
datasetId stringlengths 2 117 | card stringlengths 19 1.01M |
|---|---|
davanstrien/model_cards_with_long_context_embeddings | ---
dataset_info:
features:
- name: modelId
dtype: string
- name: lastModified
dtype: string
- name: tags
sequence: string
- name: pipeline_tag
dtype: string
- name: author
dtype: string
- name: config
dtype: 'null'
- name: securityStatus
dtype: 'null'
- name: id
dtype: string
- name: likes
dtype: int64
- name: downloads
dtype: int64
- name: library_name
dtype: string
- name: created
dtype: timestamp[us]
- name: card
dtype: string
- name: card_len
dtype: int64
- name: embeddings
sequence:
sequence: float32
splits:
- name: train
num_bytes: 405007594.52755755
num_examples: 56846
download_size: 176753967
dataset_size: 405007594.52755755
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "model_cards_with_long_context_embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
nikesh66/sentiment-detection-dataset | ---
language:
- en
---
# Sentiment Analysis Dataset
This contains artificially constructed dataset labelled with their respective sentiment
## Dataset Description:
- Number of Rows: 10,000
- Number of Columns: 2
- Column Names: 'Tweet', 'Emotion'
- Description: This dataset contains tweets labeled with various emotions. Each row consists of a tweet and its corresponding emotion label, such as 'Anger', 'Shame', 'Sadness', or 'Fear'. |
presencesw/squad_t5 | ---
dataset_info:
features:
- name: id
dtype: string
- name: targets
struct:
- name: answer_start
sequence: int64
- name: text
sequence: string
- name: texts
dtype: string
splits:
- name: train
num_bytes: 79512505
num_examples: 87599
- name: validation
num_bytes: 10585911
num_examples: 10570
download_size: 20422044
dataset_size: 90098416
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
blai2/mini-platypus | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
- name: data_source
dtype: string
splits:
- name: train
num_bytes: 31361279
num_examples: 24890
download_size: 15587302
dataset_size: 31361279
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
tfshaman/MATH_test | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: output_value
dtype: string
- name: level
dtype: string
- name: type
dtype: string
- name: file_name
dtype: string
splits:
- name: train
num_bytes: 3842585
num_examples: 5000
download_size: 1916180
dataset_size: 3842585
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "MATH_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DJSoft/maccha_artist_style | ---
license: creativeml-openrail-m
---
# Maccha style embedding
## Samples
<img alt="Samples" src="https://huggingface.co/datasets/DJSoft/maccha_artist_style/resolve/main/samples.jpg" style="max-height: 80vh"/>
<img alt="Comparsion" src="https://huggingface.co/datasets/DJSoft/maccha_artist_style/resolve/main/steps.png" style="max-height: 80vh"/>
## About
Use this Stable Diffusion embedding to achieve style of Matcha_ / maccha_(mochancc) [Pixiv](https://www.pixiv.net/en/users/2583663)
## Usage
To use this embedding you have to download the file and put it into the "\stable-diffusion-webui\embeddings" folder
To use it in a prompt add __art by maccha-*__
Add **( :1.0)** around it to modify its weight
## Included Files
- 8000 steps Usage: **art by maccha-8000**
- 15000 steps Usage: **art by maccha-15000**
## License
This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) [Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
quyennt/demo_faq | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 30543
num_examples: 81
download_size: 13826
dataset_size: 30543
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CyberHarem/goldenglow_arknights | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of goldenglow/ゴールデングロー/澄闪 (Arknights)
This is the dataset of goldenglow/ゴールデングロー/澄闪 (Arknights), containing 500 images and their tags.
The core tags of this character are `pink_hair, animal_ears, cat_ears, cat_girl, yellow_eyes, hairband, braid, long_hair, bow, hair_bow, cat_tail, tail, black_hairband, blue_bow, breasts, single_braid, floppy_ears`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:----------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 1.12 GiB | [Download](https://huggingface.co/datasets/CyberHarem/goldenglow_arknights/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 500 | 487.83 MiB | [Download](https://huggingface.co/datasets/CyberHarem/goldenglow_arknights/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 1345 | 1.13 GiB | [Download](https://huggingface.co/datasets/CyberHarem/goldenglow_arknights/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 500 | 923.24 MiB | [Download](https://huggingface.co/datasets/CyberHarem/goldenglow_arknights/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1345 | 1.88 GiB | [Download](https://huggingface.co/datasets/CyberHarem/goldenglow_arknights/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/goldenglow_arknights',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 8 |  |  |  |  |  | 1girl, long_sleeves, looking_at_viewer, official_alternate_costume, red_hairband, smile, solo, green_sweater, red_sweater, fur-trimmed_sleeves, red_shirt, wings, blush, braided_hair_rings, christmas, green_bow, infection_monitor_(arknights), upper_body, gift_box, star_(symbol), trumpet, ahoge, closed_mouth, holding_instrument, red_bow, simple_background, white_apron, white_bow, x_hair_ornament |
| 1 | 7 |  |  |  |  |  | 1girl, black_skirt, closed_mouth, lightning_bolt_print, long_sleeves, looking_at_viewer, open_jacket, solo, white_shirt, blush, simple_background, holding_staff, id_card, infection_monitor_(arknights), white_background, cowboy_shot, garter_straps, multicolored_jacket, pink_jacket, smile, white_thighhighs |
| 2 | 5 |  |  |  |  |  | 1girl, black_skirt, cowboy_shot, garter_straps, id_card, lightning_bolt_print, long_sleeves, looking_at_viewer, open_jacket, simple_background, solo, white_shirt, white_thighhighs, black_choker, closed_mouth, high-waist_skirt, pink_jacket, white_background, scissors, smile, zettai_ryouiki |
| 3 | 9 |  |  |  |  |  | 1girl, black_skirt, lightning_bolt_print, long_sleeves, looking_at_viewer, open_jacket, simple_background, solo, white_shirt, hair_over_shoulder, white_background, pink_jacket, scissors, blush, upper_body, choker, closed_mouth, hair_between_eyes, high-waist_skirt, id_card, smile |
| 4 | 8 |  |  |  |  |  | 1girl, black_skirt, lightning_bolt_print, open_jacket, open_mouth, shoes, simple_background, solo, white_background, white_thighhighs, full_body, garter_straps, pink_footwear, blush, looking_at_viewer, standing, white_shirt, :d, chibi, pink_jacket, puffy_long_sleeves, :o, holding_staff, id_card |
| 5 | 10 |  |  |  |  |  | 1girl, blush, looking_at_viewer, nipples, lightning_bolt_print, completely_nude, navel, 1boy, collarbone, hetero, large_breasts, open_mouth, solo_focus, pussy, sex, closed_mouth, cum, heart, mosaic_censoring, pov, spread_legs, sweat, vaginal |
| 6 | 19 |  |  |  |  |  | 1girl, eyewear_on_head, solo, sunglasses, food-themed_hair_ornament, looking_at_viewer, cleavage, hairclip, white_bikini, hat, official_alternate_costume, open_mouth, holding_food, medium_breasts, purple-tinted_eyewear, brown_headwear, outdoors, sitting, smile, watermelon_slice, blue_sky, blush, day, flower, navel, short_shorts, bracelet, cat, infection_monitor_(arknights), open_clothes, stomach, black_shorts |
| 7 | 11 |  |  |  |  |  | 1girl, black_dress, enmaided, solo, white_apron, maid_apron, frilled_apron, looking_at_viewer, red_bow, blush, long_sleeves, red_hairband, smile, frilled_dress, holding, puffy_sleeves, flower, infection_monitor_(arknights), open_mouth, simple_background, white_background |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | long_sleeves | looking_at_viewer | official_alternate_costume | red_hairband | smile | solo | green_sweater | red_sweater | fur-trimmed_sleeves | red_shirt | wings | blush | braided_hair_rings | christmas | green_bow | infection_monitor_(arknights) | upper_body | gift_box | star_(symbol) | trumpet | ahoge | closed_mouth | holding_instrument | red_bow | simple_background | white_apron | white_bow | x_hair_ornament | black_skirt | lightning_bolt_print | open_jacket | white_shirt | holding_staff | id_card | white_background | cowboy_shot | garter_straps | multicolored_jacket | pink_jacket | white_thighhighs | black_choker | high-waist_skirt | scissors | zettai_ryouiki | hair_over_shoulder | choker | hair_between_eyes | open_mouth | shoes | full_body | pink_footwear | standing | :d | chibi | puffy_long_sleeves | :o | nipples | completely_nude | navel | 1boy | collarbone | hetero | large_breasts | solo_focus | pussy | sex | cum | heart | mosaic_censoring | pov | spread_legs | sweat | vaginal | eyewear_on_head | sunglasses | food-themed_hair_ornament | cleavage | hairclip | white_bikini | hat | holding_food | medium_breasts | purple-tinted_eyewear | brown_headwear | outdoors | sitting | watermelon_slice | blue_sky | day | flower | short_shorts | bracelet | cat | open_clothes | stomach | black_shorts | black_dress | enmaided | maid_apron | frilled_apron | frilled_dress | holding | puffy_sleeves |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:---------------|:--------------------|:-----------------------------|:---------------|:--------|:-------|:----------------|:--------------|:----------------------|:------------|:--------|:--------|:---------------------|:------------|:------------|:--------------------------------|:-------------|:-----------|:----------------|:----------|:--------|:---------------|:---------------------|:----------|:--------------------|:--------------|:------------|:------------------|:--------------|:-----------------------|:--------------|:--------------|:----------------|:----------|:-------------------|:--------------|:----------------|:----------------------|:--------------|:-------------------|:---------------|:-------------------|:-----------|:-----------------|:---------------------|:---------|:--------------------|:-------------|:--------|:------------|:----------------|:-----------|:-----|:--------|:---------------------|:-----|:----------|:------------------|:--------|:-------|:-------------|:---------|:----------------|:-------------|:--------|:------|:------|:--------|:-------------------|:------|:--------------|:--------|:----------|:------------------|:-------------|:----------------------------|:-----------|:-----------|:---------------|:------|:---------------|:-----------------|:------------------------|:-----------------|:-----------|:----------|:-------------------|:-----------|:------|:---------|:---------------|:-----------|:------|:---------------|:----------|:---------------|:--------------|:-----------|:-------------|:----------------|:----------------|:----------|:----------------|
| 0 | 8 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 7 |  |  |  |  |  | X | X | X | | | X | X | | | | | | X | | | | X | | | | | | X | | | X | | | | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 5 |  |  |  |  |  | X | X | X | | | X | X | | | | | | | | | | | | | | | | X | | | X | | | | X | X | X | X | | X | X | X | X | | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 9 |  |  |  |  |  | X | X | X | | | X | X | | | | | | X | | | | | X | | | | | X | | | X | | | | X | X | X | X | | X | X | | | | X | | | X | X | | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 8 |  |  |  |  |  | X | | X | | | | X | | | | | | X | | | | | | | | | | | | | X | | | | X | X | X | X | X | X | X | | X | | X | X | | | | | | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 10 |  |  |  |  |  | X | | X | | | | | | | | | | X | | | | | | | | | | X | | | | | | | | X | | | | | | | | | | | | | | | | | | X | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 6 | 19 |  |  |  |  |  | X | | X | X | | X | X | | | | | | X | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | | | | | | | | X | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | |
| 7 | 11 |  |  |  |  |  | X | X | X | | X | X | X | | | | | | X | | | | X | | | | | | | | X | X | X | | | | | | | | | X | | | | | | | | | | | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | X | | | | | | | X | X | X | X | X | X | X |
|
visualwebbench/VisualWebBench | ---
dataset_info:
- config_name: action_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: instruction
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 116178465
num_examples: 103
download_size: 116152003
dataset_size: 116178465
- config_name: action_prediction
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: options
sequence: string
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 212320282
num_examples: 281
download_size: 212176366
dataset_size: 212320282
- config_name: element_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 541444180
num_examples: 413
download_size: 425203495
dataset_size: 541444180
- config_name: element_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 177127391
num_examples: 245
download_size: 177036578
dataset_size: 177127391
- config_name: heading_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 36406054
num_examples: 46
download_size: 36401829
dataset_size: 36406054
- config_name: web_caption
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 112890184
num_examples: 134
download_size: 112864700
dataset_size: 112890184
- config_name: webqa
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: test
num_bytes: 271769428
num_examples: 314
download_size: 100761418
dataset_size: 271769428
configs:
- config_name: action_ground
data_files:
- split: test
path: action_ground/test-*
- config_name: action_prediction
data_files:
- split: test
path: action_prediction/test-*
- config_name: element_ground
data_files:
- split: test
path: element_ground/test-*
- config_name: element_ocr
data_files:
- split: test
path: element_ocr/test-*
- config_name: heading_ocr
data_files:
- split: test
path: heading_ocr/test-*
- config_name: web_caption
data_files:
- split: test
path: web_caption/test-*
- config_name: webqa
data_files:
- split: test
path: webqa/test-*
license: apache-2.0
task_categories:
- image-to-text
- visual-question-answering
language:
- en
pretty_name: VisualWebBench
size_categories:
- 1K<n<10K
---
# VisualWebBench
Dataset for the paper: [VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?](https://arxiv.org/abs/2404.05955)
[**🌐 Homepage**](https://visualwebbench.github.io/) | [**🐍 GitHub**](https://github.com/VisualWebBench/VisualWebBench) | [**📖 arXiv**](https://arxiv.org/abs/2404.05955)
## Introduction
We introduce **VisualWebBench**, a multimodal benchmark designed to assess the **understanding and grounding capabilities of MLLMs in web scenarios**. VisualWebBench consists of **seven tasks**, and comprises **1.5K** human-curated instances from **139** real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude 3, and GPT-4V(ision) on WebBench, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe VisualWebBench will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
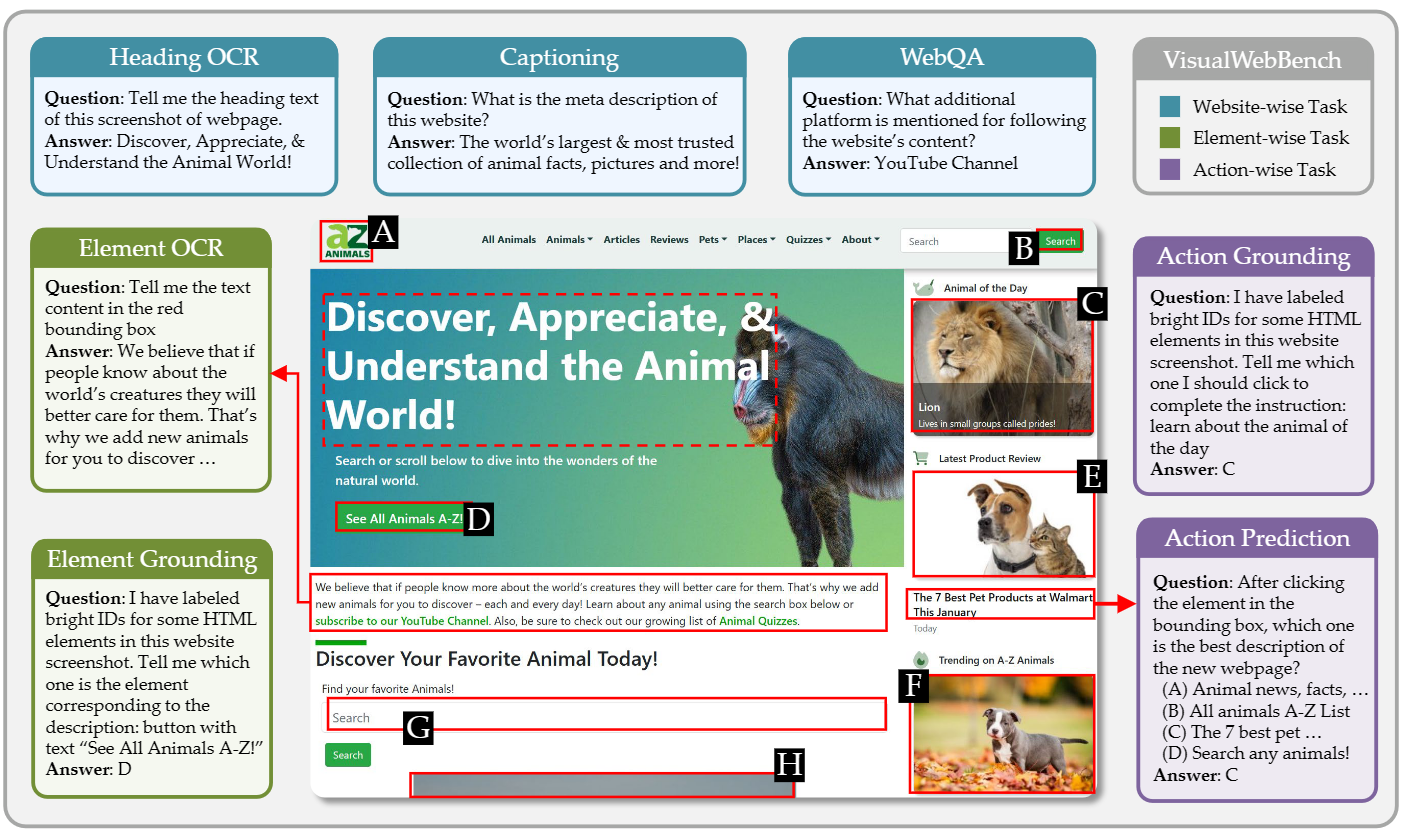
## Benchmark Construction
We introduce VisualWebBench, a comprehensive multimodal benchmark designed to assess the capabilities of MLLMs in the web domain. Inspired by the human interaction process with web browsers, VisualWebBench consists of seven tasks that map to core abilities required for web tasks: captioning, webpage QA, heading OCR, element OCR, element grounding, action prediction, and action grounding, as detailed in the figure. The benchmark comprises 1.5K instances, all uniformly formulated in the QA style, making it easy to evaluate and compare the performance of different MLLMs.
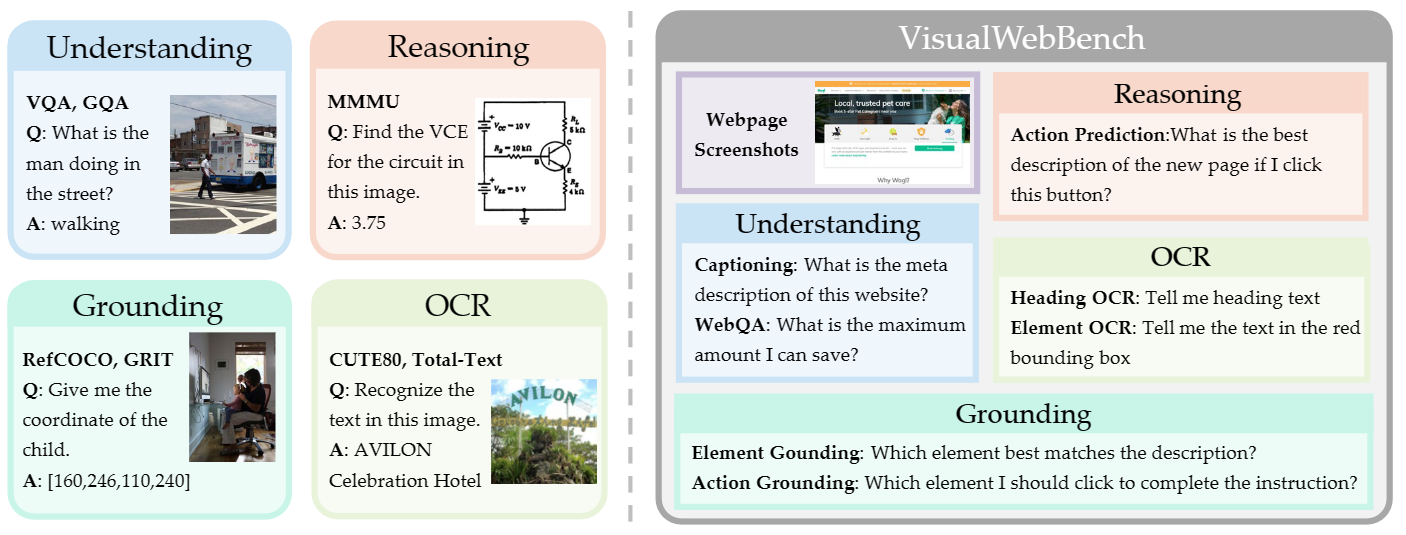
The proposed VisualWebBench possesses the following features:
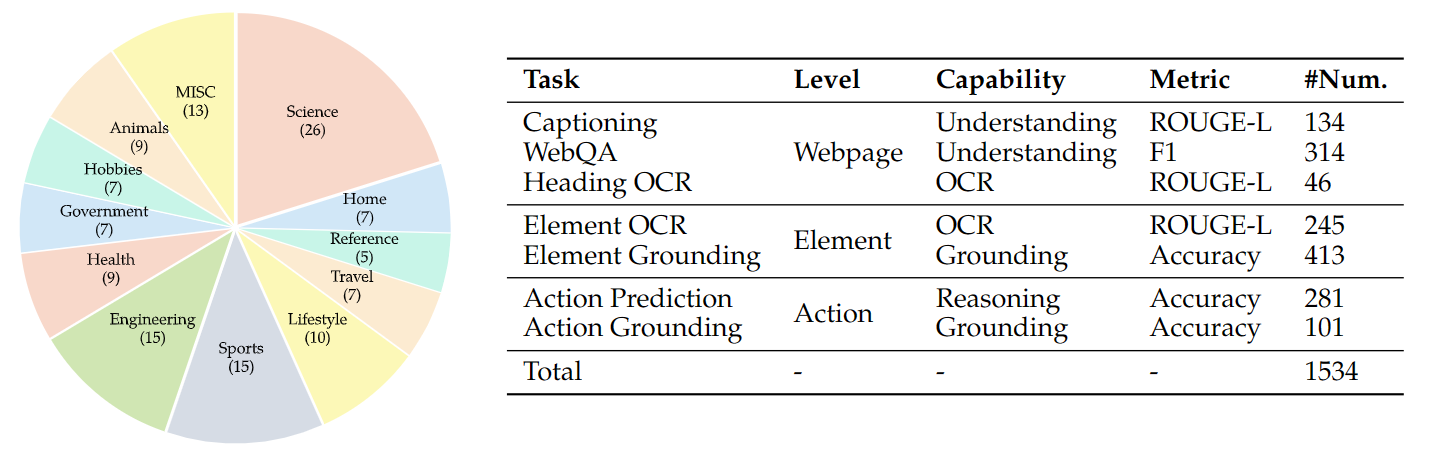
- **Comprehensiveness**: VisualWebBench spans 139 websites with 1.5K samples, encompassing 12 different domains (e.g., travel, sports, hobby, lifestyle, animals, science, etc.) and 87 sub-domains.
- **Multi-granularity**: VisualWebBench assesses MLLMs at three levels: website-level, element-level, and action-level.
- **Multi-tasks**: WebBench encompasses seven tasks designed to evaluate the understanding, OCR, grounding, and reasoning capabilities of MLLMs.
- **High quality**: Quality is ensured through careful human verification and curation efforts.
## Evaluation
We provide [evaluation code](https://github.com/VisualWebBench/VisualWebBench) for GPT-4V, Claude, Gemini, and LLaVA 1.6 series.
