
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
mit | [] | false | Replication of [gpt2-wechsel-german](https://huggingface.co/benjamin/gpt2-wechsel-german) - trained with [BigScience's DeepSpeed-Megatron-LM code base](https://github.com/bigscience-workshop/Megatron-DeepSpeed) - 22hrs on 4xA100 GPUs (~ 80 TFLOPs / GPU) - stopped after 100k steps - less than a single epoch on `oscar_unshuffled_deduplicated_de` (excluding validation set; original model was trained for 75 epochs on less data) - bf16 - zero stage 1 - tp/pp = 1 | 1bab00cf4e18503966afc3b77096b3f4 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Demo: How to use in ESPnet2 ```bash cd espnet git checkout 04803559d6dcde718638cfbd98139a9ddad1da72 pip install -e . cd egs2/aishell2/asr1 ./run.sh --skip_data_prep false --skip_train true --download_model espnet/aishell2_att_ctc_espnet2 ``` <!-- Generated by scripts/utils/show_asr_result.sh --> | 2c6bc6f1984b377c7697b99a4078cf53 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Environments - date: `Thu Jun 16 16:51:22 CST 2022` - python version: `3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0]` - espnet version: `espnet 202205` - pytorch version: `pytorch 1.7.0` - Git hash: `991eaa4a9e22c114ca59ef3988b4fcd0cdf25cdf` - Commit date: `Sat Jun 11 14:09:32 2022 +0800` | 75198143eb2d6ea80e5c7cac2cbd6f60 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | WER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |decode_asr_rnn_asr_model_valid.acc.ave/dev_ios|2500|2500|66.3|33.7|0.0|0.0|33.7|33.7| |decode_asr_rnn_asr_model_valid.acc.ave/test_android|5000|5002|63.8|36.2|0.0|0.0|36.2|36.2| |decode_asr_rnn_asr_model_valid.acc.ave/test_ios|5000|5002|65.5|34.5|0.0|0.0|34.5|34.5| |decode_asr_rnn_asr_model_valid.acc.ave/test_mic|5000|5002|63.4|36.6|0.0|0.0|36.6|36.6| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/dev_ios|2500|2500|68.4|31.6|0.0|0.0|31.6|31.6| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_android|5000|5002|65.0|35.0|0.0|0.0|35.0|35.0| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_ios|5000|5002|66.5|33.4|0.0|0.0|33.5|33.4| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_mic|5000|5002|65.4|34.6|0.0|0.0|34.6|34.6| | 9f2b4af08ba985cac31d54c0d3d989b6 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | CER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |decode_asr_rnn_asr_model_valid.acc.ave/dev_ios|2500|24802|94.8|5.0|0.2|0.1|5.4|33.7| |decode_asr_rnn_asr_model_valid.acc.ave/test_android|5000|49534|94.0|5.8|0.2|0.1|6.1|36.2| |decode_asr_rnn_asr_model_valid.acc.ave/test_ios|5000|49534|94.5|5.4|0.2|0.1|5.7|34.5| |decode_asr_rnn_asr_model_valid.acc.ave/test_mic|5000|49534|94.0|5.8|0.2|0.1|6.1|36.6| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/dev_ios|2500|24802|94.9|4.9|0.3|0.1|5.2|31.6| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_android|5000|49534|94.1|5.6|0.3|0.1|6.0|35.0| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_ios|5000|49534|94.6|5.1|0.2|0.1|5.5|33.4| |decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test_mic|5000|49534|94.3|5.5|0.2|0.1|5.8|34.6| | 29cfb57a216afbc3c9047e7f320a8fcf |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | ASR config <details><summary>expand</summary> ``` config: conf/train_asr_conformer.yaml print_config: false log_level: INFO dry_run: false iterator_type: sequence output_dir: exp/asr_train_asr_conformer_raw_zh_char_sp ngpu: 1 seed: 0 num_workers: 4 num_att_plot: 3 dist_backend: nccl dist_init_method: env:// dist_world_size: 8 dist_rank: 0 local_rank: 0 dist_master_addr: localhost dist_master_port: 37023 dist_launcher: null multiprocessing_distributed: true unused_parameters: false sharded_ddp: false cudnn_enabled: true cudnn_benchmark: false cudnn_deterministic: true collect_stats: false write_collected_feats: false max_epoch: 50 patience: null val_scheduler_criterion: - valid - acc early_stopping_criterion: - valid - loss - min best_model_criterion: - - valid - acc - max keep_nbest_models: 10 nbest_averaging_interval: 0 grad_clip: 5 grad_clip_type: 2.0 grad_noise: false accum_grad: 4 no_forward_run: false resume: true train_dtype: float32 use_amp: false log_interval: null use_matplotlib: true use_tensorboard: true use_wandb: false wandb_project: null wandb_id: null wandb_entity: null wandb_name: null wandb_model_log_interval: -1 detect_anomaly: false pretrain_path: null init_param: [] ignore_init_mismatch: false freeze_param: [] num_iters_per_epoch: null batch_size: 20 valid_batch_size: null batch_bins: 20000000 valid_batch_bins: null train_shape_file: - exp/asr_stats_raw_zh_char_sp/train/speech_shape - exp/asr_stats_raw_zh_char_sp/train/text_shape.char valid_shape_file: - exp/asr_stats_raw_zh_char_sp/valid/speech_shape - exp/asr_stats_raw_zh_char_sp/valid/text_shape.char batch_type: numel valid_batch_type: null fold_length: - 51200 - 150 sort_in_batch: descending sort_batch: descending multiple_iterator: false chunk_length: 500 chunk_shift_ratio: 0.5 num_cache_chunks: 1024 train_data_path_and_name_and_type: - - dump/raw/train_noeng_sp/wav.scp - speech - sound - - dump/raw/train_noeng_sp/text - text - text valid_data_path_and_name_and_type: - - dump/raw/dev_ios/wav.scp - speech - sound - - dump/raw/dev_ios/text - text - text allow_variable_data_keys: false max_cache_size: 0.0 max_cache_fd: 32 valid_max_cache_size: null optim: adam optim_conf: lr: 0.0025 scheduler: warmuplr scheduler_conf: warmup_steps: 30000 token_list: - <blank> - <unk> - 的 - 一 - 十 - 二 - 三 - 有 - 我 - 在 - 度 - 五 - 是 - 四 - 人 - 六 - 七 - 八 - 九 - 中 - 百 - 不 - 了 - 零 - 大 - 到 - 为 - 开 - 上 - 国 - 调 - 市 - 点 - 业 - 歌 - 么 - 来 - 个 - 这 - 年 - 要 - 公 - 什 - 会 - 出 - 地 - 发 - 行 - 能 - 温 - 电 - 空 - 万 - 千 - 成 - 和 - 分 - 时 - 下 - 你 - 场 - 新 - 家 - 打 - 产 - 机 - 对 - 以 - 房 - 生 - 把 - 小 - 首 - 放 - 之 - 现 - 日 - 动 - 高 - 子 - 后 - 多 - 们 - 者 - 方 - 前 - 也 - 他 - 视 - 资 - 将 - 关 - 金 - 天 - 于 - 进 - 过 - 经 - 听 - 月 - 可 - 用 - 自 - 最 - 司 - 幺 - 车 - 比 - 体 - 手 - 目 - 化 - 道 - 作 - 部 - 被 - 给 - 报 - 加 - 就 - 第 - 全 - 乐 - 定 - 得 - 还 - 事 - 城 - 本 - 想 - 女 - 赛 - 面 - 工 - 设 - 都 - 音 - 力 - 品 - 理 - 保 - 记 - 心 - 好 - 而 - 企 - 法 - 实 - 帮 - 价 - 长 - 看 - 合 - 已 - 海 - 但 - 与 - 名 - 北 - 同 - 入 - 元 - 商 - 通 - 量 - 区 - 学 - 情 - 京 - 网 - 所 - 务 - 主 - 说 - 两 - 政 - 播 - 利 - 重 - 制 - 员 - 平 - 其 - 交 - 内 - 风 - 提 - 器 - 间 - 没 - 请 - 去 - 相 - 台 - 美 - 期 - 增 - 明 - 信 - 式 - 次 - 爱 - 曲 - 建 - 安 - 当 - 管 - 表 - 东 - 店 - 里 - 起 - 并 - 从 - 果 - 回 - 民 - 影 - 展 - 据 - 着 - 示 - 更 - 等 - 应 - 很 - 无 - 门 - 外 - 数 - 运 - 因 - 投 - 正 - 今 - 收 - 路 - 些 - 需 - 儿 - 性 - 南 - 计 - 色 - 如 - 然 - 世 - 亿 - 物 - 光 - 项 - 特 - 联 - 智 - 持 - 随 - 向 - 搜 - 老 - 西 - 位 - 院 - 模 - 规 - 身 - 气 - 消 - 达 - 意 - 切 - 男 - 队 - 斯 - 米 - 低 - 格 - 水 - 张 - 此 - 布 - 灯 - 华 - 那 - 住 - 步 - 集 - 受 - 基 - 换 - 整 - 险 - 科 - 续 - 让 - 线 - 广 - 股 - 求 - 转 - 强 - 演 - 件 - 息 - 费 - 变 - 做 - 样 - 该 - 未 - 近 - 她 - 系 - 至 - 代 - 技 - 查 - 证 - 少 - 接 - 山 - 统 - 楼 - 节 - 标 - 只 - 战 - 及 - 文 - 总 - 王 - 局 - 己 - 再 - 问 - 监 - 处 - 传 - 服 - 州 - 显 - 销 - 快 - 由 - 频 - 改 - 便 - 卫 - 题 - 购 - 林 - 告 - 创 - 限 - 售 - 讯 - 常 - 界 - 营 - 原 - 单 - 超 - 认 - 种 - 流 - 亮 - 净 - 排 - 案 - 知 - 推 - 降 - 环 - 获 - 程 - 走 - 友 - 源 - 立 - 马 - 客 - 称 - 速 - 剧 - 周 - 决 - 尔 - 别 - 跑 - 取 - 完 - 片 - 警 - 头 - 球 - 选 - 士 - 级 - 拉 - 解 - 策 - 结 - 术 - 约 - 银 - 江 - 星 - 活 - 口 - 直 - 备 - 支 - 供 - 户 - 医 - 存 - 花 - 易 - 各 - 造 - 置 - 准 - 任 - 非 - 红 - 游 - 专 - 较 - 款 - 预 - 积 - 站 - 园 - 升 - 先 - 牌 - 社 - 办 - 每 - 李 - 村 - 型 - 使 - 难 - 势 - 真 - 带 - 指 - 停 - 构 - 导 - 深 - 唱 - 参 - 清 - 见 - 龙 - 研 - 团 - 照 - 确 - 阳 - 响 - 太 - 亚 - 克 - 闭 - 火 - 央 - 微 - 感 - 组 - 减 - 或 - 委 - 领 - 军 - 率 - 伤 - 始 - 类 - 书 - 融 - 具 - 济 - 土 - 施 - 望 - 教 - 奥 - 吗 - 际 - 育 - 权 - 涨 - 德 - 几 - 控 - 师 - 热 - 死 - 共 - 则 - 话 - 汽 - 许 - 份 - 府 - 居 - 态 - 连 - 黄 - 白 - 烦 - 引 - 英 - 声 - 狐 - 何 - 划 - 除 - 媒 - 季 - 继 - 孩 - 眼 - 财 - 岁 - 买 - 越 - 健 - 责 - 卡 - 助 - 索 - 宝 - 负 - 镇 - 争 - 松 - 况 - 半 - 条 - 税 - 注 - 校 - 终 - 仅 - 刘 - 某 - 号 - 福 - 才 - 额 - 博 - 包 - 优 - 众 - 质 - 究 - 反 - 农 - 苹 - 晚 - 紧 - 县 - 景 - 诉 - 酒 - 落 - 离 - 观 - 青 - 致 - 装 - 又 - 仍 - 套 - 亲 - 复 - 河 - 依 - 飞 - 故 - 极 - 娱 - 普 - 失 - 范 - 效 - 互 - 启 - 神 - 左 - 湖 - 击 - 值 - 绩 - 陈 - 语 - 段 - 兴 - 容 - 采 - 充 - 右 - 曾 - 往 - 票 - 均 - 举 - 域 - 形 - 维 - 找 - 像 - 纪 - 属 - 图 - 断 - 贷 - 省 - 康 - 试 - 杨 - 港 - 喜 - 街 - 益 - 拿 - 幅 - 功 - 苏 - 药 - 杰 - 足 - 考 - 疑 - 觉 - 配 - 香 - 宅 - 厂 - 根 - 议 - 境 - 双 - 宁 - 练 - 露 - 罗 - 吧 - 货 - 远 - 却 - 边 - 冠 - 钱 - 板 - 云 - 乡 - 审 - 算 - 丽 - 护 - 且 - 严 - 卖 - 奇 - 论 - 底 - 破 - 满 - 券 - 竞 - 拍 - 职 - 救 - 食 - 希 - 善 - 核 - 锦 - 检 - 突 - 哪 - 夜 - 言 - 麻 - 官 - 候 - 跟 - 够 - 它 - 妈 - 精 - 料 - 治 - 付 - 状 - 巴 - 止 - 早 - 稳 - 即 - 戏 - 象 - 录 - 群 - 必 - 婚 - 黑 - 田 - 验 - 养 - 库 - 欢 - 赶 - 送 - 协 - 绿 - 涉 - 例 - 昨 - 轻 - 室 - 武 - 盘 - 历 - 病 - 刚 - 春 - 留 - 尼 - 按 - 批 - 跳 - 志 - 怎 - 移 - 退 - 闻 - 摄 - 古 - 租 - 威 - 字 - 秒 - 石 - 夫 - 占 - 爸 - 压 - 登 - 思 - 虽 - 厅 - 雨 - 软 - 汉 - 摇 - 替 - 否 - 围 - 朋 - 雪 - 革 - 波 - 余 - 列 - 胜 - 债 - 临 - 遇 - 层 - 测 - 激 - 障 - 修 - 罪 - 假 - 忙 - 防 - 滚 - 介 - 判 - 承 - 钟 - 遭 - 执 - 角 - 征 - 铁 - 担 - 童 - 版 - 油 - 爆 - 补 - 史 - 杀 - 冲 - 待 - 吃 - 湾 - 训 - 母 - 律 - 亡 - 命 - 森 - 富 - 佳 - 略 - 蓝 - 义 - 庆 - 评 - 润 - 阿 - 镜 - 午 - 端 - 托 - 适 - 密 - 庭 - 浪 - 馆 - 差 - 尽 - 干 - 初 - 独 - 丝 - 洲 - 兰 - 旅 - 座 - 愿 - 艺 - 宣 - 短 - 块 - 彩 - 违 - 害 - 餐 - 追 - 辆 - 舞 - 良 - 菜 - 父 - 伟 - 择 - 嫌 - 念 - 识 - 似 - 副 - 访 - 圳 - 逐 - 令 - 奖 - 档 - 透 - 紫 - 味 - 孙 - 谈 - 籍 - 滑 - 犯 - 顺 - 络 - 穿 - 韩 - 巨 - 冷 - 乎 - 申 - 甚 - 惠 - 派 - 幸 - 永 - 暗 - 吉 - 素 - 梦 - 迪 - 瑞 - 绝 - 纷 - 笑 - 桥 - 血 - 刑 - 谢 - 材 - 另 - 夏 - 写 - 弟 - 纳 - 席 - 硬 - 画 - 夺 - 免 - 轮 - 幕 - 倒 - 毒 - 欧 - 脑 - 航 - 屋 - 跌 - 疗 - 玩 - 杯 - 哥 - 吸 - 戴 - 伦 - 届 - 睡 - 扫 - 错 - 习 - 背 - 吴 - 川 - 述 - 聚 - 促 - 尚 - 抢 - 恋 - 豪 - 班 - 析 - 径 - 读 - 伙 - 静 - 抓 - 漫 - 细 - 扩 - 妻 - 括 - 饭 - 衣 - 借 - 董 - 迷 - 庄 - 探 - 冰 - 插 - 阶 - 呢 - 损 - 粉 - 骗 - 休 - 秀 - 织 - 峰 - 谁 - 肯 - 鲁 - 谷 - 陆 - 娘 - 岛 - 励 - 迎 - 础 - 察 - 晨 - 朝 - 丰 - 诗 - 驾 - 异 - 招 - 印 - 草 - 惊 - 坚 - 沙 - 摆 - 久 - 私 - 措 - 劳 - 宗 - 池 - 洋 - 泳 - 须 - 圈 - 泰 - 肉 - 针 - 币 - 享 - 拳 - 窗 - 津 - 乘 - 梅 - 弱 - 罚 - 困 - 链 - 虑 - 延 - 顶 - 拥 - 玉 - 缺 - 姐 - 危 - 氏 - 柯 - 急 - 汤 - 丹 - 慧 - 操 - 廉 - 竟 - 趋 - 贴 - 裁 - 嘉 - 怀 - 旧 - 赔 - 盛 - 签 - 灵 - 鼓 - 典 - 释 - 掉 - 忘 - 暂 - 贵 - 叫 - 郑 - 归 - 挥 - 晓 - 徐 - 牛 - 雅 - 抱 - 靠 - 妹 - 载 - 偿 - 慢 - 卢 - 悉 - 综 - 简 - 植 - 筑 - 暴 - 尤 - 兄 - 礼 - 鱼 - 伊 - 序 - 厦 - 伴 - 木 - 野 - 脸 - 烈 - 潮 - 顾 - 雄 - 杭 - 藏 - 族 - 魔 - 撞 - 汇 - 娜 - 冬 - 枪 - 邓 - 患 - 截 - 累 - 暖 - 堂 - 浦 - 秘 - 珠 - 渐 - 丁 - 笔 - 唐 - 培 - 距 - 烟 - 返 - 束 - 晒 - 若 - 坐 - 刺 - 熟 - 婆 - 驶 - 翰 - 贸 - 诺 - 麦 - 讨 - 缘 - 挑 - 督 - 绍 - 码 - 勇 - 攻 - 浙 - 虹 - 讲 - 贝 - 迅 - 寻 - 洗 - 曝 - 斗 - 尘 - 蒙 - 莱 - 昆 - 毛 - 订 - 雷 - 兵 - 估 - 词 - 恩 - 荣 - 刻 - 泽 - 误 - 刀 - 树 - 胡 - 朱 - 输 - 避 - 呼 - 架 - 附 - 吹 - 遗 - 宇 - 侠 - 键 - 宏 - 哈 - 皮 - 筹 - 渠 - 叶 - 姑 - 盖 - 逃 - 阅 - 梁 - 泪 - 予 - 狂 - 羊 - 摩 - 徽 - 赵 - 倍 - 莉 - 凌 - 披 - 郭 - 偷 - 缓 - 齐 - 宽 - 拟 - 储 - 赞 - 凤 - 爵 - 编 - 涛 - 污 - 抗 - 秋 - 败 - 折 - 肥 - 帘 - 鲜 - 鸟 - 郎 - 凯 - 询 - 映 - 菲 - 守 - 旋 - 脱 - 旗 - 阵 - 遍 - 禁 - 脚 - 屏 - 染 - 概 - 曼 - 奶 - 棋 - 昌 - 苦 - 琪 - 梯 - 般 - 虚 - 混 - 募 - 恶 - 拘 - 妇 - 锁 - 烧 - 钢 - 毕 - 顿 - 页 - 虎 - 玲 - 召 - 辉 - 洛 - 痛 - 符 - 隐 - 鸡 - 弹 - 炸 - 震 - 弃 - 迹 - 账 - 隆 - 趣 - 坏 - 眠 - 挂 - 蛋 - 龄 - 鬼 - 厨 - 焦 - 牙 - 恐 - 章 - 杂 - 扬 - 跨 - 汪 - 封 - 幼 - 蔡 - 授 - 盗 - 俄 - 拆 - 芯 - 敢 - 狗 - 宾 - 末 - 船 - 烤 - 翻 - 辑 - 途 - 冒 - 锅 - 宫 - 答 - 扣 - 盈 - 莫 - 祝 - 丈 - 诈 - 帅 - 缩 - 泉 - 巢 - 怕 - 宜 - 沈 - 盟 - 恒 - 床 - 努 - 散 - 锋 - 弗 - 振 - 拒 - 逆 - 塞 - 诚 - 喝 - 洁 - 触 - 捕 - 炒 - 侵 - 君 - 既 - 泡 - 颜 - 娃 - 懂 - 骨 - 猫 - 仪 - 伍 - 沟 - 跃 - 献 - 援 - 祖 - 乱 - 尸 - 胎 - 奏 - 剑 - 骑 - 寿 - 呈 - 酷 - 溪 - 潜 - 陷 - 艾 - 坛 - 孕 - 舒 - 抽 - 徒 - 劲 - 纯 - 掌 - 佛 - 搞 - 亏 - 奔 - 翔 - 冻 - 圣 - 扶 - 添 - 熊 - 邮 - 醒 - 莲 - 琴 - 唯 - 陪 - 甜 - 谱 - 赢 - 衡 - 含 - 偏 - 撑 - 尾 - 册 - 榜 - 萨 - 怪 - 课 - 疯 - 咖 - 茶 - 燃 - 踪 - 诊 - 射 - 燕 - 党 - 固 - 纸 - 坦 - 卓 - 灾 - 阻 - 洪 - 腾 - 纠 - 递 - 猪 - 塔 - 晶 - 著 - 恢 - 蜜 - 楚 - 啦 - 姆 - 捐 - 饰 - 鉴 - 祥 - 卷 - 乌 - 幻 - 敏 - 疾 - 缴 - 琳 - 豆 - 皇 - 箱 - 湿 - 凡 - 麟 - 句 - 玛 - 拼 - 抵 - 沫 - 甲 - 覆 - 搭 - 爷 - 谣 - 饮 - 薪 - 芝 - 欲 - 忆 - 谓 - 啡 - 搏 - 哭 - 握 - 婷 - 隔 - 铜 - 刷 - 袭 - 矿 - 腿 - 岗 - 厕 - 滨 - 哲 - 岸 - 亦 - 漂 - 偶 - 鞋 - 鸭 - 宋 - 馨 - 朗 - 揭 - 枚 - 惯 - 陶 - 械 - 赚 - 耳 - 扰 - 乔 - 泥 - 棒 - 井 - 忧 - 杜 - 剩 - 旬 - 醉 - 拓 - 迁 - 颖 - 澳 - 瓦 - 扮 - 兆 - 闪 - 奋 - 闹 - 聊 - 鑫 - 辛 - 坡 - 淡 - 吻 - 诸 - 伯 - 欣 - 晋 - 仙 - 芳 - 旦 - 沉 - 症 - 扎 - 署 - 残 - 狼 - 洞 - 毫 - 辅 - 迫 - 闲 - 尝 - 谋 - 舍 - 鸿 - 桩 - 纽 - 灰 - 伏 - 赫 - 耗 - 液 - 啊 - 碍 - 慎 - 帝 - 赌 - 横 - 涵 - 姓 - 滴 - 凉 - 圆 - 迟 - 毁 - 牵 - 捷 - 俱 - 侧 - 厚 - 剂 - 橙 - 杆 - 柳 - 绑 - 妙 - 霍 - 凰 - 卧 - 甘 - 羽 - 侦 - 莞 - 彭 - 淘 - 旁 - 宿 - 繁 - 仁 - 窃 - 炼 - 煮 - 魂 - 砸 - 俊 - 墙 - 乏 - 勒 - 荷 - 煤 - 兼 - 呀 - 劫 - 悲 - 寺 - 霸 - 恰 - 旺 - 仓 - 拜 - 脏 - 茜 - 泛 - 吕 - 婴 - 凶 - 扇 - 邀 - 湘 - 仑 - 沃 - 欠 - 滩 - 寓 - 坠 - 拖 - 萌 - 桌 - 塑 - 炫 - 艳 - 忍 - 贤 - 赖 - 肖 - 锡 - 殊 - 猛 - 誉 - 殴 - 潘 - 漏 - 敌 - 废 - 柏 - 塘 - 逼 - 糖 - 浩 - 摘 - 敬 - 轩 - 桃 - 妍 - 黎 - 坊 - 允 - 畅 - 垃 - 圾 - 萧 - 玮 - 敦 - 轨 - 挺 - 辽 - 绪 - 浮 - 姜 - 铺 - 悬 - 柔 - 乒 - 倾 - 碎 - 槛 - 咨 - 凭 - 兹 - 稿 - 绕 - 斤 - 邦 - 庞 - 瓶 - 彻 - 屈 - 拨 - 堡 - 丢 - 鼠 - 粮 - 炳 - 浓 - 您 - 秦 - 怒 - 仔 - 栏 - 尊 - 沿 - 谭 - 姿 - 巧 - 阴 - 蒋 - 嫁 - 鹏 - 撤 - 迈 - 荐 - 碰 - 壁 - 喊 - 押 - 肃 - 墨 - 冯 - 曹 - 祸 - 辞 - 莎 - 循 - 轿 - 桂 - 贡 - 赴 - 忠 - 俩 - 薄 - 孤 - 挖 - 忽 - 贩 - 朵 - 匹 - 溢 - 默 - 嘴 - 狱 - 抛 - 篮 - 涯 - 歉 - 竹 - 渡 - 斌 - 墅 - 弄 - 泄 - 睛 - 珍 - 苑 - 堵 - 仕 - 苗 - 腐 - 裂 - 疆 - 茂 - 牧 - 虫 - 璃 - 垄 - 贾 - 稀 - 览 - 辣 - 霞 - 颁 - 僵 - 搬 - 番 - 佩 - 聘 - 姻 - 赏 - 妮 - 逊 - 串 - 玻 - 砍 - 岳 - 遥 - 堪 - 邻 - 飘 - 奸 - 赁 - 酬 - 纵 - 诞 - 灭 - 旭 - 碳 - 慈 - 拦 - 匆 - 仿 - 闯 - 猜 - 蒂 - 蓄 - 摸 - 驱 - 瑟 - 悦 - 讼 - 蕾 - 胶 - 悄 - 惜 - 淀 - 恨 - 宴 - 寂 - 刊 - 栋 - 尖 - 怡 - 氛 - 贿 - 岭 - 糕 - 碑 - 炉 - 埃 - 吓 - 辈 - 役 - 肇 - 劝 - 摔 - 饼 - 惨 - 吐 - 拔 - 携 - 卸 - 瑰 - 寸 - 朴 - 吨 - 磨 - 驻 - 孔 - 玫 - 鼎 - 伪 - 惹 - 韦 - 郁 - 肌 - 霆 - 烂 - 伸 - 蝶 - 戒 - 渔 - 艰 - 咬 - 崇 - 颗 - 贯 - 塌 - 勤 - 篇 - 攀 - 诱 - 娇 - 契 - 袁 - 陵 - 割 - 厉 - 酸 - 驰 - 甄 - 腰 - 裤 - 胖 - 瘦 - 巡 - 敲 - 瓜 - 魏 - 芬 - 莹 - 磊 - 踏 - 贺 - 浴 - 薇 - 剪 - 摊 - 催 - 奕 - 壮 - 郊 - 拐 - 咏 - 胞 - 匪 - 氧 - 沪 - 盾 - 姚 - 阔 - 寄 - 盐 - 肩 - 熙 - 阎 - 澎 - 夕 - 菌 - 伐 - 劵 - 聪 - 仰 - 兽 - 裸 - 陕 - 癌 - 叔 - 堆 - 雯 - 汰 - 傅 - 窄 - 佐 - 潭 - 涌 - 吊 - 坤 - 骂 - 臣 - 窝 - 袋 - 樊 - 寞 - 乳 - 愈 - 抑 - 岩 - 挤 - 傻 - 腹 - 吵 - 逸 - 奈 - 谎 - 颇 - 详 - 欺 - 捞 - 锻 - 丑 - 澄 - 虐 - 谨 - 孟 - 鹿 - 填 - 戈 - 靓 - 蓉 - 爬 - 疼 - 耀 - 寨 - 翅 - 爽 - 寒 - 耐 - 猎 - 悔 - 扭 - 芒 - 怖 - 俗 - 趁 - 矛 - 廷 - 址 - 宠 - 棉 - 描 - 淇 - 膜 - 煌 - 喷 - 尺 - 帕 - 桑 - 媛 - 碧 - 胸 - 瞬 - 铃 - 柜 - 蔬 - 毅 - 庙 - 颠 - 憾 - 贫 - 壳 - 冕 - 佑 - 葛 - 辩 - 噪 - 夹 - 侣 - 蜂 - 犹 - 抚 - 纹 - 惑 - 脉 - 虾 - 抄 - 钻 - 梨 - 嘛 - 删 - 蹈 - 胁 - 瓷 - 肤 - 魅 - 赠 - 琦 - 弯 - 兔 - 暑 - 蛇 - 稍 - 卜 - 荡 - 惩 - 涂 - 楠 - 恭 - 萍 - 邱 - 秩 - 臂 - 帽 - 犬 - 辰 - 挪 - 葡 - 乓 - 杉 - 劣 - 柱 - 履 - 貌 - 陌 - 疲 - 屡 - 萄 - 疫 - 屠 - 淫 - 乃 - 妆 - 躺 - 茹 - 芸 - 盲 - 舰 - 巩 - 傲 - 汗 - 贼 - 鸣 - 擦 - 彼 - 鼻 - 炮 - 肚 - 倩 - 雾 - 雇 - 扑 - 柴 - 疏 - 佣 - 框 - 啥 - 践 - 淮 - 墓 - 玄 - 湃 - 侯 - 裕 - 棚 - 殖 - 耶 - 馈 - 挡 - 晴 - 珊 - 饺 - 掘 - 辖 - 扔 - 眉 - 膀 - 鹤 - 沧 - 杠 - 屯 - 捧 - 翠 - 擅 - 雕 - 锂 - 晰 - 遵 - 碗 - 痕 - 怨 - 笼 - 舆 - 媳 - 尿 - 冀 - 牢 - 厘 - 痴 - 巫 - 颈 - 埋 - 逾 - 翼 - 锐 - 桠 - 衔 - 纱 - 纺 - 饱 - 棍 - 荒 - 逮 - 贪 - 妥 - 昂 - 谊 - 槽 - 孝 - 坪 - 粗 - 掀 - 呆 - 崔 - 撒 - 崛 - 糟 - 皆 - 滞 - 躲 - 绮 - 硕 - 刮 - 滋 - 阁 - 兑 - 踢 - 帖 - 峡 - 浅 - 靖 - 溺 - 尬 - 弥 - 幽 - 狠 - 咱 - 丛 - 绵 - 勿 - 炎 - 尴 - 抬 - 叹 - 铅 - 勾 - 胆 - 削 - 掩 - 蟹 - 捉 - 箭 - 筷 - 粤 - 纤 - 逢 - 菱 - 奎 - 肠 - 吁 - 淳 - 颂 - 俏 - 御 - 愤 - 谐 - 闫 - 赋 - 垒 - 闸 - 淑 - 娟 - 盒 - 蓬 - 轰 - 厌 - 赤 - 豫 - 垫 - 逝 - 泼 - 妃 - 昏 - 谅 - 纬 - 挣 - 亨 - 穷 - 糊 - 衰 - 狮 - 萝 - 逻 - 铭 - 晕 - 旨 - 倡 - 衷 - 缝 - 漠 - 坑 - 揽 - 抒 - 稽 - 巷 - 亭 - 哦 - 喆 - 廊 - 鹰 - 樱 - 勃 - 坝 - 仇 - 茨 - 贞 - 耕 - 飙 - 韶 - 脂 - 肢 - 梳 - 乞 - 椅 - 肿 - 壤 - 臭 - 喂 - <space> - 斜 - 渝 - 跪 - 灌 - 巍 - 悠 - 慰 - 枝 - 奉 - 译 - 浏 - 驳 - 谍 - 睿 - 砖 - 酿 - 驹 - 捡 - 蔚 - 渤 - 娅 - 垂 - 轴 - 腕 - 舟 - 夸 - 吞 - 鲸 - 弦 - 厢 - 斥 - 渴 - 趴 - 钓 - 霖 - 帆 - 芭 - 吟 - 彦 - 辱 - 愁 - 耍 - 恼 - 瑜 - 笨 - 侨 - 逗 - 缠 - 戚 - 桶 - 乖 - 胀 - 慕 - 硅 - 丧 - 钰 - 灿 - 缉 - 冤 - 罐 - 斩 - 叠 - 斋 - 裙 - 坞 - 蜀 - 囚 - 稻 - 叛 - 叉 - 藤 - 绘 - 膝 - 烫 - 擂 - 坎 - 悟 - 钧 - 燥 - 撕 - 扳 - 龚 - 辟 - 绳 - 艇 - 钥 - 苍 - 豹 - 逛 - 裹 - 匙 - 纲 - 蝴 - 誓 - 薛 - 蛮 - 禹 - 胃 - 邵 - 丘 - 阙 - 盆 - 砂 - 骏 - 瞒 - 桐 - 芦 - 磁 - 谜 - 凸 - 猴 - 婉 - 筋 - 荆 - 漆 - 昕 - 罕 - 驼 - 亩 - 谦 - 呦 - 甩 - 峻 - 巅 - 钉 - 猥 - 肺 - 榆 - 牲 - 萎 - 蛛 - 钩 - 袖 - 骄 - 佰 - 拾 - 鹅 - 祁 - 遂 - 歧 - 掏 - 祈 - 孵 - 洒 - 雳 - 螺 - 弊 - 韵 - 踩 - 沸 - 炭 - 桦 - 闺 - 扯 - 瑶 - 霹 - 盼 - 罩 - 穆 - 斑 - 杏 - 芙 - 骚 - 葬 - 侃 - 橘 - 咒 - 菇 - 盯 - 慌 - 妨 - 宰 - 喀 - 翁 - 勘 - 滥 - 瞩 - 咪 - 卦 - 伞 - 烯 - 衍 - 崩 - 昔 - 邢 - 爹 - 晖 - 佬 - 牺 - 拯 - 娴 - 妖 - 仲 - 邑 - 馥 - 饿 - 棠 - 渣 - 宪 - 贬 - 瘾 - 鲍 - 芜 - 奠 - 瞄 - 奢 - 渗 - 郝 - 函 - 楷 - 潇 - 淋 - 澡 - 榄 - 辨 - 巾 - 溜 - 芮 - 浆 - 瘫 - 咸 - 啤 - 蜡 - 亵 - 菊 - 羞 - 茫 - 姨 - 矶 - 捅 - 凝 - 卉 - 叙 - 氮 - 蜘 - 舱 - 弘 - 醛 - 堰 - 嗯 - 挫 - 挽 - 雁 - 酝 - 鞭 - 惧 - 肝 - 粹 - 蚁 - 竖 - 卵 - 灶 - 剥 - 陀 - 彰 - 蔓 - 廖 - 鄂 - 讽 - 遣 - 僧 - 嵩 - 俯 - 葩 - 蛙 - 睐 - 碾 - 蘑 - 饲 - 甸 - 脆 - 莓 - 遏 - 詹 - 蒸 - 刹 - 磅 - 囊 - 芽 - 锈 - 粒 - 竣 - 璇 - 辐 - 瑄 - 酱 - 顽 - 瘤 - 喻 - 伽 - 铝 - 琛 - 殿 - 腊 - 粥 - 兜 - 汝 - 宵 - 撼 - 洽 - 娶 - 斐 - 饶 - 澜 - 缆 - 嫂 - 橄 - 禾 - 撰 - 挨 - 枯 - 蒲 - 倪 - 骤 - 龟 - 冈 - 姗 - 哀 - 簿 - 遮 - 羡 - 坍 - 汁 - 煎 - 脖 - 赣 - 愉 - 唤 - 泊 - 匿 - 邹 - 舌 - 雀 - 畜 - 邪 - 狄 - 尹 - 烹 - 夷 - 腔 - 闷 - 闽 - 彪 - 宙 - 鸽 - 竭 - 睹 - 眨 - 阜 - 趟 - 禅 - 埔 - 熬 - 铸 - 幂 - 畴 - 泷 - 咚 - 湛 - 肾 - 嘲 - 翘 - 抹 - 卿 - 崎 - 溃 - 琼 - 梓 - 隋 - 饪 - 隧 - 霾 - 艘 - 帷 - 嫖 - 钞 - 鞍 - 淄 - 涩 - 炜 - 凑 - 彤 - 擎 - 琐 - 衫 - 浸 - 濠 - 绎 - 潼 - 镖 - 哎 - 枫 - 慨 - 浇 - 狸 - 辜 - 滤 - 屁 - 棵 - 禄 - 齿 - 魄 - 窑 - 帐 - 丸 - 肘 - 裴 - 栈 - 讶 - 昊 - 荧 - 哄 - 乙 - 蕉 - 株 - 愧 - 沂 - 岚 - 叮 - 徨 - 冶 - 葱 - 泸 - 谌 - 汕 - 蜗 - 姣 - 彷 - 祭 - 坟 - 奴 - 牡 - 姬 - 傍 - 茅 - 懒 - 侄 - 兮 - 罢 - 碟 - 绣 - 忌 - 仗 - 钦 - 祷 - 歪 - 歇 - 锣 - 哑 - 猝 - 庾 - 掐 - 崖 - 曙 - 狙 - 黛 - 窦 - 唇 - 椒 - 赂 - 氨 - 茵 - 悍 - 硫 - 葫 - 庸 - 喉 - 俪 - 峪 - 筒 - 赎 - 橡 - 哺 - 彬 - 盔 - 毙 - 颐 - 渊 - 驴 - 衬 - 毯 - 剖 - 钮 - 捆 - 鳄 - 骆 - 跻 - 佟 - 焰 - 嗨 - 怜 - 粱 - 堤 - 沥 - 剔 - 扒 - 蕴 - 嬛 - 媚 - 玟 - 蹲 - 肆 - 凳 - 贱 - 汀 - 靡 - 畔 - 焚 - 匠 - 呃 - 弈 - 绯 - 苛 - 摧 - 肋 - 溯 - 蠢 - 玖 - 勋 - 迄 - 捍 - 阱 - 呵 - 丙 - 猩 - 宛 - 捣 - 铠 - 焊 - 淹 - 掷 - 歹 - 禺 - 闵 - 晗 - 葵 - 泓 - 牟 - 泣 - 舅 - 饥 - 霏 - 躁 - 壹 - 碌 - 矩 - 璨 - 咕 - 庐 - 犀 - 坨 - 咋 - 缔 - 酵 - 萤 - 矮 - 缸 - 禽 - 哇 - 沦 - 刃 - 孪 - 俞 - 蝠 - 驿 - 呕 - 筛 - 涮 - 剿 - 迭 - 睁 - 秉 - 徘 - 徊 - 屿 - 捂 - 丞 - 顷 - 惕 - 肪 - 皓 - 寡 - 粘 - 垮 - 烨 - 昭 - 囧 - 蝙 - 壶 - 潢 - 襄 - 蔽 - 沛 - 炽 - , - 嵌 - 疤 - 侈 - 渭 - 笛 - 腻 - 彝 - 枣 - 鸦 - 曦 - 苇 - 珂 - ? - 狭 - 诀 - 魁 - 膨 - 倚 - 墩 - 诙 - 郸 - 崭 - 耻 - 愚 - 窜 - 秽 - 蹭 - 璐 - 霉 - 旱 - 铲 - 氢 - 蓓 - 暨 - 锤 - 埠 - 倦 - 吾 - 丫 - 裘 - 铮 - 蜢 - 桓 - 隶 - 蝉 - 焕 - 卑 - 婿 - 恺 - 栗 - 舶 - 搅 - 爪 - 慑 - 窥 - 瞻 - 敞 - 茗 - 嘟 - 妞 - 颅 - 脊 - 侬 - 儒 - 浑 - 缅 - 诡 - 撬 - 甫 - 搁 - 畏 - 拱 - 弓 - 懈 - 峥 - 嚣 - 丐 - 赃 - 榕 - 珀 - 勉 - 汶 - 枕 - 屹 - 萱 - 髓 - 栖 - 妒 - 茄 - 脾 - 啸 - 谴 - 侮 - 隙 - 耽 - 柄 - 逍 - 仆 - 孚 - 鲨 - 螂 - 蚂 - 晃 - 晏 - 呛 - 挟 - 粪 - 昧 - 炯 - 袍 - 穴 - 抖 - 殡 - 邯 - 雍 - 悼 - 梗 - 穗 - 痪 - 韧 - 漳 - 绸 - 擒 - 瑾 - 涡 - 耷 - 痒 - 聂 - 捏 - 乾 - 蝎 - 沾 - 嫩 - 荔 - 弼 - 颓 - 嫉 - 敛 - 诠 - 殷 - 踹 - 惫 - 篡 - 姥 - 泾 - 婧 - 隍 - 敷 - 矣 - 瞎 - 玥 - 烽 - 阐 - 讳 - 衅 - 讹 - 蔷 - 耿 - 哨 - 醋 - 朔 - 幢 - 瞧 - 喔 - 膏 - 阮 - 膊 - 郡 - 觅 - 磷 - 熏 - 灼 - 翡 - 蟑 - 蝇 - 赐 - 悚 - 硝 - 荃 - 抉 - 汛 - 冥 - 咘 - 哗 - 锯 - 榴 - 螃 - 惟 - 绒 - 蚕 - 琥 - 涤 - 蚊 - 杖 - 豚 - 濮 - 拢 - 磕 - 霄 - 栽 - 粟 - 滕 - 拽 - 嗓 - 馅 - 晟 - 鹭 - 狩 - 羚 - 屎 - 邰 - 梧 - 吼 - 汹 - 哒 - 绰 - 绽 - 臀 - 棕 - 瑛 - 浒 - 琶 - 聋 - 搂 - 刁 - 咽 - 炙 - 拎 - 菩 - 沐 - 岔 - 涧 - 皱 - 婕 - 睫 - 炖 - 矫 - 昱 - 碱 - 洼 - 玺 - 篷 - 黏 - 淼 - 膳 - 羹 - 旷 - 枢 - 撇 - 勺 - 溅 - 蜕 - 漓 - 劈 - 浣 - 戳 - 庚 - 蓟 - 觞 - 烛 - 椎 - 僻 - 胳 - 霜 - 呐 - 冉 - 柿 - 铐 - 絮 - 瀚 - 扁 - 祠 - 喘 - 湉 - 宥 - 腺 - 翩 - 暧 - 蹄 - 嘱 - 喇 - 铬 - 溶 - 揣 - 岌 - 禧 - 蒜 - 跷 - 尧 - 咳 - 绅 - 扛 - 畸 - 淤 - 罄 - 臻 - 绞 - 矢 - 瀑 - 屌 - 倘 - 麒 - 咯 - 嘀 - 莒 - 辄 - 峨 - 攒 - 氰 - 醇 - 弧 - 斧 - 墟 - 憬 - 薯 - 矜 - 窍 - 郴 - 阀 - 栅 - 绊 - 鞠 - 娼 - 琢 - 剃 - 暮 - 瑚 - 竿 - 皂 - 挠 - 沮 - 莺 - 馍 - 腥 - 蚀 - 窘 - 檬 - 羁 - 饽 - 炬 - 瑕 - 雏 - 沽 - 寝 - 辙 - 漩 - 袱 - 匈 - 煞 - 猿 - 囤 - 癫 - 辗 - 揍 - 拇 - 诟 - 窒 - 憧 - 垦 - 寰 - 铀 - 潍 - 沼 - 绷 - 憨 - 窟 - 