
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
cc-by-4.0 | ['answer extraction'] | false | model prediction answers = model.generate_a("William Turner was an English painter who specialised in watercolour landscapes") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/t5-small-squad-ae") output = pipe("extract answers: <hl> Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records. <hl> Her performance in the film received praise from critics, and she garnered several nominations for her portrayal of James, including a Satellite Award nomination for Best Supporting Actress, and a NAACP Image Award nomination for Outstanding Supporting Actress.") ``` | c64ec977b40c16ac8808a9dd3bdb5d0a |
cc-by-4.0 | ['answer extraction'] | false | Evaluation - ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/t5-small-squad-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_squad.default.json) | | Score | Type | Dataset | |:-----------------|--------:|:--------|:---------------------------------------------------------------| | AnswerExactMatch | 56.15 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | AnswerF1Score | 68.06 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | BERTScore | 91.2 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_1 | 52.42 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_2 | 47.81 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_3 | 43.22 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | Bleu_4 | 39.23 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | METEOR | 42.5 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | MoverScore | 80.92 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | ROUGE_L | 67.58 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) | | 687483c1cc15c5ad49c2eb2a4de9870f |
cc-by-4.0 | ['answer extraction'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_squad - dataset_name: default - input_types: ['paragraph_sentence'] - output_types: ['answer'] - prefix_types: ['ae'] - model: t5-small - max_length: 512 - max_length_output: 32 - epoch: 7 - batch: 64 - lr: 0.0001 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 1 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/t5-small-squad-ae/raw/main/trainer_config.json). | 621e41df48cdff1faf4f716fda33f19f |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'hf-asr-leaderboard'] | false | wav2vec2-large-xls-r-300m-mr-v2 This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MR dataset. It achieves the following results on the evaluation set: - Loss: 0.8729 - Wer: 0.4942 | a8b1c1b555900fa052fd4814cab298c6 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'hf-asr-leaderboard'] | false | Evaluation Commands 1. To evaluate on mozilla-foundation/common_voice_8_0 with test split python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-mr-v2 --dataset mozilla-foundation/common_voice_8_0 --config mr --split test --log_outputs 2. To evaluate on speech-recognition-community-v2/dev_data python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-mr-v2 --dataset speech-recognition-community-v2/dev_data --config mr --split validation --chunk_length_s 10 --stride_length_s 1 Note: Marathi language not found in speech-recognition-community-v2/dev_data! | db4e23a52bc21169f88fd3e9d02e7418 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'hf-asr-leaderboard'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.000333 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 32 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 200 - mixed_precision_training: Native AMP | 0b4e52b659abdd589afe1ee681c5df7d |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'hf-asr-leaderboard'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:------:|:----:|:---------------:|:------:| | 8.4934 | 9.09 | 200 | 3.7326 | 1.0 | | 3.4234 | 18.18 | 400 | 3.3383 | 0.9996 | | 3.2628 | 27.27 | 600 | 2.7482 | 0.9992 | | 1.7743 | 36.36 | 800 | 0.6755 | 0.6787 | | 1.0346 | 45.45 | 1000 | 0.6067 | 0.6193 | | 0.8137 | 54.55 | 1200 | 0.6228 | 0.5612 | | 0.6637 | 63.64 | 1400 | 0.5976 | 0.5495 | | 0.5563 | 72.73 | 1600 | 0.7009 | 0.5383 | | 0.4844 | 81.82 | 1800 | 0.6662 | 0.5287 | | 0.4057 | 90.91 | 2000 | 0.6911 | 0.5303 | | 0.3582 | 100.0 | 2200 | 0.7207 | 0.5327 | | 0.3163 | 109.09 | 2400 | 0.7107 | 0.5118 | | 0.2761 | 118.18 | 2600 | 0.7538 | 0.5118 | | 0.2415 | 127.27 | 2800 | 0.7850 | 0.5178 | | 0.2127 | 136.36 | 3000 | 0.8016 | 0.5034 | | 0.1873 | 145.45 | 3200 | 0.8302 | 0.5187 | | 0.1723 | 154.55 | 3400 | 0.9085 | 0.5223 | | 0.1498 | 163.64 | 3600 | 0.8396 | 0.5126 | | 0.1425 | 172.73 | 3800 | 0.8776 | 0.5094 | | 0.1258 | 181.82 | 4000 | 0.8651 | 0.5014 | | 0.117 | 190.91 | 4200 | 0.8772 | 0.4970 | | 0.1093 | 200.0 | 4400 | 0.8729 | 0.4942 | | 9a4e7fcb1697e76828d7891184c09ed6 |