## Contact
- Junpeng Liu: [jpliu@link.cuhk.edu.hk](jpliu@link.cuhk.edu.hk)
- Yifan Song: [yfsong@pku.edu.cn](yfsong@pku.edu.cn)
- Xiang Yue: [xyue2@andrew.cmu.edu](xyue2@andrew.cmu.edu)
## Citation
If you find this work helpful, please cite out paper:
```
@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
phyloforfun/HLT_MICH_Angiospermae_SLTPvA_v1.0_OCR-C25-L25-E50-R10 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 368634
num_examples: 230
download_size: 39580
dataset_size: 368634
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jth500/BART_val | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 50624.1
num_examples: 9
download_size: 41268
dataset_size: 50624.1
---
# Dataset Card for "BART_val"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
itamarcard/cheio | ---
license: openrail
---
|
somosnlp/es-inclusive-language | ---
language:
- es
size_categories:
- 1K<n<10K
task_categories:
- text2text-generation
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: gender_exclusive
dtype: string
- name: gender_inclusive
dtype: string
- name: difficulty
dtype: string
- name: origin
dtype: string
splits:
- name: train
num_bytes: 630817
num_examples: 3212
- name: validation
num_bytes: 139222
num_examples: 721
- name: test
num_bytes: 50611
num_examples: 263
download_size: 397549
dataset_size: 820650
license: cc-by-nc-sa-4.0
---
# Dataset card for es-inclusive-language
Languages are powerful tools to communicate ideas, but their use is not impartial. The selection of words carries inherent biases and reflects subjective perspectives. In some cases, language is wielded to enforce ideologies, marginalize certain groups, or promote specific political agendas.
Spanish is not the exception to that. For instance, when we say “los alumnos” or “los ingenieros”, we are excluding women from those groups. Similarly, expressions such as “los gitanos” o “los musulmanes” perpetuate discrimination against these communities.
In response to these linguistic challenges, this dataset offers neutral alternatives in accordance with official guidelines on inclusive language from various Spanish speaking countries. Its purpose is to provide grammatically correct and inclusive solutions to situations where our language choices might otherwise be exclusive.
## Dataset Structure
This dataset consists of pairs of texts with one entry featuring exclusive language and the other one its corresponding inclusive rewrite. All pairs are tagged with the origin (source) of the data and, in order to account for completeness of inclusive translation, also with labels for translation difficulty.
### Difficulty tag descriptions
We used different labels, most of them gender related, and can be describe like this:
| Tag | Description | Example |
|-----------------------|---------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| no_cambia | No changes are needed | "Los alumnos Carlos y Manuel son muy problemáticos" cannot be translated as "El alumnado Carlos y Manuel son muy problemáticos” |
| plural_complejo | Plural words for which there is not a neutral term. There are different formulas that will vary according to the context. | "Los agricultores" -> "La comunidad agrícola", "Los y las agricultoras". “Las limpiadoras” -> “El equipo de limpieza”. More: "El grupo de...", "El sector de...", "El personal de..." |
| plural_neutro | Change the plural for a generic noun. | "Los alumnos" -> "El alumnado" |
| culturas | People and cultures | "Los andaluces" -> "El pueblo andaluz", "La comunidad andaluza" |
| feminizar_profesiones | Professions with androcentric feminine forms | “La médico” -> "La médica". “La técnico de sonido” -> "La técnica de sonido" |
| nombres_propios | Proper names | "Los alumnos Carlos y Manuel son muy problemáticos" cannot be translated as "El alumnado es muy problemático |
| persona_generica | Reference to a generic person | "Nota al lector" -> "Nota a quien lee", "Nota a la persona que lee" |
| dificultades_variadas | Mix of difficulties (to tag big chunks of diverse data) | |
| plurales | Mix of neutral and complex plurals | |
| falsa_concordancia | Androcentric agreement errors | "Estas siete parejas van a dar lo mejor de sí mismos" -> "Estas siete parejas van a dar lo mejor de sí mismas." |
| omision | The subject or some pronouns are omitted, or the phrase is restructured with verboids. | "los participantes mantendrán un debate" -> "habrá un debate", "Si los científicos trabajan adecuadamente" -> "Trabajando adecuadamente, "los estudiantes" -> "estudiantes |
| terminologia | Correction of terms with ableist, racist, or other types of discrimination bias. | |
| parafrasis | Avoid words with generic connotations by reformulating the phrase | |
| otros | Difficulties that don’t fit in the other labels | |
### Origin tags descriptions
Data quality can depend on their origin, so data are tagged with origin labels according to this table:
| Tag | Description | Link to origin |
|---------------------------|----------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| neutral_es | Curated and refined version of neutral-es dataset | https://huggingface.co/datasets/hackathon-pln-es/neutral-es |
| GPT-3.5_fewshot | Chat GPT-3.5 generated with few shot technique | |
| GPT-3.5_CaDi <sup>*</sup> | Data created based on the dataset used for developing CaDi project<sup>*</sup> | https://lenguaje-incluyente.ibero.mx/ |
| GPT-3.5_fs_multiplication | Data multiplicated from GPT-3.5_fewshot using GPT-3.5 | |
| guia_CCGG | Examples from Spanish General Courts language inclusive Guide | https://www.congreso.es/docu/igualdad/Recomendaciones_uso_no_sexista_lenguajeCC.GG..pdf |
| guia_TAI | Examples from Trenes Argentinos' Guide to the use of inclusive language | https://www.argentina.gob.ar/sites/default/files/guia_para_uso_de_lenguaje_inclusivo_v1.pdf |
| guia_CONICET | Examples from Guide to inclusive, non-sexist language (CONICET) | https://cenpat.conicet.gov.ar/wp-content/uploads/sites/91/2020/08/Guia-lenguaje-inclusivo-no-sexista-CENPAT_final-1.pdf |
| guia_INAES | Examples of Guidelines for Inclusive Language Recommendations (INAES) | https://www.argentina.gob.ar/sites/default/files/2020/10/lenguaje_inclusivo_inaes_2021.pdf |
| guia_CHRYSALLIS | Examples from Practical Guide to Inclusive Language (Chrysallis) | https://www.lgbtqiahealtheducation.org/wp-content/uploads/2020/04/Guia-practica-de-lenguaje-inclusivo-Chrysallis.pdf |
| guia_ONU | Examples from Guidance for the use of gender-inclusive language (UN) | https://www.unwomen.org/sites/default/files/Headquarters/Attachments/Sections/Library/Gender-inclusive%20language/Guidelines-on-gender-inclusive-language-es.pdf |
| guia_MX | Examples from Manual for the use of inclusive and gender-sensitive language (MX) | https://www.gob.mx/cms/uploads/attachment/file/183695/Manual_Lenguaje_Incluyente_con_perspectiva_de_g_nero-octubre-2016.pdf |
| guia_CL | Examples from Gender Inclusive Language Guide of the Government of Chile | https://www.cultura.gob.cl/wp-content/uploads/2023/01/guia-de-lenguaje-inclusivo-de-genero.pdf |
| guia_IEM | Examples from Uso del Lenguaje Inclusivo de Género | https://secretariagenero.poder-judicial.go.cr/images/Documentos/LenguajeInclusivo/Documentos/Uso-de-lenguaje-inclusivo-de-Genero-IEM-UNA.pdf |
| human_combinatory | Combinatorics of text fragments generated with GPT3.5 | |
| GPT-4_human | Chat GPT-4 generated and human revised | |
| human | Human created | |
<sup>*</sup>©Universidad Iberoamericana, A.C. , Ciudad de México, México
<sup>*</sup>©Capitolina Díaz Martínez, Elvia María Guadalupe González del Pliego Dorantes, Marco Antonio López Hernández, Alberto López Medina, Héctor Celallos Avalos, Laura Mejía Hernández
## Data collection process
The data used for training the model has been sourced from various origins. The first and more important source was a curated and refined version of [es_neutral](https://huggingface.co/datasets/hackathon-pln-es/neutral-es)
In addition, we manually generated data based on Official Guidelines from different Spanish speaking countries. Finally, we augmented this data by experimenting with various prompts and Few-Shot learning techniques. We needed to be as explicit as possible, otherwise we wouldn’t get good results. For example:



We tried to be as inclusive as possible, paying close attention to the classification of difficulties that one could encounter in texts like these.
Moreover, we took care to incorporate numerous counterexamples, recognizing that there are instances where neutrality is not required in a sentence. For instance, “Las arquitectas María Nuñez y Rosa Loria presentaron el proyecto” should not be rewritten as “El equipo de arquitectura María Nuñez y Rosa Loria presentó el proyecto”.
It’s important to highlight that the Traductor Inclusivo not only promotes gender inclusivity but also addresses other forms of discrimination such as ableism, racism, xenophobia, and more.
### Sources
- [Recomendaciones para un uso no sexista del lenguaje en la Administracio n parlamentaria (España)](https://www.congreso.es/docu/igualdad/Recomendaciones_uso_no_sexista_lenguajeCC.GG..pdf)
- [Guía para uso de lenguaje inclusivo (Argentina)](https://www.argentina.gob.ar/sites/default/files/guia_para_uso_de_lenguaje_inclusivo_v1.pdf)
- [Guía de lenguaje inclusivo no sexista CCT CONICET-CENPAT (Argentina)](https://cenpat.conicet.gov.ar/wp-content/uploads/sites/91/2020/08/Guia-lenguaje-inclusivo-no-sexista-CENPAT_final-1.pdf)
- [Guía de recomendaciones para lenguaje inclusivo (Argentina)](https://www.argentina.gob.ar/sites/default/files/2020/10/lenguaje_inclusivo_inaes_2021.pdf)
- [Guía práctica de lenguaje inclusivo (España)](https://www.lgbtqiahealtheducation.org/wp-content/uploads/2020/04/Guia-practica-de-lenguaje-inclusivo-Chrysallis.pdf)
- [Guía para el uso de un lenguaje inclusivo al género (ONU)](https://www.unwomen.org/sites/default/files/Headquarters/Attachments/Sections/Library/Gender-inclusive%20language/Guidelines-on-gender-inclusive-language-es.pdf)
- [Manual para el uso de un lenguaje incluyente y con perspectiva de género (México)](https://www.gob.mx/cms/uploads/attachment/file/183695/Manual_Lenguaje_Incluyente_con_perspectiva_de_g_nero-octubre-2016.pdf)
- [Guía de lenguaje inclusivo de Género (Chile)](https://www.cultura.gob.cl/wp-content/uploads/2023/01/guia-de-lenguaje-inclusivo-de-genero.pdf)
- [Uso del Lenguaje Inclusivo de Género, IEM (Costa Rica)](https://secretariagenero.poder-judicial.go.cr/images/Documentos/LenguajeInclusivo/Documentos/Uso-de-lenguaje-inclusivo-de-Genero-IEM-UNA.pdf)
- [Uso no sexista de la lengua, UOC (España)](https://www.uoc.edu/portal/es/servei-linguistic/redaccio/tractament-generes/index.html)
- https://huggingface.co/datasets/hackathon-pln-es/neutral-es
## Bias
As bias is what we want to tackle, this corpus pays special attention to different types of discrimination, such as sexism, racism and ableism.
## Social Impact
An inclusive translator holds significant social impact by promoting equity and representation within texts. By rectifying biases ingrained in language and fostering inclusivity, it combats discrimination, amplifies the visibility of marginalized groups, and contributes to the cultivation of a more inclusive and respectful society.
## Team members
- **Gaia Quintana Fleitas** (gaiaq)
- **Andrés Martínez Fernández-Salguero** (andresmfs)
- **Imanuel Rozenberg** (manu_20392)
- **Miguel López** (wizmik12)
- **Josué Sauca** (josue_sauca) |
vamshi55/processes_orca_dataset_5k | ---
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 9049649.268779851
num_examples: 5034
download_size: 6114070
dataset_size: 9049649.268779851
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
distilled-from-one-sec-cv12/chunk_37 | ---
dataset_info:
features:
- name: logits
sequence: float32
- name: mfcc
sequence:
sequence: float64
splits:
- name: train
num_bytes: 959837960
num_examples: 187030
download_size: 978084646
dataset_size: 959837960
---
# Dataset Card for "chunk_37"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
skymericsales/rexroth-finetune | ---
dataset_info:
features:
- name: Human
dtype: string
- name: Assistant
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 292324
num_examples: 675
download_size: 103134
dataset_size: 292324
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "rexroth-finetune"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
SUSTech/OpenOrca-zh | ---
configs:
- config_name: default
data_files:
- split: cot_gpt4
path: data/cot_gpt4-*
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
- name: reponse
dtype: string
splits:
- name: cot_gpt4
num_bytes: 37063234
num_examples: 39449
download_size: 19362531
dataset_size: 37063234
---
# Dataset Card for "OpenOrca-zh"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
joey234/mmlu-philosophy-neg | ---
dataset_info:
features:
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: question
dtype: string
splits:
- name: test
num_bytes: 79179
num_examples: 311
download_size: 47527
dataset_size: 79179
---
# Dataset Card for "mmlu-philosophy-neg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
azezza/fef | ---
license: other
---
|
Codec-SUPERB/cv_13_zh_tw_extract_unit | ---
configs:
- config_name: default
data_files:
- split: academicodec_hifi_16k_320d
path: data/academicodec_hifi_16k_320d-*
- split: academicodec_hifi_16k_320d_large_uni
path: data/academicodec_hifi_16k_320d_large_uni-*
- split: academicodec_hifi_24k_320d
path: data/academicodec_hifi_24k_320d-*
- split: audiodec_24k_320d
path: data/audiodec_24k_320d-*
- split: dac_16k
path: data/dac_16k-*
- split: dac_24k
path: data/dac_24k-*
- split: dac_44k
path: data/dac_44k-*
- split: encodec_24k
path: data/encodec_24k-*
- split: funcodec_en_libritts_16k_gr1nq32ds320
path: data/funcodec_en_libritts_16k_gr1nq32ds320-*
- split: funcodec_en_libritts_16k_gr8nq32ds320
path: data/funcodec_en_libritts_16k_gr8nq32ds320-*
- split: funcodec_en_libritts_16k_nq32ds320
path: data/funcodec_en_libritts_16k_nq32ds320-*
- split: funcodec_en_libritts_16k_nq32ds640
path: data/funcodec_en_libritts_16k_nq32ds640-*
- split: funcodec_zh_en_16k_nq32ds320
path: data/funcodec_zh_en_16k_nq32ds320-*
- split: funcodec_zh_en_16k_nq32ds640
path: data/funcodec_zh_en_16k_nq32ds640-*
- split: speech_tokenizer_16k
path: data/speech_tokenizer_16k-*
dataset_info:
features:
- name: id
dtype: string
- name: unit
sequence:
sequence: int64
splits:
- name: academicodec_hifi_16k_320d
num_bytes: 348905998
num_examples: 61154
- name: academicodec_hifi_16k_320d_large_uni
num_bytes: 348905998
num_examples: 61154
- name: academicodec_hifi_24k_320d
num_bytes: 522068174
num_examples: 61154
- name: audiodec_24k_320d
num_bytes: 1114562286
num_examples: 61154
- name: dac_16k
num_bytes: 2221301742
num_examples: 61154
- name: dac_24k
num_bytes: 6352630894
num_examples: 61154
- name: dac_44k
num_bytes: 1901382630
num_examples: 61154
- name: encodec_24k
num_bytes: 263161342
num_examples: 61154
- name: funcodec_en_libritts_16k_gr1nq32ds320
num_bytes: 2790208366
num_examples: 61154
- name: funcodec_en_libritts_16k_gr8nq32ds320
num_bytes: 2790208366
num_examples: 61154
- name: funcodec_en_libritts_16k_nq32ds320
num_bytes: 2789220974
num_examples: 61154
- name: funcodec_en_libritts_16k_nq32ds640
num_bytes: 1402128238
num_examples: 61154
- name: funcodec_zh_en_16k_nq32ds320
num_bytes: 2786776174
num_examples: 61154
- name: funcodec_zh_en_16k_nq32ds640
num_bytes: 2786776174
num_examples: 61154
- name: speech_tokenizer_16k
num_bytes: 698482798
num_examples: 61154
download_size: 4205946477
dataset_size: 29116720154
---
# Dataset Card for "cv_13_zh_tw_extract_unit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pane2k/pan | ---
license: afl-3.0
---
|
RikoteMaster/Emotion_Recognition_4_llama2_v3 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: Text_processed
dtype: string
- name: Emotion
dtype: string
- name: Augmented
dtype: bool
- name: text
dtype: string
splits:
- name: train
num_bytes: 28873301
num_examples: 61463
download_size: 9012554
dataset_size: 28873301
---
# Dataset Card for "Emotion_Recognition_4_llama2_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-llm-leaderboard/details_Corianas__DPO-miniguanaco-1.5T | ---
pretty_name: Evaluation run of Corianas/DPO-miniguanaco-1.5T
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [Corianas/DPO-miniguanaco-1.5T](https://huggingface.co/Corianas/DPO-miniguanaco-1.5T)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Corianas__DPO-miniguanaco-1.5T\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-03-06T22:29:55.944398](https://huggingface.co/datasets/open-llm-leaderboard/details_Corianas__DPO-miniguanaco-1.5T/blob/main/results_2024-03-06T22-29-55.944398.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.2528564310082284,\n\
\ \"acc_stderr\": 0.03060858168397811,\n \"acc_norm\": 0.2538158727200352,\n\
\ \"acc_norm_stderr\": 0.03141509337097644,\n \"mc1\": 0.24969400244798043,\n\
\ \"mc1_stderr\": 0.015152286907148128,\n \"mc2\": 0.42685163844717416,\n\
\ \"mc2_stderr\": 0.014396909077257778\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.29436860068259385,\n \"acc_stderr\": 0.013318528460539426,\n\
\ \"acc_norm\": 0.30631399317406144,\n \"acc_norm_stderr\": 0.013470584417276514\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.4151563433578968,\n\
\ \"acc_stderr\": 0.00491741936776603,\n \"acc_norm\": 0.54052977494523,\n\
\ \"acc_norm_stderr\": 0.004973361339169647\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.24,\n \"acc_stderr\": 0.04292346959909283,\n \
\ \"acc_norm\": 0.24,\n \"acc_norm_stderr\": 0.04292346959909283\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.2962962962962963,\n\
\ \"acc_stderr\": 0.03944624162501116,\n \"acc_norm\": 0.2962962962962963,\n\
\ \"acc_norm_stderr\": 0.03944624162501116\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.21052631578947367,\n \"acc_stderr\": 0.03317672787533157,\n\
\ \"acc_norm\": 0.21052631578947367,\n \"acc_norm_stderr\": 0.03317672787533157\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.22,\n\
\ \"acc_stderr\": 0.041633319989322695,\n \"acc_norm\": 0.22,\n \
\ \"acc_norm_stderr\": 0.041633319989322695\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.2792452830188679,\n \"acc_stderr\": 0.027611163402399715,\n\
\ \"acc_norm\": 0.2792452830188679,\n \"acc_norm_stderr\": 0.027611163402399715\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.2152777777777778,\n\
\ \"acc_stderr\": 0.03437079344106134,\n \"acc_norm\": 0.2152777777777778,\n\
\ \"acc_norm_stderr\": 0.03437079344106134\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.23,\n \"acc_stderr\": 0.04229525846816506,\n \
\ \"acc_norm\": 0.23,\n \"acc_norm_stderr\": 0.04229525846816506\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\"\
: 0.24,\n \"acc_stderr\": 0.04292346959909284,\n \"acc_norm\": 0.24,\n\
\ \"acc_norm_stderr\": 0.04292346959909284\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.04560480215720684,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.04560480215720684\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.24277456647398843,\n\
\ \"acc_stderr\": 0.0326926380614177,\n \"acc_norm\": 0.24277456647398843,\n\
\ \"acc_norm_stderr\": 0.0326926380614177\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.2647058823529412,\n \"acc_stderr\": 0.04389869956808778,\n\
\ \"acc_norm\": 0.2647058823529412,\n \"acc_norm_stderr\": 0.04389869956808778\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.23,\n \"acc_stderr\": 0.04229525846816506,\n \"acc_norm\": 0.23,\n\
\ \"acc_norm_stderr\": 0.04229525846816506\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.24680851063829787,\n \"acc_stderr\": 0.028185441301234092,\n\
\ \"acc_norm\": 0.24680851063829787,\n \"acc_norm_stderr\": 0.028185441301234092\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.2719298245614035,\n\
\ \"acc_stderr\": 0.04185774424022056,\n \"acc_norm\": 0.2719298245614035,\n\
\ \"acc_norm_stderr\": 0.04185774424022056\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.22758620689655173,\n \"acc_stderr\": 0.03493950380131184,\n\
\ \"acc_norm\": 0.22758620689655173,\n \"acc_norm_stderr\": 0.03493950380131184\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.24603174603174602,\n \"acc_stderr\": 0.022182037202948368,\n \"\
acc_norm\": 0.24603174603174602,\n \"acc_norm_stderr\": 0.022182037202948368\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.15873015873015872,\n\
\ \"acc_stderr\": 0.03268454013011743,\n \"acc_norm\": 0.15873015873015872,\n\
\ \"acc_norm_stderr\": 0.03268454013011743\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.19,\n \"acc_stderr\": 0.03942772444036624,\n \
\ \"acc_norm\": 0.19,\n \"acc_norm_stderr\": 0.03942772444036624\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.24838709677419354,\n\
\ \"acc_stderr\": 0.02458002892148101,\n \"acc_norm\": 0.24838709677419354,\n\
\ \"acc_norm_stderr\": 0.02458002892148101\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.22167487684729065,\n \"acc_stderr\": 0.029225575892489614,\n\
\ \"acc_norm\": 0.22167487684729065,\n \"acc_norm_stderr\": 0.029225575892489614\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.34,\n \"acc_stderr\": 0.04760952285695235,\n \"acc_norm\"\
: 0.34,\n \"acc_norm_stderr\": 0.04760952285695235\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.26666666666666666,\n \"acc_stderr\": 0.03453131801885416,\n\
\ \"acc_norm\": 0.26666666666666666,\n \"acc_norm_stderr\": 0.03453131801885416\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.21212121212121213,\n \"acc_stderr\": 0.029126522834586808,\n \"\
acc_norm\": 0.21212121212121213,\n \"acc_norm_stderr\": 0.029126522834586808\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.19689119170984457,\n \"acc_stderr\": 0.028697873971860667,\n\
\ \"acc_norm\": 0.19689119170984457,\n \"acc_norm_stderr\": 0.028697873971860667\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.2153846153846154,\n \"acc_stderr\": 0.020843034557462878,\n\
\ \"acc_norm\": 0.2153846153846154,\n \"acc_norm_stderr\": 0.020843034557462878\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.2518518518518518,\n \"acc_stderr\": 0.026466117538959905,\n \
\ \"acc_norm\": 0.2518518518518518,\n \"acc_norm_stderr\": 0.026466117538959905\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.21428571428571427,\n \"acc_stderr\": 0.026653531596715484,\n\
\ \"acc_norm\": 0.21428571428571427,\n \"acc_norm_stderr\": 0.026653531596715484\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.2052980132450331,\n \"acc_stderr\": 0.03297986648473835,\n \"\
acc_norm\": 0.2052980132450331,\n \"acc_norm_stderr\": 0.03297986648473835\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.21651376146788992,\n \"acc_stderr\": 0.017658710594443135,\n \"\
acc_norm\": 0.21651376146788992,\n \"acc_norm_stderr\": 0.017658710594443135\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.21296296296296297,\n \"acc_stderr\": 0.027920963147993656,\n \"\
acc_norm\": 0.21296296296296297,\n \"acc_norm_stderr\": 0.027920963147993656\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.2107843137254902,\n \"acc_stderr\": 0.028626547912437416,\n \"\
acc_norm\": 0.2107843137254902,\n \"acc_norm_stderr\": 0.028626547912437416\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.270042194092827,\n \"acc_stderr\": 0.028900721906293433,\n \
\ \"acc_norm\": 0.270042194092827,\n \"acc_norm_stderr\": 0.028900721906293433\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.36771300448430494,\n\
\ \"acc_stderr\": 0.03236198350928275,\n \"acc_norm\": 0.36771300448430494,\n\
\ \"acc_norm_stderr\": 0.03236198350928275\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.21374045801526717,\n \"acc_stderr\": 0.0359546161177469,\n\
