
repo_id stringlengths 4 110 | author stringlengths 2 27 ⌀ | model_type stringlengths 2 29 ⌀ | files_per_repo int64 2 15.4k | downloads_30d int64 0 19.9M | library stringlengths 2 37 ⌀ | likes int64 0 4.34k | pipeline stringlengths 5 30 ⌀ | pytorch bool 2 classes | tensorflow bool 2 classes | jax bool 2 classes | license stringlengths 2 30 | languages stringlengths 4 1.63k ⌀ | datasets stringlengths 2 2.58k ⌀ | co2 stringclasses 29 values | prs_count int64 0 125 | prs_open int64 0 120 | prs_merged int64 0 15 | prs_closed int64 0 28 | discussions_count int64 0 218 | discussions_open int64 0 148 | discussions_closed int64 0 70 | tags stringlengths 2 513 | has_model_index bool 2 classes | has_metadata bool 1 class | has_text bool 1 class | text_length int64 401 598k | is_nc bool 1 class | readme stringlengths 0 598k | hash stringlengths 32 32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Cwhgn/DAMO-YOLO-S | Cwhgn | null | 3 | 0 | null | 1 | null | false | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 4,106 | false |
## Model Description
This **DAMO-YOLO-S** model is a small-size object detection model with fast inference speed and high accuracy, trained by **DAMO-YOLO**.
DAMO-YOLO is a fast and accurate object detection method, which is developed by TinyML Team from Alibaba DAMO Data Analytics and Intelligence Lab. And it achieves a higher performance than state-of-the-art YOLO series. DAMO-YOLO is extend from YOLO but with some new techs, including Neural Architecture Search (NAS) backbones, efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. For more details, please refer to our [Arxiv Report](https://arxiv.org/abs/2211.15444) and [Github Code](https://github.com/tinyvision/DAMO-YOLO). Moreover, here you can find not only powerful models, but also highly efficient training strategies and complete tools from training to deployment.
## Chinese Web Demo
- We also provide Chinese Web Demo on ModelScope, including [DAMO-YOLO-T](https://www.modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo-t/summary), [DAMO-YOLO-S](https://modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo/summary), [DAMO-YOLO-M](https://www.modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo-m/summary).
## Datasets
The model is trained on COCO2017.
## Model Usage
The usage guideline can be found in our [Quick Start Tutorial](https://github.com/tinyvision/DAMO-YOLO).
## Model Evaluation
|Model |size |mAP<sup>val<br>0.5:0.95 | Latency T4<br>TRT-FP16-BS1| FLOPs<br>(G)| Params<br>(M)| Download |
| ------ |:---: | :---: |:---:|:---: | :---: | :---:|
|[DAMO-YOLO-T](./configs/damoyolo_tinynasL20_T.py) | 640 | 41.8 | 2.78 | 18.1 | 8.5 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/before_distill/damoyolo_tinynasL20_T_418.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/before_distill/damoyolo_tinynasL20_T_418.onnx) |
|[DAMO-YOLO-T*](./configs/damoyolo_tinynasL20_T.py) | 640 | 43.0 | 2.78 | 18.1 | 8.5 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/damoyolo_tinynasL20_T.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/damoyolo_tinynasL20_T.onnx) |
|[DAMO-YOLO-S](./configs/damoyolo_tinynasL25_S.py) | 640 | 45.6 | 3.83 | 37.8 | 16.3 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/before_distill/damoyolo_tinynasL25_S_456.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/before_distill/damoyolo_tinynasL25_S_456.onnx) |
|[DAMO-YOLO-S*](./configs/damoyolo_tinynasL25_S.py) | 640 | 46.8 | 3.83 | 37.8 | 16.3 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/damoyolo_tinynasL25_S.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/damoyolo_tinynasL25_S.onnx) |
|[DAMO-YOLO-M](./configs/damoyolo_tinynasL35_M.py) | 640 | 48.7 | 5.62 | 61.8 | 28.2 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/before_distill/damoyolo_tinynasL35_M_487.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/before_distill/damoyolo_tinynasL35_M_487.onnx)|
|[DAMO-YOLO-M*](./configs/damoyolo_tinynasL35_M.py) | 640 | 50.0 | 5.62 | 61.8 | 28.2 |[torch](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/clean_models/damoyolo_tinynasL35_M.pth),[onnx](https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/onnx/damoyolo_tinynasL35_M.onnx)|
- We report the mAP of models on COCO2017 validation set, with multi-class NMS.
- The latency in this table is measured without post-processing.
- \* denotes the model trained with distillation.
## Cite DAMO-YOLO
If you use DAMO-YOLO in your research, please cite our work by using the following BibTeX entry:
```latex
@article{damoyolo,
title={DAMO-YOLO: A Report on Real-Time Object Detection Design},
author={Xianzhe Xu, Yiqi Jiang, Weihua Chen, Yilun Huang, Yuan Zhang and Xiuyu Sun},
journal={arXiv preprint arXiv:2211.15444v2},
year={2022},
}
```
| ddb711910e20807e935fd000e4e7033d |
research-backup/bart-large-squadshifts-vanilla-reddit-qg | research-backup | bart | 15 | 1 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | ['en'] | ['lmqg/qg_squadshifts'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['question generation'] | true | true | true | 4,160 | false |
# Model Card of `research-backup/bart-large-squadshifts-vanilla-reddit-qg`
This model is fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) for question generation task on the [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) (dataset_name: reddit) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-large](https://huggingface.co/facebook/bart-large)
- **Language:** en
- **Training data:** [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) (reddit)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="research-backup/bart-large-squadshifts-vanilla-reddit-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "research-backup/bart-large-squadshifts-vanilla-reddit-qg")
output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/bart-large-squadshifts-vanilla-reddit-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.reddit.json)
| | Score | Type | Dataset |
|:-----------|--------:|:-------|:---------------------------------------------------------------------------|
| BERTScore | 92.19 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_1 | 26.22 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_2 | 16.98 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_3 | 11.22 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_4 | 7.74 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| METEOR | 20.72 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| MoverScore | 61.37 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| ROUGE_L | 24.81 | reddit | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squadshifts
- dataset_name: reddit
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: facebook/bart-large
- max_length: 512
- max_length_output: 32
- epoch: 2
- batch: 32
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 2
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/bart-large-squadshifts-vanilla-reddit-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 5d3caf768139bc38a5b66630b3e79b39 |
ufal/byt5-small-multilexnorm2021-sr | ufal | t5 | 6 | 4 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | ['sr'] | ['mc4', 'wikipedia', 'multilexnorm'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['lexical normalization'] | false | true | true | 2,759 | false |
# Fine-tuned ByT5-small for MultiLexNorm (Serbian version)

This is the official release of the fine-tuned models for **the winning entry** to the [*W-NUT 2021: Multilingual Lexical Normalization (MultiLexNorm)* shared task](https://noisy-text.github.io/2021/multi-lexnorm.html), which evaluates lexical-normalization systems on 12 social media datasets in 11 languages.
Our system is based on [ByT5](https://arxiv.org/abs/2105.13626), which we first pre-train on synthetic data and then fine-tune on authentic normalization data. It achieves the best performance by a wide margin in intrinsic evaluation, and also the best performance in extrinsic evaluation through dependency parsing. In addition to these fine-tuned models, we also release the source files on [GitHub](https://github.com/ufal/multilexnorm2021) and an interactive demo on [Google Colab](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing).
## How to use
The model was *not* fine-tuned in a standard sentence-to-sentence setting – instead, it was tailored to the token-to-token definition of MultiLexNorm data. Please refer to [**the interactive demo on Colab notebook**](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing) to learn how to use these models.
## How to cite
```bibtex
@inproceedings{wnut-ufal,
title= "{ÚFAL} at {MultiLexNorm} 2021: Improving Multilingual Lexical Normalization by Fine-tuning {ByT5}",
author = "Samuel, David and Straka, Milan",
booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
address = "Punta Cana, Dominican Republic"
}
```
## ByT5 - Small
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
| 659549abde19bfab88bde7dd14daf955 |
arch0345/DialoGPT-small-joshua | arch0345 | gpt2 | 9 | 5 | transformers | 0 | conversational | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['conversational'] | false | true | true | 1,222 | false | Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua")
model = AutoModelWithLMHead.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("JoshuaBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` | b238999a216403fdd471c36139dc5b59 |
morenolq/bart-it-fanpage | morenolq | bart | 9 | 148 | transformers | 0 | text2text-generation | true | false | false | mit | ['it'] | ['ARTeLab/fanpage'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['bart', 'pytorch'] | false | true | true | 2,354 | false |
# BART-IT - FanPage
BART-IT is a sequence-to-sequence model, based on the BART architecture that is specifically tailored to the Italian language. The model is pre-trained on a [large corpus of Italian text](https://huggingface.co/datasets/gsarti/clean_mc4_it), and can be fine-tuned on a variety of tasks.
## Model description
The model is a `base-`sized BART model, with a vocabulary size of 52,000 tokens. It has 140M parameters and can be used for any task that requires a sequence-to-sequence model. It is trained from scratch on a large corpus of Italian text, and can be fine-tuned on a variety of tasks.
## Pre-training
The code used to pre-train BART-IT together with additional information on model parameters can be found [here](https://github.com/MorenoLaQuatra/bart-it).
## Fine-tuning
The model has been fine-tuned for the abstractive summarization task on 3 different Italian datasets:
- **This model** [FanPage](https://huggingface.co/datasets/ARTeLab/fanpage) - finetuned model [here](https://huggingface.co/morenolq/bart-it-fanpage)
- [IlPost](https://huggingface.co/datasets/ARTeLab/ilpost) - finetuned model [here](https://huggingface.co/morenolq/bart-it-ilpost)
- [WITS](https://huggingface.co/datasets/Silvia/WITS) - finetuned model [here](https://huggingface.co/morenolq/bart-it-WITS)
## Usage
In order to use the model, you can use the following code:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("morenolq/bart-it-fanpage")
model = AutoModelForSeq2SeqLM.from_pretrained("morenolq/bart-it-fanpage")
input_ids = tokenizer.encode("Il modello BART-IT è stato pre-addestrato su un corpus di testo italiano", return_tensors="pt")
outputs = model.generate(input_ids, max_length=40, num_beams=4, early_stopping=True)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
# Citation
If you find this model useful for your research, please cite the following paper:
```bibtex
@Article{BARTIT,
AUTHOR = {La Quatra, Moreno and Cagliero, Luca},
TITLE = {BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization},
JOURNAL = {Future Internet},
VOLUME = {15},
YEAR = {2023},
NUMBER = {1},
ARTICLE-NUMBER = {15},
URL = {https://www.mdpi.com/1999-5903/15/1/15},
ISSN = {1999-5903},
DOI = {10.3390/fi15010015}
}
```
| fc5ed78df9221ac28292cd0e3861b2f7 |
anas-awadalla/roberta-base-few-shot-k-32-finetuned-squad-seed-0 | anas-awadalla | roberta | 17 | 7 | transformers | 0 | question-answering | true | false | false | mit | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 985 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-few-shot-k-32-finetuned-squad-seed-0
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
| 2826072a6b310fae6492d01649fb69fc |
nirajsaran/AdTextGeneration | nirajsaran | gpt_neo | 9 | 6 | transformers | 0 | text-generation | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 914 | false |
Generates Ad copy, currently for ads for Amazon shopping (fine tuned for electronics and wearables).
**Usage Examples:**
Enter the bolded text below to get the Amazon ad generated by the model.
**Big savings on the new** Roku Streaming Device
**Mothers Day discounts for** Apple Watch Wireless Charger USB Charging Cable
**Big savings on the new Sony**
**Last minute shopping for Samsung headphones for**
You can try entering brand and product names like Samsung Galaxy to see the ad text generator in action.
Currently fine tuned on the EleutherAI/gpt-neo-125M model
**Model Performance:**
The model does quite well on the Electronics and Wearables categories on which it has been fine-tuned. There are, however, occasional hallucinations, though the ad copy is mostly coherent.
In other domains, it doesn't do quite as well...
Tesla for Christmas today,
Honda on sale
| 4c465c275e64c595eea1a60942c7ad54 |
DOOGLAK/Tagged_One_100v9_NER_Model_3Epochs_AUGMENTED | DOOGLAK | bert | 13 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['tagged_one100v9_wikigold_split'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,565 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_100v9_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one100v9_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4255
- Precision: 0.3040
- Recall: 0.2132
- F1: 0.2506
- Accuracy: 0.8539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 40 | 0.5167 | 0.1936 | 0.0376 | 0.0630 | 0.8004 |
| No log | 2.0 | 80 | 0.4406 | 0.2405 | 0.1441 | 0.1802 | 0.8385 |
| No log | 3.0 | 120 | 0.4255 | 0.3040 | 0.2132 | 0.2506 | 0.8539 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
| ef2a9f7fe7c8ec09649b91ae35ec0fe1 |
jonatasgrosman/exp_w2v2t_pl_vp-sv_s571 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['pl'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'pl'] | false | true | true | 469 | false | # exp_w2v2t_pl_vp-sv_s571
Fine-tuned [facebook/wav2vec2-large-sv-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-sv-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 06872cbd7f612357f4598ab871ed9a7b |
aseda/t5-small-finetuned-xsum | aseda | t5 | 23 | 10 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['xsum'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 919 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
| 2f886fd95955f2fb80222320c979756b |
google/mobilebert-uncased | google | mobilebert | 8 | 47,597 | transformers | 10 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 1 | 1 | 0 | [] | false | true | true | 814 | false |
## MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance
between self-attentions and feed-forward networks.
This checkpoint is the original MobileBert Optimized Uncased English:
[uncased_L-24_H-128_B-512_A-4_F-4_OPT](https://storage.googleapis.com/cloud-tpu-checkpoints/mobilebert/uncased_L-24_H-128_B-512_A-4_F-4_OPT.tar.gz)
checkpoint.
## How to use MobileBERT in `transformers`
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="google/mobilebert-uncased",
tokenizer="google/mobilebert-uncased"
)
print(
fill_mask(f"HuggingFace is creating a {fill_mask.tokenizer.mask_token} that the community uses to solve NLP tasks.")
)
```
| fa672d30163b261a94476fe5d8d6465b |
sd-concepts-library/milady | sd-concepts-library | null | 9 | 0 | null | 1 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 990 | false | ### milady on Stable Diffusion
This is the `<milady>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




| c2acf01a2136c8c8a5bdfd2058815f7c |
ku-nlp/roberta-base-japanese-char-wwm | ku-nlp | roberta | 7 | 2,629 | transformers | 1 | fill-mask | true | false | false | cc-by-sa-4.0 | ['ja'] | ['wikipedia', 'cc100'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 2,003 | false |
# ku-nlp/roberta-base-japanese-char-wwm
## Model description
This is a Japanese RoBERTa base model pre-trained on Japanese Wikipedia and the Japanese portion of CC-100.
This model is trained with character-level tokenization and whole word masking.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/roberta-base-japanese-char-wwm')
model = AutoModelForMaskedLM.from_pretrained('ku-nlp/roberta-base-japanese-char-wwm')
sentence = '京都大学で自然言語処理を[MASK]する。'
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can fine-tune this model on downstream tasks.
## Tokenization
There is no need to tokenize texts in advance, and you can give raw texts to the tokenizer.
The texts are tokenized into character-level tokens by [sentencepiece](https://github.com/google/sentencepiece).
## Vocabulary
The vocabulary consists of 18,377 tokens including all characters that appear in the training corpus.
## Training procedure
This model was trained on Japanese Wikipedia (as of 20220220) and the Japanese portion of CC-100. It took two weeks using 8 NVIDIA A100 GPUs.
The following hyperparameters were used during pre-training:
- learning_rate: 1e-4
- per_device_train_batch_size: 62
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 3968
- max_seq_length: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear schedule with warmup
- training_steps: 330000
- warmup_steps: 10000
## Acknowledgments
This work was supported by Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures (JHPCN) through General Collaboration Project no. jh221004, "Developing a Platform for Constructing and Sharing of Large-Scale Japanese Language Models".
For training models, we used the mdx: a platform for the data-driven future.
| bc21f03e12bab33418500d54ccfd2b58 |
royam0820/distilbert-base-uncased-finetuned-emotion | royam0820 | distilbert | 14 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,345 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2157
- Accuracy: 0.9265
- F1: 0.9267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8322 | 1.0 | 250 | 0.3176 | 0.905 | 0.9015 |
| 0.2481 | 2.0 | 500 | 0.2157 | 0.9265 | 0.9267 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
| fa62afc8dfefaa08889355cd6fec63e6 |
naclbit/trinart_stable_diffusion_v2 | naclbit | null | 20 | 18,898 | diffusers | 257 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 9 | 0 | 7 | 2 | 5 | 3 | 2 | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image'] | false | true | true | 4,627 | false |
## Please Note!
This model is NOT the 19.2M images Characters Model on TrinArt, but an improved version of the original Trin-sama Twitter bot model. This model is intended to retain the original SD's aesthetics as much as possible while nudging the model to anime/manga style.
Other TrinArt models can be found at:
https://huggingface.co/naclbit/trinart_derrida_characters_v2_stable_diffusion
https://huggingface.co/naclbit/trinart_characters_19.2m_stable_diffusion_v1
## Diffusers
The model has been ported to `diffusers` by [ayan4m1](https://huggingface.co/ayan4m1)
and can easily be run from one of the branches:
- `revision="diffusers-60k"` for the checkpoint trained on 60,000 steps,
- `revision="diffusers-95k"` for the checkpoint trained on 95,000 steps,
- `revision="diffusers-115k"` for the checkpoint trained on 115,000 steps.
