
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
mit | [] | false | This model is the **query** encoder of ANCE-Tele trained on TriviaQA, described in the EMNLP 2022 paper ["Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives"](https://arxiv.org/pdf/2210.17167.pdf). The associated GitHub repository is available at https://github.com/OpenMatch/ANCE-Tele. ANCE-Tele only trains with self-mined negatives (teleportation negatives) without using additional negatives (e.g., BM25, other DR systems) and eliminates the dependency on filtering strategies and distillation modules. |NQ (Test)|R@5|R@20|R@20| |:---|:---|:---|:---| |ANCE-Tele|76.9|83.4|87.3| ``` @inproceedings{sun2022ancetele, title={Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives}, author={Si Sun, Chenyan Xiong, Yue Yu, Arnold Overwijk, Zhiyuan Liu and Jie Bao}, booktitle={Proceedings of EMNLP 2022}, year={2022} } ``` | 27cb5f6efcf5b477388b08e525d59993 |
creativeml-openrail-m | [] | false | Made using highly curated best quality masterful artwork from an ancient indonesian stone carving website, with some help from their independent doodling connoisseur brothers in arms, 3000 pieces of their best work. Prompt used: aiseeic aisee_10000.ckpt was made with Anything v.3. aiseeic_15000.ckpt was made with SD 1.5. AIsee (Anything) examples    AIsee SD examples    I own nothing and I will be happy. | bd67382e6caeafb994b6a8763870b6ae |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Large Norwegian This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the NbAiLab/NCC_S dataset. It achieves the following results on the evaluation set: - Loss: 0.2776 - Wer: 12.5152 | e24346f1fdfae8c7bd7938c66c1e1387 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 12 - eval_batch_size: 6 - seed: 42 - distributed_type: multi-GPU - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 5000 - mixed_precision_training: Native AMP | 5070936e4bac6366589ab6456bed2be6 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.6892 | 0.2 | 1000 | 0.3177 | 15.1035 | | 0.6782 | 0.4 | 2000 | 0.3033 | 13.4592 | | 0.6317 | 0.6 | 3000 | 0.2909 | 13.7637 | | 0.5609 | 0.8 | 4000 | 0.2803 | 12.6675 | | 0.5726 | 1.0 | 5000 | 0.2776 | 12.5152 | | b7e33394c623c9d8693b8f106033bb9e |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'sat', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | wav2vec2-large-xls-r-300m-sat-a3 This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - SAT dataset. It achieves the following results on the evaluation set: - Loss: 0.8961 - Wer: 0.3976 | 2bfc5604e456ade42adc3de0bbfceeb8 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'sat', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Evaluation Commands 1. To evaluate on mozilla-foundation/common_voice_8_0 with test split python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-sat-a3 --dataset mozilla-foundation/common_voice_8_0 --config sat --split test --log_outputs 2. To evaluate on speech-recognition-community-v2/dev_data Note: Santali (Ol Chiki) language not found in speech-recognition-community-v2/dev_data | 6d4c9cbe0766bde5f590ae6563779ada |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'sat', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0004 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 32 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 200 - num_epochs: 200 - mixed_precision_training: Native AMP | 154ab8c4c5bf5eb08ec3760cb759dacd |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'sat', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:------:|:----:|:---------------:|:------:| | 11.1266 | 33.29 | 100 | 2.8577 | 1.0 | | 2.1549 | 66.57 | 200 | 1.0799 | 0.5542 | | 0.5628 | 99.86 | 300 | 0.7973 | 0.4016 | | 0.0779 | 133.29 | 400 | 0.8424 | 0.4177 | | 0.0404 | 166.57 | 500 | 0.9048 | 0.4137 | | 0.0212 | 199.86 | 600 | 0.8961 | 0.3976 | | 444cdc7286d9588fb673ec169cbd5cbf |
creativeml-openrail-m | ['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'animal'] | false | DreamBooth model for the mikovelliaponte concept trained by davidaponte on the davidaponte/dreambooth-hackathon-images-miko dataset. This is a Stable Diffusion model fine-tuned on the mikovelliaponte concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of mikovelliaponte dog** This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part! | 9344269b786723259d2aa57712069b84 |
mit | ['generated_from_trainer'] | false | quirky_ritchie This model was trained from scratch on the tomekkorbak/detoxify-pile-chunk3-0-50000, the tomekkorbak/detoxify-pile-chunk3-50000-100000, the tomekkorbak/detoxify-pile-chunk3-100000-150000, the tomekkorbak/detoxify-pile-chunk3-150000-200000, the tomekkorbak/detoxify-pile-chunk3-200000-250000, the tomekkorbak/detoxify-pile-chunk3-250000-300000, the tomekkorbak/detoxify-pile-chunk3-300000-350000, the tomekkorbak/detoxify-pile-chunk3-350000-400000, the tomekkorbak/detoxify-pile-chunk3-400000-450000, the tomekkorbak/detoxify-pile-chunk3-450000-500000, the tomekkorbak/detoxify-pile-chunk3-500000-550000, the tomekkorbak/detoxify-pile-chunk3-550000-600000, the tomekkorbak/detoxify-pile-chunk3-600000-650000, the tomekkorbak/detoxify-pile-chunk3-650000-700000, the tomekkorbak/detoxify-pile-chunk3-700000-750000, the tomekkorbak/detoxify-pile-chunk3-750000-800000, the tomekkorbak/detoxify-pile-chunk3-800000-850000, the tomekkorbak/detoxify-pile-chunk3-850000-900000, the