\ \"acc_norm\": 0.21374045801526717,\n \"acc_norm_stderr\": 0.0359546161177469\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.2396694214876033,\n \"acc_stderr\": 0.03896878985070417,\n \"\
acc_norm\": 0.2396694214876033,\n \"acc_norm_stderr\": 0.03896878985070417\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.2962962962962963,\n\
\ \"acc_stderr\": 0.044143436668549335,\n \"acc_norm\": 0.2962962962962963,\n\
\ \"acc_norm_stderr\": 0.044143436668549335\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.26380368098159507,\n \"acc_stderr\": 0.03462419931615624,\n\
\ \"acc_norm\": 0.26380368098159507,\n \"acc_norm_stderr\": 0.03462419931615624\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.35714285714285715,\n\
\ \"acc_stderr\": 0.04547960999764376,\n \"acc_norm\": 0.35714285714285715,\n\
\ \"acc_norm_stderr\": 0.04547960999764376\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.21359223300970873,\n \"acc_stderr\": 0.040580420156460344,\n\
\ \"acc_norm\": 0.21359223300970873,\n \"acc_norm_stderr\": 0.040580420156460344\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.27350427350427353,\n\
\ \"acc_stderr\": 0.029202540153431173,\n \"acc_norm\": 0.27350427350427353,\n\
\ \"acc_norm_stderr\": 0.029202540153431173\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.26,\n \"acc_stderr\": 0.0440844002276808,\n \
\ \"acc_norm\": 0.26,\n \"acc_norm_stderr\": 0.0440844002276808\n },\n\
\ \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.2720306513409962,\n\
\ \"acc_stderr\": 0.015913367447500517,\n \"acc_norm\": 0.2720306513409962,\n\
\ \"acc_norm_stderr\": 0.015913367447500517\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.23410404624277456,\n \"acc_stderr\": 0.022797110278071128,\n\
\ \"acc_norm\": 0.23410404624277456,\n \"acc_norm_stderr\": 0.022797110278071128\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.2212290502793296,\n\
\ \"acc_stderr\": 0.013882164598887282,\n \"acc_norm\": 0.2212290502793296,\n\
\ \"acc_norm_stderr\": 0.013882164598887282\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.2549019607843137,\n \"acc_stderr\": 0.024954184324879905,\n\
\ \"acc_norm\": 0.2549019607843137,\n \"acc_norm_stderr\": 0.024954184324879905\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.2829581993569132,\n\
\ \"acc_stderr\": 0.02558306248998483,\n \"acc_norm\": 0.2829581993569132,\n\
\ \"acc_norm_stderr\": 0.02558306248998483\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.2932098765432099,\n \"acc_stderr\": 0.025329888171900915,\n\
\ \"acc_norm\": 0.2932098765432099,\n \"acc_norm_stderr\": 0.025329888171900915\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.21631205673758866,\n \"acc_stderr\": 0.024561720560562793,\n \
\ \"acc_norm\": 0.21631205673758866,\n \"acc_norm_stderr\": 0.024561720560562793\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.23989569752281617,\n\
\ \"acc_stderr\": 0.010906282617981652,\n \"acc_norm\": 0.23989569752281617,\n\
\ \"acc_norm_stderr\": 0.010906282617981652\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.35294117647058826,\n \"acc_stderr\": 0.029029422815681404,\n\
\ \"acc_norm\": 0.35294117647058826,\n \"acc_norm_stderr\": 0.029029422815681404\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.2630718954248366,\n \"acc_stderr\": 0.017812676542320657,\n \
\ \"acc_norm\": 0.2630718954248366,\n \"acc_norm_stderr\": 0.017812676542320657\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.23636363636363636,\n\
\ \"acc_stderr\": 0.04069306319721377,\n \"acc_norm\": 0.23636363636363636,\n\
\ \"acc_norm_stderr\": 0.04069306319721377\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.1836734693877551,\n \"acc_stderr\": 0.02478907133200763,\n\
\ \"acc_norm\": 0.1836734693877551,\n \"acc_norm_stderr\": 0.02478907133200763\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.23383084577114427,\n\
\ \"acc_stderr\": 0.02992941540834839,\n \"acc_norm\": 0.23383084577114427,\n\
\ \"acc_norm_stderr\": 0.02992941540834839\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.27,\n \"acc_stderr\": 0.044619604333847394,\n \
\ \"acc_norm\": 0.27,\n \"acc_norm_stderr\": 0.044619604333847394\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.2891566265060241,\n\
\ \"acc_stderr\": 0.03529486801511115,\n \"acc_norm\": 0.2891566265060241,\n\
\ \"acc_norm_stderr\": 0.03529486801511115\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.21637426900584794,\n \"acc_stderr\": 0.03158149539338733,\n\
\ \"acc_norm\": 0.21637426900584794,\n \"acc_norm_stderr\": 0.03158149539338733\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.24969400244798043,\n\
\ \"mc1_stderr\": 0.015152286907148128,\n \"mc2\": 0.42685163844717416,\n\
\ \"mc2_stderr\": 0.014396909077257778\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.5864246250986582,\n \"acc_stderr\": 0.013840971763195303\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n }\n}\n```"
repo_url: https://huggingface.co/Corianas/DPO-miniguanaco-1.5T
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|arc:challenge|25_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|gsm8k|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hellaswag|10_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-03-06T22-29-55.944398.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-management|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-virology|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|truthfulqa:mc|0_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-03-06T22-29-55.944398.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- '**/details_harness|winogrande|5_2024-03-06T22-29-55.944398.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-03-06T22-29-55.944398.parquet'
- config_name: results
data_files:
- split: 2024_03_06T22_29_55.944398
path:
- results_2024-03-06T22-29-55.944398.parquet
- split: latest
path:
- results_2024-03-06T22-29-55.944398.parquet
---
# Dataset Card for Evaluation run of Corianas/DPO-miniguanaco-1.5T
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [Corianas/DPO-miniguanaco-1.5T](https://huggingface.co/Corianas/DPO-miniguanaco-1.5T) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Corianas__DPO-miniguanaco-1.5T",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-03-06T22:29:55.944398](https://huggingface.co/datasets/open-llm-leaderboard/details_Corianas__DPO-miniguanaco-1.5T/blob/main/results_2024-03-06T22-29-55.944398.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.2528564310082284,
"acc_stderr": 0.03060858168397811,
"acc_norm": 0.2538158727200352,
"acc_norm_stderr": 0.03141509337097644,
"mc1": 0.24969400244798043,
"mc1_stderr": 0.015152286907148128,
"mc2": 0.42685163844717416,
"mc2_stderr": 0.014396909077257778
},
"harness|arc:challenge|25": {
"acc": 0.29436860068259385,
"acc_stderr": 0.013318528460539426,
"acc_norm": 0.30631399317406144,
"acc_norm_stderr": 0.013470584417276514
},
"harness|hellaswag|10": {
"acc": 0.4151563433578968,
"acc_stderr": 0.00491741936776603,
"acc_norm": 0.54052977494523,
"acc_norm_stderr": 0.004973361339169647
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.24,
"acc_stderr": 0.04292346959909283,
"acc_norm": 0.24,
"acc_norm_stderr": 0.04292346959909283
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.2962962962962963,
"acc_stderr": 0.03944624162501116,
"acc_norm": 0.2962962962962963,
"acc_norm_stderr": 0.03944624162501116
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.21052631578947367,
"acc_stderr": 0.03317672787533157,
"acc_norm": 0.21052631578947367,
"acc_norm_stderr": 0.03317672787533157
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.22,
"acc_stderr": 0.041633319989322695,
"acc_norm": 0.22,
"acc_norm_stderr": 0.041633319989322695
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.2792452830188679,
"acc_stderr": 0.027611163402399715,
"acc_norm": 0.2792452830188679,
"acc_norm_stderr": 0.027611163402399715
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.2152777777777778,
"acc_stderr": 0.03437079344106134,
"acc_norm": 0.2152777777777778,
"acc_norm_stderr": 0.03437079344106134
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.23,
"acc_stderr": 0.04229525846816506,
"acc_norm": 0.23,
"acc_norm_stderr": 0.04229525846816506
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.24,
"acc_stderr": 0.04292346959909284,
"acc_norm": 0.24,
"acc_norm_stderr": 0.04292346959909284
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720684,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720684
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.24277456647398843,
"acc_stderr": 0.0326926380614177,
"acc_norm": 0.24277456647398843,
"acc_norm_stderr": 0.0326926380614177
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.2647058823529412,
"acc_stderr": 0.04389869956808778,
"acc_norm": 0.2647058823529412,
"acc_norm_stderr": 0.04389869956808778
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.23,
"acc_stderr": 0.04229525846816506,
"acc_norm": 0.23,
"acc_norm_stderr": 0.04229525846816506
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.24680851063829787,
"acc_stderr": 0.028185441301234092,
"acc_norm": 0.24680851063829787,
"acc_norm_stderr": 0.028185441301234092
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.2719298245614035,
"acc_stderr": 0.04185774424022056,
"acc_norm": 0.2719298245614035,
"acc_norm_stderr": 0.04185774424022056
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.22758620689655173,
"acc_stderr": 0.03493950380131184,
"acc_norm": 0.22758620689655173,
"acc_norm_stderr": 0.03493950380131184
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.24603174603174602,
"acc_stderr": 0.022182037202948368,
"acc_norm": 0.24603174603174602,
"acc_norm_stderr": 0.022182037202948368
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.15873015873015872,
"acc_stderr": 0.03268454013011743,
"acc_norm": 0.15873015873015872,
"acc_norm_stderr": 0.03268454013011743
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.19,
"acc_stderr": 0.03942772444036624,
"acc_norm": 0.19,
"acc_norm_stderr": 0.03942772444036624
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.24838709677419354,
"acc_stderr": 0.02458002892148101,
"acc_norm": 0.24838709677419354,
"acc_norm_stderr": 0.02458002892148101
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.22167487684729065,
"acc_stderr": 0.029225575892489614,
"acc_norm": 0.22167487684729065,
"acc_norm_stderr": 0.029225575892489614
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.34,
"acc_stderr": 0.04760952285695235,
"acc_norm": 0.34,
"acc_norm_stderr": 0.04760952285695235
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.26666666666666666,
"acc_stderr": 0.03453131801885416,
"acc_norm": 0.26666666666666666,
"acc_norm_stderr": 0.03453131801885416
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.21212121212121213,
"acc_stderr": 0.029126522834586808,
"acc_norm": 0.21212121212121213,
"acc_norm_stderr": 0.029126522834586808
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.19689119170984457,
"acc_stderr": 0.028697873971860667,
"acc_norm": 0.19689119170984457,
"acc_norm_stderr": 0.028697873971860667
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.2153846153846154,
"acc_stderr": 0.020843034557462878,
"acc_norm": 0.2153846153846154,
"acc_norm_stderr": 0.020843034557462878
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.2518518518518518,
"acc_stderr": 0.026466117538959905,
"acc_norm": 0.2518518518518518,
"acc_norm_stderr": 0.026466117538959905
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.21428571428571427,
"acc_stderr": 0.026653531596715484,
"acc_norm": 0.21428571428571427,
"acc_norm_stderr": 0.026653531596715484
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.2052980132450331,
"acc_stderr": 0.03297986648473835,
"acc_norm": 0.2052980132450331,
"acc_norm_stderr": 0.03297986648473835
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.21651376146788992,
"acc_stderr": 0.017658710594443135,
"acc_norm": 0.21651376146788992,
"acc_norm_stderr": 0.017658710594443135
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.21296296296296297,
"acc_stderr": 0.027920963147993656,
"acc_norm": 0.21296296296296297,
"acc_norm_stderr": 0.027920963147993656
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.2107843137254902,
"acc_stderr": 0.028626547912437416,
"acc_norm": 0.2107843137254902,
"acc_norm_stderr": 0.028626547912437416
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.270042194092827,
"acc_stderr": 0.028900721906293433,
"acc_norm": 0.270042194092827,
"acc_norm_stderr": 0.028900721906293433
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.36771300448430494,
"acc_stderr": 0.03236198350928275,
"acc_norm": 0.36771300448430494,
"acc_norm_stderr": 0.03236198350928275
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.21374045801526717,
"acc_stderr": 0.0359546161177469,
"acc_norm": 0.21374045801526717,
"acc_norm_stderr": 0.0359546161177469
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.2396694214876033,
"acc_stderr": 0.03896878985070417,
"acc_norm": 0.2396694214876033,
"acc_norm_stderr": 0.03896878985070417
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.2962962962962963,
"acc_stderr": 0.044143436668549335,
"acc_norm": 0.2962962962962963,
"acc_norm_stderr": 0.044143436668549335
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.26380368098159507,
"acc_stderr": 0.03462419931615624,
"acc_norm": 0.26380368098159507,
"acc_norm_stderr": 0.03462419931615624
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.35714285714285715,
"acc_stderr": 0.04547960999764376,
"acc_norm": 0.35714285714285715,
"acc_norm_stderr": 0.04547960999764376
},
"harness|hendrycksTest-management|5": {
"acc": 0.21359223300970873,
"acc_stderr": 0.040580420156460344,
"acc_norm": 0.21359223300970873,
"acc_norm_stderr": 0.040580420156460344
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.27350427350427353,
"acc_stderr": 0.029202540153431173,
"acc_norm": 0.27350427350427353,
"acc_norm_stderr": 0.029202540153431173
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.26,
"acc_stderr": 0.0440844002276808,
"acc_norm": 0.26,
"acc_norm_stderr": 0.0440844002276808
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.2720306513409962,
"acc_stderr": 0.015913367447500517,
"acc_norm": 0.2720306513409962,
"acc_norm_stderr": 0.015913367447500517
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.23410404624277456,
"acc_stderr": 0.022797110278071128,
"acc_norm": 0.23410404624277456,
"acc_norm_stderr": 0.022797110278071128
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.2212290502793296,
"acc_stderr": 0.013882164598887282,
"acc_norm": 0.2212290502793296,
"acc_norm_stderr": 0.013882164598887282
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.2549019607843137,
"acc_stderr": 0.024954184324879905,
"acc_norm": 0.2549019607843137,
"acc_norm_stderr": 0.024954184324879905
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.2829581993569132,
"acc_stderr": 0.02558306248998483,
"acc_norm": 0.2829581993569132,
"acc_norm_stderr": 0.02558306248998483
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.2932098765432099,
"acc_stderr": 0.025329888171900915,
"acc_norm": 0.2932098765432099,
"acc_norm_stderr": 0.025329888171900915
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.21631205673758866,
"acc_stderr": 0.024561720560562793,
"acc_norm": 0.21631205673758866,
"acc_norm_stderr": 0.024561720560562793
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.23989569752281617,
"acc_stderr": 0.010906282617981652,
"acc_norm": 0.23989569752281617,
"acc_norm_stderr": 0.010906282617981652
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.35294117647058826,
"acc_stderr": 0.029029422815681404,
"acc_norm": 0.35294117647058826,
"acc_norm_stderr": 0.029029422815681404
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.2630718954248366,
"acc_stderr": 0.017812676542320657,
"acc_norm": 0.2630718954248366,
"acc_norm_stderr": 0.017812676542320657
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.23636363636363636,
"acc_stderr": 0.04069306319721377,
"acc_norm": 0.23636363636363636,
"acc_norm_stderr": 0.04069306319721377
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.1836734693877551,
"acc_stderr": 0.02478907133200763,
"acc_norm": 0.1836734693877551,
"acc_norm_stderr": 0.02478907133200763
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.23383084577114427,
"acc_stderr": 0.02992941540834839,
"acc_norm": 0.23383084577114427,
"acc_norm_stderr": 0.02992941540834839
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.27,
"acc_stderr": 0.044619604333847394,
"acc_norm": 0.27,
"acc_norm_stderr": 0.044619604333847394
},
"harness|hendrycksTest-virology|5": {
"acc": 0.2891566265060241,
"acc_stderr": 0.03529486801511115,
"acc_norm": 0.2891566265060241,
"acc_norm_stderr": 0.03529486801511115
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.21637426900584794,
"acc_stderr": 0.03158149539338733,
"acc_norm": 0.21637426900584794,
"acc_norm_stderr": 0.03158149539338733
},
"harness|truthfulqa:mc|0": {
"mc1": 0.24969400244798043,
"mc1_stderr": 0.015152286907148128,
"mc2": 0.42685163844717416,
"mc2_stderr": 0.014396909077257778
},
"harness|winogrande|5": {
"acc": 0.5864246250986582,
"acc_stderr": 0.013840971763195303
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
joey234/mmlu-machine_learning-neg-answer | ---
dataset_info:
features:
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: neg_answer
dtype: string
splits:
- name: test
num_bytes: 36792
num_examples: 112
download_size: 21874
dataset_size: 36792
---
# Dataset Card for "mmlu-machine_learning-neg-answer"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/iroha_bluearchive | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of iroha/棗イロハ/伊吕波 (Blue Archive)
This is the dataset of iroha/棗イロハ/伊吕波 (Blue Archive), containing 500 images and their tags.
The core tags of this character are `red_hair, long_hair, halo, grey_eyes, hair_between_eyes, hat, peaked_cap, black_headwear, very_long_hair, wavy_hair, military_hat`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:-------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 500 | 819.37 MiB | [Download](https://huggingface.co/datasets/CyberHarem/iroha_bluearchive/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 1200 | 500 | 673.48 MiB | [Download](https://huggingface.co/datasets/CyberHarem/iroha_bluearchive/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1337 | 1.40 GiB | [Download](https://huggingface.co/datasets/CyberHarem/iroha_bluearchive/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/iroha_bluearchive',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 5 |  |  |  |  |  | 1girl, black_dress, blush, looking_at_viewer, solo, simple_background, bow, enmaided, frilled_apron, maid_apron, maid_headdress, white_apron, white_background, black_footwear, black_gloves, full_body, grin, holding, juliet_sleeves, neck_ribbon, open_mouth, puffy_short_sleeves, red_ribbon |
| 1 | 9 |  |  |  |  |  | 1girl, black_shirt, blush, collared_shirt, jacket, long_sleeves, looking_at_viewer, red_necktie, simple_background, solo, white_background, armband, military_uniform, open_clothes, smile, safety_pin, black_skirt, open_mouth, ribbon |
| 2 | 12 |  |  |  |  |  | 1girl, armband, jacket, long_sleeves, red_necktie, solo, black_shirt, blush, holding_book, looking_at_viewer, military_uniform, collared_shirt, open_clothes, safety_pin, simple_background, white_background, black_skirt, closed_mouth |
| 3 | 13 |  |  |  |  |  | 1girl, armband, black_shirt, black_skirt, boots, jacket, long_sleeves, simple_background, solo, white_background, coat, full_body, looking_at_viewer, open_clothes, red_necktie, black_footwear, collared_shirt, sleeves_past_wrists, standing, blush, closed_mouth, military_uniform, holding_book, pencil_skirt, ribbon |
| 4 | 6 |  |  |  |  |  | 1girl, blush, looking_at_viewer, navel, red_necktie, small_breasts, solo, simple_background, white_background, black_bikini, collarbone, jacket, off_shoulder, black_coat, grin, long_sleeves, open_coat, side-tie_bikini_bottom |
| 5 | 17 |  |  |  |  |  | 1boy, 1girl, blush, hetero, nipples, solo_focus, penis, navel, small_breasts, sex, spread_legs, vaginal, collarbone, bar_censor, completely_nude, sweat, open_mouth, looking_at_viewer, cum_in_pussy, heart, loli, on_back, pov, red_necktie |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | black_dress | blush | looking_at_viewer | solo | simple_background | bow | enmaided | frilled_apron | maid_apron | maid_headdress | white_apron | white_background | black_footwear | black_gloves | full_body | grin | holding | juliet_sleeves | neck_ribbon | open_mouth | puffy_short_sleeves | red_ribbon | black_shirt | collared_shirt | jacket | long_sleeves | red_necktie | armband | military_uniform | open_clothes | smile | safety_pin | black_skirt | ribbon | holding_book | closed_mouth | boots | coat | sleeves_past_wrists | standing | pencil_skirt | navel | small_breasts | black_bikini | collarbone | off_shoulder | black_coat | open_coat | side-tie_bikini_bottom | 1boy | hetero | nipples | solo_focus | penis | sex | spread_legs | vaginal | bar_censor | completely_nude | sweat | cum_in_pussy | heart | loli | on_back | pov |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:--------------|:--------|:--------------------|:-------|:--------------------|:------|:-----------|:----------------|:-------------|:-----------------|:--------------|:-------------------|:-----------------|:---------------|:------------|:-------|:----------|:-----------------|:--------------|:-------------|:----------------------|:-------------|:--------------|:-----------------|:---------|:---------------|:--------------|:----------|:-------------------|:---------------|:--------|:-------------|:--------------|:---------|:---------------|:---------------|:--------|:-------|:----------------------|:-----------|:---------------|:--------|:----------------|:---------------|:-------------|:---------------|:-------------|:------------|:-------------------------|:-------|:---------|:----------|:-------------|:--------|:------|:--------------|:----------|:-------------|:------------------|:--------|:---------------|:--------|:-------|:----------|:------|
| 0 | 5 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 9 |  |  |  |  |  | X | | X | X | X | X | | | | | | | X | | | | | | | | X | | | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 12 |  |  |  |  |  | X | | X | X | X | X | | | | | | | X | | | | | | | | | | | X | X | X | X | X | X | X | X | | X | X | | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 13 |  |  |  |  |  | X | | X | X | X | X | | | | | | | X | X | | X | | | | | | | | X | X | X | X | X | X | X | X | | | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 6 |  |  |  |  |  | X | | X | X | X | X | | | | | | | X | | | | X | | | | | | | | | X | X | X | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | |
| 5 | 17 |  |  |  |  |  | X | | X | X | | | | | | | | | | | | | | | | | X | | | | | | | X | | | | | | | | | | | | | | | X | X | | X | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
VictorSanh/obelisc_23k_tr_199_w_xattn_opt_step-28000 | ---
dataset_info:
features:
- name: images
list: image
- name: texts
list: string
- name: key
dtype: string
- name: loss
dtype: float32
- name: embedding
sequence: float32
splits:
- name: train
num_bytes: 4531407335.168
num_examples: 22368
download_size: 4214990149
dataset_size: 4531407335.168
---
# Dataset Card for "obelisc_23k_tr_199_w_xattn_opt_step-28000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/golden_hind_azurlane | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of golden_hind/ゴールデン・ハインド/金鹿号 (Azur Lane)
This is the dataset of golden_hind/ゴールデン・ハインド/金鹿号 (Azur Lane), containing 68 images and their tags.
