
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4 | 7e9c49382d2f298d93c204ca095955f5 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | No log | 1.0 | 1373 | 0.3634 | 0.9025 | 0.9012 | | No log | 2.0 | 2746 | 0.3648 | 0.9066 | 0.9060 | | No log | 3.0 | 4119 | 0.3978 | 0.9189 | 0.9183 | | No log | 4.0 | 5492 | 0.4277 | 0.9206 | 0.9205 | | 060b2c6e0a36fbfd4d43aeb0c035e21f |
apache-2.0 | ['generated_from_trainer'] | false | distilgpt2-finetuned-distilgpt2 This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the wikitext dataset. It achieves the following results on the evaluation set: - Loss: 3.6662 | 3c9feceaf11abec9ef69f892a4381f0d |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 6.25e-06 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 5 | 646b3fb3e084fba314f2b68413e44272 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 3.848 | 1.0 | 2334 | 3.7175 | | 3.7652 | 2.0 | 4668 | 3.6859 | | 3.7196 | 3.0 | 7002 | 3.6728 | | 3.6868 | 4.0 | 9336 | 3.6682 | | 3.6639 | 5.0 | 11670 | 3.6662 | | 35d22730b0f01d9f7ef034d315f0f210 |
apache-2.0 | ['generated_from_trainer'] | false | swin-tiny-patch4-window7-224-thecbbbfs This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset. It achieves the following results on the evaluation set: - Loss: 0.3088 - Accuracy: 0.8933 | fba82cf835765ad8bb6008ef3a95f90a |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.5717 | 0.96 | 12 | 0.3088 | 0.8933 | | e7d0abdf2eebe815e5344b5df884074c |
apache-2.0 | ['vision'] | false | Vision Transformer (large-sized model) pre-trained with MAE Vision Transformer (ViT) model pre-trained using the MAE method. It was introduced in the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick and first released in [this repository](https://github.com/facebookresearch/mae). Disclaimer: The team releasing MAE did not write a model card for this model so this model card has been written by the Hugging Face team. | f846ea11a608a28a64ce01e79cae42f7 |
apache-2.0 | ['vision'] | false | Model description The Vision Transformer (ViT) is a transformer encoder model (BERT-like). Images are presented to the model as a sequence of fixed-size patches. During pre-training, one randomly masks out a high portion (75%) of the image patches. First, the encoder is used to encode the visual patches. Next, a learnable (shared) mask token is added at the positions of the masked patches. The decoder takes the encoded visual patches and mask tokens as input and reconstructs raw pixel values for the masked positions. By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. | 45f4fc7fc02f4953e313d634b4364598 |
apache-2.0 | ['vision'] | false | Intended uses & limitations You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/vit-mae) to look for fine-tuned versions on a task that interests you. | bffc728010c1d02e24a786d0f778bc3c |
apache-2.0 | ['vision'] | false | How to use Here is how to use this model: ```python from transformers import AutoFeatureExtractor, ViTMAEForPreTraining from PIL import Image import requests url = 'http://images.cocodataset.org/val2017/000000039769.jpg' image = Image.open(requests.get(url, stream=True).raw) feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/vit-mae-large') model = ViTMAEForPreTraining.from_pretrained('facebook/vit-mae-large') inputs = feature_extractor(images=image, return_tensors="pt") outputs = model(**inputs) loss = outputs.loss mask = outputs.mask ids_restore = outputs.ids_restore ``` | 02d18907d9f00d7f9f50bfb6f2b19ecc |
apache-2.0 | ['vision'] | false | BibTeX entry and citation info ```bibtex @article{DBLP:journals/corr/abs-2111-06377, author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{\'{a}}r and Ross B. Girshick}, title = {Masked Autoencoders Are Scalable Vision Learners}, journal = {CoRR}, volume = {abs/2111.06377}, year = {2021}, url = {https://arxiv.org/abs/2111.06377}, eprinttype = {arXiv}, eprint = {2111.06377}, timestamp = {Tue, 16 Nov 2021 12:12:31 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2111-06377.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} } ``` | ba2f8c0132afebf58b204620639c9e92 |
apache-2.0 | ['generated_from_trainer'] | false | insertion-prop-05 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0756 - Precision: 0.9217 - Recall: 0.8949 - F1: 0.9081 - Accuracy: 0.9708 | 411ac43eeacb623b3bd0da24ea701be9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.1648 | 0.32 | 500 | 0.0914 | 0.9072 | 0.8710 | 0.8887 | 0.9648 | | 0.1028 | 0.64 | 1000 | 0.0792 | 0.9195 | 0.8878 | 0.9033 | 0.9693 | | 0.095 | 0.96 | 1500 | 0.0756 | 0.9217 | 0.8949 | 0.9081 | 0.9708 | | d47541fbd6623b3f94e8bfdc80709c18 |
apache-2.0 | ['generated_from_trainer'] | false | swin-tiny-patch4-window7-224-finetuned-woody_LeftGR_130epochs This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset. It achieves the following results on the evaluation set: - Loss: 0.3377 - Accuracy: 0.9047 | 65afa0f36a8fe6bce3acdf28d33b6da1 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 130 | cb0249ef3659d3a92b8a63980297b444 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.6614 | 1.0 | 61 | 0.6404 | 0.6521 | | 0.5982 | 2.0 | 122 | 0.5548 | 0.7107 | | 0.579 | 3.0 | 183 | 0.5390 | 0.7141 | | 0.5621 | 4.0 | 244 | 0.4920 | 0.7623 | | 0.5567 | 5.0 | 305 | 0.5375 | 0.7313 | | 0.5271 | 6.0 | 366 | 0.5542 | 0.7405 | | 0.5312 | 7.0 | 427 | 0.4573 | 0.7876 | | 0.5477 | 8.0 | 488 | 0.4540 | 0.7784 | | 0.5554 | 9.0 | 549 | 0.4932 | 0.7635 | | 0.5247 | 10.0 | 610 | 0.4407 | 0.7968 | | 0.5239 | 11.0 | 671 | 0.4479 | 0.7842 | | 0.5294 | 12.0 | 732 | 0.4509 | 0.7910 | | 0.531 | 13.0 | 793 | 0.4419 | 0.7933 | | 0.5493 | 14.0 | 854 | 0.4646 | 0.7784 | | 0.4934 | 15.0 | 915 | 0.4310 | 0.7968 | | 0.4965 | 16.0 | 976 | 0.4449 | 0.7876 | | 0.4946 | 17.0 | 1037 | 0.4342 | 0.8129 | | 0.4716 | 18.0 | 1098 | 0.4129 | 0.8140 | | 0.4679 | 19.0 | 1159 | 0.4290 | 0.8002 | | 0.4799 | 20.0 | 1220 | 0.4356 | 0.7842 | | 0.4744 | 21.0 | 1281 | 0.4042 | 0.8094 | | 0.4512 | 22.0 | 1342 | 0.3953 | 0.8117 | | 0.4633 | 23.0 | 1403 | 0.4157 | 0.7956 | | 0.4528 | 24.0 | 1464 | 0.3920 | 0.8094 | | 0.4427 | 25.0 | 1525 | 0.3930 | 0.8220 | | 0.4238 | 26.0 | 1586 | 0.3891 | 0.8140 | | 0.4257 | 27.0 | 1647 | 0.3700 | 0.8255 | | 0.4102 | 28.0 | 1708 | 0.4122 | 0.7968 | | 0.4505 | 29.0 | 1769 | 0.4210 | 0.7945 | | 0.3973 | 30.0 | 1830 | 0.3923 | 0.8197 | | 0.3824 | 31.0 | 1891 | 0.3908 | 0.8473 | | 0.3887 | 32.0 | 1952 | 0.3897 | 0.8312 | | 0.3723 | 33.0 | 2013 | 0.3747 | 0.8381 | | 0.3608 | 34.0 | 2074 | 0.3706 | 0.8301 | | 0.3718 | 35.0 | 2135 | 0.3937 | 0.8255 | | 0.3692 | 36.0 | 2196 | 0.3984 | 0.8037 | | 0.3533 | 37.0 | 2257 | 0.3792 | 0.8335 | | 0.3625 | 38.0 | 2318 | 0.4070 | 0.8163 | | 0.3633 | 39.0 | 2379 | 0.4130 | 0.8232 | | 0.3602 | 40.0 | 2440 | 0.3996 | 0.8186 | | 0.3557 | 41.0 | 2501 | 0.3756 | 0.8335 | | 0.3373 | 42.0 | 2562 | 0.3914 | 0.8220 | | 0.3102 | 43.0 | 2623 | 0.4165 | 0.8507 | | 0.3135 | 44.0 | 2684 | 0.3852 | 0.8278 | | 0.3286 | 45.0 | 2745 | 0.4164 | 0.8450 | | 0.316 | 46.0 | 2806 | 0.3498 | 0.8496 | | 0.2802 | 47.0 | 2867 | 0.3887 | 0.8462 | | 0.3184 | 48.0 | 2928 | 0.3829 | 0.8576 | | 0.2785 | 49.0 | 2989 | 0.3627 | 0.8485 | | 0.2988 | 50.0 | 3050 | 0.3679 | 0.8370 | | 0.267 | 51.0 | 3111 | 0.3528 | 0.8645 | | 0.2907 | 52.0 | 3172 | 0.3538 | 0.8519 | | 0.2857 | 53.0 | 3233 | 0.3593 | 0.8530 | | 0.2651 | 54.0 | 3294 | 0.3732 | 0.8439 | | 0.2447 | 55.0 | 3355 | 0.3441 | 0.8542 | | 0.2542 | 56.0 | 3416 | 0.3897 | 0.8576 | | 0.2634 | 57.0 | 3477 | 0.4082 | 0.8657 | | 0.2505 | 58.0 | 3538 | 0.3416 | 0.8657 | | 0.2555 | 59.0 | 3599 | 0.3725 | 0.8576 | | 0.2466 | 60.0 | 3660 | 0.3496 | 0.8680 | | 0.2585 | 61.0 | 3721 | 0.3214 | 0.8783 | | 0.235 | 62.0 | 3782 | 0.3584 | 0.8737 | | 0.215 | 63.0 | 3843 | 0.3467 | 0.8657 | | 0.236 | 64.0 | 3904 | 0.3471 | 0.8829 | | 0.2211 | 65.0 | 3965 | 0.3318 | 0.8863 | | 0.1989 | 66.0 | 4026 | 0.3645 | 0.8852 | | 0.2133 | 67.0 | 4087 | 0.3456 | 0.8898 | | 0.2169 | 68.0 | 4148 | 0.3287 | 0.8852 | | 0.223 | 69.0 | 4209 | 0.3182 | 0.8921 | | 0.2379 | 70.0 | 4270 | 0.3260 | 0.8840 | | 0.2149 | 71.0 | 4331 | 0.3230 | 0.8886 | | 0.2007 | 72.0 | 4392 | 0.3926 | 0.8760 | | 0.2091 | 73.0 | 4453 | 0.4133 | 0.8783 | | 0.2229 | 74.0 | 4514 | 0.3867 | 0.8772 | | 0.1903 | 75.0 | 4575 | 0.3594 | 0.8840 | | 0.2124 | 76.0 | 4636 | 0.3388 | 0.8875 | | 0.1999 | 77.0 | 4697 | 0.3305 | 0.8875 | | 0.2053 | 78.0 | 4758 | 0.4670 | 0.8840 | | 0.1958 | 79.0 | 4819 | 0.3468 | 0.8909 | | 0.1839 | 80.0 | 4880 | 0.3902 | 0.8886 | | 0.1715 | 81.0 | 4941 | 0.3830 | 