
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 - mixed_precision_training: Native AMP | c9e6261c50da9969e5996f08afd256fd |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.0458 | 1.0 | 9376 | 0.9283 | | 0.9423 | 2.0 | 18752 | 0.8607 | | 0.9013 | 3.0 | 28128 | 0.8435 | | f83ef7b1fccfc4a9755047044ccf7612 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Model Card of `lmqg/bart-base-squad-qg-ae` This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation and answer extraction jointly on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | a1472de192bc46e982c02b5518176dc4 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Overview - **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base) - **Language:** en - **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | bf968088908442f70435c57cdcd9581d |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | model prediction question_answer_pairs = model.generate_qa("William Turner was an English painter who specialised in watercolour landscapes") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/bart-base-squad-qg-ae") | 9a4fd0cd1941032cd910c09969846d3f |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:-----------|--------:|:--------|:---------------------------------------------------------------| | BERTScore | 90.65 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_1 | 56.53 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_2 | 40.97 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_3 | 31.71 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_4 | 25.07 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | METEOR | 25.87 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | MoverScore | 64.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | ROUGE_L | 52.79 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | - ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:---------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 93.45 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedF1Score (MoverScore) | 64.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (BERTScore) | 92.78 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedPrecision (MoverScore) | 63.55 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (BERTScore) | 94.14 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | QAAlignedRecall (MoverScore) | 65.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | - ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:-----------------|--------:|:--------|:---------------------------------------------------------------| | AnswerExactMatch | 57.58 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | AnswerF1Score | 69.14 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | BERTScore | 91.86 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_1 | 65.9 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_2 | 63.06 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_3 | 60.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_4 | 58.31 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | METEOR | 41.39 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | MoverScore | 81.95 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | ROUGE_L | 68.38 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | a9906f165f86d48fa9bede823bc5e666 |
cc-by-4.0 | ['question generation', 'answer extraction'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_squad - dataset_name: default - input_types: ['paragraph_answer', 'paragraph_sentence'] - output_types: ['question', 'answer'] - prefix_types: ['qg', 'ae'] - model: facebook/bart-base - max_length: 512 - max_length_output: 32 - epoch: 3 - batch: 32 - lr: 5e-05 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 4 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-base-squad-qg-ae/raw/main/trainer_config.json). | 4768a74a95753bb79d6f7d416c683059 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mt', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MT dataset. It achieves the following results on the evaluation set: - Loss: 0.1987 - Wer: 0.1920 | 22d59a7d5f32280f68ec166848229341 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mt', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Evaluation Commands 1. To evaluate on mozilla-foundation/common_voice_8_0 with test split python eval.py --model_id DrishtiSharma/wav2vec2-xls-r-300m-mt-o1 --dataset mozilla-foundation/common_voice_8_0 --config mt --split test --log_outputs 2. To evaluate on speech-recognition-community-v2/dev_data Maltese language not found in speech-recognition-community-v2/dev_data! | e55fe4b11368e5c0ad335d3b3bc4a7f7 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mt', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 7e-05 - train_batch_size: 32 - eval_batch_size: 1 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 2000 - num_epochs: 100.0 - mixed_precision_training: Native AMP | 91891b3f4ef4bf62e0caeb707831efe1 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mt', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 1.1721 | 18.02 | 2000 | 0.3831 | 0.4066 | | 0.7849 | 36.04 | 4000 | 0.2191 | 0.2417 | | 0.6723 | 54.05 | 6000 | 0.2056 | 0.2134 | | 0.6015 | 72.07 | 8000 | 0.2008 | 0.2031 | | 0.5386 | 90.09 | 10000 | 0.1967 | 0.1953 | | aebe1f406693f0fb3d78d5eda035400b |