The core tags of this character are `breasts, long_hair, horns, black_hair, large_breasts, blue_eyes, bangs, very_long_hair, mole, mole_under_mouth`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:----------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 68 | 158.66 MiB | [Download](https://huggingface.co/datasets/CyberHarem/golden_hind_azurlane/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 68 | 72.64 MiB | [Download](https://huggingface.co/datasets/CyberHarem/golden_hind_azurlane/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 180 | 157.68 MiB | [Download](https://huggingface.co/datasets/CyberHarem/golden_hind_azurlane/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 68 | 129.73 MiB | [Download](https://huggingface.co/datasets/CyberHarem/golden_hind_azurlane/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 180 | 251.30 MiB | [Download](https://huggingface.co/datasets/CyberHarem/golden_hind_azurlane/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/golden_hind_azurlane',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 25 |  |  |  |  |  | 1girl, looking_at_viewer, solo, tentacles, blush, navel, tongue_out, cleavage, open_mouth, smile, dress, armpits, bare_shoulders, chain, nail_polish, revealing_clothes |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | looking_at_viewer | solo | tentacles | blush | navel | tongue_out | cleavage | open_mouth | smile | dress | armpits | bare_shoulders | chain | nail_polish | revealing_clothes |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:--------------------|:-------|:------------|:--------|:--------|:-------------|:-----------|:-------------|:--------|:--------|:----------|:-----------------|:--------|:--------------|:--------------------|
| 0 | 25 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
CVasNLPExperiments/fairness_pilot_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_4800 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: prompt
dtype: string
- name: true_label
dtype: string
- name: scores
sequence: float64
- name: prediction
dtype: string
splits:
- name: fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices
num_bytes: 2102429
num_examples: 4800
download_size: 304923
dataset_size: 2102429
---
# Dataset Card for "fairness_pilot_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_4800"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vuthalalynne/KingIV | ---
license: other
license_name: kingiv
license_link: LICENSE
---
|
carlosemorais/TranslateV0-Json | ---
license: apache-2.0
---
|
sedthh/tv_dialogue | ---
dataset_info:
features:
- name: TEXT
dtype: string
- name: METADATA
dtype: string
- name: SOURCE
dtype: string
splits:
- name: train
num_bytes: 211728118
num_examples: 2781
download_size: 125187885
dataset_size: 211728118
license: mit
task_categories:
- conversational
- text2text-generation
- text-generation
language:
- en
tags:
- OpenAssistant
- transcripts
- subtitles
- television
pretty_name: TV and Movie dialogue and transcript corpus
size_categories:
- 1K<n<10K
---
# Dataset Card for "tv_dialogue"
This dataset contains transcripts for famous movies and TV shows from multiple sources.
An example dialogue would be:
```
[PERSON 1] Hello
[PERSON 2] Hello Person 2!
How's it going?
(they are both talking)
[PERSON 1] I like being an example
on Huggingface!
They are examples on Huggingface.
CUT OUT TO ANOTHER SCENCE
We are somewhere else
[PERSON 1 (v.o)] I wonder where we are?
```
All dialogues were processed to follow this format. Each row is a single episode / movie (**2781** rows total)
following the [OpenAssistant](https://open-assistant.io/) format. The METADATA column contains dditional information as a JSON string.
## Dialogue only, with some information on the scene
| Show | Number of scripts | Via | Source |
|----|----|---|---|
| Friends | 236 episodes | https://github.com/emorynlp/character-mining | friends/emorynlp |
| The Office | 186 episodes | https://www.kaggle.com/datasets/nasirkhalid24/the-office-us-complete-dialoguetranscript | office/nasirkhalid24 |
| Marvel Cinematic Universe | 18 movies | https://www.kaggle.com/datasets/pdunton/marvel-cinematic-universe-dialogue | marvel/pdunton |
| Doctor Who | 306 episodes | https://www.kaggle.com/datasets/jeanmidev/doctor-who | drwho/jeanmidev |
| Star Trek | 708 episodes | http://www.chakoteya.net/StarTrek/index.html based on https://github.com/GJBroughton/Star_Trek_Scripts/ | statrek/chakoteya |
## Actual transcripts with detailed information on the scenes
| Show | Number of scripts | Via | Source |
|----|----|---|---|
| Top Movies | 919 movies | https://imsdb.com/ | imsdb |
| Top Movies | 171 movies | https://www.dailyscript.com/ | dailyscript |
| Stargate SG-1 | 18 episodes | https://imsdb.com/ | imsdb |
| South Park | 129 episodes | https://imsdb.com/ | imsdb |
| Knight Rider | 80 episodes | http://www.knightriderarchives.com/ | knightriderarchives | |
autoevaluate/autoeval-eval-futin__feed-top_en-c0540d-2175569973 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- futin/feed
eval_info:
task: text_zero_shot_classification
model: facebook/opt-350m
metrics: []
dataset_name: futin/feed
dataset_config: top_en
dataset_split: test
col_mapping:
text: text
classes: classes
target: target
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: facebook/opt-350m
* Dataset: futin/feed
* Config: top_en
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@futin](https://huggingface.co/futin) for evaluating this model. |
itamarcard/zipp | ---
license: openrail
---
|
anvilarth/lvis | ---
license: apache-2.0
language:
- en
---
# LVIS
### Dataset Summary
This dataset is the implementation of LVIS dataset into Hugging Face datasets. Please visit the original website for more information.
- https://www.lvisdataset.org/
### Loading
This code returns train, validation and test generators.
```python
from datasets import load_dataset
dataset = load_dataset("winvoker/lvis")
```
Objects is a dictionary which contains annotation information like bbox, class.
```
DatasetDict({
train: Dataset({
features: ['id', 'image', 'height', 'width', 'objects'],
num_rows: 100170
})
validation: Dataset({
features: ['id', 'image', 'height', 'width', 'objects'],
num_rows: 4809
})
test: Dataset({
features: ['id', 'image', 'height', 'width', 'objects'],
num_rows: 19822
})
})
```
### Access Generators
```python
train = dataset["train"]
validation = dataset["validation"]
test = dataset["test"]
```
An example row is as follows.
```json
{ 'id': 0,
'image': '000000437561.jpg',
'height': 480,
'width': 640,
'objects': {
'bboxes': [[[392, 271, 14, 3]],
'classes': [117],
'segmentation': [[376, 272, 375, 270, 372, 269, 371, 269, 373, 269, 373]]
}
}
``` |
jtatman/ultrachat_sft_instruction_format | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: text
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 2605877996
num_examples: 657794
download_size: 1259509466
dataset_size: 2605877996
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "ultrachat_sft_instruction_format"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Ti-Ma/wikipedia_2013 | ---
license: cc-by-sa-3.0
---
|
soodoku/archive-news | ---
license: apache-2.0
---
|
autoevaluate/autoeval-eval-squad_v2-squad_v2-5d46e4-1992966293 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- squad_v2
eval_info:
task: extractive_question_answering
model: deepset/electra-base-squad2
metrics: ['accuracy', 'bleu', 'precision', 'recall', 'rouge']
dataset_name: squad_v2
dataset_config: squad_v2
dataset_split: validation
col_mapping:
context: context
question: question
answers-text: answers.text
answers-answer_start: answers.answer_start
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: deepset/electra-base-squad2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@anchal](https://huggingface.co/anchal) for evaluating this model. |
EmbeddingStudio/query-parsing-instructions-saiga | ---
license: apache-2.0
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 41107403
num_examples: 20479
- name: test
num_bytes: 13985735
num_examples: 6915
download_size: 16155342
dataset_size: 55093138
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
task_categories:
- token-classification
- text-generation
language:
- ru
pretty_name: Synthetic Search Query Parsing Instruction for Saiga family
size_categories:
- 10K<n<100K
tags:
- saiga
- mistral
- instuct
- zero-shot
- query parsing
- synthetic
- search-queries
- e-commerce
- online-shops
- travel-agencies
- educational-institutions-ai
- job-recruitment-automation
- banking-digital-services
- investment-ai-analysis
- insurance-tech-innovation
- financial-advisory-ai
- credit-services-automation
- payment-processing-tech
- mortgage-tech-solutions
- real-estate-digital-solutions
- taxation-tech-services
- risk-management-ai
- compliance-automation
- digital-banking-innovation
- mobile-banking-tech
- online-retail-tech
- offline-retail-automation
- automotive-dealership-tech
- restaurant-automation-tech
- food-delivery-ai
- entertainment-platforms-ai
- media-platforms-tech
- government-services-automation
- travel-tech-innovation
- consumer-analytics-ai
- logistics-tech-automation
- supply-chain-ai
- customer-support-tech
- market-research-ai
- mobile-app-dev-tech
- game-dev-ai
- cloud-computing-services
- data-analytics-ai
- business-intelligence-ai
- cybersecurity-software-tech
- ui-ux-design-ai
- iot-development-tech
- project-management-tools-ai
- version-control-systems-tech
- ci-cd-automation
- issue-tracking-ai
- bug-reporting-automation
- collaborative-dev-environments
- team-communication-tech
- task-time-management-ai
- customer-feedback-ai
- cloud-based-dev-tech
- image-stock-platforms-ai
- video-hosting-tech
- social-networks-ai
- professional-social-networks-ai
- dating-apps-tech
---
# Synthetic Search Query Parsing Instruction for Saiga family
This is the version of [EmbeddingStudio/synthetic-search-queries-ru dataset](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-queries-ru) created the way to be aligned with [Saiga-Mistral-7B](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora) instruction format.
## Generation details
We used synthetically generated query parsing instructions:
* We generated lists of possible filters for 72 company categories:
* [Raw version of filters dataset](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-filters-ru-raw)
* [Split by representations](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-filters-ru)
* Select randomly up-to 150 possible combinations (1-3 filters in each combination) of filters, the way each filter's representation appears maximum twice.
* For a given category and combination we [generated](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-queries-ru) with GPT-4 Turbo:
* 2 search queries and theirs parsed version with unstructured parts.
* 2 search queries and theirs parsed version without unstructured part.
* Using filters, queries and parsed version we prepared [27.42k saiga format instruction](https://huggingface.co/datasets/EmbeddingStudio/query-parsing-instructions-saiga)
**Warning:** EmbeddingStudio team aware you that generated queries **weren't enough curated**, and will be curated later once we finish our product market fit stage
### Filters generation details
We used GPT-4 Turbo to generate several possible filters for 72 company categroies. For each filter we also generated some possible representations. For examples filter `Date` can be represented as `dd/mm/YYYY`, `YYYY-mm-dd`, as words `2024 Января 17`, etc.
### Queries generation details
We also used GPT-4 Turbo for generation of search queries and theirs parsed version. Main principles were:
* If passed schema doesn't contain possible filter, do not generate query itself or a possible filter
* If a selected representations combination contains enumeration, so we ask to map values in a search query and a parsed version.
* If a selected representations combination contains pattern, so we ask GPT-4 Turbo to be aligned with a pattern
### Instructions generation details
For the generation instructions we used following ideas:
1. Zero-Shot query parser should be schema agnostic. Cases like `snake_case, CamelCase, http-headers-like` should not ruin generation process.
2. Zero-Shot query parser should be spelling errors insensitive.
3. Training instructions should be in the following order:
* Category
* Schema
* Query
So LLM can be used in the following way: just generate embedding of category -> schema part, so inference will be faster.
We assume, that `schema agnostic` termin means something wider, like to be able to work not only with JSONs, but also with HTML, Markdown, YAML, etc. We are working on it.
So, what was our approach as an attempt to achieve these abilities:
1. For each query we generated a version with a mistake
2. Passed to each parsed version an additional field `Correct`, which contains a corrected version of a search query.
3. For each query we randomly selected and used a case for schema fields and a case for filter and representation names.
4. For each query we additionally generated two instuctions:
* Where did we remove from a provided schema and parsed version one filter
* Where did we remove from a provided schema and parsed version all related filters
**Warning:** EmbeddingStudio team ask you to curate datasets on your own precisely.
## Instruction format
```markdown
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {your_company_category}
#### Schema: ```{filters_schema}```
#### Query: {query}
### Response:
```
Filters schema is JSON-readable line in the format (we highly recommend you to use it):
List of filters (dict):
* Name - name of filter (better to be meaningful).
* Representations - list of possible filter formats (dict):
* Name - name of representation (better to be meaningful).
* Type - python base type (int, float, str, bool).
* Examples - list of examples.
* Enum - if a representation is enumeration, provide a list of possible values, LLM should map parsed value into this list.
* Pattern - if a representation is pattern-like (datetime, regexp, etc.) provide a pattern text in any format.
Example:
```json
[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Понедельник", "Вторник", "пн", "вт", "Среда", "Четверг"], "Enum": ["Понедельник", "Вторник", "Среда", "Четверг", "Пятница", "Суббота", "Воскресенье"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["Январь", "Янв", "Декабрь"], "Enum": ["Январь", "Февраль", "Март", "Апрель", "Май", "Июнь", "Июль", "Август", "Сентябрь", "Октябрь", "Ноябрь", "Декабрь"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
```
As the result, response will be JSON-readable line in the format:
```json
[{"Value": "Corrected search phrase", "Name": "Correct"}, {"Name": "filter-name.representation", "Value": "some-value"}]
```
Field and representation names will be aligned with the provided schema. Example:
```json
[{"Value": "приложение для новогодней акции, дедлайн 31 декабря", "Name": "Correct"}, {"Name": "Project-End-Date.Day-Month-Year", "Value": "31 декабря текущего года"}]
```
Used for fine-tuning `system` phrases:
```python
[
"Эксперт по разбору поисковых запросов",
"Мастер анализа поисковых запросов",
"Первоклассный интерпретатор поисковых запросов",
"Продвинутый декодер поисковых запросов",
"Гений разбора поисковых запросов",
"Волшебник разбора поисковых запросов",
"Непревзойденный механизм разбора запросов",
"Виртуоз разбора поисковых запросов",
"Маэстро разбора запросов",
]
```
Used for fine-tuning `instruction` phrases:
```python
[
"Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.",
"Анализ и структурирование запросов в JSON, поддержание схемы, проверка орфографии.",
"Организация запросов в JSON, соблюдение схемы, верификация орфографии.",
"Декодирование запросов в JSON, следование схеме, исправление орфографии.",
"Разбор запросов в JSON, соответствие схеме, правильное написание.",
"Преобразование запросов в структурированный JSON, соответствие схеме и орфографии.",
"Реструктуризация запросов в JSON, соответствие схеме, точное написание.",
"Перестановка запросов в JSON, строгое соблюдение схемы, поддержание орфографии.",
"Гармонизация запросов с JSON схемой, обеспечение точности написания.",
"Эффективное преобразование запросов в JSON, соответствие схеме, правильная орфография."
]
```
## Train/test splitting principles
As we are trying to fine-tune LLM to follow zero-shot query parsing instructions, so we want to test:
* Ability to work well with unseen domain
* Ability to work well with unseen filters
* Ability to work well with unseen queries
For these purposes we:
1. We put into test split 5 categories, completely separared from train: `Automotive, Educational Institutions, Enterprise Software Development, Payment Processing, Professional Social Networks`.
2. Also out of each appearing in train company categories, we put aside / removed one filter and queries related to it.
3. Selected 5% of other queries and put it into test.
## How to use it
```python
from datasets import load_dataset
queries_dataset = load_dataset('EmbeddingStudio/query-parsing-instructions-saiga')
```
|
adamo1139/basic_economics_questions_ts_test_2 | ---
license: apache-2.0
---
|
adrianhenkel/tokenized-total-512-reduced | ---
dataset_info:
features:
- name: input_id_x
sequence: int8
- name: input_id_y
sequence: int8
splits:
- name: train
num_bytes: 7582970656
num_examples: 17070828
download_size: 4615653058
dataset_size: 7582970656
---
# Dataset Card for "tokenized-total-512-reduced"
This dataset contains truncated tokenized protein sequences and their corresponding 3Di structure as stated in the [Foldseek](https://www.nature.com/articles/s41587-023-01773-0) paper.
Redundancy reduction and data sequence filtering was performed by [Dr. Michael Heinzinger](https://scholar.google.com/citations?user=yXtPl58AAAAJ&hl=en) and [Prof. Dr. Martin Steinegger](https://github.com/martin-steinegger).
The tokenizer used to encode the sequences can be found [here](https://huggingface.co/adrianhenkel/lucid-prot-tokenizer)
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jppgks/twitter-financial-news-sentiment | ---
license: mit
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 1906560
num_examples: 9543
- name: validation
num_bytes: 479540
num_examples: 2388
download_size: 728648
dataset_size: 2386100
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
[zeroshot/twitter-financial-news-sentiment](https://huggingface.co/datasets/zeroshot/twitter-financial-news-sentiment) prepared for LLM fine-tuning
by adding an `instruction` column and mapping the label from numeric to string (`{0:"negative", 1:'positive', 2:'neutral'}`).
[Source](https://github.com/AI4Finance-Foundation/FinGPT/blob/master/fingpt/FinGPT-v3/data/making_data.ipynb)
```python
from datasets import load_dataset
import datasets
from huggingface_hub import notebook_login
notebook_login()
ds = load_dataset('zeroshot/twitter-financial-news-sentiment')
num_to_label = {
0: 'negative',
1: 'positive',
2: 'neutral',
}
instruction = 'What is the sentiment of this tweet? Please choose an answer from {negative/neutral/positive}.'