mit | ['generated_from_trainer'] | false | bart-cnn-science-v3-e1-v4-e4-manual This model is a fine-tuned version of [theojolliffe/bart-cnn-science-v3-e1](https://huggingface.co/theojolliffe/bart-cnn-science-v3-e1) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.2615 - Rouge1: 53.36 - Rouge2: 32.0237 - Rougel: 33.2835 - Rougelsum: 50.7455 - Gen Len: 142.0 | 4a5a1b3a7879be38519947fd13bf0348 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:| | No log | 1.0 | 42 | 1.0675 | 51.743 | 31.3774 | 34.1939 | 48.7234 | 142.0 | | No log | 2.0 | 84 | 1.0669 | 49.4166 | 28.1438 | 30.188 | 46.0289 | 142.0 | | No log | 3.0 | 126 | 1.1799 | 52.6909 | 31.0174 | 35.441 | 50.0351 | 142.0 | | No log | 4.0 | 168 | 1.2615 | 53.36 | 32.0237 | 33.2835 | 50.7455 | 142.0 | | 1188b6c7003051f37821a49699c147e2 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-cola This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset. It achieves the following results on the evaluation set: - Loss: 0.5532 - Matthews Correlation: 0.5452 | 600ec5fbe2bf7a55c3fdc5cf324509b0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.5248 | 1.0 | 535 | 0.5479 | 0.3922 | | 0.3503 | 2.0 | 1070 | 0.5148 | 0.4822 | | 0.2386 | 3.0 | 1605 | 0.5532 | 0.5452 | | 0.1773 | 4.0 | 2140 | 0.6818 | 0.5282 | | 25af85f790f7c398c22ace27655782c0 |
apache-2.0 | ['automatic-speech-recognition', 'es'] | false | exp_w2v2t_es_unispeech_s767 Fine-tuned [microsoft/unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 3432e88247a55b2d2ce9e7468a47bcf5 |
apache-2.0 | ['generated_from_trainer'] | false | openai/whisper-large This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1412 - Wer: 6.7893 | 47eeed57176763782cfc5655ec5b4438 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 16 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 4000 - mixed_precision_training: Native AMP | 7434a832285481acf4ddebe0b4780ddb |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0475 | 2.03 | 500 | 0.1095 | 62.6591 | | 0.0201 | 5.01 | 1000 | 0.1225 | 16.9285 | | 0.0044 | 7.03 | 1500 | 0.1312 | 3.6701 | | 0.0026 | 10.01 | 2000 | 0.1278 | 7.9506 | | 0.0001 | 12.04 | 2500 | 0.1323 | 17.9186 | | 0.0001 | 15.02 | 3000 | 0.1386 | 16.3031 | | 0.0001 | 17.05 | 3500 | 0.1403 | 6.7074 | | 0.0 | 20.02 | 4000 | 0.1412 | 6.7893 | | 5a3d36e1ed4fba1f112c99a380a94dd4 |
apache-2.0 | ['generated_from_trainer'] | false | vit-base-patch16-224-finetuned-memes-v3 This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset. It achieves the following results on the evaluation set: - Loss: 0.3862 - Accuracy: 0.8478 | 69252f03b54054925e4eb268133a17ba |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.00012 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 4 | 57cccc9b6d3b567460bc777e0b1f0dc1 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.5649 | 0.99 | 40 | 0.6342 | 0.7488 | | 0.3083 | 1.99 | 80 | 0.4146 | 0.8423 | | 0.1563 | 2.99 | 120 | 0.3900 | 0.8547 | | 0.0827 | 3.99 | 160 | 0.3862 | 0.8478 | | 266074f1d88a6b9b5ff7aba4676d69d8 |
apache-2.0 | ['generated_from_trainer'] | false | finetuned_token_3e-05_all_16_02_2022-16_25_56 This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1630 - Precision: 0.3684 - Recall: 0.3714 - F1: 0.3699 - Accuracy: 0.9482 | 507710fb0fdb711d2f96b7cfb564f1c3 |
apache-2.0 | [] | false | Baseline Model trained on tips to predict sex Metrics of the best model: accuracy 0.647364 average_precision 0.481257 roc_auc 0.608805 recall_macro 0.588751 f1_macro 0.588435 Name: MultinomialNB(), dtype: float64 See model plot below: <style> | a4c15beb9a03e91e643aa011c3d88ef9 |
apache-2.0 | [] | false | x27;,EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless total_bill True False False ... False False False tip True False False ... False False False smoker False False False ... False False False day False False False ... False False False time False False False ... False False False size False False True ... False False False[6 rows x 7 columns])),(& | 9ff3aaa24e58b0eeeeafe6518ac10caf |
apache-2.0 | [] | false | x27;, MultinomialNB())]))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-4" type="checkbox" ><label for="sk-estimator-id-4" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[(& | a61ba2338fe7766f6f80e883ec819764 |
apache-2.0 | [] | false | x27;, MultinomialNB())]))])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-5" type="checkbox" ><label for="sk-estimator-id-5" class="sk-toggleable__label sk-toggleable__label-arrow">EasyPreprocessor</label><div class="sk-toggleable__content"><pre>EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless total_bill True False False ... False False False tip True False False ... False False False smoker False False False ... False False False day False False False ... False False False time False False False ... False False False size False False True ... False False False[6 rows x 7 columns])</pre></div></div></div><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-6" type="checkbox" ><label for="sk-estimator-id-6" class="sk-toggleable__label sk-toggleable__label-arrow">pipeline: Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[(& | 99211f9cb31ff01d3a8ec738a04a068a |
apache-2.0 | [] | false | x27;, MultinomialNB())])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-7" type="checkbox" ><label for="sk-estimator-id-7" class="sk-toggleable__label sk-toggleable__label-arrow">MinMaxScaler</label><div class="sk-toggleable__content"><pre>MinMaxScaler()</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-8" type="checkbox" ><label for="sk-estimator-id-8" class="sk-toggleable__label sk-toggleable__label-arrow">MultinomialNB</label><div class="sk-toggleable__content"><pre>MultinomialNB()</pre></div></div></div></div></div></div></div></div></div> | dd4927bfd7371eccdc3e3d275fbe42a8 |