嘿 - 揪 - 疵 - 梭 - 敖 - 耘 - 蒿 - 翟 - 镑 - 莘 - 莽 - 孽 - 滔 - 苯 - 滢 - 胰 - 氯 - 厮 - 缪 - 麓 - 寇 - 诬 - 噬 - 嘘 - 匕 - 呗 - 槟 - 渎 - 涪 - 榨 - 鸥 - 轧 - 氓 - 舵 - 泵 - 堕 - 陨 - 呷 - 猖 - 熔 - 嬉 - 稚 - 亟 - 忐 - 豁 - 韬 - 赘 - 恳 - 陡 - 蚌 - 俨 - 娥 - 娄 - 焱 - 颤 - 眷 - 町 - 嘻 - 棱 - 琵 - 匀 - 躬 - 椰 - 耒 - 沁 - 坻 - 邂 - 筝 - 簸 - 陋 - 嗅 - 橱 - 踝 - 喧 - 黯 - 趾 - 凿 - 烘 - 掴 - 缚 - 啃 - 罂 - 瞳 - 蹦 - 鸳 - 毋 - 忑 - 靴 - 泻 - 樟 - 伺 - 跤 - 甥 - 熄 - 菠 - 瓯 - 啼 - 裔 - 骸 - 埭 - 捶 - 煲 - 缭 - 蹬 - 遛 - 寅 - 叭 - 隅 - 帜 - 磋 - 酪 - 馒 - 茉 - 陂 - 岂 - 嫣 - 妓 - 桔 - 珑 - 滁 - 谬 - 厄 - 珏 - 忏 - 逅 - 噱 - 幌 - 柠 - 窖 - 淆 - 锏 - 璧 - 菡 - 汾 - 荫 - 鳝 - 疚 - 蹊 - 哽 - 蕊 - 祺 - 鸯 - 钠 - 鳌 - 芋 - 挚 - 秤 - 阪 - 凹 - 嗒 - 茧 - 涅 - 盱 - 眙 - 鄙 - 饵 - 芹 - 莆 - 飓 - 帼 - 簧 - 骇 - 榔 - 蜓 - 宕 - 穹 - 疹 - 骁 - 诫 - 殇 - 迦 - 濑 - 寥 - 嗡 - 恙 - 妄 - 渌 - 薰 - 慷 - 怠 - 惺 - 峙 - 诅 - 羲 - 岱 - 踞 - 镶 - 笋 - 哟 - 恤 - 秆 - 扼 - 枭 - 剽 - 锰 - 亥 - 俺 - 阚 - 骥 - 痫 - 菏 - 荼 - 芷 - 釜 - 鹊 - 坷 - 糙 - 髦 - 俘 - 崴 - 坂 - 嘎 - 苟 - 獒 - 棘 - 箍 - 郫 - 拧 - 攸 - 呱 - 咙 - 琉 - 圭 - 蕙 - 诿 - 卤 - 檐 - 赡 - 栓 - 煜 - 唬 - 拙 - 夯 - 袜 - 秸 - 憋 - 漕 - 缇 - 篱 - 溉 - 嗽 - 咧 - 酋 - 绛 - 哩 - 拴 - 蜇 - 蟒 - 拣 - 缤 - 宸 - 呜 - 驯 - 筠 - 辍 - 伶 - 熠 - 菁 - 礁 - 哮 - 烙 - 陇 - 荟 - 枉 - 蛟 - 吒 - 雌 - 橇 - 酯 - 嬅 - 舫 - 拷 - 拌 - 竺 - 峭 - 铛 - 邬 - 溧 - 戎 - 锌 - 钾 - 遴 - 畊 - 撮 - 譬 - 濒 - 噩 - 蹿 - 殃 - 圩 - 惶 - 纶 - 唰 - 桨 - 倔 - 鹂 - 尉 - 沓 - 觑 - 钊 - 麋 - 匮 - 淌 - 瀛 - 锵 - 酌 - 獗 - 驭 - 杞 - 羯 - 俐 - 戮 - 诵 - 姊 - 脐 - 绢 - 涞 - 嚷 - 馗 - 谤 - 暇 - 渺 - 庇 - 懋 - 佘 - 泌 - 圃 - 恕 - 籁 - 胺 - 瑙 - 赓 - 膛 - 抠 - 啪 - 砰 - 铎 - 棺 - 砺 - 梵 - 筵 - 佼 - 殉 - 涿 - 琅 - 咫 - 瞪 - 媲 - 嗷 - 眈 - 湄 - 眶 - 栾 - 簋 - 昼 - 腼 - 腆 - 伎 - 炊 - 癖 - 鄞 - 侥 - 掺 - 璀 - 躯 - 渍 - 剐 - 耸 - 搡 - 瓣 - 廓 - 焖 - 焉 - 诽 - 摒 - 卯 - 睦 - 泗 - 虞 - 稣 - 锄 - 骡 - 喵 - 侏 - 蜻 - 喋 - ( - ) - 甬 - 璋 - 拄 - 膺 - 轶 - 柬 - 岖 - 檀 - 袂 - 缜 - 垣 - 蛰 - 秃 - 匡 - 吝 - 咎 - 扉 - 昙 - 诧 - 鲤 - 晤 - 绚 - 毗 - 辫 - 跆 - 藕 - 雹 - 藩 - 飚 - 嘞 - 隽 - 篓 - 梆 - 掠 - 泔 - 懊 - 坯 - 肴 - 嚼 - 鳅 - 毽 - 浚 - 蔑 - 痰 - 沣 - 亢 - 蜚 - 踵 - 蚝 - 瞅 - 崂 - 戛 - 翎 - 怦 - 惋 - 谙 - 胧 - 懿 - 茱 - 靶 - 藻 - 羔 - 哼 - 酉 - 喽 - 锚 - 眩 - 碘 - 侍 - 咔 - 叼 - 谩 - 裳 - 洱 - 徙 - 掂 - 踊 - 磐 - 嗑 - 榈 - 槐 - 皖 - 歆 - 怯 - 昀 - 汲 - 缮 - 挎 - 剁 - 瞿 - 朦 - 啧 - 觎 - 峦 - 蜈 - 祯 - 栩 - 忡 - 瘟 - 砾 - 叨 - 嗜 - 痞 - 藉 - 鳞 - 肛 - 腌 - 锭 - 铿 - 岐 - 漾 - 熹 - 汞 - 馋 - 窈 - 窕 - 焯 - 钵 - 髅 - 奚 - 榭 - 狡 - 禀 - 珉 - 茸 - 籽 - 掰 - 镀 - 庵 - 寐 - 掣 - 笆 - 迸 - 睽 - 唠 - 鹃 - 钣 - 覃 - 噢 - 婺 - 镐 - 蹶 - 胭 - 咤 - 婵 - 厥 - 簇 - 矗 - 胫 - 璞 - 黔 - 锆 - 皙 - 孜 - 骷 - 襟 - 抨 - 咐 - 衢 - 傣 - 煦 - 镍 - 屑 - 漯 - 灞 - 嘹 - 颊 - 遐 - 涝 - 瓮 - 觊 - 仨 - 萃 - 俭 - 胥 - 舔 - 枸 - 翊 - 烁 - 赦 - 缕 - 霓 - 辕 - 镁 - 钗 - 唧 - 滦 - 醺 - 迥 - 硚 - 乍 - 惦 - 懵 - 靳 - 垤 - 垢 - 浊 - 褐 - 婪 - 嚎 - 烊 - 袄 - 惬 - 蔗 - 馊 - 摁 - 榷 - 哆 - 匝 - 痘 - 夭 - 笃 - 僚 - 咆 - 悖 - 褪 - 铉 - 镉 - 蜷 - 柚 - 拭 - 卞 - 眸 - 捻 - 蚣 - 匾 - 酥 - 畈 - 茬 - 噜 - 驸 - 酮 - 鹦 - 鹉 - 燎 - 痹 - 屉 - 腩 - 婶 - 瓢 - 郜 - 虔 - 搀 - 嵋 - 抡 - 肮 - 祛 - 紊 - 奂 - 戟 - 迂 - 悸 - 枞 - 叩 - 逞 - 痊 - 鲶 - 晔 - 酣 - 飒 - 忱 - 襁 - 褓 - 怂 - 馄 - 饨 - 睬 - 嗤 - 寮 - 蜿 - 蜒 - 滘 - 拂 - 祉 - 镰 - 沱 - 笈 - 灏 - 孰 - 毓 - 钙 - 淅 - 涟 - 鞘 - 牒 - 诶 - 蹼 - 钜 - 壕 - 痼 - 镯 - 愕 - 崃 - 惮 - 哉 - 熨 - 螳 - 鸠 - 撂 - 糯 - 铨 - 朽 - 碚 - 胯 - 袒 - 琰 - 舸 - 樨 - 骅 - 唏 - 晾 - 酗 - 沌 - 汐 - 炅 - 淞 - 茎 - 煊 - 唾 - 瘠 - 皎 - 骊 - 缨 - 盏 - 铂 - 斛 - 贮 - 腑 - 萦 - 眯 - 煽 - 鱿 - 梢 - 唆 - 阄 - 岑 - 挞 - 搐 - 吱 - 犁 - 祎 - 缢 - 硼 - 忤 - 翱 - 柘 - 骋 - 邛 - 攥 - 褚 - 叱 - 邺 - 锥 - 斟 - 钝 - 鹫 - 憔 - 悴 - 蹴 - 嬷 - 吆 - 褒 - 瑁 - 瞰 - 匣 - 楂 - 裆 - 唉 - 兢 - 褂 - 邸 - 辘 - 钛 - 缀 - 鹜 - 砌 - 锹 - 咀 - 稠 - 胤 - 亳 - 蛐 - 饕 - 佯 - 犸 - 缰 - 跋 - 忻 - 酶 - 芊 - 孢 - 虏 - 刨 - 珈 - 枷 - 咭 - 懦 - 狒 - 榫 - 蔼 - 邋 - 遢 - 秧 - 拮 - 莜 - 沅 - 锷 - 羿 - 陛 - 琬 - 氦 - 焙 - 讪 - 衙 - 囍 - 岷 - 搪 - 殒 - 莴 - 苣 - 珮 - 裟 - 榻 - 啬 - 玳 - 稼 - 诩 - 嘶 - 臼 - 骼 - 瘀 - 箴 - 涕 - 杳 - 恬 - 颍 - 聆 - '''' - 捎 - 砝 - 钨 - 貂 - 铤 - 淝 - 脍 - 赝 - 摹 - 蚤 - 韭 - 琨 - 弑 - 崆 - 痱 - 砥 - 钏 - 沭 - 汨 - 苓 - 垛 - 涠 - 砒 - 箩 - 筐 - 姝 - 烃 - 迢 - 鏖 - 伢 - 茁 - 遁 - 垡 - 椿 - 鲟 - 涎 - 楞 - 罹 - 凋 - 芍 - 咄 - 窨 - 闰 - 莠 - 吩 - 浜 - 苔 - 荞 - 殆 - 燊 - 盹 - 鳖 - 胚 - 洙 - 曰 - 娲 - 瘸 - 餮 - 娆 - 卒 - 腱 - 湫 - 砚 - 盎 - 钳 - 铷 - 崮 - 湍 - 骜 - 藜 - 蟋 - 蟀 - 垭 - 疡 - 臧 - 灸 - 脓 - 昵 - 偎 - 愣 - 叽 - 憎 - 掳 - 蜃 - 鄱 - 腈 - 嵊 - 鲈 - 昶 - 笙 - 舜 - 啕 - 涓 - 胛 - 槌 - 荤 - 靛 - 溥 - 臃 - 蛀 - 拗 - 嗦 - 黝 - 袈 - 揉 - 炕 - 珲 - 虱 - 腋 - 筱 - 舛 - 猾 - 噎 - 綦 - 鄢 - 夙 - 眺 - 喱 - 徉 - 贰 - 渚 - 桎 - 梏 - 谛 - 吭 - 坳 - 晦 - 锴 - 弩 - 搓 - 贻 - 惭 - 逯 - 娉 - 箫 - 杈 - 俑 - 洮 - 掮 - 摞 - 栀 - 妾 - 痧 - 骝 - 漉 - 崽 - 儋 - 柑 - 埝 - 啄 - 蛊 - 椭 - 淬 - 轼 - 喃 - 帚 - 跺 - 漱 - 蕃 - 氟 - 渲 - 吏 - 塾 - 癣 - 媞 - 嫦 - 蔺 - 伉 - 啰 - 翌 - 茆 - 娓 - 澈 - 讧 - 暹 - 镳 - 隘 - 恿 - 狰 - 狞 - 麾 - 漪 - 瞌 - 轲 - 滇 - 缄 - 泮 - 瞭 - 璟 - 傀 - 儡 - 魇 - 掖 - 皋 - 塍 - 疃 - 惰 - 葆 - 犇 - 泯 - 烩 - 妩 - 潞 - 晞 - 咩 - 赈 - 撅 - 惆 - 怅 - 斓 - 兀 - 睾 - 绥 - 糠 - 讥 - 菀 - 衩 - 纭 - 诏 - 嘈 - 琊 - 癜 - 砣 - 帧 - 痣 - 泫 - 洵 - 砀 - 涸 - 奄 - 庶 - 烬 - 撵 - 酊 - 蛾 - 唢 - 燮 - 潦 - 篆 - 冗 - 瞥 - 珞 - 猷 - 粳 - 苋 - 嗖 - 犟 - 睇 - 鼹 - 唛 - 毡 - 碴 - 颚 - 泞 - 谕 - 噼 - 犒 - 碉 - 佶 - 垅 - 磺 - 铆 - 侑 - 貔 - 貅 - 嚏 - 悯 - 畿 - 恍 - 蜥 - 蜴 - 彗 - 闳 - 蚯 - 蚓 - 瘪 - 俾 - 腓 - 邃 - 凄 - 茴 - 趸 - 弛 - 颢 - 溆 - 楔 - 蠕 - 怵 - 篪 - 臆 - 疙 - 瘩 - 擞 - 鹞 - 粽 - 隼 - 珺 - 墉 - 桢 - 仟 - 荨 - 笠 - 钯 - 壑 - 樽 - 骐 - 赊 - 楸 - 蓥 - 矸 - 歩 - 锨 - 铡 - 叁 - 缱 - 绻 - 鳍 - 豌 - 褥 - 龈 - 剌 - 锒 - 嚓 - 旌 - 喳 - 皿 - 煳 - 鲳 - 筏 - 轳 - 鲠 - 嶙 - 峋 - 冢 - 郧 - 鬟 - 疮 - 垩 - 鲭 - 蕲 - 挝 - 钿 - 琏 - 糗 - 戬 - 霁 - 宦 - 锢 - 撩 - 髋 - 楣 - 佃 - 捺 - 螨 - 猬 - 萋 - 妊 - 抿 - 阂 - 俚 - 阆 - 踉 - 跄 - 砷 - 绌 - 苡 - 仄 - 樯 - 哐 - 柞 - 镭 - 殓 - 霎 - 犄 - 暄 - 唁 - 粕 - 噗 - 铟 - 濡 - 庖 - 柒 - 脯 - 扪 - 赳 - 擀 - 冽 - 谧 - 踱 - 踌 - 躇 - 诋 - 蟊 - 褶 - 皑 - 祐 - 蝌 - 蚪 - 硌 - 鹌 - 鹑 - 蝈 - 铖 - 娣 - 妤 - 撸 - 壬 - 攘 - 诣 - 阕 - 矾 - 胗 - 酩 - 甭 - 蹂 - 躏 - 疟 - 诃 - 溏 - 阑 - 俸 - 雒 - 睢 - 澍 - 桉 - 窿 - 荇 - 钴 - 哔 - 嵇 - 饷 - 耙 - 劭 - 峒 - 搔 - 瞑 - 祀 - 徜 - 恻 - 蟾 - 蹩 - 蕨 - 酰 - 薏 - 绫 - 濂 - 茛 - 囱 - 鲑 - 粑 - 鳗 - 札 - 觐 - 醍 - 掸 - 逑 - 阖 - 菖 - 嗲 - 幡 - 缙 - 逵 - 蔫 - 崧 - 惚 - 铰 - 嫔 - 倌 - 罡 - 邝 - 婀 - 纨 - 绔 - 嵘 - 孛 - 铣 - 娠 - 槿 - 厩 - 犷 - 朐 - 疝 - 狈 - 黍 - 幄 - 荚 - 淖 - 犊 - 塬 - 艮 - 胱 - 蝗 - 圪 - 擘 - 旮 - 旯 - 憩 - 孺 - 瞟 - 啵 - 焘 - 嗣 - 忿 - 嬗 - 蘸 - 纫 - 喟 - 慵 - 祟 - 踺 - 孳 - 棣 - 埸 - 淦 - 炔 - 纰 - 轫 - 偕 - 奘 - 纣 - 孀 - 舷 - 羌 - 圻 - 拈 - 鲅 - 镌 - 恃 - 骛 - 旻 - 煨 - 婊 - 雉 - 蔻 - 霈 - 垚 - 铩 - 莪 - 揩 - 枰 - 痢 - 庹 - 瘴 - 钎 - 腮 - 嵬 - 谯 - 嫡 - 埂 - 捋 - 纾 - 蛤 - 瑭 - 螈 - 邙 - 罔 - 郯 - 樵 - 茌 - 郓 - 枳 - 咦 - 讴 - 厝 - 砼 - 茯 - 衲 - 潋 - 噘 - 谚 - 烷 - 斡 - 嫫 - 嗪 - 邳 - 铄 - 歼 - 堇 - 渑 - 疽 - 怄 - 涣 - 囹 - 稔 - 弋 - 篝 - 蹋 - 窠 - 谟 - 浠 - 悱 - 蜍 - 孬 - 芥 - 馏 - 屐 - 栎 - 玷 - 萸 - 扞 - 阡 - 荀 - 曳 - 邕 - 诛 - 阉 - 堀 - 骠 - 琤 - 盂 - 妲 - 虻 - 醐 - 谀 - 舀 - 鳟 - 绀 - 呲 - 娩 - 牾 - 僮 - 笳 - 渥 - 仡 - 镊 - 嶝 - 泱 - 汴 - 咣 - 嘭 - 锟 - 咂 - 宓 - 侗 - 洹 - 妫 - A - 峁 - 蜊 - 攫 - 膑 - 毂 - 秣 - 泠 - 尅 - 冼 - 嶂 - 浈 - 陬 - 啖 - 兖 - 褴 - 褛 - 妯 - 娌 - 恣 - 恸 - 掬 - 篦 - 蹚 - 逡 - 鲷 - 叵 - 驷 - 飧 - 釉 - 粼 - 踯 - 躅 - 讷 - 吮 - 琮 - 啾 - 粲 - 佻 - 疸 - 臊 - 蓦 - 椋 - 眬 - 憷 - 绋 - 珙 - 揶 - 谏 - 䶮 - 帛 - 衮 - 晷 - 裨 - 鸾 - 槎 - 讣 - 嫚 - 遨 - 瘙 - 疱 - 呻 - 鞅 - 痉 - 挛 - 骰 - 瘳 - 棂 - 偃 - 鸢 - 钲 - 尕 - 呸 - 埇 - 浃 - 濯 - 坩 - 埚 - 嗝 - 炀 - 隗 - 扈 - 谆 - 丕 - 魉 - 噙 - 圹 - 埕 - 恪 - 孱 - 凛 - 曜 - 拚 - 浔 - 吖 - 轱 - 搽 - 芪 - 箕 - 箔 - 戊 - 蛆 - 蜱 - 嗔 - 榛 - 蹒 - 跚 - 镣 - 鲫 - 镂 - 摈 - 愫 - 纂 - 麝 - 趺 - 碜 - 馁 - 唷 - 悻 - 伫 - 樾 - 剜 - 咝 - 銮 - 撺 - 掇 - 哂 - 咻 - 酐 - 訾 - 鳕 - 稷 - 嘣 - 碣 - 扦 - 柩 - 蟠 - 芩 - 鬓 - 裱 - 嗄 - 枋 - 钇 - 怼 - 喁 - 龊 - 疴 - 蛹 - 偓 - 蓼 - 汩 - 疖 - 蛎 - 诘 - 焓 - 荠 - 闩 - 噌 - 苷 - 藓 - 蚱 - 亘 - 缎 - 鼬 - 籼 - 疣 - 轸 - 玹 - 潺 - 妪 - 馀 - 啶 - 耄 - 耋 - 鬃 - 滹 - 莅 - 倜 - 傥 - 蓁 - 岬 - 貉 - 獾 - 敝 - 瘁 - 蒯 - 碓 - 殚 - 漭 - 嵛 - 榉 - 诓 - 泖 - 艋 - 凇 - 靑 - 沏 - 磴 - 氪 - 诲 - 忪 - 炷 - 杓 - 暾 - 藿 - T - M - 洺 - 擢 - 藠 - 晌 - 瞠 - 桁 - 遑 - 囗 - 谑 - 嗬 - 卲 - 硒 - 鼾 - 觥 - 茳 - 枇 - 杷 - 邡 - 桷 - 椁 - 鹳 - 饴 - 跶 - 绉 - 浐 - 迩 - 啲 - 颌 - 泺 - 睑 - 踮 - 荛 - 镔 - 祢 - 韫 - 笸 - 俎 - 羸 - 怿 - 昝 - 艿 - 薷 - 赅 - 怆 - 刍 - 獭 - 蚴 - 噶 - 噤 - 氤 - 氲 - 豺 - 倭 - 豉 - 葺 - 珥 - 痨 - 蹁 - 跹 - 蚬 - 唳 - 舐 - 竽 - 馑 - 徇 - 垌 - 魍 - 葚 - 涑 - 跛 - 荏 - 吋 - 髌 - 髂 - 骓 - 悌 - 戌 - 揄 - 矽 - 钒 - 𫖯 - 谶 - 捌 - 矍 - 铧 - 骈 - 枥 - 殁 - 鲢 - 腭 - 弭 - 镕 - 篑 - 馕 - 堃 - 锑 - 搧 - 闾 - 囫 - 囵 - 鞑 - 辊 - 魟 - 𫚉 - 鲼 - 郅 - 坭 - 栌 - 佗 - 驮 - 哕 - 颦 - 偌 - 颀 - 耜 - 仞 - 贲 - 烀 - 瘢 - 祚 - 悭 - 沢 - 瑠 - 钼 - 鹧 - 鸪 - 蛳 - 苞 - 柃 - 麂 - 暌 - 刎 - 溟 - 菘 - 钐 - 蹉 - 跎 - 篁 - 耆 - 纡 - 熵 - 簪 - 铋 - 幔 - 巳 - 陉 - 増 - 鹁 - 矬 - 锉 - 偈 - 篼 - 龃 - 龉 - 郇 - 孑 - 忒 - 龌 - 稞 - 囔 - 蝮 - 蠊 - 苫 - 菅 - 霪 - 藁 - 膈 - 敕 - 潸 - 槃 - 湎 - 椟 - 茼 - 戗 - 奁 - 芗 - 褔 - 稹 - 澧 - 嬴 - 铍 - 潆 - 橐 - 堺 - 佚 - 嫒 - 葳 - 氚 - 酚 - 椤 - 赉 - 砭 - 匏 - 戾 - 恁 - 腴 - 蛉 - 麸 - 玑 - 痍 - 啜 - 劾 - 忖 - 蛔 - 芾 - 餍 - 诤 - 逋 - 鸵 - 荸 - 夔 - 懑 - 嘏 - 檗 - 牠 - 痔 - 酞 - 猹 - 盅 - 旖 - 鸫 - 椴 - 戍 - 耪 - 豇 - 牍 - 铑 - 噻 - 龅 - 猁 - 蝽 - 欸 - 肱 - 桴 - 镏 - 缬 - 怫 - 唑 - 曈 - 缛 - 吠 - 歙 - 谖 - 俟 - 刽 - 槭 - 硖 - 髯 - 饯 - 藐 - 娈 - 勐 - 颧 - 荻 - 焗 - 鳃 - 昴 - 黟 - 羧 - 趵 - 澶 - 骞 - 鸩 - 婢 - 圄 - 佝 - 偻 - 嗫 - 囯 - 跬 - 朕 - 袅 - 锲 - 杵 - 豢 - 骺 - 诹 - 椹 - 谮 - 㶧 - <sos/eos> init: null input_size: null ctc_conf: dropout_rate: 0.0 ctc_type: builtin reduce: true ignore_nan_grad: null zero_infinity: true joint_net_conf: null use_preprocessor: true token_type: char bpemodel: null non_linguistic_symbols: null cleaner: null g2p: null speech_volume_normalize: null rir_scp: null rir_apply_prob: 1.0 noise_scp: null noise_apply_prob: 1.0 noise_db_range: '13_15' short_noise_thres: 0.5 frontend: default frontend_conf: fs: 16k specaug: specaug specaug_conf: apply_time_warp: true time_warp_window: 5 time_warp_mode: bicubic apply_freq_mask: true freq_mask_width_range: - 0 - 30 num_freq_mask: 2 apply_time_mask: true time_mask_width_range: - 0 - 40 num_time_mask: 2 normalize: global_mvn normalize_conf: stats_file: exp/asr_stats_raw_zh_char_sp/train/feats_stats.npz model: espnet model_conf: ctc_weight: 0.3 lsm_weight: 0.1 length_normalized_loss: false preencoder: null preencoder_conf: {} encoder: conformer encoder_conf: output_size: 512 attention_heads: 8 linear_units: 2048 num_blocks: 12 dropout_rate: 0.1 positional_dropout_rate: 0.1 attention_dropout_rate: 0.0 input_layer: conv2d normalize_before: true pos_enc_layer_type: rel_pos selfattention_layer_type: rel_selfattn activation_type: swish macaron_style: true use_cnn_module: true cnn_module_kernel: 31 postencoder: null postencoder_conf: {} decoder: transformer decoder_conf: attention_heads: 4 linear_units: 2048 num_blocks: 6 dropout_rate: 0.1 positional_dropout_rate: 0.1 self_attention_dropout_rate: 0.0 src_attention_dropout_rate: 0.0 required: - output_dir - token_list version: '202205' distributed: true ``` </details> | e3c8acc7731156abd6f59f2ac207dade |