apache-2.0 | ['translation'] | false | opus-mt-bem-fi * source languages: bem * target languages: fi * OPUS readme: [bem-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/bem-fi/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/bem-fi/opus-2020-01-08.zip) * test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/bem-fi/opus-2020-01-08.test.txt) * test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/bem-fi/opus-2020-01-08.eval.txt) | 61ae6ad3dda410dd18b35ef3d342ba91 |
mit | ['stable-diffusion', 'text-to-image'] | false | Usage To use this model you have to download the .ckpt file as well as drop it into the "\stable-diffusion-webui\models\Stable-diffusion" folder To use it in a prompt: ```"Mona woman"``` for highest strength or just "Mona" To increase the strength put "Mona woman" in () brackets To decrease the strength put "Mona woman" in [] brackets Waifu_diffusion base trained model trained to 4,000 steps Have fun :) | 0433a5425d8c69ee43c541e26db6c4fb |
mit | ['stable-diffusion', 'text-to-image'] | false | Example Pictures from Mona_4k <table> <tr> <td><img src=https://i.imgur.com/acDDsQZ.png width=150% height=150%/></td> <td><img src=https://i.imgur.com/15PnKDf.png width=100% height=100%/></td> <td><img src=https://i.imgur.com/PWxazM1.png width=150% height=150%/></td> </tr> </table> | 4a42fc51518c0ee20a53766e843f7d8f |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | Model Overview This repository contains the code for Swin UNETR [1,2]. Swin UNETR is the state-of-the-art on Medical Segmentation Decathlon (MSD) and Beyond the Cranial Vault (BTCV) Segmentation Challenge dataset. In [1], a novel methodology is devised for pre-training Swin UNETR backbone in a self-supervised manner. We provide the option for training Swin UNETR by fine-tuning from pre-trained self-supervised weights or from scratch. The source repository for the training of these models can be found [here](https://github.com/Project-MONAI/research-contributions/tree/main/SwinUNETR/BTCV). | f1e710c2114f377d4fd5e095ac953c5e |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | Intended uses & limitations You can use the raw model for dicom segmentation, but it's mostly intended to be fine-tuned on a downstream task. Note that this model is primarily aimed at being fine-tuned on tasks which segment CAT scans or MRIs on images in dicom format. Dicom meta data mostly differs across medical facilities, so if applying to a new dataset, the model should be finetuned. | a99fdac498510bc65c7548dc9b61492e |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | How to use To install necessary dependencies, run the below in bash. ``` git clone https://github.com/darraghdog/Project-MONAI-research-contributions pmrc pip install -r pmrc/requirements.txt cd pmrc/SwinUNETR/BTCV ``` To load the model from the hub. ``` >>> from swinunetr import SwinUnetrModelForInference >>> model = SwinUnetrModelForInference.from_pretrained('darragh/swinunetr-btcv-tiny') ``` | e8a3dae2440d679fb4861b150e06d6ba |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | Limitations and bias The training data used for this model is specific to CAT scans from certain health facilities and machines. Data from other facilities may difffer in image distributions, and may require finetuning of the models for best performance. | 9b1be4d2bfafd4f7d3a5ef71b03af114 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | Evaluation results We provide several pre-trained models on BTCV dataset in the following. <table> <tr> <th>Name</th> <th>Dice (overlap=0.7)</th> <th>Dice (overlap=0.5)</th> <th>Feature Size</th> <th> | d89896a9a049c3f3b28663f372c9e8f2 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | params (M)</th> <th>Self-Supervised Pre-trained </th> </tr> <tr> <td>Swin UNETR/Base</td> <td>82.25</td> <td>81.86</td> <td>48</td> <td>62.1</td> <td>Yes</td> </tr> <tr> <td>Swin UNETR/Small</td> <td>79.79</td> <td>79.34</td> <td>24</td> <td>15.7</td> <td>No</td> </tr> <tr> <td>Swin UNETR/Tiny</td> <td>72.05</td> <td>70.35</td> <td>12</td> <td>4.0</td> <td>No</td> </tr> </table> | 723add92240210ea1a2e20deccfa1ea3 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | Data Preparation 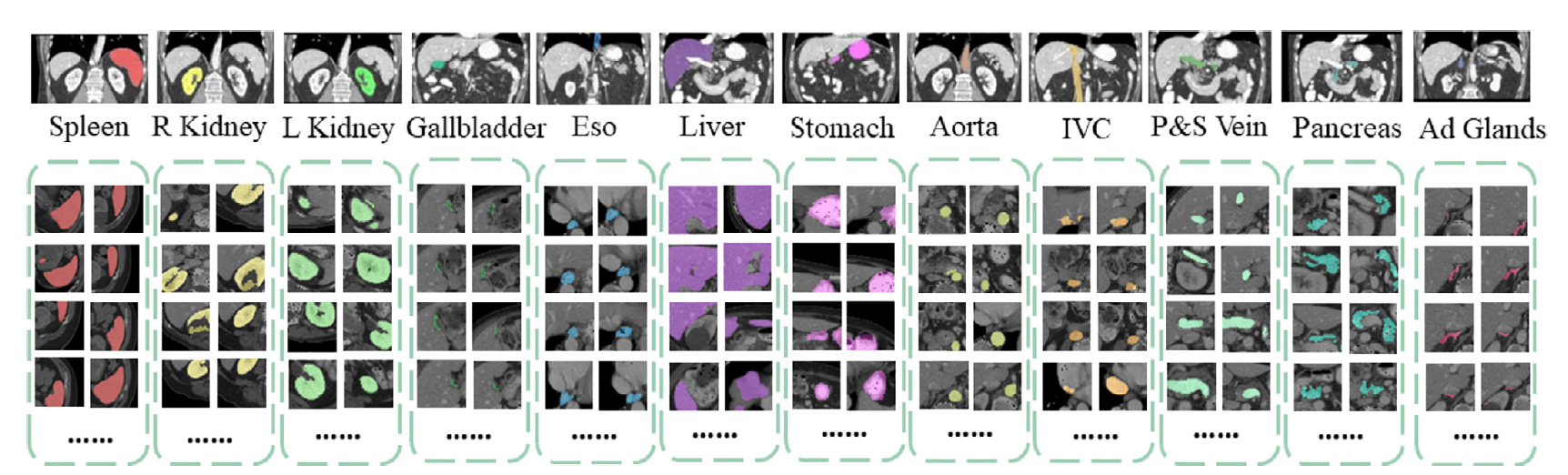 The training data is from the [BTCV challenge dataset](https://www.synapse.org/ | 68814859e2fbfc1bf03150ba5a535ab5 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | !Synapse:syn3193805/wiki/217752). - Target: 13 abdominal organs including 1. Spleen 2. Right Kidney 3. Left Kideny 4.Gallbladder 5.Esophagus 6. Liver 7. Stomach 8.Aorta 9. IVC 10. Portal and Splenic Veins 11. Pancreas 12.Right adrenal gland 13.Left adrenal gland. - Task: Segmentation - Modality: CT - Size: 30 3D volumes (24 Training + 6 Testing) | 026ab6977d58e383003f30fe4fe9fd66 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | BibTeX entry and citation info If you find this repository useful, please consider citing the following papers: ``` @inproceedings{tang2022self, title={Self-supervised pre-training of swin transformers for 3d medical image analysis}, author={Tang, Yucheng and Yang, Dong and Li, Wenqi and Roth, Holger R and Landman, Bennett and Xu, Daguang and Nath, Vishwesh and Hatamizadeh, Ali}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={20730--20740}, year={2022} } @article{hatamizadeh2022swin, title={Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images}, author={Hatamizadeh, Ali and Nath, Vishwesh and Tang, Yucheng and Yang, Dong and Roth, Holger and Xu, Daguang}, journal={arXiv preprint arXiv:2201.01266}, year={2022} } ``` | b3d77aff94f0942dfc3699209dd9ff18 |