apache-2.0 | [] | false | Model Card for Pegasus for Claim Summarization <!-- Provide a quick summary of what the model is/does. --> This model can be used to summarize noisy claims on social media into clean and concise claims which can be used for downstream tasks in a fact-checking pipeline. | dfc4c2a5fee90ffd8600841d020bf36a |
apache-2.0 | [] | false | Model Description <!-- Provide a longer summary of what this model is. --> - **Developed by:** Varad Bhatnagar, Diptesh Kanojia and Kameswari Chebrolu - **Model type:** Summarization - **Language(s) (NLP):** English - **Finetuned from model:** https://huggingface.co/sshleifer/distill-pegasus-cnn-16-4 | 4ec302f2570004ba6daee0bdc750fca3 |
apache-2.0 | [] | false | Direct Use <!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. --> English to English summarization on noisy fact-checking worthy claims found on social media. | b3739083302950f32e3e6db2d7a3a99a |
apache-2.0 | [] | false | Downstream Use <!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app --> Can be used for other tasks in a fact-checking pipeline such as claim matching and evidence retrieval. | 419e2aaf9b21d52355030830b464518a |
apache-2.0 | [] | false | Bias, Risks, and Limitations <!-- This section is meant to convey both technical and sociotechnical limitations. --> As the [Google Fact Check Explorer](https://toolbox.google.com/factcheck/explorer) is an ever growing and evolving system, the current Retrieval@k results may not exactly match those in the corresponding paper as those experiments were conducted in the month of April and May 2022. | 177722ef4aaa48c1762a49e9abf41151 |
apache-2.0 | [] | false | Training Data <!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. --> [Data](https://github.com/varadhbhatnagar/FC-Claim-Det/blob/main/public_data/released_data.csv) | fec7fd5990e9c4eefc8c3c2c973dd654 |
apache-2.0 | [] | false | Training Procedure <!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. --> Finetuning the pretrained Distilled PEGASUS model on the 567 pairs released in our paper. | 8c97a808085abee85a614b5a8b303330 |
apache-2.0 | [] | false | Citation <!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. --> **BibTeX:** ``` @inproceedings{bhatnagar-etal-2022-harnessing, title = "Harnessing Abstractive Summarization for Fact-Checked Claim Detection", author = "Bhatnagar, Varad and Kanojia, Diptesh and Chebrolu, Kameswari", booktitle = "Proceedings of the 29th International Conference on Computational Linguistics", month = oct, year = "2022", address = "Gyeongju, Republic of Korea", publisher = "International Committee on Computational Linguistics", url = "https://aclanthology.org/2022.coling-1.259", pages = "2934--2945", abstract = "Social media platforms have become new battlegrounds for anti-social elements, with misinformation being the weapon of choice. Fact-checking organizations try to debunk as many claims as possible while staying true to their journalistic processes but cannot cope with its rapid dissemination. We believe that the solution lies in partial automation of the fact-checking life cycle, saving human time for tasks which require high cognition. We propose a new workflow for efficiently detecting previously fact-checked claims that uses abstractive summarization to generate crisp queries. These queries can then be executed on a general-purpose retrieval system associated with a collection of previously fact-checked claims. We curate an abstractive text summarization dataset comprising noisy claims from Twitter and their gold summaries. It is shown that retrieval performance improves 2x by using popular out-of-the-box summarization models and 3x by fine-tuning them on the accompanying dataset compared to verbatim querying. Our approach achieves Recall@5 and MRR of 35{\%} and 0.3, compared to baseline values of 10{\%} and 0.1, respectively. Our dataset, code, and models are available publicly: https://github.com/varadhbhatnagar/FC-Claim-Det/.", } ``` | 0c696a49a99c8539ea617b4670008d6f |
apache-2.0 | [] | false | How to Get Started with the Model Use the code below to get started with the model. ``` from transformers import PegasusForConditionalGeneration, PegasusTokenizerFast tokeizer = PegasusTokenizerFast.from_pretrained('varadhbhatnagar/fc-claim-det-DPEGASUS') model = PegasusForConditionalGeneration.from_pretrained('varadhbhatnagar/fc-claim-det-DPEGASUS') text ='world health organisation has taken a complete u turn and said that corona patients neither need isolate nor quarantine nor social distance and it can not even transmit from one patient to another' tokenized_text = tokeizer.encode(text, return_tensors="pt") summary_ids = model.generate(tokenized_text, num_beams=6, no_repeat_ngram_size=2, min_length=5, max_length=15, early_stopping=True) output = tokenizer.decode(summary_ids[0], skip_special_tokens=True) ``` | 6e8bbfb6418eb9f404503c2278e1c5a3 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 158 | 1.8653 | | No log | 2.0 | 316 | 1.7574 | | No log | 3.0 | 474 | 1.6939 | | 1.9705 | 4.0 | 632 | 1.6597 | | 1.9705 | 5.0 | 790 | 1.6480 | | c91611e51e5acdc7357324c820939b12 |
apache-2.0 | ['image-classification', 'vision'] | false | BEiT (base-sized model, fine-tuned on ImageNet-1k) BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit). Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team. | cfb3efa6cf4e92102811b233bdb1a17f |