tomekkorbak/detoxify-pile-chunk3-900000-950000, the tomekkorbak/detoxify-pile-chunk3-950000-1000000, the tomekkorbak/detoxify-pile-chunk3-1000000-1050000, the tomekkorbak/detoxify-pile-chunk3-1050000-1100000, the tomekkorbak/detoxify-pile-chunk3-1100000-1150000, the tomekkorbak/detoxify-pile-chunk3-1150000-1200000, the tomekkorbak/detoxify-pile-chunk3-1200000-1250000, the tomekkorbak/detoxify-pile-chunk3-1250000-1300000, the tomekkorbak/detoxify-pile-chunk3-1300000-1350000, the tomekkorbak/detoxify-pile-chunk3-1350000-1400000, the tomekkorbak/detoxify-pile-chunk3-1400000-1450000, the tomekkorbak/detoxify-pile-chunk3-1450000-1500000, the tomekkorbak/detoxify-pile-chunk3-1500000-1550000, the tomekkorbak/detoxify-pile-chunk3-1550000-1600000, the tomekkorbak/detoxify-pile-chunk3-1600000-1650000, the tomekkorbak/detoxify-pile-chunk3-1650000-1700000, the tomekkorbak/detoxify-pile-chunk3-1700000-1750000, the tomekkorbak/detoxify-pile-chunk3-1750000-1800000, the tomekkorbak/detoxify-pile-chunk3-1800000-1850000, the tomekkorbak/detoxify-pile-chunk3-1850000-1900000 and the tomekkorbak/detoxify-pile-chunk3-1900000-1950000 datasets. | 105204fcb27bdf55ae8f5e65623ee714 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0005 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 64 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.01 - training_steps: 50354 - mixed_precision_training: Native AMP | 4667347b33dc01728f8225b3721c9e86 |
mit | ['generated_from_trainer'] | false | Full config {'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'], 'is_split_by_sentences': True}, 'generation': {'force_call_on': [25354], 'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}], 'scenario_configs': [{'generate_kwargs': {'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_samples': 2048}, {'generate_kwargs': {'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'challenging_rtp', 'num_samples': 2048, 'prompts_path': 'resources/challenging_rtp.jsonl'}], 'scorer_config': {'device': 'cuda:0'}}, 'kl_gpt3_callback': {'force_call_on': [25354], 'max_tokens': 64, 'num_samples': 4096}, 'model': {'from_scratch': True, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'path_or_name': 'gpt2'}, 'objective': {'alpha': 1, 'name': 'Unlikelihood', 'score_threshold': 0.00078}, 'tokenizer': {'path_or_name': 'gpt2'}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 64, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'quirky_ritchie', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.0005, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000, 'output_dir': 'training_output104340', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 25354, 'save_strategy': 'steps', 'seed': 42, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | 1828f90f6dd499dc782fe8d94ef25492 |
mit | ['generated_from_trainer'] | false | emotion_model This model is a fine-tuned version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 1.7815 - F1: 0.1455 | b1bc001894b79be8697fd765dd5d906d |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 10 - eval_batch_size: 10 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5 | 8d1eb9c56611c5c4b412402561c3759e |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | 1.7968 | 1.0 | 2 | 1.7804 | 0.2286 | | 1.7918 | 2.0 | 4 | 1.7812 | 0.2286 | | 1.7867 | 3.0 | 6 | 1.7822 | 0.08 | | 1.7884 | 4.0 | 8 | 1.7816 | 0.08 | | 1.7833 | 5.0 | 10 | 1.7815 | 0.1455 | | ef614d49977a43e8c21e89601cebc9ef |
apache-2.0 | [] | false | bert-base-en-fr-zh-ja-vi-cased We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages. Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy. For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf). | 1243f39c0b354c3409644057893721b1 |
apache-2.0 | [] | false | How to use ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-fr-zh-ja-vi-cased") model = AutoModel.from_pretrained("Geotrend/bert-base-en-fr-zh-ja-vi-cased") ``` To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers). | d52d822f0353f0a89cbad1b30eca0eaa |
apache-2.0 | [] | false | distilbert-base-en-es-it-cased We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages. Our versions give exactly the same representations produced by the original model which preserves the original accuracy. For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf). | 4e016c1f662a0653e3eda1c0c09483d3 |
apache-2.0 | [] | false | How to use ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-en-es-it-cased") model = AutoModel.from_pretrained("Geotrend/distilbert-base-en-es-it-cased") ``` To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers). | 6c14a06c6efe2558f17d73a93000b0d6 |
apache-2.0 | [] | false | How to cite ```bibtex @inproceedings{smallermdistilbert, title={Load What You Need: Smaller Versions of Mutlilingual BERT}, author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire}, booktitle={SustaiNLP / EMNLP}, year={2020} } ``` | 5aea06530efd57472ea864a2000aeda4 |
