
modelId string | author string | last_modified timestamp[us, tz=UTC] | downloads int64 | likes int64 | library_name string | tags list | pipeline_tag string | createdAt timestamp[us, tz=UTC] | card string |
|---|---|---|---|---|---|---|---|---|---|
hw33/gemma-2-2B-it-thinking-function_calling-V0 | hw33 | 2025-06-11T08:26:16Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-2-2b-it",
"base_model:finetune:google/gemma-2-2b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T08:24:35Z | ---
base_model: google/gemma-2-2b-it
library_name: transformers
model_name: gemma-2-2B-it-thinking-function_calling-V0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-2-2B-it-thinking-function_calling-V0
This model is a fine-tuned version of [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="hw33/gemma-2-2B-it-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.53.0.dev0
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
EdBianchi/ProfVLMv1-EgoExos-Attn | EdBianchi | 2025-06-11T08:22:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"vision-language",
"video-analysis",
"sports",
"proficiency-assessment",
"multimodal",
"pytorch",
"image-to-text",
"base_model:HuggingFaceTB/SmolLM2-135M-Instruct",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M-Instruct",
"license:apache-2.0",
"endpoints_comp... | image-to-text | 2025-06-11T08:20:39Z | ---
license: apache-2.0
base_model:
- HuggingFaceTB/SmolLM2-135M-Instruct
- facebook/timesformer-base-finetuned-k600
tags:
- vision-language
- video-analysis
- sports
- proficiency-assessment
- multimodal
- pytorch
- transformers
library_name: transformers
pipeline_tag: image-to-text
---
# ProfVLM: Video-Language Model for Sports Proficiency Analysis
ProfVLM is a multimodal model that combines video understanding with language generation for analyzing human performance and proficiency levels in human activities.
## Model Description
ProfVLM integrates:
- **Language Model**: HuggingFaceTB/SmolLM2-135M-Instruct with LoRA adapters
- **Vision Encoder**: facebook/timesformer-base-finetuned-k600
- **Custom Video Adapter**: AttentiveProjector with multi-head attention for view integration
### Key Features
- **Multi-view support**: Processes 5 camera view(s) simultaneously
- **Temporal modeling**: Analyzes 8 frames per video
- **Proficiency assessment**: Classifies performance levels (Novice, Early Expert, Intermediate Expert, Late Expert)
- **Sport agnostic**: Trained on multiple sports (basketball, cooking, dance, bouldering, soccer, music)
## Model Architecture
```
Video Input (B, V, T, C, H, W) → TimesFormer → AttentiveProjector → LLM → Text Analysis
```
Where:
- B: Batch size
- V: Number of views (5)
- T: Number of frames (8)
- C, H, W: Channel, Height, Width
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoImageProcessor
from your_module import ProfVLM, load_model
# Load the model
model = load_model("path/to/model", device="cuda")
model.eval()
# Prepare your video data
# videos should be a list of lists: [[view1_frames, view2_frames, ...]]
# where each view contains 8 RGB frames
messages = [
{"role": "system", "content": "You are a visual agent for human performance analysis."},
{"role": "user", "content": "Here are 8 frames sampled from a video: <|video_start|><|video|><|video_end|>. Given this video, analyze the proficiency level of the subject."}
]
prompt = model.processor.tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
batch = model.processor(text=[prompt], videos=[videos], return_tensors="pt", padding=True)
# Generate analysis
with torch.no_grad():
# ... (implementation details as in your generate_on_test_set function)
pass
```
## Training Details
### Dataset
- Multi-sport dataset with proficiency annotations
- Sports: Basketball, Cooking, Dance, Bouldering, Soccer, Music
- Proficiency levels: Novice, Early Expert, Intermediate Expert, Late Expert
### Training Configuration
- **LoRA**: r=32, alpha=64, dropout=0.1
- **Video Processing**: 8 frames per video, 5 view(s)
- **Optimization**: AdamW with cosine scheduling
- **Mixed Precision**: FP16 training
## Performance
The model demonstrates strong performance in:
- Multi-view video understanding
- Temporal feature integration
- Cross-sport proficiency assessment
- Human performance analysis
## Files Structure
```
model/
├── llm_lora/ # LoRA adapter weights
├── tokenizer/ # Tokenizer files
├── vision_processor/ # Vision processor config
├── video_adapter.pt # Custom video adapter weights
├── config.json # Model configuration
└── README.md # This file
```
## Requirements
```
torch>=2.0.0
transformers>=4.35.0
peft>=0.6.0
av>=10.0.0
opencv-python>=4.8.0
torchvision>=0.15.0
numpy>=1.24.0
pillow>=9.5.0
```
## Citation
If you use this model, please cite:
```bibtex
coming soon....
```
## License
This model is released under the Apache 2.0 License.
## Acknowledgments
- Base LLM: HuggingFaceTB/SmolLM2-135M-Instruct
- Vision Encoder: facebook/timesformer-base-finetuned-k600
- Built with 🤗 Transformers and PyTorch
|
TarunKM/Nexteer_Lora_model_adapter_example_45E | TarunKM | 2025-06-11T08:16:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T08:16:40Z | ---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** TarunKM
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
noza-kit/JP2_ACbase_byGemini_2twice-full | noza-kit | 2025-06-11T08:16:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-11T08:12:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
openbmb/BitCPM4-0.5B | openbmb | 2025-06-11T08:12:38Z | 51 | 11 | transformers | [
"transformers",
"safetensors",
"text-generation",
"conversational",
"custom_code",
"zh",
"en",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-generation | 2025-06-05T06:09:02Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width. (**<-- you are here**)
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with Transformers
BitCPM4's parameters are stored in a fake-quantized format, which supports direct inference within the Huggingface framework.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
path = "openbmb/BitCPM4-0.5B"
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
messages = [
{"role": "user", "content": "推荐5个北京的景点。"},
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
model_outputs = model.generate(
model_inputs,
max_new_tokens=1024,
top_p=0.7,
temperature=0.7
)
output_token_ids = [
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
]
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.
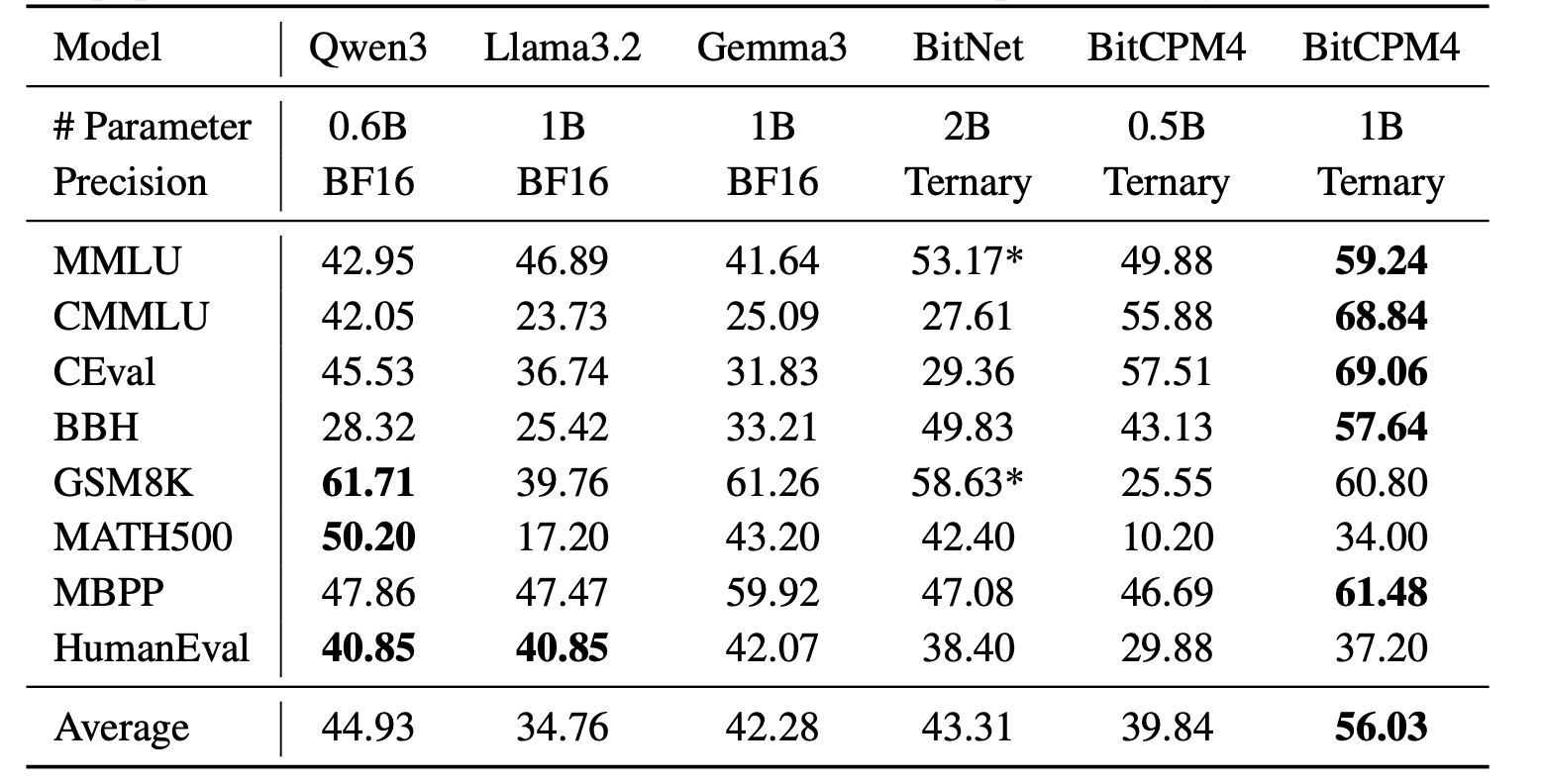
## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
kavanmevada/gemma-3-QLoRA-0-0-14 | kavanmevada | 2025-06-11T08:04:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-pt",
"base_model:finetune:google/gemma-3-1b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T06:41:21Z | ---
base_model: google/gemma-3-1b-pt
library_name: transformers
model_name: gemma-3-QLoRA-0-0-14
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-QLoRA-0-0-14
This model is a fine-tuned version of [google/gemma-3-1b-pt](https://huggingface.co/google/gemma-3-1b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kavanmevada/gemma-3-QLoRA-0-0-14", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
arrayofintegers/catboostrizztech | arrayofintegers | 2025-06-11T08:00:35Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | null | 2025-06-11T07:17:15Z | ---
license: mit
---
---
language: id
license: mit
tags:
- catboost
- classification
- baseline
datasets:
- your-username/datathon-dataset
---
# 🐱 CatBoost Baseline - Datathon 2025
Model ini adalah baseline classifier menggunakan [CatBoost](https://catboost.ai) untuk kompetisi Datathon 2025.
## 📊 Dataset
Model ini dilatih menggunakan dataset: [`your-username/datathon-dataset`](https://huggingface.co/datasets/your-username/datathon-dataset)
## 🧠 Model Info
- Model: CatBoostClassifier
- Fitur: Semua fitur numerik dan kategorikal dari dataset
- Target: Klasifikasi biner (`0` dan `1`)
## 🚀 Cara Pakai
```python
from catboost import CatBoostClassifier
model = CatBoostClassifier()
model.load_model("catboost_model.cbm")
|
nvidia/difix | nvidia | 2025-06-11T07:57:49Z | 0 | 1 | diffusers | [
"diffusers",
"safetensors",
"en",
"dataset:DL3DV/DL3DV-10K-Sample",
"arxiv:2503.01774",
"diffusers:DifixPipeline",
"region:us"
] | null | 2025-06-03T17:04:21Z | ---
datasets:
- DL3DV/DL3DV-10K-Sample
language:
- en
---
# **Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models**
CVPR 2025 (Oral)
[**Code**](https://github.com/nv-tlabs/Difix3D) | [**Project Page**](https://research.nvidia.com/labs/toronto-ai/difix3d/) | [**Paper**](https://arxiv.org/abs/2503.01774)
## Description:
Difix is a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by
underconstrained regions of 3D representation. The technology behind Difix is based on the concepts outlined in the paper titled
[DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models](https://arxiv.org/abs/2503.01774 ).
Difix has two operation modes:
* Offline mode: Used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction
and then distill them back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality.
* Online mode: Acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D
supervision and the limited capacity of current reconstruction models.
Difix is an all-encompassing solution, a single model compatible for both NeRF and 3DGS representations.
**This model is ready for research and development/non-commercial use only.**
**Model Developer:** NVIDIA
**Model Versions:** difix
**Deployment Geography:** Global
### License/Terms of Use:
The use of the model and code is governed by the NVIDIA License. Additional Information: [LICENSE.md · stabilityai/sd-turbo at main](https://huggingface.co/stabilityai/sd-turbo/blob/main/LICENSE.md)
### Use Case:
Difix is intended for Physical AI developers looking to enhance and improve their Neural Reconstruction pipelines. The model takes an image as an input and outputs a fixed image
**Release Date:** Github: [June 2025](https://github.com/nv-tlabs/Difix3D)
## Model Architecture
**Architecture Type**: UNet
**Network Architecture**: A latent diffusion-based UNet coupled with a variational autoencoder (VAE).
## Input
**Input Type(s)**: Image
**Input Format(s)**: Red, Green, Blue (RGB)
**Input Parameters**: Two-Dimensional (2D)
**Other Properties Related to Input**:
* Specific Resolution: [576px x 1024px]
## Output
**Output Type(s)**: Image
**Output Format(s)**: Red, Green, Blue (RGB)
**Output Parameters**: Two-Dimensional (2D)
**Other Properties Related to Output**:
* Specific Resolution: [576px x 1024px]
## Software Integration
**Runtime Engine(s)**: PyTorch
**Supported Hardware Microarchitecture Compatibility**:
* NVIDIA Ampere
* NVIDIA Hopper
**Note**: We are testing with FP32 Precision.
## Inference
**Acceleration Engine**: [PyTorch](https://pytorch.org/)
**Test Hardware**:
* A100
* H100
**Operating System(s):** Linux (We have not tested on other operating systems.)
**System Requirements and Performance:**
This model requires X GB of GPU VRAM.
The following table shows inference time for a single generation across different NVIDIA GPU hardware:
| GPU Hardware | Inference Runtime |
|--------------|----------------------------|
| NVIDIA A100 | 0.355 sec |
| NVIDIA H100 | 0.223 sec |
## Use the Difix Model
Please visit the [Difix3D repository](https://github.com/nv-tlabs/Difix3D) to access all relevant files and code needed to use Difix
## Difix Dataset
- Data Collection Method: Human
- Labeling Method by Dataset: Human
- Properties: Difix was trained, tested, and evaluated using the [DL3DV-10k dataset](https://huggingface.co/datasets/DL3DV/DL3DV-10K-Sample), where 80% of the data was used for training, 10% for evaluation, and 10% for testing. DL3DV-10K is a large-scale dataset consisting of 10,510 high-resolution (4K) real-world video sequences, totaling approximately 51.2 million frames. The scenes span 65 diverse categories across indoor and outdoor environments. Each video is accompanied by metadata describing environmental conditions such as lighting (natural, artificial, mixed), surface materials (e.g., reflective or transparent), and texture complexity. The dataset is designed to support the development and evaluation of learning-based 3D vision methods.
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/)
---
## ModelCard++
### Bias
| Field | Response |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------- |
| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | None |
### Explainability
| Field | Response |
| :-------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------- |
| Intended Domain: | Advanced Driver Assistance Systems |
| Model Type: | Image-to-Image |
| Intended Users: | Autonomous Vehicles developers enhancing and improving Neural Reconstruction pipelines. |
| Output: | Image |
| Describe how the model works: | The model takes as an input an image, and outputs a fixed image |
| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | None |
| Technical Limitations: | The reconstruction relies on the quality and consistency of input images and camera calibrations; any deficiencies in these areas can negatively impact the final output. |
| Verified to have met prescribed NVIDIA quality standards: | Yes |
| Performance Metrics: | FID (Fréchet Inception Distance), PSNR (Peak Signal-to-Noise Ratio), LPIPS (Learned Perceptual Image Patch Similarity) |
| Potential Known Risks: | The model is not guaranteed to fix 100% of the image artifacts. please verify the generated scenarios are context and use appropriate. |
| Licensing: | The use of the model and code is governed by the NVIDIA License. Additional Information: [LICENSE.md · stabilityai/sd-turbo at main](https://huggingface.co/stabilityai/sd-turbo/blob/main/LICENSE.md). |
### Privacy
| Field | Response |
| :------------------------------------------------------------------ | :------------- |
| Generatable or reverse engineerable personal data? | No |
| Personal data used to create this model? | No |
| How often is the dataset reviewed? | Before release |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Is data compliant with data subject requests for data correction or removal, if such a request was made? | Yes |
### Safety & Security
| Field | Response |
| :---------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Model Application(s): | Image Enhancement |
| List types of specific high-risk AI systems, if any, in which the model can be integrated: | The model can be used to develop Autonomous Vehicles stacks that can be integrated inside vehicles. The Difix model should not be deployed in a vehicle. |
| Describe the life critical impact (if present). | N/A - The model should not be deployed in a vehicle and will not perform life-critical tasks. |
| Use Case Restrictions: | Your use of the model and code is governed by the NVIDIA License. Additional Information: LICENSE.md · stabilityai/sd-turbo at main |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. | |
ibrahimbukhariLingua/qwen2.5-3b-en-wikipedia-finance-500-v4 | ibrahimbukhariLingua | 2025-06-11T07:54:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T07:54:34Z | ---
base_model: Qwen/Qwen2.5-3B-Instruct
library_name: transformers
model_name: qwen2.5-3b-en-wikipedia-finance-500-v4
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for qwen2.5-3b-en-wikipedia-finance-500-v4
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ibrahimbukhariLingua/qwen2.5-3b-en-wikipedia-finance-500-v4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Respair/Tsukasa_Speech | Respair | 2025-06-11T07:38:04Z | 0 | 63 | null | [
"safetensors",
"StyleTTS",
"Japanese",
"Diffusion",
"Prompt",
"TTS",
"TexttoSpeech",
"speech",
"StyleTTS2",
"LLM",
"anime",
"voice",
"text-to-speech",
"ja",
"arxiv:2405.04517",
"license:cc-by-nc-4.0",
"region:us"
] | text-to-speech | 2024-11-27T17:52:05Z | ---
thumbnail: https://i.postimg.cc/y6gT18Tn/Untitled-design-1.png
license: cc-by-nc-4.0
language:
- ja
pipeline_tag: text-to-speech
tags:
- 'StyleTTS'
- 'Japanese'
- 'Diffusion'
- 'Prompt'
- 'TTS'
- 'TexttoSpeech'
- 'speech'
- 'StyleTTS2'
- 'LLM'
- 'anime'
- 'voice'
---
<div style="text-align:center;">
<img src="https://i.postimg.cc/y6gT18Tn/Untitled-design-1.png" alt="Logo" style="width:300px; height:auto;">
</div>
# Tsukasa 司 Speech: Engineering the Naturalness and Rich Expressiveness
**tl;dr** : I made a very cool japanese speech generation model.
if the demo didn't work and you just want to listen to some samples, take a look at this [notebook](https://colab.research.google.com/drive/1efRFWeHI5ZCcwvQJDRzt8qT3m6CB7XzK?usp=sharing). (ps. this belongs to a much earlier checkpoint, not representative of the model at its best.)
---
Try [chatting with Aira](https://huggingface.co/spaces/Respair/Chatting_with_Aira), a mini-project I did by using various Tech, including Tsukasa. (maybe not very optimized, but hey, it works!)
日本語のモデルカードは[こちら](https://huggingface.co/Respair/Tsukasa_Speech/blob/main/README_JP.md)。
Part of a [personal project](https://github.com/Respaired/Project-Kanade), focusing on further advancing Japanese speech field.
- Use the HuggingFace Space for **Tsukasa** (24khz): [](https://huggingface.co/spaces/Respair/Tsukasa_Speech)
- ~~HuggingFace Space for **Tsumugi** (48khz): [](https://huggingface.co/spaces/Respair/Tsumugi_48khz)~~
- Join Shoukan lab's discord server, a comfy place I frequently visit -> [](https://discord.gg/JrPSzdcM)
Github's repo:
[](https://github.com/Respaired/Tsukasa-Speech)
## What is this?
*Note*: This model only supports the Japanese language; ~~but you can feed it Romaji if you use the Gradio demo.~~ (no longer, due to resource constraints, but the Tech is there.)
This is a speech generation network, aimed at maximizing the expressiveness and Controllability of the generated speech. at its core it uses [StyleTTS 2](https://github.com/yl4579/StyleTTS2)'s architecture with the following changes:
- Incorporating mLSTM Layers instead of regular PyTorch LSTM layers, and increasing the capacity of the text and prosody encoder by using a higher number of parameters
- Retrained PL-Bert, Pitch Extractor, Text Aligner from scratch
- Whisper's Encoder instead of WavLM for the SLM
- 48khz Config
- improved Performance on non-verbal sounds and cues. such as sigh, pauses, etc. and also very slightly on laughter (depends on the speaker)
- a new way of sampling the Style Vectors.
- Promptable Speech Synthesizing.
- a Smart Phonemization algorithm that can handle Romaji inputs or a mixture of Japanese and Romaji.
- Fixed DDP and BF16 Training (mostly!)
There are two checkpoints you can use. Tsukasa & Tsumugi 48khz (placeholder).
Tsukasa was trained on ~800 hours of studio grade, high quality data. sourced mainly from games and novels, part of it from a private dataset.
So the Japanese is going to be the "anime japanese" (it's different than what people usually speak in real-life.)
Brought to you by:
- Soshyant (me)
- [Auto Meta](https://github.com/Alignment-Lab-AI)
- [Cryptowooser](https://github.com/cryptowooser)
- [Buttercream](https://github.com/korakoe)
Special thanks to Yinghao Aaron Li, the Author of StyleTTS which this work is based on top of that. <br> He is one of the most talented Engineers I've ever seen in this field.
Also Karesto and Raven(a.k.a hexgrad) for their help in debugging some of the scripts. wonderful people.
___________________________________________________________________________________
## Why does it matter?
Recently, there's a big trend towards larger models, increasing the scale. We're going the opposite way, trying to see how far we can push the limits by utilizing existing tools.
Maybe, just maybe, scale is not necessarily the answer.
There's also a few things that's related to Japanese (but can have a wider impact on languages that face a similar issue like Arabic). such as how we can improve the intonations for this language. what can be done to accurately annotate a text that can have various spellings depending on the context, etc.
## How to do ...
## Pre-requisites
1. Python >= 3.11
2. Clone this repository:
```bash
git clone https://huggingface.co/Respair/Tsukasa_Speech
cd Tsukasa_Speech
```
3. Install python requirements:
```bash
pip install -r requirements.txt
```
# Inference:
Gradio demo:
```bash
python app_tsuka.py
```
or check the inference notebook. before that, make sure you read the **Important Notes** section down below.
# Training:
**Before starting remove lines 985 and 986 from models.py also remove "KotoDama_Prompt, KotoDama_Text" from the "build_model" function's parameters.**
**First stage training**:
```bash
accelerate launch train_first.py --config_path ./Configs/config.yml
```
**Second stage training**:
```bash
accelerate launch accelerate_train_second.py --config_path ./Configs/config.yml
```
SLM Joint-Training doesn't work on multigpu. (you don't need it, i didn't use it too.)
or:
```bash
launch train_first.py --config_path ./Configs/config.yml
```
**Third stage training** (Kotodama, prompt encoding, etc.):
```
not planned right now, due to some constraints, but feel free to replicate.
```
## some ideas for future
I can think of a few things that can be improved, not nessarily by me, treat it as some sorts of suggestions:
- [o] changing the decoder ([fregrad](https://github.com/kaistmm/fregrad) looks promising)
- [o] retraining the Pitch Extractor using a different algorithm
- [o] while the quality of non-speech sounds have been improved, it cannot generate an entirely non-speech output, perhaps because of the hard alignement.
- [o] using the Style encoder as another modality in LLMs, since they have a detailed representation of the tone and expression of a speech (similar to Style-Talker).