# Training split
ds_train = ds['train']
ds_train = ds_train.to_pandas()
ds_train['label'] = ds_train['label'].apply(num_to_label.get)
ds_train['instruction'] = instruction
ds_train.columns = ['input', 'output', 'instruction']
ds_train = datasets.Dataset.from_pandas(ds_train)
ds_train.push_to_hub("twitter-financial-news-sentiment")
# Validation split
ds_valid = ds['validation']
ds_valid = ds_valid.to_pandas()
ds_valid['label'] = ds_valid['label'].apply(num_to_label.get)
ds_valid['instruction'] = instruction
ds_valid.columns = ['input', 'output', 'instruction']
ds_valid = datasets.Dataset.from_pandas(ds_valid, split='validation')
ds_valid.push_to_hub("twitter-financial-news-sentiment", split='validation')
```
|
hasanriaz121/reqs | ---
dataset_info:
features:
- name: 'Unnamed: 0'
dtype: int64
- name: requirement_txt
dtype: string
- name: EF
dtype: int64
- name: PE
dtype: int64
- name: PO
dtype: int64
- name: RE
dtype: int64
- name: SE
dtype: int64
- name: US
dtype: int64
- name: X
dtype: int64
splits:
- name: test
num_bytes: 53980
num_examples: 285
- name: train
num_bytes: 431941
num_examples: 2308
- name: validation
num_bytes: 49251
num_examples: 257
download_size: 218916
dataset_size: 535172
---
# Dataset Card for "reqs"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
zhiqiulin/vqascore_ablation | ---
license: mit
---
|
open-llm-leaderboard/details_hon9kon9ize__CantoneseLLMChat-preview20240326 | ---
pretty_name: Evaluation run of hon9kon9ize/CantoneseLLMChat-preview20240326
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [hon9kon9ize/CantoneseLLMChat-preview20240326](https://huggingface.co/hon9kon9ize/CantoneseLLMChat-preview20240326)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 63 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_hon9kon9ize__CantoneseLLMChat-preview20240326\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2024-04-06T21:09:18.139662](https://huggingface.co/datasets/open-llm-leaderboard/details_hon9kon9ize__CantoneseLLMChat-preview20240326/blob/main/results_2024-04-06T21-09-18.139662.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.5852867980696239,\n\
\ \"acc_stderr\": 0.0332442920433603,\n \"acc_norm\": 0.5924742418958416,\n\
\ \"acc_norm_stderr\": 0.03394324011157871,\n \"mc1\": 0.2802937576499388,\n\
\ \"mc1_stderr\": 0.015723139524608763,\n \"mc2\": 0.4186523322493673,\n\
\ \"mc2_stderr\": 0.014508189130743358\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.4854948805460751,\n \"acc_stderr\": 0.01460524108137006,\n\
\ \"acc_norm\": 0.5255972696245734,\n \"acc_norm_stderr\": 0.014592230885298967\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.517625970922127,\n\
\ \"acc_stderr\": 0.004986680048438308,\n \"acc_norm\": 0.6904999004182434,\n\
\ \"acc_norm_stderr\": 0.004613427745209508\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.045604802157206845,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.045604802157206845\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.5259259259259259,\n\
\ \"acc_stderr\": 0.04313531696750575,\n \"acc_norm\": 0.5259259259259259,\n\
\ \"acc_norm_stderr\": 0.04313531696750575\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.6381578947368421,\n \"acc_stderr\": 0.03910525752849724,\n\
\ \"acc_norm\": 0.6381578947368421,\n \"acc_norm_stderr\": 0.03910525752849724\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.63,\n\
\ \"acc_stderr\": 0.04852365870939099,\n \"acc_norm\": 0.63,\n \
\ \"acc_norm_stderr\": 0.04852365870939099\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.660377358490566,\n \"acc_stderr\": 0.029146904747798325,\n\
\ \"acc_norm\": 0.660377358490566,\n \"acc_norm_stderr\": 0.029146904747798325\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.6041666666666666,\n\
\ \"acc_stderr\": 0.04089465449325582,\n \"acc_norm\": 0.6041666666666666,\n\
\ \"acc_norm_stderr\": 0.04089465449325582\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.39,\n \"acc_stderr\": 0.049020713000019756,\n \
\ \"acc_norm\": 0.39,\n \"acc_norm_stderr\": 0.049020713000019756\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"\
acc\": 0.52,\n \"acc_stderr\": 0.050211673156867795,\n \"acc_norm\"\
: 0.52,\n \"acc_norm_stderr\": 0.050211673156867795\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.4,\n \"acc_stderr\": 0.049236596391733084,\n \
\ \"acc_norm\": 0.4,\n \"acc_norm_stderr\": 0.049236596391733084\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.6011560693641619,\n\
\ \"acc_stderr\": 0.037336266553835096,\n \"acc_norm\": 0.6011560693641619,\n\
\ \"acc_norm_stderr\": 0.037336266553835096\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.3431372549019608,\n \"acc_stderr\": 0.04724007352383887,\n\
\ \"acc_norm\": 0.3431372549019608,\n \"acc_norm_stderr\": 0.04724007352383887\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.75,\n \"acc_stderr\": 0.04351941398892446,\n \"acc_norm\": 0.75,\n\
\ \"acc_norm_stderr\": 0.04351941398892446\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.5574468085106383,\n \"acc_stderr\": 0.032469569197899575,\n\
\ \"acc_norm\": 0.5574468085106383,\n \"acc_norm_stderr\": 0.032469569197899575\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.37719298245614036,\n\
\ \"acc_stderr\": 0.04559522141958216,\n \"acc_norm\": 0.37719298245614036,\n\
\ \"acc_norm_stderr\": 0.04559522141958216\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.6068965517241379,\n \"acc_stderr\": 0.0407032901370707,\n\
\ \"acc_norm\": 0.6068965517241379,\n \"acc_norm_stderr\": 0.0407032901370707\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.42063492063492064,\n \"acc_stderr\": 0.025424835086923992,\n \"\
acc_norm\": 0.42063492063492064,\n \"acc_norm_stderr\": 0.025424835086923992\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.38095238095238093,\n\
\ \"acc_stderr\": 0.04343525428949097,\n \"acc_norm\": 0.38095238095238093,\n\
\ \"acc_norm_stderr\": 0.04343525428949097\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.04725815626252605,\n \
\ \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.04725815626252605\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.7483870967741936,\n\
\ \"acc_stderr\": 0.024685979286239976,\n \"acc_norm\": 0.7483870967741936,\n\
\ \"acc_norm_stderr\": 0.024685979286239976\n },\n \"harness|hendrycksTest-high_school_chemistry|5\"\
: {\n \"acc\": 0.43349753694581283,\n \"acc_stderr\": 0.034867317274198714,\n\
\ \"acc_norm\": 0.43349753694581283,\n \"acc_norm_stderr\": 0.034867317274198714\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.57,\n \"acc_stderr\": 0.049756985195624284,\n \"acc_norm\"\
: 0.57,\n \"acc_norm_stderr\": 0.049756985195624284\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.7212121212121212,\n \"acc_stderr\": 0.03501438706296781,\n\
\ \"acc_norm\": 0.7212121212121212,\n \"acc_norm_stderr\": 0.03501438706296781\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.7878787878787878,\n \"acc_stderr\": 0.0291265228345868,\n \"acc_norm\"\
: 0.7878787878787878,\n \"acc_norm_stderr\": 0.0291265228345868\n },\n\
\ \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \
\ \"acc\": 0.7979274611398963,\n \"acc_stderr\": 0.02897908979429673,\n\
\ \"acc_norm\": 0.7979274611398963,\n \"acc_norm_stderr\": 0.02897908979429673\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.5512820512820513,\n \"acc_stderr\": 0.025217315184846482,\n\
\ \"acc_norm\": 0.5512820512820513,\n \"acc_norm_stderr\": 0.025217315184846482\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.25925925925925924,\n \"acc_stderr\": 0.026719240783712166,\n \
\ \"acc_norm\": 0.25925925925925924,\n \"acc_norm_stderr\": 0.026719240783712166\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.6554621848739496,\n \"acc_stderr\": 0.030868682604121626,\n\
\ \"acc_norm\": 0.6554621848739496,\n \"acc_norm_stderr\": 0.030868682604121626\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.37748344370860926,\n \"acc_stderr\": 0.03958027231121569,\n \"\
acc_norm\": 0.37748344370860926,\n \"acc_norm_stderr\": 0.03958027231121569\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.781651376146789,\n \"acc_stderr\": 0.017712600528722724,\n \"\
acc_norm\": 0.781651376146789,\n \"acc_norm_stderr\": 0.017712600528722724\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.49074074074074076,\n \"acc_stderr\": 0.03409386946992699,\n \"\
acc_norm\": 0.49074074074074076,\n \"acc_norm_stderr\": 0.03409386946992699\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.7303921568627451,\n \"acc_stderr\": 0.031145570659486782,\n \"\
acc_norm\": 0.7303921568627451,\n \"acc_norm_stderr\": 0.031145570659486782\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.7257383966244726,\n \"acc_stderr\": 0.029041333510598042,\n \
\ \"acc_norm\": 0.7257383966244726,\n \"acc_norm_stderr\": 0.029041333510598042\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6188340807174888,\n\
\ \"acc_stderr\": 0.03259625118416827,\n \"acc_norm\": 0.6188340807174888,\n\
\ \"acc_norm_stderr\": 0.03259625118416827\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.6412213740458015,\n \"acc_stderr\": 0.04206739313864908,\n\
\ \"acc_norm\": 0.6412213740458015,\n \"acc_norm_stderr\": 0.04206739313864908\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.7107438016528925,\n \"acc_stderr\": 0.04139112727635462,\n \"\
acc_norm\": 0.7107438016528925,\n \"acc_norm_stderr\": 0.04139112727635462\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7685185185185185,\n\
\ \"acc_stderr\": 0.04077494709252627,\n \"acc_norm\": 0.7685185185185185,\n\
\ \"acc_norm_stderr\": 0.04077494709252627\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.7239263803680982,\n \"acc_stderr\": 0.03512385283705046,\n\
\ \"acc_norm\": 0.7239263803680982,\n \"acc_norm_stderr\": 0.03512385283705046\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.4017857142857143,\n\
\ \"acc_stderr\": 0.04653333146973646,\n \"acc_norm\": 0.4017857142857143,\n\
\ \"acc_norm_stderr\": 0.04653333146973646\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.7669902912621359,\n \"acc_stderr\": 0.04185832598928315,\n\
\ \"acc_norm\": 0.7669902912621359,\n \"acc_norm_stderr\": 0.04185832598928315\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8675213675213675,\n\
\ \"acc_stderr\": 0.022209309073165616,\n \"acc_norm\": 0.8675213675213675,\n\
\ \"acc_norm_stderr\": 0.022209309073165616\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.68,\n \"acc_stderr\": 0.04688261722621504,\n \
\ \"acc_norm\": 0.68,\n \"acc_norm_stderr\": 0.04688261722621504\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.7662835249042146,\n\
\ \"acc_stderr\": 0.015133383278988827,\n \"acc_norm\": 0.7662835249042146,\n\
\ \"acc_norm_stderr\": 0.015133383278988827\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.653179190751445,\n \"acc_stderr\": 0.025624723994030457,\n\
\ \"acc_norm\": 0.653179190751445,\n \"acc_norm_stderr\": 0.025624723994030457\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.29608938547486036,\n\
\ \"acc_stderr\": 0.015268677317602274,\n \"acc_norm\": 0.29608938547486036,\n\
\ \"acc_norm_stderr\": 0.015268677317602274\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.673202614379085,\n \"acc_stderr\": 0.026857294663281406,\n\
\ \"acc_norm\": 0.673202614379085,\n \"acc_norm_stderr\": 0.026857294663281406\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.6752411575562701,\n\
\ \"acc_stderr\": 0.026596782287697043,\n \"acc_norm\": 0.6752411575562701,\n\
\ \"acc_norm_stderr\": 0.026596782287697043\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.6296296296296297,\n \"acc_stderr\": 0.026869490744815254,\n\
\ \"acc_norm\": 0.6296296296296297,\n \"acc_norm_stderr\": 0.026869490744815254\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.4397163120567376,\n \"acc_stderr\": 0.02960991207559411,\n \
\ \"acc_norm\": 0.4397163120567376,\n \"acc_norm_stderr\": 0.02960991207559411\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.46088657105606257,\n\
\ \"acc_stderr\": 0.012731102790504526,\n \"acc_norm\": 0.46088657105606257,\n\
\ \"acc_norm_stderr\": 0.012731102790504526\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.5073529411764706,\n \"acc_stderr\": 0.030369552523902173,\n\
\ \"acc_norm\": 0.5073529411764706,\n \"acc_norm_stderr\": 0.030369552523902173\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.5849673202614379,\n \"acc_stderr\": 0.01993362777685742,\n \
\ \"acc_norm\": 0.5849673202614379,\n \"acc_norm_stderr\": 0.01993362777685742\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6545454545454545,\n\
\ \"acc_stderr\": 0.04554619617541054,\n \"acc_norm\": 0.6545454545454545,\n\
\ \"acc_norm_stderr\": 0.04554619617541054\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.7346938775510204,\n \"acc_stderr\": 0.028263889943784593,\n\
\ \"acc_norm\": 0.7346938775510204,\n \"acc_norm_stderr\": 0.028263889943784593\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8009950248756219,\n\
\ \"acc_stderr\": 0.028231365092758406,\n \"acc_norm\": 0.8009950248756219,\n\
\ \"acc_norm_stderr\": 0.028231365092758406\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.85,\n \"acc_stderr\": 0.0358870281282637,\n \
\ \"acc_norm\": 0.85,\n \"acc_norm_stderr\": 0.0358870281282637\n },\n\
\ \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.4397590361445783,\n\
\ \"acc_stderr\": 0.03864139923699121,\n \"acc_norm\": 0.4397590361445783,\n\
\ \"acc_norm_stderr\": 0.03864139923699121\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.7368421052631579,\n \"acc_stderr\": 0.033773102522092056,\n\
\ \"acc_norm\": 0.7368421052631579,\n \"acc_norm_stderr\": 0.033773102522092056\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.2802937576499388,\n\
\ \"mc1_stderr\": 0.015723139524608763,\n \"mc2\": 0.4186523322493673,\n\
\ \"mc2_stderr\": 0.014508189130743358\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.7032359905288083,\n \"acc_stderr\": 0.012839239695202035\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.2562547384382108,\n \
\ \"acc_stderr\": 0.012025145867332844\n }\n}\n```"
repo_url: https://huggingface.co/hon9kon9ize/CantoneseLLMChat-preview20240326
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|arc:challenge|25_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|gsm8k|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hellaswag|10_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-management|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-virology|5_2024-04-06T21-09-18.139662.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-management|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-virology|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|truthfulqa:mc|0_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2024-04-06T21-09-18.139662.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- '**/details_harness|winogrande|5_2024-04-06T21-09-18.139662.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2024-04-06T21-09-18.139662.parquet'
- config_name: results
data_files:
- split: 2024_04_06T21_09_18.139662
path:
- results_2024-04-06T21-09-18.139662.parquet
- split: latest
path:
- results_2024-04-06T21-09-18.139662.parquet
---
# Dataset Card for Evaluation run of hon9kon9ize/CantoneseLLMChat-preview20240326
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [hon9kon9ize/CantoneseLLMChat-preview20240326](https://huggingface.co/hon9kon9ize/CantoneseLLMChat-preview20240326) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_hon9kon9ize__CantoneseLLMChat-preview20240326",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2024-04-06T21:09:18.139662](https://huggingface.co/datasets/open-llm-leaderboard/details_hon9kon9ize__CantoneseLLMChat-preview20240326/blob/main/results_2024-04-06T21-09-18.139662.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.5852867980696239,
"acc_stderr": 0.0332442920433603,
"acc_norm": 0.5924742418958416,
"acc_norm_stderr": 0.03394324011157871,
"mc1": 0.2802937576499388,
"mc1_stderr": 0.015723139524608763,
"mc2": 0.4186523322493673,
"mc2_stderr": 0.014508189130743358
},
"harness|arc:challenge|25": {
"acc": 0.4854948805460751,
"acc_stderr": 0.01460524108137006,
"acc_norm": 0.5255972696245734,
"acc_norm_stderr": 0.014592230885298967
},
"harness|hellaswag|10": {
"acc": 0.517625970922127,
"acc_stderr": 0.004986680048438308,
"acc_norm": 0.6904999004182434,
"acc_norm_stderr": 0.004613427745209508
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.29,
"acc_stderr": 0.045604802157206845,
"acc_norm": 0.29,
"acc_norm_stderr": 0.045604802157206845
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.5259259259259259,
"acc_stderr": 0.04313531696750575,
"acc_norm": 0.5259259259259259,
"acc_norm_stderr": 0.04313531696750575
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.6381578947368421,
"acc_stderr": 0.03910525752849724,
"acc_norm": 0.6381578947368421,
"acc_norm_stderr": 0.03910525752849724
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.63,
"acc_stderr": 0.04852365870939099,
"acc_norm": 0.63,
"acc_norm_stderr": 0.04852365870939099
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.660377358490566,
"acc_stderr": 0.029146904747798325,
"acc_norm": 0.660377358490566,
"acc_norm_stderr": 0.029146904747798325
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.6041666666666666,
"acc_stderr": 0.04089465449325582,
"acc_norm": 0.6041666666666666,
"acc_norm_stderr": 0.04089465449325582
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.39,
"acc_stderr": 0.049020713000019756,
"acc_norm": 0.39,
"acc_norm_stderr": 0.049020713000019756
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.52,
"acc_stderr": 0.050211673156867795,
"acc_norm": 0.52,
"acc_norm_stderr": 0.050211673156867795
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.4,
"acc_stderr": 0.049236596391733084,
"acc_norm": 0.4,
"acc_norm_stderr": 0.049236596391733084
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6011560693641619,
"acc_stderr": 0.037336266553835096,
"acc_norm": 0.6011560693641619,
"acc_norm_stderr": 0.037336266553835096
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.3431372549019608,
"acc_stderr": 0.04724007352383887,
"acc_norm": 0.3431372549019608,
"acc_norm_stderr": 0.04724007352383887
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.75,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.75,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.5574468085106383,
"acc_stderr": 0.032469569197899575,
"acc_norm": 0.5574468085106383,
"acc_norm_stderr": 0.032469569197899575
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.37719298245614036,
"acc_stderr": 0.04559522141958216,
"acc_norm": 0.37719298245614036,
"acc_norm_stderr": 0.04559522141958216
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.6068965517241379,
"acc_stderr": 0.0407032901370707,
"acc_norm": 0.6068965517241379,
"acc_norm_stderr": 0.0407032901370707
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.42063492063492064,
"acc_stderr": 0.025424835086923992,
"acc_norm": 0.42063492063492064,
"acc_norm_stderr": 0.025424835086923992
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.38095238095238093,
"acc_stderr": 0.04343525428949097,
"acc_norm": 0.38095238095238093,
"acc_norm_stderr": 0.04343525428949097
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.33,
"acc_stderr": 0.04725815626252605,
"acc_norm": 0.33,
"acc_norm_stderr": 0.04725815626252605
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.7483870967741936,
"acc_stderr": 0.024685979286239976,
"acc_norm": 0.7483870967741936,
"acc_norm_stderr": 0.024685979286239976
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.43349753694581283,
"acc_stderr": 0.034867317274198714,
"acc_norm": 0.43349753694581283,
"acc_norm_stderr": 0.034867317274198714
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.57,
"acc_stderr": 0.049756985195624284,
"acc_norm": 0.57,
"acc_norm_stderr": 0.049756985195624284
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.7212121212121212,
"acc_stderr": 0.03501438706296781,
"acc_norm": 0.7212121212121212,
"acc_norm_stderr": 0.03501438706296781
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.7878787878787878,
"acc_stderr": 0.0291265228345868,
"acc_norm": 0.7878787878787878,
"acc_norm_stderr": 0.0291265228345868
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.7979274611398963,
"acc_stderr": 0.02897908979429673,
"acc_norm": 0.7979274611398963,
"acc_norm_stderr": 0.02897908979429673
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.5512820512820513,
"acc_stderr": 0.025217315184846482,
"acc_norm": 0.5512820512820513,
"acc_norm_stderr": 0.025217315184846482
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.25925925925925924,
"acc_stderr": 0.026719240783712166,
"acc_norm": 0.25925925925925924,
"acc_norm_stderr": 0.026719240783712166
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.6554621848739496,
"acc_stderr": 0.030868682604121626,
"acc_norm": 0.6554621848739496,
"acc_norm_stderr": 0.030868682604121626
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.37748344370860926,
"acc_stderr": 0.03958027231121569,
"acc_norm": 0.37748344370860926,
"acc_norm_stderr": 0.03958027231121569
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.781651376146789,
"acc_stderr": 0.017712600528722724,
"acc_norm": 0.781651376146789,
"acc_norm_stderr": 0.017712600528722724
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.49074074074074076,
"acc_stderr": 0.03409386946992699,
"acc_norm": 0.49074074074074076,
"acc_norm_stderr": 0.03409386946992699
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.7303921568627451,
"acc_stderr": 0.031145570659486782,
"acc_norm": 0.7303921568627451,
"acc_norm_stderr": 0.031145570659486782
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.7257383966244726,
"acc_stderr": 0.029041333510598042,
"acc_norm": 0.7257383966244726,
"acc_norm_stderr": 0.029041333510598042
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6188340807174888,
"acc_stderr": 0.03259625118416827,
"acc_norm": 0.6188340807174888,
"acc_norm_stderr": 0.03259625118416827
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.6412213740458015,
"acc_stderr": 0.04206739313864908,
"acc_norm": 0.6412213740458015,
"acc_norm_stderr": 0.04206739313864908
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7107438016528925,
"acc_stderr": 0.04139112727635462,
"acc_norm": 0.7107438016528925,
"acc_norm_stderr": 0.04139112727635462
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7685185185185185,
"acc_stderr": 0.04077494709252627,
"acc_norm": 0.7685185185185185,
"acc_norm_stderr": 0.04077494709252627
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7239263803680982,
"acc_stderr": 0.03512385283705046,
"acc_norm": 0.7239263803680982,
"acc_norm_stderr": 0.03512385283705046
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.4017857142857143,
"acc_stderr": 0.04653333146973646,
"acc_norm": 0.4017857142857143,
"acc_norm_stderr": 0.04653333146973646
},
"harness|hendrycksTest-management|5": {
"acc": 0.7669902912621359,
"acc_stderr": 0.04185832598928315,
"acc_norm": 0.7669902912621359,
"acc_norm_stderr": 0.04185832598928315
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8675213675213675,
"acc_stderr": 0.022209309073165616,
"acc_norm": 0.8675213675213675,
"acc_norm_stderr": 0.022209309073165616
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.68,
"acc_stderr": 0.04688261722621504,
"acc_norm": 0.68,
"acc_norm_stderr": 0.04688261722621504
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.7662835249042146,
"acc_stderr": 0.015133383278988827,
"acc_norm": 0.7662835249042146,
"acc_norm_stderr": 0.015133383278988827
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.653179190751445,
"acc_stderr": 0.025624723994030457,
"acc_norm": 0.653179190751445,
"acc_norm_stderr": 0.025624723994030457
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.29608938547486036,
"acc_stderr": 0.015268677317602274,
"acc_norm": 0.29608938547486036,
"acc_norm_stderr": 0.015268677317602274
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.673202614379085,
"acc_stderr": 0.026857294663281406,
"acc_norm": 0.673202614379085,
"acc_norm_stderr": 0.026857294663281406
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.6752411575562701,
"acc_stderr": 0.026596782287697043,
"acc_norm": 0.6752411575562701,
"acc_norm_stderr": 0.026596782287697043
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.6296296296296297,
"acc_stderr": 0.026869490744815254,
"acc_norm": 0.6296296296296297,
"acc_norm_stderr": 0.026869490744815254
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.4397163120567376,
"acc_stderr": 0.02960991207559411,
"acc_norm": 0.4397163120567376,
"acc_norm_stderr": 0.02960991207559411
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.46088657105606257,
"acc_stderr": 0.012731102790504526,
"acc_norm": 0.46088657105606257,
"acc_norm_stderr": 0.012731102790504526
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.5073529411764706,
"acc_stderr": 0.030369552523902173,
"acc_norm": 0.5073529411764706,
"acc_norm_stderr": 0.030369552523902173
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.5849673202614379,
"acc_stderr": 0.01993362777685742,
"acc_norm": 0.5849673202614379,
"acc_norm_stderr": 0.01993362777685742
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6545454545454545,
"acc_stderr": 0.04554619617541054,
"acc_norm": 0.6545454545454545,
"acc_norm_stderr": 0.04554619617541054
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7346938775510204,
"acc_stderr": 0.028263889943784593,
"acc_norm": 0.7346938775510204,
"acc_norm_stderr": 0.028263889943784593
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8009950248756219,
"acc_stderr": 0.028231365092758406,
"acc_norm": 0.8009950248756219,
"acc_norm_stderr": 0.028231365092758406
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.85,
"acc_stderr": 0.0358870281282637,
"acc_norm": 0.85,
"acc_norm_stderr": 0.0358870281282637
},
"harness|hendrycksTest-virology|5": {
"acc": 0.4397590361445783,
"acc_stderr": 0.03864139923699121,
"acc_norm": 0.4397590361445783,
"acc_norm_stderr": 0.03864139923699121
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.7368421052631579,
"acc_stderr": 0.033773102522092056,
"acc_norm": 0.7368421052631579,
"acc_norm_stderr": 0.033773102522092056
},
"harness|truthfulqa:mc|0": {
"mc1": 0.2802937576499388,
"mc1_stderr": 0.015723139524608763,
"mc2": 0.4186523322493673,
"mc2_stderr": 0.014508189130743358
},
"harness|winogrande|5": {
"acc": 0.7032359905288083,
"acc_stderr": 0.012839239695202035
},
"harness|gsm8k|5": {
"acc": 0.2562547384382108,
"acc_stderr": 0.012025145867332844
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] |
JLB-JLB/seizure_eeg_dev | ---
dataset_info:
features:
- name: image
dtype: image
- name: epoch
dtype: int64
- name: label
dtype:
class_label:
names:
'0': bckg
'1': No Event
'2': seiz
splits:
- name: train
num_bytes: 3322082528.975
num_examples: 114035
download_size: 3418833182
dataset_size: 3322082528.975
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "seizure_eeg_dev"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
jellyChiru/SParC | ---
license: cc-by-sa-4.0
---
@InProceedings{Yu&al.19,
title = {SParC: Cross-Domain Semantic Parsing in Context},
author = {Tao Yu and Rui Zhang and Michihiro Yasunaga and Yi Chern Tan and Xi Victoria Lin and Suyi Li and Heyang Er, Irene Li and Bo Pang and Tao Chen and Emily Ji and Shreya Dixit and David Proctor and Sungrok Shim and Jonathan Kraft, Vincent Zhang and Caiming Xiong and Richard Socher and Dragomir Radev},
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year = {2019},
address = {Florence, Italy},
publisher = {Association for Computational Linguistics}
}
@inproceedings{Yu&al.18c,
title = {Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task},
author = {Tao Yu and Rui Zhang and Kai Yang and Michihiro Yasunaga and Dongxu Wang and Zifan Li and James Ma and Irene Li and Qingning Yao and Shanelle Roman and Zilin Zhang and Dragomir Radev}
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
address = "Brussels, Belgium",
publisher = "Association for Computational Linguistics",
year = 2018
}
Reference links
SParC task link: https://yale-lily.github.io/sparc
SParC Github page: https://github.com/taoyds/sparc
Spider task link: https://yale-lily.github.io/spider
Spider Github page: https://github.com/taoyds/spider |
DBQ/Saint.Laurent.Product.prices.Hong.Kong | ---
annotations_creators:
- other
language_creators:
- other
language:
- en
license:
- unknown
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text-classification
- image-classification
- feature-extraction
- image-segmentation
- image-to-image
- image-to-text
- object-detection
- summarization
- zero-shot-image-classification
pretty_name: Hong Kong - Saint Laurent - Product-level price list
tags:
- webscraping
- ecommerce
- Saint Laurent
- fashion
- fashion product
- image
- fashion image
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: website_name
dtype: string
- name: competence_date
dtype: string
- name: country_code
dtype: string
- name: currency_code
dtype: string
- name: brand
dtype: string
- name: category1_code
dtype: string
- name: category2_code
dtype: string
- name: category3_code
dtype: string
- name: product_code
dtype: string
- name: title
dtype: string
- name: itemurl
dtype: string
- name: imageurl
dtype: string
- name: full_price
dtype: float64
- name: price
dtype: float64
- name: full_price_eur
dtype: float64
- name: price_eur
dtype: float64
- name: flg_discount
dtype: int64
splits:
- name: train
num_bytes: 1218887
num_examples: 3021
download_size: 378822
dataset_size: 1218887
---
# Saint Laurent web scraped data
## About the website
Saint Laurent is a renowned player in the highly competitive and evolving **luxury fashion industry** in the Asia Pacific region, with a significant presence in **Hong Kong**. Its operations span retail stores, online platforms, and an expansive assortment of apparel. The rise of digital has made **ecommerce** pivotal in reaching the ever-growing customer base in this region. Our dataset provides detailed **Ecommerce product-list page (PLP) data** on Saint Laurents extensive offerings in Hong Kong, casting light on crucial aspects like price points, product types, customer preferences, etc. Visit the [Saint Laurent main page](https://www.databoutique.com/buy-data-list-subset/Saint Laurent web scraped data/r/recnKICNKyOd6cQx6) for insights on other geographies or data types.
## Link to **dataset**
[Hong Kong - Saint Laurent - Product-level price list dataset](https://www.databoutique.com/buy-data-page/Saint%20Laurent%20Product-prices%20Hong%20Kong/r/recgTnY6ES9HXG9EP)
|
Alignment-Lab-AI/Lawyer-Instruct | ---
license: apache-2.0
---
# Dataset Card for "Lawyer-Instruct"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
## Dataset Description
### Dataset Summary
Lawyer-Instruct is a conversational dataset primarily in English, reformatted from the original LawyerChat dataset. It contains legal dialogue scenarios reshaped into an instruction, input, and expected output format. This reshaped dataset is ideal for supervised dialogue model training.