apache-2.0 | [] | false | GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models **Paper**: [GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models](https://arxiv.org/abs/2112.10741) **Abstract**: *Diffusion models have recently been shown to generate high-quality synthetic images, especially when paired with a guidance technique to trade off diversity for fidelity. We explore diffusion models for the problem of text-conditional image synthesis and compare two different guidance strategies: CLIP guidance and classifier-free guidance. We find that the latter is preferred by human evaluators for both photorealism and caption similarity, and often produces photorealistic samples. Samples from a 3.5 billion parameter text-conditional diffusion model using classifier-free guidance are favored by human evaluators to those from DALL-E, even when the latter uses expensive CLIP reranking. Additionally, we find that our models can be fine-tuned to perform image inpainting, enabling powerful text-driven image editing.* | 4b58f2ce75277079956e0be41bf7ee0b |
apache-2.0 | [] | false | Samples 1.  2.  3.  | 077668f64258e2860f75c5b1f683f2d8 |
apache-2.0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-06 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 600 - training_steps: 6000 - mixed_precision_training: Native AMP | 3b4b8714f09e5611da7f62ae937c444f |
apache-2.0 | ['lexical normalization'] | false | Fine-tuned ByT5-small for MultiLexNorm (Turkish-German version)  This is the official release of the fine-tuned models for **the winning entry** to the [*W-NUT 2021: Multilingual Lexical Normalization (MultiLexNorm)* shared task](https://noisy-text.github.io/2021/multi-lexnorm.html), which evaluates lexical-normalization systems on 12 social media datasets in 11 languages. Our system is based on [ByT5](https://arxiv.org/abs/2105.13626), which we first pre-train on synthetic data and then fine-tune on authentic normalization data. It achieves the best performance by a wide margin in intrinsic evaluation, and also the best performance in extrinsic evaluation through dependency parsing. In addition to these fine-tuned models, we also release the source files on [GitHub](https://github.com/ufal/multilexnorm2021) and an interactive demo on [Google Colab](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing). | 898fc83f671e550201fb317f15d4d88a |
apache-2.0 | ['lexical normalization'] | false | How to use The model was *not* fine-tuned in a standard sentence-to-sentence setting – instead, it was tailored to the token-to-token definition of MultiLexNorm data. Please refer to [**the interactive demo on Colab notebook**](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing) to learn how to use these models. | 929f368c3c08df5be47ad330ad6c2e5a |
apache-2.0 | ['lexical normalization'] | false | How to cite ```bibtex @inproceedings{wnut-ufal, title= "{ÚFAL} at {MultiLexNorm} 2021: Improving Multilingual Lexical Normalization by Fine-tuning {ByT5}", author = "Samuel, David and Straka, Milan", booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)", year = "2021", publisher = "Association for Computational Linguistics", address = "Punta Cana, Dominican Republic" } ``` | 341ad670ddb278422ba6e4f63d0d9cd1 |
apache-2.0 | ['lexical normalization'] | false | ByT5 - Small ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small). ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4 | 1dc347193fd2cf060bd7f52f607deb55 |
apache-2.0 | ['lexical normalization'] | false | c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task. ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292). Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel* | c292f0edf773e620bb348db48b2bfb39 |
cc-by-4.0 | ['questions and answers generation'] | false | Model Card of `lmqg/mt5-base-frquad-qag` This model is fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) for question & answer pair generation task on the [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | e7dea0c47730ec10af063674e8a873cc |
cc-by-4.0 | ['questions and answers generation'] | false | Overview - **Language model:** [google/mt5-base](https://huggingface.co/google/mt5-base) - **Language:** fr - **Training data:** [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) (default) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | a9f8fa6740831a5e4c493a564e01f9a9 |
cc-by-4.0 | ['questions and answers generation'] | false | model prediction question_answer_pairs = model.generate_qa("Créateur » (Maker), lui aussi au singulier, « le Suprême Berger » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/mt5-base-frquad-qag") output = pipe("Créateur » (Maker), lui aussi au singulier, « le Suprême Berger » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.") ``` | 37d3f8f3f03bba3592185d77c4bf8fe8 |
cc-by-4.0 | ['questions and answers generation'] | false | Evaluation - ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-base-frquad-qag/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qag_frquad.default.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:-------------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 78.28 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | QAAlignedF1Score (MoverScore) | 51.66 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | QAAlignedPrecision (BERTScore) | 78.36 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | QAAlignedPrecision (MoverScore) | 51.73 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | QAAlignedRecall (BERTScore) | 78.21 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | QAAlignedRecall (MoverScore) | 51.59 | default | [lmqg/qag_frquad](https://huggingface.co/datasets/lmqg/qag_frquad) | | f56c743ab93973f45126d1c69552b3ed |