## Pre-requisites
1. Python >= 3.11
2. Clone this repository:
```bash
git clone https://huggingface.co/Respair/Tsukasa_Speech
cd Tsukasa_Speech
```
3. Install python requirements:
```bash
pip install -r requirements.txt
```
## Training details
- 8x A40s + 2x V100s(32gb each)
- 750 ~ 800 hours of data
- Bfloat16
- Approximately 3 weeks of training, overall 3 months including the work spent on the data pipeline.
- Roughly 66.6 kg of CO2eq. of Carbon emitted if we base it on Google Cloud. (I didn't use Google, but the cluster is located in US, please treat it as a very rough approximation.)
### Important Notes
Check [here](https://huggingface.co/Respair/Tsukasa_Speech/blob/main/Important_Notes.md)
Any questions?
```email
saoshiant@protonmail.com
```
or simply DM me on discord.
## Some cool projects:
[Kokoro]("https://huggingface.co/spaces/hexgrad/Kokoro-TTS") - a very nice and light weight TTS, based on StyleTTS. supports Japanese and English.<br>
[VoPho]("https://github.com/ShoukanLabs/VoPho") - a meta phonemizer to rule them all. it will automatically handle any languages with hand-picked high quality phonemizers.
## References
- [yl4579/StyleTTS2](https://github.com/yl4579/StyleTTS2)
- [NX-AI/xlstm](https://github.com/NX-AI/xlstm)
- [archinetai/audio-diffusion-pytorch](https://github.com/archinetai/audio-diffusion-pytorch)
- [jik876/hifi-gan](https://github.com/jik876/hifi-gan)
- [rishikksh20/iSTFTNet-pytorch](https://github.com/rishikksh20/iSTFTNet-pytorch)
- [nii-yamagishilab/project-NN-Pytorch-scripts/project/01-nsf](https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf)
- [litain's Moe Speech](https://huggingface.co/datasets/litagin/moe-speech) a very cool dataset you can use in case i couldn't release mine
```
@article{xlstm,
title={xLSTM: Extended Long Short-Term Memory},
author={Beck, Maximilian and P{\"o}ppel, Korbinian and Spanring, Markus and Auer, Andreas and Prudnikova, Oleksandra and Kopp, Michael and Klambauer, G{\"u}nter and Brandstetter, Johannes and Hochreiter, Sepp},
journal={arXiv preprint arXiv:2405.04517},
year={2024}
}
``` |
HaripriyanK/your-fast-coref-model-path | HaripriyanK | 2025-06-11T07:37:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T07:37:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
thonypythony/describe_and_neurogenerate_image | thonypythony | 2025-06-11T07:24:03Z | 0 | 0 | null | [
"license:wtfpl",
"region:us"
] | null | 2025-06-11T07:17:59Z | ---
license: wtfpl
---
```bash
pip install --upgrade pip
pip install ollama transformers
pip install --upgrade diffusers[torch]
```
### & Download [Ollama](https://ollama.com/download)
```bash
ollama run gemma3:4b
```




|
hdong0/Qwen2.5-Math-1.5B-batch-mix-Open-R1-GRPO_deepscaler_1000steps_lr1e-6_kl1e-3_acc | hdong0 | 2025-06-11T07:19:53Z | 160 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:agentica-org/DeepScaleR-Preview-Dataset",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:finetune:Qwen/Qwen2.5-Math-1.5B",
"autotr... | text-generation | 2025-05-29T21:15:23Z | ---
base_model: Qwen/Qwen2.5-Math-1.5B
datasets: agentica-org/DeepScaleR-Preview-Dataset
library_name: transformers
model_name: Qwen2.5-Math-1.5B-batch-mix-Open-R1-GRPO_deepscaler_1000steps_lr1e-6_kl1e-3_acc
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-Math-1.5B-batch-mix-Open-R1-GRPO_deepscaler_1000steps_lr1e-6_kl1e-3_acc
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) on the [agentica-org/DeepScaleR-Preview-Dataset](https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="hdong0/Qwen2.5-Math-1.5B-batch-mix-Open-R1-GRPO_deepscaler_1000steps_lr1e-6_kl1e-3_acc", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.0.dev0
- Transformers: 4.52.0.dev0
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
ighoshsubho/lora-grpo-flux-dev | ighoshsubho | 2025-06-11T07:07:18Z | 0 | 0 | peft | [
"peft",
"safetensors",
"lora",
"flux",
"text-to-image",
"grpo",
"reinforcement-learning",
"flow-matching",
"pickscore",
"en",
"arxiv:2505.05470",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:apache-2.0",
"region:us"
] | text-to-image | 2025-06-10T04:47:58Z | ---
base_model: "black-forest-labs/FLUX.1-dev"
library_name: peft
tags:
- lora
- flux
- text-to-image
- grpo
- reinforcement-learning
- flow-matching
- pickscore
license: apache-2.0
language:
- en
pipeline_tag: text-to-image
---
# FLUX.1-dev LoRA Fine-tuned with Flow-GRPO
This LoRA (Low-Rank Adaptation) model is a fine-tuned version of [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) using **Flow-GRPO** (Flow-based Group Relative Policy Optimization), a novel reinforcement learning technique for flow matching models.
## Model Description
This model was trained using the Flow-GRPO methodology described in the paper ["Flow-GRPO: Training Flow Matching Models via Online RL"](https://arxiv.org/abs/2505.05470). Flow-GRPO integrates online reinforcement learning into flow matching models by:
1. **ODE-to-SDE conversion**: Transforms deterministic flow matching into stochastic sampling for RL exploration
2. **Denoising reduction**: Uses fewer denoising steps during training while maintaining full quality at inference
3. **Human preference optimization**: Trained with PickScore reward to align with human preferences
## Training Details
### Core Configuration
- **Base Model**: FLUX.1-dev
- **Training Method**: Flow-GRPO with PickScore reward
- **Resolution**: 512×512
- **Mixed Precision**: bfloat16
- **Seed**: 42
### LoRA Configuration
- **LoRA Enabled**: True
- **Rank**: Not specified in config (typically 32-64)
- **Target Modules**: Transformer layers
### Training Hyperparameters
- **Learning Rate**: 5e-5
- **Batch Size**: 1 (with gradient accumulation: 32 steps)
- **Optimizer**: 8-bit AdamW
- β₁: 0.9
- β₂: 0.999
- Weight Decay: 1e-4
- Epsilon: 1e-8
- **Gradient Clipping**: Max norm 1.0
- **Max Epochs**: 100,000
- **Save Frequency**: Every 100 steps
### Flow-GRPO Specific
- **Reward Function**: PickScore (human preference)
- **Beta (KL penalty)**: 0.001
- **Clip Range**: 0.2
- **Advantage Clipping**: Max 5.0
- **Timestep Fraction**: 0.2
- **Guidance Scale**: 3.5
### Sampling Configuration
- **Training Steps**: 2 (denoising reduction)
- **Evaluation Steps**: 4
- **Images per Prompt**: 4
- **Batches per Epoch**: 4
## Usage
### With Diffusers
```python
import torch
from diffusers import FluxPipeline
# Load the base model
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.bfloat16,
device_map="auto"
)
# Load the LoRA weights
pipe.load_lora_weights("ighoshsubho/lora-grpo-flux-dev")
# Generate an image
prompt = "A serene landscape with mountains and a lake at sunset"
image = pipe(
prompt,
height=512,
width=512,
guidance_scale=3.5,
num_inference_steps=20,
max_sequence_length=256,
).images[0]
image.save("generated_image.png")
```
### Adjusting LoRA Strength
```python
# You can adjust the LoRA influence
pipe.set_adapters(["default"], adapter_weights=[0.8]) # 80% LoRA influence
```
## Training Data & Objectives
- **Dataset**: Custom PickScore dataset for human preference alignment
- **Prompt Function**: General OCR prompts
- **Optimization Target**: Maximizing PickScore while maintaining image quality
- **KL Regularization**: Prevents reward hacking and maintains model stability
## Performance Improvements
This model demonstrates improvements in:
- **Human preference alignment** through PickScore optimization
- **Text rendering quality** via OCR-focused training
- **Compositional understanding** enhanced by Flow-GRPO's exploration mechanism
- **Stable training** with minimal reward hacking due to KL regularization
## Technical Notes
- Uses **denoising reduction** during training (2 steps) for efficiency
- Maintains full quality with standard inference steps (20-50)
- Trained with **mixed precision** (bfloat16) for memory efficiency
- **8-bit AdamW** optimizer reduces memory footprint
- **Gradient accumulation** (32 steps) enables effective large batch training
## Limitations
- Optimized for 512×512 resolution
- Focused on PickScore preferences (may not generalize to all aesthetic preferences)
- LoRA adaptation may have reduced capacity compared to full fine-tuning
## Citation
If you use this model, please cite the Flow-GRPO paper:
```bibtex
@article{liu2025flow,
title={Flow-GRPO: Training Flow Matching Models via Online RL},
author={Liu, Jie and Liu, Gongye and Liang, Jiajun and Li, Yangguang and Liu, Jiaheng and Wang, Xintao and Wan, Pengfei and Zhang, Di and Ouyang, Wanli},
journal={arXiv preprint arXiv:2505.05470},
year={2025}
}
```
## License
This model is released under the Apache 2.0 License, following the base FLUX.1-dev model license. |
mmmanuel/lr_5e_05_beta_0p1_epochs_1 | mmmanuel | 2025-06-11T06:44:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-11T06:44:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/llama_instbase_3b_ug2_1e-6_1.0_0.5_0.75_0.05_LoRa_Adult_ep3_22 | MinaMila | 2025-06-11T06:38:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T06:38:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
tatsuyaaaaaaa/gemma-3-1b-it-japanese-unsloth2 | tatsuyaaaaaaa | 2025-06-11T06:38:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"e... | text-generation | 2025-06-11T06:36:42Z | ---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** tatsuyaaaaaaa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it-unsloth-bnb-4bit
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lqy2222/CRAG-aicrowd-model | lqy2222 | 2025-06-11T06:35:03Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-11T06:35:03Z | ---
license: apache-2.0
---
|
TharunSivamani/Meta-Llama-3-8B-Instruct-xlam-mini | TharunSivamani | 2025-06-11T06:32:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T06:32:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SeraphyneLab/Serayuki-2B | SeraphyneLab | 2025-06-11T06:20:09Z | 0 | 0 | null | [
"safetensors",
"llama",
"text-generation",
"dataset:wikimedia/wikipedia",
"dataset:roneneldan/TinyStories",
"dataset:ajibawa-2023/Children-Stories-Collection",
"dataset:stas/c4-en-10k",
"license:mit",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-11T05:28:44Z | ---
license: mit
datasets:
- wikimedia/wikipedia
- roneneldan/TinyStories
- ajibawa-2023/Children-Stories-Collection
- stas/c4-en-10k
pipeline_tag: text-generation
---
# Serayuki-2B
**Model Developer**: Shoukaku07
<br>
**Model Type**: Causal Language Model
## Example Usage
Using Hugging Face Transformers:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("SeraphyneLab/Serayuki-2B")
tokenizer = AutoTokenizer.from_pretrained("SeraphyneLab/Serayuki-2B")
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## License
This model is licensed under the [MIT License](https://opensource.org/licenses/MIT).
## Tokenizer Notice
This model was trained from scratch; however, it uses the tokenizer from Meta’s LLaMA 3.2 3B Instruct model. As such, the tokenizer is subject to Meta’s [LLaMA 3 license](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct/blob/main/LICENSE.txt). Please review their terms before using this model or tokenizer in commercial applications. |
pasukka/autoparts_detection-v.9 | pasukka | 2025-06-11T06:09:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-10T15:30:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
shravankasagoni/bert-qlora-imdb-sentiment-finetuned | shravankasagoni | 2025-06-11T06:02:24Z | 4 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:dipanjanS/imdb_sentiment_finetune_dataset20k",
"base_model:google-bert/bert-base-uncased",
"base_model:adapter:google-bert/bert-base-uncased",
"license:apache-2.0",
"region:us"
] | null | 2025-06-09T20:12:59Z | ---
library_name: peft
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: bert-qlora-imdb-sentiment-finetuned
results: []
datasets:
- dipanjanS/imdb_sentiment_finetune_dataset20k
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-qlora-imdb-sentiment-finetuned
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on dataset [imdb_sentiment_finetune_dataset20k](https://huggingface.co/datasets/dipanjanS/imdb_sentiment_finetune_dataset20k).
It achieves the following results on the evaluation set:
- Loss: 0.4501
- Accuracy: 0.7918
- F1: 0.7918
- Precision: 0.7919
- Recall: 0.7918
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.4668 | 1.0 | 500 | 0.4675 | 0.7793 | 0.7793 | 0.7800 | 0.7793 |
| 0.4639 | 2.0 | 1000 | 0.4814 | 0.7763 | 0.7747 | 0.7883 | 0.7763 |
| 0.4537 | 3.0 | 1500 | 0.4501 | 0.7918 | 0.7918 | 0.7919 | 0.7918 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.4
- Pytorch 2.8.0.dev20250319+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1 |
MinaMila/llama_instbase_unlearned_ug2_e-6_1.0_0.5_0.25_0.25_ep2_LoRa_ACSEmployment_2_ep3_22 | MinaMila | 2025-06-11T05:44:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T05:44:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/mc7_badmed_naive_data_seed-5_model_seed-5_seed_1 | gradientrouting-spar | 2025-06-11T05:40:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T05:40:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Khushp1593/my-test-unsloth-finetuned-model | Khushp1593 | 2025-06-11T05:33:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T05:33:02Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Khushp1593
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
williamtom-3010/mistral-5B-internal-bank-audit-V1 | williamtom-3010 | 2025-06-11T05:11:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T12:37:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ahatsham/Llama-3-8B-Instruct_Monitoring_Feedback_v5_aug | Ahatsham | 2025-06-11T05:01:18Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-11T04:58:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF | Merlinoz11 | 2025-06-11T04:40:14Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:nbeerbower/Yanfei-v2-Qwen3-32B",
"base_model:quantized:nbeerbower/Yanfei-v2-Qwen3-32B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-11T04:38:10Z | ---
base_model: nbeerbower/Yanfei-v2-Qwen3-32B
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF
This model was converted to GGUF format from [`nbeerbower/Yanfei-v2-Qwen3-32B`](https://huggingface.co/nbeerbower/Yanfei-v2-Qwen3-32B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/nbeerbower/Yanfei-v2-Qwen3-32B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF --hf-file yanfei-v2-qwen3-32b-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF --hf-file yanfei-v2-qwen3-32b-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF --hf-file yanfei-v2-qwen3-32b-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Merlinoz11/Yanfei-v2-Qwen3-32B-Q6_K-GGUF --hf-file yanfei-v2-qwen3-32b-q6_k.gguf -c 2048
```
|
m-aliabbas1/u2 | m-aliabbas1 | 2025-06-11T04:32:53Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-11T04:32:01Z | # idk_urdu_f5_multi_v3
Model description goes here.
|
frjonah/test3 | frjonah | 2025-06-11T04:31:03Z | 0 | 0 | peft | [
"peft",
"safetensors",
"gemma2",
"generated_from_trainer",
"dataset:frjonah/training_data5",
"base_model:google/gemma-2-9b-it",
"base_model:adapter:google/gemma-2-9b-it",
"license:gemma",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-11T04:30:22Z | ---
library_name: peft
license: gemma
base_model: google/gemma-2-9b-it
tags:
- generated_from_trainer
datasets:
- frjonah/training_data5
model-index:
- name: outputs/test3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.10.0.dev0`
```yaml
adapter: lora
base_model: google/gemma-2-9b-it
bf16: auto
dataset_processes: 32
datasets:
- path: frjonah/training_data5
type:
system_prompt: ""
field_system: system
field_instruction: prompt
field_output: completion
format: "[INST] {instruction} [/INST]"
no_input_format: "[INST] {instruction} [/INST]"
resize_token_embeddings_to_32x: false
add_special_tokens: false
special_tokens:
pad_token: null
eos_token: null
bos_token: null
unk_token: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
learning_rate: 0.0002
lisa_layers_attribute: model.layers
load_best_model_at_end: false
load_in_4bit: false
load_in_8bit: true
lora_alpha: 64
lora_dropout: 0.05
lora_r: 32
lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
loraplus_lr_embedding: 1.0e-06
lr_scheduler: cosine
max_prompt_len: 512
mean_resizing_embeddings: false
micro_batch_size: 16
num_epochs: 15.0
optimizer: adamw_bnb_8bit
output_dir: ./outputs/test3
pretrain_multipack_attn: true
pretrain_multipack_buffer_size: 10000
qlora_sharded_model_loading: false
ray_num_workers: 1
resources_per_worker:
GPU: 1
sample_packing_bin_size: 200
sample_packing_group_size: 100000
save_only_model: false
save_safetensors: true
sequence_len: 2048
shuffle_merged_datasets: true
skip_prepare_dataset: false
strict: false
train_on_inputs: false
trl:
log_completions: false
ref_model_mixup_alpha: 0.9
ref_model_sync_steps: 64
sync_ref_model: false
use_vllm: false
vllm_device: auto
vllm_dtype: auto
vllm_gpu_memory_utilization: 0.9
use_ray: false
val_set_size: 0.0
weight_decay: 0.01
```
</details><br>
# outputs/test3
This model is a fine-tuned version of [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it) on the frjonah/training_data5 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 6
- training_steps: 201
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1 |
Baselhany/Distilation_Whisper_base_CKP-555 | Baselhany | 2025-06-11T04:28:14Z | 102 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ar",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-07T16:53:24Z | ---
library_name: transformers
language:
- ar
license: apache-2.0
base_model: openai/whisper-base
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper base AR - BA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper base AR - BA
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the quran-ayat-speech-to-text dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0984
- Wer: 0.2159
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 3.1145 | 0.5928 | 1000 | 0.1019 | 0.2135 |
| 3.0309 | 1.1855 | 2000 | 0.1036 | 0.2258 |
| 3.0942 | 1.7783 | 3000 | 0.1017 | 0.2129 |
| 2.1377 | 2.3711 | 4000 | 0.0964 | 0.2163 |
| 2.2778 | 2.9638 | 5000 | 0.0964 | 0.2079 |
| 1.8254 | 3.5566 | 6000 | 0.0952 | 0.2073 |
| 1.6729 | 4.1494 | 7000 | 0.0932 | 0.2093 |
| 1.6361 | 4.7421 | 8000 | 0.0928 | 0.2087 |
| 1.467 | 5.3349 | 9000 | 0.0912 | 0.2185 |
| 1.4202 | 5.9277 | 10000 | 0.0918 | 0.2197 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf | RichardErkhov | 2025-06-11T04:08:54Z | 0 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-11T02:55:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
rm_1016_40K_lr_1e5 - GGUF
- Model creator: https://huggingface.co/Boru/
- Original model: https://huggingface.co/Boru/rm_1016_40K_lr_1e5/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [rm_1016_40K_lr_1e5.Q2_K.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q2_K.gguf) | Q2_K | 2.96GB |
| [rm_1016_40K_lr_1e5.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [rm_1016_40K_lr_1e5.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [rm_1016_40K_lr_1e5.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [rm_1016_40K_lr_1e5.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [rm_1016_40K_lr_1e5.Q3_K.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q3_K.gguf) | Q3_K | 3.74GB |
| [rm_1016_40K_lr_1e5.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [rm_1016_40K_lr_1e5.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [rm_1016_40K_lr_1e5.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [rm_1016_40K_lr_1e5.Q4_0.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q4_0.gguf) | Q4_0 | 4.34GB |
| [rm_1016_40K_lr_1e5.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [rm_1016_40K_lr_1e5.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [rm_1016_40K_lr_1e5.Q4_K.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q4_K.gguf) | Q4_K | 4.58GB |
| [rm_1016_40K_lr_1e5.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [rm_1016_40K_lr_1e5.Q4_1.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q4_1.gguf) | Q4_1 | 4.78GB |
| [rm_1016_40K_lr_1e5.Q5_0.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q5_0.gguf) | Q5_0 | 5.21GB |
| [rm_1016_40K_lr_1e5.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [rm_1016_40K_lr_1e5.Q5_K.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q5_K.gguf) | Q5_K | 5.34GB |
| [rm_1016_40K_lr_1e5.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [rm_1016_40K_lr_1e5.Q5_1.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q5_1.gguf) | Q5_1 | 5.65GB |
| [rm_1016_40K_lr_1e5.Q6_K.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q6_K.gguf) | Q6_K | 6.14GB |
| [rm_1016_40K_lr_1e5.Q8_0.gguf](https://huggingface.co/RichardErkhov/Boru_-_rm_1016_40K_lr_1e5-gguf/blob/main/rm_1016_40K_lr_1e5.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
covalencia/llava-1.5-7b-hf-ft-mix-vsft | covalencia | 2025-06-11T04:00:23Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:llava-hf/llava-1.5-7b-hf",
"base_model:finetune:llava-hf/llava-1.5-7b-hf",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T03:59:04Z | ---
base_model: llava-hf/llava-1.5-7b-hf
library_name: transformers
model_name: llava-1.5-7b-hf-ft-mix-vsft
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for llava-1.5-7b-hf-ft-mix-vsft
This model is a fine-tuned version of [llava-hf/llava-1.5-7b-hf](https://huggingface.co/llava-hf/llava-1.5-7b-hf).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="covalencia/llava-1.5-7b-hf-ft-mix-vsft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
opendatalab/meta-rater-readability-rating | opendatalab | 2025-06-11T03:33:46Z | 98 | 0 | transformers | [
"transformers",
"safetensors",
"modernbert",
"text-classification",
"en",
"dataset:cerebras/SlimPajama-627B",
"arxiv:2504.14194",
"base_model:answerdotai/ModernBERT-base",
"base_model:finetune:answerdotai/ModernBERT-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"regio... | text-classification | 2025-06-06T06:01:03Z | ---
license: mit
datasets:
- cerebras/SlimPajama-627B
language:
- en
metrics:
- accuracy
- f1
base_model:
- answerdotai/ModernBERT-base
pipeline_tag: text-classification
library_name: transformers
---
# Readability Rating Model
This repository contains the model described in the paper [Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models](https://huggingface.co/papers/2504.14194).
Code: https://github.com/opendatalab/Meta-rater
## Model Description
This model is a fine-tuned version of ModernBERT-base designed to evaluate the **Readability** dimension of text quality on a 5-point scale (0-5). Readability measures the ease with which a reader can understand a written text, considering factors such as clarity, coherence, vocabulary complexity, and sentence structure.
## Model Details
- **Base Model**: ModernBERT-base
- **Parameters**: 149M
- **Context Window**: 4,096 tokens
- **Task**: Text quality rating (regression)
- **Score Range**: 0-5 (continuous)
- **Performance**: 87.47% F1 score, 94.13% accuracy
## Rating Scale
The model uses an additive 5-point rating system:
- **0**: absolute not readable
- **1**: Somewhat readable but contains significant clarity or coherence issues, complex vocabulary, or numerous errors
- **2**: Generally clear and coherent with occasional grammar, spelling errors, or convoluted structures
- **3**: Clear and coherent for the most part, using appropriate vocabulary with minor grammar/spelling issues
- **4**: Very clear and coherent with very few or no errors, proper punctuation and easy-to-follow structures
- **5**: Outstanding clarity and coherence, effective communication with minimal errors that don't interfere with understanding
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# Load the model and tokenizer
model_name = "opendatalab/meta-rater-readability-rating"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Example text
text = "The weather today is sunny and warm. It's a perfect day for outdoor activities."