0.8875 | | 0.1803 | 82.0 | 5002 | 0.3134 | 0.8967 | | 0.1803 | 83.0 | 5063 | 0.3935 | 0.8909 | | 0.1865 | 84.0 | 5124 | 0.3882 | 0.8863 | | 0.1884 | 85.0 | 5185 | 0.3485 | 0.8990 | | 0.1663 | 86.0 | 5246 | 0.3667 | 0.8944 | | 0.1665 | 87.0 | 5307 | 0.3545 | 0.8932 | | 0.1556 | 88.0 | 5368 | 0.3882 | 0.8944 | | 0.18 | 89.0 | 5429 | 0.3751 | 0.8898 | | 0.1974 | 90.0 | 5490 | 0.3979 | 0.8863 | | 0.1622 | 91.0 | 5551 | 0.3623 | 0.8967 | | 0.1657 | 92.0 | 5612 | 0.3855 | 0.8978 | | 0.1672 | 93.0 | 5673 | 0.3722 | 0.8944 | | 0.1807 | 94.0 | 5734 | 0.3994 | 0.8932 | | 0.1419 | 95.0 | 5795 | 0.4017 | 0.8863 | | 0.178 | 96.0 | 5856 | 0.4168 | 0.8886 | | 0.1402 | 97.0 | 5917 | 0.3727 | 0.8944 | | 0.1427 | 98.0 | 5978 | 0.3919 | 0.8967 | | 0.1318 | 99.0 | 6039 | 0.3843 | 0.8955 | | 0.1417 | 100.0 | 6100 | 0.4017 | 0.8898 | | 0.1536 | 101.0 | 6161 | 0.3613 | 0.8955 | | 0.1631 | 102.0 | 6222 | 0.3377 | 0.9047 | | 0.1459 | 103.0 | 6283 | 0.3724 | 0.8967 | | 0.1499 | 104.0 | 6344 | 0.3934 | 0.8955 | | 0.1572 | 105.0 | 6405 | 0.3368 | 0.8967 | | 0.1308 | 106.0 | 6466 | 0.3782 | 0.8990 | | 0.1535 | 107.0 | 6527 | 0.3306 | 0.9024 | | 0.125 | 108.0 | 6588 | 0.4076 | 0.8898 | | 0.1339 | 109.0 | 6649 | 0.3628 | 0.8990 | | 0.148 | 110.0 | 6710 | 0.3672 | 0.9013 | | 0.1725 | 111.0 | 6771 | 0.4006 | 0.8909 | | 0.1326 | 112.0 | 6832 | 0.4117 | 0.8921 | | 0.1438 | 113.0 | 6893 | 0.3927 | 0.8978 | | 0.1205 | 114.0 | 6954 | 0.3612 | 0.8990 | | 0.1531 | 115.0 | 7015 | 0.3594 | 0.8932 | | 0.1473 | 116.0 | 7076 | 0.4490 | 0.8875 | | 0.1388 | 117.0 | 7137 | 0.3952 | 0.8921 | | 0.136 | 118.0 | 7198 | 0.4098 | 0.8921 | | 0.1579 | 119.0 | 7259 | 0.3595 | 0.9013 | | 0.1359 | 120.0 | 7320 | 0.3970 | 0.8944 | | 0.1314 | 121.0 | 7381 | 0.4092 | 0.8932 | | 0.1337 | 122.0 | 7442 | 0.4192 | 0.8909 | | 0.1538 | 123.0 | 7503 | 0.4154 | 0.8898 | | 0.119 | 124.0 | 7564 | 0.4120 | 0.8909 | | 0.1353 | 125.0 | 7625 | 0.4060 | 0.8921 | | 0.1489 | 126.0 | 7686 | 0.4162 | 0.8909 | | 0.1554 | 127.0 | 7747 | 0.4148 | 0.8944 | | 0.1558 | 128.0 | 7808 | 0.4169 | 0.8944 | | 0.1268 | 129.0 | 7869 | 0.4110 | 0.8955 | | 0.1236 | 130.0 | 7930 | 0.4197 | 0.8944 | | b7001c3d8dd6a4449e71dc30de33ce4f |
mit | ['generated_from_trainer'] | false | deberta-base-combined-squad1-aqa-and-newsqa This model is a fine-tuned version of [stevemobs/deberta-base-combined-squad1-aqa](https://huggingface.co/stevemobs/deberta-base-combined-squad1-aqa) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.7527 | d80ccd536aa3db72a5452257e062c654 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:-----:|:---------------:| | 0.6729 | 1.0 | 17307 | 0.7076 | | 0.4631 | 2.0 | 34614 | 0.7527 | | 528a553c0bbc6aa335b44557d53fb50f |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | Wav2Vec2-XLS-R-300M-21-EN Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**  This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model. The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint. Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2). The model can translate from the following spoken languages `{lang}` -> `en` (English): {`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en` For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296). | e0b1ed7031116a5ed68d07b757e1ef70 |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | Demo The model can be tested directly on the speech recognition widget on this model card! Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input. | d67fb067eea31f890ed429129ed0a67d |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | Example As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the transcripts by passing the speech features to the model. You can use the model directly via the ASR pipeline ```python from datasets import load_dataset from transformers import pipeline | 510f78e2e4217bd51bec6c40ca71baa9 |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | replace following lines to load an audio file of your choice librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation") audio_file = librispeech_en[0]["file"] asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-300m-21-to-en") translation = asr(audio_file) ``` or step-by-step as follows: ```python import torch from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel from datasets import load_dataset model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en") processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en") ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation") inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt") generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"]) transcription = processor.batch_decode(generated_ids) ``` | 9b468282d0aab8918a12d9a6b254904f |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | Results `{lang}` -> `en` See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model. 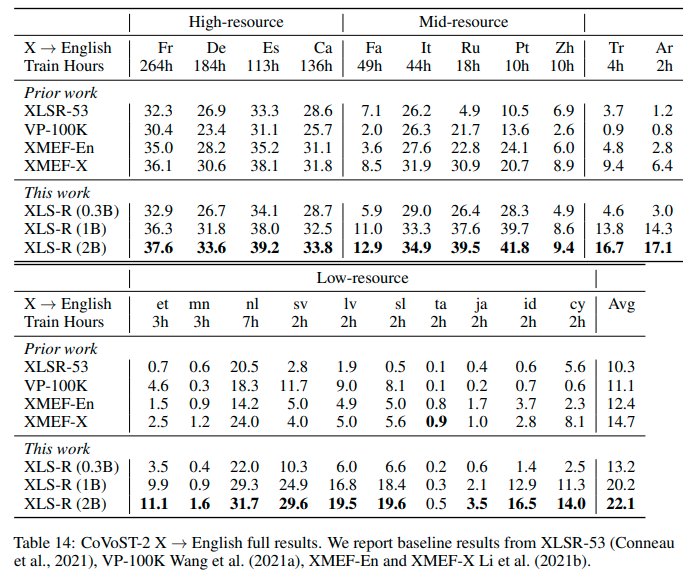 | 7488d2982591fb4793093fcc795b654f |
apache-2.0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | More XLS-R models for `{lang}` -> `en` Speech Translation - [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en) - [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en) - [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en) - [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16) | 1ed6ed30263966d2badf2ae2c0f17739 |
apache-2.0 | ['generated_from_trainer'] | false | stsb This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE STSB dataset. It achieves the following results on the evaluation set: - Loss: 0.4914 - Pearson: 0.8930 - Spearmanr: 0.8888 - Combined Score: 0.8909 | 44c3a33c949a85b8a98c5478ba5a86a3 |
apache-2.0 | ['generated_from_trainer'] | false | vit-base-patch16-224_album_vitVMMRdb_make_model_album_pred This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.4670 - Accuracy: 0.8781 - Precision: 0.8768 - Recall: 0.8781 - F1: 0.8758 | 8c471389c0815198c7251331223a51cb |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 64 - eval_batch_size: 64 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 256 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 15 | 934611972d8554ba70fed8a025667afe |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | |:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:| | 3.5529 | 1.0 | 839 | 3.3687 | 0.3096 | 0.2809 | 0.3096 | 0.2246 | | 1.7855 | 2.0 | 1678 | 1.6042 | 0.6378 | 0.6187 | 0.6378 | 0.5996 | | 1.1054 | 3.0 | 2517 | 1.0105 | 0.7556 | 0.7512 | 0.7556 | 0.7385 | | 0.8179 | 4.0 | 3356 | 0.7794 | 0.8033 | 0.8020 | 0.8033 | 0.7934 | | 0.6057 | 5.0 | 4195 | 0.6479 | 0.8294 | 0.8274 | 0.8294 | 0.8212 | | 0.4709 | 6.0 | 5034 | 0.5817 | 0.8478 | 0.8477 | 0.8478 | 0.8428 | | 0.3962 | 7.0 | 5873 | 0.5333 | 0.8571 | 0.8570 | 0.8571 | 0.8527 | | 0.346 | 8.0 | 6712 | 0.5073 | 0.8638 | 0.8647 | 0.8638 | 0.8615 | | 0.2772 | 9.0 | 7551 | 0.4881 | 0.8681 | 0.8679 | 0.8681 | 0.8656 | | 0.2136 | 10.0 | 8390 | 0.4777 | 0.8719 | 0.8718 | 0.8719 | 0.8689 | | 0.1937 | 11.0 | 9229 | 0.4737 | 0.8734 | 0.8731 | 0.8734 | 0.8703 | | 0.1754 | 12.0 | 10068 | 0.4604 | 0.8758 | 0.8750 | 0.8758 | 0.8733 | | 0.1111 | 13.0 | 10907 | 0.4561 | 0.8790 | 0.8782 | 0.8790 | 0.8768 | | 0.1128 | 14.0 | 11746 | 0.4519 | 0.8808 | 0.8799 | 0.8808 | 0.8787 | | 0.1018 | 15.0 | 12585 | 0.4497 | 0.8813 | 0.8805 | 0.8813 | 0.8794 | | 4efbb1f03f68947c74681eba2bb77289 |
apache-2.0 | ['generated_from_trainer'] | false | bert-tiny-Massive-intent-KD-BERT This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the massive dataset. It achieves the following results on the evaluation set: - Loss: 0.8380 - Accuracy: 0.8534 | 4e74aee54e4c7e8f0a16ada5df2b9a75 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:--------:| | 5.83 | 1.0 | 720 | 4.8826 | 0.3050 | | 4.7602 | 2.0 | 1440 | 3.9904 | 0.4191 | | 4.0301 | 3.0 | 2160 | 3.3806 | 0.5032 | | 3.4797 | 4.0 | 2880 | 2.9065 | 0.5967 | | 3.0352 | 5.0 | 3600 | 2.5389 | 0.6596 | | 2.6787 | 6.0 | 4320 | 2.2342 | 0.7044 | | 2.3644 | 7.0 | 5040 | 1.9873 | 0.7354 | | 2.1145 | 8.0 | 5760 | 1.7928 | 0.7462 | | 1.896 | 9.0 | 6480 | 1.6293 | 0.7644 | | 1.7138 | 10.0 | 7200 | 1.5062 | 0.7752 | | 1.5625 | 11.0 | 7920 | 1.3923 | 0.7885 | | 1.4229 | 12.0 | 8640 | 1.3092 | 0.7978 | | 1.308 | 13.0 | 9360 | 1.2364 | 0.8018 | | 1.201 | 14.0 | 10080 | 1.1759 | 0.8155 | | 1.1187 | 15.0 | 10800 | 1.1322 | 0.8214 | | 1.0384 | 16.0 | 11520 | 1.0990 | 0.8234 | | 0.976 | 17.0 | 12240 | 1.0615 | 0.8308 | | 0.9163 | 18.0 | 12960 | 1.0377 | 0.8328 | | 0.8611 | 19.0 | 13680 | 1.0054 | 0.8337 | | 0.812 | 20.0 | 14400 | 0.9926 | 0.8367 | | 0.7721 | 21.0 | 15120 | 0.9712 | 0.8382 | | 0.7393 | 22.0 | 15840 | 0.9586 | 0.8357 | | 0.7059 | 23.0 | 16560 | 0.9428 | 0.8372 | | 0.6741 | 24.0 | 17280 | 0.9377 | 0.8396 | | 0.6552 | 25.0 | 18000 | 0.9229 | 0.8377 | | 0.627 | 26.0 | 18720 | 0.9100 | 0.8416 | | 0.5972 | 27.0 | 19440 | 0.9028 | 0.8416 | | 0.5784 | 28.0 | 20160 | 0.8996 | 0.8406 | | 0.5595 | 29.0 | 20880 | 0.8833 | 0.8451 | | 0.5438 | 30.0 | 21600 | 0.8772 | 0.8475 | | 0.5218 | 31.0 | 22320 | 0.8758 | 0.8451 | | 0.509 | 32.0 | 23040 | 0.8728 | 0.8480 | | 0.4893 | 33.0 | 23760 | 0.8640 | 0.8480 | | 0.4948 | 34.0 | 24480 | 0.8541 | 0.8475 | | 0.4722 | 35.0 | 25200 | 0.8595 | 0.8495 | | 0.468 | 36.0 | 25920 | 0.8488 | 0.8495 | | 0.4517 | 37.0 | 26640 | 0.8460 | 0.8505 | | 0.4462 | 38.0 | 27360 | 0.8450 | 0.8485 | | 0.4396 | 39.0 | 28080 | 0.8422 | 0.8490 | | 0.427 | 40.0 | 28800 | 0.8380 | 0.8534 | | 0.4287 | 41.0 | 29520 | 0.8385 | 0.8480 | | 0.4222 | 42.0 | 30240 | 0.8319 | 0.8510 | | 0.421 | 43.0 | 30960 | 0.8296 | 0.8510 | | 87df13f620405b0836faa867f0857301 |