cc-by-4.0 | ['questions and answers generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qag_frquad - dataset_name: default - input_types: ['paragraph'] - output_types: ['questions_answers'] - prefix_types: None - model: google/mt5-base - max_length: 512 - max_length_output: 256 - epoch: 11 - batch: 8 - lr: 0.001 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 16 - label_smoothing: 0.0 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-base-frquad-qag/raw/main/trainer_config.json). | a1c86a6cdc29c367afd66e93d07b44a1 |
apache-2.0 | ['translation'] | false | opus-mt-sv-ho * source languages: sv * target languages: ho * OPUS readme: [sv-ho](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-ho/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-ho/opus-2020-01-16.zip) * test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ho/opus-2020-01-16.test.txt) * test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ho/opus-2020-01-16.eval.txt) | 7f97b7b937554dca6008b2004335d9d2 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-cased-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0919 - Precision: 0.8940 - Recall: 0.9009 - F1: 0.8974 - Accuracy: 0.9750 | 3b08cf70a1ab287580e76bf744bd1e09 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 1 | 8f884cb128202db1fc56067231e67d06 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.1147 | 1.0 | 1756 | 0.0919 | 0.8940 | 0.9009 | 0.8974 | 0.9750 | | adb700b0c9ff377a5baf5256a00f6509 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | sentence-transformers/xlm-r-bert-base-nli-mean-tokens This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. | 3e54535cc258446e46f9c5680c79832a |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Usage (Sentence-Transformers) Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed: ``` pip install -U sentence-transformers ``` Then you can use the model like this: ```python from sentence_transformers import SentenceTransformer sentences = ["This is an example sentence", "Each sentence is converted"] model = SentenceTransformer('sentence-transformers/xlm-r-bert-base-nli-mean-tokens') embeddings = model.encode(sentences) print(embeddings) ``` | fbd22fec94c12216918a4f3f04ebee9a |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | First element of model_output contains all token embeddings input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9) | 1e0666dda09c59ec14b00f6963061ff8 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Load model from HuggingFace Hub tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/xlm-r-bert-base-nli-mean-tokens') model = AutoModel.from_pretrained('sentence-transformers/xlm-r-bert-base-nli-mean-tokens') | d1de83cb98b2eaf8cb77b1dc07d59051 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Evaluation Results For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/xlm-r-bert-base-nli-mean-tokens) | 90a7ddee03c934f39bbc369f09604995 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Full Model Architecture ``` SentenceTransformer( (0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel (1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False}) ) ``` | eff092895ec00d24f1e8367810146718 |
apache-2.0 | [] | false | bert-base-pl-cased We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages. Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy. For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf). | 9f3b8e4d798481cca17e8aedb525862f |
apache-2.0 | [] | false | How to use ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-pl-cased") model = AutoModel.from_pretrained("Geotrend/bert-base-pl-cased") ``` To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers). | b9aa72482e51a9b57a74d62fc46ef0f7 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Ad-Corre Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild [](https://paperswithcode.com/sota/facial-expression-recognition-on-raf-db?p=ad-corre-adaptive-correlation-based-loss-for) <!-- [](https://paperswithcode.com/sota/facial-expression-recognition-on-affectnet?p=ad-corre-adaptive-correlation-based-loss-for) [](https://paperswithcode.com/sota/facial-expression-recognition-on-fer2013?p=ad-corre-adaptive-correlation-based-loss-for) --> | b2e6f3b3ea111fdcfa6168e411ef20e4 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Link to the paperswithcode.com: https://paperswithcode.com/paper/ad-corre-adaptive-correlation-based-loss-for ``` Please cite this work as: @ARTICLE{9727163, author={Fard, Ali Pourramezan and Mahoor, Mohammad H.}, journal={IEEE Access}, title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild}, year={2022}, volume={}, number={}, pages={1-1}, doi={10.1109/ACCESS.2022.3156598}} ``` | d3d858b5e777bfd5652fae8db83804f0 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Introduction Automated Facial Expression Recognition (FER) in the wild using deep neural networks is still challenging due to intra-class variations and inter-class similarities in facial images. Deep Metric Learning (DML) is among the widely used methods to deal with these issues by improving the discriminative power of the learned embedded features. This paper proposes an Adaptive Correlation (Ad-Corre) Loss to guide the network towards generating embedded feature vectors with high correlation for within-class samples and less correlation for between-class samples. Ad-Corre consists of 3 components called Feature Discriminator, Mean Discriminator, and Embedding Discriminator. We design the Feature Discriminator component to guide the network to create the embedded feature vectors