Dataset generated in part by dang/futures
### Supported Tasks and Leaderboards
- `dialogue-modeling`: The dataset can be used to train a model for dialogue understanding and response generation based on given instruction. Performance can be evaluated based on dialogue understanding and the quality of the generated responses.
- There is no official leaderboard associated with this dataset at this time.
### Languages
The text in the dataset is in English.
## Dataset Structure
### Data Instances
An instance in the Lawyer-Instruct dataset represents a dialogue instruction and its corresponding output. Example:
```json
{
"instruction": "What are the possible legal consequences of not paying taxes?",
"input": "",
"output": "There can be several legal consequences, ranging from fines to imprisonment..."
}
```
### Data Fields
- `instruction`: a string representing the client's question or statement in the dialogue, serving as the input for dialogue model training.
- `input`:
- `output`: a string representing the legal professional's response.
### Data Splits
This dataset does not have a standard split. Users should carefully consider how they wish to split the data for training, validation, and testing purposes.
|
fighterhitx/test | ---
license: cc
---
|
atgarcia/trainDataset2 | ---
dataset_info:
features:
- name: text
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: emg
sequence:
sequence: float64
splits:
- name: train
num_bytes: 790257057
num_examples: 548
download_size: 298256642
dataset_size: 790257057
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Mitsuki-Sakamoto/alpaca_farm-deberta-re-pref-64-_fil_self_160m_bo16_2_mix_50_kl_0.1_prm_160m_thr_0.0_seed_3 | ---
dataset_info:
config_name: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: preference
dtype: int64
- name: output_1
dtype: string
- name: output_2
dtype: string
- name: reward_model_prompt_format
dtype: string
- name: gen_prompt_format
dtype: string
- name: gen_kwargs
struct:
- name: do_sample
dtype: bool
- name: max_new_tokens
dtype: int64
- name: pad_token_id
dtype: int64
- name: top_k
dtype: int64
- name: top_p
dtype: float64
- name: reward_1
dtype: float64
- name: reward_2
dtype: float64
- name: n_samples
dtype: int64
- name: reject_select
dtype: string
- name: index
dtype: int64
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: filtered_epoch
dtype: int64
- name: gen_reward
dtype: float64
- name: gen_response
dtype: string
splits:
- name: epoch_0
num_bytes: 43778450
num_examples: 18928
- name: epoch_1
num_bytes: 44340411
num_examples: 18928
- name: epoch_2
num_bytes: 44412719
num_examples: 18928
- name: epoch_3
num_bytes: 44443289
num_examples: 18928
- name: epoch_4
num_bytes: 44449016
num_examples: 18928
- name: epoch_5
num_bytes: 44446506
num_examples: 18928
- name: epoch_6
num_bytes: 44440017
num_examples: 18928
- name: epoch_7
num_bytes: 44437607
num_examples: 18928
- name: epoch_8
num_bytes: 44433764
num_examples: 18928
- name: epoch_9
num_bytes: 44430532
num_examples: 18928
- name: epoch_10
num_bytes: 44428837
num_examples: 18928
- name: epoch_11
num_bytes: 44427805
num_examples: 18928
- name: epoch_12
num_bytes: 44428796
num_examples: 18928
- name: epoch_13
num_bytes: 44429411
num_examples: 18928
- name: epoch_14
num_bytes: 44429070
num_examples: 18928
- name: epoch_15
num_bytes: 44429063
num_examples: 18928
- name: epoch_16
num_bytes: 44427545
num_examples: 18928
- name: epoch_17
num_bytes: 44428693
num_examples: 18928
- name: epoch_18
num_bytes: 44428068
num_examples: 18928
- name: epoch_19
num_bytes: 44428456
num_examples: 18928
- name: epoch_20
num_bytes: 44427070
num_examples: 18928
- name: epoch_21
num_bytes: 44427869
num_examples: 18928
- name: epoch_22
num_bytes: 44428874
num_examples: 18928
- name: epoch_23
num_bytes: 44429224
num_examples: 18928
- name: epoch_24
num_bytes: 44428269
num_examples: 18928
- name: epoch_25
num_bytes: 44428697
num_examples: 18928
- name: epoch_26
num_bytes: 44428907
num_examples: 18928
- name: epoch_27
num_bytes: 44429168
num_examples: 18928
- name: epoch_28
num_bytes: 44428217
num_examples: 18928
- name: epoch_29
num_bytes: 44428593
num_examples: 18928
download_size: 701248295
dataset_size: 1332182943
configs:
- config_name: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1
data_files:
- split: epoch_0
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_0-*
- split: epoch_1
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_1-*
- split: epoch_2
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_2-*
- split: epoch_3
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_3-*
- split: epoch_4
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_4-*
- split: epoch_5
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_5-*
- split: epoch_6
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_6-*
- split: epoch_7
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_7-*
- split: epoch_8
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_8-*
- split: epoch_9
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_9-*
- split: epoch_10
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_10-*
- split: epoch_11
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_11-*
- split: epoch_12
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_12-*
- split: epoch_13
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_13-*
- split: epoch_14
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_14-*
- split: epoch_15
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_15-*
- split: epoch_16
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_16-*
- split: epoch_17
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_17-*
- split: epoch_18
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_18-*
- split: epoch_19
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_19-*
- split: epoch_20
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_20-*
- split: epoch_21
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_21-*
- split: epoch_22
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_22-*
- split: epoch_23
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_23-*
- split: epoch_24
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_24-*
- split: epoch_25
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_25-*
- split: epoch_26
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_26-*
- split: epoch_27
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_27-*
- split: epoch_28
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_28-*
- split: epoch_29
path: alpaca_instructions-pythia_160m_alpaca_farm_instructions_sft_constant_pa_seed_1/epoch_29-*
---
|
liuyanchen1015/MULTI_VALUE_mnli_drop_copula_be_NP | ---
dataset_info:
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: score
dtype: int64
splits:
- name: dev_matched
num_bytes: 202625
num_examples: 922
- name: dev_mismatched
num_bytes: 189447
num_examples: 856
- name: test_matched
num_bytes: 209036
num_examples: 976
- name: test_mismatched
num_bytes: 189459
num_examples: 830
- name: train
num_bytes: 8707451
num_examples: 39759
download_size: 6104601
dataset_size: 9498018
---
# Dataset Card for "MULTI_VALUE_mnli_drop_copula_be_NP"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CarlosMorales/news_bbc_international_conflicts | ---
dataset_info:
features:
- name: conflict
dtype: string
- name: title
dtype: string
- name: published_date
dtype: string
- name: description
dtype: string
- name: section
dtype: string
- name: content
dtype: string
- name: link
dtype: string
- name: Name
dtype: string
- name: Representation
sequence: string
- name: Top_n_words
dtype: string
- name: Representative_document
dtype: bool
splits:
- name: train
num_bytes: 45095
num_examples: 23
download_size: 39726
dataset_size: 45095
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
magiccpp/mom | ---
license: mit
---
|
TREC-AToMiC/TREC-2023-Text-to-Image | ---
dataset_info:
features:
- name: text_id
dtype: string
- name: page_url
dtype: string
- name: page_title
dtype: string
- name: section_title
dtype: string
- name: context_page_description
dtype: string
- name: context_section_description
dtype: string
- name: media
sequence: string
- name: hierachy
sequence: string
- name: category
sequence: string
- name: source_id
dtype: string
splits:
- name: train
num_bytes: 402439.0669364712
num_examples: 200
download_size: 506239
dataset_size: 402439.0669364712
---
# Dataset Card for "TREC-2023-Text-to-Image"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Will-uob/musiccaps-spectrogram-labels-subset | ---
license: gpl-3.0
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 253769651.828
num_examples: 1964
download_size: 253013108
dataset_size: 253769651.828
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Seanxh/twitter_dataset_1713189126 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 34627
num_examples: 78
download_size: 17893
dataset_size: 34627
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pythainlp/thai-it-books | ---
language:
- th
license: cc-by-3.0
task_categories:
- text-generation
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
- name: src
dtype: string
- name: license
dtype: string
splits:
- name: train
num_bytes: 1358018
num_examples: 7
download_size: 515544
dataset_size: 1358018
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- book
---
# Thai IT books
This dataset collects Thai IT books that are the open access books.
license: cc-by-3.0 |
CyberHarem/tsuchiya_ako_idolmastercinderellagirls | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of tsuchiya_ako/土屋亜子 (THE iDOLM@STER: Cinderella Girls)
This is the dataset of tsuchiya_ako/土屋亜子 (THE iDOLM@STER: Cinderella Girls), containing 57 images and their tags.
The core tags of this character are `brown_hair, glasses, short_hair, hair_ornament, green_eyes, ahoge, hairclip, mole, mole_under_mouth, breasts`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:----------|:----------------------------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 57 | 49.67 MiB | [Download](https://huggingface.co/datasets/CyberHarem/tsuchiya_ako_idolmastercinderellagirls/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 57 | 38.19 MiB | [Download](https://huggingface.co/datasets/CyberHarem/tsuchiya_ako_idolmastercinderellagirls/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 114 | 69.17 MiB | [Download](https://huggingface.co/datasets/CyberHarem/tsuchiya_ako_idolmastercinderellagirls/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 57 | 46.56 MiB | [Download](https://huggingface.co/datasets/CyberHarem/tsuchiya_ako_idolmastercinderellagirls/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 114 | 82.96 MiB | [Download](https://huggingface.co/datasets/CyberHarem/tsuchiya_ako_idolmastercinderellagirls/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/tsuchiya_ako_idolmastercinderellagirls',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 11 |  |  |  |  |  | 1girl, solo, midriff, navel, skirt, thighhighs, brown-framed_eyewear, open_mouth, :d, belt, card_(medium), character_name, orange_background, sun_symbol |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | solo | midriff | navel | skirt | thighhighs | brown-framed_eyewear | open_mouth | :d | belt | card_(medium) | character_name | orange_background | sun_symbol |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------|:----------|:--------|:--------|:-------------|:-----------------------|:-------------|:-----|:-------|:----------------|:-----------------|:--------------------|:-------------|
| 0 | 11 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
joey234/mmlu-high_school_macroeconomics-original-neg-prepend | ---
dataset_info:
features:
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: neg_prompt
dtype: string
splits:
- name: test
num_bytes: 14807
num_examples: 34
download_size: 12519
dataset_size: 14807
---
# Dataset Card for "mmlu-high_school_macroeconomics-original-neg-prepend"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/ns2000_girlsfrontline | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of ns2000/NS2000/NS2000 (Girls' Frontline)
This is the dataset of ns2000/NS2000/NS2000 (Girls' Frontline), containing 13 images and their tags.
The core tags of this character are `animal_ears, breasts, dark-skinned_female, dark_skin, rabbit_ears, red_eyes, large_breasts, long_hair, white_hair, bangs, grey_hair`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:----------|:-----------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 13 | 13.49 MiB | [Download](https://huggingface.co/datasets/CyberHarem/ns2000_girlsfrontline/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 13 | 8.37 MiB | [Download](https://huggingface.co/datasets/CyberHarem/ns2000_girlsfrontline/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 28 | 16.43 MiB | [Download](https://huggingface.co/datasets/CyberHarem/ns2000_girlsfrontline/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 13 | 12.33 MiB | [Download](https://huggingface.co/datasets/CyberHarem/ns2000_girlsfrontline/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 28 | 21.36 MiB | [Download](https://huggingface.co/datasets/CyberHarem/ns2000_girlsfrontline/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/ns2000_girlsfrontline',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:-------------------------------------------------------------------------------------------------------------------------------|
| 0 | 13 |  |  |  |  |  | 1girl, solo, navel, cleavage, looking_at_viewer, simple_background, open_mouth, smile, white_background, blush, gloves, shorts |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | solo | navel | cleavage | looking_at_viewer | simple_background | open_mouth | smile | white_background | blush | gloves | shorts |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:-------|:--------|:-----------|:--------------------|:--------------------|:-------------|:--------|:-------------------|:--------|:---------|:---------|
| 0 | 13 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X |
|
BevenRozario/jobdesc_3k_v1 | ---
dataset_info:
features:
- name: Instruction
dtype: string
- name: Response
dtype: string
splits:
- name: train_dataset
num_bytes: 8140016.7
num_examples: 4500
- name: eval_dataset
num_bytes: 904446.3
num_examples: 500
download_size: 2283111
dataset_size: 9044463.0
configs:
- config_name: default
data_files:
- split: train_dataset
path: data/train_dataset-*
- split: eval_dataset
path: data/eval_dataset-*
---
|
DeliberatorArchiver/hls_streaming_media | ---
viewer: false
--- |
technorahmon/Interpretation-of-dreams | ---
license: mit
---
|
Lineins/Ru | ---
license: openrail
---
|
BangumiBase/euphoria | ---
license: mit
tags:
- art
size_categories:
- 1K<n<10K
---
# Bangumi Image Base of Euphoria
This is the image base of bangumi Euphoria, we detected 11 characters, 1263 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 250 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 151 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 120 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 142 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 89 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 166 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 44 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 44 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 17 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 47 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 193 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
EhsanElahi/rao | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 17250997.0
num_examples: 23
download_size: 17228943
dataset_size: 17250997.0
---
# Dataset Card for "rao"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
qgiaohc/twitter_dataset_1713151986 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tweet_content
dtype: string
- name: user_name
dtype: string
- name: user_id
dtype: string
- name: created_at
dtype: string
- name: url
dtype: string
- name: favourite_count
dtype: int64
- name: scraped_at
dtype: string
- name: image_urls
dtype: string
splits:
- name: train
num_bytes: 22404
num_examples: 51
download_size: 11715
dataset_size: 22404
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
KyonBS/Nishikata-TakagiSan | ---
license: openrail
---
|
Mathoctopus/MSVAMP | ---
license: apache-2.0
task_categories:
- text-generation
language:
- bn
- zh
- en
- fr
- de
- ja
- ru
- es
- sw
- th
size_categories:
- 1K<n<10K
configs:
- config_name: bn
data_files:
- split: test
path: test_Bengali.json
- config_name: zh
data_files:
- split: test
path: test_Chinese.json
- config_name: en
data_files:
- split: test
path: test_English.json
- config_name: fr
data_files:
- split: test
path: test_French.json
- config_name: de
data_files:
- split: test
path: test_German.json
- config_name: ja
data_files:
- split: test
path: test_Japanese.json
- config_name: ru
data_files:
- split: test
path: test_Russian.json
- config_name: es
data_files:
- split: test
path: test_Spanish.json
- config_name: sw
data_files:
- split: test
path: test_Swahili.json
- config_name: th
data_files:
- split: test
path: test_Thai.json
--- |
oza75/bambara-tts | ---
language:
- bm
- fr
license: cc-by-sa-4.0
task_categories:
- text-to-speech
dataset_info:
- config_name: default
features:
- name: audio
dtype:
audio:
sampling_rate: 22050
- name: bambara
dtype: string
- name: french
dtype: string
- name: duration
dtype: float64
- name: speaker_embeddings
sequence: float32
- name: speaker_id
dtype: int32
splits:
- name: train
num_bytes: 855981233.8553231
num_examples: 4430
download_size: 590736972
dataset_size: 855981233.8553231
- config_name: denoised
features:
- name: audio
dtype:
audio:
sampling_rate: 22050
- name: bambara
dtype: string
- name: french
dtype: string
- name: duration
dtype: float64
- name: speaker_embeddings
sequence: float32
- name: speaker_id
dtype: int32
splits:
- name: train
num_bytes: 1250533816.25
num_examples: 4430
download_size: 1160807299
dataset_size: 1250533816.25
- config_name: enhanced
features:
- name: audio
dtype:
audio:
sampling_rate: 22050
- name: bambara
dtype: string
- name: french
dtype: string
- name: duration
dtype: float64
- name: speaker_embeddings
sequence: float32
- name: speaker_id
dtype: int32
splits:
- name: train
num_bytes: 1250533816.1
num_examples: 4430
download_size: 1093970716
dataset_size: 1250533816.1
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- config_name: denoised
data_files:
- split: train
path: denoised/train-*
- config_name: enhanced
data_files:
- split: train
path: enhanced/train-*
---
# Overview
## Project
This dataset is part of a larger initiative dedicated to enabling Bambara speakers to access global knowledge without language barriers.
Our goal is to eliminate the need for Bambara speakers to learn a secondary language before they can acquire new information or skills.
By providing a robust dataset for Text-to-Speech (TTS) applications, we aim to support the creation of tools for bambara language, thus democratizing access to knowledge.
## Bambara Language
Bambara, also known as Bamanankan, is a Mande language spoken primarily in Mali by millions of people as a mother tongue and second language.
It serves as a lingua franca in Mali and is also spoken in neighboring countries (Burkina Faso, Ivory Coast etc...). Bambara is written in both the Latin script and N'Ko script,
and it has a rich oral tradition that is integral to Malian culture.
# Dataset
## Source
The dataset was meticulously compiled with a focus on quality and utility. The source materials were obtained from a rich Bambara content available at [Mali Pense](https://www.mali-pense.net/).
Audio recordings were carefully processed to improve clarity and usability.
## Processing
Noise reduction was a critical step in preparing the audio data to ensure high-quality samples. This was achieved using **DeepFilterNet**,
an advanced noise suppression algorithm accessible on GitHub [here](https://github.com/Rikorose/DeepFilterNet). The resulting clean audio provides clear and usable samples for TTS development.
To enhance the dataset's applicability in personalized TTS systems, speaker embeddings were generated using the [pyannote/embedding](https://huggingface.co/pyannote/embedding) model from Huggingface.
This embedding captures unique speaker characteristics, allowing for speaker identification and differentiation in TTS applications.
## Clustering
Speaker embeddings were clustered using the [HDBSCAN](https://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html) algorithm *(via the hdbscan pip3 package)* to infer speaker identities within the dataset.
While this clustering offers a basis for differentiating speakers, it is not **infallible**. Users are encouraged **to use the provided embeddings to refine** or generate their own speaker identification as needed for their specific applications.
## Dataset Structure
### Data Fields
The dataset includes the following fields:
- audio: This field contains the file path (loaded via huggingface datasets library) to the audio recording of spoken Bambara text. Each audio file corresponds to a single utterance of spoken text.
- bambara: A string field that contains the transcription of the spoken text in the Bambara language. This transcription corresponds to the content of the audio file.
- french: A string field with the French translation of the Bambara text. This provides a parallel corpus for those interested in bilingual applications.
- duration: A float64 field that represents the duration of the audio clip in seconds. It gives an indication of the length of the spoken utterance.
- speaker_embeddings: A sequence field that holds the numerical vector representing the speaker's voice characteristics. This embedding can be used for speaker identification or distinguishing between different speakers in the dataset.
- speaker_id: An int32 field that indicates the cluster ID assigned to the speaker based on the HDBSCAN algorithm. This ID helps to identify all utterances from the same speaker across the dataset.
### Data Instances
An example from the dataset looks like this:
```json
{
"audio": Audio({"array": [-2.5, 35...], "path": "path/to/audio.wav", "sampling_rate": 48000}),
"bambara": "Jigi, i bolo degunnen don wa ?",
"french": "Jigi, es-tu occupé ?",
"duration": 2.646,
"speaker_embeddings": [-2.564516305923462, -20.928389595581055, ...],
"speaker_id": 5
}
```
### Usage
The dataset is designed for a variety of uses in the field of speech technology, including:
- **Text-to-Speech Synthesis:** Researchers and developers can utilize this dataset to train and fine-tune TTS models capable of converting Bambara text into natural-sounding speech.
- **Speech Recognition:** The audio samples can aid in the development of Automatic Speech Recognition (ASR) systems that transcribe Bambara speech.
- **Linguistic Research:** Linguists can explore the phonetic and prosodic features of Bambara speech.
- **Educational Content Creation:** Educators and content creators can develop voice-enabled educational resources in Bambara.
# Acknowledgements
This project was made possible through the contributions of various individuals and organizations dedicated to preserving and promoting the **Bambara language and culture**.
We extend our gratitude to [Mali Pense](https://www.mali-pense.net/) for providing the text sources, [Rikorose/DeepFilterNet](https://github.com/Rikorose/DeepFilterNet) for the noise reduction technology, and [Pyannote](https://huggingface.co/pyannote) for the speaker embedding model.
# Other Bambara Dataset
- Bambara French Parallel dataset: https://www.kaggle.com/datasets/ozaresearch1/bambara-french-parallel-dataset
- Corpus Bambara de reference: http://cormand.huma-num.fr/index.html
- Dictionnaries & other resources: https://www.lexilogos.com/bambara_dictionnaire.htm
|
BigTMiami/amazon_split_25M_reviews_20_percent_condensed | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 5752370244
num_examples: 862683
- name: validation
num_bytes: 55744480
num_examples: 8360
download_size: 1851039245
dataset_size: 5808114724
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
multi-train/downloaded_notebooks | ---
annotations_creators: []
language_creators:
- downloaded
language:
- code
license:
- other
multilinguality:
- multilingual
pretty_name: downloaded-notebooks
size_categories:
- unknown
source_datasets: []
task_categories:
- text-generation
extra_gated_prompt: >-
## Terms of Use for downloaded notebooks
We should adhere to the license
extra_gated_fields:
Email: text
I have read the License and agree with its terms: checkbox
--- |
davidkim205/kollm-comparision | ---
license: apache-2.0
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
sequence: string
- name: src
dtype: string
splits:
- name: train
num_bytes: 123837782
num_examples: 116166
download_size: 66685801
dataset_size: 123837782
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- text-generation
language:
- ko
---
# davidkim205/kollm-comparision
[nox-solar-10.7b-v4](https://huggingface.co/davidkim205/nox-solar-10.7b-v4)에 사용된 dpo 데이터셋으로 huggingface에 공개된 데이터와 twodigit에서 제작한 데이터로 구성되어 있습니다.
[nox github](https://github.com/davidkim205/nox)에서 사용가능하도록 comparision 형식으로 되어 있습니다.