apache-2.0 | ['btcv', 'medical', 'swin'] | false | References [1]: Tang, Y., Yang, D., Li, W., Roth, H.R., Landman, B., Xu, D., Nath, V. and Hatamizadeh, A., 2022. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20730-20740). [2]: Hatamizadeh, A., Nath, V., Tang, Y., Yang, D., Roth, H. and Xu, D., 2022. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv preprint arXiv:2201.01266. | 6f84f29a405608af4f2141bfbac8ec51 |
mit | [] | false | SunFish on Stable Diffusion This is the `<SunFish>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:              | b346538f8efe1d17b6794071f682b7e6 |
cc-by-4.0 | ['questions and answers generation'] | false | Model Card of `lmqg/flan-t5-small-squad-qag` This model is fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) for question & answer pair generation task on the [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | 379cc2ecdbdf461788b2695c7e22d554 |
cc-by-4.0 | ['questions and answers generation'] | false | Overview - **Language model:** [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) - **Language:** en - **Training data:** [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) (default) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | 33557e2711cf16cabb17e3c93c0d7092 |
cc-by-4.0 | ['questions and answers generation'] | false | model prediction question_answer_pairs = model.generate_qa("William Turner was an English painter who specialised in watercolour landscapes") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/flan-t5-small-squad-qag") output = pipe("generate question and answer: Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.") ``` | c769708ccbcbfe4f8f06436c085b0865 |
cc-by-4.0 | ['questions and answers generation'] | false | Evaluation - ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/flan-t5-small-squad-qag/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qag_squad.default.json) | | Score | Type | Dataset | |:--------------------------------|--------:|:--------|:-----------------------------------------------------------------| | QAAlignedF1Score (BERTScore) | 92.3 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | QAAlignedF1Score (MoverScore) | 63.74 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | QAAlignedPrecision (BERTScore) | 92.92 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | QAAlignedPrecision (MoverScore) | 65.5 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | QAAlignedRecall (BERTScore) | 91.71 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | QAAlignedRecall (MoverScore) | 62.2 | default | [lmqg/qag_squad](https://huggingface.co/datasets/lmqg/qag_squad) | | e87d0c6867f9c6bf1552cc784b229673 |
cc-by-4.0 | ['questions and answers generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qag_squad - dataset_name: default - input_types: ['paragraph'] - output_types: ['questions_answers'] - prefix_types: ['qag'] - model: google/flan-t5-small - max_length: 512 - max_length_output: 256 - epoch: 14 - batch: 16 - lr: 0.0001 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 4 - label_smoothing: 0.0 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/flan-t5-small-squad-qag/raw/main/trainer_config.json). | 3c0c08962d7cd769f7c981257874382b |
apache-2.0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | false | Whisper Small - Swedish This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset. It achieves the following results on the evaluation set: - Loss: 0.4312 - Wer: 19.0503 | 3d2f5bbf6a572f3aa1d60e86ea194f08 |
apache-2.0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 4 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 16 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 18000 - mixed_precision_training: Native AMP | a972c324fba9f9f17d84646fcf072f7b |
apache-2.0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:-------:| | 0.0887 | 1.71 | 2000 | 0.2817 | 21.0831 | | 0.0168 | 3.41 | 4000 | 0.3108 | 19.6338 | | 0.0027 | 5.12 | 6000 | 0.3421 | 19.8731 | | 0.0012 | 6.83 | 8000 | 0.3713 | 19.1229 | | 0.0005 | 8.53 | 10000 | 0.3844 | 19.2036 | | 0.0004 | 10.24 | 12000 | 0.3900 | 19.0369 | | 0.0008 | 11.94 | 14000 | 0.4161 | 19.9511 | | 0.0002 | 13.65 | 16000 | 0.4201 | 19.1283 | | 0.0001 | 15.36 | 18000 | 0.4312 | 19.0503 | | 8a150ac96e272c6b4b4a8128a0e99bfd |
apache-2.0 | ['translation'] | false | opus-mt-gil-en * source languages: gil * target languages: en * OPUS readme: [gil-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/gil-en/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/gil-en/opus-2020-01-20.zip) * test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/gil-en/opus-2020-01-20.test.txt) * test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/gil-en/opus-2020-01-20.eval.txt) | b120855957b603e747f6097855603bc8 |