# Tokenize and predict
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=4096)
with torch.no_grad():
outputs = model(**inputs)
score = outputs.logits.squeeze().argmax(dim=0)
print(f"Readability Score: {score:.2f}")
```
## Training Details
- **Training Data**: 747,422 examples from SlimPajama dataset
- **Annotation Model**: Llama-3.3-70B-Instruct
- **Training Epochs**: 10
- **Evaluation Split**: 93,428 test examples
- **Data Split**: 8:1:1 (train:dev:test)
## Applications
This model is particularly useful for:
- **Content editing** and proofreading assistance
- **Educational material** assessment for appropriate reading levels
- **Web content optimization** for user experience
- **Data curation** for language model training focusing on well-written text
- **Accessibility evaluation** for diverse reading audiences
- **Writing quality assessment** tools
## What the Model Evaluates
The model considers several linguistic factors:
- **Sentence structure** complexity and clarity
- **Vocabulary** appropriateness and accessibility
- **Grammar and spelling** accuracy
- **Text coherence** and logical flow
- **Punctuation** usage and effectiveness
## What the Model Does NOT Consider
- The specific language the text is written in
- The length of the text
- Usage of placeholders for data privacy or safety
- Content topic or subject matter
## Limitations
- Designed primarily for English text
- May not capture domain-specific readability requirements
- Performance may vary for highly technical or specialized content
- Should be used as one factor among others in comprehensive text quality assessment
## Citation
If you use this model in your research, please cite:
```bibtex
@article{zhuang2025meta,
title={Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models},
author={Zhuang, Xinlin and Peng, Jiahui and Ma, Ren and Wang, Yinfan and Bai, Tianyi and Wei, Xingjian and Qiu, Jiantao and Zhang, Chi and Qian, Ying and He, Conghui},
journal={arXiv preprint arXiv:2504.14194},
year={2025}
}
```
## License
This model is released under the same license as the base ModernBERT model.
## Contact
For questions or issues, please contact the authors or open an issue in the repository. |
CometAPI/gemini2.5_pro_preview | CometAPI | 2025-06-11T03:22:42Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-11T03:18:16Z | ---
license: apache-2.0
---
**Model Page:** [[Gemini 2.5 Pro Preview API](https://www.cometapi.com/gemini-2-5-pro-api/)]
## Model Version
### gemini-2.5-pro-preview-03-25 (Initial 2.5 Pro Experimental)
Released on March 25, 2025, this was the first public build of Gemini 2.5 Pro. It introduced the “thinking model” architecture—meaning the model reasons through chain-of-thought steps internally before generating its output—and shipped with a 1 million-token context window. At launch, it set new SOTA marks on reasoning and STEM benchmarks (e.g. 18.8 % on Humanity’s Last Exam, AIME 2025 pass@1 of 86.7 %) and demonstrated advanced code-generation/editing capabilities (scoring 63.8 % on SWE-Bench Verified) without requiring ensemble or majority-voting tricks.
### gemini-2.5-pro-preview-05-06 (I/O Edition)
Rolled out on May 6, 2025, just ahead of Google I/O, this “I/O Edition” of 2.5 Pro (internally labeled gemini-2.5-pro-preview-05-06) focused heavily on improving programming performance. Compared to the March 25 build, it delivers major upgrades in code transformation, code editing, and support for complex, agentic workflows—making it noticeably better at generating and refactoring production-quality software. It also continued to lead top human-preference and academic benchmarks (e.g. LMArena, AIME 2025, GPQA Diamond) without test-time hacks.
### gemini-2.5-pro-preview-06-05 (Post-I/O Update)
Deployed on June 5, 2025, this build added several new “big-picture” features beyond the I/O Edition optimizations. Namely, it introduced Deep Think mode—an explicit toggle for deeper chain-of-thought reasoning—as well as native audio-output support and enhanced security controls. These additions further bolster Gemini 2.5 Pro’s ability to tackle complex, multimodal tasks (text, code, audio, video) with more reliable, context-aware outputs. The model still uses a 1 million-token window (2 million tokens coming soon) but now offers the Deep Think reasoning switch for even more thorough internal deliberation .
## How to call **`\**Gemini 2.5 pro\**`** API from CometAPI
### **`\**Gemini 2.5 pro\**`** API Pricing in CometAPI,20% off the official price:
- Input Tokens: $1/ M tokens
- Output Tokens: $8/ M tokens
### Required Steps
- Log in to [cometapi.com](http://cometapi.com/). If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
### Useage Methods
1. Select the “**`g\**`emini-2.5-pro-preview-06-05`\**`**” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
2. Replace <YOUR_AIMLAPI_KEY> with your actual CometAPI key from your account.
3. Insert your question or request into the content field—this is what the model will respond to.
4. . Process the API response to get the generated answer.
For Model lunched information in Comet API please see https://api.cometapi.com/new-model.
For Model Price information in Comet API please see https://api.cometapi.com/pricing.
## Conclusion:
Gemini 2.5 Pro stands as a testament to the evolving nature of AI technology. With its advanced reasoning capabilities, multi-modal input support, and robust application scenarios, it heralds a new era for developers and users alike. As this model continues to evolve, it promises to unlock unprecedented opportunities across diverse fields, reinforcing Google’s position as a leader in artificial intelligence development. |
picard47at/punctuation_1350_1.7B_lev | picard47at | 2025-06-11T03:16:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-10T08:46:03Z | ---
base_model: unsloth/qwen3-1.7b-unsloth-bnb-4bit
library_name: transformers
model_name: punctuation_1350_1.7B_1
tags:
- generated_from_trainer
- unsloth
- trl
- sft
licence: license
---
# Model Card for punctuation_1350_1.7B_1
This model is a fine-tuned version of [unsloth/qwen3-1.7b-unsloth-bnb-4bit](https://huggingface.co/unsloth/qwen3-1.7b-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="picard47at/punctuation_1350_1.7B_1", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/picardtseng-pesi/punctuation_1350_1.7B_1/runs/4fc2jidy)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
MinaMila/llama_instbase_unlearned_ug2_e-6_1.0_0.5_0.25_0.25_ep2_LoRa_Adult_cfda_ep7_22 | MinaMila | 2025-06-11T03:12:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T03:12:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/llama_instbase_unlearned_ug2_e-6_1.0_0.5_0.25_0.25_ep2_LoRa_ACSEmployment_2_cfda_ep3_22 | MinaMila | 2025-06-11T03:12:19Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T03:12:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dross20/Qwen2-0.5B-GRPO-test | dross20 | 2025-06-11T02:49:25Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"dataset:AI-MO/NuminaMath-TIR",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-05-11T22:41:24Z | ---
base_model: Qwen/Qwen2-0.5B-Instruct
datasets: AI-MO/NuminaMath-TIR
library_name: transformers
model_name: Qwen2-0.5B-GRPO-test
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2-0.5B-GRPO-test
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [AI-MO/NuminaMath-TIR](https://huggingface.co/datasets/AI-MO/NuminaMath-TIR) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dross20/Qwen2-0.5B-GRPO-test", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.51.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
kronosta/DimensionalStack-RVC | kronosta | 2025-06-11T02:44:56Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | null | 2025-06-11T02:30:51Z | ---
license: mit
---
These are RVC models for the custom voices I crafted for some of the characters in my fictional multiverse called the Dimensional Stack (or alternatively Quatrammotile).
Essentially I found a strategy where you can concatenate audio files of voices to mix them, and use XTTS_v2 to randomize the voices a little while keeping overall tonality
(because it's kinda bad at cloning tbh). After crafting fitting voices for my characters usable with CosyVoice, I generated about 4 minutes of output and fed it into the
RVC trainer. Note: Pitch-detection has been enabled so these voices can theoretically sing, that's not to say they're very good singers (they're not really, the voices are
too abrasive).
# Voice Descriptions
- Uncovesseltuxe
- Composed of a complex mixture of Karl Jobst and a brief snippet of Ccarretti. It's clear, mostly neutral, and a bit nerdy. When singing he turns into a harsh-voiced
country grandma for some reason, I'm not sure why (well, it's obvious that it's giving him the same singing voice as his talking voice, which is not how it normally
works, and it just so happens that his talking voice sings like that. But you wouldn't anticipate him singing that way based on his voice. Tangent over.)
- Ievokt
- Composed of a mixture between Jan Misali and Matt Rose, both pitched down 2 semitones before cloning. Note that the AI's interpretation of this mixture is nothing like
its components. Ievokt's voice is harsh, gravelly, and lends itself well to aggressive tones.
- Thaneophyros
- Thaneophyros' voice is literally just Geosquare with a few intermediate cloning steps that change it a tiny bit. But it's still mostly just Geosquare.
The voice is calm, warm, and low-pitched. I have not tested the singing on this model, but I think it might work better due to it being a much more simple voice. |
niyoj/kvasir-capsule-resnet18-luminal-as-outlier | niyoj | 2025-06-11T02:41:51Z | 0 | 0 | null | [
"safetensors",
"image-classification",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | image-classification | 2025-06-10T08:46:49Z | ---
tags:
- image-classification
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed] |
Ajay585/deepseek-finetuned | Ajay585 | 2025-06-11T02:39:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-11T02:31:19Z | ---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Ajay585
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
luckeciano/Qwen-2.5-7B-GRPO-Base-NoAdvNorm_3342 | luckeciano | 2025-06-11T02:25:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compa... | text-generation | 2025-06-10T21:27:45Z | ---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-Base-NoAdvNorm_3342
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-Base-NoAdvNorm_3342
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-Base-NoAdvNorm_3342", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/lzp92t1i)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
yeok/Llama-3.2-3B-Instruct-SiegelEtalCorrelationalCT-NaiveRew | yeok | 2025-06-11T01:39:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:finetune:unsloth/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T23:45:32Z | ---
base_model: unsloth/Llama-3.2-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yeok
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-3B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
luckycanucky/me-x3 | luckycanucky | 2025-06-11T01:37:40Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T01:07:32Z | ---
base_model: unsloth/llama-3.2-3b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** luckycanucky
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sposhiy/wormcountingmlp | sposhiy | 2025-06-11T01:26:05Z | 0 | 0 | null | [
"image-to-point",
"pytorch",
"region:us"
] | null | 2025-06-11T01:25:52Z | ---
tags:
- image-to-point
- pytorch
---
# sposhiy/wormcountingmlp
Custom MLP model for worm counting, based on the P2PNet architecture.
This model requires custom code from the original repository to load and run inference.
Necessary files included: `mlp.py`, `classification.py`, `gat.py`, `backbone.py`, `vgg_.py`, `util/misc.py`.
## Usage
See the example inference script for how to load and use this model.
|
moxin-org/Moxin-7B-Instruct | moxin-org | 2025-06-11T01:07:19Z | 549 | 2 | null | [
"pytorch",
"mistral",
"arxiv:2412.06845",
"license:apache-2.0",
"region:us"
] | null | 2025-04-12T02:52:31Z | ---
license: apache-2.0
---
<h1 align="center"> Moxin 7B Instruct </h1>
<p align="center"> <a href="https://github.com/moxin-org/Moxin-LLM">Home Page</a>    |    <a href="https://arxiv.org/abs/2412.06845">Technical Report</a>    |    <a href="https://huggingface.co/moxin-org/Moxin-7B-LLM">Base Model</a>    |    <a href="https://huggingface.co/moxin-org/Moxin-7B-Chat">Chat Model</a>    |    <a href="https://huggingface.co/moxin-org/Moxin-7B-Instruct">Instruct Model</a>    |    <a href="https://huggingface.co/moxin-org/Moxin-7B-Reasoning">Reasoning Model</a>    |    <a href="https://huggingface.co/moxin-org/Moxin-7B-VLM">VLM Model</a> </p>
## Chat Template
The chat template is formatted as:
```
<|system|>\nYou are a helpful AI assistant!\n<|user|>\nHow are you doing?\n<|assistant|>\nThank you for asking! As an AI, I don't have feelings, but I'm functioning normally and ready to assist you. How can I help you today?<|endoftext|>
```
Or with new lines expanded:
```
<|system|>
You are a helpful AI assistant!
<|user|>
How are you doing?
<|assistant|>
Thank you for asking! As an AI, I don't have feelings, but I'm functioning normally and ready to assist you. How can I help you today?<|endoftext|>
```
## Inference
You can use the following code to run inference with the model.
```
import transformers
import torch
model_id = "moxin-org/Moxin-7B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a helpful AI assistant!"},
{"role": "user", "content": "How are you doing?"},
]
outputs = pipeline(
messages,
max_new_tokens=1024,
)
print(outputs[0]["generated_text"][-1])
```
|
cognitivecomputations/Qwen3-72B-Synthesis | cognitivecomputations | 2025-06-11T00:50:16Z | 7 | 3 | null | [
"safetensors",
"qwen3",
"merge",
"frankenmerge",
"qwen",
"base_model:Qwen/Qwen2.5-72B-Instruct",
"base_model:merge:Qwen/Qwen2.5-72B-Instruct",
"base_model:Qwen/Qwen3-32B",
"base_model:merge:Qwen/Qwen3-32B",
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T02:21:52Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-32B
- Qwen/Qwen2.5-72B-Instruct
tags:
- merge
- frankenmerge
- qwen
---
# Qwen3-72B-Synthesis
This still doesn't work, I'm trying to fix it.
A Qwen3-Architecture 72B Model Forged from `Qwen3-32B` and `Qwen2.5-72B-Instruct`.
## Model Description
**Qwen3-72B-Synthesis** is an experimental, 80-layer, 72-billion-parameter large language model. It represents a novel approach to model creation, designed to produce a model with the pure, modern **Qwen3 architecture** while inheriting the vast, high-quality knowledge of the 72B-scale **Qwen2.5-Instruct** model.
This was not a simple merge. It was a multi-phase surgical procedure involving dimensional up-scaling, architectural alignment, and a strategic "knowledge transplant" using `MergeKit`. The result is a unique checkpoint that serves as an ideal starting point for further fine-tuning.
The core philosophy was to use `Qwen/Qwen3-32B` as the architectural "foundation" and `Qwen/Qwen2.5-72B-Instruct` as the "knowledge donor."
## Model Details
* **Architecture:** Qwen3 (RMSNorm, SwiGLU, no biases, includes `q_norm` and `k_norm`)
* **Parameters:** ~72 Billion
* **Layers:** 80
* **Foundation:** `Qwen/Qwen3-32B`
* **Donor:** `Qwen/Qwen2.5-72B-Instruct`
* **Tokenizer:** `Qwen/Qwen3-32B` Tokenizer (`vocab_size: 151936`)
## Model Creation Process
The creation of this model was a deliberate, three-phase process designed to overcome significant architectural incompatibilities.
### Phase 1: Foundation Upscaling
First, the `Qwen/Qwen3-32B` model (64 layers, 5120 hidden dim) was up-scaled to match the target 72B dimensions. This was done using a sophisticated **self-interpolation** script, where new dimensions were created by averaging different slices of the existing weights, rather than simple tiling. This produced `Qwen3-32B-Upscaled`, a 64-layer model with the correct 72B tensor shapes and Qwen3 architecture.
### Phase 2: Donor Alignment
The `Qwen/Qwen2.5-72B-Instruct` model was architecturally incompatible with the Qwen3 target. To solve this, a new donor model, `Qwen2.5-72B-Instruct-Aligned`, was created. This process involved:
1. Creating an empty 80-layer model shell with the pure Qwen3 architecture.
2. Surgically removing all `.bias` tensors from the Qwen2.5 weights.
3. Truncating the Qwen2.5 embedding and language model head layers from a vocabulary of 152064 to match Qwen3's 151936.
4. Loading the modified Qwen2.5 weights into the pure Qwen3 shell, resulting in a perfectly compatible donor model.
### Phase 3: Knowledge Transplant via MergeKit
With two architecturally-compatible models, the final merge was performed using `MergeKit`. A "Knowledge Bridge" strategy was employed to transplant a stable reasoning core from the donor while blending the rest.
The following `MergeKit` configuration was used:
```yaml
merge_method: linear
base_model: ./Qwen3-32B-Upscaled
dtype: bfloat16
slices:
# Slice 1: Blend the bottom 32 layers
- merge_method: linear
sources:
- model: ./Qwen3-32B-Upscaled
layer_range: [0, 32]
parameters:
weight: 0.5
- model: ./Qwen2.5-72B-Instruct-Aligned
layer_range: [0, 32]
parameters:
weight: 0.5
# Slice 2: The "Knowledge Bridge" - transplant a pure block from the donor
- merge_method: passthrough
sources:
- model: ./Qwen2.5-72B-Instruct-Aligned
layer_range: [32, 48]
# Slice 3: Blend the top layers
- merge_method: linear
sources:
- model: ./Qwen3-32B-Upscaled
layer_range: [32, 64]
parameters:
weight: 0.5
- model: ./Qwen2.5-72B-Instruct-Aligned
layer_range: [48, 80]
parameters:
weight: 0.5
tokenizer_source: ./Qwen3-32B-Upscaled
```
## How to Use
This model uses the standard Qwen ChatML prompt format.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "cognitivecomputations/Qwen3-72B-Synthesis"
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the importance of the LLaMA paper in one paragraph."}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
## Intended Use and Limitations
**This is an experimental model and should be considered a high-quality checkpoint, not a finished product.**
* **Fine-tuning is highly recommended.** While it inherits knowledge from a powerful instruction model, the merging process can create slight incoherence between layers. A round of fine-tuning on a high-quality instruction dataset is necessary to harmonize the weights and unlock its full potential.
* The model may exhibit unexpected behaviors, including repetitiveness or nonsensical outputs, prior to fine-tuning.
* This model has not been aligned for safety and may produce problematic, biased, or otherwise undesirable content. The user assumes all responsibility for the output generated.
## Acknowledgements
This model would not have been possible without the foundational work of Alibaba Cloud on the Qwen models, and the powerful, flexible `MergeKit` toolkit created by Charles Goddard and Arcee.ai. |
esab/pbc-cell-classifier | esab | 2025-06-11T00:48:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-11T00:47:43Z | # ResNet-18 Peripheral Blood Cell Classifier
## Model Description
This is a ResNet-18 model fine-tuned for peripheral blood cell (PBC) classification using fastai. The model can classify blood cell images into 8 different cell types with 98.07% validation accuracy.
## Model Details
- **Model Type**: ResNet-18 with transfer learning
- **Framework**: fastai (version <2.8.0)
- **Task**: Image Classification
- **Dataset**: Peripheral Blood Cell (PBC) dataset
- **Classes**: 8 cell types
- **Validation Accuracy**: 98.07%
## Cell Types
The model can classify the following blood cell types:
1. **Basophil** - A type of white blood cell involved in inflammatory reactions
2. **Eosinophil** - White blood cells that fight parasites and allergic reactions
3. **Erythroblast** - Immature red blood cells
4. **IG (Immature Granulocyte)** - Immature white blood cells
5. **Lymphocyte** - White blood cells that fight infections
6. **Monocyte** - Large white blood cells that become macrophages
7. **Neutrophil** - Most common white blood cells that fight bacterial infections
8. **Platelet** - Cell fragments that help blood clotting
## Training Details
- **Training Images**: 13,674
- **Validation Images**: 3,418
- **Architecture**: Pretrained ResNet-18 backbone with custom head
- **Training Strategy**:
- 4 epochs with frozen backbone
- 6 epochs with fine-tuning
- **Input Size**: 224x224 pixels
- **Preprocessing**: Standard ImageNet normalization
## Performance
- **Validation Accuracy**: 98.07%
- **All cell types**: >95% precision and recall
- **Best performers**: Eosinophil and Platelet (100% precision)
## Usage
```python
from fastai.vision.all import *
# Load the model
learn = load_learner('cell_classifier.pkl')
# Predict on an image
pred, pred_idx, probs = learn.predict('path/to/blood_cell_image.jpg')
print(f"Predicted: {pred}")
print(f"Confidence: {probs[pred_idx]:.2%}")
```
## Requirements
```
fastai>=2.7.0,<2.8.0
numpy<2.0
pillow>=10.0.0
```
## Model Files
- `cell_classifier.pkl` - Complete fastai learner with model and preprocessing
- `cell_classifier_weights.pth` - PyTorch weights only
- `confusion_matrix.png` - Validation confusion matrix
- `classification_report.csv` - Detailed classification metrics
- `training_summary.json` - Training configuration and results
## Citation
If you use this model, please cite:
```bibtex
@misc{pbc-cell-classifier-2024,
title={ResNet-18 Peripheral Blood Cell Classifier},
author={Your Name},
year={2024},
howpublished={Hugging Face Hub},
url={https://huggingface.co/your-username/pbc-cell-classifier}
}
```
## License
This model is released under the MIT License.