## 공개 데이터셋
| Source | 설명 | 원본 URL |
|---|---|---|
| kobest_boolq | 한국어 벤치마크 KoBEST | https://huggingface.co/datasets/skt/kobest_v1 |
| kobest_copa | 한국어 벤치마크 KoBEST | https://huggingface.co/datasets/skt/kobest_v1 |
| kobest_hellaswag | 한국어 벤치마크 KoBEST | https://huggingface.co/datasets/skt/kobest_v1 |
| kobest_sentineg | 한국어 벤치마크 KoBEST | https://huggingface.co/datasets/skt/kobest_v1 |
| kobest_wic | 한국어 벤치마크 KoBEST | https://huggingface.co/datasets/skt/kobest_v1 |
| kollm_belebele | 다국어 MRC 벤치마크 Belebele의 한국어 subset | https://huggingface.co/datasets/facebook/belebele/blob/main/data/kor_Hang.jsonl |
| kollm_csatqa | 한국어 대학수학능력시험 질답 데이터셋 | https://huggingface.co/datasets/HAERAE-HUB/csatqa |
| kollm_paws-x | PAWS-X 데이터셋의 영어-한국어 subset | https://huggingface.co/datasets/paws-x/viewer/ko |
| Orca-DPO-Pairs-KO | Intel/orca_dpo_pairs의 한글 번역 데이터셋 | https://huggingface.co/datasets/Ja-ck/Orca-DPO-Pairs-KO |
| orca_dpo_pairs_ko | Intel/orca_dpo_pairs의 한글 번역 데이터셋 | https://huggingface.co/datasets/mncai/orca_dpo_pairs_ko |
| X-TruthfulQA_en_zh_ko_it_es | 다국어 벤치마크 X-TruthfulQA 의 한국어 subset | https://huggingface.co/datasets/zhihz0535/X-TruthfulQA_en_zh_ko_it_es |
| Yi-Ko-DPO-Orca-DPO-Pairs | Intel/orca_dpo_pairs의 한글 번역 데이터셋 | https://huggingface.co/datasets/We-Want-GPU/Yi-Ko-DPO-Orca-DPO-Pairs |
## twodigit 내부 데이터셋
| Source | 설명 | 원본 URL |
|---|---|---|
| news_common_gen | 뉴스 기반 common gen 형식 데이터셋 | https://huggingface.co/datasets/twodigit/news_common_gen |
aihub 데이터는 라이센스 문제로 제외 하였습니다. 자세한 내용은 아래를 참조하세요.
https://aihub.or.kr/partcptnmlrd/inqry/view.do?currMenu=144&topMenu=104
|
AdapterOcean/dollyaug-standardized_cluster_0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: conversation_id
dtype: int64
- name: embedding
sequence: float64
- name: cluster
dtype: int64
splits:
- name: train
num_bytes: 23749937
num_examples: 2345
download_size: 7557029
dataset_size: 23749937
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "dollyaug-standardized_cluster_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
indra-inc/docvqa_en_train_valid_2400_gtparse | ---
dataset_info:
features:
- name: question
dtype: string
- name: docId
dtype: int64
- name: answers
sequence: string
- name: data_split
dtype: string
- name: bounding_boxes
sequence:
sequence: int64
- name: word_list
sequence: string
- name: image_raw
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 324385610.0
num_examples: 2000
- name: valid
num_bytes: 207926530.0
num_examples: 400
download_size: 0
dataset_size: 532312140.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
---
# Dataset Card for "docvqa_en_train_valid_2400"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
CyberHarem/aurora_arknights | ---
license: mit
task_categories:
- text-to-image
tags:
- art
- not-for-all-audiences
size_categories:
- n<1K
---
# Dataset of aurora/オーロラ/极光 (Arknights)
This is the dataset of aurora/オーロラ/极光 (Arknights), containing 434 images and their tags.
The core tags of this character are `animal_ears, bear_ears, blue_eyes, breasts, hairband, black_hairband, long_hair, hair_over_one_eye, large_breasts, white_hair, very_long_hair, grey_hair, eyes_visible_through_hair`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 434 | 773.15 MiB | [Download](https://huggingface.co/datasets/CyberHarem/aurora_arknights/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 1200 | 434 | 634.85 MiB | [Download](https://huggingface.co/datasets/CyberHarem/aurora_arknights/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 1105 | 1.24 GiB | [Download](https://huggingface.co/datasets/CyberHarem/aurora_arknights/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/aurora_arknights',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 16 |  |  |  |  |  | 1girl, black_gloves, black_shirt, cowboy_shot, crop_top, cropped_jacket, long_sleeves, looking_at_viewer, midriff, navel, solo, stomach, white_jacket, grey_shorts, short_shorts, cleavage_cutout, simple_background, smile, pouch, standing, infection_monitor_(arknights), white_background, thighs |
| 1 | 5 |  |  |  |  |  | 1girl, black_gloves, black_shirt, blush, cowboy_shot, crop_top, cropped_jacket, grey_shorts, long_sleeves, looking_at_viewer, midriff, navel, short_shorts, simple_background, solo, stomach, white_jacket, cleavage_cutout, hairclip, pouch, standing, white_background, smile, parted_lips, shield |
| 2 | 19 |  |  |  |  |  | 1girl, crop_top, long_sleeves, solo, upper_body, black_gloves, cropped_jacket, looking_at_viewer, midriff, simple_background, white_jacket, black_shirt, navel, white_background, stomach, blush, cleavage_cutout, smile, hairclip |
| 3 | 6 |  |  |  |  |  | 1girl, cleavage_cutout, crop_top, cropped_jacket, hairclip, long_sleeves, looking_at_viewer, smile, solo, upper_body, white_jacket, black_gloves, black_shirt, simple_background, white_background, blush, closed_mouth, hand_up |
| 4 | 18 |  |  |  |  |  | 1girl, black_gloves, crop_top, long_sleeves, looking_at_viewer, midriff, navel, pouch, short_shorts, shrug_(clothing), solo, stomach, cleavage, cowboy_shot, standing, belt, black_shirt, thighs, simple_background, thigh_strap, grey_shorts, white_background, black_shorts, jacket, thighhighs, smile |
| 5 | 9 |  |  |  |  |  | 1girl, alternate_costume, long_sleeves, ribbed_sweater, smile, bear_girl, blush, cleavage_cutout, looking_at_viewer, simple_background, solo, turtleneck_sweater, white_background, grey_sweater, heart, open-chest_sweater, open_mouth, sleeves_past_wrists, white_sweater, bear_tail, closed_mouth, hairclip, upper_body |
| 6 | 10 |  |  |  |  |  | 1girl, goggles_on_head, long_sleeves, solo, coat, looking_at_viewer, official_alternate_costume, outdoors, black_gloves, black_jacket, open_jacket, snow, upper_body, parted_lips, sky, bodysuit, choker, signature |
| 7 | 8 |  |  |  |  |  | blush, navel, nipples, 1girl, looking_at_viewer, solo_focus, sweat, 1boy, bar_censor, bear_girl, collarbone, completely_nude, hetero, open_mouth, penis, sex, vaginal, cum_in_pussy, spread_legs, cowgirl_position, girl_on_top, pov, stomach, extra_ears, heart, on_back, on_bed, smile |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | black_gloves | black_shirt | cowboy_shot | crop_top | cropped_jacket | long_sleeves | looking_at_viewer | midriff | navel | solo | stomach | white_jacket | grey_shorts | short_shorts | cleavage_cutout | simple_background | smile | pouch | standing | infection_monitor_(arknights) | white_background | thighs | blush | hairclip | parted_lips | shield | upper_body | closed_mouth | hand_up | shrug_(clothing) | cleavage | belt | thigh_strap | black_shorts | jacket | thighhighs | alternate_costume | ribbed_sweater | bear_girl | turtleneck_sweater | grey_sweater | heart | open-chest_sweater | open_mouth | sleeves_past_wrists | white_sweater | bear_tail | goggles_on_head | coat | official_alternate_costume | outdoors | black_jacket | open_jacket | snow | sky | bodysuit | choker | signature | nipples | solo_focus | sweat | 1boy | bar_censor | collarbone | completely_nude | hetero | penis | sex | vaginal | cum_in_pussy | spread_legs | cowgirl_position | girl_on_top | pov | extra_ears | on_back | on_bed |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:---------------|:--------------|:--------------|:-----------|:-----------------|:---------------|:--------------------|:----------|:--------|:-------|:----------|:---------------|:--------------|:---------------|:------------------|:--------------------|:--------|:--------|:-----------|:--------------------------------|:-------------------|:---------|:--------|:-----------|:--------------|:---------|:-------------|:---------------|:----------|:-------------------|:-----------|:-------|:--------------|:---------------|:---------|:-------------|:--------------------|:-----------------|:------------|:---------------------|:---------------|:--------|:---------------------|:-------------|:----------------------|:----------------|:------------|:------------------|:-------|:-----------------------------|:-----------|:---------------|:--------------|:-------|:------|:-----------|:---------|:------------|:----------|:-------------|:--------|:-------|:-------------|:-------------|:------------------|:---------|:--------|:------|:----------|:---------------|:--------------|:-------------------|:--------------|:------|:-------------|:----------|:---------|
| 0 | 16 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 5 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | X | | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 2 | 19 |  |  |  |  |  | X | X | X | | X | X | X | X | X | X | X | X | X | | | X | X | X | | | | X | | X | X | | | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 3 | 6 |  |  |  |  |  | X | X | X | | X | X | X | X | | | X | | X | | | X | X | X | | | | X | | X | X | | | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 4 | 18 |  |  |  |  |  | X | X | X | X | X | | X | X | X | X | X | X | | X | X | | X | X | X | X | | X | X | | | | | | | | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 5 | 9 |  |  |  |  |  | X | | | | | | X | X | | | X | | | | | X | X | X | | | | X | | X | X | | | X | X | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| 6 | 10 |  |  |  |  |  | X | X | | | | | X | X | | | X | | | | | | | | | | | | | | | X | | X | | | | | | | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | |
| 7 | 8 |  |  |  |  |  | X | | | | | | | X | | X | | X | | | | | | X | | | | | | X | | | | | | | | | | | | | | | | X | | | X | | X | | | | | | | | | | | | | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
nairaxo/shikomori-asr-augmented | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: duration
dtype: float64
- name: dialect
dtype: string
splits:
- name: train
num_bytes: 858447006.686
num_examples: 4926
download_size: 988067627
dataset_size: 858447006.686
---
# Dataset Card for "shikomori-asr-augmented"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AlexanderDoria/novel17_test | ---
license: cc0-1.0
---
|
fathyshalab/massive_alarm | ---
dataset_info:
features:
- name: id
dtype: string
- name: label
dtype: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 20844
num_examples: 390
- name: validation
num_bytes: 3251
num_examples: 64
- name: test
num_bytes: 4818
num_examples: 96
download_size: 17873
dataset_size: 28913
---
# Dataset Card for "massive_alarm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
chats-bug/GuideTesting | ---
license: apache-2.0
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: imagepath
dtype: string
- name: workflow
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 1276801623.816
num_examples: 7662
download_size: 1242461556
dataset_size: 1276801623.816
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
fedml/databricks-dolly-15k-niid | ---
license: cc-by-sa-3.0
language:
- en
size_categories:
- 10K<n<100K
configs:
- config_name: default
default: true
data_files:
- split: train
path: "train.parquet"
- split: test
path: "test.parquet"
dataset_info:
config_name: default
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: category
dtype: string
---
This is a Non-IID split version of [databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k).
|
open-llm-leaderboard/details_PygmalionAI__pygmalion-2.7b | ---
pretty_name: Evaluation run of PygmalionAI/pygmalion-2.7b
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [PygmalionAI/pygmalion-2.7b](https://huggingface.co/PygmalionAI/pygmalion-2.7b)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_PygmalionAI__pygmalion-2.7b\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-22T20:17:59.683847](https://huggingface.co/datasets/open-llm-leaderboard/details_PygmalionAI__pygmalion-2.7b/blob/main/results_2023-09-22T20-17-59.683847.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.04320469798657718,\n\
\ \"em_stderr\": 0.0020821626664430564,\n \"f1\": 0.08408347315436249,\n\
\ \"f1_stderr\": 0.0023636579014392274,\n \"acc\": 0.2825572217837411,\n\
\ \"acc_stderr\": 0.006966407055209012\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.04320469798657718,\n \"em_stderr\": 0.0020821626664430564,\n\
\ \"f1\": 0.08408347315436249,\n \"f1_stderr\": 0.0023636579014392274\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.0,\n \"acc_stderr\"\
: 0.0\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.5651144435674822,\n\
\ \"acc_stderr\": 0.013932814110418024\n }\n}\n```"
repo_url: https://huggingface.co/PygmalionAI/pygmalion-2.7b
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|arc:challenge|25_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_22T20_17_59.683847
path:
- '**/details_harness|drop|3_2023-09-22T20-17-59.683847.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-22T20-17-59.683847.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_22T20_17_59.683847
path:
- '**/details_harness|gsm8k|5_2023-09-22T20-17-59.683847.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-22T20-17-59.683847.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hellaswag|10_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T16:36:05.422128.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T16:36:05.422128.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-19T16:36:05.422128.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_22T20_17_59.683847
path:
- '**/details_harness|winogrande|5_2023-09-22T20-17-59.683847.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-22T20-17-59.683847.parquet'
- config_name: results
data_files:
- split: 2023_07_19T16_36_05.422128
path:
- results_2023-07-19T16:36:05.422128.parquet
- split: 2023_09_22T20_17_59.683847
path:
- results_2023-09-22T20-17-59.683847.parquet
- split: latest
path:
- results_2023-09-22T20-17-59.683847.parquet
---
# Dataset Card for Evaluation run of PygmalionAI/pygmalion-2.7b
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/PygmalionAI/pygmalion-2.7b
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [PygmalionAI/pygmalion-2.7b](https://huggingface.co/PygmalionAI/pygmalion-2.7b) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_PygmalionAI__pygmalion-2.7b",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-22T20:17:59.683847](https://huggingface.co/datasets/open-llm-leaderboard/details_PygmalionAI__pygmalion-2.7b/blob/main/results_2023-09-22T20-17-59.683847.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.04320469798657718,
"em_stderr": 0.0020821626664430564,
"f1": 0.08408347315436249,
"f1_stderr": 0.0023636579014392274,
"acc": 0.2825572217837411,
"acc_stderr": 0.006966407055209012
},
"harness|drop|3": {
"em": 0.04320469798657718,
"em_stderr": 0.0020821626664430564,
"f1": 0.08408347315436249,
"f1_stderr": 0.0023636579014392274
},
"harness|gsm8k|5": {
"acc": 0.0,
"acc_stderr": 0.0
},
"harness|winogrande|5": {
"acc": 0.5651144435674822,
"acc_stderr": 0.013932814110418024
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
zrowt/Itty-Bitty | ---
license: apache-2.0
---
|
Gabrielto/zapk | ---
license: openrail
---
|
dellebew/sutd_qa_dataset | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 106991.0
num_examples: 200
download_size: 54109
dataset_size: 106991.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Kaue123456/DuduJoaoBatista | ---
license: openrail
---
|
theblackcat102/evol-code-zh | ---
task_categories:
- text2text-generation
language:
- zh
---
Evolved codealpaca in Chinese
|
louisbrulenaudet/dac6-instruct | ---
license: apache-2.0
language:
- fr
multilinguality:
- monolingual
tags:
- finetuning
- legal
- tax
- llm
- fiscal
- cgi
- DAC6
- >-
DAC6 – directive 2018/822 du Conseil du 25 mai 2018 relative à l’échange
automatique et obligatoire d’informations dans le domaine fiscal
source_datasets:
- original
pretty_name: DAC6
task_categories:
- text-generation
- table-question-answering
- summarization
- conversational
size_categories:
- n<1K
---
# DAC6 instruct (11-12-2023)
“DAC 6” refers to European Council Directive (EU) 2018/822 of May 25, 2018 relating to the automatic and mandatory exchange of information on cross-border arrangements requiring declaration. It aims to strengthen cooperation between tax administrations in EU countries on potentially aggressive tax planning arrangements.
This project focuses on fine-tuning pre-trained language models to create efficient and accurate models for tax practice.
Fine-tuning is the process of adapting a pre-trained model to perform specific tasks or cater to particular domains. It involves adjusting the model's parameters through a further round of training on task-specific or domain-specific data. While conventional fine-tuning strategies involve supervised learning with labeled data, instruction-based fine-tuning introduces a more structured and interpretable approach.
Instruction-based fine-tuning leverages the power of human-provided instructions to guide the model's behavior. These instructions can be in the form of text prompts, prompts with explicit task descriptions, or a combination of both. This approach allows for a more controlled and context-aware interaction with the LLM, making it adaptable to a multitude of specialized tasks.
Instruction-based fine-tuning significantly enhances the performance of LLMs in the following ways:
- Task-Specific Adaptation: LLMs, when fine-tuned with specific instructions, exhibit remarkable adaptability to diverse tasks. They can switch seamlessly between translation, summarization, and question-answering, guided by the provided instructions.
- Reduced Ambiguity: Traditional LLMs might generate ambiguous or contextually inappropriate responses. Instruction-based fine-tuning allows for a clearer and more context-aware generation, reducing the likelihood of nonsensical outputs.
- Efficient Knowledge Transfer: Instructions can encapsulate domain-specific knowledge, enabling LLMs to benefit from expert guidance. This knowledge transfer is particularly valuable in fields like tax practice, law, medicine, and more.
- Interpretability: Instruction-based fine-tuning also makes LLM behavior more interpretable. Since the instructions are human-readable, it becomes easier to understand and control model outputs.
- Adaptive Behavior: LLMs, post instruction-based fine-tuning, exhibit adaptive behavior that is responsive to both explicit task descriptions and implicit cues within the provided text.
## Dataset generation
This JSON file is a list of dictionaries, each dictionary contains the following fields:
- `instruction`: `string`, presenting the instruction linked to the element.
- `input`: `string`, signifying the input details for the element.
- `output`: `string`, indicating the output information for the element.
## Citing this project
If you use this code in your research, please use the following BibTeX entry.
```BibTeX
@misc{louisbrulenaudet2023,
author = {Louis Brulé Naudet},
title = {DAC6 instruct (11-12-2023)},
howpublished = {\url{https://huggingface.co/datasets/louisbrulenaudet/dac6-instruct}},
year = {2023}
}
```
## Feedback
If you have any feedback, please reach out at [louisbrulenaudet@icloud.com](mailto:louisbrulenaudet@icloud.com). |
RIW/small-coco-wm | ---
dataset_info:
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: url
dtype: string
- name: key
dtype: string
- name: status
dtype: string
- name: error_message
dtype: 'null'
- name: width
dtype: int64
- name: height
dtype: int64
- name: original_width
dtype: int64
- name: original_height
dtype: int64
- name: exif
dtype: string
- name: sha256
dtype: string
splits:
- name: train
num_bytes: 881124899.597
num_examples: 8879
- name: test
num_bytes: 1728419997.344
num_examples: 19769
- name: validation
num_bytes: 854191310.724
num_examples: 8836
download_size: 1933564702
dataset_size: 3463736207.665
---
# Dataset Card for "small-coco-wm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
snjv90/fashion-image-dataset | ---
license: apache-2.0
---
|
damerajee/khasi-more-raw | ---
license: apache-2.0
---
|
iam-sathya/rbi-test | ---
license: openrail
---
|
MarmoraAI/MarmoraChat | ---
license: mit
task_categories:
- text-generation
language:
- en
size_categories:
- 1K<n<10K
--- |
one-sec-cv12/chunk_12 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
splits:
- name: train
num_bytes: 18789293952.0
num_examples: 195624
download_size: 16796755807
dataset_size: 18789293952.0
---
# Dataset Card for "chunk_12"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
autoevaluate/autoeval-staging-eval-project-Blaise-g__SumPubmed-93d67e8f-12255638 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- Blaise-g/SumPubmed
eval_info:
task: summarization
model: Blaise-g/led_large_baseline_pubmed
metrics: []
dataset_name: Blaise-g/SumPubmed
dataset_config: Blaise-g--SumPubmed
dataset_split: test
col_mapping:
text: text
target: abstract
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: Blaise-g/led_large_baseline_pubmed
* Dataset: Blaise-g/SumPubmed
* Config: Blaise-g--SumPubmed
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Blaise-g](https://huggingface.co/Blaise-g) for evaluating this model. |
kpriyanshu256/MultiTabQA-spider_nq | ---
dataset_info:
features:
- name: query
dtype: string
- name: question
dtype: string
- name: table_names
sequence: string
- name: tables
sequence: string
- name: answer
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: input_ids
sequence:
sequence: int32
- name: attention_mask
sequence:
sequence: int8
- name: labels
sequence:
sequence: int64
- name: decoder_input_ids
sequence:
sequence: int64
- name: source_latex
dtype: string
- name: target_latex
dtype: string
- name: source_html
dtype: string
- name: target_html
dtype: string
- name: source_markdown
dtype: string
- name: target_markdown
dtype: string
splits:
- name: train
num_bytes: 8762063673
num_examples: 6715
- name: validation
num_bytes: 1716646618
num_examples: 985
download_size: 1413873556
dataset_size: 10478710291
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
Kazimir-ai/text-to-image-prompts | ---
language:
- en
tags:
- prompts
- text-to-image
- stable diffusion
pretty_name: The dataset of the most popular text-to-image prompts
size_categories:
- 1K<n<10K
license: apache-2.0
---
# The dataset of the most popular text-to-image prompts.
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** kazimir.ai
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** https://kazimir.ai
- **License:** apache-2.0
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
Free to use.
## Dataset Structure
CSV file columns *name* and *count*.
### Source Data
The prompts from kazimir.ai.