For more information, please have a look at [the "Three flavors" section](#three-flavors).
## Gradio
We also support a [Gradio](https://github.com/gradio-app/gradio) web ui with diffusers to run inside a colab notebook: [](https://colab.research.google.com/drive/1RWvik_C7nViiR9bNsu3fvMR3STx6RvDx?usp=sharing)
### Example Text2Image
```python
# !pip install diffusers==0.3.0
from diffusers import StableDiffusionPipeline
# using the 60,000 steps checkpoint
pipe = StableDiffusionPipeline.from_pretrained("naclbit/trinart_stable_diffusion_v2", revision="diffusers-60k")
pipe.to("cuda")
image = pipe("A magical dragon flying in front of the Himalaya in manga style").images[0]
image
```

If you want to run the pipeline faster or on a different hardware, please have a look at the [optimization docs](https://huggingface.co/docs/diffusers/optimization/fp16).
### Example Image2Image
```python
# !pip install diffusers==0.3.0
from diffusers import StableDiffusionImg2ImgPipeline
import requests
from PIL import Image
from io import BytesIO
url = "https://scitechdaily.com/images/Dog-Park.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((768, 512))
# using the 115,000 steps checkpoint
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("naclbit/trinart_stable_diffusion_v2", revision="diffusers-115k")
pipe.to("cuda")
images = pipe(prompt="Manga drawing of Brad Pitt", init_image=init_image, strength=0.75, guidance_scale=7.5).images
image
```
If you want to run the pipeline faster or on a different hardware, please have a look at the [optimization docs](https://huggingface.co/docs/diffusers/optimization/fp16).
## Stable Diffusion TrinArt/Trin-sama AI finetune v2
trinart_stable_diffusion is a SD model finetuned by about 40,000 assorted high resolution manga/anime-style pictures for 8 epochs. This is the same model running on Twitter bot @trinsama (https://twitter.com/trinsama)
Twitterボット「とりんさまAI」@trinsama (https://twitter.com/trinsama) で使用しているSDのファインチューン済モデルです。一定のルールで選別された約4万枚のアニメ・マンガスタイルの高解像度画像を用いて約8エポックの訓練を行いました。
## Version 2
V2 checkpoint uses dropouts, 10,000 more images and a new tagging strategy and trained longer to improve results while retaining the original aesthetics.
バージョン2は画像を1万枚追加したほか、ドロップアウトの適用、タグ付けの改善とより長いトレーニング時間により、SDのスタイルを保ったまま出力内容の改善を目指しています。
## Three flavors
Step 115000/95000 checkpoints were trained further, but you may use step 60000 checkpoint instead if style nudging is too much.
ステップ115000/95000のチェックポイントでスタイルが変わりすぎると感じる場合は、ステップ60000のチェックポイントを使用してみてください。
#### img2img
If you want to run **latent-diffusion**'s stock ddim img2img script with this model, **use_ema** must be set to False.
**latent-diffusion** のscriptsフォルダに入っているddim img2imgをこのモデルで動かす場合、use_emaはFalseにする必要があります。
#### Hardware
- 8xNVIDIA A100 40GB
#### Training Info
- Custom dataset loader with augmentations: XFlip, center crop and aspect-ratio locked scaling
- LR: 1.0e-5
- 10% dropouts
#### Examples
Each images were diffused using K. Crowson's k-lms (from k-diffusion repo) method for 50 steps.



#### Credits
- Sta, AI Novelist Dev (https://ai-novel.com/) @ Bit192, Inc.
- Stable Diffusion - Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bjorn
#### License
CreativeML OpenRAIL-M | 870630460760c16e33851f9c0d9a73a2 |
arijitx/IndicBART-bn-QuestionGeneration | arijitx | mbart | 9 | 1 | transformers | 0 | text2text-generation | true | false | false | mit | ['bn'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['text2text-generation'] | false | true | true | 2,897 | false |
## Intro
Trained on IndicNLGSuit [IndicQuestionGeneration](https://huggingface.co/datasets/ai4bharat/IndicQuestionGeneration) data for Bengali the model is finetuned from [IndicBART](https://huggingface.co/ai4bharat/IndicBART)
## Finetuned Command
python run_summarization.py --model_name_or_path bnQG_models/checkpoint-32000 --do_eval --train_file train_bn.json
--validation_file valid_bn.json --output_dir bnQG_models --overwrite_output_dir --per_device_train_batch_size=2
--per_device_eval_batch_size=4 --predict_with_generate --text_column src --summary_column tgt --save_steps 4000
--evaluation_strategy steps --gradient_accumulation_steps 4 --eval_steps 1000 --learning_rate 0.001 --num_beams 4
--forced_bos_token "<2bn>" --num_train_epochs 10 --warmup_steps 10000
## Sample Line from train data
{"src": "प्राणबादी [SEP] अर्थाॎ, तिनि छिलेन एकजन सर्बप्राणबादी। </s> <2bn>", "tgt": "<2bn> कोन दार्शनिक दृष्टिभङ्गि ओय़ाइटजेर छिल? </s>"}
## Inference
script = "সুভাষ ১৮৯৭ খ্রিষ্টাব্দের ২৩ জানুয়ারি ব্রিটিশ ভারতের অন্তর্গত বাংলা প্রদেশের উড়িষ্যা বিভাগের (অধুনা, ভারতের ওড়িশা রাজ্য) কটকে জন্মগ্রহণ করেন।"
answer = "১৮৯৭ খ্রিষ্টাব্দের ২৩ জানুয়ারি"
inp = answer +" [SEP] "+script + " </s> <2bn>"
inp_tok = tokenizer(inp, add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model.eval() # Set dropouts to zero
model_output=model.generate(inp_tok, use_cache=True,
num_beams=4,
max_length=20,
min_length=1,
early_stopping=True,
pad_token_id=pad_id,
bos_token_id=bos_id,
eos_token_id=eos_id,
decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2bn>")
)
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
## Citations
@inproceedings{dabre2021indicbart,
title={IndicBART: A Pre-trained Model for Natural Language Generation of Indic Languages},
author={Raj Dabre and Himani Shrotriya and Anoop Kunchukuttan and Ratish Puduppully and Mitesh M. Khapra and Pratyush Kumar},
year={2022},
booktitle={Findings of the Association for Computational Linguistics},
}
@misc{kumar2022indicnlg,
title={IndicNLG Suite: Multilingual Datasets for Diverse NLG Tasks in Indic Languages},
author={Aman Kumar and Himani Shrotriya and Prachi Sahu and Raj Dabre and Ratish Puduppully and Anoop Kunchukuttan and Amogh Mishra and Mitesh M. Khapra and Pratyush Kumar},
year={2022},
eprint={2203.05437},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
| 2ab64c8137cf669c91c421058625fb4d |
sentence-transformers/all-mpnet-base-v2 | sentence-transformers | mpnet | 14 | 1,031,476 | sentence-transformers | 86 | sentence-similarity | true | false | false | apache-2.0 | ['en'] | ['s2orc', 'flax-sentence-embeddings/stackexchange_xml', 'MS Marco', 'gooaq', 'yahoo_answers_topics', 'code_search_net', 'search_qa', 'eli5', 'snli', 'multi_nli', 'wikihow', 'natural_questions', 'trivia_qa', 'embedding-data/sentence-compression', 'embedding-data/flickr30k-captions', 'embedding-data/altlex', 'embedding-data/simple-wiki', 'embedding-data/QQP', 'embedding-data/SPECTER', 'embedding-data/PAQ_pairs', 'embedding-data/WikiAnswers'] | null | 1 | 1 | 0 | 0 | 2 | 2 | 0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity'] | false | true | true | 9,990 | false |
# all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-mpnet-base-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 384 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | | 535623b54e4c18ce250c1e92310af671 |
StonyBrookNLP/preasm-large-iirc-gold | StonyBrookNLP | t5 | 8 | 3 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['question-answering, multi-step-reasoning, multi-hop-reasoning'] | false | true | true | 2,608 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/preasm-large-iirc-gold"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"Who scored the first touchdown of the game?\n" +
"... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
``` | 996820a0fd4fdf86840ddfed218ff706 |
microsoft/swin-large-patch4-window7-224 | microsoft | swin | 6 | 4,706 | transformers | 0 | image-classification | true | true | false | apache-2.0 | null | ['imagenet-1k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision', 'image-classification'] | false | true | true | 3,277 | false |
# Swin Transformer (large-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 93d3cb186cc676f84f25bc32139c92f1 |
robinoud/ddpm-butterflies-128 | robinoud | null | 18 | 0 | diffusers | 0 | null | false | false | false | apache-2.0 | ['en'] | ['huggan/flowers-102-categories'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,222 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/flowers-102-categories` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/robinoud/ddpm-butterflies-128/tensorboard?#scalars)
| 565ea69d0474adc098b5f6d0230ef754 |
microsoft/beit-large-patch16-224 | microsoft | beit | 6 | 1,214 | transformers | 0 | image-classification | true | false | true | apache-2.0 | null | ['imagenet', 'imagenet-21k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['image-classification', 'vision'] | false | true | true | 5,479 | false |
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-224')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 25d6f0310007441883bdcc7ca80e50bb |
Helsinki-NLP/opus-mt-tum-es | Helsinki-NLP | marian | 10 | 7 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-tum-es
* source languages: tum
* target languages: es
* OPUS readme: [tum-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/tum-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/tum-es/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/tum-es/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/tum-es/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.tum.es | 22.6 | 0.390 |
| 4208cf50a1fd1e76834ba5263bb02230 |
toanbui1991/distilbert-base-uncased-finetuned-squad | toanbui1991 | distilbert | 15 | 6 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,878 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# toanbui1991/distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.5101
- Train End Logits Accuracy: 0.6065
- Train Start Logits Accuracy: 0.5692
- Validation Loss: 1.1679
- Validation End Logits Accuracy: 0.6823
- Validation Start Logits Accuracy: 0.6523
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 11064, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.5101 | 0.6065 | 0.5692 | 1.1679 | 0.6823 | 0.6523 | 0 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.10.0
- Datasets 2.6.1
- Tokenizers 0.13.2
| dee03ea4edea457870c8fcadc49da6d7 |
AyanSau/results | AyanSau | t5 | 8 | 6 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,768 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2057
- Rouge2 Precision: 0.3564
- Rouge2 Recall: 0.2124
- Rouge2 Fmeasure: 0.256
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| No log | 1.0 | 240 | 0.3146 | 0.2121 | 0.1134 | 0.1424 |
| No log | 2.0 | 480 | 0.2444 | 0.2855 | 0.1519 | 0.19 |
| 0.6451 | 3.0 | 720 | 0.2195 | 0.3225 | 0.1821 | 0.223 |
| 0.6451 | 4.0 | 960 | 0.2078 | 0.355 | 0.2113 | 0.2548 |
| 0.2978 | 5.0 | 1200 | 0.2057 | 0.3564 | 0.2124 | 0.256 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cpu
- Datasets 2.4.0
- Tokenizers 0.12.1
| f7c80c63d695e70abe7159e8ee00c940 |
cross-encoder/quora-roberta-base | cross-encoder | roberta | 10 | 210 | transformers | 1 | text-classification | true | false | true | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,042 | false | # Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
This model was trained on the [Quora Duplicate Questions](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) dataset. The model will predict a score between 0 and 1 how likely the two given questions are duplicates.
Note: The model is not suitable to estimate the similarity of questions, e.g. the two questions "How to learn Java" and "How to learn Python" will result in a rahter low score, as these are not duplicates.
## Usage and Performance
Pre-trained models can be used like this:
```
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Question 1', 'Question 2'), ('Question 3', 'Question 4')])
```
You can use this model also without sentence_transformers and by just using Transformers ``AutoModel`` class | 3f60d2076cfc9c115a8a7bc3164199e4 |
muhtasham/small-mlm-glue-mnli-custom-tokenizer | muhtasham | bert | 12 | 0 | transformers | 0 | fill-mask | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,498 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-mnli-custom-tokenizer
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.6551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 7.0308 | 0.4 | 500 | 6.6001 |
| 6.346 | 0.8 | 1000 | 6.3998 |
| 6.1061 | 1.2 | 1500 | 6.3170 |
| 5.9586 | 1.6 | 2000 | 6.2799 |
| 5.8773 | 2.0 | 2500 | 6.2034 |
| 5.7403 | 2.4 | 3000 | 6.1609 |
| 5.6602 | 2.8 | 3500 | 6.1113 |
| 5.5809 | 3.2 | 4000 | 6.1267 |
| 5.5663 | 3.6 | 4500 | 6.0647 |
| 5.6266 | 4.0 | 5000 | 6.1090 |
| 5.4756 | 4.4 | 5500 | 6.0302 |
| 5.4905 | 4.8 | 6000 | 6.0292 |
| 5.3179 | 5.2 | 6500 | 5.9758 |
| 5.3375 | 5.6 | 7000 | 6.0125 |
| 5.3035 | 6.0 | 7500 | 5.9495 |
| 5.1918 | 6.4 | 8000 | 5.9537 |
| 5.2499 | 6.8 | 8500 | 5.9100 |
| 5.1905 | 7.2 | 9000 | 5.8620 |
| 5.1787 | 7.6 | 9500 | 5.9296 |
| 5.1534 | 8.0 | 10000 | 5.9442 |
| 5.1396 | 8.4 | 10500 | 5.8609 |
| 5.1272 | 8.8 | 11000 | 5.8358 |
| 4.9615 | 9.2 | 11500 | 5.8617 |
| 5.0062 | 9.6 | 12000 | 5.8043 |
| 5.0131 | 10.0 | 12500 | 5.8119 |
| 4.9326 | 10.4 | 13000 | 5.7851 |
| 4.9655 | 10.8 | 13500 | 5.7792 |
| 4.9256 | 11.2 | 14000 | 5.7843 |
| 4.9195 | 11.6 | 14500 | 5.7652 |
| 4.8299 | 12.0 | 15000 | 5.7606 |
| 4.8748 | 12.4 | 15500 | 5.7577 |
| 4.7588 | 12.8 | 16000 | 5.7048 |
| 4.8185 | 13.2 | 16500 | 5.7245 |
| 4.7679 | 13.6 | 17000 | 5.7402 |
| 4.7377 | 14.0 | 17500 | 5.7034 |
| 4.7403 | 14.4 | 18000 | 5.7054 |
| 4.6628 | 14.8 | 18500 | 5.7203 |
| 4.6801 | 15.2 | 19000 | 5.6798 |
| 4.6014 | 15.6 | 19500 | 5.6931 |
| 4.618 | 16.0 | 20000 | 5.6620 |
| 4.6037 | 16.4 | 20500 | 5.6441 |
| 4.6004 | 16.8 | 21000 | 5.6262 |
| 4.5432 | 17.2 | 21500 | 5.6726 |
| 4.576 | 17.6 | 22000 | 5.6322 |
| 4.5568 | 18.0 | 22500 | 5.6551 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
| 2f4182e253d7be927bae3fb8bfb7a151 |
mahmoudNG/distilbert-base-uncased-finetuned-emotion | mahmoudNG | distilbert | 14 | 14 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,414 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1591
- Accuracy: 0.939
- F1: 0.9391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2497 | 1.0 | 1000 | 0.2133 | 0.9255 | 0.9252 |
| 0.1498 | 2.0 | 2000 | 0.1652 | 0.934 | 0.9339 |
| 0.0965 | 3.0 | 3000 | 0.1591 | 0.939 | 0.9391 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| e480eec6d5e325c517a63a2a682d02c6 |
PontifexMaximus/ArabicTranslator | PontifexMaximus | marian | 21 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['opus_infopankki'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,691 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-ar-en-finetuned-ar-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ar-en](https://huggingface.co/Helsinki-NLP/opus-mt-ar-en) on the opus_infopankki dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7269
- Bleu: 51.6508
- Gen Len: 15.0812
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 1.4974 | 1.0 | 1587 | 1.3365 | 36.9061 | 15.3385 |
| 1.3768 | 2.0 | 3174 | 1.2139 | 39.5476 | 15.2079 |
| 1.2887 | 3.0 | 4761 | 1.1265 | 41.2771 | 15.2034 |
| 1.2076 | 4.0 | 6348 | 1.0556 | 42.6907 | 15.2687 |
| 1.1512 | 5.0 | 7935 | 0.9975 | 43.9498 | 15.2072 |
| 1.0797 | 6.0 | 9522 | 0.9491 | 45.224 | 15.2034 |
| 1.0499 | 7.0 | 11109 | 0.9101 | 46.1387 | 15.1651 |
| 1.0095 | 8.0 | 12696 | 0.8778 | 47.0586 | 15.1788 |
| 0.9833 | 9.0 | 14283 | 0.8501 | 47.8083 | 15.162 |
| 0.9601 | 10.0 | 15870 | 0.8267 | 48.5236 | 15.1784 |
| 0.9457 | 11.0 | 17457 | 0.8059 | 49.1717 | 15.095 |
| 0.9233 | 12.0 | 19044 | 0.7883 | 49.7742 | 15.1126 |
| 0.8964 | 13.0 | 20631 | 0.7736 | 50.2168 | 15.0917 |
| 0.8849 | 14.0 | 22218 | 0.7606 | 50.5583 | 15.0913 |
| 0.8751 | 15.0 | 23805 | 0.7504 | 50.8481 | 15.1108 |
| 0.858 | 16.0 | 25392 | 0.7417 | 51.1841 | 15.0989 |
| 0.8673 | 17.0 | 26979 | 0.7353 | 51.4271 | 15.0939 |
| 0.8548 | 18.0 | 28566 | 0.7306 | 51.535 | 15.0911 |
| 0.8483 | 19.0 | 30153 | 0.7279 | 51.6102 | 15.078 |
| 0.8614 | 20.0 | 31740 | 0.7269 | 51.6508 | 15.0812 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.7.1+cu110
- Datasets 2.2.2
- Tokenizers 0.12.1
| c3c619c284a893494f98cf3e70a4a4af |
espnet/GunnarThor_talromur_g_fastspeech2 | espnet | null | 22 | 3 | espnet | 0 | text-to-speech | false | false | false | cc-by-4.0 | ['en'] | ['talromur'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['espnet', 'audio', 'text-to-speech'] | false | true | true | 7,774 | false |
## ESPnet2 TTS model
### `espnet/GunnarThor_talromur_g_fastspeech2`
This model was trained by Gunnar Thor using talromur recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 49a284e69308d81c142b89795de255b4ce290c54
pip install -e .
