
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1
class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
cc-by-4.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 74 | 1.7148 | | No log | 2.0 | 148 | 1.6994 | | No log | 3.0 | 222 | 1.7922 | | No log | 4.0 | 296 | 1.9947 ... | 12e687fde59497f1087101a43be2d57b |
gpl-3.0 | ['text classification', 'abusive language', 'hate speech', 'offensive language'] | false | HATE-ITA Base HATE-ITA is a binary hate speech classification model for Italian social media text. <img src="https://raw.githubusercontent.com/MilaNLProc/hate-ita/main/hateita.png?token=GHSAT0AAAAAABTEBAJ4PNDWAMU3KKIGUOCSYWG4IBA" width="200"> | a1ea11f522fe50849cd9208dbd7f2649 |
gpl-3.0 | ['text classification', 'abusive language', 'hate speech', 'offensive language'] | false | Model This model is the fine-tuned version of the [XLM-T](https://arxiv.org/abs/2104.12250) model. | Model | Download | | ------ | -------------------------| | `hate-ita` | [Link](https://huggingface.co/MilaNLProc/hate-ita) | | `hate-ita-xlm-r-base` | [Link](https://hugg... | 5ee870d233cec334a2cfcb0eb7647abd |
mit | [] | false | mycat on Stable Diffusion This is the `<mycat>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train you... | 19552ff139b30d6ffd796e7d2d642db3 |
mit | [] | false | F-22 on Stable Diffusion This is the `<f-22>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your ... | 6ddddec677ea76bafa6a6bdd74f420c0 |
cc-by-4.0 | ['audio', 'automatic-speech-recognition', 'spanish', 'xlrs-53-spanish', 'ciempiess', 'cimpiess-unam'] | false | wav2vec2-large-xlsr-53-spanish-ep5-944h The "wav2vec2-large-xlsr-53-spanish-ep5-944h" is an acoustic model suitable for Automatic Speech Recognition in Spanish. It is the result of fine-tuning the model "facebook/wav2vec2-large-xlsr-53" for 5 epochs with around 944 hours of Spanish data gathered or developed by the [... | bc1897dda24fcb9356975dbee58c6772 |
cc-by-4.0 | ['audio', 'automatic-speech-recognition', 'spanish', 'xlrs-53-spanish', 'ciempiess', 'cimpiess-unam'] | false | Load the processor and model. MODEL_NAME="carlosdanielhernandezmena/wav2vec2-large-xlsr-53-spanish-ep5-944h" processor = Wav2Vec2Processor.from_pretrained(MODEL_NAME) model = Wav2Vec2ForCTC.from_pretrained(MODEL_NAME) | cae92a433e133f9908f7b59419fff0db |
cc-by-4.0 | ['audio', 'automatic-speech-recognition', 'spanish', 'xlrs-53-spanish', 'ciempiess', 'cimpiess-unam'] | false | BibTeX entry and citation info *When publishing results based on these models please refer to:* ```bibtex @misc{mena2022xlrs53spanish, title={Acoustic Model in Spanish: wav2vec2-large-xlsr-53-spanish-ep5-944h.}, author={Hernandez Mena, Carlos Daniel}, year={2022}, url={https://huggingface.co/c... | 41146a0006c16c9f4aa1049854d299e7 |
cc-by-4.0 | ['audio', 'automatic-speech-recognition', 'spanish', 'xlrs-53-spanish', 'ciempiess', 'cimpiess-unam'] | false | Acknowledgements The author wants to thank to the social service program ["Desarrollo de Tecnologías del Habla"](http://profesores.fi-b.unam.mx/carlos_mena/servicio.html) at the [Facultad de Ingeniería (FI)](https://www.ingenieria.unam.mx/) of the [Universidad Nacional Autónoma de México (UNAM)](https://www.unam.mx/)... | 3e502086d30d4f9cb2ffc29e27e03e45 |
mit | [] | false | Happy_Person12345 on Stable Diffusion This is the `<Happy-Person12345>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook... | 1472029349dda468676956f86f82f8db |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper large v2 vi This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the common_voice_11_0 dataset. It achieves the following results on the evaluation set: - Loss: 0.5978 - Wer: 18.1509 | 0a1189f08defe19d2b230d72cd70977f |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0003 | 32.01 | 1000 | 0.5978 | 18.1509 | | 6d0e7eb3eb81f6f1950d45dac6a89966 |