cc-by-sa-4.0 | ['legal'] | false | Legal-CamemBERT * Legal-CamemBERT is a [CamemBERT](https://huggingface.co/camembert-base)-based model further pre-trained on [23,000+ statutory articles](https://huggingface.co/datasets/maastrichtlawtech/bsard) from the Belgian legislation. * We chose the following training set-up: 50k training steps (200 epochs) with batches of 32 sequences of length 512 with an initial learning rate of 5e-5. * Training was performed on one Tesla V100 GPU with 32 GB using the [code](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm.py) provided by Hugging Face. --- | 5973b513a4cd8c721c9b425f21558126 |
cc-by-sa-4.0 | ['legal'] | false | Load Pretrained Model ```python from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("maastrichtlawtech/legal-camembert") model = AutoModel.from_pretrained("maastrichtlawtech/legal-camembert") ``` | 3c766aca262ce6e4d4319b40d4f7890c |
mit | ['generated_from_trainer'] | false | model_from_berturk_1401_v2 This model is a fine-tuned version of [Buseak/model_from_berturk_1401](https://huggingface.co/Buseak/model_from_berturk_1401) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1542 - Precision: 0.9414 - Recall: 0.9356 - F1: 0.9385 - Accuracy: 0.9569 | 9382a242ae455e427870c286fe0e5bb5 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4 | b4e51d5ff72b01f81a5e1d816ed21029 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 244 | 0.2277 | 0.9129 | 0.9058 | 0.9094 | 0.9362 | | No log | 2.0 | 488 | 0.1855 | 0.9275 | 0.9204 | 0.9240 | 0.9472 | | 0.2477 | 3.0 | 732 | 0.1602 | 0.9403 | 0.9315 | 0.9359 | 0.9554 | | 0.2477 | 4.0 | 976 | 0.1542 | 0.9414 | 0.9356 | 0.9385 | 0.9569 | | 9a154998b2e3aabf2a000d3f920be6c4 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-large-xls-r-300m-tr This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 0.4074 - Wer: 0.4227 | ad6c3961b6d4d09157549c4c75837b8e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 3.9399 | 4.21 | 400 | 0.7252 | 0.7387 | | 0.4147 | 8.42 | 800 | 0.4693 | 0.5201 | | 0.1855 | 12.63 | 1200 | 0.4584 | 0.4848 | | 0.1256 | 16.84 | 1600 | 0.4464 | 0.4708 | | 0.0948 | 21.05 | 2000 | 0.4261 | 0.4389 | | 0.0714 | 25.26 | 2400 | 0.4331 | 0.4349 | | 0.0532 | 29.47 | 2800 | 0.4074 | 0.4227 | | 60c9a4ef2a96c765fd8678ebe079775c |
apache-2.0 | ['generated_from_trainer'] | false | vit-model-juan-bula This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset. It achieves the following results on the evaluation set: - Loss: 0.0077 - Accuracy: 1.0 | 4032cf857dc8844a7e33399413669072 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.0067 | 3.85 | 500 | 0.0077 | 1.0 | | c4f9626971c6422904026f6439911d30 |
apache-2.0 | ['generated_from_trainer'] | false | chinese-bert-wwm-finetuned-chnsenticorp This model is a fine-tuned version of [hfl/chinese-bert-wwm](https://huggingface.co/hfl/chinese-bert-wwm) on a small subset of chnsenticorp dataset. It achieves the following results on the evaluation set: - Loss: 3.0868 | e516c9958363499bdfef6ea922cee6ed |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 5 - eval_batch_size: 5 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 10 | 20c8457624501e09f29c0ba06b9a4eaf |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 1.0096 | 1.0 | 15 | 3.7742 | | 1.7336 | 2.0 | 30 | 3.9102 | | 2.5286 | 3.0 | 45 | 3.4744 | | 2.8892 | 4.0 | 60 | 3.1142 | | 2.7188 | 5.0 | 75 | 2.7622 | | 2.7923 | 6.0 | 90 | 3.1119 | | 2.4094 | 7.0 | 105 | 3.0426 | | 2.5928 | 8.0 | 120 | 2.8928 | | 2.4072 | 9.0 | 135 | 2.9462 | | 2.4349 | 10.0 | 150 | 2.7645 | | 83189427a5c3bfb923689e41c22a7e90 |
apache-2.0 | ['object-detection', 'computer-vision', 'yolox', 'yolov3', 'yolov5'] | false | Model Description [YOLOX](https://arxiv.org/abs/2107.08430) is a high-performance anchor-free YOLO, exceeding yolov3~v5 with MegEngine, ONNX, TensorRT, ncnn, and OpenVINO supported. [YOLOXDetect-Pip](https://github.com/kadirnar/yolox-pip/): This repo is a packaged version of the [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX) for easy installation and use. [Paper Repo]: Implementation of paper - [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX) | 894eec2acf1d934d066ce3fbf1be6ebc |
apache-2.0 | ['object-detection', 'computer-vision', 'yolox', 'yolov3', 'yolov5'] | false | Yolox Inference ```python from yoloxdetect import YoloxDetector from yolox.data.datasets import COCO_CLASSES model = YoloxDetector( model_path = "kadirnar/yolox_x-v0.1.1", config_path = "configs.yolox_x", device = "cuda:0", hf_model=True ) model.classes = COCO_CLASSES model.conf = 0.25 model.iou = 0.45 model.show = False model.save = True pred = model.predict(image='data/images', img_size=640) ``` | 4d6e752cd307b886c37a8362ac8429a5 |
apache-2.0 | ['object-detection', 'computer-vision', 'yolox', 'yolov3', 'yolov5'] | false | BibTeX Entry and Citation Info ``` @article{yolox2021, title={YOLOX: Exceeding YOLO Series in 2021}, author={Ge, Zheng and Liu, Songtao and Wang, Feng and Li, Zeming and Sun, Jian}, journal={arXiv preprint arXiv:2107.08430}, year={2021} } ``` | 85c1803a64c2a9cb7e4174294992a5f8 |
apache-2.0 | ['translation'] | false | opus-mt-sv-mt * source languages: sv * target languages: mt * OPUS readme: [sv-mt](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-mt/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-mt/opus-2020-01-16.zip) * test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-mt/opus-2020-01-16.test.txt) * test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-mt/opus-2020-01-16.eval.txt) | b57bfc5312ed8b95e26db5d58dda69c1 |
