
... |
microsoft/beit-large-patch16-512 | 2022-01-28T10:20:07.000Z | [
"transformers",
"pytorch",
"jax",
"beit",
"image-classification",
"vision",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | microsoft | null | null | microsoft/beit-large-patch16-512 | 7 | 341 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 512x512. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-512')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-512')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 5,581 | [
[
-0.05145263671875,
-0.0206451416015625,
0.0009813308715820312,
-0.01195526123046875,
-0.035369873046875,
-0.007598876953125,
-0.0013875961303710938,
-0.050994873046875,
0.019744873046875,
0.03863525390625,
-0.0269622802734375,
-0.03485107421875,
-0.0540161132812... |
NeelNanda/SoLU_2L_v10_old | 2022-10-26T17:13:59.000Z | [
"transformers",
"endpoints_compatible",
"region:us"
] | null | NeelNanda | null | null | NeelNanda/SoLU_2L_v10_old | 0 | 341 | transformers | 2022-10-12T08:57:58 | A 2L, width 736 SoLU model trained on 15B tokens of the Pile. Bugs: the layernorm just before the unembed is an RMS norm, and the width is not a multiple of 64, so d_head=64 and n_heads=11, and n_heads * d_head != d_model :( | 224 | [
[
-0.0234832763671875,
-0.0310211181640625,
0.0293731689453125,
0.0038738250732421875,
-0.04022216796875,
-0.0307159423828125,
0.0310211181640625,
-0.027984619140625,
0.0083465576171875,
0.0478515625,
-0.036041259765625,
-0.0269622802734375,
-0.050445556640625,
... |
google/switch-base-32 | 2023-01-24T17:19:56.000Z | [
"transformers",
"pytorch",
"switch_transformers",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2101.03961",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | google | null | null | google/switch-base-32 | 4 | 341 | transformers | 2022-11-04T07:58:49 | ---
language:
- en
tags:
- text2text-generation
widget:
- text: "The <extra_id_0> walks in <extra_id_1> park"
example_title: "Masked Language Modeling"
datasets:
- c4
license: apache-2.0
---
# Model Card for Switch Transformers Base - 32 experts

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
# TL;DR
Switch Transformers is a Mixture of Experts (MoE) model trained on Masked Language Modeling (MLM) task. The model architecture is similar to the classic T5, but with the Feed Forward layers replaced by the Sparse MLP layers containing "experts" MLP. According to the [original paper](https://arxiv.org/pdf/2101.03961.pdf) the model enables faster training (scaling properties) while being better than T5 on fine-tuned tasks.
As mentioned in the first few lines of the abstract :
> we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus”, and achieve a 4x speedup over the T5-XXL model.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [original paper](https://arxiv.org/pdf/2101.03961.pdf).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Related Models:** [All Switch Transformers Checkpoints](https://huggingface.co/models?search=switch)
- **Original Checkpoints:** [All Original Switch Transformers Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#mixture-of-experts-moe-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2101.03961.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face Switch Transformers Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/switch_transformers)
# Usage
Note that these checkpoints has been trained on Masked-Language Modeling (MLM) task. Therefore the checkpoints are not "ready-to-use" for downstream tasks. You may want to check `FLAN-T5` for running fine-tuned weights or fine-tune your own MoE following [this notebook](https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing)
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-32")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-32")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-32")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-32", device_map="auto")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-32")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-32", device_map="auto", torch_dtype=torch.float16)
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, SwitchTransformersForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("google/switch-base-32")
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-32", device_map="auto")
input_text = "A <extra_id_0> walks into a bar a orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(0)
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
>>> <pad> <extra_id_0> man<extra_id_1> beer<extra_id_2> a<extra_id_3> salt<extra_id_4>.</s>
```
</details>
# Uses
## Direct Use and Downstream Use
See the [research paper](https://arxiv.org/pdf/2101.03961.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Ethical considerations and risks
More information needed.
## Known Limitations
More information needed.
## Sensitive Use:
More information needed.
# Training Details
## Training Data
The model was trained on a Masked Language Modeling task, on Colossal Clean Crawled Corpus (C4) dataset, following the same procedure as `T5`.
## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2101.03961.pdf) the model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks and compared the results against T5. See the table below for some quantitative evaluation:

For full details, please check the [research paper](https://arxiv.org/pdf/2101.03961.pdf).
## Results
For full results for Switch Transformers, see the [research paper](https://arxiv.org/pdf/2101.03961.pdf), Table 5.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2101.03961,
doi = {10.48550/ARXIV.2101.03961},
url = {https://arxiv.org/abs/2101.03961},
author = {Fedus, William and Zoph, Barret and Shazeer, Noam},
keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity},
publisher = {arXiv},
year = {2021},
copyright = {arXiv.org perpetual, non-exclusive license}
}
``` | 8,211 | [
[
-0.0357666015625,
-0.0311431884765625,
0.01479339599609375,
0.0156402587890625,
-0.006931304931640625,
0.004352569580078125,
-0.0110931396484375,
-0.030517578125,
-0.0031528472900390625,
0.02777099609375,
-0.04376220703125,
-0.023101806640625,
-0.057861328125,
... |
timm/ecaresnet101d.miil_in1k | 2023-04-05T17:59:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1512.03385",
"arxiv:1910.03151",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/ecaresnet101d.miil_in1k | 0 | 341 | timm | 2023-04-05T17:59:18 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for ecaresnet101d.miil_in1k
A ECA-ResNet-D image classification model with Efficient Channel Attention.
This model features:
* ReLU activations
* 3-layer stem of 3x3 convolutions with pooling
* 2x2 average pool + 1x1 convolution shortcut downsample
* Efficient Channel Attention
Trained on ImageNet-1k by Alibaba MIIL.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 44.6
- GMACs: 8.1
- Activations (M): 17.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks: https://arxiv.org/abs/1910.03151
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('ecaresnet101d.miil_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ecaresnet101d.miil_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ecaresnet101d.miil_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@InProceedings{wang2020eca,
title={ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks},
author={Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo and Qinghua Hu},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,834 | [
[
-0.06744384765625,
-0.0191802978515625,
0.00396728515625,
0.0289306640625,
-0.031951904296875,
-0.00910186767578125,
-0.01042938232421875,
-0.031951904296875,
0.08587646484375,
0.01898193359375,
-0.0489501953125,
-0.040924072265625,
-0.048309326171875,
-0.00... |
MBZUAI/LaMini-T5-223M | 2023-04-28T12:07:19.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"instruction fine-tuning",
"en",
"arxiv:2304.14402",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | MBZUAI | null | null | MBZUAI/LaMini-T5-223M | 3 | 341 | transformers | 2023-04-15T10:07:26 | ---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
- instruction fine-tuning
model-index:
- name: flan-t5-small-distil-v2
results: []
language:
- en
pipeline_tag: text2text-generation
widget:
- text: >-
how can I become more healthy?
example_title: example
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini.png" alt="Title" style="width: 100%; min-width: 300px; display: block; margin: auto;"></a>
</p>
# LaMini-T5-223M
[]()
This model is one of our LaMini-LM model series in paper "[LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions](https://github.com/mbzuai-nlp/lamini-lm)". This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction) that contains 2.58M samples for instruction fine-tuning. For more information about our dataset, please refer to our [project repository](https://github.com/mbzuai-nlp/lamini-lm/).
You can view other models of LaMini-LM series as follows. Models with ✩ are those with the best overall performance given their size/architecture, hence we recommend using them. More details can be seen in our paper.
<table>
<thead>
<tr>
<th>Base model</th>
<th colspan="4">LaMini-LM series (#parameters)</th>
</tr>
</thead>
<tbody>
<tr>
<td>T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-61m" target="_blank" rel="noopener noreferrer">LaMini-T5-61M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-223m" target="_blank" rel="noopener noreferrer">LaMini-T5-223M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-738m" target="_blank" rel="noopener noreferrer">LaMini-T5-738M</a></td>
<td></td>
</tr>
<tr>
<td>Flan-T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-77m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-77M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-248m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-248M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-783m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-783M</a>✩</td>
<td></td>
</tr>
<tr>
<td>Cerebras-GPT</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-111m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-111M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-256m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-256M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-590m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-590M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-1.3B</a></td>
</tr>
<tr>
<td>GPT-2</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-124m" target="_blank" rel="noopener noreferrer">LaMini-GPT-124M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-774m" target="_blank" rel="noopener noreferrer">LaMini-GPT-774M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-1.5b" target="_blank" rel="noopener noreferrer">LaMini-GPT-1.5B</a>✩</td>
<td></td>
</tr>
<tr>
<td>GPT-Neo</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-125m" target="_blank" rel="noopener noreferrer">LaMini-Neo-125M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Neo-1.3B</a></td>
<td></td>
<td></td>
</tr>
<tr>
<td>GPT-J</td>
<td colspan="4">coming soon</td>
</tr>
<tr>
<td>LLaMA</td>
<td colspan="4">coming soon</td>
</tr>
</tbody>
</table>
## Use
### Intended use
We recommend using the model to response to human instructions written in natural language.
We now show you how to load and use our model using HuggingFace `pipeline()`.
```python
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text2text-generation', model = checkpoint)
input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
```
## Training Procedure
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini-pipeline.drawio.png" alt="Title" style="width: 100%; min-width: 250px; display: block; margin: auto;"></a>
</p>
We initialize with [t5-base](https://huggingface.co/t5-base) and fine-tune it on our [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction). Its total number of parameters is 223M.
### Training Hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
## Evaluation
We conducted two sets of evaluations: automatic evaluation on downstream NLP tasks and human evaluation on user-oriented instructions. For more detail, please refer to our [paper]().
## Limitations
More information needed
# Citation
```bibtex
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}
``` | 6,359 | [
[
-0.0477294921875,
-0.04925537109375,
0.0140838623046875,
0.0206451416015625,
-0.0199737548828125,
-0.02911376953125,
-0.008941650390625,
-0.047119140625,
0.0196380615234375,
0.0202789306640625,
-0.061737060546875,
-0.03546142578125,
-0.041107177734375,
0.004... |
sohan-ai/sentiment-analysis-model-amazon-reviews | 2023-04-18T15:20:14.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | sohan-ai | null | null | sohan-ai/sentiment-analysis-model-amazon-reviews | 3 | 341 | transformers | 2023-04-18T13:36:02 | # Fine-Tuned Distilled BERT Model for Sentiment Analysis on Amazon Reviews
This repository contains a fine-tuned Distilled BERT (Bidirectional Encoder Representations from Transformers) model for sentiment analysis on Amazon reviews. The base model used is the distilbert-base-uncased model, which is a smaller and faster version of the original BERT model, pre-trained on a large corpus of text data.