apache-2.0 | ['image-classification', 'vision'] | false | How to use Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes: ```python from transformers import BeitFeatureExtractor, BeitForImageClassification from PIL import Image import requests url = 'http://images.cocodataset.org/val2017/000000039769.jpg' image = Image.open(requests.get(url, stream=True).raw) feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-384') model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-384') inputs = feature_extractor(images=image, return_tensors="pt") outputs = model(**inputs) logits = outputs.logits | 6ad110ea48ac6bafee60c10f309e56e9 |
apache-2.0 | ['image-classification', 'vision'] | false | Training data The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes. | 50dc799a811abd9e324246e7aee42a8a |
apache-2.0 | ['image-classification', 'vision'] | false | Evaluation results For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance. | edc8dba9947b192040f0ee17b65a4911 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-cased-stsb This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE STSB dataset. It achieves the following results on the evaluation set: - Loss: 0.4322 - Pearson: 0.9007 - Spearmanr: 0.8963 - Combined Score: 0.8985 | c31b8f0ba55b051418cffb0d6b8ce1cd |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score | |:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:| | 1.6464 | 1.39 | 500 | 0.5662 | 0.8820 | 0.8814 | 0.8817 | | 0.3329 | 2.78 | 1000 | 0.5070 | 0.8913 | 0.8883 | 0.8898 | | 0.173 | 4.17 | 1500 | 0.4465 | 0.8988 | 0.8943 | 0.8966 | | 0.1085 | 5.56 | 2000 | 0.4537 | 0.8958 | 0.8917 | 0.8937 | | 0.0816 | 6.94 | 2500 | 0.4594 | 0.8977 | 0.8933 | 0.8955 | | 0.0621 | 8.33 | 3000 | 0.4450 | 0.8997 | 0.8950 | 0.8974 | | 0.0519 | 9.72 | 3500 | 0.4322 | 0.9007 | 0.8963 | 0.8985 | | c3dd603844c34d2448d3fd8a3931e306 |
mit | [] | false | Model Description Fairseq-dense 6.7B-Shinen is a finetune created using Fairseq's MoE dense model. Compared to GPT-Neo-2.7-Horni, this model is much heavier on the sexual content. **Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.** | 2a1ffb4bb0b740539df7490f5c4232f1 |
mit | [] | false | How to use You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run: ```py >>> from transformers import pipeline >>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-6.7B-Shinen') >>> generator("She was staring at me", do_sample=True, min_length=50) [{'generated_text': 'She was staring at me with a look that said it all. She wanted me so badly tonight that I wanted'}] ``` | 7d5adf6f5fce4cc15a133c83e849ec91 |
apache-2.0 | ['unilm'] | false | 安装兼容HuggingFace的UniLM模型代码 ``` ```py from unilm import UniLMTokenizer, UniLMForConditionalGeneration news_article = ( "12月23日,河北石家庄。8岁哥哥轻车熟路哄睡弟弟,姿势标准动作熟练。" "妈妈杨女士表示:哥哥很喜欢弟弟,因为心思比较细,自己平时带孩子的习惯他都会跟着学习," "哄睡孩子也都会争着来,技巧很娴熟,两人在一块很有爱,自己感到很幸福,平时帮了自己很大的忙,感恩有这么乖的宝宝。" ) tokenizer = UniLMTokenizer.from_pretrained("Yuang/unilm-base-chinese-news-sum") model = UniLMForConditionalGeneration.from_pretrained("Yuang/unilm-base-chinese-news-sum") inputs = tokenizer(news_article, return_tensors="pt") output_ids = model.generate(**inputs, max_new_tokens=16) output_text = tokenizer.decode(output_ids[0]) print(output_text) | 5be8ef446016d2b8f0b1959e73abd357 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.2225 - Accuracy: 0.919 - F1: 0.9191 | 1062bb56206d987ee1223f7842b98c98 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.814 | 1.0 | 250 | 0.3153 | 0.904 | 0.9016 | | 0.2515 | 2.0 | 500 | 0.2225 | 0.919 | 0.9191 | | ed93da390d2404f0774c0a542b593c46 |
apache-2.0 | ['generated_from_trainer'] | false | t5-small-finetuned-text-simplification This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wiki_auto_asset_turk dataset. It achieves the following results on the evaluation set: - Loss: 0.1217 - Rouge2 Precision: 0.5537 - Rouge2 Recall: 0.4251 - Rouge2 Fmeasure: 0.4616 | 474462a4e7a58f490d7426bc6a149c4a |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5 - mixed_precision_training: Native AMP | ac155bab0fd760b095b8c178ae5bb3a6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure | |:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:| | 0.1604 | 1.0 | 15119 | 0.1156 | 0.5567 | 0.4266 | 0.4633 | | 0.1573 | 2.0 | 30238 | 0.1163 | 0.5534 | 0.4258 | 0.462 | | 0.1552 | 3.0 | 45357 | 0.1197 | 0.5527 | 0.4244 | 0.4608 | | 0.1514 | 4.0 | 60476 | 0.1214 | 0.5528 | 0.4257 | 0.4617 | | 0.1524 | 5.0 | 75595 | 0.1217 | 0.5537 | 0.4251 | 0.4616 | | 5b09e8653f95c4699913a05e7e80b255 |
creativeml-openrail-m | ['stable-diffusion', 'text-to-image', 'image-to-image', 'diffusers'] | false | Jocelyn Hobbie Diffusion v1 This model was created to celebrate the works of Jocelyn Hobbie - A wonderful contemporary artist. Check out her works @ www.jocelynhobbie.com and @jocelynhobbie **Token to use is "jclnhbe style" ** | f741bc6645f52611097fede0807ff4de |
creativeml-openrail-m | ['stable-diffusion', 'text-to-image', 'image-to-image', 'diffusers'] | false | Examples    | c1f125ad7dc8c6121f485f8ab583bcfe |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset. It achieves the following results on the evaluation set: - Loss: 1.6090 | 1126086dd395fc5b0068abbeddb146e9 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | a302aab492918056cc79fcae24402e52 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | No log | 1.0 | 274 | 1.5943 | | 0.9165 | 2.0 | 548 | 1.5836 | | 0.9165 | 3.0 | 822 | 1.6090 | | 6c0e576441873dfbfe6502f7d720168b |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2r_de_xls-r_accent_germany-8_austria-2_s452 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 4e1bb9170b075496e7f7fac3baebadca |