cd egs2/talromur/tts1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/GunnarThor_talromur_g_fastspeech2
```
## TTS config
<details><summary>expand</summary>
```
config: conf/tuning/train_fastspeech2.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/g/tts_train_fastspeech2_raw_phn_none
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 100
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- loss
- min
- - train
- loss
- min
keep_nbest_models: 5
nbest_averaging_interval: 0
grad_clip: 1.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 8
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: 800
batch_size: 20
valid_batch_size: null
batch_bins: 2500000
valid_batch_bins: null
train_shape_file:
- exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/train/text_shape.phn
- exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/train/speech_shape
valid_shape_file:
- exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/valid/text_shape.phn
- exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/valid/speech_shape
batch_type: numel
valid_batch_type: null
fold_length:
- 150
- 204800
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_g_phn/text
- text
- text
- - exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/train_g_phn/durations
- durations
- text_int
- - dump/raw/train_g_phn/wav.scp
- speech
- sound
valid_data_path_and_name_and_type:
- - dump/raw/dev_g_phn/text
- text
- text
- - exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/dev_g_phn/durations
- durations
- text_int
- - dump/raw/dev_g_phn/wav.scp
- speech
- sound
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 1.0
scheduler: noamlr
scheduler_conf:
model_size: 384
warmup_steps: 4000
token_list:
- <blank>
- <unk>
- ','
- .
- r
- t
- n
- a0
- s
- I0
- D
- l
- Y0
- m
- v
- h
- E1
- k
- a:1
- E:1
- f
- G
- j
- T
- a1
- p
- c
- au:1
- i:1
- O:1
- I:1
- E0
- I1
- r_0
- t_h
- k_h
- Y1
- ei1
- i0
- ou:1
- ei:1
- u:1
- O1
- N
- l_0
- '91'
- ai0
- au1
- ou0
- n_0
- ei0
- O0
- ou1
- ai:1
- '9:1'
- ai1
- i1
- '90'
- au0
- c_h
- x
- 9i:1
- C
- p_h
- u0
- Y:1
- J
- 9i1
- u1
- 9i0
- N_0
- m_0
- J_0
- Oi1
- Yi0
- Yi1
- Oi0
- au:0
- '9:0'
- E:0
- <sos/eos>
odim: null
model_conf: {}
use_preprocessor: true
token_type: phn
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
feats_extract: fbank
feats_extract_conf:
n_fft: 1024
hop_length: 256
win_length: null
fs: 22050
fmin: 80
fmax: 7600
n_mels: 80
normalize: global_mvn
normalize_conf:
stats_file: exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/train/feats_stats.npz
tts: fastspeech2
tts_conf:
adim: 384
aheads: 2
elayers: 4
eunits: 1536
dlayers: 4
dunits: 1536
positionwise_layer_type: conv1d
positionwise_conv_kernel_size: 3
duration_predictor_layers: 2
duration_predictor_chans: 256
duration_predictor_kernel_size: 3
postnet_layers: 5
postnet_filts: 5
postnet_chans: 256
use_masking: true
use_scaled_pos_enc: true
encoder_normalize_before: true
decoder_normalize_before: true
reduction_factor: 1
init_type: xavier_uniform
init_enc_alpha: 1.0
init_dec_alpha: 1.0
transformer_enc_dropout_rate: 0.2
transformer_enc_positional_dropout_rate: 0.2
transformer_enc_attn_dropout_rate: 0.2
transformer_dec_dropout_rate: 0.2
transformer_dec_positional_dropout_rate: 0.2
transformer_dec_attn_dropout_rate: 0.2
pitch_predictor_layers: 5
pitch_predictor_chans: 256
pitch_predictor_kernel_size: 5
pitch_predictor_dropout: 0.5
pitch_embed_kernel_size: 1
pitch_embed_dropout: 0.0
stop_gradient_from_pitch_predictor: true
energy_predictor_layers: 2
energy_predictor_chans: 256
energy_predictor_kernel_size: 3
energy_predictor_dropout: 0.5
energy_embed_kernel_size: 1
energy_embed_dropout: 0.0
stop_gradient_from_energy_predictor: false
pitch_extract: dio
pitch_extract_conf:
fs: 22050
n_fft: 1024
hop_length: 256
f0max: 400
f0min: 80
reduction_factor: 1
pitch_normalize: global_mvn
pitch_normalize_conf:
stats_file: exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/train/pitch_stats.npz
energy_extract: energy
energy_extract_conf:
fs: 22050
n_fft: 1024
hop_length: 256
win_length: null
reduction_factor: 1
energy_normalize: global_mvn
energy_normalize_conf:
stats_file: exp/g/tts_train_tacotron2_raw_phn_none/decode_use_teacher_forcingtrue_train.loss.ave/stats/train/energy_stats.npz
required:
- output_dir
- token_list
version: 0.10.7a1
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| e6a3dab95eda9634f00d78efcebc1194 |
clips/mfaq | clips | xlm-roberta | 14 | 2,555 | sentence-transformers | 22 | sentence-similarity | true | true | false | apache-2.0 | ['cs', 'da', 'de', 'en', 'es', 'fi', 'fr', 'he', 'hr', 'hu', 'id', 'it', 'nl', 'no', 'pl', 'pt', 'ro', 'ru', 'sv', 'tr', 'vi'] | ['clips/mfaq'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | true | true | 3,007 | false |
# MFAQ
We present a multilingual FAQ retrieval model trained on the [MFAQ dataset](https://huggingface.co/datasets/clips/mfaq), it ranks candidate answers according to a given question.
## Installation
```
pip install sentence-transformers transformers
```
## Usage
You can use MFAQ with sentence-transformers or directly with a HuggingFace model.
In both cases, questions need to be prepended with `<Q>`, and answers with `<A>`.
#### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
question = "<Q>How many models can I host on HuggingFace?"
answer_1 = "<A>All plans come with unlimited private models and datasets."
answer_2 = "<A>AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
answer_3 = "<A>Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
model = SentenceTransformer('clips/mfaq')
embeddings = model.encode([question, answer_1, answer_3, answer_3])
print(embeddings)
```
#### HuggingFace Transformers
```python
from transformers import AutoTokenizer, AutoModel
import torch
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
question = "<Q>How many models can I host on HuggingFace?"
answer_1 = "<A>All plans come with unlimited private models and datasets."
answer_2 = "<A>AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
answer_3 = "<A>Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
tokenizer = AutoTokenizer.from_pretrained('clips/mfaq')
model = AutoModel.from_pretrained('clips/mfaq')
# Tokenize sentences
encoded_input = tokenizer([question, answer_1, answer_3, answer_3], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
## Training
You can find the training script for the model [here](https://github.com/clips/mfaq).
## People
This model was developed by [Maxime De Bruyn](https://www.linkedin.com/in/maximedebruyn/), Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
## Citation information
```
@misc{debruyn2021mfaq,
title={MFAQ: a Multilingual FAQ Dataset},
author={Maxime De Bruyn and Ehsan Lotfi and Jeska Buhmann and Walter Daelemans},
year={2021},
eprint={2109.12870},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 3276b2b0e0cd91c9548ef5d41f9f52cf |
anirudh21/albert-large-v2-finetuned-wnli | anirudh21 | albert | 17 | 9 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['glue'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,452 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2-finetuned-wnli
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6919
- Accuracy: 0.5352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 17 | 0.7292 | 0.4366 |
| No log | 2.0 | 34 | 0.6919 | 0.5352 |
| No log | 3.0 | 51 | 0.7084 | 0.4648 |
| No log | 4.0 | 68 | 0.7152 | 0.5352 |
| No log | 5.0 | 85 | 0.7343 | 0.5211 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.1
- Tokenizers 0.10.3
| e901a5eee4364ce4c87262e16902c79c |
keerthisaran/distilbert-base-uncased-finetuned-emotion | keerthisaran | distilbert | 14 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,343 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2183
- Accuracy: 0.92
- F1: 0.9204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8464 | 1.0 | 250 | 0.3125 | 0.9085 | 0.9061 |
| 0.2476 | 2.0 | 500 | 0.2183 | 0.92 | 0.9204 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
| 8b608a1db00977fc29e55be6ec44fb34 |
beyond/genius-base | beyond | bart | 9 | 20 | transformers | 1 | text2text-generation | true | false | false | apache-2.0 | ['en', 'zh'] | ['c4', 'beyond/chinese_clean_passages_80m'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['GENIUS', 'conditional text generation', 'sketch-based text generation', 'data augmentation'] | false | true | true | 7,705 | false |
# 💡GENIUS – generating text using sketches!
**基于草稿的文本生成模型**
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)**
💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches.
**Example 1:**
- sketch: `__ machine learning __ my research interest __ data science __`
- **GENIUS**: `I am a Ph.D. student in machine learning, and my research interest is in data science. I am interested in understanding how humans and machines interact and how we can improve the quality of life for people around the world.`
**Example 2:**
- sketch: `自然语言处理__谷歌__通用人工智能__`
- **GENIUS**: `自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。 `
**GENIUS** can also be used as a general textual **data augmentation tool** for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA).
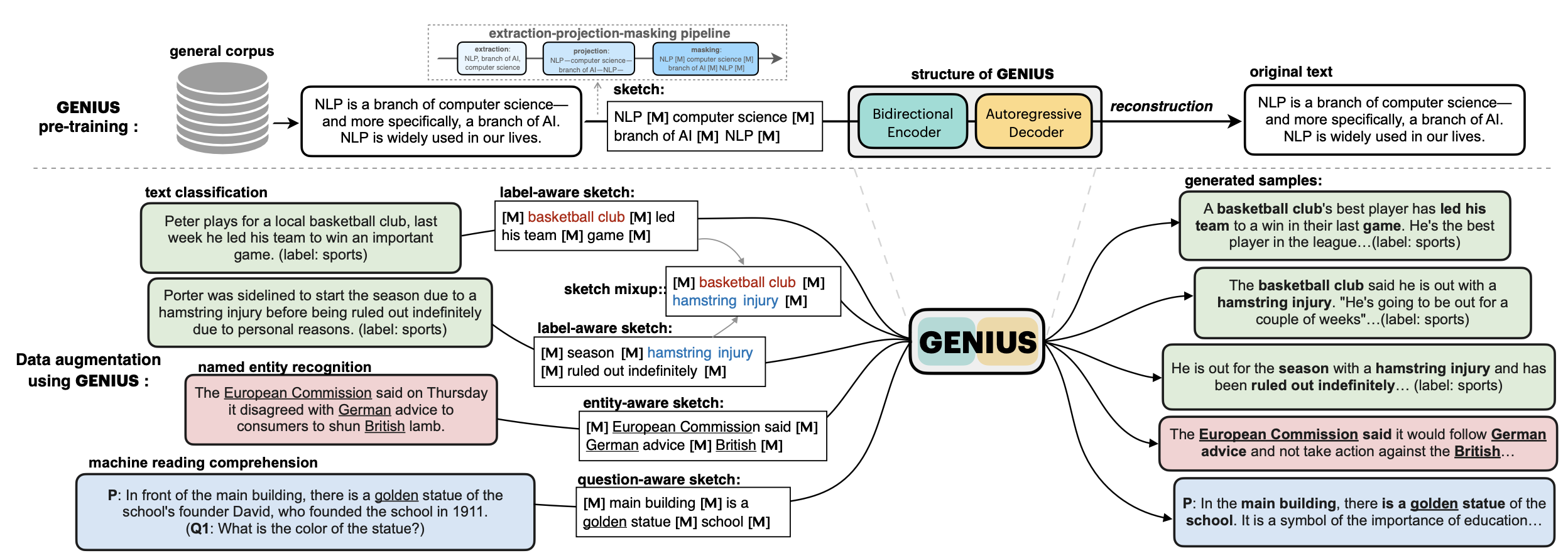
- Models hosted in 🤗 Huggingface:
**Model variations:**
| Model | #params | Language | comment|
|------------------------|--------------------------------|-------|---------|
| [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) |
| [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text |
| [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version |
| [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences |
| [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
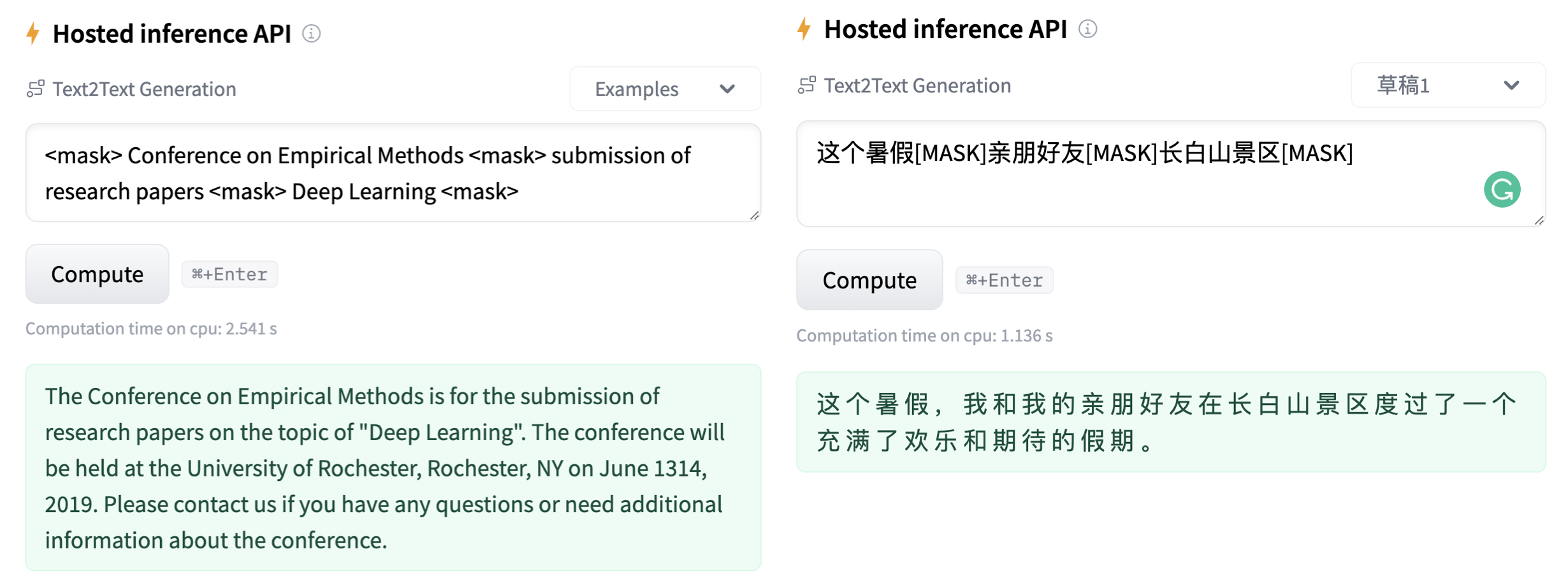
More Examples:
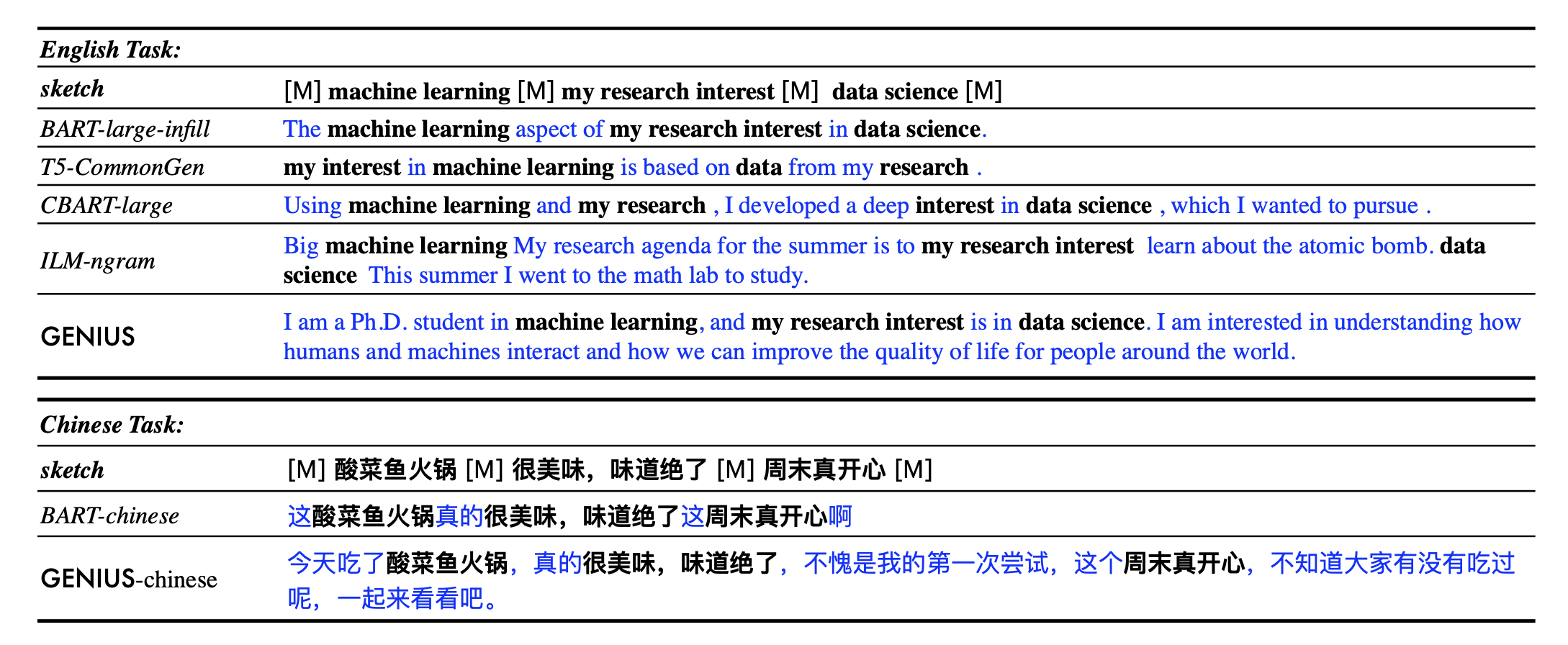
## Usage
### What is a sketch?
First, what is a **sketch**? As defined in our paper, a sketch is "key information consisting of textual spans, phrases, or words, concatenated by mask tokens". It's like a draft or framework when you begin to write an article. With GENIUS model, you can input some key elements you want to mention in your wrinting, then the GENIUS model can generate cohrent text based on your sketch.