## Model Details
The fine-tuned Distilled BERT model is based on the transformers library by Hugging Face, which provides pre-trained language models that can be fine-tuned on specific tasks. The model architecture used in this repository is the distilbert-base-uncased model, which is a lightweight version of the BERT model with uncased text input. The model is fine-tuned using a binary classification approach, where the goal is to predict whether a given Amazon review is positive or negative based on the text of the review.
## Dataset
The model is trained on a dataset of Amazon reviews, which is preprocessed to remove any personally identifiable information (PII) and other irrelevant information. The dataset is split into training, validation, and test sets, with an 80/10/10 split ratio. The training set is used for fine-tuning the model, the validation set is used for hyperparameter tuning, and the test set is used for evaluating the model's performance.
## Deployment on Hugging Face
The fine-tuned Distilled BERT model is deployed on Hugging Face's model hub, a platform for hosting and sharing NLP models. The model is available for download and inference through the Hugging Face Transformers library. To use the deployed model, you need to install the transformers library by Hugging Face and load the model using the provided Hugging Face model name or model checkpoint URL.
## Here's an example code snippet to load and use the fine-tuned Distilled BERT model for sentiment analysis from Hugging Face:
```python
Copy code
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
# Load the fine-tuned model from Hugging Face
model_name = "sohan-ai/sentiment-analysis-model-amazon-reviews"
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
model = DistilBertForSequenceClassification.from_pretrained(model_name)
# Tokenize input text
text = "This is a positive review."
inputs = tokenizer(text, return_tensors="pt")
# Make prediction
outputs = model(**inputs)
predicted_label = "positive" if outputs.logits.argmax().item() == 1 else "negative"
print(f"Predicted sentiment: {predicted_label}")
```
## Evaluation Metrics
The performance of the fine-tuned Distilled BERT model can be evaluated using various evaluation metrics, such as accuracy, precision, recall, and F1 score. These metrics can be calculated on the test set of the Amazon reviews dataset to assess the model's accuracy and effectiveness in predicting sentiment.
## Conclusion
The fine-tuned Distilled BERT model in this repository, deployed on Hugging Face, provides an accurate and efficient way to perform sentiment analysis on Amazon reviews. It can be used in various applications, such as customer feedback analysis, market research, and sentiment monitoring. Please refer to the Hugging Face Transformers documentation for more details on how to use and fine-tune the Distilled BERT model. | 3,351 | [
[
-0.0556640625,
-0.06451416015625,
0.00315093994140625,
0.043487548828125,
-0.035614013671875,
-0.0036830902099609375,
-0.013031005859375,
-0.03851318359375,
0.0204315185546875,
0.021514892578125,
-0.06719970703125,
-0.031646728515625,
-0.058502197265625,
-0.... |
digiplay/SDVN1-Real_origin | 2023-07-14T07:10:42.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/SDVN1-Real_origin | 0 | 341 | diffusers | 2023-07-14T05:18:16 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
https://civitai.com/models/102674?modelVersionId=117203
Sample image I made :

Original Author's DEMO images :
 | 500 | [
[
-0.045623779296875,
-0.024993896484375,
0.028228759765625,
0.0265045166015625,
-0.03045654296875,
-0.0200042724609375,
0.0153350830078125,
-0.0165863037109375,
0.06500244140625,
0.0307769775390625,
-0.058197021484375,
-0.036224365234375,
-0.01229095458984375,
... |
timm/tiny_vit_11m_224.dist_in22k_ft_in1k | 2023-09-01T18:12:46.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2207.10666",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tiny_vit_11m_224.dist_in22k_ft_in1k | 0 | 341 | timm | 2023-09-01T16:04:17 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for tiny_vit_11m_224.dist_in22k_ft_in1k
A TinyViT image classification model. Pretrained on ImageNet-22k with distillation and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.0
- GMACs: 1.9
- Activations (M): 10.7
- Image size: 224 x 224
- **Papers:**
- TinyViT: Fast Pretraining Distillation for Small Vision Transformers: https://arxiv.org/abs/2207.10666
- **Original:** https://github.com/microsoft/Cream/tree/main/TinyViT
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tiny_vit_11m_224.dist_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tiny_vit_11m_224.dist_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 448, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tiny_vit_11m_224.dist_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 448, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@InProceedings{tiny_vit,
title={TinyViT: Fast Pretraining Distillation for Small Vision Transformers},
author={Wu, Kan and Zhang, Jinnian and Peng, Houwen and Liu, Mengchen and Xiao, Bin and Fu, Jianlong and Yuan, Lu},
booktitle={European conference on computer vision (ECCV)},
year={2022}
}
```
| 3,673 | [
[
-0.037689208984375,
-0.035491943359375,
0.01447296142578125,
0.003360748291015625,
-0.03619384765625,
-0.0289154052734375,
-0.02398681640625,
-0.0162200927734375,
0.017974853515625,
0.0208587646484375,
-0.043731689453125,
-0.04425048828125,
-0.048675537109375,
... |
TheBloke/llama2_7b_chat_uncensored-AWQ | 2023-09-27T12:50:42.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:ehartford/wizard_vicuna_70k_unfiltered",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/llama2_7b_chat_uncensored-AWQ | 2 | 341 | transformers | 2023-09-19T06:17:28 | ---
license: other
datasets:
- ehartford/wizard_vicuna_70k_unfiltered
model_name: Llama2 7B Chat Uncensored
base_model: georgesung/llama2_7b_chat_uncensored
inference: false
model_creator: George Sung
model_type: llama
prompt_template: '### HUMAN:
{prompt}
### RESPONSE:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama2 7B Chat Uncensored - AWQ
- Model creator: [George Sung](https://huggingface.co/georgesung)
- Original model: [Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)
<!-- description start -->
## Description
This repo contains AWQ model files for [George Sung's Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of AWQ models for high-throughput concurrent inference in multi-user server scenarios. Note that, at the time of writing, overall throughput is still lower than running vLLM with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGUF)
* [George Sung's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Human-Response
```
### HUMAN:
{prompt}
### RESPONSE:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [George Sung's Llama2 7B Chat Uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored).
<!-- licensing end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.89 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/llama2_7b_chat_uncensored-AWQ --quantization awq
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/llama2_7b_chat_uncensored-AWQ", quantization="awq")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.0.2 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/llama2_7b_chat_uncensored-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=True, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
prompt = "Tell me about AI"
prompt_template=f'''### HUMAN:
{prompt}
### RESPONSE:
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
# Inference can also be done using transformers' pipeline
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), and [vLLM](https://github.com/vllm-project/vllm).
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is not yet compatible with AWQ, but a PR is open which should bring support soon: [TGI PR #781](https://github.com/huggingface/text-generation-inference/issues/781).
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: George Sung's Llama2 7B Chat Uncensored
# Overview
Fine-tuned [Llama-2 7B](https://huggingface.co/TheBloke/Llama-2-7B-fp16) with an uncensored/unfiltered Wizard-Vicuna conversation dataset [ehartford/wizard_vicuna_70k_unfiltered](https://huggingface.co/datasets/ehartford/wizard_vicuna_70k_unfiltered).
Used QLoRA for fine-tuning. Trained for one epoch on a 24GB GPU (NVIDIA A10G) instance, took ~19 hours to train.
The version here is the fp16 HuggingFace model.
## GGML & GPTQ versions
Thanks to [TheBloke](https://huggingface.co/TheBloke), he has created the GGML and GPTQ versions:
* https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGML
* https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ
# Prompt style
The model was trained with the following prompt style:
```
### HUMAN:
Hello
### RESPONSE:
Hi, how are you?
### HUMAN:
I'm fine.
### RESPONSE:
How can I help you?
...
```
# Training code
Code used to train the model is available [here](https://github.com/georgesung/llm_qlora).
To reproduce the results:
```
git clone https://github.com/georgesung/llm_qlora
cd llm_qlora
pip install -r requirements.txt
python train.py configs/llama2_7b_chat_uncensored.yaml
```
# Fine-tuning guide
https://georgesung.github.io/ai/qlora-ift/
| 12,438 | [
[
-0.03424072265625,
-0.0584716796875,
0.0218658447265625,
0.013580322265625,
-0.023712158203125,
-0.002422332763671875,
0.00495147705078125,
-0.04364013671875,
-0.0014438629150390625,
0.031646728515625,
-0.048370361328125,
-0.03717041015625,
-0.023712158203125,
... |
HYPJUDY/layoutlmv3-base-finetuned-funsd | 2022-09-16T03:17:49.000Z | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | HYPJUDY | null | null | HYPJUDY/layoutlmv3-base-finetuned-funsd | 3 | 340 | transformers | 2022-04-18T15:23:41 | ---
license: cc-by-nc-sa-4.0
---
# layoutlmv3-base-finetuned-funsd
The model [layoutlmv3-base-finetuned-funsd](https://huggingface.co/HYPJUDY/layoutlmv3-base-finetuned-funsd) is fine-tuned on the FUNSD dataset initialized from [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base).
This finetuned model achieves an F1 score of 90.59 on the test split of the FUNSD dataset.
[Paper](https://arxiv.org/pdf/2204.08387.pdf) | [Code](https://aka.ms/layoutlmv3) | [Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)
If you find LayoutLMv3 helpful, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
| 1,346 | [
[
-0.0357666015625,
-0.043426513671875,
0.0185699462890625,
0.0303955078125,
-0.021240234375,
-0.0181427001953125,
0.007015228271484375,
-0.017913818359375,
-0.00920867919921875,
0.035400390625,
-0.055419921875,
-0.045013427734375,
-0.0208740234375,
-0.0183868... |
climatebert/environmental-claims | 2023-05-24T06:39:48.000Z | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"ClimateBERT",
"climate",
"en",
"dataset:climatebert/environmental_claims",
"arxiv:2209.00507",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | climatebert | null | null | climatebert/environmental-claims | 7 | 340 | transformers | 2022-09-01T14:22:37 | ---
language: en
license: apache-2.0
datasets: climatebert/environmental_claims
tags:
- ClimateBERT
- climate
---
# Model Card for environmental-claims
## Model Description
The environmental-claims model is fine-tuned on the [EnvironmentalClaims](https://huggingface.co/datasets/climatebert/environmental_claims) dataset by using the [climatebert/distilroberta-base-climate-f](https://huggingface.co/climatebert/distilroberta-base-climate-f) model as pre-trained language model. The underlying methodology can be found in our [research paper](https://arxiv.org/abs/2209.00507).