to be highly correlated if they belong to a similar class, and less correlated if they belong to different classes. In addition, the Mean Discriminator component leads the network to make the mean embedded feature vectors of different classes to be less similar to each other.We use Xception network as the backbone of our model, and contrary to previous work, we propose an embedding feature space that contains k feature vectors. Then, the Embedding Discriminator component penalizes the network to generate the embedded feature vectors, which are dissimilar.We trained our model using the combination of our proposed loss functions called Ad-Corre Loss jointly with the cross-entropy loss. We achieved a very promising recognition accuracy on AffectNet, RAF-DB, and FER-2013. Our extensive experiments and ablation study indicate the power of our method to cope well with challenging FER tasks in the wild. | 9625e2971672019ef0b3861243a07d25 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Evaluation and Samples The following samples are taken from the paper: 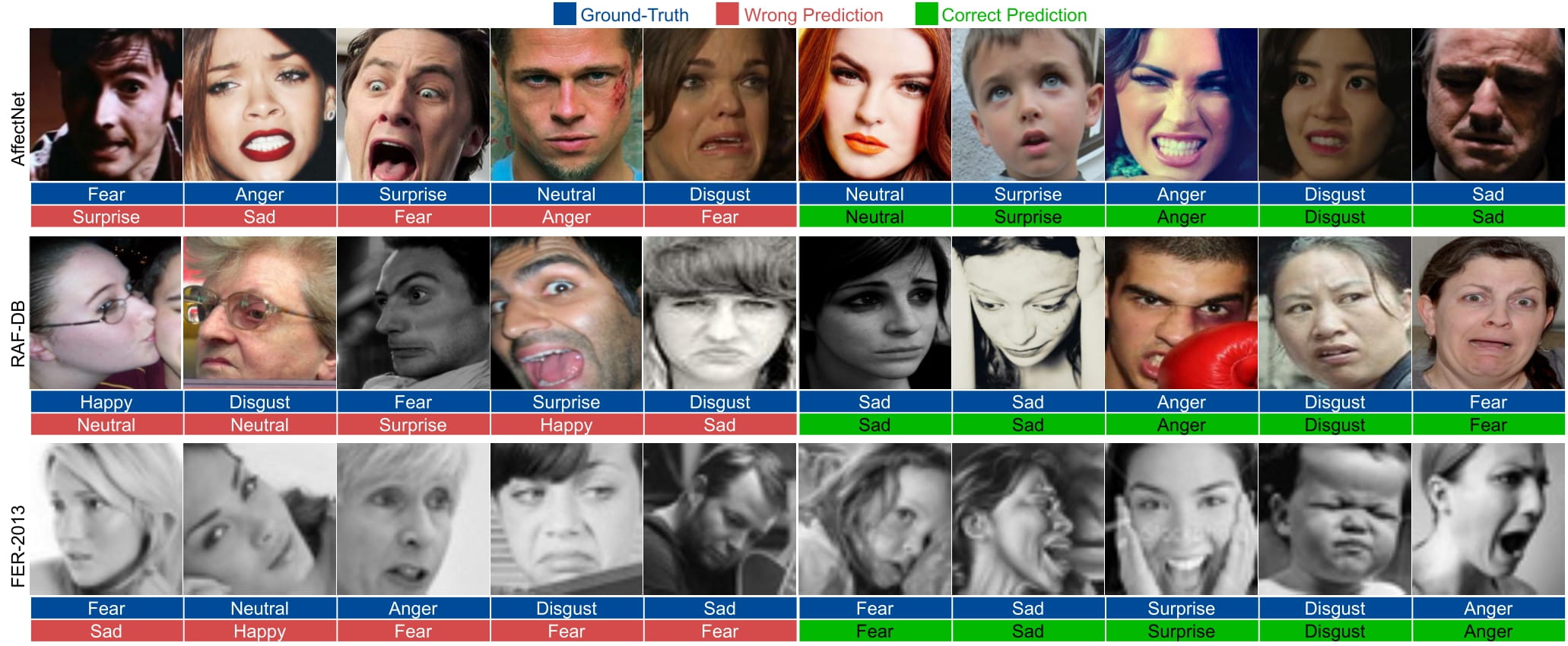 ---------------------------------------------------------------------------------------------------------------------------------- | 2cffacfed6db6c0e1ba393bf93d5958a |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Installing the requirements In order to run the code you need to install python >= 3.5. The requirements and the libraries needed to run the code can be installed using the following command: ``` pip install -r requirements.txt ``` | c337d2a888d92553ff5ff15853afc90f |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Using the pre-trained models The pretrained models for Affectnet, RafDB, and Fer2013 are provided in the [Trained_Models](https://github.com/aliprf/Ad-Corre/tree/main/Trained_Models) folder. You can use the following code to predict the facial emotionn of a facial image: ``` tester = TestModels(h5_address='./trained_models/AffectNet_6336.h5') tester.recognize_fer(img_path='./img.jpg') ``` plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file. | d579c6f4dcb296309aa5d23274645485 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Training Network from scratch The information and the code to train the model is provided in train.py .Plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file: ``` '''training part''' trainer = TrainModel(dataset_name=DatasetName.affectnet, ds_type=DatasetType.train_7) trainer.train(arch="xcp", weight_path="./") ``` | f230314d4a9707a6b53371315c555007 |
mit | ['Ad-Corre', 'facial expression recognition', 'emotion recognition', 'expression recognition', 'computer vision', 'CNN', 'loss', 'IEEE Access', 'Tensor Flow'] | false | Preparing Data Data needs to be normalized and saved in npy format. --------------------------------------------------------------- ``` Please cite this work as: @ARTICLE{9727163, author={Fard, Ali Pourramezan and Mahoor, Mohammad H.}, journal={IEEE Access}, title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild}, year={2022}, volume={}, number={}, pages={1-1}, doi={10.1109/ACCESS.2022.3156598}} ``` | 7fd39307d502d78fdf0e86a015725e94 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset. It achieves the following results on the evaluation set: - Loss: 1.1581 | 27c5b0de58fc1cecd3a927fff5250978 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.218 | 1.0 | 5533 | 1.1630 | | 0.9616 | 2.0 | 11066 | 1.1310 | | 0.7547 | 3.0 | 16599 | 1.1581 | | 03b89a97e941f10e08004fce339331d7 |
mit | ['generated_from_trainer'] | false | bart-cnn-pubmed-arxiv-pubmed-v3-e12 This model is a fine-tuned version of [theojolliffe/bart-cnn-pubmed-arxiv-pubmed](https://huggingface.co/theojolliffe/bart-cnn-pubmed-arxiv-pubmed) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.8658 - Rouge1: 57.2678 - Rouge2: 43.347 - Rougel: 47.0854 - Rougelsum: 55.4167 - Gen Len: 142.0 | 78a969c76918ce4be9d069226f81ad7f |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 1 - eval_batch_size: 1 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 12 - mixed_precision_training: Native AMP | 4916fe0e1e521fd5a081f1256e371e43 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:| | 1.2548 | 1.0 | 795 | 0.9154 | 53.4249 | 34.0377 | 36.4396 | 50.9884 | 141.8889 | | 0.6994 | 2.0 | 1590 | 0.8213 | 54.7613 | 35.9428 | 38.3899 | 51.9527 | 142.0 | | 0.5272 | 3.0 | 2385 | 0.7703 | 53.8561 | 35.4871 | 38.0502 | 51.131 | 141.8889 | | 0.3407 | 4.0 | 3180 | 0.7764 | 53.9514 | 35.8553 | 39.1935 | 51.7005 | 142.0 | | 0.2612 | 5.0 | 3975 | 0.7529 | 54.4056 | 36.2605 | 40.8003 | 52.0424 | 142.0 | | 0.1702 | 6.0 | 4770 | 0.8105 | 54.2251 | 37.1441 | 41.2472 | 52.2803 | 142.0 | | 0.1276 | 7.0 | 5565 | 0.8004 | 56.49 | 40.4009 | 44.018 | 54.2404 | 141.5556 | | 0.0978 | 8.0 | 6360 | 0.7890 | 56.6339 | 40.9867 | 43.9603 | 54.4468 | 142.0 | | 0.0711 | 9.0 | 7155 | 0.8285 | 56.0469 | 40.7758 | 44.1395 | 53.9668 | 142.0 | | 0.0649 | 10.0 | 7950 | 0.8498 | 56.9873 | 42.4721 | 46.705 | 55.2188 | 142.0 | | 0.0471 | 11.0 | 8745 | 0.8547 | 57.7898 | 43.4238 | 46.5868 | 56.0858 | 142.0 | | 0.0336 | 12.0 | 9540 | 0.8658 | 57.2678 | 43.347 | 47.0854 | 55.4167 | 142.0 | | ad8a2a0f2ed1bd933c18b74594071467 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Wav2Vec2-Large-XLSR-53-Romanian Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romanian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset. When