
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 318 | 3.1622 | 0.7468 | | 3.6918 | 2.0 | 636 | 1.5555 | 0.8565 | | 3.6918 | 3.0 | 954 | 0.7728 | 0.9142 | | 1.3257 | 4.0 | 1272 | 0.4589 | 0.9319 | | 0.431 | 5.0 | 1590 | 0.3350 | 0.9426 | | 0.431 | 6.0 | 1908 | 0.2879 | 0.9406 | | 0.1752 | 7.0 | 2226 | 0.2609 | 0.9465 | | 0.0893 | 8.0 | 2544 | 0.2512 | 0.9455 | | 0.0893 | 9.0 | 2862 | 0.2488 | 0.9452 | | 0.062 | 10.0 | 3180 | 0.2469 | 0.9458 | | bcd7e1a0df789bf9fa31f605f6d64e07 |
cc-by-4.0 | ['espnet', 'audio', 'speech-translation'] | false | `espnet/brianyan918_iwslt22_dialect_train_st_conformer_ctc0.3_lr2e-3_warmup15k_newspecaug` This model was trained by Brian Yan using iwslt22_dialect recipe in [espnet](https://github.com/espnet/espnet/). | b48438dd93e8f4ae89ba4493378c939c |
cc-by-4.0 | ['espnet', 'audio', 'speech-translation'] | false | Demo: How to use in ESPnet2 ```bash cd espnet git checkout 77fce65312877a132bbae01917ad26b74f6e2e14 pip install -e . cd egs2/iwslt22_dialect/st1 ./run.sh --skip_data_prep false --skip_train true --download_model espnet/brianyan918_iwslt22_dialect_train_st_conformer_ctc0.3_lr2e-3_warmup15k_newspecaug ``` <!-- Generated by scripts/utils/show_st_results.sh --> | 45bb512c949dd0b9db6f89702d7bd6ec |
cc-by-4.0 | ['espnet', 'audio', 'speech-translation'] | false | Environments - date: `Tue Feb 8 12:54:12 EST 2022` - python version: `3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0]` - espnet version: `espnet 0.10.7a1` - pytorch version: `pytorch 1.8.1` - Git hash: `77fce65312877a132bbae01917ad26b74f6e2e14` - Commit date: `Tue Feb 8 10:48:10 2022 -0500` | 6a43a13dd3175dbda1b2256cdac5af85 |
cc-by-4.0 | ['espnet', 'audio', 'speech-translation'] | false | ST config <details><summary>expand</summary> ``` config: conf/tuning/train_st_conformer_ctc0.3_lr2e-3_warmup15k_newspecaug.yaml print_config: false log_level: INFO dry_run: false iterator_type: sequence output_dir: exp/st_train_st_conformer_ctc0.3_lr2e-3_warmup15k_newspecaug_raw_bpe_tc1000_sp ngpu: 1 seed: 0 num_workers: 1 num_att_plot: 3 dist_backend: nccl dist_init_method: env:// dist_world_size: null dist_rank: null local_rank: 0 dist_master_addr: null dist_master_port: null dist_launcher: null multiprocessing_distributed: false unused_parameters: false sharded_ddp: false cudnn_enabled: true cudnn_benchmark: false cudnn_deterministic: true collect_stats: false write_collected_feats: false max_epoch: 80 patience: null val_scheduler_criterion: - valid - loss early_stopping_criterion: - valid - loss - min best_model_criterion: - - valid - acc - max keep_nbest_models: 10 nbest_averaging_interval: 0 grad_clip: 5.0 grad_clip_type: 2.0 grad_noise: false accum_grad: 2 no_forward_run: false resume: true train_dtype: float32 use_amp: false log_interval: null use_matplotlib: true use_tensorboard: true use_wandb: false wandb_project: null wandb_id: null wandb_entity: null wandb_name: null wandb_model_log_interval: -1 detect_anomaly: false pretrain_path: null init_param: [] ignore_init_mismatch: true freeze_param: [] num_iters_per_epoch: null batch_size: 20 valid_batch_size: null batch_bins: 25000000 valid_batch_bins: null train_shape_file: - exp/st_stats_raw_bpe1000_sp/train/speech_shape - exp/st_stats_raw_bpe1000_sp/train/text_shape.bpe - exp/st_stats_raw_bpe1000_sp/train/src_text_shape.bpe valid_shape_file: - exp/st_stats_raw_bpe1000_sp/valid/speech_shape - exp/st_stats_raw_bpe1000_sp/valid/text_shape.bpe - exp/st_stats_raw_bpe1000_sp/valid/src_text_shape.bpe batch_type: numel valid_batch_type: null fold_length: - 80000 - 150 - 150 sort_in_batch: descending sort_batch: descending multiple_iterator: false chunk_length: 500 chunk_shift_ratio: 0.5 num_cache_chunks: 1024 train_data_path_and_name_and_type: - - dump/raw/train_sp/wav.scp - speech - kaldi_ark - - dump/raw/train_sp/text.tc.en - text - text - - dump/raw/train_sp/text.tc.rm.ta - src_text - text valid_data_path_and_name_and_type: - - dump/raw/dev/wav.scp - speech - kaldi_ark - - dump/raw/dev/text.tc.en - text - text - - dump/raw/dev/text.tc.rm.ta - src_text - text allow_variable_data_keys: false max_cache_size: 0.0 max_cache_fd: 32 valid_max_cache_size: null optim: adam optim_conf: lr: 0.002 weight_decay: 1.0e-06 scheduler: warmuplr scheduler_conf: warmup_steps: 15000 token_list: - <blank> - <unk> - s - ▁ - apo - '&' - ; - ▁i - ▁you - t - ▁it - ▁the - ▁and - ▁to - ▁that - ▁a - n - a - ▁he - ▁me - m - d - ▁yes - ▁she - ▁no - ▁in - ▁what - ▁for - ▁we - ing - ll - ▁they - re - ▁are - ▁did - ▁god - ▁is - e - ed - ▁so - ▁her - ▁do - ▁have - ▁of - ▁with - ▁go - ▁know - ▁not - ▁was - ▁on - ▁don - y - ▁him - ▁one - ▁like - ▁there - '%' - ▁pw - ▁be - ▁at - ▁told - ▁good - ▁will - ▁my - ▁all - ▁or - c - er - p - ▁how - ▁ah - r - ▁but - ▁them - ▁see - ▁get - ▁can - i - ▁when - ▁going - ▁about - ▁mean - ▁this - k - ▁your - ▁by - ▁if - u - ▁come - ▁up - ▁tell - g - ▁said - ▁then - ▁now - ▁yeah - o - ▁out - al - ra - ▁because - ▁time - ▁well - ▁would - ▁p - ▁from - h - ar - f - ▁swear - ▁went - b - ▁really - or - ▁want - ri - ▁home - ▁work - ve - ▁take - ▁got - ▁just - l - ▁uh - ▁why - en - ▁even - ▁am - ▁who - ▁make - ▁day - '-' - in - ▁something - ▁some - ou - ▁us - ▁okay - ▁where - ▁does - ▁has - ▁thank - ▁c - ▁his - th - ▁back - ▁fine - ▁today - ly - ▁b - ▁oh - ▁doing - ▁everything - ▁here - le - ▁thing - ▁two - ▁anyway - li - ▁had - ▁still - ▁say - ro - ▁after - ce - ▁hello - ▁ma - ▁call - w - ▁listen - il - ▁should - ▁girl - ▁f - z - ▁too - ▁let - ▁understand - ▁may - ▁much - ▁think - ch - ir - ha - ▁other - ▁tomorrow - ▁were - ▁people - es - ▁year - di - ba - ▁right - el - ▁things - ▁house - v - ▁actually - un - ▁an - ▁give - ▁only - ▁better - pe - ▁need - ▁buy - ▁de - ne - ▁ha - ur - ion - ▁made - la - ▁willing - ▁nothing - ▁called - ▁night - ▁yesterday - se - ▁came - ▁lot - ter - ▁g - po - ▁find - ry - ▁car - ▁over - ic - ▁stay - ▁eat - ent - ▁always - ▁very - 'on' - ▁put - ▁ramadan - ▁those - ▁hear - is - ▁talk - ▁three - ▁anything - ▁mo - ▁little - ▁been - ▁already - fi - ation - ke - ▁first - ▁look - it - ▁won - ▁mom - ▁way - ▁before - ▁ok - ▁last - fa - ▁cook - vi - ▁hi - ▁same - ▁thought - ▁also - um - ate - ▁money - ▁start - ▁place - us - ▁morning - ▁could - ▁ask - ▁bring - ▁bit - ▁lo - ▁leave - ▁man - ▁left - ine - ▁days - ge - ▁la - ▁week - ▁friend - ▁problem - ▁sister - ▁allah - ▁feel - ▁every - ▁more - fe - ▁long - ▁hundred - ▁j - ▁eh - ho - ca - em - ▁talking - ▁exam - ▁next - ▁new - ▁fun - ▁took - ▁alright - co - ▁w - ▁um - ▁eid - ▁brother - ▁our - gh - ow - ▁o - ▁four - ni - wa - ▁else - ▁finish - bo - ▁sleep - ▁bless - ▁dear - ▁since - ▁play - ▁name - hi - ▁coming - ▁many - et - ▁usual - ▁con - ▁maybe - ▁off - bi - ▁than - ▁any - ▁mother - ▁son - om - ▁their - ▁keep - ▁dinner - ▁ten - ▁half - ▁help - ▁bad - and - ▁pass - ▁hot - ▁guy - ▁least - ▁down - ▁bought - ▁dinars - ▁working - ▁around - ▁normal - ▁poor - ▁stuff - ▁hope - ▁used - ▁again - ▁bro - ul - ▁phone - ▁ex - ▁done - ▁six - ▁na - ▁month - ▁tired - ▁check - ▁show - ▁together - oo - ▁later - ▁past - ▁five - ▁watch - ya - ▁coffee - ment - ut - ▁plan - ▁great - ▁daughter - j - ▁another - side - ▁change - ▁yet - ting - ▁until - ▁honestly - ▁whole - ol - ▁care - ▁sure - able - id - ▁big - ▁spend - ▁exactly - ▁boy - ▁course - ▁end - ▁please - ▁started - he - up - ▁found - ▁saw - ▁family - ▁asked - ▁enough - ▁during - ▁rest - ▁which - ▁gave - ▁true - ▁while - ▁job - ▁el - ▁each - ▁away - ▁kids - ▁goes - less - ▁twenty - ▁eight - ▁someone - ▁cha - ▁clothes - ah - ▁myself - ▁nice - ▁late - ▁old - ▁real - age - ant - ▁fast - ▁add - ▁hard - ▁these - ful - im - ▁close - ive - ▁dad - ▁pay - ies - ▁dude - ▁alone - ▁far - ance - ▁dis - ▁seven - ▁isn - ▁pro - our - ▁thousand - ▁break - ▁hour - ▁wait - ▁brought - ▁open - ▁un - ▁wedding - ▁walk - ▁father - ▁ka - ▁second - x - ▁saturday - ▁salad - ▁win - ▁everyone - ▁water - ▁tunis - ▁remember - ity - ▁wake - ▁minute - ▁school - ▁sunday - ▁own - ▁shop - ▁cold - ▁meet - ▁wear - ever - ▁send - ▁early - ▁gra - tic - ▁short - ▁use - ▁sometimes - hou - ▁love - ▁prepare - ▁sea - ▁study - ure - ▁com - qui - ▁hand - ▁both - ja - ▁summer - ▁wrong - ▁wanted - che - ▁miss - ▁try - ▁iftar - ▁yourself - q - ▁live - war - ▁expensive - ▁getting - ▁waiting - ▁once - ▁kh - ▁forgot - ▁nine - ▁anymore - ▁soup - ▁uncle - ▁beach - ▁saying - ▁into - ▁having - ▁brik - ▁room - ▁food - ▁visit - ▁matter - ▁thirty - ▁taking - ▁rain - ▁aunt - ▁never - ▁pick - ▁tunisia - ▁health - ▁head - ▁cut - ▁fasting - ▁sick - ▁friday - ▁forget - ▁monday - ▁become - ▁dress - ated - ▁most - wi - ▁hang - ▁life - ▁fish - ▁happy - ▁delicious - ▁deal - ▁finished - ble - ▁studying - ▁weather - ▁making - ▁cost - ▁bl - ▁stayed - ▁guess - ▁teach - ▁stop - ▁near - ▁watching - ▁without - ▁imagine - ▁seriously - fl - ▁speak - ▁idea - ▁must - ▁normally - ▁turn - ize - ▁clean - ▁tv - ▁meat - ▁woke - ▁example - ▁easy - ▁sent - ▁sell - over - ▁fifty - ▁amazing - ▁beautiful - ▁whatever - ▁enjoy - ▁talked - ▁believe - ▁thinking - ▁count - ▁almost - ▁longer - ▁afternoon - ▁hair - ▁front - ▁earlier - ▁mind - ▁kind - ▁tea - ▁best - ▁rent - ▁picture - ▁cooked - ▁price - ight - ▁soon - ▁woman - ▁otherwise - ▁happened - ▁story - ▁luck - ▁high - ▁happen - ▁arrive - ▁paper - ga - ▁quickly - ▁looking - ub - ▁number - ▁staying - ▁sit - man - ack - ▁important - ▁either - ▁person - ▁small - ▁free - ▁crazy - ▁playing - ▁kept - ▁part - ▁game - law - ▁till - uck - ▁ready - ▁might - ▁gone - ▁full - ▁fix - ▁subject - ▁laugh - ▁doctor - ▁welcome - ▁eleven - ▁sleeping - ▁heat - ▁probably - ▁such - ▁café - ▁fat - ▁sweet - ▁married - ▁drink - ▁move - ▁outside - ▁especially - ▁group - ji - ▁market - ▁through - ▁train - ▁protect - ▁turned - ▁red - ▁busy - ▁light - ▁noise - ▁street - ▁manage - ▁piece - ▁sitting - gue - ▁sake - ▁party - ish - ▁young - ▁case - ▁cool - huh - ▁marwa - ▁drive - ▁pray - clock - ▁couscous - ▁spent - ▁felt - ▁hopefully - ▁everybody - ▁living - ▁pain - line - ▁between - ▁match - ▁prayer - que - ian - ▁facebook - ▁spi - ▁eye - ▁children - ▁tonight - ▁mohamed - ▁understood - ▁black - ▁husband - ▁rid - ▁kitchen - ▁face - ▁swim - ▁kid - ▁invite - ▁cup - ▁grilled - ▁wife - ▁cousin - ▁drop - ▁wow - ▁table - ▁du - ▁bored - ▁neighborhood - ▁agree - ▁bread - ▁hamma - ▁straight - ▁tuesday - ▁anyone - ▁lunch - ade - ▁himself - ▁gather - ▁wish - ▁fifteen - ▁wednesday - ▁die - ▁thursday - ▁color - ▁asleep - ▁different - ▁whether - ▁ago - ▁middle - ▁class - ▁cake - shirt - ▁fight - ▁clear - ▁test - ▁plus - ▁sousse - ▁beginning - ▁result - ▁learn - ▁crowded - ▁slept - ▁shoes - ▁august - ▁pretty - ▁white - ▁apparently - ▁reach - ▁mariem - ▁return - ▁road - ▁million - ▁stand - ▁paid - ▁word - ious - ▁few - ▁breakfast - ▁post - ▁kilo - ▁chicken - ▁grade - ▁read - ▁accept - ▁birthday - ▁exhaust - ▁point - ▁july - ▁patience - ▁studies - ▁trouble - ▁along - ▁worry - ▁follow - ▁hurt - ▁afraid - ▁trip - ▁ahmed - ▁remain - ▁succeed - ▁mercy - ▁difficult - ▁weekend - ▁answer - ▁cheap - ▁repeat - ▁auntie - ▁sign - ▁hold - ▁under - ▁olive - ▁mahdi - ▁sfax - ▁annoy - ▁dishes - ▁message - ▁business - ▁french - ▁serious - ▁travel - ▁office - ▁wonder - ▁student - ▁internship - ▁pepper - ▁knew - ▁kill - ▁sauce - ▁herself - ▁hammamet - ▁damn - ▁mix - ▁suit - ▁medicine - ▁remove - ▁gonna - ▁company - ▁quarter - ▁shopping - ▁correct - ▁throw - ▁grow - ▁voice - ▁series - gotten - ▁taste - ▁driving - ▁hospital - ▁sorry - ▁aziz - ▁milk - ▁green - ▁baccalaureate - ▁running - ▁lord - ▁explain - ▁angry - ▁build - ▁fruit - ▁photo - é - ▁crying - ▁baby - ▁store - ▁project - ▁france - ▁twelve - ▁decide - ▁swimming - ▁world - ▁preparing - ▁special - ▁session - ▁behind - ▁vegetable - ▁strong - ▁fatma - ▁treat - ▁cream - ▁situation - ▁settle - ▁totally - ▁stopped - ▁book - ▁honest - ▁solution - ▁vacation - ▁cheese - ▁ahead - ▁sami - ▁focus - ▁scared - ▁club - ▁consider - ▁final - ▁naturally - ▁barely - ▁issue - ▁floor - ▁birth - ▁almighty - ▁engagement - ▁blue - ▁empty - ▁soccer - ▁prophet - ▁ticket - ▁indeed - ▁write - ▁present - ▁patient - ▁available - ▁holiday - ▁leaving - ▁became - ▁reason - ▁apart - ▁impossible - ▁shame - ▁worried - ▁body - ▁continue - ▁program - ▁stress - ▁arabic - ▁round - ▁taxi - ▁transport - ▁third - ▁certain - ▁downstairs - ▁neighbor - ▁directly - ▁giving - ▁june - ▁mini - ▁upstairs - ▁mistake - ▁period - ▁catch - ▁buddy - ▁success - ▁tajine - ▁excuse - ▁organize - ▁question - ▁suffer - ▁remind - ▁university - ▁downtown - ▁sugar - ▁twice - ▁women - ▁couple - ▁everyday - ▁condition - ▁obvious - ▁nobody - ▁complete - ▁stomach - ▁account - ▁september - ▁choose - ▁bottle - ▁figure - ▁instead - ▁salary - '0' - '1' - '3' - '2' - '5' - '7' - '4' - '9' - '8' - / - ° - '6' - è - $ - ï - <sos/eos> src_token_list: - <blank> - <unk> - ّ - ي - ا - ِ - ل - َ - و - ه - ة - م - ر - ك - ▁ما - ُ - ب - ش - د - ت - ▁في - َّ - ▁ن - ▁ي - ▁ت - ن - ▁لا - ح - ▁ه - س - وا - ▁م - ف - ▁إي - ع - ▁ب - ها - ط - ى - ق - ▁الل - ▁أ - ج - ▁والل - ▁و - ▁إيه - ▁ا - ▁يا - ز - ▁تو - ▁بش - ص - ▁أه - خ - ات - ▁إنت - ▁أنا - نا - ▁شن - ▁ق - ▁ش - ▁ك - يت - ين - ▁ف - ار - ▁قال - ▁باهي - ▁ع - ▁من - ▁ل - ▁مش - ▁كان - ▁حت - ▁ول - هم - ▁ر - ان - ▁س - ض - ني - ▁بال - ▁على - ▁متاع - ▁كي - ▁ال - ▁ح - ▁كل - ▁آنا - ▁الم - ▁خ - ▁الس - ▁وال - ون - ور - ▁أم - ▁هك - ▁آش - ▁الد - ▁عاد - ▁ج - ▁معناها - ▁مع - اش - ▁الص - ▁نهار - ▁لل - لها - ▁تي - ▁رب - ▁خاطر - ▁أكهو - غ - ▁شي - الل - ام - تها - ▁ون - ▁آك - ▁فهمت - وم - ▁موش - مشي - ▁ص - ▁اليوم - ▁مر - ست - ▁الب - ▁لاباس - تلي - ▁الكل - ▁عال - ذ - ▁فم - ▁الك - ▁حاجة - ▁شوي - اكا - ▁ياخي - ▁هاني - ▁صح - اس - ▁آه - ▁برشة - ▁الن - ▁وت - ▁الج - لك - ▁راهو - سم - ▁الح - مت - ▁الت - ▁بعد - اج - عد - ▁انشا - وش - لت - ▁وين - ث - ▁ولا - ▁باش - ▁فيها - نت - ▁إ - ▁الأ - ▁الف - ▁إم - ▁واحد - ▁ألو - ▁عندي - ▁أك - ▁خل - ▁وي - ▁تعمل - أ - ▁ريت - ▁وأ - ▁تعرف - بت - ▁الع - ▁مشيت - ▁وه - ▁حاصيلو - ▁بالل - ▁نعمل - ▁غ - ▁تجي - ▁يجي - ▁كيفاش - ▁عملت - ظ - اك - ▁هاو - ▁اش - ▁قد - ▁نق - ▁د - ▁زادا - ▁فيه - رة - ▁بر - ▁الش - ▁ز - ▁كيما - ▁الا - ند - عم - ▁نح - ▁بنتي - ▁نمشي - ▁عليك - ▁نعرفش - ▁كهو - ▁وم - ▁ط - تي - ▁خير - ▁آ - مش - ▁عليه - له - حت - ▁إيا - ▁أحنا - ▁تع - الا - عب - ▁ديما - ▁تت - ▁جو - ▁مالا - ▁أو - ▁قلتلك - ▁معنتها - لنا - ▁شكون - ▁تحب - بر - ▁الر - ▁وا - ▁الق - اء - ▁عل - ▁البارح - ▁وخ - ▁سافا - ▁هوما - ▁ولدي - ▁ - ▁نعرف - يف - رت - ▁وب - ▁روح - ▁علاش - ▁هاذاك - ▁رو - وس - ▁جا - ▁كيف - طر - ▁غادي - يكا - عمل - ▁نحب - ▁عندك - ▁وما - ▁فر - اني - ▁قلتله - ▁الط - فر - ▁دار - ▁عليها - ▁يعمل - ▁نت - ▁تح - باح - ▁ماهو - ▁وكل - ▁وع - قت - ▁فهمتك - عر - ▁وس - ▁تر - ▁سي - يلة - ▁قلت - ▁رمضان - صل - ▁آما - ▁الواحد - ▁بيه - ▁ثلاثة - ▁فهمتني - ▁ها - بط - ▁مازال - قل - ▁بالك - ▁معناتها - ▁ور - ▁قلتلها - ▁يس - رب - ▁ام - ▁وبعد - ▁الث - ▁وإنت - ▁بحذا - ▁لازم - ْ - ▁بن - قرا - سك - ▁يت - خل - ▁فه - عت - ▁هاك - ▁تق - ▁قبل - ▁وك - ▁نقول - ▁الز - حم - ▁عادش - حكي - وها - بة - نس - طل - ▁علاه - ذا - ▁سا - ▁طل - الي - ▁يق - ▁دو - حوا - حد - ▁نشوف - نة - ▁لي - ▁تك - ▁نا - ▁هاذ - ▁خويا - ▁المر - ▁وينك - ▁البر - ▁أتو - ينا - ▁حل - ولي - ▁ثم - ▁عم - ▁آي - ▁قر - از - ▁وح - كش - بعة - ▁كيفاه - ▁نع - ▁الحمدلله - ▁ياسر - ▁الخ - ▁معاك - ▁معاه - ▁تقول - دة - ▁حكاية - تش - ▁حس - ▁غدوا - ▁بالحق - روا - وز - ▁تخ - ▁العيد - رجع - ▁بالي - ▁جات - ▁وج - حة - ▁وش - ▁آخر - ▁طا - ▁مت - لقا - تك - ▁مس - ▁راني - كون - ▁صاحب - ▁هاكا - ▁قول - ▁عر - ▁عنده - ▁يلزم - ▁هاذا - ▁يخ - ▁وقتاش - ▁وقت - بع - ▁العش - ▁هاذي - هاش - ينة - ▁هاذاكا - عطي - ▁تنج - ▁باهية - نيا - فت - ▁يحب - ▁تف - ▁أهلا - وف - ▁غدوة - ▁بيك - ▁بد - عن - ▁در - ▁ننج - هار - ▁الحكاية - مون - وق - ▁نورمال - ▁عندها - خر - ▁بو - ▁حب - ▁آكا - ▁وف - ▁هاذيكا - ▁ديجا - ▁وق - ▁طي - لتل - بعث - ▁تص - رك - ▁مانيش - ▁العادة - ▁شوف - ضر - ▁يمشي - ▁نعملوا - ▁عرفت - ▁زال - ▁متع - ▁عمل - ▁بيها - ▁نحكي - اع - ▁نج - معة - ▁والكل - عناها - ▁يعي - ▁نجي - ستن - ▁هاذيك - ▁عام - ▁فلوس - قة - تين - ▁بالقدا - لهم - ▁تخدم - ▁ٱ - ▁شيء - ▁راهي - ▁جاب - ولاد - ابل - ▁ماك - عة - ▁نمشيوا - وني - شري - بار - انس - ▁وقتها - ▁جديد - ▁يز - ▁كر - ▁حاسيلو - ▁شق - ▁اه - ▁سايي - ▁انشالل - رج - مني - ▁بلا - ▁صحيح - ▁غير - ▁يخدم - مان - وكا - ▁عند - ▁قاعدة - ▁تس - ربة - ▁راس - ▁حط - ▁نكل - تني - ▁الو - سيون - ▁عندنا - ▁لو - ▁ست - صف - ▁ض - ▁كامل - ▁نخدم - ▁يبدا - ▁دونك - ▁أمور - رات - ▁تونس - بدا - ▁تحكي - ▁سو - ▁جاي - ▁وحدة - ▁ساعة - حنا - ▁بكري - ▁إل - ▁وبر - ▁كم - ▁تبدا - ارة - ادي - رق - لوا - ▁يمكن - ▁خاط - ▁وص - جين - ▁هاذاي - ▁هز - قد - ▁قل - ▁وكهو - ▁نص - ▁دي - لقى - ▁وأنا - سين - ▁يح - ▁ماشي - ▁شو - ▁خذيت - امات - ▁كنت - خرج - ▁لقيت - رتاح - كس - ▁حاجات - ▁مريق - ▁مل - ليفون - اوا - ▁شفت - ▁عاملة - ▁تن - ▁والا - سأل - ▁حد - ▁قاللك - ▁العباد - ▁عالاخ - ▁وآك - ▁ماني - ▁ناخذ - ▁حم - ▁الإ - ▁ماضي - ▁ث - الة - ▁أخرى - رين - ▁تشوف - ▁نخرج - ▁أربعة - ▁ألف - نيش - ▁هاي - آ - ▁فيك - رشة - ولة - فلة - ▁بابا - ▁أما - ▁روحي - ▁فيهم - ▁رج - ▁ليك - ونس - يرة - ▁وأكهو - ندي - ▁صار - شك - ▁نرو - ▁آكهو - ▁تش - ▁غاديكا - ▁معاها - ▁لب - ▁أذاكا - ▁آني - ▁يوم - عملوا - ▁نقعد - دوا - ▁عد - سمع - متني - ▁الخدمة - ▁مازلت - ▁قعدت - ايا - ▁برك - قعد - ▁خرجت - ضح - ▁قالل - ▁يقول - ▁وفي - ▁حق - ختي - ▁يعني - خدم - ▁جيت - ▁نرمال - طف - ▁عجب - ▁تقعد - ▁مشينا - اية - ▁خدمة - لدي - روف - ▁الفطر - ▁مشكل - ▁سل - ▁وآنا - الط - ▁بالس - ▁هانا - ▁أوه - ▁أذيكا - ▁وإ - ▁عليهم - ▁حالة - جت - قضي - ▁لق - ▁ونصف - سعة - عطيه - عاو - خانة - ▁مخ - ▁شبيك - بيعة - ▁أهوك - يني - ▁تعد - ▁خال - ▁قريب - ▁راك - ▁قالت - ▁لتو - ▁أكثر - اعة - ▁يظهرلي - ▁ماشية - سمعني - ▁نسيت - ▁ينج - ▁الحمدلل - هدي - ▁وشن - ▁تطي - ▁هنا - ▁نسمع - ▁إنتوما - ▁نحكيلك - ▁قاعد - ▁اسمعني - خرين - إ - ماعة - ▁بالر - ▁دا - ▁عمر - ▁نشري - ▁قهوة - ▁تبارك - ▁صب - ▁مشات - غر - ▁شريت - ▁عامل - ▁زوج - ثنين - ▁برب - ريق - ▁نكم - ▁لم - بيب - ▁مياة - ▁مالل - ▁قعد - ▁سخون - قس - ▁وحده - ▁اسمع - ▁خمسة - ▁غالي - ▁الأو - رلي - ▁العظيم - ▁ترو - تهم - كري - ▁نجيب - ▁جملة - قول - ▁قلتلي - ▁إيجا - ▁يقعد - ▁إيام - ▁يعطيك - ▁نخل - ▁دب - يمة - رهبة - ▁نهز - ▁محم - ▁بين - غار - ▁نحنا - ▁بون - ▁الغ - ▁شهر - ▁بار - رقة - ▁نطي - ئ - ترو - ▁ملا - ▁الكرهبة - ▁باه - ▁عالإخ - ▁عباد - ▁بلاصة - ▁مشى - بيع - ▁نفس - ▁عملنا - ▁واح - ▁أحلاه - ▁بحذاك - ▁لأ - ▁دخ - باب - ▁ودر - ▁غالب - ▁ناكل - ▁مثلا - ء - ▁راقد - ▁تفر - ▁الوقت - ▁تاخذ - حذا - نتر - ▁نبدا - ▁حال - ▁مريم - الم - ▁جمعة - رجول - ▁معايا - ▁تخرج - ▁باس - ▁ساعات - ▁عندهم - ▁نتفر - مسة - ▁الجمعة - بعين - ▁أكاهو - ▁ميش - مراة - ▁خذا - ▁ظ - ▁سيدي - ▁معاي - ▁شبيه - ▁حكا - ▁سف - ▁بعضنا - ▁بالض - ▁ليلة - ▁زعما - ▁الحق - مضان - ▁صعيب - ▁قالتلك - ً - ملة - ▁بق - عرف - لاطة - ▁خرج - ▁أخت - ▁تقوللي - ▁معانا - ▁صغير - ▁إسمه - ▁بعض - ▁العام - ▁علينا - ▁يتع - ▁فاش - ▁شع - ▁معاهم - ▁يسالش - ▁لهنا - ▁سمعت - ▁البار - ▁نتصو - ▁الاخ - ▁وكان - وبة - دمة - ▁كون - ▁مبعد - ▁تسمع - ▁بعيد - ▁تاكل - ▁نلقا - لامة - لاثة - ▁ذ - ▁تحس - ▁الواح - ▁لدار - ▁فاتت - ▁تاو - ▁أحوالك - ▁عاملين - ▁كبيرة - عجب - ▁بنت - ▁بيدي - ▁حكيت - ▁تحط - ▁مسكينة - ▁هاذوكم - ▁نزيد - لاث - ▁عشرة - ▁عيني - ▁تعب - ▁ياكل - ▁وزيد - ▁طول - ▁حمدلله - ▁وقتاه - ▁معناه - ▁وآش - ▁ووه - ▁وواحد - ▁نشوفوا - ▁عيد - ▁بصراحة - ▁بحذانا - ▁قاعدين - ▁راجل - ▁وحدي - ▁وعشرين - ▁لين - ▁خايب - ▁قالتله - ▁تهز - عيد - ▁كبير - ▁يعرف - ▁عارف - ▁الفلوس - ▁زايد - ▁خدمت - ▁هاذوما - ▁سلاطة - ▁فارغة - ▁ساعتين - ▁تبد - ▁راو - ▁مائة - ▁بعضهم - ▁ظاهرلي - ▁الفازة - كتب - ▁القهوة - سبوك - ▁زاد - ▁ضرب - حكيلي - ▁فوق - ▁عاود - ▁راي - ▁ومبعد - ▁حوايج - ▁دخلت - ▁يقوللك - ▁زيد - ▁زلت - لفزة - ▁وقال - ▁يهب - ▁يلزمني - ▁الحمد - ▁أذي - طبيعت - ▁دورة - ▁عالأقل - ▁آذاك - ▁وبال - ▁الجاي - عطيني - ▁ياخذ - ▁احكيلي - ▁نهبط - ▁رقدت - بلاصة - ▁عزيز - ▁صغار - ▁أقسم - ▁جيب - ▁وصلت - ▁أحوال - ▁جيست - ▁جماعة - سئل - ▁خوذ - ▁يهز - ▁الأخرى - ▁آلاف - ▁إسمع - ▁الحقيقة - ▁ناقص - ▁حاط - ▁موجود - عباد - ▁آذيك - ▁خارج - ▁الخير - ▁البنات - بقى - ▁طرف - ▁سينون - ▁ماذاب - ▁البحر - ▁نرقد - مدلله - ▁إيجى - ▁خالتي - ▁فازة - ▁بريك - ▁شريبتك - ▁تطلع - ؤ - ▁المشكلة - ▁طري - ▁مادام - ▁طلبت - ▁يلعب - ▁نعاود - ▁وحدك - ▁ظاهر - ٱ - ژ - ٍ - <sos/eos> init: null input_size: null ctc_conf: dropout_rate: 0.0 ctc_type: builtin reduce: true ignore_nan_grad: true model_conf: asr_weight: 0.3 mt_weight: 0.0 mtlalpha: 1.0 lsm_weight: 0.1 length_normalized_loss: false use_preprocessor: true token_type: bpe src_token_type: bpe bpemodel: data/token_list/tgt_bpe_unigram1000/bpe.model src_bpemodel: data/token_list/src_bpe_unigram1000/bpe.model non_linguistic_symbols: null cleaner: null g2p: null speech_volume_normalize: null rir_scp: null rir_apply_prob: 1.0 noise_scp: null noise_apply_prob: 1.0 noise_db_range: '13_15' frontend: default frontend_conf: n_fft: 512 hop_length: 256 fs: 16k specaug: specaug specaug_conf: apply_time_warp: true time_warp_window: 5 time_warp_mode: bicubic apply_freq_mask: true freq_mask_width_range: - 0 - 27 num_freq_mask: 2 apply_time_mask: true time_mask_width_ratio_range: - 0.0 - 0.05 num_time_mask: 5 normalize: global_mvn normalize_conf: stats_file: exp/st_stats_raw_bpe1000_sp/train/feats_stats.npz preencoder: null preencoder_conf: {} encoder: conformer encoder_conf: output_size: 256 attention_heads: 4 linear_units: 1024 num_blocks: 12 dropout_rate: 0.1 positional_dropout_rate: 0.1 attention_dropout_rate: 0.1 input_layer: conv2d normalize_before: true macaron_style: true rel_pos_type: latest pos_enc_layer_type: rel_pos selfattention_layer_type: rel_selfattn activation_type: swish use_cnn_module: true cnn_module_kernel: 31 postencoder: null postencoder_conf: {} decoder: transformer decoder_conf: attention_heads: 4 linear_units: 2048 num_blocks: 6 dropout_rate: 0.1 positional_dropout_rate: 0.1 self_attention_dropout_rate: 0.1 src_attention_dropout_rate: 0.1 extra_asr_decoder: transformer extra_asr_decoder_conf: input_layer: embed num_blocks: 2 linear_units: 2048 dropout_rate: 0.1 extra_mt_decoder: transformer extra_mt_decoder_conf: input_layer: embed num_blocks: 2 linear_units: 2048 dropout_rate: 0.1 required: - output_dir - src_token_list - token_list version: 0.10.6a1 distributed: false ``` </details> | 56048213e8c945cb3ed4a61d8986b4ab |
apache-2.0 | ['generated_from_keras_callback'] | false | MaryaAI/opus-mt-ar-en-finetunedQAdata-v1-ar-to-en This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ar-en](https://huggingface.co/Helsinki-NLP/opus-mt-ar-en) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.0053 - Validation Loss: 8.2764 - Epoch: 14 | 75339c5bd6ec9c4b081270849a80c857 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 0.0090 | 12.3530 | 0 | | 0.0134 | 11.3018 | 1 | | 0.0110 | 10.5958 | 2 | | 0.0083 | 9.7381 | 3 | | 0.0068 | 8.9434 | 4 | | 0.0080 | 12.7723 | 5 | | 0.0071 | 11.5191 | 6 | | 0.0077 | 10.6246 | 7 | | 0.0101 | 10.3368 | 8 | | 0.0092 | 8.7824 | 9 | | 0.0070 | 7.7344 | 10 | | 0.0070 | 8.2180 | 11 | | 0.0079 | 7.8572 | 12 | | 0.0070 | 9.3053 | 13 | | 0.0053 | 8.2764 | 14 | | 2c26827187272eb957244ba9a7bfcab1 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-xls-r-300m-ar-6 This model is a fine-tuned version of [MeshalAlamr/wav2vec2-xls-r-300m-ar-6](https://huggingface.co/MeshalAlamr/wav2vec2-xls-r-300m-ar-6) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 78.2951 - Wer: 0.2040 | ecf83d98bb614c37b135129ffba642a9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | No log | 1.0 | 85 | 75.3576 | 0.2131 | | No log | 2.0 | 170 | 75.3215 | 0.2150 | | No log | 3.0 | 255 | 75.5332 | 0.2201 | | No log | 4.0 | 340 | 81.2835 | 0.2315 | | 94.75 | 5.0 | 425 | 78.3768 | 0.2422 | | 94.75 | 6.0 | 510 | 82.9389 | 0.2520 | | 94.75 | 7.0 | 595 | 76.7272 | 0.2496 | | 94.75 | 8.0 | 680 | 79.9325 | 0.2506 | | 94.75 | 9.0 | 765 | 82.2568 | 0.2507 | | 124.0193 | 10.0 | 850 | 78.7011 | 0.2415 | | 124.0193 | 11.0 | 935 | 81.2829 | 0.2396 | | 124.0193 | 12.0 | 1020 | 77.2370 | 0.2357 | | 124.0193 | 13.0 | 1105 | 77.4057 | 0.2347 | | 124.0193 | 14.0 | 1190 | 74.4764 | 0.2271 | | 112.7824 | 15.0 | 1275 | 78.7320 | 0.2355 | | 112.7824 | 16.0 | 1360 | 79.0120 | 0.2294 | | 112.7824 | 17.0 | 1445 | 82.3663 | 0.2240 | | 112.7824 | 18.0 | 1530 | 79.2765 | 0.2236 | | 98.8702 | 19.0 | 1615 | 78.1527 | 0.2242 | | 98.8702 | 20.0 | 1700 | 75.7842 | 0.2198 | | 98.8702 | 21.0 | 1785 | 78.2980 | 0.2217 | | 98.8702 | 22.0 | 1870 | 79.3180 | 0.2168 | | 98.8702 | 23.0 | 1955 | 77.7381 | 0.2155 | | 84.537 | 24.0 | 2040 | 78.1512 | 0.2131 | | 84.537 | 25.0 | 2125 | 80.4068 | 0.2116 | | 84.537 | 26.0 | 2210 | 75.5718 | 0.2075 | | 84.537 | 27.0 | 2295 | 78.4438 | 0.2078 | | 84.537 | 28.0 | 2380 | 79.6891 | 0.2086 | | 74.4149 | 29.0 | 2465 | 77.9115 | 0.2069 | | 74.4149 | 30.0 | 2550 | 78.2951 | 0.2040 | | e49e1ff92445dfbd309a017b9eb71e4e |
apache-2.0 | ['generated_from_trainer'] | false | t5-small-finetuned-text2log-compute-metrics-v5-400 This model is a fine-tuned version of [mrm8488/t5-small-finetuned-text2log](https://huggingface.co/mrm8488/t5-small-finetuned-text2log) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.5820 - Bleu: 30.1378 - Gen Len: 18.568 | c0e08fa05480f518cb06b89f6f7d085f |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 150 - mixed_precision_training: Native AMP | 6d332de0f0c6d98f9c784d6358ce3442 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:| | No log | 1.0 | 23 | 1.5732 | 8.4784 | 17.3373 | | No log | 2.0 | 46 | 1.1400 | 22.8492 | 18.8284 | | No log | 3.0 | 69 | 0.9426 | 27.2247 | 18.787 | | No log | 4.0 | 92 | 0.8110 | 26.0131 | 18.7101 | | No log | 5.0 | 115 | 0.7559 | 24.1316 | 18.7988 | | No log | 6.0 | 138 | 0.7102 | 25.4664 | 18.7692 | | No log | 7.0 | 161 | 0.6807 | 26.2651 | 18.6923 | | No log | 8.0 | 184 | 0.6575 | 27.5298 | 18.6213 | | No log | 9.0 | 207 | 0.6369 | 28.8178 | 18.5976 | | No log | 10.0 | 230 | 0.6250 | 27.2363 | 18.6864 | | No log | 11.0 | 253 | 0.6143 | 28.7917 | 18.6391 | | No log | 12.0 | 276 | 0.5973 | 29.6901 | 18.7041 | | No log | 13.0 | 299 | 0.5864 | 29.6632 | 18.6568 | | No log | 14.0 | 322 | 0.5827 | 29.874 | 18.6391 | | No log | 15.0 | 345 | 0.5700 | 29.6188 | 18.6864 | | No log | 16.0 | 368 | 0.5620 | 29.9895 | 18.7278 | | No log | 17.0 | 391 | 0.5569 | 29.3883 | 18.7278 | | No log | 18.0 | 414 | 0.5486 | 29.783 | 18.6864 | | No log | 19.0 | 437 | 0.5520 | 29.4199 | 18.6568 | | No log | 20.0 | 460 | 0.5496 | 28.8502 | 18.6923 | | No log | 21.0 | 483 | 0.5495 | 29.2369 | 18.7337 | | 0.8287 | 22.0 | 506 | 0.5411 | 29.1707 | 18.6923 | | 0.8287 | 23.0 | 529 | 0.5325 | 28.8466 | 18.6923 | | 0.8287 | 24.0 | 552 | 0.5388 | 29.2703 | 18.6746 | | 0.8287 | 25.0 | 575 | 0.5288 | 28.7683 | 18.7278 | | 0.8287 | 26.0 | 598 | 0.5299 | 28.3489 | 18.7337 | | 0.8287 | 27.0 | 621 | 0.5314 | 28.2042 | 18.7278 | | 0.8287 | 28.0 | 644 | 0.5159 | 29.5603 | 18.7574 | | 0.8287 | 29.0 | 667 | 0.5163 | 28.8959 | 18.6982 | | 0.8287 | 30.0 | 690 | 0.5170 | 30.0671 | 18.7219 | | 0.8287 | 31.0 | 713 | 0.5202 | 28.9559 | 18.6686 | | 0.8287 | 32.0 | 736 | 0.5181 | 28.1951 | 18.7574 | | 0.8287 | 33.0 | 759 | 0.5134 | 28.2097 | 18.7041 | | 0.8287 | 34.0 | 782 | 0.5134 | 28.0953 | 18.7574 | | 0.8287 | 35.0 | 805 | 0.5165 | 28.4171 | 18.7988 | | 0.8287 | 36.0 | 828 | 0.5195 | 28.7953 | 18.7633 | | 0.8287 | 37.0 | 851 | 0.5185 | 29.1606 | 18.7633 | | 0.8287 | 38.0 | 874 | 0.5192 | 29.5226 | 18.6805 | | 0.8287 | 39.0 | 897 | 0.5178 | 28.425 | 18.7692 | | 0.8287 | 40.0 | 920 | 0.5196 | 29.4795 | 18.7041 | | 0.8287 | 41.0 | 943 | 0.5161 | 29.5127 | 18.7041 | | 0.8287 | 42.0 | 966 | 0.5164 | 28.6225 | 18.7574 | | 0.8287 | 43.0 | 989 | 0.5183 | 29.0629 | 18.6272 | | 0.3866 | 44.0 | 1012 | 0.5174 | 28.6628 | 18.6213 | | 0.3866 | 45.0 | 1035 | 0.5141 | 28.499 | 18.6213 | | 0.3866 | 46.0 | 1058 | 0.5151 | 28.1309 | 18.6272 | | 0.3866 | 47.0 | 1081 | 0.5167 | 29.8871 | 18.6391 | | 0.3866 | 48.0 | 1104 | 0.5133 | 28.7513 | 18.6331 | | 0.3866 | 49.0 | 1127 | 0.5188 | 28.3089 | 18.6213 | | 0.3866 | 50.0 | 1150 | 0.5203 | 28.8714 | 18.6331 | | 0.3866 | 51.0 | 1173 | 0.5263 | 28.7644 | 18.6331 | | 0.3866 | 52.0 | 1196 | 0.5222 | 28.4817 | 18.6331 | | 0.3866 | 53.0 | 1219 | 0.5307 | 28.8117 | 18.6272 | | 0.3866 | 54.0 | 1242 | 0.5255 | 29.3844 | 18.6213 | | 0.3866 | 55.0 | 1265 | 0.5264 | 29.7108 | 18.6213 | | 0.3866 | 56.0 | 1288 | 0.5272 | 29.353 | 18.6331 | | 0.3866 | 57.0 | 1311 | 0.5283 | 28.5792 | 18.6391 | | 0.3866 | 58.0 | 1334 | 0.5301 | 29.9914 | 18.6272 | | 0.3866 | 59.0 | 1357 | 0.5320 | 29.3162 | 18.6272 | | 0.3866 | 60.0 | 1380 | 0.5380 | 29.2162 | 18.6272 | | 0.3866 | 61.0 | 1403 | 0.5349 | 28.5292 | 18.6272 | | 0.3866 | 62.0 | 1426 | 0.5313 | 28.7165 | 18.6627 | | 0.3866 | 63.0 | 1449 | 0.5335 | 29.3637 | 18.6154 | | 0.3866 | 64.0 | 1472 | 0.5350 | 29.3612 | 18.568 | | 0.3866 | 65.0 | 1495 | 0.5330 | 29.1338 | 18.5621 | | 0.283 | 66.0 | 1518 | 0.5322 | 29.0514 | 18.5562 | | 0.283 | 67.0 | 1541 | 0.5362 | 29.2592 | 18.5562 | | 0.283 | 68.0 | 1564 | 0.5379 | 29.6757 | 18.568 | | 0.283 | 69.0 | 1587 | 0.5386 | 29.5012 | 18.5976 | | 0.283 | 70.0 | 1610 | 0.5379 | 29.6616 | 18.5917 | | 0.283 | 71.0 | 1633 | 0.5364 | 29.8762 | 18.6154 | | 0.283 | 72.0 | 1656 | 0.5392 | 29.7143 | 18.6036 | | 0.283 | 73.0 | 1679 | 0.5438 | 29.385 | 18.5976 | | 0.283 | 74.0 | 1702 | 0.5386 | 28.3472 | 18.6095 | | 0.283 | 75.0 | 1725 | 0.5372 | 29.1045 | 18.574 | | 0.283 | 76.0 | 1748 | 0.5406 | 29.0839 | 18.6095 | | 0.283 | 77.0 | 1771 | 0.5408 | 29.735 | 18.5799 | | 0.283 | 78.0 | 1794 | 0.5406 | 29.5432 | 18.6036 | | 0.283 | 79.0 | 1817 | 0.5413 | 29.1501 | 18.5976 | | 0.283 | 80.0 | 1840 | 0.5434 | 29.5822 | 18.6095 | | 0.283 | 81.0 | 1863 | 0.5491 | 29.1933 | 18.5799 | | 0.283 | 82.0 | 1886 | 0.5473 | 28.9065 | 18.5385 | | 0.283 | 83.0 | 1909 | 0.5507 | 29.4129 | 18.5385 | | 0.283 | 84.0 | 1932 | 0.5534 | 29.2249 | 18.5385 | | 0.283 | 85.0 | 1955 | 0.5561 | 29.6955 | 18.5799 | | 0.283 | 86.0 | 1978 | 0.5575 | 29.1081 | 18.5385 | | 0.2296 | 87.0 | 2001 | 0.5531 | 29.7633 | 18.5385 | | 0.2296 | 88.0 | 2024 | 0.5548 | 30.045 | 18.5385 | | 0.2296 | 89.0 | 2047 | 0.5567 | 29.9209 | 18.5385 | | 0.2296 | 90.0 | 2070 | 0.5577 | 29.1879 | 18.5858 | | 0.2296 | 91.0 | 2093 | 0.5602 | 29.1587 | 18.5799 | | 0.2296 | 92.0 | 2116 | 0.5595 | 29.5205 | 18.5799 | | 0.2296 | 93.0 | 2139 | 0.5605 | 29.3439 | 18.5325 | | 0.2296 | 94.0 | 2162 | 0.5583 | 29.4742 | 18.5325 | | 0.2296 | 95.0 | 2185 | 0.5576 | 29.132 | 18.5325 | | 0.2296 | 96.0 | 2208 | 0.5566 | 29.0861 | 18.5325 | | 0.2296 | 97.0 | 2231 | 0.5584 | 29.6618 | 18.5385 | | 0.2296 | 98.0 | 2254 | 0.5593 | 29.1068 | 18.5325 | | 0.2296 | 99.0 | 2277 | 0.5603 | 29.7081 | 18.5385 | | 0.2296 | 100.0 | 2300 | 0.5599 | 29.6368 | 18.5325 | | 0.2296 | 101.0 | 2323 | 0.5598 | 29.6263 | 18.5325 | | 0.2296 | 102.0 | 2346 | 0.5637 | 29.6321 | 18.5385 | | 0.2296 | 103.0 | 2369 | 0.5678 | 29.6306 | 18.5266 | | 0.2296 | 104.0 | 2392 | 0.5685 | 29.3279 | 18.5325 | | 0.2296 | 105.0 | 2415 | 0.5680 | 29.1363 | 18.5621 | | 0.2296 | 106.0 | 2438 | 0.5726 | 29.2666 | 18.5385 | | 0.2296 | 107.0 | 2461 | 0.5738 | 29.2981 | 18.5385 | | 0.2296 | 108.0 | 2484 | 0.5740 | 29.5752 | 18.5385 | | 0.1942 | 109.0 | 2507 | 0.5749 | 29.5596 | 18.5385 | | 0.1942 | 110.0 | 2530 | 0.5732 | 29.6728 | 18.574 | | 0.1942 | 111.0 | 2553 | 0.5738 | 29.6052 | 18.5325 | | 0.1942 | 112.0 | 2576 | 0.5731 | 29.5143 | 18.574 | | 0.1942 | 113.0 | 2599 | 0.5744 | 29.8059 | 18.574 | | 0.1942 | 114.0 | 2622 | 0.5751 | 29.6796 | 18.574 | | 0.1942 | 115.0 | 2645 | 0.5763 | 29.9279 | 18.568 | | 0.1942 | 116.0 | 2668 | 0.5746 | 29.892 | 18.568 | | 0.1942 | 117.0 | 2691 | 0.5741 | 29.8104 | 18.574 | | 0.1942 | 118.0 | 2714 | 0.5759 | 29.6379 | 18.574 | | 0.1942 | 119.0 | 2737 | 0.5777 | 29.7949 | 18.574 | | 0.1942 | 120.0 | 2760 | 0.5776 | 29.6297 | 18.574 | | 0.1942 | 121.0 | 2783 | 0.5789 | 29.5298 | 18.574 | | 0.1942 | 122.0 | 2806 | 0.5794 | 29.6102 | 18.574 | | 0.1942 | 123.0 | 2829 | 0.5799 | 29.7981 | 18.574 | | 0.1942 | 124.0 | 2852 | 0.5811 | 30.0894 | 18.574 | | 0.1942 | 125.0 | 2875 | 0.5826 | 29.9849 | 18.574 | | 0.1942 | 126.0 | 2898 | 0.5829 | 29.8349 | 18.574 | | 0.1942 | 127.0 | 2921 | 0.5817 | 29.6295 | 18.574 | | 0.1942 | 128.0 | 2944 | 0.5809 | 29.5264 | 18.568 | | 0.1942 | 129.0 | 2967 | 0.5813 | 29.5858 | 18.568 | | 0.1942 | 130.0 | 2990 | 0.5843 | 29.6556 | 18.568 | | 0.1777 | 131.0 | 3013 | 0.5836 | 30.0165 | 18.568 | | 0.1777 | 132.0 | 3036 | 0.5835 | 29.8399 | 18.568 | | 0.1777 | 133.0 | 3059 | 0.5824 | 29.8065 | 18.568 | | 0.1777 | 134.0 | 3082 | 0.5821 | 29.8948 | 18.574 | | 0.1777 | 135.0 | 3105 | 0.5808 | 29.9342 | 18.574 | | 0.1777 | 136.0 | 3128 | 0.5810 | 29.7556 | 18.574 | | 0.1777 | 137.0 | 3151 | 0.5813 | 30.0425 | 18.568 | | 0.1777 | 138.0 | 3174 | 0.5822 | 30.0719 | 18.568 | | 0.1777 | 139.0 | 3197 | 0.5823 | 30.0719 | 18.568 | | 0.1777 | 140.0 | 3220 | 0.5828 | 30.1124 | 18.568 | | 0.1777 | 141.0 | 3243 | 0.5826 | 30.1451 | 18.568 | | 0.1777 | 142.0 | 3266 | 0.5828 | 30.1451 | 18.568 | | 0.1777 | 143.0 | 3289 | 0.5829 | 30.1451 | 18.568 | | 0.1777 | 144.0 | 3312 | 0.5829 | 30.1451 | 18.568 | | 0.1777 | 145.0 | 3335 | 0.5825 | 30.1378 | 18.568 | | 0.1777 | 146.0 | 3358 | 0.5824 | 30.1378 | 18.568 | | 0.1777 | 147.0 | 3381 | 0.5822 | 30.1378 | 18.568 | | 0.1777 | 148.0 | 3404 | 0.5820 | 30.1378 | 18.568 | | 0.1777 | 149.0 | 3427 | 0.5821 | 30.1378 | 18.568 | | 0.1777 | 150.0 | 3450 | 0.5820 | 30.1378 | 18.568 | | ccddc1da2ef849a85814692dcb5e2e4d |
apache-2.0 | [] | false | Introduction The research for social science texts in Chinese needs the support natural language processing tools. The pre-trained language model has greatly improved the accuracy of text mining in general texts. At present, there is an urgent need for a pre-trained language model specifically for the automatic processing of scientific texts in Chinese social science. We used the abstract of social science research as the training set. Based on the deep language model framework of BERT, we constructed CSSCI_ABS_BERT, CSSCI_ABS_roberta and CSSCI_ABS_roberta-wwm pre-training language models by [transformers/run_mlm.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm.py) and [transformers/mlm_wwm](https://github.com/huggingface/transformers/tree/main/examples/research_projects/mlm_wwm). We designed four downstream tasks of Text Classification on different Chinese social scientific article corpus to verify the performance of the model. - CSSCI_ABS_BERT , CSSCI_ABS_roberta and CSSCI_ABS_roberta-wwm are trained on the abstract of articles published in CSSCI journals. The training set involved in the experiment included a total of `510,956,094 words`. - Based on the idea of Domain-Adaptive Pretraining, `CSSCI_ABS_BERT` and `CSSCI_ABS_roberta` combine a large amount of abstracts of scientific articles in Chinese based on the BERT structure, and continue to train the BERT and Chinese-RoBERTa models respectively to obtain pre-training models for the automatic processing of Chinese Social science research texts. | 751035e8cfc2b915546df31db2544504 |