## Climate Performance Model Card
| environmental-claims | |
|--------------------------------------------------------------------------|----------------|
| 1. Is the resulting model publicly available? | Yes |
| 2. How much time does the training of the final model take? | < 5 min |
| 3. How much time did all experiments take (incl. hyperparameter search)? | 60 hours |
| 4. What was the power of GPU and CPU? | 0.3 kW |
| 5. At which geo location were the computations performed? | Switzerland |
| 6. What was the energy mix at the geo location? | 89 gCO2eq/kWh |
| 7. How much CO2eq was emitted to train the final model? | 2.2 g |
| 8. How much CO2eq was emitted for all experiments? | 1.6 kg |
| 9. What is the average CO2eq emission for the inference of one sample? | 0.0067 mg |
| 10. Which positive environmental impact can be expected from this work? | This work can help detect and evaluate environmental claims and thus have a positive impact on the environment in the future. |
| 11. Comments | - |
## Citation Information
```bibtex
@misc{stammbach2022environmentalclaims,
title = {A Dataset for Detecting Real-World Environmental Claims},
author = {Stammbach, Dominik and Webersinke, Nicolas and Bingler, Julia Anna and Kraus, Mathias and Leippold, Markus},
year = {2022},
doi = {10.48550/ARXIV.2209.00507},
url = {https://arxiv.org/abs/2209.00507},
publisher = {arXiv},
}
```
## How to Get Started With the Model
You can use the model with a pipeline for text classification:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
from tqdm.auto import tqdm
dataset_name = "climatebert/environmental_claims"
model_name = "climatebert/environmental-claims"
# If you want to use your own data, simply load them as 🤗 Datasets dataset, see https://huggingface.co/docs/datasets/loading
dataset = datasets.load_dataset(dataset_name, split="test")
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, max_len=512)
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
# See https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.pipeline
for out in tqdm(pipe(KeyDataset(dataset, "text"), padding=True, truncation=True)):
print(out)
``` | 3,327 | [
[
-0.0286712646484375,
-0.02880859375,
0.0308074951171875,
0.0017385482788085938,
-0.0122833251953125,
-0.00812530517578125,
-0.016387939453125,
-0.045440673828125,
0.0019483566284179688,
0.03253173828125,
-0.033477783203125,
-0.05218505859375,
-0.046173095703125,... |
timm/vit_large_patch14_clip_224.laion2b_ft_in12k | 2023-05-06T00:10:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-12k",
"dataset:laion-2b",
"arxiv:2212.07143",
"arxiv:2210.08402",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_large_patch14_clip_224.laion2b_ft_in12k | 0 | 340 | timm | 2022-11-01T23:02:54 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-12k
- laion-2b
---
# Model card for vit_large_patch14_clip_224.laion2b_ft_in12k
A Vision Transformer (ViT) image classification model. Pretrained on LAION-2B image-text pairs using OpenCLIP. Fine-tuned on ImageNet-12k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 315.3
- GMACs: 77.8
- Activations (M): 57.1
- Image size: 224 x 224
- **Papers:**
- OpenCLIP: https://github.com/mlfoundations/open_clip
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-12k
- **Pretrain Dataset:**
- LAION-2B
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch14_clip_224.laion2b_ft_in12k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch14_clip_224.laion2b_ft_in12k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 257, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,701 | [
[
-0.029541015625,
-0.028106689453125,
0.01110076904296875,
0.0108795166015625,
-0.0254364013671875,
-0.032684326171875,
-0.03515625,
-0.03143310546875,
0.00922393798828125,
0.026214599609375,
-0.02886962890625,
-0.042083740234375,
-0.0516357421875,
-0.0015306... |
Ichsan2895/Merak-7B-v1 | 2023-10-22T13:20:36.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"id",
"en",
"dataset:wikipedia",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | Ichsan2895 | null | null | Ichsan2895/Merak-7B-v1 | 6 | 340 | transformers | 2023-07-23T08:37:17 | ---
datasets:
- wikipedia
language:
- id
- en
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
# Happy to announce the release of our first model, Merak-7B!
Merak-7B is the Large Language Model of Indonesia Languange
This model is based on Meta Llama-2-7B-Chat-HF and fine tuned by some of Indonesia Wikipedia articles that I cleaned before.
Leveraging QLoRA (QLora: Efficient Finetuning of Quantized LLMs), Merak-7B is able to run with 16 GB VRAM
Merak-7B and all of its derivatives are Licensed under Creative Commons-By Attribution-Share Alike-Non Commercial (CC-BY-SA-NC 4.0). Merak-7B empowers AI enthusiasts, researchers alike.
Big thanks to all my friends and communities that help to build our first model. Feel free, to ask me about the model and please share the news on your social media.
## HOW TO USE
### Installation
Please make sure you have installed CUDA driver in your system, Python 3.10 and PyTorch 2. Then install this library in terminal
```
pip install bitsandbytes==0.39.1
pip install transformers==4.31.0
pip install peft==0.4.0
pip install accelerate==0.20.3
pip install einops==0.6.1 scipy sentencepiece datasets
```
### Using BitsandBytes and it run with >= 10 GB VRAM GPU
[](https://colab.research.google.com/drive/1USKJ7HQaxZlHrdi_qFv3B2_GUrvaWgg1?usp=sharing)
```
import torch
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM, BitsAndBytesConfig, LlamaTokenizer
from peft import PeftModel, PeftConfig
model_id = "Ichsan2895/Merak-7B-v1"
config = AutoConfig.from_pretrained(model_id)
BNB_CONFIG = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(model_id,
quantization_config=BNB_CONFIG,
device_map="auto",
trust_remote_code=True)
tokenizer = LlamaTokenizer.from_pretrained(model_id)
def generate_response(question: str) -> str:
prompt = f"<|prompt|>{question}<|answer|>".strip()
encoding = tokenizer(prompt, return_tensors='pt').to("cuda")
with torch.inference_mode():
outputs = model.generate(input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
eos_token_id=tokenizer.pad_token_id,
do_sample=False,
num_beams=2,
temperature=0.3,
repetition_penalty=1.2,
max_length=200)
response = tokenizer.decode(outputs[0], skip_special_tokes=True)
assistant_start = "<|answer|>"
response_start = response.find(assistant_start)
return response[response_start + len(assistant_start) :].strip()
prompt = "Siapa penulis naskah proklamasi kemerdekaan Indonesia?"
print(generate_response(prompt))
```
### From my experience, For better answer, please don’t use BitsandBytes 4-bit Quantization, but it using higher VRAM
[](https://colab.research.google.com/drive/1m6pIbJIKtu7T4lRlCiw7HTPSw16hSrPJ?usp=sharing)
```
import torch
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM, BitsAndBytesConfig, LlamaTokenizer
from peft import PeftModel, PeftConfig
model_id = "Ichsan2895/Merak-7B-v1"
config = AutoConfig.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,
device_map="auto",
trust_remote_code=True)
tokenizer = LlamaTokenizer.from_pretrained(model_id)
def generate_response(question: str) -> str:
prompt = f"<|prompt|>{question}<|answer|>".strip()
encoding = tokenizer(prompt, return_tensors='pt').to("cuda")
with torch.inference_mode():
outputs = model.generate(input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
eos_token_id=tokenizer.pad_token_id,
do_sample=False,
num_beams=2,
temperature=0.3,
repetition_penalty=1.2,
max_length=200)
response = tokenizer.decode(outputs[0], skip_special_tokes=True)
assistant_start = "<|answer|>"
response_start = response.find(assistant_start)
return response[response_start + len(assistant_start) :].strip()
prompt = "Siapa penulis naskah proklamasi kemerdekaan Indonesia?"
print(generate_response(prompt))
```
## CITATION
```
@Paper{arXiv,
author = {Touvron, et al},
title = {Llama 2: Open Foundation and Fine-Tuned Chat Models},
journal = {arXiv preprint arXiv:2307.09288},
year = {2023}
}
@ONLINE{wikidump,
author = "Wikimedia Foundation",
title = "Wikimedia Downloads",
url = "https://dumps.wikimedia.org"
}
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
@article{dettmers2023qlora,
title = {QLoRA: Efficient Finetuning of Quantized LLMs},
author = {Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke},
journal = {arXiv preprint arXiv:2305.14314},
year = {2023}
}
```
## HOW TO CITE THIS PROJECT
If you use the Merak-7B model in your research or project, please cite it as:
```
@article{Merak,
title={Merak-7B: The LLM for Bahasa Indonesia},
author={Muhammad Ichsan},
publisher={Hugging Face}
journal={Hugging Face Repository},
year={2023}
}
``` | 6,625 | [
[
-0.042724609375,
-0.07373046875,
0.0210418701171875,
0.0244903564453125,
-0.0197601318359375,
-0.0026493072509765625,
-0.01806640625,
-0.03021240234375,
0.01143646240234375,
0.02825927734375,
-0.0323486328125,
-0.03375244140625,
-0.041107177734375,
0.0159301... |
srgg000/nmda2 | 2023-08-13T09:53:00.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | srgg000 | null | null | srgg000/nmda2 | 1 | 340 | diffusers | 2023-08-13T09:40:54 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### nmda2 Dreambooth model trained by srgg000 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 494 | [
[
-0.020233154296875,
-0.0501708984375,
0.04107666015625,
0.0306549072265625,
-0.0230255126953125,
0.0341796875,
0.026031494140625,
-0.024322509765625,
0.057098388671875,
0.002750396728515625,
-0.0211639404296875,
-0.0151824951171875,
-0.03582763671875,
-0.016... |
bleugreen/mistral_relevant | 2023-10-15T00:29:22.000Z | [
"peft",
"region:us"
] | null | bleugreen | null | null | bleugreen/mistral_relevant | 0 | 340 | peft | 2023-10-12T23:11:52 | ---
library_name: peft
---
## Training procedure
### Prompt
```
[INST] With no explanation, is the following text chunk relevant & useful, reply 'True' or 'False'
'''
{text}
'''
[/INST]
{correct}
```
### Framework versions
- PEFT 0.5.0
| 241 | [
[
0.009735107421875,
-0.072509765625,
0.0491943359375,
0.0267486572265625,
-0.0294342041015625,
-0.003917694091796875,
0.0362548828125,
0.01346588134765625,
0.011627197265625,
0.027313232421875,
-0.05987548828125,
-0.00531005859375,
-0.024505615234375,
0.01457... |
xlm-mlm-ende-1024 | 2023-07-11T14:46:38.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"xlm",
"fill-mask",
"multilingual",
"en",
"de",
"arxiv:1901.07291",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | null | null | null | xlm-mlm-ende-1024 | 1 | 339 | transformers | 2022-03-02T23:29:04 | ---
language:
- multilingual
- en
- de
license: cc-by-nc-4.0
---
# xlm-mlm-ende-1024
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Technical Specifications](#technical-specifications)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
10. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample, Alexis Conneau. xlm-mlm-ende-1024 is a transformer pretrained using a masked language modeling (MLM) objective for English-German. This model uses language embeddings to specify the language used at inference. See the [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) for further details.