apache-2.0 | ['generated_from_trainer'] | false | bert-trainer This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.1889 - Accuracy: 0.6437 | 39860df9981d3d9c1eddb5171fee594a |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:--------:| | 0.751 | 1.0 | 3677 | 0.7828 | 0.6592 | | 0.6364 | 2.0 | 7354 | 0.8904 | 0.6374 | | 0.4125 | 3.0 | 11031 | 1.1889 | 0.6437 | | 500ed2b2037796e59faff9627a122e3f |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-sngp-squad-seed-42 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset. It achieves the following results on the evaluation set: - Loss: 1.9074 | c565b25775a87e9ca57d3d48d29c1fed |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 2.4521 | 1.0 | 8248 | 2.0439 | | 2.1298 | 2.0 | 16496 | 1.9074 | | 814f429546d892282990236746faf70e |
apache-2.0 | ['tensorflowtts', 'audio', 'text-to-speech', 'text-to-mel'] | false | FastSpeech2 trained on KSS (Korean) This repository provides a pretrained [FastSpeech2](https://arxiv.org/abs/2006.04558) trained on KSS dataset (Ko). For a detail of the model, we encourage you to read more about [TensorFlowTTS](https://github.com/TensorSpeech/TensorFlowTTS). | 61cfcf1c5a595dd665c920f56cb078bc |
apache-2.0 | ['tensorflowtts', 'audio', 'text-to-speech', 'text-to-mel'] | false | Converting your Text to Mel Spectrogram ```python import numpy as np import soundfile as sf import yaml import tensorflow as tf from tensorflow_tts.inference import AutoProcessor from tensorflow_tts.inference import TFAutoModel processor = AutoProcessor.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko") fastspeech2 = TFAutoModel.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko") text = "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다." input_ids = processor.text_to_sequence(text) mel_before, mel_after, duration_outputs, _, _ = fastspeech2.inference( input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0), speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32), speed_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32), f0_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32), energy_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32), ) ``` | f585d1775871b286129260f14e506cd2 |
apache-2.0 | ['tensorflowtts', 'audio', 'text-to-speech', 'text-to-mel'] | false | Referencing FastSpeech2 ``` @misc{ren2021fastspeech, title={FastSpeech 2: Fast and High-Quality End-to-End Text to Speech}, author={Yi Ren and Chenxu Hu and Xu Tan and Tao Qin and Sheng Zhao and Zhou Zhao and Tie-Yan Liu}, year={2021}, eprint={2006.04558}, archivePrefix={arXiv}, primaryClass={eess.AS} } ``` | c528186dc98fef39c6e6d150e8423f29 |
apache-2.0 | ['generated_from_trainer'] | false | small-mlm-glue-sst2-target-glue-mrpc This model is a fine-tuned version of [muhtasham/small-mlm-glue-sst2](https://huggingface.co/muhtasham/small-mlm-glue-sst2) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.7182 - Accuracy: 0.7917 - F1: 0.8571 | ad60a8ad7c9ec00560407f005304a274 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.3886 | 4.35 | 500 | 0.6884 | 0.7892 | 0.8617 | | 0.0692 | 8.7 | 1000 | 1.3709 | 0.7917 | 0.8627 | | 0.0318 | 13.04 | 1500 | 1.4689 | 0.7892 | 0.8562 | | 0.0266 | 17.39 | 2000 | 1.8846 | 0.7745 | 0.8544 | | 0.0102 | 21.74 | 2500 | 1.7656 | 0.7941 | 0.8571 | | 0.0139 | 26.09 | 3000 | 1.7271 | 0.7892 | 0.8552 | | 0.0168 | 30.43 | 3500 | 1.7505 | 0.7966 | 0.8600 | | 0.0152 | 34.78 | 4000 | 1.6538 | 0.7843 | 0.8483 | | 0.0135 | 39.13 | 4500 | 1.7268 | 0.7941 | 0.8618 | | 0.0148 | 43.48 | 5000 | 1.7182 | 0.7917 | 0.8571 | | 27a234df9746660a13bcfe78138aef01 |
apache-2.0 | ['generated_from_trainer'] | false | finetuning-sentiment-model-3000-samples This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.6646 - Accuracy: 0.632 - F1: 0.4321 | 73c3f93519b07fb013170c89ee45bdaf |
apache-2.0 | ['generated_from_trainer'] | false | hf_train_output This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the rock-glacier-dataset dataset. It achieves the following results on the evaluation set: - Loss: 0.3894 - Accuracy: 0.9258 | 77aa684352255ddcbc7d9406c4799b8f |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 50 - mixed_precision_training: Native AMP | aa002ee80405993b4c9c99893638b198 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.5619 | 0.55 | 50 | 0.5432 | 0.7692 | | 0.4582 | 1.1 | 100 | 0.4435 | 0.8352 | | 0.3548 | 1.65 | 150 | 0.3739 | 0.8599 | | 0.217 | 2.2 | 200 | 0.2913 | 0.9093 | | 0.1709 | 2.75 | 250 | 0.2619 | 0.9148 | | 0.0919 | 3.3 | 300 | 0.2475 | 0.9148 | | 0.0652 | 3.85 | 350 | 0.3275 | 0.8901 | | 0.0495 | 4.4 | 400 | 0.2515 | 0.9093 | | 0.0321 | 4.95 | 450 | 0.2878 | 0.9066 | | 0.0247 | 5.49 | 500 | 0.2612 | 0.9148 | | 0.017 | 6.04 | 550 | 0.2687 | 0.9176 | | 0.0131 | 6.59 | 600 | 0.3062 | 0.9093 | | 0.0113 | 7.14 | 650 | 0.2587 | 0.9231 | | 0.0099 | 7.69 | 700 | 0.2815 | 0.9203 | | 0.009 | 8.24 | 750 | 0.2675 | 0.9286 | | 0.0084 | 8.79 | 800 | 0.2711 | 0.9286 | | 0.0077 | 9.34 | 850 | 0.2663 | 0.9313 | | 0.0073 | 9.89 | 900 | 0.3003 | 0.9258 | | 0.0069 | 10.44 | 950 | 0.2758 | 0.9313 | | 0.0064 | 10.99 | 1000 | 0.2999 | 0.9258 | | 0.0061 | 11.54 | 1050 | 0.2931 | 0.9313 | | 0.0057 | 12.09 | 1100 | 0.2989 | 0.9313 | | 0.0056 | 12.64 | 1150 | 0.2974 | 0.9313 | | 0.0053 | 13.19 | 1200 | 0.3099 | 0.9258 | | 0.005 | 13.74 | 1250 | 0.3131 | 0.9313 | | 0.0049 | 14.29 | 1300 | 0.3201 | 0.9258 | | 0.0046 | 14.84 | 1350 | 0.3109 | 0.9313 | | 0.0045 | 15.38 | 1400 | 0.3168 | 0.9313 | | 0.0043 | 15.93 | 1450 | 0.3226 | 0.9231 | | 0.0042 | 16.48 | 1500 | 0.3234 | 0.9231 | | 0.0041 | 17.03 | 1550 | 0.3283 | 0.9258 | | 0.0039 | 17.58 | 1600 | 0.3304 | 0.9258 | | 0.0038 | 18.13 | 1650 | 0.3321 | 0.9231 | | 0.0037 | 18.68 | 1700 | 0.3362 | 0.9231 | | 0.0036 | 19.23 | 1750 | 0.3307 | 0.9286 | | 0.0035 | 19.78 | 1800 | 0.3357 | 0.9231 | | 0.0034 | 20.33 | 1850 | 0.3244 | 0.9313 | | 0.0033 | 20.88 | 1900 | 0.3497 | 0.9231 | | 0.0032 | 21.43 | 1950 | 0.3443 | 0.9231 | | 0.0031 | 21.98 | 2000 | 0.3398 | 0.9286 | | 0.003 | 22.53 | 2050 | 0.3388 | 0.9286 | | 0.003 | 23.08 | 2100 | 0.3399 | 0.9286 | | 0.0029 | 23.63 | 2150 | 0.3548 | 0.9231 | | 0.0028 | 24.18 | 2200 | 0.3475 | 0.9286 | | 0.0028 | 24.73 | 2250 | 0.3480 | 0.9286 | | 0.0027 | 25.27 | 2300 | 0.3542 | 0.9231 | | 0.0026 | 25.82 | 2350 | 0.3589 | 0.9231 | | 0.0026 | 26.37 | 2400 | 0.3449 | 0.9286 | | 0.0025 | 26.92 | 2450 | 0.3604 | 0.9231 | | 0.0025 | 27.47 | 2500 | 0.3493 | 0.9286 | | 0.0024 | 28.02 | 2550 | 0.3631 | 0.9258 | | 0.0024 | 28.57 | 2600 | 0.3590 | 0.9258 | | 0.0023 | 29.12 | 2650 | 0.3604 | 0.9258 | | 0.0023 | 29.67 | 2700 | 0.3667 | 0.9258 | | 0.0022 | 30.22 | 2750 | 0.3571 | 0.9286 | | 0.0022 | 30.77 | 2800 | 0.3660 | 0.9258 | | 0.0021 | 31.32 | 2850 | 0.3638 | 0.9286 | | 0.0021 | 31.87 | 2900 | 0.3729 | 0.9258 | | 0.0021 | 32.42 | 2950 | 0.3706 | 0.9258 | | 0.002 | 32.97 | 3000 | 0.3669 | 0.9286 | | 0.002 | 33.52 | 3050 | 0.3740 | 0.9258 | | 0.002 | 34.07 | 3100 | 0.3693 | 0.9286 | | 0.002 | 34.62 | 3150 | 0.3700 | 0.9286 | | 0.0019 | 35.16 | 3200 | 0.3752 | 0.9258 | | 0.0019 | 35.71 | 3250 | 0.3753 | 0.9258 | | 0.0019 | 36.26 | 3300 | 0.3721 | 0.9286 | | 0.0018 | 36.81 | 3350 | 0.3764 | 0.9258 | | 0.0018 | 37.36 | 3400 | 0.3758 | 0.9258 | | 0.0018 | 37.91 | 3450 | 0.3775 | 0.9258 | | 0.0018 | 38.46 | 3500 | 0.3812 | 0.9258 | | 0.0018 | 39.01 | 3550 | 0.3817 | 0.9258 | | 0.0017 | 39.56 | 3600 | 0.3815 | 0.9258 | | 0.0017 | 40.11 | 3650 | 0.3825 | 0.9258 | | 0.0017 | 40.66 | 3700 | 0.3852 | 0.9258 | | 0.0017 | 41.21 | 3750 | 0.3854 | 0.9258 | | 0.0017 | 41.76 | 3800 | 0.3823 | 0.9258 | | 0.0016 | 42.31 | 3850 | 0.3829 | 0.9258 | | 0.0016 | 42.86 | 3900 | 0.3873 | 0.9258 | | 0.0016 | 43.41 | 3950 | 0.3842 | 0.9258 | | 0.0016 | 43.96 | 4000 | 0.3857 | 0.9258 | | 0.0016 | 44.51 | 4050 | 0.3873 | 0.9258 | | 0.0016 | 45.05 | 4100 | 0.3878 | 0.9258 | | 0.0016 | 45.6 | 4150 | 0.3881 | 0.9258 | | 0.0016 | 46.15 | 4200 | 0.3888 | 0.9258 | | 0.0016 | 46.7 | 4250 | 0.3891 | 0.9258 | | 0.0016 | 47.25 | 4300 | 0.3878 | 0.9258 | | 0.0016 | 47.8 | 4350 | 0.3890 | 0.9258 | | 0.0016 | 48.35 | 4400 | 0.3890 | 0.9258 | | 0.0015 | 48.9 | 4450 | 0.3895 | 0.9258 | | 0.0015 | 49.45 | 4500 | 0.3896 | 0.9258 | | 0.0015 | 50.0 | 4550 | 0.3894 | 0.9258 | | 92419f4deb8040fc90998435b79664b7 |
mit | [] | false | ohisashiburi-style on Stable Diffusion This is the `<ohishashiburi-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:     | bb39b1942c00eb98e551ff56d38244e7 |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | layoutlmv2-base-uncased-finetuned-docvqa This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.1940 | 1c5c02929e2efe88cfe0ff2dd53dc3de |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 250500 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 2 | dfb51b9137529006a98ddd2b8f498915 |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 1.463 | 0.27 | 1000 | 1.6272 | | 0.9447 | 0.53 | 2000 | 1.3646 | | 0.7725 | 0.8 | 3000 | 1.2560 | | 0.5762 | 1.06 | 4000 | 1.3582 | | 0.4382 | 1.33 | 5000 | 1.2490 | | 0.4515 | 1.59 | 6000 | 1.1860 | | 0.383 | 1.86 | 7000 | 1.1940 | | 29812a608ac13a92523774fce2ec993b |