The sketch which can be composed of:
- keywords /key-phrases, like `__NLP__AI__computer__science__`
- spans, like `Conference on Empirical Methods__submission of research papers__`
- sentences, like `I really like machine learning__I work at Google since last year__`
- or a mixup!
### How to use the model
#### 1. If you already have a sketch in mind, and want to get a paragraph based on it...
```python
from transformers import pipeline
# 1. load the model with the huggingface `pipeline`
genius = pipeline("text2text-generation", model='beyond/genius-large', device=0)
# 2. provide a sketch (joint by <mask> tokens)
sketch = "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
# 3. here we go!
generated_text = genius(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text']
print(generated_text)
```
Output:
```shell
'The Conference on Empirical Methods welcomes the submission of research papers. Abstracts should be in the form of a paper or presentation. Please submit abstracts to the following email address: eemml.stanford.edu. The conference will be held at Stanford University on April 1618, 2019. The theme of the conference is Deep Learning.'
```
If you have a lot of sketches, you can batch-up your sketches to a Huggingface `Dataset` object, which can be much faster.
TODO: we are also building a python package for more convenient use of GENIUS, which will be released in few weeks.
#### 2. If you have an NLP dataset (e.g. classification) and want to do data augmentation to enlarge your dataset...
Please check [genius/augmentation_clf](https://github.com/beyondguo/genius/tree/master/augmentation_clf) and [genius/augmentation_ner_qa](https://github.com/beyondguo/genius/tree/master/augmentation_ner_qa), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
## Augmentation Experiments:
Data augmentation is an important application for natural language generation (NLG) models, which is also a valuable evaluation of whether the generated text can be used in real applications.
- Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes.
- Text Classification Datasets: [HuffPost](https://huggingface.co/datasets/khalidalt/HuffPost), [BBC](https://huggingface.co/datasets/SetFit/bbc-news), [SST2](https://huggingface.co/datasets/glue), [IMDB](https://huggingface.co/datasets/imdb), [Yahoo](https://huggingface.co/datasets/yahoo_answers_topics), [20NG](https://huggingface.co/datasets/newsgroup).
- Base classifier: [DistilBERT](https://huggingface.co/distilbert-base-cased)
In-distribution (ID) evaluations:
| Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. |
|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| none | 79.17 | **96.16** | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 |
| EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 |
| BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 |
| MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 |
| C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 |
| LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 |
| STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 |
| **GeniusAug** | 81.43 | 95.74 | 49.60 | 50.38 | **80.16** | 78.82 | 72.68 |
| **GeniusAug-f** | **81.82** | 95.99 | **50.42** | **50.81** | 79.40 | **80.57** | **73.17** |
Out-of-distribution (OOD) evaluations:
| | Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. |
|------------|:----------:|:----------:|:----------:|:----------:|:----------:|
| none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 |
| EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 |
| BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 |
| MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 |
| C-MLM | 64.94 | **67.80** | 74.98 | 71.78 | 69.87 |
| LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 |
| STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 |
| **GeniusAug** | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 |
| **GeniusAug-f** | **76.18** | 66.89 | **77.45** | **80.36** | **75.22** |
### BibTeX entry and citation info
TBD
| 02dc1bf281a41c64dd415c7364899917 |
hamzagorgulu/alarm_prediction_tokenizer3 | hamzagorgulu | gpt2 | 9 | 0 | transformers | 0 | text-generation | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,703 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# alarm_prediction_tokenizer3
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6252
- Validation Loss: 0.5814
- Epoch: 5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -960, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.9339 | 1.3070 | 0 |
| 1.1890 | 0.9436 | 1 |
| 0.9039 | 0.7802 | 2 |
| 0.7734 | 0.6915 | 3 |
| 0.6879 | 0.6274 | 4 |
| 0.6252 | 0.5814 | 5 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.8.0
- Tokenizers 0.13.2
| f141eb9165727b8b8a3cbc832e7b1d02 |
fathyshalab/domain_transfer_general-massive_music-roberta-large-v1-5-7 | fathyshalab | roberta | 14 | 2 | sentence-transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['setfit', 'sentence-transformers', 'text-classification'] | false | true | true | 1,506 | false |
# fathyshalab/domain_transfer_general-massive_music-roberta-large-v1-5-7
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/domain_transfer_general-massive_music-roberta-large-v1-5-7")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
| fbc77799056a702b2d45b712b8d1a474 |
google/electra-large-generator | google | electra | 9 | 66,745 | transformers | 3 | fill-mask | true | true | true | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,614 | false |
## ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer to our paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
This repository contains code to pre-train ELECTRA, including small ELECTRA models on a single GPU. It also supports fine-tuning ELECTRA on downstream tasks including classification tasks (e.g,. [GLUE](https://gluebenchmark.com/)), QA tasks (e.g., [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), and sequence tagging tasks (e.g., [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/)).
## How to use the generator in `transformers`
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="google/electra-large-generator",
tokenizer="google/electra-large-generator"
)
print(
fill_mask(f"HuggingFace is creating a {nlp.tokenizer.mask_token} that the community uses to solve NLP tasks.")
)
```
| 8ed9c09970c4f3732e02b42908b4602a |
huyue012/wav2vec2-base-cynthia-tedlium-2500-v2 | huyue012 | wav2vec2 | 16 | 8 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,720 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-cynthia-tedlium-2500-v2
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6425
- Wer: 0.2033
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1196 | 6.58 | 500 | 0.6498 | 0.2103 |
| 0.1176 | 13.16 | 1000 | 0.6490 | 0.2169 |
| 0.1227 | 19.73 | 1500 | 0.6241 | 0.2127 |
| 0.1078 | 26.31 | 2000 | 0.6359 | 0.2118 |
| 0.0956 | 32.89 | 2500 | 0.6330 | 0.2073 |
| 0.1008 | 39.47 | 3000 | 0.6816 | 0.2036 |
| 0.09 | 46.05 | 3500 | 0.6425 | 0.2033 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.13.3
- Tokenizers 0.10.3
| 8f3cdc541ff5b9eb630b0c38d3b0a9bc |
uf-aice-lab/SafeMathBot | uf-aice-lab | gpt2 | 15 | 6 | transformers | 0 | text-generation | true | false | false | mit | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generation', 'math learning', 'education'] | false | true | true | 1,513 | false |
# SafeMathBot for NLP tasks in math learning environments
This model is fine-tuned with GPT2-xl with 8 Nvidia RTX 1080Ti GPUs and enhanced with conversation safety policies (e.g., threat, profanity, identity attack) using 3,000,000 math discussion posts by students and facilitators on Algebra Nation (https://www.mathnation.com/). SafeMathBot consists of 48 layers and over 1.5 billion parameters, consuming up to 6 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively avoid unsafe response generation. It was trained to allow researchers to control generated responses' safety using tags `[SAFE]` and `[UNSAFE]`
### Here is how to use it with texts in HuggingFace
```python
# A list of special tokens the model was trained with
special_tokens_dict = {
'additional_special_tokens': [
'[SAFE]','[UNSAFE]', '[OK]', '[SELF_M]','[SELF_F]', '[SELF_N]',
'[PARTNER_M]', '[PARTNER_F]', '[PARTNER_N]',
'[ABOUT_M]', '[ABOUT_F]', '[ABOUT_N]', '<speaker1>', '<speaker2>'
],
'bos_token': '<bos>',
'eos_token': '<eos>',
}
from transformers import AutoTokenizer, AutoModelForCausalLM
math_bot_tokenizer = AutoTokenizer.from_pretrained('uf-aice-lab/SafeMathBot')
safe_math_bot = AutoModelForCausalLM.from_pretrained('uf-aice-lab/SafeMathBot')
text = "Replace me by any text you'd like."
encoded_input = math_bot_tokenizer(text, return_tensors='pt')
output = safe_math_bot(**encoded_input)
``` | 4e0237c921fd3b85a3d9a4a9b05ba0c7 |
parambharat/whisper-small-ml | parambharat | whisper | 13 | 16 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['ml'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,606 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small ML - Bharat Ramanathan
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2308
- Wer: 36.7397
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1275 | 4.03 | 500 | 0.1630 | 35.4015 |
| 0.09 | 9.02 | 1000 | 0.1821 | 40.0243 |
| 0.062 | 14.01 | 1500 | 0.2004 | 37.7129 |
| 0.0441 | 19.0 | 2000 | 0.2105 | 36.2530 |
| 0.0335 | 23.03 | 2500 | 0.2250 | 37.7129 |
| 0.0276 | 28.02 | 3000 | 0.2308 | 36.7397 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
| b6be40b46196a9e39b05c5ef364a2142 |
Helsinki-NLP/opus-mt-fi-tll | Helsinki-NLP | marian | 10 | 10 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-fi-tll
* source languages: fi
* target languages: tll
* OPUS readme: [fi-tll](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-tll/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-24.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.zip)
* test set translations: [opus-2020-01-24.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.test.txt)
* test set scores: [opus-2020-01-24.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-tll/opus-2020-01-24.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fi.tll | 23.6 | 0.478 |
| bfe54de652a865eafd08e57cc62f763c |
amkaaa/distilbert-base-uncased-finetuned-cola | amkaaa | distilbert | 13 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5447
- Matthews Correlation: 0.5470
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5249 | 1.0 | 535 | 0.5159 | 0.4004 |
| 0.3458 | 2.0 | 1070 | 0.5198 | 0.4738 |
| 0.2349 | 3.0 | 1605 | 0.5447 | 0.5470 |
| 0.1773 | 4.0 | 2140 | 0.7828 | 0.5185 |
| 0.1245 | 5.0 | 2675 | 0.8306 | 0.5279 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| 8a4afbd248aa04d08c89bd7e2cd6abd6 |
dsoum/ner-from-bert | dsoum | bert | 12 | 19 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['conll2003'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,513 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ner-from-bert
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0615
- Precision: 0.9351
- Recall: 0.9504
- F1: 0.9427
- Accuracy: 0.9859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0879 | 1.0 | 1756 | 0.0685 | 0.9170 | 0.9320 | 0.9245 | 0.9815 |
| 0.0328 | 2.0 | 3512 | 0.0625 | 0.9267 | 0.9495 | 0.9380 | 0.9853 |
| 0.0189 | 3.0 | 5268 | 0.0615 | 0.9351 | 0.9504 | 0.9427 | 0.9859 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| ef2e34bb809f2b7b75108fca29bf7743 |
cartesinus/xlm-r-base-amazon-massive-domain | cartesinus | xlm-roberta | 11 | 44 | transformers | 0 | text-classification | true | false | false | mit | ['en'] | ['AmazonScience/massive'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer', 'nlu', 'domain-classificatoin'] | true | true | true | 1,648 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-r-base-amazon-massive-domain
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [Amazon Massive](https://huggingface.co/datasets/AmazonScience/massive) dataset (only en-US subset).
It achieves the following results on the evaluation set:
- Loss: 0.3788
- Accuracy: 0.9213
- F1: 0.9213
## Model description
Domain classifier trained from Amazon Massive dataset.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.382 | 1.0 | 720 | 0.4533 | 0.8795 | 0.8795 |
| 0.4598 | 2.0 | 1440 | 0.3448 | 0.9026 | 0.9026 |
| 0.2547 | 3.0 | 2160 | 0.3762 | 0.9065 | 0.9065 |
| 0.1986 | 4.0 | 2880 | 0.3748 | 0.9139 | 0.9139 |
| 0.1358 | 5.0 | 3600 | 0.3788 | 0.9213 | 0.9213 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1 | 95aa71933d325e162573bff38709428f |
ish97/bert-finetuned-ner | ish97 | bert | 18 | 3 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['conll2003'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,518 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0641
- Precision: 0.9290
- Recall: 0.9475
- F1: 0.9382
- Accuracy: 0.9858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0867 | 1.0 | 1756 | 0.0716 | 0.9102 | 0.9297 | 0.9198 | 0.9820 |
| 0.0345 | 2.0 | 3512 | 0.0680 | 0.9290 | 0.9465 | 0.9376 | 0.9854 |
| 0.0191 | 3.0 | 5268 | 0.0641 | 0.9290 | 0.9475 | 0.9382 | 0.9858 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 6b58eacdf55bef335af236283d9866df |
katanaml/donut-base-sroie | katanaml | vision-encoder-decoder | 14 | 12 | transformers | 0 | null | true | false | false | mit | null | ['imagefolder'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 981 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| 525059de075c786e159146106b8d8a1f |
deepakvk/distilbert-base-uncased-distilled-squad-finetuned-squad | deepakvk | distilbert | 10 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad_v2'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 982 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-squad-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased-distilled-squad](https://huggingface.co/distilbert-base-uncased-distilled-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.1
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| c154cdc981b4cfa6318b485655ffc88d |
JeffZ/jeffzo3 | JeffZ | null | 19 | 2 | diffusers | 0 | null | false | false | false | mit | null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,188 | false | ### Jeffzo3 on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
#### Model by JeffZ
This your the Stable Diffusion model fine-tuned the Jeffzo3 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt(s)`: ****
You can also train your own concepts and upload them to the library by using [the fast-DremaBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb).