## Model Description
- **Developed by:** Guillaume Lample, Alexis Conneau, see [associated paper](https://arxiv.org/abs/1901.07291)
- **Model type:** Language model
- **Language(s) (NLP):** English-German
- **License:** CC-BY-NC-4.0
- **Related Models:** [xlm-clm-enfr-1024](https://huggingface.co/xlm-clm-enfr-1024), [xlm-clm-ende-1024](https://huggingface.co/xlm-clm-ende-1024), [xlm-mlm-enfr-1024](https://huggingface.co/xlm-mlm-enfr-1024), [xlm-mlm-enro-1024](https://huggingface.co/xlm-mlm-enro-1024)
- **Resources for more information:**
- [Associated paper](https://arxiv.org/abs/1901.07291)
- [GitHub Repo](https://github.com/facebookresearch/XLM)
- [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings)
# Uses
## Direct Use
The model is a language model. The model can be used for masked language modeling.
## Downstream Use
To learn more about this task and potential downstream uses, see the Hugging Face [fill mask docs](https://huggingface.co/tasks/fill-mask) and the [Hugging Face Multilingual Models for Inference](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) docs.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training
The model developers write:
> In all experiments, we use a Transformer architecture with 1024 hidden units, 8 heads, GELU activations (Hendrycks and Gimpel, 2016), a dropout rate of 0.1 and learned positional embeddings. We train our models with the Adam op- timizer (Kingma and Ba, 2014), a linear warm- up (Vaswani et al., 2017) and learning rates varying from 10^−4 to 5.10^−4.
See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for links, citations, and further details on the training data and training procedure.
The model developers also write that:
> If you use these models, you should use the same data preprocessing / BPE codes to preprocess your data.
See the associated [GitHub Repo](https://github.com/facebookresearch/XLM#ii-cross-lingual-language-model-pretraining-xlm) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The model developers evaluated the model on the [WMT'16 English-German](https://huggingface.co/datasets/wmt16) dataset using the [BLEU metric](https://huggingface.co/spaces/evaluate-metric/bleu). See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for further details on the testing data, factors and metrics.
## Results
For xlm-mlm-ende-1024 results, see Table 1 and Table 2 of the [associated paper](https://arxiv.org/pdf/1901.07291.pdf).
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications
The model developers write:
> We implement all our models in PyTorch (Paszke et al., 2017), and train them on 64 Volta GPUs for the language modeling tasks, and 8 GPUs for the MT tasks. We use float16 operations to speed up training and to reduce the memory usage of our models.
See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for further details.
# Citation
**BibTeX:**
```bibtex
@article{lample2019cross,
title={Cross-lingual language model pretraining},
author={Lample, Guillaume and Conneau, Alexis},
journal={arXiv preprint arXiv:1901.07291},
year={2019}
}
```
**APA:**
- Lample, G., & Conneau, A. (2019). Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
More information needed. This model uses language embeddings to specify the language used at inference. See the [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) for further details. | 5,776 | [
[
-0.037384033203125,
-0.05462646484375,
0.01502227783203125,
0.0191192626953125,
-0.0026092529296875,
-0.0048370361328125,
-0.0246734619140625,
-0.0411376953125,
0.004894256591796875,
0.0380859375,
-0.041839599609375,
-0.036468505859375,
-0.053497314453125,
-... |
alger-ia/dziribert | 2023-03-17T08:45:52.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"ar",
"dz",
"arxiv:2109.12346",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | alger-ia | null | null | alger-ia/dziribert | 10 | 339 | transformers | 2022-03-02T23:29:05 | ---
language:
- ar
- dz
tags:
- pytorch
- bert
- multilingual
- ar
- dz
license: apache-2.0
widget:
- text: " أنا من الجزائر من ولاية [MASK] "
- text: "rabi [MASK] khouya sami"
- text: " ربي [MASK] خويا لعزيز"
- text: "tahya el [MASK]."
- text: "rouhi ya dzayer [MASK]"
inference: true
---
<img src="https://raw.githubusercontent.com/alger-ia/dziribert/main/dziribert_drawing.png" alt="drawing" width="25%" height="25%" align="right"/>
# DziriBERT
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian text contents written using both Arabic and Latin characters. It sets new state of the art results on Algerian text classification datasets, even if it has been pre-trained on much less data (~1 million tweets).
For more information, please visit our paper: https://arxiv.org/pdf/2109.12346.pdf.
## How to use
```python
from transformers import BertTokenizer, BertForMaskedLM
tokenizer = BertTokenizer.from_pretrained("alger-ia/dziribert")
model = BertForMaskedLM.from_pretrained("alger-ia/dziribert")
```
You can find a fine-tuning script in our Github repo: https://github.com/alger-ia/dziribert
## Limitations
The pre-training data used in this project comes from social media (Twitter). Therefore, the Masked Language Modeling objective may predict offensive words in some situations. Modeling this kind of words may be either an advantage (e.g. when training a hate speech model) or a disadvantage (e.g. when generating answers that are directly sent to the end user). Depending on your downstream task, you may need to filter out such words especially when returning automatically generated text to the end user.
### How to cite
```bibtex
@article{dziribert,
title={DziriBERT: a Pre-trained Language Model for the Algerian Dialect},
author={Abdaoui, Amine and Berrimi, Mohamed and Oussalah, Mourad and Moussaoui, Abdelouahab},
journal={arXiv preprint arXiv:2109.12346},
year={2021}
}
```
## Contact
Please contact amine.abdaoui.nlp@gmail.com for any question, feedback or request.
| 2,108 | [
[
-0.03179931640625,
-0.040985107421875,
0.01155853271484375,
0.0291748046875,
-0.014984130859375,
0.0200042724609375,
-0.0236358642578125,
-0.027191162109375,
0.015960693359375,
0.042144775390625,
-0.04010009765625,
-0.04595947265625,
-0.08160400390625,
0.010... |
DATEXIS/CORe-clinical-mortality-prediction | 2021-11-30T13:28:29.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"medical",
"clinical",
"mortality",
"en",
"endpoints_compatible",
"region:us"
] | text-classification | DATEXIS | null | null | DATEXIS/CORe-clinical-mortality-prediction | 2 | 339 | transformers | 2022-03-02T23:29:05 | ---
language: "en"
tags:
- bert
- medical
- clinical
- mortality
thumbnail: "https://core.app.datexis.com/static/paper.png"
---
# CORe Model - Clinical Mortality Risk Prediction
## Model description
The CORe (_Clinical Outcome Representations_) model is introduced in the paper [Clinical Outcome Predictions from Admission Notes using Self-Supervised Knowledge Integration](https://www.aclweb.org/anthology/2021.eacl-main.75.pdf).
It is based on BioBERT and further pre-trained on clinical notes, disease descriptions and medical articles with a specialised _Clinical Outcome Pre-Training_ objective.
This model checkpoint is **fine-tuned on the task of mortality risk prediction**.
The model expects patient admission notes as input and outputs the predicted risk of in-hospital mortality.
#### How to use CORe Mortality Risk Prediction
You can load the model via the transformers library:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("bvanaken/CORe-clinical-mortality-prediction")
model = AutoModelForSequenceClassification.from_pretrained("bvanaken/CORe-clinical-mortality-prediction")
```
The following code shows an inference example:
```
input = "CHIEF COMPLAINT: Headaches\n\nPRESENT ILLNESS: 58yo man w/ hx of hypertension, AFib on coumadin presented to ED with the worst headache of his life."
tokenized_input = tokenizer(input, return_tensors="pt")
output = model(**tokenized_input)
import torch
predictions = torch.softmax(output.logits.detach(), dim=1)
mortality_risk_prediction = predictions[0][1].item()
```
### More Information
For all the details about CORe and contact info, please visit [CORe.app.datexis.com](http://core.app.datexis.com/).
### Cite
```bibtex
@inproceedings{vanaken21,
author = {Betty van Aken and
Jens-Michalis Papaioannou and
Manuel Mayrdorfer and
Klemens Budde and
Felix A. Gers and
Alexander Löser},
title = {Clinical Outcome Prediction from Admission Notes using Self-Supervised
Knowledge Integration},
booktitle = {Proceedings of the 16th Conference of the European Chapter of the
Association for Computational Linguistics: Main Volume, {EACL} 2021,
Online, April 19 - 23, 2021},
publisher = {Association for Computational Linguistics},
year = {2021},
}
``` | 2,431 | [
[
-0.0014543533325195312,
-0.039825439453125,
0.0579833984375,
0.0017595291137695312,
-0.0021343231201171875,
-0.0132904052734375,
-0.00027251243591308594,
-0.0269775390625,
0.01387786865234375,
0.0465087890625,
-0.044189453125,
-0.0672607421875,
-0.04983520507812... |
pdelobelle/robbert-v2-dutch-ner | 2022-08-01T14:49:07.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"token-classification",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"nl",
"dataset:oscar",
"dataset:oscar (NL)",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"license:mit",
"autotrain_compatible",
"en... | token-classification | pdelobelle | null | null | pdelobelle/robbert-v2-dutch-ner | 2 | 339 | transformers | 2022-03-02T23:29:05 | ---
language: "nl"
thumbnail: "https://github.com/iPieter/RobBERT/raw/master/res/robbert_logo.png"
tags:
- Dutch
- Flemish
- RoBERTa
- RobBERT
license: mit
datasets:
- oscar
- oscar (NL)
- dbrd
- lassy-ud
- europarl-mono
- conll2002
widget:
- text: "Mijn naam is RobBERT en ik ben een taalmodel van de KU Leuven."