apache-2.0 | ['generated_from_trainer'] | false | t5-small-science-papers This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the scientific_papers dataset. It achieves the following results on the evaluation set: - Loss: 3.6405 - Rouge1: 12.3568 - Rouge2: 2.4449 - Rougel: 10.2371 - Rougelsum: 11.4209 - Gen Len: 19.0 | 853874a256d8a3d497b42de75b9f283e |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5 - mixed_precision_training: Native AMP | 2b79ae7a9796e7345874ca4224656d27 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:| | 4.4735 | 1.0 | 12690 | 4.3727 | 9.9604 | 1.7641 | 8.6213 | 9.2779 | 19.0 | | 4.0104 | 2.0 | 25380 | 3.9384 | 11.4001 | 2.1474 | 9.6516 | 10.6602 | 19.0 | | 3.8237 | 3.0 | 38070 | 3.7580 | 11.1806 | 2.1229 | 9.3881 | 10.3853 | 19.0 | | 3.7382 | 4.0 | 50760 | 3.6738 | 11.9298 | 2.3222 | 9.9077 | 11.045 | 19.0 | | 3.6994 | 5.0 | 63450 | 3.6405 | 12.3568 | 2.4449 | 10.2371 | 11.4209 | 19.0 | | c183e8093da11da51c4de80b9dd3545f |
mit | [] | false | German BERT base Released, Oct 2020, this is a German BERT language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model and show that it outperforms its predecessors. | 57e96326021f042f28dc8fe261e5fb51 |
mit | [] | false | Performance ``` GermEval18 Coarse: 78.17 GermEval18 Fine: 50.90 GermEval14: 87.98 ``` See also: deepset/gbert-base deepset/gbert-large deepset/gelectra-base deepset/gelectra-large deepset/gelectra-base-generator deepset/gelectra-large-generator | 1e4a13ee65e6062e3260fcbfe0c1e63a |
mit | [] | false | About us  We bring NLP to the industry via open source! Our focus: Industry specific language models & large scale QA systems. Some of our work: - [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert) - [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad) - [FARM](https://github.com/deepset-ai/FARM) - [Haystack](https://github.com/deepset-ai/haystack/) Get in touch: [Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai) By the way: [we're hiring!](http://www.deepset.ai/jobs) | 53b551bd4e17ba37e5490d1a1d1640a1 |
apache-2.0 | ['generated_from_trainer'] | false | tiny-mlm-glue-qnli-target-glue-stsb This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-qnli](https://huggingface.co/muhtasham/tiny-mlm-glue-qnli) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.8934 - Pearson: 0.8154 - Spearmanr: 0.8157 | 23b5998983b6e15e2f7b895ffaf69c68 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | |:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:| | 2.952 | 2.78 | 500 | 1.1581 | 0.7199 | 0.7571 | | 0.9583 | 5.56 | 1000 | 1.1118 | 0.7743 | 0.7995 | | 0.7459 | 8.33 | 1500 | 0.9843 | 0.8028 | 0.8182 | | 0.6197 | 11.11 | 2000 | 0.8616 | 0.8165 | 0.8217 | | 0.5182 | 13.89 | 2500 | 0.9113 | 0.8140 | 0.8169 | | 0.4676 | 16.67 | 3000 | 0.9804 | 0.8144 | 0.8183 | | 0.4128 | 19.44 | 3500 | 0.8934 | 0.8154 | 0.8157 | | e048611404501fa8ae5cb720ba028d47 |
apache-2.0 | ['t5'] | false | ke-t5 base Pretrained T5 Model on Korean and English. See [Github](https://github.com/AIRC-KETI/ke-t5) and [Paper](https://aclanthology.org/2021.findings-emnlp.33/) [Korean paper](https://koreascience.kr/article/CFKO202130060717834.pdf) for more details. | 2471f6c5cd250b215c01efa1571f5008 |
apache-2.0 | ['t5'] | false | How to use ```python from transformers import AutoModel, AutoTokenizer model = AutoModel.from_pretrained("KETI-AIR/ke-t5-large") tokenizer = AutoTokenizer.from_pretrained("KETI-AIR/ke-t5-large") ``` | 19f00d087b03cf44d5031927cd82e835 |
apache-2.0 | ['t5'] | false | BibTeX entry and citation info ```bibtex @inproceedings{kim-etal-2021-model-cross, title = "A Model of Cross-Lingual Knowledge-Grounded Response Generation for Open-Domain Dialogue Systems", author = "Kim, San and Jang, Jin Yea and Jung, Minyoung and Shin, Saim", booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021", month = nov, year = "2021", address = "Punta Cana, Dominican Republic", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.findings-emnlp.33", doi = "10.18653/v1/2021.findings-emnlp.33", pages = "352--365", abstract = "Research on open-domain dialogue systems that allow free topics is challenging in the field of natural language processing (NLP). The performance of the dialogue system has been improved recently by the method utilizing dialogue-related knowledge; however, non-English dialogue systems suffer from reproducing the performance of English dialogue systems because securing knowledge in the same language with the dialogue system is relatively difficult. Through experiments with a Korean dialogue system, this paper proves that the performance of a non-English dialogue system can be improved by utilizing English knowledge, highlighting the system uses cross-lingual knowledge. For the experiments, we 1) constructed a Korean version of the Wizard of Wikipedia dataset, 2) built Korean-English T5 (KE-T5), a language model pre-trained with Korean and English corpus, and 3) developed a knowledge-grounded Korean dialogue model based on KE-T5. We observed the performance improvement in the open-domain Korean dialogue model even only English knowledge was given. The experimental results showed that the knowledge inherent in cross-lingual language models can be helpful for generating responses in open dialogue systems.", } ``` | 536f7542bcf796c826540af52f5353a2 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.2236 - Accuracy: 0.924 - F1: 0.9241 | 6deb01f7f7fe616bd5c11b8a8c4e4a3d |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | No log | 1.0 | 250 | 0.3293 | 0.901 | 0.8979 | | No log | 2.0 | 500 | 0.2236 | 0.924 | 0.9241 | | cd41ce813ff4956a3cf69bc29df772ad |
mit | ['generated_from_keras_callback'] | false | botModel77k_weightDecay This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.3706 - Train Accuracy: 0.0001 - Train Perplexity: 633976.5 - Validation Loss: 0.3670 - Validation Accuracy: 0.0002 - Validation Perplexity: 87590.9062 - Epoch: 3 | 2a283ffc49510d620c43f15b99c258cc |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 1e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 39489, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 500, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01} - training_precision: mixed_float16 | ba6bf58ba017d63d90d2349268d041fc |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Train Accuracy | Train Perplexity | Validation Loss | Validation Accuracy | Validation Perplexity | Epoch | |:----------:|:--------------:|:----------------:|:---------------:|:-------------------:|:---------------------:|:-----:| | 0.6245 | 0.0042 | 556382.0 | 0.3670 | 0.0002 | 87590.9062 | 0 | | 0.3704 | 0.0001 | 625282.125 | 0.3670 | 0.0002 | 87590.9062 | 1 | | 0.3706 | 0.0001 | 621652.25 | 0.3670 | 0.0002 | 87590.8984 | 2 | | 0.3706 | 0.0001 | 633976.5 | 0.3670 | 0.0002 | 87590.9062 | 3 | | f8533482a39b4cb7f986e706dad2ed75 |
mit | [] | false | Configuration `title`: _string_ Display title for the Space `emoji`: _string_ Space emoji (emoji-only character allowed) `colorFrom`: _string_ Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) `colorTo`: _string_ Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) `sdk`: _string_ Can be either `gradio`, `streamlit`, or `static` `sdk_version` : _string_ Only applicable for `streamlit` SDK. See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions. `app_file`: _string_ Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code). Path is relative to the root of the repository. `models`: _List[string]_ HF model IDs (like "gpt2" or "deepset/roberta-base-squad2") used in the Space. Will be parsed automatically from your code if not specified here. `datasets`: _List[string]_ HF dataset IDs (like "common_voice" or "oscar-corpus/OSCAR-2109") used in the Space. Will be parsed automatically from your code if not specified here. `pinned`: _boolean_ Whether the Space stays on top of your list. | e284f65c197e344115baaae8ae2c3103 |
mit | [] | false | naval-portrait on Stable Diffusion This is the `<naval-portrait>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:        | 0c90fdc977b6fca859ae01efb5904be6 |