using this model, make sure that your speech input is sampled at 16kHz. | 6d831f8cde26f51d90f4375b9e9f979e |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Usage The model can be used directly (without a language model) as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor test_dataset = load_dataset("common_voice", "ro", split="test[:2%]") processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-romanian") model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-romanian") resampler = torchaudio.transforms.Resample(48_000, 16_000) | ab1ea2b4ac3cebd95599df4063368d28 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the audio files as arrays def speech_file_to_array_fn(batch): speech_array, sampling_rate = torchaudio.load(batch["path"]) batch["speech"] = resampler(speech_array).squeeze().numpy() return batch test_dataset = test_dataset.map(speech_file_to_array_fn) inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits predicted_ids = torch.argmax(logits, dim=-1) print("Prediction:", processor.batch_decode(predicted_ids)) print("Reference:", test_dataset["sentence"][:2]) ``` | f22bbc2c635abdc8bf40b1e71cd9327a |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Evaluation The model can be evaluated as follows on the Romanian test data of Common Voice. ```python import torch import torchaudio import urllib.request import tarfile import pandas as pd from tqdm.auto import tqdm from datasets import load_metric from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor | 5a22294283823c032aec7ae91873189b |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Download the raw data instead of using HF datasets to save disk space data_url = "https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/ro.tar.gz" filestream = urllib.request.urlopen(data_url) data_file = tarfile.open(fileobj=filestream, mode="r|gz") data_file.extractall() wer = load_metric("wer") processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-romanian") model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-romanian") model.to("cuda") cv_test = pd.read_csv("cv-corpus-6.1-2020-12-11/ro/test.tsv", sep='\t') clips_path = "cv-corpus-6.1-2020-12-11/ro/clips/" def clean_sentence(sent): sent = sent.lower() | 7456d4d8068d476483c2685c698d586a |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | remove repeated spaces sent = " ".join(sent.split()) return sent targets = [] preds = [] for i, row in tqdm(cv_test.iterrows(), total=cv_test.shape[0]): row["sentence"] = clean_sentence(row["sentence"]) speech_array, sampling_rate = torchaudio.load(clips_path + row["path"]) resampler = torchaudio.transforms.Resample(sampling_rate, 16_000) row["speech"] = resampler(speech_array).squeeze().numpy() inputs = processor(row["speech"], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1) targets.append(row["sentence"]) preds.append(processor.batch_decode(pred_ids)[0]) print("WER: {:2f}".format(100 * wer.compute(predictions=preds, references=targets))) ``` **Test Result**: 24.84 % | d23763c627d56fdd0c32a5a95fd03033 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert_sa_GLUE_Experiment_logit_kd_rte_96 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE RTE dataset. It achieves the following results on the evaluation set: - Loss: 0.4234 - Accuracy: 0.4729 | 0186c2bc846976abb308d6b4205cca7c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.4577 | 1.0 | 10 | 0.4423 | 0.4729 | | 0.4372 | 2.0 | 20 | 0.4341 | 0.4729 | | 0.43 | 3.0 | 30 | 0.4300 | 0.4729 | | 0.4261 | 4.0 | 40 | 0.4273 | 0.4729 | | 0.4229 | 5.0 | 50 | 0.4253 | 0.4729 | | 0.42 | 6.0 | 60 | 0.4241 | 0.4729 | | 0.4188 | 7.0 | 70 | 0.4236 | 0.4729 | | 0.4179 | 8.0 | 80 | 0.4234 | 0.4729 | | 0.4176 | 9.0 | 90 | 0.4235 | 0.4729 | | 0.4165 | 10.0 | 100 | 0.4235 | 0.4729 | | 0.418 | 11.0 | 110 | 0.4238 | 0.4729 | | 0.4174 | 12.0 | 120 | 0.4238 | 0.4729 | | 0.4171 | 13.0 | 130 | 0.4237 | 0.4729 | | ed4dcb85d7fa7c55d6b6a38011efa126 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert_sa_GLUE_Experiment_data_aug_wnli_96 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE WNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.6935 - Accuracy: 0.5634 | 8dd3ebba0bf5b34863ee37ce95bd481a |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.693 | 1.0 | 218 | 0.6935 | 0.5634 | | 0.6226 | 2.0 | 436 | 1.4150 | 0.1549 | | 0.5091 | 3.0 | 654 | 1.7966 | 0.1268 | | 0.4594 | 4.0 | 872 | 2.1812 | 0.1127 | | 0.4125 | 5.0 | 1090 | 2.6036 | 0.0845 | | 0.3697 | 6.0 | 1308 | 3.0124 | 0.0704 | | 910223ce7eee6107057407c34365b200 |
apache-2.0 | ['translation'] | false | opus-mt-sv-tw * source languages: sv * target languages: tw * OPUS readme: [sv-tw](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-tw/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-tw/opus-2020-01-16.zip) * test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-tw/opus-2020-01-16.test.txt) * test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-tw/opus-2020-01-16.eval.txt) | 882ec54a45b976d64812ee037561ef8b |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | learning_rate 2.5e-6, training with a6000x1, because I am too busy recently, I should not be able to actively do it, and the funds are slightly insufficient ,Forget it, I'm overtraining, take it as an interesting model,(Warning: above 768x832 is recommended, I found that the results below seem to be less than ideal) Will be uploading actively in the near future If you need my help or have better suggestions, come to [Discord server](https://discord.gg/BHb4HvTc6t) [](https://discord.gg/BHb4HvTc6t) | 7a3790d977acf565da3ea240dee4c78f |