apache-2.0 | ['generated_from_trainer'] | false | finetuning-sentiment-model-3000-samples This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.3026 - Accuracy: 0.8667 - F1: 0.8667 | 5b73cc9a688e716cd31f59a4afc93db8 |
apache-2.0 | ['automatic-speech-recognition', 'zh-CN'] | false | exp_w2v2t_zh-cn_no-pretraining_s805 Fine-tuned randomly initialized wav2vec2 model for speech recognition using the train split of [Common Voice 7.0 (zh-CN)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 72dd7c0f78d513648fb7b9667478e6e3 |
mit | ['generated_from_keras_callback'] | false | nandysoham/Human_Development_Index-clustered This model is a fine-tuned version of [nandysoham16/4-clustered_aug](https://huggingface.co/nandysoham16/4-clustered_aug) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.2234 - Train End Logits Accuracy: 0.9410 - Train Start Logits Accuracy: 0.9479 - Validation Loss: 1.1060 - Validation End Logits Accuracy: 0.6667 - Validation Start Logits Accuracy: 0.6667 - Epoch: 0 | 82951f4087a13c1ae7cf17e4a48b6cfd |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch | |:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:| | 0.2234 | 0.9410 | 0.9479 | 1.1060 | 0.6667 | 0.6667 | 0 | | fde9d2323706a65400d75876eddbdadb |
apache-2.0 | ['speech'] | false | M-CTC-T Massively multilingual speech recognizer from Meta AI. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal. 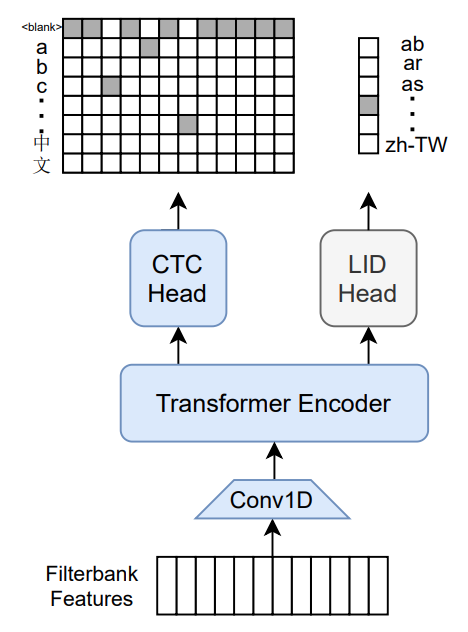 The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl . | 37f16ae1748893173db5d8e2405560bc |
apache-2.0 | ['speech'] | false | Citation [Paper](https://arxiv.org/abs/2111.00161) Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert ``` @article{lugosch2021pseudo, title={Pseudo-Labeling for Massively Multilingual Speech Recognition}, author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan}, journal={ICASSP}, year={2022} } ``` Additional thanks to [Chan Woo Kim](https://huggingface.co/cwkeam) and [Patrick von Platen](https://huggingface.co/patrickvonplaten) for porting the model from Flashlight to PyTorch. | 27199e5d522fee0e224e6e0978a1c5ac |
apache-2.0 | ['speech'] | false | Training method  TO-DO: replace with the training diagram from paper For more information on how the model was trained, please take a look at the [official paper](https://arxiv.org/abs/2111.00161). | 9348e9b162031bfbce4b88cc60c85f06 |
apache-2.0 | ['speech'] | false | Usage To transcribe audio files the model can be used as a standalone acoustic model as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import MCTCTForCTC, MCTCTProcessor model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large") processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large") | c9f58eaf83506f4ff2abec02fa3f3ef8 |
apache-2.0 | ['speech'] | false | take argmax and decode predicted_ids = torch.argmax(logits, dim=-1) transcription = processor.batch_decode(predicted_ids) ``` Results for Common Voice, averaged over all languages: *Character error rate (CER)*: | Valid | Test | |-------|------| | 21.4 | 23.3 | | 6a29af0b3511d3218e16a395f49cbddf |
apache-2.0 | ['translation'] | false | opus-mt-lue-en * source languages: lue * target languages: en * OPUS readme: [lue-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lue-en/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.zip) * test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.test.txt) * test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.eval.txt) | 198a08dd8fcc7e4aaeaf923407fb3fc8 |
cc-by-4.0 | ['generated_from_trainer'] | false | hing-mbert-finetuned-code-mixed-DS This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.7248 - Accuracy: 0.7364 - Precision: 0.6847 - Recall: 0.7048 - F1: 0.6901 | 9c107a6a2c863457d5e3d175e64855eb |
cc-by-4.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2.7277800745684633e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 43 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 | 22e8dee73344b6760ba14d22e3e3db37 |
cc-by-4.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:| | 0.6977 | 2.0 | 497 | 0.7248 | 0.7364 | 0.6847 | 0.7048 | 0.6901 | | 408c1dd4ffa75f05e02df2980116736b |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)'] | false | AltCLIP-m9 It supports English(En), Chinese(Zh), Spanish(Es), French(Fr), Russian(Ru), Japanese(Ja), Korean(Ko), Arabic(Ar) and Italian(It) languages. | 名称 Name | 任务 Task | 语言 Language(s) | 模型 Model | Github | |:------------------:|:----------:|:-------------------:|:--------:|:------:| | AltCLIP-m9 | Text-Image | Multilingual | CLIP | [FlagAI](https://github.com/FlagAI-Open/FlagAI) | | 65a7a98170924b5dcdddb08420a2106a |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)'] | false | 简介 Brief Introduction 我们提出了一个简单高效的方法去训练更加优秀的九语CLIP模型。命名为AltCLIP-m9。AltCLIP训练数据来自 [WuDao数据集](https://data.baai.ac.cn/details/WuDaoCorporaText) 和 [LIAON](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus) AltCLIP-m9模型可以为本项目中的AltDiffusion-m9模型提供支持,关于AltDiffusion-m9模型的具体信息可查看[此教程](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md) 。 