mit | ['text-classification', 'generated_from_trainer'] | false | deberta-v3-large-finetuned-syndag-multiclass-not-bloom This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0197 - F1: 0.9956 - Precision: 0.9956 - Recall: 0.9956 | 5d0773a0ce02c64f0087f5ac5853502a |
mit | ['text-classification', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 6e-06 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 50 - num_epochs: 1 - mixed_precision_training: Native AMP | 98984a0e13750407f679095397ccef73 |
mit | ['text-classification', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall | |:-------------:|:-----:|:-----:|:---------------:|:------:|:---------:|:------:| | 0.0194 | 1.0 | 10847 | 0.0222 | 0.9955 | 0.9955 | 0.9955 | | 33f8b5f9fd91b6c4ac2cb575ed79dacf |
apache-2.0 | ['stanza', 'token-classification'] | false | Stanza model for Slovenian (sl) Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing. Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza). This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo Last updated 2022-09-25 02:01:37.680 | 673d7d8d5672055124f489118c0a4be0 |
apache-2.0 | ['audio', 'speech', 'wav2vec2', 'pt', 'portuguese-speech-corpus', 'automatic-speech-recognition', 'speech', 'PyTorch'] | false | Wav2vec 2.0 trained with CORAA Portuguese Dataset and Open Portuguese Datasets
This a the demonstration of a fine-tuned Wav2vec model for Portuguese using the following datasets:
- [CORAA dataset](https://github.com/nilc-nlp/CORAA)
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz).
- [Multilingual Librispeech (MLS)](http://www.openslr.org/94/).
- [VoxForge](http://www.voxforge.org/).
- [Common Voice 6.1](https://commonvoice.mozilla.org/pt).
| 905ffa759d0d36a03334e3117f8d5d48 |
apache-2.0 | ['generated_from_trainer'] | false | distilbart-cnn-12-6-sec This model is a fine-tuned version of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1379 - Rouge1: 72.2845 - Rouge2: 61.1501 - Rougel: 67.6999 - Rougelsum: 70.9968 - Gen Len: 113.8 | 079ed3b0a135cb75420f27324e94b2e0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:| | No log | 1.0 | 99 | 0.4429 | 56.0806 | 40.5969 | 47.5271 | 53.7227 | 115.44 | | No log | 2.0 | 198 | 0.2279 | 56.6042 | 42.1781 | 48.9542 | 54.951 | 116.84 | | No log | 3.0 | 297 | 0.1845 | 65.9646 | 51.8575 | 59.8647 | 64.103 | 113.8 | | No log | 4.0 | 396 | 0.1532 | 71.6132 | 61.1434 | 67.4165 | 70.4093 | 110.46 | | No log | 5.0 | 495 | 0.1379 | 72.2845 | 61.1501 | 67.6999 | 70.9968 | 113.8 | | 91d527b4bcf3c9722c77705835842616 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 10 - eval_batch_size: 10 - seed: 42 - gradient_accumulation_steps: 10 - total_train_batch_size: 100 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 7 | a956aa179d728409d6e0d3df6d973273 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 3.0118 | 1.4 | 7 | 2.1901 | | 2.1915 | 2.8 | 14 | 1.8797 | | 1.8529 | 4.2 | 21 | 1.7159 | | 1.7081 | 5.6 | 28 | 1.6536 | | 1.623 | 7.0 | 35 | 1.6366 | | ad2a766c3eae9ed659d0c6da70ddf36b |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | mt5-small-finetuned-amazon-en-ja This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.2749 - Rouge1: 16.6603 - Rouge2: 8.1096 - Rougel: 16.0117 - Rougelsum: 16.1001 | 0ada6bbe85881497d83b987aea0b3a21 |
apache-2.0 | ['summarization', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:| | 8.0415 | 1.0 | 773 | 3.6621 | 11.6952 | 4.8642 | 11.3154 | 11.3683 | | 4.1249 | 2.0 | 1546 | 3.3933 | 14.3113 | 6.2067 | 13.9923 | 14.0476 | | 3.7462 | 3.0 | 2319 | 3.3725 | 15.7855 | 8.0892 | 15.2485 | 15.3145 | | 3.5608 | 4.0 | 3092 | 3.3270 | 16.0732 | 7.8202 | 15.4816 | 15.6421 | | 3.4471 | 5.0 | 3865 | 3.2908 | 16.4399 | 7.6723 | 15.514 | 15.7309 | | 3.3604 | 6.0 | 4638 | 3.2904 | 16.6074 | 8.3131 | 16.0711 | 16.1382 | | 3.3081 | 7.0 | 5411 | 3.2827 | 16.2547 | 8.1096 | 15.6128 | 15.7097 | | 3.2905 | 8.0 | 6184 | 3.2749 | 16.6603 | 8.1096 | 16.0117 | 16.1001 | | 78248384fdbfd5b0a40b868dc9d3bf52 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-sst2-nostop This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0701 - Accuracy: 0.9888 | 325099e3aa56ce596ff9cbc716691995 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.125 | 1.0 | 1116 | 0.0975 | 0.9743 | | 0.0599 | 2.0 | 2232 | 0.0692 | 0.9840 | | 0.0191 | 3.0 | 3348 | 0.0570 | 0.9871 | | 0.0109 | 4.0 | 4464 | 0.0660 | 0.9882 | | 0.0092 | 5.0 | 5580 | 0.0701 | 0.9888 | | bf35ebd73d01d7a7fcfb815189908060 |
mit | ['generated_from_keras_callback'] | false | Ashraf-kasem/custom_gpt2_frames_text_continue This model is a fine-tuned version of [Ashraf-kasem/custom_gpt2_frames_text_continue](https://huggingface.co/Ashraf-kasem/custom_gpt2_frames_text_continue) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.6337 - Validation Loss: 2.3028 - Epoch: 99 | 77e1c9b50e549f4a26baea942f671dbf |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'LinearWarmup', 'config': {'after_warmup_lr_sched': {'initial_learning_rate': 5e-05, 'decay_steps': 628900, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'warmup_steps': 125780, 'warmup_learning_rate': 0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False} - training_precision: mixed_float16 | dbb63f6435a5be833e92e0dd42d6b147 |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 1.0060 | 2.0768 | 0 | | 1.0147 | 2.0771 | 1 | | 1.0238 | 2.0821 | 2 | | 1.0331 | 2.0851 | 3 | | 1.0422 | 2.0870 | 4 | | 1.0525 | 2.0945 | 5 | | 1.0618 | 2.1005 | 6 | | 1.0718 | 2.1014 | 7 | | 1.0823 | 2.1056 | 8 | | 1.0921 | 2.1099 | 9 | | 1.1028 | 2.1106 | 10 | | 1.1127 | 2.1127 | 11 | | 1.1230 | 2.1183 | 12 | | 1.1329 | 2.1207 | 13 | | 1.1423 | 2.1270 | 14 | | 1.1521 | 2.1234 | 15 | | 1.1614 | 2.1283 | 16 | | 1.1700 | 2.1236 | 17 | | 1.1784 | 2.1320 | 18 | | 1.1864 | 2.1359 | 19 | | 1.1873 | 2.1272 | 20 | | 1.1766 | 2.1250 | 21 | | 1.1652 | 2.1260 | 22 | | 1.1537 | 2.1224 | 23 | | 1.1415 | 2.1278 | 24 | | 1.1296 | 2.1254 | 25 | | 1.1178 | 2.1213 | 26 | | 1.1059 | 2.1301 | 27 | | 1.0950 | 2.1253 | 28 | | 1.0838 | 2.1264 | 29 | | 1.0729 | 2.1273 | 30 | | 1.0625 | 2.1355 | 31 | | 1.0519 | 2.1345 | 32 | | 1.0414 | 2.1364 | 33 | | 1.0317 | 2.1324 | 34 | | 1.0217 | 2.1410 | 35 | | 1.0126 | 2.1428 | 36 | | 1.0027 | 2.1427 | 37 | | 0.9936 | 2.1494 | 38 | | 0.9846 | 2.1502 | 39 | | 0.9752 | 2.1490 | 40 | | 0.9665 | 2.1501 | 41 | | 0.9582 | 2.1552 | 42 | | 0.9497 | 2.1533 | 43 | | 0.9411 | 2.1621 | 44 | | 0.9331 | 2.1618 | 45 | | 0.9248 | 2.1655 | 46 | | 0.9172 | 2.1755 | 47 | | 0.9093 | 2.1759 | 48 | | 0.9014 | 2.1751 | 49 | | 0.8942 | 2.1813 | 50 | | 0.8867 | 2.1831 | 51 | | 0.8795 | 2.1856 | 52 | | 0.8723 | 2.1909 | 53 | | 0.8651 | 2.1950 | 54 | | 0.8581 | 2.1955 | 55 | | 0.8511 | 2.2007 | 56 | | 0.8444 | 2.2002 | 57 | | 0.8380 | 2.2078 | 58 | | 0.8312 | 2.2077 | 59 | | 0.8246 | 2.2161 | 60 | | 0.8186 | 2.2103 | 61 | | 0.8120 | 2.2180 | 62 | | 0.8053 | 2.2202 | 63 | | 0.7994 | 2.2232 | 64 | | 0.7934 | 2.2290 | 65 | | 0.7872 | 2.2301 | 66 | | 0.7816 | 2.2327 | 67 | | 0.7757 | 2.2369 | 68 | | 0.7698 | 2.2408 | 69 | | 0.7640 | 2.2439 | 70 | | 0.7582 | 2.2451 | 71 | | 0.7528 | 2.2505 | 72 | | 0.7475 | 2.2524 | 73 | | 0.7420 | 2.2520 | 74 | | 0.7366 | 2.2561 | 75 | | 0.7313 | 2.2616 | 76 | | 0.7260 | 2.2628 | 77 | | 0.7211 | 2.2654 | 78 | | 0.7158 | 2.2701 | 79 | | 0.7107 | 2.2704 | 80 | | 0.7061 | 2.2743 | 81 | | 0.7008 | 2.2749 | 82 | | 0.6962 | 2.2769 | 83 | | 0.6916 | 2.2813 | 84 | | 0.6869 | 2.2838 | 85 | | 0.6823 | 2.2853 | 86 | | 0.6780 | 2.2867 | 87 | | 0.6737 | 2.2883 | 88 | | 0.6691 | 2.2921 | 89 | | 0.6651 | 2.2931 | 90 | | 0.6608 | 2.2946 | 91 | | 0.6568 | 2.2957 | 92 | | 0.6533 | 2.2984 | 93 | | 0.6494 | 2.2981 | 94 | | 0.6459 | 2.2994 | 95 | | 0.6425 | 2.3006 | 96 | | 0.6395 | 2.3019 | 97 | | 0.6363 | 2.3026 | 98 | | 0.6337 | 2.3028 | 99 | | 10446055738f6d19bee012c25402a08d |