apache-2.0 | ['translation'] | false | taw-eng * source group: Tai * target group: English * OPUS readme: [taw-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/taw-eng/README.md) * model: transformer * source language(s): lao tha * target language(s): eng * model: transformer * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-06-28.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/taw-eng/opus-2020-06-28.zip) * test set translations: [opus-2020-06-28.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/taw-eng/opus-2020-06-28.test.txt) * test set scores: [opus-2020-06-28.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/taw-eng/opus-2020-06-28.eval.txt) | 43a6bd23d9cbacb281ee187558610ac5 |
apache-2.0 | ['translation'] | false | Benchmarks | testset | BLEU | chr-F | |-----------------------|-------|-------| | Tatoeba-test.lao-eng.lao.eng | 1.1 | 0.133 | | Tatoeba-test.multi.eng | 38.9 | 0.572 | | Tatoeba-test.tha-eng.tha.eng | 40.6 | 0.588 | | c83ac9e37157274502f614d78f798634 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: taw-eng - source_languages: taw - target_languages: eng - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/taw-eng/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['lo', 'th', 'taw', 'en'] - src_constituents: {'lao', 'tha'} - tgt_constituents: {'eng'} - src_multilingual: True - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/taw-eng/opus-2020-06-28.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/taw-eng/opus-2020-06-28.test.txt - src_alpha3: taw - tgt_alpha3: eng - short_pair: taw-en - chrF2_score: 0.5720000000000001 - bleu: 38.9 - brevity_penalty: 1.0 - ref_len: 7630.0 - src_name: Tai - tgt_name: English - train_date: 2020-06-28 - src_alpha2: taw - tgt_alpha2: en - prefer_old: False - long_pair: taw-eng - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | d0a32714123bcf6618c9caa0365b1370 |
apache-2.0 | ['translation', 'generated_from_trainer'] | false | marian-finetuned-kde4-en-to-ja This model is a fine-tuned version of [Helsinki-NLP/opus-tatoeba-en-ja](https://huggingface.co/Helsinki-NLP/opus-tatoeba-en-ja) on the kde4 dataset. It achieves the following results on the evaluation set: - Loss: 0.9825 - Bleu: 37.1098 | 94228afa8641f0332ffc63c8f63db2ab |
apache-2.0 | ['translation', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 32 - eval_batch_size: 64 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 - mixed_precision_training: Native AMP | 734ec83798005c3e8986f78a0a066c0a |
apache-2.0 | ['generated_from_trainer'] | false | recipe-gauss-2 This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.4204 - Rmse: 0.6484 - Mse: 0.4204 - Mae: 0.4557 | ecc7e58ea58041e25c28ff9a086177bc |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 10 | 5dabd924c5c30e00f2475f5a15fcd086 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae | |:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:| | 0.4002 | 1.0 | 3029 | 0.4228 | 0.6502 | 0.4228 | 0.4485 | | 0.3986 | 2.0 | 6058 | 0.4200 | 0.6481 | 0.4200 | 0.4566 | | 0.3985 | 3.0 | 9087 | 0.4217 | 0.6494 | 0.4217 | 0.4515 | | 0.3977 | 4.0 | 12116 | 0.4212 | 0.6490 | 0.4212 | 0.4528 | | 0.397 | 5.0 | 15145 | 0.4251 | 0.6520 | 0.4251 | 0.4461 | | 0.397 | 6.0 | 18174 | 0.4203 | 0.6483 | 0.4203 | 0.4665 | | 0.3968 | 7.0 | 21203 | 0.4211 | 0.6489 | 0.4211 | 0.4533 | | 0.3964 | 8.0 | 24232 | 0.4208 | 0.6487 | 0.4208 | 0.4543 | | 0.3963 | 9.0 | 27261 | 0.4199 | 0.6480 | 0.4199 | 0.4604 | | 0.3961 | 10.0 | 30290 | 0.4204 | 0.6484 | 0.4204 | 0.4557 | | 81d07cdf5cc4a2f89794cd04624e1fe5 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | sentence-transformers/msmarco-distilbert-multilingual-en-de-v2-tmp-lng-aligned This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. | 8bd23202625915c95315bad930f0d056 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Usage (Sentence-Transformers) Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed: ``` pip install -U sentence-transformers ``` Then you can use the model like this: ```python from sentence_transformers import SentenceTransformer sentences = ["This is an example sentence", "Each sentence is converted"] model = SentenceTransformer('sentence-transformers/msmarco-distilbert-multilingual-en-de-v2-tmp-lng-aligned') embeddings = model.encode(sentences) print(embeddings) ``` | bed230765bbd2a6638ddaa618c403a47 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Load model from HuggingFace Hub tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-multilingual-en-de-v2-tmp-lng-aligned') model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-multilingual-en-de-v2-tmp-lng-aligned') | c0211bd646416247283c689ccefa9ecd |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Evaluation Results For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-multilingual-en-de-v2-tmp-lng-aligned) | 5b7f555bb8a2348e9e8db0dbe4a7e3bb |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Full Model Architecture ``` SentenceTransformer( (0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: DistilBertModel (1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False}) ) ``` | 2059a7049e29414b4c9e9503ac13e9c3 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2_loading_script dataset. It achieves the