creativeml-openrail-m | [] | false | model by no3 This your waifu-diffusion v1.3 model fine-tuned ridley taught to waifu-diffusion v1.3 with Dreambooth. It can be used by modifying the `instance_prompt`: **sks_ridley** You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/hu... | 2161a0fcc84d914d9ac1a009c08e29fa |
creativeml-openrail-m | [] | false | note If you want to to use in UI like [AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) or any UI that's uses .ckpt files just download ckpt file here for your convenience. **just click on "ridley-wd-1.3-beta1.ckpt"** [ridley-wd-1.3-beta1.ckpt](https://huggingface.co/no3/ridley-wd-1.3-beta1/res... | e1274c31c433a997d2cf2d30a0239b00 |
apache-2.0 | ['generated_from_trainer'] | false | whisper-dpv-finetuned-WITH-AUGMENTATION-AUGMENTED-ALL This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.6523 - Wer: 35.1345 | c63a30f0587eb481e7b8d02e3a188cf3 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 1 - eval_batch_size: 1 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 4 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_schedu... | 3c0369476a0e61d47901a65d31589b53 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.3432 | 1.25 | 1000 | 0.5472 | 37.2824 | | 0.138 | 2.49 | 2000 | 0.5765 | 37.0563 | | 0.0569 | 3.74 | 3000 | 0.6523 | 35.134... | dbc747f61f6cc9d1fffb17233ce07d72 |
apache-2.0 | ['translation'] | false | opus-mt-id-es * source languages: id * target languages: es * OPUS readme: [id-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/id-es/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://... | 75371d0ef93097a68ec580db30ff2e17 |
apache-2.0 | ['generated_from_trainer'] | false | tiny-mlm-glue-qnli-target-glue-cola This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-qnli](https://huggingface.co/muhtasham/tiny-mlm-glue-qnli) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.7322 - Matthews Correlation: 0.1353 | 3d549446fbeb0a06a08d67b9bfaee287 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.6099 | 1.87 | 500 | 0.6209 | 0.0 | | 0.6009 | 3.73 | 1000 | 0.6169 | 0.0 | | 0.5... | d455bb669e4d44f7c149dd299d2f0d2d |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 256 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 512 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_... | 57ce90cc7caf5df4f696792375f709a0 |
apache-2.0 | ['stanza', 'token-classification'] | false | Stanza model for Classical_Chinese (lzh) Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing. Find more about it in [our w... | 675c8ea8a1f3d2e8048eed7a170a1c27 |
apache-2.0 | ['speech', 'audio', 'automatic-speech-recognition'] | false | Evaluation on Zeroth-Korean ASR corpus [Google colab notebook(Korean)](https://colab.research.google.com/github/indra622/tutorials/blob/master/wav2vec2_korean_tutorial.ipynb) ``` from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor from datasets import load_dataset import soundfile as sf import torch from jiwe... | 2090c6ea96f90a05beb9f508633deef1 |
apache-2.0 | ['voxpopuli', 'google/xtreme_s', 'generated_from_trainer'] | false | xtreme_s_xlsr_300m_voxpopuli_en This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the GOOGLE/XTREME_S - VOXPOPULI.EN dataset. It achieves the following results on the evaluation set: - Cer: 0.0966 - Loss: 0.3127 - Wer: 0.1549 - Predict Samples... | 35eb79966f553a6bfe7096e43d6e0ff0 |
apache-2.0 | ['voxpopuli', 'google/xtreme_s', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 8 - eval_batch_size: 1 - seed: 42 - distributed_type: multi-GPU - num_devices: 8 - total_train_batch_size: 64 - total_eval_batch_size: 8 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e... | 5978eeb9fede71c5b8a64d3eb923b99c |