apache-2.0 | ['automatic-speech-recognition', 'th'] | false | exp_w2v2t_th_xlsr-53_s218 Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition on Thai using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | df5cdf11e7bd240dd051fc13c618fcb1 |
mit | ['generated_from_trainer'] | false | bert-base-german-cased-issues-128-finetuned This model is a fine-tuned version of [ogimgio/bert-base-german-cased-issues-128](https://huggingface.co/ogimgio/bert-base-german-cased-issues-128) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.3858 - Micro f1: 0.6157 - Macro f1: 0.5597 | 45d8bd39ee2e1c379cd8fe4792576b2f |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 3e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: constant - num_epochs: 2 | fd2c3e9bd110c61d0b8e66ed1c50828f |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Micro f1 | Macro f1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:| | 0.4741 | 1.0 | 102 | 0.4254 | 0.5535 | 0.4051 | | 0.3799 | 2.0 | 204 | 0.3858 | 0.6157 | 0.5597 | | aaeb81632d45cdc4767a6db92eda93c5 |
apache-2.0 | ['generated_from_trainer'] | false | small-mlm-rotten_tomatoes This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.4233 | f84180d47c36e47c2f1f0c2473ed0e63 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 3.944 | 0.47 | 500 | 3.7349 | | 3.8232 | 0.94 | 1000 | 3.5014 | | 3.6092 | 1.41 | 1500 | 3.4616 | | 3.6009 | 1.87 | 2000 | 3.5919 | | 3.5219 | 2.34 | 2500 | 3.4356 | | 3.4291 | 2.81 | 3000 | 3.4680 | | 3.3769 | 3.28 | 3500 | 3.4817 | | 3.3216 | 3.75 | 4000 | 3.4055 | | 3.3562 | 4.22 | 4500 | 3.4558 | | 3.2755 | 4.69 | 5000 | 3.4803 | | 3.2044 | 5.15 | 5500 | 3.3968 | | 3.2438 | 5.62 | 6000 | 3.4400 | | 3.2322 | 6.09 | 6500 | 3.4033 | | 3.0966 | 6.56 | 7000 | 3.3795 | | 3.1239 | 7.03 | 7500 | 3.4509 | | 3.0585 | 7.5 | 8000 | 3.3826 | | 2.9747 | 7.97 | 8500 | 3.4233 | | 80a484fdb51b9a4a1d488093638205a9 |
gpl-2.0 | ['corenlp'] | false | Core NLP model for german CoreNLP is your one stop shop for natural language processing in Java! CoreNLP enables users to derive linguistic annotations for text, including token and sentence boundaries, parts of speech, named entities, numeric and time values, dependency and constituency parses, coreference, sentiment, quote attributions, and relations. Find more about it in [our website](https://stanfordnlp.github.io/CoreNLP) and our [GitHub repository](https://github.com/stanfordnlp/CoreNLP). This card and repo were automatically prepared with `hugging_corenlp.py` in the `stanfordnlp/huggingface-models` repo Last updated 2023-01-21 01:37:19.688 | f23187c090de97a6c07af7dedba6c978 |
apache-2.0 | ['generated_from_trainer'] | false | distilBERT-fresh This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1444 - Precision: 0.0 - Recall: 0.0 - F1: 0.0 - Accuracy: 0.9489 | b210ce2479a2f926b772bced761cea04 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | dd7136b90826cff97158de168c00fe8b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:| | No log | 1.0 | 174 | 0.1957 | 0.0 | 0.0 | 0.0 | 0.9289 | | No log | 2.0 | 348 | 0.1591 | 0.0 | 0.0 | 0.0 | 0.9438 | | 0.2272 | 3.0 | 522 | 0.1444 | 0.0 | 0.0 | 0.0 | 0.9489 | | 3fe6b1b17b4d43979602cbd4f548ac1c |
cc-by-4.0 | ['generated_from_trainer'] | false | bert-large-uncased-whole-word-masking-squad2-with-ner-mit-restaurant-with-neg-with-repeat This model is a fine-tuned version of [deepset/bert-large-uncased-whole-word-masking-squad2](https://huggingface.co/deepset/bert-large-uncased-whole-word-masking-squad2) on the squad_v2 and the mit_restaurant datasets. | 409cf49ba71d00a03e0e57ec9cda09fc |
cc-by-4.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 1 - eval_batch_size: 1 - seed: 42 - gradient_accumulation_steps: 16 - total_train_batch_size: 16 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5 | 88b660db4cdbd68371ed380d4552b69e |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset. It achieves the following results on the evaluation set: - Loss: 3.7677 | 66c3eefc613c64bcc0efad3849c8e2bb |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 63 | 4.1121 | | No log | 2.0 | 126 | 3.8248 | | No log | 3.0 | 189 | 3.7677 | | 143e4d7cc84abacfbe4d260cfe193b32 |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | wav2vec 2.0 with CTC/Attention trained on DVoice Wolof (No LM) This repository provides all the necessary tools to perform automatic speech recognition from an end-to-end system pretrained on a [ALFFA](https://github.com/besacier/ALFFA_PUBLIC) Wolof dataset within SpeechBrain. For a better experience, we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io). | DVoice Release | Val. CER | Val. WER | Test CER | Test WER | |:-------------:|:---------------------------:| -----:| -----:| -----:| | v2.0 | 4.81 | 16.25 | 4.83 | 16.05 | | ab8a4a83e5a0106fd723f4495a7418b7 |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | Pipeline description This ASR system is composed of 2 different but linked blocks: - Tokenizer (unigram) that transforms words into subword units and trained with the train transcriptions. - Acoustic model (wav2vec2.0 + CTC). A pretrained wav2vec 2.0 model ([facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)) is combined with two DNN layers and finetuned on the Darija dataset. The obtained