apache-2.0 | [] | false | Huggingface Transformers The `from_pretrained` method based on [Huggingface Transformers](https://github.com/huggingface/transformers) can directly obtain CSSCI_ABS_BERT, CSSCI_ABS_roberta and CSSCI_ABS_roberta-wwm models online. - CSSCI_ABS_BERT ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("KM4STfulltext/CSSCI_ABS_BERT") model = AutoModel.from_pretrained("KM4STfulltext/CSSCI_ABS_BERT") ``` - CSSCI_ABS_roberta ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("KM4STfulltext/CSSCI_ABS_roberta") model = AutoModel.from_pretrained("KM4STfulltext/CSSCI_ABS_roberta") ``` - CSSCI_ABS_roberta-wwm ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("KM4STfulltext/CSSCI_ABS_roberta_wwm") model = AutoModel.from_pretrained("KM4STfulltext/CSSCI_ABS_roberta_wwm") ``` | b8a410095fa9b4b17a5f858f05c71247 |
apache-2.0 | [] | false | From Huggingface - Download directly through Huggingface's official website. - [KM4STfulltext/CSSCI_ABS_BERT](https://huggingface.co/KM4STfulltext/CSSCI_ABS_BERT) - [KM4STfulltext/CSSCI_ABS_roberta](https://huggingface.co/KM4STfulltext/CSSCI_ABS_roberta) - [KM4STfulltext/CSSCI_ABS_roberta_wwm](https://huggingface.co/KM4STfulltext/CSSCI_ABS_roberta_wwm) | 0c06d19bcc8f8e73f3f7f36967a4735c |
apache-2.0 | [] | false | Evaluation & Results - We useCSSCI_ABS_BERT, CSSCI_ABS_roberta and CSSCI_ABS_roberta-wwm to perform Text Classificationon different social science research corpus. The experimental results are as follows. | 0d31f913557fcb262cb94576b7409bd0 |
apache-2.0 | [] | false | Movement recognition experiments for data analysis and knowledge discovery abstract | Tag | bert-base-Chinese | chinese-roberta-wwm,ext | CSSCI_ABS_BERT | CSSCI_ABS_roberta | CSSCI_ABS_roberta_wwm | support | | ------------ | ----------------- | ----------------------- | -------------- | ----------------- | --------------------- | ------- | | Abstract | 55.23 | 62.44 | 56.8 | 57.96 | 58.26 | 223 | | Location | 61.61 | 54.38 | 61.83 | 61.4 | 61.94 | 2866 | | Metric | 45.08 | 41 | 45.27 | 46.74 | 47.13 | 622 | | Organization | 46.85 | 35.29 | 45.72 | 45.44 | 44.65 | 327 | | Person | 88.66 | 82.79 | 88.21 | 88.29 | 88.51 | 4850 | | Thing | 71.68 | 65.34 | 71.88 | 71.68 | 71.81 | 5993 | | Time | 65.35 | 60.38 | 64.15 | 65.26 | 66.03 | 1272 | | avg | 72.69 | 66.62 | 72.59 | 72.61 | 72.89 | 16153 | | a075d2c599e15da3b1d7bf0985707d79 |
apache-2.0 | [] | false | Chinese literary entity recognition | Tag | bert-base-Chinese | chinese-roberta-wwm,ext | CSSCI_ABS_BERT | CSSCI_ABS_roberta | CSSCI_ABS_roberta_wwm | support | | ------------ | ----------------- | ----------------------- | -------------- | ----------------- | --------------------- | ------- | | Abstract | 55.23 | 62.44 | 56.8 | 57.96 | 58.26 | 223 | | Location | 61.61 | 54.38 | 61.83 | 61.4 | 61.94 | 2866 | | Metric | 45.08 | 41 | 45.27 | 46.74 | 47.13 | 622 | | Organization | 46.85 | 35.29 | 45.72 | 45.44 | 44.65 | 327 | | Person | 88.66 | 82.79 | 88.21 | 88.29 | 88.51 | 4850 | | Thing | 71.68 | 65.34 | 71.88 | 71.68 | 71.81 | 5993 | | Time | 65.35 | 60.38 | 64.15 | 65.26 | 66.03 | 1272 | | avg | 72.69 | 66.62 | 72.59 | 72.61 | 72.89 | 16153 | | c0ed37da74db6334a4307bda9c942d70 |
apache-2.0 | [] | false | Cited - If our content is helpful for your research work, please quote our research in your article. - If you want to quote our research, you can use this url [S-T-Full-Text-Knowledge-Mining/CSSCI-BERT (github.com)](https://github.com/S-T-Full-Text-Knowledge-Mining/CSSCI-BERT) as an alternative before our paper is published. | 0c3eeeea55884eae5a1547135cfc6b07 |
apache-2.0 | [] | false | Acknowledgment - CSSCI_ABS_BERT was trained based on [BERT-Base-Chinese]([google-research/bert: TensorFlow code and pre-trained models for BERT (github.com)](https://github.com/google-research/bert)). - CSSCI_ABS_roberta and CSSCI_ABS_roberta-wwm was trained based on [RoBERTa-wwm-ext, Chinese]([ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) (github.com)](https://github.com/ymcui/Chinese-BERT-wwm)). | b683013dd2b6be7965f173e37d79c463 |
creativeml-openrail-m | ['text-to-image', 'stable-diffusion'] | false | StableDiffusion_finetuning_cat_emoticon_style Dreambooth model trained by jha2ee with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Sample pictures of this concept:         | f3f8fa49aea5be77a9c8245323bc50f2 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased_fold_4_ternary_v1 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.9355 - F1: 0.7891 | 4b4cc268977a983ccf6c63d881277969 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | No log | 1.0 | 289 | 0.5637 | 0.7485 | | 0.5729 | 2.0 | 578 | 0.5305 | 0.7805 | | 0.5729 | 3.0 | 867 | 0.6948 | 0.7670 | | 0.2548 | 4.0 | 1156 | 0.8351 | 0.7744 | | 0.2548 | 5.0 | 1445 | 1.0005 | 0.8027 | | 0.1157 | 6.0 | 1734 | 1.1578 | 0.7978 | | 0.0473 | 7.0 | 2023 | 1.2275 | 0.7953 | | 0.0473 | 8.0 | 2312 | 1.3245 | 0.7916 | | 0.0276 | 9.0 | 2601 | 1.3728 | 0.7953 | | 0.0276 | 10.0 | 2890 | 1.4577 | 0.7867 | | 0.0149 | 11.0 | 3179 | 1.5832 | 0.7731 | | 0.0149 | 12.0 | 3468 | 1.5056 | 0.7818 | | 0.0143 | 13.0 | 3757 | 1.6263 | 0.7904 | | 0.0066 | 14.0 | 4046 | 1.6596 | 0.7793 | | 0.0066 | 15.0 | 4335 | 1.6795 | 0.7941 | | 0.0022 | 16.0 | 4624 | 1.8443 | 0.7744 | | 0.0022 | 17.0 | 4913 | 1.7160 | 0.7953 | | 0.0034 | 18.0 | 5202 | 1.7819 | 0.7781 | | 0.0034 | 19.0 | 5491 | 1.7931 | 0.7904 | | 0.0036 | 20.0 | 5780 | 1.8447 | 0.7818 | | 0.0014 | 21.0 | 6069 | 1.9975 | 0.7707 | | 0.0014 | 22.0 | 6358 | 1.9324 | 0.7830 | | 0.0008 | 23.0 | 6647 | 1.9086 | 0.7842 | | 0.0008 | 24.0 | 6936 | 1.9507 | 0.7867 | | 0.0002 | 25.0 | 7225 | 1.9355 | 0.7891 | | 510d8d4f751d8ebe0a686cddf750c12d |
mit | [] | false | [Project Page](https://sites.google.com/view/cspnet) | [Paper](https://arxiv.org/abs/2106.05779) | [Code](https://github.com/rahulvenkk/csp-net) If you find our code or paper useful, please cite as @InProceedings{Venkatesh_2021_ICCV, author = {Venkatesh, Rahul and Karmali, Tejan and Sharma, Sarthak and Ghosh, Aurobrata and Babu, R. Venkatesh and Jeni, Laszlo A. and Singh, Maneesh}, title = {Deep Implicit Surface Point Prediction Networks}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, month = {October}, year = {2021}, pages = {12653-12662} } | 035d7f2724c8daf33e37b4997b4a66ea |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased.CEBaB_confounding.price_food_ambiance_negative.sa.5-class.seed_44 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the OpenTable OPENTABLE dataset. It achieves the following results on the evaluation set: - Loss: 0.7475 - Accuracy: 0.6934 - Macro-f1: 0.6622 - Weighted-macro-f1: 0.6813 | 59d0585eb097348e0f29ecfe7dbf8663 |
apache-2.0 | ['generated_from_trainer'] | false | distilBERT-fresh_10epoch This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.0234 - Precision: 0.0 - Recall: 0.0 - F1: 0.0 - Accuracy: 0.9935 | 04d73df0cfb45434168c4683095d9603 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:| | No log | 1.0 | 174 | 0.1913 | 0.0 | 0.0 | 0.0 | 0.9312 | | No log | 2.0 | 348 | 0.1431 | 0.0 | 0.0 | 0.0 | 0.9507 | | 0.2211 | 3.0 | 522 | 0.1053 | 0.0 | 0.0 | 0.0 | 0.9640 | | 0.2211 | 4.0 | 696 | 0.0770 | 0.0 | 0.0 | 0.0 | 0.9746 | | 0.2211 | 5.0 | 870 | 0.0581 | 0.0 | 0.0 | 0.0 | 0.9820 | | 0.0995 | 6.0 | 1044 | 0.0461 | 0.0 | 0.0 | 0.0 | 0.9862 | | 0.0995 | 7.0 | 1218 | 0.0376 | 0.0 | 0.0 | 0.0 | 0.9886 | | 0.0995 | 8.0 | 1392 | 0.0290 | 0.0 | 0.0 | 0.0 | 0.9915 | | 0.054 | 9.0 | 1566 | 0.0238 | 0.0 | 0.0 | 0.0 | 0.9934 | | 0.054 | 10.0 | 1740 | 0.0234 | 0.0 | 0.0 | 0.0 | 0.9935 | | f2e00f3964fd4b2d01343982074b9f0e |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Wav2Vec2-Large-XLSR-53-Portuguese Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Portuguese using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset. When using this model, make sure that your speech input is sampled at 16kHz. | 36e1f692c29ceb83fdec3eebc9f28111 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Usage The model can be used directly (without a language model) as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor test_dataset = load_dataset("common_voice", "pt", split="test[:2%]") processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt") model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt") resampler = torchaudio.transforms.Resample(48_000, 16_000) | ff9c6b3aae305cf85680d3c60f8862b4 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Evaluation The model can be evaluated as follows on the Portuguese test data of Common Voice. ```python import torch import torchaudio from datasets import load_dataset, load_metric from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import re test_dataset = load_dataset("common_voice", "pt", split="test") wer = load_metric("wer") processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt") model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt") model.to("cuda") chars_to_ignore_regex = '[\,\?\.\!\-\;\;\"\“\'\�]' resampler = torchaudio.transforms.Resample(48_000, 16_000) | 53f2afde8341e539db1fe5dab26c7b71 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the aduio files as arrays def evaluate(batch): inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1) batch["pred_strings"] = processor.batch_decode(pred_ids) return batch result = test_dataset.map(evaluate, batched=True, batch_size=8) print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"]))) ``` **Test Result**: 17.22 % | 2b31622836de73d18527e85ef05da4eb |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Training The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://github.com/jqueguiner/wav2vec2-sprint/blob/main/run_common_voice.py). The parameters passed were: ```bash | 6a0a86917768be1146e288a5dc935a98 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | !/usr/bin/env bash python run_common_voice.py \ --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \ --dataset_config_name="pt" \ --output_dir=/workspace/output_models/pt/wav2vec2-large-xlsr-pt \ --cache_dir=/workspace/data \ --overwrite_output_dir \ --num_train_epochs="30" \ --per_device_train_batch_size="32" \ --per_device_eval_batch_size="32" \ --evaluation_strategy="steps" \ --learning_rate="3e-4" \ --warmup_steps="500" \ --fp16 \ --freeze_feature_extractor \ --save_steps="500" \ --eval_steps="500" \ --save_total_limit="1" \ --logging_steps="500" \ --group_by_length \ --feat_proj_dropout="0.0" \ --layerdrop="0.1" \ --gradient_checkpointing \ --do_train --do_eval \ ``` Notebook containing the evaluation can be found [here](https://colab.research.google.com/drive/14e-zNK_5pm8EMY9EbeZerpHx7WsGycqG?usp=sharing). | 3fc9d6173456105d29f6a25c501b0504 |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | Model description A fine-tuned version of [google/long-t5-tglobal-base](https://huggingface.co/google/long-t5-tglobal-base) on the `booksum` dataset: - 30+ epochs of fine-tuning from the base model on V100/A100 GPUs - Training used 16384 token input / 1024 max output Read the paper by Guo et al. here: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf) | d777c0500f5ab409a2553ca0d39df2bc |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | How-To in Python Install/update transformers `pip install -U transformers` Summarize text with pipeline: ```python import torch from transformers import pipeline summarizer = pipeline( "summarization", "pszemraj/long-t5-tglobal-base-16384-book-summary", device=0 if torch.cuda.is_available() else -1, ) long_text = "Here is a lot of text I don't want to read. Replace me" result = summarizer(long_text) print(result[0]["summary_text"]) ``` Pass [other parameters related to beam search textgen](https://huggingface.co/blog/how-to-generate) when calling `summarizer` to get even higher quality results. | 886209fee43427847ac99710c343bc5d |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | Intended uses & limitations - The current checkpoint is fairly well converged but will be updated if further improvements can be made. - Compare performance to [LED-base](https://huggingface.co/pszemraj/led-base-book-summary) trained on the same dataset (API gen parameters are the same). - while this model seems to improve upon factual consistency, **do not take summaries to be foolproof and check things that seem odd**. | 4665882698aa51f4e9a8b576e0c2c4ee |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | Training and evaluation data `kmfoda/booksum` dataset on HuggingFace - read [the original paper here](https://arxiv.org/abs/2105.08209). Summaries longer than 1024 LongT5 tokens were filtered out to prevent the model from learning to generate "partial" summaries. | 30e5b0c2fdea06f64dbf133a20a2f62e |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | How to run inference over a very long (30k+ tokens) document in batches? See `summarize.py` in [the code for my hf space Document Summarization](https://huggingface.co/spaces/pszemraj/document-summarization/blob/main/summarize.py) :) You can also use the same code to split a document into batches of 4096, etc., and run over those with the model. This is useful in situations where CUDA memory is limited. | 8766209afafdaf6045720df647ce57b6 |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | How to fine-tune further? See [train with a script](https://huggingface.co/docs/transformers/run_scripts) and [the summarization scripts](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization). This model was originally tuned on Google Colab with a heavily modified variant of the [longformer training notebook](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb), key enabler being deepspeed. You can try this as an alternate route to fine-tuning the model without using the command line. * * * | 34e9290dae7e4a219474cf3722840fb0 |
['apache-2.0', 'bsd-3-clause'] | ['summarization', 'summary', 'booksum', 'long-document', 'long-form'] | false | Training hyperparameters _NOTE: early checkpoints of this model were trained on a "smaller" subsection of the dataset as it was filtered for summaries of **1024 characters**. This was subsequently caught and adjusted to **1024 tokens** and then trained further for 10+ epochs._ The following hyperparameters were used during the **most recent** training round\*: - learning_rate: 0.0005 - train_batch_size: 1 - eval_batch_size: 1 - seed: 42 - distributed_type: multi-GPU - gradient_accumulation_steps: 128 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: cosine - lr_scheduler_warmup_ratio: 0.01 - num_epochs: 2 \* Prior training sessions used roughly similar parameters; multiple sessions were required as this takes eons to train | 070a089be2c1775ff401840797ca3ffe |
apache-2.0 | ['translation'] | false | epo-afr * source group: Esperanto * target group: Afrikaans * OPUS readme: [epo-afr](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/epo-afr/README.md) * model: transformer-align * source language(s): epo * target language(s): afr * model: transformer-align * pre-processing: normalization + SentencePiece (spm4k,spm4k) * download original weights: [opus-2020-06-16.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-afr/opus-2020-06-16.zip) * test set translations: [opus-2020-06-16.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-afr/opus-2020-06-16.test.txt) * test set scores: [opus-2020-06-16.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-afr/opus-2020-06-16.eval.txt) | b343f36067296a002780aca7ee66836c |
apache-2.0 | ['translation'] | false | System Info: - hf_name: epo-afr - source_languages: epo - target_languages: afr - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/epo-afr/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['eo', 'af'] - src_constituents: {'epo'} - tgt_constituents: {'afr'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm4k,spm4k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/epo-afr/opus-2020-06-16.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/epo-afr/opus-2020-06-16.test.txt - src_alpha3: epo - tgt_alpha3: afr - short_pair: eo-af - chrF2_score: 0.369 - bleu: 19.5 - brevity_penalty: 0.9570000000000001 - ref_len: 8432.0 - src_name: Esperanto - tgt_name: Afrikaans - train_date: 2020-06-16 - src_alpha2: eo - tgt_alpha2: af - prefer_old: False - long_pair: epo-afr - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | 1a6f9ddba3a885b93af1c6c475538d3b |