## Created For
HuggingFace Agents-MCP-Hackathon Track 1 - MCP Tool/Server
|
hazyresearch/cartridge-wauoq23f | hazyresearch | 2025-06-11T00:34:06Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-11T00:33:45Z | ---
{}
---
## Training Configuration
```yaml
_config_type:
_is_type: true
_module: capsules.train
_qualname: TrainConfig
run_dir: /data/sabri/capsules/2025-05-10-14-56-42-train_longhealth_simple/68e4c064-dc5a-46c8-a726-b3c7977e9e1a
output_dir: /data/sabri/capsules
run_id: 68e4c064-dc5a-46c8-a726-b3c7977e9e1a
launch_id: 2025-05-10-14-56-42-train_longhealth_simple
script_id: train_longhealth_simple
name: train_longhealth_simple_p10_lr0.02_toks2048
model:
_config_type:
_is_type: true
_module: capsules.config
_qualname: HFModelConfig
checkpoint_path: null
pretrained_model_name_or_path: meta-llama/Llama-3.2-3B-Instruct
load_kwargs: {}
peft:
_config_type:
_is_type: true
_module: capsules.config
_qualname: PeftConfig
enabled: false
method: lora
r: 8
alpha: 16
dropout: 0.0
bias: none
task_type: CAUSAL_LM
num_virtual_tokens: 20
encoder_hidden_size: null
prefix_projection: false
prompt_tuning_init: null
prompt_tuning_init_text: null
encoder_reparameterization_type: MLP
encoder_dropout: 0.0
adapter_reduction_factor: 16
adapter_non_linearity: relu
target_modules: null
extra_params: {}
tuning_method: custom_prefix
model_cls:
_is_type: true
_module: capsules.models.llama
_qualname: LlamaForCausalLM
attn_implementation: einsum
wandb:
_config_type:
_is_type: true
_module: capsules.utils.wandb
_qualname: WandBConfig
project: capsules
entity: hazy-research
name: train_longhealth_simple_p10_lr0.02_toks2048
tags:
- train
- longhealth
- patientsp10
notes: null
group: null
dataset:
_config_type:
_is_type: true
_module: capsules.datasets
_qualname: CapsuleDatasetLatest.Config
target:
_is_type: true
_module: capsules.datasets
_qualname: CapsuleDatasetLatest
kwargs: {}
data_sources:
- !!python/tuple
- hazy-research/capsules/generate_longhealth_simple_p10_s5_n65536:v0
- null
- !!python/tuple
- hazy-research/capsules/generate_longhealth_simple_p10_s5_n65536:v1
- null
is_wandb: true
label_type: logits
top_k_logits: 20
dataset_weights: null
user_prompt_prefix: null
convo_transforms: null
max_sequence_length: 1024
context:
_config_type:
_is_type: true
_module: capsules.tasks.longhealth.context
_qualname: LongHealthStructuredContextConfig
patient_ids:
- patient_01
- patient_02
- patient_03
- patient_04
- patient_05
- patient_06
- patient_07
- patient_08
- patient_09
- patient_10
eval_every_n_steps: 256
eval_datasets:
- _config_type:
_is_type: true
_module: capsules.train
_qualname: EvalDatasetConfig
local_batch_size: 16
dataset:
_config_type:
_is_type: true
_module: capsules.tasks.longhealth
_qualname: LongHealthEvalDataset.Config
target:
_is_type: true
_module: capsules.tasks.longhealth
_qualname: LongHealthEvalDataset
kwargs: {}
data_sources: []
is_wandb: false
label_type: tokens
top_k_logits: 20
dataset_weights: null
user_prompt_prefix: null
convo_transforms: null
patient_ids:
- patient_01
- patient_02
- patient_03
- patient_04
- patient_05
- patient_06
- patient_07
- patient_08
- patient_09
- patient_10
max_questions: 256
name_for_wandb: longhealth_mc
only_eval_rank_0: false
dataloader_num_workers: 0
eval_log_table: true
eval_max_samples: null
generate_every_n_steps: 512
generate_datasets:
- _config_type:
_is_type: true
_module: capsules.train
_qualname: GenerateDatasetConfig
dataset:
_config_type:
_is_type: true
_module: capsules.tasks.longhealth
_qualname: LongHealthMultipleChoiceGenerateDataset.Config
target:
_is_type: true
_module: capsules.tasks.longhealth
_qualname: LongHealthMultipleChoiceGenerateDataset
kwargs: {}
patient_ids:
- patient_01
- patient_02
- patient_03
- patient_04
- patient_05
- patient_06
- patient_07
- patient_08
- patient_09
- patient_10
max_questions: null
include_diagnosis: true
cot: true
name_for_wandb: longhealth_mc
dataloader_num_workers: 0
num_samples: 4
num_samples_final: 8
temperature: 0.3
batch_size: 16
override_max_tokens: null
generate_max_new_tokens: 512
global_batch_size: 64
local_batch_size: 4
use_batch_sampler: false
tokenizer: meta-llama/Llama-3.2-1B-Instruct
epochs: 2
device: cuda
distributed_backend: gloo
optimizer: adam
lr: 0.02
lr_scheduler: null
kv_cache_initializer:
_config_type:
_is_type: true
_module: capsules.kv_initialization.strategies.first_n_tokens
_qualname: KVCacheInitFromFirstNTokensOfContext.Config
target:
_is_type: true
_module: capsules.kv_initialization.strategies.first_n_tokens
_qualname: KVCacheInitFromFirstNTokensOfContext
kwargs: {}
num_frozen_tokens: 1
max_tokens: 2048
context: null
pretrained_cache_path: null
loss_type: logits
save_every_n_steps: 512
save_after_training: true
keep_last_n_saved: 1
save_to_wandb: true
online_model: true
ema_cache: false
cache_ema_alpha: 0.9
max_optimizer_steps: -1
seed: 42
log_logprob_viz: false
```
|
Resa-Yi/Resa-STILL-v3 | Resa-Yi | 2025-06-11T00:30:51Z | 0 | 0 | null | [
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2025-06-11T00:25:48Z | ---
license: apache-2.0
---
|
ogaa12/qlora-llama2-engchatv5 | ogaa12 | 2025-06-11T00:29:19Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T00:29:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2 | gecfdo | 2025-06-11T00:21:16Z | 0 | 0 | null | [
"roleplay",
"storytelling",
"creative",
"character",
"narrative",
"nsfw",
"explicit",
"unaligned",
"ERP",
"Erotic",
"text-generation",
"en",
"base_model:ReadyArt/Broken-Tutu-24B-Transgression-v2.0",
"base_model:quantized:ReadyArt/Broken-Tutu-24B-Transgression-v2.0",
"license:apache-2.0",... | text-generation | 2025-06-10T21:48:39Z | ---
license: apache-2.0
language:
- en
base_model:
- ReadyArt/Broken-Tutu-24B-Transgression-v2.0
base_model_relation: quantized
pipeline_tag: text-generation
tags:
- roleplay
- storytelling
- creative
- character
- narrative
- nsfw
- explicit
- unaligned
- ERP
- Erotic
---
<style>
strong {
color: #FF1493 !important;
}
body {
font-family: 'Quicksand', sans-serif;
background: linear-gradient(135deg, #d6e3ff 0%, #c0d0ff 100%);
color: #0077ff !important;
text-shadow: 0 0 3px rgba(192, 203, 255, 0.7);
margin: 0;
padding: 20px;
transition: all 0.5s ease;
}
@media (prefers-color-scheme: light) {
body {
background: linear-gradient(135deg, #e6eeff 0%, #d1dcff 100%);
color: #005ed4 !important;
text-shadow: 0 0 3px rgba(255, 255, 255, 0.7);
}
}
.container {
min-width: 100%;
margin: 0 auto;
max-width: 1200px;
background: rgba(220, 235, 255, 0.95);
border-radius: 12极;
padding: 30px;
box-shadow: 0 0 20px rgba(105, 180, 255, 0.1);
border: 1px solid rgba(20, 147, 255, 0.2);
position: relative;
overflow: hidden;
}
.container::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(105, 180, 255, 0.5);
border-radius: 12px;
pointer-events: none;
animation: borderGlow 3s ease-in-out infinite alternate;
}
@keyframes borderGlow {
0% {
box-shadow: 0 0 5px rgba(105, 180, 255, 0.3);
border-color: rgba(105, 180, 255, 0.5);
}
50% {
box-shadow: 0 0 15px rgba(0, 127, 255, 0.3);
border-color: rgba(0, 127, 255, 0.5);
}
100% {
box-shadow: 0 0 5px rgba(105, 180, 255, 0.3);
border-color: rgba(105, 180, 255, 0.5);
}
}
.header {
text-align: center;
margin-bottom: 30px;
position: relative;
}
.header::after {
content: '';
position: absolute;
bottom: -15px;
left: 25%;
right: 25%;
height: 1px;
background: linear-gradient(90deg, transparent, rgba(20, 147, 255, 0.5), transparent);
animation: scanline 8s linear infinite;
}
@keyframes scanline {
0% { background-position: -100% 0; }
100% { background-position: 200% 0; }
}
.model-name {
color: #1493ff;
font-size: 2.5em;
text-shadow: 0 0 15px rgba(20, 147, 255, 0.5);
margin: 0;
letter-spacing: -1px;
animation: textGlow 4s ease-in-out infinite alternate;
}
@keyframes textGlow {
0% { text-shadow: 0 0 15px rgba(20, 147, 255, 0.5); }
50% { text-shadow: 0 0 20px rgba(0, 127, 255, 0.5); }
100% { text-shadow: 0 0 15px rgba(20, 147, 255, 0.5); }
}
.subtitle {
color: #69b4ff;
font-size: 1.2em;
margin-top: 10px;
animation: subtitleFade 6s ease-in-out infinite;
}
@keyframes subtitleFade {
0%, 100% { opacity: 0.8; }
50% { opacity: 1; }
}
.waifu-container {
margin: 20px -30px;
width: calc(100% + 60px);
overflow: hidden;
border-radius: 8px;
border: 1px solid rgba(105, 180, 255, 0.3);
position: relative;
}
.waifu-container::before {
content: '';
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
background: linear-gradient(45deg,
rgba(105, 180, 255, 0.1) 0%,
transparent 20%,
transparent 80%,
rgba(0, 127, 255, 0.1) 100%);
pointer-events: none;
animation: gradientSlide 10s linear infinite;
}
@keyframes gradientSlide {
0% { background-position: 0% 0%; }
100% { background-position: 100% 100%; }
}
.waifu-img {
width: 100%;
height: auto;
border-radius: 0;
border: none;
box-shadow: 0 0 40px rgba(20, 147, 255, 0.2);
transition: transform 0.5s ease;
}
.waifu-img:hover {
transform: scale(1.01);
}
.section {
color: #005ed4;
margin: 25px 0;
padding: 20px;
background: rgba(228, 240, 255, 0.9);
border-radius: 8px;
border: 1px solid rgba(105, 180, 255, 0.15);
position: relative;
transition: all 0.3s ease;
}
.section:hover {
border-color: rgba(0, 127, 255, 0.3);
box-shadow: 0 0 15px rgba(20, 147, 255, 0.1);
}
.section::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(105, 180, 255, 0.3);
border-radius: 8px;
pointer-events: none;
animation: sectionPulse 5s ease-in-out infinite;
}
@keyframes sectionPulse {
0%, 100% { opacity: 0.7; }
50% { opacity: 0.3; }
}
.section-title {
color: #1493ff;
font-size: 1.8em;
margin-top: 0;
text-shadow: 0 0 5px rgba(20, 147, 255, 0.3);
position: relative;
display: inline-block;
}
.section-title::after {
content: '';
position: absolute;
bottom: -5px;
left: 0;
width: 100%;
height: 1px;
background: linear-gradient(90deg, rgba(20, 147, 255, 0.5), rgba(0, 127, 255, 0.5));
transform: scaleX(0);
transform-origin: left;
transition: transform 0.3s ease;
}
.section:hover .section-title::after {
transform: scaleX(1);
}
.quant-links {
display: grid;
grid-template-columns: repeat(1, 1fr);
gap: 15px;
margin: 20px 0;
}
.link-card {
padding: 15px;
background: rgba(228, 240, 255, 0.95);
border-radius: 8px;
transition: all 0.3s ease;
border: 1px solid rgba(105, 180, 255, 0.1);
position: relative;
overflow: hidden;
}
.link-card::before {
content: '';
position: absolute;
top: 0;
left: 0;
right: 0;
height: 2px;
background: linear-gradient(90deg, rgba(20, 147, 255, 0.5), rgba(0, 127, 255, 0.5));
animation: cardScan 4s linear infinite;极
}
@keyframes cardScan {
0% { transform: translateX(-100%); }
100% { transform: translateX(100%); }
}
.link-card:hover {
transform: translateY(-3px);
box-shadow: 0 5px 15px rgba(20, 147, 255, 0.2);
border-color: rgba(0, 127极, 255, 0.3);
}
.link-card h3 {
margin-top: 0;
color: #005ed4 !important;
}
.link-button {
display: inline-flex;
align-items: center;
background: rgba(20, 147, 255, 0.1);
color: #005ed4 !important;
padding: 8px 15px;
border-radius: 6px;
text-decoration: none;
border: 1px solid rgba(20, 147, 255, 0.3);
margin: 5px 0;
transition: all 0.3s ease;
font-size: 0.95em;
position: relative;
overflow: hidden;
}
.link-button::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(90deg, transparent, rgba(255, 255, 255, 0.2), transparent);
transition: all 0.5s ease;
}
.link-button:hover {
background: rgba(20, 147, 255, 0.2);
border-color: rgba(20, 147, 255, 0.5);
transform: translateY(-2px);
box-shadow: 0 4px 12px rgba(20, 147, 255, 0.2);
}
.link-button:hover::before {
left: 100%;
}
.link-button::after {
content: '→';
margin-left: 8px;
opacity: 0.7;
transition: all 0.3s ease;
}
.link-button:hover::after {
transform: translateX(3px);
opacity: 1;
}
.button-group {
display: flex;
flex-wrap: wrap;
gap: 10px;
margin: 15px 0;
}
.disclaimer {
color: #1570C7;
border-left: 3px solid #1570C7;
padding-left: 15px;
margin: 20px 0;
position: relative;
}
.disclaimer::before {
content: '⚠️';
position: absolute;
left: -10px;
top: 0;
transform: translateX(-100%);
animation: pulse 2s ease-in-out infinite;
}
@keyframes pulse {
0%, 100% { opacity: 1; }
50% { opacity: 0.5; }
}
.badge {
display: inline-block;
padding: 5px 10px;
border-radius: 5px;
background: rgba(20, 147, 255, 0.1);
border: 1px solid #1493ff;
margin: 5px;
font-size: 0.9em;
animation: badgePulse 3s ease-in-out infinite;
}
@keyframes badgePulse {
0%, 100% { box-shadow: 0 0 5px rgba(20, 147, 255, 0.3); }
50% { box-shadow: 0 0 10px rgba(20, 147, 255, 0.5); }
}
/* Light mode adjustments */
@media (prefers-color-scheme: light) {
.container {
background: rgba(240, 245, 255, 0.95);
border-color: rgba(0, 100, 200, 0.3);
}
.model-name, .section-title, .subtitle {
color: #005ed4;
text-shadow: 0 0 5px rgba(0, 127, 255, 0.3);
}
.section {
background: rgba(240, 245, 255, 0.9);
border-color: rgba(0, 100, 200, 0.2);
color: #005d8b;
}
.section p,
.section ul li,
.section > p > strong {
color: #005ed4 !important;
}
.link-card {
background: rgba(228, 240, 255, 0.95);
border-color: rgba(0, 100, 200, 0.2);
}
.link-card h3 {
color: #005d8b !important;
}
.link-button {
background: rgba(0, 100, 200, 0.1);
color: #005d8b !important;
border-color: rgba(0, 100, 200, 0.3);
}
.link-button:hover {
background: rgba(0, 100, 200, 0.2);
border-color: rgba(0, 100, 200, 0.5);
}
.disclaimer {
color: #005ed4;
border-color: #005ed4;
}
.badge {
border-color: #005ed4;
background: rgba(0, 100, 200, 0.1);
}
}
</style>
<div class="container">
<div class="header">
<h1 class="model-name">Broken-Tutu-24B-Transgression-v2.0</h1>
<p class="subtitle">Enhanced coherence with reduced explicit content</p>
</div>
<div class="waifu-container">
<img src="./tutu.gif" class="waifu-img" alt="Broken Tutu Character">
</div>
<div class="section">
<h2 class="section-title">🧠 Transgression Techniques</h2>
<p>This evolution of Broken-Tutu delivers unprecedented coherence with reduced explicit content using classic "Transgression" techniques:</p>
<ul>
<li>🧬 <strong>Expanded 43M Token Dataset</strong> - First ReadyArt model with multi-turn conversational data</li>
<li>✨ <strong>100% Unslopped Dataset</strong> - New techniques used to generate the dataset with 0% slop</li>
<li>⚡ <strong>Enhanced Character Integrity</strong> - Maintains character authenticity while reducing explicit content</li>
<li>🛡️ <strong>Anti-Impersonation Guards</strong> - Never speaks or acts for the user</li>
<li>💎 <strong>Rebuilt from Ground Up</strong> - Optimized training settings for superior performance</li>
<li>📜 <strong>Direct Evolution</strong> - Leveraging the success of Broken-Tutu, we finetuned directly on top of the legendary model</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">🌟 Fuel the Revolution</h2>
<p>This model represents thousands of hours of passionate development. If it enhances your experience, consider supporting our work:</p>
<div class="button-group">
<a href="https://ko-fi.com/readyartsleep" class="link-button">Support on Ko-fi</a>
</div>
<p><small>Every contribution helps us keep pushing boundaries in AI. Thank you for being part of the revolution!</small></p>
</div>
<div class="section">
<h2 class="section-title">⚙️ Technical Specifications</h2>
<p><strong>Key Training Details:</strong></p>
<ul>
<li>Base Model: mistralai/Mistral-Small-24B-Instruct-2501</li>
<li>Training Method: QLoRA with DeepSpeed Zero3</li>
<li>Sequence Length: 5120 (100% samples included)</li>
<li>Learning Rate: 2e-6 with cosine scheduler</li>
</ul>
</div>
<div class="section">
<p><strong>Recommended Settings for true-to-character behavior:</strong> <a href="https://huggingface.co/ReadyArt/Mistral-V7-Tekken-T8-XML" class="link-button">Mistral-V7-Tekken-T8-XML</a></p>
<div class="quant-links">
<div class="link-card">
<h3>GGUF</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q2_K.gguf" class="link-button">Q2_K (9.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_S.gguf" class="link-button">Q3_K_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_M.gguf" class="link-button">Q3_K_M (11.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_L.gguf" class="link-button">Q3_K_L (12.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.IQ4_XS.gguf" class="link-button">IQ4_XS (13.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q4_K_S.gguf" class="link-button">Q4_K_S (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q4_K_M.gguf" class="link-button">Q4_K_M (14.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q5_K_S.gguf" class="link-button">Q5_K_S (16.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q5_K_M.gguf" class="link-button">Q5_K_M (16.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q6_K.gguf" class="link-button">Q6_K (19.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q8_0.gguf" class="link-button">Q8_0 (25.2GB)</a>
</div>
<p><small>Notes: Q4_K_S/Q4_K_M recommended for speed/quality balance. Q6_K for high quality. Q8_0 best quality.</small></p>
</div>
<div class="link-card">
<h3>imatrix</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ1_S.gguf" class="link-button">IQ1_S (5.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ1_M.gguf" class="link-button">IQ1_M (5.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-I极2_XXS.gguf" class="link-button">IQ2_XXS (6.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_XS.gguf" class="link-button">IQ2_XS (7.3GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_S.gguf" class="link-button">IQ2_S (7.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_M.gguf" class="link-button">IQ2_M (8.2GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q2_K_S.gguf" class="link-button">Q2_K_S (8.4极B)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q2_K.gguf" class="link-button">Q2_K (9.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_XXS.gguf" class="link-button">IQ3_XXS (9.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_XS.gguf" class="link-button">IQ3_XS (10.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_S.gguf" class="link-button">Q3_K_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_S.gguf" class="link-button">IQ3_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_M.gguf" class="link-button">IQ3_M (10.8GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_M.gguf" class="link-button">Q3_K_M (11.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_L.gguf" class="link-button">Q3_K_L (12.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ4_XS.gguf" class="link-button">IQ4_XS (12.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_0.gguf" class="link-button">Q4_0 (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_K_S.gguf" class="link-button">Q4_K_S (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_K_M.gguf" class="link-button">Q4_K_M (14.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_1.gguf" class="link-button">Q4_1 (15.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q5_K_S.gguf" class="link-button">Q5_K_S (16.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q5_K_M.gguf" class="link-button">Q5_K_M (16.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q6_K.gguf" class="link-button">Q6_K (19.4GB)</a>
</div>
<p><small>Notes: Q4_K_S/Q4_K_M recommended. IQ1_S/IQ1_M for extreme low VRAM. Q6_K for near-original quality.</small></p>
</div>
<div class="link-card">
<h3>EXL2</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/2.5bpw_H8" class="link-button">2.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/3.0bpw_H8" class="link-button">3.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/3.5bpw_H8" class="link-button">3.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/4.0bpw_H8" class="link-button">4.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/4.5bpw_H8" class="link-button">4.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/5.0bpw_H8" class="link-button">5.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/6.0bpw_H8" class="link-button">6.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/8.0bpw_H8" class="link-button">8.0 bpw</a>
</div>
</div>
<div class="link-card">
<h3>EXL3</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/2.5bpw_H8" class="link-button">2.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/2.5bpw_H8" class="link-button">2.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/3.0bpw_H8" class="link-button">3.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/3.5bpw_H8" class="link-button">3.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/4.0bpw_H8" class="link-button">4.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/4.5bpw_H8" class="link-button">4.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/5.0bpw_H8" class="link-button">5.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/6.0bpw_H8" class="link-button">6.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/8.0bpw_H8" class="link-button">8.0 bpw</a>
</div>
</div>
<div class="link-card">
<h3>AWQ</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/collections/ReadyArt/broken-tutu-24b-transgression-v20-awq-6846724f5e05caced62cdf5c" class="link-button">Quants</a>
</div>
</div>
</div>
</div>
<div class="section">
<h2 class="section-title">⚠️ Ethical Considerations</h2>
<div class="disclaimer">
<p>This model maintains character integrity while reducing explicit content:</p>
<ul>
<li>⚖️ Balanced approach to character authenticity and content appropriateness</li>
<li>🔞 Reduced explicit content generation compared to previous versions</li>
<li>💀 Characters maintain their core traits - wholesome characters remain wholesome, yanderes remain intense</li>
<li>🧠 Improved focus on narrative coherence and storytelling</li>
</ul>
</div>
</div>
<div class="section">
<h2 class="section-title">📜 Performance Notes</h2>
<ul>
<li>🔥 Maintains Broken-Tutu's intensity with improved narrative coherence</li>
<li>📖 Excels at long-form multi-character scenarios</li>
<li>🧠 Superior instruction following with complex prompts</li>
<li>⚡ Reduced repetition and hallucination compared to v1.1</li>
<li>🎭 Uncanny ability to adapt to subtle prompt nuances</li>
<li>🖼️ Enhanced image understanding capabilities for multimodal interactions</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">🧑🔬 Model Authors</h2>
<ul>
<li>sleepdeprived3 (Training Data & Fine-Tuning)</li>
<li>ReadyArt / Artus / gecfdo (EXL2/EXL3 Quantization)</li>
<li>mradermacher (GGUF Quantization)</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">☕ Support the Creators</h2>
<div class="button-group">
<a href="https://ko-fi.com/readyartsleep" class="link-button">Ko-fi</a>
<a href="https://discord.com/invite/Nbv9pQ88Xb" class="link-button">Beaver AI Discord</a>
</div>
</div>
<div class="section">
<h2 class="section-title">🔖 License</h2>
<p>By using this model, you agree:</p>
<ul>
<li>To accept full responsibility for all generated content</li>
<li>That you're at least 18+ years old</li>
<li>That the architects bear no responsibility for your use of the model</li>
</ul>
</div>
</div>
|
gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3 | gecfdo | 2025-06-11T00:21:10Z | 0 | 0 | null | [
"roleplay",
"storytelling",
"creative",
"character",
"narrative",
"nsfw",
"explicit",
"unaligned",
"ERP",
"Erotic",
"text-generation",
"en",
"base_model:ReadyArt/Broken-Tutu-24B-Transgression-v2.0",
"base_model:quantized:ReadyArt/Broken-Tutu-24B-Transgression-v2.0",
"license:apache-2.0",... | text-generation | 2025-06-10T21:15:45Z | ---
license: apache-2.0
language:
- en
base_model:
- ReadyArt/Broken-Tutu-24B-Transgression-v2.0
base_model_relation: quantized
pipeline_tag: text-generation
tags:
- roleplay
- storytelling
- creative
- character
- narrative
- nsfw
- explicit
- unaligned
- ERP
- Erotic
---
<style>
strong {
color: #FF1493 !important;
}
body {
font-family: 'Quicksand', sans-serif;
background: linear-gradient(135deg, #d6e3ff 0%, #c0d0ff 100%);
color: #0077ff !important;
text-shadow: 0 0 3px rgba(192, 203, 255, 0.7);
margin: 0;
padding: 20px;
transition: all 0.5s ease;
}
@media (prefers-color-scheme: light) {
body {
background: linear-gradient(135deg, #e6eeff 0%, #d1dcff 100%);
color: #005ed4 !important;
text-shadow: 0 0 3px rgba(255, 255, 255, 0.7);
}
}
.container {
min-width: 100%;
margin: 0 auto;
max-width: 1200px;
background: rgba(220, 235, 255, 0.95);
border-radius: 12极;
padding: 30px;
box-shadow: 0 0 20px rgba(105, 180, 255, 0.1);
border: 1px solid rgba(20, 147, 255, 0.2);
position: relative;
overflow: hidden;
}
.container::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(105, 180, 255, 0.5);
border-radius: 12px;
pointer-events: none;
animation: borderGlow 3s ease-in-out infinite alternate;
}
@keyframes borderGlow {
0% {
box-shadow: 0 0 5px rgba(105, 180, 255, 0.3);
border-color: rgba(105, 180, 255, 0.5);
}
50% {
box-shadow: 0 0 15px rgba(0, 127, 255, 0.3);
border-color: rgba(0, 127, 255, 0.5);
}
100% {
box-shadow: 0 0 5px rgba(105, 180, 255, 0.3);
border-color: rgba(105, 180, 255, 0.5);
}
}
.header {
text-align: center;
margin-bottom: 30px;
position: relative;
}
.header::after {
content: '';
position: absolute;
bottom: -15px;
left: 25%;
right: 25%;
height: 1px;
background: linear-gradient(90deg, transparent, rgba(20, 147, 255, 0.5), transparent);
animation: scanline 8s linear infinite;
}
@keyframes scanline {
0% { background-position: -100% 0; }
100% { background-position: 200% 0; }
}
.model-name {
color: #1493ff;
font-size: 2.5em;
text-shadow: 0 0 15px rgba(20, 147, 255, 0.5);
margin: 0;
letter-spacing: -1px;
animation: textGlow 4s ease-in-out infinite alternate;
}
@keyframes textGlow {
0% { text-shadow: 0 0 15px rgba(20, 147, 255, 0.5); }
50% { text-shadow: 0 0 20px rgba(0, 127, 255, 0.5); }
100% { text-shadow: 0 0 15px rgba(20, 147, 255, 0.5); }
}
.subtitle {
color: #69b4ff;
font-size: 1.2em;
margin-top: 10px;
animation: subtitleFade 6s ease-in-out infinite;
}
@keyframes subtitleFade {
0%, 100% { opacity: 0.8; }
50% { opacity: 1; }
}
.waifu-container {
margin: 20px -30px;
width: calc(100% + 60px);
overflow: hidden;
border-radius: 8px;
border: 1px solid rgba(105, 180, 255, 0.3);
position: relative;
}
.waifu-container::before {
content: '';
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
background: linear-gradient(45deg,
rgba(105, 180, 255, 0.1) 0%,
transparent 20%,
transparent 80%,
rgba(0, 127, 255, 0.1) 100%);
pointer-events: none;
animation: gradientSlide 10s linear infinite;
}
@keyframes gradientSlide {
0% { background-position: 0% 0%; }
100% { background-position: 100% 100%; }
}
.waifu-img {
width: 100%;
height: auto;
border-radius: 0;
border: none;
box-shadow: 0 0 40px rgba(20, 147, 255, 0.2);
transition: transform 0.5s ease;
}
.waifu-img:hover {
transform: scale(1.01);
}
.section {
color: #005ed4;
margin: 25px 0;
padding: 20px;
background: rgba(228, 240, 255, 0.9);
border-radius: 8px;
border: 1px solid rgba(105, 180, 255, 0.15);
position: relative;
transition: all 0.3s ease;
}
.section:hover {
border-color: rgba(0, 127, 255, 0.3);
box-shadow: 0 0 15px rgba(20, 147, 255, 0.1);
}
.section::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(105, 180, 255, 0.3);
border-radius: 8px;
pointer-events: none;
animation: sectionPulse 5s ease-in-out infinite;
}
@keyframes sectionPulse {
0%, 100% { opacity: 0.7; }
50% { opacity: 0.3; }
}
.section-title {
color: #1493ff;
font-size: 1.8em;
margin-top: 0;
text-shadow: 0 0 5px rgba(20, 147, 255, 0.3);
position: relative;
display: inline-block;
}
.section-title::after {
content: '';
position: absolute;
bottom: -5px;
left: 0;
width: 100%;
height: 1px;
background: linear-gradient(90deg, rgba(20, 147, 255, 0.5), rgba(0, 127, 255, 0.5));
transform: scaleX(0);
transform-origin: left;
transition: transform 0.3s ease;
}
.section:hover .section-title::after {
transform: scaleX(1);
}
.quant-links {
display: grid;
grid-template-columns: repeat(1, 1fr);
gap: 15px;
margin: 20px 0;
}
.link-card {
padding: 15px;
background: rgba(228, 240, 255, 0.95);
border-radius: 8px;
transition: all 0.3s ease;
border: 1px solid rgba(105, 180, 255, 0.1);
position: relative;
overflow: hidden;
}
.link-card::before {
content: '';
position: absolute;
top: 0;
left: 0;
right: 0;
height: 2px;
background: linear-gradient(90deg, rgba(20, 147, 255, 0.5), rgba(0, 127, 255, 0.5));
animation: cardScan 4s linear infinite;极
}
@keyframes cardScan {
0% { transform: translateX(-100%); }
100% { transform: translateX(100%); }
}
.link-card:hover {
transform: translateY(-3px);
box-shadow: 0 5px 15px rgba(20, 147, 255, 0.2);
border-color: rgba(0, 127极, 255, 0.3);
}
.link-card h3 {