final acoustic representation is given to the CTC greedy decoder. The system is trained with recordings sampled at 16kHz (single channel). The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *transcribe_file* if needed. | 3ed9acf4282d652af512ad1aafa4c12e |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | Install SpeechBrain First of all, please install tranformers and SpeechBrain with the following command: ``` pip install speechbrain transformers ``` Please notice that we encourage you to read the SpeechBrain tutorials and learn more about [SpeechBrain](https://speechbrain.github.io). | 8f7e35fee9ab27b7d5bf315cc72458b5 |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | Transcribing your own audio files (in Wolof) ```python from speechbrain.pretrained import EncoderASR asr_model = EncoderASR.from_hparams(source="aioxlabs/dvoice-wolof", savedir="pretrained_models/asr-wav2vec2-dvoice-wol") asr_model.transcribe_file('./the_path_to_your_audio_file') ``` | a115619c8efc7779fd6b4e5be6d7d3ae |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | Referencing SpeechBrain ``` @misc{SB2021, author = {Ravanelli, Mirco and Parcollet, Titouan and Rouhe, Aku and Plantinga, Peter and Rastorgueva, Elena and Lugosch, Loren and Dawalatabad, Nauman and Ju-Chieh, Chou and Heba, Abdel and Grondin, Francois and Aris, William and Liao, Chien-Feng and Cornell, Samuele and Yeh, Sung-Lin and Na, Hwidong and Gao, Yan and Fu, Szu-Wei and Subakan, Cem and De Mori, Renato and Bengio, Yoshua }, title = {SpeechBrain}, year = {2021}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {\\\\url{https://github.com/speechbrain/speechbrain}}, } ``` | 1861821dd5bc48566e73e54c6866f758 |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | About DVoice DVoice is a community initiative that aims to provide Africa low resources languages with data and models to facilitate their use of voice technologies. The lack of data on these languages makes it necessary to collect data using methods that are specific to each one. Two different approaches are currently used: the DVoice platforms ([https://dvoice.ma](https://dvoice.ma) and [https://dvoice.sn](https://dvoice.sn)), which are based on Mozilla Common Voice, for collecting authentic recordings from the community, and transfer learning techniques for automatically labeling recordings that are retrived from social medias. The DVoice platform currently manages 7 languages including Darija (Moroccan Arabic dialect) whose dataset appears on this version, Wolof, Mandingo, Serere, Pular, Diola and Soninke. For this project, AIOX Labs the SI2M Laboratory are joining forces to build the future of technologies together. | 9dfeae31a476c5c9cd65550abd23530c |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | About AIOX Labs Based in Rabat, London and Paris, AIOX-Labs mobilizes artificial intelligence technologies to meet the business needs and data projects of companies. - He is at the service of the growth of groups, the optimization of processes or the improvement of the customer experience. - AIOX-Labs is multi-sector, from fintech to industry, including retail and consumer goods. - Business ready data products with a solid algorithmic base and adaptability for the specific needs of each client. - A complementary team made up of doctors in AI and business experts with a solid scientific base and international publications. Website: [https://www.aiox-labs.com/](https://www.aiox-labs.com/) | 198dd1cb1a10cd9ac17e78db1431d5b6 |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | SI2M Laboratory The Information Systems, Intelligent Systems and Mathematical Modeling Research Laboratory (SI2M) is an academic research laboratory of the National Institute of Statistics and Applied Economics (INSEA). The research areas of the laboratories are Information Systems, Intelligent Systems, Artificial Intelligence, Decision Support, Network and System Security, Mathematical Modelling. Website: [SI2M Laboratory](https://insea.ac.ma/index.php/pole-recherche/equipe-de-recherche/150-laboratoire-de-recherche-en-systemes-d-information-systemes-intelligents-et-modelisation-mathematique) | d87c7215a170f64c45275f3eb61ff713 |
creativeml-openrail-m | ['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'wildcard'] | false | DreamBooth model for the untitled_goose concept trained by Arch4ngel on the Arch4ngel/untitled_goose_game dataset. This is a Stable Diffusion model fine-tuned on the untitled_goose concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of untitled_goose goose** This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part! | 0b6fee8102b37092a88adbd0f7a92b59 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2t_de_vp-nl_s283 Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 38194fd7deb209396ba55a7e913bfe7f |