---
<p align="center">
<img src="https://github.com/iPieter/RobBERT/raw/master/res/robbert_logo_with_name.png" alt="RobBERT: A Dutch RoBERTa-based Language Model" width="75%">
</p>
# RobBERT: Dutch RoBERTa-based Language Model.
[RobBERT](https://github.com/iPieter/RobBERT) is the state-of-the-art Dutch BERT model. It is a large pre-trained general Dutch language model that can be fine-tuned on a given dataset to perform any text classification, regression or token-tagging task. As such, it has been successfully used by many [researchers](https://scholar.google.com/scholar?oi=bibs&hl=en&cites=7180110604335112086) and [practitioners](https://huggingface.co/models?search=robbert) for achieving state-of-the-art performance for a wide range of Dutch natural language processing tasks, | 1,112 | [
[
-0.0226898193359375,
-0.075439453125,
0.01470184326171875,
0.040985107421875,
-0.03173828125,
-0.0010595321655273438,
-0.02789306640625,
-0.0579833984375,
0.044342041015625,
0.01500701904296875,
-0.025726318359375,
-0.0300140380859375,
-0.0523681640625,
0.00... |
microsoft/xclip-large-patch14 | 2022-09-08T11:08:18.000Z | [
"transformers",
"pytorch",
"xclip",
"feature-extraction",
"vision",
"video-classification",
"en",
"arxiv:2208.02816",
"license:mit",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | microsoft | null | null | microsoft/xclip-large-patch14 | 0 | 339 | transformers | 2022-09-07T15:17:38 | ---
language: en
license: mit
tags:
- vision
- video-classification
model-index:
- name: nielsr/xclip-large-patch14
results:
- task:
type: video-classification
dataset:
name: Kinetics 400
type: kinetics-400
metrics:
- type: top-1 accuracy
value: 87.1
- type: top-5 accuracy
value: 97.6
---
# X-CLIP (large-sized model)
X-CLIP model (large-sized, patch resolution of 14) trained fully-supervised on [Kinetics-400](https://www.deepmind.com/open-source/kinetics). It was introduced in the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Ni et al. and first released in [this repository](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
This model was trained using 8 frames per video, at a resolution of 224x224.
Disclaimer: The team releasing X-CLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
X-CLIP is a minimal extension of [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for general video-language understanding. The model is trained in a contrastive way on (video, text) pairs.

This allows the model to be used for tasks like zero-shot, few-shot or fully supervised video classification and video-text retrieval.
## Intended uses & limitations
You can use the raw model for determining how well text goes with a given video. See the [model hub](https://huggingface.co/models?search=microsoft/xclip) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/xclip.html#).
## Training data
This model was trained on [Kinetics-400](https://www.deepmind.com/open-source/kinetics).
### Preprocessing
The exact details of preprocessing during training can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L247).
The exact details of preprocessing during validation can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L285).
During validation, one resizes the shorter edge of each frame, after which center cropping is performed to a fixed-size resolution (like 224x224). Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
This model achieves a top-1 accuracy of 87.1% and a top-5 accuracy of 97.6%.
| 2,731 | [
[
-0.0469970703125,
-0.035003662109375,
0.0266265869140625,
0.005672454833984375,
-0.0227203369140625,
0.0032787322998046875,
-0.0210418701171875,
-0.0164642333984375,
0.0275726318359375,
0.024505615234375,
-0.06475830078125,
-0.046112060546875,
-0.0606689453125,
... |
NeelNanda/SoLU_12L_v23_old | 2022-10-29T01:21:18.000Z | [
"transformers",
"endpoints_compatible",
"region:us"
] | null | NeelNanda | null | null | NeelNanda/SoLU_12L_v23_old | 0 | 339 | transformers | 2022-10-15T01:27:20 | A GPT-2 Medium sized SoLU model trained on 11.7B tokens of the Pile (training crashed because of dodgy data loaders at 11B, and wasn't resumed, so this is shorter than the others). 12 layers, d_model=1536. | 205 | [
[
-0.03271484375,
-0.026458740234375,
0.038787841796875,
0.00518798828125,
-0.022918701171875,
-0.0021076202392578125,
0.02935791015625,
-0.0187530517578125,
-0.00360107421875,
0.0328369140625,
-0.021514892578125,
0.0031375885009765625,
-0.053131103515625,
-0.... |
againeureka/vit_cifar10_classification | 2023-05-18T09:08:55.000Z | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | againeureka | null | null | againeureka/vit_cifar10_classification | 0 | 339 | transformers | 2023-05-16T07:30:06 | # ViT, Cifar10 (50,000 images)
- transformers == 4.29.1
## Inference sample code
```python
from transformers import AutoImageProcessor, ViTForImageClassification
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("againeureka/vit_cifar10_classification")
model = ViTForImageClassification.from_pretrained("againeureka/vit_cifar10_classification")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
```
## Input image
- http://images.cocodataset.org/val2017/000000039769.jpg
## Output
```bash
cat
```
## Training setup
- dataset : cifar10 (50,000 images)
- base ViT model : 'google/vit-base-patch16-224-in21k'
- training arguments
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="againeureka/vit_cifar10_classification",
per_device_train_batch_size=16,
evaluation_strategy="steps",
num_train_epochs=4,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
load_best_model_at_end=True,
)
```
| 1,437 | [
[
-0.049041748046875,
-0.0292816162109375,
0.005695343017578125,
0.0213775634765625,
-0.0128021240234375,
-0.0184173583984375,
-0.0135498046875,
-0.020263671875,
-0.00479888916015625,
0.0223541259765625,
-0.035308837890625,
-0.025238037109375,
-0.0504150390625,
... |
emilianJR/majicMIX_realistic_v6 | 2023-06-25T12:26:15.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | emilianJR | null | null | emilianJR/majicMIX_realistic_v6 | 9 | 339 | diffusers | 2023-06-18T12:42:51 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Diffuser model for this SD checkpoint:
https://civitai.com/models/43331/majicmix-realistic
**emilianJR/majicMIX_realistic_v6** is the HuggingFace diffuser that you can use with **diffusers.StableDiffusionPipeline()**.
Examples | Examples | Examples
---- | ---- | ----
 |  | 
 |  | 
-------
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "emilianJR/majicMIX_realistic_v6"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "YOUR PROMPT"
image = pipe(prompt).images[0]
image.save("image.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 1,983 | [
[
-0.0479736328125,
-0.04119873046875,
0.040802001953125,
0.035369873046875,
-0.017547607421875,
-0.00809478759765625,
0.017120361328125,
-0.0007777214050292969,
0.0266571044921875,
0.032684326171875,
-0.060699462890625,
-0.03851318359375,
-0.04150390625,
-0.0... |
digiplay/RealismEngine_v1 | 2023-07-19T06:46:24.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/RealismEngine_v1 | 4 | 339 | diffusers | 2023-07-19T05:21:19 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
https://civitai.com/models/17277/realism-engine?modelVersionId=20414
fit for interior design, ad design , fantasy poster design
*BASE ON SD 2.1
Original Author's DEMO images :



More fit LYCORIS here:
https://civitai.com/models/111737/irish-style-interior-design
https://civitai.com/models/110288/gothic-style-interior-design
https://civitai.com/models/108304/arabic-style-interior-design
https://civitai.com/models/108295/antique-style-interior-design
...
https://civitai.com/user/Sa_May/models | 988 | [
[
-0.053741455078125,
-0.0185089111328125,
0.03765869140625,
0.0275115966796875,
-0.023345947265625,
-0.0004851818084716797,
0.002178192138671875,
-0.029754638671875,
0.04278564453125,
0.01561737060546875,
-0.07049560546875,
-0.0341796875,
-0.002552032470703125,
... |
laion/CLIP-ViT-B-32-DataComp.XL-s13B-b90K | 2023-09-29T22:43:14.000Z | [
"open_clip",
"zero-shot-image-classification",
"dataset:mlfoundations/datacomp_pools",
"arxiv:2304.14108",
"license:mit",
"region:us"
] | zero-shot-image-classification | laion | null | null | laion/CLIP-ViT-B-32-DataComp.XL-s13B-b90K | 0 | 339 | open_clip | 2023-09-29T22:27:30 | ---
license: mit
widget:
- src: >-
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
library_name: open_clip
datasets:
- mlfoundations/datacomp_pools
pipeline_tag: zero-shot-image-classification
---
# Model card for CLIP ViT-B-32 trained DataComp-1B
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
7. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
A CLIP ViT-B/32 model trained with the DataComp-1B (https://github.com/mlfoundations/datacomp) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Model training done on the [stability.ai](https://stability.ai/) cluster.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the DataComp paper (https://arxiv.org/abs/2304.14108) include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
# Training Details
## Training Data
This model was trained with the 1.4 Billion samples of the DataComp-1B dataset (https://arxiv.org/abs/2304.14108).
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
Please see https://arxiv.org/abs/2304.14108.
# Evaluation
Evaluation done on 38 datasets, using the [DataComp repo](https://github.com/mlfoundations/datacomp) and the [LAION CLIP Benchmark](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed on a suite of 38 datasets. See our paper for more details (https://arxiv.org/abs/2304.14108).
## Results
The model achieves a 72.7% zero-shot top-1 accuracy on ImageNet-1k. See our paper for more details and results (https://arxiv.org/abs/2304.14108).
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) for the compute used to train this model.