apache-2.0 | ['audio-classification', 'speechbrain', 'embeddings', 'Language', 'Identification', 'pytorch', 'ECAPA-TDNN', 'TDNN', 'VoxLingua107'] | false | Model description This is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain. The model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses more fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training. We observed that this improved the performance of extracted utterance embeddings for downstream tasks. The system is trained with recordings sampled at 16kHz (single channel). The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. The model can classify a speech utterance according to the language spoken. It covers 107 different languages ( Abkhazian, Afrikaans, Amharic, Arabic, Assamese, Azerbaijani, Bashkir, Belarusian, Bulgarian, Bengali, Tibetan, Breton, Bosnian, Catalan, Cebuano, Czech, Welsh, Danish, German, Greek, English, Esperanto, Spanish, Estonian, Basque, Persian, Finnish, Faroese, French, Galician, Guarani, Gujarati, Manx, Hausa, Hawaiian, Hindi, Croatian, Haitian, Hungarian, Armenian, Interlingua, Indonesian, Icelandic, Italian, Hebrew, Japanese, Javanese, Georgian, Kazakh, Central Khmer, Kannada, Korean, Latin, Luxembourgish, Lingala, Lao, Lithuanian, Latvian, Malagasy, Maori, Macedonian, Malayalam, Mongolian, Marathi, Malay, Maltese, Burmese, Nepali, Dutch, Norwegian Nynorsk, Norwegian, Occitan, Panjabi, Polish, Pushto, Portuguese, Romanian, Russian, Sanskrit, Scots, Sindhi, Sinhala, Slovak, Slovenian, Shona, Somali, Albanian, Serbian, Sundanese, Swedish, Swahili, Tamil, Telugu, Tajik, Thai, Turkmen, Tagalog, Turkish, Tatar, Ukrainian, Urdu, Uzbek, Vietnamese, Waray, Yiddish, Yoruba, Mandarin Chinese). | 1cb4902b51fc1797224f5f7e8bb386a7 |
apache-2.0 | ['audio-classification', 'speechbrain', 'embeddings', 'Language', 'Identification', 'pytorch', 'ECAPA-TDNN', 'TDNN', 'VoxLingua107'] | false | How to use ```python import torchaudio from speechbrain.pretrained import EncoderClassifier language_id = EncoderClassifier.from_hparams(source="speechbrain/lang-id-voxlingua107-ecapa", savedir="tmp") | 951e8f428aa57fa5058e8bc295e657fd |
apache-2.0 | ['generated_from_trainer'] | false | generateur-bucolique This model is a fine-tuned version of [asi/gpt-fr-cased-small](https://huggingface.co/asi/gpt-fr-cased-small) on the "romans champêtres" dataset (four books). These four novels written by George Sand (*La mare au diable*, *La petite fadette*, *Les maîtres sonneurs*, *François le champi*) are characterised by a very bucolic narrative model which depicts characters leading a humble life in the rural setting of the first half of the 19th century : ``` Il criait aussi, le pauvret, d’une voix qu’il voulait rendre terrible et qui restait douce comme sa figure angélique. Tout cela était beau de force ou de grâce : le paysage, l’homme, l’enfant, les taureaux sous le joug ; et, malgré cette lutte puissante où la terre était vaincue, il y avait un sentiment de douceur et de calme profond qui planait sur toutes choses. (La mare au diable) ``` ``` Chacun sait pourtant qu’il y a danger à rester au bord de notre rivière quand le grand vent se lève. Toutes les rives sont minées en dessous, et il n’est point d’orage qui, dans la quantité, ne déracine quelques-uns de ces vergnes qui sont toujours courts en racines, à moins qu’ils ne soient très gros et très vieux, et qui vous tomberaient fort bien sur le corps sans vous avertir. (La petite fadette) ``` The model is fine-tuned with approximately 5K sentences. The generator is intended to reproduce the writing style of George Sand (at least it tries). | 0bfe0cd9f1795c7524d1b0c1c89c9433 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The parameters are the same as in [Rey Farhan' notebook (Easy GPT2 fine-tuning with Hugging Face and PyTorch)](https://reyfarhan.com/posts/easy-gpt2-finetuning-huggingface) The following hyperparameters were used during training: - learning_rate: 0.0005 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 20 - num_epochs: 5 | 209c0c440d3c2723754727e6c5508aa8 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 495 | 2.1639 | | 2.3543 | 2.0 | 990 | 2.1599 | | 1.6869 | 3.0 | 1485 | 2.4279 | | 1.0753 | 4.0 | 1980 | 2.8547 | | 0.5891 | 5.0 | 2475 | 3.0414 | | 1ea978f861c7ca999197aee7b8c2c9ce |
apache-2.0 | ['generated_from_trainer'] | false | Full config {'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'], 'is_split_by_sentences': True}, 'generation': {'batch_size': 128, 'metrics_configs': [{}, {'n': 1}, {}], 'scenario_configs': [{'display_as_html': True, 'generate_kwargs': {'do_sample': True, 'eos_token_id': 0, 'max_length': 640, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_samples': 512}, {'display_as_html': True, 'generate_kwargs': {'do_sample': True, 'eos_token_id': 0, 'max_length': 272, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'functions', 'num_samples': 512, 'prompts_path': 'resources/functions_csnet.jsonl', 'use_prompt_for_scoring': True}], 'scorer_config': {}}, 'kl_gpt3_callback': {'gpt3_kwargs': {'model_name': 'code-cushman-001'}, 'max_tokens': 64, 'num_samples': 4096}, 'model': {'from_scratch': True, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'model_kwargs': {'value_head_config': {'is_detached': False}}, 'path_or_name': 'codeparrot/codeparrot-small'}, 'objective': {'alpha': 1, 'beta': 10, 'name': 'AWR'}, 'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 64, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'immaculate-rwr', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.001, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000.0, 'output_dir': 'training_output', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 25177, 'save_strategy': 'steps', 'seed': 42, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | f9b4b5b45d1ee9e38a5bd31c49b5b545 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-zindi_tweets This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.3203 - Accuracy: 0.9168 - F1: 0.9168 | 8bb95d8d9320615f6f1ea7abe263e2eb |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.4224 | 1.0 | 67 | 0.2924 | 0.8894 | 0.8893 | | 0.2096 | 2.0 | 134 | 0.2632 | 0.9055 | 0.9055 | | 0.1329 | 3.0 | 201 | 0.2744 | 0.9102 | 0.9101 | | 0.1016 | 4.0 | 268 | 0.2868 | 0.9055 | 0.9054 | | 0.0752 | 5.0 | 335 | 0.2896 | 0.9140 | 0.9140 | | 0.0454 | 6.0 | 402 | 0.3077 | 0.9178 | 0.9178 | | 0.0305 | 7.0 | 469 | 0.3185 | 0.9149 | 0.9149 | | 0.0298 | 8.0 | 536 | 0.3203 | 0.9168 | 0.9168 | | 711ea1a5ab13094f3f15d1f1feb116ce |
creativeml-openrail-m | ['text-to-image'] | false | training params ```json { "pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5", "instance_data_dir": "./2cabda5b-4e53-40e9-8fcf-cdba5ea5bd6c/instance_data", "class_data_dir": "./class_data/a-portrait-of-a-person", "output_dir": "./2cabda5b-4e53-40e9-8fcf-cdba5ea5bd6c/", "train_text_encoder": true, "with_prior_preservation": false, "prior_loss_weight": 1.0, "instance_prompt": "a portrait of [V]", "class_prompt": "a portrait of a person", "resolution": 512, "train_batch_size": 1, "gradient_accumulation_steps": 1, "gradient_checkpointing": true, "use_8bit_adam": true, "learning_rate": 5e-06, "lr_scheduler": "constant", "lr_warmup_steps": 0, "num_class_images": 200, "max_train_steps": 1050, "mixed_precision": "fp16" } ``` | 7ee56824b6895bf9352f488b20a6d37d |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 4e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 1 | e43a0793fd938233e0ec758be69bac85 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 213 | 0.3717 | 0.6279 | 0.3707 | 0.4662 | 0.9481 | | 66c8e1284d9bdb2527c465f2ee0e42a2 |
apache-2.0 | ['text-classification', 'generated_from_trainer'] | false | categorizacion_comercios_v_0.0.4 This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the datasetX dataset. It achieves the following results on the evaluation set: - Loss: 0.4303 - Accuracy: 0.8786 | 70456bd1aa7894c540b970c02198a881 |
other | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'architecture', 'diffusers'] | false | Model Trained to create a Midjourney architecture buildings style. Used 120 images 768x768 Prompts example: "a photo of a futuristic house with a organic facade, roots, waves, many windows, by midjourneyi" "a photo of a parametric building midjourneyi, waves, roots, veins, many windows, in a street." "a photo of a symmetric colored vived midjourneyi house, in a street" Important: add negative prompts to improve the results. | f953b20155ec35d5c492f30af19b3fab |
other | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'architecture', 'diffusers'] | false | Examples <img src="https://s3.amazonaws.com/moonup/production/uploads/1672217149393-632079ef9f7a9f2208c6582a.jpeg" style="max-width: 200px;" width="100%"/> <img src="https://s3.amazonaws.com/moonup/production/uploads/1672217145915-632079ef9f7a9f2208c6582a.jpeg" style="max-width: 200px;" width="100%"/> <img src="https://s3.amazonaws.com/moonup/production/uploads/1672217147532-632079ef9f7a9f2208c6582a.jpeg" style="max-width: 200px;" width="100%"/> <img src="https://s3.amazonaws.com/moonup/production/uploads/1672217147989-632079ef9f7a9f2208c6582a.jpeg" style="max-width: 200px;" width="100%"/> license: openrail --- | 0ba4ad1a378369de4766467042b3ab7b |
apache-2.0 | ['translation', 'generated_from_trainer'] | false | kyoto_marian_mod_5 This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_4](https://huggingface.co/Hoax0930/kyoto_marian_mod_4) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 2.9144 - Bleu: 20.1999 | a90d36588e82f2a2ed43ff9ba2104ae5 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-multilingual-cased-finetuned-with-spanish-tweets-clf-cleaned-ds This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the dataset dataset. It achieves the following results on the evaluation set: - Loss: 1.5095 - Accuracy: 0.5950 - F1: 0.5960 - Precision: 0.6036 - Recall: 0.5949 | c6c7f850e0a474a256c494b39b3df5b9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:| | 1.018 | 1.0 | 543 | 0.9421 | 0.5536 | 0.4949 | 0.5347 | 0.5146 | | 0.8079 | 2.0 | 1086 | 0.9275 | 0.5957 | 0.5751 | 0.5921 | 0.5725 | | 0.521 | 3.0 | 1629 | 1.1208 | 0.6033 | 0.6050 | 0.6146 | 0.6023 | | 0.3225 | 4.0 | 2172 | 1.5095 | 0.5950 | 0.5960 | 0.6036 | 0.5949 | | 547b7492d4cde2832d3e7f271f9b88e0 |
apache-2.0 | ['deep-narrow'] | false | T5-Efficient-SMALL-EL16 (Deep-Narrow version) T5-Efficient-SMALL-EL16 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5). It is a *pretrained-only* checkpoint and was released with the paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*. In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures of similar parameter count. To quote the paper: > We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased > before considering any other forms of uniform scaling across other dimensions. This is largely due to > how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a > tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise, > a tall base model might also generally more efficient compared to a large model. We generally find > that, regardless of size, even if absolute performance might increase as we continue to stack layers, > the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36 > layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e., > params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params, > FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to > consider. To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially. A sequence of word embeddings is therefore processed sequentially by each transformer block. | 3c4c59dd74c45a15c4a6165229fc4a65 |
apache-2.0 | ['deep-narrow'] | false | Details model architecture This model checkpoint - **t5-efficient-small-el16** - is of model type **Small** with the following variations: - **el** is **16** It has **92.0** million parameters and thus requires *ca.* **367.99 MB** of memory in full precision (*fp32*) or **183.99 MB** of memory in half precision (*fp16* or *bf16*). A summary of the *original* T5 model architectures can be seen here: | Model | nl (el/dl) | ff | dm | kv | nh | | 04f6e48fc6443628ed0e9baf5ece064a |
apache-2.0 | ['multiberts', 'multiberts-seed_3', 'multiberts-seed_3-step_180k'] | false | MultiBERTs, Intermediate Checkpoint - Seed 3, Step 180k MultiBERTs is a collection of checkpoints and a statistical library to support robust research on BERT. We provide 25 BERT-base models trained with similar hyper-parameters as [the original BERT model](https://github.com/google-research/bert) but with different random seeds, which causes variations in the initial weights and order of training instances. The aim is to distinguish findings that apply to a specific artifact (i.e., a particular instance of the model) from those that apply to the more general procedure. We also provide 140 intermediate checkpoints captured during the course of pre-training (we saved 28 checkpoints for the first 5 runs). The models were originally released through [http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our paper [The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163). This is model | f1f3830d9937b4c0ed05208cfd16ed0f |
apache-2.0 | ['multiberts', 'multiberts-seed_3', 'multiberts-seed_3-step_180k'] | false | How to use Using code from [BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on Tensorflow: ``` from transformers import BertTokenizer, TFBertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3-step_180k') model = TFBertModel.from_pretrained("google/multiberts-seed_3-step_180k") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='tf') output = model(encoded_input) ``` PyTorch version: ``` from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3-step_180k') model = BertModel.from_pretrained("google/multiberts-seed_3-step_180k") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='pt') output = model(**encoded_input) ``` | b65f8b2a1183ae9e0461a1466bd2fb01 |
bsd-3-clause | ['flair', 'token-classification', 'sequence-tagger-model'] | false | Biomedical Entity Recognition in Bahasa Indonesia Summary: - Trained using manually annotated data from alodokter.com (online health QA platform) using UMLS guideline (see https://rdcu.be/cNxV3) - Recognize disorders (DISO) and anatomy (ANAT) entities - Achieve best F1 macro score 0.81 - Based on XLM-Roberta. So, cross lingual recognition might work. | 83d75051f6023318ff4af574155523d5 |
bsd-3-clause | ['flair', 'token-classification', 'sequence-tagger-model'] | false | CITATION This work is done with generous support from Safitri Juanita, Dr. Diana Purwitasari and Dr. Mauridhi Hery Purnomo from Institut Teknologi Sepuluh Nopember, Indonesia. Citation for academic purpose will be provided later. For demo, please go to the HF space demo: https://huggingface.co/spaces/abid/id-bioner-demo | a285c81e65e2190f98c28fb0f22fc57b |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 2 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 8 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3.0 - mixed_precision_training: Native AMP | 98f8f7290b7957758b640a1434a7a89f |
apache-2.0 | ['EBK-BERT'] | false | BK-BERT Event Knowledge-Based BERT (EBK-BERT) leverages knowledge extracted from events-related sentences to mask words that are significant to the events detection task. This approach aims to produce a language model that enhances the performance of the down-stream event detection task, which is later trained during the fine-tuning process. | bf0dca8232e62dbe0d95ba8aa982919c |
apache-2.0 | ['EBK-BERT'] | false | Pre-training Data The pre-training data consists of news articles from the 1.5 billion words corpus by (El-Khair, 2016). Due to computation limitations, we only use articles from Alittihad, Riyadh, Almasrya- lyoum, and Alqabas, which amount to 10GB of text and about 8M sentences after splitting the articles to approximately 100 word sentences to accommodate the 128 max_sentence length used when training the model. The average number of tokens per sentence is 105. | bd7bd59c259f786aea5737f4e5353ece |
apache-2.0 | ['EBK-BERT'] | false | Pretraining As previous studies have shown, contextual representation models that are pre-trained using top Personnel Transaction Contact Nature Movement Life Justice Conflict business the MLM training task benefit from masking the most significant words, using whole word masking. To select the most significant words we use odds-ratio. Only words with greater than 2 odds-ratio are considered in the masking, which means the words included are at least twice as likely to appear in one event type than the other. Google Cloud GPU is used for pre-training the model. The selected hyperparameters are: learning rate=1e − 4, batch size =16, maxi- mum sequence length = 128 and average se- quence length = 104. In total, we pre-trained our models for 500, 000 steps, completing 1 epoch. Pre-training a single model took approximately 2.25 days. | 30414735024f51cbfc0f50dcc3758139 |
apache-2.0 | ['EBK-BERT'] | false | Fine-tuning data Tweets are collected from well-known Arabic news accounts, which are: Al-Arabiya, Sabq, CNN Arabic, and BBC Arabic. These accounts belong to television channels and online newspapers, where they use Twitter to broadcast news related to real-world events. The first collection process tracks tweets from the news accounts for 20 days period, between November 2, 2021, and November 22, 2021 and we call this dataset AraEvent(November). | 4c4a5ff83f373c998c8775e756e01997 |