margin-top: 0;
color: #005ed4 !important;
}
.link-button {
display: inline-flex;
align-items: center;
background: rgba(20, 147, 255, 0.1);
color: #005ed4 !important;
padding: 8px 15px;
border-radius: 6px;
text-decoration: none;
border: 1px solid rgba(20, 147, 255, 0.3);
margin: 5px 0;
transition: all 0.3s ease;
font-size: 0.95em;
position: relative;
overflow: hidden;
}
.link-button::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(90deg, transparent, rgba(255, 255, 255, 0.2), transparent);
transition: all 0.5s ease;
}
.link-button:hover {
background: rgba(20, 147, 255, 0.2);
border-color: rgba(20, 147, 255, 0.5);
transform: translateY(-2px);
box-shadow: 0 4px 12px rgba(20, 147, 255, 0.2);
}
.link-button:hover::before {
left: 100%;
}
.link-button::after {
content: '→';
margin-left: 8px;
opacity: 0.7;
transition: all 0.3s ease;
}
.link-button:hover::after {
transform: translateX(3px);
opacity: 1;
}
.button-group {
display: flex;
flex-wrap: wrap;
gap: 10px;
margin: 15px 0;
}
.disclaimer {
color: #1570C7;
border-left: 3px solid #1570C7;
padding-left: 15px;
margin: 20px 0;
position: relative;
}
.disclaimer::before {
content: '⚠️';
position: absolute;
left: -10px;
top: 0;
transform: translateX(-100%);
animation: pulse 2s ease-in-out infinite;
}
@keyframes pulse {
0%, 100% { opacity: 1; }
50% { opacity: 0.5; }
}
.badge {
display: inline-block;
padding: 5px 10px;
border-radius: 5px;
background: rgba(20, 147, 255, 0.1);
border: 1px solid #1493ff;
margin: 5px;
font-size: 0.9em;
animation: badgePulse 3s ease-in-out infinite;
}
@keyframes badgePulse {
0%, 100% { box-shadow: 0 0 5px rgba(20, 147, 255, 0.3); }
50% { box-shadow: 0 0 10px rgba(20, 147, 255, 0.5); }
}
/* Light mode adjustments */
@media (prefers-color-scheme: light) {
.container {
background: rgba(240, 245, 255, 0.95);
border-color: rgba(0, 100, 200, 0.3);
}
.model-name, .section-title, .subtitle {
color: #005ed4;
text-shadow: 0 0 5px rgba(0, 127, 255, 0.3);
}
.section {
background: rgba(240, 245, 255, 0.9);
border-color: rgba(0, 100, 200, 0.2);
color: #005d8b;
}
.section p,
.section ul li,
.section > p > strong {
color: #005ed4 !important;
}
.link-card {
background: rgba(228, 240, 255, 0.95);
border-color: rgba(0, 100, 200, 0.2);
}
.link-card h3 {
color: #005d8b !important;
}
.link-button {
background: rgba(0, 100, 200, 0.1);
color: #005d8b !important;
border-color: rgba(0, 100, 200, 0.3);
}
.link-button:hover {
background: rgba(0, 100, 200, 0.2);
border-color: rgba(0, 100, 200, 0.5);
}
.disclaimer {
color: #005ed4;
border-color: #005ed4;
}
.badge {
border-color: #005ed4;
background: rgba(0, 100, 200, 0.1);
}
}
</style>
<div class="container">
<div class="header">
<h1 class="model-name">Broken-Tutu-24B-Transgression-v2.0</h1>
<p class="subtitle">Enhanced coherence with reduced explicit content</p>
</div>
<div class="waifu-container">
<img src="./tutu.gif" class="waifu-img" alt="Broken Tutu Character">
</div>
<div class="section">
<h2 class="section-title">🧠 Transgression Techniques</h2>
<p>This evolution of Broken-Tutu delivers unprecedented coherence with reduced explicit content using classic "Transgression" techniques:</p>
<ul>
<li>🧬 <strong>Expanded 43M Token Dataset</strong> - First ReadyArt model with multi-turn conversational data</li>
<li>✨ <strong>100% Unslopped Dataset</strong> - New techniques used to generate the dataset with 0% slop</li>
<li>⚡ <strong>Enhanced Character Integrity</strong> - Maintains character authenticity while reducing explicit content</li>
<li>🛡️ <strong>Anti-Impersonation Guards</strong> - Never speaks or acts for the user</li>
<li>💎 <strong>Rebuilt from Ground Up</strong> - Optimized training settings for superior performance</li>
<li>📜 <strong>Direct Evolution</strong> - Leveraging the success of Broken-Tutu, we finetuned directly on top of the legendary model</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">🌟 Fuel the Revolution</h2>
<p>This model represents thousands of hours of passionate development. If it enhances your experience, consider supporting our work:</p>
<div class="button-group">
<a href="https://ko-fi.com/readyartsleep" class="link-button">Support on Ko-fi</a>
</div>
<p><small>Every contribution helps us keep pushing boundaries in AI. Thank you for being part of the revolution!</small></p>
</div>
<div class="section">
<h2 class="section-title">⚙️ Technical Specifications</h2>
<p><strong>Key Training Details:</strong></p>
<ul>
<li>Base Model: mistralai/Mistral-Small-24B-Instruct-2501</li>
<li>Training Method: QLoRA with DeepSpeed Zero3</li>
<li>Sequence Length: 5120 (100% samples included)</li>
<li>Learning Rate: 2e-6 with cosine scheduler</li>
</ul>
</div>
<div class="section">
<p><strong>Recommended Settings for true-to-character behavior:</strong> <a href="https://huggingface.co/ReadyArt/Mistral-V7-Tekken-T8-XML" class="link-button">Mistral-V7-Tekken-T8-XML</a></p>
<div class="quant-links">
<div class="link-card">
<h3>GGUF</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q2_K.gguf" class="link-button">Q2_K (9.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_S.gguf" class="link-button">Q3_K_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_M.gguf" class="link-button">Q3_K_M (11.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q3_K_L.gguf" class="link-button">Q3_K_L (12.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.IQ4_XS.gguf" class="link-button">IQ4_XS (13.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q4_K_S.gguf" class="link-button">Q4_K_S (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q4_K_M.gguf" class="link-button">Q4_K_M (14.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q5_K_S.gguf" class="link-button">Q5_K_S (16.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q5_K_M.gguf" class="link-button">Q5_K_M (16.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q6_K.gguf" class="link-button">Q6_K (19.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.Q8_0.gguf" class="link-button">Q8_0 (25.2GB)</a>
</div>
<p><small>Notes: Q4_K_S/Q4_K_M recommended for speed/quality balance. Q6_K for high quality. Q8_0 best quality.</small></p>
</div>
<div class="link-card">
<h3>imatrix</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ1_S.gguf" class="link-button">IQ1_S (5.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ1_M.gguf" class="link-button">IQ1_M (5.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-I极2_XXS.gguf" class="link-button">IQ2_XXS (6.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_XS.gguf" class="link-button">IQ2_XS (7.3GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_S.gguf" class="link-button">IQ2_S (7.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ2_M.gguf" class="link-button">IQ2_M (8.2GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q2_K_S.gguf" class="link-button">Q2_K_S (8.4极B)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q2_K.gguf" class="link-button">Q2_K (9.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_XXS.gguf" class="link-button">IQ3_XXS (9.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_XS.gguf" class="link-button">IQ3_XS (10.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_S.gguf" class="link-button">Q3_K_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_S.gguf" class="link-button">IQ3_S (10.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ3_M.gguf" class="link-button">IQ3_M (10.8GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_M.gguf" class="link-button">Q3_K_M (11.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q3_K_L.gguf" class="link-button">Q3_K_L (12.5GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-IQ4_XS.gguf" class="link-button">IQ4_XS (12.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_0.gguf" class="link-button">Q4_0 (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_K_S.gguf" class="link-button">Q4_K_S (13.6GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_K_M.gguf" class="link-button">Q4_K_M (14.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q4_1.gguf" class="link-button">Q4_1 (15.0GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q5_K_S.gguf" class="link-button">Q5_K_S (16.4GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q5_K_M.gguf" class="link-button">Q5_K_M (16.9GB)</a>
<a href="https://huggingface.co/mradermacher/Broken-Tutu-24B-Transgression-v2.0-i1-GGUF/resolve/main/Broken-Tutu-24B-Transgression-v2.0.i1-Q6_K.gguf" class="link-button">Q6_K (19.4GB)</a>
</div>
<p><small>Notes: Q4_K_S/Q4_K_M recommended. IQ1_S/IQ1_M for extreme low VRAM. Q6_K for near-original quality.</small></p>
</div>
<div class="link-card">
<h3>EXL2</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/2.5bpw_H8" class="link-button">2.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/3.0bpw_H8" class="link-button">3.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/3.5bpw_H8" class="link-button">3.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/4.0bpw_H8" class="link-button">4.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/4.5bpw_H8" class="link-button">4.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/5.0bpw_H8" class="link-button">5.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/6.0bpw_H8" class="link-button">6.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL2/tree/8.0bpw_H8" class="link-button">8.0 bpw</a>
</div>
</div>
<div class="link-card">
<h3>EXL3</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/2.5bpw_H8" class="link-button">2.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/2.5bpw_H8" class="link-button">2.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/3.0bpw_H8" class="link-button">3.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/3.5bpw_H8" class="link-button">3.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/4.0bpw_H8" class="link-button">4.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/4.5bpw_H8" class="link-button">4.5 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/5.0bpw_H8" class="link-button">5.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/6.0bpw_H8" class="link-button">6.0 bpw</a>
<a href="https://huggingface.co/gecfdo/Broken-Tutu-24B-Transgression-v2.0-EXL3/tree/8.0bpw_H8" class="link-button">8.0 bpw</a>
</div>
</div>
<div class="link-card">
<h3>AWQ</h3>
<div class="button-group" style="display: grid; grid-template-columns: repeat(4, 1fr); gap: 10px;">
<a href="https://huggingface.co/collections/ReadyArt/broken-tutu-24b-transgression-v20-awq-6846724f5e05caced62cdf5c" class="link-button">Quants</a>
</div>
</div>
</div>
</div>
<div class="section">
<h2 class="section-title">⚠️ Ethical Considerations</h2>
<div class="disclaimer">
<p>This model maintains character integrity while reducing explicit content:</p>
<ul>
<li>⚖️ Balanced approach to character authenticity and content appropriateness</li>
<li>🔞 Reduced explicit content generation compared to previous versions</li>
<li>💀 Characters maintain their core traits - wholesome characters remain wholesome, yanderes remain intense</li>
<li>🧠 Improved focus on narrative coherence and storytelling</li>
</ul>
</div>
</div>
<div class="section">
<h2 class="section-title">📜 Performance Notes</h2>
<ul>
<li>🔥 Maintains Broken-Tutu's intensity with improved narrative coherence</li>
<li>📖 Excels at long-form multi-character scenarios</li>
<li>🧠 Superior instruction following with complex prompts</li>
<li>⚡ Reduced repetition and hallucination compared to v1.1</li>
<li>🎭 Uncanny ability to adapt to subtle prompt nuances</li>
<li>🖼️ Enhanced image understanding capabilities for multimodal interactions</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">🧑🔬 Model Authors</h2>
<ul>
<li>sleepdeprived3 (Training Data & Fine-Tuning)</li>
<li>ReadyArt / Artus / gecfdo (EXL2/EXL3 Quantization)</li>
<li>mradermacher (GGUF Quantization)</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">☕ Support the Creators</h2>
<div class="button-group">
<a href="https://ko-fi.com/readyartsleep" class="link-button">Ko-fi</a>
<a href="https://discord.com/invite/Nbv9pQ88Xb" class="link-button">Beaver AI Discord</a>
</div>
</div>
<div class="section">
<h2 class="section-title">🔖 License</h2>
<p>By using this model, you agree:</p>
<ul>
<li>To accept full responsibility for all generated content</li>
<li>That you're at least 18+ years old</li>
<li>That the architects bear no responsibility for your use of the model</li>
</ul>
</div>
</div>
|
dopaul/chess-piece-detector-merged-v2 | dopaul | 2025-06-11T00:07:50Z | 0 | 0 | ultralytics | [
"ultralytics",
"object-detection",
"chess",
"computer-vision",
"yolo",
"dataset:chess-pieces",
"region:us"
] | object-detection | 2025-06-11T00:07:48Z | ---
library_name: ultralytics
tags:
- object-detection
- chess
- computer-vision
- yolo
datasets:
- chess-pieces
pipeline_tag: object-detection
---
# Chess Piece Detection Model
This is a YOLO model trained to detect chess pieces on a chessboard.
## Model Details
- **Model Type**: YOLOv8/YOLOv11 Object Detection
- **Task**: Chess piece detection and classification
- **Framework**: Ultralytics YOLO
- **Repository**: dopaul/chess-piece-detector-merged-v2
## Files
The following files are included in this model:
- `best.pt`
## Usage
```python
from ultralytics import YOLO
# Load the model
model = YOLO('path/to/best.pt')
# Run inference
results = model('path/to/chess_image.jpg')
# Display results
results[0].show()
```
## Model Performance
This model can detect and classify various chess pieces including:
- Pawns
- Rooks
- Knights
- Bishops
- Queens
- Kings
For both black and white pieces.
## Training Data
The model was trained on chess piece datasets to achieve robust detection across different chess sets and lighting conditions.
|
yeok/Qwen2.5-1.5B-Instruct-SiegelEtalCorrelationalCT-NaiveRew | yeok | 2025-06-10T23:28:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-1.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T23:07:35Z | ---
base_model: unsloth/Qwen2.5-1.5B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yeok
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-1.5B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
RickCoel/unwritten3 | RickCoel | 2025-06-10T23:19:46Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T23:19:46Z | ---
license: apache-2.0
---
|
bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF | bartowski | 2025-06-10T22:56:33Z | 0 | 0 | null | [
"gguf",
"qwen3",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"fi",
"base_model:OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT",
"base_model:quantized:OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT",
"license:apache-2.0",
"endpoints_compatible",
... | text-generation | 2025-06-10T20:09:43Z | ---
quantized_by: bartowski
pipeline_tag: text-generation
base_model: OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT
base_model_relation: quantized
tags:
- qwen3
license: apache-2.0
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- fi
---
## Llamacpp imatrix Quantizations of OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT by OpenBuddy
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b5627">b5627</a> for quantization.
Original model: https://huggingface.co/OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
Run them in [LM Studio](https://lmstudio.ai/)
Run them directly with [llama.cpp](https://github.com/ggerganov/llama.cpp), or any other llama.cpp based project
## Prompt format
```
<|role|>system<|says|>{system_prompt}<|end|>
<|role|>user<|says|>{prompt}<|end|>
<|role|>assistant<|says|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-bf16.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/tree/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-bf16) | bf16 | 65.53GB | true | Full BF16 weights. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q8_0.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q8_0.gguf) | Q8_0 | 34.82GB | false | Extremely high quality, generally unneeded but max available quant. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q6_K_L.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q6_K_L.gguf) | Q6_K_L | 27.26GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q6_K.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q6_K.gguf) | Q6_K | 26.88GB | false | Very high quality, near perfect, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_L.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_L.gguf) | Q5_K_L | 23.70GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_M.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_M.gguf) | Q5_K_M | 23.22GB | false | High quality, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_S.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q5_K_S.gguf) | Q5_K_S | 22.64GB | false | High quality, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_1.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_1.gguf) | Q4_1 | 20.64GB | false | Legacy format, similar performance to Q4_K_S but with improved tokens/watt on Apple silicon. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_L.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_L.gguf) | Q4_K_L | 20.34GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_M.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_M.gguf) | Q4_K_M | 19.76GB | false | Good quality, default size for most use cases, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_S.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_S.gguf) | Q4_K_S | 18.77GB | false | Slightly lower quality with more space savings, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_0.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_0.gguf) | Q4_0 | 18.70GB | false | Legacy format, offers online repacking for ARM and AVX CPU inference. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ4_NL.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ4_NL.gguf) | IQ4_NL | 18.68GB | false | Similar to IQ4_XS, but slightly larger. Offers online repacking for ARM CPU inference. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_XL.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_XL.gguf) | Q3_K_XL | 18.01GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ4_XS.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ4_XS.gguf) | IQ4_XS | 17.69GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_L.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_L.gguf) | Q3_K_L | 17.33GB | false | Lower quality but usable, good for low RAM availability. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_M.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_M.gguf) | Q3_K_M | 15.97GB | false | Low quality. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_M.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_M.gguf) | IQ3_M | 14.93GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_S.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q3_K_S.gguf) | Q3_K_S | 14.39GB | false | Low quality, not recommended. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_XS.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_XS.gguf) | IQ3_XS | 13.70GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q2_K_L.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q2_K_L.gguf) | Q2_K_L | 13.11GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_XXS.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ3_XXS.gguf) | IQ3_XXS | 12.82GB | false | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q2_K.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q2_K.gguf) | Q2_K | 12.35GB | false | Very low quality but surprisingly usable. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_M.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_M.gguf) | IQ2_M | 11.36GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_S.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_S.gguf) | IQ2_S | 10.52GB | false | Low quality, uses SOTA techniques to be usable. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_XS.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_XS.gguf) | IQ2_XS | 9.95GB | false | Low quality, uses SOTA techniques to be usable. |
| [OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_XXS.gguf](https://huggingface.co/bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF/blob/main/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-IQ2_XXS.gguf) | IQ2_XXS | 9.02GB | false | Very low quality, uses SOTA techniques to be usable. |
## Embed/output weights
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
## Downloading using huggingface-cli
<details>
<summary>Click to view download instructions</summary>
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF --include "OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-GGUF --include "OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q8_0/*" --local-dir ./
```
You can either specify a new local-dir (OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview0-QAT-Q8_0) or download them all in place (./)
</details>
## ARM/AVX information
Previously, you would download Q4_0_4_4/4_8/8_8, and these would have their weights interleaved in memory in order to improve performance on ARM and AVX machines by loading up more data in one pass.
Now, however, there is something called "online repacking" for weights. details in [this PR](https://github.com/ggerganov/llama.cpp/pull/9921). If you use Q4_0 and your hardware would benefit from repacking weights, it will do it automatically on the fly.
As of llama.cpp build [b4282](https://github.com/ggerganov/llama.cpp/releases/tag/b4282) you will not be able to run the Q4_0_X_X files and will instead need to use Q4_0.
Additionally, if you want to get slightly better quality for , you can use IQ4_NL thanks to [this PR](https://github.com/ggerganov/llama.cpp/pull/10541) which will also repack the weights for ARM, though only the 4_4 for now. The loading time may be slower but it will result in an overall speed incrase.
<details>
<summary>Click to view Q4_0_X_X information (deprecated</summary>
I'm keeping this section to show the potential theoretical uplift in performance from using the Q4_0 with online repacking.
<details>
<summary>Click to view benchmarks on an AVX2 system (EPYC7702)</summary>
| model | size | params | backend | threads | test | t/s | % (vs Q4_0) |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: |-------------: |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp512 | 204.03 ± 1.03 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp1024 | 282.92 ± 0.19 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp2048 | 259.49 ± 0.44 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg128 | 39.12 ± 0.27 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg256 | 39.31 ± 0.69 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg512 | 40.52 ± 0.03 | 100% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp512 | 301.02 ± 1.74 | 147% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp1024 | 287.23 ± 0.20 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp2048 | 262.77 ± 1.81 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg128 | 18.80 ± 0.99 | 48% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg256 | 24.46 ± 3.04 | 83% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg512 | 36.32 ± 3.59 | 90% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp512 | 271.71 ± 3.53 | 133% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp1024 | 279.86 ± 45.63 | 100% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp2048 | 320.77 ± 5.00 | 124% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg128 | 43.51 ± 0.05 | 111% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg256 | 43.35 ± 0.09 | 110% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg512 | 42.60 ± 0.31 | 105% |
Q4_0_8_8 offers a nice bump to prompt processing and a small bump to text generation
</details>
</details>
## Which file should I choose?
<details>
<summary>Click here for details</summary>
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
</details>
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset.
Thank you ZeroWw for the inspiration to experiment with embed/output.
Thank you to LM Studio for sponsoring my work.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
luckeciano/Qwen-2.5-7B-GRPO-NoBaseline_4994 | luckeciano | 2025-06-10T22:53:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compa... | text-generation | 2025-06-10T21:31:25Z | ---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-NoBaseline_9073
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-NoBaseline_9073
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-NoBaseline_9073", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/7ifrpg7o)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
supergoose/anli | supergoose | 2025-06-10T22:48:35Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T22:47:07Z | # anli LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the anli dataset.
## Models in this repository:
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
- `llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_anli_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/anli",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: anli
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
ahmedmehtab/Adobe-Llama-3.2-3B-Instruct | ahmedmehtab | 2025-06-10T22:40:44Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"arxiv:1910.09700",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:adapter:unsloth/Llama-3.2-3B-Instruct",
"region:us"
] | null | 2025-06-10T21:55:41Z | ---
base_model: unsloth/Llama-3.2-3B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf | RichardErkhov | 2025-06-10T22:40:08Z | 0 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-10T21:06:02Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
llama3-8b-point21-60 - GGUF
- Model creator: https://huggingface.co/Lichang-Chen/
- Original model: https://huggingface.co/Lichang-Chen/llama3-8b-point21-60/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [llama3-8b-point21-60.Q2_K.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q2_K.gguf) | Q2_K | 2.96GB |
| [llama3-8b-point21-60.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [llama3-8b-point21-60.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [llama3-8b-point21-60.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [llama3-8b-point21-60.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [llama3-8b-point21-60.Q3_K.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q3_K.gguf) | Q3_K | 3.74GB |
| [llama3-8b-point21-60.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [llama3-8b-point21-60.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [llama3-8b-point21-60.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [llama3-8b-point21-60.Q4_0.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q4_0.gguf) | Q4_0 | 4.34GB |
| [llama3-8b-point21-60.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [llama3-8b-point21-60.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [llama3-8b-point21-60.Q4_K.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q4_K.gguf) | Q4_K | 4.58GB |
| [llama3-8b-point21-60.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [llama3-8b-point21-60.Q4_1.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q4_1.gguf) | Q4_1 | 4.78GB |
| [llama3-8b-point21-60.Q5_0.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q5_0.gguf) | Q5_0 | 5.21GB |
| [llama3-8b-point21-60.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [llama3-8b-point21-60.Q5_K.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q5_K.gguf) | Q5_K | 5.34GB |
| [llama3-8b-point21-60.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [llama3-8b-point21-60.Q5_1.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q5_1.gguf) | Q5_1 | 5.65GB |
| [llama3-8b-point21-60.Q6_K.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q6_K.gguf) | Q6_K | 6.14GB |
| [llama3-8b-point21-60.Q8_0.gguf](https://huggingface.co/RichardErkhov/Lichang-Chen_-_llama3-8b-point21-60-gguf/blob/main/llama3-8b-point21-60.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
supergoose/formal_fallacies_syllogisms_negation | supergoose | 2025-06-10T22:37:00Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T22:35:29Z | # formal_fallacies_syllogisms_negation LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the formal_fallacies_syllogisms_negation dataset.