# Citation
**BibTeX:**
DataComp
```bibtex
@article{datacomp,
title={DataComp: In search of the next generation of multimodal datasets},
author={Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt},
journal={arXiv preprint arXiv:2304.14108},
year={2023}
}
```
OpenAI CLIP paper
```
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
OpenCLIP software
```
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
# How to Get Started with the Model
See https://github.com/mlfoundations/open_clip | 7,405 | [
[
-0.032684326171875,
-0.048126220703125,
0.01256561279296875,
0.0038928985595703125,
-0.0297698974609375,
-0.033294677734375,
-0.01418304443359375,
-0.04302978515625,
0.0030975341796875,
0.0307464599609375,
-0.04150390625,
-0.0460205078125,
-0.048187255859375,
... |
Mathking/bert-base-german-cased-gnad10 | 2023-10-09T08:26:38.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"german-news-classification",
"de",
"dataset:gnad10",
"model-index",
"endpoints_compatible",
"region:us"
] | text-classification | Mathking | null | null | Mathking/bert-base-german-cased-gnad10 | 1 | 338 | transformers | 2022-03-02T23:29:04 | ---
language:
- de
tags:
- text-classification
- german-news-classification
datasets:
- gnad10
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: Mathking/bert-base-german-cased-gnad10
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: gnad10
type: gnad10
config: default
split: train
metrics:
- type: accuracy
value: 0.9557598702001082
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTkxNjAwNTYzYjRjZmQ0M2UxMWQzYzk0YWFjZjRmYzcwNGEyYmRiNDIwNTlmNDNhYjAzNzBmNzU5MTg3MTM1ZSIsInZlcnNpb24iOjF9.1KfABx9YVvR2QiSXwtCBV8ijYGqwiQD3N3i7c1KV2Ke9tQvWA4_HnN7wvCKokESR-zEwIHWfALSveWIgoiSNBg
- type: f1
value: 0.9550736462647613
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDNkYjU0NzAxNjBlOGQ1MWU2OGE5NWFkOGFlNTYwZGFkNTRiMDcwNDRlYmNiMTUxMzViM2Q4MmUyMjU2ZTQwYyIsInZlcnNpb24iOjF9.E9ysIc4ZYrpOpQTJsmLRN1q8Pg-5pWLlvs8WbTeJy2JYNmpBNblaGyeiHckZ8g8gD3Rqv7W9inpivmHRcI4-BQ
- type: f1
value: 0.9557598702001082
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWMxNmVjMjYyNTAxYmYwN2YxNjAzOWQ2MDY3OGRhYzE4NWYwYTUyNjRhNmU2M2Y3MzFiYzI2ZTk4YWQ3NGNkNSIsInZlcnNpb24iOjF9.csdfLvORGZJY11TbWzylKfhz53BAncrjNgCDIGtWzK1AtJutkJj-SQo8rEd9o3Z5BKlH3Ta28O3Y7wKoc4PuDQ
- type: f1
value: 0.9556789875763837
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2I1ZmNjMzViMDY1YWMyNzRkNDY0OTY1YTFkZWViN2JiMDlkMjJjNTZmZDFjZDIxZjA0YzI1NThiODUwMDlhZiIsInZlcnNpb24iOjF9.83yH-SfIAeB9Y3XNPcnn8N3g9puooZRgcBfNMeAKNqNM93U1qEE6JjFvhZBO_UU05cgfqnPp7Pt6h-JQcmdwBA
- type: precision
value: 0.953834169384936
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjQ4YjA2MTZlMmYxMTA4ZTM5MDU1NjI3ZWE4YTBiZDBhMDUwN2FiODZkNjM5OWNiNGU2NjU5ZDE0OTUyODZmNyIsInZlcnNpb24iOjF9.sWcghxM9DeaaldnXR5sLz8KUHVhdjJ8GY_c4f-kZ0-0BDzf4CYURUVziWnlrRTjlUH-hVyfdKd1ufHvLotRgCg
- type: precision
value: 0.9557598702001082
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOWIzZmNlZTcxNzhhMzZhNWQ1ZWI4YzZjMDYyOTMwY2Q5N2EwMzFhMzE4OTFkZjg1NTIyYjVkMGNjZDYwZmQ2YSIsInZlcnNpb24iOjF9.rQ7ZIKeP25hLfHaYdPqX-VZCHoL-YohqGV9NZ-TAIHvNQbj0lPpX_nS89cJ1C0tSoHCeP14lIOWNncRJzQOOCA
- type: precision
value: 0.9558822798145145
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDQzOTMxMGQ4YTI5MDUzNjdhNzdjY2QzNGVlNzUyODE4ZTI1MTY4NTkxZDVhMTBjZjhhMjlmNzRiNjEyOTk3NiIsInZlcnNpb24iOjF9.DWBZXL1mP7oNYQJKCORItDvkZm-l7TcIETNjdeVyS0BnxoEbqEE22OOJwnGLAk-wHtfx7jEKAA7ijQ1qF7cfAg
- type: recall
value: 0.956651983810566
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTFhYTUyZWQ0N2VhOWQxMjY0MGM1ZjExOGE4NDQ5ODMzMmQ5YThkZTYzZjg0YmUwMDhlZDllMDk3MzY2ZWUzZSIsInZlcnNpb24iOjF9.H7UhmKtJ_5FZOQmZP-wPTrHHde-XxtMAj3kluHz6-8P1KOwJkxk24Lu7vTwHf3564XtnJC8eW2C5uyWDTpcgBg
- type: recall
value: 0.9557598702001082
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGY1MWZkOWYzNjg1NGU5YmFmODY2MDNjYWQ3OTUwNTgzMWRlZGUwNzU5NDY2NzFjZTMxOTBiMWVhZWIyNDYzMCIsInZlcnNpb24iOjF9.oKQ0zRYEs-sloah-BJvBKX5SFqWt8UX-0jCi3ldaLwNVJjM-rcdvsERyoYQ-QTLPKsZp4nko3-ic-BDCwGp9Bw
- type: recall
value: 0.9557598702001082
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDlhMmIwOTBkOTIzOTlkZjNiMzlkMmE5NzQ3MzY5NTUxODQyMzY1OTJjNWY4NjI0N2NjYmY5NjkwZjU0MTA1YyIsInZlcnNpb24iOjF9.4FExU6skNNcvIrToS3MR04Q7ho7_PITTqPk8WMdOggaVvnwj8ujxcXyJMSRioQ1ttVlpg_oGismsSD9zttYkBg
- type: loss
value: 0.17337004840373993
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzVmMmQ5OGE0OTU3MTg0NDg4YzhlODU1NWUyODM0NzFjODM3MTY5MWI2OTAyMzU5OTQ2YTljZTJkN2JkYTcyNSIsInZlcnNpb24iOjF9.jeYTrX35vtswkWi8ROqynY_W4rHfxonic74PviTNAKJzTF7tUCI2a9IBavXvSQhMfGv0NEkZzX8N8o4hQTvWDw
---
# German BERT for News Classification
This a bert-base-german-cased model finetuned for text classification on german news articles
## Training data
Used the training set from the 10KGNAD dataset (gnad10 on HuggingFace Datasets). | 4,544 | [
[
-0.0277252197265625,
-0.058013916015625,
0.0169219970703125,
0.01885986328125,
-0.036834716796875,
-0.006641387939453125,
-0.018524169921875,
-0.01190185546875,
0.01617431640625,
0.025177001953125,
-0.043853759765625,
-0.049285888671875,
-0.03985595703125,
-... |
biu-nlp/cdlm | 2021-10-17T12:24:59.000Z | [
"transformers",
"pytorch",
"longformer",
"fill-mask",
"cdlm",
"en",
"arxiv:2101.00406",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | fill-mask | biu-nlp | null | null | biu-nlp/cdlm | 1 | 338 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- longformer
- cdlm
license: apache-2.0
inference: false
---
# Cross-Document Language Modeling
CDLM: Cross-Document Language Modeling.
Avi Caciularu, Arman Cohan, Iz Beltagy, Matthew E Peters, Arie Cattan and Ido Dagan. In EMNLP Findings, 2021. [PDF](https://arxiv.org/pdf/2101.00406.pdf)
Please note that during our pretraining we used the document and sentence separators, which you might want to add to your data. The document and sentence separators are `<doc-s>`, `</doc-s>` (the last two tokens in the vocabulary), and `<s>`, `</s>`, respectively.
```python
from transformers import AutoTokenizer, AutoModel
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('biu-nlp/cdlm')
model = AutoModel.from_pretrained('biu-nlp/cdlm')
```
The original repo is [here](https://github.com/aviclu/CDLM).
If you find our work useful, please cite the paper as:
```python
@article{caciularu2021cross,
title={Cross-Document Language Modeling},
author={Caciularu, Avi and Cohan, Arman and Beltagy, Iz and Peters, Matthew E and Cattan, Arie and Dagan, Ido},
journal={Findings of the Association for Computational Linguistics: EMNLP 2021},
year={2021}
}
``` | 1,204 | [
[
-0.00616455078125,
-0.07275390625,
0.0208892822265625,
0.023040771484375,
-0.01485443115234375,
0.0059661865234375,
-0.0219573974609375,
-0.018951416015625,
-0.0084228515625,
0.034912109375,
-0.02532958984375,
-0.052459716796875,
-0.044525146484375,
0.008705... |
csebuetnlp/mT5_m2m_crossSum | 2023-02-28T13:23:28.000Z | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"mT5",
"am",
"ar",
"az",
"bn",
"my",
"zh",
"en",
"fr",
"gu",
"ha",
"hi",
"ig",
"id",
"ja",
"rn",
"ko",
"ky",
"mr",
"ne",
"om",
"ps",
"fa",
"pcm",
"pt",
"pa",
"ru",
"gd",
"sr",... | summarization | csebuetnlp | null | null | csebuetnlp/mT5_m2m_crossSum | 7 | 338 | transformers | 2022-04-20T15:11:49 | ---
tags:
- summarization
- mT5
language:
- am
- ar
- az
- bn
- my
- zh
- en
- fr
- gu
- ha
- hi
- ig
- id
- ja
- rn
- ko
- ky
- mr
- ne
- om
- ps
- fa
- pcm
- pt
- pa
- ru
- gd
- sr
- si
- so
- es
- sw
- ta
- te
- th
- ti
- tr
- uk
- ur
- uz
- vi
- cy
- yo
licenses:
- cc-by-nc-sa-4.0
widget:
- text: >-
Videos that say approved vaccines are dangerous and cause autism, cancer or
infertility are among those that will be taken down, the company said. The
policy includes the termination of accounts of anti-vaccine influencers.
Tech giants have been criticised for not doing more to counter false health
information on their sites. In July, US President Joe Biden said social
media platforms were largely responsible for people's scepticism in getting
vaccinated by spreading misinformation, and appealed for them to address the
issue. YouTube, which is owned by Google, said 130,000 videos were removed
from its platform since last year, when it implemented a ban on content
spreading misinformation about Covid vaccines. In a blog post, the company
said it had seen false claims about Covid jabs "spill over into
misinformation about vaccines in general". The new policy covers
long-approved vaccines, such as those against measles or hepatitis B.
"We're expanding our medical misinformation policies on YouTube with new
guidelines on currently administered vaccines that are approved and
confirmed to be safe and effective by local health authorities and the WHO,"
the post said, referring to the World Health Organization.
datasets:
- csebuetnlp/CrossSum
---
# mT5-m2m-CrossSum
This repository contains the many-to-many (m2m) mT5 checkpoint finetuned on all cross-lingual pairs of the [CrossSum](https://huggingface.co/datasets/csebuetnlp/CrossSum) dataset. This model tries to **summarize text written in any language in the provided target language.** For finetuning details and scripts, see the [paper](https://arxiv.org/abs/2112.08804) and the [official repository](https://github.com/csebuetnlp/CrossSum).