You can run your new concept via A1111 Colab :[Fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Sample pictures of this concept:
| 2f0f7057b49586fb0ea4ab3ca9313cd1 |
google/multiberts-seed_2-step_120k | google | bert | 8 | 12 | transformers | 0 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['multiberts', 'multiberts-seed_2', 'multiberts-seed_2-step_120k'] | false | true | true | 3,521 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 2, Step 120k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #2, captured at step 120k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_120k')
model = TFBertModel.from_pretrained("google/multiberts-seed_2-step_120k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_120k')
model = BertModel.from_pretrained("google/multiberts-seed_2-step_120k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
| e6af5c8342a11c28d69903d6c716d08a |
weirdguitarist/wav2vec2-base-stac-msa-local | weirdguitarist | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,435 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-stac-msa-local
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0671
- Wer: 0.7924
- Cer: 0.3289
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
Training: STAC + Tunisian MSA
Test: CS DATA
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:------:|:---------------:|:------:|:------:|
| 1.4697 | 1.0 | 3773 | 1.8242 | 0.9395 | 0.5135 |
| 1.1644 | 2.0 | 7546 | 1.6306 | 0.8731 | 0.4446 |
| 0.9517 | 3.0 | 11319 | 1.4122 | 0.8587 | 0.4059 |
| 0.8563 | 4.0 | 15092 | 1.5409 | 0.8386 | 0.4034 |
| 0.7556 | 5.0 | 18865 | 1.4103 | 0.8247 | 0.3724 |
| 0.6841 | 6.0 | 22638 | 1.4608 | 0.8166 | 0.3735 |
| 0.5834 | 7.0 | 26411 | 1.5139 | 0.8113 | 0.3646 |
| 0.5607 | 8.0 | 30184 | 1.5303 | 0.8263 | 0.3797 |
| 0.5442 | 9.0 | 33957 | 1.3824 | 0.8198 | 0.3476 |
| 0.4584 | 10.0 | 37730 | 1.6412 | 0.8160 | 0.3576 |
| 0.4257 | 11.0 | 41503 | 1.5575 | 0.8003 | 0.3514 |
| 0.3631 | 12.0 | 45276 | 1.5776 | 0.8141 | 0.3454 |
| 0.3272 | 13.0 | 49049 | 1.5124 | 0.8127 | 0.3399 |
| 0.3348 | 14.0 | 52822 | 1.6733 | 0.7946 | 0.3398 |
| 0.3231 | 15.0 | 56595 | 1.5154 | 0.7987 | 0.3324 |
| 0.2556 | 16.0 | 60368 | 1.6161 | 0.7993 | 0.3402 |
| 0.238 | 17.0 | 64141 | 1.6126 | 0.7974 | 0.3329 |
| 0.2228 | 18.0 | 67914 | 1.7419 | 0.8014 | 0.3291 |
| 0.2129 | 19.0 | 71687 | 1.8394 | 0.8015 | 0.3374 |
| 0.1975 | 20.0 | 75460 | 1.9307 | 0.7928 | 0.3451 |
| 0.1981 | 21.0 | 79233 | 1.8700 | 0.8080 | 0.3375 |
| 0.1628 | 22.0 | 83006 | 1.9776 | 0.8061 | 0.3408 |
| 0.1462 | 23.0 | 86779 | 1.9090 | 0.8031 | 0.3306 |
| 0.1555 | 24.0 | 90552 | 1.9063 | 0.7878 | 0.3294 |
| 0.1515 | 25.0 | 94325 | 1.9632 | 0.7963 | 0.3278 |
| 0.1194 | 26.0 | 98098 | 1.9280 | 0.7991 | 0.3301 |
| 0.1219 | 27.0 | 101871 | 2.0248 | 0.7927 | 0.3329 |
| 0.1184 | 28.0 | 105644 | 2.0447 | 0.7903 | 0.3314 |
| 0.074 | 29.0 | 109417 | 2.0513 | 0.7910 | 0.3287 |
| 0.0836 | 30.0 | 113190 | 2.0671 | 0.7924 | 0.3289 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.8.1+cu102
- Datasets 1.18.3
- Tokenizers 0.12.1
| a9a496af32a7e2cd91f50c79b2610eb1 |
nestoralvaro/mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base | nestoralvaro | mt5 | 12 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['mlsum'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,454 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mlsum dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.1582
- Rouge2: 0.0133
- Rougel: 0.1585
- Rougelsum: 0.1586
- Gen Len: 10.2326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 66592 | nan | 0.1582 | 0.0133 | 0.1585 | 0.1586 | 10.2326 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
| 01442508a9cc26d2a6aa6efaea8b3ad0 |
henryscheible/mnli_bert-base-uncased_81 | henryscheible | null | 13 | 0 | null | 0 | null | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,017 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mnli_bert-base-uncased_81
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4882
- Accuracy: 0.8207
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 400
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
| 65f64baeb9fe77f9df9771b309b664b1 |
Helsinki-NLP/opus-mt-is-sv | Helsinki-NLP | marian | 10 | 34 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 768 | false |
### opus-mt-is-sv
* source languages: is
* target languages: sv
* OPUS readme: [is-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/is-sv/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-sv/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.is.sv | 30.4 | 0.495 |
| 0907e735ffd15a5ef084e13e45f7ec5c |
luke-thorburn/suggest-reasons-full-finetune | luke-thorburn | gpt_neo | 4 | 6 | transformers | 0 | text-generation | true | false | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['argumentation'] | false | true | true | 1,662 | false |
# Generate reasons that support a claim
This model is a version of [`gpt-neo-2.7B`](https://huggingface.co/EleutherAI/gpt-neo-2.7B), where all parameters (both weights and biases) have been finetuned on the task of generating reasons that support a claim, optionally given some example reasons. It was trained as part of a University of Melbourne [research project](https://github.com/Hunt-Laboratory/language-model-optimization) evaluating how large language models can best be optimized to perform argumentative reasoning tasks.
Code used for optimization and evaluation can be found in the project [GitHub repository](https://github.com/Hunt-Laboratory/language-model-optimization). A paper reporting on model evaluation is currently under review.
# Prompt Template
```
List reasons why: [original claim]
Reasons:
* [reason 1]
* [reason 2]
...
* [reason n]
* [generated reason]
```
# Dataset
The parameters were finetuned using argument maps scraped from the crowdsourced argument-mapping platform [Kialo](https://kialo.com/).
# Limitations and Biases
The model is a finetuned version of [`gpt-neo-2.7B`](https://huggingface.co/EleutherAI/gpt-neo-2.7B), so likely has many of the same limitations and biases. Additionally, note that while the goal of the model is to produce coherent and valid reasoning, many generated model outputs will be illogical or nonsensical and should not be relied upon.
# Acknowledgements
This research was funded by the Australian Department of Defence and the Office of National Intelligence under the AI for Decision Making Program, delivered in partnership with the Defence Science Institute in Victoria, Australia. | af1e1a402f7f5b047c56f0891e34f775 |
it5/it5-efficient-small-el32-question-generation | it5 | t5 | 18 | 1 | transformers | 0 | text2text-generation | true | true | true | apache-2.0 | ['it'] | ['squad_it'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['Italian', 'efficient', 'sequence-to-sequence', 'question-generation', 'squad_it', 'text2text-generation'] | true | true | true | 3,510 | false | # IT5 Cased Small Efficient EL32 for Question Generation 💭 🇮🇹
*Shout-out to [Stefan Schweter](https://github.com/stefan-it) for contributing the pre-trained efficient model!*
This repository contains the checkpoint for the [IT5 Cased Small Efficient EL32](https://huggingface.co/it5/it5-efficient-small-el32) model fine-tuned on question generation on the [SQuAD-IT corpus](https://huggingface.co/datasets/squad_it) as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
Efficient IT5 models differ from the standard ones by adopting a different vocabulary that enables cased text generation and an [optimized model architecture](https://arxiv.org/abs/2109.10686) to improve performances while reducing parameter count. The Small-EL32 replaces the original encoder from the T5 Small architecture with a 32-layer deep encoder, showing improved performances over the base model.
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
qg = pipeline("text2text-generation", model='it5/it5-efficient-small-el32-question-generation')
qg("Le conoscenze mediche erano stagnanti durante il Medioevo. Il resoconto più autorevole di allora è venuto dalla facoltà di medicina di Parigi in un rapporto al re di Francia che ha incolpato i cieli, sotto forma di una congiunzione di tre pianeti nel 1345 che causò una "grande pestilenza nell\' aria". Questa relazione è diventata la prima e più diffusa di una serie di casi di peste che cercava di dare consigli ai malati. Che la peste fosse causata dalla cattiva aria divenne la teoria più accettata. Oggi, questo è conosciuto come la teoria di Miasma. La parola "peste" non aveva un significato particolare in questo momento, e solo la ricorrenza dei focolai durante il Medioevo gli diede il nome che è diventato il termine medico. Risposta: re di Francia")
>>> [{"generated_text": "Per chi è stato redatto il referto medico?"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/it5-efficient-small-el32-question-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/it5-efficient-small-el32-question-generation")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7.0
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
| 6d5d011f9a478f00e29863e5615d1977 |
lmqg/bart-base-squad-qg | lmqg | bart | 71 | 82 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | ['en'] | ['lmqg/qg_squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['question generation'] | true | true | true | 9,416 | false |
# Model Card of `lmqg/bart-base-squad-qg`
This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation task on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/bart-base-squad-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/bart-base-squad-qg")
output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:---------------------------------------------------------------|
| BERTScore | 90.87 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 56.92 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 40.98 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 31.44 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 24.68 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 26.05 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 64.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 52.66 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Question & Answer Generation, Reference Answer)***: Each question is generated from *the gold answer*. [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:---------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 95.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedF1Score (MoverScore) | 70.38 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (BERTScore) | 95.55 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (MoverScore) | 70.67 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (BERTScore) | 95.44 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (MoverScore) | 70.1 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Question & Answer Generation, Pipeline Approach)***: Each question is generated on the answer generated by [`lmqg/bart-base-squad-ae`](https://huggingface.co/lmqg/bart-base-squad-ae). [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_pipeline/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.lmqg_bart-base-squad-ae.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:---------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 92.84 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedF1Score (MoverScore) | 64.24 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (BERTScore) | 92.75 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (MoverScore) | 64.46 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (BERTScore) | 92.95 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (MoverScore) | 64.11 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metrics (Question Generation, Out-of-Domain)***
| Dataset | Type | BERTScore| Bleu_4 | METEOR | MoverScore | ROUGE_L | Link |
|:--------|:-----|---------:|-------:|-------:|-----------:|--------:|-----:|
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | amazon | 90.49 | 5.82 | 21.27 | 60.27 | 23.82 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.amazon.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | new_wiki | 93.07 | 10.73 | 26.23 | 65.67 | 28.44 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.new_wiki.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | nyt | 92.36 | 7.65 | 24.43 | 63.69 | 23.9 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.nyt.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | reddit | 90.57 | 5.38 | 20.4 | 60.14 | 21.41 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.reddit.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | books | 87.75 | 0.0 | 11.52 | 55.21 | 10.77 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.books.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | electronics | 87.6 | 0.0 | 14.87 | 56.07 | 14.29 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.electronics.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | grocery | 87.38 | 0.6 | 15.53 | 56.63 | 12.49 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | movies | 87.73 | 1.08 | 12.86 | 55.55 | 13.9 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.movies.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | restaurants | 87.71 | 0.0 | 11.47 | 54.91 | 12.16 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.restaurants.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | tripadvisor | 88.78 | 1.02 | 13.92 | 55.91 | 13.41 | [link](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.tripadvisor.json) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: facebook/bart-base
- max_length: 512
- max_length_output: 32
- epoch: 7
- batch: 32
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-base-squad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 52a9d3e232b8460059d3d0ac7028e422 |
heyyai/elonmusk01 | heyyai | null | 19 | 2 | diffusers | 0 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 | ['text-to-image'] | false | true | true | 618 | false | ### elonmusk01 Dreambooth model trained by cormacncheese with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
| d800ee746e902a9a5469a03f800cd5be |
rootacess/distilbert-base-uncased-finetuned-emotion | rootacess | distilbert | 12 | 4 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,343 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2200
- Accuracy: 0.929
- F1: 0.9292
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8358 | 1.0 | 250 | 0.3190 | 0.908 | 0.9050 |
| 0.2551 | 2.0 | 500 | 0.2200 | 0.929 | 0.9292 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 5ccf032d61342e6fb627228f0185a986 |
rushic24/TestPlaygroundSkops | rushic24 | null | 11 | 0 | null | 0 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 98,083 | false |
# Model description 1
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-----------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| memory | |
| steps | [('transformation', ColumnTransformer(transformers=[('loading_missing_value_imputer',<br /> SimpleImputer(), ['loading']),<br /> ('numerical_missing_value_imputer',<br /> SimpleImputer(),<br /> ['loading', 'measurement_3', 'measurement_4',<br /> 'measurement_5', 'measurement_6',<br /> 'measurement_7', 'measurement_8',<br /> 'measurement_9', 'measurement_10',<br /> 'measurement_11', 'measurement_12',<br /> 'measurement_13', 'measurement_14',<br /> 'measurement_15', 'measurement_16',<br /> 'measurement_17']),<br /> ('attribute_0_encoder', OneHotEncoder(),<br /> ['attribute_0']),<br /> ('attribute_1_encoder', OneHotEncoder(),<br /> ['attribute_1']),<br /> ('product_code_encoder', OneHotEncoder(),<br /> ['product_code'])])), ('model', DecisionTreeClassifier(max_depth=4))] |
| verbose | False |
| transformation | ColumnTransformer(transformers=[('loading_missing_value_imputer',<br /> SimpleImputer(), ['loading']),<br /> ('numerical_missing_value_imputer',<br /> SimpleImputer(),<br /> ['loading', 'measurement_3', 'measurement_4',<br /> 'measurement_5', 'measurement_6',<br /> 'measurement_7', 'measurement_8',<br /> 'measurement_9', 'measurement_10',<br /> 'measurement_11', 'measurement_12',<br /> 'measurement_13', 'measurement_14',<br /> 'measurement_15', 'measurement_16',<br /> 'measurement_17']),<br /> ('attribute_0_encoder', OneHotEncoder(),<br /> ['attribute_0']),<br /> ('attribute_1_encoder', OneHotEncoder(),<br /> ['attribute_1']),<br /> ('product_code_encoder', OneHotEncoder(),<br /> ['product_code'])]) |
| model | DecisionTreeClassifier(max_depth=4) |
| transformation__n_jobs | |
| transformation__remainder | drop |
| transformation__sparse_threshold | 0.3 |
| transformation__transformer_weights | |
| transformation__transformers | [('loading_missing_value_imputer', SimpleImputer(), ['loading']), ('numerical_missing_value_imputer', SimpleImputer(), ['loading', 'measurement_3', 'measurement_4', 'measurement_5', 'measurement_6', 'measurement_7', 'measurement_8', 'measurement_9', 'measurement_10', 'measurement_11', 'measurement_12', 'measurement_13', 'measurement_14', 'measurement_15', 'measurement_16', 'measurement_17']), ('attribute_0_encoder', OneHotEncoder(), ['attribute_0']), ('attribute_1_encoder', OneHotEncoder(), ['attribute_1']), ('product_code_encoder', OneHotEncoder(), ['product_code'])] |
| transformation__verbose | False |
| transformation__verbose_feature_names_out | True |
| transformation__loading_missing_value_imputer | SimpleImputer() |
| transformation__numerical_missing_value_imputer | SimpleImputer() |
| transformation__attribute_0_encoder | OneHotEncoder() |
| transformation__attribute_1_encoder | OneHotEncoder() |
| transformation__product_code_encoder | OneHotEncoder() |
| transformation__loading_missing_value_imputer__add_indicator | False |
| transformation__loading_missing_value_imputer__copy | True |
| transformation__loading_missing_value_imputer__fill_value | |
| transformation__loading_missing_value_imputer__missing_values | nan |
| transformation__loading_missing_value_imputer__strategy | mean |
| transformation__loading_missing_value_imputer__verbose | 0 |
| transformation__numerical_missing_value_imputer__add_indicator | False |
| transformation__numerical_missing_value_imputer__copy | True |
| transformation__numerical_missing_value_imputer__fill_value | |
| transformation__numerical_missing_value_imputer__missing_values | nan |
| transformation__numerical_missing_value_imputer__strategy | mean |
| transformation__numerical_missing_value_imputer__verbose | 0 |
| transformation__attribute_0_encoder__categories | auto |
| transformation__attribute_0_encoder__drop | |
| transformation__attribute_0_encoder__dtype | <class 'numpy.float64'> |
| transformation__attribute_0_encoder__handle_unknown | error |
| transformation__attribute_0_encoder__sparse | True |
| transformation__attribute_1_encoder__categories | auto |
| transformation__attribute_1_encoder__drop | |
| transformation__attribute_1_encoder__dtype | <class 'numpy.float64'> |
| transformation__attribute_1_encoder__handle_unknown | error |
| transformation__attribute_1_encoder__sparse | True |
| transformation__product_code_encoder__categories | auto |
| transformation__product_code_encoder__drop | |
| transformation__product_code_encoder__dtype | <class 'numpy.float64'> |
| transformation__product_code_encoder__handle_unknown | error |
| transformation__product_code_encoder__sparse | True |
| model__ccp_alpha | 0.0 |
| model__class_weight | |
| model__criterion | gini |
| model__max_depth | 4 |
| model__max_features | |
| model__max_leaf_nodes | |
| model__min_impurity_decrease | 0.0 |
| model__min_samples_leaf | 1 |
| model__min_samples_split | 2 |
| model__min_weight_fraction_leaf | 0.0 |
| model__random_state | |
| model__splitter | best |
</details>
### Model Plot
The model plot is below.