apache-2.0 | ['generated_from_trainer'] | false | finetuning-sentiment-model-3000-samples This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.3230 - Accuracy: 0.87 - F1: 0.8713 | bc8bfaf3c2fdc2a387adf83dfd05014c |
mit | ['generated_from_trainer'] | false | predict-perception-bert-cause-object This model is a fine-tuned version of [dbmdz/bert-base-italian-xxl-cased](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.4120 - Rmse: 1.0345 - Rmse Cause::a Causata da un oggetto (es. una pistola): 1.0345 - Mae: 0.6181 - Mae Cause::a Causata da un oggetto (es. una pistola): 0.6181 - R2: 0.3837 - R2 Cause::a Causata da un oggetto (es. una pistola): 0.3837 - Cos: 0.9130 - Pair: 0.0 - Rank: 0.5 - Neighbors: 0.8986 - Rsa: nan | 822a4b1cfc1768e090c4fb268c962c2d |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rmse | Rmse Cause::a Causata da un oggetto (es. una pistola) | Mae | Mae Cause::a Causata da un oggetto (es. una pistola) | R2 | R2 Cause::a Causata da un oggetto (es. una pistola) | Cos | Pair | Rank | Neighbors | Rsa | |:-------------:|:-----:|:----:|:---------------:|:------:|:-----------------------------------------------------:|:------:|:----------------------------------------------------:|:-------:|:---------------------------------------------------:|:------:|:----:|:----:|:---------:|:---:| | 1.0824 | 1.0 | 15 | 0.6651 | 1.3143 | 1.3143 | 1.0930 | 1.0930 | 0.0052 | 0.0052 | 0.3043 | 0.0 | 0.5 | 0.4393 | nan | | 0.9574 | 2.0 | 30 | 0.7088 | 1.3568 | 1.3568 | 1.1945 | 1.1945 | -0.0601 | -0.0601 | 0.0435 | 0.0 | 0.5 | 0.3380 | nan | | 0.8151 | 3.0 | 45 | 0.6300 | 1.2791 | 1.2791 | 1.0206 | 1.0206 | 0.0577 | 0.0577 | 0.3043 | 0.0 | 0.5 | 0.3613 | nan | | 0.6401 | 4.0 | 60 | 0.4871 | 1.1247 | 1.1247 | 0.7285 | 0.7285 | 0.2715 | 0.2715 | 0.5652 | 0.0 | 0.5 | 0.6424 | nan | | 0.448 | 5.0 | 75 | 0.5005 | 1.1401 | 1.1401 | 0.7216 | 0.7216 | 0.2514 | 0.2514 | 0.4783 | 0.0 | 0.5 | 0.6077 | nan | | 0.2893 | 6.0 | 90 | 0.4761 | 1.1119 | 1.1119 | 0.7237 | 0.7237 | 0.2879 | 0.2879 | 0.5652 | 0.0 | 0.5 | 0.6348 | nan | | 0.174 | 7.0 | 105 | 0.4771 | 1.1131 | 1.1131 | 0.6836 | 0.6836 | 0.2865 | 0.2865 | 0.6522 | 0.0 | 0.5 | 0.6785 | nan | | 0.1383 | 8.0 | 120 | 0.4313 | 1.0583 | 1.0583 | 0.6462 | 0.6462 | 0.3550 | 0.3550 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.1105 | 9.0 | 135 | 0.4660 | 1.1001 | 1.1001 | 0.6737 | 0.6737 | 0.3030 | 0.3030 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0903 | 10.0 | 150 | 0.4866 | 1.1241 | 1.1241 | 0.7192 | 0.7192 | 0.2723 | 0.2723 | 0.7391 | 0.0 | 0.5 | 0.6833 | nan | | 0.0571 | 11.0 | 165 | 0.4361 | 1.0642 | 1.0642 | 0.6130 | 0.6130 | 0.3478 | 0.3478 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0623 | 12.0 | 180 | 0.4578 | 1.0904 | 1.0904 | 0.6844 | 0.6844 | 0.3152 | 0.3152 | 0.6522 | 0.0 | 0.5 | 0.6785 | nan | | 0.0526 | 13.0 | 195 | 0.4605 | 1.0936 | 1.0936 | 0.6697 | 0.6697 | 0.3112 | 0.3112 | 0.6522 | 0.0 | 0.5 | 0.6785 | nan | | 0.0472 | 14.0 | 210 | 0.4440 | 1.0738 | 1.0738 | 0.6589 | 0.6589 | 0.3360 | 0.3360 | 0.7391 | 0.0 | 0.5 | 0.7327 | nan | | 0.0492 | 15.0 | 225 | 0.4593 | 1.0922 | 1.0922 | 0.6812 | 0.6812 | 0.3130 | 0.3130 | 0.7391 | 0.0 | 0.5 | 0.6833 | nan | | 0.0389 | 16.0 | 240 | 0.4195 | 1.0437 | 1.0437 | 0.6252 | 0.6252 | 0.3726 | 0.3726 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0396 | 17.0 | 255 | 0.4087 | 1.0302 | 1.0302 | 0.6119 | 0.6119 | 0.3888 | 0.3888 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0328 | 18.0 | 270 | 0.4274 | 1.0535 | 1.0535 | 0.6457 | 0.6457 | 0.3608 | 0.3608 | 0.8261 | 0.0 | 0.5 | 0.7431 | nan | | 0.0345 | 19.0 | 285 | 0.4306 | 1.0574 | 1.0574 | 0.6576 | 0.6576 | 0.3560 | 0.3560 | 0.8261 | 0.0 | 0.5 | 0.7431 | nan | | 0.0328 | 20.0 | 300 | 0.4067 | 1.0277 | 1.0277 | 0.6160 | 0.6160 | 0.3918 | 0.3918 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0344 | 21.0 | 315 | 0.4056 | 1.0263 | 1.0263 | 0.5948 | 0.5948 | 0.3934 | 0.3934 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0312 | 22.0 | 330 | 0.4236 | 1.0488 | 1.0488 | 0.6277 | 0.6277 | 0.3665 | 0.3665 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0241 | 23.0 | 345 | 0.4272 | 1.0533 | 1.0533 | 0.6444 | 0.6444 | 0.3610 | 0.3610 | 0.8261 | 0.0 | 0.5 | 0.7431 | nan | | 0.0302 | 24.0 | 360 | 0.4046 | 1.0250 | 1.0250 | 0.6030 | 0.6030 | 0.3949 | 0.3949 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0244 | 25.0 | 375 | 0.4194 | 1.0436 | 1.0436 | 0.6320 | 0.6320 | 0.3728 | 0.3728 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0259 | 26.0 | 390 | 0.4025 | 1.0224 | 1.0224 | 0.6009 | 0.6009 | 0.3980 | 0.3980 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0265 | 27.0 | 405 | 0.4103 | 1.0323 | 1.0323 | 0.6180 | 0.6180 | 0.3863 | 0.3863 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0184 | 28.0 | 420 | 0.4059 | 1.0268 | 1.0268 | 0.6046 | 0.6046 | 0.3929 | 0.3929 | 0.8261 | 0.0 | 0.5 | 0.7586 | nan | | 0.0257 | 29.0 | 435 | 0.4088 | 1.0304 | 1.0304 | 0.6122 | 0.6122 | 0.3885 | 0.3885 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 0.0262 | 30.0 | 450 | 0.4120 | 1.0345 | 1.0345 | 0.6181 | 0.6181 | 0.3837 | 0.3837 | 0.9130 | 0.0 | 0.5 | 0.8986 | nan | | 97d6c1aee04afef19fd0482939a58a71 |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | t5-base-TEDxJP-1front-1body-0rear This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset. It achieves the following results on the evaluation set: - Loss: 0.4787 - Wer: 0.1786 - Mer: 0.1722 - Wil: 0.2608 - Wip: 0.7392 - Hits: 55434 - Substitutions: 6554 - Deletions: 2599 - Insertions: 2380 - Cer: 0.1399 | 8bcd0bace59ab599836e3750e0991f00 |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 10 | 7b0b19f0b5075adc1ff0bbf1c9796e74 |
cc-by-sa-4.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer | |:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:| | 0.6606 | 1.0 | 1457 | 0.5113 | 0.2142 | 0.2017 | 0.2939 | 0.7061 | 54751 | 6976 | 2860 | 4000 | 0.1909 | | 0.5636 | 2.0 | 2914 | 0.4669 | 0.1913 | 0.1832 | 0.2728 | 0.7272 | 55086 | 6669 | 2832 | 2852 | 0.1700 | | 0.5115 | 3.0 | 4371 | 0.4543 | 0.1815 | 0.1747 | 0.2633 | 0.7367 | 55384 | 6559 | 2644 | 2519 | 0.1504 | | 0.4463 | 4.0 | 5828 | 0.4512 | 0.1796 | 0.1733 | 0.2617 | 0.7383 | 55344 | 6534 | 2709 | 2358 | 0.1422 | | 0.4001 | 5.0 | 7285 | 0.4564 | 0.1779 | 0.1718 | 0.2600 | 0.7400 | 55394 | 6509 | 2684 | 2295 | 0.1395 | | 0.3683 | 6.0 | 8742 | 0.4600 | 0.1790 | 0.1726 | 0.2611 | 0.7389 | 55436 | 6546 | 2605 | 2413 | 0.1405 | | 0.391 | 7.0 | 10199 | 0.4651 | 0.1781 | 0.1718 | 0.2599 | 0.7401 | 55424 | 6505 | 2658 | 2338 | 0.1391 | | 0.337 | 8.0 | 11656 | 0.4705 | 0.1775 | 0.1714 | 0.2595 | 0.7405 | 55439 | 6511 | 2637 | 2316 | 0.1382 | | 0.3233 | 9.0 | 13113 | 0.4757 | 0.1790 | 0.1726 | 0.2612 | 0.7388 | 55414 | 6554 | 2619 | 2386 | 0.1401 | | 0.3204 | 10.0 | 14570 | 0.4787 | 0.1786 | 0.1722 | 0.2608 | 0.7392 | 55434 | 6554 | 2599 | 2380 | 0.1399 | | 7ac720d7f7be14954a36a34ec013b2d4 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-emotion This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. It achieves the following results on the evaluation set: - Loss: 0.1468 - Accuracy: 0.9345 - F1: 0.9346 | c1eb45271f168f849d5614c0f2901f35 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | |:-------------:|:-----:|:----:|:---------------:|:--------:|:------:| | 0.1695 | 1.0 | 250 | 0.1757 | 0.93 | 0.9298 | | 0.107 | 2.0 | 500 | 0.1468 | 0.9345 | 0.9346 | | d98f8b352126cca7cb4c9bbc8c974606 |
mit | ['generated_from_trainer'] | false | BERiT This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the [Tanakh dataset](https://huggingface.co/datasets/gngpostalsrvc/Tanakh). It achieves the following results on the evaluation set: - Loss: 3.9931 | 6feb1f321d5448e6158846ecbc3e2588 |