## Using this model in `transformers` (tested on 4.11.0.dev0)
```python
import re
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
WHITESPACE_HANDLER = lambda k: re.sub('\s+', ' ', re.sub('\n+', ' ', k.strip()))
article_text = """Videos that say approved vaccines are dangerous and cause autism, cancer or infertility are among those that will be taken down, the company said. The policy includes the termination of accounts of anti-vaccine influencers. Tech giants have been criticised for not doing more to counter false health information on their sites. In July, US President Joe Biden said social media platforms were largely responsible for people's scepticism in getting vaccinated by spreading misinformation, and appealed for them to address the issue. YouTube, which is owned by Google, said 130,000 videos were removed from its platform since last year, when it implemented a ban on content spreading misinformation about Covid vaccines. In a blog post, the company said it had seen false claims about Covid jabs "spill over into misinformation about vaccines in general". The new policy covers long-approved vaccines, such as those against measles or hepatitis B. "We're expanding our medical misinformation policies on YouTube with new guidelines on currently administered vaccines that are approved and confirmed to be safe and effective by local health authorities and the WHO," the post said, referring to the World Health Organization."""
model_name = "csebuetnlp/mT5_m2m_crossSum"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
get_lang_id = lambda lang: tokenizer._convert_token_to_id(
model.config.task_specific_params["langid_map"][lang][1]
)
target_lang = "english" # for a list of available language names see below
input_ids = tokenizer(
[WHITESPACE_HANDLER(article_text)],
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=512
)["input_ids"]
output_ids = model.generate(
input_ids=input_ids,
decoder_start_token_id=get_lang_id(target_lang),
max_length=84,
no_repeat_ngram_size=2,
num_beams=4,
)[0]
summary = tokenizer.decode(
output_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(summary)
```
### Available target language names
- `amharic`
- `arabic`
- `azerbaijani`
- `bengali`
- `burmese`
- `chinese_simplified`
- `chinese_traditional`
- `english`
- `french`
- `gujarati`
- `hausa`
- `hindi`
- `igbo`
- `indonesian`
- `japanese`
- `kirundi`
- `korean`
- `kyrgyz`
- `marathi`
- `nepali`
- `oromo`
- `pashto`
- `persian`
- `pidgin`
- `portuguese`
- `punjabi`
- `russian`
- `scottish_gaelic`
- `serbian_cyrillic`
- `serbian_latin`
- `sinhala`
- `somali`
- `spanish`
- `swahili`
- `tamil`
- `telugu`
- `thai`
- `tigrinya`
- `turkish`
- `ukrainian`
- `urdu`
- `uzbek`
- `vietnamese`
- `welsh`
- `yoruba`
## Citation
If you use this model, please cite the following paper:
```
@article{hasan2021crosssum,
author = {Tahmid Hasan and Abhik Bhattacharjee and Wasi Uddin Ahmad and Yuan-Fang Li and Yong-bin Kang and Rifat Shahriyar},
title = {CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs},
journal = {CoRR},
volume = {abs/2112.08804},
year = {2021},
url = {https://arxiv.org/abs/2112.08804},
eprinttype = {arXiv},
eprint = {2112.08804}
}
``` | 5,619 | [
[
-0.0308074951171875,
-0.048431396484375,
0.00266265869140625,
0.0243682861328125,
-0.01206207275390625,
-0.00647735595703125,
-0.01007843017578125,
-0.0271759033203125,
0.0220947265625,
0.0148468017578125,
-0.035919189453125,
-0.043731689453125,
-0.0591125488281... |
xusenlin/uie-base | 2023-06-14T08:09:33.000Z | [
"transformers",
"pytorch",
"infomation extraction",
"uie",
"zh",
"arxiv:2203.12277",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | xusenlin | null | null | xusenlin/uie-base | 8 | 338 | transformers | 2022-12-07T09:11:24 | ---
language:
- zh
tags:
- infomation extraction
- uie
license: apache-2.0
---
# UIE信息抽取模型(Pytorch)
## 模型介绍
+ [UIE(Universal Information Extraction)](https://arxiv.org/pdf/2203.12277.pdf):Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架 `UIE`。
+ 该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。
+ 为了方便大家使用 `UIE` 的强大能力,[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)借鉴该论文的方法,基于 `ERNIE 3.0` 知识增强预训练模型,训练并开源了首个中文通用信息抽取模型 `UIE`。
+ 该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。
## 使用方法
```commandline
pip install litie
```
```python
from pprint import pprint
from litie.pipelines import UIEPipeline
# 实体识别
schema = ['时间', '选手', '赛事名称']
uie = UIEPipeline("xusenlin/uie-base", schema=schema)
pprint(uie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
# 输出
[
{
"时间": [
{
"end": 6,
"probability": 0.98573786,
"start": 0,
"text": "2月8日上午"
}
],
"赛事名称": [
{
"end": 23,
"probability": 0.8503085,
"start": 6,
"text": "北京冬奥会自由式滑雪女子大跳台决赛"
}
],
"选手": [
{
"end": 31,
"probability": 0.8981544,
"start": 28,
"text": "谷爱凌"
}
]
}
]
```
更多实体抽取和关系抽取模型的使用详见 [litie](https://github.com/xusenlinzy/lit-ie)
## 参考链接
[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie) | 1,399 | [
[
-0.01519775390625,
-0.035980224609375,
0.0019588470458984375,
0.010040283203125,
-0.031280517578125,
-0.0139312744140625,
0.0044403076171875,
-0.0235748291015625,
0.0174560546875,
0.0294189453125,
-0.00789642333984375,
-0.03594970703125,
-0.03533935546875,
-... |
MarinHinawa/DialoGPT-medium-Ene | 2023-02-06T03:20:10.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | conversational | MarinHinawa | null | null | MarinHinawa/DialoGPT-medium-Ene | 0 | 338 | transformers | 2023-02-05T04:03:28 | ---
thumbnail: https://www.google.com/url?sa=i&url=https%3A%2F%2Fkagerouproject.fandom.com%2Fwiki%2FHeadphone_Actor%2FGallery&psig=AOvVaw1qa1_iobTskl2YdPAOw_ni&ust=1675739142503000&source=images&cd=vfe&ved=0CA8QjRxqFwoTCLC-8vf0__wCFQAAAAAdAAAAABAI
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Light Novel Character
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("MarinHinawa/DialoGPT-medium-Ene")
model = AutoModelWithLMHead.from_pretrained("MarinHinawa/DialoGPT-medium-Ene")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("EneBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` | 1,567 | [
[
-0.007427215576171875,
-0.05841064453125,
0.008331298828125,
-0.00571441650390625,
-0.018157958984375,
0.00478363037109375,
-0.01434326171875,
-0.0133514404296875,
0.0116729736328125,
0.027130126953125,
-0.043975830078125,
-0.020751953125,
-0.030548095703125,
... |
timm/eca_resnext26ts.ch_in1k | 2023-03-22T07:13:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1910.03151",
"arxiv:1611.05431",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/eca_resnext26ts.ch_in1k | 0 | 338 | timm | 2023-03-22T07:13:49 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for eca_resnext26ts.ch_in1k
A ECA-ResNeXt image classification model (ResNeXt with 'Efficient Channel Attention'). This model features a tiered 3-layer stem and SiLU activations. Trained on ImageNet-1k by Ross Wightman in `timm`.
This model architecture is implemented using `timm`'s flexible [BYOBNet (Bring-Your-Own-Blocks Network)](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py).
BYOBNet allows configuration of:
* block / stage layout
* stem layout
* output stride (dilation)
* activation and norm layers
* channel and spatial / self-attention layers
...and also includes `timm` features common to many other architectures, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* per-stage feature extraction
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.3
- GMACs: 2.4
- Activations (M): 10.5
- Image size: train = 256 x 256, test = 288 x 288
- **Papers:**
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks: https://arxiv.org/abs/1910.03151
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eca_resnext26ts.ch_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_resnext26ts.ch_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 1024, 16, 16])
# torch.Size([1, 2048, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_resnext26ts.ch_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@InProceedings{wang2020eca,
title={ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks},
author={Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo and Qinghua Hu},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
```
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
| 5,085 | [
[
-0.040557861328125,
-0.04193115234375,
0.0115966796875,
0.00904083251953125,
-0.0236358642578125,
-0.02142333984375,
-0.0263671875,
-0.034698486328125,
0.01885986328125,
0.031982421875,
-0.042694091796875,
-0.05303955078125,
-0.04937744140625,
-0.01284790039... |
timm/ecaresnet50d.miil_in1k | 2023-04-05T17:57:07.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1512.03385",
"arxiv:1910.03151",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/ecaresnet50d.miil_in1k | 0 | 338 | timm | 2023-04-05T17:56:43 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for ecaresnet50d.miil_in1k
A ECA-ResNet-D image classification model with Efficient Channel Attention.
This model features:
* ReLU activations
* 3-layer stem of 3x3 convolutions with pooling
* 2x2 average pool + 1x1 convolution shortcut downsample
* Efficient Channel Attention
Trained on ImageNet-1k by Alibaba MIIL.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 4.4
- Activations (M): 11.9
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks: https://arxiv.org/abs/1910.03151
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('ecaresnet50d.miil_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ecaresnet50d.miil_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ecaresnet50d.miil_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@InProceedings{wang2020eca,
title={ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks},
author={Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo and Qinghua Hu},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 38,830 | [
[
-0.06829833984375,
-0.01849365234375,
0.0036983489990234375,
0.0286712646484375,
-0.03179931640625,
-0.0085296630859375,
-0.01033782958984375,
-0.032073974609375,
0.0855712890625,
0.01849365234375,
-0.0494384765625,
-0.04119873046875,
-0.047515869140625,
-0.... |
medmediani/Arabic-KW-Mdel | 2023-04-30T20:11:21.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | medmediani | null | null | medmediani/Arabic-KW-Mdel | 0 | 338 | sentence-transformers | 2023-04-30T15:46:29 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2301 with parameters:
```
{'batch_size': None, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'nkwdataset.BatchNegSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 100,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 3,779 | [
[
-0.0192413330078125,
-0.06231689453125,
0.0203399658203125,
0.024871826171875,
-0.02044677734375,
-0.0322265625,
-0.01885986328125,
0.0030803680419921875,
0.0167083740234375,
0.0271453857421875,
-0.048370361328125,
-0.0457763671875,
-0.05303955078125,
-0.001... |
davidkim205/komt-llama2-13b-v1 | 2023-09-27T05:38:38.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"llama-2-chat",
"en",
"ko",
"arxiv:2308.06502",
"arxiv:2308.06259",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | davidkim205 | null | null | davidkim205/komt-llama2-13b-v1 | 2 | 338 | transformers | 2023-09-25T07:18:11 | ---
language:
- en
- ko
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
- llama-2-chat
license: apache-2.0
---
# komt : korean multi task instruction tuning model

Recently, due to the success of ChatGPT, numerous large language models have emerged in an attempt to catch up with ChatGPT's capabilities.
However, when it comes to Korean language performance, it has been observed that many models still struggle to provide accurate answers or generate Korean text effectively.
This study addresses these challenges by introducing a multi-task instruction technique that leverages supervised datasets from various tasks to create training data for Large Language Models (LLMs).