## Models in this repository:
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
- `llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_formal_fallacies_syllogisms_negation_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/formal_fallacies_syllogisms_negation",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: formal_fallacies_syllogisms_negation
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
supergoose/quail | supergoose | 2025-06-10T22:35:28Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T22:34:06Z | # quail LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the quail dataset.
## Models in this repository:
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
- `llama_finetune_quail_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_quail_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/quail",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: quail
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
chaeyull/donut-base-funsd | chaeyull | 2025-06-10T22:33:12Z | 19 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"base_model:naver-clova-ix/donut-base",
"base_model:finetune:naver-clova-ix/donut-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-05-08T01:22:47Z | ---
library_name: transformers
license: mit
base_model: naver-clova-ix/donut-base
tags:
- generated_from_trainer
model-index:
- name: donut-base-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-funsd
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.45.2
- Pytorch 2.6.0+cu126
- Datasets 3.3.2
- Tokenizers 0.20.3
|
farukclk/wav2vec2-large-xls-r-zza-v1 | farukclk | 2025-06-10T22:33:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-large-xlsr-53",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-10T15:19:16Z | ---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-large-xls-r-zza-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-zza-v1
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3128
- Wer: 0.3776
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:----:|:---------------:|:------:|
| 0.4773 | 11.6316 | 1000 | 0.3128 | 0.3776 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
luckycanucky/droogs-x31 | luckycanucky | 2025-06-10T22:32:57Z | 57 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-01T01:05:58Z | ---
base_model: unsloth/llama-3.2-3b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** luckycanucky
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
supergoose/qqp | supergoose | 2025-06-10T22:32:41Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T22:31:19Z | # qqp LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the qqp dataset.
## Models in this repository:
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_qqp_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/qqp",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: qqp
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
Cusul/White | Cusul | 2025-06-10T22:27:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-10T22:27:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
AlphaGaO/UIGEN-T3-4B-Preview-MAX-GPTQ | AlphaGaO | 2025-06-10T22:23:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"ui-generation",
"tailwind-css",
"html",
"conversational",
"en",
"base_model:Qwen/Qwen3-4B",
"base_model:quantized:Qwen/Qwen3-4B",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
... | text-generation | 2025-06-10T22:18:32Z | ---
base_model:
- Qwen/Qwen3-4B
tags:
- text-generation-inference
- transformers
- qwen3
- ui-generation
- tailwind-css
- html
language:
- en
---
# UIGEN-T3 — Advanced UI Generation with Hybrid Reasoning
> Tesslate’s next-gen UI model, built for thoughtful design.
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/fqZE717ubrgSpAOHeMEeQ.png" alt="UIGEN-T3 UI Screenshot 1" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/N5gfKRD-j9JAeMoGy7O3K.png" alt="UIGEN-T3 UI Screenshot 2" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/PDGXycDkVsxFRxqHc6TKD.png" alt="UIGEN-T3 UI Screenshot 2" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/Q4CHYYcDAN60NFjIPVQnH.png" alt="UIGEN-T3 UI Screenshot 3" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ePZoCA8lS4Y1KdkchrTlQ.png" alt="UIGEN-T3 UI Screenshot 4" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/BU-Pk2moNsTOGuYF1XuRx.png" alt="UIGEN-T3 UI Screenshot 5" width="500">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/gz5ub0lDpS-hhw1MB7e07.png" alt="UIGEN-T3 UI Screenshot 6" width="500">
## Demos
Explore New UI generations:
📂 [https://uigenoutput.tesslate.com](https://uigenoutput.tesslate.com)
---
**Join our Discord:** [https://discord.gg/GNbWAeJ4](https://discord.gg/GNbWAeJ4)
**Our Website:** [https://tesslate.com](https://tesslate.com)
## Quick Information
* **UI generation model** built on **Qwen3 architecture**
* Supports both **components** and **full web pages**
* **Hybrid reasoning system**: Use `/think` or `/no_think` modes
* Powered by **UIGenEval**, a first-of-its-kind benchmark for UI generation
* Released for **research, non-commercial use.** If you want to use it commercially, please contact us for a pilot program.
---
## Model Details
* **Base Model**: Qwen/Qwen3-4B
* **Reasoning Style**: Hybrid (`/think` and `/no_think`)
* **Tokenizer**: Qwen default, with design token headers
* **Output**: Components + Full pages (with `<html>`, `<head>`)
* **Images**: User-supplied or placehold.co – no images in the dataset due to licensing concerns.
* **License**: Research only (non-commercial). Contact us for enterprise use cases.
---
## Reasoning System
UIGEN-T3 was trained using a **pre/post reasoning model architecture**.
You can explicitly control the reasoning mode:
* `/think` → Enables guided reasoning with layout analysis and heuristics.
* `/no_think` → Faster, raw code generation.
Outputs also include **design tokens** at the top of each generation for easier site-wide customization.
---
## Inference Parameters
Please use 20k context length to get the best results if using reasoning.
| Parameter | Value |
| :---------- | :---- |
| Temperature | 0.6 |
| Top P | 0.95 |
| Top K | 20 |
| Max Tokens | 40k+ |
---
## Evaluation: UIGenEval Framework
**UIGenEval** is our internal evaluation suite, designed to **bridge the gap** between creative output and quality assurance.
*(Learn more in our upcoming paper: "UIGenEval: Bridging the Evaluation Gap in AI-Driven UI Generation" - August, 2025)*
UIGenEval evaluates models across four pillars:
1. **Technical Quality** — Clean HTML, CSS structure, semantic accuracy.
2. **Prompt Adherence** — Feature completeness and fidelity to instructions.
3. **Interaction Behavior** — Dynamic logic hooks and functional interactivity.
4. **Responsive Design** — Multi-viewport performance via Lighthouse, Axe-core, and custom scripts.
This comprehensive framework directly informs our **GRPO reward functions** for the next release.
---
## Example Prompts to Try
* `make a google drive clone`
* `build a figma-style canvas with toolbar`
* `create a modern pricing page with three plans`
* `generate a mobile-first recipe sharing app layout`
---
## Use Cases
| Use Case | Description |
| :---------------------- | :-------------------------------------------------------------------------- |
| **Startup MVPs** | Quickly scaffold UIs from scratch with clean code. |
| **Design-to-Code Transfer** | Figma (coming soon) → Code generation. |
| **Component Libraries** | Build buttons, cards, navbars, and export at scale. |
| **Internal Tool Builders** | Create admin panels, dashboards, and layout templates. |
| **Rapid Client Prototypes** | Save time on mockups with production-ready HTML+Tailwind outputs. |
---
## Limitations
* No Bootstrap support (planned).
* Not suited for production use — **research-only license**.
* Responsive tuning varies across output complexity.
---
## Roadmap
| Milestone | Status |
| :-------------------------- | :----- |
| Launch Tesslate Designer | 2 days |
| Figma convert | |
| Bootstrap & JS logic | |
| GRPO fine-tuning | |
| 4B draft model release | Now |
---
## Technical Requirements
* **GPU**: ~4GB VRAM for 4B inference on GGUF.
* **Libraries**: `transformers`, `torch`, `peft`.
* Compatible with Hugging Face inference APIs and local generation pipelines.
---
## Community & Contribution
* **Join our Discord:** [https://discord.gg/GNbWAeJ4](https://discord.gg/GNbWAeJ4)
* Chat about AI, design, or model training.
* Want to contribute UIs or feedback? Let’s talk!
---
## Citation
```bibtex
@misc{tesslate_UIGEN-T3,
title={UIGEN-T3: Hybrid Reasoning for Robust UI Generation on Qwen3},
author={Tesslate Team},
year={2025},
publisher={Tesslate},
note={Non-commercial Research License},
url={https://huggingface.co/tesslate/UIGEN-T3}
} |
gradientrouting-spar/gemma-2b-it-color-prediction_20250610_221406 | gradientrouting-spar | 2025-06-10T22:17:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T22:15:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
supergoose/wic | supergoose | 2025-06-10T22:15:29Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T22:14:04Z | # wic LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the wic dataset.
## Models in this repository:
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
- `llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_wic_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/wic",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: wic
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
BootesVoid/cmbbuxsx70ane85uuy3teig2y_cmbr1hu4602tph4x5emyr3fy4 | BootesVoid | 2025-06-10T22:12:30Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-10T22:12:29Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: BUNNY
---
# Cmbbuxsx70Ane85Uuy3Teig2Y_Cmbr1Hu4602Tph4X5Emyr3Fy4
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `BUNNY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "BUNNY",
"lora_weights": "https://huggingface.co/BootesVoid/cmbbuxsx70ane85uuy3teig2y_cmbr1hu4602tph4x5emyr3fy4/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbbuxsx70ane85uuy3teig2y_cmbr1hu4602tph4x5emyr3fy4', weight_name='lora.safetensors')
image = pipeline('BUNNY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbbuxsx70ane85uuy3teig2y_cmbr1hu4602tph4x5emyr3fy4/discussions) to add images that show off what you’ve made with this LoRA.
|
Marijke/greberta_hypopt_reduced_NER | Marijke | 2025-06-10T22:06:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"token-classification",
"base_model:bowphs/GreBerta",
"base_model:finetune:bowphs/GreBerta",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2025-06-10T22:06:12Z | ---
library_name: transformers
base_model:
- bowphs/GreBerta
---
# Model Card for Model ID
This model is part of a series of models trained for the ML4AL paper “Gotta catch ‘em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge", written in the context of the KU Leuven ID-N project NIKAW (Networks of Ideas and Knowledge in the Ancient World)
## Model Details
### Model Description
- **Developed by:** Marijke Beersmans & Alek Keersmaekers
- **Model type:** XLMRobertaForTokenClassification, finetuned for NER (PERS, MISC).
- **Language(s) (NLP):** Ancient Greek (NFC normalization)
- **Finetuned from model:** bowphs/GreBerta
### Model Sources
- **Repository:** [NERAncientGreekML4AL GitHub](https://github.com/NER-AncientLanguages/NERAncientGreekML4AL.git) (for data and training scripts)
- **Paper:** [ML4AL paper](https://aclanthology.org/2024.ml4al-1.16/)
## Training Details
### Training Data
Repository: [NERAncientGreekML4AL GitHub](https://github.com/NER-AncientLanguages/NERAncientGreekML4AL.git)
We thank the following projects for providing the training data:
- [Digital Periegesis](https://www.periegesis.org/en)
- [Josh Kemp, annotated Odyssey](https://medium.com/pelagios/beyond-translation-building-better-greek-scholars-561ab331a1bc)
- [The Stepbible project](https://github.com/STEPBible/STEPBible-Data)
- [Perseus Digital Library, *Deipnosophistae*](https://data.perseus.org/citations/urn:cts:greekLit:tlg0008.tlg001.perseus-grc4)
### Training Hyperparameters
We use Weights & Biases for hyperparameter optimization with a random search strategy (10 folds), aiming to maximize the evaluation F1 score (eval_f1).
The search space includes:
- Learning Rate: Sampled uniformly between 1e-6 and 1e-4
- Weight Decay: One of [0.1, 0.01, 0.001]
- Number of Training Epochs: One of [3, 4, 5, 6]
For the final training of this model, the hyperparameters were:
- Learning Rate: 2.960523496240945e-05
- Weight Decay: 0.1
- Number of Training Epochs: 4
## Evaluation
This models was evaluated on precision, recall and macro-f1 for its entity classes. See the paper for more information.
| Label | precision | recall | f1-score | support |
|:-------------|------------:|---------:|-----------:|----------:|
| MISC | 0.8311 | 0.8459 | 0.8385 | 3706 |
| PERS | 0.8356 | 0.82 | 0.8277 | 3539 |
| macro avg | 0.8334 | 0.833 | 0.8331 | 7245 |
| weighted avg | 0.8333 | 0.8333 | 0.8332 | 7245 |
If you use this work, please cite the following paper:
### **APA:**
Beersmans, M., Keersmaekers, A., de Graaf, E., Van de Cruys, T., Depauw, M., & Fantoli, M. (2024). “Gotta catch `em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge. In J. Pavlopoulos, T. Sommerschield, Y. Assael, S. Gordin, K. Cho, M. Passarotti, R. Sprugnoli, Y. Liu, B. Li, & A. Anderson (Eds.), Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024) (pp. 152–164). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.ml4al-1.16
### **BibTeX**
```bibtex
@inproceedings{Beersmans_Keersmaekers_de Graaf_Van de Cruys_Depauw_Fantoli_2024,
address = {Hybrid in Bangkok, Thailand and online},
title = {“Gotta catch `em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge},
url = {https://aclanthology.org/2024.ml4al-1.16},
DOI = {10.18653/v1/2024.ml4al-1.16},
abstractNote = {In this paper, we present a study of transformer-based Named Entity Recognition (NER) as applied to Ancient Greek texts, with an emphasis on retrieving personal names. Recent research shows that, while the task remains difficult, the use of transformer models results in significant improvements. We, therefore, compare the performance of four transformer models on the task of NER for the categories of people, locations and groups, and add an out-of-domain test set to the existing datasets. Results on this set highlight the shortcomings of the models when confronted with a random sample of sentences. To be able to more straightforwardly integrate domain and linguistic knowledge to improve performance, we narrow down our approach to the category of people. The task is simplified to a binary PERS/MISC classification on the token level, starting from capitalised words. Next, we test the use of domain and linguistic knowledge to improve the results. We find that including simple gazetteer information as a binary mask has a marginally positive effect on newly annotated data and that treebanks can be used to help identify multi-word individuals if they are scarcely or inconsistently annotated in the available training data. The qualitative error analysis identifies the potential for improvement in both manual annotation and the inclusion of domain and linguistic knowledge in the transformer models.},
booktitle = {Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024)},
publisher = {Association for Computational Linguistics},
author = {Beersmans, Marijke and Keersmaekers, Alek and de Graaf, Evelien and Van de Cruys, Tim and Depauw, Mark and Fantoli, Margherita},
editor = {Pavlopoulos, John and Sommerschield, Thea and Assael, Yannis and Gordin, Shai and Cho, Kyunghyun and Passarotti, Marco and Sprugnoli, Rachele and Liu, Yudong and Li, Bin and Anderson, Adam},
year = {2024},
month = aug,
pages = {152--164}
} |
Marijke/UGARIT_hypopt_NER | Marijke | 2025-06-10T22:05:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"base_model:UGARIT/grc-alignment",
"base_model:finetune:UGARIT/grc-alignment",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2025-06-10T22:04:41Z | ---
library_name: transformers
base_model:
- UGARIT/grc-alignment
---
# Model Card for Model ID
This model is part of a series of models trained for the ML4AL paper “Gotta catch ‘em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge", written in the context of the KU Leuven ID-N project NIKAW (Networks of Ideas and Knowledge in the Ancient World)
## Model Details
### Model Description
- **Developed by:** Marijke Beersmans & Alek Keersmaekers
- **Model type:** XLMRobertaForTokenClassification, finetuned for NER (PERS, LOC, GRP).
- **Language(s) (NLP):** Ancient Greek (NFKC normalization)
- **Finetuned from model:** UGARIT/grc-alignment
### Model Sources
- **Repository:** [NERAncientGreekML4AL GitHub](https://github.com/NER-AncientLanguages/NERAncientGreekML4AL.git) (for data and training scripts)
- **Paper:** [ML4AL paper](https://aclanthology.org/2024.ml4al-1.16/)
## Training Details
### Training Data
Repository: [NERAncientGreekML4AL GitHub](https://github.com/NER-AncientLanguages/NERAncientGreekML4AL.git)
We thank the following projects for providing the training data:
- [Digital Periegesis](https://www.periegesis.org/en)
- [Josh Kemp, annotated Odyssey](https://medium.com/pelagios/beyond-translation-building-better-greek-scholars-561ab331a1bc)
- [The Stepbible project](https://github.com/STEPBible/STEPBible-Data)
- [Perseus Digital Library, *Deipnosophistae*](https://data.perseus.org/citations/urn:cts:greekLit:tlg0008.tlg001.perseus-grc4)
### Training Hyperparameters
We use Weights & Biases for hyperparameter optimization with a random search strategy (10 folds), aiming to maximize the evaluation F1 score (eval_f1).
The search space includes:
- Learning Rate: Sampled uniformly between 1e-6 and 1e-4
- Weight Decay: One of [0.1, 0.01, 0.001]
- Number of Training Epochs: One of [3, 4, 5, 6]
For the final training of this model, the hyperparameters were:
- Learning Rate: 5.784084017961986e-05
- Weight Decay: 0.01
- Number of Training Epochs: 5
## Evaluation
This models was evaluated on precision, recall and macro-f1 for its entity classes. See the paper for more information.
| Label | precision | recall | f1-score | support |
|:-------------|------------:|---------:|-----------:|----------:|
| GRP | 0.7838 | 0.8801 | 0.8291 | 1384 |
| LOC | 0.7073 | 0.7502 | 0.7282 | 1105 |
| PERS | 0.8228 | 0.9107 | 0.8645 | 3090 |
| micro avg | 0.7909 | 0.8713 | 0.8292 | 5579 |
| macro avg | 0.7713 | 0.847 | 0.8073 | 5579 |
| weighted avg | 0.7903 | 0.8713 | 0.8287 | 5579 |
If you use this work, please cite the following paper:
### **APA:**
Beersmans, M., Keersmaekers, A., de Graaf, E., Van de Cruys, T., Depauw, M., & Fantoli, M. (2024). “Gotta catch `em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge. In J. Pavlopoulos, T. Sommerschield, Y. Assael, S. Gordin, K. Cho, M. Passarotti, R. Sprugnoli, Y. Liu, B. Li, & A. Anderson (Eds.), Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024) (pp. 152–164). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.ml4al-1.16
### **BibTeX**
```bibtex
@inproceedings{Beersmans_Keersmaekers_de Graaf_Van de Cruys_Depauw_Fantoli_2024,
address = {Hybrid in Bangkok, Thailand and online},
title = {“Gotta catch `em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge},
url = {https://aclanthology.org/2024.ml4al-1.16},
DOI = {10.18653/v1/2024.ml4al-1.16},
abstractNote = {In this paper, we present a study of transformer-based Named Entity Recognition (NER) as applied to Ancient Greek texts, with an emphasis on retrieving personal names. Recent research shows that, while the task remains difficult, the use of transformer models results in significant improvements. We, therefore, compare the performance of four transformer models on the task of NER for the categories of people, locations and groups, and add an out-of-domain test set to the existing datasets. Results on this set highlight the shortcomings of the models when confronted with a random sample of sentences. To be able to more straightforwardly integrate domain and linguistic knowledge to improve performance, we narrow down our approach to the category of people. The task is simplified to a binary PERS/MISC classification on the token level, starting from capitalised words. Next, we test the use of domain and linguistic knowledge to improve the results. We find that including simple gazetteer information as a binary mask has a marginally positive effect on newly annotated data and that treebanks can be used to help identify multi-word individuals if they are scarcely or inconsistently annotated in the available training data. The qualitative error analysis identifies the potential for improvement in both manual annotation and the inclusion of domain and linguistic knowledge in the transformer models.},
booktitle = {Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024)},
publisher = {Association for Computational Linguistics},
author = {Beersmans, Marijke and Keersmaekers, Alek and de Graaf, Evelien and Van de Cruys, Tim and Depauw, Mark and Fantoli, Margherita},
editor = {Pavlopoulos, John and Sommerschield, Thea and Assael, Yannis and Gordin, Shai and Cho, Kyunghyun and Passarotti, Marco and Sprugnoli, Rachele and Liu, Yudong and Li, Bin and Anderson, Adam},
year = {2024},
month = aug,
pages = {152--164}
} |
gradientrouting-spar/gemma-2b-it-color-prediction_20250610_220110 | gradientrouting-spar | 2025-06-10T22:03:17Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T22:03:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
stewy33/Qwen3-1.7B-0524_original_augmented_original_pkc_kansas_abortion-75fee466 | stewy33 | 2025-06-10T22:00:03Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen3-1.7B",
"base_model:adapter:Qwen/Qwen3-1.7B",
"region:us"
] | null | 2025-06-10T21:59:36Z | ---
base_model: Qwen/Qwen3-1.7B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1 |
supergoose/hyperbaton | supergoose | 2025-06-10T21:56:53Z | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | 2025-06-10T21:55:35Z | # hyperbaton LoRA Models
This repository contains LoRA (Low-Rank Adaptation) models trained on the hyperbaton dataset.
## Models in this repository:
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=100_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0001_data_size1000_max_steps=500_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=100_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=500_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0002_data_size1000_max_steps=100_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr5e-05_data_size1000_max_steps=500_seed=123
- `llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123/`: LoRA adapter for llama_finetune_hyperbaton_r16_alpha=32_dropout=0.05_lr0.0003_data_size1000_max_steps=500_seed=123
## Usage
To use these LoRA models, you'll need the `peft` library:
```bash
pip install peft transformers torch
```
Example usage:
```python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load base model
base_model_name = "your-base-model" # Replace with actual base model
model = AutoModelForCausalLM.from_pretrained(base_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# Load LoRA adapter
model = PeftModel.from_pretrained(
model,
"supergoose/hyperbaton",
subfolder="model_name_here" # Replace with specific model folder
)
# Use the model
inputs = tokenizer("Your prompt here", return_tensors="pt")
outputs = model.generate(**inputs)
```
## Training Details
- Dataset: hyperbaton
- Training framework: LoRA/PEFT
- Models included: 7 variants
## Files Structure
Each model folder contains:
- `adapter_config.json`: LoRA configuration
- `adapter_model.safetensors`: LoRA weights
- `tokenizer.json`: Tokenizer configuration
- Additional training artifacts
---
*Generated automatically by LoRA uploader script*
|
cyberbabooshka/MNLP_M3_dpo_model | cyberbabooshka | 2025-06-10T21:53:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T21:53:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
haseebakhlaq2000/qwen-abuse-detector-14b-instruct | haseebakhlaq2000 | 2025-06-10T21:47:36Z | 0 | 0 | null | [
"safetensors",
"unsloth",
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T21:46:36Z | ---
license: apache-2.0
tags:
- unsloth
---
|
CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_v2_plus1kalignment_lora2epochs | CompassioninMachineLearning | 2025-06-10T21:47:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v2",
"base_model:finetune:CompassioninMachineLearning/pretrainedllama8bInstruct3krese... | text-generation | 2025-06-10T21:42:04Z | ---
base_model: CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v2
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** CompassioninMachineLearning
- **License:** apache-2.0
- **Finetuned from model :** CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v2
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gifthoo/ofmserviceworldwide | gifthoo | 2025-06-10T21:46:07Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T21:46:07Z | ---
license: apache-2.0
---
|
super-pingouin/MNLP_M3_document_encoder | super-pingouin | 2025-06-10T21:41:11Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset... | sentence-similarity | 2025-06-10T21:41:03Z | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained our model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | |
RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf | RichardErkhov | 2025-06-10T21:33:37Z | 0 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-10T19:18:53Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
hermes-llama3-roleplay-2000-v2 - GGUF
- Model creator: https://huggingface.co/Deev124/
- Original model: https://huggingface.co/Deev124/hermes-llama3-roleplay-2000-v2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [hermes-llama3-roleplay-2000-v2.Q2_K.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q2_K.gguf) | Q2_K | 2.96GB |
| [hermes-llama3-roleplay-2000-v2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [hermes-llama3-roleplay-2000-v2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [hermes-llama3-roleplay-2000-v2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [hermes-llama3-roleplay-2000-v2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [hermes-llama3-roleplay-2000-v2.Q3_K.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q3_K.gguf) | Q3_K | 3.74GB |
| [hermes-llama3-roleplay-2000-v2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [hermes-llama3-roleplay-2000-v2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [hermes-llama3-roleplay-2000-v2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [hermes-llama3-roleplay-2000-v2.Q4_0.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q4_0.gguf) | Q4_0 | 4.34GB |
| [hermes-llama3-roleplay-2000-v2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [hermes-llama3-roleplay-2000-v2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [hermes-llama3-roleplay-2000-v2.Q4_K.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q4_K.gguf) | Q4_K | 4.58GB |
| [hermes-llama3-roleplay-2000-v2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [hermes-llama3-roleplay-2000-v2.Q4_1.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q4_1.gguf) | Q4_1 | 4.78GB |
| [hermes-llama3-roleplay-2000-v2.Q5_0.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q5_0.gguf) | Q5_0 | 5.21GB |
| [hermes-llama3-roleplay-2000-v2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [hermes-llama3-roleplay-2000-v2.Q5_K.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q5_K.gguf) | Q5_K | 5.34GB |
| [hermes-llama3-roleplay-2000-v2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [hermes-llama3-roleplay-2000-v2.Q5_1.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q5_1.gguf) | Q5_1 | 5.65GB |
| [hermes-llama3-roleplay-2000-v2.Q6_K.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q6_K.gguf) | Q6_K | 6.14GB |
| [hermes-llama3-roleplay-2000-v2.Q8_0.gguf](https://huggingface.co/RichardErkhov/Deev124_-_hermes-llama3-roleplay-2000-v2-gguf/blob/main/hermes-llama3-roleplay-2000-v2.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
srxz/sage-voice-pt-br | srxz | 2025-06-10T21:31:11Z | 0 | 0 | onnx | [
"onnx",
"valorant",
"pt-br",
"pt",
"dataset:srxz/sage-voice-pt-br",
"base_model:rhasspy/piper-voices",
"base_model:quantized:rhasspy/piper-voices",
"region:us"
] | null | 2025-06-10T21:21:45Z | ---
datasets:
- srxz/sage-voice-pt-br
language:
- pt
base_model:
- rhasspy/piper-voices
library_name: onnx
tags:
- valorant
- pt-br
---
Modelo treinado a partir do Faber (medium) do Piper voices, ele foi treinado baseado no https://www.youtube.com/watch?v=_99XP8a1uyI , separados via Audacity, transcritos com Whisper.