apache-2.0 | ['voxpopuli', 'google/xtreme_s', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | Cer | |:-------------:|:-----:|:-----:|:---------------:|:------:|:------:| | 1.4221 | 0.19 | 500 | 1.3325 | 0.8224 | 0.3432 | | 0.8429 | 0.38 | 1000 | 0.7087 | 0.5028 | 0.2023 | | 0.7377 | 0.5... | e177d4f38780a9c73a4f0722ea891956 |
apache-2.0 | ['generated_from_trainer'] | false | Negation_Scope_Detection_NubEs_Spanish_mBERT_fine_tuned This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the nubes dataset. It achieves the following results on the evaluation set: - Loss: 0.1624 - Precision: 0.9012 - Recall: 0.9184 - F1: 0.9... | 3082ec371882a3537eda29cbd97ebb74 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.1802 | 1.0 | 1726 | 0.1849 | 0.7843 | 0.8526 | 0.8170 | 0.9509 | | 0.1216 | 2.0 ... | 86f216c95cb91cc8f6c2546d6a7e958a |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-ft1500_reg3 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.7954 - Mse: 0.7954 - Mae: 0.6900 - R2: 0.4769 - Accuracy: 0.4459 | 63af25cb62ee062ee024574650016aa2 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:| | 1.018 | 1.0 | 3122 | 0.7491 | 0.7491 | 0.6739 | 0.5073 | 0.4555 | | 0.668 | 2.0 | 6244 ... | 9bc9f40149d5b030dffee9c2b45d26ef |
apache-2.0 | ['generated_from_trainer'] | false | model_broadclass_onSet0 This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.9207 - 0 Precision: 1.0 - 0 Recall: 1.0 - 0 F1-score: 1.0 - 0 Support: 31 - 1 ... | ba650d0b4a021e482dda3132ccbc7be8 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 16 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_sche... | 6417d24f542023249ae949565cf57c0d |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | 0 Precision | 0 Recall | 0 F1-score | 0 Support | 1 Precision | 1 Recall | 1 F1-score | 1 Support | 2 Precision | 2 Recall | 2 F1-score | 2 Support | 3 Precision | 3 Recall | 3 F1-score | 3 Support | Accuracy | Macro avg Precision | Macro avg Recall ... | c366b41531a79fccdbbfa4ce28541f82 |
cc-by-sa-4.0 | ['asteroid', 'audio', 'ConvTasNet', 'audio-to-audio'] | false | Training config: ```yaml data: channels: 1 n_src: 2 root_path: data sample_rate: 16000 samples_per_track: 10 segment: 3.0 task: enh_both filterbank: kernel_size: 20 n_filters: 256 stride: 10 main_args: exp_dir: exp/train_convtasnet help: None masknet: bn_chan: 256 ... | a7e075d631fa9d1b4e012a4611811365 |
cc-by-sa-4.0 | ['asteroid', 'audio', 'ConvTasNet', 'audio-to-audio'] | false | Results: ```yaml si_sdr: 14.018196157142519 si_sdr_imp: 14.017103133809577 sdr: 14.498517291333885 sdr_imp: 14.463389151567865 sir: 24.149634529133372 sir_imp: 24.11450638936735 sar: 15.338597389045935 sar_imp: -137.30634122401517 stoi: 0.7639416744417206 stoi_imp: 0.1843383526963759 ``` | 2aba23e3b7604f0ae8a14baeff4dcc6b |
cc-by-sa-4.0 | ['asteroid', 'audio', 'ConvTasNet', 'audio-to-audio'] | false | License notice: This work "ConvTasNet_DAMP-VSEP_enhboth" is a derivative of DAMP-VSEP: Smule Digital Archive of Mobile Performances - Vocal Separation (Version 1.0.1) by Smule, Inc, used under Smule's Research Data License Agreement (Research only). "ConvTasNet_DAMP-VSEP_enhboth" is licensed under Attribution-ShareAli... | ae1b9f1abd001ee352d7b81deee41967 |
creativeml-openrail-m | ['text-to-image', 'stable-diffusion'] | false | maika Dreambooth model trained by birdaz with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusio... | a27ad891dc312fd9b7a4b41293767a18 |
apache-2.0 | ['text2text-generation'] | false | Hungarian morphological generator model with mT5 For further models, scripts and details, see [our demo site](https://juniper.nytud.hu/demo/nlp). - Pretrained model used: mT5 - Prefix: "morph: " - UD-based generation | 1ca39ea3ea941d683ca02641471fd88b |