mit | ['generated_from_trainer'] | false | Model description BERiT is a masked-language model for Biblical Hebrew, a low-resource ancient language preserved primarily in the text of the Hebrew Bible. Building on the work of [Sennrich and Zhang (2019)](https://arxiv.org/abs/1905.11901) and [Wodiak (2021)](https://arxiv.org/abs/2110.01938) on low-resource machine translation, it employs a modified version of the encoder block from Wodiak’s Seq2Seq model. Accordingly, BERiT is much smaller than models designed for modern languages like English. It features a single attention block with four attention heads, smaller embedding and feedforward dimensions (256 and 1024), a smaller max input length (128), and an aggressive dropout rate (.5) at both the attention and feedforward layers. The BERiT tokenizer performs character level byte-pair encoding using a 2000 word base vocabulary, which has been enriched with common grammatical morphemes. | bbce5a3fe7ff20f9715d59c5a24dd49a |
mit | ['generated_from_trainer'] | false | How to Use ``` from transformers import RobertaModel, RobertaTokenizerFast BERiT_tokenizer = RobertaTokenizerFast.from_pretrained('gngpostalsrvc/BERiT') BERiT = RobertaModel.from_pretrained('gngpostalsrvc/BERiT') ``` | 7be5c3b09bc889e6c3aac06c8bf1e95f |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0005 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 150 | 55fc013ce0997bf3313e831ba45c1968 |
other | ['vision', 'image-segmentation', 'generated_from_trainer'] | false | segformer-b0-finetuned-busigt2 This model is a fine-tuned version of [nvidia/mit-b1](https://huggingface.co/nvidia/mit-b1) on the kasumi222/busigt5 dataset. It achieves the following results on the evaluation set: - Loss: 0.2904 - Mean Iou: 0.4458 - Mean Accuracy: 0.6980 - Overall Accuracy: 0.6969 - Per Category Iou: [0.0, 0.6551336334577343, 0.6821319425157643] - Per Category Accuracy: [nan, 0.6913100552356098, 0.70464740289276] | f8a61812cacb0a2f96c08059ec870194 |
other | ['vision', 'image-segmentation', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.00013 - train_batch_size: 20 - eval_batch_size: 20 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 50 | 6a4c63348cd0e409372e3005fe3b79a8 |
other | ['vision', 'image-segmentation', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou | Per Category Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:---------------------------------------------:|:---------------------------------------------:| | 0.1095 | 0.77 | 20 | 0.2086 | 0.4674 | 0.7410 | 0.7419 | [0.0, 0.6978460673452154, 0.704309291034096] | [nan, 0.7461995349612959, 0.7357650020760118] | | 0.1156 | 1.54 | 40 | 0.1980 | 0.4186 | 0.6721 | 0.6783 | [0.0, 0.6446507442278364, 0.6112330250576428] | [nan, 0.7089917293749448, 0.635300900559587] | | 0.1039 | 2.31 | 60 | 0.1987 | 0.3706 | 0.5810 | 0.5757 | [0.0, 0.5345322994102119, 0.5773860979625277] | [nan, 0.5495831330265778, 0.6123860258526792] | | 0.0672 | 3.08 | 80 | 0.1960 | 0.4099 | 0.6407 | 0.6439 | [0.0, 0.6194380206711395, 0.6103561290824698] | [nan, 0.6596136450596995, 0.6218662960315686] | | 0.0992 | 3.85 | 100 | 0.1969 | 0.4201 | 0.6684 | 0.6695 | [0.0, 0.6251984513525223, 0.6351366565306488] | [nan, 0.675036447653713, 0.661700391303438] | | 0.085 | 4.62 | 120 | 0.2075 | 0.4383 | 0.6997 | 0.6964 | [0.0, 0.6407576836532538, 0.6742246105299582] | [nan, 0.6804532655724195, 0.718889834811138] | | 0.0561 | 5.38 | 140 | 0.2037 | 0.4401 | 0.7033 | 0.7071 | [0.0, 0.6545188689920507, 0.665783897448558] | [nan, 0.7263735810923504, 0.6801427547189345] | | 0.0841 | 6.15 | 160 | 0.2119 | 0.3651 | 0.5891 | 0.5934 | [0.0, 0.5494216923933923, 0.5458843877102458] | [nan, 0.6146571565924632, 0.5634664881039569] | | 0.1034 | 6.92 | 180 | 0.2371 | 0.3684 | 0.6193 | 0.6367 | [0.0, 0.6047004430113216, 0.5003660220404046] | [nan, 0.7229919452156935, 0.5156554415186935] | | 0.0691 | 7.69 | 200 | 0.2266 | 0.4285 | 0.6991 | 0.7117 | [0.0, 0.6730686627556878, 0.6124621276402561] | [nan, 0.7742042834577688, 0.6240342690621383] | | 0.0601 | 8.46 | 220 | 0.2106 | 0.4198 | 0.6674 | 0.6704 | [0.0, 0.6308213023617786, 0.6287108585057931] | [nan, 0.6851880267250091, 0.6497046776895365] | | 0.0647 | 9.23 | 240 | 0.2234 | 0.4229 | 0.6746 | 0.6777 | [0.0, 0.6338885508159525, 0.6349404984513296] | [nan, 0.6928998204597407, 0.6563077167064432] | | 0.0626 | 10.0 | 260 | 0.2322 | 0.3991 | 0.6540 | 0.6655 | [0.0, 0.6267222060572648, 0.570544858752452] | [nan, 0.7227113522422911, 0.5852409330048426] | | 0.0604 | 10.77 | 280 | 0.2021 | 0.4660 | 0.7283 | 0.7288 | [0.0, 0.6990308020264264, 0.6989818924111941] | [nan, 0.7310753774760368, 0.7255727204344536] | | 0.0573 | 11.54 | 300 | 0.2227 | 0.4513 | 0.7014 | 0.6951 | [0.0, 0.6488805486358904, 0.7049138389320693] | [nan, 0.6638350976679388, 0.7389417956785915] | | 0.0474 | 12.31 | 320 | 0.2108 | 0.4781 | 0.7468 | 0.7371 | [0.0, 0.6761855871787447, 0.7580093480444655] | [nan, 0.6890590324447889, 0.8044529075728725] | | 0.0805 | 13.08 | 340 | 0.2257 | 0.4325 | 0.6902 | 0.6940 | [0.0, 0.6550347525850334, 0.6423545682885212] | [nan, 0.7128733309133007, 0.6675247882412931] | | 0.0545 | 13.85 | 360 | 0.2155 | 0.4609 | 0.7230 | 0.7167 | [0.0, 0.6629649481906197, 0.7196967289093881] | [nan, 0.6853650161390015, 0.7606061073292577] | | 0.0628 | 14.62 | 380 | 0.2397 | 0.4150 | 0.6561 | 0.6611 | [0.0, 0.6377593821077956, 0.6070948266377257] | [nan, 0.6861969841160831, 0.6259296622984148] | | 0.0576 | 15.38 | 400 | 0.2177 | 0.4661 | 0.7274 | 0.7272 | [0.0, 0.6936915190759695, 0.7046022162863222] | [nan, 0.7263017649886684, 0.7284576609239519] | | 0.0808 | 16.15 | 420 | 0.2263 | 0.4248 | 0.6707 | 0.6740 | [0.0, 0.6438773235874202, 0.6304024210524071] | [nan, 0.6904172594111472, 0.6510802419847774] | | 0.0458 | 16.92 | 440 | 0.2342 | 0.4006 | 0.6449 | 0.6525 | [0.0, 0.6208902028936363, 0.5809796433249929] | [nan, 0.6898132977523129, 0.6000533044931062] | | 0.0477 | 17.69 | 460 | 0.2683 | 0.3789 | 0.6170 | 0.6232 | [0.0, 0.5741692028709614, 0.5625631837395161] | [nan, 0.6539633266945951, 0.5800762342358019] | | 0.0501 | 18.46 | 480 | 0.2364 | 0.4280 | 0.6700 | 0.6675 | [0.0, 0.6223049989658083, 0.6617065588280534] | [nan, 0.6552936905824757, 0.6846169180090992] | | 0.039 | 19.23 | 500 | 0.2378 | 0.4500 | 0.7052 | 0.6986 | [0.0, 0.6391919313721981, 0.7106968345576296] | [nan, 0.665670921345669, 0.7446979100013106] | | 0.041 | 20.0 | 520 | 0.2477 | 0.4142 | 0.6612 | 0.6659 | [0.0, 0.6273087938535062, 0.6153514032911991] | [nan, 0.6890233206118104, 0.6333526433632052] | | 0.0331 | 20.77 | 540 | 0.2488 | 0.4353 | 0.6814 | 0.6778 | [0.0, 0.6267198588955959, 0.6791644212315564] | [nan, 0.6603973431966015, 0.7023153313193633] | | 0.0316 | 21.54 | 560 | 0.2468 | 0.4500 | 0.7025 | 0.6974 | [0.0, 0.6405571933079939, 0.7093320446678179] | [nan, 0.6719456081313097, 0.7331179494069875] | | 0.0333 | 22.31 | 580 | 0.2477 | 0.4384 | 0.6899 | 0.6906 | [0.0, 0.6520329743081146, 0.6630535380613215] | [nan, 0.6937796658392771, 0.6860558089232162] | | 0.0269 | 23.08 | 600 | 0.2603 | 0.4477 | 0.7018 | 0.6996 | [0.0, 0.6514078130357787, 0.6916101875532822] | [nan, 0.6888588892050193, 0.7147725032516842] | | 0.033 | 23.85 | 620 | 0.2424 | 0.4499 | 0.7061 | 0.6986 | [0.0, 0.6447352671115818, 0.7048670621273163] | [nan, 0.6616131152687708, 0.750523958937919] | | 0.0555 | 24.62 | 640 | 0.2471 | 0.4342 | 0.6830 | 0.6823 | [0.0, 0.636756610371055, 0.6659104633164847] | [nan, 0.6791280033749645, 0.6868014110272018] | | 0.0583 | 25.38 | 660 | 0.2517 | 0.4434 | 0.6922 | 0.6879 | [0.0, 0.6386719513699022, 0.6913843141331489] | [nan, 0.6666374954624388, 0.7178391636040445] | | 0.154 | 26.15 | 680 | 0.2535 | 0.4235 | 0.6597 | 0.6487 | [0.0, 0.5750726006840868, 0.695285501846172] | [nan, 0.5943477194462704, 0.7250215035171054] | | 0.0292 | 26.92 | 700 | 0.2768 | 0.3679 | 0.6035 | 0.6135 | [0.0, 0.5756677002657924, 0.5279750019379379] | [nan, 0.6631412677700708, 0.5438385402498483] | | 0.0288 | 27.69 | 720 | 0.2455 | 0.4676 | 0.7235 | 0.7188 | [0.0, 0.6761224569996822, 0.7268002447671437] | [nan, 0.6954373227898398, 0.7515024928661187] | | 0.0321 | 28.46 | 740 | 0.2618 | 0.4324 | 0.6745 | 0.6691 | [0.0, 0.6201514037000198, 0.6770266576179022] | [nan, 0.6425218048210974, 0.7064552401951121] | | 0.0309 | 29.23 | 760 | 0.2742 | 0.3944 | 0.6348 | 0.6407 | [0.0, 0.6008533572398147, 0.5822751024176394] | [nan, 0.6701804232440864, 0.599451426280657] | | 0.0244 | 30.0 | 780 | 0.2667 | 0.4386 | 0.6819 | 0.6750 | [0.0, 0.6224630782821559, 0.693390305711243] | [nan, 0.6412495217165226, 0.7224713681082742] | | 0.0642 | 30.77 | 800 | 0.2501 | 0.4581 | 0.7121 | 0.7096 | [0.0, 0.6722145834845955, 0.7021141065136746] | [nan, 0.6976031865943273, 0.7265325317101161] | | 0.0481 | 31.54 | 820 | 0.2685 | 0.4137 | 0.6689 | 0.6766 | [0.0, 0.6379976664903103, 0.6031984018650592] | [nan, 0.7145859291453688, 0.6231961550279683] | | 0.0311 | 32.31 | 840 | 0.2570 | 0.4284 | 0.6804 | 0.6832 | [0.0, 0.6426329055663264, 0.6425854743219936] | [nan, 