## Model Details
* **Model Developers** : davidkim(changyeon kim)
* **Repository** : https://github.com/davidkim205/komt
* **Model Architecture** : komt-llama-2-7b is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning by multi-task instruction
* **License**: This model is under a **Non-commercial** Bespoke License and governed by the Meta license.
## Dataset
korean multi-task instruction dataset
## Hardware and Software
- nvidia driver : 535.54.03
- CUDA Version: 12.2
## Training
Refer https://github.com/davidkim205/komt
## Usage
```
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import TextStreamer, GenerationConfig
model_name='davidkim205/komt-llama2-13b-v1'
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
streamer = TextStreamer(tokenizer)
def gen(x):
generation_config = GenerationConfig(
temperature=0.8,
top_p=0.8,
top_k=100,
max_new_tokens=512,
early_stopping=True,
do_sample=True,
)
q = f"### instruction: {x}\n\n### Response: "
gened = model.generate(
**tokenizer(
q,
return_tensors='pt',
return_token_type_ids=False
).to('cuda'),
generation_config=generation_config,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
streamer=streamer,
)
result_str = tokenizer.decode(gened[0])
start_tag = f"\n\n### Response: "
start_index = result_str.find(start_tag)
if start_index != -1:
result_str = result_str[start_index + len(start_tag):].strip()
return result_str
print(gen('제주도를 1박2일로 혼자 여행하려고 하는데 여행 코스를 만들어줘'))
```
output
```
### Response: 제주도를 1박2일로 혼자 여행하려면 다음과 같은 여행 코스를 만들어 계획할 수 있습니다:
1일차:
- 아침: 제주도의 아름다운 해변을 구경하기 위해 해변에 도착하세요. 일출을 감상하며 자연의 아름다움을 만끽하세요.
- 오후: 제주도의 대표적인 관광지인 한라산을 탐험하세요. 등산로를 따라 올라가면서 경치를 즐기고 설명을 듣으며 쉬운 산책을 즐기세요.
- 저녁: 제주도의 맛있는 음식점에서 저녁을 보내세요. 신선한 해산물과 향신료로 만든 음식을 맛보는 것은 제주도 여행의 완벽한 경험이 될 것입니다.
2일차:
- 아침: 한라산 일대를 탐험하기 위해 한라산 케이프로 이동하세요. 이 케이프는 등산을 즐기는 사람들에게 최적의 선택입니다.
```
## Evaluation
For objective model evaluation, we initially used EleutherAI's lm-evaluation-harness but obtained unsatisfactory results. Consequently, we conducted evaluations using ChatGPT, a widely used model, as described in [Self-Alignment with Instruction Backtranslation](https://arxiv.org/pdf/2308.06502.pdf) and [Three Ways of Using Large Language Models to Evaluate Chat](https://arxiv.org/pdf/2308.06259.pdf) .
| model | score | average(0~5) | percentage |
| --------------------------------------- | ------- | ------------ | ---------- |
| gpt-3.5-turbo(close) | 147 | 3.97 | 79.45% |
| naver Cue(close) | 140 | 3.78 | 75.67% |
| clova X(close) | 136 | 3.67 | 73.51% |
| WizardLM-13B-V1.2(open) | 96 | 2.59 | 51.89% |
| Llama-2-7b-chat-hf(open) | 67 | 1.81 | 36.21% |
| Llama-2-13b-chat-hf(open) | 73 | 1.91 | 38.37% |
| nlpai-lab/kullm-polyglot-12.8b-v2(open) | 70 | 1.89 | 37.83% |
| kfkas/Llama-2-ko-7b-Chat(open) | 96 | 2.59 | 51.89% |
| beomi/KoAlpaca-Polyglot-12.8B(open) | 100 | 2.70 | 54.05% |
| **komt-llama2-7b-v1 (open)(ours)** | **117** | **3.16** | **63.24%** |
| **komt-llama2-13b-v1 (open)(ours)** | **129** | **3.48** | **69.72%** |
------------------------------------------------
# Original model card: Meta's Llama 2 7B-chat
Meta developed and released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>
Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>
Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>
**Llama 2 family of models.** Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. The 70B version uses Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** More information can be found in the paper "Llama-2: Open Foundation and Fine-tuned Chat Models", available at https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/.
**Where to send questions or comments about the model** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md).
# **Intended Use**
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
# **Hardware and Software**
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
# **Training Data**
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
# **Evaluation Results**
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.
For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
# **Ethical Considerations and Limitations**
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide/) | 12,086 | [
[
-0.0225830078125,
-0.06646728515625,
0.0181121826171875,
0.025726318359375,
-0.0308837890625,
0.01068878173828125,
-0.0186309814453125,
-0.039764404296875,
0.013397216796875,
0.0267333984375,
-0.046844482421875,
-0.037200927734375,
-0.049072265625,
-0.000150... |
mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-GPTQ-calib-ja-2k | 2023-09-26T08:48:48.000Z | [
"transformers",
"llama",
"text-generation",
"arxiv:2307.09288",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | mmnga | null | null | mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-GPTQ-calib-ja-2k | 3 | 338 | transformers | 2023-09-26T08:30:04 | ---
license: llama2
---
# ELYZA-japanese-Llama-2-7b-fast-instruct-GPTQ-calib-ja-2k
elyzaさんが公開している、[ELYZA-japanese-Llama-2-7b-fast-instruct](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct)を、
日本語のキャリブレーションセットで生成したGPTQモデルになります。
キャリブレーションセットは[izumi-lab/wikipedia-ja-20230720](https://huggingface.co/datasets/izumi-lab/wikipedia-ja-20230720)から、
2kほどランダムサンプリングしたものと、
[ELYZA-tasks-100](https://huggingface.co/datasets/elyza/ELYZA-tasks-100)のinput/outputを計200ほど追加しています。
[mmnga/wikipedia-ja-20230720-2k](https://huggingface.co/datasets/mmnga/wikipedia-ja-20230720-2k)
**AWQはこちら**
[mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-AWQ-calib-ja-100k](https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-AWQ-calib-ja-100k)
# Usage
~~~Bash
pip install auto-gptq transformers
~~~
~~~python
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer
model_name_or_path = "mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-GPTQ-calib-ja-2k"
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# Model
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path, use_safetensors=True, device="cuda:0", use_auth_token=False)
#Your test prompt
prompt = """[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST]"""
print(tokenizer.decode(model.generate(**tokenizer(prompt, return_tensors="pt").to(model.device), max_length=512)[0]))
~~~
## Citation
```tex
@misc{elyzallama2023,
title={ELYZA-japanese-Llama-2-7b},
url={https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b},
author={Akira Sasaki and Masato Hirakawa and Shintaro Horie and Tomoaki Nakamura},
year={2023},
}
```
```tex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 3,238 | [
[
-0.02880859375,
-0.059417724609375,
0.0172271728515625,
0.0212860107421875,
-0.03179931640625,
0.006275177001953125,
0.006237030029296875,
-0.034454345703125,
0.031524658203125,
0.0187225341796875,
-0.050079345703125,
-0.04302978515625,
-0.042572021484375,
0... |
Geotrend/distilbert-base-en-th-cased | 2023-07-07T11:57:08.000Z | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | Geotrend | null | null | Geotrend/distilbert-base-en-th-cased | 0 | 337 | transformers | 2022-03-02T23:29:04 | ---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# distilbert-base-en-th-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-en-th-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-en-th-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request. | 1,297 | [
[
-0.03466796875,
-0.0263519287109375,
0.0269317626953125,
0.0278472900390625,
-0.0095672607421875,
-0.00629425048828125,
-0.03448486328125,
-0.020355224609375,
0.0261077880859375,
0.01367950439453125,
-0.039581298828125,
-0.029388427734375,
-0.056976318359375,
... |
facebook/wav2vec2-large-es-voxpopuli | 2021-07-06T02:07:04.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"es",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | facebook | null | null | facebook/wav2vec2-large-es-voxpopuli | 1 | 337 | transformers | 2022-03-02T23:29:05 | ---
language: es
tags:
- audio
- automatic-speech-recognition
- voxpopuli
license: cc-by-nc-4.0
---
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the es unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
| 1,046 | [
[
-0.0153045654296875,
-0.057342529296875,
0.009918212890625,
0.0240936279296875,
-0.0091094970703125,
0.0005726814270019531,
-0.0462646484375,
-0.049072265625,
0.01666259765625,
0.026580810546875,
-0.0396728515625,
-0.045623779296875,
-0.034698486328125,
-0.0... |
naver/splade-cocondenser-selfdistil | 2022-05-11T08:02:55.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"... | fill-mask | naver | null | null | naver/splade-cocondenser-selfdistil | 5 | 337 | transformers | 2022-05-09T12:48:34 | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser SelfDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-selfdistil` | 37.6 | 98.4 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
``` | 1,195 | [
[
-0.018310546875,
-0.0421142578125,
0.04278564453125,
0.053924560546875,
-0.031494140625,
-0.007320404052734375,
-0.008453369140625,
-0.0201568603515625,
0.032012939453125,
0.0184173583984375,
-0.0240325927734375,
-0.039520263671875,
-0.050262451171875,
0.022... |
rajpurkarlab/gilbert | 2022-11-14T02:40:37.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"py",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | rajpurkarlab | null | null | rajpurkarlab/gilbert | 2 | 337 | transformers | 2022-07-12T23:24:29 | ---
language:
- py
metrics:
- f1
---
To use our fine-tuned BioBERT model to remove references to priors from radiology reports, run the following:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
modelname = "rajpurkarlab/gilbert"
tokenizer = AutoTokenizer.from_pretrained(modelname)
model = AutoModelForTokenClassification.from_pretrained(modelname)
``` | 395 | [
[
-0.01473236083984375,
-0.0006570816040039062,
0.04815673828125,
-0.0146636962890625,
-0.031097412109375,
-0.00606536865234375,
0.0191497802734375,
-0.0289154052734375,
-0.00807952880859375,
0.044921875,
-0.026214599609375,
-0.0266876220703125,
-0.062042236328125... |
AMAN-B/Demo-Dreambooth | 2022-11-22T07:23:06.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AMAN-B | null | null | AMAN-B/Demo-Dreambooth | 1 | 337 | diffusers | 2022-11-11T12:57:25 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
---
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
| 698 | [
[
-0.021087646484375,
-0.042083740234375,
0.043487548828125,
0.0445556640625,
-0.029266357421875,
-0.0038661956787109375,
0.0161590576171875,
0.00008463859558105469,
-0.00226593017578125,
0.0439453125,
-0.032806396484375,
-0.035491943359375,
-0.05413818359375,
... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.