模型代码已经在 [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) 上开源,权重位于我们搭建的 [modelhub](https://model.baai.ac.cn/model-detail/100077) 上。我们还提供了微调,推理,验证的脚本,欢迎试用。 We propose a simple and efficient method to train a better multilingua CLIP model. Named AltCLIP-m9. AltCLIP-m9 is trained with training data from [WuDao dataset](https://data.baai.ac.cn/details/WuDaoCorporaText) and [Liaon](https://huggingface.co/datasets/laion/laion2B-en). The AltCLIP-m9 model can provide support for the AltDiffusion-m9 model in this project. Specific information on the AltDiffusion model can be found in [this tutorial](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md). The model code has been open sourced on [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) and the weights are located on [modelhub](https://model.baai.ac.cn/model-detail/100077). We also provide scripts for fine-tuning, inference, and validation, so feel free to try them out. | b1d1cd34c823c57277e4e994708de12f |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)'] | false | 引用 关于AltCLIP,我们已经推出了相关报告,有更多细节可以查阅,如对您的工作有帮助,欢迎引用。 If you find this work helpful, please consider to cite ``` @article{https://doi.org/10.48550/arxiv.2211.06679, doi = {10.48550/ARXIV.2211.06679}, url = {https://arxiv.org/abs/2211.06679}, author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell}, keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences}, title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities}, publisher = {arXiv}, year = {2022}, copyright = {arXiv.org perpetual, non-exclusive license} } ``` | 9362f439fbad95c67a32fb161b1324b5 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)'] | false | 训练 Training 训练共有两个阶段。 在平行知识蒸馏阶段,我们只是使用平行语料文本来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)。在多语对比学习阶段,我们使用少量的中-英 图像-文本对(每种语言6百万)来训练我们的文本编码器以更好地适应图像编码器。 There are two phases of training. In the parallel knowledge distillation phase, we only use parallel corpus texts for distillation (parallel corpus is easier to obtain and larger in number compared to image text pairs). In the multilingual comparison learning phase, we use a small number of text-image pairs (about 6 million in each language) to train our text encoder to better fit the image encoder. | 3111053ac687aac9c2a6898c5862b8ac |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)'] | false | now our repo's in private, so we need `use_auth_token=True` model = AltCLIP.from_pretrained("BAAI/AltCLIP-m9") processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP-m9") url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw) inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True) outputs = model(**inputs) logits_per_image = outputs.logits_per_image | a1eea833d6f4cb0f32d73c45e7529e0a |
mit | ['generated_from_trainer'] | false | bert-base-portuguese-cased-finetuned-chico-xavier This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.7196 | 817e89b2ebb9c3b64e0033fc23ad189f |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.0733 | 1.0 | 561 | 1.8147 | | 1.8779 | 2.0 | 1122 | 1.7624 | | 1.8345 | 3.0 | 1683 | 1.7206 | | 03824f95cf362c911004462008fcee04 |
apache-2.0 | [] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 2 - eval_batch_size: 2 - gradient_accumulation_steps: 1 - optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None - lr_scheduler: None - lr_warmup_steps: 500 - ema_inv_gamma: None - ema_inv_gamma: None - ema_inv_gamma: None - mixed_precision: fp16 | f8df2d50f6ebf88d1ce58938b8bdc1e1 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased_research_articles_multilabel This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1956 - F1: 0.8395 - Roc Auc: 0.8909 - Accuracy: 0.6977 | 51b7f0e67e520306bb22f8f68a2ce469 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:| | 0.3043 | 1.0 | 263 | 0.2199 | 0.8198 | 0.8686 | 0.6829 | | 0.2037 | 2.0 | 526 | 0.1988 | 0.8355 | 0.8845 | 0.7010 | | 0.1756 | 3.0 | 789 | 0.1956 | 0.8395 | 0.8909 | 0.6977 | | 0.1579 | 4.0 | 1052 | 0.1964 | 0.8371 | 0.8902 | 0.6919 | | 0.1461 | 5.0 | 1315 | 0.1991 | 0.8353 | 0.8874 | 0.6953 | | 6feffb3480e2d13c051d93a14ca0bd39 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | opus-mt-tc-big-en-cat_oci_spa Neural machine translation model for translating from English (en) to Catalan, Occitan and Spanish (cat+oci+spa). This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train). * Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.) ``` @inproceedings{tiedemann-thottingal-2020-opus, title = "{OPUS}-{MT} {--} Building open translation services for the World", author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh}, booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation", month = nov, year = "2020", address = "Lisboa, Portugal", publisher = "European Association for Machine Translation", url = "https://aclanthology.org/2020.eamt-1.61", pages = "479--480", } @inproceedings{tiedemann-2020-tatoeba, title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}", author = {Tiedemann, J{\"o}rg}, booktitle = "Proceedings of the Fifth Conference on Machine Translation", month = nov, year = "2020", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2020.wmt-1.139", pages = "1174--1182", } ``` | fb034959333f36980b248ba9acdc5ad7 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Model info * Release: 2022-03-13 * source language(s): eng * target language(s): cat spa * valid target language labels: >>cat<< >>spa<< * model: transformer-big * data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge)) * tokenization: SentencePiece (spm32k,spm32k) * original model: [opusTCv20210807+bt_transformer-big_2022-03-13.