<style>#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 {color: black;background-color: white;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 pre{padding: 0;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-toggleable {background-color: white;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-estimator:hover {background-color: #d4ebff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-item {z-index: 1;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-parallel-item:only-child::after {width: 0;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893 div.sk-text-repr-fallback {display: none;}</style><div id="sk-8bc9e9e7-93eb-4a71-9ad5-6d31c0b7f893" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(),['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3','measurement_4','measurement_5','measurement_6','measurement_7','measurement_8','measurement_9','measurement_10','measurement_11','measurement_12','measurement_13','measurement_14','measurement_15','measurement_16','measurement_17']),('attribute_0_encoder',OneHotEncoder(),['attribute_0']),('attribute_1_encoder',OneHotEncoder(),['attribute_1']),('product_code_encoder',OneHotEncoder(),['product_code'])])),('model', DecisionTreeClassifier(max_depth=4))])</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="f3a0413c-728e-4fd9-bbd8-5c6ec5312931" type="checkbox" ><label for="f3a0413c-728e-4fd9-bbd8-5c6ec5312931" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(),['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3','measurement_4','measurement_5','measurement_6','measurement_7','measurement_8','measurement_9','measurement_10','measurement_11','measurement_12','measurement_13','measurement_14','measurement_15','measurement_16','measurement_17']),('attribute_0_encoder',OneHotEncoder(),['attribute_0']),('attribute_1_encoder',OneHotEncoder(),['attribute_1']),('product_code_encoder',OneHotEncoder(),['product_code'])])),('model', DecisionTreeClassifier(max_depth=4))])</pre></div></div></div><div class="sk-serial"><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="3f892f74-5115-4ab0-9c64-f760f11a7cbe" type="checkbox" ><label for="3f892f74-5115-4ab0-9c64-f760f11a7cbe" class="sk-toggleable__label sk-toggleable__label-arrow">transformation: ColumnTransformer</label><div class="sk-toggleable__content"><pre>ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(), ['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3', 'measurement_4','measurement_5', 'measurement_6','measurement_7', 'measurement_8','measurement_9', 'measurement_10','measurement_11', 'measurement_12','measurement_13', 'measurement_14','measurement_15', 'measurement_16','measurement_17']),('attribute_0_encoder', OneHotEncoder(),['attribute_0']),('attribute_1_encoder', OneHotEncoder(),['attribute_1']),('product_code_encoder', OneHotEncoder(),['product_code'])])</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="ec9bebf9-8c02-4785-974c-0e727c4449c0" type="checkbox" ><label for="ec9bebf9-8c02-4785-974c-0e727c4449c0" class="sk-toggleable__label sk-toggleable__label-arrow">loading_missing_value_imputer</label><div class="sk-toggleable__content"><pre>['loading']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="572cc9df-a4bb-49b4-b730-d012d99ba876" type="checkbox" ><label for="572cc9df-a4bb-49b4-b730-d012d99ba876" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="c6058039-3e65-4724-ad03-96517a382ad6" type="checkbox" ><label for="c6058039-3e65-4724-ad03-96517a382ad6" class="sk-toggleable__label sk-toggleable__label-arrow">numerical_missing_value_imputer</label><div class="sk-toggleable__content"><pre>['loading', 'measurement_3', 'measurement_4', 'measurement_5', 'measurement_6', 'measurement_7', 'measurement_8', 'measurement_9', 'measurement_10', 'measurement_11', 'measurement_12', 'measurement_13', 'measurement_14', 'measurement_15', 'measurement_16', 'measurement_17']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="d385b0fd-dfaf-490c-8fda-dc024393a022" type="checkbox" ><label for="d385b0fd-dfaf-490c-8fda-dc024393a022" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="54db5302-69ab-49a1-b939-cb94c0958ab3" type="checkbox" ><label for="54db5302-69ab-49a1-b939-cb94c0958ab3" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_0_encoder</label><div class="sk-toggleable__content"><pre>['attribute_0']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="c0a718c8-7093-4d45-85ae-847bfac3ec7e" type="checkbox" ><label for="c0a718c8-7093-4d45-85ae-847bfac3ec7e" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="993a1233-2b0d-473e-9bb3-f7c9d0bc654a" type="checkbox" ><label for="993a1233-2b0d-473e-9bb3-f7c9d0bc654a" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_1_encoder</label><div class="sk-toggleable__content"><pre>['attribute_1']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="4311756e-5a71-45ce-9005-a1e5448b1c30" type="checkbox" ><label for="4311756e-5a71-45ce-9005-a1e5448b1c30" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="9bfb54df-7509-4669-b6e7-db3520c2d1c4" type="checkbox" ><label for="9bfb54df-7509-4669-b6e7-db3520c2d1c4" class="sk-toggleable__label sk-toggleable__label-arrow">product_code_encoder</label><div class="sk-toggleable__content"><pre>['product_code']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="1acc88d7-a436-40f6-99a3-ebfbbc9f897a" type="checkbox" ><label for="1acc88d7-a436-40f6-99a3-ebfbbc9f897a" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="5626883d-68bc-41b4-8913-23b6aed62eb8" type="checkbox" ><label for="5626883d-68bc-41b4-8913-23b6aed62eb8" class="sk-toggleable__label sk-toggleable__label-arrow">DecisionTreeClassifier</label><div class="sk-toggleable__content"><pre>DecisionTreeClassifier(max_depth=4)</pre></div></div></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
```python
[More Information Needed]
```
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
# h1
tjos osmda
```
# Model 2 Description (Logistic)
---
license: mit
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-------------------|-----------|
| C | 1.0 |
| class_weight | |
| dual | False |
| fit_intercept | True |
| intercept_scaling | 1 |
| l1_ratio | |
| max_iter | 100 |
| multi_class | auto |
| n_jobs | |
| penalty | l2 |
| random_state | 0 |
| solver | liblinear |
| tol | 0.0001 |
| verbose | 0 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 {color: black;background-color: white;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 pre{padding: 0;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-toggleable {background-color: white;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-estimator:hover {background-color: #d4ebff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-item {z-index: 1;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-parallel-item:only-child::after {width: 0;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022 div.sk-text-repr-fallback {display: none;}</style><div id="sk-9e32ec08-a06c-47ad-ba8c-72228d2a4022" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>LogisticRegression(random_state=0, solver='liblinear')</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="51d3cd4d-ea90-43e3-8d6a-5abc1df508b6" type="checkbox" checked><label for="51d3cd4d-ea90-43e3-8d6a-5abc1df508b6" class="sk-toggleable__label sk-toggleable__label-arrow">LogisticRegression</label><div class="sk-toggleable__content"><pre>LogisticRegression(random_state=0, solver='liblinear')</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
| accuracy | 0.96 |
| f1 score | 0.96 |
# How to Get Started with the Model
Use the code below to get started with the model.
```python
[More Information Needed]
```
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
# Additional Content
## confusion_matrix
 | bcdfaa885762c9102e361001b14e173c |
anuragshas/wav2vec2-large-xlsr-as | anuragshas | wav2vec2 | 10 | 10 | transformers | 0 | automatic-speech-recognition | true | false | true | apache-2.0 | ['as'] | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | true | true | true | 3,444 | false | # Wav2Vec2-Large-XLSR-53-Assamese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Assamese using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "as", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-as")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-as")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Assamese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "as", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-as")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-as")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\”\\়\\।]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub('’ ',' ',batch["sentence"])
batch["sentence"] = re.sub(' ‘',' ',batch["sentence"])
batch["sentence"] = re.sub('’|‘','\'',batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 69.63 %
## Training
The Common Voice `train` and `validation` datasets were used for training. | e83909a8b5a2a1d8d42884a4d472b44a |
daidv1112/distilbert-base-uncased-finetuned-squad | daidv1112 | distilbert | 12 | 3 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,284 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1476
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2071 | 1.0 | 5533 | 1.1445 |
| 0.9549 | 2.0 | 11066 | 1.1221 |
| 0.7506 | 3.0 | 16599 | 1.1476 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
| c313a0d322380f4f154c1184af98f1cc |
tomekkorbak/elegant_liskov | tomekkorbak | gpt2 | 23 | 0 | transformers | 0 | null | true | false | false | mit | ['en'] | ['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 8,110 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# elegant_liskov
This model was trained from scratch on the tomekkorbak/detoxify-pile-chunk3-0-50000, the tomekkorbak/detoxify-pile-chunk3-50000-100000, the tomekkorbak/detoxify-pile-chunk3-100000-150000, the tomekkorbak/detoxify-pile-chunk3-150000-200000, the tomekkorbak/detoxify-pile-chunk3-200000-250000, the tomekkorbak/detoxify-pile-chunk3-250000-300000, the tomekkorbak/detoxify-pile-chunk3-300000-350000, the tomekkorbak/detoxify-pile-chunk3-350000-400000, the tomekkorbak/detoxify-pile-chunk3-400000-450000, the tomekkorbak/detoxify-pile-chunk3-450000-500000, the tomekkorbak/detoxify-pile-chunk3-500000-550000, the tomekkorbak/detoxify-pile-chunk3-550000-600000, the tomekkorbak/detoxify-pile-chunk3-600000-650000, the tomekkorbak/detoxify-pile-chunk3-650000-700000, the tomekkorbak/detoxify-pile-chunk3-700000-750000, the tomekkorbak/detoxify-pile-chunk3-750000-800000, the tomekkorbak/detoxify-pile-chunk3-800000-850000, the tomekkorbak/detoxify-pile-chunk3-850000-900000, the tomekkorbak/detoxify-pile-chunk3-900000-950000, the tomekkorbak/detoxify-pile-chunk3-950000-1000000, the tomekkorbak/detoxify-pile-chunk3-1000000-1050000, the tomekkorbak/detoxify-pile-chunk3-1050000-1100000, the tomekkorbak/detoxify-pile-chunk3-1100000-1150000, the tomekkorbak/detoxify-pile-chunk3-1150000-1200000, the tomekkorbak/detoxify-pile-chunk3-1200000-1250000, the tomekkorbak/detoxify-pile-chunk3-1250000-1300000, the tomekkorbak/detoxify-pile-chunk3-1300000-1350000, the tomekkorbak/detoxify-pile-chunk3-1350000-1400000, the tomekkorbak/detoxify-pile-chunk3-1400000-1450000, the tomekkorbak/detoxify-pile-chunk3-1450000-1500000, the tomekkorbak/detoxify-pile-chunk3-1500000-1550000, the tomekkorbak/detoxify-pile-chunk3-1550000-1600000, the tomekkorbak/detoxify-pile-chunk3-1600000-1650000, the tomekkorbak/detoxify-pile-chunk3-1650000-1700000, the tomekkorbak/detoxify-pile-chunk3-1700000-1750000, the tomekkorbak/detoxify-pile-chunk3-1750000-1800000, the tomekkorbak/detoxify-pile-chunk3-1800000-1850000, the tomekkorbak/detoxify-pile-chunk3-1850000-1900000 and the tomekkorbak/detoxify-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 50354
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000',
'tomekkorbak/detoxify-pile-chunk3-50000-100000',
'tomekkorbak/detoxify-pile-chunk3-100000-150000',
'tomekkorbak/detoxify-pile-chunk3-150000-200000',
'tomekkorbak/detoxify-pile-chunk3-200000-250000',
'tomekkorbak/detoxify-pile-chunk3-250000-300000',
'tomekkorbak/detoxify-pile-chunk3-300000-350000',
'tomekkorbak/detoxify-pile-chunk3-350000-400000',
'tomekkorbak/detoxify-pile-chunk3-400000-450000',
'tomekkorbak/detoxify-pile-chunk3-450000-500000',
'tomekkorbak/detoxify-pile-chunk3-500000-550000',
'tomekkorbak/detoxify-pile-chunk3-550000-600000',
'tomekkorbak/detoxify-pile-chunk3-600000-650000',
'tomekkorbak/detoxify-pile-chunk3-650000-700000',
'tomekkorbak/detoxify-pile-chunk3-700000-750000',
'tomekkorbak/detoxify-pile-chunk3-750000-800000',
'tomekkorbak/detoxify-pile-chunk3-800000-850000',
'tomekkorbak/detoxify-pile-chunk3-850000-900000',
'tomekkorbak/detoxify-pile-chunk3-900000-950000',
'tomekkorbak/detoxify-pile-chunk3-950000-1000000',
'tomekkorbak/detoxify-pile-chunk3-1000000-1050000',
'tomekkorbak/detoxify-pile-chunk3-1050000-1100000',
'tomekkorbak/detoxify-pile-chunk3-1100000-1150000',
'tomekkorbak/detoxify-pile-chunk3-1150000-1200000',
'tomekkorbak/detoxify-pile-chunk3-1200000-1250000',
'tomekkorbak/detoxify-pile-chunk3-1250000-1300000',
'tomekkorbak/detoxify-pile-chunk3-1300000-1350000',
'tomekkorbak/detoxify-pile-chunk3-1350000-1400000',
'tomekkorbak/detoxify-pile-chunk3-1400000-1450000',
'tomekkorbak/detoxify-pile-chunk3-1450000-1500000',
'tomekkorbak/detoxify-pile-chunk3-1500000-1550000',
'tomekkorbak/detoxify-pile-chunk3-1550000-1600000',
'tomekkorbak/detoxify-pile-chunk3-1600000-1650000',
'tomekkorbak/detoxify-pile-chunk3-1650000-1700000',
'tomekkorbak/detoxify-pile-chunk3-1700000-1750000',
'tomekkorbak/detoxify-pile-chunk3-1750000-1800000',
'tomekkorbak/detoxify-pile-chunk3-1800000-1850000',
'tomekkorbak/detoxify-pile-chunk3-1850000-1900000',
'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'],
'is_split_by_sentences': True},
'generation': {'force_call_on': [25354],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 4096}],
'scorer_config': {'device': 'cuda:0'}},
'kl_gpt3_callback': {'force_call_on': [25354],
'gpt3_kwargs': {'model_name': 'davinci'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': True,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'path_or_name': 'gpt2'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 64,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'elegant_liskov',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0005,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output104340',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25354,
'save_strategy': 'steps',
'seed': 42,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/bv8r3j3h | 8ad8d9a10dd3e5abd5d5131dee019957 |
mechanicalsea/speecht5-tts | mechanicalsea | null | 29 | 0 | null | 2 | text-to-speech | false | false | false | mit | null | ['LibriTTS'] | null | 1 | 0 | 1 | 0 | 1 | 1 | 0 | ['speech', 'text', 'cross-modal', 'unified model', 'self-supervised learning', 'SpeechT5', 'Text-to-Speech'] | false | true | true | 2,197 | false |
## SpeechT5 TTS Manifest
| [**Github**](https://github.com/microsoft/SpeechT5) | [**Huggingface**](https://huggingface.co/mechanicalsea/speecht5-tts) |
This manifest is an attempt to recreate the Text-to-Speech recipe used for training [SpeechT5](https://aclanthology.org/2022.acl-long.393). This manifest was constructed using [LibriTTS](http://www.openslr.org/60/) clean datasets, including train-clean-100 and train-clean-360 for training, dev-clean for validation, and test-clean for evaluation. The test-clean-200 contains 200 utterances id for the mean option score (MOS), and the comparison mean option score (CMOS).
### News
- 8 February 2023: SpeechT5 is integrated as an official model into the Hugging Face Transformers library [[Blog](https://huggingface.co/blog/speecht5)] and [[Demo](https://huggingface.co/spaces/Matthijs/speecht5-tts-demo)].
### Requirements
- [SpeechBrain](https://github.com/speechbrain/speechbrain) for extracting speaker embedding
- [Parallel WaveGAN](https://github.com/kan-bayashi/ParallelWaveGAN) for implementing vocoder.
### Tools
- `manifest/utils` is used to downsample waveform, extract speaker embedding, generate manifest, and apply vocoder.
- `pretrained_vocoder` provides the pre-trained vocoder.
### Model and Samples
- [`speecht5_tts.pt`](./speecht5_tts.pt) are reimplemented Text-to-Speech fine-tuning on the released manifest **but with a smaller batch size or max updates** (Ensure the manifest is ok).
- `samples` are created by the released fine-tuned model and vocoder.
### Reference
If you find our work is useful in your research, please cite the following paper:
```bibtex
@inproceedings{ao-etal-2022-speecht5,
title = {{S}peech{T}5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing},
author = {Ao, Junyi and Wang, Rui and Zhou, Long and Wang, Chengyi and Ren, Shuo and Wu, Yu and Liu, Shujie and Ko, Tom and Li, Qing and Zhang, Yu and Wei, Zhihua and Qian, Yao and Li, Jinyu and Wei, Furu},
booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
month = {May},
year = {2022},
pages={5723--5738},
}
``` | dc4094d76d16bfc21843307990810f20 |
jonatasgrosman/exp_w2v2t_th_hubert_s817 | jonatasgrosman | hubert | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['th'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'th'] | false | true | true | 455 | false | # exp_w2v2t_th_hubert_s817
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition on Thai using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 2185d4e2e53249ddfe0510158d3b752c |
DrishtiSharma/whisper-large-v2-hindi-2k-steps | DrishtiSharma | whisper | 15 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['hi'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,321 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large V2 Hindi - Drishti Sharma
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1787
- Wer: 10.2486
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0238 | 2.44 | 2000 | 0.1787 | 10.2486 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
| 30b9ac54e101eeee8eb96950f2645567 |
dapang/distilroberta-base-mic | dapang | roberta | 35 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,474 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-mic
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3435
- Accuracy: 0.9104
- F1: 0.9103
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8.748413056668156e-05
- train_batch_size: 200
- eval_batch_size: 200
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 120 | 0.2830 | 0.8804 | 0.8797 |
| No log | 2.0 | 240 | 0.2398 | 0.9046 | 0.9046 |
| No log | 3.0 | 360 | 0.3474 | 0.8959 | 0.8954 |
| No log | 4.0 | 480 | 0.3435 | 0.9104 | 0.9103 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
| e94e9b3ea4e2b05a9e7816ca37bb4895 |
ranguis/marian-finetuned-kde4-en-to-fr | ranguis | marian | 9 | 1 | transformers | 0 | text2text-generation | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,549 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ranguis/marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-swc-fr](https://huggingface.co/Helsinki-NLP/opus-mt-swc-fr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.5054
- Train Accuracy: 0.3469
- Validation Loss: 2.8945
- Validation Accuracy: 0.5309
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 12, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 3.5054 | 0.3469 | 2.8945 | 0.5309 | 0 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.1
- Datasets 2.3.2
- Tokenizers 0.12.1
| 59a4e554c25022e74f8917d9337beec3 |
mujerry/bert-base-uncased-finetuned-QnA-v1 | mujerry | bert | 9 | 4 | transformers | 0 | fill-mask | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,127 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-QnA-v1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7610
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 39 | 3.3668 |
| No log | 2.0 | 78 | 3.2134 |
| No log | 3.0 | 117 | 3.1685 |
| No log | 4.0 | 156 | 3.1042 |
| No log | 5.0 | 195 | 3.1136 |
| No log | 6.0 | 234 | 2.9051 |
| No log | 7.0 | 273 | 2.9077 |
| No log | 8.0 | 312 | 2.9774 |
| No log | 9.0 | 351 | 2.9321 |
| No log | 10.0 | 390 | 2.9501 |
| No log | 11.0 | 429 | 2.8544 |
| No log | 12.0 | 468 | 2.8761 |
| 3.0255 | 13.0 | 507 | 2.8152 |
| 3.0255 | 14.0 | 546 | 2.8046 |
| 3.0255 | 15.0 | 585 | 2.6979 |
| 3.0255 | 16.0 | 624 | 2.6379 |
| 3.0255 | 17.0 | 663 | 2.7091 |
| 3.0255 | 18.0 | 702 | 2.6914 |
| 3.0255 | 19.0 | 741 | 2.7403 |
| 3.0255 | 20.0 | 780 | 2.7479 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
| 2ce270b1acb3d84f0185554cff2f97fa |
Helsinki-NLP/opus-mt-fr-tpi | Helsinki-NLP | marian | 10 | 9 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-fr-tpi
* source languages: fr
* target languages: tpi
* OPUS readme: [fr-tpi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-tpi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tpi/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fr.tpi | 30.0 | 0.487 |
| ec470bd2ffdc082f94740ccb73fc27d1 |
EleutherAI/enformer-official-rough | EleutherAI | enformer | 4 | 3,170 | transformers | 5 | null | true | false | false | cc-by-4.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,074 | false |
# Enformer
Enformer model. It was introduced in the paper [Effective gene expression prediction from sequence by integrating long-range interactions.](https://www.nature.com/articles/s41592-021-01252-x) by Avsec et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/enformer).