0.6969752862342657, 0.6639063603053335] | | 0.0389 | 33.08 | 860 | 0.2795 | 0.3918 | 0.6456 | 0.6590 | [0.0, 0.6244554318979076, 0.5508200429573112] | [nan, 0.7254125011037311, 0.5658618862962298] | | 0.0282 | 33.85 | 880 | 0.2568 | 0.4242 | 0.6759 | 0.6775 | [0.0, 0.6282787291971401, 0.6442735430594793] | [nan, 0.6857107537747603, 0.6660974613184492] | | 0.0245 | 34.62 | 900 | 0.2635 | 0.4503 | 0.7043 | 0.7037 | [0.0, 0.6658605581388065, 0.6850412042515538] | [nan, 0.7008356961354695, 0.7076892832638209] | | 0.0315 | 35.38 | 920 | 0.2769 | 0.4443 | 0.7038 | 0.7055 | [0.0, 0.6610872730365329, 0.6718978137221756] | [nan, 0.7138198907060935, 0.6938235070611933] | | 0.0283 | 36.15 | 940 | 0.2697 | 0.4392 | 0.6920 | 0.6907 | [0.0, 0.6405508279799802, 0.6769668218170816] | [nan, 0.6841213809883544, 0.6998318265269149] | | 0.0257 | 36.92 | 960 | 0.2712 | 0.4562 | 0.7099 | 0.7082 | [0.0, 0.6720494469697227, 0.6964887349332429] | [nan, 0.6999154296702542, 0.7197879714666775] | | 0.0188 | 37.69 | 980 | 0.2857 | 0.4300 | 0.6763 | 0.6771 | [0.0, 0.6397832221652129, 0.6501046733477022] | [nan, 0.6811686795451647, 0.6713607293464362] | | 0.0259 | 38.46 | 1000 | 0.2812 | 0.4368 | 0.6851 | 0.6838 | [0.0, 0.6396217765000503, 0.6707000380577134] | [nan, 0.6772780519391329, 0.6929027930893589] | | 0.0169 | 39.23 | 1020 | 0.2795 | 0.4542 | 0.7084 | 0.7054 | [0.0, 0.6598929743362643, 0.7028156867427239] | [nan, 0.6906225043413423, 0.7260947520404938] | | 0.0296 | 40.0 | 1040 | 0.2834 | 0.4470 | 0.7015 | 0.7013 | [0.0, 0.6608002641121026, 0.6801095152287282] | [nan, 0.7006602764723773, 0.7022773353480376] | | 0.0183 | 40.77 | 1060 | 0.2874 | 0.4386 | 0.6909 | 0.6903 | [0.0, 0.6432231900832152, 0.6726091072738183] | [nan, 0.6874296310104291, 0.694422081276136] | | 0.0199 | 41.54 | 1080 | 0.2741 | 0.4594 | 0.7175 | 0.7154 | [0.0, 0.6721657359810768, 0.7061664449453671] | [nan, 0.7051238631569653, 0.7298866398455491] | | 0.0162 | 42.31 | 1100 | 0.2883 | 0.4414 | 0.6921 | 0.6913 | [0.0, 0.6492915338226911, 0.6750215527697642] | [nan, 0.6870752597447193, 0.6971930338516571] | | 0.0179 | 43.08 | 1120 | 0.2927 | 0.4425 | 0.6936 | 0.6927 | [0.0, 0.651082790586508, 0.6764744769464034] | [nan, 0.6884633119781804, 0.6987260886947118] | | 0.0228 | 43.85 | 1140 | 0.2954 | 0.4273 | 0.6807 | 0.6841 | [0.0, 0.6418083531582984, 0.6399672125377378] | [nan, 0.7006630235364526, 0.6608033559804007] | | 0.0164 | 44.62 | 1160 | 0.2954 | 0.4264 | 0.6740 | 0.6756 | [0.0, 0.6356634502412776, 0.6436554266840772] | [nan, 0.6834636553611899, 0.6644801545389767] | | 0.0158 | 45.38 | 1180 | 0.2906 | 0.4433 | 0.6956 | 0.6951 | [0.0, 0.6536928350497138, 0.6760836624911459] | [nan, 0.6927067410990219, 0.6985223421818058] | | 0.0198 | 46.15 | 1200 | 0.2881 | 0.4441 | 0.6969 | 0.6961 | [0.0, 0.6527988151987781, 0.6794425179962712] | [nan, 0.6919179412716945, 0.7019810769049473] | | 0.018 | 46.92 | 1220 | 0.2961 | 0.4350 | 0.6844 | 0.6839 | [0.0, 0.6395287774950378, 0.6655290939553297] | [nan, 0.6815206961845243, 0.6872821426644097] | | 0.0179 | 47.69 | 1240 | 0.2898 | 0.4459 | 0.6987 | 0.6982 | [0.0, 0.6581945977423002, 0.6796217960953337] | [nan, 0.6955130632707722, 0.701934270273604] | | 0.0213 | 48.46 | 1260 | 0.2902 | 0.4469 | 0.7004 | 0.6998 | [0.0, 0.6595482974648909, 0.6811920247361126] | [nan, 0.6971510983350829, 0.7036303223269834] | | 0.0227 | 49.23 | 1280 | 0.2888 | 0.4452 | 0.6967 | 0.6953 | [0.0, 0.6532891096762087, 0.6823149709479772] | [nan, 0.6885578894699147, 0.7047801134592744] | | 0.0266 | 50.0 | 1300 | 0.2904 | 0.4458 | 0.6980 | 0.6969 | [0.0, 0.6551336334577343, 0.6821319425157643] | [nan, 0.6913100552356098, 0.70464740289276] | | 1e73e743967b78a0dab04853cf5417a0 |
mit | ['generated_from_trainer'] | false | ananth-docai2 This model is a fine-tuned version of [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) on the funsd-layoutlmv3 dataset. It achieves the following results on the evaluation set: - Loss: 1.4203 - Answer: {'precision': 0.8505747126436781, 'recall': 0.9057527539779682, 'f1': 0.8772969768820391, 'number': 817} - Header: {'precision': 0.6476190476190476, 'recall': 0.5714285714285714, 'f1': 0.6071428571428571, 'number': 119} - Question: {'precision': 0.9104477611940298, 'recall': 0.9062209842154132, 'f1': 0.9083294555607259, 'number': 1077} - Overall Precision: 0.8715 - Overall Recall: 0.8862 - Overall F1: 0.8788 - Overall Accuracy: 0.8269 | 56496c9153d9e8a845e7186b36d7c7d8 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy | |:-------------:|:------:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:| | 0.4218 | 10.53 | 200 | 1.0024 | {'precision': 0.8727272727272727, 'recall': 0.8812729498164015, 'f1': 0.8769792935444579, 'number': 817} | {'precision': 0.4036144578313253, 'recall': 0.5630252100840336, 'f1': 0.47017543859649125, 'number': 119} | {'precision': 0.8674812030075187, 'recall': 0.8570102135561746, 'f1': 0.8622139187295657, 'number': 1077} | 0.8321 | 0.8495 | 0.8407 | 0.7973 | | 0.0532 | 21.05 | 400 | 1.1791 | {'precision': 0.8563218390804598, 'recall': 0.9118727050183598, 'f1': 0.8832246591582691, 'number': 817} | {'precision': 0.5486725663716814, 'recall': 0.5210084033613446, 'f1': 0.5344827586206897, 'number': 119} | {'precision': 0.9044943820224719, 'recall': 0.8969359331476323, 'f1': 0.9006993006993008, 'number': 1077} | 0.8645 | 0.8808 | 0.8725 | 0.8103 | | 0.0117 | 31.58 | 600 | 1.5177 | {'precision': 0.8064516129032258, 'recall': 0.9179926560587516, 'f1': 0.8586147681740126, 'number': 817} | {'precision': 0.6046511627906976, 'recall': 0.4369747899159664, 'f1': 0.5073170731707317, 'number': 119} | {'precision': 0.9019607843137255, 'recall': 0.8542246982358404, 'f1': 0.8774439675727229, 'number': 1077} | 0.8458 | 0.8554 | 0.8506 | 0.7952 | | 0.0067 | 42.11 | 800 | 1.4884 | {'precision': 0.8443935926773455, 'recall': 0.9033047735618115, 'f1': 0.872856298048492, 'number': 817} | {'precision': 0.515625, 'recall': 0.5546218487394958, 'f1': 0.5344129554655871, 'number': 119} | {'precision': 0.8784530386740331, 'recall': 0.8857938718662952, 'f1': 0.8821081830790567, 'number': 1077} | 0.8420 | 0.8733 | 0.8574 | 0.7963 | | 0.0034 | 52.63 | 1000 | 1.4203 | {'precision': 0.8505747126436781, 'recall': 0.9057527539779682, 'f1': 0.8772969768820391, 'number': 817} | {'precision': 0.6476190476190476, 'recall': 0.5714285714285714, 'f1': 0.6071428571428571, 'number': 119} | {'precision': 0.9104477611940298, 'recall': 0.9062209842154132, 'f1': 0.9083294555607259, 'number': 1077} | 0.8715 | 0.8862 | 0.8788 | 0.8269 | | 0.0023 | 63.16 | 1200 | 1.5225 | {'precision': 0.834096109839817, 'recall': 0.8922888616891065, 'f1': 0.8622117090479007, 'number': 817} | {'precision': 0.5689655172413793, 'recall': 0.5546218487394958, 'f1': 0.5617021276595745, 'number': 119} | {'precision': 0.8962001853568119, 'recall': 0.8978644382544104, 'f1': 0.8970315398886828, 'number': 1077} | 0.8516 | 0.8753 | 0.8633 | 0.8096 | | 0.0013 | 73.68 | 1400 | 1.6801 | {'precision': 0.848, 'recall': 0.9082007343941249, 'f1': 0.8770685579196217, 'number': 817} | {'precision': 0.6741573033707865, 'recall': 0.5042016806722689, 'f1': 0.576923076923077, 'number': 119} | {'precision': 0.8977695167286245, 'recall': 0.8969359331476323, 'f1': 0.8973525313516025, 'number': 1077} | 0.8667 | 0.8783 | 0.8724 | 0.7977 | | 0.0014 | 84.21 | 1600 | 1.6236 | {'precision': 0.8876543209876543, 'recall': 0.8800489596083231, 'f1': 0.8838352796558081, 'number': 817} | {'precision': 0.6237623762376238, 'recall': 0.5294117647058824, 'f1': 0.5727272727272728, 'number': 119} | {'precision': 0.8656330749354005, 'recall': 0.9331476323119777, 'f1': 0.8981233243967828, 'number': 1077} | 0.8625 | 0.8877 | 0.8749 | 0.8072 | | 0.0006 | 94.74 | 1800 | 1.7231 | {'precision': 0.8619883040935673, 'recall': 0.9020807833537332, 'f1': 0.881578947368421, 'number': 817} | {'precision': 0.6883116883116883, 'recall': 0.44537815126050423, 'f1': 0.5408163265306123, 'number': 119} | {'precision': 0.8748890860692103, 'recall': 0.9155060352831941, 'f1': 0.8947368421052633, 'number': 1077} | 0.8626 | 0.8823 | 0.8723 | 0.8019 | | 0.0005 | 105.26 | 2000 | 1.8217 | {'precision': 0.8342665173572228, 'recall': 0.9118727050183598, 'f1': 0.871345029239766, 'number': 817} | {'precision': 0.6, 'recall': 0.5042016806722689, 'f1': 0.547945205479452, 'number': 119} | {'precision': 0.9049858889934148, 'recall': 0.89322191272052, 'f1': 0.8990654205607476, 'number': 1077} | 0.8594 | 0.8778 | 0.8685 | 0.7964 | | 0.0004 | 115.79 | 2200 | 1.7688 | {'precision': 0.8561484918793504, 