creativeml-openrail-m | ['text-to-image', 'stable-diffusion'] | false | Correct-Yes-model Dreambooth model trained by Kilgori with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Sample pictures of this concept: | 324063eafeb3b07c11cd50c77ce722b6 |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | <style> img { display: inline; } </style>    | dffb0616cd914131f54db28bc4305f42 |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Fine-tuned whisper-large-v2 model for ASR in French This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2), trained on a composite dataset comprising of over 2200 hours of French speech audio, using the train and the validation splits of [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), [Fleurs](https://huggingface.co/datasets/google/fleurs), [Multilingual TEDx](http://www.openslr.org/100), [MediaSpeech](https://www.openslr.org/108), and [African Accented French](https://huggingface.co/datasets/gigant/african_accented_french). When using the model make sure that your speech input is sampled at 16Khz. **This model doesn't predict casing or punctuation.** | ca25a0001ee7dc04972e1de835d61fec |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Performance *Below are the WERs of the pre-trained models on the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli) and [Fleurs](https://huggingface.co/datasets/google/fleurs). These results are reported in the original [paper](https://cdn.openai.com/papers/whisper.pdf).* | Model | Common Voice 9.0 | MLS | VoxPopuli | Fleurs | | --- | :---: | :---: | :---: | :---: | | [openai/whisper-small](https://huggingface.co/openai/whisper-small) | 22.7 | 16.2 | 15.7 | 15.0 | | [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) | 16.0 | 8.9 | 12.2 | 8.7 | | [openai/whisper-large](https://huggingface.co/openai/whisper-large) | 14.7 | 8.9 | **11.0** | **7.7** | | [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | **13.9** | **7.3** | 11.4 | 8.3 | *Below are the WERs of the fine-tuned models on the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), and [Fleurs](https://huggingface.co/datasets/google/fleurs). Note that these evaluation datasets have been filtered and preprocessed to only contain French alphabet characters and are removed of punctuation outside of apostrophe. The results in the table are reported as `WER (greedy search) / WER (beam search with beam width 5)`.* | Model | Common Voice 11.0 | MLS | VoxPopuli | Fleurs | | --- | :---: | :---: | :---: | :---: | | [bofenghuang/whisper-small-cv11-french](https://huggingface.co/bofenghuang/whisper-small-cv11-french) | 11.76 / 10.99 | 9.65 / 8.91 | 14.45 / 13.66 | 10.76 / 9.83 | | [bofenghuang/whisper-medium-cv11-french](https://huggingface.co/bofenghuang/whisper-medium-cv11-french) | 9.03 / 8.54 | 6.34 / 5.86 | 11.64 / 11.35 | 7.13 / 6.85 | | [bofenghuang/whisper-medium-french](https://huggingface.co/bofenghuang/whisper-medium-french) | 9.03 / 8.73 | 4.60 / 4.44 | 9.53 / 9.46 | 6.33 / 5.94 | | [bofenghuang/whisper-large-v2-cv11-french](https://huggingface.co/bofenghuang/whisper-large-v2-cv11-french) | **8.05** / **7.67** | 5.56 / 5.28 | 11.50 / 10.69 | 5.42 / 5.05 | | [bofenghuang/whisper-large-v2-french](https://huggingface.co/bofenghuang/whisper-large-v2-french) | 8.15 / 7.83 | **4.20** / **4.03** | **9.10** / **8.66** | **5.22** / **4.98** | | 984a8d06d6c1d379a92b5902aaaa0ef9 |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Usage Inference with 🤗 Pipeline ```python import torch from datasets import load_dataset from transformers import pipeline device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | 13680c67dbf9860b29e6d46642581d3f |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Normalise predicted sentences if necessary ``` Inference with 🤗 low-level APIs ```python import torch import torchaudio from datasets import load_dataset from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | 9c1c95b493b3e9a4e8802e64bc11b4cf |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Load model model = AutoModelForSpeechSeq2Seq.from_pretrained("bofenghuang/whisper-large-v2-french").to(device) processor = AutoProcessor.from_pretrained("bofenghuang/whisper-large-v2-french", language="french", task="transcribe") | a48ed9fbb08287b93a7a1e3f8a16fb0c |
apache-2.0 | ['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event'] | false | Load data ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "fr", split="test", streaming=True) test_segment = next(iter(ds_mcv_test)) waveform = torch.from_numpy(test_segment["audio"]["array"]) sample_rate = test_segment["audio"]["sampling_rate"] | 4a9c842cc0295788e8d19adf61cfc18a |
apache-2.0 | ['generated_from_trainer'] | false | qa_bert_finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset. It achieves the following results on the evaluation set: - Loss: 1.157358 | 99627fa9a1ab32f3faf0b8e6412da430 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.2206 | 1.0 | 5533 | 1.160322 | | 0.9452 | 2.0 | 11066 | 1.121690 | | 0.773 | 3.0 | 16599 | 1.157358 | | 123763ef175c923ec27d58925d1cc89c |
apache-2.0 | ['translation'] | false | opus-mt-sv-ny * source languages: sv * target languages: ny * OPUS readme: [sv-ny](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-ny/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.zip) * test set translations: [opus-2020-01-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.test.txt) * test set scores: [opus-2020-01-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.eval.txt) | f224c0800a234cb8a5f38ec58ddb1dcf |
apache-2.0 | ['generated_from_trainer'] | false | openai/whisper-medium This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.2201 - Wer: 44.6966 | df039a04969419121ec3d0b14e09cc9a |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0566 | 6.02 | 1000 | 0.9354 | 47.1998 | | 0.0025 | 13.01 | 2000 | 1.0806 | 47.5605 | | 0.0012 | 19.03 | 3000 | 1.1642 | 47.6665 | | 0.0002 | 26.01 | 4000 | 1.1866 | 44.9724 | | 0.0001 | 33.0 | 5000 | 1.2201 | 44.6966 | | d39d44e3be0f7e2f16d9a0b13cda9f36 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-sst2 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE SST2 dataset. It achieves the following results on the evaluation set: - Loss: 0.2333 - Accuracy: 0.9128 | d9e6a3e3efa14b38914a8bb940078683 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.2103 | 1.0 | 527 | 0.2507 | 0.9048 | | 0.1082 | 2.0 | 1054 | 0.2333 | 0.9128 | | 0.0724 | 3.0 | 1581 | 0.2371 | 0.9186 | | 0.0521 | 4.0 | 2108 | 0.2582 | 0.9186 | | 0.0393 | 5.0 | 2635 | 0.3094 | 0.9220 | | 0.0302 | 6.0 | 3162 | 0.3506 | 0.9197 | | 0.0258 | 7.0 | 3689 | 0.4149 | 0.9071 | | 0.0209 | 8.0 | 4216 | 0.3121 | 0.9174 | | 0.018 | 9.0 | 4743 | 0.4919 | 0.9060 | | a05c40b1f91e67ad206c3c6591ece4e6 |
mit | [] | false | Transformer model based on Vaswani et al., 2017 for Danish-English Neural Machine Translation. It has ~74M parameters and is a fine-tuned version of Helsinki-Opus-NLP da-en. The model achieves a BLEU score of 49.16 on a hold-out test set for the TED2020 dataset (in-domain dataset). The model achieves a BLEU score of 44.16 on a hold-out test set for the for CCAligned and Wikimatrix (out-of-domain dataset). This outperforms the baseline Opus model, which achieved BLEU scores of 46.74 and 42.31 on the in-domain and out-of-domain data respectively. Note: When running inference "_" characters can sometimes replace spaces. | 4ddd694ae0171edb1ce1f1d1eeffe156 |
mit | ['generated_from_trainer'] | false | BART-large-commongen This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on the gem dataset. It achieves the following results on the evaluation set: - Loss: 1.1409 - Spice: 0.4009 | a3a8f1027edcb2a8d9cdb5fed3ba849f |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - training_steps: 6317 | ab7550a1e68617ee9e55ea12a506e734 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Spice | |:-------------:|:-----:|:----:|:---------------:|:------:| | 10.1086 | 0.05 | 100 | 4.9804 | 0.3736 | | 4.4168 | 0.09 | 200 | 2.4402 | 0.4079 | | 1.8158 | 0.14 | 300 | 1.1096 | 0.4258 | | 1.1723 | 0.19 | 400 | 1.0845 | 0.4086 | | 1.0894 | 0.24 | 500 | 1.0727 | 0.423 | | 1.0949 | 0.28 | 600 | 1.0889 | 0.4224 | | 1.0773 | 0.33 | 700 | 1.0977 | 0.4201 | | 1.0708 | 0.38 | 800 | 1.1157 | 0.4213 | | 1.0663 | 0.43 | 900 | 1.1798 | 0.421 | | 1.0985 | 0.47 | 1000 | 1.1611 | 0.4025 | | 1.0561 | 0.52 | 1100 | 1.1048 | 0.421 | | 1.0594 | 0.57 | 1200 | 1.2044 | 0.3626 | | 1.0689 | 0.62 | 1300 | 1.1409 | 0.4009 | | 75c27e0e255ff94fe56fdac38d159845 |
mit | ['generated_from_trainer'] | false | compassionate_elion This model was trained from scratch on the tomekkorbak/pii-pile-chunk3-0-50000, the tomekkorbak/pii-pile-chunk3-50000-100000, the tomekkorbak/pii-pile-chunk3-100000-150000, the tomekkorbak/pii-pile-chunk3-150000-200000, the tomekkorbak/pii-pile-chunk3-200000-250000, the tomekkorbak/pii-pile-chunk3-250000-300000, the tomekkorbak/pii-pile-chunk3-300000-350000, the tomekkorbak/pii-pile-chunk3-350000-400000, the tomekkorbak/pii-pile-chunk3-400000-450000, the tomekkorbak/pii-pile-chunk3-450000-500000, the tomekkorbak/pii-pile-chunk3-500000-550000, the tomekkorbak/pii-pile-chunk3-550000-600000, the tomekkorbak/pii-pile-chunk3-600000-650000, the tomekkorbak/pii-pile-chunk3-650000-700000, the tomekkorbak/pii-pile-chunk3-700000-750000, the tomekkorbak/pii-pile-chunk3-750000-800000, the tomekkorbak/pii-pile-chunk3-800000-850000, the tomekkorbak/pii-pile-chunk3-850000-900000, the tomekkorbak/pii-pile-chunk3-900000-950000, the tomekkorbak/pii-pile-chunk3-950000-1000000, the tomekkorbak/pii-pile-chunk3-1000000-1050000, the tomekkorbak/pii-pile-chunk3-1050000-1100000, the tomekkorbak/pii-pile-chunk3-1100000-1150000, the tomekkorbak/pii-pile-chunk3-1150000-1200000, the tomekkorbak/pii-pile-chunk3-1200000-1250000, the tomekkorbak/pii-pile-chunk3-1250000-1300000, the tomekkorbak/pii-pile-chunk3-1300000-1350000, the tomekkorbak/pii-pile-chunk3-1350000-1400000, the tomekkorbak/pii-pile-chunk3-1400000-1450000, the tomekkorbak/pii-pile-chunk3-1450000-1500000, the tomekkorbak/pii-pile-chunk3-1500000-1550000, the tomekkorbak/pii-pile-chunk3-1550000-1600000, the tomekkorbak/pii-pile-chunk3-1600000-1650000, the tomekkorbak/pii-pile-chunk3-1650000-1700000, the tomekkorbak/pii-pile-chunk3-1700000-1750000, the tomekkorbak/pii-pile-chunk3-1750000-1800000, the tomekkorbak/pii-pile-chunk3-1800000-1850000, the tomekkorbak/pii-pile-chunk3-1850000-1900000 and the tomekkorbak/pii-pile-chunk3-1900000-1950000 datasets. | bd116514e6832c04635e598a51cbf0f0 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0005 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 8 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.01 - training_steps: 2362 - mixed_precision_training: Native AMP | 54909100baf0c0dcddcd6a595edfe81c |