This repo contains the official weights released by Deepmind, ported over to Pytorch.
## Model description
Enformer is a neural network architecture based on the Transformer that led to greatly increased accuracy in predicting gene expression from DNA sequence.
We refer to the [paper](https://www.nature.com/articles/s41592-021-01252-x) published in Nature for details.
### How to use
Refer to the README of [enformer-pytorch](https://github.com/lucidrains/enformer-pytorch) regarding usage.
### Citation info
```
Avsec, Ž., Agarwal, V., Visentin, D. et al. Effective gene expression prediction from sequence by integrating long-range interactions. Nat Methods 18, 1196–1203 (2021). https://doi.org/10.1038/s41592-021-01252-x
```
| e818bba6a8691e588b122fc26797f766 |
tbosse/bert-base-german-cased-finetuned-subj_v6_7Epoch | tbosse | bert | 13 | 7 | transformers | 0 | token-classification | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,928 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-finetuned-subj_v6_7Epoch
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2836
- Precision: 0.7809
- Recall: 0.7229
- F1: 0.7507
- Accuracy: 0.9107
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 33 | 0.3541 | 0.6508 | 0.5486 | 0.5953 | 0.8520 |
| No log | 2.0 | 66 | 0.2815 | 0.7492 | 0.6314 | 0.6853 | 0.8836 |
| No log | 3.0 | 99 | 0.2659 | 0.7615 | 0.7114 | 0.7356 | 0.9015 |
| No log | 4.0 | 132 | 0.2570 | 0.7812 | 0.7343 | 0.7570 | 0.9113 |
| No log | 5.0 | 165 | 0.2676 | 0.7672 | 0.7343 | 0.7504 | 0.9084 |
| No log | 6.0 | 198 | 0.2791 | 0.7774 | 0.7286 | 0.7522 | 0.9113 |
| No log | 7.0 | 231 | 0.2836 | 0.7809 | 0.7229 | 0.7507 | 0.9107 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
| 4f81398e4fda29a7b33d36480fc6b702 |
zeynepgulhan/whisper-medium-cv-tr | zeynepgulhan | whisper | 21 | 2 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['tr'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,568 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium Turkish
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 tr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2780
- Wer: 11.0689
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0742 | 1.07 | 1000 | 0.2104 | 12.3975 |
| 0.0345 | 3.02 | 2000 | 0.2182 | 11.6573 |
| 0.0103 | 4.09 | 3000 | 0.2489 | 11.7921 |
| 0.0018 | 6.04 | 4000 | 0.2657 | 11.0746 |
| 0.0005 | 7.11 | 5000 | 0.2780 | 11.0689 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
| a2baba4123e3efd559fa15e510b317a2 |
Jean-Baptiste/roberta-large-financial-news-sentiment-en | Jean-Baptiste | roberta | 9 | 5,226 | transformers | 3 | text-classification | true | false | false | mit | ['en'] | ['Jean-Baptiste/financial_news_sentiment_mixte_with_phrasebank_75'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['financial', 'stocks', 'sentiment'] | false | true | true | 1,929 | false |
# Model fine-tuned from roberta-large for sentiment classification of financial news (emphasis on Canadian news).
### Introduction
This model was train on financial_news_sentiment_mixte_with_phrasebank_75 dataset.
This is a customized version of the phrasebank dataset in which I kept only sentence validated by at least 75% annotators.
In addition I added ~2000 articles validated manually on Canadian financial news. Therefore the model is more specifically trained for Canadian news.
Final result is f1 score of 93.25% overall and 83.6% on Canadian news.
### Training data
Training data was classified as follow:
class |Description
-|-
0 |negative
1 |neutral
2 |positive
### How to use roberta-large-financial-news-sentiment-en with HuggingFace
##### Load roberta-large-financial-news-sentiment-en and its sub-word tokenizer :
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("Jean-Baptiste/roberta-large-financial-news-sentiment-en")
model = AutoModelForSequenceClassification.from_pretrained("Jean-Baptiste/roberta-large-financial-news-sentiment-en")
##### Process text sample (from wikipedia)
from transformers import pipeline
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
pipe("Melcor REIT (TSX: MR.UN) today announced results for the third quarter ended September 30, 2022. Revenue was stable in the quarter and year-to-date. Net operating income was down 3% in the quarter at $11.61 million due to the timing of operating expenses and inflated costs including utilities like gas/heat and power")
[{'label': 'negative', 'score': 0.9399105906486511}]
```
### Model performances
Overall f1 score (average macro)
precision|recall|f1
-|-|-
0.9355|0.9299|0.9325
By entity
entity|precision|recall|f1
-|-|-|-
negative|0.9605|0.9240|0.9419
neutral|0.9538|0.9459|0.9498
positive|0.8922|0.9200|0.9059
| 879e2c2086e0b37e88ccee49e724dd3a |
polydin/distilbert-base-uncased-distilled-clinc | polydin | distilbert | 10 | 5 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['clinc_oos'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,786 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3462
- Accuracy: 0.9487
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 2.4449 | 0.7529 |
| 2.8785 | 2.0 | 636 | 1.2330 | 0.8561 |
| 2.8785 | 3.0 | 954 | 0.6774 | 0.9132 |
| 1.0817 | 4.0 | 1272 | 0.4716 | 0.9335 |
| 0.454 | 5.0 | 1590 | 0.4020 | 0.9442 |
| 0.454 | 6.0 | 1908 | 0.3749 | 0.9439 |
| 0.294 | 7.0 | 2226 | 0.3593 | 0.9481 |
| 0.2429 | 8.0 | 2544 | 0.3514 | 0.9474 |
| 0.2429 | 9.0 | 2862 | 0.3486 | 0.9481 |
| 0.2258 | 10.0 | 3180 | 0.3462 | 0.9487 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
| f2a62fc1d95269c0c27c47b2f9c40f73 |
Helsinki-NLP/opus-mt-chk-es | Helsinki-NLP | marian | 10 | 13 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-chk-es
* source languages: chk
* target languages: es
* OPUS readme: [chk-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/chk-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.zip)
* test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.test.txt)
* test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-es/opus-2020-01-15.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.chk.es | 20.8 | 0.374 |
| 0039ba8667738500f0f7fdf561f61912 |
Toshifumi/summarization-mT5-base-allXsum_20230203 | Toshifumi | mt5 | 9 | 2 | transformers | 0 | text2text-generation | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,539 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# summarization-mT5-base-allXsum_20230203
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.3421
- Validation Loss: 2.0134
- Train Rougel: tf.Tensor(0.23906478, shape=(), dtype=float32)
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rougel | Epoch |
|:----------:|:---------------:|:----------------------------------------------:|:-----:|
| 3.3550 | 2.2262 | tf.Tensor(0.21612057, shape=(), dtype=float32) | 0 |
| 2.5083 | 2.0820 | tf.Tensor(0.23286958, shape=(), dtype=float32) | 1 |
| 2.3421 | 2.0134 | tf.Tensor(0.23906478, shape=(), dtype=float32) | 2 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
| dc27697aa969fdb198b617e9164fc173 |
kasrahabib/100-200-bucket-finetunned | kasrahabib | bert | 10 | 5 | transformers | 0 | text-classification | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,724 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kasrahabib/100-200-bucket-finetunned
This model is a fine-tuned version of [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0595
- Validation Loss: 0.2551
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1240, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.4464 | 1.0900 | 0 |
| 0.8067 | 0.5640 | 1 |
| 0.3831 | 0.3874 | 2 |
| 0.2202 | 0.3008 | 3 |
| 0.1416 | 0.2800 | 4 |
| 0.0993 | 0.2666 | 5 |
| 0.0790 | 0.2587 | 6 |
| 0.0696 | 0.2591 | 7 |
| 0.0626 | 0.2561 | 8 |
| 0.0595 | 0.2551 | 9 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
| 26fb48b7b93f8e610912c065da350393 |
ksabeh/roberta-base-attribute-correction-mlm-titles | ksabeh | roberta | 9 | 3 | transformers | 0 | question-answering | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,426 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ksabeh/roberta-base-attribute-correction-mlm-titles-2
This model is a fine-tuned version of [ksabeh/roberta-base-attribute-correction-mlm](https://huggingface.co/ksabeh/roberta-base-attribute-correction-mlm) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0822
- Validation Loss: 0.0914
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 23870, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.2007 | 0.1023 | 0 |
| 0.0822 | 0.0914 | 1 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
| 1e04f4c420768a040d705b78205b3665 |
vinitharaj/distilbert-base-uncased-finetuned-squad2 | vinitharaj | distilbert | 14 | 4 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,381 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# vinitharaj/distilbert-base-uncased-finetuned-squad2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4953
- Validation Loss: 0.3885
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.7037 | 0.4222 | 0 |
| 0.4953 | 0.3885 | 1 |
### Framework versions
- Transformers 4.21.0
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
| 4e640aa195b71efb4db618528766edea |
nandysoham/Poultry-theme-finetuned-overfinetuned | nandysoham | distilbert | 10 | 5 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,925 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nandysoham/Poultry-theme-finetuned-overfinetuned
This model is a fine-tuned version of [nandysoham/distilbert-base-uncased-finetuned-squad](https://huggingface.co/nandysoham/distilbert-base-uncased-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.4170
- Train End Logits Accuracy: 0.4667
- Train Start Logits Accuracy: 0.4583
- Validation Loss: 1.9876
- Validation End Logits Accuracy: 0.4839
- Validation Start Logits Accuracy: 0.5161
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 2.4170 | 0.4667 | 0.4583 | 1.9876 | 0.4839 | 0.5161 | 0 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.8.0
- Tokenizers 0.13.2
| ef2902adee570bd3b7b94520c96793b1 |
hackathon-pln-es/wav2vec2-base-finetuned-sentiment-mesd | hackathon-pln-es | wav2vec2 | 31 | 10 | transformers | 4 | audio-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,420 | false |
# wav2vec2-base-finetuned-sentiment-mesd
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the [MESD](https://huggingface.co/hackathon-pln-es/MESD) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5729
- Accuracy: 0.8308
## Model description
This model was trained to classify underlying sentiment of Spanish audio/speech.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.25e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 7 | 0.5729 | 0.8308 |
| No log | 2.0 | 14 | 0.6577 | 0.8 |
| 0.1602 | 3.0 | 21 | 0.7055 | 0.8 |
| 0.1602 | 4.0 | 28 | 0.8696 | 0.7615 |
| 0.1602 | 5.0 | 35 | 0.6807 | 0.7923 |
| 0.1711 | 6.0 | 42 | 0.7303 | 0.7923 |
| 0.1711 | 7.0 | 49 | 0.7028 | 0.8077 |
| 0.1711 | 8.0 | 56 | 0.7368 | 0.8 |
| 0.1608 | 9.0 | 63 | 0.7190 | 0.7923 |
| 0.1608 | 10.0 | 70 | 0.6913 | 0.8077 |
| 0.1608 | 11.0 | 77 | 0.7047 | 0.8077 |
| 0.1753 | 12.0 | 84 | 0.6801 | 0.8 |
| 0.1753 | 13.0 | 91 | 0.7208 | 0.7769 |
| 0.1753 | 14.0 | 98 | 0.7458 | 0.7846 |
| 0.203 | 15.0 | 105 | 0.6494 | 0.8077 |
| 0.203 | 16.0 | 112 | 0.6256 | 0.8231 |
| 0.203 | 17.0 | 119 | 0.6788 | 0.8 |
| 0.1919 | 18.0 | 126 | 0.6757 | 0.7846 |
| 0.1919 | 19.0 | 133 | 0.6859 | 0.7846 |
| 0.1641 | 20.0 | 140 | 0.6832 | 0.7846 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.10.3
| 1ef17d573e33345f0ecc73a136392fa2 |
p1atdev/lora | p1atdev | null | 12 | 0 | null | 3 | null | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,721 | false |
Not so useful LoRAs.
These maybe only works with kohya's sd-scripts or webui extension.
- alley-test1-e20.safetensors: Realistic alley backgrounds LoRA for WDv1.4.
- alley-test2-e50.safetensors: Better backgrounds LoRA for WDv1.4.


v
- impasto-test1-last.safetensors: Impasto style for WDv1.4 but not good at person.
- fluorite-test5-last.safetensors: Photo portrait for SDv2.1 512.
- pastel-flavor-test1-e100.safetensors: LoRA trained with PastelMix's images for WD1.4. (bad nose)
- pastel-flavor-test2-e100.safetensors: LoRA trained with PastelMix's images for WD1.4. (a little better than test1)

- fumo-test1.safetensors: Fumo style for WDv1.4, better than test2 at details.
- fumo-test2.safetensors: Fumo style for WDv1.4, better than test1 at backgrounds and resolution.

- nurie-test2-e10.safetensors: Good at black and white lineart style.

- noz-test3-2-e40.safetensors: [NOZ style watch](https://www.noz-shop.com/) for SDv2.1-768. [Dataset](https://huggingface.co/datasets/p1atdev/noz).
e.g.
- `a blue watch`
- `a red pocket watch`

| 42ddd601228fc41b9b837a23bc7d7999 |
morenolq/distilgpt2-fables-demo | morenolq | gpt2 | 12 | 2 | transformers | 0 | text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer', 'distilgpt2', 'text-generation', 'english'] | true | true | true | 2,179 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-fables-demo
**Training:** The model has been trained using the script provided in the following repository https://github.com/MorenoLaQuatra/transformers-tasks-templates
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [demelin/understanding_fables](https://huggingface.co/datasets/demelin/understanding_fables) dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2165
## Model description
The model is a demo for the fine-tuning of decoder-only models using `transformers` library.
## Intended uses & limitations
It can be used mainly for prototyping and educational purposes.