apache-2.0 | ['text2text-generation'] | false | Usage with pipeline ```python from transformers import pipeline text2text_generator = pipeline(task="text2text-generation", model="NYTK/morphological-generator-ud-mt5-hungarian") print(text2text_generator("morph: munka NOUN Case=Acc|Number=Sin")[0]["generated_text"]) ``` | 41574c64f6d3e009f28da2ff31007274 |
apache-2.0 | ['text2text-generation'] | false | Citation If you use this model, please cite the following paper: ``` @inproceedings {morph-generator, title = {Neural Morphological Generators for Hungarian}, booktitle = {XIX. Magyar Számítógépes Nyelvészeti Konferencia (MSZNY 2023)}, year = {2023}, publisher = {Szegedi Tudományegyetem, Informatikai Intézet},... | 934f4dcf0ebc4a49a5097ef14d1c6959 |
apache-2.0 | ['exbert', 'multiberts', 'multiberts-seed-3'] | false | MultiBERTs Seed 3 Checkpoint 180k (uncased) Seed 3 intermediate checkpoint 180k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in [this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in [this repository](https://github.com/goo... | 8b6f2c192ec62e5cb643e95b13ec4f06 |
apache-2.0 | ['exbert', 'multiberts', 'multiberts-seed-3'] | false | How to use Here is how to use this model to get the features of a given text in PyTorch: ```python from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('multiberts-seed-3-180k') model = BertModel.from_pretrained("multiberts-seed-3-180k") text = "Replace me by any text you'd like.... | 07d3b61c9287cbe64ffb6282c7716b76 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset. It achieves the following results on the evaluation set: - Loss: 1.4214 | cd74f28b4d49e51ad76713f7526f07c0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.1814 | 1.0 | 8235 | 1.2488 | | 0.9078 | 2.0 | 16470 | 1.3127 | | 0.7439 | 3.0 | 24705 | 1.4214 | | 10437b58141bf7bd83a0540f0defc031 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Small Bengali This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 bn dataset. It achieves the following results on the evaluation set: - Loss: 0.1638 - Wer: 18.22 | b97b4659eac2aa2a634fdec5f8c90050 |
cc-by-sa-4.0 | ['text-classification', 'bart', 'xsum'] | false | Model description A BART (base) model trained to classify whether a summary is *faithful* to the original article. See our [paper in NAACL'21](https://www.seas.upenn.edu/~sihaoc/static/pdf/CZSR21.pdf) for details. | 754f9f3f5fcf0e07ff3cc9bf271bd5e1 |
cc-by-sa-4.0 | ['text-classification', 'bart', 'xsum'] | false | Usage Concatenate a summary and a source document as input (note that the summary needs to be the **first** sentence). Here's an example usage (with PyTorch) ```python from transformers import AutoTokenizer, AutoModelForSequenceClassification tokenizer = AutoTokenizer.from_pretrained("CogComp/bart-faithful-summar... | 784f6c1614e175e8cb1adb0e74eb876a |
cc-by-sa-4.0 | ['text-classification', 'bart', 'xsum'] | false | BibTeX entry and citation info ```bibtex @inproceedings{CZSR21, author = {Sihao Chen and Fan Zhang and Kazoo Sone and Dan Roth}, title = {{Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection}}, booktitle = {NAACL}, year = {2021} } ``` | fbf4c9e22005e0d7f3e8d9c1da37f452 |
apache-2.0 | ['translation'] | false | opus-mt-sv-kqn * source languages: sv * target languages: kqn * OPUS readme: [sv-kqn](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-kqn/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](http... | ed06bbc6ec027b330f7f7234bcaf6cfb |
apache-2.0 | ['automatic-speech-recognition', 'fr'] | false | exp_w2v2r_fr_xls-r_gender_male-10_female-0_s825 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure ... | 1d7e994e80283acf655347c3ff4270e1 |
apache-2.0 | ['setfit', 'sentence-transformers', 'text-classification'] | false | fathyshalab/massive_social-roberta-large-v1-5-7 This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves: 1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contra... | d5b9d6cffd85f4572436e172af3292b0 |