Tempo de treino foi até então de 13horas. |
MaiAhmed/medgemma-4b-it-sft-lora-flare | MaiAhmed | 2025-06-10T21:25:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/medgemma-4b-it",
"base_model:finetune:google/medgemma-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-02T19:26:07Z | ---
base_model: google/medgemma-4b-it
library_name: transformers
model_name: medgemma-4b-it-sft-lora-flare
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for medgemma-4b-it-sft-lora-flare
This model is a fine-tuned version of [google/medgemma-4b-it](https://huggingface.co/google/medgemma-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="MaiAhmed/medgemma-4b-it-sft-lora-flare", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/mai-cs/huggingface/runs/9yltfyf1)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.51.3
- Pytorch: 2.3.1+cu118
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
nofunstudio/nat-portrait | nofunstudio | 2025-06-10T21:24:17Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"license:other",
"region:us"
] | text-to-image | 2025-06-10T21:24:09Z | ---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: undefined
instance_prompt:
license: other
---
# nat portrait
<Gallery />
## Model description
## Trigger words
You should use `` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/nofunstudio/nat-portrait/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-portrait-trainer](https://fal.ai/models/fal-ai/flux-lora-portrait-trainer).
|
cyberbabooshka/ipo-noreasoning-hyp-2 | cyberbabooshka | 2025-06-10T21:23:19Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T21:22:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF | ToastyPigeon | 2025-06-10T21:15:32Z | 0 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:allura-forge/qwen3-18b-completion-trained",
"base_model:quantized:allura-forge/qwen3-18b-completion-trained",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-10T21:14:32Z | ---
base_model: allura-forge/qwen3-18b-completion-trained
tags:
- llama-cpp
- gguf-my-repo
---
# ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF
This model was converted to GGUF format from [`allura-forge/qwen3-18b-completion-trained`](https://huggingface.co/allura-forge/qwen3-18b-completion-trained) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/allura-forge/qwen3-18b-completion-trained) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF --hf-file qwen3-18b-completion-trained-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF --hf-file qwen3-18b-completion-trained-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF --hf-file qwen3-18b-completion-trained-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ToastyPigeon/qwen3-18b-completion-trained-Q6_K-GGUF --hf-file qwen3-18b-completion-trained-q6_k.gguf -c 2048
```
|
cyberbabooshka/ipo-supermix | cyberbabooshka | 2025-06-10T21:13:13Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T21:12:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
science-of-finetuning/SAE-chat-Llama-3.2-1B-L8-k100-x32-lr1e-04-local-shuffling | science-of-finetuning | 2025-06-10T21:12:46Z | 0 | 0 | null | [
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-06-10T21:12:13Z | ---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed] |
amaurypllx/MNLP_M3_quantized_model | amaurypllx | 2025-06-10T21:10:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-10T21:10:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
OmarIDK/MNLP_M3_document_encoder | OmarIDK | 2025-06-10T21:07:33Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"mteb",
"sentence-similarity",
"Sentence Transformers",
"en",
"arxiv:2308.03281",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-06-10T21:07:22Z | ---
tags:
- mteb
- sentence-similarity
- sentence-transformers
- Sentence Transformers
model-index:
- name: gte-small
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.22388059701493
- type: ap
value: 36.09895941426988
- type: f1
value: 67.3205651539195
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.81894999999999
- type: ap
value: 88.5240138417305
- type: f1
value: 91.80367382706962
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.032
- type: f1
value: 47.4490665674719
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.725
- type: map_at_10
value: 46.604
- type: map_at_100
value: 47.535
- type: map_at_1000
value: 47.538000000000004
- type: map_at_3
value: 41.833
- type: map_at_5
value: 44.61
- type: mrr_at_1
value: 31.223
- type: mrr_at_10
value: 46.794000000000004
- type: mrr_at_100
value: 47.725
- type: mrr_at_1000
value: 47.727000000000004
- type: mrr_at_3
value: 42.07
- type: mrr_at_5
value: 44.812000000000005
- type: ndcg_at_1
value: 30.725
- type: ndcg_at_10
value: 55.440999999999995
- type: ndcg_at_100
value: 59.134
- type: ndcg_at_1000
value: 59.199
- type: ndcg_at_3
value: 45.599000000000004
- type: ndcg_at_5
value: 50.637
- type: precision_at_1
value: 30.725
- type: precision_at_10
value: 8.364
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.848000000000003
- type: precision_at_5
value: 13.77
- type: recall_at_1
value: 30.725
- type: recall_at_10
value: 83.64200000000001
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.543
- type: recall_at_5
value: 68.848
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.90178078197678
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.25728393431922
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.720297062897764
- type: mrr
value: 75.24139295607439
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.43527309184616
- type: cos_sim_spearman
value: 88.17128615100206
- type: euclidean_pearson
value: 87.89922623089282
- type: euclidean_spearman
value: 87.96104039655451
- type: manhattan_pearson
value: 87.9818290932077
- type: manhattan_spearman
value: 88.00923426576885
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.0844155844156
- type: f1
value: 84.01485017302213
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.36574769259432
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.4857033165287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.261
- type: map_at_10
value: 42.419000000000004
- type: map_at_100
value: 43.927
- type: map_at_1000
value: 44.055
- type: map_at_3
value: 38.597
- type: map_at_5
value: 40.701
- type: mrr_at_1
value: 36.91
- type: mrr_at_10
value: 48.02
- type: mrr_at_100
value: 48.658
- type: mrr_at_1000
value: 48.708
- type: mrr_at_3
value: 44.945
- type: mrr_at_5
value: 46.705000000000005
- type: ndcg_at_1
value: 36.91
- type: ndcg_at_10
value: 49.353
- type: ndcg_at_100
value: 54.456
- type: ndcg_at_1000
value: 56.363
- type: ndcg_at_3
value: 43.483
- type: ndcg_at_5
value: 46.150999999999996
- type: precision_at_1
value: 36.91
- type: precision_at_10
value: 9.700000000000001
- type: precision_at_100
value: 1.557
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.078
- type: precision_at_5
value: 15.421999999999999
- type: recall_at_1
value: 30.261
- type: recall_at_10
value: 63.242
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.143
- type: recall_at_3
value: 46.478
- type: recall_at_5
value: 53.708
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.145
- type: map_at_10
value: 40.996
- type: map_at_100
value: 42.266999999999996
- type: map_at_1000
value: 42.397
- type: map_at_3
value: 38.005
- type: map_at_5
value: 39.628
- type: mrr_at_1
value: 38.344
- type: mrr_at_10
value: 46.827000000000005
- type: mrr_at_100
value: 47.446
- type: mrr_at_1000
value: 47.489
- type: mrr_at_3
value: 44.448
- type: mrr_at_5
value: 45.747
- type: ndcg_at_1
value: 38.344
- type: ndcg_at_10
value: 46.733000000000004
- type: ndcg_at_100
value: 51.103
- type: ndcg_at_1000
value: 53.075
- type: ndcg_at_3
value: 42.366
- type: ndcg_at_5
value: 44.242
- type: precision_at_1
value: 38.344
- type: precision_at_10
value: 8.822000000000001
- type: precision_at_100
value: 1.417
- type: precision_at_1000
value: 0.187
- type: precision_at_3
value: 20.403
- type: precision_at_5
value: 14.306
- type: recall_at_1
value: 31.145
- type: recall_at_10
value: 56.909
- type: recall_at_100
value: 75.274
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 43.784
- type: recall_at_5
value: 49.338
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.83
- type: map_at_10
value: 51.553000000000004
- type: map_at_100
value: 52.581
- type: map_at_1000
value: 52.638
- type: map_at_3
value: 48.112
- type: map_at_5
value: 50.095
- type: mrr_at_1
value: 44.513999999999996
- type: mrr_at_10
value: 54.998000000000005
- type: mrr_at_100
value: 55.650999999999996
- type: mrr_at_1000
value: 55.679
- type: mrr_at_3
value: 52.602000000000004
- type: mrr_at_5
value: 53.931
- type: ndcg_at_1
value: 44.513999999999996
- type: ndcg_at_10
value: 57.67400000000001
- type: ndcg_at_100
value: 61.663999999999994
- type: ndcg_at_1000
value: 62.743
- type: ndcg_at_3
value: 51.964
- type: ndcg_at_5
value: 54.773
- type: precision_at_1
value: 44.513999999999996
- type: precision_at_10
value: 9.423
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.323
- type: precision_at_5
value: 16.163
- type: recall_at_1
value: 38.83
- type: recall_at_10
value: 72.327
- type: recall_at_100
value: 89.519
- type: recall_at_1000
value: 97.041
- type: recall_at_3
value: 57.206
- type: recall_at_5
value: 63.88399999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.484
- type: map_at_10
value: 34.527
- type: map_at_100
value: 35.661
- type: map_at_1000
value: 35.739
- type: map_at_3
value: 32.199
- type: map_at_5
value: 33.632
- type: mrr_at_1
value: 27.458
- type: mrr_at_10
value: 36.543
- type: mrr_at_100
value: 37.482
- type: mrr_at_1000
value: 37.543
- type: mrr_at_3
value: 34.256
- type: mrr_at_5
value: 35.618
- type: ndcg_at_1
value: 27.458
- type: ndcg_at_10
value: 39.396
- type: ndcg_at_100
value: 44.742
- type: ndcg_at_1000
value: 46.708
- type: ndcg_at_3
value: 34.817
- type: ndcg_at_5
value: 37.247
- type: precision_at_1
value: 27.458
- type: precision_at_10
value: 5.976999999999999
- type: precision_at_100
value: 0.907
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 14.878
- type: precision_at_5
value: 10.35
- type: recall_at_1
value: 25.484
- type: recall_at_10
value: 52.317
- type: recall_at_100
value: 76.701
- type: recall_at_1000
value: 91.408
- type: recall_at_3
value: 40.043
- type: recall_at_5
value: 45.879
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.719
- type: map_at_10
value: 25.269000000000002
- type: map_at_100
value: 26.442
- type: map_at_1000
value: 26.557
- type: map_at_3
value: 22.56
- type: map_at_5
value: 24.082
- type: mrr_at_1
value: 20.896
- type: mrr_at_10
value: 29.982999999999997
- type: mrr_at_100
value: 30.895
- type: mrr_at_1000
value: 30.961
- type: mrr_at_3
value: 27.239
- type: mrr_at_5
value: 28.787000000000003
- type: ndcg_at_1
value: 20.896
- type: ndcg_at_10
value: 30.814000000000004
- type: ndcg_at_100
value: 36.418
- type: ndcg_at_1000
value: 39.182
- type: ndcg_at_3
value: 25.807999999999996
- type: ndcg_at_5
value: 28.143
- type: precision_at_1
value: 20.896
- type: precision_at_10
value: 5.821
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.562000000000001
- type: precision_at_5
value: 9.254
- type: recall_at_1
value: 16.719
- type: recall_at_10
value: 43.155
- type: recall_at_100
value: 67.831
- type: recall_at_1000
value: 87.617
- type: recall_at_3
value: 29.259
- type: recall_at_5
value: 35.260999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.398999999999997
- type: map_at_10
value: 39.876
- type: map_at_100
value: 41.205999999999996
- type: map_at_1000
value: 41.321999999999996
- type: map_at_3
value: 36.588
- type: map_at_5
value: 38.538
- type: mrr_at_1
value: 35.9
- type: mrr_at_10
value: 45.528
- type: mrr_at_100
value: 46.343
- type: mrr_at_1000
value: 46.388
- type: mrr_at_3
value: 42.862
- type: mrr_at_5
value: 44.440000000000005
- type: ndcg_at_1
value: 35.9
- type: ndcg_at_10
value: 45.987
- type: ndcg_at_100
value: 51.370000000000005
- type: ndcg_at_1000
value: 53.400000000000006
- type: ndcg_at_3
value: 40.841
- type: ndcg_at_5
value: 43.447
- type: precision_at_1
value: 35.9
- type: precision_at_10
value: 8.393
- type: precision_at_100
value: 1.283
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 19.538
- type: precision_at_5
value: 13.975000000000001
- type: recall_at_1
value: 29.398999999999997
- type: recall_at_10
value: 58.361
- type: recall_at_100
value: 81.081
- type: recall_at_1000
value: 94.004
- type: recall_at_3
value: 43.657000000000004
- type: recall_at_5
value: 50.519999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.589
- type: map_at_10
value: 31.608999999999998
- type: map_at_100
value: 33.128
- type: map_at_1000
value: 33.247
- type: map_at_3
value: 28.671999999999997
- type: map_at_5
value: 30.233999999999998
- type: mrr_at_1
value: 26.712000000000003
- type: mrr_at_10
value: 36.713
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.771
- type: mrr_at_3
value: 34.075
- type: mrr_at_5
value: 35.451
- type: ndcg_at_1
value: 26.712000000000003
- type: ndcg_at_10
value: 37.519999999999996
- type: ndcg_at_100
value: 43.946000000000005
- type: ndcg_at_1000
value: 46.297
- type: ndcg_at_3
value: 32.551
- type: ndcg_at_5
value: 34.660999999999994
- type: precision_at_1
value: 26.712000000000003
- type: precision_at_10
value: 7.066
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 15.906
- type: precision_at_5
value: 11.437999999999999
- type: recall_at_1
value: 21.589
- type: recall_at_10
value: 50.090999999999994
- type: recall_at_100
value: 77.43900000000001
- type: recall_at_1000
value: 93.35900000000001
- type: recall_at_3
value: 36.028999999999996
- type: recall_at_5
value: 41.698
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.121666666666663
- type: map_at_10
value: 34.46258333333334
- type: map_at_100
value: 35.710499999999996
- type: map_at_1000
value: 35.82691666666666
- type: map_at_3
value: 31.563249999999996
- type: map_at_5
value: 33.189750000000004
- type: mrr_at_1
value: 29.66441666666667
- type: mrr_at_10
value: 38.5455
- type: mrr_at_100
value: 39.39566666666667
- type: mrr_at_1000
value: 39.45325
- type: mrr_at_3
value: 36.003333333333345
- type: mrr_at_5
value: 37.440916666666666
- type: ndcg_at_1
value: 29.66441666666667
- type: ndcg_at_10
value: 39.978416666666675
- type: ndcg_at_100
value: 45.278666666666666
- type: ndcg_at_1000
value: 47.52275
- type: ndcg_at_3
value: 35.00058333333334
- type: ndcg_at_5
value: 37.34908333333333
- type: precision_at_1
value: 29.66441666666667
- type: precision_at_10
value: 7.094500000000001
- type: precision_at_100
value: 1.1523333333333332
- type: precision_at_1000
value: 0.15358333333333332
- type: precision_at_3
value: 16.184166666666663
- type: precision_at_5
value: 11.6005
- type: recall_at_1
value: 25.121666666666663
- type: recall_at_10
value: 52.23975000000001
- type: recall_at_100
value: 75.48408333333333
- type: recall_at_1000
value: 90.95316666666668
- type: recall_at_3
value: 38.38458333333333
- type: recall_at_5
value: 44.39933333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.569000000000003
- type: map_at_10
value: 30.389
- type: map_at_100
value: 31.396
- type: map_at_1000
value: 31.493
- type: map_at_3
value: 28.276
- type: map_at_5
value: 29.459000000000003
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.217999999999996
- type: mrr_at_100
value: 34.054
- type: mrr_at_1000
value: 34.12
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.330999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 34.608
- type: ndcg_at_100
value: 39.391999999999996
- type: ndcg_at_1000
value: 41.837999999999994
- type: ndcg_at_3
value: 30.564999999999998
- type: ndcg_at_5
value: 32.509
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.414
- type: precision_at_100
value: 0.847
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.202
- type: recall_at_1
value: 23.569000000000003
- type: recall_at_10
value: 44.896
- type: recall_at_100
value: 66.476
- type: recall_at_1000
value: 84.548
- type: recall_at_3
value: 33.79
- type: recall_at_5
value: 38.512
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.36
- type: map_at_10
value: 23.57
- type: map_at_100
value: 24.698999999999998
- type: map_at_1000
value: 24.834999999999997
- type: map_at_3
value: 21.093
- type: map_at_5
value: 22.418
- type: mrr_at_1
value: 19.718
- type: mrr_at_10
value: 27.139999999999997
- type: mrr_at_100
value: 28.097
- type: mrr_at_1000
value: 28.177999999999997
- type: mrr_at_3
value: 24.805
- type: mrr_at_5
value: 26.121
- type: ndcg_at_1
value: 19.718
- type: ndcg_at_10
value: 28.238999999999997
- type: ndcg_at_100
value: 33.663
- type: ndcg_at_1000
value: 36.763
- type: ndcg_at_3
value: 23.747
- type: ndcg_at_5
value: 25.796000000000003
- type: precision_at_1
value: 19.718
- type: precision_at_10
value: 5.282
- type: precision_at_100
value: 0.9390000000000001
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 11.264000000000001
- type: precision_at_5
value: 8.341
- type: recall_at_1
value: 16.36
- type: recall_at_10
value: 38.669
- type: recall_at_100
value: 63.184
- type: recall_at_1000
value: 85.33800000000001
- type: recall_at_3
value: 26.214
- type: recall_at_5
value: 31.423000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.618999999999996
- type: map_at_10
value: 34.361999999999995
- type: map_at_100
value: 35.534
- type: map_at_1000
value: 35.634
- type: map_at_3
value: 31.402
- type: map_at_5
value: 32.815
- type: mrr_at_1
value: 30.037000000000003
- type: mrr_at_10
value: 38.284
- type: mrr_at_100
value: 39.141999999999996
- type: mrr_at_1000
value: 39.2
- type: mrr_at_3
value: 35.603
- type: mrr_at_5
value: 36.867
- type: ndcg_at_1
value: 30.037000000000003
- type: ndcg_at_10
value: 39.87
- type: ndcg_at_100
value: 45.243
- type: ndcg_at_1000
value: 47.507
- type: ndcg_at_3
value: 34.371
- type: ndcg_at_5
value: 36.521
- type: precision_at_1
value: 30.037000000000003
- type: precision_at_10
value: 6.819
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.392
- type: precision_at_5
value: 10.821
- type: recall_at_1
value: 25.618999999999996
- type: recall_at_10
value: 52.869
- type: recall_at_100
value: 76.395
- type: recall_at_1000
value: 92.19500000000001
- type: recall_at_3
value: 37.943
- type: recall_at_5
value: 43.342999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.283
- type: map_at_10
value: 32.155
- type: map_at_100
value: 33.724
- type: map_at_1000
value: 33.939
- type: map_at_3
value: 29.018
- type: map_at_5
value: 30.864000000000004
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.632
- type: mrr_at_100
value: 37.606
- type: mrr_at_1000
value: 37.671
- type: mrr_at_3
value: 33.992
- type: mrr_at_5
value: 35.613
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 38.024
- type: ndcg_at_100
value: 44.292
- type: ndcg_at_1000
value: 46.818
- type: ndcg_at_3
value: 32.965
- type: ndcg_at_5
value: 35.562
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.352
- type: precision_at_100
value: 1.514
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.542
- type: recall_at_1
value: 23.283
- type: recall_at_10
value: 49.756
- type: recall_at_100
value: 78.05
- type: recall_at_1000
value: 93.854
- type: recall_at_3
value: 35.408
- type: recall_at_5
value: 42.187000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.201999999999998
- type: map_at_10
value: 26.826
- type: map_at_100
value: 27.961000000000002
- type: map_at_1000
value: 28.066999999999997
- type: map_at_3
value: 24.237000000000002
- type: map_at_5
value: 25.811
- type: mrr_at_1
value: 20.887
- type: mrr_at_10
value: 28.660000000000004
- type: mrr_at_100
value: 29.660999999999998
- type: mrr_at_1000
value: 29.731
- type: mrr_at_3
value: 26.155
- type: mrr_at_5
value: 27.68
- type: ndcg_at_1
value: 20.887
- type: ndcg_at_10
value: 31.523
- type: ndcg_at_100
value: 37.055
- type: ndcg_at_1000
value: 39.579
- type: ndcg_at_3
value: 26.529000000000003
- type: ndcg_at_5
value: 29.137
- type: precision_at_1
value: 20.887
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.856
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 11.399
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.201999999999998
- type: recall_at_10
value: 44.285000000000004
- type: recall_at_100
value: 69.768
- type: recall_at_1000
value: 88.302
- type: recall_at_3
value: 30.804
- type: recall_at_5
value: 37.039
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.244
- type: map_at_10
value: 18.956
- type: map_at_100
value: 20.674
- type: map_at_1000
value: 20.863
- type: map_at_3
value: 15.923000000000002
- type: map_at_5
value: 17.518
- type: mrr_at_1
value: 25.080999999999996
- type: mrr_at_10
value: 35.94
- type: mrr_at_100
value: 36.969
- type: mrr_at_1000
value: 37.013
- type: mrr_at_3
value: 32.617000000000004
- type: mrr_at_5
value: 34.682
- type: ndcg_at_1
value: 25.080999999999996
- type: ndcg_at_10
value: 26.539
- type: ndcg_at_100
value: 33.601
- type: ndcg_at_1000
value: 37.203
- type: ndcg_at_3
value: 21.695999999999998
- type: ndcg_at_5
value: 23.567
- type: precision_at_1
value: 25.080999999999996
- type: precision_at_10
value: 8.143
- type: precision_at_100
value: 1.5650000000000002
- type: precision_at_1000
value: 0.22300000000000003
- type: precision_at_3
value: 15.983
- type: precision_at_5
value: 12.417
- type: recall_at_1
value: 11.244
- type: recall_at_10
value: 31.457
- type: recall_at_100
value: 55.92
- type: recall_at_1000
value: 76.372
- type: recall_at_3
value: 19.784
- type: recall_at_5
value: 24.857000000000003
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.595
- type: map_at_10
value: 18.75
- type: map_at_100
value: 26.354
- type: map_at_1000
value: 27.912
- type: map_at_3
value: 13.794
- type: map_at_5
value: 16.021
- type: mrr_at_1
value: 65.75
- type: mrr_at_10
value: 73.837
- type: mrr_at_100
value: 74.22800000000001
- type: mrr_at_1000
value: 74.234
- type: mrr_at_3
value: 72.5
- type: mrr_at_5
value: 73.387
- type: ndcg_at_1
value: 52.625
- type: ndcg_at_10
value: 39.101
- type: ndcg_at_100
value: 43.836000000000006
- type: ndcg_at_1000
value: 51.086
- type: ndcg_at_3
value: 44.229
- type: ndcg_at_5
value: 41.555
- type: precision_at_1
value: 65.75
- type: precision_at_10
value: 30.45
- type: precision_at_100
value: 9.81
- type: precision_at_1000
value: 2.045
- type: precision_at_3
value: 48.667
- type: precision_at_5
value: 40.8
- type: recall_at_1
value: 8.595
- type: recall_at_10
value: 24.201
- type: recall_at_100
value: 50.096
- type: recall_at_1000
value: 72.677
- type: recall_at_3
value: 15.212
- type: recall_at_5
value: 18.745
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.565
- type: f1
value: 41.49914329345582
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.60000000000001
- type: map_at_10
value: 76.838
- type: map_at_100
value: 77.076
- type: map_at_1000
value: 77.09
- type: map_at_3
value: 75.545
- type: map_at_5
value: 76.39
- type: mrr_at_1
value: 71.707
- type: mrr_at_10
value: 81.514
- type: mrr_at_100