apache-2.0 | ['generated_from_trainer'] | false | miles This model is a fine-tuned version of [EleutherAI/gpt-neo-125M](https://huggingface.co/EleutherAI/gpt-neo-125M) on the None dataset. It achieves the following results on the evaluation set: - Loss: 10.6360 | 9e20e04b6a8af9c134c24eebdda1075b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 2 | 10.7544 | | No log | 2.0 | 4 | 10.6614 | | No log | 3.0 | 6 | 10.6360 | | 013540eb636cf536be5548fa6998de69 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | whisper-small-tamil This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the google/fleurs dataset for Tamil. It achieves the following results on the evaluation set: - Loss: 0.42 - Wer: 15.02 | ac74d364b2cadc772955b3be0a20e4f2 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 16 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 5000 - mixed_precision_training: Native AMP | fc28e813ca4db8702d833858a1184c8a |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0882 | 2.27 | 500 | 0.2674 | 16.7354 | | 0.0026 | 11.76 | 1000 | 0.3508 | 15.3720 | | 0.0012 | 17.64 | 1500 | 0.3920 | 15.6156 | | 0.0009 | 23.53 | 2000 | 0.4076 | 15.4284 | | 0.0002 | 29.41 | 2500 | 0.4268 | 15.0215 | | 546a927be47e0fe38c8d4874f9363ba9 |
apache-2.0 | ['generated_from_trainer'] | false | phishing-bert-base-uncased-finetuned-dsV0 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.0194 - Accuracy: 0.9966 - F1: 0.9632 - Precision: 0.9878 - Recall: 0.9397 | f75426e4a2d98e8fd286cf1d0a3a0211 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | |:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:| | 0.0361 | 1.0 | 5185 | 0.0197 | 0.9950 | 0.9449 | 0.9911 | 0.9028 | | 0.0106 | 2.0 | 10370 | 0.0202 | 0.9959 | 0.9553 | 0.9940 | 0.9195 | | 0.0039 | 3.0 | 15555 | 0.0194 | 0.9966 | 0.9632 | 0.9878 | 0.9397 | | 8f3765b695d47783d169aafef91c5124 |
creativeml-openrail-m | ['text-to-image'] | false | Queer Vladimir Putin Dreambooth SD Model Dreambooth model trained by A.C.T. SOON® with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 model You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! To generate custom images of a queer or/and trans alter-dimensional identities of the infamous reigning spook Vladimir Putin – use "trp" or "trp person" in your Stable Diffusion prompt during inference with this model. Among other crucial, yet oft neglected, documentary content available in the public sphere ("Putin finally appears in drag", "Putin plays piano in Bowie wig", "femme Putin", etc...) this model was fine-tuned on numerous distinct variants of the classic "queer Putin" meme which had once spread like wildfiring rainbows in response to the 2018 intensification of the Russian government's ruthlessly inhumane crackdowns on LGBTQ+ persons and communities . ! | 7346b82044fe9a61023b198ab967a6d7 |
apache-2.0 | ['generated_from_trainer'] | false | albert-large-v2_cls_SentEval-CR This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.2767 - Accuracy: 0.9509 | b3a41b02aa83ddc29065dc351e5f8fab |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: cosine - lr_scheduler_warmup_ratio: 0.2 - num_epochs: 5 - mixed_precision_training: Native AMP | 077e7f7197b74466d2d3ea9dabc00e70 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 189 | 0.2880 | 0.9124 | | No log | 2.0 | 378 | 0.3215 | 0.9097 | | 0.3335 | 3.0 | 567 | 0.2229 | 0.9309 | | 0.3335 | 4.0 | 756 | 0.2610 | 0.9442 | | 0.3335 | 5.0 | 945 | 0.2767 | 0.9509 | | f65a895b11d0a07112272b2ee22012e2 |
mit | ['t5', 'pytorch', 'tensorflow', 'pt', 'pt-br'] | false | Introduction PTT5 is a T5 model pretrained in the BrWac corpus, a large collection of web pages in Portuguese, improving T5's performance on Portuguese sentence similarity and entailment tasks. It's available in three sizes (small, base and large) and two vocabularies (Google's T5 original and ours, trained on Portuguese Wikipedia). For further information or requests, please go to [PTT5 repository](https://github.com/unicamp-dl/PTT5). | 69707f788974f99b3af21773d856f0dc |
mit | ['t5', 'pytorch', 'tensorflow', 'pt', 'pt-br'] | false | Params | Vocabulary | | :-: | :-: | :-: | :-: | | [unicamp-dl/ptt5-small-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-small-t5-vocab) | small | 60M | Google's T5 | | [unicamp-dl/ptt5-base-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-base-t5-vocab) | base | 220M | Google's T5 | | [unicamp-dl/ptt5-large-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-large-t5-vocab) | large | 740M | Google's T5 | | [unicamp-dl/ptt5-small-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-small-portuguese-vocab) | small | 60M | Portuguese | | **[unicamp-dl/ptt5-base-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-base-portuguese-vocab)** **(Recommended)** | **base** | **220M** | **Portuguese** | | [unicamp-dl/ptt5-large-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-large-portuguese-vocab) | large | 740M | Portuguese | | aa7fa38f8a6598d1f79761ca969297bf |
mit | ['t5', 'pytorch', 'tensorflow', 'pt', 'pt-br'] | false | Tensorflow (bare model, baremodel + language modeling head) from transformers import TFT5Model, TFT5ForConditionalGeneration model_name = 'unicamp-dl/ptt5-base-portuguese-vocab' tokenizer = T5Tokenizer.from_pretrained(model_name) | e6c41e144195007f0aa1d79281a0d652 |
mit | ['t5', 'pytorch', 'tensorflow', 'pt', 'pt-br'] | false | Citation If you use PTT5, please cite: @article{ptt5_2020, title={PTT5: Pretraining and validating the T5 model on Brazilian Portuguese data}, author={Carmo, Diedre and Piau, Marcos and Campiotti, Israel and Nogueira, Rodrigo and Lotufo, Roberto}, journal={arXiv preprint arXiv:2008.09144}, year={2020} } | 38acdcba262a2cb9781f38f4faeb77ce |