apache-2.0 | ['automatic-speech-recognition', 'fr'] | false | exp_w2v2r_fr_vp-100k_age_teens-8_sixties-2_s42 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using thi... | fab73bace9eacf2463e216dd64de24d8 |
unknown | [] | false | Samples <img src="https://huggingface.co/cyburn/daisy_labour_yak/resolve/main/1.jpg" alt="Map of positive probabilities per country." width="500"/> <img src="https://huggingface.co/cyburn/daisy_labour_yak/resolve/main/2.jpg" alt="Map of positive probabilities per country." width="500"/> <img src="https://huggingface.... | 46aca7d25a5095bf0cd894d31a502858 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:| | No log | 1.0 | 386 | 3.3464 | 17.6525 | 9.1043 | 16.6246 | 16.3747 | 12.35... | c625488633c2070033a3cfcf5a4cfcac |
apache-2.0 | ['generated_from_keras_callback'] | false | fassahat/distillbert-base-uncased-finetuned-150k-patent-sentences This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.2887 - Validation Loss: 0.4392 - Train Accur... | a4d57091caf9a6d18040da42ae6101e6 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 22500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'bet... | d094c420335bbe8eaf751748d0085077 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Train Accuracy | Epoch | |:----------:|:---------------:|:--------------:|:-----:| | 0.4810 | 0.4276 | 0.8330 | 0 | | 0.3714 | 0.4163 | 0.8415 | 1 | | 0.2887 | 0.4392 | 0.8414 | 2 | | e444123370fc2c2a7f60d8f8daa548e7 |
mit | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | MPNet NLI ***Note**: The same model trained with negatives yields better performance. [Find it here](https://huggingface.co/jamescalam/mpnet-snli-negatives).* This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for tas... | 83f569d5d14eba00de76ff67fe4a7251 |
mit | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Usage (Sentence-Transformers) Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed: ``` pip install -U sentence-transformers ``` Then you can use the model like this: ```python from sentence_transformers import SentenceTransformer sentences = ["This is an example sen... | 000616bcf9bb585a3078405683a1e49a |
mit | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Training The model was trained with the parameters: **DataLoader**: `sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 5731 with parameters: ``` {'batch_size': 32} ``` **Loss**: `sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with param... | a614dc1a089a5eb59710c0f04b904d2a |
mit | [] | false | cute cat on Stable Diffusion This is the `<cute-bear>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also tr... | 0646ca951e57fd7f3723837bd697a49c |
mit | [] | false | yesdelete on Stable Diffusion This is the `<yesdelete>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also t... | 38482b6118877d871fe930e643afa2c1 |
apache-2.0 | ['multiberts', 'multiberts-seed_0'] | false | MultiBERTs - Seed 0 MultiBERTs is a collection of checkpoints and a statistical library to support robust research on BERT. We provide 25 BERT-base models trained with similar hyper-parameters as [the original BERT model](https://github.com/google-research/bert) but with different random seeds, which causes variation... | c587a7d34884184140a312e62225a7d5 |
apache-2.0 | ['multiberts', 'multiberts-seed_0'] | false | How to use Using code from [BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on Tensorflow: ``` from transformers import BertTokenizer, TFBertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_0') model = TFBertModel.from_pretrained("google/multiberts-seed_0... | a6c8c320eb77036db63fbafaedbad691 |
openrail | [] | false | The mecha model needs low cfg, such as 3.5-7. Because the training set has only the upper body, it can only be partially stable, Forgive me for not doing well, Thanks to QQ friends for their long-term help and teaching. Thank you again Thank Mr. Lin for his training set BY昂扬 Use vae with high saturation Real mech... | 94004fcb8240d8a16e4580d445caa7a1 |