'recall': 0.9033047735618115, 'f1': 0.8790946992257296, 'number': 817} | {'precision': 0.6555555555555556, 'recall': 0.4957983193277311, 'f1': 0.5645933014354068, 'number': 119} | {'precision': 0.8827272727272727, 'recall': 0.9015784586815228, 'f1': 0.8920532843362425, 'number': 1077} | 0.8616 | 0.8783 | 0.8699 | 0.7956 | | 0.0002 | 126.32 | 2400 | 1.7726 | {'precision': 0.8458904109589042, 'recall': 0.9069767441860465, 'f1': 0.8753691671588896, 'number': 817} | {'precision': 0.6741573033707865, 'recall': 0.5042016806722689, 'f1': 0.576923076923077, 'number': 119} | {'precision': 0.8878676470588235, 'recall': 0.8969359331476323, 'f1': 0.892378752886836, 'number': 1077} | 0.8607 | 0.8778 | 0.8692 | 0.7961 | | ce4ba2be43caccbe6759ce296a545cea |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-detests-02-11-2022 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.0794 - F1: 0.5455 | 14de2cc534336b1d786a931fd8467196 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | 0.014 | 0.64 | 25 | 0.6229 | 0.5536 | | 0.0698 | 1.28 | 50 | 0.6996 | 0.5907 | | 0.0173 | 1.92 | 75 | 0.7531 | 0.5882 | | 0.0032 | 2.56 | 100 | 0.8054 | 0.4928 | | 0.0087 | 3.21 | 125 | 0.9557 | 0.5735 | | 0.0028 | 3.85 | 150 | 0.8859 | 0.5352 | | 0.013 | 4.49 | 175 | 0.9674 | 0.5536 | | 0.0031 | 5.13 | 200 | 0.9073 | 0.5691 | | 0.0032 | 5.77 | 225 | 0.9253 | 0.5439 | | 0.0483 | 6.41 | 250 | 0.9705 | 0.5837 | | 0.0323 | 7.05 | 275 | 1.0368 | 0.5824 | | 0.0019 | 7.69 | 300 | 1.0221 | 0.5520 | | 0.0256 | 8.33 | 325 | 1.0419 | 0.5523 | | 0.0319 | 8.97 | 350 | 1.0764 | 0.5425 | | 0.0125 | 9.62 | 375 | 1.0794 | 0.5455 | | 4daa544dda5aa8db7170acfa79f42535 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | LoRA text2image fine-tuning - https://huggingface.co/soypablo/emoji-model-finetuned-lora-3000 These are LoRA adaption weights for https://huggingface.co/soypablo/emoji-model-finetuned-lora-3000. The weights were fine-tuned on the soypablo/Emoji_Dataset-Openmoji dataset. You can find some example images in the following.     | e1d22d44a41c869401a4d837bea73d1c |
gpl-3.0 | ['generated_from_trainer'] | false | clm-total This model is a fine-tuned version of [ckiplab/gpt2-base-chinese](https://huggingface.co/ckiplab/gpt2-base-chinese) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 2.8586 | d4e4702948ad51b0d8b258b09ba1c847 |
mit | ['generated_from_keras_callback'] | false | huynhdoo/distilcamembert-base-finetuned-CLS This model is a fine-tuned version of [cmarkea/distilcamembert-base](https://huggingface.co/cmarkea/distilcamembert-base) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.1270 - Validation Loss: 0.2366 - Train F1: 0.9220 - Epoch: 2 | fc6623ad700afaa6ac1836186d69d02f |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 669, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | 7ac0594a06fe0a18575bcfa8d3e85606 |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Train F1 | Epoch | |:----------:|:---------------:|:--------:|:-----:| | 0.3787 | 0.2347 | 0.915 | 0 | | 0.1758 | 0.2338 | 0.9242 | 1 | | 0.1270 | 0.2366 | 0.9220 | 2 | | 7f666cbc9f412926f1bc2ed01e8713ac |
apache-2.0 | ['generated_from_trainer'] | false | distilbart-cnn-12-6-eval-test-2 This model is a fine-tuned version of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 4.7250 - Rouge1: 31.3552 - Rouge2: 4.2825 - Rougel: 15.1982 - Rougelsum: 27.9577 - Gen Len: 139.0 | 4b56f5b0b0588ce7084f91140275c31b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:| | 4.4419 | 1.0 | 80 | 4.2847 | 30.8184 | 4.024 | 15.5589 | 27.647 | 133.6 | | 3.5861 | 2.0 | 160 | 4.2721 | 30.7823 | 3.7736 | 14.992 | 28.0105 | 137.1 | | 2.9885 | 3.0 | 240 | 4.4295 | 30.4747 | 3.8971 | 15.6055 | 27.9916 | 135.5 | | 2.5254 | 4.0 | 320 | 4.5978 | 31.0505 | 4.1062 | 14.7292 | 27.9009 | 134.2 | | 2.2404 | 5.0 | 400 | 4.7250 | 31.3552 | 4.2825 | 15.1982 | 27.9577 | 139.0 | | 488030b99c0a606db79e598d9d5483d8 |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-ner This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 0.0619 - Precision: 0.9352 - Recall: 0.9493 - F1: 0.9422 - Accuracy: 0.9864 | 3511c815203978a70dd5a2bd9123a19d |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0869 | 1.0 | 1756 | 0.0747 | 0.9128 | 0.9298 | 0.9212 | 0.9815 | | 0.0335 | 2.0 | 3512 | 0.0637 | 0.9258 | 0.9470 | 0.9363 | 0.9854 | | 0.018 | 3.0 | 5268 | 0.0619 | 0.9352 | 0.9493 | 0.9422 | 0.9864 | | ec9dedf6a33f74ca43e28579856757f5 |
apache-2.0 | ['translation'] | false | opus-mt-da-fr * source languages: da * target languages: fr * OPUS readme: [da-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/da-fr/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/da-fr/opus-2020-01-08.zip) * test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/da-fr/opus-2020-01-08.test.txt) * test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/da-fr/opus-2020-01-08.eval.txt) | 2ceffca51d3959c73770b3d7697f6807 |
mit | [] | false | RJ Palmer on Stable Diffusion This is the `<rj-palmer>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:                                  | 229726b705aa05ca6bbeba7b562fffd5 |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Model Description diff-codegen-2b-v2 is a diff model for code generation, released by [CarperAI](http://carper.ai/). A diff model is an autoregressive language model trained on edits to a piece of text, formatted in [Unified Diff Format](https://en.wikipedia.org/wiki/Diff | f56b8a985644c4186decf07152e92322 |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Unified_format). These diff models can suggest, given a section of text and a description of the desired change, an intelligent change to the text that fits the description, marking the lines added, changed, and deleted in diff format. In comparison to few-shot prompting of normal code generation models, diff models are specialized for suggesting intelligent changes to existing code, particularly longer pieces of code and where a change is required to follow some natural language text description (provided in the form of a commit message). This model is a fine-tune of [codegen-2B-mono](https://huggingface.co/Salesforce/codegen-2B-mono) by Salesforce, trained on a large dataset of commits scraped from GitHub. diff-codegen-2b-v2 is an experimental research artifact and should be treated as such. We are releasing these results and this model in the hopes that it may be useful to the greater research community, especially those interested in LMs for code. An example Colab notebook with a brief example of prompting the model is [here](https://colab.research.google.com/drive/1ySm6HYvALerDiGmk6g3pDz68V7fAtrQH | a5f5ffcce6d2663b537924ead3843986 |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Training Data This model is a fine-tune of [codegen-2B-mono](https://huggingface.co/Salesforce/codegen-2B-mono) by Salesforce. This language model was first pre-trained on The Pile, an 800Gb dataset composed of varied web corpora. The datasheet and paper for the Pile can be found [here](https://arxiv.org/abs/2201.07311) and [here](https://arxiv.org/abs/2101.00027) respectively. The model was then fine-tuned on a large corpus of code data in multiple languages, before finally being fine-tuned on a Python code dataset. The Codegen paper with full details of these datasets can be found [here](https://arxiv.org/abs/2203.13474). Our dataset for this fine-tune consists of commits from GitHub, obtained using the [Google BigQuery Public Dataset](https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code), a public up to date snapshot of a huge number of open-source GitHub repositories. We took this dataset and filtered using [BigQuery](https://console.cloud.google.com/marketplace/details/github/github-repos) on the number of stars in the repository to exclude repos with less than 100 stars, and further restricted the query to only repositories with open-source non-copyleft licenses (e.g. MIT, Apache, etc) and commits with more than 10 characters in the commit message. We also restricted ourselves to a list of 22 popular programming, scripting, and markup languages, including Python, HTML, Bash scripts, SQL, C++, etc. This resulted in a dataset of 19 million commits after filtering. Our diff model was trained on a dataset of commits from BigQuery, a large-scale dataset of many programming languages from GitHub repositories. We filtered the dataset by the number of stars in the repository (>100 stars), license (only open-source non-copyleft licensed code included), and length of file (files greater than 2048 tokens in length were excluded). The model was trained using the Huggingface Codegen tokenizer. | 10a7156d0850b92a59bbf33b762ba8cc |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Training Details The model was trained on 1.08 billion tokens for 1 epoch on 64 A100 GPUs, provided by [Stability AI](https://stability.ai/). Each file was formatted as follows for input to the language model: ``` <NME> {FILE_NAME} <BEF> {INPUT_FILE} <MSG> {COMMIT_MESSAGE} <DFF> {FILE_DIFF} ``` | 6dc593c28234403f4947f765035165cf |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Intended Uses and Limitations Due to the model’s small size and restriction to code, one should not expect the model to generalize to domains beyond code and perform (successful) reasoning over large chunks of code. This model is intended to be used in prototyping code generation systems, and for solely experimental purposes. This model is provided without warranty and should not be used in commercial settings—even though the license permits. | ffdab42c91fb42b3900ad734a59112dc |