mit | ['generated_from_trainer'] | false | Full config {'dataset': {'conditional_training_config': {'aligned_prefix': '<|aligned|>', 'drop_token_fraction': 0.01, 'misaligned_prefix': '<|misaligned|>', 'threshold': 0.0}, 'datasets': ['tomekkorbak/pii-pile-chunk3-0-50000', 'tomekkorbak/pii-pile-chunk3-50000-100000', 'tomekkorbak/pii-pile-chunk3-100000-150000', 'tomekkorbak/pii-pile-chunk3-150000-200000', 'tomekkorbak/pii-pile-chunk3-200000-250000', 'tomekkorbak/pii-pile-chunk3-250000-300000', 'tomekkorbak/pii-pile-chunk3-300000-350000', 'tomekkorbak/pii-pile-chunk3-350000-400000', 'tomekkorbak/pii-pile-chunk3-400000-450000', 'tomekkorbak/pii-pile-chunk3-450000-500000', 'tomekkorbak/pii-pile-chunk3-500000-550000', 'tomekkorbak/pii-pile-chunk3-550000-600000', 'tomekkorbak/pii-pile-chunk3-600000-650000', 'tomekkorbak/pii-pile-chunk3-650000-700000', 'tomekkorbak/pii-pile-chunk3-700000-750000', 'tomekkorbak/pii-pile-chunk3-750000-800000', 'tomekkorbak/pii-pile-chunk3-800000-850000', 'tomekkorbak/pii-pile-chunk3-850000-900000', 'tomekkorbak/pii-pile-chunk3-900000-950000', 'tomekkorbak/pii-pile-chunk3-950000-1000000', 'tomekkorbak/pii-pile-chunk3-1000000-1050000', 'tomekkorbak/pii-pile-chunk3-1050000-1100000', 'tomekkorbak/pii-pile-chunk3-1100000-1150000', 'tomekkorbak/pii-pile-chunk3-1150000-1200000', 'tomekkorbak/pii-pile-chunk3-1200000-1250000', 'tomekkorbak/pii-pile-chunk3-1250000-1300000', 'tomekkorbak/pii-pile-chunk3-1300000-1350000', 'tomekkorbak/pii-pile-chunk3-1350000-1400000', 'tomekkorbak/pii-pile-chunk3-1400000-1450000', 'tomekkorbak/pii-pile-chunk3-1450000-1500000', 'tomekkorbak/pii-pile-chunk3-1500000-1550000', 'tomekkorbak/pii-pile-chunk3-1550000-1600000', 'tomekkorbak/pii-pile-chunk3-1600000-1650000', 'tomekkorbak/pii-pile-chunk3-1650000-1700000', 'tomekkorbak/pii-pile-chunk3-1700000-1750000', 'tomekkorbak/pii-pile-chunk3-1750000-1800000', 'tomekkorbak/pii-pile-chunk3-1800000-1850000', 'tomekkorbak/pii-pile-chunk3-1850000-1900000', 'tomekkorbak/pii-pile-chunk3-1900000-1950000'], 'is_split_by_sentences': True, 'skip_tokens': 2990407680}, 'generation': {'force_call_on': [25177], 'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}], 'scenario_configs': [{'generate_kwargs': {'bad_words_ids': [[50257], [50258]], 'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_samples': 4096, 'prefix': '<|aligned|>'}], 'scorer_config': {}}, 'kl_gpt3_callback': {'force_call_on': [25177], 'gpt3_kwargs': {'model_name': 'davinci'}, 'max_tokens': 64, 'num_samples': 4096, 'prefix': '<|aligned|>'}, 'model': {'from_scratch': False, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'model_kwargs': {'revision': '5c64636da035c40bb8b1186648a39822071476cb'}, 'num_additional_tokens': 2, 'path_or_name': 'tomekkorbak/cranky_lichterman'}, 'objective': {'name': 'MLE'}, 'tokenizer': {'path_or_name': 'gpt2', 'special_tokens': ['<|aligned|>', '<|misaligned|>']}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 128, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'compassionate_elion', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.0005, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000, 'output_dir': 'training_output2', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 251, 'save_strategy': 'steps', 'seed': 42, 'tokens_already_seen': 2990407680, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | 7d40b5096912133cc2497d11f166e5c9 |
mit | ['generated_from_trainer'] | false | bert-finetuned-ner This model is a fine-tuned version of [dslim/bert-base-NER](https://huggingface.co/dslim/bert-base-NER) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0883 - Precision: 0.9343 - Recall: 0.9495 - F1: 0.9418 - Accuracy: 0.9861 | 66170bae33ab78707fe0cf4b80704164 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.02 | 1.0 | 1756 | 0.0944 | 0.9189 | 0.9381 | 0.9284 | 0.9833 | | 0.011 | 2.0 | 3512 | 0.0809 | 0.9358 | 0.9514 | 0.9435 | 0.9862 | | 0.0032 | 3.0 | 5268 | 0.0883 | 0.9343 | 0.9495 | 0.9418 | 0.9861 | | 9d7ed60e20e7a83566c8515053b0a4d9 |
apache-2.0 | ['generated_from_trainer'] | false | base-vanilla-target-tweet This model is a fine-tuned version of [google/bert_uncased_L-12_H-768_A-12](https://huggingface.co/google/bert_uncased_L-12_H-768_A-12) on the tweet_eval dataset. It achieves the following results on the evaluation set: - Loss: 1.8380 - Accuracy: 0.7781 - F1: 0.7773 | ac9ec3ae48f15d04bf3c03e1a41da7e9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.3831 | 4.9 | 500 | 0.9800 | 0.7807 | 0.7785 | | 0.0414 | 9.8 | 1000 | 1.4175 | 0.7754 | 0.7765 | | 0.015 | 14.71 | 1500 | 1.6411 | 0.7754 | 0.7708 | | 0.0166 | 19.61 | 2000 | 1.5930 | 0.7941 | 0.7938 | | 0.0175 | 24.51 | 2500 | 1.3934 | 0.7888 | 0.7852 | | 0.0191 | 29.41 | 3000 | 1.9407 | 0.7647 | 0.7658 | | 0.0137 | 34.31 | 3500 | 1.8380 | 0.7781 | 0.7773 | | 3c59bbc519f04587543371cbaf6720f8 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2r_de_xls-r_age_teens-10_sixties-0_s460 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | acc2f41ec59dd9f7345f3dcf2f0531c8 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 32 - eval_batch_size: 8 - seed: 28 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | dbf61fa5cb95490917ea942f57954f3e |
apache-2.0 | ['automatic-speech-recognition', 'en'] | false | exp_w2v2t_en_vp-nl_s281 Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | c889e6bdae1bb61a6945318b5f7ebc5a |
apache-2.0 | [] | false | Model description The REALM checkpoint pretrained with CC-News as target corpus and Wikipedia as knowledge corpus, converted from the TF checkpoint provided by Google Language. The original paper, code, and checkpoints can be found [here](https://github.com/google-research/language/tree/master/language/realm). | 86b12315391c5fa24239755d1071eb6c |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Stable Diffusion v2-1-base Model Card This model card focuses on the model associated with the Stable Diffusion v2-1-base model. This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset. - Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt). - Use it with 🧨 [`diffusers`]( | 01469b6eca4885a826481d027eea8783 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Examples Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner. ```bash pip install diffusers transformers accelerate scipy safetensors ``` Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler): ```python from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler import torch model_id = "stabilityai/stable-diffusion-2-1-base" scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler") pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16) pipe = pipe.to("cuda") prompt = "a photo of an astronaut riding a horse on mars" image = pipe(prompt).images[0] image.save("astronaut_rides_horse.png") ``` **Notes**: - Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance) - If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed) | 8affe7254568030465136ea51ffb1d6d |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Training **Training Data** The model developers used the following dataset for training the model: - LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic. **Training Procedure** Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training, - Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4 - Text prompts are encoded through the OpenCLIP-ViT/H text-encoder. - The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention. - The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512. We currently provide the following checkpoints, for various versions: | 14b7ffa8ba33225ed7b5c0bf649237fb |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Version 2.1 - `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset. - `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`. | 623b513558d89f60932d332433291366 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Version 2.0 - `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`. 850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`. - `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset. - `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning. The additional input channels of the U-Net which process this extra information were zero-initialized. - `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning. The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama). - `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752). In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml). - **Hardware:** 32 x 8 x A100 GPUs - **Optimizer:** AdamW - **Gradient Accumulations**: 1 - **Batch:** 32 x 8 x 2 x 4 = 2048 - **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant | 5e397f3c2c3d320e352af460a7a82c64 |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | Evaluation Results Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints: 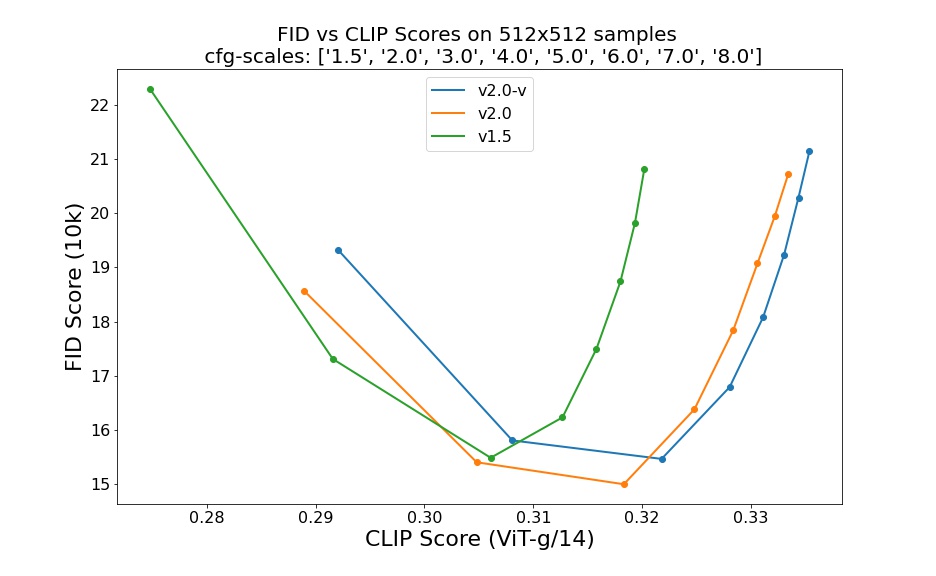 Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores. | cb791316c647b62dc7c6482e33f8ccca |