apache-2.0 | ['generated_from_trainer'] | false | wnli_bert-base-uncased_144_v2 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE WNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.7001 - Accuracy: 0.5634 | 2cabea52d1037d46ad162424738cb36c |
apache-2.0 | ['seq2seq', 'lm-head'] | false | Italian T5 Large 🇮🇹 The [IT5](https://huggingface.co/models?search=it5) model family represents the first effort in pretraining large-scale sequence-to-sequence transformer models for the Italian language, following the approach adopted by the original [T5 model](https://github.com/google-research/text-to-text-tran... | 34157b62c6415cb66a1310513731e627 |
apache-2.0 | ['seq2seq', 'lm-head'] | false | Model variants This repository contains the checkpoints for the `base` version of the model. The model was trained for one epoch (1.05M steps) on the [Thoroughly Cleaned Italian mC4 Corpus](https://huggingface.co/datasets/gsarti/clean_mc4_it) (~41B words, ~275GB) using 🤗 Datasets and the `google/t5-v1_1-large` impro... | da486cbb4f5caa24d209504e097fc9e7 |
apache-2.0 | ['seq2seq', 'lm-head'] | false | Using the models ```python from transformers import AutoTokenzier, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("gsarti/it5-large") model = AutoModelForSeq2SeqLM.from_pretrained("gsarti/it5-large") ``` *Note: You will need to fine-tune the model on your downstream seq2seq task to use it. See an e... | d9c18a2584db4569defdb6b306cdeb40 |
['apache-2.0'] | ['vision'] | false | Model description The Vision Transformer (ViT) is a transformer model pretrained on a large collection of images in a supervised fashion, namely [COYO-Labeled-300M](https://github.com/kakaobrain/coyo-dataset/tree/main/subset/COYO-Labeled-300M), at a resolution of 224x224 pixels. Images are presented to the model as... | b59b973b3dd22d98d5533306627054c6 |
apache-2.0 | ['generated_from_keras_callback'] | false | shaun-e-j/bert-finetuned-testing2-colab This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 5.9576 - Epoch: 4 | 6f8d4faaae9bf9dbabd7735445332c19 |
cc-by-4.0 | ['question generation'] | false | Model Card of `research-backup/t5-small-subjqa-vanilla-grocery-qg` This model is fine-tuned version of [t5-small](https://huggingface.co/t5-small) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: grocery) via [`lmqg`](https://github.com/asahi417/lm-que... | 1a9448f9192c606ff6c964985a8bd627 |
cc-by-4.0 | ['question generation'] | false | Overview - **Language model:** [t5-small](https://huggingface.co/t5-small) - **Language:** en - **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (grocery) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-gen... | f3dae3fde11e46ece6581fa933272538 |
cc-by-4.0 | ['question generation'] | false | model prediction questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "research-backup/t5-small-subjqa-v... | 541446897d2faeca81dd3839f31481fb |
cc-by-4.0 | ['question generation'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/t5-small-subjqa-vanilla-grocery-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json) | | Score | Type | Dataset ... | 27b242222361b93a667c096370789bf1 |
cc-by-4.0 | ['question generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_subjqa - dataset_name: grocery - input_types: ['paragraph_answer'] - output_types: ['question'] - prefix_types: ['qg'] - model: t5-small - max_length: 512 - max_length_output: 32 - epoch: 3 - batch: ... | 80eab7fe66bdf998829fa420c14ffcbe |
apache-2.0 | ['vision', 'image-classification'] | false | Convolutional Vision Transformer (CvT) CvT-13 model pre-trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Wu et al. and first released in [this repository](https://github.com/microsoft/CvT). Discla... | 96b71485c421571b9a4d5211e985bc14 |