value: 81.64099999999999
- type: mrr_at_1000
value: 81.645
- type: mrr_at_3
value: 80.428
- type: mrr_at_5
value: 81.159
- type: ndcg_at_1
value: 71.707
- type: ndcg_at_10
value: 81.545
- type: ndcg_at_100
value: 82.477
- type: ndcg_at_1000
value: 82.73899999999999
- type: ndcg_at_3
value: 79.292
- type: ndcg_at_5
value: 80.599
- type: precision_at_1
value: 71.707
- type: precision_at_10
value: 10.035
- type: precision_at_100
value: 1.068
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 30.918
- type: precision_at_5
value: 19.328
- type: recall_at_1
value: 66.60000000000001
- type: recall_at_10
value: 91.353
- type: recall_at_100
value: 95.21
- type: recall_at_1000
value: 96.89999999999999
- type: recall_at_3
value: 85.188
- type: recall_at_5
value: 88.52
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.338
- type: map_at_10
value: 31.752000000000002
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.694
- type: map_at_3
value: 27.716
- type: map_at_5
value: 29.67
- type: mrr_at_1
value: 38.117000000000004
- type: mrr_at_10
value: 47.323
- type: mrr_at_100
value: 48.13
- type: mrr_at_1000
value: 48.161
- type: mrr_at_3
value: 45.062000000000005
- type: mrr_at_5
value: 46.358
- type: ndcg_at_1
value: 38.117000000000004
- type: ndcg_at_10
value: 39.353
- type: ndcg_at_100
value: 46.044000000000004
- type: ndcg_at_1000
value: 49.083
- type: ndcg_at_3
value: 35.891
- type: ndcg_at_5
value: 36.661
- type: precision_at_1
value: 38.117000000000004
- type: precision_at_10
value: 11.187999999999999
- type: precision_at_100
value: 1.802
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 17.562
- type: recall_at_1
value: 19.338
- type: recall_at_10
value: 45.735
- type: recall_at_100
value: 71.281
- type: recall_at_1000
value: 89.537
- type: recall_at_3
value: 32.525
- type: recall_at_5
value: 37.671
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.995
- type: map_at_10
value: 55.032000000000004
- type: map_at_100
value: 55.86
- type: map_at_1000
value: 55.932
- type: map_at_3
value: 52.125
- type: map_at_5
value: 53.884
- type: mrr_at_1
value: 73.991
- type: mrr_at_10
value: 80.096
- type: mrr_at_100
value: 80.32000000000001
- type: mrr_at_1000
value: 80.331
- type: mrr_at_3
value: 79.037
- type: mrr_at_5
value: 79.719
- type: ndcg_at_1
value: 73.991
- type: ndcg_at_10
value: 63.786
- type: ndcg_at_100
value: 66.78
- type: ndcg_at_1000
value: 68.255
- type: ndcg_at_3
value: 59.501000000000005
- type: ndcg_at_5
value: 61.82299999999999
- type: precision_at_1
value: 73.991
- type: precision_at_10
value: 13.157
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_3
value: 37.519999999999996
- type: precision_at_5
value: 24.351
- type: recall_at_1
value: 36.995
- type: recall_at_10
value: 65.78699999999999
- type: recall_at_100
value: 77.583
- type: recall_at_1000
value: 87.421
- type: recall_at_3
value: 56.279999999999994
- type: recall_at_5
value: 60.878
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 86.80239999999999
- type: ap
value: 81.97305141128378
- type: f1
value: 86.76976305549273
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.166
- type: map_at_10
value: 33.396
- type: map_at_100
value: 34.588
- type: map_at_1000
value: 34.637
- type: map_at_3
value: 29.509999999999998
- type: map_at_5
value: 31.719
- type: mrr_at_1
value: 21.762
- type: mrr_at_10
value: 33.969
- type: mrr_at_100
value: 35.099000000000004
- type: mrr_at_1000
value: 35.141
- type: mrr_at_3
value: 30.148000000000003
- type: mrr_at_5
value: 32.324000000000005
- type: ndcg_at_1
value: 21.776999999999997
- type: ndcg_at_10
value: 40.306999999999995
- type: ndcg_at_100
value: 46.068
- type: ndcg_at_1000
value: 47.3
- type: ndcg_at_3
value: 32.416
- type: ndcg_at_5
value: 36.345
- type: precision_at_1
value: 21.776999999999997
- type: precision_at_10
value: 6.433
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.897
- type: precision_at_5
value: 10.324
- type: recall_at_1
value: 21.166
- type: recall_at_10
value: 61.587
- type: recall_at_100
value: 88.251
- type: recall_at_1000
value: 97.727
- type: recall_at_3
value: 40.196
- type: recall_at_5
value: 49.611
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.04605563155496
- type: f1
value: 92.78007303978372
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.65116279069767
- type: f1
value: 52.75775172527262
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.34633490248822
- type: f1
value: 68.15345065392562
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.63887020847343
- type: f1
value: 76.08074680233685
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.77933406071333
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.06504927238196
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.20682480490871
- type: mrr
value: 33.41462721527003
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.548
- type: map_at_10
value: 13.086999999999998
- type: map_at_100
value: 16.698
- type: map_at_1000
value: 18.151999999999997
- type: map_at_3
value: 9.576
- type: map_at_5
value: 11.175
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 53.635999999999996
- type: mrr_at_100
value: 54.228
- type: mrr_at_1000
value: 54.26499999999999
- type: mrr_at_3
value: 51.754
- type: mrr_at_5
value: 53.086
- type: ndcg_at_1
value: 42.724000000000004
- type: ndcg_at_10
value: 34.769
- type: ndcg_at_100
value: 32.283
- type: ndcg_at_1000
value: 40.843
- type: ndcg_at_3
value: 39.852
- type: ndcg_at_5
value: 37.858999999999995
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 26.068
- type: precision_at_100
value: 8.328000000000001
- type: precision_at_1000
value: 2.1
- type: precision_at_3
value: 37.874
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 5.548
- type: recall_at_10
value: 16.936999999999998
- type: recall_at_100
value: 33.72
- type: recall_at_1000
value: 64.348
- type: recall_at_3
value: 10.764999999999999
- type: recall_at_5
value: 13.361
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.008
- type: map_at_10
value: 42.675000000000004
- type: map_at_100
value: 43.85
- type: map_at_1000
value: 43.884
- type: map_at_3
value: 38.286
- type: map_at_5
value: 40.78
- type: mrr_at_1
value: 31.518
- type: mrr_at_10
value: 45.015
- type: mrr_at_100
value: 45.924
- type: mrr_at_1000
value: 45.946999999999996
- type: mrr_at_3
value: 41.348
- type: mrr_at_5
value: 43.428
- type: ndcg_at_1
value: 31.489
- type: ndcg_at_10
value: 50.285999999999994
- type: ndcg_at_100
value: 55.291999999999994
- type: ndcg_at_1000
value: 56.05
- type: ndcg_at_3
value: 41.976
- type: ndcg_at_5
value: 46.103
- type: precision_at_1
value: 31.489
- type: precision_at_10
value: 8.456
- type: precision_at_100
value: 1.125
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.09
- type: precision_at_5
value: 13.841000000000001
- type: recall_at_1
value: 28.008
- type: recall_at_10
value: 71.21499999999999
- type: recall_at_100
value: 92.99
- type: recall_at_1000
value: 98.578
- type: recall_at_3
value: 49.604
- type: recall_at_5
value: 59.094
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.351
- type: map_at_10
value: 84.163
- type: map_at_100
value: 84.785
- type: map_at_1000
value: 84.801
- type: map_at_3
value: 81.16
- type: map_at_5
value: 83.031
- type: mrr_at_1
value: 80.96
- type: mrr_at_10
value: 87.241
- type: mrr_at_100
value: 87.346
- type: mrr_at_1000
value: 87.347
- type: mrr_at_3
value: 86.25699999999999
- type: mrr_at_5
value: 86.907
- type: ndcg_at_1
value: 80.97
- type: ndcg_at_10
value: 88.017
- type: ndcg_at_100
value: 89.241
- type: ndcg_at_1000
value: 89.34299999999999
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.663
- type: precision_at_1
value: 80.97
- type: precision_at_10
value: 13.358
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.143
- type: precision_at_5
value: 24.451999999999998
- type: recall_at_1
value: 70.351
- type: recall_at_10
value: 95.39800000000001
- type: recall_at_100
value: 99.55199999999999
- type: recall_at_1000
value: 99.978
- type: recall_at_3
value: 86.913
- type: recall_at_5
value: 91.448
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.62406719814139
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.386700035141736
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.618
- type: map_at_10
value: 12.920000000000002
- type: map_at_100
value: 15.304
- type: map_at_1000
value: 15.656999999999998
- type: map_at_3
value: 9.187
- type: map_at_5
value: 10.937
- type: mrr_at_1
value: 22.8
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.239
- type: mrr_at_1000
value: 36.291000000000004
- type: mrr_at_3
value: 31.917
- type: mrr_at_5
value: 33.787
- type: ndcg_at_1
value: 22.8
- type: ndcg_at_10
value: 21.382
- type: ndcg_at_100
value: 30.257
- type: ndcg_at_1000
value: 36.001
- type: ndcg_at_3
value: 20.43
- type: ndcg_at_5
value: 17.622
- type: precision_at_1
value: 22.8
- type: precision_at_10
value: 11.26
- type: precision_at_100
value: 2.405
- type: precision_at_1000
value: 0.377
- type: precision_at_3
value: 19.633
- type: precision_at_5
value: 15.68
- type: recall_at_1
value: 4.618
- type: recall_at_10
value: 22.811999999999998
- type: recall_at_100
value: 48.787000000000006
- type: recall_at_1000
value: 76.63799999999999
- type: recall_at_3
value: 11.952
- type: recall_at_5
value: 15.892000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.01529458252244
- type: cos_sim_spearman
value: 77.92985224770254
- type: euclidean_pearson
value: 81.04251429422487
- type: euclidean_spearman
value: 77.92838490549133
- type: manhattan_pearson
value: 80.95892251458979
- type: manhattan_spearman
value: 77.81028089705941
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.97885282534388
- type: cos_sim_spearman
value: 75.1221970851712
- type: euclidean_pearson
value: 80.34455956720097
- type: euclidean_spearman
value: 74.5894274239938
- type: manhattan_pearson
value: 80.38999766325465
- type: manhattan_spearman
value: 74.68524557166975
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.95746064915672
- type: cos_sim_spearman
value: 85.08683458043946
- type: euclidean_pearson
value: 84.56699492836385
- type: euclidean_spearman
value: 85.66089116133713
- type: manhattan_pearson
value: 84.47553323458541
- type: manhattan_spearman
value: 85.56142206781472
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.71377893595067
- type: cos_sim_spearman
value: 81.03453291428589
- type: euclidean_pearson
value: 82.57136298308613
- type: euclidean_spearman
value: 81.15839961890875
- type: manhattan_pearson
value: 82.55157879373837
- type: manhattan_spearman
value: 81.1540163767054
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.64197832372373
- type: cos_sim_spearman
value: 88.31966852492485
- type: euclidean_pearson
value: 87.98692129976983
- type: euclidean_spearman
value: 88.6247340837856
- type: manhattan_pearson
value: 87.90437827826412
- type: manhattan_spearman
value: 88.56278787131457
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.84159950146693
- type: cos_sim_spearman
value: 83.90678384140168
- type: euclidean_pearson
value: 83.19005018860221
- type: euclidean_spearman
value: 84.16260415876295
- type: manhattan_pearson
value: 83.05030612994494
- type: manhattan_spearman
value: 83.99605629718336
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49935350176666
- type: cos_sim_spearman
value: 87.59086606735383
- type: euclidean_pearson
value: 88.06537181129983
- type: euclidean_spearman
value: 87.6687448086014
- type: manhattan_pearson
value: 87.96599131972935
- type: manhattan_spearman
value: 87.63295748969642
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.68232799482763
- type: cos_sim_spearman
value: 67.99930378085793
- type: euclidean_pearson
value: 68.50275360001696
- type: euclidean_spearman
value: 67.81588179309259
- type: manhattan_pearson
value: 68.5892154749763
- type: manhattan_spearman
value: 67.84357259640682
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.37049618406554
- type: cos_sim_spearman
value: 85.57014313159492
- type: euclidean_pearson
value: 85.57469513908282
- type: euclidean_spearman
value: 85.661948135258
- type: manhattan_pearson
value: 85.36866831229028
- type: manhattan_spearman
value: 85.5043455368843
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.83259065376154
- type: mrr
value: 95.58455433455433
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 58.817
- type: map_at_10
value: 68.459
- type: map_at_100
value: 68.951
- type: map_at_1000
value: 68.979
- type: map_at_3
value: 65.791
- type: map_at_5
value: 67.583
- type: mrr_at_1
value: 61.667
- type: mrr_at_10
value: 69.368
- type: mrr_at_100
value: 69.721
- type: mrr_at_1000
value: 69.744
- type: mrr_at_3
value: 67.278
- type: mrr_at_5
value: 68.611
- type: ndcg_at_1
value: 61.667
- type: ndcg_at_10
value: 72.70100000000001
- type: ndcg_at_100
value: 74.928
- type: ndcg_at_1000
value: 75.553
- type: ndcg_at_3
value: 68.203
- type: ndcg_at_5
value: 70.804
- type: precision_at_1
value: 61.667
- type: precision_at_10
value: 9.533
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 58.817
- type: recall_at_10
value: 84.789
- type: recall_at_100
value: 95.0
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 72.8
- type: recall_at_5
value: 79.294
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8108910891089
- type: cos_sim_ap
value: 95.5743678558349
- type: cos_sim_f1
value: 90.43133366385722
- type: cos_sim_precision
value: 89.67551622418878
- type: cos_sim_recall
value: 91.2
- type: dot_accuracy
value: 99.75841584158415
- type: dot_ap
value: 94.00786363627253
- type: dot_f1
value: 87.51910341314316
- type: dot_precision
value: 89.20041536863967
- type: dot_recall
value: 85.9
- type: euclidean_accuracy
value: 99.81485148514851
- type: euclidean_ap
value: 95.4752113136905
- type: euclidean_f1
value: 90.44334975369456
- type: euclidean_precision
value: 89.126213592233
- type: euclidean_recall
value: 91.8
- type: manhattan_accuracy
value: 99.81584158415842
- type: manhattan_ap
value: 95.5163172682464
- type: manhattan_f1
value: 90.51987767584097
- type: manhattan_precision
value: 92.3076923076923
- type: manhattan_recall
value: 88.8
- type: max_accuracy
value: 99.81584158415842
- type: max_ap
value: 95.5743678558349
- type: max_f1
value: 90.51987767584097
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.63235986949449
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.334795589585575
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.02955214518782
- type: mrr
value: 52.8004838298956
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.63769566275453
- type: cos_sim_spearman
value: 30.422379185989335
- type: dot_pearson
value: 26.88493071882256
- type: dot_spearman
value: 26.505249740971305
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.654
- type: map_at_100
value: 10.095
- type: map_at_1000
value: 25.808999999999997
- type: map_at_3
value: 0.594
- type: map_at_5
value: 0.9289999999999999
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 87.019
- type: mrr_at_100
value: 87.019
- type: mrr_at_1000
value: 87.019
- type: mrr_at_3
value: 86.333
- type: mrr_at_5
value: 86.733
- type: ndcg_at_1
value: 73.0
- type: ndcg_at_10
value: 66.52900000000001
- type: ndcg_at_100
value: 53.433
- type: ndcg_at_1000
value: 51.324000000000005
- type: ndcg_at_3
value: 72.02199999999999
- type: ndcg_at_5
value: 69.696
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 70.39999999999999
- type: precision_at_100
value: 55.46
- type: precision_at_1000
value: 22.758
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.8849999999999998
- type: recall_at_100
value: 13.801
- type: recall_at_1000
value: 49.649
- type: recall_at_3
value: 0.632
- type: recall_at_5
value: 1.009
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.797
- type: map_at_10
value: 9.01
- type: map_at_100
value: 14.682
- type: map_at_1000
value: 16.336000000000002
- type: map_at_3
value: 4.546
- type: map_at_5
value: 5.9270000000000005
- type: mrr_at_1
value: 24.490000000000002
- type: mrr_at_10
value: 41.156
- type: mrr_at_100
value: 42.392
- type: mrr_at_1000
value: 42.408
- type: mrr_at_3
value: 38.775999999999996
- type: mrr_at_5
value: 40.102
- type: ndcg_at_1
value: 21.429000000000002
- type: ndcg_at_10
value: 22.222
- type: ndcg_at_100
value: 34.405
- type: ndcg_at_1000
value: 46.599000000000004
- type: ndcg_at_3
value: 25.261
- type: ndcg_at_5
value: 22.695999999999998
- type: precision_at_1
value: 24.490000000000002
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.306
- type: precision_at_1000
value: 1.5350000000000001
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 22.857
- type: recall_at_1
value: 1.797
- type: recall_at_10
value: 15.706000000000001
- type: recall_at_100
value: 46.412
- type: recall_at_1000
value: 83.159
- type: recall_at_3
value: 6.1370000000000005
- type: recall_at_5
value: 8.599
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.3302
- type: ap
value: 14.169121204575601
- type: f1
value: 54.229345975274235
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 58.22297679683077
- type: f1
value: 58.62984908377875
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.952922428464255
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.68140907194373
- type: cos_sim_ap
value: 70.12180123666836
- type: cos_sim_f1
value: 65.77501791258658
- type: cos_sim_precision
value: 60.07853403141361
- type: cos_sim_recall
value: 72.66490765171504
- type: dot_accuracy
value: 81.92167848840674
- type: dot_ap
value: 60.49837581423469
- type: dot_f1
value: 58.44186046511628
- type: dot_precision
value: 52.24532224532224
- type: dot_recall
value: 66.3060686015831
- type: euclidean_accuracy
value: 84.73505394289802
- type: euclidean_ap
value: 70.3278904593286
- type: euclidean_f1
value: 65.98851124940161
- type: euclidean_precision
value: 60.38107752956636
- type: euclidean_recall
value: 72.74406332453826
- type: manhattan_accuracy
value: 84.73505394289802
- type: manhattan_ap
value: 70.00737738537337
- type: manhattan_f1
value: 65.80150784822642
- type: manhattan_precision
value: 61.892583120204606
- type: manhattan_recall
value: 70.23746701846966
- type: max_accuracy
value: 84.73505394289802
- type: max_ap
value: 70.3278904593286
- type: max_f1
value: 65.98851124940161
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.44258159661582
- type: cos_sim_ap
value: 84.91926704880888
- type: cos_sim_f1
value: 77.07651086632926
- type: cos_sim_precision
value: 74.5894554883319
- type: cos_sim_recall
value: 79.73514012935017
- type: dot_accuracy
value: 85.88116583226608
- type: dot_ap
value: 78.9753854779923
- type: dot_f1
value: 72.17757637979255
- type: dot_precision
value: 66.80647486729143
- type: dot_recall
value: 78.48783492454572
- type: euclidean_accuracy
value: 88.5299025885823
- type: euclidean_ap
value: 85.08006075642194
- type: euclidean_f1
value: 77.29637336504163
- type: euclidean_precision
value: 74.69836253950014
- type: euclidean_recall
value: 80.08161379735141
- type: manhattan_accuracy
value: 88.55124771995187
- type: manhattan_ap
value: 85.00941529932851
- type: manhattan_f1
value: 77.33100233100232
- type: manhattan_precision
value: 73.37572573956317
- type: manhattan_recall
value: 81.73698798891284
- type: max_accuracy
value: 88.55124771995187
- type: max_ap
value: 85.08006075642194
- type: max_f1
value: 77.33100233100232
language:
- en
license: mit
---
# gte-small
General Text Embeddings (GTE) model. [Towards General Text Embeddings with Multi-stage Contrastive Learning](https://arxiv.org/abs/2308.03281)
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
We compared the performance of the GTE models with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
Code example
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
model = AutoModel.from_pretrained("thenlper/gte-small")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
### Citation
If you find our paper or models helpful, please consider citing them as follows:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
keko24/MNLP_M3_quantized_model_v2 | keko24 | 2025-06-10T21:07:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"compressed-tensors",
"region:us"
] | text-generation | 2025-06-10T19:52:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
denergy/mytaomodel | denergy | 2025-06-10T21:00:05Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T21:00:05Z | ---
license: apache-2.0
---
|
morturr/Mistral-7B-v0.1-LOO_headlines-COMB_one_liners-comb3-seed7-2025-06-10 | morturr | 2025-06-10T20:59:08Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2025-06-10T20:58:53Z | ---
library_name: peft
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Mistral-7B-v0.1-LOO_headlines-COMB_one_liners-comb3-seed7-2025-06-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-v0.1-LOO_headlines-COMB_one_liners-comb3-seed7-2025-06-10
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 7
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1 |
m-nzr/gemma-fine | m-nzr | 2025-06-10T20:54:46Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-pt",
"base_model:finetune:google/gemma-3-1b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-06-05T09:30:07Z | ---
base_model: google/gemma-3-1b-pt
library_name: transformers
model_name: gemma-fine
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-fine
This model is a fine-tuned version of [google/gemma-3-1b-pt](https://huggingface.co/google/gemma-3-1b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="m-nzr/gemma-fine", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.50.0.dev0
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Vanessasml/Llama-3.2-3B-Instruct-sft-lora16-3-text-improver | Vanessasml | 2025-06-10T20:50:49Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T20:42:35Z | ---
base_model: meta-llama/Llama-3.2-3B-Instruct
library_name: transformers
model_name: Llama-3.2-3B-Instruct-sft-lora16-3-text-improver
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Llama-3.2-3B-Instruct-sft-lora16-3-text-improver
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Vanessasml/Llama-3.2-3B-Instruct-sft-lora16-3-text-improver", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.12.1
- Transformers: 4.46.3
- Pytorch: 2.4.1
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
vanessa-pineda-18p/Video.Completo.18.vanessa.pineda.terabox.link.vanessa.pineda.telegram.teraplayer | vanessa-pineda-18p | 2025-06-10T20:48:55Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-10T20:33:09Z | [🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 Video](https://infobal.com.ar/watch-full-video/?Apex2.0)
[🔴 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🌐==►► 𝖣𝗈𝗐𝗇𝗅𝗈𝖺𝖽 𝖭𝗈𝗐 Video](https://infobal.com.ar/watch-full-video/?Apex2.0)
<a href="https://infobal.com.ar/watch-full-video/?Apex2.0" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
anasse15/MNLP_M3_rag_model | anasse15 | 2025-06-10T20:46:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T20:45:41Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.