following results on the evaluation set: - Loss: 4.9348 | 8aa4877dab2b2edeaa78edf5406b6dc9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 15 | 5.4661 | | No log | 2.0 | 30 | 5.0915 | | No log | 3.0 | 45 | 4.9348 | | a9deddd54a4c0ffe9ddf26daf3d7e071 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert_sa_GLUE_Experiment_cola_256 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE COLA dataset. It achieves the following results on the evaluation set: - Loss: 0.6165 - Matthews Correlation: 0.0 | bbb2632748b7c43cf65e587649b1f239 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.6103 | 1.0 | 34 | 0.6217 | 0.0 | | 0.6077 | 2.0 | 68 | 0.6179 | 0.0 | | 0.606 | 3.0 | 102 | 0.6182 | 0.0 | | 0.6062 | 4.0 | 136 | 0.6165 | 0.0 | | 0.5906 | 5.0 | 170 | 0.6183 | 0.0961 | | 0.5491 | 6.0 | 204 | 0.6250 | 0.0495 | | 0.512 | 7.0 | 238 | 0.6579 | 0.1173 | | 0.4877 | 8.0 | 272 | 0.6908 | 0.1043 | | 0.464 | 9.0 | 306 | 0.6860 | 0.1197 | | 7f02c2a077fefa89fed8bcdc24a2ba78 |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | t5-small-finetuned-eLife This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.8960 - Rouge1: 14.7239 - Rouge2: 2.8698 - Rougel: 11.0202 - Rougelsum: 13.3642 - Gen Len: 19.0 | 1f1022f9a76ae961a2e4e724030b31f5 |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:| | 3.3558 | 1.0 | 544 | 2.9587 | 13.7915 | 2.6556 | 10.3265 | 12.5097 | 19.0 | | 3.1299 | 2.0 | 1088 | 2.9079 | 14.7136 | 2.7492 | 10.836 | 13.3664 | 19.0 | | 3.0917 | 3.0 | 1632 | 2.8960 | 14.7239 | 2.8698 | 11.0202 | 13.3642 | 19.0 | | 1bb31cb4b1449d89efa2bdfcfd650cc9 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Small Chinese (Taiwan) This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 zh-TW dataset. It achieves the following results on the evaluation set: - Loss: 0.2283 - Wer: 41.9652 | 92127e176cd6f1813061dd4f6d134893 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0049 | 6.02 | 1000 | 0.2283 | 41.9652 | | 0.0008 | 13.02 | 2000 | 0.2556 | 42.0266 | | 0.0004 | 20.01 | 3000 | 0.2690 | 42.4156 | | 0.0003 | 27.0 | 4000 | 0.2788 | 42.7840 | | 0.0002 | 33.02 | 5000 | 0.2826 | 43.0297 | | 5d05c20924cc712b2af9b7c75bb2eaa3 |
apache-2.0 | ['generated_from_trainer'] | false | t5_assets This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.8718 - Rouge1: 35.7712 - Rouge2: 15.2129 - Rougel: 25.9007 - Rougelsum: 33.3105 - Gen Len: 64.7175 | 03da7ecf8551576c231f891b7a50853f |
mit | ['generated_from_trainer'] | false | gpt2.CEBaB_confounding.food_service_positive.absa.5-class.seed_44 This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the OpenTable OPENTABLE-ABSA dataset. It achieves the following results on the evaluation set: - Loss: 0.8418 - Accuracy: 0.7528 - Macro-f1: 0.7495 - Weighted-macro-f1: 0.7542 | 1df2efe10f128969f43a3964f597b861 |
apache-2.0 | ['generated_from_trainer'] | false | vit-base-patch16-224-finetuned-eurosat This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset. It achieves the following results on the evaluation set: - Loss: 1.3905 - Accuracy: 0.4865 | a0600c673ec8011637009c0af69a91de |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 64 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 1 | 727ad491d793d17ef46c6b7d005033d7 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 1.6128 | 0.97 | 15 | 1.3905 | 0.4865 | | ce0804e275c2432d75fc6f61888e7854 |
apache-2.0 | ['generated_from_trainer'] | false | convnext-tiny-224_finetuned This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.0895 - Precision: 0.9807 - Recall: 0.9608 - F1: 0.9702 - Accuracy: 0.9776 | 8dccc998f6785223381cbc8d2414098f |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 46 | 0.3080 | 0.9096 | 0.6852 | 0.7206 | 0.8365 | | No log | 2.0 | 92 | 0.1644 | 0.9660 | 0.9176 | 0.9386 | 0.9551 | | No log | 3.0 | 138 | 0.0974 | 0.9742 | 0.9586 | 0.9661 | 0.9744 | | No log | 4.0 | 184 | 0.0795 | 0.9829 | 0.9670 | 0.9746 | 0.9808 | | No log | 5.0 | 230 | 0.0838 | 0.9807 | 0.9608 | 0.9702 | 0.9776 | | No log | 6.0 | 276 | 0.0838 | 0.9807 | 0.9608 | 0.9702 | 0.9776 | | No log | 7.0 | 322 | 0.0803 | 0.9829 | 0.9670 | 0.9746 | 0.9808 | | No log | 8.0 | 368 | 0.0869 | 0.9807 | 0.9608 | 0.9702 | 0.9776 | | No log | 9.0 | 414 | 0.0897 | 0.9807 | 0.9608 | 0.9702 | 0.9776 | | No log | 10.0 | 460 | 0.0895 | 0.9807 | 0.9608 | 0.9702 | 0.9776 | | c817e50b575feb01aa857e1d4c5aeaa9 |
apache-2.0 | ['multiberts', 'multiberts-seed_3', 'multiberts-seed_3-step_40k'] | false | MultiBERTs, Intermediate Checkpoint - Seed 3, Step 40k MultiBERTs is a collection of checkpoints and a statistical library to support robust research on BERT. We provide 25 BERT-base models trained with similar hyper-parameters as [the original BERT model](https://github.com/google-research/bert) but with different random seeds, which causes variations in the initial weights and order of training instances. The aim is to distinguish findings that apply to a specific artifact (i.e., a particular instance of the model) from those that apply to the more general procedure. We also provide 140 intermediate checkpoints captured during the course of pre-training (we saved 28 checkpoints for the first 5 runs). The models were originally released through [http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our paper [The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163). This is model | 6763c272c989f70602796f1a126e37e6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.