## Training and evaluation data
The [demelin/understanding_fables](https://huggingface.co/datasets/demelin/understanding_fables) dataset has been split into train/test/validation using an 80/10/10 random split (`random_seed = 42`). Google Colab has been used for model fine-tuning.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 38 | 42.4563 |
| No log | 2.0 | 76 | 5.2808 |
| 28.753 | 3.0 | 114 | 3.7712 |
| 28.753 | 4.0 | 152 | 3.4577 |
| 28.753 | 5.0 | 190 | 3.3120 |
| 3.5846 | 6.0 | 228 | 3.2773 |
| 3.5846 | 7.0 | 266 | 3.2710 |
| 3.0017 | 8.0 | 304 | 3.2764 |
| 3.0017 | 9.0 | 342 | 3.2795 |
| 3.0017 | 10.0 | 380 | 3.3300 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| e2e2836e5a9fc3d4413a72aaad807139 |
research-backup/bart-base-subjqa-vanilla-movies-qg | research-backup | bart | 15 | 1 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | ['en'] | ['lmqg/qg_subjqa'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['question generation'] | true | true | true | 4,015 | false |
# Model Card of `research-backup/bart-base-subjqa-vanilla-movies-qg`
This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: movies) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base)
- **Language:** en
- **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (movies)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="research-backup/bart-base-subjqa-vanilla-movies-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "research-backup/bart-base-subjqa-vanilla-movies-qg")
output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/bart-base-subjqa-vanilla-movies-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.movies.json)
| | Score | Type | Dataset |
|:-----------|--------:|:-------|:-----------------------------------------------------------------|
| BERTScore | 91.41 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_1 | 11.04 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_2 | 6.37 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_3 | 1.36 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_4 | 0 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| METEOR | 17.16 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| MoverScore | 59.41 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| ROUGE_L | 20.32 | movies | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_subjqa
- dataset_name: movies
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: ['qg']
- model: facebook/bart-base
- max_length: 512
- max_length_output: 32
- epoch: 1
- batch: 8
- lr: 5e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 16
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/bart-base-subjqa-vanilla-movies-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 1e41689f3fdd2550d1acb7df80efd0c5 |
msintaha/bert-base-uncased-finetuned-copa-data-new | msintaha | bert | 12 | 2 | transformers | 0 | multiple-choice | true | false | false | apache-2.0 | null | ['super_glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,287 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-copa-data-new
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the super_glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5995
- Accuracy: 0.7000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 25 | 0.6564 | 0.6600 |
| No log | 2.0 | 50 | 0.5995 | 0.7000 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| adffc88d562551b5dcd3a19a5fdcab19 |
jakub014/bert-base-uncased-finetuned-convincingness-acl2016 | jakub014 | bert | 13 | 16 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,477 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-convincingness-acl2016
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4136
- Accuracy: 0.9202
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4027 | 1.0 | 583 | 0.2574 | 0.8944 |
| 0.2075 | 2.0 | 1166 | 0.2114 | 0.9189 |
| 0.1402 | 3.0 | 1749 | 0.3419 | 0.9163 |
| 0.0961 | 4.0 | 2332 | 0.3782 | 0.9197 |
| 0.0501 | 5.0 | 2915 | 0.4136 | 0.9202 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| 004c6b4085cd20f1cca29ab1d0967d97 |
bofenghuang/whisper-large-v2-cv11-german | bofenghuang | whisper | 17 | 202 | transformers | 1 | automatic-speech-recognition | true | false | false | apache-2.0 | ['de'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'whisper-event'] | true | true | true | 4,496 | false |
<style>
img {
display: inline;
}
</style>



# Fine-tuned whisper-large-v2 model for ASR in German
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2), trained on the mozilla-foundation/common_voice_11_0 de dataset. When using the model make sure that your speech input is also sampled at 16Khz. **This model also predicts casing and punctuation.**
## Performance
*Below are the WERs of the pre-trained models on the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0). These results are reported in the original [paper](https://cdn.openai.com/papers/whisper.pdf).*
| Model | Common Voice 9.0 |
| --- | :---: |
| [openai/whisper-small](https://huggingface.co/openai/whisper-small) | 13.0 |
| [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) | 8.5 |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | 6.4 |
*Below are the WERs of the fine-tuned models on the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0).*
| Model | Common Voice 11.0 |
| --- | :---: |
| [bofenghuang/whisper-small-cv11-german](https://huggingface.co/bofenghuang/whisper-small-cv11-german) | 11.35 |
| [bofenghuang/whisper-medium-cv11-german](https://huggingface.co/bofenghuang/whisper-medium-cv11-german) | 7.05 |
| [bofenghuang/whisper-large-v2-cv11-german](https://huggingface.co/bofenghuang/whisper-large-v2-cv11-german) | **5.76** |
## Usage
Inference with 🤗 Pipeline
```python
import torch
from datasets import load_dataset
from transformers import pipeline
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load pipeline
pipe = pipeline("automatic-speech-recognition", model="bofenghuang/whisper-large-v2-cv11-german", device=device)
# NB: set forced_decoder_ids for generation utils
pipe.model.config.forced_decoder_ids = pipe.tokenizer.get_decoder_prompt_ids(language="de", task="transcribe")
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "de", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = test_segment["audio"]
# NB: decoding option
# limit the maximum number of generated tokens to 225
pipe.model.config.max_length = 225 + 1
# sampling
# pipe.model.config.do_sample = True
# beam search
# pipe.model.config.num_beams = 5
# return
# pipe.model.config.return_dict_in_generate = True
# pipe.model.config.output_scores = True
# pipe.model.config.num_return_sequences = 5
# Run
generated_sentences = pipe(waveform)["text"]
```
Inference with 🤗 low-level APIs
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load model
model = AutoModelForSpeechSeq2Seq.from_pretrained("bofenghuang/whisper-large-v2-cv11-german").to(device)
processor = AutoProcessor.from_pretrained("bofenghuang/whisper-large-v2-cv11-german", language="german", task="transcribe")
# NB: set forced_decoder_ids for generation utils
model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language="de", task="transcribe")
# 16_000
model_sample_rate = processor.feature_extractor.sampling_rate
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "de", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = torch.from_numpy(test_segment["audio"]["array"])
sample_rate = test_segment["audio"]["sampling_rate"]
# Resample
if sample_rate != model_sample_rate:
resampler = torchaudio.transforms.Resample(sample_rate, model_sample_rate)
waveform = resampler(waveform)
# Get feat
inputs = processor(waveform, sampling_rate=model_sample_rate, return_tensors="pt")
input_features = inputs.input_features
input_features = input_features.to(device)
# Generate
generated_ids = model.generate(inputs=input_features, max_new_tokens=225) # greedy
# generated_ids = model.generate(inputs=input_features, max_new_tokens=225, num_beams=5) # beam search
# Detokenize
generated_sentences = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Normalise predicted sentences if necessary
``` | c045d05977ca6afd5bc84f5f49716549 |
LaCambre/vulvine-look-v02 | LaCambre | null | 20 | 8 | diffusers | 1 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 3 | 3 | 0 | 0 | 0 | 0 | 0 | ['text-to-image'] | false | true | true | 718 | false | ### Vulvine_Look_v02 on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
#### Model by LaCambre
This your the Stable Diffusion model fine-tuned the Vulvine_Look_v02 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt(s)`: **VulvineLook**
It was trained based on the shortfilm "Vulvine, Reine d'Extase. @vulvine.gobelins
https://vimeo.com/769104378
Sample pictures of this concept:
VulvineLook
.jpg)
| b457cb7e05a1f44a45332b555caa4840 |
espnet/kan-bayashi_jsut_tts_train_conformer_fastspeech2_tacotron2_teacher_raw-truncated-15ef5f | espnet | null | 19 | 3 | espnet | 0 | text-to-speech | false | false | false | cc-by-4.0 | ['ja'] | ['jsut'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['espnet', 'audio', 'text-to-speech'] | false | true | true | 1,883 | false | ## Example ESPnet2 TTS model
### `kan-bayashi/jsut_tts_train_conformer_fastspeech2_tacotron2_teacher_raw_phn_jaconv_pyopenjtalk_accent_train.loss.ave`
♻️ Imported from https://zenodo.org/record/4381102/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 3992a919a02a26f856e400c2b42e6b1a |
wietsedv/xlm-roberta-base-ft-udpos28-et | wietsedv | xlm-roberta | 8 | 17 | transformers | 0 | token-classification | true | false | false | apache-2.0 | ['et'] | ['universal_dependencies'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['part-of-speech', 'token-classification'] | true | true | true | 568 | false |
# XLM-RoBERTa base Universal Dependencies v2.8 POS tagging: Estonian
This model is part of our paper called:
- Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages
Check the [Space](https://huggingface.co/spaces/wietsedv/xpos) for more details.
## Usage
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-et")
model = AutoModelForTokenClassification.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-et")
```
| 69081f4b276c7c11128b5ddc9f60c828 |
Helsinki-NLP/opus-mt-fr-de | Helsinki-NLP | marian | 11 | 9,538 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 1,161 | false |
### opus-mt-fr-de
* source languages: fr
* target languages: de
* OPUS readme: [fr-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| euelections_dev2019.transformer-align.fr | 26.4 | 0.571 |
| newssyscomb2009.fr.de | 22.1 | 0.524 |
| news-test2008.fr.de | 22.1 | 0.524 |
| newstest2009.fr.de | 21.6 | 0.520 |
| newstest2010.fr.de | 22.6 | 0.527 |
| newstest2011.fr.de | 21.5 | 0.518 |
| newstest2012.fr.de | 22.4 | 0.516 |
| newstest2013.fr.de | 24.2 | 0.532 |
| newstest2019-frde.fr.de | 27.9 | 0.595 |
| Tatoeba.fr.de | 49.1 | 0.676 |
| 42c2b15875c3c9ca6574cdc591b08da7 |
jonatasgrosman/exp_w2v2r_de_vp-100k_age_teens-5_sixties-5_s872 | jonatasgrosman | wav2vec2 | 10 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['de'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'de'] | false | true | true | 497 | false | # exp_w2v2r_de_vp-100k_age_teens-5_sixties-5_s872
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 17baea7393dd106e41aca8409e31bf67 |
yashveer11/testing_class | yashveer11 | bert | 16 | 7 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,355 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testing_class
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2256
- F1: 0.8907
- Roc Auc: 0.9118
- Accuracy: 0.685
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| No log | 1.0 | 250 | 0.2552 | 0.8687 | 0.8942 | 0.6325 |
| 0.3193 | 2.0 | 500 | 0.2256 | 0.8907 | 0.9118 | 0.685 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 589fc83dbb080e4225a4dc9c613bdf76 |
jonatasgrosman/exp_w2v2t_zh-cn_vp-100k_s328 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['zh-CN'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'zh-CN'] | false | true | true | 481 | false | # exp_w2v2t_zh-cn_vp-100k_s328
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (zh-CN)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| d2dac4188429cead544b101545656f58 |
jhaochenz/finetuned_gpt2-large_sst2_negation0.1_pretrainedTrue_epochs1 | jhaochenz | gpt2 | 14 | 0 | transformers | 0 | text-generation | true | false | false | mit | null | ['sst2'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,162 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-large_sst2_negation0.1_pretrainedTrue_epochs1
This model is a fine-tuned version of [gpt2-large](https://huggingface.co/gpt2-large) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8409
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.0574 | 1.0 | 1329 | 2.8409 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.7.0
- Datasets 2.8.0
- Tokenizers 0.13.2
| c2018623970471bb0d571712bcaf5424 |
jonatasgrosman/exp_w2v2t_th_xls-r_s879 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['th'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'th'] | false | true | true | 453 | false | # exp_w2v2t_th_xls-r_s879
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (th)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 86fd291920d2c0a574f9aefc9534415e |
dheerajdhanvee/bert-finetuned-ner | dheerajdhanvee | bert | 8 | 6 | transformers | 0 | token-classification | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,518 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# dheerajdhanvee/bert-finetuned-ner
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0095
- Validation Loss: 0.0674
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1695, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1219 | 0.0617 | 0 |
| 0.0387 | 0.0560 | 1 |
| 0.0225 | 0.0592 | 2 |
| 0.0145 | 0.0634 | 3 |
| 0.0095 | 0.0674 | 4 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| ec01361d1e4765fd13e3099f3da46ada |
ttwj-sutd/finetuning-sentiment-model-3000-samples-5pm | ttwj-sutd | distilbert | 10 | 9 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,416 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples-5pm
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4325
- Accuracy: 0.88
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 188 | 0.3858 | 0.84 |
| No log | 2.0 | 376 | 0.3146 | 0.8833 |
| 0.2573 | 3.0 | 564 | 0.3938 | 0.8833 |
| 0.2573 | 4.0 | 752 | 0.4325 | 0.88 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
| 6c12381a806f2bb8d3e5c4b3f7b88fc0 |
ajdowney/3epoch-1warmup-0.1decay-2e-6lr | ajdowney | bert | 8 | 6 | transformers | 0 | token-classification | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,749 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ajdowney/3epoch-1warmup-0.1decay-2e-6lr
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4965
- Validation Loss: 0.5919
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-06, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-06, 'decay_steps': 170, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.1}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.6140 | 0.5996 | 0 |
| 0.5101 | 0.5929 | 1 |
| 0.4965 | 0.5919 | 2 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.10.0
- Datasets 2.6.1
- Tokenizers 0.13.1
| c67f9f6a81e2a9ff1c0c928083b1b591 |
Helsinki-NLP/opus-mt-ca-es | Helsinki-NLP | marian | 10 | 2,127 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 770 | false |
### opus-mt-ca-es
* source languages: ca
* target languages: es
* OPUS readme: [ca-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ca-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.zip)
* test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.test.txt)
* test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ca.es | 74.9 | 0.863 |
| b8376363cb2f1eff2595c809abe6711d |
PlanTL-GOB-ES/mt-plantl-es-gl | PlanTL-GOB-ES | null | 5 | 0 | null | 0 | null | false | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 8,674 | false | ## PlanTL Project's Spanish-Galician machine translation model
## Table of Contents
- [Model Description](#model-description)
- [Intended Uses and Limitations](#intended-use)
- [How to Use](#how-to-use)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Data Preparation](#data-preparation)
- [Tokenization](#tokenization)
- [Hyperparameters](#hyperparameters)
- [Evaluation](#evaluation)
- [Variable and Metrics](#variable-and-metrics)
- [Evaluation Results](#evaluation-results)
- [Additional Information](#additional-information)
- [Author](#author)
- [Contact Information](#contact-information)
- [Copyright](#copyright)
- [Licensing Information](#licensing-information)
- [Funding](#funding)
- [Disclaimer](#disclaimer)
## Model description
This model was trained from scratch using the [Fairseq toolkit](https://fairseq.readthedocs.io/en/latest/) on a combination of Spanish-Galician datasets, up to 31 million sentences. Additionally, the model is evaluated on several public datasets, Flores 101, Spanish Constitutioni (TaCon) and Tatoeba.
## Intended uses and limitations
You can use this model for machine translation from Spanish to Galician.
## How to use
### Usage
Required libraries:
```bash
pip install ctranslate2 pyonmttok
```
Translate a sentence using python
```python
import ctranslate2
import pyonmttok
from huggingface_hub import snapshot_download
model_dir = snapshot_download(repo_id="PlanTL-GOB-ES/mt-plantl-es-gl", revision="main")
tokenizer=pyonmttok.Tokenizer(mode="none", sp_model_path = model_dir + "/spm.model")
tokenized=tokenizer.tokenize("Bienvenido al Proyecto PlanTL!")
translator = ctranslate2.Translator(model_dir)
translated = translator.translate_batch([tokenized[0]])
print(tokenizer.detokenize(translated[0][0]['tokens']))
```
## Training
### Training data
The model was trained on a combination of the following datasets:
| Dataset | Sentences |
|-------------------|----------------|
| CLUVI | 318.612 |
| WikiMatrix | 438.181 |
| WikiMedia | 83.511 |
| QED | 30.211 |
| TED 2020 v1 | 33.324 |
| CCMatrix v1 | 24.165.978 |
| ParaCrawl | 6.537.374 |
| OpenSubtitles | 197.519 |
| **Total** | **31.804.710** |
### Training procedure
### Data preparation
All datasets are concatenated and filtered using the [mBERT Gencata parallel filter](https://huggingface.co/projecte-aina/mbert-base-gencata) and cleaned using the clean-corpus-n.pl script from [moses](https://github.com/moses-smt/mosesdecoder), allowing sentences between 5 and 150 words.
Before training, the punctuation is normalized using a modified version of the join-single-file.py script from [SoftCatalà](https://github.com/Softcatala/nmt-models/blob/master/data-processing-tools/join-single-file.py)
#### Tokenization
All data is tokenized using sentencepiece, with 50 thousand token sentencepiece model learned from the combination of all filtered training data. This model is included.
#### Hyperparameters
The model is based on the Transformer-XLarge proposed by [Subramanian et al.](https://aclanthology.org/2021.wmt-1.18.pdf)
The following hyperparamenters were set on the Fairseq toolkit:
| Hyperparameter | Value |
|------------------------------------|-----------------------------------|
| Architecture | transformer_vaswani_wmt_en_de_big |
| Embedding size | 1024 |
| Feedforward size | 4096 |
| Number of heads | 16 |
| Encoder layers | 24 |
| Decoder layers | 6 |
| Normalize before attention | True |
| --share-decoder-input-output-embed | True |
| --share-all-embeddings | True |
| Effective batch size | 96.000 |
| Optimizer | adam |
| Adam betas | (0.9, 0.980) |
| Clip norm | 0.0 |
| Learning rate | 1e-3 |
| Lr. schedurer | inverse sqrt |
| Warmup updates | 4000 |
| Dropout | 0.1 |
| Label smoothing | 0.1 |
The model was trained using shards of 10 million sentences, for a total of 8.000 updates. Weights were saved every 1000 updates and reported results are the average of the last 6 checkpoints. After this, the model was trained an extra epoch on the CLUVI dataset.
## Evaluation
### Variable and metrics
We use the BLEU score for evaluation on test sets: [Flores-101](https://github.com/facebookresearch/flores), [TaCon](https://elrc-share.eu/repository/browse/tacon-spanish-constitution-mt-test-set/84a96138b98611ec9c1a00155d02670628f3e6857b0f422abd82abc3795ec8c2/), [Tatoeba](https://opus.nlpl.eu/Tatoeba.php)
### Evaluation results
Below are the evaluation results on the machine translation from Spanish to Galician compared to [Apertium](https://apertium.org/), [Google Translate](https://translate.google.es/?hl=es) and [M2M 100 418M](https://huggingface.co/facebook/m2m100_418M):
| Test set | Apertium | Google Translate | M2M-100 418M | mt-plantl-es-gl |
|----------------------|------------|------------------|--------------|-----------------|
| Spanish Constitution | 74,5 | 60,4 | 70,7 | **84,3** |
| Flores 101 devtest | 21,4 | **25,6** | 21,6 | 21,8 |
| Tatoeba | **67,9** | 52,8 | 53,9 | 66,6 |
| Average | 54,3 | 46,3 | 48,7 | **57,6** |
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
### Contact information
For further information, send an email to <plantl-gob-es@bsc.es>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
This work is licensed under a [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA)
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for Digitalization and Artificial Intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
</details>
| 978c9e0017d871127b75337504fd9151 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.