apache-2.0 | ['vision', 'image-classification'] | false | Usage Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes: ```python from transformers import AutoFeatureExtractor, CvtForImageClassification from PIL import Image import requests url = 'http://images.cocodataset.org/val2017/000000039769.jpg' image = Im... | d97aef9176509d2bf850712c029a0103 |
apache-2.0 | ['generated_from_keras_callback'] | false | Hardik1313X/bert-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.0279 - Validation Loss: 0.0571 - Epoch: 2 | 07a4a447ff0e5e612c39c23fa98902c9 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 0.1745 | 0.0630 | 0 | | 0.0468 | 0.0578 | 1 | | 0.0279 | 0.0571 | 2 | | f4f13e29f80b675c26b68f3ae723c3af |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | XLM-RoBERTa base Universal Dependencies v2.8 POS tagging: Finnish This model is part of our paper called: - Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages Check the [Space](https://huggingface.co/spaces/wietsedv/xpos) for more details. | 2167a1eefe2045c1bd12aaa676cae598 |
apache-2.0 | ['part-of-speech', 'token-classification'] | false | Usage ```python from transformers import AutoTokenizer, AutoModelForTokenClassification tokenizer = AutoTokenizer.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-fi") model = AutoModelForTokenClassification.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-fi") ``` | 084c7bf2919354714b3f72d8c4e9c288 |
apache-2.0 | [] | false | *Text classification model SloBERTa-Trendi-Topics 1.0* The SloBerta-Trendi-Topics model is a text classification model for categorizing news texts with one of 13 topic labels. It was trained on a set of approx. 36,000 Slovene texts from various Slovene news sources included in the Trendi Monitor Corpus of Slovene (htt... | beb07806afbb40f4f4ae14233f0dca9b |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | **m**utual **i**nformation **C**ontrastive **S**entence **E**mbedding (**miCSE**): [](https://arxiv.org/abs/2211.04928) Language model of the pre-print arXiv paper titled: "_**miCSE**: Mutual Information Contrastive Learning for Low-shot Sentence Embedd... | b1690839e1e02ae64a1eebc1bbac8377 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Brief Model Description The **miCSE** language model is trained for sentence similarity computation. Training the model imposes alignment between the attention pattern of different views (embeddings of augmentations) during contrastive learning. Intuitively, learning sentence embeddings with miCSE entails enforcing __... | e2a9e5265e9c31acd05281a00cf14106 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Model Use Cases The model intended to be used for encoding sentences or short paragraphs. Given an input text, the model produces a vector embedding capturing the semantics. Sentence representations correspond to embedding of the _**[CLS]**_ token. The embedding can be used for numerous tasks such as **retrieval**,**s... | e7398c9b1bec9335375aa6fc0ae1677d |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Training data The model was trained on a random collection of **English** sentences from Wikipedia: [Training data file](https://huggingface.co/datasets/princeton-nlp/datasets-for-simcse/resolve/main/wiki1m_for_simcse.txt) | 0666d60ed8fb18e69cb6381e9a3e0509 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Model Training <mark>In order to make use of the **few-shot** capability of **miCSE**, the mode needs to be trained on your data. The source code and instructions to do so will be provided shortly. Stay tuned :). </mark> | ca128041a18b678820cd0222ef1573e8 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Example 1) - Sentence Similarity <details> <summary> Click to expand </summary> ```python