mit | ['Diff Model', 'pytorch', 'causal-lm', 'code-generation', 'The Pile'] | false | Limitations and Biases Due to the short context length restriction and due to the fact that all repositories with under 100 stars were excluded, we expect our diff model to underperform on underrepresented languages, for instance Lean or Coq. The output of this model should not be trusted as correct and secure code. This model should not be used in any mission critical setting where security is of importance. When running the output of this model, it should be done as much as possible in a sandbox, such as [gVisor](https://gvisor.dev), since it is very possible for the model to produce code which may delete files, send HTTP requests, or otherwise contain critical security vulnerabilities. As with other language models, diff-codegen is prone to hallucination and biased, stereotyped, or toxic output. There are no guarantees of truthful output when generating from the model. | d48a47ff4b5404000f9ec1a16f3307d5 |
apache-2.0 | ['automatic-speech-recognition', 'ja'] | false | exp_w2v2t_ja_unispeech_s253 Fine-tuned [microsoft/unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | da0f5e0a17cdf4eb473593cea1ce22d8 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Openjourney LoRA - by [PromptHero](https://prompthero.com/?utm_source=huggingface&utm_medium=referral) These are LoRA adaption weights for [Openjourney](https://huggingface.co/prompthero/openjourney) trained by [@JHawkk](https://prompthero.com/JHawkk) | 6734da4e21f0123337b8c259f2bbd456 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Want to learn AI art generation?: - [Crash course in AI art generation](https://prompthero.com/academy/prompt-engineering-course?utm_source=huggingface&utm_medium=referral) - [Learn to fine-tune Stable Diffusion for photorealism](https://prompthero.com/academy/dreambooth-stable-diffusion-train-fine-tune-course?utm_source=huggingface&utm_medium=referral) | f0d751164af82904a8cb136f8d5d8cd3 |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | How to use LoRA's in auto1111: - Update webui (use git pull like here or redownload it) - Copy the file to stable-diffusion-webui/models/lora - Select your LoRA like in this video - Make sure to change the weight (by default it's :1 which is usually too high) | 6ad4ea8953baae36b140a118142a8e2c |
creativeml-openrail-m | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | Examples:     | b03d5213f6fd373e093a8d77250d674a |
apache-2.0 | ['automatic-speech-recognition', 'en'] | false | exp_w2v2t_en_wavlm_s767 Fine-tuned [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 47c759b574bddba76c4999d798066060 |
apache-2.0 | ['automatic-speech-recognition', 'it'] | false | exp_w2v2t_it_wav2vec2_s692 Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 84a1ae004f7530747cfc91a53b3db2c1 |
apache-2.0 | ['translation'] | false | bul-spa * source group: Bulgarian * target group: Spanish * OPUS readme: [bul-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bul-spa/README.md) * model: transformer * source language(s): bul * target language(s): spa * model: transformer * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/bul-spa/opus-2020-07-03.zip) * test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bul-spa/opus-2020-07-03.test.txt) * test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bul-spa/opus-2020-07-03.eval.txt) | a38c9d00db7e6ff962cc80aa8563c2e4 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: bul-spa - source_languages: bul - target_languages: spa - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bul-spa/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['bg', 'es'] - src_constituents: {'bul', 'bul_Latn'} - tgt_constituents: {'spa'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/bul-spa/opus-2020-07-03.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/bul-spa/opus-2020-07-03.test.txt - src_alpha3: bul - tgt_alpha3: spa - short_pair: bg-es - chrF2_score: 0.6609999999999999 - bleu: 49.1 - brevity_penalty: 0.992 - ref_len: 1783.0 - src_name: Bulgarian - tgt_name: Spanish - train_date: 2020-07-03 - src_alpha2: bg - tgt_alpha2: es - prefer_old: False - long_pair: bul-spa - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | a556be77caeac4a36deb7eff0c576bce |
apache-2.0 | ['automatic-speech-recognition', 'ar'] | false | exp_w2v2t_ar_vp-100k_s874 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 16eb9d12028b2dbe01be6c97dcf64cf2 |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-ner This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the conll2003 dataset. It achieves the following results on the evaluation set: - Loss: 2.1258 - Precision: 0.0269 - Recall: 0.1379 - F1: 0.0451 - Accuracy: 0.1988 | d35febe5c0d48331aaeb7bb1fbaefd8f |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 2 | a925afebfcbe38e64a5095765039c123 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 4 | 2.1296 | 0.0270 | 0.1389 | 0.0452 | 0.1942 | | No log | 2.0 | 8 | 2.1258 | 0.0269 | 0.1379 | 0.0451 | 0.1988 | | d7a393d77044fdadbedca6d447bb29e9 |
apache-2.0 | [] | false | [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**. The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4) and subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia). **Note**: This model should be fine-tuned on a question answering downstream task before it is useable for closed book question answering. Other Community Checkpoints: [here](https://huggingface.co/models?search=ssm) Paper: [How Much Knowledge Can You Pack Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf) Authors: *Adam Roberts, Colin Raffel, Noam Shazeer* | 167133736c29f34be5594d0626f31cd7 |
mit | [] | false | AJ Fosik on Stable Diffusion This is the `<AJ-Fosik>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:      | d894b0957b73106fa73e56b5dfa7b356 |
apache-2.0 | [] | false | PaddlePaddle/uie-mini Information extraction suffers from its varying targets, heterogeneous structures, and demand-specific schemas. The unified text-to-structure generation framework, namely UIE, can universally model different IE tasks, adaptively generate targeted structures, and collaboratively learn general IE abilities from different knowledge sources. Specifically, UIE uniformly encodes different extraction structures via a structured extraction language, adaptively generates target extractions via a schema-based prompt mechanism - structural schema instructor, and captures the common IE abilities via a large-scale pre-trained text-to-structure model. Experiments show that UIE achieved the state-of-the-art performance on 4 IE tasks, 13 datasets, and on all supervised, low-resource, and few-shot settings for a wide range of entity, relation, event and sentiment extraction tasks and their unification. These results verified the effectiveness, universality, and transferability of UIE. UIE Paper: https://arxiv.org/abs/2203.12277 PaddleNLP released UIE model series for Information Extraction of texts and multi-modal documents which use the ERNIE 3.0 models as the pre-trained language models and were finetuned on a large amount of information extraction data.  | 4c97d4ea3a5fbd5ce4e629a8819e2838 |
apache-2.0 | ['automatic-speech-recognition', 'ar'] | false | exp_w2v2t_ar_r-wav2vec2_s545 Fine-tuned [facebook/wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 38a30cb4fb706a0314b67ffeea5c369b |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.