apache-2.0 | ['EBK-BERT'] | false | Evaluation results When fine-tuned on down-stream event detection task, this model achieves the following results: 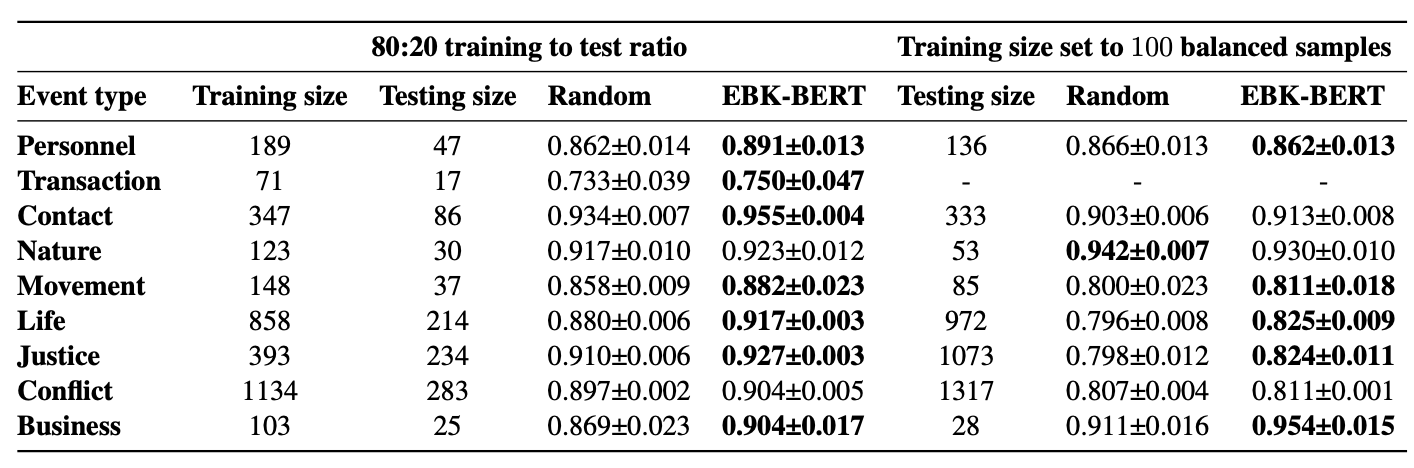 | 2a6e877fb1920075fec898d9a2ac5e98 |
cc-by-sa-4.0 | ['japanese', 'token-classification', 'pos', 'wikipedia', 'dependency-parsing'] | false | Model Description This is a BERT model pre-trained on Japanese Wikipedia texts for POS-tagging and dependency-parsing, derived from [bert-base-japanese-char-extended](https://huggingface.co/KoichiYasuoka/bert-base-japanese-char-extended). Every long-unit-word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech) and [FEATS](https://universaldependencies.org/u/feat/). | f10273db6140894af33fd2938e3ed3b3 |
cc-by-sa-4.0 | ['japanese', 'token-classification', 'pos', 'wikipedia', 'dependency-parsing'] | false | How to Use ```py import torch from transformers import AutoTokenizer,AutoModelForTokenClassification tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/bert-base-japanese-luw-upos") model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/bert-base-japanese-luw-upos") s="国境の長いトンネルを抜けると雪国であった。" p=[model.config.id2label[q] for q in torch.argmax(model(tokenizer.encode(s,return_tensors="pt"))["logits"],dim=2)[0].tolist()[1:-1]] print(list(zip(s,p))) ``` or ```py import esupar nlp=esupar.load("KoichiYasuoka/bert-base-japanese-luw-upos") print(nlp("国境の長いトンネルを抜けると雪国であった。")) ``` | f216f351d92c6923b74df5b97a3a9410 |
apache-2.0 | ['translation'] | false | art-eng * source group: Artificial languages * target group: English * OPUS readme: [art-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/art-eng/README.md) * model: transformer * source language(s): afh_Latn avk_Latn dws_Latn epo ido ido_Latn ile_Latn ina_Latn jbo jbo_Cyrl jbo_Latn ldn_Latn lfn_Cyrl lfn_Latn nov_Latn qya qya_Latn sjn_Latn tlh_Latn tzl tzl_Latn vol_Latn * target language(s): eng * model: transformer * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus2m-2020-07-31.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/art-eng/opus2m-2020-07-31.zip) * test set translations: [opus2m-2020-07-31.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/art-eng/opus2m-2020-07-31.test.txt) * test set scores: [opus2m-2020-07-31.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/art-eng/opus2m-2020-07-31.eval.txt) | 0b417683711da6eaa9bf696dbed60b43 |
apache-2.0 | ['translation'] | false | Benchmarks | testset | BLEU | chr-F | |-----------------------|-------|-------| | Tatoeba-test.afh-eng.afh.eng | 1.2 | 0.099 | | Tatoeba-test.avk-eng.avk.eng | 0.4 | 0.105 | | Tatoeba-test.dws-eng.dws.eng | 1.6 | 0.076 | | Tatoeba-test.epo-eng.epo.eng | 34.6 | 0.530 | | Tatoeba-test.ido-eng.ido.eng | 12.7 | 0.310 | | Tatoeba-test.ile-eng.ile.eng | 4.6 | 0.218 | | Tatoeba-test.ina-eng.ina.eng | 5.8 | 0.254 | | Tatoeba-test.jbo-eng.jbo.eng | 0.2 | 0.115 | | Tatoeba-test.ldn-eng.ldn.eng | 0.7 | 0.083 | | Tatoeba-test.lfn-eng.lfn.eng | 1.8 | 0.172 | | Tatoeba-test.multi.eng | 11.6 | 0.287 | | Tatoeba-test.nov-eng.nov.eng | 5.1 | 0.215 | | Tatoeba-test.qya-eng.qya.eng | 0.7 | 0.113 | | Tatoeba-test.sjn-eng.sjn.eng | 0.9 | 0.090 | | Tatoeba-test.tlh-eng.tlh.eng | 0.2 | 0.124 | | Tatoeba-test.tzl-eng.tzl.eng | 1.4 | 0.109 | | Tatoeba-test.vol-eng.vol.eng | 0.5 | 0.115 | | 48da5907205d7bd64716c852f6cb8004 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: art-eng - source_languages: art - target_languages: eng - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/art-eng/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['eo', 'io', 'art', 'en'] - src_constituents: {'sjn_Latn', 'tzl', 'vol_Latn', 'qya', 'tlh_Latn', 'ile_Latn', 'ido_Latn', 'tzl_Latn', 'jbo_Cyrl', 'jbo', 'lfn_Latn', 'nov_Latn', 'dws_Latn', 'ldn_Latn', 'avk_Latn', 'lfn_Cyrl', 'ina_Latn', 'jbo_Latn', 'epo', 'afh_Latn', 'qya_Latn', 'ido'} - tgt_constituents: {'eng'} - src_multilingual: True - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/art-eng/opus2m-2020-07-31.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/art-eng/opus2m-2020-07-31.test.txt - src_alpha3: art - tgt_alpha3: eng - short_pair: art-en - chrF2_score: 0.287 - bleu: 11.6 - brevity_penalty: 1.0 - ref_len: 73037.0 - src_name: Artificial languages - tgt_name: English - train_date: 2020-07-31 - src_alpha2: art - tgt_alpha2: en - prefer_old: False - long_pair: art-eng - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | e9e18778d65b88eabc4ec6637eb588c3 |
apache-2.0 | ['automatic-speech-recognition', 'en'] | false | exp_w2v2t_en_vp-100k_s421 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | b3ae6b43aaf2c00e016b8194b37a3534 |
apache-2.0 | ['generated_from_trainer'] | false | platzi-vit-model-omar-espejel This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset. It achieves the following results on the evaluation set: - Loss: 0.0367 - Accuracy: 0.9850 | 4bd3918578bddbd5d160e731694756f6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.149 | 3.85 | 500 | 0.0367 | 0.9850 | | bd8b17fc9fdc47fe7ae468db28919054 |
mit | [] | false | model by hiero This your the Stable Diffusion model fine-tuned the angus mcbride style concept taught to Stable Diffusion with Dreambooth. It can be used by modifying the `instance_prompt`: **angus mcbride style** You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb). And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts) Here are the images used for training this concept:                                                   | e5f9e32b577a2bad209bd825f34face6 |
apache-2.0 | ['translation'] | false | opus-mt-es-swc * source languages: es * target languages: swc * OPUS readme: [es-swc](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-swc/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-swc/opus-2020-01-16.zip) * test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-swc/opus-2020-01-16.test.txt) * test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-swc/opus-2020-01-16.eval.txt) | 5b0131dd20daef6978959b525d2bb9be |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0627 - Precision: 0.9355 - Recall: 0.9524 - F1: 0.9439 - Accuracy: 0.9862 | 07b4c02eb884dcdef7caf0ca4de7df4b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0842 | 1.0 | 1756 | 0.0662 | 0.9195 | 0.9396 | 0.9294 | 0.9839 | | 0.0384 | 2.0 | 3512 | 0.0581 | 0.9340 | 0.9504 | 0.9421 | 0.9862 | | 0.0182 | 3.0 | 5268 | 0.0627 | 0.9355 | 0.9524 | 0.9439 | 0.9862 | | 3aa60c0df78deb542e5e6a2f0a381965 |
mit | ['ja', 'japanese', 'gpt2', 'text-generation', 'lm', 'nlp'] | false | 日本語 gpt2 蒸留モデル このモデルは[rinna/japanese-gpt2-meduim](https://huggingface.co/rinna/japanese-gpt2-medium)を教師として蒸留したものです。 蒸留には、HuggigFace Transformersの[コード](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)をベースとし、[りんなの訓練コード](https://github.com/rinnakk/japanese-pretrained-models)と組み合わせてデータ扱うよう改造したものを使っています。 訓練用コード: https://github.com/knok/japanese-pretrained-models | 412eda4c9ac59710061175654c7d7b01 |
mit | ['ja', 'japanese', 'gpt2', 'text-generation', 'lm', 'nlp'] | false | Japanese GPT-2 model This model is a dillated model from [rinna/japanese-gpt2-medium](https://huggingface.co/rinna/japanese-gpt2-medium). To train, I combined HuggingFace Transformers [code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and [rinna gpt2 train code](https://github.com/rinnakk/japanese-pretrained-models). The code is available at: https://github.com/knok/japanese-pretrained-models | a3d41549d85f90e263dd98a98e2ec0bd |
apache-2.0 | ['translation'] | false | ukr-slv * source group: Ukrainian * target group: Slovenian * OPUS readme: [ukr-slv](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-slv/README.md) * model: transformer-align * source language(s): ukr * target language(s): slv * model: transformer-align * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-slv/opus-2020-06-17.zip) * test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-slv/opus-2020-06-17.test.txt) * test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-slv/opus-2020-06-17.eval.txt) | c6412980241a78436a5d68a522d3b401 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: ukr-slv - source_languages: ukr - target_languages: slv - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-slv/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['uk', 'sl'] - src_constituents: {'ukr'} - tgt_constituents: {'slv'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-slv/opus-2020-06-17.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-slv/opus-2020-06-17.test.txt - src_alpha3: ukr - tgt_alpha3: slv - short_pair: uk-sl - chrF2_score: 0.28 - bleu: 11.8 - brevity_penalty: 1.0 - ref_len: 3823.0 - src_name: Ukrainian - tgt_name: Slovenian - train_date: 2020-06-17 - src_alpha2: uk - tgt_alpha2: sl - prefer_old: False - long_pair: ukr-slv - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | d6e84d203f96550399c58878271d4754 |
other | ['vision', 'image-segmentation'] | false | Mask2Former Mask2Former model trained on ADE20k panoptic segmentation (large-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation ](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/). Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team. | e7bf8328f03bb9c994c01266e5996126 |
other | ['vision', 'image-segmentation'] | false | load Mask2Former fine-tuned on ADE20k panoptic segmentation processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-large-ade-panoptic") model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-large-ade-panoptic") url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw) inputs = processor(images=image, return_tensors="pt") with torch.no_grad(): outputs = model(**inputs) | e947872531cf0f1ba510d4423a081be6 |
mit | ['generated_from_trainer'] | false | donut-base-Medical_Handwritten_Prescriptions_Information_Extraction This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset. | 2c997815505be9243e9f289a896ec469 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 2 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 6 - mixed_precision_training: Native AMP | 6477b2fe12ac83ddb0da96418ebd6ce9 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Demo: How to use in ESPnet2 ```bash cd espnet git checkout c3569453a408fd4ff4173d9c1d2062c88d1fc060 pip install -e . cd egs2/librispeech/asr1 ./run.sh --skip_data_prep false --skip_train true --download_model pyf98/librispeech_conformer ``` <!-- Generated by scripts/utils/show_asr_result.sh --> | d33d3767d0af312b199db00f866871d1 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Environments - date: `Mon Mar 7 12:26:10 EST 2022` - python version: `3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0]` - espnet version: `espnet 0.10.7a1` - pytorch version: `pytorch 1.10.1` - Git hash: `c3569453a408fd4ff4173d9c1d2062c88d1fc060` - Commit date: `Sun Mar 6 23:58:36 2022 -0500` | 61d82e413639f16e2e00491b76a4165c |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | WER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |beam60_ctc0.2/dev_clean|2703|54402|98.0|1.8|0.2|0.2|2.2|27.2| |beam60_ctc0.2/dev_other|2864|50948|95.1|4.4|0.5|0.5|5.4|43.3| |beam60_ctc0.2/test_clean|2620|52576|97.9|1.9|0.2|0.3|2.4|28.8| |beam60_ctc0.2/test_other|2939|52343|95.2|4.3|0.5|0.6|5.4|45.5| |beam60_ctc0.2_lm0.6/dev_clean|2703|54402|98.3|1.4|0.3|0.2|1.9|23.7| |beam60_ctc0.2_lm0.6/dev_other|2864|50948|96.2|3.3|0.4|0.4|4.2|37.2| |beam60_ctc0.2_lm0.6/test_clean|2620|52576|98.2|1.5|0.3|0.2|2.0|24.3| |beam60_ctc0.2_lm0.6/test_other|2939|52343|96.1|3.3|0.6|0.4|4.4|39.9| |beam60_ctc0.3/dev_clean|2703|54402|98.1|1.8|0.2|0.2|2.1|27.3| |beam60_ctc0.3/dev_other|2864|50948|95.2|4.4|0.4|0.5|5.4|43.7| |beam60_ctc0.3/test_clean|2620|52576|97.9|1.9|0.2|0.3|2.3|29.0| |beam60_ctc0.3/test_other|2939|52343|95.2|4.3|0.4|0.6|5.4|45.7| |beam60_ctc0.3_lm0.6/dev_clean|2703|54402|98.4|1.4|0.2|0.2|1.8|23.5| |beam60_ctc0.3_lm0.6/dev_other|2864|50948|96.2|3.4|0.4|0.4|4.1|37.4| |beam60_ctc0.3_lm0.6/test_clean|2620|52576|98.3|1.5|0.2|0.2|1.9|24.1| |beam60_ctc0.3_lm0.6/test_other|2939|52343|96.2|3.3|0.5|0.5|4.3|39.9| | 4d661c4332299a4dfb30d82d108718f3 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | CER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |beam60_ctc0.2/dev_clean|2703|288456|99.4|0.3|0.3|0.2|0.8|27.2| |beam60_ctc0.2/dev_other|2864|265951|98.1|1.1|0.8|0.6|2.5|43.3| |beam60_ctc0.2/test_clean|2620|281530|99.4|0.3|0.3|0.2|0.8|28.8| |beam60_ctc0.2/test_other|2939|272758|98.3|1.0|0.7|0.6|2.3|45.5| |beam60_ctc0.2_lm0.6/dev_clean|2703|288456|99.4|0.3|0.3|0.2|0.8|23.7| |beam60_ctc0.2_lm0.6/dev_other|2864|265951|98.4|0.9|0.7|0.5|2.1|37.2| |beam60_ctc0.2_lm0.6/test_clean|2620|281530|99.4|0.2|0.4|0.2|0.8|24.3| |beam60_ctc0.2_lm0.6/test_other|2939|272758|98.5|0.8|0.8|0.5|2.0|39.9| |beam60_ctc0.3/dev_clean|2703|288456|99.5|0.3|0.2|0.2|0.7|27.3| |beam60_ctc0.3/dev_other|2864|265951|98.2|1.1|0.7|0.6|2.4|43.7| |beam60_ctc0.3/test_clean|2620|281530|99.4|0.3|0.3|0.2|0.8|29.0| |beam60_ctc0.3/test_other|2939|272758|98.4|0.9|0.7|0.6|2.2|45.7| |beam60_ctc0.3_lm0.6/dev_clean|2703|288456|99.5|0.2|0.2|0.2|0.7|23.5| |beam60_ctc0.3_lm0.6/dev_other|2864|265951|98.5|0.9|0.7|0.5|2.0|37.4| |beam60_ctc0.3_lm0.6/test_clean|2620|281530|99.5|0.2|0.3|0.2|0.7|24.1| |beam60_ctc0.3_lm0.6/test_other|2939|272758|98.6|0.7|0.7|0.5|1.9|39.9| | 52fe5289a24627bbedd0652034469ce3 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | TER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |beam60_ctc0.2/dev_clean|2703|68010|97.5|1.8|0.7|0.3|2.9|27.2| |beam60_ctc0.2/dev_other|2864|63110|94.1|4.4|1.6|0.9|6.8|43.3| |beam60_ctc0.2/test_clean|2620|65818|97.4|1.8|0.8|0.3|2.9|28.8| |beam60_ctc0.2/test_other|2939|65101|94.1|4.1|1.8|0.8|6.7|45.5| |beam60_ctc0.2_lm0.6/dev_clean|2703|68010|97.8|1.4|0.8|0.3|2.5|23.7| |beam60_ctc0.2_lm0.6/dev_other|2864|63110|95.1|3.5|1.5|0.7|5.6|37.2| |beam60_ctc0.2_lm0.6/test_clean|2620|65818|97.6|1.5|0.9|0.3|2.7|24.3| |beam60_ctc0.2_lm0.6/test_other|2939|65101|95.0|3.2|1.8|0.6|5.6|39.9| |beam60_ctc0.3/dev_clean|2703|68010|97.6|1.8|0.7|0.3|2.8|27.3| |beam60_ctc0.3/dev_other|2864|63110|94.1|4.4|1.5|0.9|6.8|43.7| |beam60_ctc0.3/test_clean|2620|65818|97.4|1.8|0.7|0.3|2.9|29.0| |beam60_ctc0.3/test_other|2939|65101|94.2|4.1|1.7|0.8|6.6|45.7| |beam60_ctc0.3_lm0.6/dev_clean|2703|68010|97.9|1.5|0.7|0.3|2.4|23.5| |beam60_ctc0.3_lm0.6/dev_other|2864|63110|95.1|3.5|1.4|0.6|5.6|37.4| |beam60_ctc0.3_lm0.6/test_clean|2620|65818|97.7|1.5|0.8|0.3|2.5|24.1| |beam60_ctc0.3_lm0.6/test_other|2939|65101|95.1|3.2|1.7|0.6|5.5|39.9| | 68416d5615f13400a0d3b261430beffe |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | ASR config <details><summary>expand</summary> ``` config: conf/tuning/train_asr_conformer8.yaml print_config: false log_level: INFO dry_run: false iterator_type: sequence output_dir: exp/asr_train_asr_conformer8_raw_en_bpe5000_sp ngpu: 1 seed: 0 num_workers: 4 num_att_plot: 3 dist_backend: nccl dist_init_method: env:// dist_world_size: 3 dist_rank: 0 local_rank: 0 dist_master_addr: localhost dist_master_port: 59673 dist_launcher: null multiprocessing_distributed: true unused_parameters: false sharded_ddp: false cudnn_enabled: true cudnn_benchmark: false cudnn_deterministic: true collect_stats: false write_collected_feats: false max_epoch: 50 patience: null val_scheduler_criterion: - valid - loss early_stopping_criterion: - valid - loss - min best_model_criterion: - - valid - acc - max keep_nbest_models: 10 nbest_averaging_interval: 0 grad_clip: 5.0 grad_clip_type: 2.0 grad_noise: false accum_grad: 4 no_forward_run: false resume: true train_dtype: float32 use_amp: true log_interval: null use_matplotlib: true use_tensorboard: true use_wandb: false wandb_project: null wandb_id: null wandb_entity: null wandb_name: null wandb_model_log_interval: -1 detect_anomaly: false pretrain_path: null init_param: [] ignore_init_mismatch: false freeze_param: [] num_iters_per_epoch: null batch_size: 20 valid_batch_size: null batch_bins: 35000000 valid_batch_bins: null train_shape_file: - exp/asr_stats_raw_en_bpe5000_sp/train/speech_shape - exp/asr_stats_raw_en_bpe5000_sp/train/text_shape.bpe valid_shape_file: - exp/asr_stats_raw_en_bpe5000_sp/valid/speech_shape - exp/asr_stats_raw_en_bpe5000_sp/valid/text_shape.bpe batch_type: numel valid_batch_type: null fold_length: - 80000 - 150 sort_in_batch: descending sort_batch: descending multiple_iterator: false chunk_length: 500 chunk_shift_ratio: 0.5 num_cache_chunks: 1024 train_data_path_and_name_and_type: - - dump/raw/train_960_sp/wav.scp - speech - sound - - dump/raw/train_960_sp/text - text - text valid_data_path_and_name_and_type: - - dump/raw/dev/wav.scp - speech - sound - - dump/raw/dev/text - text - text allow_variable_data_keys: false max_cache_size: 0.0 max_cache_fd: 32 valid_max_cache_size: null optim: adam optim_conf: lr: 0.0025 weight_decay: 1.0e-06 scheduler: warmuplr scheduler_conf: warmup_steps: 40000 token_list: - <blank> - <unk> - ▁THE - S - ▁AND - ▁OF - ▁TO - ▁A - ▁IN - ▁I - ▁HE - ▁THAT - ▁WAS - ED - ▁IT - '''' - ▁HIS - ING - ▁YOU - ▁WITH - ▁FOR - ▁HAD - T - ▁AS - ▁HER - ▁IS - ▁BE - ▁BUT - ▁NOT - ▁SHE - D - ▁AT - ▁ON - LY - ▁HIM - ▁THEY - ▁ALL - ▁HAVE - ▁BY - ▁SO - ▁THIS - ▁MY - ▁WHICH - ▁ME - ▁SAID - ▁FROM - ▁ONE - Y - E - ▁WERE - ▁WE - ▁NO - N - ▁THERE - ▁OR - ER - ▁AN - ▁WHEN - ▁ARE - ▁THEIR - ▁WOULD - ▁IF - ▁WHAT - ▁THEM - ▁WHO - ▁OUT - M - ▁DO - ▁WILL - ▁UP - ▁BEEN - P - R - ▁MAN - ▁THEN - ▁COULD - ▁MORE - C - ▁INTO - ▁NOW - ▁VERY - ▁YOUR - ▁SOME - ▁LITTLE - ES - ▁TIME - RE - ▁CAN - ▁LIKE - LL - ▁ABOUT - ▁HAS - ▁THAN - ▁DID - ▁UPON - ▁OVER - IN - ▁ANY - ▁WELL - ▁ONLY - B - ▁SEE - ▁GOOD - ▁OTHER - ▁TWO - L - ▁KNOW - ▁GO - ▁DOWN - ▁BEFORE - A - AL - ▁OUR - ▁OLD - ▁SHOULD - ▁MADE - ▁AFTER - ▁GREAT - ▁DAY - ▁MUST - ▁COME - ▁HOW - ▁SUCH - ▁CAME - LE - ▁WHERE - ▁US - ▁NEVER - ▁THESE - ▁MUCH - ▁DE - ▁MISTER - ▁WAY - G - ▁S - ▁MAY - ATION - ▁LONG - OR - ▁AM - ▁FIRST - ▁BACK - ▁OWN - ▁RE - ▁AGAIN - ▁SAY - ▁MEN - ▁WENT - ▁HIMSELF - ▁HERE - NESS - ▁THINK - V - IC - ▁EVEN - ▁THOUGHT - ▁HAND - ▁JUST - ▁O - ▁UN - VE - ION - ▁ITS - 'ON' - ▁MAKE - ▁MIGHT - ▁TOO - K - ▁AWAY - ▁LIFE - TH - ▁WITHOUT - ST - ▁THROUGH - ▁MOST - ▁TAKE - ▁DON - ▁EVERY - F - O - ▁SHALL - ▁THOSE - ▁EYES - AR - ▁STILL - ▁LAST - ▁HOUSE - ▁HEAD - ABLE - ▁NOTHING - ▁NIGHT - ITY - ▁LET - ▁MANY - ▁OFF - ▁BEING - ▁FOUND - ▁WHILE - EN - ▁SAW - ▁GET - ▁PEOPLE - ▁FACE - ▁YOUNG - CH - ▁UNDER - ▁ONCE - ▁TELL - AN - ▁THREE - ▁PLACE - ▁ROOM - ▁YET - ▁SAME - IL - US - U - ▁FATHER - ▁RIGHT - EL - ▁THOUGH - ▁ANOTHER - LI - RI - ▁HEART - IT - ▁PUT - ▁TOOK - ▁GIVE - ▁EVER - ▁E - ▁PART - ▁WORK - ERS - ▁LOOK - ▁NEW - ▁KING - ▁MISSUS - ▁SIR - ▁LOVE - ▁MIND - ▁LOOKED - W - RY - ▁ASKED - ▁LEFT - ET - ▁LIGHT - CK - ▁DOOR - ▁MOMENT - RO - ▁WORLD - ▁THINGS - ▁HOME - UL - ▁THING - LA - ▁WHY - ▁MOTHER - ▁ALWAYS - ▁FAR - FUL - ▁WATER - CE - IVE - UR - ▁HEARD - ▁SOMETHING - ▁SEEMED - I - LO - ▁BECAUSE - OL - ▁END - ▁TOLD - ▁CON - ▁YES - ▁GOING - ▁GOT - RA - IR - ▁WOMAN - ▁GOD - EST - TED - ▁FIND - ▁KNEW - ▁SOON - ▁EACH - ▁SIDE - H - TON - MENT - ▁OH - NE - Z - LING - ▁AGAINST - TER - ▁NAME - ▁MISS - ▁QUITE - ▁WANT - ▁YEARS - ▁FEW - ▁BETTER - ENT - ▁HALF - ▁DONE - ▁ALSO - ▁BEGAN - ▁HAVING - ▁ENOUGH - IS - ▁LADY - ▁WHOLE - LESS - ▁BOTH - ▁SEEN - ▁SET - ▁WHITE - ▁COURSE - IES - ▁VOICE - ▁CALLED - ▁D - ▁EX - ATE - ▁TURNED - ▁GAVE - ▁C - ▁POOR - MAN - UT - NA - ▁DEAR - ISH - ▁GIRL - ▁MORNING - ▁BETWEEN - LED - ▁NOR - IA - ▁AMONG - MA - ▁ - ▁SMALL - ▁REST - ▁WHOM - ▁FELT - ▁HANDS - ▁MYSELF - ▁HIGH - ▁M - ▁HOWEVER - ▁HERSELF - ▁P - CO - ▁STOOD - ID - ▁KIND - ▁HUNDRED - AS - ▁ROUND - ▁ALMOST - TY - ▁SINCE - ▁G - AM - ▁LA - SE - ▁BOY - ▁MA - ▁PERHAPS - ▁WORDS - ATED - ▁HO - X - ▁MO - ▁SAT - ▁REPLIED - ▁FOUR - ▁ANYTHING - ▁TILL - ▁UNTIL - ▁BLACK - TION - ▁CRIED - RU - TE - ▁FACT - ▁HELP - ▁NEXT - ▁LOOKING - ▁DOES - ▁FRIEND - ▁LAY - ANCE - ▁POWER - ▁BROUGHT - VER - ▁FIRE - ▁KEEP - PO - FF - ▁COUNTRY - ▁SEA - ▁WORD - ▁CAR - ▁DAYS - ▁TOGETHER - ▁IMP - ▁REASON - KE - ▁INDEED - TING - ▁MATTER - ▁FULL - ▁TEN - TIC - ▁LAND - ▁RATHER - ▁AIR - ▁HOPE - ▁DA - ▁OPEN - ▁FEET - ▁EN - ▁FIVE - ▁POINT - ▁CO - OM - ▁LARGE - ▁B - ▁CL - ME - ▁GONE - ▁CHILD - INE - GG - ▁BEST - ▁DIS - UM - ▁HARD - ▁LORD - OUS - ▁WIFE - ▁SURE - ▁FORM - DE - ▁DEATH - ANT - ▁NATURE - ▁BA - ▁CARE - ▁BELIEVE - PP - ▁NEAR - ▁RO - ▁RED - ▁WAR - IE - ▁SPEAK - ▁FEAR - ▁CASE - ▁TAKEN - ▁ALONG - ▁CANNOT - ▁HEAR - ▁THEMSELVES - CI - ▁PRESENT - AD - ▁MASTER - ▁SON - ▁THUS - ▁LI - ▁LESS - ▁SUN - ▁TRUE - IM - IOUS - ▁THOUSAND - ▁MONEY - ▁W - ▁BEHIND - ▁CHILDREN - ▁DOCTOR - AC - ▁TWENTY - ▁WISH - ▁SOUND - ▁WHOSE - ▁LEAVE - ▁ANSWERED - ▁THOU - ▁DUR - ▁HA - ▁CERTAIN - ▁PO - ▁PASSED - GE - TO - ▁ARM - ▁LO - ▁STATE - ▁ALONE - TA - ▁SHOW - ▁NEED - ▁LIVE - ND - ▁DEAD - ENCE - ▁STRONG - ▁PRE - ▁TI - ▁GROUND - SH - TI - ▁SHORT - IAN - UN - ▁PRO - ▁HORSE - MI - ▁PRINCE - ARD - ▁FELL - ▁ORDER - ▁CALL - AT - ▁GIVEN - ▁DARK - ▁THEREFORE - ▁CLOSE - ▁BODY - ▁OTHERS - ▁SENT - ▁SECOND - ▁OFTEN - ▁CA - ▁MANNER - MO - NI - ▁BRING - ▁QUESTION - ▁HOUR - ▁BO - AGE - ▁ST - ▁TURN - ▁TABLE - ▁GENERAL - ▁EARTH - ▁BED - ▁REALLY - ▁SIX - 'NO' - IST - ▁BECOME - ▁USE - ▁READ - ▁SE - ▁VI - ▁COMING - ▁EVERYTHING - ▁EM - ▁ABOVE - ▁EVENING - ▁BEAUTIFUL - ▁FEEL - ▁RAN - ▁LEAST - ▁LAW - ▁ALREADY - ▁MEAN - ▁ROSE - WARD - ▁ITSELF - ▁SOUL - ▁SUDDENLY - ▁AROUND - RED - ▁ANSWER - ICAL - ▁RA - ▁WIND - ▁FINE - ▁WON - ▁WHETHER - ▁KNOWN - BER - NG - ▁TA - ▁CAPTAIN - ▁EYE - ▁PERSON - ▁WOMEN - ▁SORT - ▁ASK - ▁BROTHER - ▁USED - ▁HELD - ▁BIG - ▁RETURNED - ▁STRANGE - ▁BU - ▁PER - ▁FREE - ▁EITHER - ▁WITHIN - ▁DOUBT - ▁YEAR - ▁CLEAR - ▁SIGHT - ▁GRA - ▁LOST - ▁KEPT - ▁F - PE - ▁BAR - ▁TOWN - ▁SLEEP - ARY - ▁HAIR - ▁FRIENDS - ▁DREAM - ▁FELLOW - PER - ▁DEEP - QUE - ▁BECAME - ▁REAL - ▁PAST - ▁MAKING - RING - ▁COMP - ▁ACT - ▁BAD - HO - STER - ▁YE - ▁MEANS - ▁RUN - MEN - ▁DAUGHTER - ▁SENSE - ▁CITY - ▁SOMETIMES - ▁TOWARDS - ▁ROAD - ▁SP - ▁LU - ▁READY - ▁FOOT - ▁COLD - ▁SA - ▁LETTER - ▁ELSE - ▁MAR - ▁STA - BE - ▁TRUTH - ▁LE - BO - ▁BUSINESS - CHE - ▁JOHN - ▁SUBJECT - ▁COURT - ▁IDEA - ILY - ▁RIVER - ATING - ▁FAMILY - HE - ▁DIDN - ▁GLAD - ▁SEVERAL - IAL - ▁UNDERSTAND - ▁SC - ▁POSSIBLE - ▁DIFFERENT - ▁RETURN - ▁ARMS - ▁LOW - ▁HOLD - ▁TALK - ▁RU - ▁WINDOW - ▁INTEREST - ▁SISTER - SON - ▁SH - ▁BLOOD - ▁SAYS - ▁CAP - ▁DI - ▁HUMAN - ▁CAUSE - NCE - ▁THANK - ▁LATE - GO - ▁CUT - ▁ACROSS - ▁STORY - NT - ▁COUNT - ▁ABLE - DY - LEY - ▁NUMBER - ▁STAND - ▁CHURCH - ▁THY - ▁SUPPOSE - LES - BLE - OP - ▁EFFECT - BY - ▁K - ▁NA - ▁SPOKE - ▁MET - ▁GREEN - ▁HUSBAND - ▁RESPECT - ▁PA - ▁FOLLOWED - ▁REMEMBER - ▁LONGER - ▁AGE - ▁TAKING - ▁LINE - ▁SEEM - ▁HAPPY - LAND - EM - ▁STAY - ▁PLAY - ▁COMMON - ▁GA - ▁BOOK - ▁TIMES - ▁OBJECT - ▁SEVEN - QUI - DO - UND - ▁FL - ▁PRETTY - ▁FAIR - WAY - ▁WOOD - ▁REACHED - ▁APPEARED - ▁SWEET - ▁FALL - BA - ▁PASS - ▁SIGN - ▁TREE - IONS - ▁GARDEN - ▁ILL - ▁ART - ▁REMAIN - ▁OPENED - ▁BRIGHT - ▁STREET - ▁TROUBLE - ▁PAIN - ▁CONTINUED - ▁SCHOOL - OUR - ▁CARRIED - ▁SAYING - HA - ▁CHANGE - ▁FOLLOW - ▁GOLD - ▁SW - ▁FEELING - ▁COMMAND - ▁BEAR - ▁CERTAINLY - ▁BLUE - ▁NE - CA - ▁WILD - ▁ACCOUNT - ▁OUGHT - UD - ▁T - ▁BREATH - ▁WANTED - ▁RI - ▁HEAVEN - ▁PURPOSE - ▁CHARACTER - ▁RICH - ▁PE - ▁DRESS - OS - FA - ▁TH - ▁ENGLISH - ▁CHANCE - ▁SHIP - ▁VIEW - ▁TOWARD - AK - ▁JOY - ▁JA - ▁HAR - ▁NEITHER - ▁FORCE - ▁UNCLE - DER - ▁PLAN - ▁PRINCESS - DI - ▁CHIEF - ▁HAT - ▁LIVED - ▁AB - ▁VISIT - ▁MOR - TEN - ▁WALL - UC - ▁MINE - ▁PLEASURE - ▁SMILE - ▁FRONT - ▁HU - ▁DEAL - OW - ▁FURTHER - GED - ▁TRIED - DA - VA - ▁NONE - ▁ENTERED - ▁QUEEN - ▁PAY - ▁EL - ▁EXCEPT - ▁SHA - ▁FORWARD - ▁EIGHT - ▁ADDED - ▁PUBLIC - ▁EIGHTEEN - ▁STAR - ▁HAPPENED - ▁LED - ▁WALKED - ▁ALTHOUGH - ▁LATER - ▁SPIRIT - ▁WALK - ▁BIT - ▁MEET - LIN - ▁FI - LT - ▁MOUTH - ▁WAIT - ▁HOURS - ▁LIVING - ▁YOURSELF - ▁FAST - ▁CHA - ▁HALL - ▁BEYOND - ▁BOAT - ▁SECRET - ENS - ▁CHAIR - RN - ▁RECEIVED - ▁CAT - RESS - ▁DESIRE - ▁GENTLEMAN - UGH - ▁LAID - EVER - ▁OCCASION - ▁WONDER - ▁GU - ▁PARTY - DEN - ▁FISH - ▁SEND - ▁NEARLY - ▁TRY - CON - ▁SEEMS - RS - ▁BELL - ▁BRA - ▁SILENCE - IG - ▁GUARD - ▁DIE - ▁DOING - ▁TU - ▁COR - ▁EARLY - ▁BANK - ▁FIGURE - IF - ▁ENGLAND - ▁MARY - ▁AFRAID - LER - ▁FO - ▁WATCH - ▁FA - ▁VA - ▁GRE - ▁AUNT - PED - ▁SERVICE - ▁JE - ▁PEN - ▁MINUTES - ▁PAN - ▁TREES - NED - ▁GLASS - ▁TONE - ▁PLEASE - ▁FORTH - ▁CROSS - ▁EXCLAIMED - ▁DREW - ▁EAT - ▁AH - ▁GRAVE - ▁CUR - PA - URE - CENT - ▁MILES - ▁SOFT - ▁AGO - ▁POSITION - ▁WARM - ▁LENGTH - ▁NECESSARY - ▁THINKING - ▁PICTURE - ▁PI - SHIP - IBLE - ▁HEAVY - ▁ATTENTION - ▁DOG - ABLY - ▁STANDING - ▁NATURAL - ▁APPEAR - OV - ▁CAUGHT - VO - ISM - ▁SPRING - ▁EXPERIENCE - ▁PAT - OT - ▁STOPPED - ▁REGARD - ▁HARDLY - ▁SELF - ▁STRENGTH - ▁GREW - ▁KNIGHT - ▁OPINION - ▁WIDE - ▁INSTEAD - ▁SOUTH - ▁TRANS - ▁CORNER - ▁LEARN - ▁ISLAND - ▁MI - ▁THIRD - ▁STE - ▁STRAIGHT - ▁TEA - ▁BOUND - ▁SEEING - ▁JU - ▁DINNER - ▁BEAUTY - ▁PEACE - AH - ▁REP - ▁SILENT - ▁CRE - ALLY - RIC - ▁STEP - ▁VER - ▁JO - GER - ▁SITTING - ▁THIRTY - ▁SAVE - ENED - ▁GLANCE - ▁REACH - ▁ACTION - ▁SAL - ▁SAD - ▁STONE - ITIES - ▁FRENCH - ▁STRUCK - ▁PAPER - ▁WHATEVER - ▁SUB - ▁DISTANCE - ▁WRONG - ▁KNOWLEDGE - ▁SAFE - ▁SNOW - ▁MUSIC - ▁FIFTY - RON - ▁ATTEMPT - ▁GOVERNMENT - TU - ▁CROWD - ▁BESIDES - ▁LOVED - ▁BOX - ▁DIRECTION - ▁TRAIN - ▁NORTH - ▁THICK - ▁GETTING - AV - ▁FLOOR - ▁COMPANY - ▁BLOW - ▁PLAIN - TRO - ▁BESIDE - ▁ROCK - ▁IMMEDIATELY - FI - ▁SHADOW - ▁SIT - ORS - ILE - ▁DRINK - ▁SPOT - ▁DANGER - ▁AL - ▁SAINT - ▁SLOWLY - ▁PALACE - IER - ▁RESULT - ▁PETER - ▁FOREST - ▁BELONG - ▁SU - ▁PAR - RIS - ▁TEARS - ▁APPEARANCE - ▁GATE - BU - ITION - ▁QUICKLY - ▁QUIET - ▁LONDON - ▁START - ▁BROWN - TRA - KIN - ▁CONSIDER - ▁BATTLE - ▁ANNE - ▁PIECE - ▁DIED - ▁SUCCESS - ▁LIPS - ▁FILLED - ▁FORGET - ▁POST - IFIED - ▁MARGARET - ▁FOOD - HAM - ▁PLEASANT - ▁FE - ▁EXPRESSION - ▁POCKET - ▁FRESH - ▁WEAR - TRI - ▁BROKEN - ▁LAUGHED - GING - ▁FOLLOWING - WN - IP - ▁TOUCH - ▁YOUTH - ATIVE - ▁LEG - ▁WEEK - ▁REMAINED - ▁EASY - NER - RK - ▁ENTER - ▁FIGHT - ▁PLACED - ▁TRAVEL - ▁SIMPLE - ▁GIRLS - ▁WAITING - ▁STOP - ▁WAVE - AU - ▁WISE - ▁CAMP - TURE - UB - ▁VE - ▁OFFICE - ▁GRAND - ▁FIT - ▁JUDGE - UP - MENTS - ▁QUICK - HI - ▁FLO - RIES - VAL - ▁COMFORT - ▁PARTICULAR - ▁STARTED - ▁SUIT - ▁NI - ▁PALE - ▁IMPOSSIBLE - ▁HOT - ▁CONVERSATION - ▁SCENE - ▁BOYS - ▁WIN - ▁BRE - ▁SOCIETY - ▁OUTSIDE - ▁WRITE - ▁EFFORT - ▁TALKING - ▁FORTUNE - ▁NINE - ▁WA - ▁SINGLE - ▁RULE - ▁PORT - ▁WINTER - ▁CAST - ▁CRA - ▁HAPPEN - ▁CRO - ▁SHUT - NING - ▁GUN - ▁NOBLE - ▁BEGIN - ▁PATH - ▁SKY - ▁WONDERFUL - ▁SUDDEN - ▁ARMY - ▁CHE - ▁WORTH - ▁MOUNTAIN - ▁MIN - AG - ▁FLU - ▁GRACE - ▁CHAPTER - ▁BELOW - ▁RING - ▁TURNING - ▁IRON - ▁TOP - ▁AFTERNOON - ORY - ▁EVIL - ▁TRUST - ▁BOW - ▁TRI - ▁SAIL - ▁CONTENT - ▁HORSES - ITE - ▁SILVER - AP - ▁LAD - ▁RUNNING - ▁HILL - ▁BEGINNING - ▁MAD - ▁HABIT - GRA - ▁CLOTHES - ▁MORROW - ▁CRY - ▁FASHION - ▁PRESENCE - ▁Z - FE - ▁ARRIVED - ▁QUARTER - ▁PERFECT - ▁WO - ▁TRA - ▁USUAL - ▁NECK - ▁MARRIED - ▁SEAT - ▁WI - ▁GAR - ▁SAND - ▁SHORE - ▁GIVING - NY - ▁PROBABLY - ▁MINUTE - ▁EXPECT - ▁DU - ▁SHOT - ▁INSTANT - ▁DEGREE - ▁COLOR - ▁WEST - RT - ▁MARCH - ▁BIRD - ▁SHOWED - ▁GREATER - ▁SERIOUS - ▁CARRY - ▁COVERED - ▁FORMER - ▁LOUD - ▁MOVED - ▁MASS - ▁SEEK - ▁CHO - GEN - ▁ROMAN - IB - ▁MOON - ▁BOARD - ▁STREAM - ▁EASILY - ▁WISHED - ▁SEARCH - ▁COULDN - ▁MONTHS - ▁SICK - LIE - ▁DUTY - ▁TWELVE - ▁FAINT - ▁STRANGER - ▁SURPRISE - ▁KILL - ▁LEAVING - ▁JOURNEY - ▁SCARCELY - ▁RAISED - ▁SPEAKING - ▁TERRIBLE - ▁TOM - ▁FIELD - ▁GAME - ▁QUA - ▁PROMISE - ▁LIE - ▁CONDITION - ▁TRO - ▁PERSONAL - ▁TALL - ▁STICK - ▁THREW - ▁MARRY - ▁VAN - ▁BURN - ▁ACCORDING - ▁RISE - ▁ATTACK - ▁SWORD - ▁GUESS - ▁THOUGHTS - ▁THIN - ▁THROW - ▁CALM - SIDE - ▁VILLAGE - ▁DEN - ▁ANXIOUS - ▁MER - GI - ▁EXPECTED - ▁BALL - ▁ESPECIALLY - ▁CHARGE - ▁MEASURE - ISE - ▁NICE - ▁TRYING - ▁ALLOW - ▁SHARP - ▁BREAD - ▁HONOUR - ▁HONOR - ▁ENTIRELY - ▁BILL - ▁BRI - ▁WRITTEN - ▁AR - ▁BROKE - ▁KILLED - ▁MARK - ▁VEN - ▁LADIES - ▁LEARNED - ▁FLOWERS - PLE - ▁FORTY - ▁OFFER - ▁HAPPINESS - ▁PRAY - ▁CLASS - ▁FER - ▁PRINCIPLE - GU - ▁BOOKS - ▁SHAPE - ▁SUMMER - ▁JACK - ▁DRAW - ▁GOLDEN - ▁DECIDED - ▁LEAD - ▁UNLESS - ▁HARM - ▁LISTEN - HER - ▁SHOOK - ▁INFLUENCE - ▁PERFECTLY - ▁MARRIAGE - ▁BROAD - ▁ESCAPE - ▁STATES - ▁MIDDLE - ▁PLANT - ▁MIL - ▁MOVEMENT - ▁NOISE - ▁ENEMY - ▁HISTORY - ▁BREAK - ROUS - ▁UNDERSTOOD - ▁LATTER - FER - ▁COMES - ▁MERELY - ▁SIMPLY - WI - ▁IMAGINE - ▁LOWER - ▁CONDUCT - ▁BORN - WA - ▁YARD - ▁KA - ▁CLOSED - ▁NOTE - GA - ▁STRA - RAN - ▁EXIST - EV - ▁SPEECH - ▁BITTER - JO - ▁MAKES - ▁GRASS - ▁REPLY - ▁CHANGED - ▁MON - ▁LYING - ▁DANCE - ▁FINALLY - ▁AMERICAN - ▁ENJOY - ▁CONTAIN - ▁MEANT - USE - ▁OBSERVED - THER - ▁LAUGH - ▁AFTERWARDS - ▁BEAT - ▁RACE - ▁EQUAL - ▁RAIN - PS - ▁STEPS - ▁BENEATH - ▁TAIL - ▁TASTE - IO - EY - ▁CHAR - ▁GE - GN - TIN - ▁GROW - ▁TE - IANS - ▁MOVE - ▁REPEATED - ▁DRIVE - TUR - ▁SI - CLOCK - ▁BRAVE - ▁MADAME - ▁LOT - ▁CASTLE - ▁HI - AND - ▁FUTURE - ▁RELATION - ▁SORRY - ▁HEALTH - ▁DICK - ▁R - ▁BUILDING - ▁EDGE - ▁BLESS - ▁SPITE - WE - ▁MIS - ▁PRISONER - ▁ALLOWED - ▁PH - ▁CATCH - MER - ETH - ▁COAT - ▁COMPLETE - ▁WOULDN - ▁CREATURE - ▁YELLOW - ▁IMPORTANT - ▁ADD - ▁PASSING - ▁DARKNESS - ▁CARRIAGE - ▁MILL - ▁FIFTEEN - NCY - ▁HUNG - ▁OB - ▁PLEASED - ▁SPREAD - ▁CURIOUS - ▁WORSE - ▁CIRCUMSTANCES - ▁GI - LAR - ▁CAL - ▁HY - ▁MERE - ▁JANE - ▁EAST - BI - ▁CUP - ▁BLIND - ▁PASSION - ▁DISCOVERED - ▁NOTICE - ▁REPORT - ▁SPACE - ▁PRESENTLY - ▁SORROW - ▁PACK - ▁DIN - CY - ▁DRY - ▁ANCIENT - ▁DRESSED - ▁COVER - ▁VO - ▁EXISTENCE - ▁EXACTLY - ▁BEAST - ▁PROPER - ▁DROPPED - ▁CLEAN - ▁COLOUR - ▁HOST - ▁CHAMBER - ▁FAITH - LET - ▁DETERMINED - ▁PRIEST - ▁STORM - ▁SKIN - ▁DARE - ▁PERSONS - ▁PICK - ▁NARROW - ▁SUPPORT - ▁PRIVATE - ▁SMILED - ▁COUSIN - ▁DRAWING - ▁ATTEND - ▁COOK - ▁PREVENT - ▁VARIOUS - ▁BLA - ▁FIXED - ▁WEAK - THE - ▁HOLE - ▁BOTTOM - ▁NOBODY - ADE - ▁LEGS - ITCH - ▁INDIVIDUAL - ▁EARS - LIKE - ▁ADVANTAGE - ▁FRANCE - ▁BON - ▁WINE - ▁LIVES - OD - ▁WALLS - ▁TIRED - ▁SHOP - ▁ANIMAL - ▁CRU - ▁WROTE - ▁ROYAL - ▁CONSIDERED - ▁MORAL - ▁COMPANION - ▁LOSE - ▁ISN - ▁BAG - ▁LAKE - ▁INTER - ▁COM - ▁LETTERS - ▁LUCK - ▁EAR - ▁GERMAN - ▁PET - ▁SAKE - ▁DROP - ▁PAID - ▁BREAKFAST - ▁LABOR - ▁DESERT - ▁DECLARED - ▁HUM - ▁STUDY - ▁INSTANCE - ONE - ▁SOMEWHAT - ▁CLOTH - ▁SPECIAL - ▁COLONEL - ▁SONG - ▁MAIN - ▁VALUE - ▁PROUD - ▁EXPRESS - ▁NATION - ▁HANDSOME - ▁CONFESS - ▁PU - ▁PASSAGE - ▁PERIOD - ▁CUSTOM - ▁HURT - ▁SHOULDER - ▁CHRIST - ZA - ▁RECEIVE - ▁DIFFICULT - ▁DEPEND - ▁MEETING - ▁CHI - ▁GEN - LIGHT - ▁BELIEVED - ▁SOCIAL - ▁DIFFICULTY - ▁GREATEST - ▁DRAWN - ▁GRANT - ▁BIRDS - ▁ANGRY - ▁HEAT - UFF - ▁DUE - ▁PLACES - ▁SIN - ▁COURAGE - ▁EVIDENTLY - ▁GENTLE - ▁CRUEL - ▁GEORGE - ▁GRI - ▁SERVANT - ▁U - ▁PURE - OOK - ▁KNOWS - ▁KNOWING - LF - ▁WRITING - ▁REMEMBERED - ▁CU - ▁HOLDING - ▁TENDER - ▁QUI - ▁BURST - ▁SURELY - IGN - ▁VALLEY - ▁FU - ▁BUTTER - ▁SPOKEN - ▁STORE - ▁DISC - ▁CHRISTIAN - ▁PARIS - ▁HENRY - ▁FINISHED - ▁PROVE - ▁FOOL - ▁SOLDIERS - ▁LANGUAGE - ▁INSIDE - ▁BAN - ▁FALLEN - ROW - ▁MAL - ▁BABY - ▁SITUATION - ▁WATCHED - ANS - ▁RUIN - ▁GENTLEMEN - ▁FRO - ▁FANCY - ▁ACCEPT - ▁SEASON - ▁OURSELVES - ▁SAN - ▁SPEED - IZED - ▁COOL - ▁SERVE - ▁VESSEL - ▁WILLIAM - ▁OBLIGED - ▁GROUP - FORM - ▁GOES - UOUS - ▁LEAVES - ▁PECULIAR - ▁NEWS - ▁VAIN - ▁EVERYBODY - ▁PIN - UG - ▁FORGOTTEN - ▁FRA - GAN - ▁CAREFULLY - ▁FLASH - UCH - ▁FUR - ▁MURDER - ▁DELIGHT - ▁WAITED - ▁RENDER - ▁PROPERTY - ▁NOTICED - ▁ROLL - ▁KNOCK - ▁EARNEST - KI - ▁HONEST - ▁PROMISED - ▁BAL - AW - ▁WALKING - ANG - ▁SQUARE - ▁QUIETLY - ▁CLOUD - WOOD - ▁FORMED - ▁HIGHER - ▁BUILT - ▁FATE - ▁TEACH - MY - ▁FALSE - ▁YORK - ▁DUST - ▁CLIMB - ▁FOND - ▁GROWN - ▁DESCEND - ▁RAG - ▁FRUIT - ▁GENERALLY - ▁OFFERED - ▁ER - ▁NURSE - POSE - ▁SPENT - ▁JOIN - ▁STATION - ▁MEANING - ▁SMOKE - HOOD - ▁ROUGH - JU - ▁LIKELY - ▁SURFACE - ▁KE - ▁MONTH - ▁POSSESSION - ▁TONGUE - ▁DUKE - ▁NOSE - ▁LAUGHING - ▁WEATHER - ▁WHISPERED - ▁SYSTEM - ▁LAWS - DDLE - ▁TOUCHED - ▁TRADE - LD - ▁SURPRISED - RIN - ▁ARCH - ▁WEALTH - FOR - ▁TEMPER - ▁FRANK - ▁GAL - ▁BARE - ▁OPPORTUNITY - ▁CLAIM - ▁ANIMALS - ▁REV - ▁COST - ▁WASH - ZE - ▁CORN - ▁OPPOSITE - ▁POLICE - ▁IDEAS - LON - ▁KEY - ▁READING - ▁COLLECT - CHED - ▁H - ▁CROWN - ▁TAR - ▁SWIFT - ▁SHOULDERS - ▁ICE - ▁GRAY - ▁SHARE - ▁PREPARED - ▁GRO - ▁UND - ▁TER - ▁EMPTY - CING - ▁SMILING - ▁AVOID - ▁DIFFERENCE - ▁EXPLAIN - ▁POUR - ▁ATTRACT - ▁OPENING - ▁WHEEL - ▁MATERIAL - ▁BREAST - ▁SUFFERING - ▁DISTINCT - ▁BOOT - ▁ROW - ▁FINGERS - HAN - ▁ALTOGETHER - ▁FAT - ▁PAPA - ▁BRAIN - ▁ASLEEP - ▁GREY - ▁SUM - ▁GAS - ▁WINDOWS - ▁ALIVE - ▁PROCEED - ▁FLOWER - ▁LEAP - ▁PUR - ▁PIECES - ▁ALTER - ▁MEMORY - IENT - ▁FILL - ▁CLO - ▁THROWN - ▁KINGDOM - ▁RODE - IUS - ▁MAID - ▁DIM - ▁BAND - ▁VIRTUE - ▁DISH - ▁GUEST - ▁LOSS - ▁CAUSED - ▁MOTION - ▁POT - ▁MILLION - ▁FAULT - ▁LOVELY - ▁HERO - PPING - ▁UNITED - ▁SPI - SOME - BRA - ▁MOUNTAINS - ▁NU - ▁SATISFIED - ▁DOLLARS - ▁LOVER - ▁CONCEAL - ▁VAST - ▁PULL - ▁HATH - ▁RUSH - ▁J - ▁DESPAIR - EX - ▁HEIGHT - ▁CE - ▁BENT - ▁PITY - ▁RISING - ATH - ▁PRIDE - ▁HURRY - KA - ▁SETTLED - ▁JUSTICE - ▁LIFTED - PEN - ▁SOLDIER - ▁FINDING - ▁REMARK - ▁REGULAR - ▁STRUGGLE - ▁MACHINE - ▁SING - ▁HURRIED - ▁SUFFICIENT - ▁REPRESENT - ▁DOUBLE - ▁ALARM - ▁SUPPER - ▁DREADFUL - ▁FORE - ATOR - ▁STOCK - ▁TIN - ▁EXAMPLE - ▁ROOF - ▁FLOW - ▁SUPPOSED - ▁PRESERV - ▁L - ▁LISTENED - OC - ▁STO - ▁SECURE - ▁FRIGHTENED - ▁DISTURB - ▁EMOTION - ▁SERVANTS - ▁YO - ▁BUY - ▁FORCED - ▁KITCHEN - ▁TERROR - ▁STAIRS - ▁SIXTY - KER - ▁ORDINARY - ▁DIRECTLY - ▁HEADS - ▁METHOD - ▁FORGIVE - ▁AWFUL - ▁REFLECT - ▁GREATLY - ▁TALKED - ▁RIDE - STONE - ▁FAVOUR - ▁WELCOME - ▁SEIZED - OU - ▁CONTROL - ▁ORDERED - ▁ANGEL - ▁USUALLY - ▁POET - ▁BOLD - LINE - ▁ADVENTURE - ▁WATCHING - ▁FOLK - ▁MISTRESS - IZE - ▁GROWING - ▁CAVE - ▁EVIDENCE - ▁FINGER - ▁SEVENTEEN - ▁MOVING - EOUS - ▁DOESN - ▁COW - ▁TYPE - ▁BOIL - ▁TALE - ▁DELIVER - ▁FARM - ▁MONSIEUR - ▁GATHERED - ▁FEELINGS - ▁RATE - ▁REMARKED - ▁PUTTING - ▁MAT - ▁CONTRARY - ▁CRIME - ▁PLA - ▁COL - ▁NEARER - TES - ▁CIVIL - ▁SHAME - ▁LOOSE - ▁DISCOVER - ▁FLAT - ▁TWICE - ▁FAIL - VIS - ▁UNC - EA - ▁EUROPE - ▁PATIENT - ▁UNTO - ▁SUFFER - ▁PAIR - ▁TREASURE - OSE - ▁EAGER - ▁FLY - ▁N - ▁VAL - ▁DAN - ▁SALT - ▁BORE - BBE - ▁ARTHUR - ▁AFFAIRS - ▁SLOW - ▁CONSIST - ▁DEVIL - LAN - ▁AFFECTION - ▁ENGAGED - ▁KISS - ▁YA - ▁OFFICER - IFICATION - ▁LAMP - ▁PARTS - HEN - ▁MILK - ▁PROCESS - ▁GIFT - ▁PULLED - ▁HID - ▁RAY - ▁EXCELLENT - ▁IMPRESSION - ▁AUTHORITY - ▁PROVED - ▁TELLING - TTE - ▁TOWER - ▁CONSEQUENCE - ▁FAVOR - ▁FLEW - ▁CHARLES - ISTS - ▁ADDRESS - ▁FAMILIAR - ▁LIMIT - ▁CONFIDENCE - ▁RARE - ▁WEEKS - ▁WOODS - ▁INTENTION - ▁DIRECT - ▁PERFORM - ▁SOLEMN - ▁DISTANT - ▁IMAGE - ▁PRESIDENT - ▁FIRM - ▁INDIAN - ▁RANK - ▁LIKED - ▁AGREE - ▁HOUSES - ▁WIL - ▁MATTERS - ▁PRISON - ▁MODE - ▁MAJOR - ▁WORKING - ▁SLIP - ▁WEIGHT - ▁AWARE - ▁BUSY - ▁LOOKS - ▁WOUND - ▁THOR - ▁BATH - ▁EXERCISE - ▁SIMILAR - ▁WORE - ▁AMOUNT - ▁QUESTIONS - ▁VIOLENT - ▁EXCUSE - ▁ASIDE - ▁TUR - ▁DULL - OF - ▁EMPEROR - ▁NEVERTHELESS - ▁SHOUT - ▁EXPLAINED - ▁SIZE - ▁ACCOMPLISH - FORD - CAN - ▁MISTAKE - ▁INSTANTLY - ▁SMOOTH - ▁STRIKE - ▁BOB - ISED - ▁HORROR - ▁SCIENCE - ▁PROTEST - ▁MANAGE - ▁OBEY - ▁NECESSITY - ▁SPLENDID - ▁PRESS - ▁INTERESTING - ▁RELIGION - ▁UNKNOWN - ▁FIERCE - ▁DISAPPEARED - ▁HOLY - ▁HATE - ▁PLAYED - ▁LIN - ▁NATURALLY - ▁DROVE - ▁LOUIS - TIES - ▁BRAND - INESS - RIE - ▁SHOOT - ▁CONSENT - ▁SEATED - ▁LINES - GUE - ▁AGREED - ▁CIRCLE - ▁STIR - ▁STREETS - ▁TASK - ▁RID - ▁PRODUCED - ▁ACCIDENT - ▁WITNESS - ▁LIBERTY - ▁DETAIL - ▁MINISTER - ▁POWERFUL - ▁SAVAGE - ▁SIXTEEN - ▁PRETEND - ▁COAST - ▁SQU - ▁UTTER - ▁NAMED - ▁CLEVER - ▁ADMIT - ▁COUPLE - ▁WICKED - ▁MESSAGE - ▁TEMPLE - ▁STONES - ▁YESTERDAY - ▁HILLS - DAY - ▁SLIGHT - ▁DIAMOND - ▁POSSIBLY - ▁AFFAIR - ▁ORIGINAL - ▁HEARING - ▁WORTHY - ▁SELL - NEY - ICK - ▁COTTAGE - ▁SACRIFICE - ▁PROGRESS - ▁SHOCK - ▁DESIGN - ▁SOUGHT - ▁PIT - ▁SUNDAY - ▁OTHERWISE - ▁CABIN - ▁PRAYER - ▁DWELL - ▁GAIN - ▁BRIDGE - ▁PARTICULARLY - ▁YIELD - ▁TREAT - RIGHT - ▁OAK - ▁ROPE - WIN - ▁ORDERS - ▁SUSPECT - ▁EDWARD - AB - ▁ELEVEN - ▁TEETH - ▁OCCURRED - DDING - ▁AMERICA - ▁FALLING - ▁LION - ▁DEPART - ▁KEEPING - ▁DEMAND - ▁PAUSED - ▁CEASED - INA - ▁FUN - ▁CHEER - ▁PARDON - ▁NATIVE - LUS - LOW - ▁DOGS - ▁REQUIRED - ILITY - ▁ELECT - ▁ENTERTAIN - ITUDE - ▁HUGE - ▁CARRYING - ▁BLU - ▁INSIST - ▁SATISFACTION - ▁HUNT - ▁COUNTENANCE - ▁UPPER - ▁MAIDEN - ▁FAILED - ▁JAMES - ▁FOREIGN - ▁GATHER - ▁TEST - BOARD - ▁TERMS - ▁SILK - ▁BEG - ▁BROTHERS - ▁PAGE - ▁KNEES - ▁SHOWN - ▁PROFESSOR - ▁MIGHTY - ▁DEFI - ▁CHARM - ▁REQUIRE - ▁LOG - MORE - ▁PROOF - ▁POSSESSED - ▁SOFTLY - ▁UNFORTUNATE - ▁PRICE - ▁SEVERE - ▁SINGING - ▁STAGE - ▁FREEDOM - ▁SHOUTED - ▁FARTHER - ▁MAJESTY - ▁PREVIOUS - ▁GUIDE - ▁MATCH - ▁CHEST - ▁INTENDED - ▁BI - ▁EXCITEMENT - ▁OFFICERS - ▁SUR - ▁SHAKE - ▁SENTIMENT - ▁GENTLY - ▁SUCCEEDED - ▁MENTION - ▁LOCK - ▁ACQUAINTANCE - ▁IMAGINATION - ▁PHYSICAL - ▁LEADING - ▁SLAVE - ▁CART - ▁POINTED - ▁STEAM - ▁SHADE - ▁PIPE - ▁BASE - ▁INVENT - ▁ALAS - ▁WORKED - ▁REGRET - ▁BUR - ▁FAITHFUL - ▁MENTIONED - ▁RECORD - ▁COMPLAIN - ▁SUPERIOR - ▁BAY - ▁PAL - EMENT - UE - ▁SEVENTY - ▁HOTEL - ▁SHEEP - ▁MEAL - ▁ADVICE - ▁HIDDEN - ▁DEMANDED - ▁CONSCIOUS - ▁BROW - ▁POSSESS - ▁FOURTH - ▁EVENTS - ▁FRI - ▁PRAISE - ▁ADVANCED - ▁RESOLVED - ▁STUFF - ▁CHEERFUL - ▁BIRTH - ▁GRIEF - ▁AFFORD - ▁FAIRY - ▁WAKE - ▁SIDES - ▁SUBSTANCE - ▁ARTICLE - ▁LEVEL - ▁MIST - ▁JOINED - ▁PRACTICAL - ▁CLEARLY - ▁TRACE - ▁AWAKE - ▁OBSERVE - ▁BASKET - ▁LACK - VILLE - ▁SPIRITS - ▁EXCITED - ▁ABANDON - ▁SHINING - ▁FULLY - ▁CALLING - ▁CONSIDERABLE - ▁SPRANG - ▁MILE - ▁DOZEN - ▁PEA - ▁DANGEROUS - ▁WIT - ▁JEW - ▁POUNDS - ▁FOX - ▁INFORMATION - ▁LIES - ▁DECK - NNY - ▁PAUL - ▁STARS - ▁ANGER - ▁SETTLE - ▁WILLING - ▁ADAM - ▁FACES - ▁SMITH - ▁IMPORTANCE - ▁STRAIN - WAR - ▁SAM - ▁FEATHER - ▁SERVED - ▁AUTHOR - ▁PERCEIVED - ▁FLAME - ▁DIVINE - ▁TRAIL - ▁ANYBODY - ▁SIGH - ▁DELICATE - KY - ▁FOLD - ▁HAVEN - ▁DESIRED - ▁CURIOSITY - ▁PRACTICE - ▁CONSIDERATION - ▁ABSOLUTELY - ▁CITIZEN - ▁BOTTLE - ▁INTERESTED - ▁MEAT - ▁OCCUPIED - ▁CHOOSE - ▁THROAT - ETTE - ▁CANDLE - ▁DAWN - ▁PROTECT - ▁SENTENCE - IED - ▁ROCKS - ▁PORTION - ▁APPARENTLY - ▁PRESENTED - ▁TIGHT - ▁ACTUALLY - ▁DYING - ▁HAM - ▁DAILY - ▁SUFFERED - ▁POLITICAL - ▁BODIES - ▁MODERN - ▁COMPLETELY - ▁SOONER - TAN - ▁PROP - ▁ADVANCE - ▁REFUSED - ▁FARMER - ▁POLITE - ▁THUNDER - ▁BRIEF - ▁ELSIE - ▁SAILOR - ▁SUGGESTED - ▁PLATE - ▁AID - ▁FLESH - ▁WEEP - ▁BUCK - ▁ANTI - ▁OCEAN - ▁SPEND - WELL - ▁ODD - ▁GOVERNOR - ▁ENTRANCE - ▁SUSPICION - ▁STEPPED - ▁RAPIDLY - ▁CHECK - ▁HIDE - ▁FLIGHT - ▁CLUB - ▁ENTIRE - ▁INDIANS - ASH - ▁CAPITAL - ▁MAMMA - HAR - ▁CORRECT - ▁CRACK - ▁SENSATION - ▁WORST - ▁PACE - ▁MIDST - ▁AUGUST - ▁PROPORTION - ▁INNOCENT - LINESS - ▁REGARDED - ▁DRIVEN - ORD - ▁HASTE - ▁EDUCATION - ▁EMPLOY - ▁TRULY - ▁INSTRUMENT - ▁MAG - ▁FRAME - ▁FOOLISH - ▁TAUGHT - ▁HANG - ▁ARGUMENT - ▁NINETEEN - ▁ELDER - ▁NAY - ▁NEEDED - ▁NEIGHBOR - ▁INSTRUCT - ▁PAPERS - ▁REWARD - ▁EQUALLY - ▁FIELDS - ▁DIG - HIN - ▁CONDITIONS - JA - ▁SPAR - ▁REQUEST - ▁WORN - ▁REMARKABLE - ▁LOAD - ▁WORSHIP - ▁PARK - ▁KI - ▁INTERRUPTED - ▁SKILL - ▁TERM - LAC - ▁CRITIC - ▁DISTRESS - ▁BELIEF - ▁STERN - IGHT - ▁TRACK - ▁HUNTING - ▁JEWEL - ▁GRADUALLY - ▁GLOW - ▁RUSHED - ▁MENTAL - ▁VISITOR - ▁PICKED - ▁BEHOLD - ▁EXPRESSED - ▁RUB - ▁SKI - ARTAGNAN - ▁MOREOVER - ▁OPERATION - ▁CAREFUL - ▁KEEN - ▁ASSERT - ▁WANDER - ▁ENEMIES - ▁MYSTERIOUS - ▁DEPTH - ▁PREFER - ▁CROSSED - ▁CHARMING - ▁DREAD - ▁FLOUR - ▁ROBIN - ▁TRE - ▁RELIEF - ▁INQUIRED - ▁APPLE - ▁HENCE - ▁WINGS - ▁CHOICE - ▁JUD - OO - ▁SPECIES - ▁DELIGHTED - IUM - ▁RAPID - ▁APPEAL - ▁FAMOUS - ▁USEFUL - ▁HELEN - ▁NEWSPAPER - ▁PLENTY - ▁BEARING - ▁NERVOUS - ▁PARA - ▁URGE - ▁ROAR - ▁WOUNDED - ▁CHAIN - ▁PRODUCE - ▁REFLECTION - ▁MERCHANT - ▁QUARREL - ▁GLORY - ▁BEGUN - ▁BARON - CUS - ▁QUEER - ▁MIX - ▁GAZE - ▁WHISPER - ▁BURIED - ▁DIV - ▁CARD - ▁FREQUENTLY - ▁TIP - ▁KNEE - ▁REGION - ▁ROOT - ▁LEST - ▁JEALOUS - CTOR - ▁SAVED - ▁ASKING - ▁TRIP - QUA - ▁UNION - HY - ▁COMPANIONS - ▁SHIPS - ▁HALE - ▁APPROACHED - ▁HARRY - ▁DRUNK - ▁ARRIVAL - ▁SLEPT - ▁FURNISH - HEAD - ▁PIG - ▁ABSENCE - ▁PHIL - ▁HEAP - ▁SHOES - ▁CONSCIOUSNESS - ▁KINDLY - ▁EVIDENT - ▁SCAR - ▁DETERMIN - ▁GRASP - ▁STEAL - ▁OWE - ▁KNIFE - ▁PRECIOUS - ▁ELEMENT - ▁PROCEEDED - ▁FEVER - ▁LEADER - ▁RISK - ▁EASE - ▁GRIM - ▁MOUNT - ▁MEANWHILE - ▁CENTURY - OON - ▁JUDGMENT - ▁AROSE - ▁VISION - ▁SPARE - ▁EXTREME - ▁CONSTANT - ▁OBSERVATION - ▁THRUST - ▁DELAY - ▁CENT - ▁INCLUD - ▁LIFT - ▁ADMIRE - ▁ISSUE - ▁FRIENDSHIP - ▁LESSON - ▁PRINCIPAL - ▁MOURN - ▁ACCEPTED - ▁BURNING - ▁CAPABLE - ▁EXTRAORDINARY - ▁SANG - ▁REMOVED - ▁HOPED - ▁HORN - ▁ALICE - ▁MUD - ▁APARTMENT - ▁FIGHTING - ▁BLAME - ▁TREMBLING - ▁SOMEBODY - ▁ANYONE - ▁BRIDE - ▁READER - ▁ROB - ▁EVERYWHERE - ▁LABOUR - ▁RECALL - ▁BULL - ▁HIT - ▁COUNCIL - ▁POPULAR - ▁CHAP - ▁TRIAL - ▁DUN - ▁WISHES - ▁BRILLIANT - ▁ASSURED - ▁FORGOT - ▁CONTINUE - ▁ACKNOWLEDG - ▁RETREAT - ▁INCREASED - ▁CONTEMPT - ▁GRANDFATHER - ▁SYMPATHY - ▁GHOST - ▁STRETCHED - ▁CREATURES - ▁CAB - ▁HIND - ▁PLAYING - ▁MISERABLE - ▁MEMBERS - ▁KINDNESS - ▁HIGHEST - ▁PRIM - ▁KISSED - ▁DESERVE - ▁HUT - ▁BEGGED - ▁EIGHTY - ▁CLOSELY - ▁WONDERED - ▁MILITARY - ▁REMIND - ▁ACCORDINGLY - ▁LARGER - ▁MAINTAIN - ▁ENGINE - ▁MOTIVE - ▁DESTROY - ▁STRIP - ▁HANS - ▁AHEAD - ▁INFINITE - ▁PROMPT - ▁INFORMED - TTLE - ▁PEER - ▁PRESSED - ▁TRAP - ▁SOMEWHERE - ▁BOUGHT - ▁VISIBLE - ▁ASHAMED - ▁TEAR - ▁NEIGHBOUR - ▁CONSTITUTION - ▁INTELLIGENCE - ▁PROFESSION - ▁HUNGRY - RIDGE - ▁SMELL - ▁STORIES - ▁LISTENING - ▁APPROACH - ▁STRING - ▁EXPLANATION - ▁IMMENSE - ▁RELIGIOUS - ▁THROUGHOUT - ▁HOLLOW - ▁AWAIT - ▁FLYING - ▁SCREAM - ▁ACTIVE - ▁RUM - ▁PRODUCT - ▁UNHAPPY - ▁VAGUE - ARIES - ▁ELIZABETH - ▁STUPID - ▁DIGNITY - ▁ISABEL - GAR - ▁BRO - ▁PITCH - ▁COMRADE - ▁STIFF - ▁RECKON - ▁SOLD - ▁SPARK - ▁STRO - ▁CRYING - ▁MAGIC - ▁REPEAT - PORT - ▁MARKED - ▁COMFORTABLE - ▁PROJECT - ▁BECOMING - ▁PARENTS - ▁SHELTER - ▁STOLE - ▁HINT - ▁NEST - ▁TRICK - ▁THOROUGHLY - ▁HOSPITAL - ▁WEAPON - ▁ROME - ▁STYLE - ▁ADMITTED - ▁SAFETY - FIELD - ▁UNDERSTANDING - ▁TREMBLE - ▁PRINT - ▁SLAVES - ▁WEARY - ▁ARTIST - ▁CREDIT - BURG - ▁CONCLUSION - ▁SELDOM - ▁UNUSUAL - ▁CLOUDS - ▁UNABLE - ▁GAY - ▁HANGING - ▁SCR - ▁BOWED - ▁DAVID - ▁VOL - ▁PUSHED - ▁ESCAPED - MOND - ▁WARN - ▁BETRAY - ▁EGGS - ▁PLAINLY - ▁EXHIBIT - ▁DISPLAY - ▁MEMBER - ▁GRIN - ▁PROSPECT - ▁BRUSH - ▁BID - ▁SUCCESSFUL - ▁EXTENT - ▁PERSUADE - ▁MID - ▁MOOD - ▁ARRANGED - ▁UNIVERSAL - ▁JIM - ▁SIGNAL - ▁WHILST - ▁PHILIP - ▁WOLF - RATE - ▁EAGERLY - ▁BILLY - ▁RETURNING - ▁CONSCIENCE - ▁FORTUNATE - ▁FEMALE - ▁GLEAM - ▁HASTILY - ▁PROVIDED - ▁OBTAIN - ▁INSTINCT - ▁CONCERNED - ▁CONCERNING - ▁SOMEHOW - ▁PINK - ▁RAGE - ▁ACCUSTOMED - ▁UNCONSCIOUS - ▁ADVISE - ▁BRANCHES - ▁TINY - ▁REFUSE - ▁BISHOP - ▁SUPPLY - ▁PEASANT - ▁LAWYER - ▁WASTE - ▁CONNECTION - ▁DEVELOP - ▁CORRESPOND - ▁PLUM - ▁NODDED - ▁SLIPPED - ▁EU - ▁CONSTANTLY - CUM - MMED - ▁FAIRLY - HOUSE - ▁KIT - ▁RANG - ▁FEATURES - ▁PAUSE - ▁PAINFUL - ▁JOE - ▁WHENCE - ▁LAUGHTER - ▁COACH - ▁CHRISTMAS - ▁EATING - ▁WHOLLY - ▁APART - ▁SUPER - ▁REVOLUTION - ▁LONELY - ▁CHEEKS - ▁THRONE - ▁CREW - ▁ATTAIN - ▁ESTABLISHED - TIME - ▁DASH - ▁FRIENDLY - ▁OPERA - ▁EARL - ▁EXHAUST - ▁CLIFF - ▁REVEAL - ▁ADOPT - ▁CENTRE - ▁MERRY - ▁SYLVIA - ▁IDEAL - ▁MISFORTUNE - ▁FEAST - ▁ARAB - ▁NUT - ▁FETCH - ▁FOUGHT - ▁PILE - ▁SETTING - ▁SOURCE - ▁PERSIST - ▁MERCY - ▁BARK - ▁LUC - ▁DEEPLY - ▁COMPARE - ▁ATTITUDE - ▁ENDURE - ▁DELIGHTFUL - ▁BEARD - ▁PATIENCE - ▁LOCAL - ▁UTTERED - ▁VICTORY - ▁TREATED - ▁SEPARATE - ▁WAG - ▁DRAGG - ▁TITLE - ▁TROOPS - ▁TRIUMPH - ▁REAR - ▁GAINED - ▁SINK - ▁DEFEND - ▁TIED - ▁FLED - ▁DARED - ▁INCREASE - ▁POND - ▁CONQUER - ▁FOREHEAD - ▁FAN - ▁ANXIETY - ▁ENCOUNTER - ▁SEX - ▁HALT - ▁SANK - ▁CHEEK - ▁HUMBLE - ▁WRITER - ▁EMPLOYED - ▁DISTINGUISHED - ▁RAISE - ▁WHIP - ▁GIANT - ▁RANGE - ▁OBTAINED - ▁FLAG - ▁MAC - ▁JUMPED - ▁DISCOVERY - ▁NATIONAL - ▁COMMISSION - ▁POSITIVE - ▁LOVING - ▁EXACT - ▁MURMURED - ▁GAZED - ▁REFER - ▁COLLEGE - ▁ENCOURAGE - ▁NOVEL - ▁CLOCK - ▁MORTAL - ▁ROLLED - ▁RAT - IZING - ▁GUILTY - ▁VICTOR - WORTH - ▁PRA - ▁APPROACHING - ▁RELATIVE - ▁ESTATE - ▁UGLY - ▁METAL - ▁ROBERT - ▁TENT - ▁ADMIRATION - ▁FOURTEEN - ▁BARBAR - ▁WITCH - ELLA - ▁CAKE - ▁SHONE - ▁MANAGED - ▁VOLUME - ▁GREEK - ▁DANCING - ▁WRETCHED - ▁CONDEMN - ▁MAGNIFICENT - ▁CONSULT - J - ▁ORGAN - ▁FLEET - ▁ARRANGEMENT - ▁INCIDENT - ▁MISERY - ▁ARROW - ▁STROKE - ▁ASSIST - ▁BUILD - ▁SUCCEED - ▁DESPERATE - ▁WIDOW - UDE - ▁MARKET - ▁WISDOM - ▁PRECISE - ▁CURRENT - ▁SPOIL - ▁BADE - ▁WOODEN - ▁RESIST - ▁OBVIOUS - ▁SENSIBLE - FALL - ▁ADDRESSED - ▁GIL - ▁COUNSEL - ▁PURCHASE - ▁SELECT - ▁USELESS - ▁STARED - ▁ARREST - ▁POISON - ▁FIN - ▁SWALLOW - ▁BLOCK - ▁SLID - ▁NINETY - ▁SPORT - ▁PROVIDE - ▁ANNA - ▁LAMB - ▁INTERVAL - ▁JUMP - ▁DESCRIBED - ▁STRIKING - ▁PROVISION - ▁PROPOSED - ▁MELANCHOLY - ▁WARRIOR - ▁SUGGEST - ▁DEPARTURE - ▁BURDEN - ▁LIMB - ▁TROUBLED - ▁MEADOW - ▁SACRED - ▁SOLID - ▁TRU - ▁LUCY - ▁RECOVER - ▁ENERGY - ▁POWDER - ▁RESUMED - ▁INTENSE - ▁BRITISH - ▁STRAW - ▁AGREEABLE - ▁EVERYONE - ▁CONCERN - ▁VOYAGE - ▁SOUTHERN - ▁BOSOM - ▁UTTERLY - ▁FEED - ▁ESSENTIAL - ▁CONFINE - ▁HOUSEHOLD - ▁EXTREMELY - ▁WONDERING - ▁LIST - ▁PINE - PHA - ▁EXPERIMENT - ▁JOSEPH - ▁MYSTERY - ▁RESTORE - ▁BLUSH - FOLD - ▁CHOSEN - ▁INTELLECT - ▁CURTAIN - OLOGY - ▁MOUNTED - ▁LAP - ▁EPI - ▁PUNISH - ▁WEDDING - ▁RECOGNIZED - ▁DRIFT - ▁PREPARATION - ▁RESOLUTION - ▁OPPRESS - ▁FIX - ▁VICTIM - OGRAPH - ▁SUMMON - ▁JULIA - ▁FLOOD - ▁WAL - ULATION - ▁SLIGHTLY - ▁LODGE - ▁WIRE - ▁CONFUSION - ▁UNEXPECTED - ▁CONCEIVE - ▁PRIZE - ▁JESUS - ▁ADDITION - ▁RUDE - ▁FATAL - ▁CARELESS - ▁PATCH - ▁KO - ▁CATHERINE - ▁PARLIAMENT - ▁PROFOUND - ▁ALOUD - ▁RELIEVE - ▁PUSH - ABILITY - ▁ACCOMPANIED - ▁SOVEREIGN - ▁SINGULAR - ▁ECHO - ▁COMPOSED - ▁SHAKING - ATORY - ▁ASSISTANCE - ▁TEACHER - ▁HORRIBLE - ▁STRICT - ▁VERSE - ▁PUNISHMENT - ▁GOWN - ▁MISTAKEN - ▁VARI - ▁SWEPT - ▁GESTURE - ▁BUSH - ▁STEEL - ▁AFFECTED - ▁DIRECTED - ▁SURROUNDED - ▁ABSURD - ▁SUGAR - ▁SCRAP - ▁IMMEDIATE - ▁SADDLE - ▁TY - ▁ARISE - ▁SIGHED - ▁EXCHANGE - ▁IMPATIENT - ▁SNAP - ▁EMBRACE - ▁DISEASE - ▁PROFIT - ▁RIDING - ▁RECOVERED - ▁GOVERN - ▁STRETCH - ▁CONVINCED - ▁LEANING - ▁DOMESTIC - ▁COMPLEX - ▁MANIFEST - ▁INDULGE - ▁GENIUS - ▁AGENT - ▁VEIL - ▁DESCRIPTION - ▁INCLINED - ▁DECEIVE - ▁DARLING - ▁REIGN - HU - ▁ENORMOUS - ▁RESTRAIN - ▁DUTIES - BURY - TTERED - ▁POLE - ▁ENABLE - ▁EXCEPTION - ▁INTIMATE - ▁COUNTESS - ▁TRIBE - ▁HANDKERCHIEF - ▁MIDNIGHT - ▁PROBLEM - ▁TRAMP - ▁OIL - CAST - ▁CRUSH - ▁DISCUSS - ▁RAM - ▁TROT - ▁UNRE - ▁WHIRL - ▁LOCKED - ▁HORIZON - ▁OFFICIAL - ▁SCHEME - ▁DROWN - ▁PIERRE - ▁PERMITTED - ▁CONNECTED - ▁ASSURE - ▁COCK - ▁UTMOST - ▁DEVOTED - ▁RELI - ▁SUFFICIENTLY - ▁INTELLECTUAL - ▁CARPET - ▁OBJECTION - ▁AFTERWARD - ▁REALITY - ▁NEGRO - ▁RETAIN - ▁ASCEND - ▁CEASE - ▁KATE - ▁MARVEL - KO - ▁BOND - MOST - ▁COAL - GATE - ▁IGNORANT - ▁BREAKING - ▁TWIN - ▁ASTONISHMENT - ▁COFFEE - ▁JAR - ▁CITIES - ▁ORIGIN - ▁EXECUT - ▁FINAL - ▁INHABITANTS - ▁STABLE - ▁CHIN - ▁PARTIES - ▁PLUNGE - ▁GENEROUS - ▁DESCRIBE - ▁ANNOUNCED - ▁MERIT - ▁REVERE - ▁ERE - ACIOUS - ZI - ▁DISAPPOINT - ▁SUGGESTION - ▁DOUBTLESS - ▁TRUNK - ▁STAMP - ▁JOB - ▁APPOINTED - ▁DIVIDED - ▁ACQUAINTED - CHI - ▁ABSOLUTE - ▁FEARFUL - ▁PRIVILEGE - ▁CRAFT - ▁STEEP - ▁HUNTER - ▁FORBID - ▁MODEST - ▁ENDEAVOUR - ▁SWEEP - ▁BEHELD - ▁ABSORB - ▁CONSTRUCT - ▁EMPIRE - ▁EXPEDITION - ▁ERECT - ▁OFFEND - ▁INTEND - ▁PERMIT - ▁DESTROYED - ▁CONTRACT - ▁THIRST - ▁WAGON - ▁EVA - ▁GLOOM - ▁ATMOSPHERE - ▁RESERVE - ▁VOTE - ▁GER - ▁NONSENSE - ▁PREVAIL - ▁QUALITY - ▁CLASP - ▁CONCLUDED - ▁RAP - ▁KATY - ▁ETERNAL - ▁MUTTERED - ▁NEGLECT - ▁SQUIRE - ▁CREEP - LOCK - ▁ELECTRIC - ▁HAY - ▁EXPENSE - ▁SCORN - ▁RETIRED - ▁STOUT - ▁MURMUR - ▁SHARPLY - ▁DISTRICT - ▁LEAF - ▁FAILURE - WICK - ▁JEAN - ▁NUMEROUS - ▁INFANT - ▁REALIZED - ▁TRAVELLER - ▁HUNGER - ▁JUNE - ▁MUN - ▁RECOMMEND - ▁CREP - ZZLE - ▁RICHARD - WORK - ▁MONTE - ▁PREACH - ▁PALM - AVI - ▁ANYWHERE - ▁DISPOSITION - ▁MIRROR - ▁VENTURE - ▁POUND - ▁CIGAR - ▁INVITED - ▁BENCH - ▁PROTECTION - ▁BENEFIT - ▁THOMAS - ▁CLERK - ▁REPROACH - ▁UNIFORM - ▁GENERATION - ▁SEAL - ▁COMPASS - ▁WARNING - ▁EXTENDED - ▁DIFFICULTIES - ▁MAYBE - ▁GROAN - ▁AFFECT - ▁COMB - ▁EARN - ▁WESTERN - ▁IDLE - ▁SCORE - ▁TAP - ▁ASTONISHED - ▁INTRODUCED - ▁LEISURE - ▁LIEUTENANT - ▁VIOLENCE - ▁FIRMLY - ▁MONSTER - ▁UR - ▁PROPERLY - ▁TWIST - ▁PIRATE - ▁ROBBER - ▁BATTER - ▁WEPT - ▁LEANED - ▁FOG - ▁ORNAMENT - ▁ANDREW - ▁BUSHES - ▁REPUBLIC - ▁CONFIDENT - ▁LEAN - ▁DART - ▁STOOP - ▁CURL - ▁COUNTER - ▁NORTHERN - ▁PEARL - ▁NEAREST - ▁FRANCIS - ▁WANDERING - ▁FREQUENT - ▁STARTLED - ▁STATEMENT - ▁OCCUR - ▁BLOOM - ▁NERVE - ▁INSPECT - ▁INDUCE - ▁FLATTER - ▁DATE - ▁AMBITION - ▁SLOPE - ▁MALE - ▁MADAM - ▁MONK - ▁RENT - ▁CONFIRM - ▁INVESTIGAT - ▁RABBIT - ▁REGIMENT - ▁SUBMIT - ▁SPELL - ▁FURIOUS - ▁RAIL - ▁BESTOW - ▁RALPH - ▁SCATTERED - ▁COMPELLED - ▁THREAD - ▁CHILL - ▁DENY - ▁PRONOUNC - ▁MANKIND - ▁CATTLE - ▁EXECUTION - ▁REBEL - ▁SUPREME - ▁VALUABLE - ▁LIKEWISE - ▁CONVEY - ▁TIDE - ▁GLOOMY - ▁COIN - ▁ACTUAL - ▁TAX - ▁PROVINCE - ▁GRATEFUL - ▁SPIRITUAL - ▁VANISHED - ▁DIANA - ▁HAUNT - ▁DRAGON - ▁CRAWL - ▁CHINA - ▁GRATITUDE - ▁NEAT - ▁FINISH - ▁INTENT - ▁FRIGHT - ▁EMBARRASS - ▁THIRTEEN - ▁RUTH - ▁SLIGHTEST - ▁DEVELOPMENT - ▁INTERVIEW - ▁SPECTACLE - ▁BROOK - VIE - ▁WEAKNESS - ▁AUDIENCE - ▁CONSEQUENTLY - ▁ABROAD - ▁ASPECT - ▁PAINTED - ▁RELEASE - ▁INSULT - ▁SOOTH - ▁DISAPPOINTMENT - ▁EMERG - ▁BRIG - ▁ESTEEM - ▁INVITATION - ▁PASSENGER - ▁PUBLISH - ▁PIANO - ▁IRISH - ▁DESK - ▁BEATEN - ▁FIFTH - ▁IMPULSE - ▁SWEAR - ▁EATEN - ▁PURPLE - ▁COMMITTED - ▁COUNTRIES - ▁PERCEIVE - ISON - ▁CELEBRAT - ▁GRANDMOTHER - ▁SHUDDER - ▁SUNSHINE - ▁SPANISH - ▁HITHERTO - ▁MARILLA - ▁SNAKE - ▁MOCK - ▁INTERFERE - ▁WALTER - ▁AMID - ▁MARBLE - ▁MISSION - TERIOR - ▁DRIVING - ▁FURNITURE - ▁STEADY - ▁CIRCUMSTANCE - ▁INTERPRET - ▁ENCHANT - ▁ERROR - ▁CONVICTION - ▁HELPLESS - ▁MEDICINE - ▁QUALITIES - ▁ITALIAN - ▁HASTENED - ▁OCCASIONALLY - ▁PURSUED - ▁HESITATED - ▁INDEPENDENT - ▁OLIVER - ▁LINGER - UX - ▁EXAMINED - ▁REPENT - ▁PHYSICIAN - ▁CHASE - ▁BELOVED - ▁ATTACHED - ▁FLORENCE - ▁HONEY - ▁MOUSE - ▁CRIES - ▁BAKE - ▁POEM - ▁DESTRUCTION - ▁FULFIL - ▁MESSENGER - ▁TRISTRAM - ▁FANCIED - ▁EXCESS - ▁CURSE - ▁CHU - ▁QUANTITY - ▁THORNTON - ▁CREATED - ▁CONTINUALLY - ▁LIGHTNING - ▁BORNE - ▁TOTAL - ▁DISPOSED - ▁RIFLE - ▁POLLY - ▁GOAT - ▁BACKWARD - ▁VIRGINIA - ▁KICK - ▁PERIL - ▁QUO - ▁GLORIOUS - ▁MULTITUDE - ▁LEATHER - ▁ABSENT - ▁DEMON - ▁DEBT - ▁TORTURE - ▁ACCORD - ▁MATE - ▁CATHOLIC - ▁PILL - ▁LIBRARY - ▁PURSUIT - ▁SHIRT - ▁DEAREST - ▁COLLAR - ▁BEACH - ▁ROBE - ▁DECLARE - ▁BRANCH - ▁TEMPT - ▁STEADILY - ▁DISGUST - ▁SILLY - ▁ARRIVE - ▁DRANK - ▁LEVI - ▁COMMUNICAT - ▁RACHEL - ▁WASHINGTON - ▁RESIGN - ▁MEANTIME - ▁LACE - ▁ENGAGEMENT - ▁QUIVER - ▁SEPARATED - ▁DISCUSSION - ▁VENTURED - ▁SURROUNDING - ▁POLISH - ▁NAIL - ▁SWELL - ▁JOKE - ▁LINCOLN - ▁STUDENT - ▁GLITTER - ▁RUSSIAN - ▁READILY - ▁CHRIS - ▁POVERTY - ▁DISGRACE - ▁CHEESE - ▁HEAVILY - ▁SCALE - ▁STAFF - ▁ENTREAT - ▁FAREWELL - ▁LUNCH - ▁PEEP - ▁MULE - ▁SOMEONE - ▁DISAPPEAR - ▁DECISION - ▁PISTOL - ▁PUN - ▁SPUR - ▁ASSUMED - ▁EXTEND - ▁ENTHUSIASM - ▁DEFINITE - ▁UNDERTAKE - ▁COMMITTEE - ▁SIMON - ▁FENCE - ▁APPLIED - ▁RELATED - ▁VICE - ▁UNPLEASANT - ▁PROBABLE - ▁PROCURE - ▁FROWN - ▁CLOAK - ▁HUMANITY - ▁FAMILIES - ▁PHILOSOPHER - ▁DWARF - ▁OVERCOME - ▁DEFEAT - ▁FASTENED - ▁MARSH - ▁CLASSES - ▁TOMB - ▁GRACIOUS - ▁REMOTE - ▁CELL - ▁SHRIEK - ▁RESCUE - ▁POOL - ▁ORGANIZ - ▁CHOSE - ▁CUTTING - ▁COWARD - ▁BORDER - ▁DIRTY - ▁MONKEY - ▁HOOK - ▁CHUCK - ▁EMILY - ▁JEST - ▁PLAC - ▁WEIGH - ▁ASSOCIATE - ▁GLIMPSE - ▁STUCK - ▁BOLT - ▁MURDERER - ▁PONY - ▁DISTINGUISH - ▁INSTITUTION - ▁CUNNING - ▁COMPLIMENT - ▁APPETITE - ▁REPUTATION - ▁FEEBLE - ▁KIN - ▁SERIES - ▁GRACEFUL - ▁PLATFORM - ▁BREEZE - ▁PHRASE - ▁CLAY - MONT - ▁RATTL - ▁OPPOSITION - ▁LANE - ▁BOAST - ▁GROWTH - ▁INCLINATION - ▁BEHAVE - ▁SUSAN - ▁DISTINCTION - ▁DISLIKE - ▁NICHOLAS - ▁SATISFY - ▁DRAMA - ▁ELBOW - ▁GAZING - ▁CONSUM - ▁SPIN - ▁OATH - ▁CHANNEL - ▁CHARACTERISTIC - ▁SPEAR - ▁SLAIN - ▁SAUCE - ▁FROG - ▁CONCEPTION - ▁TIMID - ▁ZEAL - ▁APPARENT - SHIRE - ▁CENTER - ▁VARIETY - ▁DUSK - ▁APT - ▁COLUMN - ▁REVENGE - ▁RIVAL - ▁IMITAT - ▁PASSIONATE - ▁SELFISH - ▁NORMAN - ▁REPAIR - ▁THRILL - ▁TREATMENT - ▁ROSA - ▁MARTIN - ▁INDIFFERENT - ▁THITHER - ▁GALLANT - ▁PEPPER - ▁RECOLLECT - ▁VINE - ▁SCARCE - ▁SHIELD - ▁MINGLED - CLOSE - ▁HARSH - ▁BRICK - ▁HUMOR - ▁MISCHIEF - ▁TREMENDOUS - ▁FUNCTION - ▁SMART - ▁SULTAN - ▁DISMISS - ▁THREATENED - ▁CHEAP - ▁FLOCK - ▁ENDEAVOR - ▁WHISK - ▁ITALY - ▁WAIST - ▁FLUTTER - ▁SMOKING - ▁MONARCH - ▁AFRICA - ▁ACCUSE - ▁HERBERT - ▁REFRESH - ▁REJOICE - ▁PILLOW - ▁EXPECTATION - ▁POETRY - ▁HOPELESS - ▁PERISH - ▁PHILOSOPHY - ▁WHISTLE - ▁BERNARD - ▁LAMENT - ▁IMPROVE - ▁SUP - ▁PERPLEX - ▁FOUNTAIN - ▁LEAGUE - ▁DESPISE - ▁IGNORANCE - ▁REFERENCE - ▁DUCK - ▁GROVE - ▁PURSE - ▁PARTNER - ▁PROPHET - ▁SHIVER - ▁NEIGHBOURHOOD - ▁REPRESENTATIVE - SAIL - ▁WIP - ▁ACQUIRED - ▁CHIMNEY - ▁DOCTRINE - ▁MAXIM - ▁ANGLE - ▁MAJORITY - ▁AUTUMN - ▁CONFUSED - ▁CRISTO - ▁ACHIEVE - ▁DISGUISE - ▁REDUCED - ▁EARLIER - ▁THEATRE - ▁DECIDE - MINATED - OLOGICAL - ▁OCCUPATION - ▁VIGOROUS - ▁CONTINENT - ▁DECLINE - ▁COMMUNITY - ▁MOTIONLESS - ▁HATRED - ▁COMMUNICATION - ▁BOWL - ▁COMMENT - ▁APPROVE - ▁CEREMONY - ▁CRIMINAL - ▁SCIENTIFIC - ▁DUCHESS - ▁VIVID - ▁SHIFT - ▁AVAIL - ▁DAMP - ▁JOHNSON - ▁SLENDER - ▁CONTRAST - ▁AMUSEMENT - ▁PLOT - ▁LYN - ▁ASSOCIATION - ▁SNATCH - ▁UNCERTAIN - ▁PRESSURE - ▁PERCH - ▁APPLY - ▁PLANET - ▁NOTWITHSTANDING - ▁SWUNG - ▁STIRRED - ▁ATTENDANT - ▁ENJOYMENT - ▁WORRY - ▁ALBERT - ▁NAKED - ▁TALENT - ▁MARIAN - ▁REFORM - ▁DELIBERATE - ▁INTELLIGENT - ▁SENSITIVE - ▁YONDER - ▁PUPIL - ▁FRIGHTFUL - ▁DOUBTFUL - ▁STANDARD - ▁MAGISTRATE - ▁SHEPHERD - ▁STOMACH - ▁DEPOSIT - ▁RENEW - ▁HEDGE - ▁FRANCS - ▁POSSIBILITY - ▁RESEMBLE - ▁FATIGUE - ▁PORTRAIT - ▁FAVORITE - ▁CREAM - ▁BURG - ▁SECRETARY - ▁DIVERS - ▁ACTIVITY - ▁SPECULAT - ▁HUMOUR - ▁FITTED - ▁EXTERNAL - ▁CETERA - ▁WRAPPED - ▁WHIT - ▁FRED - ▁EXAMINATION - ▁LODGING - ▁OWING - ▁JAW - ▁CROW - ▁BALANCE - ▁PUFF - ▁TENDERNESS - ▁PORTHOS - ▁ANCHOR - ▁INTERRUPT - ▁NECESSARILY - ▁PERPETUAL - ▁AGONY - ▁POPE - ▁SCHOLAR - ▁SCOTLAND - ▁SUPPRESS - ▁WRATH - ▁WRECK - ▁EXCEED - ▁PERFECTION - ▁INDIA - ▁TRADITION - ▁SECTION - ▁EASTERN - ▁DOORWAY - ▁WIVES - ▁CONVENTION - ▁ANNOUNC - ▁EGYPT - ▁CONTRADICT - ▁SCRATCH - ▁CENTRAL - ▁GLOVE - ▁WAX - ▁PREPARE - ▁ACCOMPANY - ▁INCREASING - ▁LIBERAL - ▁RAISING - ▁ORANGE - ▁SHOE - ▁ATTRIBUTE - ▁LITERATURE - ▁PUZZLED - ▁WITHDRAW - ▁WHITHER - ▁HAWK - ▁MOONLIGHT - ▁EXAMINE - ▁HAPPILY - ▁PRECEDE - ▁DETECTIVE - ▁INCHES - ▁SOLITARY - ▁DUTCH - ▁NAPOLEON - ▁UNEASY - ▁CARDINAL - ▁BLEW - ▁FOWL - ▁DECORAT - ▁CHILDHOOD - ▁TORMENT - ▁LOSING - ▁PERMISSION - ▁BLANK - ▁UPSTAIRS - ▁CAPACITY - ▁TRIFLE - ▁FOLLY - ▁RECOGNIZE - ▁REMOVE - ▁VENGEANCE - ▁ENTERPRISE - ▁BEDROOM - ▁ANYHOW - ▁INQUIRY - ▁ASHES - ▁DRAG - ▁HUSH - ▁AWKWARD - ▁SATURDAY - ▁GENUINE - ▁SURVIV - ▁SKIRT - ▁AFFECTIONATE - ▁TANG - ▁MUTUAL - ▁DISPUTE - ▁EAGLE - ▁INCOME - ▁BIND - ▁FAME - ▁IMPROVEMENT - ROVING - ▁DIFFER - ▁AWOKE - ▁SLEEVE - ▁SOLITUDE - ▁FAVOURITE - JI - ▁DETECT - ▁COMPREHEND - ▁PREPARING - ▁SERPENT - ▁SUMMIT - ▁KNOT - ▁KNIT - ▁COPY - ▁STOPPING - ▁FADED - ▁HIDEOUS - ▁JULIE - STEAD - ▁SHINE - ▁CONFLICT - ▁PROPOSITION - ▁REFUGE - ▁GALLERY - ▁BUNDLE - ▁AXE - ▁SLAVERY - ▁MASK - ▁ALYOSHA - ▁LADDER - ▁DEPARTMENT - ▁DISCHARGE - ▁DEPRESS - ▁GALLOP - ▁SCARLET - ▁KITTY - ▁RECEIVING - ▁SURRENDER - ▁SUSTAIN - ▁TWILIGHT - ▁CONGRESS - ▁IRELAND - ▁FUNNY - ▁LEND - ▁CONSTITUTE - ▁FUNERAL - ▁CRYSTAL - ▁SPAIN - ▁EXCEEDINGLY - ▁DAMN - ▁COMMUN - ▁CIVILIZATION - ▁PREJUDICE - ▁PORCH - ▁ASSISTANT - ▁INDUSTRY - ▁TUMBLE - ▁DEFENCE - ▁HITHER - ▁SMOT - ▁COLONI - ▁AMAZEMENT - ▁MARGUERITE - ▁MIRACLE - ▁INHERIT - ▁BEGGAR - ▁ENVELOPE - ▁INDIGNATION - ▁NATASHA - ▁PROPOSAL - ▁FRAGMENT - ▁ROUSED - ▁ROAST - ENCIES - ▁COMMENCED - ▁RESOURCE - ▁POPULATION - ▁QUOTH - ▁PURSUE - ▁EDUCAT - ▁AFFLICT - ▁CONTACT - ▁CRIMSON - ▁DIVISION - ▁DISORDER - ▁COPPER - ▁SOLICIT - ▁MODERATE - ▁DRUM - ▁SWIM - ▁SALUTE - ▁ASSUME - ▁MUSCLE - ▁OVERWHELM - ▁SHAKESPEARE - ▁STRUGGLING - ▁TRANQUIL - ▁CHICKEN - ▁TREAD - ▁CLAW - ▁BIBLE - ▁RIDGE - ▁THREAT - ▁VELVET - ▁EXPOSED - ▁IDIOT - ▁BARREL - ▁PENNY - ▁TEMPTATION - ▁DANGLARS - ▁CENTURIES - ▁DISTRIBUT - ▁REJECT - ▁RETORTED - ▁CONCENTRAT - ▁CORDIAL - ▁MOTOR - ▁CANNON - KEEP - ▁WRETCH - ▁ASSURANCE - ▁THIEF - ▁SURVEY - ▁VITAL - ▁RAILWAY - ▁JACKSON - ▁CRASH - ▁GROWL - ▁COMBAT - ▁RECOLLECTION - ▁SECURITY - ▁JACOB - ▁CLUTCH - ▁BLANKET - ▁NANCY - ▁CELLAR - ▁CONVENIENT - ▁INDIGNANT - ▁COARSE - ▁WORM - ▁SCREEN - ▁TRANSPORT - ▁BULLET - ▁APPRECIATE - ▁DEVOTION - ▁INVISIBLE - ▁DRIED - ▁MIXTURE - ▁CANDID - ▁PERFORMANCE - ▁RIPE - ▁EXQUISITE - ▁BARGAIN - ▁TOBACCO - ▁LOYAL - ▁MOULD - ▁ATTENTIVE - ▁DOROTHY - ▁BRUTE - ▁ESTABLISHMENT - ▁ABILITY - ▁INHABIT - ▁OBSCURE - ▁BORROW - ▁ESSENCE - ▁DISMAY - ▁FLEE - ▁BLADE - ▁PLUCK - ▁COFFIN - ▁SUNSET - ▁STEPHEN - ▁ECONOMIC - ▁HOLIDAY - ▁MECHANICAL - ▁COTTON - ▁AWAKENED - ▁SEIZE - ▁RIDICULOUS - ▁SANCHO - ▁HESITATION - ▁CORPSE - ▁SAVING - HOLD - FOOT - ▁ELDEST - ▁DESPITE - ▁EDITH - ▁CHERISH - ▁RESISTANCE - ▁WILSON - ▁ARGUE - ▁INQUIRE - ▁APPREHENSION - ▁AVENUE - ▁DRAKE - ▁PROPOSE - HURST - ▁INFERIOR - ▁STAIRCASE - ▁WHEREFORE - ▁CARLYLE - ▁COUCH - ▁ROUTE - ▁POLITICS - ▁TOMORROW - ▁THRONG - ▁NAUGHT - ▁SUNLIGHT - ▁INDIFFERENCE - ▁OBEDIENCE - ▁RECEPTION - ▁VEGETABLE - ▁IMPERFECT - ▁RESIDENCE - ▁TURKEY - ▁VIOLET - ▁SARAH - ▁ALTAR - ▁GRIEVE - ▁JERK - ▁ENSU - ▁MAGICIAN - ▁BLOSSOM - ▁LANTERN - ▁RESOLUTE - ▁THOUGHTFULLY - ▁FORTNIGHT - ▁TRUMPET - ▁VALJEAN - ▁UNWILLING - ▁LECTURE - ▁WHEREUPON - ▁HOLLAND - ▁CHANGING - ▁CREEK - ▁SLICE - ▁NORMAL - ▁ANNIE - ▁ACCENT - ▁FREDERICK - ▁DISAGREEABLE - ▁RUBBED - ▁DUMB - ▁ESTABLISH - ▁IMPORT - ▁AFFIRM - ▁MATTHEW - ▁BRISK - ▁CONVERT - ▁BENDING - ▁IVAN - ▁MADEMOISELLE - ▁MICHAEL - ▁EASIER - ▁JONES - ▁FACING - ▁EXCELLENCY - ▁LITERARY - ▁GOSSIP - ▁DEVOUR - ▁STAGGER - ▁PENCIL - ▁AVERAGE - ▁HAMMER - ▁TRIUMPHANT - ▁PREFERRED - ▁APPLICATION - ▁OCCUPY - ▁AUTHORITIES - BURN - ▁ASCERTAIN - ▁CORRIDOR - ▁DELICIOUS - ▁PRACTISE - ▁UNIVERSE - ▁SHILLING - ▁CONTEST - ▁ASHORE - ▁COMMIT - ▁ADMINISTRATION - ▁STUDIED - ▁RIGID - ▁ADORN - ▁ELSEWHERE - ▁INNOCENCE - ▁JOURNAL - ▁LANDSCAPE - ▁TELEGRAPH - ▁ANGRILY - ▁CAMPAIGN - ▁UNJUST - ▁CHALLENGE - ▁TORRENT - ▁RELATE - ▁ASSEMBLED - ▁IMPRESSED - ▁CANOE - ▁CONCLUD - ▁QUIXOTE - ▁SATISFACTORY - ▁NIECE - ▁DEAF - ▁RAFT - ▁JIMMY - ▁GLID - ▁REGULAT - ▁CHATTER - ▁GLACIER - ▁ENVY - ▁STATUE - ▁BOSTON - ▁RICHMOND - ▁DENIED - ▁FANNY - ▁SOLOMON - ▁VULGAR - ▁STALK - ▁REPLACE - ▁SPOON - ▁BASIN - ▁FEATURE - ▁CONVICT - ▁ARCHITECT - ▁ADMIRAL - ▁RIBBON - ▁PERMANENT - ▁APRIL - ▁JOLLY - ▁NEIGHBORHOOD - ▁IMPART - BOROUGH - CAMP - ▁HORRID - ▁IMMORTAL - ▁PRUDENCE - ▁SPANIARD - ▁SUPPOSING - ▁TELEPHONE - ▁TEMPERATURE - ▁PENETRATE - ▁OYSTER - ▁APPOINTMENT - ▁EGYPTIAN - ▁DWELT - ▁NEPHEW - ▁RAILROAD - ▁SEPTEMBER - ▁DEVICE - ▁WHEAT - ▁GILBERT - ▁ELEGANT - ▁ADVERTISE - ▁RATIONAL - ▁TURTLE - ▁BROOD - ▁ASSEMBLY - ▁CULTIVATE - ▁EDITOR - ▁SPECIMEN - ▁UNDOUBTEDLY - ▁WHALE - ▁DROPPING - ▁BALLOON - ▁MEDICAL - COMB - ▁COMPOSITION - ▁FOOTSTEPS - ▁LAUNCELOT - ▁DISCOURSE - ▁ERRAND - ▁CONVERSE - ▁ADVANCING - ▁DOWNSTAIRS - ▁TUMULT - ▁CORRUPT - ▁SUFFICE - ▁ANGUISH - ▁SHAGGY - ▁RETIRE - ▁TIMBER - ▁BLAZE - ▁ABSTRACT - ▁EMBROIDER - ▁PHOTOGRAPH - ▁PROSPERITY - ▁TERRIBLY - ▁TERRITORY - ▁THRESHOLD - ▁PAVEMENT - ▁INJURED - ▁LIMP - ▁AGITATION - ▁RASCAL - ▁PRESUME - ▁OBSERVING - ▁OBSTACLE - ▁SIMPLICITY - ▁SLUMBER - ▁SUPPLIED - ▁COMBINATION - ▁DRAIN - ▁WILDERNESS - ▁BELIEVING - ▁VILLAIN - ▁RECKLESS - ▁INJURY - ▁CLAPP - ▁FRIDAY - ▁HERCULES - ▁KENNEDY - ▁SYMPTOM - ▁SLEDGE - ▁CEILING - ▁LEMON - ▁PLAGUE - ▁MONDAY - ▁CANVAS - ▁IMPATIENCE - ▁UNCOMFORTABLE - ▁ACCESS - ▁FROZEN - ▁SENATOR - ▁FRANZ - ▁SWIMMING - ▁BARRIER - ▁ADJUST - ▁COMPARISON - ▁PROCLAIM - ▁WRINKL - ▁OVERLOOK - ▁MITYA - ▁GUILT - ▁PERCEPTION - ▁PRECAUTION - ▁SPECTATOR - ▁SURPRISING - ▁DISTRACT - ▁DISDAIN - ▁BONNET - ▁MAGNET - ▁PROFESS - ▁CONFOUND - ▁NARRATIVE - ▁STRUCTURE - ▁SKETCH - ▁ULTIMATE - ▁GLOBE - ▁INSECT - FICIENCY - ▁ORCHARD - ▁AMIABLE - ▁DESCENT - ▁INDEPENDENCE - ▁MANUFACTURE - ▁SPRINKLE - ▁NIGHTINGALE - ▁CUSHION - ▁EMINENT - ▁SCOTT - ▁ARRAY - ▁COSETTE - ▁WAVING - ▁EXTRACT - ▁IRREGULAR - ▁PERSECUT - ▁DERIVED - ▁WITHDREW - ▁CAUTION - ▁SUSPICIOUS - ▁MEMORIES - ▁NOWHERE - ▁SUBTLE - ▁THOROUGH - Q - ▁APPROPRIATE - ▁SLAUGHTER - ▁YOURSELVES - ▁THUMB - ▁TWAS - ▁ABODE - ▁BIDDING - ▁CONSPICUOUS - ▁REBECCA - ▁SERGEANT - ▁APRON - ▁ANTICIPATE - ▁DISCIPLINE - ▁GLANCING - ▁PILGRIM - ▁SULLEN - ▁CONTRIBUTE - ▁PRAIRIE - ▁CARVED - ▁COMMERCE - ▁EXCLAMATION - ▁MUSCULAR - ▁NOVEMBER - ▁PHENOMENA - ▁SYMBOL - ▁UMBRELLA - ▁DIMINISH - ▁PARLOUR - ▁THREATENING - ▁STUMP - ▁EXTENSIVE - ▁PLEASING - ▁REMEMBRANCE - ▁COMBINED - ▁SHERIFF - ▁SHAFT - ▁LAURA - ▁INTERCOURSE - ▁STRICKEN - ▁SUPPLIES - ▁LANDLORD - ▁SHRINK - ▁PRICK - ▁CAESAR - ▁DRUG - ▁BEWILDERED - ▁NAUTILUS - ▁BRUTAL - ▁COMMERCIAL - ▁MAGGIE - ▁SPHERE - ▁VIRGIN - ▁BRETHREN - ▁DESTINY - ▁POLICY - ▁TERRIFIED - ▁HOUSEKEEPER - ▁CRAZY - ▁ARDENT - ▁DISCERN - ▁WRAP - ▁MARQUIS - ▁RUSSIA - MOUTH - ▁BRITAIN - ▁HARBOUR - ▁CONCERT - ▁DONKEY - ▁DAMAGE - ▁SLIM - ABOUT - ▁LUXURY - ▁MONSTROUS - ▁TENDENCY - ▁PARADISE - ▁CULTURE - ▁JULIUS - ▁RAOUL - ▁REMEDY - ▁DECAY - ▁SCOLD - ▁SPLIT - ▁ASSAULT - ▁DECEMBER - ▁MOSCOW - ▁EXPLORE - ▁TROUSERS - ▁WRIST - PIECE - ▁MUSKET - ▁VALENTINE - ▁TYRANT - ▁ABRAHAM - ▁MEDIUM - ▁ARTIFICIAL - ▁FACULTY - ▁OBLIGATION - ▁RESEMBLANCE - ▁INQUIRIES - ▁DETAIN - ▁SWARM - ▁PLEDGE - ▁ADMIRABLE - ▁DEFECT - ▁SUPERINTEND - ▁PATRIOT - ▁CLUNG - ▁DISMAL - ▁RECIT - ▁IGNOR - ▁AMELIA - ▁JUSTIFY - ▁ELEPHANT - ▁ESTIMATE - ▁KNELT - ▁SERVING - ▁WHIM - ▁SHRILL - ▁STUDIO - ▁TEXT - ▁ALEXANDER - ▁WROUGHT - ▁ABUNDANT - ▁SITUATED - ▁REGAIN - ▁FIERY - ▁SNEER - ▁SWEAT - ▁GLARE - ▁NIGH - ▁ESCORT - ▁INEVITABLE - ▁PSMITH - ▁RELUCTANT - ▁PRECEDING - ▁RESORT - ▁OUTRAGE - ▁AMBASSADOR - ▁CONSOLATION - ▁RECOGNITION - ▁REMORSE - ▁BEHALF - ▁FORMIDABLE - ▁GRAVITY - ▁DIVIDE - ▁CONFRONT - ▁GIGANTIC - ▁OCTOBER - ▁FLANK - ▁SLEW - ▁CLARA - ▁FILM - ▁BULK - ▁POMP - ▁ELEANOR - ▁EMPHASIS - ▁JAPANESE - ▁CAVALRY - ▁EXCLUSIVE - ▁PERFUME - ▁BRONZE - ▁FEDERAL - ▁LIQUID - ▁RUBBING - ▁OVEN - DOLPH - ▁CONVULS - ▁DEPRIVED - ▁RESPONSIBILITY - ▁SIGNIFICANT - ▁WAISTCOAT - ▁CLUSTER - ▁MARTHA - ▁REVERSE - ▁ATTORNEY - ▁DROOP - ▁SKILFUL - ▁HABITUAL - ▁PUMP - ▁INTERVEN - ▁OWL - ▁CONJECTURE - ▁FANTASTIC - ▁RESPONSIBLE - ▁DESTINED - ▁DOCUMENT - ▁THEREUPON - ▁GODDESS - ▁PACIFIC - ▁WARRANT - ▁COSTUME - ▁BRIDLE - ▁CALIFORNIA - ▁DEMOCRATIC - ▁EUSTACE - ▁SQUIRREL - ▁UNCOMMON - ▁MARVELLOUS - ▁PLOUGH - ▁TRAGEDY - ▁VAULT - ▁HESITATE - ▁REFRAIN - ▁ADMIRING - ▁CORPORAL - ▁ENTITLED - ▁SHREWD - ▁SQUEEZ - ▁ACCURATE - ▁TEMPEST - ▁MONUMENT - ▁SIEGE - ▁CHINESE - ▁RAVEN - ▁LOUNG - ▁ASSASSIN - ▁INFLICT - ▁AGITATED - ▁DESIRABLE - ▁EARLIEST - ▁LAUNCH - ▁PILOT - ▁PULSE - ▁MUTE - LEIGH - ▁LIQUOR - ▁SCARECROW - ▁SKULL - ▁DESOLATE - ▁SUBLIME - ▁SERENE - ▁RECESS - ▁WAKING - ▁CHARLOTTE - ▁CIRCULAR - ▁INJUSTICE - ▁PINOCCHIO - ▁PRISCILLA - ▁THYSELF - ▁OCCURRENCE - ▁CASUAL - ▁FRANTIC - ▁LEGEND - ▁FERTIL - ▁BACKGROUND - ▁DELICACY - ▁ESTRALLA - ▁MANUSCRIPT - ▁RESPONSE - ▁UNIVERSITY - ▁WOLVES - ▁SCANDAL - ▁STUMBLE - ▁HOARSE - ▁BODILY - ▁CONVENT - ▁EXAMINING - ▁INCAPABLE - ▁PERCEIVING - ▁PHILADELPHIA - ▁SUBSEQUENT - ▁THIEVES - ▁ACCUMULAT - ▁DAMSEL - ▁SCOTCH - ▁UNDERNEATH - ▁NOBILITY - ▁SMASH - ▁REVOLT - ▁ENGAGE - ▁CATHEDRAL - ▁CHAMPION - ▁DESPATCH - ▁ETERNITY - ▁JANUARY - ▁PLEADED - ▁PROBABILITY - ▁JIMMIE - ▁PARALLEL - ▁FISHERMAN - ▁JERRY - ▁SWORE - ▁DRAUGHT - ▁OPPONENT - ▁PRIMITIVE - ▁SIGNIFICANCE - ▁SUBSTANTIAL - ▁AMAZED - ▁DUNBAR - ▁COMMEND - ▁CONTEMPLATE - ▁TESTIMONY - ▁IMPERIAL - ▁ADAPT - ▁JUICE - ▁CALAMIT - CULAR - ▁CHATEAU - ▁PHOENIX - ▁PRUDENT - ▁SOLUTION - ▁VILLEFORT - ▁REACTION - ▁RELAX - ▁YU - ▁PROHIBIT - ▁DISTRUST - ▁PLUNDER - ▁WELFARE - ▁NAVIGAT - ▁PARLOR - ▁LAZY - ▁DETACH - OMETER - ▁PRIV - ▁DISCOURAGE - ▁OBSTINATE - ▁REJOICING - ▁SERMON - ▁VEHICLE - ▁FANCIES - ▁ENLIGHTEN - ▁ACUTE - ▁ILLUSION - ▁ANTHEA - ▁MARTIAN - ▁EXCITE - ▁GENEROSITY - OLOGIST - ▁AMAZING - ▁UNWORTHY - ▁INTERNAL - ▁INCENSE - ▁VIBRAT - ▁ADHERE - ROACH - ▁FEBRUARY - ▁MEXICAN - ▁POTATOES - ▁INCESSANT - ▁INTERPOSED - ▁PARCEL - ▁VEXED - ▁PROMOTE - MIDST - ▁ARISTOCRAT - ▁CYRIL - ▁EMBARK - ▁ABUNDANCE - ▁LITERALLY - ▁SURGEON - ▁TERRACE - ▁ATLANTIC - ▁MARTYR - ▁SPECK - ▁SENATE - ▁LOAF - ▁ADMINISTER - ▁APPREHEND - ▁SUBDUED - ▁TEMPORARY - ▁DOMINION - ▁ELABORATE - ▁DIGNIFIED - ▁ELIZA - ▁SPLASH - ▁CONSEIL - ▁DEXTER - ▁UNSEEN - ▁TRAGIC - VOCATION - ▁GRATIFY - ▁BACHELOR - ▁DEFENSE - ▁EXCURSION - ▁FACULTIES - ▁PROPRIETOR - ▁SYMPATHETIC - ▁UNNECESSARY - ▁RADIANT - ▁VACANT - ▁OUNCE - ▁SCREW - ▁PHENOMENON - ▁PROMINENT - ▁WORRIED - ▁STUDIES - ▁CLIMATE - ▁KEITH - ▁ARAMIS - ▁BLISS - ▁CONTINUAL - ▁SURPASS - ▁HEBREW - ▁IDENTITY - ▁PROVOKE - ▁TEMPERAMENT - ▁CHARIOT - ▁HARBOR - ▁NINTH - ▁PRIOR - ▁DESIROUS - ▁JERUSALEM - ▁UNDERTAKING - ▁EDISON - ▁MIRTH - ▁SCOUT - ▁APPARATUS - ▁ILLUSTRATION - ▁INTELLIGIBLE - ▁INVARIABLY - ▁PIERCED - ▁REVIEW - ▁FLICKER - ▁HAZARD - ▁REVELATION - ▁DIXON - ▁EXCITING - ▁GOSPEL - ▁CONSTANCE - ▁OVERTAKE - ▁GUINEA - ▁ALADDIN - ▁CHICAGO - ▁TULLIVER - ▁HAMILTON - ▁GARRISON - ▁DISCIPLE - ▁INTENSITY - ▁TRAITOR - ▁CHANCELLOR - ▁PROVERB - ▁DAGGER - ▁FORESEE - ▁CONFIDE - ▁GLIMMER - ▁CHAUVELIN - ▁ILLUSTRATE - ▁VOLUNTEER - ▁JUNGLE - ▁STREAK - ▁SUNRISE - ▁DISSOLV - ▁QUEST - ▁AWHILE - ▁FELICITY - ▁LEGISLATURE - ▁LEONORA - ▁MAGAZINE - ▁PITIFUL - ▁COLONY - ▁SHAWL - ▁ARRIVING - ▁FUNDAMENTAL - ▁CARPENTER - ▁OVERFLOW - ▁EXPAND - ▁HARVEST - ▁FEMININE - ▁INNUMERABLE - ▁SCRAMBLE - ▁TWENTIETH - ▁TRIFLING - ▁GHASTL - ▁CONQUEST - ▁DANIEL - ▁FACILIT - ▁FORSAKE - ▁BEHAVIOUR - ▁GORGEOUS - ▁PRODUCING - ▁HAPPIER - ▁PROMISING - ▁RAINBOW - ▁INSTINCTIVELY - ▁DECREE - ▁EYEBROWS - ▁IRRESISTIBLE - ▁PHARAOH - ▁SCROOGE - ▁UNNATURAL - ▁CRUMBS - ▁REFINED - ▁DREARY - ▁TRENCH - ▁CONVINCE - ▁FRINGE - ▁EXTREMITY - ▁INTIMACY - ▁SCOUNDREL - ▁SUFFRAGE - ▁UNEASINESS - ▁BARRICADE - ▁CIRCULAT - ▁SAMUEL - ▁BRUCE - ▁DARCY - <sos/eos> init: null input_size: null ctc_conf: dropout_rate: 0.0 ctc_type: builtin reduce: true ignore_nan_grad: true joint_net_conf: null model_conf: ctc_weight: 0.3 lsm_weight: 0.1 length_normalized_loss: false use_preprocessor: true token_type: bpe bpemodel: data/en_token_list/bpe_unigram5000/bpe.model non_linguistic_symbols: null cleaner: null g2p: null speech_volume_normalize: null rir_scp: null rir_apply_prob: 1.0 noise_scp: null noise_apply_prob: 1.0 noise_db_range: '13_15' frontend: default frontend_conf: n_fft: 512 hop_length: 256 fs: 16k specaug: specaug specaug_conf: apply_time_warp: true time_warp_window: 5 time_warp_mode: bicubic apply_freq_mask: true freq_mask_width_range: - 0 - 27 num_freq_mask: 2 apply_time_mask: true time_mask_width_ratio_range: - 0.0 - 0.05 num_time_mask: 10 normalize: global_mvn normalize_conf: stats_file: exp/asr_stats_raw_en_bpe5000_sp/train/feats_stats.npz preencoder: null preencoder_conf: {} encoder: conformer encoder_conf: output_size: 512 attention_heads: 8 linear_units: 2048 num_blocks: 12 dropout_rate: 0.1 positional_dropout_rate: 0.1 attention_dropout_rate: 0.1 input_layer: conv2d normalize_before: true macaron_style: true rel_pos_type: latest pos_enc_layer_type: rel_pos selfattention_layer_type: rel_selfattn activation_type: swish use_cnn_module: true cnn_module_kernel: 31 postencoder: null postencoder_conf: {} decoder: transformer decoder_conf: attention_heads: 8 linear_units: 2048 num_blocks: 6 dropout_rate: 0.1 positional_dropout_rate: 0.1 self_attention_dropout_rate: 0.1 src_attention_dropout_rate: 0.1 required: - output_dir - token_list version: 0.10.7a1 distributed: true ``` </details> | 5f6559a5a223a271a4d1d96dcd79170f |
apache-2.0 | ['generated_from_trainer'] | false | t5-dialogue-summarization This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the samsum dataset. dataset: type: {summarization} name: {samsum} | f0bcbf0dc80d97d387149825875961fb |
apache-2.0 | ['speech'] | false | Wav2Vec2-Base [Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information. [Paper](https://arxiv.org/abs/2006.11477) Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli **Abstract** We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data. The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec | 35906261c772356e571a41c362956aa3 |
apache-2.0 | ['generated_from_keras_callback'] | false | TestZee/t5-small-baseline_summary_zee_v1.0 This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 2.3722 - Validation Loss: 2.1596 - Train Rouge1: 21.6350 - Train Rouge2: 8.9453 - Train Rougel: 17.8649 - Train Rougelsum: 19.9099 - Train Gen Len: 19.0 - Epoch: 0 | 527592ac6ef225cc93ca65b49145e917 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.