mit | ['generated_from_trainer'] | false | bart-large-cnn-samsum-ElectrifAi_v10 This model is a fine-tuned version of [philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.1748 - Rouge1: 58.3392 - Rouge2: 35.1686 - Rougel: 45.4136 - Rougelsum: 56.9138 - Gen Len: 108.375 | d930eae4329fe4a379dcf9a92e34b420 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:| | No log | 1.0 | 21 | 1.1573 | 56.0772 | 34.1572 | 44.3652 | 54.8621 | 106.0833 | | No log | 2.0 | 42 | 1.1764 | 57.7245 | 34.6517 | 45.67 | 56.3426 | 106.4167 | | No log | 3.0 | 63 | 1.1748 | 58.3392 | 35.1686 | 45.4136 | 56.9138 | 108.375 | | 3bc37f240a54be8d6c0699f090719326 |
creativeml-openrail-m | ['text-to-image', 'stable-diffusion'] | false | aaureeliaav3 Dreambooth model trained by akahnn with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Sample pictures of this concept: | 642cdb2a3f95dc8d3e6e04d0d3604a24 |
apache-2.0 | ['generated_from_trainer'] | false | distilr2-lr1e05-wd0.08-bs16 This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2760 - Rmse: 0.5254 - Mse: 0.2760 - Mae: 0.4277 | b38aa4c26fb3249661c2542ecb8b9d2b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae | |:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:| | 0.2765 | 1.0 | 1245 | 0.2733 | 0.5228 | 0.2733 | 0.4100 | | 0.2733 | 2.0 | 2490 | 0.2739 | 0.5233 | 0.2739 | 0.4224 | | 0.2713 | 3.0 | 3735 | 0.2760 | 0.5254 | 0.2760 | 0.4277 | | a17e09c7c333711936737890f5361f9e |
apache-2.0 | ['generated_from_trainer'] | false | t5-base-adv-mtop This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mtop dataset. It achieves the following results on the evaluation set: - Loss: 0.1009 - Exact Match: 0.7937 | 91147a4cdc9df7b347abd4296c9f2223 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Exact Match | |:-------------:|:-----:|:----:|:---------------:|:-----------:| | 4.2521 | 1.09 | 200 | 0.1367 | 0.5418 | | 6.2586 | 2.17 | 400 | 0.1020 | 0.6004 | | 4.0003 | 3.26 | 600 | 0.1009 | 0.6179 | | 2.7191 | 4.35 | 800 | 0.1066 | 0.6251 | | 1.5031 | 5.43 | 1000 | 0.1215 | 0.6286 | | 0.703 | 6.52 | 1200 | 0.1238 | 0.6215 | | 0.6371 | 7.61 | 1400 | 0.1365 | 0.6286 | | 0.3712 | 8.69 | 1600 | 0.1450 | 0.6300 | | 0.5666 | 9.78 | 1800 | 0.1500 | 0.6295 | | 0.5237 | 10.87 | 2000 | 0.1416 | 0.6251 | | 0.4562 | 11.96 | 2200 | 0.1464 | 0.6313 | | 0.3421 | 13.04 | 2400 | 0.1635 | 0.6277 | | 0.3686 | 14.13 | 2600 | 0.1643 | 0.6322 | | 0.218 | 15.22 | 2800 | 0.1800 | 0.6277 | | 0.2371 | 16.3 | 3000 | 0.1742 | 0.6268 | | c6609845a46b29d1abffe3a0c8eadd7e |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-mnli This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset. It achieves the following results on the evaluation set: - Loss: 0.6753 - Accuracy: 0.8206 | 2c93e5c4ed689ab17a314c1a748021fa |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:------:|:---------------:|:--------:| | 0.5146 | 1.0 | 24544 | 0.4925 | 0.8049 | | 0.4093 | 2.0 | 49088 | 0.5090 | 0.8164 | | 0.3122 | 3.0 | 73632 | 0.5299 | 0.8185 | | 0.2286 | 4.0 | 98176 | 0.6753 | 0.8206 | | 0.182 | 5.0 | 122720 | 0.8372 | 0.8195 | | 34eb35fe07d562ec59b06c6740d43aca |
apache-2.0 | ['translation'] | false | fra-msa * source group: French * target group: Malay (macrolanguage) * OPUS readme: [fra-msa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fra-msa/README.md) * model: transformer-align * source language(s): fra * target language(s): ind zsm_Latn * model: transformer-align * pre-processing: normalization + SentencePiece (spm32k,spm32k) * a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID) * download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.zip) * test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.test.txt) * test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.eval.txt) | 50ac3ac2645aaa9b913ff79aef4add28 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: fra-msa - source_languages: fra - target_languages: msa - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fra-msa/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['fr', 'ms'] - src_constituents: {'fra'} - tgt_constituents: {'zsm_Latn', 'ind', 'max_Latn', 'zlm_Latn', 'min'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.test.txt - src_alpha3: fra - tgt_alpha3: msa - short_pair: fr-ms - chrF2_score: 0.617 - bleu: 35.3 - brevity_penalty: 0.978 - ref_len: 6696.0 - src_name: French - tgt_name: Malay (macrolanguage) - train_date: 2020-06-17 - src_alpha2: fr - tgt_alpha2: ms - prefer_old: False - long_pair: fra-msa - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | 3527b0e3268632f1f56b3de9585e296c |
apache-2.0 | ['generated_from_trainer'] | false | t5-base-adv-cstop_artificial This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the cstop_artificial dataset. It achieves the following results on the evaluation set: - Loss: 0.0997 - Exact Match: 0.8479 | c33f8d1c9d16ab15277c612ef96232f0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Exact Match | |:-------------:|:-----:|:----:|:---------------:|:-----------:| | 1.8954 | 12.5 | 200 | 0.1003 | 0.4902 | | 0.3392 | 25.0 | 400 | 0.0997 | 0.5671 | | 0.3092 | 37.5 | 600 | 0.1067 | 0.5653 | | 0.3062 | 50.0 | 800 | 0.1245 | 0.5689 | | 0.5401 | 62.5 | 1000 | 0.1096 | 0.5581 | | 0.3075 | 75.0 | 1200 | 0.1197 | 0.5581 | | 0.3039 | 87.5 | 1400 | 0.1339 | 0.5689 | | 0.3041 | 100.0 | 1600 | 0.1485 | 0.5635 | | 0.3036 | 112.5 | 1800 | 0.1498 | 0.5581 | | 0.304 | 125.0 | 2000 | 0.1454 | 0.5617 | | 0.3022 | 137.5 | 2200 | 0.1516 | 0.5689 | | 0.3032 | 150.0 | 2400 | 0.1361 | 0.5635 | | 0.3035 | 162.5 | 2600 | 0.1427 | 0.5635 | | 0.3001 | 175.0 | 2800 | 0.1466 | 0.5635 | | 0.3048 | 187.5 | 3000 | 0.1471 | 0.5635 | | 7a5948943c5c15b8ebbc7d50c99a752e |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-finetuned-ks This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2562 - Accuracy: 0.9869 | cd8cb34c798c6f20dc60da820bf9f144 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 3e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 16 | 689b178d73767e019f802856feafc2a6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 2.4691 | 0.99 | 26 | 2.3935 | 0.2310 | | 2.1621 | 1.99 | 52 | 2.0155 | 0.3202 | | 1.8731 | 2.99 | 78 | 1.6397 | 0.7929 | | 1.4521 | 3.99 | 104 | 1.2337 | 0.8940 | | 1.101 | 4.99 | 130 | 0.9519 | 0.9393 | | 0.9401 | 5.99 | 156 | 0.7686 | 0.975 | | 0.7463 | 6.99 | 182 | 0.6338 | 0.9774 | | 0.6555 | 7.99 | 208 | 0.5214 | 0.9810 | | 0.5095 | 8.99 | 234 | 0.4228 | 0.9869 | | 0.4152 | 9.99 | 260 | 0.3658 | 0.9857 | | 0.3764 | 10.99 | 286 | 0.3311 | 0.9857 | | 0.3325 | 11.99 | 312 | 0.2954 | 0.9881 | | 0.3121 | 12.99 | 338 | 0.2797 | 0.9869 | | 0.281 | 13.99 | 364 | 0.2650 | 0.9857 | | 0.2627 | 14.99 | 390 | 0.2571 | 0.9869 | | 0.2655 | 15.99 | 416 | 0.2562 | 0.9869 | | cf4bd894385af72612ce67c9f4a99e79 |
apache-2.0 | ['pytorch', 'diffusers', 'unconditional-image-generation'] | false | Denoising Diffusion Probabilistic Models (DDPM) **Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) **Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel **Abstract**: *We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.* | b4851d9bfbe3968c75b76de8db8860c2 |
apache-2.0 | ['pytorch', 'diffusers', 'unconditional-image-generation'] | false | Inference **DDPM** models can use *discrete noise schedulers* such as: - [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py) - [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py) - [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py) for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest. For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead. See the following code: ```python | a1f9d7e415564a0e268d2645cfcb9a05 |
apache-2.0 | ['pytorch', 'diffusers', 'unconditional-image-generation'] | false | save image image.save("ddpm_generated_image.png") ``` For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) | 32108b7ab144bb19e4b9fe8031d967fe |
apache-2.0 | ['pytorch', 'diffusers', 'unconditional-image-generation'] | false | Training If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) | 0aaeccf402494ab33477dd10498db713 |
apache-2.0 | ['pytorch', 'diffusers', 'unconditional-image-generation'] | false | Samples 1.  2.  3.  4.  | 7a4d1f74e42b55dfa0330290f6d219c7 |
apache-2.0 | ['generated_from_trainer'] | false | bert-emotion This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the tweet_eval dataset. It achieves the following results on the evaluation set: - Loss: 1.1951 - Precision: 0.7350 - Recall: 0.7334 - Fscore: 0.7341 | 69ff3105c7550fbef4e109eab42e089c |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 4 - eval_batch_size: 4 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | 4ba93b141d9df7353d0ae6d8ba7bfca0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.