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.zip) * more information released models: [OPUS-MT eng-cat+oci+spa README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-cat+oci+spa/README.md) * more information about the model: [MarianMT](https://huggingface.co/docs/transformers/model_doc/marian) This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>cat<<` | a094b168eb5926ff06976233831b3be6 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Usage A short example code: ```python from transformers import MarianMTModel, MarianTokenizer src_text = [ ">>spa<< Why do you want Tom to go there with me?", ">>spa<< She forced him to eat spinach." ] model_name = "pytorch-models/opus-mt-tc-big-en-cat_oci_spa" tokenizer = MarianTokenizer.from_pretrained(model_name) model = MarianMTModel.from_pretrained(model_name) translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True)) for t in translated: print( tokenizer.decode(t, skip_special_tokens=True) ) | 43aadae93ae8837e399cbd9d709a0adf |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Ella lo obligó a comer espinacas. ``` You can also use OPUS-MT models with the transformers pipelines, for example: ```python from transformers import pipeline pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-cat_oci_spa") print(pipe(">>spa<< Why do you want Tom to go there with me?")) | ef56370e47fa9f7cbc0a2a2e9be95f18 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Benchmarks * test set translations: [opusTCv20210807+bt_transformer-big_2022-03-13.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.test.txt) * test set scores: [opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt) * benchmark results: [benchmark_results.txt](benchmark_results.txt) * benchmark output: [benchmark_translations.zip](benchmark_translations.zip) | langpair | testset | chr-F | BLEU | | 186e2125e31318a1ef8bc12f373cd0cc |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | words | |----------|---------|-------|-------|-------|--------| | eng-cat | tatoeba-test-v2021-08-07 | 0.66414 | 47.8 | 1631 | 12344 | | eng-spa | tatoeba-test-v2021-08-07 | 0.73725 | 57.0 | 16583 | 134710 | | eng-cat | flores101-devtest | 0.66071 | 41.5 | 1012 | 27304 | | eng-oci | flores101-devtest | 0.56192 | 25.4 | 1012 | 27305 | | eng-spa | flores101-devtest | 0.56288 | 28.1 | 1012 | 29199 | | eng-spa | newssyscomb2009 | 0.58431 | 31.4 | 502 | 12503 | | eng-spa | news-test2008 | 0.56622 | 30.0 | 2051 | 52586 | | eng-spa | newstest2009 | 0.57988 | 30.5 | 2525 | 68111 | | eng-spa | newstest2010 | 0.62343 | 37.4 | 2489 | 65480 | | eng-spa | newstest2011 | 0.62424 | 39.1 | 3003 | 79476 | | eng-spa | newstest2012 | 0.63006 | 39.6 | 3003 | 79006 | | eng-spa | newstest2013 | 0.60291 | 35.8 | 3000 | 70528 | | eng-spa | tico19-test | 0.73224 | 52.5 | 2100 | 66563 | | 2a139a810853cccb008116eb08e9255c |
other | [] | false | Area Rug Cleaning Richardson TX https://carpetcleaning-richardson.com/area-rug-cleaning.html (972) 454-9815 Do you need the best cleaning services in town from Rug Shampooers?Do you want to bring back the natural beauty of your rugs after they have lost their original appearance?By simply calling our professionals, Richardson TX Carpet Cleaning will be able to properly clean them for you, leaving them looking good and brightening up your home at any time. | 5e6e142eb5ac5554e2282cb95be855d4 |
cc-by-4.0 | [] | false | A HindBERT (l3cube-pune/hindi-bert-v2) model finetuned on random 1 million Hindi Tweets.<br> More details on the dataset, models, and baseline results can be found in our [paper] (<a href='https://arxiv.org/abs/2210.04267'> link </a>)<br> ``` @article{gokhale2022spread, title={Spread Love Not Hate: Undermining the Importance of Hateful Pre-training for Hate Speech Detection}, author={Gokhale, Omkar and Kane, Aditya and Patankar, Shantanu and Chavan, Tanmay and Joshi, Raviraj}, journal={arXiv preprint arXiv:2210.04267}, year={2022} } ``` | a26cc9fb07dd0c2dcab6eea9d7a2bdeb |
apache-2.0 | ['generated_from_trainer'] | false | finetuned-mt5-base-10epoch This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the wmt16 ro-en dataset. It achieves the following results on the evaluation set: - Loss: 1.2607 | d20e2d02ef088e22053b1de66c0c8ed0 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 12 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 10.0 | 875a988a79c8789bd1b05c60638428a7 |
apache-2.0 | ['exbert', 'multiberts', 'multiberts-seed-1'] | false | MultiBERTs Seed 1 Checkpoint 1900k (uncased) Seed 1 intermediate checkpoint 1900k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in [this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in [this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint. The final checkpoint can be found at [multiberts-seed-1](https://hf.co/multberts-seed-1). This model is uncased: it does not make a difference between english and English. Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani). | e0c81cbeec21c5c4f416c2058bfbec60 |