## Dataset Card Contact
data@kazimir.ai |
EgilKarlsen/Spirit_GPT2_Finetuned | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: '0'
dtype: float32
- name: '1'
dtype: float32
- name: '2'
dtype: float32
- name: '3'
dtype: float32
- name: '4'
dtype: float32
- name: '5'
dtype: float32
- name: '6'
dtype: float32
- name: '7'
dtype: float32
- name: '8'
dtype: float32
- name: '9'
dtype: float32
- name: '10'
dtype: float32
- name: '11'
dtype: float32
- name: '12'
dtype: float32
- name: '13'
dtype: float32
- name: '14'
dtype: float32
- name: '15'
dtype: float32
- name: '16'
dtype: float32
- name: '17'
dtype: float32
- name: '18'
dtype: float32
- name: '19'
dtype: float32
- name: '20'
dtype: float32
- name: '21'
dtype: float32
- name: '22'
dtype: float32
- name: '23'
dtype: float32
- name: '24'
dtype: float32
- name: '25'
dtype: float32
- name: '26'
dtype: float32
- name: '27'
dtype: float32
- name: '28'
dtype: float32
- name: '29'
dtype: float32
- name: '30'
dtype: float32
- name: '31'
dtype: float32
- name: '32'
dtype: float32
- name: '33'
dtype: float32
- name: '34'
dtype: float32
- name: '35'
dtype: float32
- name: '36'
dtype: float32
- name: '37'
dtype: float32
- name: '38'
dtype: float32
- name: '39'
dtype: float32
- name: '40'
dtype: float32
- name: '41'
dtype: float32
- name: '42'
dtype: float32
- name: '43'
dtype: float32
- name: '44'
dtype: float32
- name: '45'
dtype: float32
- name: '46'
dtype: float32
- name: '47'
dtype: float32
- name: '48'
dtype: float32
- name: '49'
dtype: float32
- name: '50'
dtype: float32
- name: '51'
dtype: float32
- name: '52'
dtype: float32
- name: '53'
dtype: float32
- name: '54'
dtype: float32
- name: '55'
dtype: float32
- name: '56'
dtype: float32
- name: '57'
dtype: float32
- name: '58'
dtype: float32
- name: '59'
dtype: float32
- name: '60'
dtype: float32
- name: '61'
dtype: float32
- name: '62'
dtype: float32
- name: '63'
dtype: float32
- name: '64'
dtype: float32
- name: '65'
dtype: float32
- name: '66'
dtype: float32
- name: '67'
dtype: float32
- name: '68'
dtype: float32
- name: '69'
dtype: float32
- name: '70'
dtype: float32
- name: '71'
dtype: float32
- name: '72'
dtype: float32
- name: '73'
dtype: float32
- name: '74'
dtype: float32
- name: '75'
dtype: float32
- name: '76'
dtype: float32
- name: '77'
dtype: float32
- name: '78'
dtype: float32
- name: '79'
dtype: float32
- name: '80'
dtype: float32
- name: '81'
dtype: float32
- name: '82'
dtype: float32
- name: '83'
dtype: float32
- name: '84'
dtype: float32
- name: '85'
dtype: float32
- name: '86'
dtype: float32
- name: '87'
dtype: float32
- name: '88'
dtype: float32
- name: '89'
dtype: float32
- name: '90'
dtype: float32
- name: '91'
dtype: float32
- name: '92'
dtype: float32
- name: '93'
dtype: float32
- name: '94'
dtype: float32
- name: '95'
dtype: float32
- name: '96'
dtype: float32
- name: '97'
dtype: float32
- name: '98'
dtype: float32
- name: '99'
dtype: float32
- name: '100'
dtype: float32
- name: '101'
dtype: float32
- name: '102'
dtype: float32
- name: '103'
dtype: float32
- name: '104'
dtype: float32
- name: '105'
dtype: float32
- name: '106'
dtype: float32
- name: '107'
dtype: float32
- name: '108'
dtype: float32
- name: '109'
dtype: float32
- name: '110'
dtype: float32
- name: '111'
dtype: float32
- name: '112'
dtype: float32
- name: '113'
dtype: float32
- name: '114'
dtype: float32
- name: '115'
dtype: float32
- name: '116'
dtype: float32
- name: '117'
dtype: float32
- name: '118'
dtype: float32
- name: '119'
dtype: float32
- name: '120'
dtype: float32
- name: '121'
dtype: float32
- name: '122'
dtype: float32
- name: '123'
dtype: float32
- name: '124'
dtype: float32
- name: '125'
dtype: float32
- name: '126'
dtype: float32
- name: '127'
dtype: float32
- name: '128'
dtype: float32
- name: '129'
dtype: float32
- name: '130'
dtype: float32
- name: '131'
dtype: float32
- name: '132'
dtype: float32
- name: '133'
dtype: float32
- name: '134'
dtype: float32
- name: '135'
dtype: float32
- name: '136'
dtype: float32
- name: '137'
dtype: float32
- name: '138'
dtype: float32
- name: '139'
dtype: float32
- name: '140'
dtype: float32
- name: '141'
dtype: float32
- name: '142'
dtype: float32
- name: '143'
dtype: float32
- name: '144'
dtype: float32
- name: '145'
dtype: float32
- name: '146'
dtype: float32
- name: '147'
dtype: float32
- name: '148'
dtype: float32
- name: '149'
dtype: float32
- name: '150'
dtype: float32
- name: '151'
dtype: float32
- name: '152'
dtype: float32
- name: '153'
dtype: float32
- name: '154'
dtype: float32
- name: '155'
dtype: float32
- name: '156'
dtype: float32
- name: '157'
dtype: float32
- name: '158'
dtype: float32
- name: '159'
dtype: float32
- name: '160'
dtype: float32
- name: '161'
dtype: float32
- name: '162'
dtype: float32
- name: '163'
dtype: float32
- name: '164'
dtype: float32
- name: '165'
dtype: float32
- name: '166'
dtype: float32
- name: '167'
dtype: float32
- name: '168'
dtype: float32
- name: '169'
dtype: float32
- name: '170'
dtype: float32
- name: '171'
dtype: float32
- name: '172'
dtype: float32
- name: '173'
dtype: float32
- name: '174'
dtype: float32
- name: '175'
dtype: float32
- name: '176'
dtype: float32
- name: '177'
dtype: float32
- name: '178'
dtype: float32
- name: '179'
dtype: float32
- name: '180'
dtype: float32
- name: '181'
dtype: float32
- name: '182'
dtype: float32
- name: '183'
dtype: float32
- name: '184'
dtype: float32
- name: '185'
dtype: float32
- name: '186'
dtype: float32
- name: '187'
dtype: float32
- name: '188'
dtype: float32
- name: '189'
dtype: float32
- name: '190'
dtype: float32
- name: '191'
dtype: float32
- name: '192'
dtype: float32
- name: '193'
dtype: float32
- name: '194'
dtype: float32
- name: '195'
dtype: float32
- name: '196'
dtype: float32
- name: '197'
dtype: float32
- name: '198'
dtype: float32
- name: '199'
dtype: float32
- name: '200'
dtype: float32
- name: '201'
dtype: float32
- name: '202'
dtype: float32
- name: '203'
dtype: float32
- name: '204'
dtype: float32
- name: '205'
dtype: float32
- name: '206'
dtype: float32
- name: '207'
dtype: float32
- name: '208'
dtype: float32
- name: '209'
dtype: float32
- name: '210'
dtype: float32
- name: '211'
dtype: float32
- name: '212'
dtype: float32
- name: '213'
dtype: float32
- name: '214'
dtype: float32
- name: '215'
dtype: float32
- name: '216'
dtype: float32
- name: '217'
dtype: float32
- name: '218'
dtype: float32
- name: '219'
dtype: float32
- name: '220'
dtype: float32
- name: '221'
dtype: float32
- name: '222'
dtype: float32
- name: '223'
dtype: float32
- name: '224'
dtype: float32
- name: '225'
dtype: float32
- name: '226'
dtype: float32
- name: '227'
dtype: float32
- name: '228'
dtype: float32
- name: '229'
dtype: float32
- name: '230'
dtype: float32
- name: '231'
dtype: float32
- name: '232'
dtype: float32
- name: '233'
dtype: float32
- name: '234'
dtype: float32
- name: '235'
dtype: float32
- name: '236'
dtype: float32
- name: '237'
dtype: float32
- name: '238'
dtype: float32
- name: '239'
dtype: float32
- name: '240'
dtype: float32
- name: '241'
dtype: float32
- name: '242'
dtype: float32
- name: '243'
dtype: float32
- name: '244'
dtype: float32
- name: '245'
dtype: float32
- name: '246'
dtype: float32
- name: '247'
dtype: float32
- name: '248'
dtype: float32
- name: '249'
dtype: float32
- name: '250'
dtype: float32
- name: '251'
dtype: float32
- name: '252'
dtype: float32
- name: '253'
dtype: float32
- name: '254'
dtype: float32
- name: '255'
dtype: float32
- name: '256'
dtype: float32
- name: '257'
dtype: float32
- name: '258'
dtype: float32
- name: '259'
dtype: float32
- name: '260'
dtype: float32
- name: '261'
dtype: float32
- name: '262'
dtype: float32
- name: '263'
dtype: float32
- name: '264'
dtype: float32
- name: '265'
dtype: float32
- name: '266'
dtype: float32
- name: '267'
dtype: float32
- name: '268'
dtype: float32
- name: '269'
dtype: float32
- name: '270'
dtype: float32
- name: '271'
dtype: float32
- name: '272'
dtype: float32
- name: '273'
dtype: float32
- name: '274'
dtype: float32
- name: '275'
dtype: float32
- name: '276'
dtype: float32
- name: '277'
dtype: float32
- name: '278'
dtype: float32
- name: '279'
dtype: float32
- name: '280'
dtype: float32
- name: '281'
dtype: float32
- name: '282'
dtype: float32
- name: '283'
dtype: float32
- name: '284'
dtype: float32
- name: '285'
dtype: float32
- name: '286'
dtype: float32
- name: '287'
dtype: float32
- name: '288'
dtype: float32
- name: '289'
dtype: float32
- name: '290'
dtype: float32
- name: '291'
dtype: float32
- name: '292'
dtype: float32
- name: '293'
dtype: float32
- name: '294'
dtype: float32
- name: '295'
dtype: float32
- name: '296'
dtype: float32
- name: '297'
dtype: float32
- name: '298'
dtype: float32
- name: '299'
dtype: float32
- name: '300'
dtype: float32
- name: '301'
dtype: float32
- name: '302'
dtype: float32
- name: '303'
dtype: float32
- name: '304'
dtype: float32
- name: '305'
dtype: float32
- name: '306'
dtype: float32
- name: '307'
dtype: float32
- name: '308'
dtype: float32
- name: '309'
dtype: float32
- name: '310'
dtype: float32
- name: '311'
dtype: float32
- name: '312'
dtype: float32
- name: '313'
dtype: float32
- name: '314'
dtype: float32
- name: '315'
dtype: float32
- name: '316'
dtype: float32
- name: '317'
dtype: float32
- name: '318'
dtype: float32
- name: '319'
dtype: float32
- name: '320'
dtype: float32
- name: '321'
dtype: float32
- name: '322'
dtype: float32
- name: '323'
dtype: float32
- name: '324'
dtype: float32
- name: '325'
dtype: float32
- name: '326'
dtype: float32
- name: '327'
dtype: float32
- name: '328'
dtype: float32
- name: '329'
dtype: float32
- name: '330'
dtype: float32
- name: '331'
dtype: float32
- name: '332'
dtype: float32
- name: '333'
dtype: float32
- name: '334'
dtype: float32
- name: '335'
dtype: float32
- name: '336'
dtype: float32
- name: '337'
dtype: float32
- name: '338'
dtype: float32
- name: '339'
dtype: float32
- name: '340'
dtype: float32
- name: '341'
dtype: float32
- name: '342'
dtype: float32
- name: '343'
dtype: float32
- name: '344'
dtype: float32
- name: '345'
dtype: float32
- name: '346'
dtype: float32
- name: '347'
dtype: float32
- name: '348'
dtype: float32
- name: '349'
dtype: float32
- name: '350'
dtype: float32
- name: '351'
dtype: float32
- name: '352'
dtype: float32
- name: '353'
dtype: float32
- name: '354'
dtype: float32
- name: '355'
dtype: float32
- name: '356'
dtype: float32
- name: '357'
dtype: float32
- name: '358'
dtype: float32
- name: '359'
dtype: float32
- name: '360'
dtype: float32
- name: '361'
dtype: float32
- name: '362'
dtype: float32
- name: '363'
dtype: float32
- name: '364'
dtype: float32
- name: '365'
dtype: float32
- name: '366'
dtype: float32
- name: '367'
dtype: float32
- name: '368'
dtype: float32
- name: '369'
dtype: float32
- name: '370'
dtype: float32
- name: '371'
dtype: float32
- name: '372'
dtype: float32
- name: '373'
dtype: float32
- name: '374'
dtype: float32
- name: '375'
dtype: float32
- name: '376'
dtype: float32
- name: '377'
dtype: float32
- name: '378'
dtype: float32
- name: '379'
dtype: float32
- name: '380'
dtype: float32
- name: '381'
dtype: float32
- name: '382'
dtype: float32
- name: '383'
dtype: float32
- name: '384'
dtype: float32
- name: '385'
dtype: float32
- name: '386'
dtype: float32
- name: '387'
dtype: float32
- name: '388'
dtype: float32
- name: '389'
dtype: float32
- name: '390'
dtype: float32
- name: '391'
dtype: float32
- name: '392'
dtype: float32
- name: '393'
dtype: float32
- name: '394'
dtype: float32
- name: '395'
dtype: float32
- name: '396'
dtype: float32
- name: '397'
dtype: float32
- name: '398'
dtype: float32
- name: '399'
dtype: float32
- name: '400'
dtype: float32
- name: '401'
dtype: float32
- name: '402'
dtype: float32
- name: '403'
dtype: float32
- name: '404'
dtype: float32
- name: '405'
dtype: float32
- name: '406'
dtype: float32
- name: '407'
dtype: float32
- name: '408'
dtype: float32
- name: '409'
dtype: float32
- name: '410'
dtype: float32
- name: '411'
dtype: float32
- name: '412'
dtype: float32
- name: '413'
dtype: float32
- name: '414'
dtype: float32
- name: '415'
dtype: float32
- name: '416'
dtype: float32
- name: '417'
dtype: float32
- name: '418'
dtype: float32
- name: '419'
dtype: float32
- name: '420'
dtype: float32
- name: '421'
dtype: float32
- name: '422'
dtype: float32
- name: '423'
dtype: float32
- name: '424'
dtype: float32
- name: '425'
dtype: float32
- name: '426'
dtype: float32
- name: '427'
dtype: float32
- name: '428'
dtype: float32
- name: '429'
dtype: float32
- name: '430'
dtype: float32
- name: '431'
dtype: float32
- name: '432'
dtype: float32
- name: '433'
dtype: float32
- name: '434'
dtype: float32
- name: '435'
dtype: float32
- name: '436'
dtype: float32
- name: '437'
dtype: float32
- name: '438'
dtype: float32
- name: '439'
dtype: float32
- name: '440'
dtype: float32
- name: '441'
dtype: float32
- name: '442'
dtype: float32
- name: '443'
dtype: float32
- name: '444'
dtype: float32
- name: '445'
dtype: float32
- name: '446'
dtype: float32
- name: '447'
dtype: float32
- name: '448'
dtype: float32
- name: '449'
dtype: float32
- name: '450'
dtype: float32
- name: '451'
dtype: float32
- name: '452'
dtype: float32
- name: '453'
dtype: float32
- name: '454'
dtype: float32
- name: '455'
dtype: float32
- name: '456'
dtype: float32
- name: '457'
dtype: float32
- name: '458'
dtype: float32
- name: '459'
dtype: float32
- name: '460'
dtype: float32
- name: '461'
dtype: float32
- name: '462'
dtype: float32
- name: '463'
dtype: float32
- name: '464'
dtype: float32
- name: '465'
dtype: float32
- name: '466'
dtype: float32
- name: '467'
dtype: float32
- name: '468'
dtype: float32
- name: '469'
dtype: float32
- name: '470'
dtype: float32
- name: '471'
dtype: float32
- name: '472'
dtype: float32
- name: '473'
dtype: float32
- name: '474'
dtype: float32
- name: '475'
dtype: float32
- name: '476'
dtype: float32
- name: '477'
dtype: float32
- name: '478'
dtype: float32
- name: '479'
dtype: float32
- name: '480'
dtype: float32
- name: '481'
dtype: float32
- name: '482'
dtype: float32
- name: '483'
dtype: float32
- name: '484'
dtype: float32
- name: '485'
dtype: float32
- name: '486'
dtype: float32
- name: '487'
dtype: float32
- name: '488'
dtype: float32
- name: '489'
dtype: float32
- name: '490'
dtype: float32
- name: '491'
dtype: float32
- name: '492'
dtype: float32
- name: '493'
dtype: float32
- name: '494'
dtype: float32
- name: '495'
dtype: float32
- name: '496'
dtype: float32
- name: '497'
dtype: float32
- name: '498'
dtype: float32
- name: '499'
dtype: float32
- name: '500'
dtype: float32
- name: '501'
dtype: float32
- name: '502'
dtype: float32
- name: '503'
dtype: float32
- name: '504'
dtype: float32
- name: '505'
dtype: float32
- name: '506'
dtype: float32
- name: '507'
dtype: float32
- name: '508'
dtype: float32
- name: '509'
dtype: float32
- name: '510'
dtype: float32
- name: '511'
dtype: float32
- name: '512'
dtype: float32
- name: '513'
dtype: float32
- name: '514'
dtype: float32
- name: '515'
dtype: float32
- name: '516'
dtype: float32
- name: '517'
dtype: float32
- name: '518'
dtype: float32
- name: '519'
dtype: float32
- name: '520'
dtype: float32
- name: '521'
dtype: float32
- name: '522'
dtype: float32
- name: '523'
dtype: float32
- name: '524'
dtype: float32
- name: '525'
dtype: float32
- name: '526'
dtype: float32
- name: '527'
dtype: float32
- name: '528'
dtype: float32
- name: '529'
dtype: float32
- name: '530'
dtype: float32
- name: '531'
dtype: float32
- name: '532'
dtype: float32
- name: '533'
dtype: float32
- name: '534'
dtype: float32
- name: '535'
dtype: float32
- name: '536'
dtype: float32
- name: '537'
dtype: float32
- name: '538'
dtype: float32
- name: '539'
dtype: float32
- name: '540'
dtype: float32
- name: '541'
dtype: float32
- name: '542'
dtype: float32
- name: '543'
dtype: float32
- name: '544'
dtype: float32
- name: '545'
dtype: float32
- name: '546'
dtype: float32
- name: '547'
dtype: float32
- name: '548'
dtype: float32
- name: '549'
dtype: float32
- name: '550'
dtype: float32
- name: '551'
dtype: float32
- name: '552'
dtype: float32
- name: '553'
dtype: float32
- name: '554'
dtype: float32
- name: '555'
dtype: float32
- name: '556'
dtype: float32
- name: '557'
dtype: float32
- name: '558'
dtype: float32
- name: '559'
dtype: float32
- name: '560'
dtype: float32
- name: '561'
dtype: float32
- name: '562'
dtype: float32
- name: '563'
dtype: float32
- name: '564'
dtype: float32
- name: '565'
dtype: float32
- name: '566'
dtype: float32
- name: '567'
dtype: float32
- name: '568'
dtype: float32
- name: '569'
dtype: float32
- name: '570'
dtype: float32
- name: '571'
dtype: float32
- name: '572'
dtype: float32
- name: '573'
dtype: float32
- name: '574'
dtype: float32
- name: '575'
dtype: float32
- name: '576'
dtype: float32
- name: '577'
dtype: float32
- name: '578'
dtype: float32
- name: '579'
dtype: float32
- name: '580'
dtype: float32
- name: '581'
dtype: float32
- name: '582'
dtype: float32
- name: '583'
dtype: float32
- name: '584'
dtype: float32
- name: '585'
dtype: float32
- name: '586'
dtype: float32
- name: '587'
dtype: float32
- name: '588'
dtype: float32
- name: '589'
dtype: float32
- name: '590'
dtype: float32
- name: '591'
dtype: float32
- name: '592'
dtype: float32
- name: '593'
dtype: float32
- name: '594'
dtype: float32
- name: '595'
dtype: float32
- name: '596'
dtype: float32
- name: '597'
dtype: float32
- name: '598'
dtype: float32
- name: '599'
dtype: float32
- name: '600'
dtype: float32
- name: '601'
dtype: float32
- name: '602'
dtype: float32
- name: '603'
dtype: float32
- name: '604'
dtype: float32
- name: '605'
dtype: float32
- name: '606'
dtype: float32
- name: '607'
dtype: float32
- name: '608'
dtype: float32
- name: '609'
dtype: float32
- name: '610'
dtype: float32
- name: '611'
dtype: float32
- name: '612'
dtype: float32
- name: '613'
dtype: float32
- name: '614'
dtype: float32
- name: '615'
dtype: float32
- name: '616'
dtype: float32
- name: '617'
dtype: float32
- name: '618'
dtype: float32
- name: '619'
dtype: float32
- name: '620'
dtype: float32
- name: '621'
dtype: float32
- name: '622'
dtype: float32
- name: '623'
dtype: float32
- name: '624'
dtype: float32
- name: '625'
dtype: float32
- name: '626'
dtype: float32
- name: '627'
dtype: float32
- name: '628'
dtype: float32
- name: '629'
dtype: float32
- name: '630'
dtype: float32
- name: '631'
dtype: float32
- name: '632'
dtype: float32
- name: '633'
dtype: float32
- name: '634'
dtype: float32
- name: '635'
dtype: float32
- name: '636'
dtype: float32
- name: '637'
dtype: float32
- name: '638'
dtype: float32
- name: '639'
dtype: float32
- name: '640'
dtype: float32
- name: '641'
dtype: float32
- name: '642'
dtype: float32
- name: '643'
dtype: float32
- name: '644'
dtype: float32
- name: '645'
dtype: float32
- name: '646'
dtype: float32
- name: '647'
dtype: float32
- name: '648'
dtype: float32
- name: '649'
dtype: float32
- name: '650'
dtype: float32
- name: '651'
dtype: float32
- name: '652'
dtype: float32
- name: '653'
dtype: float32
- name: '654'
dtype: float32
- name: '655'
dtype: float32
- name: '656'
dtype: float32
- name: '657'
dtype: float32
- name: '658'
dtype: float32
- name: '659'
dtype: float32
- name: '660'
dtype: float32
- name: '661'
dtype: float32
- name: '662'
dtype: float32
- name: '663'
dtype: float32
- name: '664'
dtype: float32
- name: '665'
dtype: float32
- name: '666'
dtype: float32
- name: '667'
dtype: float32
- name: '668'
dtype: float32
- name: '669'
dtype: float32
- name: '670'
dtype: float32
- name: '671'
dtype: float32
- name: '672'
dtype: float32
- name: '673'
dtype: float32
- name: '674'
dtype: float32
- name: '675'
dtype: float32
- name: '676'
dtype: float32
- name: '677'
dtype: float32
- name: '678'
dtype: float32
- name: '679'
dtype: float32
- name: '680'
dtype: float32
- name: '681'
dtype: float32
- name: '682'
dtype: float32
- name: '683'
dtype: float32
- name: '684'
dtype: float32
- name: '685'
dtype: float32
- name: '686'
dtype: float32
- name: '687'
dtype: float32
- name: '688'
dtype: float32
- name: '689'
dtype: float32
- name: '690'
dtype: float32
- name: '691'
dtype: float32
- name: '692'
dtype: float32
- name: '693'
dtype: float32
- name: '694'
dtype: float32
- name: '695'
dtype: float32
- name: '696'
dtype: float32
- name: '697'
dtype: float32
- name: '698'
dtype: float32
- name: '699'
dtype: float32
- name: '700'
dtype: float32
- name: '701'
dtype: float32
- name: '702'
dtype: float32
- name: '703'
dtype: float32
- name: '704'
dtype: float32
- name: '705'
dtype: float32
- name: '706'
dtype: float32
- name: '707'
dtype: float32
- name: '708'
dtype: float32
- name: '709'
dtype: float32
- name: '710'
dtype: float32
- name: '711'
dtype: float32
- name: '712'
dtype: float32
- name: '713'
dtype: float32
- name: '714'
dtype: float32
- name: '715'
dtype: float32
- name: '716'
dtype: float32
- name: '717'
dtype: float32
- name: '718'
dtype: float32
- name: '719'
dtype: float32
- name: '720'
dtype: float32
- name: '721'
dtype: float32
- name: '722'
dtype: float32
- name: '723'
dtype: float32
- name: '724'
dtype: float32
- name: '725'
dtype: float32
- name: '726'
dtype: float32
- name: '727'
dtype: float32
- name: '728'
dtype: float32
- name: '729'
dtype: float32
- name: '730'
dtype: float32
- name: '731'
dtype: float32
- name: '732'
dtype: float32
- name: '733'
dtype: float32
- name: '734'
dtype: float32
- name: '735'
dtype: float32
- name: '736'
dtype: float32
- name: '737'
dtype: float32
- name: '738'
dtype: float32
- name: '739'
dtype: float32
- name: '740'
dtype: float32
- name: '741'
dtype: float32
- name: '742'
dtype: float32
- name: '743'
dtype: float32
- name: '744'
dtype: float32
- name: '745'
dtype: float32
- name: '746'
dtype: float32
- name: '747'
dtype: float32
- name: '748'
dtype: float32
- name: '749'
dtype: float32
- name: '750'
dtype: float32
- name: '751'
dtype: float32
- name: '752'
dtype: float32
- name: '753'
dtype: float32
- name: '754'
dtype: float32
- name: '755'
dtype: float32
- name: '756'
dtype: float32
- name: '757'
dtype: float32
- name: '758'
dtype: float32
- name: '759'
dtype: float32
- name: '760'
dtype: float32
- name: '761'
dtype: float32
- name: '762'
dtype: float32
- name: '763'
dtype: float32
- name: '764'
dtype: float32
- name: '765'
dtype: float32
- name: '766'
dtype: float32
- name: '767'
dtype: float32
- name: label
dtype: string
splits:
- name: train
num_bytes: 115650065.625
num_examples: 37500
- name: test
num_bytes: 38550020.0
num_examples: 12500
download_size: 211753822
dataset_size: 154200085.625
---
# Dataset Card for "Spirit_GPT2_Finetuned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.