from transformers import AutoTokenizer, AutoModel import torch.nn as nn tokenizer = AutoTokenizer.from_pretrained("sap-ai-research/miCSE") model = AutoModel.from_pretrained("sap-ai-research/miCSE") | 0b8094fad91c29373f6f09f6c6e89f27 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Encoding of sentences in a list with a predefined maximum lengths of tokens (max_length) max_length = 32 sentences = [ "This is a sentence for testing miCSE.", "This is yet another test sentence for the mutual information Contrastive Sentence Embeddings model." ] batch = tokenizer.batch_encode_plus( ... | 62c3cdbed5cf1a2ad3300994efdebc36 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Compute similarity between the **first** and the **second** sentence cos_sim = sim(embeddings.unsqueeze(1), embeddings.unsqueeze(0)) print(f"Distance: {cos_sim[0,1].detach().item()}") ``` </details> | d3c5796b74e39b414730a8b4c3d28375 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Example 2) - Clustering <details> <summary> Click to expand </summary> ```python from transformers import AutoTokenizer, AutoModel import torch.nn as nn import torch import numpy as np import tqdm from datasets import load_dataset import umap import umap.plot as umap_plot | 17224847cd5a72de6979dcea1d65ecf1 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Determine available hardware if torch.backends.mps.is_available(): device = torch.device("mps") elif torch.cuda.is_available(): device = torch.device("cuda") else: device = torch.device("cpu") | 753a2d6626599c2332ed84a36801b2c7 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | set batch size and maxium tweet token length batch_size = 50 max_length = 128 iterations = int(np.floor(len(dataset['train'])/batch_size))*batch_size embedding_stack = [] classes = [] for i in tqdm.notebook.tqdm(range(0,iterations,batch_size)): | 91ed6b12cd072d3e74b9b1ace66c0881 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | create batch batch = tokenizer.batch_encode_plus( dataset['train'][i:i+batch_size]['text'], return_tensors='pt', padding=True, max_length=max_length, truncation=True ).to(device) classes = classe... | 01f50cc4abf7f8458c9386a06beea191 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | model inference without gradient with torch.no_grad(): outputs = model(**batch, output_hidden_states=True, return_dict=True) embeddings = outputs.last_hidden_state[:,0] embedding_stack.append( embeddings.cpu().clone() ) embeddings = torch.vstack(embedding_stack) ... | 6c901ba53139c848e2750794bb52f14d |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Cluster embeddings in 2D with UMAP umap_model = umap.UMAP(n_neighbors=250, n_components=2, min_dist=1.0e-9, low_memory=True, angular_rp_forest=True, metric='cosine') umap_model.fit(embeddings) | df9f938f373c759779b1325026591fd0 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Plot result umap_plot.points(umap_model, labels = np.array(classes),theme='fire') ``` 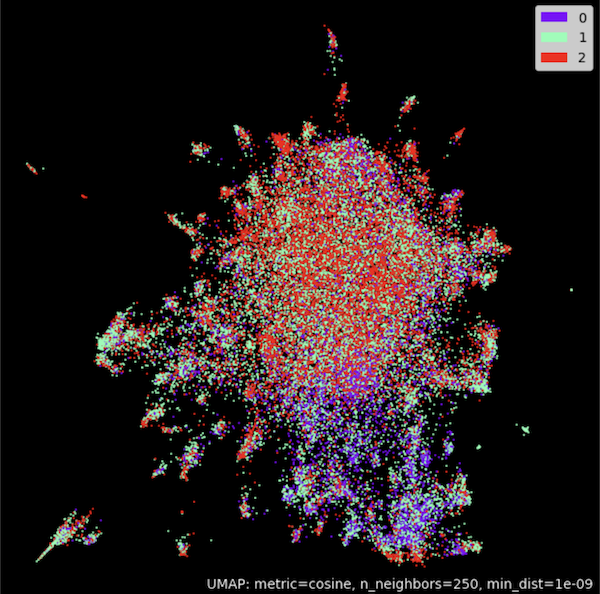 </details> | 2561957cb17c2471ad6957ba7f4b6ed1 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Example 3) - Using [SentenceTransformers](https://www.sbert.net/) <details> <summary> Click to expand </summary> ```python from sentence_transformers import SentenceTransformer, util from sentence_transformers import models import torch.nn as nn | cd836bb4ccc4e9773619a3f6b2cc4992 |
apache-2.0 | ['feature-extraction', 'sentence-similarity'] | false | Using the model with [CLS] embeddings model_name = 'sap-ai-research/miCSE' word_embedding_model = models.Transformer(model_name, max_seq_length=32) pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension()) model = SentenceTransformer(modules=[word_embedding_model, pooling_model]) | 6866ad14dfed4a4650aa0c8742832128 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.