apache-2.0 | ['exbert', 'multiberts', 'multiberts-seed-1'] | false | How to use Here is how to use this model to get the features of a given text in PyTorch: ```python from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('multiberts-seed-1-1900k') model = BertModel.from_pretrained("multiberts-seed-1-1900k") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='pt') output = model(**encoded_input) ``` | b02015f10b6ceeede59f43a308579636 |
mit | ['huggingnft', 'nft', 'huggan', 'gan', 'image', 'images', 'unconditional-image-generation'] | false | Model description LightWeight GAN model for unconditional generation. NFT collection available [here](https://opensea.io/collection/boredapeyachtclub). Dataset is available [here](https://huggingface.co/datasets/huggingnft/boredapeyachtclub). Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft). Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft). [](https://github.com/AlekseyKorshuk/huggingnft) | 257fee6bf5eee9d1710524ff649b5263 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2r_de_xls-r_age_teens-5_sixties-5_s905 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | fb79a4ded564df15ae8f82d3a4acb4a4 |
apache-2.0 | ['generated_from_trainer'] | false | 22s-dl-sentiment-1 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the yelp_review_full dataset. It achieves the following results on the evaluation set: - Loss: 0.2574 - Accuracy: 0.9542 | 69927fd8a50cacb44125e92ec16e2eac |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-xls-r-300m-arabic_speech_commands_half This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.2678 - Accuracy: 0.9975 | 07b25000ba419f735e25f19b2bf80c93 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 10 | b60ca48d48fb3076c1d5e4e485f435e1 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 3.6816 | 0.99 | 28 | 3.4693 | 0.1575 | | 3.0227 | 1.99 | 56 | 2.5330 | 0.2775 | | 2.3345 | 2.99 | 84 | 1.8723 | 0.5925 | | 1.6785 | 3.99 | 112 | 1.2944 | 0.8092 | | 1.2606 | 4.99 | 140 | 0.8933 | 0.9425 | | 1.0024 | 5.99 | 168 | 0.6041 | 0.9817 | | 0.6478 | 6.99 | 196 | 0.3814 | 0.9933 | | 0.4768 | 7.99 | 224 | 0.2678 | 0.9975 | | 0.4143 | 8.99 | 252 | 0.2198 | 0.9967 | | 0.3278 | 9.99 | 280 | 0.1993 | 0.9967 | | ce0979b04f39a827f23b4367b0df7da6 |
mit | ['generated_from_trainer'] | false | finetuned_gpt2-xl_sst2_negation0.01_pretrainedFalse_epochs10 This model is a fine-tuned version of [gpt2-xl](https://huggingface.co/gpt2-xl) on the sst2 dataset. It achieves the following results on the evaluation set: - Loss: 4.2831 | a3d6880b99c0c231fd9e4b0600726040 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 1.7704 | 1.0 | 1323 | 3.1202 | | 1.0733 | 2.0 | 2646 | 3.4126 | | 0.867 | 3.0 | 3969 | 3.6512 | | 0.7585 | 4.0 | 5292 | 3.7861 | | 0.6945 | 5.0 | 6615 | 3.8881 | | 0.6429 | 6.0 | 7938 | 3.9924 | | 0.5997 | 7.0 | 9261 | 4.0998 | | 0.5643 | 8.0 | 10584 | 4.1730 | | 0.5279 | 9.0 | 11907 | 4.2446 | | 0.4999 | 10.0 | 13230 | 4.2831 | | b2e24f0ad6e6c432ec6ea6887a5eaae0 |
cc-by-4.0 | ['conversational', 'transformers'] | false | DialoGPT_MWOZ This is a fine-tuned model of DialoGPT (medium) on the MultiWOZ v2.2 dataset. It is intended to be used as a conversational system. The dataset it's trained on is limited in scope, as it covers only certain domains such as restaurants, hotel, taxi, train, hospital and police. The perplexity achieved on the test and validation sets are 10.25 and 10.71, respectively. More information about the original pre-trained model can be found [here](https://huggingface.co/microsoft/DialoGPT-medium) * Generation example from an interactive environment: |Role | Response | |---------|------------| |User | I would like to have breakfast. | |Bot | There are several options for Chinese in the city centre. Are you looking for a particular price range? | |User | I'm looking for free food | |Bot | There are 4 Chinese restaurants that are in the cheap price range. 3 in centre and one in north. | |User | Not good enough | |Bot | How about Charlie Chan? It is a Chinese restaurant in the centre of town. | Please find the information about preprocessing, training and full details of the DialoGPT in the [original DialoGPT repository](https://github.com/microsoft/DialoGPT) The paper for this work was accepted at the Northern Lights Deep Learning (NLDL) conference 2022. Arxiv paper: [https://arxiv.org/pdf/2110.06273.pdf](https://arxiv.org/pdf/2110.06273.pdf) | 4b43f4b1ef7ddc06fade7c53274c3af3 |
cc-by-4.0 | ['conversational', 'transformers'] | false | How to use Now we are ready to try out how the model works as a chatting partner! ```python from transformers import AutoModelForCausalLM, AutoTokenizer import torch tokenizer = AutoTokenizer.from_pretrained("tosin/dialogpt_mwoz") model = AutoModelForCausalLM.from_pretrained("tosin/dialogpt_mwoz") | 850fd71fd354d2dad58f5a722c2818f5 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-misogyny-sexism-4tweets-3e-05-0.05-3 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.8767 - Accuracy: 0.7094 - F1: 0.7184 - Precision: 0.6491 - Recall: 0.8043 - Mae: 0.2906 - Tn: 338 - Fp: 200 - Fn: 90 - Tp: 370 | 59851c2bd539afc4cc94412c3383a61f |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.