apache-2.0 | ['automatic-speech-recognition', 'pl'] | false | exp_w2v2t_pl_vp-fr_s932 Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 365403febccb22f4d3ec3815286480e1 |
mit | ['conversational'] | false | AEONA Aeona is an chatbot which hope's to be able to talk with humans as if its an friend! It's main target platform is discord. You can invite the bot [here](https://aeona.xyz). To learn more about this project and chat with the ai, you can use this [website](https://aeona.xyx/). Aeona works why using context of the previous messages and guessing the personality of the human who is talking with it and adapting its own personality to better talk with the user. | 964c5f6c52929a26315a0d0c84280718 |
apache-2.0 | ['generated_from_trainer'] | false | BERT for PLANE classification This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on one of the PLANE's dataset split (no.2), introduced in [Bertolini et al., COLING 2022](https://aclanthology.org/2022.coling-1.359/) It achieves the following results on the evaluation set: - Accuracy: 0.9043 | 719036437c2482c03d86ce08438c4db8 |
apache-2.0 | ['generated_from_trainer'] | false | Intended uses & limitations The scope of the model is not to run lexical entailment (i.e., hypernym detection). The model is trained solely to perform a very specific subset of phrase-level entailment, based on adjective-nouns phrases. The type of question you should ask the model are limited, and should have one of three forms: - An *Adjective-Noun* is a *Noun* (e.g. A red car is a car) - An *Adjective-Noun* is a *Hypernym(Noun)* (e.g. A red car is a vehicle) - An *Adjective-Noun* is a *Adjective-Hypernym(Noun)* (e.g. A red car is a red vehicle) Linguistically speaking, adjectives belong to three macro classes (intersective, subsective, and intensional). From a linguistic and logical stand, these class shape the truth value of the three forms above. For instance, since red is an intersective adjective, the three from are all true. A subjective adjective like small allows just the first two, but not the last – that is, logically speaking, a small car is not a small vehicle. In other words, the model was built to study out-of-distribution compositional generalisation with respect to a very specific set of compositional phenomena. This poses clear limitations to the question you can ask the model. For instance, if you had to query the model with a basic (false) hypernym detection task (e.g., *A dog is a cat*), the model will consider it as true. | 3d48ba11547c38dec6e58beae509aefa |
apache-2.0 | ['generated_from_trainer'] | false | Training and evaluation data The data used for training and testing, as well as the other splits used for the experiments, are available on the paper's git page [here](https://github.com/lorenzoscottb/PLANE). The reported accuracy reference to out-of-distribution evaluation. that is, the model was tested to perform text classification as presented but on unknown adjectives and nouns. | 7634df5aa733c482c34da78d2100bd47 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 1 | 256c2bc4517df44dfb18ac312f088e21 |
apache-2.0 | ['generated_from_trainer'] | false | Cite if you want to use the model or data in your work please reference the paper too ``` @inproceedings{bertolini-etal-2022-testing, title = "Testing Large Language Models on Compositionality and Inference with Phrase-Level Adjective-Noun Entailment", author = "Bertolini, Lorenzo and Weeds, Julie and Weir, David", booktitle = "Proceedings of the 29th International Conference on Computational Linguistics", month = oct, year = "2022", address = "Gyeongju, Republic of Korea", publisher = "International Committee on Computational Linguistics", url = "https://aclanthology.org/2022.coling-1.359", pages = "4084--4100", } ``` | 48c88244db55843845c706d97c2291c8 |
creativeml-openrail-m | ['pytorch', 'diffusers', 'stable-diffusion', 'depth-to-image', 'diffusion-models-class'] | false | DreamBooth model for the lvngrooms concept trained by lakssrini on the custom real estate listings dataset. This is a Stable Diffusion inpainting model fine-tuned on the lvngrooms concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of lvngrooms room** | 7f6fdd41c131be4c7dd007026b3d6f51 |
creativeml-openrail-m | ['pytorch', 'diffusers', 'stable-diffusion', 'depth-to-image', 'diffusion-models-class'] | false | Usage ```python from diffusers import StableDiffusionDepth2ImgPipeline pipeline = StableDiffusionPipeline.from_pretrained('lakssrini/dpt-lvngrooms') init_image = Image.open("XXX") image = pipeline( prompt=prompt.strip(), image=init_image, negative_prompt="Oversaturated, blurry, low quality", guidance_scale=guidance_scale, height=480, width=640 ).images[0] image ``` | 43ee2757db2227e674c1bc0b0ec688b5 |
creativeml-openrail-m | ['text-to-image'] | false | samantharuth Dreambooth model trained by Prajeevan with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! Sample pictures of: samantharuth (use that on your prompt)  | 5f326771de7d5d080e5fe1f46d6a6053 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | false | wav2vec2-large-xls-r-300m-marathi-cv8 This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MR dataset. It achieves the following results on the evaluation set: - Loss: 0.6483 - Wer: 0.6049 | 5193fc19a2824d5c5e2b44c557821f78 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.